
Antonelli 25 26 genn 2011 - aslcagliari.it · ed i rapporti tra le osservazioni (*, /); ... ÎDati...
91
Progetto Formativo Aziendale “Il controllo delle infezioni correlate all’assistenza” Dott. Antonello Antonelli Cagliari, 25-26.01.2011 Antonello Antonelli wPianificazione e Controllo Strategico wQualità e Risk Management Progetto Formativo Aziendale “Il controllo delle ICA” (Infezioni Correlate all’Assistenza)
Transcript of Antonelli 25 26 genn 2011 - aslcagliari.it · ed i rapporti tra le osservazioni (*, /); ... ÎDati...

Progetto Formativo Aziendale“Il controllo delle infezioni correlate all’assistenza”
Dott. Antonello Antonelli
Cagliari, 25-26.01.2011
Antonello Antonelli
Pianificazione e Controllo StrategicoQualità e Risk Management
Progetto Formativo Aziendale
“Il controllo delle ICA”(Infezioni Correlate all’Assistenza)

Principi di statistica ed epidemiologiaapplicati alle scienze biomediche
STATISTICA
Comunicare l’un l’altro, scambiarsi informazioni è natura.Tener conto delle informazioni che ci vengono date, è cultura.
J. W. Goethe
Da:M. Nonis L. Lorenzoni“Guida alla versione 19.0 del sistema DRG”Il Pensiero Scientifico Editore

BIO STATISTICA
Concetti, metodologiae strumenti dellastatistica . . .
. . . applicati allediscipline bio-mediche:1. Biologia;2. Medicina;3. Scienze naturali;4. Psicologia;5. . . .
STATISTICA
“Strumento per governare l’incertezza”
1. Statistica descrittiva:ha a che fare con la presentazione, organizzazione e sintesi dei dati (tabelle, grafici, indici di sintesi).
2. Statistica Inferenziale:ci permette di generalizzare i risultati ottenuti dai dati raccolti da un campione ad una popolazione più ampia(Stima di parametri, Test di ipotesi).

OBIETTIVI
1. Descrivere i daticondensare anche un gran numero di dati rilevati in pochi valori riassuntivi, capaci di indicare importanti proprietà del fenomeno oggetto di indagine.
2. Classificaredescrivere ed analizzare gruppi definiti di popolazione sulla base di caratteristiche comuni misurate dalle variabili rilevate.
3. Esplorare le relazionidefinire e descrivere le relazioni tra le variabili rilevate.
4. Valutare ipotesistabilire quanto è verosimile che esista una relazione tra le variabili (cioè, fare inferenze sulla popolazione da cui i dati sono tratti).
5. Fare previsioniutilizzare i dati raccolti per prevedere i valori che ci si aspetta di trovare nella popolazione oggetto di indagine in particolari condizioni.
6. Generare ipotesile fasi precedentemente descritte permettono di avere una maggior comprensione del fenomeno in studio ed è possibile avanzare proposte o ambiti di indagine.

Tutti questi obiettivi hanno lo stesso problema: la variabilità, che è la fonte principale dell’incertezza che abbiamo nell’osservare, indagare i fenomeni di nostro interesse.
Infatti, le caratteristiche d’interesse della popolazione variano (es. età, presenza di malattie croniche, durata della degenza, ecc.) e variano le relazioni tra le variabili nella popolazione studiata (es. età -> presenza di malattie croniche).
Il tutto varia da popolazione a popolazionee nella stessa popolazione, nel tempo.
Tutta questa variabilità comporta uncerto grado di incertezza in ogni analisi.
Punto di partenza i dati definizione:
Rappresentazione,
in formati e secondo criteri predefiniti,
di un fenomeno di interesse.
Lo stesso fenomeno può essere rappresentato
in formati e criteri diversi
dando origine a dati diversi!

Formati Criteri
Sintetici
Analitici
Generali
Specifici
ESEMPIO:La condizione diabete può essere rappresentata:
1. in un formato dicotomico:presente vs assente (1 – 0)
2. secondo scale categoriche di gravità:assente → valore ennesimo di massima gravità
3. attraverso codici descrittivi di modalità specifiche di presentazione (la ICD9-CM descrive il diabete attraverso 40 codici diversi e tra loro combinabili).

Anche fenomeni variabili, direttamente misurabili,possono essere rappresentati da dati diversi!
Ad esempio l’età può essere rappresentata:
- In giorni;- In anni compiuti;- In classi pluriennali.
In ogni caso, per ciascun formato devono essere espliciti i criteri utilizzati per attribuire ciascuno dei valori previsti CLASSIFICAZIONE.
1. Caratteristiche anagrafiche;2. Caratteristiche socio-demografiche;3. Esposizioni ambientali e/o occupazionali;4. Condizioni cliniche;5. Processi assistenziali;6. Trattamenti;7. Esiti;8. Abitudini e stili di vita;9. Costi;10.Struttura;11.Attività;. . . . . . . . . .
Quali i dati di interesse?

I dati sono definiti sulla base dei fenomeni che rappresentano e dalla loro capacità di
rappresentarli.
I dati compongono l’informazione,ma non equivalgono all’informazione!
I dati sono solo su qualcosa, l’informazione invece è sempre per qualcosa o per qualcuno!
Proprietà formali dei dati
1. Relazione di equivalenza (=,≠): i membri di una stessa sottoclasse devono essereequivalenti rispetto alla proprietà misurata.
2. Relazione di posizione (<,>): è possibileordinare logicamente le modalità;
3. Relazioni aritmetiche (+,-,x, :):sono definite le distanze relative (+, -);ed i rapporti tra le osservazioni (*, /);
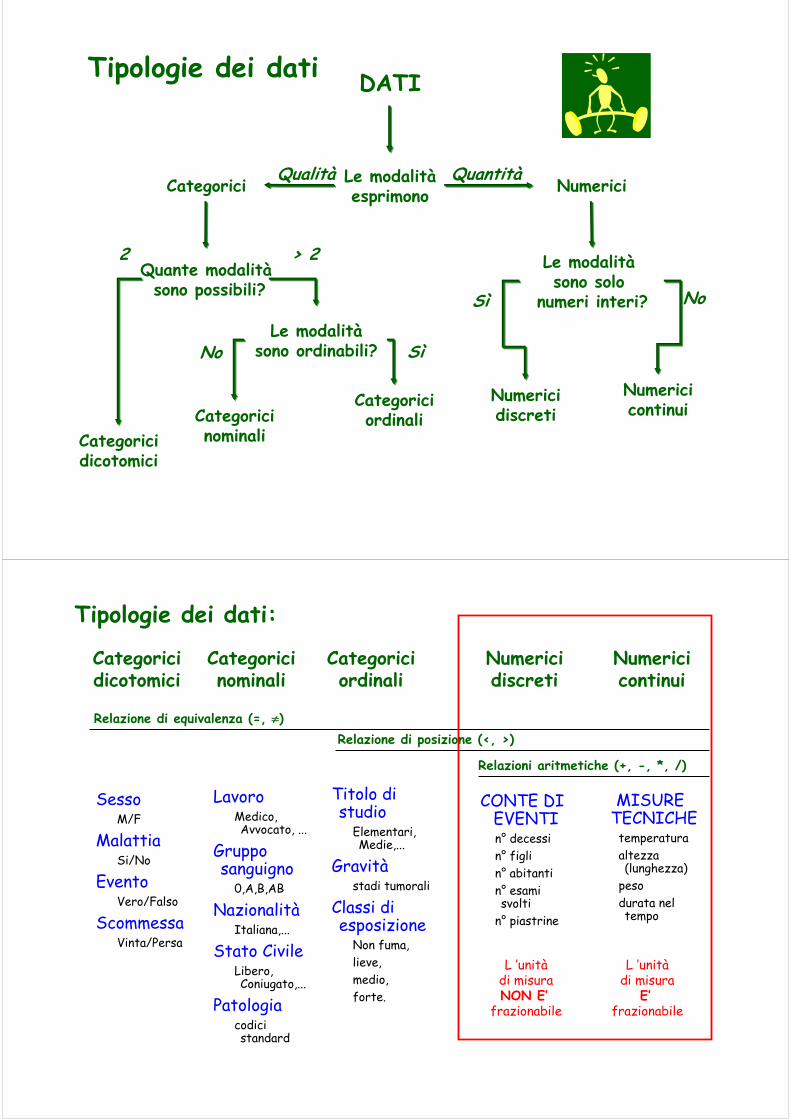
Qualità Quantità
Tipologie dei dati
Categorici
DATI
Categoricidicotomici
Numerici
Le modalitàsono ordinabili?
Le modalitàesprimono
Quante modalitàsono possibili?
Le modalitàsono solo
numeri interi?
2 > 2
Categoriciordinali
Sì
Categoricinominali
No
Numericidiscreti
Sì
Numericicontinui
No
Relazioni aritmetiche (+, -, *, /)
Tipologie dei dati:
Categoricidicotomici
Categoricinominali
Categoriciordinali
Numericidiscreti
Numericicontinui
Relazione di posizione (<, >)Relazione di equivalenza (=, ≠)
SessoM/F
MalattiaSi/No
EventoVero/Falso
ScommessaVinta/Persa
LavoroMedico, Avvocato, ...
Gruppo sanguigno
0,A,B,AB
NazionalitàItaliana,...
Stato CivileLibero, Coniugato,...
Patologiacodici standard
Titolo di studio
Elementari, Medie,...
Gravitàstadi tumorali
Classi di esposizione
Non fuma,lieve,medio,forte.
CONTE DI EVENTIn° decessin° figlin° abitantin° esami svolti
n° piastrine
MISURE TECNICHE
temperaturaaltezza (lunghezza)
pesodurata nel tempo
L ’unitàdi misuraNON E’
frazionabile
L ’unitàdi misura
E’frazionabile

GERGO (®):
Una pluralità di elementi, tutti portatori di un dato carattere, costituisce un INSIEME STATISTICO rispetto a quel carattere se, in almeno due degli elementi dell’insieme, il carattere si presenta con modalità differenti.
Gli elementi che compongono un insieme statistico si dicono UNITA’ STATISTICHE.
Un carattere rispetto al quale è definito un insieme statistico è una VARIABILE STATISTICA.
PROTOCOLLO ELEMENTARE
La successione dei valori di un dato carattere (ad
esempio l’età), senza alcun ordinamento è definita come
protocollo elementare: 19, 25, 30, … …, n.
La variabile rappresentante il carattere si indica con la
lettera latina maiuscola (X, Y, Z … );
Il valore della variabile con la lettera latina minuscola
(x, y, z …);
La numerosità del campione con n.
Il protocollo elementare si può schematizzare come: x1 ,
x2 , x3 … , xj …, xn ovvero {Xj} j=1, 2, 3, …, n.

