
AppuntiStatistica Univers Varese
189
Universit ` a degli Studi dell’Insubria Appunti ed Esempi di Statistica ad uso degli studenti Paolo Tenconi
-
Upload
ppiccolini -
Category
Documents
-
view
230 -
download
0
description
statistica
Transcript of AppuntiStatistica Univers Varese

Universita degli Studi dell’Insubria
Appunti ed Esempi di Statisticaad uso degli studenti
Paolo Tenconi

Paolo Tenconi: Appunti di Statistica
2

Indice
1 Introduzione 91.1 I Dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.1.1 Classificazione dei Dati . . . . . . . . . . . . . . . . . . . . . . . . 91.2 Aree della Statistica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
I Statistica Descrittiva 13
2 Analisi Univariata 172.1 Distribuzioni di Frequenza . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1.1 Dati Nominali, Ordinali e Quantitativi Discreti . . . . . . . . . . . 172.1.2 Dati Quantitativi Continui . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Funzione di Ripartizione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.2.1 Dati Ordinali e Quantitativi Discreti . . . . . . . . . . . . . . . . . 212.2.2 Dati Quantitativi Continui . . . . . . . . . . . . . . . . . . . . . . 22
2.3 Indici di Posizione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.3.1 Moda e Classe Modale . . . . . . . . . . . . . . . . . . . . . . . . . 242.3.2 Medie alla Chisini . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.3.3 Quantili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.4 Indici di Variabilita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322.4.1 Considerazioni Aggiuntive . . . . . . . . . . . . . . . . . . . . . . . 35
2.5 Indici di Simmetria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.6 La Concentrazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.6.1 Dati in Distribuzione Unitaria . . . . . . . . . . . . . . . . . . . . 372.6.2 Dati in Distribuzione di Frequenza . . . . . . . . . . . . . . . . . . 38
3 Analisi Bivariata 413.1 Dati In Distribuzione di Frequenza . . . . . . . . . . . . . . . . . . . . . . 43
3.1.1 Frequenze Congiunte, Marginali e Condizionate . . . . . . . . . . . 433.1.2 Dipendenza Statistica . . . . . . . . . . . . . . . . . . . . . . . . . 453.1.3 Dipendenza in Media o Regressiva . . . . . . . . . . . . . . . . . . 483.1.4 Dipendenza Correlativa . . . . . . . . . . . . . . . . . . . . . . . . 51
3.2 Dati In Distribuzione Unitaria . . . . . . . . . . . . . . . . . . . . . . . . 543.2.1 Dipendenza Correlativa . . . . . . . . . . . . . . . . . . . . . . . . 543.2.2 Dipendenza in Media (Regressione Lineare) . . . . . . . . . . . . . 55
3

Paolo Tenconi: Appunti di Statistica
4 Esercizi di Statistica Descrittiva 59
II Probabilita 77
5 Teoria (Cenni) 795.1 Esperimento ed Eventi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 795.2 Teorie della Probabilita . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.2.1 Classica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 805.2.2 Frequentista . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 805.2.3 Soggettiva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 815.2.4 Assiomatica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.3 Proprieta della Probabilita . . . . . . . . . . . . . . . . . . . . . . . . . . 825.3.1 Teorema delle Probabilita Totali . . . . . . . . . . . . . . . . . . . 825.3.2 Teorema delle Probabilita Composte . . . . . . . . . . . . . . . . . 825.3.3 Teorema di Bayes . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6 Variabili Casuali 856.1 Variabili Casuali Discrete . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
6.1.1 Bernoulli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 866.1.2 Binomiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 866.1.3 Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 876.1.4 Uniforme Discreta . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.2 Variabili Casuali Continue . . . . . . . . . . . . . . . . . . . . . . . . . . . 896.2.1 Uniforme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.2.2 Esponenziale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.2.3 Normale Univariata . . . . . . . . . . . . . . . . . . . . . . . . . . 916.2.4 Normale Multivariata . . . . . . . . . . . . . . . . . . . . . . . . . 93
6.3 Momenti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 946.4 Disuguaglianza di Cebicev . . . . . . . . . . . . . . . . . . . . . . . . . . . 946.5 Trasformazione di Variabile . . . . . . . . . . . . . . . . . . . . . . . . . . 956.6 Esempi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.6.1 Bernoulli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 966.6.2 Binomiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 966.6.3 Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 976.6.4 Esponenziale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 976.6.5 Normale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
7 Convergenza 997.1 In Distribuzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 997.2 In Probabilita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1007.3 In Media r-esima . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1007.4 Quasi Certa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1017.5 Legge Debole dei Grandi Numeri . . . . . . . . . . . . . . . . . . . . . . . 101
4

Paolo Tenconi: Appunti di Statistica
7.6 Teorema del Limite Centrale . . . . . . . . . . . . . . . . . . . . . . . . . 101
8 Esercizi di Probabilita 103
III Statistica Inferenziale 123
9 Introduzione 1259.1 Campionamento da Variabili Casuali: il “Modello Statistico” . . . . . . . . 125
9.1.1 Costruzione del Modello Statistico . . . . . . . . . . . . . . . . . . 126
10 Metodi di Stima 12910.1 Approccio Bayesiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12910.2 Approccio Frequentista . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
10.2.1 Proprieta degli Stimatori . . . . . . . . . . . . . . . . . . . . . . . 130
11 Stima Puntuale 13511.1 Metodo Analogico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13511.2 Metodo dei Momenti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13511.3 Massima Verosimiglianza . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
12 Esercizi di Stima Puntuale 141
13 Stima Intervallare 15113.1 Intervalli di Confidenza per la Media . . . . . . . . . . . . . . . . . . . . . 154
13.1.1 Varianza Nota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15413.1.2 Varianza ignota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
13.2 Intervalli di Confidenza per la Varianza . . . . . . . . . . . . . . . . . . . 15513.2.1 Premessa: Varianza Campionaria e Distribuzione χ2 . . . . . . . . 15513.2.2 Media nota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15613.2.3 Media Ignota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
13.3 Intervalli di Confidenza per Stimatori di Massima Verosimiglianza . . . . 157
14 Esercizi di Stima Intervallare 159
15 Prova delle Ipotesi 16515.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
15.1.1 Definizioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16615.1.2 Tipi di Ipotesi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16615.1.3 Errori e Potenza del Test . . . . . . . . . . . . . . . . . . . . . . . 16715.1.4 Soglia critica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17115.1.5 Considerazioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
15.2 Test di Ipotesi per la Media . . . . . . . . . . . . . . . . . . . . . . . . . . 17615.2.1 Varianza Nota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17615.2.2 Varianza ignota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
5

Paolo Tenconi: Appunti di Statistica
15.3 Test di Ipotesi per la Varianza . . . . . . . . . . . . . . . . . . . . . . . . 17715.3.1 Media nota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17715.3.2 Media Ignota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
15.4 Confronto Fra Medie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17815.4.1 Varianze Note . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17815.4.2 Varianze Ignote . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
15.5 Test del Rapporto di Verosimiglianza . . . . . . . . . . . . . . . . . . . . . 179
16 Esercizi Prova delle Ipotesi 181
6

Premessa
Le presenti note sono intese come ausilio allo studio per i corsi di Statistica di Base e diStatistica Inferenziale. I capitoli con esercizi saranno ulteriormente arricchiti in futuro,cosı come alcune parti teoriche. Le caselle ombreggiate indicano definizioni e concetti diun certo rilievo, mentre le caselle a doppia bordatura sono atte ad evidenziare le formuleprincipali.
Qualsiasi commento, suggerimento o segnalazione di eventuali errori sara gradito.
Varese, Febbraio 2007
Paolo Tenconi
7

Paolo Tenconi: Appunti di Statistica
8

1 Introduzione
1.1 I Dati
I dati costituiscono l’oggetto di analisi della statistica. E’ utile figurarli organizzatitabularmente:
1.1.1 Classificazione dei Dati
Gli strumenti statistici adottati variano sulla base della natura dei caratteri e sull’esaus-tivita delle unita statistiche nei confronti del fenomeno sotto indagine
1.1.1.1 Natura dei Caratteri
Qualitativo
– Nominale: fenomeno non quantitativo non soggetto ad ordinamento (definitoanche mutabile o sconnesso)
– Ordinale: fenomeno non quantitativo passibile di ordinamento (definito ancherettilineo)
Quantitativo
– discreto: espresso numericamente e assumente un insieme numerabile (finitoo infinito) di modalita
9

Paolo Tenconi: Appunti di Statistica
– continuo: espresso numericamente ed assumente potenzialmente tutto in in-sieme di valori compresi in un intervallo
Infine un carattere e trasferibile se puo essere redistribuito fra le unita statistiche.
Ad esempio per i caratteri relativi alla tabella precedente, Sesso e nominale (non trasferi-bile), Titolo di studio e ordinale (non trasferibile), Eta e quantitativo discreto (nontrasferibile), mentre Reddito e quantitativo continuo (trasferibile).
1.1.1.2 Esaustivita dell’indagine
Definiamo popolazione la totalita dei casi pertinenti all’indagine. Distinguiamo fra
Censimento: tutta la popolazione viene rilevata
Campionamento: parte della popolazione e rilevata a causa di ostacoli di varianatura. Esso e frutto di
– Sperimentazione– Osservazione
Acquisizione: parte della popolazione e rilevata ma senza un rigoroso piano di cam-pionamento, ossia la quota di popolazione non e rappresentativa della popolazione.Ad esempio i dati raccolti da una societa commerciale sui propri clienti costitu-iscono una parte dei potenziali clienti, ma non ne rappresentano un campionerappresentativo poiche distorti dal fatto che essi sono gia clienti).
10

Paolo Tenconi: Appunti di Statistica
1.2 Aree della Statistica
Statistica Descrittiva: attraverso metodi grafici ed indici e volta alla sintesi deidati. Applicata alla popolazione conduce a risultati certi, mentre applicata a partedella popolazione ha mera significato di analisi esplorativa.
Statistica Inferenziale: cerca di raggiungere conclusioni circa la popolazionedisponendo di una limitata conoscenza di essa (campione), i risultati sono quindisoggetti ad incertezza. La natura filosofica attribuita all’incertezza ha dato luogoa varie scuole inferenziali
– Frequentista– Bayesiana– Fiduciale– Verosimiglianza
Data Mining: insieme di tecniche volte all’analisi di grosse mole di dati (casie caratteri), nata dalla fusione di varie discipline quali scienza dell’informazione,computer science e statistica. Non si tratta quindi di una disciplina prettamentestatistica, soprattutto per il fatto che spesso i dati su cui si trova ad operare nonsono campioni rappresentativi, bensı mere acquisizioni di dati non rappresentativedella popolazione, percio l’incertezza delle conclusioni a cui giunge non e definibilerigorosamente.
11

Paolo Tenconi: Appunti di Statistica
12

Parte I
Statistica Descrittiva
13


Paolo Tenconi: Appunti di Statistica
* T
ratt
amen
to d
iffer
ente
per
dat
i qua
ntit
ativ
i dis
cret
i e q
uant
itat
ivi c
ontin
ui**
Tra
ttam
ento
ana
logo
per
dat
i qua
ntita
tivi d
iscr
eti e
con
tinui
(pe
r qu
esti
ulti
mi s
i pre
nde
il v
alor
e ce
ntra
le d
i ogn
i cl
asse
), q
uant
ili e
sclu
si
1) S
olo
per
dati
“sec
onda
ri”
(in
dist
ribu
zion
e di
freq
uenz
a)2)
Tra
ttam
ento
diff
eren
te fr
a da
ti se
cond
ari e
dat
i “gr
ezzi
”
Stat
istica
Des
critt
iva
Univa
riata
Biva
riata
Dist
r. di
Fr
eque
nza
Funz
. di
Ripa
rtizio
ne
Indi
ci**
: P
osizi
one
Var
iabi
lità F
orm
a
Dist
r. Fr
eq.
Cong
iunt
a1
Dipe
nden
za:
Sta
tistic
a1
Reg
ress
iva C
orre
lativ
a
Gra
fici*
2
15

Paolo Tenconi: Appunti di Statistica
16

2 Analisi Univariata
2.1 Distribuzioni di Frequenza
I dati tabulari frutto della rilevazione sono definiti grezzi o organizzati in distribuzioneunitaria. Ad esempio se abbiamo rilevato il colore degli occhi dei presenti in un’aula ladistribuzione unitaria potrebbe apparire come di seguito
Casi 1 2 3 4 5 6 7 ... N=20Colore Occhi V C C A V C V ... C
N = 20 numero di casi osservati
V = V erdi, C = Castani, A = Azzurri
Il primo passo consiste nella costruzione della distribuzione di frequenza essa per i carat-teri nominali, ordinali, quantitativi discreti subisce un trattamento comune. Per i datiquantitativi continui si opera diversamente.
2.1.1 Dati Nominali, Ordinali e Quantitativi Discreti
Frequenze Assolute: conteggio delle singole modalita occorse
Frequenze Relative: percentuale di riscontro delle singole modalita
Relativamente all’esempio sul colore degli occhi ipotizziamo di avere rilevato quantosegue
Frequenze
Assolute RelativeAzzurri 3 0,15Castani 12 0,6Verdi 5 0,25
piu formalmente anziche la precedente rappresentazione tabulare si utilizza la seguenteforma
X ≡
A C V3 12 5
X ≡
A C V0, 15 0, 6 0, 25
17

Paolo Tenconi: Appunti di Statistica
nelle pagine a seguire indicheremo con k il numero di modalita che la distribuzione di frequenza assume (nell’esempio
vi sono k = 3 modalita)
xi le singole modalita (nell’esempio A,C,V)
ni le frequenze assolute
fi le frequenze relative, vale sempre la relazione∑k
i=1 fi = 1
N il numero di casi osservati, si noti in proposito che∑k
i=1 ni = N
La rappresentazione grafica della distribuzione di frequenza (assoluta e relativa) avvienetramite grafico a barre oppure con grafico a torta (sconsigliato)
Azzurri Castani Verdi
Frequenze Assolute
Modalità
n i
02
46
810
12
Azzurri Castani Verdi
Frequenze Relative
Modalità
f i
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Per i dati ordinali e quantitativi discreti l’unica prescrizione nella costruzione e rappre-sentazione grafica della distribuzione di frequenza consiste nell’ordinare crescentementeda sinistra verso destra le modalita osservate.
2.1.2 Dati Quantitativi Continui
Il mero conteggio delle singole modalita e impossibile in caso di dati quantitativi continuiin quanto essi assumono un numero troppo elevato di modalita (potenzialmente infinito).Si creano quindi delle classi opportune per le quali vengono calcolate
18

Paolo Tenconi: Appunti di Statistica
Frequenze (assolute e relative)
Densita di frequenza
avremo k classi e per ognuna di esse calcoleremo le densita come segue
hi =fi
di
dove con di si intende l’ampiezza della classe. Quindi la densita di frequenza e un tassonormalizzato di frequenza atto ad eliminare l’effetto distorsivo introdotto dalla scelta diclassi di ampiezze differenti.
Indicheremo con di l’ampiezza di una generica classe
hi la densita di frequenza della classe
ci−1 l’estremo inferiore della classe
ci l’estremo superiore della classe
Ipotizziamo di indicare con X il reddito rilevato sui cittadini di una determinata citta.Potremmo creare tre classi ed osservare quanto segue:
X ≡
0 ` 1000 1000 ` 1500 1500 ` 50000, 25 0, 4 0, 35
e conveniente sintetizzare in una tabella la moteplicita di misure sin qui menzionate
ci−1 ` ci fi di hi
0 ` 1000 0,25 1000 0, 25/10001000 ` 1500 0,4 500 0, 4/5001500 ` 5000 0,35 3500 0, 35/3500
la rappresentazione grafica avviene mediante istogramma
19
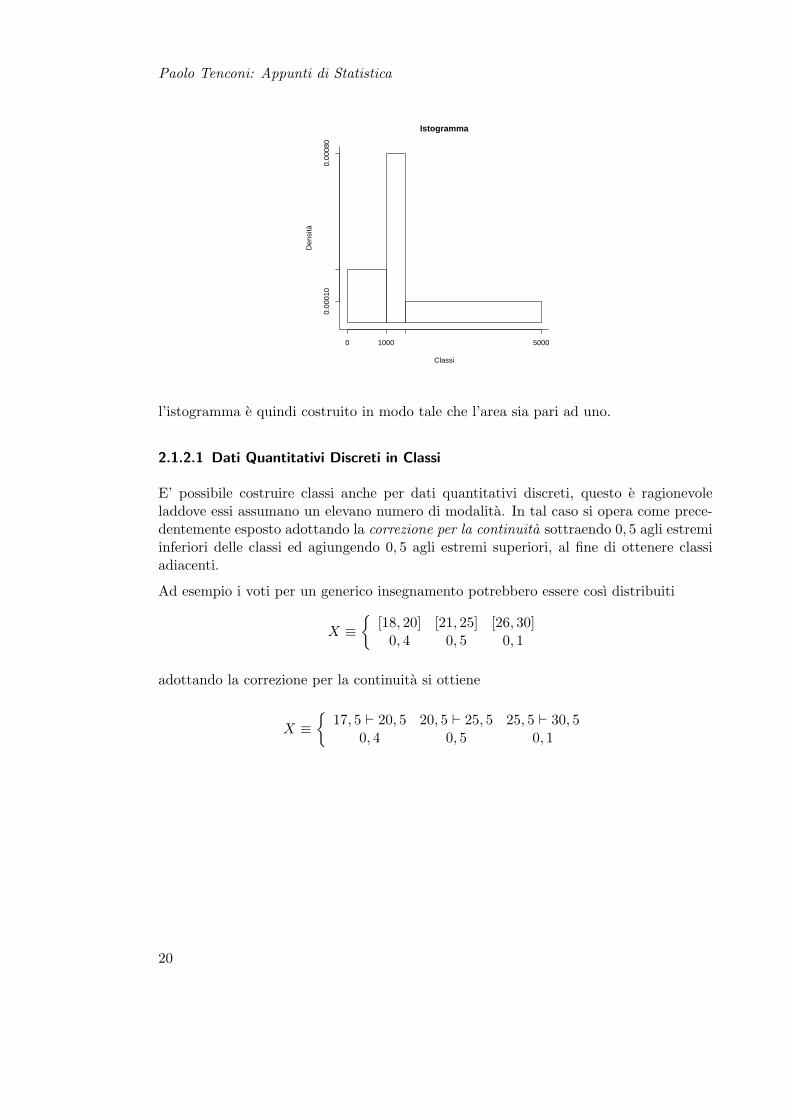
Paolo Tenconi: Appunti di Statistica
Istogramma
Classi
Den
sità
0 1000 5000
0.00
010
0.00
080
l’istogramma e quindi costruito in modo tale che l’area sia pari ad uno.
2.1.2.1 Dati Quantitativi Discreti in Classi
E’ possibile costruire classi anche per dati quantitativi discreti, questo e ragionevoleladdove essi assumano un elevano numero di modalita. In tal caso si opera come prece-dentemente esposto adottando la correzione per la continuita sottraendo 0, 5 agli estremiinferiori delle classi ed agiungendo 0, 5 agli estremi superiori, al fine di ottenere classiadiacenti.
Ad esempio i voti per un generico insegnamento potrebbero essere cosı distribuiti
X ≡
[18, 20] [21, 25] [26, 30]0, 4 0, 5 0, 1
adottando la correzione per la continuita si ottiene
X ≡
17, 5 ` 20, 5 20, 5 ` 25, 5 25, 5 ` 30, 50, 4 0, 5 0, 1
20

Paolo Tenconi: Appunti di Statistica
2.2 Funzione di Ripartizione
La funzione di ripartizione e costituita dalle frequenze cumulate ed esprime la quotadelle frequenze attribuibili alle modalita non superiori ad una specifica di esse; essa none determinabile per dati nominali in quanto non soggetti ad ordinamento. In via generalequindi
F (x) = Fr (X ≤ x)
essa gode delle seguenti proprieta: F (x) ∈ [0, 1] , F (−∞) = 0 , F (+∞) = 1 .
2.2.1 Dati Ordinali e Quantitativi Discreti
Limiteremo l’analisi ai soli dati quantitativi discreti. La forma analitica della funzionedi ripartizione e
F (X) =
0 , x < x1
F (xj) =∑j
i=1 fi , x1...xk
1 , x > xk
ad esempio per X ≡−1 0 3 50, 1 0, 25 0, 15 0, 5
F (X) =
0 , x ∈ (−∞,−1)0 + 0, 1 = 0, 1 , x ∈ [−1, 0)0, 1 + 0, 25 = 0, 35 , x ∈ [0, 3)0, 35 + 0, 15 = 0, 5 , x ∈ [3, 5)0, 5 + 0, 5 = 1 , x ∈ [5,+∞)
nella successiva rappresentazione grafica si noti la continuita da destra della funzione
21
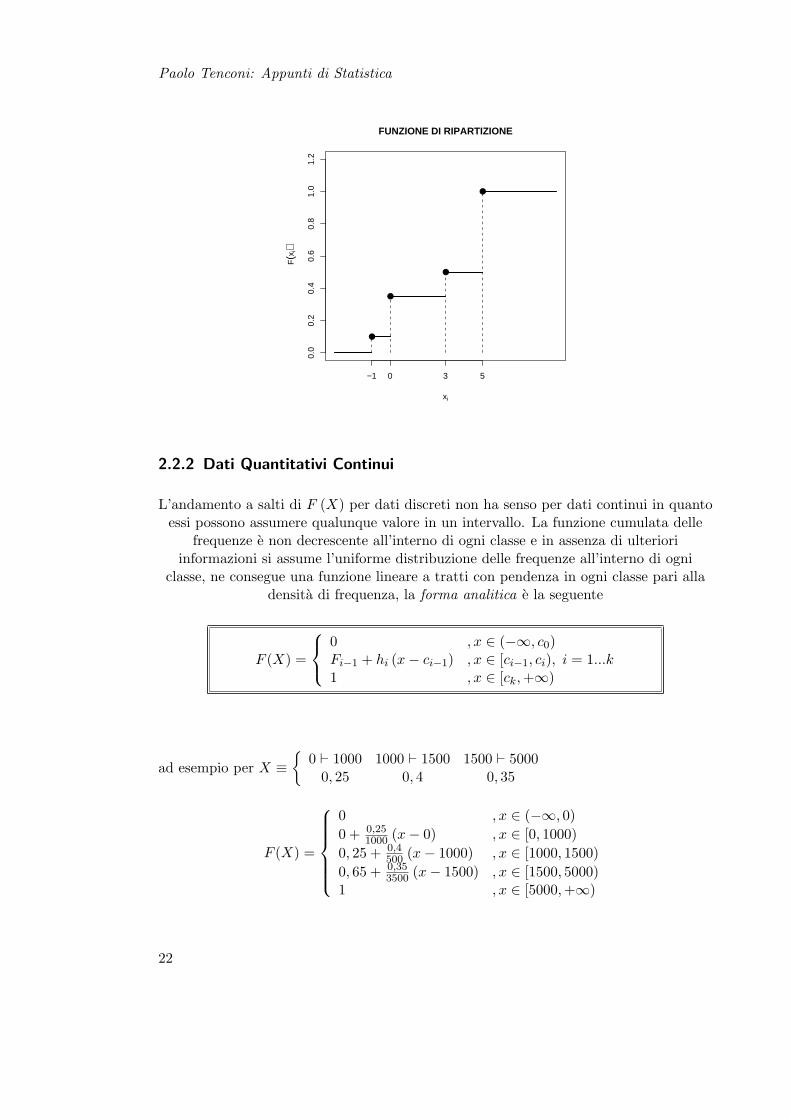
Paolo Tenconi: Appunti di Statistica
FUNZIONE DI RIPARTIZIONE
xi
F(x
i)
−1 0 3 5
0.0
0.2
0.4
0.6
0.8
1.0
1.2
2.2.2 Dati Quantitativi Continui
L’andamento a salti di F (X) per dati discreti non ha senso per dati continui in quantoessi possono assumere qualunque valore in un intervallo. La funzione cumulata delle
frequenze e non decrescente all’interno di ogni classe e in assenza di ulterioriinformazioni si assume l’uniforme distribuzione delle frequenze all’interno di ogni
classe, ne consegue una funzione lineare a tratti con pendenza in ogni classe pari alladensita di frequenza, la forma analitica e la seguente
F (X) =
0 , x ∈ (−∞, c0)Fi−1 + hi (x− ci−1) , x ∈ [ci−1, ci),1 , x ∈ [ck,+∞)
i = 1...k
ad esempio per X ≡
0 ` 1000 1000 ` 1500 1500 ` 50000, 25 0, 4 0, 35
F (X) =
0 , x ∈ (−∞, 0)0 + 0,25
1000 (x− 0) , x ∈ [0, 1000)0, 25 + 0,4
500 (x− 1000) , x ∈ [1000, 1500)0, 65 + 0,35
3500 (x− 1500) , x ∈ [1500, 5000)1 , x ∈ [5000,+∞)
22
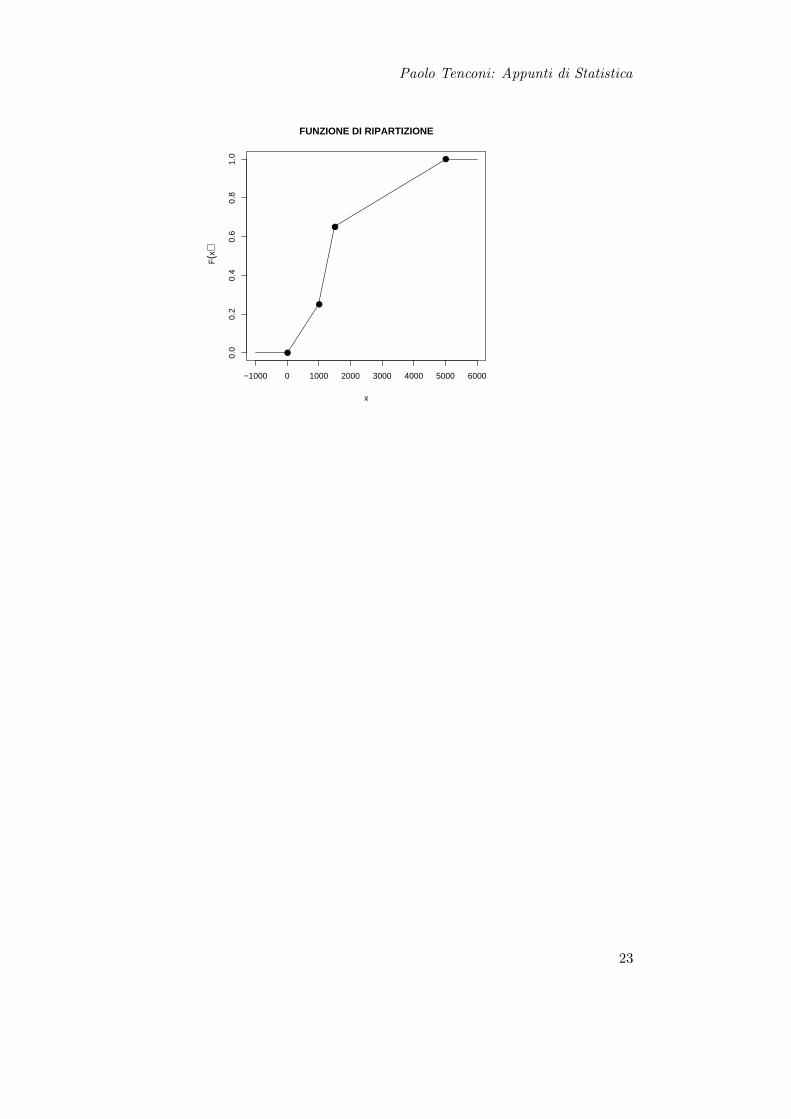
Paolo Tenconi: Appunti di Statistica
−1000 0 1000 2000 3000 4000 5000 6000
0.0
0.2
0.4
0.6
0.8
1.0
FUNZIONE DI RIPARTIZIONE
x
F(x
)
23
Paolo Tenconi: Appunti di Statistica
2.3 Indici di Posizione
Indicano dove e collocato il fenomeno osservato. Ne esistono vari, ognuno con propri-eta, pregi e difetti peculiari, pertanto e sempre consigliabile un utilizzo congiunto. Neprenderemo in considerazione i principali.
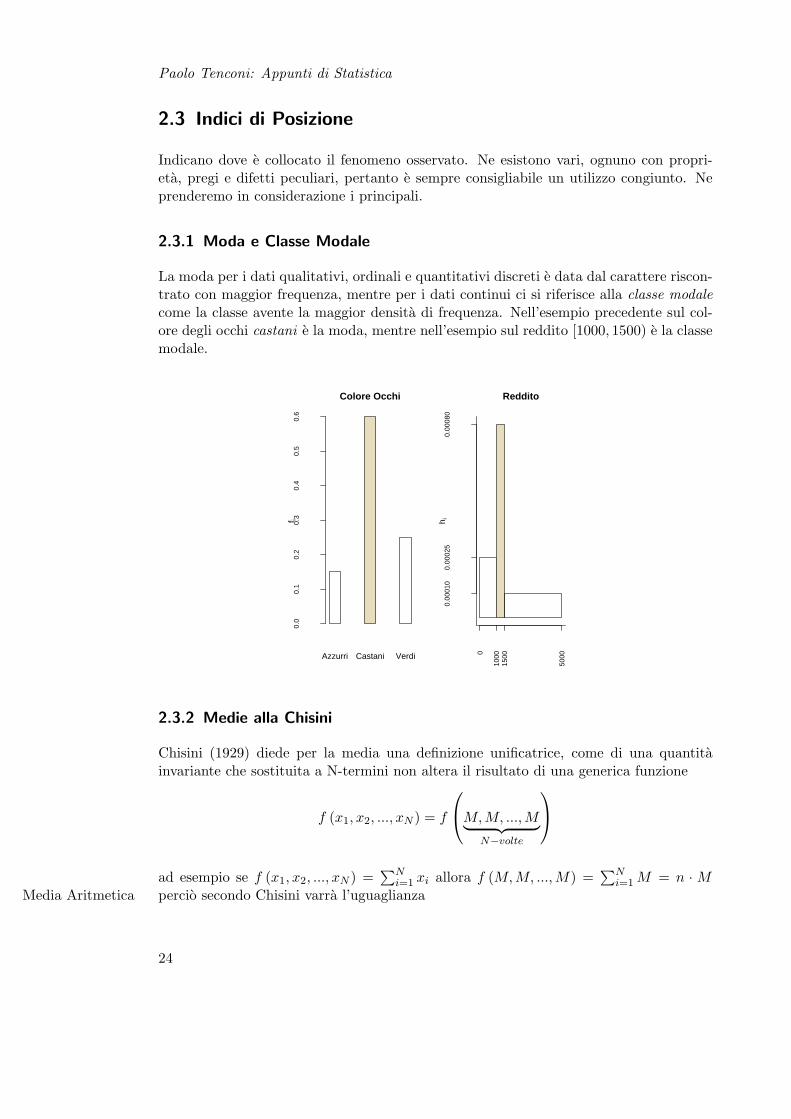
2.3.1 Moda e Classe Modale
La moda per i dati qualitativi, ordinali e quantitativi discreti e data dal carattere riscon-trato con maggior frequenza, mentre per i dati continui ci si riferisce alla classe modalecome la classe avente la maggior densita di frequenza. Nell’esempio precedente sul col-ore degli occhi castani e la moda, mentre nell’esempio sul reddito [1000, 1500) e la classemodale.
Azzurri Castani Verdi
Colore Occhi
f i0.
00.
10.
20.
30.
40.
50.
6
Reddito
h i
0
1000
1500
5000
0.00
010
0.00
025
0.00
080
2.3.2 Medie alla Chisini
Chisini (1929) diede per la media una definizione unificatrice, come di una quantitainvariante che sostituita a N-termini non altera il risultato di una generica funzione
f (x1, x2, ..., xN ) = f
M,M, ..., M︸ ︷︷ ︸N−volte
ad esempio se f (x1, x2, ..., xN ) =
∑Ni=1 xi allora f (M,M, ..., M) =
∑Ni=1 M = n · M
percio secondo Chisini varra l’uguaglianzaMedia Aritmetica
24

Paolo Tenconi: Appunti di Statistica
N∑i=1
xi = n ·M
⇒ M =∑N
i=1 xi
N
proprio la media aritmetica. Essa puo essere riespressa in varie forme per essere calcolatasu dati grezzi, distribuzione delle frequenze assolute e relative. Le tre formule sonosostanzialmente identiche, supponiamo di aver osservato i seguenti dati grezzi
X = 3; 1; 1; 1; 3; 5; 1; 5
calcolata su dati grezzi avremo che
M (X) =∑N
i=1 xi
N=
3 + 1 + 1 + 1 + 3 + 5 + 1 + 58
=208
disponendo in modo crescente gli addendi al numeratore
M (X) =(1 + 1 + 1 + 1) + (3 + 3) + (5 + 5)
8
=1× 4 + 3× 2 + 5× 2
8=
208
=∑k
i=1 xi · ni
N
e spezzando gli addendi
M (X) = 1× 48
+ 3× 28
+ 5× 28
=k∑
i=1
xi · fi
Per i dati continui per classi nelle due ultime formulazioni xicorrisponde al valore centraledella classe xi = (ci − ci−1) /2
25

Paolo Tenconi: Appunti di Statistica
In sintesi la media puo essere calcolata equivalentemente come segue:
M(X) =∑N
i=1 xi
N
=∑k
i=1 xi · ni
N
=k∑
i=1
xi · fi
Questa triplice scrittura opera anche su alcuni degli indici di variabilitae forma che incontreremo oltre.
essa gode delle seguenti proprieta
1.∑N
i=1 (xi −M (X)) = 0 , la somma degli scarti rispetto alla media e zero
2. minc
∑Ni=1 (xi − c)2 = M (X) , la media aritmetica minimizza la varianza
3. M (X) ∈ [min (X) ;max (X)] , internalita: la media e compresa fra il minimo edil massimo
4. M (α + βX) = α+βM (X) , la media di una trasformazione lineare dei dati e parialla medesima trasformazione lineare applicata alla media dei dati
5. M (X) = 1N
∑kj=1 Mj (X)× nj , la media e ricavabile come media ponderata delle
medie di ciascuno dei k sottogruppi ciascuno di ampiezza nj
Non sempre la media aritmetica e adatta nel senso che non lascia invariata la visione delfenomeno, ad esempio per un capitale investito in regime di capitalizzazione compostaper tre anni ai tassi r1 = 0, 03; r2 = 0, 04; r3 = 0, 07 ci si potrebbe domandare qualesia stato il tasso medio ottenuto nei tre anni, ovviamente la condizione e che il capitalefinale (montante) sia il medesimo, applicando l’enunciato di Chisini
Montante = C (1 + r1) (1 + r2) (1 + r3) = C (1 + r) (1 + r) (1 + r)
C ×N∏
i=1
(1 + ri) = C (1 + r)3
e isolando r
r = 3
√√√√ 3∏i=1
(1 + ri)− 1
Media Geometrical’espressione precedente e proprio la media geometrica dei tassi di interesse. Per uninsieme generico di xi avremo
26

Paolo Tenconi: Appunti di Statistica
Mg(X) = N
√√√√ N∏i=1
xi
= N
√√√√ k∏i=1
xnii
=k∏
i=1
xfii
essa gode delle seguenti proprieta
1. Mg (X) ∈ [min (X) ;max (X)] , internalita: e compresa fra il minimo ed il massimo
2. Mg (X) ≤ M (X) , e sempre non superiore alla media aritmetica
3. M (αX) = αMg (X) , invarianza rispetto a cambiamenti di scala
4. Mg (X) = exp M [log (X)]Media Armonica
Un altro tipo di media che si riscontra sovente e la media armonica
Ma(X) =N∑N
i=1 x−1i
=N∑k
i=1 x−1i ni
=1∑k
i=1 x−1i fi
1. Ma (X) ∈ [min (X) ;max (X)] , internalita: e compresa fra il minimo ed il massimo
2. Ma (X) ≤ Mg (X) ≤ M (X) , e sempre non superiore rispetto alla media geomet-rica
3. M (αX) = αMg (X) , invarianza rispetto a cambiamenti di scalaMedie potenziate
Un’importante sottoclasse delle medie di Chisini e dato dalle medie potenziate, ricopronoun ruolo di un certo rilievo in ambito statistico. Definendo f (x1, ...xN ) =
∑Ni=1 xs
i =f (M, ...M) =
∑Ni=1 M s = n ·M s
27

Paolo Tenconi: Appunti di Statistica
Ms(X) =
[∑Ni=1 xs
i
N
]1/s
=
[∑ki=1 xs
ini
N
]1/s
=
[k∑
i=1
xsifi
]1/s
in particolare per s = 1 si ottiene la media aritmetica, s = 2 la media quadratica, s = −1la media armonica, mentre per s → 0 si ottiene la media geometrica.Una proprieta delle medie potenziate e che Ms < Ms se s < s, quindi M (X) > Mg (X) >Ma (X).
2.3.3 Quantili
Il quantile di ordine α ∈ [0, 1) e il minor valore che, dopo aver organizzato i dati inmodo crescente (piu precisamente in ordine non decrescente), lascia alla propria sinistrala proporzione α dei dati.
Indicheremo il quantile con
qα (X) , α ∈ [0, 1]
di uso comune sono tre quantili α = 0, 25 noto come primo quartile, lo indicheremo con Q1 (X)
α = 0, 50 noto come mediana (o secondo quartile) , loindicheremo con Me (X) oppure Q2 (X)
α = 0, 75 noto come terzo quartile , lo indicheremo con Q3 (X)
2.3.3.1 Dati in Distribuzione Unitaria
In tal caso si applica la definizione appena fornita: i dati grezzi X vengono ordinati inmodo non decrescente in una nuova distribuzione unitaria X dopodiche si procede adidentificare l’elemento che soddisfa la definizione di quantile
qα (X) = X[(N ·α)+]
28
Paolo Tenconi: Appunti di Statistica
l’operatore[(N · α)+
]indica il valore alla posizione (N · α)+ dove l’operatore (...)+ indica
l’intero superiore in caso di risultato non intero.
Nel caso α = 0, 5 (mediana) la procedura e leggermente differente
Se N dispari Q2 (X) = X[(N+1)/2]
Se N pari Q2 (X) = X[N/2]+X[N/2+1]
2
Ad esempio dato il seguente insieme di 24 osservazioni X ≡ 1, 4, 1, 5, 7, 5, 1, 1, 5, 7, 1, 1, 7, 1, 5, 7, 5, 5, 1, 4, 1, 1, 7, 5si ottiene l’ordinamento non decrescente X ≡ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 4, 4, 5, 5, 5, 5, 5, 5, 5, 7, 7, 7, 7, 7, ricaviamo i tre quartili
Q1 (X) = X[(24·0,25)+] = X[6+] = X[6] = 1
Q2 (X) = X[24/12]+X[24/12+1]
2 = 4+52
Q3 (X) = X[(24·0,75)+] = X[18+] = X[18] = 5
2.3.3.2 Dati in Distribuzione di Frequenza
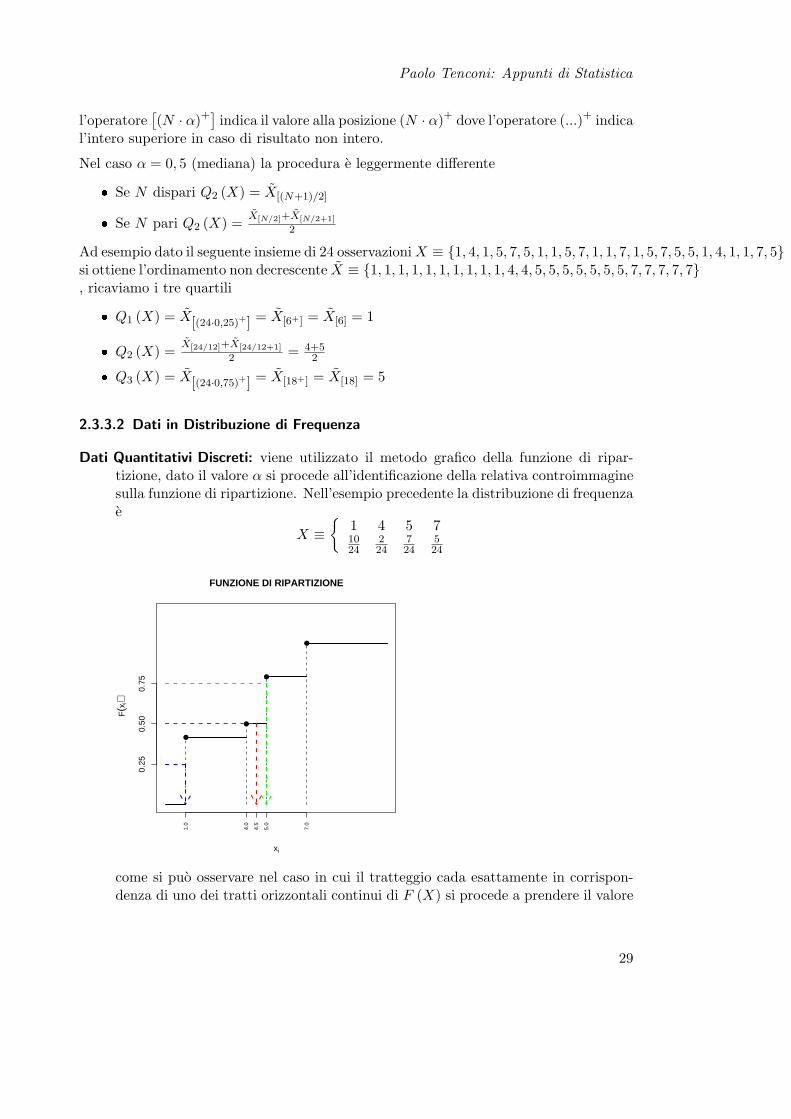
Dati Quantitativi Discreti: viene utilizzato il metodo grafico della funzione di ripar-tizione, dato il valore α si procede all’identificazione della relativa controimmaginesulla funzione di ripartizione. Nell’esempio precedente la distribuzione di frequenzae
X ≡
1 4 5 71024
224
724
524
FUNZIONE DI RIPARTIZIONE
xi
F(x
i)
1.0
4.0
4.5
5.0
7.0
0.25
0.50
0.75
come si puo osservare nel caso in cui il tratteggio cada esattamente in corrispon-denza di uno dei tratti orizzontali continui di F (X) si procede a prendere il valore
29
Paolo Tenconi: Appunti di Statistica
medio compreso fra gli estremi del tratto. Nell’esempio grafico quindi Q1 (X) = 1, Q2 (X) = 4+5
2 = 4.5 e Q3 (X) = 5 .
Dati Quantitativi Continui: e possibile calcolare esattamente la controimmagine in ognipunto di F (X). Si procede come segue:
1. Si individua la classe contenente la soluzione
2. qα (X) = ci−1 + α−Fi−1
hi
ove ci−1e l’estremo inferiore della classe, hi e la densita di classe, Fi−1
la cumulata nell’estremo inferiore
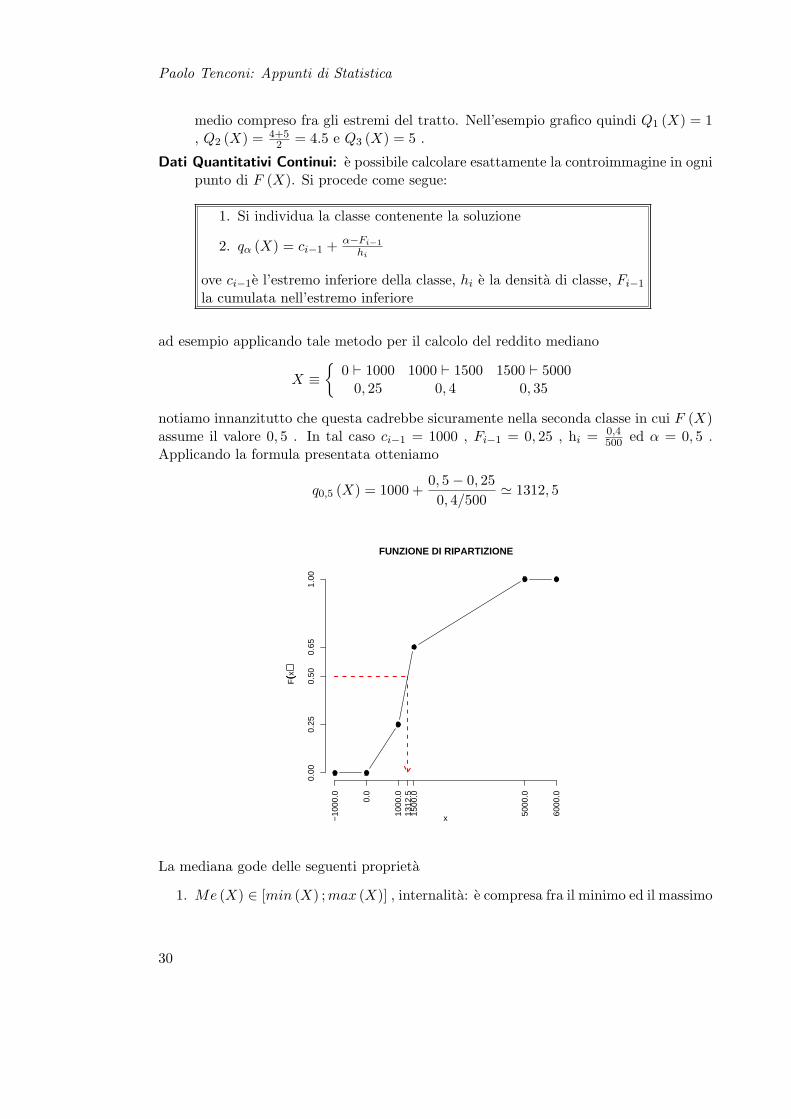
ad esempio applicando tale metodo per il calcolo del reddito mediano
X ≡
0 ` 1000 1000 ` 1500 1500 ` 50000, 25 0, 4 0, 35
notiamo innanzitutto che questa cadrebbe sicuramente nella seconda classe in cui F (X)assume il valore 0, 5 . In tal caso ci−1 = 1000 , Fi−1 = 0, 25 , hi = 0,4
500 ed α = 0, 5 .Applicando la formula presentata otteniamo
q0,5 (X) = 1000 +0, 5− 0, 250, 4/500
' 1312, 5
FUNZIONE DI RIPARTIZIONE
x
F((x
))
1 2
3
4
5 6
−10
00.0 0.0
1000
.013
12.5
1500
.0
5000
.0
6000
.0
0.00
0.25
0.50
0.65
1.00
La mediana gode delle seguenti proprieta
1. Me (X) ∈ [min (X) ;max (X)] , internalita: e compresa fra il minimo ed il massimo
30

