
Progetto e Realizzazione di un programma …cianca/ Il libro di apertura 44 2.4.2 L’analisi delle...
280
I Indice generale INDICE GENERALE I INTRODUZIONE 1 0.1 Intelligenza artificiale = conoscenza + ricerca 1 0.2 L’importanza degli scacchi come dominio di applicazione 5 0.3 Gli strumenti 6 0.3.1 La base teorica 6 0.3.2 Il supporto a implementazione e sperimentazione 7 0.4 La struttura della tesi 9 ALGORITMI DI RICERCA SEQUENZIALE DI ALBERI DI GIOCO 12 1.1 Introduzione 12 1.2 Alberi di gioco 13 1.2.1 Algoritmo minimax: una strategia di controllo 15 1.2.2 La funzione di valutazione, l’effetto orizzonte e la ricerca quiescente 17 1.2.3 Ordine di visita dell’albero di gioco: discesa a scandaglio (depth-first search) 19 1.3 Algoritmi di ricerca sequenziale 19 1.3.1 L’algoritmo αβ 20 1.3.2 Alcune varianti dell’algoritmo αβ 26 1.3.3 Euristiche per migliorare la ricerca αβ 28 1.3.4 Numeri di cospirazione: un esempio di approfondimento selettivo 35 GNUCHESS: UN GIOCATORE SEQUENZIALE DI SCACCHI 39 2.1 Introduzione 39 2.2 Descrizione architetturale di GnuChess 39 2.3 La rappresentazione della posizione 41 2.3.1 La dislocazione dei pezzi in gioco 41 2.3.2 Il giocatore che ha la mossa 42 2.3.3 Sequenza delle mosse giocate 42 2.3.4 La possibilità di arrocco, la regola delle 50 mosse e la patta per ripetizione 43 2.4 La scelta della mossa 44 2.4.1 Il libro di apertura 44 2.4.2 L’analisi delle continuazioni 45 2.5 La modalità di gioco 59 2.6 L’interprete dei comandi 59 2.6 Il ruolo di GnuChess nella tesi 61 LINDA 63 3.1 Introduzione 63 3.2 Il modello Linda di programmazione distribuita 65 3.2.1 Gli oggetti 65 3.2.2 Gli operatori 68 3.3 Network C-Linda 74 3.3.1 Variazioni rispetto al modello 74 3.3.2 L’ambiente di programmazione 76 3.4 Lo stile di programmazione 77 3.4.1 Strutture dati distribuite 78 3.4.2 L’interazione fra processi 82 3.5 Alcuni cenni riguardo l’implementazione 89 3.6 Il ruolo di Linda nella tesi 92 ALGORITMI DI RICERCA PARALLELA DI ALBERI DI GIOCO 93 4.1 Il criterio di valutazione delle prestazioni degli algoritmi paralleli 93 4.2 Tipi di approccio alla parallelizzazione della ricerca 93 4.3 Effetto delle euristiche nella ricerca parallela 109 ALGORITMI DI DECOMPOSIZIONE DELL’ALBERO DI GIOCO 112 5.1 Introduzione 112 5.2 Algoritmi di decomposizione dell’albero di gioco 114 5.2.1 Algoritmi di decomposizione statica 115 5.2.2 Algoritmi di decomposizione dinamica 157
Transcript of Progetto e Realizzazione di un programma …cianca/ Il libro di apertura 44 2.4.2 L’analisi delle...

I
Indice generaleINDICE GENERALE IINTRODUZIONE 10.1 Intelligenza artificiale = conoscenza + ricerca10.2 L’importanza degli scacchi come dominio di applicazione 50.3 Gli strumenti 60.3.1 La base teorica 60.3.2 Il supporto a implementazione e sperimentazione 70.4 La struttura della tesi 9ALGORITMI DI RICERCA SEQUENZIALE DI ALBERI DI GIOCO 121.1 Introduzione121.2 Alberi di gioco 131.2.1 Algoritmo minimax: una strategia di controllo151.2.2 La funzione di valutazione, l’effetto orizzonte e la ricerca quiescente171.2.3 Ordine di visita dell’albero di gioco: discesa a scandaglio (depth-first search) 191.3 Algoritmi di ricerca sequenziale 191.3.1 L’algoritmo αβ 201.3.2 Alcune varianti dell’algoritmo αβ 261.3.3 Euristiche per migliorare la ricerca αβ 281.3.4 Numeri di cospirazione: un esempio di approfondimento selettivo35GNUCHESS: UN GIOCATORE SEQUENZIALE DI SCACCHI 392.1 Introduzione392.2 Descrizione architetturale di GnuChess 392.3 La rappresentazione della posizione 412.3.1 La dislocazione dei pezzi in gioco 412.3.2 Il giocatore che ha la mossa422.3.3 Sequenza delle mosse giocate422.3.4 La possibilità di arrocco, la regola delle 50 mosse e la patta per ripetizione432.4 La scelta della mossa442.4.1 Il libro di apertura 442.4.2 L’analisi delle continuazioni452.5 La modalità di gioco 592.6 L’interprete dei comandi 592.6 Il ruolo di GnuChess nella tesi 61LINDA 633.1 Introduzione633.2 Il modello Linda di programmazione distribuita 653.2.1 Gli oggetti 653.2.2 Gli operatori 683.3 Network C-Linda 743.3.1 Variazioni rispetto al modello743.3.2 L’ambiente di programmazione 763.4 Lo stile di programmazione 773.4.1 Strutture dati distribuite 783.4.2 L’interazione fra processi 823.5 Alcuni cenni riguardo l’implementazione 893.6 Il ruolo di Linda nella tesi 92ALGORITMI DI RICERCA PARALLELA DI ALBERI DI GIOCO 934.1 Il criterio di valutazione delle prestazioni degli algoritmi paralleli934.2 Tipi di approccio alla parallelizzazione della ricerca 934.3 Effetto delle euristiche nella ricerca parallela 109ALGORITMI DI DECOMPOSIZIONE DELL’ALBERO DI GIOCO 1125.1 Introduzione1125.2 Algoritmi di decomposizione dell’albero di gioco 1145.2.1 Algoritmi di decomposizione statica1155.2.2 Algoritmi di decomposizione dinamica 157

II
5.3 Conclusioni 182LA DISTRIBUZIONE DELLA CONOSCENZA 1856.1 Introduzione1856.2 Conoscenza e dominio dei giochi 1876.2.1 Uno studio della conoscenza terminale nel gioco degli scacchi1906.3 La distribuzione della conoscenza terminale 1926.3.1 La struttura del giocatore parallelo 1946.3.2 La determinazione finale della mossa: il criterio di selezione2006.3.3 Una valutazione separata dei criteri di distribuzione della conoscenza e dei criteri diselezione 2146.4 Una rassegna di idee per la distribuzione della conoscenza dirigente 2216.4.1 Giocatore parallelo con istanze di ricerca di tipo forza bruta 2216.4.2 Giocatore parallelo con istanze di ricerca di tipo selettivo2236.4.3 Giocatore parallelo misto 2246.5 Conclusioni 225CONCLUSIONI E LAVORI FUTURI 2277.1 Valutazione del raggiungimento degli obbiettivi e conclusioni 2287.1.1 Linda 2287.1.2 La distribuzione della ricerca2317.1.3 La distribuzione della conoscenza 2327.2 Lavori futuri 2337.2.1 Linda 2337.2.2 Giocatori artificiali paralleli 235BIBLIOGRAFIA 244POSIZIONI DI BRATKO -KOPEC 240

1
Capitolo 0Introduzione
0.1 Intelligenza artificiale = conoscenza + ricercaIl termine intelligenza artificiale sta ad indicare quella branca dellascienza che si occupa dello studio dei problemi decisionali e dellaloro soluzione attraverso il calcolatore. Quest’ultimo è dunqueastratto ad una entità capace di operare autonomamente dellescelte.
Conoscenza e ricerca sono le componenti fondamentali di unsistema capace di prendere decisioni: ciascuna di esse èresponsabile, in modo diverso, delle sue prestazioni. In particolarela conoscenza determina la qualità delle scelte, mentre la ricercastabilisce quanto velocemente esse sono ottenute.
Il presente lavoro intende limitare il suo dominio di indagine ad unasotto-classe molto significativa di sistemi "intelligenti": quella deigiocatori artificiali.
Il tipo di giochi che sarà preso in considerazione è quello che vedecoinvolti 2 avversari e gode delle proprietà di informazione perfetta(in ogni fase del gioco sono note ai giocatori tutte le mosse legali) esomma-zero (ciò che un giocatore perde è equivalente al guadagnodell’altro).
In questo ambito per giocatore artificiale deve intendersi un sistemacapace di ricoprire autonomamente il ruolo di uno dei giocatori e dioperare delle scelte (nel rispetto delle regole del gioco) mirate adun vantaggio locale (miglioramento dal suo punto di vista di certecondizioni del gioco) o assoluto (vittoria di una partita) nei confrontidell’avversario.
Per questa classe di sistemi la ricerca è intesa come lo sviluppodelle linee di gioco future con lo scopo di valutare e confrontarequali conseguenze possono determinare scelte (mosse) diverseoperate al livello dello stato corrente del gioco. La struttura chemodella questo tipo di ricerca è un albero (detto di gioco) i cui nodirappresentano posizioni future di gioco raggiunte attraverso mosselegali (gli archi) [Abr89]. La profondità di questo albero quantifica laproiezione nel futuro del giocatore.
La conoscenza del dominio è presente, in un giocatore artificiale, induplice veste [Ber82]:• per guidare la ricerca suggerendo in quale ordine approfondiremosse alternative (conoscenza dirigente)• per stabilire quanto è "appetibile" (o meno) il raggiungimento diuna certa posizione (conoscenza terminale).Shannon ha proposto una classificazione anche per la ricerca[Sha50]:• con forza-bruta: sono esaminate fino ad una certa profondità tuttele possibili scelte

2
• selettiva (o guidata dalla conoscenza): sono esplorate solo quellealternative che appaiono fornire (con elevata probabilità) ilmaggiore contributo per la determinazione della soluzione.
La finalità principale di questo lavoro è lo studio in ambientedistribuito di vari aspetti di conoscenza e ricerca e delle lorointerazioni reciproche. Utilizzando il dominio applicativo del giocodegli scacchi sarà sperimentata la distribuzione di alcuni metodi diricerca con forza bruta e proposto (e sperimentato) un nuovoapproccio allo sviluppo di giocatori paralleli basato sul concetto di"distribuzione della conoscenza".
Gli scacchi costituiscono un terreno ideale per lo studio di taliproblematiche poiché per questo gioco le prestazioni di ungiocatore artificiale sono fortemente dipendenti sia dal suoalgoritmo di ricerca che dalla conoscenza del domino di cui essodispone; in seguito saranno presentati altri argomenti a sostegno diquesta scelta.
Le prestazioni di un giocatore artificiale sono misurate dalla suaforza, dalla qualità del suo gioco: per quali motivi scaturiscel’esigenza di giocatori paralleli? come può contribuire ladistribuzione della sua ricerca e della sua conoscenza a migliorarele prestazioni di un giocatore?
Le righe che seguono intendono dare una risposta intuitiva a taliquesiti attraverso un breve e suggestivo viaggio nell’esperienzaacquisita negli ultimi decenni riguardo l’importanza relativa diconoscenza e ricerca in un giocatore artificiale.
Nel mondo dei giochi con 2 avversari e a somma-zero èriconosciuto che i migliori programmi utilizzano tecniche di ricercacon forza bruta: scacchi, dama [Sam60] e othello [Ros81] ne sonoesempi. La ricerca con forza bruta ha il vantaggio di ridurre laconoscenza del dominio richiesta.
La valutazione di una posizione del gioco, sia che sia operata da unuomo che da un calcolatore, è il tentativo di indicare quanto essasia favorevole in considerazione delle sue prospettive future. Laricerca a maggiori profondità può sostituire queste predizioniattraverso un esplicito attraversamento del futuro mediante il qualesono risolte alcune delle incertezze.
Estendendo all’estremo questa considerazione, un giocatorecapace di operare ricerche ad illimitate profondità ha bisogno dellasola conoscenza necessaria ad individuare posizioni di vittoria,sconfitta e parità. Si viene così a delineare l’apparente paradossoche può essere creato un programma capace di giocareperfettamente disponendo di conoscenza pressoché nulla deldominio. Purtroppo le dimensioni degli alberi esplorati daglialgoritmi di ricerca con forza bruta crescono esponenzialmente conla profondità ed in generale non è quindi possibile raggiungere glistati terminali del gioco.
La profondità di ricerca costituisce l’orizzonte della visione futuradel giocatore: quale influenza può avere la sua forzata limitazione?

3
Newborn ha stimato che raddoppiando la potenza di calcolo di ungiocatore artificiale (attraverso calcolatori più veloci o migliorialgoritmi di ricerca) aumenta di una quantità costante la sua forza[New79]. Chiaramente un programma più veloce può esaminare unmaggior numero di nodi e quindi raggiungere profondità maggioridell’albero.
Da queste considerazioni emerge l’importanza dello sviluppo dialgoritmi di ricerca paralleli in quanto capaci di garantire unamaggiore velocità di calcolo e quindi di estendere l’orizzontedell’analisi delle continuazioni del gioco.
Questo approccio non è di per se soddisfacente:• la legge di corrispondenza fra la velocità di calcolo e le prestazionidel giocatore diviene meno evidente quando quest’ultimeraggiungono quelle dei migliori giocatori umani [Tho82].
• il guadagno (speedup) che gli algoritmi paralleli di ricerca su alberidi gioco garantiscono rispetto a quelli sequenziali tende astabilizzarsi con l’aumentare del numero di processori: Finkel eFishburn hanno dimostrato che in condizioni ottime esso è o( N)dove N è il numero di processori [FinFis82].
Un approccio duale a quello presentato è quello di fare affidamentosu una notevole conoscenza del dominio che permetta di valutareaccuratamente le posizioni del gioco utilizzando una ricercaminima; questo è anche lo schema che guida le scelte dei giocatoriumani. Portando questa idea al suo estremo un giocatore con unaprofonda conoscenza del gioco potrebbe non avere bisogno dialcuna ricerca.
I giochi più complessi, tuttavia, richiedono un’enorme quantità diconoscenza. Si consideri ad esempio il gioco degli scacchi:• PARADISE è un programma che usa ben 200 regole diproduzione solo per pianificare alcune conquiste di materiale osituazioni di matto [Wil79];
• la soluzione corretta di alcuni problemi di finale necessita didecine di regole [Sch86]:• re e pedone contro re (KP vs. K) richiede 38 regole• re, pedone e torre in settima riga contro re e torre (KP/r7 vs. KR)richiede 110 regole• re e torre contro re e cavallo (KR vs. KN) è risolto con 65 regole.Indicare quantità di regole senza specificarne il significato ècertamente non significativo; tuttavia queste statistiche assolvono ilcompito di illustrare l’enorme complessità già di un piccolosottoinsieme del gioco degli scacchi.
Poiché un giocatore artificiale non può dunque disporre di tutta laconoscenza necessaria ad ottenere un gioco perfetto resta aperto ilproblema di determinare quale conoscenza ha maggioreimportanza.
Schaeffer ha dimostrato che l’importanza relativa di differenticategorie di conoscenza è fortemente influenzata dallo stato delgioco [Sch86]: nel gioco degli scacchi, ad esempio, nella fase di

4
mediogioco è fondamentale il controllo delle case centrali, mal’importanza di questa conoscenza scema nel finale di partita.In questo ambito il significato di distribuire la conoscenza è didisporre di più giocatori con diversa conoscenza del dominio checooperano suggerendo ciascuno la migliore mossa rispetto alproprio punto di vista; emergono evidenti due vantaggi di questoapproccio:
• l’applicazione di conoscenza ha un suo costo computazionale equindi deve essere limitata nella sua quantità; disponendo però dipiù giocatori è possibile estendere la quantità di conoscenzacomplessiva suddividendola fra di essi.
• non esiste un ordinamento assoluto per importanza relativa dellecategorie di conoscenza. Quello che è fissato all’interno di ungenerico giocatore artificiale è normalmente il risultato diesperienza e di tecniche "trial-and-error", cioè di approssimazioniper tentativi della soluzione migliore: nulla garantisce, però, che ilrisultato di questo procedimento sia effettivamente quello ottimale.La distribuzione della conoscenza permette di avere anchegiocatori che pur disponendo di conoscenza comune, attribuisconoalle componenti di essa importanza relativa differente.
Deve essere sottolineata l’assoluta novità di questo approccio nelprogetto di un giocatore artificiale parallelo (in [Alt91] è tuttaviadescritta una "rudimentale" anticipazione di questa idea). La suavalidità deve dunque essere confermata dalla realesperimentazione: questo costituisce uno degli obbiettivi principali diquesto lavoro.
Allo stato dell’arte nessuna delle due soluzioni estreme descritte(giocatore artificiale con sola ricerca o con sola conoscenza) puòcondurre ad un sistema capace di concorrere con i migliori giocatoriumani: l’unico percorso praticabile è quindi quello di un approcciointermedio in cui entrambe le componenti coesistono. In analogia aquesta considerazione è lecito chiedersi:
ha significato combinare in un unico giocatore parallelo sia ladistribuzione della ricerca che della conoscenza?è questo il futuro della ricerca in questo ramo dell’intelligenzaartificiale?Il presente lavoro intende, attraverso un’analisi separata delle dueforme di parallelismo, gettare le basi per il progetto di un unicogiocatore parallelo che scaturisca da questa duplice distribuzione.
0.2 L’importanza degli scacchi come dominio diapplicazione
Il gioco degli scacchi costituisce un eccellente dominio per ilconfronto e lo sviluppo di studi e metodi aventi per oggetto sistemi"intelligenti".
In [Sch86] e [HLMSW92] sono discussi i motivi di tale convinzione:• la maggior parte dei sistemi esperti è caratterizzata da un piccoloe ben definito insieme di condizioni di ingresso e di uscita. Per

5
questa classe di sistemi possono essere enumerate tutte lepossibili soluzioni: la loro "intelligenza" può quindi essereimplementata attraverso una semplice consultazione di tabellepredefinite. La complessità inerente di un sistema esperto capacedi giocare a scacchi emerge dal numero di possibili stati del gioco:≈10120 [DGr65]. Essi sono decisamente troppi per raccogliereesperienza che permetta un gioco perfetto per ognuno di essi. Persuperare questo problema il giocatore artificiale deve usufruire diconoscenza generale che gli permetta di descrivere e "risolvere" ilmaggior numero possibile di stati. Il risultato è una conoscenzarelativamente inesatta (in questo caso si parla di euristica) la qualeè fonte di errore. Questa proprietà è caratteristica di tutti i sistemiesperti più complessi e ciò conferisce generalità al dominio degliscacchi.
• il gioco è da sempre considerato di "intelligenza"; esso costituisceuna sfida intellettuale che gli ultimi 200 anni di intensa ricerca nonhanno sminuito di interesse ed esaurito l’analisi di tutti i suoiaspetti;
• le regole del gioco sono ben definite: ciò di fa esso un utiledominio per il test di metodi applicati normalmente a problemi nondiscreti (probabilistici);
• il dominio può essere facilmente decomposto in sottodomini perisolare alcuni problemi (ad es. si può pensare ad un sistemacapace di giocare bene i finali di partita);
• esiste il sistema ELO [CFC84], una metrica internazionale divalutazione delle prestazioni che permette di attribuire un valoreassoluto alle qualità di un certo giocatore;
• molta della conoscenza scacchistica deve essere ancora valutatanegli effetti che produce quando incorporata in un giocatoreartificiale;
• il gioco degli scacchi è molto noto e ciò permette al ricercatore divalutare direttamente i risultati del sistema da lui sviluppato; ciò nonè sempre possibile: in molte applicazioni lo studioso non hafamiliarità con il dominio di applicazione e deve fare spessoaffidamento sull’opinione di esperti.
0.3 Gli strumenti0.3.1 La base teorica
Lo strumento fondamentale cui farà affidamento questolavoro è l’esperienza acquisita negli ultimi decenni dalmondo scientifico per ciò che riguarda i sistemi "intelligenti"ed in particolare i giocatori artificiali.
La maggior parte degli studiosi ha concentrato l’attenzionesulla componente di ricerca dei sistemi. In questo ambito imetodi di ricerca con forza bruta sono stati i più esplorati edil risultato più importante di tanto impegno è l’algoritmo αβ[KnuMoo75]. La sua caratteristica è di eseguire una visitadell’albero di gioco in ordine depth-first e di operare dei tagli

6
dello spazio di ricerca (in modo analogo agli algoritmibranch-and-bound). Per taglio si intende la capacità diindividuare, prima della loro esplorazione, sottoalberi checertamente non contengono la soluzione. Il vantaggio dieseguire tagli riduce la complessità della ricerca, anche seessa rimane esponenziale rispetto alla profondità massimada essa raggiunta.
Le proprietà degli algoritmi di ricerca selettiva non sono stateancora sufficientemente investigate poiché di norma essisono dipendenti dal dominio e i modelli matematici che lidescrivono generalmente complessi e di tipo probabilistico.L’algoritmo dei numeri di cospirazione di McAllester[McA85;Sch90] costituisce tuttavia un esempio convincenteper efficacia di algoritmo di ricerca selettiva indipendente daldominio.
Come già precisato, l’attenzione di questo lavoro sisoffermerà sullo studio di giocatori artificiali paralleli. Inquesto settore i ricercatori hanno impegnato i maggiori sforzinello studio della parallelizzazione dell’algoritmo αβ. Taleproblema si è rivelato estremamente difficile: mentre alcunirisultati di simulazioni hanno promesso buone prestazioni[Lin83; AkBaDo82], alcune implementazioni reali hannorivelato modesti speedup [MaOlSc85; New85]. Al di là di uncerto numero di processori le prestazioni si stabilizzano finoal punto in cui l’introduzione di nuove risorse di elaborazioneproduce effetti negativi. I principali problemi che affliggono laparallelizzazione αβ sono l’overhead di sincronizzazione,cioè il costo che deriva dai tempi in cui i processori sonoinoperosi e l’overhead di ricerca, conseguenza delladeficienza di informazioni nell’ambiente globale aiprocessori.
Fra gli algoritmi αβ paralleli quello che è emerso come piùvantaggioso è PVSplit [MarCam82]: è relativamentesemplice da capire ed implementare e ha garantito risultatisoddisfacenti in presenza di un piccolo numero di processori[MaOlSc85; New85].
Allo stato dell’arte rimane tuttavia aperta la discussione suquale sia la migliore implementazione di αβ in presenza didecine o centinaia di processori [Sch89].
Gli studi nel campo della conoscenza sono inerentementedipendenti dal dominio di applicazione. In questo ambito iproblemi più importanti sono la scelta della conoscenza dicui deve disporre un sistema e la determinazionedell’importanza relativa delle "porzioni" che la compongono.Tali problematiche non rientrano nel campo di interesse delpresente lavoro il quale intende suggerire metodi di"gestione" (in particolare di distribuzione) della conoscenzaindipendenti dal dominio. Dovendo però sperimentare

7
queste idee e dare significato concreto a tali esperimenti, sidovrà comunque "manipolare" conoscenza appartenente adun dominio reale (gli scacchi). L’approccio sarà quello diconsiderare come validi i risultati di alcuni ricercatori [Sch86]senza questionare sulle scelte e i metodi che li hannooriginati.
L’unico riferimento per lo sviluppo dell’idea di distribuzionedella conoscenza è il lavoro di Althöfer [Alt91]: egli haeseguito alcuni esperimenti con giocatori paralleli di scacchicostituiti da giocatori sequenziali commerciali che cooperanosuggerendo ciascuno la propria migliore mossa eselezionando quale scelta finale la mossa maggiormenteproposta. In esso la distribuzione della conoscenza èimplicita nella diversità dei singoli giocatori. Taledistribuzione è però casuale, non scaturisce cioèdall’applicazione di criteri e metodi generali: il concepimento,l’analisi e la sperimentazione di questi sarà invece uno deitemi di questo lavoro.
0.3.2 Il supporto a implementazione esperimentazione
Il supporto per l’implementazione e la sperimentazione delleidee che saranno proposte è costituito dai seguentistrumenti:
• l’architettura parallela• il linguaggio di programmazione• il giocatore sequenziale di riferimentoL’architettura parallela è una rete locale di 11 SUN 4Sparcstation collegate in Ethernet.Le caratteristiche principali di questa architettura chedovranno essere tenute in considerazione in sede diprogetto dei programmi e di discussione dei risultati sono:
• l’assenza di memoria condivisa e quindi la possibilità dicooperare fra processori unicamente attraverso lo scambiofisico di messaggi attraverso la rete;
• l’accoppiamento medio fra i processori: l’affidabilità e lavelocità con cui avvengono le comunicazioniinter-processore si pongono a metà fra quelle elevate diarchitetture a parallelismo massiccio e quelle decisamenteinferiori di reti esterne. Il costo di una comunicazione èdell’ordine del millisecondo.
Il linguaggio di programmazione distribuita utilizzato èC-Linda: si tratta di una estensione del linguaggiosequenziale C con le primitive del modello Linda dicooperazione fra processi [CarGel90].
Linda è un nuovo modello di programmazione parallela i cuimeccanismi di comunicazione sono basati sul concetto distrutture dati distribuite, cioè che possono essere manipolate

8
simultaneamente da più processi. In Linda esse sonoimplementate attraverso un modello di memoria denominatospazio delle tuple [CarGel89]. Questo è una memoriaglobale condivisa fra i processi (anche se la suaimplementazione non richiede necessariamente lacondivisione di memoria fisica).
Gli elementi dello spazio delle tuple sono una sequenzaordinata di valori chiamati tuple. Su di essi sono definite leseguenti operazioni:
• out: deposito di una nuova tupla• in: lettura e rimozione di una tupla• rd: lettura (senza rimozione) di una tupla La comunicazione fra i processi è dunque mediata dallospazio delle tuple. La sincronizzazione fra processi è attuatadall’attesa della disponibilità delle tuple desiderate: leprimitive in e rd, infatti, sono bloccanti, cioè sospendono ilprocesso che le invoca fino a che nello spazio delle tuplenon compare (per effetto di un altro processo) la tuplaattesa.
Linda fornisce una primitiva molto semplice, chiamata eval,per la creazione di un nuovo processo sequenziale; laparticolarità dei processi così creati è di costituire tupleattive: al momento della loro terminazione essi generano unrisultato che è parte della stessa tupla che è divenuta orapassiva e può essere letta e rimossa come qualsiasi altra.
Linda non costituirà semplicemente uno strumento di lavoro,ma sarà anche oggetto di analisi. Uno dei principali obbiettividi questa tesi, infatti, è valutare il suo modello dicomunicazione quando applicato in un dominio reale.Particolare attenzione sarà rivolta alle proprietà espressive edi efficienza di questo linguaggio.
Le prestazioni dei giocatori paralleli che scaturiranno siadalla distribuzione della ricerca che della conoscenzasaranno confrontate con quelle di un giocatore artificialesequenziale che quindi costituirà il termine di misura econfronto per tutti i miglioramenti incorporati in essi. Lascelta di tale giocatore è caduta su GnuChess, unprogramma di scacchi prodotto dalla OSF (progetto GNU). Imotivi di questa scelta sono molteplici:
• GnuChess è relativamente semplice: il suo codice sicompone di circa 4000 linee in C. Un sufficiente livello diconfidenza con esso può quindi essere ottenuto in tempipiuttosto brevi ( approssimativamente 15 giorni).
• le prestazioni del giocatore sono notevoli: nonostante lasua semplicità è caratterizzato da una considerevole qualitàdi gioco. Quanto detto trova conferma nelle vittorie da essoriportate nelle edizioni ’92 e ’93 del torneo annuale supiattaforma stabile1 fra giocatori artificiali di scacchi.

9
• il programma è di pubblico dominio: ciò fa di esso unterreno comune di confronto e di scambio fra molti deiricercatori del settore.
• la struttura del programma è abbastanza modulare: questaproprietà permette il suo utilizzo come libreria di funzioni. Inquesta veste GnuChess (in particolare alcune delle suefunzionalità) costituirà l’interfaccia fra gli algoritmi sviluppatiin questo lavoro, in generale indipendenti dal dominio diapplicazione, ed il dominio in cui essi saranno sperimentati:il gioco degli scacchi.
0.4 La struttura della tesiLa prima parte di questa dissertazione (Capitoli 1-4) sarà dedicataad una descrizione più attenta degli strumenti necessari allosviluppo ed alla sperimentazione di nuovi metodi di distribuzionedella ricerca e della conoscenza all’interno di un giocatoreartificiale; la discussione di quest’ultimi e la presentazione deirelativi risultati sperimentali sarà invece oggetto della secondaparte della tesi (Capitoli 5-6).
In particolare nel Capitolo 1 si intende prendere conoscenza dellostato dell’arte nel campo della ricerca sequenziale degli alberi digioco. Sarà inclusa la presentazione del concetto di albero di giococome modello matematico e di alcuni algoritmi di visita dell’albero.Particolare enfasi sarà posta nella introduzione degli algoritmi conforza bruta: minimax, αβ e le sue varianti. Saranno inoltre passatein rassegna alcune delle euristiche di ricerca mirate a migliorarel’efficienza di tali algoritmi. Quale rappresentante dell’approccioselettivo sarà descritto l’algoritmo dei numeri di cospirazione diMcAllester.
Il capitolo 2 ha per argomento la descrizione strutturale diGnuChess. Essa si articolerà attraverso l’analisi dellarappresentazione discreta degli stati del gioco, la presentazionedell’algoritmo e delle euristiche di ricerca ed infine delle modalità digioco e dell’interfaccia di i/o. Particolare attenzione sarà dedicataalla funzione di valutazione statica, cioè la componente cheraccoglie la conoscenza terminale del giocatore: sarà infattiproposta una sua decomposizione logica che costituirà nel Capitolo6 la base per la sperimentazione dei metodi di distribuzione dellaconoscenza. Lo studio di un giocatore reale (quale GnuChess è)rappresenterà inoltre un’utile verifica di alcune delle indicazioniteoriche raccolte nel Capitolo 1.
Il Capitolo 3 sarà dedicato alla presentazione di Linda, il linguaggiodi programmazione distribuita attraverso il quale saranno descrittigli algoritmi classici di ricerca (Capitolo 4) e che costituiràstrumento di progetto ed implementazione delle nuove idee primacitate (Capitoli 5 e 6). Sarà presentato lo spazio delle tuple, cioè ilmodello di comunicazione su cui tale linguaggio è basato, e glioperatori su esso definiti. La discussione dell’operatore eval dicreazione dei processi suggerirà l’introduzione del modello

10
master-worker, vale a dire il paradigma di programmazioneconcorrente che sarà preso a riferimento nei Capitoli 5 e 6 nelprogetto della cooperazione fra processi. Verrà inoltre presentatoNetwork C-Linda, cioè l’istanza di Linda impiegata in questo lavoro,e fornite indicazioni sullo stile di programmazione in Lindaattraverso gli esempi:
• di alcune strutture dati distribuite• della descrizione in Linda di varie forme di comunicazione• di sincronizzazione fra processi.Ad epilogo del capitolo verranno accennate le problematiche diimplementazione del linguaggio con particolare attenzione allarealizzazione su rete locale (l’architettura parallela di riferimento perquesto lavoro).
Il Capitolo 4 descrive lo stato dell’arte nell’ambito della ricercaparallela degli alberi di gioco. Saranno presentate diverse classi disoluzioni:
• parallelismo nell’esecuzione di attività che riguardano i nodiindividualmente• ricerca con finestre parallele (parallel aspiration search)• mapping dello spazio di ricerca nei processori• decomposizione dell’albero di giocoMolto spazio sarà dedicato agli algoritmi di decomposizione i qualicostituiranno oggetto di approfondimento e sperimentazione nelCapitolo 5. In particolare sarà formalizzata una nuovaclassificazione di tali metodi attraverso la quale si intende stabiliremaggiore "ordine" all’interno di questo insieme estremamentecomplesso di algoritmi e fissare una nuova terminologia chefavorisca la distinzione fra le loro proprietà salienti.Successivamente saranno illustrati i motivi di degrado di questialgoritmi e alcuni esempi fra i più significativi: l’algoritmo base,mandatory work first, PVSplit e le sue varianti. Sarà infine discussal’efficacia in ambiente distribuito delle euristiche di ricerca utilizzatecon successo in ambiente sequenziale.
Il Capitolo 5 concerne il progetto e la sperimentazione di alcunimetodi di distribuzione della ricerca. In particolare sarà presa inconsiderazione la realizzazione in Linda di alcuni algoritmi didecomposizione dell’albero di gioco. A partire dall’algoritmo basesaranno sviluppati algoritmi via via più complessi in termini digranularità2. Oltre a conseguire una maggiore efficienza questimiglioramenti saranno mirati a capire quali classi di problemipossono essere risolti in Linda senza pregiudicare le prestazioni.Sarà inoltre sviluppato un algoritmo "generale" di decomposizione ilcui principale scopo non è quello dell’efficienza, ma di costituireuna struttura estremamente flessibile adatta per lo studio "rapido"di qualsiasi metodo di decomposizione: la proprietà dell’algoritmoideato, infatti, è di essere "parametrico" rispetto al criterio didecomposizione, cioè di avere isolato tale criterio in un unico

11
modulo rendendo così trasparente la gestione distribuita dellaricerca ed in particolare la cooperazione fra i processi.Il Capitolo 6 introduce il concetto nuovo di "distribuzione dellaconoscenza". Sarà discussa l’importanza della conoscenza neldominio dei giochi e presentati alcuni risultati riguardantil’attribuzione di importanza relativa a diverse categorie diconoscenza scacchistica [Sch86]. Di seguito sarà spiegata lastruttura di un giocatore parallelo costituito da più istanze dellostesso giocatore sequenziale (GnuChess), ma con diversaconoscenza terminale. L’attribuzione di conoscenza ai diversigiocatori avviene in rispetto di un criterio chiamato appunto didistribuzione. I giocatori cooperano suggerendo ciascuno la propriamossa e determinando la migliore, fra quelle suggerite, sulla basedi un criterio di selezione. Saranno ideati e sperimentati diversicriteri di distribuzione e di selezione. In particolare verrannosuggerite metriche per la valutazione separata di tali criteripermettendo così di scinderne gli effetti sulle prestazionicomplessive del giocatore parallelo. In conclusione sarà discussa lapossibilità di distribuzione della conoscenza dirigente intendendocon questo termine la cooperazione di giocatori sequenziali cheadottano differenti algoritmi ed euristiche di ricerca.
Il capitolo 7 presenterà un sommario del lavoro svolto e offriràsuggerimenti per le ricerche future.

12
Capitolo 1Algoritmi di ricerca sequenziale dialberi di gioco
1.1 IntroduzioneLa teoria dei giochi è una branca relativamente giovane dellamatematica. La sua finalità è lo studio di problemi decisionali checoinvolgono in generale più persone (o agenti, o partiti).
Nella classe di problemi menzionata le persone coinvolte(solitamente chiamate giocatori) hanno interessi differenti e miranoad ottenere soluzioni diverse: esse competono l’una contro l’altraper ottimizzare il proprio profitto.
Esempi di problemi decisionali con più partiti non sono soltantogiochi da tavolo quali gli scacchi o il bridge, ma anche problemicontrattuali fra un venditore ed un acquirente oppure dicompetizione sul mercato da parte di più aziende. La teoria deigiochi, dunque, non limita il suo dominio applicativo al solo ambitodei giochi, ma fornisce un insieme di strumenti (nella forma dimodelli e risultati matematici) che trovano applicazione in moltealtre discipline come le scienze economiche, sociologiche,sociobiologiche e politiche [Thu92].
L’attenzione degli studiosi di questa disciplina si è concentrata, findai suoi albori, sull’analisi di una classe particolare di problemi cheprende il nome di giochi di due persone, a somma zero e coninformazione perfetta; i componenti di tale classe sono accomunatida medesime caratteristiche [vNeMor44]:
• il numero dei giocatori è 2• ciò che un giocatore perde equivale al guadagno dell’altro(somma zero)• tutte le mosse legali sono note ad entrambi i giocatori in ogni fasedella partita (informazione perfetta).Gli esempi più rappresentativi di questo insieme sono scacchi,dama, othello, tic-tac-toe, ecc.Il dominio di indagine del presente lavoro è proprio questa classe digiochi.In questo capitolo è introdotto il modello matematico discreto su cuiè basata la teoria di questi problemi: l’albero di gioco [Sha50]. Èinoltre presentata una rassegna di algoritmi e risultati teoricisviluppati sia in ambiente sequenziale che parallelo.
1.2 Alberi di giocoSi definisce albero di gioco una struttura ad albero i cui nodirappresentano stati del gioco e ciascun arco una trasformazione ditale stato originata dell’esecuzione di un’azione (o mossa) legale,cioè ammessa dalle regole del gioco.

13
••• ••• ••••••
••• ••••••
•••a2-a4 g1-h3a2-a3
a7-a6 a7-a5 a7-a6 g8-h6
20 stati del gioco differenti dopo una mossa del bianco
400 stati del gioco differenti dopo una mossa di entrambi i giocatori
20 mosse legali alla radice dell’albero
nodo ≡ stato del gioco
arco ≡ mossa legale
Fig. 1.1 Albero di gioco negli scacchi
In Fig. 1.1 è illustrato l’albero di gioco degli scacchi:• il nodo radice definisce l’impostazione iniziale della scacchiera• gli archi che lo collegano ai nodi successori individuano l’insiemedi aperture legali• ogni cammino a partire dalla radice rappresenta una differentepartita.Si supponga che il gioco abbia realmente raggiunto un certo stato(corrente) e si consideri il sottoalbero dell’albero di gioco la cuiradice è il nodo che rappresenta questo stato. Tale sottoalberodescrive tutti i possibili sviluppi futuri della partita: anche questo èun albero di gioco. Normalmente quando si parla "dell’albero digioco" ci si riferisce implicitamente proprio a quello relativo allostato corrente poiché descrive completamente ciò che è importanteper un giocatore: il futuro del gioco.
Più formalmente, l’albero di gioco è dunque una struttura definita inmaniera ricorsiva consistente di un nodo radice rappresentante lostato iniziale e di un insieme finito di archi indicanti mosse legali inquel nodo. Gli archi puntano a potenziali stati successivi ognunodei quali, a sua volta, è la radice di un nuovo albero di gioco.
Un nodo che non ha archi uscenti è un nodo terminale o foglia edindividua una posizione per la quale non vi sono mosse legali. Se lo

14
stato corrente è una foglia, allora il gioco ha termine. Ad ogni fogliaè associato un valore (ad esempio: VITTORIA, SCONFITTA oPAREGGIO) che sintetizza l’esito finale della partita.
Dato un nodo, il numero di archi uscenti ne definisce il fan-out,mentre la distanza dalla radice ne individua la profondità. Il terminefattore di diramazione è usato per indicare il valore medio delfan-out per un dato albero di gioco.
Profondità 3
Profondità 2
Profondità 1
Profondità 0
nodo radice ≡ stato iniziale
nodo non terminale ≡ stato intermedio
nodo terminale ≡ stato finale
una variante
Fig. 1.2 Un albero di gioco uniforme
Un albero di gioco si dice uniforme se tutti i nodi non terminalihanno lo stesso fan-out e tutti i nodi foglia sono alla stessaprofondità. Un albero uniforme con fattore di diramazione w e
profondità d contiene un totale di dw =i=1
d∑
d+1w −1w −1
nodi, dw dei quali
sono terminali.
L’albero di gioco uniforme di Fig. 1.2 ha un fattore di diramazione 2e profondità 3.Un cammino dal nodo radice ad uno dei nodi terminali identificauna particolare istanza di partita ed è chiamato variante.Il modello albero di gioco è discreto e quindi molto adatto ad essererappresentato in un calcolatore. Ciò che si vuole ottenere è direndere un computer capace di giocare in maniera autonoma,possibilmente ai livelli dei giocatori umani più esperti; vedremo nelseguito come questa possibilità dipenda da molti fattori,principalmente dalla potenza di calcolo a disposizione.
Come può un calcolatore operare una decisione di naturastrategica quale, in un certo stato del gioco, l’esecuzione dellamossa più vantaggiosa ? Esso è istruito (programmato) aselezionare la mossa "migliore" secondo una strategia di controllo.
1.2.1 Algoritmo minimax: una strategia di controllo

15
Per strategia di controllo si intende una procedura dicontrollo del flusso del gioco che suggerisce ad un giocatorequale mossa scegliere.
L’algoritmo minimax è l’esempio più importante di strategiadi controllo per la classe di giochi in esame [Abr89]. Essorealizza una brutale ricerca su di un albero di gioco, nellaquale è eseguito un esame esaustivo di tutte le possibilisequenze di mosse fino ai nodi terminali dell’albero. I risultatidi tale visita sono fatti risalire (backing-up) lungo l’albero alfine di determinare un valore numerico (valore minimax) daassociare al nodo radice. Il valore così ottenuto identifica lamigliore mossa nella posizione cui il nodo radice si riferisce;in particolare è chiamata variante principale la sequenza dimosse dalla radice al nodo terminale lungo la quale è risalitoil valore minimax del nodo radice.
L’algoritmo minimax poggia sull’ipotesi di gioco perfetto: inogni posizione del gioco i giocatori selezionano sempre lamossa migliore secondo il loro punto di vista.
Assunto che MAX e MIN sono i nomi dei due giocatori, siintende ora descrivere formalmente come vengonoassegnati i valori minimax ai nodi dell’albero di gioco.
I valori dei nodi foglia identificano l’esito finale del gioco dalpunto di vista di MAX. Ai nodi non terminali, invece, i valorisono associati in maniera ricorsiva: il valore di un nodo in cuispetta a MAX la mossa è ottenuto massimizzando i valori deisuoi successori. Analogamente, se il nodo descrive unaposizione in cui è MIN a dover muovere, allora il suo valoreè il minimo dei valori dei successori (i valori sintetizzanosempre il punto di vista di MAX e quindi il suo antagonistacerca di minimizzarli nella loro risalita verso la radice).
Una misura della complessità degli algoritmi di ricerca sualberi di gioco è il numero dei nodi terminali visitati. In unalbero di gioco uniforme con fattore di diramazione b eprofondità d questo numero è fisso e pari a bd.
Una variante della ricerca minimax è l’algoritmo negamax[KnuMoo75]. I due metodi sono essenzialmente gli stessi,ma nella ricerca negamax al livello superiore nell’albero digioco è fatto risalire il valore negato dei suoi sottoalberi. Intale maniera i valori di un sottoalbero di un nodo sonosempre considerati dal punto di vista del giocatore cui spettamuovere in quel nodo. Pertanto l’algoritmo computa sempreil massimo di questi valori e non deve preoccuparsi di qualegiocatore debba muovere.
In Fig. 1.3a e Fig. 1.3b sono raffigurati i due algoritmi.

16
Massimizza
Minimizza
Massimizza
Massimizza
3 9 2 1
3 2
3 9 2
-3
1
-2
3 3
Fig. 1.3a Metodo minimax Fig. 1.3b Metodonegamax
La maggior parte dei giochi più interessanti generano alberidi gioco le cui dimensioni sono troppo grandi per consentireuna ricerca completa; basti pensare che è stato stimato cheil numero medio di nodi contenuti in un chess-tree (l’albero digioco degli scacchi) è circa 10120 [dGr65].
In questi giochi la ricerca è troncata ad un certo stadiointermedio individuando così nell’albero una frontiera diricerca, cioè un insieme di nodi interni (non terminali) nonespandibili a causa di limiti computazionali.
A questi nodi, chiamati tip, è associato un insieme diinformazioni sulle quali è applicata una funzione divalutazione statica, la cui natura è strettamente legata allospecifico dominio del gioco. Il valore di ritorno da talefunzione rappresenta una stima del valore effettivo del nodotip, ovvero del suo valore minimax.
La suddetta funzione esegue pertanto una valutazionequantitativa; questa è il risultato dell’elaborazione di alcuneespressioni aritmetiche legate ad alcune caratteristiche dellaposizione valutata [Cia92]. Normalmente essa ha strutturapolinomiale, cioè scaturisce dalla combinazione lineare dellevalutazioni separate di caratteristiche distinte della genericaposizione p:
f(p) = ai ⋅ t i(p)i
∑
dove ti individua una generica "sotto-valutazione" e ai unamisura della rispettiva importanza.In molti giochi l’evidenza empirica mostra come l’inerenteinaffidabilità della funzione di valutazione statica diminuiscecon l'aumentare della profondità della ricerca [Abr89].
In Fig. 1.4 è presentato integralmente l’algoritmo minimax inversione negamax3. Le funzioni genmoves, makemove,undomove e evaluate sono dipendenti dal dominio: la primadetermina i successori di una posizione, mentre le dueseguenti gestiscono lo stato corrente del gioco eseguendo eretraendo l’esecuzione di una mossa; l’ultima, infine, èproprio la funzione di valutazione statica.

17
int minimax (position *p,int depth){position *successor;int nmoves, score, value, ind;if (depth==0) /* raggiunta la profondità massima di ricerca?*/
return (evaluate(p)); /* è applicata la funzionedi valutazione statica */nmoves=genmoves (p,&successor); / *generazione mosse */if (nmoves==0) /* nodo terminale? */
return (evaluate(p));score=- ∞; /* inizializzazione del valore minimaxparziale *//* ricerca del massimo score fra quello di tutti isottoalberi */for (ind=0;ind<nmoves;ind++)
{makemove (successor+ind); /* esegui mossa */value=-minimax(successor+ind,depth-1);if (value>score)
score=value;undomove (successor+ind); /* retrai la mossa
valutata */}
return (score);}Fig. 1.4 Algoritmo minimax (versione negamax)
1.2.2 La funzione di valutazione, l’effetto orizzontee la ricerca quiescente
Quando la ricerca raggiunge un nodo terminale di un alberodi gioco è invocata una funzione di valutazione statica perassegnare un valore alla posizione corrente. Tale funzionenon tiene conto di quanto potrà accadere nelle mossesuccessive allo stato del gioco esaminato. L’insieme diquesti nodi foglia, tutti posti ad una fissata profondità,costituisce un orizzonte al di là del quale la funzione divalutazione non ha visibilità. Questo fatto può esseresorgente di gravi errori di valutazione dovuti appunto aquesto fenomeno conosciuto come effetto orizzonte [Ber73].
Vi sono posizioni che più di altre possono essere fonte dierrore e la loro caratterizzazione dipende fortemente dalgioco in esame. Esse sono chiamate instabili.
Ad esempio negli scacchi sono considerate instabili posizioniche occorrono dopo la cattura di un pezzo o dopo unoscacco al re.
Si cerca di diminuire l’effetto orizzonte estendendo diqualche mossa la ricerca oltre i nodi foglia consideratiinstabili: questa estensione è chiamata ricerca quiescente.
La ricerca quiescente può comportare un sensibile aumentodella complessità computazionale. Per limitare questooverhead si restringe l’esplorazione oltre il nodo terminale adun sottoinsieme delle mosse legali. Ad esempio, se lacattura di un pezzo ha originato una posizione instabile,

18
allora durante la ricerca quiescente sono analizzatesolamente le mosse di cattura, contenendo così la crescitadelle dimensioni dell’albero di gioco.
profondità nominale di ricerca
nodo terminale instabile
Fig. 1.5 Albero di gioco visitato da una ricercaquiescente
In Fig. 1.5 è illustrato l’albero di gioco esploratodall’algoritmo minimax in combinazione con la ricercaquiescente: si osservi come solo alcune linee di gioco siestendano oltre la profondità massima fissata dall’algoritmominimax (denominata profondità nominale di ricerca).
1.2.3 Ordine di visita dell’albero di gioco: discesaa scandaglio (depth -first search)
Accanto alle regole per far risalire il valore minimax verso laradice è importante definire l’ordine di visita dell’albero digioco.
Il calcolo del valore minimax di un nodo è eseguitogeneralmente con una visita a scandaglio (depth-firstsearch) realizzata con una forma di backtracking.
I numeri con cui sono etichettati i nodi di Fig. 1.6 mostranol’ordine di generazione degli stessi nodi in una visita ascandaglio. Il vantaggio principale di questo ordine di ricercaè l’estrema semplicità della procedura di gestione(facilmente modellabile tramite ricorsione) ed il modestospazio di memoria richiesto. Quest’ultimo è infatti lineare conla lunghezza del cammino corrente dalla radice e contieneuna struttura a pila composta dei nodi di questo cammino.

19
13121198754
1062
3
1
Fig. 1.6 Ordine di generazione dei nodi in una ricerca ascandaglio
1.3 Algoritmi di ricerca sequenzialeData una posizione p in un gioco a somma zero di 2 giocatori efissato un albero di gioco che rappresenti tutte le possibilicontinuazioni del gioco a partire da p, lo scopo di un algoritmo diricerca è quello di determinare il valore minimax del nodo p. Questovalore sarà una approssimazione di quello reale nel caso chel’albero visitato sia parziale, cioè i valori associati ai suoi nodi tipnon siano esatti, ma frutto di una stima.
L’algoritmo minimax ottiene correttamente questa finalità, ma ad uncosto computazionale insoddisfacente.A partire dal 1950 un’importante osservazione ha determinato losviluppo di una tecnica di ricerca che ora è uno standard: esiste uninsieme di mosse facilmente riconoscibile che non sarannoselezionate dall’algoritmo minimax.
Il metodo che poggia su tale considerazione si chiama αβ-pruning.1.3.1 L’algoritmo αβ
L’algoritmo αβ produce lo stesso risultato della ricercaminimax, ma ad un minor costo. Esso, infatti, effettua deitagli (cutoff) lungo l’albero di gioco, ovvero determinasottoalberi che non contengono il valore minimax ottimo peril nodo radice e quindi non procede alla loro visita. L’esattaorigine dell’algoritmo αβ non è nota; i primi documenti in cuiè discusso in dettaglio sono [EdwHar63] e [Bru63].
L’algoritmo opera tenendo traccia dei limiti dell’intervallo(α,β) all’interno del quale deve essere contenuto il valoreminimax di un nodo. L’intervallo (α,β) è chiamato finestra αβ(αβ-window).
In particolare il parametro α è un limite inferiore per il valoreche deve essere assegnato ad un nodo che massimizza,

20
mentre β è un limite superiore per il valore di un nodo cheminimizza sui valori dei successori. Sono "recisi" i nodi il cuivalore cade al di fuori dell’intervallo (α,β) ed i rispettivisottoalberi non ancora visitati sono quindi ignorati dallaricerca.
Gli esempi che seguono illustrano una giustificazioneintuitiva del metodo ed una classificazione dei tagli [Cia92;KnuMoo75].
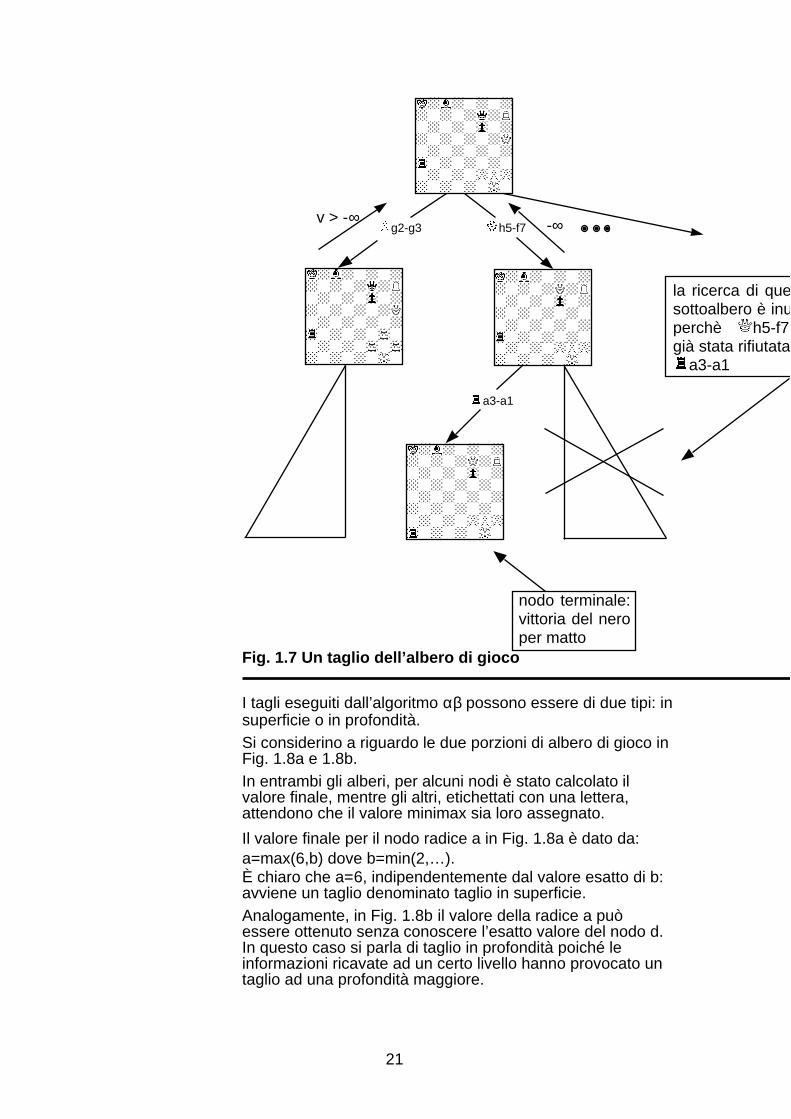
Si consideri l’albero di gioco di Fig. 1.7. La prima mossavalutata dal bianco è g2-g3 il cui valore minimax è v > -∞.La successiva mossa valutata è h5-f7; in risposta a talemossa è analizzata la mossa a3-a1 la quale originaimmediatamente il matto per il nero: indipendentementedalle altre mosse di risposta del nero il valore minimax finaleper la mossa h5-f7 equivale ad una sconfitta (=-∞) e quindiquesta non è una scelta conveniente per il bianco.
Nella situazione descritta, pertanto, la porzione delsottoalbero inesplorato relativa a h5-f7 è inutile che vengavisitata ed è quindi "tagliata" dalla ricerca. In particolare sidice che la mossa h5-f7 è stata confutata (rifiutata) dallamossa a3-a1, cioè questa rappresenta una risposta adessa sufficiente a dimostrarne l’inopportunità.
21
g2-g3 h5-f7
a3-a1
v > -∞ -∞
nodo terminale: vittoria del nero per matto
la ricerca di questo sottoalbero è inutile perchè h5-f7 è già stata rifiutata da
a3-a1
Fig. 1.7 Un taglio dell’albero di gioco
I tagli eseguiti dall’algoritmo αβ possono essere di due tipi: insuperficie o in profondità.Si considerino a riguardo le due porzioni di albero di gioco inFig. 1.8a e 1.8b.In entrambi gli alberi, per alcuni nodi è stato calcolato ilvalore finale, mentre gli altri, etichettati con una lettera,attendono che il valore minimax sia loro assegnato.
Il valore finale per il nodo radice a in Fig. 1.8a è dato da:a=max(6,b) dove b=min(2,…).È chiaro che a=6, indipendentemente dal valore esatto di b:avviene un taglio denominato taglio in superficie.Analogamente, in Fig. 1.8b il valore della radice a puòessere ottenuto senza conoscere l’esatto valore del nodo d.In questo caso si parla di taglio in profondità poiché leinformazioni ricavate ad un certo livello hanno provocato untaglio ad una profondità maggiore.

22
a
6
2
a
6
b
d
c
2
2
Fig. 1.8a Taglio in superficie Fig. 1.8b Taglio inprofondità
Al fine di assicurare che sia trovato il corretto valore minimaxdella radice i parametri α e β sono inizializzatirispettivamente a -∞ e +∞. Essi saranno poi aggiornatidurante la visita dell’albero di gioco.
Normalmente l’utilizzo dell’algoritmo αβ è stabilito da unachiamata di funzione della forma:MM=alphabeta(p,alpha,beta,depth)dove p è un puntatore ad una struttura che descrive lo statodel gioco nel nodo esplorato; (alpha,beta) è la finestra αβ edepth la lunghezza massima del cammino di ricercaespressa come numero di semi-mosse (ply). Il valore MMritornato dalla funzione è il valore minimax per la posizionep.
Fig. 1.9 illustra una versione negamax dell’algoritmo αβ.La versione dell’algoritmo proposta è molto semplice edovrebbe essere estesa per tenere traccia della mossaottimale trovata.
int alphabeta(position *p,int alpha,int beta,int depth){position *successor;int nmoves,score,value,ind;if (depth==0)
return (evaluate(p));nmoves=genmoves(p,&successor);if (nmoves==0)
return (evaluate(p));score=alpha; /* il valore minimax parziale ha valoreiniziale alpha e non - ∞ */

23
for (ind=0;i<nmoves;ind++){makemove(successor+ind);value=-alphabeta(successor+ind,-beta,-score,depth-1);undomove(successor+ind);if (value>score) /* il valore calcolato fornisce
un miglioramento? */score=value;
if (score>=beta) /* un taglio? */return(score); /* la visita del restante
sottoalbero è "recisa" */}
return (score);}Fig. 1.9 Algoritmo αβ (versione negamax)
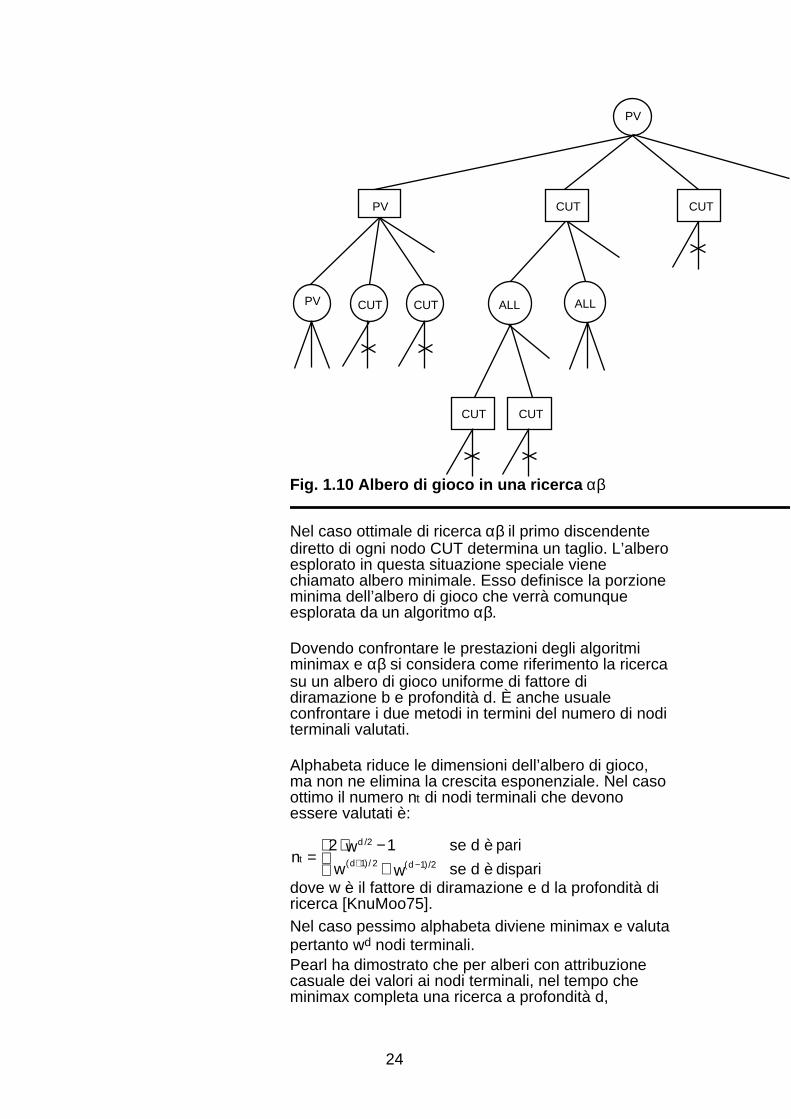
1.3.1.1 L’efficienza dell’algoritmo αβKnuth e Moore hanno ridefinito la struttura di unalbero di gioco quando è oggetto di una ricercaαβ [KnuMoo75]. Essi hanno classificato i nodi che locompongono in tre categorie:
• nodi PV: sono i nodi che compongono lacontinuazione principale (principal variation), cioè ilprimo cammino dalla radice ad un nodo terminale cheviene esaminato nella ricerca4.
• nodi CUT: rappresentano alternative dei nodi PV.Sono gli unici nodi in cui possono avvenire tagli.• nodi ALL: sono nodi successori dei nodi CUT. A lorovolta i successori dei nodi ALL sono ancora di tipoCUT.
Mentre tutti i sottoalberi dei nodi PV e ALL sonosempre esplorati, solamente un sottoinsieme deisottoalberi dei nodi CUT sarà preso in considerazionea causa dei tagli.
Fig. 1.10 illustra la struttura presentata.
24
PV
CUT
PV
CUT PV ALLALL
CUT CUT
CUTCUT
Fig. 1.10 Albero di gioco in una ricerca αβ
Nel caso ottimale di ricerca αβ il primo discendentediretto di ogni nodo CUT determina un taglio. L’alberoesplorato in questa situazione speciale vienechiamato albero minimale. Esso definisce la porzioneminima dell’albero di gioco che verrà comunqueesplorata da un algoritmo αβ.
Dovendo confrontare le prestazioni degli algoritmiminimax e αβ si considera come riferimento la ricercasu un albero di gioco uniforme di fattore didiramazione b e profondità d. È anche usualeconfrontare i due metodi in termini del numero di noditerminali valutati.
Alphabeta riduce le dimensioni dell’albero di gioco,ma non ne elimina la crescita esponenziale. Nel casoottimo il numero nt di nodi terminali che devonoessere valutati è:
nt =2 ⋅ d /2w −1 se d è pari
(d+1)/ 2w + (d −1)/2w se d è dispari
dove w è il fattore di diramazione e d la profondità diricerca [KnuMoo75].Nel caso pessimo alphabeta diviene minimax e valutapertanto wd nodi terminali.Pearl ha dimostrato che per alberi con attribuzionecasuale dei valori ai nodi terminali, nel tempo cheminimax completa una ricerca a profondità d,

25
alphabeta esplora in media un albero di profondità4
3d [Pea82].
Va sottolineato che la prestazione ottimale è ottenutasolo quando la prima mossa considerata ad ogninodo è la migliore. In questo caso l’albero si diceperfettamente ordinato. In generale, un albero digioco è ordinato se la mossa migliore in un genericonodo è fra le prime ad essere esaminata.
Il caso pessimo, invece, si crea quando le mossesono ordinate in ordine inverso: dalla peggiore allamigliore.
L’efficienza dell’algoritmo αβ è tanto più grandequanto più forte è l’ordinamento dell’albero[SlaDix69]. Poiché la differenza fra le dimensionidell’albero minimale e massimale sono notevoli, èimperativo ottenere un buon ordinamento dei nodiinterni; in alcuni dei paragrafi successivi sarà estesala discussione di questo problema.
1.3.1.2 Una caratterizzazione dell’alberominimale
L’albero minimale è quello esplorato dall’algoritmo αβin condizioni ottime di ordinamento dell’albero digioco.
È possibile dare una definizione più formale di alberominimale.Per semplificare l’esposizione è introdotta la seguenteterminologia: il primo arco uscente da un nodo puntaal "figlio sinistro", mentre gli altri puntano ai figli"destri".
Fig. 1.11 Albero di gioco minimale
La struttura dell’albero minimale è definitaricorsivamente dalle regole:• il nodo radice fa parte dell’albero minimale

26
• il figlio sinistro di un nodo dell’albero minimaleappartiene esso stesso all’albero minimale• il figlio sinistro di ogni figlio destro di un nododell’albero minimale fa parte anch’esso dell’alberominimale.
In Fig. 1.11 è evidenziato l’albero minimale di unalbero di gioco uniforme di profondità 3 e fattore didiramazione 3.
1.3.2 Alcune varianti dell’algoritmo αβ1.3.2.1 Aspiration search
L’efficienza di un algoritmo αβ è strettamente legataal numero di tagli che riesce a produrre. La probabilitàdi operare un taglio nella ricerca di un albero di giocoè tanto maggiore quanto più stringente è l’intervallofra i parametri α e β.
In alcune applicazioni, fra le quali gli scacchi, esistonometodi per stimare con buona approssimazione ilvalore minimax di una posizione. A partire da questastima V e fissato un margine di errore err, si originauna ricerca αβ con una finestra iniziale (V-err,V+err)in sostituzione della finestra canonica (-∞,+∞). Questafinestra più stringente (detta aspiration window)"aspira" a contenere il valore minimax corretto, da cuiil nome del metodo: aspiration search [MarCam82].
int aspiration_search (position *p,int v,int err,intdepth){int alpha,beta,value;alpha=v-err;beta=v+err;value = alphabeta(p,alpha,beta,depth);if (value>=beta) /* fallimento superiore? */
value=alphabeta (p,beta,+ ∞,depth)else if (v<=alpha) /* fallimento inferiore? */
value=alphabeta(p,- ∞,alpha,depth);return(value);}Fig. 1.12 Aspiration search
Naturalmente esiste il rischio che il valore stimatorisulti errato ed il valore minimax cada al di fuori dellaaspiration window. In tale evenienza la ricerca deveessere ripetuta con una differente finestra di ricerca.
In Fig. 1.12 è descritto l’algoritmo aspiration search.1.3.2.2 Falphabeta (Fail-soft Alphabeta)
Falphabeta [FisFin80;MarCam82] è una variantedell’algoritmo αβ molto utile quando impiegata incombinazione con aspiration search.

