
Quaderni - DCPS · 1904 e il decennio successivo). ... tipici della sociologia, ... La misurazione...
112
Quaderni di Ricerca quaderni di ricerca Introduzione all’Analisi Fattoriale per la ricerca sociale Roberto Albano
Transcript of Quaderni - DCPS · 1904 e il decennio successivo). ... tipici della sociologia, ... La misurazione...

Quadernidi Ricercaquaderni di ricerca
Introduzione all’Analisi Fattoriale per la ricerca sociale
Roberto Albano

Copertina e grafica: 24HoursDesign, Chiara Figone, Torino
STAMPATO CON IL CONTRIBUTO DELL’UNIVERSITÀ DEGLI STUDI DI TORINO – DI-PARTIMENTO DI SCIENZE SOCIALI – CON FONDI MIUR COFIN 2001“STUDIO DEI MECCANISMI DI SOCIALIZZAZIONE”(COORD. PROF. LOREDANA SCIOLLA)
Quaderni di Ricerca del Dipartimento di Scienze sociali dell' Università di Torinon°4, giugno 2004
Introduzione all'analisi fattoriale per la ricerca sociale di Roberto Albano
Per conto della redazione dei Quaderni di Ricerca del Dipartimento di Scienze Sociali dell’Università di Torino, questo saggio è stato valutato da Mario Chieppa, Luca Ricolfi e Michele Roccato.
Edizioni Libreria Stampatori Via S. Ottavio, 15 1024 Torino tel. 011836778 - fax 011836232 e-mail: [email protected] 88-88057-50-1

INDICE
Premessa pag. 5
Introduzione pag. 7
1.Presentazione informale della tecnica pag. 11 1.1. L'Analisi Fattoriale unidimensionale pag. 11 1.2. L'Analisi Fattoriale multidimensionale pag. 15 1.3. I passi caratteristici della tecnica e quelli supplementari pag. 16
2.Pre-condizioni pag. 21 2.1.L'input minimo della tecnica pag. 21 2.2. Costruzioni delle variabili e del campione pag. 26
3.Il modello pag. 29 3.1.Aspetti terminologici pag. 29 3.2.Gli assunti sulla struttura fattoriale pag. 31 3.3.Analisi fattorile e Analisi in Componenti Principali pag. 32 3.4.Dall'input alla matrice riprodotta pag. 36 3.5.L'estrazione dei fattori: stima dei minimi quadrati e di massima verosimiglianza pag. 45 3.6.Metodi di rotazione ortogonale e obliqua pag. 47 3.7.La stima dei punteggi fattoriali pag. 53
4.La valutazione della soluzione pag. 55 4.1.Indici descrittivi pag. 55 4.2.Un indice inferenziale pag. 58 4.3.Valutazione della significatività dei fattori pag. 59
5.Istruzioni software pag. 63
6.Un'applicazione alla ricerca sociale pag. 75

7.Per concludere: dall'Analisi fattoriale Esplorativa a quella Confermativa pag. 85
Appendice I. Elementi di algebra matriciale pag. 89
Appendice II. Le matrici di prodotti scalari derivate dalla CxV pag. 101
Bibliografia di riferimento pag. 105

Caro Peter, molto gentile da parte sua spedirmi un libro con la spiegazione
dell’Ulisse di James Joyce. Adesso mi ci vuole un altro libro con la spiegazione di questo
saggio di Stuart Gilbert, il quale, se la memoria non mi falla, è l’autore del celebre ritratto di George Washington esposto al Metropolitan
Museum. Mi rendo conto che tra i due c’è una duecentina d’anni di differenza, ma chiunque
sia in grado di spiegare Joyce dev’essere molto vecchio e saggio.
GROUCHO MARX
Premessa
Sull’Analisi fattoriale esiste una letteratura sterminata, una abbondante selezione della quale (per nulla esaustiva) è riportata nella bibliografia del presente saggio. Questa ennesima trattazione è quella di un ricerca-tore sociale, non un matematico di professione, che si rivolge agli stu-denti (soprattutto di corsi di laurea specialistica e dottorandi) e ai colle-ghi della stessa area che si avvicinano per la prima volta alla tecnica, ma che non sono a digiuno di conoscenze statistiche e metodologiche più “di base”. Allo stesso tempo, cerca di differenziarsi da gran parte delle pubblicazioni divulgative in lingua italiana, a mio modesto parere, un po’ troppo semplicistiche. L’Analisi Fattoriale è una tecnica complessa, sia dal punto di vista for-male sia dal punto di vista di utilizzo. Per questo ritengo che ci sia uno spazio da colmare tra la letteratura altamente formalizzata che scoraggia gran parte dei non matematici (si veda, uno per tutti, il volume di Basi-
5

levski, citato qui in bibliografia), e quella divulgativa. Non so quanto questo scritto ci riesca: mi sembra che il mio sforzo sia molto simile a quello fatto da Claudio Barbaranelli nel suo recente Analisi dei dati(2003); mentre io mi rivolgo ai ricercatori sociali, egli dà un taglio psi-cometrico (i problemi che affrontiamo sono perciò in parte diversi; sul piano della formalizzazione, il suo livello è più alto del mio, conforme-mente ai programmi di Psicometria e di corsi affini attivati in buona par-te delle Facoltà di Psicologia in Italia). E’ comunque innegabile che la lettura del presente scritto richieda un certo sforzo ai lettori. Ho infatti mantenuto molti aspetti formali, quelli minimi indispensabili per una corretta comprensione della tecnica, cer-cando quando possibile di ‘tradurre’ in termini più semplici. Si presup-pone che il lettore abbia le conoscenze che si acquisiscono mediamente dando un esame di statistica e uno di metodologia della ricerca sociale (quantitativa). A chi dovesse ancora procurarsele consiglio i due seguenti testi tra i tanti:
- per quanto concerne la statistica, R.Albano, S.Testa, Introduzione alla statistica per la ricerca sociale, Carocci, Roma 2002
- per quanto riguarda invece la metodologia, P.Corbetta, Metodo-logia e tecniche della ricerca sociale, il Mulino, 1999, Parte se-conda e Parte quarta
6

Introduzione
Tra le numerose tecniche di analisi dei dati, una delle più anziane è l’Analisi Fattoriale. La sua ‘doppia’ invenzione si può collocare all’i-nizio del Novecento: - in ambito statistico il punto di riferimento principale per l’analisi fatto-riale (e per altre tecniche affini) è un articolo del 1901 di Karl Pearson, in cui si fa uso di strumenti di analisi matematica a quel tempo già consoli-dati, come la distribuzione normale multivariata di Bravais e la teoria de-gli autovalori e autovettori delle trasformazioni lineari; - parallelamente, essa venne proposta in ambito psicometrico da Charles Spearman e da alcuni suoi collaboratori per misurare l’intelligenza negli esseri umani (qui la datazione è più incerta, ma si può collocare tra il 1904 e il decennio successivo). Questa tecnica ha trovato in seguito un notevole successo in diversi campi del sapere scientifico: certamente in notevole misura nelle scienze sociali e psicologiche (ma non solo in queste). Le ragioni di questo successo risiedono essenzialmente nel fatto che l’analisi fattoriale permette di misurare proprietà che non hanno una defi-nizione semplice e netta sul piano teorico e, conseguentemente, non sono rilevabili sul piano empirico mediante una singola operazione di misura-zione. Le discipline sociali e psicologiche, come è noto, fanno un ampio uso di concetti che non sono direttamente osservabili: si pensi a concetti come l’autoritarismo, l’intelligenza, la secolarizzazione, la partecipazione politica e così via; non è pensabile che proprietà come queste possano es-sere rilevate con un unico strumento di rilevazione come avviene per e-sempio nella misurazione dell’altezza fisica di una persona, della sua età, del suo stato civile. Se nel caso della statura è possibile individuare una
7

precisa operazione empirica di misurazione, il cui risultato sarà inequivo-cabilmente l’altezza di quella persona, le cose non sono così semplici quando di quello stesso soggetto si vuole invece misurare proprietà più complesse e non osservabili direttamente; lo stesso discorso vale quando si misurano proprietà non attribuibili a soggetti individuali ma a aggregati umani o attori collettivi (la secolarizzazione, la modernizzazione o altri costrutti analoghi, tipici della sociologia, oppure costrutti come il clima organizzativo, tipici della psicologia sociale). In casi come quelli appena citati, i termini empirici sono più di uno e sono detti indicatori; il rapporto tra indicatori empirici e concetto teori-co sottostante, che d’ora in avanti qualificheremo come fattore latente,o ‘dimensione’, è stato conseguentemente definito rapporto di indica-zione (Marradi, 1980, p. 40). Gli indicatori, comunque vengano individuati e per quanto numerosi essi siano, stanno in un rapporto di implicazione con il concetto teorico che si presuppone essi misurino, mentre lo spazio semantico di quest’ultimo non è in pratica quasi mai riducibile allo spazio occupato dagli indicatori (Cfr. Corbetta, 1999, pp. 46-52). Gli indicatori devono essere quindi riferiti ad aspetti semantici distinti, ma almeno in parte comuni, del concetto che si vuole misurare. Nella ricerca sociale l’uso della analisi fattoriale è in genere mirato a ricon-durre un insieme di variabili a una dimensione comune, o anche di-mensioni analiticamente distinte a una meta-proprietà. A titolo di e-sempio: un gruppo di variabili può essere ricondotto alla dimensione del ‘dogmatismo’, un altro gruppo alla ‘xenofobia’, un altro ancora al conformismo; queste e altre dimensioni possono essere poi ricondotte a un concetto più generale quale è quello di ‘autoritarismo’, nel senso per esempio previsto dalla celebre ‘teoria della personalità autoritaria’ di Adorno-Horkheimer1.L’utilizzo di indicatori molto simili, al limite variabili solo nella forma linguistica produce invece fattori di scarso interesse sostantivo; tuttavia, l’analisi fattoriale condotta su variabili molto simili può avere finalità di
1 L’analisi fattoriale applicata alla scala F di Adorno non ha peraltro confermato la struttura dell’Autoritarismo prevista dagli studiosi della scuola di Francoforte. Rin-grazio il reviewer che me lo ha fatto notare.
8

tipo metodologico: ad esempio per valutare in che misura diverse for-mulazioni linguistiche siano intercambiabili. L’Analisi Fattoriale parte dagli indicatori (i significans del termine non osservativo) e dalle loro interrelazioni, per individuare, mediante oppor-tune operazioni matematiche, le dimensioni ad essi sottostante. Ciò non significa, che con tale tecnica identifichiamo sempre a posteriori i fattori latenti. La loro individuazione ex post caratterizza uno stile di ricerca che definiamo esplorativo, contrapposto a uno stile confermativo, in cui il ricercatore definisce a priori, sulla base della riflessione teorica, la struttu-ra dei legami tra le componenti del modello. In questa introduzione all’Analisi Fattoriale, al modello confermativo saranno comunque dedica-ti solo brevi cenni in conclusione. Sull’Analisi Fattoriale esplorativa sono state sollevate importanti criti-che circa la sua fondatezza sul versante matematico-statistico e sulla va-lidità scientifica dei risultati che produce. Non saranno qui affrontate le considerazioni di carattere epistemologico che sono emerse nel dibattito tra sostenitori e detrattori della tecnica. Sarà invece presentato un qua-dro generale degli aspetti più tecnici, vale a dire dei metodi con cui il ricercatore può individuare un numero di dimensioni latenti di molto in-feriore a quello di un insieme di variabili manifeste (ossia gli indicatori operativizzati: cfr. Corbetta, 1999, p. 93), ma capaci di rendere conto del-le relazioni intercorrenti tra queste ultime. Un’ulteriore limitazione di campo consiste nel considerare esclusivamente il modello per così dire ‘classico’ dell’Analisi Fattoriale esplorativa, che è un modello lineare nel-le variabili e nei parametri (al pari, per fare un esempio che dovrebbe es-sere noto al lettore, della regressione lineare multipla). Per semplicità indicheremo d’ora in avanti l’Analisi Fattoriale come og-getto della presente trattazione sottintendendo, salvo indicazione contra-ria, ‘Lineare’ ed ‘Esplorativa’.
9


1. Presentazione informale della tecnica
1.1. L’analisi Fattoriale unidimensionale Obiettivo dell’Analisi Fattoriale è quello di interpretare le covaria-zioni tra un numero elevato di variabili osservate empiricamente, le variabili manifeste, come se fossero dovute all’effetto di variabili non direttamente osservabili definite fattori latenti comuni. Il caso più semplice, da cui conviene iniziare, è quello unidimensionale, cioè a un solo fattore latente. Una rappresentazione grafica e un esempio serviranno a chiarire quanto detto.
Figura 1
X1 X2
Xi XM
Le variabili X1 , X2 , … , XM, indicate in un riquadro, sono quelle rileva-te originariamente, ad esempio mediante la somministrazione di un que-stionario; La ‘F’ cerchiata rappresenta invece il fattore comune latente.
F
11

Si parte dalle relazioni tra le coppie di variabili manifeste, rappresentate dalle frecce bidirezionali che collegano a coppie le variabili manifeste, per inferire l’esistenza di un fattore comune sottostante che renda conto, almeno in una parte significativa, del comportamento di ognuna delle variabili osser-vate, ma soprattutto che sia in grado di rendere conto, in massima parte, dell’interrelazione tra le variabili manifeste. La misurazione del fattore latente comune non è dunque un’operazione em-pirica indipendente dalla misurazione delle variabili manifeste, anche se sul piano logico si deve pensare al fattore latente come qualcosa di analiticamen-te distinto dalle variabili manifeste. Fatta questa distinzione, va ora richiesto al lettore un ulteriore sforzo con-cettuale: per comprendere il senso ultimo dell’Analisi Fattoriale occorre rappresentare il rapporto tra fattore latente comune e variabili manifeste come un rapporto di dipendenza in le ultime sono le variabili da spiegare; inoltre dobbiamo aggiungere altre entità latenti, anch’esse non osservabili ma ipotetiche al pari del fattore comune.
Figura 2
X1 X2 ... Xi ... XM
U1 U2 .... Ui .… UM
Il cerchio più grande nella figura 2, rappresenta ancora il fattore latente comune; quelli più piccoli rappresentano invece i fattori unici, variabili anch’esse non osservabili, ognuna delle quali influenza una sola variabi-le manifesta Xi.
F
12

Come dobbiamo interpretare le frecce che vanno dai fattori latenti alle variabili manifeste? In questo passaggio critico si colloca il senso dell’Analisi Fattoriale: interpretare le relazioni tra le variabili manifeste come covariazioni in assenza di causazione. Ma questa è la definizione di correlazione spuria (Corbetta, 1999, p.619), ossia quella associazione tra due variabili A e B che scompare quando si tiene sotto controllo una terza variabile C da cui dipendono sia A che B. Con l’importante differenza che le frecce della figura 2 non rappresentano una dipendenza genuina, perché le entità in gioco non sono semanticamente autonome (per questo motivo, al fine di marcare anche graficamente l’inseparabilità sul piano empirico di explanans e explananda, abbiamo tratteggiato le frecce). Per riassumere: attraverso un input costituito da indici di associazione tra variabili (correlazioni lineari o altro) e particolari procedure matematiche e statistiche, stabiliamo con una procedura abduttiva (cioè induttiva e de-duttiva) un rapporto di dipendenza sui generis, che interessa entità rilevate empiricamente (explananda) e entità solo ipotetiche (explanans). Al Fat-tore Comune (F) è attribuito il compito di interpretare le relazioni tra le variabili e questo è l’obiettivo prioritario di ogni Analisi Fattoriale. O-gnuno dei legami tra fattore comune e variabili manifeste è rappresentato da un numero am, indicante il peso che il primo ha sulle seconde2. Ai Fat-tori unici va il compito di interpretare la variabilità residua di ogni varia-bile manifesta. È utile a questo punto procedere con un esempio. Supponiamo di aver misurato nelle province italiane un certo insieme di variabili (espresse in tassi e percentuali) tra cui le seguenti: a) parroci per abitante, b) matrimoni con rito religioso sul totale dei ma-trimoni, c) affiliati a organizzazioni religiose, d) rapporto tra Interruzio-ni Volontarie di Gravidanza e abbandono di neonati, e) numero di ore lavorate alla domenica sul totale delle ore lavorate, f) frequenza ai riti religiosi, g) fiducia nella chiesa ecc. Immaginiamo poi che le variabili risultino legate tra loro, cioè che al va-riare dell’una corrisponda una covariazione in qualche misura dell’altra, 2 Questi a rappresentano la capacità predittiva del fattore latente; è anche possibile cal-colare il contributo di ogni variabile manifesta al punteggio dell’individuo sul fattore; questo torna utile nel calcolo dei punteggi fattoriali (di cui diremo nel par. 3.7), che av-viene solo dopo aver identificato i fattori latenti.
13

talvolta in senso positivo (per esempio b) e c)), tal altra in senso negati-vo (per esempio e) ed f)). Già una semplice ispezione visiva della ma-trice R può portarci alla individuazione di una dimensione generale sottostante con la quale interpretare con parsimonia le relazioni osser-vate: potrebbe probabilmente far emergere il diverso grado di secola-rizzazione, cioè della perdita di influenza della religione e della Chiesa nella società locale. Tuttavia è facile intuire che quanto maggiore è il numero di variabili osservate, tanto più difficile risulterà considerare simultaneamente le correlazioni se ci affidiamo a una mera esplorazio-ne informale della matrice di correlazioni. Con sole 10 variabili per esempio abbiamo 45 correlazioni diverse da prendere in considerazio-ne. Più in generale, se le variabili, sono M le correlazioni tra tutte le possibili coppie di variabili, escluse le permutazioni, sono:
2
)1M(M -Ö .
L’analisi fattoriale è utile proprio per la riduzione della complessità re-lativa all’osservazione di processi articolati e complessi (come può esse-re appunto la ‘secolarizzazione’) mediante la rilevazione di un certo numero di indicatori. Se il fattore individuato sia poi un’entità concre-tamente distinta dalle variabili manifeste, o se si tratti di un fattore solo analiticamente distinto ma operativamente definito da quelle, una mera astrazione matematica (un costrutto dotato di capacità euristica), è que-stione che dipende dallo sviluppo della teoria in quel campo e dalle scel-te epistemologiche del ricercatore.
14
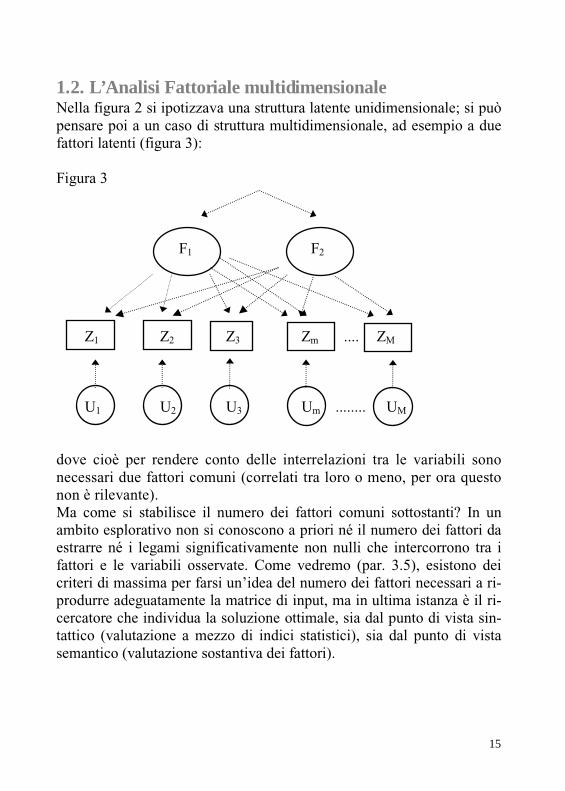
1.2. L’Analisi Fattoriale multidimensionale Nella figura 2 si ipotizzava una struttura latente unidimensionale; si può pensare poi a un caso di struttura multidimensionale, ad esempio a due fattori latenti (figura 3):
Figura 3
F1 F2
Z1 Z2 Z3 Zm .... ZM
U1 U2 U3 Um ........ UM
dove cioè per rendere conto delle interrelazioni tra le variabili sono necessari due fattori comuni (correlati tra loro o meno, per ora questo non è rilevante). Ma come si stabilisce il numero dei fattori comuni sottostanti? In un ambito esplorativo non si conoscono a priori né il numero dei fattori da estrarre né i legami significativamente non nulli che intercorrono tra i fattori e le variabili osservate. Come vedremo (par. 3.5), esistono dei criteri di massima per farsi un’idea del numero dei fattori necessari a ri-produrre adeguatamente la matrice di input, ma in ultima istanza è il ri-cercatore che individua la soluzione ottimale, sia dal punto di vista sin-tattico (valutazione a mezzo di indici statistici), sia dal punto di vista semantico (valutazione sostantiva dei fattori).
15

1.3. I passi caratteristici della tecnica e quelli supplementari Prima di passare a considerare gli aspetti formali della tecnica, descri-viamo a grandi linee i passi procedurali che caratterizzano una Analisi Fattoriale.
1) Il primo passo in una Analisi Fattoriale consiste nella selezione di un insieme di indicatori, per i quali si ipotizza l’esistenza di uno o più fatto-ri latenti comuni sottostanti. I criteri di selezione variano in funzione degli obiettivi della ricerca e delle risorse disponibili. Si possono individuare due modalità estrema-mente diverse di selezione delle variabili manifeste: - una prima modalità consiste nel condurre l’analisi fattoriale su una
selezione di variabili rilevate in ricerche precedenti; questa modalità rientra nella cosiddetta analisi secondaria dei dati (Corbetta, 1999, p. 192); accanto all’evidente vantaggio dal punto di vista dell’impiego di risorse, va evidenziato che le variabili disponibili po-trebbero essere inadeguate allo scopo di individuare i fattori latenti comuni ipotizzati dal ricercatore;
- una seconda modalità prevede la costruzione di nuovi indicatori, o la selezione di item da repertori (nazionali o internazionali), comunque da rilevare in una nuova ricerca; in questo caso, in genere si hanno già a priori alcune ipotesi sulle dimensioni latenti che si intendono misura-re (perlomeno sul numero).
In pratica poi ci si muove combinando analisi secondaria dei dati e nuove rilevazioni, tra formulazione di nuovi indicatori e selezione dai repertori.
2) Il secondo passo è la costruzione di una matrice contenente misure di concordanza tra tutte le coppie di variabili manifeste. Nell’Analisi Fat-toriale Esplorativa, tale matrice contiene frequentemente correlazioni lineari, ma l’input può variare in funzione del livello di scala delle va-riabili manifeste (par. 2.1), nonché della finalità della ricerca: ad esem-pio, nel confronto tra campioni distinti, l’utilizzo delle K matrici varian-ze-covarianze (dove K è il numero dei campioni a confronto), in luogo della matrice di correlazioni permette di calcolare e confrontare le me-die dei fattori nei gruppi).
16