Paolo Tenconi: Appunti di Statistica
2. minc
∑Ni=1 |xi − c| = Me (X) , minimizza lo scarto semplice medio
3. Me (α + βX) = α + βMe (X) , la media di una trasformazione lineare dei dati epari alla medesima trasformazione lineare applicata alla media dei dati
31

Paolo Tenconi: Appunti di Statistica
2.4 Indici di Variabilita
Indicano quanto il fenomento e disperso, cioe quanto tende ad assumere modalita differ-enti fra i casi.
Tranne che per gli indici piu semplici (basati su statistiche d’ordine - cioe i quantili), lagran parte appartenenti a questa classe prevede che per gni caso osservato venga calco-lata una distanza fra esso ed un centro (ad esempio la media), dopodiche la totalita delledistanze cosı generate viene sintetizzata con ben precisi indici di posizione (principal-mente media e mediana). In questa ottica vanno intesi la varianza, lo scarto quadraticomedio e gli scarti semplici. Indicando con ∆ la misura distanza adottata, c il centro e Gl’indice di sintesi
Υ (X) = G [∆ (X; c)]
Ad esempio per il seguente insieme di dati
Casi 1 2 3 4 5 6 7xi 3 5 1 3 5 7 18
calcoliamo i due centri M (X) = 6, Q2 (X) = 5 ; scegliamo inoltre come misure di dis-tanza la differenza quadratica ed in valore assoluto attorno alla media e la sola differenzain valore assoluto attorno alla mediana
Casi xi (xi −M (X))2 |xi −M (X) | |xi −Q2 (X) |1 3 9 3 22 5 1 1 03 1 25 5 44 3 9 3 25 5 1 1 06 7 1 1 27 18 144 12 13
Varianza
sintetizziamo le prima colonna prendendone la media, otteniamo cosı la varianza
32

Paolo Tenconi: Appunti di Statistica
σ2 (X) = M[(X −M (X))2
]=
∑Ni=1 (xi −M (X))2
N
=∑k
i=1 (xi −M (X))2 · ni
N
=k∑
i=1
(xi −M (X))2 · fi
nel nostro caso quindi
σ2 (X) =(3− 6)2 + (5− 6)2 + (1− 6)2 + (3− 6)2 + (5− 6)2 + (7− 6)2 + (18− 6)2
7
=(1− 6)2 × 1 + (3− 6)2 × 2 + (5− 6)2 × 2 + (7− 6)2 × 1 + (18− 6)2 × 1
7
= (1− 6)2 × 17
+ (3− 6)2 × 27
+ (5− 6)2 × 27
+ (7− 6)2 × 17
+ (18− 6)2 × 17
' 27, 14
utile e di frequente utilizzo e la seguente riscrittura della varianza, utile fra l’altro inambito di calcolo manuale
σ2 (X) = M(X2)−M (X)2
e importante non confondere i due addendi, il primo e la media dei quadrati (nel nos-
tro caso M(X2)
=P7
i=2 x2i
7 = 32+52+12+32+52+72+182
7 ' 63.143 mentre il secondo e ilquadrato della media aritmetica semplice M (X)2 = 62la loro differenza da appunto27, 14.
Il numeratore delle prime due espressioni della varianza e noto come devianza D (X) = Devianza∑Ni=1 (xi −M (X))2 =
∑ki=1 (xi −M (X))2 ni Scarto quadratico
medioLa radice quadrata della varianza e nota come scarto quadratico medio
σ (X) =√
σ2 (X)
relativamente all’esempio precedente σ (X) ' 5, 21.
La media della seconda colonna da vita allo scarto semplice medio Scarto semplicemedio
33

Paolo Tenconi: Appunti di Statistica
SSM (X) = M [|X −M (X)|] =∑N
i=1 |x−M (X) |N
=∑k
i=1 |xi −M (X) | · ni
N
=k∑
i=1
|x−M (X) | · fi
coi dati precedenti si ha SSM (X) ' 3, 71.
Segnaliamo infino lo scarto semplice medio dalla mediana
M [|X −Q2 (X)|] =∑N
i=1 |x−Q2 (X) |N
=∑k
i=1 |xi −Q2 (X) | · ni
N
=k∑
i=1
|x−Q2 (X) | · fi
il quale per i dati precedenti risulta essere M [|X −Q2 (X)|] ' 3, 29 e lo scarto semplicemediano dalla mediana , che si ottiene come mediana dell’ultima colonna della tabellaprecedente.
Q2 [|X −Q2 (X) |] = 2
esso gode della particolarita di essere resistente (robusto) verso osservazioni anomale(valori estremi dovuti alla natura del fenomeno o ad errori di registrazione dei dati).
Al fine di confrontare la variabilita fra fenomeni simili si ricorre allo scarto quadraticoCoefficiente divariazione medio relativizzato rispetto alla media, noto come coefficiente di variazione
CV (X) =σ (X)|M (X) |
infine due misure di variabilita basate su statistiche d’ordine sono il range o campo divariazione
∆c (X) = max (X)−min (X) = 18− 1 = 17
e la differenza interquartilica
∆q (X) = Q3 (X)−Q1 (X)
34

Paolo Tenconi: Appunti di Statistica
2.4.1 Considerazioni Aggiuntive
Definiamo momento centrale di ordine s Momento centrale∑Ni=1 (xi −M (X))s
N=∑k
i=1 (xi −M (X))s ni
N=
k∑i=1
(xi −M (X))s fi
come caso particolare per s = 2 si ottiene la varianza.
2.4.1.1 Proprieta di devianza, varianza e scarto quadratico medio
Valgono le seguenti proprieta
1. D (X) ≥ 0, V (X) ≥ 0, σ (X) ≥ 0 ed assumono valore zero se tutti i casi assumonouguale modalita
2. D (X) =∑N
i=1 x2i −N ·M (X)2 , V (X) = M
(X2)−M (X)21
3. Per Y = α + βX allora D (Y ) = β2D (X) , V (Y ) = β2V (X) , σ (Y ) = |b|σ (X)
1Dim: ponendo µ = M (X) abbiamo
σ2 (X) =
kXi=1
(xi − µ) f2i
=
kXi=1
x2
i + µ2 − 2xiµfi
=
kXi=1
x2i fi + µ2
kXi=1
fi
| z =1
−2µ
kXi=1
xifi
| z =µ
= MX2−M (X)2
35
Paolo Tenconi: Appunti di Statistica
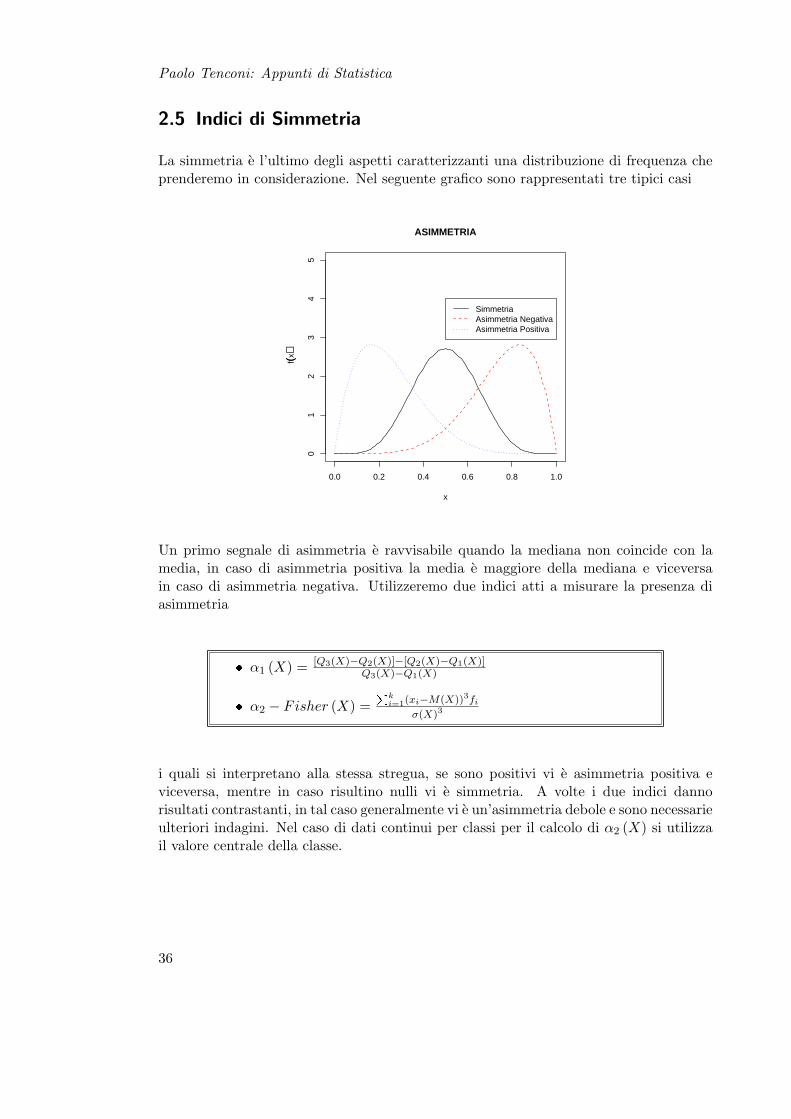
2.5 Indici di Simmetria
La simmetria e l’ultimo degli aspetti caratterizzanti una distribuzione di frequenza cheprenderemo in considerazione. Nel seguente grafico sono rappresentati tre tipici casi
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
ASIMMETRIA
x
f((x))
SimmetriaAsimmetria NegativaAsimmetria Positiva
Un primo segnale di asimmetria e ravvisabile quando la mediana non coincide con lamedia, in caso di asimmetria positiva la media e maggiore della mediana e viceversain caso di asimmetria negativa. Utilizzeremo due indici atti a misurare la presenza diasimmetria
α1 (X) = [Q3(X)−Q2(X)]−[Q2(X)−Q1(X)]Q3(X)−Q1(X)
α2 − Fisher (X) =Pk
i=1(xi−M(X))3fi
σ(X)3
i quali si interpretano alla stessa stregua, se sono positivi vi e asimmetria positiva eviceversa, mentre in caso risultino nulli vi e simmetria. A volte i due indici dannorisultati contrastanti, in tal caso generalmente vi e un’asimmetria debole e sono necessarieulteriori indagini. Nel caso di dati continui per classi per il calcolo di α2 (X) si utilizzail valore centrale della classe.
36

Paolo Tenconi: Appunti di Statistica
2.6 La Concentrazione
Lo studio della concentrazione riguarda l’analisi della ripartizione della totalita del carat-tere fra le varie unita statistiche; ha quindi senso solo per caratteri trasferibili. Di seguitoindicheremo con Y un carattere preventivamente ordinato in modo non decrescente.
2.6.1 Dati in Distribuzione Unitaria
Un carattere si dice equidistribuito se ognuna delle N unita statistiche ne possiedePNi=1 yi
N = AN , ossia una quota pari alla media aritmetica. In tutti gli altri casi si ha
concentrazione, in particolare massima concentrazione se y1 = ...yN−1 = 0 e yN = A .In tutti gli altri casi e necessario determinare il grado di concentrazione, definiamo
Ammontare del carattere posseduto dalle i unita piu povere: Ai =∑i
j=1 yj
Ammontare relativo del carattere posseduto dalle i unita piu povere: Qi = AiA
Ammontare relativo del carattere posseduto dalle i unita piu povere in ipotesi diequidistribuzione: Pi = i
N
Unendo le coppie di punti (Pi, Qi) si ottiene la curva di concentrazione di Lorenz , mentrela retta di punti (Pi, Pi) rappresenta la retta di equidistribuzione. L’area compresa fraqueste due curve e l’area di concentrazione
Ac =12− 1
2
[N∑
i=1
(Pi − Pi−1) (Qi + Qi−1)
], P0 = Q0 = 0
l’area di concentrazione massima teorica e Amax = N−12N , percio l’area relativa di
concentrazione eG =
2N
N − 1Ac
essa coincide (quindi utilizzeremo la stessa lettera) col
rapporto di concentrazione di Gini
G =∑N−1
i=1 (Pi −Qi)∑N−1i=1 Pi
= 1−∑N−1
i=1 Qi∑N−1i=1 Pi
l’indice G di Gini (quindi anche l’area di concentrazione relativa) assumono valore nulloin caso di equidistribuzione ed 1 in caso di massima concentrazione.
Ad esempio si consideri la seguente rilevazione x = 1; 1; 1; 3; 5; 5; 5; 10; 10; 20 , ap-plicando quanto sopra otteniamo Ac ' 0, 234 e G ' 0, 5191 con la seguente curva diLorenz
37
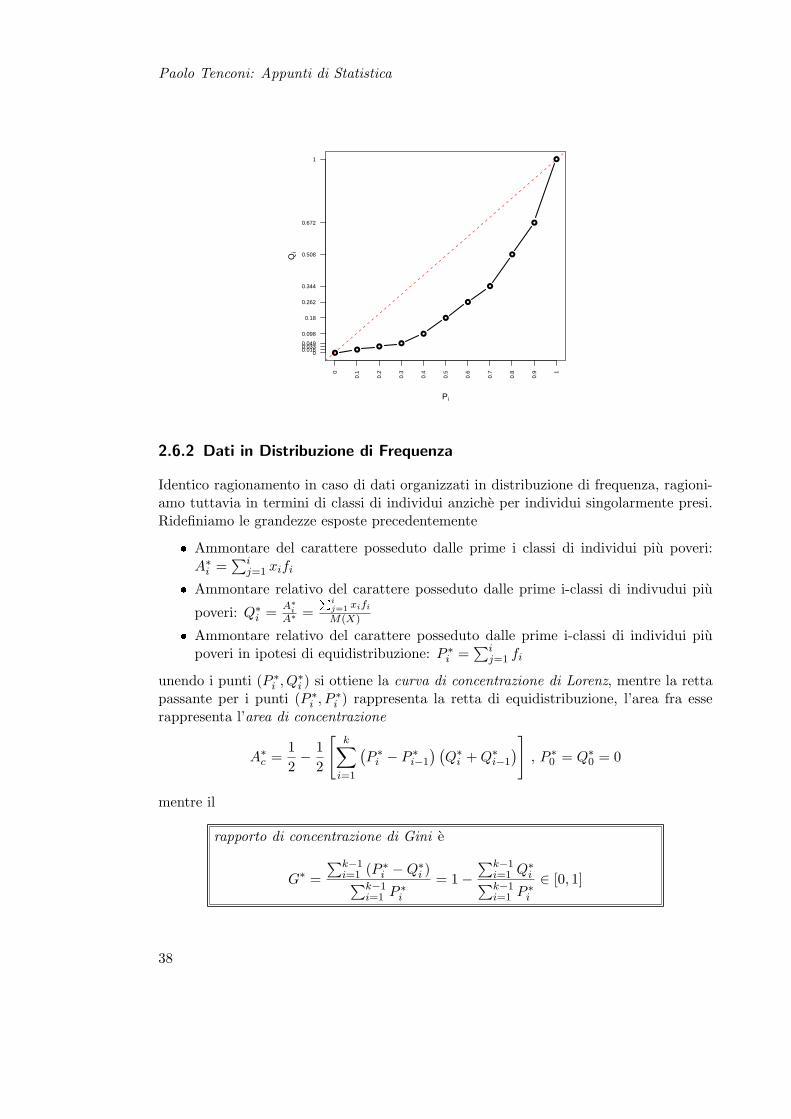
Paolo Tenconi: Appunti di Statistica
Pi
Qi
00.0160.0330.049
0.098
0.18
0.262
0.344
0.508
0.672
1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9 1
2.6.2 Dati in Distribuzione di Frequenza
Identico ragionamento in caso di dati organizzati in distribuzione di frequenza, ragioni-amo tuttavia in termini di classi di individui anziche per individui singolarmente presi.Ridefiniamo le grandezze esposte precedentemente
Ammontare del carattere posseduto dalle prime i classi di individui piu poveri:A∗
i =∑i
j=1 xifi
Ammontare relativo del carattere posseduto dalle prime i-classi di indivudui piu
poveri: Q∗i = A∗i
A∗ =Pi
j=1 xifi
M(X)
Ammontare relativo del carattere posseduto dalle prime i-classi di individui piupoveri in ipotesi di equidistribuzione: P ∗
i =∑i
j=1 fi
unendo i punti (P ∗i , Q∗
i ) si ottiene la curva di concentrazione di Lorenz, mentre la rettapassante per i punti (P ∗
i , P ∗i ) rappresenta la retta di equidistribuzione, l’area fra esse
rappresenta l’area di concentrazione
A∗c =
12− 1
2
[k∑
i=1
(P ∗
i − P ∗i−1
) (Q∗
i + Q∗i−1
)], P ∗
0 = Q∗0 = 0
mentre il
rapporto di concentrazione di Gini e
G∗ =∑k−1
i=1 (P ∗i −Q∗
i )∑k−1i=1 P ∗
i
= 1−∑k−1
i=1 Q∗i∑k−1
i=1 P ∗i
∈ [0, 1]
38
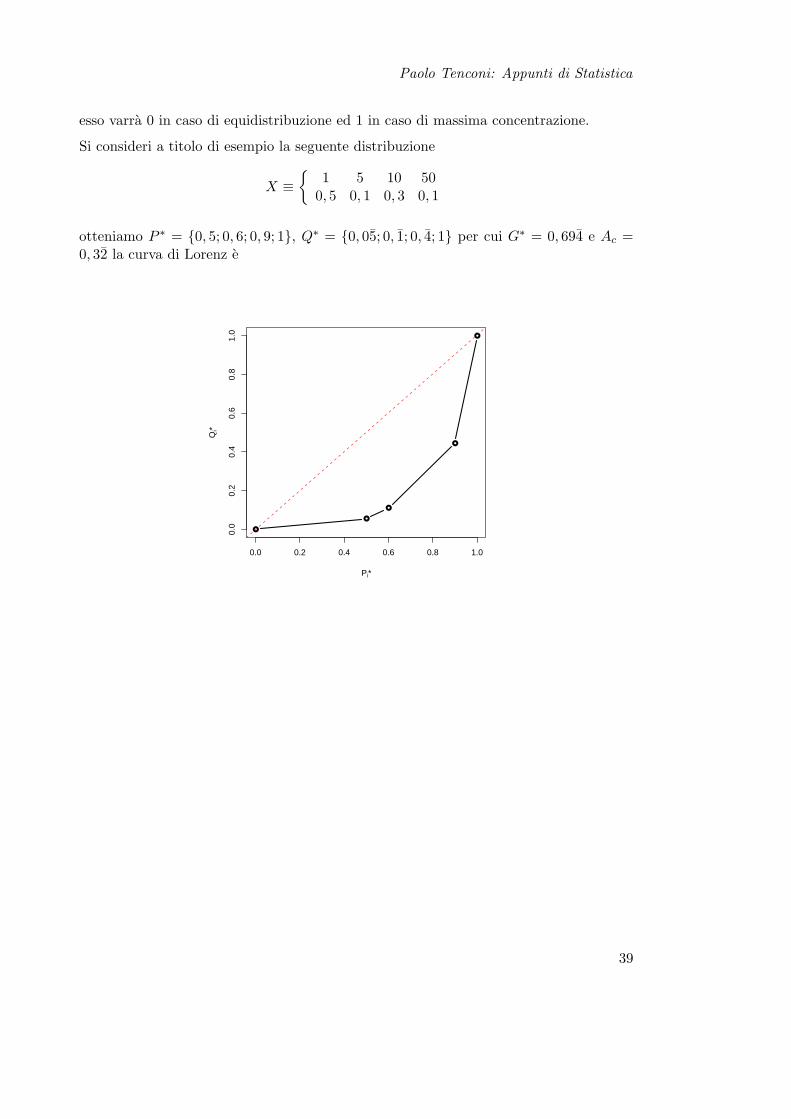
Paolo Tenconi: Appunti di Statistica
esso varra 0 in caso di equidistribuzione ed 1 in caso di massima concentrazione.
Si consideri a titolo di esempio la seguente distribuzione
X ≡
1 5 10 500, 5 0, 1 0, 3 0, 1
otteniamo P ∗ = 0, 5; 0, 6; 0, 9; 1, Q∗ = 0, 05; 0, 1; 0, 4; 1 per cui G∗ = 0, 694 e Ac =0, 32 la curva di Lorenz e
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Pi*
Qi*
39

Paolo Tenconi: Appunti di Statistica
40
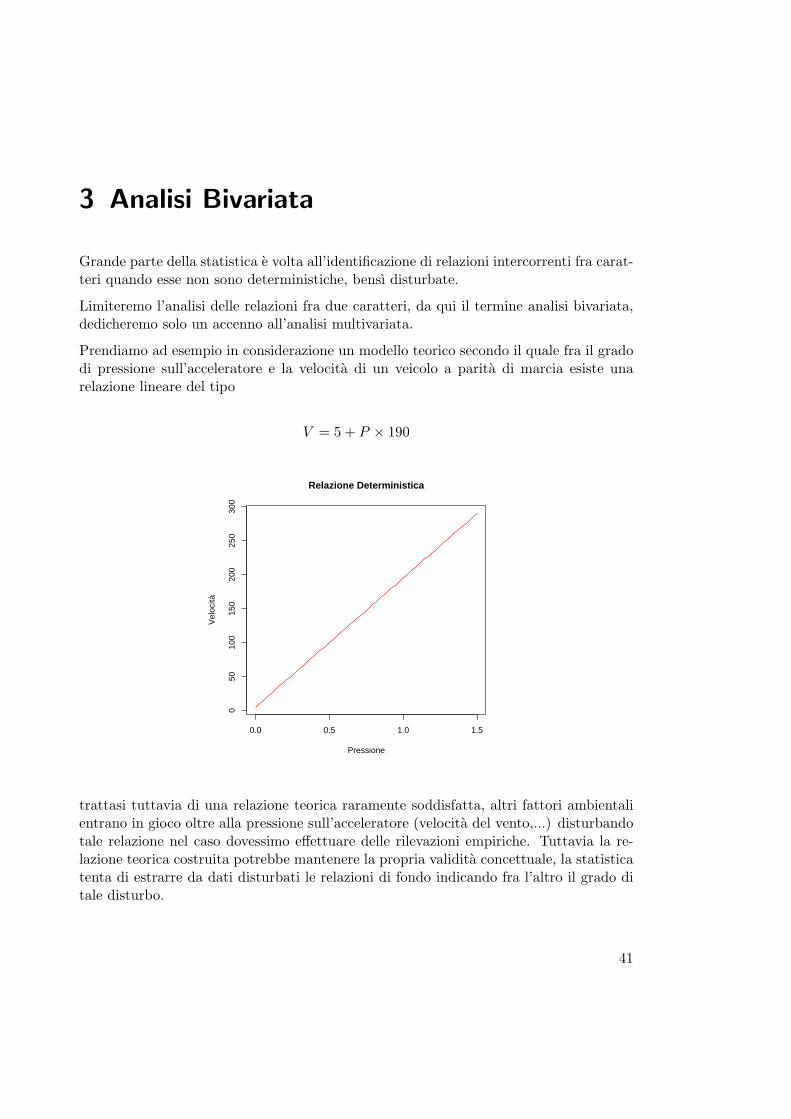
3 Analisi Bivariata
Grande parte della statistica e volta all’identificazione di relazioni intercorrenti fra carat-teri quando esse non sono deterministiche, bensı disturbate.
Limiteremo l’analisi delle relazioni fra due caratteri, da qui il termine analisi bivariata,dedicheremo solo un accenno all’analisi multivariata.
Prendiamo ad esempio in considerazione un modello teorico secondo il quale fra il gradodi pressione sull’acceleratore e la velocita di un veicolo a parita di marcia esiste unarelazione lineare del tipo
V = 5 + P × 190
0.0 0.5 1.0 1.5
050
100
150
200
250
300
Relazione Deterministica
Pressione
Vel
ocità
trattasi tuttavia di una relazione teorica raramente soddisfatta, altri fattori ambientalientrano in gioco oltre alla pressione sull’acceleratore (velocita del vento,...) disturbandotale relazione nel caso dovessimo effettuare delle rilevazioni empiriche. Tuttavia la re-lazione teorica costruita potrebbe mantenere la propria validita concettuale, la statisticatenta di estrarre da dati disturbati le relazioni di fondo indicando fra l’altro il grado ditale disturbo.
41
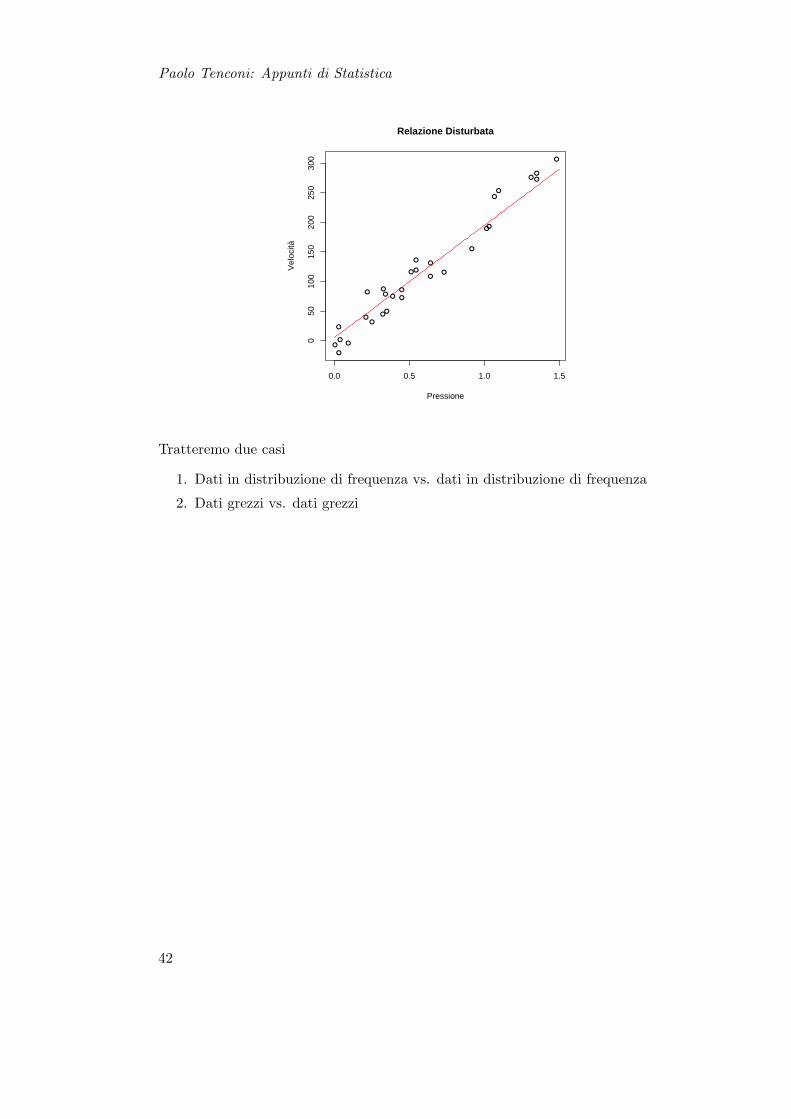
Paolo Tenconi: Appunti di Statistica
0.0 0.5 1.0 1.5
050
100
150
200
250
300
Relazione Disturbata
Pressione
Vel
ocità
Tratteremo due casi
1. Dati in distribuzione di frequenza vs. dati in distribuzione di frequenza
2. Dati grezzi vs. dati grezzi
42

Paolo Tenconi: Appunti di Statistica
3.1 Dati In Distribuzione di Frequenza
Limiteremo gli esempi al caso in cui una delle due variabili e discreta (X) mentre l’altracontinua per classi (Y).
Consideriamo il seguente esempio in cui X = Anni di Scolarita e Y = Reddito Mensile;potremmo osservare la seguente tabella
Y\X 5 8 13 180 ` 1000 0,1 0,03 0,02 0 0,15
1000 ` 1500 0,05 0,1 0,18 0,17 0,51500 ` 5000 0,05 0,07 0,1 0,13 0,35
0,2 0,2 0,3 0,3 1
3.1.1 Frequenze Congiunte, Marginali e Condizionate
3.1.1.1 Frequenze Congiunte
In prima analisi l’interesse e rivolto alle frequenze congiunte, assolute o relative. Nellatabella precedente la frequenza alla prima riga/seconda colonna indica che il 3% deicasi osservati e pertinente a soggetti con 8 anni di scolarita e un reddito compresonell’intervallo 0 ` 1000 , identico ragionamento per le altre celle.
indicando con i la generica riga e j la generica colonna della tabellacon R righe e C colonne, definiamo frequenze congiunte le frequenzecontenute nelle singole celle
nij per frequenze assolute
fij per frequenze relative
3.1.1.2 Distribuzioni Marginali
Partendo dalle frequenze congiunte e possibile calcolare le frequenze marginali e costruirele distribuzioni marginali
43

Paolo Tenconi: Appunti di Statistica
Definiamo frequenze marginali le frequenze a margine di tabella per il carattere indicato sulla prima riga (nell’esempio X)
– n•j =∑R
i=1 nij se trattasi di frequenze assolute
– f•j =∑R
i=1 fij se trattasi di frequenze relative
per il carattere indicato sulla prima colonna (nell’esempio Y)
– ni• =∑C
j=1 nij se trattasi di frequenze assolute
– fi• =∑C
j=1 fij se trattasi di frequenze relative
nei dati in esempio abbiamo le seguenti distribuzioni marginali
Y ≡
0 ` 1000 1000 ` 1500 1500 ` 50000, 15 0, 5 0, 35
X ≡
5 8 13 180, 2 0, 2 0, 3 0, 3
3.1.1.3 Distribuzioni Condizionate
Come si distribuisce Y se limitiamo l’analisi ai soli casi in cui X=5? La risposta ad unatale domanda e nota come distribuzione condizionata, nel nostro esempio abbiamo
Y |X = 5 ≡
0 ` 1000 1000 ` 1500 1500 ` 50000,10,2
0,0502
0,050,2
prendiamo la prima modalita 0 ` 1000 , in questo caso la frequenza congiunta
f (Y = 0 ` 1000;X = 5) = 0, 1
deve essere relativizzata al fatto che stiamo limitando l’analisi ai soli soggetti che hannostudiato 5 anni, quindi il 20% della popolazione, da qui il fatto che f (Y = 0 ` 1500|X = 5) =0, 1/0, 2 = 0, 5 . Stesso ragionamento per le altre modalita della distribuzione condizion-ata.
Quante distribuzioni condizionate possiamo costruire? Le seguenti: Y |X = 5; Y |X =8; Y |X = 13; Y |X = 18 e X|Y = 0 ` 1000; X|Y = 1000 ` 1500; X|Y = 1500 ` 5000.
44

Paolo Tenconi: Appunti di Statistica
Definiamo distribuzione di Y condizionata a X = xh
Y |X = xh ≡
y1 ... yk
f(y1,xh)f(xh) ... f(yk,xh)
f(xh)
analogamente per la distribuzione di Xcondizionata a Y = yh
X|Y = yh ≡
x1 ... xk
f(x1,yh)f(yh) ... f(xk,yh)
f(yh)
3.1.2 Dipendenza Statistica
Il massimo grado di indipendenza statistica lo si raggiunge quando le distribuzioni con-dizionate di Y |X = x sono tutte identiche fra loro (e coincidenti con la distribuzionemarginale di Y) e quando X|Y = y lo sono fra loro stesse (e coincidenti con la dis-tribuzione marginale di X). Questo accade nella tabella di massima indipendenza statis-tica
Definiamo tabella teorica di massima indipendenza statistica la tabellale cui frequenze congiunte sono date da
fij = fi• × f•j , ∀ i, j se trattasi di frequenze relative
nij = ni•×n•j
N , ∀ i, j se trattasi di frequenze assolutein tal caso esprimiamo l’indipendenza simbolicamente in questo modo:X ⊥S Y .
Coi dati in esempio otteniamo la seguente tabella teorica di massima indipendenza
Y\X 5 8 13 180 ` 1000 0,03 0,03 0,045 0,045 0,15
1000 ` 1500 0,1 0,1 0,15 0,15 0,51500 ` 5000 0,07 0,07 0,105 0,105 0,35
0,2 0,2 0,3 0,3 1
E’ possibile verificare che le distribuzioni condizionate Y |X per questa tabella sono fraloro identiche
Y |X = 5; 8; 13; 18 = Y ≡
0 ` 1000 1000 ` 1500 1500 ` 50000, 15 0, 5 0, 35
45
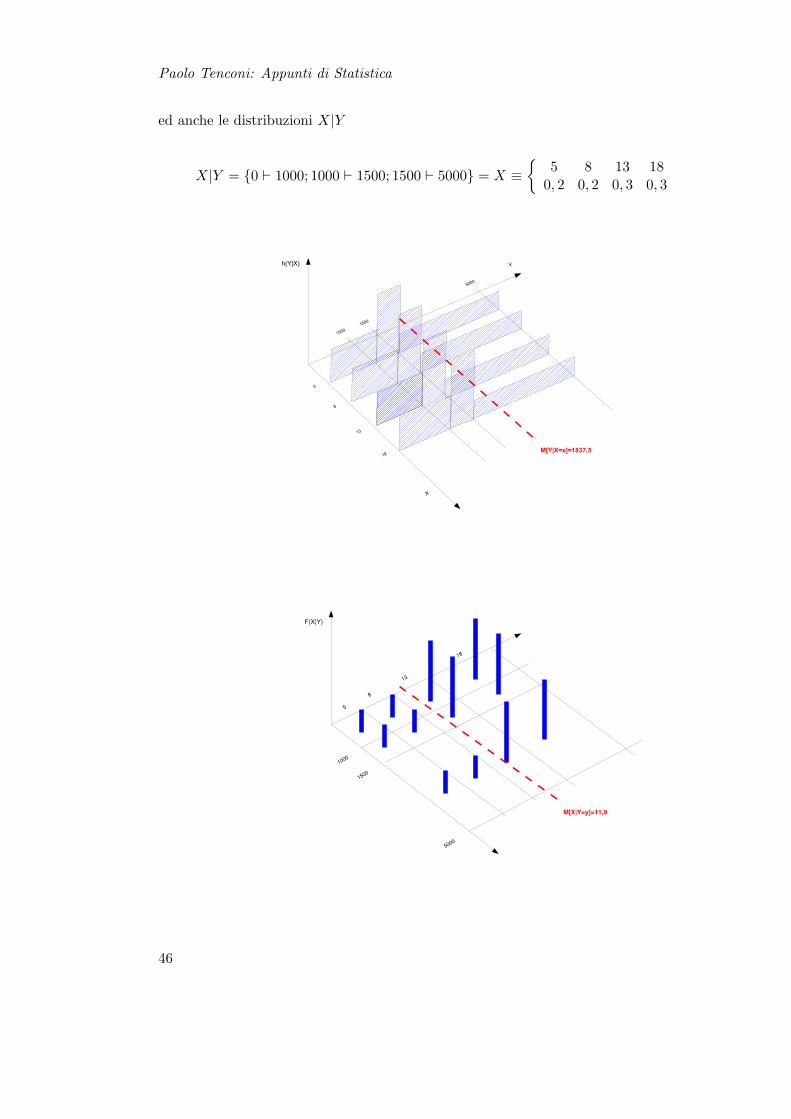
Paolo Tenconi: Appunti di Statistica
ed anche le distribuzioni X|Y
X|Y = 0 ` 1000; 1000 ` 1500; 1500 ` 5000 = X ≡
5 8 13 180, 2 0, 2 0, 3 0, 3
1000
1500
5000
5
8
13
18
Y
X
h(Y|X)
M[Y|X=x]=1837,5
1000
1500
5000
5
8
13
18
M[X|Y=y]=11,9
F(X|Y)
46

Paolo Tenconi: Appunti di Statistica
Pearson ha proposto un indice atto alla misurazione della distanza fra la tabella dellefrequenze osservate e la tabella teorica di massima indipendenza statistica
L’indice χ2 (assoluto) di Pearson viene espresso in varie forme
χ2 = N ·R∑
i=1
C∑j=1
(n2
ij
ni• × n•j
)− 1
=R∑
i=1
C∑j=1
(ni,j − ni,j)2
ni,j
= N ·R∑
i=1
C∑j=1
(fi,j − fi,j
)2
fi,j
le quantita (nij − nij) sono note come contingenze assolute, mentre(fij − fij
)contingenze relative. Si preferisce la versione relativizzata dell’indice di Pearson
χ2 =χ2
N ·min (R− 1) ; (C − 1)∈ [0, 1]
in caso di massima indipendenza l’indice sara prossimo a zero (la tabella osser-vata coincide con quella teorica), mentre in caso di dipendenza statistica saradiverso da zero, in particolare prossimo a uno in caso di perfetta dipendenzastatistica.
Nel nostro esempio risulta che
χ2 =0, 267794
2= 0, 1339
quindi non esiste indipendenza statistica.
3.1.2.1 La Perfetta Dipendenza Statistica
In caso di perfetta dipendenza statistica nota la modalita assunta da una delle due vari-abili, e possibile risalire alla modalita assunta dall’altra. Indicando con •una frequenzanon nulla
x1 x2 x3
y1 •y2 •y3 •
47

Paolo Tenconi: Appunti di Statistica
come si puo notare se X = x1 e certo che Y = y1 , stesso ragionamento per le altre xi eoperando all’inverso da Y verso X . Se la tabella non e quadrata il ragionamento operasolo nella direzione della variabile con un minor numero di modalita
x1 x2 x3
y1 •y2 • •
qui nota X = xj e possibile risalire con certezza a Y = yi ma non viceversa (infatti seY = y2 non sappiamo se X = x2 oppure X = x3).
3.1.3 Dipendenza in Media o Regressiva
E’ un concetto non simmetrico, nel senso che e dfferente studiare Y⊥RX e X⊥RY. Questo tipo di indagine ha senso quando una delle due variabili causa logicamentel’altra
variabile indipendente: causa (nel nostro esempio scolarita)
variabile dipendente: effetto (nel nostro esempio reddito)
studiare la dipendenza regressiva di “Y dato X” richiede la determinazione delle dis-tribuzioni condizionate Y |X = x e le rispettive medie per verificare come queste variano.
Nel nostro esempio studieremo quindi M [Y |X = 5; 8; 13; 18] utilizzando a tal fine unatabella delle distribuzioni condizionate
Y\X f (Y |X = 5) f (Y |X = 8) f (Y |X = 13) f (Y |X = 18)0 ` 1000 0,5 0,15 0, 06 0
1000 ` 1500 0,25 0,5 0,6 0, 561500 ` 5000 0,25 0,35 0, 3 0, 43M [Y |X = x] 1375 1837,5 1866, 6 2116, 6V [Y |X = x] 1265625 1139219 990555,6 982222,2
Valgono le due seguenti importanti relazioni
M [Y ] = M [M (Y |X)] =k∑
i=1
M [Y |Xi] f (Xi)
48
Paolo Tenconi: Appunti di Statistica
nel nostro esempio M [Y ] = 1375 · 0, 2 + 1837 · 0, 2 + 1866, 6 · 0, 3 + 2116, 6 · 0, 3 = 1837, 5.
La seconda proprieta e nota come scomposizione della varianza
V [Y ]︸ ︷︷ ︸V arianza Tot.
= M [V (Y |X)]︸ ︷︷ ︸Media varianze condiz.
V arianza Residua
+ V [M (Y |X)]︸ ︷︷ ︸V arianza fra medie condiz.
V arianza Spiegata
coi dati per l’esempio in questione M [V (Y |X)] = 1265625·0, 2+1139219·0, 2+990555, 6·0, 3 + 982222, 2 · 0, 3 = 1072802, 083 , mentre V [M (Y |X)] = (1375− 1837, 5)2 · 0, 2 +(1837, 5− 1837, 5)2 ·0, 2+(1866, 6− 1837, 5)2 ·0, 3+(2116, 6− 1837, 5)2 ·0, 3 = 66416, 67,da cui V (Y ) = 1072802, 083 + 66416, 67 = 1139218, 75.
Studiare la dipendenza in media di Y |X significa1. Determinare l’andamento delle medie condizionate M [Y |X = x]
2. Determinare la significativita della relazione tramite il grado divarianza spiegata in rapporto alla varianza totale di Y
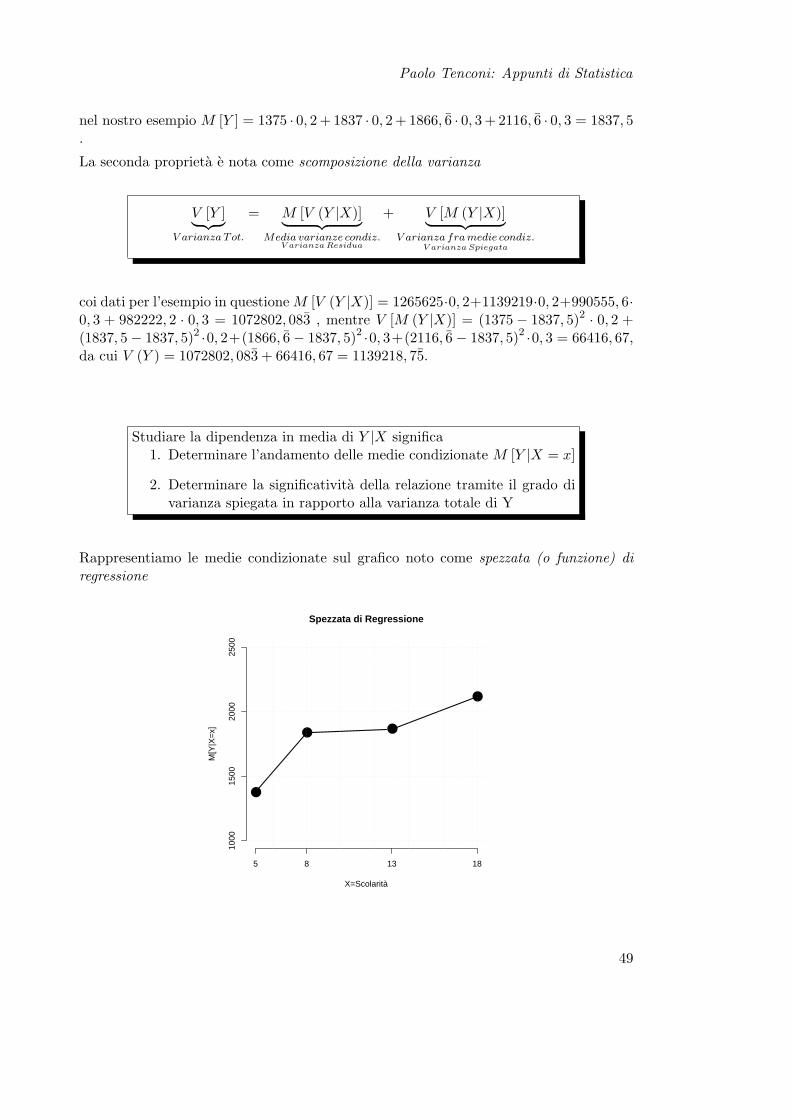
Rappresentiamo le medie condizionate sul grafico noto come spezzata (o funzione) diregressione
Spezzata di Regressione
X=Scolarità
M[Y
|X=
x]
5 8 13 18
1000
1500
2000
2500
49

