
SISTEMI INFORMATIVI AZIENDALI - venus.unive.itvenus.unive.it/borg/SistInf-2.pdf · Con i circoletti...
43
Prof. Andrea Borghesan venus.unive.it/borg [email protected] Ricevimento: Alla fine di ogni lezione Modalità esame: scritto 1 SISTEMI INFORMATIVI AZIENDALI
Transcript of SISTEMI INFORMATIVI AZIENDALI - venus.unive.itvenus.unive.it/borg/SistInf-2.pdf · Con i circoletti...

Prof. Andrea Borghesan
venus.unive.it/borg
Ricevimento:
Alla fine di ogni lezione
Modalità esame: scritto
1
SISTEMI INFORMATIVI AZIENDALI

Data Warehousing.
Introduzione 1/2
I data warehousing sono il nucleo di gran parte dei DSS
(Decision Support System)
Sono progettati per gestire grandi quantità di dati e fornire
rapidamente informazioni, rapporti e analisi.
“[…] collezine di dati, a supporto del processo decisionale
manageriale orientata al soggetto, integrata, non volatile e dipendente
dal tempo”. Bill Inmon, seconda metà anni „80
“un singolo, completo e consistente deposito di dati, ottenuti da diverse
fonti e resi disponibili agli utenti finali in maniera tale da poter essere
immediatamente fruibili”. Barry Devlin, IBM System Journal
2

Data Warehousing.
Introduzione 2/2
I primi esempi di architetture di questo tipo vengono presentate
da IBM e Hewlett-Packard, rispettivamente negli anni 1991 e
1993.
Da allora le tecnologie e terminologie si sono evolute, oggi con
data warehouse si intende non solo la base di dati utilizzata
come supporto alle decisioni, ma più ampiamente un sistema
composto anche dalle applicazioni che servono per estrarre,
analizzare e presentare i dati.
Oggi i più grandi produttori di DBMS mettono a disposizione
strumenti per gestire sistemi informazionali inesistenti fino a 5
anni fa.
3

Metodologia OLAP
Negli anni „80 Edgar Codd inventò il termine OLTP (On-Line
Transaction Processing) e propose 12 criteri per individuare
un sistema di questo tipo (i criteri vennero ampiamente
accettati come standard di riferimento).
Nel 1993, Codd scrisse un articolo dal titolo “Providing OLAP
(On Line Analytical Processing to user analysts”. In tale
documento proponeva delle regole per definire un la
metodologia OLAP ma causa il basso contenuto matematico-
formale tali regole non vennero prese in considerazione.
Nel 1995, L‟OLAP Report propose nuove regole e propose una
semplice formula per dare una definizione precisa.
La cosiddetta regola FASMI
4

FASMI 1/2
Scomponendo tale acronimo, si ottengono le regole principali:
Fast, i sistemi OLAP hanno un uso interattivo. Mediamente
deve rispondere entro 5 secondi, 1 secondo per le domande
più facili e mai superare i 20 secondi di ritardo.
Analytical, il sistema deve riuscire ad elaborare analisi
statistiche in maniera abbastanza semplice per l‟utente finale,
in particolare deve:
Eseguire nuovi calcoli a partire da calcoli fatti
precedentemente
Fornire risposte a richieste specifiche particolari
Rappresentare i dati elaborati secondo diverse modalità
(tabellare, report o grafico) senza che l’utente scriva righe
di codice5

FASMI 2/2
Shared, i sistemi OLAP sono utilizzati da diversi utenti ne
consegue che il sistema deve fornire delle regole per la
sicurezza al fine di garantire la riservatezza dei dati. Se l‟utente
può modificare i dati deve essere garantito l‟accesso
concorrente (aspetto sottovalutato in quanto di solito l‟accesso
ai dati è di sola lettura).
Multidimensional, è il requisito più importante, significa
rappresentare i dati in multidimensione.
Informational, deve contenere tutte le informazioni
necessarie indipendentemente esse siano immagazzinate
Per ottenere le caratteristiche FASMI si usano varie tecnologie,
tipo architetture client-server o metodi di calcolo parallelo6
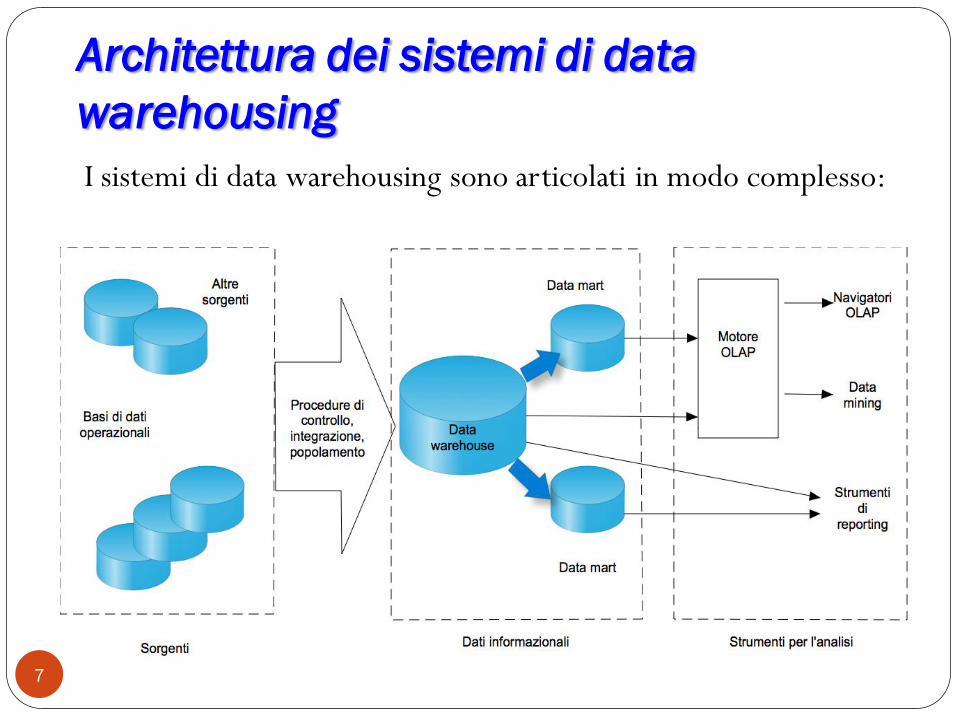
Architettura dei sistemi di data
warehousing
I sistemi di data warehousing sono articolati in modo complesso:
7

