
Elementi Cap 9
58
Giulio Cesare Barozzi Giovanni Dore Enrico Obrecht Elementi di Analisi Matematica Volume 2 Versione preliminare – 2013
-
Upload
gigilombrico -
Category
Documents
-
view
80 -
download
2
description
Matematica dore obrecht barozzi elementi geometria
Transcript of Elementi Cap 9

Giulio Cesare Barozzi
Giovanni Dore
Enrico Obrecht
Elementi di
Analisi Matematica
Volume 2
Versione preliminare – 2013

Tutti i diritti riservati.

9Concetti introduttivi
algebrici e geometrici
In questo Capitolo introduttivo vengono trattati alcuni argomenti di carattere alge-
brico e geometrico. E probabile che lo studente li abbia gia incontrati, almeno inparte, in corsi precedenti; tuttavia e opportuno un loro studio accurato, anche alloscopo di fissare simboli, notazioni e definizioni.
9.1. Spazi vettoriali
Sia n ∈ N∗ ; indichiamo gli elementi di R
n con simboli del tipo
x = (x1, x2, . . . , xn) , y = (y1, y2, . . . , yn) , . . . .
Useremo talvolta un linguaggio geometrico, parlando di punti di Rn , anziche dielementi. I numeri reali x1, x2, . . . , xn vengono detti le coordinate di un
puntocoordinate di x .
Definiamo la somma tra due elementi di Rn e il prodotto tra un numero reale eun elemento di Rn .
9.1.1. Definizione. somma e prodotto
per scalare in Rn
Nell’insieme Rn delle n -ple ordinate di numeri reali defi-niamo le seguenti operazioni. Se x = (x1, x2, . . . , xn),y = (y1, y2, . . . , yn) ∈ Rn ,a ∈ R , poniamo
x+ y = (x1 + y1, x2 + y2, . . . , xn + yn) , (9.1.1)
ax = (a x1, a x2, . . . , a xn) . (9.1.2)
Si osservi che il simbolo di somma al primo membro della (9.1.1) indica l’operazionedi addizione in Rn , mentre quelli al secondo membro indicano l’analoga operazionein R ; considerazioni dello stesso tipo possono essere fatte per la seconda uguaglianza.
9.1.2. Osservazione A rigore la moltiplicazione di un numero reale per un elementodi Rn non e un’operazione in Rn nel senso specificato alla fine della Sezione 0.5; sitratta infatti di una funzione da R× Rn a Rn .
9.1.3. Osservazione Nel caso n = 2 , la definizione di addizione ora data coincide
con quella relativa all’addizione tra numeri complessi (v. Def. 3.1.1).
9.1.4. Esempio Siano x,y ∈ R2 , con
x =(
2,√2)
, y =
(
2
3,−2
√2
)
,
G. C. Barozzi G. Dore E. Obrecht

2 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
e a = 3 ; si ha:
x+y =
(
2 +2
3,√2 +
(
−2√2)
)
=
(
8
3, −
√2
)
, ax =(
3·2, 3√2)
=(
6, 3√2)
.
Siano u,v ∈ R3 , con
u = (1,−2, 4) , v =
(
3
2,1
4, e
)
,
e b = −2 ; si ha:
u+ v =
(
1 +3
2, −2 +
1
4, 4 + e
)
=
(
5
2, − 7
4, 4 + e
)
,
bu =(
−2 · 1,−2 · (−2),−2 · 4)
= (−2, 4, −8) .
Sono di verifica immediata le proprieta associativa e commutativa dell’addizione:
∀x,y, z ∈ Rn , (x+ y) + z = x+ (y + z) ;
∀x,y ∈ Rn , x+ y = y + x .
L’elemento neutro dell’addizione e 0 = (0, 0, . . . , 0) :
∀x ∈ Rn , x+ 0 = 0+ x = x .
Ogni x = (x1, x2, . . . , xn) ∈ Rn possiede un opposto, che e unico, e viene indica-to −x ; si ha −x = (−x1,−x2, . . . ,−xn) :
∀x ∈ Rn , x+ (−x) = (−x) + x = 0 .
Si ha poi, ∀a, b ∈ R , ∀x,y ∈ Rn ,
a(x+ y) = ax+ ay , (a+ b)x = ax+ bx ,
a(bx) = (ab)x , 1x = x .
Poniamo inoltre x− y = x+ (−y) .
9.1.5. Teorema. L’insieme Rn , munito delle operazioni (9.1.1) e (9.1.2), e unospazio vettoriale reale, cioe sul campo R .
Poiche Rn e uno spazio vettoriale (abbreviato s.v.), i suoi elementi vengono anchedettivettore vettori.
Per indicare un vettoreconvenzione sulle
notazioniutilizziamo sempre il carattere corsivo neretto . Nel se-
guito di questo Volume usiamo sistematicamente, e senza ulteriore avviso, la seguentenotazione: se c ∈ Rn , indichiamo una sua coordinata con la stessa lettera in ca-rattere corsivo chiaro, munita di un pedice numerico che ne indica la posizione; adesempio c3 indica la terza coordinata del vettore c .
Ricordiamo, per comodita del lettore e per uniformare le notazioni, la definizionedi spazio vettoriale e gli aspetti piu importanti dell’algebra lineare che ci saranno utilinel seguito.
9.1.6. Definizione.spazio vettoriale Siano K un campo e V un insieme non vuoto. Dicia-mo che V e uno spazio vettoriale sul campo K quando sono definite un’opera-zione + , detta addizione, e una funzione m , detta moltiplicazione per scalari,
+: V × V → V , m : K× V → V ,
che verificano le proprieta seguenti:
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.1. Spazi vettoriali 3
(1) ∀x,y, z ∈ V , (x+ y) + z = x+ (y + z) ,
(2) ∀x,y ∈ V , x+ y = y + x ,
(3) ∃0 ∈ V , tale che ∀x ∈ V , x+ 0 = 0+ x = x ,
(4) ∀x ∈ V , ∃ − x ∈ V , tale che x+ (−x) = −x+ x = 0 ,
(5) ∀x,y ∈ V , ∀a ∈ K , m(a,x+ y) = m(a,x) +m(a,y) ,
(6) ∀x ∈ V , ∀a, b ∈ K , m(a+ b,x) = m(a,x) +m(b,x) ,
(7) ∀x ∈ V , ∀a, b ∈ K , m(
a ,m(b,x))
= m(ab,x) ,
(8) ∀x ∈ V , m(1,x) = x .
Gli elementi scalaredel campo K vengono detti scalari.
Nel seguito, anziche scrivere m(a,x) , scriveremo semplicemente ax per indicareil risultato della moltiplicazione dello scalare a per il vettore x . Per indicare lasomma dei vettori v1, . . . ,vp useremo sistematicamente la notazione gia usata per inumeri reali e complessi:
∑p
i=1 vi .
9.1.7. Osservazione Le seguenti proprieta sono di facile verifica:
∀a ∈ K , a0 = 0 ; ∀x ∈ V , 0x = 0 , (−1)x = −x ;
qui 0 e 1 indicano gli elementi neutri di K .
9.1.8. Definizione. insieme
linearmente
indipendente,
linearmente
dipendente
Sia V uno spazio vettoriale sul campo K . Diciamo che uninsieme finito { v1,v2, . . . ,vp} ⊂ V e linearmente indipendente quando, per ognic1, c2, . . . , cp ∈ K , da
p∑
i=1
ci vi = 0
segue che gli scalari ci sono tutti nulli. Si dice anche che i vettori v1,v2, . . . ,vp
sono linearmente indipendenti.
In caso contrario diciamo che l’insieme { v1,v2, . . . ,vp} e linearmente dipen-
dente; cio significa che esistono p scalari d1, d2, . . . , dp ∈ K , non tutti nulli, taliche
∑p
i=1 di vi = 0 . In questo caso, si dice anche che i vettori v1,v2, . . . ,vp sonolinearmente dipendenti.
Un vettore della forma∑p
i=1 civi viene detto combinazione
linearecombinazione lineare dell’insieme
di vettori { v1,v2, . . . ,vp} e gli scalari c1, c2, . . . , cp vengono detti coefficienti dellacombinazione lineare. Pertanto l’insieme { v1,v2, . . . ,vp} e linearmente indipenden-te quando l’unica combinazione lineare dei suoi elementi che si annulla e quella cheha tutti i coefficienti nulli.
9.1.9. Esempio Nello spazio vettoriale R2 consideriamo v1 = (1, 1) , v2 = (2, 1) ,
v3 = (−2,−2) . L’insieme { v1,v2} e linearmente indipendente, mentre gli insiemi{ v1,v3} e { v1,v2,v3} sono linearmente dipendenti.
Infatti l’uguaglianza c1v1 + c2v2 = 0 si traduce nel sistema lineare omogeneo
{
c1 + 2c2 = 0 ,
c1 + c2 = 0 ,
che ammette soltanto la soluzione nulla c1 = c2 = 0 . Si ha poi v3 = −2v1 , cioe2v1 + v3 = 0 e quindi 2v1 + 0 v2 + v3 = 0 .
G. C. Barozzi G. Dore E. Obrecht

4 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.1.10. Esempio Nello spazio vettoriale R3 , siano v1 = (1, 1, 2) , v2 = (2, 0, 1) ,
v3 = (−2,−2, 0) , v4 = (0,−2, 1) . L’insieme { v1,v2,v3} e linearmente indipen-dente, mentre l’insieme { v2,v3,v4} e linearmente dipendente.
Infatti l’uguaglianza c1 v1 + c2 v2 + c3 v3 = 0 equivale al sistema omogeneo
c1 + 2c2 − 2c3 = 0 ,
c1 − 2c3 = 0 ,
2c1 + c2 = 0 ,
che ammette soltanto la soluzione nulla c1 = c2 = c3 = 0 , in quanto il determinantedella matrice dei coefficienti vale −8 .
Al contrario, l’uguaglianza c2 v2 + c3 v3 + c4 v4 = 0 equivale al sistema omogeneo
2c2 − 2c3 = 0 ,
− 2c3 − 2c4 = 0 ,
c2 + c4 = 0 ,
che ammette soluzioni non nulle; basta scegliere c2 = c3 , c4 = −c3 . Ponendo, adesempio, c3 = 1 , abbiamo c2 = 1 , c4 = −1 ; dunque v2 + v3 − v4 = 0 .
9.1.11. Definizione.sottospazio
vettorialeSiano V uno spazio vettoriale sul campo K e W ⊆ V .
Diciamo che W e un sottospazio vettoriale (o anche, piu semplicemente, un sotto-
spazio) di V quando W , munito dell’addizione e della moltiplicazione per scalariereditate da V , e uno spazio vettoriale su K .
Non e difficile mostrare il seguente risultato.
9.1.12. Teorema. Siano V uno spazio vettoriale sul campo K e W ⊆ V .Allora W e un sottospazio vettoriale di V se, e solo se,
∀x,y ∈ W , ∀a ∈ K , x+ y ∈ W , ax ∈ W .
9.1.13. Osservazione Ogni sottospazio W di uno s.v. V contiene il vettore 0 ,poiche, se x ∈ W , allora 0x = 0 .
Sono evidentemente sottospazi dello s.v. V l’insieme { 0} e V stesso. Questisono detti i sottospazisottospazio banale banali di V .
9.1.14. Esempio L’insieme W1 = { (t, t) ∈ R2 | t ∈ R} e un sottospazio di R2
diverso dai sottospazi banali.
Figura 9.1.1
Il sottospazio W1 di R2 definito nell’Es. 9.1.14.
1
1
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.1. Spazi vettoriali 5
9.1.15. Esempio Sono esempi di sottospazi non banali di R3 gli insiemi
W2 ={
(x, y, z) ∈ R3∣
∣ x+ 2y + 3z = 0}
, W3 ={
(x, y, z) ∈ R3∣
∣ x = 2y = 3z}
.
9.1.16. Definizione. sottospazio
generato da un
insieme finito
Siano V uno s.v. sul campo K ed E = { v1,v2, . . . ,vp}un sottoinsieme finito di V . Chiamiamo sottospazio generato da E l’insiemedelle combinazioni lineari di elementi di E :
{
p∑
i=1
ci vi
∣
∣
∣
∣
∣
c1, c2, . . . , cp ∈ K
}
.
Indichiamo tale sottospazio col simbolo l(E) .
9.1.17. Osservazione La terminologia introdotta nella definizione precedente e
appropriata, perche l(E) e effettivamente un sottospazio vettoriale di V .
Infatti, se x =∑p
i=1 ci vi ∈ l(E) , y =∑p
i=1 di vi ∈ l(E) e a ∈ K , risulta
x + y =∑p
i=1(ci + di)vi , ax =∑p
i=1(a ci)vi . Se ne conclude che l(E) e unsottospazio, in virtu del Teor. 9.1.12.
9.1.18. Definizione. spazio vettoriale
finitamente
generato
Sia V uno spazio vettoriale sul campo K . Diciamo che Ve finitamente generato se esiste un sottoinsieme finito E di V , tale che V = l(E) ;in formule: esiste E = {w1,w2, . . . ,wp} tale che
∀v ∈ V , ∃c1, c2, . . . , cp ∈ K : v =
p∑
i=1
ciwi .
9.1.19. Osservazione Esistono spazi vettoriali che non sono finitamente generati.Si consideri, ad esempio, l’insieme P dei polinomi a coefficienti reali, munito delleusuali operazioni di somma e di moltiplicazione per un numero reale. Esso e evi-dentemente uno spazio vettoriale. Sia { p1, p2, . . . , pr} un insieme finito di polinomi;detto m il massimo grado dei polinomi pi , ogni loro combinazione lineare
∑r
k=1 ckpke un polinomio di grado non superiore a m . Poiche in P esistono polinomi di gradomaggiore di m , ad esempio xm+1 , l’insieme finito considerato non genera P .
Uno s.v. viene s.v. di dimensione
finita, infinitaanche detto di dimensione finita se e finitamente generato, di
dimensione infinita in caso contrario.
9.1.20. Definizione. baseSiano V uno s.v. finitamente generato e B un suosottoinsieme finito. Diciamo che B e una base per V quando:
(1) B e linearmente indipendente;
(2) V = l(B) .
Pertanto una base di V e un sottoinsieme finito linearmente indipendente chegenera tutto lo spazio. Se { v1,v2, . . . ,vp} e una base di V e x =
∑p
k=1 ckvk ,gli scalari ck sono univocamente determinati e vengono detti le componenti di un
vettorecomponenti di x
nella base considerata. Infatti, se esistono c1, c2, . . . , cp e d1, d2, . . . , dp tali chex =
∑p
k=1 ck vk =∑p
k=1 dk vk , allora
0 =
p∑
k=1
ck vk −p∑
k=1
dk vk =
p∑
k=1
(ck − dk)vk ;
poiche { v1, . . . ,vp} e linearmente indipendente, risulta ck = dk , per k = 1, 2, . . . , p .
Per gli spazi vettoriali di dimensione finita vale il seguente fondamentale risultato.
G. C. Barozzi G. Dore E. Obrecht

6 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.1.21. Teorema. Sia V uno s.v. finitamente generato, diverso dallo spaziobanale { 0} . Allora V possiede una base e tutte le basi di V hanno lo stessonumero di elementi.
La definizione che segue e giustificata dal precedente teorema.
9.1.22. Definizione.dimensione di uno
spazio vettorialeSia V uno s.v. finitamente generato. Se V = { 0} ,
diciamo che V ha dimensione 0 . Se V 6= { 0} , diciamo che ha dimensione n ,se n e il numero degli elementi di una sua qualunque base. Indichiamo col simbolodimV la dimensione di V .
Dalla definizione di dimensione segue che un sottospazio di uno s.v. di dimensione nha dimensione minore o uguale a n .
Se V e uno s.v. di dimensione n , ci si chiede se esistano insiemi costituiti da nvettori che siano linearmente indipendenti ma non generano tutto V , oppure generanotutto V pur essendo linearmente dipendenti. La risposta e negativa per entrambe lequestioni. Vale infatti il
9.1.23. Teorema (dell’alternativa).teorema
dell’alternativaIn uno s.v. di V dimensione n , un insieme
di n vettori o e una base oppure e linearmente dipendente e non genera V .
Esaminiamo lo s.v. Rn .
9.1.24. Teorema. Lo spazio vettoriale Rn ha dimensione n .
Dimostrazione. E sufficiente esibire una base costituita da n vettori. Poniamo
e1 = (1, 0, 0, . . . , 0) ,
e2 = (0, 1, 0, . . . , 0) ,
. . . . . . . . . . . . . . . . . . . . .
en = (0, 0, 0, . . . , 1) .
A parole: per k = 1, 2, . . . n , tutte le coordinate di ek sono nulle, tranne la k -esimache vale 1 . L’insieme { e1, e2, . . . , en} e linearmente indipendente. Infatti, sia
n∑
k=1
ckek = 0 ,
con c1, c2, . . . , cn ∈ R . Scrivendo questa uguaglianza per coordinate si ottienec1 = 0 , c2 = 0 , . . . , cn = 0 .
Si ha poi, ∀x = (x1, x2, . . . , xn) ∈ Rn ,
x = (x1, 0, . . . , 0) + (0, x2, . . . , 0) + · · ·+ (0, 0, . . . , xn) =
= x1 e1 + x2 e2 + · · ·+ xn en =
n∑
k=1
xk ek .
Dunque ogni x ∈ Rn si puo scrivere come combinazione lineare dei vettori ek equindi l
(
{ e1, e2, . . . , en})
= Rn . Questo prova che { e1, e2, . . . , en} e una ba-
se di Rn .
Poichebase canonica
di Rn
le componenti di x rispetto alla base esplicitata sono le coordinate di x
stesso, tale base viene detta la base canonica di Rn .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.1. Spazi vettoriali 7
Per n = 3 , i vettori della base canonica vengono spesso indicati nei libri di Fisicacon le lettere i , j e k , rispettivamente.
Figura 9.1.2
I vettori e1 = (1, 0, 0) , e2 = (0, 1, 0) ,
e3 = (0, 0, 1) costituiscono la base cano-nica di R
3 .
9.1.25. Esempio Sia Cn l’insieme delle n -ple ordinate di numeri complessi. Se
w = (w1, w2, . . . , wn) ∈ Cn , z = (z1, z2, . . . , zn) ∈ Cn e α ∈ C , poniamo:
w + z = (w1 + z1, w2 + z2, . . . , wn + zn) ,
αw = (αw1, αw2, . . . , αwn) .
L’insieme Cn , munito di queste operazioni e uno spazio vettoriale sul campo C . None difficile dimostrare che Cn ha dimensione n , definendo, in modo del tutto analogoa Rn , la base canonica.
Rileviamo esplicitamente che questo fatto non deve trarre in inganno; ad esem-pio, C e uno spazio vettoriale complesso di dimensione 1 , ma lo rappresentiamogeometricamente mediante un piano, C
2 e uno spazio vettoriale complesso di dimen-sione 2 , ma dovrebbe essere pensato analogo a uno spazio reale a 4 dimensioni, ecc.
9.1.26. Esempio Consideriamo lo s.v. Rn[x] costituito dai polinomi pn di grado≤ n a coefficienti reali, tali cioe che
pn(x) = a0 + a1x+ . . .+ anxn , ak ∈ R , k = 0, 1, . . . , n ,
ivi compreso il polinomio identicamente nullo. Posto
f0 : R → R , f0(x) = 1 , fk : R → R , fk(x) = xk , k = 1, 2, . . . , n ,
risulta l ({ f0, . . . , fn}) = Rn[x] . Inoltre, questi monomi sono anche linearmenteindipendenti; infatti, se a0, a1, . . . , an ∈ R , l’uguaglianza
∑n
k=0 akfk = 0 significa
∀x ∈ R , a0 + a1x+ · · ·+ anxn = 0 ,
da cui segue (v. il Principio di identita dei polinomi 3.5.13)
a0 = a1 = · · · = an = 0.
Se ne conclude che lo s.v. in esame ha dimensione n+ 1 .
Considerazioni analoghe valgono per lo s.v. dei polinomi di grado ≤ n a coefficienticomplessi.
In Analisi gli unici campi di scalari che presentano interesse sono R e C .
Concludiamo questa Sezione con un risultato molto importante.
G. C. Barozzi G. Dore E. Obrecht