Paolo Tenconi: Appunti di Statistica
costriamo in seguito il rapporto di correlazione che vale zero nel caso in cui la varianzaspiegata e nulla e 1 se essa coincide con la varianza totale
η2 =vs
vt= 1− vr
vt∈ [0, 1)
per il nostro esempio abbiamo η2 = 0, 058 prossimo a zero quindi la variabile in-dipendente spiega poca parte della varianza totale della variabile dipendente, perciola relazione e statisticamente debole.
3.1.3.1 Relazioni con l’indipendenza statistica
Il seguente grafico attraverso un esempio da un’idea della relazione che intercorre fraindipendenza statistica e regressiva.
Relazioni fra Indipendenza Statistica e Regressiva
Indipendenza Statistica(Distr. Condizionate identiche)
Indipendenza Regressiva(Medie Condizionate identiche)
⇒
⇐
Distribuzioni identiche generano
medie identiche
Medie identiche possono sorgere da distribuzioni
differenti (es. grafico seguente)
x1
x2
Y
X
F(Y|X)
M[Y|x1]=M[Y|X2] maF[Y|x1]≠F[Y|X2]
50

Paolo Tenconi: Appunti di Statistica
3.1.4 Dipendenza Correlativa
Quando fra Xe Y esiste un legame che non necessariamente vede in una delle due variabilila causa dell’altra, serve un indice simmetrico che misuri il grado di associazione fraesse. In tal caso ci si riferisce all’associazione fra caratteri ed e sinonimo di movimentocongiunto, nel senso che all’aumentare di X, Y tende generalmente a muoversi nessastessa direzione o in quella opposta, fermo restando che in caso di assenza di associazioneil movimento di Y sarebbe indeterminato. In caso di non associazione indicheremosimbolicamente X ⊥C Y .
Due indici misurano l’associazione, la covarianza
COV (X, Y ) =∑N
i=1 (xi −M (X)) (yi −M (Y ))N
=R∑
i=1
C∑j=1
(xi −M (X)) (yj −M (Y )) fi,j
= M (X · Y )−M (X) M (Y )
la quale ha un’interpretezione esclusivamente di segno, se positiva indica comovimentocongiunto positivo, mentre se e negativa indica comovimento opposto; infine se e nullanon vi e dipendenza correlativa.
Il secondo indice e il coefficiente di correlazione lineare che oltre ad un’interpretazionedi segno permette anche un’interpretazione sul grado di associazione lineare presente inquanto esso varia fra -1 e 1
ρ (X, Y ) =COV (X, Y )σ (X) σ (Y )
∈ [−1, 1]
nel seguente grafico vi sono alcuni esempi in merito, si noti l’ultimo grafico in cui puressendoci una relazione stretta ma non lineare il coefficiente di correlazione e basso
51

Paolo Tenconi: Appunti di Statistica
−2 −1 0 1 2
−2
−1
01
2
ρ = 0.08
x
y
−2 −1 0 1 2
2.0
2.5
3.0
3.5
4.0
ρ = 0.96
x
y
−2 −1 0 1 2
2.0
2.5
3.0
3.5
4.0
ρ = 0.75
x
y
−2 −1 0 1 2
2.0
2.5
3.0
3.5
4.0
ρ = −0.97
x
y
−2 −1 0 1 2
2.5
3.0
3.5
4.0
ρ = −0.81
x
y
−2 −1 0 1 2
510
15
ρ = 0.22
x
y
per quanto riguarda l’esempio sulla relazione fra reddito e anni di scolarita, rammen-tando che M (X) = 11, 9 e M (Y ) = 1837, 5 e calcolando per ogni cella la quantita(xi −M (X)) (yj −M (Y )) fi,j otteniamo la seguente tabella
Y\X 5 8 13 18
0 ` 1000(5− 11, 9)×(500− 1837, 5)×0, 1
(8− 11, 9)×(500− 1837, 5)×0, 03
(13− 11, 9)×(500− 1837, 5)×0, 02
(18− 11, 9)×(500− 1837, 5)×0
1000 ` 1500(5− 11, 9)×(1250− 1837, 5)×0, 05
(8− 11, 9)×(1250− 1837, 5)×0, 1
(13− 11, 9)×(1250− 1837, 5)×0, 18
(18− 11, 9)×(1250− 1837, 5)×0, 17
1500 ` 5000(5− 11, 9)×(3250− 1837, 5)×0, 05
(8− 11, 9)×(3250− 1837, 5)×0, 07
(13− 11, 9)×(3250− 1837, 5)×0, 1
(18− 11, 9)×(3250− 1837, 5)×0, 13
sommando poi tutte le celle otteniamo, come da definizione, la covarianza
COV (X, Y ) =R∑
i=1
C∑j=1
(xi −M (X)) (yj −M (Y )) fi,j = 1158, 75
abbiamo stabilito che esiste associazione positiva, determiniamone ora il grado
ρ (X, Y ) =COV (X, Y )σ (X) σ (Y )
=1158, 75
24, 09× 1139218, 75= 0, 2212
giudichiamo la correlazione come positiva medio-bassa.
E’ piu agevole adottare la formulazione COV (X, Y ) = M (X · Y ) − M (X) M (Y ) inquanto si dispone gia di M (X) e M (Y ) , facendo uso per la variabile continua per classi
52
Paolo Tenconi: Appunti di Statistica
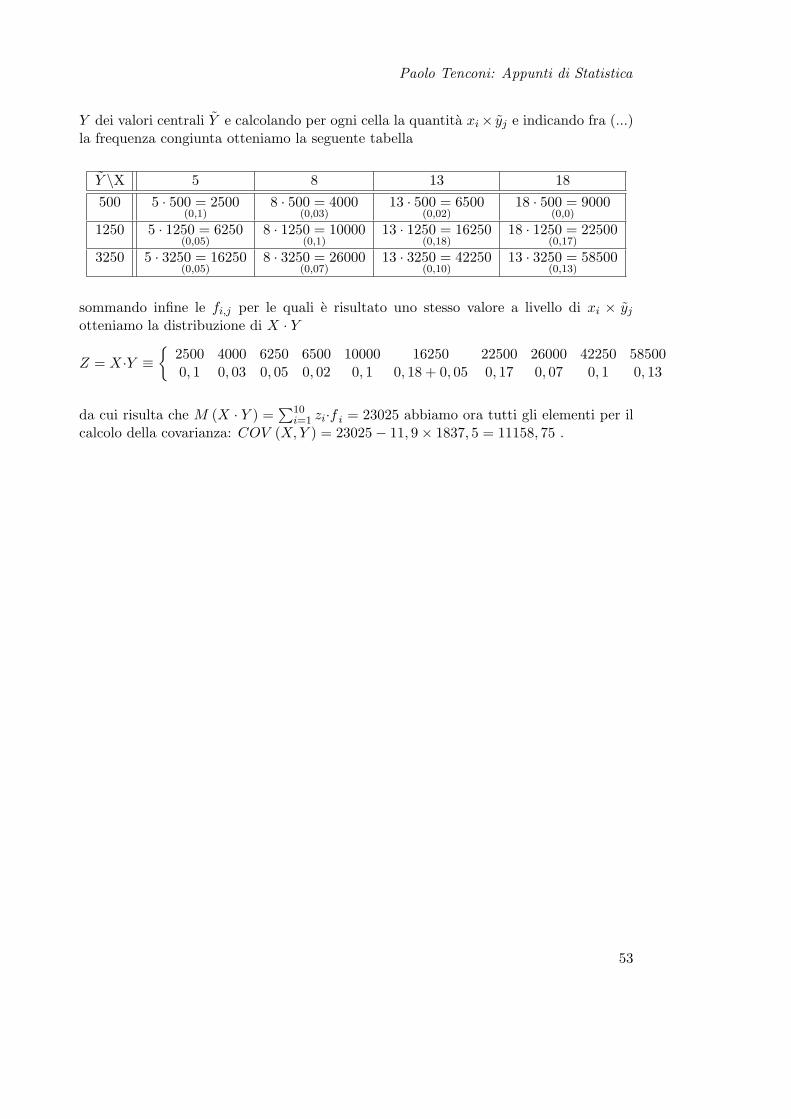
Y dei valori centrali Y e calcolando per ogni cella la quantita xi× yj e indicando fra (...)la frequenza congiunta otteniamo la seguente tabella
Y \X 5 8 13 18500 5 · 500 = 2500
(0,1)8 · 500 = 4000
(0,03)13 · 500 = 6500
(0,02)18 · 500 = 9000
(0,0)
1250 5 · 1250 = 6250(0,05)
8 · 1250 = 10000(0,1)
13 · 1250 = 16250(0,18)
18 · 1250 = 22500(0,17)
3250 5 · 3250 = 16250(0,05)
8 · 3250 = 26000(0,07)
13 · 3250 = 42250(0,10)
13 · 3250 = 58500(0,13)
sommando infine le fi,j per le quali e risultato uno stesso valore a livello di xi × yj
otteniamo la distribuzione di X · Y
Z = X·Y ≡
2500 4000 6250 6500 10000 16250 22500 26000 42250 585000, 1 0, 03 0, 05 0, 02 0, 1 0, 18 + 0, 05 0, 17 0, 07 0, 1 0, 13
da cui risulta che M (X · Y ) =∑10
i=1 zi·f i = 23025 abbiamo ora tutti gli elementi per ilcalcolo della covarianza: COV (X, Y ) = 23025− 11, 9× 1837, 5 = 11158, 75 .
53
Paolo Tenconi: Appunti di Statistica
3.2 Dati In Distribuzione Unitaria
3.2.1 Dipendenza Correlativa
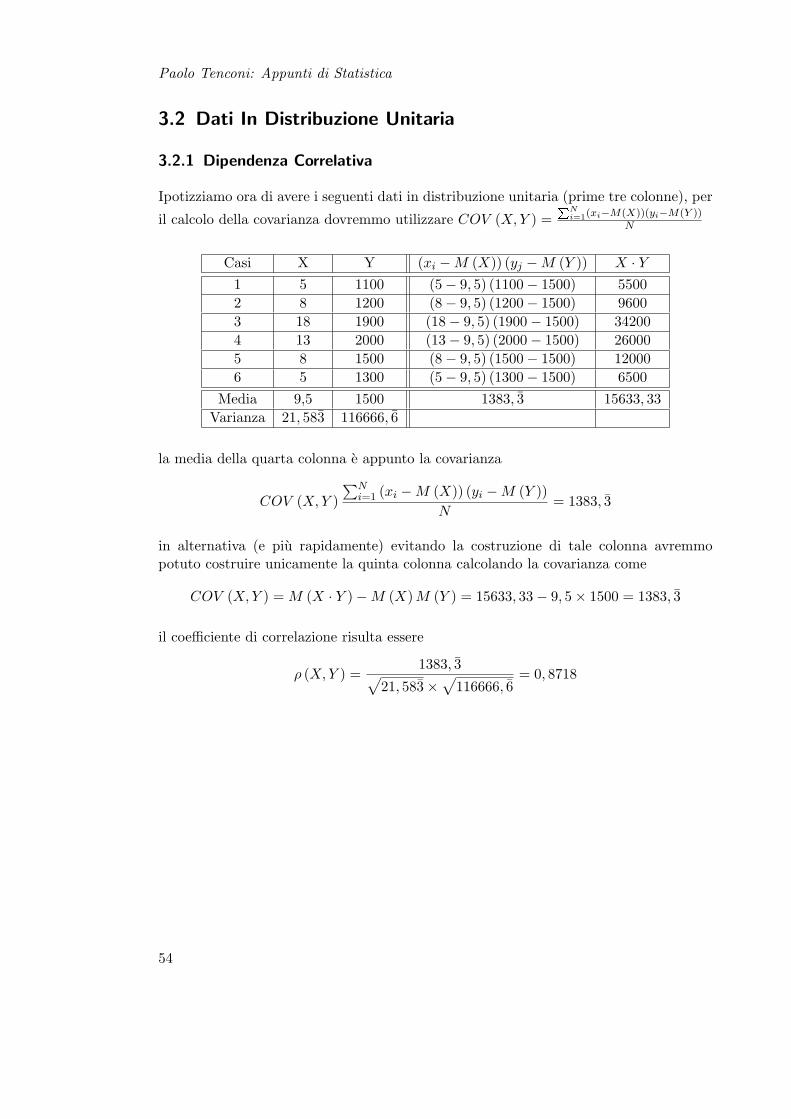
Ipotizziamo ora di avere i seguenti dati in distribuzione unitaria (prime tre colonne), per
il calcolo della covarianza dovremmo utilizzare COV (X, Y ) =PN
i=1(xi−M(X))(yi−M(Y ))N
Casi X Y (xi −M (X)) (yj −M (Y )) X · Y1 5 1100 (5− 9, 5) (1100− 1500) 55002 8 1200 (8− 9, 5) (1200− 1500) 96003 18 1900 (18− 9, 5) (1900− 1500) 342004 13 2000 (13− 9, 5) (2000− 1500) 260005 8 1500 (8− 9, 5) (1500− 1500) 120006 5 1300 (5− 9, 5) (1300− 1500) 6500
Media 9,5 1500 1383, 3 15633, 33Varianza 21, 583 116666, 6
la media della quarta colonna e appunto la covarianza
COV (X, Y )∑N
i=1 (xi −M (X)) (yi −M (Y ))N
= 1383, 3
in alternativa (e piu rapidamente) evitando la costruzione di tale colonna avremmopotuto costruire unicamente la quinta colonna calcolando la covarianza come
COV (X, Y ) = M (X · Y )−M (X) M (Y ) = 15633, 33− 9, 5× 1500 = 1383, 3
il coefficiente di correlazione risulta essere
ρ (X, Y ) =1383, 3√
21, 583×√
116666, 6= 0, 8718
54
Paolo Tenconi: Appunti di Statistica
3.2.2 Dipendenza in Media (Regressione Lineare)
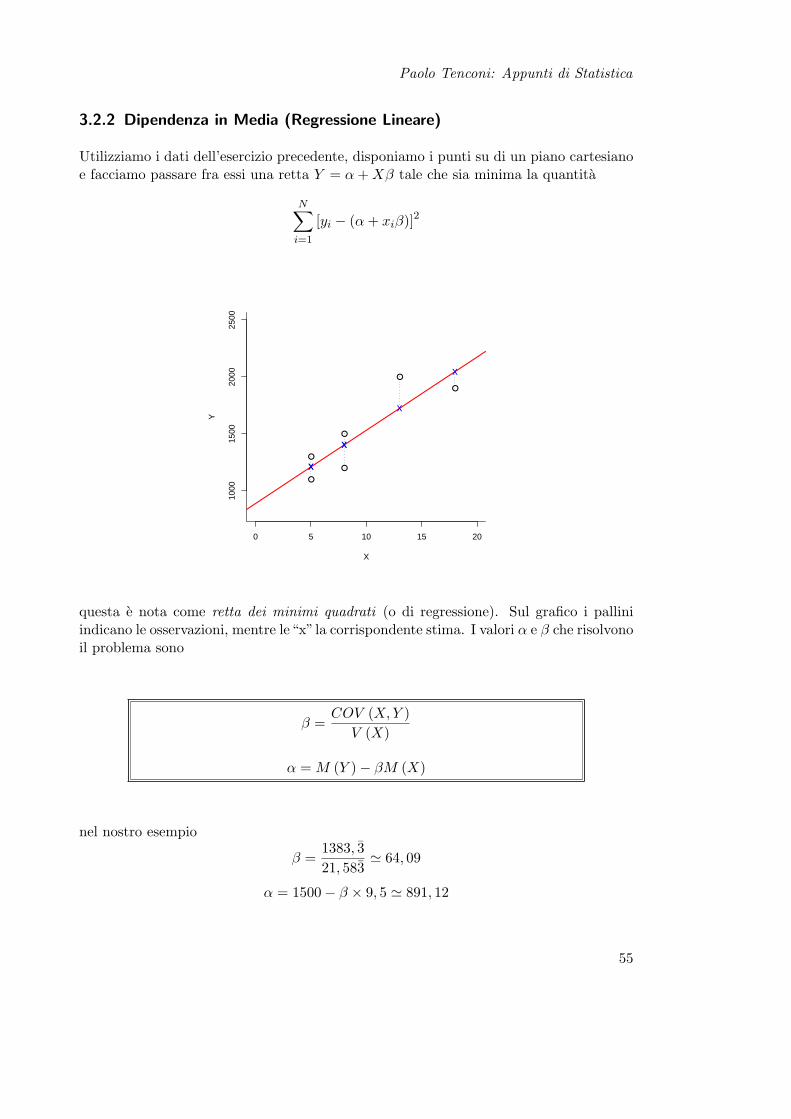
Utilizziamo i dati dell’esercizio precedente, disponiamo i punti su di un piano cartesianoe facciamo passare fra essi una retta Y = α + Xβ tale che sia minima la quantita
N∑i=1
[yi − (α + xiβ)]2
0 5 10 15 20
1000
1500
2000
2500
X
Y
x
x
x
x
x
x
questa e nota come retta dei minimi quadrati (o di regressione). Sul grafico i palliniindicano le osservazioni, mentre le“x”la corrispondente stima. I valori α e β che risolvonoil problema sono
β =COV (X, Y )
V (X)
α = M (Y )− βM (X)
nel nostro esempio
β =1383, 321, 583
' 64, 09
α = 1500− β × 9, 5 ' 891, 12
55

Paolo Tenconi: Appunti di Statistica
3.2.2.1 Scomposizione della Varianza e R2
Per ogni yi osservato siamo in grado ora di associare un yi stimato
yi = 891, 12 + xi × 64, 09
commettendo un errore εi = yi − yi
Casi X Y Y = α + Xβ ε = Y − Y
1 5 1100 1211,58 -111,582 8 1200 1403,86 -203,863 18 1900 2044,79 -144,794 13 2000 1724,32 275,685 8 1500 1403,86 96,146 5 1300 1211,58 88,42
Media 1500 1500 0Varianza 116666, 6 88661,52 28005,15
Dall’esame delle medie e varianze delle colonne della tabella riemergono due importantirelazioni, legate a quanto rilevato gia in sede di analisi di dati in distribuzione di frequenza
M (Y ) = M(Y)
V (Y )︸ ︷︷ ︸V arianza Totale
= V(Y)
︸ ︷︷ ︸V arianza Spiegata
+ V (ε)︸ ︷︷ ︸V arianza Residua
che e il noto teorema di scompo-
sizione della varianza
siamo alla ricerca di un indice che valga zero se V(Y)
= 0 e che valga uno se V(Y)
=
V (Y ) ; parimenti a quanto operato per l’identificazione dell’indice η2 questo e dato da
R2 = 1− V (ε)V (Y )
=V(Y)
V (Y )∈ [0, 1]
ovviamente quanto R2 e piu prossimo a uno tanto migliore sara la qualita dell’interpo-lazione, viceversa nel caso in cui R2 sia basso. Unicamente nel caso bivariato vale larelazione R2 = ρ (X, Y )2 di notevole comodita per il calcolo manuale.
Nel nostro esempio R2 = 88661,52116666,6
' 0, 76 un valore medio alto che indica un buon gradodi interpolazione.
Osservazione: a parita di α, β un diverso R2 implica maggiore o minore forza dellarelazione lineare, come evidenziato nel seguente grafico
56
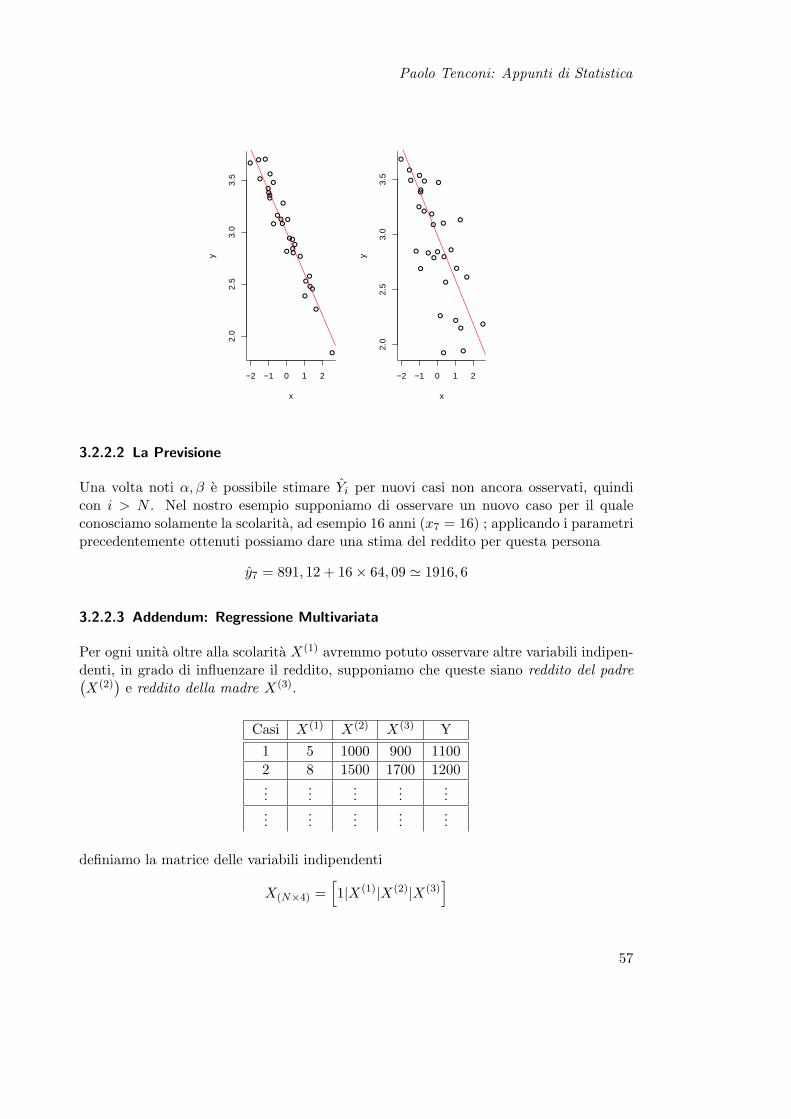
Paolo Tenconi: Appunti di Statistica
−2 −1 0 1 2
2.0
2.5
3.0
3.5
x
y
−2 −1 0 1 22.
02.
53.
03.
5
x
y
3.2.2.2 La Previsione
Una volta noti α, β e possibile stimare Yi per nuovi casi non ancora osservati, quindicon i > N . Nel nostro esempio supponiamo di osservare un nuovo caso per il qualeconosciamo solamente la scolarita, ad esempio 16 anni (x7 = 16) ; applicando i parametriprecedentemente ottenuti possiamo dare una stima del reddito per questa persona
y7 = 891, 12 + 16× 64, 09 ' 1916, 6
3.2.2.3 Addendum: Regressione Multivariata
Per ogni unita oltre alla scolarita X(1) avremmo potuto osservare altre variabili indipen-denti, in grado di influenzare il reddito, supponiamo che queste siano reddito del padre(X(2)
)e reddito della madre X(3).
Casi X(1) X(2) X(3) Y1 5 1000 900 11002 8 1500 1700 1200...
......
......
......
......
...
definiamo la matrice delle variabili indipendenti
X(N×4) =[1|X(1)|X(2)|X(3)
]
57

Paolo Tenconi: Appunti di Statistica
ove la prima colonna e un vettore unitario, la relazione lineare ora diviene
Y = Xβ + ε
con
β =
β0
β1
β2
β3
che costituisce il vettore dei parametri che devono essere stimati affinche sia minima laquantita (indicando con “T” la matrice trasposta)
(Y −Xβ)T (Y −Xβ)
la soluzione e identificata attraverso semplici passaggi di minimizzazione di funzione
Minβ
(Y −Xβ)T (Y −Xβ)
= Y T Y − Y T Xβ − (Xβ)T Y − (Xβ)T (Xβ)= Y T Y − 2Y T Xβ − βT
(XT X
)β
derivando rispetto a β e uguagliando a zero
∂[Y T Y − 2Y T Xβ − βT
(XT X
)β]
∂β= −2Y T X − 2
(XT X
)β = 0
β =(XT X
)−1XT Y
Il resto dell’analisi (previsione, calcolo di R2) e identico al caso con una sola variabileindipendente.
58

4 Esercizi di Statistica Descrittiva
59
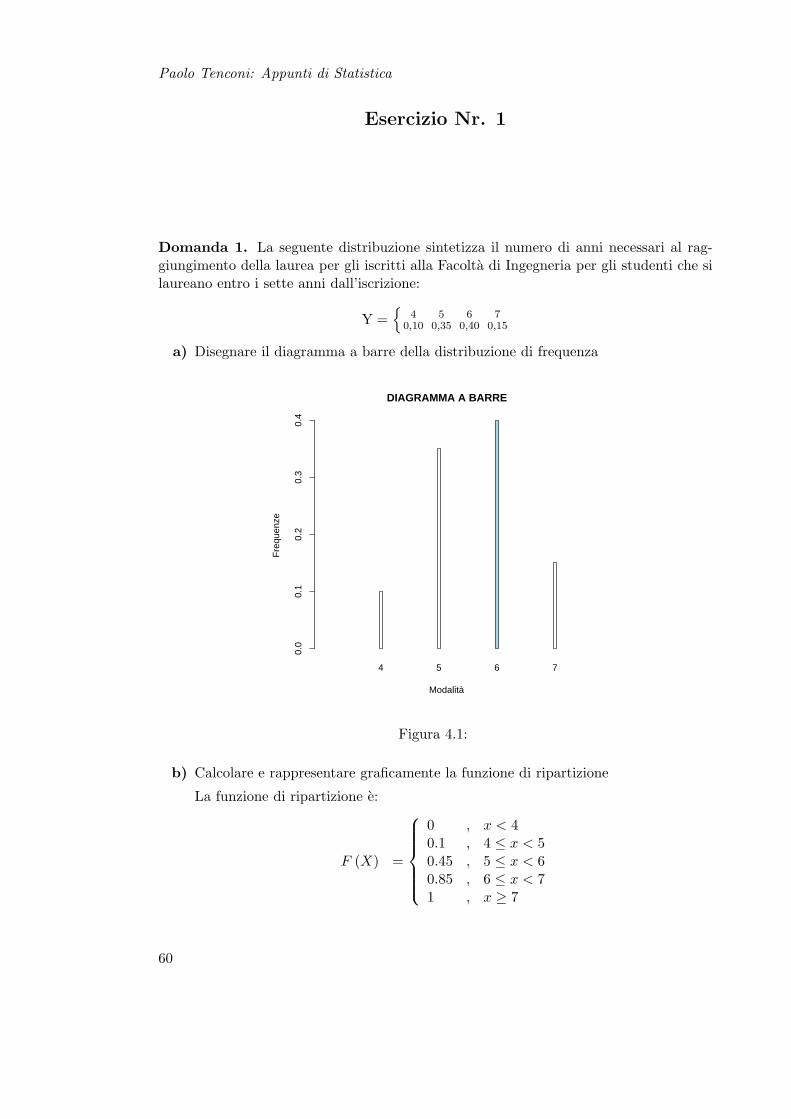
Paolo Tenconi: Appunti di Statistica
Esercizio Nr. 1
Domanda 1. La seguente distribuzione sintetizza il numero di anni necessari al rag-giungimento della laurea per gli iscritti alla Facolta di Ingegneria per gli studenti che silaureano entro i sette anni dall’iscrizione:
Y =
40,10
50,35
60,40
70,15
a) Disegnare il diagramma a barre della distribuzione di frequenza
4 5 6 7
DIAGRAMMA A BARRE
Modalità
Fre
quen
ze
0.0
0.1
0.2
0.3
0.4
Figura 4.1:
b) Calcolare e rappresentare graficamente la funzione di ripartizione
La funzione di ripartizione e:
F (X) =
0 , x < 40.1 , 4 ≤ x < 50.45 , 5 ≤ x < 60.85 , 6 ≤ x < 71 , x ≥ 7
60
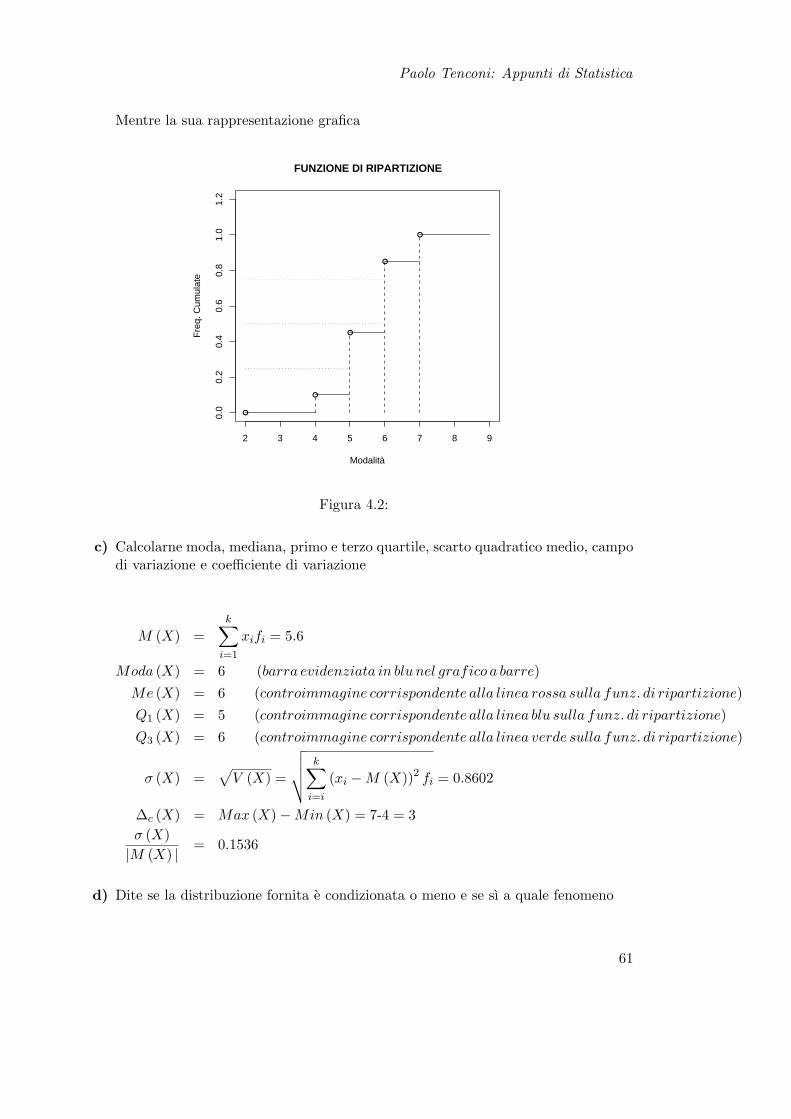
Paolo Tenconi: Appunti di Statistica
Mentre la sua rappresentazione grafica
2 3 4 5 6 7 8 9
0.0
0.2
0.4
0.6
0.8
1.0
1.2
FUNZIONE DI RIPARTIZIONE
Modalità
Fre
q. C
umul
ate
Figura 4.2:
c) Calcolarne moda, mediana, primo e terzo quartile, scarto quadratico medio, campodi variazione e coefficiente di variazione
M (X) =k∑
i=1
xifi = 5.6
Moda (X) = 6 (barra evidenziata in blu nel grafico a barre)Me (X) = 6 (controimmagine corrispondente alla linea rossa sulla funz. di ripartizione)Q1 (X) = 5 (controimmagine corrispondente alla linea blu sulla funz. di ripartizione)Q3 (X) = 6 (controimmagine corrispondente alla linea verde sulla funz. di ripartizione)
σ (X) =√
V (X) =
√√√√ k∑i=i
(xi −M (X))2 fi = 0.8602
∆c (X) = Max (X)−Min (X) = 7-4 = 3σ (X)|M (X) |
= 0.1536
d) Dite se la distribuzione fornita e condizionata o meno e se sı a quale fenomeno
61

Paolo Tenconi: Appunti di Statistica
La distribuzione e condizionata al fatto che il numero di anni necessari al rag-giungimento della laurea sia non superiore a sette. Quindi se intendiamo con Yla distribuzione di frequenza riguardante iL tempo impiegato per raggiungere lalaurea per tutti gli iscritti otteniamo
X ≡ Y |anni ≤ 7
e) La Facolta di Ingegneria dispone inoltre del dato per cui il tempo medio di coloroche si laureano oltre il settimo anno e di 9 anni e questi costituiscono il 10% deltotale dei laureati, si calcoli il tempo medio di raggiugimento della laurea per tuttigli studenti della Facolta di Ingegneria
Avendo indicato con Y la distribuzione di frequenza relativa al numero di anninecessari al raggiungimento della laurea per tutti gli studenti, otteniamo:
M (Y ) = M (Y |anni ≤ 7)× .9 + M (Y |anni > 7)× .1
avendo posto X = Y |anni ≤ 7 otteniamo
M (Y ) = M (X)× .9 + M (Y |anni > 7)× .1= 5.6× .9 + 9× .1 = 5.94
Domanda 2. La Facolta intende inoltre verificare se esiste una relazione fra numerodi anni impiegati a conseguire la laurea e quota di esami del primo anno superati consuccesso entro il primo anno di corso.La seguente tabella raccoglie, in via esemplificata, i dati rilevati sugli studenti fino adoggi laurati
X=Esami SostenutiY=AnniLaurea 0% 50% 100%4 ? 0.03 0.065 0.05 0.1 0.26 0.07 0.06 0.277 0.1 0.05 0
a) Si calcoli la frequenza congiunta mancante f(Y = 4, X = 0%)
Una distribuzione di frequenza multivariata deve, come nel caso univariato, rispettarela condizione per cui la somma della frequenza di tutte le modalita possibili sommia uno:
r∑i=1
c∑j=1
fij = 1
62

Paolo Tenconi: Appunti di Statistica
f11 = 1− .99 = .01
b) si calcoli la funzione di regressione (spezzata di regressione) del numero di anninecessari al conseguimento della laurea (Y) sulla quota di esami superati entro ilprimo anno dall’iscrizione (X) e la si rappresenti graficamente
Dobbiamo costruire le tre distribuzioni condizionate Y |X = x
Y |X = 0% ≡
4 5 6 7
0.010.23
0.050.23
0.070.23
0.10.23
Y |X = 50% ≡
4 5 6 7
0.030.24
0.10.24
0.060.24
0.050.24
Y |X = 100% ≡
4 5 6 7
0.060.53
0.20.53
0.270.53
00.53
e calcolarne le rispettive medie
M (Y |X = x) =4∑
i=1
yif (yi|X = x)
M (Y |X = 0%) =1
0.23[0.01× 4 + 0.05× 5 + 0.07× 6 + 0.1× 7] = 6.1304
M (Y |X = 50%) =1
0.24[0.03× 4 + 0.1× 5 + 0.06× 6 + 0.05× 7] = 5.5417
M (Y |X = 100%) =1
0.53[0.06× 4 + 0.2× 5 + 0.27× 6 + 0× 7] = 5.3962
E’ evidente la relazione negativa che intercorre fra percentuale di esami sostenutial primo anno e tempo impiegato per il raggiungimento della laurea, questo fattoe del tutto ragionevole.
c) Si calcoli la distribuzione di frequenza della percentuale di esami sostenuti il primoanno. Ritenete che la direzione didattica possa ritenersi soddisfatta dei risultati?
Si tratta di calcolare la distribuzione marginale di X
X ≡
0% 50% 100%0.23 0.24 0.53
Il fatto che piu della meta degli studenti sostenga nel corso del primo anno tuttigli esami previsti e da ritenersi soddisfacente per la direzione didattica.
63
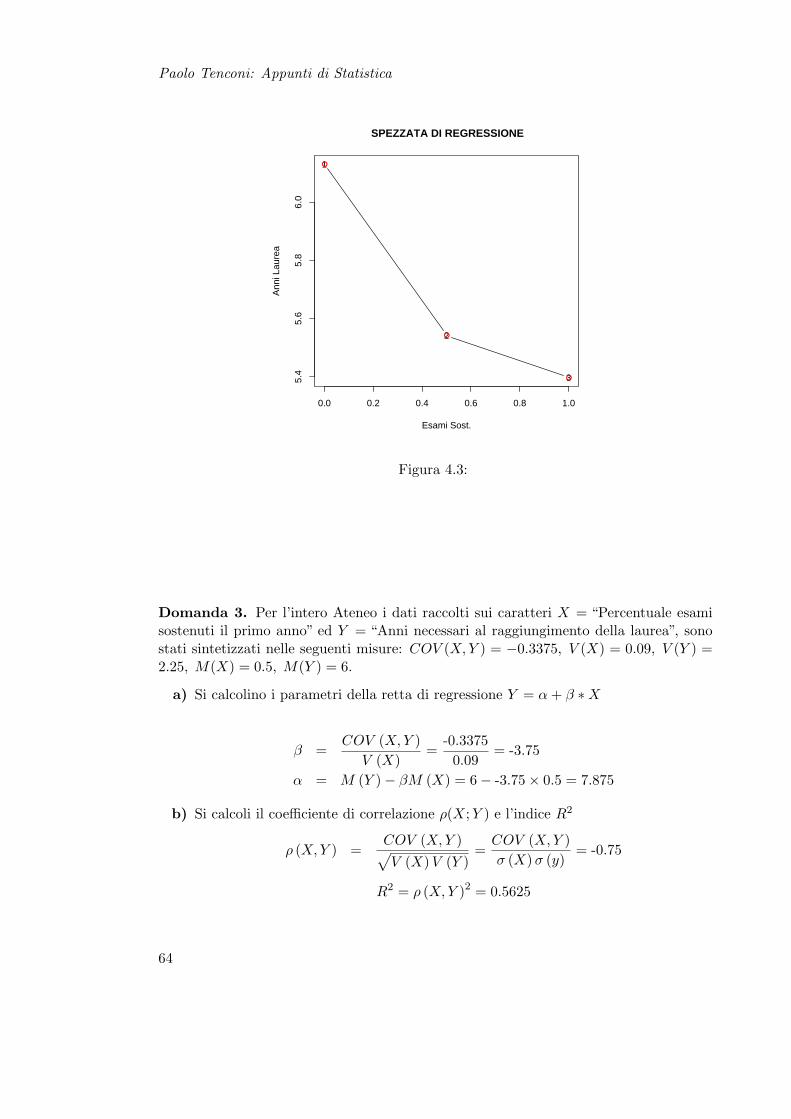
Paolo Tenconi: Appunti di Statistica
0.0 0.2 0.4 0.6 0.8 1.0
5.4
5.6
5.8
6.0
SPEZZATA DI REGRESSIONE
Esami Sost.
Ann
i Lau
rea
1
2
3
Figura 4.3:
Domanda 3. Per l’intero Ateneo i dati raccolti sui caratteri X = “Percentuale esamisostenuti il primo anno” ed Y = “Anni necessari al raggiungimento della laurea”, sonostati sintetizzati nelle seguenti misure: COV (X, Y ) = −0.3375, V (X) = 0.09, V (Y ) =2.25, M(X) = 0.5, M(Y ) = 6.
a) Si calcolino i parametri della retta di regressione Y = α + β ∗X
β =COV (X, Y )
V (X)=
-0.33750.09
= -3.75
α = M (Y )− βM (X) = 6− -3.75× 0.5 = 7.875
b) Si calcoli il coefficiente di correlazione ρ(X;Y ) e l’indice R2
ρ (X, Y ) =COV (X, Y )√V (X) V (Y )
=COV (X, Y )σ (X) σ (y)
= -0.75
R2 = ρ (X, Y )2 = 0.5625
64

Paolo Tenconi: Appunti di Statistica
c) Si calcoli in media quanto impiega a raggiungere la laurea in Ateneo uno studenteche ha sostenuto il 75% degli esami previsti al primo anno
y (.75) = α + β × .75 = 7.875+-3.75× .75 = 5.0625
65

Paolo Tenconi: Appunti di Statistica
Esercizio Nr. 2
Domanda 1. Data la seguente distribuzione statistica, riguardante il numero di tenta-tivi necessari per superare l’esame di Statistica, con media M(X) = 8, 45
X =
?0,15
70,4
100,25
150,2
a) Determinare il valore della modalita mancante x1 e disegnare il diagramma a barredella distribuzione di frequenza
Avendo a disposizione il valore di M (X) possiamo ricavare il valore mancante x1
attraverso la seguente relazione:
M (X) =4∑
i=1
(xi −M (X)) fi
8.45 = x1 × 0.15 + 7× 0.4 + 10× 0.25 + 15× 0.2
x1 =8.45− (7× 0.4 + 10× 0.25 + 15× 0.2)
0.15= 1
b) Calcolare e rappresentare graficamente la funzione di ripartizione
La funzione di ripartizione e:
F (X) =
0 , x < 40.15 , 4 ≤ x < 50.55 , 5 ≤ x < 60.8 , 6 ≤ x < 71 , x ≥ 7
Mentre la sua rappresentazione grafica
c) Calcolarne moda, mediana, primo e terzo quartile, differenza interquartilica, scarto
66
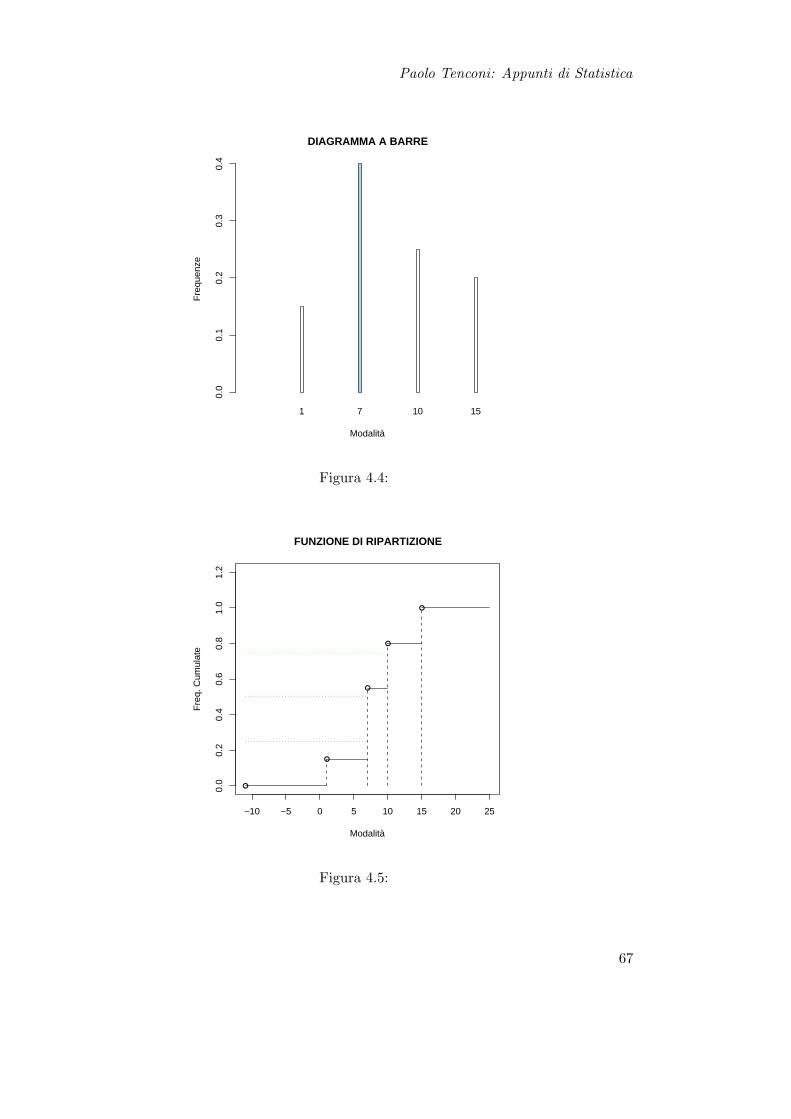
Paolo Tenconi: Appunti di Statistica
1 7 10 15
DIAGRAMMA A BARRE
Modalità
Fre
quen
ze
0.0
0.1
0.2
0.3
0.4
Figura 4.4:
−10 −5 0 5 10 15 20 25
0.0
0.2
0.4
0.6
0.8
1.0
1.2
FUNZIONE DI RIPARTIZIONE
Modalità
Fre
q. C
umul
ate
Figura 4.5:
67

