
Universit a degli Studi di Udine - fisica.uniud.itcobal/Site/TeoriaDegliErrori.pdf · Laboratorio...
33
Universit` a degli Studi di Udine – Corsi di Laurea in Ingegneria Laboratorio di Fisica Trattamento dei Dati Sperimentali e Teoria degli Errori Indice 1 Introduzione 2 1.1 Gli strumenti di misura ............................. 3 1.2 Gli errori di misura ............................... 4 1.3 Trattazione dei dati sperimentali: approccio pratico alla teoria degli errori 5 1.3.1 Istogramma delle misure e ruolo del valor medio ........... 6 1.3.2 Scarti, varianza e deviazione standard ................. 7 1.3.3 Forma analitica della distribuzione delle misure ........... 9 1.4 Popolazione, campione e deviazione standard del campione ......... 9 2 Probabilit` a e distribuzioni di probabilit` a 10 2.1 Il concetto di probabilit` a ............................ 10 2.2 Distribuzioni di probabilit`a ........................... 13 2.3 La distribuzione binomiale ........................... 14 2.4 La distribuzione di Poisson ........................... 16 2.5 La distribuzione di Gauss o distribuzione normale degli errori ........ 19 3 Applicazioni e ulteriori sviluppi della Teoria degli Errori 22 3.1 La deviazione standard della media ...................... 23 3.2 Propagazione degli errori ............................ 24 3.3 Il metodo dei minimi quadrati ......................... 25 3.4 Fit di dati sperimentali con il metodo dei minimi quadrati ......... 28 A Calcolo di n e σ 2 per la distribuzione binomiale 31 B Distribuzione normale: normalizzazione, valor medio e deviazione stan- dard 32 1
Transcript of Universit a degli Studi di Udine - fisica.uniud.itcobal/Site/TeoriaDegliErrori.pdf · Laboratorio...

Universita degli Studi di Udine – Corsi di Laurea in Ingegneria
Laboratorio di Fisica
Trattamento dei Dati Sperimentali eTeoria degli Errori
Indice
1 Introduzione 21.1 Gli strumenti di misura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Gli errori di misura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 Trattazione dei dati sperimentali: approccio pratico alla teoria degli errori 5
1.3.1 Istogramma delle misure e ruolo del valor medio . . . . . . . . . . . 61.3.2 Scarti, varianza e deviazione standard . . . . . . . . . . . . . . . . . 71.3.3 Forma analitica della distribuzione delle misure . . . . . . . . . . . 9
1.4 Popolazione, campione e deviazione standard del campione . . . . . . . . . 9
2 Probabilita e distribuzioni di probabilita 102.1 Il concetto di probabilita . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2 Distribuzioni di probabilita . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.3 La distribuzione binomiale . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4 La distribuzione di Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.5 La distribuzione di Gauss o distribuzione normale degli errori . . . . . . . . 19
3 Applicazioni e ulteriori sviluppi della Teoria degli Errori 223.1 La deviazione standard della media . . . . . . . . . . . . . . . . . . . . . . 233.2 Propagazione degli errori . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.3 Il metodo dei minimi quadrati . . . . . . . . . . . . . . . . . . . . . . . . . 253.4 Fit di dati sperimentali con il metodo dei minimi quadrati . . . . . . . . . 28
A Calcolo di n e σ2 per la distribuzione binomiale 31
B Distribuzione normale: normalizzazione, valor medio e deviazione stan-dard 32
1

1 Introduzione
Sulla base dell’osservazione di determinati fenomeni, la fisica si propone di formulareprecise relazioni fra le grandezze fisiche che caratterizzano i fenomeni stessi. Tali relazioni,una volta che siano state confermate da ripetute esperienze, assumono il carattere dileggi. Un insieme di leggi puo quindi venire inquadrato in una teoria che, naturalmente,sara tanto piu efficace quanto capace di predire un gran numero di risultati di successiviesperimenti, non necessariamente legati a quelli che l’hanno determinata.
Nell’ambito di un tale approccio si potrebbe obiettare che la formulazione di preciserelazioni fra grandezze fisiche dipende sostanzialmente dalla possibilita di attribuire inmodo univoco negli esperimenti un valore (la misura) a ciascuna delle grandezze in gioco.Analogamente, la conferma o la smentita di tali relazioni in successivi esperimenti, cosıcome la verifica delle predizioni di una teoria, sembrerebbero condizionate dall’esigenzache l’osservazione dei fenomeni fisici sia fatta con una precisione assoluta. Puo succedereche lo stesso fatto sperimentale possa essere descritto da teorie diverse, che prediconorisultati poco diversi tra loro; se vogliamo allora riconoscere la teoria corretta, dobbiamopoter controllare e distinguere quale dei risultati predetti sia quello che effettivamente siverifica.
In realta, anche ponendo la massima attenzione nella misura delle grandezze fisiche none mai possibile raggiungere una precisione assoluta. Ad esempio, se si misura piu volte lalunghezza di una sbarra con uno strumento adatto, per esempio un comparatore(1), non sitrova sempre lo stesso identico risultato. Analogamente, nella misura di una qualsiasi altragrandezza fisica con apparecchi sufficientemente precisi (il senso di quest’affermazione sichiarira in seguito) troviamo valori diversi in corrispondenza a diverse misure.
Potrebbe sembrare quindi che l’intero castello della fisica sia poco saldo, nel senso chenessuna delle leggi trovate e matematicamente precisa, in quanto risultato di misure nonesatte. Lo stesso concetto di grandezza fisica sembrerebbe entrare in crisi, dato che unadelle sue proprieta caratteristiche, la sua misura, e in realta inattuabile.(2)
Tuttavia e possibile superare tali difficolta, e i risultati dimostrano la correttezza delmetodo, se si ammette che a ciascuna grandezza corrisponda un suo valore vero, ma chenella sperimentazione, per una serie di spiacevoli quanto inevitabili circostanze, tale valorevero non sia determinabile se non in modo approssimato. Partendo da questa ipotesi sipuo allora costruire una teoria che permetta, a partire da un insieme di misure dellagrandezza, di determinare un valore che attendibilmente si avvicini al valore vero dellastessa. In altre parole, si puo dire che, poiche non e possibile misurare i valori veri dellegrandezze fisiche, le relazioni che si possono scrivere tra di esse non sono effettivamente maiesatte in senso matematico, ma rappresentano invece un’estrapolazione, con l’intesa che,se conoscessimo i valori veri delle grandezze in gioco, essi le soddisferebbero esattamente.E quindi importante saper trattare i risultati delle misure, sia per poter formulare delleleggi, cioe relazioni oggettive tra le grandezze che non risentano delle fluttuazioni delleloro misure, sia per confrontare con esse i risultati di ulteriori esperimenti che possonoconfermare o smentire la validita delle teorie che su tali leggi sono state costruite.
(1)E uno strumento di misura utilizzato per misure di spostamento lineare la cui precisione puo anchesuperare il centesimo di millimetro.
(2)Una classe di grandezze fisiche e definita tale se, oltre a potervi introdurre il concetto di eguaglianzae l’operazione di somma, e anche possibile scegliere al suo interno un valore della grandezza unitaria inmodo che qualsiasi altra grandezza della classe sia esprimibile attraverso un numero (la sua misura), checi dice quante volte l’unita e contenuta nella grandezza stessa.
2

La presente nota si propone di introdurre concetti quali errore di misura, precisione eaccuratezza di una misura, probabilita e distribuzione di probabilita, media e deviazionestandard e di molte altre nozioni necessarie alla trattazione statistica dei dati sperimentali.Come usuale, ci riferiremo a tale complesso di argomenti e temi con il termine di Teoriadel Errori. Sebbene questa nota non possa essere vista come un trattato completo sullaTeoria degli Errori, essa costituisce una buona introduzione alla stessa: lo scopo principalee quello di dare allo studente del primo anno di Ingegneria gli strumenti necessari per poteraffrontare l’analisi delle misure in semplici esperimenti di fisica.
1.1 Gli strumenti di misura
Tante sono le grandezze fisiche che si possono misurare e molti sono gli strumenti chesi sono realizzati per la loro misura. Mentre fino a qualche decade fa la maggior partedei misuratori erano di tipo analogico, oggigiorno si utilizzano preferibilmente strumentidi tipo digitale. I primi sono caratterizzati dall’avere una scala graduata e la letturadel valore della grandezza in esame viene effettuata individuando la posizione di un agomobile o di un indice sulla scala stessa; nei secondi invece il valore della grandezza edirettamente espresso in forma numerica su un display.
Figura 1: Strumenti di misura analogici (a sinistra) e digitali (a destra)
A parte le caratteristiche estetico–ergonomiche dei diversi strumenti di misura (checomunque possono influire sulla loro praticita d’uso), la qualita (o meno) di un certomisuratore e determinata da una serie di fattori che e bene qui menzionare:
• Intervallo di funzionamento – E dato dal valore minimo (soglia) e dal valo-re massimo (portata) della grandezza da misurare che lo strumento e in grado difornire. Fuori da questo intervallo la qualita della misura non e garantita e (atten-zione!!) in alcuni casi (in particolare nel caso di misuratori di grandezze elettriche)e possibile che in queste condizioni estreme lo strumento possa anche danneggiarsi(... mai superare la portata delle strumento!).
• Prontezza – E associata al tempo necessario (tempo caratteristico τ) affinche lostrumento risponda ad una variazione della grandezza. Rappresenta la rapidita concui lo strumento e in grado di fornire il risultato di una misura. Il valore dellaprontezza puo variare molto da strumento a strumento e puo dipendere anche daltipo di grandezza misurata.
• Sensibilita – E il rapporto tra la variazione del valore misurato R e la variazione delvalore reale E della grandezza considerata, per variazioni arbitrariamente piccole:
S =∆R
∆E
Esiste una variazione ∆E limite al di sotto della quale ∆R diventa non visualizzabileoppure si confonde con il rumore intrinseco dello strumento. Cio determina la
3

