
Utilizzo dei processi aziendali per la co simulazione di modelli dinamici
80
UNIVERSITÀ DEGLI STUDI DI TRIESTE Dipartimento di Ingegneria e Architettura Corso di Studi in Ingegneria Informatica Utilizzo dei processi aziendali per la co-simulazione di modelli dinamici Tesi di Laurea Magistrale Laureando: Besian POGACE Relatore: Chiar.mo Prof. Alberto BARTOLI Correlatore: Ph.D. Carlos KAVKA _____________________________________ ANNO ACCADEMICO 2015-2016
-
Upload
besian-pogace -
Category
Engineering
-
view
51 -
download
3
Transcript of Utilizzo dei processi aziendali per la co simulazione di modelli dinamici

UNIVERSITÀ DEGLI STUDI DI TRIESTE
Dipartimento di Ingegneria e Architettura
Corso di Studi in Ingegneria Informatica
Utilizzo dei processi aziendali per la co-simulazione di modelli dinamici
Tesi di Laurea Magistrale
Laureando: Besian POGACE
Relatore: Chiar.mo Prof. Alberto BARTOLI
Correlatore: Ph.D. Carlos KAVKA
_____________________________________
ANNO ACCADEMICO 2015-2016

Indice
1 Introduzione 1
2 Simulazione con FMI 32.1 Introduzione a FMI . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 FMI for Model Exchange . . . . . . . . . . . . . . . . . . . . 42.1.2 FMI for Co-Simulation . . . . . . . . . . . . . . . . . . . . . . 92.1.3 Struttura di un FMU . . . . . . . . . . . . . . . . . . . . . . 10
2.2 FMI 1.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.1 FMU Software Development Kit (SDK) . . . . . . . . . . . . 122.2.2 Struttura dei file sorgenti dei modelli . . . . . . . . . . . . . . 122.2.3 Esempi di modelli della SDK . . . . . . . . . . . . . . . . . . 16
2.3 Simulazione con Simulation X . . . . . . . . . . . . . . . . . . . . . . 172.3.1 Creazione di pendulum.fmu . . . . . . . . . . . . . . . . . . . 182.3.2 Co-simulazione di bouncingBall.fmu e inc.fmu . . . . . . . . . 18
2.4 Problemi di co-simulazione . . . . . . . . . . . . . . . . . . . . . . . 192.4.1 Co-simulazioni di modelli con retroazione . . . . . . . . . . . 202.4.2 Co-simulazione di modelli senza retroazione . . . . . . . . . . 21
2.5 FMI 2.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3 BPMN 263.1 Introduzione a BPMN . . . . . . . . . . . . . . . . . . . . . . . . . . 263.2 Elementi di primo livello . . . . . . . . . . . . . . . . . . . . . . . . . 273.3 Elementi di secondo livello . . . . . . . . . . . . . . . . . . . . . . . . 32
4 Utilizzo di BPMN 2.0 per la Co-simulazione 354.1 Analisi di progetto . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.2 Diagramma BPMN di co-simulazione . . . . . . . . . . . . . . . . . . 364.3 Esecuzione con BPMN Engine . . . . . . . . . . . . . . . . . . . . . 39
4.3.1 Activiti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.3.2 Elementi BPMN di Activiti . . . . . . . . . . . . . . . . . . . 414.3.3 JavaFMI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
i

5 Realizzazione del progetto 455.1 Simulazione di bouncingBall.fmu in Activiti . . . . . . . . . . . . . . 455.2 File di configurazione della simulazione . . . . . . . . . . . . . . . . . 515.3 Diagramma BPMN finale per la co-simulazione . . . . . . . . . . . . 525.4 SimulationServer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.5 Esecuzione e confronto con SimulationX . . . . . . . . . . . . . . . . 575.6 Interfaccia utente per la configurazione (MasterCreator) . . . . . . . 59
6 Conclusioni 636.1 Conclusioni personali dell’autore . . . . . . . . . . . . . . . . . . . . 64
A 68
ii

Elenco delle figure
2.1 Struttura interna di modello FMU . . . . . . . . . . . . . . . . . . . 112.2 Esempio di co-simulazione in SimulationX . . . . . . . . . . . . . . . 192.3 schema di descrizione in FMI 2.0 . . . . . . . . . . . . . . . . . . . . 24
3.1 Task del primo livello . . . . . . . . . . . . . . . . . . . . . . . . . . 283.2 Sub-process espanso (sinistra) e incapsulato (destra) . . . . . . . . . 293.3 Gateway di primo livello . . . . . . . . . . . . . . . . . . . . . . . . . 293.4 Alcuni start event e end event di primo livello . . . . . . . . . . . . . 303.5 Data object e data store . . . . . . . . . . . . . . . . . . . . . . . . . 313.6 Eventi intermedi di secondo livello . . . . . . . . . . . . . . . . . . . 323.7 Categorie degli eventi intermedi . . . . . . . . . . . . . . . . . . . . . 323.8 L’event gateway di secondo livello . . . . . . . . . . . . . . . . . . . . 333.9 Task di secondo livello . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.1 Diagramma BPMN di collaborazione tra processo Master e processiSlave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2 Diagramma BPMN del processo Slave . . . . . . . . . . . . . . . . . 384.3 Espansione del sub-process Simulation . . . . . . . . . . . . . . . . . 38
5.1 Primo diagramma semplice di simulazione di bouncingBall.fmu visua-lizzato in Eclipse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2 Seconda soluzione, con le fasi di simulazione, visualizzata in Eclipse . 465.3 Visualizzazione del processo slave per la terza soluzione in Eclipse . 495.4 Visualizzazione del sub-process Simulate in Eclipse . . . . . . . . . . 505.5 Visualizzazione dell’intero processo master finale in Eclipse . . . . . 535.6 (a) Simulazione con Activiti (b) Simulazione con SimulationX . . . . 585.7 Schermata iniziale di MasterCreator . . . . . . . . . . . . . . . . . . 595.8 Schermata di inserimento modello . . . . . . . . . . . . . . . . . . . 605.9 Schermata iniziale con modelli inseriti . . . . . . . . . . . . . . . . . 615.10 Schermata di inserimento dipendenza di input . . . . . . . . . . . . . 62
iii

Capitolo 1
Introduzione
Il progetto di tesi esposto nel presente elaborato ha avuto come obiettivo la defini-zione di una metodologia per la creazione del processo master per la co-simulazionedi modelli dinamici. Tale metodologia e stata formalizzata utilizzando un linguaggiostandard per la modellazione di processi aziendali. Il progetto si e inserito nelle at-tivita di ricerca dell’azienda ESTECO S.p.A., che mi ha ospitato come tirocinantee tesista. ESTECO infatti da anni studia come coniugare simulazioni di modellidinamici e workflow di processi aziendali.
L’interesse per le simulazioni di modelli e in continua crescita nell’ingegneriamoderna. L’aumento delle conoscenze e delle capacita computazionali ha permes-so agli ingegneri di trattare un numero sempre maggiore di argomenti e problemisempre piu complessi. Proprio la complessita, nonche altri fattori come i costi ol’impraticabilita reale di vari esperimenti, hanno determinato un interesse crescentenei confronti delle simulazioni in ambienti controllati e i relativi strumenti per laloro realizzazione. Tuttavia l’esistenza di molteplici tipi di simulazioni, di modelli,di strumenti e di ambiti di studio rappresenta un ostacolo all’integrazione finale dirisultati, la quale e determinante per renderli utili a livello pratico. Spesso questiproblemi sono risolti con metodi ad hoc, analizzando i casi specifici; tuttavia, lasoluzione definitiva al problema dell’integrazione consiste nel fornire agli strumentidi simulazione degli standard ben definiti.
L’interfaccia FMI (Functional Mockup Interface) si sta affermando come unodei principali standard in grado di supportare la creazione e lo scambio di modellidinamici tra vari strumenti, nonche di eseguire simulazioni di tali modelli [1]. Perquesti motivi FMI e lo standard scelto per la prima parte del progetto di tesi dedicataalle simulazioni di modelli dinamici. Si noti pero che l’interfaccia non definisce delleregole chiare nel processo di orchestrazione di vari modelli durante la simulazione.
Per quanto riguarda i workflow di processi aziendali, da anni l’attenzione del-l’azienda ESTECO e rivolta all’utilizzo di standard per la loro costruzione, conparticolare attenzione a BPMN (Business Process Model and Notation). Da alcunistudi e progetti svolti e emerso che questo standard possiede potenzialita di utiliz-
1

zo trasversali, che vanno oltre i processi aziendali e che possono essere sfruttate incampo ingegneristico.
L’obiettivo finale dell’intero progetto consiste dunque nell’utilizzare lo standardBPMN, per riuscire a coordinare simulazioni di modelli creati con l’interfaccia FMI.Questo obiettivo presenta delle difficolta, principalmente nel fatto che i due stan-dard non sono stati sviluppati per essere utilizzati insieme, in quanto appartengonoad ambiti molto diversi. Oltre a questo, entrambi gli standard sono relativamenterecenti (l’attuale versione per entrambi e la 2.0), sono utilizzati maggiormente inambito lavorativo dalle aziende e poco utilizzati in ambito accademico. Di conse-guenza la ricerca di informazioni per lo studio dei due standard o di lavori che nefanno uso e molto limitata. Durante la realizzazione di questo progetto, nella fasedi ricerca bibliografica, non sono stati trovati materiali nella letteratura che abbianocercato di raggiungere un obiettivo simile a quello appena presentato.
In conclusione di questa introduzione si illustrano brevemente il contenuto deicapitoli di cui si compone il presente elaborato. Il secondo e il terzo capitolo sonoincentrati, rispettivamente, sullo studio degli standard FMI e BPMN, e ne appro-fondiscono in particolare le caratteristiche ritenute piu importanti e utili in funzionedel progetto di tesi. Lo studio dello standard FMI comprende una fase realizzativadi modelli basati su tale standard, di cui sono presentati alcuni esempi nel relativocapitolo. Il capitolo 4 descrive in dettaglio la fase di analisi, studio e progettazioneper l’utilizzo contemporaneo e sinergico dei due standard al fine di raggiungere gliobiettivi prefissati. Nel capitolo viene presentato in particolare lo schema concet-tuale di simulazione modellato con BPMN, che rappresenta il punto di partenzadel progetto; vengono inoltre esaminate le diverse possibilita di esecuzione di taleschema. Il quinto capitolo e interamente dedicato alla fase realizzativa del progetto.In dettaglio, nel capitolo viene descritta la costruzione del diagramma eseguibile pergestire l’orchestrazione, la costruzione di un servizio su cui il diagramma si appoggiaper la computazione dei modelli e la costruzione di un interfaccia utente per con-figurare l’intera simulazione. Il sesto e ultimo capitolo presenta le conclusioni sullavoro svolto.
2

Capitolo 2
Simulazione con FMI
2.1 Introduzione a FMI
FMI (Functional Mock-Up Interface) e un’interfaccia standard progettata per lamodellizzazione e la simulazione di sistemi complessi, dove gli elementi individualipossono appartenere a un insieme eterogeneo di discipline dell’ingegneria, potendoanche questi essere stati sviluppati con degli strumenti indipendenti. L’obiettivo diquesta interfaccia e quello di riuscire a rappresentare interamente i modelli (fisici,meccanici, elettrici, ecc.) usati per la simulazione tramite delle funzioni e strutturedati predefinite, fornendo una maggiore facilita di interazione con gli strumenti disimulazione dei modelli, nonche tra diversi modelli in una co-simulazione.
FMI e stato sviluppato inizialmente come parte del progetto europeo MODE-LISAR [2], iniziato nel 2008. Questo progetto si focalizzava sull’utilizzo dello stan-dard FMI nell’ambito dell’ingegneria automobilistica, e in parte sullo standard AU-TOSAR [3]. Per tali motivi FMI risulta maggiormente utilizzato all’interno deglistrumenti di sviluppo industriale delle aziende partner del progetto MODELISAR(DassaultSystemes, Daimler AG, Qtronic, SimpackGmbH, Trialog, Volkswagen A.G,Volvo, per citarne alcuni). Tuttavia la specifica dello standard FMI non e stretta-mente legata con i modelli di simulazioni automobilistici, e quindi l’utilizzo di questostandard si puo trovare anche in altri ambiti, come quello energetico, ferroviario,aeronautico, aereospaziale [4].
Il numero di tool di simulazione che si basano su FMI sta crescendo rapidamente,grazie ad alcune loro caratteristiche, come la facilita di utilizzo che conferiscono allepiattaforme di simulazioni, la facolta di proteggere la proprieta intellettuale e digarantire licenze in modo molto facilitato ai simulatori sviluppati [5].
Lo standard FMI e composto di due parti principali: FMI for Model Exchan-ge e FMI for Co-Simulation. In poche parole, la prima serve per la creazione deimodelli che implementano l’interfaccia, mentre la seconda serve a definire le intera-zioni tra modelli, quando questi vengono messi nello stesso ambiente di simulazione.
3

Nelle prossime sezioni saranno illustrate in maniere piu approfondite queste duecomponenti principali dello standard.
2.1.1 FMI for Model Exchange
Questa prima parte dello standard FMI permette di creare modelli eseguibili cherappresentino interamente modelli semplici di discipline diverse, oppure sistemi com-posti dinamici e direttamente simulabili. I modelli cosı generati sono chiamati FMU(Functional Mock-Up Unit). Essi implementano l’interfaccia definita in FMI forModel Exchange e possono essere eseguiti da qualsiasi ambiente di modellazionee simulazione; quest’ultimo puo, infatti, implementare a sua volta l’interfaccia, inquanto i modelli non contengono informazioni o file di configurazione relativi a unsimulatore specifico [4].
L’interfaccia consiste delle seguenti parti:
• Interfaccia del modello: tutte le funzioni necessarie per la descrizione delmodello vengono elaborate tramite l’esecuzione di funzioni standardizzate nellinguaggio ’C’. L’utilizzo di questo linguaggio di programmazione e dovuto allasua alta portabilita tra vari sistemi (si noti che il linguaggio ’C’ e impiegato inquasi tutti i sistemi di controllo dedicati), e alla sua maggiore efficienza rispettoad altri linguaggi (in [6] viene fatto un confronto tra ’C’ e Java, facendo notarecome le versioni in Java siano piu lente nelle esecuzioni di circa 30
• Schema di descrizione del modello: che illustra la struttura e il contenutodi un file XML (eXtensible Markup Language) generato dagli strumenti dimodellazione. Il file XML contiene le definizioni delle variabili del modelloin forma standard. In questo modo e possibile separare queste definizionidalle effettive istanze in esecuzione del modello. Questo porta a una riduzionedei costi per ottenere tali informazioni, in quanto il caso contrario porterebbeuna ridondanza di informazioni sulle variabili, un fenomeno noto con il termineoverhead. Inoltre la rappresentazione grafica della descrizione dei modelli vienerealizzata dagli sviluppatori di strumenti che implementano l’interfaccia FMI.
Descrizione matematica del modello
I modelli sono sistemi dinamici descritti da equazioni algebriche, differenziali e di-screte. Il compito dell’interfaccia Model Exchange e di risolvere numericamente talisistemi. Essi sono di tipo continuo a tratti (piecewise continuous system), dove lediscontinuita possono avvenire in determinati istanti chiamati eventi. Gli eventisono noti a priori, oppure sono definiti in modo implicito.
La rappresentazione dell’esecuzione del modello avviene grazie agli stati del mo-dello, che si suddividono tra quelli continui e quelli a tempo discreto. Gli staticontinui sono un insieme di numeri reali (raggruppati in un vettore) che seguonouna funzione continua rispetto al tempo per determinati intervalli. Gli stati a tempo
4

discreto, invece, sono insiemi di variabili reali, intere, di tipo stringa e di tipo logico(logica booleana), che sono costanti per determinati intervalli e cambiano solo almomento di un evento.
L’istante in cui avviene un evento puo essere definito in una delle seguenticondizioni, producendo il piu breve istante temporale:
• Un istante ti che e stato predefinito al momento di un precedente istanteti−1, dal FMU, oppure dall’ambiente di simulazione dovuto a un cambiamentodiscontinuo degli input (descritto in seguito). Gli eventi definiti in questomodo sono chiamati eventi temporali.
• Un istante in cui un indicatore di evento zj(t) cambia il suo dominio da zj > 0a zj < 0 o viceversa. Eventi definiti in questi istanti sono chiamati eventi distato.
• Un istante definito da una funzione chiamata alla fine di ogni passo di inte-grazione (step). Questi eventi sono usati per esempio per modificare dinami-camente i valori di alcuni stati, che non sono numericamente ammissibili. Essivengono chiamati eventi di step.
Un modello potrebbe contenere altre variabili, che descriveremo in seguito, chepossono essere rappresentati, come per gli stati, da insiemi di reali, interi, booleani estringhe, e che sono continue a tratti in funzione del tempo. Similmente agli stati, levariabili non reali possono subire cambiamenti solo dopo un evento. Queste variabiliprendono il significato di parametri, variabili di input, variabili di output e variabiliinterne. I parametri sono valori che rimangono costanti dopo l’inizializzazione delmodello. Le variabili di input e output sono pensate per essere usate nelle connes-sioni fra modelli. Le variabili interne non vengono usate nelle connessioni ma sonousate all’interno dei modelli con lo scopo di ispezionare i risultati.
Un FMU e inizializzato da una funzione che assegna ad alcune delle variabilidei valori iniziali, dati come parametri alla funzione. Per permettere l’utilizzo dialgoritmi specializzati di inizializzazione, la funzione viene lasciata per essere de-finita dallo strumento che implementa l’interfaccia, ma gli argomenti che verrannoutilizzati come parametri di questa funzione sono definiti nello schema di descrizionedel modello.
L’inizializzazione viene seguita da una fase di integrazione continua del model-lo. In pratica, a istanti predefiniti dall’ambiente di simulazione, viene effettuato ilcalcolo delle derivate per gli stati continui, e se ci sono interconnessioni tra modelli,vengono fatti i passaggi dei dati dalle variabili di output a quelle di input e vengonosalvati i risultati di interesse. L’integrazione continua, come spiegato precedente-mente, viene interrotta dagli eventi (eventi temporali, di stato o di step). Quandoavviene un evento viene chiamata una funzione che calcola i nuovi valori per gli stati(continui e discreti).
5

Nel seguito di questo capitolo, si presenta un’interfaccia in linguaggio ’C’ distri-buita dal sito ufficiale dello standard FMI [7].
Schema di descrizione del modello
Tutte le informazioni di un modello, escludendo le sue equazioni, sono salvate in unfile di testo in formato XML, e seguono una struttura ben definita in uno schemaXSD (XML Schema Definition). In particolare, la descrizione contiene le variabilidel modello e i loro attributi, come il nome, l’unita di misura, il valore iniziale didefault e cosı via.
In seguito si mostra un esempio del file XML che descrive il modello, estratto da[8]:
<?xmlversion="1.0"encoding="UTF8"?>
<fmiModelDescription fmiVersion="1.0"
modelName="Modelica.Mechanics.Rotational.Examples.Friction"
modelIdentifier="Modelica_Mechanics_Rotational_Examples_Friction"
guid="{8c4e810f-3df3-4a00-8276-176fa3c9f9e0}"
description="Drive train with clutch and brake" version="3.1"
generationTool="Dymola Version 7.4, 2010-01-25"
generationDateAndTime="2009-12-22T16:57:33Z"
variableNamingConvention="structured" numberOfContinuousStates="6"
numberOfEventIndicators="34">
<UnitDefinitions>
<BaseUnitunit="rad">
<DisplayUnitDefinitiondisplayUnit="deg"gain="57.2957795130823"/>
</BaseUnit>
</UnitDefinitions>
<TypeDefinitions>
<Type name="Modelica.SIunits.Torque">
<RealTypequantity="MomentOfInertia"unit="kg.m2"min="0.0"/>
</Type>
<Type name="Modelica.SIunits.AngularVelocity">
<RealTypequantity="AngularVelocity"unit="rad/s"/>
</Type>
</TypeDefinitions>
<DefaultExperimentstartTime="0.0"stopTime="3.0"tolerance="0.0001"/>
<ModelVariables>
<ScalarVariable name="inertia1.J" valueReference="16777217"
description="Moment of inertia" variability="parameter">
<RealdeclaredType="Modelica.SIunits.Torque"start="1"/>
</ScalarVariable>
<ScalarVariable name="inertia1.w" valueReference="33554433"
description="Absolute angular velocity of component (= der(phi))">
<RealdeclaredType="Modelica.SIunits.AngularVelocity"start="100"/>
</ScalarVariable>
...
</ModelVariables>
</fmiModelDescription>
6

Per semplicita si descrivono solo lo schema di livello piu alto (top level, nell’esem-pio fmiModelDescription) e quello delle variabili (ModelVariables). Una descrizioneintegrale dello schema seguito nell’esempio si puo trovare in [8].
Il top level schema contiene una serie di attributi XML dell’elemento ”radi-ce” del documento che definiscono le proprieta globali del modello, e una serie dielementi XML, che come si nota dall’esempio piu sopra, sono: UnitDefinitions, Ty-peDefinitions, DefaultExperiment e ModelVariables. L’ultimo elemento tra questi,ma che non si trova nell’esempio, e l’elemento VendorAnnotations, opzionalmenteusato dagli strumenti di modellazione per tenere informazioni di proprio interesse.
In seguito si elencano gli attributi dell’elemento ”radice” seguendo lo schema didescrizione del modello presentato in [8]:
• fmiVersion: versione dello standard FMI for Model Exchange usata a creareil file XML.• modelName: il nome del modello.• modelIdentifier: la stringa che viene utilizzata come prefisso dei nomi delle
funzioni del modello e come nome del file in cui tutte le informazioni delmodello vengono salvate.• guid: sta per ”GloballyUniqueIDentifier” ed e un identificatore univoco del
modello.• description: descrizione breve del modello.• author: nome ed organizzazione dell’autore del modello.• version: versione del modello.• generationTool: nome dello strumento (tool) che ha generato il file XML.• generationDateAndTime: data e ora quando e stato generato il file XML.• variableNamingConvention: definisce se i nomi seguono una particolare
convenzione.• numberOfContinuousStates: indica il numero degli stati continui del mo-
dello.• numberOfEventIndicators: indica il numero degli indicatori di eventi.
L’elemento XML che descrive le variabili di modello, ModelVariables, e la partecentrale della descrizione del modello, e consiste di un set ordinato di elementiScalarVariable, che rappresenta una sola variabile, di un solo tipo tra reale, intero,booleano, stringa o un tipo definito all’interno dell’elemento TypeDefinitions. Gliattributi dell’elemento ScalarVariable sono:
• name: il nome pieno e univoco della variabile (le variabili sono identificatedal nome in un FMU).• valueReference: serve per identificare la variabile all’interno dell’interfaccia
del modello e viene specificata dallo strumento che genera le funzioni.• description: descrizione opzionale per il significato della variabile.• variability: definisce come i valori per questa variabile possono cambiare.
Puo assumere solo alcuni valori tra cui:
7