Paolo Tenconi: Appunti di Statistica
quadratico medio, campo di variazione e coefficiente di variazione
Moda (X) = 7 (barra evidenziata in blu nel grafico a barre)Me (X) = 7 (controimmagine corrispondente alla linea rossa sulla funz. di ripartizione)Q1 (X) = 7 (controimmagine corrispondente alla linea blu sulla funz. di ripartizione)Q3 (X) = 10 (controimmagine corrispondente alla linea verde sulla funz. di ripartizione)∆q (X) = Q3 (X)−Q1 (X) = 3
σ (X) =√
V (X) =
√√√√ k∑i=i
(xi −M (X))2 fi = 4.2834
∆c (X) = Max (X)−Min (X) = 15-1 = 14σ (X)|M (X) |
= 0.5069
c) Calcolare un opportuno indice di asimmetria e concludere sulla presenza di asim-metria negativa o positiva
α2Fisher =∑4
i=1 (xi −M (X))3 fi
σ3=
∑4i=1 (xi −M (X))3 fi√∑4i=1 (xi −M (X))2 fi
3 = -0.0777
α1 =(Q3 (X)−Me (X))− (Me (X)−Q1 (X))
Q3 (X)−Q1 (X)= 1
I segni dei valori assunti dai due indici sono discordi, questo induce ad una nonchiara presenza di asimmetria positiva o negativa. Dall’osservazione del grafico abarre tuttavia si puo concludere a favore di una parziale presenza di asimmetriapositiva.
Domanda 2. Sia data la seguente distribuzione di frequenza marginale di X trattada uno studio su 2500 impiegati e riguardante il numero di ore trascorse giornalmentedavanti al PC:
X =
00,30
30,25
50,35
80,10
Nota inoltre la funzione di regressione di Y (indice di qualita della vista) su X:
M [Y |X = 0] = 3, 5 M [Y |X = 3] = 2, 1 M [Y |X = 5] = 2, 3 M [Y |X = 8] = 1, 5
68

Paolo Tenconi: Appunti di Statistica
a) Calcolare M[Y]
Dal noto teorema per cui la media delle medie condizionate e uguale alla medianon condizionata, ossia tradotto in formule
M (Y ) =k∑
i=1
M (Y |X = xi) f (xi)
M (Y ) = M (Y |X = 0) f (X = 0) + M (Y |X = 3) f (X = 3) ++ M (Y |X = 5) f (X = 5) + M (Y |X = 8) f (X = 8)
M (Y ) = 3.5× 0.3 + 2.1× 0.25 + 2.3× 0.35 + 1.5× 0.1 = 2.53
b) La devianza spiegata DS
Indicando con ni le frequenze assolute ottenute da ni = fi × N dove N = 2500(casi osservati), otteniamo la devianza spiegata con la seguente formula:
DS =4∑
i=1
(M (Y |X = xi)−M (X))2 ni
DS = (3.5− 2.53)2 × 750 + (3.5− 2.53)2 × 750 ++ (2.3− 2.53)2 × 875 + (1.5− 2.53)2 × 250 == 1132.75
c) Sia inoltre DY = 2300 la devianza totale, si calcoli il rapporto di correlazione η2
Il rapporto di correlazione η2 e dato dal rapporto fra devianza spiegata (calcolataal punto precedente) e devianza totale:
η2 =DS
DY=
1132.752300
= 0.4925
Domanda 3. Da uno studio sulla relazione tra due fenomeni X e Y sono state effet-tuate N=100 rilevazioni. Note le seguenti quantita di sintesi M(Y ) = 1, 9 M(X) =2, 7 M(XY ) = 3, 4 M(X2) = 15 calcolare quanto segue:
a) Varianza, devianza, covarianza e codevianza di X
V (X) = M(X2)−M (X)2 = 15− 2.72 = 7.71
69

Paolo Tenconi: Appunti di Statistica
D (X) = V (X)×N = 771
COV (X) = M (XY )−M (X)×M (Y ) = 3.4− 2.7× 1.9 = -1.73
C (X, Y ) = COV (X, Y )×N = -173
b) I coefficienti α e β della retta di regressione y = α + βX
β =C (X, Y )D (X)
=C(X,Y )
ND(X)
N
=COV (X, Y )V AR (X)
= -0.2244
α = M (Y )− β ×M (X) = 2.5058
c) Si interpretino i parametri ottenuti per la retta di regressione e si indichi la moti-vazione per la quale la covarianza assume sempre lo stesso segno del parametro β
Il punto fondamentale e l’esistenza di una relazione negativa fra la variabile Y e lavariabile X . Quindi ad un aumento di X corrisponde una diminuzione di Y .Tale informazione era sin dall’inizio desumibile dal segno assunto dalla covarianza,infatti il segno di essa e sempre identico al segno del coefficiente β della retta diregressione, la motivazione e facilmente desumibile dalla formula di β
β =COV (X, Y )
V (X)
visto che V (X) assume sempre segno positivo, e inevitabile che β assuma semprelo stesso segno di COV (X, Y ).
d) Noto l’indice di correlazione ρ(X;Y ) = −0, 45 si calcoli e si interpreti l’indice dideterminazione r2
r2 = ρ (X, Y )2 = -0.452 = 0.2025
Come sappiamo r2 ∈ [0, 1] e questo per valori prossimi a zero indica un adattamentonon buono della retta di regressione.
70
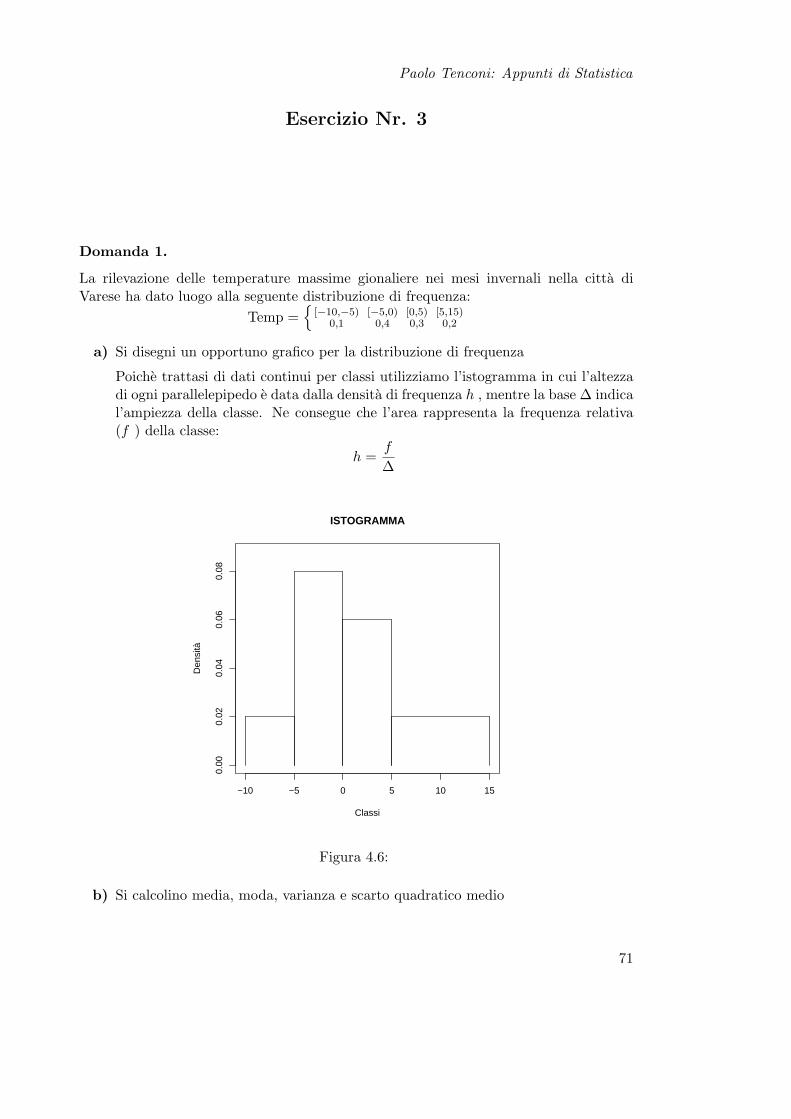
Paolo Tenconi: Appunti di Statistica
Esercizio Nr. 3
Domanda 1.
La rilevazione delle temperature massime gionaliere nei mesi invernali nella citta diVarese ha dato luogo alla seguente distribuzione di frequenza:
Temp =
[−10,−5)0,1
[−5,0)0,4
[0,5)0,3
[5,15)0,2
a) Si disegni un opportuno grafico per la distribuzione di frequenza
Poiche trattasi di dati continui per classi utilizziamo l’istogramma in cui l’altezzadi ogni parallelepipedo e data dalla densita di frequenza h , mentre la base ∆ indical’ampiezza della classe. Ne consegue che l’area rappresenta la frequenza relativa(f ) della classe:
h =f
∆
−10 −5 0 5 10 15
0.00
0.02
0.04
0.06
0.08
ISTOGRAMMA
Classi
Den
sità
Figura 4.6:
b) Si calcolino media, moda, varianza e scarto quadratico medio
71

Paolo Tenconi: Appunti di Statistica
Rammentando che per il calcolo di media, varianza e scarto quadratico medio ci siriconduce al caso di una distribuzione discreta prendendo il valore medio di ogniclasse, otteniamo una nuova distribuzione
X ≡ −10+(−5)
2−5+0
20+52
5+152
.1 .4 .3 .2
M (X) ≡ M(X)
=4∑
i=1
xi × fi =
= -7.5× 0.1 + -2.5× 0.4 + 2.5× 0.3 + 10× 0.2 = 1
V (X) ≡ V(X)
=4∑
i=1
(xi −M
(X))2
× fi = 29
σ (X) ≡ σ(X)
=√
V(X)
= 5.39
Mentre il calcolo della moda e differente rispetto a quanto visto per le distribuzionidiscrete, infatti in questo caso la classe modale e quella che presenta la massimadensita
Moda (X) = −5 ` 0
Domanda 2. Si dia la definizione formale di funzione di ripartizione, la si calcoli per idati di cui all’esercizio 1 e la si rappresenti graficamente.
F (x) = Freq (X < x)
Essa presenta le seguenti proprieta
Monotonicita crescente
0 ≤ F (x) ≤ 1
72
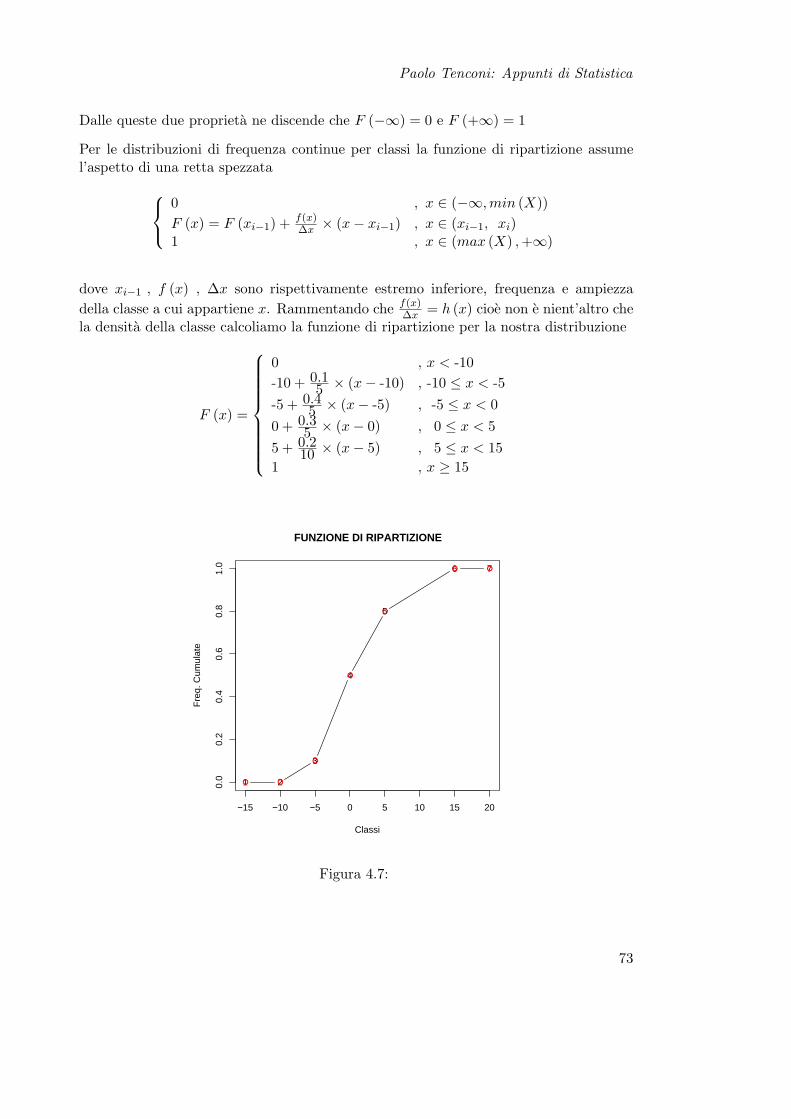
Paolo Tenconi: Appunti di Statistica
Dalle queste due proprieta ne discende che F (−∞) = 0 e F (+∞) = 1
Per le distribuzioni di frequenza continue per classi la funzione di ripartizione assumel’aspetto di una retta spezzata
0 , x ∈ (−∞,min (X))F (x) = F (xi−1) + f(x)
∆x × (x− xi−1) , x ∈ (xi−1, xi)1 , x ∈ (max (X) ,+∞)
dove xi−1 , f (x) , ∆x sono rispettivamente estremo inferiore, frequenza e ampiezzadella classe a cui appartiene x. Rammentando che f(x)
∆x = h (x) cioe non e nient’altro chela densita della classe calcoliamo la funzione di ripartizione per la nostra distribuzione
F (x) =
0 , x < -10-10 + 0.1
5 × (x− -10) , -10 ≤ x < -5-5 + 0.4
5 × (x− -5) , -5 ≤ x < 00 + 0.3
5 × (x− 0) , 0 ≤ x < 55 + 0.2
10 × (x− 5) , 5 ≤ x < 151 , x ≥ 15
−15 −10 −5 0 5 10 15 20
0.0
0.2
0.4
0.6
0.8
1.0
FUNZIONE DI RIPARTIZIONE
Classi
Fre
q. C
umul
ate
1 2
3
4
5
6 7
Figura 4.7:
73

Paolo Tenconi: Appunti di Statistica
Domanda 3.
Si dispone inoltre delle temperature gionaliere in tutti i comuni della Provincia di Varesee dell’altitudine in metri di ogni comune. Questo tipo di dati ha dato origine alla seguentetabella a doppia entrata:
X=AltitudineY=Temperatura [200, 300) [300, 400) [400, 1000)[−10,−5) 0,05 0,08 0,15[−5, 0) 0,07 0,10 0,15[0, 5) 0,12 0,10 0,07[5, 15) 0,07 0,03 0,01
a) Si calcoli la funzione di regressione (spezzata di regressione) della temperatura (Y)sull’altitudine dei comuni (X) e la si rappresenti graficamente
Si tratta di calcolare le medie condizionate
M (Y |X = x) =4∑
i=1
yi × fyi|X=x =4∑
i=1
yi ×fyi,x
fx
Trattandosi di variabili continue per classi, ricorriamo alla discretizzazione di Ycome di consueto
M (Y |X = 200 ` 300) = -7.5× 0.050.31
+ -2.5× 0.070.31
+ 2.5× 0.120.31
+ 10× 0.070.31
= 1.45
M (Y |X = 300 ` 400) = -7.5× 0.080.31
+ -2.5× 0.10.31
+ 2.5× 0.10.31
+ 10× 0.030.31
= -0.97
M (Y |X = 400 ` 1000) = -7.5× 0.150.38
+ -2.5× 0.150.38
+ 2.5× 0.070.38
+ 10× 0.010.38
= -3.22
74
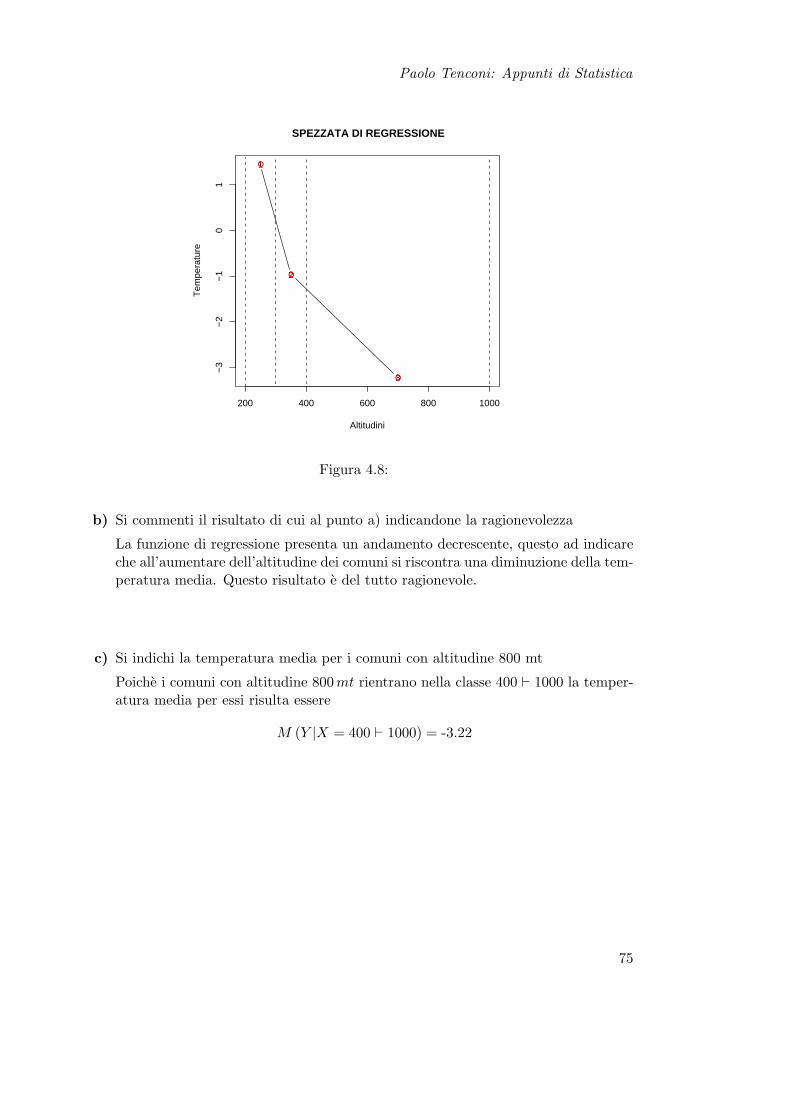
Paolo Tenconi: Appunti di Statistica
200 400 600 800 1000
−3
−2
−1
01
SPEZZATA DI REGRESSIONE
Altitudini
Tem
pera
ture
1
2
3
Figura 4.8:
b) Si commenti il risultato di cui al punto a) indicandone la ragionevolezza
La funzione di regressione presenta un andamento decrescente, questo ad indicareche all’aumentare dell’altitudine dei comuni si riscontra una diminuzione della tem-peratura media. Questo risultato e del tutto ragionevole.
c) Si indichi la temperatura media per i comuni con altitudine 800 mt
Poiche i comuni con altitudine 800mt rientrano nella classe 400 ` 1000 la temper-atura media per essi risulta essere
M (Y |X = 400 ` 1000) = -3.22
75

Paolo Tenconi: Appunti di Statistica
76

Parte II
Probabilita
77


5 Teoria (Cenni)
5.1 Esperimento ed Eventi
Abbiamo identificato nella popolazione la totalita dei dati afferenti una determinatarealta. Esiste un tipo particolare di popolazione che e il frutto di un esperimento il cuirisultato da luogo ad eventi elementari il cui esito e incerto. Sulla base degli eventielementari siamo interessati alla determinazione della probabilita di occorrenza di unsottoinsieme di eventi elementari, definiti come eventi.
Ad esempio consideriamo la probabilita di ottenere un numero pari nel lancio di un dado:
Esperimento: lancio del dado
Eventi elementari: insieme dei risultati che si possono ottenere a ogni lancio1; 2; 3; 4; 5; 6
Eventi: abbiamo scelto una partizione dei risultati tale che si possa ottenenerepari, dispari
e consuetudine rappresentare insiemisticamente l’esperimento
13
5
2
4
6
Dispari
Pari
Se indichiamo con Ei il generico evento a cui siamo interesati e con ωj il generico eventoelementare e palese che
P [Ei] =∑
ωj∈Ei
P (ωj)
79

Paolo Tenconi: Appunti di Statistica
cioe la probabilita dell’evento Ei e dato dalla somma delle probabilita dei singoli eventielementari appartenenti a Ei.
Nell’esempio appena citato P [pari] = P [ω = 2] + P [ω = 4] + P [ω = 6]
Ma come si determinano le probabilita degli eventi elementari ωj?Vi sono varie teorie basate sul significato intrinseco di probabilita
Classica
Frequentista
Soggettiva
Assiomatica
5.2 Teorie della Probabilita
5.2.1 Classica
E’ la teorica piu antica secondo la quale
P [ωj ] =#Casi Favorevoli
#Casi Possibili
(l’operatore # indica la numerosita). Il limite di questa teoria e che questo concettodi probabilita si puo applicare ad esperimenti in cui i casi possibili sono tutti equiprob-abili. Quindi funziona nell’esempio del dado, avendosi che P [ω = 2] = 1
6 ;P [ω = 4] =16 ;P [ω = 6] = 1
6 e quindi P [pari] = 12 . Ma gia questo apparato non funzionerebbe con
esperimento con un dado anche dichiaratamente truccato.
5.2.2 Frequentista
E’ succeduta a quella classica a causa delle limitazioni di quest’ultima. Come determinareP [ωj ] nell’esempio del dado truccato? Secondo la teoria frequentista
P [ωj ] = limn→∞#Successi
#Tentativi
cioe la probabilita emerge naturalmente come percentuale di successi ripetendo l’esper-imento all’infinito (da qui il nome di teoria frequentista), si noti che la probabilita eoggettiva e insita nell’oggetto di indagine.
Tuttavia anche questa teoria ha dei limiti: non sempre l’esperimento e ripetibile e spessoquando lo e non e detto che le condizioni in cui viene ripetuto siano immutabili.
80

Paolo Tenconi: Appunti di Statistica
5.2.3 Soggettiva
La probabilita di un evento e data dalla fiducia che un soggetto ha nel suo verificarsi,intesa questa come la somma di denaro che il soggetto e disposto a pagare per ottenere“1” in caso di successo e zero in caso di insuccesso. Si noti che la probabilita ora non epiu insita nell’oggetto di indagine, ma nella mente di chi la osserva (da qui il termineteoria soggettiva), questo costituisce un punto debole per i fautori dell’oggettivita dellaprobabilita, infatti soggetti diversi, in virtu di una differente avversione al rischio, avran-no giudizi differenti circa il verificarsi di un medesimo evento. Il vantaggio principale edovuto alla possibilita di applicare la probabilita anche ad eventi irripetibili (si consideriad esempio la probabilita che l’uomo metta piede su Marte nei prossimo 10 anni).
5.2.4 Assiomatica
E’ una teoria astratta basata su postulati. Evita quindi di definire cosa sia la probabilita,fornendo le caratteristiche minime che un apparato deve possedere affinche si possaparlare di probabilita.
Dato un esperimento per il quale siamo interessati alla probabilita di uno o piueventi (che contengono eventi elementari)
Sugli eventi (trattati come insiemi) sono definite le operazioni di unione, inter-sezione, negazione e differenza
Definiamo σ − algebra la classe di eventi tali che
– Ω ∈
– se A ∈ ⇒ A ∈
–⋃∞
k=1 Ak ∈
Data una σ− algebra definiamo probabilita una funzione che associa ad ogni A ∈ unnumero ∈ [0, 1]
P : −→ [0, 1]
tale probabilita deve soddisfare i seguenti assiomi:
1. Eventi sottoinsieme di Ω formano una σ − algebra
2. P [A] ∈ [0, 1] ,∀A ∈
3. P [Ω] = 1
4. Se A ∩B = ∅ ⇒ P [A ∪B] = P [A] + P [B]
5. P[⋃∞
n=1 An] =∑∞
n=1 P [An] , per An a due a due incompatibili
Dagli assiomi discendono una serie di proprieta della probabilita, fra cui analizzeremo leprincipali
Teorema delle probabilita totali
81

Paolo Tenconi: Appunti di Statistica
Teorema delle probabilita composte
Teorema di Bayes
5.3 Proprieta della Probabilita
5.3.1 Teorema delle Probabilita Totali
Ci limiteremo al caso di due eventi
P [A ∪B] = P (A) + P (B)− P (A ∩B)
mentre e semplice determinare P (A) e P (B), per quanto riguarda P (A ∩B) distin-guiamo tre casi:
1. A∩B = ∅ in tal caso gli eventi sono incompatibili percio P (A ∪B) = P (A)+P (B)
2. A ∩B 6= ∅ in tal caso gli eventi sono compatibili e distinguiamo due casi
a) A e B sono due eventi indipendenti A ⊥ B quindi per definizione P (A ∩B) =P (A) · P (B), ne segue che P (A ∪B) = P (A) + P (B)− P (A) P (B)
b) A e B sono eventi dipendenti in tal caso per determinare P (A ∩B) si ricorreal seguenti teorema delle probabilita composte
5.3.2 Teorema delle Probabilita Composte
P (A ∩B) = P (A|B) P (B) = P (B|A) P (A)
ad esempio consideriamo gli eventi A = oggi piove = 0, 2 e B = uso lamoto = 0, 4e supponiamo tre scenari
1. Se A∩B 6= ∅ significa che A e B sono incompatibili (ossia se piove io non uso maila moto), in tal caso P (A ∪B) = 0, 2 + 0, 4 = 0, 6
2. Se la probabilita che io usi la moto non e influenzata dal fatto che piova o menoallora A e B sono indipendenti e P (B|A) = P
(B|A
)= P (B) quindi per il teorema
delle probabilita composte P (A ∩B) = P (B|A) P (A) = P (B) P (A) , da cioP (A ∪B) = 0, 2 + 0, 4− 0, 2× 0, 4
3. Se la probabilita che io usi la moto e influenzata dal fatto che piova o meno,allora A e B non sono indipendenti, e necessario quindi conoscere P (B|A) oppureP (A|B) per determinare P (A ∩B) . Supponiamo che P (B|A) = 0, 1 cioe laprobabilita che io usi la moto quando piove e del 10% - quindi molto ridottarispetto al suo utilizzo in generale - per il teorema delle probabilita composteP (A ∩B) = P (B|A) P (A) = 0, 1× 0, 2 quindi P (A ∪B) = 0, 2 + 0, 4− 0, 1× 0, 2
82

Paolo Tenconi: Appunti di Statistica
5.3.3 Teorema di Bayes
Dato un evento E le cui cause possono essere varie Ai, i = 1, ...n1 , note le probabilita apriori sul verificarsi delle singole cause P (Ai) , note le P (E|Ai) ossia le probabilita chesi manifesti E posto che si e manifestata la generica causa Ai vogliamo determinare leprobabilita a posteriori P (Ai|E) cioe posto che sia accaduto E si vuole determinare laprobabilita che sia stato causato dal generico Ai, questo e possibile grazie al teorema diBayes
P (Ai|E) =P (E|Ai) P (Ai)∑ni=1 P (E|Ai) P (Ai)
consideriamo il seguente esempio
E il paziente ha la tosse cronica
A1 il paziente ha l’influenza P (A1) = 0, 2
A2 il paziente ha la bronchite P (A2) = 0, 1
A3 il paziente ha l’AIDS P (A3) = 0, 05
A4 il paziente e sano P (A4) = 0, 65
sono note le probabilita che il paziente sviluppi la tosse cronica posto che soffra diA1, A2, A3, A4: P (E|A1) = 0, 2 P (E|A2) = 0, 8 P (E|A3) = 0, 5 P (E|A4) = 0, 01
posto che il paziente ha la tosse cronica, quale e la probabilita ce cio sia dovuto adinfluenza, bronchite,...?
Sia P (E) =∑4
i=1 P (E|Ai) P (Ai) = 0, 1515 (denominatore del teorema di Bayes),determiniamo le singole P (Ai|E)
P (A1|E) = P (E|A1)P (A1)P4i=1 P (E|Ai)P (Ai)
= 0,2×0,20,1515 = 0, 2640
P (A2|E) = P (E|A2)P (A2)P4i=1 P (E|Ai)P (Ai)
= 0,8×0,10,1515 = 0, 5281
P (A3|E) = P (E|A3)P (A3)P4i=1 P (E|Ai)P (Ai)
= 0,5×0,050,1515 = 0, 1650
P (A4|E) = P (E|A4)P (A4)P4i=1 P (E|Ai)P (Ai)
= 0,01×0,650,1515 = 0, 0429
Osservazione: a priori la probabilita che un soggetto sia sano e P (A4) = 0, 65. In seguitoosserviamo che ha la tosse cronica (E), quindi abbiamo bisogno di aggiornare la nostraP (A4)con P (A4|E)e sicuramente sara ribassata alla luce del fatto che P (E|A4)e bassa(cioe molto raro che un soggetto sano abbia la tosse cronica), per il teorema di BayesP (A4|E) = 0, 0429 . Ragionamento analogo per gli altri Ai.
1Le cause Ai sono necessarie (almeno una accade) ed incompatibili.
83

Paolo Tenconi: Appunti di Statistica
84

6 Variabili Casuali
Una variabile casuale e una funzione che associa ad ogni evento elementare ωj un numeroreale. Puo essere una funzione di tipo“uno a uno”o di tipo“molti a uno”, cioe a differentiωj puo essere associato uno stesso numero reale.
ω1
ω2
ω3
ω4
ω5
x1
x2
x3
ℝ
Ad esempio nel lancio del dado, possiamo creare una variabile casuale che associ il numero1 se esce pari ed il numero 0 se esce dispari. Percio f (ω1 = 1) = 0, f (ω2 = 2) = 1,f (ω3 = 3) = 0, f (ω4 = 4) = 1 , f (ω5 = 5) = 0 , f (ω6 = 6) = 1 da cui
X ≡
0 1P (X = 0) P (X = 1)
P (X = 0) = P (ω1) + P (ω3) + P (ω5) = 12 , P (X = 1) = P (ω2) + P (ω4) + P (ω6) = 1
2
6.1 Variabili Casuali Discrete
Assumono un insieme distinto di n-valori (finito o infinito), affinche si tratti di variabilecasuale devono essere rispettate le seguenti proprieta
P (xi) ∈ [0, 1] ,∀i
∑ni=1 P (xi) = 1
su di esse vale quanto detto per le distribuzioni di frequenza per dati quantitativi discreti.
85
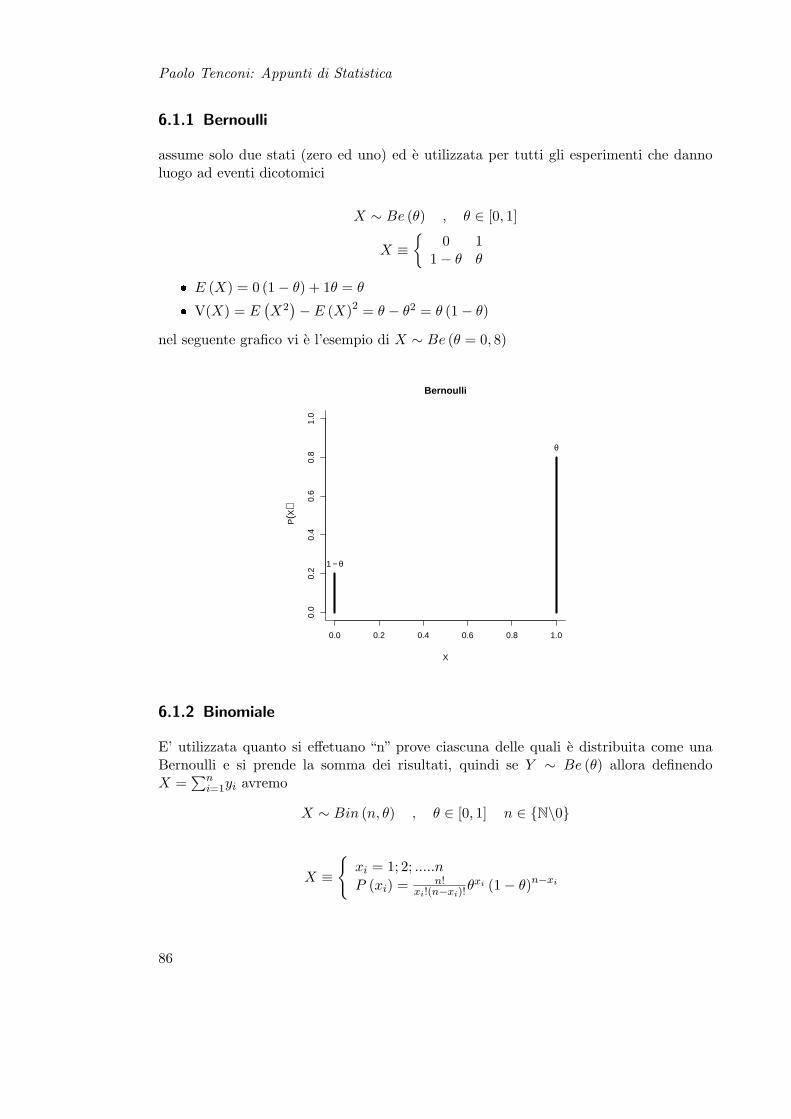
Paolo Tenconi: Appunti di Statistica
6.1.1 Bernoulli
assume solo due stati (zero ed uno) ed e utilizzata per tutti gli esperimenti che dannoluogo ad eventi dicotomici
X ∼ Be (θ) , θ ∈ [0, 1]
X ≡
0 11− θ θ
E (X) = 0 (1− θ) + 1θ = θ
V(X) = E(X2)− E (X)2 = θ − θ2 = θ (1− θ)
nel seguente grafico vi e l’esempio di X ∼ Be (θ = 0, 8)
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Bernoulli
X
P(X
)
1 − θ
θ
6.1.2 Binomiale
E’ utilizzata quanto si effetuano “n” prove ciascuna delle quali e distribuita come unaBernoulli e si prende la somma dei risultati, quindi se Y ∼ Be (θ) allora definendoX =
∑ni=1yi avremo
X ∼ Bin (n, θ) , θ ∈ [0, 1] n ∈ N\0
X ≡
xi = 1; 2; .....nP (xi) = n!
xi!(n−xi)!θxi (1− θ)n−xi
86
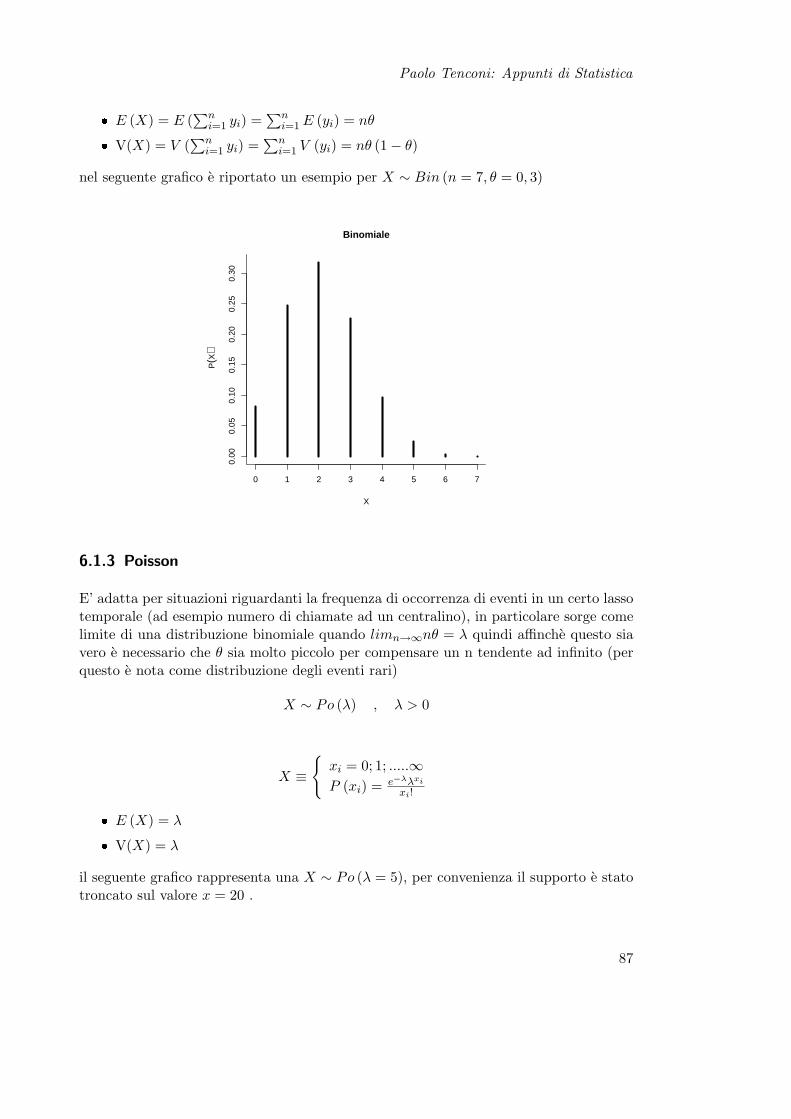
Paolo Tenconi: Appunti di Statistica
E (X) = E (∑n
i=1 yi) =∑n
i=1 E (yi) = nθ
V(X) = V (∑n
i=1 yi) =∑n
i=1 V (yi) = nθ (1− θ)
nel seguente grafico e riportato un esempio per X ∼ Bin (n = 7, θ = 0, 3)
0 1 2 3 4 5 6 7
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Binomiale
X
P(X
)
6.1.3 Poisson
E’ adatta per situazioni riguardanti la frequenza di occorrenza di eventi in un certo lassotemporale (ad esempio numero di chiamate ad un centralino), in particolare sorge comelimite di una distribuzione binomiale quando limn→∞nθ = λ quindi affinche questo siavero e necessario che θ sia molto piccolo per compensare un n tendente ad infinito (perquesto e nota come distribuzione degli eventi rari)
X ∼ Po (λ) , λ > 0
X ≡
xi = 0; 1; .....∞P (xi) = e−λλxi
xi!
E (X) = λ
V(X) = λ
il seguente grafico rappresenta una X ∼ Po (λ = 5), per convenienza il supporto e statotroncato sul valore x = 20 .
87
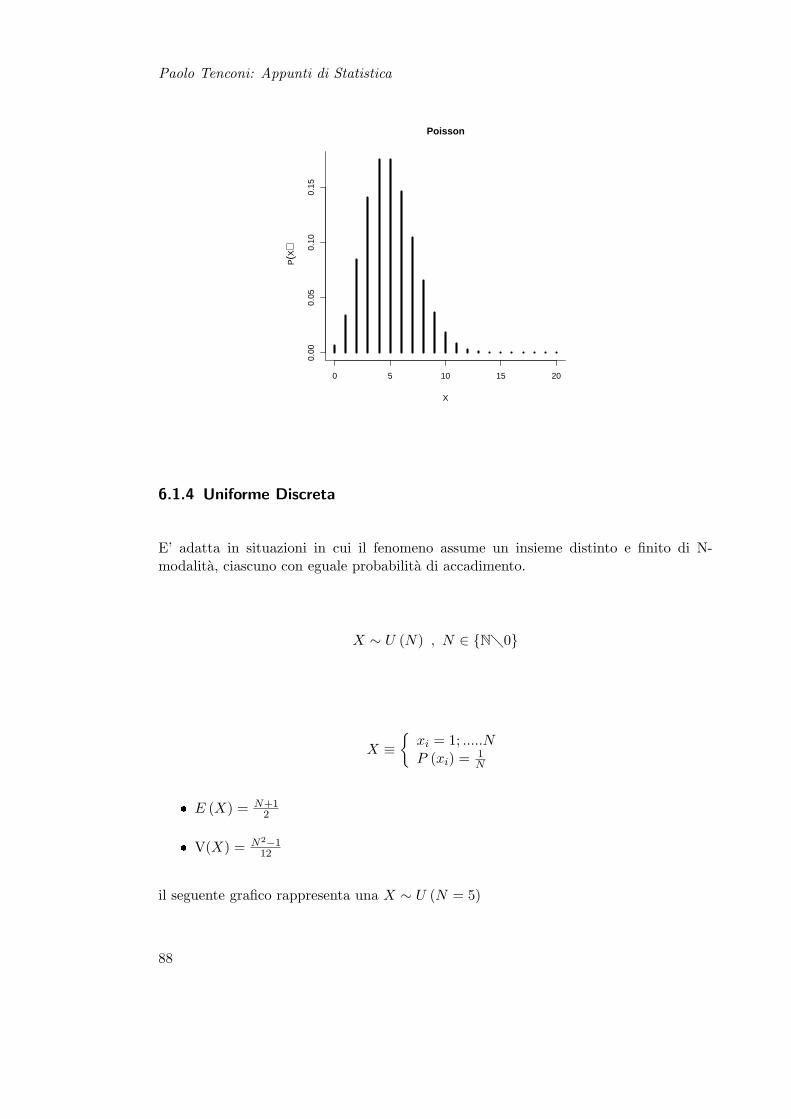
Paolo Tenconi: Appunti di Statistica
0 5 10 15 20
0.00
0.05
0.10
0.15
Poisson
X
P(X
)
6.1.4 Uniforme Discreta
E’ adatta in situazioni in cui il fenomeno assume un insieme distinto e finito di N-modalita, ciascuno con eguale probabilita di accadimento.
X ∼ U (N) , N ∈ N0
X ≡
xi = 1; .....NP (xi) = 1
N
E (X) = N+12
V(X) = N2−112
il seguente grafico rappresenta una X ∼ U (N = 5)
88