3) Il terzo passo consiste nel determinare in via induttiva, a partire dai dati contenuti nell’input minimo, il numero K ottimale di fattori latenti comuni, in grado di riprodurre fedelmente (a meno di uno scarto mini-mo) le correlazioni tra le M variabili manifeste (K<<M). La determina-zione a priori del numero dei fattori avviene invece in un quadro che è già, almeno in parte, di analisi confermativa.
4) Il quarto passo consiste nella stima dei parametri, ossia dei coeffi-cienti di impatto dei fattori latenti sulle variabili manifeste. Questo pas-so è detto comunemente estrazione3 dei fattori. Per estrarre i fattori so-no stati sviluppati diversi metodi computazionali, anche molto diversi tra loro. I diversi metodi hanno in comune il fatto di basarsi sullo stesso modello (equazione fondamentale e assunti: alcuni assunti sono neces-sari per l’applicazione di ogni metodo, altri solo per alcuni). Ciò che cambia è il metodo statistico con cui vengono stimati i parametri di tale modello (Metodo dei Minimi Quadrati, della Massima Verosimiglianza ecc.). Attraverso tali stime si riproduce al meglio (secondo criteri prefis-sati) l’input minimo con una matrice delle correlazioni riprodotte;quest’ultima è talvolta impiegata per individuare il numero dei fattori da estrarre; è inoltre sempre utile nella valutazione della soluzione fattoria-le. I parametri stimati vengono raggruppati in una pattern matrix, che rappresenta il nucleo della soluzione di una analisi fattoriale. Mediante questi coefficienti si cerca di fornire una interpretazione semantica dei fattori estratti; in altri termini, si tenta di dare ai fattori latenti un nome, un’etichetta, che sintetizzi il contenuto delle variabili manifeste, guar-dando soprattutto a quelle che presentano i coefficienti più elevati. In un’indagine sui consumi, ad esempio, se i coefficienti più elevati per un certo fattore riguardano comportamenti come ‘andare a teatro’, ‘ascolta-re musica classica’, ‘leggere saggistica’ ecc., potremo definire il fattore con un’etichetta del tipo ‘consumi colti’.
3 Per alcuni sarebbe più opportuno parlare di costruzione dei fattori, data la loro natura non osservativa. Estrazione è comunque il termine più diffuso nella lettera-tura teorica, a prescindere dagli orientamenti epistemologici degli autori, nonché nelle istruzioni dei software dedicati a questa tecnica.
17

5) Fin qui abbiamo considerato passi essenziali della tecnica. Il quinto passo, detto della rotazione dei fattori, non è obbligatorio. Esso si pre-senta solo quando i fattori comuni sono almeno due. La rotazione è utile per semplificare l’operazione di interpretazione dei fattori, d cui parla-vamo al termine del punto precedente. L’operazione di rotazione si chiama così perché le variabili manifeste possono essere viste come punti-vettore in uno spazio a K dimensioni, dove K è il numero dei fat-tori. Ciò che viene ruotato sono dunque gli assi di riferimento, cioè pro-prio i fattori. La rotazione non fa altro che ridefinire in modo più oppor-tuno le coordinate dei vettori che rappresentano le variabili, lasciando inalterata la posizione relativa di tali vettori; tale operazione lascia per-ciò inalterata la soluzione da un punto di vista globale. Essa però ha un’utilità di carattere semantico, se i fattori estratti sono due o più. Nella pattern matrix non ruotata, di solito, ogni variabile ha legami diversi da zero con più fattori; ciò rende difficile distinguere i fattori e interpretar-li. Con la rotazione, si cerca, in linea di massima, di far passare gli assi di riferimento (fattori) tra addensamenti di punti-vettore (variabili) in modo che risultino il più distinti possibile da altri addensamenti, che sa-ranno attraversati da altri assi. Anche per le rotazioni sono disponibili metodi diversi; esse sono classi-ficabili in rotazioni ortogonali, dove la rotazione degli assi è soggetta al vincolo della perpendicolarità tra gli assi, e rotazioni oblique, dove tale vincolo è rilasciato del tutto o parzialmente. Nel caso di rotazioni obli-que, il passo che stiamo esaminando si articola nei tre seguenti sottopassi: - costruzione della pattern matrix, contenente i coefficienti di regressio-
ne standardizzati delle variabili manifeste sui fattori latenti comuni; - costruzione della structure matrix, contenente le correlazioni tra le va-
riabili manifeste e i fattori latenti comuni (nella rotazione ortogonale coincide con la pattern matrix);
- costruzione della matrice di correlazione tra i fattori latenti.
6) L’ultimo passo dell’Analisi Fattoriale come tecnica di analisi multi-variata è la valutazione del modello. Si cerca, con l’ausilio di apposite statistiche, descrittive e in alcuni casi inferenziali, di valutare quanto il modello teorico si adatta alla struttura empirica dei dati. Inoltre, facendo
18

ricorso ad alcuni parametri standard rintracciabili nella letteratura, si può valutare la significatività sostanziale dei fattori estratti.
7) Spesso, chi fa uso dell’Analisi Fattoriale prosegue con un passo sup-plementare: la stima dei punteggi fattoriali (factor scores). Esso consi-ste nell’attribuire a ogni caso della matrice CxV un punteggio, che rap-presenta la posizione su ognuno dei fattori comuni estratti. L’input mi-nimo in questo caso è rappresentato dalla matrice di correlazione e dalla matrice Casi per Variabili. Si parla di stima dei punteggi fattoriali, perché nella Analisi Fattoriale non è possibile calcolarli esattamente essendo questa tecnica un modello probabilistico4. In tal modo l’Analisi Fattoriale viene ad assumere una posizione a cavallo tra il mondo delle tecniche di analisi multivariata, che studiano la relazioni tra variabili, e quello delle tecniche di asse-gnazione (Ricolfi, 2002, p. 4 e ss.) che producono nuove variabili. I punteggi fattoriali possono poi venire impiegati a loro volta in altre tec-niche di analisi dei dati, a anche solo trattati mediante procedure statisti-che mono- e bivariate.
4 Il calcolo esatto dei punteggi individuali è invece possibile in una tecnica simile, ma formalmente e sostantivamente diversa, che è l’Analisi in Componenti Princi-pali (si veda il par. 3.3)
19


2. Pre-condizioni
2.1. L’input minimo della tecnica Nell’Analisi Fattoriale, l’input minimo, vale a dire la matrice dati con-tenente l’informazione sufficiente e necessaria per applicare la tecnica di analisi (Ricolfi, 2002, p. 14), è tipicamente una matrice R di correla-zioni prodotto-momento (note anche come correlazioni lineari di Bra-vais-Pearson), calcolata a partire da una matrice Casi per Variabili (CxV)5. Le variabili dovrebbero essere, a rigore, almeno a livello di scala di intervalli; tuttavia, poiché tale condizione spesso non è soddisfatta nella ri-cerca sociale, considereremo i correttivi e le cautele necessari per utilizzare questa sofisticata tecnica in presenza di variabili di livello inferiore. Indichiamo innanzitutto come condizione veramente imprescindibile, che la matrice CxV, perlomeno nella parte che intendiamo utilizzare per calco-lare l’input minimo, sia column conditional nell’accezione di Carroll e A-rabie (1980), ossia permetta confronti tra le celle per ogni singola colonna. E’ stato mostrato, anche empiricamente, che le misure di atteggiamenti (ad esempio le tanto utilizzate scale Likert o i termometri), non rispettano sem-pre questa condizione, in quanto i soggetti intervistati utilizzano lo strumen-to di misura in modo diverso; questo uso idiosincratico delle scale di rispo-sta rientra in una più ampia categoria di ‘distorsioni’ involontarie del dato reale che nella letteratura psicometrica è indicata come response style (Ja-ckson, Messick, 1958). In tal caso, se si vuole applicare l’analisi fattoriale, si dovrebbero compiere innanzitutto delle manipolazioni dei punteggi
5 Seppur raramente nell’analisi esplorativa, talvolta l’input minimo è costituito dalla matrice varianze-covarianze, V (Comrey, Lee, 1992, trad. it. 1995, p. 399): soprat-tutto quando si intende stimare anche la media e la varianza dei fattori latenti.
21

grezzi tali da rendere la matrice CxV column conditional. Marradi (1979, 19952) ha proposto una soluzione a tale problema nota come procedura di deflazione dei dati. Questa procedura richiede però batterie di item piutto-sto numerose e fortemente eterogenee, cioè attinenti a temi diversi; pertanto non sempre è possibile ricorrere alla deflazione. In ogni caso, è importante che in sede di rilevazione dei dati vengano presi tutti gli accorgimenti che possono attenuare al massimo tale tipo di distorsione6.In secondo luogo, una rigorosa applicazione dell’Analisi Fattoriale richie-derebbe che le coppie di variabili abbiano una distribuzione normale bi-variata. Ricordiamo che da una distribuzione normale bivariata deriva una relazione lineare tra X e Y (mentre non è vero il contrario). Se X e Y hanno una distribuzione normale bivariata, esse sono da considerarsi in-dipendenti allorquando la loro correlazione sia prossima a 0 (Mood, 1974, trad. it. 1988, p. 175); in caso contrario, una correlazione pari a 0 non in-dica necessariamente indipendenza: le variabili potrebbero infatti essere correlate in modo non lineare. L’assenza di distribuzioni normali bivariate non comporta necessariamente l’abbandono del modello fattoriale lineare, a patto che le relazioni intercorrenti tra le variabili manifeste e quelle tra le variabili manifeste e i fattori siano approssimativamente di tipo lineare. Un altro assunto, quello di multinormalità7, è invece indispensabile solo se desideriamo compiere valutazioni circa la significatività statistica del numero di fattori (Harman, 19763, p. 24 e capp. 9-10). La normalità è una caratteristica di cui possono godere pienamente solo variabili almeno a livello di scala di intervalli. Tuttavia, come abbiamo già detto, nella ricerca sociale si dispone raramente di esse; perlopiù so-no disponibili variabili quasi-cardinali (Marradi, 19952), ossia varia-bili in cui non esiste la possibilità di verificare empiricamente l’effettiva uguaglianza degli intervalli tra le varie modalità. Se si dispone di varia-bili con una distribuzione univariata quasi-normale, possiamo prendere anche in considerazione l’idea (Comrey, Lee, 1992, trad. it. 1995, p. 47) di sottoporle alla procedura di normalizzazione, che consiste nel con- 6 Come quelle di altro tipo, del resto. Per una rassegna sistematica delle cause di infedeltà dei dati rilevati a mezzo questionario rimandiamo a Roccato, 2003. 7 È necessario prestare attenzione su quale tipo di normalità stiamo trattando: k variabili con distribuzione normale univariata non hanno necessariamente una distribuzione normale multivariata (Landenna, Marasini, Ferrari 1997, vol. I, p. 440).
22

vertire i punteggi grezzi in punteggi standardizzati e nel forzarli ad as-sumere la curva normale (Vidotto, Xausa, Pedon, 1996, pp. 224-6). Che cosa fare invece quando si dispone di variabili non cardinali o quasi-cardinali in cui la distribuzione è decisamente lontana dalla forma norma-le? La letteratura metodologica offre a tal proposito indicazioni e valuta-zioni discordanti. Alcuni sostengono che, in pratica, se il numero di cate-gorie della variabile è sufficientemente ampio (diciamo a partire da sei o sette modalità), si possono calcolare le correlazioni prodotto-momento su qualsiasi variabile con modalità ordinate, senza ottenere eccessive distor-sioni: ciò in ragione della robustezza mostrata dalle correlazioni prodot-to-momento in studi di simulazione8. Altri, per mantenere un più stretto rigore metodologico, propongono delle varianti all’input minimo, miranti a ridurre le distorsioni che potrebbero insorgere nel calcolo di correlazioni prodotto-momento su questo tipo di variabili (soprattutto effetti di atte-nuazione della forza della relazione). Semplificando al massimo, vediamo alcune tra le più importanti varianti proposte per variabili ordinali9. Conviene distinguere tre situazioni so-stanzialmente diverse che possono portare a ottenere una misurazione ordinale; da ognuna di esse deriva un diverso input minimo ‘ideale’ per l’Analisi Fattoriale.
a) I dati sono originariamente rilevati su scale continue; tuttavia la pre-senza di un ampio errore di misurazione può rendere opportuno sostitui-re i valori originari con un numero minore di modalità solo ordinate. Come esempio, immaginiamo di aver intervistato un gruppo di individui e di aver chiesto di indicare quale sia il loro gradimento per un numero ele-vato di partiti. E’ presumibile che diversi elementi alimentino l’errore di va-lutazione dato dal soggetto (incertezza intrinseca, livello di attenzione ecc.): il passaggio da una misura a livello di rapporti a una ordinale ha il vantaggio di attenuare l’errore (Il sig. Rossi ha risposto che su una scala di gradimento da 0 a 100 valuta ‘20’ il partito A, ‘50’ il partito B e così 8 Questa posizione non è sempre accuratamente argomentata dai suoi sostenitori; esistono comunque anche delle basi teoriche che sono state sviluppate a partire dai primi studi di simulazione compiuti da Labovitz già alla fine degli anni Sessanta (Cfr. Labovitz, 1970; O’Brien, 1979). 9 Per una trattazione più approfondita si rinvia a Basilevsky, 1994, cap. 8.
23

via; al partito Q, il quindicesimo della lista dà un voto pari a ‘15’. I par-titi A e Q hanno quindi ricevuto valutazioni diverse, ma in realtà è pro-babile che per il sig. Rossi in pratica essi si equivalgano). Un altro caso in cui può essere utile questo abbassamento del livello di scala è quello in cui le variabili presentano relazioni non lineari: la ridu-zione a un numero limitato di modalità costituenti una variabile ordinale può avere come effetto quello di linearizzare le relazioni. In casi come questi, dove cioè le variabili sono originariamente continue ma trasfor-mate per opportunità in ordinali, la misura di concordanza più appro-priata è il coefficiente di correlazione per ranghi di Spearman.
b) Le modalità di ciascuna variabile sono genuinamente ordinali: le re-lazioni tra modalità sono rappresentabili esclusivamente con gli operato-ri “maggiore di” e “minore di”. Esempi pertinenti alla ricerca sociale sono: il titolo di studio; il livello di carriera aziendale; alcuni indici di status sociale; le graduatorie di un certo numero di soggetti osservati, in base ad alcune competenze di tipo psico-sociale mostrate in una serie di prove; l’ordine di importanza dato a un insieme di oggetti, per esempio istituzioni sociali. Un approccio consigliato nella letteratura specialistica consiste nel ri-corre a operatori di concordanza non parametrici, come il tau di Ken-dall; un’altra strada, più pragmatica, è quella di ignorare la natura non metrica dei dati, ricorrendo a misure euclidee come il coefficiente di correlazione di Spearman (Basilevsky, 1994, p. 512 e ss.).
c) I dati sono all’origine rilevati su scale ordinali; tuttavia si può assu-mere ragionevolmente che la proprietà rilevata sia per sua natura conti-nua. Questo approccio, noto come underlying variable approach (cfr. Kampen, Swyngendouw, 2000), può essere seguito da chi analizza scale quasi-cardinali, come capita per esempio nella misura degli atteggia-menti. Il coefficiente adatto può essere anche in questo caso la correla-zione per ranghi di Spearman; tuttavia, se è plausibile assumere che il continuum sottostante a ogni rilevazione ordinale sia distribuito nor-malmente, la misura di concordanza più appropriata è il coefficiente di correlazione policorica, se entrambe le variabili osservate sono ordina-
24

li, oppure la correlazione poliseriale, nel caso che una di esse sia una variabile continua (Jöreskog, Sörbom, 1986).
E’ decisamente sconsigliabile ricorrere all’Analisi Fattoriale Lineare se le relazioni tra le variabili non sono monotoniche (condizione controlla-bile previamente mediante una ispezione dei diagrammi di dispersionedi tutte le distribuzioni congiunte tra coppie di variabili). In tal caso in-fatti, non solo le stime dei parametri saranno distorte, ma è anche eleva-to il rischio che la soluzione ottenuta sia caratterizzata da eccesso di di-mensionalità10. Nel caso di relazioni monotoniche non lineari sarebbe meglio linearizzare le relazioni tra variabili mediante una opportuna tra-sformazione matematica (ad esempio logaritmica). Infine, un avvertimento per quanto riguarda l’applicazione, molto diffu-sa, dell’Analisi Fattoriale a batterie di item dicotomici. Una prima obie-zione potrebbe essere che essa non è lecita in quanto le variabili non so-no continue; tale obiezione può però essere facilmente superata appli-cando per esempio l’underlying variable approach e calcolando in que-sto caso le correlazioni tetracoriche (o quelle biseriali, se una delle due variabili osservate è continua). Il vero problema però è un altro. Oc-corre infatti tenere presente che la relazione tra un fattore e un item di-cotomico non può essere lineare, perlomeno non su tutto il continuum del fattore (ma al massimo in un certo intervallo centrale, escluse cioè le code della distribuzione: questo discorso non suonerà nuovo a chi ha e-sperienza del cosiddetto modello lineare di probabilità, cioè la regres-sione lineare con una variabile dipendente dicotomica). A rigore sarebbe perciò meglio passare ai modelli della Item Response Theory, in cui il modello per lo studio dei dati non è la retta ma la curva logistica (o altre curve sigmoidali). Tuttavia spesso nella ricerca sociale, le variabili osser-vate hanno un basso parametro di discriminazione (o ‘sensibilità’): in
10 Sul tema, noto anche come ‘problema di Coombs’ si veda la trattazione appro-fondita in Ricolfi, 1999, p. 254. Va inoltre segnalato che sono stati sviluppati mo-delli di analisi fattoriale non lineare, che però esulano dalla presente trattazione. Per chi fosse interessato al tema, il riferimento teorico principale è l’opera dello psicometrico Roderick P. McDonald che ha elaborato tali modelli a partire dall’inizio degli anni ’60. La sua teoria è stata implementata nel software NO-HARM da Colin Fraser.
25

altri termini, le curve che rappresentano il legame tra variabili manifeste e fattori latenti sono meno ‘ripide’, il modello lineare rappresenta una buo-na approssimazione (cfr. McDonald, 1982); ne deriva che è possibile uti-lizzare a fini esplorativi l’analisi fattoriale classica. Ai fini della presente esposizione è sufficiente aver fatto cenno all’esistenza delle varianti dell’input minimo dell’Analisi Fattoriale E-splorativa; d’ora in avanti ci atterremo a una posizione per così dire ‘tra-dizionale’, considerando come input minimo una matrice di corre-lazioni prodotto-momento calcolate su variabili cardinali (o assimilabili) legate tra loro e con il fattore latente in modo lineare (o quasi).
2.2. Costruzione delle variabili e del campione L’applicazione corretta dell’analisi fattoriale richiede che la costruzione delle variabili avvenga secondo alcune regole. - Un primo importante pre-requisito è che le variabili manifeste siano per
costruzione indipendenti. Con ciò non si intende dire che non devono pre-sentare concordanza (correlazioni o covarianze), condizione che invece è auspicabile. L’indipendenza in questione è di carattere logico: lo stato di un soggetto sulla variabile Y deve risultare da una rilevazione empirica autonoma, non da una derivazione logica a partire dalla conoscenza dello stato del soggetto sulla variabile X. Un esempio in cui non si dà indipen-denza logica è costituito dai bilanci-tempo delle persone, in cui le variabi-li, che rappresentano la quantità di ore giornaliere dedicata a certe attività, sono soggette a un vincolo di riga.11 In casi come questi si dà perfetta o quasi perfetta multicollinearità (Blalock, 1960, trad. It. 1984, p.603). Nel caso di perfetta multicollinearità la tecnica non funziona, in quanto la ma-trice di correlazioni non è invertibile (operazione che è alla base di molte procedure di analisi fattoriale), o non dà risultati affidabili. Ci sono altre situazioni in cui le variabili non sono indipendenti per costruzione. È il caso per esempio delle domande a scelta forzata, o ‘punteggi ipsativi’ in cui si chiede al soggetto di indicare tra M elementi i K (con K<M) per lui
11 Se un soggetto destina 10 delle sue ore giornaliere all’attività lavorativa, potrà dedicarne al massimo 14 a quella non lavorativa: se attività lavorativa e attività non lavorativa sono due variabili, esse non sono logicamente indipendenti, perché sot-toposte a un vincolo ben preciso (la somma di riga è costante).
26

più importanti o preferiti. Spesso, per ognuno degli elementi si costruisce una variabile che ha come valore il rango attribuitogli da ciascun sogget-to. In questi casi non si dà necessariamente collinearità (soprattutto se K<<M), ma è chiaro che le variabili costruite a partire da questa domanda non sono indipendenti; qui il problema principale è che esse potrebbero non risultare correlate anche quando una relazione in effetti esiste12.
- Altra condizione importante è che le variabili siano effettivamente tali: dobbiamo cioè preoccuparci che il campo di variazione delle variabili sia sufficientemente esteso. Le variabili con scarsa dispersione intorno al valore centrale risulterebbero infatti necessariamente poco correlate con altre variabili (per rendersene conto basta pensare alla formula dell’indice di covarianza). È importante che le domande siano capaci di discriminare posizioni diverse sulla proprietà che si vuole misurare; inoltre, nessuna restrizione nel campo di variabilità delle variabili deve essersi verificata in seguito a peculiarità nel metodo di selezione del campione (per esempio: misurare l’interesse per la politica in un cam-pione di lettori di una rivista politica fornirebbe molto probabilmente risposte del tutto o quasi del tutto omogenee).
In merito alle modalità di scelta dei casi e alla numerosità campionaria sono opportune le seguenti considerazioni. a) Il campione non deve essere necessariamente probabilistico; tale re-
quisito è indispensabile soltanto se si vogliono stimare i parametri di una popolazione obiettivo. La casualità del campione non è invece necessaria in altri ambiti altrettanto importanti e frequenti della ricerca scientifica, a cui facciamo solo un breve cenno rimandando per la loro
12 Questo per vari motivi. Immaginiamo di sottoporre una lista di 15 oggetti agli intervistati e che sia chiesto loro di indicare quali oggetti pongono nei primi 5 po-sti. Per ogni oggetto verrà costruita una variabile che avrà come campo di variazio-ne potenziale i valori interi da 1 a 6, dove 6 significa che l’oggetto non rientra nei primi cinque. Se per ipotesi un oggetto della lista non viene mai scelto tra i primi 5, la variabile corrispondente sarà una costante (una sfilza di 6) e risulterà necessa-riamente incorrelata con altre variabili. Un altro esempio: gli oggetti A e B vengo-no collocati sempre al primo e secondo posto, ora l’uno ora l’altro. Se avessimo lasciato libero l’intervistato di dare a ciascun oggetto un voto indipendente, a-vremmo magari scoperto che spesso i due oggetti ricevono lo stesso voto. Con il metodo dei punteggi ipsativi è facile cioè ottenere un correlazione più attenuata, o tendenzialmente negativa, rispetto al metodo delle valutazioni indipendenti.
27

