
la nuova maturità commerciale 2015 redatta dal gruppo ... nuova... · 1.3.1 Frequenza assoluta e...
57
Introduzione alla statistica per la nuova maturità commerciale 2015 redatta dal gruppo cantonale di matematica per i CPC
-
Upload
nguyenkhanh -
Category
Documents
-
view
217 -
download
0
Transcript of la nuova maturità commerciale 2015 redatta dal gruppo ... nuova... · 1.3.1 Frequenza assoluta e...

Introduzione alla statistica
per
la nuova maturità commerciale 2015
redatta dal
gruppo cantonale di matematica per i CPC


Indice
1 Statistica monovariata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.1 Scheda introduttiva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.1.1 Come si svolge un’indagine statistica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2 La statistica induttiva e la statistica descrittiva . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2.1 I caratteri qualitativi e i caratteri quantitativi . . . . . . . . . . . . . . . . . . . . . . . . 61.2.2 Dai censimenti ai sondaggi d’opinione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3 Le tabelle di frequenza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.1 Frequenza assoluta e relativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.2 Frequenza cumulata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.4 Le classi di frequenza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.4.1 Suddivisione dei dati in classi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.4.1.1 Note e definizioni sulla suddivisione in classi . . . . . . . . . . . . . . . . . . . . . 101.5 La rappresentazione grafica dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.5.1 Diagramma a colonne e istogramma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.5.2 Poligono delle frequenze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.5.3 Areogramma o torta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.5.4 Ogiva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.6 Gli indici di posizione centrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.6.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.6.2 La media aritmetica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.6.3 La media ponderata e la media per classi . . . . . . . . . . . . . . . . . . . . . . . . . . 151.6.4 La mediana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.6.5 La classe mediana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.6.6 La mediana per classi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.6.7 I percentili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.6.8 La moda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.6.9 Quando e quale indicatore di posizione centrale usare? . . . . . . . . . . . . . . . . . 20
1.7 Gli indici di variabilità (o di dispersione) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211.7.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211.7.2 Il campo di variazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.7.3 I quartili e lo scarto interquartile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.7.4 Box-plot di Tukey e gli outliers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241.7.5 Lo scarto quadratico medio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251.7.6 Lo scarto quadratico per classi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271.7.7 La distribuzione gaussiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
1.8 Esercizi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2 Popolazione e campione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.1.1 La popolazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.1.2 Il campione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.2 Attività pratica con un foglio di calcolo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.2.1 Creazione dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.2.2 Elaborazione dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.2.3 Discussione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.3 La stima . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.3.1 Considerazioni su campione e popolazione . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3

2.3.2 Stima di una media puntuale con i limiti di confidenza . . . . . . . . . . . . . . . . . 36
3 Statistica bivariata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.2 La correlazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2.1 Correlazione e regressione lineare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.2.2 La covarianza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.2.3 Il coefficiente di correlazione r di Pearson . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.3 La regressione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.3.1 Il metodo dei minimi quadrati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.3.2 L’errore nelle regressioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.3.3 La scelta della variabile indipendente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.3.4 Scarti quadratici e pendenza delle rette di regressione . . . . . . . . . . . . . . . . . . 42
3.4 Connessioni e contingenze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.4.1 Connessione tra due mutabili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.4.2 Connessioni tra una mutabile ed una variabile . . . . . . . . . . . . . . . . . . . . . . . 46
3.5 Esercizi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4 Test formativi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.1 Statistica monovariata (80 minuti) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 514.2 Regressione e correlazione (80 minuti) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5 Esercizi di approfondimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.1 Radioattività e cinghiali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 535.2 Un fantoccio ai raggi X . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 545.3 Dosimetri in una centrale nucleare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555.4 Impianti di riscaldamento in Svizzera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.5 Turismo e pernottamenti in Svizzera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4 Indice

Capitolo 1
Statistica monovariata
1.1 Scheda introduttiva
Nell’esperienza quotidiana siamo posti di fronte a molteplici decisioni da prendere: per esempiodecidere come investire i nostri risparmi, se acquistare un’automobile in contanti o a leasing, ...
Mentre alcune scelte vengono basate su un semplice ragionamento logico, altre richiedono la dispo-nibilità di precise informazioni e la capacità di interpretarle correttamente. Per prendere decisionicorrette è necessario disporre dei dati relativi alla scelta da compiere: ma i dati grezzi spesso nonci rivelano immediatamente il loro vero significato.
La statistica è uno strumento fondamentale per il supporto alle decisioni, in ogni settore applicativo.Non basta infatti disporre di semplici dati per fare le scelte giuste: i dati vanno raccolti, analizzatied elaborati con strumenti adatti (per esempio tabelle e grafici). Essi vanno poi interpretati evalutati con gli opportuni metodi statistici.
Dati + Metodi statistici = Informazioni
1.1.1 Come si svolge un’indagine statistica
1. Definire un tema (situazione, problema,...). Individuare con precisione l’obiettivo che l’inda-gine si propone di raggiungere, definendo con accuratezza i termini del problema a cuibisogna dare risposta (per esempio: analizzare l’afflusso di clienti in un negozio secondo gliorari per determinarne in seguito l’orario di apertura/chiusura e la presenza di personale incerte fasce orarie; il legame tra produzione industriale e consumo di energia elettrica).
2. Definire le variabili che ci interessano in maniera da poter individuare, senza possibilità diequivoco, i valori che esse assumono nelle singole unità.
3. Fissare metodi (su tutta la popolazione / su un campione), mezzi (interviste, questionari,misurazioni, osservazioni, ...) e tempi entro i quali effettuare il rilevamento e l’elaborazionedei dati.
4. Rilevazione dei dati secondo il piano di lavoro deciso.
5. Spoglio dei dati e loro sistemazione in forme di facile lettura quali tabelle e grafici.
6. Elaborazione dei dati: mediante osservazione grafica ed operazioni matematiche si sintetiz-zano i risultati e si dà un’idea concreta della ripartizione dei caratteri rilevati. Analisi deidati tramite:
• indici di centralità: media (media ponderata), mediana, moda
• indici di dispersione e distribuzione: campo di variazione, scarto quadratico medio,quartili, percentili.
5

7. Interpretare i dati dando un giudizio di merito sul significato dei risultati utile per svilupparenuovi approfondimenti ed ipotesi.
1.2 La statistica induttiva e la statistica descrittiva
Immagina di parlare con uno sconosciuto e di raccogliere informazioni sulle sue abitudini, suisuoi gusti, sul suo stato di salute. Potresti dedurre un ritratto significativo di questa persona.Se raccogliessi le stesse informazioni per un gruppo di persone, diciamo mille, e ti accorgessi chealcune risposte si assomigliano e altre differiscono completamente le une dalle altre, cosa potrestidedurne? Potresti fare, in qualche modo, un ritratto di gruppo?
A volte anche molte informazioni possono essere inutili, se non sono ben organizzate. In tal caso puòessere utile raggruppare e sintetizzare i dati: in questo modo si rinuncia a parte dell’informazioneche essi contengono, ma si guadagna in leggibilità e facilità di interpretazione. In particolare sipossono elaborare tanti dati relativi a individui singoli per trarne informazioni sulla popolazionenel suo complesso. A seconda poi di come questi dati vengono raggruppati è possibile studiareaspetti diversi del problema in esame.
La statistica si occupa proprio dei modi di raccogliere e analizzare dati relativi a un certo gruppo dipersone (gli studenti di una scuola, gli abitanti di un quartiere, gli elettori di una regione, ...) o dioggetti (le automobili, i dischi, i libri, ...), per trarne conclusioni e fare previsioni. Il gruppo presoin considerazione viene anche detto popolazione. Spesso viene presa in esame soltanto una partedella popolazione, detta campione, scelta in modo che rappresenti l’intero gruppo. Per esempio,per conoscere il parere dei telespettatori su un certo programma, si può intervistare soltanto unpiccolo numero di essi, che si ritenga però un campione rappresentativo. Dalle osservazioni relativeal campione possono essere tratte conclusioni valide per tutta la popolazione. I metodi per ottenererisultati soddisfacenti in questo delicato procedimento di passaggio dal campione alla popolazionesono studiati da quella parte della statistica detta statistica induttiva (o inferenza statistica).
In questa prima scheda ci limiteremo a studiare alcuni degli strumenti matematici utilizzati perdescrivere i dati relativi a un certo gruppo (in questo caso si parla di statistica descrittiva) lasciandoa schede successive la parte inferenziale.
1.2.1 I caratteri qualitativi e i caratteri quantitativi
Gli elementi di una popolazione si chiamano anche unità statistiche. È possibile studiare diversecaratteristiche di tali unità e ogni caratteristica rappresenta un carattere della popolazione. Icaratteri possono essere di due tipi:
• qualitativi se vengono descritti con parole
• quantitativi se invece vengono descritti mediante numeri.
Per esempio, se scegliamo come unità statistiche gli studenti di una scuola, alcuni caratteri quali-tativi sono il sesso, il paese di provenienza, il mezzo di trasporto usato per raggiungere la scuola;sono invece caratteri quantitativi l’età, il peso, la statura. Ogni carattere viene descritto mediantele modalità con cui esso si può manifestare.
Esempio 1.1. Caratteri e modalità
1. Il carattere sesso ha due modalità: maschile e femminile;
6 Statistica monovariata

2. Il carattere mezzo di trasporto ha più modalità: treno, autobus, motorino, ...
3. Anche il carattere età ha più modalità: 14, 15, 16, ... (se espresso in anni).
1.2.2 Dai censimenti ai sondaggi d’opinione
L’utilizzo di dati statistici per ottenere informazioni utili per il governo degli stati, quali il numerodi abitanti, di soldati, di addetti ai vari mestieri, ecc. risale ai popoli antichi, in particolare ai Cinesie agli Egizi. Nella Bibbia sono descritti più censimenti fra gli Ebrei, tra i quali il più noto è quellodi Mosè nel deserto del Sinai. Anche i Romani fecero diversi censimenti: famoso quello durante ilquale nacque Gesù.
Un passo avanti nell’elaborazione statistica si ebbe in Inghilterra, intorno alla metà del 1600,con l’ “aritmetica politica”, principalmente a opera del matematico John Graunt. A causa dellepestilenze, a Londra venivano pubblicate settimanalmente le liste delle morti e quelle delle nascite.Graunt utilizzò quel materiale osservando, attraverso il calcolo di percentuali, regolarità quali ilmaggior numero di nascite maschili rispetto a quelle femminili, il legame fra suicidi e professioni,la diminuzione delle nascite nei periodi di carestia. Era la prima volta che venivano cercate dellerelazioni tra i dati raccolti.
Un ulteriore momento importante nella storia della statistica si ebbe quando, nell’Ottocento, sitrovò un collegamento con la probabilità.
Infine è dell’ultimo secolo uno sviluppo sempre più ampio della statistica come scienza matematicaa sé stante. L’applicazione di tale scienza, mediante indagini a campione, investe i campi piùsvariati, dai fenomeni sociali a quelli meteorologici.
1.3 Le tabelle di frequenza
1.3.1 Frequenza assoluta e relativa
Esempio 1.2. In un questionario abbiamo chiesto ai 28 studenti di una classe di indicare con leseguenti lettere i mezzi di trasporto con cui vengono di solito a scuola
A: automobile;
P: a piedi;
M: mezzi pubblici (autobus,treno,battello,ecc);
T: treno;
C: bicicletta.
Abbiamo ottenuto i seguenti risultati:
A, M, M, M, P, A, M, M, P, M, C, A, M, M, M, C, P, M, M, C, C, A, M, M, M, M, A, C, B, B
Dalla lettura di questa sequenza, è difficile trarre informazioni, perché i risultati si susseguono inmodo disordinato.
Costruiamo allora una tabella, dove nella prima colonna mettiamo le diverse modalità. percorriamopoi la sequenza dei risultati facendo un segno, per esempio una barra /, di fianco alle diversemodalità ogni volta che esse si verificano. Alla fine contiamo il numero di segni per ogni modalità e
1.3 Le tabelle di frequenza 7

lo scriviamo nella terza colonna. Tale numero rappresenta la frequenza della modalità considerata.L’automobile ha una frequenza 5, la bicicletta una frequenza 7 e così via.
Nota 1.3. Spesso la frequenza prende il nome di frequenza assoluta.
Modalità Occorrenze Frequenza
Automobile ///// 5
A piedi /// 3
Mezzi pubblici ///// ///// ///// 15
Bicicletta ///// // 7
Totale 30
Tabella 1.1. Distribuzione di frequenza delle modalità
Più spesso interessa il valore della frequenza confrontato con il numero totale delle unità statistiche.Infatti siamo in situazioni diverse se, per esempio, la frequenza di una modalità è 5 rispetto aun totale di 30 o se, invece, è 5 rispetto a un totale di 300. Per questo motivo viene calcolata lafrequenza relativa, di cui diamo la definizione.
Definizione 1.4. La frequenza relativa di una modalità è il quoziente fra la frequenza dellamodalità e il numero totale delle unità statistiche.
frequenza relativa=frequenza assoluta
totale delle frequenze(1.1)
Nell’esempio precedente la frequenza della modalità automobile è 5, ossia 5 studenti su 30 sonoaccompagnati in automobile; pertanto la frequenza relativa è:
fA=5
30=
1
6F 0.167 (1.2)
La frequenza relativa può essere espressa anche in percentuale, moltiplicandola per 100: la fre-quenza percentuale della modalità a piedi è il 10%. Questo significa che, in una distribuzione conle stesse caratteristiche di quella data, su un campione di 100 studenti 10 verrebbero a piedi.
Modalità Frequenza Frequenza relativa Frequenza relativa percentuale
Automobile 5 1
616.7%
A piedi 3 1
1010%
Mezzi pubblici 15 1
250%
Bicicletta 7 7
3023.3%
Totale 30 1 100%
Tabella 1.2. Le frequenze relative del problema introduttivo
Nota 1.5. La somma delle frequenza relative alle diverse modalità è 1, e in percentuale è 100%.
8 Statistica monovariata

Nota 1.6. Si noti che la frequenza relativa (e anche quella percentuale) possono anche essereinterpretate come probabilità frequentiste1.1. Riferendosi all’esempio precedente si potrebbe peresempio affermare che, in base al rilevamento eseguito, la probabilità che uno studente si rechia scuola con i mezzi pubblici è pari al 0.5 (50%). Chiaramente per avere valori di probabilitàattendibili è necessario che l’indagine statistica sia svolta su un ampia raccolta dei dati.
1.3.2 Frequenza cumulata
Per affrontare al questione della frequenza cumulata è necessario prendere in considerazione unesempio in cui le modalità siano quantitative (scalari), in modo tale che ci possa essere un ordinelogico crescente dei dati. A tal proposito si osservi l’esempio sottostante.
Esempio 1.7. Sono state intervistate 30 famiglie con figli di un certo quartiere e i risultati sonostati riportati nella tabella seguente:
N di figli per famiglia Frequenza Fr. relativa percentuale Fr. cumulata percentuale
1 12 40% 40%
2 9 30% 70%
3 6 20% 90%
>3 3 10% 100%
Tabella 1.3. Dati delle interviste alle famiglie, da completare
Definizione 1.8. La frequenza cumulata è la somma della frequenza del singolo dato e dellefrequenze dei dati che lo precedono nell’ordine.
Si noti come la frequenza cumulata è pari alla frequenza della singola modalità, sommata con lafrequenza di tutte le modalità che la precedono. Coi i dati ordinati in modo crescente l’algoritmodi calcolo della frequenza cumulata prevede di sommare la frequenza della singola modalità con lafrequenza cumulata della modalità precedente (v. tabella 1.3)
1.4 Le classi di frequenza
1.4.1 Suddivisione dei dati in classi
Spesso in un’indagine statistica succede che le singole modalità con cui i dati possono appariresono molto numerose e di conseguenza le frequenze per le singole modalità hanno valori moltobassi o nulli. Questa situazione è tipica quando si prendono in considerazione dati provenienti damisurazioni precise. Si osservi qui l’esempio di due gruppi di ragazze in un’attività di educazionefisica che svolgono un test di salto in lungo con partenza da fermo.
Esempio 1.9. Dati del test di salto in lungo in due gruppi di educazione fisica
1.1. Per le definizioni della probabilità classica e di quella frequentista si rimanda alla relativa pagina di wikipedia(https://it.wikipedia.org/wiki/Probabilità) o a specifici testi di approfondimento.
1.4 Le classi di frequenza 9
1.36 1.61 1.85
1.36 1.62 1.86
1.46 1.65 1.88
1.46 1.65 1.90
1.50 1.67 1.94
1.53 1.67 2.12
1.54 1.75
1.60 1.78
Tabella 1.4. Gruppo A
1.30 1.64 1.84
1.45 1.72 1.95
1.48 1.73 1.95
1.58 1.74 2.16
1.62 1.75
1.62 1.78
Tabella 1.5. Gruppo B
In casi come questo è utile raggruppare le frequenze in classi, determinando la frequenza di ogniclasse. Nella tabella seguente consideriamo cinque classi.
Classe (min. - max.) Valore centrale Fr. assol. Fr. rel. % Fr. cumul. Fr cumul. %
1.20 - 1.40 1.30 2 9 % 2 9 %
1.40 - 1.60 1.50 5 23 % 7 32 %
1.60 - 1.80 1.70 9 40 % 16 72 %
1.80 - 2.00 1.90 5 23 % 21 95 %
2.00 - 2.20 2.10 1 5 % 22 100 %
Tabella 1.6. Gruppo A: salti organizzati per classi
Il raggruppamento in classi fornisce meno informazioni (per esempio, non sappiamo quanto valgonoesattamente i 6 salti compresi fra 1.40 e 1.60), però fornisce una sintesi più leggibile della prova.
1.4.1.1 Note e definizioni sulla suddivisione in classi
Nota 1.10. Per costruire la tabella si determinano innanzitutto il campo di variazione dei daticalcolando la differenza tra il valore massimo e quello minimo.
Nota 1.11. Si determina il numero di classi prendendo un numero intero che si avvicina alla radicequadrata del numero di dati da classificare.
Numero di classiF Numero di dati√
(1.3)
Nota 1.12. Si calcola l’ampiezza di una singola classe (indicativamente) dividendo il campo divariazione per il numero di classi. Poi occorre arrotondare questo risultato ad un valore comodo. Aquesto punto si può iniziare a definire i minimi ed i massimi delle singole classi e successivamentesi classificano i dati.
Nota 1.13. Di solito l’estremo inferiore di ciascuna classe viene considerato incluso dalla classe,mentre quello superiore è escluso. Per esempio, nella Tabella 5, il valore 1.60 è inserito nella classe1.60 - 1.80 e non nella classe 1.40 - 1.60.
Definizione 1.14. L’ampiezza della classe è la differenza dei suoi estremi. Nell’esempio dellaTabella 7, la prima classe ha ampiezza 1,40 – 1,20 = 0,20. Solitamente le classi hanno tutte lastessa ampiezza (possono fare eccezione la prima e l’ultima classe).
10 Statistica monovariata