Paolo Tenconi: Appunti di Statistica
1 2 3 4 5
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Uniforme Discreta
X
P(X
)
6.2 Variabili Casuali Continue
Assumono un’infinita continua di valori in un intervallo, percio la probabilita di unpreciso valore x e nulla, mentre ha senso definire la probabilita che si verifichi un numeroentro un intervallo, avendo definito con f la funzione di densita
P X ∈ [x1, x2] =∫ x2
x1
f (x) dx
le proprieta che la funzione di densita deve rispettare sono
f (x) ≥ 0
∫ +∞−∞ f (x) dx = 1
si noti che f svolge il ruolo dell’istogramma per dati continui per calssi, ma con classidi ampiezza infinitesima. La probabilita nulla per un generico punto x e dimostrabilesemplicemente
P (X = x) = lim∆x→0
∫ x+∆x
xf (x) dx =
∫ x
xf (x) dx = 0
definiamo la funzione di ripartizione
F (x) =∫ x
−∞f (t) dt
da cui P (X ∈ [x1, x2]) = F (x2)− F (x1)
89
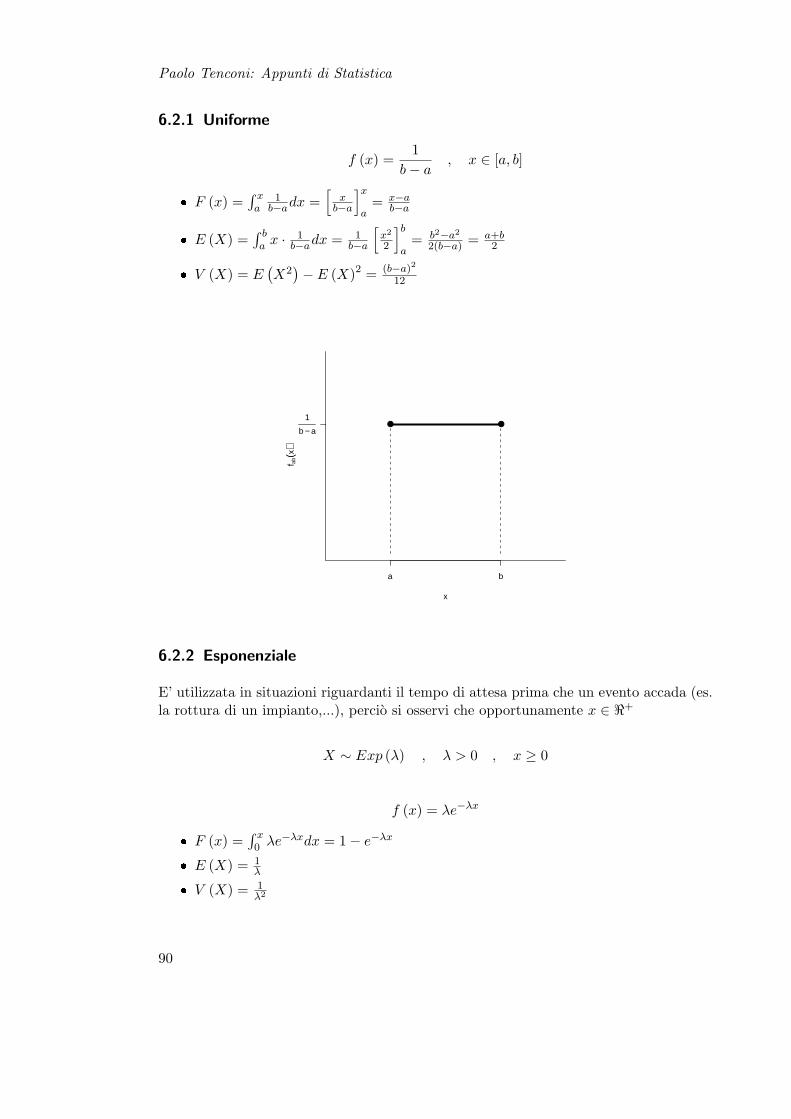
Paolo Tenconi: Appunti di Statistica
6.2.1 Uniforme
f (x) =1
b− a, x ∈ [a, b]
F (x) =∫ xa
1b−adx =
[x
b−a
]xa
= x−ab−a
E (X) =∫ ba x · 1
b−adx = 1b−a
[x2
2
]ba
= b2−a2
2(b−a) = a+b2
V (X) = E(X2)− E (X)2 = (b−a)2
12
x
f ab(x
)
a b
1
b − a
6.2.2 Esponenziale
E’ utilizzata in situazioni riguardanti il tempo di attesa prima che un evento accada (es.la rottura di un impianto,...), percio si osservi che opportunamente x ∈ <+
X ∼ Exp (λ) , λ > 0 , x ≥ 0
f (x) = λe−λx
F (x) =∫ x0 λe−λxdx = 1− e−λx
E (X) = 1λ
V (X) = 1λ2
90
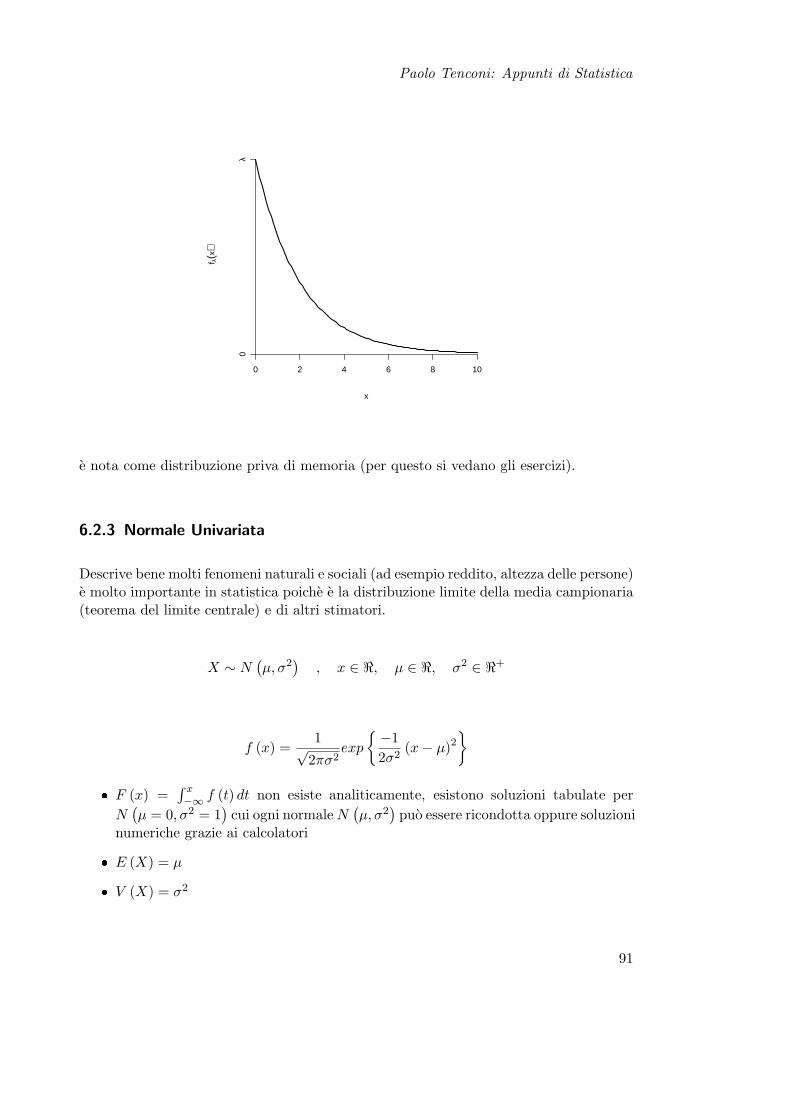
Paolo Tenconi: Appunti di Statistica
x
f λ(x
)
0λ
0 2 4 6 8 10
e nota come distribuzione priva di memoria (per questo si vedano gli esercizi).
6.2.3 Normale Univariata
Descrive bene molti fenomeni naturali e sociali (ad esempio reddito, altezza delle persone)e molto importante in statistica poiche e la distribuzione limite della media campionaria(teorema del limite centrale) e di altri stimatori.
X ∼ N(µ, σ2
), x ∈ <, µ ∈ <, σ2 ∈ <+
f (x) =1√
2πσ2exp
−12σ2
(x− µ)2
F (x) =∫ x−∞ f (t) dt non esiste analiticamente, esistono soluzioni tabulate per
N(µ = 0, σ2 = 1
)cui ogni normale N
(µ, σ2
)puo essere ricondotta oppure soluzioni
numeriche grazie ai calcolatori
E (X) = µ
V (X) = σ2
91
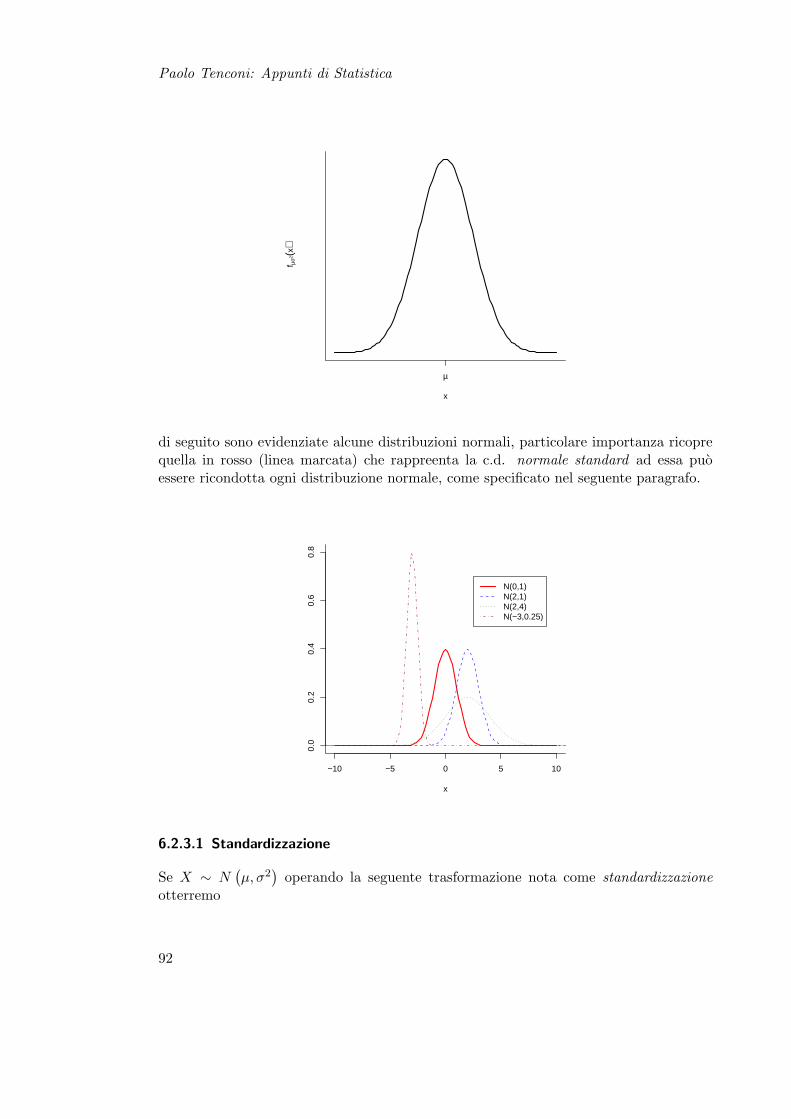
Paolo Tenconi: Appunti di Statistica
x
f µσ2 (x
)
µ
di seguito sono evidenziate alcune distribuzioni normali, particolare importanza ricoprequella in rosso (linea marcata) che rappreenta la c.d. normale standard ad essa puoessere ricondotta ogni distribuzione normale, come specificato nel seguente paragrafo.
−10 −5 0 5 10
0.0
0.2
0.4
0.6
0.8
x
N(0,1)N(2,1)N(2,4)N(−3,0.25)
6.2.3.1 Standardizzazione
Se X ∼ N(µ, σ2
)operando la seguente trasformazione nota come standardizzazione
otterremo
92
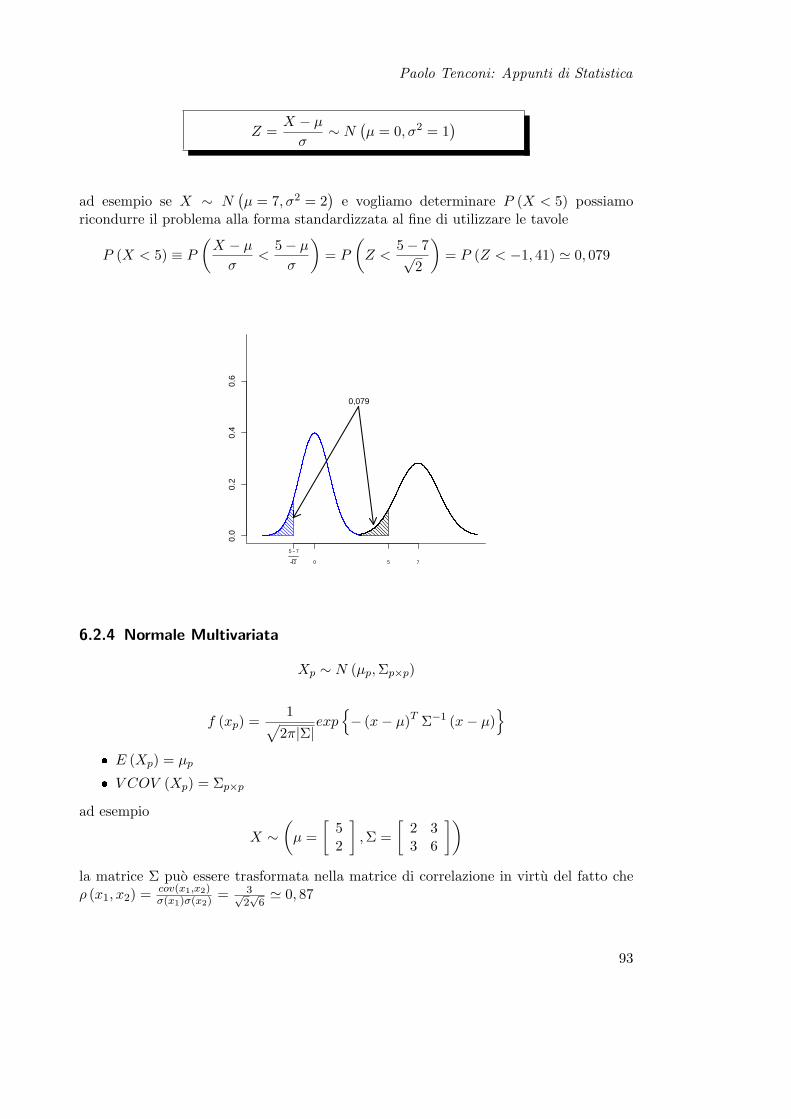
Paolo Tenconi: Appunti di Statistica
Z =X − µ
σ∼ N
(µ = 0, σ2 = 1
)
ad esempio se X ∼ N(µ = 7, σ2 = 2
)e vogliamo determinare P (X < 5) possiamo
ricondurre il problema alla forma standardizzata al fine di utilizzare le tavole
P (X < 5) ≡ P
(X − µ
σ<
5− µ
σ
)= P
(Z <
5− 7√2
)= P (Z < −1, 41) ' 0, 079
5 − 7
2 0 5 7
0.0
0.2
0.4
0.6
0,079
6.2.4 Normale Multivariata
Xp ∼ N (µp,Σp×p)
f (xp) =1√
2π|Σ|exp
− (x− µ)T Σ−1 (x− µ)
E (Xp) = µp
V COV (Xp) = Σp×p
ad esempio
X ∼(
µ =[
52
],Σ =
[2 33 6
])la matrice Σ puo essere trasformata nella matrice di correlazione in virtu del fatto cheρ (x1, x2) = cov(x1,x2)
σ(x1)σ(x2) = 3√2√
6' 0, 87
93

Paolo Tenconi: Appunti di Statistica
6.3 Momenti
E’ possibile sintetizzare ogni variabile casuale, discreta o continua, attraverso gli indicidi posizione, variabilita e forma indicati precedentemente nella parte inerente la statis-tica descrittiva. Prendendo ad esempio i principali (a sinistra indicheremo la formulaper variabili casuali discrete, mentre a destra per quelle continue) abbiamo il momentocentrale (rispetto all’origine)
µs =k∑
i=1
xsip (xi)
∫ +∞
−∞xsf (x) dx
si noti che per s = 1 si ottiene il valore atteso. Il momento centrale rispetto alla mediae dato da
µs =k∑
i=1
(xi − µ)s p (xi)∫ +∞
−∞(x− µ)s f (x) dx
la varianza si ottiene per s = 2. L’indice di asimmetria di Fisher per una variabilecasuale di conseguenza e dato da
α2 =µ3
[µ2]32
=µ3
σ3
6.4 Disuguaglianza di Cebicev
Media e varianza forniscono importanti informazioni sulla natura della variabile casuale,la disuguaglianza di Cebicev stabilisce che per qualunque distribuzione
P (|X − µ| < λσ) ≥ 1− 1λ2
, λ > 0
l’importanza di tale teorema si ravvisa appunto nella sua generalita verso ogni dis-tribuzione identificando un limite inferiore per la massa di probabilita racchiusa nel-l’intervallo simmetrico attorno alla media di semiampiezza λσ (quindi proporzionale allaradice della varianza), come evidenziato nel seguente grafico
94
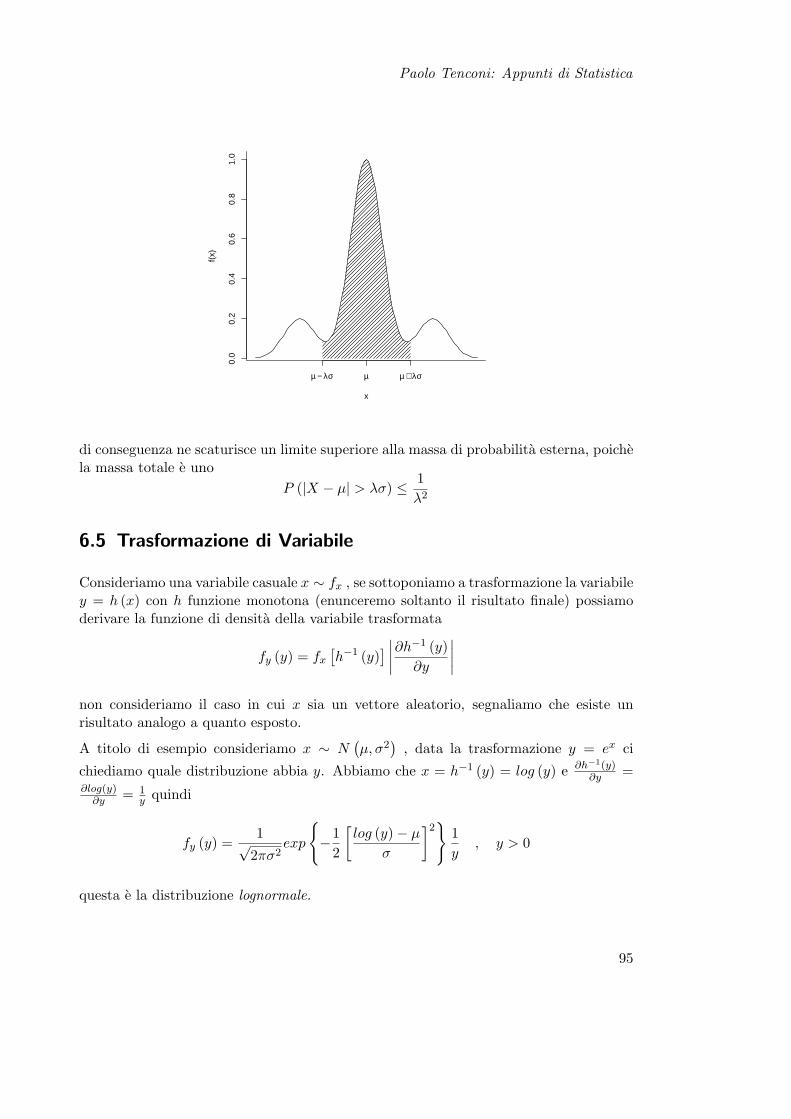
Paolo Tenconi: Appunti di Statistica
x
f(x)
µ − λσ µ µ + λσ
0.0
0.2
0.4
0.6
0.8
1.0
di conseguenza ne scaturisce un limite superiore alla massa di probabilita esterna, poichela massa totale e uno
P (|X − µ| > λσ) ≤ 1λ2
6.5 Trasformazione di Variabile
Consideriamo una variabile casuale x ∼ fx , se sottoponiamo a trasformazione la variabiley = h (x) con h funzione monotona (enunceremo soltanto il risultato finale) possiamoderivare la funzione di densita della variabile trasformata
fy (y) = fx
[h−1 (y)
] ∣∣∣∣∂h−1 (y)∂y
∣∣∣∣non consideriamo il caso in cui x sia un vettore aleatorio, segnaliamo che esiste unrisultato analogo a quanto esposto.
A titolo di esempio consideriamo x ∼ N(µ, σ2
), data la trasformazione y = ex ci
chiediamo quale distribuzione abbia y. Abbiamo che x = h−1 (y) = log (y) e ∂h−1(y)∂y =
∂log(y)∂y = 1
y quindi
fy (y) =1√
2πσ2exp
−1
2
[log (y)− µ
σ
]2
1y
, y > 0
questa e la distribuzione lognormale.
95

Paolo Tenconi: Appunti di Statistica
Nel caso di variabili casuali discrete, se il numero di modalita non e troppo elevato, epossibile ricorrere alla trasformazione manuale delle singole xi . Ad esempio se
X ≡
−2 0 30, 15 0, 6 0, 25
in seguito alla trasformazione Y = X2 otteniamo
Y ≡
0 3 40, 6 0, 25 0, 15
6.6 Esempi
6.6.1 Bernoulli
Le pompe idriche xyz hanno una probabilita di guastarsi nel primo anno del 10%.L’evento e dicotomico (guasta/non-guasta) quindi la distibuzione adatta e la Bernoulli
ω1 = non− guasta
ω2 = guasta
X (ω1) = 0 , X (ω2) = 1
X ≡
0 10, 9 0, 1
6.6.2 Binomiale
Abbiamo acquistato 5 pompe xyz , determiniamo la probabilita che nel primo anno sene guastino 0,1,2,3,4,5. Se il guasto per ogni pompa e distribuito come una Bernoulliallora il numero totale dei guasti sara distribuito come una Binomiale
X ∼ Bin (n = 5, θ = 0, 1)
P (X = 0) = 5!0!(5−0)!0, 100, 95−0 = 0, 59049
P (X = 1) = 5!1!(5−1)!0, 110, 95−1 = 0, 32805
P (X = 2) = 5!2!(5−2)!0, 120, 95−2 = 0, 0729
P (X = 3) = 5!3!(5−3)!0, 130, 95−3 = 0, 0081
P (X = 4) = 5!4!(5−4)!0, 140, 95−4 = 0, 00045
P (X = 5) = 5!5!(5−5)!0, 150, 95−5 = 0, 00001
possiamo calcolare la probabilita di eventi piu complessi, ad esempio la probabilita diavere almeno un guasto P (X ≥ 1) = 1 − P (X = 0) = 1 − 0, 59 = 0, 41. Il numero diguasti medi (ossia il numero medio di guasti che avrebbero molte imprese che hannoacquistato 5 pompe xyz ) E (X) = nθ = 5 · 0, 1 = 0, 5
96

Paolo Tenconi: Appunti di Statistica
6.6.3 Poisson
Il numero medio di fulmini che cadono durante un temporale in 10 km quadrati nell’arcodi un’ora e 3, ritenendo appropriata la distribuzione di poisson (ad esempio possiamoritenere che ogni attimo - leggasi tentativo - sia buono per un fulmine (quindi infini-ti tentativi), ma che la probabilita che questo si scateni in un attimo - leggasi comeprobabilita di successo in una bernoulli - sia molto piccolo)
X ∼ Po (λ = 3)
calcoliamo quanto segue
Probabilita che un fulmine cada nella prossima ora P (X = 1) = e−331
3! = 0, 1494
Probabilita che non cadano fulmini P (X = 0) = e−330
0! = 0, 0498
Fulmini che cadono in media (ossia se prendessimo molti temporali, facendo lamedia del numero di fulmini in un’ora in 10 km quadrati) E (X) = 3
Distribuzione del numero di fulmini in un temporale di 3 ore in 10 km quadratiY ∼ Po (λ = 3 · 3)
Probabilita che in 3 ore non cadano fulmini P (Y = 0) = e−990
o! = 0, 0001
6.6.4 Esponenziale
Il tempo di attesa medio affinche si verifichi la prossima piena presso il torrente xyz e di3 settimane. Delineare la variabile casuale “tempo di attesa per la prossima piena”.
Se il fenomeno non ha memoria, nel senso che il tempo per la prossima piena non einfluenzato da quanto tempo e trascorso dalla piena precedente, allora e adatta unadistribuzione esponenziale.
X ∼ Exp
(λ =
13
)Calcoliamo quanto segue
Probabilita che la piena avvenga entro la prossima settimana∫ 10 f (x) dx = F (1)−
F (0) =[1− e−
13·1]−[1− e−
13·0]
= 0, 2835− 0 = 0, 2835
Probabilita che la piena avvenga nella prima settimana del mese prossimo, postoche da qui al prossimo mese non ci sono state piene (poiche P (A|B) = P (A∩B)
P (B) )
P (X ∈ [4, 5] |X > 4) =P (X ∈ [4, 5]) ∩ (X > 4)
P (X > 4)
P (X ∈ [4, 5]) = F (5)− F (4) =[1− e−
135]−[1− e−
134]
= 0, 074722
97

Paolo Tenconi: Appunti di Statistica
P (X > 4) = 1− P (X ≤ 4) = F (4) = 0, 263597
P (X ∈ [4, 5] |X > 4) =0, 0747220, 263597
= 0, 2835
la quale si noti e identica alla probabilita di alluvione nella prossima settimana,quindi se le condizioni dell’esprimento sono immutate (non ci sono state alluvionifino ad ora e da qui al prossimo mese) la probabilita di alluvione nella settimanae identica alla probabilita di alluvione nella prima settimana del prossimo mese.
6.6.5 Normale
La distribuzione del peso in kg dei cigni del lago di Varese segue una legge normale deltipo
X ∼ N(µ = 5;σ2 = 0, 25
) determinare la probabilita di osservare cigni con peso superiore ai 6 kg
P (X > 6) ≡ P
(X − 5√
0, 25>
6− 5√0, 25
)= P (Z > 2) = 0, 0228
determinare P X ∈ (4, 825; 6)
P X ∈ (4, 825; 6) ≡ P
Z ∈
(4, 825− 5√
0, 25;
6− 5√0, 25
)= 0, 9772− 0, 3632 = 0, 614
98
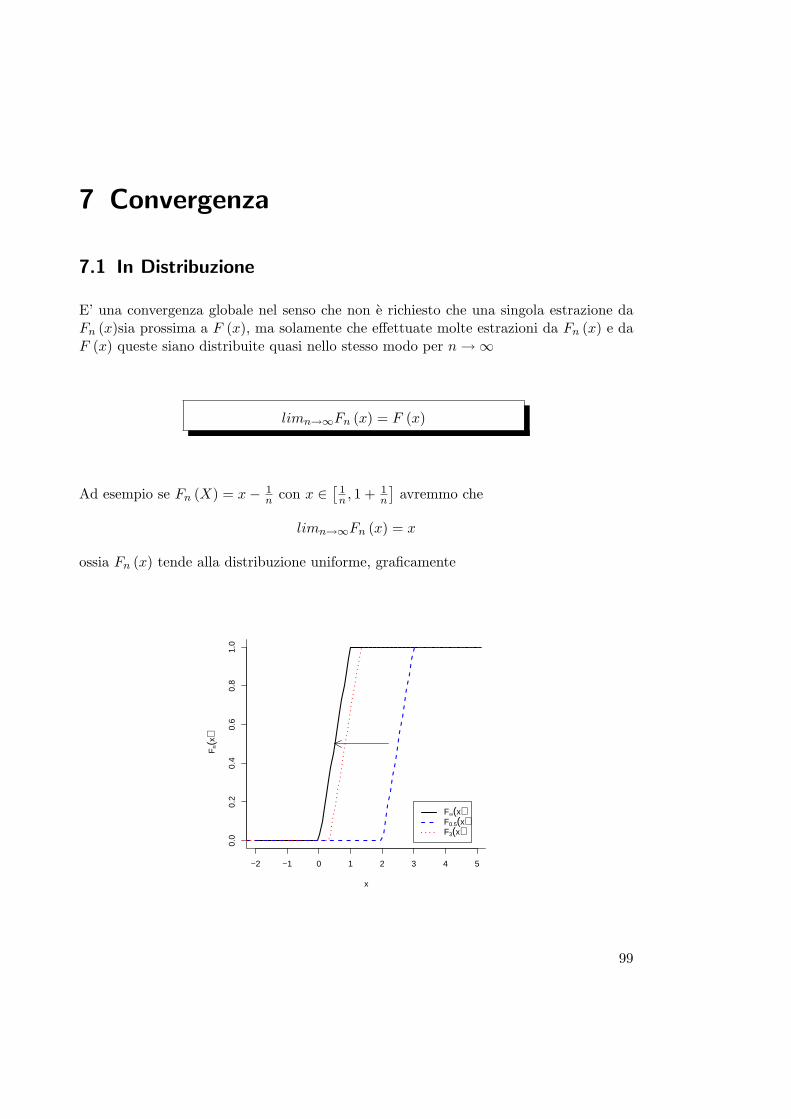
7 Convergenza
7.1 In Distribuzione
E’ una convergenza globale nel senso che non e richiesto che una singola estrazione daFn (x)sia prossima a F (x), ma solamente che effettuate molte estrazioni da Fn (x) e daF (x) queste siano distribuite quasi nello stesso modo per n →∞
limn→∞Fn (x) = F (x)
Ad esempio se Fn (X) = x− 1n con x ∈
[1n , 1 + 1
n
]avremmo che
limn→∞Fn (x) = x
ossia Fn (x) tende alla distribuzione uniforme, graficamente
−2 −1 0 1 2 3 4 5
0.0
0.2
0.4
0.6
0.8
1.0
x
Fn(x
)
F∞(x)F0.5(x)F3(x)
99
Paolo Tenconi: Appunti di Statistica
7.2 In Probabilita
E’ una richiesta piu forte rispetto alla convergenza in distribuzione, ora e richiesto cheestraendo coppie di numeri casuali (da Fn (x) e F (x)) e prendendone le differenze, laprobabilita di osservare differenze assolute < ε tende a zero per n →∞
limn→∞P [|Xn −X| < ε] = 1
equivalentemente ogni coppia di punti (x, xn) dovra disporsi sulla bisettrice entro lebande ±ε con probabilita prossima a uno per n →∞
x
x n
−3 −2 −1 1 2 3
−3
−2
−1
− ε
ε
1
2
3
si noti che X puo essere una costante.
7.3 In Media r-esima
Se estraiamo coppie di numeri casuali da Fn (X) e F (X) calcolando gli scarti |xn − x|Rper ogni coppia e prendendone la media, se essa → 0 per n →∞ abbiamo convergenzain media R-esima
limn→∞E|Xn −X|R = 0
100

Paolo Tenconi: Appunti di Statistica
7.4 Quasi Certa
Non ha rilevanza ai nostri fini, e la convergenza piu forte
P [limn→∞Xn = X] = 1
7.5 Legge Debole dei Grandi Numeri
Se estraiamo (in forma indipendente) molti numeri da una stessa variabile casuale conmedia µ allora la media di questi numeri estratti sara tanto piu prossima alla vera mediaµ se il numero di estrazioni →∞.
limn→∞P[|Xn −X| < ε
]= 1
ossia la media campionaria tende in probabilita alla vera media della variabile casuale.
7.6 Teorema del Limite Centrale
E’ un teorema fondamentale (da qui il nome“centrale”) in quanto su di esso poggia partedella teoria statistica asintotica (basata su grandi campioni).
Qualunque sia la distribuzione della variabile casuale (Bernoulli, Binomiale,...) la rispet-tiva media campionaria tende ad una distribuzione normale centrata sulla vera media µe con varianza sempre piu piccola per campioni sempre piu ampi.
Xnn→∞→ N
(µ,
σ2
n
)con
Xn =Pn
i=1 xi
n
xiiid (indipendenti ed identicamente dis-tribuite)
µ e σ2finite
101

Paolo Tenconi: Appunti di Statistica
102

8 Esercizi di Probabilita
103
Paolo Tenconi: Appunti di Statistica
Probabilita Totali
Nell’esperimento “lancio di un dado” si calcoli la probabilita dell’evento “numero pari ominore uguale a tre”
P pari∪ ≤ 3 = P pari+ P ≤ 3 − P pari∩ ≤ 3
=36
+36− 1
6
13
2
46
A
B
5
A ∩B
Come si puo notare, essendo gli eventi A e B non incompatibili (a livello insiemistico cioe denotato dal fatto che i relativi insiemi sono non disgiunti), abbiamo dovuto sottrarnea probabilita dell’intersezione, al fine di evitare doppi conteggi circa le probabilita. Talee appunto la logica del teorema delle probabilita totali che qui riportiamo
P A ∪B = P A+ P B − P A ∩B
104

Paolo Tenconi: Appunti di Statistica
Probabilita Composte
Il teorema delle probabilita composte ci aiuta a calcolare la probabilita di verificarsi diuno o piu eventi.
P A ∩B = P A|BP B = P B|AP A
Sempre nel lancio di un dado, calcolare la probabilita che “esca un numero pari e minoreuguale a quattro.
P Pari∩ ≤ 4 = P Pari| ≤ 4 × P ≤ 4
=24× 4
6=
13
1
3
2
4
6B
A
5
PA ∩ B = PA|B × PB
Come caso particolare abbiamo l’indipendenza fra eventi (da non confondersi con l’in-compatibilita), il caso in cui cioe P A|B = P A. Cio significa che la probabilitadi verificarsi di Anon e influenzata dal fatto che si sia verificato B ; nel nostro esempioinfatti la probabilita che esca un numero pari non e influenzata dal fatto che sia uscito unnumero ≤ 4 (infatti in entrambi i casi abbiamo una probabilita 0,5 che esca un numeropari). In tale caso la formula delle probabilita composte si semplifica nella seguente
P A ∩B = P A × P B
Ma attenzione¸ funziona solo in caso di indipendenza: nell’esempio precedente avrebbefunzionato infatti
P Pari∩ ≤ 4 = P Pari × P ≤ 4
=12× 4
6=
13
105

Paolo Tenconi: Appunti di Statistica
Calcoliamo ora P Pari∩ ≤ 3 in tal caso non abbiamo indipendenza, infatti PPari| ≤ 3 6=P Pari e quindi corretto utilizzare la seguente formula
P Pari∩ ≤ 3 = P Pari| ≤ 3 × P ≤ 3 =13× 1
2=
16
sarebbe invece scorretto utilizzare la seguente
P Pari∩ ≤ 3 = P Pari × P ≤ 3 =12× 1
2=
14
Si calcoli ora la probabilita che esca un numero minore o uguale a quattro, posto che siauscito un numero pariR: qui dobbiamo fare uso della relazione indicata in precedenza P A ∩B = P A|BP B =P B|AP A . Nel nostro caso A=Pari , B=≤ 4, ci viene chiesto insomma di cal-colare P B|A, con semplici passaggi algebrici isoliamo tale membro e troviamo cheP B|A = PA∩B
PA
P ≤ 4|pari =P pari∩ ≤ 4
P pari
=P pari| ≤ 4 × P ≤ 4
P pari| ≤ 4 · P ≤ 4+ P pari| > 4 · P > 4
=24 + 4
624 ·
46 + 1
2 ·26
=23
106
Paolo Tenconi: Appunti di Statistica
Leggi di De Morgan
Prima legge
A ∪B = A ∩ B
A ∪B
A
B
A ∩ B
A
B
C
A
B
C
Seconda legge:
A ∩B = A ∪ B
A
B
A
B
C
A
B
C
A ∩B
A ∪ B
107
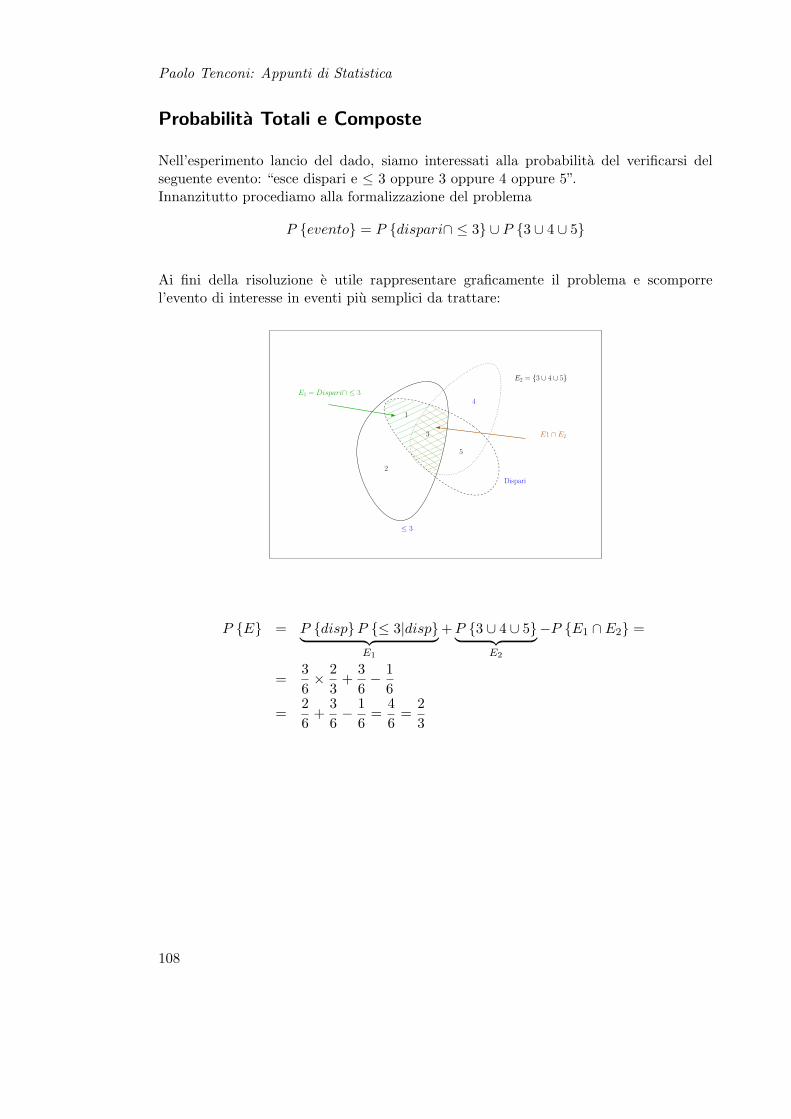
Paolo Tenconi: Appunti di Statistica
Probabilita Totali e Composte
Nell’esperimento lancio del dado, siamo interessati alla probabilita del verificarsi delseguente evento: “esce dispari e ≤ 3 oppure 3 oppure 4 oppure 5”.Innanzitutto procediamo alla formalizzazione del problema
P evento = P dispari∩ ≤ 3 ∪ P 3 ∪ 4 ∪ 5
Ai fini della risoluzione e utile rappresentare graficamente il problema e scomporrel’evento di interesse in eventi piu semplici da trattare:
2
1
3
5
4
≤ 3
Dispari
E2 = 3 ∪ 4 ∪ 5
E1 = Dispari∩ ≤ 3
E1 ∩ E2
P E = P dispP ≤ 3|disp︸ ︷︷ ︸E1
+P 3 ∪ 4 ∪ 5︸ ︷︷ ︸E2
−P E1 ∩ E2 =
=36× 2
3+
36− 1
6
=26
+36− 1
6=
46
=23
108

Paolo Tenconi: Appunti di Statistica
Marginalizzazione
Sia data la seguente lotteria: da un’urna contenente 5 palline bianche e 10 nere se pescouna pallina bianca partecipo alla lotteria A, mentre se pesco una pallina nera partecipoalla lotteria B. Nella lotteria A si possono vincere 10 euro con probabilita 0,5 e perdernealtrettanti con probabilita 0,5. Nella lotteria B invece si ha una probabilita di 0,1 divincere 10 euro ed una probabilita 0,9 di perderne altrettanti.Formulare la variabile aleatoria “vincita-perdita di euro”
X ≡
−10 101− p p
Calcolare la vincita attesaPer la risoluzione ci puo avvalere, a condizione che gli eventi Bi siano fra loro indipendentied esaustivi, della seguente relazione
P Ah =k∑
i=1
P (Ah|Bi)× P (Bi)
Nel nostro caso A1 = 1 − p mentre A2 = p sfruttando quanto appena detto otteniamo,indicando con lA = lotteriaA e con lB = lotteriaB
P (−10) = 1− p = P (−10|lA) · P (lA) + P (−10|lB) · P (lB)P (10) = p = P (10|lA) · P (lA) + P (10|lB) · P (lB)
esplicitando la formula per la media otteniamo
E (X) = −10× P (−10) + 10× P (10)
sostituendo quanto sopra determinato otteniamo
E (X) = −10 P (−10|lA) · P (lA) + P (−10|lB) · P (lB)++ 10 P (10|lA) · P (lA) + P (10|lB) · P (lB)
e riordinando i termini
E (X) = −10× P (−10|lA) P (lA) + 10× P (10|lA) P (lA)++ −10× P (−10|lB) P (lB) + 10× P (10|lB) P (lB)
E (X) = P (lA) −10× P (−10|lA) + 10× P (10|lA)++ P (lB) −10× P (−10|lB) + 10× P (10|lB)
109

Paolo Tenconi: Appunti di Statistica
E (X) = P (lA)× E [lA] + P (lA)× E [lB]
E (X) =515×[10 · 1
2− 10 · 1
2
]+
1015×[10 · 1
10− 10 · 9
10
]= −5, 3
Si calcoli p
p = P (10|lA) · P (lA) + P (10|lB) · P (lB)
=515× 1
2+
1015× 1
10= 0, 23
Si calcoli lo scarto quadratico medio della V.A. X
V (X) = [−10− (−5, 3)]2 × 0, 23 + [10− (−5, 3)]2 × (1− 0, 23)σ (X) =
√V (X) = 8, 459
Teorema di Bayes
Siano note le probabilita di verificarsi delle seguenti patologie: HIV, Epatite ed Influenza.Siano note altresı le probabilita che un soggetto, posto che abbia una delle tre patologie,mostri la presenza di un certo sintomo S . Si proceda al calcolo che un soggetto abbiauna delle patologie, posto che denoti la presenza del sintomo S .P [HIV ] = 0, 01 P [Ep] = 0, 05 P [Infl] = 0, 94P [S|HIV ] = 0, 7 P [S|Ep] = 0, 5 P [S|Infl] = 0, 1
Per calcolare quanto richiesto, viene in aiuto il teorema di Bayes. Esso entra in gio-co tipicamente quando viene chiesto di “invertire” l’ordine in cui appare una probabilitacondizionata, nel nostro caso siamo interessati genericamente a P [patologia|sintomo]
P [patj |S] =P (S|patj)× P (patj)∑3i=1 P (S|pati)× P (pati)
P (HIV ) · P (S|HIV ) = 0, 007P (Ep) · P (S|Ep) = 0, 025
P (Inf) · P (S|Inf) = 0, 0943∑
i=1
P (pati) P (S|pati) = 0, 007 + 0, 025 + 0, 094 = 0, 126
P (HIV |S) =0, 0070, 126
= 0, 0556
P (Ep|S) =0, 0250, 126
= 0, 1984
P (Infl|S) =0, 0940, 126
= 0, 7460
110

Paolo Tenconi: Appunti di Statistica
Si supponga che il paziente sia di ritorno da un viaggio in Asia, ricalcolare P [pati|S ∩Asia]sapendo che P [HIV |Asia] = 0, 05 P [Ep|Asia] = 0, 15 P [Infl|Asia] = 0, 8R: In questo caso basta sostituire P [pati] con la nuova che tiene conto della visita inAsia P [pati|Asia] , muta insomma la nostra valutazione “a priori” sulla patologia
P [patj |S ∩Asia] =P (S|patj)× P (patj |Asia)∑3i=1 P (S|pati)× P (pati|Asia)
Si supponga di non sapere se il paziente sia stato in Asia o meno, ma di conosceregenericamente che la probabilita che P [Asia] = 0, 1. Ricavare P
[patj |S ∩Asia
]R: sfruttando la generica relazione secondo cui
P [A|B] = P [A|B,C]× P [C] + P[A|B,C
]× P
[C]
P [patj |S] = P [patj |S ∩Asia]× P [Asia] + P[patj |S ∩Asia
]× P
[Asia
]⇒ P
[patj |S ∩Asia
]=
P [patj |S]− P [patj |S ∩Asia]× P [Asia]P[Asia
]non ci resta che sosituire gli elementi calcolati precedentemente per giungere a quantosegue
P[HIV |S, Asia
]= 0, 0413
P[Ep|Asia
]= 0, 1766
P[Infl|Asia
]= 0, 7821
111

Paolo Tenconi: Appunti di Statistica
Uniforme Discreta
In questo esercizio verificheremo il funzionamento della formula (abbreviata) per il calcolodella media nel caso in cui la distribuzione di probabilita non assuma valori nell’intervallo1, 2, ...NSi data la seguente distribuzione di probabilita
X ≡
1 2 ... N1N
1N ... 1
N
Sapendo che E (X) = 2, 5 determinare N
E (X) =N∑
i=1
xifi =1N
N∑i=1
i︸︷︷︸=
N(N+1)2
=N(N+1)
2
N=
N + 12
sfruttando l’identita E(X) = N+12 possiamo ricavare N conoscendo la media
N = 2× E(X)− 1= 2× 2, 5− 1 = 4
Si assuma ora che la distribuzione uniforme discreta sia la seguente
X ≡
10 11 ... 1415
15 ... 1
5
Verifichiamo che in tale caso non opera piu la formula data precedentemente
E (X) =5∑
i=1
xifi = 12
N(N+1)2
N=
14·152
14= 7, 5
l’erroneita della formula e evidente, in quanto il risultato non soddisfa la proprieta diinternalita della media aritmetica.
Si trasformi la distribuzione di probabilita in modo da peter utilizzare la formula sem-plificata E (X) = N(N+1)/2
N
X = X − [min (X)− 1]
⇒ X = X + min (X)− 1
112