trattazione più approfondita ai principali testi di metodologia della ri-cerca (Cfr. per esempio Bruschi, 1999):
- nell’ambito di una ricerca pilota, che precede la ricerca vera e propria, in cui l’obiettivo è unicamente di testare gli strumenti (questionario, scale ecc.); - quando il campione coincide con la popolazione obiettivo; - quando la ricerca non ha un taglio idiografico ma nomologico, mirante cioè a individuare regolarità universalmente valide; si noti di passaggio che questo secondo caso è poco frequente al di fuori di situazioni sperimentali13.
b) Con campioni piccoli, l’errore casuale dei coefficienti di correlazione meno attendibili determina un aumento del valore assoluto delle correla-zioni stesse (Guertin, Bailey, 1970, cit. in Comrey, Lee 1992, trad. it. 1995). All’aumentare della numerosità campionaria, aumenta di solito l’attendibilità14 delle correlazioni statisticamente diverse da zero, ma esse tendono a diminuire in modulo. Secondo Comrey e Lee, 50 casi sono un numero decisamente scarso; 200 casi sono ritenuti un numero adeguato; campioni particolarmente numerosi (N=1000) sono richiesti se si usano correlazioni diverse da quelle prodotto-momento di Pearson, per ottenere lo stesso livello di stabilità dei coefficienti di correlazione (Comrey, Lee, cit. p. 284). Si tratta comunque di indicazioni molto generali che non vanno prese in modo assoluto: ogni ricerca presenta delle specificità, su cui il ri-cercatore è chiamato a una attenta riflessione, anche per quanto riguarda la numerosità campionaria.
13 Anche nella ricerca quasi-sperimentale o non-sperimentale accade di generaliz-zare i risultati ottenuti a una popolazione non specifica, soprattutto quando si stu-diano relazioni tra le variabili (il ricercatore non è interessato ai casi, se non in quanto ‘supporto’ attraverso il quale le variabili possono manifestarsi); devono pe-rò esserci delle buone ragioni per non considerare i risultati come idiosincratici alle unità selezionate. Questi temi, riguardanti la generalizzabilità dei risultati di una ricerca empirica, vengono rubricati dai metodologi sotto la voce ‘validità della ri-cerca’ (Cfr. Cook, Campbell, 1979). 14 Ossia, in termini molto generali, la riproducibilità del risultato in prove ripetute ceteris paribus; per un approfondimento si veda Corbetta, 1999, p. 125 e ss.
28

3. Il modello
3.1 Aspetti terminologici Consideriamo l’equazione di base dell’Analisi Fattoriale:
Zmn = am1F1n + am2F2n + ...... + amkFkn +......+ amKFKn + Umn
dove Zmn è il punteggio standardizzato della variabile m-esima per l'indivi-duo n-esimo amk è detto saturazione o loading della variabile manifesta m-esima sul fattore k-esimo, con k<m; Fkn è il punteggio standardizzato del k-esimo fattore comune per l’individuo n-esimo (factor score);Umn è il punteggio standardizzato dell’m-esimo fattore unico per l’individuo n-esimo.
Ognuno dei fattore unici si può idealmente scomporre così15:
U = S + E
dove S rappresenta il fattore specifico che influisce sulla corrisponden-te variabile manifesta Z, mentre E è l’errore accidentale. E’ definita co-
15 Per semplificare, ometterò le indicizzazioni delle variabili ogni volta che ciò non sia causa di fraintendimenti; colgo l’occasione per scusarmi con il lettore che ha una certa dimestichezza con la matematica per il mio scarso rigore notazionale, ma preferisco, per quanto possibile, mettermi dalla parte di chi affronta la lettura delle formule con una certa fatica.
29

munalità di una variabile manifesta la quantità:ä=
K
kmka
1
2 . La comunalità
di una variabile viene talvolta indicata con h2 e rappresenta cioè la parte di varianza di una variabile manifesta spiegata dai fattori comuni
Il fattore U elevato al quadrato determina la cosiddetta unicità; essa è data quindi dalla somma di S2 e di E2, che sono definite rispettivamente specificità e varianza dell’errore stocastico.
Consideriamo ora il seguente sistema di equazioni:
MKMKMMM
KK
KK
UFaFaFaZ
UFaFaFaZ
UFaFaFaZ
++++=
++++=
++++=
.......
.
.
.......
.......
2211
222221212
112121111
Esso prende il nome di factor pattern; raccogliendo gli elementi a in una matrice A:
ùùùù
ú
ø
éééé
ê
è
MKMM
K
K
aaa
aaa
aaa
........
::::
........
........
21
22221
11211
otteniamo la cosiddetta pattern matrix.
Consideriamo ora un altro sistema di equazioni:
mKFFmkFFmFFmFZ
FFmKFFmkFFmmFZ
arararar
rararaar
kKKKKm
Kkm
+++++=
+++++=
...............
.
.
...............
21
11211
21
21
che definiamo factor structure.
30

Raccogliendo in modo opportuno i termini posti a sinistra nel sistema di equazioni in una matrice S, ovvero come segue:
ùùùùù
ú
ø
ééééé
ê
è
KMMM
K
FZFZFZ
FZFZFZ
rrr
rrr
........
::::
........
21
12111
otteniamo la cosiddetta structure matrix. Ricordiamo che quest’ultima matrice è distinguibile dalla pattern matrix solo quando si effettua una rotazione obliqua.
Infine, una puntualizzazione circa l’uso del termine saturazione. Par-liamo di saturazioni, senza ulteriori specificazioni, per indicare i co-efficienti da stimare quando ci riferiamo alla soluzione non ruotata oppure ruotata in modo ortogonale. Nel caso di rotazioni oblique in-vece, poiché le matrici di parametri fornite dalla tecnica per interpre-tare i fattori sono due, A e S, chiameremo regression loading gli e-lementi della pattern matrix e correlation loading gli elementi della structure matrix.
3.2. Gli assunti sulla struttura fattoriale Si sarà notata una certa somiglianza del modello dell’analisi fattoriale con quello ben più noto della regressione multipla; tuttavia, a diffe-renza di quanto avviene in quest’ultima, i fattori, cioè le variabili indi-pendenti nel modello fattoriale, sono variabili inosservabili e quindi incognite. Senza porre ulteriori restrizioni, la stima del modello non sarebbe possibile: infatti si potrebbero individuare infiniti valori per i parametri a e per i fattori F, tutti in grado di soddisfare le equazioni del modello. Il modello della Analisi Fattoriale esplorativa si basa perciò sui se-guenti assunti: E (Fk) = 0 (il valore medio di ciascun fattore comune è pari a zero); Var (Fk) = 1 (la varianza di ciascun fattore comune è pari a uno);
31

Cov (Fk, Um) = 0 (i fattori comuni sono indipendenti, o ortogonali, ri-spetto ai fattori unici); Cov (Um, Uj) = 0 (i fattori unici sono ortogonali tra loro). Inoltre, senza perdita di generalità, si assume che:
Cov (Fk, Fj) = 0
(vedremo però che tale condizione viene spesso rilasciata in fase di ro-tazione dei fattori e precisamente nelle rotazioni oblique).
3.3. Analisi fattoriale e Analisi in Componenti principali Alla base della Analisi fattoriale riposa l'idea che ognuno dei punteggi Z che concorrono a produrre la matrice di correlazioni possa essere e-spresso come somma ponderata del punteggio nei fattori comuni e di quello del fattore unico (a sua volta composto da un fattore specifico e un fattore di errore). I punteggi Z, F, U sono tutti standardizzati, pertanto aventi media pari a 0 e varianza pari a 1. Le saturazioni (amj), che ricordiamo sono oggetto di stima nella Analisi Fattoriale, hanno di norma valore compreso tra -1 e +1 (escludendo per ora il discorso delle rotazioni oblique). L’Analisi in Componenti Principali, tecnica sviluppata da Hotelling negli anni Trenta – ma le cui basi sono già contenute nei lavori degli statistici Bravais (cit. in B asilevsky, 1994, p. 99) e Pearson (1901) – non va confusa con l’Analisi Fattoriale. Osserviamo l’equazione della Analisi in Componenti Principali16:
Zmn = pm1C1n + pm2C2n + ...... + pmMCMn
Ognuna delle M variabili osservate è descritta linearmente nei termini di M nuove componenti incorrelate: C1 C2...CM.Le componenti a loro volta non sono nient’altro che combinazioni li-neari delle variabili Z. Le componenti sono costruite in modo tale che
16 La notazione cambia volutamente, per marcare la differenza con l’Analisi Fat-toriale.
32

la prima spieghi la % massima di varianza del sistema, la seconda la % massima di varianza residua e così via; analiticamente abbiamo:
C1 = c11Z1 + c12Z2 + ...... + c1MZM = ä=
M
mmmZc
11
VAR (C1) = max
sotto il vincolo che: ä=
=M
mmc
1
21 1
Nella Analisi Fattoriale ognuna delle M variabili osservate è ridescritta linearmente nei termini di K fattori comuni (con K<<M), di un fattore specifico e di una componente stocastica. Nella Analisi in Componenti Principali si vuole spiegare un numero M di variabili manifeste con un numero M di componenti che variamente contribuiscono alle varianze dei test. Le differenze con la Analisi Fattoriale si attenuano per quanto concerne i risultati ottenuti con la Analisi in Componenti Principali troncata, quando cioè si trattiene un numero di K di componenti molto inferiore al numero M di variabili manifeste. L’Analisi in Componenti Principali troncata fornisce la seguente scis-sione di una matrice di Correlazioni (o VarCov):
R(MÖM) = KP (MÖK) Ö KP' (KÖM) + D(MÖM)
dove KP rappresenta una matrice di pesi di K componenti principali, KP'è la sua trasposta e D è la matrice contenente i residui dovuti al fatto che non abbiamo considerato le ultime M–K componenti (in pedice tra pa-rentesi è indicato l’ordine di ciascuna matrice). Questa variante della Analisi in Componenti Principali è spesso utiliz-zata al posto della Analisi Fattoriale vera e propria. Ciò trova le sue origini nella maggior semplicità concettuale di questa tecnica e in una posizione epistemologica improntata all’empirismo: quest’ultima rifiu-ta il concetto di variabile latente e l’idea stessa che il dato empirico si possa considerare composto da ‘segnale puro’ (quello determinato dai fattori comuni) e da ‘rumore’ (determinato dal fattore specifico e dalla componente erratica). Le due tecniche non sono comunque in alcun modo equivalenti da un
33

punto di vista logico, anche se spesso (ma non necessariamente) posso-no portare a risultati molto simili. L’Analisi in Componenti Principali, nella sua versione completa o in quella troncata, è una tecnica orientata alla varianza di un sistema di e-quazioni lineari: essa ha infatti come funzione obiettivo quella di riscri-vere un sistema di variabili, sostituendo a queste delle componenti ordi-nabili per quantità di varianza spiegata da ognuna del sistema comples-sivo. Un’Analisi in Componenti Principali si ritiene riuscita se un nume-ro ridotto di componenti, K, riesce a riprodurre gran parte (indicativa-mente, l’80-90%) della varianza del sistema originario. L’Analisi Fattoriale si ‘nutre’ invece di covariazioni tra le variabili: la funzione obiettivo, comunque venga specificata, mira a annullare tali covariazioni imputandole all’azione di fattori latenti comuni. La varian-za spiegata, come vedremo è un by-product: non è quasi mai l’obiettivo principale di una Analisi Fattoriale. Per la misurazione di costrutti teorici a mezzo di indicatori è più impor-tante l’Analisi Fattoriale: questa tecnica è in grado di filtrare la parte in-dicante degli indicatori dal ‘rumore’, composto dall’errore di misurazio-ne e dai fattori unici. Con l’Analisi in Componenti Principali troncata invece rumore e segnale puro sono codificati insieme. Se il modello generatore di dati è:
R(MÖM) = KA (MÖK) Ö KA' (KÖM) + U(MÖM)
dove KA è un matrice di parametri da stimare e U una matrice di distur-bi, si può essere tentati di usare per tale stima la scissione di R fornita dalla Analisi in Componenti Principali troncata (vedi sopra): le strutture del processo generatore e della suddetta scissione sembrerebbero essere isomorfe. Ma così non è: la matrice U è diagonale (i fattori unici si as-sumono mutuamente incorrelati), mentre non lo è la matrice D.Quindi KP non approssima di norma KA.I risultati di una Analisi Fattoriale e di una Analisi in Componenti Prin-cipali troncata possono essere molto simili (nella seconda le saturazioni sono inflazionate rispetto alla prima, ma presentano lo stesso pattern)(Harman, 19763, p. 135); in particolare i risultati non differiscono so-stanzialmente quando:
34

- le comunalità sono molto alte (cioè se il rumore è basso: cosa che avviene molto di rado nelle scienze sociali e del comportamento);
- il numero di variabili osservate è molto ampio; al loro aumentare, in-fatti, il peso dei valori in diagonale diminuisce rispetto a quello delle covarianze.
Quando le risorse di calcolo erano scarse si ricorreva all’Analisi in Componenti Principali troncata in luogo dell’Analisi Fattoriale per ri-durre la complessità dei calcoli. Oggi comunque questa giustificazione è venuta meno; va segnalato tuttavia che alcuni importanti software stati-stici trattano, a nostro parere in modo fuorviante, L’Analisi in Compo-nenti Principali come uno dei diversi metodi di estrazione dei fattori nell’Analisi Fattoriale. L’Analisi in Componenti Principali troncata è una tecnica utile per altri scopi: primo fra tutti quello di costruire indici sintetici a partire da batte-rie più o meno ampie di item in cui non è rintracciabile una precisa struttura latente17.Sino qui abbiamo considerato il rapporto tra variabili osservate e costrutto teorico come un rapporto di indicazione. Sono definiti reflective indica-tors (Bagozzi, 1994, p. 331) quegli indicatori che ‘riflettono’ alcune pro-prietà della dimensione sottostante: per usare una metafora, noi guardia-mo il costrutto latente attraverso le lenti delle variabili manifeste. Se un insieme di indicatori riflessivi è riferito alla stessa dimensione è lecito at-tendersi che essi covarino (stiamo misurando la stessa proprietà con stru-menti diversi). Inoltre, poiché la variabile latente ha una sua realtà par-zialmente autonoma dagli indicatori, si può applicare il concetto di inter-cambiabilità degli indicatori empirici (Lazarsfeld,1965, in Cardano, Miceli (a cura di), 1991, p. 127 e ss.): possiamo osservare la stessa pro-prietà latente mediante una diversa batteria di indicatori. Diversi sono i cosiddetti causal indicators o formative indicators (Ba-gozzi, 1994, p. 331; Bollen, 2001, p. 7283): questi sono indicatori che presi singolarmente misurano certi aspetti di una proprietà più complessa, la quale è data, per definizione, dalla somma dei suoi indicatori. In questo
17 Per usi più specialistici nella data analysis della Analisi in Componenti Principa-li rinviamo a Dunteman, 1989
35

caso non è assolutamente richiesto che gli indicatori mostrino una qual-siasi struttura di covarianza: non stiamo misurando una variabile latente responsabile delle covariazioni delle variabili manifeste, ma stiamo ‘costi-tuendo’ una proprietà complessa sommando un insieme di proprietà più semplici che possono anche essere in competizione tra loro (ad es.i con-sumi alcolici). Inoltre non ha senso parlare di intercambiabilità degli indi-catori: un set diverso di indicatori costituisce una proprietà necessaria-mente diversa.
3.4. Dall’input alla matrice riprodotta A partire dai punteggi Z (variabili manifeste standardizzate) vogliamo risalire alla matrice delle saturazioni, passando attraverso la matrice di correlazioni (quest’ultima, ricordiamo, è l’input minimo). Per com-prendere tale processo, si faccia in un primo momento il ragionamento inverso: cioè si immagini che sia nota la parte destra dell’equazione fondamentale e che oggetto di calcolo siano le variabili Z. Si tratta na-turalmente di un puro esperimento mentale, con cui facciamo finta di conoscere il punteggio degli individui (dei casi, più in generale) sui fattori latenti (comuni, specifici e di errore), nonché i coefficienti (sa-turazioni) con cui tali punteggi si combinano in modo additivo. Per ricavare i valori delle variabili Z ricorreremmo allora alla seguente operazione matriciale:
ùùùù
ú
ø
éééé
ê
è
=
ùùùùùùùùù
ú
ø
ééééééééé
ê
è
³
ùùùù
ú
ø
éééé
ê
è
MNMM
N
MNM
N
KNK
N
MKMM
K
K
zzz
zz
zzz
UU
UU
FF
FF
aaa
aaa
aaa
....
....:
....
....
....
:::
....
....
:::
....
1
:
1
1
....
::::
....
....
21
2221
11211
1
111
1
111
21
22221
11211
dove K è il numero dei fattori comuni, M è il numero delle variabili ma-nifeste, N il numero dei casi.
36

In termini più sintetici possiamo scrivere:
Au Ö Fu = Z(MÖ(K+M)) ((K+M)ÖN) (MÖN)
Nell’Analisi Fattoriale compiamo il percorso inverso a quello appena ipotizzato: a partire dalla conoscenza della matrice Z cerchiamo di risa-lire agli elementi contenuti nelle celle della matrice Au, o meglio quelli contenuti nelle sue prime K colonne; chiamiamo A questa porzione di matrice, che come abbiamo già visto è la pattern matrix.Analogamente, chiamiamo F la parte superiore di Fu, cioè le prime K righe di quest’ultima. I valori amk contenuti nella pattern matrix, possono essere interpretati come i pesi beta delle regressioni delle variabili osservate sui fattori la-tenti nonché, se escludiamo il caso delle rotazioni oblique, come coeffi-cienti di correlazione tra variabili manifeste e fattori comuni. Vediamo ora come, conoscendo la matrice Z e calcolando le correlazioni tra le variabili si può giungere a stimare gli elementi della matrice A.Se nella formula della correlazione prodotto-momento:
ä=
==N
1njnmnjmmj ZZ
N
1)Z,Z(Covr
sostituiamo il membro di destra dell’equazione di base (vedi par. 2.4) otteniamo:
ä=
++++Ö
++++=
N
n jnKnjKnjnj
mnKnmKnmnmmj UFaFaFa
UFaFaFa
Nr
1 2211
2211
)...(
)...(1
Assumendo che i fattori siano tutti incorrelati fra loro (condizione che può essere rilasciata dopo aver stimato il modello, in sede di rotazione), e svolgendo il prodotto precedente otteniamo:
2 2 21 1 1 2 2 2
1
1( ... )
N
mj m j n m j n mK jK Knn
r a a F a a F a a FN =
= + + +ä
37

inoltre, essendo i fattori espressi anch’essi in unità standardizzate, abbiamo che:
1FN1 2
F
N
1n
2n ==ä
=
s
Pertanto possiamo semplificare e scrivere:
rmj = am1Öaj1 + am2Öaj2 + ... + amKÖajK
in altri termini, la correlazione tra la variabile m-esima e la variabile j-esima, corrisponde alla sommatoria dei prodotti delle loro saturazioni fattoriali nei fattori comuni.
Considerando simultaneamente tutte le rmj otteniamo la matrice di corre-lazione; in notazione matriciale:
Ru=1/NÖ(ZÖZ¡)
Poiché:
Z = Au Ö Fu
possiamo scrivere:
'u
'uu
uu AFF
AR Öùùú
ø
ééê
è ÖÖ=
N
e semplificando, avendo assunto che i fattori siano tra loro incorrelati, si ottiene:
Ru=AuÖAu¡
Infine, ammesso che i nostri assunti siano validi e senza riguardo per ora a ciò che compare nelle celle della diagonale principale, possiamo scri-vere in notazione matriciale:
Rcom = A Ö A¡
38

ricordando che con A si indica la parte di matrice Au contenente solo i coefficienti dei fattori comuni. Quest’ultima equazione è chiamata fun-damental factor theorem (Thurstone, 1935). Ru e Rcom sono identiche tranne che nella diagonale principale: Ru con-tiene degli 1, Rcom contiene le comunalità (h2). Ciò equivale a dire: per spiegare le correlazioni tra variabili, sono sufficienti i fattori comuni. Per spiegare la varianza totale sono necessari i fattori comuni e quelli unici. Il processo di estrazione dei fattori può seguire diversi metodi; i-nizia nell’approccio tradizionale, che possiamo associare al nome di Thurstone, con una matrice Rcom, dopo che sono state stimate in qualche modo le comunalità e inserite nella diagonale principale18.Le stime iniziali per le comunalità di solito usate sono o le correlazioni multiple al quadrato di ogni variabile con le restanti variabili, o la corre-lazione più alta in una riga della matrice di correlazione. Il processo prosegue, mediante iterazioni, sino a che per esempio, secondo certi pa-rametri prefissati, le stime delle comunalità non si stabilizzano, oppure sino a che non si ottiene una matrice Rrepr sufficientemente simile a Rcom negli elementi extradiagonali. Mentre Rcom, a eccezione della diagonale principale, contiene valori em-pirici, Rrepr contiene valori teorici, ricavati dal modello. Sono stati svilup-pati molti metodi per identificare una matrice di saturazioni tale che:
AÖA¡=Rrepr@Rcom
Due di questi metodi saranno tra poco illustrati. Per ottenere AÖA¡=Ru
si utilizza l’Analisi in Componenti Principali (dove, ricordiamo, non ci sono fattori specifici e di errore). Ciò richiede una matrice A della stessa grandezza di Ru. Scopo invece dell’analisi fattoriale è quello di spiegare una matrice R di dimensione M con una matrice L di dimen-sione MÖK, con K<<M. 18 L’idea di mettere le comunalità nella diagonale principale è stata legittimata da Thurstone. Il rango di una matrice di correlazioni, raramente è minore del numero di variabili correlate; quindi se il numero dei fattori deve essere uguale al rango si mancherebbe l’obiettivo principale della Factor Analysis. Ripetute prove empiriche convinsero Thurstone che la tecnica di sostituire le autocorrelazioni con le comu-nalità aveva l’effetto di ridurre il rango della matrice (Thurstone, 1947, p. 484).
39

