
(12 CFU) A.A 2015/2016 CdL Sociologia e Criminologia...
48
Statistica Sociale e Criminale (12 CFU) A.A. 2015/2016 CdL Sociologia e Criminologia Simone Di Zio
Transcript of (12 CFU) A.A 2015/2016 CdL Sociologia e Criminologia...

Statistica Sociale e Criminale
(12 CFU)
A.A. 2015/2016
CdL Sociologia e Criminologia
Simone Di Zio

Dove siamo…
MODULO 3. L’Inferenza statistica
3.1 Probabilità e variabili casuali
3.2 Le tecniche di campionamento
3.3 Inferenza da “Esperimento statistico”
3.4 Inferenza da “Popolazioni finite”
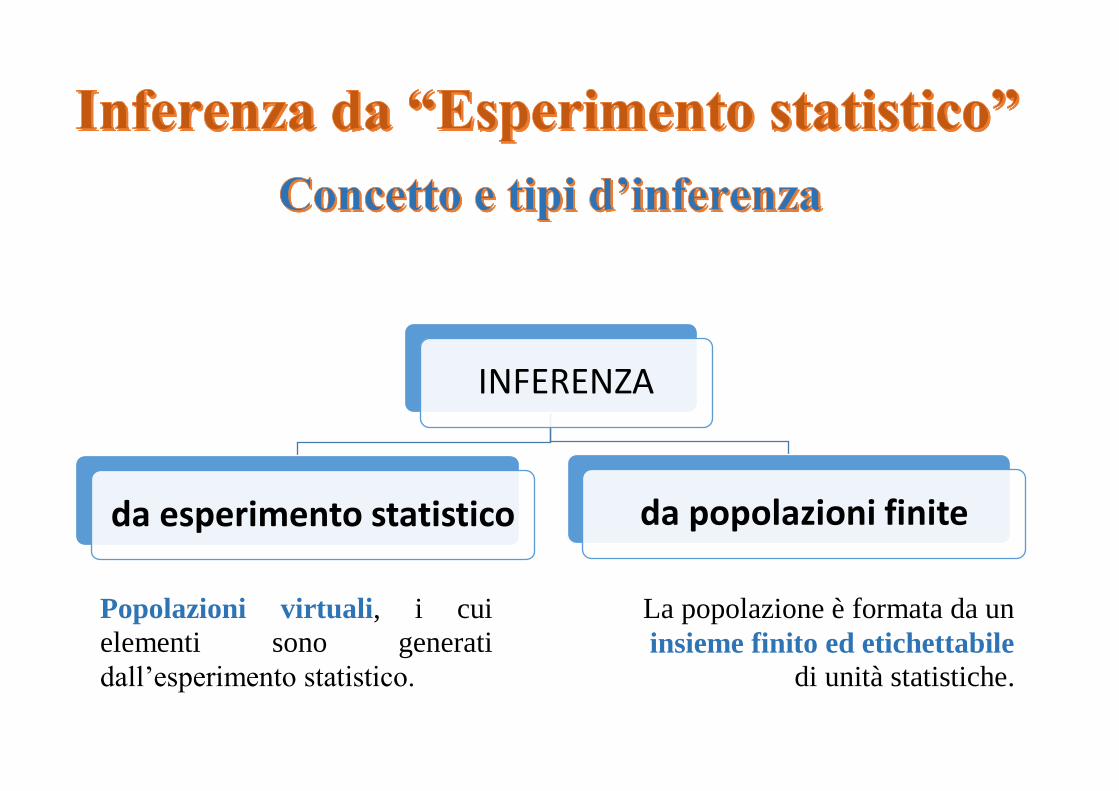
INFERENZA
da esperimento statistico da popolazioni finite
Popolazioni virtuali, i cui
elementi sono generati
dall’esperimento statistico.
La popolazione è formata da un
insieme finito ed etichettabile
di unità statistiche.
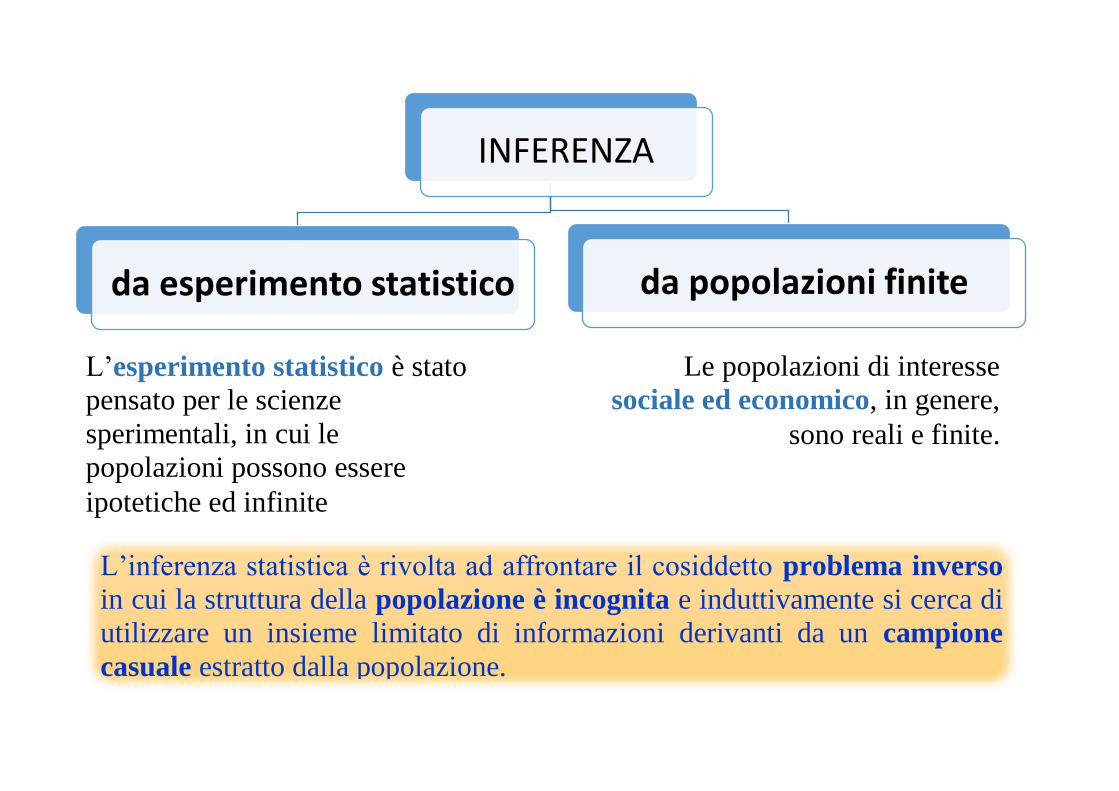
INFERENZA
da esperimento statistico da popolazioni finite
L’esperimento statistico è stato
pensato per le scienze
sperimentali, in cui le
popolazioni possono essere
ipotetiche ed infinite
Le popolazioni di interesse
sociale ed economico, in genere,
sono reali e finite.
L’inferenza statistica è rivolta ad affrontare il cosiddetto problema inverso
in cui la struttura della popolazione è incognita e induttivamente si cerca di
utilizzare un insieme limitato di informazioni derivanti da un campione
casuale estratto dalla popolazione.
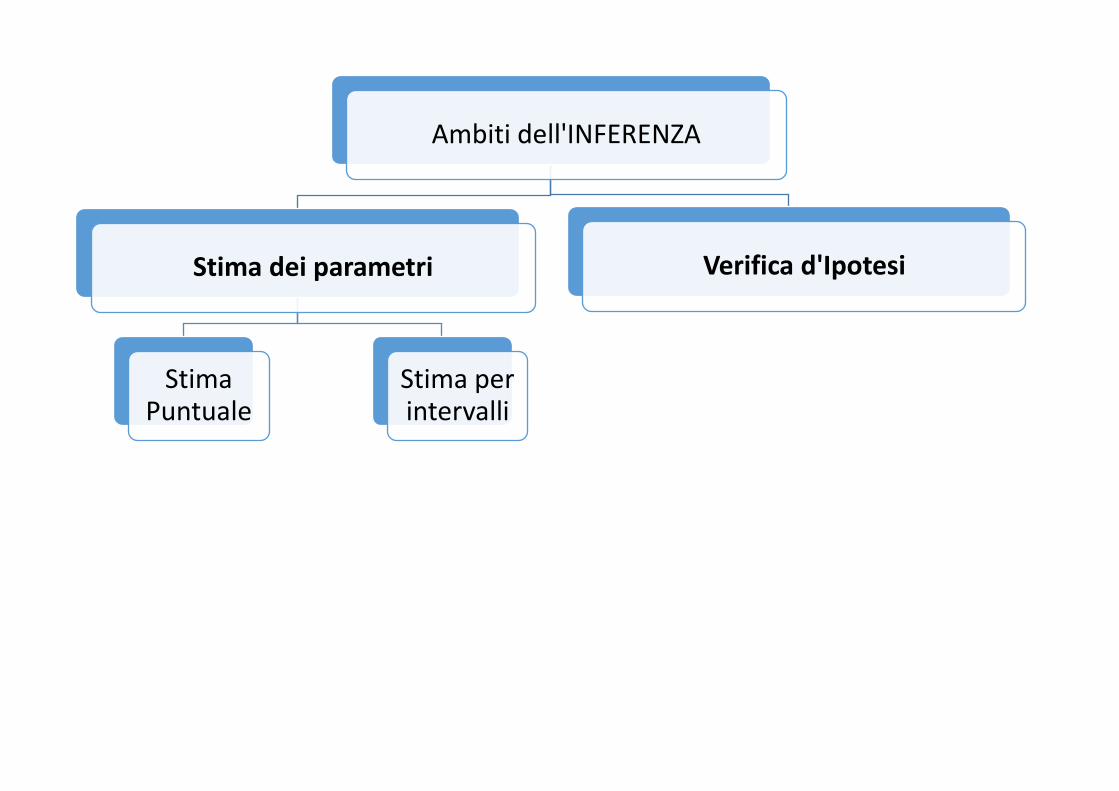
Ambiti dell'INFERENZA
Stima dei parametri
Stima Puntuale
Stima per intervalli
Verifica d'Ipotesi
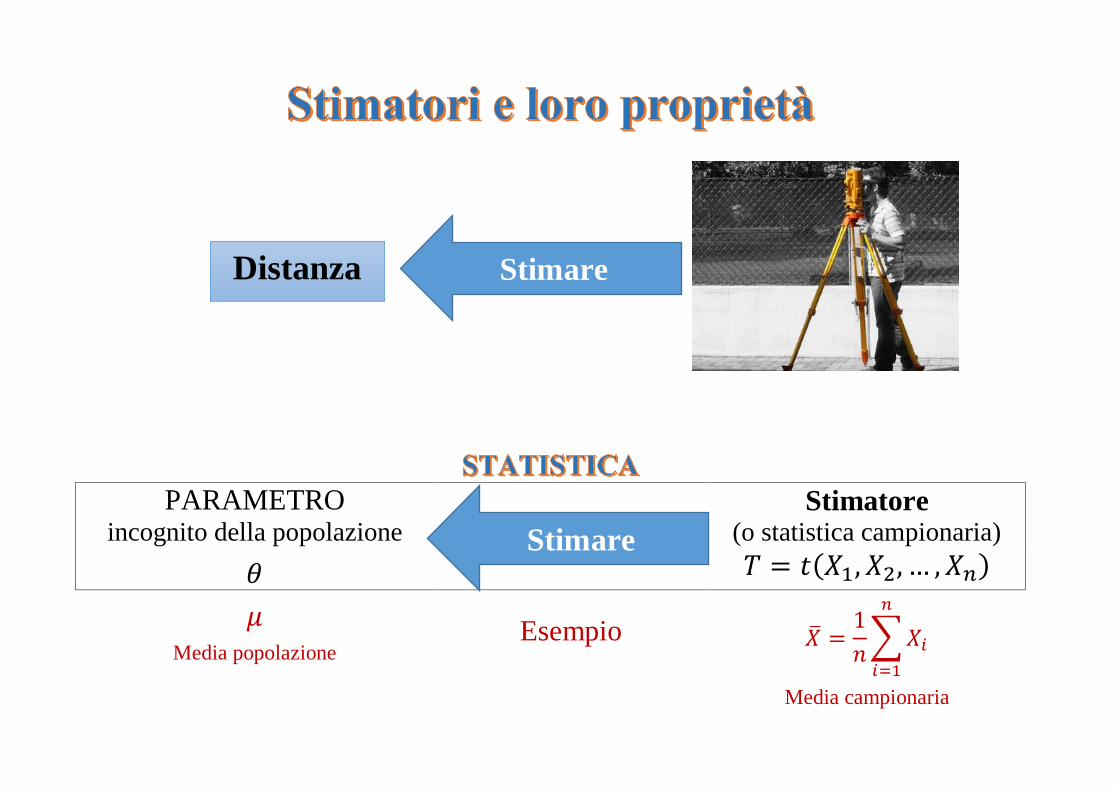
PARAMETRO incognito della popolazione
Stimatore (o statistica campionaria)
𝜃 𝑇 = 𝑡(𝑋1, 𝑋2, … , 𝑋𝑛)
𝜇
Media popolazione Esempio �̅� =
1
𝑛∑ 𝑋𝑖
𝑛
𝑖=1
Media campionaria
Stimare Distanza
Stimare