Nota 1.15. È buona norma (ma non è obbligatorio) utilizzate classi di dimensione omogenee, cioècon l’ampiezza uguale. Questo agevola la costruzione degli istogrammi. A volte vengono utilizzateclassi aperte per i limiti inferiori e superiori delle suddivisioni.
Definizione 1.16. Si chiama valore centrale la media tra gli estremi di ogni singola classe.Nell’esempio della Tabella 7, la prima classe ha il proprio valore centrale pari a 1.30. Questo valorerisulterà molto importante per le successive operazioni di calcolo e di rappresentazione grafica.
1.20+ 1.402
= 1.30 (1.4)
Esercizio 1.1. Creare un’opportuna tabella delle frequenze per i salti del gruppo B elencati nella tabella 1.5
1.5 La rappresentazione grafica dei dati
I dati statistici e le loro frequenze si possono rappresentare graficamente. Esaminiamo in questoparagrafo i tipi principali di rappresentazione grafica, riprendendo gli esempi del paragrafo prece-dente.
1.5.1 Diagramma a colonne e istogramma
Queste due rappresentazioni grafiche sono molto usate; sono apparentemente simili. In realtà se siguardano attentamente ci sono differenze sostanziali.
Per il diagramma a colonne si tracciano rettangoli la cui altezza è definita dalla frequenza assoluta(o anche relativa). La base del rettangolo non ha particolari vincoli, anche se solitamente sonotutte con la stessa ampiezza. Con il diagramma a colonne si può dare una rappresentazione graficaanche a dati che hanno modalità qualitative (Figura 1.1).
L’istogramma, al contrario del diagramma a colonne ha un vincolo molto più stretto. L’areadel rettangolo deve essere proporzionale alla frequenza. Per questo motivo è possibile costruireun istogramma unicamente con dati che hanno modalità quantitative. Si riportano in un pianocartesiano, sull’asse Ox i valori estremi delle classi (minimi e massimi) ottenendo così dei segmentile cui lunghezze rappresentano le ampiezze degli intervalli. Si disegnano poi dei rettangoli chehanno per base tali segmenti e la cui area è proporzionale alla frequenza della classe. Per ottenerela proporzionalità desiderata solitamente sull’asse Oy non si riporta la frequenza ma il rapporto fre-quenza/ampiezza della classe (Figura 1.2). Nel caso particolare (ma comunque piuttosto frequente)in cui le classi hanno tutte ampiezze uguali si può procedere riportando sull’asse Oy semplicementela frequenza.
Figura 1.1. Diagramma a colonne Tabella 1.1 Figura 1.2. Istogramma Tabella 1.6
1.5 La rappresentazione grafica dei dati 11
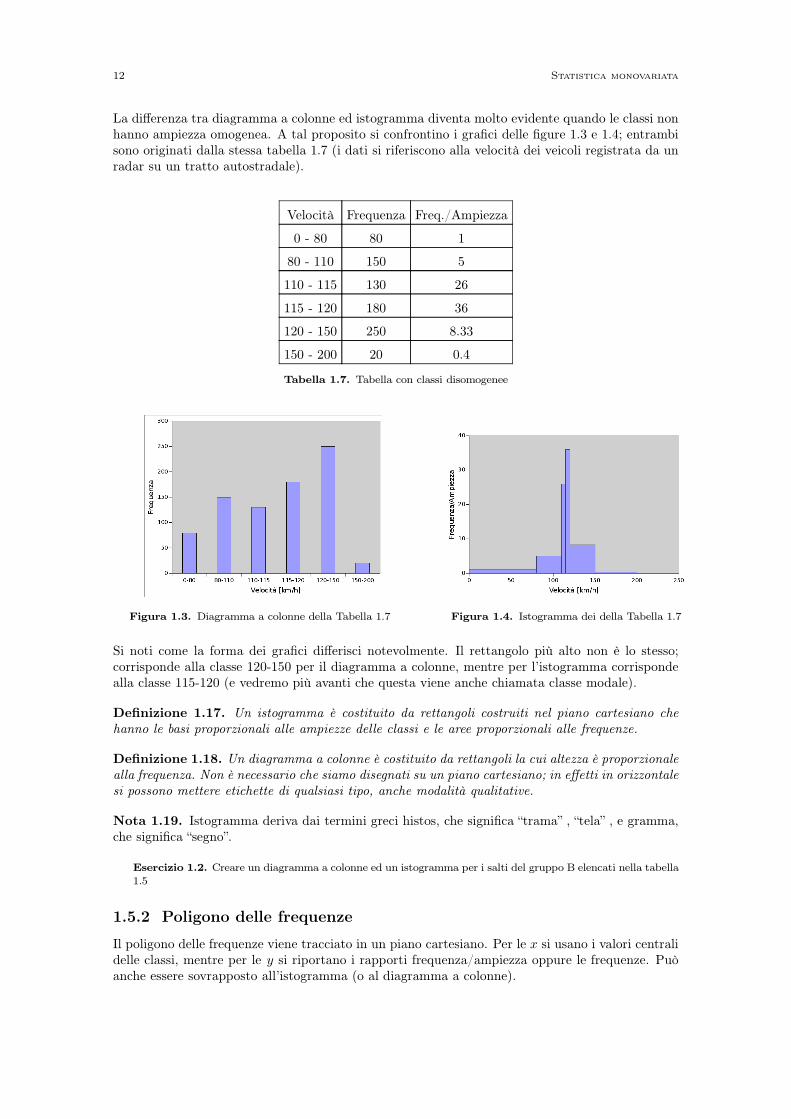
La differenza tra diagramma a colonne ed istogramma diventa molto evidente quando le classi nonhanno ampiezza omogenea. A tal proposito si confrontino i grafici delle figure 1.3 e 1.4; entrambisono originati dalla stessa tabella 1.7 (i dati si riferiscono alla velocità dei veicoli registrata da unradar su un tratto autostradale).
Velocità Frequenza Freq./Ampiezza
0 - 80 80 1
80 - 110 150 5
110 - 115 130 26
115 - 120 180 36
120 - 150 250 8.33
150 - 200 20 0.4
Tabella 1.7. Tabella con classi disomogenee
Figura 1.3. Diagramma a colonne della Tabella 1.7 Figura 1.4. Istogramma dei della Tabella 1.7
Si noti come la forma dei grafici differisci notevolmente. Il rettangolo più alto non è lo stesso;corrisponde alla classe 120-150 per il diagramma a colonne, mentre per l’istogramma corrispondealla classe 115-120 (e vedremo più avanti che questa viene anche chiamata classe modale).
Definizione 1.17. Un istogramma è costituito da rettangoli costruiti nel piano cartesiano chehanno le basi proporzionali alle ampiezze delle classi e le aree proporzionali alle frequenze.
Definizione 1.18. Un diagramma a colonne è costituito da rettangoli la cui altezza è proporzionalealla frequenza. Non è necessario che siamo disegnati su un piano cartesiano; in effetti in orizzontalesi possono mettere etichette di qualsiasi tipo, anche modalità qualitative.
Nota 1.19. Istogramma deriva dai termini greci histos, che significa “trama” , “tela” , e gramma,che significa “segno”.
Esercizio 1.2. Creare un diagramma a colonne ed un istogramma per i salti del gruppo B elencati nella tabella1.5
1.5.2 Poligono delle frequenze
Il poligono delle frequenze viene tracciato in un piano cartesiano. Per le x si usano i valori centralidelle classi, mentre per le y si riportano i rapporti frequenza/ampiezza oppure le frequenze. Puòanche essere sovrapposto all’istogramma (o al diagramma a colonne).
12 Statistica monovariata
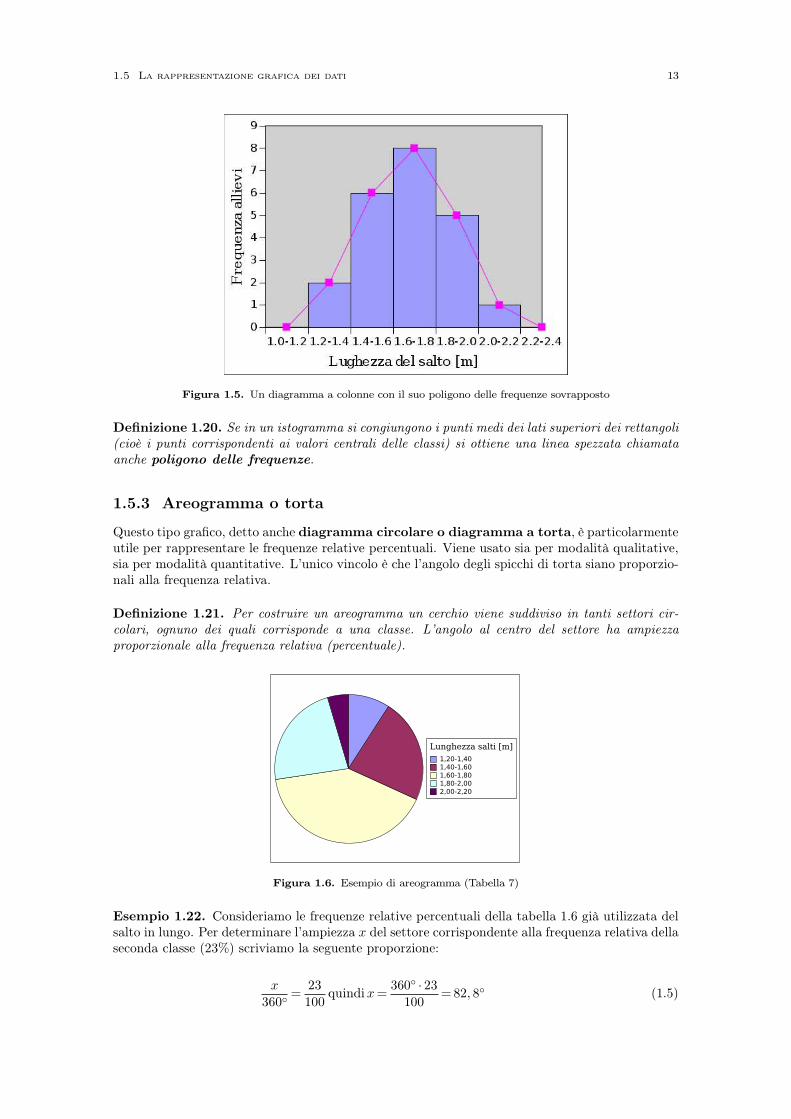
Figura 1.5. Un diagramma a colonne con il suo poligono delle frequenze sovrapposto
Definizione 1.20. Se in un istogramma si congiungono i punti medi dei lati superiori dei rettangoli(cioè i punti corrispondenti ai valori centrali delle classi) si ottiene una linea spezzata chiamataanche poligono delle frequenze.
1.5.3 Areogramma o torta
Questo tipo grafico, detto anche diagramma circolare o diagramma a torta, è particolarmenteutile per rappresentare le frequenze relative percentuali. Viene usato sia per modalità qualitative,sia per modalità quantitative. L’unico vincolo è che l’angolo degli spicchi di torta siano proporzio-nali alla frequenza relativa.
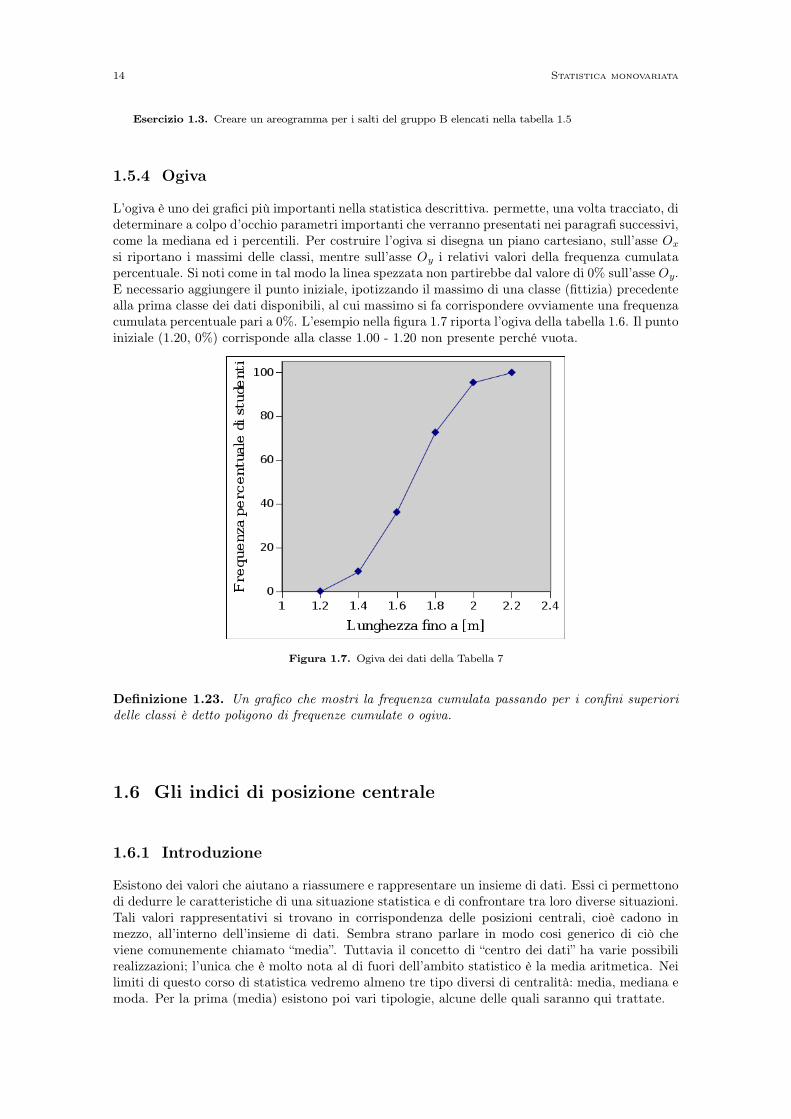
Definizione 1.21. Per costruire un areogramma un cerchio viene suddiviso in tanti settori cir-colari, ognuno dei quali corrisponde a una classe. L’angolo al centro del settore ha ampiezzaproporzionale alla frequenza relativa (percentuale).
Lunghezza salti [m]
1,20-1,40
1,40-1,60
1,60-1,80
1,80-2,00
2,00-2,20
Figura 1.6. Esempio di areogramma (Tabella 7)
Esempio 1.22. Consideriamo le frequenze relative percentuali della tabella 1.6 già utilizzata delsalto in lungo. Per determinare l’ampiezza x del settore corrispondente alla frequenza relativa dellaseconda classe (23%) scriviamo la seguente proporzione:
x
360◦=
23100
quindix=360◦ · 23
100= 82, 8◦ (1.5)
1.5 La rappresentazione grafica dei dati 13
Esercizio 1.3. Creare un areogramma per i salti del gruppo B elencati nella tabella 1.5
1.5.4 Ogiva
L’ogiva è uno dei grafici più importanti nella statistica descrittiva. permette, una volta tracciato, dideterminare a colpo d’occhio parametri importanti che verranno presentati nei paragrafi successivi,come la mediana ed i percentili. Per costruire l’ogiva si disegna un piano cartesiano, sull’asse Ox
si riportano i massimi delle classi, mentre sull’asse Oy i relativi valori della frequenza cumulatapercentuale. Si noti come in tal modo la linea spezzata non partirebbe dal valore di 0% sull’asse Oy.E necessario aggiungere il punto iniziale, ipotizzando il massimo di una classe (fittizia) precedentealla prima classe dei dati disponibili, al cui massimo si fa corrispondere ovviamente una frequenzacumulata percentuale pari a 0%. L’esempio nella figura 1.7 riporta l’ogiva della tabella 1.6. Il puntoiniziale (1.20, 0%) corrisponde alla classe 1.00 - 1.20 non presente perché vuota.
Figura 1.7. Ogiva dei dati della Tabella 7
Definizione 1.23. Un grafico che mostri la frequenza cumulata passando per i confini superioridelle classi è detto poligono di frequenze cumulate o ogiva.
1.6 Gli indici di posizione centrale
1.6.1 Introduzione
Esistono dei valori che aiutano a riassumere e rappresentare un insieme di dati. Essi ci permettonodi dedurre le caratteristiche di una situazione statistica e di confrontare tra loro diverse situazioni.Tali valori rappresentativi si trovano in corrispondenza delle posizioni centrali, cioè cadono inmezzo, all’interno dell’insieme di dati. Sembra strano parlare in modo cosi generico di ciò cheviene comunemente chiamato “media”. Tuttavia il concetto di “centro dei dati” ha varie possibilirealizzazioni; l’unica che è molto nota al di fuori dell’ambito statistico è la media aritmetica. Neilimiti di questo corso di statistica vedremo almeno tre tipo diversi di centralità: media, mediana emoda. Per la prima (media) esistono poi vari tipologie, alcune delle quali saranno qui trattate.
14 Statistica monovariata