Ricapitolando, le matrici di correlazione coinvolte nella Analisi Fattoriale sono: Ru (correlazioni osservate), Rcom (correlazioni osservate e comunalità nella diagonale principale); Rrepr, correlazioni riprodotte dal modello. Si può per completezza considerare Rres, la matrice dei residui, data dall’operazione Rcom - Rrepr; sebbene essa derivi da questa semplice opera-zione algebrica, l’abbiamo messa in risalto perché essa risulta importante per la valutazione del modello, o in alcuni metodi di estrazione è addirittura l’argomento della funzione obiettivo del-l’algoritmo. Considereremo tra breve due dei metodi di estrazione dei fattori oggi più diffusi. E’ però opportuno soffermarsi dapprima sul modo con cui l’Analisi in Componenti Principali individua le componenti; in tal mo-do avremo ulteriori elementi di differenziazione delle due tecniche. Per semplicità consideriamo due sole variabili osservate, X e Y, e assu-miamo che la loro distribuzione sia normale bivariata. Graficamente ot-teniamo una figura simile a un copricapo di paglia, di forma tondeggian-te se la correlazione tra X e Y è assente.
Figura 4
Per rappresentare graficamente la presenza di una correlazione, si sup-ponga di ‘tirare’ il cappello (elastico) lungo due direzioni opposte: più si tira (più la correlazione è alta), più il cappello assomiglierà alla parte centrale di un cappello da carabiniere.
40

Figura 5
Guardiamo ora la nostra relazione bivariata dall’alto, immaginando una correlazione positiva moderata. Possiamo usare come metodo di rappre-sentazione le curve di livello (per semplificare ulteriormente considere-remo ora le due corrispondenti variabili standardizzate).
Figura 6
Elevati valori di X tendono a associarsi prevalentemente a valori alti di Y (e viceversa): pertanto i punti si addensano nei quadranti I e III. Le curve di livello (o ‘isoipse’19) formano delle ellissi concentriche (in assenza di relazione avremmo avuto dei cerchi concentrici); queste ellissi sono attra-versate longitudinalmente dall’asse P1 (asse maggiore). Un secondo asse P2 (asse minore) viene tracciato perpendicolarmente a P1.
19 L’isoipsa è una curva che congiunge i punti che stanno a una stessa altezza: ri-cordiamo che stiamo osservando una distribuzione in tre dimensioni.
41
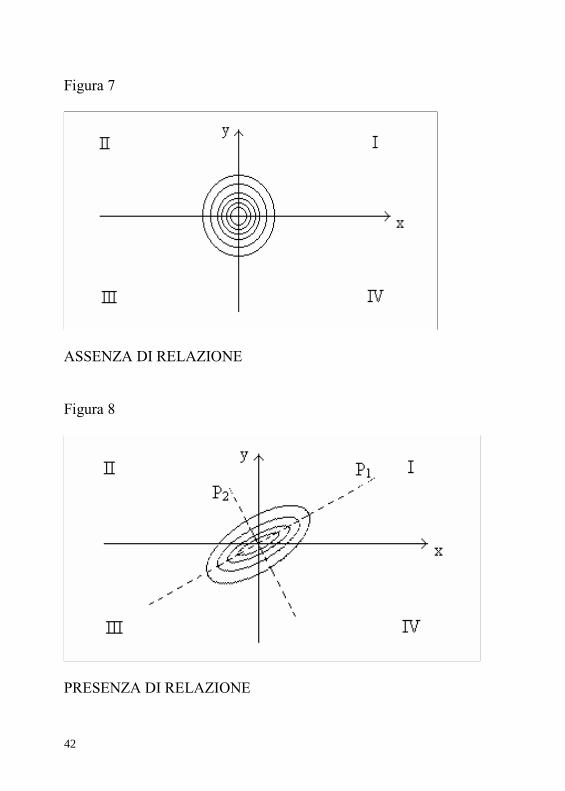
Figura 7
ASSENZA DI RELAZIONE
Figura 8
PRESENZA DI RELAZIONE
42

Supponiamo di voler rappresentare la posizione relativa di ogni punto in riferimento a uno solo dei due assi. La scelta cadrà naturalmente sull’asse P1, perché esso è più vicino all’insieme dei punti delle ellissi di quanto non lo sia P2 (e ogni altro possibile asse). È importante sottolineare come non faccia differenza localizzare i punti rispetto agli assi P1 e P2 piuttosto che in riferimento agli assi X e Y; infatti anche se la rotazione muta le coordinate dei punti, non c’è alcuna perdita o aggiunta di informazione su questi ultimi. Se invece usiamo un solo as-se per localizzare i punti, c’è perdita di informazione: possiamo localizza-re ogni singolo punto solo approssimativamente; il margine di incertezza (o errore), è tanto più alto quanto meno stretta è la correlazione tra le va-riabili. Con l’asse principale, la perdita di informazione è minore. Nel ca-so (puramente ipotetico) di correlazione perfetta, P1 conterrebbe tutta l’informazione utile per descrivere la posizione dei punti nel piano. Ovviamente il discorso si può generalizzare a relazioni multivariate e, in riferimento agli assi principali, può essere esteso anche a relazioni biva-riate e multivariate con distribuzioni non normali20.In generale, la retta che individua l’asse principale è quella per la quale è minima la somma dei quadrati delle distanze dei punti dalla stessa tracciate perpendicolarmente (analogamente a quanto accade nella co-siddetta regressione ortogonale: Cfr. Malinvaud, 1964, trad. it. 1969). Un altro modo di dire che la prima componente è quella che contiene il maggiore ammontare di informazione, è che essa spiega una quantità di varianza dei dati maggiore di quanto possa spiegare ogni altra compo-nente. L’A.C.P in effetti procede proprio estraendo le componenti in or-dine decrescente della quantità di varianza spiegata da ognuna. Compito della Analisi in Componenti Principali è quello di riparame-trizzare le variabili in modo da ricavare una gerarchia di componenti ba-sata sulla loro capacità di riassumere informazione. Lo strumento fondamentale per arrivare a tale scomposizione e gerar-chizzazione dell’informazione è dato dalla equazione caratteristica, che in forma matriciale sintetica si esprime così:
RÖv=lÖv 20 Va ricordato che da una distribuzione normale bivariata consegue una relazione lineare, ma non viceversa: Cfr. Blalock, 1960, trad. it. 1984, p.486.
43

dove v e l sono rispettivamente un autovettore e un autovalore associa-ti alla matrice R (si vedano i richiami di algebra matriciale in appendi-ce). L’autovalore rappresenta la quantità di varianza spiegata da una componente.Una matrice di correlazioni empiriche ha di solito più auto-valori non nulli: nell’Analisi in Componenti Principali questi di norma sono tanti quanti le variabili osservate (M) (a meno che non vi siano casi di collinearità che però vanno evitati come si è già detto); gli M autova-lori hanno M autovettori associati. La formula dell’equazione caratteri-stica può perciò essere scritta come segue:
R(v1, v2, .... vM)=( l1v1, l2v2, ....lMvM)
o meglio:
RÖV=VÖLL
dove L è una matrice diagonale con valori l1, l2, l3, ....lM, posti in or-dine decrescente. Gli elementi di ogni autovettore, dopo che questo sia stato ‘normalizza-to’ (cioè dopo che ogni suo elemento sia stato diviso per la lunghezza dell’autovettore, e poi moltiplicato per la radice dell’autovalore associa-to), costituiscono le saturazioni che soddisfano la seguente proprietà:
222
21
2 ....max Mmmmm aaah +++=
Occorre in altri termini massimizzare la varianza spiegata dal fattore m-esimo, sotto la seguente condizione:
ä=
Ö=M
mkmjmjk aar
1
Ovviamente il valore massimo di Am su matrici di correlazioni è pari a 1. Nella Analisi in Componenti Principali troncata si individuano le prime K componenti (K<<M) che insieme spiegano una buona percentuale di va-rianza, ignorando quelle che ci fanno perdere poca informazione sui punti. Se l’Analisi in Componenti Principali è orientata a spiegare la varianza, l’Analisi Fattoriale è invece mirata a dare conto delle correlazioni (o delle covarianze) tra le variabili manifeste come fenomeno interpretabi-le con la presenza di fattori sottostanti. In pratica, come abbiamo già vi-
44

sto ciò equivale a regredire le variabili osservate su uno o più fattori ipo-tetici, non direttamente osservati, su cui si fanno alcuni assunti.
3.5. L’estrazione dei fattori: stima dei minimi quadrati e di massima verosimiglianza Il primo metodo di estrazione di Fattori che prendiamo in considerazio-ne è il Metodo dei Minimi Quadrati Ordinari, o ‘non ponderati’, d’ora in avanti ULS (Unweighted Least Squares). La logica di tale me-todo è quella di determinare il valore dei parametri in modo da mini-mizzare i residui (contenuti in Rres) derivanti dalla differenza tra la ma-trice di correlazioni originaria e quella riprodotta. Il numero di fattori da estrarre viene individuato prima di iniziare il pro-cesso di stima dei parametri. I criteri più utilizzate sono i seguenti: - il numero dei fattori può essere previsto sulla base di un ragionamen-
to teorico-deduttivo, o sulla base di altre pre-cognizioni del ricercato-re (in questo caso però sarebbe più opportuno passare all’approccio confermativo);
- si può iniziare fissando K=1 e poi procedere a successive elaborazio-ni aumentando K di una unità per volta, sino a quando si trova una soluzione soddisfacente;
- si può adottare uno dei molti criteri basati sul rendimento marginale di ogni fattore estratto: molti manuali (per es. Comrey, Lee, 1992, trad. 1995, p. 146 e ss.) propongono il criterio dell’autovalore >1 di Kaiser-Guttman21, oppure lo Scree test di Cattell22.
21 L’autovalore rappresenta la quota di varianza spiegata dal fattore; ogni fattore in più estratto spiega una quota progressivamente decrescente di varianza; la regola proposta da Kaiser è giustificata dal fatto che valori pari o inferiori a 1 portano a considerare fattori che ‘spiegano’ meno varianza del sistema di quanto ne possegga ciascun fattore. 22 In un diagramma di caduta degli autovalori, lo scree è il punto a partire dal quale ln+1 - ln @ cost. Se il criterio di Kaiser si basa su un’analogia con la teoria economica dell’utilità marginale, qui ci troviamo invece di fronte a una analogia con la geologia, e precisamente con la misurazione dei burroni: ‘scree’ è infatti la ‘falda detritica’ che si adagia ai piedi di un burrone; come i detriti creano disturbo nella misurazione della reale altezza di un burrone, e quindi non vanno considerati, così nello scree test oc-
45

Una volta individuato il numero di fattori da estrarre, l’algoritmo calcola i parametri in modo che questi permettano la ricostruzione della matrice originaria nel modo più fedele possibile per quanto riguarda gli elementi extra-diagonali23.Il nucleo della soluzione consiste nella minimizzazione della seguente funzione:
FULS = ½[Tr (Ru - Rrepr)2]
dove Rrepr è la matrice di correlazioni riprodotte, contenente degli uno in diagonale principale, proprio come Ru. In altre parole, la funzione da minimizzare è data dalla somma dei quadrati delle differenze tra corre-lazioni osservate e correlazioni riprodotte mediante le saturazioni24.
Veniamo ora brevemente al metodo di stima della Massima Verosimi-glianza, o ML (Maximum Likelihood). L’applicazione di questo metodo è particolarmente indicata quando: - si è in possesso di un campione probabilistico; - si può assumere che le variabili manifeste seguano una distribuzione normale multivariata.
Sotto tali condizioni, il metodo fornisce le stime dei parametri della po-polazione che più verosimilmente hanno prodotto le correlazioni osser-
corre scartare i fattori che formano nel diagramma di caduta degli autovalori una sor-ta di falda detritica ai piedi dei fattori con autovalori molto più elevati. 23 Nella diagonale troviamo le comunalità di ogni variabile; a differenza di altre pro-cedure di estrazione dei fattori, qui le comunalità sono un by-product dell’algoritmo e non un punto di inizio. Ciò da un lato costituisce un vantaggio, poiché evita il pro-blema, controverso, della corretta stima a priori delle comunalità; d’altro canto può portare a soluzioni improprie, definite in letteratura come Heywood Case, caratteriz-zate da valori di comunalità maggiori di uno e dunque assurdi. 24 Un altro metodo della famiglia dei minimi quadrati, molto utilizzato, è quello dei Minimi Quadrati Generalizzati, o GLS (Generalized Least Squares). Il criterio di minimizzazione è lo stesso, ma le correlazioni sono pesate inversamente per l’unicità delle variabili: in tal modo si assegna maggior peso alle variabili con ele-vate comunalità (cioè si dà più peso alle stime più stabili).
46

vate25. ML, in generale (non solo nell’analisi fattoriale), produce stima-tori che sono preferibili a quelli prodotti con altri metodi, sempre che siano pienamente realizzate le premesse26.
3.6. Metodi di rotazione ortogonale e obliqua Per comprendere il problema della rotazione dei fattori è utile immagi-nare uno spazio cartesiano che abbia come assi di riferimento i fattori estratti. Per semplicità, rappresentiamo graficamente solo due fattori la-tenti (F1 e F2) e due variabili manifeste (VA e VB). Sul piano cartesiano identificato dai due fattori (assi) possiamo rappresentare geometrica-mente ognuna delle due variabili come un vettore individuato da una coppia di coordinate che corrispondono alle saturazioni delle variabili sui fattori. Le saturazioni delle variabili sui fattori rappresentano il si-stema di coordinate (ascissa e ordinata).
Figura 9
25 Anche ML, come GLS, assegna maggior peso alle variabili con grandi comunali-tà. La funzione da minimizzare è: FML = Tr (RRcom
-1) + ln |Rcom| - ln|R| - m dove m è il numero di variabili. 26 Il discorso è volutamente generico, data la complessità dell’argomento. Per un approfondimento di livello intermedio sugli stimatori e i metodi stima cfr. Albano, Testa, 2002, par. 6.3; per una trattazione più analitica, Cfr. Piccolo, 20002 cap. XV e XVI. Va detto inoltre che ML, a differenza degli altri metodi, produce stime sca-le free, indipendenti dall’unità di misura delle variabili manifeste. Pertanto, con ML, la soluzione è la stessa sia che si abbia come input la matrice V varianze-covarianze, sia la matrice R.
47

Nel nostro esempio, la variabile VA ha saturazione a1A=0.5 sul fattore F1
e a2A=0.4 sul fattore F2.La variabile VB ha saturazione a 1B= a 2B=0.6 su entrambi i fattori. uo-tando gli assi di riferimento è possibile cambiare il sistema di coordinate dei punti-vettore, lasciando inalterata la posizione relativa (correlazione) di questi ultimi. La somma dei quadrati delle saturazioni per ogni varia-bile resta invariata. Ruotando per esempio di un angolo q =30° entrambi gli assi (rotazione ortogonale), otteniamo le nuove coordinate dei punti-vettore (e dunque le nuove saturazioni) in un sistema di riferimento nuovo (con assi fattoriali F'
1 e F'2) che rispetto al precedente conserva la
perpendicolarità tra i fattori.
Figura 10
La variabile VA ha ora saturazione a '1A =0.63 sul fattore F'
1 e a '2A =0.1
sul fattore F'2.
La variabile VB ha saturazione a '1B =0.82 su sul fattore F'
1 e a '2B =0.22
sul fattore F'2.
I valori delle saturazioni ruotate sono stati ottenuti applicando le se-guenti formule, ricavate con una serie di passaggi di trigonometria:
a '1A = a 1A cosq + a 2A senq e a '
2A = a 2A cosq - a 1A senqa '
1B = a 1B cosq + a 2B senq e a '2B = a 2B cosq - a 1B senq
Pertanto, è evidente che esiste un numero praticamente infinito di rota-zioni possibili già solo per due fattori; il numero di soluzioni cresce ul-
48

teriormente all’aumentare del numero dei fattori. Inoltre, si ricorderà che sino ad ora abbiamo vincolato, per semplicità, i fattori a essere ortogonali tra loro. Ma una volta estratti i fattori, ottenute la matrice Rrepr e le comunalità, non è più necessario vincolare i fattori all’ortogonalità, se ciò non appare utile a fini interpretativi. Occorrono dunque dei criteri per scegliere una rotazione tra le tante possibili. Un primo approccio consiste nella scelta della soluzione che a un esame grafico soddisfa maggiormente il ricercatore. La scelta può essere attua-ta sulla base di una valutazione sintetica by intuition, oppure basata su qualche criterio analitico di interpretazione, ma in ogni caso è ampia-mente guidata dalla capacità soggettiva di riconoscimento di pattern (addensamenti di punti-vettore). Le cosiddette ‘rotazioni a mano’, ri-chiedono da parte del ricercatore una certa esperienza, soprattutto quan-do ci sono molti fattori da esaminare e le variabili non formano cluster facilmente distinguibili. Una seconda strada, la più praticata, è quella di affidarsi ai criteri anali-tico-matematici di rotazione implementati nei metodi di rotazione pre-senti nei package statistici. Si tratta di regole formalizzate, che non ri-chiedono valutazioni del ricercatore nell’applicazione al caso singolo27.
I metodi analitici che andiamo ora a considerare si basano in gran parte su un principio generale, proposto da Thurstone nel 1947: il principio della struttura semplice. Esso non fa altro che riprendere un canone più generale della spiegazione scientifica, quello della semplicità, o par-simonia, della spiegazione scientifica. Nella rotazione fattoriale, per raggiungere la struttura semplice si devo-no rispettare alcune regole; ci limitiamo a sintetizzarle in due principi (per una maggior precisione si veda Harman, 19763, p. 98): - nella matrice fattoriale ruotata, ogni variabile deve avere almeno un
loading nullo, ma possibilmente anche di più; - ogni fattore deve avere almeno K loading nulli (K: numero dei fattori
27 Il fatto che si tratti di regole a-priori non significa che siano ‘migliori’ di quelle che richiedono il giudizio del ricercatore: per una critica serrata dei metodi analitici si veda Comrey, Lee, 1992, trad. it. 1995 pp. 228 e seguenti.
49

comuni) , e questi devono essere diversi tra i vari fattori.
Secondo Cattell (1978, cit. in Kline, 1994, trad. it. 1997, p. 69), i fattori a struttura semplice oltre alla facilità di interpretazione godono delle se-guenti proprietà: - sono più facilmente replicabili; la replicabilità della struttura semplice
si estende anche ai casi in cui le variabili rilevate non siano del tutto identiche a quelle rilevate nella ricerca precedente;
- negli studi su matrici artificiali, in cui i fattori sottostanti (detti ‘pla-smodi’) sono noti, è stato dimostrato che le rotazioni verso una struttu-ra semplice producono fattori che approssimano quelli reali28.
Prima di considerare alcuni dei metodi di rotazione analitici più diffusi nei package statistici, riprendiamo la distinzione, già accennata, tra ro-tazioni ortogonali e rotazioni oblique. Se le prime sono caratterizzate dal vincolo della perpendicolarità degli as-si, nel caso delle rotazioni oblique invece si permette una certa libertà, di grado più o meno ampio, nello stabilire l’ampiezza dell’angolo formato dalle coppie di fattori: detto in altro modo, si permette ai fattori stessi di essere tra loro correlati. Ci si può chiedere il perché di questa ulteriore complicazione. Come osservava Cattell per la ricerca psicologica, e e-stendendo tale osservazione alla ricerca sociale, è quanto mai improbabile pensare che i concetti misurati in questi campi di indagine siano totalmen-te distinti e incorrelati. D’altro canto, se i fattori sono effettivamente in-correlati ciò emergerà anche con una rotazione obliqua29.Ricordiamo che se la rotazione è obliqua, otteniamo due matrici distinte di parametri: la pattern matrix e la structure matrix. La scelta di ricorrere alla seconda piuttosto che alla pattern matrix per interpretare il significato
28 Può essere utile talvolta quantificare la semplicità fattoriale di una variabile o di un fattore, o della matrice dei loading nel suo complesso; alcune semplici misure sono riportate in Barbaranelli, 2003, p. 151-2. 29 Quanto appena detto non significa che la rotazione obliqua sia sempre preferibile. Spesso nell’analisi esplorativa si forzano i fattori all’ortogonalità per renderli chiara-mente distinguibili e per decidere quanti sono in effetti dotati di un significato sostanti-vo autonomo. In un passo successivo, una volta chiarito il numero di fattori da estrar-re, sarà opportuno, a meno di ragioni specifiche, ricorrere a una rotazione obliqua.
50

sostantivo dei fattori estratti è piuttosto soggettiva. Se i fattori sono poco correlati, le due matrici non sono molto diverse; se sono molto correlati, la structure matrix contiene in genere valori più elevati e ciò rende dif-ficile distinguere i diversi fattori tra loro. In pratica, conviene ricorrere alla structure matrix in sede di etichettamento dei fattori quando già dall’esame della pattern matrix emergono dubbi sulla effettiva distin-guibilità di due fattori: se le variabili manifeste risultano correlate allo stesso modo con entrambi i fattori, si può rafforzare l’ipotesi che il fat-tore sostantivo in realtà sia uno solo. La structure matrix infine può es-sere usata, dopo che l’operazione di etichettamento è già avvenuta, per individuare variabili che, pur non risultano validi indicatori di un fattore latente, siano comunque delle proxy di questo30.Nel caso di rotazioni ortogonali, per costruzione i fattori sono incorrela-ti; la pattern e la structure matrix coincidono e contengono le correla-zioni tra variabili manifeste e fattori latenti comuni.
- Varimax Varimax massimizza la somma delle varianze delle saturazioni al qua-drato calcolate in ogni colonna della pattern matrix (diciamo: max V). Ciò ha come effetto, in linea di principio, quello di ottenere che parte delle saturazioni di ogni colonna siano molto prossime a 1, altre molto prossime a zero e poche saturazioni di grandezza intermedia; in tal mo-do i fattori tendono a essere molto distinti tra loro (cosicché l’ope-razione di etichettamento dovrebbe essere agevolata). Non sempre è possibile ottenere una struttura semplice mantenendo l’ortogonalità dei fattori; se però ciò è possibile, allora Varimax è la procedura più efficace.
30 Un esempio è l’uso che fa Inglehart (1990, trad. it 1993, p. 46) della variabile ‘grado di soddisfazione per la propria vita’ per rilevare il civismo degli intervistati; in questo caso è molto chiaro che non c’è un rapporto di indicazione bensì una re-lazione empirica spuria. Un ricercatore che avesse a disposizione per l’analisi se-condaria dei dati contenenti il grado di soddisfazione per la propria vita potrebbe anche spingersi, con molte cautele, a fare alcune considerazioni sul civismo, anche in assenza di adeguati indicatori di quest’ultimo.
51