Elementi dei sistemi di data
warehousing a due livelli:
Primo livello, sorgenti dei dati:
i sistemi informazionali solitamente non generano dati
propri ma rielaborano dati provenienti da altre applicazioni
Secondo livello, aree di memorizzazione dei dati informazionali:
data warehouse vero e proprio ed eventualmente data
mart tematici
Primo e secondo livello sono connessi dalle procedure di
popolamento che, basandosi sul modello di integrazione e sulle
regole di controllo e integrazione dei dati, convertono i dati
sorgente in dati multidimensionali, consistenti, completi,
corretti8

Modelli concettuali per data
warehouse
I sistemi informazionali sono soggetti a frequenti modifiche
soprattutto per l‟approccio ciclico al loro sviluppo;
Solitamente viene realizzato un primo nucleo attorno ai fatti di
maggior interesse per l‟azienda, e da questo si procede poi per
sviluppo successivi.
Sono stati proposti diversi modelli concettuali ma ad oggi nessuno
si è affermato come standard.
In queste dispense si presenta il modello DFM (Dimensional Fact
Model) proposto da Golfarelli nel 1988.
Si tratta di un modello multidimensionale grafico definito per le
problematiche tipiche del data warehousing.
9

Dimensional Fact Model
Il DFM descrive i fatti attorno a cui si struttura un data
warehouse, fornisce dunque una visione concettuale di alto
livello.
Ogni fatto è delineabile tramite uno schema che rappresenta
le misure e le informazioni descrittive associate al fatto e
specifica anche le dimensioni.
Nello schema DFM i fatti sono rappresentati tramite un
rettangolo (nome del fatto + misure che lo descrivono).
Con i circoletti vengono rappresentate le dimensioni.
Gli attributi descrittivi sono collegati al fatto tramite una
linea.
10
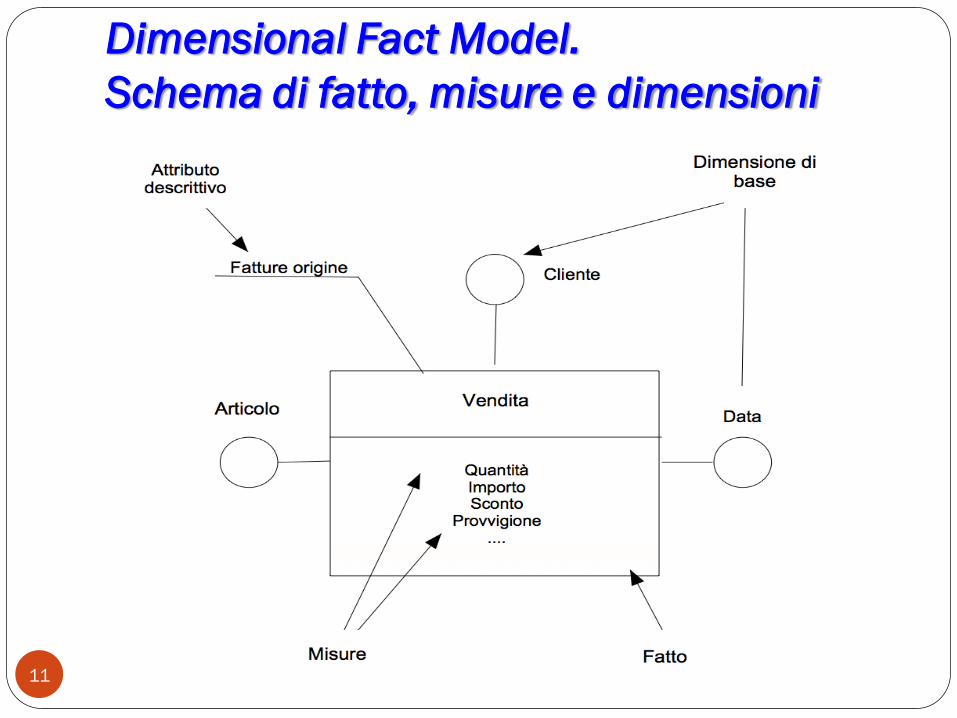
Dimensional Fact Model.
Schema di fatto, misure e dimensioni
11
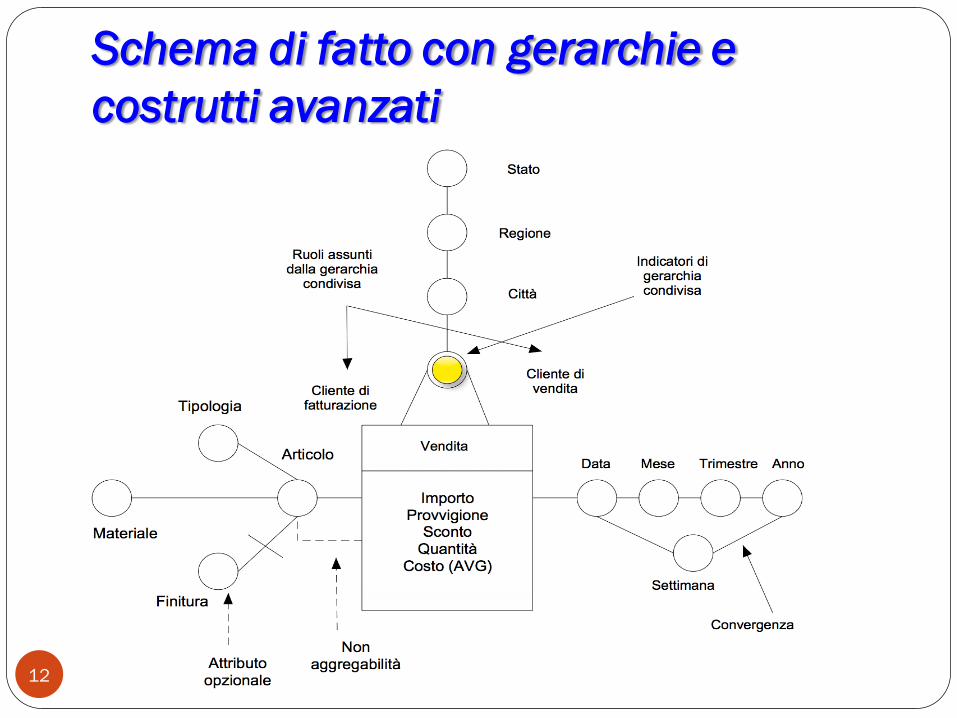
Schema di fatto con gerarchie e
costrutti avanzati
12