Lo stimatore è una variabile casuale.
Ha pertanto una sua propria distribuzione campionaria
Conoscendo la distribuzione campionaria è possibile capire se lo stimatore scelto
produrrà stime più o meno vicine al parametro incognito della popolazione.
Quindi, per uno stesso parametro esistono più stimatori (così come per una
distanza si possono usare più strumenti di misura)
Per poter scegliere il “migliore” bisognerà prima stabilire quali sono le proprietà
che uno stimatore deve possedere.
Come scelgo
il migliore?

Uno stimatore 𝑇 del parametro incognito della popolazione 𝜃 si definisce
corretto (o non distorto) se il suo valore atteso è uguale al parametro vero della
popolazione:
𝑬(𝑻) = 𝜽
per ogni valore di 𝜃.
Nell’ipotesi di infiniti campioni di dimensione 𝑛, il valore che lo stimatore assume
per ognuno di tali campioni avrebbe una media pari a 𝜃
Nel caso in cui 𝐸(𝑇) è diverso da 𝜃 si dice che lo stimatore è distorto:
𝑫(𝑻) = 𝑬(𝑻) − 𝜽

Uno stimatore è tanto più efficiente quanto più i valori si addensano intorno al
valore vero del parametro cui si riferisce.
L’errore di stima è la differenza fra stimatore e parametro incognito:
𝑻 − 𝜽
è logico aspettarsi che per buon stimatore esso sia più piccolo possibile.
L’Errore Quadratico Medio dello stimatore 𝑇 relativo a un parametro 𝜃 è:
𝑴𝑺𝑬(𝑻) = 𝑬[(𝑻 − 𝜽)𝟐]
L’efficienza è una proprietà relativa, cioè si evince dal confronto di due o più
stimatori. Dati due stimatori 𝑇1 e 𝑇2, entrambi del parametro 𝜃, diremo che 𝑇1 è
più efficiente di 𝑇2 se e solo se
𝑀𝑆𝐸(𝑇1) < 𝑀𝑆𝐸(𝑇2)

Per le proprietà della correttezza e dell’efficienza si considera fissa la dimensione
campionaria 𝑛.
A queste se ne aggiungono altre che invece vengono dette proprietà asintotiche,
cioè si prende in considerazione il comportamento dello stimatore al crescere
della dimensione campionaria (questa condizione si esprime con 𝑛 → ∞)
La consistenza indica l’aumentare della precisione dello stimatore all’aumentare
della numerosità campionaria 𝑛.
Uno stimatore 𝑇𝑛 di un parametro 𝜃 è consistente in probabilità se per ogni 𝜖 >0:
𝐥𝐢𝐦𝒏→∞
𝑷(|𝑻𝒏 − 𝜽| < 𝝐) = 𝟏
per ogni valore di 𝜃. Il limite della probabilità che il valore assoluto dello scarto fra stimatore e parametro sia
piccolissima, cioè inferiore a un 𝜖 piccolo a piacere, è pari a uno.

Quando un parametro della popolazione è stimato con un valore singolo, questo
valore è detto stima puntuale del parametro.
Uno dei parametri più importanti della popolazione è la media 𝜇
Partendo da un campione casuale 𝑋1, 𝑋2, … , 𝑋𝑛 di dimensione 𝑛, la media
campionaria �̅� è uno stimatore puntuale della media della popolazione 𝜇:
�̅� =𝑋1 + 𝑋2 + ⋯ + 𝑋𝑛
𝑛
Essendo noto che 𝐸(�̅�) = 𝜇 si tratta di uno stimatore corretto.

È la proporzione di unità che presentano un certo attributo.
Dato un campione casuale di 𝑛 unità, uno stimatore puntuale della proporzione
𝝅 è la proporzione campionaria.
La stima puntuale di 𝜋 si ottiene come somma delle 𝑥𝑖 diviso 𝑛:
�̅� =𝑥1 + 𝑥2 + ⋯ + 𝑥𝑛
𝑛
�̅� è uno stimatore corretto di 𝜋, in quanto 𝐸(�̅�) = 𝜋.