- QuartimaxTende a rendere massima la somma delle varianze delle saturazioni al quadrato di ogni riga (diciamo max Q): ciò avviene quando una variabile è caricata su un solo fattore. Essa enfatizza pertanto la semplicità di inter-pretazione delle variabili, al contrario di Varimax che enfatizza la sempli-cità di interpretazione dei fattori. Spesso dà origine a un fattore generale, avente saturazioni medio-elevate su tutto il set di variabili. Per tale motivo non viene usato, a meno che non ci siano buone ragioni per ipotizzare l’esistenza di un fattore generale.
- Equamax (o Equimax o Orthomax) Se Quartimax semplifica l’interpretabilità delle righe (variabili) della Pattern Matrix, e Varimax quella delle colonne (fattori), Equamax applica entrambi i criteri con un peso appropriato (diciamo: max aQ + bV).
- Direct ObliminLe soluzioni analitiche delle rotazioni oblique alla struttura semplice so-no numerose (Gorsuch nel 1983 ne illustrava 19, considerandole solo un campione!). Rotazioni oblique analoghe a Varimax sono Covarimin e Biquartimin; analoga a Quartimax è Quartimin. Direct Oblimin è analo-ga a Equamax. Il grado di massima correlazione tra i fattori permessa è governato da un parametro d; di solito è fissato a un valore tale da non permettere una correlazione troppo elevata tra i fattori.
- Promax Questo metodo inizia con una soluzione ortogonale, quale potrebbe essere Varimax. Le saturazioni ottenute vengono poi elevate a potenza: al cre-scere dell’esponente le grandezze delle saturazioni diminuiranno e tale diminuzione sarà tanto più rapida quanto più piccoli sono i valori di par-tenza. La prima soluzione ortogonale viene poi ruotata con un metodo o-bliquo in modo tale da approssimare al meglio la matrice delle saturazioni elevate a potenza31. I fattori risulteranno tanto più correlati tra loro, quan-
31 La rotazione di una matrice di loading verso una matrice obiettivo, seguendo al-cune regole poste a priori (analogamente a quanto avviene nella rotazione verso
52

to più alte sono le potenze a cui sono elevate le saturazioni iniziali.
3.7. La stima dei punteggi fattoriali L'analisi Fattoriale potrebbe ritenersi conclusa una volta estratto un ade-guato numero di fattori e fornita un’interpretazione plausibile. A questo punto però il ricercatore può procedere oltre con un passo sup-plementare, rappresentato dalla stima dei punteggi fattoriali. L'utilità di tali punteggi consiste nel fatto di sostituire dei profili di risposta composti da un numero di stati su variabili manifeste solitamente elevato con dei profili composti da pochi stati su variabili latenti. Inoltre, attraverso una rappre-sentazione grafica dei punteggi individuali sui piani individuati da coppie di fattori, è possibile riconoscere profili di risposta anomali (outliers).A differenza dell'Analisi in Componenti Principali, dove i punteggi indivi-duali vengono calcolati esattamente perché manca la componente aleatoria, nel modello di Analisi Fattoriale essi possono essere soltanto stimati. Alcuni autori ritengono adeguati i coefficienti contenuti nella Pattern Matrix, cioè i regression loading, per la stima dei factor score (Kline, 1994, trad. it. 1997). In realtà, come abbiamo già avuto modo di osser-vare commentando le figure 1 e 2, le saturazioni non rappresentano il contributo delle variabili manifeste alla individuazione dei fattori, ma la dipendenza delle prime dai secondi (per una critica più dettagliata si ve-da Marradi, 1980). È più corretto dunque calcolare dei ‘pesi’ appositi, detti factor score coefficients.Esistono vari metodi per stimare i punteggi fattoriali; uno dei più diffusi è il metodo della regressione, di seguito descritto. Il punteggio indivi-duale sul fattore comune può essere stimato come combinazione lineare delle variabili originarie ricorrendo alla seguente equazione:
Fkn = p1kZ1n + p2kZ2n + ...... + pmkZmn +...... + pMkZMn
dove: Fkn è il punteggio standardizzato del fattore k-esimo per l'in-dividuo n-esimo
una struttura semplice) è detta soluzione di Procuste. In questo caso la matrice o-biettivo è quella dei loading della prima soluzione elevati a potenza.
53

pmk è il coefficiente di regressione standardizzato della variabile m-esima sul fattore k-esimo Zmn è il punteggio standardizzato della variabile m-esima per l'individuo n-esimo
L’equazione differisce da quella di una normale regressione multipla, in quanto non solo i pesi fattoriali p sono ignoti, ma anche la variabile di-pendente F. Quindi il problema diventa quello di stimare i pesi p, senza conoscere i punteggi fattoriali, perché anzi questi andranno calcolati successivamen-te, una volta che i p saranno noti. Fortunatamente, per ottenere i pesi p è irrilevante conoscere i punteggi fattoriali; si può sfruttare invece l’informazione contenuta nelle correla-zioni tra le variabili manifeste (ricavabili dalla matrice di input) e nelle correlazioni tra le variabili manifeste e i fattori comuni (ricavabili struc-ture matrix, o pattern matrix se la rotazione è ortogonale). L’equazione in forma matriciale che lega questi tre tipi di dati è la seguente (per semplicità consideriamo un singolo fattore latente comune, F):
R Ö p = rmF
dove R è la matrice delle correlazioni tra le variabili manifeste, p è il vettore colonna che contiene i pesi fattoriali da stimare, e rmF è un vetto-re colonna delle correlazioni tra le variabili e il fattore comune F. In altri termini, ognuna delle correlazioni tra le singole variabili manifeste e il fattore comune è data dalla somma ponderata di tutte le correlazioni tra la i-esima variabile manifesta e tutte le altre (compresa l’autocorrelazione). Per trovare i pesi fattoriali dobbiamo perciò risolvere la seguente equa-zione:
p = R-1 Ö rMf
ammesso che R sia invertibile.
54

4. La valutazione della soluzione
Nella valutazione del risultato complessivo di una Analisi Fattoriale E-splorativa occorre tenere ben distinti due obiettivi: - stabilire quanto il modello è adatto a sintetizzare e descrivere i dati nel
campione considerato (vedi par. 4.1); - stabilire quanto il modello è significativo da un punto di vista inferen-
ziale (4.2); ovviamente l’applicazione di valutazioni inferenziali pre-suppone che il campione sia probabilistico.
La ricerca di misure complessive di fit non esaurisce la problematica della valutazione: è anche necessario considerare criteri di valutazione locali, soprattutto riferiti a ogni singolo fattore estratto (4.3).
4.1. Indici descrittiviSono tre i criteri principali per valutare globalmente il successo di una Analisi Fattoriale da un punto di vista descrittivo (Ricolfi, 1987): - della varianza spiegata, o comunalità; - della parsimonia; - dell’adattamento.
Per varianza spiegata (o comunalità) si intende la capacità dei fattori estratti di rendere conto della variabilità presente nell’insieme delle va-riabili manifeste. Naturalmente al crescere della dimensionalità del mo-dello fattoriale, ossia all’aumentare del numero di fattori latenti, aumen-
55

ta la quota di varianza spiegata. In altre parole, all’aumentare dei benefi-ci (in termini di comunalità totale) richiesti al modello teorico aumenta-no anche i costi da affrontare, soprattutto in termini di un maggior nu-mero di fattori estratti. In sede di valutazione dell’esito di una Analisi Fattoriale, si impone dunque la necessità di ricorrere, in aggiunta ad un criterio di varianza spiegata, anche ad un criterio di parsimonia della soluzione. Per esem-pio: un modello che riproduce il 60% della varianza totale di un insieme di otto item, è un buon risultato se il numero di fattori utilizzati è pari a 2, piuttosto scadente se i fattori sono quattro. Il criterio della varianza spiegata e quello della parsimonia si possono combinare in un unico criterio di rendimento32 che tenga conto al con-tempo dei costi e dei benefici dell’analisi. Il rendimento globale di una soluzione fattoriale si calcola nel seguente modo:
rend = K
Mh2 Ö
dove: h2 è la comunalità (varianza spiegata dai fattori comuni) M è il numero delle variabili K è il numero dei fattori
Sulla scorta di diverse ricerche empiriche, possiamo adottare la regola del pollice che quest’indice non sia inferiore a 2: questo risultato indica che i benefici ottenuti sono doppi rispetto ai costi sostenuti. Un tale ren-dimento è auspicabile indipendentemente dalla percentuale di varianza spiegata e dal numero di fattori estratti. L’idea di un indice di adattamento per la valutazione del modello si può trovare già in Thurstone (1947), anche se è soprattutto grazie ai lavori di Harman e Jones (1966) della metà degli anni sessanta che questo criterio di valutazione si è affermato. Con il termine adattamento si intende la capacità dei fattori estratti di riprodurre le correlazioni tra le variabili originarie. Secondo Thurstone, dopo aver estratto il primo fattore, si deve verifica-re la significatività della matrice dei residui: dunque, per i residui diver-
32 Dal momento che il criterio di rendimento non è logicamente indipendente ri-spetto quelli di varianza spiegata e parsimonia, esso non compare nell’elenco dei criteri di fit descrittivo.
56

si da zero, valutare la probabilità che tale differenza sia casuale. Se tale matrice contiene residui significativamente diversi da zero, occorre e-strarre un secondo fattore, e così via (in realtà per Thurstone questo era un criterio di scelta del numero dei fattori, e non un criterio di valuta-zione del fit del modello). Presa alla lettera questa indicazione, ha però lo svantaggio di portare a una rappresentazione il più delle volte poco parsimoniosa. Ci chiedia-mo allora: per giudicare soddisfacente una soluzione di una Analisi Fattoriale, tutti i residui devono essere non significativamente diversi da zero o la maggior parte di essi? E nel caso la risposta fosse la se-conda: in che percentuale? Occorre dire che non esistono a tal proposi-to risposte precise. Una regola di buon senso è quella di lasciare al ri-cercatore la scelta di tale percentuale, possibilmente fatta prima di ini-ziare l’analisi fattoriale. Presentiamo due modi di formalizzare il criterio dell’adattamento: un primo indice di valutazione, che chiamiamo repr, può essere ricavato dalla matrice Rres: si conta il numero di residui maggiori di |0,05| e se ne calcola la percentuale sul totale dei residui. In linea di massima, una percentuale di residui minore del 10% è considerata soddisfacente; con numerosità campionarie basse (diciamo al di sotto di 1000 casi) si pos-sono considerare soddisfacenti anche valori un po’ più elevati. Un altro indice di adattamento si può utilizzare se viene applicato ULS, ricorrendo allo stesso valore della funzione di adattamento usata come criterio di estrazione dei fattori. Poiché il valore di tale funzione dipende dal numero di variabili osservate, il suo valore minimo va relativizzato. Per rendere la misura indipendente dall’ordine della matrice di corre-lazione (pari al numero delle variabili) si utilizza come criterio l’indice RMSR (Root Mean Squared Residuals), che ha la seguente formula:
2/12mjd
2/)1M(M1
RMSR ùú
øéê
èÖ
-= ä
dove d indica lo scarto tra correlazioni effettive e riprodotte, M il nume-ro delle variabili. Come rule of thumb si può ritenere soddisfacente un RMSR ¢ 0,05 te-
57

nendo conto che si tratta di una regola molto lasca. In una Analisi Fattoriale, a differenza di quanto avviene nella Analisi in Componenti Principali, il primato non dovrebbe andare alla coppia parsi-monia e varianza, bensì alla coppia parsimonia e adattamento. Ciò è abba-stanza facile da comprendere, se si ricorda che l’Analisi Fattoriale mira principalmente a spiegare una ampia serie di correlazioni con pochi fattori. Ciò non significa che la varianza spiegata non conta nulla, ma solo che in linea di massima dovrebbe essere secondaria rispetto all’adattamento.
4.2. Un indice inferenziale Quando si utilizza come metodo di estrazione ML (o anche GLS), nell’output viene fornito anche un indice di bontà di adattamento del mo-dello ai dati, con il quale si valuta se il numero dei fattori estratti è suffi-ciente a rendere conto delle relazioni tra variabili manifeste. Per campioni probabilistici estratti da popolazioni normali multivariate, la statistica test tende, al crescere della numerosità campionaria, a distribuirsi secondo la variabile aleatoria chi quadrato (Albano, Testa, 2002, p. 181-2). Occorre sottolineare una importante differenza circa l’interpretazione di questa statistica per la valutazione della bontà di adattamento del modello rispetto a quella, probabilmente familiare a molti tra i lettori, adottata nel test di associazione tra variabili categoriali (tavole di con-tingenza). In questo secondo caso, lo ricordiamo, i valori alti della statistica-test permettono di respingere l’ipotesi nulla che afferma l’assenza di rela-zione tra le variabili (Albano, Testa, 2002, pp. 234 e ss.). Nel caso in esame invece, sono desiderabili valori bassi della statistica-test, che ci permettano di non respingere l’ipotesi nulla, che afferma che i dati ri-prodotti dal modello non sono significativamente diversi da quelli ori-ginari (il che equivale a dire che il numero di fattori estratti è suffi-ciente a interpretare la matrice di correlazioni). Supponiamo di avere sottoposto ad analisi fattoriale una batteria di 20 item, e di essere incerti sul numero di fattori da estrarre. Supponiamo inoltre che ci siano le condizioni per applicare ML, e che i risultati di due prove, rispettivamente a 6 e a 7 fattori, siano i seguenti:
58
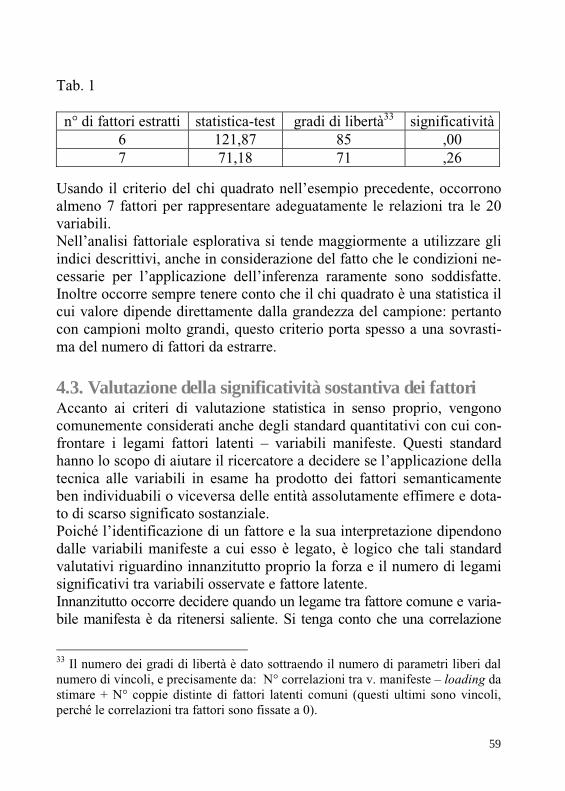
Tab. 1
n° di fattori estratti statistica-test gradi di libertà33 significatività 6 121,87 85 ,00 7 71,18 71 ,26
Usando il criterio del chi quadrato nell’esempio precedente, occorrono almeno 7 fattori per rappresentare adeguatamente le relazioni tra le 20 variabili. Nell’analisi fattoriale esplorativa si tende maggiormente a utilizzare gli indici descrittivi, anche in considerazione del fatto che le condizioni ne-cessarie per l’applicazione dell’inferenza raramente sono soddisfatte. Inoltre occorre sempre tenere conto che il chi quadrato è una statistica il cui valore dipende direttamente dalla grandezza del campione: pertanto con campioni molto grandi, questo criterio porta spesso a una sovrasti-ma del numero di fattori da estrarre.
4.3. Valutazione della significatività sostantiva dei fattori Accanto ai criteri di valutazione statistica in senso proprio, vengono comunemente considerati anche degli standard quantitativi con cui con-frontare i legami fattori latenti – variabili manifeste. Questi standard hanno lo scopo di aiutare il ricercatore a decidere se l’applicazione della tecnica alle variabili in esame ha prodotto dei fattori semanticamente ben individuabili o viceversa delle entità assolutamente effimere e dota-to di scarso significato sostanziale. Poiché l’identificazione di un fattore e la sua interpretazione dipendono dalle variabili manifeste a cui esso è legato, è logico che tali standard valutativi riguardino innanzitutto proprio la forza e il numero di legami significativi tra variabili osservate e fattore latente. Innanzitutto occorre decidere quando un legame tra fattore comune e varia-bile manifesta è da ritenersi saliente. Si tenga conto che una correlazione
33 Il numero dei gradi di libertà è dato sottraendo il numero di parametri liberi dal numero di vincoli, e precisamente da: N° correlazioni tra v. manifeste – loading da stimare + N° coppie distinte di fattori latenti comuni (questi ultimi sono vincoli, perché le correlazioni tra fattori sono fissate a 0).
59

pari a 0,3 indica che il 9% della varianza della seconda è riprodotta dal primo. Questo valore è considerato generalmente come la soglia minima di salienza di una correlazione variabile manifesta – fattore latente. Pertanto, le variabili manifeste da utilizzare per identificare il fattore dovrebbero ave-re una correlazione con quest’ultimo uguale o superiore a tale soglia. Que-sto limite inferiore non è però da interpretare in modo troppo rigido: si pos-sono accettare anche valori leggermente inferiori se il modello è parsimo-nioso. Ma nella scelta di tale soglia intervengono anche valutazioni di carat-tere disciplinare. Questo livello infatti può anche essere abbassato in una ricerca dove abbiamo a che fare con costrutti molto sfaccettati (perché irri-ducibilmente complessi, come capita spesso in sociologia, o perché ancora poco raffinati da un punto di vista concettuale).34
Comrey e Lee (1992, trad. it. 1995, p. 317) propongono il seguente standard per decidere dell’utilità potenziale di una variabile manifesta nell’interpretazione del fattore (tab. 2).
Tabella 2 correlazione (*) % di varianza spiegata valutazione ,71 50% eccellente ,63 40% molto buona ,55 30% buona ,45 20% sufficiente ,32 10% scarsa
(*) Si ricorda che esse coincidono con le saturazioni quando si è attua-ta una rotazione ortogonale; nel caso di rotazione obliqua le correla-zioni sono contenute nella structure matrix. Fattori con correlazioni solo sufficienti o scarse richiedono cautela nell’interpretazione. Con molte valutazioni buone si può essere un po’ più definitivi nel dare un
34 In psicometria, il livello minimo accettato dei loading è di solito più elevato, in quanto i fattori latenti oggetto di misura sono costrutti più circoscritti nella defini-zione. Una pratica è quella di eliminare gli item con loading più bassi e condurre nuovamente l’Analisi Fattoriale (pratica ripresa anche nella ricerca sociale: cfr. Marradi in Borgatta, Jackson, 1981, Gangemi, 1982).
60

nome al fattore35.
Per valutare la significatività sostantiva dei fattori estratti, vanno consi-derati tre aspetti strettamente interconnessi: a) la sovradeterminazione dei fattori; b) la significazione, ossia l’attribuzione di un significato, soprattutto at-traverso i marker; c) la gerarchia dei fattori.
a) Per sovradeterminazione dei fattori si intende l’esistenza di un buon numero di variabili con saturazioni significativamente diverse da zero nel fattore (quando la rotazione è obliqua è bene considerare i regression loa-ding per decidere se un fattore è sovradeterminato o meno).
b) Alcune delle saturazioni significativamente diverse da zero, diciamo non meno di tre, devono essere elevate solo su un fattore; le variabili con saturazioni elevate su un solo fattore sono chiamate marker nella letteratura psicometrica. Se ci sono troppe variabili complesse i fattori saranno difficilmente distinguibili e interpretabili.
c) D’altro canto, fattori identificati solo da variabili molto simili fra loro da un punto di vista di contenuto semantico sono di scarso interesse; si parla in tal caso di fattori situati a un livello molto basso nella gerarchia dei fattori. Conviene eliminare i ‘doppioni’ e vedere se emerge ugual-mente il fattore. Oppure si può procedere a una sotto-estrazione, cioè e-strarre un numero inferiore di fattori anche se ciò peggiora il fit del mo-dello.
35 A volte emergono fattori che sono idiosincratici agli specifici casi scelti (cioè non emergerebbero se avessimo selezionato altre unità). Per evitare questo proble-ma, Nunnally propone una regola-del-pollice: è necessario che i casi siano almeno 10 volte più numerosi delle variabili manifeste (Nunnally, 1978).
61