LA RAPPRESENTAZIONE DEI DATILe tabelle di sintesi dei dati - tabelle a singola entrata
Generalitàpresentano i dati in forma analitica o sintetica, organizzati secondo righe e colonneè presentata la distribuzione di frequenza di UN SOLO carattere statistico
A seconda dei tipi di datiDati nominali ed ordinali
Rappresentazione di tutte le modalità possibiliDato numerici discreti e continui
Dati aggregati per classi
1001.0050Totale
10020.021>85|
98100.10575-85|
88100.10565-75|
78100.10555-65|
68220.221145-55|
46120.12635-45|
34260.261325-35|
880.084≤25
Cum.Frequenze relative %
Frequenze relative
Frequenze assoluteEtà (in anni)

Distribuzione per Genere
27
23
0
5
10
15
20
25
30
M F
Genere
Fre
qu
enze
ass
olu
te
Distribuzione per Genere
M; 27
F; 23

Distribuzione per titolo di studio
0
5
10
15
20
25
nessuno licenza elementare scuola mediainferiore
scuola mediasuperiore
laurea
Titolo di studio
Fre
qu
en
ze a
ss
olu
te
Distribuzione per stato civile
0
5
10
15
20
25
celibe/nubile coniugato/a vedovo/a divorziato/a
Fre
qu
en
ze a
ss
olu
te

Distribuzione altezza
0
5
10
15
152 155 156 158 160 162 163 164 165 166 168 170 172 174 175 176 178 180 183 187 190
Fre
qu
enze
ass
olu
te
Distribuzione altezza
0
0.1
0.2
0.3
152 155 156 158 160 162 163 164 165 166 168 170 172 174 175 176 178 180 183 187 190
Fre
qu
enze
rel
ativ
e
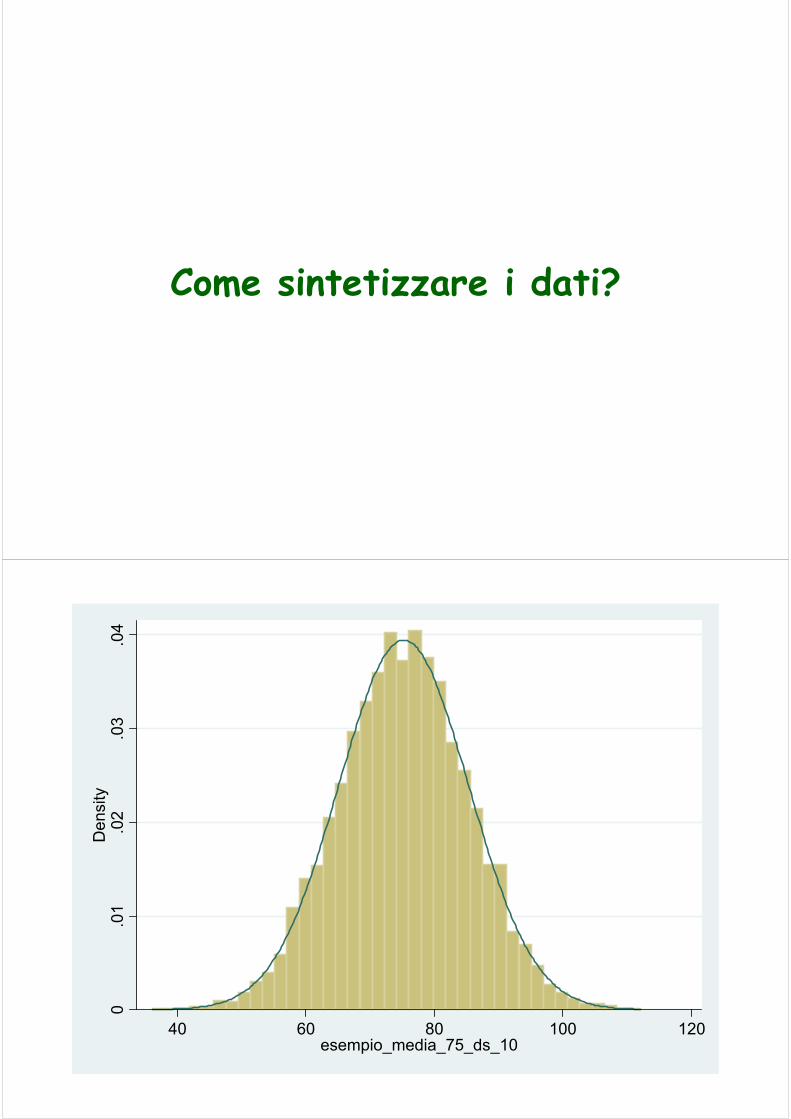
Come sintetizzare i dati?
0.0
1.0
2.0
3.0
4D
ensi
ty
40 60 80 100 120esempio_media_75_ds_10

Con l’analisi statistica possiamo sintetizzare il risultato delle osservazioni in uno, o più, indicatori:
capaci di riassumere, in un singolo valore, una specifica caratteristica delle osservazioni stesse.
In statistica descrittiva distinguiamo:Indici di tendenza centrale
che esprimono il valore “tipico”Indici di dispersione
che esprimono quanto strettamente i dati si raggruppano intorno al valore ”tipico”
Indici di forma (!) . . . Un’altra volta!che esprimono le caratteristiche di “simmetria” e “curvatura” della distribuzione dei dati
Indici di tendenza centraleMODA
Il valore, che si presenta più frequentemente nella popolazione o nel campione;
Per i dati numerici continui, è necessario prima raggruppare in classi le osservazioni;
Si determina contando le frequenza delle modalità;
Non tiene conto di tutte le altre modalità;
Utile per sospettare la co-presenza di più popolazioni.

MEDIANAIl valore, che, dopo aver posto le osservazioni in ordine crescente, divide la distribuzione in due gruppi di eguale numerosità;Nelle serie dispari è il valore al centro della distribuzione ordinata - (n+1)/2esima posizione;Nelle serie pari è la media dei due valori al centro della distribuzione ordinata - media tra n/2 esima e (n/2)+1 esima;E’ detta anche 50° percentile;Non è sensibile ai valori estremi;E’ l’indice di sintesi nelle distribuzioni asimmetriche.
MEDIA ARITMETICALa somma di tutti i valori rilevati divisa per la numerositàEsiste solo per i dati numerici continui e discreti;Sintetizza tutti i dati: è il valore “più vicino” a tutte le singole osservazioni;
Minimizza la somma degli scarti quadratici;E’ valida soprattutto per i dati che seguono una distribuzione di frequenza normale;E’ sensibile ai valori estremi.

MEDIA ARITMETICA - esempioIl volume espiratorio forzato in 13 adolescenti asmatici
(in litri):2.3, 2.1, 3.5, 2.6, 2.8, 2.8, 4.0, 2.2, 2.6, 3.0, 4.0, 2.8, 3.3Somma dei 13 valori xi:2.3+2.1+3.5+2.6+2.8+2.8+4.0+2.2+2.6+3.0+4.0+2.8+3.3= 38Divisione per n=13.38 / 13 = 2.9
n
xx
n
1ii∑
==Quanto sarebbe FEV dei soggetti che
abbiamo studiato, se fossero tutti uguali!
Indici di dispersioneRANGE (ampiezza dell’intervallo min - max)
E’ un indice sintetico dato dalla differenza tra il valore più grande e il valore più piccolo di una distribuzione. E’ l’ampiezza del più piccolo intervallo contenente tutte le osservazioni.Si applica solo alle variabili numeriche;Misura la dispersione;E’ molto poco “stabile”, perché dipende solo dai valori estremi. Per renderlo arbitrariamente grande basta modificare un singolo dato.

QUANTILI, PERCENTILIPer QUANTILI si intendono i valori (compresi nell’intervallo min-max) che suddividono la distribuzione di una variabile numerica in gruppi ordinati e di eguale numerosità (non di uguale ampiezza):
Decili -> dieci gruppiQuintili -> cinque gruppiQuartili -> quattro gruppi
Centili (o percentili) -> cento gruppi; sono chiamati anche PERCENTILI e suddividono la distribuzione in 100 gruppi di uguale numerosità, ad esempio pesi o altezze di bambini - Un bambino che superi il 90% percentile avrà dunque un valore (es. di altezza) superiore al 90% di tutti i bambini considerati.
DIFFERENZA INTERQUARTILEE’ la differenza tra il quartile superiore (75°
percentile) e il quartile inferiore (25° percentile).E’ l’ampiezza dell’intervallo che contiene il 50%
centrale dei dati;Misura la dispersione;Non è influenzata dai valori estremi;E’ stabile - la modifica di un solo dato produce un
effetto limitato su di essa;
NB: sia il range che la differenza interquartilesono singoli numeri, non intervalli.

Diagrammi a scatola(box & whiskers plot)
Sono utili per sintetizzare le distribuzioni di frequenza e valutarne l’asimmetriaLa scatola centrale si estende dal 25° percentile al 75°percentile (i “quartili” dei dati)La linea dentro la scatola rappresenta la mediana Le linee al di fuori della scatola si estendono ai valori adiacenti, osservazioni piùestreme che non superano piùdi 1,5 volte l’ altezza della scatola esternamente ad ognuno dei quartili
VARIANZAE’ un valore sintetico che vuole esprimere la distanza
media di ogni singola osservazione dalla media aritmetica del campione:
Idealmente, la distanza media delle osservazioni dalla media artimetica del campione si potrebbe studiare calcolando la media aritmetica dei semplici scarti. Tuttavia, per la stessa definizione della; media artimetica, la somma degli scarti è pari a zeroAllora, per evitare l’ azzeramento della somma degli scarti, si calcola la media dei quadrati degli scarti.

n
xn
ii∑
=
−= 1
2
2
)( μσ
VARIANZA
Esiste solo per i dati numerici continui e
discreti;
E’ valida soprattutto per i dati che seguono
una distribuzione di frequenza normale;
E’ piuttosto sensibile ai valori estremi;
La sua unità di misura non è quella delle
osservazioni e della media . . . è al
quadrato!