La varianza della popolazione è un altro importante parametro oggetto di stima.
Ricordiamo che è
𝜎2 = 𝑉𝑎𝑟(𝑋) = 𝐸[(𝑋 − 𝜇)2]
dove 𝜇 è la media della popolazione.
Uno stimatore puntuale corretto della varianza della popolazione è dato da:
𝑆2 =1
𝑛 − 1∑(𝑋𝑖 − �̅�)2
𝑛
𝑖=1
Quindi 𝐸(𝑆2) = 𝜎2 per ogni 𝜎2 > 0.

𝑆2 =1
𝑛 − 1∑(𝑋𝑖 − �̅�)2
𝑛
𝑖=1
si definisce varianza campionaria corretta, per distinguerlo dalla varianza
campionaria che è data da
1
𝑛∑ (𝑋𝑖 − �̅�)2𝑛
𝑖=1
e che invece è uno stimatore distorto della varianza.

Nella pratica si ha un solo campione, per cui la stima puntuale difficilmente darà
il valore esatto del parametro della popolazione.
È preferibile allora stimare due estremi, entro i quali tutti i valori sono possibili
stime del parametro, secondo un certo grado di plausibilità.
per un intervallo di confidenza della media della popolazione 𝜇, si devono
calcolare due valori (diciamo 𝒒𝟏 𝑒 𝒒𝟐) simmetrici rispetto alla stima puntuale
della media campionaria, che sappiamo essere �̅�.
L’intervallo di confidenza è un intervallo di valori - determinato sulla base di
un campione - che si ritiene contenere il vero parametro (incognito della
popolazione) con un prefissato grado di fiducia.

Significa che la quantità |𝑞1 − �̅�| è uguale alla quantità |𝑞2 − �̅�|.
Dire che il livello di confidenza è prefissato significa assegnare una probabilità:
𝑷(𝒒𝟏 < 𝝁 < 𝒒𝟐) = 𝟏 − 𝜶
N.B.: sono gli estremi dell’intervallo (𝑞1 𝑒 𝑞2) che variano al variare del campione
Il parametro incognito (nel nostro esempio 𝜇) è fisso!
Quindi, 1 − 𝛼 è la probabilità che l’intervallo contenga il parametro incognito
della popolazione.
�̅� 𝑞1 𝑞2
|𝑞1 − �̅�| |𝑞2 − �̅�|
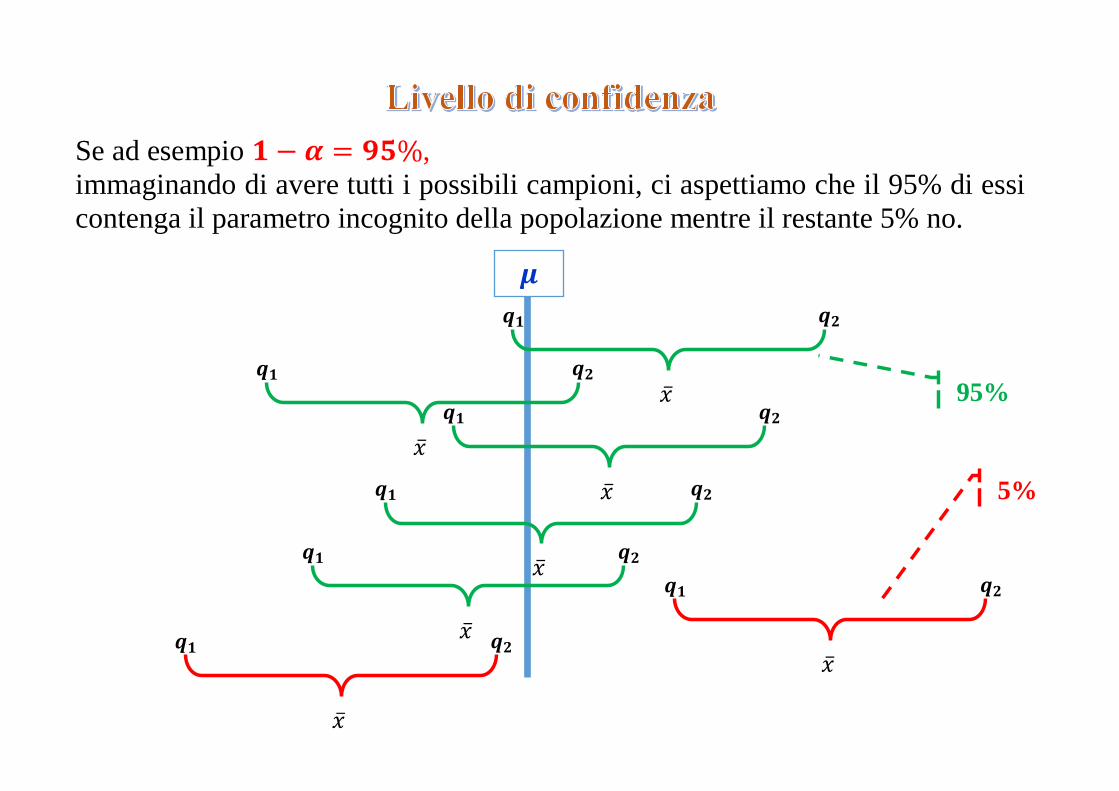
Se ad esempio 𝟏 − 𝜶 = 𝟗𝟓%,
immaginando di avere tutti i possibili campioni, ci aspettiamo che il 95% di essi
contenga il parametro incognito della popolazione mentre il restante 5% no.
𝝁
𝒒𝟏 𝒒𝟐
�̅�
𝒒𝟏 𝒒𝟐
�̅�
𝒒𝟏 𝒒𝟐
�̅�
𝒒𝟏 𝒒𝟐
�̅� 𝒒𝟏 𝒒𝟐
�̅�
𝒒𝟏 𝒒𝟐
�̅�
𝒒𝟏 𝒒𝟐
�̅�
95%
5%

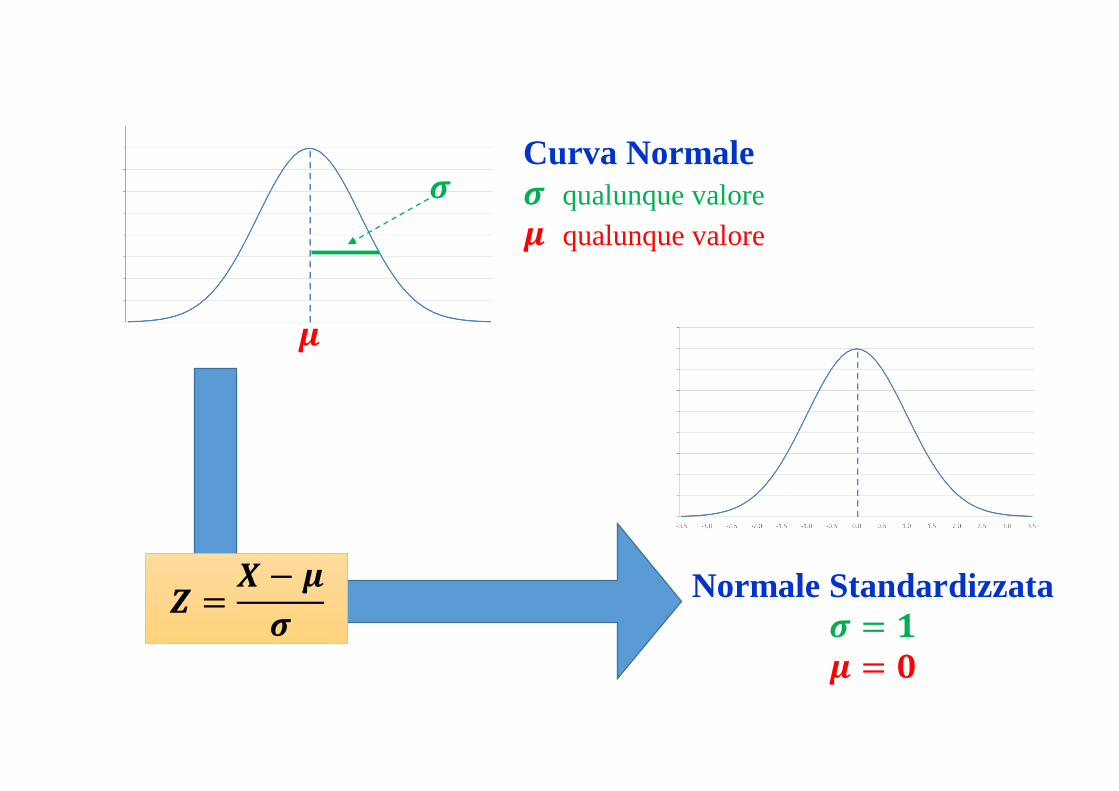
Una variabile Normale è caratterizzata da due soli parametri: 𝜇, 𝜎2
Quando una variabile 𝑋 si distribuisce normalmente si scrive 𝑋~𝑁(𝜇, 𝜎2)
Ma a seconda dei valori assunti da 𝜇 e 𝜎2 ho una curva diversa. Significa che
ogni volta dovrei calcolare integrali diversi.
Allora si preferisce trasformarla in una Variabile Standardizzata, di cui si
conoscono tutte le aree, senza calcolare nessun integrale.
Curva Normale
𝝈 qualunque valore
𝝁 qualunque valore
𝝁
𝝈
Normale Standardizzata
𝝈 = 𝟏
𝝁 = 𝟎
𝒁 =𝑿 − 𝝁
𝝈