E il modello Entità-Relazione?
Il diagramma Entità-relazione può esser utilizzato per descriver
un modello multidimensionale ma risulta di difficile lettura.
Esso appare ridondante, sovradimensionato.
Il problema sta nel fatto che le varie regole di associazione
rappresentano, salvo rari casi, vincoli di dipendenza
funzionale.
Come si può notare dalla figura successiva il DFM sembra essere
l‟unico candidato a descrivere chiaramente/intuitivamente la
struttura di un ipercubo.
13
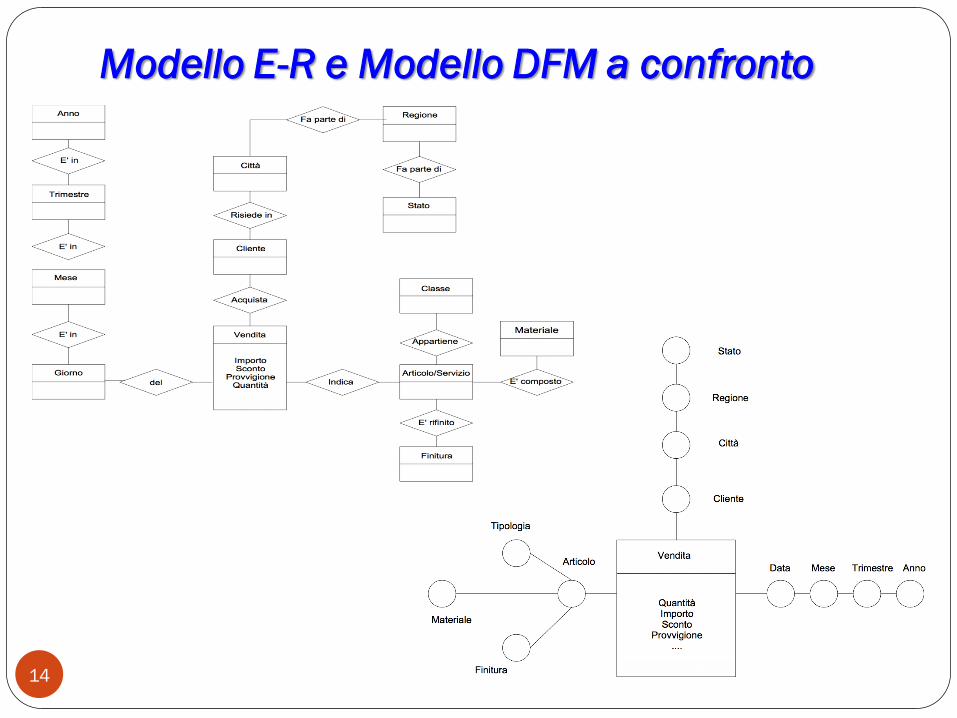
Modello E-R e Modello DFM a confronto
14

Modelli logici per il data warehouse
Combinando le basi di dati con le varie tipologie di
interrogazioni (linguaggio SQL o MDX) si ottengono diversi
tipi di modelli logici:
ROLAP: Relational OLAP
MOLAP: Multidimensional OLAP
HOLAP:Hybrdi OLAP
15

ROLAP
Tramite l‟approccio ROLAP la struttura multidimensionale dei
fatti viene realizzata completamente su database relazionali. Le
interrogazioni vengono effettuate tramite il linguaggio SQL
tramite funzioni di aggregazione.
I vantaggi derivanti da tale approccio sono:
Minor occupazione di spazio (spazio = dati salvati nel db)
Maggiore diffusione degli strumenti relazionali tra gli
operatori del settore dunque maggiore facilità d‟uso
Svantaggi:
Non si possono effettuare query multidimensionali su
strutture dati relazionali (denormalizzazione e precalcolo di
query aggregative più frequentemente utilizzate)
16

MOLAPTramite l‟approccio MOLAP il data warehouse memorizza i dati
usando strutture intrinsecamente multidimensionali, i dati
vengono memorizzati in matrici e vettori e l‟accesso è posizionale.
I vantaggi derivanti da tale approccio sono:
Ottime prestazioni dovuta alla struttura dimensionali di partenza
Facilità di interrogazione e massima efficacia nell‟analisi dei dati
rispetto ai database relazionali
Svantaggi:
Grande utilizzo di spazio su disco per immagazzinare i dati
Mancanza di standard, le strutture e le convenzioni di
interrogazione spesso sono proprietarie delle software house e
rendono così difficile l‟integrazione fra sistemi diversi e complessa
la migrazione verso altri sistemi17

HOLAP
L‟approccio HOLAP è una soluzione intermedia che combina i
vantaggi MOLAP e ROLAP. Il data warehouse contiene tutti i fatti
elementari e le strutture informative legate alle dimensioni e viene
implementato su base dati relazionale.
I vantaggi derivanti da tale approccio sono:
L‟uso di tecnologie relazionali standard permette maggiore
scalabilità del sistema
Le aggregazioni di alto livello vengono archiviati direttamente in
basi di dati multidimensionali
18