QUALE DENOMINATORE PER LA VARIANZA?
La formula della varianza che abbiamo visto prima (media aritmetica degli scarti quadratici) è quella giusta se vogliamo semplicemente descrivere le nostre osservazioni.
Tuttavia, se passiamo dalla statistica descrittiva a quella inferenziale, le cose cambiano leggermente.Molto spesso avremo bisogno di stimare la varianza di una variabile in una popolazione sulla base delle osservazioni fatte su un campione.
n
μxσ
n
ii∑ -
1=
2
2)(
=
Se nella formula sostituiamo la media osservata nel campione alla media “vera” (ma ignota) della popolazione sottostimiamo sistematicamente la varianza (la media “vera”rende minima la somma degli scarti quadratici).Questo problema viene risolto riducendo di un’unità il denominatore, dividendo quindi per (n-1) anziché per n.
Alcuni programmi (e.g. Excel) permettono di scegliere il denominatore, altri (e.g. Stata) usano n-1.
1
)(= 1=
2
2
-
∑ -
n
xxσ
n
ii
“Se vi dovete preoccupare della differenza tra n ed n-1, allora probabilmente siete già fuori strada, perché state cercando di sostanziare la
vostra ipotesi con dati insufficienti”

La variabilità: indici di dispersioneDEVIAZIONE STANDARD
E’ un valore sintetico che vuole esprimere la distanza media di ogni singola osservazione dalla media aritmetica del campione
E’ la radice quadrata della varianza, e ne ha le stesse proprietà.Riporta l’indice di precisione alla stessa scala della media aritmetica.
COEFFICIENTE DI VARIAZIONEE’ un indice che rapporta il valore della deviazione standard alla media del corrispondente campione
E’ detto anche “Deviazione Standard Relativa”.E’ utile per confrontare tra loro la precisione di metodi diversi.
LA DISTRIBUZIONE NORMALE(Curva Gaussiana)
Oltre le distribuzioni di frequenza relative a un numero finito di casi si possono utilizzare distribuzioni con un numero di casi infinitamente grande.
L’istogramma che ne deriva è rappresentato da curve continue esprimibili attraverso equazioni matematiche.
La distribuzione normale è una di queste curve.

Carl Friedrich Gauss30 aprile 1777 – 23 febbraio 1855
e σ2
μ)(x
π2σ
1p(x) 2
2
−= −

LA FORMA DELLA DISTRIBUZIONE NORMALE
L’area di ogni rettangolo rappresenta la proporzione di casi che ricade nella classe.
L’area compresa sotto la curva continua all’interno di ogni classe data può essere uguagliata all’area del rettangolo corrispondente.
Con l’aumentare del numero dei rettangoli la somma delle aree dei rettangoli stessi si avvicina sempre di piùall’area sottesa alla curva continua completa.
Considerato che la somma delle aree dei rettangoli corrisponde ad una unità questo sarà vero anche per l’area sottesa alla curva continua costruita.

Spesso è necessario determinare la proporzione di casi che ricadono entro un dato intervallo ed èimportante sfruttare una proprietà della curva normale:
L’area sottesa alla porzione di curva che vi è tra le media e una ordinata posta a una distanza data, determinata in termini di unità di deviazione standard, è costante.
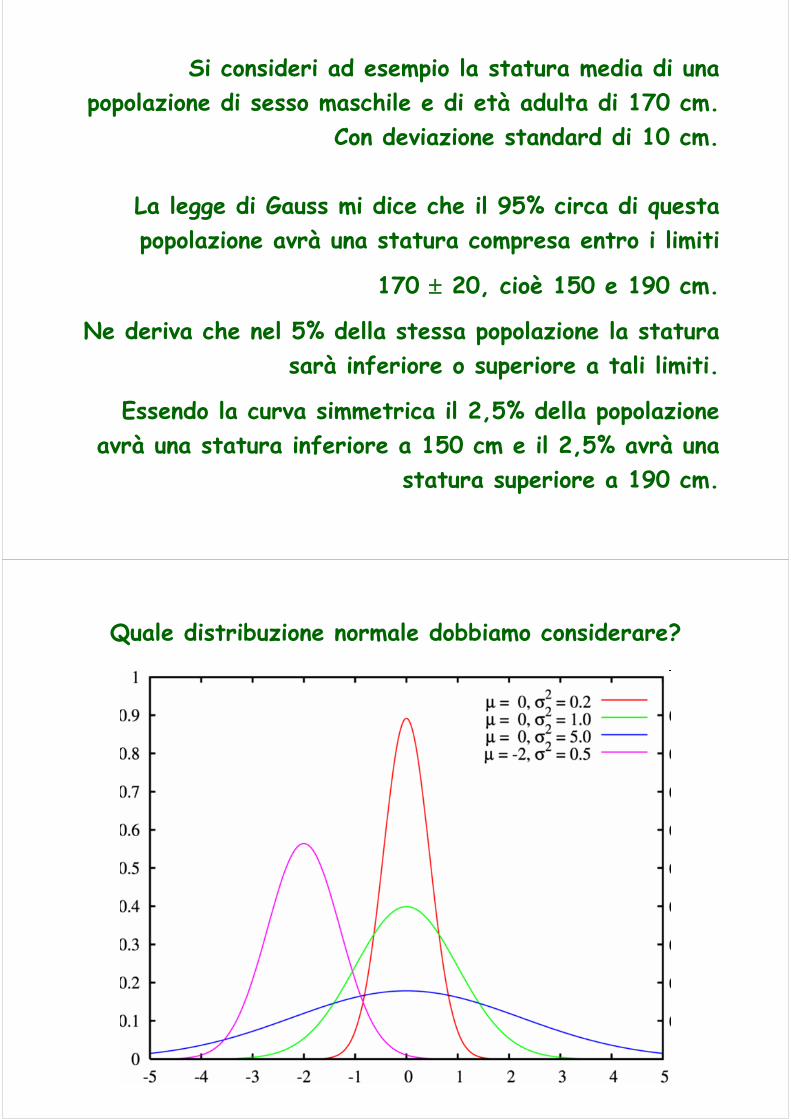
Si consideri ad esempio la statura media di una popolazione di sesso maschile e di età adulta di 170 cm.
Con deviazione standard di 10 cm.
La legge di Gauss mi dice che il 95% circa di questa popolazione avrà una statura compresa entro i limiti
170 ± 20, cioè 150 e 190 cm.
Ne deriva che nel 5% della stessa popolazione la statura sarà inferiore o superiore a tali limiti.
Essendo la curva simmetrica il 2,5% della popolazione avrà una statura inferiore a 150 cm e il 2,5% avrà una
statura superiore a 190 cm.
Quale distribuzione normale dobbiamo considerare?

DISTRIBUZIONE GAUSSIANA STANDARDIZZATA
Per agevolare il ricercatore la variabile x viene trasformata in una nuova variabile:
La distribuzione standardizzata presenta il vantaggio di consentire la predisposizione di tabelle che permettono di calcolare porzioni di area della distribuzione in relazione a determinati valori z.
σxxz -=
STANDARDIZZAZIONE DELLA NORMALE
Non è necessario che le distanze dalla media siano sempre multipli esatti della deviazione standard.
E’ sempre possibile determinare l’area sottesa alla porzione di curva delimitata da due ordinate.
Infatti, è possibile trasformare ogni curva normale in modo da permettere di calcolare il numero di casi sottostante ogni porzione della curva mediante l’uso di una tabella.

Quale frazione di casi ricade nell’intervallo 50 e 65?
Una distribuzione normale, media 0 e σ 1 viene indicata come curva standardizzata e Z è il valore standardizzato.
Una z di valore 1,5 indica che la distanza tra l’ordinata è a 1,5 σ dalla media.
Esistono tabelle che riportano per tutti le ordinate della curva standardizzata qual’è la proporzione di area sottesa.
s
xxz
−
−= 5,1
10
5065=
−=z
I valori di z sono riportati nella prima colonna a sinistra e nella riga posta in alto
Le prime due cifre di z si leggono sulla colonna, l’ultima sulla prima riga.
I vari numeri riportati nella tabella individuano la proporzione dell’area che è sottesa alla curva delimitate da un lato dalla media e dall’altro dall’ordinata z.
Esempio precedenteUno z di valore 1,5 indica che l’ordinata è a 1,5 σ dalla media.L’area delimitata dai punti (z = 1,5) è 0,4332.

ANALISI DI UN FENOMENO
Popolazione
Statisticadescrittiva
Statisticainferenziale
?Campione
Una variabile numericasappiamo si distribuiscenella popolazione generale di riferimento con media μ e deviazionestandard σ. . . . . ma μ e σ non sono noti!
e σ2
μ)(x
π2σ
1p(x) 2
2
−= −
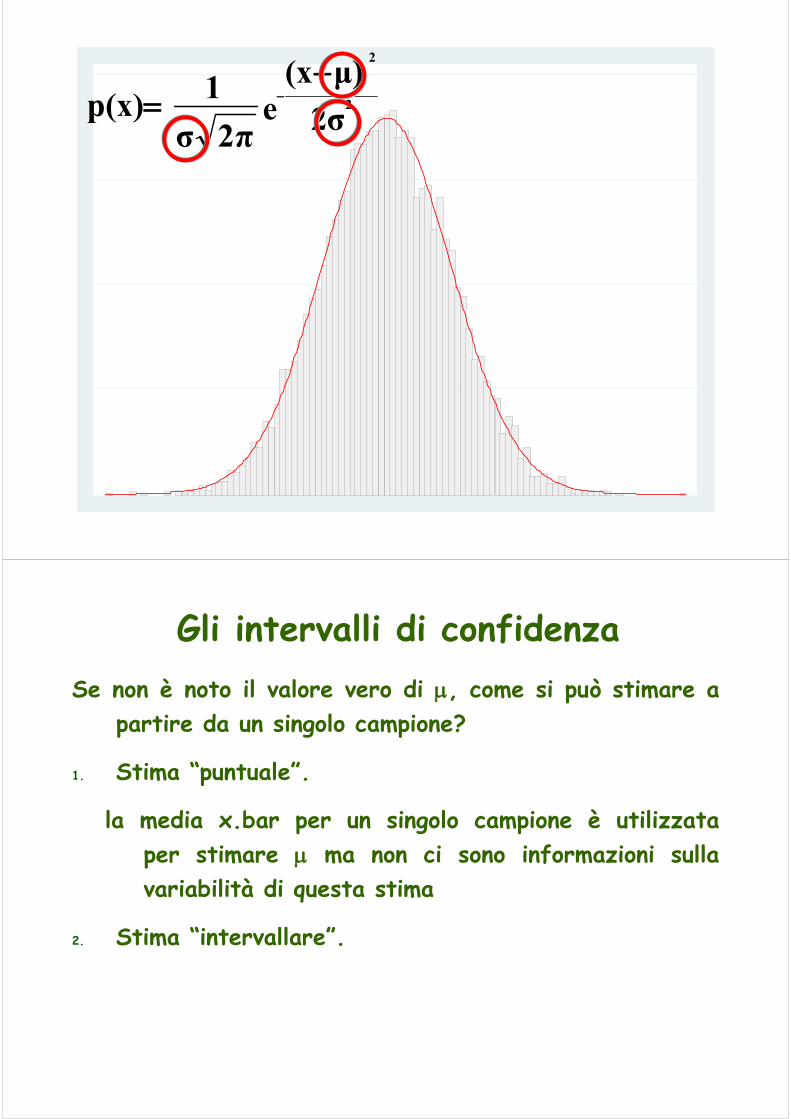
Gli intervalli di confidenzaSe non è noto il valore vero di μ, come si può stimare a
partire da un singolo campione?
1. Stima “puntuale”.
la media x.bar per un singolo campione è utilizzataper stimare μ ma non ci sono informazioni sullavariabilità di questa stima
2. Stima “intervallare”.