Uso della Tavola della Variabile Casuale
Normale Standardizzata Valori della funzione di ripartizione della V.C. Normale standardizzata:
Φ(𝑧𝛼) = 𝑃(𝑍 ≤ 𝑧𝛼) = 1 − 𝛼.
I valori della tavola corrispondono all’area sottesa alla funzione di densità della
Normale standardizzata, per 𝑧 compreso tra −∞ e 𝑧𝛼.

1. Si supponga ad esempio di dover cercare il valore dell’area corrispondente a
𝑧𝛼 = 1.96, ovvero la probabilità 𝑃(𝑍 ≤ 1.96).
𝑃(𝑍 ≤ 1.96) = 0.975
2. Cercare la probabilità corrispondente a 𝑧𝛼 = −1.96 .
𝑃(𝑍 ≤ −1.96) = 1 − 0.975 = 0.025
3. Si immagini ora di cercare l’area compresa fra −1.2 e 1.5. Si tratta della
probabilità 𝑃(−1.2 ≤ 𝑍 ≤ 1.5).
𝑃(𝑍 ≤ 1.5) − 𝑃(𝑍 ≤ −1.2).
𝑃(𝑍 ≤ 1.5) = 0.9332
𝑃(𝑍 ≤ −1.2) = 1 − 0.8849 = 0.1151
pertanto 𝑃(−1.2 ≤ 𝑍 ≤ 1.5) = 0.9332 − 0.1151 = 0.8181.

Problema inverso
Conoscendo il valore di un’area si deve trovare il corrispondente valore di 𝒛𝜶.
: 𝛼 = 0.025, siamo interessati a trovare il valore di zeta corrispondente
a quest’area, ovvero 𝑧0.025.
Siccome 𝑃(𝑍 ≤ 𝑧𝛼) = 1 − 𝛼 allora l’area che dobbiamo cercare sulla tavola è
pari a 𝑃(𝑍 ≤ 𝑧0.025) = 0.975.
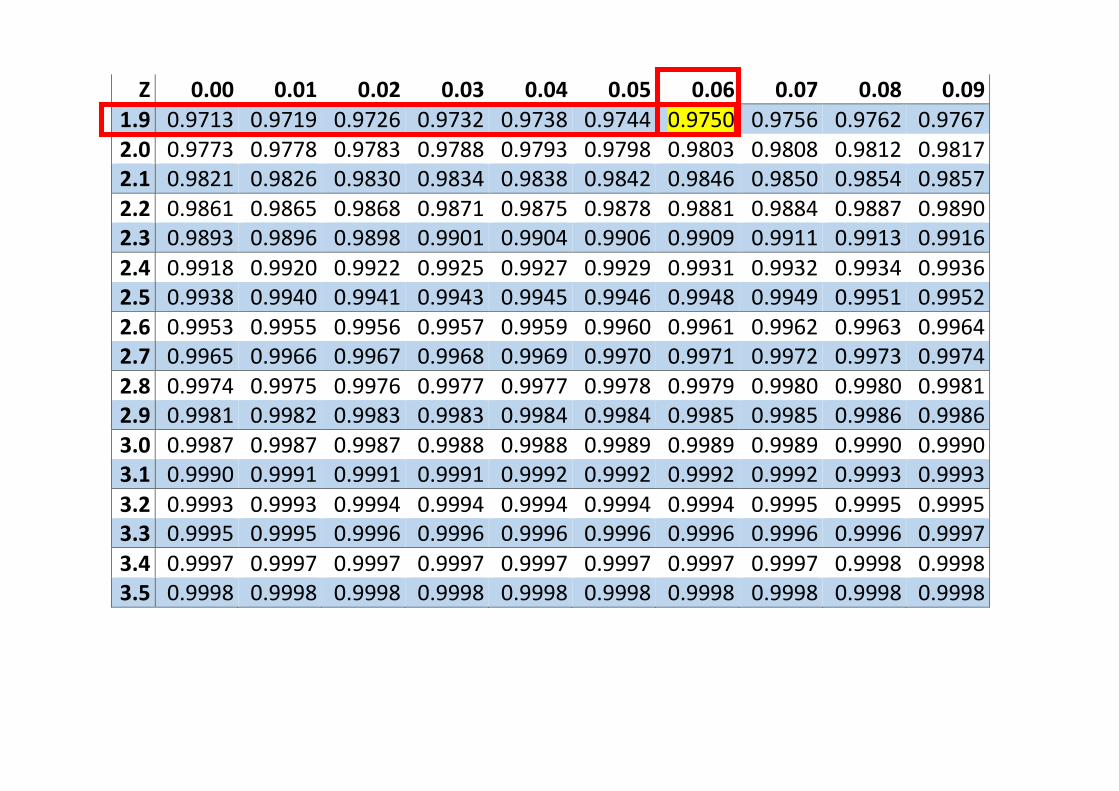
Si cerca il valore più vicino a 0.975.
Si trova all’incrocio fra la riga con intestazione 1.9 e la colonna con intestazione
0.06. Pertanto 𝑧0.025 = 1.96.

TAVOLA della Funzione di ripartizione Φ(𝑍) della variabile casuale Normale standardizzata
Z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0 0.5000 0.5040 0.5080 0.5120 0.5160 0.5199 0.5239 0.5279 0.5319 0.5359 0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5754 0.2 0.5793 0.5832 0.5871 0.5910 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141 0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.6480 0.6517 0.4 0.6554 0.6591 0.6628 0.6664 0.6700 0.6736 0.6772 0.6808 0.6844 0.6879 0.5 0.6915 0.6950 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.7190 0.7224
0.6 0.7258 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7518 0.7549 0.7 0.7580 0.7612 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852 0.8 0.7881 0.7910 0.7939 0.7967 0.7996 0.8023 0.8051 0.8079 0.8106 0.8133 0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.8340 0.8365 0.8389 1.0 0.8413 0.8438 0.8461 0.8485 0.8508 0.8531 0.8554 0.8577 0.8599 0.8621 1.1 0.8643 0.8665 0.8686 0.8708 0.8729 0.8749 0.8770 0.8790 0.8810 0.8830 1.2 0.8849 0.8869 0.8888 0.8907 0.8925 0.8944 0.8962 0.8980 0.8997 0.9015 1.3 0.9032 0.9049 0.9066 0.9082 0.9099 0.9115 0.9131 0.9147 0.9162 0.9177
1.4 0.9192 0.9207 0.9222 0.9236 0.9251 0.9265 0.9279 0.9292 0.9306 0.9319 1.5 0.9332 0.9345 0.9357 0.9370 0.9382 0.9394 0.9406 0.9418 0.9430 0.9441
1.6 0.9452 0.9463 0.9474 0.9485 0.9495 0.9505 0.9515 0.9525 0.9535 0.9545 1.7 0.9554 0.9564 0.9573 0.9582 0.9591 0.9599 0.9608 0.9616 0.9625 0.9633 1.8 0.9641 0.9649 0.9656 0.9664 0.9671 0.9678 0.9686 0.9693 0.9700 0.9706
Z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
1.9 0.9713 0.9719 0.9726 0.9732 0.9738 0.9744 0.9750 0.9756 0.9762 0.9767 2.0 0.9773 0.9778 0.9783 0.9788 0.9793 0.9798 0.9803 0.9808 0.9812 0.9817 2.1 0.9821 0.9826 0.9830 0.9834 0.9838 0.9842 0.9846 0.9850 0.9854 0.9857 2.2 0.9861 0.9865 0.9868 0.9871 0.9875 0.9878 0.9881 0.9884 0.9887 0.9890 2.3 0.9893 0.9896 0.9898 0.9901 0.9904 0.9906 0.9909 0.9911 0.9913 0.9916
2.4 0.9918 0.9920 0.9922 0.9925 0.9927 0.9929 0.9931 0.9932 0.9934 0.9936 2.5 0.9938 0.9940 0.9941 0.9943 0.9945 0.9946 0.9948 0.9949 0.9951 0.9952 2.6 0.9953 0.9955 0.9956 0.9957 0.9959 0.9960 0.9961 0.9962 0.9963 0.9964 2.7 0.9965 0.9966 0.9967 0.9968 0.9969 0.9970 0.9971 0.9972 0.9973 0.9974 2.8 0.9974 0.9975 0.9976 0.9977 0.9977 0.9978 0.9979 0.9980 0.9980 0.9981 2.9 0.9981 0.9982 0.9983 0.9983 0.9984 0.9984 0.9985 0.9985 0.9986 0.9986 3.0 0.9987 0.9987 0.9987 0.9988 0.9988 0.9989 0.9989 0.9989 0.9990 0.9990 3.1 0.9990 0.9991 0.9991 0.9991 0.9992 0.9992 0.9992 0.9992 0.9993 0.9993
3.2 0.9993 0.9993 0.9994 0.9994 0.9994 0.9994 0.9994 0.9995 0.9995 0.9995 3.3 0.9995 0.9995 0.9996 0.9996 0.9996 0.9996 0.9996 0.9996 0.9996 0.9997
3.4 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9998 0.9998 3.5 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998