1.6.2 La media aritmetica
Supponiamo di voler confrontare i risultati delle prove di salto in lungo del gruppo A (tabella 1.4)con quelli del gruppo B (tabella 1.5)
Affiancando le tabelle delle frequenze dei due gruppi (tabella 1.8), scopriamo che non è facilestabilire se la prova è andata meglio per il gruppo A o per il gruppo B.
Classe Fr. gruppo B Fr. gruppo A
1.20-1.40 1 2
1.40-1.60 3 5
1.60-1.80 8 9
1.80-2.00 3 5
2.00-2.20 1 1
Tabella 1.8. Confronto delle frequenze
Calcolando invece la media aritmetica relativa ai due gruppi di dati otteniamo un’informazionesintetica della distribuzione dei dati. Procedendo in maniera piuttosto intuitiva al calcolo dellamedia (tecnicamente si tratta della media aritmetica) si può procedere con un confronto.
La media del gruppo A del salto in lungo è:
XA=1.36+ 1.46+ 1.62+ .+ 1.78+ 2.12+ 1.86
22F 1.671 (1.6)
Quella del gruppo B invece:
XB=
1.95+ 2.16+ 1.95+ .+ 1.45+ 1.73+ 1.4816
F 1, 706 (1.7)
Poiché MB>MA possiamo dire che le studentesse del gruppo B hanno mediamente saltato megliodi quelle del gruppo A.
Definizione 1.24. La media aritmetica simbolizzata con M oppure con X di n numeriX1, X2, , Xn è il quoziente tra la loro somma e il numero n.
X =X1+X2+ +Xn
n=
∑
j=1
n
Xj
n(1.8)
Nell’esempio precedente abbiamo utilizzato la media come valore di sintesi, ossia come un valoreche riassume una caratteristica di un insieme di dati. Inoltre possiamo notare che, in questi esempi,la media si trova proprio nella zona della distribuzione dove si addensano maggiormente i risultati.Quando un valore di sintesi ha questa proprietà diciamo che è un buon indice di posizione
centrale. Come vedremo, non sempre la media è un buon indice di posizione centrale.
1.6.3 La media ponderata e la media per classi
Consideriamo la seguente tabella, relativa ai voti assegnati ad un lavoro scritto di matematica diuna classe ottenuti in un compito e calcoliamo la media (tabella 1.9).
1.6 Gli indici di posizione centrale 15

Voti Xj Frequenza fj fj ×Xj Frequenza relativa
3 2 6 9 %
3.5 7 24.5 32 %
4 8 32 36 %
4.5 3 13.5 14 %
5 2 10 9 %
Tabella 1.9. Media ponderata, esempio
X =3+ 3+ 3.5+ 3.5+ 3.5+ 3.5+ 3.5+ 3.5+ 3.5+4+ 4+4+4+4+ 4+ 4+4+ 4.5+ 4.5+ 4.5+5+ 5
22=F3.91 (1.9)
Utilizzando le frequenze si può anche scrivere nel seguente modo:
X =3× 2+ 3.5× 7+ 4× 8+ 4.5× 3+5× 2
2+7+8+3+2F 3.91 (1.10)
Le frequenze rappresentano i diversi "pesi" che devono avere i singoli voti nel calcolo della media.Più grande è la frequenza di un voto, maggiore è l’influenza che esso ha sul valore medio. La mediacalcolata in questo modo può essere considerata come caso particolare di un più generale tipo dimedia, chiamata media ponderata.
Definizione 1.25. Dati i numeri X1,X2, ,Xn e associati ad essi i numeri w1,w2, ,wn detti pesichiamiamo media aritmetica ponderata X il quoziente fra la somma dei prodotti dei numeriper i loro pesi e la somma dei pesi stessi.
X =w1X1+w2X2+ +wnXn
w1+w2+ +wn=
∑
j=1
n
wjXj
∑
j=1
n
wj
(1.11)
Nota 1.26. La media aritmetica può essere considerata un caso particolare di media ponderatain cui tutti i pesi sono uguali a 1.
Esercizio 1.4. Se durante l’anno scolastico nelle prove scritte di una data materia si sono ottenute le seguentinote: 4.5; 5.3; 4.1. Ciascuna delle note ha fattore di ponderazione 1. In una prova finale di maggio si ottiene lanota 5.7 e questa ha fattore di ponderazione 2. Si calcoli la media prima e dopo la prova finale, considerando ifattori di ponderazione.
Si osserverà che il calcolo della media nell’esempio intuitivo introdotto precedentemente con le classidei salti ha una grossa familiarità con la formula del calcolo per la media ponderata. In effetti ècosì. Infatti nel caso in cui si avessero a disposizione unicamente dati organizzati in classi la mediapuò essere calcolata con la formula sottostante in cui i pesi wj sono sostituiti dalle frequenze fj ei valori Xj nello specifico sono i valori centrali delle classi.
X =f1X1+ f2X2+ + fnXn
f1+ f2+ + fn=
∑
j=1
n
fjXj
∑
j=1
n
fj
(1.12)
Esercizio 1.5. Si calcoli la media ponderata usando i dati della Tabella 1.6 e si confronti il risultato con ilcalcolo già svolto della media aritmetica.
16 Statistica monovariata

1.6.4 La mediana
Abbiamo già detto che la media non è sempre un buon indice di posizione centrale. A dimostrazionedi tale fatto analizziamo l’esempio qui riportato.
Esempio 1.27. Ecco sette valori. Si tratta delle età in anni dei componenti di una comitiva. Sesi osservano si avrà l’impressione di aver di fronte un gruppo di bambini guidati da un adulto (adesempio un gruppo sportivo con l’allenatore):
8 12 7 9 4 10 55
Calcolandone la media aritmetica si ottiene il seguente risultato:
X =8+ 12+7+9+4+ 10+ 55
7= 15 (1.13)
Con una media si è tentati di pensare ad una comitiva di adolescenti la cui età media è 15 anni;succede perché in questo caso la media non è un buon indice di posizione centrale in quanto tutti ivalori, tranne il 55, sono minori di 15. È proprio la presenza dell’età di 55 anni, molto maggiore aquella degli altri, che "sposta" il valore medio rispetto alla posizione centrale. In queste situazionisi preferisce utilizzare un indice di posizione diverso, chiamato mediana, la cui determinazioneavviene, dopo aver ordinato in modo crescente i dati, nel modo indicato nella figura 1.8 :
Figura 1.8. Schema per la determinazione della mediana per una serie pari o dispari di valori
Pertanto nell’esempio 1.27 la mediana risulta essere 9. Questo dato ci restituisce un’immagine dellacomitiva un po più realistica di quanto ottenuto con la media.
Esempio 1.28. Cerchiamo, per esempio, la mediana dei seguenti otto valori di eta di un’altracomitiva:
36 22 41 8 33 46 38 44
Nel caso in cui il numero di dati fosse pari, come nell’esempio 1.28 dopo aver ordinato i dati siprocederebbe al calcolo della media dei valori centrali, come mostrato nella seconda parte dellaFigura 1.8, ottenendo il valore pari a 37.
1.6 Gli indici di posizione centrale 17

Definizione 1.29. Data la sequenza ordinata di n numeri X1, X2, , Xn la mediana è: il valorecentrale, se n è dispari; la media aritmetica dei due valori centrali, se n è pari. Pertanto:
• Si sceglie il dato centrale se i dati sono dispari.
• Si sceglie la media tra i due valori centrali se i dati sono pari.
Nota 1.30. La mediana di una sequenza di numeri suddivide la sequenza in due gruppi contenentilo stesso numero di elementi.
1.6.5 La classe mediana
Per determinare la classe mediana di dati organizzati in classi bisogna determinare innanzitutto lefrequenze cumulate e poi determinare in quale classe si trova la frequenza che è pari alla metà deltotale delle frequenze (50% della frequenza cumulata percentuale). Si osservi la Tabella 1.10 relativaal numero di prove scritte e/o orali accumulate da un gruppo di studenti durante un semestre.
N. di prove Fr. ass. Fr. cumul. Fr. cumul %
1 2 2 6.67
2 8 10 33.33
3 12 22 73.33
4 6 28 93.33
5 2 30 100%
Tabella 1.10. Numero di prove con nota per una classe di studenti
Osservando la frequenza cumulate si vede che il 50% è inserito sicuramente nella terza classe (dal33.33 al 73.33 %). Quindi la classe corrispondente a 3 prove scritte è la classe mediana di questadistribuzione di frequenze.
1.6.6 La mediana per classi
Ci sono situazioni in cui si vuole ricavare la mediana ma è unicamente disponibile una tabella dellefrequenza. In tal caso esiste una specifica formula (1.14) che permette di estrapolare una stimadella mediana dai dati della tabella delle frequenze. Tale stima corrisponde esattamente alla letturagrafica della corrispondente ogiva. Per esempio riferendosi alla Tabella 1.6 del salto in lungo si puòcalcolare la mediana applicando la seguente formula:
M =L1+
(
N
2− (∑
f)1
fmediana
)
· c (1.14)
In cui si ha la seguente simbologia:
L1 = confine inferiore della classemediana
N = frequenza totale
(∑
f)1 = Sommadelle frequenze di tutte le classi inferiori alla classemediana
fmediana = frequenza della classemediana
c = ampiezza della classemediana
18 Statistica monovariata

Nella fattispecie si ha che la classe mediana è quella con l’intervallo 1.60 - 1.80. Quindi sostituendonella formula 1.14 proposta nella Tabella 1.11 si ha:
M = 1.60+
(
222− 7
9
)
· 0.2F 1.6889 (1.15)
1.6.7 I percentili
Per estensione, modificando leggermente la formula della mediana per classi si può calcolare unqualsiasi valore percentuale all’interno dei dati, determinando quanto verrebbe letto dall’ogiva (vediFigura 1.7). In questo caso P corrisponde al percentile1.2. Chiaramente bisogna per ogni calcolodeterminare qual è la classe di riferimento.
M =L1+
(
P
100N − (
∑
f)1
fmediana
)
· c (1.16)
Esercizio 1.6. Determinate il 35◦ e il 60◦ percentile (P35 eP60) della distribuzione della Tabella 1.6.
Esercizio 1.7. Leggere e verificare col calcolo P20 e P85 della distribuzione della Tabella 1.6.
1.6.8 La moda
Immaginiamo di dover rilevare, su una popolazione di bambini in un asilo, qual è il colore dei capellidominante. Trattandosi di una variabile statistica qualitativa e non quantitativa non è possibilené calcolare la media aritmetica, né individuare una mediana (le modalità non sono ordinabili conun criterio oggettivo). Bisogna quindi utilizzare un altro indice di posizione chiamato moda. Lamoda può comunque essere essere determinata anche su dati quantitativi.
Definizione 1.31. Date una serie di modalità o di valori si chiama moda quel valore o quellamodalità a cui corrisponde la frequenza massima.
Figura 1.9. Un esempio di determinazione della moda tra una serie di valori
Considerando i seguenti valori:
3 8 2 3 5 1 7 3 5 3 15 2 10 3 12 4
per determinare la moda si procede innanzitutto ad ordinarli (in senso crescente):
1 2 2 3 3 3 3 3 4 5 5 7 8 10 12 15
Osserviamo che il 3 ha una frequenza molto maggiore (appare 5 volte) rispetto agli altri e vicinoal 3 si trovano molti degli altri valori presenti. In questo caso la moda di questo insieme di valori è 3.
1.2. Per una discussione sulle formule di calcolo per i percentili sui dati grezzi (ci varie alternative non universalmenteaccettate) si rimanda all’apposita pagina di wikipedia. https://en.wikipedia.org/wiki/Percentile
1.6 Gli indici di posizione centrale 19
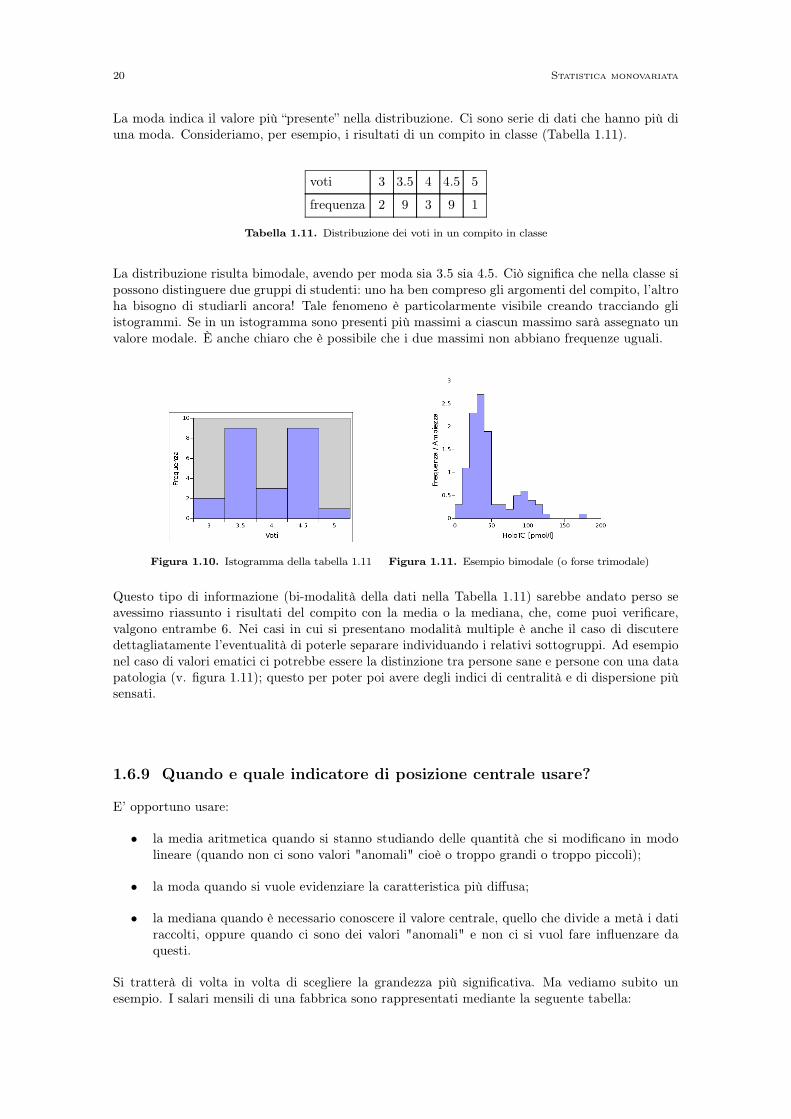
La moda indica il valore più “presente” nella distribuzione. Ci sono serie di dati che hanno più diuna moda. Consideriamo, per esempio, i risultati di un compito in classe (Tabella 1.11).
voti 3 3.5 4 4.5 5
frequenza 2 9 3 9 1
Tabella 1.11. Distribuzione dei voti in un compito in classe
La distribuzione risulta bimodale, avendo per moda sia 3.5 sia 4.5. Ciò significa che nella classe sipossono distinguere due gruppi di studenti: uno ha ben compreso gli argomenti del compito, l’altroha bisogno di studiarli ancora! Tale fenomeno è particolarmente visibile creando tracciando gliistogrammi. Se in un istogramma sono presenti più massimi a ciascun massimo sarà assegnato unvalore modale. È anche chiaro che è possibile che i due massimi non abbiano frequenze uguali.
Figura 1.10. Istogramma della tabella 1.11 Figura 1.11. Esempio bimodale (o forse trimodale)
Questo tipo di informazione (bi-modalità della dati nella Tabella 1.11) sarebbe andato perso seavessimo riassunto i risultati del compito con la media o la mediana, che, come puoi verificare,valgono entrambe 6. Nei casi in cui si presentano modalità multiple è anche il caso di discuteredettagliatamente l’eventualità di poterle separare individuando i relativi sottogruppi. Ad esempionel caso di valori ematici ci potrebbe essere la distinzione tra persone sane e persone con una datapatologia (v. figura 1.11); questo per poter poi avere degli indici di centralità e di dispersione piùsensati.
1.6.9 Quando e quale indicatore di posizione centrale usare?
E’ opportuno usare:
• la media aritmetica quando si stanno studiando delle quantità che si modificano in modolineare (quando non ci sono valori "anomali" cioè o troppo grandi o troppo piccoli);
• la moda quando si vuole evidenziare la caratteristica più diffusa;
• la mediana quando è necessario conoscere il valore centrale, quello che divide a metà i datiraccolti, oppure quando ci sono dei valori "anomali" e non ci si vuol fare influenzare daquesti.
Si tratterà di volta in volta di scegliere la grandezza più significativa. Ma vediamo subito unesempio. I salari mensili di una fabbrica sono rappresentati mediante la seguente tabella:
20 Statistica monovariata

Paga mensile in CHF Nř di persone che la ricevono
43’000 1 (il proprietario)
14’400 1
9’500 2
5’600 3
5’200 19
4’500 22
4’200 2
Tabella 1.12. Esempio con dati disomogenei
Calcoliamo ora i vari indici di posizione centrale studiati:
Media aritmetica = 5’988 CHF
Mediana = 5’200 CHF
Moda = 4’500 CHF
Cosa possiamo dedurre da queste informazioni?
• La media aritmetica ci dice che se il denaro fosse distribuito equamente (cioè in modo cheognuno ricevesse la stessa somma) ciascun dipendente avrebbe diritto a 5’988 CHF al mese.In questo caso, però, la media non è un buon indice di posizione centrale perché il salariodel proprietario è un valore anomalo.
• La mediana ci indica che circa la metà degli impiegati ricevono un salario di 5’200 CHF el’altra metà di più. Non ci indica però quanto di più o quanto di meno rispetto ai 5’200 CHF.
• La moda ci dice che la paga mensile più comune è di 4’500 CHF.
L’esempio ora dato ci mostra che media, mediana e moda rappresentano cose diverse.
Quindi se siete il proprietario della fabbrica e volete fare buona pubblicità alla vostra aziendautilizzerete la media aritmetica e direte: "Lo stipendio medio dei miei dipendenti è di ben 5’988CHF mensili".
Se invece rappresentate i lavoratori all’interno di un sindacato utilizzerete la moda e potrete dire:"Lo stipendio modale all’interno di questa fabbrica è di soli 4’500 CHF mensili!".
Ecco un piccolo esempio che vi mostra come la statistica può "mentire" se usata impropriamente!
1.7 Gli indici di variabilità (o di dispersione)
1.7.1 Introduzione
Oltre che i valori centrali, la statistica studia come i diversi dati si situano intorno ai valori medi,quanto sono distanti, cioè quanto si disperdono o al contrario quanto sono vicini, cioè quanto siraccolgono attorno ad essi. Consideriamo le due sequenze di valori:
a) 12 24 32 43 56 74 88
b) 42 43 44 46 49 52 53
1.7 Gli indici di variabilità (o di dispersione) 21