Paolo Tenconi: Appunti di Statistica
X ≡
1 2 ... 515
15 ... 1
5
E(X)
=N + 1
2=
5 + 12
= 3
E (X) = E[X + (min(X)− 1)
]︸ ︷︷ ︸
E[X+α]=α+E[X]
= [min (X)− 1] + E[X]
= 10− 1 + 3 = 12
Binomiale Bernoulli e Poisson
Da un mazzo di carte se pesco piu di tre figure su 5 tentativi mi viene dato un importoin euro pari al numero di auto che passeranno nella prossima ora.Sapendo che il numero medio di auto che transita in un quarto d’ora sia 5 si proceda alcalcolo di quanto segue:
Formulare la variabile aleatoria “numero di figure” pescate
X ≡
0 1 2 3 4 5(
5xi
) (1240
)xi(1− 12
40
)5−xi
Determinare P [X ≥ 3]
P [X ≥ 3] = P (3) + P (4) + P (5) = 0, 1323 + 0, 0284 + 0, 0243 = 0, 16308
Descrivere la variabile aleatoria “procedo / non procedo” al conteggio delle auto
Y ∼ Be (θ = 0, 16308)
mediamente quante volte¸ ripetendo l’esperimento, si procedera al conteggio delle auto?R: basta utilizzare la formula per il valore atteso della Bernoulli
E (Y ) = θ = 0, 16308
Si indichi la variabile aleatoria “numero di auto in 1 ora”R: Si tratta di una Poisson¸ con parametro (nota bene) λ = 5× 4︸ ︷︷ ︸
nr. auto×nr quarti d′ora
Z ∼ Po (λ = 20)
113

Paolo Tenconi: Appunti di Statistica
Z ≡
0 1 2 ..... +∞e−λλzi
zi!
Si calcoli E [vincite|nr. figure ≥ 3]R: E´semplicemente il valore atteso della Poisson: E [vincite|nr. figure ≥ 3] = λ = 20
Si calcoli la probabilita di vincere 20 euro posto che il numero di figure estratte sia≥ 3R: P [Z = 20|nr. figure ≥ 3] = e−202020
20! = 8, 88%Probabilita di non vincere posto che il numero di figure estratte dia ≥ 3R: P [Z = 0|nr. figure ≥ 3] = e−20200
0! = 2, 06e− 9
Si dica ora quale e la probabilita di non vincereR: non e piu presente la condizione che il numero di carte estratte sia stato ≥ 3. Inquesto caso la probabilita di non vincere e data dalla somma della probabilita di estrarreun numero di carte inferiore a 3 e della probabilita che non passi nessuna auto posto chesi sia proceduto al conteggio delle auto (cioe posto che il numero di carte estratte siastato ≥ 3).
P [non vincere] = P [X < 3] + P [X ≥ 3 eZ = 0]= P [X < 3] + P [X ≥ 3 ∩ Z = 0]︸ ︷︷ ︸
P (A∩B)=P (A|B)P (B)
= P [X < 3] + P [Z = 0|X ≥ 3]× P [X ≥ 3] == (1− 0, 16308) + 2, 06e− 9× 0, 16308︸ ︷︷ ︸
'0
= 0, 83692
Si calcoli ora P [vincere 20 euro]R: anche in questo caso non e presente la condizione. La probabilita di vincere 20 euro edata dal verificarsi di due eventi congiuntamente: pescare un numero di carte ≥ 3e chepassino esattamente 20 auto
P [vincere 20 euro] = P [passano 20 auto e nr. figure ≥ 3]= P [Z = 20 ∩X ≥ 3]= P [Z = 20|X ≥ 3]× P [X ≥ 3]= 0, 0888...× 0, 16308 = 0, 0145
114

Paolo Tenconi: Appunti di Statistica
Uniforme Continua
I voti ottenuti in due materie d’esame sono cosı distribuiti:
Matematica (X) ∼ U [10, 20]
Statistica (Y ) ∼ U [8, 30]
Due studenti stanno per sostenere l’esame di matematica l’uno e l’esame di statistical’alto. Determinare la probabilita che sicuramente l’esaminando di statistica prendaun voto ≥del suo collega.R: La certezza di ha solo se il voto di statistica sara ≥ 20 , quindi
P [Y ≥ 20] =∫ 30
20
130− 8
dx
=[
x− 830− 8
]30
20
= 1− 0, 54... = 0, 4545
Quante volte e piu probabile il verificarsi di X in [10, 20]rispetto ad Y?R: si tratta di un semplice rapporto tra integrali
P [X ∈ (10, 20)]P [Y ∈ (10, 20)]
=
∫ 2010
120−10dx∫ 20
101
30−8dy=
1∫ 2010
130−8dy
=1
0, 45...' 2, 2
Calcolare il voto in corrispondenza del quale P (X ≤ x) = P (Y ≤ y)R: E’ il punto in cui le funzioni di ripartizione F (X) e F (Y ) si incrociano¸quindi:
x− 830− 8
=x− 1020− 10
x− 822
=x− 10
1010(x− 8) + (10− x)22
220= 0
10x− 80 + 220− 22x = 0−12x + 140 = 0
x =14012
= 11, 6
115

Paolo Tenconi: Appunti di Statistica
Esponenziale
Le batterie per telefonino xyz hanno una durata media di 2 anni
Indicare una distribuzione di probabilita appropriata per modellare il carattere.R: La distribuzione esponenziale e appropriata in quanto ha supporto positivo e continuo,in virtu del fatto che E [X] = 1
λ ⇒ λ = 1E[X] = 1
2 quindi
X ∼ Exp
(λ =
12
)f(x) = λe−λx
F (x) =∫ x
0λe−λxdx = 1− e−λx
Indicare la probabilita che
le batterie durino piu di un anno
P [X > 1] =∫ +∞
1
12e−
12xdx = 1−
∫ 1
0
12e−
12xdx
= 1−[1− e−
12·1]
= e−12 ' 0, 6065
le batterie durino piu di due anni
P [X > 2] = 1−∫ 2
0
12e−
12xdx = 1−
[1− e−
12·2]
= e−1 ' 0, 3679
batterie con un anno di vita non debbano essere cambiate nel corso dell’annosuccessivo
P [X > 2|X > 1] =P [X > 2 ∩X > 1]
P [X > 1]=
P [X > 2]P [X > 1]
=e−
12·2
e−12·1' 0, 6065
Si noti che P [X > 2|X > 1] = P [X > 1] , questo significa che la probabilita didurata residua non e influenzata da quanto la batteria sia vecchia. Questo dipendedalla particolare conformazione della distribuzione esponenziale che e appuntodefinita distribuzione con assenza di memoria.
in una famiglia in cui ci sono 5 telefonini comprati lo scorso anno almeno unabatteria vada sostituita nel corso dell’anno
116

Paolo Tenconi: Appunti di Statistica
R: utilizziamo una distribuzione binomiale il cui parametro θ rappresenta la proba-bilita di sostituzione di una batteria di un anno di vita nel corso del anno a venire,esattamente il complementare di quanto calcolato al punto precedente, quindi
Z ∼ Bin
[n = 5; θ = 1− e−
12·2
e−12·1
]
P [X ≥ 1] = 1− P [0] ' 0, 9179
117

Paolo Tenconi: Appunti di Statistica
Normale
Notazione
Una breve premessa sulla notazione che utilizzeremo nel corso della serie di esercizi sullanormale.Data la seguente distribuzione di probabilita
X ∼ N (µ, σ)
definiamo standardizzazione la seguente operazione
Z =x− µ
σ∼ N (0, 1)
inoltre definiamo la funzione di ripartizione di una N (0, 1) con la seguente simbologia
Φ (x) =∫ x
−∞N (0, 1) dx
La motivazione per cui si ricorre al processo di standardizzazione sta nel fatto che l’in-tegrale di una generica distribuzione normale non e risolvibile analiticamente, tuttaviae sempre possibile ricondurre qualsiasi tipo di distribuzione normale alla N(0,1), per laquale sono disponibili tavole che ne riportano la soluzione numerica dell’integrale, inalternativa ad esse e possibile ricorrere a software prettamente statistico o con funzionistatistiche (ad esempio Excel della Microsoft) .
Esercizi con le tavole
Data la distribuzione di probabilita X ∼ N (0, 1) si proceda al calcolo di quanto segue
P (X ≤ 1, 96) = Φ(1, 96) = 0, 975
P(X ≤ −1, 88) = Φ(−1, 88) = 1−Φ(1, 88) = 1− 0, 03
P(−1, 5 ≤ X ≤ 0, 5) = Φ(0, 5)−Φ(−1, 5) = 0, 69146− 0, 66807 ' 0, 6247
Data la distribuzione di probabilita X ∼ N (µ = 3;σ = 2)
Dare l’espressione per P (X ≥ 4, 5)
P (X ≥ 4, 5) =∫ +∞
4,5
1√
2π32exp
[−1
2 · 32(x− 3)2
]dx non risolvibile analiticamente
118

Paolo Tenconi: Appunti di Statistica
Calcolare P (X ≥ 4, 5) . Per la soluzione dobbiamo ricondurre la distribuzione allanormale standardizzata e cercare la soluzione sulle tavole
P (X ≥ 4, 5) = 1− P (X < 4, 5)
≡ 1− P
(X − µ
σ<
4, 5− µ
σ
)= 1− P
(Z <
4, 5− 32
)= 1−Φ
(4, 5− 3
2
)= 1−Φ (0, 075) = 0, 47011
Dato il punto z = −1 relativo alla N (0, 1) si risalga al punto corrispondente diuna N (µ = 3;σ = 2)R: si tratta di effettuare l’operazione inversa rispetto alla standardizzazione
z =x− µ
σ⇒ x = µ + z · σ
x = 3 + (−1) · 2 = 1
Esercizio
Il rendimento di un titolo azionario e distribuito come una normale¸ R ∼ N (µ = 0, 02;σ = 0, 1).Si determini:la probabilita di avere rendimenti negativi
P (X < 0) ≡ P
(X − 0, 02
0, 1<
0− 0, 020, 1
)= Φ
(0− 0, 02
0, 1
)= 0, 4207
la probabilita di avere “rendimenti estremi” nel senso di avere rendimenti superiori al 5%oppure inferiori all’1%
P (X > 0, 05) ∪ P (X < −0, 01)≡ P
(X−0,02
0,1 > 0,05−0,020,1
)∪ P
(X−0,02
0,1 < −0,01−0,020,1
)=[1−Φ
(0,05−0,02
0,1
)]+ Φ
(−0,01−0,02
0,1
)= [1− 0, 61791] + 0, 38209 = 0, 76418
Esercizio
Si supponga di volere un titolo azionario la cui probabilita di rendimenti negativi sia del40% e la probabilita di rendimenti inferiori al 10% sia dell’1%. Supposto che i rendi-menti siano distribuiti normalmente si proceda alla determinazione delle caratteristiche
119

Paolo Tenconi: Appunti di Statistica
che tale titolo deve possedereR: la distribuzione normale e caratterizzata da media e varianza, dobbiamo quindi giun-gere alla loro identificazione a partire dai due elementi forniti, si tratta quindi di metterea punto un sistema di due equazioni con due incognite
P (X < 0) = 0, 4P (X < −0, 1) = 0, 01 P(
X−µσ < 0−µ
σ
)= 0, 4
P(
X−µσ < −0,1−µ
σ
)= 0, 01 Φ
(0−µ
σ
)= 0, 4
Φ(−0,1−µ
σ
)= 0, 01
dobbiamo quindi cercare sulle tavole della N(0,1) i due punti z1e z2 che lasciano allapropria sinistra un’area pari a 0, 4 e 0, 01 , essi corrispondono ai punti z1 = −0, 25 ez2 = −2, 33 quindi 0−µ
σ = −0, 25−0,1−µ
σ = −2, 33
non ci resta che operare per sostituzione, nella prima equazione isoliamo la primaincognita
µ = 0, 25σ
sostituiamo µ nella seconda equazione
µ = −0, 1 + 2, 33× σ
0, 25σ = −0, 1 + 2, 33× σ
σ =0, 1
2, 33− 0, 25' 0, 0481
sostituiamo ora questo valore nella prima equazione
µ = 0, 25σ
µ = 0, 25× 0, 12, 33− 0, 25
' 0, 012
Il titolo che soddisfa i requisiti imposti ha rendimenti, R, t.c.
R ∼ N (µ = 0, 012;σ = 0, 0481)
120

Paolo Tenconi: Appunti di Statistica
Verifichiamo che¸ approssimativamente¸ tale titolo abbia le caratteristiche richieste
P [R < 0] ≡ P
[R− 0, 012
0, 0481<
0− 0, 0120, 0481
]= Φ
(0− 0, 01200, 04807
)= 0, 40129 ' 0, 40
P [R < −0, 1] ≡ P
[R− 0, 012
0, 0481<−0, 1− 0, 012
0, 0481
]= Φ
(−0, 1− 0, 0120
0, 04807
)= 0, 009031 ' 0, 01
come richiesto.
121

Paolo Tenconi: Appunti di Statistica
122

Parte III
Statistica Inferenziale
123


9 Introduzione
Riprendendo lo schema iniziale circa l’estensivita delle osservazioni disponibili, anal-izziamo meglio il concetto di popolazione alla luce del capitolo inerente la probabilita.Possiamo idealmente identificare due tipi di popolazioni
Popolazioni Finite per loro natura riguardano fenomeni relativi ad un insieme ben lim-itato e preciso tale che e possibile averne una totale conoscenza. Se solo parte ditale fenomeno e nota, questa si definisce allora campione da popolazione finita
Popolazione Infinita e illimitata in quanto frutto di un meccaniscmo generatore di risul-tati (meccanismo generatore della probabilita) quindi e impossibile averne una to-tale conoscenza in quanto illimitata. Se sono noti alcuni risultati generati da talemeccaniscmo, questi si definiscono campione da variabile casuale
Ci limiteremo all’analisi di popolazioni infinite.
9.1 Campionamento da Variabili Casuali: il “Modello Statistico”
Illustriamo i concetti con un semplice esempio: costruiamo una slot machine e la tariamoin modo che la probabilita di vittoria sia 0,1. La popolazione e potenzialmente infini-ta, poiche dalla slot machine possono essere generati infiniti tentativi. Il meccanismogeneratore della probabilita e la slot machine
noi costruttori ne conosciamo il parametro di taratura, quindi siamo in grado dirispondere a domande quali la probabilita di vittoria, probabilita di ottenere xsuccessi posto che si effettuano n tentativi,... Questo e il dominio di applicazionedel probabilista il quale noto il meccanisco generatore della probabilita tenta dirispondere alla probabilita di accadimento di eventi complessi.
coloro che non hanno costruito la slot machine, ignari del parametro di taratura,dovrebbero tentare di stimarlo per poi rispondere a domande menzionate sopraquali numero medio di successi,... questo e proprio il compito dello statistico ilquale
– tramite esperimento ottiene un campione dalla popolazione (campionamentoda variabile casuale)
– utilizza un metodo atto alla stima del parametro incognito
125

Paolo Tenconi: Appunti di Statistica
Quest’ultimo passaggio e noto come inferenza ed e espletato attraverso la costruzione diun modello statistico. Si noti che nella realta colui che costruisce e determina la taraturadi un meccanismo generatore della probabilita e la natura o il formarsi di comportamentisociali. Quindi l’unica conoscenza di cui disponiamo sono i risultati di tale meccanismo,allo statistico quindi il compito di svelarla.
9.1.1 Costruzione del Modello Statistico
Un modello statistico e costituito da tre elementi fondamentali, ricavati idealmentesecondo i seguenti passaggi
1. Osservazione di un campione1 estratto o frutto del fenomeno generatore dellaprobabilita
2. Identificazione della natura di tale meccanismo generatore, ossia scelta della vari-abile casuale che meglio approssima la natura del fenomeno
3. Stima della parametrizzazione piu opportuna della variabile casuale scelta alla lucedel campione oservato
M.S. ≡x(n),
∏ni=1 Pθ (xi) , θ ∈ Θ
x(n) : campione di n-osservazioni
∏ni=1 Pθ (xi) : probabilita congiunta del campione (
∏ni=1 poiche
sono osservazioni indipendenti, P e la variabile casuale scelta,mentre θ e la parametrizzazione piu opportuna)
θ ∈ Θ : Θ e il campo di esistenza del parametro della variabilecasuale, ossia l’insieme dei valori entro cui va scelto il parametropiu opportuno
Il problema fondamentale dell’inferenza e dato dalla stima di θ edalla definizione dell’incertezza ad essa legata dovuta alla parzialeosservazione della popolazione.
Riprendendo l’esempio della slot machine vediamo come si comporta lo statistico
1. Estrazione di un campione di ampiezza n (ad esempio n=50) assegnando 1=suc-cesso, 0=insuccesso
x(50) = 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, ...1, 01Assumeremo che le singole estrazioni siano indipendenti ed identicamente distribuite, in sintesi iid.
126

Paolo Tenconi: Appunti di Statistica
2. Identificazione del meccanismo (scelta della v.c.), il risultato di ogni prova e dico-tomico (successo/insuccesso) quindi la v.c. adatta e la Bernoulli
3. Scelta del parametro che caratterizza la Bernoulli, per tale distribuzione sappiamoche θ ∈ [0, 1] quindi esso andra ricercato entro tale intervallo.
in sintesi
M.S. ≡
x(50) = 0, 1, 0, 0, ... ,
50∏i=1
θxi (1− θ)1−xi , θ ∈ [0, 1]
la scelta (stima) della parametrizzazione θ piu opportuna sara l’oggetto del prossimocapitolo.
Si osservi che la definizione di modello statistico data e la sua stima permette unavolta stimato il parametro ignoto θ di ricavare di conseguenza tutti i momenti teoricidella distribuzione della popolazione. Ad esempio indicando con θ la stima data dallostatistico per θ e supponendo che sia θ = 0, 15 e naturale avere di conseguenza comestime per media e varianza della popolazione E (X) = θ = 0, 15 e V (X) = θ
(1− θ
)=
0, 15 (1− 0, 15) = 0, 1275. Tuttavia in alcuni casi l’interesse del ricercatore potrebbeessere limitato solo ad alcuni aspetti della popolazinoe, in questi casi e possibile tentare distimare dirrettamente questi aspetti specifici della popolazione (generalmente costituitida determinate misure di sintesi come ad esempio media, varianza, minimo, massimo,ecc.).
Prenderemo in considerazione metodi per stimare Media
Varianza
Parametro θdella popolazione.
127

Paolo Tenconi: Appunti di Statistica
128

10 Metodi di Stima
I metodi di stima per giungere alla determinazione della media, varianza oppure θ dellapopolazione sono vari, in dipendenza fra l’altro anche dell’approccio filosofico adottato.
10.1 Approccio Bayesiano
Il parametro incognito θ e la realizzazione di una variabile casuale, per la quale disponi-amo di una distribuzione di probabilita a priori che provvediamo a coniugare alla realtaosservata (campione) per giungere ad una distribuzione aggiornata di distribuzione diprobabilita detta a posteriori
P (θ|Y ) =P (Y |θ) P (θ)∫P (Y |θ) P (θ) dθ
con P (θ) distribuzione a priori, P (Y |θ) realta osservata, P (θ|Y ) distribuzione a poste-riori e
∫P (Y |θ) P (θ) dθ costante di normalizzazione.
La formula altro non e se non il teorema di Bayes in ambito continuo, poiche θ assumeusualmente un continuum di valori in un intervallo.
Quindi per l’approccio bayesiano il teorema di Bayes e il metodo distima adatto.
10.2 Approccio Frequentista
E’ basato sul concetto di ripetizione dell’esperimento (qui l’esperimento e l’estrazione diun campione). Secondo il paradigma frequentista un metodo di stima deve soddisfaredeterminate carattteristiche affinche sia accettabile e preferibile rispetto ad altri metodi.Tali caratteristiche sono fondate sul comportamento del metodo di stima al ripetersidell’esperimento (estrazione di altri campioni).
129

Paolo Tenconi: Appunti di Statistica
Si noti che non viene fornito alcun metodo di stima, solo le prescrizioniche questo deve soddisfare. In tale ambito sono stati proposti varimetodi, fra cui
Metodo dei momenti
Massima verosimiglianza
Metodo generalizzato dei momenti
Stimatori-M
Metodo analogico
baseremo la trattazione sull’approccio frequentista, studiando il metodo analogico, ilmetodo dei momenti e la massima verosmiglianza.
10.2.1 Proprieta degli Stimatori
Definiamo stimatore un generico metodo che ci consente di determinare θ ed e basatosull’unica informazione disponibile, il campione. Quindi
Uno stimatore o statistica e una funzione campionaria
θ = T (x)
θ e la stima ossia il risultato ottenuto appplicando lo stimatoreal campione osservato
T e lo stimatore, cioe la funzione applicata al campione x
10.2.1.1 Stimatore Corretto
Uno stimatore e corretto quando applicando T (x) a svariati campioni, la media dellestime θ coincide con il vero (e incognito) valore θ del meccanismo generatore dellaprobabilita
E [T (x)] = θ
130

Paolo Tenconi: Appunti di Statistica
10.2.1.2 Consistenza
Si ottiene quando lo stimatore e consistente in probabilita
limn→∞P |Tn (x)− θ| < ε = 1
cioe la probabilita di selezionare un campione per cui la stima θ e vicina al vero valoreignoto θ in misura minore di ε tende a 1 per ogni ε piccolo a piacere, basta infattiaumentare l’ampiezza campionaria.
E’ difficile dimostrare la convergenza in probabilita di uno stimatore, piu semplicee invece la dimostrazione di convergenza in media quadratica che implica quella inprobabilita, quindi si utilizzera spesso questa
limn→∞E[(Tn (x)− θ)2
]= 0 ⇒ limn→∞P [|Tn (x)− θ| < ε] = 1
e possibile scomporre E[(Tn (x)− θ)2
]= E [Tn (x)]− θ2 +V [Tn (x)] il primo addendo
a destra e noto come bias2 (bias e la distorsione dello stimatore) mentre il secondorappresenta la varianza dello stimatore, se entrambe queste quantita → 0 allora si haconvergenza in media quadratica
limn→∞ E [Tn (x)]− θ2 = 0 , correttezza asintotica
limn→∞V [Tn (x)] = 0 , varianza asintotica nulla
quindi
se Tn e corretto basta calcolare limn→∞V [Tn (x)] per dimostrare la consistenza inmedia quadratica
altrimenti bisogna dimostrare che valgono le due proprieta di correttezza asintoticae varianza asintotica nulla
131
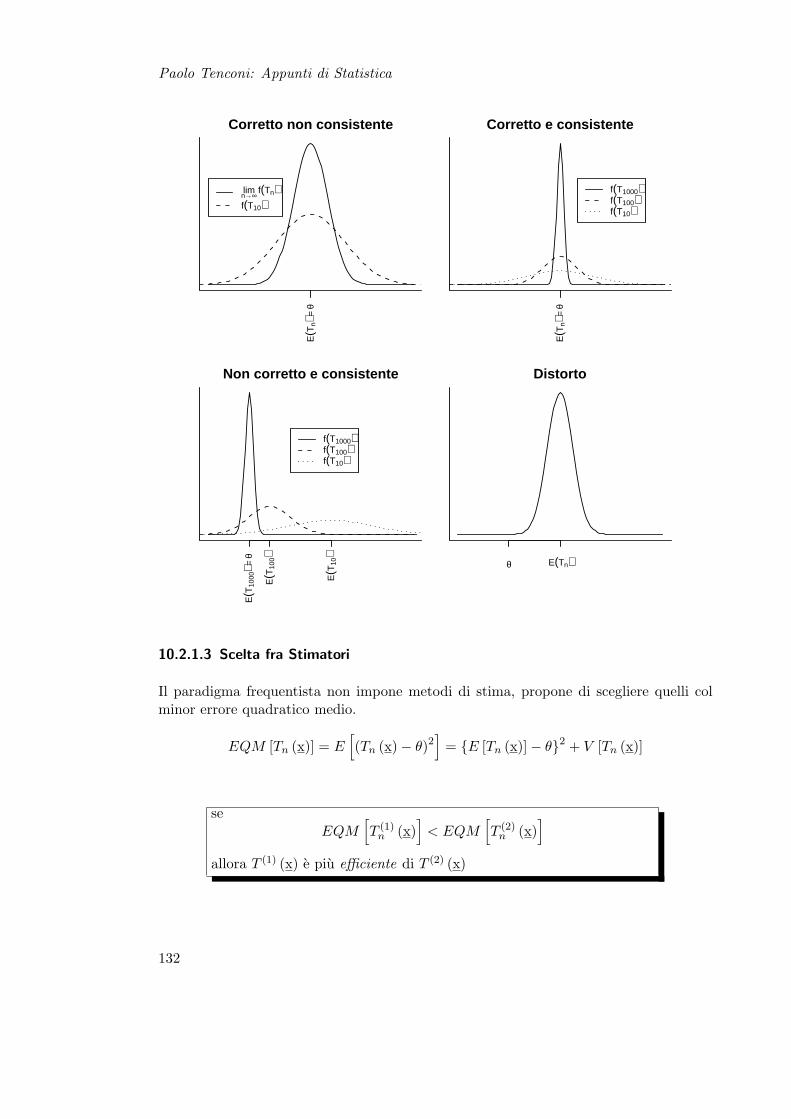
Paolo Tenconi: Appunti di Statistica
Corretto non consistente
E(T
n)=
θ
limn→∞
f(Tn)f(T10)
Corretto e consistente
E(T
n)=
θ
f(T1000)f(T100)f(T10)
Non corretto e consistente
E(T
1000
)=θ
E(T
100)
E(T
10)
f(T1000)f(T100)f(T10)
Distorto
θ E(Tn)
10.2.1.3 Scelta fra Stimatori
Il paradigma frequentista non impone metodi di stima, propone di scegliere quelli colminor errore quadratico medio.
EQM [Tn (x)] = E[(Tn (x)− θ)2
]= E [Tn (x)]− θ2 + V [Tn (x)]
seEQM
[T (1)
n (x)]
< EQM[T (2)
n (x)]
allora T (1) (x) e piu efficiente di T (2) (x)
132

Paolo Tenconi: Appunti di Statistica
.
Infine si noti che se due stimatori sono corretti entrambi hanno E [Tn (x)]− θ2 = 0quindi la scelta fra stimatori si riduce al confronto fra le varianze degli stimatori
V[T (1)
n (x)]
< V[T (2)
n (x)]
133

Paolo Tenconi: Appunti di Statistica
134

11 Stima Puntuale
11.1 Metodo Analogico
Siamo interessati a un aparticolare quantita per la popolazione, adottiamo come stima-tore di questa la medesima quantita calcolata sul campione (a meno di lieve correzionida valutarsi caso per caso).
Ad esempio
Per la media della popolazione utilizziamo la media del campione
E (X) =∑n
i=1 xi
n
Per il minimo della popolazione utilizziamo il minimo del campione
min (X) = min (x)
Per la varianza dela popolazione utilizziamo la varianza corretta del campione
V (X) =∑n
i=1 (xi − x)2
n− 1
si noti che al denominatore abbiamo utilizzato (n− 1) poiche rende lo stimatorecorretto.
11.2 Metodo dei Momenti
E’ volto alla stima di θ, inteso questo come un vettore di k-parametri ed e basato sul-l’uguaglianza di k momenti teorici della distribuzione della popolazione coi k corrispon-denti momenti empirici campionari, isolando e risolvendo per il parametro incognitosostituendo infine i momenti teorici coi momenti empirici.
θ = g (µ1, µ2, ..., µk)θ = g (µ1, µ2, ..., µk)
135

Paolo Tenconi: Appunti di Statistica
dove
momenti teorici: µ1 = E (X) , ..., µk = E(Xk)
momenti campionari: µ1 =Pn
i=1 xi
n , ..., µk =Pn
i=1 xki
n
ad esempio se X ∼ Be (θ), abbiamo k = 1, quindi ci serve una sola equazione diuguaglianza, scegliamo il momento primo. Momento primo teorico E (X) = θ, momentoprimo campionario
Pni=1 xi
n = θ . Studiamone correttezza e consistenza
E(θ)
= E
[∑ni=1 xi
n
]=
1n
E
[n∑
i=1
xi
]=
1n
E
[n∑
i=1
xi
]=
1n
n∑i=1
E (xi) =1n
nθ = θ, corretto
V(θ)
= V
(∑ni=1 xi
n
)=
1n2
V
[∑ni=1 xi
n
]=
1n2
n∑i=1
V (xi) =1n2
nθ (1− θ) =θ (1− θ)
n, consistente
consistente poiche limn→∞θ(1−θ)
n = 0. Abbiamo consistenza in media quadratica e diconseguenza consistenza in probabilita.
Come secondo esempio consideriamo X ∼ Exp (λ) , un solo parametro, quindi e suffi-ciente una sola equazione e scegliendo il momento primo sappiamo che
E (X) =1λ
il metodo dei momenti suggerisce di isolare λ , λ = 1E(X) , quindi g (µ) = 1
µ , basta
quindi applicare tale funzione momento empirico µ =Pn
i=1 xi
n
λ =1Pn
i=1 xi
n
=n∑n
i=1 xi
vediamo infine un esempio con due parametri, se X ∼ N[µ, σ2
]abbiamo che θ =
(µ, σ2
)quindi k = 2 ci servono quindi due equazioni
µ = E (X)µ2 = µ2 + σ2 = E (X)2 + V (X)
µ =
Pni=1 xi
n
µ2 =Pn
i=1 x2i
n = µ2 + σ2
⇒ σ2 = µ2 − µ2 =∑n
i=1 x2i
n−[∑n
i=1 xi
n
]2
=∑n
i=1 (xi − x)2
n
µ =∑n
i=1 xi
n
come si puo notare σ2e asintoticamente corretto.
136

Paolo Tenconi: Appunti di Statistica
11.3 Massima Verosimiglianza
Si tratta di identificare il θ che rende massima la probabilita congiunta del campioneosservato, ossia il θ che rende piu verosimile il fatto di aver osservato il campione estratto
Maxθ
n∏i=1
Pθ (xi)︸ ︷︷ ︸L(θ)
L (θ) e la funzione di verosimiglianza intesa come funzione del parametro θ, mentre ilcampione di dati osservati x e considerato come fisso.
Lo stimatore di massima verosimiglianza gode delle seguenti proprieta
θas∼ N
[θ, I (θ)−1
]con I (θ) = −E
∂2
∂θ2 log [L (θ)]
nota come informazione attesasi Fisher
Invarianza per cui se g e una funzione invertibile allora consideranto λ = g (θ) nesegue che λMV = g
(θMV
)Osservazioni
si preferisce massimizzare la log-verosimiglianza ` (θ) = log [L (θ)] (con log intesocome logaritmo naturale) anziche L (θ).
Informazione osservata: i (θ) = −[l′′ (θ)
∣∣∣θMV
]ed indica quanto poco verosimili
sono i valori θ nell’intorno del valore θMV cioe quanto velocemente la verosimiglian-za cade non appena ci spostiamo dal punto di massimo.
Varianza stimata (osservata): per θMV e di conseguenza
V(θMV
)= [i (θ)]−1
Efficienza: fra gli stimatori asintoticamente corretti θMV e quello a varianza mini-ma (piu efficiente), questo e noto come disuguaglianza di Cramer-Rao.
Esempio: il caso della slot machine col metodo dei momenti ha dato come stima θMM =Pni=1 xi
n . Utilizziamo il criterio della massima verosimiglianza
maxθ
n∏i=1
θxi (1− θ)1−xi ≡ maxθ
log
n∏
i=1
θxi (1− θ)1−xi
=n∑
i=1
log
θxi (1− θ)1−xi
=
n∑i=1
xilog (θ) +n∑
i=1
(1− xi) log (1− θ)
137

Paolo Tenconi: Appunti di Statistica
`′ (θ) = 0
∑ni=1 xi
θ+∑n
i=1 xi
1− θ− n
1− θ= 0
(1− θ)∑n
i=1 xi + θ∑n
i=1 xi − nθ
θ (1− θ)= 0
verificata quando∑n
i=1 xi − nθ = 0 cioe per
θMV =∑n
i=1 xi
n
E[θMV
]=
1n
E
(n∑
i=1
xi
)=
1n· nθ = θ
`′′ (θ) =∂
∂θ
[∑ni=1 xi − nθ
θ (1− θ)
]=−nθ (1− θ)− (
∑ni=1 xi − nθ) (1− 2θ)
θ (1− θ)2
−E[`′′ (θ)
]= I (θ) =
nθ (1− θ) +
E(Pn
i=1 xi)︷︸︸︷nθ −nθ
(1− 2θ)
θ (1− θ)2=
n
θ (1− θ)
percio
θMV ∼ N
[θ,
θ (1− θ)n
]
l’informazione osservata e
−`′′ (θ) =nPn
i=1 xi
n
(1−
Pni=1 xi
n
) =n
θMV
(1− θMV
)
supponiamo di avere osservato un campione di ampiezza n = 150 e tale che∑150
i=1 xi = 93, la funzione di logverosimiglianza graficamente risulta essere
138
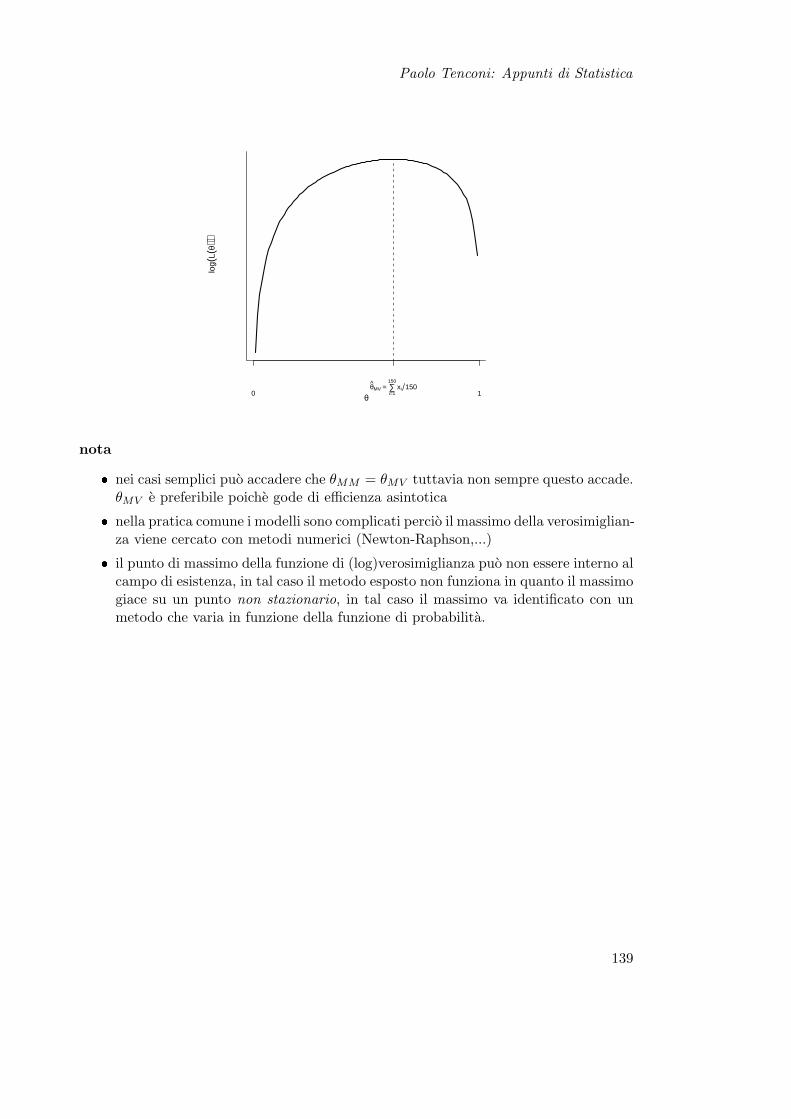
Paolo Tenconi: Appunti di Statistica
θ
log(
L(θ)
)
0θMV = ∑
i=1
150xi 150
1
nota
nei casi semplici puo accadere che θMM = θMV tuttavia non sempre questo accade.θMV e preferibile poiche gode di efficienza asintotica
nella pratica comune i modelli sono complicati percio il massimo della verosimiglian-za viene cercato con metodi numerici (Newton-Raphson,...)
il punto di massimo della funzione di (log)verosimiglianza puo non essere interno alcampo di esistenza, in tal caso il metodo esposto non funziona in quanto il massimogiace su un punto non stazionario, in tal caso il massimo va identificato con unmetodo che varia in funzione della funzione di probabilita.
139

Paolo Tenconi: Appunti di Statistica
140

12 Esercizi di Stima Puntuale
141

Paolo Tenconi: Appunti di Statistica
Richiami di Matematica
In quanto segue viene presentato un breve richiamo alle principali regole di semplificazione¸utili in ambito di massima verosimiglianza (nel seguito indicata con MV).
1. log∏n
i=1 xi =∑n
i=1 log(xi)
2. logαβ = βlogα
3.∑n
i=1(kxi + yi) = k∑n
i=1 xi +∑n
i=1 yi
4.∑n
i=1 k = nk
5. ∂∂θ [log(g(θ)] = g′(θ)
g(θ)
Ecco una semplice funzione a cui possiamo applicare le precedenti regole al fine digiungere alla determinazione del punto di massimo
f (θ) =n∏
i=1
(xk
i θh)
g(θ) = log [f (θ)] = logn∏
i=1
(xk
i θh)
=n∑
i=1
log(xk
i θh)
=n∑
i=1
klog (xi) + hlog(θ)
= kn∑
i=1
log (xi)+n∑
i=1
hlog (θ)
= kn∑
i=1
log (xi)+ n× h · log(θ)
142

Paolo Tenconi: Appunti di Statistica
Esercizio
Sia data la seguente distribuzione di probabilita
X ≡−1 0 1 2p(xi) = θ|xi|(1− θ)2−|xi|
Stimare θ col metodo dei momenti.R: E’ necessario eguagliare il momento I della popolazione, µ(X) , al momento I delcampione, Xe risolvere quindi per il parametro incognito
µ = X
=4∑
i=1
xip(xi)
sviluppiamo la distribuzione di probabilita:
X ≡
−1 0 1 2θ(1− θ) (1− θ)2 θ(1− θ) θ2
µ = −1× θ(1− θ) + 0× (1− θ)2 + 1× θ(1− θ) + 2× θ2
= −θ(1− θ) + θ(1− θ) + 2θ2
= 2θ2
Per il metodo dei momenti, µ (X) = X, quindi
2θ2 = X
θ =
√X
2
143

Paolo Tenconi: Appunti di Statistica
Stimare θ con il metodo della M.V.
L(θ) =n∏
i=1
θ|xi|(1− θ)2−|xi|
`(θ) = log [L (θ)] = log
n∏i=1
θ|xi|(1− θ)2−|xi|
=n∑
i=1
log
θ|xi|(1− θ)2−|xi|
=n∑
i=1
logθ|xi| + log(1− θ)2−|xi|
=
n∑i=1
|xi| · logθ + 2− |xi| · log(1− θ)
=n∑
i=1
|xi| · logθ+n∑
i=1
2log (1θ) −n∑
i=1
|xi|log (1− θ)
= log(θ)n∑
i=1
|xi|+ n · 2log(1− θ)− log(1− θ)n∑
i=1
|xi|
Giunti a questo punto¸ procediamo all’identificazione del punto di massimo della funzione(ora semplificata) di log-verosimiglianza `(θ), tramite annullamento della derivata prima:
∂`(θ)∂θ
= `′(θ) =∑n
i=1 |xi|θ
− 2n
1− θ+∑n
i=1 |xi|1− θ
`′(θ) = 0∑ni=1 |xi|
θ− 2n
1− θ+∑n
i=1 |xi|1− θ
= 0
(1− θ)∑n
i=1 |xi| − 2n + θ∑n
i=1 |xi|θ(1− θ)
= 0
l’equazione e soddisfatta quando il numeratore assume valore zero¸quindi risolviamo laseguente equazione:
(1− θ)n∑
i=1
|xi| − 2n + θn∑
i=1
|xi| = 0
n∑i=1
|xi| − 2θn = 0
ne consegue che lo stimatore di MV e
ˆθMV =∑n
i=1 |xi|2n
144

Paolo Tenconi: Appunti di Statistica
Poisson
La variabile aleatoria X e distribuita secondo la distibuzione di probabilita (notevole) diPoisson: X ∼ Po(λ),determinare lo stimatore di massima verosimiglianza per λ :
Come primo passo dobbiamo giungere alla forma semplificata della log-verosimiglianza
L(λ) =n∏
i=1
e−λλxi
xi!
`(λ) = log [L(λ)] = log
n∏
i=1
e−λλxi
xi!
=n∑
i=1
log
e−λλxi
xi!
=n∑
i=1
log(e−λ) + log(λxi)− log(xi!)
=n∑
i=1
−λ log(e)︸ ︷︷ ︸=1
+xilog(λ)− log(xi!)
= −nλ + logλ
n∑i=1
xi −n∑
i=1
log(xi!)
Procediamo ora all’annullamento della derivata prima:
∂`(λ)∂λ
= 0
−n +∑n
i=1 xi
λ= 0
−λn +∑n
i=1 xi
λ= 0
Tale equazione e soddisfatta quando il numeratore assume valore zero
−λn +n∑
i=1
xi = 0
λ =∑n
i=1 xi
n
Verifichiamo ora che lo stimatore di MV sia effettivamente un punto di massimo, verifi-cando che il segno della derivata seconda della funzione sia negativo in tale punto
145

Paolo Tenconi: Appunti di Statistica
∂2`(λ)∂λ2
=−nλ + nλ−
∑ni=1 xi
λ2
=−nλ + nλ−
∑ni=1 xi
λ2
=−∑n
i=1 xi
λ2
Nel punto di massimo di verosimiglianza sappiamo che λ =Pn
i=1 xi
n ¸ sostituiamo quindiquesta espressione a λ nella precedente formula
∂2`(λ)∂λ2
∣∣∣∣λ=λMV
=−∑n
i=1 xi
(∑n
i=1 xi)2
possiamo constatare facilmente che
∂2`(λ)∂λ2
∣∣∣∣λ=λMV
< 0
poiche il denominatore e sempre positivo (si tratta di un quadrato)¸ mentre il numeratoreassume un valore negativo poiche si tratta della negazione della somma di valori esclusi-vamente positivi (dovuti al fatto che xi ∈ 0, 1, 2, ... +∞) Correttezza dello stimatoredi MV
E [λMV ] =[∑n
i=1 xi
n
]=
1n
E
[n∑
i=1
xi
]=
1n
n∑i=1
E(xi) =n · λn
= λ
Consistenza dello stimatore di MV
V [λMV] = V
[∑ni=1 xi
n
]=
1n2
V
[n∑
i=1
xi
]=
1n2
n∑i=1
V (xi) =n · λn2
=λ
n
=⇒ limn→+∞
V [λMV] = 0
alla medesima conclusione si poteva giungere attraverso l’importante teorema per cui
λMV ∼ N
λ,−E
[∂2`(λ)∂λ2
∣∣∣∣λ=λMV
]−1
applicando tale teorema al nostro caso, utilizzando quanto gia calcolato in precedenza,
146
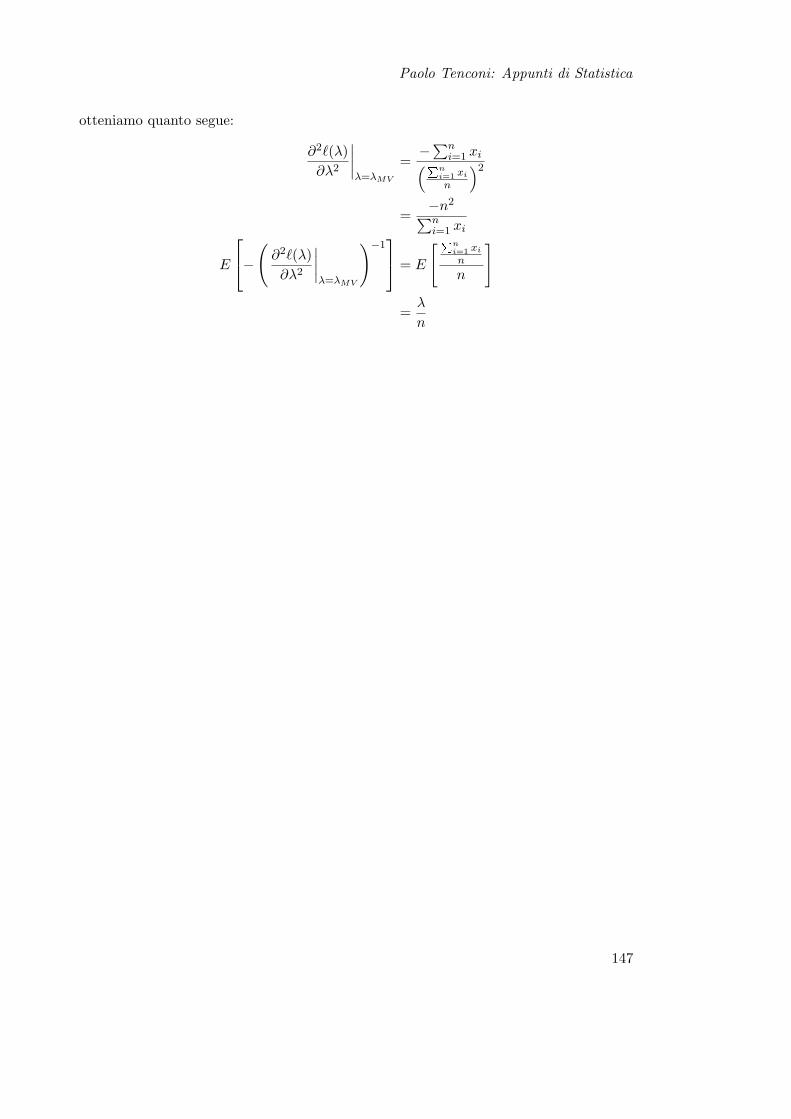
Paolo Tenconi: Appunti di Statistica
otteniamo quanto segue:
∂2`(λ)∂λ2
∣∣∣∣λ=λMV
=−∑n
i=1 xi(Pni=1 xi
n
)2
=−n2∑ni=1 xi
E
−( ∂2`(λ)∂λ2
∣∣∣∣λ=λMV
)−1 = E
[Pni=1 xi
n
n
]
=λ
n
147