ESERCIZI SULLA NORMALE
Sapendo che la lunghezza media delle foglie in un bosco: N(μ = 6, σ2 = 4)
Trovare:
1. % di foglie > 5cm
2. % di foglie fino a 5cm
3. % fra 5 e 7cm
4. % di foglie < 3cm
Prima di usare la tavola si passa sempre per la standardizzazione dei valori:
1. 5−6
2= −0.5
2. 5−6
2= −0.5
3. 5−6
2= −0.5
7−6
2= 0.5
4. 3−6
2= −1.5
Poi si ragiona sulla tavola
della Normale
Standardizzata

Immaginiamo di volere stimare la superficie media 𝜇 delle abitazioni di una città.
Da uno studio precedente sappiamo che 𝝈 = 𝟖.
Campione di 𝒏 = 𝟓𝟎 appartamenti.
Media campionaria �̅� = 𝟏𝟐𝟎 mq (stima puntuale del parametro).
Si vuole determinare l’intervallo di confidenza per 𝜇 a un livello di confidenza di
95%, sotto l’ipotesi di Normalità.
Si sa che la media campionaria si distribuisce normalmente:
�̅�~𝑁 (𝜇;𝜎2
𝑛)
Nel nostro esempio abbiamo 𝜎2 𝑛⁄ = 64 50⁄ = 1.28.
𝜎2 = 82

Si costruisce quindi la variabile casuale normale standardizzata 𝑍:
𝑍 =�̅� − 𝜇
√1.28=
�̅� − 𝜇
1.13
che sappiamo si distribuisce secondo una 𝑁(0; 1).
Con la tavola è possibile verificare che i valori di 𝑍 che formano un intervallo
simmetrico attorno allo 0 con probabilità pari a 0.95 sono −𝟏. 𝟗𝟔 e 𝟏. 𝟗𝟔.
Tali estremi sono indicati con −𝑍𝛼 2⁄ e 𝑍𝛼 2⁄ .
Per cui possiamo scrivere la seguente relazione:
𝑃(−𝑍𝛼 2⁄ ≤ 𝑍 ≤ 𝑍𝛼 2⁄ ) = 1 − 𝛼
Nel nostro esempio abbiamo:
𝑃(−1.96 ≤ 𝑍 ≤ 1.96) = 0.95

Ora, si tratta di sostituire a 𝑍 la sua espressione:
𝑃 (−𝑍𝛼 2⁄ ≤�̅� − 𝜇
𝜎 √𝑛⁄≤ 𝑍𝛼 2⁄ ) = 1 − 𝛼
Che nel nostro esempio diventa:
𝑃 (−1.96 ≤�̅� − 𝜇
√1.28≤ 1.96) = 0.95
…passaggi algebrici…
𝑃(−1.96 ∙ √1.28 ≤ �̅� − 𝜇 ≤ 1.96 ∙ √1.28) = 0.95
𝑃(𝜇 − 1.96 ∙ √1.28 ≤ �̅� ≤ 𝜇 + 1.96 ∙ √1.28) = 0.95
𝑃(𝜇 − 2.22 ≤ �̅� ≤ 𝜇 + 2.22) = 0.95

𝑃(𝜇 − 2.22 ≤ �̅� ≤ 𝜇 + 2.22) = 0.95
Questa relazione dice che la probabilità di estrarre dalla popolazione un campione
la cui media (�̅�) sia distante da 𝜇 al massimo di 2.22 è pari a 0.95.
Cioè, se costruiamo un intervallo attorno alla media campionaria �̅� del tipo:
[�̅� − 2.22; �̅� + 2.22]
questo intervallo conterrà il valore incognito della popolazione 𝜇 con probabilità
0.95.
Possiamo pertanto scrivere:
𝑃(�̅� − 2.22 ≤ 𝜇 ≤ �̅� + 2.22) = 0.95

Gli estremi dell’intervallo sono
𝒒𝟏 = �̅� − 𝟐. 𝟐𝟐 𝒒𝟐 = �̅� + 𝟐. 𝟐𝟐
queste sono due variabili casuali, perché dipendono da �̅�.
Quindi questo intervallo è lo stimatore intervallo di confidenza
[�̅� − 2.22; �̅� + 2.22],
Sostituendo a �̅� la sua realizzazione campionaria �̅� = 120 si ottiene l’intervallo
di confidenza stimato.
[120 − 2.22; 120 + 2.22]
[𝟏𝟏𝟕. 𝟕𝟖; 𝟏𝟐𝟐. 𝟐𝟐]

Errore molto comune: dire che 𝜇 sia compreso all’interno dell’intervallo trovato
con una probabilità pari a 1 − 𝛼.
Dopo l’estrazione del nostro campione e il calcolo dei due estremi, non sapremo
mai se questo contiene o meno il parametro incognito 𝜇.
Possiamo solo dire che si ha un elevato grado di fiducia, o confidenza, che
l’intervallo stimato contenga il valore di 𝜇.
In ogni caso, essendo 𝜇 fisso, non bisogna dire che esso è contenuto
nell’intervallo di confidenza, ma è più corretto dire che l’intervallo di
confidenza contiene, con un certo grado di fiducia, il parametro 𝜇.