5. Istruzioni software
Le procedure computazionali che stanno alla base dell’Analisi Fattoriale si trovano implementate nei package e nei software statistici più diffusi. Vediamo ora come si esegue un’analisi fattoriale con il package SPSS (ver. 9.0)36; verranno inoltre mostrati i principali oggetti che costitui-scono l’output ottenuto con questo software. Prima di passare all’esame di alcuni esempi realizzati con SPSS è utile riepilogare i principali ele-menti che sono coinvolti nella tecnica:
1. La matrice di input (tipicamente la matrice di correlazioni diretta-mente immessa dal ricercatore o calcolata dalla procedura a partire dalla CxV);
2. L'elenco delle variabili di cui andrà specificato il nome e il modo di trattare gli eventuali valori mancanti (missing values);
3. Il criterio con cui stabilire il numero di fattori da estrarre; 4. Il metodo di estrazione dei fattori; 5. Il metodo dell’eventuale rotazione dei fattori; 6. Il metodo dell’eventuale stima dei punteggi fattoriali;
SPSS offre un'ampia scelta di opzioni per ciascuno di questi punti che dovrebbero, a rigore, essere ognuno oggetto di attente valutazioni da parte dell’analista.
36 Al momento della revisione finale di questo paper (maggio 2004) è disponibile la versione 12.0 di SPSS; tuttavia, dal nostro punto di vista, non ci sono cambiamenti procedurali significativi rispetto alla versione qui considerata.
63

Il package, come per ogni altra tecnica, offre dei valori di default, cioè predefiniti; sconsigliamo però un loro uso acritico: infatti è proprio in questo caso che si corre il rischio di incappare in uno dei maggiori errori metodologici che si annidano nella procedura FACTOR così come è implementata. SPSS, come altri package del resto, considera il metodo di estrazione delle Componenti Principali (PC) come metodo di default per un’analisi fattoriale. Da quanto abbiamo detto in precedenza, do-vrebbe essere a questo punto chiaro che invece le due tecniche non an-drebbero confuse.
A questo punto è utile riassumere in un quadro sinottico i valori di de-fault del package (perlomeno per quanto concerne gli aspetti principali delle sintassi).
Tabella 3 Matrice dati in input CxV Trasformazione in input minimo Correlazioni Metodo di estrazione Componenti Principali Numero di fattori da estrarre Numero di autovalori ²1Metodo di rotazione nessunoNumero max di iterazioni per la convergenza nell’estrazione
25
Soglia di convergenza nell’estrazione (*) p<0,001Criterio di convergenza per la rotazione nessunoValori mancanti LISTWISE
(*)Questo valore rappresenta la soglia sotto cui l'algoritmo converge, interrompendo le iterazioni. Ciò accade quando l'incremento del valore di comunalità è minore di 0,001.
Di seguito sono riportate le istruzioni di tre diversi programmi con SPSS, ciascuno dei quali si differenzia dagli altri per alcune scelte di analisi.
64

**1° Programma** FACTOR /VARIABLES v1 to v12 /MISSING LISTWISE /PRINT UNIVARIATE INITIAL REPR EXTRACTION ROTATION /PLOT EIGEN ROTATION /CRITERIA FACTORS (3) ITERATE (25) /EXTRACTION ULS /CRITERIA ITERATE (25) DELTA (0) /ROTATION OBLIMIN
/METHOD CORRELATION.
Nell’ordine, le istruzioni di questo programma indicano: - quali sono le variabili coinvolte, in questo caso dalla v1 alla v12 nel-
la CxV [VARIABLES]; - il criterio adottato per trattare i missing values [MISSING LISTWISE37];- la richiesta di fornire nell’output le statistiche descrittive monovaria-
te (media e deviazione standard) per ogni variabile manifesta [PRINT UNIVARIATE]; la soluzione iniziale cioè le statistiche iniziali con tanti fattori quante sono le variabili manifeste e i relativi eigenvalue [PRINT INITIAL]; la matrice delle correlazioni riprodotte [PRINT REPR] dove sulla diagonale principale sono presenti le comunalità stimate, nel triangolo sinistro inferiore le correlazioni riprodotte, nel triangolo destro superiore i residui tra le correlazioni osservate e quelle riprodotte e in calce è riportata la percentuale di residui con valore assoluto maggiore di 0,05; la soluzione a 3 fattori non ruotata [PRINT EXTRACTION]; la soluzione a 3 fattori ruotata [PRINT ROTATION], cioè la pattern matrix, la structure matrix e la matrice di correlazione tra i fattori;
- Il grafico di caduta degli autovalori (scree plot) [PLOT EIGEN] e il gra-fico con la rappresentazione delle variabili manifeste nello spazio fatto-riale ruotato avente come assi i fattori estratti [PLOT ROTATION];
- il criterio di scelta del numero di fattori da estrarre; in questo caso viene fissato a 3 [CRITERIA FACTORS (3)]; il numero massimo di ite-razioni dell’algoritmo di stima delle saturazioni [ITERATE (25)];
- Il metodo di estrazione prescelto [EXTRACTION ULS]; 37 Listwise significa esclusione dall’analisi di tutti i casi che hanno almeno un valo-re mancante su una qualunque delle variabili manifeste introdotte nel modello.
65

- Il metodo di rotazione in questo caso direct oblimin [ROTATION
OBLIMIN], con parametro di obliquità d fissato a zero, come di de-fault [DELTA(0)]; il numero massimo di iterazioni dell’algoritmo di rotazione [CRITERIA ITERATE (25)];
- l’input minimo è rappresentato dalla matrice di correlazioni [ME-THOD=CORRELATION].
**2° Programma** FACTOR /VARIABLES v1 to v12 /MISSING PAIRWISE /PRINT UNIVARIATE INITIAL REPR EXTRACTION ROTATION /FORMAT SORT /CRITERIA FACTORS (4) ITERATE (25) /EXTRACTION ML /CRITERIA ITERATE (25) /ROTATION VARIMAX
/SAVE = REG(ALL)/METHOD CORRELATION.
Rispetto al programma precedente, le differenze riguardano: il criterio adottato per trattare i missing values [MISSING PAIRWISE38]; - la richiesta di ordinare le variabili manifeste della pattern e della
structure matrix secondo valori decrescenti delle saturazioni sui ri-spettivi fattori latenti [FORMAT SORT];
- il numero di fattori da estrarre, fissato a 4 [CRITERIA FACTORS (4)]; - il metodo di estrazione prescelto [EXTRACTION ML]; - il metodo di rotazione prescelto [ROTATION VARIMAX]
38 Pairwise significa selezione di casi per coppie di variabili, a fronte di quella ge-neralizzata rappresentata da Listwise. Ciò significa nel nostro caso che dovendo calcolare la correlazione tra le variabili manifeste X1 e X2 si considerano validi tutti quei casi che non hanno missing su una delle due variabili, indipendentemente dal fatto che abbiano missing su altre coppie di variabili. L’utilizzo di questo criterio ha il vantaggio di trattare più informazione rispetto a listwise, ma può dare origine a matrici non positive semidefinite e quindi non processabili dalla tecnica.
66

- la stima dei punteggi fattoriali con il metodo della regressione, che vengono salvati come nuove variabili nella matrice dei dati [SAVE = REG(ALL)].
**3° Programma** FACTOR
/MATRIX=IN (COR=*)/PRINT INITIAL REPR EXTRACTION /CRITERIA MINEIGEN (1) ITERATE(25) /EXTRACTION GLS/CRITERIA ITERATE (50)/ROTATION NOROTATE/METHOD CORRELATION.
Gli elementi di novità in quest’ultimo programma sono:
- i dati di input sono rappresentati da una matrice delle correlazioni tra le variabili manifeste [MATRIX=IN (COR=*)];
- il numero di fattori estratti è stabilito sulla base del numero di ei-genvalues maggiori di 1 [CRITERIA MINEIGEN (1)];
- il metodo di estrazione è [EXTRACTION GLS]; - gli assi fattoriali non vengono ruotati [ROTATION NOROTATE]; - il numero massimo di iterazioni dell’algoritmo di rotazione [CRITE-
RIA ITERATE(50)]
Riepilogando i principali elementi informativi che compaiono nell’output della procedura FACTOR sono i seguenti:
1. Statistiche descrittive 2. Comunalità (iniziali e finali) 3. Varianza totale spiegata (iniziale e finale) 4. Grafico decrescente degli autovalori (eigenvalues) 5. Matrice fattoriale (Factor matrix)6. Matrice delle correlazioni riprodotte
- Comunalità riprodotte sulla diagonale principale - Residui nel triangolo superiore
7. Matrice dei modelli (Pattern matrix)
67

8. Matrice di struttura (Structure matrix)9. Matrice di correlazione tra i fattori 10. Matrice dei coefficienti di punteggio fattoriale
Serviamoci ora di un esempio classico dal punto di vista didattico, tratto da Lawley e Maxwell (1963). Sono stati raccolti i voti di profitto di 220 studenti su 6 test scolastici (variabili manifeste): gaelico (Z1), inglese (Z2), storia (Z3), aritmetica (Z4), algebra (Z5), geometria (Z6). L'obiettivo di questo studio era quello di individuare dei fattori latenti che fossero in grado di spiegare le interrelazioni tra i 6 test di profitto. Per prima co-sa sono state calcolate le correlazioni tra tutte le coppie di variabili e raggruppate nella matrice delle correlazioni:
Tabella 4 1,000
,439 1.000 ,410 ,351 1.000,288 ,354 ,164 1.000,329 ,320 ,190 ,595 1.000,248 ,329 ,181 ,470 ,464 1.000
Si tratta della matrice delle correlazioni osservate Ru nella cui diago-nale principale sono presenti valori pari a 1 (autocorrelazione di cia-scuna variabile).
Per raggiungere l'obiettivo prefissato è stata eseguita una factor tramite il seguente programma: FACTOR /MATRIX=IN (COR=*) /PRINT INITIAL REPR EXTRACTION ROTATION /PLOT EIGEN ROTATION /CRITERIA FACTORS(2) ITERATE(25) /EXTRACTION ULS /CRITERIA ITERATE(25) /ROTATION OBLIMIN.
Si noti che nell'esempio presentato abbiamo rinunciato ad adottare i va-
68

lori di default della tecnica, per operare precise scelte: - L'input della tecnica è rappresentato da una matrice di correlazioni
osservate che viene letta come "matrice dati" dall'editor dei dati di SPSS. L'istruzione MATRIX IN al posto di quella vista negli esempi precedenti (VARIABLES) consente di avere in ingresso una matrice di correlazione anziché una di dati grezzi.
- Come metodo di estrazione abbiamo optato per Unweighted Least Squares
- Circa il numero di fattori da estrarre si è deciso di estrarne 2, assu-mendo le indicazioni fornite dagli autori dello studio. Il numero di fattori estratti non sarebbe comunque diverso se adottassimo il crite-rio dell’eigenvalue >1 (quello di default).
- Per quel che riguarda il metodo di rotazione prescelto, è stata opera-ta una rotazione obliqua con il metodo OBLIMIN senza modificare il default relativo all’angolo di rotazione (d=0).
Qui di seguito riportiamo alcuni elementi dell'output:
Tabella 5
Varianza totale spiegata
2,733 45,548 45,548 2,223 37,042 37,042
1,130 18,830 64,378 ,592 9,863 46,905,615 10,253 74,630
,601 10,020 84,651,525 8,747 93,397
,396 6,603 100,000
Fattore12
34
56
Totale % di varianza % cumulata Totale % di varianza % cumulata
Autovalori iniziali Pesi dei fattori non ruotati
Metodo di estrazione: Minimi quadrati non pesati.
69

Figura 11
Grafico decrescente degli autovalori
Fattore
654321
Aut
ovalo
re
3,0
2,5
2,0
1,5
1,0
,5
0,0
Tabella 6
Matrice fattoriale a
,587 ,379,594 ,236,431 ,412
,712 -,336,701 -,276,584 -,184
gaelicoinglesestoriaaritmetica
algebrageometria
1 2
Fattore
Metodo estrazione: minimi quadrati non pesati.
2 fattori estratti. 5 iterazioni richieste.a.
70
Tab
ella
7
Co
rrel
azio
ni r
ipro
do
tte
,488
b,4
38,4
09,2
91,3
07,2
73,4
38,4
08b
,353
,344
,351
,303
,409
,353
,356
b,1
69,1
88,1
76,2
91,3
44,1
69,6
21b
,592
,478
,307
,351
,188
,592
,567
b,4
60
,273
,303
,176
,478
,460
,375
b
,001
1,0
009
-,00
28,0
223
-,02
51,0
011
-,00
22,0
101
-,03
11,0
255
,000
9-,
0022
-,00
46,0
017
,005
0
-,00
28,0
101
-,00
46,0
031
-,00
78,0
223
-,03
11,0
017
,003
1,0
042
-,02
51,0
255
,005
0-,
0078
,004
2
gael
ico
ingl
ese
stor
ia
aritm
etic
aal
gebr
age
omet
ria
gael
ico
ingl
ese
stor
iaar
itmet
ica
alge
bra
geom
etria
Cor
rela
zion
e rip
rodo
tta
Res
idui
a
gael
ico
ingl
ese
stor
iaar
itmet
ica
alge
bra
geom
etria
Met
odo
di e
stra
zion
e: M
inim
i qua
drat
i non
pes
ati.
I res
idui
ven
gono
cal
cola
ti tr
a le
cor
rela
zion
i oss
erva
te e
rip
rodo
tte. S
ono
disp
onib
ili 0
(,0
%)
resi
dui n
onrid
onda
nti c
on v
alor
i ass
olut
i mag
gior
i di 0
,05.
a.
Com
unal
ità r
ipro
dotte
b.
71
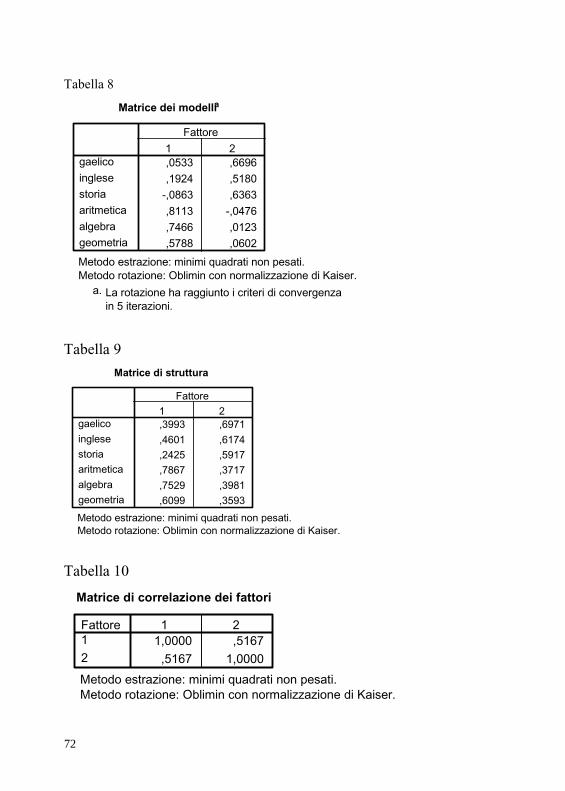
Tabella 8
Matrice dei modellia
,0533 ,6696,1924 ,5180
-,0863 ,6363
,8113 -,0476,7466 ,0123,5788 ,0602
gaelico
inglesestoriaaritmetica
algebrageometria
1 2
Fattore
Metodo estrazione: minimi quadrati non pesati. Metodo rotazione: Oblimin con normalizzazione di Kaiser.
La rotazione ha raggiunto i criteri di convergenzain 5 iterazioni.
a.
Tabella 9
Matrice di struttura
,3993 ,6971
,4601 ,6174,2425 ,5917,7867 ,3717
,7529 ,3981,6099 ,3593
gaelico
inglesestoriaaritmetica
algebrageometria
1 2Fattore
Metodo estrazione: minimi quadrati non pesati. Metodo rotazione: Oblimin con normalizzazione di Kaiser.
Tabella 10
Matrice di correlazione dei fattori
1,0000 ,5167,5167 1,0000
Fattore12
1 2
Metodo estrazione: minimi quadrati non pesati. Metodo rotazione: Oblimin con normalizzazione di Kaiser.
72
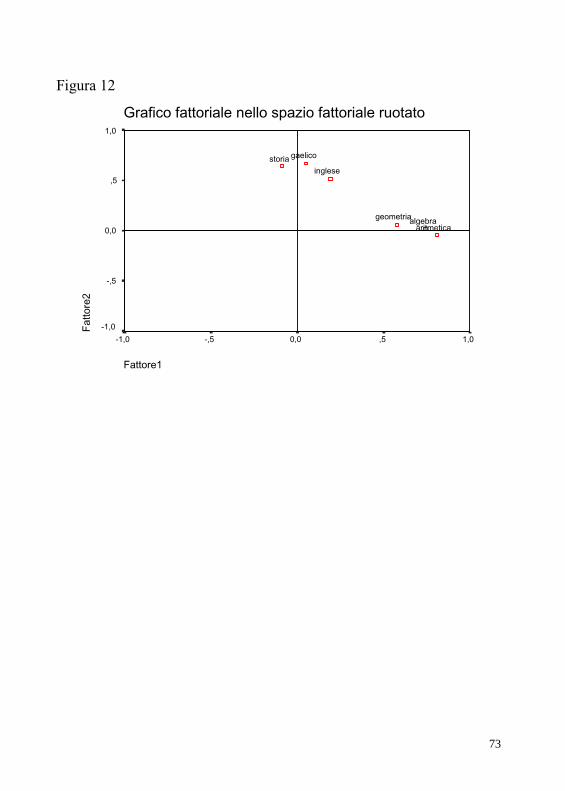
Figura 12
Grafico fattoriale nello spazio fattoriale ruotato
Fattore1
1,0,50,0-,5-1,0
Fat
tore
2
1,0
,5
0,0
-,5
-1,0
geometriaalgebraaritmetica
storiainglese
gaelico
73


6. Un’applicazione alla ricerca sociale
Faremo ora riferimento a un’analisi secondaria, condotta sui dati della EVS – European Values Survey del 1990, che ha avuto tra i suoi prin-cipali obiettivi l’individuazione delle dimensioni fondamentali su cui si articola la sfera dei valori morali della cittadinanza, “intesi come giudizi su ciò che è bene e ciò che è male, giustificabile o ingiustifica-bile rispetto a un insieme di atti nei confronti dei beni pubblici e dei diritti della persona” (Sciolla, 1999, p. 282). Questa analisi ha riguar-dato oltre all’Italia anche la Francia, la Gran Bretagna, la ex Repubbli-ca Federale Tedesca e la ex Repubblica Democratica Tedesca, fa parte di una più ampia ricerca sulla cultura civica in Italia (per approfondi-menti rinviamo a: Albano, Loera, 2004; Loera, 2004; Sciolla, cit.; Sciolla 2003) . Vediamo il modo con cui, utilizzando l’Analisi Fatto-riale, si è giunti a individuare le dimensioni fondamentali della morale. Come sottolinea Sciolla nell’articolo citato, la sfera dei valori morali “si presenta assai più complessa e meno omogenea di quanto si è soliti pensare” (per ulteriori approfondimenti Cfr. Sciolla, Negri, 1996, e Sciolla, 1997). Analizzando i dati della EVS 1990 relativi ai paesi cita-ti, si possono evidenziare tre dimensioni sottostanti a un certo numero di atteggiamenti verso: - atti lesivi di interessi pubblici, collettivi o privati, che definiamo di-mensione del ‘civismo’ in senso stretto (ovviamente è considerato ‘civi-co’ un rifiuto di tali atti);
75

- comportamenti nella sfera privata che sono oggetto di disputa circa la loro legittimità dal punto di visto religioso, morale e del diritto; eti-chettiamo questa dimensione come ‘liberalismo morale’ (si considera liberale, laica o persino libertaria, una posizione che non condanna moralmente questo tipo di comportamenti);
- comportamenti di assunzione di rischio per sé e per gli altri, propensione a generare confusione e provocazione, ovvero dimensione del ‘rischio’.
Tabella 11 etichetta descrizione
abuso benefici ottenere dallo Stato benefici a cui non si ha diritto no biglietto non pagare il biglietto sull’autobus evadere tasse evadere (in tutto o in parte) le tasse ricettazione comprare oggetti rubati joyriding guidare senza permesso l’auto di altri usare hashish usare marijuana o hashish denaro trovato tenersi del denaro trovato mentire dire il falso nel proprio interesse relazioni extracon. avere relazioni con persona sposata sesso tra minori avere relazioni sessuali tra minorenni bustarelle accettare bustarelle nell’adempimento del proprio dovere omosessualità l’omosessualità prostituzione la prostituzione aborto l’aborto divorzio il divorzio scontro polizia avere uno scontro con la polizia eutanasia l’eutanasia suicidio il suicidio danno auto non segnalare il danno fatto a auto in sosta minacce a lavoratori minacciare i lavoratori che non scioperano uccidere per difesa uccidere per difendersi assassinio politico uccidere per motivi politici inquinare disperdere rifiuti nell’ambiente guidare ubriachi guidare in stato di ubriachezza
76