Stime per intervalliFino a questo punto abbiamo trattato l’analisi delle caratteristiche di una popolazione, calcolando media, varianza ecc. ossia quantità chiamate genericamente parametri.Quando l’osservazione dei dati riguarda solo un sottoinsieme della popolazione, ovvero si svolge un’indagine campionaria, l’analisi riguarderà solo i dati osservati.Quando un parametro della popolazione è stimato attraverso un singolo valore, tale valore è chiamato stima puntuale del parametro.
Oltre al valore puntuale di una stima, è interessante conoscere qual è il margine di errore connesso alla stima stessa.Si possono stabilire dei limiti entro i quali si ha una certa confidenza (1-α) che vi sia compreso il vero valore del parametro nella popolazione:
LIMITI FIDUCIALILIMITI FIDUCIALILimiti di affidabilitLimiti di affidabilitàà della stimadella stima
L’intervallo che definiscono si chiamaINTERVALLO FIDUCIALEINTERVALLO DI CONFIDENZA.

Infatti, ci chiediamo se xbar è una buona stima di μ. Purtroppo, essendo μ ignoto ciò è impossibile.
n
xx
n
1ii∑
==
Le proprietà della media campionaria si ricavano teoricamente ipotizzando di poter estrarre da una popolazione tutti i possibili campioni distinti di una determinata dimensione. Calcolata la media su ciascuno di questi, si ricava la sua distribuzione, che è detta:
distribuzione campionaria delle mediedistribuzione campionaria delle medie..Se il campionamento è casuale semplice, la media di questa distribuzione è uguale a μ ovvero la media campionaria è uno stimatore corretto o non distorto della media della popolazione. (Teorema Limite Centrale)
Se la distribuzione non è centrata, lo stimatore si dice distorto. Le medie campionarie avranno una variabilitàpiù o meno elevata intorno al valore della media μ della popolazione.Il grado di addensamento della distribuzione campionaria intorno alla propria media si esprime con il termine efficienza e si misura con l’errore standard (nota σ):
Se σ è stimato con numerosità campionaria >60 allora:
n=ES σ
nsES ≈
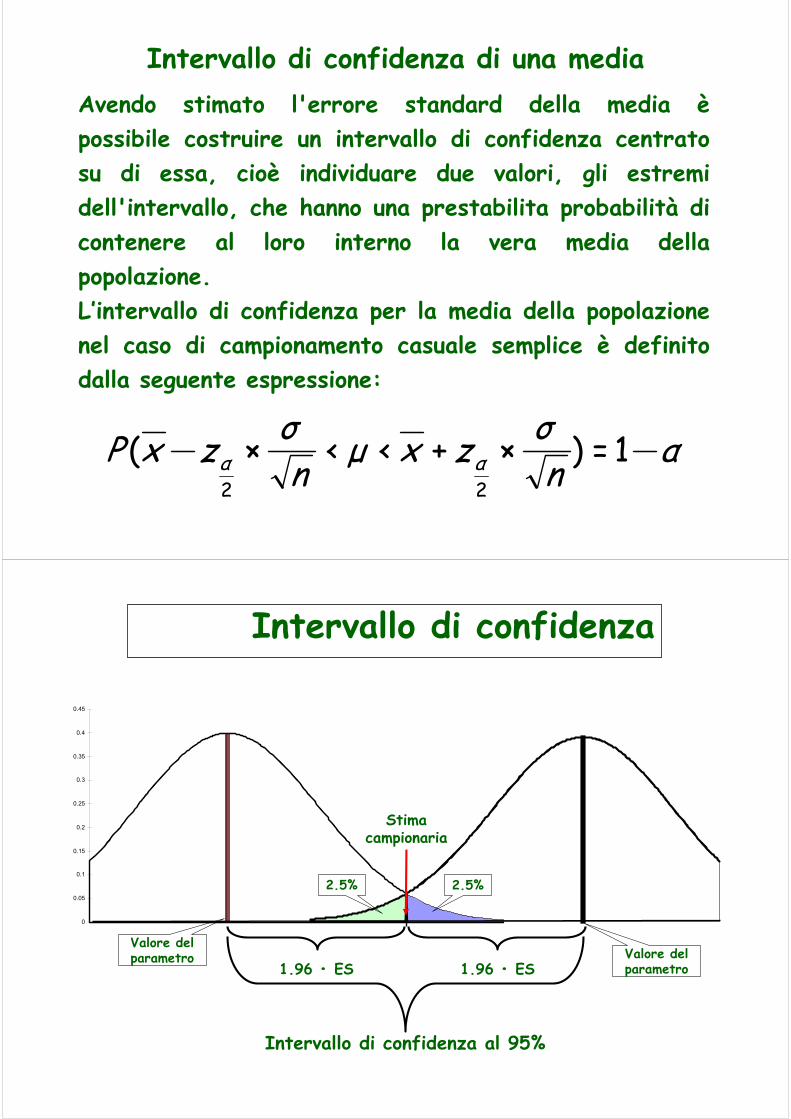
Intervallo di confidenza di una mediaAvendo stimato l'errore standard della media èpossibile costruire un intervallo di confidenza centrato su di essa, cioè individuare due valori, gli estremi dell'intervallo, che hanno una prestabilita probabilità di contenere al loro interno la vera media della popolazione. L’intervallo di confidenza per la media della popolazione nel caso di campionamento casuale semplice è definito dalla seguente espressione:
αnσzxμn
σzxP αα 1=)×+<<×(22
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
Valore del parametro
Intervallo di confidenza
2.5%
1.96 • ESValore del parametro
2.5%
1.96 • ES
Stima campionaria
Intervallo di confidenza al 95%

Intervallo di confidenza di una media
In generale la varianza della popolazione non è nota quindi è necessario sostituirla con la sua stima.Se la numerosità campionaria è elevata (n>60) allora vale l’approssimazione alla normale con la varianza stimata sulla base di quella calcolata sul campione.Ma se abbiamo numerosità inferiori, allora l’intervallo di confidenza per la media della popolazione diviene:
αnstxμn
stxP αα 1=)×+<<×(22
dove t è il quantile della distribuzione t di student con (n-1) gradi di libertà ed s è la varianza campionaria corretta (n-1 al denominatore).
La distribuzione t di StudentSe la deviazione standard σ della popolazione non è nota, non sempre è corretto utilizzare la distribuzionenormale standard per il calcolo degli intervalli di confidenza (n sufficientemente grande - >60)!
Si utilizza allora la deviazione standard del campione (s) ed un’altra distribuzione di probabilità continua, la distribuzione t di Student.
Introdotta dal matematico inglese William Sealy Gosset(1876-1937), che pubblicava articoli di statistica con lo pseudonimo di “Student”
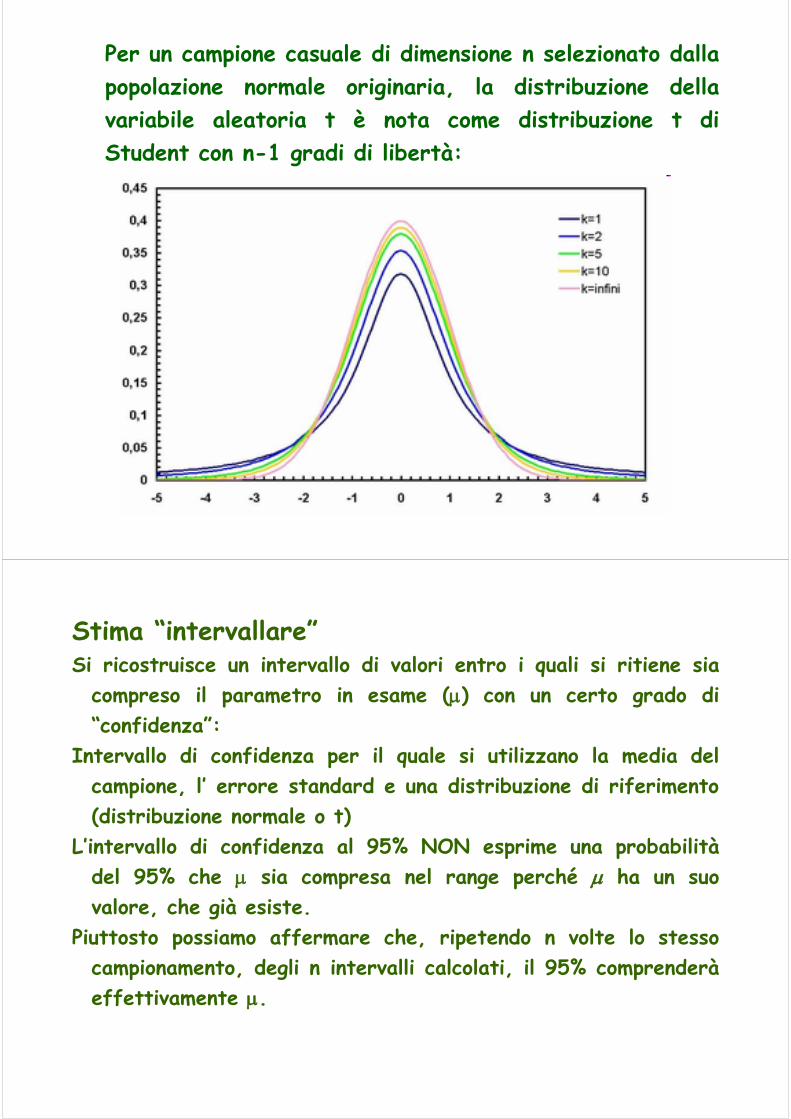
Per un campione casuale di dimensione n selezionato dallapopolazione normale originaria, la distribuzione dellavariabile aleatoria t è nota come distribuzione t di Student con n-1 gradi di libertà:
Stima “intervallare”Si ricostruisce un intervallo di valori entro i quali si ritiene sia
compreso il parametro in esame (μ) con un certo grado di “confidenza”:
Intervallo di confidenza per il quale si utilizzano la media del campione, l’ errore standard e una distribuzione di riferimento(distribuzione normale o t)
L’intervallo di confidenza al 95% NON esprime una probabilitàdel 95% che μ sia compresa nel range perché μ ha un suovalore, che già esiste.
Piuttosto possiamo affermare che, ripetendo n volte lo stessocampionamento, degli n intervalli calcolati, il 95% comprenderàeffettivamente μ.