Sul parametro incognito della popolazione viene formulata un’ipotesi.
Essa potrà essere rifiutata o meno secondo l’evidenza empirica dei dati
campionari.
La prima cosa da fare è definire un’ipotesi, che si chiama ipotesi nulla: 𝑯𝟎.
Un’ipotesi statistica è un’affermazione su un parametro, 𝜃, della popolazione.
𝑯𝟎: 𝜽 = 𝟔
Deve essere definita sempre una seconda ipotesi, ipotesi alternativa: 𝑯𝟏.
Una contro-congettura sul parametro oggetto di indagine.
𝑯𝟏: 𝜽 ≠ 𝟔
𝑯𝟏: 𝜽 > 𝟔
𝑯𝟏: 𝜽 < 𝟔)
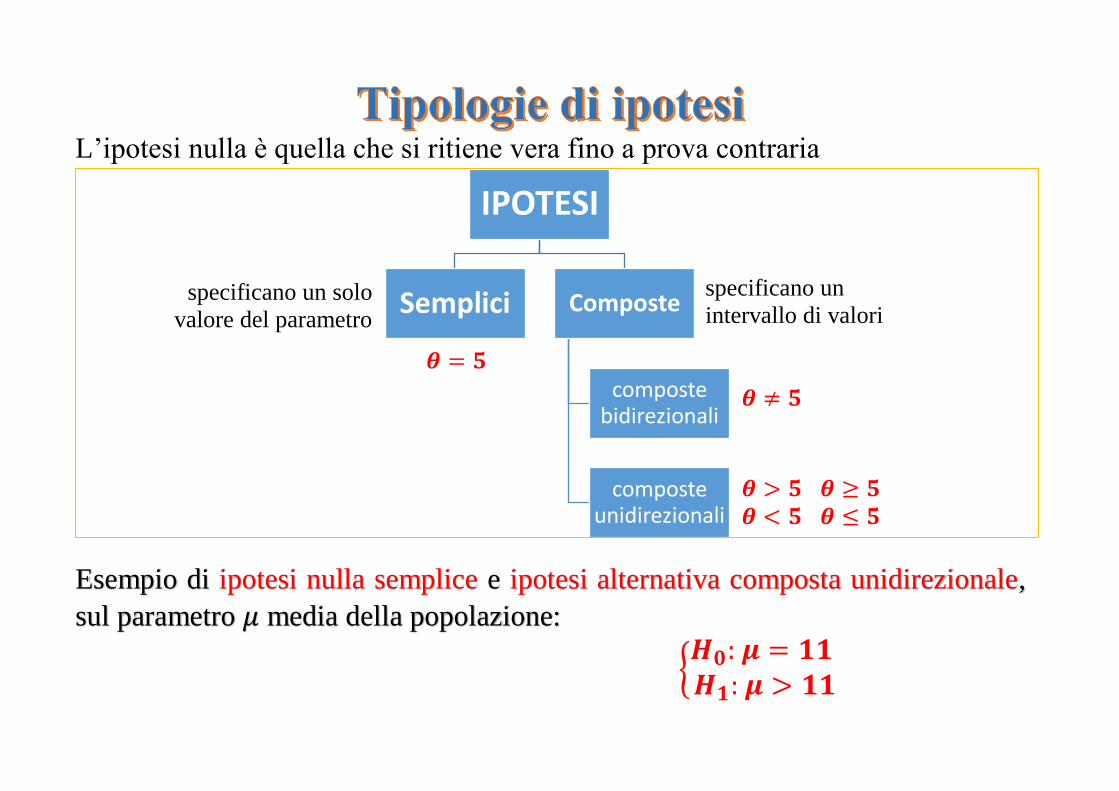
L’ipotesi nulla è quella che si ritiene vera fino a prova contraria
Esempio di ipotesi nulla semplice e ipotesi alternativa composta unidirezionale,
sul parametro 𝜇 media della popolazione:
{𝑯𝟎: 𝝁 = 𝟏𝟏 𝑯𝟏: 𝝁 > 𝟏𝟏
IPOTESI
Semplici Composte
composte bidirezionali
composte unidirezionali
specificano un solo
valore del parametro
specificano un
intervallo di valori
𝜽 ≠ 𝟓
𝜽 > 𝟓 𝜽 ≥ 𝟓
𝜽 < 𝟓 𝜽 ≤ 𝟓
𝜽 = 𝟓

Il Test è una regola con cui si decide se accettare o rifiutare l’ipotesi nulla 𝐻0.
Supponiamo di avere un campione casuale di numerosità 𝑛, estratto da una
popolazione normale, con media 𝜇 = 𝜇0 e varianza 𝜎2.
Vogliamo fare verifica di ipotesi sulla media campionaria �̅�.
Si sa che �̅� si distribuisce con media uguale a quella della popolazione e varianza
pari a 𝜎2 𝑛⁄ .
Quindi sotto l’ipotesi nulla 𝜇 = 𝜇0 abbiamo la seguente distribuzione per �̅�:
�̅�~𝑁 (𝜇0,𝜎2
𝑛)
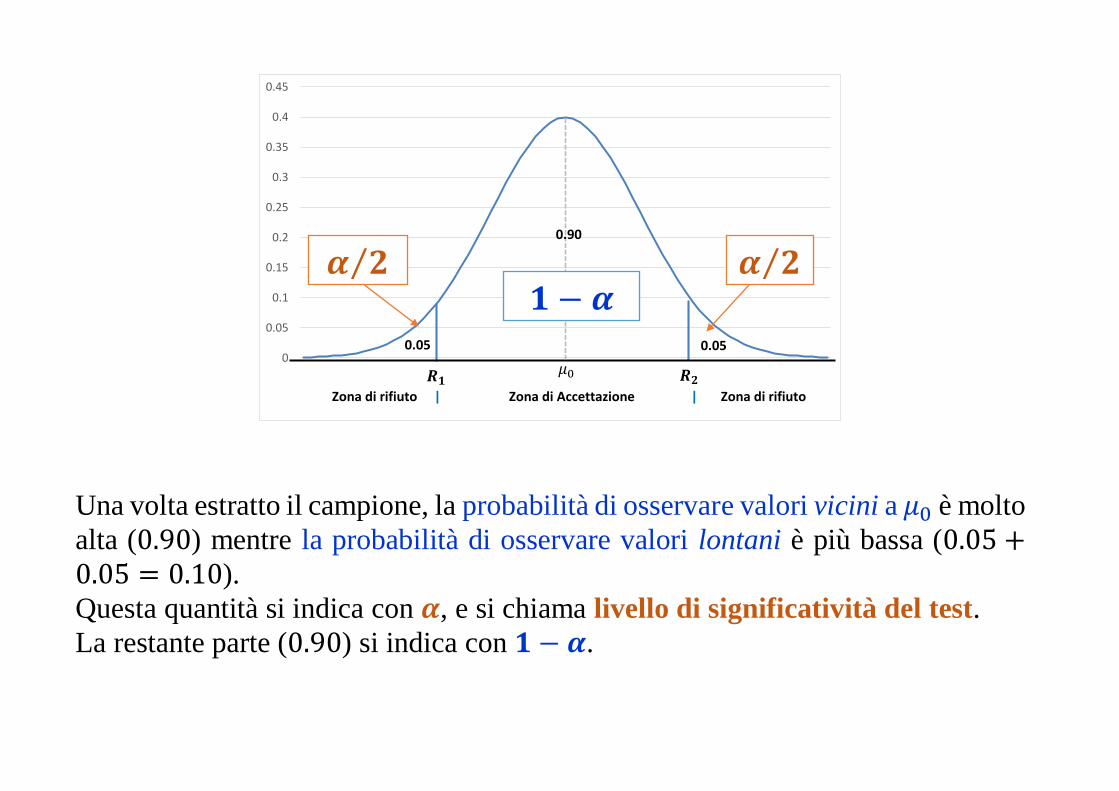
Una volta estratto il campione, la probabilità di osservare valori vicini a 𝜇0 è molto
alta (0.90) mentre la probabilità di osservare valori lontani è più bassa (0.05 +0.05 = 0.10).
Questa quantità si indica con 𝜶, e si chiama livello di significatività del test.
La restante parte (0.90) si indica con 𝟏 − 𝜶.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-3.5
-3.0
-2.5
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
Zona di rifiuto | Zona di Accettazione | Zona di rifiuto
0.90
0.05 0.05
𝟏 − 𝜶
𝜶 𝟐⁄ 𝜶 𝟐⁄
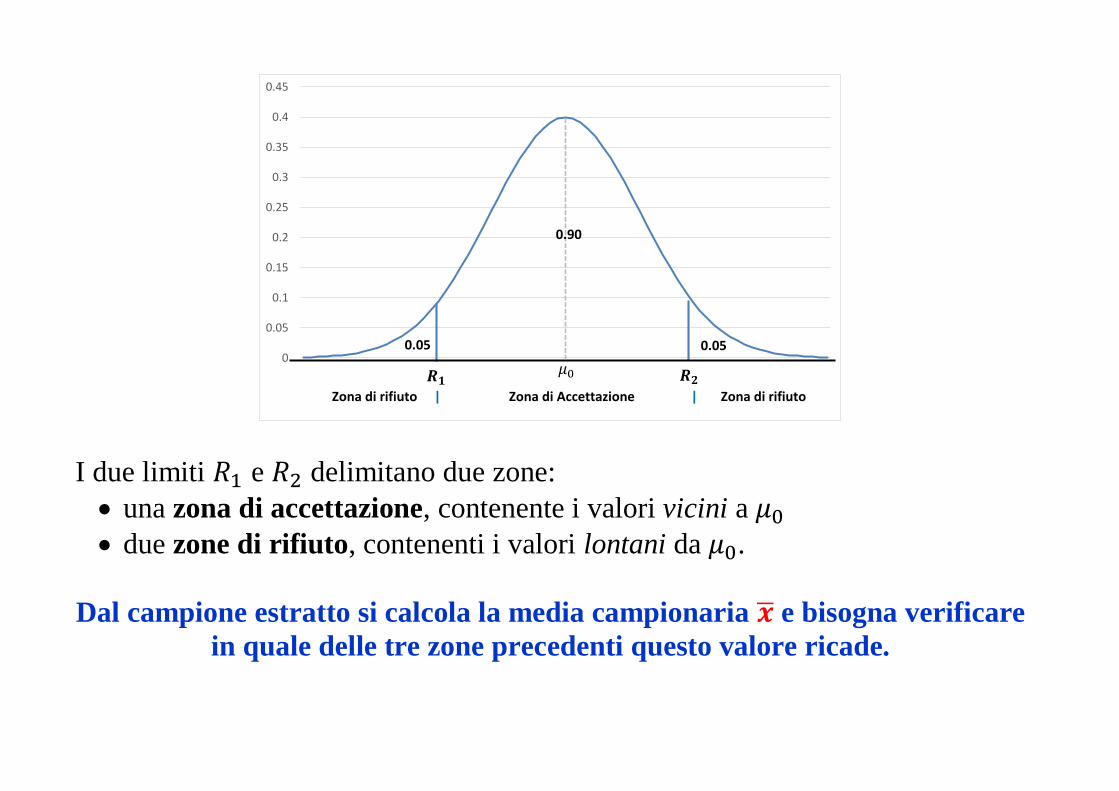
I due limiti 𝑅1 e 𝑅2 delimitano due zone:
una zona di accettazione, contenente i valori vicini a 𝜇0
due zone di rifiuto, contenenti i valori lontani da 𝜇0.
Dal campione estratto si calcola la media campionaria �̅� e bisogna verificare
in quale delle tre zone precedenti questo valore ricade.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-3.5
-3.0
-2.5
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
Zona di rifiuto | Zona di Accettazione | Zona di rifiuto
0.90
0.05 0.05
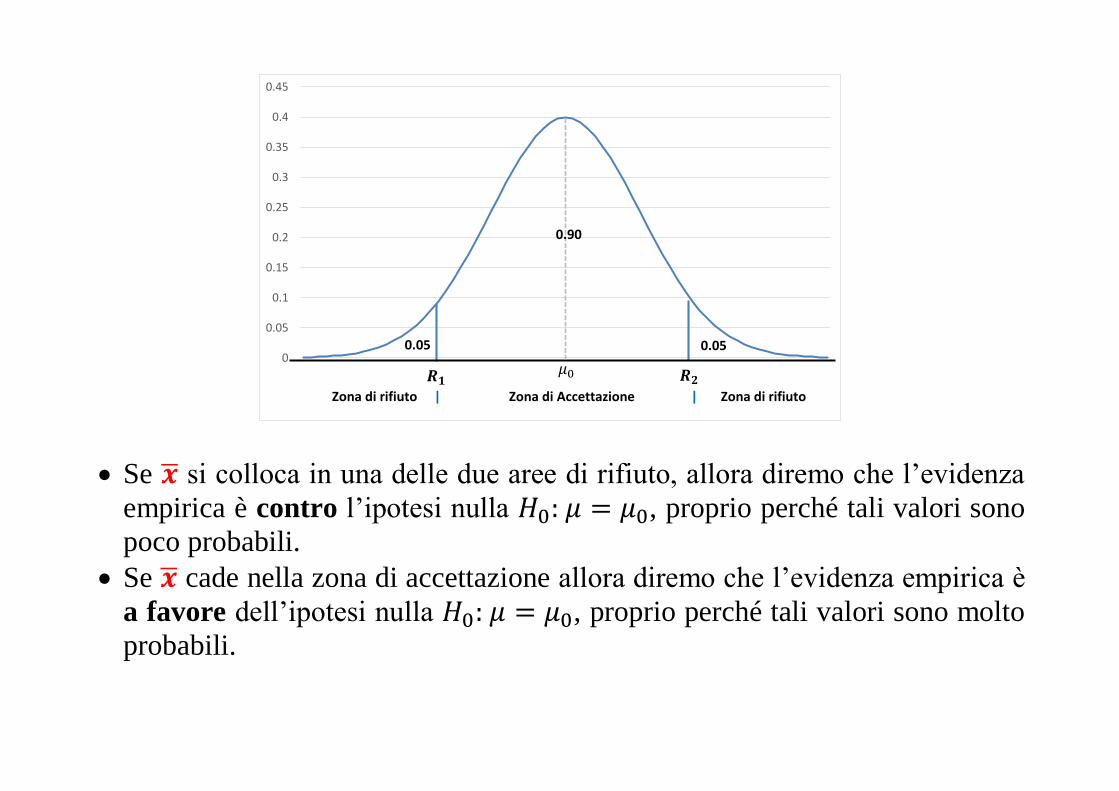
Se �̅� si colloca in una delle due aree di rifiuto, allora diremo che l’evidenza
empirica è contro l’ipotesi nulla 𝐻0: 𝜇 = 𝜇0, proprio perché tali valori sono
poco probabili.
Se �̅� cade nella zona di accettazione allora diremo che l’evidenza empirica è
a favore dell’ipotesi nulla 𝐻0: 𝜇 = 𝜇0, proprio perché tali valori sono molto
probabili.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-3.5
-3.0
-2.5
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
Zona di rifiuto | Zona di Accettazione | Zona di rifiuto
0.90
0.05 0.05