sensibilita minima dello strumento, ovvero la minima variazione della grandezzafisica che e in grado di produrre un effetto.
• Precisione – Misura il grado di convergenza (o dispersione) delle misure rilevatedallo strumento (rispetto al loro valor medio) in corrispondenza di uno stesso valoredella grandezza in ingresso. Tale dispersione corrisponde a quella che chiameremodeviazione standard rispetto alla media campionaria. La precisione e spesso indicatain termini relativi (in percentuale) rispetto al valore di ”fondo scala” (portata)dello strumento: essa determina il numero di cifre significative con cui potra essereespresso il valore della grandezza misurata.
• Accuratezza – Misura il grado di corrispondenza tra il dato teorico, ottenibileda una serie di valori misurati (la media del campione di dati) e il dato reale odi riferimento; indica, cioe, la vicinanza del valore trovato a quello reale. Quindi,la differenza tra precisione e accuratezza sta nel fatto che la prima valuta quantole misure sono raggruppate nell’intorno del valor medio, invece la seconda valutaquanto tale valor medio e vicino al valore vero della grandezza.
1.2 Gli errori di misura
Postulato che per ciascuna grandezza esista un valore vero, ci si potrebbe chiedere perquale ragione la misura non riesca direttamente a far riprodurre ogni volta tale valore.La risposta piu semplice ed implicita e che nella misura reale vengono commessi erroriche possono esse di diversa natura, ma che in pratica possono ricondursi alle seguenti treclassi:
• Errori dovuti all’applicazione di un metodo non corretto. Ad esempio, si commetteun errore di questo tipo quando non si tiene conto nella caduta dei gravi della resi-stenza dell’aria, per cui a corpi di densita diversa vengono a corrispondere differentileggi del moto, risultato questo certamente scorretto.
• Errori dovuti all’impiego di apparecchi o di personale inefficienti; per esempio, senella misura della lunghezza di un bastone, ad esempio di 80 cm circa, usiamo unmetro pieghevole di legno in cui, per errore, il fabbricante abbia omesso uno deipezzi pieghevoli intermedi di lunghezza 20 cm, e non ci siamo accorti di questofatto, riterremo in buona fede che il bastone sia lungo 100 cm, commettendo cosısistematicamente, un errore di 20 cm. Analogamente, commettiamo un’erroredello stesso tipo nel caso in cui, pur essendo il metro pieghevole ben costruito, cidimenticassimo di svolgerlo completamente, e quindi, convinti di usare un metro di100 cm di lunghezza, facessimo le misure con uno di 80 cm!
• Errori dovuti a cause incontrollabili, sempre presenti in gran numero, ognuna dellequali contribuisce poco all’inesattezza della misura e in modo variabile. Esempidi tali cause sono moti dell’aria piu o meno sensibili che possono influenzare gliapparecchi, la diversa dilatazione termica degli strumenti per effetto della maggioreo minore vicinanza dell’operatore, la non sempre identica reazione dei centri nervosinell’operatore che, in misure ripetute, puo portare ad apprezzare in maniera diversatraguardi spaziali o temporali, ecc.
Delle tre categorie ora esposte, le prime due, che influiscono sull’accuratezza di unamisura, sono legate ai cosiddetti errori sistematici, mentre la terza, che limita la pre-cisione di una misura, rappresenta la classe degli errori accidentali o errori casuali.
4
Da quanto detto finora appare chiaro che gli errori sistematici, sebbene di difficile in-dividuazione, una volta che ne siano state scoperte le cause, possone venire eliminaticompletamente. In linea di principio, percio, se non esistessero gli errori casuali si po-trebbe riuscire in una misura ad ottenere il valore vero della grandezza in esame. E perquesto che spesso conviene ripetere la misura di una grandezza fisica con metodi e stru-menti diversi, cosicche da un’eventuale differenza nei risultati sia piu facile individuaregli errori sistematici, nell’ipotesi che essi non siano gli stessi, o comunque contribuiscanodiversamente nei differenti procedimenti. Invece, per quanto riguarda gli errori casuali,avendo un’origine incontrollabile e variabile, che sfugge anche ad un attento controllo, none possibile eliminarli del tutto. E per questo che, anche in assenza di errori sistematici,non e possibile misurare i valori veri delle grandezze, ed e essenziale stabilire l’influenzadegli errori casuali per poter assegnare al risultato delle misure un valido significato.
La teoria degli errori tiene conto soltanto degli errori casuali, supponendo, cioe, chesiano stati del tutto eliminati quelli sistematici o che, per lo meno, essi siano cosı piccolida essere trascurabili rispetto agli errori casuali. D’altra parte, sebbene i risultati che siottengono con tale approccio saranno validi sotto queste ipotesi, se un errore sistematicoviene rilevato dopo l’applicazione della teoria degli errori, si puo tenerne conto anche a po-steriori e spesso e possibile correggere completamente i risultati eliminandone totalmentegli effetti senza dover ripetere le misure.
1.3 Trattazione dei dati sperimentali: approccio pratico allateoria degli errori
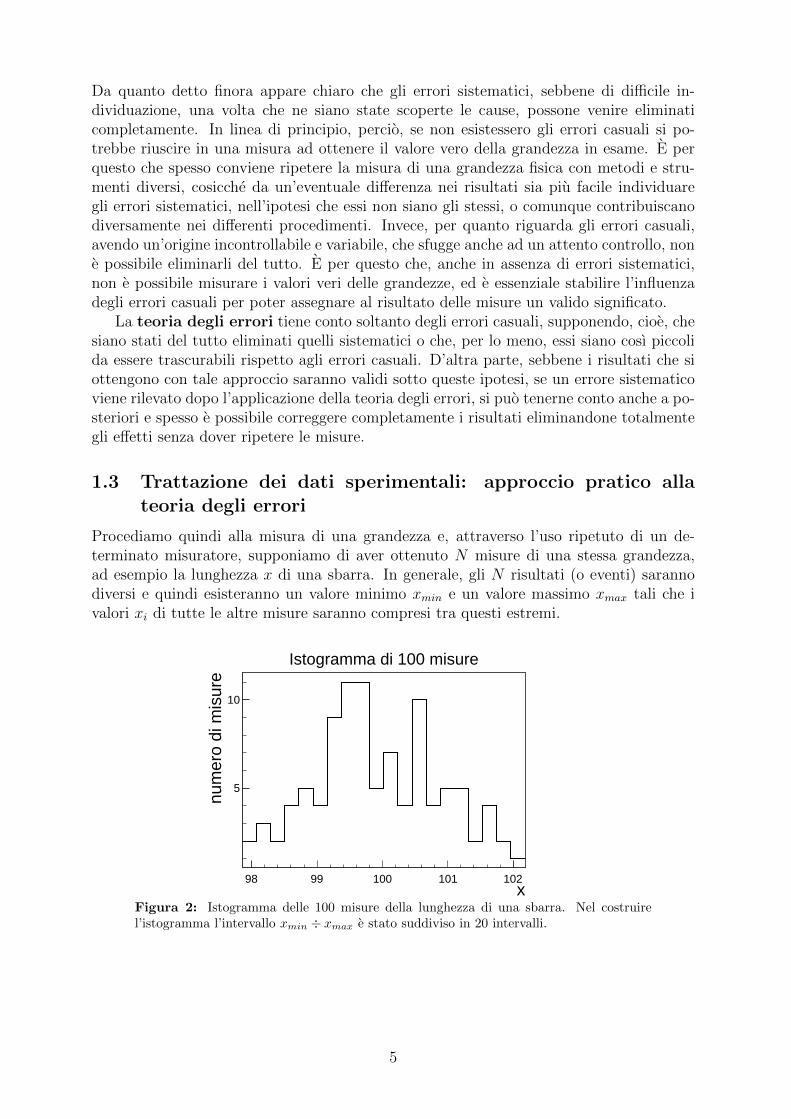
Procediamo quindi alla misura di una grandezza e, attraverso l’uso ripetuto di un de-terminato misuratore, supponiamo di aver ottenuto N misure di una stessa grandezza,ad esempio la lunghezza x di una sbarra. In generale, gli N risultati (o eventi) sarannodiversi e quindi esisteranno un valore minimo xmin e un valore massimo xmax tali che ivalori xi di tutte le altre misure saranno compresi tra questi estremi.
x98 99 100 101 102
num
ero
di m
isur
e
5
10
Istogramma di 100 misure
Figura 2: Istogramma delle 100 misure della lunghezza di una sbarra. Nel costruirel’istogramma l’intervallo xmin ÷ xmax e stato suddiviso in 20 intervalli.
5
1.3.1 Istogramma delle misure e ruolo del valor medio
Consideriamo un metodo (molto utilizzato) che ci permette velocemente di avere un’ideadi come si distribuiscono le misure. Riportiamo xmin e xmax su di un asse x e dividiamol’intervallo xmin ÷ xmax in un numero n (con 1 � n � N) di parti uguali di ampiezza∆x = (xmax − xmin)/n (larghezza del bin): avremo cosı diviso la serie di misure ottenutein n gruppi, nel j–esimo dei quali entrano a far parte le nj misure con
xmin + (j − 1)∆x ≤ xi ≤ xmin + j∆x.
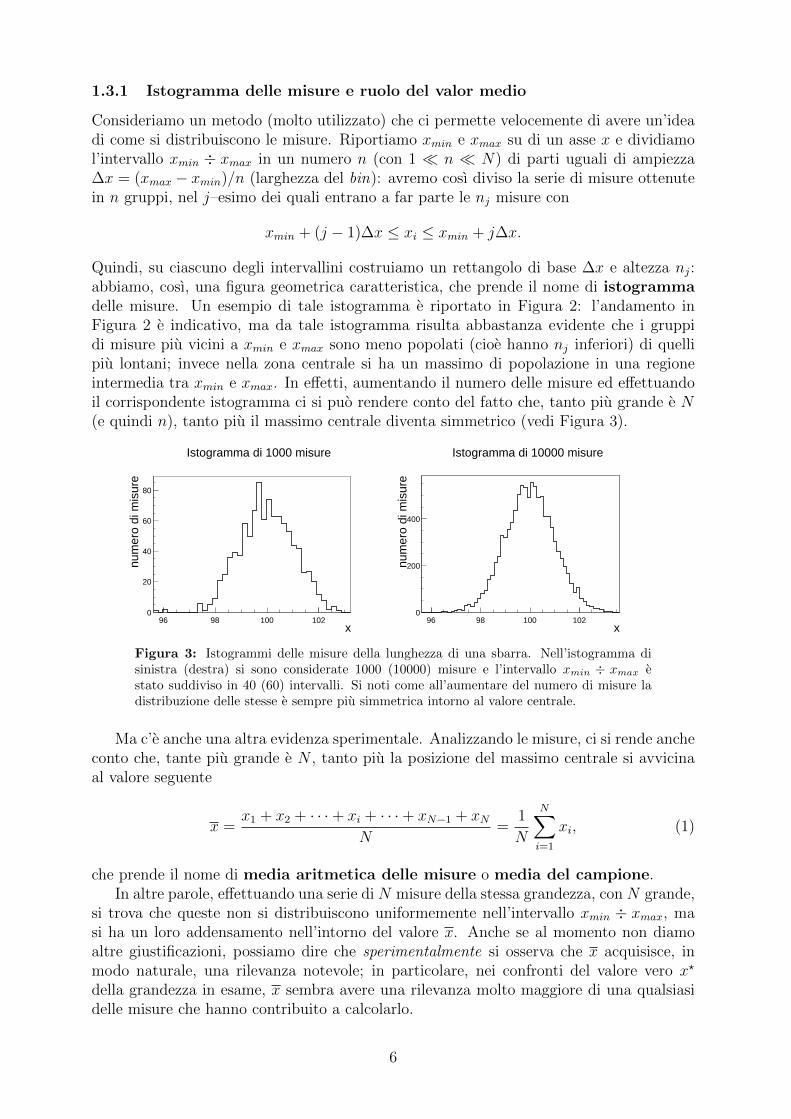
Quindi, su ciascuno degli intervallini costruiamo un rettangolo di base ∆x e altezza nj:abbiamo, cosı, una figura geometrica caratteristica, che prende il nome di istogrammadelle misure. Un esempio di tale istogramma e riportato in Figura 2: l’andamento inFigura 2 e indicativo, ma da tale istogramma risulta abbastanza evidente che i gruppidi misure piu vicini a xmin e xmax sono meno popolati (cioe hanno nj inferiori) di quellipiu lontani; invece nella zona centrale si ha un massimo di popolazione in una regioneintermedia tra xmin e xmax. In effetti, aumentando il numero delle misure ed effettuandoil corrispondente istogramma ci si puo rendere conto del fatto che, tanto piu grande e N(e quindi n), tanto piu il massimo centrale diventa simmetrico (vedi Figura 3).
x96 98 100 102
num
ero
di m
isur
e
0
20
40
60
80
Istogramma di 1000 misure
x96 98 100 102
num
ero
di m
isur
e
0
200
400
Istogramma di 10000 misure
Figura 3: Istogrammi delle misure della lunghezza di una sbarra. Nell’istogramma disinistra (destra) si sono considerate 1000 (10000) misure e l’intervallo xmin ÷ xmax estato suddiviso in 40 (60) intervalli. Si noti come all’aumentare del numero di misure ladistribuzione delle stesse e sempre piu simmetrica intorno al valore centrale.
Ma c’e anche una altra evidenza sperimentale. Analizzando le misure, ci si rende ancheconto che, tante piu grande e N , tanto piu la posizione del massimo centrale si avvicinaal valore seguente
x =x1 + x2 + · · ·+ xi + · · ·+ xN−1 + xN
N=
1
N
N∑i=1
xi, (1)
che prende il nome di media aritmetica delle misure o media del campione.In altre parole, effettuando una serie di N misure della stessa grandezza, con N grande,
si trova che queste non si distribuiscono uniformemente nell’intervallo xmin ÷ xmax, masi ha un loro addensamento nell’intorno del valore x. Anche se al momento non diamoaltre giustificazioni, possiamo dire che sperimentalmente si osserva che x acquisisce, inmodo naturale, una rilevanza notevole; in particolare, nei confronti del valore vero x?
della grandezza in esame, x sembra avere una rilevanza molto maggiore di una qualsiasidelle misure che hanno contribuito a calcolarlo.
6

1.3.2 Scarti, varianza e deviazione standard
Una volta determinato il valore x, definiamo scarto della misura xi, e lo indicheremo conil simbolo si, la quantita
si = xi − x.Si noti che, per definizione, e
N∑i=1
si = 0, (2)
dato che
N∑i=1
si =N∑i=1
(xi − x) =N∑i=1
xi −Nx = N
(1
N
N∑i=1
xi − x)
= N(x− x) = 0.
s (scarto)4− 2− 0 2 4
alte
zze
norm
aliz
zate
0
0.2
0.4
100 misure
1000 misure
10000 misure
Istogrammi degli scarti
Figura 4: Istogrammi normalizzati degli scarti dalla media delle 1000 misure della lun-ghezza di un bastone. Per poterli meglio confrontare, si e utilizzato lo stesso bin per tuttie 3 gli istogrammi; si noti come all’aumentare del numero di misure, la corrispondentedistribuzione risulti via via meglio definita.
Se ora vogliamo costruire un istogramma degli scarti, e facile rendersi conto del fattoche esso non differisce sostanzialmente da quello costruito con gli xi, se non per il fattoche l’istogramma risultante e traslato di x lungo l’asse x. Si ha cosı ancora la stessa figurageometrica caratteristica con un massimo pronunciato in vicinanza di x, che ora pero cadea s = 0 (vedi Figura 4). Tuttavia, dato che
∑Ni=1 si = 0, e tenuto conto della simmetria
intorno a s = 0, conviene in generale costruire un istogramma degli scarti in modo un pocodiverso: e precisamente, sull’asse s si riportano degli intervallini di lunghezza ∆s = ∆x,il primo dei quali sia centrato intorno a s = 0, e gli altri risultino a questo adiacenti,sia per s > 0 sia per s < 0. Per il resto il procedimento e identico a prima, e cioe suciascuno degli intervallini si costruisce un rettangolo di altezza uguale a nj, numero dimisure il cui scarto cade nell’intervallino in questione. Il risultato e un istogramma moltosimile al precedente, tanto piu quanto piu grande e N e quindi piu piccolo e ∆s. L’area A
7