ESEMPIOa. Ho misurato la pressione sistolica a 100 studenti, che
considero rappresentativi di una popolazione (reale o teorica) molto più ampia.
b. Nel campione la media è 123.4 mmHg e la deviazione standard (calcolata con n-1) è 14.0 mmHg
Cosa posso dire sul valore medio della pressione sistolica nellapopolazione?
La prima considerazione, che non ha a che fare con l’inferenza statistica, dovrà essere sulla qualità delle misure fatte!
La seconda considerazione, che non ha a che fare con l’inferenza statistica, dovrà essere sulla possibilità di selection bias nel campione osservato!
Supponiamo che questi problemi non ci siano.
La stima puntuale del parametro ignoto sarà, ovviamente, uguale alla media campionaria: Xbar = 123.4 mmHg
Per costruire un intervallo di confidenza dovrò considerare la distribuzione campionaria del mio stimatore, che è, per ogni valore μ del parametro, una distribuzione normale se:La distribuzione della pressione nella popolazione è, almeno
approssimativamente, normale.oppureLa distribuzione non è normale, ma il campione è sufficientemente grande
(teorema del limite centrale).

La deviazione standard della distribuzione campionaria della media, chiamata errore standard della media, èdato da ES(x) = σ/√n.
Per trovare dei valori del parametro che darebbero luogo, in caso di campionamento ripetuto, a meno del 5% dei campioni caratterizzati da valori dello stimatore uguali, o più estremi, di quello osservato, sfrutto la conoscenza dei percentili della distribuzione normale standardizzata.
Infatti, so che se il parametro fosse maggiore di Xbar + 1.96 • σ/√n
la coda della distribuzione campionaria a sinistra di X conterrebbe meno del 2.5% di probabilità.
Analogamente, se il parametro fosse minore diXbar - 1.96 • σ/√n
la coda della distribuzione campionaria a destra di X conterrebbe meno del 2.5% di probabilità.
Ne concludo che:Xbar ± 1.96 • σ/√n
è un intervallo di confidenza al 95% per la media osservata.

Purtroppo, non conosco σ!
La formula precedente si può usare:nella (improbabile) ipotesi di conoscere la varianza della
variabile nella popolazioneper campioni grandi (n>60), utilizzando la varianza
campionaria (calcolata con n-1) come stimatore della varianza della popolazione
Nel nostro caso (n=100), l’intervallo di confidenza al 95% sarà:123.4 ± 1.96 • 14/√100 = (120.66, 126.14)
Antonello Antonelli
Pianificazione e Controllo StrategicoQualità e Risk Management
Progetto Formativo Aziendale
“Il controllo delle ICA”(Infezioni Correlate all’Assistenza)

Principi di statistica ed epidemiologiaapplicati alle scienze biomediche
EPIDEMIOLOGIA
Dal punto di vista etimologico, epidemiologia è una parola composita di origine greca, che letteralmente
significa «discorso riguardo alla popolazione»
DEFINIZIONE DI EPIDEMIOLOGIA

A parte il chiaro riferimento all’infettivologia(su cui si è mossa primariamente)
la definizione più consona è, forse:
LO STUDIO DELLA FREQUENZA, DISTRIBUZIONE E DETERMINANTI DI SALUTE/MALATTIA (e non solo)(e non solo)NELLE POPOLAZIONI.
. . . cioè l’analisi di tutti quei fenomeniin un certo qual modo
correlati con lo stato di salute/malattia . . .
1° occorre sottolineare che l’attività non è sul singolo individuo ma si studia un dato fenomeno collettivamente in più individui, evidentemente organizzati o classificati in popolazioni.
Infatti, l'epidemiologia “attuale” è disciplina che si occupa di valutare tanti fenomeni +/- correlati con la salute (sia umana, sia veterinaria) esclusivamente a livello di popolazione, piuttosto che di individuo (esemplare).
Il singolo è importantesolo in quanto parte di un collettivo

Lo studio dei fenomeni correlati con la salute in senso esteso comporta chiarire alcune parole chiave:
FREQUENZA – “quanto” il fenomeno compare;DISTRIBUZIONE – “dove” e “quando” il fenomeno compare;DETERMINANTI – “fattori” che se mutano producono una variazione della frequenza o distribuzione del fenomeno di interesse;SALUTE/MALATTIA – oggetto delle analisi e valutazioni sono sia gli individui malati, sia sani;POPOLAZIONI – gruppi di individui “raggruppabili” in base ad alcuni fattori in comune (classificazione naturale e/o logicamente indotta).
L’EPIDEMIOLOGIA è una disciplina che ha delle specifiche sue proprie ed integra metodi e strumenti di altre (matematica, statistica, biologia, medicina,. . . ):
questo aspetto la configura come estremamente
MULTIDISCIPLINARE
Disciplina che studia lo stato Salute/Malattia e i fenomeni ad esse correlati attraverso:
l’osservazione della distribuzione e dell’andamento della Salute/Malattia nelle popolazioni;l’individuazione dei fattori influenzanti;la programmazione di azioni preventive o curative
(epidemiologia sperimentale ed epidemiologia dei servizi)

AMBITI DI APPLICAZIONE:• studio dei fenomeni epidemici;• ricostruzione della storia naturale delle malattie e
della loro diffusione – nesso di causalità;• identificazione fattori di rischio e di fattori
protettivi;• valutazione degli interventi sanitari preventivi,
diagnostici e terapeutici;• definizione delle priorità in sanità pubblica• valutazione di efficacia, efficienza e qualità dei
servizi sanitari;• evidence per la soluzione di problemi legali;• . . . . . .
Storia dell’epidemiologia
Il primo RCT dell’umanità

La Sacra Bibbia: Libro di Daniele - Capitolo 1 (3-16)
I RAGAZZI EBREI ALLA CORTE DI NABUCODONOSOR, re di Babilonia
(…) Il re ordinò ad Asfenàz, capo dei suoi funzionari di corte, di condurgli
giovani israeliti di stirpe reale o di famiglia nobile, senza difetti, di
bell'aspetto, dotati di ogni scienza, educati, intelligenti e tali da poter
stare nella reggia, per essere istruiti nella scrittura e nella lingua dei
Caldei.
Il re assegnò loro una razione giornaliera di vivande e di vino della sua
tavola; dovevano esser educati per tre anni, al termine dei quali sarebbero
entrati al servizio del re. (…) Ma Daniele decise in cuor suo di non
contaminarsi con le vivande del re e con il vino dei suoi banchetti e chiese
al capo dei funzionari di non farlo contaminare.
Dio fece sì che Daniele incontrasse la benevolenza e la simpatia del capo dei
funzionari. Però Asfenàz disse a Daniele: "Io temo che il re mio signore, che
ha stabilito quello che dovete mangiare e bere, trovi le vostre facce più magre
di quelle degli altri giovani della vostra età e io così mi renda colpevole davanti
al re". Ma Daniele disse al custode, al quale il capo dei funzionari aveva
affidato Daniele, Anania, Misaele e Azaria: "Mettici alla prova per dieci giorni,
dandoci da mangiare legumi e da bere acqua, poi si confrontino, alla tua
presenza, le nostre facce con quelle dei giovani che mangiano le vivande del re;
quindi deciderai di fare con noi tuoi servi come avrai constatato". Egli
acconsentì e fece la prova per dieci giorni; terminati questi, si vide che le loro
facce erano più belle e più floride di quelle di tutti gli altri giovani che
mangiavano le vivande del re.
Da allora in poi il sovrintendente fece togliere l'assegnazione delle vivande e
del vino e diede loro soltanto legumi.

MISURE DI FREQUENZA DEI FENOMENI
Attività fondamentale in epidemiologia è la quantificazione
dei fenomeni di interesse e dei fattori ad essi correlati.
La conoscenza del numero di individui portatori di una data
malattia o a cui carico è erogata una data prestazione in
una popolazione, è funzionale a dimensionare e prevedere
l'evoluzione del fenomeno nel tempo.
Contare i singoli casi, senza fornire alcun significativo
riferimento, è raramente utile in epidemiologia.
Dati utilizzabili ed interpretabili debbono essere espressi in
FORMATI ADEGUATI.
MISURE DI FREQUENZA: Intro
• PROPORZIONE (proportion)
• TASSO (rate)
• RAPPORTO (ratio)

PROPORZIONE (proportion)⇒ È una frazione;⇒ il numeratore è compreso nel
denominatore;⇒ adimensionale;⇒ 0 - 1 (0 – 100%).
Ad esempio la % di maschiin una popolazione.
TASSO (rate)⇒ Variazione di una grandezza per ognivariazione unitaria di un’altra(generalmente tempo);
⇒ i valori possono variare da 0 + ∞;⇒ istantaneo o medio;⇒ dimensionale.
Ad esempio la velocità in km/h.