Zona di accettazione e le conseguenti zone di rifiuto dipendono dal livello di
significatività del test.
Nella pratica si usano per 𝜶 valori 0.01, 0.05 e 0.10.
Gli estremi 𝑅1 e 𝑅2 che fanno da confine fra zona di accettazione e zona di rifiuto
sono tecnicamente detti valori critici.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-3.5
-3.0
-2.5
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
Zona di rifiuto | Zona di Accettazione | Zona di rifiuto
0.90
0.05 0.05
valori
critici

La statistica test si utilizza per decidere se il campione osservato porta ad
accettare o rifiutare l’ipotesi nulla.
In genere è un buon stimatore del parametro su cui è formulata l’ipotesi.
Per verificare un’ipotesi sulla media della popolazione, si usa come statistica test
la media campionaria:
�̅� =∑ 𝑋𝑖
𝑛𝑖=1
𝑛
di cui conosciamo la distribuzione campionaria: �̅�~𝑁 (𝜇0,𝜎2
𝑛).

Definiamo le ipotesi nulla e alternativa.
Ipotesi nulla posta pari al vecchio rendimento, cioè 18. In alternativa, siccome
interessa capire se il rendimento è variato, si definisce una ipotesi bidirezionale.
{𝐻0: 𝜇 = 18 𝐻1: 𝜇 ≠ 18

{𝐻0: 𝜇 = 18 𝐻1: 𝜇 ≠ 18
A questo punto bisogna determinare le zone di accettazione e di rifiuto.
Dalla tavola si evince che i valori critici per un livello di significatività 𝛼 = 0.05
sono 𝑅1 = −1.96 e 𝑅2 = 1.96
Si utilizza una trasformazione della statistica test media campionaria, che già
conosciamo:
𝑍 =�̅� − 𝜇0
𝜎 √𝑛⁄
Ora bisogna calcolare il valore della statistica test

I dati che abbiamo sono:
18; valore della media della popolazione (valore sotto ipotesi nulla 𝜇0 = 18)
18.5; risultato sul campione di appezzamenti (media campionaria �̅� = 18.5)
𝜎 = 1.3; scarto quadratico medio (è noto)
𝑛 = 30; numerosità campionaria.
Applichiamo la statistica test:
𝑍 =�̅� − 𝜇0
𝜎 √𝑛⁄=
18.5 − 18
1.3 √30⁄= 2.11
Confronto con i valori critici
2.11 > 1.96 si conclude che la statistica cade nella regione di rifiuto.
RIFIUTO ACCETTO
RIFIUTO
-1.96 1.96 2.11
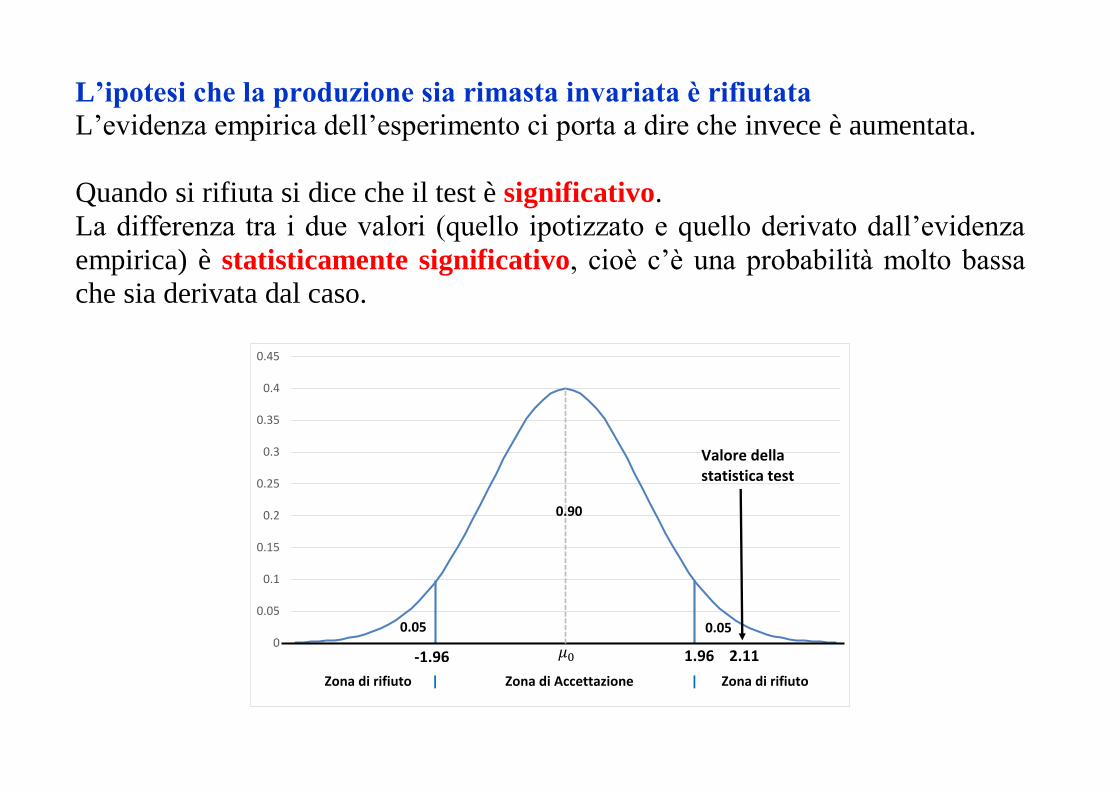
L’ipotesi che la produzione sia rimasta invariata è rifiutata
L’evidenza empirica dell’esperimento ci porta a dire che invece è aumentata.
Quando si rifiuta si dice che il test è significativo.
La differenza tra i due valori (quello ipotizzato e quello derivato dall’evidenza
empirica) è statisticamente significativo, cioè c’è una probabilità molto bassa
che sia derivata dal caso.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-3.5
-3.0
-2.5
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5Zona di rifiuto | Zona di Accettazione | Zona di rifiuto
0.90
0.05 0.05
-1.96 1.96 2.11
Valore della statistica test