– ”constant”: il valore e fisso e non cambia.– ”parameter”: il valore non cambia dopo l’inizializzazione del modello.– ”discrete”: il valore puo cambiare durante l’inizializzazione e con gli
eventi.– ”continuous”: non ci sono restrizioni, ma solo le variabili reali possono
avere questo valore.
• causality: definisce come la variabile viene resa visibile all’esterno del mo-dello. E un’informazione necessaria quando si hanno connessioni tra diversimodelli FMU. Puo assumere solo i seguenti valori:
– ”input”: il valore puo essere dato da fuori, inizialmente prende il valoreassegnato all’attributo start (vedi sotto).
– ”output”: il valore puo essere utilizzato in una connessione.– ”internal”: alla variabile si puo solo chiederle il valore per salvarla come
risultato, e si puo assegnare un valore solo prima della fine dell’inizializ-zazione.
– ”none”: la variabile non influenza le equazioni del modello, e serve soloai tool che effettuano la simulazione.
• alias: definisce se la variabile rispettiva e un alias.
Per descrivere il tipo di una variabile solo uno tra gli elementi Real, Integer,Boolean, String o Enumeration puo essere presente all’interno di ScalarVariable.Gli attributi di questi elementi sono:
• declaredType: se presente, e il nome di un tipo definito in TypeDefinitions.Per Enumeration quest’attributo e richiesto obbligatoriamente.• start: valore iniziale della variabile, assegnata anche nelle funzioni dell’inter-
faccia del modello.• fixed: definisce il significato dell’attributo start, se causality non e ”input”.
Quest’attributo e ammesso solo se e presente anche start, e puo assumere ivalori:
– true: significa che start e il valore iniziale della variabile (dopo l’inizia-lizzazione la variabile ha il valore di start).
– false: significa che start e un valore ipotetico (dopo l’inizializzazione lavariabile puo avere un valore diverso da start).
In fine, l’elemento ScalarVariable puo contenere un elemento DirectDependency,il quale definisce la dipendenza di una variabile di output dagli input. Questoelemento e presente solo nelle variabili che hanno l’attributo causality uguale a”output”. Se non presente, implica che la variabile (di output) dipende direttamenteda tutte le variabili di input. Se presente, lista i nomi di tutte le variabili in input(con causality = ”input”) da cui dipende direttamente, ciascuno rappresentato daun elemento Name.
8

2.1.2 FMI for Co-Simulation
Diversamente da FMI for Model Exchange, questa seconda parte dello standard FMIserve per riuscire ad accoppiare (coupling) due o piu modelli in un ambiente di co-simulazione. La co-simulazione e una tecnica di simulazione per sistemi accoppiati(tempo continuo e tempo discreto), che sfrutta la struttura modulare dei problemi diaccoppiamento in tutte le fasi del processo di simulazione, cioe preparazione iniziale,integrazione temporale e post-processing [4].
Lo standard definisce che in un ambiente di co-simulazione lo scambio di dati tradue sottosistemi avviene solamente in alcuni punti discreti di comunicazione (com-munication point). Nel periodo in mezzo a due punti di comunicazione i sottosistemisono elaborati in modo indipendente da altri, ciascuno dal proprio risolutore, chia-mato solver. L’algoritmo di controllo dello scambio di dati tra i sottosistemi vienechiamato Master, e si preoccupa della sincronizzazione della comunicazione tra isolver delle simulazioni, che in questa gerarchia sono meglio noti come Slaves.
FMI for Co-Simulation rende disponibile un’interfaccia per la comunicazionetra il master e gli slave, e supporta una classe estesa e generica di algoritmi ma-ster. Da notare comunque che la definizione degli algoritmi master non fa partedell’interfaccia.
Ci sono due modi di fornire all’ambiente di co-simulazione degli slave: sottosi-stemi forniti del loro specifico solver, che possono essere simulati come componentistand-alone (un file dll), oppure sottosistemi con il proprio strumento di simulazio-ne, in cui sono stati costruiti. Entrambi i modi sono trattati dallo standard FMI forCo-Simulation.
Precedentemente si e visto come nella descrizione del modello ci sono informa-zioni che possono aiutare il master a specificare come la comunicazione tra modelliavviene in un ambiente di co-simulazione. Oltre a quelle informazioni, l’interfac-cia FMI for Co-Simulation ne aggiunge altre specifiche agli slave, che sono degliindicatori di capacita (capability flags) per caratterizzare l’abilita nel sostenere al-goritmi master avanzati, come ad esempio, la possibilita di poter usare degli stepdi comunicazione variabili, estrapolazione di segnale di ordini piu grandi, o altroancora.
L’interfaccia passa attraverso tutte le fasi del processo di simulazione, partendoda quella di impostazione e inizializzazione dei modelli, nella quale il master analizzale connessioni tra i vari modelli, carica in memoria gli FMU necessari, crea tuttele istanze e assegna i valori iniziali per ciascuna di esse. In seguito si procede conl’integrazione temporale, in cui ciascun modello viene simulato individualmente inintervalli di tempo e lo scambio di dati viene orchestrato dal master nei communi-cation point definiti prima, accedendo a delle variabili o assegnandoli dei valori. Infine, vengono elaborati a posteriori i dati e visualizzati i risultati, ciascuno in modoindipendente per qualsiasi sottosistema, e viene liberata la memoria usata dai FMU.
L’interfaccia, similmente a FMI for Model Exchange, consiste delle due parti:interfaccia di co-simulazione e lo schema di descrizione della co-simulazione. La
9

prima consiste di una serie di funzioni in linguaggio ’C’ per lo scambio di valori trainput e output, e per lo scambio di informazioni legate alla situazione (status) delleistanze. La seconda definisce lo schema di un file in formato XML, che contiene,oltre alle informazioni sul modello nel caso dell’interfaccia Model Exchange, altrelegate alla simulazione, come ad esempio gli indicatori di capacita descritti prima.
La descrizione dell’interfaccia di co-simulazione viene lasciata alla sezione 2.2.1.
Schema di descrizione della co-simulazione
Per quanto riguarda lo schema di descrizione della co-simulazione, essa utilizza lestesse convenzioni e i tipi di dati dello schema XML definito per FMI for ModelExchange, con in aggiunta due importanti differenze:
1. La definizione dello schema principale in formato XSD (fmiModelDescrip-tion.xsd) e stata modificata aggiungendo un ulteriore elemento Implementa-tion.
2. Un file di schema per questo elemento e stato aggiunto per definire gli elementinecessari al supporto della descrizione della co-simulazione.
L’elemento Implementation definisce un tipo di ”implementazione” nel conte-sto di co-simulazione, che puo essere solo uno degli elementi CoSimulation Tooloppure CoSimulation StandAlone. Questi due tipi sono stati descritti in preceden-za in questo capitolo. Il primo definisce un sottosistema con il proprio strumentodi simulazione, mentre il secondo definisce il sottosistema fornito del proprio sol-ver. Entrambi questi due elementi contengono l’elemento Capabilities, mentre soloCoSimulation Tool contiene l’elemento Model.
L’elemento Capabilities definisce gli indicatori di capacita descritti in preceden-za, come la possibilita di gestire dimensioni variabili di step di comunicazione, digestione degli eventi, di rifiutare e ripetere uno step di comunicazione, di inter-polazione di input continui, e altri ancora. L’elemento Model definisce il modelloassociato allo slave, che deve essere eseguito dal simulatore. In alcuni casi questoelemento puo contenere piu elementi File che definiscono altri file necessari (possonoessere altri modelli, file di calibrazione, ecc.) al modello.
La descrizione integrale dello schema e contenuto nella specifica dello standardFMI for Co-Simulation in [4].
2.1.3 Struttura di un FMU
Un modello FMU e un file con l’estensione .fmu, che in realta consiste di un file zipche ”impacchetta” le seguenti componenti:
• Le sorgenti in linguaggio C’ del modello, nelle quali vengono implementate lefunzioni dell’interfaccia FMI, alcune delle quali verranno spiegate in dettaglionelle prossime parti.
10

• Opzionalmente, le sorgenti in forma compilata (DLL o shared libraries) delmodello, le quali sono direttamente eseguibili.• Il file XML della descrizione del modello, che contiene tutta l’informazione
statica per le variabili necessarie al modello. Inoltre questo file viene usatopure dal master per costruire una rete di dipendenze che dirige il modo in cuiviene svolta l’esecuzione della simulazione.• Altri file con informazione supplementare per il modello (documentazione
integrativa, immagini, altro).
Un esempio di struttura interna di un FMU si vede nella figura 2.1.
Figura 2.1: Struttura interna di modello FMU
2.2 FMI 1.0
La descrizione fino ad ora fatta di FMI si basa sulla prima versione dello standard,rilasciata nel 2010, mentre l’attuale versione dello standard e la 2.0 rilasciata nel2014. In questo paragrafo continueremo ad analizzare piu in dettaglio lo standard,basandoci sulla versione 1.0, per descrivere l’interfaccia e l’ambiente di sviluppo dimodelli (Software Development Kit) rilasciati con questa versione.
La descrizione della versione 2.0 viene rilasciata a una parte successiva deldocumento, facendo notare le principali differenze con la versione 1.0.
Il motivo principale per il quale questo lavoro si e focalizzato principalmentesulla prima versione, sta nel fatto che e quella piu usata e supportata da strumentidi creazione modelli e di simulazione. Molti strumenti di software sono ancora infase di sviluppo per supportare la seconda versione, mentre alcuni la supportano soloparzialmente. Una tabella indicativa di come vengono supportate le due versioni datutti i software conosciuti che implementano l’interfaccia FMI, si puo trovare sulsito ufficiale dello standard [9].
11

2.2.1 FMU Software Development Kit (SDK)
La FMU SDK e un kit gratuito fornito da QTronic( [10]) con lo scopo di mostraregli usi fondamentali degli FMU, di aiutare lo sviluppo di software e modelli che sibasano sull’interfaccia FMI e in piu servire come punto di partenza per lo sviluppodi applicazioni che importano ed esportano gli FMU.
La sua distribuzione viene fatta tramite un file zip che contiene:
• Delle sorgenti in linguaggio ’C’ contenenti le funzioni delle interfacce per Mo-del Exchange e Co-Simulation, che sono descritte all’interno della specificadell’interfaccia FMI [4] [8], e che vengono usati per la creazione di modelli,• Delle sorgenti in linguaggio ’C’ per alcuni modelli FMU (discreti e continui),
i rispettivi file XML per la descrizione dei modelli, e altre informazioni legatea ciascun modello (ad es. immagini, documentazione, ecc.),• Un parser XML per estrarre informazioni dalle descrizioni del modello,• Dei file batch per la compilazione dei modelli, e la costruzione degli FMU,• Delle sorgenti in linguaggio ’C’ per l’implementazione di un semplice simula-
tore, che permette di simulare gli FMU e scrivere i risultati in un file CSV,• Dei file batch per la simulazione degli FMU.
Tutte queste risorse esistono per entrambe le versioni di FMI (a parte il file batchper la creazione dei modelli che crea direttamente modelli per entrambe versioni, eil file batch per la simulazione di FMU).
Nella seguente sezione si presenta piu in dettaglio come sono strutturate le sor-genti in ’C’ dei modelli, analizzando in dettaglio le funzioni dell’interfaccia, e lefunzioni che bisogna implementare per la creazione dei modelli. Queste funzio-ni e la struttura dei file che li contengono sono facilmente osservabili grazie alladistribuzione della SDK.
2.2.2 Struttura dei file sorgenti dei modelli
Gli FMU possono contenere file sorgenti diversi in base al fatto che implementinol’interfaccia Model Exchange oppure quella Co-Simulation. La convenzione per que-sti file stabilisce che tutti i nomi di funzioni (in ’C’) e di definizione dei tipi debbanoiniziare con il prefisso ”fmi”.
Normalmente le funzioni dell’interfaccia che devono essere implementate fannoparte del file principale in linguaggio ’C’ del modello (questo file prende il nome dal-l’attributo modelIdentifier all’interno del file XML di descrizione del modello). Alloro interno essi devono includere fmuTemplate.h, un header file, e fmuTemplate.c,che sono identici per tutti i modelli (si trovano in condivisione con tutti). fmu-Template.h a sua volta puo includere in se uno tra gli header file fmiFunctions.h ofmiModelFunctions.h, nei casi in cui si usa l’interfaccia Co-Simulation (CS) o ModelExchange (ME), rispettivamente.
12

Ulteriormente fmiFunctions.h include il header file fmiPlatformTypes.h nel pro-prio interno, mentre fmiModelFunctions.h include fmiModelTypes.h.
fmiModelTypes.h(ME) e fmiPlatformTypes.h(CS)
Possiedono le definizioni dei tipi per gli argomenti in input e in output delle funzio-ni. Per aiutare la portabilita, come argomenti delle funzioni non vengono usati tipidel linguaggio ’C’, ma vengono ridefiniti con degli alias. Questi header file vengo-no usati sia dal modello sia dal simulatore. I tipi definiti in questi brevi file sono:fmiComponent, fmiValueReference, fmiUndefinedValueReference, fmiReal, fmiInte-ger, fmiBoolean, fmiString. Inoltre vengono anche definiti i due valori fmiTrue efmiFalse per il tipo fmiBoolean.
fmiModelFunctions.h(ME) e fmiFunctions.h(CS)
Contengono i prototipi delle funzioni che vengono rese accessibili agli ambienti disimulazione. In modo da avere piu istanze per ciascun modello, i nomi di que-ste funzioni vengono modificati a tempo di esecuzione, e il nome risultante saracomposto dal nome del prototipo della funzione unito al nome dell’identificatoredel modello. Questi header file contengono anche le definizioni di altri tipi come:fmiStatus, fmiCallbackLogger, fmiCallbackAllocateMemory, fmiCallbackFreeMemo-ry, fmiStepFinished (solo per CS), fmiCallbackFunctions (raggruppa le precedenti 3(4 per CS)), fmiEventInfo e fmiStatusKind (solo per CS).
fmuTemplate.h(ME)
Aggiunge alle definizioni effettuate dai file che importa, altre che definiscono il tipoModelState e il tipo ModelInstance. Inoltre definisce la struttura di dati per levariabili del modello, in cui le variabili vengono raggruppate secondo il loro tipo(fmiReal, fmiBoolean, ...), ordinate in array nominati brevemente per identificare iltipo (con nomi come r, b, ecc. rispettivamente per real, boolean, ecc.), e identificatetramite il loro valore di riferimento (value reference, fmiValueReference). Vienedefinito anche un array per contenere gli indicatori degli eventi, chiamata pos(z),con z l’indice dell’indicatore.
fmuTemplate.c(ME)
Come si puo intuire dal nome, e una sorta di template contenente codice che eidentico per tutti i modelli. Serve per definire quasi tutte le funzioni che vengonoutilizzate dagli ambienti di simulazione per gestire i modelli, lasciando non definitesolo alcune che devono essere implementate in maniera diversa in base alle carat-teristiche del modello (sono implementate nel file sorgente principale, che ha comenome l’identificatore del modello).
13

In seguito si elencano alcune funzioni importanti in questo file, con una brevedescrizione del loro utilizzo.
• Inizialmente, sono definite le funzioni per la gestione delle istanze del modello.La funzione instantiateModel serve per creare una nuova istanza del modello,e allocarla in memoria insieme con altri dati di sua appartenenza. Inoltre essachiama la funzione setStartValues, che deve essere implementata nella sorgenteprincipale del modello, e che permette di assegnare dei valori iniziali alle va-riabili del modello. La funzione init serve per inizializzare il modello e chiamala funzione initialize, che e una delle funzioni da implementare nella sorgen-te principale del modello, usata per definire l’evento iniziale del modello. Lafunzione terminate invece serve per terminare il modello, ossia assegnare allostato del modello il valore modelTerminated. In fine, la funzione freeInstanceserve a liberare la memoria occupata dall’istanza del modello (e i suoi dati)una volta che la sua esecuzione e stata terminata.
• In seguito, sono definite le funzioni per l’assegnazione e l’estrazione dei valoridelle variabili, funzioni che sono generalmente note con i nomi di setter e getterrispettivamente. Per i setter ci sono le funzioni fmiSetReal, fmiSetInteger, fmi-SetBoolean, fmiSetString, e per i getter ci sono dei nomi analoghi (fmiGetReal,...).
• La funzione fmiGetDerivatives serve, come si intuisce dal nome, per calcolare lederivate per le variabili reali. Al suo interno viene chiamata la funzione getReal,che e una funzione da implementare nella sorgente principale del modello, in cuivengono definite le equazioni differenziali. La funzione getReal viene chiamataanche all’interno della funzione fmiGetContinuousStates, che calcola i valoridegli stati continui.
• La funzione fmiGetEventIndicators viene utilizzata per ottenere gli indicatoridegli eventi, e chiama la funzione getEventIndicator, che e una funzione daimplementare nella sorgente principale, la quale controlla il dominio degli in-dicatori degli eventi in modo da notare cambiamenti che indicano gli eventi(come spiegato in 2.1.1).
• La funzione fmiEventUpdate viene chiamata quando l’istanza del modello ri-scontra un evento. Essa chiama al proprio interno la funzione eventUpdate,che e una funzione da implementare nella sorgente principale, che contiene ilcodice da eseguire con il triggering di un evento.
• La funzione fmiSetTime e utilizzata per assegnare alle istanze dei modelli iltempo di esecuzione della simulazione.
• La funzione getStatus serve all’ambiente di simulazione a interrogare lo statoattuale delle istanze, descritto con uno dei valori di tipo fmiStatus.
14

• Alla fine di questo elenco, ci sono le funzioni fmiDoStep e fmiCancelStep. fmi-DoStep e una delle funzioni piu importanti (sicuramente la piu lunga conside-rando le righe di codice) di questo file. Essa serve per svolgere l’integrazionetemporale della simulazione, svolgendo uno step dell’istanza in cui calcola inuovi valori delle variabili, chiamando la funzione getReal, e la funzione getE-ventIndicator per controllare se si e riscontrato un evento, e in caso positivochiamando anche eventUpdate. La funzione fmiCancelStep viene usata nel ca-so sia necessario rifiutare uno step (nella versione originale della distribuzionedella SDK essa ritorna uno status di errore).
Sorgente principale del modello
Per la descrizione di un modello usando l’interfaccia FMI, puo bastare definire solo lasorgente principale del modello e il file di descrizione del modello (in formato XML).Per questo, tale sorgente e un elemento fondamentale per la rappresentazione delmodello dove vengono definite le caratteristiche principali tramite variabili e funzioniche si descriveranno.
Inizialmente, all’interno di questo file, vengono definite delle variabili, che rap-presentano informazioni contenute anche nella descrizione del modello, per creareun collegamento inconfondibile tra i due file, creando un’unica rappresentazione delmodello. Queste variabili sono l’identificatore del modello, MODEL IDENTIFIER,e l’identificatore univoco GUID (GloballyUniqueIDentifier). In seguito, vengono de-finiti dei parametri che indicano il numero di variabili per ciascun tipo, il numero distati, e il numero di indicatori di evento. I valori di questi parametri sono utilizzatidalle funzioni all’interno del file fmuTemplate.c. Successivamente, sono definite levariabili del modello, ciascuna rappresentata da un nome univoco, a cui viene as-sociato un valore, che e il valore di riferimento delle variabili all’interno dell’arraydi tipo di appartenenza (valuereference, come indicato in sezione 2.2.2). Tra questevariabili vengono definite quelle di stato, cioe che servono a rappresentare lo statodella simulazione, inserendole all’interno dell’array STATES.
Come descritto precedentemente, in questo file vengono implementate le fun-zioni: setStartValues, initialize, getReal, getEventIndicator ed eventUpdate. Questefunzioni, fondamentali per la descrizione del modello e delle sue dinamiche, sonospiegate come segue:
• setStartValues: viene chiamato da instantiateModel, e serve a stabilire deivalori per tutte le variabili dell’istanza che ammettono un valore iniziale.Inoltre vengono anche determinati i valori di dominio per gli indicatori dieventi.• initialize: chiamato da init, aggiudica il primo evento temporale della simu-
lazione, se ce n’e uno.• getReal: chiamato da piu di una funzione, serve a ritornare i valori per
tutte le variabili dell’istanza. I valori ritornati sono risultato di un calcolo
15

effettuato con le formule lineari o differenziali del sistema scritte in linguaggio’C’ all’interno di questa funzione.• getEventIndicator: viene chiamato da fmiGetEventIndicators e fmiDoStep,
e serve per indicare gli indicatori di evento, come descritto in precedenza.• eventUpdate: viene chiamato da piu funzioni, quando si riscontra un even-
to. Serve per eseguire le funzionalita implementate all’interno e decidereeventualmente il prossimo evento.
2.2.3 Esempi di modelli della SDK
Tra i contenuti della SDK si trovano degli esempi di modelli che sono stati costruitidagli sviluppatori della SDK, seguendo l’interfaccia FMI. Inizialmente essi sono di-stribuiti con dei file sorgenti (quello principale, fmuTemplate.c, fmuTemplate.h, ...)accompagnati dal file di descrizione modello (modelDescription.xml) e da immaginie documentazione rispettiva.
Alcuni file batch, distribuiti anche essi nella SDK, rendono possibile la compila-zione dei file sorgente, e grazie alla lettura del modelDescription.xml (con dei parserXML), costruiscono i modelli nella forma di un FMU (in formato .fmu).
Altri file batch usano delle altre sorgenti della SDK per simulare i modelli, escrivere i risultati in un file di formato CSV, di nome results.csv.
I modelli sono i seguenti:
• inc: e un modello matematico che incrementa un contatore di un’unita perogni secondo di tempo di simulazione. Ha uno stato in cui l’istanza vieneterminata, ed e quando il contatore raggiunge il valore 13. Questo e un mo-dello che mostra l’utilizzo della funzione eventUpdate implementandola comedecisore del prossimo evento.• dq: e un modello matematico dell’equazione di test di Dahlquist. Il modello
mostra come creare un modello con equazioni differenziali per ottenere unasoluzione analitica.• values: e un modello che non appartiene a nessuna particolare disciplina, ma
che mostra come utilizzare tutti i tipi di variabili dell’interfaccia FMI.• vanDerPol: e un modello matematico dell’oscillatore di Van DerPol. Come
dq, anche questo modello mostra come utilizzare equazioni differenziali per lasimulazione di un sistema, ma in questo caso si usano due variabili di stato.• bouncingBall : e un modello fisico che simula una pallina che viene lasciata
in caduta libera da una certa altezza, sotto soltanto l’effetto della forza digravita. Al momento di collisione con il suolo, si scatena un evento che fa rim-balzare la pallina sul verso opposto, facendola riprendere quota fino a fermarsiper poi riscendere, come normalmente accade a un tale sistema fisico reale.Questo modello ha anche una costante di elasticita la quale, se minore di uno,fa perdere velocita nel rimbalzare, percio la quota massima raggiungibile in
16

seguito e minore a quella precedente. In questo modo la pallina tende ad avvi-cinarsi sempre di piu al suolo con il passare del tempo. Il modello non ha unostato finale almeno che non venga fermato dalla simulazione, ma continua adaver un moto oscillatorio con la quota che si avvicina sempre di piu al valoredel suolo. Questo e un modello che mostra l’utilizzo degli indicatori di eventi,di come si possono utilizzare gli stati del modello e di come un modello fisicopuo essere descritto con l’interfaccia FMI.
I due modelli su cui si focalizzera di piu per il progetto di questa tesi sonobouncingBall e inc, e una loro interazione in un ambiente di co-simulazione verradescritta nel prossimo paragrafo.
2.3 Simulazione con Simulation X
Uno degli obiettivi principali dello standard FMI e di rendere possibile a un FMUesportato (costruito) da un particolare software, a poter operare con altri strumentidi vari tipi e produttori, e rendere possibile a strumenti che importano (accettano)FMU esportati da altri, di orchestrare la comunicazione tra gli ultimi [11].
Molti software di simulazione offrono la possibilita di importare modelli FMUnei propri ambienti, e uno tra questi, utilizzato nel progetto di questa tesi per lasimulazione dei modelli esempio descritti precedentemente, e SimulationX [12]. Lasimulazione con questo software ha permesso di studiare piu facilmente i modelli e lostandard, grazie anche a una migliore visualizzazione di dati rispetto alla simulazionefornita nella SDK. In piu questo software offre la possibilita di creare un ambientedi co-simulazione con piu modelli, costruendo una rete di connessione tra modelli inmaniera veloce e intuitiva, grazie all’interfaccia utente. La co-simulazione grazie aquesto software, sara affrontata piu avanti in questa sezione.
SimulationX e un software CAE per la simulazione, la modellazione, l’analisi el’ottimizzazione dei sistemi complessi, ed e stato sviluppato da ITI GmbH (da inizio2016 opera con il nome ESI ITI GmbH, in quanto acquistato dall’ESI Group [13]).La principale caratteristica di questo software e la rappresentazione interattiva deimodelli tramite l’interfaccia utente, e che si possano interconnettere facilmente conazioni di tipo drag and drop. Questo software e noto anche per aver adottato ilsupporto al linguaggio orientato agli oggetti Modelica (open-source), che e uno deilinguaggi principali usati per la creazione di modelli di simulazione (sviluppato daModelica Association, organizzazione non-profit strettamente legata allo standardFMI).
Inoltre SimulationX rende possibile l’uso del software in modo gratuito, graziealla versione Student Edition, per uso accademico, la quale e stata usata per lesimulazioni che verranno descritte piu avanti. Da notare che questa versione offrefunzionalita molto piu limitate rispetto alla versione completa del software, come disolito accade in questi tipi di distribuzione del software.
17