dell’istogramma e data dalla somma delle aree dei rettangoli da cui e costituito, ciascunadelle quali e pari a nj∆s; si ha quindi
A =∑j
nj∆s = N∆s.
Dividendo gli nj dell’istogramma degli scarti per tale area si ottengono gli istogramminormalizzati degli scarti mostrati in Figura 4. Da questa figura si capisce che, sebbenecon diversi gradi di approssimazione, gli scarti tendono a distribuirsi nell’intorno di s = 0in un modo ben preciso e che l’istogramma delinea un andamento tanto meglio definitoquanto piu alto e il numero di misure effettuato.
L’analisi di questi istogrammi e il fatto che gli scarti misurano la distanza dei singolivalori da x ci inducono a pensare che la larghezza della distribuzione degli scarti debbaessere correlata alla qualita della misura: tanto piu stretta e la distribuzione, tanto piuprecisa sara la misura! Percio, e ragionevole supporre che attraverso gli scarti si possacostruire una grandezza che risulti in stretta relazione con la larghezza della distribuzione.
In effetti, tenendo presente la simmetria degli scarti (da cui segue la (2)), la piusemplice funzione a cui possiamo pensare e la seguente
σ2 =1
N
N∑i=1
s2i =1
N
N∑i=1
(xi − x)2, (3)
che viene usualmente detta varianza o scarto quadratico medio. Si capisce immedia-tamente che tale grandezza o, meglio ancora, la cosiddetta deviazione standard
σ =
√√√√ 1
N
N∑i=1
s2i =
√√√√ 1
N
N∑i=1
(xi − x)2, (4)
ci da una misura delle dimensioni medie degli scarti e che quindi dovra necessariamenteessere correlata alla larghezza della distribuzione degli stessi.
E interessante notare che il modo in cui e costruita la varianza permette dare unaprima giustificazione teorica(3) al fatto di poter vedere x come una buona stima del valorevero x? della grandezza in esame. Infatti, denominiamo con xv l’ipotetico valore vero dellagrandezza e, una volta ottenute le N misure, calcoliamo quello che potremmo denominare(in analogia con lo scarto quadratico medio σ2) l’errore quadratico medio:
ε2 =1
N
N∑i=1
(xi − xv)2.
Non conoscendo pero il valore effettivo di xv, supponiamo di vedere ε2 come funzione dixv e chiediamoci come debba comportarsi al variare di xv stesso. In particolare, dato ilsignificato di ε2, e ragionevole aspettarsi che tanto piu xv e vicino al valore vero, tantopiu piccolo sia ε2.
A tal fine possiamo cercare il valore di xv che minimizza ε2, e questo si puo fareimponendo l’annullamento della sua derivata rispetto ad xv. Si ottiene
dε2
dxv= 0 ⇒ − 2
N
N∑i=1
(xi − xv) = 0 ⇒ NN∑i=1
xv =N∑i=1
xi ⇒ xv =1
N
N∑i=1
xi,
(3)Torneremo piu avanti su questo punto.
8

Questo dimostra che la media aritmetica delle misure rende minimo l’errore quadraticomedio. Senza la pretesa di rigore assoluto, tale risultato da valore sia all’uso di x comestima piu corretta del valore vero della grandezza, sia a quello di σ come parametro conil quale valutare la precisione della misura.
1.3.3 Forma analitica della distribuzione delle misure
Per completare questo primo approccio alla trattazione dei dati sperimentali, possiamodomandarci se l’andamento degli scarti mostrato possa essere descritto analiticamente dauna relazione funzionale. In effetti, un’ottima interpolazione degli istogrammi normaliz-zati mostrati in Figura 4, tanto migliore quanto maggiore e N , e fornita dalla funzionedi Gauss
f(x) = Ce−h2(x−µ)2 ,
dove C e una costante, h e il cosiddetto modulo di precisione e x = µ corrisponde allaposizione del massimo della funzione (si veda anche in Appendice B la dimostrazione delfatto che µ e anche pari al valor medio x della distribuzione di Gauss).
In effetti, la migliore interpolazione dell’istogramma normalizzato degli scarti (vediFigura 4 ci da (in accordo con quanto calcolato in Appendice B) una funzione di Gaussdel tipo
f(x) =h√π
e−h2(x−µ)2 . (5)
Questo significa che la curva di Gauss qui scritta corrisponde al limite a cui tendel’istogramma normalizzato per N →∞ e ∆s→ 0.
E facile vedere quale sia il significato di h. Limitandoci ad osservazioni intuitive,supponiamo di aver effettuato due serie di misure della stessa grandezza, ma con meto-di diversi: avremo due istogrammi normalizzati (come quelli di Figura 4), in generaledifferenti, dai quali potremo estrapolare due funzioni di Gauss del tipo delle seguenti
f1(x) =h1√π
e−h21(x−µ1)2 ; f2(x) =
h2√π
e−h22(x−µ2)2 ,
dove µ1 e µ2 saranno essenzialmente uguali dato anche i valori medi delle due serie dimisure lo dovrebbero essere.
Sia, per esempio, h1 > h2, cioe l’istogramma corrispondente alla prima serie di misureha un massimo piu alto di quello della seconda serie. Conseguentemente, poiche i dueistogrammi hanno la stessa area, il primo istogramma dovra calare a zero piu rapidamentedel secondo e cosı la corrispondente curva di Gauss. Per la prima serie, quindi, si deveavere un maggior addensamento delle misure intorno al valor medio, e quindi, scarti inmedia minori in valore assoluto che non per la seconda serie. Ne segue che, nell’ipotesih1 > h2, il primo metodo di misura porta a minori fluttuazioni nei risultati, e quindi epiu preciso del secondo. Tanto piu grande e h, tanto piu la misura e precisa; da questo ilnome che abbiamo dato ad h.
1.4 Popolazione, campione e deviazione standard del campione
Nel precedente paragrafo (sezione 1.3.3) abbiamo delineato il fatto che l’analisi statisticadelle misure di una grandezza mostra che le stesse si distribuiscono secondo una distribu-zione che e tanto piu simile alla distribuzione di Gauss, quanto piu alto e numero di misureeffettuate. In effetti, non c’e limite ne al numero di misure che potremmo effettuare, ne
9

al numero di valori che potremmo ottenere per la grandezza (la grandezza e continua).Riferendoci a questo insieme infinito di possibili valori parleremo di popolazione. Nel-la realta, invece, possiamo effettuare solo un numero finito di misure ottenendo cosı uncampione (finito) della popolazione della grandezza in esame.
Quindi, nella realta, potendo disporre solo di un campione (costituito da N elementi)e non dell’intera popolazione (infinita), le quantita statistiche che possiamo calcolaredovrebbero essere pensate come relative al campione e non alla popolazione; solo nel limitedi N →∞ tali quantita approssimeranno il valore corrispondente all’intera popolazione.
A tale scopo e importante menzionare che la definizione di varianza (e di deviazionestandard) che abbiamo dato nella sezione 1.3.2 riguarda l’intera popolazione. Nel casodi un campione, che in effetti il caso usuale, la definizione di varianza piu consona e laseguente
σ2c =
1
N − 1
N∑i=1
(xi − x)2. (6)
Come si vede nella (6), le definizioni di σ2c e σ2 differiscono solo per il fatto di aver
sostituito l’N della (3) con N − 1. La definizione di varianza del campione data dalla(6) deriva dal fatto che, una volta definito il valor medio del campione,(4) la validita della(2) suggerisce che solo N − 1 scarti siano realmente indipendenti fra loro. D’altra parte,si noti che essendo
σ2c =
N
N − 1σ2,
tanto piu grande sara N , tanto piu piccola sara la differenza tra la varianza del campionee quella della popolazione.
In analogia con la (4), si definisce deviazione standard del campione la seguente:
σc =
√√√√ 1
N − 1
N∑i=1
(xi − x)2. (7)
In modo da distinguere deviazione standard del campione da quella della popolazioneσ, l’abbiamo denominata σc dove il c a pedice ci ricorda che si riferisce al campione.Tuttavia, e bene sottolineare, che spesso, per entrambe, viene utilizzato lo stesso simbolo,sottintendendo che, a seconda che si consideri l’intera popolazione o un campione finito,venga utilizzata la rispettiva definizione con N o N − 1.
2 Probabilita e distribuzioni di probabilita
L’andamento gaussiano che abbiamo trovato per gli scarti dalla media di una serie di Nmisure puo essere in qualche modo giustificato sul piano teorico: per fare questo tuttaviae bene introdurre qualche concetto di calcolo delle probabilita.
2.1 Il concetto di probabilita
Se lanciamo una moneta in aria, sappiamo che la probabilita che venga testa e il 50%. Segettiamo un dado, sappiamo ancora che la probilita che esca 5 e 1/6.
(4)Il valor medio x risulta sempre definito come x = 1N
∑Ni=1 xi sia per il campione che per l’intera
popolazione.
10

Che cosa significa questo in realta? Ad ogni lancio della moneta esce o testa o croce.Cio che vogliamo dire con quel 50% e che se lanciamo la moneta un numero grande divolte, il numero di volte che uscira testa sara all’incirca uguale alla meta del totale deilanci. Allo stesso modo, per i lanci di un dado, il 5 uscira (come gli altri numeri) in unsesto dei lanci.
Si dovrebbe precisare che nel problema del lancio della moneta abbiamo detto chetanto piu grande e il numero dei lanci, tannto piu vicino ad 1/2 sara il rapporto tra ilnumero di volte che esce testa e il totale dei lanci stessi. Questo non significa che il numerodi lanci in cui esce testa si avvicina a quello in cui esce croce. Ad esempio, per 100 lanciun risultato soddisfacente dal punto di vista delle probabilita e 52 volte testa; per 10000lanci, invece 5020 volte testa sarebbe altrettanto accettabile. Nel secondo caso il rapportoe molto piu vicino ad 1/2 che nel primo, ma la differenza tra il numero delle volte che escetesta e quello delle volte che esce croce e piu grande. In effetti, si potrebbe dimostrare chee probabile che tale differenza diventi molto grande, nonostante il rapporto tra il numerodi tentativi favorevoli a testa (croce) e il numero totale dei lanci si avvicini ad 1/2.(5)
Se sappiamo calcolare la probabilita per alcuni semplici eventi, come il lancio di unamoneta o di un dado, possiamo calcolare la probabilita per eventi piu complessi cherisultino composti da questi. Ad esempio, supponiamo di lanciare due monete contempo-raneamente e supponiamo di voler calcolare la probabilita che esca croce su una e testasull’altra. Ogni moneta puo dar luogo a testa o croce con uguale probabilita e quindi,per il lancio combinato avremo quattro possibilita: due volte testa; una testa e una croce;una croce e una testa; due volte croce. I quattro casi sono equiprobabili e quindi ognunoavra probabilita 1/4. Dato che due dei quattro casi soddisfano la nostra richiesta, possia-mo dire che la probabilita cercata e pari ad 1/2. Allo stesso modo, le probabilita che siabbiano due teste o due croci e 1/4.
Si noti che le probabilita sono date da numeri sempre minori di 1 e che se sommiamole probabilita di tutti i possibili eventi otteniamo 1.
Altro problema: supponiamo di avere due dadi a sei facce (su ogni faccia e riportato unnumero diverso, da 1 a 6). Considerando il lancio dei due dadi proponiamoci di calcolarela probabilita di ottenere 7 sommando i numeri usciti su ogni dado. Dato che ogni dadoha 6 possibilta equiprobabili, per la coppia di dadi avremo 36 possibili risultati, tuttiequiprobabili (se lanciassimo n dadi, il numero dei casi sarebbe 6n). In quanti di questicasi la somma dei numeri sui dadi da 7? E facile vedere che 6 sono i casi favorevoli. Equindi, essendo la probabilita di ogni caso pari a 1/36, la probabilita di avere 7 sara parialla somma di quella dei 6 casi favorevoli e cioe 6/36 = 1/6. Procedendo in questo modie nalizzando tutti i casi possibili, si vede che la somma dei numeri sui dadi puo assumere11 diversi valori (2, 3, 4, . . ., 12) e conteggiando i casi favorevoli ad ogni somma possiamocostruire la seguente tabella
Somma 2 3 4 5 6 7 8 9 10 11 12Casi favorevoli 1 2 3 4 5 6 5 4 3 2 1
Probabilita 1/36 1/18 1/12 1/9 5/36 1/6 5/36 1/9 1/12 1/18 1/36
Tabella 1: Probabilita corrispondenti ai diversi valori della somma dei numeri usciti nellancio di due dadi.
(5)Cosı, se ci si trova a scommettere del denaro con qualcuno e si e in perdita, e sbagliato crederedi potersi rifare di quello che si e perduto, dopo un numero sufficientemente grande di prove. C’e unaprobabilita del 50% che si perda sempre di piu.
11