Schemi multidimensionali su basi di dati
relazionali
Considerata la vasta adozione di base di dati relazionali per
implementare data warehouse, si passa ora a descrivere i modelli di
implementazione su schemi logici relazionali (schema a stella e
schema a fiocco di neve).
Nei modelli ROLAP e HOLAP si utilizza lo schema a stella.
Uno schema a stella permette di creare uno schema relazionale
partendo dallo schema di fatto: è composto da una tabella
principale chiamata tabella dei fatti che memorizza un elemento
per ogni fatto elementare, tramite campi chiave si
“associano/relazionano” gli elementi dimensionali
memorizzati nelle tabelle delle dimensioni. Ogni fatto contiene
tante chiavi esterne quante sono le dimensioni che lo
descrivono.19
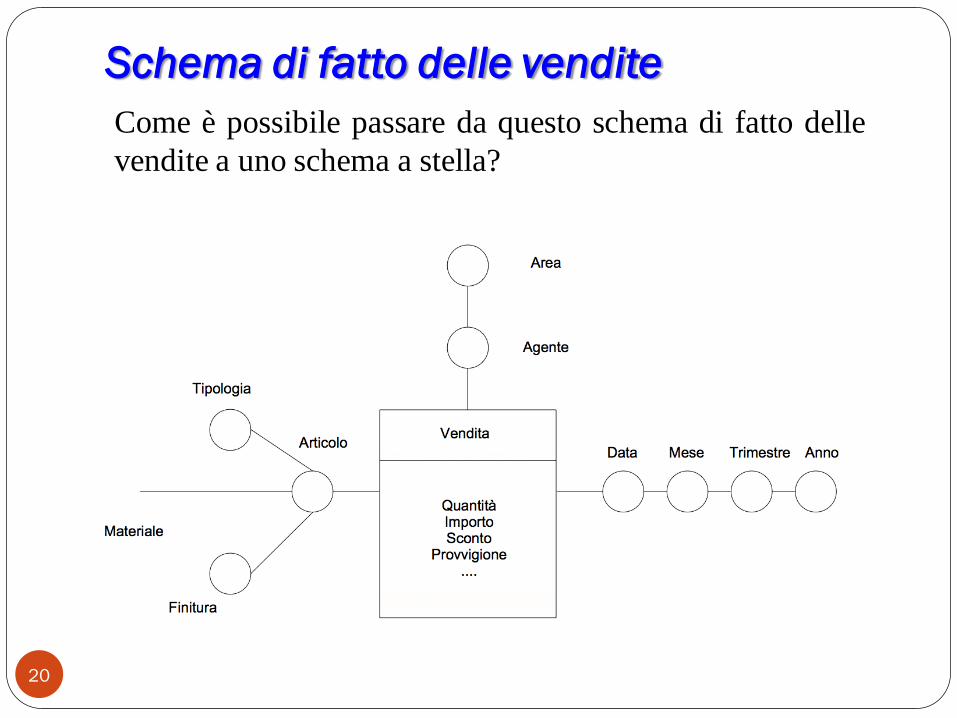
Schema di fatto delle vendite
20
Come è possibile passare da questo schema di fatto delle
vendite a uno schema a stella?
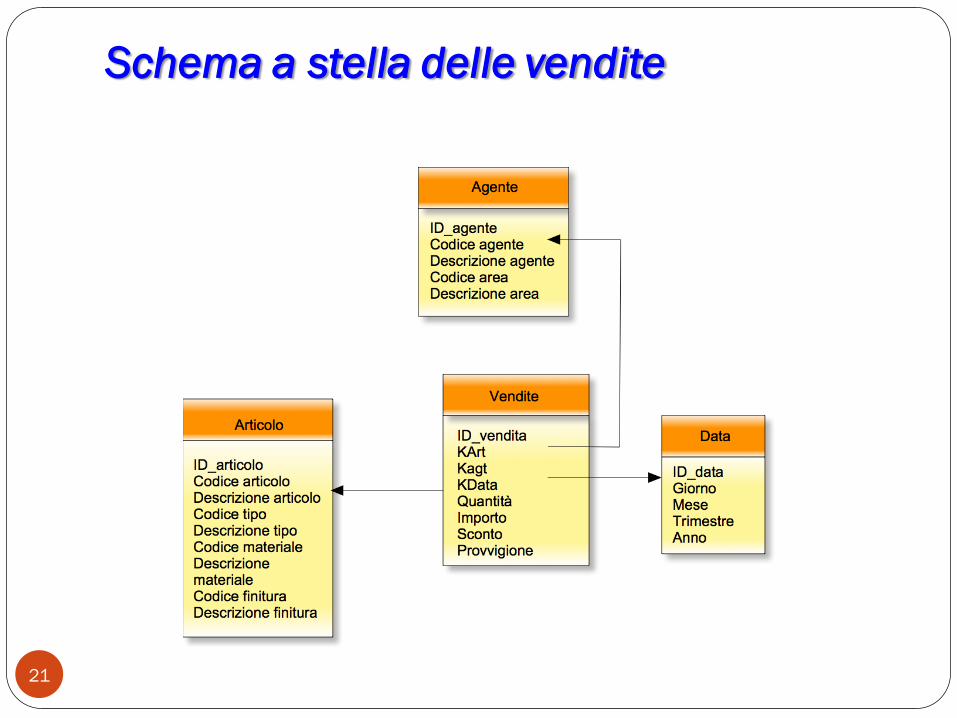
Schema a stella delle vendite
21

Osservazioni sul passaggio da schema di
fatto a schema a stella
Nello schema a stella le tabelle delle dimensioni sono
completamente denormalizzate e incuranti della ridondanza.
Un‟unica Join è sufficiente per recuperare tutti di dati presenti
nel db ma la struttura è scarsamente intuitiva.
Lo schema a stella permette di massimizzare la velocità di
estrazione dei dati.
22

Schema a fiocco di neve
Lo schema a fiocco di neve ha la caratteristica di ridurre la
denormalizzazione delle tabelle esplicitando alcune dipendenze
funzionali.
Se tale schema è altamente consigliato per il fatto che segue
maggiormente le regole di normalizzazione e dunque separa
in maniera logica i soggetti-entità essendo la struttura più
complessa porta a rallentamenti nell’estrarre le informazioni
dovuto al fatto che bisogna fare molte più join fra tabelle.
23