27
L’algoritmo è ottenuto apportando due modifiche allafunzione alphabeta di Fig. 1.9:• la variabile score è inizializzata a -∞ invece che alvalore di alpha• l’invocazione ricorsiva diventa:value=-alphabeta(successor,-beta,-max(alpha,score),depth-1);Quando l’algoritmo falphabeta è usato in aspirationsearch fornisce un limite più stringente per il valorecorretto se la prima ricerca fallisce (visitando lo stessonumero di nodi dell’algoritmo αβ).
1.3.2.3 PVS (Principal Variation Search) ed ilconcetto di finestra minimale
Palphabeta [FisFin80] e Scout [Pea80] sono duealgoritmi che hanno introdotto un approccio differenteal calcolo efficiente dell’esatto valore minimax. L’ideaalla base di questi algoritmi è l’assunzione che laprima mossa esaminata in ogni posizione sia lamigliore. Emerge quindi un insieme di mosse chedefinisce un cammino che rappresenta l’ipoteticacontinuazione principale.
Gli algoritmi operano inizialmente una ricerca lungoquesto cammino associando un valore statico al nodofoglia raggiunto. Successivamente si passa averificare se le mosse alternative a quelle delcammino esaminato apportano o meno valutazioniminimax migliori. Questo tipo di test è meno costosodella computazione del valore minimax per tutti isottoalberi relativi. Tuttavia, qualora una mossaalternativa origini un valore migliore, essa definisce lanuova continuazione principale corrente ed ènecessario operare una nuova ricerca nel suosottoalbero per conoscere il suo esatto valoreminimax.
L’operazione di test è spesso realizzata facendo usodel concetto di finestra minimale (minimal window):una finestra di tipo αβ della forma (V,V+1).
Tale finestra è detta minimale perché non contienealcun valore. Fig. 1.13 mostra un esempio dialgoritmo di ricerca con finestra minimale.
Mentre la prima mossa è valutata in manieraricorsiva, l’esame delle mosse alternative prevedeche inzialmente sia invocata una ricerca falphabetacon minimal window (V,V+1), dove V è il migliorvalore minimax trovato fino a quel momento. Loscopo di tale chiamata è proprio quello di controllarese l’alternativa ha un valore migliore. Ogni volta chetale condizione si verifica è eseguita ancora una

28
ricerca falphabeta con una finestra più estesa al finedi computare il valore esatto.
int mws(position *p){position *successor;int nmoves,score,value,ind;nmoves=genmoves(p,&successor);if (nmoves==0)
return(evaluate(p));score=-mws(successor); /* valutazione lungo lavariante principale */for (ind=1;i<nmoves;ind++)
{value=-falphabeta(successor+ind,-score-1,-
score);if (value>score) /* l’alternativa contiene
un valore migliore? */score=-falphabeta(successor+ind,- ∞,-
value);}
return(score);}Fig. 1.13 Ricerca con finestra minimale
PVS (principal variation search) è un esempio diapplicazione all’algoritmo αβ del concetto di ricercacon finestra minimale [MarCam82]. L’algoritmo,descritto in Fig. 1.14, estende infatti questa ricercacon la gestione di una finestra (α,β) al fine diaumentare il numero di tagli prodotti durante la visitadell’albero di gioco e rendere così possibile ancheuna combinazione del metodo con una forma diaspiration search.
int pvs(position *p,int alpha,int beta,int depth){position *successor;int nmoves,score,value,ind;if (depth==0)
return(evaluate(p));nmoves=genmoves(p,&successor);if (nmoves==0)
return(evaluate(p));best=-pvs(successor,-beta,-alpha,depth-1);for (ind=1;i<nmoves;ind++)
{if (best>=beta)
return(score);alpha=max(score,alpha);value=-pvs(successor+ind,-alpha-1,-
alpha,depth-1);if ((value>alpha) && (value<beta))
score=-pvs(successor,-beta,-value,depth-1);
else if (value>score)score=value;
}return(score);}

29
Fig. 1.14 PVS
Va sottolineata la forte dipendenza dell’efficienza diPVS rispetto al più o meno forte ordinamentodell’albero. Infatti un albero di gioco non ordinatocontiene molti nodi interni il cui valore minimax èmigliore dei fratelli più anziani e ciò implica unaduplice visita del sottoalbero ad essi associato.
Esiste quindi la possibilità che una ricerca PVSesamini più nodi di un algoritmo αβ. I vantaggicomputazionali di PVS emergono quando è realizzatoin combinazione con delle euristiche che stabilisconoun ordinamento nella generazione delle mosse, taleda aumentare la probabilità che le mosse valutate perprime siano le migliori.
1.3.3 Euristiche per migliorare la ricerca αβL’algoritmo αβ è divenuto uno standard di ricerca grazie allasua capacità di trovare sempre la combinazione di mossemigliore pur esaminando un minor numero di mosse rispettoa minimax.
È stato spiegato come le prestazioni di questo algoritmosiano fortemente dipendenti dall’ordinamento dei nodi internidell’albero: se la migliore mossa non è esplorata per prima,allora è necessario un lavoro addizionale per verificare cheun’altra mossa è migliore di quella presunta ottima. Ciò puòaccadere più volte in una ricerca: il caso pessimo occorrequando le mosse sono esplorate in ordine inverso rispetto alloro effetivo valore.
Nella pratica l’albero visitato non è mai quello minimale.Poiché le dimensioni dell’albero sono fortemente influenzatedall’ordine con cui le mosse sono visitate, è importante chela mossa migliore sia esaminata al più presto. Esaminarequesta mossa per prima non è sempre possibile: ciò infattistarebbe a significare che la migliore mossa è nota a priori equindi non si avrebbe bisogno di alcuna ricerca. Sono statisviluppati metodi che, con un elevato grado di probabilità,sono in grado di predire la mossa migliore, permettendo cosìdi visitarla per prima [MarCam82].
In seguito sono presentate alcune euristiche, definite diricerca, il cui scopo è di migliorare la ricerca αβ favorendo laminimizzazione delle dimensioni dell’albero visitato.
1.3.3.1 Approfondimento iterativo (Iterativedeepening)
A differenza degli algoritmi finora visti che sonospecifici per i giochi a somma zero di 2 giocatori,l’approfondimento iterativo è un paradigma di ricercaassolutamente generale.

30
Inserito nel contesto dei metodi αβ, esso definisce unprocesso iterativo nel quale si fa uso della ricerca conprofondità nominale (d-1) per preparare la successivaricerca a profondità d. In altre parole viene primaeseguita una visita completa dei nodi a profondità 1,poi a profondità 2, a profondità 3 e così via.
I vantaggi offerti da tale tecnica sono molti:• limitazione in tempo della ricerca: fissata una soglialimite per il tempo totale di ricerca, questa procede aprofondità massime successive fino a che il limitetemporale non è raggiunto.
• controllo della ricerca: in alcune applicazioni, adesempio l’analisi di certi finali negli scacchi, lasoluzione può essere trovata dopo un numero esiguodi mosse. In tale contesto l’algoritmo di ricerca nonconosce a quale profondità nell’albero di giocoincontrerà la soluzione. Vi sarebbe un’enorme perditadi efficienza se un problema risolvibile in una mossafosse analizzato da una ricerca a profondità 5!
La tecnica di approfondimento iterativo elimina taleanomalia garantendo che un problema di N mosse siarisolto da una ricerca di profondità al più N.
• ordinamento delle mosse: dopo ogni iterazione lalista delle mosse legali nel nodo radice vieneriordinata in maniera che le mosse risultate migliori inuna data ricerca siano esaminte per prime nellasuccessiva iterazione. In particolare, la continuazioneprincipale trovata nella iterazione (d-1) rappresenta lasequenza iniziale di mosse esplorate nella d_esimaricerca.
• miglioramento di aspiration search: il valore minimaxfinale di ritorno dalla ricerca a profondità (d-1) puòessere usato come centro di una aspiration windownella iterazione successiva. È molto probabile chequesta finestra contenga il valore minimax dellanuova ricerca.
Il maggiore vantaggio di iterative deepening è però il• riempimento delle tabelle: diverse euristiche chesaranno introdotte tra breve fanno riferimento atabelle in cui sono conservate informazioni del tipo: lavalutazione di certe posizioni oppure quali mossehanno prodotto un taglio.
Il metodo di approfondimento iterativo favorisce, adesempio, il frequente ripresentarsi di posizioni giàanalizzate e rende pertanto molto significativol’utilizzo di queste tavole. I vantaggi di questa tecnicafurono dimostrati per primo da Chess 4.5 [SlaAtk77],

31
uno dei più potenti programmi di scacchi degli anni’70 e poi provati formalmente da Korf [Kor85].Esiste una forma alternativa di approfondimentoiterativo, in cui la successiva iterazione prevede chela ricerca sia condotta ad una profondità massimaaumentata di 2 rispetto all’iterazione corrente. Talemetodologia è giustificata formalmente da Nau in[Nau82]. Egli ha dimostrato la tendenza della ricercaminimax ha restituire valutazioni vincenti per ilgiocatore quando essa è condotta a profondità disparie perdenti se a profondità pari. I valori ritornati daricerche a profondità alterne formano dunque duesequenze distinte che devono essere considerateseparatamente. È quindi evidente lo scopo in questatecnica di preservare continuità fra iterazionisuccessive, evitando l’alternarsi di linee di giocodifensive e di attacco.
int iterative_deepening (position *p,int maxdepth){int value, d;for (d=1;d<=maxdepth;d++)
{value=alphabeta(p,- ∞,+ ∞,d);sort(p); /* le mosse sono riordinate in
modo che la migliore sia visitataper prima nella successiva iterazione */}
return(value);}Fig. 1.15 Iterative deepening
In Fig. 1.15 è illustrato un algoritmo di ricerca cheimplementa la tecnica di approfondimento iterativoinsieme ad un meccanismo di ordinamento nellagenerazione delle mosse al livello della radice(top-level).
1.3.3.2 Tabella delle trasposizioni(Transposition Table)
Durante la ricerca di un albero di gioco il medesimostato del gioco può presentarsi più volte. La ragione diquesto fenomeno è la presenza di trasposizioni: lostesso stato del gioco è raggiunto da sequenze dimosse differenti.
Invece di valutare nuovamente queste posizioniricorrenti si recuperano da una tabella le informazioniottenute da una valutazione precedente dello stessonodo.
Ogni riga di tale tabella, detta appunto delletrasposizioni [MarCam82], rappresenta una posizione

32
del gioco. Tali righe sono gestite conun’organizzazione hash per favorirne un breve tempodi ricerca. È quindi definita una funzione hashh: stato→int che associa ad ogni posizione unachiave intera utilizzata per indicizzare la tabella.
I campi che normalmente compongono un inelemento della tabella delle trasposizioni sono iseguenti:
• lock• giocatore• lunghezza• valore• flagL’esigenza del campo lock è legata alla possibilità chela funzione hash non sia uniforme, cioè che posizionidifferenti siano mappate nella stessa chiave:
h(si)=h(sj) e si≠sj
Il campo lock contiene l’identificatore della posizionerappresentata nella riga. Qual è il suo utilizzo?Si supponga che debba essere analizzato ilsottoalbero relativo alla posizione X. La funzione hashdetermina che R=h(X) è la riga corrispondente ad Xnella tabella.
Si consideri l’ipotesi che nella riga R sia giàmemorizzata la posizione Y. Viene allora confrontatoil campo lock della riga R con l’identificatore di X: seessi non coincidono si deve valutare la posizione X inquanto nessuna informazione in suo merito ècontenuta nella tabella.
Il risultato della valutazione di X verrà sostituito aquello di Y nella riga R solo se la profondità dellavalutazione di X è maggiore di quella di Y (registratanel campo lunghezza di R). In tale modo vieneconservata l’informazione più costosa in terminicomputazionali.
Il campo giocatore indica il punto di vista secondo ilquale la valutazione è avvenuta. Il valore di unaposizione valutata da un giocatore è diverso, ingenerale, dalla valutazione negata effettuatadall’avversario nella stessa posizione. Infatti il calcolodel valore minimax è influenzato dal fatto che ilgiocatore corrente sia in attacco o in difesa, intesoche è considerato in attacco il giocatore cui spetta lamossa nel nodo radice.
Il campo lunghezza indica la profondità delsottoalbero valutato. Normalmente la tabella èriempita con valutazioni la cui profondità deve esseresuperiore ad un certo valore di soglia; questa scelta è

33
dovuta al fatto che la memorizzazione e la lettura diinformazioni relative alla valutazione di piccolisottoalberi è più costosa della sua nuova valutazionea causa dell’overhead introdotto dalla gestione dellatabella.
Il campo valore contiene la valutazione calcolata perla posizione. Questa è il valore minimax oppure unasua limitazione superiore o inferiore a secondo diquanto specificato nel campo flag. Deve essere infattichiarito che l’algoritmo αβ calcola il valore minimax diun nodo solo se quest’ultimo cade nella finesta (α,β)iniziale. In generale il valore v(p) restituitodall’algoritmo è nella seguente relazione con l’esattovalore minimax mm(p) della posizione:
• v(p)≤α ⇒ v(p)>mm(p) (il fallimento inferiorefornisce una limitazione superiore)• α<v(p)<β ⇒ v(p)=mm(p) (il valore calcolato è quelloesatto)• v(p)≥β ⇒ v(p)<mm(p) (il fallimento superiorefornisce una limitazione inferiore)Si osservi la tabella delle trasposizioni al lavoro: seuna posizione raggiunta durante la ricerca è giàcontenuta nella tabella ed il campo giocatore coincidecon quello corrente, allora si controlla se il valore nelcampo lunghezza è ≥ alla rimanente profondità diricerca per la posizione corrente. Se tale test hasuccesso, i contenuti dei campi valore e flag possonoessere usati per accelerare o sopprimere lavalutazione della posizione. In caso contrario laposizione deve essere valutata nuovamente poiché leinformazioni nella tabella riguardano un suosottoalbero non sufficientemente esteso.
Tale euristica restringe le dimensioni dell’albero digioco. La riduzione è maggiore in situazioni di gioco incui è alta la probabilità di generare trasposizioni, adesempio nei finali degli scacchi dove si hanno pochipezzi ed un elevato numero di mosse reversibili.
1.3.3.3 Euristica dei killerViene denominata killer una mossa che ha prodottoun taglio durante la ricerca αβ di un dato sottoalbero[Cia92;MarCam82]. Tale tecnica è basatasull’intuizione che una mossa killer possa produrreulteriori tagli nell’analisi di altri sottoalberi.
Si consideri a riguardo la situazione scacchistica diFig. 1.16 in cui la mossa spetta al nero. Molte dellemosse del nero (ad esempio a7-a6) sonofacilmente confutate dalla minaccia al re portata dal

34
bianco: h4xh7; vi sono infatti poche mosse cheprevengono tale minaccia. L’euristica dei killerprevede che la mossa h4xh7 sia ricordata per lesua proprietà di avere confutato almeno una mossadel nero: nell’analisi delle successive mosse del neroessa sarà esaminata come prima mossa di rispostanella speranza di ottenere una loro rapidaconfutazione.
Fig. 1.16 Euristica dei killer
Normalmente per ogni livello dell’albero di gioco vienegestita una breve lista di mosse killer. Generando perprime le mosse killer si cerca quindi di massimizzarela probabilità che una linea di gioco che sarà originedi un taglio sia recisa molto presto risparmiando cosìtempo di ricerca.
L’euristica dei killer può comportare un riordinamentodelle mosse sia dinamico che statico.Nella prima situazione il riordinamento è fattonell’ambito della stessa visita dell’albero di gioco: unamossa killer che ha prodoto un taglio al livello npotrebbe essere tentata ai livelli n, n-2, n-4, …(sempre che qui sia legale) prima che siano generatele restanti alternative.
L’ordinamento statico delle mosse è invece effettuatotra una iterazione e la successiva in una metodologiadi approfondimento iterativo.
1.3.3.4 Tabella delle confutazioni (o dellerefutazioni)
Il maggiore svantaggio della tabella delle trasposizioniè la sua dimensione. La tabella delle confutazioniintende conservare i principali giovamenti della tabelladelle trasposizioni, ma richiedendo una minoreoccupazione di memoria [Sch86].

35
Questa euristica è introdotta in combinazione conquella di approfondimento iterativo. Dopo ogni ricercaa profondità d, sono memorizzate in una tabella(tavola delle confutazioni) certe sequenze di mossedal nodo radice al nodo foglia.
Ogni riga della tabella rappresenta una mossa legalenella radice. Per la mossa risultata migliore dopol’ultima iterazione la tabella contiene la continuazioneprincipale, mentre per le sue mosse alternativememorizza una sequenza di al più d mosse sufficientia confutare queste mosse. Nella successiva ricerca aprofondità (d+1) la tabella è utilizzata per guidare ognimossa lungo una potenziale linea di confutazioneriducendo così sensibilmente il tempo dicomputazione.
La tabella delle confutazioni deve memorizzare lacontinuazione principale per ognuna delle mossecandidate al top-level. Le sue dimensioni sono quindi:
maxw ⋅maxddove maxw è il numero massimo di discendenti dellaradice (per gli scacchi tipicamente 35, ma, nel casopeggiore, circa 90) e maxd è la massima profondità diricerca [MarPop85].
1.3.3.5 Tabella historyAnche la tabella history [FeMyMo90] rappresenta unmetodo efficiente ed economico per riordinare isuccessori di un nodo non terminale.
L’idea alla base di questa euristica è che una mossarisultata la migliore in una posizione, con moltaprobabilità è altrettanto valida in altre posizioni dove èlegale.
Ad esempio in una posizione tipica degli scacchi sonocirca 35 le mosse legali, ma solamente una piccolaporzione di esse merita considerazione. Una mossache è risultata la migliore in una certa posizione è conforte probabilità la migliore anche in posizioni "simili".L’euristica in oggetto prevede che la ricerca tengamemoria di quali mosse sono risultate migliori così daesaminarle per prime in una nuova posizione (in cuisono legali) nella speranza di migliorare l’ordinamentodei nodi interni e quindi le dimensioni della ricerca.
In particolare la tabella history ricorda per una mossam il numero di posizioni visitate in cui m è statariconosciuta essere la migliore oppure causa di untaglio. Tale conteggio costituisce una misura dellaprobabilità che una mossa risulti la migliore inposizioni future.

36
Nei giocatori artificiali di scacchi la tabella history èimplementata come segue:• una mossa è individuata dalla coppia (casa dipartenza, casa di arrivo); il numero di ingressi dellatabella è dunque pari alle possibili combinazioni pertale coppia moltiplicate per 2 in modo da poterdistinguere le mosse del bianco da quelle del nero:
ingressi _ tavola _history = 64 ⋅64 ⋅2 = 8196• ogni volta che una mossa risulta la migliore in unaricerca a profondità d è sommato al valore correntedella mossa un punteggio dipendente da d: hasignificato attribuire maggior merito ad una mossache è risultata migliore in una ricerca a profonditàmaggiore rispetto ad un’altra. Valori tipici per questoincremento sono:
incremento (d) = 2 ⋅ d oppure incremento (d) = d2Risultati sperimentali hanno dimostrato che questaeuristica costituisce un’ottima base di conoscenza peri meccanismi di ordinamento delle mosse: la suaefficacia è confrontabile con quella della tabella delletrasposizioni [Sch86].
1.3.4 Numeri di cospirazione: un esempio diapprofondimento selettivo
Shannon classifica i metodi di ricerca degli alberi di gioco indue categorie [Sha50]. Nella prima sono riuniti i metodi diricerca brutale (come gli algoritmi minimax ed αβ), nei qualisono considerate tutte le mosse possibili fino ad una fissataprofondità. Il secondo approccio è quello della ricercaselettiva nel quale è usata una base di conoscenza(dipendente dall’applicazione) per selezionare un insieme dimosse "plausibili" che saranno le sole considerate. Questametodologia non pone limiti alla profondità di ricerca (laricerca di posizioni quiescenti costituisce un esempio di taleapproccio).
La classificazione di Shannon ha suggerito lo sviluppo di unapproccio intermedio chiamato approfondimento selettivo[Sch90]. L’idea è di esplorare porzioni diverse dell’albero aprofondità diverse, stabilite, in generale, da un criteriodipendente dall’applicazione. Formalmente questo tipo diricerca non è brutale perché non tutte le mosse sonoesplorate fino alla stessa profondità, ma non è neppureselettiva poiché nessuna delle alternative possibili vieneignorata (seppure alcune verranno analizzate con più"interesse").
L’algoritmo dei numeri di cospirazione di McAllester [McA85]è un esempio molto attraente di approfondimento selettivopoiché il criterio di selezione dei nodi da espandere è
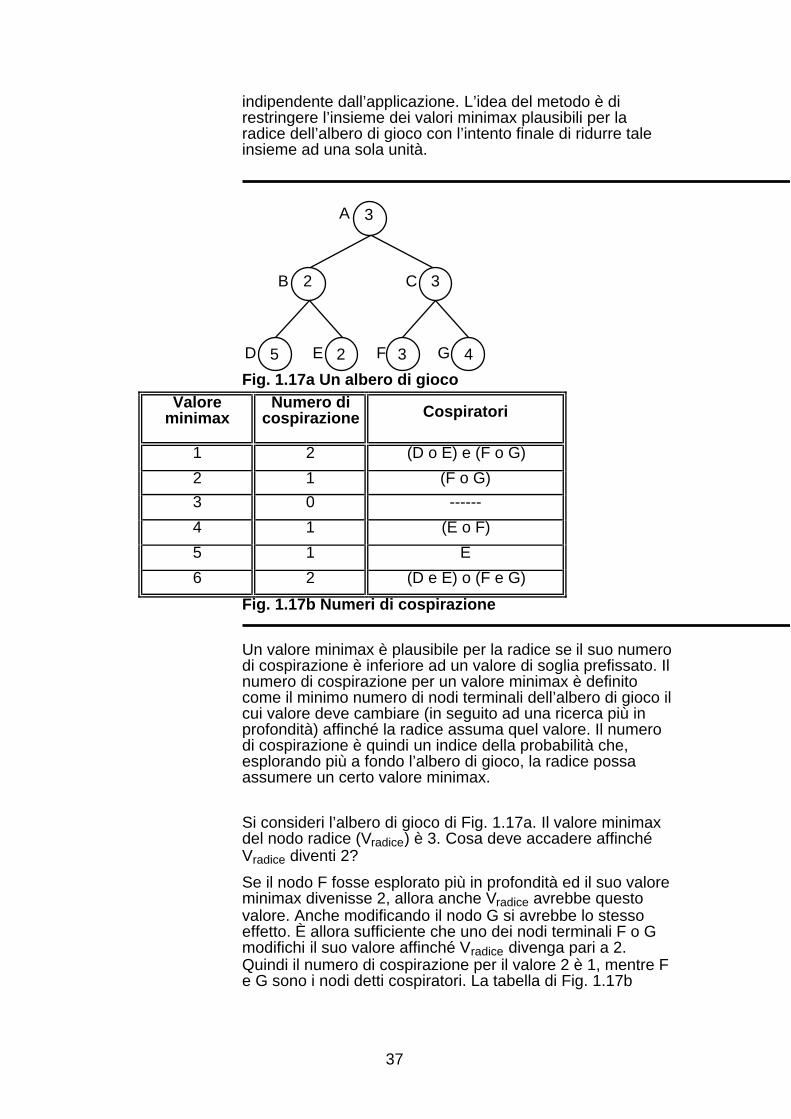
37
indipendente dall’applicazione. L’idea del metodo è direstringere l’insieme dei valori minimax plausibili per laradice dell’albero di gioco con l’intento finale di ridurre taleinsieme ad una sola unità.
3
4
3
2
5 2 3
A
B C
D E F G
Fig. 1.17a Un albero di giocoValore
minimaxNumero di
cospirazione Cospiratori
1 2 (D o E) e (F o G)
2 1 (F o G)
3 0 ------
4 1 (E o F)
5 1 E
6 2 (D e E) o (F e G)
Fig. 1.17b Numeri di cospirazione
Un valore minimax è plausibile per la radice se il suo numerodi cospirazione è inferiore ad un valore di soglia prefissato. Ilnumero di cospirazione per un valore minimax è definitocome il minimo numero di nodi terminali dell’albero di gioco ilcui valore deve cambiare (in seguito ad una ricerca più inprofondità) affinché la radice assuma quel valore. Il numerodi cospirazione è quindi un indice della probabilità che,esplorando più a fondo l’albero di gioco, la radice possaassumere un certo valore minimax.
Si consideri l’albero di gioco di Fig. 1.17a. Il valore minimaxdel nodo radice (Vradice) è 3. Cosa deve accadere affinchéVradice diventi 2?
Se il nodo F fosse esplorato più in profondità ed il suo valoreminimax divenisse 2, allora anche Vradice avrebbe questovalore. Anche modificando il nodo G si avrebbe lo stessoeffetto. È allora sufficiente che uno dei nodi terminali F o Gmodifichi il suo valore affinché Vradice divenga pari a 2.Quindi il numero di cospirazione per il valore 2 è 1, mentre Fe G sono i nodi detti cospiratori. La tabella di Fig. 1.17b

38
elenca gli altri numeri di cospirazione per l’intervallo [1,6] divalori minimax.Come vengono calcolati i numeri di cospirazione ?
#define MIN 0#define MAX 1int consp_n(position node,int v,int type){int cn,ms,i;m=node.minimaxvalue;if (v==m)
cn=0;else if (node.depth==0)
cn=1;else if ((type==MAX) && (v<m) || (type==MIN) && (v>m))
{cn=0;for(i=0;i<node.nmoves;i++)
{ms=(*node.sons[i]).minimaxvalue;if ((type==MAX) && (ms>v) || (type==MIN) &&
(ms<v))cn+=consp_ n(*node.sons[i],v,!type);
}}
else{cn=consp_n (* node.sons[0],v,!type);for(i=1;i<node.nmoves;i++)
cn= min(cn,consp_n(*node.sons[i],!type);}
return(cn);}Fig. 1.18 Calcolo dei numeri di cospirazione
In un nodo di tipo MAX, come ad esempio la radice, se sivuole aumentare il valore minimax è sufficiente cambiare ilvalore di uno solo dei successori e quindi il numero dicospirazione associato al nuovo valore è pari al più piccolodei numeri di cospirazione nei successori. Se invece si vuolediminuire il valore minimax portandolo a V, allora dovrannodecrescere tutti i successori il cui valore è maggiore di V. Sidovrà quindi sommare i numeri di cospirazione di V in questinodi per ottenere quello in MAX. Se il nodo è di tipo MINvale il ragionamento inverso.
I numeri di cospirazione di un valore minimax V sono quindicalcolati ricorsivamente a partire dai nodi terminali il cuivalore è 0 oppure 1 a secondo che la loro valutazione staticacoincida o meno con V.
In Fig. 1.18 è illustrata questa tecnica di calcolo dei numeridi cospirazione.Come vengono utilizzati i numeri di cospirazione?Ad un dato istante della ricerca i valori plausibili per la radicesono ristretti all’intervallo [Vmin,Vmax]. L’algoritmo sceglie, fragli estremi dell’intervallo, quello (V) più distante dal valoreattuale della radice. Successivamente l’algoritmo espande

39
un insieme dei cospiratori per V nel tentativo di portare a V ilvalore della radice. Se tale operazione ha successo deveessere ridefinito l’intervallo dei valori plausibili, altrimenti sicontrolla se il nuovo numero di cospirazione per V hasuperato la soglia permettendo così di restringere l’intervallodi valori plausibili. Queste operazioni vengono iterate fintantoche tale intervallo non contiene un solo valore5.
In [Sch90] è presentata una versione algoritmica completadel metodo.

39
Capitolo 2GnuChess: un giocatoresequenziale di scacchi
2.1 IntroduzioneGnuChess è un sistema software per la gestione di partite discacchi in grado di giocare in modo autonomo contro un avversarioumano o contro se stesso. Il sistema è strutturato in moduliprogrammati in linguaggio C.
GnuChess costituirà il termine di misura e confronto delleprestazioni dei giocatori paralleli che scaturiranno siadall’applicazione dei metodi di distribuzione della ricerca che dellaconoscenza (Capitoli 5 e 6). Quali sono le motivazioni della sceltadi questo particolare giocatore?
• GnuChess è relativamente semplice: il suo codice si compone dicirca 4000 linee. Un sufficiente livello di confidenza con esso puòquindi essere ottenuto in tempi piuttosto brevi (approssimativamente 15 giorni).
• le prestazioni del giocatore sono notevoli: nonostante la suasemplicità è caratterizzato da una considerevole qualità di gioco.Quanto detto trova conferma nelle vittorie da esso riportate nelleedizioni ’92 e ’93 del torneo annuale su piattaforma stabile fragiocatori artificiali di scacchi.
• il programma è di pubblico dominio: ciò fa di esso un terrenocomune di confronto e di scambio fra molti dei ricercatori delsettore.
• la struttura del programma è abbastanza modulare: questaproprietà permette il suo utilizzo come libreria di funzioni. In questaveste GnuChess (in particolare alcune delle sue funzionalità)costituirà l’interfaccia fra gli algoritmi sviluppati in questo lavoro (ingenerale indipendenti dal dominio di applicazione) ed il dominio incui essi saranno sperimentati: il gioco degli scacchi.
2.2 Descrizione architetturale di GnuChessLa Fig. 2.1 descrive ad alto livello l’architettura di GnuChessutilizzando un formalismo per la rappresentazione del flusso diinformazioni fra i moduli.
Modalità Di Gioco e Posizione corrente sono strutture dati globalicontenenti informazioni riguardo il tipo di gioco chiesto dall’utente elo stato corrente della partita.
Il modulo Schedulatore ordina nel tempo l’esecuzione delle dueattività principali del programma: l’inserimento dei comandi o dellamossa dell’utente (Interprete comandi) e la scelta della mossamigliore da parte del calcolatore (Selezione mossa). Ad esempionella modalità di gioco: "computer vs human" le due funzionalità

40
sono invocate alternativamente fino a che l’utente non modifica(con alcuni comandi) la modalità di gioco corrente.
Esegui/Ritira Mossa
Schedulatore
InterpreteComandi
Selezione Mossa
Timer
Interruzione
ModalitàDi Gioco
PosizioneCorrente
DispositivoDi Uscita
DispositivoDi Ingresso
modulo
Legenda
flusso diinformazioni
struttura dati
unitàperiferica
Fig. 2.1 Struttura a moduli di GnuChess
Il modulo Esegui/Ritira Mossa ha la funzione di aggiornare laposizione corrente a secondo che una mossa sia aggiunta alla listadi quelle giocate o sia invece ritirata. L’implementazione di questafunzionalità è fortemente legata alla rappresentazione dellaposizione.
In un generico istante solamente uno dei moduli descritti è attivo equindi non esiste alcuna forma di parallelismo o cooperazione fraessi.
Esiste invece concorrenza fra il modulo di scelta della mossa ed imoduli gestore delle "interruzioni esterne" (Interruzione) e contatoredi tempo (Timer): questi ultimi assolvono infatti la funzione disospendere la ricerca della mossa quando l’utente lo richiedeespressamente (attraverso il dispositivo d’ingresso) o è statoconsumato il tempo massimo di ricerca.
I paragrafi seguenti intendono approfondire alcune scelte diprogetto ed implementative fatte in GnuChess per realizzare lefunzionalità più importanti di supporto ad un programma che giocaa scacchi.
2.3 La rappresentazione della posizioneÈ un insieme di strutture dati globali che descrivono lo statocorrente della partita.
2.3.1 La dislocazione dei pezzi in gioco

41
L’astrazione della scacchiera e dei pezzi disposti su essaprevede la codifica numerica delle case e dei pezzi stessi.La generica casa è rappresentata da un valore interocontenuto nell’intervallo [0,63].La casa identificata dall’intero sq occupa la riga R(sq) e lacolonna C(sq) così definite6:R(sq) = (sq / 8) = (sq >> 3) R(sq)∈ [0,7]C(sq) = (sq % 8) = (sq & 7)C(sq)∈ [0,7]I pezzi sono rappresentati da due informazioni aventicodifiche distinte: il tipo ed il colore. In GnuChess vienecodificato esplicitamente anche il fatto che una casa sq siavuota: essa contiene il pezzo nullo il cui colore è il neutro.
I codici di rappresentazione usati sono indicati in Tab. 2.1a eTab. 2.1b.La posizione viene rappresentata in modo ridondante contecniche di associazione:• associazione casella/pezzo: è descritta da due vettori di 64posizioni (board e color) destinati ad associare ad ogni casa(codificata dall’indice dei vettori) rispettivamente il pezzo chela occupa ed il suo colore (rappresentati secondo il codiceprima descritto).
• associazione pezzo/casella: per ogni giocatore vienegestito un vettore di riferimenti alla scacchiera (PieceList)che indica le case occupate dai suoi pezzi.
Queste informazioni, ridondanti rispetto alla associazionecasella/pezzo, non sono sufficienti di per sé a rappresentareuna posizione. Infatti l’indice del vettore non esprime lacodifica di un pezzo, ma soltanto l’ordine con cui esso èstato individuato durante l’analisi della scacchiera.
Fa eccezione il re la cui casa è sempre contenuta nellaposizione di indice 0 del vettore. L’associazionepezzo/casella è memorizzata in maniera esplicita perchémolto conveniente in elaborazioni particolari come, adesempio, la generazione delle mosse legali.
Colore Codice
bianco 0nero 1
neutro 2
Tab. 2.1a Codifica del colore
Pezzo Codice
nullo 0
P 1

42
cavalloT 2
alfiB 3
R 4
donnaQ 5
K 6
Tab. 2.1b Codifica dei pezzi2.3.2 Il giocatore che ha la mossa
Questa informazione non è rappresentata esplicitamente.I giocatori sono identificati da una coppia di variabili(computer e opponent) contenenti il colore dei propri pezzi. Ilgiocatore cui spetta la mossa è stabilito dal flusso diprogramma del modulo Schedulatore. Esso infatti alterna larichiesta di esecuzione della semimossa nei confronti primadell’uno e poi dell’altro giocatore.
2.3.3 Sequenza delle mosse giocateUna generica semimossa viene rappresentata dalla coppia(f,t) dove f è la codifica della casa di partenza e t la codificadi quella d’arrivo del pezzo mosso. Le mosse di arroccosono descritte (in modo non ambiguo) dallo spostamento delre.
Spesso la mossa è sintetizzata da un unico intero M ottenutoattraverso una manipolazione della codifica binaria degliinteri f e t:
M = (f << 8 | t).Questa rappresentazione assume significato se affiancata aquella della dislocazione dei pezzi: entrambe sononecessarie per identificare il pezzo mosso, l’eventualecattura, lo scacco al re, ecc.
GnuChess tiene conto del numero di semimosse giocate(GameCnt).In un vettore di dati strutturati (GameList) esso ricorda tuttele semimosse che hanno portato allo stato corrente delgioco.
Oltre alla coppia (f,t) per ogni semimossa sono ricordateinformazioni7 utili per la compilazione di statistiche sullapartita:
• l’eventuale pezzo catturato• il tempo impiegato nella scelta• se la mossa è stata scelta dal calcolatore ed in tal caso:• la profondità della ricerca• la valutazione numerica della mossa• il numero di nodi dell’albero di gioco visitati.In particolare è molto importante la conoscenza dell’ultimasemimossa fatta perché consente di stabilire la legalità di

43
una cattura "en passant". GnuChess ricorda direttamente inuna variabile globale (epsquare) la possibilità o meno diquesto tipo di cattura:
epsquare=-1 ⇔ cattura en passant illegaleepsquare=sq∈ [0,63] ⇔ un pedone che puòcatturare nella casa sq può eseguire la cattura en passant
2.3.4 La possibilità di arrocco, la regola delle 50mosse e la patta per ripetizione
Per ogni giocatore è memorizzato se ha eseguito la mossadi arrocco (castld). Nel caso in cui essa non sia stata giocatasi deve conoscere la sua eventuale legalità.
Per questa ed altre finalità GnuChess memorizza quantevolte ciascuna casa è stata occupata da un pezzo poi mosso(Mvboard). Questa informazione consente di stabilire se il ree la torre di arrocco sono mai state mosse dalla loro casainiziale.
Una variabile (Game50) ricorda il numero ordinale dell’ultimasemimossa che ha provocato una cattura, una mossa dipedone, un arrocco o una promozione. Questa informazioneè indispensabile per controllare l’attivazione della regola dipatta delle 50 mosse (il controllo avviene sul numero disemimosse: Gamecnt-Game50>99).
La stessa variabile è utilizzata insieme alla lista delle mossegiocate anche per stabilire l’avvenuta o meno patta perripetizione di mosse. Infatti la variabile Game50 indica lasemimossa a partire dalla quale deve partire l’analisi per ilconteggio delle ripetizioni: le mosse di pedone, di cattura, diarrocco e di promozione sono infatti le sole irreversibili.
2.4 La scelta della mossaGnuChess adotta due diversi metodi di scelta della mossa asecondo della fase della partita:• la consultazione del libro di apertura (durante l’apertura) e• l’analisi delle continuazioni (durante le fasi di mediogioco e difinale)I due metodi sono mutuamente esclusivi.
2.4.1 Il libro di aperturaDurante lo stadio iniziale del gioco il programma gestisce unlibro di apertura cui si fa riferimento nella scelta della mossaquando l’apertura si sviluppa lungo linee di gioco note8.
Il libro di apertura è memorizzato in un archivio permanentedove le linee di gioco sono sequenze di mosserappresentate in notazione algebrica. Durante il gioco unacopia del libro di apertura risiede in memoria centrale.
Nel trasferimento dall’archivio alla memoria le mosse sonoconvertite dalla notazione algebrica per essererappresentate nella codifica numerica interna di GnuChessdescritta in 2.2.1.

44
Come vengono utilizzate le informazioni del libro di apertura?GnuChess esamina ogni linea di gioco del libro alla ricercadi una corrispondenza perfetta tra le prime mosse di questae la sequenza di mosse che ha portato allo stato correntedel gioco. La linea di apertura per cui questo confronto hasuccesso suggerisce la mossa che sarà giocata dalcalcolatore.
Il programma adotta un criterio di selezione casuale nel casoin cui nel libro esistano più varianti della linea di aperturaseguita. Se nessuna sequenza di mosse del libro concordacon quella della partita (Book=NULL) il programma non potràpiù fare uso di esso nella scelta delle mosse successive edovrà ricorrere all’analisi delle continuazioni.
Una lacuna di GnuChess è la mancata gestione delletrasposizioni nelle linee di apertura: non sono identificatecome conosciute linee di gioco che differiscono da quelle dellibro per una permutazione di mosse; per poter essereconsiderate dovrebbero essere memorizzate esplicitamentenel libro a discapito della occupazione di memoria.
2.4.2 L’analisi delle continuazioniAbbandonata la fase di apertura GnuChess non può più fareaffidamento sui "suggerimenti" del libro di apertura, ma deveoperare una valutazione degli sviluppi della partita cuipossono condurre tutte le mosse possibili nella posizionecorrente per poter poi scegliere la migliore di esse. Questaanalisi è realizzata attraverso la visita dell’albero di giocoassociato allo stato corrente.
2.4.2.1 L’albero di giocoFissata una posizione l’albero di gioco ne rappresentatutte le possibili continuazioni: i nodi descrivono leposizioni raggiunte, mentre gli archi le mosse legaliche portano da una posizione alla successiva (cfr.2.2).
In GnuChess non esiste una struttura dati ad alberoche riproduce esplicitamente l’albero di gioco. Ai finidella ricerca della mossa migliore, infatti, non èconveniente rappresentare l’intero albero di giocopoiché solo una porzione di esso è significativa per lostato corrente della sua esplorazione.
A partire dalla posizione iniziale (radice) l’albero èsviluppato contemporaneamente alla sua visita: ognivolta che deve essere valutata una nuova posizionevengono generate tutte le mosse possibili a partire daquesta. Così l’albero si estende in profondità; leposizioni raggiunte saranno però rappresentatesoltanto al momento della loro valutazione.
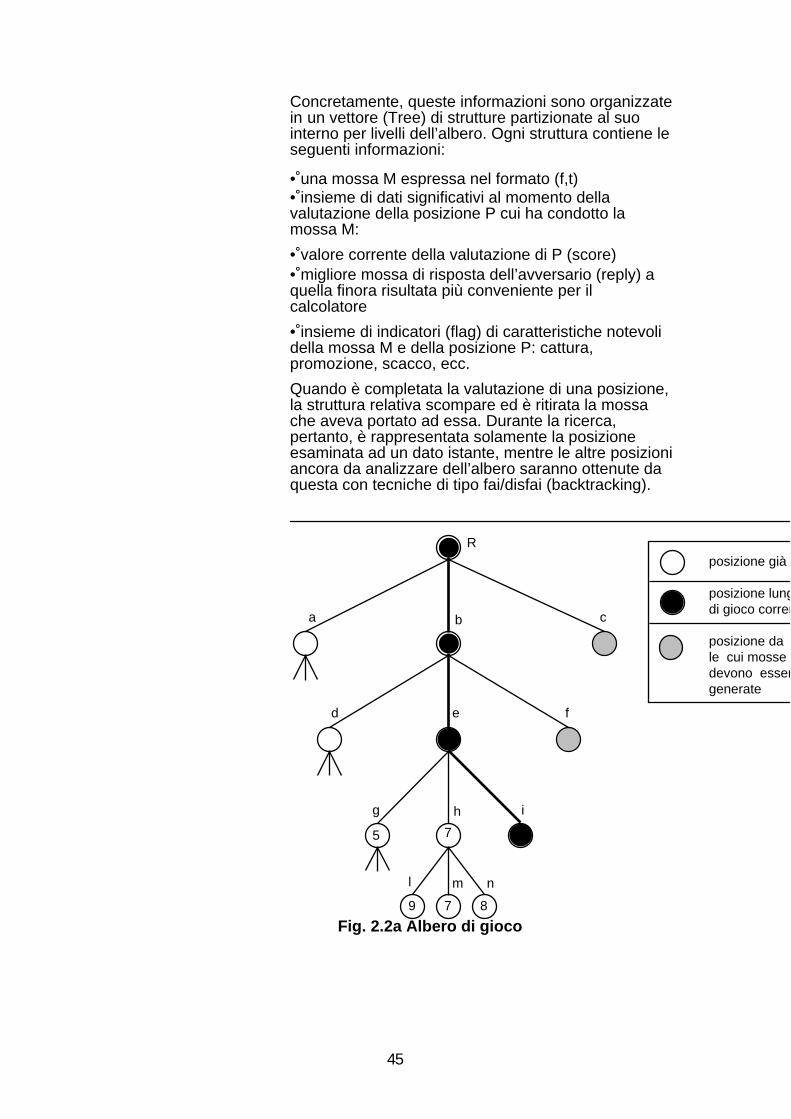
45
Concretamente, queste informazioni sono organizzatein un vettore (Tree) di strutture partizionate al suointerno per livelli dell’albero. Ogni struttura contiene leseguenti informazioni:
• una mossa M espressa nel formato (f,t)• insieme di dati significativi al momento dellavalutazione della posizione P cui ha condotto lamossa M:
• valore corrente della valutazione di P (score)• migliore mossa di risposta dell’avversario (reply) aquella finora risultata più conveniente per ilcalcolatore
• insieme di indicatori (flag) di caratteristiche notevolidella mossa M e della posizione P: cattura,promozione, scacco, ecc.
Quando è completata la valutazione di una posizione,la struttura relativa scompare ed è ritirata la mossache aveva portato ad essa. Durante la ricerca,pertanto, è rappresentata solamente la posizioneesaminata ad un dato istante, mentre le altre posizioniancora da analizzare dell’albero saranno ottenute daquesta con tecniche di tipo fai/disfai (backtracking).
79 8
5
R
a b c
d e f
g h i
l m n
7
posizione già valutata
posizione lungo la lineadi gioco corrente
posizione da esplorarele cui mosse possibilidevono essere ancoragenerate
Fig. 2.2a Albero di gioco

46
livello 1
livello 2
livello 3
livello 4
abc
de
g
n
Tree
f
t
score
reply
flag
a4
a7
7
m
promozione=nocattura=siscacco=si
f
ih
lm
Fig. 2.2b Albero di gioco in GnuChess
Fig. 2.2b fornisce un’istantanea di queste strutturedati in una fase intermedia della visita dell’albero digioco di Fig. 2.2a.
2.4.2.2 La generazione delle mosseL’operazione cardine nella creazione dell’albero digioco è la generazione di tutte le mosse possibili inuna data posizione. La struttura dati fondamentale sucui opera il modulo generatore di mosse è dunque larappresentazione della posizione.
In GnuChess la generazione riguarda un insieme dimosse pseudolegali: oltre alle mosse legalmentepossibili questo insieme comprende anche quelle chelasciano il proprio re sotto scacco. Quest’ultime nonvengono eliminate in fasi successive, ma concorronoalla individuazione di situazioni di matto o di stallo incui esse sono le uniche mosse pseudolegali possibili;naturalmente alle posizioni che queste determinanovengono associati valori numerici (10001-ply, doveply è la distanza della posizione dalla radice in terminidi mosse) tali che esse non possano essere maiselezionate.
Il metodo di calcolo delle mosse implementato daGnuChess è molto efficiente ed è basato su insiemi dimappe dei movimenti [Cia92].
L’idea generale dell’algoritmo è di calcolare unagrande quantità di informazioni prima che il giocoabbia inizio. I dati che vengono precalcolati sono tuttele mosse possibili per ogni pezzo a partire da unacasa qualsiasi e senza tenere conto della presenza di

47
altri pezzi sulla scacchiera. Il calcolo di questi datiutilizza i vettori di movimento i quali per ogni pezzodefiniscono la relazione matematica fissa esistente frale coordinate di partenza e l’insieme delle coordinatedelle case che esso può raggiungere con unospostamento minimo9 (Fig. 2.3).
Le informazioni così ottenute sono contenute in unvettore del tipo:struct sqdati {
short prossimaposizione;short prossima direzione;
};struct sqdati datiposizione[8][64][64];/* datiposizione[tipopezzo][origine][destinazione]*/Il seguente esempio spiega il significato di questeinformazioni: la prima destinazione per una torre in d4è memorizzata in
datiposizione[torre][d4][d4].prossimaposizioneSupponiamo che questa sia d3 e che non siaoccupata da un altro pezzo: la successiva casa diarrivo sarà in
datiposizione[torre][d4][d3].prossimaposizioneSe invece d3 è occupato da un altro pezzo la mossaseguente è indatiposizione[torre][d4][d3].prossimadirezioneGrazie a questi dati l’unica cosa da fare al momentodella generazione delle mosse è controllarel’eventuale collisione con altri pezzi.
Pezzi non scivolanti
Pezzi scivolanti

48
Pezzo Vettore di movimento (k è la casa di partenza)
P k+7, k+8, k+9, k+16
T k+6, k+10, k+15, k+17, k-6, k-10, k-15, k-17
B k+7, k+9, k-7, k-9
R k+1, k+8, k-1, k-8
Q k+1, k+7, k+8, k+9, k-1, k-7, k-8, k-9
K k+1, k+7, k+8, k+9, k-1, k-7, k-8, k-9
p k-7, k-8, k-9, k-16
Fig. 2.3 Vettori di movimento
2.4.2.3 La scelta della migliore continuazioneL’analisi delle continuazioni del gioco a partire dallaposizione corrente prevede la visita dell’albero digioco associato e la valutazione dei nodi incontrati suesso.
In GnuChess queste operazioni sono condottesecondo l’euristica di approfondimento iterativo (cfr.1.3.3.1): la visita dell’albero viene ripetuta più volte,ma ad ogni iterazione la profondità del sottoalberoesplorato viene aumentata di una unità.
La prima visita è condotta fino al primo livellodell’albero; il processo iterativo termina quando èraggiunta la massima profondità di ricerca(MaxSearchDepth) oppure è scaduto il tempomassimo di ricerca (ResponseTime+ExtraTime).
Ad ogni iterazione viene prodotta una nuovavalutazione numerica (score) della posizione allaradice e la continuazione principale (PrVar) che hadeterminato questo valore.
GnuChess considera affidabile una valutazione chedifferisce di poco da quelle ottenute nelle iterazioniprecedenti. Per misurare il grado di stabilità dellevalutazioni ne viene calcolata una media pesata(Zscore(i-1)) con la quale confrontare la valutazionecorrente (scorei). Essa è definita così:
Zscorei = 0 se i = 0
Zscore( i -1) + score i
2se i > 0
dove i è il numero di iterazioni (coincide con laprofondità di esplorazione dell’albero).In GnuChess l’algoritmo di valutazione della posizionecorrente scaturisce dalla combinazione del metodo

49
aspiration-search (cfr. 1.3.2.1) con l’algoritmo diricerca su alberi di gioco denominato falphabeta (cfr.1.3.2.2).
2.4.2.3.1 Aspiration -searchLa tecnica aspiration-search permette direalizzare la ricerca alpha-beta con unafinestra (alpha,beta) iniziale più stringente dellafinestra canonica (-∞,+∞) migliorando cosìl’efficienza della visita.
Non è tuttavia da escludere la possibilità che laricerca non abbia successo perché il valoredella radice (valore minimax) non è contenutonella finestra iniziale; in tal caso la ricerca deveessere reiterata con una finestra che contienesicuramente il valore minimax. Quest’ultimasarà della forma (score,+∞) se la prima ricercaha prodotto un fallimento superiore, mentresarà (-∞,score) se il fallimento è stato inferiore(score è il valore ritornato dalla prima ricerca).
La caratteristica fondamentale del metodoaspiration-search è la determinazione dellafinestra iniziale. In GnuChess essa èaggiornata ad ogni iterazione del metodo diapprofondimento iterativo sulla base dei valoriassociati alla radice nelle iterazioni precedenti.In particolare, se alpha e beta sono gli estremidi tale finestra essi sono determinati come inTab. 2.3:
iterazione alpha beta
i=1 scoreroot-90 scoreroot+90
i>1
if (Zscorei<scorei)Zscorei-Awndw-zwndwi
elsescorei-Awndw-zwndwi
scorei+Bwndw
Tab. 2.3 Determinazione della finestra(alpha, beta)Nella prima iterazione non si ha alcuna stimadel valore minimax della radice e quindi ilprogramma esegue una valutazione statica(scoreroot) della posizione corrente (è lastessa valutazione statica che sarà operata suinodi foglia dell’albero di gioco durante laricerca αβ).

50
Questa stima non è sicuramente affidabileperché non tiene nessun conto dellecontinuazioni del gioco, ma è soddisfacente seusata come centro di una finestra αβ.
Nelle iterazioni successive, invece, il centrodella finestra è fissato dal valore minimaxricavato dall’ultima ricerca. Awndw e Bwndwsono valori costanti che definisconol’estensione inferiore e superiore della finestraa partire dal suo centro. Si noti una certaasimmetria nella determinazione dei dueestremi. GnuChess sembra infatti intenzionatoa voler limitare al minimo la possibilità di unfallimento inferiore. In questo caso, infatti, iltempo massimo di ricerca viene incrementatodi 10 volte il tempo inizialmente fissato; ciò nonavviene nel caso di fallimento superiore. Laragione di questa scelta è che un fallimentoinferiore sta ad indicare una situazione per ilgiocatore che ha la mossa decisamentepeggiore di quanto era stato stimato e quindideve essere prevista un’analisi molto più inprofondità di tutte le possibili continuazioni. Iltermine zwndwi tende appunto ad estendereinferiormente la finestra di una quantitàproporzionale alla distanza rispetto al valore 0delle valutazioni sin qui ottenute10:
zwndwi = 20+Zscorei
12Fig. 2.4 mostra schematicamentel’implementazione dei metodi diapprofondimento iterativo e di aspiration-search in GnuChess.
int iterative_deepening(position *p,intMaxSearchDepth){int score,scoreroot,alpha,beta,zscore,zwndw;scoreroot=scoreposition(p);init_z(&zscore,&zwndw);init_window(&alpha,&beta,scoreroot);for (d=1;d<MaxSearchDepth && !timeout();d++)
{score=falphabeta(p,alpha,beta,d);if (score<alpha)
score=falphabeta(p,-9000,score,d);
else if (score>beta)score=falphabeta(p,score,9000,d);
update_z(&zscore,&zwndw,score);update_window(&alpha,&beta,zscore,zwndw
,score)}
return (score);

51
}Fig. 2.4 Approfondimento iterativo easpiration-search in GnuChess
2.4.2.3.2 L’algoritmo di ricerca:falphabeta
Falphabeta è l’algoritmo di base usato daGnuChess per calcolare il valore minimax dellaradice dell’albero di gioco.
La sua particolarità è che, fissata la finestrainiziale (alpha,beta), esso determina un limitesuperiore più stringente (rispetto ai valori alphao beta) per il valore corretto qualora la ricercadetermini un fallimento. Questa informazione èutile perché rende più efficiente la ripetizionedella ricerca stabilita da aspiration-search.
In Fig. 2.5 è descritta la versione dell’algoritmofalphabeta in GnuChess.
#define mate 9999#define stalemate -9998int falphabeta (position *p,int alpha,intbeta,int depth)
{position *p;int quiet,nmoves,score,best,i;score=evaluate(p,&quiet);if ((score==mate) || (score==stalemate))
/* stato finale */return (score);
if (!quiet) /* se la posizione è turbolenta*/extend_depth(&depth); /* la profondità
di ricerca aumenta */if (depth==0)
return (score);nmoves=movelist(p,&successor);best=-12000; /* il valore minimax di un nodo ècertamente maggiore di -12000 */if (best>alpha)
alpha=best;

52
for (i=1;(i<=nmoves) &&(best<beta);i++;successor++)
{makemove(successor);score=-falphabeta(successor,-beta,-
alpha,depth-1)undomove(successor);if (score>best)
{best=score;if (best>alpha)
alpha=best;}
}return (best);)
Fig. 2.5 Algoritmo falphabeta inGnuChess
L’ordine di visita dell’albero di gioco è ascandaglio.Un aspetto interessante di questa visita è chela funzione di valutazione è applicata anche ainodi interni. La valutazione statica di un nodo,oltre che restituire una stima del suo valoreminimax, determina informazioni di caratteregenerale sullo stato del gioco che sarannoutilizzate da alcune delle euristicheimplementate nella ricerca.
2.4.2.3.3 Euristiche per migliorare laricerca
GnuChess completa l’algoritmo falphabeta conun certo numero di metodi finalizzati amigliorare l’affidabilità e l’efficienza dellaricerca.
2.4.2.3.3.1 L’estensione dellaprofondità di visita: la ricercaquiescente
Il programma implementa un criterio diestensione della profondità nominale diricerca. La motivazione del metodo è diottenere una valutazione più affidabiledelle posizioni turbolente (instabili)analizzandone continuazioni più lunghe.
L’analisi di turbolenza di una posizioneutilizza informazioni dedotte al momentodell’esecuzione della mossa che haportato alla posizione (MakeMove) edurante la valutazione statica diquest’ultima. In questa analisiGnuChess distingue fra posizioni internee terminali nell’albero di gioco.

53
Sia N una posizione posta al livello Plyin una ricerca di profondità nominale Sd.Si supponga in generale che la ricercanel sottoalbero di N sia già stata estesae sia D (D≥Sd-Ply) la sua profondità.
Sia inoltre S la valutazione statica di N e(α, β) la finestra corrente.
N è instabile se è non terminale e:• il re è in scacco e Ply=D-1 (si intendedare all’avversario un’altra possibilità discacco)
• c’è una minaccia di promozione daparte dell’avversario• vi è stata una ricattura nella mossaprecedente e α ≤ S ≤ β.
Se N è una posizione terminale (Ply≥D),essa è considerata instabile quando:• S ≥ α e il re è in scacco• S ≥ α e l’avversario minaccia unapromozione• S ≥ α, Ply=Sd+1 e almeno due pezzidel giocatore che ha la mossa sonoinchiodati
• S ≤ β e l’avversario minaccia lo scaccomatto.In tutti questi casi la profondità delsottoalbero di N viene estesa di unaunità divenendo D+1.
Le posizioni terminali per cui non sonoverificate le precedenti condizioni distabilità sono considerate comunqueinstabili. La ricerca quiescente riguardaperò soltanto una porzione del lorosottoalbero: quella in cui i nodi sonogenerati da mosse di cattura o dipromozione.
La ricerca quiescente non puòcomunque estendersi di più di 11 mosseoltre la profondità nominale Sddell’albero di gioco.
2.4.2.3.3.2 La tabella delletrasposizioni
GnuChess gestisce due tabelle ditrasposizioni: una residente in memoriae l’altra in un archivio permanente. Latabella in memoria ha carattere localead una partita ed il suo contenuto è

54
cancellato all’inizio di ogni partita. Letabelle ricordano per le posizionivalutate il valore minimax o una sualimitazione (inferiore o superiore).
L’accesso alle tabelle è realizzato inmodo associativo tramite una funzionehash da posizioni in interi. Tale funzionehash è così definita: prima che la partitaabbia inizio viene generato un numeropseudo-casuale11 per ogni pezzo e perogni casa che esso può occupare.
Data la dislocazione dei pezzi e lacodifica binaria dei numeri associati allaposizione di ciascun pezzo, vienecalcolato lo XOR di tali valori ottenendocosì un unico intero che è l’indice dellatabella cercato. Con la stessa tecnicaviene associato ad ogni posizione unidentificatore numerico che permette dicontrollare il fenomeno delle collisioninell’accesso hash.
Ogni elemento della tabella è strutturatonei seguenti campi:• hashbd: è l’identificatore dellaposizione memorizzata. Se accedendoalla tabella l’identificatore dellaposizione corrente non coincide con ilvalore di questo campo si deveaccedere all’elemento di indicesuccessivo. Questa operazione puòessere ripetuta un numero limitato divolte (rehash=6)
• score: è il valore calcolato per laposizione memorizzata• flag: dice se score è il valore minimaxcorretto (truescore) oppure una sualimitazione inferiore (lowerbound) osuperiore (upperbound)
• depth: è la profondità dell’albero digioco esplorato nel calcolo di score• mv : è la mossa che ha generato laposizione.Le informazioni contenute nella tabellasono usate dall’algoritmo di ricerca solose il contenuto del campo depth è ≥della profondità del sottoalbero daesplorare. In questa eventualità essepermettono di restringere la finestra di

55
ricerca (flag==lowerbound ||flag==upperbound) o di sopprimere lavisita (flag==truescore).
La tabella nell’archivio permanente èacceduta nel caso in cui quella inmemoria non contenga informazionisulla posizione corrente. Tuttavia,poiché l’accesso all’archivio è moltocostoso in termini di tempo, essocontiene solamente la valutazione disottoalberi molto profondi (depth>5) eche riguardano lo stadio iniziale delgioco (GameCnt<12): le posizioni diquesta fase, infatti, sono le sole adavere una probabilità significativa diripresentarsi in partite differenti.
2.4.2.3.3.3 L’ordinamento dellemosse
GnuChess impiega alcune euristicheper l’ordinamento delle mosse generate.L’idea è di analizzare per prime lemosse "migliori" in modo da confutarevelocemente le altre alternativesfruttando la proprietà di taglio deisottoalberi dell’algoritmo alphabeta. Ilprogramma gestisce alcune strutturedati che rappresentano una base diconoscenza per stabilire l’efficacia diogni mossa possibile.
Una di queste strutture dati è la varianteprincipale: il vettore (PrVar) delle mosseche compongono la migliorecontinuazione trovata nella iterazioneprecedente del metodo diapprofondimento iterativo.
GnuChess gestisce anche una lista dikiller (killr1, killr2, kill3) per ogni livellodell’albero di gioco. Per killer si intendeuna mossa che è risultata la migliore inuna posizione e che non è di catturadell’ultimo pezzo mosso (come si vedràqueste mosse sono trattateseparatamente attribuendo ad essemaggiore valore). In particolare killr1 ekillr2 ricordano killer che hanno prodottoun taglio nell’albero, mentre le mosse ditipo killr3 non hanno questa proprietà.

56
La tabella history è costituita da unnumero fisso di posizioni (8192)contenenti un intero; esse possonoessere accedute in modo associativo.
Ogni elemento della tabella rappresentauna mossa codificata in termini dellacasa di partenza, della casa di arrivo edel colore del pezzo mosso (cfr.1.3.3.5).
Per ogni mossa si da una misura dellasua qualità in termini del numero di volteche essa è stata scelta come migliore.In particolare se J è la mossa stabilitacome migliore dalla esplorazione di unalbero di profondità D, history[J] vieneincrementato di 2 ⋅D unità (si assegnamaggior merito a mosse scelte daesplorazioni più profonde in quanto piùaffidabili).
I contenuti della continuazioneprincipale, delle liste di killer e dellatabella history sono inizializzati (=0) ognivolta che il calcolatore deve selezionareuna nuova mossa.
Durante la fase di generazione ad ognimossa viene assegnato un punteggioche permette di ordinare le mosse almomento della visita dell’albero di gioco.Tale valore viene calcolato sommandopiù punteggi acquisiti dalla mossa perognuna di certe proprietà di cui puòeventualmente godere.
Sia J la mossa valutata e ply il livellodell’albero in cui è giocata; Tab. 2.4elenca queste proprietà ed il relativopeso.
Proprietà Punteggio
J è nella continuazione principale 2000
promozione con donna 800
promozione con torre 600
minaccia di promozione 600
promozione con cavallo 550
promozione con alfiere 500

57
cattura dell’ultimo pezzo mosso 500
cattura valore[pezzo catturato]
killr1[ply] 60
killr2[ply] 50
killr3[ply] 40
killr1[ply-2] (se ply>2) 30
"history" killer history[J]
Tab. 2.4 Punteggi per l’ordinamentodelle mosse
2.4.2.3.4 La funzione di valutazioneData una posizione la funzione di valutazioneassocia ad essa un valore numerico che nesintetizza il gradimento da parte del giocatorecui spetta la mossa.
In GnuChess il metodo di valutazione èsensibile alla fase del gioco in cui è applicato:la partita è suddivisa in stadi sulla base delnumero e valore dei pezzi ancora in gioco(pedoni e re esclusi).
In tale modo viene diversificato il valore dipezzi che assumono maggiore importanza incerti momenti particolari della partita (adesempio la torre nel finale). Allo stesso modosono modificati i pesi attribuiti ad alcuneproprietà della posizione anch’essi dipendentidalla fase della partita.
In Tab. 2.5a e Tab. 2.5b sono presentatirispettivamente i valori dei singoli pezzi e lasuddivisione della partita in stadi operata daGnuChess. Il parametro stage è il fattore dicorrezione dei punteggi prima menzionato: siosservi che il suo valore aumenta con ilprogredire del gioco.
La funzione di valutazione f di GnuChess è, daun punto di vista logico, parametrica rispettoalla posizione p valutata ed al giocatore g cuispetta la mossa in p.
Essa ha struttura polinomiale; in particolare èdefinita dalla relazione:
f(p,g) = [ ti(p,g) - ti(p, ′ g )i∑ ]
dove g′ è l’avversario di g e ti un genericotermine che valuta una delle caratteristichedella posizione p dal punto di vista di uno deigiocatori.

58
Pezzo Valore
P 100
cavalloT
350
B 355
R 550
donnaQ
1100
K 1200
Tab. 2.5a Valore dei pezzi
M = ∑ del valore dei pezzi sullascacchiera eccettuato pedoni e re
Fase del gioco Fattore di correzionedei punteggi
M > 6600 apertura 0
1400 ≤ M ≤ 6600 mediogioco 6600−M520
M < 1400 finale 10
Tab 2.5b Suddivisione della partita in stadiQual è l’identità dei termini citati?Di seguito è presentato un lororaggruppamento logico in 7 insiemi disgiuntidenominati categorie di valutazione. Taleclassificazione sarà presa in considerazionenel Capitolo 4 come strumento di base per lostudio di alcune metodologie di distribuzionedella conoscenza.
Le categorie di valutazione di GnuChess sonodunque le seguenti:• il materiale: è la somma del valore dei pezzisulla scacchiera (tali valori sono quelli indicatiin Fig. 2.5a).
• il valore posizionale dei pezzi: il valore di ognipezzo è modificato per tenere conto della casache occupa, cioè della efficacia relativa che unpezzo ha se posizionato in zone diverse dellascacchiera. Questa valutazione ha inizio primadell’esplorazione dell’albero di gioco: è infattianalizzata la posizione corrente (alla radice

59
dell’albero) per compilare le mappe di controllodello spazio.Si tratta di strutture dati che associano ad ognicasa il valore strategico che un pezzo (di uncerto tipo e di un certo colore) avrebbe seoccupasse quella casa. Al momento dellaeffettiva applicazione della funzione divalutazione queste mappe permettono diricavare direttamente il valore posizionale di unpezzo. In Fig. 2.6 è presentata la mappa dicontrollo dello spazio relativa al cavallo.
7 0 4 8 10 10 8 4 0
6 4 8 16 20 20 16 8 4
5 8 16 24 28 28 24 16 8
4 10 20 28 32 32 28 20 10
3 10 20 28 32 32 28 20 10
2 8 16 24 28 28 24 16 8
1 4 8 16 20 20 16 8 4
0 0 4 8 10 10 8 4 0
0 1 2 3 4 5 6 7
Fig. 2.6 Un esempio di mappa di controllodello spazio
In questa categoria di valutazione è anchecompresa l’attribuzione di bonus per i pezziche assumono maggiore importanza nelle fasiavanzate della partita.
È inoltre attribuito un ulteriore merito per ilpossesso di entrambi gli alfieri edanalogamente per la coppia di cavalli.
• mobilità e combinazioni di attacco.La mobilità di un giocatore è il numero dimosse legali che esso ha nella posizionecorrente. GnuChess limita questa valutazionesolamente agli alfieri ed alle torri.
L’analisi delle combinazioni di attacco è unacomponente molto "offensiva" della funzione divalutazione. In particolare sono riconosciutecombinazioni di alfiere e torre per la minacciadi pezzi avversari (pin e xray). Un’ulteriorecaratteristica di tale categoria di valutazione èdi incoraggiare il controllo con alfiere e torredelle case adiacenti il re nemico e

60
l’occupazione con cavallo e regina di case aminima distanza da esso.• la sicurezza del re: sono assegnate penalitàse il re può essere minacciato, se le caseadiacenti sono controllate da pezzi nemici (inparticolare la regina) e se non vi sono pedonivicino ad esso.
• la struttura pedonale: sono riconosciuteparticolari configurazioni deficitarie dellastruttura pedonale come pedoni isolati, doppiatio triplicati. È invece concesso un punteggio dimerito ai pedoni passati o che comunque nonhanno pedoni avversari lungo la propriacolonna. I pedoni centrali sono considerati piùimportanti degli altri e per essi viene esaminatol’avanzamento rispetto alla casa iniziale e lamobilità.
• la protezione dei pezzi: per ciascun pezzovengono calcolati il numero di minacceavversarie ed il numero di pezzi amici che loproteggono. L‘eventuale penalità dipende nonsolo da queste quantità, ma anche dal tipo deipezzi coinvolti: ad esempio è consideratacritica la situazione di un pezzo minacciato dauno di valore inferiore rispetto ad esso erispetto ai pezzi che lo proteggono.
Una penalità aggiuntiva è prevista se il numerocomplessivo di pezzi indifesi supera un valoredi soglia (≥2).
• relazione pezzi-struttura pedonale: il valoreposizionale di ciascun pezzo viene modificatoper tenere conto dell‘influenza su esso di certeconfigurazioni dei pedoni.
Ad esempio la torre è valorizzata se la colonnache occupa è semiaperta o aperta; il re èinvece penalizzato dalla occupazione di unacolonna semiaperta, dalla assenza di propripedoni nelle file adiacenti ed in generale dallalontananza complessiva da tutti i pedoni.
Infine, GnuChess assegna un bonus per certeposizioni finali che sa essere vincenti. Si trattadi facili finali in cui il perdente ha solo il re. Inparticolare il programma ha un conoscenza deifinali di:
• pedone e re contro re (KPK) e• cavallo, alfiere e re contro re (KBNK).