RAPPORTO (ratio)⇒ Frazione;⇒ il numeratore non è parte del denominatore;
⇒ dimensionale.
Ad esempio il rapporto M/F.
INCIDENZA E PREVALENZA
Le misure di frequenza delle malattie possono descrivere:
1. L'insieme di tutti i casi esistenti in un determinato momento e in una determinata popolazione;
2. il verificarsi di nuovi casi.
A questo scopo si usano quindi due misure fondamentali: prevalenza e incidenza.
Caso unità statistica in osservazione interessata dal modificarsi del fenomeno in studio.
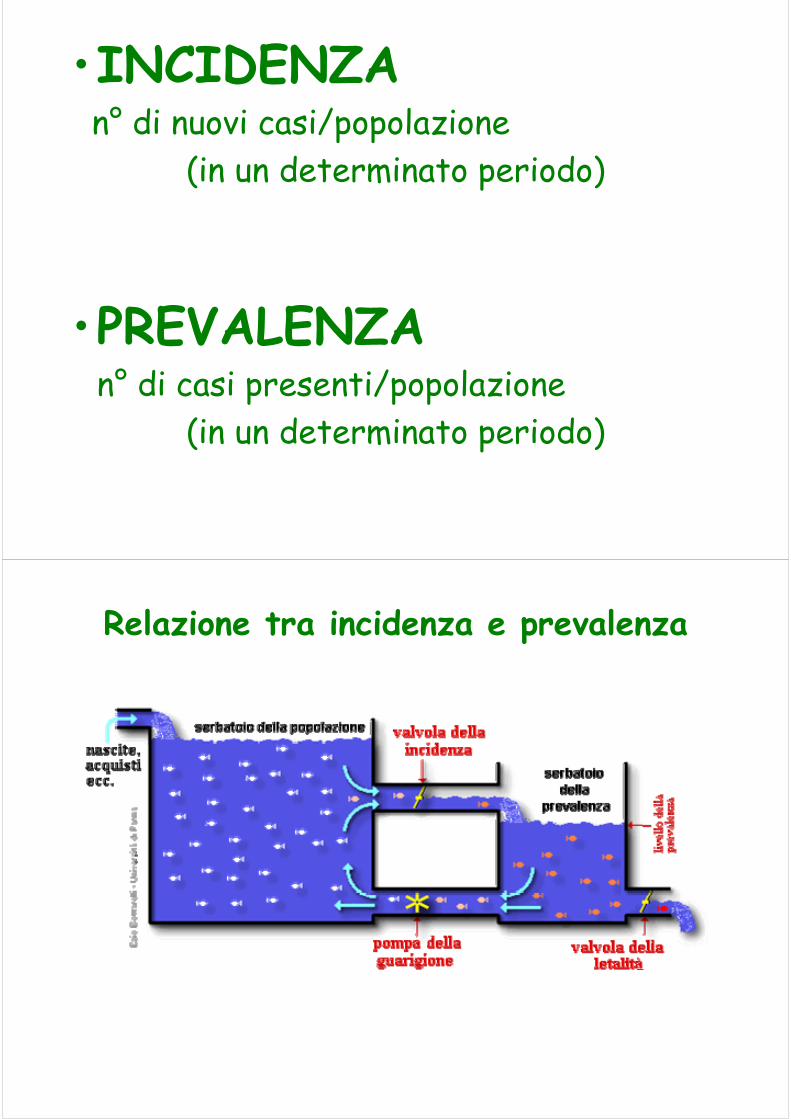
•INCIDENZAn° di nuovi casi/popolazione
(in un determinato periodo)
•PREVALENZAn° di casi presenti/popolazione
(in un determinato periodo)
Relazione tra incidenza e prevalenza

MISURE DI INCIDENZA• Rischio (risk)• Tasso (rate)
Rischio(Incidenza Cumulativa)
È la probabilità per un individuo di una data popolazione e senza il fenomeno in studio di sviluppare lo stesso in un intervallo di tempo definito.
È adimensionale (senza unità di misura)!Ha un valore nell’intervallo 0 – 1!
IC = n° nuovi casi / T popolazione all’inizio del periodo di analisi in un dato Δt.
Proporzione della popolazione in studio che in un determinato periodo di tempo manifesta il fenomeno di interesse (Rischio individuale / P di manifestare il fenomeno).

Tasso (rate)(Densità di Incidenza)
Potenziale istantaneo di manifestare il fenomeno (divenire caso) per unità di tempo, al tempo definito, in rapporto alla dimensione della popolazione a “rischio”al tempo definito.
Ha la dimensione 1/tempo!Riferito alla popolazione.Riferito ad un punto nel tempo.I = n° casi / Σ persone – tempo.È una misura istantanea della “forza” di manifestarsi di
un dato fenomeno!Normalmente si utilizza un moltiplicatore (x 10, x100).
(esempio di Tasso Medio)
MISURE DI PREVALENZA• Prevalenza puntualeProbabilità che un individuo sia caso al tempo definito t.
• Prevalenza di periodoProbabilità che un individuo sia caso nell’intervallo Δt.
Si parla anche di TASSO di PREVALENZA puntuale o di periodo come:
P = n° di individui che manifestano il fenomeno in un dato momento / n° complessivo di individui nella popolazione in quel dato momento.

RelazioneIncidenza - Prevalenza
Se Incidenza e Durata sono stabili, la Prevalenza si può approssimare al prodotto dell’incidenza per la durata:
P = I x DAd esempio: I = 10 casi per 10.000 individui l’anno
D = 2 anniP = 20/10.000.
L’ODDSIl rapporto tra la probabilità di un evento e la
probabilità di un non evento:ODDS di Incidenza: I / 1-IODD di prevalenza: P/ 1-P

n(a+b+c+d)
b+da+c
c+ddcExp-
a+bbaExp+
Noncasi
CasiLe tabelle di contingenza
500400100
38032060Exp-
1208040Exp+
Noncasi
Casi

Misure di associazione: il RRLo scopo di uno studio epidemiologico è quantificare l’associazione tra esposizione ed esito di interesse.Per raggiungere tale obiettivo, si deve confrontare l’incidenza di malattia in un gruppo di individui esposti al fattore di rischio di interesse con l’incidenza in un gruppo di persone non esposte.Il rapporto tra incidenza negli esposti e incidenza nei non esposti allo stesso fattore di rischio è definito RISCHIO RELATIVO (RR) e rappresenta l’eccedenza di rischio degli esposti rispetto ai non esposti:
d)+c/(c
b)+a/(a=
I
I=RR
-E
+E
Il Rischio Relativo (Risk Ratio) costituisce una misura della forza dell’associazione tra fattore di rischio e malattia e dovrebbe risultare pari a 1 (o un valore molto vicino, considerando la fluttuazione dovuta al caso) se il fattore non ha influenza nello sviluppo della malattia.
Esso risulta, invece, tanto più elevato quanto più l’esposizione è associata alla malattia.
Se il RR ha un valore inferiore a 1, il fattore considerato esplica un’azione protettiva nei confronti dell’insorgenza della malattia.

Se RR=1 (il valore è compreso all’interno dell’IC)questo significa che non c’è eccesso di rischio nel gruppo degli esposti. Quindi non c’è una relazione dimostrata tra la malattia e l’esposizione.
Se RR >>1questo significa che esiste un eccesso di rischio nel gruppo degli esposti. Quindi esiste una relazione tra l’esposizione al fattore studiato e la presenza della malattia. Il fattore può essere considerato come un fattore di rischio. Si conclude affermando che se un individuo è esposto, il rischio di contrarre la malattia è RR volte superiore rispetto a chi non è esposto.
0 1 ∞
RR<1Fattore protettivo
RR=1Assenza Rischio
RR>1Fattore di Rischio

500400100
38032060Exp-
1208040Exp+
Non
casi
Casi
500400100
38032060Exp-
1208040Exp+
Non
casi
Casi
R Exp+ = 40/120 = 0.33R Exp- = 60/380 = 0.16RR E+ vs E- RE+/RE- = 0.33/0.16 = 2.0
Allo stesso modo, ma con specifiche di calcolo differenti si calcolano:
Rapporto tra Tassi (Rate Ratio)Rapporto tra Odds (Odds Ratio)Rapporto tra Prevalenze (Prevalence Ratio)
NB: in inglese Rapporto tra Rischi e Rapporto tra Tassi ha lo stesso acronimo RR!

INTRODUZIONE AL DISEGNO DEGLI STUDI
EPIDEMIOLOGICI
Studio epidemiologico- Processo;
- Documentato dal disegno . . . alla realizzazione;
- Finalizzato a produrre “prove (evidence) empiriche” su un argomento dato.

Studio epidemiologico1° Obiettivo dello studio
Ipotesi di ricerca;
2° Disegno
identificare il disegno di studio che valuta con maggiore validità ed efficienza l’ipotesi di ricerca (.doc).
Esperienza in una popolazione dell’occorrenza di stati/eventi di
salute in rapporto a caratteristiche/esposizioni.
Studio epidemiologico

“Catturata” da uno studio epidemiologico è l’occorrenza di
outcome in funzione di un determinante, tenendo conto di confondenti e modificatori di
effetto!
Per “fare inferenza”
Studio epidemiologico
Obiettivo generale:Massimizzare VALIDITÀ
(capacità di “misurare” quello che “veramente” accade nella
popolazione)
Al costo (dello studio)più basso possibile.
Studio epidemiologico

SEMPLIFICAZIONEDELLA REALTA’
(nessuno studio potrà mai specificare tutti i possibili confondenti e modificatori di effetto)
IMPOSSIBILE RAPPRESENTARE LA COMPLESSITA’ DELLA
NATURA
Studio epidemiologico
Unità di osservazione
- INDIVIDUI-EVENTI
- GRUPPI DI INDIVIDUI-EVENTIcd studi ecologici