Si definiscono due diversi tipi di errore:
Errore del I tipo: rifiutare l’ipotesi nulla 𝐻0 quando essa è in realtà vera;
Errore del II tipo: accettare l’ipotesi nulla 𝐻0 quando essa è in realtà falsa.
, paziente infartuato
Test ematico
L’ipotesi nulla è che il valore del test sia intorno a un valore medio (𝐻0: 𝜇 = 𝜇0),
significa che non c’è stato infarto.
Errore del I tipo: dire che il paziente ha un infarto (rifiuto 𝐻0) quando invece
non ce l’ha.
Errore del II tipo: dire che l’infarto non c’è (non rifiuto 𝐻0) quando in realtà
c’è.

Decisione scaturita dal test
Situazione
reale
Accetto 𝑯𝟎
Dico al paziente
che non c’è infarto
Rifiuto 𝑯𝟎
Dico al paziente
che c’è un infarto
𝑯𝟎 è vera
l’infarto non c’è
Decisione corretta
Probabilità 𝟏 − 𝜶
Errore del I tipo
Probabilità 𝜶
𝑯𝟎 è falsa
l’infarto c’è
Errore del II tipo
Probabilità 𝜷
Decisione corretta
Probabilità 𝟏 − 𝜷
Il livello di significatività del test è 𝛼 (probabilità di commettere un errore del I
tipo)
È il rischio che il ricercatore è disposto a commettere nel rifiutare l’ipotesi nulla
quando è vera.
(Il medico dice al paziente che ha un infarto quando in realtà è sano)

1. Dati del problema: �̅� = 39, 𝜇0 = 35, 𝜎 = 8, 𝑛 = 15;
2. Definizione ipotesi: l’interesse è capire se c’è un aumento del tempo medio
di percorrenza ipotesi alternativa unidirezionale;
{𝐻0: 𝜇 = 35 𝐻1: 𝜇 > 35
3. Scelta della statistica test: si considera la statistica test 𝑍 =�̅�−𝜇0
𝜎 √𝑛⁄;

4. Scelta livello di significatività: da studi precedenti si utilizza un livello di
significatività pari a 2%, quindi 𝛼 = 0.02;
5. Determinazione zona di rifiuto: dalla tavola della Normale standardizzata
si torva che 𝑧 corrispondente a 𝛼 = 0.02 è 𝑧0.02 = 2.06. Dato che l’ipotesi
alternativa è unidirezionale la zona di rifiuto è data dai valori maggiori di 2.06,
ovvero 𝑅 = {𝑧 > 2.06};
6. Calcolo statistica test: utilizzando i dati il valore della statistica test è:
𝑍 =�̅�−𝜇0
𝜎 √𝑛⁄=
39−35
8 √15⁄= 1.936;
7. Decisione finale: il valore della statistica test cade nella zona di accettazione
dell’ipotesi nulla dato che 1.936 < 2.06.
Si conclude pertanto che il tempo medio di percorrenza degli
autobus di questa città non è aumentato.
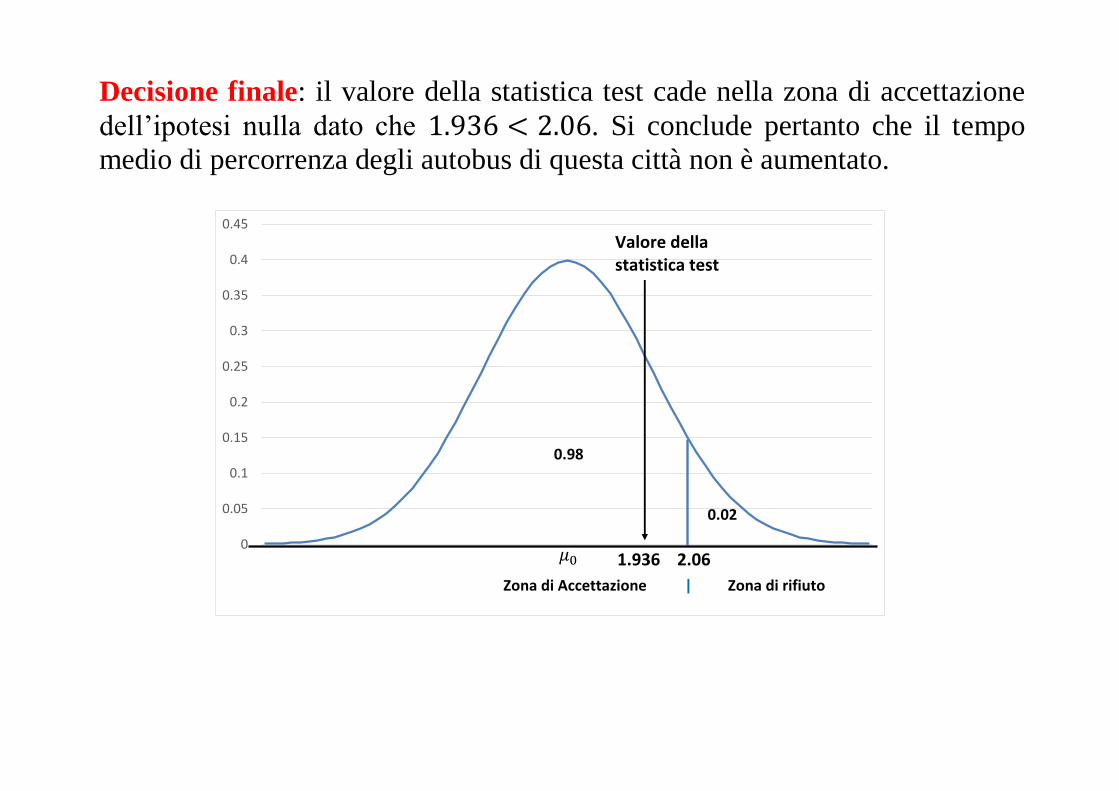
Decisione finale: il valore della statistica test cade nella zona di accettazione
dell’ipotesi nulla dato che 1.936 < 2.06. Si conclude pertanto che il tempo
medio di percorrenza degli autobus di questa città non è aumentato.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-3.5
-3.0
-2.5
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5Zona di Accettazione | Zona di rifiuto
0.98
0.02
1.936 2.06
Valore della statistica test














![HIn + H O H O + In Ka= [H O ] pH= pKa + log [In [HIn] [HIn ... · CLASSE 2 A ocb 22/11/2009 ISIS A. PONTI PROF Mauro Sabella chimica@smauro.it 1 DETERMINAZIONE DELL’INTERVALLO DI](https://static.fdocumenti.com/doc/165x107/5c76ce9709d3f220278c144c/hin-h-o-h-o-in-ka-h-o-ph-pka-log-in-hin-hin-classe-2-a-ocb.jpg)