61
Per effetto di tale bonus il giocatore è portato asacrificare o scambiare pezzi per raggiungererapidamente questi finali.
2.5 La modalità di giocoUna partita può essere giocata secondo diverse modalità chepossono cambiare anche tra una mossa e l’altra a discrezionedell’utente. La modalità di gioco corrente viene memorizzata in unastruttura dati globale contenente le seguenti informazioni:
• computer/opponent è il colore dei pezzi del computer e dell’avversarioumano
• bothside=true il computer gioca per entrambi i giocatori
• force=true l’utente inserisce le mosse per entrambi i giocatori
• TCminutes è il livello di gioco del computer.È un valore numerico che determina il tempo di ricerca:ResponseTime=TCminutes*60
• MaxSearchDepth è la massima profondità di ricerca. Anche questo datoinfluenza la qualità del gioco del computer
• easy=false(true) il computer è abilitato (disabilitato) a "pensare" durantela scelta della mossa dell’avversario
• hash=false/true l’utilizzo delle tabelle di trasposizioni è disabilitato(abilitato)
• Book=false/true il computer non può (può) consultare il libro di apertura
• rcptr=false/true l’euristica della ricattura è disabilitata (abilitata)
Una modifica della modalità di gioco può essere richiestadall’utente con un comando inserito nel dispositivo d’ingresso ed èresa effettiva dal modulo di interpretazione dei comandi.
2.6 L’interprete dei comandiIl modulo di interpretazione dei comandi realizza l’interfaccia diingresso con l’utente. I comandi sono ordini o informazioni chel’utente comunica al programma in una forma dipendente dallaimplementazione. Mentre il modulo di scelta della mossa è comunea tutte le versioni di GnuChess, esistono moduli di interfaccia più omeno elaborati a secondo del tipo di calcolatore ed in particolaredelle sue capacità grafiche.
Il modulo di interpretazione dei comandi può essere visto anchecome interfaccia di uscita in quanto l’interpretazione della maggiorparte dei comandi implementa funzionalità per la comunicazione diinformazioni all’utente.
I comandi che possono essere inseriti sono di diverso tipo: alcunimodificano la modalità di gioco o la posizione corrente, altririguardano la visualizzazione di informazioni, altri ancora richiedonola lettura o la memorizzazione in archivi permanenti di informazionisulla partita. Le tabelle Tab. 2.6 (a,b,c,d,e) elencano i comandi
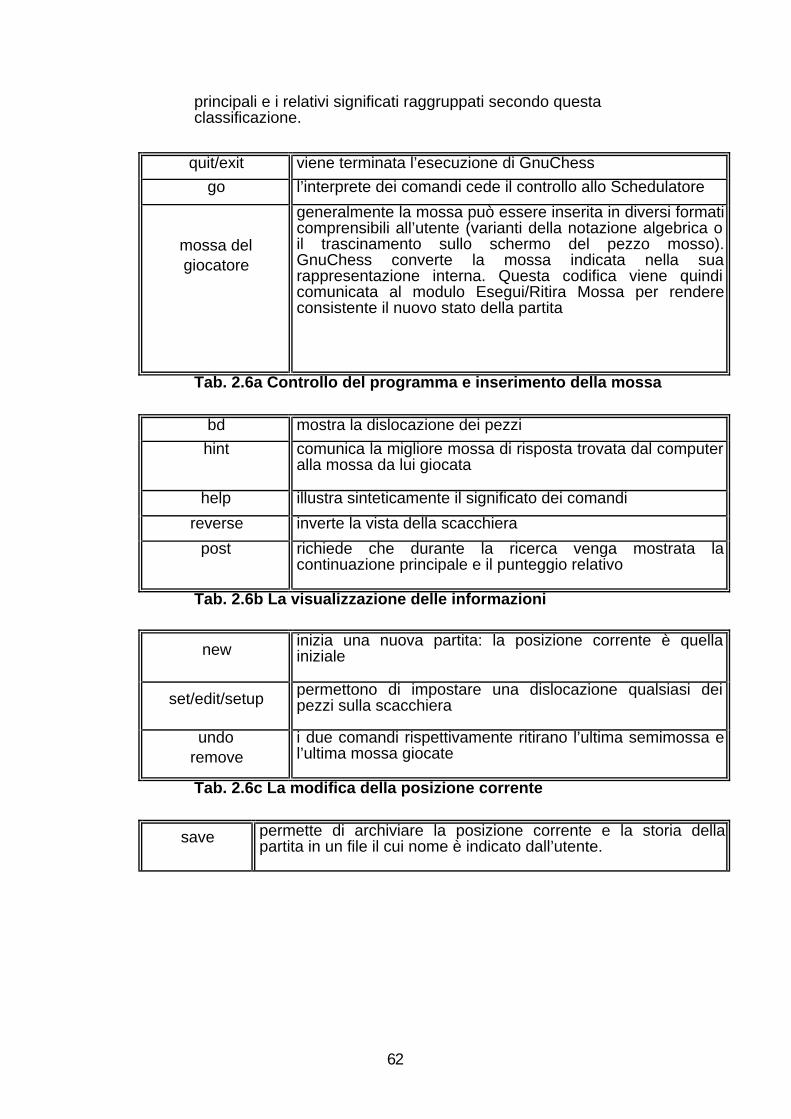
62
principali e i relativi significati raggruppati secondo questaclassificazione.
quit/exit viene terminata l’esecuzione di GnuChess
go l’interprete dei comandi cede il controllo allo Schedulatore
mossa delgiocatore
generalmente la mossa può essere inserita in diversi formaticomprensibili all’utente (varianti della notazione algebrica oil trascinamento sullo schermo del pezzo mosso).GnuChess converte la mossa indicata nella suarappresentazione interna. Questa codifica viene quindicomunicata al modulo Esegui/Ritira Mossa per rendereconsistente il nuovo stato della partita
Tab. 2.6a Controllo del programma e inserimento della mossa
bd mostra la dislocazione dei pezzi
hint comunica la migliore mossa di risposta trovata dal computeralla mossa da lui giocata
help illustra sinteticamente il significato dei comandi
reverse inverte la vista della scacchiera
post richiede che durante la ricerca venga mostrata lacontinuazione principale e il punteggio relativo
Tab. 2.6b La visualizzazione delle informazioni
newinizia una nuova partita: la posizione corrente è quellainiziale
set/edit/setuppermettono di impostare una dislocazione qualsiasi deipezzi sulla scacchiera
undoremove
i due comandi rispettivamente ritirano l’ultima semimossa el’ultima mossa giocate
Tab. 2.6c La modifica della posizione corrente
save permette di archiviare la posizione corrente e la storia dellapartita in un file il cui nome è indicato dall’utente.

63
get
permette di recuperare le informazioni su una partitamemorizzate su archivio permanente. Viene reso corrente lostato del gioco al momento dell’archiviazione in modo da poterproseguire la partita. Oltre a questo sono accedute altreinformazioni statistiche come la lista delle mosse giocate, il tempodi ricerca e i nodi visitati dal computer nella scelta delle suemosse.
Tab. 2.6d Gestione degli archivi delle partite
both abilita/disabilita il computer a giocare per entrambi i giocatori
force abilita/disabilita l’utente a giocare per entrambi i giocatori
switch inverte di posto i due giocatori facendo sì che il computer inizi laricerca della mossa successiva
depthlevel/clock
si richiede di modificare rispettivamente la profondità massima diricerca e il tempo massimo di ricerca del computer
hash abilita/disabilita l’utilizzo delle tabelle di trasposizioni
book inibisce la consultazione del libro di apertura
easy
abilita/disabilita il computer a "pensare" durante la sceltadell’avversario. Quando questa modalità di gioco è attivata ilcomputer assume che l’avversario giocherà quella che luiconsidera la migliore mossa di risposta (PrVar[2]) alla mossa dalui giocata. Il computer impiega il tempo di scelta dell’avversarioper cercare la sua mossa successiva. L’avversario segnala cheha fatto la sua scelta inviando un segnale di tipo interruzione chearresta questa ricerca. Se egli giocherà veramente la mossapronosticata il programma avrà già esplorato buona partedell’albero di gioco, altrimenti tutto il lavoro andrà perduto.
Tab. 2.6e La modifica della modalità di gioco2.6 Il ruolo di GnuChess nella tesi
Nel seguito della tesi GnuChess costituirà un utile strumento ai finiimplementativi e sperimentali delle idee che saranno presentate edapprofondite nei Capitoli 5 e 6. In particolare, nell’ambitodell’approfondimento degli algoritmi paralleli di ricerca operato nelCapitolo 5, esso sarà utilizzato alla stregua di una libreria difunzioni. Gli algoritmi che saranno presentati in quella sede, infatti,pur essendo indipendenti dal dominio di applicazione, fannotuttavia riferimento a funzionalità classiche di gestione dell’albero digioco (generazione di mosse, esecuzione e retrazione di unamossa, valutazione statica dei nodi terminali, ecc.) le quali sonoinerentemente dipendenti dal dominio. Poiché il progetto e larealizzazione di queste funzionalità esula dagli obbiettivi di questo

64
lavoro, esse saranno prelevate integralmente dal codice diGnuChess. Quest’ultimo, tuttavia, non è una libreria di funzioni, maun programma di gioco finalizzato alla minimizzazione diridondanze e costi computazionali in nome di una massimizzazionedelle prestazioni: in virtù di queste esigenze la sua struttura non èperfettamente modulare e quindi ci si dovrà attendere qualchedifficoltà nella "estrazione" delle funzionalità di nostro interesseprima citate; tali eventuali impedimenti saranno eventualmentedenunciati nel Capitolo 7 in sede di commento conclusivo.
Nel Capitolo 6, invece, GnuChess rivestirà un duplice ruolo.In particolare esso sarà impiegato nello sviluppo di un giocatoreparallelo costituito dalla replica di sue istanze. L’unica differenza fratali istanze di GnuChess sarà la conoscenza terminale in esseincorporata e quindi la rispettiva funzione di valutazione. Solamentequesta sezione del suo programma sarà dunque modificata (tral’altro in minima parte), mentre il resto della sua struttura rimarràinalterato.
Le prestazioni del giocatore parallelo così ottenuto saranno valutatesulla base della sua qualità di gioco: GnuChess costituirà, qualeavversario, un valido banco di prova di tali performance.

63
Capitolo 3Linda
3.1 IntroduzioneLinda è un linguaggio di coordinazione caratterizzato da pochesemplici operazioni basate sul paradigma di programmazioneparallela chiamato comunicazione generativa. Linda non è unlinguaggio di programmazione completo [CarGel90]: esso vapiuttosto interpretato come un insieme di oggetti ed operazioni (suessi definite) inteso per essere integrato con un linguaggio diprogrammazione preesistente (linguaggio di base). Il risultato ditale estensione è dunque un "dialetto" del linguaggio di basearricchito con costrutti per descrivere e controllare la concorrenza.La classificazione più appropriata per Linda è di linguaggio dicoordinamento, cioè finalizzato alla gestione ed alla coesione inunico programma di più attività separate.
È più corretto pensare a Linda come ad un modello diprogrammazione parallela piuttosto che ad un reale supporto allaconcorrenza: Linda può essere istanziato (implementato) inmolteplici modi e contesti dipendenti, ad esempio, dall’architetturadel sistema (uniprocessore, multicalcolatore, rete locale dicalcolatori, ecc.) o dal linguaggio di base. Particolare attenzionesarà rivolta nel seguito all’analisi di una di tali istanze del modelloLinda: il sistema Network C-Linda per reti di workstation [Lin90];questo è il supporto reale utilizzato per lo sviluppo e lasperimentazione delle idee e degli algoritmi oggetto del presentelavoro.
Ciò che distingue un linguaggio di coordinazione da unosequenziale è la disponibilità di costrutti per la creazione ed ilcoordinamento (comunicazione + sincronizzazione) di più flussi diesecuzione (processi).
Linda è un modello di creazione e coordinamento di processiortogonale al linguaggio di base in cui è incorporato: non hainteresse cosa e come computa ciascun flusso di esecuzione,bensì solo il modo con cui tali flussi (visti dunque come scatolenere) sono creati ed è permesso loro di cooperare.
Il modello su cui si fonda Linda prende il nome di comunicazionegenerativa. Se due processi devono comunicare, essi nonscambiano messaggi (modello ad ambiente locale) o condividonouna variabile (modello ad ambiente globale); al contrario, ilprocesso mittente della comunicazione genera un nuovo oggetto(chiamato tupla) che deposita in una regione accessibile ed esternaa tutti i processi (chiamata spazio delle tuple). Il processodestinatario è così in grado di accedere a tale area per prelevare latupla e quindi con essa il contenuto della comunicazione. Lacreazione dei processi è trattata alla stessa maniera: un processoche intende creare un secondo processo concorrente genera una

64
"tupla attiva" che affida allo spazio delle tuple. Una tupla attivaesegue una sequenza di computazioni indipendente dal processoche l’ha generata, per poi trasformare se stessa in una tuplaordinaria (passiva).
Un’implicazione di questo modello è che comunicazione ecreazione di processi sono due aspetti della stessa operazione: percreare un processo viene generata una tupla attiva che sitrasformerà in una passiva, mentre nella comunicazione vienegenerata direttamente una tupla passiva. In entrambi i casi siottiene lo stesso risultato: lo spazio delle tuple viene arricchito conun nuovo oggetto che potrà essere acceduto da qualsiasi processointeressato ad esso.
Altra proprietà rimarchevole del modello è che i dati sono scambiatinella forma di oggetti persistenti (e non di messaggi transitori). Ildestinatario della comunicazione, infatti, oltre a rimuovere la tuplagenerata dal mittente può anche accedere ad essa senza"consumarla", cioè permettendo che essa rimanga nello spaziodelle tuple dove anche altri processi potranno leggerla.
Linda permette di organizzare collezioni di tuple in stutture datidistribuite, cioè strutture accessibili simultaneamente da piùprocessi. L’unificazione prima descritta fra la creazione dei processie dei dati significa che si può organizzare collezioni di processi instrutture dati attive [CarGel88]: ogni processo componente lastruttura dati attiva è un flusso di computazione al cui terminediviene un elemento della struttura dati passiva che è ritornatacome risultato della computazione complessiva.
Le implicazioni del modello di comunicazione generativa siestendono oltre la programmazione parallela: il modello intendeessere applicato ad altre forme di comunicazione che non siano lasola cooperazione fra processi dello stesso programma parallelo.Lo spazio delle tuple si presenta come un flessibile meccanismoanche per la comunicazione fra programmi scritti in linguaggidiversi, o fra un programma-utente ed il sistema operativo, oppureancora fra un programma ed una futura versione di se stesso[CarGel89].
Lo spazio delle tuple esiste indipendentemente dalle computazionidei programmi (visti come scatole nere), siano essi primitive disistema o programmi-utente scritti in un linguaggio qualsivoglia. Leattuali implementazioni di Linda, tuttavia, concentrano per ilmomento l’attenzione sulla sola comunicazione fra processi di unostesso programma parallelo.
Le pagine seguenti offriranno una presentazione più accurata delmodello di programmazione distribuita basato sullo spazio delletuple; seguirà la descrizione di C-Linda e una caratterizzazionedello stile di programmazione in Linda con alcuni esempi diimplementazione di strutture dati distribuite e di interazione fra iprocessi. Ad epilogo di questa sezione saranno prodotti alcunicenni sulle tecniche di realizzazione di Linda, con particolare

65
attenzione all’implementazione su architetture parallele conmemoria distribuita.
3.2 Il modello Linda di programmazione distribuitaLinda si basa sulla nozione di spazio delle tuple che costituiscel’ambiente astratto attraverso il quale più flussi di esecuzioneindipendenti (processi) interagiscono.
Lo spazio delle tuple è dunque una memoria condivisa; essoconsiste di una collezione di elementi strutturalmente omogeneichiamati tuple acceduti in modo associativo e non attraversoindirizzamento.
In questo ambiente le tuple possono essere inserite, lette, rimosseo valutate. Linda definisce per ciascuna di queste funzioniun’operazione che la realizza. Tali operazioni hanno proprietà diatomicità: è così garantito che più processi possano operare"simultaneamente" sullo spazio delle tuple in modo consistente.
3.2.1 Gli oggetti3.2.1.1 Le tuple
Una tupla è una sequenza ordinata di campi. Ad ognicampo è associato un tipo di dato; i tipi di datopossibili sono quelli fissati dal linguaggio di base.Ciascun campo di una tupla contiene un valore deltipo ad esso associato ed è per questa ragionechiamato campo attuale12.
Il valore di un campo attuale può originare da fontidiverse: il contenuto di una variabile, il risultato diun’invocazione di funzione o una costante. Una tuplaè quindi il risultato di un certo insieme di computazionifinalizzate al calcolo dei valori dei propri campi.
Quando è calcolata una tupla? e da chi?Una risposta completa a questi quesiti sarà formulatacon la presentazione degli operatori per lagenerazione di tuple. Per il momento è importantetrarre beneficio delle precedenti considerazioni perintrodurre una classificazione delle tuple in duecategorie:
• tuple-dato (passive)• tuple-processo (attive).Informalmente si può definire una tupla passiva comeuna tupla completamente calcolata, i cui campicontengono effettivamente un valore attuale del tipoassociato al campo. Una tupla attiva, invece, ècaratterizzata dall’avere un sottoinsieme dei suoicampi con un valore non definitivamente calcolato ela cui valutazione è ancora in progresso. Piùchiaramente, alcuni dei campi di una tupla attiva noncontengono un dato, ma del codice la cui esecuzioneavrà inizio al momento della generazione della tupla.

66
Formalmente, le linee di codice in un campo di unatupla attiva definiscono una funzione il cui codominioè il tipo di dato associato al campo; il valore ritornatoda detta funzione andrà a sostituire lo stesso codiceche l’ha descritta nel campo corrispondente dellatupla. Quando tutti i campi di una tupla attiva sonostati calcolati essa diviene a tutti gli effetti unatupla-dato passiva, indistinguibile dalle altre tuple-dato.
Esempio 3.1In un programma parallelo di scacchi si vuolecondividere al livello dei processi una struttura datichiamata mappa di controllo dello spazio. Essaassocia ad ogni casa della scacchiera il valorestrategico che avrebbe un certo pezzo se questo laoccupasse; il contenuto della mappa dipende dallostato corrente della partita ed è quindi aggiornatoperiodicamente dopo un certo numero di mosse (in3.3.2.3.4 sarà discusso un esempio di utilizzo di talestruttura dati).
In Linda è possibile implementare tale condivisionememorizzando la mappa in un insieme di tuple con laseguente struttura logica:
(tipo di pezzo,casa,valore strategico)Un esempio di una di queste tuple è13:("mappa",'c',51,312) (1)Questa tupla è composta da quattro campi: un vettoredi caratteri, un carattere e due interi. Si tratta di unatupla passiva poiché tutti i suoi campi contengono unvalore del tipo corrispondente. Il significato di questatupla è: il valore strategico di un cavallo ('c' ≈ cavallo)nella casa identificata con il codice numerico 51 è312.
Siano le dichiarazioni:struct scacchiera {... };char pezzo;int casa;int valore(char p,int c,structscacchiera s);La tupla (1) potrebbe ad esempio originare dallavalutazione della tupla non valutata:("mappa",pezzo,casa,valore(pezzo,casa,s)) (2)Mentre il primo campo contiene un valore costante, ilsecondo e terzo riferiscono due variabili e l’ultimol’invocazione di una funzione. Se la tupla (2) è inseritanello spazio delle tuple prima di essere valutata,

67
allora essa è un esempio di tupla attiva. In questocaso, dal momento della sua generazione, la tupla èsottoposta ad un processo di autovalutazione che laporterà a trasformarsi nella tupla passiva (1).
3.2.1.2 Lo spazio delle tupleTutte le tuple sono riunite logicamente all’interno di ununico ambiente astratto: lo spazio delle tuple. Essopuò contenere un numero qualsiasi di copie dellastessa tupla (non è quindi un insieme).
Lo spazio delle tuple può essere visto come unamemoria. Tale memoria è unica per ogni programmaLinda. Essa è globale ai processi ed è condivisa daessi, cioè qualsiasi processo può accedervi e ciòsenza vincoli o privilegi rispetto agli altri (a meno chequesti non siano previsti esplicitamente dalprogrammatore).
In Linda lo spazio delle tuple è l’unico e fondamentaletramite per la comunicazione e la sincronizzazione frai processi. Tutte le interazioni vedono dunquecoinvolti tre agenti: il processo mittente cheinteragisce con lo spazio delle tuple e quest’ultimoche interagisce con il processo destinatario.
Nella maggioranza dei modelli tradizionali diprogrammazione parallela l’interazione fra processi èimplementata completamente all’interno del supportoa tempo di esecuzione del linguaggio ed è quinditrasparente al programmatore che vede quindicoinvolti nell’interazione due soli agenti: il mittente e ildestinatario della comunicazione. In Linda, invece,l’intermediario della comunicazione (lo spazio delletuple) è visibile al programmatore cui spetta "l’onere"di programmare le modalità della mediazione.
3.2.2 Gli operatoriIl modello Linda definisce quattro operatori fondamentali perla manipolazione delle tuple:• out per la generazione di tuple passive• in per la rimozione di tuple passive• rd per la lettura di tuple passive• eval per la generazione di tuple attiveIn un’implementazione reale di Linda è tuttavia possibileincontrare ulteriori operatori che si aggiungono a quelli dibase elencati. In C-Linda, ad esempio, sono presenti glioperatori inp e rdp che costituiscono una variante in forma dipredicato rispettivamente di in e rd.
3.2.2.1 outL’operatore out aggiunge una nuova tupla allo spaziodelle tuple.

68
Un’invocazione di questo operatore ha la formagenerale:out(P 1,P 2,...,P n).I parametri P1, P2, . . ., Pn definiscono i campi dellanuova tupla. Tale tupla è prima valutata in ogni suocampo e quindi inserita nello spazio delle tuple.L’operatore out non è bloccante: il processo invocanteriprende la sua esecuzione non appena hacompletato, nel suo ambiente, la valutazione dellatupla.
Esempio 3.2Data un certa disposizione sulla scacchiera, sisupponga di voler creare nello spazio delle tuple laporzione della mappa di controllo dello spazio relativaad un generico pezzo. Per far questo si può definire lafunzione:
void calcola_mappa(char pezzo,structscacchiera s)
{int i;for(i=0;i<64;i++)
out("mappa",pezzo,i,valore(pezzo,i,s));
}3.2.2.2 in
L’operatore in "tenta" di rimuovere una tupla dallospazio delle tuple.L’invocazione dell’operatore ha la forma generale:in(P 1,P 2,...,P n)I parametri P1, P2, . . ., Pn definiscono un nuovooggetto chiamato antitupla. Si tratta di uno "schema ditupla" attraverso il quale si seleziona un sottospazio dituple il cui contenuto e struttura interna dei tipicoincidono con quello dello schema.
La struttura di una antitupla è quindi analoga a quelladi una tupla: una sequenza ordinata di campi "tipati".In questo caso, però, un campo può essere attuale oformale. Un campo attuale contiene un valore del tipoad esso associato (come per le tuple); un campoformale, invece, è un segnaposto: ha un tipo, ma nonun valore. La presenza di un formale in una antituplaè segnalata dall'occorrenza di una variabile dellostesso tipo del campo.
Esempio 3.3Un esempio di antitupla è:("mappa",'c',casa,?val)

69
I primi tre campi di essa sono attuali, mentre il quartoè formale. Il tipo di quest’ultimo è quello con cui èstata dichiarata la variabile val.
La funzione di una antitupla è dunque quella di"indirizzare" tuple all’interno dello spazio delle tuple.Le tuple non hanno né indirizzo né nome: l’unicomodo per essere riferite è quello di indicare unoschema (antitupla) che sia compatibile con la lorostruttura e contenuto. La modalità di indirizzamento èdunque associativa; per molti aspetti essa può esseremessa in analogia con quella che caratterizza ilriferimento di un oggetto in una base di datirelazionale.
Resta ancora da risolvere un’importante questione:dato lo spazio delle tuple S ed una antitupla a, qualisono le tuple in S che a riferisce?
Sono quelle che rispettano le regole dicorrispondenza con a.Def. (regole di corrispondenza o matching):Una tupla t corrisponde ad una antitupla a se:• t ed a hanno lo stesso numero di campi e• per ogni coppia (ct,ca) di campi corrispondentiposizionalmente di t ed a:• ct e ca sono dello stesso tipo e• ct e ca sono in accordo, cioè:a) se ca è un attuale, allora il valore in ct èuguale a quello in ca; le regole di uguaglianzasono quelle definite dal linguaggio di base peroggetti dello stesso tipo;b) se ca è un formale, invece, ct e ca sonosicuramente in accordo.Esempio 3.4Si consideri l’antitupla a:("mappa",'c',51,?val)dove val è di tipo int.La tupla t:("mappa",'c',51,312)rispetta i vincoli di corrispondenza con a.Lo stesso non vale per la tupla:("mappa",'c',51,312.0)poiché l’ultimo campo non è dello stesso tipo delcorrispondente di a.Sia ora l’antitupla b:("mappa",?pezzo,51,?val)Si osservi come b costituisca uno schema di tupla piùgenerale rispetto ad a in quanto non fissa il valore delsecondo campo. Come conseguenza, se Ta è

70
l’insieme delle tuple che corrispondono ad a e Tbl’analogo per l’antitupla b, allora Ta ⊆ Tb.
Alla luce delle definizioni di antitupla e delle regole dicorrispondenza è finalmente possibile descrivere lasemantica (informale) dell’operatore in:
sia S lo spazio delle tuple, a una antitupla e T={t1, t2, .. ., tn} l’insieme delle tuple in S corrispondenti ad a;l’esecuzione del comando in(a) si articola nelleseguenti fasi:
• selezione di una tupla corrispondente ad a: fra letuple dell’insieme T ne viene scelta una secondo uncriterio casuale14 (nondeterministicamente). Sel’insieme T è vuoto, allora l’esecuzione del comandoviene sospesa fino a che una tupla corrispondente ada non viene inserita nello spazio S per essere quindiselezionata dal comando stesso.
• rimozione ed assegnamento attuali-formali: la tupla tselezionata viene rimossa nella sua interezza dallospazio delle tuple. Selezione e rimozione di t devonocostituire un’azione atomica: questa condizioneimpedisce la situazione inconsistente con lespecifiche del modello in cui più processi accedono erimuovono la stessa tupla. Inoltre, se nella antitupla asono presenti dei campi formali, allora alle variabiliche li denotano vengono assegnati i valori attualicontenuti nei campi corrispondenti di t.
Esempio 3.5Nell’ormai familiare programma di scacchi si vuoleimplementare la creazione in parallelo della mappa dicontrollo dello spazio. Una possibile soluzione èaffidare a processi diversi il calcolo relativo a pezzidiversi. Sia M un processo coordinatore con funzionedi assegnare questi compiti ai processi serventi15. SiaW uno di questi; nel corpo di W sarà contenuto ilcodice:
in("calcola_mappa",?pezzo,?s);calcola_mappa(pezzo,s);in cui è stata utilizzata la funzione definitanell’Esempio 3.2.Il processo W rimuove uno dei lavori previsti dalcoordinatore, impedendo così che anche altri processiserventi lo accedano ed eseguano quindi inutilmentela sua stessa computazione.
Nel caso non vi siano occorrenze di lavori nellospazio delle tuple il comando in produce l’effetto disincronizzare W con M, poiché lo sospende fino alverificarsi dell’evento "M ha depositato un nuovolavoro nello spazio delle tuple".

71
3.2.2.3 rdL’operatore rd permette di leggere il contenuto di unatupla.La forma generale di una sua invocazione è analogaa quella dell’operatore in:rd(P 1,P 2,...,P n)I parametri P1, P2, . . ., Pn definiscono un’antitupla. Glieffetti dell’operatore rd sono del tutto identici a quellidi in per quanto riguarda le fasi di selezione edassegnamento attuali-formali. Tuttavia la tupla riferitarimane (immutata) nello spazio delle tuple, dove puòcosì essere ancora acceduta.
Questa operazione, dunque, non modifica il contenutodello spazio delle tuple; essa è utilizzata unicamenteper i suoi effetti laterali: assegnamento dei formali esincronizzazione.
Riguardo la sincronizzazione va sottolineato, infatti,che anche l’operatore rd prevede la sospensione delprocesso qualora nessuna tupla "corrisponda"all’antitupla che esso ha per argomento.
Esempio 3.6Le informazioni contenute nella struttura dati definitanell’Esempio 3.1 possono essere lette con l’operatorerd eseguendo:
rd("mappa",'c',casa,?val);se ad esempio si vuole conoscere il valore strategicodel cavallo nella posizione della scacchiera riferitadalla variabile casa.
3.2.2.4 evalL’operatore eval aggiunge una tupla attiva allo spaziodelle tuple.L’invocazione di questo operatore ha la forma:eval(P 1,P 2,...,P n)Come per l’operatore out, i parametri P1, P2, . . ., Pndefiniscono i campi della nuova tupla. Contrariamentead esso, però, la tupla è valutata solo dopo che essaè stata inserita nello spazio delle tuple. Implicitamenteciò comporta la creazione di nuovi processi destinatialla valutazione in parallelo di tutti i campi della tupla.Solo quando tutti i suoi campi sono stati valutati latupla diviene un’ordinaria tupla passiva che puòessere finalmente acceduta nel modo usuale con glioperatori in o rd.
In dettaglio, l’esecuzione di un’operazione eval causala seguente sequenza di attività:• vengono stabiliti nell’ambiente del processoinvocante i legami per i nomi citati esplicitamente

72
nella tupla. A questo punto il processo può continuarela sua esecuzione con il comando successivo ad eval.• ogni campo della tupla che è argomento di eval èora valutato indipendentemente ed in modo asincronorispetto agli altri processi. La valutazione dei campiavviene in parallelo: per ognuno di essi viene quindicreato un nuovo processo. Essa ha luogo in uncontesto in cui sono ereditati dall’ambiente delprocesso invocante la eval i legami per i soli nomiriferiti esplicitamente nell’invocazione del costrutto.
• quando ogni campo è stato valutato completamentela tupla passiva costituita dai valori così calcolatidiviene parte dello spazio delle tuple.
Ancora un’osservazione: il codice per la valutazionedi un campo di una tupla attiva può contenerequalsiasi costrutto Linda, anche un’ulterioreinvocazione dell’operatore eval.
3.2.2.4.1 Il modello master -workerLa primitiva eval è lo strumento Linda chepermette di creare processi. La pluralità diprocessi è normalmente finalizzata allasoluzione efficiente di un certo problema laquale scaturisce dalla cooperazione fra iprocessi. Quali criteri regolano talecooperazione?
Esistono diversi modelli di cooperazione la cuiapplicabilità dipende dalle caratteristiche dellinguaggio parallelo e del problema.
Un modello che può essere applicato ad unaestesa classe di problemi e che può esserefacilmente ed efficientemente attuato in Linda èil paradigma master-worker (o ad agenda)[Bal91].
L’idea alla base di questo approccio è ilconcetto di distribuzione dinamica del lavorofra i processori, intendendo per lavoro uncompito, un’elaborazione necessaria ai finidella soluzione finale del problema.L’architettura logica di comunicazione indottada questo modello ha la seguente struttura:
• un processo master (o coordinatore) chegenera i lavori• uno o più processi worker (o serventi)indistinguibili che eseguono i lavori e ingenerale restituiscono il risultato di questi almaster cui ne compete la gestione
Il modello sottintende la presenza a livellologico di 2 strutture dati:

73
• l’insieme dei lavori (agenda) e• l’insieme dei risultati dei lavoriQuesto modello può essere applicato a queiproblemi che possono essere suddivisi in unalista (generalmente ordinata) di compiti daeseguire. I worker estraggono ripetutamentequest’ultimi e li eseguono fino al loroesaurimento.
Come può essere attuata in Linda la creazionedi questa struttura di cooperazione?È il processo master che, intendendo disporredi n serventi eseguirà:for(i=0;i<n;i++)
eval("worker",worker());La programmazione della cooperazione framaster e worker sarà ampiamente discussa neiCapitoli 4 e 5 dove il paradigma omonimocostituirà lo strumento teorico di base per lasoluzione dei problemi affrontati.
Esempio 3.7In alternativa ad una soluzione fondata sulparadigma master-worker (Esempio 3.5), lacreazione in parallelo della mappa di controllodello spazio può essere realizzataimplementando questa come una struttura dativiva, cioè che si "auto-calcola". In Linda unastruttura viva è costituita da tuple attive, lequali saranno generate nell’esempio con uncomando del tipo:
eval("mappa",pezzo,casa,valore(pezzo,casa,s));Questo comando crea implicitamente quattronuovi processi per la valutazione dei campidella tupla. Il processo che calcolavalore(pezzo,casa,s) fa questo in un contestoin cui i nomi valore, pezzo, casa e s hanno lostesso valore che avevano nell’ambiente delprocesso che ha invocato eval. Qualsiasivariabile libera nel corpo della funzione valorediversa da quelle elencate va consideratacome non inizializzata perché non riferitaesplicitamente nel comando eval.
3.3 Network C-LindaC-Linda è un’istanza, un’implementazione reale del modello Linda.Esso risulta dalla integrazione del linguaggio sequenziale C con illinguaggio di coordinamento Linda. C-Linda è dunque un linguaggiodi programmazione concorrente completo:

74
• Linda fornisce gli strumenti per cementare in un unico programmaparallelo più computazioni indipendenti;• C permette di programmare in sequenziale ciascun flussoseparato di computazione.
3.3.1 Variazioni rispetto al modelloIl linguaggio di programmazione C-Linda implementaabbastanza fedelmente il modello Linda. In esso ritroviamooggetti e strumenti oramai familiari: le tuple, lo spazio delletuple e i quattro operatori di base: out, in, rd ed eval. Tuttaviaincontriamo anche alcune novità rispetto alla definizione delmodello formulata.
3.3.1.1 Gli operatori inp e rdpÈ già stata sottolineata la proprietà dei costrutti in e rddi sospendere il processo che li esegue qualora nonesista alcuna tupla corrispondente all’antitupla fornitaloro in argomento. Il fatto che entrambi gli operatoridestinati al recupero delle tuple presentino questacaratteristica può apparire una limitazione allaespressività del linguaggio.
Si supponga infatti di voler programmare la seguentesituazione: un processo P deve eseguire il comandoC1 se nello spazio delle tuple è presente la tupla t, ilcomando C2 altrimenti. Seppure non impossibile,descrivere questo scenario con i soli operatori Lindadi base non è immediato ed intuitivo.
Quello di cui si avrebbe bisogno è la possibilità ditestare la presenza o meno di una tupla nell’omonimospazio. Per soddisfare questa esigenza C-Lindamette a disposizione due nuovi operatori: inp e rdp.
Si tratta di varianti in forma di predicatorispettivamente di in e rd. A differenza di quest’ultimi,però, inp e rdp non causano la sospensione delprocesso invocante in assenza della tupla cercata.
Analizziamo in dettaglio gli effetti prodotti dalla loroesecuzione:• argomento dei due operatori è una antitupla. Essicercano di localizzare nello spazio delle tuple unatupla corrispondente ad essa;
• in caso di ricerca fallimentare viene ritornato il valore0, altrimenti viene eseguito l’assegnamento attuali-formali e ritornato il valore 1 (nel caso di inp si haanche la rimozione della tupla trovata).
L’utilizzo di questi operatori deve essere fatto concautela poiché la loro efficienza è fortementedipendente dall’implementazione reale. In alcunesituazioni, in cui vi siano particolari esigenze riguardole prestazioni dei programmi, è quindi preferibile

75
rinunciare a queste forme di predicato e ricorrere atecniche alternative (uso di tuple contatore o tuplesemaforo) [CarGel90].
Esempio 3.8Si vuole fondare l’implementazione di un giocatoreparallelo di scacchi sul modello master-worker.In una soluzione banale il processo masterdistribuisce lavoro ai worker fino a che ve ne sononon occupati e di seguito si assegna lui stesso dellavoro. Completata la sua fase di calcolo essocontrolla se vi sono dei risultati in arrivo dai worker,eventualmente li gestisce e successivamenteriesegue ciclicamente le operazioni descritte fino adesaurimento dei lavori. In questo contesto emergel’utilità dei nuovi operatori inp e rdp:
while (!fine_lavori()){while (!fine_lavori() &&
!rdp("worker_liberi,0))distribuisci_un_lavoro();
if (!fine_lavori())esegui_un_lavoro();
while (inp("risultato",?r))gestisci_risultato(r);
}3.3.1.2 Campi formali anonimi
C-Linda permette di definire un campo formale di unaantitupla come anonimo; ciò significa che a talecampo non è associata alcuna variabile. Un campoformale anonimo esprime la volontà di non conoscereil contenuto del campo corrispondente di una certatupla. L’esecuzione dei comandi in(a) o rd(a) in cuil’antitupla a contiene un campo formale anonimocomporta infatti l’omissione dell’assegnamentoattuale-formale per quel campo. Il vantaggio chederiva da questo meccanismo è duplice:
• sensibile risparmio in tempo di esecuzione nel casodi campi di grosse dimensioni• risparmio di spazio e linee di codice per ladichiarazione della variabile destinata alla ricezionedel campo attuale della tupla che sarebbe altrimentinecessaria.
Esempio 3.9In un programma parallelo basato sul paradigmamaster-worker talvolta accade che un lavoro L,decomposto in sottolavori affidati a processi worker,non sia più necessario (ad esempio per l’occorrere diun taglio in una visita alpha-beta di un albero di gioco)

76
rendendo così inutile l’esecuzione dei sottolavori. Inquesta eventualità il gestore del lavoro L deverimuovere dalla lista dei lavori i sottolavori di L nonancora prelevati dai processi worker. In questaoperazione non è interessante il contenuto delle tuplerimosse: è quindi appropriato l’utilizzo di campi formalianonimi:
while (inp("sottolavoro_L",?structdescrizione_lavoro));/* descrizione lavoro è un nome di tipoe non una variabile */
3.3.2 L’ambiente di programmazioneUn linguaggio di coordinamento supporta la creazione diprocessi e la loro interazione. Entrambi questi servizi sono disolito resi disponibili direttamente dal sistema operativo inuna qualche forma accessibile al programmatore. Sipotrebbe quindi evitare l’utilizzo di un linguaggio dicoordinamento e fare affidamento sul sistema operativoquale supporto alla programmazione concorrente. Questastrategia è semplice, ma sfortunatamente primitiva. Adifferenza di una libreria di primitive del sistema operativo,un linguaggio di coordinamento è supportato da uncompilatore e da un ambiente di sviluppo e controllo deiprogrammi.
Il compilatore è il componente più importante del sistemaC-Linda. È implementato come un pre-compilatore il qualetrasforma le operazioni Linda in "normali" operazioni Cottenendo così un codice completamente in C che saràsuccessivamente tradotto dal compilatore standard di questolinguaggio.
Il compilatore C-Linda è ottimizzante, cioè mirato a tradurre icostrutti Linda in modo che la loro esecuzione sia efficiente.Vediamo un esempio di ottimizzazione volta a ridurre iltempo di ricerca di una tupla: tuple ed antituple sonopartizionate in classi di equivalenza in base alla loro struttura(numero, tipo e valore dei campi). In base a tale partizionetuple di una classe non possono corrispondere ad antitupledi un’altra; in questo modo il numero di confronti che devonoessere fatti per la ricerca di una tupla sono notevolmenteridotti, dato che la ricerca è limitata alle tuple di una solaclasse di equivalenza e non all’intero spazio delle tuple. Lacreazione della partizione appena descritta è completamentea carico del compilatore Linda. L’implementazione delmodello Linda sarebbe improponibile in assenza di uncompilatore ottimizzante dato il degrado delle prestazioniche ne deriverebbe [Lin90].
L’ambiente di programmazione C-Linda comprende ancheun complesso ed efficace insieme di utilità per l’assistenza

77
del programmatore nello sviluppo e la correzione deiprogrammi [CarGel90]. Alcuni di questi strumenti sono moltoad alto livello (Tuplescope); essi possono fornire, adesempio, una visualizzazione grafica degli oggetti (tuple) edegli agenti (processi) che compongono un programmaLinda e descriverne dinamicamente l’evoluzione durantel’esecuzione.
3.4 Lo stile di programmazioneLa maggioranza dei linguaggi paralleli non consente ai processi dicondividere dati in maniera diretta (linguaggi ad ambiente locale).Nei linguaggi in cui tale condivisione è invece prevista (linguaggi adambiente globale) normalmente la consistenza degli oggetti comuniviene garantita mettendo a disposizione del programmatoreoperatori elementari del tipo lock-unlock con i quali si riesce adefinire come sezione critica la porzione di codice relativaall’accesso ai suddetti oggetti.
La proprietà caratterizzante del modello Linda è la possibilità offertaai processi di condividere direttamente dati e di accedere ad essi inmodo consistente garantendo l’atomicità degli accessi al livello deicostrutti concorrenti, liberando così il programmatore dal tedioso (espesso fonte di errori) lavoro di programmazione delle sezionicritiche.
In Linda le strutture dati condivise sono memorizzate come insiemidi tuple nello spazio delle tuple. Un numero qualsiasi di processipuò manipolare tuple simultaneamente poiché gli operatori sullospazio delle tuple sono definiti intrinsecamente come consistenti.
Nel contesto della presente discussione garantire la consistenzasignifica impedire che un processo legga o modifichi un oggettomentre un altro processo sta modificando quest’ultimo. Una tuplanon può essere alterata fisicamente; per modificare logicamenteuna tupla un processo deve rimuoverla con in e quindi reinserirneuna versione modificata usando out. Come conseguenza di questoapproccio l’operazione rd non può mai ritornare "un’istantanea"inconsistente del contenuto di una tupla: se infatti essa è eseguitamentre la tupla è modificata da un altro processo, quella tupla saràfisicamente assente dallo spazio delle tuple e l’operazione rd saràsospesa fino a che la tupla non sarà completamente modificata,cioè reinserita nello spazio delle tuple.
Verranno ora illustrati alcuni esempi di strutture dati distribuite, cioèstrutture condivise dai processi e memorizzate nello spazio delletuple.
3.4.1 Strutture dati distribuiteL’insieme delle strutture dati convenzionali può esserepartizionato in tre categorie:• strutture i cui elementi sono identici o indistinguibili• strutture i cui elementi sono distinguibili attraverso un nome• strutture i cui elementi sono riconosciuti dalla loro posizione

78
L’esempio più significativo nel mondo sequenziale distrutture appartenenti alla prima categoria sono imulti-insiemi (bag), cioè insiemi in cui uno stesso dato puòessere replicato più volte. La seconda categoria comprenderecord, oggetti istanza di classi, memorie associative,collezione di asserzioni in stile Prolog, ecc. La terzacategoria include vettori, liste, grafi, alberi e così via.
Ognuna di queste categorie convenzionali è rappresentabilein forma distribuita. Tuttavia la versione distribuita di questestrutture non gioca sempre lo stesso ruolo dell’analogasequenziale. Infatti vi sono fattori non presenti nel mondosequenziale che invece rivestono un ruolo fondamentalenella costruzione di strutture dati distribuite. Primo fra questiil problema della sincronizzazione che emerge dal fatto chepiù processi asincroni possono accedere simultaneamentead una struttura distribuita.
3.4.1.1 Strutture con elementi identici oindistinguibili
SemaforoLa più elementare delle strutture dati distribuite è ilsemaforo.In Linda un semaforo (a conteggio) è niente più cheuna collezione di elementi identici.All’operazione V sul semaforo S corrisponde il codiceLinda:out("S");mentre per eseguire P su S:in("S");Per inizializzare il semaforo al valore n si deveeseguire out ("S") n volte.BagBag è una struttura dati sulla quale sono definite dueoperazioni: "aggiungi un elemento" e "preleva unelemento". In questo caso gli elementi nonnecessitano di essere identici, ma sono manipolatisecondo modalità che fanno di essi indistinguibili.
Non importante nella programmazione sequenziale,questa struttura dati ricopre un ruolo rilevante inambiente parallelo. La versione più semplice delparadigma master-worker, infatti, è basato sullacondivisione di un bag di lavori (agenda). Un lavoro èaggiunto al bag "lavori" usando:
out("lavori",Descrizione_lavoro);e prelevato con:in("lavori",?Nuovo_lavoro);
3.4.1.2 Strutture con accesso per nomeLe applicazioni parallele spesso richiedono l’accessoad una collezione di elementi distinguibili attraverso

79
un nome. Tale struttura dati ricorda i tipi record delPascal o struct del C.In Linda possiamo memorizzare ogni elemento intuple della forma: (nome, valore).In analogia ai tipi struct del C, la prima parte dellatupla individua il nome del campo della struttura e laseconda il suo contenuto.
Per leggere un elemento i processi eseguono:rd(nome,?valore);e per modificarlo:in(nome,?vecchio_valore);out(nome,nuovo_valore);
3.4.1.3 Strutture con accesso per posizioneQuesta categoria di strutture dati può essere a suavolta suddivisa in due sottogruppi in funzionedell’ordine di accesso agli elementi:
• strutture con ordine di accesso casuale• strutture i cui elementi possono essere acceduti inun solo ordine.
3.4.1.3.1 Strutture ad accesso casuale: ivettori
In Linda un vettore può essere implementatocon un insieme di tuple della forma:(nome_vettore,indice,valore)Estendendo questa definizione ai vettori multi-dimensionali, un vettore di n dimensioni èdescritto da tuple della forma:
(nome_vettore,indice 1,indice 2,...,indice n,valore)Volendo ad esempio leggere l’elemento nellacolonna 3 e riga 5 di una matrice M saràeseguito:
rd("M",3,5,?val);
3.4.1.3.2 Strutture ordinateLe strutture dati "ordinate" costituiscono ilsecondo tipo di strutture i cui elementi sonoacceduti per posizione. Nello spazio delle tupleè possibile costruire qualsiasi oggetto di questotipo. L’idea è di collegare gli elementi di questestrutture attraverso nomi logici e non perindirizzi (come invece avviene per i vettori).
Vediamo alcuni esempi.ListeSia C una cella "cons" che collega gli oggetti Ae B; essa può essere rappresentata dalla tupla:("C","cons",["A","B"])Se A è un atomo avremo:("A","atomo",valore)

80
GrafiUn generico grafo G è definito dalla coppia (N,A), dove N è un insieme di nodi ed A l’insiemedi archi che collegano i nodi in N. Una naturalerappresentazione di G nello spazio delle tuplevede associata ad ogni nodo una tupla del tipo:
(nome_nodo,[nodo 1,nodo 2,...,nodo n])dove [nodo1,nodo2,. . .,nodon] è il vettorecontenente i nomi dei nodi con cui il nodonome_nodo è collegato.
Nel caso in cui gli archi in A siano etichettaticon un valore, allora la tupla conterrà unulteriore campo:
(nome_nodo,[nodo 1,nodo 2,...,nodon],[val 1,val 2,...,val n])Si noti che l’implementazione descritta èpossibile solo se è supportata la possibilità dimemorizzare nelle tuple vettori di lunghezzavariabile (ciò è vero per gli attuali sistemiC-Linda).
CodeUna struttura di tipo coda è una sequenzaordinata di elementi che possono essereinseriti da più processi (scrittori). L’ordine deglielementi è quello di inserzione: i primi adessere immessi saranno i primi ad essereacceduti in lettura (principio FIFO). Ad un datoistante la sequenza può essere acceduta indue soli punti: la "coda" per inserire e la "testa"per estrarre un elemento.
Vi sono molte varianti per questa categoria didati; le più interessanti per i nostri scopi sonochiamate code-in e code-read.
In una coda-in i processi (lettori) possonorimuovere l’elemento in testa alla sequenza.Se più processi tentano di rimuovere unelemento simultaneamente, l’accesso alla codaè serializzato in modo arbitrario a tempo diesecuzione. Un processo che tenta larimozione da una coda vuota viene sospesofino all’inserzione di un nuovo elemento.
Nel caso di una coda-read più processipossono leggere la sequenza di elementisimultaneamente: ogni lettore legge il primoelemento, quindi il secondo e così via (lalettura non comporta la rimozione). Nellaeventualità di una sequenza vuota anche inquesto caso i processi verranno sospesi .

81
I tipi di coda presentati sono facilmentedefinibili in Linda. In entrambi i casi la codaconsiste di una serie di tuple numerate:
("coda",1,val1)("coda",2,val2)...("coda",n,valn)L’indice dell’elemento in coda alla sequenzaviene memorizzato in una tupla che funge dapuntatore di estrazione:
("coda","puntatore_coda",8)Per "appendere" un nuovo elemento alla codaun processo esegue:in("coda","puntatore_coda",?indice);out("coda","puntatore_coda",indice+1);out("coda",indice+1,nuovo_elemento);In una coda-in si ha bisogno anche di una tuplaper memorizzare l’indice del valore in testa; larimozione di un elemento è così implementatadal codice:
in("coda","puntatore_testa",?indice);out("coda","puntatore_testa",indice+1);in("coda",indice,?elemento);È interessante osservare che quando la coda èvuota i processi sospesi sono sbloccati nellostesso ordine di sospensione.
In una coda-read non si ha necessità di unpuntatore condiviso all’elemento di testa. Ogniprocesso lettore gestisce un suo puntatorelocale; per leggere ogni elemento dellasequenza:
indice=1;while (1)
{rd("coda",indice++,?elemento)
;...}
Analizziamo alcune specializzazioni di questestrutture dati.Quando una coda-in è acceduta da un soloprocesso lettore può essere ancora omesso ilpuntatore globale di testa e tale processo puòusare un indice locale di estrazione.

82
Analogamente, quando un solo processo puòinserire elementi nella coda non è necessariomantenere nello spazio delle tuple il puntatoredi inserzione poiché può essere reso locale alprocesso scrittore.
3.4.2 L’interazione fra processiVi sono due motivi per cui due o più processi possonointeragire: comunicare dati o sincronizzarsi. Spesso le dueattività si sovrappongono all’interno di un’unica interazione.
I meccanismi che Linda mette a disposizione per"descrivere" l’interazione fra processi sono estremamenteflessibili. Gli esempi che seguono intendono dimostrarequesta affermazione rivelando come in Linda sia possibileimplementare con facilità schemi di comunicazione esincronizzazione caratteristici di altri modelli diprogrammazione parallela. Gli stessi esempi farannoemergere, oltre alla versatilità di Linda, anche ulterioriproprietà caratterizzanti.
3.4.2.1 La comunicazioneCome punto di partenza per introdurre le tecniche dicomunicazione in Linda consideriamo il meccanismodi comunicazione più intuitivo e conosciuto: loscambio di messaggi. In questo schema i processicomunicano inviando l’un l’altro dei messaggi. Glistrumenti a disposizione dei processi sono dueoperazioni primitive: send (invia messaggio) e receive(ricevi messaggio). Normalmente l’identità del partnerdella comunicazione è contenuta esplicitamente inuno degli argomenti di queste primitive(comunicazione con nomi di modulo): comeriferimento per la discussione sarà considerata questatecnica. Se un processo mittente S ha un messaggiom per un destinatario R, allora S usa un comando deltipo send(R, m) ed R invoca receive(S, x), dove x èuna variabile del tipo opportuno.
Lo scambio dei messaggi può essere di vario tipo inquanto la comunicazione gode di proprietà chepossono essere istanziate in modi diversi (adesempio sincronia e simmetria). Analizziamo qualcheesempio notevole che rivela come Linda consenta didescrivere in modo naturale tali forme dicomunicazione.
Esempio 3.10Siano le seguenti dichiarazioni:typedef char nome_modulo[];typedef messaggio ...;nome_modulo mittente;messaggio m,m1,m2,x,risultato;

83
Comunicazione simmetrica e sincronaIn questa forma di comunicazione sono coinvolti duesoli processi i quali si nominano reciprocamente edevono sincronizzarsi fino al completamento dellacomunicazione.
Si definisca una tupla-messaggio della forma:(nome_mittente, nome_destinatario,
messaggio)Utilizzando i costrutti concorrenti di Linda questaforma di comunicazione sarà così implementata:
S ::...m = ...;out("S","R",m);in("R","S","ricevuto");/* S si sincronizza con R in attesa chequesto riceva il messaggio m */...
R ::...in("S","R",?x);out("R","S","ricevuto");...Comunicazione simmetrica con rendez-vous estesoIn questo caso la comunicazione è ancora sincrona,ma il messaggio di risposta del destinatario non èfinalizzato soltanto alla sincronizzazione, ma contieneanche un’informazione di ritorno per il mittente. InLinda:
S ::...m = ...;out("S","R",m);in("R","S",?risultato);/* in una situazione più generale Spotrebbe ricevere il risultato anchenon immediatamente dopo la suarichiesta */
...
R ::...in("S","R",?m);risultato=f(m,...);out("R","S",risultato);...Comunicazione asincronaIn questa forma di comunicazione il processomittente, una volta inviato il messaggio, non sisospende in attesa che esso sia ricevuto. Perrealizzare questo schema si ha bisogno di una

84
qualche memoria che contenga il messaggionon ancora ricevuto dal destinatario: in Linda questamemoria è messa a disposizione dallo spazio delletuple.
Nel caso di comunicazione simmetrica ed asincronaavremo:
S ::...m1= ...;out("S","R",m1);/* S non si sincronizza con laricezione da parte di R dei suoimessaggi */
...m2 = ...;out("S","R",m2);...
R ::...in("S","R",?x);...in("S","R",?x);...Si osservi come il mittente S sia libero di inviaremessaggi ad R anche se da quest’ultimo non haancora ricevuto suoi messaggi precedenti. In questaeventualità non possono essere fatte assunzionisull’ordine con cui saranno ricevuti i messaggi.Affinché i messaggi siano ricevuti nello stesso ordinedi invio essi dovranno essere organizzati in unastruttura dati distribuita più complessa (ad esempiouna coda-in con un solo produttore ed un soloconsumatore).
Comunicazione asimmetricaQuesta forma di comunicazione prevede ilcoinvolgimento di un numero generico di processimittenti e destinatari.
Si parla di asimmetria in ingresso quando unprocesso può ricevere un messaggio da uno fra piùpossibili mittenti. In questo caso l’implementazioneLinda non obbliga la tupla-messaggio a contenere ilnome del mittente, a meno che tale informazione sianecessaria al destinatario (di sicuro nel caso dicomunicazione sincrona):
S ::...m = ...;/* questa è una comunicazioneasimmetrica in ingresso sincrona */

85
out("S","R",m);in("R","S","ricevuto");...
R ::...in(?mittente,"R",?x);out("R",mittente,"ricevuto");/* R è in grado di conoscere da qualedei mittenti possibili ha ricevuto ilmessaggio e quindi a chi inviare latupla di sincronizzazione */
...Un’altra forma di asimmetria è quella in uscita: unmessaggio può essere raccolto da più processidestinatari. Per questo tipo di comunicazione si hannodue possibili semantiche:
• partner unico: la comunicazione è stabilita con unosolo uno fra più possibili destinatari. In questo caso ilmessaggio è contenuto in una tupla in cui non èspecificato il nome del destinatario. Il realedestinatario sarà quel processo che per primoeseguirà il comando in di rimozione di tale tupla. Inuna situazione reale ci si aspetta che il mittenteintenda eseguire una sequenza di comunicazioni diquesto tipo, dove vi sarà alternanza più o menocasuale fra i processi destinatari nella ricezione deivari messaggi. L’interazione attraverso una strutturadel tipo coda-in è un caso particolare di questo tipo dicomunicazione (in essa è fissato l’ordine, FIFO, diricezione dei messaggi).
• diffusione (broadcasting): il messaggio è ricevuto datutti i possibili destinatari. È già stata incontrataquesta forma di comunicazione in occasione dellapresentazione della struttura coda-read. Vasottolineata la generalità di questo meccanismo inquanto può essere applicato anche nei casi in cui ilmittente non conosca né l’identità né il numero deipossibili destinatari del suo messaggio. Il problema diquesta struttura è che essa non prevede la rimozioneautomatica del messaggio quando esso è statoraccolto da tutti i destinatari. Qualora sia noto almittente il numero n dei destinatari si può risolverebanalmente questo inconveniente generando unatupla-messaggio per ognuno di essi:
S ::...{int i;m = ...;

86
for (i=0;i<n;i++)out(m);
}...È chiaro che nel caso in cui la comunicazione siasincrona16, cioè il mittente M si sospende fino a che ilmessaggio non è stato ricevuto da tutti i destinatari, ènecessaria un’ulteriore struttura distribuita perimplementare la "sveglia" di M (ad esempio una tuplacontatore):
S ::...{short i;m = ...;out("contatore",n);for (i=0;i<n;i++)
out(m);in("contatore",0);/* S si sincronizza con la ricezione dim da parte di tutti i destinatari */}...
R ::...{int indice;in(?x);in("contatore",?indice);out("contatore",indice-1);/* (indice-1) destinatari non hannoancora ricevuto il messaggio */}
...Gli esempi presentati hanno dimostrato che in Lindapossono essere implementate una grande varietà diforme di comunicazione. Ma qual è la forma dicomunicazione più elementare e naturale in Linda?
Consideriamo i comandi di base per l’invio e laricezione di un messaggio:out(m);ein(?x);Questi costrutti sono sufficienti a stabilire lo scambiocompleto di un messaggio. In questo caso èsottintesa una forma di comunicazione asincrona conasimmetria sia in ingresso che in uscita. Questa è laforma di comunicazione di base in Linda; qualsiasialtra può essere ottenuta specializzando quest’ultima.