Esse sono costituite dallo stesso numero di valori e, per entrambe, la media è 47. Tuttavia la distri-buzione dei valori intorno al valore medio 47 è diversa per le due sequenze: i valori della secondasequenza sono più vicini al valore medio, mentre quelli della prima sono più sparsi. In statistica,per indicare questo fatto, si dice che le due sequenze hanno diversa dispersione o variabilità.
Per misurare la variabilità si usano degli indici di variabilità quali il campo di variazione, loscarto quadratico medio e lo scarto interquartile.
1.7.2 Il campo di variazione
Definizione 1.32. Il campo di variazione di una sequenza di numeri, ordinati in modo crescente,è la differenza fra il numero maggiore e il minore.
Nella sequenza a) il campo di variazione è 88− 12= 76, nella sequenza b) è 53− 42= 11.
Una misura della dispersione che elimini l’inconveniente dato dal campo di variazione che non riescea descrivere come si distribuiscono i dati che si trovano fra il minimo ed il massimo. Si osservicome nella Figura 1.12 i dati in rosso ed in verde hanno il campo di variazione molto simile, puravendo globalmente delle dispersioni molto diverse.
Figura 1.12. Rappresentazione schematica di tre insiemi di dati con il relativo campo di variazione
1.7.3 I quartili e lo scarto interquartile
Si può cominciare col valutare la dispersione intorno alla mediana M grazie allo scarto interquartile.Il calcolo dei quartili in realtà è abbastanza complicato ma noi ci restringeremo a dei sempliciesempi.
Definizione 1.33. Come la mediana divide la serie statistica in due parti di uguale importanza,i quartili sono valori della variabile statistica che dividono la serie in quattro gruppi di ugualeimportanza.
Si indica con:
• Q1 - il primo quartile o quartile inferiore
• Q2 - il secondo quartile che coincide con la mediana
• Q3 - il terzo quartile o quartile superiore
• Q3−Q1 è detto scarto interquartile
Esempio 1.34. Riportiamo i voti del compito di matematica in una classe di 25 alunni:
• ragazze: 3 3.25 3.5 3.5 4 4 4.25 4.25 4.5 4.5
22 Statistica monovariata

• ragazzi: 2.5 2.5 3 3 3 3 3 4 4 4 5 5 5 5.5 5.5
I voti delle ragazze e dei ragazzi hanno lo stesso andamento? Questi dati possono essere esaminaticon i procedimenti mostrati in precedenza. Si può considerare:
• la rappresentazione grafica con due istogrammi
• la media, che in entrambi i casi vale circa 3.8
• la mediana, che in entrambi i casi è 4
Noi vogliamo valutare la dispersione dei dati intorno alla mediana.
Consideriamo i voti delle ragazze, in questo caso abbiamo un numero pari di dati e quindi lamediana risulta essere il valore medio fra i due dati centrali
3 3.25 3.5 3.5 4 4 4.25 4.25 4.5 4.5
Con la procedura di determinazione della mediana (che è 4), si ottengono i due sottoinsiemi di datiseguenti:
a) 3 3.25 3.5 3.5 4
b) 4 4.25 4.25 4.5 4.5
Di ciascuna di questi due insiemi si può di nuovo calcolare la mediana (quindi la mediana dellamediana) individuando:
− nel primo gruppo il dato 3.5;
− nel secondo gruppo il dato 4.25.
In questo modo i dati vengono suddivisi in quattro parti ugualmente numerose per questo i valoriprima individuati prendono i seguenti nomi:
Q1= 3.5 Q2=M =4 Q3= 4.25
Calcoliamo ora lo scarto interquartile:
Q3−Q1= 4.25−3.5= 0.75 (1.17)
Valutiamo ora i quartili e la differenza interquartile relativi ai voti dei ragazzi, in questo casoabbiamo un numero dispari di dati e la mediana risulta quindi essere il dato centrale evidenziatoin grassetto:
2.5 2.5 3 3 3 3 3 4 4 4 5 5 5 5.5 5.5
Abbiamo quindi i dati suddivisi in due insiemi ugualmente numerosi:
a) 2.5 2.5 3 3 3 3 3
b) 4 4 5 5 5 5.5 5.5
Di ciascuna di queste parti si può di nuovo calcolare la mediana, individuando:
− nel primo gruppo il dato 3;
− nel secondo gruppo il dato 5.
1.7 Gli indici di variabilità (o di dispersione) 23

Si trova allora:
Q1=3 Q2=M =4 Q3=5
Calcoliamo ora lo scarto interquartile:
Q3−Q1=5− 3=2 (1.18)
Lo scarto interquartile dei voti delle ragazze (0.75) è minore di quello dei ragazzi (2), si può cosìconcludere che i voti delle ragazze sono meno dispersi attorno alla mediana rispetto a quelli deiragazzi.
Nella Figura 1.13 si vede come lo scarto interquartile riesce a differenziare meglio la situazioneschematica con tre diverse tipologie di dati proposta nella precedente Figura 1.12.
Figura 1.13. Rappresentazione schematica di tre diversi insiemi di dati con i relativi scarti interquartili
1.7.4 Box-plot di Tukey e gli outliers
Un ulteriore metodo di rappresentazione dei dati che serve ad evidenziare la dispersione è il boxplot. Si tratta di una procedura non parametrica legata a mediana e scarto interquartile. Unesempio di box-plot lo trovate qui sotto nella figura 1.14.
Figura 1.14. Box-plot di un campione di HoloTC (dati diversi rispetto alla figura 1.11)
Il box plot viene costruito su un asse cartesiano. Il centro della scatola (box) evidenziato dalla lineacentrale corrisponde al valore della mediana. i bordi del box sono costituiti dal primo Q1 e terzo Q3
quartile. I baffi (whiskers) vengono determinati moltiplicando per 1.51.3 lo scarto interquartile. Siprende questa distanza a partire dai bordi della scatola (Q1 e Q3) e si va a vedere qual è il valoreinferiore alla mediana che ancora è all’interno di questo intervallo. Il baffo viene così determinatodal valore di questo dato. La stessa cosa viene fatta per il valore più alto, nella direzione opposta.
Spesso vengono poi visualizzati gli outliers (cioè i punti che sono al di fuori dei whiskers) distin-guendo tra outliers interni (colorazione piena della figura 1.14), cioè con una distanza dalla mediananell’intervallo da 1.5 a 3 scarti interquartili e outliers esterni (colorazione vuota nella figura 1.14)con uno scarto superiore a 3 scarti interquartili dalla mediana.
1.3. Alla domanda “Perché 1.5” Tukey rispose testualmente: “Perché uno è poco due è troppo”. S tratta di un valorepuramente arbitrario, fissato in base all’esperienza accumulata nell’abito della ricerca statistica.
24 Statistica monovariata
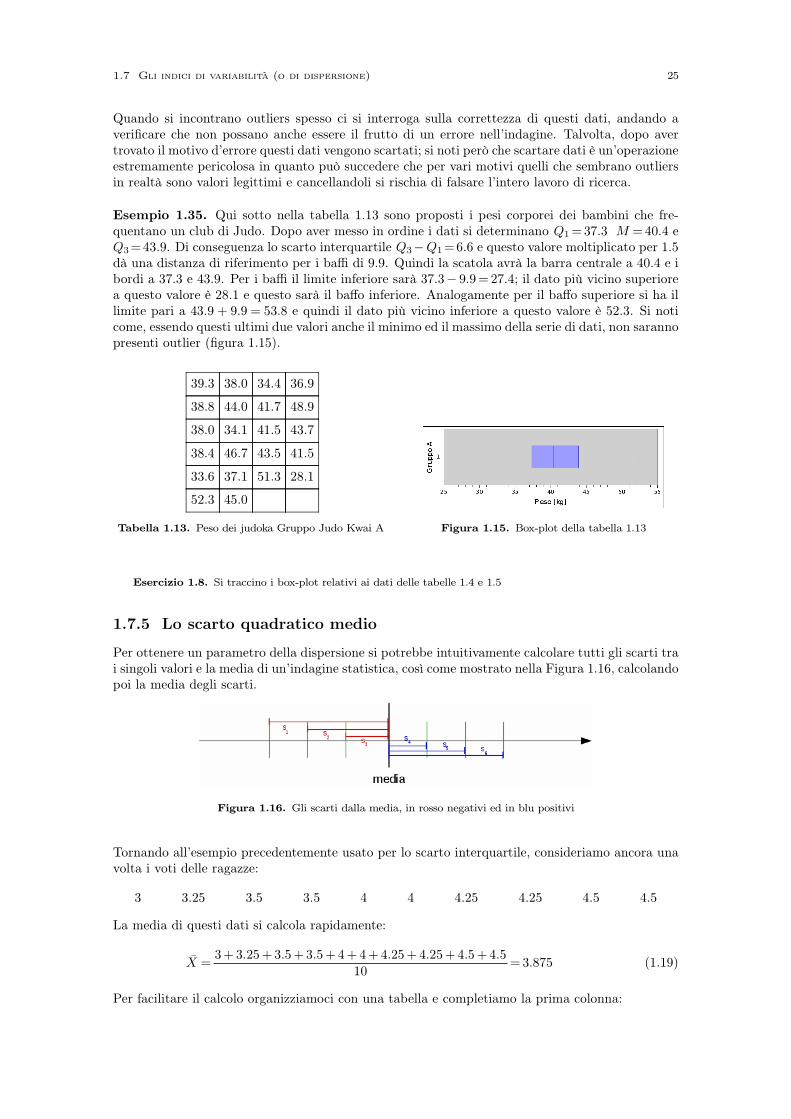
Quando si incontrano outliers spesso ci si interroga sulla correttezza di questi dati, andando averificare che non possano anche essere il frutto di un errore nell’indagine. Talvolta, dopo avertrovato il motivo d’errore questi dati vengono scartati; si noti però che scartare dati è un’operazioneestremamente pericolosa in quanto può succedere che per vari motivi quelli che sembrano outliersin realtà sono valori legittimi e cancellandoli si rischia di falsare l’intero lavoro di ricerca.
Esempio 1.35. Qui sotto nella tabella 1.13 sono proposti i pesi corporei dei bambini che fre-quentano un club di Judo. Dopo aver messo in ordine i dati si determinano Q1= 37.3 M = 40.4 eQ3=43.9. Di conseguenza lo scarto interquartile Q3−Q1=6.6 e questo valore moltiplicato per 1.5dà una distanza di riferimento per i baffi di 9.9. Quindi la scatola avrà la barra centrale a 40.4 e ibordi a 37.3 e 43.9. Per i baffi il limite inferiore sarà 37.3− 9.9= 27.4; il dato più vicino superiorea questo valore è 28.1 e questo sarà il baffo inferiore. Analogamente per il baffo superiore si ha illimite pari a 43.9 + 9.9 = 53.8 e quindi il dato più vicino inferiore a questo valore è 52.3. Si noticome, essendo questi ultimi due valori anche il minimo ed il massimo della serie di dati, non sarannopresenti outlier (figura 1.15).
39.3 38.0 34.4 36.9
38.8 44.0 41.7 48.9
38.0 34.1 41.5 43.7
38.4 46.7 43.5 41.5
33.6 37.1 51.3 28.1
52.3 45.0
Tabella 1.13. Peso dei judoka Gruppo Judo Kwai A Figura 1.15. Box-plot della tabella 1.13
Esercizio 1.8. Si traccino i box-plot relativi ai dati delle tabelle 1.4 e 1.5
1.7.5 Lo scarto quadratico medio
Per ottenere un parametro della dispersione si potrebbe intuitivamente calcolare tutti gli scarti trai singoli valori e la media di un’indagine statistica, così come mostrato nella Figura 1.16, calcolandopoi la media degli scarti.
Figura 1.16. Gli scarti dalla media, in rosso negativi ed in blu positivi
Tornando all’esempio precedentemente usato per lo scarto interquartile, consideriamo ancora unavolta i voti delle ragazze:
3 3.25 3.5 3.5 4 4 4.25 4.25 4.5 4.5
La media di questi dati si calcola rapidamente:
X =3+ 3.25+ 3.5+ 3.5+4+4+ 4.25+ 4.25+ 4.5+ 4.5
10= 3.875 (1.19)
Per facilitare il calcolo organizziamoci con una tabella e completiamo la prima colonna:
1.7 Gli indici di variabilità (o di dispersione) 25

Xj nota Xj − X (Xj − X)2
3 −0.875 0.765625
3.25 −0.625 0.390625
3.5 −0.375 0.140625
3.5 −0.375 0.140625
4 0.125 0.015625
4 0.125 0.015625
4.25 0.375 0.140625
4.25 0.375 0.140625
4.5 0.625 0.390625
4.5 0.625 0.390625
Totale 0 2.53125
Tabella 1.14. Media delle note, scarti semplici e quadratici
Si è arrivati dunque ad un risultato molto particolare: la somma degli scarti dalla media vale zero.Questo risultato è un caso legato ai dati esaminati o ha un valore più generale?
Definizione 1.36. La somma degli scarti semplici di una media aritmetica è sempre 0; si trattadi una proprietà fondamentale della media aritmetica.
Per valutare la dispersione intorno alla media i dovrà dunque eliminare l’inconveniente degli scartipositivi (in blu) che compensano quelli negativi (in rosso nella Figura 1.16). Un metodo che lastatistica utilizza molto spesso è il seguente: calcolare la media non più degli scarti, ma dei quadratidegli scarti, quadrati che sono tutti certamente positivi.
Si ottiene, nel caso esaminato, l’espressione:
σ2=
(−0.875)2+(−0.625)2+2 · (−0.375)2+2 · (0.125)2+2 · (0.375)2+2 · (0.625)2
10F 0.2531 (1.20)
Oppure, più semplicemente riempendo la seconda colonna della tabella è sufficiente prendernel’ultimo elemento e dividerlo per il numero dei dati, in questo caso 10.
Il risultato prende anche il nome di varianza; si ha dunque che la varianza di più dati si ottienecalcolando la media dei quadrati degli scarti dalla media.
Per sottolineare la presenza dei quadrati degli scarti, la varianza si indica spesso con il simboloadottato prima, e cioè: varianza = σ2. La lettera greca σ (si legge “sigma”) indica lo scarto
quadratico medio. Quindi per ottenere lo scarto quadratico medio si fa la radice quadrata dellavarianza.
Definizione 1.37. Lo scarto quadratico medio di una sequenza di numeri X1, X2, , Xn è laradice quadrata della media aritmetica dei quadrati degli scarti dei numeri stessi dalla loro mediaaritmetica.
σ=(X1− X )2+(X2− X )2+ +(Xn− X )2
n
√
=
∑
j=1
n
(Xj − X)2
n
√
√
√
√
(1.21)
26 Statistica monovariata

Nota 1.38. Lo scarto quadratico medio viene anche detto deviazione standard.
Varianza e scarto quadratico medio sono i più noti e diffusi indici di variabilità intorno alla media.
Così, confrontando ancora una volta i voti dei ragazzi e delle ragazze, si trova:
− voti dei ragazzi: media X = 3.867 σ2= 1.6733 σ= 1.2936
− voti delle ragazze: media X = 3.875 σ2= 0.2531 σ= 0.5031
e quindi, anche se la media è circa la stessa, si nota subito che i voti delle ragazze sono dispersiintorno alla media meno di quelli dei ragazzi.
Per sintetizzare più dati occorre il valore di sintesi accompagnato da un indice di
variabilità.
Le considerazioni svolte in questi ultimi due paragrafi suggeriscono di osservare sempre attenta-mente i dati statistici che tanto spesso sono presentati dai mezzi di informazione. Per sintetizzarepiù dati in modo corretto ed esauriente, occorre fornire un indice di posizione centrale, accompa-gnato da un indice di variabilità; così si ha che:
− la mediana senza la differenza interquartile dà un’informazione incompleta;
− la media può fornire una sintesi scorretta se non è accompagnata dalla varianza o dalloscarto quadratico medio.
1.7.6 Lo scarto quadratico per classi
Nel caso in cui disponiamo di dati raccolti in classi è possibile ugualmente calcolare lo scartoquadratico medio. Si assume come valore rappresentativo il valore centrale xi di ogni classe e larelativa frequenza fi. Lo scarto quadratico medio allora:
σ=f1 · (X1− X )2+ f2 · (X2− X )2+ + fn · (Xn− X)2
f1+ f2+ + fn
√
=
∑
j=1
n
fj · (Xj − X)2
∑
j=1
n
fj
√
√
√
√
√
√
√
(1.22)
Esempio 1.39. Consideriamo la tabella seguente che indica le altezza s.l.m di alcuni comuni
Altitudini Valore centrale Xj Frequenza Xj · fj (Xj − X)2 (Xj − X )2 · fj0− 50 25 8 200 12792.29 101610.32
50− 100 75 70 5250 3931.29 275190.30
100− 150 125 71 8875 161.29 11451.59
150− 200 175 62 10850 1391.29 86259.98
200− 250 225 27 6075 7621.29 205774.83
250− 300 275 7 1925 18851.29 131959.03
300− 350 325 3 975 35081.29 105243.87
Totale 248 34150 79739.03 917489.92
Tabella 1.15. Altitudine in [m/s.l.m.] di alcuni comuni: tabella con gli scarti
Costruiamo la tabella seguente che ci permetterà di calcolare lo scarto quadratico medio.
1.7 Gli indici di variabilità (o di dispersione) 27