8 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.1.27. Teorema. Siano V uno s.v. di dimensione n ∈ N∗ e F un suo sottoin-sieme finito linearmente indipendente. Se F non e una base per V , allora esisteun sottoinsieme finito G di V , tale che F ∪G e una base di V .
Dimostrazione. Se F = { v1,v2, . . . ,vp} non e una base di V , allora esistey1 ∈ V che non e combinazione lineare degli elementi di F . Mostriamo che l’in-sieme F ∪ {y1} e linearmente indipendente. Infatti, siano c1, c2, . . . , cp+1 ∈ K , taliche
p∑
i=1
civi + cp+1y1 = 0 .
Se fosse cp+1 6= 0 , allora y1 = −(1/cp+1)∑p
i=1 civi e quindi y1 apparterreb-
be a l(F ) , contrariamente all’ipotesi. Allora cp+1 = 0 e quindi∑p
i=1 civi = 0 ;poiche F e linearmente indipendente, ne consegue che tutti i ck sono nulli, comesi voleva. Pertanto F ∪ { y1} e linearmente indipendente. Se la dimensione di Ve p+ 1 , allora F ∪ {y1} e una base per V , per il Teorema dell’alternativa 9.1.23.In caso contrario, scegliamo y2 ∈ V , che non puo essere scritto come combinazionelineare degli elementi di F ∪ {y1} e ripetiamo il ragionamento precedente.
Iterando questa procedura, otteniamo un insieme linearmente indipendente di nelementi, che pertanto costituisce una base di V .
9.2. Trasformazioni lineari
Le funzioni piu importanti che operano fra spazi vettoriali sono quelle lineari.
9.2.1. Definizione.trasformazione
lineareSiano V e W s.v. sul campo K e T : V → W . Diciamo
che la funzione T e una trasformazione lineare o, piu semplicemente, che e linearequando:
(1) ∀x,y ∈ V , T (x+ y) = T (x) + T (y) ;
(2) ∀x ∈ V , ∀a ∈ K , T (ax) = aT (x) .
Nel seguito indicheremo con L(V,W ) l’insieme delle trasformazioni linearida V a W .
9.2.2. Osservazione Affinche la definizione posta abbia senso e necessario che ildominio di T sia uno s.v. Analogamente, anche i valori di T devono appartenere auno s.v.
9.2.3. Osservazione Dalla definizione precedente segue che, se T ∈ L(V,W ) ,
∀x,y ∈ V , ∀a, b ∈ K , T (ax+ by) = aT (x) + bT (y) .
9.2.4. Osservazione Se S,T ∈ L(V,W ) e a ∈ K , poniamo:
S + T : V → W , (S + T )(x) = S(x) + T (x) ,
aT : V → W , (aT )(x) = aT (x) .
Munito di queste operazioni, L(V,W ) risulta uno s.v. su K .
9.2.5. Esempio Siano V e W s.v. sul campo K . Allora
T 1 : V → W , T 1(x) = 0 ,
e una trasformazione lineare.
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.2. Trasformazioni lineari 9
9.2.6. Esempio Sia V uno s.v. Allora
T 2 : V → V , T 2(x) = x ,
e una trasformazione lineare.
9.2.7. Esempio Sia
T3 : R2 → R , T3(x, y) = 2x+ 3y .
Allora T3 e una trasformazione lineare.
9.2.8. Esempio Sappiamo, dai Teor. 4.3.1 e 5.3.7, che C1(R,R) e C(R,R) sonos.v. Sia
D : C1(R,R) → C(R,R) , D(f) = f ′ ;
allora D e una trasformazione lineare.
9.2.9. Esempio Sia
INT : C([0, 1] ,R) → R , INT (f) =
∫ 1
0
f(x) dx ;
allora INT e una trasformazione lineare (v. Teor. 6.3.13).
9.2.10. Osservazione Siano V e W s.v. sul campo K e T ∈ L(V,W ) . Allora
T (0) = 0 . Infatti, sex ∈ V , si ha
T (0) = T (x− x) = T (x)− T (x) = 0 .
9.2.11. Teorema. Siano V , W e Z s.v. sul campo K . Se T ∈ L(V,W ) eS ∈ L(W,Z) , allora S ◦ T ∈ L(V, Z) .
Dimostrazione. Siano u1,u2 ∈ V e a ∈ K ; si ha:
(S ◦ T )(u1 + u2) = S(
T (u1 + u2))
= S(
T (u1) + T (u2))
=
= S(
T (u1))
+ S(
T (u2))
= (S ◦ T )(u1) + (S ◦ T )(u2) ;
(S ◦ T )(au1) = S(
T (au1))
= S(
aT (u1))
= aS(
T (u1))
= a(S ◦ T )(u1) .
Questo prova che S ◦ T e lineare.
Vale il risultato seguente.
9.2.12. Teorema. Siano V e W s.v. sul campo K e T ∈ L(V,W ) . Allora:
(1) l’immagine di T e un sottospazio vettoriale di W ;
(2) l’insieme kerT = {x ∈ V | T (x) = 0} e un sottospazio vettoriale di V .
Il simbolo ker e un’abbreviazione della parola inglese kernel, che significa nucleo.
Dimostrazione. Siano y1,y2 ∈ T (V ) e a ∈ K ; allora esistono x1,x2 ∈ V , taliche T (x1) = y1 , T (x2) = y2 . Si ha
y1 + y2 = T (x1) + T (x2) = T (x1 + x2) ∈ T (V ) ;
ay1 = aT (x1) = T (ax1) ∈ T (V ) .
Per il Teor. 9.1.12 la prima affermazione e provata.
G. C. Barozzi G. Dore E. Obrecht

10 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Siano u1,u2 ∈ V , tali che T (u1) = T (u2) = 0 e a ∈ K . Si ha:
T (u1 + u2) = T (u1) + T (u2) = 0+ 0 = 0 ;
T (au1) = aT (u1) = a0 = 0 .
Ancora per il Teor. 9.1.12 anche la seconda affermazione e provata.
9.2.13. Definizione.nucleo di una
trasformazione
lineare
Siano V e W s.v. sul campo K e T ∈ L(V,W ) ; ilsottospazio kerT = {x ∈ V | T (x) = 0} di V si chiama nucleo di T .
Il prossimo risultato mostra che la verifica dell’iniettivita di una trasformazionelineare e molto piu semplice rispetto all’analoga verifica per una funzione arbitraria.
9.2.14. Teorema. Siano V e W s.v. sul campo K e T ∈ L(V,W ) . Allora T
e iniettiva se, e solo se, kerT = { 0} .
Dimostrazione. Supponiamo T iniettiva. Poiche, per l’Oss. 9.2.10, T (0) = 0 ,deve essere T (x) 6= 0 quando x 6= 0 ; quindi, kerT = { 0} .
Viceversa, sia kerT = { 0} ; consideriamo x1,x2 ∈ V , tali che T (x1) = T (x2) .Allora
T (x1 − x2) = T (x1)− T (x2) = 0 ;
quindi x1 − x2 ∈ kerT e allora x1 = x2 Questo prova che T e iniettiva.
9.2.15. Teorema. Siano V e W s.v. sul campo K , T ∈ L(V,W ) ev1,v2, . . . ,vp ∈ V . Se T e iniettiva e { v1,v2, . . . ,vp} e linearmente indi-pendente, allora anche {T (v1),T (v2), . . . ,T (vp)} e linearmente indipendente.
Dimostrazione. Siano c1, c2, . . . , cp ∈ K , tali che
0 =
p∑
i=1
ciT (vi) = T
(
p∑
i=1
civi
)
.
Poiche T e iniettiva, per il Teor. 9.2.14 risulta∑p
i=1 civi = 0 e quindi, per lalineare indipendenza dei vi , anche ci = 0 , per i = 1, 2, . . . , p . Ne segue che anche{T (v1),T (v2), . . . ,T (vp)} e linearmente indipendente.
9.2.16. Teorema. Siano V e W s.v. sul campo K e supponiamo V didimensione finita. Se T ∈ L(V,W ) , allora
dimT (V ) + dimkerT = dimV .
In particolare, T (V ) ha dimensione finita e non superiore a quella di V .
Dimostrazione. La tesi e banale se T e nulla. Sia dunque T non nulla; supponia-mo dapprima kerT = { 0} e sia { v1,v2, . . . ,vp} una base di V . Mostriamo che{T (v1),T (v2), . . . ,T (vp)} e una base di T (V ) . La lineare indipendenza di questoinsieme segue dal Teor. 9.2.15, poiche in questo caso T e iniettiva, per il Teor. 9.2.14.Inoltre, se y ∈ T (V ) , ∃x ∈ V , tale che T (x) = y . Siano c1, c2, . . . , cp ∈ K , taliche x =
∑p
i=1 civi , da cui
y = T
(
p∑
i=1
civi
)
=
p∑
i=1
ciT (vi) .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.2. Trasformazioni lineari 11
Pertanto, l(
{T (v1),T (v2), . . . ,T (vp)})
= T (V ) . Quindi, in questo caso, si ha
dimT (V ) = dimV .
Se kerT 6= { 0} , per il Teor. 9.1.21 esiste una base di kerT , sia { v1,v2, . . . ,vk} .Per il Teor. 9.1.27 esistono vk+1,vk+2, . . . ,vk+r ∈ V , tali che { v1,v2, . . . ,vk+r} euna base di V . Per dimostrare il teorema e allora sufficiente provare che T (V ) ha
dimensione r . La restrizione di T a l(
{ vk+1,vk+2, . . . ,vk+r})
e iniettiva, perche
T (x) = 0 implica che x e combinazione lineare di v1,v2, . . . ,vk ; pertanto, per il
Teor. 9.2.15, l’insieme T(
{ vk+1,vk+2, . . . ,vk+r})
e linearmente indipendente. Inol-
tre, esso genera T (V ) . Infatti, sia y ∈ T (V ) ; allora ∃x =∑k+r
i=1 civi , tale cheT (x) = y . Si ha
y = T
(
k+r∑
i=1
ci vi
)
=
k+r∑
i=1
ci T (vi) =
k+r∑
i=k+1
ci T (vi) ;
questo prova che dimT (V ) = r , come si voleva.
Nel resto di questa Sezione ci occupiamo di trasformazioni lineari da Rn a Rm ,cominciando col determinare tutte le trasformazioni lineari da Rn a R .
Esaminiamo dapprima un caso molto semplice. Sia T ∈ L(R2,R) ; se u = (x, y) =xe1 + y e2 ∈ R2 , si ha
T (u) = T (xe1 + y e2) = xT (e1) + y T (e2) = a1x+ a2y ,
dove abbiamo indicato con ai il numero reale T (ei) . Quindi le trasformazioni linearida R
2 a R hanno la forma (x, y) 7→ a1x + a2y . Lo studente verifichi il viceversa,cioe che, ∀a1, a2 ∈ R , la funzione (x, y) 7→ a1x+ a2y e lineare.
Sia ora T ∈ L(Rn,R) . Se x =∑n
i=1 xi ei , si ha
T (x) = T
(
n∑
i=1
xi ei
)
=
n∑
i=1
xi T (ei) =
n∑
i=1
ai xi ,
dove abbiamo indicato con ai il numero reale T (ei) . Quindi le trasformazioni linearida Rn a R hanno la forma (x1, x2, . . . , xn) 7→ ∑n
i=1 aixi . Lo studente verifichi il
viceversa, cioe che, ∀a1, a2, . . . , an ∈ R , la funzione (x1, x2, . . . , xn) 7→∑n
i=1 aixi elineare.
Pertanto T ∈ L(Rn,R) se, e solo se, esistono a1, a2, . . . , an ∈ R , tali che
T (x1, x2, . . . , xn) =n∑
i=1
ai xi .
Riassumendo:
9.2.17. Teorema. Sia T ∈ L(Rn,R) ; allora T (x1, x2, . . . , xn) =∑n
i=1 ai xi ,dove ai = T (ei) per i = 1, 2, . . . , n .
Viceversa, se a ∈ Rn , allora T : Rn → R , con T (x) =∑n
i=1 ai xi , e lineare.
Il teorema mostra che T (x) o e la funzione nulla oppure e un polinomio omogeneodi primo grado nelle coordinate di x .
La definizione seguente introduce funzioni lineari da Rn a R di particolare im-portanza.
G. C. Barozzi G. Dore E. Obrecht

12 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.2.18. Definizione.proiezione su
un assePoniamo, per i = 1, 2, . . . , n ,
πi : Rn → R , πi(x1, x2, . . . , xn) = xi ;
pertanto, πi associa a ogni vettore di Rn la sua i -esima coordinata. Questafunzione viene detta proiezione sull’ i -esimo asse.
9.2.19. Esempio Se u = (x, y) ∈ R2 , si ha
π1(u) = x , π2(u) = y .
Ad esempio, se u = (3,−5) , si ha π1(u) = 3 , π2(u) = −5 .
Se v = (x, y, z) ∈ R3 , si ha
π1(v) = x , π2(v) = y , π3(v) = z .
Ad esempio, se v =(
1, 1/2,√3)
, si ha π1(v) = 1 , π2(v) = 1/2 , π3(v) =√3 .
Sia T ∈ L(Rn,Rm) . Allora, se x ∈ Rn , risulta T (x) ∈ Rm e quindi
T (x) =(
T1(x), T2(x), . . . , Tm(x))
,
dove Ti = πi ◦ T . E allora naturale scrivere T = (T1, T2, . . . , Tm) . Le funzioni avalori reali Ti vengono dette le componenti della funzione vettoriale T .
La dimostrazione del risultato seguente e immediata.
9.2.20. Teorema. Sia T ∈ L(Rn,Rm) , con T = (T1, T2, . . . , Tm) . AlloraTi ∈ L(Rn,R) , per i = 1, 2, . . . ,m .
Viceversa, se Si ∈ L(Rn,R) , per i = 1, 2, . . . ,m , allora
S = (S1, S2, . . . , Sm) ∈ L(Rn,Rm) .
Determiniamo tutte le trasformazioni lineari da Rn a R
m . Se T = (T1, T2, . . . , Tm)e una di queste, per il Teor. 9.2.20 risulta Ti ∈ L(Rn,R) . Pertanto (v. Teor. 9.2.17)esistono ai1, ai2, . . . , ain ∈ R , tali che, ∀x ∈ Rn , si ha
Ti(x) =
n∑
k=1
aik xk , i = 1, 2, . . . ,m .
La trasformazione lineare e quindi individuata dagli m · n numeri reali aik ; e deltutto naturale organizzare tali numeri in una matrice. Per motivi che vedremo frapoco e opportuno considerare questa come una matrice con m righe e n colonne.Poniamo dunque
A =
a11 a12 . . . a1na21 a22 . . . a2n...
.... . .
...am1 am2 . . . amn
.
Poiche il vettore x ∈ Rn ha n componenti, e opportuno pensarlo come una matricecolonna, con n righe e 1 colonna. Tale identificazione sara utilizzata sistematica-mente nel seguito. Osserviamo che, effettuando il prodotto righe per colonne dellamatrice A per la matrice colonna x , il che e lecito perche il numero delle colonne di
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.2. Trasformazioni lineari 13
A e pari al numero delle righe di x , si ottiene
Ax =
a11 a12 . . . a1na21 a22 . . . a2n...
.... . .
...am1 am2 . . . amn
x1
x2
...xn
=
∑n
k=1 a1kxk∑n
k=1 a2kxk
...∑n
k=1 amkxk
=
T1(x)T2(x)
...Tm(x)
= T (x) .
D’ora in poi indicheremo con il simbolo Mm,n(R) l’insieme delle matrici realicon m righe e n colonne, dette anche matrici di tipo m × n . La matrice indicatacon A e stata ottenuta a partire dalle funzioni Ti e quindi a partire dalla funzione T .
La procedura, naturalmente, si puo invertire: se A ∈ Mm,n(R) , allora essaindividua una funzione lineare T da Rn a Rm , quella definita da
T (x) = Ax ,
dove Ax indica il prodotto righe per colonne di A per la matrice colonna x .
Osserviamo che ogni colonna della matrice A puo essere pensata come una matricecolonna e quindi puo rappresentare un vettore di Rm ; in particolare,
a11a21...
am1
= T (e1) ,
cioe la prima colonna della matrice A coincide col valore della funzione lineare T
nel primo vettore della base canonica. Analogamente, si ha
a12a22...
am2
= T (e2) ,
e cosı via.
Si ottiene quindi il seguente risultato.
9.2.21. Teorema. Sia T ∈ L(Rn,Rm) ; allora T (x) = Ax , dove A ∈ Mm,n(R)e individuata dalle uguaglianze
a1ja2j...
amj
= T (ej) , j = 1, 2, . . . , n . (9.2.1)
Viceversa, se B ∈ Mm,n(R) , la funzione
S : Rn → R, S(x) = Bx ,
e lineare.
La matrice A viene detta la matrice associata
a una
trasformazione
lineare
matrice associata a T rispetto alle basi canonichedi Rn e di Rm . Poiche useremo quasi sempre le basi canoniche, diremo che lamatrice A e associata a T , senza ulteriori precisazioni.
9.2.22. Teorema. Siano T 1,T 2 ∈ L(Rn,Rm) , A1, A2 le matrici ad esse asso-ciate, a ∈ R ; allora la matrice associata a T 1 + T 2 e A1 +A2 , quella associataad aT 1 e aA1 .
G. C. Barozzi G. Dore E. Obrecht