2.3.1 Creazione di pendulum.fmu
Per provare un’implementazione pratica dell’interfaccia FMI, e stato costruito unsemplice modello fisico, chiamato pendulum. Questo modello imita un pendolo fisicoideale, sul quale agisce soltanto la forza di gravita, e il quale puo essere inizializzatolasciandolo in caduta libera oppure dandogli una velocita iniziale, da qualsiasi puntodi partenza nell’intervallo di ±90◦ dal punto di equilibrio.
A questo modello si puo assegnare un valore di input che si trova nell’intervalloprecedente, che rappresenta un ostacolo per il pendolo, facendolo rimbalzare nelladirezione opposta al momento di collisione, simile al caso in bouncingBall.fmu. Ineffetti, ci sono alcune analogie tra i modelli, ma su pendulum.fmu si hanno equazionidifferenziali con piu parametri, e soprattutto si e creato un modello che interagiscecon altri grazie agli input/output, che e una caratteristica mancante degli altriesempi di modelli della SDK.
Il modello e stato realizzato usando la SDK, implementando le funzioni comedescritto in precedenza. In seguito alla realizzazione del modello, sono state eseguitevarie simulazioni con SimulationX, in cui si e notato come il modello rispecchia lecaratteristiche dei modelli reali.
2.3.2 Co-simulazione di bouncingBall.fmu e inc.fmu
La simulazione individuale dei modelli bouncingBall.fmu e inc.fmu con Simulatio-nX, produce risultati identici alla simulazione effettuata con la SDK, facilmenteconfrontabili in quanto i modelli hanno una bassa complessita di simulazione.
In seguito alla simulazione individuale, si e cercato di sfruttare SimulationX percreare un ambiente di co-simulazione, e aggiungere i due modelli in esso. Per farequesto, si e dovuto fare delle modifiche ai modelli, in quanto non possiedono variabilidi input e output per lo scambio di valori. In particolare, sono stati creati due nuovimodelli (per mantenere le risorse dei modelli originali invariate) che rappresentanoi precedenti, ma con alcune modifiche. Il nuovo modello di bouncingBall ha duevariabili aggiuntive, dove la prima e un parametro che specifica il valore inizialedell’altezza da cui la pallina viene lasciata cadere, mentre il secondo e un valorein input, che rappresenta il livello del suolo con cui la pallina dovrebbe scontrarsi.Per questo modello, il suolo puo essere un valore costante durante l’esecuzione dellasimulazione, oppure variabile nel tempo secondo una funzione. Per rispondere ainuovi comportamenti introdotti nel modello, sono state modificate anche le funzionigetEventIndicators ed eventUpdate.
In piu nel nuovo modello di bouncingBall, gli stati sono definiti come valori inoutput, per fornire informazioni agli altri modelli in comunicazione.
Nell’ambiente di co-simulazione sara il modello inc modificato a fornire comeinput i valori per determinare il livello del suolo del modello bouncingBall. Per farequesto il nuovo modello inc possiede tre variabili di cui i primi due sono dei parametriche indicano un valore iniziale e il valore del passo di incremento o decremento a
18
ogni iterazione, mentre il terzo rappresenta il valore finale calcolato, che viene fornitocome input al modello bouncingBall.
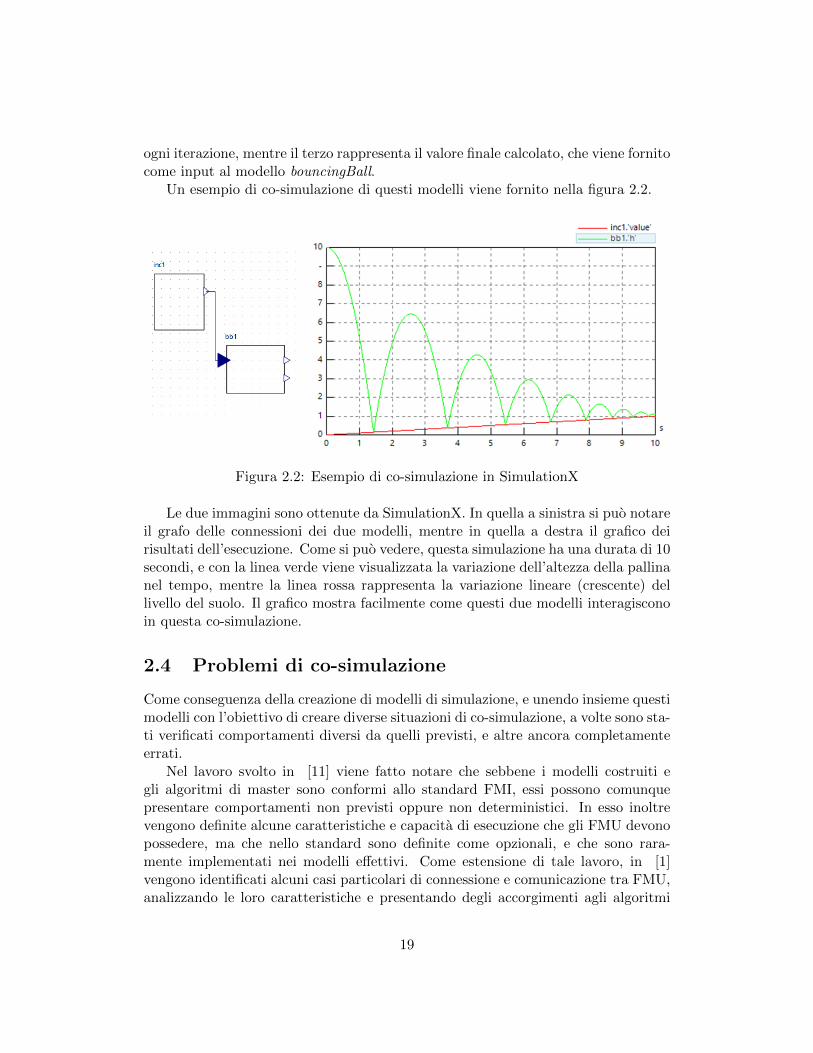
Un esempio di co-simulazione di questi modelli viene fornito nella figura 2.2.
Figura 2.2: Esempio di co-simulazione in SimulationX
Le due immagini sono ottenute da SimulationX. In quella a sinistra si puo notareil grafo delle connessioni dei due modelli, mentre in quella a destra il grafico deirisultati dell’esecuzione. Come si puo vedere, questa simulazione ha una durata di 10secondi, e con la linea verde viene visualizzata la variazione dell’altezza della pallinanel tempo, mentre la linea rossa rappresenta la variazione lineare (crescente) dellivello del suolo. Il grafico mostra facilmente come questi due modelli interagisconoin questa co-simulazione.
2.4 Problemi di co-simulazione
Come conseguenza della creazione di modelli di simulazione, e unendo insieme questimodelli con l’obiettivo di creare diverse situazioni di co-simulazione, a volte sono sta-ti verificati comportamenti diversi da quelli previsti, e altre ancora completamenteerrati.
Nel lavoro svolto in [11] viene fatto notare che sebbene i modelli costruiti egli algoritmi di master sono conformi allo standard FMI, essi possono comunquepresentare comportamenti non previsti oppure non deterministici. In esso inoltrevengono definite alcune caratteristiche e capacita di esecuzione che gli FMU devonopossedere, ma che nello standard sono definite come opzionali, e che sono rara-mente implementati nei modelli effettivi. Come estensione di tale lavoro, in [1]vengono identificati alcuni casi particolari di connessione e comunicazione tra FMU,analizzando le loro caratteristiche e presentando degli accorgimenti agli algoritmi
19

master per ciascuno dei casi, in modo da ottenere delle esecuzioni di simulazionedeterministiche. Questi casi sono raggruppati nelle seguenti due categorie:
• Co-simulazioni di modelli che contengono retroazione: simulazioni in cui loscambio di variabili ha inizio e fine nello stesso FMU. In questa categoria sihanno due varianti: retroazione diretta e retroazione ritardata.• Co-simulazioni di modelli senza retroazione: simulazioni in cui si puo speci-
ficare un ordine di esecuzione per gli FMU. Le varianti per questa categoriasono:
– Modelli con lo stesso passo di esecuzione.– Modelli con passo diverso di esecuzione, ma di base comune.– Modelli con passo di esecuzione e base diverse.
Nelle seguenti sezioni presentiamo ciascuna di queste varianti, introducendo an-che le caratteristiche che gli FMU devono avere e gli accorgimenti sugli algoritmimaster, proposti in questo studio.
2.4.1 Co-simulazioni di modelli con retroazione
La prima variante di questi modelli, in cui gli FMU sono connessi in retroazione,e questa e diretta. Questo significa che si ha una dipendenza interna diretta dellevariabili di output da quelle di input e che nel modello e presente un ciclo algebrico,cioe i valori delle variabili di output sono funzioni di se stesse nello stesso step disimulazione. I cicli algebrici si possono risolvere con il metodo di iterazioni di puntofisso (iterazione funzionale), noto in letteratura anche come il metodo iterativo diPicard [14]. Nella co-simulazione, questo metodo iterativo si puo adattare definendoun algoritmo master in questo modo:
1. Per ciascun FMU:
(a) Salva lo stato del FMU e gli output(b) Simula FMU(c) Collega i valori di output con gli altri FMU
2. Per ciascun FMU:
(a) Ripristina lo stato del FMU(b) Se l’output non converge e le condizioni dello step non sono state soddi-
sfate, torna al passo 1.
Per riuscire ad adottare questo tipo di master, gli FMU devono essere in gradodi sopportare le procedure di salvataggio e ripristino del loro stato completo, mecca-nismo noto come rollback. La versione 1.0 dello standard FMI non definisce questomeccanismo, diversamente dalla versione 2.0, che aggiunge le funzioni necessarie agliFMU, come si vedra in seguito di questo documento, nella sezione 2.5.
20

La seconda variante di questi modelli contiene una retroazione ritardata. Questoquando alla presenza di uno schema di connessioni tra FMU con retroazione, ci siaalmeno una dipendenza di output da input, che sia ritardata rispetto alle dipendenzedirette. In generale, questo tipo di dipendenza non produce piu un ciclo algebrico,percio rende piu semplice la soluzione delle equazioni, pero in un ambiente di co-simulazione, si hanno delle complicazioni, in quanto in un certo istante un FMUpuo ricevere come input, valori di output calcolati in step di simulazione errati.Per risolvere questo problema, si usa il meccanismo di rollback, presentando unalgoritmo master come questo:
1. Per FMUx con dipendenza ritardata:
(a) Salva lo stato del FMUx
(b) Simula FMUx
(c) Collega i valori di output con gli altri FMU
2. Per gli altri FMU:
(a) Simula FMU(b) Collega gli output con altri FMU.
3. Ripristina lo stato di FMUx e simula FMUx.
In generale, l’algoritmo puo essere utilizzato anche nel caso in cui FMUx nonabbia dipendenza ritardata. In questo caso il primo FMU simulato deve sostituireFMUx in questo algoritmo (usato per eseguire i passi 1 e 3).
A livello pratico, e stato possibile costruire un modello di co-simulazione di que-sta categoria (la prima variante), utilizzando due istanze del modello creato pendu-lum.fmu, le quali scambiano in input/output, informazioni legate alla loro posizionee velocita, per verificare le situazioni di collisioni. Eseguendo la co-simulazionecon SimulationX, si sono verificati errori di computazione nei momenti di collisionetra pendoli, in quanto l’algoritmo master per l’orchestrazione della simulazione nonpossiede gli accorgimenti mostrati in precedenza.
2.4.2 Co-simulazione di modelli senza retroazione
In questo tipo di co-simulazione, non ci sono cicli di connessione, e questo significache l’esecuzione degli FMU puo seguire un ordine preciso, partendo da un certoFMU e finendo in un altro l’esecuzione per quel step di comunicazione.
La prima variante di questi e quella in cui tutti gli FMU hanno lo stesso stepdi comunicazione. In questi casi non sono necessari aggiustamenti dell’algoritmomaster.
La seconda variante e quella in cui gli FMU non hanno lo stesso step di comu-nicazione, ma comunque questi step sono tali che quello maggiore e anche quelliintermedi sono multipli del piu piccolo step, chiamato base. Per questa variante
21

si hanno altri due casi. Seguendo l’ordine di simulazione, se un FMU ha uno steph1, minore rispetto al seguente, con uno step h2, esso si deve simulare tante voltequanto il multiplo di h1 per produrre lo step del FMU seguente, cioe k volte, doveh2 = k∗h1. Nel caso inverso invece, se un FMU1 ha uno step maggiore del seguente,FMU2, i suoi valori di output devono essere interpolati per tutti gli step necessaridal seguente FMU, analogamente al caso precedente per k volte. Per questo secondocaso si ha il seguente aggiustamento all’algoritmo master:
1. Simula FMU1
2. Simula FMU2
(a) Interpola il valore di output di FMU1 per lo step di comunicazione.(b) Simula FMU2.(c) Se FMU2 non e stato simulato k volte, vai al passo 2.
La terza variante e simile alla seconda variante, con la differenza che gli stepnon hanno una base in comune. Anche per questa variante si hanno due casi, comela precedente. Il primo e quello in cui un FMU1 ha uno step inferiore al seguente,FMU2. In questo caso non si puo praticare la soluzione della variante precedente,cioe simulare per k volte, ma bisogna verificare una corrispondenza degli step dicomunicazione, il che significa che si deve verificare se la simulazione per k volteporta a un output corretto per simulare FMU2. Nel caso in cui non ci sia unacorrispondenza bisogna eseguire un’estrapolazione del valore di output da 1, primadi passare questo valore a FMU2. Il seguente e l’aggiustamento che si effettuaall’algoritmo master:
1. Simula FMUx
(a) Calcola k.(b) Simula FMUx k volte.(c) Se si verifica una corrispondenza con step di FMU seguente, salta al passo
3.
2. Estrapola il valore di output per lo step del FMU seguente.3. Passa il valore di output al FMU seguente.4. Simula FMU seguente.
Per quanto riguarda il secondo caso di questa variante, si esegue un aggiusta-mento all’algoritmo master come nella variante precedente, in cui i valori di outputdal primo FMU vengono interpolati per ogni step di comunicazione del secondo.L’aggiustamento che viene effettuato al master e lo stesso, con l’eccezione dellasimulazione di FMU2 per k volte.
Con SimulationX, e stato possibile eseguire la simulazione di modelli di co-simulazione di questa categoria. Uno degli esempi per questi modelli e quello pre-sentato precedentemente con le versioni modificate di inc.fmu e bouncingBall.fmu.
22

La simulazione per questi modelli puo essere eseguita per ciascuna delle 3 varianti,ossia per lo stesso step, step diversi ma con la stessa base, oppure step diversi conbase diversa.
2.5 FMI 2.0
La seconda versione dello standard FMI e stata rilasciata nel 2014. Questa versionecomporta grandi cambiamenti rispetto alla 1.0, e nel seguito di questa sezione ver-ranno descritti quelli principali. Da notare che la versione 2.0 non e retro compatibilecon i modelli costruiti tramite la versione 1.0 dello standard.
Come prima cosa, in FMI 1.0 si ha una separazione tra le interfacce Model Ex-change e Co-Simulation, definite in due documenti diversi, mentre in questa versioneentrambe le interfacce sono descritte nello stesso documento e sono state unificate inuna. Con questa unione un FMU implementa entrambe le interfacce simultaneamen-te, e nella descrizione del modello (in XML) esistono nuovi elementi ModelExchangee Co-Simulation che indicano quale interfaccia e stata implementata. In seguito el’ambiente di simulazione a stabilire quale interfaccia usare, chiamando la rispettivafunzione di inizializzazione, fmi2InstantiateModel o fmi2InstantiateSlave.
Da notare inoltre che tutte le funzioni in linguaggio ’C’ dell’interfaccia possiedonoun nuovo prefisso fmi2.
FMI 2.0 possiede anche la possibilita di salvare e ripristinare lo stato intero diun FMU, che consiste di informazioni legate alle variabili (stati, parametri, valori ininput, identificatori dei file, stato interno del FMU), e che permette il meccanismodi rollback, utile per alcuni algoritmi master, come spiegato in precedenza. Unavolta ripristinato lo stato di un FMU, da esso si puo procedere con la simulazioneinterrotta. Lo stato di un FMU puo essere anche serializzato e copiato in un vettoredi byte. Questo permette di salvare lo stato di un FMU in un file, e permette le ini-zializzazioni da stati stabili (nel caso di modelli in cui l’inizializzazione e dispendiosadal punto di vista computazionale [15]).
Altri cambiamenti in questa versione si vedono nella categorizzazione delle va-riabili esposte. All’interno della descrizione del modello, l’attributo causality dellevariabili e stato modificato per accettare uno dei seguenti valori:
• ”parameter”: una variabile dal valore costante durante la simulazione eindipendente.• ”input”: come nella versione 1.0.• ”output”: come nella versione 1.0.• ”local”: valore calcolato da altre variabili, non utilizzato da altri modelli.
L’attributo variability delle variabili che descrive come la variabile cambia neltempo, in questa versione, oltre ad accettare i valori ”constant”, ”discrete” e ”con-tinuous” come nella versione 1.0, puo accettare anche altri due valori:
23

• ”fixed”: il valore della variabile e fisso dopo l’inizializzazione (come ”para-meter” in 1.0).• ”tunable”: il valore della variabile e costante per intervalli di tempo tra
due eventi causati esternamente al modello. Questo significa che questi valoripossono essere ”messi a punto” (tuning) durante una simulazione (vedere [15]).
Ancora sulla descrizione delle variabili, la descrizione delle dipendenze delle va-riabili di output da quelle di input e stata modificato, rimuovendo l’elemento Direct-Dependency dalla descrizione delle variabili, e inserendo un nuovo elemento Model-Structure come ”figlio” dell’elemento fmiModelDescription, che e provvisto di listeordinate per descrivere gli input, le derivate e gli output.
La figura 2.3 mostra lo schema di descrizione del modello per la versione 2.0,dove si notano i cambiamenti descritti sopra.
Figura 2.3: schema di descrizione in FMI 2.0
Un’altra funzionalita nuova introdotta in FMI 2.0 e quella del calcolo delle de-rivate parziale delle variabili (di input o di stato), nonche la creazione di matrici
24

Jacobiane, che puo essere utilizzata dai metodi di integrazione implicita, per lalinearizzazione del FMU, o per usarle nei filtri estesi di Kalman, per citare alcuni.
In fine, altre modifiche che meritano essere menzionate sono:
• Una gestione precisa degli eventi temporali.• Definizione delle unita di misure migliorata.• Rimozione dell’alias nella definizione delle variabili.• Introduzione di un ordine per listare le variabili (input, output, stati continui),
utile per la linearizzazione degli FMU.
La versione 2.0 dello standard FMI porta novita importanti per le funzionalitadei modelli che implementano questa interfaccia, la piu importante delle quali e pro-babilmente l’introduzione del concetto di stato interno di un FMU, e le funzionalitaper salvarlo e ripristinarlo, descritte in precedenza.
Nonostante questo, come accennato in precedenza, la versione 2.0 non e ancoramolto diffusa tra gli strumenti che implementano questo standard. Alcuni di loroimplementano solo una parte, come per esempio l’importazione o esportazione diFMU creati con 2.0, mentre altri sono ancora in fase di implementazione di questaversione. Oltre a questo, e da notare che i software che hanno gia svolto un’imple-mentazione completa della seconda versione, non potevano essere usati per questoprogetto di tesi, in quanto sono distribuiti con una licenza non gratuita.
La SDK distribuita dal sito ufficiale dello standard, per la 2.0 contiene gli stessiesempi di modelli visti precedentemente (bouncingBall, inc, dq, ecc.). Questi mo-delli pero, a parte essere implementati con le funzioni definite in versione 2.0, noncontengono un’implementazione effettiva delle nuove funzionalita introdotte, e ledifferenze con i modelli della versione precedente sono poche.
Per questi motivi, in questo progetto di tesi e stata sfruttata la versione FMI 1.0con modelli creati utilizzando questa versione.
25