Dalle prime tre colonne si ricava che la media è:
X =34150248
F 137.7 (1.23)
Lo scarto quadratico medio è allora:
σ=917489.92
248
√
F 60.824 (1.24)
Significa quindi che l’altitudine media dei comuni è di 137.7 [m], ma ci si deve preparare a superareun dislivello medio sopra e sotto di essa pari a σ= 60.824 [m].
Nota 1.40. Si osservi come la media e la deviazione standard abbiano la stessa unità di misura.Questo permette di esprimere lo scostamento anche in maniera relativa (percentuale). Tale valore,detto coefficiente di variazione, è invece privo di unità di misura, è utile soprattutto perconfrontare metodi di analisi diversi tra loro e si calcola con la seguente formula:
CV=100 ·σX
% (1.25)
Nel caso dei comuni il coefficiente di variazione dell’altezza s.l.m. è:
CV=100 · 60.824
137.7= 44.17% (1.26)
1.7.7 La distribuzione gaussiana
Consideriamo ancora la distribuzione relativa ai risultati del salto di un gruppo di studentesse. Ilsuo poligono delle frequenze (Figura 2) ha una forma particolare, detta anche “a campana” . Seaumentassimo il numero dei risultati, prendendo in considerazione, per esempio, tutte le studen-tesse di una stessa scuola o quelle di più scuole, il poligono delle frequenze molto probabilmente siavvicinerebbe sempre di più a una particolare curva teorica detta curva normale o gaussiana
(o di Gauss).
Figura 1.17. Curva di Gauss
Il calcolo dello scarto quadratico medio σ assume particolare importanza nelle distribuzioni gaus-siane, perché è collegato al modo in cui le frequenze si distribuiscono attorno al valore medio M.
28 Statistica monovariata

Da un’analisi del grafico si possono fare alcune osservazioni:
− la simmetria della curva rispetto alla retta x= X significa che intorno al valore medio tuttigli altri si distribuiscono con la stessa frequenza per valori equidistanti da X ;
− nei punti X −σ e X + σ la curva presenta due flessi. Pertanto se σ ha un valore piccolo (equindi c’è poca dispersione attorno al valore medio) la curva è stretta; se invece σ è grande,la curva è larga e c’è molta dispersione attorno al valore medio.
Questo significa che la forma della curva dipende da σ. Si può dimostrare che:
− il 68,27% dei casi osservati è compreso tra M − σ e M + σ
− il 95,45% dei casi osservati è compreso tra M − 2 ·σ e M +2 ·σ
− il 99,73% dei casi osservati è compreso tra M − 3 ·σ e M +3 ·σ
Tali percentuali sono valide anche per distribuzioni moderatamente asimmetriche.
Figura 1.18. La curva di Gauss e le percentuali delle casistiche in base a σ
Da queste informazioni, essendo la distribuzione simmetrica rispetto alla media X , se ne possonoricavare altre. Per esempio, è vero che il 15,87% dei valori è maggiore di X +σ.
Infatti i valori maggiori di X +σ o minori di X −σ sono:
100% - 68,27% = 31,73% (1.27)
Quindi quelli maggiori di X +σ sono:
31, 73%2
= 15, 87% (1.28)
In modo analogo si ricava che il 2,28% dei valori è maggiore di X +2σ (o minore di X − 2σ).
Esercizio 1.9. La statura in una popolazione adulta composta da 24’000’000 di persone ha una distri-buzione gaussiana. Sapendo che nella popolazione studiata la media è X = 1.75m e lo scarto quadraticomedio σ = 0.05m, quante persone hanno un’altezza compresa tra 1.70m e 1.80m? Quante maggiore di1.85m? E quante minore di 1.70 (ovviamente saranno solamente approssimazioni ancorché piuttosto atten-dibili)? [16’384’800;547’200;3’808’800]
1.7 Gli indici di variabilità (o di dispersione) 29

1.8 Esercizi
Esercizio 1.10. Una indagine statistica su un campione di 50 bambini che frequentano la prima classe dellescuole elementari e relativa al loro peso corporeo ha fornito i seguenti dati espressi in Kg.
27.5 32.5 28.9 30.2 30.1 28.2 29.5 31.2 27.3 30.031.1 33.0 35.2 32.7 28.4 30.7 29.4 25.6 26.5 31.532.3 30.0 30.5 35.7 32.4 33.3 29.2 30.5 30.8 31.427.9 29.8 28.5 31.6 32.0 30.2 37.1 32.6 34.0 34.036.1 31.3 29.8 34.1 32.6 34.7 33.6 29.8 30.6 31.5
Costruisci una distribuzione di frequenza adeguata e il relativo istogramma.
Esercizio 1.11. Rappresenta graficamente mediante un diagramma a rettangoli e mediante un areogrammala seguente tabella relativa al numero di occupati come lavoratori dipendenti nei vari settori di attività in unacerta città.
Settore Agricoltura Industria Commercio AltroN. occupati 200 900 950 380
Esercizio 1.12. Ecco i pesi di un campione di 18 compresse a base di vitamina C espressi in grammi
4.2 3.9 4 4.2 4.1 4.2 4.3 4.1 4.24.3 4.0 4.1 4.2 4.1 4.2 4 4.3 4.2
Costruisci la distribuzione di frequenza e rappresenta i dati graficamente.
Calcola la media ponderata. È uguale a quella aritmetica? Perché?
Esercizio 1.13. Da una indagine statistica su un campione di 5000 ragazzi e 5000 ragazze di età compresa frai 10 e i 16 anni sulle attività sportive svolte, sono emersi i seguenti risultati (un individuo potrebbe praticarepiù di uno sport!)
Attività Maschi Femmine
Calcio 3200 58Tennis 1050 895Atletica 629 1580Sci 2570 2476Altro 605 1312Nessuno sport 596 1720
Rappresenta con un diagramma a rettangoli e con un areogramma i dati della tabella in ciascuno dei due casi
Esercizio 1.14. La seguente tabella riporta la produzione di vino di un certo anno in alcuni paesi europei.Rappresenta i dati con un diagramma a rettangoli. Costruisci poi la tabella delle frequenze relative e il corri-spondente diagramma a torta.
Paese Germania Francia Italia Grecia Portogallo Spagna
Vino/[hl] 9500 64000 64000 5000 3500 24000
Esercizio 1.15. La seguente tabella indica la variazione percentuale del consumo di carne bovina negli ultimisei mesi del 2000 in alcuni stati europei. Rappresenta graficamente i dati
Paese Ger. Italia Spagna Grecia Port. Francia Austria Belgio G.Br.Perc. -50% -42% -35% -30% -25% -20% -15% -10% +3%
30 Statistica monovariata

Esercizio 1.16. Esaminando 100 pagine dattiloscritte si sono riscontrati i seguenti numeri di errori per pagina:35 pagine con 1 errore; 25 pagine con 2 errori; 18 pagine con 3 errori; 12 pagine con 4 errori; 4 pagine con 6errori e le rimanenti senza errori.
a) Rappresenta la distribuzione di frequenza relativa e assoluta degli errori per pagina.
b) Costruisci un grafico delle frequenze
c) Calcola la media degli errori per pagina con la formula per le medie ponderate
Esercizio 1.17. Un campione estratto dalla popolazione degli abitanti di una città ha dato la seguentecomposizione:
Fascia d’età 0-20 21-40 41-60 Oltre 60N. componenti 29% 32% 24% 15%
Sapendo che il campione ha ampiezza 5000, calcola le frequenze assolute di ogni classe. Rappresenta poi i daticon un areogramma. [1450; 1600; 1200; 750]
Esercizio 1.18. Calcola la media aritmetica della seguente distribuzione
Modalità 2 4 6 8 10Frequenza 8 12 20 24 18
[6.78]
Esercizio 1.19. Trova la moda e la mediana della seguente distribuzione statistica che riguarda il numero divolte che un gruppo di ragazzi sono stati interrogati in una certa materia:
Interrogazioni 2 3 4 5 6 7 8Frequenza 10 15 20 28 18 12 4
Esercizio 1.20. In un gruppo di ginnaste di livello agonistico si è rilevato che l’età di inizio dell’attività èdistribuita nel seguente modo:
Età di inizio 4 5 6 7 8 9 10 11 12Numero ginnaste 1 6 11 4 6 4 0 2 1
Calcola la media aritmetica, (e anche quella quadratica e armonica), la mediana e la moda. In base ai datirilevati su questo gruppo, a quale età è più opportuno iniziare l’attività per raggiungere in ginnastica un livelloagonistico. [7; 7.3; 6.6; 8; 6]
Esercizio 1.21. Un autotreno deve percorrere 15 Km. I primi 5 sono in città e vengono coperti ad una velocitàdi 1 Km/h. I restanti 10 Km sono in periferia e il mezzo transita con una velocità di10 Km/h. Trova la velocitàmedia costante necessaria affinché lo stesso tragitto venga percorso impiegando lo stesso tempo. [2.5 Km/h]
Esercizio 1.22. Durante una gara di corsa di 60 metri piani si sono rilevati i seguenti dati:
Tempo/[s] 10.9 11.1 11.2 11.4 11.6 11.7 12N. studenti 1 3 8 12 6 4 1
Determina il tempo medio, la moda e la mediana [11.4; 11.4; 11.4]
Esercizio 1.23. Rappresenta graficamente nel modo più opportuno la seguente distribuzione di frequenze:
Modalità 1 2 3 4 5 6 7Frequenza 12 15 16 25 18 10 5
Calcola poi la media aritmetica, la moda e la mediana della distribuzione e lo scarto quadraticomedio [M=3.71; moda=4; mediana=4; σ=1.66]
1.8 Esercizi 31

Esercizio 1.24. Una ditta che deve acquistare una macchina per produrre tondini in ferro, deve effettuarela sua scelta fra due offerte. La decisione viene affidata ad un controllo di qualità che rileva i dati relativi aidiametri dei tondini su un campione di 100. La tabella riporta i dati relativi alle misurazioni per le due macchinecontraddistinte dalle lettere A e B
Diametro /[mm] 9.75 9.80 9.85 9.90 9.95 10.0 10.5Frequenza di A 0 9 26 30 26 9 0Frequenza di B 2 4 20 48 20 4 2
Dopo aver disegnato il diagramma di questa distribuzione, calcola la media ponderata e lo scarto quadraticomedio. Quale delle due macchine offre una maggior affidabilità? [σA=0, 0555; σB=0, 0968]
Esercizio 1.25. Prendendo come riferimento i dati dell’esercizio 1.10 sul peso corporeo degli allievi, calcola lamedia aritmetica, la mediana, la classe modale relativa alla distribuzione di frequenza scelta, nonché lo scartoquadratico medio della media aritmetica. Determinate tutti i decili dalla vostra distribuzione di classe.
Esercizio 1.26. Biometrica di classe: dividetevi in sottogruppi di 3 al massimo; raccogliete un dato biometricoriferito agli allievi della vostra classe (per esempio n◦ scarpe, statura, peso, età, lunghezza di un dito, diametrodella scatola cranica, girovita, lunghezza del braccio, ecc); costruite un grafico appropriato dei dati raccoltie determinate la media, lo scarto quadratico medio, la mediana e la moda dei dati. Preparate un lucido perpresentare i dati al resto della classe.
32 Statistica monovariata

Capitolo 2
Popolazione e campione
2.1 Introduzione
2.1.1 La popolazione
Nel mondo reale molte valutazioni statistiche hanno una quantità molto grande o addiritturainfinita di possibili osservazioni. per esempio se si volesse calcolare la statura media della popo-lazione maschile mondiale ci si confronterebbe con alcuni miliardi di dati. Oltretutto a causadel ricambio generazionale questi dati continuerebbero a modificarsi e nel tempo tenderebberoall’infinito. Anche limitando la propria indagine ad un gruppo più ristretto, come ad esempio lastatura media dei maschi svizzeri, o la statura media degli allievi maschi delle scuole professionali siavrebbe comunque a che fare con una raccolta dei dati piuttosto onerosa. Questi insiemi completi diosservazioni statistiche vengono definiti in statistica come popolazione. Per praticità ed economicitàspesso, se si è interessati ad un dato parametro, si preferisce lavorare su un insieme più ristrettodi dati che viene definito campione.
2.1.2 Il campione
Come detto nel paragrafo precedente, se si procede con una raccolta limitata di dati si ha ache fare con un campione. Per esempio prendendo in esame la statura media dei maschi dellescuole professionali del Cantone quale popolazione dei dati, ecco che la statura media dei maschiall’interno di una classe costituisce un possibile campione.
La numerosità del campione corrisponde al numero di dati (in questo caso di stature di maschi)disponibili. La numerosità incide molto sulla rappresentatività del campione. Campioni moltopiccoli possono avere la media dei propri valori molto scostata rispetto alla media della popolazione;al contrario campioni più grandi riescono ad essere più rappresentativi e quindi fornire un’immaginepiù precisa di quanto avviene nella popolazione.
Tuttavia la dimensione del campione non è l’unico parametro che ne valida la rappresentatività.
Si pensi per esempio ai sondaggi preelettorali. Se il sondaggio venisse svolto sabato sera davantiad una discoteca darebbe inevitabilmente dei risultati di intenzione di voto molto diversi da quelliche si otterrebbero eseguendo lo stesso sondaggio di domenica mattina all’entrata della chiesa.Questo perché i soggetti che frequentano l’uno o l’altro luogo hanno probabilmente un profilo di età/ estrazione sociale / reddito / molto diversi tra loro. e importante quindi che quando si pianificauna raccolta dei dati si tenga conto di tutto ciò e che si procede in modo da ottenere dati aderentia quello che può essere il profilo della popolazione.
Per quanto possa sembrare a prima vista contro intuitivo, l’estrazione a caso dei dati diretta-mente dal bacino della popolazione è il miglior metodo che permette di avere dati rappresentativi.Ragionando in termini preelettorali, questo potrebbe corrispondere ad un sondaggio telefonicoeffettuato contattando gli elettori componendo il numero a caso. (A dire il vero anche con questometodo è risaputo che le persone tendono a non rispondere in modo in modo sincero, non fidandosidell’interlocutore sconosciuto; quindi per quanto riguarda i sondaggi preelettorali, la faccendarisulta essere particolarmente complessa).
Per questo motivo si propone qui di seguito un’attività che usa l’estrazione casuale dei dati da unbacino che può essere simulata facilmente usando un foglio di calcolo elettronico.
33

2.2 Attività pratica con un foglio di calcolo
2.2.1 Creazione dei dati
Due “popolazioni” di dati vengono generate tramite un generatore di numeri casuali, ciascuno conalmeno 1000 osservazioni:
i. una prima distribuzione usando la funzione =randbetween(min,max) ottenendo cosi unadistribuzione rettangolare. I parametri min e max possono essere scelti a piacimento (peresempio (0,10000).
ii. una seconda distribuzione usando la funzione =randexp(p). Il parametro ppuò essere sceltoa piacimento (per usare dati in una forchetta simile a quella del punto i si consiglia di usarep = 2000). Si ottiene una distribuzione a decadimento esponenziale, con una coda moltolunga.
2.2.2 Elaborazione dei dati
a) Si costruisce una tabella delle frequenze e quindi un istogramma delle popolazioni ottenute(i e ii) e si osserva la forma dei dati. Si determini anche il valore della media (media dellapopolazione µ e dello scarto quadratico σ).
b) Successivamente si estraggono con l’apposito strumento del F.C. (tendina, oppure funzione=randdiscrete()) un set di 100 campioni, ciascuno di dimensione n=4, (cioè ciascun cam-pione è composto da 4 elementi estratti dalla popolazione) dai dati del punti i.
c) Per ciascun campione si calcola la media del campione (simbolo x ). Si calcola anche loscarto quadratico (simbolo s) .
d) Si costruisca un istogramma delle 100 medie campionarie x . Come sono distribuite le medie?Sono distribuite in modo analogo a quello dei dati di partenza?
e) Si calcola la media delle medie campionarie x ; solitamente questa media delle medie vienechiamata “valore atteso delle medie campionarie” e viene indicato col simbolo M(x ). Siconfronti questi valore con quello della media della popolazione µ. Che cosa si nota?
f) Si calcola lo scarto quadratico delle medie campionarie, quello che comunemente vienechiamato errore standard (ES). Si confronta tale valore con lo scarto quadratico della popo-lazione σ, verificando se la relazione nella Tabella 23 sottostante è vera.
g) Si calcola la media degli scarti quadratici di ciascun campione (cioè tecnicamente M(s) e lasi paragoni allo scarto quadratico della popolazione σ. Si dovrebbe notare che questa mediaè sistematicamente più bassa dello scarto quadratico della popolazione.
h) Usando il tasto F9 si può far rigenerare al F.C. i valori casuali e quindi far ricalcolare tuttii parametri. Si provi ad osservare come variano i valori calcolati (nei punti e, f, g) e gliistogrammi in questo processo.
i) Si calcola con l’apposita funzione del F.C: lo scarto quadratico corretto s chiamato spessoanche scarto quadratico campionario. Si calcoli poi la media degli scarti campionari M(s)e si confronti questo valore atteso con lo scarto della popolazione σ, usando F9.
34 Popolazione e campione

j) Si estrae una nuova serie di 100 campioni, stavolta di dimensione n=25 e si ripetano i puntiprecedenti (b-i). Che cosa si nota?
k) Si estraggono due nuove serie di campioni (n= 16 e n= 49) per i dati ii e si ripetano tuttele procedure precedenti. Come sono gli istogrammi delle medie campionarie?
2.2.3 Discussione
Si osservi la seguente tabella e si confrontino le varie relazioni con quanto sviluppato nel punto 2.2.2.
Media Scarto quadratico
Popolazione(tutto l’universo, spesso infi-nito,spesso unicamente ipotiz-zato)
µ σ
Distribuzione di frequenza deicampioni(più campioni ciascuno diampiezza n)
M(x )= µ
DS(x )= σ
n√ =ES
M(s)� σ
M(s)= σ
Campione(Un campione di n elementi)
x
s=∑
(x− x)2
n
√
s =∑
(x− x)2
n− 1
√
Tabella 2.1. Relazioni fondamentali tra popolazione, campione e distribuzione campionaria
2.2 Attività pratica con un foglio di calcolo 35