14 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Siano T ∈ L(Rn,Rm) , S ∈ L(Rm,Rp) e siano A e B le matrici associate aS e a T , rispettivamente; allora la matrice associata a S ◦ T e AB (prodottorighe per colonne).
Dimostrazione. La prima affermazione segue direttamente dal Teor. 9.2.21.
Occupiamoci della composizione di due trasformazioni lineari, che sappiamo essereuna trasformazione lineare in base al Teor. 9.2.11. Si ha, ∀v ∈ Rn e ∀w ∈ Rm ,T (v) = Bv , S(w) = Aw ; allora
(S ◦ T )(v) = S(
T (v))
= S(Bv) = A(Bv) = (AB)v.
Questo prova la seconda affermazione.
v ∈ Rn
S T
w = Bv ∈ Rm
Aw = AB v ∈ Rp→ → → →ST
Figura 9.2.1
Composizione di due trasformazioni lineari.
9.2.23. Osservazione Facciamo notare che le matrici A e B considerate nelladimostrazione del teorema precedente sono di tipo p×m e m× n , rispettivamente;allora e possibile eseguirne il prodotto AB , ottenendo una matrice p× n .
9.3. Lo spazio euclideo Rn
In questa Sezione introduciamo una nuova struttura sullo s.v. Rn , quella di spazioeuclideo; questa si realizza mediante l’introduzione del prodotto scalare.
9.3.1. Definizione. Siano x = (x1, x2, . . . , xn),y = (y1, y2, . . . , yn) ∈ Rn ; chia-miamoprodotto scalare prodotto scalare di x e y il numero reale
x • y = x1 y1 + x2 y2 + · · ·+ xn yn =n∑
k=1
xk yk . (9.3.1)
Lo spazio vettoriale Rn , munito del prodotto scalare, viene dettospazio euclideo spazio euclideo
di dimensione n .
9.3.2. Osservazione A differenza dell’addizione tra vettori, il prodotto scalare, nelcaso piu significativo n > 1 , non e un’operazione in Rn , cioe una funzione da Rn×Rn
a Rn , bensı e una funzione da Rn × Rn a R .
9.3.3. Esempio Siano x = (1, 3) , y = (−1, 4) ; allora x •y = 1 · (−1)+ 3 · 4 = 11 .
9.3.4. Esempio Siano x =(
1/2,√2, 3)
, y = (1, 3, π) ; allora
x • y =1
2· 1 +
√2 · 3 + 3 · π =
1
2+ 3(√2 + π
)
.
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.3. Lo spazio euclideo Rn 15
9.3.5. Teorema (proprieta del prodotto scalare). proprieta del
prodotto scalareValgono le seguenti proprieta:
(1) ∀x,y, z ∈ Rn , (x+ y) • z = x • z + y • z ;
(2) ∀x,y ∈ Rn , ∀a ∈ R , (ax) • y = a (x • y) ;
(3) ∀x,y ∈ Rn , x • y = y • x ;
(4) ∀x ∈ Rn , x • x ≥ 0 ; inoltre, x • x = 0 se, e solo se, x = 0 .
La dimostrazione del Teorema e immediata. Le uguaglianze ai punti (1) e (2)esprimono la linearita del prodotto scalare rispetto al primo argomento, mentre la (3)stabilisce la commutativita del prodotto scalare; per quest’ultima proprieta, sussistela linearita anche rispetto al secondo argomento:
x • (y + z) = x • y + x • z , x • (ay) = a (x • y) .
Pertanto, si dice che il prodotto scalare e una funzione bilineare da Rn × Rn a R .
9.3.6. Osservazione Se T ∈ L(Rn,R) , allora esiste a ∈ Rn , tale che
∀x ∈ Rn , T (x) = a • x .
Si tratta semplicemente di una rilettura del Teor. 9.2.17. In questo caso la matriceassociata a T e
(
a1 a2 . . . an)
= ta , cioe la matrice riga trasposta di a .
9.3.7. Osservazione Il prodotto scalare ha un notevole significato geometrico. Con-
sideriamo, per ora, solo il caso n = 2 ; allora i vettori x = (x1, x2) e y = (y1, y2) ,che supponiamo diversi da 0 , possono essere identificati con i numeri complessix = x1 + ix2 e y = y1 + iy2 , rispettivamente. Esprimiamoli in forma polare
x = |x| eit , y = |y| eis ,dove t, s ∈ R . Si ha
x • y = x1y1 + x2y2 = Re(xy∗) = Re(
|x|eit |y|e−is)
=
= |x| |y|Re(
ei(t−s))
= |x| |y| cos(t− s) .
Pertanto, il prodotto scalare di due vettori e uguale al prodotto dei loro modulimoltiplicato per il coseno dell’angolo da essi formato. Se i vettori sono linearmentedipendenti, tale coseno vale 1 oppure −1 e quindi il prodotto scalare e uguale alprodotto dei moduli ovvero all’opposto di questo prodotto. Se invece formano unangolo retto, il loro prodotto scalare e nullo.
L’osservazione precedente motiva la seguente definizione.
9.3.8. Definizione. vettori ortogonaliSiano x,y ∈ Rn ; diciamo che i vettori x e y sonoortogonali quando x • y = 0 .
9.3.9. Esempio In base alla definizione, il vettore nullo e ortogonale a ogni vettoredi Rn : infatti ∀x ∈ Rn , x • 0 = 0 ; esso e l’unico vettore che goda di tale proprieta.
9.3.10. Esempio I vettori di R2 (1,−2) e (2, 1) sono ortogonali. I vettori di R
3
(1, 1,−2) , (1, 1, 1) e (2,−2, 0) sono a due a due ortogonali.
9.3.11. Esempio I vettori della base canonica sono a due due ortogonali; piuprecisamente si ha, come subito si verifica,
eh • ek =
{
0 , se h 6= k ,
1 , se h = k .
G. C. Barozzi G. Dore E. Obrecht

16 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.3.12. Osservazione Sia E = { v1,v2, . . . ,vp} un insieme finito di vettori di(
Rn)∗
.1 Se gli elementi di E sono a due a due ortogonali, cioe vi • vj = 0 , quandoi 6= j , allora E e linearmente indipendente. Infatti, siano c1, c2, . . . , cp ∈ R , tali che
p∑
i=1
civi = 0 .
Moltiplicando scalarmente entrambi i membri per il vettore vk , si ottiene
0 = 0 • vk =
(
p∑
i=1
civi
)
• vk =
p∑
i=1
ci(vi • vk) = ckvk • vk;
poiche vk • vk 6= 0 , per la (4) del Teor. 9.3.5, ne deriva ck = 0 .
Il viceversa e falso; vi sono insiemi linearmente indipendenti i cui elementi non sonoa due a due ortogonali. Ad esempio i vettori w1 = (1, 0) e w2 = (1, 1) non sonoortogonali, perche w1 •w2 = 1 6= 0 ; pero c1w1+c2w2 = 0 significa (c1+c2, c2) = 0 ,da cui c1 = c2 = 0 .
9.3.13. Definizione.norma Sia x ∈ Rn ; chiamiamo norma di x il numero reale nonnegativo
‖x‖ =√x • x =
√
√
√
√
n∑
k=1
x2k . (9.3.2)
modulo Talvolta la norma viene anche detta modulo del vettore.
9.3.14. Osservazione Per n = 1 la norma si riduce al valore assoluto in R ; per
n = 2 la norma di x = (x1, x2) e il modulo di (x1, x2) , pensato come numerocomplesso.
9.3.15. Osservazione Se x 6= 0 , allora il vettore
1
‖x‖ x
ha norma uguale a 1 ; si dice anche che esso e unversore versore di Rn .
9.3.16. Teorema (proprieta della norma).proprieta della
normaValgono le seguenti proprieta:
(1) ∀x ∈ Rn , si ha ‖x‖ ≥ 0 ; inoltre, ‖x‖ = 0 , se, e solo se, x = 0 ;
(2) ∀a ∈ R, ∀x ∈ Rn , si ha ‖ax‖ = |a| ‖x‖ ;(3) ∀x,y ∈ Rn , si ha ‖x+ y‖ ≤ ‖x‖+ ‖y‖ ;(4) ∀x,y ∈ Rn , si ha
∣
∣‖x‖ − ‖y‖∣
∣ ≤ ‖x− y‖ ;
(5) ∀x ∈ Rn , |xk| ≤ ‖x‖ ≤∑n
i=1 |xi| , per k = 1, 2, . . . , n .
Dimostrazione. Le proprieta (1) e (2) seguono subito dalla definizione. La primadisuguaglianza della (5) segue subito dalla definizione di norma, mentre la secondasegue dalla generalizzazione alla somma di n addendi della (4) del Teor. 0.6.13.
La (3) e la (4), come le disuguaglianze analoghe per il valore assoluto di un numeroreale (v. (3) e (4) del Teor. 0.6.8) e per il modulo di un numero complesso (v. (5)e (6) del Teor. 3.1.10), viene detta disuguaglianza triangolare. Alla sua dimostrazionepremettiamo il seguente risultato, noto come disuguaglianza di Cauchy-Schwarz dai
1Qui e nel seguito, se B ⊆ Rn , indichiamo col simbolo B∗ l’insieme B \ { 0} .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.3. Lo spazio euclideo Rn 17
nomi di Augustin Louis Cauchy (piu volte citato) e Hermann Amandus Schwarz(1843-1921).
x
y
x + y
||x||
||y||
||x + y||
Figura 9.3.1
La norma della somma di due vettori non
supera la somma delle rispettive norme.
9.3.17. Teorema (disuguaglianza di Cauchy-Schwarz). disuguaglianza di
Cauchy-SchwarzSiano x,y ∈ Rn ; allora
|x • y| ≤ ‖x‖ ‖y‖ . (9.3.3)
Dimostrazione. La tesi e ovvia se x = 0 o y = 0 . In caso contrario, supponiamoanzitutto ‖x‖ = ‖y‖ = 1 . Si ha
0 ≤ ‖x− y‖2 = (x− y) • (x− y) = ‖x‖2 − 2(x • y) + ‖y‖2 = 2− 2(x • y) ;
pertanto x • y ≤ 1 . Visto che ‖−x‖ = 1 , si ha anche −(x • y) = (−x) • y ≤ 1 .Quindi |x • y| ≤ 1 = ‖x‖ ‖y‖ .
In generale, se x,y ∈(
Rn)∗
, i vettori x/‖x‖ e y/‖y‖ hanno norma 1 , pertanto,per quanto gia dimostrato, si ha
|x • y|‖x‖ ‖y‖ =
∣
∣
∣
∣
x
‖x‖•
y
‖y‖
∣
∣
∣
∣
≤ 1 ,
da cui si ottiene immediatamente la (9.3.3).
9.3.18. Osservazione Nel caso ‖x‖ = ‖y‖ = 1 , questa dimostrazione prova anche
che si ha x • y = ‖x‖ ‖y‖ se, e solo se, ‖x− y‖ = 0 , cioe x = y . Da cio segue
che, se x,y ∈(
Rn)∗
, si ha x • y = ‖x‖ ‖y‖ se, e solo se, x/‖x‖ = y/‖y‖ , cioey =
(
‖y‖/‖x‖)
x . Cio significa che x e y sono linearmente dipendenti e y = sx ,con s ∈ R∗
+ , cioe y appartiene alla semiretta individuata da x .
In modo simile si verifica che vale l’uguaglianza x • y = −‖x‖ ‖y‖ se, e solo se,y = sx , con s ∈ R∗
− .
Fine della dimostrazione del Teorema 9.3.16. Riprendiamo la dimostrazionedella (3). Poiche consideriamo una disuguaglianza tra numeri reali non negativi, per
il Teor. 0.6.4 essa e equivalente a ‖x+ y‖2 ≤(
‖x‖+ ‖y‖)2
. In virtu delle proprietadel prodotto scalare si ha
‖x+ y‖2 = (x+ y) • (x+ y) = ‖x‖2 + 2(x • y) + ‖y‖2 ≤
≤ ‖x‖2 + 2 |x • y|+ ‖y‖2 ≤ ‖x‖2 + 2 ‖x‖ ‖y‖+ ‖y‖2 =(
‖x‖+ ‖y‖)2
.
Abbiamo sfruttato il fatto che ogni numero reale non supera il proprio valore assolutoe successivamente la disuguaglianza di Cauchy-Schwarz (9.3.3).
G. C. Barozzi G. Dore E. Obrecht

18 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Rimane da dimostrare la (4), nota comeseconda
disuguaglianza
triangolare
seconda disuguaglianza triangolare. Si ha
‖x‖ = ‖x− y + y‖ ≤ ‖x− y‖+ ‖y‖ ,
cioe
‖x‖ − ‖y‖ ≤ ‖x− y‖ .Scambiando y con x e tenendo presente che ‖x− y‖ = ‖y − x‖ , si ottiene
‖y‖ − ‖x‖ ≤ ‖x− y‖ .
Le due disuguaglianze ottenute equivalgono alla (4).
Vale il Teorema di Pitagora, assieme al suo inverso.
9.3.19. Teorema (di Pitagora).teorema di
PitagoraSiano x , y ∈ Rn ; allora
‖x+ y‖2 = ‖x‖2 + ‖y‖2 se, e solo se, x • y = 0 . (9.3.4)
Dimostrazione. Basta utilizzare l’uguaglianza, stabilita poco sopra,
‖x+ y‖2 = ‖x‖2 + 2 (x • y) + ‖y‖2 .
Il Teorema di Pitagora si estende al caso di piu di due vettori: se x1,x2, . . . ,xr
sono r vettori a due a due ortogonali, r ≤ n , allora
∥
∥
∥
∥
∥
r∑
k=1
xk
∥
∥
∥
∥
∥
2
=
r∑
k=1
‖xk‖2 . (9.3.5)
Se r > 2 la (9.3.5) non implica l’ortogonalita dei vettori x1,x2, . . . ,xr ; ad esempio
i vettori v1 = (1, 0, 0) , v2 = (0, 1, 0) , v3 = (1/√2,−1/
√2, 0) di R3 verificano tale
uguaglianza, ma non sono a due a due ortogonali.
9.3.20. Osservazione Se x e y sono vettori non nulli di R3 e α e la misuradell’angolo convesso tra di essi, allora
x • y = ‖x‖ ‖y‖ cosα, da cui cosα =x • y
‖x‖ ‖y‖ .
L’affermazione e stata provata nell’Oss. 9.3.18 se x e y sono linearmente dipendenti.
Figura 9.3.2
Il teorema del coseno consente di calcolarela lunghezza di un lato di un triangolo apartire dalle lunghezze dei due lati restantie dal coseno dell’angolo compreso tra essi.
x
y
||x||
||y||||x – y||
α
0
In caso contrario, consideriamo il triangolo che ha per vertici l’origine e i punti x
e y ; per il Teorema del coseno,
‖y − x‖2 = ‖x‖2 + ‖y‖2 − 2 ‖x‖ ‖y‖ cosα .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.3. Lo spazio euclideo Rn 19
Poiche
‖y − x‖2 = (y − x) • (y − x) = y • (y − x)− x • (y − x) =
= ‖y‖2 − y • x− x • y + ‖x‖2 = ‖x‖2 + ‖y‖2 − 2x • y ,
otteniamo x • y = ‖x‖‖y‖ cosα , come si voleva.
Lo stesso ragionamento vale anche in Rn , con n ∈ N , n > 3 .
9.3.21. Definizione. base ortogonale,
base ortonormaleSia {w1,w2, . . . ,wn} una base di Rn . Diciamo che essa
e una base ortogonale quando wi •wj = 0 , se i 6= j . Diciamo che essa e una base
ortonormale quando
wi • wj =
{
0 , se i 6= j ,
1 , se i = j .
L’Es. 9.3.11 assicura che la base canonica di Rn e ortonormale.
Se {w1,w2, . . . ,wn} e una base ortogonale di Rn , si possono calcolare con facilitale componenti di un vettore in questa base. Infatti, se x ∈ Rn , ∃c1, c2, . . . , cn ∈ R ,tali che
x =
n∑
i=1
ciwi .
Moltiplicando scalarmente entrambi i membri di questa uguaglianza per il vettore wj ,otteniamo
x • wj =
(
n∑
i=1
ciwi
)
• wj =
n∑
i=1
ci(wi • wj) = cj‖wj‖2 ,
da cui
cj =x • wj
‖wj‖2. (9.3.6)
Se la base considerata e ortonormale, la formula precedente si semplifica ulteriormente
cj = x • wj .
Pertanto, se {w1,w2, . . . ,wn} e una base ortonormale di Rn e x ∈ Rn ,
x =
n∑
i=1
(x • wi)wi .
Per mezzo della norma, possiamo definire la distanza tra due punti di Rn .
9.3.22. Definizione. distanzaSiano x,y ∈ Rn ; chiamiamo distanza tra x e y il numeroreale non negativo
d(x,y) = ‖x− y‖. (9.3.7)
Si osservi che ‖x‖ = d(x,0) .
9.3.23. Teorema. La funzione d : Rn × Rn → R+ gode delle seguenti proprieta:
(1) ∀x,y ∈ Rn , d(x,y) ≥ 0 ; inoltre, d(x,y) = 0 se, e solo se, x = y ;
(2) ∀x,y ∈ Rn , d(x,y) = d(y,x) ;
(3) ∀x,y, z ∈ Rn , d(x, z) ≤ d(x,y) + d(y, z) .
Occupiamoci infine di un’operazione definita solamente in dimensione 3: il prodottovettoriale; essa e di grande di grande interesse per le applicazioni fisiche.
G. C. Barozzi G. Dore E. Obrecht