Capitolo 3
BPMN
3.1 Introduzione a BPMN
BPMN sta per Business Process Model and Notation, ed e uno standard utilizzatoper modellare i processi aziendali. La modellazione viene fatta tramite una de-scrizione grafica dei processi aziendali, simile ai diagrammi di flusso, usati da anninell’ambito. Questa rappresentazione grafica e associata in maniera univoca a unlinguaggio standard e queste due parti insieme compongono lo standard BPMN.
Nel corso degli anni sono emerse varie notazioni per la modellazione di processi,spesso proprietarie agli strumenti di modellazione e sistemi di gestione del workflow.Alcuni standard affermati sono XPDL (XML Process Definition Language) e BPEL(Business Process Execution Language).
BPMN e originariamente un progetto della Business Process Management Ini-tiative (BPMI), un consorzio di compagnie per lo sviluppo di software pensato co-me rappresentazione grafica di processi descritti con BPML, un altro linguaggio dimodellazione di processi che puo essere eseguito da un BPMS (Business ProcessManagement System). I BPMS sono dei sistemi che possono controllare ed eseguiredei processi seguendo dei modelli appropriati o descrizioni formali di questi processi.Per quanto riguarda BPML, il suo sviluppo e stato abbandonato in favore di BPEL.
Nel 2004 fu rilasciata la prima versione di BPMN e, nel 2006, dopo che BPMIdivento parte dell’OMG (Object Management Group), venne accettata come stan-dard OMG. Un altro standard che fa parte di questo gruppo e il noto UML (UnifiedModeling Language). L’attuale versione, 2.0, fu rilasciata nel 2011 e segno un grandecambiamento per lo standard in quanto oltre agli elementi grafici definisce anche larappresentazione seguendo un modello semantico. Tale modello fa sı che gli elementivengano rappresentati con una struttura XML, che segue uno schema XSD definitodalla specifica BPMN 2.0, permettendo cosı anche la possibilita di esecuzione (ri-nunciando a BPML e BPEL) e di rendere possibile lo scambio di diagrammi trasoftware di modellazione ed esecuzione di processi in modo formalizzato e efficiente.
26

L’obiettivo di BPMN non e solo quello di standardizzare la rappresentazionedei processi aziendali ma anche di avvicinare molti livelli aziendali all’utilizzo deidiagrammi per questi processi. Tradizionalmente l’utilizzo di diagrammi di processiaziendali veniva svolto maggiormente a livello manageriale e serviva agli altri livelliaziendali come informazione indicativa delle loro richieste, mentre con l’utilizzo diquesto standard si riduce il margine tra la descrizione dei processi aziendali e l’imple-mentazione tecnica. In effetti la sua rappresentazione grafica con quadrati, frecce,rombi, cerchi, ecc. mantiene la familiarita con i vecchi diagrammi di flusso usatinegli ultimi 25 anni, e dall’altro lato gli utilizzatori vengono avvicinati maggiormen-te alla programmazione in quanto questi elementi sono interpretabili ed eseguibili.Inoltre lo standard contiene anche operazioni di iterazione sui dati, come cicli everifica di condizioni, gestione di eccezioni, transazioni e altri elementi ispirati allaprogrammazione.
Un’altra caratteristica importante di BPMN e che permette l’estendibilita deipropri elementi e attributi, al patto di verificare che i nuovi modelli costruiti sianoaderenti alla specifica.
Tutte queste caratteristiche rendono lo standard BPMN uno dei principali attoritra gli standard per la modellazione dei processi aziendali. Il numero degli strumentiche utilizzano questo standard e sempre piu grande, e una grande parte di questisono elencati nel sito ufficiale dello standard [16]. Inoltre il numero sempre in crescitadi siti web, blog e pubblicazioni dimostrano un continuo aumento di interesse perquesto standard [17].
Nel sito ufficiale si possono trovare anche vari esempi di diagrammi, che conten-gono vari elementi dello standard. Nel proseguo di questo capitolo verranno descrittie analizzati alcuni elementi principali, molti dei quali sono importanti per il progettodi questa tesi. Questa descrizione e simile a quella svolta in [18], dove gli elemen-ti vengono separati in due gruppi principali. Il primo gruppo, chiamato nel testodi riferimento come primo livello, e una palette che raccoglie gli elementi che sonosufficienti per la modellazione descrittiva dei processi. Il secondo gruppo o secondolivello, aggiunge elementi piu complessi e meno comuni al primo, completando cosıl’intero standard BPMN.
3.2 Elementi di primo livello
Gli elementi di questo gruppo servono a descrivere la gran maggioranza dei processiaziendali, a patto che essi non possiedano comportamenti dovuti ad eventi. Adeccezione dei flussi e degli eventi legati ai messaggi, questi elementi sono ereditatidai tradizionali diagrammi di flusso. In seguito si descrive ciascuno degli elementi evengono illustrate per ciascuno immagini della rappresentazione grafica nell’editordi BeePMN [19].
Le attivita, meglio note come activity, rappresentano una unita di lavoro effettua-to durante il processo. Esse sono visualizzate come rettangoli con vertici arrotondati.
27

Una activity puo essere un task (compito) oppure un sub-process (sottoprocesso). Iltask e un elemento ”atomico”, nel senso che non possiede parti interne descrivibili ela sua azione e lo stato finale del suo compimento vengono suggerite dal suo nome.Un sub-process invece e un elemento composto, contenente vari elementi al propriointerno, e viene modellato come un processo di secondo ordine, con sequenze diesecuzione per gli elementi interni.
I task sono visualizzati come le activity ma hanno un’icona nell’angolo, cherappresenta il tipo del task. Ci sono 8 tipi di task, ma per questo livello si definisconoi 3 che sono:
• User task: un task che deve essere svolto da una persona (utente).• Service task: un activity automatico, cioe l’azione viene svolta automatica-
mente quando l’esecuzione del processo (sequence flow) raggiunge questo task,senza l’intervento dell’utente. In processi eseguibili questo task indica che ilcompito viene svolto da un servizio esterno.• Abstract task: il tipo di task non e definito.
Figura 3.1: Task del primo livello
Un sub-process ha piu modi di visualizzazione. Esso puo essere incapsulato(collapsed), cioe viene visualizzato come un normale activity con un simbolo [+] nellaparte sotto centrale. In alternativa puo essere espanso, cioe viene visualizzato comeun quadrato ingrandito con all’interno il diagramma di secondo ordine che descriveil sub-process. Al momento dell’arrivo dell’esecuzione al sub-process, questa passaallo start event del diagramma di secondo ordine, mentre al raggiungimento delend event del sub-process, l’esecuzione prosegue fuori dall’elemento nel diagrammaprincipale. Gli elementi start event ed end event verranno descritti piu avanti. Unaregola importante definita dallo standard e quella che nel diagramma di secondoordine lo start event non deve avere un tipo: l’inizio del diagramma interno alsub-process e scatenato solo dall’arrivo dell’esecuzione.
Una variante di sub-process e quella che viene chiamata ad-hoc. La caratteristicadi questa variante di sub-process e che non tutti gli elementi interni possono essereeseguiti seguendo un ordine per completarlo.
I sub-process sono distinti da altri chiamati call activity, che sono dei sub-process”riusabili”, in quanto sono definiti indipendentemente dal processo, e possono essere
28

Figura 3.2: Sub-process espanso (sinistra) e incapsulato (destra)
usati anche in altri processi senza essere modificati. La visualizzazione dei callactivity e diversa dai sub-process perche e caratterizzata da un bordo piu spesso delquadrato.
Un gateway, un altro elemento del primo livello, e un elemento visualizzato comeun rombo che serve per controllare l’esecuzione dividendola in due o piu cammini.I gateway sono divisi in due categorie: esclusivi e paralleli. I gateway esclusivi, notianche con il nome XOR gateway, rendono possibile solo uno dei cammini per fareproseguire l’esecuzione del processo, valutando un’espressione o condizione sui datidel processo. Un gateway di questo tipo viene contraddistinto da una ’X’ all’internodel rombo, ma puo anche essere visualizzato con nessun simbolo. I gateway paralleliinvece separano l’esecuzione in entrata dell’elemento in piu esecuzioni che devonoessere eseguite in parallelo senza restrizioni di condizioni, e sono contraddistinti daun simbolo ’+’ dentro il rombo.
Figura 3.3: Gateway di primo livello
Altro caso di utilizzo per i gateway e quando abbiamo piu flussi di esecuzione inentrata, e solo un flusso in uscita. In tal caso il gateway esclusivo accetta soltanto ilprimo flusso ad arrivare per ciascuna esecuzione, ignorando i restanti flussi per quellaesecuzione, che potrebbero giungere in seguito. Dall’altro lato, il gateway paralleloin questo caso aspetta finche tutti i flussi in entrata siano arrivati al gateway primadi permettere al flusso in uscita di proseguire l’esecuzione. In questo caso il gatewayparallelo ha il ruolo di sincronizzare i flussi che di solito sono stati separati da unaltro gateway parallelo precedentemente.
29

Lo start event e visualizzato come un cerchio con bordo sottile, ed e un altroelemento del primo livello. Un processo deve avere almeno un start event, chee l’elemento dove l’esecuzione ha inizio. L’icona all’interno del cerchio, chiamatatrigger, indica il tipo di evento che scatena l’inizio dell’esecuzione di un processo.Il trigger puo essere di tipo message, in cui l’inizio avviene dopo il ricevimento diun messaggio, di tipo timer, cioe un evento temporaneo, di tipo multiple, in cuil’inizio avviene via molteplici tipi di eventi, e ultimo, di tipo none, cioe di tiponon specificato o se l’inizio avviene manualmente da un task. Come spiegato inprecedenza, i sub-process devono possedere un start event di tipo none.
Figura 3.4: Alcuni start event e end event di primo livello
Analogamente agli start event, si hanno gli end event, che indicano la fine di uncammino nei processi e sottoprocessi. Gli end event sono visualizzati nei diagrammicome cerchi con un bordo piu spesso. L’icona all’interno del cerchio negli end event,indica il tipo di segnale lanciato alla fine del cammino. In questo primo livelloabbiamo quattro tipi: none, message, terminate, multiple. Il none end event nonlancia nessun segnale come risultato, gli end event di tipo message lanciano unmessaggio, gli end event di tipo multiple possono lanciare piu di un segnale (adesempio due messaggi diversi) come risultato finale, e in fine l’end event di tipoterminate indica che il processo oppure il sottoprocesso che arriva a questo elementotermina immediatamente, anche se contiene cammini paralleli ancora in esecuzione.
Lo sequence flow, una freccia continua nei diagrammi, rappresenta il flusso diesecuzione dei processi. Una sequenza di linee di flusso e confinata a stare all’internodi un ordine di processo, percio non puo oltrepassare i bordi di un sub-process o diun process pool (la descrizione dei pool viene fatta in seguito).
I message flow, dall’altro canto, sono delle linee tratteggiate che rappresentanoun flusso di messaggi all’interno di un processo. Essi possono collegare qualsiasi tipodi activity, message event, o black-box pool. Inoltre, gli elementi connessi da questelinee possono appartenere a processi diversi.
Un pool (piscina), e un rettangolo di solito allungato in orizzontale ma che puoessere disegnato anche verticalmente, che serve come contenitore di processo, cioe
30

contiene al proprio interno tutti gli elementi che compongono il processo, collegatidalle sequence flow. Se visualizzato in orizzontale il pool contiene un’etichetta nellaparte sinistra la quale e il proprio nome identificativo (nella visualizzazione verticalel’etichetta si trova in alto). I pool possono anche non visualizzare gli elementi alproprio interno ma renderli impliciti. In questo caso vengono chiamati black-boxpool, cioe sono come delle scatole nere, e servono nei diagrammi con piu processi(pool) per descrivere la collaborazione tra questi. Tale collaborazione avviene grazieai flussi di messaggi scambiati tra i processi.
Opzionalmente i pool possono essere suddivisi in quelli che vengono chiamati laneo piste, che servono per associare alcune attivita dei processi a determinati attori,ruoli, dipartimenti, o qualsiasi tipo di categorizzazione che gli si vuole attribuire.
I pool e lane sono concetti ereditati dai tradizionali diagrammi di flusso.Le text annotations (annotazioni testuali) sono utilizzati nei diagrammi come
informazione aggiuntiva testuale per gli elementi. Essi infatti non possono esserenon collegati ad un elemento preciso del diagramma, e questo collegamento vienefatto tramite le associations (associazioni), le quali sono visualizzati come una lineadi puntini equidistanti. Le text annotations e le associations sono degli artifacts,elementi di informazione aggiuntiva che non influiscono l’esecuzione del processo.
Figura 3.5: Data object e data store
Gli ultimi elementi descritti in questo paragrafo e quindi appartenenti al primolivello, sono quelli per la descrizione dei dati e del loro flusso (data flow). Prima dellaversione 2.0 di BPMN, essi facevano parte degli artifacts, mentre in questa versioneessi sono definiti come elementi, di nome data object e data store. Il data object rap-presenta una variabile locale del processo, temporanea in quanto esiste solo durantel’esecuzione del processo. La sua visualizzazione e simile a un foglio con un angolopiegato, come comunemente vengono visualizzati anche i file. Il data store dall’altrolato, rappresenta dati persistenti, informazioni che comunemente vengono dispostenei database. In effetti la sua visualizzazione e quella che tradizionalmente vieneassociata ai database. Questi elementi devono essere legati grazie alle associationsa degli elementi, come ad esempio attivita, eventi, sequence flow, message flow, ecc.
31

3.3 Elementi di secondo livello
In questa sezione vengono descritti gli elementi dello standard BPMN, aggiuntivi aquelli descritti nella sezione precedente. Comunque per la semplicita del documentovengono descritti solo quelli utilizzati nel progetto di tesi.
Come prima cosa si nota che il secondo livello si focalizza maggiormente sulcompletamento della sottoclasse degli eventi. Nel primo livello si nota come il flussodi esecuzione procede con il completamento delle attivita in modo sequenziale, e glieventi definiscono solo l’inizio e la fine dell’esecuzione. Nel secondo livello vengonointrodotti, oltre a tipi aggiuntivi per start event ed end event, gli eventi intermediche permettono altri tipi di comportamenti all’esecuzione di un processo.
Figura 3.6: Eventi intermedi di secondo livello
Gli eventi intermedi sono visualizzati come cerchi con un doppio bordo, e comeper gli altri eventi visti, il simbolo all’interno indica il tipo di trigger dell’evento.Alcuni tipi di trigger introdotti con questo secondo livello sono:
• Timer, dovuto a una durata temporale.• Signal, dovuto a un segnale. Un segnale differisce da un messaggio in quanto
viene lanciato per tutto il processo (broadcast), mentre il messaggio ha undestinatario specificato.• Conditional, dovuto al cambiamento di condizioni su alcuni dati (si effettua
un monitoraggio continuo di questi dati).• Error, dovuto a un errore nell’esecuzione.
Figura 3.7: Categorie degli eventi intermedi
Gli eventi intermedi sono divisi in quattro categorie principali: catching, thro-wing, boundary interrupting e boundary non-interrupting. I throwing intermediate
32

event (caratterizzati da un’icona scura), sono quelli che fanno innescare un deter-minato evento, mentre i catching intermediate event sono quelli in cui l’esecuzioneprosegue in seguito (che ”catturano” l’esecuzione). I boundary sono eventi assegnatiall’esecuzione di un sub-process o task (sono disegnati sul bordo di questi elementi),e possono interrompere o meno la loro esecuzione per innescare un evento.
In questo livello viene definito anche un nuovo tipo per i gateway, l’event gateway.Questo gateway e visualizzato con un rombo con all’interno un multiple intermediateevent. La scelta del percorso viene fatta in base al tipo di evento che il gatewaycattura, ed e una regola BPMN che ogni percorso uscente dal gateway deve terminarein un intermediate catching event.
Figura 3.8: L’event gateway di secondo livello
Per quanto riguarda i tipi di task, alcuni nuovi per questo livello sono:
• Send task: quasi identico come funzione all’intermediate message throwingevent, in quanto manda un messaggio ad un destinatario.• Receive task: serve per ricevere un messaggio, come message catching event.• Script task: simile al service task, ma in questo caso, nei processi eseguibili,
questo task contiene un piccolo programma, di linguaggio Javascript o Groovy,contenuto all’interno del XML e che deve essere eseguito dal motore.
Figura 3.9: Task di secondo livello
Sempre sulle activity, questo livello introduce dei modi offerti da BPMN per nonfarle completare fino a che non vengono eseguite un certo numero di volte. Il primo,loop activity, imita il ciclo do-while della programmazione, cioe fa ripetere l’attivitain continuo fin quando non si raggiunge una determinata condizione. Il secondo,
33

multi-instance activity, e il ciclo for-each, il quale determina il numero totale divolte da fare eseguire l’attivita. Similmente a questo secondo modo, la multiple pooloffre la possibilita di eseguire piu processi in parallelo.
34

Capitolo 4
Utilizzo di BPMN 2.0 per laCo-simulazione
Come spiegato nell’introduzione di questo documento, l’obiettivo di questo progettodi tesi e stato quello di riuscire a usare lo standard BPMN nella costruzione di pro-cessi che riescano ad orchestrare modelli creati con l’interfaccia FMI in un ambientedi co-simulazione.
Nei precedenti capitoli sono stati descritti i due standard principali di questoprogetto di tesi: FMI e BPMN. Bisogna notare come questi standard appartengonoad ambiti molto diversi. Il primo e pensato come standard per la creazione di modellie la loro simulazione, principalmente nell’ambito ingegneristico, e maggiormentein quello automobilistico. Il secondo invece e stato pensato come uno strumentoper offrire una rappresentazione semplice e univoca dei processi aziendali, legatimaggiormente al mondo del business e manageriale. Questi standard non sono statidefiniti per essere usati insieme e collaborare direttamente per raggiungere l’obiettivospiegato sopra. In effetti, in una prima fase di analisi non sono stati trovati lavoriprecedenti che cercassero di utilizzare insieme questi due standard.
4.1 Analisi di progetto
Molti strumenti che eseguono simulazioni di modelli, necessitano di uno schemagrafico in input che rappresenta le connessioni tra i modelli, e che di solito vienecostruito o modificato dall’utente. Ma la parte principale per eseguire la simulazionee l’algoritmo master che gestisce la simulazione dei modelli e che coordina le lorointerazioni, lo scambio di dati e la gestione delle eccezioni. Gli algoritmi del masterdi solito sono proprietari e vengono nascosti all’utente. Come spiegato in preceden-za, lo standard FMI non definisce come costruire un algoritmo master, ma lasciaagli strumenti che implementano lo standard ad applicare i propri algoritmi. Nellaspecifica dello standard [4] viene mostrato solo un esempio in forma di pseudoco-
35

dice per descrivere un possibile algoritmo per il coordinamento di modelli durantela computazione.
Il progetto di questa tesi parte dall’idea di utilizzare BPMN per trasformareil pseudocodice di quest’algoritmo master in un diagramma di processo BPMN.L’idea e nata all’interno del gruppo di ricerca di ESTECO, in una collaborazioneche include l’autore di questo documento, per un articolo gia accettato che verrapresentato nella 2016 IEEE International Symposium on Systems Engineering (IS-SE) [20]. Questo lavoro cerca di esplorare le potenzialita di BPMN, per sfruttarlenella rappresentazione grafica integrale dello schema delle connessioni fra modelli,come anche appunto nella costruzione di processi per la gestione dell’orchestrazionedei modelli, che e il focus del progetto di tesi. Una versione integrale dell’articolo sitrova nell’appendice di questo documento.
Nelle prossime sezioni di questo capitolo si descrive la fase di analisi del proget-to di tesi. Nella sezione 4.2 viene descritto in dettaglio il diagramma concettualecreato basandosi sull’algoritmo master in pseudocodice della specifica FMI. Talediagramma e una rappresentazione solo visuale di quello che sara alla fine il dia-gramma BPMN per la co-simulazione. Per realizzare un diagramma eseguibile estato prima scelto e analizzato un framework capace di interpretare ed eseguire glielementi BPMN. Questo framework viene trattato nella sezione 4.3 di questo capi-tolo, analizzando alcune differenze importanti rispetto allo standard BPMN nellaimplementazione degli elementi. Inoltre, in tale sezione vengono presentati ancheuno strumento che aiuta la costruzione di diagrammi eseguibili dal framework e unalibreria che permette l’esecuzione di modelli FMU all’interno di tale framework.
La fase di realizzazione del diagramma eseguibile viene esposta nel capitolo 5, incui viene descritto inizialmente la costruzione di un diagramma per la simulazionedi un unico modello e in seguito la costruzione di un diagramma generico per lasimulazione di numerosi modelli. Oltre a questo per l’esecuzione dei modelli FMUe stato necessario realizzare un servizio servlet e un’interfaccia utente che permettela configurazione della simulazione in modo semplificato, anche queste trattate nelprossimo capitolo.
4.2 Diagramma BPMN di co-simulazione
In questo paragrafo si analizza lo schema BPMN concettuale costruito per l’orche-strazione dell’intera simulazione di due FMU, come succede anche nell’algoritmodella specifica FMI su cui si basa questo diagramma. Questi FMU sono connessicome nell’esempio presentato in [1], cioe sono due integratori interconnessi in unoschema di retroazione, e ad ogni iterazione della simulazione si effettua uno scambiodi dati tra i due.
In figura 4.1 si presenta l’intero diagramma BPMN per la simulazione. Neldiagramma i pool che rappresentano i due processi slave sono mostrati come black-box pool, e si puo notare che la visualizzazione della collaborazione tra i processi
36

Figura 4.1: Diagramma BPMN di collaborazione tra processo Master e processiSlave
slave e il processo master viene fatta in modo esplicito mostrando lo scambio deimessaggi. Nel processo master si nota come l’esecuzione passa sequenzialmente perquattro fasi diverse, rappresentate dai rispettivi sub-process visualizzati in modoincapsulato. Queste fasi corrispondono a quelle descritte nel secondo capitolo, sullaparte della co-simulazione, e sono:
• Instantiation: avvio dei processi slave con rispettivo caricamento degli FMU.• Initialization: fase di inizializzazione dei modelli.• Simulation: esecuzione della simulazione con l’iterazione nel tempo.• Shutdown: fase di terminazione e de-allocazione dalla memoria degli FMU.
I sub-process mandano messaggi ai processi slave che a loro volta eseguono lefunzioni dell’interfaccia FMI e ottengono da esse i risultati che passano in seguitoal processo master. La figura 4.2 illustra il diagramma BPMN per i processi slave.
Il processo slave ha come inizio un message start event, il che significa che co-mincia la sua esecuzione solo dopo aver ricevuto un messaggio dal processo master.La maggior parte dei service task usati sono dei richiami alle funzioni principalidell’interfaccia FMI viste nel capitolo 2, e quindi verranno usati per eseguire quellefunzioni. Da notare che l’esecuzione dell’intermediate throwing message event inseguito all’esecuzione del task Initialize porta ad un event gateway. Il compito ditale gateway, come descritto nel capitolo 3, e quello di assegnare l’esecuzione a unodei quattro eventi successivi. Questo dovuto dal fatto che i task getReal, setReal edoStep sono eseguiti per tutte le iterazioni. Lo scambio di dati tra i processi mastere slave viene fatto grazie al passaggio dei data object.
37
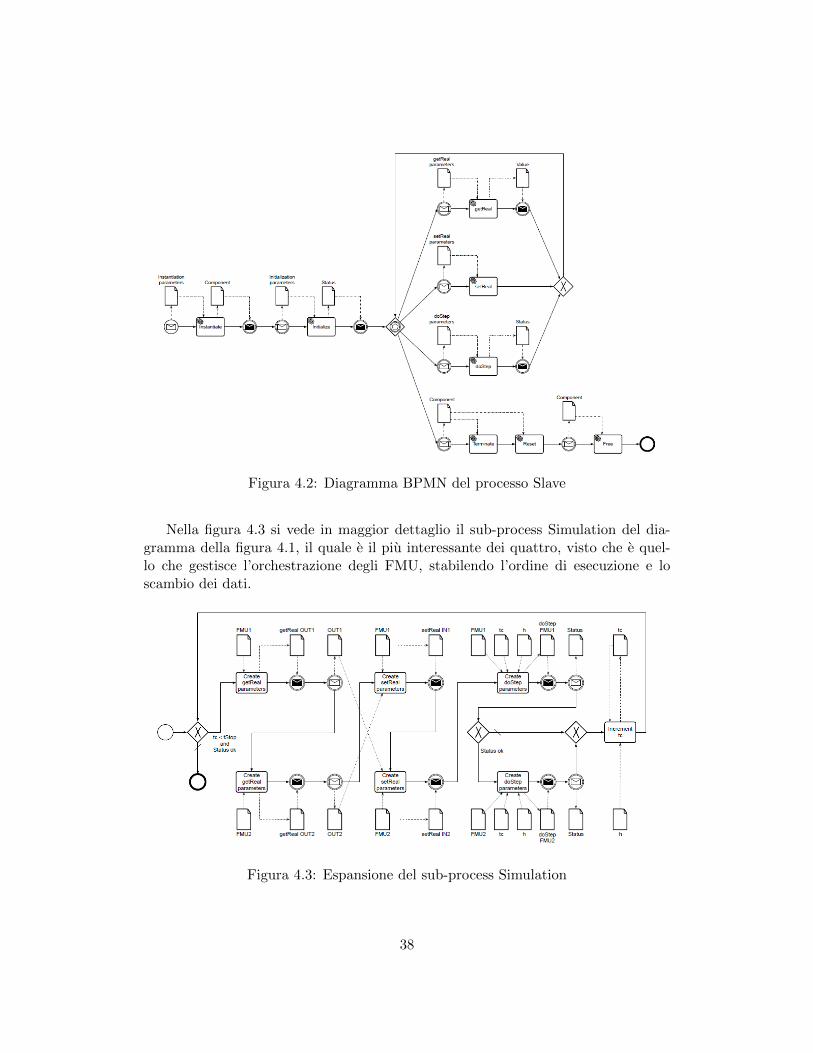
Figura 4.2: Diagramma BPMN del processo Slave
Nella figura 4.3 si vede in maggior dettaglio il sub-process Simulation del dia-gramma della figura 4.1, il quale e il piu interessante dei quattro, visto che e quel-lo che gestisce l’orchestrazione degli FMU, stabilendo l’ordine di esecuzione e loscambio dei dati.
Figura 4.3: Espansione del sub-process Simulation
38