Schema a fiocco di neve delle vendite
24

Istanza di dati sullo schema a stella delle
vendite
Dimensione Articolo
ID Codice
articolo
Descrizione
articolo
Codice
tipologia
Descrizione
tipologia
Codice
materiale
Descrizione
materiale
Codice
finitura
Descrizione
finitura
… …
1822 S104H46 Sedia Olga
h.46
S Sedie Pn Pino naturale ZZZ Finitura
assente
1823 S104H78 Sgabello Olga
h.78
S Sedie Pn Pino naturale ZZZ Finitura
assente
1824 S105H46 Sedia Ugo
h.46
S Sedie Nn Noce
nazionale
CER Ceratp
… …
25
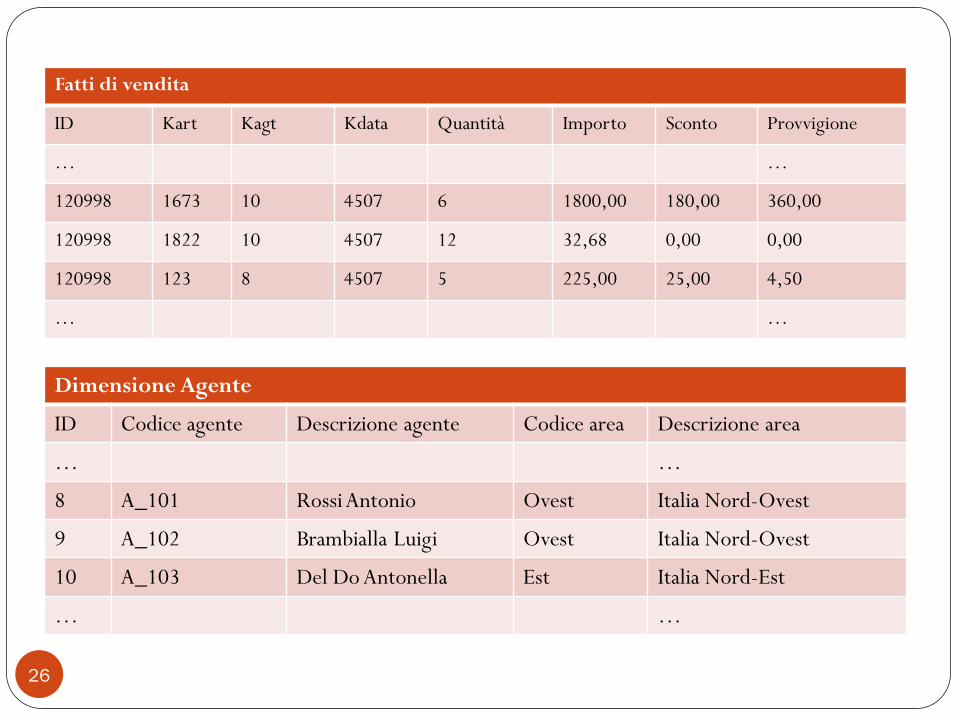
Fatti di vendita
ID Kart Kagt Kdata Quantità Importo Sconto Provvigione
… …
120998 1673 10 4507 6 1800,00 180,00 360,00
120998 1822 10 4507 12 32,68 0,00 0,00
120998 123 8 4507 5 225,00 25,00 4,50
… …
Dimensione Agente
ID Codice agente Descrizione agente Codice area Descrizione area
… …
8 A_101 Rossi Antonio Ovest Italia Nord-Ovest
9 A_102 Brambialla Luigi Ovest Italia Nord-Ovest
10 A_103 Del Do Antonella Est Italia Nord-Est
… …
26
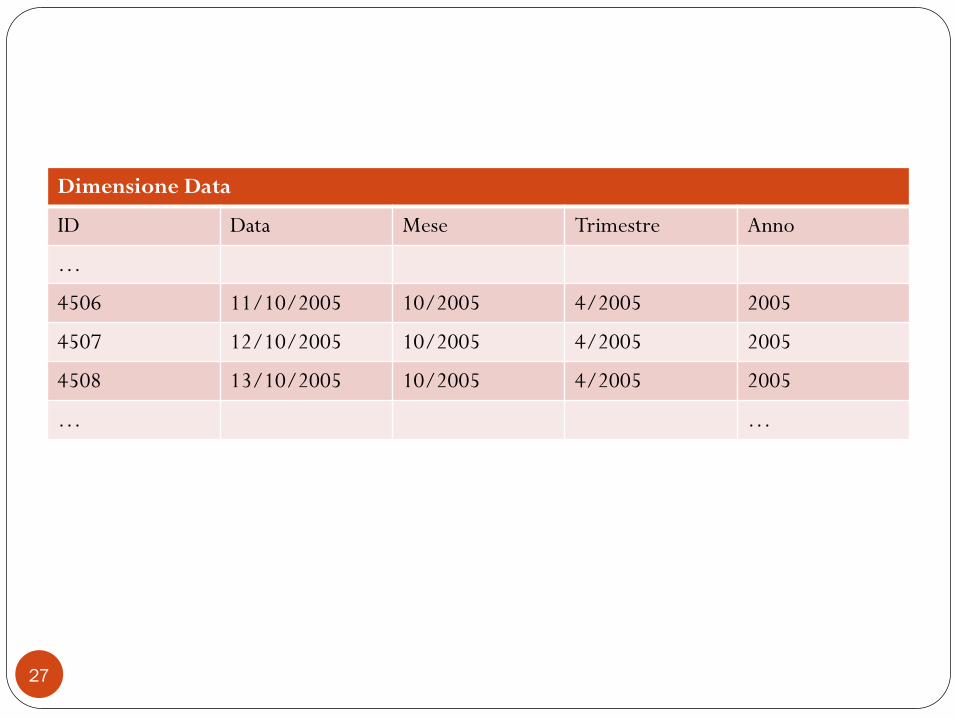
Dimensione Data
ID Data Mese Trimestre Anno
…
4506 11/10/2005 10/2005 4/2005 2005
4507 12/10/2005 10/2005 4/2005 2005
4508 13/10/2005 10/2005 4/2005 2005
… …
27
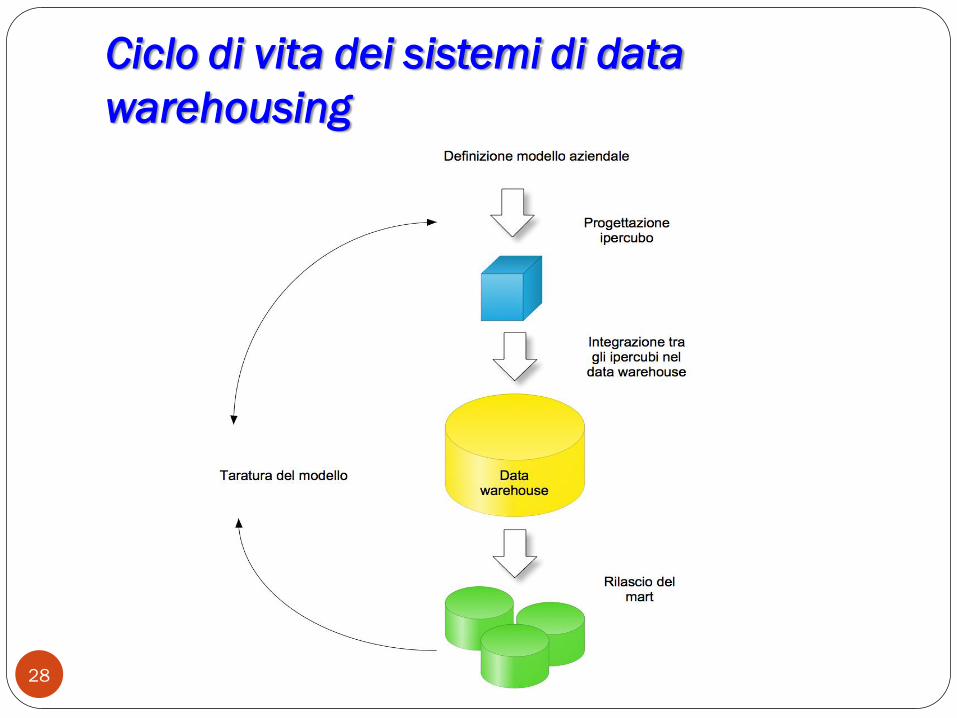
Ciclo di vita dei sistemi di data
warehousing
28