2.3 La stima
2.3.1 Considerazioni su campione e popolazione
Nel paragrafo 3.2 si è visto che la media di un campione è un buon stimatore della media dellapopolazione e che lo scarto campionario è un buon stimatore dello scarto quadratico della popola-zione. Per questo motivo in molte situazioni per stimare il valore di una popolazione si finisce perraccogliere un campione di dati dal quale poi si cerca di dedurre qualcosa di più generale. Tuttaviaè anche chiaro che un singolo campione è soggetto ad avere un errore e che deve essere tenuto inconsiderazione. Per questo motivo esiste un modo standard di indicare la stima di un valore mediodeterminato da un campione.
2.3.2 Stima di una media puntuale con i limiti di confidenza
L’intervallo di confidenza per la stima di una media di una popolazione µ utilizzando una mediacampionaria x e la deviazione standard campionaria s di un campione di dimensione n è laseguente:
µ= x ± 1.96 · s
n√ (2.1)
Il valore 1.96 deriva dal fatto che solitamente si accetta una probabilità massima del 5% che lamedia della popolazione sia al di fuori di questa forchetta di dati. Si tenga anche conto che ilvalore 1.96 è generalmente accettato solo se n> 30. Per valori più bassi questa costante tende adaumentare (per esempio per n= 20 è 2.09 e per n= 10 è 2.26; per ciascuna numerosità di dati sipuò dare il valore esatto estratto dalla tabella di Student). Indagini con n< 10 hanno pochissimovalore scientifico. Una trattazione completa di questo argomento richiede una dotazione orariaspecifica che non è disponibile e pertanto si rimanda a corsi specifici di approfondimento.
Esempio 2.1. In un lotto di produzione di formaggio vallemaggia (di un determinato caseificio)consistente in 36 forme da 4 kg (nominali) si trova un peso medio di 4.05 kg e una deviazionestandard campionaria di 0.4 kg.
Per stimare il peso medio della popolazione delle possibili forme di formaggio µ del caseificio sicalcola:
µ= 4.05± 1.96 · 0.4
36√ = 4.05± 0.13kg (2.2)
Quindi si conclude che la media del peso delle forme di formaggio prodotte dal caseificio probabil-mente 4.05 con una probabilità al 95% che effettivamente si trovi tra i valori 3.92 - 4.18 kg.
36 Popolazione e campione

Capitolo 3
Statistica bivariata
3.1 Introduzione
Quando l’osservazione statistica porta alla rilevazione di dati esprimibili come coppie ordinate dinumeri (xi; yi) si pone sia il problema di determinare se sussiste una relazione tra le due grandezzee in caso affermativo, la funzione che permette di collegare i valori di xi con quelli di yi. Talefunzione viene chiamata funzione interpolante o funzione di regressione.
3.2 La correlazione
3.2.1 Correlazione e regressione lineare
In questo piccolo riassunto ci si vuole concentrare unicamente su correlazione e regressioni lineari.Non ci si occupa di correlazioni con funzioni più complicate, come le curve esponenziali, logarit-miche, polinomiche, ecc.
3.2.2 La covarianza
Esempio 3.1. Un indagine statistica ha rilevato contemporaneamente il reddito e la spesa per ilvitto di dieci famiglie. Tali dati sono riportati nella tabella sottostante.
Famiglia Reddito Spesa R− R (R− R )2 S − S (S − S )2 (R− R )(S − S )
1 7500 2200
2 4200 1800
3 6210 2040
4 6900 2100
5 5400 1920
6 5100 1860
7 5700 2160
8 8700 2400
9 4500 1770
10 5190 1830
Totale 59400 20100 0 0
Tabella 3.1. Dati reddito / vitto da completare
37

Figura 3.1. Grafico tra reddito e vitto. Le linee tratteggiate corrispondono alle rispettive medie.
Si osservi come i punti tendono ad addensarsi attorno ad una retta. Questo fenomeno è tipicoquando si è in presenza di una correlazione tra le due grandezze osservate. L’osservazione del graficochiaramente non è una valutazione oggettiva della correlazione tra le due grandezze che inveceviene determinata tramite il calcolo della covarianza e del coefficiente di correlazione.
Definizione 3.2. Si dice covarianza fra X e Y la media aritmetica dei prodotti degli scarti semplici
cov(X,Y )=
∑
(Xi− X) · (Yi− Y )
n(3.1)
Avviso 3.3. Se a scarti positivi (negativi) di X corrispondono scarti positivi (negativi) di Y larelazione lineare fra i due fenomeni è diretta (punti nel I e III quadrante). In questo caso la sommadei prodotti degli scarti è positiva e quindi cov(X,Y )> 0.
Avviso 3.4. Se a scarti positivi (negativi) di X corrispondono scarti negativi (positivi) di Y larelazione lineare fra i due fenomeni è inversa (punti nel II e IV quadrante). In questo caso la sommadei prodotti degli scarti è negativa e quindi si ha cov(X,Y )< 0.
Avviso 3.5. Se la covarianza è uguale a 0 vuol dire che non c’è relazione di tipo lineare tra i duefenomeni. Ciò però non esclude che ci sia una relazione di un altro tipo (parabolico, esponenziale,ecc).
Si osservi la figura 3.2 che evidenzia i contributi positivi e negativi alla covarianza, sempre relativoall’esempio 3.1.
38 Statistica bivariata

Figura 3.2. Contributi dei singoli scarti alla covarianza
3.2.3 Il coefficiente di correlazione r di Pearson
La covarianza ha un punto debole fondamentale. Non è un parametro con valore assoluto, madipende dalle unità di misura dei dati. Questo porta al fatto che se è vero che più il valore siallontana da zero e più i punti si avvicinano ad una retta, in realtà non si definisce un massimovalore per il quale i punti si trovano perfettamente su una retta; nemmeno si riesce a definire unasoglia minima oltre la quale la correlazione è garantita. Per questo motivo nella maggior partedei casi la covarianza è unicamente una tappa intermedia che porta al calcolo del coefficiente dicorrelazione lineare (o coefficiente di Pearson).
Definizione 3.6. Il coefficiente di correlazione lineare è la media aritmetica dei prodotti dei valoriosservati espressi in unità standard. Il coefficiente di correlazione lineare è simbolizzato con una r(oppure con una ρ dell’alfabeto greco).
r=cov(X,Y )
σX ·σY(3.2)
Nota 3.7. Il valore di r è compreso tra −1 e 1
−16 r6 1 (3.3)
Nota 3.8. Valori positivi di r indicano l’esistenza di una relazione lineare diretta. Aumentando(diminuendo) i valori di X aumentano (diminuiscono) i valori di Y .
Nota 3.9. Valori negativi di r indicano l’esistenza di una relazione lineare inversa. Aumentando(diminuendo) i valori di X diminuiscono (aumentano) quelli di Y .
Nota 3.10. Se r = 0 non esiste una relazione lineare tra i valori X e Y . Ciò non esclude chepossa sussistere una relazione di altro tipo. In realtà difficilmente si ottiene esattamente 0 anchese non vi è una correlazione tra le due grandezze. Per determinare con certezza se la correlazionesussiste esistono vari metodi che comunque vanno al di là dello scopo di questo testo. Si segnalatuttavia come regola empirica che quando il valore di r si trova nell’intervallo −0.356 r6 0.35 sipuò ragionevolmente affermare che NON sussiste una correlazione.
3.2 La correlazione 39

Esercizio 3.1. Si calcoli il coefficiente di correlazione lineare dei dati dell’esempio 3.1, completando opportu-namente la tabella prestampata.
3.3 La regressione
3.3.1 Il metodo dei minimi quadrati
Considerando ancora una volta l’esempio 3.1 ci si potrebbe chiedere quale sia la retta migliore checi descrive la relazione tra reddito e vitto. Si potrebbe procedere in modo grafico (e soggettivo)provando a disegnare una retta di regressione in modo che sia il più possibile “al centro” dei datidel grafico.
Tuttavia esiste un metodo algebrico esatto per eseguire tale operazione. Tale metodo si chiamametodo dei minimi quadrati. Con tale metodo cerchiamo la pendenza a e l’ordinata all’origine b
della retta che meglio esprime la relazione tra i valori di X e di Y .
f(x)= y= ax+ b (3.4)
Chiaramente nessun punto (tranne casi eccezionali) si troverà esattamente sulla retta. Bisogneràfar in modo che la distanza misurata in verticale dal punto effettivo (Xi; Yi) e il punto teoricocalcolato con la funzione (Xi: Yi) sia la minore possibile. Pertanto, sussistendo anche il problemadato dal fatto che alcune differenze risulteranno negative e altre positive, si cercherà di rendereminima i quadrati delle differenze tra i valori di Yi calcolati e quelli reali Yi
∑
(Yi−Yi)2=minimo (3.5)
Graficamente parlando il miglior accostamento è trovato riducendo gli scarti verticali dalla retta.
Per operare la determinazione di tale minimo si deve ricorrere a strumenti matematici moltoavanzati (differenziali parziali di funzioni a più variabili) e quindi una dimostrazione dettagliatadel procedimento che porta alla definizione della seguente formula per il calcolo della pendenza edell’ordinata all’origine è al di là degli obiettivi di questo testo. Si può saltare quindi la derivazionematematica della formula e utilizzare direttamente il risultato, qui sotto riportato:
a=nΣxiyi−Σyi ·Σxi
nΣxi2− (Σxi)2
(3.6)
b=Σxi
2 ·Σyi−Σxi ·Σxiyi
nΣxi2− (Σxi)2
(3.7)
Esempio 3.11. In uno studio si sono comparate le velocità massime di alcuni veicoli e si ècercato di mettere in relazione questo valore con la potenza del motore in questione. La variabileindipendente è la potenza
Potenza 70 63 72 60 66 70 74 65 62 67 65 68Velocità 155 150 180 135 156 168 178 160 132 145 139 152
Tabella 3.2. Dati di potenza e velocità di 12 veicoli
a= 3.21565 b=−60.7461 r= 0.863234 Es= 7.51528
40 Statistica bivariata
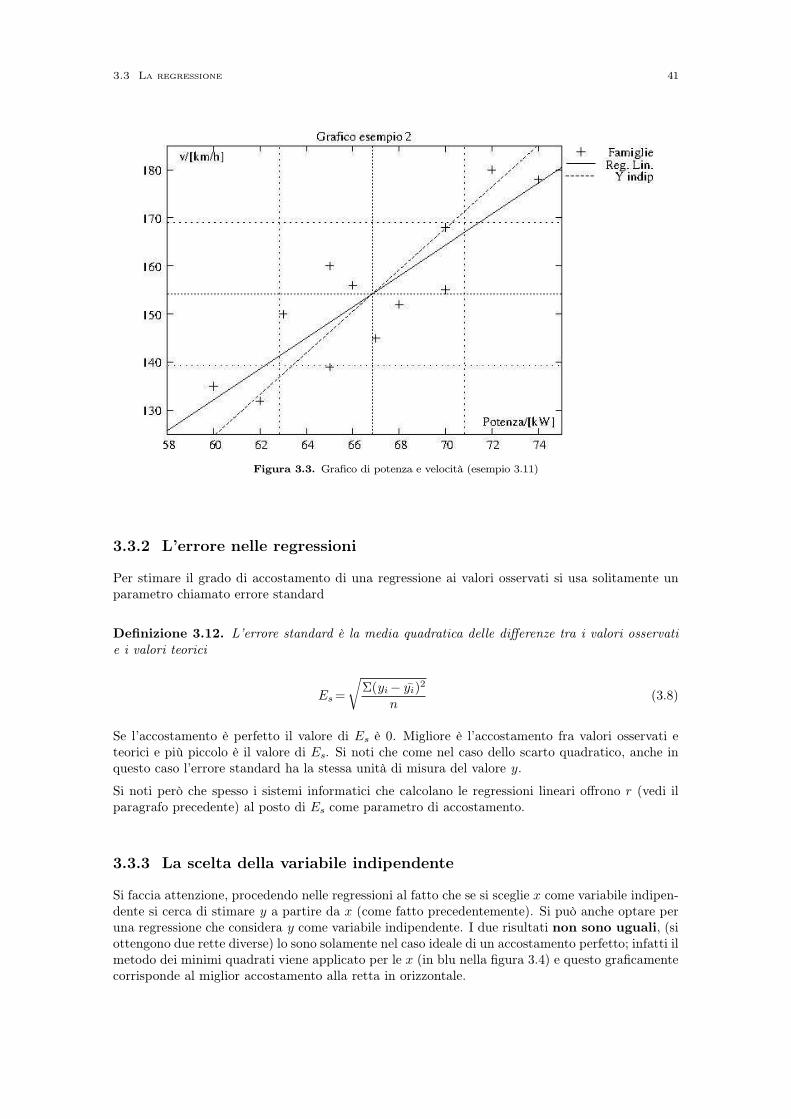
Figura 3.3. Grafico di potenza e velocità (esempio 3.11)
3.3.2 L’errore nelle regressioni
Per stimare il grado di accostamento di una regressione ai valori osservati si usa solitamente unparametro chiamato errore standard
Definizione 3.12. L’errore standard è la media quadratica delle differenze tra i valori osservatie i valori teorici
Es=Σ(yi− yi)2
n
√
(3.8)
Se l’accostamento è perfetto il valore di Es è 0. Migliore è l’accostamento fra valori osservati eteorici e più piccolo è il valore di Es. Si noti che come nel caso dello scarto quadratico, anche inquesto caso l’errore standard ha la stessa unità di misura del valore y.
Si noti però che spesso i sistemi informatici che calcolano le regressioni lineari offrono r (vedi ilparagrafo precedente) al posto di Es come parametro di accostamento.
3.3.3 La scelta della variabile indipendente
Si faccia attenzione, procedendo nelle regressioni al fatto che se si sceglie x come variabile indipen-dente si cerca di stimare y a partire da x (come fatto precedentemente). Si può anche optare peruna regressione che considera y come variabile indipendente. I due risultati non sono uguali, (siottengono due rette diverse) lo sono solamente nel caso ideale di un accostamento perfetto; infatti ilmetodo dei minimi quadrati viene applicato per le x (in blu nella figura 3.4) e questo graficamentecorrisponde al miglior accostamento alla retta in orizzontale.
3.3 La regressione 41

Figura 3.4. Minimi quadrati delle y in rosso e delle x in blu
Per il calcolo con y indipendente si usano le seguenti formule:
a=nΣxiyi−Σyi ·Σxi
nΣyi2− (Σyi)2
(3.9)
b=Σyi
2 ·Σxi−Σyi ·Σxiyi
nΣyi2− (Σyi)2
(3.10)
I coefficienti così calcolati corrispondono a quelli per la retta inversa. Per paragonarli a quellicalcolati con le formule precedenti (equazioni 3.6 e 3.7) bisogna invertire nuovamente l’equazionedella retta. Si veda il grafico precedente che riporta entrambe le rette (la seconda tratteggiata).
Esercizio 3.2. Si calcoli la retta di regressione con la variabile y come indipendente per l’esempio precedente(esempio 2) che è già riportata nel grafico (funzione tratteggiata).
3.3.4 Scarti quadratici e pendenza delle rette di regressione
Si lascia dimostrare che la pendenza a della retta di regressione è anche uguale al rapporto tra gliscarti dei valori di y e quelli di x moltiplicato per r
a= r · σy
σx(3.11)
Nota 3.13. Per accostamenti molto buoni (r≃1) si può approssimare la pendenza a con il rapportotra i due scarti quadratici.
42 Statistica bivariata

3.4 Connessioni e contingenze
Finora abbiamo trattato la correlazione tra modalità x e y scalari (variabili) facendo capo a graficisul piano cartesiano e a una serie di strumenti statistici per valutare la bontà della relazione trale due grandezze, strumenti che rielaborano i dati scalari.
Tuttavia spesso ci si confronta con modalità non scalari (mutabili) e si cerca di evidenziare corre-lazioni tra due mutabili, oppure tra una mutabile ed una variabile. A tal proposito si osservino isuccessivi paragrafi con esempi per entrambi i casi
3.4.1 Connessione tra due mutabili
Per presentare le tecniche che consentono una valutazione della connessione tra due mutabiliviene qui presa in considerazione una statistica pubblicata dall’ufficio federale di statistica3.1 chesuddivide gli allievi delle scuole del grado secondario II in base alla formazione più alta presentenella famiglia di origine. Si tratta di una tabella delle frequenze congiunte nij in cui i dati vengonoclassificati in base a due insiemi di mutabili (nell’esempio sono la formazione secondaria dei figlivs la formazione dei genitori)3.2.
Gr. second. II/Form. Genitori nij Nessuna ind. Obbligo Secondario II Terziario Totali marg.
Maturità liceale 5 5 28 62 100
Scuola di cultura generale 7 12 41 40 100
AFC in 4 anni 9 10 48 33 100
AFC in 3 anni 14 15 47 25 101
Certif. fed. form. pratica 21 29 38 12 100
Totali marg. 56 71 202 172 501
Tabella 3.3. Suddivisione del livello secondario II in base alla formazione scolastica dei genitori
Si noti come nella tabella 3.3 sono presenti i totali marginali con fondo grigio (le somme per righee colonne) e, nell’angolo in basso a destra il totale globale di tutte le frequenze, evidenziato ingrassetto.
Solitamente dati di questo tipo vengono rappresentati tramite un diagramma a colonne tridimen-sionale come quello della figura 3.4. L’altezza delle colonne è determinata dalla frequenza assoluta(e/o %) delle singole combinazioni di modalità. Le colonne vengono messe in ordine rispettandola struttura della tabella.
Tabella 3.4. Diagramma 3D della tabella 3.3
3.1. http://www.bfs.admin.ch/bfs/portal/it/index/news/medienmitteilungen.Document.197746.pdf3.2. Si noti come spesso le “tabelle delle frequenze congiunte” vengono chiamate “tabelle di contingenza”, generandoconfusione con le contingenze vere e proprie.
3.4 Connessioni e contingenze 43