Definiamo allora probabilita di un evento come il rapporto tra il numero di casi favore-voli all’evento in esame e il numero totale di casi possibili. Analogamente, per un singolodado, la probabilita di un determinato valore e 1/6, mentre la probabilita di ottenere unnumero pari o dispari e 3/6 = 1/2. Dalla definizione data di probabilita segue che, seabbiamo due eventi incompatibili, nel senso che il verificarsi dell’uno porta all’impossi-bilita del verificarsi dell’altro, la probabilita che si verifichi uno qualunque dei due eventie data dalla somma delle probabilita di ciascuno indipendentemente. Infatti, il numero dicasi favorevoli risulta proprio la somma dei casi favorevoli a ciascun diverso evento, men-tre il numero di casi possibili resta lo stesso. Cosı nel lancio di un dado ritroviamo che laprobabilita che si ottenga un numero dispari e proprio 1/2, e analogamente per il pari, inquanto un evento dispari corrisponde al verificarsi di uno qualunque degli eventi 1, 3, 5 equesti sono incompatibili: poiche per ciascuno si ha la probabilita 1/6, la probabilita diun evento dispari risulta essere
1
6+
1
6+
1
6=
1
2.
Insistiamo nel sottolineare che questa regola vale solo per eventi incompatibili. Sup-poniamo, infatti, di voler calcolare la probabilita che un giorno dell’anno sia festivo: laprobabilita che sia domenica e 52/365 (52 domeniche in un anno, casi favorevoli; 365 gior-ni, casi possibili), mentre, se consideriamo che ci siano altre 17 ricorrenze festive, religioseo civili, avremo una probabilita pari a 17/365 di un evento di questo genere. Ma i due tipidi evento non sono incompatibili, perche non e escluso che una festa civile o religiosa cadaproprio di domenica. Percio la probabilita di un giorno non puo essere calcolata dallasomma delle probabilita (52/365 + 17/365): per una corretta valutazione della probabi-lita richiesta bisognera invece determinare il totale del numero di casi favorevoli all’eventofestivo, che risultera, per esempio, pari a 67 (se 2 delle festivita suddette cadono di do-menica). Si avra allora una probabilita di giorno festivo pari a 67/365 < 69/365. In altreparole, per calcolare la probabilita di uno qualunque tra piu eventi bisogna, nel computodei casi favorevoli, contare una volta sola quelli che sono comuni. Per questo motivo laprobabilita di uno qualunque di piu eventi, e sempre minore o, al piu, uguale alla sommadelle probabilita dei singoli eventi. Come immediata applicazione di quanto finora espostosi trova che, se abbiamo N eventi possibili, la probabilita che avvenga indifferentementeuno qualunque di essi e 1, corrispondente, come ovvio, alla certezza.
Supponiamo di avere ora due o piu sistemi fisici, ciascuno con un certo numero di statipossibili, e supponiamo di conoscere anche la probabilita degli eventi di ciascun sistema.Consideriamo quindi il sistema complessivo costituito dai diversi sistemi in esame: dalladefinizione di probabilita si trova che la probabilita (composta) di un evento globale, incui, cioe, si presenti contemporaneamente un determinato evento per ciascuno dei sistemicostituenti, e data dal prodotto delle probabilita per ciascuno degli eventi parziali. Cosı, seabbiamo un dado a 6 numeri e una moneta con testa e croce, la probabilita che lanciandoliinsieme si trovi, per esempio, un evento globale costituito da 1 (per il dado) e testa (perla moneta) e data da 1/6 · 1/2 = 1/12, essendo 1/6 e 1/2 le probabilita rispettive di 1 peril dado e testa per la moneta. Applicando le due regole esposte di somma e prodotto delleprobabilita si ritrovano facilmente i risultati relativi al lancio di due dadi, in cui si voglia,cioe, determinare la probabilita di un certo valore per la somma dei numeri di ciascundado. Ad esempio, una somma uguale a 4 sara ottenuta attraverso le tre coppie 1 e 3, 2e 2, 3 e 1; con la regola delle probabilita composte troviamo
p(1, 3) = p1(1)× p2(3) =1
6· 1
6=
1
36
12
dove p1 e p2 si identificano con le probabilita per il primo e secondo dado. Ovviamente,per le altre due coppie si ottiene la stessa probabilita e quindi la probabilita di avere unasomma 4 per i due dadi e
psomma(4) = p(1, 3) + p(2, 2) + p(3, 1) =3
36=
1
12,
in perfetto accordo con quanto mostrato
2.2 Distribuzioni di probabilita
Allo scopo di introdurre l’idea di distribuzione di probabilita, supponiamo di lanciare 10monete simultaneamente e di voler calcolare la probabilita che, ad esempio, 4 monetepresentino testa e le restanti croce. In generale, il problema consistera nel calcolare laprobabilita associata ad avere n monete con testa e le restanti 10 − n con croce con nintero compreso tra 0 e 10. La risposta a tale domanda corrispondera ad una serie dinumeri, f(n), uno per ogni valore di n; cioe, per ogni n si ottiene un valore f(n) chefornisce la probabilita dell’evento caratterizzato dal numero n. Una funzione di questotipo e detta distribuzione di probabilita.
Se il campo di variabilita dell’indice n include tutti i possibili eventi (sara generalmentequesto il tipo di problemi che affronteremo), allora la somma di tutte le probabilita deveessere 1 (la certezza). Cioe ∑
n
f(n) = 1, (8)
dove si suppone che la somma sia estesa a tutti i possibili valori di n.Si da il caso che, in effetti, nel paragrafo precedente, abbiamo gia costruito la distri-
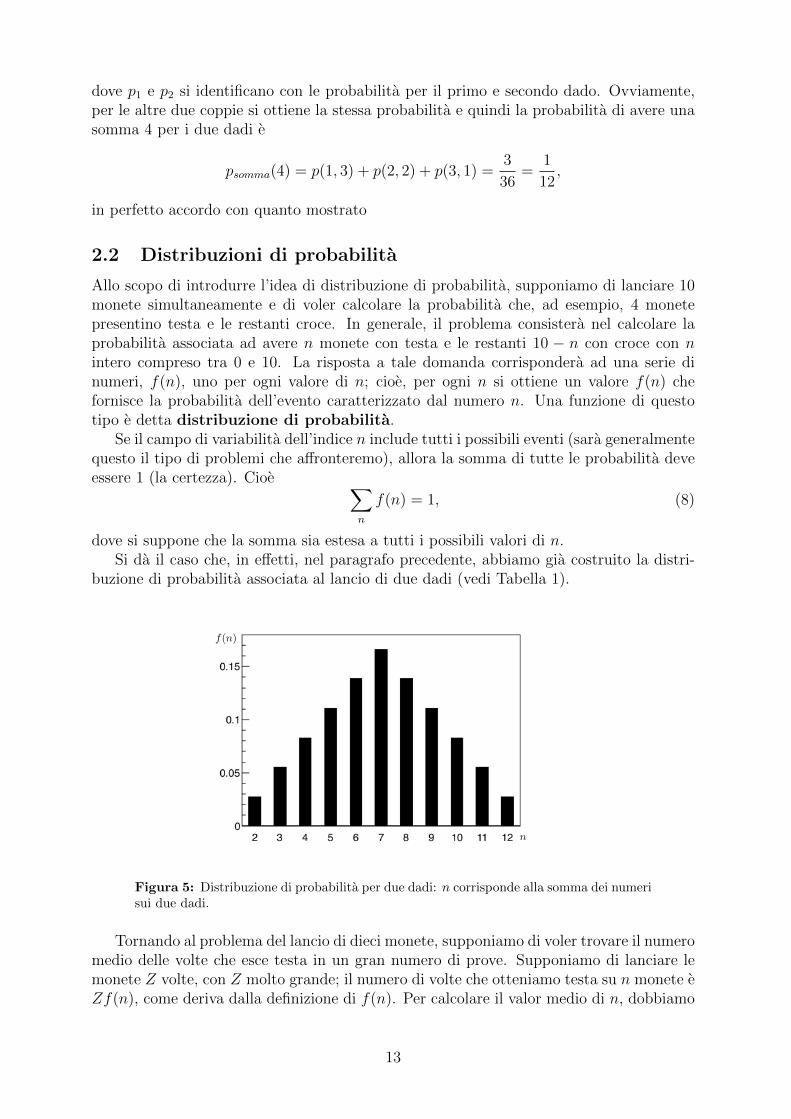
buzione di probabilita associata al lancio di due dadi (vedi Tabella 1).
n
f(n)
Figura 5: Distribuzione di probabilita per due dadi: n corrisponde alla somma dei numerisui due dadi.
Tornando al problema del lancio di dieci monete, supponiamo di voler trovare il numeromedio delle volte che esce testa in un gran numero di prove. Supponiamo di lanciare lemonete Z volte, con Z molto grande; il numero di volte che otteniamo testa su n monete eZf(n), come deriva dalla definizione di f(n). Per calcolare il valor medio di n, dobbiamo
13