Paolo Tenconi: Appunti di Statistica
Scelta fra Stimatori
La popolazione oggetto di indagine assume una distribuzione di Poisson X ∼ Po(λ),vengono proposti i due seguenti stimatori per λ : T1 =
Pni=1 xi
n e T2 = x1+x22 . Deter-
minare la correttezza di entrambi gli stimatori e si scelga quale dei due e il miglioreattraverso un opportuno criterio.
E [T1] = E
[∑ni=1 xi
n
]=
1n
E
[n∑
i=1
xi
]=
nλ
n= λ
E [T2] = E
[x1 + x2
2
]=
12
[E (x1) + E (x2)] =12
[λ + λ] =2λ
2= λ
Essendo gli stimatori entrambi corretti, li confrontiamo attraverso la loro varianza:
V [T1] = V
[∑ni=1 xi
n
]=
1n2
V
[n∑
i=1
xi
]=
1n2
n∑i=1
V (xi) =n · λn2
=λ
n
V [T2] = V
[x1 + x2
2
]=
14V [x1 + x2] =
14
[V (x1) + V (x2)] =14
[λ + λ] =2λ
4=
λ
2
ne consegue che per n > 2 V [T1] < V [T2] e quindi preferibile.
Si concluda sulla proprieta di consistenza in senso forte dei due stimatori:
limn→+∞
[T1] = 0
limn→+∞
V [T2] =λ
2
quindi mentre T1 gode della proprieta di consistenza¸ T2 ne e privo.
148

Paolo Tenconi: Appunti di Statistica
Binomiale
Da un’urna, contenente palline bianche e nere in proporzione incognita, 5 persone ef-fettuando 3 tentativi ciascuna con reimmissione¸ hanno ottenuto il seguente numero dipalline bianche: X ≡ 1, 2, 3, 0, 2. Proporre una distribuzione teorica appropriata peril numero di palline bianche estratte¸si proceda alla stima del parametro incognito colmetodo di MV, col metodo dei momenti e si indichi la stima per il campione ottenuto.
Distribuzione teorica: X ∼ Bin(n = 3, θ =?)
Stima di MV:
L(θ) =5∏
i=1
(3xi
)θxi(1− θ)3−xi
`(θ) = log [L(θ)] =5∑
i=1
log
(3xi
)θxi(1− θ)3−xi
=5∑
i=1
log
(3xi
)+ xilog(θ) + (3− xi) log (1− θ)
=5∑
i=1
log
(3xi
)+ log (θ)
5∑i=1
xi + log (1− θ)5∑
i=1
(3− xi)
∂`(θ)∂θ
= 0 +∑5
i=1 xi
θ−∑5
i=1 (3− xi)1− θ
=(1− θ)
∑5i=1 xi − θ
∑5i=1 (3− xi)
θ(1− θ)
procedendo al calcolo di ∂`(θ)∂θ = 0 che e soddisfatta quando il numeratore si annulla¸
otteniamo quanto segue:
(1− θ)5∑
i=1
xi − θ
5∑i=1
(3− xi) = 0
5∑i=1
xi − θ · 5 · 3 = 0
θ =∑5
i=1 xi
5 · 3
per quanto riguarda il nostro campione, otteniamo quindi:
θMV =1 + 2 + 3 + 0 + 2
5 · 3= 0, 53
149

Paolo Tenconi: Appunti di Statistica
Stima col metodo dei momenti:
µ = X5
3θ = X5
θ =X5
3
=
P5i=1 xi
5
3=∑5
i=1 xi
5 · 3
150

13 Stima Intervallare
Analizzando le proprieta possedute dagli stimatori e emerso il loro comportamentoin ipotesi di estrazione e loro applicazione a molti campioni. Nella realta pratica sipuo estrarre solitamente un solo campione, e percio vitale prendere in considerazionel’incertezza campionaria.
Un intervallo di confidenza e dato dalla differenza fra due statistiche T1 = T1 (x) eT2 = T2 (x) tali che
T1 < T2
Pθ
[T1 < τ (θ) < T2
]= 1− α , α ∈ [0, 1]
da un punto di vista informale un intervallo di confidenza e un ’esten-sione del concetto di stima puntuale (es. metodo dei momenti, mas-sima verosimiglianza,...) nel senso che tali stime vengono racchiusedentro un intervallo tale che prima di estrarre uno dei possibili cam-pioni vi e una probabilita 1 − α che tale intervallo contenga il veroparametro incognito della popolazione, dopo aver estratto il campionesi ha una confidenza (non probabilita) 1− α che l’intervallo identifica-to per il campione osservato contenga il vero parametro ignoto dellapopolazione.
Riprendendo l’esempio della slot machine, in cui sappiamo (avendola costruita) che θ =0, 1 ipotizziamo di estrarre molti campioni, su ognuno di essi stimiamo θ con uno deimetodi proposti (es. massima verosimiglianza), nel grafico che segue i pallini sono ilrisultato di tale stima (che ricordiamo essere
Pni=1 xi
n ). Essi quasi sicuramente noncoincideranno con il vero valore θ = 0, 1 tuttavia possiamo corredarli di un invervallotale che una quota di campioni 1−α abbia l’intervallo che interseca il vero valore θ = 0, 1.
151
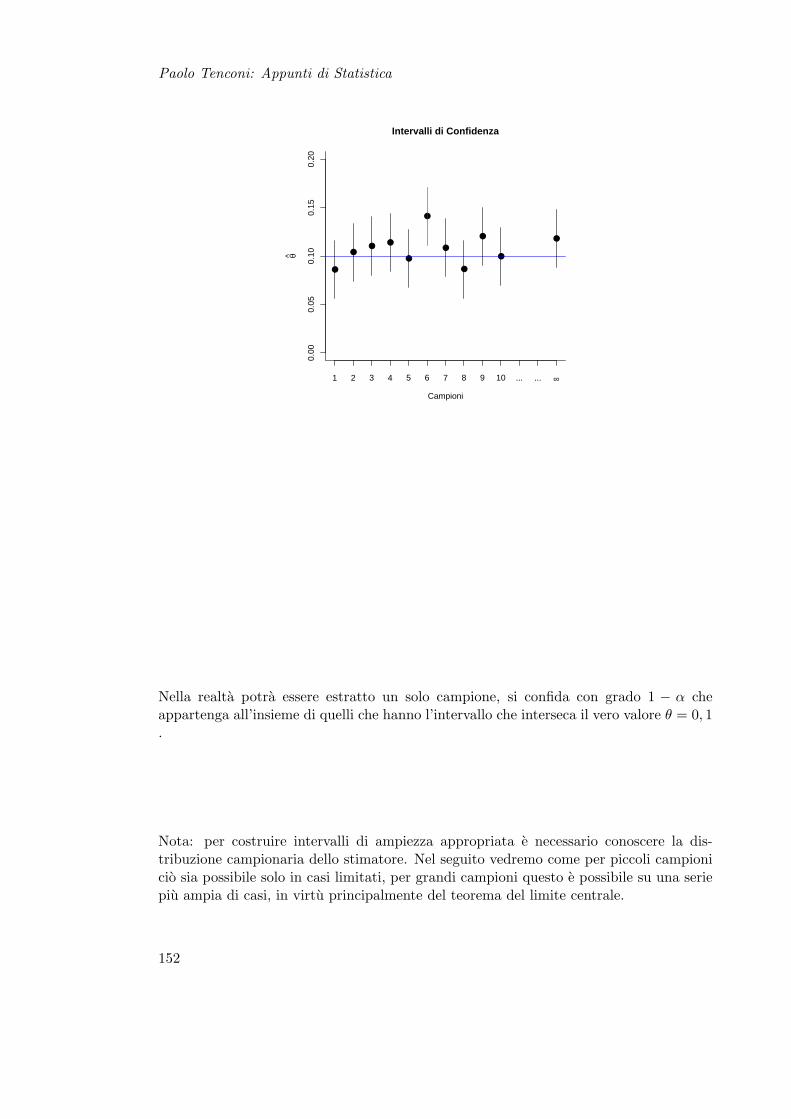
Paolo Tenconi: Appunti di Statistica
Intervalli di Confidenza
Campioni
θ
1 2 3 4 5 6 7 8 9 10 ... ... ∞
0.00
0.05
0.10
0.15
0.20
Nella realta potra essere estratto un solo campione, si confida con grado 1 − α cheappartenga all’insieme di quelli che hanno l’intervallo che interseca il vero valore θ = 0, 1.
Nota: per costruire intervalli di ampiezza appropriata e necessario conoscere la dis-tribuzione campionaria dello stimatore. Nel seguito vedremo come per piccoli campionicio sia possibile solo in casi limitati, per grandi campioni questo e possibile su una seriepiu ampia di casi, in virtu principalmente del teorema del limite centrale.
152
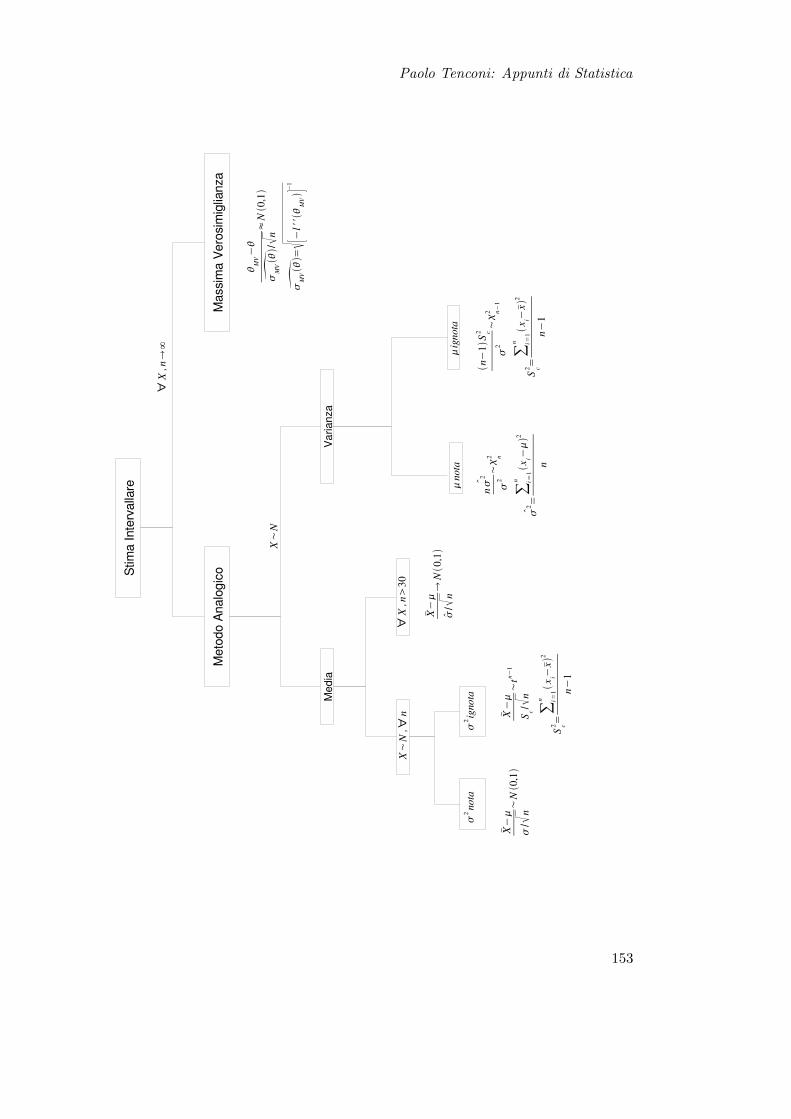
Paolo Tenconi: Appunti di Statistica
Stim
a In
terv
alla
re
Met
odo
Anal
ogico
Mas
sima
Vero
simig
lianz
a
Med
iaVa
rianz
a
2no
ta
2 igno
ta
X−
/
n~N0
,1
X−
S c/n
~tn−
1
S c2 =∑
i=1
nx i−
x2
n−1
X~
N,∀
n∀
X,n
30
X−
/
nN0,
1
no
ta
igno
ta
n
2
2~
n2
2 =∑
i=1
nx i−
2
n
n−
1S c2
2
~
n−1
2
S c2 =∑
i=1
nx i−
x2
n−1
M
V−
M
V/n
≈N0
,1
M
V=
[−l'
'
MV ]−
1
∀X
,n∞
X~
N
153

Paolo Tenconi: Appunti di Statistica
13.1 Intervalli di Confidenza per la Media
13.1.1 Varianza Nota
x− µ
σ/√
n∼ N (0, 1)
dove µ e la vera media, σ2 la vera varianza ed n l’ampiezza campionaria. Significa che sedisponiamo di molti campioni e ad ognuno applichiamo lo stimatore media campionariacon successiava standardizzazione, tali medie trasformate seguiranno una distribuzioneN (0, 1).
Nota bene: tale risultato
Se X ∼ N e valido ∀n Se X N e valido solo per n > 30, in virtu del teorema del limite centrale
In virtu di quanto affermato e possibile costruire l’intervallo di confidenza in due passaggi,se
P
−Zα/2 ≤
x− µ
σ/√
n≤ Zα/2
= 1− α
isolando µ otteniamo l’intervallo di confidenza di livello 1− α
P
x− Zα/2 ·
σ√n≤ µ ≤ x + Zα/2 ·
σ√n
= 1− α
13.1.2 Varianza ignota
Premesso che indicheremo la varianza campionaria corretta (si veda 13.2.1) come segue
S2c =
∑ni=1 (xi − x)2
n− 1
13.1.2.1 X ∼ N e ∀n
x− µ
Sc/√
n∼ tn−1
di conseguenza
P
−tn−1
α/2 ≤x− µ
Sc/√
n≤ tn−1
α/2
= 1− α
P
x− tn−1
α/2
Sc√n≤ µ ≤ x + tn−1
α/2
Sc√n
= 1− α
154

Paolo Tenconi: Appunti di Statistica
13.1.2.2 n > 30 e ∀X
x− µ
σ/√
n∼ N (0, 1)
P
−Zα/2 ≤
x− µ
σ/√
n≤ Zα/2
= 1− α
P
x− Zα/2 ·
σ√n≤ µ ≤ x + Zα/2 ·
σ√n
= 1− α
dove σ e un’opportuna stima per σ .
13.2 Intervalli di Confidenza per la Varianza
Quanto tratteremo varra solo per popolazioni normali X ∼ N .
13.2.1 Premessa: Varianza Campionaria e Distribuzione χ2
13.2.1.1 Varianza Campionaria Corretta
Quando la vera media della popolazione µ e ignota lo stimatore non distorto per lavarianza e la varianza campionaria corretta
S2c (X) =
∑ni=1 (xi − x)2
n− 1
dimostriamo la non correttezza della varianza
S2 =1n
n∑i=1
(xi − x)2 =1n
n∑i=1
[(xi − µ) + (µ− x)]2 =
=1n
n∑i=1
(xi − µ)2 +1n
n∑i=1
(x− µ)2 − 2n
(x− µ)n∑
i=1
(xi − µ)︸ ︷︷ ︸n(x−µ)
=1n
n∑i=1
(xi − µ)2 − (x− µ)2
155

Paolo Tenconi: Appunti di Statistica
E(S2)
= E
[1n
n∑i=1
(xi − µ)2 − (x− µ)2]
=
=1n
n∑i=1
E (xi − µ)2︸ ︷︷ ︸V (xi)=σ2
−E (x− µ)2︸ ︷︷ ︸V (x)=σ2
n
=
=1n
n∑i=1
σ2 − σ2
n=
=n− 1
nσ2 6= σ2
e necessaria una correzione nn−1 a S2 affinche lo stimatore sia corretto, il nuovo stimatore
e noto appunto come varianza campionaria corretta
S2c =
n
n− 1S2 =
∑ni=1 (xi − x)2
n− 1
13.2.1.2 Variabile Casuale χ2
Se X ∼ N (0, 1) la variabile data da
Y =n∑
i=1
x2i ∼ χ2
(n)
e nota come chi-quadrato con n gradi di liberta, per la quale esistono tavole statisticherelative ai vari gradi di liberta n = 1, 2, ...
13.2.2 Media nota
Se la vera media µ e nota la stima puntuale non distorta per la varianza e
σ2 =∑n
i=1 (xi − µ)2
n
la quantita
nσ2
σ2=
n∑i=1
xi − µ
σ︸ ︷︷ ︸N(0,1)
2
∼ χ2(n)
156

Paolo Tenconi: Appunti di Statistica
identificando i valori che lasciano sulle code di tale distribuzione la massa α/2 ciascuno
P
χ2
(n),1−α2≤ nσ2
σ2≤ χ2
(n), α2
= 1− α
isolando σ2 otteniamo l’intervallo di confidenza
P
nσ2
χ2(n), α
2
≤ σ2 ≤ nσ2
χ2(n),1−α
2
= 1− α
13.2.3 Media Ignota
In tal caso lo stimatore non distorto per la varianza, come visto, e la varianza campionariacorretta S2
c =Pn
i=1(xi−x)2
n−1 , si dimostra che
(n− 1) S2c
σ2∼ χ2
(n−1)
similarmente a quanto precedentemente osservato per il caso dei media nota abbiamo
P
χ2
(n−1),1−α2≤ (n− 1) σ2
σ2≤ χ2
(n−1), α2
= 1− α
isolando σ2 otteniamo l’intervallo di confidenza
P
(n− 1) σ2
χ2(n−1), α
2
≤ σ2 ≤ (n− 1) σ2
χ2(n−1),1−α
2
= 1− α
13.3 Intervalli di Confidenza per Stimatori di MassimaVerosimiglianza
Gli stimatori di MV ricoprono un ruolo centrale nella stima statistica, ne analizzeremoquindi la costruzione di intervalli di confidenza.
Abbiamo enunciato cheθMV
as∼ N[θ, I (θ)−1
]tuttavia I (θ) e ignota, vi sono alcune soluzioni alternative per ottenerne una stima, noiscegliamo la seguente
I (θ) = i (θ) = −`′′ (θ)∣∣∣θMV
157

Paolo Tenconi: Appunti di Statistica
per grandi campioni l’utilizzo di i (θ) in lugo di I (θ) non crea grossi scostamenti, valequindi l’approssimazione
θMV − θ
σMV (θ) /√
n≈ N (0, 1)
σMV (θ) =
√[−`′′ (θ)
∣∣∣θMV
]−1
quindi procedendo come per la media otteniamo il seguente intervallo di confidenza perθ
P
θMV − Zα/2
σMV (θ)√n
≤ θ ≤ θMV + Zα/2σMV (θ)√
n
= 1− α
158

14 Esercizi di Stima Intervallare
159

Paolo Tenconi: Appunti di Statistica
Popolazione Normale
Da due indagini campionarie sul reddito (indicato con “R”) di Francesi ed Italiani concampioni di ampiezza 100, e risultato quanto segue: RFR = 30 RIT = 30. Supponendoche entrambe le popolazioni abbiano distribuzione normale con σFR = 8 , σIT = 10 , siproceda al calcolo di quanto segue:
Formulazione del problema:
RIT ∼ N (µIT =?;σIT = 10)RFR ∼ N (µFR;σFR = 8)
Determinare gli intervalli di confidenza al 95% per le medie di entrambi i Paesi specif-icando di quanto e maggiore lıntervallo italiano rispetto a quello francese, dandone unamotivazione:Indicando con A tali intervalli
AIT =[
¯RIT +
σIT√n× Z0,05/2
]−[
¯RIT −
σIT√n× Z0,05/2
]AFR =
[¯
RFR +σFR√
n× Z0,05/2
]−[
¯RFR −
σFR√n× Z0,05/2
]sostituendo quanto in nostro possesso otteniamo le seguenti ampiezze intervallari per idue Paesi:
AFR =[30 +
810× 1, 96
]−[30− 8
10× 1, 96
]= 3, 136
AIT =[30 +
1010× 1, 96
]−[30− 10
10× 1, 96
]= 3, 92
quindi per quanto riguarda il rapporto tra i due intervalli:
AIT
AFR=
3, 923, 136
= 1, 25
concludiamo quindi sul fatto che AIT e del 25% maggiore di AFR.in quanto σIT > σFR
Volendo ottenere per l’Italia un intervallo di confidenza di ampiezza identica a quellofrancese¸ si indichi il grado di confidenza necessario
AFR = RFR ±σFR
10× 1, 96
δIT =σIT
10× h = δFR =
σFR
10× 1, 96
h =σFR
σIT× 1, 96 =
810× 1, 96 = 1, 568 ' 1, 57
160

Paolo Tenconi: Appunti di Statistica
a questo punto non ci resta che trovare sulle tavole della N(0,1) a quale livello diconfidenza α/2 corrisponde h∫ 1,57
−∞N(0, 1)dx = 0, 9418
⇒ ˜α/2 = 1− 0, 9418α =2 · (1− 0, 9418) = 0, 1164
Determinare l’ampiezza campionaria n affinche, a parita di intervallo di confidenza conla Francia, l’Italia mangenga la medesima confidenza:
δFR =σFR√
n× 1, 96 =
810× 1, 96
δFR = δIT =σIT√
n× 1, 96
⇒ n =[σIT · 1, 96
δFR
]2
=[
σIT
σFR×√
n
]2
=[108× 10
]2
= 156, 25 ' 157 notare arrotondamento
Ripetere i calcoli relativi al secondo punto¸ in ipotesi che il campione sia di 20 personee che le varianze siano non note e SIT = 7 , SFR = 6genericamente R−µ
σ ∼ tn−1, quindi
AIT = 30± 7√20× t20−1
0,025 = 20± 7√20× 2, 093 ' 6, 55
AFR = 30± 6√20× t20−1
0,025 = 20± 6√20× 2, 093 ' 5, 62
AIT
AFR=
6, 555, 62
= 1, 165
161

Paolo Tenconi: Appunti di Statistica
Bernoulli
Si supponga che 5 estrazioni indipendenti da un’urna contenente palline bianche e nerein proporzione incognita, abbia dato luogo alla seguente successione di eventi: X ≡B,N,N,N,B.Riterreste opportuna l’approssimazione per la media campionaria X ∼ N
(θ, σ2/n
)?
R: No, la popolazione non e distribuita normalmente e l’ampiezza campionaria e troppoesigua perche si applichi il teorema del limite centrale.
Binomiale
Da un’urna contenente palline bianche e nere in proporzione incognita, si procede all’es-trazione con reimmissione da parte di 50 persone con tre tentativi ciascuna. La mediacampionaria ottenua risulta essere 1,8.Si proceda al calcolo di quanto segue:
Indicare la distribuzione della popolazione:
X ∼ Bin (m = 3, θ =?)
Indicare la formula per la media¸ varianza e scarto quadratico medio della popolazione:
E(X) = m · θV (X) = m · θ (1− θ)
σ(X) =√
m · θ (1− θ)
Indicare la formula per la distribuzione della media campionaria:
X ∼ N
(3 · θ, σ =
√3 · θ(1− θ)
50
)
Trovare gli estremi x1e x2 (centrati) di un intervallo che garantisce una confidenza α/2 =1%attraverso il processo di standardizzazione
Z =X − 3θ√
3·θ(1−θ)50
∼ N (0, 1)
troviamo z1e z2 al livello α/2 (utilizzando le tavole) z1 = −2, 326 , z2 = 2, 326con la trasformazione inversa della standardizzazione ricaviamo ora x1e x2:
x1,2 = x± 2, 326× S√50
162

Paolo Tenconi: Appunti di Statistica
dobbiamo ricavare S, sapendo che S = nθ(1−θ), dobbiamo ricavare θ avendo come datola media campionaria della binomiale
X = 3 · θ = 1, 8 ⇒ θ =1, 83
= 0, 6
S =√
3θ(1− θ) =√
3 · 0, 6 · 0, 4 =√
0, 72
quindi
x1,2 = 1, 8± 2, 326×√
0, 7250
= 1, 52088 ; 2, 07912
Determinare la stima puntuale di θ ed il relativo intervallo di confidenza al livello α/2 =1%E’ una trasformazione lineare di variabile normale, ne risulta un’altra variabile normale:
X = 3θ ⇒ θ =X
3
non ci resta che calcolare media e scarto quadratico medio della nomale cosı trasformata:
E (θ) = E
(X
3
)=
13E(X)
=3 · θ3
= θ
V (θ) = V
(X
3
)=
132
V(X)
=3·θ(1−θ)
n
32=
3 · θ(1− θ)32 · n
=θ(1− θ)
3n
quindi
θ ∼ N
[θ ; σ =
√θ(1− θ)
3n
]
abbiamo ora tutti gli elementi per ricavare gli intervalli di confidenza
θ1,2 = θ ± 2, 326×
√θ(1− θ
)3n
= 0, 6± 2, 326×√
0, 6 · 0, 43 · 50
= 0, 50696 ; 0, 69304
di fatto risulta verificato che θ = X3 e che θ1,2 = x1,2
3
163

Paolo Tenconi: Appunti di Statistica
Poisson
La societa autostrade desidera verificare se il numero medio orario di auto che transitacon telepass e identico al numero medio di auto che utilizza Viacard.
Si indichi un’appropriata distribuzione per la popolazione:
Xvc ∼ Po (λvc =?)Xtp ∼ Po (λtp =?)
L’indagine campionaria ha dato luogo a quanto segue: ampiezza campionaria nvc =70 , ntp = 100 ; media campionaria Xvc = 320 , Xtp = 400determinare un’approssimazione opportuna per la differenza tra le due medie ed unintervallo di confidenza al 95%
D = Xtp − Xvc ∼ N
[λtp − λvc ; σ =
√λtp
ntp+
λvc
nvc
]
⇒(Xtp − Xvc
)− (λtp − λvc)√
λtp
ntp+ λvc
nvc
∼ N (0, 1)
d1,2 = (xtp − xvc)± zα/2 ×√
xtp
ntp+
xvc
nvc
= (400− 320)± 1, 96×√
400100
+32070
' 74, 26 ; 85, 74
164
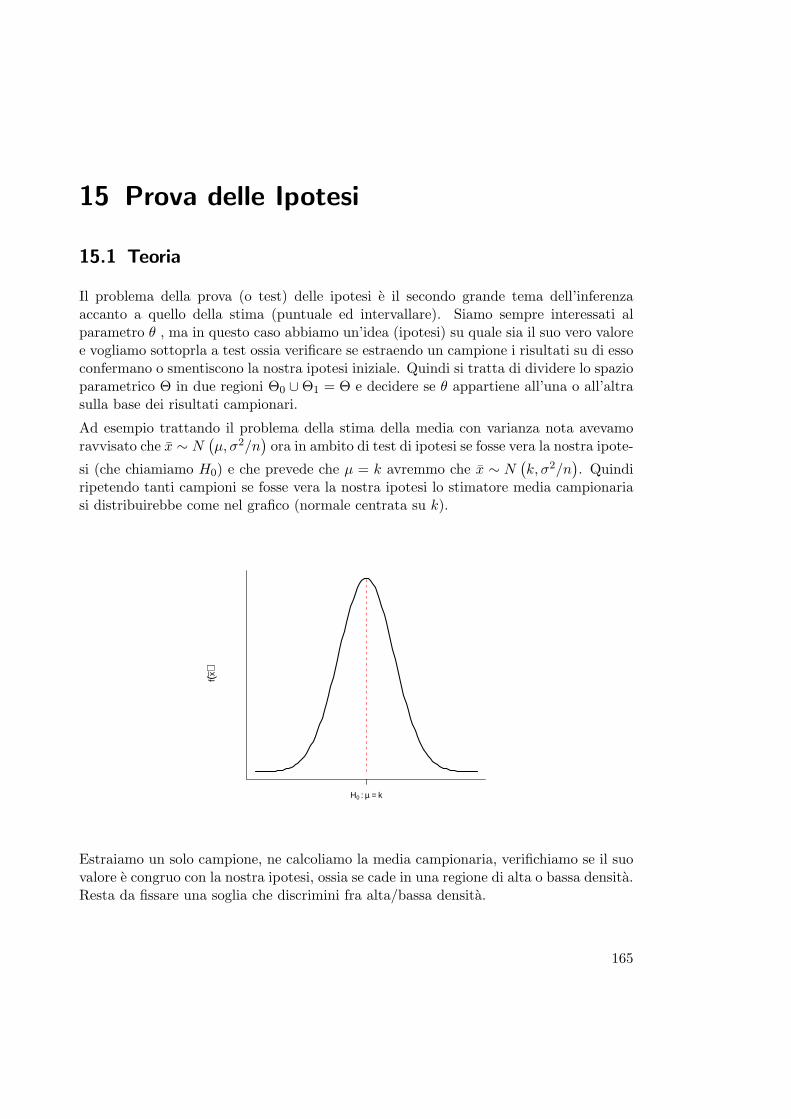
15 Prova delle Ipotesi
15.1 Teoria
Il problema della prova (o test) delle ipotesi e il secondo grande tema dell’inferenzaaccanto a quello della stima (puntuale ed intervallare). Siamo sempre interessati alparametro θ , ma in questo caso abbiamo un’idea (ipotesi) su quale sia il suo vero valoree vogliamo sottoprla a test ossia verificare se estraendo un campione i risultati su di essoconfermano o smentiscono la nostra ipotesi iniziale. Quindi si tratta di dividere lo spazioparametrico Θ in due regioni Θ0 ∪Θ1 = Θ e decidere se θ appartiene all’una o all’altrasulla base dei risultati campionari.
Ad esempio trattando il problema della stima della media con varianza nota avevamoravvisato che x ∼ N
(µ, σ2/n
)ora in ambito di test di ipotesi se fosse vera la nostra ipote-
si (che chiamiamo H0) e che prevede che µ = k avremmo che x ∼ N(k, σ2/n
). Quindi
ripetendo tanti campioni se fosse vera la nostra ipotesi lo stimatore media campionariasi distribuirebbe come nel grafico (normale centrata su k).
f(x)
H0 : µ = k
Estraiamo un solo campione, ne calcoliamo la media campionaria, verifichiamo se il suovalore e congruo con la nostra ipotesi, ossia se cade in una regione di alta o bassa densita.Resta da fissare una soglia che discrimini fra alta/bassa densita.
165

Paolo Tenconi: Appunti di Statistica
15.1.1 Definizioni
Definiamo ipotesi una bipartizione dello spazio parametrico di Pθ (x) θ ∈ Θ in dueregioni Θ0 ∪Θ1 = Θ tali che Θ0 ∩Θ1 = ∅ , distinguendo fra
H0 : θ ∈ Θ0
H1 : θ ∈ Θ1
H0e l’ipotesi nulla, mentre H1 ipotesi alternativa. Siamo interessati a decidere se il verovalore θ appartiene a Θ0 o a Θ1. A questo scopo utilizziamo una procedura di test (osemplicemente test) la quale e una partizione dello spazio di tutti i possibili campioni indue regioni, l’una che conduce all’accettazione di H0 l’altra al suo rifiuto. Tale partizioneusualmente e conseguita tramite l’utilizzo di una statistica test T = t (x) per la qualeviene costruita una partizione in due regioni (accettazione/rifiuto); essa a sua voltainduce una bipartizione di accettazione/rifiuto anche nello spazio dei campioni.
Graficamente la partizione con statistica test e rappresentabile come segue
Accettazione Rifiuto
Spazio dei campioni
Spazio della statistica testA: Accettazione B: Rifiuto
Soglia Critica c*
in questo caso se applicando t (x) all’unico campione che possiamo selezionare avvieneche t (x) > c∗ rifiutiamo l’ipotesi H0 e viceversa se t (x) ≤ c∗.
Non resta che identificare c∗ ottimale.
15.1.2 Tipi di Ipotesi
Distinguiamo fra i seguenti test di ipotesi
Ipotesi semplici H0 : θ = θ0
H1 : θ = θ1
Ipotesi composte: in tal caso H1 e un intervallo
166

Paolo Tenconi: Appunti di Statistica
– Unilaterale H0 : θ ≤ θ0
H1 : θ > θ0equivalente a−−−−−−−−−→
H0 : θ = θ0
H1 : θ > θ0H0 : θ ≥ θ0
H1 : θ < θ0equivalente a−−−−−−−−−→
H0 : θ = θ0
H1 : θ < θ0
– Bilaterale H0 : θ = θ0
H1 : θ 6= θ0
15.1.3 Errori e Potenza del Test
Il test induce una bipartizione in Θ = Θ0∪Θ1 tuttavia esso e soggetto a errore nel sensoche puo accadere che
t(x) ∈ B ma θ ∈ Θ0 errore di prima specie (rifiuto H0 quando essa e vera),indichiamo con α = P (rif H0|H0 vera) la probabilita di commettere un errore diprima specie
t(x) ∈ A ma θ ∈ Θ1 errore di seconda specie (rifiuto H1quando essa e vera),indichiamo con β = P (rif H1|H1 vera)la probabilita di commettere un errore diseconda specie
L’errore di prima specie generalmente e l’errore piu grave, nel senso che le azioni con-seguenti alla relativa decisione di rifiuto di H0 quando e vera, darebbero luogo a notevolidanni, non cosı per quanto riguarda l’errore di seconda specie, considerato meno grave.Ad esempio nel test di un farmaco un conto e dare il via al commercio di un farmacotossico, un altro e minore e rinunciare al commercio di un farmaco buono.
Definiamo potenza del test 1 − β = P (acc H1|H1 vera), per ipotesi composte si trattadi funzione di potenza, intesa come potenza del test al variare di θ nell’intervallo Θ1. Iltutto e rissumibile nella seguente matrice
Azione\Realta H0 vera H1 vera
Accettazione diH0 Errore II specie (β)Accettazione diH1 Errore I specie (α) Potenza del test (1− β)
15.1.3.1 Esemplificazioni Grafiche
Adottando criteri che saranno piu chiari nei paragrafi successivi, ipotizziamo ad esempioche X ∼ N
(µ, σ2 = 25
). Procediamo a decidere in merito al seguente test di ipotesi
H0 : µ = 40H1 : µ = 43
167
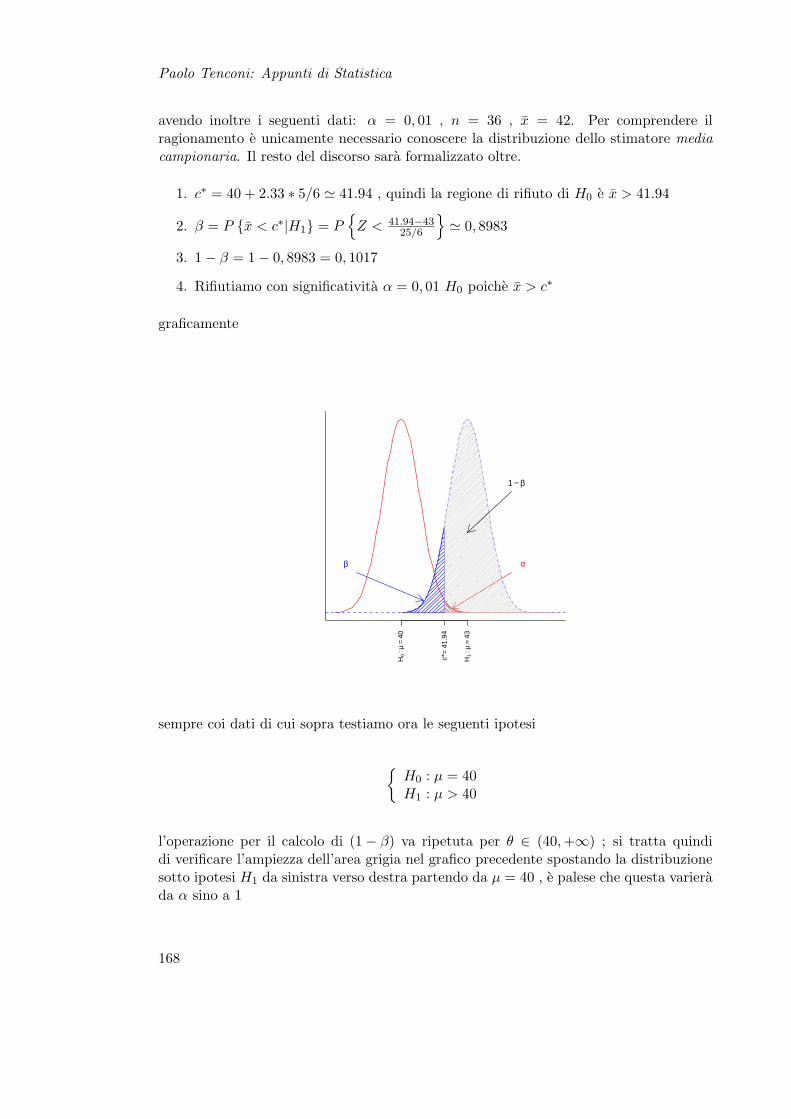
Paolo Tenconi: Appunti di Statistica
avendo inoltre i seguenti dati: α = 0, 01 , n = 36 , x = 42. Per comprendere ilragionamento e unicamente necessario conoscere la distribuzione dello stimatore mediacampionaria. Il resto del discorso sara formalizzato oltre.
1. c∗ = 40 + 2.33 ∗ 5/6 ' 41.94 , quindi la regione di rifiuto di H0 e x > 41.94
2. β = P x < c∗|H1 = P
Z < 41.94−4325/6
' 0, 8983
3. 1− β = 1− 0, 8983 = 0, 1017
4. Rifiutiamo con significativita α = 0, 01 H0 poiche x > c∗
graficamente
H0
:µ=
40
c*=
41.
94
H1
:µ=
43
β α
1 − β
sempre coi dati di cui sopra testiamo ora le seguenti ipotesi
H0 : µ = 40H1 : µ > 40
l’operazione per il calcolo di (1− β) va ripetuta per θ ∈ (40,+∞) ; si tratta quindidi verificare l’ampiezza dell’area grigia nel grafico precedente spostando la distribuzionesotto ipotesi H1 da sinistra verso destra partendo da µ = 40 , e palese che questa varierada α sino a 1
168
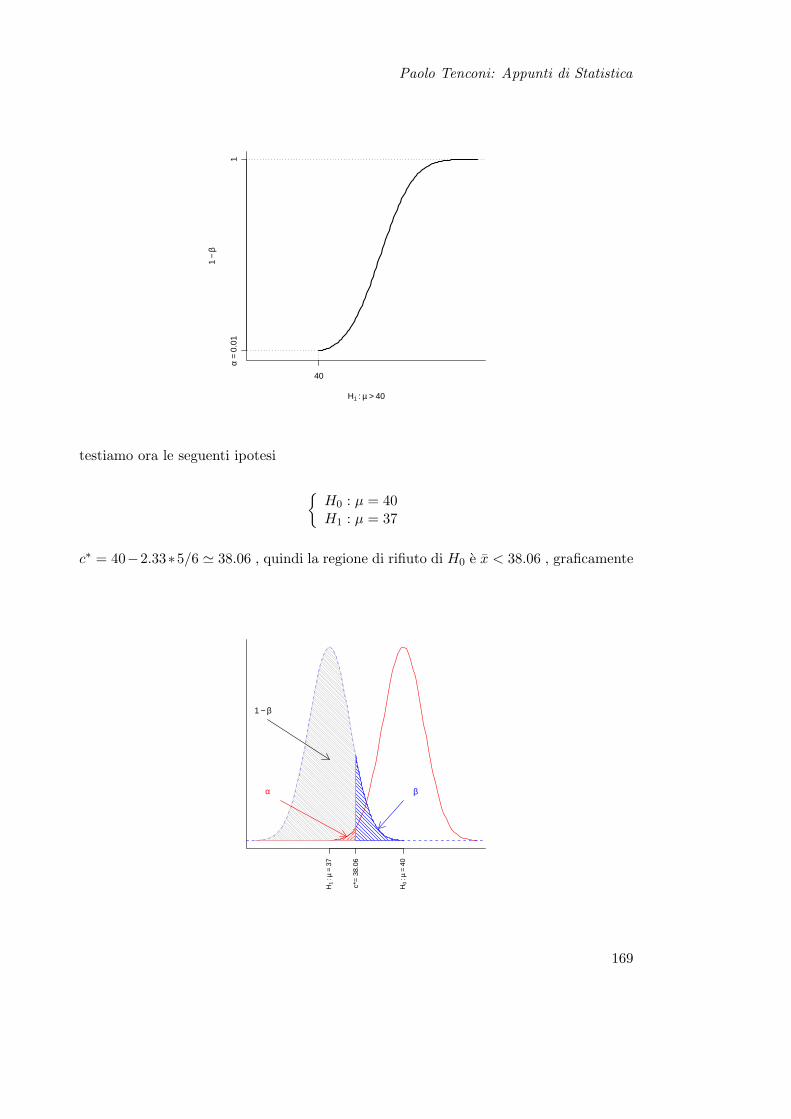
Paolo Tenconi: Appunti di Statistica
H1 : µ > 40
1−
β
40
α=
0.01
1
testiamo ora le seguenti ipotesi
H0 : µ = 40H1 : µ = 37
c∗ = 40−2.33∗5/6 ' 38.06 , quindi la regione di rifiuto di H0 e x < 38.06 , graficamente
H1
:µ=
37
c*=
38.
06
H0
:µ=
40
βα
1 − β
169
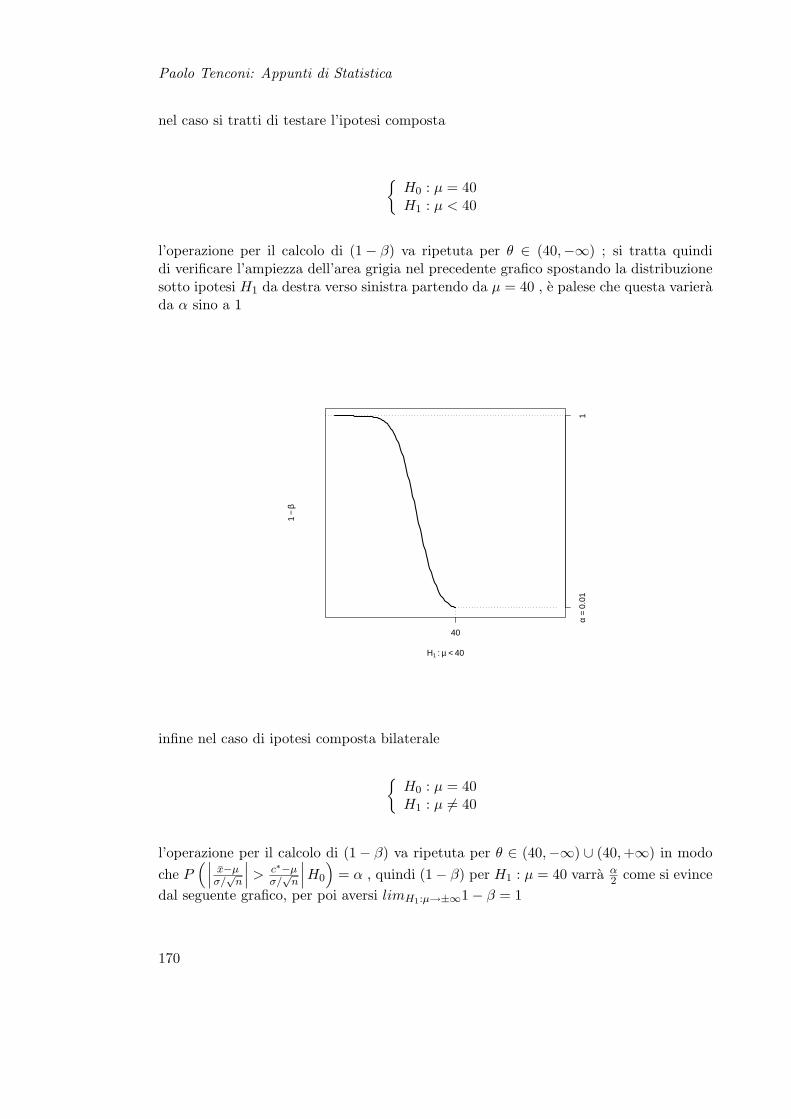
Paolo Tenconi: Appunti di Statistica
nel caso si tratti di testare l’ipotesi composta
H0 : µ = 40H1 : µ < 40
l’operazione per il calcolo di (1− β) va ripetuta per θ ∈ (40,−∞) ; si tratta quindidi verificare l’ampiezza dell’area grigia nel precedente grafico spostando la distribuzionesotto ipotesi H1 da destra verso sinistra partendo da µ = 40 , e palese che questa varierada α sino a 1
H1 : µ < 40
1−
β
40
α=
0.01
1
infine nel caso di ipotesi composta bilaterale
H0 : µ = 40H1 : µ 6= 40
l’operazione per il calcolo di (1− β) va ripetuta per θ ∈ (40,−∞) ∪ (40,+∞) in modoche P
(∣∣∣ x−µσ/√
n
∣∣∣ > c∗−µσ/√
n
∣∣∣H0
)= α , quindi (1− β) per H1 : µ = 40 varra α
2 come si evincedal seguente grafico, per poi aversi limH1:µ→±∞1− β = 1
170
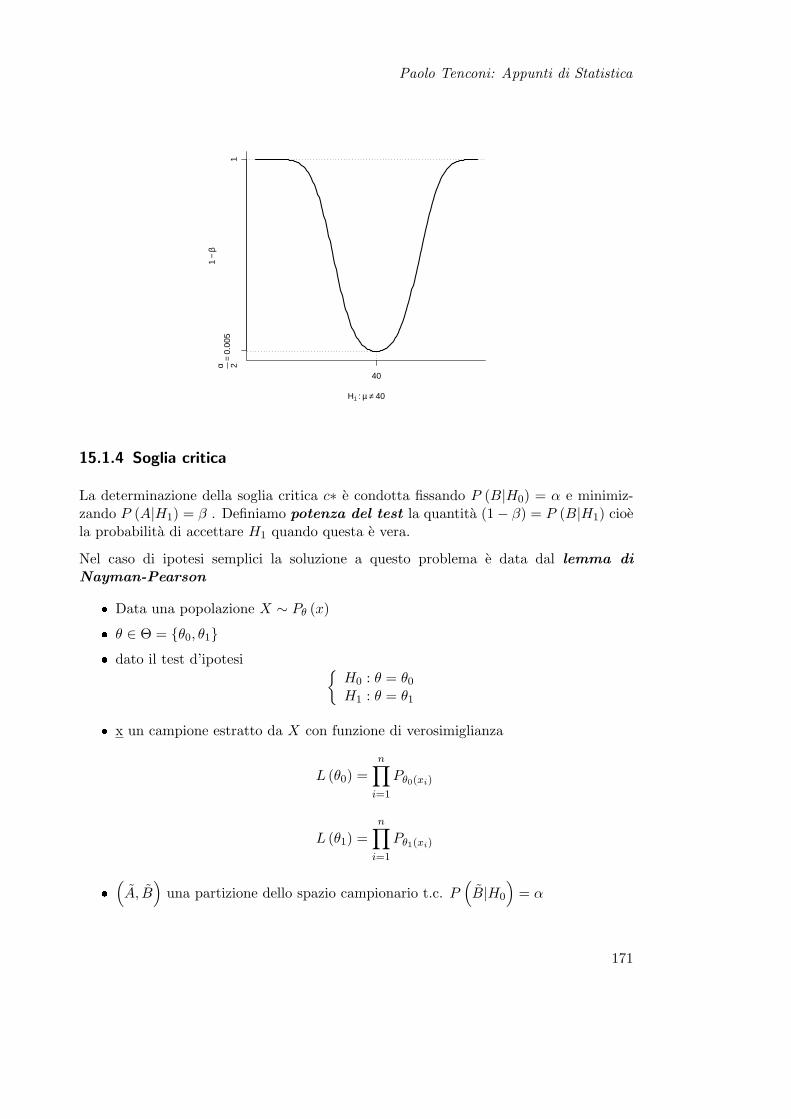
Paolo Tenconi: Appunti di Statistica
H1 : µ ≠ 40
1−
β
40
α 2=
0.00
51
15.1.4 Soglia critica
La determinazione della soglia critica c∗ e condotta fissando P (B|H0) = α e minimiz-zando P (A|H1) = β . Definiamo potenza del test la quantita (1− β) = P (B|H1) cioela probabilita di accettare H1 quando questa e vera.
Nel caso di ipotesi semplici la soluzione a questo problema e data dal lemma diNayman-Pearson
Data una popolazione X ∼ Pθ (x)
θ ∈ Θ = θ0, θ1
dato il test d’ipotesi H0 : θ = θ0
H1 : θ = θ1
x un campione estratto da X con funzione di verosimiglianza
L (θ0) =n∏
i=1
Pθ0(xi)
L (θ1) =n∏
i=1
Pθ1(xi)
(A, B
)una partizione dello spazio campionario t.c. P
(B|H0
)= α
171