In questa figura, il gateway che segue lo start event fa un controllo sui dati tc,tStop e Status, che sono delle variabili del processo che rappresentano rispettiva-mente un determinato tempo della simulazione, il tempo di fine esecuzione, e lostato generale di questa. Come si puo notare, questo sub-process contiene tre partiprincipali che corrispondono alle funzionalita di getter, setter e doStep viste nellasezione 2.2.2 e ciascuna di queste viene svolta per entrambi gli FMU. Si ricordache le getter servono per ottenere i valori di interesse per la simulazione da delledeterminate variabili, al contrario dei setter che assegnano dei nuovi valori per levariabili input degli FMU. La funzione doStep esegue i calcoli corrispondenti a undeterminato step h.
In queste figure si puo notare che vengono usate solo le funzioni getReal e SetReal,e vengono omessi i getter e setter per gli altri tipi di dati per mantenere semplice lavisualizzazione dei diagrammi.
Importante ripetere che questo diagramma rispecchia l’algoritmo master in formadi pseudocodice proposto dalla specifica FMI, ma niente vieta ad avere diagrammiBPMN che siano diversi da questo, per simulare degli FMU. In effetti, non si puoavere un diagramma BPMN general-purpose capace di effettuare tutti i tipi di si-mulazioni. Oltre a questo per ciascun algoritmo master potrebbero corrisponderepiu diagrammi diversi. Ma questo e un ulteriore vantaggio che BPMN dispone ver-so altri strumenti di simulazione, in quanto offre agli utenti maggiore facilita nellascelta e costruzione degli algoritmi.
4.3 Esecuzione con BPMN Engine
Nella sezione precedente e stata presentata una prima fase concettuale del progettoed e stata analizzata la rappresentazione grafica dell’esecuzione dei modelli con pro-cessi BPMN, con la conseguente creazione del diagramma dei processi. In questasezione invece si presentano i dettagli legati all’analisi dell’esecuzione effettiva deldiagramma. Come descritto precedentemente, la rappresentazione visuale dei dia-grammi BPMN e corrisposta univocamente da una rappresentazione in linguaggioXML. Questo ha dato a molteplici strumenti la possibilita di interpretare univo-camente questo linguaggio, in modo da interpretare ed eseguire automaticamenteciascun elemento BPMN, e di conseguenza eseguire processi interi. Questi strumentisono meglio noti con il nome di BPMN Engine (motori di esecuzione).
Tra molti BPMN engine che sono in circolazione, la scelta per il progetto diquesta tesi e ricaduta su Alfresco Activiti [21]. Alfresco Activiti e un frameworkche comprende piu strumenti, tra cui l’engine, e nella prossima sottosezione sipresenteranno le sue caratteristiche che sono di interesse per il progetto.
39

4.3.1 Activiti
Lo sviluppo di Activiti ha inizio nel 2010 come proseguo di jBPM [22] da due deiprincipali sviluppatori di quest’ultimo, al momento del passaggio presso l’aziendaAlfresco [23]. In effetti, la prima versione rilasciata di Activiti fu la 5.0, per indicarela continuazione da jBPM 4.
Per il progetto di questa tesi viene usata la distribuzione Activiti Communityche contiene i seguenti strumenti:
• Engine: il motore di esecuzione di workflow BPMN.• Explorer: un’applicazione web che permette di fare deploy di processi, ini-
ziare la loro esecuzione, osservare l’andamento delle esecuzioni, e altro ancora.• Modeler: un’applicazione web per la creazione grafica di workflow.
In alternativa al Modeler, per la creazione di diagrammi BPMN e stato usato unplug-in per l’IDE Eclipse [24], Activiti Designer, il quale verra trattato nel seguitodi questo capitolo.
Activiti Engine e il nucleo di questa piattaforma, ed e un motore di esecuzionein linguaggio Java. Questo motore e composto dal Process engine, che gestisce iprocessi e mette a disposizione vari servizi utili, e un altro motore che implementala specifica BPMN 2.0 e fornisce un’interfaccia per permettere l’interazione con iservizi dell’engine [25].
Activiti Explorer e un’applicazione web eseguibile su qualsiasi web server (ades. Apache Tomcat), che tra varie funzionalita permette all’utente di caricare ipropri processi BPMN all’interno, per poi eseguirli e monitorarne l’andamento. Essocontiene anche un database configurabile dall’utente, in cui vengono salvati datilegati alle esecuzioni, agli utenti che utilizzano l’applicazione, dati storici, ecc. Infine oltre alla visualizzazione grafica degli errori, vengono mantenuti anche dei filedi log per molti tipi di informazioni, aspetti questi che sono molto utili allo sviluppodi processi eseguibili BPMN.
Activiti Designer (Eclipse)
Activiti Designer, il plug-in di Eclipse, offre la possibilita di creare facilmente dia-grammi BPMN, utilizzando la propria palette degli elementi di tale standard. Pur-troppo, rispetto allo standard, la palette presenta un numero inferiore di elementi,e ci sono alcune caratteristiche che sono diverse dalle definizioni in BPMN. Questosi rispecchia anche nel motore di esecuzione di Activiti, nel quale non sono stateimplementate molte funzionalita legate ad alcuni elementi, o addirittura non sonoinclusi altri elementi per intero. Oltre alla creazione e modifica grafica dei diagram-mi, Activiti Designer offre anche la possibilita di accedere alla rappresentazioneXML. Questo e risultato molto utile durante il lavoro per il progetto di tesi, inquanto il plug-in ha mostrato comportamenti errati (ad es. non visualizzazione di
40

elementi esistenti nel diagramma). Detto questo, il plug-in e risultato uno strumentoimportante per lo sviluppo del progetto di tesi.
Una feature molto importante del Designer e quella di deployment di un dia-gramma BPMN. Siccome Activiti e un motore creato in linguaggio Java, un proget-to costruito con il Designer puo utilizzare delle classi Java esterne (come si vedranella prossima sezione). Facendo il deploy di questo progetto, vengono creati auto-maticamente un file BAR e, in caso di presenza di classi esterne Java, un file JARcon all’interno le classi.
Il file BAR contiene il diagramma BPMN creato, che si puo caricare all’internodell’interfaccia grafica dell’applicazione web Activiti Explorer. Al momento di cari-camento l’applicazione e capace di indicare anche eventuali errori di costruzione deldiagramma, molto utili per il debugging.
4.3.2 Elementi BPMN di Activiti
In questa sottosezione si descrive l’implementazione degli elementi in Activiti, mo-strando principalmente quelli di rilevanza per il progetto che presentano caratteri-stiche diverse dagli elementi specificati nello standard BPMN. L’implementazionedi alcuni di questi, come message flow [26], e progettata ad essere effettuata nelleprossime versioni che verranno rilasciate.
Per quanto riguarda le classi Java interne all’engine Activiti, non verranno de-scritte per semplicita del documento, ma per ulteriori dettagli si puo consultare laguida all’utente messa a disposizione dal sito ufficiale [27].
Inizialmente si descrive l’implementazione dei task in Activiti. Oltre ai task vistinel capitolo 3, Activiti estende lo standard con altri nuovi come Email, Manual,Mule, Camel, e Shell, ma che non verranno spiegati in questa sezione, in quanto nonsono di interesse per il progetto di questa tesi. Le service task in Activiti sono stateimplementate come Java Service Task e Web Service Task.
Il primo, Java Service Task, e un task in cui viene invocata una classe esternaal diagramma, in linguaggio Java. Questa classe deve implementare una delle in-terfacce JavaDelegate o ActivityBehavior. Il secondo, Web Service Task, invoca inmodo sincrono un Web service esterno. Per usare questo secondo tipo di servicetask bisogna specificare l’implementazione e un riferimento dell’operazione dei webservice.
Da notare anche l’elemento Java Receive Task, implementazione del receive taskdi BPMN, che serve per ricevere messaggi.
Per quanto riguarda appunto i messaggi, e stata accennata sopra come i mes-sage flow non sono ancora supportati dall’engine (sebbene si trova come elementoall’interno della palette dell’Activiti Designer, e abbia un’univoca rappresentazioneXML, esso non e eseguibile dall’engine). Oltre a questo, gli elementi send task eintermediate throwing message event, che dovrebbero secondo lo standard essereusati per la spedizione di messaggi, non ci sono in Activiti. La comunicazione via
41

messaggi viene comunque realizzata in altri modi, che pero non rispettano intera-mente lo standard BPMN. I messaggi sono rappresentati da elementi <message> nelXML (specificati come proprieta del processo nell’Activiti Designer). L’elemento<messageEventDefinition> viene usato all’interno dei message event (start o in-termediate) i quali ricevono il messaggio, per creare il ”binding” tra appunto l’eventoe il messaggio. L’azione della trasmissione dei messaggi da mittente a destinatario,viene fatta tramite la correlazione dei processi, e viene spiegato in dettaglio nelprossimo capitolo.
Un’altra particolarita di Activiti e che non sono definiti gli elementi BPMN dataobject e data store, che servono per contenere le variabili del processo e per passa-re dati tra vari elementi. Per realizzare questa necessita, le variabili del processovengono mantenute in modo implicito all’interno del processo, e si possono accederetramite delle funzioni. Quelle piu semplici con cui si possono accedere sono:
execution.getVariables();
execution.getVariables(Collection<String> variableNames);
execution.getVariable(String variableName);
execution.setVariables(Map<String, object> variables);
execution.setVariable(String variableName, Object value);
In queste istruzioni le variabili sono richieste (o assegnate) da un’esecuzione.Una variante di queste funzioni e quella in cui le variabili sono assegnate come local,cioe sono visibili solo a una determinata esecuzione e non alle altre esecuzioni delprocesso. Oltre alle esecuzioni, le variabili possono essere usate in Activiti anche neiJava delegate, espressioni, task listener, script, ecc. Le variabili che possono esserecontenute all’interno di un processo sono di uno dei seguenti tipi Java:
• String,• Integer,• Short,• Long,• Double,• Boolean,• Date,• Classe serializzabile (che implementa Serializable),• Sequenza di byte.
Per quanto riguarda i gateway, questa descrizione si focalizza maggiormentesull’utilizzo dei gateway esclusivi. L’implementazione di tutti i tipi di gateway seguele indicazioni dello standard, ma la configurazione del gateway esclusivo differisce.In dettaglio, al gateway si puo assegnare quale dei suoi cammini uscenti e quello didefault. Le espressioni per le condizioni che fanno scegliere un determinato camminodevono essere assegnati ai sequence flow uscenti del gateway.
42

Sebbene Activiti non risulta completo, ed e in continuo sviluppo per il miglio-ramento e aggiunta di componenti, esso e un ottimo strumento per la creazione edesecuzione di workflow per processi aziendali BPMN 2.0.
4.3.3 JavaFMI
L’ultimo tassello mancante per riuscire a eseguire i modelli FMU all’interno dell’en-gine Activiti, e di riuscire ad eseguire le funzioni dell’interfaccia FMI per gestire lasimulazione dei modelli. In particolare si e cercato di costruire un ponte tra l’enginein linguaggio Java e le funzioni in linguaggio ’C’. La soluzione a questo si e trovatanella libreria JavaFMI [28].
La libreria JavaFMI e composta di tre parti: FmuWrapper, che serve per l’im-portazione di FMU esistenti dentro ad un’applicazione Java, e FmuFramework eFmuBuilder, che servono sul lato opposto a costruire FMU da applicazioni Java.L’interesse di questa tesi e usare gli FMU precedentemente costruiti con FMU-SDK (sezione 2.2.3) nell’engine Activiti, quindi serve utilizzare la prima componenteFmuWrapper.
import org.javafmi.wrapper.generic.*;
public class Simulation101{
public static void main(String[] args){
double startTime = 0;
double stopTime = 20;
double stepSize = 0.01;
Simulation simulation = new Simulation("C:/Program
Files/fmusdk/fmu10/fmu/cs/x64/bouncingBall.fmu");
simulation.init(startTime, stopTime);
simulation.write("h").with(10.0);
for(int i=0; i < 2000; i++){
double value = simulation.read("h").asDouble();
System.out.println(value);
simulation.doStep(stepSize);
}
simulation.terminate();
}
}
Nel codice sopra viene mostrato un semplice esempio di esecuzione del modellobouncingBall.fmu dentro a una classe Java.
L’oggetto Simulation rappresenta interamente un’istanza di modello. In essosono presenti tutte le variabili interne che sono state costruite da FmuWrapper,basandosi sulla descrizione del modello in XML.
Facendo un confronto tra il codice sopra con il diagramma concettuale del pro-cesso slave BPMN, visto in precedenza si puo osservare un’associazione univoca
43

tra le funzioni che si possono eseguire sull’oggetto Simulation e i service task delprocesso slave, cioe:
• Il task Instantiation corrisponde alla creazione di un nuovo oggetto Simulation,• Il task Initialization corrisponde alla funzione init,• Il task getReal corrisponde alla funzione read (in questo caso si applica asDou-
ble in seguito, analogamente per gli altri tipi di variabili),• Il task setReal corrisponde a write,• Il task doStep corrisponde alla funzione doStep,• Il task Terminate corrisponde alla funzione terminate.
In questo modo, queste funzioni sono indicative delle fasi in cui un diagrammaBPMN per la co-simulazione di modelli FMU puo passare.
FmuWrapper offre ancora un’altra classe, chiamata Access, la quale permetteagli algoritmi master che utilizzano questa libreria ad avere accesso a tutte le fun-zioni FMI di una Simulation. Questo permette a determinati algoritmi effettuareoperazioni particolari sui modelli, per esempio richiedere le derivate direzionali delmodello, come mostrato nel seguente codice:
Simulation simulation = new Simulation("path/to/foo.fmu");
simulation.init(...);
Access access = new Access(simulation);
double[] dirDerivatives = access.getDirectionalDerivative(...);
44

Capitolo 5
Realizzazione del progetto
Nel presente capitolo si descrive in dettaglio la fase di realizzazione del progetto diquesto elaborato. La realizzazione consiste nella creazione del diagramma BPMNeseguibile in Activiti, capace di orchestrare la simulazione di un numero non definitodi modelli FMU. Il diagramma si basa sullo schema concettuale del quarto capito-lo, con la differenza che la creazione in questo caso viene svolta con gli elementiBPMN implementati da Activiti. Come descritto nella sezione 4.3, ci sono moltecaratteristiche di tali elementi che differiscono da quelle nello standard.
Per realizzare il diagramma finale di co-simulazione e stato prima creato undiagramma per la simulazione di un unico modello. La prima sezione percorretre soluzioni per questo primo diagramma, partendo da quella meno dettagliata,per proseguire la descrizione analizzando le caratteristiche riportate dall’aggiuntadi dettagli. In seguito, la seconda sezione per questo capitolo descrive la creazionedi una struttura di dati per la separazione della configurazione delle simulazionidal diagramma. Nella terza sezione viene descritto il diagramma finale, che si basasulle soluzioni presentate nella sezione 5.1 e utilizza la struttura di configurazionepresentata nella sezione 5.2. Nella quarta sezione viene descritta la creazione delservizio esterno su cui il diagramma finale si appoggia per eseguire i modelli. Lasezione 5.5 presenta un esempio di esecuzione del diagramma finale e in fine, lasezione 5.6 descrive la creazione dell’interfaccia utente, per la creazione facilitatadella struttura di configurazione.
5.1 Simulazione di bouncingBall.fmu in Activiti
In questa sezione si descrive la realizzazione di un diagramma per la simulazionedi un unico modello, bouncingBall.fmu visto nella sezione 2.2.3. Il primo diagram-ma presentato nella figura 5.1 mostra una prima realizzazione di un processo persimulare il modello.
Tale processo ha un unico service task che serve per chiamare una classe Javacontenente il codice visto nella sezione 4.3.3, il quale serve per eseguire l’intera
45

Figura 5.1: Primo diagramma semplice di simulazione di bouncingBall.fmuvisualizzato in Eclipse
simulazione in tutte le sue fasi. Sebbene questo diagramma risulta elementare, essosi e rivelato molto utile per la parte iniziale della realizzazione, in quanto ha permessodi capire:
• Come utilizzare il plug-in di Eclipse, Activiti Designer per la costruzione didiagrammi eseguibili,• Come caricare il diagramma costruito all’interno dell’applicazione Activiti
Explorer ed eseguirlo,• Come configurare un service task per poter chiamare una classe Java.
Tuttavia tale versione semplificata della simulazione non permette la gestionedelle diversi fasi della simulazione in modo indipendente, e tale gestione e necessariain una simulazione di piu di un modello.
Figura 5.2: Seconda soluzione, con le fasi di simulazione, visualizzata in Eclipse
46

Per avere maggiori dettagli questa prima soluzione e stata spezzata nelle fasi disimulazione viste nel diagramma concettuale. Il diagramma della figura 5.2 mostrauna seconda realizzazione.
La particolarita di questa realizzazione e la divisione del diagramma in due pro-cessi master e slave, rappresentati dai due pool. Entrambi i processi passano perquattro fasi di simulazione, marcate in rosso nella figura. La fase di integrazionetemporale viene svolta per intero dal service task Do Step e in pratica chiama laparte riguardante il ciclo for del codice visto nella sezione 4.3.3. Questa soluzione,come la prima, comporta un vantaggio rispetto alla realizzazione finale, come vienedescritto nella sezione 5.5. In seguito vengono descritte alcune caratteristiche deldiagramma introdotte con questa soluzione. Inizialmente, anche se nel diagrammasono disegnate con linee tratteggiate i message flow, essi non sono supportati dal-l’engine di Activiti come descritto in 4.3.2. Nonostante questo i processi master eslave comunicano tramite lo scambio di messaggi. Questo e stato svolto creandodegli service task per effettuare l’invio di messaggi, dovuto alla mancanza di altrielementi per tale azione, come spiegato in 4.3.2. In piu, se necessario, ai messaggisi possono assegnare delle variabili, per effettuare lo scambio di dati tra i processimaster e slave, nel seguente modo:
HashMap<String, Object> transportVariables = new HashMap<>();
transportVariables.put(...);
...
runtimeService.messageEventReceived("MessageName", msgExecution.getId(),
transportVariables);
In questo codice, la funzione messageEventReceived esegue l’effettiva consegnadel messaggio all’esecuzione rappresentata dalla variabile msgExecution. Questa ese-cuzione viene ottenuta a runtime facendo una ricerca (query) su tutte le esecuzioni.La query ritorna un’unica esecuzione che aspetta di ricevere un determinato messag-gio, e in questo esempio tale messaggio ha come nome ”MessageName”. In Activiti,ExecutionQuery e l’oggetto, ottenuto dalla RuntimeService, su cui si possono farele ricerche di esecuzioni.
Nel seguito si descrivono gli utilizzi definiti per i task creati. Per lo scambio dimessaggi sono utilizzati otto service task, come visualizzato nel diagramma, con-tenenti istruzioni simili al codice presentato. Gli altri 4 service task, posizionatinella parte superiore del diagramma servono per eseguire le istruzioni sull’oggettoSimulation della libreria JavaFMI, rappresentazione della simulazione.
Riguardo a questi ultimi 4 service task si presenta un problema importante perla realizzazione. Nella prima soluzione vista in questa sezione (figura 5.1), l’interalogica del service task e contenuta all’interno del file Java chiamato dal task, e l’og-getto di classe Simulation creato, come anche altre variabili della simulazione, nonsono stati usati al di fuori di questo task. In questa seconda proposta di realizzazio-ne, i 4 task hanno necessita di condividere l’oggetto che rappresenta la simulazionedi bouncingBall. L’oggetto Simulation pero non puo essere salvato all’interno del
47

processo slave, in quanto e un oggetto complesso e non serializzabile.Bisogna ricordare che la versione di FMI usata in questo progetto e la 1.0. La
versione FMI 2.0 sorvola questo problema siccome le sue funzioni getFMUstatee setFMUstate permettono il salvataggio e ripristino di una simulazione, sebbenequesta non sia serializzabile.
Per risolvere il problema presentato si e pensato di appoggiarsi ad un servizioesterno al diagramma, creato per l’esecuzione della simulazione. Questo servizioesterno e in pratica un servlet Java [29] in ascolto di richieste HTTP, che mantieneal proprio interno gli oggetti Simulation, e che applica a questi delle azioni in base allerichieste che gli arrivano. Il servlet cosı costruito e stato chiamato SimulationServer,e una sua descrizione dettagliata viene fatta nella sezione 5.4.
Per ritornare ai service task della parte superiore del diagramma, essi sono rea-lizzati in modo da comunicare con il servlet. La comunicazione viene effettuata condelle richieste HTTP di tipo POST, dove vengono inserite delle coppie nome-valoreche specificano il tipo di azione che il servlet deve fare e altri parametri necessariper la simulazione. La risposta del server contiene a sua volta dati riguardanti lasimulazione, utili al master. Le richieste e le risposte vengono effettuate con l’aiutodella libreria Apache HttpClient [30]. Il codice seguente presenta un esempio diquesta comunicazione, estratto dal service task Initialize:
String connectionURL = "http://localhost:8080/SimulationServer/simulation";
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost httpPost = new HttpPost(connectionURL);
List<NameValuePair> reqParams = new ArrayList<>();
reqParams.add(new BasicNameValuePair("message", "initialize"));
reqParams.add(new BasicNameValuePair("simulationID", simulationID));
...
try{
httpPost.setEntity(new UrlEncodedFormEntity(reqParams));
}
catch(UnsupportedEncodingException uee){
uee.printStackTrace();
}
try{
CloseableHttpResponse response = httpclient.execute(httpPost);
try{
int status = response.getStatusLine().getStatusCode();
if((status >= 200) && (status < 301)){
HttpEntity respEntity = response.getEntity();
List<NameValuePair> respParams = URLEncodedUtils.parse(respEntity);
Iterator<NameValuePair> iterator = respParams.iterator();
while(iterator.hasNext()){
NameValuePair nvp = iterator.next();
String attName = nvp.getName();
...
}
iterator.remove();
}
48