87
3.4.2.1.1 Alcune proprietà del modello dicomunicazione
Una caratteristica fondamentale del modelloLinda di programmazione distribuita èl’ortogonalità della comunicazione. Da essaderivano un certo numero di proprietàcaratterizzanti [Gel85].
La comunicazione in Linda è ortogonale nelsenso che sia il mittente che il destinatario nonhanno alcuna conoscenza dell’identità delpartner. Generalmente questa caratteristicanon è presente nei linguaggi diprogrammazione concorrente in virtù del fattoche il mittente nomina (esplicitamente o meno)il destinatario della comunicazione.
L’ortogonalità della comunicazione ha dueimportanti conseguenze: il disaccoppiamentoin spazio e tempo dei processi. Una terzaproprietà, a sua volta, trae origine dalle primedue e prende il nome di condivisionedistribuita.
Disaccoppiamento in spazioQuesta proprietà si riferisce al fatto che unatupla contenuta nello spazio delle tuple puòessere acceduta da un numero qualsiasi diprocessi con spazi degli indirizzi disgiunti. Ilinguaggi concorrenti di norma permettono inun costrutto di ricezione di "importare" datioriginati in uno qualsiasi fra più spazi degliindirizzi diversi. Allo stesso modo Lindaconsente anche ad un mittente di inviare deidati in uno qualsiasi fra più spazi degli indirizzidistinti.
Disaccoppiamento in tempoUna tupla inserita nell’omonimo spazio tramiteout o eval rimane in esso fino a che non èrimossa da un costrutto in corrispondente.Supponiamo che il processo mittente S terminila sua esecuzione senza che la tupla da luigenerata sia stata ancora "consumata". Lindapermette anche ad un processo R, la cuiesecuzione ha inizio successivamente allaterminazione di S, di prelevare la tupla e quindicompletare la comunicazione. In Linda è quindipossibile stabilire una comunicazione fraprocessi non solo con spazi disgiunti, maanche disgiunti in tempo.
Condivisione distribuita

88
Linda consente ad n processi con spazi degliindirizzi disgiunti di condividere una qualchevariabile v memorizzando questa nello spaziodelle tuple. La definizione degli operatori Lindagarantisce l’atomicità e quindi la consistenzadegli accessi a v. Non è quindi necessario,come nei linguaggi ad ambiente locale, cheuna variabile condivisa sia implementataall’interno di un processo o modulo gestore.
3.4.2.2 La sincronizzazioneNon sempre l’interazione fra processi comporta unpassaggio di informazioni (dati di ingresso, risultatiintermedi o finali, ecc.). Talvolta essa può esserefinalizzata alla sola sincronizzazione: un processo sipone in attesa che si verifichi un certo evento la cuiattuazione dipende dal comportamento di altriprocessi. Nei linguaggi di programmazioneconcorrente di norma la sincronizzazione èimplementata con gli stessi strumenti messi adisposizione per la comunicazione, in quanto da unpunto di vista concettuale la sincronizzazione fraprocessi è una comunicazione poiché comportaimplicitamente il passaggio dell’informazione: "si èverificato l’evento X". Anche in Linda ritroviamoquesta filosofia: come per la comunicazione, è ancoralo spazio delle tuple l’ambiente di base perl’implementazione della sincronizzazione.
Esempio 3.11Sia un gruppo di n processi. In ogni processo siadefinito un punto di sincronizzazione, cioè un puntodel loro flusso di esecuzione sul quale essi sisospendono in attesa del verificarsi di uno stessoevento E. Sia E = "tutti i processi del gruppo hannoraggiunto il rispettivo punto di sincronizzazione".
La situazione descritta si presenta frequentementenelle applicazioni parallele; essa può esserefacilmente tradotta in codice Linda definendo unanuova struttura dati distribuita che può esserechiamata "barriera di sincronizzazione". Si tratta diuna tupla contatore destinata a tenere memoria delnumero di processi che ancora devono raggiungere labarriera stessa.
La tupla sarà inizializzata con:out("barriera",n);Raggiunto il punto di sincronizzazione, ogni processodel gruppo eseguirà il codice:in("barriera",?val);out("barriera",val-1);

89
rd("barriera",0);Si osservi come il verificarsi dell’evento E su cui ogniprocesso si sincronizza sia stato modellato conl’evento Linda: "introduzione di ("barriera",0) nellospazio delle tuple".
3.5 Alcuni cenni riguardo l’implementazioneIl modello Linda può essere implementato su vari tipi di architettureaffrontando, a seconda di esse, difficoltà e problematiche diprogetto di varia natura. Le righe che seguono intendono offrire unarapida rassegna di tali problematiche, con lo scopo primario dichiarire il peso computazionale reale dei meccanismi concorrenti diLinda.
Si consideri inizialmente un’architettura convenzionale di tipouniprocessore sequenziale. L’implementazione di Linda su questotipo di macchina è finalizzato al solo sviluppo dei programmi ed allasimulazione del comportamento che essi avrebbero su architettureparallele17 [CCCG85].
Su questa architettura esistono implementazioni reali di C-Lindaposte al livello di astrazione immediatamente superiore a quellodell’architettura e che quindi non poggiano su un sistema operativo.Questi sistemi sono composti di due parti: il compilatore ed ilnucleo (o supporto a tempo di esecuzione del linguaggio) cheimplementa la multiprogrammazione. Ad eccezione di alcuneprimitive di basso livello del nucleo, il sistema è scritto in C ed ilcompilatore usa lo stesso C come linguaggio intermedio: è stata giàsottolineata la caratterizzazione del compilatore Linda come pre-processore destinato a tradurre i costrutti concorrenti in codice C(intercalato da eventuali invocazioni delle funzionalità di nucleo).
Lo spazio delle tuple è implementato come una tabella hashglobale ai processi. Ciascuna posizione della tabella può contenereal più una tupla. Ogni volta che è invocata un’operazione sullospazio delle tuple viene calcolato l’indirizzo hash associato allatupla (nel caso di out o eval) o all’antitupla (nel caso di in o rd )18.Mantenere la consistenza della tabella hash è facile: le funzionalitàdi nucleo, che implementano tutte le operazioni sullo spazio delletuple, sono eseguite con priorità superiore a quella dei processiutente e così solo un processo alla volta può essere attivo nellospazio delle tuple.
Lo schema presentato può essere esteso facilmente adun’architettura multiprocessore con memoria comune [CCCG85]. Inquesto caso il problema è evitare che lo spazio delle tuple divengaun collo di bottiglia, cioè che l’accesso ad esso sia serializzatoanche quando i processi intendano accedere simultaneamente asue porzioni indipendenti. La soluzione è partizionare (sotto laguida del compilatore) lo spazio delle tuple in sottostrutture edassociare ad ognuna di esse un meccanismo di lock: laserializzazione degli accessi sarà locale a tali sottostrutture e nonriguarderà più l’intero spazio delle tuple. Il degrado delle prestazioni

90
risultante sarà tanto minore quanto maggiore sarà la cardinalitàdella partizione (emerge ancora chiara l’influenza dell’analisi delcompilatore sull’efficienza dei programmi paralleli).
Si consideri ora un’architettura con nodi di elaborazione che noncondividono memoria (tipo rete locale o multiprocessore conmemoria distribuita). Implementare Linda su questo tipo dipiattaforma significa risolvere due sottoproblemi:
• dove memorizzare le tuple?• come realizzarne la ricerca?Almeno 2 schemi implementativi appaiono plausibili [CCCG85;Gel85]. Seppure logicamente equivalenti, essi determinano peròcomportamenti differenti a tempo di esecuzione.
• out distribuita: in questa soluzione l’esecuzione di out(t) fa sì chela tupla t sia comunicata per diffusione ad ogni nodo dielaborazione; ogni nodo memorizza quindi localmente una copiacompleta dello spazio delle tuple.
L’esecuzione di in(a) su un generico nodo Nin innesca la ricercalocale di una tupla t corrispondente ad a. Se la ricerca ha successo,ciò viene notificato al nodo N0 che ha originato la tupla t. Se N0risponde con un messaggio (diffuso a tutti i nodi) "ok per lacancellazione di t", la tupla è rimossa localmente da ogni nodo e"concessa" al processo che ha invocato in. Se però N0 risponde aNin con il messaggio "accesso negato", ciò significa che unprocesso in esecuzione su un altro nodo ha tentato di rimuovere tsimultaneamente a Nin ed è a lui che N0 ha concesso la rimozione.Se l’iniziale ricerca locale prodotta da in(a) non ha successo, alloral’antitupla a è memorizzata in una struttura dati locale; tutte lesuccessive tuple in arrivo saranno confrontate con le antituplesospese: qualora sia verificata una corrispondenza verrà innescatoil meccanismo già descritto di interazione con gli altri nodi.L’implementazione per rd è analoga a quella di in, fatta eccezioneper lo scambio di messaggi con gli altri nodi: appena è individuatauna tupla corrispondente, essa è ritornata immediatamente alprocesso invocante rd.
• in distribuita: questo secondo schema è duale al primo. Sono leantituple ad essere diffuse a tutti i nodi, mentre le tuple rimangononel solo nodo di origine fino a che esse non sono richiesteesplicitamente. L’esecuzione di out(t) origina la ricerca locale diun’antitupla a cui t corrisponda. Se tale ricerca ha successo, allora tè inviata al nodo che ha originato l’antitupla a; in alternativa, essarimane nell’area locale fino all’arrivo di un’antitupla corrispondente.
Questa è anche la soluzione implementativa di Network C-Linda,cioè l’implementazione su rete utilizzata in questo lavoro.Normalmente si preferisce questo approccio per le implementazionisu rete a causa della non elevata affidabilità delle comunicazioni laquale potrebbe essere origine di notevole overhead al momentodella "diffusione di tuple" in una soluzione con "out distribuita". Leimplicazioni di questa scelta sono una notevole efficienza delle

91
applicazioni parallele dove le scritture nello spazio delle tuple sonopiù frequenti rispetto alle letture; purtroppo questo non è il casodelle applicazioni sviluppate nel presente lavoro: in 5.2.1.4.1saranno indicate alcune tecniche di programmazione per limitare ilcosto complessivo delle letture.
Il primo schema ha il vantaggio di implementare moltoefficientemente l’operazione rd, ma comporta una notevole occupa-zione di memoria poiché ogni nodo contiene una copia dello spaziodelle tuple.
Un terzo schema cerca di combinare le qualità dei precedenti.L’idea è di distribuire a tutti i nodi sia le tuple che le antituple. Unnodo N che riceve una tupla t la memorizza localmente se:
• t ha dimensioni inferiori ad un certo valore k (e quindi non gravapesantemente sull’occupazione di memoria) oppure• è gia stata acceduta precedentemente una tupla con la stessastruttura di t da parte di un processo in esecuzione su N.Il nodo di origine di una tupla mantiene in ogni caso una sua copialocale, fintanto che essa è presente nello spazio delle tuple. Inquesto schema ogni nodo tiene memoria delle tuple di maggioreinteresse, cioè che hanno maggiore probabilità di essere acceduteda un processo allocato in quel nodo. Quando un nodo "scarta" unatupla t di cui invece avrà bisogno successivamente non intervienealcun errore logico: al momento dell’esecuzione dell’operazionein(a) o rd(a) corrispondente, l’antitupla a verrà "diffusa" a tutti i nodied in particolare al nodo che ha originato t il quale in rispostainvierà nuovamente ad N la tupla richiesta.
3.6 Il ruolo di Linda nella tesiLa presenza di Linda in questo lavoro ha molteplici giustificazioni:oltre all’interesse suscitato dalla novità del suo modello dicomunicazione ed alla conseguente esigenza di una suavalutazione all’interno di un dominio reale di applicazione, essosarà investigato per le sue qualità espressive e per l’efficienzaottenibile nella soluzione di istanze della classe di problemi che ciproponiamo di studiare. Un giudizio sulle sue qualità espressive edi efficienza sarà espresso nella sezione dedicata alle conclusioni(Capitolo 7).
Nel Capitolo 4 Linda consentirà di descrivere alcuni algoritmiparalleli classici di ricerca su alberi di gioco.Nel Capitolo 5, invece, il linguaggio sarà impiegato nel progetto enella implementazione di alcuni algoritmi di decomposizionedell’albero di gioco: sarà questo il suo vero banco di prova. Ladiversa granularità del parallelismo degli algoritmi citati, infatti,consentirà di impegnare Linda in diverse classi di applicazioniparallele il cui principale requisito è l’efficienza.
Il Capitolo 6 concerne il progetto di un giocatore parallelo costituitoda istanze (con ricerca indipendente) di uno stesso programmasequenziale (GnuChess). La cooperazione presente in questogiocatore sarà anch’essa attuata mediante lo spazio delle tuple: in

92
questo dominio Linda sarà impiegato nel coordinamento ad altolivello di "lunghi" flussi sequenziali di elaborazione.

93
Capitolo 4Algoritmi di ricerca parallela dialberi di gioco
Questo capitolo intende presentare una rassegna di soluzioni classiche alproblema della distribuzione della ricerca di alberi di gioco. La maggiorparte delle idee e degli algoritmi che verranno descritti sarà ripresa nelCapitolo 5 per discuterne l’attuazione in Linda.
4.1 Il criterio di valutazione delle prestazioni deglialgoritmi paralleli
Un’importante misura dell’efficienza di un algoritmo paralleloè lo speedup. Questo parametro è definito come il rapportotra il tempo di esecuzione della implementazionesequenziale dell’algoritmo e quello della versione parallela[Sch89].
L’obiettivo ideale è di ottenere valori per lo speedup cheaumentino linearmente con il numero di processori usati.Purtroppo questo risultato è difficile da ottenere per glialgoritmi paralleli di ricerca su alberi di gioco. Esistono infattidiversi motivi di degrado delle prestazioni di questa classe dialgoritmi che vengono indicati con il termine overhead[Sch89].
Overhead in tempo (OT) esprime una misura quantitativadell’overhead totale: è la perdita percentuale di speedupconfrontata con lo speedup ideale. È espressa come:
OT = tempo con N CPU( ) ⋅N
tempo con 1 CPU4.2 Tipi di approccio alla parallelizzazione dellaricerca
Esistono diverse fonti di parallelismo nella ricerca di alberi digioco le quali hanno originato approcci completamentedifferenti al processo di parallelizzazione della ricercasequenziale:
• parallelismo nell’esecuzione di attività che riguardano i nodiindividualmente (ad es. valutazione statica dei nodi terminalio generazione delle mosse)
• ricerca con finestre parallele (parallel aspiration search)• mapping dello spazio di ricerca nei processori• decomposizione dell’albero di gioco
4.2.1 Parallelismo nella funzione divalutazione statica
Una considerevole porzione del tempo di ricerca èspesa nella valutazione statica dei nodi terminali. Laqualità delle scelte strategiche operate durante il

94
gioco è fortemente legata alla affidabilità e quindi allacomplessità della funzione di valutazione.Spesso si sceglie di praticare una valutazione staticasemplice e grossolana preferendo impiegare il tempodi ricerca nel condurre esplorazioni più in profonditànell’albero di gioco. Il tempo dedicato alla valutazionedei nodi terminali può tuttavia essere ridottodistribuendo tale operazione su più processori,ciascuno dedicato a valutare differenti termini dellafunzione di valutazione. I risultati del lavoro cosìpartizionato saranno riuniti per originare un unicovalore per la posizione esaminata. Chiaramente lospeedup massimo ottenibile è limitato dallascomponibilità e modularità della funzione divalutazione implementata.
Deep-Thought [AnCaNo90] è un giocatore artificialedi scacchi che fa uso di hardware specifico perl’esecuzione della valutazione statica. In particolareesso consiste di due componenti denominatirispettivamente valutatore veloce e lento:
• l’hardware per la valutazione veloce aggiorna itermini della funzione di valutazione che possonoessere calcolati in modo incrementale, cioè a mano amano che vengono eseguite o retratte le mosse. Taleaggiornamento avviene in parallelo alle altre fasi diesplorazione interna dell’albero; quando saràraggiunto un nodo terminale parte dei suoi terminisaranno quindi già valutati.
• i restanti termini della funzione di valutazione sonocalcolati dal valutatore lento quando la ricerca arrivaad un nodo terminale. Il loro calcolo è completatomolto rapidamente poiché la risorsa di elaborazionead esso dedicata utilizza un insieme di tabelleindirizzate via hardware. Ogni tabella contieneinformazioni riguardanti proprietà salienti di unaposizione aggiornate durante la ricerca (strutturapedonale, pedoni passati e disposizione delle torri)
4.2.2 Generazione in parallelo delle mosseLa generazione delle mosse è un’altra operazionemolto frequente nella ricerca su un albero di gioco edin generale incide pesantemente sul tempo globale diesecuzione.
Negli scacchi, ad esempio, la velocità di generazionedelle mosse è il fattore che limita le dimensioni dellaricerca poiché le regole che governano il movimentodei pezzi sono piuttosto complicate.

95
Un accorgimento desiderabile è dunque lagenerazione in parallelo di tutte le mosse relative adun nodo.
In riferimento agli scacchi, ogni colonna dellascacchiera potrebbe essere assegnata ad unprocessore; ognuno genererà tutte le mosse per tutti ipezzi disposti sulla propria colonna. Poiché ognicolonna può contenere più pezzi di un’altra ènecessaria una forma di bilanciamento del carico,cioè un riassegnamento dei lavori per mantenere tuttii processori attivi. In questa tecnica un motivo didegrado delle prestazioni è dovuto al fatto che permolti nodi non è necessario generare tutte le mosse(a causa di tagli) e così parte del lavoro andràperduto.
Il metodo descritto si presta per una suaimplementazione in hardware, cioè che utilizzicomponenti architetturali progettati ad hoc.
HITECH [Ebe87] è un esempio di giocatore reale discacchi che utilizza hardware specifico per lagenerazione in parallelo delle mosse. In particolare èimpiegata una matrice 8x8 di processori, uno per ognicasa della scacchiera: ciascun processore calcola inparallelo agli altri le mosse legali per il pezzo cheoccupa la casa cui è associato (ammesso che essanon sia vuota). Il generatore parallelo determinasolamente la mossa successiva che deve essereesplorata.
Esso implementa inoltre l’ordinamento delle mosse:quella suggerita è la mossa con maggiore priorità; lapriorità di una mossa è una stima del suo valore ed èattribuita autonomamente dal processore che l’hagenerata. Ogni processore deposita la priorità dellasua migliore mossa su un bus accedibile da tutti glialtri: quando il processore con la mossa a più altapriorità riconosce che nessun altro dispone di mossamigliore, esso presenta la sua mossa al modulodedicato al controllo della ricerca.
4.2.3 Ricerca con finestre parallele(Aspiration search parallela)
L’algoritmo aspiration search sequenziale tenta diavere successo nella ricerca disponendo di unafinestra iniziale (X,Y) più stringente della finestrainfinita (-∞,+∞). Se la prima ricerca fallisce, alloraessa è ripetuta con la finestra (-∞,X) o (Y,+∞) asecondo del fallimento (rispettivamente inferiore osuperiore).

96
Avendo a disposizione 3 processori si potrebbepensare di iniziare la ricerca sulle finestre (-∞,X),(X,Y) e (Y,+∞) simultaneamente. Solamente una diqueste ricerche parallele troverà la soluzione, ma ciòavverrà in un tempo minore della ricerca sequenzialecon finestra (-∞,+∞), poiché finestre più stringentideterminano un numero maggiore di tagli.
In generale, avendo N processori si possonocondurre in parallelo N ricerche su finestre disgiunte.Numerosi esperimenti hanno dimostrato che lospeedup del metodo è limitato da un fattore 5 o 6,indipendentemente dal numero di processori. Laragione di questa limitazione è che esiste una partefissa dell’albero di gioco (albero minimale) che ogniprocessore deve visitare. Tuttavia, quando sonoutilizzati pochi processori (N=2 o 3), lo speedup puòanche essere superlineare (maggiore di N) [Bau78a].
4.2.4 Mapping dello spazio di ricerca neiprocessori
L’idea alla base di questo approccio è di stabilire unacorrispondenza fissa fra uno stato della ricerca (nododell’albero) e un particolare processore; taleassociazione è decisa da una funzione hash.
La ricerca diviene la percorrenza in parallelo dicammini multipli con generazione e trasmissione dinodi da processore a processore.
Il vantaggio di questa forma di parallelismo è visibilenei problemi in cui lo spazio di ricerca contiene moltereplicazioni degli stessi stati: uno stato sarà semprevalutato dallo stesso processore e quindi, disponendodi una memoria delle valutazioni precedenti (ad es.tabella delle trasposizioni) la valutazione di tale statosarà effettuata una sola volta.
Normalmente i nodi dell’albero sono generati durantela ricerca e quindi comunicati dinamicamente aiprocessori corrispondenti [EHMN90]. La limitazione diquesto approccio è che a causa del trasferimentodello stato da processore a processore l’overhead dicomunicazione può divenire insostenibile.
Al contrario, Stiller ha trasferito staticamente un interospazio di ricerca in una Connection Machine [Sti91]. Ildominio è l’analisi di finali di scacchi; il suo algoritmoopera attraverso un’analisi retrogada: esso, cioè,esegue una ricerca esaustiva all’indietro a partire daposizioni di matto per risalire fino al finale che siintende studiare. Questo metodo ha permesso dirisolvere posizioni finali il cui numero di mosse

97
necessarie a forzare lo scacco matto è superiore aquello di qualsiasi altra posizione finora risolta.
4.2.5 Decomposizione dell’albero di giocoMentre il metodo aspiration search parallelo assegnaogni processore alla ricerca dell’intero albero di gioco,il metodo di decomposizione divide l’albero insottoalberi e stabilisce che sottoalberi diversi sianoesplorati da processori in generale distinti. Taleapproccio al parallelismo non prevede, in linea diprincipio, limitazioni per lo speedup. La prospettiva diprestazioni elevate ha fatto sì che i maggiori sforzinella ricerca siano stati concentrati nella direzionetracciata da questa classe di algoritmi paralleli.
4.2.5.1 Formalizzazione e classificazionedei metodi di decomposizione.
Non esiste un modo unico di "decomporre" laricerca di un albero di gioco: la molteplicità disoluzioni possibili rende necessaria una loroclassificazione tale da evidenziare le proprietàdi approcci alla decomposizione omogenei. Siconsiderino a riguardo le definizioni formulatedi seguito.
Def. (decomposizione):Sia A un albero di gioco costituito dall’insiemeN={N1,...,Nn} di nodi (interni e terminali); siainoltre P={P1,...,Pm} un insieme di processori.
Si definisce decomposizione di A in P unafunzione D: N→P che associa ad ogni nodo diA uno dei processori in P.
Def. (processo esploratore e processosupervisore):Sia D una decomposizione dell’albero di giocoA nell’insieme P di processori; sia N l’insiemedi nodi in A con Ni∈N. Si definisce esploratore(o responsabile) di Ni (secondo D) ilprocessore D(Ni). Sia inoltre padre:N→N lafunzione che associa ad un nodo il propriopredecessore (essa considera il nodo radicepadre di se stesso); è definito supervisore di Ni(secondo D) il processore D(padre(Ni)).
Qual è il significato di queste definizioni?La definizione di decomposizione comefunzione intende sottolineare che lavalutazione di ogni sottoalbero dell’albero digioco è "affidata" ad un solo processorechiamato esploratore.

98
Sia ad esempio (Ni,Pj) una delle relazioniindotte dalla funzione di decomposizione D; siosservi che Ni identifica completamente ilsottoalbero Si di cui è radice: il significato dellarelazione è dunque che il valore minimax (ouna sua limitazione) del sottoalbero Si deveessere calcolato dal processore Pj. Lavalutazione di Si richiede la conoscenza deivalori minimax dei sottoalberi le cui radici sonoi successori di Ni: la funzione D definisce unesploratore anche per ciascuno di questisottoalberi. Sia Ns uno dei successori di Ni ePs=D(Ns) il rispettivo esploratore: che legameesiste fra i processori Pi e Ps?
È stabilita una dipendenza di Ps nei confronti diPi in quanto il valore del sottoalbero lui affidatoè utilizzato solo da Pi ed è quindi a questoprocessore che deve rispondere del suooperato. In questo caso Pi viene definitosupervisore di Ns ad evidenziare il ruolo cheesso assume di gestore del risultato dellavalutazione di Ns.
La decomposizione di un albero di giocoinduce, quindi, una relazione gerarchica fra iprocessori che può essere descritta da unastruttura ad albero. Tale relazione variadinamicamente (cioè durante la visitacomplessiva dell’albero) in funzione delrapporto di "parentela" esistente fra isottoalberi visitati ad un dato istante daiprocessori. Può ad esempio accadere, infatti,che in una fase successiva della visita sia Pi adover comunicare l’esito della sua ricerca a Psin quanto il sottoalbero da lui visitato ècontenuto in quello di cui Ps è responsabile.

99
Root
P4 P3N32N31
N41 N42
N35 N36
N21 N22 N23
P1
P4
P3
P2
P3
P1
P2
P2N33 N34 P2P1
Fig. 4.19a Decomposizione: associazionenodo -processore
P1: N33→N22→RootP2: N35→N41→N23→N34
P3: N32→N42→N36
P4: N31→N21
Fig. 4.19b Decomposizione: ordine divalutazione dei nodi da parte dei singoliprocessori
L’albero di gioco di Fig. 4.19a descrive unesempio di decomposizione. I nodi sonoetichettati con il nome del processoreresponsabile del sottoalbero di cui sono radice.Si osservi come alcuni processori sianoresponsabili di più sottoalberi. Ad un datoistante della visita, tuttavia, essi sarannoimpegnati nella valutazione di al più unsottoalbero. La specifica di una istanza didecomposizione deve quindi esserecompletata con l’ordine di valutazione, da partedi ciascun processore, dei sottoalberi di cuiesso è responsabile. Tale informazionecostituisce la componente "dinamica" delconcetto di decomposizione; in Fig. 4.19b netroviamo un esempio in relazione all’albero diFig. 4.19a.
Non è in generale possibile stabilirestaticamente l’ordine con cui saràeffettivamente completata la visita deisottoalberi, in quanto legato alle velocitàrelative dei processori. Tuttavia si intuisce lapresenza di punti di sincronizzazione che
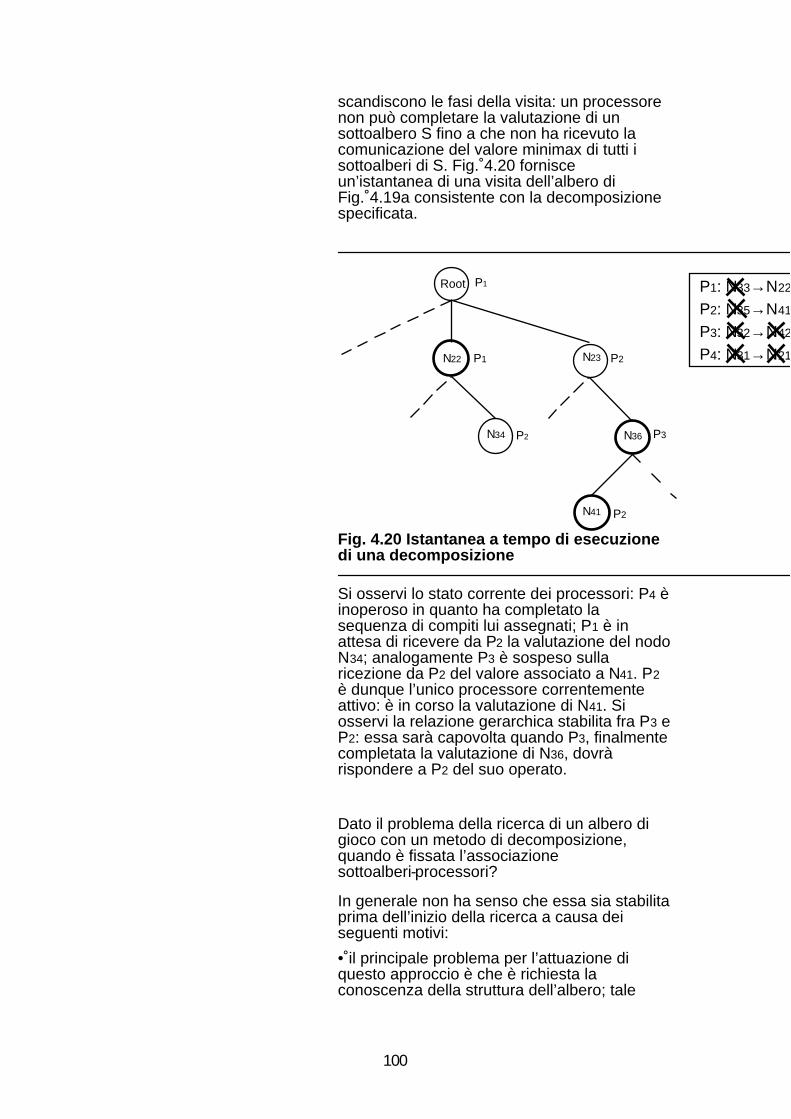
100
scandiscono le fasi della visita: un processorenon può completare la valutazione di unsottoalbero S fino a che non ha ricevuto lacomunicazione del valore minimax di tutti isottoalberi di S. Fig. 4.20 fornisceun’istantanea di una visita dell’albero diFig. 4.19a consistente con la decomposizionespecificata.
P1: N33→N22→RootP2: N35→N41→N23→N34
P3: N32→N42→N36
P4: N31→N21
Root
N41
N36
N22 N23
P1
P2
P3
P1
P2
N34 P2
Fig. 4.20 Istantanea a tempo di esecuzionedi una decomposizione
Si osservi lo stato corrente dei processori: P4 èinoperoso in quanto ha completato lasequenza di compiti lui assegnati; P1 è inattesa di ricevere da P2 la valutazione del nodoN34; analogamente P3 è sospeso sullaricezione da P2 del valore associato a N41. P2è dunque l’unico processore correntementeattivo: è in corso la valutazione di N41. Siosservi la relazione gerarchica stabilita fra P3 eP2: essa sarà capovolta quando P3, finalmentecompletata la valutazione di N36, dovràrispondere a P2 del suo operato.
Dato il problema della ricerca di un albero digioco con un metodo di decomposizione,quando è fissata l’associazionesottoalberi-processori?
In generale non ha senso che essa sia stabilitaprima dell’inizio della ricerca a causa deiseguenti motivi:
• il principale problema per l’attuazione diquesto approccio è che è richiesta laconoscenza della struttura dell’albero; tale

101
informazione è, per la maggior parte deidomini, molto costosa sia in tempo che inspazio;
• la proprietà dell’algoritmo αβ di tagliare lavisita di certi sottoalberi rende inutile la ricercadi alcuni di essi. Non è possibile stabilirestaticamente l’identità di questi sottoalberi equindi fissare a priori una distribuzioneuniforme del carico. Lo scenario atteso altempo della visita sarebbe il seguente: alcuniprocessori più "fortunati" completeranno primadegli altri la visita dei sottoalberi di cui sonoresponsabili (grazie alla maggiore efficacia deitagli da essi prodotti) e resteranno inoperosifino al completamento della visita complessiva.Qualsiasi soluzione a questo problema deveessere di natura dinamica, cioè deveprevedere meccanismi che durante la visitapermettano di riassegnare a processoriinoperosi sottoalberi già associati a processorisovraccarichi.
Una classificazione dei metodi didecomposizione in base al tempo in cui èfissata la decomposizione è dunque pocosignificativa in quanto l’unico approccioplausibile è quello di tipo dinamico. Ha invecesenso distinguere le diverse soluzioni in baseal tempo in cui esse stabiliscono i nodidell’albero in cui deve avvenire una realedecomposizione.
Def. (nodo di decomposizione):Sia D la decomposizione dell’albero Anell’insieme P di processori e Ni un nodo di A;Ni è un nodo di decomposizione (secondo D)⇔ ∃Nj: Ni=padre(Nj) e D(Nj)≠D(Ni).
Si definisce dunque di decomposizione unnodo in cui avviene una distribuzione dellaricerca, cioè dove alcuni dei propri sottoalberisono esplorati da processori diversi dal suoresponsabile. In funzione di questa definizionepuò essere formulata la seguenteclassificazione dei metodi di decomposizione instatici e dinamici:
• un algoritmo di decomposizione statica fissaa priori l’identità di tutti i nodi didecomposizione;

102
• in un algoritmo di decomposizione dinamica,invece, una parte dei nodi di decomposizione èdesignata durante la ricerca.
Le definizioni proposte saranno recuperate nelCapitolo 5 dove costituiranno strumentiessenziali nella discussione degli algoritmidiscussi in quella sede.
4.2.5.2 Motivi di degrado delleprestazioni nei metodi didecomposizione
Le principali cause della limitazione delleprestazioni nell’approccio di decomposizionesono [Sch89]:
• overhead di ricerca (OR): in ambientesequenziale tutte le informazioni ricavate finoad un dato punto della ricerca sono disponibiliper effettuare decisioni quali il taglio di unsottoalbero.
In ambiente distribuito le stesse informazionipossono essere disperse su macchine diversee quindi non completamente utilizzabili: ciò puòportare ad una esplorazione non necessaria diuna porzione dell’albero di gioco. La crescitadelle dimensioni dell’albero è chiamataoverhead di ricerca. Tale forma di degrado puòessere approssimata osservando che ladimensione dell’albero esplorato èproporzionale al tempo di ricerca. OR è piùprecisamente calcolato dalla relazione:
OR =nodi visitati da N CPU s
nodi visitati da 1 CPU−1
Va notato come, in talune occasioni,l’incompletezza di informazioni è vantaggiosa.Si supponga, ad esempio, che il secondo figlio,ma non il primo, di un nodo CUT determini untaglio. La versione sequenziale esplorerebbeinteramente il sottoalbero più a sinistra prima diconsiderare il successivo e scoprire così iltaglio.
Visitando i due sottoalberi in parallelo puòaccadere che il taglio venga individuatopermettendo di arrestare rapidamente laricerca nel sottoalbero più a sinistra. Questaosservazione potrebbe giustificare un valoredello speedup che supera il numero deiprocessori, ma purtroppo la situazionedescritta è poco probabile poiché il taglio si

103
presenta più frequentemente nel primosottoalbero.• overhead di comunicazione (OC): è il caricoaddizionale che un programma parallelo devesopportare quando è impiegato tempo nontrascurabile per la comunicazione deimessaggi fra i processi. Questo costo puòessere limitato in fase di programmazionescegliendo opportunamente le dimensioni e lafrequenza dei messaggi. Una stima di OC èdata dal prodotto fra il numero di messaggiinviati e il costo medio di un messaggio.
• overhead di sincronizzazione (OS): è il costoche occorre quando alcuni dei processori sonoinattivi. In teoria tutti i processori dovrebberoessere occupati nello svolgere lavoro utile pertutto il tempo di esecuzione. Nella realtàquesto comportamento ideale viene menoquando un processo deve sincronizzarsi conun altro determinando attesa attiva. Potrebbeaccadere ad esempio che un processo Pvoglia agire su un oggetto condiviso accedibilein mutua esclusione, mentre un altro processoQ sta già operando su quell’oggetto. Ilprocesso P rimarrà bloccato (e quindi inattivo)fintanto che Q non abbia completato la suaoperazione. Tale overhead può presentarsianche quando un processo è in attesa checerti risultati, senza i quali non può continuare,gli siano forniti da un altro.
L’overhead complessivo OT è funzione delletre forme di overhead elencate:OT = f (OR, OC, OS)Per massimizzare le prestazioni di un algoritmoparallelo è necessario minimizzare i vari tipi dioverhead. Purtroppo essi non sonomutuamente indipendenti e lo sforzo nellaminimizzazione di uno di essi può risultarenell’aggravio di un altro. Ad esempio lariduzione dell’overhead di ricerca richiedenormalmente un aumento del numero dellecomunicazioni.
4.2.5.3 L’algoritmo base didecomposizione ed il concetto digerarchia dei processori

104
Come introduzione ai metodi didecomposizione dell’albero di gioco si osservil’algoritmo19 di Fig. 4.21.
/* si suppone che l’albero dei processori siarappresentato in una forma distribuita fra inodi; ogni processore ha delle variabililocali contenenti le seguenti informazioni:ME=identificatore del processore;NSONS=numero di sottoprocessori */#define update_alpha(VALUE)\{\if (VALUE>alpha)\
alpha=VALUE;\if (alpha>=beta)\
{\terminate(); /* implementa la
terminazione di tutti i sottoprocessori */ \return(alpha);\}\
}\int treesplit(position p,int alpha,intbeta,int depth){int nmoves,result,free,ind;position *successor;if (depth==0)
return(evaluate(p));if (NSONS==0)
return(alphabeta(p,alpha,beta,depth));nmoves=genmoves(p,&successor);if (nmoves==0)
return(evaluate(p));for (i=0,free=NSONS;i<nmoves;ind++)
{eval
("split",ME,treesplit(*(successor+ind), - beta, -alpha,depth - 1));
free--;if (free==0)
{in ("split",ME,?result);free++;update_alpha(-result);}
}while (free<NSONS)
{in ("split",ME,?result);free++ ;update_alpha(-result);}
return(alpha);}Fig. 4.21 Algoritmo base di decomposizione
Si tratta di un algoritmo di decomposizionestatica estremamente semplice il qualeprevede che la distribuzione della ricerca, cioèl’attribuzione della visita di sottoalberi aprocessori distinti, avvenga al livello dellaradice.
Quella presentata è tuttavia una versionegeneralizzata secondo la quale un processore

105
può affidare a sua volta parte dello spazio diricerca di cui è responsabile ad un suosotto-processore: tale possibilità è dipendentedalla struttura logica e topologica deiprocessori utilizzati complessivamente.
In particolare ad un processore arbitrario èassegnato il compito di supervisore dellaricerca. Questo distribuisce l’esplorazione delsottoalbero più a sinistra della radice alsottoprocessore P1, il secondo sottoalbero alsottoprocessore P2 e così via. I sottoprocessoriritornano il risultato della loro visita alsupervisore, il quale sulla base di tutti i valoricomunicati calcola il valore minimax dell’alberodi gioco.
Ogni sottoprocessore ha a disposizione deiprocessori di livello ancora inferiore cui è liberodi distribuire l’analisi di certe porzioni delsottoalbero assegnatogli (in questo caso ilsottoprocessore si comporta da supervisore).Ovviamente ogni processore possiede unlimitato numero F di sottoprocessori. Se tutti isuoi sottoprocessori sono occupati, deveattendere che uno fra questi sia nuovamentedisponibile per assegnargli una parteinesplorata del suo sottoalbero.
P1
P1
P1 P3 P2 P4
P2
Fig. 4.22 Gerarchia di processori
L’organizzazione descritta introduce unagerarchia fra i processori descrivibile tramite unalbero uniforme con fattore di diramazione F eprofondità D (Fig. 4.22). Dopo D livelli disubappalto della ricerca un processore dovràvalutare da solo il sottoalbero assegnato.

106
Questo processore occupa un nodo foglianell’albero dei processori ed è chiamatoesploratore.
Questa organizzazione limita le comunicazioniinterprocessore, ma fa diminuire lacondivisione di informazioni originando così unpesante overhead di ricerca.
Un esempio di raffinamento del metodo è:poiché i processori supervisore sonolungamente inattivi in attesa che unsottoprocessore abbia completato la ricerca,parte del loro tempo di cpu potrebbe essereimpiegato per eseguire la visita di unsottoalbero non ancora assegnato[MarCam82]. Questa tecnica è chiarita daFig. 4.22.
Diversi studiosi hanno cercato di migliorarequesto algoritmo di base. L’approcciomandatory work first dovuto ad Akl, Barnard eDoran ne è un esempio [AkBaDo82].
4.2.5.4 Mandatory work firstMandatory work first è un metodo che impiegaun pool di processori in una ricerca parallelacondotta in due fasi.
Nel primo stadio della ricerca è esploratasoltanto una porzione ben definita dell’albero digioco: l’albero minimale. Nella seconda visita èesaminato il resto dell’albero di gioco usando ilimiti α e β trovati durante la prima ricerca.
Durante le due fasi della ricerca l’algoritmogestisce una lista di sottoalberi da visitarestabilita da esplorazioni precedenti. Iprocessori prelevano un sottoalbero dalla lista,lo visitano, comunicano il risultato e talvoltaaggiungono lavoro alla lista.
L’algoritmo opera una classificazione dei figli diciascun nodo. Il primo figlio di un nodo èchiamato figlio sinistro. Il sottoalberocontenente questo figlio è detto sottoalberosinistro ed è esplorato da un processo di tipoS. Tutti gli altri figli di un nodo sono chiamatifigli destri e sono contenuti nei sottoalberidestri visitati da processi di tipo D.
Dato un nodo il sottoalbero sinistro vieneesplorato da un processo S finché non è fattorisalire al nodo il valore del figlio sinistro. Perottenere questo scopo il processo S generaprocessi (di tipo sia S che D) per esplorare tutti

107
i sottoalberi del figlio sinistro. Parallelamente,per ognuno dei figli destri è ricavato un valoretemporaneo.
Questi valori sono confrontati con il valorefinale del figlio sinistro per produrre eventualitagli. Questo valore temporaneo è calcolato daun processo D, il quale genera processi S e Dper valutare il sottoalbero sinistro del figliodestro cui è associato. Se non è generato untaglio la visita del sottoalbero destro continuagenerando un processo D per esplorare ilsecondo sottoalbero del figlio destro. Taleprocesso viene arrestato quando il sottoalberodestro è stato completamente esplorato o si haun taglio.
L’algoritmo di Fig. 4.23 illustra questo evolversidi attivazione e terminazione di processi S e D.
/* l’algoritmo ricorda fra parentesi angolate(< e >) i punti dove inserire le attività perla gestione dei valori minimax intermedi efinali */typedef tuple_name ...;int mandatory_work_first(position *p,intdepth){tuple_name roothandled,lsondone;void handle(position*,int,int,int,tuple_name,tuple_name);handle(*p,depth,TRUE,FALSE,roothandled,lsondone);in(roothandled);<return minimax value>;}void handle(position p,int depth,int left,intparentleft,tuple_name done,tuple_name lsiblingdone){tuple_name sondone,lsdone;position *successor;int nmoves,cutoff,i;if (depth==0)
{< valuta posizione >;if (!left && parentleft)
in(lsiblingdone);}
else{nmoves=genmoves(p,&successor);if (left)
{
for(i=1;i<=nmoves;i++,successor++)
eval("split",handle(successor,depth-1,i==0,left,sondone,lsondone));
for (i=1;i<=nmoves;i++)in(sondone);
}else
{

108
cutoff=false;for (i=1;i<=nmoves &&
!cutoff;i++,successor++){
handle(successor,i==1,left,sondone,lsondone);
in(lsiblingdone);out(lsiblingdone);cutoff=<il mio valore
temporaneo è peggiore di quello di mio padre>;}
}}
< modifica, se migliorato, il valore di miopadre >;if (left && leftparent)
out(lsiblingdone);out(done);}Fig. 4.23 Mandatory work first
Il vantaggio di questo algoritmo è la riduzionedell’overhead di ricerca in quanto è eseguitosolo il lavoro che è stato dimostrato esserenecessario.
Nonostante questo metodo proponga lapossibilità di prestazioni ottime (in termini dicomplessità in tempo), il suo utilizzo reale èproblematico a causa dell’enorme spazio dimemoria necessario per memorizzare tutte levalutazioni parziali dei nodi dell’albero[AkBaDo82].
4.2.5.5 PVSplit (Principal VariationSplitting)
PVSplit è un algoritmo parallelo di ricerca αβmolto efficiente nella visita di alberi di giocofortemente ordinati [MarCam82;MarPop85].
Per comprendere l’idea del metodo è utileesaminare la natura dell’albero visitato da unalgoritmo αβ in condizioni ottime diordinamento. Abbiamo già discusso dellaclassificazione dei nodi di un albero di gioco in3 tipi: PV, CUT e ALL.
L’efficacia della ricerca αβ deriva dal fatto che inodi CUT possono essere tagliati prima chel’albero relativo sia completamente esplorato. Ilmassimo beneficio da questo taglio si ottienequando il miglior valore per il parametro A èdisponibile. L’idea del metodo è di cercare ditrovare questo valore prima che inizil’esplorazione dei nodi CUT.

109
p0
p
p
p
p
mv
mv
mv
mv
1
2
1
2
n-1
n-1
n-2
n-2
Questi sottoalberi sono suddivisidinamicamente fra i processoried esplorati in parallelo.
Le alternative alla variazione principale sono esplorate inparallelo quando il figlio sinistroe` stato valutato completamente.
Fig. 4.24 Albero di gioco in PVsplit
Inizialmente tutti i processori sono impiegatinella ricerca del sottoalbero più a sinistra delnodo radice, dove si assume sia contenuta laprincipal variation. In questo modo la mossapiù promettente è valutata molto velocementee la successiva decomposizione della restanteparte dell’albero di gioco vede i processoriiniziare la loro visita con una buona finestra diricerca. Ciò consente più tagli ed un minoreoverhead di ricerca rispetto all’algoritmo basedi decomposizione.
#define update_alpha(VALUE)\{\if (VALUE>alpha)\
alpha=VALUE;\if (alpha>=beta)\
{\terminate(); /* implementa la
terminazione di tutti i sottoprocessori */ \return(alpha);\}\
}\int pvsplit (position *p,int alpha,intbeta,int length){position *successor;int nmoves,result,i;if (length==0)
return (treesplit(*p,alpha,beta));nmoves=genmoves(p,&successor);if (nmoves==0)
return(evaluate(p));alpha=-pvsplit (successor,-beta,-alpha,length-1);

110
if (alpha>=beta)return(alpha) ;
for (ind=1,free=NSONS;i<nmoves;ind++){eval
("pvsplit",treesplit(*(successor+ind),-beta,-alpha,length-1));
free--;if (!free)
{in("pvsplit",?result);free++;update_alpha(-result);}
}while (free<NSONS)
{in ("pvsplit",?result);free ++;update_alpha(-result);}
return (alpha);}Fig. 4.25 PVSplit
Analizziamo questo algoritmo più in dettaglio.PVSplit esegue una sequenza di ricerchesecondo l’euristica di approfondimentoiterativo.
Sia mv1, ..., mvn-1 la continuazione principaletrovata nella (n-1)_esima iterazione e siano p0,p1, ..., pn-1 i nodi corrispondenti, dove p0 è ilnodo radice e pn-1 la posizione raggiunta altermine della sequenza (Fig. 4.24). Questi nodisono chiamati nodi splitting.
Quando la n-esima iterazione ha inizio tutti iprocessori sono impiegati nella valutazione(secondo l’algoritmo di decomposizione dibase) dell’albero avente come radice pn-1.
Quando tale ricerca è completata il valoreminimax di pn-1 risale fino a pn-2 e le rimanentimosse legali in pn-2 sono suddivisedinamicamente fra i processori ed esplorate inparallelo.
Terminata la valutazione di pn-2, il suo valore èfatto risalire fino a pn-3 e così via. Taleprocesso è ripetuto per ogni nodo splitting finoa che le mosse nella radice sono finalmentesuddivise fra i processori per produrre il valoreminimax finale ed una nuova principal variationper la succesiva iterazione.
In Fig. 4.25 è presentata una versione C-Lindadi PVSplit.
4.2.5.6 Varianti dell’algoritmo PVSplit

111
L’overhead di sincronizzazione è il motivoprincipale delle prestazioni non soddisfacenti diPVSplit.
La soluzione proposta da Schaeffer è diriutilizzare processori inattivi per "assistere"quelli attivi. La sua idea ha originato l’algoritmoDPVSplit (Dynamic PVSplit) [Sch89].
PVSplit è basato su un’organizzazione staticadella gerarchia di processori ed impedisce cosìche i nodi foglia di questa gerarchia possanorendere divisibile il lavoro assegnato edusufruire dell’aiuto di altri processori.
In DPVSplit è proposta l’idea di una strutturaad albero dinamica per i processori. Esiste unprocesso supervisore ed un insieme diesploratori. Ogni esploratore riceve dalsupervisore un lavoro (divisibile) ed applicaPVSplit al sottoalbero corrispondente a questolavoro. Quando il supervisore non ha piùsottoalberi da distribuire, cerca un esploratoreE1 inattivo per aiutare un esploratore E2 nelcompletare la sua ricerca. E1 dovrà risponderea E2 del risultato della ricerca.
DPVSplit riduce sensibilmente l’overhead disincronizzazione, ma non completamente: unprocessore che ha assegnato lavoro a certiesploratori deve attendere che tutti questiabbiano terminato prima di iniziare una nuovaricerca.
Il metodo introduce, rispetto a PVSplit, unmaggior numero di comunicazioni a causadella maggiore cooperazione tra i processori. Èmaggiore anche l’overhead di ricerca in quantodalla frammentazione dei lavori risulta unaperdita di informazioni. Infatti se un sottoalberoè visitato dallo stesso processore le tavolehistory e delle trasposizioni possono essereutilizzate col massimo beneficio, ma se partedel sottoalbero è esplorata su un altroprocessore molte informazioni non sonoreperibili nelle tavole locali e non possonooriginare certi tagli.
Vi sono due aspetti di PVSplit che hannosuggerito a Newborn l’idea per il progetto di unnuovo algoritmo parallelo [New88].
La filosofia di PVSplit è di far risalire moltovelocemente verso ogni nodo splitting lavalutazione del nodo splitting successivo, così

112
che questo valore possa essere usato da tutti iprocessori quando essi intraprendono l’analisidelle rimanenti mosse in quel nodo.
Una seconda caratteristica di PVSplit è chetutti i processori devono aver completato lapropria ricerca nella iterazione corrente primache la successiva inizi: quei processori cheterminano la ricerca prima di altri restanoinattivi in attesa che questi finiscano.
L’algoritmo UIDPABS (UnsynchronizedIteratively Deepening Parallel Alpha BetaSearch) è una variante di PVSplit che nonpresenta le due caratteristiche ricordate[New88].
Questo metodo di ricerca procede seguendo ipassi:1. durante le prime due iterazioni tutti iprocessori fanno le stesse ricerche perdeterminare un efficace ordinamento dellemosse generate nella radice. Il valore finaleottenuto dalla seconda iterazione è usato comecentro di una finestra αβ utilizzata nellesuccessive iterazioni. La possibilità di disporredi una buona finestra αβ riduce l’urgenza di farrisalire la valutazione dei nodi splitting verso laradice.
2. le mosse alla radice sono ripartiteuniformemente fra i processori3. ogni processore intraprende una ricercaiterativa sull’albero definito dal propriosottoinsieme di mosse con la finestra inizialedefinita in 1.
La ricerca è indipendente fra i processori,anche rispetto a iterazioni successive: unprocessore può trovarsi nel mezzo della 6a
iterazione, mentre un altro è ancora alle presecon la 5a
4. se la ricerca di un processore fallisce lafinestra αβ viene traslata verso l’alto o verso ilbasso a secondo che il fallimento sia superioreo inferiore. Inizia così una nuova ricerca. Difronte ad un nuovo fallimento, tuttavia,l’esplorazione sarà ritentata con una finestraαβ tale da contenere sicuramente la soluzione
5. la ricerca globale ha termine quando èraggiunto un certo tempo limite di esecuzione.UIDPABS dimostra che due caratteristichefondamentali di PVSplit (sincronizzazione fra

113
iterazioni successive e veloce valutazione dellavariante principale) non sono requisitinecessari di un algoritmo parallelo efficiente.
4.3 Effetto delle euristiche nella ricerca parallelaNella implementazione delle soluzioni parallele di ricerca αβsi è continuato a fare uso di euristiche con l’intento dimigliorarne l’efficienza. L’efficacia di queste euristiche èrimasta inalterata nel passaggio da ambiente sequenziale aparallelo?
Le tabelle di trasposizione continuano ad essere pienamenteefficaci, a patto che tutti i processori accedano alla stessatabella globale. Essendo tuttavia consultata moltofrequentemente essa diviene un collo di bottiglia per lerichieste dei processori causando così un aumento deglioverheads di sincronizzazione e comunicazione.
Un processore potrebbe fare qualcosa di utile mentre è inattesa della risposta alla sua interrogazione; ad esempioiniziare a visitare il successivo sottoalbero. Se l’informazionerichiesta non è nella tabella allora non si è perso del tempo,altrimenti è utilizzato il primo pervenuto fra i risultati dellaricomputazione del sottoalbero e la risposta dalla tabella.
Una soluzione che riduce i tempi di accesso alla tabela delletrasposizioni è di suddividere la stessa in diverse partizionied associare ciascuna ad un processore. La tabella rimanecondivisa fra i processori, ma è minore la probabilità che duedi essi debbano sincronizzarsi sulla stessa porzione. Lagestione della tabella diviene però più complessa enormalmente un processore è dedicato a definire econtrollare il routing delle interrogazioni, anche se talvoltasono gli stessi processori a conoscere quale fra di essidispone dell’informazione cercata.
Esiste la possibilità che ogni processore mantenga unapropria tabella locale di trasposizioni. Questa soluzioneaumenta l’overhead di ricerca in quanto può accadere cheun processore valuti un sottoalbero già esplorato da un altro;offre però il vantaggio di non ritardare l’accesso alla tabella.
La preferenza della soluzione centralizzata rispetto alladistribuita è fortemente dipendente dalle dimensioni dellatabella e dalle connessioni fra i processori.
L’implementazione delle altre basi di conoscenza, come latabella history, la lista dei killer e la tabella delle confutazionipresenta problemi analoghi a quelli appena visti.
L’efficacia dei meccanismi di ordinamento delle mosse èlegata al tipo di algoritmo di ricerca.Ad esempio essi sono poco utili nell’algoritmo didecomposizione di base. I programmi sequenziali usano ilrisultato della valutazione del primo sottoalbero per tagliaregrossa parte del resto dell’albero. Se tutti i sottoalberi di un

114
nodo sono esplorati in parallelo, questo risultato non èdisponibile quando inizia la valutazione degli altri sottoalberi.Viceversa in algoritmi paralleli che sono efficienti nellaricerca di alberi fortemente ordinati (PVSplit), i meccanismidi ordinamento sono essenziali.
Sono stati già discussi i problemi introdotti in algoritmidistribuiti dall’utilizzo della tecnica di approfondimentoiterativo: si ha un incremento dell’overhead disincronizzazione perché tutti i processori devono attendere ilcompletamento della corrente iterazione prima di affrontarela successiva. È già stata analizzata una soluzione a questoinconveniente che però introduce una più complessastrategia di schedulazione dei lavori.

112
Capitolo 5Algoritmi di decomposizionedell’albero di gioco
5.1 IntroduzioneNell’ambito della presente discussione per distribuzione dellaricerca si deve intendere l’impiego di una molteplicità di risorse dielaborazione (processori) nel portare a termine la visita di un alberodi gioco in accordo con un generico algoritmo di ricerca. Oggetto diquesta fase del lavoro è proprio lo studio e la verifica sperimentaledi alcuni metodi di distribuzione della ricerca.
Analisi e sperimentazione di tali metodi verranno sviluppateisolando e minimizzando ogni dipendenza dal dominio diapplicazione. In particolare ogni processore impiegato nella ricercadistribuita fruirà della stessa conoscenza del dominio, rendendocosì ciascuno di essi indistinguibile sotto questo punto di vista.
Nel Capitolo 4 è stata presentata una classificazione dei metodi didistribuzione della ricerca su alberi di gioco unitamente ad unarassegna dei più significativi; già in quella sede furono enfatizzateimportanza ed efficacia di un particolare insieme di algoritmidistribuiti di ricerca: quelli detti di decomposizione dell’albero digioco. L’attenzione sarà focalizzata proprio su questa classe dialgoritmi. Quali le motivazioni di questa scelta?
Gli algoritmi di decomposizione sono stati oggetto di esaurientistudi e sperimentazioni per quanto concerne, almeno,l’implementazione su architetture con limitato parallelismo (nr. diprocessori ≤ 12). L’affacciarsi di architetture a parallelismomassiccio ha nuovamente riaperto la discussione riguardo leprestazioni dei diversi algoritmi di decomposizione; tuttavia alcunirisultati sperimentali appaiono confermare la bontà di soluzionialgoritmiche risultate già "vincenti" in presenza di un numero esiguodi processori [FeMyMo90; FMMV89]. Non potrebbe dunqueapparire ozioso un nuovo lavoro di analisi e sperimentazione di talialgoritmi su un’architettura a limitato parallelismo quale una rete diworkstation?
Deve essere chiaro che le finalità di questo stadio del lavoroesulano dallo sviluppo di un nuovo algoritmo distribuito di visita dialberi di gioco avente prestazioni confrontabili o superiori a quelledei migliori già individuati. L’obbiettivo che si intende conseguire èinvece un esame quanto più completo del modello dicomunicazione basato su spazi di tuple, condotto rispetto aparametri di valutazione quali la facilità di programmazione el’efficienza. In quest’ottica gli algoritmi di decomposizione sirivelano uno strumento di test "completo". Al variare del criterio didecomposizione, infatti, essi divengono rappresentativi di unospettro molto esteso di problemi, con granularità del parallelismo

113
che va dalla grana grossa alla grana fine. La scelta di concentraregli sforzi su una classe di algoritmi abbondantemente sperimentativa inoltre inquadrata nell’esigenza di disporre di un numerosufficiente di risultati sperimentali ottenuti su diverse architetturehardware e software, tali così da costituire essenziali termini diconfronto per i risultati che saranno presentati in questo lavoro.
Il linguaggio Linda concretizza un modello di programmazioneparallela relativamente nuovo e quindi sperimentato in un numerolimitato di domini (fra i primi si ricordano moltiplicazione di matrici edecomposizione LU [CaGeLe88], confronto di sequenze di DNA edatabase con ricerca parallela [CarGel88a], algoritmibranch-and-bound e sistemi esperti [FacGel88], programmi di ray-tracing [LeiWhi88]). L’area dei problemi di ricerca guidata daeuristiche si propone pressoché inesplorata dalla programmazionein Linda; in quest’area i metodi di decomposizione dell’albero digioco costituiscono esempi di notevole complessità, così da rivelaredi suggestivo interesse la loro sperimentazione in Linda.
Questa fase del lavoro si svilupperà dunque attraverso l’analisi el’implementazione di alcuni algoritmi di decomposizione dell’alberodi gioco. L’esplorazione di tali algoritmi procederà in modoincrementale rispetto alla complessità delle interazioni che essiinducono fra i processori. Inizialmente saranno quindi presentatimetodi di decomposizione con minima cooperazione;successivamente verranno esaminate forme di interazione fraprocessori via via più complesse. Questo tipo di approccio sipresenta di notevole interesse data la natura degli algoritmi paralleliin analisi. Essi nascono come generalizzazione nel distribuitodell’algoritmo sequenziale αβ. La visita in parallelo di porzionidisgiunte dell’albero di gioco origina overhead di ricerca rispettoall’algoritmo sequenziale; questa forma di overhead contribuisce aldegrado delle prestazioni. Il suo manifestarsi deriva dal fatto che iprocessori non hanno una visione globale di informazioni da essiricavate durante la visita di rispettive porzioni dell’albero. I metodi didecomposizione con forme di cooperazione più complesse sonofinalizzati, generalmente, alla riduzione dell’overhead di ricercaattraverso una maggiore condivisione di queste informazioni. Percontro, un aumento delle interazioni determina un maggior numerodi comunicazioni e punti di sincronizzazione, motivi anche questi didegrado delle prestazioni. Sarà di primario interesse verificare finoa quale grado di condivisione i vantaggi che derivano dallariduzione dell’overhead di ricerca non sono vanificati dall’aumentodel degradi legati alla comunicazione ed alla sincronizzazione.
Sono necessarie analoghe considerazioni riguardo quei metodi didecomposizione finalizzati al bilanciamento del carico fra iprocessori e quindi alla riduzione del degrado legato allasincronizzazione. Questa classe di metodi, infatti, origina unaumento delle comunicazioni e, più importante, dell’overhead diricerca. Si può dunque osservare che la determinazione di un

114
algoritmo distribuito di ricerca efficiente deriva da soluzioni dicompromesso (trade-off) che minimizzino complessivamente tuttele forme di degrado delle prestazioni. Le considerazioni sin quiformulate fanno presagire l’impossibilità di esistere di un algoritmodi decomposizione universalmente ottimo, le cui prestazioni, cioè,non dipendano dagli strumenti software impiegati nellaprogrammazione delle interazioni e soprattutto dall’architetturahardware parallela sulla quale l’algoritmo è implementato.
Questa realtà, peraltro comune a molte classi di algoritmi paralleli,conferisce un ulteriore significato al presente lavoro; esso puòessere interpretato come esempio di metodologia di ricerca guidatadall’ambiente di programmazione e di sperimentazione.
L’indagine sperimentale affronterà inizialmente i metodi didecomposizione statica e successivamente quelli di naturadinamica. Nel corso del Capitolo sarà inoltre presentata lasperimentazione nel distribuito di alcune euristiche di ordinamentodei nodi interni dell’albero di gioco.
5.2 Algoritmi di decomposizione dell’albero di giocoSi consideri l’algoritmo sequenziale αβ (Fig. 1.9). Esso descrive lavisita di un albero di gioco in ordine depth-first, sviluppata fino aduna profondità finita e finalizzata al calcolo del valore minimax delnodo alla radice dell’albero. Gli algoritmi di decomposizionecostituiscono una generalizzazione in ambiente distribuitodell’algoritmo αβ. Essi, infatti, definiscono una classe di metodi didistribuzione della visita da esso indotta; la caratteristica di questoapproccio è che la ricerca su sottoalberi distinti dell’albero di giocoè a carico di processori in generale diversi e quindi condottasimultaneamente.
Gli algoritmi di decomposizione possono essere partizionati in duesottoclassi:• algoritmi con decomposizione statica• algoritmi con decomposizione dinamica.La natura statica della decomposizione deriva, per il primo tipo dialgoritmi, dal fatto che i nodi di decomposizione sono fissati a priori,cioè prima che la visita dell’albero di gioco abbia inizio.
Gli algoritmi di decomposizione dinamica, invece, prevedono cheun nodo interno venga designato o meno come di decomposizionesolamente al momento della visita dell’albero.
5.2.1 Algoritmi di decomposizione statica5.2.1.1 L’algoritmo base di decomposizione
In 4.2.5.3 è stato presentato un algoritmo didecomposizione definito di base, data la suasemplicità. Tale algoritmo introduce un’architetturalogica di comunicazione denominata albero deiprocessori. Si consideri la versione semplificata di talealgoritmo in cui l’albero dei processori ha profondità 1(Fig. 5.1).

115
Supervisore
Esploratore1 Esploratore2 Esploratore(N-1)
Fig. 5.1 Algoritmo base: albero dei processori
Qual è il significato di questo schema dicomunicazione?Dato un insieme di N processori, solamente uno diessi è supervisore, mentre i restanti N-1 sonoesploratori. Il processore supervisore è il responsabiledel nodo radice e quindi della ricerca dell’intero alberodi gioco. Il suo compito è distribuire ai suoisottoprocessori la visita dei sottoalberi della radice. Laparticolare struttura dell’albero dei processoriimpedisce qualsiasi forma di subappalto della ricerca:gli esploratori, divenuti su incarico del supervisoreresponsabili di uno dei sottoalberi della radice,devono completare sequenzialmente la visita diquest’albero non potendo disporre dellacollaborazione di propri sottoprocessori. L’algoritmo didecomposizione che emerge da questo approccioinduce la presenza di un unico nodo didecomposizione: la radice dell’albero di gioco (Fig.5.2). La distribuzione della ricerca è dunque confinataunicamente al top-level dell’albero, dove è stabilito unnumero di ricerche sequenziali pari ai successori dellaradice.
È evidente la relazione gerarchica stabilita fra ilprocessore supervisore e tutti gli esploratori: essospecifica quali sottoalberi della radice devono esserevisitati, mentre gli esploratori debbono completare talivisite e rispondere al supervisore del loro operatocomunicandone il risultato. Quest’ultimo gestiscedinamicamente (cioè durante la ricerca) tali risultati,così da "migliorare" la ricerca20 dei sottoalberi nonancora distribuiti.

116
Sono "distribuite" solo le mosse al top-level
La ricerca dei sottoalberi della radice è sequenziale
La radice è l’unico nodo di decomposizione
Fig. 5.2 Algoritmo base: la decomposizionedell’albero di gioco
È dinamica anche l’attribuzione agli esploratori dellavisita dei sottoalberi. Il supervisore non ha interesse aconoscere quale degli esploratori visiterà un certosottoalbero: ciò che per esso è importante è chesiano completate tutte le visite richieste e nonl’identità degli agenti che le hanno prodotte. Gliesploratori appaiono quindi al supervisore comeindistinguibili data, inoltre, la loro omogeneità: tuttisvolgono la stessa attività, cioè la ricerca sequenzialeαβ. La comunicazione da parte del master dellarichiesta di ricerca di un nuovo sottoalbero è quindi ditipo asimmetrico in uscita: è rivolta a tutti gliesploratori, ma potrà essere "consumata" solamentedal primo di essi che la riceverà.
Le interazioni descritte fanno emergere un’architetturalogica di comunicazione perfettamente assimilabile almodello master-worker di programmazione parallela(Fig. 5.3). Esiste infatti un’analogia perfetta fra agentied azioni dell’algoritmo in esame e quelli descrittinella definizione del modello (cfr. 3.2.2.4.1): unprocesso master (supervisore) genera un insiemeordinato (nel presente caso l’ordine è casuale) dilavori (ricerca αβ di sottoalberi della radice);l’esecuzione dei lavori è ad opera di un insieme diprocessi worker omogenei ed indistinguibili(esploratori) i quali comunicano il risultato delrispettivo lavoro (valore minimax del sottoalberovisitato) al master cui ne compete l’elaborazione(aggiornamento del valore minimax dell’albero e dellafinestra αβ da utilizzare nei successivi lavori).