20 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.3.24. Definizione.prodotto vettoriale Siano a, b ∈ R3 ; il prodotto vettoriale di a e b (nell’or-dine) e il vettore di R3
a× b = (a2 b3 − a3 b2, a3 b1 − a1 b3, a1 b2 − a2 b1) ,2 (9.3.8)
cioe il vettore che si ottiene sviluppando (formalmente) secondo gli elementi dellaprima riga il determinante
det
e1 e2 e3a1 a2 a3b1 b2 b3
= det
(
a2 a3b2 b3
)
e1 − det
(
a1 a3b1 b3
)
e2 + det
(
a1 a2b1 b2
)
e3 .
9.3.25. Esempio Si verifica subito che
e1 × e2 = e3 , e2 × e3 = e1 , e3 × e1 = e2
e che ∀a ∈ R3 , a× a = 0 .
9.3.26. Esempio Siano a = (2, 1, 1) , b = (−3/2, 2, 3/2) ; allora
a× b = (−1/2,−9/2, 11/2) .
Figura 9.3.3
Il prodotto vettoriale di
a = (2, 1, 1) e b = (−3/2, 2, 3/2)
(in colore) e
a× b = (−1/2,−9/2, 11/2)
(in nero).
x1
x2
x3
Siano c = (1, 1, 2) , d =(
1,−1,−√2)
; allora, c× d =(
2−√2, 2 +
√2,−2
)
.
9.3.27. Osservazione Se a e b sono vettori non nulli di R3 e α e la misura
dell’angolo convesso tra di essi, allora
‖a× b‖ = ‖a‖ ‖b‖ sinα .Infatti,
‖a× b‖2 = (a2b3 − a3b2)2 + (a3b1 − a1b3)
2 + (a1b2 − a2b1)2 =
= a22b23 + a23b
22 − 2a2a3b2b3 + a21b
23 + a23b
21 − 2a1a3b1b3 + a21b
22 + a22b
21 − 2a1a2b1b2 =
= a21(b22 + b23) + a22(b
21 + b33) + a23(b
21 + b22)− 2a1a2b1b2 − 2a1a3b1b3 − 2a2a3b2b3 =
= ‖a‖2‖b‖2 − a21b21 − a22b
22 − a23b
23 − 2a1a2b1b2 − 2a1a3b1b3 − 2a2a3b2b3 =
= ‖a‖2‖b‖2 − (a1b1 + a2b2 + a3b3)2 =
= ‖a‖2‖b‖2 − (a • b)2 = ‖a‖2‖b‖2(1 − cos2 α) = ‖a‖2‖b‖2 sin2 α ,
dove, nel penultimo passaggio, abbiamo utilizzato l’Oss. 9.3.20. Di qui segue quantoasserito.
2In alcuni testi il prodotto vettoriale dei vettori a e b viene indicato con il simbolo a ∧ b .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.3. Lo spazio euclideo Rn 21
a
a
bb
a b
a b
e 1
e 1
e 3
e 3
e 2
e 2
α
α
Figura 9.3.4
La norma del prodotto vettoriale di due vettori e uguale all’area del parallelogramma costrui-to su di essi. A sinistra abbiamo: a = (1, 3, 1) , b = (−1/2, 2, 1) , a × b = (1,−3/2, 7/2) ;l’angolo tra i due vettori e acuto: a • b = 13/2 > 0 . A destra abbiamo a = (1, 3, 1) ,b = (−1,−2, 1) , a× b = (5,−2, 1) ; l’angolo tra i due vettori e ottuso: a • b = −6 < 0 .
Geometricamente: la norma del prodotto vettoriale a× b coincide con l’area delparallelogramma costruito sui vettori a e b .
Infatti, se uno dei vettori e nullo, il prodotto vettoriale e nullo; se {a, b} elinearmente dipendente, allora α = 0 oppure α = π e il prodotto vettoriale e nullo.
Supponiamo ora {a, b} linearmente indipendente. Se α = π/2 , a e b sonoortogonali e il parallelogramma e un rettangolo, la cui area e ‖a‖ ‖b‖ = ‖a× b‖ . Seα < π/2 , ‖b‖ sinα e l’altezza, rispetto alla base a , del parallelogramma, la cui areae ‖a× b‖ = ‖a‖ ‖b‖ sinα .
Se infine α > π/2 , ‖b‖ sin(π−α) = ‖b‖ sinα e l’altezza, rispetto alla base a , delparallelogramma, la cui area e ancora ‖a‖ ‖b‖ sinα = ‖a× b‖ .
Semplici, anche se talvolta laboriose, verifiche provano il risultato seguente.
9.3.28. Teorema. Siano a, b, c ∈ R3 , α, β, γ ∈ R ; valgono le proprieta:
(1) a× b = −b× a ;
(2) a× (β b+ γ c) = β a× b+ γ a× c, (αa+ β b)× c = αa× c+ β b× c ;
(3) (a× b) • a = (a× b) • b = 0 ;
(4) a× b = 0 se, e solo se, a e b sono linearmente dipendenti.
Dalle uguaglianze (3) segue che, se a, b ∈ R3 , allora a× b e ortogonale sia ad a
che a b (e quindi anche a ogni loro combinazione lineare). Tali uguaglianze seguonodal fatto che, per ogni terna di vettori a, b, c di R3 si ha (con evidente significatodei simboli)
a • (b× c) = b • (c× a) = c • (a× b) = det
a1 a2 a3b1 b2 b3c1 c2 c3
.
Questo numero reale viene detto prodotto triploprodotto triplo dei vettori a , b e c , nell’ordine.Lo studente verifichi che il valore assoluto del prodotto triplo e uguale al volume delparallelepipedo che ha un vertice nell’origine e i vettori a , b e c come spigoli.
Se a , b e c sono complanari, il loro prodotto triplo e nullo.
G. C. Barozzi G. Dore E. Obrecht

22 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.4. Rette e piani in Rn
In questa Sezione scriviamo, in diverse forme, le equazioni di rette, piani e loro gene-ralizzazioni in uno spazio euclideo di dimensione qualunque. Cominciamo con la defi-nizione di retta passante per l’origine; partendo da questa risultera agevole introdurregli altri concetti e le diverse forme di equazioni che ci servono.
9.4.1. Definizione.retta passante per
l’origineSia v ∈
(
Rn)∗
; chiamiamo retta passante per l’origine, divettore direttore v , l’insieme
r = { tv | t ∈ R} . (9.4.1)
Si verifica immediatamente che tale retta e un sottospazio vettoriale di dimensio-ne 1 di Rn e precisamente l
(
{v})
.
Diciamo che l’equazione parametrica della retta r e x = tv , dove il parametroe il numero reale t . La precedente equazione vettoriale equivale al sistema di nequazioni scalari
x1 = t v1 ,
x2 = t v2 ,...
...
xn = t vn .
(9.4.2)
Le equazioni parametriche forniscono una descrizione della retta r , perche indivi-duano la funzione
g : R → Rn , g(t) = tv ,
di cui la retta e l’immagine.
La definizione di retta generica (non passante necessariamente per l’origine) siottiene dalla precedente con una traslazione.
9.4.2. Definizione.retta Siano c ∈ Rn e v ∈(
Rn)∗
; chiamiamo retta passanteper c di vettore direttore v l’insieme
r = { c+ tv | t ∈ R} . (9.4.3)
e3e v c
c v
3
e1e1
e2 e2
+
Figura 9.4.1
A sinistra: la retta in R3 passante per l’origine, di vettore direttore v = (1, 1/2, 1) (in
colore); a destra: la retta passante per il punto c = (1/2, 1/2, 1) (in nero), avente lo stessovettore direttore.
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.4. Rette e piani in Rn 23
Questa retta e un lateralelaterale3 del sottospazio vettoriale l(
{v})
. In questo caso,l’equazione parametrica della retta r e x = c + tv , equivalente al sistema di nequazioni scalari
x1 = c1 + t v1 ,
x2 = c2 + t v2 ,...
...
xn = cn + t vn .
E ben noto dalla geometria elementare che per due punti distinti del piano passauna e una e sola retta. Mostriamo che la stessa affermazione vale in un qualunquespazio Rn , con n ≥ 2 . Siano dunque a, b ∈ Rn , con a 6= b . Se la retta cercatapassa per il punto a , essa ha equazione parametrica
x = a+ tv ,
dove il vettore v ∈(
Rn)∗
e arbitrario. Imponendo che la retta passi anche per b ,otteniamo che deve esistere s ∈ R tale che sia a + sv = b , da cui segue che v
e b−a sono linearmente dipendenti. Scelto quindi, ad esempio, v = b−a , la rettadi equazione parametrica x = a+t(b−a) passa per i due punti dati. Le considerazioniche ci hanno portato a scegliere il vettore direttore v mostra che due rette passantiper a e per b devono passare per a e avere vettori direttori linearmente dipendenti;pertanto le due rette coincidono.
Quanto precede suggerisce la definizione seguente.
9.4.3. Definizione. segmentoSiano a, b ∈ Rn , con a 6= b . Chiamiamo segmento diestremi a e b l’insieme
{x ∈ Rn | x = a+ t(b− a), t ∈ [0, 1]}
e lo indichiamo col simbolo [a, b] .
E evidente che tale segmento e contenuto nella retta passante per a e b . Ilsimbolo utilizzato per indicare un segmento coincide con quello utilizzato per indicareun intervallo limitato e chiuso di R , ma il contesto non consentira di equivocare ilsignificato.
Mostriamo, almeno per n = 2 e n = 3 , che le rette posseggono delle equazione
cartesiana di una
retta
equazioni
cartesiane, probabilmente piu familiari allo studente.
Sia n = 2 ; scriviamo x , y al posto di x1 , x2 e consideriamo il caso di una rettapassante per l’origine; siano
{
x = t v1 ,
y = t v2 ,(9.4.4)
le sue equazioni parametriche. Poiche v 6= 0 , almeno una delle sue coordinate ediversa da 0 ; per fissare le idee supponiamo v1 6= 0 . Allora, dalle (9.4.4), otteniamo
t =x
v1,
che, sostituita nell’altra equazione, fornisce
y =v2v1
x ,
da cuiv1y − v2x = 0 ;
3In luogo di laterale si dice anche sottospazio affine.
G. C. Barozzi G. Dore E. Obrecht

24 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
questa e l’equazione cartesiana di una retta passante per l’origine. Analogo risul-tato avremmo ottenuto supponendo v2 6= 0 . La procedura seguita ha portatoall’eliminazione del “parametro” t dalle equazioni della retta.
Viceversa, sia a ∈(
R2)∗
e consideriamo
E ={
(x, y) ∈ R2∣
∣ a1 x+ a2 y = 0}
;
si e soliti dire che E e individuato dall’equazione cartesiana
a1 x+ a2 y = 0 ; (9.4.5)
mostriamo che si tratta di una retta in R2 , passante per l’origine. Infatti, poichea 6= 0 , almeno una delle sue coordinate e diversa da 0 ; ad esempio, sia a1 6= 0 .Allora, otteniamo
x = − a2a1
y
e quindi, ponendo t = y , ne deriva che i punti di E possono essere rappresentatimediante le equazioni parametriche
{
x = − a2a1
t ,
y = t .
Questa e l’equazione parametrica della retta passante per l’origine e di vettore diret-tore (−a2/a1, 1) .
Pertanto, l’equazione parametrica e l’equazione cartesiana sono due diversi modidi rappresentare lo stesso l’insieme.
Figura 9.4.2
La retta di equazione x+2y = 0 e il vettore
a essa normale a = (1, 2) .
a
e1
e2
Vogliamo segnalare il significato geometrico del vettore a , le cui componenticompaiono nella (9.4.5); poiche tale equazione puo essere scritta nella forma
a • (x, y) = 0 ,
essa rappresenta l’insieme dei punti ortogonali al vettore a . Ne consegue che a e unvettore normale a
una rettavettore normale (o, come anche si dice, ortogonale) a tutti (e soltanto) i punti dellaretta r .
Questa rappresentazione mostra anche che una retta in R2 passante per l’originee il nucleo di una trasformazione lineare T ∈ L(R2,R) ; in questo caso si puo scegliereT (x, y) = a1x+ a2y .
L’equazione cartesiana di una retta passante per il punto c ∈ R2 si ottiene dal-la (9.4.5), traslando del vettore c la retta passante per l’origine; tale equazionediventa quindi
a1(x− c1) + a2(y − c2) = 0 .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.4. Rette e piani in Rn 25
Sia ora n = 3 e consideriamo il caso di una retta passante per l’origine; siano
x = t v1 ,
y = t v2 ,
z = t v3 ,
(9.4.6)
le sue equazioni parametriche. Poiche v 6= 0 , almeno una delle sue coordinate ediversa da 0 ; per fissare le idee supponiamo v1 6= 0 . Allora, dalle (9.4.6) otteniamo
t =x
v1,
che, sostituita nelle altre equazioni, fornisce
y =v2v1
x ,
z =v3v1
x ,
da cui{
v2 x− v1 y = 0 ,
v3 x− v1 z = 0 ;(9.4.7)
questo sistema di due equazioni scalari costituisce l’equazione cartesiana di una ret-ta. Analogo risultato avremmo ottenuto, supponendo v2 6= 0 oppure v3 6= 0 . Laprocedura seguita ha portato all’eliminazione del “parametro” t dalle equazioni dellaretta. Si noti che la matrice dei coefficienti del sistema (9.4.7)
(
v2 −v1 0v3 0 −v1
)
ha rango 2 , perche la sottomatrice di ordine 2 formata con le ultime due colonne hadeterminante diverso da 0 , in quanto v1 6= 0 .
Viceversa, sia
A =
(
a11 a12 a13a21 a22 a23
)
una matrice di rango 2 e consideriamo l’insieme
E ={
(x, y) ∈ R2∣
∣ a11x+ a12y + a13z = 0, a21x+ a22y + a23z = 0}
,
cioe l’insieme dei punti individuato dal sistema di equazioni cartesiane{
a11 x+ a12 y + a13 z = 0 ,
a21 x+ a22 y + a23 z = 0 ;(9.4.8)
mostriamo che E e una retta passante per l’origine. Infatti, poiche A ha rango 2 ,almeno uno dei suoi minori del secondo ordine e diverso da 0 ; ad esempio, se lasottomatrice
B =
(
a11 a12a21 a22
)
ha determinante diverso da 0 , dalla (9.4.8) ricaviamo(
xy
)
= −B−1
(
a13 za23 z
)
.
Se
B−1 =
(
d11 d12d21 d22
)
,
G. C. Barozzi G. Dore E. Obrecht

26 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
l’insieme E risulta descritto dalle equazioni parametriche
x = −(d11a13 + d12a23) t ,
y = −(d21a13 + d22a23) t ,
z = t .
Il sistema (9.4.8) assicura che una retta in R3 passante per l’origine e il nucleo diuna funzione lineare T ∈ L(R3,R2) ; in questo caso possiamo scegliere
T (x, y, z) = A
xyz
,
dove A e la matrice 2×3 e di rango 2 associata a T . Ancora una volta l’equazioneparametrica e l’equazione cartesiana sono due diversi modi di rappresentare lo stessoinsieme.
Mediante una traslazione, otteniamo le equazioni parametriche e cartesiana di unaretta passante per il punto c , che sono, rispettivamente,
x = c1 + t v1 ,
y = c2 + t v2 ,
z = c3 + t v3 ,
e{
a11(x− c1) + a12(y − c1) + a13(z − c3) = 0 ,
a21(x− c1) + a22(y − c2) + a23(z − c3) = 0 .(9.4.9)
Passiamo ora a esaminare i piani di R3 .
9.4.4. Definizione.piano
passante per
l’origine
Siano v,w ∈(
R3)∗
, tali che { v,w} sia linearmente in-dipendente; chiamiamo piano passante per l’origine, di vettori direttori v e w ,l’insieme
π = { tv + sw | t, s ∈ R} . (9.4.10)
Osserviamo che π = l(
{ v,w})
e un sottospazio vettoriale di dimensione 2 di R3 ,
di cui { v,w} e una base.
Diciamo che π e unpiano coordinato piano coordinato quando esso e generato da due vettori dellabase canonica. Chiameremo piano xy quello generato dai vettori e1, e2 , piano xzquello generato dai vettori e1, e3 , piano yz quello generato dai vettori e2, e3 .
La (9.4.10) e l’equazione parametrica del piano π (in forma vettoriale); essaequivale a
x = t v1 + sw1 ,
y = t v2 + sw2 ,
z = t v3 + sw3 .
(9.4.11)
I parametri sono i due numeri reali t e s . L’equazione parametrica fornisce unadescrizione di π , perche individua la funzione
g : R2 → R3 , g(t, s) = tv + sw ,
di cui π e l’immagine.
Poiche { v,w} e linearmente indipendente, la matrice
v1 w1
v2 w2
v3 w3
(9.4.12)
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.4. Rette e piani in Rn 27
vw
e3
e1
Figura 9.4.3
Il piano in R3 , passante per l’origine, in-
dividuato dai vettori v = (1, 1, 1) e w =(−1, 1/2, 1) .
ha rango 2 e pertanto esiste un suo minore del secondo ordine diverso da 0 ; sia, adesempio, detB 6= 0 , dove
B =
(
v1 w1
v2 w2
)
.
Se
B−1 =
(
d11 d12d21 d22
)
,
allora{
t = d11 x+ d12 y ,
s = d21 x+ d22 y ,
ondez = (d11v3 + d21w3)x+ (d12v3 + d22w3)y ;
questa e l’equazione cartesiana del piano π .
Analogo risultato si sarebbe ottenuto supponendo diverso da 0 un altro minoredel secondo ordine della matrice (9.4.12).
9.4.5. Esempio Siano dati i piani passanti per l’origine di equazioni
{
x+ y − z = 0 ,
x+ 2y + z = 0 ;
con i simboli usati poco sopra, abbiamo
A =
(
1 1 −11 2 1
)
.
Scegliendo come B la sottomatrice formata con le prime due colonne di A , abbiamosuccessivamente
B =
(
1 11 2
)
, B−1 =
(
2 −1−1 1
)
,
(
xy
)
= −B−1
(
−zz
)
=
(
3z−2z
)
.
Dunque la retta intersezione e rappresentata dalle equazioni parametriche
x = 3t ,
y = −2t ,
z = t .
G. C. Barozzi G. Dore E. Obrecht