}
else System.out.println("*\tThe request was not sent correctly. Status
code: " + status);
}
finally{
response.close();
}
}
L’ultimo task da descrivere per il diagramma della figura 5.2 e lo script task.Esso serve ad assegnare i parametri di inizializzazione della simulazione, in dettaglio,i tempi di inizio (tStart) e fine (tStop) e lo step di simulazione (tStep).
Le due soluzioni presentate fino a questo punto della sezione effettuano la si-mulazione di bouncingBall.fmu, il quale e un modello che non possiede variabili diinput/output. Per riuscire ad eseguire modelli che possiedono tali tipi di variabili,il master deve possedere le funzioni getter e setter.
La terza soluzione che viene presentata in questa sezione introduce queste duefunzioni, che vengono eseguite da degli service task.
La figura 5.3 illustra il processo Slave di questa terza soluzione. Questo processoe molto simile a quello del diagramma concettuale presentato nella sezione 4.2.
Figura 5.3: Visualizzazione del processo slave per la terza soluzione in Eclipse
In esso si nota la presenza di un’event gateway, il quale gestisce il flusso diesecuzioni in base al messaggio in arrivo dal processo master, similmente a quantovisto nella sezione 4.2. La gestione delle azioni eseguite dai task viene fatta comenella seconda variante, sia per i messaggi che per la comunicazione con il servlet. Lefrecce entranti e uscenti dal pool hanno un ruolo solo grafico in quanto rappresentanoi messaggi che sono scambiati con il processo master, ma non sono elementi eseguibilidall’engine.
Per quanto riguarda il processo master, anche esso subisce alcune modifiche conl’aggiunta di task per eseguire le funzioni getter e setter. Il service task ”Send DoStepMessage” del diagramma precedente viene sostituito da un sub-process chiamato”Simulate SubProcess”, che viene illustrato nella figura 5.4.
49

Figura 5.4: Visualizzazione del sub-process Simulate in Eclipse
Come per il processo slave, anche questo sub-process e simile a quello presentatonel diagramma concettuale del capitolo 4, con la differenza che gestisce l’iterazionedi un unico modello. La presenza di un parallel gateway significa che l’esecuzioneviene divisa in altre due parallele. Questa separazione viene fatta perche i datiricavati con le funzioni getter possono servire ad entrambi i camini dell’esecuzione.Rispettivamente il primo serve per assegnare i valori con le funzioni setter, il secondoper la visualizzazione dei valori nei risultati finali. Nel caso effettivo della simulazionedi bouncingBall il task corrispondente ai setter non e utilizzato per il fatto che questomodello non possiede variabili di input. Il task e invece necessario per simulazioni didue o un numero maggiore di modelli, che corrisponde al caso del diagramma finaledi questo progetto. I dati dei risultati finali della simulazione sono salvati in un fileCSV, similmente a come visto nel master presente nella SDK di FMI.
Lo script task trovatosi nel sub-process effettua un semplice incremento per lavariabile tC, rappresentazione dell’istante di esecuzione della simulazione, aggiun-gendone il valore di tStep.
Da notare come nei tre workflow BPMN proposti in questa sezione, i parametridi configurazione della simulazione sono definiti durante la creazione dei task e perla maggior parte tali parametri sono fondamentali per l’algoritmo master, il qualeagisce in base ai loro valori. Alcuni esempi di variabili di configurazione sono:
• Gli istanti tStart, tStop, e tStep che vengono definiti nello script task diinizializzazione,• Nello script task vengono definiti anche i valori di inizializzazione che differi-
scono da quelli di default, nella descrizione del modello in XML,• I valori da presentare nei risultati sono scelti all’interno del task ”Write Va-
riables To File”.
Una simulazione con valori di configurazione diversi richiederebbe all’utilizzatoredi questo framework di modificare gli elementi del diagramma, il che significa lamodifica anche delle classi Java in certi casi. Di conseguenza, tale modifica comporta
50

la ripetizione delle procedure per il ricaricamento del diagramma nell’applicazioneActiviti Explorer, dove esso viene eseguito. Per evitare questa inconvenienza, neldiagramma finale viene separata la configurazione della simulazione dalla creazionedegli elementi. Nella seguente sezione viene descritta questa soluzione, anticipandola descrizione del diagramma finale di co-simulazione, svolta nella sezione 5.4.
5.2 File di configurazione della simulazione
Altri strumenti di simulazione di modelli richiedono una fase iniziale di configurazio-ne, in cui l’utente specifica molte informazioni (modelli usati, connessioni tra essi,valori iniziali, ecc.). Per questo progetto si e pensato di raccogliere queste infor-mazioni in un’unica struttura dati, che in seguito puo essere usata dal diagrammaBPMN per la creazione ed esecuzione della simulazione. La modifica dei valori diconfigurazione richiederebbe il cambiamento solo della struttura dati e non quellodel diagramma.
Per la struttura dati e stato scelto di avere un unico oggetto JSON [31] (Ja-vaScript Object Notation) rappresentato in forma testuale all’interno del file ”ma-ster.txt”. L’uso di JSON e dovuto principalmente al fatto che permette di rappre-sentare oggetti complessi con una sintassi molto semplice. Inoltre l’utilizzo dellalibreria Java-Json [32] permette una facile gestione di strutture JSON all’internodel codice Java eseguito nella simulazione.
In JSON ci sono due principali costrutti:
• Oggetto JSON: un insieme non ordinato di coppie nome-valore.• Array JSON: una lista ordinata di valori.
Un valore in JSON puo essere una stringa, un numero, un oggetto, un array, unvalore booleano true o false, oppure un valore null (non definito).
Ritornando al file master.txt, l’oggetto JSON principale contiene i seguenti 3array JSON:
• ”simulations”, che contiene gli oggetti che rappresentano le simulazioni,• ”outputs”, che contiene oggetti che descrivono i valori in output di ciascuna
simulazione,• ”in depend”, che contiene oggetti che definiscono le dipendenze degli input
dagli output.
Per ciascuna simulazione vengono allocati 3 oggetti in questi 3 array, in modotale da trovarsi nella stessa posizione di ordine negli array.
Per semplicita di annotazione, in questo documento verra chiamato con il nomesimulation l’oggetto tipo all’interno di ”simulations”. Questo oggetto rappresentaun’istanza in esecuzione e contiene le seguenti coppie nome-valore:
51

• ”url”: una stringa che definisce il filepath in cui si trova il file FMU delmodello,• ”tStart”: un numero che indica il tempo di inizio simulazione per il modello,• ”tStop”: un numero che indica il tempo di fine simulazione per il modello,• ”tStep”: un numero che indica lo step di comunicazione per il modello,• ”init vars”: un oggetto che contiene le informazioni sui valori iniziali di
alcune variabili del modello,• ”result vars”: un oggetto che indica i nomi delle variabili richieste dall’utente
per visualizzare la loro variazione nel tempo, al termine dell’esecuzione.
L’oggetto tipo all’interno di ”in depend” contiene coppie nome-valore, ma po-trebbe essere anche vuoto (nel caso in cui non ci sono collegamenti degli input per ilmodello). Il nome di ciascuna coppia rappresenta un dato input, mentre il valore euna array di lunghezza 2, di cui il primo elemento indica la simulation, e il secondoindica il nome della variabile di output connessa all’input.
Siccome in JSON non si riescono a distinguere i dati numerici interi dai reali, si edovuto ricorrere a degli accorgimenti sugli oggetti ”init vars”, ”result vars” e quelliall’interno di ”outputs”. Per indicare al master il tipo di variabile, ciascuno di questicontiene 4 coppie nome-valore, dal nome ”doubles”, ”ints”, ”strings” e ”boolean”,per rappresentare ciascun tipo.
Come si puo notare, tale struttura appena descritta e difficile da gestire manual-mente da un utente, siccome per la modifica dei dati serve una modifica dell’oggettoJSON, e se svolta manualmente puo molto probabilmente essere causa di errori.Per questo motivo e stata costruita un’interfaccia utente che riesca a creare in modosemplice il file di configurazione. La costruzione di tale interfaccia viene descrittanella sezione 5.6.
5.3 Diagramma BPMN finale per la co-simulazione
Nella presente sezione viene descritta la costruzione del diagramma finale di co-simulazione. Il diagramma e stato creato come sviluppo dell’ultimo diagrammadescritto nella sezione 5.1, per rendere possibile la simulazione di numerosi modelli,la coordinazione delle loro esecuzioni e gestire correttamente lo scambio di dati.Inoltre, diversamente dalle soluzioni della sezione 5.1, questo diagramma e statocostruito in modo tale da essere configurato dal file master.txt mostrato in 5.2.
Il processo slave in questo diagramma rimane invariato graficamente, mentresubisce alcuni accorgimenti nelle classi Java che vengono utilizzate dagli servicetask del diagramma. Per tale motivo la descrizione in questa sezione si focalizzamaggiormente sul processo master, il quale ha subito numerose modifiche sia alivello grafico che nelle funzionalita. La figura 5.5 visualizza tale processo master.
Inizialmente si puo notare la presenza di numerosi sub-process, ciascuno rappre-sentante una delle fasi di simulazione. I processi di secondo ordine, trovati all’interno
52

Figura 5.5: Visualizzazione dell’intero processo master finale in Eclipse
53

di questi sub-process possiedono una struttura identica. In seguito allo start event,e stato posizionato un service task per l’invio di messaggi e dati al processo slave.Il ricevimento del messaggio viene svolto dal message intermediate event allocato inseguito allo service task. Il secondo service task e stato utilizzato per poter agire inbase al messaggio ricevuto, principalmente salvare i dati ottenuti dal processo slave.Un altro particolare per questi sub-process e che sono definiti come multi-instance.Come spiegato nella sezione 3.3, questo permette di eseguire il processo di secondoordine un numero di volte definito. Questo numero e calcolato in base agli oggettisimulation contenuti nel file master.txt, ossia il numero di modelli da simulare.
L’esecuzione del processo master ha inizio con il task Master Setup. Questotask ha il compito di leggere il file master.txt, e di estrarre da esso le informazioninecessarie per la simulazione (modelli da simulare, gli output, dipendenze degliinput). In particolare il numero di simulazioni viene salvato in una variabile cheverra utilizzata dai multi-instance sub-process del processo.
In seguito viene eseguito il sub-process Instantiate, il quale invia un messaggioal message start event del processo slave. Si puo notare che il processo slave non estato trasformato in multi-instance, dovuto questo al fatto che Activiti definisce chel’invio di ciascun messaggio ad un message start event comporta alla creazione di unnuovo processo. Il nuovo processo slave possiede un id di processo (procId) diversodagli altri, il quale lo trasferisce al processo master, insieme all’id di simulazione(simId) ottenuto dal servlet (la spiegazione di questo viene fatta in sezione 5.4).
Al ricevimento del messaggio da parte dell’intermediate message catching eventdel sub-process Instantiate, segue il task Complete Instantiation. Questo task hail compito di inserire le variabili procId e simId all’interno dell’oggetto simulazionerispettivo (variabile del processo master), e sono usate in seguito per effettuare lacorrelazione tra processi. Per correlazione si intende la determinazione del processogiusto tra quelli in ascolto di un certo messaggio. Questo viene fatto aggiungendoalla query sulle esecuzioni, vista nella sezione 5.1, una ulteriore condizione che utiliz-za l’id di processo. La correlazione e obbligatoria per ciascun scambio di messaggi,in modo da avere una giusta corrispondenza tra le simulazioni memorizzate nelprocesso master e i processi slave che li rappresentano. Eseguendo dei sub-processmulti-instance come nel diagramma finale, puo capitare che ci siano piu esecuzioniin ascolto dello stesso messaggio. Per questo motivo le variabili procId e simId sonosempre presenti nei task che spediscono messaggi verso l’altro processo.
Il sub-process Initialize si esegue in modo simile a quanto visto nel sub-processInstantiate. Dopo la terminazione di tutte le istanze del sub-process Initialize hainizio la fase di co-simulazione tra modelli con l’esecuzione del task Prepare Simula-tion. Il compito di questo task e quello di preparare all’interno del processo mastertutte le variabili utili alla simulazione. In particolare:
• Si decidono gli istanti di inizio e fine esecuzione analizzando le variabili tStarte tStop di tutte le simulazioni.
54

• La variabile in dependency del processo master contiene le dipendenze degliinput dagli output di tutte le simulation in esecuzione. Questo task modificaquesta variabile assegnando a tutti gli elementi interni l’id della simulation acui appartengono.• Vengono creati degli oggetti JSON wQuery e iQuery, che servono per indicare
quali sono le variabili di interesse per cui interrogare il servlet, e ottenere iloro valori, rispettivamente utili nella scrittura dei risultati e nell’assegnazionedi valori in input.
All’interno del sub-process Simulate sono stati inseriti i sub-process per le fun-zioni getter e setter. I compiti di questi task sono elencati in seguito:
• Il task Send GetMessage estrae ”results vars” dal determinato simulation, sic-come rappresenta i valori richiesti per stamparli nel file dei risultati. Oltre aquesto estrae gli output di quel simulation, e spedisce tutti i dati al processoslave.
• I dati vengono passati dal processo slave al servlet, il quale li utilizza percostruire oggetti contenenti i valori di interesse. Questi valori arrivano al taskRecord Values che ha il compito di salvarli all’interno degli oggetti wQuerye iQuery creati. Dopo l’esecuzione del sub-process Get, questi due oggetticontengono i dati necessari per il seguito dell’esecuzione.
• wQuery viene usato dal task Save Current Results, per estrare i dati e conver-tirli in una linea di formato CSV.
• iQuery viene usato dal task Send SetMessage, il quale ottiene i dati di unadeterminata simulation. Inoltre, per lo stesso simulation, ottiene anche ledipendenze degli input dagli output, e spedisce tutto al processo slave.
• Questi dati sono utilizzati dal servlet per assegnare nuovi valori in input allevariabili connesse.
Concluse le fasi di Get e Set, l’esecuzione passa al task Prepare Iteration. Que-sto task e fondamentale per l’algoritmo master, in quanto stabilisce le condizioniper la simulazione di ciascun modello. La sua esecuzione produce una mappa divalori booleani, ciascuno dei quali e un verdetto sulla simulazione o no del modelloa cui viene assegnato. In seguito viene effettuata un’iterazione su questa mappa,eseguendo sequenzialmente l’operazione doStep, la quale non cambia rispetto allasoluzione precedente. Durante questa sequenza di esecuzioni vengono fatti dei con-trolli continui sullo stato generale della simulazione da parte degli exclusive gateway(nella parte destra del sub-process). In seguito viene effettuato l’incremento dellavariabile tC, e l’esecuzione arriva al ”primo” exclusive gateway (nella parte sinistra),che esegue un controllo sulle condizioni per determinare se si deve fare una nuovaiterazione oppure terminare il sub-process.
55

Il sub-process Terminate ha il compito di rimuove le simulazioni e i dati corri-spondenti dalle variabili di processo.
In fine il task Write Results to File ha il compito di scrivere i risultati memoriz-zati su un file CSV.
5.4 SimulationServer
Come descritto in precedenza, SimulationServer e un servlet Java utilizzato in que-sto progetto per gestire gli slave, ovvero i modelli simulati, in quanto questi oggettinon possono essere contenuti come variabili nei processi BPMN. La gestione di questislave viene fatta per tutte le fasi dell’esecuzione.
Per fare questo, il servlet e configurato per ricevere richieste HTTP di tipo Postdai service task del diagramma di co-simulazione. Tali richieste devono possederedei parametri (coppie nome-valore), il primo dei quali specifica il tipo di azione chesi vuole eseguire. Questo primo parametro viene chiamato message, indica qualefunzione del servlet utilizzare (indicata nella lista seguente in corsivo, corrispondentea quella eseguibile sui modelli con JavaFMI) e puo assumere uno dei seguenti valori:
• ”instantiate”, esegue la funzione instantiateSlave,• ”initialize”, esegue la funzione initializeSlave,• ”get”, esegue la funzione getVars,• ”set”, esegue la funzione setVars,• ”doStep”, esegue la funzione doStep,• ”terminate”, esegue la funzione terminate,
Il servlet gestisce gli slave, memorizzandoli su una mappa e attribuendo a cia-scuno un identificativo. Questo gli permette in seguito di distinguere a quale slaveassociare una richiesta ricevuta. Per questo motivo tutte le richieste che si devonoeseguire su un slave esistente nel servlet devono contenere un parametro simulatio-nID. Il valore per questo parametro viene assegnato al momento della creazione delslave (fase Instantiation della co-simulazione) e in seguito scambiato tra il processoBPMN e il servlet. Nel codice seguente viene mostrato come esempio la funzione in-stantiateSlave, dove si nota la creazione dell’oggetto Simulation e la memorizzazionedi esso in una mappa.
void instantiateSlave(HttpServletRequest request, HttpServletResponse response)
throws IOException {
String url = request.getParameter("url");
Integer index = Integer.parseInt(request.getParameter("index"));
if(url != null){
Simulation simulation = new Simulation(url);
int simID = simCounter.use();
slaves.put(simID, simulation);
// simID => response
response.setContentType("application/x-www-form-urlencoded");
56

String data = "simulationID=" +simID+ "&index=" + index;
PrintWriter out = response.getWriter();
out.println(data);
}
}
La risposta HTTP che il server ritorna al processo BPMN, puo contenere deiparametri, come visto per la richiesta, oppure un oggetto JSON in forma testuale.Il secondo caso succede solo per le richieste con il parametro message uguale a”get” o ”set”. L’oggetto JSON nella risposta contiene l’id dello slave in questione,e nel caso di ”get” altri due oggetti JSON, che sono degli insiemi di valori usatirispettivamente in wQuery e iQuery, come descritto nella sezione 5.3. L’insiemedestinato ad inserirsi in iQuery, viene ottenuto in seguito dalla funzione setVars, cheinsieme alle dipendenze degli input per quella simulation, li utilizza per assegnarenuovi valori in input allo slave corrispondente.
Per concludere, la funzione terminate del servlet, oltre che eseguire la funzionecorrispondente di JavaFMI (con lo stesso nome), rimuove la entry dello slave dallamappa.
5.5 Esecuzione e confronto con SimulationX
Per concludere lo sviluppo del diagramma master per la co-simulazione sono statefatte delle simulazioni concrete di modelli FMU. Le capacita di simulazione del ma-ster sono notevoli in quanto permette la gestione di tutte le varianti di co-simulazionedi slave senza retroazione, tipologia questa trattata nella sezione 2.4.2.
L’immagine 5.6a presenta un confronto, risultato delle simulazioni eseguite tra-mite il diagramma BPMN realizzato e SimulationX. La simulazione di SimulationX ela stessa mostrata nella sezione 2.3.2 e si e riproposta per essere eseguita in Activiti,configurando il file master.txt in modo appropriato.
Le misurazioni effettuate sui tempi di esecuzione della co-simulazione hanno fattonotare una differenza sostanziale nel confronto. Tale differenza e comprensibile inquanto l’esecuzione in Activiti richiede l’interazione di molte tecnologie. Il tempo diesecuzione su Activiti e inoltre fortemente dipendente dallo step di comunicazionescelto: riducendo lo step si aumenta notevolmente il tempo di esecuzione. Dall’altrolato pero aumentando lo step comporta a diminuire la precisione della simulazione,e una bassa precisione puo portare a simulazioni errate. Per questi motivi bisognacercare di assegnare dei valori di step appropriati, in modo da non comportaresvantaggi consistenti da una parte o dall’altra.
Rispetto a SimulationX o altri strumenti di simulazioni, il diagramma costruitopossiede numerosi vantaggi. Esso offre molte liberta all’utente nell’utilizzo deglialgoritmi master per la simulazione, e l’inserimento o la modifica del diagrammae facile in quanto consiste maggiormente di modifiche di elementi grafici BPMN.Un vantaggio molto importante, come descritto in precedenza in questo documento,
57
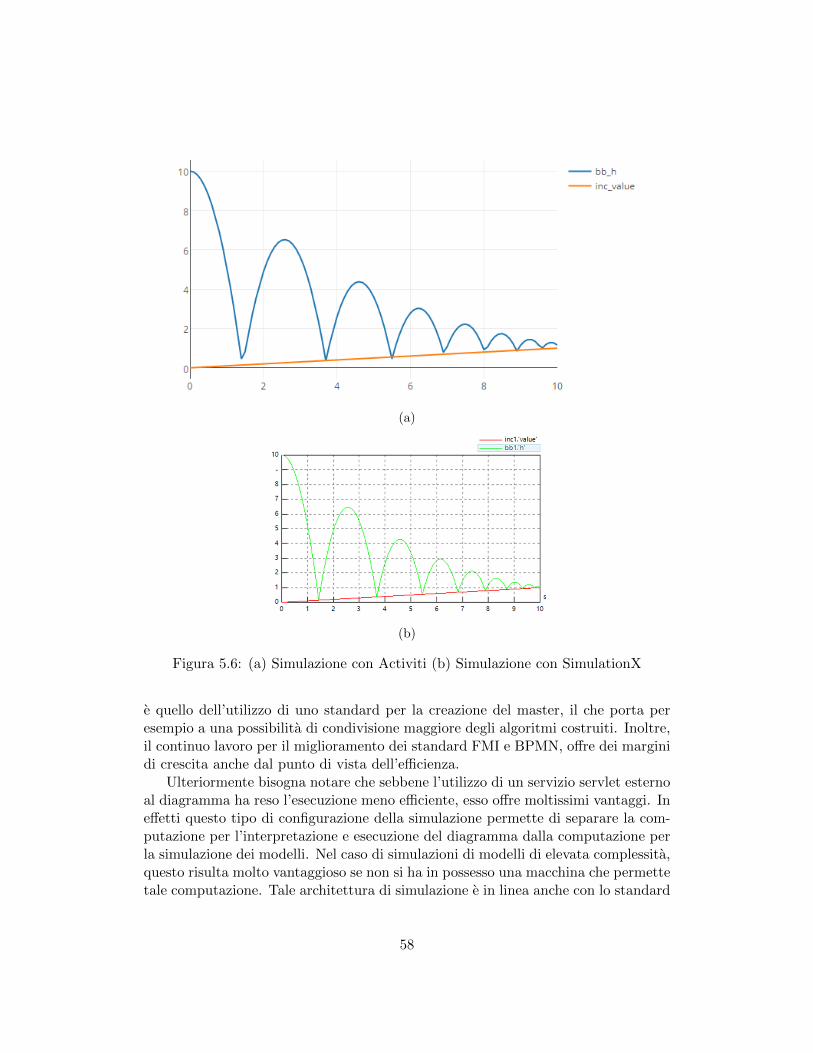
(a)
(b)
Figura 5.6: (a) Simulazione con Activiti (b) Simulazione con SimulationX
e quello dell’utilizzo di uno standard per la creazione del master, il che porta peresempio a una possibilita di condivisione maggiore degli algoritmi costruiti. Inoltre,il continuo lavoro per il miglioramento dei standard FMI e BPMN, offre dei marginidi crescita anche dal punto di vista dell’efficienza.
Ulteriormente bisogna notare che sebbene l’utilizzo di un servizio servlet esternoal diagramma ha reso l’esecuzione meno efficiente, esso offre moltissimi vantaggi. Ineffetti questo tipo di configurazione della simulazione permette di separare la com-putazione per l’interpretazione e esecuzione del diagramma dalla computazione perla simulazione dei modelli. Nel caso di simulazioni di modelli di elevata complessita,questo risulta molto vantaggioso se non si ha in possesso una macchina che permettetale computazione. Tale architettura di simulazione e in linea anche con lo standard
58