Per verificare la sussistenza di una tendenza, per altro visibile ad occhio, che a formazione piùelevata dei genitori corrisponde una frequenza di scuole più impegnative, si procede innanzituttodimostrando che i dati non sono distribuiti in modo casuale. Per tale dimostrazione ci si avvaledel test del Chi quadrato χ2 i cui passaggi logici sono descritti qui di seguito.
Si calcolano innanzitutto le frequenze teoriche che dovrebbero corrispondere ad una distribuzionecasuale, moltiplicando le rispettive frequenze marginali e dividendo per la frequenza totale, comemostrato nella tabella
Fr. teor. tij Nessuna ind. Obbligo Secondario II Terziario Tot. marg.
Maturità liceale 56 · 100501
= 11.178 14.172 40.319 34.331 100
Scuola di cultura generale 11.178 14.172 40.319 34.331 100
AFC in 4 anni 11.178 14.172 40.319 34.331 100
AFC in 3 anni 11.289 14.313 40.723 34.675 101
Certif. fed. form. pratica 11.178 14.172 40.319 34.331 100
Totali marg. 56 71 202 172 501
Figura 3.5. Frequenze teoriche della tabella 3.3
Poi si calcolano le contingenze cij, cioè gli scarti tra i valori effettivi e quelli teorici.
Contingenze cij Nessuna ind. Obbligo Secondario II Terziario Tot. marg.
Maturità liceale 5− 11.178=−6.178 -9.172 -12.319 27.669 100
Scuola di cultura generale -4.178 -2.172 0.681 5.669 100
AFC in 4 anni -2.178 -4.172 7.681 -1.331 100
AFC in 3 anni 2.711 0.687 6.277 -9.675 101
Certif. fed. form. pratica 9.822 14.828 -2.319 -22.331 100
Totali marg. 56 71 202 172 501
Tabella 3.5. Contingenze per la tabella 3.3
Infine si calcolano i contributi al χ2 (quadrato delle contingenze divise per la frequenza teoricacij2
tij)
Contributi per il χ2 Nessuna ind. Obbligo Secondario II Terziario Tot. marg.
Maturità liceale (−6.178)2
11.178= 3.414 5.936 3.764 22.299 100
Scuola di cultura generale 1.561 0.333 0.011 0.9356 100
AFC in 4 anni 0.424 1.228 1.463 0.052 100
AFC in 3 anni 0.651 0.033 0.968 2.699 101
Certif. fed. form. pratica 8.631 15.515 0.133 14.526 100
Totali marg. 56 71 202 172 501
Tabella 3.6. Contribui al Chi quadrato della tabella 3.3
Il Chi quadrato χ2 non è altro che la somma di tutti questi contributi, come mostrato dalla formula3.12
χn2 =ΣiΣj
cij2
tij(3.12)
44 Statistica bivariata

Il quale va paragonato nelle tabelle del Chi quadrato3.3 con i gradi di libertà ν calcolati come vienemostrato nella formula 3.13, in cui k è il numero di colonne e h il numero di righe della tabella.
ν=(k− 1)(h− 1) (3.13)
Se il valore del χn2 supera quello tabellato si ha la certezza che i dati non sono disposti in modo
casuale, ma che invece è presente una una tendenza.
Si ottiene χstat2 = 84.579 che è molto più grande del valore di riferimento con ν= 12 gradi di libertà
che, letto dalle apposite tabelle è pari a χcrit.95,ν=62 = 21.03. Si deduce quindi che i dati non sono
distribuiti in modo casuale e che quindi c’è una tendenza. Per andare ulteriormente a comprenderequesta tendenza e avere un parametro simile a quello del coefficiente di correlazione lineare r sipuò calcolare il φc di Cramer3.4 (evoluzione del φ di Pearson) usando la seguente formula:
φc=χ2
N (k− 1)
√
(3.14)
In cui N è il totale delle frequenze e k il valore più basso della dimensione r× c della tabella. Nelcaso precedente, essendo la tabella 5× 4 si ha:
φc=84.579
501 · (4− 1)
√
= 0.237 (3.15)
il che corrisponde ad una correlazione modesta, visto che l’indice φc può assumere valori tra0 (nessuna correlazione) ed 1 (correlazione perfetta, ma solo in tabelle quadrate r × r, in casocontrario il valore massimo è un po’ inferiore ad 1).
A partire dalla tabella 3.3 si può anche costruire un’ulteriore tabella contenente le frequenze relativeo anche le frequenze relative percentuali, come mostrato in 3.7; questa tabella è utile se si vuoleragionare in termini di probabilità frequentista, come proposto in precedenza nella nota 1.6.
Freq. rel. % nij Nessuna ind. Obbligo Secondario II Terziario Totali marg.
Maturità liceale 0.998% 0.998% 5.589% 12.375% 19.960%
Scuola di cultura generale 1.397% 2.395% 8.184% 7.984% 19.960%
AFC in 4 anni 1.796% 1.996% 9.581% 6.587% 19.960%
AFC in 3 anni 2.794% 2.994% 9.381% 4.990% 20.160%
Certificati fed. form. pratica 4.192% 5.788% 7.585% 2.395% 19.960%
Totali marg. 11.178% 14.172% 40.319% 34.331% 100.000%
Tabella 3.7. Probabilità frequentiste (frequenze relative percentuali) della tabella 3.3
Esercizio 3.3. Si interpreti la tabella 3.7 determinando:
• La probabilità che uno studente preso a caso tra quelli che hanno un AFC ottenuto in 4 anni abbia ungenitore con un titolo terziario. [0.33]
• La probabilità che un figlio di un genitore con formazione terziaria ottenga una maturità liceale. [0.36]
• La probabilità che uno studente a caso abbia un certificato federale di formazione pratica. [0.1996]
3.3. Per le tabelle dei valori critici ed un approfondimento degli aspetti teorici che esulano dallo scopo di questadispensa si rimanda a testi specifici, ad esempio la monografia di statistica applicata del prof. Soliani, capitolo 3(copyleft).
3.4. Si tratta di uno dei vari metodi proposti per normalizzare il χ2 nell’intervallo [0; 1]; ne esistono svariati altri.
3.4 Connessioni e contingenze 45

3.4.2 Connessioni tra una mutabile ed una variabile
Per esemplificare la situazione un esempio di indagine statistica svolta con un intervista a 1000lavoratori di cui è stato analizzato il reddito lordo e la formazione scolastica. Qui sotto trovate latabella dei dati delle frequenze congiunte nij e la relativa elaborazione statistica con un diagrammaa colonne tridimensionale. In questa tipologia di dati le frequneze congiunte sono classificate condue insiemi di criteri, uno costituito da mutabili (formazione) e l’altro costituito da una suddivi-sione in classi della variabile (reddito).
Reddito [kCHF] / Formazione nij 0-40 40-80 80-120 120-160 Totali marginali
Uni/SUP 43 71 148 118 380
Apprendistato 65 245 174 63 547
Obbligo 35 29 7 2 73
Totali marginali 143 345 329 183 1000
Tabella 3.8. Stipendi suddivisi per formazione scolastica
Figura 3.6. Diagramma a colonne 3D
Per valutare se esiste una correlazione (cioè in questo caso se a maggiore formazione corrisponde unreddito maggiore) si ricorre nuovamente ad un test sull’omogeneità. Si ipotizza che se non ci fossenessun collegamento tra le due grandezze allora le frequenze sarebbero distribuite casualmente e,in base ai totali marginali, si può calcolare il valore teorico che ciascuna classe dovrebbe assumere,come mostrato nella tabella.
Freq. teorica tij 0-40 40-80 80-120 120-160 Totali marg.
Uni/SUP 380 · 1431000
= 54.34 380 · 3451000
= 131.1 125.02 69.54 380
Apprendistato 547 · 1431000
= 78.221 188.715 179.963 100.101 547
Obbligo 10.439 25.185 24.017 13.359 73
Totali marginali 143 345 329 183 1000
Tabella 3.9. Frequenze teoriche della tabella 3.8 calcolate sulla base dei totali marginali
In modo simile a quanto fatto nel capitolo precedente si calcolano poi le contingenze e i contributial χ2.
46 Statistica bivariata
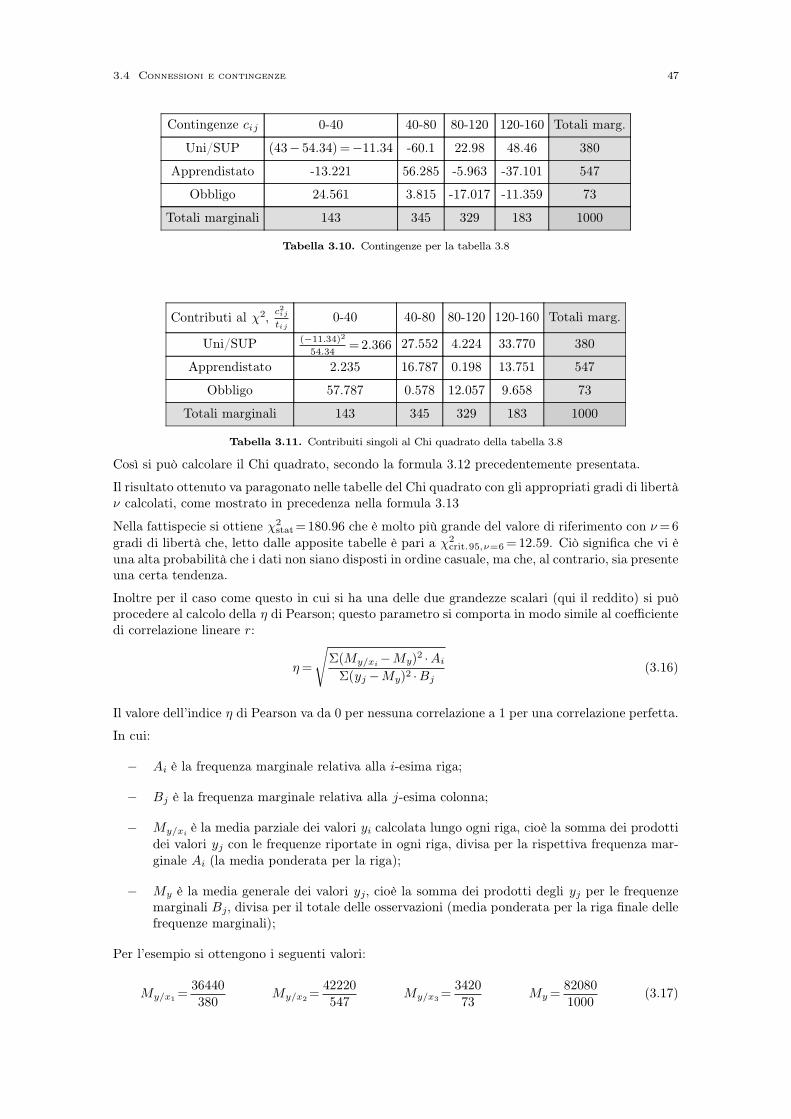
Contingenze cij 0-40 40-80 80-120 120-160 Totali marg.
Uni/SUP (43− 54.34) =−11.34 -60.1 22.98 48.46 380
Apprendistato -13.221 56.285 -5.963 -37.101 547
Obbligo 24.561 3.815 -17.017 -11.359 73
Totali marginali 143 345 329 183 1000
Tabella 3.10. Contingenze per la tabella 3.8
Contributi al χ2,cij2
tij0-40 40-80 80-120 120-160 Totali marg.
Uni/SUP (−11.34)2
54.34= 2.366 27.552 4.224 33.770 380
Apprendistato 2.235 16.787 0.198 13.751 547
Obbligo 57.787 0.578 12.057 9.658 73
Totali marginali 143 345 329 183 1000
Tabella 3.11. Contribuiti singoli al Chi quadrato della tabella 3.8
Così si può calcolare il Chi quadrato, secondo la formula 3.12 precedentemente presentata.
Il risultato ottenuto va paragonato nelle tabelle del Chi quadrato con gli appropriati gradi di libertàν calcolati, come mostrato in precedenza nella formula 3.13
Nella fattispecie si ottiene χstat2 = 180.96 che è molto più grande del valore di riferimento con ν=6
gradi di libertà che, letto dalle apposite tabelle è pari a χcrit.95,ν=62 = 12.59. Ciò significa che vi è
una alta probabilità che i dati non siano disposti in ordine casuale, ma che, al contrario, sia presenteuna certa tendenza.
Inoltre per il caso come questo in cui si ha una delle due grandezze scalari (qui il reddito) si puòprocedere al calcolo della η di Pearson; questo parametro si comporta in modo simile al coefficientedi correlazione lineare r:
η=Σ(My/xi
−My)2 ·Ai
Σ(yj −My)2 ·Bj
√
(3.16)
Il valore dell’indice η di Pearson va da 0 per nessuna correlazione a 1 per una correlazione perfetta.
In cui:
− Ai è la frequenza marginale relativa alla i-esima riga;
− Bj è la frequenza marginale relativa alla j-esima colonna;
− My/xiè la media parziale dei valori yi calcolata lungo ogni riga, cioè la somma dei prodotti
dei valori yj con le frequenze riportate in ogni riga, divisa per la rispettiva frequenza mar-ginale Ai (la media ponderata per la riga);
− My è la media generale dei valori yj, cioè la somma dei prodotti degli yj per le frequenzemarginali Bj, divisa per il totale delle osservazioni (media ponderata per la riga finale dellefrequenze marginali);
Per l’esempio si ottengono i seguenti valori:
My/x1=
36440380
My/x2=
42220547
My/x3=
342073
My=820801000
(3.17)
3.4 Connessioni e contingenze 47

quindi sostituendo si ha:
η=176238.12
1438873.6
√
≃ 0.35 (3.18)
che corrisponde ad una connessione moderata. Anche l’indice η può assumere valori da 0 a 1.
48 Statistica bivariata

3.5 Esercizi
Esercizio 3.4. Da una rivista specializzata di automobilismo si hanno i seguenti dati riferiti a 5 autovetture
Vettura Cilindrata V. max km con 10 lA 1300 130 90B 1600 145 87C 1800 160 84D 2000 170 75E 2500 190 62
Si costruiscano opportuni diagrammi cartesiani mettendo in relazione cilindrata e v. max e cilindrata e consumi.Si determinino poi i coefficienti di correlazione r. [0.993;−0.975]
Esercizio 3.5. La tabella sotto riportata indica l’indice del costo per le assicurazioni malattia negli USA(100=1967). Si trovi la retta di regressione, si stimi l’indice per l’anno 1985 e quello per l’anno 1975.
Anno 1976 1977 1978 1979 1980 1981 1982 1983 1984Indice 184.7 202.4 219.4 239.7 265.9 294.5 328.7 357.3 378.0
[400.4; 148.5]
Esercizio 3.6. Sono dati i dettagli di otto punti di vendita di una catena di grandi magazzini. Si analizzinoquesti dati con gli strumenti di correlazione e regressione.
Punto di vendita Superficie in m2 Numero addetti Incassi giornalieriA 640 16 8.4B 2100 40 19.2C 1200 28 15.0D 1040 24 14.0E 860 22 12.6F 1600 32 16.4G 1500 30 15.8H 980 24 13.6
Esercizio 3.7. La tabella sottostante riporta i dati di pressione e volume di un gas. Considerando che i gasgenericamente hanno una correlazione tra questi due parametri data dall’equazione.
Volume V 54.3 61.8 72.4 88.7 118.6 194.0Pressione P 61.2 49.5 37.6 28.4 19.2 10.1
P · V γ =C
con γ e C costanti si linearizza la formula applicando un logaritmo e si trovino queste due costanti con unaregressione lineare. [γ= 1.40;C = 1.60×104]
Esercizio 3.8. La seguente tabella riporta i voti di alcuni studenti in algebra e fisica. Si trovino le dure retteinterpolanti, sia per fisica, sia per algebra come variabile indipendente. Se uno studente ha ottenuto 75 in algebraquale voto ci si deve attendere abbia ottenuto a fisica? E uno che ha ottenuto 95 in fisica quanto presumibilmenteavrà ottenuto in algebra? Si valuti la qualità della correlazione con la determinazione di r.
Algebra 75 80 93 65 87 71 98 68 84 77Fisica 82 78 86 72 91 80 95 72 89 74
Esercizio 3.9. Dovendo interpolare i dati della seguente tabella cerca di capire qual è il tipo di funzione piùopportuno e, linearizzando opportunamente i dati, esegui la regressione
x 1 2 3 4 5 6y 2.969 3.094 3.224 3.359 3.501 3.648
f(x)= 2.85 · 1.042x
3.5 Esercizi 49

Esercizio 3.10. In un circondario scolastico viene eseguita un’indagine che analizza il tempo di percorrenzacasa-scuola in funzione del’ordine scolastico.
Minuti tratta 0-20 20-40 40-80V.C. 10 30 60 Totale
Elementari 155 8 1 164Medie inf. 68 75 21 164Medie sup. 22 76 66 164
Totale 245 159 88 492
i. Valutare la connessione [χ2= 244.62, χcrit2 = 9.49, η= 0.6232]
ii. Calcolare il tempo medio della tratta per gli allievi della scuola elementare, media inferiore e mediasuperiore.
iii. Calcolare la probabilità che un alunno che impiega dai 20 ai 40 minuti sia iscritto alle medie inferiori.[
75159
= 0.472]
iv. Calcolare il tempo medio globale di percorrenza. [25.41]
Esercizio 3.11. Un’industria alimentare ha condotto una indagine al fine di scoprire eventuali connessionitra la professione e il tipo di bevanda usata a colazione fra 1200 persone di una grande città. I risultati sonoriportati nella tabella sottostante.
The Caffè Cioccolata Soft drink Latte TotaleStudenti 42 25 19 216 94 396Impiegati 219 156 34 96 42 547Quadri 72 112 12 24 37 257Totale 333 293 65 336 173 1200
i. Si valuti la connessione con gli indici presentati a lezione [χ2= 362.51, χcrit2 = 15.51φc= 0.3887]
ii. Si calcoli la probabilità che un impiegato prediliga il the.
iii. Si calcoli la probabilità che un estimatore della cioccolata sia uno studente.[
1965
]
iv. Si calcoli la probabilità percentuale della preferenza della cioccolata.
50 Statistica bivariata