28 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Viceversa, sia a ∈(
R3)∗
; allora l’insieme
E ={
(x, y, z) ∈ R3∣
∣ a1 x+ a2 y + a3 z = 0}
e un piano passante per l’origine. Infatti, supponiamo a3 6= 0 ; allora,
z = −a1a3
x− a2a3
y ;
pertanto,
E =
{
(x, y, z) ∈ R3
∣
∣
∣
∣
x = t, y = s, z = − a1a3
t− a2a3
s, (t, s) ∈ R2
}
;
quindi E e il piano passante per l’origine di equazioni parametriche
x = t ,
y = s ,
z = − a1a3
t− a2a3
s .
Vogliamo segnalare il significato geometrico del vettore a , le cui componenti com-paiono nella definizione di E ; l’equazione che in essa compare puo essere scritta nellaforma
a • (x, y, z) = 0 ,
dunque a evettore
normale
a un piano
un vettore ortogonale a tutti (e solo) i punti del piano E ; si dice ancheche il vettore a e normale al piano in esame (v. Fig. 9.4.4).
Questa rappresentazione mostra anche che un piano in R3 passante per l’originee il nucleo di una trasformazione lineare T ∈ L(R3,R) ; in questo caso possiamoscegliere T (x, y, z) = a1 x+ a2 y + a3 z .
Figura 9.4.4
Il vettore a = (1, 1, 1) e normale al piano
in R3 , passante per l’origine, di equazione
x+ y + z = 0 .
e2
ea3
e1
L’esempio seguente mostra un’utilizzazione del prodotto vettoriale, introdotto nellaprecedente Sezione, per passare dall’equazione cartesiana di un piano passante perl’origine alla sua rappresentazione parametrica.
9.4.6. Esempio Consideriamo un piano π in R3 , passante per l’origine, di equa-
zione cartesiana a •(x, y, z) = 0 ; poiche π e un sottospazio vettoriale di dimensione 2di R3 , vogliamo individuarne una base.
Se a e proporzionale ad uno dei vettori della base canonica, allora una base di πe costituita dai rimanenti vettori della base canonica; ad esempio, se a = (0, 0, 1) ,una base di π e { e1, e2} .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.4. Rette e piani in Rn 29
Se a non e proporzionale ad alcun vettore della base canonica, ma appartienea uno dei piani coordinati, allora possiamo scegliere come di base di π il vettoredella base canonica ortogonale al piano coordinato in questione e il prodotto vetto-riale di questo con a ; ad esempio, se a = (1, 1, 0) , possiamo scegliere come base{ e3,a× e3} = { (0, 0, 1), (1,−1, 0)} .
Infine, se a non appartiene ad alcun piano coordinato, possiamo scegliere comevettori di una base di π i prodotti vettoriali di a con due vettori qualunque dellabase canonica:
v = a× e1 , w = a× e2 ;
il piano generato da v e da w e{
x ∈ R3∣
∣ x = tv + sw , t, s ∈ R}
.
Ad esempio, se a = (1, 1, 1) , il piano ha equazione cartesiana x+ y + z = 0 ; unasua base e costituita dai vettori
v = a× e1 = (0, 1,−1) , w = a× e2 = (−1, 0, 1) ,
e le sue equazioni parametriche sono
x = −s ,
y = t ,
z = −t+ s .
Il vettore v appartiene alla retta intersezione tra il piano dato e il piano coordina-to yz , il vettore w appartiene alla retta intersezione tra il piano dato e il pianocoordinato xz .
e3
e1
e2
v
vw
Figura 9.4.5
Il piano di equazione x+y+z = 0 , conside-rato nell’Es. 9.4.6, puo essere rappresentatoparametricamente come
x = tv + sw ,
con v = (0, 1,−1) , w = (−1, 0, 1) .
La definizione di piano arbitrario (non passante necessariamente per l’origine) siottiene dalla precedente con una traslazione.
9.4.7. Definizione. pianoSiano c ∈ R3 , v,w ∈(
R3)∗
, tali che { v,w} sia linear-mente indipendente; chiamiamo piano passante per c di vettori direttori v e w
l’insiemeπ = { c+ tv + sw | t, s ∈ R} . (9.4.13)
G. C. Barozzi G. Dore E. Obrecht

30 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Questo piano e un laterale del sottospazio vettoriale precedentemente considerato.
Le equazioni parametriche e cartesiana di un piano passante per il punto c ∈ R3 siottengono immediatamente per traslazione del vettore c ; esse sono, rispettivamente
x = c1 + t v1 + sw1,
y = c2 + t v2 + sw2,
z = c3 + t v3 + sw3 ,
e
a1(x− c1) + a2(y − c2) + a3(y − c3) = 0 .
Le considerazioni svolte sui piani di R3 consentono di interpretare l’equazionecartesiana della retta (9.4.9) come l’intersezione di due piani; tali piani non sonoparalleli, perche la matrice dei coefficienti del sistema in oggetto ha rango 2 .
piani paralleli Due piani sono paralleli quando sono entrambi laterali dello stesso sottospaziovettoriale; in tal caso essi coincidono oppure non hanno punti in comune.
Nel caso dell’equazione cartesiana della retta (9.4.9), i punti di una retta passanteper l’origine sono ortogonali sia ai vettori ortogonali al primo piano, sia a quelliortogonali al secondo piano.
A questo punto, seguendo lo schema utilizzato per rette e piani, e possibile definireanche enti geometrici lineari di dimensione qualunque, purche minore della dimensionedello spazio euclideo in cui stiamo operando.
9.4.8. Definizione.k -piano passante
per l’origineSiano k ∈ { 1, 2, . . . , n−1} , v1,v2, . . . ,vk ∈ Rn linearmen-
te indipendenti. Chiamiamo k -piano (o anche piano di dimensione k ) passanteper l’origine e di vettori direttori i vi l’insieme
{
k∑
i=1
tivi
∣
∣
∣
∣
∣
ti ∈ R , i = 1, 2, . . . , k
}
= l(
{ vi | i = 1, 2, . . . , k})
.
Se k = 1 abbiamo una retta, se k = 2 un piano ordinario. Chiamiamoiperpiano iperpiano
un piano di dimensione n− 1 .
Le equazioni parametriche di un k -piano contengono pertanto k parametri reali.Lo studente dovrebbe verificare che le equazioni cartesiane di un k -piano sono formateda un sistema di n− k equazioni lineari linearmente indipendenti; in particolare, uniperpiano e individuato da una sola equazione cartesiana.
La generalizzazione a k -piani non passanti per l’origine non presenta difficolta.
Le considerazioni svolte in questa Sezione ci suggeriscono di introdurre la nozionedi complemento ortogonale di un sottospazio di Rn .
9.4.9. Definizione.complemento
ortogonaleSia V un sottospazio di Rn ; il suo complemento ortogonale
e l’insieme dei vettori di Rn che sono ortogonali a ogni vettore di V :
V ⊥ = {w ∈ Rn | w • v = 0 , ∀v ∈ V } .
E immediato verificare che V ⊥ e un sottospazio di Rn ; se w1,w2 ∈ V ⊥ ec1, c2 ∈ R , allora
∀v ∈ V , (c1w1 + c2w2) • v = c1(w1 • v) + c2(w2 • v) = 0 .
Per dimostrare che w appartiene a V ⊥ e sufficiente verificare la sua ortogonalita aivettori di una base di V .
Le dimensioni dei sottospazi V e V ⊥ sono legate da una semplice relazione.
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.5. Proiezione ortogonale 31
9.4.10. Teorema. Sia V un sottospazio di Rn ; allora
dimV + dimV ⊥ = n .
Omettiamo la dimostrazione del Teorema enunciato; in precedenza l’abbiamo veri-ficato quando n = 2 per i sottospazi di dimensione 1 e quando n = 3 per i sottospazidi dimensione 1 e 2 .
Concludiamo questa Sezione definendo una tipologia di sottoinsiemi di Rn dinotevole interesse.
9.4.11. Definizione. insieme convessoUn insieme A ⊆ Rn si dice convesso se esso contiene ognisegmento i cui estremi gli appartengano. In formule:
∀x,y ∈ A , [x,y] ⊆ A.
Figura 9.4.6
Due insiemi non convessi in R2 .
Se si rivede la Def. 2.1.1, si riconosce che gli insiemi convessi in R sono gli intervallie soltanto essi. Piu interessante la nozione di insieme convesso in R2 . Sono convessii rettangoli, i rombi, i poligoni regolari, i cerchi ecc.; la Fig. 9.4.6 mostra due insieminon convessi. Il complementare di un insieme convesso e, in generale, non convesso;fanno eccezione i semipiani: sia che essi contengano la retta che ne costituisce l’origine,sia che non la contengano, i rispettivi complementari sono ancora insiemi convessi.
Se si rivede l’Oss. 5.7.3, si riconosce che la funzione f : I → R , dove I e unintervallo di R , e convessa se, e solo se, e convesso l’insieme dei punti del piano chestanno “sopra” il suo grafico (qualche Autore usa il termine epigrafico):
{
(x, y) ∈ R2∣
∣ x ∈ I , y ≥ f(x)}
.
9.5. Proiezione ortogonale
Siano dati in Rn la retta r per l’origine di equazione parametrica x = tv e un
punto x0 non appartenente ad essa; la proiezione ortogonale di x0 su r e il puntox∗ ∈ r per cui x0 − x∗ e ortogonale a v : (x0 − x∗) • v = 0 , cioe
(x0 − tv) • v = 0, dunque t =x0 • v
‖v‖2 .
Ne segue che la proiezione ortogonale di x0 su r e
x∗ =x0 • v
‖v‖2 v . (9.5.1)
G. C. Barozzi G. Dore E. Obrecht

32 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Figura 9.5.1
Proiezione ortogonale di un punto su una
retta passante per l’origine.
v
x0
x
x
*
e1
e2
La proiezione ortogonale x∗ e l’approssimazione ottima di x0 mediante elementidella retta r , cioe
∀x ∈ r , ‖x0 − x∗‖ ≤ ‖x0 − x‖ .Infatti il vettore x∗ − x , in quanto differenza tra due vettori di r , e proporzionalea v , mentre x0−x∗ e ortogonale a v per definizione. Ne segue, in virtu del Teoremadi Pitagora 9.3.5,
‖x0 − x‖2 = ‖(x0 − x∗) + (x∗ − x)‖2 = ‖x0 − x∗‖2 + ‖x∗ − x‖2 ≥ ‖x0 − x∗‖2.
Il risultato precedente si estende dalle rette per l’origine (sottospazi di dimensio-ne 1 ) ai sottospazi di dimensione k con 1 ≤ k < n , cioe ai k -piani passanti perl’origine.
9.5.1. Teorema. Sia Vk un k -piano passante per l’origine in Rn , con1 ≤ k < n ; per ogni x0 ∈ Rn esiste uno e un solo x∗ ∈ Vk tale che x0 − x∗ siaortogonale a Vk .
Il vettore x∗ si chiamaproiezione
ortogonaleproiezione ortogonale di x0 su Vk .
L’ortogonalita di x0 − x∗ a Vk significa che tale vettore e ortogonale ad ognivettore di Vk , il che equivale a dire che esso e ortogonale a ciascuno dei vettoriv1,v2, . . . ,vk di una sua base: (x0 − x∗) • vi = 0 , cioe
x∗ • vi = x0 • vi , per i = 1, 2, . . . , k . (9.5.2)
Poiche x∗ ∈ Vk si ha
x∗ = t1 v1 + t2 v2 + . . .+ tk vk ,
quindi ciascuna delle (9.5.2) e un’equazione lineare nelle incognite t1, t2, . . . , tk chesono le componenti del vettore x∗ rispetto alla base. Per determinare tali incognite,bisogna dunque risolvere un sistema lineare di k equazioni in altrettante incognite;si puo dimostrare che la matrice dei coefficienti ha determinante non nullo e dunqueil sistema stesso ammette una e una sola soluzione.
Tuttavia se la base e ortogonale, la soluzione del sistema in esame e quasi imme-diata; in tal caso (v. (9.3.6)) sappiamo che
ti =x∗ • vi
‖vi‖2. (9.5.3)
Poiche la (9.5.2) assicura che x∗ • vi = x0 • vi , si ha
x∗ =
k∑
i=1
x0 • vi
‖vi‖2vi . (9.5.4)
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.6. Forme quadratiche 33
Se y ∈ Vk , per l’ortogonalita tra i vettori x0 − x∗ e x∗ − y , il Teorema diPitagora 9.3.19 implica che
‖x0 − y‖2 = ‖(x0 − x∗) + (x∗ − y )‖2 = ‖x0 − x∗‖2 + ‖x∗ − y ‖2 ≥ ‖x0 − x∗‖2,
quindi
∀y ∈ Vk , ‖x0 − x∗‖ ≤ ‖x0 − y‖ , (9.5.5)
cioe x∗ e l’approssimazione ottima di x0 mediante elementi di Vk . L’ortogonalitatra x0 − x∗ e x∗ implica poi che
‖x0‖2 = ‖x0 − x∗‖2 + ‖x∗‖2 ,
da cui
‖x∗‖2 ≤ ‖x0‖2 . (9.5.6)
Ma la (9.5.4) mostra che x∗ e somma di vettori a due a due ortogonali, dunque ilquadrato della sua norma si calcola mediante il Teorema di Pitagora (v. (9.3.5)):
‖x∗‖2 =
k∑
i=1
t2i ‖vi‖2 =
k∑
i=1
(x0 • vi)2
‖vi‖2,
dove abbiamo sfruttato l’espressione per ti fornita dalla (9.5.4). In definitiva
k∑
i=1
(x0 • vi)2
‖vi‖2≤ ‖x0‖2. (9.5.7)
Abbiamo ottenuto un caso particolare della cosiddetta disuguaglianza di Bessel, dalnome dell’astronomo tedesco Friedrich Wilhelm Bessel (1784-1846).
9.5.2. Esempio Consideriamo i vettori v1 = (1, 1, 1, 1) e v2 = (1,−1, 1,−1)
in R4 ; essi sono tra loro ortogonali e generano il sottospazio
V2 = { t1 v1 + t2 v2 | t1, t2 ∈ R} .
I vettori di V2 si scrivono dunque (t1 + t2, t1 − t2, t1 + t2, t1 − t2) ; pertanto essisono caratterizzati dal fatto che la prima coordinata e uguale alla terza e la secondae uguale alla quarta
V2 ={
x = (x1, x2, x3, x4) ∈ R4∣
∣ x1 = x3, x2 = x4
}
.
Consideriamo x0 = (1, 2, 3, 4) /∈ V2 ; per determinare la sua proiezione ortogonalesu V2 dobbiamo calcolare
‖v1‖2 = ‖v2‖2 = 4 , x0 • v1 = 10 , x0 • v2 = −2 .
La (9.5.4) fornisce dunque
x∗ =5
2v1 −
1
2v2 = (2, 3, 2, 3) .
Suggeriamo allo studente di verificare la disuguaglianza di Bessel (9.5.6).
9.6. Forme quadratiche
Sappiamo dal Teor. 9.2.17 che una trasformazione lineare (non nulla) da Rn a R e un
polinomio omogeneo di primo grado. Ricordiamo che un polinomio si dice omogeneo
quando tutti i suoi termini hanno lo stesso grado. Risulta di notevole interesse siaper la Geometria sia per l’Analisi studiare i polinomi omogenei di secondo grado.
G. C. Barozzi G. Dore E. Obrecht