FMI, il quale prevede anche casi di calcolo distribuito di una co-simulazione [4].
5.6 Interfaccia utente per la configurazione (Master-Creator)
Come visto in questo capitolo, il diagramma BPMN creato richiede come prima cosaun file master.txt il quale contiene la configurazione della co-simulazione che si ese-gue. I dati della configurazione sono organizzati in una struttura JSON, contenutain forma testuale nel file master.txt.
Sebbene la rappresentazione dei dati in un oggetto JSON e molto semplice, essanon e intuitiva e comprensibile da un utente non esperto. Inoltre la modifica manualedel file puo portare a errori sui dati e come risultato anche errori nell’esecuzionedella simulazione. Questi errori sono molto difficili da rilevare durante l’esecuzionee portano a risultati sbagliati.
Per tutti questi motivi si e pensato di costruire un’interfaccia utente trami-te la quale stabilire la configurazione iniziale della simulazione, e permettere lacostruzione automatica del file master.txt.
L’interfaccia utente dal nome MasterCreator, e stata creata in linguaggio Java,utilizzando una architettura software di tipo MVC (Model-View-Controller) [33].Per la costruzione di tale interfaccia e stato utilizzato l’IDE NetBeans [34], perchepermette la creazione rapida degli elementi grafici tramite comandi ”drag & drop”,con la generazione del codice corrispondente in automatico.
La figura 5.7 mostra la schermata iniziale di questa applicazione.
Figura 5.7: Schermata iniziale di MasterCreator
59

La sezione a destra della schermata serve per visualizzare i modelli gia presentinell’applicazione. Nella figura sopra non risultano presenti modelli e una primaazione che l’utente deve effettuare e l’inserimento di un modello. L’inserimentodel modello avviene come conseguenza di varie azioni, la prima delle quali e lapressione del pulsante ”Add...”, la quale fa visualizzare la finestra della figura 5.8dall’applicazione.
Figura 5.8: Schermata di inserimento modello
In seguito si deve decidere il file FMU del modello che si vuole aggiungere. Perfare questo l’utente deve premere il pulsante in alto a sinistra nella figura 5.8, laquale fa apparire un’ulteriore finestra dall’applicazione. Tale finestra di dialogo conl’utente permette di navigare nel file system per trovare e scegliere il file necessario.
Bisogna ricordare che, come spiegato nel capitolo 2, il file FMU e in pratica unfile ZIP contenente altri file tra cui modelDescription.xml, descrizione del modello.
Una volta selezionato il file, si carica nell’applicazione tramite la funzione load-Simulation la quale esegue i seguenti passi:
1. L’applicazione cerca e carica il file modelDescription.xml.2. Utilizzando un parser XML si estraggono i dati delle variabili e vengono inseriti
nei oggetti JSON: variables, inputs e outputs. L’oggetto variables contiene i
60

Figura 5.9: Schermata iniziale con modelli inseriti
dati per tutte le variabili del modello, inputs contiene quelli degli input eoutputs contiene i dati per gli output.
3. Nelle tre sezioni della finestra in figura 5.8, indicate con i nomi ”Obligatory Pa-rameters”, ”Initial Values” e ”Pick Result Variables”, vengono visualizzati deicampi di inserimento dati. La prima delle tre sezioni contiene i valori che sonoindispensabili nella configurazione della simulazione. ”Initial Values” contienevalori utilizzati per definire quelli iniziali, e ”Pick Result Variables” contienedelle checkbox per selezionare per quali variabili visualizzarne i risultati.
La pressione del pulsante ”Add Simulation” da parte dell’utente fa proseguirel’applicazione con la raccolta di tutti i dati inseriti per aggiungere informazioni alladeterminata istanza di modello creata. Con l’aggiunta di tali dati, viene inseritoanche un nuovo elemento nella lista dei modelli della schermata iniziale e vienechiusa la finestra della figura 5.8.
La figura 5.9 mostra due modelli inseriti nell’applicazione. Si puo notare comedi fianco al nome del modello e presente la scritta in rosso ”Inputs not set!”, il chesignifica che non sono state definite le dipendenze degli input dagli output per quelmodello.
La definizione delle dipendenze viene fatta con la pressione del pulsante ”SetInputs” da parte dell’utente, avendo scelto nella lista il nome del modello a cui ap-plicare tale definizione. L’applicazione non permette la creazione del file master.txtse non sono state definite le dipendenze degli input di tutti i modelli. Una voltapremuto il pulsante, all’utente viene visualizzata la finestra della figura 5.10.
La finestra inizialmente mostra tutti i nomi degli input con alla loro destra dellecombo box con i nomi di tutti modelli presenti nell’applicazione. Nel momento incui l’utente sceglie uno di questi nomi della combo box, viene visualizzata sulla
61

Figura 5.10: Schermata di inserimento dipendenza di input
destra un’altra combo box che contiene i nomi di tutti gli output del modello scelto.Questa procedura deve essere eseguita per tutti gli input in modo da concluderequesta azione di definizione delle dipendenze. Una volta terminata tale azione, lascritta in rosso viene sostituita da un’altra di color verde con il messaggio ”Inputset!”.
La pressione del pulsante ”Edit” della finestra principale fa apparire una finestrasimile a quella vista nella figura 5.8, in cui si possono modificare i dati del modelloselezionato. Il pulsante ”Remove” intuitivamente fa rimuovere il modello seleziona-to e tutti i dati appartenenti dall’applicazione. La pressione del pulsante ”Selectfolder...” fa dialogare l’utente con un’altra finestra per la selezione della cartella incui salvare il master.txt da creare. Infine, il pulsante ”Finish” esegue la creazionedi tale file e fa terminare l’applicazione.
62

Capitolo 6
Conclusioni
La realizzazione del progetto presentato in questa tesi non puo che essere soddi-sfacente, avendo raggiunto gli obiettivi posti nella parte iniziale. L’esecuzione dimodelli FMU con il diagramma BPMN finale descritto nel capitolo 5 ha prodottodei risultati di simulazione in linea con gli altri strumenti che svolgono questo com-pito. Anche se i modelli simulati non possiedono complessita rilevanti, il progetto eriuscito nel creare un nuovo tipo di approccio alla co-simulazione. Con questi tipidi risultati si puo concludere che e stato possibile utilizzare lo standard BPMN pereseguire co-simulazioni di modelli dinamici creati con l’interfaccia FMI. Importantepuntualizzare che non ci sono lavori o studi precedenti a conoscenza dell’autore dellatesi che abbiano cercato di raggiungere tale obiettivo.
Il raggiungimento dell’obiettivo non implica comunque che il lavoro di questoprogetto non possa essere proseguito. Gli argomenti che sono stati trattati durantelo svolgimento del progetto, aprono la strada ad altri studi e progetti. In piu, ilprogetto realizzato in questa tesi puo essere ulteriormente migliorato ed esteso. Inseguito si presenta una lista di idee per possibili sviluppi futuri.
• Il processo di esecuzione dei modelli puo essere reso piu robusto, per prevederemolti casi di errori ed eccezioni. Trattandosi di un prototipo, nel progettorealizzato la gestione delle eccezioni sulle classi della libreria Java-Json nonviene fatto in modo totale, oppure la presenza di errori nei dati non vienegestita in modo completo, portando in alcuni casi a simulazioni errate.
• Si puo provare a costruire una ulteriore soluzione di questo progetto che utilizzala versione 2.0 dell’interfaccia FMI.
• Si potrebbero costruire dei tipi di algoritmi piu complessi per la simulazione,con in seguito uno studio di confronto tra varie soluzioni.
• Si possono cercare di studiare dei modi per aumentare l’efficienza del diagram-ma nell’esecuzione delle simulazioni, per permettere l’esecuzione di modelli piu
63

complessi. I studi possono essere svolti su tecnologie alternative oppure sul-le estensioni di quelle esistenti (ad es. le estensioni di elementi in BPMN eActiviti).
• Si puo effettuare un miglioramento all’interfaccia utente MasterCreator, comeanche creare un’interfaccia utente grafica per la visualizzazione dei dati finalidi esecuzione, piuttosto che la scrittura degli ultimi nel file CSV.
6.1 Conclusioni personali dell’autore
La realizzazione di questa tesi mi ha fatto acquisire molte esperienze positive. Ilprogetto svolto aveva dimensioni e complessita importanti, con cui non mi ero maiscontrato in precedenza. Inoltre la tesi tratta una varieta di argomenti di cui non ave-vo conoscenza precedente, come ad esempio l’interfaccia FMI, lo standard BPMN,le diverse librerie utilizzate per la realizzazione, l’esecuzione impegnativa di BPMNin Activiti, e tanto altro. Per ciascuna di queste e servito ovviamente un periodo distudio approfondito.
Lo svolgimento della tesi negli ambienti di lavoro di ESTECO e un altro fattoreche mi ha dato delle esperienze importanti. In tale periodo ho acquisito molteconoscenze sul mondo lavorativo, guadagnando esperienze sia dal punto di vistaprofessionale che quello umano, una cosa che considero molto importante e di cuifaro uso nel futuro. In particolare l’esperienza guadagnata con la collaborazione perla pubblicazione dell’articolo in [20] e stata unica e molto soddisfacente.
64

Bibliografia
[1] B. Van Acker, J. Denil, H. Vangheluwe, and P. De Meulenaere, “Generationof an Optimised Master Algorithm for FMI Co-simulation,” in Proceedingsof the Symposium on Theory of Modeling & Simulation: DEVS IntegrativeM&S Symposium, ser. DEVS ’15. San Diego, CA, USA: Society forComputer Simulation International, 2015, pp. 205–212. [Online]. Available:http://dl.acm.org/citation.cfm?id=2872965.2872993
[2] ITEA, “MODELISAR,” https://itea3.org/project/modelisar.html, 2008-2011.
[3] Elektrobit, “AUTomotive Open System Architecture,” https://www.elektrobit.com/products/ecu/technologies/autosar/, 2016.
[4] Modelica Association Project, “Functional Mock-up Interface for Co-Simulation,” https://svn.modelica.org/fmi/branches/public/specifications/v1.0/FMI for CoSimulation v1.0.pdf, 2010.
[5] J. Batteh, J. Gohl, A. Pitchaikani, A. Duggan, and N. Fateh, “AutomatedDeployment of Modelica Models in Excel via Functional Mockup Interface andIntegration with modeFRONTIER,” in Proceedings of the 11th InternationalModelica Conference, 2015.
[6] V. Galtier, S. Vialle, C. Dad, J.-P. Tavella, J.-P. Lam-Yee-Mui, andG. Plessis, “MI-based Distributed Multi-simulation with DACCOSIM,” inProceedings of the Symposium on Theory of Modeling & Simulation: DEVSIntegrative M&S Symposium, ser. DEVS ’15. San Diego, CA, USA: Societyfor Computer Simulation International, 2015, pp. 39–46. [Online]. Available:http://dl.acm.org/citation.cfm?id=2872965.2872971
[7] FMI, ”https://fmi-standard.org/”.
[8] Modelica Association Project, “Functional Mock-up Interface for Mo-del Exchange,” https://svn.modelica.org/fmi/branches/public/specifications/v1.0/FMI for ModelExchange v1.0.pdf, 2010.
[9] FMI, https://fmi-standard.org/tools/.
65

[10] QTronic GmbH, https://www.qtronic.de, 2006.
[11] D. Broman, C. Brooks, L. Greenberg, E. A. Lee, M. Masin, S. Tripakis,and M. Wetter, “Determinate Composition of FMUs for Co-simulation,”in Proceedings of the Eleventh ACM International Conference on EmbeddedSoftware, ser. EMSOFT ’13. Piscataway, NJ, USA: IEEE Press, 2013,pp. 2:1–2:12. [Online]. Available: http://dl.acm.org/citation.cfm?id=2555754.2555756
[12] ITI, “Simulationx,” https://www.simulationx.com, 2016.
[13] ESI Group, “Acquisition of ITI GmbH,” http://tinyurl.com/jll2muz, 2016.
[14] Wikipedia, “Fixed-point iteration,” https://en.wikipedia.org/wiki/Fixed-point iteration.
[15] T. Blochwitz, M. Otter, J. Akesson, M. Arnold, C. Clauss, H. Elmqvist,M. Friedrich, A. Junghanns, J. Mauss, D. Neumerkel, H. Olsson, and A. Viel,“Functional Mockup Interface 2.0: The Standard for Tool independentExchange of Simulation Models,” pp. 173–184, 2012. [Online]. Available:http://dx.doi.org/10.3384/ecp12076173
[16] BPMN, “BPMN specification - business process model and notation,” www.bpmn.org.
[17] T. Allweyer, BPMN 2.0: Introduction to the Standard for BusinessProcess Modeling. Books on Demand, 2010, p. 10. [Online]. Available:https://books.google.it/books?id=fdlC7K\ 3dzEC
[18] B. Silver, BPMN Method and Style, Second Edition, with BPMN Implementer’sGuide, 2nd ed. Cody-Cassidy Press, 2012.
[19] BeePMN, “BeePMN,” https://www.beepmn.com/editor/.
[20] IEEE, “IEEE ISSE 2016 — IEEE International Symposium on SystemsEngineering 2016,” http://2016.ieeeisse.org/.
[21] Alfresco Software Ltd., “Alfresco,” http://www.alfresco.com/.
[22] jbpm, “jbpm,” http://www.jbpm.org/.
[23] Process Developments, “Alfresco creates Activiti,” http://processdevelopments.blogspot.it/2010/05/alfresco-creates-activiti.html.
[24] Eclipse, “Eclipse,” http://www.eclipse.org/.
[25] M. Cella, “Progetto e realizzazione di motori BPMN 2.0 estensibili per workflowscientifici e loro valutazione sperimentale,” Master’s thesis, Universita degliStudi di Trieste, 2011.
66

[26] Activiti, “Interprocess communication,” https://forums.activiti.org/content/interprocess-communication-message-flow.
[27] ——, “User guide,” http://activiti.org/userguide/index.html.
[28] Atlassian Inc., “siani/JavaFMI/wiki/Home,” https://bitbucket.org/siani/javafmi/wiki/Home.
[29] Oracle, “Java Servlet,” http://docs.oracle.com/javaee/7/api/javax/servlet/Servlet.html.
[30] Apache, “HttpClient,” http://hc.apache.org/httpclient-3.x/.
[31] JSON, “Json,” http://www.json.org/.
[32] Java2s, “Download javajson,” http://www.java2s.com/Code/Jar/j/Downloadjavajsonjar.htm.
[33] Tutorials Point, “MVC Framework Introduction,” https://www.tutorialspoint.com/mvc framework/mvc framework introduction.htm.
[34] NetBeans, “NetBeans,” https://netbeans.org/.
67

Appendice A
68

Solving Time-Dependent Coupled Systems ThroughFMI Co-Simulation and BPMN Process
OrchestrationDario Campagna, Carlos Kavka, Alessandro Turco
ESTECO SpAArea Science Park,
Padriciano 99, 34149 Trieste, ItalyEmail: [last name]@esteco.com
Besian Pogace∗, Carlo Poloni†Dipartimento di Ingegneria e Architettura
Universita di TriesteV. Valerio 8, 34100 Trieste, Italy
Email: ∗[email protected], †[email protected]
Abstract—In this work we present a synergic integration ofthe Functional Mock-Up Interface (FMI) and Business ProcessModel and Notation (BPMN) standards aimed at managingcoupled system simulations. The expressiveness of the BPMNdiagrams enabled us to define the relationship between theinvolved systems and guarantees a one-to-one correspondencewith an XML file which is the starting point for the automationand the Functional Mock-Up Unit (FMU) orchestration. For thatpurpose we describe a typical (although non-standard) masteralgorithm governing the time-dependent simulation of a coupledsystem. The dependency diagram and the execution algorithmrely on a very limited set of BPMN extension elements since thestandard already offers a range of basic elements which facilitatethe implementation of a specific execution environment for FMIco-simulation. This study explores the theoretical issues behindthe FMI-BPMN integration and the practical implementationproblems. The final result is the complete BPMN diagram forthe master algorithm, fully interfaced with the FMI functions ofthe FMU execution blocks.
I. INTRODUCTION
Modern engineering more and more relies on numericalsimulations which have progressively expanded their applica-tion fields and increased in accuracy. Computer experimentscan be used in the design phase of almost any product totest responses under the entire range of known physical lawsand conditions. This enormous complexity is typically handledby highly specialized software applications, each of whichperforms focused analyses in a single or a narrow set of dis-ciplines (mechanical stress, fluid dynamics, thermodynamics,acoustics, etc.).
Questions arise when composite analyses are needed [1],for example simulating the interaction of multiple componentsor mixing different physics (fluid-structure interaction forinstance). Theoretical issues are added to computational andInformation Technology (IT) integration problems: how candifferent simulation software co-operate? Data formats may bedifferent, programming languages and execution environmentscan be incompatible; commercial solutions are typically notcustomizable, whereas academic research codes often targetcutting-edge specific problems rather than generic issues. Any
integration requires a lot of manual work which can be tootime consuming for industrial applications.
The adoption of common standards is a possible answerto integration and interoperability problems. The FunctionalMock-Up Interface [2] is emerging as the leading industrystandard to support model exchange and co-simulation [3]. Itsmain feature is the encapsulation of different model executorsin pre-defined shells which provide all functions and datastructures to interact with them and orchestrate them.
However, the complexity of engineering projects requires afurther step. Model execution is only a block in a larger mosaicof activities. We could describe manufacturing and engineeringprojects like the Russian matryoshka dolls: they have severallayers that should not be kept separated (the idea of concurrentengineering is not so new [4] but it perfectly applies to currenttrends). Standards too have to communicate with and integrateone with another.
This paper focuses on combining the Functional Mock-UpInterface (FMI) and the Business Process Model and Notation(BPMN) standards for process description, orchestration andautomation. The use of BPMN to control model executionsperformed through Functional Mock-Up Units (FMUs) hasa double advantage: firstly, it enables a better and clearermanagement of the underlying models as we will explain inthe following sections, and secondly it connects the simulationprocess level to the enterprise activity management level [5].
The co-simulation part of the FMI standard focuses on theinteraction among models. It has a master-slave architecturewhere the FMU are the slaves and the ad hoc algorithmsor tools implement the master logic. The standard does notimpose a specific master algorithm, because there is a trade-offbetween complexity and accuracy. Literature proposes a smallbut significant number of algorithms and techniques whichcover all the possible scenarios, at least in form of pseudo-code programs, with, for instance, different time rates [3] andfeedback loops [6].
Our work focuses on the modeling of a basic masteralgorithm using BPMN and explaining how to adapt it tomore complex or specific scenarios. Moreover, we also use

this standard to model the dependency diagram representingthe relationships among the FMUs involved in co-simulation.BPMN enables to tailor its palette with extension elementsthe syntax of which is defined by the standard itself. We usethis feature to integrate it with FMI functions but we havelimited the number of custom elements as much as reasonablyfeasible.
The first two subsections describe the FMI and the BPMNstandards respectively. Section II presents the state of theart in the field of FMI master algorithm representation andimplementation. Section III shows how BPMN artifacts canvisually and clearly represent the dependencies among theFMU interacting in a co-simulation scenario, whereas SectionIV describes the proposed master algorithm BPMN model. Weconclude with Section V including our plans for executing theproposed model on different BPMN engines and Section VIdiscussing the results of this work.
A. Functional Mock-Up Interface
The FMI standard is designed for modeling and simulatingcomplex systems (the elements of which may come fromdifferent engineering disciplines and domains) with indepen-dent tools. It was initially developed within the EuropeanProject MODELISAR [7] and it is currently supported by anincreasing number of industrial partners and tools, mainly inthe automotive engineering field [2]. FMI-based simulators arerapidly spreading due to the flexibility they offer for simulationplatforms, protection of Intellectual Property and the potentialthey have for flexible licensing of deployed simulators [8]. Thestandard is composed of two parts: FMI for Model Exchangeand FMI for Co-Simulation.
FMI for Model Exchange is used for the creation of exe-cutable models representing dynamic systems. These models,called FMUs, implement the interface defined by FMI forModel Exchange and can be run by any compliant modelingand simulation environment since they do not use simulator-specific header files [2]. A FMU is distributed as a “.zip” file,which contains the following elements.
• A model implementation and its solver in source codeand/or compiled form (DLL / Shared libraries).
• A model description XML file containing the staticinformation on all needed/generated parameters. This fileis used by the master to build a dependency networkguiding the execution.
• Other files with supplementary information (e.g. docu-mentation, images).
FMI for Co-Simulation provides a standard interface forcoupling two or more FMUs in a co-simulation environment,exploiting their modular structure in all stages of the simula-tion process. The FMUs describe the external (input/output)structure of the components and implements an internal simu-lation algorithm (solver). A co-simulation model is a collectionof interconnected FMUs which in a co-simulation environmentare called slaves. FMI for Co-Simulation consists of two parts.
• A set of standardized “C” functions for controlling theslaves (loading, advancing time in a co-simulation, get-
ting and setting variables and so forth). It defines the dataexchange for inputs and outputs and provides informationon the status throughout the simulation (Co-Simulationinterface).
• An XML (eXtensible Markup Language) file containinginformation on all exposed variables required for dataexchange (input, output, parameters and so forth), ca-pability information (the ability of the slave to supportvariable communication step-sizes, higher order signalextrapolation and so forth) and the internal dependenciesbetween input and output ports (Co-Simulation Descrip-tion Schema).
A master algorithm, also called just master, is used to orches-trate the co-simulation of the slaves and their data exchangethrough inputs and outputs. The standard does not imposethe adoption of a specific master, leaving users and tooldevelopers with the choice of the best fitting algorithm fortheir model. However, the standard provides an example of ageneric implementation which goes through a certain numberof phases of a simulation.
1) Instantiation and initialization phase. All the FMUs areinstantiated and loaded into the memory and when everyinstance is ready, the master sets their initial values andparameters following the graph of connections of thevarious components.
2) Computation phase. The co-simulation is performed andthe master is responsible for the proper orchestration ofthe FMU instances. In this phase the advancing of timein each FMU is done by calling the fmiDoStep func-tion; the interaction with exposed variables is done bycalling fmiGetXXX and fmiSetXXX functions, wherethe Xs represent the different types of data (integer,double, etc.).
3) Termination phase. The simulation is completed and theresults are made available.
FMI is very useful for composing systems with componentsrepresenting timed behavior, including physical dynamics anddiscrete events. However, FMUs and masters have to bedesigned carefully to avoid non-deterministic or unexpectedbehaviors [6].
B. Business Process Model and Notation
BPMN was originally developed by the Business ProcessManagement Initiative (BPMI) which released the first versionin 2004. In June 2005 BPMI joined the Object ManagementGroup (OMG) and a new BPMN Specification document wasreleased in 2006. Version 2.0 of BPMN was developed be-tween 2010 and 2013. The latest version (2.0.2) was formallypublished by ISO as the 2013 edition standard: ISO/IEC19510. When referring to BPMN in the following sectionswe intend this last edition.
BPMN rapidly became the de facto standard for processmodeling since it offers a simple and expressive look and feelto business analysts and provides the foundation for processimplementation. Indeed, each graphical element is translated