Capitolo 4
Test formativi
4.1 Statistica monovariata (80 minuti)
I seguenti dati si riferiscono alle spese giornaliere registrate da una famiglia nel mese di novembre.
50 70 65 100 80 65 40 98 40 1055 70 100 0 60 84 65 50 50 4052 110 50 30 70 60 0 42 55 7244 58 46 0 105 67 22 96 82 15
• Costruisci una distribuzione di classi adeguata, indicando valore centrale, frequenza, fre-quenza relativa %, e frequenza cumulata %; (10p)
• Prepara un istogramma dei dati; (8p)
• Prepara un diagramma a colonne (8p)
• Prepara un areogramma (facoltativo) (8p)
• Traccia l’ogiva (8p)
• Calcola la media della spesa, la moda e commenta con questo dato l’istogramma ottenuto(8p)
• Calcola la mediana e lo scarto interquartile (8p)
• Traccia un box plot dei dati (8p)
• Calcola la media ponderata e lo scarto ponderato medio usando la tabella delle frequenze(12p)
• Confronta media e mediana commentando i dati (6p)
51

4.2 Regressione e correlazione (80 minuti)
Esercizio 4.1. Qui sono riportati i dati relativi alle dimensioni della circonferenza cranica di un feto a partiredalla tredicesima settimana di gravidanza. Sulla base dei dati:
i. si tracci un grafico dei dati;
ii. si determini la correlazione dei dati con il coefficiente di Pearson;
iii. si determini la retta di regressione;
iv. si estrapoli la dimensione del cranio per la quarta settimana;
v. si commentino i risultati ottenuti, osservando attentamente il grafico.
Settimana 13 18 23 28 33 38Circonf. in mm 82 155 215 260 305 330
Esercizio 4.2. Nella tabella seguente sono riportate le lunghezze di 30 foglie di lauro, registrate al millimetropiù prossimo; usando il supporto informatico:
i. si costruisca una distribuzione di frequenza adeguata con limiti tabulati, limiti reali, valore centrale eampiezza della classe indicati in modo esplicito;
ii. si calcolino media mediana e scarto quadratico medio ponderati;
iii. Si tracci un istogramma dei dati;
iv. Si calcolino P5, P90, D6, P30 e Q3 dalla tabella delle frequenze.
138 164 150 132 144 125 149 157 146 158140 147 136 148 152 144 168 126 138 176163 119 154 165 146 173 142 147 135 153
52 Test formativi

Capitolo 5
Esercizi di approfondimento
5.1 Radioattività e cinghiali
Esercizio 5.1. Tracce di cesio 137, oltre la soglia prevista dai regolamenti in caso di incidente nucleare, sonostati trovati nella lingua e nel diaframma di 27 cinghiali del comprensorio alpino della Valsesia, in provincia diVercelli (Piemonte). Sono stati analizzati campioni di capi abbattuti nel 2012-2013.
I campioni erano stati prelevati per essere sottoposti ad una indagine sulla trichinellosi, una malattia parassitariache colpisce prevalentemente suini e cinghiali. Successivamente gli stessi campioni sono stati sottoposti a untest di screening per la ricerca del radionuclide cesio 137, così come previsti da una Raccomandazione dellaCommissione europea (2003/274/CE).
I risultati hanno evidenziato la presenza di un numero consistente di campioni con livelli di cesio 137 superioria 600 [Bq/Kg] (Becquerel per chilogrammo). I valori dei campioni oscillano tra 0 e 5621 [Bq/Kg] e 27 campionipresentano valori al di sopra dei 600 [Bq/Kg]5.1.
Ad oggi dei 27 con valore superiore alla soglia ne sono stati inviati dieci al Centro italiano di referenza nazionaleper la ricerca della radioattività nel settore zootecnico veterinario per la Puglia e la Basilicata; nove sono staticonfermati, con la metodica accreditata, con valori superiori ai 600 [Bq/Kg]. Uno ha un valore attorno ai 500[Bq/Kg]. per gli altri campioni è data la misurazione preliminare.
Nr capo 1 2 3 4 5 6 7 8 9 10
Radioattività [Bq/Kg] 497 631 721 1083 601 2031 744 902 3124 5621
Età stimata [anni] 0.5 1 1.5 3 1 5 1.5 2 7 9
Tabella 5.1. Misure del centro Nazionale
Nr capo 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
Radioattività [Bq/Kg] 640 2050 1190 940 760 830 510 1550 810 510 770 1390 660 3280 3710 1250 690
Età stimata [anni] 1 4 3 1.5 1 2 0.5 6 1.5 1 2 3 1 5 7 3 2
Tabella 5.2. Misure preliminari
i. Si analizzi sia inmodo grafico, sia con il calcolo degli opportuni parametri, la correlazione tra l’età stimatae il livello di radioattività sui dati della tabella 5.1
ii. Si confrontino i dati della tabella 5.1 e quelli della tabella 5.2 calcolando gli opportuni parametri statisticie producendo per entrambe le tabelle grafici per visualizzare correttamente i grafici
iii. (facoltativo) Si provi ad applicare un logaritmo sui dati della tabella 5.1 tracciando nuovamente i graficie ricalcolando i parametri di correlazione. Che cosa si può ragionevolmente affermare?
5.1. Liberamente ispirato a http://www.ticinonews.ch/articolo.aspx?id=292586&rubrica=15
53
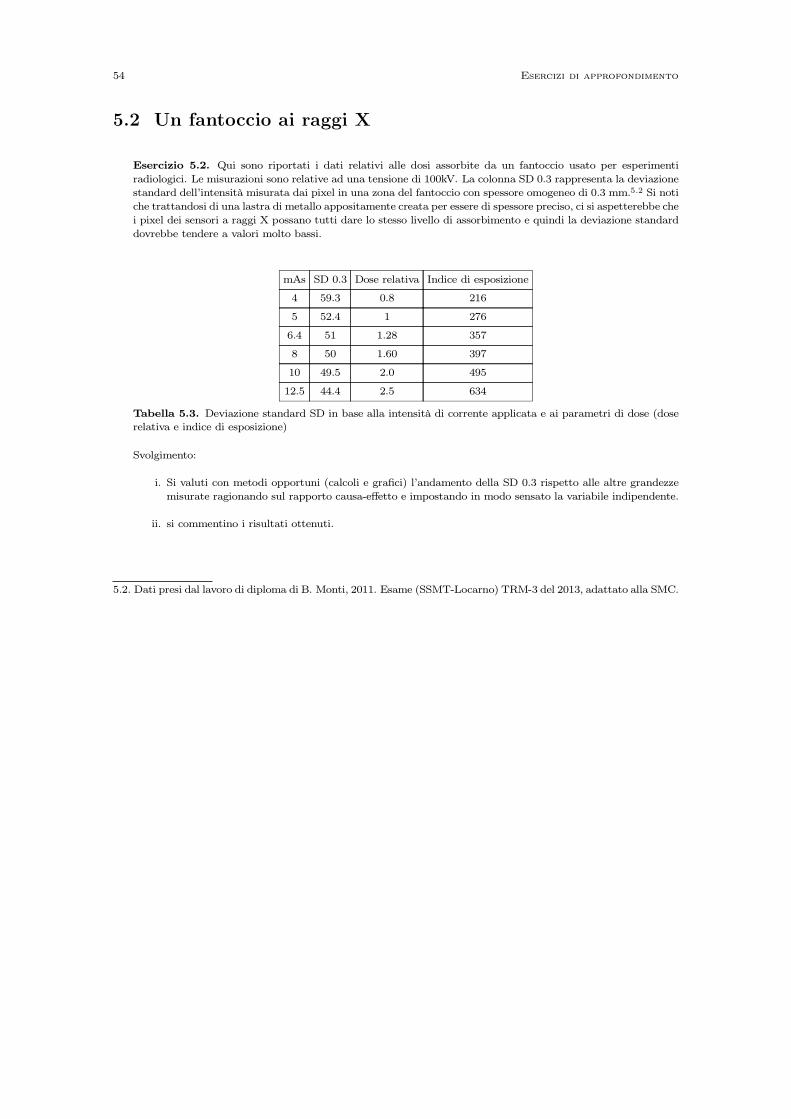
5.2 Un fantoccio ai raggi X
Esercizio 5.2. Qui sono riportati i dati relativi alle dosi assorbite da un fantoccio usato per esperimentiradiologici. Le misurazioni sono relative ad una tensione di 100kV. La colonna SD 0.3 rappresenta la deviazionestandard dell’intensità misurata dai pixel in una zona del fantoccio con spessore omogeneo di 0.3 mm.5.2 Si notiche trattandosi di una lastra di metallo appositamente creata per essere di spessore preciso, ci si aspetterebbe chei pixel dei sensori a raggi X possano tutti dare lo stesso livello di assorbimento e quindi la deviazione standarddovrebbe tendere a valori molto bassi.
mAs SD 0.3 Dose relativa Indice di esposizione
4 59.3 0.8 216
5 52.4 1 276
6.4 51 1.28 357
8 50 1.60 397
10 49.5 2.0 495
12.5 44.4 2.5 634
Tabella 5.3. Deviazione standard SD in base alla intensità di corrente applicata e ai parametri di dose (doserelativa e indice di esposizione)
Svolgimento:
i. Si valuti con metodi opportuni (calcoli e grafici) l’andamento della SD 0.3 rispetto alle altre grandezzemisurate ragionando sul rapporto causa-effetto e impostando in modo sensato la variabile indipendente.
ii. si commentino i risultati ottenuti.
5.2. Dati presi dal lavoro di diploma di B. Monti, 2011. Esame (SSMT-Locarno) TRM-3 del 2013, adattato alla SMC.
54 Esercizi di approfondimento

5.3 Dosimetri in una centrale nucleare
Esercizio 5.3. Qui sotto si trovano i valori diurni in µSv registrati da 18 dosimetri personali dei dipendentidi una centrale nucleare5.3. Si tenga in considerazione che il valore medio diurno che si misura solitamente è di4.7 µSv/giorno e la relativa deviazione standard è di 8 µSv/giorno.
9.1 2.2
2.3 5.4
4.4 1.7
250.9 12.3
0.7 8.9
3.2 112.3
6.5 6.6
1.8 0.9
16.7 3.7
Tabella 5.4. Dati dei dosimetri in µSv/giorno
Svolgimento:
i. Si traccino opportuni grafici per visualizzare i dati. Si noti che sarà sicuramente necessario tracciare unbox-plot.
ii. Si valutino gli indici di centralità e di dispersione, commentandone i risultati in base anche ai graficiottenuti nell’attività precedente.
iii. È avvenuto un piccolo incedente nucleare?
5.3. Liberamente adattato dall’esame (SSMT-Locarno) TRM-3 del 2011.
5.3 Dosimetri in una centrale nucleare 55
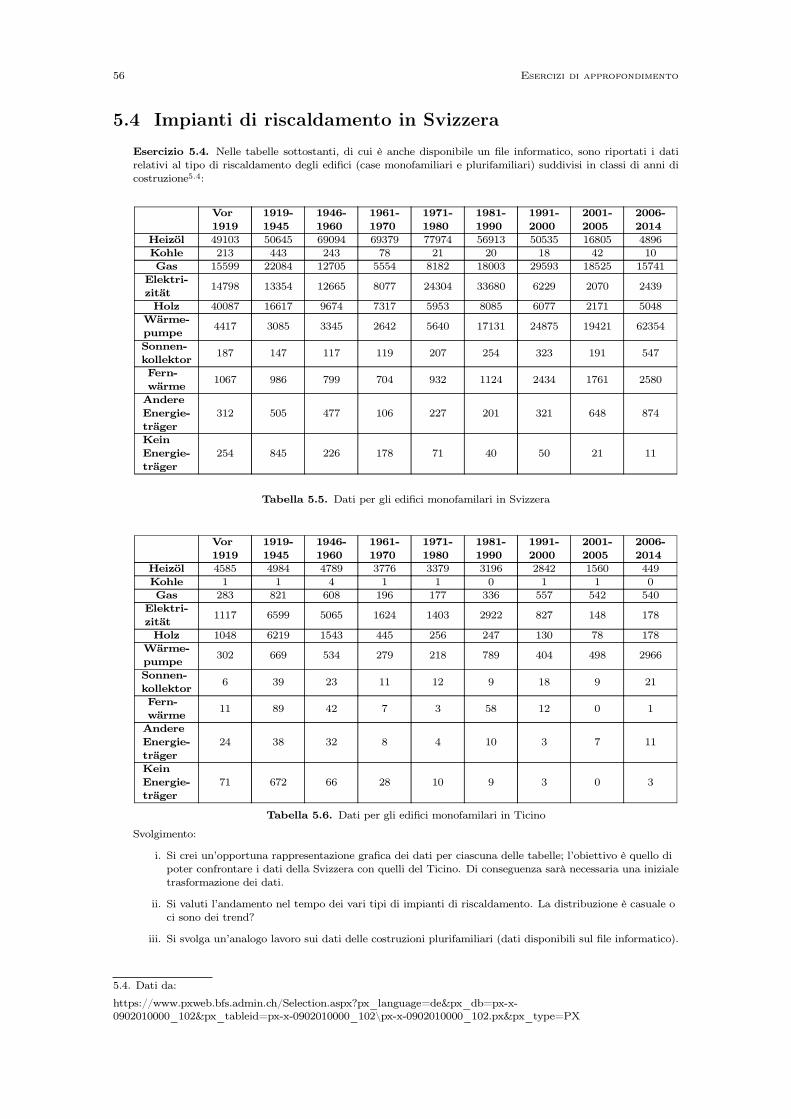
5.4 Impianti di riscaldamento in Svizzera
Esercizio 5.4. Nelle tabelle sottostanti, di cui è anche disponibile un file informatico, sono riportati i datirelativi al tipo di riscaldamento degli edifici (case monofamiliari e plurifamiliari) suddivisi in classi di anni dicostruzione5.4:
Vor
1919
1919-
1945
1946-
1960
1961-
1970
1971-
1980
1981-
1990
1991-
2000
2001-
2005
2006-
2014
Heizöl 49103 50645 69094 69379 77974 56913 50535 16805 4896Kohle 213 443 243 78 21 20 18 42 10Gas 15599 22084 12705 5554 8182 18003 29593 18525 15741
Elektri-
zität14798 13354 12665 8077 24304 33680 6229 2070 2439
Holz 40087 16617 9674 7317 5953 8085 6077 2171 5048Wärme-
pumpe4417 3085 3345 2642 5640 17131 24875 19421 62354
Sonnen-
kollektor187 147 117 119 207 254 323 191 547
Fern-
wärme1067 986 799 704 932 1124 2434 1761 2580
Andere
Energie-
träger
312 505 477 106 227 201 321 648 874
Kein
Energie-
träger
254 845 226 178 71 40 50 21 11
Tabella 5.5. Dati per gli edifici monofamilari in Svizzera
Vor
1919
1919-
1945
1946-
1960
1961-
1970
1971-
1980
1981-
1990
1991-
2000
2001-
2005
2006-
2014Heizöl 4585 4984 4789 3776 3379 3196 2842 1560 449Kohle 1 1 4 1 1 0 1 1 0Gas 283 821 608 196 177 336 557 542 540
Elektri-
zität1117 6599 5065 1624 1403 2922 827 148 178
Holz 1048 6219 1543 445 256 247 130 78 178Wärme-
pumpe302 669 534 279 218 789 404 498 2966
Sonnen-
kollektor6 39 23 11 12 9 18 9 21
Fern-
wärme11 89 42 7 3 58 12 0 1
Andere
Energie-
träger
24 38 32 8 4 10 3 7 11
Kein
Energie-
träger
71 672 66 28 10 9 3 0 3
Tabella 5.6. Dati per gli edifici monofamilari in Ticino
Svolgimento:
i. Si crei un’opportuna rappresentazione grafica dei dati per ciascuna delle tabelle; l’obiettivo è quello dipoter confrontare i dati della Svizzera con quelli del Ticino. Di conseguenza sarà necessaria una inizialetrasformazione dei dati.
ii. Si valuti l’andamento nel tempo dei vari tipi di impianti di riscaldamento. La distribuzione è casuale oci sono dei trend?
iii. Si svolga un’analogo lavoro sui dati delle costruzioni plurifamiliari (dati disponibili sul file informatico).
5.4. Dati da:
https://www.pxweb.bfs.admin.ch/Selection.aspx?px_language=de&px_db=px-x-0902010000_102&px_tableid=px-x-0902010000_102\px-x-0902010000_102.px&px_type=PX
56 Esercizi di approfondimento

5.5 Turismo e pernottamenti in Svizzera
Esercizio 5.5. Nell’apposito file informatico trovate i dati relativi al numero di ospiti e al numero di pernot-tamenti (notti) registrate nel settore alberghiero svizzero dal 2005 al 20155.5.
Svolgimento:
i. Concentrandosi su 5 paesi di provenienza estera (Germania, USA, Russia, Giappone, Arabia Saudita)si proponga un’analisi grafica che evidenzi se c’è stato un aumento o una diminuzione di questo settoreeconomico.
ii. Si provi a dare un’interpretazione dei dati considerando l’andamento del franco CHF e dell’economiaglobale.
5.5. http://www.bfs.admin.ch/bfs/portal/de/index/themen/10/03/blank/key/02/01.Document.64549.xls
5.5 Turismo e pernottamenti in Svizzera 57












![IMPIANTI DI DISTRIBUZIONE - freedom.dicea.unifi.itfreedom.dicea.unifi.it/Claroline-1.3.1/0060838/document/acquedotti/... · impianto di pompaggio (può ... 0 24 V [m3] V c Cumulata](https://static.fdocumenti.com/doc/165x107/5c677c2509d3f28e058bc9e9/impianti-di-distribuzione-impianto-di-pompaggio-puo-0-24-v-m3-v-c.jpg)