Paolo Tenconi: Appunti di Statistica
allora se esiste k t.c.
B =
x :
∏ni=1 Pθ1(xi)∏ni=1 Pθ0(xi)
≥ k
A =
x :
∏ni=1 Pθ1(xi)∏ni=1 Pθ0(xi)
< k
e t.c. sia vero che P (B|H0) = α allora il test basato su (A,B) e il piu potente (cioe conminor β = P (A|H1) .
Esempio: X ∼ N(µ, σ2 = 625
) H0 : µ = 40H1 : µ = 45
α = 0, 15 , n = 36 , x = 46, 02
B =
x :1
25√
2πexp
−12
∑36i=1
(xi−45
25
)21
25√
2πexp
−12
∑36i=1
(xi−40
25
)2 > k
dopo alcune esemplificazioni ed applicando il logaritmo
B :36∑i=1
xi ≥ 125log (k) + 1530
e dividendo per n
B : x ≥ 3, 47log (k) + 42, 5︸ ︷︷ ︸c∗
standardizzando x per la quale conosciamo la distribuzione sotto H0
B :x− 4025/
√36
≥ c ∗ −4025/
√36
vogliamo determinare c∗ t.c. P (B|H0) = α = 0, 15 quindi c∗−4025/
√36
= Zα = 1, 0365 ,
c∗ = 40 + 1, 036525√36
' 44, 32
B : x ≥ 44, 32
quindi accettiamo H1poiche il test impone tale decisione per x ≥ 44, 32.
Per quanto concerne la potenza del test 1− β = P x > c ∗ |H1 = P
Z ≥ 46,02−45
25/√
36
=
0, 936
172
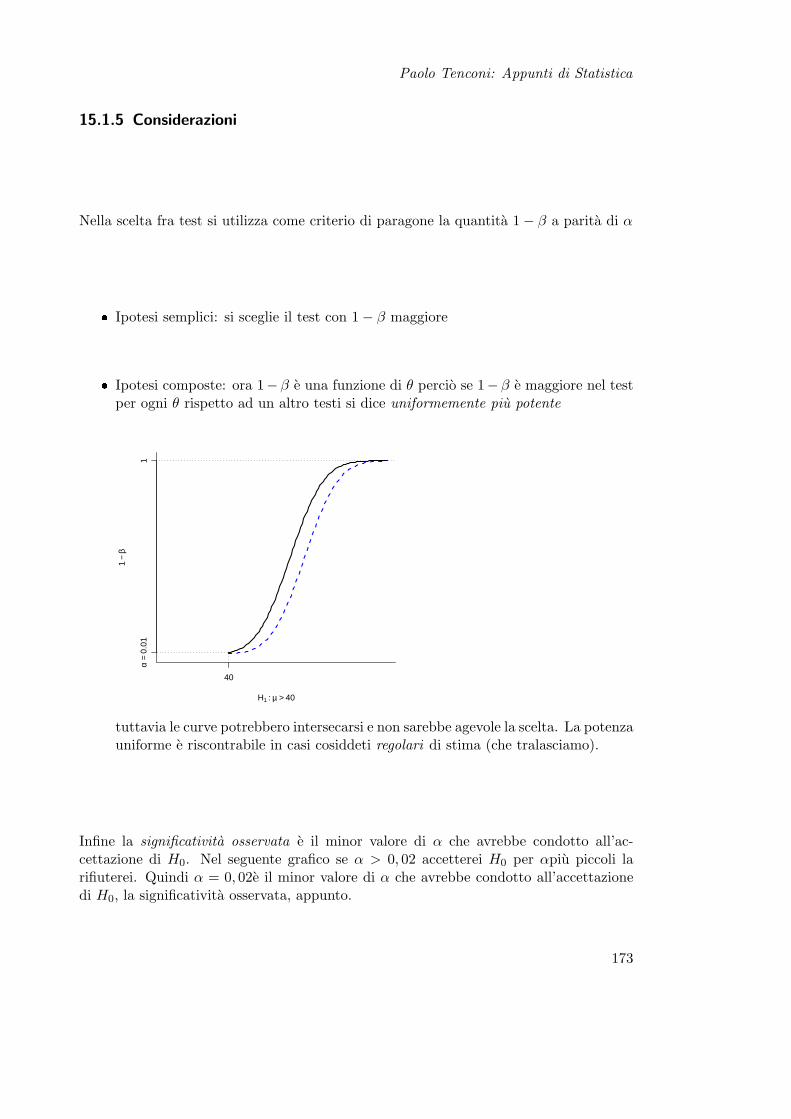
Paolo Tenconi: Appunti di Statistica
15.1.5 Considerazioni
Nella scelta fra test si utilizza come criterio di paragone la quantita 1− β a parita di α
Ipotesi semplici: si sceglie il test con 1− β maggiore
Ipotesi composte: ora 1− β e una funzione di θ percio se 1− β e maggiore nel testper ogni θ rispetto ad un altro testi si dice uniformemente piu potente
H1 : µ > 40
1−
β
40
α=
0.01
1
tuttavia le curve potrebbero intersecarsi e non sarebbe agevole la scelta. La potenzauniforme e riscontrabile in casi cosiddeti regolari di stima (che tralasciamo).
Infine la significativita osservata e il minor valore di α che avrebbe condotto all’ac-cettazione di H0. Nel seguente grafico se α > 0, 02 accetterei H0 per αpiu piccoli larifiuterei. Quindi α = 0, 02e il minor valore di α che avrebbe condotto all’accettazionedi H0, la significativita osservata, appunto.
173
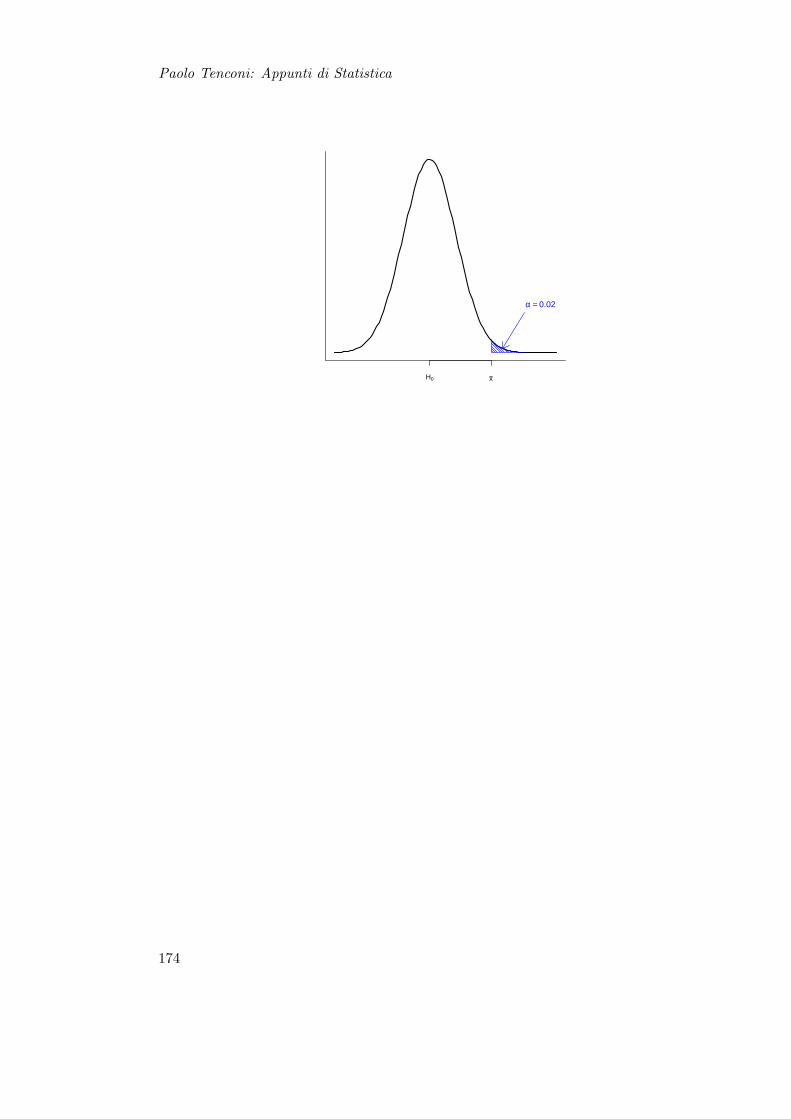
Paolo Tenconi: Appunti di Statistica
H0 x
α = 0.02
174
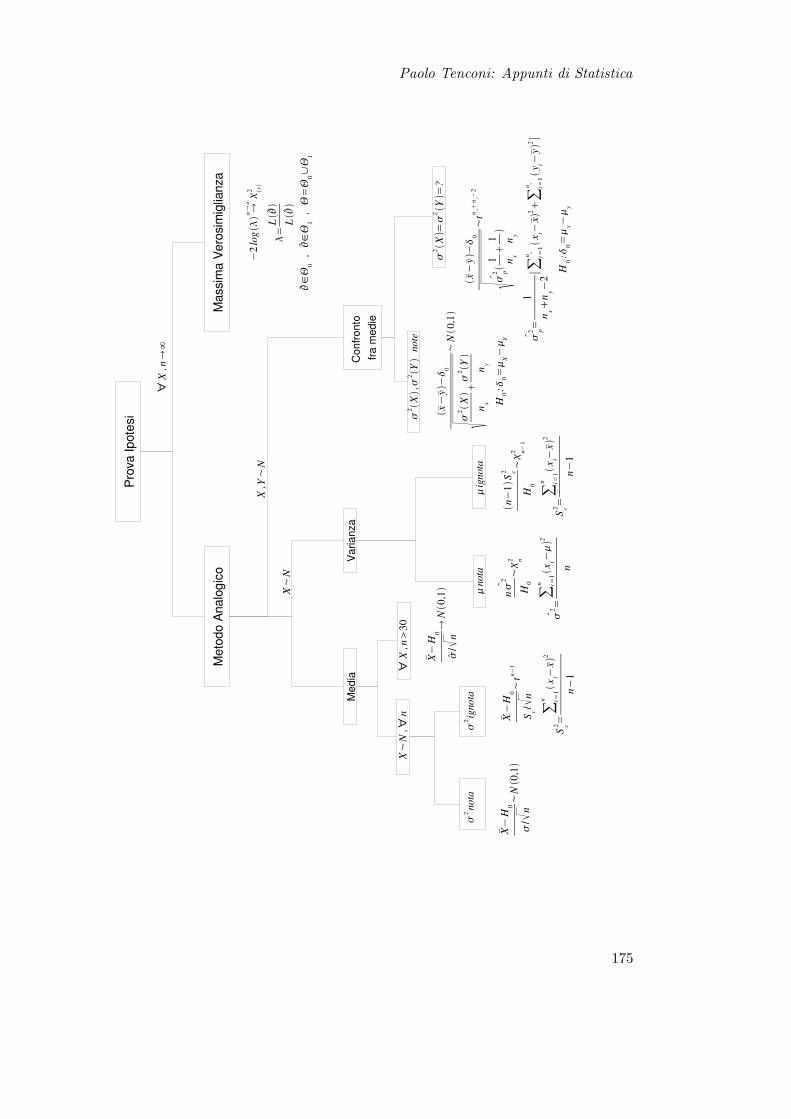
Paolo Tenconi: Appunti di Statistica
Prov
a Ip
otes
i
Met
odo
Anal
ogico
Mas
sima
Vero
simig
lianz
a
Med
iaVa
rianz
a
2no
ta
2 igno
ta
X−H
0
/
n~
N0
,1
X−
H0
S c/n
~tn−
1
S c2 =∑
i=1
nx i−
x2
n−1
X~
N,∀
n∀
X,n
30
X−H
0
/
n
N0,
1 no
ta
igno
ta
n
2
H0
~
n2
2 =∑
i=1
nx i−
2
n
n−
1S c2
H0
~
n−1
2
S c2 =∑
i=1
n
x i−x
2
n−1
−2l
ogn
∞
r2
=
L
L
∈
0, ∈
1,=
0∪
1
∀X
,n∞
X~
N
Conf
ront
o fra
med
ie
X,Y
~N
2
X,
2 Y
note
2
X=
2Y
=?
x−
y−
0
2
X
n x
2 Y
n y
~N0,
1
H0:
0=
X−
Y
x−
y−
0
p2
1 n x1 n y
~tn x
n y−2
p2 =
1n x
n y−2[ ∑
i=1
n x
x i−x
2 ∑
i=1
n yy i−
y2 ]
H0:
0=
x−
y
175

Paolo Tenconi: Appunti di Statistica
15.2 Test di Ipotesi per la Media
Si rammenta che indicheremo con B la regione di rifiuto per H0 .
15.2.1 Varianza Nota
x− µ
σ/√
n
H0∼ N (0, 1)
dove µ e la vera media, σ2 la vera varianza ed n l’ampiezza campionaria. Allora per iseguenti test
H0 : µ = µ0
H1 : µ > µ0, B : x ≥ µ0 + Zα
σ√n
H0 : µ = µ0
H1 : µ < µ0, B : x ≤ µ0 − Zα
σ√n
H0 : µ = µ0
H1 : µ 6= µ0, B :
x ≤ µ0 − Zα/2
σ√n∪ x ≥ µ0 + Zα/2
σ√n
Nota bene: tale risultato
Se X ∼ N e valido ∀n Se X N e valido solo per n > 30, in virtu del teorema del limite centrale
15.2.2 Varianza ignota
Premesso che indicheremo la varianza campionaria corretta come segue
S2c =
∑ni=1 (xi − x)2
n− 1
15.2.2.1 X ∼ N , ∀n
x− µ
Sc/√
n
H0∼ tn−1
di conseguenza H0 : µ = µ0
H1 : µ > µ0, B : x ≥ µ0 + tn−1
α
Sc√n
H0 : µ = µ0
H1 : µ > µ0, B : x ≤ µ0 − tn−1
α
Sc√n
H0 : µ = µ0
H1 : µ 6= µ0, B :
x ≤ µ0 − tn−1
α/2
Sc√n∪ x ≥ µ0 + tn−1
α/2
Sc√n
176

Paolo Tenconi: Appunti di Statistica
15.2.2.2 n > 30 , ∀X
x− µ
σ/√
n
H0∼ N (0, 1)
H0 : µ = µ0
H1 : µ > µ0, B : x ≥ µ0 + Zα
σ√n
H0 : µ = µ0
H1 : µ < µ0, B : x ≤ µ0 − Zα
σ√n
H0 : µ = µ0
H1 : µ 6= µ0, B :
x ≤ µ0 − Zα/2
σ√n∪ x ≥ µ0 + Zα/2
σ√n
dove σ2 e un’opportuna stima per la varianza.
15.3 Test di Ipotesi per la Varianza
Quanto tratteremo varra solo per popolazioni normali X ∼ N .
15.3.1 Media nota
Se la vera media µ e nota la stima puntuale non distorta per la varianza e
σ2 =∑n
i=1 (xi − µ)2
n
la quantita
nσ2
σ2=
n∑i=1
xi − µ
σ︸ ︷︷ ︸N(0,1)
2
H0∼ χ2(n)
H0 : σ2 = σ2
0
H1 : σ2 > σ20
, B : σ2 >σ2
0
n· χ2
(n),αH0 : σ2 = σ2
0
H1 : σ2 < σ20
, B : σ2 <σ2
0
n· χ2
(n),1−αH0 : σ2 = σ2
0
H1 : σ2 6= σ20
, B :
σ2 <σ2
0
n· χ2
(n),1−α/2 ∪ σ2 >σ2
0
n· χ2
(n),α/2
177

Paolo Tenconi: Appunti di Statistica
15.3.2 Media Ignota
In tal caso lo stimatore non distorto per la varianza, come visto, e la varianza campionariacorretta S2
c =Pn
i=1(xi−x)2
n−1 , si dimostra che
(n− 1) S2c
σ2
H0∼ χ2(n−1)
similarmente a quanto precedentemente osservato per il caso dei media nota abbiamo
H0 : σ2 = σ2
0
H1 : σ2 > σ20
, B : S2c >
σ20
n− 1· χ2
(n−1),αH0 : σ2 = σ2
0
H1 : σ2 < σ20
, B : S2c <
σ20
n− 1· χ2
(n−1),1−αH0 : σ2 = σ2
0
H1 : σ2 6= σ20
, B :
S2c <
σ20
n− 1· χ2
(n−1),1−α/2 ∪ S2c >
σ20
n− 1· χ2
(n−1),α/2
15.4 Confronto Fra Medie
Ora abbiamo due popolazioni X, Y entrambe distribuite normalmente da cui estraiamoun campione per ognuna. Siamo interessati alla verifica di ipotesi sulla quantita µX −µY = δ0 avendo estratto due campioni di ampiezza rispettivamente nx, ny.
15.4.1 Varianze Note
(x− y)− δ0√σ2
Xnx
+ σ2Y
ny
H0∼ N (0, 1)
H0 : δ = δ0
H1 : δ > δ0, B : (x− y) ≥ δ0 + Zα
√σ2
X
nx+
σ2Y
nyH0 : δ = δ0
H1 : δ < δ0, B : (x− y) ≤ δ0 − Zα
√σ2
X
nx+
σ2Y
nyH0 : δ = δ0
H1 : δ 6= δ0, B :
(x− y) ≤ δ0 − Zα
√σ2
X
nx+
σ2Y
ny∪ (x− y) ≥ δ0 + Zα
√σ2
X
nx+
σ2Y
ny
nota: usualmente siamo interessati a δ0 = 0.
178

Paolo Tenconi: Appunti di Statistica
15.4.2 Varianze Ignote
In tal caso dobbiamo essere certi che almeno σ2X = σ2
Y = σ2, se cosı e
(x− y)− δ0√σ2
p
(1
nx+ 1
ny
) H0∼ tnx+ny−2
dove σ2p costituisce una stima di σ2
σ2p =
1nx + ny − 2
[nx∑i=1
(xi − x)2 +n∑
i=1
(yi − y)2]
le regioni B si ricavano identicamente come nel caso di varianze note, utilizzanto tnx+ny−2e√
σ2p
(1
nx+ 1
ny
)in luogo di N (0, 1) e
√σ2
Xnx
+ σ2Y
nyH0 : δ = δ0
H1 : δ > δ0, B : (x− y) ≥ δ0 + t
nx+ny−2α
√σ2
p
(1nx
+1ny
)
H0 : δ = δ0
H1 : δ < δ0, B : (x− y) ≤ δ0 − t
nx+ny−2α
√σ2
p
(1nx
+1ny
)
H0 : δ = δ0
H1 : δ 6= δ0, B :
(x− y) ≤ δ0 − t
nx+ny−2α/2
√σ2
p
(1nx
+1ny
)∪ (x− y) ≥ δ0 + t
nx+ny−2α/2
√σ2
p
(1nx
+1ny
)
Nel caso σ2X 6= σ2
Y esistono soluzioni approssimate, in alternativa se nx, ny → ∞ operal’approssimazione normale
(x− y)− δ0√S2
c (x)nx
+ S2c (y)ny
H0∼ N (0, 1)
e si procede come per il caso di varianze note.
15.5 Test del Rapporto di Verosimiglianza
Il lemma di Neyman-Pearson e estensibile al caso di ipotesi composte tramite il test delrapporto fra verosimiglianze
H0 : θ ∈ Θ0
H1 : θ ∈ Θ1, conΘ = Θ0 ∪Θ1
179

Paolo Tenconi: Appunti di Statistica
cerchiamo il massimo di verosimiglianza nell’intero spazio parametrico Θ e successiva-mente nel suo sottoinsieme Θ0
L(θ)
= Maxθ∈Θ
L (θ)
L(θ)
= Maxθ∈Θ0
L (θ)
sicuramente il fatto che il massimo viene cercato in una regione ristretta di Θ comportache L
(θ)≤ L
(θ)
varra quindi che
λ (x) =L(θ)
L(θ) ∈ [0, 1]
nel caso vengano sottoposti a vincolo r parametri si dimostra che
−2log (λ) n→∞−→ χ2(r)
quindi accetteremo H0 se −2log (λ) > χ2(r),α .
180

16 Esercizi Prova delle Ipotesi
181

Paolo Tenconi: Appunti di Statistica
Normale
L’Unione Europea ha fissato come parametro di giudizio il livello medio di inquinamentonei centri abitati. Si ritiene accettabile una media inferiore a 20.Avendo indicato con X = livello di inquinamento ed estraendo un campione di n citta sie ottenuto quanto segue:XIT = XFR = 22si dispone inoltre delle seguenti informazioni:σIT = 3 σFR = 5XIT ∼ N(·, ·) XFR ∼ N(·, ·)n = 15 , ampiezza campionariaα = 0, 05 significativitdel testSi sottoponga ad ipotesi statistica per entrambi i Paesi quanto segue:
H0 : µ ≤ 20H1 : µ > 20
Calcolare la regione di rifiuto
c∗ = µ0 + zα ×σ√n
c∗IT = 20 + 1, 645× 3√15
= 21, 27
c∗FR = 20 + 1, 645× 5√15
= 22, 13
percio rifiutiamo H0 per l’Italia in quanto XIT > c∗IT , mentre non rifiutiamo H0 perla Francia in quanto XFR < c∗FR.
Determinare il livello di significativita osservato (p-value):
αIT = Pr
X − 20
3√15
>22− 20
3√15
= Pr Z > 2, 58 = 0, 0049
αFR = Pr
X − 20
5√15
>22− 20
5√15
= Pr Z > 1, 55 = 0, 0606
la decisione di accettazione/rifiuto di H0e raggiungibile altresı confrontando il livellodi significativita richiesto, α , con il livello di significativita osservato, α. Infatti perl’Italia rifiutiamo H0poiche αIT < α, mentre nel caso della Francia accettiamo H0poicheαFR > α.
182

Paolo Tenconi: Appunti di Statistica
Differenza tra medie (Normale)
Due gestori patrimoniali sottopongono ad ipotesi statistica i rendimenti annuali generatidall’inizio della loro attivita. Avendo indicato con R i rendimenti, i dati di cui si disponesono i seguenti:Tizio: RT ∼ N(·;σ) nT = 5 ST = 0, 02 RT = 0, 09Caio: RC ∼ N(·;σ) nC = 8 SC = 0, 01 RC = 0, 12
Verificare l’uguaglianza della performance dei due gestori con una significativita del testα = 0, 05
H0 : µT = µC
H1 : µT 6= µC
la statistica test e (RT − RC
)− (µT − µC)√
(nT−1)S2T +(nC−1)S2
CnT +nC−2
(1
nT+ 1
nC
) ∼ tnT +nC−2
z =(0, 09− 0, 12)− 0√
4×0,022+7×0,015+8−2
(15 + 1
8
) ' −3, 64
|z| >∣∣zα/2
∣∣⇒ rifiutoH0
quindi non posso concludere circa la parita di performance dei due gestori a livelloα = 0, 05
Con lo stesso livello di significativita testare la minore abilita di Tizio:
H0 : µT = µC
H1 : µT < µC
in questo caso si tratta di un’ipotesi unilaterale ed e sufficiente, al fine di concludere infavore di H0 , verificare se per il valore precedentemente ottenuto z = −3, 64 risulta che
|z| > |−zα|−2, 075 > −1, 797
poiche la relazione e falsa non possiamo concludere in favore di H0, cioe circa l’uguaglian-za di performance fra i due gestori.
183

Paolo Tenconi: Appunti di Statistica
Binomiale
Un’urna contenente palline bianche (B) e nere (N), viene sottoposta all’ipotesi secondocui la proporzione di queste sia identica. Da un campione di 40 persone, in cui ciascunaha effettuato 4 tentativi, e stata ottenuta la media campionaria X = 1, 50. Indicandocon Fr la frequenza, sottoporre ad ipotesi statistica quanto segue
H0 : Fr(B)Fr(N) = 1
H1 : Fr(B)Fr(N) < 1
Determinare la distribuzione di Xsotto l’ipotesi H0
¯X|H0 ∼N
(4× 0, 5;σ =
√4× 0, 5(1− 0, 5)
40
)
Ipotizzando come appropriata la distribuzione binomiale per la popolazione “numero dipalline bianche estratte” X ∼ Bin (n = 4, θ =?), il problema decisionale e esprimibilenella seguente maniera
H0 : n× θ = n2
H1 : n× θ < n2
H0 : 4× θ = 2H1 : 4× θ < 2
Prendere una decisione in favore di H0oppoure di H1ad un livello di significativita α =0, 01 sulla base del risultato campionario
z =1, 50− 4× 0, 5√
4×0,5(1−0,5)40
= −3, 16
poiche
z < −zα/2
−3, 16 < −2, 326
accettiamo H1, quindi con un livello di significativita α = 0, 01 possiamo concluderecirca la minore presenza nell’urna delle palline bianche rispetto alle palline nere.
184

Tavole Statistiche
185


Paolo Tenconi: Appunti di Statistica
Φ(z) =
Z z
−∞
1√
2πexp
−
t2
2
dt
z 0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09
0,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,5359
0,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,5753
0,2 0,5793 0,5832 0,5871 0,5910 0,5948 0,5987 0,6026 0,6064 0,6103 0,6141
0,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,6517
0,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,6879
0,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,7224
0,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,7549
0,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,7852
0,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,8133
0,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,8389
1,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,8621
1,1 0,8643 0,8665 0,8686 0,8708 0,8729 0,8749 0,8770 0,8790 0,8810 0,8830
1,2 0,8849 0,8869 0,8888 0,8907 0,8925 0,8944 0,8962 0,8980 0,8997 0,9015
1,3 0,9032 0,9049 0,9066 0,9082 0,9099 0,9115 0,9131 0,9147 0,9162 0,9177
1,4 0,9192 0,9207 0,9222 0,9236 0,9251 0,9265 0,9279 0,9292 0,9306 0,9319
1,5 0,9332 0,9345 0,9357 0,9370 0,9382 0,9394 0,9406 0,9418 0,9429 0,9441
1,6 0,9452 0,9463 0,9474 0,9484 0,9495 0,9505 0,9515 0,9525 0,9535 0,9545
1,7 0,9554 0,9564 0,9573 0,9582 0,9591 0,9599 0,9608 0,9616 0,9625 0,9633
1,8 0,9641 0,9649 0,9656 0,9664 0,9671 0,9678 0,9686 0,9693 0,9699 0,9706
1,9 0,9713 0,9719 0,9726 0,9732 0,9738 0,9744 0,9750 0,9756 0,9761 0,9767
2,0 0,9772 0,9778 0,9783 0,9788 0,9793 0,9798 0,9803 0,9808 0,9812 0,9817
2,1 0,9821 0,9826 0,9830 0,9834 0,9838 0,9842 0,9846 0,9850 0,9854 0,9857
2,2 0,9861 0,9864 0,9868 0,9871 0,9875 0,9878 0,9881 0,9884 0,9887 0,9890
2,3 0,9893 0,9896 0,9898 0,9901 0,9904 0,9906 0,9909 0,9911 0,9913 0,9916
2,4 0,9918 0,9920 0,9922 0,9925 0,9927 0,9929 0,9931 0,9932 0,9934 0,9936
2,5 0,9938 0,9940 0,9941 0,9943 0,9945 0,9946 0,9948 0,9949 0,9951 0,9952
2,6 0,9953 0,9955 0,9956 0,9957 0,9959 0,9960 0,9961 0,9962 0,9963 0,9964
2,7 0,9965 0,9966 0,9967 0,9968 0,9969 0,9970 0,9971 0,9972 0,9973 0,9974
2,8 0,9974 0,9975 0,9976 0,9977 0,9977 0,9978 0,9979 0,9979 0,9980 0,9981
2,9 0,9981 0,9982 0,9982 0,9983 0,9984 0,9984 0,9985 0,9985 0,9986 0,9986
3,0 0,9987 0,9987 0,9987 0,9988 0,9988 0,9989 0,9989 0,9989 0,9990 0,9990
3,1 0,9990 0,9991 0,9991 0,9991 0,9992 0,9992 0,9992 0,9992 0,9993 0,9993
3,2 0,9993 0,9993 0,9994 0,9994 0,9994 0,9994 0,9994 0,9995 0,9995 0,9995
3,3 0,9995 0,9995 0,9995 0,9996 0,9996 0,9996 0,9996 0,9996 0,9996 0,9997
3,4 0,9997 0,9997 0,9997 0,9997 0,9997 0,9997 0,9997 0,9997 0,9997 0,9998
Φ (z) 0,900 0,950 0,975 0,990 0,995 0,999
z 1,282 1,645 1,960 2,326 2,576 3,090
187
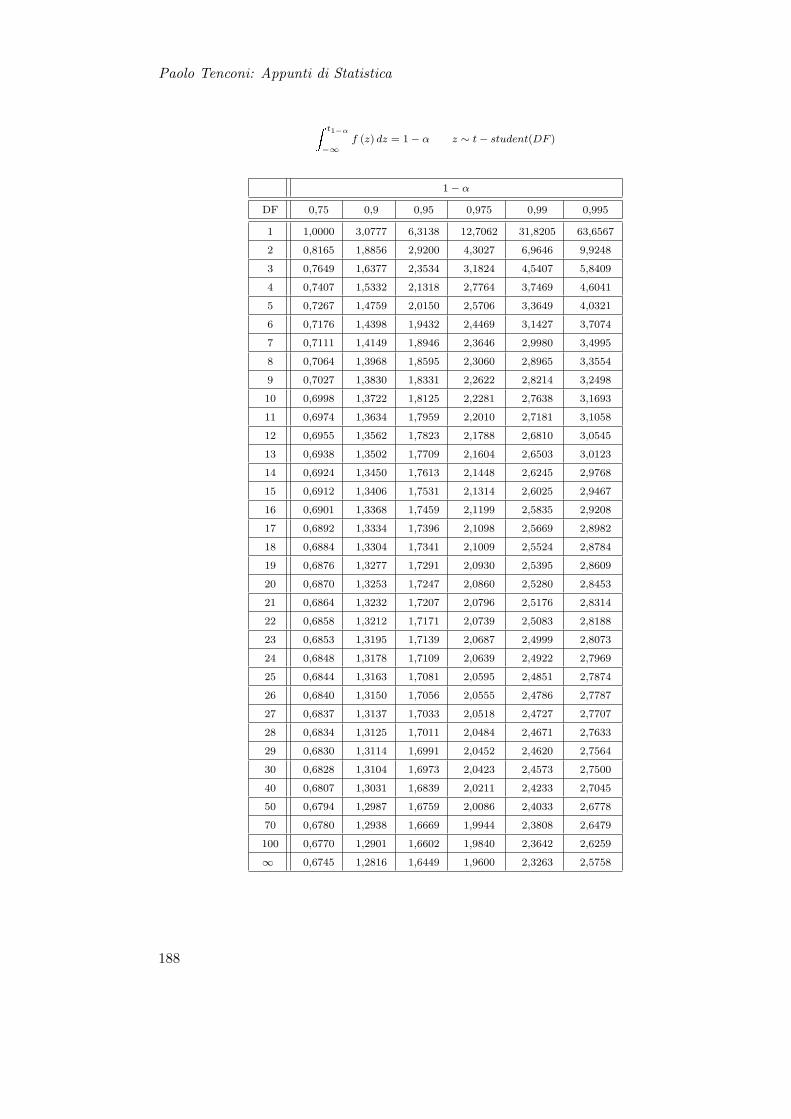
Paolo Tenconi: Appunti di Statistica
Z t1−α
−∞f (z) dz = 1− α z ∼ t− student(DF )
1− α
DF 0,75 0,9 0,95 0,975 0,99 0,995
1 1,0000 3,0777 6,3138 12,7062 31,8205 63,6567
2 0,8165 1,8856 2,9200 4,3027 6,9646 9,9248
3 0,7649 1,6377 2,3534 3,1824 4,5407 5,8409
4 0,7407 1,5332 2,1318 2,7764 3,7469 4,6041
5 0,7267 1,4759 2,0150 2,5706 3,3649 4,0321
6 0,7176 1,4398 1,9432 2,4469 3,1427 3,7074
7 0,7111 1,4149 1,8946 2,3646 2,9980 3,4995
8 0,7064 1,3968 1,8595 2,3060 2,8965 3,3554
9 0,7027 1,3830 1,8331 2,2622 2,8214 3,2498
10 0,6998 1,3722 1,8125 2,2281 2,7638 3,1693
11 0,6974 1,3634 1,7959 2,2010 2,7181 3,1058
12 0,6955 1,3562 1,7823 2,1788 2,6810 3,0545
13 0,6938 1,3502 1,7709 2,1604 2,6503 3,0123
14 0,6924 1,3450 1,7613 2,1448 2,6245 2,9768
15 0,6912 1,3406 1,7531 2,1314 2,6025 2,9467
16 0,6901 1,3368 1,7459 2,1199 2,5835 2,9208
17 0,6892 1,3334 1,7396 2,1098 2,5669 2,8982
18 0,6884 1,3304 1,7341 2,1009 2,5524 2,8784
19 0,6876 1,3277 1,7291 2,0930 2,5395 2,8609
20 0,6870 1,3253 1,7247 2,0860 2,5280 2,8453
21 0,6864 1,3232 1,7207 2,0796 2,5176 2,8314
22 0,6858 1,3212 1,7171 2,0739 2,5083 2,8188
23 0,6853 1,3195 1,7139 2,0687 2,4999 2,8073
24 0,6848 1,3178 1,7109 2,0639 2,4922 2,7969
25 0,6844 1,3163 1,7081 2,0595 2,4851 2,7874
26 0,6840 1,3150 1,7056 2,0555 2,4786 2,7787
27 0,6837 1,3137 1,7033 2,0518 2,4727 2,7707
28 0,6834 1,3125 1,7011 2,0484 2,4671 2,7633
29 0,6830 1,3114 1,6991 2,0452 2,4620 2,7564
30 0,6828 1,3104 1,6973 2,0423 2,4573 2,7500
40 0,6807 1,3031 1,6839 2,0211 2,4233 2,7045
50 0,6794 1,2987 1,6759 2,0086 2,4033 2,6778
70 0,6780 1,2938 1,6669 1,9944 2,3808 2,6479
100 0,6770 1,2901 1,6602 1,9840 2,3642 2,6259
∞ 0,6745 1,2816 1,6449 1,9600 2,3263 2,5758
188

Paolo Tenconi: Appunti di Statistica
Z u
0f (z) dz = 1− α z ∼ χ2
DF
1−
α
DF
0,0
05
0,0
10
0,0
25
0,0
50
0,1
00
0,2
50
0,5
00
0,7
50
0,9
00
0,9
50
0,9
75
0,9
90
0,9
95
13,9
3E-0
05
1,5
7E-0
04
9,8
2E-0
04
3,9
3E-0
03
0,0
16
0,1
02
0,4
55
1,3
22,7
13,8
45,0
26,6
37,8
8
20,0
10
0,0
20
0,0
51
0,1
03
0,2
11
0,5
75
1,3
92,7
74,6
15,9
97,3
89,2
110,6
30,0
72
0,1
15
0,2
16
0,3
52
0,5
84
1,2
13
2,3
74,1
16,2
57,8
19,3
511,3
412,8
4
40,2
07
0,2
97
0,4
84
0,7
11
1,0
64
1,9
23
3,3
65,3
97,7
89,4
911,1
413,2
814,8
6
50,4
12
0,5
54
0,8
31
1,1
45
1,6
10
2,6
75
4,3
56,6
39,2
411,0
712,8
315,0
916,7
5
60,6
76
0,8
72
1,2
37
1,6
35
2,2
04
3,4
55
5,3
57,8
410,6
412,5
914,4
516,8
118,5
5
70,9
89
1,2
39
1,6
90
2,1
67
2,8
33
4,2
55
6,3
59,0
412,0
214,0
716,0
118,4
820,2
8
81,3
41,6
52,1
82,7
33,4
95,0
77,3
410,2
213,3
615,5
117,5
320,0
921,9
5
91,7
32,0
92,7
3,3
34,1
75,9
8,3
411,3
914,6
816,9
219,0
221,6
723,5
9
10
2,1
62,5
63,2
53,9
44,8
76,7
49,3
412,5
515,9
918,3
120,4
823,2
125,1
9
11
2,6
3,0
53,8
24,5
75,5
87,5
810,3
413,7
17,2
819,6
821,9
224,7
226,7
6
12
3,0
73,5
74,4
5,2
36,3
8,4
411,3
414,8
518,5
521,0
323,3
426,2
228,3
13
3,5
74,1
15,0
15,8
97,0
49,3
12,3
415,9
819,8
122,3
624,7
427,6
929,8
2
14
4,0
74,6
65,6
36,5
77,7
910,1
713,3
417,1
221,0
623,6
826,1
229,1
431,3
2
15
4,6
5,2
36,2
67,2
68,5
511,0
414,3
418,2
522,3
125
27,4
930,5
832,8
16
5,1
45,8
16,9
17,9
69,3
111,9
115,3
419,3
723,5
426,3
28,8
532
34,2
7
17
5,7
6,4
17,5
68,6
710,0
912,7
916,3
420,4
924,7
727,5
930,1
933,4
135,7
2
18
6,2
67,0
18,2
39,3
910,8
613,6
817,3
421,6
25,9
928,8
731,5
334,8
137,1
6
19
6,8
47,6
38,9
110,1
211,6
514,5
618,3
422,7
227,2
30,1
432,8
536,1
938,5
8
20
7,4
38,2
69,5
910,8
512,4
415,4
519,3
423,8
328,4
131,4
134,1
737,5
740
21
8,0
38,9
10,2
811,5
913,2
416,3
420,3
424,9
329,6
232,6
735,4
838,9
341,4
22
8,6
49,5
410,9
812,3
414,0
417,2
421,3
426,0
430,8
133,9
236,7
840,2
942,8
23
9,2
610,2
11,6
913,0
914,8
518,1
422,3
427,1
432,0
135,1
738,0
841,6
444,1
8
24
9,8
910,8
612,4
13,8
515,6
619,0
423,3
428,2
433,2
36,4
239,3
642,9
845,5
6
25
10,5
211,5
213,1
214,6
116,4
719,9
424,3
429,3
434,3
837,6
540,6
544,3
146,9
3
26
11,1
612,2
13,8
415,3
817,2
920,8
425,3
430,4
335,5
638,8
941,9
245,6
448,2
9
27
11,8
112,8
814,5
716,1
518,1
121,7
526,3
431,5
336,7
440,1
143,1
946,9
649,6
4
28
12,4
613,5
615,3
116,9
318,9
422,6
627,3
432,6
237,9
241,3
444,4
648,2
850,9
9
29
13,1
214,2
616,0
517,7
119,7
723,5
728,3
433,7
139,0
942,5
645,7
249,5
952,3
4
30
13,7
914,9
516,7
918,4
920,6
24,4
829,3
434,8
40,2
643,7
746,9
850,8
953,6
7
189


