Ciclo di vita. Osservazioni 1/2
Come ha evidenziato la figura precedente, la costruzione di un
sistema di data warehouse avviene con un approccio iterativo, si
parte con la costruzione del primo ipercubo (di solito il più
significativo, le vendite).
Successivamente se ne aggiungono altri dando luogo a un processo
continuo di evoluzione del sistema di supporto delle decisioni.
Tale approccio è interessante perché:
L‟utilità dei sistemi di supporto alle decisioni viene apprezzata
dopo che si sono ottenuti i primi risultati positivi
Essendo considerati utili ma non necessari, costruire un sistema
“chiavi in mano” sarebbe un investimento iniziale troppo costoso
L‟approccio iterativo permette di tarare al meglio il sistema
29

Tecniche di analisi dei dati
Analisi OLAP
Un data warehouse mette a disposizione dell‟utente strumenti al
fine di analizzare i dati senza seguire percorsi predeterminati.
L‟analisi OLAP è la principale modalità di fruizione dei dati,
permette di navigare nei dati ed esplorare interattivamente i fatti.
Il principio fondamentale è: esplorazione guidata dalle ipotesi.
L‟utente formula un‟ipotesi, inoltra la richiesta alla base di dati
multidimensionale e la verifica.
Spesso le interrogazioni discendono da interrogazioni fatte
precedentemente.
30

Tecniche di analisi dei dati
Analisi OLAP
Le principali tecniche di analisi dei dati sono:
Drill down, letteralmente trivellare, scavare, scendere in
profondità => verso un maggior dettaglio di informazioni
Roll up o Drill up, letteralmente arrotolare => significa
aggregare le informazioni
Slice, affettare => limita l‟analisi dei dati fissando una
dimensione
Dice, tagliare a cubetti => limita l‟analisi “ai cubetti” fissando
uno o più attributi
Pivot, girare attorno ad un perno => ruota l‟ipercubo
permettendo la ridisposizione delle dimensioni per esporre i dati
31

Drill DownL‟operazione di drill down permette di partire da un livello di
presentazione dei dati molto generale e approfondire i dettagli passo
per passo aggiungendo una dimensione di analisi.
Esempio (si riprenda lo schema di fatto delle vendite) di una prima
interrogazione che riporta il confronto sulle quantità vendute
annualmente per prodotto e area:
32
Prodotto Area 2003 2004 Confronto
Articolo 1 Centro 60 56 7%
Est 203 220 8%
Ovest 64 64 0%
I dati evidenziano una mancata crescita ad Ovest. È possibile
aggiungere il dettaglio dei nomi degli agenti che distribuiscono i
prodotti nella zona?