117
Supervisore
Esploratore1
Esploratore2
Esploratore(N-1)
Agenda di lavori
Risultati dei lavori
Ricerca di un sottoalbero della radice
Valore minimax di un successore della radice
Fig. 5.3 Algoritmo base: architettura logica dicomunicazione
5.2.1.1.1 Il progetto della cooperazioneattraverso lo spazio delle tuple
Il linguaggio Linda costituisce uno strumentoestremamente espressivo nellaprogrammazione di interazioni fra processibasate sul modello master-worker. Il motivo èche in generale è agevole ed immediata ladefinizione come insieme di tuple dellestrutture:
• agenda, cioè della struttura atta a conservare(ed eventualmente ordinare) la lista di lavoriancora inevasi
• insieme dei risultati prodotti dal lavoro deiworker.In riferimento all’algoritmo di decomposizionein esame, entrambe queste strutture sonoimplementate come strutture dati distribuite ditipo bag.
L’agenda di lavori è implementata da tuple ilcui schema è:("job", subtree)Il campo subtree identifica univocamente unodei sottoalberi della radice. In un albero digioco deterministico un suo sottoalbero èindividuato dal rispettivo nodo radice. Talenodo, come qualsiasi altro, rappresenta unostato del gioco; in generale questainformazione è di grosse dimensioni (si pensialla rappresentazione della posizione dei pezzinegli scacchi) e quindi il costo della sua

118
comunicazione può risultare molto elevato.Data la particolarità dell’algoritmo di base èpossibile un’ottimizzazione per cui il tipo diquesto campo può essere ridotto ad un intero.Si osservi infatti che:
• è nota staticamente l’identità dell’unico nododi decomposizione• è realistica l’assunzione che, dato uno statodel gioco, il generatore di mosse di ogniprocessore generi quest’ultime nel medesimoordine.
Grazie a queste particolarità dell’algoritmo dibase il campo subtree conterrà unicamentel’indice ordinale della mossa al top-level che haoriginato il sottoalbero che deve esserevisitato. Al fine di garantire la correttezza diquesto approccio la ricerca complessiva deveessere preceduta da una fase diinizializzazione in cui ogni esploratore:
• riceve dal supervisore la posizione alla radicedell’albero di gioco (anche per questainterazione è possibile l’ottimizzazione in cuiviene comunicato l’indice della mossarealmente giocata) e
• genera autonomamente la sequenza dimosse al top-level.La completa specifica della visita αβ di unalbero di gioco si compone, oltre che del nodoradice, anche dei limiti della finestra (alpha,beta) e della profondità nominale di ricerca.Quest’ultima informazione è costante e vienequindi comunicata per diffusione a tutti iprocessori prima che la ricerca abbia inizio. Altop-level la finestra (alpha, beta), invece, vieneaggiornata dinamicamente dai risultati ritornatidagli esploratori; i suoi limiti devono quindicostituire parte integrante della specifica di unlavoro. Perché questi dati non sono alloracontenuti nei campi delle tuple che definisconol’agenda?
Si considerino a riguardo le seguentiosservazioni:• si supponga che l’algoritmo non sia inserito inuna ricerca di tipo aspiration21; questa ipotesiha come implicazione che la finestra iniziale αβal top-level sia: (-∞,+∞). Il limite superiore +∞ ècostante durante l’intera ricerca e quindi già

119
noto agli esploratori; lo score (così è anchechiamato il limite inferiore α), invece, puòaumentare dinamicamente. Esso rappresenta ilvalore minimax associato alla migliore fra lemosse già esplorate; il suo aggiornamento è acura del supervisore ed ha luogo qualora unesploratore ritorni una valutazione per lamossa assegnatagli maggiore dello scorecorrente, divenendo così essa il nuovo score. Ilvalore attuale dello score è quindi notosolamente al supervisore; un generico lavorodovrà quindi includere logicamente questainformazione.
• come accennato, una possibile soluzione èquella di inserire lo score corrente in un campoaggiuntivo della tupla-lavoro. Questo tipo diapproccio si rivela però insoddisfacente inprospettiva di una futura "evoluzione"dell’algoritmo. Si consideri, ad esempio, ilseguente scenario: il supervisore ha inserito inagenda un nuovo lavoro L contenente ilsottoalbero P ed il valore S1 per lo scorecorrente; successivamente un esploratoretermina la sua ricerca provocando unmiglioramento dello score che assume oravalore S2. Supponendo che il lavoro L non siastato ancora rimosso dall’agenda, si osservicome esso contenga un valore per lo scorenon aggiornato. L’aggiornamento di questocampo è certamente inefficiente, in quantorichiede rimozione ed inserimento anche delleinformazioni di specifica del sottoalbero(rimaste comunque inalterate). Tale situazionesi verifica tanto più frequentemente quantomaggiore è il tempo medio di permanenza inagenda dei lavori; nel caso dell’algoritmo base,tuttavia, tale tempo è molto basso rendendocosì impercettibile il fenomeno descritto (ilmotivo sarà spiegato fra breve).
• soluzione alternativa è quella di separarefisicamente le informazioni relative alsottoalbero e allo score. Si osservi comequest’ultimo non costituisca elemento didistinzione fra i lavori; lavori generaticonsecutivamente conterranno con moltaprobabilità lo stesso score (a meno di un suoaggiornamento nel tempo intermedio fra le duegenerazioni). Ai fini della correttezza

120
dell’algoritmo tale informazione non deveessere necessariamente trasmessa; la suafinalità è unicamente velocizzare la ricerca. Ciòche è importante è stabilire una forma dicondivisione dello score fra supervisore edesploratori. Ogni soluzione ragionevole aquesto problema deve prevedere che ciascunesploratore mantenga una copia locale delvalore dello score e che questa vengaaggiornata periodicamente; il fatto che taleaggiornamento abbia luogo al momento dellaricezione di un nuovo lavoro è solo una fra lepossibili scelte.
L’approccio che emerge dalla presentediscussione è l’implementazione dellacondivisione dello score mediante una strutturadati del tipo variabile distribuita; essa saràcaratterizzata da un’unica tupla con struttura
("score", valore)aggiornata dal supervisore ed acceduta in solalettura dagli esploratori. Questa soluzione godedi interessanti proprietà che offrono lo spuntoper alcune riflessioni di carattere generale:
• contrariamente alla prima soluzionepresentata, ora il supervisore partecipaattivamente alla condivisione dello scoresolamente quando è necessario, cioè quando ilsuo valore deve essere aggiornato; i riflessisull’efficienza sono evidenti: nel caso di unalbero ordinato lo score al top-level vienemodificato molto raramente poiché i suoimiglioramenti saranno prodotti con moltaprobabilità solamente dalle prime mosse altop-level.
• la soluzione permette di applicare conmaggiore grado di libertà uno dei criteri cardinedella programmazione parallela: il principio diautonomia dei moduli. Essa offre infatti aimoduli esploratori la possibilità di decidereautonomamente quando aggiornare la copialocale dello score; il rispetto del principio diautonomia è generalmente origine di unastruttura di interazioni flessibile che nel casodella presente discussione significa potersperimentare facilmente frequenze diverse diaggiornamento locale dello score (ad es.basate su intervalli di tempo regolari inalternativa alla frequenza di aggiornamento

121
scandita dall’evento "ricezione di un nuovolavoro").• la condivisione di una variabile distribuita ècausa di serializzazione fra i processori; ildegrado prodotto da tale fenomeno èproporzionale alla durata media della relativasezione critica (cioè del tempo di accesso allavariabile) ed alla frequenza con cui esso simanifesta (nella fattispecie pari alla frequenzadell’operazione di aggiornamento). L’incidenzadi questo degrado sull’algoritmo di base èminima poiché la quasi totalità degli accessialla variabile "score" è in lettura e la frequenzarelativa degli aggiornamenti è, come spiegato,molto limitata.
È finalmente definita un’agenda in cui i lavorisono inseriti dal supervisore e prelevati dagliesploratori.
La ricerca αβ trae beneficio dal fatto che lemosse "migliori" (con maggiore valoreminimax) siano valutate per prime; è perquesto motivo che le mosse prodottedall’omonimo generatore sonosuccessivamente ordinate in base ad una lorovalutazione statica. Il supervisore inserisce ilavori nell’agenda nello stesso ordine dellemosse al top-level cui essi si riferiscono.L’organizzazione dell’agenda in una struttura ditipo bag rende però i lavori indistinguibili; ciòimplica che l’ordine di estrazione dei lavori nonrispetti in generale l’ordine cronologico diinserimento. Perché, dunque, nonimplementare l’agenda come una struttura datidistribuita più complessa (ad es. coda-in) chepermetta di preservare l’ordinamento dei lavorial momento dell’estrazione?
Questo tipo di soluzione si rivelerà necessarioin algoritmi più complessi onde limitarel’overhead di ricerca. Tuttavia l’algoritmo dibase gode di una proprietà per cui la rinunciaall’ordinamento dei lavori non determina unreale aumento dell’overhead di ricerca offrendocosì il vantaggio di disporre di un’agenda dilavori con struttura semplice e con accesso adessa più efficiente. Tale proprietà consiste nelfatto che il supervisore conosce, in ogni istantedella ricerca, il numero di esploratori inattivi. Diconseguenza, esso inserisce un nuovo lavoro

122
in agenda solamente se almeno un esploratoreè già pronto a raccoglierlo; la trasmissione diun lavoro viene quindi ritardata fino almomento in cui è possibile la sua immediataesecuzione. Da un punto di vista logico tutti ilavori presenti contemporaneamente in agendavengono dunque rimossi simultaneamente,rendendo così superflua una loro gestioneordinata.
Il fatto che il supervisore generi un lavoro solose almeno un esploratore è libero costituisceinoltre il motivo per cui il tempo medio dipermanenza dei lavori in agenda è pressochétrascurabile.
Anche l’insieme di risultati prodotti dai moduliesploratori sono organizzati in una strutturadati distribuita di tipo bag. Le tuple chedefiniscono questa struttura hanno il seguenteschema:
("result", value, subtree)Il campo value contiene il valore minimax per ilsottoalbero della radice identificato dalcontenuto del campo subtree. La presenza diquest’ultima informazione non è necessaria aifini del calcolo del valore minimax complessivo,ma è tuttavia indispensabile per ladeterminazione della migliore mossa.
La decisione precedentemente operata di nongestire l’ordinamento dei lavori in agendarende impossibile stabilire qualcheordinamento significativo per la struttura dirisultati. Quali vantaggi avrebbe comportato lascelta di recuperare i risultati nello stessoordine con cui i rispettivi lavori sono statigenerati ed inseriti in agenda?
Si consideri la ricerca di un albero di giocoperfettamente ordinato: in questo caso lalettura ordinata dei risultati fa sì che lo scorevenga aggiornato una sola volta (dal risultatodella visita della prima mossa); in tale albero,infatti, essendo la prima mossa anche lamigliore, il suo valore non potrà esseremigliorato da nessuna delle successive visite.Un primo vantaggio che quindi emerge perquesto approccio è una limitazione del numerodi aggiornamenti dello score. Si osservi inoltreche elaborare per primi i risultati delle mossepresunte migliori consente in generale di

123
ottenere uno score parziale più elevato equindi un maggiore restringimento dellafinestra αβ utilizzata nei successivi lavori conconseguente riduzione dell’overhead di ricerca.
Va considerato, tuttavia, che il tempo dicompletamento dei lavori è impredicibile datala natura della ricerca αβ per cui la ricerca didue alberi delle stesse dimensioni puòrichiedere la visita di insiemi di nodi differenti incardinalità anche qualche ordine di grandezza.Ciò implica che l’ordine con cui i lavori sonocompletati non rispetta in generale quello concui essi hanno avuto inizio. La soluzione inesame presenta dunque la grave inefficienza diforzare il supervisore nell’attesa del risultatorelativo all’esplorazione della mossa piùpromettente, anche nell’eventualità che sianogià disponibili i risultati di altri lavori.L’organizzazione dei risultati in una struttura ditipo bag elimina invece questo problemapermettendo la gestione di un risultato nonappena esso viene generato.
5.2.1.1.2 Il flusso di controllo interno deiprocessi.
A completamento della presentazionedell’algoritmo di base segue l’analisi del flussodi controllo interno dei moduli supervisore edesploratore.
Si consideri inizialmente il modulo supervisore:la relativa implementazione in Linda è descrittain Fig. 5.4. Il codice proposto separa la fase digestione centrale della ricerca (funzionemaster) dalle fasi di inizializzazione eterminazione della stessa (funzionemaster_main). Tale decomposizione intendeisolare la parte caratterizzante dell’algoritmo (lafase centrale di ricerca) dalle altre aventicarattere generale e che non sarannoinutilmente replicate nella successivapresentazione di alcune varianti dell’algoritmo.
/* le costanti simboliche NEWPOS e QUITidentificano tipi di lavoro differenti dalla
normale ricerca αβ di alberi di gioco:rispettivamente la ricezione di un nuovoalbero e la terminazione del processo*/#define NEW_POSITION -1#define QUIT -2int master_main(int n_worker,int depth){

124
position *root,*successor;int nmoves,minimax,i,master(),worker();for (i=0;i<n_worker;i++)
eval ("worker",worker(depth)); /*creazione struttura di worker */while (!end())
{load_new_position (&root); /* un nuovo
albero di gioco */nmoves=genmoves(root,&successor);if (nmoves==0) /* non è necessaria
nessuna ricerca? */return(evaluate(root));
out ("root",*root); /* comunica aiworker il nuovo albero */
out ("sincr",n_worker);for (i=0;i<n_worker;i++)
out ("job",NEW_POSITION); /*richiesta di lettura del nuovo albero */
in ("sincr",0); /* il master proseguesolo dopo che tutti i worker hanno ricevuto
il nuovo albero */minimax=master(n_worker,nmoves,depth,su
ccessor); /* fase centrale della ricerca */in ("root",*root); /* rimozione
dell‘albero visitato */}
for (i=0;i<n_worker;i++){out ("job",QUIT); /* comunicazione di
terminazione dell‘elaborazione */in ("worker", 0); /* la terminazione
di un worker fa sì che larelativa tupla attiva divenga passiva equindi rimovibile dallo spazio delle
tuple*/}
return (0);}int master(int n_worker,int nmoves){int nmoves,local_score,subtree,free,best;local_score=-INFINITE; /* inizializzazionecopia locale dello score */out ("score", local_score); /*inizializzazione score globale */free = n_worker;subtree = 1;while ((subtree <= nmoves) || (free<n_worker))/* il ciclo termina quando sono stati
distribuiti tutti i lavori e recuperatitutti i risultati */if ((subtree <= nmoves) && (free>0)) /*
c‘è ancora lavoro da distribuire e almenouno degli esploratori è libero? */
{out ("job",subtree); /*
inserimento in agenda di un lavoro di ricerca*/
free--;subtree++;}
else /* attesa del completamento dialmeno un lavoro */
{in ("result",?value,?r_subtree);
/* recupero di un risultato */if (value>local_score) /*
miglioramento dello score? */{

125
local_score=value; /*aggiornamento locale dello score */
in ("score",?int);out("score",local_score);
/* aggiornamento globale dello score */best=r_subtree;}
free++;}
in ("score",?int); /* la tupla "score" varimossa per non produrre effetti laterali
indesiderati nelle successive ricerche*/return (local_score);}Fig. 5.4 Algoritmo base: flusso di controllodel processo master
La funzione master_main descrive unasuccessione ciclica di ricerche di alberi di giocointendendo simulare così la situazionegenerale che si verifica in una partita reale.Tale sequenza è preceduta da una fase inizialein cui viene creata la struttura di processiworker. In particolare viene creata una tuplaattiva per ciascuno di essi; tale tupla innescal’esecuzione asincrona della funzione worker(Fig. 5.5). Detta funzione ha un unicoparametro formale: la profondità nominale diricerca; questo parametro di ricerca può esseregià comunicato in questa fase perché assuntocostante in tutte le ricerche. Normalmente nellalista di parametri formali è presente anche unidentificatore (o nome) del generico worker chepermette al master di stabilire, in situazionieccezionali, interazioni di tipo simmetrico conesso. La sua assenza nella funzione workerevidenzia ancora maggiormente la completaindistinguibilità di questi processi.
Creazione e terminazione di processi sonoattività computazionalmente costose; nonappaiono quindi efficienti soluzioni cheprevedono la creazione di una struttura diworker per ogni nuova ricerca. L’approcciocorretto è invece che nella ricerca di tutti glialberi di gioco venga utilizzata la stessastruttura di worker. In questo e molti altridomini è quindi certamente da preferire ilprogetto di un unico tipo di modulo worker confunzionalità generali, capace però dispecializzarsi quando necessario impedendocosì di ricorrere ad una sua sostituzione

126
qualora l’elaborazione richieda una modificadinamica delle funzioni ad esso richieste.
int worker(int depth){position *root,*successor,*tree_pointer;intnmoves,subtree,score,value,job_type,quit,s;quit=false;while(!quit)
{in ("job",?job_type);switch (job_type)
{case QUIT: /* fine */
quit=true;break;
case NEW_POSITION: /* la ricercariguarda nuovo albero di gioco */
in ("position",?*root);in ("sincr",?s);out ("sincr",s-1);
nmoves=genmoves(root,&successor);break;
default: /* il job riguarda
una normale ricerca sequenziale αβ */subtree=job_type;
tree_pointer=success or+subtree-1;makemove(tree_pointer);rd ("score",?score); /*
aggiornamento score locale */value=-
alphabeta(tree_pointer,-INFINITE,-score,depth);
out ("result",value,subtree);undomove(tree_pointer);break;
}}
return (0);}Fig. 5.5 Algoritmo base: flusso di controllodi un processo worker
Nel caso di problemi di ricerca, qualoraesistano parametri che differenzino una ricercadalla precedente, è ragionevole che lacomunicazione di questi (da master a worker)avvenga come una normale interazionemediata da scambio di tuple passive.Nell’algoritmo in esame tale interazioneriguarda unicamente la comunicazione perdiffusione del nodo radice del nuovo albero digioco; essa avviene prima dell’inizio dellaricerca. Si osservi come il master completiquesta interazione sincronizzandosi con laricezione di questa informazione da parte di

127
tutti i moduli worker. Punti di sincronizzazionecome questo sono normalmente origine diinefficienza; il loro inserimento è perònecessario al fine di garantire la correttezzadell’algoritmo. Nel caso specificodell’implementazione di Fig. 5.4 le velocitàrelative dei processi potrebbero essere tali percui, in assenza del punto di sincronizzazione,un modulo worker potrebbe ricevere un lavorodi ricerca prima della specifica dell’albero digioco cui essa si riferisce.
La ricezione del nuovo nodo radice costituisceper i worker un lavoro di natura diversa rispettoalla normale ricerca αβ; lo stesso vale per lacomunicazione di fine elaborazione formulatadal master una volta completato il ciclo diricerche. In situazioni come questa di lavoricon diverso significato come può il processoworker identificare il tipo di lavoro prelevatodall’agenda?
La soluzione generale in Linda è inserire nellatupla-lavoro un campo che ne indichiesplicitamente il tipo. Nella presenteimplementazione è stata possibileun’ottimizzazione: il tipo di lavoro e la suadescrizione occupano lo stesso campo dellatupla-lavoro. I lavori di "lettura nodo radice" e"fine elaborazione" non sono infattiaccompagnati da descrizione; prevedendo peressi identificatori numerici diversi dai possibilivalori che può assumere la descrizione dellavoro "ricerca αβ", l’identificazione diquest’ultimo tipo di lavoro avvieneimplicitamente per esclusione.
La fase ciclica della funzione master_main sichiude con la rimozione di tutte le tuple passiveancora presenti nello spazio omonimo.Seppure non necessaria ai fini della ricerca(ormai completata), questa operazione èindispensabile nel garantire la correttezza: lapresenza di tuple "spurie" potrebbe infatticreare interazioni indesiderate durante lesuccessive ricerche.
Si consideri la funzione master; essa descrivela fase centrale di distribuzione e controllodella ricerca. Il flusso di controllo evidenzial’intercalarsi durante la ricerca complessiva

128
delle due funzionalità predominanti del modulomaster:• creazione ed inserimento in agenda di unnuovo lavoro e• ricezione di un risultato e conseguentegestione.L’implementazione proposta dà priorità allaprima attività: viene generato un nuovo lavoronon appena un modulo esploratore si rendedisponibile per la sua elaborazione.L’informazione "numero di esploratoridisponibili", seppure di natura globale aimoduli, viene gestita localmente dalsupervisore; egli, infatti, è in grado di dedurreche un esploratore non è più occupato dalverificarsi dell’evento "ricezione di un risultato".Il modulo supervisore è così in grado distabilire autonomamente quando inserire inagenda un nuovo lavoro: immediatamentedopo la ricezione di un risultato.
Il codice della funzione master descrive ilprocedere della ricerca attraverso tre fasiconsecutive:
• start-up: è la fase iniziale in cui il mastergenera un numero di lavori pari a quello degliesploratori; quest’ultimi vengono quindiimpegnati nella loro totalità fin dall’inizio dellaricerca. Ad epilogo di questa attività ilsupervisore si sospende nell’attesa dellaricezione del primo dei risultati che sarannoinseriti nell’omonima struttura dati distribuita.
• fase intermedia: in questo stadio la ricezionedi un risultato e la produzione di un nuovolavoro di ricerca si alternano regolarmente.Questo comportamento del supervisore limitaperò il tempo di occupazione del genericoesploratore il quale, dopo aver prodotto unrisultato, è costretto ad attendere che esso siaricevuto ed elaborato dal supervisore prima dipoter disporre di un nuovo lavoro. Unapossibile soluzione a questo problema èrilasciare l’eccessivo accoppiamentosupervisore-esploratore facendo sì che ilnumero medio L di lavori in agenda sia nonnullo. Da un punto di vista implementativo èsufficiente che nella fase di start-up sianoinseriti in agenda (L+Nw) lavori, dove Nw è ilnumero di esploratori. La costante L deve

129
essere dimensionata in modo da sopportarevariazioni improvvise delle velocità relative deimoduli (ad es. esploratori che completanorapidamente la ricerca) o situazioni eccezionali(ad es. completamento simultaneo di piùlavori); essa non può però superare certi valoridi soglia a causa dei problemi di mancatoordinamento dei lavori ed overhead di ricercache ne deriverebbero. Questo tipo di soluzionesarà tuttavia sperimentato nello studio deimetodi di decomposizione dinamica.L’inefficienza presentata sarà invece eliminatacon un approccio differente, applicato ad unadelle varianti dell’algoritmo di base cheverranno presentate in seguito (cfr. 5.2.1.1.2).
• attesa finale: è la fase conclusiva in cui ilsupervisore, dopo avere distribuito la ricerca ditutti i sottoalberi al top-level, attende laricezione dei risultati degli ultimi lavori nonancora completati. Questa fase rivela unagrave inefficienza: l’agenda di lavori rimarràvuota fino alla fine della ricerca e quindi ogniesploratore diverrà definitivamente inoperosodopo avere completato il proprio lavoro e ciòfino a che tutti gli altri non avranno terminato ilrispettivo. Tale problema costituisce un casoparticolare di distribuzione del carico nonuniforme. I metodi di decomposizione staticasoffrono inevitabilmente di questo problema, ameno che essi prevedano un’analisi statica delcarico la quale permetta di programmare ilcompletamento pressoché contemporaneodegli ultimi lavori (essa è comunque di nonrealistica attuazione per problemi di ricercaαβ). I metodi con decomposizione dinamica,invece, risolvono in modo naturale i problemidella natura appena descritta.
Si consideri, infine, la funzione worker di Fig.5.5 la quale descrive il flusso di controllo di ungenerico esploratore. Esso si sviluppaattraverso il ciclico ripetersi delle operazioni:
• estrazione di un lavoro dall’agenda• identificazione del tipo di lavoro ricevuto esua esecuzione.Il codice proposto mette in risalto l’operazionedi selezione del tipo di lavoro e separa in modonetto le azioni corrispondenti a ciascuna

130
classe; il dettaglio di quest’ultime è già statoimplicitamente discusso.
5.2.1.1.3 I risultati sperimentaliIn questa sezione sono presentati ed analizzatii risultati della sperimentazione dell’algoritmobase applicato al dominio degli scacchi.
Tale algoritmo e tutti i successivi che verrannopresentati saranno sottoposti agli stessi test divalutazione delle prestazioni; questa sceltapermetterà immediati confronti. Leconsiderazioni che seguiranno riguardol’organizzazione degli esperimenti devonoquindi intendersi di carattere generale.
L’algoritmo verrà impegnato nella esplorazionedi posizioni di test; in particolare è stato sceltol’insieme di 24 posizioni di Bratko-Kopec[BraKop82] (riportato integralmente inAppendice A). Si tratta di posizioniappositamente ideate per valutare la qualità digioco di un giocatore automatico di scacchi.Deve essere chiaro, tuttavia, che questasperimentazione intende stimare unicamentel’efficienza dell’algoritmo distribuito e non laqualità delle sue scelte; quest’ultima, infatti,dipende pesantemente dalla conoscenza deldominio confinata nella funzione di valutazionee la cui analisi esula dagli scopi di questasezione.
La finalità principale degli esperimenti è quelladi confrontare le prestazioni dell’algoritmodistribuito con quelle della sua versionesequenziale. L’algoritmo base didecomposizione sarà confrontato ovviamentecon l’algoritmo αβ. Alcuni degli algoritmiparalleli presentati in seguito conterrannoeuristiche per il miglioramento della ricerca: illoro algoritmo sequenziale di riferimento saràin tal caso alphabeta arricchito delle stesseeuristiche.
La sperimentazione degli algoritmi èaccompagnata dalla raccolta di parametristatistici con i quali si intende porre in risaltovari aspetti della dinamica della loroesecuzione.
I parametri più importanti per la valutazione diun programma parallelo riguardano i tempi dielaborazione. Essendo l’architettura hardwarecostituita da una rete di workstation, cioè

131
macchine multiutente e quindi noncompletamente dedicate all’esecuzione diun’unica applicazione, classifichiamo i possibilitempi di elaborazione in:
• tempo reale (o assoluto): misura la durataeffettiva degli esperimenti, quale cioèapparirebbe ad un osservatore umano cheassistesse al loro evolversi;
• tempo di macchina (o di CPU): misura iltempo realmente dedicato dalla macchina agliesperimenti, "depurando" così il tempo realedelle frazioni in cui la macchina serve altriutenti.
Data la visita di una generica posizione di test,il parametro temporale più interessante è iltempo complessivo T di ricerca dell’albero digioco ad essa associato.
Per l’algoritmo sequenziale il tempo di ricerca èmisurato come l’intervallo che intercorre fral’invocazione al top-level della funzionericorsiva αβ ed il suo completamento. Leprestazioni dell’algoritmo sequenzialecostituiscono il metro di valutazione deglialgoritmi distribuiti e quindi la loro misura nonpuò essere influenzata dalle condizioni dicarico (per loro natura variabili) della macchinasu cui essa è operata. Per questo motivo iltempo complessivo T viene misurato cometempo di macchina.
Il tempo di ricerca dell’algoritmo parallelo vienemisurato dal processo master: esso èl’intervallo fra l’inizio della distribuzione delnuovo nodo radice e l’acquisizione del suovalore minimax finale.
Per gli algoritmi paralleli è molto difficoltosol’utilizzo del tempo di macchina quale metrica:ciò richiederebbe l’analisi dei tempi macchinadi ogni workstation impegnata nella ricerca eduna loro complessa sintesi in unico datostatistico. Il tempo di ricerca verrà dunquemisurato come tempo reale; questa scelta nonpregiudica la validità degli esperimenti poichéessa comporta un’approssimazione per difettodell’effettivo valore degli algoritmi paralleli22.
Il confronto fra l’algoritmo parallelo e la suaversione sequenziale viene sintetizzato dallospeedup (o guadagno) S, inteso come rapportotra il tempo complessivo Ts di ricerca

132
sequenziale ed il tempo complessivo Tpimpiegato dalla versione parallela sullo stessoalbero di gioco:
S =TS
TP
Lo speedup S è un indice assoluto indicante ilguadagno in termini di velocità computazionaleintrodotto dalla sostituzione dell’algoritmosequenziale con una sua versione parallela.
Altro parametro assoluto è l’efficienza relativaE; esso normalizza lo speedup S rispetto alnumero di processori impiegati:
E =SN
=TS
TP ⋅NL’efficienza relativa è utile quale misura deldegrado complessivo delle prestazioni; essainfatti scaturisce dal confronto fra il guadagnoreale e quello ideale.
I parametri statistici sin qui definiti sono di tipogenerale ed utilizzati come metriche standardnella valutazione dell’efficienza di algoritmiparalleli. La loro definizione intendeimplicitamente che i processori sono identici.Ciò che in generale avviene quandol’architettura hardware è costituita da una retelocale è che le risorse di elaborazione sonoeterogenee e quindi con prestazioni differenti.In questo contesto le prestazioni degli algoritmisequenziale e parallelo sono difficilmenteconfrontabili attraverso i parametrici statistici Sed E. Per tenere conto di questa situazione ilcalcolo del tempo complessivo di ricerca Tdeve essere corretto di un fattore che dipendedalle velocità relative di elaborazione dellesingole macchine:
• sia l’insieme di processori P={P1,P2,...,PN} ePr∈P un processore di riferimento;
• sia vi la velocità di elaborazione23 delprocessore Pi (i=1..N);• ad ogni processore è associato un peso diche esprime la velocità relativa di elaborazionerispetto al processore Pr:
di =vi
vr (i = 1..N)
• il fattore di correzione fc è così calcolato:

133
fc =N
di
i=1
N
∑• Dato il tempo di ricerca complessivo T, ilvalore che sarà effettivamente assunto perquesto parametro è:
fc ⋅ TIl fattore medio di produzione Fpm è unparametro che permette di valutare l’effettivoimpiego produttivo dei processori durante iltempo complessivo T di ricerca; esso è cosìdefinito:
• sia N il numero totale dei processori e Tpi
(i=1..N) il tempo dedicato dall’i-esimoprocessore ad attività produttiva, cioèall’esecuzione di lavoro del tipo "ricerca αβ";
• la media aritmetica Tpm dei singoli contributiTpi (i=1..N) esprime il tempo che in media unprocessore dedica alla ricerca; il fattore mediodi produzione normalizza questo parametrorispetto alla durata T della ricerca costituendocosì un indice assoluto:
Fpm =Tpm
T=
Tpi
i=1
N
∑T
Nell’algoritmo di base proposto il modulomaster non esegue attività produttiva e quindi ilsuo tempo di produzione è nullo. In questocaso particolare verrà riportato anche il tempomedio di produzione dei soli moduli worker(Fpmw), così da isolare il comportamentoeccezionale del master.
Il parametro Fpm consentirà di stimare ilbilanciamento del carico indotto dall’algoritmoparallelo; è infatti tale proprietà ad influiremaggiormente sull’utilizzo produttivo deiprocessori. Più in generale esso daràindicazioni sull’incidenza complessiva deidegradi legati alla sincronizzazione ed allacomunicazione.
Altro importante dato statistico è la dimensionedella ricerca; essa è quantificata dal numerototale N di nodi dell’albero visitati(interni+terminali).
Il confronto fra le dimensioni della ricercasequenziale (Ns) e parallela (Np) permette distimare l’overhead di ricerca OR:

134
OR =Np
Ns−1
Parametro tipico di un algoritmo di ricerca è lamisura VR della quantità di ricerca elaboratanell’unità di tempo (velocità di ricerca):
VR =NT
Anche per questo parametro è possibile ilconfronto fra la sperimentazione nelsequenziale e nel parallelo; a riguardo ècalcolato un indice assoluto analogo allospeedup:
• siano VRs e VRp rispettivamente le velocità diricerca sequenziale e parallela;• si definisce guadagno di velocità Svr ilparametro:
Svr =VRp
VRs
Nell’ipotesi realistica di overhead di ricerca nonnegativo vale la relazione: Svr≥S. Si osservi,infatti, che sul valore dell’indice Svr non incidel’overhead di ricerca; esso consente quindi diisolare e valutare gli effetti delle altre forme didegrado delle prestazioni.
La sperimentazione effettiva dell’algoritmo dibase è stata preceduta da una serie di test diverifica delle velocità di elaborazione dellesingole workstation. Ciascuna di esse è stataimpegnata nella ricerca sequenziale conprofondità 5-ply della posizione nr.1 diBratko-Kopec; quale indice della velocità dielaborazione è stata considerata la velocità diricerca (espressa in nodi/sec). Questi testhanno evidenziato una limitata eterogeneitàdelle 11 macchine a disposizione (SUN 4)evidenziando una partizione delle stesse indue gruppi di macchine omogenee (ladifferenza relativa di prestazioni di workstationappartenenti allo stesso gruppo è inferiore al5%):
• 8 workstation (compresa quella di riferimento)meno veloci;• 3 workstation con velocità di elaborazionesuperiore di un fattore 1.7 alla macchina diriferimento.
Questi dati consentono di calcolare il fattore dicorrezione del tempo complessivo di ricerca;tale valore è funzione di numero e tipo di

135
workstation impiegate nella ricerca parallela.Ad esempio nel caso di sperimentazione contutte le 11 macchine esso è costante:
fc =
vi
vri=1
N
∑N
=8 ⋅1+ 3 ⋅1.7
11≅ 1.19
Un parametro della ricerca di alberi di gioco èla sua profondità nominale. Per tutti gliesperimenti essa è stata fissata a 5-ply. Lemotivazioni di questa scelta sono duplici: lasperimentazione su profondità inferiori apparenon significativa date le limitate dimensionidell’albero, mentre la scelta di profonditàmaggiori di 5-ply è resa proibitiva dai tempieccessivi necessari al suo completamento.
Tutti gli algoritmi paralleli implementati sonoparametrici rispetto al numero di processoriimpiegati nella ricerca. L’esplorazione delleposizioni di Bratko-Kopec verrà ripetuta condiversi valori di questo parametro, così datracciare la dipendenza funzionale deiparametri statistici rispetto ad esso. Lo studiodella loro variabilità permetterà inoltre dianticipare il comportamento dell’algoritmo inpresenza di un numero di processori ancoramaggiore del massimo a disposizione perl’esecuzione di questi esperimenti.
Per motivi di spazio non sarà riportato ildettaglio dei parametri statistici calcolati perogni posizione di test, bensì una loro naturalegeneralizzazione basata sulla somma deitempi di ricerca e del numero di nodi visitati nelciclo di esplorazione di tutte le posizioni.
Alcune considerazioni di carattere teoricointendono spiegare quali valori di efficienza sidevono attendere dalla sperimentazione di talealgoritmo:
• l’efficienza dell’algoritmo base èproporzionale al rapporto B/Nw fra il fattore didiramazione dell’albero di gioco ed il numero diesploratori [MarCam82];
• per un albero di gioco con valore tipico B=40,una ricerca sequenziale αβ è equivalente aduna ricerca esaustiva (algoritmo minimax) di unalbero con fattore B=7 di diramazione [Gil72].Pertanto, se l’algoritmo di decomposizionefosse sperimentato su un’architettura di Nw=40

136
esploratori, lo speedup medio che si dovrebbeottenere è 7.In Tab. 5.1b è presentato il risultato dellasperimentazione dell’algoritmo base didecomposizione, mentre in Tab. 5.1a èspiegato il significato delle colonne di Tab. 5.1b(tale legenda avrà valore anche per lesuccessive tabelle).
nr. proc il numero complessivo di processori (master+worker)
T il tempo complessivo di ricerca (misurato in secondi) necessarioalla esplorazione di tutte le 24 posizioni di test
N il numero totale di nodi visitati nella ricerca di tutte le posizioni ditest
S lo speedup (=T1
Tnr.proc)
E l’efficienza relativa (=S
nr.proc)
Fpm il fattore medio di produzione
Fpmw il fattore medio di produzione dei worker
SO l’overhead di ricerca (=Nnr .proc
N1−1)
VR la velocità di ricerca (=NT
)
SVR il guadagno di velocità (=VRnr.proc
VR1)
Tab. 5.1a Sommario dei parametri statistici
nr. proc T(sec) N (nodi) S E Fpm Fpmw SO VR (nodi/sec) Svr
1 8301 5347545 --- --- --- --- --- 644 ---3 4571 5754203 1.82 0.61 0.66 0.98 0.08 1259 1.95
5 2770 6599460 3.00 0.60 0.75 0.93 0.23 2382 3.707 2242 7236560 3.70 0.53 0.71 0.83 0.35 3228 5.01
9 1988 7876769 4.18 0.46 0.68 0.77 0.47 3962 6.15
11 1786 8521288 4.65 0.42 0.66 0.73 0.59 4771 7.41
Tab. 5.1b Algoritmo base didecomposizione: sperimentazioneIl dato statistico più rilevante è rappresentatodai valori molto bassi dello speedup. Il motivodi prestazioni tanto deludenti risiede nella forteincidenza complessiva delle forme di degrado;il parametro E (efficienza relativa) spiegainoltre come essa sia tanto maggiore quantopiù elevato è il numero di processori.
L’esame in dettaglio di ciascuna forma didegrado evidenzia una diversa variabilità infunzione del numero di processori:

137
• overhead di ricerca: l’aumento della quantitàdi nodi visitati procede di pari passo con quellodei processori; il degrado maggiore è statoinfatti ottenuto dalla versione dell’algoritmo con11 processori che ha visitato il 59% di nodi inpiù rispetto all’algoritmo sequenziale.L’incidenza di questa forma di degrado sulleprestazioni è notevole: si confrontino ariguardo i valori dello speedup S e i rispettiviguadagni Svr nella velocità della ricerca;quest’ultimo dato statistico può essereinterpretato come lo speedup che si sarebbeottenuto in assenza di overhead di ricerca. Idati statistici relativi alla ricerca con 11processori, ad esempio, rivelano una perdita diefficienza del 37% causata da questa forma didegrado (Svr=7.41 >> S=4.65).
L’entità del degrado si rivela molto elevata seconfrontata con valori tipici di altri algoritmi. Lacausa di tale comportamento è dovuta allaminima condivisione: i moduli esploratoricooperano (con mediazione del supervisore)solamente all’inizio ed alla fine della propriaricerca (rispettivamente aggiornando la copiadello score e comunicando il risultato dellaricerca). Durante la fase centrale è dunque loronegata la possibilità di fruire dei risultatiprodotti dagli altri esploratori, inducendo cosìuna ricerca più svantaggiosa rispettoall’algoritmo sequenziale dove la ricerca di unsottoalbero può avvalersi dei risultati di tutte lericerche precedenti (Fig. 5.6).

138
tempo
in questo intervallo di tempo si completano k ricerche
durata della (i-k)-esima ricerca
inizio (i-k)-esima ricerca inizio i-esima ricerca fine (i-k)-esima ricerca
Nell‘ipotesi che la (i-k)-esima ricerca migliori il valore corrente dello score, la i-esima ricerca non potra` usufruire di questo miglioramento poiche` gia` iniziata.La ricerca sequenziale non soffre di questo problema perche` la i-esima ricerca ha inizio solo dopo che sono terminate tutte le ricerche (i-k) con k>0.
Fig. 5.6 Dipendenza dell’overhead di ricercadalle velocità relative dei processi
Perché l’overhead di ricerca è funzionecrescente del numero di processori?La ricerca αβ trae beneficio dal calcolo quantopiù immediato di un elevato valore parzialedello score; il suo valore iniziale è -∞ e conesso avranno inizio le visite dei primi Nwsottoalberi della radice (Nw è il numero diesploratori): è evidente il degrado rispetto allaricerca sequenziale dove già la visita delsecondo sottoalbero potrà contare su unabuona approssimazione del valore ottimo delloscore (quella calcolata dalla ricerca del primosottoalbero). Il fenomeno non riguarda solo laricerca dei sottoalberi iniziali: in generale lamaggiore distribuzione aumenta anche laprobabilità che una ricerca Ri non benefici delmiglioramento dello score prodotto dallaricerca Ri-k (attivata precedentemente) proprioperché Ri ha avuto inizio prima che Ri-k fossecompletata.
• overhead di sincronizzazione ecomunicazione: il fattore medio di produzioneFpm fornisce indicazioni su queste forme didegrado. Si osservi lo strano andamento diquesto fattore in funzione del numero diprocessori: crescente fino a 5 processori (75%)e poi decrescente fino a 11 dove si ottiene lostesso fattore acquisito con 3 processori

139
(66%). Si confrontino questi valori con il fattoredi produzione medio riferito ai soli esploratori ilquale presenta andamento costantementedecrescente. La causa della discordanza fra lavariabilità dei due parametri di produzione èl’attività non produttiva (dal punto di vista dellaricerca αβ) del modulo supervisore. Essosvolge sole mansioni di coordinatore e per lamaggior parte del tempo complessivo di ricercaT è sospeso in attesa di interagire con gliesploratori: questa situazione è tipica inimplementazioni basate sul modellomaster-worker. Nell’ipotesi (finora assuntaimplicitamente) che ogni modulo sia allocato suun processore diverso, in virtù dell’elevatotempo di sospensione del supervisore si vienea creare un forte inutilizzo del processore chelo ospita. Soluzione immediata a questoproblema è che il supervisore ed uno degliesploratori siano allocati sullo stessoprocessore. Tuttavia tale soluzione è nondescrivibile nello standard di Linda essendol’allocazione dei processi trasparente alprogrammatore; si consideri, inoltre, che ilparadigma master-worker operaefficientemente solo se il master è in grado digenerare lavoro velocemente in modo datenere occupati tutti i worker: se essocondividesse il tempo di CPU con un altroprocesso i suoi tempi di risposta potrebberoessere così rallentati da influire sensibilmentesulle prestazioni complessive.
All’aumentare del numero di esploratori larinuncia alla produttività del processore cheospita il supervisore diviene meno influente;per contro, cresce il numero medio diesploratori inattivi durante la fase finale dellaricerca (il fattore Fpmw è infatti decrescente).Sono questi i motivi di degrado che affliggonomaggiormente la produzione: la lorocombinazione giustifica l’andamento nonmonotono del fattore Fpm. Il costo dellecomunicazioni incide invece sulla produzionein modo costante e trascurabile: il numero diinterazioni fra moduli sono infatti in numeroesiguo (proporzionale al fattore di diramazionedell’albero) ed indipendente dalla quantità diprocessori.

140
5.2.1.2 Varianti dell’algoritmo base didecomposizione: l’impiego del master nellaricerca
I risultati sperimentali hanno sottolineato i riflessisull’efficienza del mancato impiego nella ricerca αβdel processore destinato all’esecuzione del processosupervisore. Non disponendo di strumenti in Linda peril controllo dell’allocazione dei processi, il recupero"produttivo" del tempo in cui il supervisore è sospesoin attesa del completamento di un esploratore deveessere programmato esplicitamente. A riguardo sonopresentate due differenti soluzioni.
5.2.1.2.1 Un approccio intuitivoSi vuole applicare all’algoritmo base didecomposizione l’idea seguente: una volta cheè stato distribuito lavoro sufficiente adimpegnare tutti gli esploratori, il modulosupervisore esegue il lavoro relativo al primosottoalbero della radice non ancora distribuito;solamente dopo aver completato tale compitoesso sarà nuovamente assegnato alle suemansioni di supervisione. Durante la fase diricerca il supervisore diviene a tutti gli effetti unesploratore: l’architettura logica dicomunicazione di Fig. 5.1 deve essere dunquemodificata per tenere conto di questa nuovasituazione (Fig. 5.7).
Supervisore Esploratore1 Esploratore2 Esploratore(N-1)
Supervisore
Fig. 5.7 Architettura logica dicomunicazione con impiego nella ricercadel processo supervisore
Le modifiche apportate al modulo supervisoresono trasparenti ai moduli esploratori il cuiflusso di controllo rimane invariato rispetto allaprima versione dell’algoritmo base. Esse sonoinoltre confinate nella fase centrale della

141
ricerca che per il modulo supervisore èdescritta dalla funzione master in Fig. 5.8.
#define update_local_and_global_score\{\local_score=value;\in ("score",?int);\out ("score",local_score);\best=r_subtree;\}\int master(int n_worker,int nmoves,intdepth,position *successor){int nmoves,local_score,subtree,free,best;local_score=-INFINITE;out ("score", local_score);free=n_worker;subtree=1;while ((subtree <= nmoves) || (free<n_worker))
if (subtree <=nmoves){if (free>0) /* si distribuisce
lavoro appena un worker è libero*/{out ("job",subtree);free--;subtree++;}
else{if (inp
("result",?value,?r_subtree)) /* si testa seun esploratore
ha completato il suo lavoro */free++;
else /* invece disospendersi nell‘attesa dei
risultati degli esploratori ilsupervisore
diviene lui stesso esploratore */{
tree_pointer=successor+subtree-1;
makemove(tree_pointer);value=-
alphabeta(tree_pointer,-INFINITE,-local_score,depth);
undomove(tree_pointer);r_subtree=subtree;}
if (value>local_score)
update_local_and_global_score;/* la gestione dei risultati è realizzatadalla stessa porzione di codice,indipendentemente dal fatto che essi sianoprodotti dagli esploratori o dal supervisore*/
}}
else /* attesa finale delcompletamento degli ultimi lavori */
{in ("result",?value,?r_subtree);if (value>local_score)

142
update_local_and_global_score;free++;}
in ("score",?int);return (local_score);}Fig. 5.8 Impiego nella ricerca delsupervisore: un approccio intuitivo
Il codice in Linda evidenzia la priorità che ilmodulo supervisore assegna alla gestione deilavori rispetto alla sua nuova attività diesploratore: quest’ultima è infatti intrapresasolo se:
• (free==0): è stato distribuito un numero dilavori sufficiente ad impegnare tutti gliesploratori e
• (inp("result",?value,?r_subtree)==false):nessun esploratore ha completato la suaricerca
Il modulo supervisore implementa in mododiverso rispetto agli esploratori le fasi iniziale efinale dell’esecuzione di un lavoro: il prelievo diquest’ultimo e la comunicazione del relativorisultato non sono infatti mediati da strutturedati distribuite; lo scambio logico di questeinformazioni avviene all’interno dello stessomodulo e non è quindi necessaria alcunainterazione sullo spazio delle tuple.
I dati statistici di Tab. 5.2 descrivono i risultatidella sperimentazione di questa nuovaversione dell’algoritmo base.
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 8301 5347545 --- --- --- --- 644 ---
3 4544 5860668 1.83 0.61 0.70 0.10 1290 2.005 3173 6330053 2.62 0.52 0.66 0.18 1995 3.10
7 2779 6867688 2.99 0.43 0.61 0.28 2471 3.84
9 2517 7310806 3.30 0.37 0.57 0.37 2905 4.51
11 2310 7990369 3.59 0.33 0.54 0.49 3459 5.37
Tab. 5.2 Sperimentazione dell’impiego nellaricerca del supervisoreL’approccio proposto si è rivelato fallimentare:il confronto con la prima versione dell’algoritmobase evidenzia una notevole riduzione dellospeedup, maggiormente visibile conl’aumentare del numero di processori.

143
La spiegazione di risultati tanto deludenti èancora una volta suggerita dall’esame delfattore di produzione Fpm il quale evidenzia untempo di utilizzo troppo esiguo delle risorse dielaborazione. Con 11 processori, ad esempio,si ha Fpm=0.54: ciò significa che un genericoprocessore è stato inoperoso durante il 46%del tempo complessivo di ricerca. Tali valoripossono essere giustificati solo da unastrategia di distribuzione dei lavori inefficiente.Un modulo esploratore che produce unrisultato durante la fase centrale della ricercadiviene inoperoso fino a che il supervisore nonrileva questo evento e produce di conseguenzaun nuovo lavoro. Nella nuova versionedell’algoritmo il modulo supervisore èimpegnato per la maggior parte del suo tempodi elaborazione nella ricerca di sottoalberi e lefunzioni di supervisione possono solointercalarsi fra una ricerca e la successiva; acausa del suo duplice compito il supervisorenon è in grado di rilevare prontamente ilcompletamento di un altro lavoro: ciò avverràsolo dopo che avrà terminato il suo lavorocorrente. Pertanto un generico esploratoreverrà sospeso per un tempo che in media èpari alla metà del tempo medio di ricerca di unsottoalbero della radice.
Per effetto dell’aumentata inoperosità deiprocessori si è però avuta una diminuzionedell’overhead di ricerca. I due parametri sonoinfatti direttamente collegati: il fatto che imoduli esploratore si sospendano più a lungoin attesa dell’attribuzione di un nuovo lavoroaumenta la probabilità che quest’ultimo noninizi prima che anche altri esploratori abbianocompletato il proprio e possa così beneficiaredell’eventuale aggiornamento dello score daessi prodotto.
Il miglioramento dell’overhead di ricerca ècomunque irrisorio rispetto all’entità delproblema legato all’eccessivo inutilizzo deiprocessori. In conclusione il confronto fra i duealgoritmi proposti vede dunque vincente laprima versione evidenziando così come larinuncia di un processore alla ricerca siacomunque conveniente se ciò comporta un

144
elevato bilanciamento del carico fra i moduliworker.
5.2.1.2.2 Una modifica del paradigmamaster -worker: un modello dicooperazione alla pari
Le due versioni dell’algoritmo base sin quidescritte hanno evidenziato prestazioniinsoddisfacenti. Le principali cause di taleinefficienza sono rispettivamente:
• l’impiego di un processore (quello su cui èallocato il modulo supervisore) durante la fasecentrale di ricerca per sole finalità di gestione
• l’indisponibilità immediata di nuovo lavoro perl’esploratore che ha completato la ricerca di unsottoalbero.
La presenza di questi problemi non è intrinsecanell’algoritmo di base, ma scaturisce dalparadigma di programmazione parallela con ilquale è stato implementato: il modellomaster-worker. La presente sezione intendeapportare alcune modifiche a tale modello alfine di limitare (o addirittura eliminare) entrambii motivi di degrado elencati.
L’idea che si intende sperimentare è confinareil ruolo del master a quello di solo generatoredi lavori; tale attività, inoltre, viene completataprima che la ricerca effettiva abbia inizio. Lagestione dei risultati prodotti dal lavoro degliesploratori è invece completamente a carico diquest’ultimi.
Immediata conseguenza di questo approccio èche si rende inutile la presenza di un processomaster durante la ricerca dell’albero di gioco; larisorsa di elaborazione da esso occupata puòessere quindi assegnata all’esecuzione deilavori senza creare problemi di ritardo nelladistribuzione dei lavori. L’attività di gestionedella ricerca del modulo supervisore saràdunque decomposta in tre fasi consecutive:
• generazione ed inserimento in agenda di tuttii lavori;• conversione nel ruolo di esploratore;• rilevamento dell’avvenuto completamento ditutti i lavori e prelievo del risultato finale.Nella prima fase il modulo supervisoreinserisce in agenda i lavori relativi alla ricercadi tutti i sottoalberi della radice. Tale approccio

145
rende insoddisfacente l’implementaziondedell’agenda come una struttura dati distribuitadi tipo bag in quanto l’indistinguibilità dei lavoriindotta da questa struttura ne sopprimel’ordinamento. Nelle versioni precedentidell’algoritmo questo effetto poteva essereconsiderato trascurabile poiché l’esecuzioneordinata dei lavori veniva controllata dalmodulo supervisore il quale si limitava agenerare solo i lavori necessari ad occupare gliesploratori inoperosi: il "disordine" prodottodall’agenda avrebbe comunque interessato ingenerale un numero esiguo di lavoriconsecutivi (nell’ordine di generazione).L’inserimento contemporaneo (da un punto divista logico) di tutti i lavori in un’agenda di tipobag induce, invece, un ordine di prelievo deilavori completamente casuale. Per questimotivi la struttura di lavori deve essereimplementata come una coda; la struttura datidistribuita che soddisfa tale requisito è lacoda-in (cfr. 3.4.1.3.2). Alcune proprietàdell’algoritmo base rendono tuttavia sufficienteuna versione semplificata di tale struttura dati:si osservi infatti che la descrizione dei lavori(l’indice del sottoalbero della radice da visitare)coincide con la posizione che essi occupanonella sequenza che si intende mantenereordinata. Pertanto l’indice di estrazione dellacoda (head) contiene di per se tuttal’informazione necessaria alla descrizione di unlavoro. Di conseguenza l’agenda saràimplementata da un’unica tupla della forma:
("head",subtree)La sua presenza indica che è già stataimpegnata la ricerca dei primi (subtree-1)sottoalberi della radice e la successiva avràper oggetto il subtree-esimo.
L’operazione logica di inserimento di tutti ilavori è dunque ridotta alla inizializzazionedella tupla appena detta:
out ("head",1);Il prelievo di un nuovo lavoro è inveceimplementato dall’incremento logico del camposubtree:
in ("head",?subtree);out ("head",subtree+1);

146
Sia NMOVES il numero di mosse al top-level: ilcampo subtree non è più incrementato dopoche ha raggiunto il valore (NMOVES+1), cioèdopo che anche l’ultimo lavoro è statoprelevato. La presenza della tupla ("head",NMOVES+1) permetterà di riconoscere lo statodi terminazione della ricerca.
Completata l’inizializzazione della struttura dilavori il modulo supervisore diviene unesploratore alla pari di tutti gli altri. Scomparedunque la figura di un amministratore econtrollore unico della ricerca: la gestioneglobale non è più centralizzata, ma distribuitafra gli esploratori.
L’elaborazione dei risultati della ricercacompete ora ai moduli esploratore: essicooperano infatti aggiornando il valore correntedello score al top-level; questa informazione ècondivisa da tutti i moduli in quantoimplementata come variabile distribuita. Inparticolare l’esploratore che completa la ricercadi un sottoalbero verifica lui stesso se ilrisultato da essa prodotto migliora il valorecorrente dello score. La consistenza di questeoperazioni viene garantita dalla indivisibilità deicostrutti Linda:
in ("score",?old_score);new_score=(value>old_score) ?value : old_score;out ("score",new_score);Fig. 5.9 sottolinea le modifiche apportateall’architettura logica di comunicazioneevidenziando la gestione alla pari dello scorecorrente in opposizione a quella centralizzatadel modello master-worker.
Supervisore
inserimento in agenda di tutti i lavori
Esploratore2Esploratore1 EsploratoreN
Score
Agenda
Agenda
Supervisore
Score
prelievo dello score finale
Supervisore -> EsploratoreN EsploratoreN -> Supervisore

147
Fig. 5.9 Architettura logica di cooperazionealla pari
L’applicabilità del modello di cooperazionepresentato è certamente meno generale diquella del modello master-worker rigoroso.Sono infatti proprietà particolari dell’algoritmobase che rendono questo modello una validastruttura per un’implementazione efficiente:
• è possibile stabilire a priori l’identità dei lavoriche dovranno essere eseguiti: in molteapplicazioni i nuovi lavori che sono generatidipendono dai risultati prodotti dall’esecuzionedei precedenti e quindi il metodo non èapplicabile poiché la generazione dei lavorideve avvenire dinamicamente durante il tempodella loro esecuzione.
• il numero dei lavori realmente necessari èfissato prima dell’inizio della ricerca: spessonei problemi di ricerca, pur essendo definibilestaticamente l’insieme di lavori da completare, irisultati intermedi rendono un sottoinsieme diessi non necessario. Questa sarebbe stata lasituazione se la finestra αβ al top-level nonfosse stata (-∞,+∞), ma (α,β) e lo scoreparziale avesse superato il limite β: avendoottenuto un taglio la ricerca dei restantisottoalberi è inutile e tale è quindi anchel’inserimento iniziale in agenda dei relativilavori. In generale l’inefficienza introdotta èproporzionale al numero medio di lavori"tagliati" ed alle dimensioni della lorodescrizione.
• l’elaborazione dei risultati dei lavori richiedeun tempo trascurabile rispetto alla loroesecuzione. In generale questa operazioneagisce su informazioni globali ai moduli e deveessere eseguita in modo indivisibile: se la suadurata non fosse trascurabile essa sarebbeorigine di frequenti collisioni perl’aggiornamento delle strutture condivise, diconseguenti serializzazioni degli accessi allerelative sezioni critiche e in definitiva di unaumento dell’overhead di sincronizzazione. Laminimizzazione della durata delle sezionicritiche viene proposta in letteratura come unodei requisiti fondamentali per la limitazione deldegrado della performance.

148
• il generico worker è in grado di rilevare inmodo autonomo la condizione terminale di"agenda vuota". Questa condizione ènecessaria affinché il modulo supervisore,"confuso" durante la ricerca fra gli altriesploratori, sia in grado di riconoscere la finedei lavori per potere ripristinare il suo ruolo diprivilegio.
Nella terza e conclusiva fase della ricerca,infatti, il supervisore riacquista la suasingolarità. In particolare esso si sincronizzacon l’evento "completamento di tutti i lavori": ilfatto che il supervisore abbia già rilevatol’assenza di lavori in agenda non implica infattiche gli ultimi lavori prelevati siano stati tutticompletati. Quest’ultimo evento vienericonosciuto indirettamente grazie alrilevamento di un altro evento di cui esso èlogica conseguenza: "tutti gli esploratori hannorilevato la condizione di agenda vuota". Solodopo tale verifica il valore corrente dello scorepuò essere assunto come finale e letto dallarelativa variabile distribuita.
Fig. 5.10 descrive in Linda le idee sin quidescritte presentando l’algoritmo base cosìmodificato alle prese con la fase centrale dellaricerca.
La funzione worker_search è eseguita sia dalmodulo supervisore che dagli esploratori; perquest’ultimi essa è invocata all’interno di unafunzione worker più esterna (non presentata infigura) dopo che è avvenuta la ricezione delnodo radice del nuovo albero di gioco daesplorare. La coincidenza della funzione dicontrollo interno della ricerca sottolinea il ruolocompletamente alla pari (con i moduliesploratore) che il modulo supervisore assumedurante questa fase.
int master(int n_worker,int nmoves,intdepth,position *successor){int nmoves,score,best;void worker_search();out("score",-INFINITE); /* inizializzazionescore globale */out("ending_workers",n_worker+1);out("head",1); /* riempimento agenda ≈inizializzazione puntatore alla testa dellacoda - lavori */

149
worker_search(nmoves,depth,successor); /*supervisore >> esploratore */in("ending_workers",0); /* attesacompletamento di tutti i lavori ≈ tutti gliesploratori hannorilevato l‘evento "agenda vuota" */in("head",nmoves+1);in("score",?score); /* prelievo score finale*/return(score);}void worker_search(int nmoves,intdepth,position *successor){intsubtree,tree_pointer,value,initial_score,current_score,quit,e_w;quit=false;while (!quit)
{in("head",?subtree); /* prelievo lavoro
≈ rimozione puntatore di estrazione */if (subtree==(nmoves+1)) /* agenda
vuota? */{out("head",subtree); /* la
condizione di terminazione deve poter essererilevata
anche dagli altri esploratori */in ("ending_workers",?e_w);out ("ending_workers",e_w-1);quit=true;}
else{out("head",subtree+1); /*
aggiornamento puntatore di estrazione */tree_pointer=successor+subtree-1;makemove(tree_point er);rd ("score",?initial_score); /*
aggiorna copia locale dello score */value=-alphabeta(tree_pointer,-
INFINITE,-initial_score,depth);undomove(tree_pointer);if (value>initial_score) /*
migliorata la copia locale dello score? */{in
("score",current_score); /* inizio sezionecritica di aggiornamento
dello score globale */if (value>current_score)
/* miglioramento? */
current_score=value;out
("score",current_score); /* fine sezionecritica */
}}
}}Fig. 5.10 Implementazione dell’algoritmobase con cooperazione alla pari
La sperimentazione dell’algoritmo presentato,documentata in Tab. 5.3, intende verificare il

150
miglioramento dei motivi di degrado che hannoafflitto le prime due versioni dell’algoritmobase.
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 8301 5347545 --- --- --- --- 644 ---3 3298 6156027 2.52 0.84 0.96 0.15 1867 2.90
5 2382 6945194 3.48 0.70 0.91 0.30 2916 4.53
7 2064 7524137 4.02 0.57 0.81 0.41 3645 5.669 1798 8186074 4.62 0.51 0.77 0.53 4553 7.07
11 1751 8746752 4.74 0.43 0.71 0.64 4995 7.75
Tab. 5.3 Algoritmo base con cooperazionealla pari: sperimentazione.In Fig. 5.11 è riportato il confronto fra le curvedello speedup della nuova versionedell’algoritmo base e della prima proposta. Ilmiglioramento delle prestazioni può essereosservato su tutte le configurazioni diprocessori; il motivo di questo risultato èdovuto alla maggiore produttività media deiprocessori. Come atteso, infatti, gli esploratoririescono a cooperare in modo efficiente nellaricezione dei lavori e nell’elaborazione deirelativi risultati.
Nr. processori
Sp
ee
du
p
0
1
2
3
4
5
6
0 3 5 7 9 11
master-worker
alla pari
Fig. 5.11 Confronto dello speedup delleversioni dell’algoritmo base concooperazione master -worker e alla pari

151
Un dato sorprendente è costituito dal sensibileaumento dell’overhead di ricerca: esso ha unaduplice spiegazione:
• rispetto alla versione basata sul modellomaster-worker rigoroso il parallelismo realenella ricerca è aumentato di una unità: ciòimplica una maggiore distribuzione(decomposizione) dell’albero di gioco e quindiun aumento dell’overhead di ricerca;
• il tempo di attesa del generico esploratore frail completamento di un lavoro (nel presentecaso si intende esecuzione ed elaborazionedel risultato) e l’inizio del successivo si puòassumere minore rispetto alla prima versionein quanto l’assegnamento del lavoro è gestitoautonomamente ed è inoltre eliminato il ritardodovuto al suo inserimento in agenda.Conseguenza della riduzione di questo tempodi attesa è una minore probabilità perun’esploratore di usufruire dell’aggiornamentoprodotto da un altro che ha completato la suaricerca dopo di esso.
Si osservi come la differenza fra le prestazionidei due algoritmi a confronto diminuisca conl’aumentare del numero di processori finoquasi ad annullarsi in presenza di 11 di essi.La situazione descritta non è casuale: conl’aumento dei processori, infatti, i due algoritmitendono a ridurre i vantaggi e svantaggireciproci fino ad una situazione limite in cuiessi hanno le stesse prestazioni. Taleintuizione è confortata da alcuneconsiderazioni di carattere analitico:
• sia P il numero complessivo di processori esia E(P) il numero di processori impiegati comeesploratori;
• sia il coefficiente C(P) così definito:
C(P) =Emaster - worker(P)
Ealla_ pari(P)=
P -1P
• il rapporto fra i fattori di produzione dei duealgoritmi è proporzionale al coefficiente C(P),mentre il rapporto fra i rispettivi overhead diricerca è inversamente proporzionale ad esso;
• si osservi che limp→ ∞
C(P) = 1 e limp→ ∞
1C(P)
= 1
• in conclusione, assumendo (con realisticaapprossimazione) che le principali forme didegrado siano funzione del solo numero di

152
processori E(P) impegnati nella esplorazione,si può affermare che i due algoritmi siequivalgono asintoticamente nelle prestazioni.
5.2.1.3 Lo studio degli algoritmi su alberi digioco ordinati: approfondimento iterativo eriordinamento dei nodi al top -level
Tutti gli algoritmi finora presentati prevedono losviluppo di un’unica ricerca condotta fino allaprofondità nominale dell’albero di gioco.L’ordinamento dei nodi al top-level in questo caso èpovero in quanto fissato dal generatore di mosse.L’efficienza della ricerca αβ è fortemente condizionatadall’ordine di visita dei nodi (soprattutto di quelli altop-level); fondare la sperimentazione degli algoritmiαβ paralleli sulla ricerca di alberi di gioco il cui gradodi ordinamento è impredicibile può quindi condurre agrossolani errori di valutazione.
Si è così scelto di uniformare la ricerca a soli alberi digioco ordinati: di conseguenza essa deve esserearricchita di strumenti per l’ordinamento dinamico deinodi.
In particolare la ricerca unica a profondità nominale èsostituita da una successione di ricerche definite inrispetto dell’euristica denominata approfondimentoiterativo. La versione "distribuita" di questa euristica èperfettamente analoga a quella sequenziale:
• è fissata una profondità iniziale di ricerca INIT eduna massima MAX (pari alla profondità nominale);• viene condotta fino a profondità INIT la ricercaparallela dell’albero di gioco (ad esempio guidatadall’algoritmo base di decomposizione);
• la ricerca in parallelo viene reiterata a profonditàaumentata di una unità. Questo procedimento vieneripetuto fino a raggiungere profondità MAX di ricerca.
Si osservi che le dimensioni degli alberi di giocoesplorati nelle prime iterazioni potrebbero essere cosìridotte da rendere non conveniente un approccioparallelo alla loro ricerca: la decomposizione di questialberi potrebbe infatti causare un costo dellecomunicazioni molto più elevato di quello di unaricerca sequenziale. La soluzione generale è dunquefissare una profondità di soglia al di sopra della qualela ricerca è parallela, mentre per profondità inferioriessa è realizzata sequenzialmente. Questoaccorgimento determina un’evidente overhead disincronizzazione: se P è il numero di processori, (P-1)di essi sono inoperosi per tutta la durata delle prime

153
ricerche sequenziali. Tale degrado può comunqueconsiderarsi trascurabile poiché questo tempo diattesa è irrisorio rispetto a quello necessario acompletare la ricerca a profondità superiori.
L’euristica di approfondimento iterativo è finalizzata acreare uno scenario di ricerca che favorisca l’efficaciadella quasi totalità delle euristiche di ordinamento deinodi; per il momento, tuttavia, verrà considerata lasola euristica denominata riordinamento dei nodi altop-level.
L’idea alla base di questa euristica è portare in testaall’ordinamento dei nodi al top-level quelli la cuivalutazione ha prodotto, durante la i-esima iterazione,un miglioramento dello score; gli effetti di questoriordinamento si rifletteranno positivamente sulla(i+1)-esima e successive iterazioni.
L’applicazione di quest’ultima euristica all’algoritmobase con cooperazione alla pari comportal’introduzione di nuove strutture dati distribuite:
• l’ordine dei nodi al top-level deve essere noto a tutti imoduli; non è più possibile distribuire questainformazione implicitamente poiché l’ordinamento nonè quello fissato dal generatore di mosse, ma varia daun’iterazione all’altra. Supponendo un numeroNMOVES di mosse al top-level si renderà necessaria lamemorizzazione del loro ordine in una struttura datidistribuita di tipo vettore di NMOVES elementi ciascunoindividuato dalla tupla con schema:
("order",index,subtree)il cui significato è: il sottoalbero subtree occupa laposizione index nell’ordinamento corrente.• il prelievo di un lavoro si articola ora in due fasi:• lettura della posizione che esso occupa nellasequenza:in ("head",?INDEX);out ("head",INDEX+1);• lettura dal vettore di ordinamento della descrizionedel lavoro corrispondente all’indice letto:in ("order",INDEX,?subtree);Si osservi come l’insieme di tuple e operazioni suesse indicate definiscano nel complesso una strutturadati di tipo coda-in.
• le informazioni necessarie all’aggiornamento delvettore di ordinamento sono prodotte dagli esploratoridurante la ricerca; esse si compongono di:
• una variabile distribuita con funzione di contatore delnumero di miglioramenti dello score ottenuti durantel’iterazione corrente:

154
("counter",count)• una lista ordinata distribuita contenentel’identificatore dei sottoalberi la cui valutazione haprovocato miglioramento dello score:
("improver",index,subtree)Tali strutture dati sono così aggiornate: all’internodella sezione critica che definisce per il moduloesploratore l’aggiornamento dello score globale, se siverifica un miglioramento del suo valore, vengonoeseguite le seguenti operazioni:
in ("counter",?count);count=count++;out ("counter",count);out ("improver",count,subtree);/* subtree = indice del sottoalberovisitato */• l’aggiornamento del vettore di ordinamento èeseguito dal modulo master; esso avviene prima cheabbia inizio una nuova iterazione (da un punto di vistalogico questa operazione coincide con l’inserimentoordinato in agenda di tutti i lavori). In particolare vienescandita secondo l’ordine di inserzione la listadistribuita di sottoalberi che hanno migliorato lo score:ciascuno di essi viene portato in testa all’ordinamentocomplessivo delle mosse al top-level. Questoprocedimento fa sì che il primo sottoalbero presentenel vettore di ordinamento sia quello relativo all’ultimoaggiornamento dello score o in altre parole risultatomigliore durante l’iterazione precedente.
La sperimentazione dell’algoritmo così ottenuto èstata effettuata fissando i parametri dell’euristica diapprofondimento iterativo come segue: INIT=2-ply,MAX=5-ply e la soglia per l’applicazione della ricercaparallela pari a 3-ply.
Quale algoritmo sequenziale di confronto è statoconsiderato αβ arricchito delle versioni sequenzialidelle due euristiche descritte (le profondità INIT eMAX sono le stesse scelte per la versione parallela).
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 6740 4529971 --- --- --- --- 672 ---3 2884 5415125 2.34 0.78 0.94 0.20 1878 2.79
5 2229 6307062 3.02 0.60 0.87 0.39 2830 4.217 2007 7317370 3.36 0.48 0.80 0.62 3646 5.42
9 1839 8187769 3.67 0.41 0.75 0.81 4452 6.62
11 1825 8980505 3.69 0.34 0.71 0.98 4921 7.32

155
Tab. 5.4 Algoritmo base con approfondimentoiterativo e riordinamento dei nodi al top -level:sperimentazione
Si confrontino i dati sperimentali di Tab. 5.4 relativialla nuova versione dell’algoritmo base con quelliottenuti in assenza delle nuove euristiche diordinamento dei nodi (Tab. 5.3). Il dato statistico piùallarmante è il notevole aumento dell’overhead diricerca (98% con 11 processori!!). Si osservi come ilnumero assoluto N dei nodi visitati sia quasi invariatoed è addirittura maggiore in presenza di 9 e 11processori. La versione sequenziale, al contrario, traegrosso beneficio dall’inserimento delle nuoveeuristiche: la porzione di albero visitata è ridottadel 17%.
I motivi di un contributo così diverso delle euristichealla ricerca parallela rispetto alla sequenziale èancora dovuto al problema della ricerca dei primi Psottoalberi (P è il numero dei processori): per essil’ordinamento reciproco non ha valore perché sonorimossi contemporaneamente al fine di impegnare dasubito tutti i processi; la ricerca di questi sottoalberi sipresume sia molto più lunga rispetto ai successivi acausa dello score iniziale per loro ancora pari a -∞: diconseguenza le tecniche di ordinamento dei nodiapportano vantaggi minimi (per l’algoritmo base).
Si deve considerare, inoltre, che rispetto all’algoritmocon assenza di approfondimento iterativo, il conteggiodei nodi tiene conto anche dei nodi visitati durantetutte le iterazioni che precedono l’ultima: questooverhead giustifica l’aumento in assoluto del numerodi nodi registrato con numero di processori superiorea 9.
Si osservi, infine, una diminuzione in generale del 2%del fattore medio di produzione: su questo dato graval’overhead supplementare di sincronizzazioneaccumulato durante le ricerche precedenti quella aprofondità massima.
5.2.1.4 La riduzione dell’overhead di ricercaLa sperimentazione di alcune versioni dell’algoritmobase di decomposizione ha permesso di evidenziarela notevole riduzione delle prestazioni di cui è causal’overhead di ricerca. L’analisi di tali versioni ha giàevidenziato i principali motivi che originano undegrado così elevato:
• assenza di condivisione dello score durante laricerca e

156
• score iniziale pari a -∞ per i primi Nw lavori (Nw =numero di esploratori).Verranno presentati di seguito due algoritmi cheintendono risolvere i problemi appena elencati.
5.2.1.4.1 La condivisione dello scoreSi consideri come riferimentol’implementazione dell’algoritmo base che haevidenziato la migliore performance, cioèquella basata sul modello di cooperazione allapari. Si vuole applicare a questa struttura laseguente idea: i moduli esploratori aggiornanola rispettiva copia locale dello score anchedurante la ricerca di un sottoalbero. Lo scopodi questo nuovo approccio è garantire unamaggiore cooperazione fra i moduli esploratorei quali sono così in grado di beneficiare giàdurante l’esecuzione del lavoro corrente deimiglioramenti prodotti dagli altri.
La struttura in Linda delle versionidell’algoritmo base già proposte facilital’applicazione di questa idea in quanto era giàprevista la presenza di una variabile distribuitadestinata a contenere il valore dello score eidentificata dallo schema di tupla:
("score",value)L’aggiornamento della copia locale dello scorepuò quindi essere implementata inserendol’operazione di lettura di tale variabile inqualsiasi punto della ricerca αβ:
rd ("score",?global_score)Resta aperta la discussione riguardo lafrequenza di lettura: un aggiornamento moltofrequente tenderebbe ad annullare l’overheaddi ricerca; tuttavia la lettura di una variabiledistribuita comporta un’azione sullo spaziodelle tuple il cui costo dipendedall’implementazione delle primitive Linda. Talecosto non può considerarsi trascurabile nelcaso di approccio con "in distribuita" (quale è ilcaso del sistema Linda usato nel presentelavoro) in quanto l’operazione rd determina unao più comunicazioni fisiche fra i processori;come conseguenza la frequenza di lettura delloscore globale deve essere limitata in modo daimpedire che i vantaggi ottenuti con lariduzione dell’overhead di ricerca sianovanificati dall’eccessivo aumento dell’overheaddi comunicazione.