La batteria è composta da 24 item relativi a giudizi di giustificabilità di azioni, rilevati con una scala di valutazione che va da 1 (mai giustifica-to) a 10 (sempre giustificato); gli argomenti sottoposti al giudizio degli intervistati sono riportati nella tabella 11.
Vediamo ora i risultati dell’applicazione del modello di analisi fattoriale.
Le scelte operate sono uguali per tutte le analisi qui riportate, con una unica eccezione relativa al campione della Germania dell’est (vedi nota 35). La matrice di input è sempre una matrice di correla-zioni prodotto-momento, calcolate con il programma PRELIS su 6 censored39 e 18 variabili di tipo ordinale normalizzate. Sono state considerate below censored (cioè a ‘pavimento’) quelle variabili che presentano almeno il 70% dei rispondenti nella modalità inferiore (modalità 1 della scala)40. Il metodo di estrazione dei fattori utilizza-to è quello dei minimi quadrati non pesati, ULS; anche se il tipo di campionamento avrebbe potuto legittimare l’uso di ML, abbiamo preferito utilizzare un metodo distribution-free (tenuto anche conto che non si intendeva utilizzare la statistica chi quadrato, data la nu-merosità dei campioni). Per la rotazione è stata utilizzato il metodo direct oblimin, in quanto era nelle nostre aspettative che questi fattori avessero ampie aree di sovrapposizione semantica e che quindi fosse-
39 Accade spesso che nella rilevazione di atteggiamenti i punteggi grezzi siano forte-mente concentrati ad un estremo della distribuzione: detto in altri termini, un’ampia frazione del campione risponde utilizzando una categoria estrema della scala, che as-sume il nome di categoria ‘pavimento’ o ‘soffitto’ a seconda che si collochi al valore più basso o a più alto della scala di misurazione (per quanto concerne il nostro di-scorso: ingiustificabilità / giustificabilità del comportamento). Queste variabili sono note come censored variables e richiedono un trattamento particolare (ma molto si-mile al calcolo delle correlazioni policoriche) per il loro impiego nel calcolo di una matrice di momenti (Jöreskog, Sörbom, 1986). 40 Si tratta di una scelta volontariamente restrittiva; i motivi sono due: uno è quello di non avere troppe variabili censored per le quali le categorie di rispo-sta diverse da quella estrema sono considerate come aventi distanze uguali (scale di intervalli); il secondo è di natura più pratica, e concerne il fatto che tale soglia permette di individuare, con poche significative eccezioni, sempre le stesse censored nei cinque campioni nazionali.
77

ro correlati. Per la rotazione è stata utilizzato il metodo direct obli-min, in quanto era nelle nostre aspettative che questi fattori avessero ampie aree di sovrapposizione semantica e che quindi fossero correlati. 41
41 Nel campione complessivo le correlazioni tra fattori sono le seguenti: civi-smo*diritti=,46; diritti*rischio=,32; civismo*rischio=,61. Per una corretta interpretazione delle correlazioni tra i fattori occorre ricordare l’orientamento degli indicatori: questi sono tutti costituiti da scale che variano da 1 = ‘comportamento mai giustificabile’ a 10 = ‘comportamento sempre giustificabile’ Di conseguenza i tre fattori latenti, ancorati alle variabili manifeste, costituiscono tre continuum dove l’estremo sinistro individua una po-sizione di ‘rigidità’, nel senso di assoluto divieto dei comportamenti implicati; l’estremo destro, viceversa, individua una posizione di totale ‘permissivismo’; infine, il punto cen-trale del continuum individua coloro che hanno una concezione condizionale (‘relativisti-ca’ dei divieti. Si tenga conto che il parametro d, che governa il grado di obliquità massi-ma, è stato lasciato a 0, cioè il valore di default del programma, perché così si ottiene una matrice di loading che si avvicina alla struttura semplice (nota come direct quartimin)(Cfr. Comrey, Lee, 19922, trad. it. 1995, p. 488). E’ possibile che questi valori aumentino se si permette un grado di obliquità massimo (d=0,8). Per il campione della Germania dell’est è stato necessario diminuire il grado massimo di obliquità (d= -1) per avere alme-no quattro variabili con loading significativi sul fattore civismo.
78

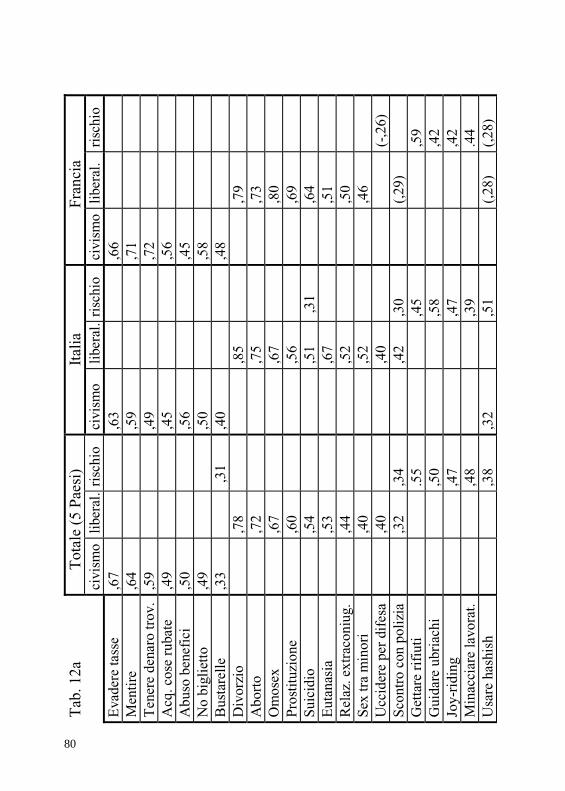
Tab
. 12a
Tot
ale
(5 P
aesi
)
Ita
lia
Fra
ncia
civi
smo
liber
al.
risc
hio
civi
smo
liber
al.
risc
hio
civi
smo
liber
al.
risc
hio
Eva
dere
tass
e ,6
7
,6
3
,6
6
M
entir
e ,6
4
,5
9
,7
1
T
ener
e de
naro
trov
.,5
9
,4
9
,7
2
A
cq. c
ose
ruba
te
,49
,45
,56
Abu
so b
enef
ici
,50
,56
,45
No
bigl
ietto
,4
9
,5
0
,5
8
B
usta
relle
,3
3
,31
,40
,48
Div
orzi
o
,78
,85
,79
A
bort
o
,72
,75
,73
O
mos
ex
,6
7
,6
7
,8
0
Pros
tituz
ione
,60
,56
,69
Su
icid
io
,5
4
,5
1 ,3
1
,64
E
utan
asia
,53
,67
,51
R
elaz
. ext
raco
niug
.
,44
,52
,50
Se
x tr
a m
inor
i
,40
,52
,46
U
ccid
ere
per
dife
sa
,4
0
,4
0
(-,2
6)
Scon
tro
con
poliz
ia
,3
2 ,3
4
,42
,30
(,
29)
G
etta
re r
ifiu
ti
.5
5
,4
5
,5
9 G
uida
re u
bria
chi
,50
,58
,42
Joy-
ridi
ng
,47
,47
,42
Min
acci
are
lavo
rat.
,48
,39
.44
Usa
re h
ashi
sh
,38
,32
,5
1
(,28
) (,
28)
80

Ass
assi
nio
polit
ico
,38
,49
(,29
) D
anno
aut
o
,3
9 ,3
4
,32
,39
N°
casi
: 61
44
1600
85
4 V
aria
nza
spie
gata
: 37
,2%
38
,2%
38
,6%
R
endi
men
to
2,98
3,
06
3,09
R
epr:
9%
10
%
15%
So
no r
ipor
tati
i va
lori
² |,
30|;
quan
do t
utti
i lo
adin
g di
una
var
iabi
le m
anif
esta
son
o in
feri
ori
a ta
le
sogl
ia è
rip
orta
to t
ra (
) qu
ello
più
gra
nde;
i l
oadi
ng d
el f
atto
re ‘
liber
alis
mo’
nel
le c
olon
ne ‘
tota
le’,
‘I
talia
’, ‘
Fran
cia’
e d
el f
atto
re ‘
risc
hio’
nel
la c
olon
na ‘
tota
le’
e ‘I
talia
’, s
ono
stat
i rif
less
i, ci
oè c
am-
biat
i di s
egno
.
81

Tab
. 12b
G
erm
ania
ove
st
G
ran
Bre
tagn
a
Ger
man
ia e
st (
*)
ci
vism
odi
ritti
ri
schi
o ci
vism
o lib
eral
. ri
schi
o ci
vism
olib
eral
. ri
schi
o E
vade
re ta
sse
,71
,74
,31
,4
8 M
entir
e ,6
4
,6
8
,6
2
T
ener
e de
naro
tr
ov.a
to
,52
,55
,47
Ric
etta
zion
e ,5
1
,5
4
,5
8 A
buso
ben
efic
i ,4
5
,4
8
,5
5 N
o bi
glie
tto
,39
,59
,57
Bus
tare
lle
,30
,42
,49
Div
orzi
o
,78
,71
,69
A
bort
o
,69
,74
,66
O
mos
ex
,7
8
,6
1
,6
1
Pros
tituz
ione
,70
,61
,54
Su
icid
io
,5
9
,4
9
,4
7
Eut
anas
ia
,3
6
,5
4
,4
1
Rel
azio
ni
extr
acon
iug.
,42
,40
,35
Sex
tra
min
ori
,4
7
(,24
)
,32
,3
9
Ucc
ider
e pe
r di
fesa
,4
2
,4
3
,4
8
Scon
tro
con
poliz
ia
,35
,31
,43
,3
1 ,3
4 In
quin
are
,63
,33
,50
Gui
dare
ubr
iach
i
,5
1
,5
3
,5
5
82

Joy-
ridi
ng
,44
,59
,65
Min
acci
are
lavo
-ra
t.
,5
5
,4
5
,3
5
Usa
re h
ashi
sh
,36
,3
6 ,3
8 -,
33
,5
8 A
ssas
sini
o
polit
ico
,39
,30
(,19
)
Dan
no a
uto
,62
,49
,51
N°
casi
: 13
83
1274
10
33
Var
ianz
a sp
iega
ta:
40,2
%
37,8
%
35,2
%
Ren
dim
ento
3,
22
3,02
2,
82
Rep
r:
11%
13
%
13%
So
no r
ipor
tati
i val
ori ²
|,30
|; qu
ando
tutti
i lo
adin
g di
una
var
iabi
le m
anif
esta
son
o in
feri
ori a
tale
so-
glia
è r
ipor
tato
tra
() q
uello
più
gra
nde;
i lo
adin
g de
l fat
tore
‘ci
vism
o’ n
ella
col
onna
‘G
erm
ania
ove
st’
e ‘G
erm
ania
est
’, e
del
fat
tore
‘lib
eral
ism
o’ n
ella
col
onna
‘G
erm
ania
ove
st’
sono
sta
ti ri
fles
si.
(*)
Para
met
ro d
elta
di r
otaz
ione
Obl
imin
: -1.
83

Con la stessa parametrizzazione si è proceduto anche all’estrazione di due soli fattori. La soluzione a tre fattori infatti, pur essendo sod-disfacente sul piano dell’adattamento42 in quattro Paesi su cinque, produce un fattore non sovradeterminato nella Germania dell’est. Con la soluzione a due fattori, si ottiene in tutti Paesi una netta di-stinzione tra una dimensione del ‘liberalismo’ e una dimensione che si potrebbe definire ‘responsabilità’ su cui saturano le variabili dei fattori ‘civismo’ e ‘rischio’ della soluzione a tre (peraltro ‘civismo’ e ‘rischio’ sono fortemente correlate seppur distinguibili, anche nella soluzione a tre fattori). Tuttavia, la soluzione a due fattori è notevol-mente peggiore dal punto di vista della capacità del modello di ripro-durre fedelmente le correlazioni tra le variabili43, come si può vedere dai valori dell’indice ‘adattamento’ riportati in tabella 13:
Tabella 13 Adattamento Varianza
spiegata Rendimento
Totale (5 Paesi) 16% 34,8% 2,78 Italia 22% 34,9% 2,79 Francia 24% 35,3% 2,82 Germania ovest 22% 37,1% 2,97 Germania est 19% 32,4% 2,59 Gran Bretagna 19% 35,3% 2,82
42 L’adattamento è stato valutato mediante la percentuale di residui tra correlazioni osservate e correlazioni riprodotte dal modello che sono superiori a |0,05|. Più que-sta percentuale tende a zero, più le correlazioni riprodotte sono considerabili so-stanzialmente uguali a quelle osservate. E’ stata scelta a priori una percentuale in-torno al 10-15% come valore-soglia di tale indice. Questo valore può essere consi-derato eccessivo vista l’ampiezza dei campioni; tuttavia occorre sempre tener conto del rischio di un’inflazionamento, dovuto al response-style, del numero di fattori latenti necessari per riprodurre le correlazioni osservate. 43 Migliora invece il rendimento cioè il rapporto tra comunalità totale e numero di fattori estratti. Questo indice risulta però anche buono nella soluzione a tre: anche in quel caso è al di sopra del valore soglia, 2, (Cfr. par. 4.1).
84

7. Per concludere: dall’Analisi FattorialeEsplorativaa quella Confermativa
Una trattazione dell’Analisi Fattoriale, pur in forma introduttiva, richiede alcuni brevi cenni al modello confermativo, proposto e sviluppato dallo statistico svedese Karl Jöreskog a partire dai primi anni ’70 del secolo scorso (per una trattazione approfondita rinviamo a Corbetta, 1999). Il modello confermativo rappresenta certamente un approccio evoluto perché supera le indeterminatezze del modello esplorativo. Abbiamo visto che il modello esplorativo, non impone alcun vincolo a priori circa il numero dei fattori da estrarre, sui loading, sui legami tra i fattori (comuni e unici). Il modello confermativo permette di porre dei vincoli su ognuno di questi parametri, ma più spesso solo su alcuni di essi. Come minimo il ricercatore specifica a priori il numero di fat-tori latenti. Spesso si desidera ruotare la matrice originariamente calcolata dalla tec-nica verso una matrice bersaglio. Ciò comporta specificare quali loa-ding sono liberi, devono cioè essere stimati dal modello, e quali sono fissati a 0, cioè sono ritenuti nulli a priori. In alcuni casi si desidera ‘an-corare’ i fattori a determinate variabili manifeste, cosa che si ottiene fis-sando il relativo loading al valore di ‘1’. In tal modo viene data al fatto-
85

re una unità di misura (Long, 1983). Ancora: talvolta si ritiene che due indicatori siano intercambiabili, e quindi si dichiara l’uguaglianza di due loading, che poi vengono stimati dal modello con valori eguali. Gli esempi potrebbero proseguire ma ci sembrano sufficienti ad aver da-to un’idea di cosa significhi spostarsi in un ambito confermativo; può essere utile a questo punto fornire una rappresentazione grafica che aiu-ta a cogliere la differenza tra questo approccio e quello esplorativo (si confronti con la figura 3):
Figura 13
F1 F2
1 1
X1 X2 X3 X4 X5 X6
U1 U2 U3 U4 U5 U6
Nell’esempio raffigurato si è imposto che: - i fattori siano due; - i fattori non siano correlati; - marker del primo fattore è, a priori, la variabile X1;- marker del secondo fattore è, a priori, la variabile X6;- il primo fattore è saturato dalle prime tre variabili manifeste e l’altro dalla seconda terna; - due fattori unici sono dichiarati come correlati.
Nell’analisi fattoriale confermativa la matrice di input è spesso una ma-trice varianze-covarianze; l’informazione in essa contenuta, oltre che al-la stima dei loading, permette anche di stimare la media e la varianza di
86

ciascun fattore, cosa che può essere utile soprattutto nell’analisi compa-rativa (tornando all’esempio del capitolo 6, potremmo chiederci se il fat-tore del civismo ha una media superiore in Italia o altrove). Anche nell’Analisi Fattoriale confermativa si possono impiegare più metodi di stima dei parametri; il più utilizzato è in genere Maximum Li-kelihood a meno di necessità specifiche. Esistono molti software per l’Analisi Fattoriale confermativa: LISREL (il più noto), EQS, AMOS e altri ancora.
Va detto che l’approccio confermativo è ancora poco diffuso tra chi fa ricerca sociale, mentre si va affermando in campi contigui (per esempio in psicometria). Infine, non vorremmo che passasse l’idea per cui tutto sommato il mo-dello esplorativo rappresenta un modello ‘superato’, perché così non è. Se l’analisi fattoriale confermativa è la via più adeguata in un contesto di giustificazione, quindi in un campo maturo della riflessione teorica, quella esplorativa resta uno strumento indispensabile in un contesto del-la scoperta, quindi per ‘esplorare’ appunto oggetti su cui lo stato della riflessione teorica non mette il ricercatore in grado di formulare ipotesi di ricerca sufficientemente dettagliate.
87


Appendice I Elementi di algebra matriciale
- scalari, vettori, matrici
Chiamiamo scalare un qualsiasi numero reale. L’algebra matriciale si distingue da quella scalare (o elementare) in quanto consiste di operazioni che comprendono oggetti più complessi degli scalari. Questi oggetti sono rappresentati dai vettori e dalle matrici.Si dice vettore un insieme di scalari ordinato su una riga o su una colon-na. Se la disposizione degli scalari è orizzontale si parla di vettore-riga,se è verticale di vettore-colonna.Due esempi, rispettivamente di un vettore-riga e di un vettore-colonna, sono i seguenti:
[+1 -7 +0.3];
+
-
+
è
ê
ééé
ø
ú
ùùù
4
2
1
Il segno ‘+’ può essere sottinteso e quindi omesso. Si noti che l’ordine è importante; i due seguenti vettori sono distinti in quanto hanno gli stessi scalari ma ordinati in modo diverso:
[1 -7 0.3] ; [-7 1 0.3]
89

Un vettore può talvolta essere riscritto come combinazione lineare di al-tri vettori. Si considerino ad esempio i tre seguenti vettori:
a = [1 -2 5] ; b = [0 1 0] ; c = [1 0 5]
c può essere riscritto come combinazione lineare di a e b:
c = a + 2Öb.
Da un punto di vista geometrico un vettore è un segmento orientato, immerso in uno spazio K-dimensionale, così individuato: v = (v1, v2,v3,...vk); i valori nella parentesi sono dette componenti e si interpretano come coordinate. Si definisce lunghezza o norma di un vettore v e si denota con ||v|| il ri-sultato della seguente espressione:
||v|| = v v vK12
22 2+ +. . ..
Un insieme di scalari ordinato su righe e colonne è detto matrice.
1 7 0 3
4 5 2
-
-
è
êé
ø
úù
.
Come è facile vedere, una matrice si può considerare alternativamente come un insieme ordinato di vettori-colonna (affiancati) o di vettori-riga (impilati)44. D’altro canto i vettori possono essere visti come matrici particolari (al limite anche uno scalare). La dimensione di una matrice, più precisamente detta ordine della ma-trice, si esprime nel modo seguente: (RÖC) , dove R è il numero delle righe che moltiplica C, il numero del-le colonne. Se R=C, cioè se il numero delle righe coincide con quello delle colonne, siamo in presenza di una matrice quadrata; in caso contrario la matrice è detta rettangolare. 44 Consideriamo qui solo matrici a due entrate cioè rappresentabili sul piano; l’algebra matriciale comunque opera anche su matrici cubiche e ipercubiche.
90

In una matrice quadrata possiamo individuare la diagonale principalecome quell’insieme di valori posti sulla diagonale che va dall’angolo in alto a sinistra a quello in basso a destra. Quando gli elementi, posti so-pra e sotto la diagonale principale, individuati dalla stessa coppia di in-dici (ma invertiti), sono uguali allora la matrice è detta simmetrica.
1 3 0 5
3 4 2
0 5 2 0
-
-
è
ê
ééé
ø
ú
ùùù
.
.
- espressione di un sistema di equazioni lineari mediante matrici
Un sistema di M equazioni lineari in K incognite si può scrivere nella seguente forma:
W1 = a11F1 + a12F2 + ...... + a 1kFk +......+ a 1KFK
:Wm = a m1F1 + a m2F2 + ...... + a mkFk +......+ a mKFK
:WM = a M1F1 + a M2F2 + ...... + a MkFk +......+ a MKFK
in alternativa possiamo esprimere lo stesso sistema come segue:
ùùùùùù
ú
ø
éééééé
ê
è
MKMkMMM
mKmkmmm
Kk
aaaaW
aaaaW
aaaaW
......
:
......
:
......
21
21
1112111
Questa scrittura più compatta è detta matrice completa del sistema.
91

- matrici speciali: diagonale, scalare, identità, triangolare, unitaria, nulla
Una matrice quadrata è detta diagonale quando tutti gli elementi esterni alla diagonale principale hanno valore zero. Se solo gli elementi sotto la diagonale principale sono tutti uguali a zero, la matrice è detta triangolare superiore; viceversa, se solo gli elementi sopra la diagonale sono tutti uguali a zero è detta triangolare inferiore.Una matrice diagonale K, in cui gli elementi posti sulla diagonale prin-cipale sono uguali a un valore costante k, è detta matrice scalare. È faci-le verificare che:
KÖA = AÖK = kÖA = AÖk.
Una matrice scalare con k = 1, è detta matrice identità, ed è indicata con I; essa presenta analogie con il numero 1 nell’algebra scalare: per esem-pio il prodotto di una matrice A con una matrice identità è uguale alla matrice A stessa; più in generale si dice che I è l’elemento neutro rispet-to al prodotto. Una matrice quadrata o rettangolare (o un vettore) contenente solo valo-ri 1 è una matrice-unitaria (vettore-unitario).Analoga al numero 0 dell’algebra scalare è la matrice nulla (o il vettore nullo), i cui elementi sono tutti pari a 0: essa rappresenta l’elemento neutro rispetto all’addizione.
- Operazioni tra matrici e tra matrici e scalari: addizione, prodotto, potenze
Due matrici, A e B possono essere sommate o sottratte se sono compati-bili rispetto alla somma; perché lo siano devono essere dello stesso or-dine. Il risultato sarà una matrice C dello stesso ordine, in cui ogni ele-mento cij sarà dato dalla somma (o sottrazione) di aij e bij.
92

Esempio. 1 3 05
3 4 2
0 5 2 0
2 4 05
3 1 2
3 6 2 0
3 7 1
6 3 4
31 4 0
-
-
è
ê
ééé
ø
ú
ùùù+
-
-
è
ê
ééé
ø
ú
ùùù=
-è
ê
ééé
ø
ú
ùùù
.
.
.
. .
Una matrice A, qualunque sia il suo ordine, è moltiplicabile per uno sca-lare k. Il risultato dell’operazione è una matrice dello stesso ordine in cui gli elementi si ottengono moltiplicando quelli di A per k.
Esempio. 1 3 0 5
3 4 2
0 5 2 0
4
4 12 2
12 16 8
2 8 0
-
-
è
ê
ééé
ø
ú
ùùùÖ =
-
-
è
ê
ééé
ø
ú
ùùù
.
.
Due matrici, A e B possono essere moltiplicate se sono compatibili ri-spetto al prodotto; perché lo siano, è necessario che il numero di colon-ne della prima sia uguale al numero di righe della seconda. Detto altri-menti, se la prima è di ordine (NÖK) la seconda deve essere di ordine (KÖM) (dove M e N possono essere uguali o diversi). Il risultato sarà una matrice di ordine (NÖM) i cui elementi si ottengono secondo la seguente formula:
c a bnm nk kmk
K
= Ö=ä
1
Esempio. 1 2
05 0
3 2
4 0 3
2 0 5 1
0 1 5
2 0 15
16 1 7
-
-
è
ê
ééé
ø
ú
ùùùÖ
-è
êé
ø
úù =
- -
-
è
ê
ééé
ø
ú
ùùù
..
.
Si noti che la moltiplicazione tra matrici non gode della proprietà com-mutativa: i due prodotti AÖB e BÖA, ammesso che siano possibili en-trambi, non danno di norma lo stesso risultato.
93