moltiplicare ogni valore di n per il numero di volte in cui lo stesso n si e presentato,sommare questi prodotti e dividere per Z. Cioe
n =1
Z
∑n
nZf(n) =∑n
nf(n). (9)
Il fatto che Z si semplifichi in questa espressione significa che, ovviamente, in un grannumero di prove il valore di n sara indipendente da Z. L’espressione di n data dalla (9)puo essere pensata come una media pesata dei valori di n, con i pesi uguali alle probabilita;la somma dei pesi in questo caso e uguale ad 1.
Il calcolo di n con il metodo espresso dalla (9) per la distribuzione del lancio dei duedadi (Tabella 1 e Figura 5) porta a n = 7. Questo valore non dovrebbe sorprendere datoche le probabilita sono simmetricamente distribuite intorno al valore n = 7. Intuitiva-mente, si comprende che due diversi valori di n alla stessa distanza da 7 (uno alla suasinistra e l’altro alla sua destra), hanno la stessa probabilita.
Utilizzando il metodo espresso nella (9) si puo calcolare il valor medio di qualunquealtra quantita; ad esempio il valor medio di n2 e dato da
n2 =∑n
n2f(n). (10)
Ma allora e interessante calcolare il valor medio dello scarto quadrato (n− n)2 che, comeabbiamo visto nella (3) corrisponde alla varianza.(6) Avremo
σ2 =∑n
(n− n)2f(n), (11)
che puo anche essere espresso nella forma seguente
σ2 =∑n
(n− n)2f(n) =∑n
[n2 + n2 − 2nn]f(n) =
=∑n
n2f(n) + n2∑n
f(n)− 2n∑n
nf(n) = (12)
= n2 + n2 − 2n2 = n2 − n2
dove si e sfruttata la normalizzazione di f(n),∑
n f(n) = 1. Nel caso della distribuzionef(n) per il lancio dei due dadi abbiamo σ2 = 105/36 = 2 + 11/12 e quindi una deviazionestandard σ =
√105/36 ≈ 1.71.
2.3 La distribuzione binomiale
Si abbiano N eventi indipendenti, ognuno dei quali abbia una probabilita p di verificarsi equindi una probabilita 1− p di non verificarsi. Quale sara la probabilita che esattamenten degli eventi si verifichino?
Facciamo un esempio per chiarire la situazione. Supponiamo di avere 5 petardi che sipresumono identici, che per un difetto di fabbrica non sempre esplodono quando accesi:statisticamente, solo i 3/4 dei petardi esplodono. In altre parole la probabilita che unpetardo esploda e p = 3/4 e che faccia cilecca e 1 − p = 1/4. Il numero di eventi
(6)Dato che anche le probabilita si suppongono estrapolate dall’intera popolazione, ovviamene, lavarianza suddetta e quella della popolazione.
14
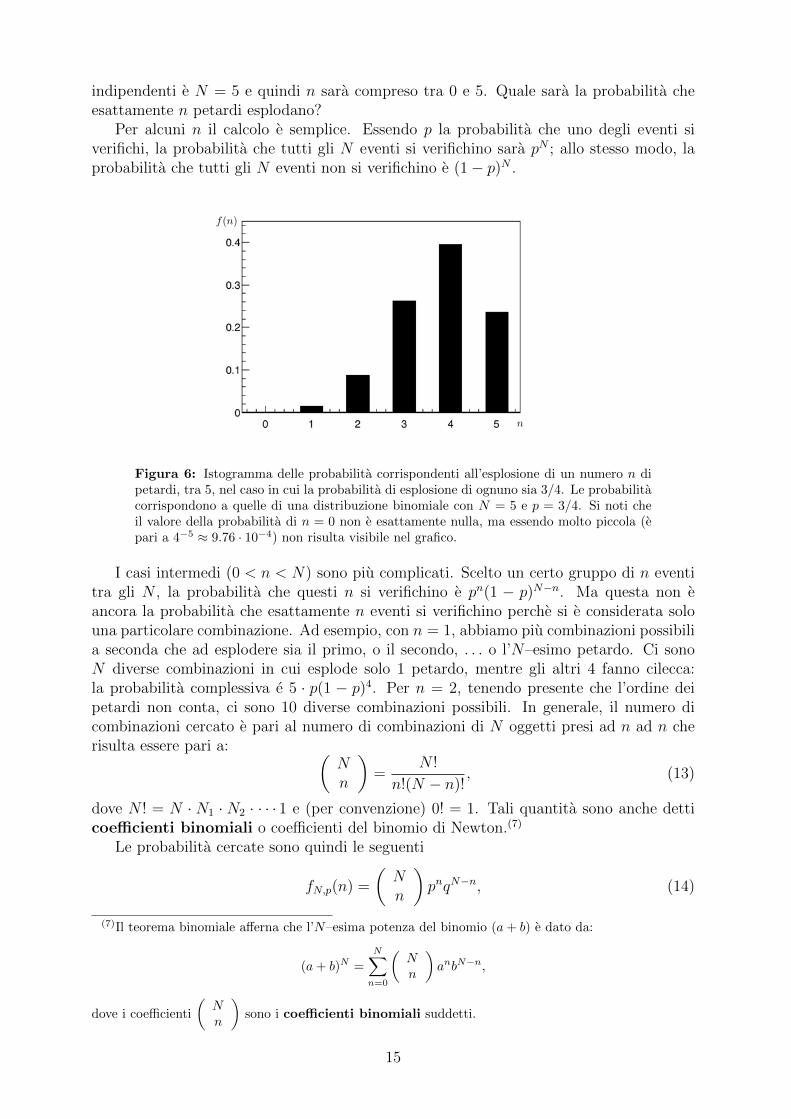
indipendenti e N = 5 e quindi n sara compreso tra 0 e 5. Quale sara la probabilita cheesattamente n petardi esplodano?
Per alcuni n il calcolo e semplice. Essendo p la probabilita che uno degli eventi siverifichi, la probabilita che tutti gli N eventi si verifichino sara pN ; allo stesso modo, laprobabilita che tutti gli N eventi non si verifichino e (1− p)N .
n
f(n)
Figura 6: Istogramma delle probabilita corrispondenti all’esplosione di un numero n dipetardi, tra 5, nel caso in cui la probabilita di esplosione di ognuno sia 3/4. Le probabilitacorrispondono a quelle di una distribuzione binomiale con N = 5 e p = 3/4. Si noti cheil valore della probabilita di n = 0 non e esattamente nulla, ma essendo molto piccola (epari a 4−5 ≈ 9.76 · 10−4) non risulta visibile nel grafico.
I casi intermedi (0 < n < N) sono piu complicati. Scelto un certo gruppo di n eventitra gli N , la probabilita che questi n si verifichino e pn(1 − p)N−n. Ma questa non eancora la probabilita che esattamente n eventi si verifichino perche si e considerata solouna particolare combinazione. Ad esempio, con n = 1, abbiamo piu combinazioni possibilia seconda che ad esplodere sia il primo, o il secondo, . . . o l’N–esimo petardo. Ci sonoN diverse combinazioni in cui esplode solo 1 petardo, mentre gli altri 4 fanno cilecca:la probabilita complessiva e 5 · p(1 − p)4. Per n = 2, tenendo presente che l’ordine deipetardi non conta, ci sono 10 diverse combinazioni possibili. In generale, il numero dicombinazioni cercato e pari al numero di combinazioni di N oggetti presi ad n ad n cherisulta essere pari a: (
Nn
)=
N !
n!(N − n)!, (13)
dove N ! = N · N1 · N2 · · · · 1 e (per convenzione) 0! = 1. Tali quantita sono anche detticoefficienti binomiali o coefficienti del binomio di Newton.(7)
Le probabilita cercate sono quindi le seguenti
fN,p(n) =
(Nn
)pnqN−n, (14)
(7)Il teorema binomiale afferna che l’N–esima potenza del binomio (a+ b) e dato da:
(a+ b)N =
N∑n=0
(Nn
)anbN−n,
dove i coefficienti
(Nn
)sono i coefficienti binomiali suddetti.
15
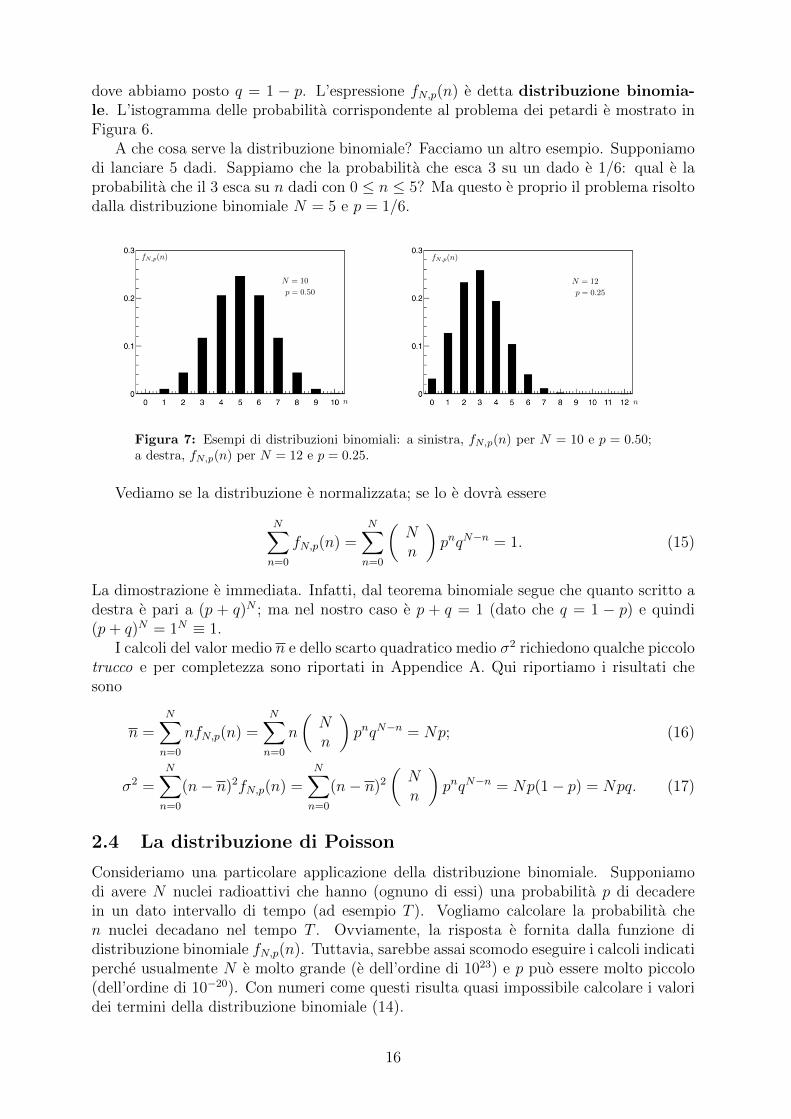
dove abbiamo posto q = 1 − p. L’espressione fN,p(n) e detta distribuzione binomia-le. L’istogramma delle probabilita corrispondente al problema dei petardi e mostrato inFigura 6.
A che cosa serve la distribuzione binomiale? Facciamo un altro esempio. Supponiamodi lanciare 5 dadi. Sappiamo che la probabilita che esca 3 su un dado e 1/6: qual e laprobabilita che il 3 esca su n dadi con 0 ≤ n ≤ 5? Ma questo e proprio il problema risoltodalla distribuzione binomiale N = 5 e p = 1/6.
n
fN,p(n)
N = 10
p = 0.50
n
fN,p(n)
N = 12
p = 0.25
Figura 7: Esempi di distribuzioni binomiali: a sinistra, fN,p(n) per N = 10 e p = 0.50;a destra, fN,p(n) per N = 12 e p = 0.25.
Vediamo se la distribuzione e normalizzata; se lo e dovra essere
N∑n=0
fN,p(n) =N∑n=0
(Nn
)pnqN−n = 1. (15)
La dimostrazione e immediata. Infatti, dal teorema binomiale segue che quanto scritto adestra e pari a (p + q)N ; ma nel nostro caso e p + q = 1 (dato che q = 1 − p) e quindi(p+ q)N = 1N ≡ 1.
I calcoli del valor medio n e dello scarto quadratico medio σ2 richiedono qualche piccolotrucco e per completezza sono riportati in Appendice A. Qui riportiamo i risultati chesono
n =N∑n=0
nfN,p(n) =N∑n=0
n
(Nn
)pnqN−n = Np; (16)
σ2 =N∑n=0
(n− n)2fN,p(n) =N∑n=0
(n− n)2(Nn
)pnqN−n = Np(1− p) = Npq. (17)
2.4 La distribuzione di Poisson
Consideriamo una particolare applicazione della distribuzione binomiale. Supponiamodi avere N nuclei radioattivi che hanno (ognuno di essi) una probabilita p di decaderein un dato intervallo di tempo (ad esempio T ). Vogliamo calcolare la probabilita chen nuclei decadano nel tempo T . Ovviamente, la risposta e fornita dalla funzione didistribuzione binomiale fN,p(n). Tuttavia, sarebbe assai scomodo eseguire i calcoli indicatiperche usualmente N e molto grande (e dell’ordine di 1023) e p puo essere molto piccolo(dell’ordine di 10−20). Con numeri come questi risulta quasi impossibile calcolare i valoridei termini della distribuzione binomiale (14).
16

Fortunatamente, proprio in considerazione dell’ordine di N e p, possiamo ricorrere adelle approssimazioni. I valori estremi di N e p suggeriscono infatti che in tali condizionila distribuzione cercata corrisponda all’estrapolazione della distribuzione binomiale nellimite di N → ∞ e p → 0. In effetti, e bene notare che, mentre N e p assumono valoriestremi, il valor medio della distribuzione Np rimane finito. Denoteremo tale prodottocon
Np = a. (18)
Facciamo quindi le considerazioni che ci porteranno ad estrarre la distribuzione cer-cata.(8) Innanzitutto una considerazione essenziale: se p e una quantita molto piccola,il numero medio di eventi sara in genere molto inferiore ad N ; quindi i valori di n a cuisaremo interessati saranno estremamente piu piccoli di N . Conseguentemente, tenendopresente che n << N , nei coefficienti binomiali:(
Nn
)=
N !
n!(N − n)!=N(N − 1)(N − 2) · · · (N − n+ 1)
n!,
possiamo notare che il numeratore e costituito dal prodotto di n termini tutti poco diversida N . In queste condizioni potremo scrivere(
Nn
)≈ Nn
n!.
Percio abbiamo
fN,p ≈Nn
n!pn(1− p)N−n =
(Np)n
n!· (1− p)N
(1− p)n .
Ora notiamo che, essendo p esiguo ed n relativamente piccolo, la potenza (1 − p)n saraessenzialmente identica ad 1 e potra essere eliminata. Eliminando ancheN dall’espressioneprecedente attraverso la (18) possiamo scrivere
fN,p ≈ f(n) =an
n!· (1− p)a/p =
an
n!·[(1− p)1/p
]a.
Non rimane che valutare la quantita (1− p)1/p che, tenendo presente il valore estremodi p possiamo far corrispondere al limite(9)
limp→0
(1− p)1/p =1
e.
Pertanto, la distribuzione cercata assume la seguente forma
fa(n) =ane−a
n!,
che e detta distribuzione di Poisson.Il legame tra questa distribuzione e la distribuzione binomiale ci dice subito che il
valor medio di n en = a.
(8)Senza la pretesa di essere matematicamente rigorosi, cercheremo di essere ragionevoli nell’introduzionedelle diverse approssimazioni.
(9)Questo e un limite notevole calcolato in tutti i testi di analisi matematica.
17
n
fa(n)
a = 2.0
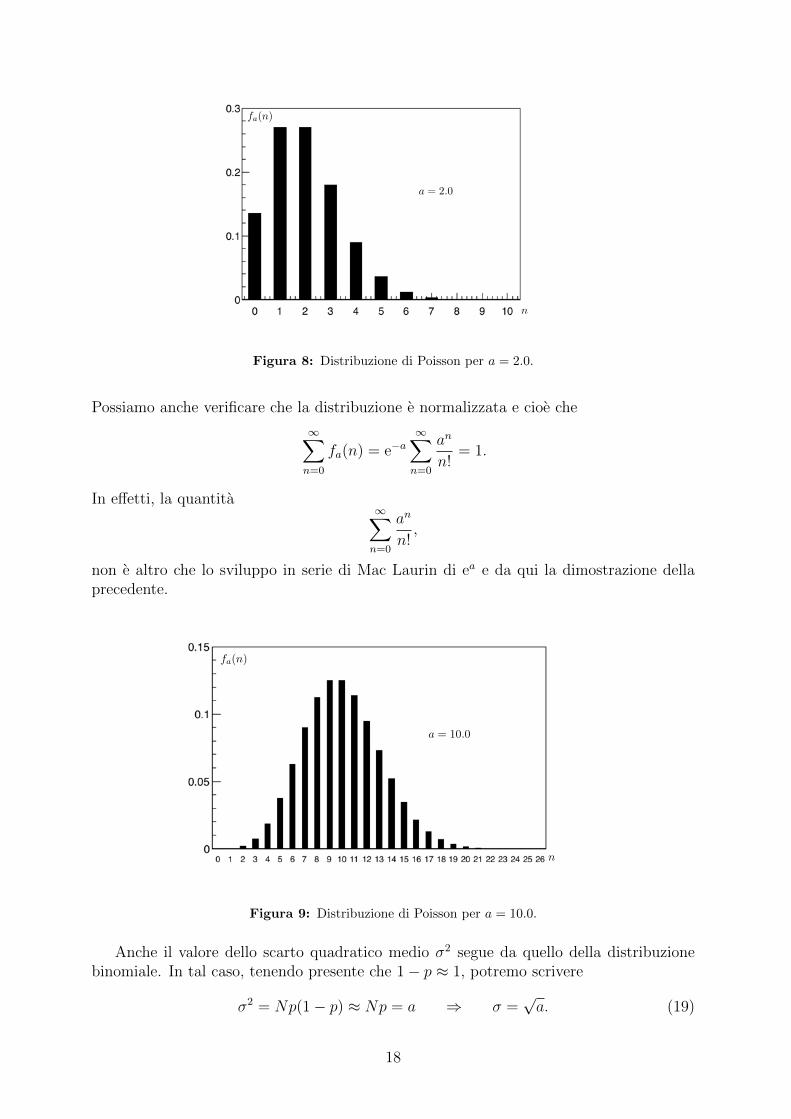
Figura 8: Distribuzione di Poisson per a = 2.0.
Possiamo anche verificare che la distribuzione e normalizzata e cioe che
∞∑n=0
fa(n) = e−a∞∑n=0
an
n!= 1.
In effetti, la quantita∞∑n=0
an
n!,
non e altro che lo sviluppo in serie di Mac Laurin di ea e da qui la dimostrazione dellaprecedente.
n
fa(n)
a = 10.0
Figura 9: Distribuzione di Poisson per a = 10.0.
Anche il valore dello scarto quadratico medio σ2 segue da quello della distribuzionebinomiale. In tal caso, tenendo presente che 1− p ≈ 1, potremo scrivere
σ2 = Np(1− p) ≈ Np = a ⇒ σ =√a. (19)
18