157
La condivisione dello score avrebbecertamente avuto implementazione piùefficiente in un sistema Linda con "outdistribuita": infatti le caratteristiche delproblema sono tali da considerare trascurabileil numero di scritture nello spazio delle tuple(una per lavoro) rispetto al numero di letture ditipo rd (che si vorrebbe idealmente pari alnumero di nodi visitati).
È interessante osservare come in questacircostanza il progetto implementativodell’algoritmo non possa prescindere daconsiderazioni che riguardanol’implementazione di uno dei livelli sottostantinella gerarchia di un sistema informativo: illinguaggio di programmazione.
Al fine di rispettare il requisito di efficienza èstato necessario sviluppare una soluzionedipendente dall’implementazione delle primitiveLinda.
L’idea alla base dell’approccio adottato èlimitare le letture dello score globale alle sole"utili". Si definisce utile una lettura che modifica(e quindi migliora) la copia dello score locale almodulo: se fra due letture consecutive il valoreglobale dello score non è stato modificato laseconda di queste è da considerarsi (aposteriori) di nessun giovamento alla ricerca equindi il suo costo computazionale (elevato inun sistema con "in distribuita") decisamentemale investito.
L’utilità della sua lettura costituisce per lo scoreun attributo la cui conoscenza è però globale aimoduli: infatti essi non sono in grado distabilire autonomamente se il valore delloscore è stato modificato dopo la loro ultimalettura. Di conseguenza stabilire l’utilità dellalettura comporta in ogni caso un’interazionecon gli altri moduli: tuttavia le proprietàdell’implementazione con "in distribuita"permettono di implementare questa operazionecon un costo trascurabile.
L’idea è la seguente:• dopo ogni lettura dello score globale ilgenerico modulo esploratore inserisce nellospazio delle tuple una tupla privata construttura:
("improved",my_identifier)

158
Per tupla privata si intende una tupla dove unodei campi contiene il "nome" del modulo che laha creata (tipicamente un identificatorenumerico).
• quando un modulo modifica il valore delloscore esso rimuove le tuple private di tutti glialtri esploratori;
• un modulo esploratore è così in grado diconoscere l’avvenuto o meno aggiornamentodello score verificando se la sua tupla privata èancora presente nello spazio delle tuple:
"utilità della lettura" = rdp("improved",my_identifier)
In un sistema con "in distribuita" un modulo haaccesso privilegiato alle tuple private poichéfisicamente già presenti nella propria arealocale di memoria. Le operazioni di rimozionedi tutte le tuple private ed il tentativo di letturadi una tupla inesistente (rdp senza successo)sono molto costose; tuttavia esse si verificanoin numero molto limitato poiché tale è il numeromedio di miglioramenti dello score dai qualitraggono origine. La situazione che siverificherà con maggiore frequenza è invece lalettura con successo della tupla privata il cuicompletamento ha costo trascurabile ed il cuisignificato è "lettura inutile dello score globale".
La descrizione dell’algoritmo è completatadall’indicazione delle fasi della ricerca αβ in cuiviene eseguito il test descritto: nella versioneche verrà sperimentata esso avviene prima divalutare ciascuna delle mosse al primo livellodel sottoalbero attribuito al genericoesploratore.
L’implementazione descritta non rispettapienamente il principio di indistinguibilità deiprocessi worker poiché introduce il concetto dinomi di moduli: essi sono stabiliti dal master almomento della creazione dei worker; aciascuno di essi è comunicato il proprioidentificatore. Non è necessario che un moduloconosca il nome degli altri: la rimozione delletuple private può essere infatti implementatacon un ciclo del tipo:
while (inp ("improved",?int));Tab. 5.5 illustra la valutazione sperimentaledella soluzione proposta.

159
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 6740 4529971 --- --- --- --- 672 ---
3 2689 4995937 2.51 0.84 0.94 0.10 1858 2.765 1854 5346599 3.64 0.73 0.88 0.18 2884 4.29
7 1485 5634915 4.54 0.65 0.81 0.24 3795 5.65
9 1315 5936185 5.13 0.57 0.77 0.31 4514 6.72
11 1280 6726213 5.27 0.48 0.74 0.48 5255 7.82
Tab. 5.5 Condivisione dello score:sperimentazioneI risultati ottenuti, se confrontati con quellirelativi alla versione dell’algoritmo in assenzadi condivisione (Tab. 5.4), rivelano unasorprendente efficacia del metodo presentato:l’overhead di ricerca SO è ridotto in generaledella metà (del 62% nel confronto con 9processori). La diminuzione di questa forma didegrado si è riflessa positivamentesull’efficienza: lo speedup con il massimonumero di processori è aumentato del 42%(3.69 → 5.27).
I risultati per il fattore di produzione Fpm sonoun’approssimazione superiore del valore reale:essi non sono infatti depurati dei tempi di"improduttività" legati all’aggiornamento dellacopia locale dello score. L’incidenza deldegrado appena citato può tuttavia esserededotta come segue:
• sia P il numero di processori, Fpmr il fattore diproduzione reale e OC una misura del degradodovuto alla condivisione dello score; sonoallora verificate le seguenti relazioni:
SVR = P ⋅Fpmr ⇒ Fpmr =SVR
PFpm = Fpmr + OC⇒ OC= Fpm - Fpmr
• si consideri i valori di questi parametririguardo la sperimentazione con 11 processori:
Fpmr(11) = SVR
P= 7.82
11= 0.71
OC(11) = Fpm − Fpmr = 0.74 − 0.71 = 0.03Il costo delle comunicazioni introdotte dalmetodo descritto non è quindi trascurabile;tuttavia gli enormi benefici da esso apportatiriguardo la riduzione dell’overhead di ricercarendono tale costo più che accettabile.
5.2.1.4.2 PVSplitFra gli algoritmi classici di decomposizionestatica dell’albero di gioco PVSplit (e le sue

160
varianti) è senza dubbio fra i più efficienti. Essorappresenta una naturale generalizzazionedell’algoritmo base: la decomposizione di baseè applicata ricorsivamente lungo la varianteprincipale così da impegnare inizialmente tutti iprocessi nella valutazione del primosottoalbero della radice. Completata questavisita iniziale, la ricerca dei restanti sottoalberiviene sviluppata analogamente a quantoavveniva nella decomposizione base; ladifferenza fondamentale è che tutti i sottoalberisuccessivi al primo sono esplorati disponendodi un buono score iniziale: il valore minimaxdella prima mossa valutata. Tale score saràtanto migliore quanto più accurato èl’ordinamento iniziale al top-level: l’algoritmotrae quindi indubbio beneficio dall’approcciocon approfondimento iterativo in combinazionecon il riordinamento dinamico delle mosse altop-level.
Visto come evoluzione dell’algoritmo base,l’obbiettivo che intende perseguire l’algoritmoPVSplit è dunque limitare il gravissimooverhead di ricerca provocato dalla ricerca conscore iniziale -∞ del primo gruppo disottoalberi.
Le proprietà di questo algoritmo sono già stateampiamente discusse in sede di rassegna;questa sezione del lavoro intende descrivereuna possibile implementazione in Linda. Ilprogetto di questa assume come fondamental’algoritmo base con cooperazione alla pari. Laversione di PVSplit che si vuole realizzareintende infatti applicare tale algoritmo lungo lavariante principale dell’albero di gioco. I nodiche compongono tale variante costituisconodunque i nodi di decomposizione: ladistribuzione della ricerca deve avvenire incorrispondenza di ciascuno di essi (Fig. 5.12).

161
Nodi di decomposizione
In generale la decomposizione lungo la variante principale è interrotta quando il livello raggiunto è uguale ad una costante THRESOLD≥0: questo sottoalbero è quindi visitato sequenzialmente
La visita delle alternative alle posizioni lungo la variante principale avviene in sequenziale
Fig. 5.12 PVSplit: la decomposizionedell’albero di gioco
Si consideri l’i-esimo nodo Ni lungo la varianteprincipale e i suoi NMOVES i successori:• la valutazione del primo di essi è eseguitaattraverso l’invocazione ricorsiva dello stessoalgoritmo PVSplit; la definizione classicadell’algoritmo stabilisce quale condizione diterminazione dell’annidamento ricorsivo ilraggiungimento del nodo della varianteprincipale a profondità massima: la suavalutazione è operata dalla funzione divalutazione statica.
Argomenti legati al controllodell’overhead di comunicazione suggerisconotuttavia di attivare la decomposizione lungo lavariante principale solo fino ad una profonditàdi soglia, oltre la quale risulta invece piùefficiente una visita sequenziale del sottoalberorimasto.
• la visita dei restanti (NMOVES i-1) successori èrealizzata in rispetto dell’algoritmo base concooperazione alla pari. Sono possibili anche inquesto contesto tutte le ottimizzazioni caratteri-stiche dell’algoritmo base; condizioneessenziale per la loro applicabilità è che tutti imoduli siano a conoscenza del nodo didecomposizione (nella fattispecie Ni e più ingenerale la porzione della variante principaleinteressata dalla decomposizione). Nel caso di

162
generatore di mosse deterministico essi sonoin grado di individuare autonomamente lavariante principale; nell’ipotesi di ricerca conapprofondimento iterativo, tuttavia, la varianteprincipale viene aggiornata dopo ogniiterazione: in questa ipotesi essa deve essereforzatamente memorizzata in una struttura datidistribuita.
int master(int n_worker,int depth,intTHRESOLD)/* il parametro THRESOLD rappresenta il valoredi soglia per il livello di ricerca oltre il
quale la ricerca è sequenziale αβ */{position *root;int nmoves,minimax,i,pvsplit_master(),worker();for (i=0;i<n_worker;i++)
eval ("worker",worker(depth,THRESOLD));while (!end())
{load_new_position (&root);out ("root",*root);out ("sincr",n_worker);for (i=0;i<n_worker;i++)
out ("job",NEW_POSITION);in ("sincr",0);/* inizio discesa ricorsiva lungo la
variante principale */minimax=pvsplit_master(n_worker,root,de
pth,THRESOLD,1);in ("root",*root);}
for (i=0;i<n_worker;i++){out ("job",QUIT);in ("worker", 0);}
return (0);}int pvsplit_master(int n_worker,position*pv_node,int depth,int THRESOLD,int ply){position *successor;int nmoves,score;void worker_search ();if (ply>THRESOLD) /* ricerca sequenziale? */
return (alphabeta (pv_node,-INFINITE,INFINITE,depth));nmoves=genmoves(pv_node,&successor);if (nmoves==0) /* terminazione dellavariante principale per assenza di mosse? */
return(evaluate(pv_node) );makemove(successor);/* prosegue la discesa ricorsiva lungo lavariante principale */score=-pvsplit_master(n_worker,successor,depth-1,THRESOLD,ply+1);undomove(successor);/* inizio della fase di decomposizione conalgoritmo base delle mosse alternative allavariante principale */

163
out ("score",score); /* lo score iniziale èora pari al valore minimax della
variante principale */out ("head",2); /* la decomposizione inizia apartire dal secondo sottoalbero */out ("ending_workers",n_workers+1);/* il supervisore diviene esploratore perattuare la cooperazione alla pari */worker_search(nmoves,depth,successor);in ("head",nmoves+1);in ("score",?score);/* score rappresenta il valore minimax per ilnodo lungo la variante principale posto allivello superiore rispetto a quello in cui èavvenuta la decomposizione */return (score);}Fig. 5.13a PVSplit: flusso di controllo delmasterint worker(int depth,int THRESOLD){position *root;int job_type,quit;quit=false;while(!quit)
{in ("job",?job_type);switch (job_type)
{case QUIT: /* fine */
quit=true;break;
case NEW_POSITION: /* la ricercariguarda nuovo albero di gioco */
in ("position",?*root);in ("sincr",?s);out ("sincr",s-1);/* inizio discesa
ricorsiva lungo la variante principale */
pvsplit_worker(root,depth,THRESOLD,1);break;}
}return (0);}void pvsplit_worker(position *pv_node,intTHRESOLD,int ply){position *successor;int nmoves;void worker_search();nmoves=genmoves(pv_node,&successor);if (nmoves>0)
{if (ply>THRESOLD) /* la discesa
ricorsiva prosegue, come per il master, finoalla profondità di soglia */
{makemove(successor);pvsplit_worker(successor,depth-
1,THRESOLD,ply+1);undomove(successor);}
/* il worker è sincronizzato con g lialtri moduli per dare inizio alla
decomposizione con cooperazione allapari */
worker_search(nmoves,depth,successor);

164
}return ();}Fig. 5.13b PVSplit: flusso di controllo di unworker
In Fig. 5.13 è illustrata una descrizione in Lindadell’algoritmo PVSplit basata sulle idee appenaproposte.
Le funzioni master e pvsplit_master di Fig.5.13a descrivono complessivamente il flusso dicontrollo del modulo supervisore. In particolarela funzione master riguarda le fasi iniziale efinale della ricerca la cui gestione è simile aquella già descritta per l’algoritmo base.
Componente caratterizzante dell’algoritmo èinvece la fase centrale di ricerca descritta dallafunzione ricorsiva master_pvsplit. Si osservi lapresenza del parametro di soglia THRESOLDad indicare il livello fino al quale la varianteprincipale può essere valutata in parallelo. Lavalutazione di tale variante viene fatta risaliredal basso verso l’alto: la prima decomposizioneavrà quale nodo radice il nodo al livelloTHRESOLD della variante principale; lasuccessiva, invece, quello al livello(THRESOLD-1) e così via fino al nodo radicedell’intero albero di gioco.
Durante la risalita verso tale nodo ad ognilivello il modulo supervisore attiva unadecomposizione con cooperazione alla pari: lafunzione worker_search da esso invocata è lastessa presentata durante l’introduzione diquesto metodo (Fig. 5.10). L’architettura logicadi comunicazione si trasforma dinamicamenteda modello master-worker a modello alla pari(e viceversa) tante volte quanti sono i nodi didecomposizione: il modulo supervisore, infatti,divenuto esploratore per cooperare alladecomposizione dell’i-esimo livello dellavariante principale, ritorna dopo ilcompletamento di questa al suo ruolo singolaredi supervisore per "preparare" la successivadecomposizione al livello (i-1).
La funzione ricorsiva pvsplit_worker in Fig.5.13b descrive la fase di ricerca di un moduloesploratore. Essa è attivata all’interno dellafunzione worker non appena è ricevuto il nodo

165
radice del nuovo albero di gioco. I moduliesploratore "percorrono" la variante principalein sincronia con il supervisore:
• inizialmente essi scendono lungo talevariante fino al nodo al livello THRESOLD: quiattendono che il supervisore completi lavalutazione sequenziale dei nodi della varianteposti a profondità inferiori e che dia vita allaprima decomposizione inserendo lavoro inagenda;
• il modello di decomposizione alla paripermette ad ogni esploratore di riconoscerel’avvenuto esaurimento dei lavori in agenda equindi di risalire di un livello lungo la varianteprincipale per poi sincronizzarsi con il modulosupervisore per l’inizio della successivadecomposizione. Questo processo è reiteratofino a raggiungere il nodo radice dove ha luogola decomposizione finale.
Occorre sottolineare fin d’ora la presenza dipunti di sincronizzazione lungo tutta la varianteprincipale esplorata in parallelo dovuti all’attesadel completamento di tutti i lavori relativi alladecomposizione corrente: quale incidenza essihanno sull’efficienza?
L’algoritmo PVSplit è stato proposto per le suecapacità di ridurre l’overhead di ricerca: quantovale quantitativamente questo miglioramento?
La sperimentazione in Linda intende risolverequesti quesiti. Quello realmente sperimentato èPVSplit arricchito delle euristiche diapprofondimento iterativo (con parametriINIT=2-ply e MAX=5-ply) e riordinamento altop-level; è stato fissato inoltreTHRESOLD=3-ply. Infine, gli esperimenti sonostati eseguiti con e senza il metodo dicondivisione dello score presentato nellaprecedente sezione (comunque applicato allasola decomposizione al top-level).
I risultati di entrambi gli algoritmi PVSplit cosìottenuti sono riportati rispettivamente inTab. 5.6a e Tab. 5.6b.
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 6740 4529971 --- --- --- --- 672 ---3 2693 4949981 2.50 0.83 0.91 0.09 1838 2.73
5 1931 5349308 3.49 0.70 0.82 0.18 2770 4.12

166
7 1659 5657469 4.06 0.58 0.75 0.25 3410 5.07
9 1502 6130143 4.49 0.50 0.67 0.35 4081 6.07
11 1446 6445828 4.66 0.42 0.60 0.42 4458 6.63
Tab. 5.6a PVSplit: sperimentazione
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 6740 4529971 --- --- --- --- 672 ---3 2640 4770665 2.55 0.85 0.91 0.05 1807 2.69
5 1797 5020905 3.75 0.75 0.84 0.11 2794 4.167 1443 5228542 4.67 0.67 0.77 0.15 3623 5.39
9 1255 5358664 5.37 0.60 0.71 0.18 4270 6.35
11 1210 5704328 5.57 0.51 0.64 0.26 4714 7.01
Tab. 5.6b PVSplit con condivisione delloscore: sperimentazioneL’obbiettivo prefissato di ridurre l’overhead diricerca è stato pienamente raggiunto daPVSplit: si osservi come l’entità della riduzionedi questa forma di degrado sia ancoramaggiore di quella ottenuta dal giàsorprendente metodo di condivisione delloscore (Tab. 5.5).
Tuttavia l’efficienza complessiva rivelata daPVSplit è inferiore rispetto ad esso; il motivo diquesto risultato è spiegato dal confronto fra ifattori di produzione dei due algoritmi: PVSplitpresenta valori notevolmente ridotti per questoparametro (del 14% con 11 processori!). Lacausa di questo crollo della produttività mediadei moduli è legata alla già discussa presenzadei punti di sincronizzazione lungo la varianteprincipale. Questo degrado può essere ridottoprevedendo una più accorta distribuzione delcarico, tale da impegnare tutti i moduli fino alcompletamento di ciascuna decomposizione.
A questo overhead deve aggiungersi il costodelle comunicazioni necessarie alcompletamento di ciascuna decomposizione;ognuna di queste prevede lo stesso numero dicomunicazioni, indipendentemente dal livello incui essa avviene (è una proprietà dell’algoritmobase). Di conseguenza l’overhead dicomunicazione è amplificato, rispettoall’algoritmo con sola decomposizione, delnumero di nodi della variante principale cui èapplicata la valutazione in parallelo.
L’algoritmo che scaturisce dalla combinazionedi PVSplit con la tecnica di condivisione dello

167
score è caratterizzato da un’ancora piùsensibile riduzione dell’overhead di ricerca(Tab. 5.6b): la sovrapposizione dei due metodinon riduce, quindi, l’efficacia di entrambi.Questo dato conferma che essi operano ilrispettivo miglioramento su porzioni disgiuntedell’albero di gioco:
• PVSplit nella ricerca dei sottoalberi dalsecondo al P-esimo (P è il numero di processi)• il metodo di condivisione nella ricerca deisottoalberi successivi al P-esimo.L’efficienza ottenuta da PVSplit incombinazione con la condivisione dello score èla massima fra tutti gli algoritmi parallelisperimentati. Si osservi che su essa continuacomunque a gravare pesantemente l’overheadcausato dai punti di sincronizzazione lungo lavariante principale: questo problema saràrisolto integrando l’algoritmo con un approcciodinamico alla decomposizione dell’albero digioco mirato a ridurre lo sbilanciamento nelladistribuzione dei carichi di lavoro.
5.2.2 Algoritmi di decomposizione dinamicaIl problema principale che affligge gli algoritmi didecomposizione statica dell’albero di gioco è la difficoltà diottenere un bilanciamento ottimale del carico. Inun’implementazione basata sul modello master-worker essaè motivata dalla proprietà di indivisibilità dei lavori: una voltaassegnata ad un processo la ricerca di un sottoalbero essadeve essere completata sequenzialmente. Al momentodell’attribuzione del lavoro è difficile stimarne il costocomputazionale necessario al suo completamento. Sequesta informazione fosse disponibile, il lavoro potrebbeessere schedulato in base ad un criterio di minimizzazionedei tempi di disoccupazione dei processi. Poiché questa nonè la realtà per la classe dei problemi di ricerca αβ, glialgoritmi con decomposizione statica non sono in grado dirimediare dinamicamente a distribuzioni pessime del carico:l’ultimo lavoro ancora in sospeso in un punto disincronizzazione potrebbe richiedere un tempoarbitrariamente lungo per il suo completamento.
Una soluzione al problema è rendere divisibile il lavoroassegnato ad un esploratore, così da autorizzarequest’ultimo alla decomposizione del sottoalbero di cui èresponsabile. Nelle prossime sezioni questa nuova ideaverrà applicata all’algoritmo base (e quindi di riflesso aPVSplit) e nel progetto di un algoritmo di decomposizionedinamica più generale.

168
5.2.2.1 Un primo approccio: algoritmo basecon subappalto dinamico della ricerca
L’algoritmo base costituisce, in virtù della suasemplicità, una struttura ideale per la sperimentazionedi un approccio dinamico alla distribuzione dell’alberodi gioco. In particolare l’attenzione sarà focalizzatasulla sua fase finale; essa ha inizio nell’istante in cui èprelevato l’ultimo lavoro in agenda e si protrae fino alcompletamento di tutti i lavori. In questo stadiodell’esecuzione dell’algoritmo i moduli checompletano la rispettiva ricerca divengonodefinitivamente inoperosi. L’overhead causato daquesta proprietà dell’algoritmo può essere ridottoimpegnando tali moduli in aiuto di quelli la cui ricercaè ancora in corso. L’applicazione di questa idea esigeche un modulo esploratore sia in grado di raccogliereuna o più richieste di collaborazione e di decomporrela ricerca corrente assumendone così il ruolo disupervisore.
Per il momento questa idea sarà applicata alla solavalutazione dei successori della radice; nullaimpedisce, tuttavia, che essa possa esseregeneralizzata anche ai livelli inferiori dell’albero: ilfatto che i vantaggi di questo metodo sianointuitivamente maggiori quando applicato ai livellisuperiori fa preferire lo studio della versionesemplificata di questa tecnica.
Per effetto delle modifiche descritte, identità e numerodei nodi di decomposizione non sono prevedibili apriori; la probabilità che un successore della radicediventi un nodo di decomposizione è proporzionalealla durata della sua valutazione e alla posizione cheoccupa nell’ordinamento al top-level: il fatto chequesto evento si verifichi è però impredicibile inquanto dipendente dalle velocità relative dei moduli.L’algoritmo che scaturisce da questo approccio deveessere dunque classificato come di decomposizionedinamica.
L’assistenza ai moduli che non hanno completato illavoro al top-level può essere attuata attraverso molteforme di cooperazione; quella che verrà descritta diseguito è quindi solo una possibile soluzione.
Si faccia riferimento all’implementazionedell’algoritmo base con cooperazione alla pari e siconsideri il seguente scenario a tempo di esecuzione:
• il modulo esploratore Ef ha completato il propriolavoro di ricerca al top-level e rileva che l’agenda Atop

169
di lavori al top-level è vuota: la ricerca complessiva èquindi entrata nella sua fase finale.Ef si accorge, inoltre, che altri moduli non hannocompletato il rispettivo lavoro al top-level e devequindi comunicare la propria disponibilità acollaborare nella loro esecuzione: questainformazione viene tuttavia notificata ad uno solo fraquelli di essi che ancora non hanno avuto coscienzadel nuovo stato della ricerca complessiva (sia Er talemodulo);
• in conseguenza dell’evento descritto il modulo Er,cui è affidata la ricerca del sottoalbero S, decomponela porzione di S non ancora esplorata potendo oradisporre dell’aiuto di altri esploratori;
• il modulo Ef non viene impegnato solamentenell’assistenza di Er, ma di tutti i moduli che hannotramutato la loro ricerca da sequenziale a parallela.
P1 P2 P3 P4
P1 P2 P4
P3
P1 P4
P2 P3
Rs={P1,P2,P3,P4}Rp=∅F=∅
Rs={P1,P4}Rp={P2}F={P3}
Rs={P4}Rp={P1}F={P2,P3}
Rs=∅Rp={P4}F={P1,P2,P3}
P1 P2 P3
P4
P3 termina la ricerca ed informa P2 della sua disponibilità a collaborare: P2 distribuisce la propria ricerca
Terminazione di P2 e distribuzione della ricerca di P1
Terminazione di P1 e distribuzione della ricerca di P4
cooperazione alla pari
cooperazione alla pari tra i processori al primo livello e master-worker fra questi e quelli al secondo livello
cooperazione master-worker
Fase finale della ricerca: l‘agenda è vuota

170
Fig. 5.14 Variazione dinamica dell’architetturalogica di comunicazione
L’insieme dei processi è quindi partizionato in tresottoinsiemi variabili dinamicamente:• l’insieme F dei processi che hanno completato illavoro al top-level e offrono la loro collaborazione aiprocessi "ritardatari";
• l’insieme Rp dei processi che non hanno terminato ilproprio lavoro al top-level, ma avendo ricevuto ladisponibilità dei moduli in F, ne hanno distribuitol’esecuzione;
• l’insieme Rs dei moduli ritardatari che proseguononel sequenziale l’adempimento del lavoro di cui sonoresponsabili.
Quello che accade è dunque che quando un moduloin (Rp U Rs) completa il lavoro al top-level essodiviene membro dell’insieme F e determina ilpassaggio nell’insieme Rp di un elemento di Rs (ameno che già Rs=∅). La sequenza di eventi descrittain Fig. 5.14 esemplifica quanto appena descrittoevidenziando la variazione dinamica dell’architetturalogica di comunicazione.
Questo approccio intende limitare il numero didecomposizioni attivate dinamicamente in modo cheesso sia al più pari al numero di moduli in F: ladecomposizione determina, come noto, costi talvoltaelevati e deve quindi essere avviata solo se esiste unsufficiente numero medio di esploratori a suosostegno.
Il fatto che un modulo in F collabori con tutti i moduliin Rp semplifica l’implementazione della cooperazioneche viene originata dal subappalto dei lavori altop-level. È prevista la presenza di un’unica strutturadati distribuita Asub in cui sono inseriti i lavori generatida tutti i moduli (master) in Rp; i moduli (worker) in Feseguono i lavori prelevati da Asub e ne depongono irisultati in una struttura distribuita Rsub.
Da un punto di vista logico le strutture Asub e Rsubsono in realtà composte da un numero disottostrutture pari al numero di moduli master. Si puòpensare che ad ogni master siano associate unastruttura di lavori ed una di risultati; un genericolavoro identifica infatti il modulo che lo ha generatocontenendo l’indice ordinale del sottoalbero altop-level di cui esso è responsabile: il modulo workerè così in grado di riconoscere il suo "datore di lavoro"e stabilire in quale delle sottostrutture di Rsub

171
depositare il risultato del lavoro. In particolare lastruttura di tupla che descrive un generico lavoro è("job_help",top - subt ree,subtree,alpha,beta)Il campo top-subtree è l’identificatore del masterappena spiegato; il campo subtree, invece, identificala mossa di risposta (a quella al top-level con indicetop-subtree) che deve essere valutata dal worker.Essendo la decomposizione in analisi attivata ad unlivello inferiore a quello della radice non è possibileper il processo worker ricavare autonomamente lafinestra αβ iniziale e deve quindi essere memorizzatafisicamente nella descrizione del lavoro.
Il generico worker vede la struttura Asub come unica inquanto i lavori sono dal suo punto di vistaindistinguibili: l’identità del successivo modulo masterdi cui esso sarà alle dipendenze è stabilita in modonondeterministico al momento dell’estrazione dellavoro. In questo istante è fissata una relazionegerarchica temporanea con il modulo master che hagenerato il lavoro la quale ha durata fino al depositodel relativo risultato.
Lo schema di tupla per un generico risultato è:("result_help",value,top - subtree)A differenza di quanto avveniva nella prima versionedell’algoritmo base, in questo caso la presenza delcampo top-subtree è necessaria poiché deveidentificare il supervisore cui è indirizzato il risultato(nella circostanza, infatti, esso non è unico).
Si è preferito implementare la cooperazione fra imoduli in Rp e quelli in F secondo il modellomaster-worker con la variante dell’auto-attribuzione dilavoro da parte del master (cfr. 5.2.1.2.1). Questascelta è motivata dai seguenti argomenti:
• il problema dovuto all’attesa dei worker che il mastertermini la ricerca che si è assegnato e possa quindigenerare nuovo lavoro è risolto prevedendo che ilnumero medio di lavori nell’agenda Asub sia non nullo.Il numero di lavori contenuti in essa è un’informazionedistribuita fra i moduli: tale valore deve infatti rimanereal di sotto di un certo limite massimo e deve quindipoter essere controllato dinamicamente dai moduli.
Il motivo della limitazione delle dimensioni dell’agendaè di ridurre il tempo medio di deposito di un lavoro: ciòmantiene entro un’approssimazione accettabilel’ordinamento dei lavori e impedisce che il masterdebba sopportare una lunga attesa per ilcompletamento degli ultimi di essi. Un valore

172
ragionevole per il limite in questione è il numerocorrente di worker, cioè di moduli presentinell’insieme F. La cardinalità di tale insieme aumentadinamicamente: di conseguenza questa informazione,essendo globale ai moduli, deve essere anch’essamemorizzata in una struttura dati distribuita. Lagestione della struttura di lavori richiede pertantol’utilizzo di due variabili distribuite con schema:
("njobs",nj)e("maxjobs",max)• il metodo di cooperazione alla pari appare nonefficace in quanto non può usufruire delleottimizzazioni possibili nell’algoritmo base: ladecomposizione in esame ha luogo al secondo livellodell’albero e può dunque essere terminata da untaglio il che renderebbe inutile l’inserimento in Asubdei lavori relativi alla valutazione dei sottoalberiancora inesplorati; quest’ultima operazione è costosapoiché, come visto, la descrizione del lavoro è orainformazione più complessa e quindi determina unmaggiore overhead di comunicazione.
L’algoritmo presenta dunque un approccio nonuniforme all’implementazione della distribuzione dellaricerca: mentre la decomposizione statica al livellodella radice è implementata attraverso il metodo dicooperazione alla pari, quella dinamica operata allivello dei suoi successori avviene nel rispetto delmodello master-worker.
#define END_HELP -1int my_identifier; /* identificatore del modulo */int master (int n_worker,int nmoves,intdepth,position *successor){int score;void around_search ();out ("score",-INFINITE);out ("head",1);out ("ending_top - level",n_worker+1);out ("sincr",n_worker);out ("njobs",0);out ("maxjobs",0);/* supervisore >> esploratore: ha inizio ladecomposizione al top - level con cooperazione allapari */around_search (int nmoves,int depth,position*successor);in ("njobs",0);in ("maxjobs",n_worker);/* la tupla ("job_help",END_HELP,0,0,0)) indica aimoduli dell‘insieme F che tutti i lavori al top - levelsono stati completati: essa può essere rimossasoltanto quando è stata letta da tutti essi; la tuplacon etichetta "sincr" permette di controllare ilverificarsi di questo evento */

173
in ("sincr",0);in ("job_help",END_HELP,0,0,0);in ("score",?score);return (score);}void around_search (int nmoves,int depth,position*successor){int w,max;void worker_help();/* viene inserita nello spazio delle tuple una tuplaprivata la cui presenza indica che per il momento nonè possibile usufruire della collaborazione di altrimoduli */out ("help",my_identifier);/* la funzione worker_search è la stessa vistanell‘implementazione dell‘algoritmo base concooperazione alla pari, con la sola eccezione che lafunzione di ricerca sequenziale alphabeta èsostituita dalla funzione help_alphabeta il cuicodice è presentato in seguito */worker_search (nmoves,depth,successor);in ("ending_top - level",?w);w--;if (w>0) /* vi sono ancora moduli che non hannocompletato il lavoro al top - level? */
{in ("maxjobs",?max);out ("maxjobs",max+1); /* è aggiornata la
dimensione massima dell‘agenda Asub */out ("ending_top - level",w);inp ("help",my_identifier); /* il modulo ha
completato il lavoro al top - level */inp ("help",?int); /* un nuovo modulo può
decomporre dinamicamente la sua ricercacorrente *//* il modulo inizia il ciclo di prelievo ed
esecuzione dei lavori richiesti daimoduli in Rp */worker_help (depth,successor);}
else /* il presente modulo ha completato l‘ultimolavoro al top - level */
out ("job_help",END_HELP,0,0,0); /* e comunicaquesto evento a tutti gli altri
moduli */}void worker_help (int depth,position *successor){int value,w,quit;position *tree_pointer;quit=false;while (!quit)
{in
("job_help",?top - subtree,?subtree,?alpha,?beta);if (top - subtree==END_HELP) /* fine
collaborazione? */{out ("job_help",EN D_HELP,0,0,0);in ("sincr",?w);out ("sincr",w-1);quit=true;}
else /* è richiesta l‘esecuzione di un nuovolavoro */
{in ("njobs",?nj);out ("njobs",nj-1);

174
/* si scende di due livelli a partiredalla radice per individuare il
sottoal bero di cui è richiesta lavalutazione */
go_down(successor,top - subtree,subtree,&tree_pointer);
/* ora si ha la normale ricerca
sequenziale αβ*/value=-
alphabeta(tree_pointer,alpha,beta,depth-1);/* vengono "ritirate" le due mosse
top - subtree e su btree ripristinandocosì lo stato iniziale */go_up (successor,top - subtree,subtree);out ("result",top - subtree,value);}
}}int top_alphabeta (position *p,int alpha,int beta,intdepth,int top - subtree){if (depth==0)
return (evaluate(p));nmoves=generate(p,&successor);if (nmoves==0)
return (evaluate(p));parallel=false;wait_result=0;best=alpha;for (ind=1;ind<=nmove;ind++)
{tree_pointer=successor+ind-1;makemove(tree_pointer);dec=false;
/* si continua a verificare la presenza della tuplaprivata con etichetta "help" fino a che la suaassenza comunica al modulo la collaborazione di altrimoduli e quindi l‘abilitazione a decomporre lapresente ricerca */
if (parallel ||(parallel=!rdp("help",my_identifier)))
{in ("njobs",?nj);rd ( "maxjobs",?max);if (dec=(nj<max)) /* agenda piena? */
out ("njobs",nj+1);else
out ("njobs",nj);}
if (dec) /* deve essere generato un nuovolavoro */
{out ("job_help",top - subtree,ind,-beta,-
best);wait_result++;}
else /* la valuta zione della corrente mossaavviene in sequenziale */
value=-alphabeta(tree_pointer,-beta,-best,depth-1);
undomove(tree_pointer);/* viene prima elaborato, se presente, il risultatodella ricerca sequenziale e di seguito viene testatala presenza dei risultati dei lavori distribuiti inprecedenza (cui segue la relativa elaborazione */
while ((!dec) || (wait_result && inp("result",top - subtree,?value)))
{if (!dec)
dec=true;

175
elsewait_result--;
if (value>best)best=value;
if (best>=beta ) /* un taglio? */{
/* devono essere rimossi, in quanto inutili, i lavoriinseriti in agenda e "fortunatamente" non ancoraprelevati dai worker */
if (parallel && wait_result)remove (top - subtree,
wait_result);return (best);}
}/* se la ricerca è stata decomposta dinamicamenteviene attivata l‘attesa finale dei risultati deilavori non ancora ricevuti */if (parallel)
while (wait_result>0){in ("result",top - subtree,?value);wait_result--;if (value>best)
best=value;if (b est>=beta)
{if (wait_result)
remove(top - subtree,wait_result);
return (best);}
}return (best);}Fig. 5.15 Introduzione di decomposizionedinamica nell’algoritmo base
In Fig. 5.15 sono descritte in Linda le modificheapportate all’algoritmo base per implementare ladecomposizione dinamica descritta. Molte delle nuoveidee sono state realizzate utilizzando tecniche diprogrammazione Linda già descritte: si osservi, adesempio, l’impiego di una tupla privata perminimizzare il costo del test di verifica delladisponibilità a collaborare da parte di altri moduli.
La funzione worker_search (Fig. 5.10) che descrive lacooperazione alla pari che ha luogo al livello dellaradice è ora "avvolta" dalla funzione around_searchinvocata sia dal modulo master che dai moduli worker(il codice di quest’ultimi non è riportato perchéinvariato rispetto alla precedente implementazionedell’algoritmo base). Lo scopo di questa funzione ègestire il passaggio di un modulo al ruolo dicollaboratore di quegli esploratori che ancora nonhanno ancora completato l’esecuzione del propriolavoro al top-level.
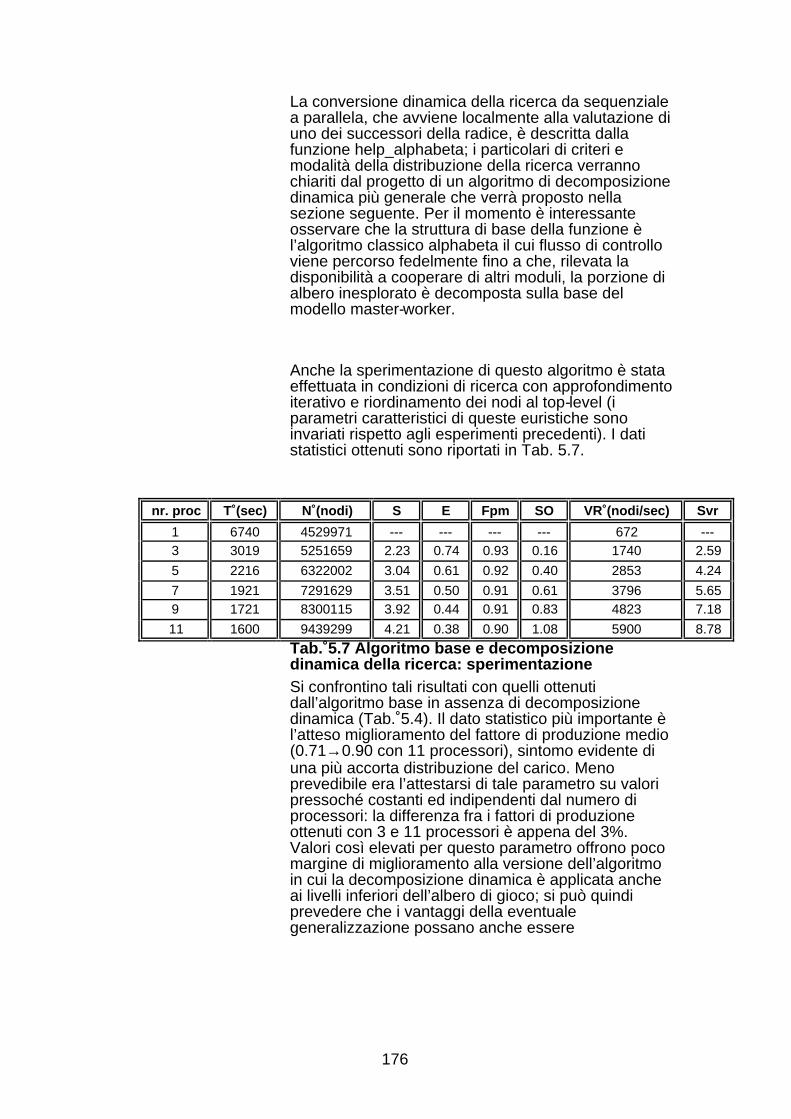
176
La conversione dinamica della ricerca da sequenzialea parallela, che avviene localmente alla valutazione diuno dei successori della radice, è descritta dallafunzione help_alphabeta; i particolari di criteri emodalità della distribuzione della ricerca verrannochiariti dal progetto di un algoritmo di decomposizionedinamica più generale che verrà proposto nellasezione seguente. Per il momento è interessanteosservare che la struttura di base della funzione èl’algoritmo classico alphabeta il cui flusso di controlloviene percorso fedelmente fino a che, rilevata ladisponibilità a cooperare di altri moduli, la porzione dialbero inesplorato è decomposta sulla base delmodello master-worker.
Anche la sperimentazione di questo algoritmo è stataeffettuata in condizioni di ricerca con approfondimentoiterativo e riordinamento dei nodi al top-level (iparametri caratteristici di queste euristiche sonoinvariati rispetto agli esperimenti precedenti). I datistatistici ottenuti sono riportati in Tab. 5.7.
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 6740 4529971 --- --- --- --- 672 ---3 3019 5251659 2.23 0.74 0.93 0.16 1740 2.59
5 2216 6322002 3.04 0.61 0.92 0.40 2853 4.24
7 1921 7291629 3.51 0.50 0.91 0.61 3796 5.659 1721 8300115 3.92 0.44 0.91 0.83 4823 7.18
11 1600 9439299 4.21 0.38 0.90 1.08 5900 8.78
Tab. 5.7 Algoritmo base e decomposizionedinamica della ricerca: sperimentazioneSi confrontino tali risultati con quelli ottenutidall’algoritmo base in assenza di decomposizionedinamica (Tab. 5.4). Il dato statistico più importante èl’atteso miglioramento del fattore di produzione medio(0.71→0.90 con 11 processori), sintomo evidente diuna più accorta distribuzione del carico. Menoprevedibile era l’attestarsi di tale parametro su valoripressoché costanti ed indipendenti dal numero diprocessori: la differenza fra i fattori di produzioneottenuti con 3 e 11 processori è appena del 3%.Valori così elevati per questo parametro offrono pocomargine di miglioramento alla versione dell’algoritmoin cui la decomposizione dinamica è applicata ancheai livelli inferiori dell’albero di gioco; si può quindiprevedere che i vantaggi della eventualegeneralizzazione possano anche essere
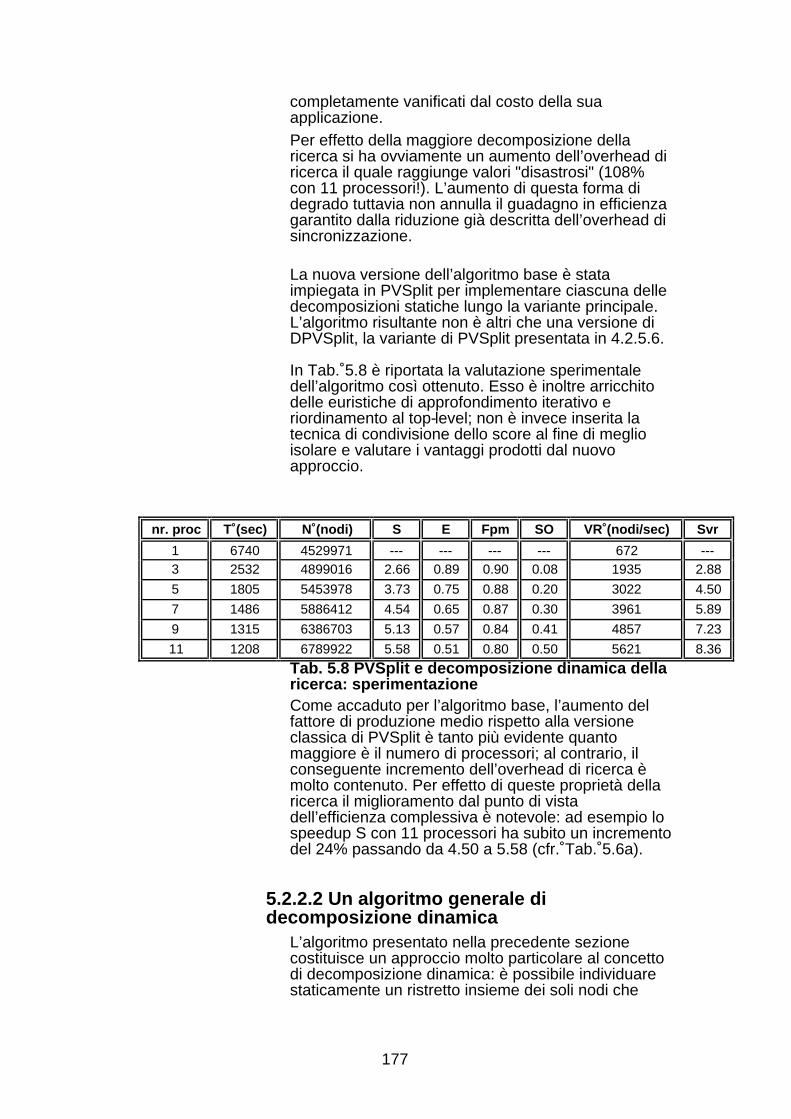
177
completamente vanificati dal costo della suaapplicazione.Per effetto della maggiore decomposizione dellaricerca si ha ovviamente un aumento dell’overhead diricerca il quale raggiunge valori "disastrosi" (108%con 11 processori!). L’aumento di questa forma didegrado tuttavia non annulla il guadagno in efficienzagarantito dalla riduzione già descritta dell’overhead disincronizzazione.
La nuova versione dell’algoritmo base è stataimpiegata in PVSplit per implementare ciascuna delledecomposizioni statiche lungo la variante principale.L’algoritmo risultante non è altri che una versione diDPVSplit, la variante di PVSplit presentata in 4.2.5.6.
In Tab. 5.8 è riportata la valutazione sperimentaledell’algoritmo così ottenuto. Esso è inoltre arricchitodelle euristiche di approfondimento iterativo eriordinamento al top-level; non è invece inserita latecnica di condivisione dello score al fine di meglioisolare e valutare i vantaggi prodotti dal nuovoapproccio.
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 6740 4529971 --- --- --- --- 672 ---3 2532 4899016 2.66 0.89 0.90 0.08 1935 2.88
5 1805 5453978 3.73 0.75 0.88 0.20 3022 4.50
7 1486 5886412 4.54 0.65 0.87 0.30 3961 5.89
9 1315 6386703 5.13 0.57 0.84 0.41 4857 7.23
11 1208 6789922 5.58 0.51 0.80 0.50 5621 8.36
Tab. 5.8 PVSplit e decomposizione dinamica dellaricerca: sperimentazioneCome accaduto per l’algoritmo base, l’aumento delfattore di produzione medio rispetto alla versioneclassica di PVSplit è tanto più evidente quantomaggiore è il numero di processori; al contrario, ilconseguente incremento dell’overhead di ricerca èmolto contenuto. Per effetto di queste proprietà dellaricerca il miglioramento dal punto di vistadell’efficienza complessiva è notevole: ad esempio lospeedup S con 11 processori ha subito un incrementodel 24% passando da 4.50 a 5.58 (cfr. Tab. 5.6a).
5.2.2.2 Un algoritmo generale didecomposizione dinamica
L’algoritmo presentato nella precedente sezionecostituisce un approccio molto particolare al concettodi decomposizione dinamica: è possibile individuarestaticamente un ristretto insieme dei soli nodi che

178
possono divenire, dinamicamente, di decomposizione(i successori della radice per la versione base e lealternative alla variante principale per la versioneapplicata a PVSplit). Quella che si intende sviluppare,invece, è una struttura algoritmica assolutamentegenerale che consenta, a priori, di attuare ladistribuzione della ricerca localmente a qualsiasi nodointerno dell’albero di gioco.
La definizione di decomposizione dinamica formulatanel Capitolo 2 non chiarisce alcune proprietà delladecomposizione stessa:
• in quale momento della visita è stabilita l’eventualedecomposizione di un nodo (in alternativa alla suaricerca sequenziale)?
• chi la stabilisce?• e in base a quali criteri?
5.2.2.2.1 Fasi della ricerca in cui èfissata la decomposizione
Si ritiene esista una sola risposta ragionevoleal primo dei tre quesiti: la decomposizioneviene decisa esclusivamente nel corso dellavalutazione del nodo cui essa si riferisce.L’idea è dunque di ritardare l’eventualedecomposizione di un sottoalbero fino almomento in cui si rende necessaria la suaesplorazione.
A chiarimento di questo approccio si consideril’albero di gioco di Fig. 5.16; il processore P èresponsabile della sua valutazione in quantoassociato al nodo radice24. Si consideril'ordine di visita depth-first indottodall'algoritmo αβ; esso stabilisce che isuccessori della radice siano valutatinell'ordine: N1, N2, N3.
N1 N2 N3
P
??
Root

179
Fig. 5.16 Assegnamento dinamico deiresponsabili dei nodi
Si supponga che la visita sia in corso e ilsottoalbero relativo a N1 sia stato già valutato.Nel caso in cui tale valutazione non abbiaprodotto un taglio si rende necessaria la visitadel sottoalbero N2: è in questo momento cheviene creata l’associazione nodo-processorerelativa ad N2. Un qualche agente (la cuiidentità è per il momento lasciata imprecisata)stabilisce, su richiesta di P, quale processoresarà responsabile del sottoalbero di N2; nullaesclude che sia lo stesso P il processoredesignato. In questa eventualità P verràimpegnato nella valutazione di N2 e soloquando questa sarà completata verrà presa inconsiderazione la "sorte" di N3 (a meno di uneventuale taglio25). Se P fosse qualificatocome responsabile di tutti i suoi successori,allora il nodo radice sarebbe di fatto non didecomposizione.
Si supponga, invece, che sia fissato per N2 unresponsabile Q diverso da P: la radice divieneun nodo di decomposizione. Non è ragionevoleche P si sospenda in attesa che Q completi lavalutazione di N2: che ne sarebbe delparallelismo? È infatti facile dimostrare che inconseguenza di questa soluzione vi sarebbe alpiù un processore attivo, mentre tutti gli altrisarebbero sospesi in attesa di ricevere unrisultato (o privi di attività). L’intuizione correttaè dunque che P si disinteressi delcompletamento o meno della visita di N2 epassi a considerare la valutazione delsuccessore seguente (N3) facendo sì che peresso sia decretato un responsabile ed abbiaquindi inizio la sua visita. In generale, dunque,la valutazione del sottoalbero N3 procede inparallelo a quella di N2.
I vantaggi di questo approccio emergonoevidenti:• il problema di decomporre la visita di un certosottoalbero viene preso in considerazione solose essa è realmente necessaria. Come giàspiegato, infatti, la ricerca di alcuni sottoalberi

180
è soppressa dalle proprietà di tagliodell’algoritmo αβ;
• è favorita l’applicazione di strumenti per ilcontrollo e la regolazione dell’overhead diricerca e del parallelismo reale dell’algoritmo;si ha così la possibilità di sviluppare algoritmi didecomposizione dove la combinazione delledue proprietà appena elencate sia tale damassimizzarne le prestazioni complessive;
• sono stabilite condizioni per l’applicazioneefficace di meccanismi per il bilanciamento delcarico: una forte limitazione alla disuniformitàdella distribuzione del carico è infatti garantitadalla possibilità di impiegare processoriinoperosi nel sostenere la ricerca ancoraincompleta di alcuni altri.
5.2.2.2.2 Il responsabile delladecomposizione
È il momento di chiarire l’identità dell’agenteavente il compito di decidere delladecomposizione di un nodo, cioè di fissare (surichiesta del suo responsabile) i processoriresponsabili dei suoi successori. La trattazionenon può prescindere da alcuni cenni riguardo iltipo di conoscenza necessaria per prenderequesta decisione. Tale conoscenza può esseredi duplice natura:
• conoscenza locale e• conoscenza globale.Sia il problema di designare il responsabile diun nodo S. Gli attributi di località e globalitàdella conoscenza sono in riferimento alprocessore P supervisore di S. Perconoscenza locale si intende pertanto l’insiemedi informazioni disponibili localmente ad unsupervisore, parte cioè del suo ambiente equindi accessibili senza alcuna interazione conagenti esterni. Un esempio di conoscenzalocale è il livello che il nodo S occupanell’albero oppure la profondità del sottoalberodi cui esso è radice.
Si supponga per il momento che ladesignazione del responsabile di un genericonodo S sia effettuata esclusivamente sullabase di conoscenza locale al suo supervisore.In questa ipotesi è immediato indicare inquest’ultimo il misterioso agente destinato alla

181
nomina del responsabile del nodo S: sonoquindi i processori supervisori cheautonomamente decidono (tempi e modalità)della decomposizione del sottoalbero loroaffidato.
Limitare il tipo di conoscenza alla sola localeoffre il vantaggio di escludere interazioni framoduli e quindi di rendere estremamenteefficiente il completamento della scelta delresponsabile di un nodo.
Un esempio di informazione globale è, adesempio, il numero di processori in stato "idle"(cioè che attendono sia loro assegnata lavalutazione di un nuovo nodo) oppure ilnumero di ricerche già distribuite, ma ancoranon riconosciute e iniziate dagli esploratori loroassegnati. Perché, in generale, si rendenecessario anche questo tipo di conoscenza?
L’assenza di conoscenza globale impedisce alsupervisore di avere informazioni sullo statocomplessivo della ricerca ed in particolaresull’occupazione o meno degli altri processori.Di conseguenza è impedita l’attuazione diqualsiasi meccanismo per una soluzionedinamica del problema del bilanciamento delcarico. Queste considerazioni rendononecessaria anche l’inclusione di questo tipo diconoscenza se non vuole essere pregiudicatal’efficienza complessiva della ricerca parallela.
La soluzione generale che include il ricorso adentrambe le forme di conoscenza prevede chela designazione del responsabile di un nodo Savvenga in due fasi:
• sia P il supervisore di S; la conoscenza localea P è incorporata in un test booleano il qualestabilisce se l’esploratore di S deve essere lostesso P. Questo primo stadio assolve dunquela funzione di filtrare secondo un certo criterio(inserito nel test) quei nodi la cui valutazionenon si vuole distribuire indipendentementedallo stato complessivo della ricerca;
• nel caso in cui il test locale a P dia esitonegativo si deve ricorrere all’analisi dello statoglobale della ricerca e in base a questafinalmente fissare l’esploratore di S (nullaesclude che esso possa essere P).
La seconda fase rende necessaria l’interazionefra i processori nella decisione dinamica della

182
decomposizione o meno di un nodo. Comeavviene la gestione della conoscenza globale equali interazioni inter-modulo sono necessariealla sua distribuzione?
• in un sistema di programmazione parallela adambiente locale la scelta sarebbe forzata: unmodulo con sole finalità di gestore mantienenel suo ambiente tutta la conoscenza"logicamente" globale. Esso interagisce con imoduli di ricerca per aggiornare (in modoconsistente) tali informazioni. La sua funzioneprincipale è tuttavia applicare il criterio"globale" di attribuzione di un processoreall’esplorazione di un nodo quando ciò èrichiesto dal supervisore di quest’ultimo: si puòpresumere che quest’attività sia completatadalla comunicazione di due messaggi, direttirispettivamente all’esploratore designato (conla descrizione della ricerca lui assegnata) e alsupervisore stesso (contenente l’identitàdell’esploratore).
• in un sistema Linda, invece, alla gestionecentralizzata delle informazioni globali sipreferisce una cooperazione alla pari mediatadall’organizzazione delle informazioni in unastruttura dati distribuita (l’efficacia di questomodello è stata dimostratanell’implementazione dell’algoritmo base). Lasoluzione che verrà presentata è basata suquesto modello.
È dunque previsto che tutta la conoscenzaglobale sia memorizzata in strutture datidistribuite e "gestita" dagli stessi processoridestinati alla ricerca. L’idea che si vuolesviluppare è che il test locale del supervisore Pdi un nodo N sia generalizzato e sia basatoanche su una porzione della conoscenzaglobale: esso stabilisce definitivamente sel’esplorazione di N deve essere distribuita (cioèassegnata ad un processore diverso da P) odeve proseguire sequenzialmente (P divieneanche suo esploratore). Nella prima delle dueeventualità il lavoro di ricerca di N vienedepositato in una struttura dati distribuita. Siosservi che la designazione dell’esploratore diN non è ancora avvenuta: essa sarà attuataimplicitamente quando uno dei processori,divenuto inoperoso, rimuoverà per primo la

183
richiesta di ricerca di N dalla strutturadistribuita appena detta. Sia Q tale processore;assunto il ruolo di esploratore di N esso devequindi completarne la valutazione ed infinecomunicare il risultato a P. Il tipo di relazioneche è stata stabilita dinamicamente fra P e Q èla stessa che lega il modulo master e uno deimoduli worker nel paradigma diprogrammazione parallela omonimo. Si osserviche il nodo di cui Q è divenuto esploratore puòdiventare anch’esso di decomposizione; Q puòquindi rivestire, contemporaneamente al ruolodi worker, anche quello di master delladistribuzione della ricerca al livello inferiore.
Localmente ad un nodo N di decomposizioneviene dunque creato quell’insieme di strutturedati distribuite ed interazioni inter-modulo checaratterizzano il modello master-worker: il ruolodel master è rivestito dal supervisore di N,mentre quello di worker dagli esploratori (≠ dalsupervisore) dei successori di N. Dei modulicoinvolti in questa interazione solamente ilmaster rimane invariato; al contrario, lastruttura di worker si evolve dinamicamente inquanto ogni worker è legato ad un nodo didecomposizione solo per il tempo dellavalutazione di uno dei suoi successori. Essopuò cioè assumere il ruolo di worker anche indecomposizioni diverse che procedono inparallelo26, passando dal servizio di un masterall’altro; completata la valutazione di un nodo,infatti, la scelta del successivo da esplorare fraquelli presenti nelle strutture di lavori relative atutte le decomposizioni in corso ènondeterministica e non può essere influenzatadalla storia dei precedenti servizi di quelprocessore. Si può pensare che dal punto divista del generico processore (worker) i lavoripresenti in strutture distinte fanno parte diun’unica struttura generale dove sonoindistinguibili.
Un nodo N diviene di decomposizione nelmomento in cui avviene la prima distribuzionedella ricerca di uno dei suoi successori; è inquesto momento che la ricerca di N passa dasequenziale a parallela e sono createlogicamente le strutture di lavori e di risultatinecessarie alla sua implementazione. La

184
rimozione logica di quest’ultime avvienequando è completata la valutazione di N.
5.2.2.2.3 I criteri di decomposizioneAncora uno dei tre interrogativi iniziali deveessere risolto: in base a quali criteri è decisa ladecomposizione o meno di un nodo dell’alberodi gioco?
Considerazioni precedenti hanno dimostratoche la risposta a questa domanda è legata allasoluzione di un altro sottoproblema: stabilire seun nodo di cui un processore è supervisoredeve essere esplorato dallo stesso processoreoppure distribuito ad uno diverso. Questadecisione, operata autonomamente dalsupervisore, può essere descritta da un’unicafunzione booleana; quest’ultima incorpora ilcriterio di decomposizione, cioè l’insieme diregole che determina i nodi di decomposizionee i particolari della loro decomposizione (cioèquali dei successori sono distribuiti nellarispettiva esplorazione).
Il criterio di decomposizione rappresenta laparte caratterizzante di un algoritmo didecomposizione: l’avere confinato questacomponente in un’unica funzione booleanasignifica avere definito una struttura softwareestremamente flessibile, capace di ospitarefacilmente qualsiasi algoritmo della classe inanalisi (sia esso di tipo statico o dinamico).
Come noto, l’applicazione del criterio didecomposizione da parte di un supervisorerichiede conoscenza che può essere locale oglobale a tale processore. L’acquisizione dellaconoscenza globale è, in termini di efficienza,molto più costosa. Poiché il numero diinvocazioni della funzione booleana di test èelevato (pari, in una ricerca, al numero di nodivisitati), un criterio di decomposizioneragionevole deve limitare quanto possibile lanecessità delle informazioni globali. L’ideagenerale è decomporre il criterio didecomposizione in due sottocriteri,rispettivamente applicati alle porzioni locale eglobale della conoscenza di cui essonecessita. Il criterio "locale" ha la funzione difiltrare quei nodi che, indipendentemente dallostato globale della ricerca, non è convenienteesplorare in parallelo; l’acquisizione della

185
conoscenza globale e l’applicazione delsottocriterio relativo hanno luogo solonell’ipotesi che il sottocriterio locale "approvi"l’eventuale distribuzione del sottoalbero inesame.
In questa porzione di albero non puo` avvenire distribuzione della ricerca
I nodi di questa sezione possono essere decomposti
DT
hres
old
DThresold è la profondità minima perche` possa avvenire la distribuzione
Fig. 5.17 Sottocriterio di decomposizionebasato sulla dimensione del sottoalbero
Sono ora elencati alcuni esempi di sottocriterilocali:• sottocriteri basati sulle dimensioni delsottoalbero: vengono esclusi dalla distribuzionesottoalberi di piccole dimensioni in quantol’entità del degrado indotto dalla ricercaparallela (in particolare quello dovuto allecomunicazioni) fa preferire in questi casi lavisita sequenziale. La determinazione delladimensione di soglia non è realisticamenteottenibile con metodi analitici perché ciòrichiederebbe un troppo complesso studioquantitativo delle forme di degrado; la tecnicapiù semplice è quella empirica del"trial-and-error" che procede perapprossimazioni successive della soluzionemigliore.
La misura più corretta delle dimensioni di unalbero è il numero di nodi; purtroppo questainformazione non può essere nota prima che lavisita αβ abbia inizio. È comunque possibilestimare con buona approssimazione il numerodi nodi che saranno visitati conoscendo la

186
profondità dell’albero e la larghezza dellafinestra αβ iniziale [Bau78b]: il costo delcalcolo di tale stima non è comunquetrascurabile poiché include operazioni comel’elevamento a potenza e la radice.
Una soluzione più semplice è approssimare ledimensioni dell’albero con la sua profondità[Eli90]: ciò induce una partizione dei nodi indue sottoinsiemi come illustrato in Fig. 5.17.
• il criterio "young-brothers-wait" [FMMV89]:questo è il primo di una serie di criteri finalizzatia ridurre l’overhead di ricerca; tali criteri hannosignificato solo nell’ipotesi di alberi (almenoparzialmente) ordinati. Il criterio stabilisce che ilprimo successore di un nodo deve esserecompletamente valutato prima che possaavere inizio la visita dei successivi. Il datolocale necessario per applicare questo metodoè l’ordine di visita I (rispetto ai suoi "fratelli") delnodo N in esame: se I=1, allora il nodo deveessere valutato dal suo supervisore (e quindinon distribuito). Si osservi come in questaeventualità è garantito che la decomposizionedei fratelli sia presa in considerazione solodopo l’avvenuta valutazione di N.
Una naturale generalizzazione di questometodo è che sia impedita la distribuzione deiprimi K (K≥1) successori; la valutazione diquesti nodi avverrà dunque in sequenza. Inquesto caso la condizione sufficiente adimpedire la distribuzione del nodo è: I>K, doveI è l’indice ordinale del nodo cui è applicato ilcriterio.
La giustificazione del criterio è che se i nodiinterni dell’albero di gioco sono ordinati, alloracon elevata probabilità la migliore mossa èindividuata da uno dei nodi più a sinistra;visitare completamente i sottoalberi relativi atali nodi prima di affidare i successivi ad altriprocessori significa ottenere una finestra αβmigliore per la ricerca di quest’ultimi.
• limitazione del numero di successori visitati inparallelo: si intende limitare il massimoparallelismo ottenibile localmente alladecomposizione di un nodo. Lo scopo diquesto approccio è anch’esso di limitare ilproblema dovuto al fatto che le ricerche disuccessori successivi non usufruiscano dei

187
risultati di visite iniziate precedentemente, maancora incomplete. Anche per questo controlloè necessario un dato esclusivamente locale alsupervisore: il numero di nodi la cui ricerca èstata da esso distribuita, ma dei quali non èstato ancora restituito il risultato.
I seguenti criteri, invece, sono basati suconoscenza globale:• limitazione del numero di lavori in attesa diessere eseguiti. Si consideri la struttura logicacomplessiva di tutti i lavori (come appare ad ungenerico worker): il criterio intende limitare ilnumero massimo di lavori che possono essereospitati in essa; lo scopo è ridurre l’overhead disincronizzazione. Infatti se le richieste diservizio fossero in numero eccessivo rispetto alnumero di serventi, ciò determinerebbeun’attesa eccessiva da parte dei richiedenti.Nel caso del presente algoritmo tale attesasarebbe concentrata nella fase finale delladecomposizione di un nodo quando, stabilitaper tutti i successori la distribuzione o la visitasequenziale (già completata), il supervisore sisincronizza nella ricezione di tutti i risultati nonancora comunicati. Un valore tipico per ladimensione massima della struttura di lavori èil numero totale di processori. L’informazioneglobale coinvolta in questo criterio è il numerodi nodi presenti nell’agenda generale.L’implementazione in Linda prevede a riguardola definizione di una variabile distribuita confunzione di contatore, incrementata dalsupervisore che distribuisce un nuovo lavoro edecrementata dal worker che completal’estrazione di uno di essi.
• distribuzione solo se esiste almeno un nodoinoperoso (idle): il criterio previene l’eccessivapermanenza di un lavoro in agenda e quindiriduce anch’esso l’overhead disincronizzazione poiché minimizza il tempoche intercorre fra la domanda di un servizio e ilcompletamento di questo. In questo casol’informazione globale è il numero di processoriinoperosi; la relativa implementazione in Lindaè analoga a quella descritta per il contatore dilavori in agenda.