Drill Down
33
Dalla tabella si capisce che il mancato aumento del fatturato è originato
da un solo agente (Raiteri) che ha addirittura un trend negativo.
Tale operazione di drill down è rappresentata graficamente tramite
l‟ipercubo:
Prodotto Area Agente 2003 2004 Confronto
Articolo 1 Est Dal Farra 43 52 21%
Del Do 24 25 4%
Mansi 28 30 7%
Trevisan 28 30 7%
Ovest Brambilla 89 93 4%
Cozzi 71 75 6%
Raiteri 13 11 -15%
Rossi 27 28 4%
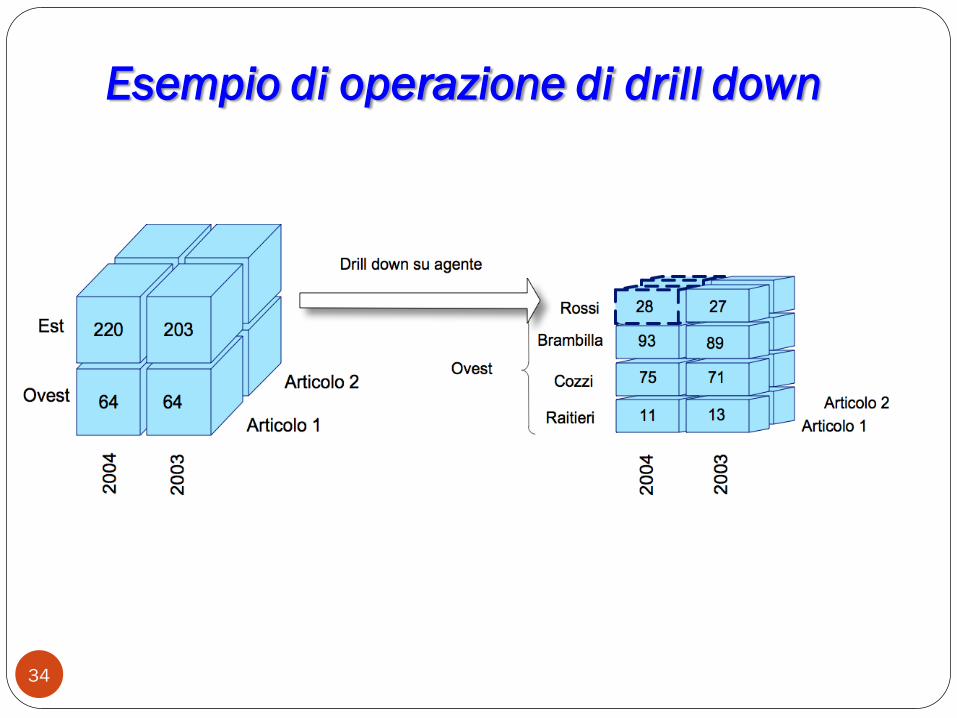
Esempio di operazione di drill down
34
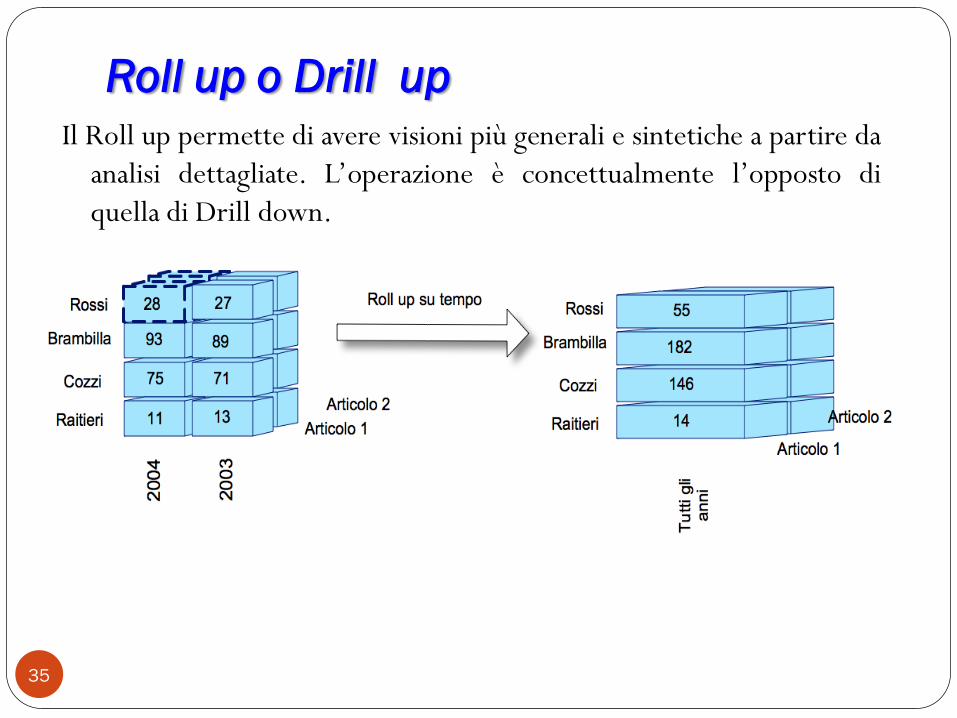
Roll up o Drill up
35
Il Roll up permette di avere visioni più generali e sintetiche a partire da
analisi dettagliate. L‟operazione è concettualmente l‟opposto di
quella di Drill down.
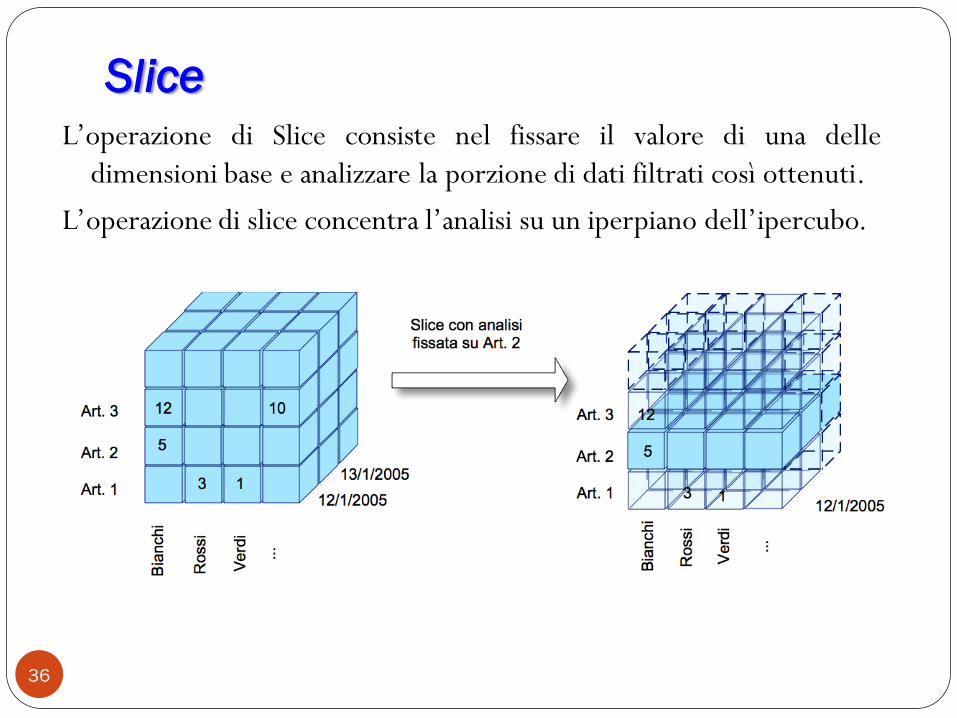
Slice
36
L‟operazione di Slice consiste nel fissare il valore di una delle
dimensioni base e analizzare la porzione di dati filtrati così ottenuti.
L‟operazione di slice concentra l‟analisi su un iperpiano dell‟ipercubo.