Ecco un’esempio in cui puo essere utilizzata la distribuzione di Poisson. Supponiamodi avere 1020 atomi di un ipotetico elemento radioattivo i cui nuclei emettono particelle α(atomi di elio ionizzati).(10) Supponiamo che il decadimento sia costante e pari a 2 · 10−20
atomi al secondo, il che significa che la probabilita per ogni nucleo di decadere in unsecondo e di 2 · 10−20. Questo corrisponde ad una vita media di 1012 anni, piuttostolunga, ma non al di fuori della realta.
Supponiamo ora di osservare questo campione di materiale per molti intervalli, cia-scuno della durata di un secondo. Quale la probabilita di osservare zero emissioni in unintervallo? Una emissione? Due? ecc. Le risposte sono fornite dalla distribuzione di Pois-son fa(n) utilizzando a = Np = 1020 · 2 · 10−20 = 2 e sono rappresentate nell’istogrammain Figura 8. In Figura 9 e mostrato l’istogramma corrispondente alla distribuzione diPoisson con a = 10.
2.5 La distribuzione di Gauss o distribuzione normale degli er-rori
Ci siamo occupati finora del caso di distribuzioni di probabilita relative a sistemi chepossono assumere solo stati discreti; conseguentemente, anche la variabile corrispondentea tali stati assumeva solo valori discreti (o interi). Al contrario, in questo paragrafo cioccuperemo di una distribuzione di probabilita in cui lo stato del sistema puo variare concontinuita. La distribuzione che prenderemo in esame e la distribuzione di Gauss dettaanche distribuzione normale degli errori.
Questa distribuzione e importante per varie ragioni: i) descrive la distribuzionedegli errori casuali in molti tipi di misure; ii) e possibile dimostrare che, anche se isingoli errori non seguono questa distribuzione, le medie di gruppi di dati di questo tipo sidistribuiscono (se abbastanza numerosi) secondo la legge di Gauss. Infatti, considerandogruppi di osservazioni (misure) che seguono una certa distribuzione f(x) (di qualsiasitipo), prendendone N e facendone la media, allora, purche N sia molto grande, le medieseguono la distribuzione di Gauss.(11)
La distribuzione di Gauss puo essere vista come un risultato analitico derivato daelementari considerazioni matematiche o, come abbiamo gia accennato nel paragrafo 1.3.3,come una formula empirica che si e trovato essere in accordo con la distribuzione realedegli errori casuali. Da un punto di vista teorico si puo fare la ragionevole affermazioneche ogni errore accidentale (casuale) si puo pensare come il risultato di un gran numero dierrori elementari, tutti di uguale entita, e ciascuno con uguale probabilita di produrre unavariazione in eccesso o in difetto. La distribuzione di Gauss puo cosı essere consideratacome una forma limite della distribuzione binomiale, quando in quest’ultima il numero Ndegli eventi indipendenti (corrispondenti agli errori elementari) diventa elevato, mentre laprobabilita p di successo di ogni prova (la probabilita di ogni errore elementare di esserepositivo) e 1/2. Un tale calcolo va al di la degli scopi di questa introduzione alla teoriadegli errori e non la riporteremo.
D’altra parte, molti sono dell’avviso che la vera giustificazione della validita della leggedi Gauss e della sua applicazione nel trattare gli errori casuali sta nel fatto che, nellapratica, le osservazioni sperimentali seguono tale distribuzione (come abbiamo detto nella
(10)Una tale situazione potrebbe essere plausibile per un raro e instabile isotopo delle terre rare, con unpeso atomico vicino a 150. In questo caso 1020 atomi corrispondono ad una massa dell’ordine di 25 mg.(11)Questo e il risultato del cosiddetto teorema del limite centrale che vale con la sola condizione che
la varianza della distribuzione originaria, f(x), sia finita. Tale teorema e molto importante negli sviluppipiu avanzati della statistica matematica.
19

sezione 1.3.3). Per tale ragione, la distribuzione gaussiana viene anche usualmente indicatacome legge normale degli errori; percio, quando gli errori seguono tale distribuzionesi dice che sono distribuiti normalmente.
x− 1h x+ 1
hx
f(x)f(x)
x
h√π
eh√π
Figura 10: Funzione di distribuzione di Gauss. Sono indicati i punti di ascissa x =x± 1/h, in corrispondenza dei quali la curva assume un valore pari a h/
√πe.
Come abbiamo gia visto nella sezione 1.3.3 la distribuzione di Gauss ha la forma
f(x) =h√π
e−h2(x−µ)2 . (20)
dove h e detto modulo di precisione e µ (vedi Appendice B) e pari alla media dellapopolazione x. Questa distribuzione e diversa da quelle viste fino ad ora perche ora lavariabile x e una variabile continua e non un indice intero come nella binomiale o in quelladi Poisson. Questo caratteristica richiede qualche precisazione sul significato della f(x).Nella Figura 10 mostriamo il grafico di f(x). Il massimo della funzione si presenta a x = xe la sua ordinata e pari ad h/
√π. In corrispondenza delle ascisse x = x ± 1
hla funzione
assume il valore he√π.
Da questo possiamo capire (si e gia visto nella sezione 1.3.3) che al variare di h lacurva diventa alta e stretta per grandi valori di h, bassa e larga per bassi valoridi h. Questo fatto e legato al significato vero e proprio della f(x) e al fatto che il suo valorenon corrisponde (come succedeva per le distribuzioni discrete) alla probabilita del valorex. Infatti, essendo x una variabile continua, la probabilita che essa assuma esattamenteun particolare valore e nulla! Invece, quello che ha senso e, ad esempio, chiederci quantovale la probabilita che x assuma un valore compreso tra a e b.
Cosı l’esatta interpretazione della funzione f(x) e che per un piccolo intervallo dx,f(x)dx corrisponde alla probabilita che una misura cada nell’intervallo x, x + dx . Con-seguentemente, come mostrato anche in Figura 11, la probabilita che x cada in un puntoqualunque dell’intervallo a÷ b e
P (a, b) =
∫ b
a
f(x)dx.
Quindi, dato che x puo assumere qualsiasi valore tra −∞ e +∞, se la funzione didistribuzione e normalizzata, deve essere∫ +∞
−∞f(x)dx = 1.
20

f(x)
dx
bax
Figura 11: Rappresentazione grafica delle probilita per una distribuzione continua (quie considerata la distribuzione di Gauss). Le aree tratteggiate rappresentano le probabilitacha ha una misura di cadere nei rispettivi intervalli.
Come dimostrato in Appendice B la forma (20) della distribuzione di Gauss e normalizzataed inoltre il suo valor medio e pari a
x =
∫ +∞
−∞xf(x)dx = µ.
D’altra parte (vedi in Appendice B) si dimostra che tra il modulo di precisione e lavarianza della distribuzione vale la seguente
σ =1√2h,
che permette di scrivere la distribuzione di Gauss nella forma seguente
f(x) =1√2πσ
e−(x−x)2
2σ2
che costituisce la forma universalmente utilizzata per la distribuzione normale.
x− σ x+ σx
f(x)f(x)
x
1e√2πσ
√2πσ1
Figura 12: Funzione di distribuzione di Gauss. Si noti che sono indicati gli stessi puntiindicati in Figura 10, ma ora le posizioni e le quote sono espresse in termini della deviazionestandard σ.
21

Possiamo utilizzare la distribuzione di Gauss per calcolare la probabilita che una mi-sura cada in un intervallo prefissato. In particolare, e interessante calcolare la probabilitache una misura cada in un intervallo di semi–ampiezza nσ (con n intero) intorno ad x.Cioe la quantita
Pnσ =1√2πσ
∫ x+nσ
x−nσe−
(x−x)2
2σ2 dx
Operando il cambio di variabile t = (x− x)/σ la precedente diventa
Pnσ =1√2π
∫ +n
−ne−t
2/2dt =
√2
π
∫ n
0
e−t2/2dt
L’integrale in questione non e calcolabile analiticamente, ma puo essere valutato numeri-camente con precisione molto elevata. I valori delle probilita suddette per n = 1, 2, 3 sonoi seguenti:
Pσ = 0.683; P2σ = 0.954; P3σ = 0.997.
Questi valori mostrano che la probabilita che ha una misura di cadere in un intervallodi semi–ampiezza σ intorno ad x e dell 68.3%; di semi–ampiezza 2σ e del 95.4%; disemi–ampiezza 3σ e del 99.7%.
Talvolta, queste probabilita possono essere utilizzate per elaborare un criterio peranalizzare i propri dati sperimentali ed eventualmente scartarne qualcuno. Ad esempio,il valore di P3σ ci dice che la probabilita che una ha misura di cadere al di fuori di unintervallo di semi–ampiezza 3σ di x e del 3 per mille (molto improbabile!). Quindi, datauna serie di misure che si supponga distribuita normalmente, calcolato il valor medio xe la deviazione standard σ, sarebbe improbabile trovare che uno o piu dati della serienon rientrino nell’intervallo x ± 3σ. Se questo succede, potremmo pensare che, forse,nell’effettuare quelle misure sia intervenuto qualche errore aggiuntivo (sistematico) che haprodotto quella discrepanza; potremmo cioe pensare che i valori ottenuti in quelle misuresiano stati inficiati da fattori che non rientrano nelle casualita attinenti alla distribuzionenormale. In base a questo criterio, tali dati potrebbero essere eliminati dal set dellemisure.
Il criterio appena descritto puo dare buoni risultati, ma e bene suggerire una certacautela nella sua applicazione. Se, da una parte, il criterio puo dar modo di individuareed eliminare alcuni dati, dall’altra, la sua applicazione indiscriminata potrebbe portareall’eliminazione di gran parte dei dati stessi. Infatti, dopo ogni applicazione del criterio (edopo aver eliminato i dati che cadono fuori dall’intervallo x± 3σ), con i dati rimanenti sideve procedere al ricalcolo dei nuovi x e σ; questo potrebbe innescare un processo a catenache potrebbe portare a ridurre entro limiti inaccettabili la consistenza del campione inesame.
3 Applicazioni e ulteriori sviluppi della Teoria degli
Errori
Tutto cio che abbiamo detto a proposito della probabilita e delle distribuzioni di proba-bilita costituisce le fondamenta su cui costruire tecniche, anche complesse, per il tratta-mento statistico dei dati. Nelle seguenti sezioni ci occuperemo di una serie di risultati edi strumenti statistici sviluppati a partire da quanto fin qui visto.
22

3.1 La deviazione standard della media
Consideriamo una questione molto importante: qual e la relazione tra la deviazionestandard di un set di misure e la precisione del valor medio?
Rispondiamo a tale domanda estendendo le idee che abbiamo gia introdotto. Prima ditutto, supponiamo di avere N misure che seguono la distribuzione di Gauss. Calcoliamola media x e la deviazione standard σ. Supponiamo poi di considerare un’altro set di Nmisure e di calcolare i nuovi x e σ: questi, non necessariamente, saranno uguali a quellidel precedente gruppo, ma ci aspettiamo che la differenza tra i valori medi dei due gruppisia molto inferiore a quanto ogni misura differisce dalle rispettive medie.
Continuando a collezionare misure, supponiamo di averne messi insieme M set co-stituiti da N misure ciascuno. Inoltre, ognuno di questi sara caratterizzato da un valormedio xk (k = 1, 2, . . . ,M) e da una deviazione standard σk. Se M e abbastanza grande,potremmo anche pensare di analizzare la distribuzione degli xk: quale sara la deviazionestandard della media (e cioe la deviazione standard della distribuzione delle medie)?In base a quanto detto prima ci aspettiamo che tale deviazione standard sia piu piccola diognuna delle σk. Inoltre, il suo valore ci dara un’indicazione della precisione che possiamoassegnare agli xk.
Denotiamo con σm la suddetta deviazione standard della media, con xik l’i–esimo(i = 1, 2, . . . , N) dato del k–esimo (k = 1, 2, . . . ,M) set di misure e con X la mediacomplessiva su tutte le MN misure (che corrisponde anche alla media delle medie xk).
La varianza delle misure individuali e
σ2 =1
MN
M∑k=1
N∑i=1
(xik −X)2 =1
MN
M∑k=1
N∑i=1
s2ik, (21)
dove gli sik = xik −X sono gli scarti delle singole misure da X. Invece la varianza dellamedia e
σ2m =
1
M
M∑k=1
(xk −X)2 =1
M
M∑k=1
S2k ,
dove gli Sk = xk −X sono gli scarti delle medie xk dalla media X.Notando che
Sk = xk −X =1
N
N∑i=1
xik −X =1
N
N∑i=1
(xik −X) =1
N
N∑i=1
sik.
e, inserendo questa nella precedente, si ottiene
σ2m =
1
M
M∑k=1
(1
N
N∑i=1
sik
)2
=1
MN2
M∑k=1
(N∑i=1
sik
)2
. (22)
Sviluppando il quadrato della della sommatoria nell’ultimo termine della (22) si ottiene(N∑i=1
sik
)2
=N∑i=1
s2ik +N∑j>i
sjksik,
e quindi
σ2m =
1
MN2
M∑k=1
N∑i=1
s2ik +1
MN2
M∑k=1
N∑j>i
sjksik. (23)
23