188
5.2.2.2.4 Un chiarimento delle finalitàdell’algoritmo
Sono state finalmente chiarite tutte lecaratteristiche generali di un algoritmo didecomposizione dinamica parametrico rispettoal criterio di decomposizione; sono state inoltrefornite alcune indicazioni sulla suaimplementazione in Linda.
Si osservi che l’implementazione su questastruttura algoritmica degli algoritmi base ePVSplit sarebbe immediata data la semplicitàdel criterio di decomposizione di entrambi; laperformance degli algoritmi così ottenutisarebbe tuttavia inferiore a quella delleimplementazioni presentate nei paragrafiprecedenti: perché?
La flessibilità dell’algoritmo generale didecomposizione non può essere sinonimo diefficienza: il requisito di generalità con cui essoè stato concepito ha impedito di tenere conto diottimizzazioni possibili solo per un certo tipo dicriteri di decomposizione. La struttura softwareprogettata intende essere essenzialmente unostrumento di ricerca che permetta di stimarecon immediatezza le prestazioni di nuovi criteridi decomposizione, senza la necessità di doverogni volta ridefinire la struttura di interazioniinter-processo. È così suggerito un approccioallo sviluppo di un algoritmo parallelo di ricercaαβ che prevede due fasi consecutive:
• una prima fase di selezione del criterio didecomposizione più promettente e,successivamente
• una fase di specializzazione dell’algoritmogenerale che tenga conto delle caratteristichedel criterio di decomposizione emerso dallaprima fase in modo da massimizzarnel’efficienza.
Quale esemplificazione dei concetti appenaespressi saranno messe in evidenza alcunedelle ottimizzazioni già viste negli algoritmibase e PVSplit che non possono essereapplicate nell’algoritmo generale didecomposizione dinamica.
5.2.2.2.5 La descrizione del lavorodi ricerca.
Gli algoritmi di decomposizione staticapresentati nei paragrafi precedenti

189
prevedevano un insieme di nodi didecomposizione limitato e noto a priori;queste caratteristiche avevanopermesso di identificare un nodo, la cuivalutazione doveva essere distribuita,attraverso il solo indice posizionale.Questa ottimizzazione era applicataanche nei casi in cui l’ordinamento deinodi interessati alla distribuzione fossevariabile dinamicamente e quindiobbligato ad essere memorizzato instrutture globali (cfr. 5.2.1.3): essarestava infatti conveniente in virtù delnumero esiguo di tali nodi.
L’algoritmo generale di decomposizionedinamica, invece, prevede che unoqualsiasi dei nodi dell’albero di giocopossa divenire di decomposizione.Questa proprietà fa sì che un nodo lacui esplorazione debba esseredistribuita possa essere identificatoesclusivamente dalla suarappresentazione completa; l’identifica-zione di un nodo attraverso un sistemadi indici posizionali richiederebbe ingenerale la definizione di una strutturadistribuita di dimensioni proporzionali aquelle dell’albero di gioco. Inconseguenza le operazioni di deposito eprelievo di un lavoro acquisiscono uncosto relativo molto elevato e sonoquindi origine di un maggiore degrado dicomunicazione. L’incidenza di taleoverhead sarà più sensibile in quellearchitetture parallele dove lacomunicazione fisica fra processori èmeno efficiente (ad es. reti diworkstation).
5.2.2.2.5.1 Segnature, alberi disegnature e gestione dei tagli
L’algoritmo generale prevede che piùnodi di decomposizione possano essereesplorati in parallelo; questa proprietàrende necessario, per un genericoworker, identificare la struttura di risultatiin cui depositare l’esito del suo lavoro.Si osservi che quale identificatore di tale
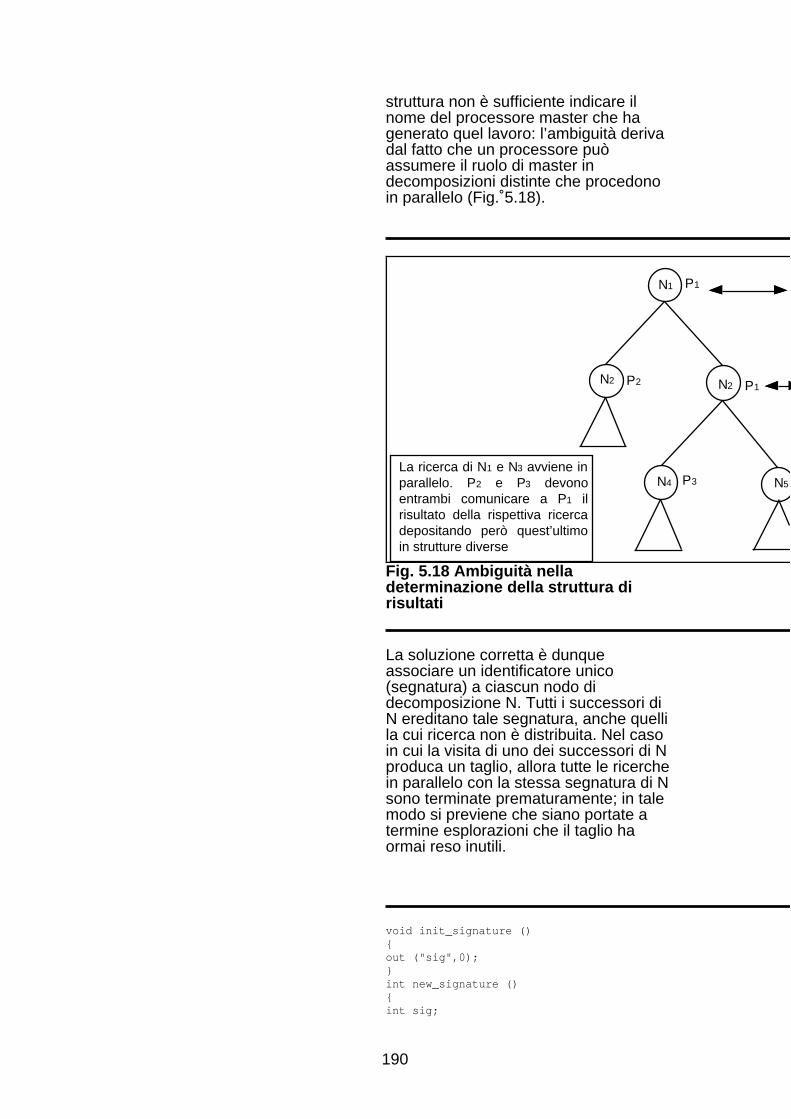
190
struttura non è sufficiente indicare ilnome del processore master che hagenerato quel lavoro: l’ambiguità derivadal fatto che un processore puòassumere il ruolo di master indecomposizioni distinte che procedonoin parallelo (Fig. 5.18).
P1
P2 P1
P3 P1
N1
N2 Decomposizione di N3: struttura di risultati
N4 N5
N2
La ricerca di N1 e N3 avviene in parallelo. P2 e P3 devono entrambi comunicare a P1 il risultato della rispettiva ricerca depositando però quest’ultimo in strutture diverse
Decomposizione di N1: struttura di risultati
Fig. 5.18 Ambiguità nelladeterminazione della struttura dirisultati
La soluzione corretta è dunqueassociare un identificatore unico(segnatura) a ciascun nodo didecomposizione N. Tutti i successori diN ereditano tale segnatura, anche quellila cui ricerca non è distribuita. Nel casoin cui la visita di uno dei successori di Nproduca un taglio, allora tutte le ricerchein parallelo con la stessa segnatura di Nsono terminate prematuramente; in talemodo si previene che siano portate atermine esplorazioni che il taglio haormai reso inutili.
void init_signature (){out ("sig",0);}int new_signature (){int sig;

191
in ("sig",?sig);out ("sig",sig+1);return (sig);}Fig. 5.19 Segnatura
In Fig. 5.19 sono presentate le funzioniin Linda che implementano lacooperazione fra i moduli perl’attribuzione della segnatura ad unnuovo nodo di decomposizione.
Una proprietà dell’algoritmo generale è ilsubappalto della ricerca; esso puòavvenire, in generale, in qualunquelivello dell’albero. Questa caratteristicaconsente anche l’annidamento delsubappalto, limitatamente alla profonditàdell’albero ed al numero di processori.
Ogni nuovo nodo di decomposizione èaccompagnato da una nuova segnatura;può dunque accadere, in virtù delsubappalto della ricerca, che nodi di unostesso sottoalbero presentino segnaturedifferenti. Quando viene generato untaglio al top-level di detto sottoalbero,tutte le ricerche in parallelo (contenutein esso) dovrebbero essere arrestate,anche se aventi segnature differenti.
L’implementazione di tale idea è basatasulla gestione dell’albero dellesegnature: è una struttura dati distribuitacontenente la relazione gerarchica fra lesegnature associate alle decomposizioniin corso. La radice di questo albero è lasegnatura della radice dell’albero digioco.
Si supponga, ad esempio, che la ricercaabbia raggiunto un nodo che haereditato, al momento della suagenerazione, la segnatura S del padre;si supponga che tale nodo divenga didecomposizione: ad esso vieneassociata una nuova ed unica segnaturaT. In questo caso all’albero dellesegnature è aggiunto un nodo conetichetta T come successore del nodocon etichetta S. Quando viene prodottoun taglio da una ricerca con segnaturaS, allora sono terminate in cascata tutte

192
le ricerche parallele con segnatura S ocon qualsiasi discendente dellasegnatura S nell’albero delle segnature.
In Fig. 5.20a è mostrato un ipoteticoalbero di gioco. Le linee tratteggiateindividuano sottoalberi distribuiti ad altriprocessori; l’etichetta dei nodirappresenta invece la segnatura locale.L’albero di gioco contiene quattrodecomposizioni locali. Durante ladecomposizione (a) sono distribuiti ilavori relativi ai sottoalberi più a sinistra;le altre decomposizioni prevedonoinvece la distribuzione di un solo lavoro.Fig. 5.20b presenta l’albero dellesegnature corrispondente a talescenario.
Si supponga che sia generato un taglioal livello della decomposizione (a) acausa della valutazione del sottoalberopiù a sinistra: tutte le ricerche consegnature 1, 2, 3 e 4 saranno terminate.Si ipotizzi, invece, che il taglio siaprodotto al livello della decomposizione(b) dalla visita del sottoalbero più adestra: in questo caso saranno "uccise"solamente le segnature 2 e 4.
0→1
1 1 1→2
1→3
3 113
1
1111
1 1 2→4 2
2 24 4
(a)
(b)
(c) (d)
I nodi di decomposizione sostituiscono una nuova segnatura a quella ereditata dal nodo padre
Fig. 5.20a Attribuzione dellasegnatura

193
0
1
23
4
Fig. 5.20b Albero delle segnature
In Fig. 5.21 è descrittal’implementazione in Linda dell’alberodelle segnature, delle sue operazioni diaggiornamento e, ad esse legata, dellagestione della terminazione prematuradelle ricerche provocata dai tagli αβ.
Si osservi che l’implementazione comestruttura dati distribuita dell’albero dellesegnature è più semplice di quellasuggerita nel paragrafo 3.4.1.3.2 perstrutture ad albero. In questo casol’albero non è memorizzato per nodi, maper archi; esso è infatti definito da tuplecon struttura:
("sig_tree", father, son)
int killed (sig)int sig;{return (!rdp("no_cut",sig));}int add_signature (int master_sig, intnew_sig){out ("sig_tree", master_sig,worker_sig); /* aggiungo un nuovo nodo*/if (killed (master_sig)) /* la ricercaè stata uccisa? */
{/* il processo deve rimuovere essostesso il nuovo nodo dell‘albero dellesegnature, a meno che ciò non sia giàavvenuto ad opera del processo che haprodotto il taglio e cui spetta lagestione della terminazione deiprocessi ad essa interessati */
inp ("sig_tree", master_sig,worker_sig);
return (false);}
else

194
return (true); /* la creazionedel nuovo nodo "di segnatura" ha avutosuccesso */}/* la funzione kill_subtree ha perargomento la segnatura delladecomposizione al livello della quale èstato prodotto il taglio; la suafunzione è di rimuovere il nododell‘albero delle segnature relativo atale segnatura e di invocare lafunzione ricorsiva kill_sons cherimuove dallo stesso albero lesegnature più in profondità */int kill_subtree (int mysig){void kill_sons ();/* è possibile che l‘occorrere di taglisimultanei (quando relativi adecomposizioni annidate) faccia sì chepiù processi concorrano alla rimozionedi un nodo dell‘albero delle segnature;il controllo che segue garantisce lacorrettezza di tale rimozione */if (inp ("sig_tree", ?int, mysig))
{in ("no_cut", mysig); /* la
presenza di questa tupla comunica chetutte
le ricerche con segnatura mysigdevono essere
terminate prematurament e */kill_sons (mysig); /* applica la
terminazione a tutte le segnature chediscendono da mysig */return (true);}
elsereturn (false);
}void kill_sons (int sig){int sig_son;while (inp ("sig_tree", mysig,?sig_son))
{in ("no_cut", sig_son);kill_sons(sig_son);}
}Fig. 5.21 Gestione dell’albero dellesegnature
A completamento della descrizione dellagestione dei tagli deve essere precisatoche:
• la richiesta di terminazione forzata diuna ricerca viene rilevata dal processoche la sta eseguendo testando(funzione killed) la presenza o meno diuna particolare tupla (con etichetta"no_cut") il cui contenuto è la segnaturadella propria ricerca; la frequenza di tale

195
test dipende dal compromesso ottimalefra il costo di un test e i vantaggi (intermini di overhead di ricerca) apportatida un pronto rilevamento della richiestadi terminazione;
• la rimozione del sottoalbero dellesegnature interessato da un taglio e ditutte le relative tuple con etichetta"no-cut" è a cura del processo che lo haprodotto. Può accadere che sianogenerati simultaneamente due o piùtagli al livello di decomposizioni chesono annidate: quale dei processi deverimuovere il sottoalbero di segnature piùinterno?
Sarà il primo di essi che rimuoverà ilnodo ("sigtree",father,sig), dove sigcostituisce la segnatura di talesottoalbero: è l’indivisibilitàdell’operazione Linda di rimozione dituple (in) a garantire la correttezza diquesta soluzione.
5.2.2.2.6 I risultati sperimentaliL’algoritmo è stato sperimentato applicando adesso diversi criteri di decomposizionedinamica; in questa sede sono presentati i datistatistici ricavati per due di essi:
• criterio A: il criterio locale stabilisce che nonpossa essere distribuita la visita di sottoalbericon profondità≥2 ed applica la regola"young-brothers-wait"; il criterio globale,invece, prevede che possa essere generato unlavoro solo se esiste un processo in stato "idle"e non siano già presenti in agenda (P-1) lavori,dove P è il numero di processi.
• criterio B: rispetto al criterio A è disabilitata lagestione dell’albero delle segnature ed èmodificato il criterio globale prevedendo che unlavoro possa essere deposto in agenda anchese non esiste nessun processo inoperoso.
In Tab. 5.9 e Tab. 5.10 sono riportati i risultatisperimentali relativi a tali criteri.
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 8301 5347545 --- --- --- --- 644 ---3 3797 6206534 2.19 0.73 0.85 0.16 1635 2.54
5 2634 6829036 3.15 0.63 0.82 0.28 2593 4.02
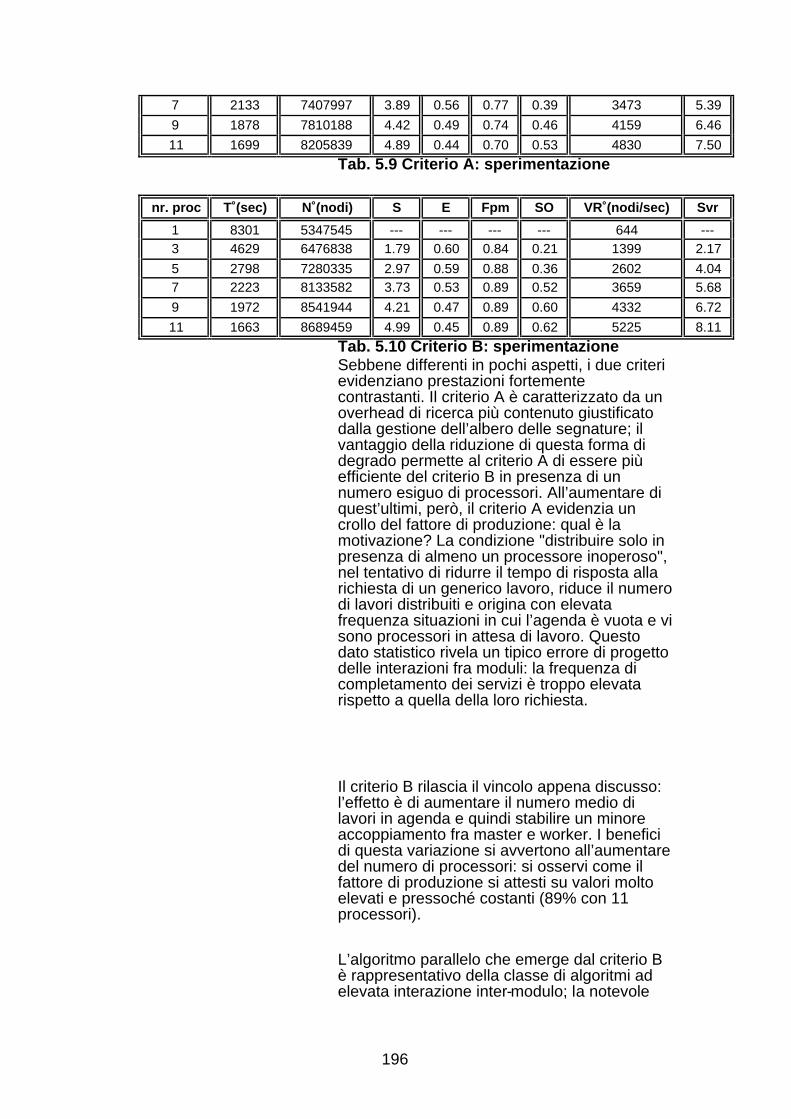
196
7 2133 7407997 3.89 0.56 0.77 0.39 3473 5.39
9 1878 7810188 4.42 0.49 0.74 0.46 4159 6.46
11 1699 8205839 4.89 0.44 0.70 0.53 4830 7.50
Tab. 5.9 Criterio A: sperimentazione
nr. proc T (sec) N (nodi) S E Fpm SO VR (nodi/sec) Svr
1 8301 5347545 --- --- --- --- 644 ---3 4629 6476838 1.79 0.60 0.84 0.21 1399 2.17
5 2798 7280335 2.97 0.59 0.88 0.36 2602 4.047 2223 8133582 3.73 0.53 0.89 0.52 3659 5.68
9 1972 8541944 4.21 0.47 0.89 0.60 4332 6.72
11 1663 8689459 4.99 0.45 0.89 0.62 5225 8.11
Tab. 5.10 Criterio B: sperimentazioneSebbene differenti in pochi aspetti, i due criterievidenziano prestazioni fortementecontrastanti. Il criterio A è caratterizzato da unoverhead di ricerca più contenuto giustificatodalla gestione dell’albero delle segnature; ilvantaggio della riduzione di questa forma didegrado permette al criterio A di essere piùefficiente del criterio B in presenza di unnumero esiguo di processori. All’aumentare diquest’ultimi, però, il criterio A evidenzia uncrollo del fattore di produzione: qual è lamotivazione? La condizione "distribuire solo inpresenza di almeno un processore inoperoso",nel tentativo di ridurre il tempo di risposta allarichiesta di un generico lavoro, riduce il numerodi lavori distribuiti e origina con elevatafrequenza situazioni in cui l’agenda è vuota e visono processori in attesa di lavoro. Questodato statistico rivela un tipico errore di progettodelle interazioni fra moduli: la frequenza dicompletamento dei servizi è troppo elevatarispetto a quella della loro richiesta.
Il criterio B rilascia il vincolo appena discusso:l’effetto è di aumentare il numero medio dilavori in agenda e quindi stabilire un minoreaccoppiamento fra master e worker. I beneficidi questa variazione si avvertono all’aumentaredel numero di processori: si osservi come ilfattore di produzione si attesti su valori moltoelevati e pressoché costanti (89% con 11processori).
L’algoritmo parallelo che emerge dal criterio Bè rappresentativo della classe di algoritmi adelevata interazione inter-modulo; la notevole

197
decomposizione dell’albero di gioco che essoinduce determina infatti una fitta rete dicomunicazioni fra i processi relative alladistribuzione dei lavori ed al recupero deirispettivi risultati. Per questa classe di algoritmiè interessante analizzare l’incidenza dellecomunicazioni sulla performance complessiva.
Si considerino i valori del fattore di produzionemedio Fpm in Tab. 5.10: essi non indicano lareale produttività di un generico processoperché comprensivi anche della porzione ditempo che li ha visti impegnati nellecomunicazioni. Il dato statistico Fpm devedunque essere scorporato nelle duecomponenti Fpmr (produzione reale) e OC(overhead di comunicazione) adottando ilmetodo illustrato nel paragrafo 5.2.1.4.1; inTab. 5.11 è presentato il dettaglio di talistatistiche.
nr. proc. Fpm Fpmr OC
3 0.85 0.84 0.015 0.88 0.80 0.08
7 0.89 0.80 0.09
9 0.89 0.75 0.1411 0.89 0.73 0.16
Tab. 5.11 Criterio B: componenti del fattoremedio di produzioneI dati di Tab. 5.11 parlano di un overhead dicomunicazione tutt’altro che trascurabile; suesso incidono l’elevato numero di interazioniinter-processore che caratterizzano l’algoritmoe l’inefficienza con cui esse sono tipicamenteeseguite in un’architettura parallela di tipo retelocale. La natura dell’algoritmo impediscel’utilizzo delle primitive Linda nel limitare ilnumero di informazioni che devono esserefisicamente scambiate fra i processori. Inproposito sono state viste tecniche (come l’usodi tuple private) che favoriscono l’accesso ainformazioni globali già presenti nella memorialocale del processore e che quindi nonrichiedono interazioni fisiche inter-processore.Tuttavia esse non sono applicabilinell’algoritmo in analisi: l’informazione il cuicosto di comunicazione è maggiore, la

198
descrizione di un lavoro, non è mai ricevutadallo stesso processo che la ha generata edeve essere sempre trasferita fisicamente tradue processori.
5.3 ConclusioniIn questo capitolo abbiamo studiato come utilizzare Linda nellarealizzazione di alcuni algoritmi di decomposizione dell’albero digioco.
A partire da un algoritmo relativamente semplice, l’algoritmo base,sono state applicate ad esso nuove idee che ne hannoprogressivamente migliorato le prestazioni.
Nel corso della discussione è stato più volte verificato che ingenerale non esiste un unico modo di attuare in Linda talimiglioramenti, ma ne esiste comunque uno più efficiente.
Ad esempio è stato indicato dagli esperimenti che per la classe diproblemi studiata il modello di cooperazione alla pari, quandoattuabile, è preferibile al modello master-worker, anche se, tuttavia,la differenza in termini di prestazioni fra le due scelte si attenuaall’aumentare del numero di processori.
Abbiamo inoltre "scoperto" che in certe situazioni è la stessaimplementazione dello spazio delle tuple a condizionare le sceltedel programmatore di applicazioni: in 5.2.1.4.1 è stata proposta unatecnica di programmazione, basata sull’uso di tuple private, volta aridurre il costo di condivisione di una struttura dati in un sistemaLinda con "in distribuita" quando tale struttura è acceduta piùfrequentemente in lettura piuttosto che in aggiornamento.
Abbiamo utilizzato quale misura delle prestazioni degli algoritmi unparametro standard: lo speedup S. Abbiamo verificato cheraggiungere il limite ideale per questo parametro (N se N è ilnumero di processori impegnati della ricerca) è compito assaidifficile. Nel corso degli esperimenti è stata rilevata la presenza di 3principali motivi che hanno contribuito al degrado delle prestazioni:
• il costo delle comunicazioni fra processori (overhead dicomunicazione)• la parziale condivisione dei risultati intermedi (overhead di ricerca)• la distribuzione non uniforme del carico di lavoro (overhead disincronizzazione)È stato appurato il forte legame esistente fra queste forme didegrado: la riduzione di una ha sempre determinato l’aumento diun’altra; l’algoritmo base con decomposizione dinamica al top-level(cfr. Tab. 5.7), ad esempio, è quello che ha garantito il migliorebilanciamento del carico (Fpm=90% con 11 processori), ma haanche generato l’overhead di ricerca più disastroso (SO=108% con11 processori). La conoscenza di questa realtà ci ha guidato nellosviluppo di soluzioni algoritmiche mirate ad ottenere il migliorebilanciamento (trade-off) fra le forme di degrado, cioè aminimizzare la loro incidenza complessiva e non di una sola diesse.

199
I risultati sperimentali hanno dimostrato che tale situazione ottimaleè favorita dall’algoritmo PVSplit quando è combinato con il concettodi condivisione dello score (S=5.57 con 11 processori;cfr. Tab. 5.6b) o con quello di distribuzione dinamica (S=5.58 con11 processori; cfr. Tab. 5.8).
I valori per lo speedup appena indicati assumono significato solo seconfrontati con quelli ottenuti da altri ricercatori nellasperimentazione di algoritmi simili.
In [MaOlSc86] viene segnalato uno speedup per PVSplit di 3.66con una rete di 5 workstation misurato in base alla esplorazionefino a profondità 7-ply delle 24 posizioni di Bratko-Kopec; lospeedup da noi ottenuto per PVSplit con lo stesso numero diprocessori è 3.49 (= 3.75 se si considera il miglioramento indottodalla condivisione dello score; cfr. Tab. 5.6a e 5.6b). Tale valore èmolto soddisfacente e testimonia che l’implementazione in Lindadella classe di problemi da noi studiati può garantire prestazioniapprezzabili. Ad avvalorare tale affermazione si deve tenere inconsiderazione il fatto che i nostri esperimenti sono stati eseguiticon profondità di ricerca 5-ply. È stato infatti verificato che lospeedup migliora all’aumentare della profondità di ricerca[MaOlSc86]; il motivo di tale relazione è che i vari tipi di degradodelle prestazioni introdotti dal parallelismo sono maggiormentedissipati all’interno di ricerche più durature e quindi hanno minoreimpatto sulle prestazioni.
In [Sch89] è riportato uno speedup per DPVSplit di 4.78 ottenutocon 7 processori (ricerca a profondità 7-ply). Lo speedup da noiottenuto per lo stesso algoritmo, con identico numero di processorie ricerca a 5-ply, è 4.54 (cfr. Tab. 5.8).
In conclusione l’implementazione in Linda e su rete locale dei"migliori" algoritmi di decomposizione statica determina prestazioniconfrontabili con quelle ottenute per gli stessi algoritmi in altriambienti di ricerca.
La realizzazione in Linda di algoritmi con distribuzione dinamicadella ricerca ha rivelato prestazioni deludenti (cfr. Tab. 5.9 e 5.10).Tale inefficienza è intrinseca in questa classe di algoritmi o è stataoriginata dall’ambiente in cui essi sono stati valutati?
Gli eccellenti risultati ottenuti dalla sperimentazione di tali algoritmisulla base di altre architetture parallele appaiono confermarequesta seconda ipotesi:
• in [Eli90] è presentato Oracol, un solutore di problemi di scacchi ilcui algoritmo di ricerca è parallelo con decomposizione dinamicadell’albero di gioco. Il massimo speedup riportato è 5.5 ottenuto suun’architettura multiprocessore con memoria condivisa e costituitada 10 processori.
• in [FeMyMo92] è presentato un algoritmo di decomposizionedinamica basato sul criterio "young-brothers-wait". La suarealizzazione, avvenuta su un sistema di transputer composto di

200
256 processori, ha garantito uno speedup sorprendente: 126(ricerca a 8-ply).Questi risultati sperimentali suggeriscono che l’implementazionedegli algoritmi di decomposizione dinamica può generareprestazioni notevoli, ma solo in architetture con memoria condivisao distribuite con grosso accoppiamento fra i processori. In questiambienti, infatti, il costo delle interazioni interprocessore è moltominore rispetto a quello di una rete locale e sono quindi più adatteper ospitare applicazioni a grana piuttosto fine come gli algoritmi didecomposizione dinamica.
Sarebbe interessante verificare su queste architetture parallele (edin particolare su quelle a parallelismo massiccio):• l’atteso miglioramento delle prestazioni dell’algoritmo generale didecomposizione dinamica da noi proposto• la convergenza asintotica (all’aumentare dei processori) previstain [MaOlSc86] verso un valore costante dello speedup per i metodidi decomposizione statica.

93

185
Capitolo 6La distribuzione della conoscenza
6.1 IntroduzioneI giocatori artificiali di scacchi che usano più processori hannonormalmente la seguente caratteristica: nella scelta della mossatutti i processori cooperano per completare nel modo più efficientela visita dell’albero di gioco associato alla posizione corrente. Insostanza avviene una distribuzione della ricerca fra istanzeindistinguibili di uno stesso giocatore artificiale (Capitolo 5).
Il tipo di giocatore parallelo che descriviamo in questo capitolo,invece, si fonda su un approccio differente: ogni processorecostituisce un’istanza di ricerca dell’albero di gioco indipendentedalle altre. Vengono quindi condotte in parallelo tante ricerchequanti sono i processori. La cooperazione fra le istanze avviene aposteriori, quando cioè ognuna di esse ha proposto la sua mossamigliore e viene allora applicata una regola (denominata criterio diselezione) per la scelta finale di una fra tutte le mosse proposte.
Ciò che di fatto è stabilita da questo nuovo approccio è unadistribuzione della conoscenza. Le istanze di ricerca sono infattitutte diverse in quanto incorporano una differente conoscenza deldominio di applicazione.
Il concetto di conoscenza deve essere chiarito e messo in relazionealla classe di problemi in analisi; Berliner ha proposto unaclassificazione in due categorie della conoscenza applicata aproblemi di ricerca su alberi di gioco [Ber82]:
• conoscenza dirigente: è usata per guidare la ricerca e suggerirel’ordine in cui i discendenti di un nodo devono essere esaminati. Inbase a questa definizione si può intendere che istanze condifferenti algoritmi di visita dell’albero di gioco presentano unadifferente conoscenza dirigente.
• conoscenza terminale: è usata al livello dei nodi terminali perindicare quanto è desiderabile raggiungere una certa posizione.Due istanze differiscono dunque nella rispettiva conoscenzaterminale se hanno funzioni di valutazione diverse.
Il nuovo approccio che sarà descritto si distingue per la suapressoché assoluta originalità: solamente in [Alt91], infatti, èpresentato lo studio di un giocatore parallelo basato su unadistribuzione "rudimentale" della conoscenza. In esso ciascunaistanza di ricerca è costituita da un giocatore artificialecommerciale; il criterio di selezione è di tipo a maggioranza (odemocratico): la mossa che ha ottenuto il maggior numero diproposte è quella che sarà effettivamente giocata.
Tale giocatore parallelo presenta alcuni problemi:• in condizioni di torneo (cioè con limitazione del tempo di ricerca)le varie istanze sono eterogenee in termini di forza di gioco e ciòcomporta un contributo negativo per il giocatore parallelo da parte

186
dei giocatori più deboli. I risultati sperimentali, infatti, hannodimostrato che il giocatore parallelo è decisamente più debole diquello sequenziale più forte (fra quelli che lo compongono).
• i giocatori commerciali sono stati impiegati come delle scatolenere, cioè senza conoscerne l’algoritmo e le euristiche di ricercanonché la conoscenza catturata dalla funzione di valutazione. Laconoscenza di queste informazioni avrebbe potuto aiutare nelladefinizione di un criterio di selezione più efficace nel migliorare laqualità di gioco del giocatore parallelo.
Intuitivamente il successo di questo nuovo approccio dipende dallascelta dell’insieme di istanze di ricerca: una scelta casuale (comequella descritta in [Alt91]) non appare certo il metodo più efficace.
Non meno importante, però, è la determinazione di un criterio diselezione che rifletta la conoscenza delle caratteristiche delleistanze e sia quindi in grado di "pesare" la qualità della ricerca diciascuna istanza.
Le finalità che si intende perseguire con gli esperimenti cheverranno descritti sono:• stabilire quali combinazioni di istanze inducono la migliore qualitàdi gioco. L’intento non è di realizzare un unico e fortissimogiocatore parallelo, bensì classificare in funzione della loro efficaciale varie possibilità di associare istanze di ricerca diverse. Unacombinazione di istanze verrà indicata efficace solo se il giocatoreparallelo che ne scaturisce è più forte di tutte le sue istanzeconsiderate singolarmente.
• individuare criteri di selezione generali e possibilmenteindipendenti dal dominio capaci di combinare al meglio le qualitàdelle istanze di ricerca.
La grossa differenza rispetto al lavoro in [Alt91] sarà il progettodelle istanze. In particolare si tenterà di creare classi di istanze,dove ci si aspetta che i componenti di ciascuna classe "stiano beneinsieme", vale a dire abbiano qualche caratteristica comune chefaccia ben sperare nella loro combinazione all’interno dello stessogiocatore parallelo.
Se questo tipo di esperimenti avesse successo, cioè si riuscisse astabilire uno o più metodi di combinare insieme più istanze diricerca tali che il giocatore risultante sia più forte di ogni singolaistanza, questo risultato aprirebbe nuove prospettive di ricerca; conle argomentazioni che seguiranno verrà chiarito il perché di questaaffermazione.
Una naturale obiezione a questo tipo di approccio è la notevoleridondanza (dovuta alla visita multipla dello stesso albero di gioco)e lo "spreco" di risorse: il lavoro di un’istanza può risultare inutilequalora la mossa da essa proposta non sia la prescelta dal criteriodi selezione.
Tuttavia allo stato dell’arte, e come abbiamo visto nel Capitolo 5,esiste un limite per il numero di processori impiegati in un algoritmoparallelo di ricerca oltre il quale non si ottiene alcun beneficio

187
dall’aumento di risorse di elaborazione. Una soluzione a talelimitazione può essere quella di combinare le due forme diparallelismo: ogni istanza di ricerca è costituita da un pool diprocessori che realizzano la ricerca dell’albero di gioco in accordoad un certo algoritmo parallelo (parallelismo introdotto a bassolivello); a più alto livello, invece, sta il giocatore parallelo oggettodella presente trattazione, il quale non ha alcuna visibilità delparallelismo interno delle istanze. Il vantaggio che ne deriva èevidente: ogni istanza ha migliorato la sua qualità di gioco (laricerca parallela consente una esplorazione più in profonditàdell’albero) e di ciò risente positivamente la qualità del giocatorecomplessivo. Sarebbe di grosso interesse quantificare speri-mentalmente questo miglioramento verificando così anche lecaratteristiche ed i problemi di questa soluzione mista.
Alla luce di quanto detto la presenza di ridondanza va accolta comeun fatto positivo in quanto offre un ampio margine di miglioramentoper i futuri perfezionamenti del metodo.
Il presente lavoro intende indagare, in particolare, metodologie didistribuzione della conoscenza terminale. In particolare nelprossimo paragrafo sarà discusso il legame fra conoscenza e teoriadei giochi e presentato uno studio della conoscenza terminale nelgioco degli scacchi. Quest’ultimo costituirà un utile fondamento alseguente progetto e realizzazione di un giocatore parallelocostituito da istanze con diversa conoscenza terminale.
La distribuzione della conoscenza dirigente sarà tuttavia oggetto diuna breve discussione in cui saranno motivate alcune intuizionisulla reale efficacia di questo approccio e proposte alcune linee diricerca futura.
6.2 Conoscenza e dominio dei giochiCon la crescente consapevolezza delle potenzialità raggiunte daisistemi esperti, l’ingegneria della conoscenza è divenuta unadisciplina unanimemente riconosciuta. La responsabilità principaledell’ingegnere della conoscenza è raccogliere l’esperienzaacquisita dagli esperti di un certo dominio ed esprimerla in unaforma manipolabile da un calcolatore.
Per la maggior parte dei domini esiste un’incredibile quantità diinformazioni disponibili, non tutte necessarie per ottenereprestazioni di alto livello. In generale un programma di gioco nonpuò conoscere qualsiasi informazione necessaria ad ottenere unaperfetta condotta di gioco: quale parte della conoscenza è alloraimportante?
Ad ogni porzione di conoscenza è associata un’importanza relativa.Ad esempio nel gioco degli scacchi conoscere che "il vantaggio diuna regina di solito implica vincere la partita" appare moltoimportante. Al contrario, un giocatore professionista di scacchipotrebbe non incontrare in tutta la sua vita un finale di partitaparticolare; si potrebbe concludere che conoscere come giocarecorrettamente quel certo finale è relativamente poco importante:

188
tale però rimane solo fino a quando quel finale non occorrerealmente!Comprendere l’importanza relativa delle "porzioni" di conoscenza èun passo necessario per lo sviluppo di un programma di gioco chemassimizzi la qualità delle sue scelte minimizzando peròridondanza ed inefficienza.
Riguardo il gioco degli scacchi è stata accumulata, nei secoli,un’enorme quantità di conoscenza. A partire da questa l’ingegneredella conoscenza deve determinare quale sottoinsieme è piùimportante sia contenuto in un programma; nozioni meno importantipotranno tuttavia essere aggiunte in seguito. Il consulto con altriesperti può probabilmente essere necessario per un consenso sullescelte di base; dopo questo, però, la ricerca dovrà fare affidamentounicamente su tecniche trial-and-error e sull’esperienza via viaacquisita.
È convinzione diffusa che per aumentare la forza di un giocatoreartificiale è sufficiente arricchirlo di quanta più conoscenza èpossibile. Essa ha fondamento nella maggioranza dei sistemiesperti (o almeno appare averne); in un programma di gioco,tuttavia, tale intuizione non ha valore assoluto. Si osservi che lecomponenti della conoscenza devono operare come una squadra equindi la qualità di gioco dipende anche dagli effetti di una lorocombinazione; potrebbe quindi accadere che risulti migliore non unprogramma con maggiore conoscenza, ma uno le cui componentioperano meglio insieme [Sch86].
Argomento della presente sezione di lavoro è il progetto di ungiocatore parallelo costituito da istanze di ricerca differenti; ciò chediversifica tali istanze è la rispettiva conoscenza del dominio diapplicazione. Questo tipo di problema introduce un livello dicomplessità supplementare: all’individuazione della conoscenza siaggiunge la questione della sua distribuzione. L’obbiettivo che siintende perseguire è lo sviluppo di metodologie (possibilmenteindipendenti dal dominio) riguardanti questo secondo aspetto. Lasperimentazione di queste non può però prescindere

189
da argomenti che riguardano il dominio cui sono applicate: comesuperare questo ostacolo?La soluzione è stata quella di utilizzare i risultati noti di uno studiomolto articolato di principi di selezione ed ordinamento dellaconoscenza applicati al dominio degli scacchi [Sch86]. Tali risultatiriguardano proprio il dominio di sperimentazione del presentelavoro; essi costituiranno quindi la risposta a qualsiasi interrogativoche, nel corso del progetto e sperimentazione della distribuzionedella conoscenza, sarà inerente il particolare dominio cui ladistribuzione è applicata. Gli argomenti della citata ricerca sono orapresentati in sintesi.
6.2.1 Uno studio della conoscenza terminale nelgioco degli scacchi
Il lavoro di Schaeffer costituisce un’esplorazione sistematicadelle componenti di un giocatore sequenziale di scacchi;particolare attenzione è dedicata allo studio dellaconoscenza terminale, cioè quella incorporata nella funzionedi valutazione [Sch86].
Tale tipo di conoscenza non è basata su regole; essaconsiste invece di frammenti di programma aventi lo scopodi riconoscere particolari caratteristiche e proprietà di unaposizione del gioco e, per ciascuna di esse, indicare unvalore numerico che ne rifletta il gradimento o meno da partedel giocatore cui spetta la mossa27. I valori così ottenutisono combinati linearmente per determinare la valutazionecomplessiva della posizione.
In particolare sono state fissate da Schaeffer 8 categorie diconoscenza applicata al mediogioco di una partita di scacchie di seguito valutata l’importanza relativa di ognuna. Talicategorie sono tipicamente rappresentate in ogniprogramma di scacchi e quindi la loro valutazione assumeun significato generale. Esse sono elencate di seguito:
• materiale (M)• spazio e mobilità (SM)• debolezza pedonale (PW)• sicurezza del re (KS)• controllo del centro (CC)• struttura pedonale (PS)• punteggio incrementale (IS) indicante la somma di punteggiaccumulati lungo il cammino dalla radice al nodo terminaleassegnati in base a certe proprietà delle mosse incontrate
• pianificatore (PL) che assegna punteggi addizionali amosse che rispettano un certo piano di azioneIl primo esperimento eseguito da Schaeffer è stato quello diaggiungere in modo incrementale le categorie di conoscenzae valutare la forza del giocatore così ottenuto. In Tab. 6.1sono indicati i punteggi così ottenuti espressi nello standard
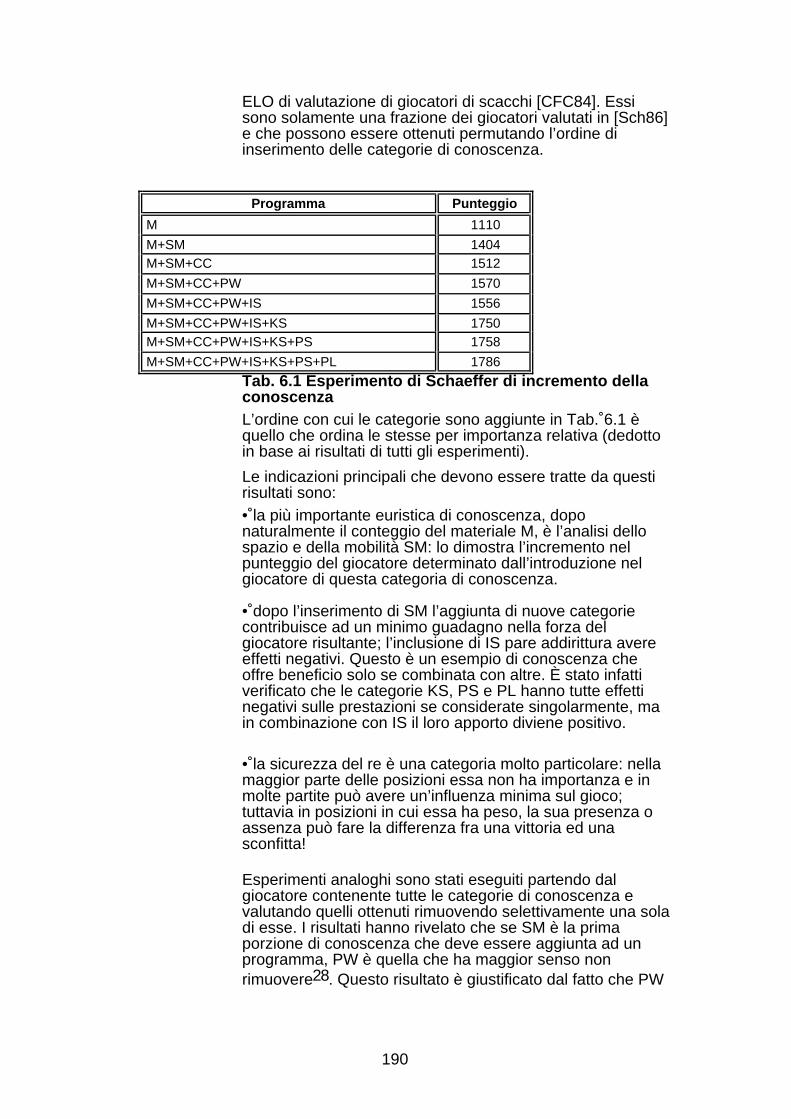
190
ELO di valutazione di giocatori di scacchi [CFC84]. Essisono solamente una frazione dei giocatori valutati in [Sch86]e che possono essere ottenuti permutando l’ordine diinserimento delle categorie di conoscenza.
Programma Punteggio
M 1110
M+SM 1404M+SM+CC 1512
M+SM+CC+PW 1570
M+SM+CC+PW+IS 1556
M+SM+CC+PW+IS+KS 1750M+SM+CC+PW+IS+KS+PS 1758
M+SM+CC+PW+IS+KS+PS+PL 1786
Tab. 6.1 Esperimento di Schaeffer di incremento dellaconoscenzaL’ordine con cui le categorie sono aggiunte in Tab. 6.1 èquello che ordina le stesse per importanza relativa (dedottoin base ai risultati di tutti gli esperimenti).
Le indicazioni principali che devono essere tratte da questirisultati sono:• la più importante euristica di conoscenza, doponaturalmente il conteggio del materiale M, è l’analisi dellospazio e della mobilità SM: lo dimostra l’incremento nelpunteggio del giocatore determinato dall’introduzione nelgiocatore di questa categoria di conoscenza.
• dopo l’inserimento di SM l’aggiunta di nuove categoriecontribuisce ad un minimo guadagno nella forza delgiocatore risultante; l’inclusione di IS pare addirittura avereeffetti negativi. Questo è un esempio di conoscenza cheoffre beneficio solo se combinata con altre. È stato infattiverificato che le categorie KS, PS e PL hanno tutte effettinegativi sulle prestazioni se considerate singolarmente, main combinazione con IS il loro apporto diviene positivo.
• la sicurezza del re è una categoria molto particolare: nellamaggior parte delle posizioni essa non ha importanza e inmolte partite può avere un’influenza minima sul gioco;tuttavia in posizioni in cui essa ha peso, la sua presenza oassenza può fare la differenza fra una vittoria ed unasconfitta!
Esperimenti analoghi sono stati eseguiti partendo dalgiocatore contenente tutte le categorie di conoscenza evalutando quelli ottenuti rimuovendo selettivamente una soladi esse. I risultati hanno rivelato che se SM è la primaporzione di conoscenza che deve essere aggiunta ad unprogramma, PW è quella che ha maggior senso nonrimuovere28. Questo risultato è giustificato dal fatto che PW

191
gioca un ruolo molto importante in ambienti ricchi diconoscenza, mentre la sua efficacia relativa è molto minorein presenza di poca conoscenza. Ciò spiega come certaconoscenza necessiti del giusto ambiente con cui interagireper poter ottenere i migliori risultati.
6.3 La distribuzione della conoscenza terminaleQuesta sezione del lavoro intende indagare il progetto e larealizzazione di una classe di giocatori paralleli costituiti da istanzedi ricerca caratterizzate da funzioni di valutazione diverse(conoscenza terminale). Al fine di isolare lo studio delladistribuzione di questa sola forma di conoscenza, la conoscenzadirigente, cioè l’unione di algoritmo ed euristiche di ricerca, sarà lastessa per tutte le istanze.
Ciò che si vuole ottenere sono indicazioni generali sull’efficacia diquesto nuovo approccio; è dunque necessario selezionare funzionidi valutazione significative, che siano cioè il risultato disuggerimenti di giocatori esperti. La scelta di funzioni che origininogiocatori molto deboli o comunque dalle qualità di giocoestremamente eterogenee potrebbe falsare la verifica sperimentaledelle idee che saranno proposte. La scelta delle funzioni divalutazione non deve dunque essere casuale.
In letteratura sono riportate numerose raccolte di funzioni divalutazione proposte da esperti: una possibile soluzione è quella diimplementare fedelmente alcune di esse. Questo approcciopresenta alcuni problemi:
• l’implementazione exnovo di funzioni di valutazione può originarebug di programmazione oppure non essere la più efficiente perquella funzione. Questo secondo aspetto appare moltointeressante; si consideri ad esempio il progetto di una routine per ilcalcolo della mobilità dei pezzi. Questa conoscenza è moltoimportante (cfr. 6.2.1); tuttavia il suo costo computazionale èelevato poiché sottintende il conteggio delle mosse legali per ognipezzo: abbiamo verificato che l’implementazione di questa euristicadi conoscenza come routine separata ha effetti disastrosi sulleprestazioni. La soluzione efficiente è invece integrare il suddettoconteggio all’interno del generatore di mosse.
L’implementazione efficiente delle funzioni di valutazione non èdunque immediata e richiede, invece, uno studio approfondito dellesue caratteristiche e della sua integrazione nella struttura di ricerca:l’analisi di queste attività esula dagli obbiettivi del presente lavoro.
• l’implementazione di funzioni di valutazione è operazione costosae "rischiosa"; ciò è in contrasto con il desiderio di disporre di unnumero elevato di esse, tale da definire un numero di giocatoriparalleli sufficiente a dare valore statistico alla valutazionesperimentale della nuova filosofia di distribuzione.
I problemi discussi sono risolti facilmente attraverso la"rielaborazione" dell’implementazione di un’unica funzione divalutazione sufficientemente testata nella sua correttezza e qualità;

192
come è possibile ricavare da un’unica funzione una molteplicitàindefinita di funzioni diverse?Si consideri un giocatore artificiale P preesistente (ad esempioGnuChess). L’idea è quella di decomporre la funzione divalutazione di P nelle componenti (chiamate parametri dellafunzione) sommate linearmente29 nella valutazione statica di unnodo terminale. Questa decomposizione equivale ad unaseparazione delle categorie di conoscenza terminale. Combinandoinsieme solo una parte della conoscenza contenuta nella funzioneoriginaria si ottengono funzioni di valutazione completamentedifferenti.
Più formalmente, data la funzione di valutazione F sia Df l’insiemedelle categorie di conoscenza che scaturiscono dalla suadecomposizione: ciascun sottoinsieme di Df individua unaparticolare funzione di valutazione.
Il numero di funzioni che possono essere dunque definite è pari allacardinalità dell’insieme delle parti di Df (=2N se N sono gli elementidi Df). Tali considerazioni sono valide nell’ipotesi che ciascunacategoria mantenga, nella ricombinazione lineare, lo stesso pesoche essa aveva nella funzione F originaria; in caso contrario ilnumero di possibili funzioni ottenibili attraverso il metodo descritto èinfinito perché tale è il numero di possibili attribuzioni di pesi.
Le istanze di ricerca che costituiranno il generico giocatoreparallelo saranno caratterizzate da una diversa funzione divalutazione scelta fra quelle ottenute nel modo descritto.
Il risultato di questo approccio è avere integrato istanze di ricercacon diversa conoscenza terminale. In particolare esse eseguonouna valutazione specializzata di una posizione in quanto la loroconoscenza terminale è una parte di quella generalmentecontenuta in un programma: ad esempio avremo un’istanza chevaluta soltanto la mobilità dei pezzi, un’altra il materiale ed un’altraancora la struttura pedonale e la sicurezza del re.
Intuitivamente ciascuna istanza così ottenuta è più debole delprogramma originario in quanto ha minore conoscenza rispetto adesso. È lecito dunque chiedere quali benefici possa portare laforma di parallelismo in analisi; le seguenti osservazioni sorreggonol’ipotesi che questo metodo migliori realmente la qualità di gioco delgiocatore iniziale:
• nell’ipotesi che ogni categoria di conoscenza del giocatore dipartenza P sia contenuta in almeno un’istanza, complessivamenteil giocatore parallelo dispone della stessa conoscenza di P;
• la classica ricerca su albero di gioco condotta con il metodo αβconsente di individuare la migliore mossa, ma non permette didedurre una stima del valore delle mosse restanti. Il metodo inoggetto, invece, consente di ricavare un insieme di mosse valide,risultate le migliori rispetto a diversi tipi di valutazione delleposizioni terminali;

193
• la funzione di valutazione di ogni singola istanza è più semplice diquella originale e quindi il suo calcolo più efficiente. Quello che siattende è pertanto un guadagno in termini di profondità di ricerca(seppure minimo).
È dimostrato da studi psicologici che la scelta della mossa da partedi un giocatore esperto si riduca ad un’analisi di poche mossesignificative [HLMSW92]. In generale tali mosse "valide"presentano vantaggi diversi l’una rispetto all’altra. Quello che ci siaspetta dal giocatore parallelo in analisi è che le varie istanzepropongano mosse diverse, ciascuna migliore secondo unaparticolare visuale di gioco.
Un evidente problema di questo metodo è che talvolta mosseovviamente svantaggiose non siano riconosciute come tali dallefunzioni di valutazione parziale e quindi possano non essererifiutate immediatamente dall’algoritmo αβ. A parziale soluzione diquesto problema può aiutare l’osservazione che qualsiasi tipo divalutazione non può prescindere da certi tipi fondamentali dianalisi, quale ad esempio quella del materiale. Un vincolo che deveessere dunque imposto è che la categoria di conoscenza chevaluta il materiale sia presente nella funzione di valutazione di tuttele istanze.
6.3.1 La struttura del giocatore paralleloIl linguaggio Linda ed il programma di scacchi GnuChess(Capitolo 3) costituiscono gli strumenti attraverso i quali saràdescritto e sperimentato un esempio concreto di giocatoreparallelo basato sul concetto di distribuzione dellaconoscenza terminale. Il ruolo di questi strumenti è ilseguente: a partire da un unico giocatore sequenziale(GnuChess) si vuole creare (attraverso le primitive Linda)una struttura di istanze di questo giocatore che cooperanoattraverso lo spazio delle tuple e che siano parametricherispetto alla funzione di valutazione (Fig. 6.1a).
GnuChess
Gnuchess
Gnuchess
GnuchessGnuchess Spazio delletuple
Linda
Giocatore parallelo
Fig. 6.1a Coordinamento di istanze di un giocatoresequenziale

194
GnuChess
funzione divalutazione
posizione
mossa
statistiche
Fig. 6.1b Interfaccia del giocatore sequenziale
Questo tipo di progetto intende verificare, fra l’altro,l’efficacia di Linda nella "parallelizzazione" di programmisequenziali; con questo termine si intende il "riutilizzo" dimoduli di programmi sequenziali nel definire programmiparalleli dove essi descrivono il flusso di controllo interno deiprocessi. Questo tipo di approccio alla programmazioneparallela è indubbiamente vantaggioso in quanto riducequesta attività alla sola descrizione del coordinamentointer-modulo, esonerando il programmatore dalla definizionedella parte sequenziale dei processi. La sua applicabilità nonsempre è possibile poiché fortemente influenzata dallaportabilità e dalla modularità del software sequenzialenonché dalle caratteristiche del linguaggio di coordinamento.
La funzionalità di ricerca di GnuChess è stata quindiriutilizzata nella sua interezza, considerando essa un bloccounico, una scatola nera di cui interessa la sola interfaccia(Fig. 6.1b). Le uniche modifiche ad essa apportate hannoriguardato la funzione di valutazione nei riguardi della qualeè stata resa parametrica; questa operazione ha richiesto uncambiamento minimo del codice sequenziale poiché, comespiegato in 6.3, la funzione originaria deve esserereimpiegata integralmente, anche se decompostafisicamente nelle porzioni di codice che calcolano euristichedi valutazione distinte.
In 2.4.2.3.4 è stata proposta una possibile decomposizionelogica della funzione di valutazione di GnuChess: essacostituisce il riferimento per l’applicazione del metodo digenerazione di funzioni di valutazione descritto in 6.3. Diseguito sono elencate le categorie di conoscenza individuatedalla suddetta decomposizione:
• materiale (M)• valore posizionale dei pezzi (B)• mobilità (di torre e alfiere) e combinazioni di attacco (X)• sicurezza del re (K)• struttura pedonale (P)• protezione dei pezzi (A)• relazione pezzi-struttura pedonale (R)La scelta di decomporre la funzione di valutazione secondole categorie di conoscenza appena elencate non è statacasuale, ma guidata dalle indicazioni del lavoro di Schaeffer

195
[Sch86]: si osservi, infatti, la corrispondenza fra molte diqueste euristiche e quelle utilizzate nel suo esperimento eriportate in 6.2.1.
La codifica della funzione di valutazione che comprende le euristiche: • materiale (M) • sicurezza del re (K) • struttura pedonale (P)è:
M B X K P A R
1 01 1 000(1001100) = (76)2 10
Fig. 6.2 Codifica numerica della funzione di valutazione
La funzione di valutazione di una generica istanza è ottenutaincludendo o meno il contributo che deriva dal calcolo diciascuna delle N (=7) euristiche di valutazione elencate. Lefunzioni che sono originate da questo metodo possonoessere facilmente codificate con un intero appartenenteall’intervallo [0,2N-1]; in Fig. 6.2 è descritto un esempio di talecodifica.
Il flusso di controllo che scandisce il calcolo della funzione divalutazione è quindi invariato rispetto a quello di GnuChess;la sola eccezione è l’inserzione di controlli dinamici cheverificano, in base alla codifica della funzione, quali routinedi valutazione debbano essere attraversate.
Quanto descritto permette di disporre di un codice unico perl’implementazione di tutte le funzioni di valutazione essendola specializzazione di quest’ultime rimandata al tempo diesecuzione.
Oltre all’evidente vantaggio di non dover programmare ognidiversa funzione di valutazione, la struttura descritta si rivelaestremamente flessibile: si osservi come sia possibilecambiare dinamicamente la funzione di valutazione correntesemplicemente modificandone la codifica numerica. Il prezzodi questi benefici è il costo dei controlli dinamici cheimplementano la decodifica della funzione di valutazione; ingenerale esso può essere considerato trascurabile seconfrontato con il tempo di esecuzione complessivo delprogramma30.
Quando e come avviene la cooperazione fra le istanze diGnuChess che compongono il giocatore parallelo?La ricerca di ciascuna istanza è sequenziale ed indipendentedalle altre: durante il suo svolgimento non si avrà dunquealcuna interazione fra processi. La cooperazione è stabilitanel momento in cui, terminata la rispettiva ricerca, le istanze

196
si "incontrano" per suggerire la propria mossa e "decidere"(applicando un criterio di selezione) quale fra quelleproposte sia preferibile giocare.
Il modello di programmazione parallela con cui è statoimplementato il coordinamento delle attività descritte è ilmaster-worker. In particolare una delle istanze (master) èstata arricchita con funzionalità di gestione e coordinamentodell’operato delle altre (worker).
Il flusso di controllo del processo coordinatore scandisce glistadi attraversati dal giocatore parallelo:• la creazione dei processi worker: uno dei parametri delprocesso coordinatore è la descrizione del giocatoreparallelo intesa come la specifica del numero P di istanzeche lo compongono e della funzione di valutazione(codificata) di ciascuna di esse.
Sulla base di queste informazioni sono create (P-1) istanzedi ricerca cui è comunicata la rispettiva funzione divalutazione; anche il processo coordinatore sarà impegnatonella ricerca e quindi si attribuirà esso stesso una dellefunzioni di valutazione previste.
La creazione della struttura di istanze avviene una sola voltaed è concentrata nella fase preliminare del gioco.• la ricerca: il processo coordinatore implementa l’interfacciadi i/o del giocatore parallelo. In particolare esso è l’unicaistanza cosciente del momento in cui il giocatore parallelodeve eseguire la scelta della mossa: quando questa ènecessaria esso richiede a ciascuna istanza che sia iniziatala rispettiva ricerca. Di seguito anch’esso intraprende lapersonale ricerca in parallelo alle altre.
Non è necessario che la descrizione del lavoro richiesto aiprocessi worker contenga la rappresentazione completadello stato del gioco (disposizione dei pezzi, possibilità diarrocco, ecc.) poiché ogni istanza ne mantiene una copialocale; l’aggiornamento di questa informazione richiede peròche il processo master comunichi ai worker le mosse chevengono via via realmente eseguite. È preferita questascelta perché il costo della gestione locale dello stato delgioco è decisamente inferiore al suo periodico trasferimentototale.
La durata della ricerca è la stessa per tutte le istanze ed ècostante durante tutto l’arco di una partita. La terminazionedelle ricerche sarà quindi pressoché simultanea: ciò ha ilvantaggio di impegnare produttivamente tutte le istanzedurante la fase complessiva di ricerca.
L’implementazione di euristiche di amministrazione deltempo è stata evitata perché dipendenti dal dominio e didifficile concezione in un giocatore parallelo come quello inanalisi: le istanze sono indipendenti e quindi il risparmio di

197
tempo deciso autonomamente da una potrebbe esserevanificato dalla ricerca prolungata di un’altra.• l’applicazione del criterio di selezione: al termine dellarispettiva ricerca ogni worker comunica al master la mossaritenuta migliore. Essa è accompagnata da un insieme didati statistici inerenti alcune proprietà della visita completata.Sulla base di queste informazioni e di quelle ottenute dallapropria ricerca il coordinatore applica il criterio di selezionedeterminando così la mossa definitiva. L’esito di questascelta sarà comunque reso noto ai processi worker i qualipotranno così aggiornare la copia locale dello stato delgioco.
In Fig. 6.3 è descritta in Linda l’architettura software appenadiscussa.Si osservi che l’implementazione proposta non rispettafedelmente il modello master-worker poiché in realtà iprocessi worker non sono indistinguibili, ma è attribuito loroun identificatore numerico al momento della rispettivacreazione.
La presenza di tale identificatore è giustificata dal fatto che ilprocesso master deve conoscere non solo la mossa sceltada ciascun worker, ma anche da quale di questi essa è stataproposta.
void master (int n_istances,int *functions){int my_function,quit,istance;move *moves,move_selected,mv;statistics *search_data,stats;my_function=functions[0]; /* è assegnata la funzione divalutazione del master *//* segue la creazione dei worker e l’attribuzione dellerispettive funzioni di valutazione */for (istance=1;istance<n_istances;istance++)
eval ("istance",worker(istance,functions[istance]));NewGame (); /* è la funzione di GnuChess che inizializza lostato del gioco *//* l’area di memoria per i vettori moves e search data deveessere allocata dinamicamente */memory_alloc (n_istances,&moves,&search_data);quit=false;while (quit)
{if (side_to_move()==PARALLEL_PLAYER) /* la mossa
spetta al giocatore parallelo? */{/* è richiesta la ricerca di tutti i worker */for (i=1;i<=n_istances;i ++)
out ("job",i,DO_SEARCH);/* anche il master conduce la sua esplorazione
dell’albero di gioco */moves[0]=SelectMove (my_function,
&search_data[0])/* inizia la raccolta delle mosse suggerite
dai worker */for (istance=1;istance<=n_istances;i stance++)
{

198
in("istance_move",?istance,?mv,?stats);
moves[istance]=mv;search_data[istance]=stats;}
move_selected=criteria(move,search_data); /* criterio diselezione */
}else /* deve essere raccolta la mossa
dell’avversario del giocatore parallelo */move_selected=other_player_search ();
MakeMove (move_selected); /* aggiornamento dellostato del gioco */
if (quit=end_gamep()) /* fine partita? */for (istance=1;istance<n_istances;istance++)
out ("job",istance,QUIT);else /* i worker devono aggiornare la loro copia
dello stato del gioco */{out ("move_selected",move_selected);out ("sincr",n_istances-1);for (istance=1;istance<n_istances;istance++)
out ("job",istance,DO_MOVE);in ("sincr,0); /* per problemi d i correttezza
il master non può inserire nuovi jobin agenda prima che tutti i worker abbiano raccolto larichiesta di aggiornamento della copia dello stato delgioco */
inp ("move_selected",move_selected);}
}for (i=1;i<n_istances;i++) /* è verificata la terminazionecorretta dei worker */
in ("istance",0);return ();}int worker (int identifier,int my_function){int job,quit,s;move mv;statistics stats;NewGame ();quit=false;while (!quit)
{in ("job",identifier,?job); /* ricezione job */switch (job);
{case DO_SEARCH:
/* è richiesta la ricerca sequenzialedella posizione corrente */
mv=SelectMove (my_function, &stats)out
("istance_move",identifier,mv,stats);break;
case DO_MOVE:rd ("move_selected",?mv);MakeMove (m v); /* aggiornamento dello
stato del gioco */in ("sincr",?s);out ("sincr",s-1);break;
case QUIT:quit=true;break;
default:break;
}}
return (0);

199
}Fig. 6.3 Coordinamento delle istanze di ricerca
L’attribuzione di un nome ai processi worker consente inoltredi risolvere in modo efficiente problemi di correttezza legatial prelievo dei lavori. A riguardo si osservi che la forma dicomunicazione che deve essere stabilita fra il coordinatore ele altre istanze è asimmetrica in uscita con diffusione:l’esecuzione di un lavoro è richiesta a tutte le istanze. Alcontrario, la forma di comunicazione fra il master e i workerstabilita dal paradigma omonimo è anch’essa asimmetrica inuscita, ma non avviene per diffusione poiché ogni lavorodeve essere eseguito da un unico worker.
6.3.2 La determinazione finale della mossa: ilcriterio di selezione
Al momento di scegliere la migliore mossa in una dataposizione il giocatore parallelo origina tante ricerche quantesono le istanze che lo compongono. Ogni ricerca èindipendente dalle altre e viene condotta sullo stesso alberodi gioco; i nodi visitati differiranno da un’istanza all’altrapoiché i diversi valori attribuiti ai nodi terminali dallerispettive funzioni di valutazione inducono tagli dell’alberodiscordanti.
Ogni istanza di ricerca ritorna la mossa risultata migliore inseguito alla propria visita ed il valore minimax associato. Ilproblema della determinazione della mossa che il giocatoreparallelo dovrà giocare si riduce ora alla selezione di una fratutte le mosse proposte dalle istanze di ricerca. Tale scelta èformulata in accordo ad un certo criterio chiamato appunto diselezione. La discussione seguente intende presentare unarassegna di criteri di selezione ponendo maggiore enfasi suquelli indipendenti dal dominio di applicazione.
6.3.2.1 Criteri di selezione a maggioranzasemplice e generalizzata (con pesi costanti)
Il criterio di selezione più ovvio è quello detto amaggioranza semplice (o democratico): la mossa cheha ottenuto maggiori preferenze è quella che saràeffettivamente giocata; in caso di parità la scelta ècasuale.
Il criterio democratico è indipendente dal dominio ed èquindi di applicazione generale. Tuttavia esso soffre,a causa della sua semplicità, di alcuni problemi:
• non viene tenuta in considerazione la forza relativadelle istanze;• la mossa selezionata è (in generale) il risultato diun’analisi parziale delle sue proprietà (a causa dellaspecializzazione delle funzioni di valutazione). La

200
situazione sgradevole che può quindi scaturire è chetale mossa, risultata la migliore sotto molti punti divista, risulti scadente sotto alcuni altri pregiudicandodrammaticamente la qualità del gioco qualora venissescelta; il criterio democratico non fornisce strumentiper rilevare e risolvere questo problema. Sarebbeimportante stimare con quale frequenza puòpresentarsi questo fenomeno ed al suo occorrerequale influenza esso può avere sulla forza delgiocatore artificiale.
• vi sono aspetti di una posizione del gioco che hannomaggiore importanza. È indubbio che negli scacchi unvantaggio di materiale conduce quasi certamente allavittoria, mentre lo stesso non è così evidente per unvantaggio nella struttura pedonale o nel controllo delcentro.
Gli esperimenti presentati in 6.2.1 hanno dimostratoche alcune euristiche di valutazione sono più efficacidi altre nel migliorare la forza di gioco. Va inoltreconsiderato come l’importanza di un’euristica siadipendente dalla posizione corrente del gioco epertanto l’importanza relativa delle euristiche divalutazione può variare durante l’arco di una partita.Ad esempio l’analisi della sicurezza del re assumeimportanza quando la partita sta per volgere alla suafase finale, mentre il controllo del centro ha maggiorepeso negli stadi iniziale e centrale. Il criterio diselezione a maggioranza semplice non tiene conto diqueste considerazioni; il rischio è dunque che in unasituazione di gioco in cui non abbiano incidenzavalutazioni riguardo la sicurezza del re o la strutturapedonale, una mossa venga erroneamente sceltasolo perché risultata migliore sotto questi punti diosservazione.
Per risolvere (parzialmente) alcuni dei problemipresentati si può pensare di adottare una versionegeneralizzata del criterio di selezione a maggioranza.
L’idea è di associare un peso a ciascuna delle mosseproposte dalle istanze di ricerca. Questo peso riflettel’importanza attribuita ad una certa mossa per essererisultata migliore secondo un tipo di valutazionepiuttosto che un altro. La somma dei pesi accumulatida una mossa scelta da una o più istanze nedetermina il valore. La mossa selezionata è dunquequella cui è associato il maggior valore.
È evidente come il criterio di selezione a maggioranzasemplice rappresenti un caso particolare della

201
versione generalizzata dove tutti i pesi hanno valoreunitario.Tale metodo permette di eliminare situazioni di sceltacasuale se si stabiliscono pesi che impediscano a piùmosse di accumulare lo stesso valore complessivo.
Il vantaggio che deriva da questo criterio è lapossibilità di attribuire maggiore importanza adeuristiche di valutazione considerate più affidabili; diriflesso avranno peso superiore le scelte di quelleistanze la cui funzione di valutazione contiene lecategorie di conoscenza terminale ritenute piùefficaci.
Quando avviene l’attribuzione dei pesi? E sulla basedi quali informazioni?La risposta più semplice a tali quesiti è prevedere chei pesi siano costanti, cioè indipendenti dalla posizionein cui deve avvenire la scelta della mossa. Ciòsignifica che a tutte le mosse proposte da una stessaistanza verrà sempre attribuito lo stesso peso. Inquesto caso il peso diviene una proprietà costantedell’istanza, o meglio della sua funzione divalutazione: esso costituisce un indice generaledell’importanza relativa della conoscenza in essacontenuta.
Generalizzazione della soluzione con pesi costanti è ilcriterio con pesi variabili: i pesi attributi alle mossescelte da un’istanza possono variare da unaposizione di gioco all’altra. Questo approccioidentifica una classe di criteri di selezioneestremamente complessa che sarà indagata nelparagrafo 6.3.2.3. Per il momento sarà valutatal’efficacia di alcuni dei criteri sin qui illustrati attraversouna loro applicazione al giocatore parallelo descrittoin 6.3.1.
6.3.2.2 La valutazione sperimentale delgiocatore parallelo
Ciò che si intende sperimentare sono:• alcuni modi di distribuire la conoscenza terminale frale istanze e• alcuni criteri di selezione.Dalle possibili combinazioni di questi due aspetti e alvariare del numero delle istanze traggono origine unelevato numero di giocatori paralleli.
Il problema è confrontare la qualità di gioco di taligiocatori eseguendo esperimenti di durata noneccessiva, ma statisticamente attendibili.