34 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.6.1. Definizione.forma quadratica Chiamiamo forma quadratica in Rn una funzione
q : Rn → R , q(x) =
n∑
i,j=1
aijxixj ,
dove aij ∈ R .
Evidentemente, se q non e il polinomio nullo, esso e omogeneo di secondo grado.
Osserviamo che, senza limitare la generalita, possiamo supporre aij = aji . Infatti,poiche xixj = xjxi , possiamo scrivere
aijxixj + ajixjxi =1
2(aij + aji)xixj +
1
2(aij + aji)xjxi ;
ponendo bij = 1/2(aij + aji) , otteniamo
bij = bji ,
n∑
i,j=1
aijxixj =
n∑
i,j=1
bijxixj .
Nel seguito, supponiamo dunque aij = aji .
Poiche i numeri aij sono n2 , e naturale organizzarli in una matrice quadrata diordine n
A =
a11 a12 . . . a1na21 a22 . . . a2n...
.... . .
...an1 an2 . . . ann
.
Per quanto detto sopra, la matrice A e simmetrica:matrice
simmetrica,
matrice trasposta
A = tA ; con tA indichiamola matrice trasposta di A , cioe quella ottenuta da essa scambiando le righe con lecolonne.
Il prodotto della matrice A per il vettore x ∈ Rn fornisce ancora un vettoredi R
n ; possiamo quindi farne il prodotto scalare ancora con x ,
Ax • x =
n∑
i=1
(
n∑
j=1
aijxj
)
xi = q(x) .
Pertanto a ogni forma quadratica e associata in maniera univoca una matrice qua-drata e simmetrica di ordine n ; viceversa, a ogni matrice quadrata e simmetrica diordine n e associata una forma quadratica in Rn .
9.6.2. Esempio Consideriamo la matrice simmetrica
B =
1 2 12 −1 31 3 2
;
la forma quadratica a essa associata e
q : R3 → R , q(x, y, z) = x2 − y2 + 2z2 + 4xy + 2xz + 6yz .
Il risultato seguente e di dimostrazione immediata.
9.6.3. Teorema. Sia q una forma quadratica in Rn . Allora:
(1) q(0) = 0 .
(2) Sia v ∈(
Rn)∗
; allora, ∀t ∈ R∗ , q(tv) = t2q(v) , quindi una formaquadratica ha segno costante su ciascuna retta passante per l’origine.
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.6. Forme quadratiche 35
L’utilita delle forme quadratiche deriva, in larga misura, dalla proprieta di invarian-za del segno su ogni retta passante per l’origine. Ai fini delle applicazioni al calcolodifferenziale per funzioni di piu variabili e importante classificare le forme quadratichein base ai segni dei valori che esse assumono.
9.6.4. Definizione. forma quadratica
definita,
semidefinita, non
definita
Sia q(x) = Ax • x una forma quadratica; diciamo che essa(e la matrice A associata) e
(1) definita positiva se, ∀x ∈(
Rn)∗
, q(x) > 0 ;
(2) definita negativa se, ∀x ∈(
Rn)∗
, q(x) < 0 ;
(3) non definita (oppure indefinita) se assume valori sia positivi che negativi;
(4) semidefinita positiva se, ∀x ∈ Rn , q(x) ≥ 0 ;
(5) semidefinita negativa se, ∀x ∈ Rn , q(x) ≤ 0 .
9.6.5. Osservazione Poiche q(0) = 0 , la classificazione di q dipende dall’imma-
gine della sua restrizione a(
Rn)∗
.
9.6.6. Osservazione La forma quadratica identicamente nulla e sia semidefinitapositiva sia semidefinita negativa.
9.6.7. Osservazione Se la matrice A e definita (positiva o negativa), essa e cer-tamente invertibile. In caso contrario esisterebbe c 6= 0 tale che Ac = 0 . Ma allorasarebbe Ac • c = 0 , contro l’ipotesi.
9.6.8. Esempio Consideriamo le tre matrici
A1 =
(
1 00 1
)
, A2 =
(
1 00 0
)
, A3 =
(
1 00 −1
)
,
a cui sono associate le forme quadratiche in R2 (v. Fig. 9.6.1)
q1(x, y) = x2 + y2 , q2(x, y) = x2 , q3(x, y) = x2 − y2 .
E immediato riconoscere che la prima e definita positiva, la seconda semidefinitapositiva (ma non e definita positiva, perche q2(e2) = 0 ), la terza non definita (si haq3(e1) = 1 , q3(e2) = −1) .
xx
x
y
yy
Figura 9.6.1
Da sinistra a destra: grafici dei polinomi q1 , q2 , q3 dell’Es. 9.6.8, cioe le superficie diequazione z = q1(x, y) , z = q2(x, y) , z = q3(x, y) , rispettivamente.
G. C. Barozzi G. Dore E. Obrecht

36 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
9.6.9. Esempio Si considerino le forme quadratiche in R3 :
q4(x, y, z) = x2 + y2 + z2 ,
q5(x, y, z) = x2 − yz ,
q6(x, y, z) = −x2 − z2 ,
q7(x, y, z) = x2 + y2 + z2 + xy .
Lasciamo al lettore la scrittura delle corrispondenti matrici; si verifichi poi cheq4 e definita positiva, q5 e non definita, q6 e semidefinita negativa, q7 e defi-nita positiva. Quest’ultimo fatto non e immediato; partendo dalla disuguaglianza(x+ y)2 = x2 + y2 + 2xy ≥ 0 , otteniamo
xy ≥ − 1
2(x2 + y2) .
Allora, ∀(x, y, z) ∈(
R3)∗
,
q7(x, y, z) = x2 + y2 + z2 + xy ≥ x2 + y2 + z2 − 1
2(x2 + y2) =
=1
2(x2 + y2) + z2 > 0 .
Vogliamo poter classificare una forma quadratica in base all’esame della matrice aessa associata. La situazione e semplice se n = 2 .
9.6.10. Teorema. Siano q una forma quadratica non nulla in R2 :
q(x, y) = A
(
xy
)
• (x, y) =
(
a11 a12a21 a22
)(
xy
)
• (x, y) = a11 x2 + 2a12 xy + a22 y
2 .
Allora q e
(1) definita positiva se, e solo se, a11 > 0 e detA > 0 ;
(2) definita negativa se, e solo se, a11 < 0 e detA > 0 ;
(3) non definita se, e solo se, detA < 0 ;
(4) semidefinita positiva se detA = 0 e almeno uno tra a11 e a22 e maggioredi 0 ;
(5) semidefinita negativa se detA = 0 e almeno uno tra a11 e a22 e minoredi 0 .
Dimostrazione. Se y 6= 0 , possiamo scrivere
q(x, y) = y2(a11t2 + 2a12t+ a22) ,
avendo posto t = x/y . Il segno del polinomio entro parentesi tonde e governato dalsuo discriminante (v. Fig. 2.3.1 e la discussione che la precede)
∆
4= (a12)
2 − a11a22 = − detA.
Il polinomio assume valori sia positivi sia negativi se, e solo se, ∆/4 > 0 , cioedetA < 0 . In questo caso la forma quadratica e non definita e (3) e provato.
Se ∆/4 < 0 , il polinomio ha segno costante: positivo, se a11 > 0 e negativo se
a11 < 0 . Anche il viceversa di questa affermazione e ovviamente vero. E poi ovvioche q(x, 0) = a11x
2 ha lo stesso segno di a11 . Questo prova (1) e (2) .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.6. Forme quadratiche 37
Infine sia detA = a11a22 − a212 = 0 . Se a11 6= 0 , risulta
q(x, y) = a11
(
x2 + 2a12a11
xy +a212a211
y2)
= a11
(
x+a12a11
y
)2
;
quindi q(x, y) ≥ 0 , ∀(x, y) ∈ R2 , se a11 > 0 , mentre q(x, y) ≤ 0 , ∀(x, y) ∈ R2 , sea11 < 0 . Analogamente si prova che q(x, y) ≥ 0 , ∀(x, y) ∈ R2 , se a22 > 0 , mentreq(x, y) ≤ 0 , ∀(x, y) ∈ R2 , se a22 < 0 . Questo prova (4) e (5) .
Osserviamo che questo teorema consente sempre di classificare una forma quadra-tica non nulla q .
Infatti, se detA > 0 , allora a11a22 ≥ detA > 0 , quindi deve essere a11 6= 0 esiamo nel caso (1) o (2); se detA < 0 , allora siamo nel caso (3). Infine, quandodetA = 0 si ha (a12)
2 = a11a22 , percio se a11 e a22 fossero entrambi uguali a 0 ,sarebbe nullo anche a12 , e la forma quadratica sarebbe nulla. Quindi almeno unotra a11 e a22 e diverso da 0 e siamo nel caso (4) o (5).
La classificazione di una forma quadratica in n variabili, con n > 2 , non e al-trettanto semplice; se si rivede l’Es. 9.6.9, si riconosce che e immediato classificarele forme q4 e q5 , in quanto in esse le variabili compaiono soltanto al quadrato, maabbiamo visto che non e altrettanto semplice classificare la forma q7 .
Una forma quadratica p , in cui le variabili compaiono soltanto al quadrato, hamatrice associata B tale che bij = 0 , se i 6= j ; pertanto la matrice B e matrice diagonalediagonale
B =
b11 0 . . . 00 b22 . . . 0...
.... . .
...0 0 . . . bnn
e la forma quadratica e
p(x) =n∑
i=1
bii x2i .
In questo caso la classificazione della forma quadratica e particolarmente semplice;infatti, poiche p(ei) = bii , si riconosce che:
(1) p e definita positiva se (e solo se) bii > 0 , per i = 1, 2, . . . , n ;
(2) p e definita negativa se (e solo se) bii < 0 , per i = 1, 2, . . . , n ;
(3) p e non definita se (e solo se) esistono due indici i e j tali che bii < 0 , bjj > 0 ;
(4) p e semidefinita positiva se (e solo se) bii ≥ 0 , per i = 1, 2, . . . , n ;
(5) p e semidefinita negativa se (e solo se) bii ≤ 0 , per i = 1, 2, . . . , n .
Ci si chiede se sia possibile riscrivere una forma quadratica generica q , medianteun opportuno cambiamento di variabili, in modo che, le nuove variabili compaianosoltanto al quadrato.
Sia { v1,v2, . . . ,vn} una base di Rn (v. Def. 9.1.20); se x ∈ Rn , si puo scrivere
x =
n∑
i=1
uivi ,
dove u1, u2, . . . , un sono le componenti di x rispetto a tale base. Ne segue
q(x) = Ax • x = A(
n∑
i=1
uivi
)
•
(
n∑
j=1
ujvj
)
=(
n∑
i=1
uiAvi
)
•
(
n∑
j=1
ujvj
)
=
=
n∑
i,j=1
(Avi • vj)uiuj .
(9.6.1)
G. C. Barozzi G. Dore E. Obrecht

38 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Abbiamo dunque ottenuto una forma quadratica nelle variabili ui , avente comecoefficienti i numeri Avi • vj .
E possibile scegliere la base { v1,v2, . . . ,vn} in modo che tali coefficienti sianonulli per i 6= j ? La risposta a tale domanda e affermativa, ma richiede notevolipremesse su argomenti di Algebra lineare.
9.6.11. Definizione.autovettore,
autovaloreSia A ∈ Mn,n(R) ; diciamo che il vettore v ∈
(
Rn)∗
e unautovettore di A se esiste λ ∈ R , tale che
Av = λv . (9.6.2)
In tal caso si dice che λ e l’autovalore corrispondenti a v .
In termini geometrici: gli autovettori individuano le direzioni che restano invariantiad opera della trasformazione lineare x 7→ Ax .
Se la (9.6.2) e soddisfatta, v e soluzione non nulla del sistema lineare omogeneo
(A− λIn)v = 0
dove In e lamatrice identita matrice identita di ordine n :
In =
1 0 . . . 00 1 . . . 0...
.... . .
...0 0 . . . 1
.
Ne segueequazione
caratteristicache λ e un autovalore se, e solo se, e soluzione dell’equazione algebrica
det(A− λIn) = 0,
detta equazione caratteristica di A . Il polinomio al primo membro, dettopolinomio
caratteristicopolinomio
caratteristico di A , e
det(A− λIn) = det
a11 − λ a12 . . . a1na21 a22 − λ . . . a2n...
.... . .
...an1 an2 . . . ann − λ
=
= (−1)n(λn + c1λn−1 + . . .+ cn) ,
dove i coefficienti ci sono reali. L’equazione caratteristica e dunque un’equazionealgebrica di grado n e, per quanto sappiamo dalla Sezione 3.5, essa ha al piu nsoluzioni.
Semolteplicita
algebrica di un
autovalore
λ e un autovalore, dunque una soluzione dell’equazione caratteristica, esso hauna molteplicita (v. Def. 3.5.6) che chiameremo molteplicita algebrica dell’autovalore.
9.6.12. Osservazione E evidente che, se la matrice e diagonale,
A =
a11 0 . . . 00 a22 . . . 0...
.... . .
...0 0 . . . ann
,
allora l’equazione caratteristica e∏n
i=1(aii − λ) = 0 ; pertanto gli autovalori sono glielementi della diagonale.
L’insieme degli autovettori che hanno λ come autovalore corrispondente, unita-mente al vettore nullo, e un sottospazio vettoriale di Rn , perche costituisce il nucleodella trasformazione lineare che ha A− λIn come matrice associata.
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.6. Forme quadratiche 39
9.6.13. Definizione. autospazioSiano A ∈ Mn,n(R) e λ un autovalore di A . Chiamiamoautospazio relativo all’autovalore λ il sottospazio vettoriale
{x ∈ Rn | (A− λIn)x = 0} .
9.6.14. Esempio Consideriamo la matrice reale non simmetrica
B =
(
0 1−1 0
)
,
la cui equazione caratteristica e
det(B − λI2) = det
(
−λ 1−1 −λ
)
= λ2 + 1 = 0 ,
che non ha soluzioni in R . Pertanto B non possiede autovalori.
Le matrici simmetriche godono di alcune notevoli proprieta per quanto riguardaautovalori e autovettori.
9.6.15. Teorema. autovalori e
autovettori delle
matrici
simmetriche
Sia A ∈ Mn,n(R) una matrice simmetrica. Allora:
(1) A ha r autovalori λ1, λ2, . . . , λr tra loro distinti, di molteplicita rispetti-vamente m1,m2, . . . ,mr , con m1 +m2 + · · ·+mr = n ;
(2) per ogni i = 1, 2, . . . , r , il sistema lineare omogeneo
(A− λiIn)x = 0
ha mi soluzioni linearmente indipendenti, dunque lo s.v. delle soluzioni hadimensione mi ;
(3) autovettori relativi ad autovalori diversi sono ortogonali;
(4) esiste una base ortonormale di Rn costituita da autovettori di A .
La proprieta espressa dal punto (2) afferma che l’autospazio relativo all’autovalo-re λi e un sottospazio di Rn di dimensione mi ; la proprieta (3) stabilisce che gliautospazi relativi ad autovalori distinti sono ortogonali, mentre dalla (4) segue che,se in ogni autospazio si sceglie una base ortonormale, l’unione di tali basi costituisceuna base ortonormale di Rn .
Se si lascia cadere l’ipotesi che la matrice A sia simmetrica, le quattro affermazioniin cui si articola la tesi del teorema enunciato non valgono piu. Abbiamo appenavisto l’Es. 9.6.14 in cui viene mostrata una semplice matrice non simmetrica priva diautovalori. Si considerino ancora gli esempi seguenti.
9.6.16. Esempio Consideriamo la matrice non simmetrica
B =
1 0 01 2 01 0 3
,
la cui equazione caratteristica e
(1− λ)(2 − λ)(3 − λ) = 0.
Agli autovalori λ1 = 1 , λ2 = 2 , λ3 = 3 , corrispondono i sistemi omogenei
(B − I3)x = 0 , (B − 2I3)x = 0 , (B − 3I3)x = 0 ,
G. C. Barozzi G. Dore E. Obrecht