as an XML element and both are precisely described in thestandard. Moreover, the XML representation includes the socalled hidden attributes which are technical details necessaryfor the execution but which are not shown in the diagrams toimprove their readability. As a consequence, BPMN modelsare used to communicate and interchange the business require-ments of a business process, as well as to execute them onenterprise engines.
It is worth mentioning the improvements made in the currentedition of the standard with respect to the original because theyare the main reason of its success. In particular:
• the execution semantics for all BPMN elements has beendeclared.
• the extensibility mechanism for model and graphicalextensions has been introduced.
• the definition of human interactions has been improved.• the choreography model and Conversation View for Col-
laboration diagrams have been added.The power of this standard, beside the number of software
applications implementing it, can be measured by the degree ofre-usability of the model encoded with it. BPMN is a modularformat that can be used to exchange models (including thediagram layout) among different tools. OMG has a sub-groupdedicated to enforce and test this feature (MIWG, ModelInterchange Working Group [9]).
A number of desktop and web applications supportingBPMN are available. For example, Camunda [10], TrisotechBPMN Modeler [11], Yaoqiang [12], GenMyModel [13],Signavio Process Editor [14], Signavio Workflow [15], Ac-tiviti [16], BeePMN [17] and so forth, just to name a few.As regards workflow editing, these applications differ in thedegree of compliance to the standard, the number of BPMNelements available for workflow editing and the implementedcollaborative features (if any). Only some of them supportworkflow execution.
II. RELATED WORKSFMI for Co-simulation does not define a standard graphi-
cal or textual representation of a co-simulation scenario. Inparticular, it does not specify a way to describe how theinvolved FMUs are coupled. The specification only states thatsubsystem composition may be performed in different waysand typically results in some form of a component-connectiongraph structure [2].
In [18] the authors show that the signal flow for thecoupled simulators can be described by a direct graph withthe simulators as nodes and the exchanged data as edges. Adomain-specific language (DSL) to explicitly model differentco-simulation setups is presented in [3]. The DSL abstractsyntax consists of three classes: the FMU class defines aFMU object, the port class defines the exposed FMU (inputand output) variables, the relation class describes the internalrelations, the input-output dependencies within an FMU andthe external relations between FMUs in a co-simulation model.The concrete syntax uses a rectangle shape to represent anFMU object, whereas port and relation objects are represented
as colored triangles and arrows respectively. Both the modelname and ideal step-size of an FMU object are representedwithin the rectangle shape. Different colors are used todifferentiate between input/output ports and internal/externalrelations. Colors are also used to distinguish the delayedfeedthrough and the direct feedthrough relations in the internalrelations. Information such as the ideal step-size and internalrelations are modeled by the DSL because the author in [3]found them to be crucial for the generation of an optimizedmaster algorithm.
There are many works concerning the development ofplatforms for running FMI-based co-simulations. For example,in [19] the authors propose MOKA, an object-oriented frame-work for FMU development, integration and co-simulation.In this framework the master executes scripts written in adomain-specific language which represents the co-simulationscenarios with finite state machines. The authors are currentlyconducting a study to use the same master code and run thedifferent simulation scenarios with the goal of avoiding the re-compilation of the framework every time the scenario changes.
Some works also include a graphical representation of co-simulation master algorithms. For example, Galtier et al. [20]describes a DACCOSIM-based multi-simulation system withan interface enabling the user to describe how to intercon-nect FMUs and with the automatic generation of the coderequired for their orchestration. The system performs paralleland distributed simulation and supports decentralized dataexchange between the FMUs considering both constant andvariable step simulation. An extension of the Ptolemy IIplatform called FIDE is presented in [21]. FIDE has graphicaluser interface, simulation engine and code generation featuresenabling users to arrange a collection of FMUs and compilethem in a portable and embeddable executable that efficientlyco-simulates the ensemble. The FMUs are orchestrated by amaster algorithm that deterministically combines discrete andcontinuous-time dynamics.
To the best of our knowledge no other works presenting theuse of the BPMN standard to represent co-simulation masteralgorithms have been published.
III. BPMN AS CO-SIMULATION REPRESENTATION
We propose the adoption of the BPMN standard instead ofan ad-hoc language for representing co-simulation problems.This standard possesses all necessary elements to representthe coupling of FMUs involved in co-simulation. Moreover,with the addition of two extension elements, it is possible tomodel step-size and internal relations information within thesame model. We corroborate these statements with the samecase study presented in [3], which is a basic sine generatorcomposed of two integrators interconnected with an invertedfeedback loop, commonly referred to as the ”circle test”.To co-simulate the circle test two FMUs are used. The firstcontains the first integrator with an inverted input, whereas thesecond contains the other integrator. Both the FMUs have oneinput and one output related by a delayed feedthrough.

~
FMU1 FMU2
OUT1
OUT2to IN1
to IN2
Fig. 1. BPMN representation of co-simulation problem
Figure 1 shows the BPMN diagram modeling the circletest. The two FMUs are represented by Tasks labeled FMU1and FMU2 respectively. Their input and output variables aremodeled as Data Input and Data Output (these elementsare internal to Tasks and have no graphical representation).External relations are represented with Data Associations andData Objects. We use a Data Object OUT1 to couple theData Output of FMU1 with the Data Input of FMU2. TheData Object OUT2 couples the Data Output of FMU2 to theData Input of FMU1. Tasks and Data Objects are containedin an Ad-Hoc Sub-Process - a specialized type of Sub-Processgrouping of activities with no required sequence relationships.
To model FMU step-size and internal relations we proposetwo extension elements called step size and internal relationsrespectively. These extensions are simply additional tags inthe XML element defining a Task. The following is the XMLSchema Definition (XSD) for the stepSize extension.
<xsd:schema><xsd:element name="stepSize"
type="xsd:decimal"/></xsd:schema>
The internal relations extension allows users to define thedelayed/directed input-output dependencies of an FMU. Thefollowing is the XSD for the internalRelations extension.
<xsd:schema><xsd:element name="internalRelations"
type="InternalRelations"/><xsd:complexType name="InternalRelations"><xsd:sequence><xsd:element name="relation"
type="Relation"maxOccurs="unbounded"/>
</xsd:sequence></xsd:complexType><xsd:complexType name="Relation"><xsd:attribute name="delayedFeedthrough"
type="xsd:boolean"/><xsd:sequence><xsd:element name="from" type="xsd:IDREF"/><xsd:element name="to" type="xsd:IDREF"/></xsd:sequence>
</xsd:complexType>
</xsd:schema>
An input-output dependency is represented by a relationelement with a boolean attribute indicating whether it isdelayed or direct, a from child element referencing a DataInput and a to child element referencing a Data Output.
The following XML fragment shows the proposed exten-sions in use for the Task FMU1 of Figure 1.
<bpmn:definitions>...<bpmn:extension mustUnderstand="false"definition="cs:stepSize"/>
<bpmn:extension mustUnderstand="false"definition="cs:internalRelations"/>
...<bpmn:process>...<bpmn:task name="FMU1">...<bpmn:extensionElements><cs:stepSize>0.1</cs:stepSize><cs:internalRelations><cs:relation delayedFeedthrough="true"><cs:from>IN1</from><cs:to>OUT1</to>
</cs:relation></cs:internalRelations>
</bpmn:extensionElements></bpmn:task>...</bpmn:process>...
</bpmn:defintions>
Given the FMU model descriptions for the subsystemsinvolved in a co-simulation problem, it should be possible toautomatically generate a BPMN model without external rela-tion representations in a way similar to what is described in [3]to generate a non-reticulated baseline of the co-simulationmodel expressed with the DSL. Such model could then becompleted by adding Data Objects and Data Associations tointerconnect the FMUs.
The proposed representation of co-simulation problems hassome advantages with respect to the DSL presented in [3].Firstly, it is based on a well known existing standard supportedby different vendors [9]. Secondly, it hides information whichis mostly relevant for master algorithm generation, whichcan be automatically extracted from FMU model descriptionsand which could lead to visualization problems in the DSLrepresentation if multiple input-output internal relations arepresent. Moreover, BPMN can be used to represent the masteralgorithm too, as we will show in the next Section.
IV. BPMN AS CO-SIMULATION ORCHESTRATOR
FMI for Co-Simulation supports both classic brute forceapproaches and sophisticated algorithms for the orchestrationof an entire co-simulation but as said before it is up to theend users or tool developers to design a master algorithmguaranteeing a deterministic execution of the FMUs. Anapproach to achieve such deterministic execution is presentedin [6]. A generic master algorithm for FMI co-simulation is

Instantiation Initialization Simulation Shutdown
Master
FMU1
FMU2
FMU1instantiationparameters
FMU2instantiationparameters
Component
Component
FMU1initializationparameters
FMU2initializationparameters
Status
Status
Component Component
Component Component
getRealparameters
Value
setRealparameters
doStepparameters
Status
getRealparameters
ValuedoStep
parameterssetReal
parameters
Status
Fig. 2. BPMN model for co-simulation orchestration
described in [18]. A model-to-text transformation that enablesthe automatic generation of a master algorithm speciallydesigned for a given co-simulation model is proposed in [3].
We propose the use of BPMN to orchestrate the entire co-simulation and hence model a master algorithm. We demon-strate the validity of the proposed standard for this purposeby modeling the simple master algorithm given in [2] (thisalgorithm is similar to the manually implemented algorithmshown in [3]). The use of BPMN for both co-simulationrepresentation and orchestration leads to a reduced numberof model transformations and formalisms necessary to obtaina master algorithm from the FMU model descriptions (withrespect to the workflow presented in [3]), an abstraction of themaster algorithm from programming languages and a graphicalrepresentation of master algorithms and co-simulation slaves.
A BPMN model for the orchestration of the setup shownin Figure 1 is shown in Figure 2. The model consists ofthree Pools. FMU1 and FMU2 represent the two co-simulationslaves, whereas Master models the master algorithm decom-posed in the four sub-phases described in [2]. Each sub-phaseis represented by a Sub-Process that sends/receives messagesto/from slave processes for invoking FMI interface functionsand obtaining their return values.
Figure 3 shows the BPMN process of a co-simulation slave,i.e. the content of the Pools FMU1 and FMU2 in Figure 2. Weassume the existence of an external FMU simulator that canbe invoked through Service Tasks for the execution of FMIinterface functions. The process shown in Figure 3 starts itsexecution as soon as a message containing the parameters forinstantiating an FMU is received by the Start Message Event.Such message will be sent by a master process. The message
payload is passed to the Instantiate Service Task. It invokesthe fmiInstantiateSlave function and stores the returnvalue in the Component Data Object. Then the Component issent back to the master process and the slave waits for the FMIinitialization parameters. Once the fmiInitializeSlavefunction is invoked by Initialize and its return value is sentto the master, the slave is ready to process fmiGetReal,fmiSetReal, fmiDoStep requests or to terminate, resetand free the FMU.
The most interesting of the four Sub-Processes in the MasterPool shown in Figure 2 is Simulation. It is the core part ofthe master algorithm. Figure 4 shows the expanded SimulationSub-Process and it is a BPMN representation of the followingpseudo-code:
while ((tc < tStop) && (status == fmiOK)) {fmiGetReal(FMU1, ..., 1, OUT1);fmiGetReal(FMU2, ..., 1, OUT2);
fmiSetReal(FMU1, ..., 1, OUT2);fmiSetReal(FMU2, ..., 1, OUT1);
status = fmiDoStep(FMU1, tc, h, fmiTrue);if (status == fmiOK)status = fmiDoStep(FMU2, tc, h, fmiTrue);
tc += h;}
All involved variables (e.g., tc, status) are modeled byData Objects. Data Objects are also used to store FMI inter-face function parameters and return values. The while-loopand the if-statement are modeled using Exclusive Gateways.FMI interface function calls are modeled with a task that

Instantiate Initialize
getReal
Instantiationparameters Component
Initializationparameters Status
getRealparameters Value
setReal
setRealparameters
doStep
doStepparameters Status
Terminate
Component
Reset Free
Component
Fig. 3. BPMN representation of co-simulation slave
Create getReal
parameters
Create getReal
parameters
OUT1FMU1
FMU2
getReal OUT1
OUT2getReal OUT2
Create setReal
parameters
Create setReal
parameters
FMU1
FMU2
setReal IN1
setReal IN2
tc < tStopand
Status ok
Create doStep
parameters
FMU1 tc hdoStepFMU1 Status
Create doStep
parameters
FMU2 tc h doStepFMU2
Status
Status ok
Increment tc
tc
h
Fig. 4. BPMN model for Simulation sub-process

generates function parameters followed by an IntermediateMessage Throw Event which sends the parameters to a co-simulation slave. When the invoked function has a returnvalue, an Intermediate Message Catch Event is used to receivea message from a co-simulation slave.
The algorithm we modeled using BPMN is very simple. Itdoes not take into account input-output dependencies and itdoes not exploit any adaptation to deal with the feedback loopof the setup shown in Figure 1. Even though its executionmay produce erroneous simulation results, it demonstratesthat BPMN is suitable for the co-simulation master algorithmrepresentation. Advanced optimized algorithms, such as thealgorithm presented in [3], can still be modeled with BPMNsince arrays can be represented using Data Object Collectionsand for-loops can be modeled through Exclusive Gateways,activity loops or multi-instance activities.
A complete BPMN model for the orchestration of the setupshown in Figure 1 is available at goo.gl/UzFtiZ.
V. FUTURE WORKS
We are currently implementing the proposed FMI co-simulation environment in the Activiti BPM platform [16],in particular due to its wide availability, whereas a robustimplementation in the BeePMN [22] engine is foreseen forthe near future. The master algorithms implemented in BPMNwill be made available online as examples in the collaborationarea of the BeePMN web site [17].
Our proposal has a very intuitive graphical method fordefining and exploring the properties of master algorithmsbased on a well-defined standard. However, since it followsa very different approach in comparison with more traditionalschemes, we plan to compare its run-time performance withthe other methodologies.
Implementations of other master algorithms will be per-formed, with and without the feedback loop, with fixed andvariable step size [23] and including step rejection. Examplesare expected to be published in the collaboration area of theBeePMN web site.
We plan to study and implement a method inspired by themethod presented in [3] to automatically generate a BPMNmodel representing an optimized master algorithm given aBPMN representation of a co-simulation problem.
A more detailed study of known limitations of the currentFMI specification will be analyzed, particularly when consid-ering reactive systems [6]. Formal requirement modeling for asimulation-based verification to automatically test and verifyrequirements [24] by simulation is also under consideration.
VI. CONCLUSIONS
The Functional Mock-Up Interface is an emerging as aleading technology which encourages cooperation in the indus-trial design field. It provides a standard interface for couplingphysical models which may be coming from different do-mains and may have been developed with different simulationsoftware tools. FMI is particularly effective in addressingproblems like the export and the import of model components
in simulation tools for model exchange, providing also abase for the standardization of co-simulation interfaces innonlinear dynamic systems. However, even if some guidelinesare presented in the standard, no specifications for the co-simulation master algorithm are formally defined.
This paper shows the use of an already existing standardfor the co-simulation representation, without the introductionof an ad-hoc defined domain specific language. The proposedrepresentation, based on the BPMN standard, involves the en-tire orchestration, modeling and co-simulation setup. Throughthe graphical representation of BPMN the proposed approachprovides an easy and intuitive method for defining, visualizing,exchanging and comparing different implementations of mas-ter algorithms. The proposal goes beyond a mere formalism torepresent master algorithms since the XML-based executablerepresentation of BPMN provides an immediate support forthe master algorithm execution without the need for anyadditional steps that might be required to create executablerepresentations. The parallel execution of FMU-based slaves isautomatically supported through the multiple thread executionbased on BPMN independent asynchronous processes. Conve-nient features of the BPMN representation help hide from themaster algorithm graphical definition information that is onlyrequired at execution time, supporting the creation of easy-to-understand master algorithm diagrams.
The main contribution of this paper is an approach intendedfor supporting end users and tool vendors in developingoptimized master algorithms that guarantee the deterministicexecution of the FMUs. We are confident that the definitionof master algorithms in a standard graphical language willmake it easier to support new enhancements in future FMIspecifications which may be necessary to support more com-plex co-simulation scenarios such as those required for reactivesystems [25].
REFERENCES
[1] T. Blochwitz, M. Otter, M. Arnold, C. Bausch, C. Clau, H. Elmqvist,A. Junghanns, J. Mauss, M. Monteiro, T. Neidhold, D. Neumerkel,H. Olsson, J.-V. Peetz, and S. Wolf, “The Functional Mockup Interfacefor Tool independent Exchange of Simulation Models,” in Proceedingsof the 8th International Modelica Conference 2011.
[2] Modelica Association Project, “Functional Mock-up Interface for Co-Simulation,” https://svn.modelica.org/fmi/branches/public/specifications/v1.0/FMI for CoSimulation v1.0.pdf, 2010.
[3] B. Van Acker, J. Denil, H. Vangheluwe, and P. De Meulenaere, “Gen-eration of an Optimised Master Algorithm for FMI Co-simulation,” inProceedings of the Symposium on Theory of Modeling & Simulation:DEVS Integrative M&S Symposium, ser. DEVS ’15. San Diego, CA,USA: Society for Computer Simulation International, 2015, pp. 205–212.
[4] A. Kusiak, Concurrent Engineering: Automation, Tools and Techniques.Wiley, 1992.
[5] D. Campagna, S. Costanzo, C. Kavka, A. Turco, and C. Poloni,“Leveraging the BPMN Standard to Govern Engineering Processes in aCollaborative Environment,” in proceedings of the IEEE InternationalSymposium on System Engineering (ISSE), Rome, Italy, 2015.
[6] D. Broman, C. Brooks, L. Greenberg, E. A. Lee, M. Masin, S. Tripakis,and M. Wetter, “Determinate Composition of FMUs for Co-simulation,”in Proceedings of the Eleventh ACM International Conference onEmbedded Software, ser. EMSOFT ’13. Piscataway, NJ, USA: IEEEPress, 2013, pp. 2:1–2:12.
[7] ITEA, “MODELISAR,” https://itea3.org/project/modelisar.html, 2008–2011.

[8] J. Batteh, J. Gohl, A. Pitchaikani, A. Duggan, and N. Fateh, “AutomatedDeployment of Modelica Models in Excel via Functional MockupInterface and Integration with modeFRONTIER,” in Proceedings of the11th International Modelica Conference, Versailles, France, 2015.
[9] OMG, “The BPMN Model Interchange Working Group,” http://www.omgwiki.org/bpmn-miwg, 2016.
[10] Camunda, “Camunda Modeler,” https://camunda.org/bpmn/tool/, 2014.[11] Trisotech, “Trisotech BPMN Modeler,” http://www.trisotech.com/
bpmn-modeler, 2015.[12] Yaoqiang Inc., “Yaoqiang,” http://bpmn.sourceforge.net, 2009.[13] GenMyModel, “GenMyModel,” https://www.genmymodel.com, 2013.[14] Signavio GmbH, “Signavio Process Editor,” http://www.signavio.com/
products/process-editor/, 2013.[15] ——, “Signavio Workflow,” http://www.signavio.com/products/
workflow/, 2016.[16] Alfresco, “Activiti,” http://activiti.org/index.html, 2013.[17] ESTECO SpA, “BeePMN platform,” http://www.beepmn.com, 2016.[18] J. Bastian, C. Clauß, S. Wolf, and P. Schneider, “Master for co-
simulation using FMI,” in 8th International Modelica Conference,Dresden, 2011.
[19] M. Aslan, H. Oguztuzun, U. Durak, and K. Taylan, “MOKA: An Object-oriented Framework for FMI Co-simulation,” in Proceedings of theConference on Summer Computer Simulation, ser. SummerSim ’15. SanDiego, CA, USA: Society for Computer Simulation International, 2015,pp. 1–8.
[20] V. Galtier, S. Vialle, C. Dad, J.-P. Tavella, J.-P. Lam-Yee-Mui, andG. Plessis, “Fmi-based distributed multi-simulation with daccosim,” inProceedings of the Symposium on Theory of Modeling & Simulation:DEVS Integrative M&S Symposium, ser. DEVS ’15. Society forComputer Simulation International, 2015, pp. 39–46.
[21] F. Cremona, M. Lohstroh, S. Tripakis, C. Brooks, and E. A. Lee, “Fide:An fmi integrated development environment,” in Proceedings of the 31stAnnual ACM Symposium on Applied Computing, ser. SAC ’16. ACM,2016, pp. 1759–1766.
[22] D. Campagna, S. Costanzo, C. Kavka, and A. Turco, “Exploiting WebTechnologies to Connect Business Process Management and Engineer-ing,” in proceedings of the 11th International Joint Conference onSoftware Technologies and Applications ICSOFT-EA, Lisbon, Portugal,2016.
[23] T. Schierz, M. Arnold, and C. Claus, “Co-Simulation with communi-cation step size control in an FMI compatible master algorithm,” inProceedings of the 11th International Modelica Conference, Versailles,France, 2015.
[24] M. Otter, N. Thuy, D. Bouskela, L. Buffoni, H. Elmqvist, P. Fritzson,A. Garro, A. Jardin, H. Olsson, M. Payelleville, W. Schamai, E. Thomas,and A. Tundis, “Formal Requirements Modeling for Simulation-BasedVerification,” in Proceedings of the 11th International Modelica Con-ference, Versailles, France, 2015.
[25] D. Broman, L. Greenberg, E. A. Lee, M. Masin, S. Tripakis, and M. Wet-ter, “Requirements for Hybrid Cosimulation Standards,” in Proceedingsof 18th ACM International Conference on Hybrid Systems: Computationand Control HSCC, Seattle, WA, USA, 2015, pp. 179 – 188.


