Tipologia dei dati- PRIMARI
raccolti per lo scopo dello studio (ad hoc);
- SECONDARI raccolti originariamente per altri scopi (ad es. sistemi informativi).
Tipologie di Studio epidemiologico
osservazionali/analiticisperimentali/osservazionaliretrospettivi/prospettici… … … …
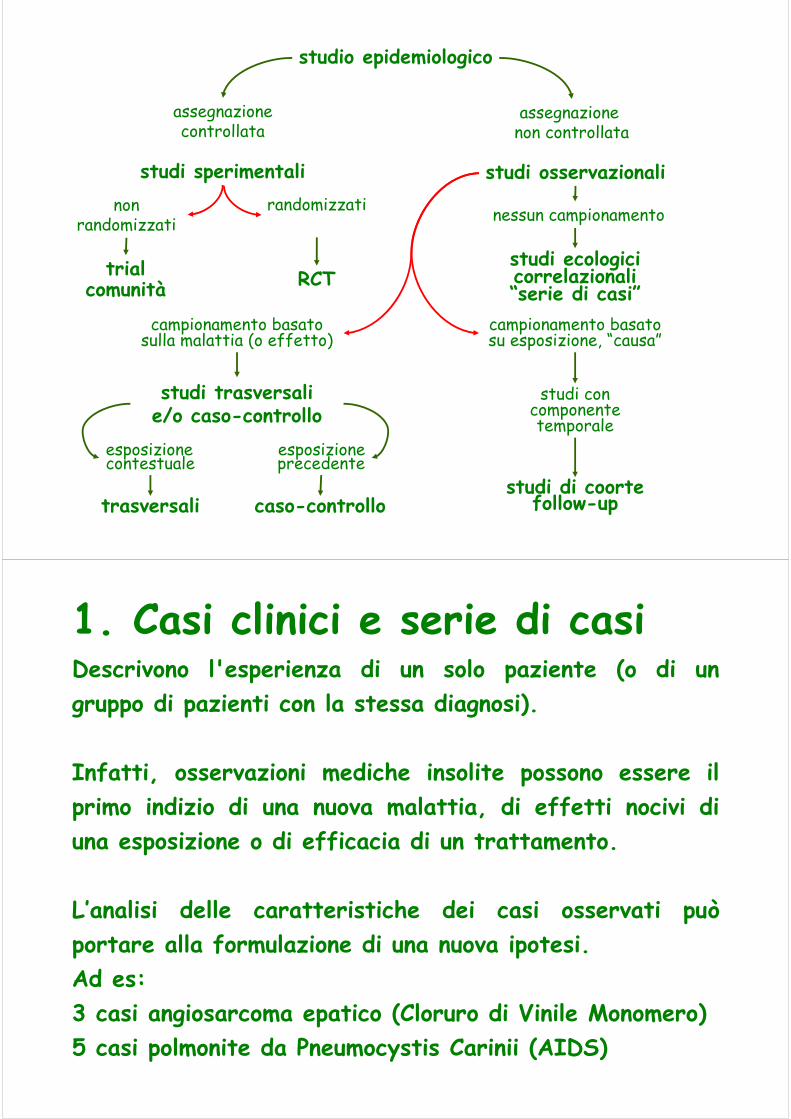
studio epidemiologico
studi sperimentali studi osservazionali
assegnazionecontrollata
assegnazione non controllata
nonrandomizzati
randomizzati
trialcomunità RCT
campionamento basatosulla malattia (o effetto)
nessun campionamento
studi ecologicicorrelazionali“serie di casi”
campionamento basatosu esposizione, “causa”
studi trasversalie/o caso-controllo
studi di coortefollow-up
esposizionecontestuale
esposizioneprecedente
trasversali caso-controllo
studi concomponentetemporale
Descrivono l'esperienza di un solo paziente (o di un gruppo di pazienti con la stessa diagnosi).
Infatti, osservazioni mediche insolite possono essere il primo indizio di una nuova malattia, di effetti nocivi di una esposizione o di efficacia di un trattamento.
L’analisi delle caratteristiche dei casi osservati può portare alla formulazione di una nuova ipotesi.Ad es:3 casi angiosarcoma epatico (Cloruro di Vinile Monomero)5 casi polmonite da Pneumocystis Carinii (AIDS)
1. Casi clinici e serie di casi

Abbiamo interesse ad indagare sulla plausibile relazione tra
PESO ALLA NASCITA dei neonatie
CONSUMO DI PESCE
Disponibili:- dati di popolazione sul peso alla nascita;- dati di popolazione su consumo di pesce
Possiamo affrontare unoSTUDIO DI CORRELAZIONE / ECOLOGICO
2. Studi ecologici e serie temporali

2000
2500
3000
3500
4000
0 100 200 300 400 500consumo pesce pro-capite (gr./giorno)
peso
med
io a
lla
nasc
ita
(gr.
)
Studio di correlazione, ecologico → alcune indicazioni:• Il peso alla nascita aumenta in relazione al consumo di
pesce, . . . E ciò si osserva in più popolazioni!Ma:1.Non sappiamo se sono le persone che mangiano più
pesce ad avere bambini di più alto peso alla nascita!2.Le popolazioni con più alto consumo di pesce potrebbero
essere diverse per:• caratteristiche genetiche;• fumo;• altri comportamenti alimentari;• caratteristiche gestazionali;
3.Direzione dell’associazione (?).

Studio di correlazione, ecologico:
Mostra una associazione tra caratteristiche (peso alla nascita e consumo di pesce) della popolazionedella popolazione;
Ma poiché le “Unità di osservazione” sono “popolazioni” e non individui >>>>
>>>> nulla possiamo dire sull>>>> nulla possiamo dire sull’’associazione tra consumo di associazione tra consumo di pesce degli individui (esposizione) e peso alla nascita pesce degli individui (esposizione) e peso alla nascita (esito) dei bambini che nascono da questi individui.(esito) dei bambini che nascono da questi individui.
Gli studi ecologici e le serie temporali . . .
Vantaggi: usano informazione già disponibile, veloci, poco costosi → "primo passo“!Svantaggi:• impossibile collegare esposizione e malattia nei singoli• individui componenti la popolazione;• mancanza di controllo dei fattori di confondimento;• incapacità di definire direzione dell'associazione.
Inoltre: la mancanza di correlazione non esclude la presenza dell'associazione e presentano difficoltà ad
indentificare relazioni non lineari.

Negli studi ecologici si usano misure che rappresentano caratteristiche di intere popolazioni
per descrivere una malattia in relazione a un fattore di interesse!
sigarette vendute (procapite)
mor
ti p
er m
alat
tia
coro
nari
ca
Studi ecologici e serie temporali: esempi . . .
Frequenza dell’utilizzo di cinture di sicurezza e numero di casi di infortunio in Gran Bretagna
Uso
delle
cint
ure
di s
icur
ezza
(%)
No
di in
fort
uni
4000
2000
3000
0
1000
1982 1983Legge sulle cinture di sicurezza in vigore
20
40
60
80
100
0MG OM L MF A SA ALG GAMFGDNS O N D

Indagine campionaria di popolazione (ad un dato t)
• Campione di madri;
• Raccolta informazioni “retrospettiva” e “concorrente”:
→ su esposizioni (comportamenti alimentari in gravidanza) ed altri possibili confondenti;
→ esito (peso alla nascita del bambino)!
3. Studi trasversali (cross-sectional)
Problemi:Dimensioni del campione, rispetto a:
→ Distribuzione attesa dell’esposizione - consumo pesce→ Distribuzione attesa dell’esito - peso alla nascita→ Effetto (RR) che si vuole stimare.
Funzionalmente al livello di precisione (significativitàstatistica che voglio utilizzare) . . . il valore di alfa!
Misura contemporanea e retrospettiva di esito, esposizione e confondenti;Impossibile valutare la “Direzione” delle eventuali associazioni osservate.

STUDI TRASVERSALI
STIMARE LA PREVALENZA DI UNA CONDIZIONE/MALATTIA/EVENTO/ESPOSIZIONE
A UN TEMPO DEFINITOIN UNA SPECIFICA POPOLAZIONE
CAMPIONE CASUALE DELLA POPOLAZIONE
“PARTICOLARISTICI”
I RISULTATI SI APPLICANO ALLA POPOLAZIONE ED AL TEMPO DELLO STUDIO
Poiché l'esposizione e la presenza di malattia sono rilevati nello stesso punto del tempo in molti casi non èpossibile stabilire se l'esposizione è precedente (o susseguente) l'insorgere della malattia.
Cautela nell'interpretazione!
Inoltre: poiché sono studiati i casi prevalenti (e non gli incidenti), i dati ottenuti rifletteranno sempre i determinanti della sopravvivenza (oltre agli eventuali fattori causali).
Il problema dell’uovo e della gallina

STUDI TRASVERSALI(fotografia della realtà)
Misura contemporanea di esposizioni ed esito!
STUDI LONGITUDINALI(film della realtà)
Misura longitudinale di esposizioni ed esito!
CASI: BAMBINI CON ALTO PESO ALLA NASCITAESITO: ALTO PESO ALLA NASCITAESPOSIZIONE: CONSUMO DI PESCE (DELLE MADRI)
Studiamo i comportamenti alimentari, particolarmente il consumo di pesce, durante la gravidanza delle madri dei bambini con alto peso alla nascita per valutare una possibile associazione causale.
Cerchiamo di misurare anche possibili “confondenti”!
STUDI LONGITUDINALI

Casi
t
MisuraESPOSIZIONE
STUDIO
Controlli
t
MisuraESPOSIZIONE
STUDIO
Quale confronto? Occorrono i Controlli.Non Casi: bambini con peso alla nascita normale!Su cui indagare la medesima esposizione (Madri di bambini NON con alto peso alla nascita; madri dalla stessa popolazione delle madri da cui avrebbero potuto nascere/essere osservati i casi.

Definizione concettuale di StudioCASO - CONTROLLO
Si indaga contestualmente sull’esposizione dei casi e di un certo numero di controlli rappresentativi della stessa
popolazione da cui sono originati i casi.
In tal modo si ottengono informazioni da confrontare sugli eventuali differenti livelli di esposizione tra casi e controlli (consumo di pesce in gravidanza delle madri).
Manifestazione del caso ed esposizione sono longitudinali!(l’indagine è retrospettiva)
Selezionati . . . .
e
casi
controlli

Per ogni individuo è accertata l’eventuale esposizione al fattore di rischio in studio:
E+ E- E+ E-
casi controlli
?b+da+c
?dcExp-
?baExp+
ControlliCasiQuale misura di associazione ?

?407
?252Exp-
?155Exp+
ControlliCasiIl rapporto tra ODDS (OR)
Odds Casi = (5/7):((1-(5/7)) = (5/7):(2/7) = 2.5Odds Cont = (15/40):((1-(15/40)) = (15/40):(25/40) = 0.6OR Casi vs Cont O_Casi/O_Cont = 2.5/0.6 = 4.2• limiti nella misura dei confondenti• distorsioni nella misura “retrospettiva” di esposizione e confondenti• selezione dei controlli• no stima incidenza
?407
?252Exp-
?155Exp+
ControlliCasi
?407
?252Exp-
?155Exp+
ControlliCasi

Coorte
t
Osservazione
E+STUDIO
E-
n casi/non casi
n casi/non casi
Arruoliamo una coorte di donne di donne gravide e sulla base della misura dell’esposizione (comportamento alimentare consumo di pesce) classifichiamo ESPOSTI e NON ESPOSTI (gruppo di confronto).• Rileviamo e misuriamo potenziali confondenti• Follow-up gravidanza• Misura esito peso alla nascita.
Definizione concettuale di StudioCOORTE
Metodo di studio epidemiologico in cui possa essere identificato un sottoinsieme di una popolazione definita che è, è stato, o può essere nel futuro esposto o non esposto, o esposto in misura diversa, ad uno o più fattori che si ipotizza possano influenzare la probabilità di verificarsi di una data malattia o di un altro evento d'interesse.COORTE:gruppo di persone che condividono una esperienza comune entro un intervallo di tempo definito.