Dice
37
Anche l‟operazione di Dice riduce l‟insieme dei fatti elementari
considerati nell‟analisi ma lo fa su più dimensioni e fissando valori
per coordinate dimensionali di qualsiasi livello.
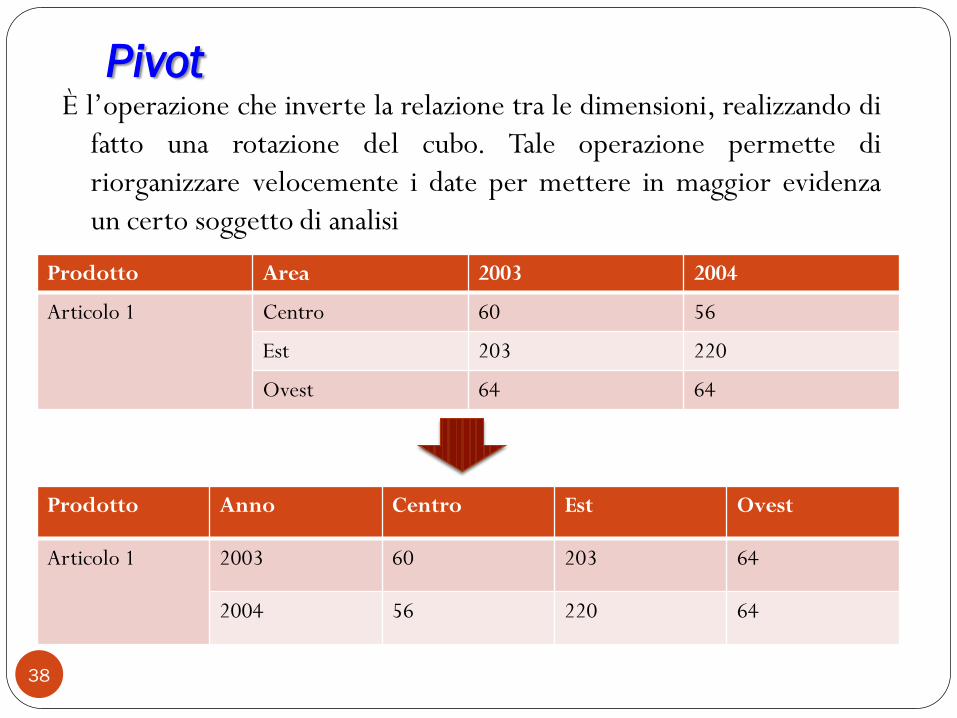
Pivot
38
È l‟operazione che inverte la relazione tra le dimensioni, realizzando di
fatto una rotazione del cubo. Tale operazione permette di
riorganizzare velocemente i date per mettere in maggior evidenza
un certo soggetto di analisi
Prodotto Area 2003 2004
Articolo 1 Centro 60 56
Est 203 220
Ovest 64 64
Prodotto Anno Centro Est Ovest
Articolo 1 2003 60 203 64
2004 56 220 64

Aree di applicazione nei sistemi aziendali
39
Le aree di applicazione dei sistemi di data warehousing sono
molteplici.
Le più tradizionali sono quelle che permettono l’analisi delle vendite
e il rapporto con il cliente.
Negli ultimi anni si inizia anche ad analizzare altri settori come la
gestione del personale, la logistica, il controllo di qualità.
Di seguito verranno analizzati brevemente gli schemi di fatto utilizzati.
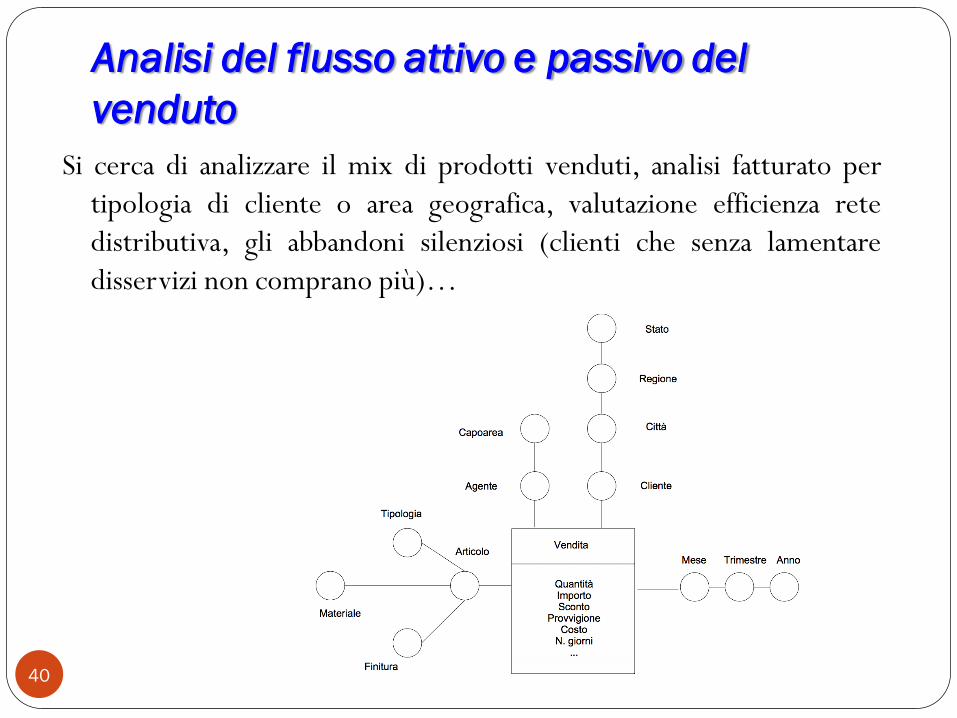
Analisi del flusso attivo e passivo del
venduto
40
Si cerca di analizzare il mix di prodotti venduti, analisi fatturato per
tipologia di cliente o area geografica, valutazione efficienza rete
distributiva, gli abbandoni silenziosi (clienti che senza lamentare
disservizi non comprano più)…

Controllo di gestione
41
In questo ambito si fanno analisi di marginalità su clienti o prodotti,
analisi tra budget e consuntivi. In figura uno schema di fatto per
l‟analisi di marginalità.

Controllo di qualità
42
In questo ambito si fanno analisi sui reclami, sulla non conformità ed
eventuali azioni correttive, sulle manutenzioni e sull‟efficienza dei
flussi documentali generali
Schema di fatto analisi
sulle non conformità

CRM
43
In questo ambito si fanno analisi orientate a comprendere la relazione
dell‟azienda con il mercato. Ambiti di indagine sono l‟efficacia delle
promozioni o azioni di fidelizzazione, l‟esito di campagne di
telemarketing.
Schema di fatto servizio
assistenza clienti




![anno 4° - n. 2 febbraio 2012 - venus.unive.itvenus.unive.it/venescus/judo/athlon net/athlon_net_2012_02[1].pdf · FONDAMENTI DI BIOMECCANICA ... (esaurito) 7. BIOMECCANICA DELLA](https://static.fdocumenti.com/doc/165x107/5c698b7409d3f26b7d8b4b6c/anno-4-n-2-febbraio-2012-venusunive-netathlonnet2012021pdf-fondamenti.jpg)




![anno 4° - n. 1 gennaio 2012 - venus.unive.itvenus.unive.it/venescus/judo/athlon net/athlon_net_2012_01[1].pdf · lare predilezione per il canottaggio e spese una intera esistenza](https://static.fdocumenti.com/doc/165x107/5c6880d909d3f29b758b936e/anno-4-n-1-gennaio-2012-venusunive-netathlonnet2012011pdf-lare.jpg)