Poiché l’ordine dei fattori è importante, occorre usare un linguaggio più preciso di quello usato nell’algebra scalare, dove si direbbe che ‘a mol-tiplica b’ o viceversa. Consideriamo per esempio il prodotto BÖA: si dice che ‘B pre-moltiplica A’, oppure che ‘A post-moltiplica B’.In un prodotto tra una qualsiasi matrice di ordine MÖK e una qualsiasi matrice di ordine KÖM, se M<K si parla di prodotto interno; se M²K si parla di prodotto esterno. Il prodotto interno di due vettori (necessaria-mente con lo stesso numero di elementi) ha come risultato uno scalare, e pertanto è detto prodotto scalare; il prodotto esterno di due vettori inve-ce ha come risultato una matrice quadrata con un numero di righe e di colonne pari al numero di elementi dei vettori originari.
L’operazione di elevazione a potenza è applicabile solo a matrici qua-drate: Am = AÖAÖ ...ÖA (m volte A).Come nell’algebra scalare un qualsiasi numero elevato a 0 è pari per con-venzione a 1, cioè l’elemento neutro rispetto al prodotto, anche nell’algebra matriciale una qualsiasi matrice (quadrata) elevata a 0 è uguale all’e-lemento neutro rispetto al prodotto che qui è rappresentato dalla matrice I.
L’operazione di divisione di una matrice per un’altra non è definita nell’algebra matriciale; tuttavia, come nell’algebra scalare, si può vede-re la divisione come la moltiplicazione di una matrice per l’inversa di un’altra (vedi oltre).
- Valori caratteristici associati a una matrice: rango, traccia, de-terminante, autovalori e autovettori
Si definisce rango di una matrice il numero di vettori linearmente indipen-denti contenuti in una matrice A, che può essere quadrata o rettangolare. Una matrice quadrata che ha rango uguale al numero delle righe e delle colonne, cioè all’ordine, si dice di rango pieno.
94

Di una matrice quadrata qualsiasi si può calcolare la traccia, cioè quello sca-lare ottenuto sommando tutti gli elementi posti sulla diagonale principale:
Tr {A} = än
iiia
Abbiamo visto che in genere AÖB¸BÖA; notiamo ora che le tracce dei due prodotti, se sono entrambi definiti, coincidono, ovvero:
Tr {AÖB} = Tr {BÖA}
Data una generica matrice A (2Ö2):
a a
a a11 12
21 22
è
êé
ø
úù
il determinante è dato dall’operazione:
a11Öa22-a12Öa21.
Indichiamo ora a11Öa22 e a12Öa21 con la locuzione ‘prodotti elementari’ di A.In generale un prodotto elementare ha N fattori, con N che dipende dall’ordine della matrice (NÖN); questi fattori sono elementi provenienti dalla matrice secondo la regola che da ogni riga e ogni colonna deve es-sere estratto un solo elemento. Una matrice di ordine (NÖN) ha N! pro-dotti elementari. Si noti che per individuare facilmente gli elementi dei prodotti elemen-tari si può seguire la seguente regola: costruire tutte le permutazioni semplici dei valori che può assumere o-gnuno dei due pedici di ciascun elemento aij.In una matrice di ordine (2Ö2) i valori assumibili da ognuno dei due pe-dici sono 1 e 2; le permutazioni semplici sono (1,2) e (2,1); in una ma-trice di ordine (3Ö3) le permutazioni semplici sono (1,2,3), (2,3,1) (3,1,2) (1,3,2) (2,1,3) (3,2,1); e così via. A questo punto è facile individuare i prodotti elementari con una tabel-lina come la seguente (il primo pedice assume sempre i valori in ordine crescente, in questo caso 1, 2, 3; il secondo pedice assume i valori della
95

colonna delle permutazioni):
prodotti elementari permutazione associata a11a22a33 (1,2,3) a12a23a32 (2,3,1) a13a21a32 (3,1,2) a11a23a32 (1,3,2) a12a21a33 (2,1,3) a13a22a31 (3,2,1)
Possiamo ora dare una definizione generale di determinante: quello scala-re ottenuto dalla somma di tutti i prodotti elementari dotati di segno. Resta quindi da definire il segno del prodotto elementare. Per farlo torniamo alla tabella precedente, seconda colonna. Definiamo pari la prima serie (1,2,3) (per definizione) e pari tutte quelle permuta-zioni in cui si conta un numero pari di spostamenti di valori rispetto alla prima serie per ottenere la permutazione; si definiscono dispari le altre permutazioni. Quando la permutazione è pari, il prodotto elementare è di segno positi-vo, altrimenti è di segno negativo.
Aggiungiamo ora alla tabella precedente altre due colonne:
prodotti elementari
permutazione associata
pari o dispari prodotti con segno
a11a22a33 (1,2,3) pari +a11a22a33
a12a23a32 (2,3,1) pari +a12a23a31
a13a22a31 (3,1,2) pari +a13a21a32
a11a23a32 (1,3,2) dispari -a11a23a32
a12a21a33 (2,1,3) dispari -a12a21a33
a13a22a31 (3,2,1) dispari -a13a22a31
Il determinante gode di una serie di proprietà, tra cui le due seguenti
96

(che non dimostriamo): - Det {AÖB} = Det {A} Ö Det {B}- Se X è una matrice triangolare, superiore o inferiore, allora, il suo
determinante è uguale al prodotto degli elementi della diagonale principale.
Quest’ultima proprietà è sfruttata per calcolare il determinante di matrici di ordine superiore a 3, dopo averle opportunamente trasformate in ma-trici triangolari (argomento per il quale rimandiamo a testi specialistici).
Dati una matrice quadrata A, un vettore v compatibile per la postmolti-plicazione e uno scalare l, tali da soddisfare la seguente relazione:
AÖv=lÖv,
allora l viene detto autovalore (o eigenvalue) e v autovettore.Una matrice può avere più autovalori e autovettori e questi ultimi hanno la caratteristica di essere linearmente indipendenti.
- Ulteriori operazioni su singole matrici: trasposizione, inversione, estrazione di diagonale, partizione.
Data una matrice A di ordine (MÖK), si definisce trasposta di A e si de-nota con A', quella matrice di ordine (KÖM) la cui prima colonna è la prima riga di A, la cui seconda colonna è la seconda riga di A e così via sino alla K-esima colonna (che è la K-esima riga di A).
Esempio:
A =
1 3 0 5
4 4 7
2 8 0
-
-
è
ê
ééé
ø
ú
ùùù
.
A' =
1 4 2
3 4 8
05 7 0
-
-
è
ê
ééé
ø
ú
ùùù.
Si noti che una matrice simmetrica è uguale alla sua trasposta.
97

Una matrice può essere moltiplicata per la sua trasposta e il risultato è una matrice quadrata simmetrica detta prodotto-momento.Se AÖA' = A'ÖA = I, la matrice A è detta ortogonale.Ricordando quanto detto circa la traccia di un prodotto tra matrici, ab-biamo che:
Tr {AÖA'} = Tr { A'ÖA} = ään
i
m
j
2ija
Il valore assunto da Tr {AÖA'} è una misura di quanto A differisce dalla matrice nulla. Più in generale, la differenza tra due matrici A e B di ordine (MÖN), può essere riassunta nella quantità:
d2 = Tr {(A-B)Ö(B-A)'} = ään
i
m
j
2jiij )ba(
Si noti che d2 = 0 solo se A=B.
Una matrice A (NÖN) post-moltiplicata da un vettore (NÖ1) e contempo-raneamente pre-moltiplicata dallo stesso vettore trasposto fornisce un valore scalare d detto forma quadratica; in formula: d=x'ÖAÖxIl legame con le equazioni quadratiche è facilmente osservabile con un esempio come il seguente. Sia:
ax2 + 2bxy + cy2 = dun’equazione quadratica (i termini sono variabili al quadrato o prodotti di variabili). In forma matriciale la precedente equazione diventa:
[ ] d=ùú
øéê
èÖùú
øéê
èÖ
y
x
cb
bayx
Le forme quadratiche non sono limitate a due variabili.
Una matrice quadrata con forma quadratica positiva o nulla (d²0) è det-ta positiva semidefinita.
98

Una matrice simmetrica e positiva semidefinita è detta gramiana; la gramianità di una matrice è una condizione importante nell’analisi dei dati: per esempio è un pre-requisito per un modello di analisi fattoriale, in quanto una matrice non gramiana produce degli autovalori negativi (cioè delle varianze negative).
L’operazione di inversione è definita solo per le matrici quadrate; se A è una matrice quadrata, si definisce inversa di A e si indica solitamente con la notazione A-1 quella matrice che post -moltiplicata o pre-moltiplicata da A fornisce (in entrambi i casi) la matrice I.Non tutte le matrici quadrate sono invertibili: se non lo sono si dicono singolari.Per valutare a priori se la matrice è non singolare, e quindi invertibile, si può calcolarne il rango oppure il determinante: se essa non è di rango pieno o, il che è equivalente, ha determinante uguale a 0, non è invertibile. Inoltre, come si può dimostrare a partire dal fatto che Det {AÖB} = Det {A} Ö Det {B}:
Det {A-1} = 1/Det {A}.
L’estrazione della diagonale, indicata dall’operatore Diag, è un’operazione definita solo per le matrici quadrate: essa consiste nella costruzione di un vettore-colonna, i cui elementi coincidono, nello stes-so ordine dall’alto verso il basso con quelli della matrice in argomento.
Talvolta è utile esprimere un insieme di sottomatrici distinte combinando-le in una sola matrice, detta a blocchi; viceversa talvolta è utile vedere un’unica grande matrice come un insieme concatenato di sottomatrici. Per esempio la seguente matrice:
C =
ùùùù
ú
ø
éééé
ê
è
2221
1211
2221
1211
bb00
bb00
00aa
00aa
99

in cui gli indici sono stati appositamente scelti per mostrarne la partizio-ne, si compone di quattro sottomatrici A (2Ö2), 0 (2Ö2), 0 (2Ö2), B (2Ö2)concatenate in modo opportuno. In forma sintetica si può scrivere:
C=B0
0A
100

Appendice II Le matrici di prodotti scalariderivate dalla CxV
Molte tecniche di analisi dei dati hanno come input minimo una matrice derivata dalla matrice Casi x Variabili (CxV). Queste matrici, frutto di opportune manipolazioni della CxV, contengono dati che possono esse-re rappresentati da distanze tra vettori (le righe o le colonne della CxV) o da prodotti scalari di vettori (anche in questo caso: le righe o le colon-ne della CxV). Il coefficiente di correlazione è un prodotto scalare; infatti, quando cor-reliamo due variabili, non facciamo altro che trasformare l’informazione contenuta in due vettori, x e y (variabili standardizzate) in un singolo scalare pxy:
pxy = x'·y = ä=
I
iii yx
1
dove I è il numero di elementi dei vettori. L’argomento delle matrici di prodotti scalari riguarda direttamente l’Analisi Fattoriale: questa, come abbiamo visto, opera perlopiù a partire da matrici di correlazione o (nell’analisi confermativa) di varianze-covarianze. È opportuno dunque fornire un quadro delle trasformazioni che si possono effettuare sulla matrice CxV al fine di ottenere speciali matrici di input per l’analisi dei dati; non verrà tuttavia fornito un qua-dro esaustivo ma si porterà l’attenzione su alcune matrici derivate dalla CxV che servono per l’Analisi Fattoriale.
101

Consideriamo una matrice X, Casi per Variabili, di formato NÖM; per sem-plicità consideriamo solo il caso in cui X è costituita interamente di variabi-li cardinali scalate sulla stessa unità di misura. Definiamo ora due matrici ausiliarie, la cui informazione è comunque già contenuta nella matrice Xe quindi è da essa ricavabile: ciò ci permetterà di descrivere in forma matriciale alcune trasformazioni della matrice CxV utili ai nostri scopi. - La prima matrice, M, ha lo stesso formato della matrice X: essa si può vedere come replica, per N volte, del vettore riga contenente le medie di colonna della matrice X. Algebricamente si ricava dalla matrice X me-diante l’espressione:
M = N-1 Ö U Ö X
dove N è lo scalare che rappresenta il numero delle righe della matrice X e U è una matrice unitaria di dimensioni NÖN.- La seconda matrice ausiliaria è la matrice diagonale S di formato MÖM, contenente le varianze delle M colonne di X. Si ricava dalla ma-trice X mediante l’espressione:
S = diag N-1/2 Ö (X-M)’Ö (X-M) ÖN-1/2]
Passiamo ora a definire tre trasformazioni-base sulla matrice X:
centratura X - M trasformazione di tutte le variabili in scarti alle medie di colonna
uniformazione X Ö S-1/2 divisione di tutte le variabili per le deviazioni standard di colonna, cioè uniformazione a 1 delle varianze di colonna
normalizzazione* X Ö N-1/2 contrazione uniforme della scala di tutte le variabili (di un fattore pari al reciproco della radice quadrata di N)
* da non confondere con la normalizzazione intesa come forzatura di una distribuzione empirica a una distribuzione normale
Condotte simultaneamente, le prime due trasformazioni danno luogo al-la cosiddetta standardizzazione delle variabili. Le tre trasformazioni descritte operano sulla matrice CxV vista come insieme di vettori colonna, cioè guardano alle variabili (anche se non
102

approfondiamo il tema, segnaliamo di passaggio che le medesime tra-sformazioni possono anche essere definite operando sulla matrice CxV intesa come insieme di vettori riga).
Le trasformazioni che abbiano descritto, oltre che sulla matrice X pos-sono essere condotte sulla matrice risultante dal prodotto della matrice X con se stessa, e precisamente:
P = X’ Ö X
La matrice P è una matrice simmetrica di dimensione MÖM che contiene i prodotti e gli autoprodotti scalari delle colonne della matrice X.Applichiamo ora le trasformazioni di centratura, uniformazione e nor-malizzazione alla matrice P.
centratura P - (M’ Ö M)uniformazione S-1/2 Ö P Ö S-1/2
normalizzazione N-1/2 Ö P Ö N-1/2
Come si vede, le trasformazioni sono definite in modo analogo a quelle operanti sulla matrice X.Poiché con P ci troviamo di fronte a una matrice di prodotti scalari è e-vidente che anche l’uso delle matrici ausiliarie cambia: al posto della matrice M nella centratura abbiamo il prodotto della trasposta di M con M stessa; uniformazione e normalizzazione sono effettuate con una doppia moltiplicazione, pre- e post-, della matrice P rispettivamente con l’inversa della radice quadrata di S e con l’inverso della radice quadrata dello scalare N. Se alla matrice P applichiamo contemporaneamente le operazioni di centratura e normalizzazione otteniamo la matrice di Varianze-Covarianze (COV); se applichiamo tutte e tre le operazioni otteniamo la matrice di Correlazioni (CORR). Abbiamo così ottenuto, a partire dalla matrice CxV le due matrici tipi-camente utilizzate nell’Analisi Fattoriale.
103


Bibliografia di riferimento
ALBANO R.,.TESTA S. 2002 Introduzione alla statistica per la ricerca sociale, Carocci,
Roma
ALBANO R., LOERA B. 2004 La struttura dei valori di cittadinanza. L’analisi fattoriale
per lo studio delle configurazioni valoriali, Working Paper, Torino, in corso di pubblicazione
BAGOZZI R.P (ed). 1994 Principles of Marketing Research, Blackwell, Oxford (UK)
BARBARANELLI C. 2003 Analisi dei dati. Tecniche multivariate per la ricerca psico-
logica e sociale, LED, Milano
BASILEVSKY A. 1994 Statistical Factor Analysis and Related Methods. Theory
and Application, Wiley, New York
BLALOCK H. M. Jr. 1960 Social Statistics, Mc Graw Hill, New York 19793, (trad. it. Sta-
tistica per la ricerca sociale, il Mulino, Bologna 1984)
BOLLEN, K. A. 2001 Indicator: Methodology, in: SMELSER N. J., BALTES
P.B. (editors-in-chief), International Encyclopedia of the Social and Behavioral Sciences, Elsevier Science, Oxford (UK) pp. 7282-7287
BRUSCHI A. 1999 Metodologia delle scienze sociali, Mondadori, Milano
105

CARROLL J.D., ARABIE P.1980 Multidimensional Scaling, ‘Annual Review of Psychology’, 31
CATTELL R.1978 The Scientific Use of Factor Analysis in the Behavioral and
Life Sciences, Plenum Press, New York
COMREY A.L., LEE H. B.1992 a First Course in Factor Analysis, Erlbaum Hillsdale (NJ),
2nd ed., (trad. it. Introduzione all’analisi fattoriale, Led, Milano 1995)
COOK T.D., CAMPBELL D.T.1979 Quasi-Experimantation. Design and Analysis Issues for
Field Settings, Houghton Mifflin Co., Boston
CORBETTA P.2002 Metodi di analisi multivariata per le scienze sociali, il Mu-
lino, Bologna, 2a ed.
CORBETTA P.1999 Metodologia e tecniche della ricerca sociale, il Mulino, Bolo-
gna
DUNTEMAN G.H.1989 Principal Component Analysis, Sage Univ. Paper, 69,
Beverly Hills
GANGEMI G.1982 Criteri guida nell’analisi fattoriale. Dalla Simple Structure
alla Two-Stage Component Analysis, ‘Quaderni di Socio-logia’, 1, pp. 73-92
GORSUCH1983 Factor Analysis, L. Erlbaum Assoc., Hillsdale (NJ), 2nd ed.
GUERTIN W.H., BAILEY J. P.1970 Introduction to Modern Factor Analysis, Edward, Ann Ar-
bor
106

HARMAN H.1967 Modern Factor Analysis, Univ. Of Chicago Press, Chicago,
19763
HARMAN H., JONES W.H.1966 Factor Analysis by Minimizing Residuals (Minres), ‘Psy-
chometrika’, 31, pp. 351-68
HOTELLING H.1933 Analysis of a Complex of Statistical Variables into Princi-
pal Components, ‘Journal of Educational Psychology’, 24, pp.417-41 e pp. 498-520
INGLEHART R.1990 Culture Shift in Advanced Industrial Society, Princeton,
Princeton Univ. Press, (trad. it. Valori e cultura politica nella società industriale avanzata, Padova, Liviana, 1993)
JACKSON D.N., MESSICK S.1958 Content and Style in Personality Assessment, ‘Psychologi-
cal bulletin’, 55, pp.243-52
JÖRESKOG K.G., SÖRBOM D.1986 Prelis. A Program for Multivariate Data Screening and
Data Summarization. A Preprocessor for Lisrel, Scien-tific Software Inc., Mooresville (Indiana)
KAMPEN J., SWYNGEDOUW M.2000 The Ordinal Controversy Revisited, ‘Quality and Quan-
tity’, 34, pp. 87-102
KLINE P.1994 An Easy Guide to Factor Analysis, Routledge, London, (trad.
it. Guida facile all’analisi fattoriale, Astrolabio, Roma 1997)
107

LABOVITZ S.1970 The Assignment of Numbers to Rank Order Categories,
‘American Sociological Review’, 35, pp. 515-24
LANDENNA G., MARASINI D., FERRARI P.1997 Probabilità e variabili casuali, il Mulino, Bologna
LAWLEY D. N., MAXWELL A. E.1963 Factor Analysis as a Statistical Method, Butterworth, Lon-
don
LAZARSFELD P.F.1958 Evidence and Inference in Social Research, ‘Dedalus’, vol.
87 (trad. it. Dai concetti agli indicatori empirici, in: CAR-DANO M., MICELI R. (a cura di), Il linguaggio delle va-riabili. Strumenti per la ricerca sociale, Rosenberg & Sel-liers, Torino, 1991)
LOERA B.2004 Valori civili e partecipazione politica. Un contributo allo
studio del rapporto tra cultura e democrazia, Tesi di Dot-torato, Università di Torino
LONG J. S.1983 Confirmatory Factor Analysis: a Preface to Lisrel, Sage,
Beverly Hills
MALINVAUD E.1964 Méthodes statistiques de l'économétrie, Dunod, Paris (trad.
it. Metodi statistici dell'econometria, Utet, Torino 1969)
MARRADI A.1979 Dimensioni dello spazio politico in Italia, ‘Rivista Italiana
di Scienza Politica’, 2
MARRADI A.1980 Concetti e metodi per la ricerca sociale, La Giuntina, Firenze
108

MARRADI A.1981 Factor Analysis as an Aid in the Formation and Refinement
of Empirically Useful Concepts, in: BORGATTA E.F., JACKSON D.J. (eds), Factor Analysis and Measurement in Sociological Research. A Multidimensional Perspecitve,Sage, London-Beverly Hills
MARRADI A.1995 L’analisi monovariata, Angeli, Milano, 2a ed.
MCDONALD R.P.1982 Linear Versus Nonlinear Models in Item Response Theory,
‘Applied Psychological Measurement’, 4, Fall, pp. 379-96
MOOD A.M., GRAYBILL F.A., BOES D.C.1974 Introduction to the Theory of Statistics, McGraw Hill, New
York (trad. it. Introduzione alla statistica, McGraw Hill Libri Italia, Milano 1988)
NUNNALLY J.C. 1978 Psychometric Theory, McGraw Hill, New York
O’BRIEN R.M.1979 The Use of Pearson’s R with Ordinal Data, ‘American So-
ciological Review’, vol. 44, October, pp. 851-57
PEARSON K.1901 On Lines and Planes of Closest Fit to Systems of Points in
Space, ‘Philosophical Magazine’, ser. 2, 6, pp. 559-72
RICOLFI L.1987 Sull’ambiguità dei risultati delle analisi fattoriali, ‘Qua-
derni di Sociologia’, 8, pp. 95-129
RICOLFI L.2002 Manuale di analisi dei dati. Fondamenti, Laterza, Bari
109

ROCCATO M.2003 Desiderabilità sociale e acquiescenza. Alcune trappole del-
le inchieste e dei sondaggi, Led, Milano
SCIOLLA L.1999 Religione civile e valori della cittadinanza, ‘Rassegna Ita-
liana di Sociologia’, 2, 1999, pp. 269-92
SCIOLLA L.2003 Quale capitale sociale? Partecipazione associativa, fiducia
e spirito civico, ‘Rassegna Italiana di Sociologia’, 2, pp. 257-90
THURSTONE L.L.1935 The Vectors of Mind, Chicago
THURSTONE L.L.1947 Multiple Factor Analysis, Chicago
110


Finito di stampare nel giugno 2004 dalla Viva s.r.l - via Forlì, 56 - Torino


