Si indaga su un campione rappresentativo della popolazione d’interesse per un dato Δt, raccogliendo informazioni su esposizione ed altre variabili d’interesse.L’esposizione o meno al fattore indagato discrimina la classificazione di esposti/controlli.Il follow-up della coorte permette di valutare l’insorgenza dei casi (incidenza) ed alla fine del Δt si potranno esprimere le misure di associazione.Esposizione e manifestazione casi sono longitudinali!(la relazione esposizione - esito è prospettica)
Studi di coorte
sinonimi:• follow -up• studi longitudinali• studi prospettici• studi d'incidenza• concurrent studies ...
terminologia varia e incongruente perchè riferita a:diversi elementi del disegnodiverse relazioni temporali

COORTE “CHIUSA”- Ingresso definito dal verificarsi di un evento/ condizione- Uscita impossibile
POPOLAZIONE DINAMICA- Ingresso definito da uno stato- Uscita definita dal cessare dello stato
Studi di coorte popolazione in studio
RETROSPETTIVI / PROSPETTICIIn uno studio di coorte l'esperienza della popolazione osservata è caratterizzata da una sequenza temporale definita.
Questa sequenza temporale, pur non modificando la sua direzione, può essere allocata nel presente o nel passato rispetto allo spazio temporale in cui l'osservatore si trova.

esposizione esito
studio studio studio“prospettico” “retrospettivo”
STUDIO DI COORTEe . . . il tempo!
t
RETROSPETTIVI / PROSPETTICI
La definizione è relativa al tempo di calendario di conduzione dello studio vs il tempo di calendario cui si riferiscono gli eventi (esposizioni ed esiti) ;
Riferisce alla direzione dell’accertamento dell’esposizione e dell’esito;
Nel senso dell’inferenza causale non cambia la logica, semmai è differente l’accuratezza nell’accertamento di un qualcosa che è avvenuto in passato!

STUDIO DI COORTE
Nell’esempio della relazione tra consumo di pesce in gravidanza ed alto peso alla nascita, il gruppo di confronto fornisce una stima dell’occorrenza attesa di esito (alto peso nascita) nel gruppo degli esposti in assenza dell’esposizione!
In ogni caso esposti e non esposti sono selezionati in modo non casuale.
Evoluzione successiva nella definizione del protocollo di studio comporta che:
sarebbe necessario assegnare la popolazione in studio all’esposizione in modo CASUALE.
Cioe’ . . .
Fare in modo che esposti (trattati) e non esposti (controlli) differiscano tra di loro solamente per l’esposizione (trattamento) e per “caso”
““RANDOMIZZAZIONERANDOMIZZAZIONE””

STUDIO RANDOMIZZATO CONTROLLATORANDOMIZED CONTROLLED TRIAL (RCT)
• Randomizzazione = confrontabilità all’inizio dello studio, no confondimento• Cecità (Blinding) = compliance e misura dell’esito confrontabili, no misclassificazione differenzialeIsolamento dell’effetto dell’esposizione allo studio
Gli RCT sono fondamentalmente degli studi di coorte in cui l’assegnazione all’esposizione non è casuale ma predefinita dallo sperimentatore su individui confrontabili (ossia provenienti dalla stessa popolazione di riferimento)!
Nell’esempio dell’alto peso e consumo di pesce:
Esposizione/trattamento = dieta ad alto contenuto di pesce o ω3 acidi grassi
Randomizzazione = donne gravide assegnate casualmente al trattamento
Cecità (Blinding) = le persone arruolate non sanno se sono trattate/esposte – non sanno cosa mangiano ( x ω3acidi grassi)
Isolamento = ai non-esposti/non-trattati alimento simile ai trattati ma senza ω3 acidi grassi

Se si osserva una differenza di occorrenza dell’esito tra esposti e non esposti . . .
1. EFFETTO DELL’ESPOSIZIONE
2. ALTRE ETEROGENEITA’ TRA GRUPPI (difetti di randomizzazione)
3. CASO
A5.1
"Uno dei maggiori disordini dello spirito è
vedere ciò che si vuole vedere“
. e, conseguentemente, ancor piùNON vedere ciò che NON si vuol VEDERE!

La distorsione dei risultatinegli
STUDI EPIDEMIOLOGICIBIAS e Modificazione d’effetto
Qualsiasi tendenza nella raccolta, l'analisi, l'interpretazione, la pubblicazione o la revisione dei dati, che possa portare a conclusioni che sono sistematicamente diverse dalla verità (Last, 2001).
Un processo a qualsiasi stato di inferenza che tende a produrre risultati che si discostano sistematicamente dai veri valori (Fletcher et al, 1988).
Errore sistematico nella progettazione o conduzione di uno studio (Szklo et al, 2000).
Cosa è il Bias?

Gli Errori possono essere differenziali (sistematici) o non differenziale (casuali).
Errore Casualeuso di misure non valide che incide in modo analogo
per casi e non casi Errore Differenziale
uso di misure non valide che incide in modo diverso per casi e non casi
Il termine “bias” dovrebbe essere riservato per gli errori differenziali o sistematici.
Il Bias è l’errore sistematico
0
2
4
6
8
10
12
14
0 5 10 15 20 25 30 35
Errore casuale

0
2
4
6
8
10
12
14
0 5 10 15 20 25 30
Errore sistematico
Caso o BiasIl Caso provoca un errore casuale (errore di misura)! Il Bias provoca un errore sistematico (staratura)!
Gli errori casuali tenderanno ad annullarsi l'un l'altro proporzionalmente all’aumento della dimensione del campione!
Gli errori sistematici non si annulleranno a vicenda qualunque sia la dimensione del campione!
Il Caso determina l’inevitabile imprecisione dei risultati.Il Bias genera risultati inesatti!

Il caso è un elemento delle nostreosservazioni, misure o
determinazioni assolutamenteinevitabile, imprescindibile!
Il bias, la distorsione sistematica, è un elemento assolutamente
arginabile, controllabile o evitabile!
Classificazione• Bias di selezione Natura del campione non rappresentativa
• Bias di Informazione (misclassificazione)
Errori nella misurazione di esposizione o malattia
• Bias di confondimentoDistorsione della relazione esposizione - malattia da parte di altri fattori.
Bias differenti non si escludono a vicenda

Ad esempio in uno Studio caso-controllo . . . I controlli hanno meno probabilità di esposizione vs casi. Esito: tumore al cervello;Esposizione: linee elettriche ad alta tensione
Casi scelti in aree dove non vi sono linee elettricheControlli scelti in aree dove vi sono linee elettriche
Differenze sistematiche tra i casi ed i controlli
Bias di selezione:Differenze selettive tra i gruppi in confronto che alterano il rapporto tra esposizione e esito
Self-bias di selezione: Ad esempio, si desidera determinare la prevalenza di infezione da HIV Arruolamento di volontari per la fase di test
É questa una popolazione adeguata per trarre delleconclusioni?
Healthy worker effect (effetto lavoratore sano)
È un'altra forma di auto-bias di selezione cioè un processo di "Auto-screening“ per cui (ad esempio in coorti lavorative) le persone che sono malate si auto-eliminano dalla popolazione lavorativa attiva

Bias di selezione (altro esempio) Bias Diagnostico (o di workup):
La diagnosi (selezione dei casi) può essere influenzata dalla conoscenza sull’esposizione.Ad esempio in uno Studio caso-controllo dove l’esito èla malattia polmonare e l’esposizione è l’abitudine al fumo!
Il radiologo, consapevole che il soggetto fuma, durante la lettura dell’esame può essere indotto ad osservare con maggiore attenzione una radiografia o ad iper-valutare determinate evidenze diagnostiche.
Bias di InformazioneFonti:
• Soggetto• Osservatore• Strumenti

Recall bias:I soggetti esposti hanno una maggiore probabilità di
ricordare l'esposizione ed i casi tendono a valutare con più attenzione la loro storia passata alla ricerca di spiegazioni della loro malattia.
I controlli, di contro, non avendo percezione della malattia, possono esaminare meno attentamente la loro storia passata.
In particolare si verifica:- in studi caso-controllo;- negli studi retrospettivi (o a posteriori).
Individui con grave malattia tendono ad avere ricordi più completi quindi più informazioni
sull’esposizione.
Persone che sono consapevoli di essere i partecipanti di uno studio si comportano in
maniera diversa (effetto Hawthorne).

Come controllare il Bias di Informazione- Cecità (Blinding)
Impedisce a intervistatori e investigatori di conoscere quali sono i casi e quali i controlli o chi èesposto e chi no!
- Uso di questionari Utilizzare più domande che chiedono le stesseinformazioni (agisce come doppio-check)
- Precisione Diagnosi formulata in base a raccolta di dati provenienti da varie fonti o con strumentazione piùprecisa.
Bias di Confondimento o Fattore di confondimento o . . .
CONFONDENTE
Un terzo fattore, ASSOCIATO sia all’esposizione, sia all’esito, e che determina, parzialmente o completamente, l’associazione tra i due.

Esposizione Esito
CONFONDENTEUn confondente, per essere tale deve:
1. Essere associato con l’esposizione senza esserne unaconseguenza;
2. Essere associato all’esito indipendentementedall’esposizione;
3. Non entrare nel nesso di causalità tra E+ ed esito.
. . . in una relazione E+ vs Esito
Caffè K polm.
FUMODall’analisi dei dati scopriamo che l’assunzione di caffè
(ed il dosaggio) è associata alla comparsa di K polmonare. C’è confondimento?
1. Chi beve caffè è spesso fumatore;
2. Il fumo è associato al K polmonare;
Il fumo è un confondente dell’associazione (falsa) traassunzione di caffè e K polmonare.
Un Un esempioesempio

Come controllare i fattori di confondimento?Nello fase di progettazione dello studio1. RESTRIZIONE di soggetti in base al potenziale
fattore di confondimento;2. ASSEGNAZIONE RANDOM di soggetti ai gruppi di
studio;3. MATCHING i soggetti per potenziali fattori di
confondimento assicurando così la distribuzione tra i gruppi di studio.
Nell’analisi dei datiANALISI STRATIFICATE: analisi della varianza a più fattori, analisi con tecniche di regressione (es. della covarianza), modellizzazione.
1100101Exp-
110040Exp+
mesipersona
CasiTUn esempio di Confondimento
RT = 0.4

1001Exp-
100020Exp+
Mesipersona
CasiGiovani
1000100Exp-
10020Exp+
Mesipersona
CasiAnziani
RT = 2.0 RT = 2.0
2.00.10010001000.20010020
2.00.01010010.020100020
0.40.09211001010.036110040

Modificazione di effetto(interazione)
E’ la variazione della associazione esposizione-effetto relativamente ai livelli di una terza variabile - il modificatore di effetto, appunto.
E’ una proprietà intrinseca del fenomeno esposizione-effetto.
Non c’è disegno che la possa evitare se c’è.Matematicamente si può quantificare e pertanto, poichéè un fenomeno interessante . . . . . . occorre sia DESCRITTO!


