40 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
cioe
0 = 0
x1 + x2 = 0
x1 + 2x3 = 0
,
−x1 = 0
x1 = 0
x1 + x3 = 0
,
−2x1 = 0
x1 − x2 = 0
x1 = 0
;
che hanno, fra le altre, le soluzioni non nulle v1 = (−2, 2, 1) , v2 = (0, 1, 0) ev3 = (0, 0, 1) nell’ordine. Come si vede, v1 non e ortogonale ne a v2 , ne a v3 .
9.6.17. Esempio Consideriamo la matrice non simmetrica
B =
1 0 01 2 00 1 2
,
la cui equazione caratteristica e
(1− λ)(2 − λ)2 = 0 ;
essa ha la soluzione semplice λ1 = 1 e la soluzione doppia λ2 = 2 . Agli autovalori λ1
e λ2 corrispondono i sistemi omogenei (B − I3)x = 0 , (B − 2I3)x = 0 , cioe
0 = 0
x1 + x2 = 0
x2 + x3 = 0
,
−x1 = 0
x1 = 0
x2 = 0
.
Il primo sistema ha le soluzioni (α,−α, α) , mentre il secondo ha le soluzioni i (0, 0, α) ,con α ∈ R . Dunque l’autospazio corrispondente all’autovalore 2 ha dimensione 1 ,anche se tale autovalore ha molteplicita algebrica 2 . In tal caso si dice che l’autovalorehamolteplicita
geometrica di un
autovalore
molteplicita geometrica 1 . Non si puo dunque trovare una base di autovettori.
Riprendiamo in esame il ragionamento che ci ha condotto alla (9.6.1), supponendonuovamente che A sia una matrice simmetrica. Se scegliamo come base di Rn la baseortonormale costituita da autovettori della matrice A , la cui esistenza e affermata dalTeor. 9.6.15, otteniamo, per i coefficienti dalla forma quadratica in esame, l’espressione
Avi • vj = λivi • vj =
{
λi , se i = j ,
0 , altrimenti.
La (9.6.1) si riscrive dunque
q(x) = Ax • x =n∑
i=1
λi u2i ;
pertanto, in questa base, la forma quadratica q presenta solo termini in cui com-paiono i quadrati delle variabili. I coefficienti di questi termini sono gli autovaloridella matrice A : questo equivale ad affermare che la matrice associata alla formaquadratica risulta diagonale in una base formata da autovettori. Per quanto abbia-mo osservato sulle forme quadratiche di questo tipo, possiamo formulare il seguenterisultato.
9.6.18. Teorema. Siano A ∈ Mn,n(R) una matrice simmetrica e q la formaquadratica a essa associata. Detti λ1, . . . , λr gli autovalori distinti di A , si ha:
(1) q e definita positiva se, e solo se, λi > 0 , per i = 1, 2, . . . , r ;
(2) q e definita negativa se, e solo se, λi < 0 , per i = 1, 2, . . . , r ;
(3) q e non definita se, e solo se, possiede almeno un autovalore positivo e unonegativo;
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.6. Forme quadratiche 41
(4) q e semidefinita positiva se, e solo se, λi ≥ 0 , per i = 1, 2, . . . , r ;
(5) q e semidefinita negativa se, e solo se, λi ≤ 0 , per i = 1, 2, . . . , r .
9.6.19. Esempio Consideriamo ancora la forma quadratica q7 dell’Es. 9.6.9, la cuimatrice associata e
B =
1 1/2 01/2 1 00 0 1
;
il polinomio caratteristico e
det(B − λI3) = det
1− λ 1/2 01/2 1− λ 00 0 1− λ
= (1 − λ)
(
(1 − λ)2 − 1
4
)
,
come si riconosce sviluppando il determinante secondo gli elementi della terza riga.Dunque B ha gli autovalori λ1 = 3/2 , λ2 = 1 , λ3 = 1/2 che sono positivi epertanto la forma quadratica q7 e definita positiva, come gia sappiamo.
Poiche la ricerca degli autovalori di una matrice puo essere difficoltosa, soprattuttose n e grande, risulta utile il seguente risultato, alla cui formulazione dobbiamopremettere alcune notazioni.
Sia A una matrice quadrata di ordine n ,
A =
a11 a12 . . . a1na21 a22 . . . a2n...
.... . .
...an1 an2 . . . ann
.
Consideriamone il minore formato con le prime k righe e le prime k colonne; poniamocioe, per k = 1, 2, . . . , n ,
∆k = det
a11 a12 . . . a1ka21 a22 . . . a2k...
.... . .
...ak1 ak2 . . . akk
.
Evidentemente ∆n = detA .
9.6.20. Teorema (criterio di Sylvester4). criterio di
SylvesterSiano q una forma quadratica in Rn
e A la matrice a essa associata. Allora:
(1) q e definita positiva se, e solo se, ∆k > 0 , k = 1, 2, . . . , n ;
(2) q e definita negativa se, e solo se, (−1)k∆k > 0 , k = 1, 2, . . . , n ;
(3) se esiste h pari, tale che ∆h < 0 , allora q e non definita.
La condizione (2) significa che sono positivi i determinanti ∆k con k pari, negativiquelli con k dispari.
La relazione tra il segno dei minori ∆k e il fatto che la forma quadratica q asso-ciata alla matrice A sia o meno definita risulta immediata se A e diagonale. Infatti,
4Dal nome del matematico inglese James Joseph Sylvester (1814-1897).
G. C. Barozzi G. Dore E. Obrecht

42 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
in questo caso
∆k = det
a11 0 . . . 00 a22 . . . 0...
.... . .
...0 0 . . . ann
=
k∏
i=1
aii
e gli aii coincidono con gli autovalori di A (v. Oss. 9.6.12). Pertanto i mino-ri ∆k sono tutti positivi se, e solo se, tutti gli autovalori di A sono positivi;per il Teor. 9.6.18 cio equivale al fatto che q sia definita positiva. Inoltre, poiche
(−1)k∆k =∏k
i=1(−aii) , si ha (−1)k∆k > 0 , per k = 1, 2, . . . , n , se, e solo se, tuttigli autovalori di A sono negativi, e cio equivale al fatto che q sia definita negativa.Infine, se esiste h pari tale che ∆h < 0 , allora il prodotto di un numero pari diautovalori e negativo, quindi almeno uno di essi e positivo e uno e negativo, percio qe non definita.
9.6.21. Osservazione Alcuni Autori chiamano sottomatrice principale di Nord-Ovest della matrice A la sottomatrice formata dagli elementi delle prime k righe edelle prime k colonne di A : e precisamente quella che ha come determinante ∆k .L’aggettivo principale significa che abbiamo prelevato da A gli elementi appartenentia certe righe (nel nostro caso le prime k righe) e alle colonne aventi gli stessi indici.
9.6.22. Esempio Consideriamo ancora la forma quadratica q7 dell’Es. 9.6.9, la cuimatrice associata e
B =
1 1/2 01/2 1 00 0 1
.
Si trova
∆1 = 1, ∆2 = det
(
1 1/21/2 1
)
=3
4, ∆3 = detB =
3
4;
dunque q7 e definita positiva, come gia sappiamo.
9.6.23. Esempio Consideriamo ancora la forma quadratica q dell’Es. 9.6.2, la cuimatrice associata e
B =
1 2 12 −1 31 3 2
.
Si trova
∆1 = 1 , ∆2 = det
(
1 22 −1
)
= −5 ;
dunque q e non definita.
9.6.24. Esempio Consideriamo la forma quadratica in R4
q(x) = x21 + x2
2 + x23 + x2
4 + x1x2 + x1x3 + x1x4 + x2x3 + x2x4 + x3x4 ,
cui e associata la matrice
B =
1 1/2 1/2 1/21/2 1 1/2 1/21/2 1/2 1 1/21/2 1/2 1/2 1
.
Si trova, con qualche calcolo,
∆1 = 1 , ∆2 =3
4, ∆3 =
1
2, ∆4 =
5
16;
dunque q e definita positiva.
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.7. Coniche 43
9.7. Coniche
Una famiglia notevole di curve del piano, studiate fin dall’antichita, e costituita dalleconicheconiche, cosı chiamate perche possono essere ottenute intersecando un doppio cono
circolare con un piano. Daremo le equazioni di tali curve prima in forma cartesiana,cioe mediante equazioni in cui intervengono soltanto le coordinate dei punti ad esseappartenenti, poi in forma parametrica.
9.7.1. Definizione. ellisseSiano f1,f2 ∈ R2 e a ∈ R
∗+ tale che 2a > d(f1,f2) ; si
chiama ellisse di fuochi f1 e f2 l’insieme{
(x, y) ∈ R2∣
∣ d(
(x, y),f1
)
+ d(
(x, y),f2
)
= 2a}
. (9.7.1)
1
1
c
a
b
Hx, yL
Figura 9.7.1
L’ellisse e l’insieme dei punti del piano per cuie costante la somma delle distanze dai fuochi.In figura l’ellisse con a = 2 , c = 1.2 .
Se f1 6= f2 , per ottenere l’equazione dell’ellisse in forma semplice, scegliamof1 = (−c, 0) , f2 = (c, 0) , con c ∈ ]0, a[ . Allora, con alcuni calcoli, si deduce dalla(9.7.1) che l’ellisse e l’insieme dei punti (x, y) per cui
x2
a2+
y2
b2= 1 , con b =
√
a2 − c2 . (9.7.2)
Il punto medio del segmento [f1,f2] viene detto centro dell’ellisse, in quanto ecentro di simmetria per l’ellisse stessa. Tra le rette passanti per l’origine rivestonoparticolare importanza la retta passante per i fuochi e l’asse del segmento [f1,f2] ,perpendicolare alla retta precedente; esse sono assi di simmetria dell’ellisse. I puntid’intersezione dell’ellisse con tali rette vengono vengono detti vertici dell’ellisse; leloro coordinate sono (±a, 0) e (0,±b) .
I segmenti congiungenti un vertice di un’ellisse con il centro si chiamano semiassi ;le loro lunghezze sono i numeri reali a e b .
Se f1 = f2 , si ha c = 0 , a = b , percio i fuochi coincidono col centro e l’ellisse euna circonferenza.
L’ellisse puo essere rappresentata in forma parametrica dalle equazioni{
x = a cos t ,
y = b sin t , t ∈ [0, 2π] .(9.7.3)
Se a < b , tanto l’equazione cartesiana quanto le equazioni parametriche descrivonoancora un’ellisse, ma i fuochi appartengono all’asse y , e precisamente sono i punti
(0,±c) con c =√b2 − a2 .
G. C. Barozzi G. Dore E. Obrecht

44 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Figura 9.7.2
L’ellisse in forma parametrica: i punti dell’el-lisse si ottengono come intersezione tra la ret-ta parallela all’asse y passante per il punto(a cos t, a sin t) e la retta parallela all’asse xpassante per il punto (b cos t, b sin t) .
a
b
t
1
1
1
1
Figura 9.7.3
A sinistra l’ellisse con a = 2 , b = 1.5 ; a destra l’ellisse con a = 1.8 , b = 2.1 .
9.7.2. Definizione.iperbole Siano f1,f2 ∈ R2 due punti distinti, a ∈ R∗+ tale che
2a < d(f1,f2) ; si chiama iperbole di fuochi f1 e f2 l’insieme{
(x, y) ∈ R2∣
∣
∣
∣d(
(x, y),f1
)
− d(
(x, y),f2
)∣
∣ = 2a}
. (9.7.4)
L’iperbole consta di due rami, individuati rispettivamente dalle condizioni
d(
(x, y),f1
)
− d(
(x, y),f2
)
= 2a , d(
(x, y),f2
)
− d(
(x, y),f1
)
= 2a ;
ciascuno di tali rami e contenuto in uno dei due semipiani in cui l’asse del segmento[f1,f2] divide il piano. I due rami sono tra loro simmetrici rispetto a tale asse;esso viene chiamato asse non trasverso, in quanto non interseca l’iperbole, mentrela retta passante per i fuochi e detta asse trasverso. Anch’essa e asse di simmetriadell’iperbole.
Per ottenere l’equazione dell’iperbole nella forma piu semplice, scegliamo ancoraf1 = (−c, 0) , f2 = (c, 0) , dove ora c > a . Con alcuni calcoli si dimostra allora che
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.7. Coniche 45
l’iperbole e l’insieme dei punti (x, y) per cui
x2
a2− y2
b2= 1 , con b =
√
c2 − a2 . (9.7.5)
1
1
ca
bHx, yL
Figura 9.7.4
L’iperbole e l’insieme dei punti del piano percui e costante la differenza delle distanze daifuochi. In figura l’iperbole con a = 1.5 ,c = 2.5 . In nero sono indicati gli asintoti.
L’intersezione dell’iperbole con l’asse trasverso e costituita dai punti (±a, 0) , icosiddetti vertici dell’iperbole.
L’iperbole puo essere rappresentata in forma parametrica dalle equazioni{
x = ±a cosh t ,
y = b sinh t , t ∈ R .(9.7.6)
Suggeriamo allo studente di rivedere le Fig. 2.5.1 e 2.5.2. Le rette di equazioney = ±(b/a)x sono asintoti dell’iperbole. Se a = b l’iperbole si dice iperbole equilateraequilatera; in talcaso gli asintoti sono tra loro perpendicolari.
Se i fuochi dell’iperbole vengono scelti sull’asse y , dunque sono i punti (0, c) ,(0,−c) , si ottiene l’equazione dell’iperbole nella forma
− x2
a2+
y2
b2= 1 ;
in tal caso i due rami dell’iperbole sono tra loro simmetrici rispetto all’asse x , checostituisce l’asse non trasverso.
9.7.3. Definizione. parabolaSiano r una retta in R2 e f ∈ R2 un punto nonappartenente a essa; si chiama parabola di fuoco f e direttrice r l’insieme
{
(x, y) ∈ R2∣
∣ d(
(x, y),f)
= d(
(x, y), r)}
, (9.7.7)
dove la distanza di (x, y) da r e la distanza tra (x, y) e la sua proiezioneortogonale su r (v. (9.5.1)).
Discende dalla definizione che la retta condotta dal fuoco perpendicolarmente alladirettrice e l’unico asse di simmetria della parabola. L’intersezione di tale asse con laparabola e l’unico vertice della parabola stessa.
Per ottenere l’equazione della parabola nella forma piu semplice, scegliamo comedirettrice la retta di equazione y = −d e come fuoco f = (0, d) con d ∈ R∗
+ . Con
G. C. Barozzi G. Dore E. Obrecht
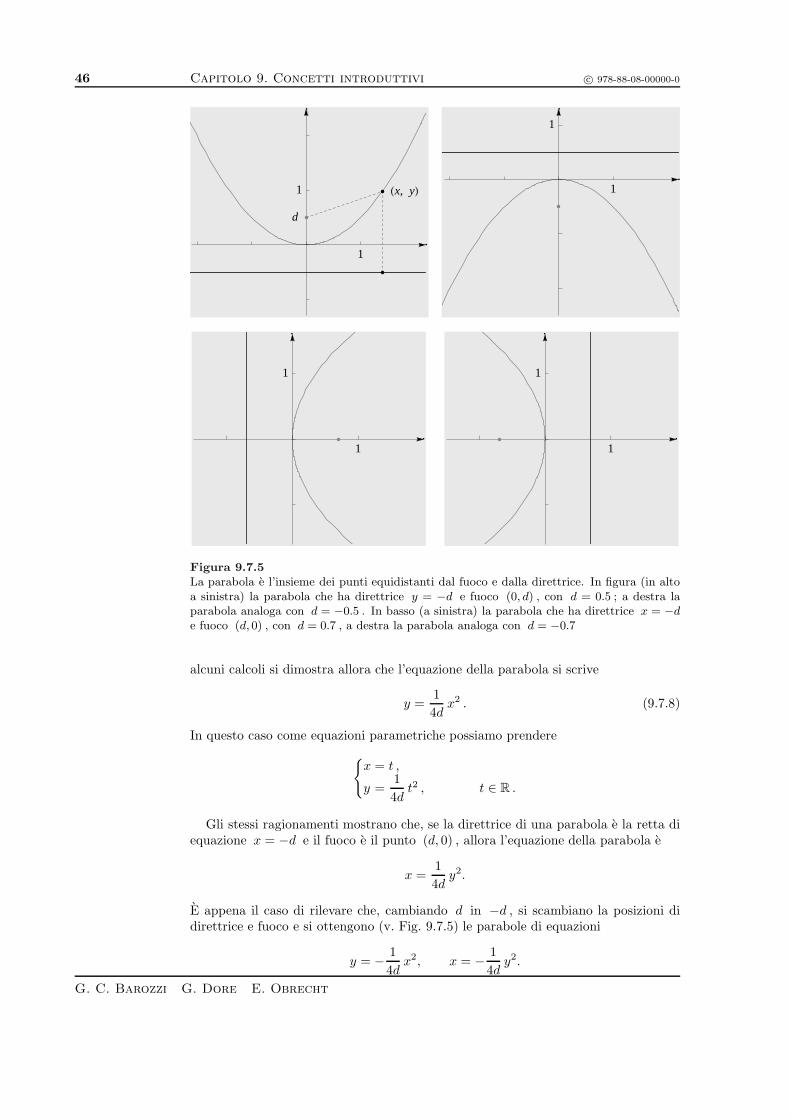
46 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
1
1
d
Hx, yL 1
1
1
1
1
1
Figura 9.7.5
La parabola e l’insieme dei punti equidistanti dal fuoco e dalla direttrice. In figura (in altoa sinistra) la parabola che ha direttrice y = −d e fuoco (0, d) , con d = 0.5 ; a destra laparabola analoga con d = −0.5 . In basso (a sinistra) la parabola che ha direttrice x = −de fuoco (d, 0) , con d = 0.7 , a destra la parabola analoga con d = −0.7
alcuni calcoli si dimostra allora che l’equazione della parabola si scrive
y =1
4dx2 . (9.7.8)
In questo caso come equazioni parametriche possiamo prendere
{
x = t ,
y =1
4dt2 , t ∈ R .
Gli stessi ragionamenti mostrano che, se la direttrice di una parabola e la retta diequazione x = −d e il fuoco e il punto (d, 0) , allora l’equazione della parabola e
x =1
4dy2.
E appena il caso di rilevare che, cambiando d in −d , si scambiano la posizioni didirettrice e fuoco e si ottengono (v. Fig. 9.7.5) le parabole di equazioni
y = − 1
4dx2, x = − 1
4dy2.
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.7. Coniche 47
Abbiamo visto, nella Sezione 2.3, che ogni polinomio di secondo grado in unavariabile puo essere considerato come il grafico di una parabola con direttrice parallelaall’asse delle ascisse e dunque asse di simmetria parallelo all’asse delle ordinate.
Le equazioni delle coniche che abbiamo descritto sono state ottenute scegliendoun sistema di coordinate strettamente collegato con le proprieta di simmetria dellaconica in esame. Semplici traslazioni consentono di scrivere le equazioni delle conichei cui assi sono paralleli (ma non necessariamente coincidenti) con gli assi coordinati.Traslando l’origine nel punto (α, β) , si hanno pertanto equazioni del tipo seguente
(x− α)2
a2+
(y − β)2
b2= 1
per l’ellisse,
(x− α)2
a2− (y − β)2
b2= 1, − (x− α)2
a2+
(y − β)2
b2= 1
per l’iperbole,
y − β =1
4d(x − α)2 , y − β = − 1
4d(x − α)2 ,
x− α =1
4d(y − β)2 , x− α = − 1
4d(y − β)2
per la parabola.
Le equazioni delle coniche fin qui illustrate sono state ottenute uguagliando a zeroun polinomio di secondo grado in due variabili; rimandando all’Es. 10.5.13 per unadefinizione precisa di tale concetto, ci limitiamo a osservare che le coniche ottenuteruotando quelle ora studiate, hanno ancora equazioni fornite dall’annullamento di unpolinomio di secondo grado, in due variabili, di forma in generale piu complessa.
9.7.4. Esempio Consideriamo l’iperbole equilatera di equazione x2 − y2 = a2 edeterminiamo l’equazione dell’iperbole che si ottiene ruotandola attorno all’origine diun angolo di π/4 radianti in senso antiorario.
Tale rotazione muta il punto (x, y) nel punto (x′, y′) dove(
x′
y′
)
=
(
1/√2 −1/
√2
1/√2 1/
√2
)(
xy
)
.
Al riguardo si tenga presente il Teor. 9.2.21, osservando che la rotazione in esame
muta i vettori della base canonica di R2 rispettivamente nei vettori
(
1/√2, 1/
√2)
e(
−1/√2, 1/
√2)
. Si ha dunque, invertendo la formula precedente,(
xy
)
=
(
1/√2 1/
√2
−1/√2 1/
√2
)(
x′
y′
)
,
cioe x =(
1/√2)
(x′ + y′) , y =(
1/√2)
(−x′ + y′) . Sostituendo nell’equazionedell’iperbole si ottiene
1
2(x′ + y′)2 − 1
2(−x′ + y′)2 = a2 , cioe x′y′ =
a2
2.
Sorge spontanea la domanda se l’insieme dei punti che annullano un polinomio disecondo grado in due variabili sia sempre una conica; la risposta e negativa, comemostra il seguente semplice esempio.
9.7.5. Esempio Si consideri l’equazione
x2 + y2 + 1 = 0 .
Si tratta di un’equazione polinomiale di secondo grado in due variabili, ma l’insiemedei punti che la soddisfano e vuoto.
G. C. Barozzi G. Dore E. Obrecht