Il secondo termine di tale relazione contiene il prodotto di scarti diversi che, sappiamoessere, nel caso di distribuzioni normali (e siamo in tali condizioni), positivi o negati-vi con ugual probabilita. A causa di cio, il termine che contiene le sommatorie in cuicompaiono tali prodotti, nel caso di grandi valori di M ed N , tenderanno ad annullarsi.Conseguentemente, con buona approssimazione possiamo scrivere
σ2m =
1
MN2
M∑k=1
N∑i=1
s2ik (24)
A prima vista, tale espressione puo sembrare molto simile alla (21), ma un confronto piuaccurato ci mostra che
σ2m =
σ2
No anche σm =
σ√N
(25)
Possiamo quindi asserire che: la deviazione standard della media σm di un set di Nmisure e pari, semplicemente, alla deviazione standard delle misure σ divisathe la radice quadrata di N .
La deviazione standard della media e utilizzata universalmente per descrivere la preci-sione della media di un set di misure. Il risultato appena ottenuto ci permette di calcolarela precisione che possiamo assegnare al valor medio ricavato da una serie di misure.
3.2 Propagazione degli errori
La teoria degli errori presentata fin qui e riferita alla misura diretta, o relativa, di gran-dezze fisiche; come sappiamo, tuttavia, molte grandezze fisiche vengono misurate in modoindiretto, cioe si ricava il loro valore da quella di altre grandezze, legate alla grandezza inesame da relazioni funzionali del tipo z = f(a, b, c, . . .), che possono essere, per esempio,le espressioni di leggi fisiche. Qui a, b, c, . . . rappresentano le grandezze che vengonomisurate direttamente, alle quali si applicano le considerazioni precedenti. Ci si domandacome l’imprecisione nella misura di a, b, c, . . . si rifletta sulla misura di z: la risposta edata dalla legge di propagazione degli errori, che vogliamo qui introdurre.
Essendo z? = f(a?, b?, c?, . . .), ci aspettiamo che, effettuando una serie di N misure conN grande, di a, b, c, . . ., ed esaminando la distribuzione delle zi = f(ai, bi, ci, . . .), questasia centrata intorno ad un valore medio z = f(a, b, c, . . .). Cio e infatti quanto si trova;anzi la distribuzione delle zi e, con ottima approssimazione, interpolata ancora da unadistribuzione normale, caratterizzata da un σz che, come vedremo, e legato ai σa, σb, σc,ecc. delle diverse misure dirette che concorrono alla determinazione di z.
Il differenziale di z e dato dall’espressione
dz =
[∂f
∂a
]da+
[∂f
∂b
]db+
[∂f
∂c
]dc+ . . .
e se le quantita da = ∆a, db = ∆b, . . . sono sufficientemente piccole, e la f(a, b, c, . . .) eabbastanza regolare, cosa che ammettiamo senz’altro, potremo scrivere
∆z =
[∂f
∂a
]∆a+
[∂f
∂b
]∆b+
[∂f
∂c
]∆c+ . . .
Se ora con ∆a si rappresenta lo scarto sa,i = ai − a sulla misura delle singole ai, eanalogamente per b e c, si avra
∆zi = zi − z = z(ai, bi, ci, . . .)− z(a, b, c, . . .) ≈[∂f
∂a
]sa,i +
[∂f
∂b
]sb,i +
[∂f
∂c
]sc,i + . . .
24

dove le derivate parziali[∂f∂a
],[∂f∂b
],[∂f∂c
]sono calcolate in a = a, b = b, c = c, ecc.
Calcoliamo l’errore quadratico medio σz; abbiamo
σ2z =
1
N
N∑i=1
s2z,i =1
N
N∑i=1
[∂f
∂asa,i +
∂f
∂bsb,i +
∂f
∂csc,i + . . .
]2=
=1
N
N∑i=1
{[∂f
∂a
]2s2a,i +
[∂f
∂b
]2s2b,i +
[∂f
∂c
]2s2c,i + . . .
}2
+
+1
N
N∑i=1
{2
[∂f
∂a
] [∂f
∂b
]sa,isb,i + 2
[∂f
∂a
] [∂f
∂c
]sa,isc,i + 2
[∂f
∂b
] [∂f
∂c
]sb,isc,i + . . .
}Analogamente a quanto visto nella precedente sezione, i termini nella seconda parentesigraffa possono venire trascurati rispetto agli altri, in quanto essendovi la stessa probabilitaper ciascuno di essere positivo o negativo, nella sommatoria per N grande vi sarannotermini a due a due uguali in modulo, ma di segno opposto, che si elideranno l’un l’altro.Pertanto, la relazione cercata per la σ2
z e la seguente
σ2z =
[∂f
∂a
]2σ2a +
[∂f
∂b
]2σ2b +
[∂f
∂c
]2σ2c + . . . (26)
Analogamente, se per ciascuna delle grandezze a, b, c, . . . si fanno piu serie di misure,potremo definire una varianza della media per z dato attraverso le (25), da
σ2z,m =
[∂f
∂a
]2σ2a,m +
[∂f
∂b
]2σ2b,m +
[∂f
∂c
]2σ2c,m + . . . (27)
Questa relazione, a differenza delle (25), resta corretta anche se delle grandezze a, b, c, . . .e stato fatto un numero diverso di misure (e non lo stesso numero N).
Come semplici applicazione di quanto ottenuto, consideriamo le 3 relazioni funzionaliseguenti
z1 = ka; z2 = a+ b; z3 =a
b,
con k costante e le variabili a e b distribuite normalmente e con le deviazioni standard σae σb. L’applicazione della (26) e molto facile e ci permette di scrivere le seguenti:
σ2z1
=
[∂z1∂a
]2σ2a = k2σ2
a ⇒ σz1 = kσa; (28)
σ2z2
=
[∂z2∂a
]2σ2a +
[∂z2∂b
]2σ2b = σ2
a + σ2b ⇒ σz2 =
√σ2a + σ2
b ; (29)
σ2z3
=
[∂z3∂a
]2σ2a +
[∂z3∂b
]2σ2b =
1
b2
[σ2a +
a2
b2σ2b
]⇒ σz3 =
√1
b2
[σ2a +
a2
b2σ2b
](30)
3.3 Il metodo dei minimi quadrati
Veniamo ora ad un metodo molto potente tramite il quale e possibile estrarre il massimo diinformazioni da un set di dati sperimentali. Tale metodo si basa sul cosiddetto principio
25

dei minimi quadrati che a sua volta puo essere derivato dal principio di massimaverosimiglianza che vale per dati che seguono la distribuzione normale.
Il principio dei minimi quadrati puo essere enunciato in questo modo: il valore piuprobabile x di una certa grandezza puo essere ricavato considerandone un setdi misure xi (con i = 1, . . . , N) e scegliendo il valore che minimizza la sommadegli scarti quadrati
N∑i=1
(x− xi)2 (31)
In effetti abbiamo gia visto una tale espressione (in pratica e alla base della definizionedi scarto quadratico medio) e abbiamo gia visto che la sua minimizzazione (vedi nellasezione (1.3.2) porta a vedere x come migliore stima del valore vero della grandezza.
Ma qual e la ragione del fatto che la minimizzazione della somma degli scarti al qua-drato debba portare ad estrarre il valore piu probabile della grandezza? Per rispondere aquesta domanda consideriamo la probabilita associata ad un set di misure xi assumendoche tali misure seguano la distribuzione normale. La probabilita in questione, cioe laprobabilita che una misura cada in un intervallo di ampiezza dx intorno a xi e
Pi =1√2πσ
e−(x−xi)
2
2σ2 dx,
dove σ e la deviazione standard del set di dati a cui xi appartiene. Corrispondentemente, laprobabilita di ottenere il set completo delleN misure sara pari al prodotto delle probabilita
P = P1 · P2 · · · · · PN
=
(1√2πσ
e−(x−x1)
2
2σ2 dx
)· · · · ·
(1√2πσ
e−(x−xN )2
2σ2 dx
)(32)
=
(dx√2πσ
)Ne−
∑Ni=1
(x−xi)2
2σ2
Quindi, la probabilita P di osservare l’intero gruppo di valori xi dipende dal valore di x checompare nell’espressione (32). Per un valore di x molto diverso da tutti gli xi, l’esponentesara molto negativo e, corrispondentemente, P sara molto bassa. In altre parole, e moltoimprobabile che tutte le misure siano molto lontane dal valore vero della grandezza.
In effetti, se abbiamo ottenuto proprio quel set di misure (e non un’altro), la sua pro-babilita deve essere molto elevata! Il principio di massima verosimiglianza asserisceche questo sia proprio il set di misure piu probabile e percio, in accordo con questa af-fermazione, la probabilita P associata a tale set di misure dovra essere massima. Questoporta alla scelta del valore di x che minimizza la quantita
M(x) =N∑i=1
(x− xi)22σ2
(33)
che compare nell’esponente nell’espressione (32). Questa quantita e detta somma deiminimi quadrati. Il principio di massima verosimiglianza porta quindi alla conclusioneche bisogna minimizzare M(x), il che e equivalente (in questo caso) a minimizzare lasomma
∑Ni=1(x− xi)2, come abbiamo gia visto.
La deviazione standard del valore piu probabile di x, e cioe x, puo essere ricavataattraverso la propagazione degli errori applicata all’espressione
x = x =1
N
N∑i=1
xi,
26

intesa come funzione delle N variabili xi, associando ad esse le deviazioni standard delladistribuzione da cui provengono e cioe σ. Percio utilizzando la (26) ricaviamo che lavarianza della media σ2
m e data dalla seguente
σ2m =
[∂x
∂x1
]2σ2 +
[∂x
∂x2
]2σ2 + · · ·+
[∂x
∂xN
]2σ2 =
N∑i=1
[∂x
∂xi
]2σ2,
Notando che e [ ∂x∂xi
] = 1/N si ottiene
σ2m =
N∑i=1
σ2
N2=σ2
N, (34)
in perfetto accordo con la (25).Capita, talvolta, di avere a disposizione per una stessa grandezza piu set di misure
ognuno con il suo valor medio xj e con la propria deviazione standard σj (supporremoj = 1, 2, . . . ,M). In effetti, e utile confrontare misure di una stessa grandezza effettuatecon metodi e precisioni diverse; la coerenza (o meno) tra i diversi risultati permette divalutare sia la bonta dei diversi metodi, sia l’eventuale presenza di errori sistematici nellemisure. Come si puo fare in tali casi a ricavare il valore piu probabile della grandezza ela corrispondente deviazione standard?
Il metodo dei minimi quadrati esposto sopra ci viene in soccorso. Analogamente acome abbiamo proceduto sopra, ora, supponendo che i dati dei diversi set di misure sianodistribuiti normalmente, la probabilita del set di valori medi xj sara data da
P =(dx)M
(√
2π)Nσ1σ2 · · · σMe−
∑Mj=1
(x−xj)2
2σ2j (35)
In questo caso la somma dei minimi quadrati e
M(x) =M∑j=1
(x− xj)22σ2
j
, (36)
e minimizzando M(x) (seguendo ancora il principio di massima verosimiglianza) si ottiene
dM
dx=
d
dx
M∑j=1
(x− xj)22σ2
j
= 0 ⇒ x
M∑j=1
1
σ2j
=M∑j=1
xjσ2j
da cui segue
x = x =
∑Mj=1
xjσ2j∑M
j=11σ2j
. (37)
Il valore piu probabile si ottiene come media pesata delle medie dei vari set di dati pesatecon gli inversi delle varianze delle stesse.
La varianza del valore piu probabile si ottiene, ancora una volta, applicando la propa-gazione degli errori alla (37) intesa come funzione degli xi. Quindi
σ2m =
[∂x
∂x1
]2σ21 +
[∂x
∂x2
]2σ22 + · · ·+
[∂x
∂xM
]2σ2M =
M∑j=1
[∂x
∂xj
]2σ2j ,
27