48 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Gli esempi seguenti mostrano coniche “degeneri”.
9.7.6. Esempio Consideriamo l’equazione
x2 + y2 = 0 .
Si tratta ancora di un’equazione polinomiale di secondo grado in due variabili, mal’insieme dei punti che la soddisfano e il singoletto { (0, 0)} .
9.7.7. Esempio Consideriamo l’equazione
a2x2 − b2y2 = 0 ,
con a e b non entrambi nulli, che possiamo scrivere nella forma
(ax− by)(ax+ by) = 0 ;
dunque l’insieme dei punti che soddisfano l’equazione data e l’unione di due rette, oanche una sola retta se uno dei coefficienti a oppure b e nullo.
9.8. Quadriche
Le coniche sono le curve piane piu semplici dopo le rette; vogliamo ora esaminarele superficie tridimensionali piu semplici dopo i piani: lequadriche quadriche. Le equazionicartesiane di queste superficie si ottengono uguagliando a 0 un polinomio di secondogrado in tre variabili.
Esaminiamo i vari tipi di quadriche. Cominciamoellissoide dall’ellissoide. Dati a, b, c ∈ R∗+ ,
l’ellissoide e la superficie di R3 descritta dall’equazione
x2
a2+
y2
b2+
z2
c2= 1 . (9.8.1)
Poiche ciascuno degli addendi a primo membro non puo superare 1 , l’ellissoide econtenuto nel parallelepipedo [−a, a]× [−b, b]× [−c, c] .
I piani coordinati sono piani di simmetria, gli assi coordinati sono assi di simmetriae l’origine delle coordinate e centro di simmetria per l’ellissoide. Ad esempio, se(x0, y0, z0) e un punto che verifica la (9.8.1), lo stesso vale per il punto (−x0, y0, z0) .
I punti di intersezione degli assi con l’ellissoide vengono detti vertici dell’ellissoide;essi sono (±a, 0, 0) , (0,±b, 0) , (0, 0,±c) .
Intersecando l’ellissoide con piani paralleli ai piani coordinati, l’intersezione, senon e vuota, e un’ellisse, eventualmente ridotta a un punto. Ad esempio, scegliendoil piano z = z0 con |z0| < c , la curva intersezione ha equazioni
x2
a2+
y2
b2= 1− z20
c2,
z = z0 ;
chiamando λ2 , con λ ∈ R∗+ , il secondo membro della prima equazione, si ha
x2
λ2a2+
y2
λ2b2= 1 ,
cioe si tratta di un’ellisse di semiassi λa , λb . Se a = b si ottiene una circonferenza;in tal caso l’ellissoide (9.8.1) e una superficie di rotazione, vale a dire puo essereottenuto ruotando attorno all’asse z l’ellisse di equazioni
x2
a2+
z2
c2= 1 ,
y = 0 .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.8. Quadriche 49
Figura 9.8.1
Quattro ellissoidi. I due ellissoidi in basso sono superficie di rotazione attorno all’asse z .
Analoghe considerazioni se e verificata una delle uguaglianze a = c oppure b = c .Se poi risulta a = b = c , l’ellissoide e la sfera di centro l’origine e raggio a .
Si osservi che se a = b , possiamo scrivere l’equazione dell’ellissoide nella forma
r2
a2+
z2
c2= 1 ,
avendo posto
r =√
x2 + y2 . (9.8.2)
Dunque r e la distanza del punto (x, y, z) dall’asse z .
L’ellissoide e rappresentato in forma parametrica dalle equazioni
x = a cosu sin v ,
y = b sinu sin v ,
z = c cos v , u ∈ [0, 2π] , v ∈ [0, π] .
Consideriamo ora iperboloide a una
faldal’iperboloide a una falda (detto anche iperboloide iperbolico).
Esso e rappresentato dall’equazione
x2
a2+
y2
b2− z2
c2= 1 , (9.8.3)
G. C. Barozzi G. Dore E. Obrecht

50 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
con a, b, c ∈ R∗+ .
Analogamente al caso dell’ellissoide, i piani coordinati sono piani di simmetria, gliassi coordinati sono assi di simmetria e l’origine delle coordinate e centro di simmetriaper l’iperboloide a una falda.
Di natura ben diversa sono invece le intersezioni con i piani coordinati: l’inter-sezione col piano y = 0 e l’iperbole di equazione x2/a2 − z2/c2 = 1 , l’intersezionecol piano x = 0 e l’iperbole di equazione y2/b2 − z2/c2 = 1 . Le intersezioni piuinteressanti si hanno con piani paralleli al piano xy ; infatti, se z0 ∈ R , l’intersezionecol piano z = z0 e l’ellisse di equazioni
x2
a2+
y2
b2= 1 +
z20c2
,
z = z0 .
Se indichiamo con λ2 il secondo membro della prima equazione, con λ > 0 , l’ellisseha equazione
x2
λ2a2+
y2
λ2b2= 1
e quindi i suoi semiassi misurano λa e λb . Pertanto questi semiassi hanno lunghezzastrettamente crescente al crescere di |z0| ; ne consegue che l’ellisse per cui i semiassisono minimi si ottiene quando z0 = 0 . Questo giustifica il nome di linea di strizione
per l’ellisse di equazioni
x2
a2+
y2
b2= 1 ,
z = 0 .
Se a = b tutte le ellissi considerate sono circonferenze e dunque l’iperboloide e unasuperficie di rotazione attorno all’asse z . In tal caso la sua equazione si puo scrivere(v. (9.8.2))
r2
a2− z2
c2= 1 .
Figura 9.8.2
Due iperboloidi a una falda; quella a destra e una superficie di rotazione attorno all’asse z .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.8. Quadriche 51
L’iperboloide a una falda e rappresentato in forma parametrica dalle equazioni
x = a√u2 + 1 cos v ,
y = b√u2 + 1 sin v ,
z = c u , u ∈ R , v ∈ [0, 2π] ,
oppure anche
x = a coshu cos v ,
y = b coshu sin v ,
z = c sinhu , u ∈ R , v ∈ [0, 2π] .
Consideriamo ora iperboloide a due
faldel’iperboloide a due falde (detto anche iperboloide ellittico), rap-
presentato dall’equazione
−x2
a2− y2
b2+
z2
c2= 1 , (9.8.4)
dove a, b, c ∈ R∗+ , o, se si preferisce,
x2
a2+
y2
b2=
z2
c2− 1 . (9.8.5)
Anche in questo caso i piani coordinati sono piani di simmetria, gli assi coor-dinati sono assi di simmetria e l’origine delle coordinate e centro di simmetria perl’iperboloide a due falde.
L’intersezione col piano y = 0 e l’iperbole di equazione −x2/a2+z2/c2 = 1 ; analo-gamente l’intersezione col piano x = 0 e l’iperbole di equazione −y2/b2 + z2/c2 = 1 .Entrambe queste iperboli hanno i fuochi sull’asse z .
Dall’equazione (9.8.5) si riconosce immediatamente che i punti dell’iperboloide adue falde hanno quota z , tale che |z| ≥ c . Gli unici punti di questa quadricache hanno quota uguale a c o a −c sono le intersezioni con l’asse z e vengonodetti i vertici dell’iperboloide. Se |z0| > c l’intersezione dell’iperboloide col piano diequazione z = z0 e l’ellisse di equazioni
x2
a2+
y2
b2=
z20c2
− 1 ,
z = z0 .
Indicando con λ2 il secondo membro della prima equazione, con λ > 0 , si ha l’ellissedi equazioni
x2
λ2a2+
y2
λ2b2= 1 ,
z = z0 .
Anche in questo caso i semiassi dell’ellisse crescono strettamente al crescere di |z0| .Se a = b questa ellisse e una circonferenza e dunque l’iperboloide a due falde e
una superficie di rotazione attorno all’asse z , la cui equazione puo essere scritta
r2
a2=
z2
c2− 1 .
In generale, se si interseca l’iperboloide con il piano z =√2 c , si ha l’ellisse
x2
a2+
y2
b2= 1 ,
dunque i parametri a e b dell’iperboloide possono essere interpretati come i semiassidi tale ellisse.
G. C. Barozzi G. Dore E. Obrecht

52 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Figura 9.8.3
Due iperboloidi a due falde; a sinistra e mostrata (in nero) anche l’ellisse intersezione col
piano z =√2 c .
La falda dell’iperboloide contenuta nel semispazio z > 0 e rappresentata in formaparametrica dalle equazioni
x = a√u2 − 1 cos v ,
y = b√u2 − 1 sin v ,
z = c u , u ∈ [1,+∞[ , v ∈ [0, 2π] ,
mentre le stesse equazioni, ma con u ∈ ]−∞,−1] , v ∈ [0, 2π] , rappresentano la faldacontenuta nel semispazio z < 0 .
Alternativamente si possono usare le equazioni parametriche
x = a sinhu cos v ,
y = b sinhu sin v ,
z = c coshu , u ∈ R+ , v ∈ [0, 2π] ,
per la falda contenuta nel semispazio z > 0 , e le stesse equazioni per x e y , maz = −c coshu , u ∈ R+ , per la falda contenuta nel semispazio z < 0 .
Consideriamo ora ilparaboloide
ellitticoparaboloide ellittico. Dati a, b ∈ R∗
+ , consideriamo la superficiedescritta dall’equazione cartesiana
x2
a2+
y2
b2= z . (9.8.6)
Questa quadrica e interamente contenuta nel semispazio z ≥ 0 , i piani x = 0 ey = 0 sono piani di simmetria, mentre l’asse z e asse di simmetria per il paraboloide.L’origine delle coordinate, che e il punto intersezione dell’asse con il paraboloide vienedetto il vertice del paraboloide. Osserviamo che questa quadrica non possiede centridi simmetria.
Le intersezioni di tale superficie con i piani coordinati xz e yz hanno equazioniz = x2/a2 e z = y2/b2 , dunque sono parabole che hanno come asse l’asse z , conla concavita rivolta verso il semiasse positivo z . L’intersezione con un qualsivogliapiano contenente l’asse z e una parabola analoga. L’intersezione col piano z = z0 ,
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.8. Quadriche 53
con z0 ∈ R∗+ e l’ellisse di equazioni
x2
a2+
y2
b2= z0 ,
z = z0 ;
ponendo λ =√z0 , dunque z0 = λ2 , la prima equazione diventa
x2
λ2a2+
y2
λ2b2= 1 ,
cioe l’equazione dell’ellisse di semiassi λa , λb . Se a = b si ottiene una circonferenzae allora il paraboloide (9.8.6) e una superficie di rotazione attorno all’asse z , la cuiequazione puo essere scritta
r2
a2= z .
Figura 9.8.4
Due paraboloidi ellittici; quello di destra e una superficie di rotazione attorno all’asse z .
Il paraboloide ellittico e rappresentato in forma parametrica dalle equazioni
x = a u cos v ,
y = b u sin v ,
z = u2 , u ∈ R+ , v ∈ [0, 2π] .
Veniamo al paraboloide
iperbolicoparaboloide iperbolico (detto anche paraboloide a sella) descritto dal-
l’equazione
x2
a2− y2
b2= z , (9.8.7)
dove a, b ∈ R∗+ .
Anche questa quadrica non ha un centro di simmetria. I piani x = 0 e y = 0 sonopiani di simmetria, mentre l’asse z e asse di simmetria.
L’intersezione di tale superficie con il piano y = 0 e la parabola di equazionez = x2/a2 , che ha la concavita rivolta verso il semiasse z positivo. Lo stesso accade sesi interseca con un qualunque piano parallelo al piano xz , cioe un piano di equazioney = y0 con y0 ∈ R assegnato. Se invece si interseca col piano x = 0 , o conun qualunque piano parallelo al piano yz , si ottiene una parabola con la concavitarivolta verso il semiasse z negativo.
G. C. Barozzi G. Dore E. Obrecht

54 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Figura 9.8.5
Due paraboloidi iperbolici; nella figura di sinistra sono mostrate le rette di intersezione colpiano z = 0 .
Se poi si interseca il paraboloide iperbolico con un piano del tipo z = z0 , conz0 ∈ R fissato, si ottiene la curva di equazioni
x2
a2− y2
b2= z0 ,
z = z0 .
Se z0 > 0 , posto λ =√z0 , dunque z0 = λ2 , si ottiene
x2
λ2a2− y2
λ2b2= 1 .
Si tratta di un’iperbole con i fuochi appartenenti ad una retta parallela all’asse x .
Se invece z0 < 0 , posto λ =√
|z0| , dunque z0 = −λ2 , si ottiene
− x2
λ2a2+
y2
λ2b2= 1 .
Questa volta si tratta di un’iperbole con i fuochi appartenenti ad una parallela al-l’asse y . Se poi z0 = 0 , cioe intersechiamo il paraboloide col piano xy , otteniamol’equazione
x2
a2− y2
b2= 0 .
Questa equazione si spezza nel prodotto (x/a− y/b)(x/a+ y/b) = 0 , dunque rappre-senta l’unione delle due rette di equazione x/a = y/b e x/a = −y/b . Il paraboloideiperbolico non e in alcun caso una superficie di rotazione.
Abbiamo gia considerato un paraboloide ellittico e un paraboloide iperbolico comegrafici di forme quadratiche nell’Es. 9.6.8.
Consideriamocilindro ulteriori tipi di quadriche: i cilindri. Se p(x, y) = 0 e l’equazionedi una conica γ nel piano xy (dunque p e un polinomio di secondo grado nellevariabili x e y ), consideriamo la superficie di R3
{
(x, y, z) ∈ R3∣
∣ p(x, y) = 0}
. (9.8.8)
In termini espliciti: la superficie in questione e costituita da tutti (e solo) i puntiche appartengono alle rette parallele all’asse z passanti per un punto della conica γ .
G. C. Barozzi G. Dore E. Obrecht

c© 978-88-08-00000-0 9.8. Quadriche 55
Appartengono a tali rette tutti (e soltanto) i punti (x, y, z) ∈ R3 tali che p(x, y) = 0 .La conica γ viene detta direttrice,
generatricedirettrice del cilindro e le rette parallele all’asse z generatrici
del cilindro stesso.
A seconda del tipo di conica direttrice abbiamo il cilindro ellittico (v. Fig. 9.8.6 asinistra), di equazione
x2
a2+
y2
b2= 1 ,
con a, b ∈ R∗+ , il cilindro iperbolico (v. Fig. 9.8.6 a destra), di equazione
x2
a2− y2
b2= 1 ,
con a, b ∈ R∗+ , il cilindro parabolico(v. Fig. 9.8.7 a sinistra), di equazione
y = ax2 ,
con a ∈ R∗ .
Figura 9.8.6
Il cilindro che ha come direttrice l’ellisse di equazione x2/a2+y2/b2 = 1 , con a = 2 , b = 1.5(a sinistra). Il cilindro che ha come direttrice l’iperbole di equazione y2−x2 = 1 (a destra).
Naturalmente possiamo anche considerare cilindri per i quali la conica direttricee contenuta nel piano xz e le generatrici sono parallele all’asse y , oppure cilindriper i quali la conica direttrice appartiene al piano yz e le generatrici sono paralleleall’asse x . Nell’Es. 9.6.8 abbiamo considerato il cilindro parabolico di equazionez = x2 (v. Fig. 9.6.1, grafico al centro); esso ha come direttrice la parabola avente lastessa equazione, contenuta nel piano xz , e le generatrici parallele all’asse y .
Consideriamo un ultimo tipo di quadrica: il conocono. Data un’ellisse γ contenuta nelpiano xy e un punto v non appartenente a esso, il cono di vertice v e direttrice γsi ottiene considerando l’unione delle rette passanti per v e per un punto di γ . Talirette sono dette le generatrici del cono.
Se v = (0, 0, h) , con h 6= 0 , e l’ellisse ha equazioni
x2
a2+
y2
b2= 1 ,
z = 0 ,
G. C. Barozzi G. Dore E. Obrecht

56 Capitolo 9. Concetti introduttivi c© 978-88-08-00000-0
Figura 9.8.7
A sinistra: il cilindro che ha come direttrice la parabola y = x2 − 1 ; a destra il cono cheha come direttrice l’ellisse x2/a2 + y2/b2 = 1 , con a = 2 , b = 1.5 , e come vertice il puntov = (0, 0, 2.5) .
si riconosce che l’equazione cartesiana del cono e
x2
a2+
y2
b2=
(z − h)2
h2.
I piani di equazione x = 0 , y = 0 e z = h sono piani di simmetria per il cono, lerette di equazioni
{
x = 0 ,
z = h ,e
{
y = 0 ,
z = h .
nonche l’asse z sono assi di simmetria, il vertice e centro di simmetria.
Le equazioni parametriche del cono si scrivono
x = ah− u
hcos v ,
y = bh− u
hsin v ,
z = u , u ∈ R , v ∈ [0, 2π] .
G. C. Barozzi G. Dore E. Obrecht


