Osservando che ora e∂x
∂xj=
1/σ2j∑M
k=1 1/σ2k
,
sostituendo nella precedente si ha
σ2m =
M∑j=1
(1/σ2
j∑Mk=1 1/σ2
k
)2
σ2j =
∑Mj=1 1/σ2
j(∑Mk=1 1/σ2
k
)2 =1∑M
k=1 1/σ2k
.
Cioe
1
σ2m
=M∑j=1
1
σ2j
.
Da questa si vede che la varianza della media pesata e minore di una qualsiasi dellevarianze individuali. Inoltre, nel caso in cui la varianze dei diversi set di dati siano uguali,si riottiene il risultato gia visto nella (34).
3.4 Fit di dati sperimentali con il metodo dei minimi quadrati
Un’altro problema dove il metodo dei minimi quadrati rivela appieno le sue doti e nell’in-terpolazione (fit) di dati sperimentali che, teoricamente, dovrebbero disporsi secondo unacurva funzione di certi parametri. Per chiarire il problema consideriamo il caso classicoin cui vengano effettuate delle misure di velocita in funzione del tempo per un corpo chesegue un moto uniformemente accelerato. Teoricamente, dette v0 la velocita iniziale e al’accelerazione, al variare del tempo la velocita v del corpo dovrebbe seguire la legge
v(t) = v0 + at (38)
Supponiamo che durante il moto del corpo vengano effettuate N misure di velocita agliistanti ti (non necessariamente equispaziati); vi sara l’i–esimo valore sperimentale perla velocita. Effettuata la misura avremo quindi un set composto da N coppie di valori(ti, vi). Un’esempio di dati di questo tipo e mostrato in Figura 13.
Seguendo l’idea alla base del metodo dei minimi quadrati e tenendo presente che idati, teoricamente, dovrebbero seguire la legge (38), possiamo definire la seguente sommadei minimi quadrati
M(v0, a) =N∑i=1
(v0 + ati − vi)2.
Si noti che, se i dati seguissero perfettamente la legge (38), allora introducendo i giustivalori di v0 ed a, M(v0, a) si annullerebbe. Nel caso reale, essendo presenti degli errori dimisura, i dati non saranno perfettamente allineati lungo una retta e quindi per nessunacoppia di valori (v0, a) la somma suddetta si annullera. Tuttavia, seguendo il principiodei minimi quadrati, possiamo procedere alla sua minimizzazione.
A differenza di quanto visto in precedenza, ora M e funzione di due parametri, v0 ada. In tal caso, per la sua minimizzazione dobbiamo imporre che entrambe le derivate diM rispetto ai due parametri di annullino. Cioe
∂M
∂v0= 0;
∂M
∂a= 0.
28
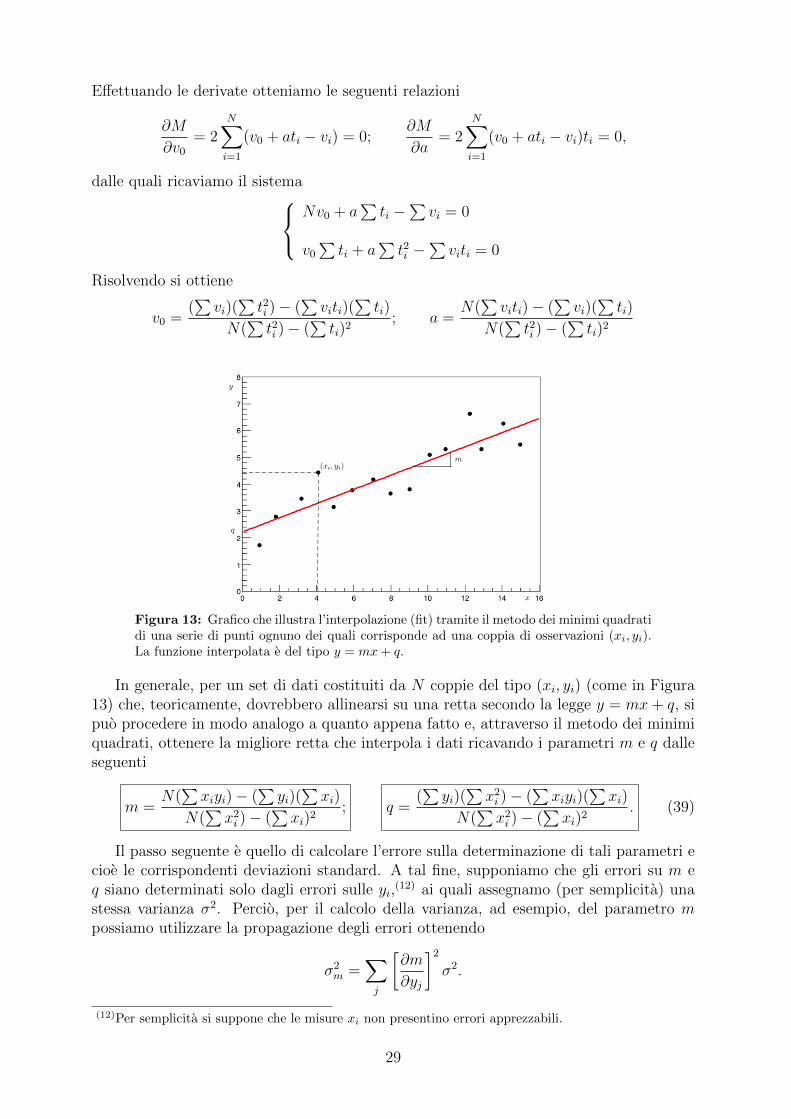
Effettuando le derivate otteniamo le seguenti relazioni
∂M
∂v0= 2
N∑i=1
(v0 + ati − vi) = 0;∂M
∂a= 2
N∑i=1
(v0 + ati − vi)ti = 0,
dalle quali ricaviamo il sistemaNv0 + a
∑ti −
∑vi = 0
v0∑ti + a
∑t2i −
∑viti = 0
Risolvendo si ottiene
v0 =(∑vi)(∑t2i )− (
∑viti)(
∑ti)
N(∑t2i )− (
∑ti)2
; a =N(∑viti)− (
∑vi)(∑ti)
N(∑t2i )− (
∑ti)2
x
y
(xi, yi)
q
m
Figura 13: Grafico che illustra l’interpolazione (fit) tramite il metodo dei minimi quadratidi una serie di punti ognuno dei quali corrisponde ad una coppia di osservazioni (xi, yi).La funzione interpolata e del tipo y = mx+ q.
In generale, per un set di dati costituiti da N coppie del tipo (xi, yi) (come in Figura13) che, teoricamente, dovrebbero allinearsi su una retta secondo la legge y = mx+ q, sipuo procedere in modo analogo a quanto appena fatto e, attraverso il metodo dei minimiquadrati, ottenere la migliore retta che interpola i dati ricavando i parametri m e q dalleseguenti
m =N(∑xiyi)− (
∑yi)(∑xi)
N(∑x2i )− (
∑xi)2
; q =(∑yi)(∑x2i )− (
∑xiyi)(
∑xi)
N(∑x2i )− (
∑xi)2
. (39)
Il passo seguente e quello di calcolare l’errore sulla determinazione di tali parametri ecioe le corrispondenti deviazioni standard. A tal fine, supponiamo che gli errori su m eq siano determinati solo dagli errori sulle yi,
(12) ai quali assegnamo (per semplicita) unastessa varianza σ2. Percio, per il calcolo della varianza, ad esempio, del parametro mpossiamo utilizzare la propagazione degli errori ottenendo
σ2m =
∑j
[∂m
∂yj
]2σ2.
(12)Per semplicita si suppone che le misure xi non presentino errori apprezzabili.
29

Quindi, le derivate parziali sono valutate attraverso la prima delle (39). Ad esempio, siha
∂
∂yj
(∑i
xiyi = xj
);
∂
∂yj
(∑i
yi = 1
),
e conseguentemente
∂m
∂yj=
Nxj −∑xi
N(∑x2i )− (
∑xi)2
⇒[∂m
∂yj
]2=N2x2j − 2Nxj
∑xi + (
∑xi)
2
[N(∑x2i )− (
∑xi)2]2
.
Percio, si ricava
σ2m =
N2∑xi2−N(
∑xi)
2
[N(∑x2i )− (
∑xi)2]2
σ2 =Nσ2
N(∑x2i )− (
∑xi)2
.
Analogamente, per il parametro q si ha
σ2q =
σ2∑x2i
N(∑x2i )− (
∑xi)2
.
Abbiamo qui mostrato, per semplicita, l’applicazione del metodo dei minimi quadratial fit di dati sperimentali con una curva espressa da una relazione lineare. Tuttavia, ebene sottolineare, che il metodo permette di affrontare anche fit molto piu impegnatividi questo in cui, ad esempio, la curva da interpolare puo essere costituita da polinomidi grado anche elevato o, addirittura, da funzioni trascendenti. In tali casi, l’espressionedella somma dei minimi quadrati puo diventare particolarmente complessa e, spesso, ilprocesso di minimizzazione deve essere fatto per via numerica.
30

APPENDICI
A Calcolo di n e σ2 per la distribuzione binomiale
Sappiamo che la distribuzione e normalizzata e quindi vale la seguente(13)∑(Nn
)pn(1− p)N−n = 1
Derivando ambo i membri rispetto a p abbiamo∑(Nn
)[npn−1(1− p)N−n − (N − n)pn(1− p)N−n−1
]= 0,
che puo essere riscritta nella forma∑(Nn
)npn−1(1− p)N−n
=∑(
Nn
)(N − n)pn(1− p)N−n−1
= N∑(
Nn
)pn(1− p)N−n−1 −
∑(Nn
)npn(1− p)N−n−1.
o anche∑n
(Nn
)[pn−1(1− p)N−n + pn(1− p)N−n−1] = N
∑(Nn
)pn(1− p)N−n−1
Ora moltiplichiamo ambo i membri per p(1− p) e otteniamo∑n
(Nn
)[(1− p)pn(1− p)N−n + ppn(1− p)N−n]
= Np∑(
Nn
)pn(1− p)N−n (40)
Combinando i due termini nella sommatoria a primo membro e tenendo presente che ladistribuzione e normalizzata si ottiene∑
n
(Nn
)pn(1− p)N−n =
∑nfN,p(n) = Np (41)
il che dimostra che per la distribuzione binomiale e
n = Np.
Per valutare lo scarto quadratico medio dobbiamo procedere al calcolo della seguente
σ2 =∑
(n− n)2fN,p(n) = n2 − n2,
come gia mostrato nella (12).
(13)In questa e nelle seguenti espressioni nelle sommatorie, per comodita di scrittura, ometteremo l’indicen sottintendendo che le stesse siano sempre effettuate da n = 0 a N .
31

Avendo gia ottenuto n, dobbiamo quindi valutare
n2 =∑
n2fN,p(n)
A tal fine consideriamo l’equazione (41) e deriviamo ancora una volta rispetto a p. Siottiene ∑
n
(Nn
)[npn−1(1− p)N−n − (N − n)pn(1− p)N−n−1] = N.
Moltiplicando per p(1− p) e riarrangiando i termini come prima si ha∑(Nn
)n2pn(1− p)N−n −Np
∑(Nn
)npn(1− p)N−n = Np(1− p),
e conseguentemente
n2 =∑(
Nn
)n2pn(1− p)N−n =
= Np∑(
Nn
)npn(1− p)N−n +Np(1− p) = N2p2 +Np(1− p). (42)
In definitivaσ2 = n2 − n2 = Np(1− p),
e conseguentemente la deviazione standard della distribuzione binomiale e
σ =√Np(1− p).
B Distribuzione normale: normalizzazione, valor me-
dio e deviazione standard
Nei calcoli che seguono faremo uso dei due seguenti integrali notevoli∫ +∞
−∞e−z
2
dz =√π;
∫ +∞
−∞z2e−z
2
dz =
√π
2, (43)
che non dimostreremo.La forma generale della distribuzione normale e la seguente
f(x) = Ce−h2(x−µ)2 , (44)
dove C e una costante e h e µ sono rispettivamente il cosiddetto modulo di precisione eil valore di x corrispondente alla posizione in cui la f(x) e massima.
La normalizzazione di tale distribuzione corrisponde alla validita della seguente∫ +∞
−∞f(x)dx = C
∫ +∞
−∞e−h
2(x−µ)2dx = 1. (45)
Con il seguente cambio di variabile
h(x− µ) = z ⇒ x =z
h+ µ; dx =
1
hdz, (46)
32

il primo membro della (45) diventa
C
∫ +∞
−∞e−h
2(x−µ)2dx =C
h
∫ +∞
−∞e−z
2
dz,
e da questa, facendo uso della prima delle (43), segue che, la normalizzazione della(44) comporta C = h/
√π. Conseguentemente, la forma della distribuzione normale
normalizzata e
f(x) =h√π
e−h2(x−µ)2dx, (47)
Il valor medio della distribuzione normale e data dalla
x =
∫−∞
xf(x)dx =h√π
∫ +∞
−∞xe−h
2(x−µ)2dx,
alla quale, utilizzando il cambio di variabile (46) visto in precedenza, si puo dare la forma
1√π
∫ +∞
−∞
(zh
+ µ)
e−z2
dz =1√π
[1
h
∫ +∞
−∞ze−z
2
dz + µ
∫ +∞
−∞e−z
2
dz
]. (48)
Il primo dei due integrali tra le parentesi quadre della (48) e nullo, dato che la funzioneze−z
2e una funzione dispari. Sostituendo poi nel secondo integrale il valore della seconda
delle (43), si ottiene,
x =
∫ +∞
−∞xf(x)dx = µ,
il che giustifica il fatto che nella (5) µ e stato sostituito da x.Infine, calcoliamo la varianza della distribuzione normale, dato dalla seguente
σ2 =
∫ +∞
−∞(x− x)f(x)dx =
h√π
∫ +∞
−∞(x− µ)2e−h
2(x−µ)2dx.
Effettuando il solito cambio di variabile (46) otteniamo
σ2 =1
h2√π
∫ +∞
−∞z2e−z
2
dz,
e, sfruttando la seconda delle (43), si ricava
σ =1√2h.
Esprimendo quindi il modulo di precisione h in termini della deviazione standard σ ladistribuzione normale puo essere scritta nella forma piu comunemente usata
f(x) =1√2πσ
e−(x−µ)2
2σ2 .
33


