202
Il criterio più ovvio per la valutazione della forza di ungiocatore è osservarlo alle prese con una partitacompleta.
Ciò che si vorrebbe ottenere è un punteggio chesintetizzi la sua qualità di gioco rispetto agli altrigiocatori paralleli. La soluzione più corretta sarebbequella di far giocare una serie di N partite fra ciascunadelle possibili coppie di giocatori paralleli; tuttavia ilnumero totale di partite risulterebbe eccessivo:
N ⋅K ⋅(K −1)2
se K è il numero di giocatori
In alternativa a quella appena descritta, la soluzioneadottata è stata quella di fissare un avversario unicoper tutti i giocatori paralleli riducendo così il numerodelle partite di valutazione a N⋅ K.
Il confronto fra la qualità dei giocatori paralleli èdunque indiretto poiché avviene comparando ilnumero di vittorie riportate da ciascuno nei riguardidell’avversario comune.
Il giocatore scelto come avversario dei giocatoriparalleli è proprio la versione originale diGnuChess31. Questa soluzione ha il pregio dievidenziare direttamente se la distribuzione dellaconoscenza ha portato benefici rispetto al giocatoreoriginario (GnuChess) in cui la stessa conoscenza èinvece concentrata.
Sono stati inoltre ristretti i limiti di una generica partitaescludendo la sua fase finale; il motivo è che durantequesto stadio ha importanza solo una limitataporzione di conoscenza terminale e ciò potrebbecondizionare erroneamente la valutazionecomplessiva dei giocatori. In particolare la partita ètroncata dopo un prefissato numero di mosse; essapuò quindi concludersi per i seguenti motivi:
• situazione di patta• situazione di matto• raggiunto limite massimo di semi-mosse (=100)È stato inoltre inibito l’utilizzo del libro di aperturepoiché questo potrebbe condurre il gioco versoposizioni "non equilibrate", dove ad esempio una fortedebolezza della struttura pedonale potrebbe favorirequei giocatori paralleli dove esiste una maggioreridondanza fra le istanze di questa categoria diconoscenza.
In particolare ogni giocatore parallelo G disputacontro GnuChess un torneo di 20 partite; il colore digioco è assegnato equamente ai due giocatori: Gdisputerà 10 partite con il bianco e 10 con il nero.

203
Il valore finale di G è calcolato sommando i punteggiottenuti in ogni partita; il punteggio p ricavato da G inuna partita dipende dalla condizione di terminazionedi quest’ultima; i valori che esso può assumere sonoriportati in Fig. 6.4.
p=
0
0.5
1
in caso di sconfitta
in caso di patta
in caso di vittoria
in caso di raggiuntolimite max. di mosse
0 se score < -PV
1 se score > PV
score+PV
2PVse -PV ≤ score ≤ PV
PV = valore posizionale equivalente ad un pedone (100)score = stima del valore posizionale della posizione finale dal punto di vista del giocatore parallelo
Fig. 6.4 Attribuzione del punteggio in una singolapartita
Un problema molto difficoltoso è proposto dai casi diterminazione forzata della partita in cui non esiste unchiaro vincitore; in generale, tuttavia, uno dei giocatoriavrà accumulato un vantaggio posizionale che alungo termine potrebbe con molta probabilità rivelarsidecisivo: in questo caso esso viene ritenuto vincitoredella partita.
Per tenere conto di queste situazioni viene utilizzatala funzione di valutazione di GnuChess (che contienel’insieme completo di euristiche di valutazione) perstimare il vantaggio posizionale (eventualmentenegativo) del giocatore parallelo G. Esso vieneconfrontato con un valore posizionale costante perstabilire la vittoria o meno di G; tale valore è fissatoarbitrariamente pari al valore PV di un pedone. Cosasuccede se |score| ≤ PV?
Piuttosto che definire la fascia intermedia [-PV,+PV]come "area di patta" ed associare ad essa ilpunteggio 0.5 di equilibrio, si è preferito dare
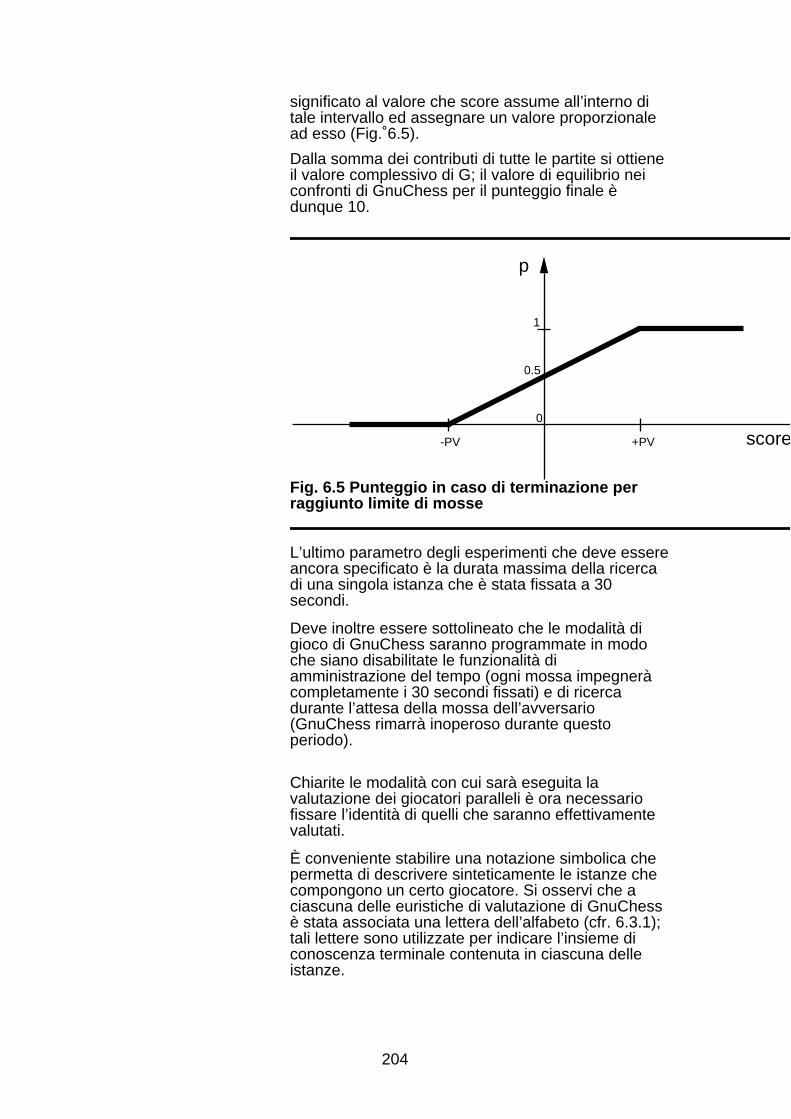
204
significato al valore che score assume all’interno ditale intervallo ed assegnare un valore proporzionalead esso (Fig. 6.5).
Dalla somma dei contributi di tutte le partite si ottieneil valore complessivo di G; il valore di equilibrio neiconfronti di GnuChess per il punteggio finale èdunque 10.
0.5
1
0
-PV +PV
p
score
Fig. 6.5 Punteggio in caso di terminazione perraggiunto limite di mosse
L’ultimo parametro degli esperimenti che deve essereancora specificato è la durata massima della ricercadi una singola istanza che è stata fissata a 30secondi.
Deve inoltre essere sottolineato che le modalità digioco di GnuChess saranno programmate in modoche siano disabilitate le funzionalità diamministrazione del tempo (ogni mossa impegneràcompletamente i 30 secondi fissati) e di ricercadurante l’attesa della mossa dell’avversario(GnuChess rimarrà inoperoso durante questoperiodo).
Chiarite le modalità con cui sarà eseguita lavalutazione dei giocatori paralleli è ora necessariofissare l’identità di quelli che saranno effettivamentevalutati.
È conveniente stabilire una notazione simbolica chepermetta di descrivere sinteticamente le istanze checompongono un certo giocatore. Si osservi che aciascuna delle euristiche di valutazione di GnuChessè stata associata una lettera dell’alfabeto (cfr. 6.3.1);tali lettere sono utilizzate per indicare l’insieme diconoscenza terminale contenuta in ciascuna delleistanze.

205
Ad esempio con la notazione (MB)(MX)(MBXK) siintende indicare un giocatore parallelo costituito da 3istanze di ricerca, dove ciascuna utilizza nella propriafunzione di valutazione le euristiche racchiuse dallacoppia di parentesi corrispondente.
La generazione dei giocatori paralleli che sarannovalutati non è casuale, ma in accordo a criteri(intuitivi) di distribuzione della conoscenza: sarannoadottati 4 di essi. L’applicazione di alcuni di questinecessita dell’ordinamento per importanza relativadelle euristiche di valutazione.
L’ordinamento delle euristiche di GnuChess è statofissato facendo tesoro delle indicazioni fornite dagliesperimenti di Schaeffer (cfr. 6.2.1); esso è in sintesiil seguente: M, B, X, K, P, A, R.
La descrizione dei criteri di distribuzione èindipendente dal numero e dall’identità delleeuristiche di valutazione: sia dunque E1,E2,…,EN unagenerica sequenza ordinata di esse.
Sia inoltre n (numero di istanze) ≤ N (numerocomplessivo di euristiche); sono allora definiti iseguenti criteri di distribuzione della conoscenza:
• a. minima conoscenza: G(n)=(E1)(E2)…(En).Ogni istanza contiene una sola euristica divalutazione fra le prime n dell’ordinamento.• b. distribuzione bilanciata: le funzioni di valutazionedi tutte le istanze contengono lo stesso numero dieuristiche; inoltre ogni euristica è presente in unostesso numero di istanze (compatibilmente con ilrispetto del primo vincolo).
• c. distribuzione sbilanciata:G(n)=(E1…EN)(E1)…(En/2)(E1E2…EN-1)…(E1E2…En/2En/2+1…EN).
Una delle istanze ha la stessa funzione divalutazione di GnuChess; metà delle altre istanzecontiene solo una euristica fra le prime n/2dell’ordinamento, mentre le restanti contengono tuttele euristiche eccettuato una fra le (n/2-1) menoefficaci.
• d. distribuzione incrementale:G(n)=(E1)(E1E2)…(E1E2…En).La prima istanza contiene la sola conoscenza piùimportante, la successiva anche la secondadell’ordinamento, ecc.
Si osservi che i metodi b. e c. possono essereapplicati anche se n>N; il metodo b., inoltre, nonrichiede un ordinamento preliminare delle categorie diconoscenza.

206
Ciascuno dei metodi elencati è stato applicato nelladefinizione di giocatori costituiti da un numero diistanze che va da 3 a 6. Sono dunque scaturiti 16giocatori paralleli la cui natura è descritta in Tab. 6.2.
Si osservi che la conoscenza relativa al materiale èpresente in tutte le istanze (per i motivi spiegati in6.3): i criteri di distribuzione tengono quindi contosolamente delle restanti euristiche di valutazione.

207
Criterio didistribuzione
Etichetta Giocatore parallelo
3a (MB)(MX)(MK)Minima 4a (MB)(MX)(MK)(MP)
conoscenza 5a (MB)(MX)(MK)(MP)(MA)6a (MB)(MX)(MK)(MP)(MA)(MR)
3b (MBXP)(MBKR)(MXKA)Distribuzione 4b (MBXA)(MBKR)(MXPA)(MKPR)
bilanciata 5b (MBXK)(MBKA)(MBPR)(MXKR)(MXPA)
6b (MBXK)(MBKA)(MBPR)(MXPA)(MXAR)(MKPR)
3c (MB)(MX)(MBXKPAR)Distribuzione 4c (MB)(MX)(MBXKPAR)(MBXKPA)
sbilanciata 5c (MB)(MX)(MK)(MBXKPAR)(MBXKPA)6c (MB)(MX)(MK)(MBXKPAR)(MBXKPA)(MBXKPR)
3d (MB)(MBX)(MBXK)
Distribuzione 4d (MB)(MBX)(MBXK)(MBXKP)incrementale 5d (MB)(MBX)(MBXK)(MBXKP)(MBXKPA)
6d (MB)(MBX)(MBXK)(MBXKP)(MBXKPA)(MBXKPAR)
Tab. 6.2 Giocatori paralleli con distribuzione dellaconoscenza terminale.Quale criterio di selezione sarà adottato dai giocatoriparalleli?A riguardo sono stati stabiliti 2 differenti criteri del tipoa maggioranza con pesi costanti. Il peso che èattribuito ad una generica istanza è calcolato comesegue:
• per ognuna delle euristiche di valutazione è fissatoun peso che tenga conto dell’ordinamento indottodalla loro importanza relativa; in Tab. 6.3 sono indicatii pesi attribuiti alle euristiche di GnuChess in relazioneai due criteri di selezione che si intende applicare.
Criterio di selezione
Euristica Semplice Generalizzato
M 130 30
B 121 21
X 115 15
K 110 10
P 106 6
A 103 3
R 101 1

208
Tab. 6.3 Attribuzione di pesi alle euristiche divalutazione• sia I=(Ei1Ei2…Eik) una generica istanza e sia P:E→int la funzione che associa ad un’euristica divalutazione il rispettivo peso.
Il peso dell’istanza I è calcolato come la mediaaritmetica dei pesi associati alle euristiche contenutenella sua funzione di valutazione:
peso(I) =P(Ei j)
j=1
k
∑k
• sia M={m1,…,mn} l’insieme di mosse proposte dalleistanze di ricerca ed in particolare sia Ii={Ii1,…,Iip}l’insieme di istanze che hanno "votato" la mossa mi(i=1..n); il valore vi di tale mossa è calcolato come lasomma dei pesi delle istanze contenute in Ii:
vi = peso(I ij)j=1
p
∑Può finalmente avvenire la selezione finale:mossa selezionata = max(v1,…,vn).Si osservi che i pesi fissati dal primo criterio inTab. 6.3 fanno sì che il criterio a maggioranza siaequivalente alla sua versione semplificata: è scelta lamossa più votata; l’unica differenza è che la soluzionedi situazioni di parità non è casuale, ma tiene contodei pesi delle istanze.
Il criterio denominato "Generalizzato" è invece unclassico esempio di criterio con maggioranzageneralizzata; esso infatti prevede che una mossavotata dalla maggioranza relativa delle istanze possaanche non essere selezionata se il "peso" delleistanze che l’hanno proposta non riflette sufficientefiducia riguardo la loro scelta: in questo caso i valoridei pesi sono stati fissati in modo assolutamentearbitrario, nel rispetto della sola logica di favorirepesantemente le categorie di conoscenza cheoccupano le prime posizioni nell’ordinamentoprecedentemente fissato.
La sperimentazione dei due criteri di selezione haportato a 32 il numero di giocatori paralleli valutati;complessivamente sono state quindi eseguite 640partite.
Deve essere precisato che le partite non sono stateeseguite in ambiente distribuito, ma simulateattraverso codice scritto completamente in C; i motiviche hanno determinato questa scelta sono duplici:
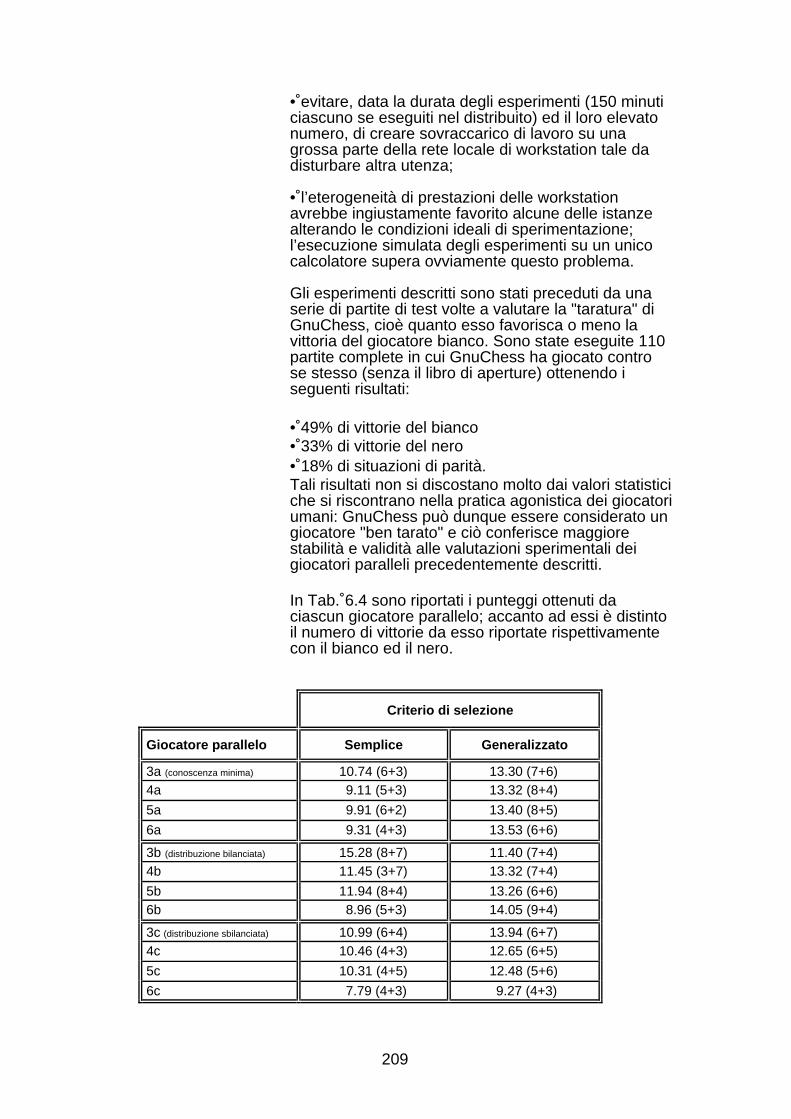
209
• evitare, data la durata degli esperimenti (150 minuticiascuno se eseguiti nel distribuito) ed il loro elevatonumero, di creare sovraccarico di lavoro su unagrossa parte della rete locale di workstation tale dadisturbare altra utenza;
• l’eterogeneità di prestazioni delle workstationavrebbe ingiustamente favorito alcune delle istanzealterando le condizioni ideali di sperimentazione;l’esecuzione simulata degli esperimenti su un unicocalcolatore supera ovviamente questo problema.
Gli esperimenti descritti sono stati preceduti da unaserie di partite di test volte a valutare la "taratura" diGnuChess, cioè quanto esso favorisca o meno lavittoria del giocatore bianco. Sono state eseguite 110partite complete in cui GnuChess ha giocato controse stesso (senza il libro di aperture) ottenendo iseguenti risultati:
• 49% di vittorie del bianco• 33% di vittorie del nero• 18% di situazioni di parità.Tali risultati non si discostano molto dai valori statisticiche si riscontrano nella pratica agonistica dei giocatoriumani: GnuChess può dunque essere considerato ungiocatore "ben tarato" e ciò conferisce maggiorestabilità e validità alle valutazioni sperimentali deigiocatori paralleli precedentemente descritti.
In Tab. 6.4 sono riportati i punteggi ottenuti daciascun giocatore parallelo; accanto ad essi è distintoil numero di vittorie da esso riportate rispettivamentecon il bianco ed il nero.
Criterio di selezione
Giocatore parallelo Semplice Generalizzato
3a (conoscenza minima) 10.74 (6+3) 13.30 (7+6)4a 9.11 (5+3) 13.32 (8+4)
5a 9.91 (6+2) 13.40 (8+5)
6a 9.31 (4+3) 13.53 (6+6)
3b (distribuzione bilanciata) 15.28 (8+7) 11.40 (7+4)4b 11.45 (3+7) 13.32 (7+4)
5b 11.94 (8+4) 13.26 (6+6)6b 8.96 (5+3) 14.05 (9+4)
3c (distribuzione sbilanciata) 10.99 (6+4) 13.94 (6+7)4c 10.46 (4+3) 12.65 (6+5)
5c 10.31 (4+5) 12.48 (5+6)
6c 7.79 (4+3) 9.27 (4+3)

210
3d (distribuzione incrementale) 11.94 (5+5) 10.21 (6+4)4d 14.61 (7+6) 11.38 (3+6)
5d 12.43 (7+5) 8.05 (4+2)
6d 7.72 (1+5) 8.12 (5+2)
Tab. 6.4 Valutazione sperimentale dei giocatoriparalleli.I risultati di Tab. 6.4 sono di complessainterpretazione. Alcuni aspetti emergono tuttaviaevidenti:
• il 75% dei giocatori paralleli ha ottenuto unpunteggio >10 e si è quindi dimostrato più forte diGnuChess; questo risultato è decisamenteincoraggiante perché dimostra che in generale ladistribuzione della conoscenza determina beneficisulla qualità di gioco;
• è sorprendente il fatto che, tranne in pocheeccezioni, i giocatori paralleli risentono negativamentedell’aumento del numero di istanze; il motivo diquesto risultato potrebbe essere una distribuzionedelle euristiche non oculata per cui l’inserimento dinuove istanze estende l’insieme di mosse propostefavorendo la possibilità di scegliere una mossa nonvalida.
• nel confronto fra i diversi criteri di distribuzione si èrivelato più efficace quello di distribuzione bilanciata;rispetto agli altri criteri esso prevede che tutte leistanze contengano un sufficiente numero di categoriedi conoscenza.
Gli esperimenti di Schaeffer hanno dimostrato checerte categorie sono più efficaci se combinate conaltre: il fatto che gli altri criteri stabiliscano istanze conun minore numero medio di categorie di conoscenzapuò quindi spiegare la minore qualità della loroperformance.
• come atteso, il criterio di selezione a maggioranzageneralizzato ha conferito maggiore efficacia aigiocatori paralleli; fanno eccezione i giocatori generaticon distribuzione incrementale della conoscenza per iquali la versione semplice del criterio a maggioranzasi è rivelata migliore. Un possibile motivo di questaanomalia è che i pesi attribuiti alle istanze di taligiocatori con il criterio generalizzato non nerispecchino la reale forza relativa e quindi favoriscanole scelte delle istanze più deboli.
Le considerazioni appena espresse offrono utiliindirizzi per lo sviluppo di ricerche future, ma noncostituiscono conclusioni definitive; troppe, infatti,

211
sono state le scelte arbitrarie operate durante ilprogetto degli esperimenti: l’ordinamento delleeuristiche, la scelta dei criteri di distribuzione e diselezione, la limitazione della durata delle partite el’attribuzione dei punteggi. A queste deve aggiungersil’errore statistico indotto dal numero non elevato dipartite che hanno caratterizzato ogni torneo.
6.3.2.3 Criteri di selezione a maggioranzageneralizzata con pesi variabili
In un criterio di selezione a maggioranzageneralizzata, la soluzione più generale perl’attribuzione di pesi è consentirne la variabilità, cioèfissare una loro dipendenza nei confronti di alcunecaratteristiche della posizione cui è applicata lascelta.
Intuitivamente l’approccio con pesi variabili sipresenta più affidabile perché offre una soluzione aiproblemi già denunciati riguardo la variabilità diimportanza relativa delle varie euristiche. Quest’ultimasoluzione, tuttavia, richiede ulteriore conoscenza deldominio per poter essere applicata. Dalla qualità edalla complessità di tale conoscenza dipendel’affidabilità del metodo.
Una possibile soluzione è eseguire a priori un’analisidella posizione iniziale (possibilmente con un sistemaesperto) per dedurne caratteristiche generali volte acapire quali delle euristiche di valutazione abbianomaggiore importanza in quel caso particolare.
Un metodo molto più semplice ed usato in modoanalogo nel calcolo tradizionale della funzione divalutazione, è invece quello di suddividere l’arco dellapartita in stadi e dedurre lo stadio cui appartiene laposizione corrente dal semplice conteggio dei pezzisulla scacchiera. In questo caso la determinazione deipesi risulta comunque approssimativa; inoltre solo peralcune euristiche è possibile stabilire l’importanzarelativa che esse hanno in stadi distinti della partita.Nonostante questo il metodo appare più promettentedella versione con pesi costanti.
Ciò che è auspicabile è la determinazione di metodiche permettano di stabilire una dipendenza dei pesidelle funzioni di valutazione non solo nei confronti delnumero di pezzi, ma anche della loro disposizionesulla scacchiera.
I metodi appena suggeriti sono dipendenti dal dominiodi applicazione. In seguito sarà indagata l’efficacia dialcuni criteri con pesi variabili dove l’attribuzione di

212
questi è indipendente dal dominio e fa riferimento aproprietà generali della ricerca di alberi di gioco: ilvalore minimax e la profondità di ricerca raggiunta.
6.3.2.3.1 Criteri di selezione basati suivalori minimax delle migliori mosse
Ogni istanza di ricerca produce come risultatola mossa considerata migliore dal suo punto diosservazione ed il valore minimax ad essaassociato. In che modo il criterio di selezionepuò essere condizionato anche da questovalore?
L’applicabilità dei criteri di selezione cheverranno descritti in seguito è vincolata dallaveridicità della seguente ipotesi HP1:
tutte le funzioni di valutazione hanno lo stessovalore di equilibrio (normalmente lo zero) fra idue giocatori e sono tarate in modo che due diesse che ritornano lo stesso valore nellavalutazione della stessa posizione intendonoesprimere la stessa quantità di vantaggio (osvantaggio) posizionale.
Dato il giocatore parallelo G costituito dalleistanze I1,I2,…,In si supponga che l’istanza I1ritorni la mossa M1 con valore minimax V1 edanalogamente per l’istanza I2 siano la mossaM2 ed il valore V2 il frutto della sua ricerca. Sisupponga inoltre che la funzione di valutazionedi I1 sia basata sull’euristica E1 e quella di I2sull’euristica E2.
Sia V1>V2. Se è verificata l’ipotesi HP1 allora lalinea di gioco proposta da I1 conduce ad unaposizione in cui il vantaggio rispetto all’euristicaE1 è maggiore del vantaggio rispetto ad E2nella posizione cui guida la scelta di I2. Ècertamente frettoloso concludere che la sceltadi I1 sia migliore. Il problema è che nelconfronto non si è tenuto conto della situazionedi partenza, cioè del vantaggio rispetto alle dueeuristiche nella posizione alla radice dellaricerca.
Supponiamo, ad esempio, che E1 riguardi lastruttura pedonale ed E2 la sicurezza del re.Siano F1 ed F2 le rispettive funzioni divalutazione di I1 ed I2, P la posizione iniziale eP1, P2 le posizioni terminali delle variantiprincipali delle due istanze.

213
Siano i seguenti valori: F1(P)=10, F2(P)=0,V1=F1(P1)=11, V2=F2(P2)=8.È evidente come in P vi sia una vantaggiosastruttura pedonale, mentre riguardo lasicurezza del re si ha un perfetto equilibrio.Seppure V1>V2, cioè il vantaggio nella strutturapedonale in P1 è maggiore di quello nellasicurezza del re in P2, la variazione relativa allaposizione iniziale Fi(Pi)-Fi(P) calcolata per I2 èmaggiore di quella per I1. In questa situazionesembra ragionevole preferire la proposta di I2.
Ipotizziamo di poter valutare a posteriori(conclusa la ricerca delle istanze) i valoriF1(P2) e F2(P1) (è sufficiente che le istanze diricerca ritornino non solo la miglior mossa, mal’intera continuazione principale). Siano allora:F1(P2)=4 e F2(P1)=-2.
Questi dati svelano il seguente scenario: lamossa M1 ottiene un miglioramento minimoriguardo la struttura pedonale, ma non degrada(anzi migliora) la sicurezza del re; M2, invece,conduce ad un grosso miglioramento rispettoalla sua euristica, ma cancella completamenteil notevole vantaggio iniziale della strutturapedonale. Queste nuove informazionicapovolgono nuovamente la preferenza nellascelta, a vantaggio della mossa M1 rivelatasipiù "stabile".
L’idea di valutare la variazione relativa allaradice delle valutazioni prodotte dalle istanze diricerca sembra promettere un valido aiuto allaselezione della migliore mossa, in particolarenella individuazione (e quindi eliminazione) diquelle mosse che seppure migliori secondocerte euristiche celano un comportamentodisastroso secondo alcune altre.
6.3.2.3.2 Criteri basati sulla profondità diricerca delle istanze
In un approccio a pesi variabili il valore dei pesipotrebbe essere variato in funzione dellaprofondità di ricerca raggiunta da ciascunaistanza. In condizioni di torneo è ragionevoleaffidare ad ogni istanza lo stesso tempo diricerca. In questo arco di tempo le istanzeraggiungono profondità massime dell’albero digioco in generale diverse. L’idea è di confidaremaggiormente nelle ricerche più profonde.

214
Il problema che può sorgere con questo tipo disoluzione è il seguente: alcune funzioni divalutazione richiedono più tempo per esserecalcolate e quindi le istanze relative ad essesaranno quelle che in media raggiungeranno leminori profondità di ricerca; l’effetto potrebbeessere quello di penalizzare (giustamente?)sempre le proposte delle stesse istanze.
6.3.2.4 Criteri di selezione con visita selettivaa posteriori dell’albero di gioco
Un differente approccio per l’implementazione delcriterio di selezione è prevedere una ricerca aposteriori dell’albero di gioco le cui mosse al top-levelsono le sole proposte dalle istanze; in particolare:
• sia fissata una funzione di valutazione F che tengaconto di un insieme quanto più completo di categoriedi conoscenza terminale: potrebbe essere la funzioneoriginale che è stata decomposta oppure una piùcomplessa;
• F è impiegata in una nuova ricerca su albero digioco dove le mosse alla radice sono limitate a quelleproposte dalle istanze di ricerca (o un lorosottoinsieme già selezionato secondo qualchecriterio). La mossa risultata migliore da questa ricercaè quella che sarà effettivamente giocata.
Uno dei parametri di questo criterio è la durata dellaricerca a posteriori rispetto a quella delle istanze;nell’assegnamento di tale valore si deve tenere contodel vantaggio di poter disporre, nella nuova ricerca,della cooperazione di tutte le istanze (potrebbeessere impiegato uno degli algoritmi di distribuzionedella ricerca presentati nel Capitolo 5).
Una possibile soluzione è vincolare questa nuovaesplorazione ad una profondità massima ben inferiorea quella raggiunta dalle singole istanze: in questocaso la funzione F potrà essere anche moltocomplessa poiché applicata ad un limitato numero dinodi terminali e quindi il maggiore costo del suocalcolo inciderà minimamente sull’efficienzacomplessiva.
Questo approccio si presenta molto efficace nelriconoscere, fra quelle proposte, mosse scadenti nelcomplesso; tuttavia appare inaffidabile nel risolvere lascelta fra mosse parimenti valide in quanto questaavverrebbe sulla base della conoscenza di linee digioco troppo brevi.

215
Si può quindi pensare di impiegare con efficaciaquesto metodo in una prima fase di "scrematura"delle mosse candidate. Quando usato per questoscopo il criterio potrebbe essere modificato comesegue: per ogni mossa candidata viene calcolatol’esatto valore minimax rispetto ad una profonditàprefissata ed alla stessa funzione di valutazione F. Inquesto caso la valutazione a posteriori di ciascunamossa è a cura della stessa istanza di ricerca che laha proposta. In questo modo si ottiene unordinamento delle mosse in funzione dei rispettivivalori minimax che evidenzierà la grossolanainefficacia di alcune di esse.
La sperimentazione di questo criterio di selezione e diquelli a maggioranza con pesi variabili non avverràcon lo svolgimento di partite complete a causadell’eccessivo numero che ne deriverebbe. Lavalutazione dei giocatori avverrà invece attraversol’esplorazione di un elevato numero di posizioni di teste sarà illustrata in 6.3.3.1; questo metodo,estremamente più rapido, ha comunque notevolevalore statistico.
6.3.3 Una valutazione separata dei criteri didistribuzione della conoscenza e dei criteri diselezione
Si consideri un giocatore parallelo G definito perdistribuzione della conoscenza; sia M l’insieme di mosseproposte, ad un certo turno di gioco, dalle istanze di G: unasituazione sgradita che può presentarsi è che la mossa"migliore" non faccia parte dell’insieme M di candidate.
Il problema è che una mossa è considerata migliore quandomassimizza i vantaggi sotto tutti gli aspetti del giococonsiderati nel loro complesso e ciò può verificarsi anche seessa non è la migliore in nessuno di questi aspetticonsiderati singolarmente. Le istanze di G contengono ingenerale solo una parte della conoscenza terminale e quindipotrebbero facilmente incorrere in questo errore.
La soluzione di questo problema risiede nella possibilità diogni istanza di ricerca di proporre una graduatoria di mossealle spalle della migliore. In questo modo anche una mossaritenuta valida in tutte le ricerche, ma che non risulta lamigliore in nessuna di esse, avrebbe qualche possibilità diessere selezionata. Purtroppo le informazioni necessarie perquesto tipo di soluzione non possono essere raccolte se siutilizza l’algoritmo αβ, in quanto per ottenere un ordinamentodei valori minimax di tutte le mosse sarebbe necessario

216
visitare interamente l’albero di gioco (come avviene per ilsolo algoritmo minimax).Un possibile criterio di valutazione di un giocatore parallelopotrebbe essere quello di controllare la frequenza con cui lamigliore mossa è proposta da almeno una delle sue istanze.Il concetto di migliore mossa è piuttosto astratto ed ingenerale impossibile rendere oggettivo; una sua buonaapprossimazione potrebbe essere quella di considerare"migliore" la mossa che giocherebbe il campione del mondo.
Si osservi che la metrica descritta non è influenzata dalcriterio di selezione; in realtà essa dipende solamente dallaqualità di gioco delle singolo istanze e non tiene dunque innessun conto la loro cooperazione a posteriori. Essaesprime dunque le capacità potenziali di un giocatoreparallelo: esse potrebbero essere confermate o invecepregiudicate dal criterio di selezione. L’efficacia di un criteriodi selezione può essere misurata proprio in base alla suacapacità di fare emergere la mossa migliore nei casi in cuiessa è presente nell’insieme di candidate.
Le idee appena proposte saranno applicate in alcuniesperimenti basati sulla esplorazione di posizioni di test.
6.3.3.1 Progetto e risultati di alcuniesperimenti con posizioni di test
Le metriche di valutazione dei criteri di distribuzione eselezione descritte in 6.3.3 sono ora formalizzate peressere applicate in esperimenti basati sulla ricerca diun insieme di posizioni di test.
Sia P={P1,…,Pn} un insieme di n posizioni di giocodistinte e sia best(Pi) (i=1..n) la mossa "migliore" perla posizione Pi.
Sia G un giocatore parallelo costituito dall’insieme diistanze I={I1,…,Ik}.È definita la seguente metrica Cd per la valutazionedel criterio di distribuzione della conoscenza che haprodotto G:
• sia MG(Pi)={mi1,…,mis} (s≤k) l’insieme di mossescelte dalle istanze di G per la posizione Pi (i=1..n);• sia dG: P→{0,1} la funzione così definita:
dG(p) =
1 se best(p) ∈M(p)
0 altrimenti
• infine:
CD(G) =dG(Pi)
i=1
n
∑n
Analogamente è definita la metrica Cs di valutazionedel criterio di selezione di G:

217
• sia SelG(Pi) la mossa scelta da G dopol’applicazione del criterio di selezione alle mosseMG(Pi) proposte dalle sue istanze per la posizione Pi(i=1..n);
• sia la funzione dG:P→{0,1}:
sG(p) =1 se SelG(p) = best(p)
0 altrimenti
• la funzione Val calcola il valore complessivo di Gnormalizzando rispetto al totale delle posizioni ilnumero di mosse "giuste":
Val(G) =sG(Pi )
i=1
n
∑n
La definizione della metrica Val è valida anche pergiocatori sequenziali e potrà dunque essere usataanche per valutare le prestazioni di GnuChess.
• per stimare l’influenza del criterio di selezione sulvalore del giocatore, il valore Val(G) deve esserenormalizzato rispetto al "degrado" introdotto dalladistribuzione della conoscenza:
Cs(G) =Val(G)CD(G)
=sG(Pi)
i=1
n
∑CD(G)
In [Ana90] è presentata un’analisi statistica dimetriche della stessa natura di quelle appenadescritte che ne giustifica la validità (in particolare èindicata una sufficiente correlazione statistica fraqueste metriche e la reale qualità di gioco).
Gli esperimenti saranno eseguiti su un insieme di 500posizioni scacchistiche tratte da [LanSmi93]: sonouna raccolta di posizioni relative alla fase dimediogioco appositamente studiate per testare laqualità di un giocatore. Per ciascuna di esse è nota lamossa migliore.
I giocatori paralleli impegnati in questo esperimentosono quelli di Tab. 6.2. Per ridurre il tempo di CPUnecessario al completamento dell’esperimento essonon è stato eseguito in ambiente distribuito, mautilizzando una versione simulata sequenziale deigiocatori paralleli. Una possibile ottimizzazione è laseguente: si osservi che alcune istanze sequenzialisono ripetute in più giocatori paralleli; di conseguenzala ricerca delle posizioni da parte di queste istanzepuò essere eseguita una sola volta. La prima fasedell’esperimento è dunque quella di isolare le istanzesequenziali che compongono tutti i giocatori paralleli eraccogliere le mosse scelte da ognuno di essi in

218
seguito alla ricerca di ciascuna posizione; insieme aquest’ultime saranno memorizzati anche tutti i datistatistici (relativi alle ricerche) che saranno necessariall’applicazione, in una fase successiva, dei diversicriteri di selezione.
Il tempo di ricerca di una posizione è stato fissato a60 secondi.In Tab. 6.5 è riportata la valutazione delle istanzesequenziali impegnate nella prima fase.L’esperimento ha confermato che tutte le istanzesequenziali sono singolarmente più deboli diGnuChess; ciò significa che la soppressione diconoscenza terminale dalla funzione di valutazione diGnuChess determina in generale effetti negativi sullaqualità del giocatore sequenziale.
Sarebbe interessante verificare se l’insieme diposizioni "risolte" con successo da ogni istanzasequenziale è un sottoinsieme di quello relativo aGnuChess, cioè se le prestazioni di ogni istanza sono"coperte" da quelle di quest’ultimo.
A questo proposito sono state contate il numero Nt diposizioni in cui almeno uno fra tutti i giocatori diTab. 6.5 ha individuato la mossa migliore; il valorerisultante è sorprendente: Nt=271! Il significato diquesto risultato è che in 144 posizioni (≡28.8% deltotale) almeno uno dei giocatori con minoreconoscenza terminale ha operato una scelta dimigliore qualità rispetto a GnuChess. Questo datostatistico è molto importante perché dimostra chel’approccio con distribuzione della conoscenza puòpotenzialmente raddoppiare le prestazioni delgiocatore sequenziale originario; naturalmente ilnumero delle istanze, la loro identità e il criterio diselezione finale determinano le reali prestazioni delgiocatore parallelo.
Istanza sequenziale G sG(Pi)i=1
n
∑ Val(G)
(MB) 91 0.182(MX) 93 0.186
(MK) 78 0.156
(MP) 107 0.214(MA) 86 0.172
(MR) 83 0.166
(MBX) 107 0.214
(MBXK) 104 0.208
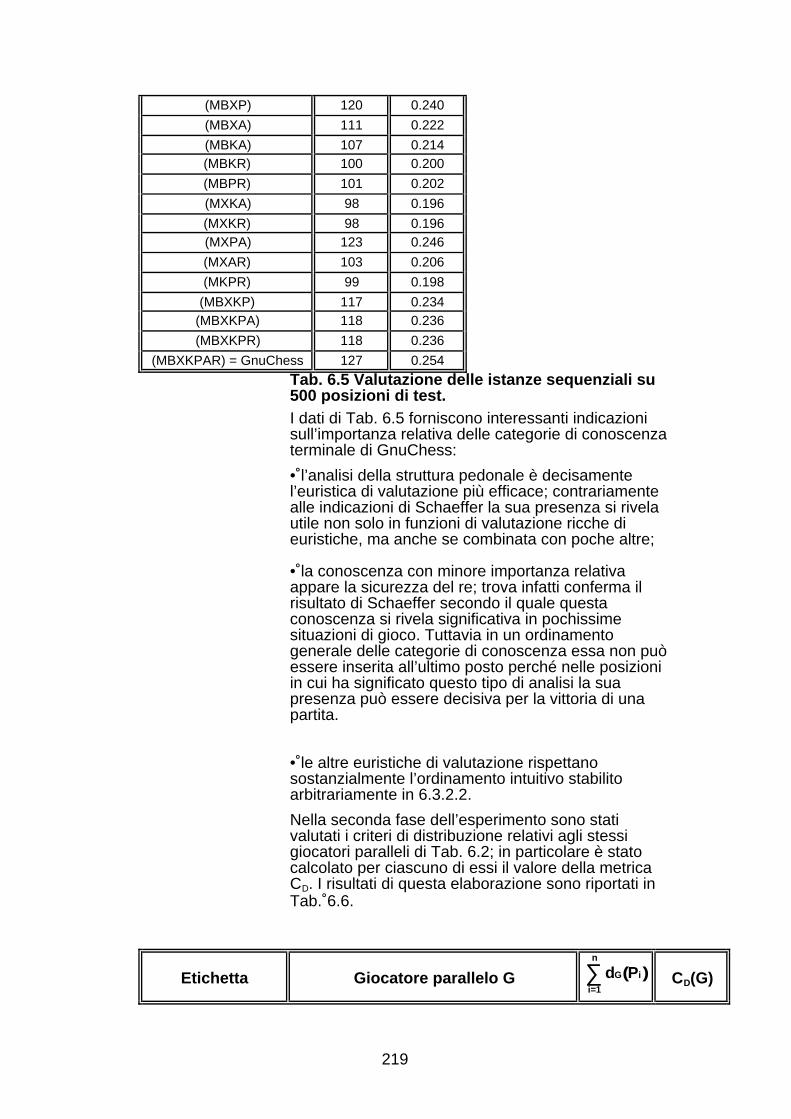
219
(MBXP) 120 0.240
(MBXA) 111 0.222
(MBKA) 107 0.214(MBKR) 100 0.200
(MBPR) 101 0.202
(MXKA) 98 0.196
(MXKR) 98 0.196(MXPA) 123 0.246
(MXAR) 103 0.206
(MKPR) 99 0.198
(MBXKP) 117 0.234(MBXKPA) 118 0.236
(MBXKPR) 118 0.236
(MBXKPAR) = GnuChess 127 0.254
Tab. 6.5 Valutazione delle istanze sequenziali su500 posizioni di test.I dati di Tab. 6.5 forniscono interessanti indicazionisull’importanza relativa delle categorie di conoscenzaterminale di GnuChess:
• l’analisi della struttura pedonale è decisamentel’euristica di valutazione più efficace; contrariamentealle indicazioni di Schaeffer la sua presenza si rivelautile non solo in funzioni di valutazione ricche dieuristiche, ma anche se combinata con poche altre;
• la conoscenza con minore importanza relativaappare la sicurezza del re; trova infatti conferma ilrisultato di Schaeffer secondo il quale questaconoscenza si rivela significativa in pochissimesituazioni di gioco. Tuttavia in un ordinamentogenerale delle categorie di conoscenza essa non puòessere inserita all’ultimo posto perché nelle posizioniin cui ha significato questo tipo di analisi la suapresenza può essere decisiva per la vittoria di unapartita.
• le altre euristiche di valutazione rispettanosostanzialmente l’ordinamento intuitivo stabilitoarbitrariamente in 6.3.2.2.
Nella seconda fase dell’esperimento sono stativalutati i criteri di distribuzione relativi agli stessigiocatori paralleli di Tab. 6.2; in particolare è statocalcolato per ciascuno di essi il valore della metricaCD. I risultati di questa elaborazione sono riportati inTab. 6.6.
Etichetta Giocatore parallelo G dG(Pi)i=1
n
∑ CD(G)
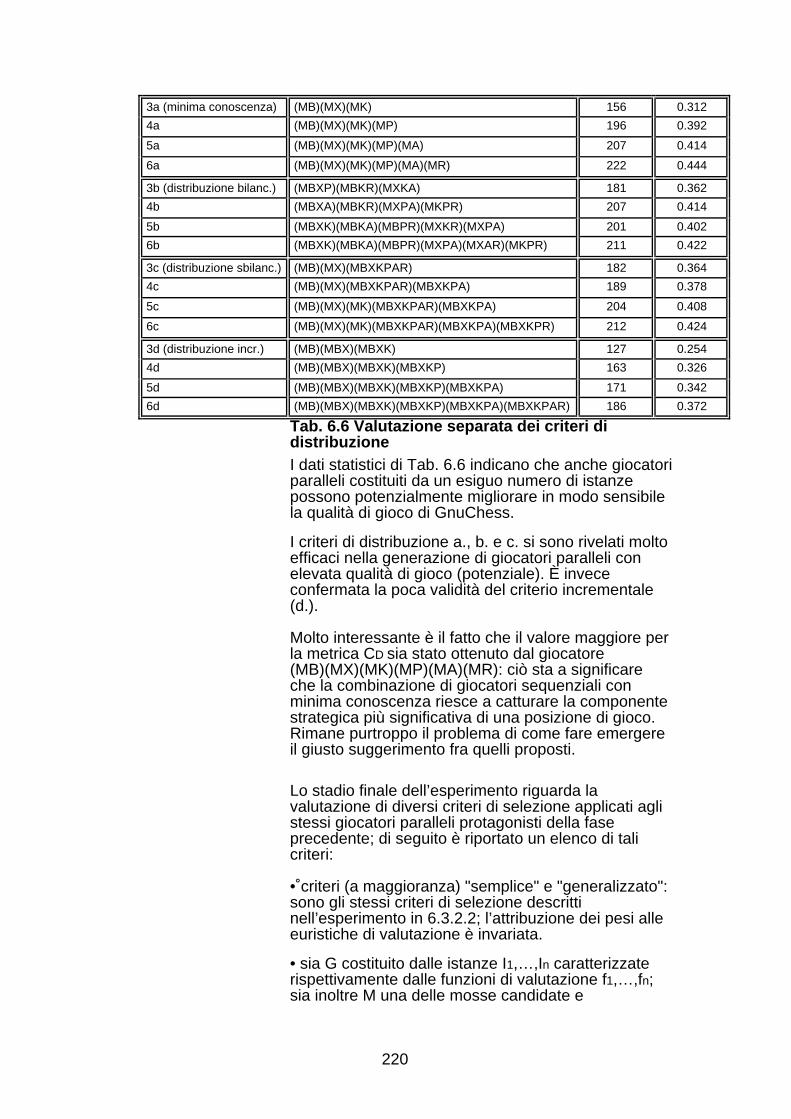
220
3a (minima conoscenza) (MB)(MX)(MK) 156 0.312
4a (MB)(MX)(MK)(MP) 196 0.392
5a (MB)(MX)(MK)(MP)(MA) 207 0.414
6a (MB)(MX)(MK)(MP)(MA)(MR) 222 0.444
3b (distribuzione bilanc.) (MBXP)(MBKR)(MXKA) 181 0.362
4b (MBXA)(MBKR)(MXPA)(MKPR) 207 0.414
5b (MBXK)(MBKA)(MBPR)(MXKR)(MXPA) 201 0.402
6b (MBXK)(MBKA)(MBPR)(MXPA)(MXAR)(MKPR) 211 0.422
3c (distribuzione sbilanc.) (MB)(MX)(MBXKPAR) 182 0.364
4c (MB)(MX)(MBXKPAR)(MBXKPA) 189 0.378
5c (MB)(MX)(MK)(MBXKPAR)(MBXKPA) 204 0.408
6c (MB)(MX)(MK)(MBXKPAR)(MBXKPA)(MBXKPR) 212 0.424
3d (distribuzione incr.) (MB)(MBX)(MBXK) 127 0.254
4d (MB)(MBX)(MBXK)(MBXKP) 163 0.326
5d (MB)(MBX)(MBXK)(MBXKP)(MBXKPA) 171 0.342
6d (MB)(MBX)(MBXK)(MBXKP)(MBXKPA)(MBXKPAR) 186 0.372
Tab. 6.6 Valutazione separata dei criteri didistribuzioneI dati statistici di Tab. 6.6 indicano che anche giocatoriparalleli costituiti da un esiguo numero di istanzepossono potenzialmente migliorare in modo sensibilela qualità di gioco di GnuChess.
I criteri di distribuzione a., b. e c. si sono rivelati moltoefficaci nella generazione di giocatori paralleli conelevata qualità di gioco (potenziale). È invececonfermata la poca validità del criterio incrementale(d.).
Molto interessante è il fatto che il valore maggiore perla metrica CD sia stato ottenuto dal giocatore(MB)(MX)(MK)(MP)(MA)(MR): ciò sta a significareche la combinazione di giocatori sequenziali conminima conoscenza riesce a catturare la componentestrategica più significativa di una posizione di gioco.Rimane purtroppo il problema di come fare emergereil giusto suggerimento fra quelli proposti.
Lo stadio finale dell’esperimento riguarda lavalutazione di diversi criteri di selezione applicati aglistessi giocatori paralleli protagonisti della faseprecedente; di seguito è riportato un elenco di talicriteri:
• criteri (a maggioranza) "semplice" e "generalizzato":sono gli stessi criteri di selezione descrittinell’esperimento in 6.3.2.2; l’attribuzione dei pesi alleeuristiche di valutazione è invariata.
• sia G costituito dalle istanze I1,…,In caratterizzaterispettivamente dalle funzioni di valutazione f1,…,fn;sia inoltre M una delle mosse candidate e

221
IM={IM1,…,IMk} l’insieme di istanze che la ha proposta;saranno sperimentati i seguenti criteri a maggioranzacon pesi variabili (differenziati per il criterio diattribuzione del peso wM):
• valore minimax: sia P la posizione iniziale e Pi laposizione terminale della variante principale calcolatadalla istanza Ii (i=1..n). Sono allora definiti i seguenticriteri di selezione:
wM = [ fMi
i=1
k
∑ (PMi)- fMi(P)] (analisi locale del valore
minimax)
wM = [f j(PMi)- fj(P)]j=1
n
∑i=1
k
∑ (analisi globale del valore
minimax)• profondità: il peso di una mossa è funzione dellaprofondità di ricerca raggiunta dalla istanza IMi∈IM; dinorma la ricerca a profondità Di non è completata(perché interrotta a causa dell’evento "raggiuntotempo max. di ricerca") ed è dunque importantetenere conto del numero Nmi di mosse al top-levelesplorate completamente.
È inoltre definita una costante C (=100)sufficientemente grande da rendere il parametro Nmdecisivo nel confronto fra i pesi di due mosse soloquando la somma delle rispettive profondità massimeè la stessa. Si osservi che di fatto il criterio è amaggioranza semplice con soluzione dei casi di paritàdi voti basata sulle profondità di ricerca:
wM = C⋅Di + Nmi( )i=1
k
∑• visita selettiva a posteriori: saranno sperimentatedue versioni di questo metodo. Entrambe prevedonouna ricerca a profondità massima prefissata (=3-ply).La ricerca è sequenziale poiché, data la limitataprofondità, è trascurabile il tempo necessario al suocompletamento; la ricerca a posteriori è selettivaperché limitata ad un sottoinsieme delle mosse altop-level. In particolare i due criteri si distinguono perl’identità di tale sottoinsieme:
• il criterio generale prevede che esso coincida conl’insieme di mosse candidate da almeno un’istanza;• il criterio semplificato prevede invece che la ricercariguardi solamente le mosse che hanno ottenuto ilmaggior numero di voti; la ricerca a posteriori èdunque inutile nel caso in cui vi sia un’unica mossapiù votata.

222
Criteri di selezione
Maggioran.semplice
Maggioran.generalizz.
Profonditàricerca
Minimaxlocale
Minimaxglobale
Posteriorisemplice
Posteriorigenerale
G Val Cs Val Cs Val Cs Val Cs Val Cs Val Cs Val Cs
3a 0.180 0.577 0.180 0.577 0.184 0.590 0.208 0.667 0.178 0.571 0.182 0.583 0.180 0.577
4a 0.200 0.510 0.200 0.510 0.204 0.520 0.226 0.577 0.174 0.444 0.182 0.464 0.194 0.495
5a 0.210 0.507 0.210 0.507 0.216 0.522 0.228 0.551 0.176 0.425 0.182 0.440 0.200 0.483
6a 0.202 0.455 0.202 0.455 0.212 0.477 0.214 0.482 0.172 0.387 0.182 0.410 0.196 0.441
3b 0.232 0.641 0.232 0.641 0.256 0.707 0.242 0.669 0.220 0.608 0.240 0.663 0.232 0.641
4b 0.244 0.589 0.244 0.589 0.242 0.585 0.242 0.585 0.206 0.498 0.226 0.546 0.224 0.541
5b 0.232 0.577 0.232 0.577 0.232 0.577 0.232 0.577 0.206 0.512 0.210 0.522 0.220 0.547
6b 0.232 0.550 0.232 0.550 0.224 0.531 0.224 0.531 0.210 0.498 0.210 0.498 0.220 0.521
3c 0.200 0.549 0.200 0.549 0.222 0.610 0.248 0.681 0.200 0.549 0.182 0.500 0.200 0.549
4c 0.242 0.640 0.242 0.640 0.242 0.640 0.246 0.651 0.200 0.529 0.182 0.481 0.220 0.582
5c 0.236 0.578 0.236 0.578 0.236 0.578 0.234 0.574 0.174 0.426 0.182 0.446 0.202 0.495
6c 0.238 0.561 0.232 0.547 0.236 0.557 0.232 0.547 0.180 0.425 0.182 0.429 0.202 0.476
3d 0.206 0.811 0.206 0.811 0.214 0.843 0.214 0.843 0.202 0.795 0.186 0.732 0.206 0.811
4d 0.204 0.626 0.204 0.626 0.204 0.626 0.212 0.650 0.198 0.607 0.186 0.571 0.192 0.589
5d 0.216 0.632 0.216 0.632 0.216 0.632 0.216 0.632 0.198 0.579 0.186 0.544 0.210 0.614
6d 0.214 0.575 0.214 0.575 0.216 0.581 0.218 0.586 0.196 0.527 0.186 0.500 0.198 0.532
Valorimedi
0.218 0.586 0.218 0.585 0.222 0.598 0.227 0.613 0.193 0.524 0.193 0.521 0.206 0.556
Tab. 6.7 Valutazione dei criteri di selezione ecomplessiva dei giocatori paralleli.In Tab. 6.7 sono riportati i dati statistici relativi allavalutazione (metrica Val) dei giocatori paralleliscaturiti dall’applicazione dei criteri di selezioneelencati; la metrica Cs, inoltre, consente di stimarel’efficacia di detti criteri indipendentemente dalladistribuzione della conoscenza terminale.
I risultati di Tab. 6.7 sono deludenti: solamente ungiocatore parallelo è riuscito a migliorare leprestazioni di GnuChess: il giocatore 3b con criterio diselezione basato sulla profondità di ricerca (lo stessogiocatore che aveva ottenuto la massima valutazionenell’esperimento basato su tornei di partite complete;cfr. Tab. 6.4).
Complessivamente, pertanto, i criteri di selezioneproposti non sono riusciti a far emergere(sistematicamente) la mossa migliore, sebbene essafosse contenuta nell’insieme di candidate.
Dal confronto fra i diversi criteri di selezione appareevidente l’inefficacia dei criteri basati sulla visita

223
selettiva a posteriori, evidentemente eseguita troppopoco in profondità (solo 3-ply nei nostri esperimenti).Sorprende la validità dell’approccio basato sulconfronto della variazione del valore minimax riferitolocalmente a ciascuna funzione di valutazione(minimax locale); è però ancora più strana ladeludente performance del criterio minimax globale,nonostante esso sia della stessa natura delprecedente: è stata quindi negata sperimentalmentel’intuizione descritta in 6.3.2.3.1 secondo cuil’approccio con analisi "globale" delle variazioni deivalori minimax avrebbe dovuto costituire unmiglioramento di quello con natura "locale".
6.4 Una rassegna di idee per la distribuzione dellaconoscenza dirigente
Il significato di distribuire la conoscenza dirigente è combinare in ununico giocatore parallelo più giocatori sequenziali che adottanoalgoritmi di ricerca diversi.
Gli algoritmi di ricerca su alberi di gioco sono stati classificati in duecategorie: di tipo forza bruta e selettivi.Gli algoritmi della prima classe analizzano tutte le possibili linee digioco fino ad una profondità massima, mentre quelli selettiviestendono a profondità differenti le varie linee di gioco preferendoquelle più promettenti.
La trattazione seguente intende isolare lo studio della distribuzionedella sola conoscenza dirigente: sarà quindi assunto che tutte leistanze contengano la stessa conoscenza terminale e quindi lamedesima funzione di valutazione.
6.4.1 Giocatore parallelo con istanze di ricerca ditipo forza bruta
Fra gli algoritmi con forza bruta alcuni sono più efficienti (αβcontro minimax) e quindi riescono, a parità di tempo, araggiungere maggiori profondità dell’albero di gioco.Nell’ipotesi di stessa funzione di valutazione, fra duericerche di tipo forza bruta che raggiungono profonditàdiverse dell’albero, con molta probabilità sarà più affidabile ilrisultato della ricerca più profonda.
Se esiste una sola mossa M con il miglior valore minimax(calcolato rispetto alla profondità D) allora tutte le ricerchecon forza bruta (qualsiasi sia l’algoritmo) che raggiungono laprofondità massima D proporranno la mossa M.
Se invece ci sono più mosse con il miglior valore minimax(rispetto alla profondità D) nulla si può dire su quale, fraqueste, sarà scelta dalle istanze con ricerca a profondità D etantomeno può essere prevista la concordanza delleproposte (queste scelte dipendono dal particolareordinamento delle mosse nell’albero di gioco).

224
Sembra allora decisione ragionevole considerare fra glialgoritmi con forza bruta soltanto i più efficienti, vale a direl’algoritmo αβ e le sue varianti. Ciò che si aspetta è che nonvi sia, fra questi, un algoritmo che vada sempre più inprofondità rispetto agli altri, altrimenti il lavoro di quest’ultimiverrebbe sempre scartato.
Questa prima discussione ha già introdotto un necessariocriterio di selezione fra le mosse proposte da algoritmi cheadottano differente ricerca con forza bruta:
sia D={d1,d2,…,dn} l’insieme di profondità massime raggiuntedalle n istanze I1,I2,…,In che usano forza bruta e siad=max(d1,d2,…,dn). Se Imaxdepth è l’insieme delle istanze chehanno raggiunto la profondità d, la scelta finale sarà limitataalle sole mosse proposte dalle istanze in Imaxdepth.
Supponiamo che gli unici algoritmi usati dalle istanze sianodi tipo forza bruta. Intuitivamente il giocatore artificialerisulterà almeno di pari forza rispetto a ciascuna delle sueistanze considerata singolarmente. Scegliendo infatti ilcriterio di selezione prima descritto il giocatore parallelogiocherà una mossa frutto di una ricerca condotta aprofondità maggiore o uguale di quella raggiunta da ognunadelle sue istanze.
Se la congettura appena espressa fosse dimostratasperimentalmente ciò costituirebbe un risultato di notevoleimportanza.
È noto come l’efficienza degli algoritmi di tipo αβ dipendadalla frequenza dei tagli nella visita e come questa siastrettamente dipendente dall’ordinamento dei nodi. Peralcuni algoritmi questa dipendenza è più marcata, come adesempio per quelli basati sul concetto di "finestra minimale".Dato che il grado di ordinamento dell’albero di gioco èvariabile, in alcune ricerche questi ultimi algoritmi andrannopiù in profondità rispetto a ricerche αβ meno influenzatedall’ordinamento dell’albero, mentre in altre (con alberi digioco non fortemente ordinati) questa situazione saràribaltata.
Il giocatore parallelo in analisi tende a superare questaintrinseca dipendenza delle prestazioni dei singoli algoritmidall’ordinamento dell’albero poiché che esso sarà sempreguidato nella sua scelta dall’istanza scesa più in profondità,quella cioè che ha tratto maggiore vantaggio dal particolareordinamento dell’albero.
Questo approccio può risultare vantaggioso anche quando leistanze fanno uso diverso della stessa euristica.Si consideri ad esempio l’euristica "aspiration search" e sisupponga che due istanze facciano uso di questa euristica esi differenzino però nella sua applicazione per quantoconcerne la dimensione iniziale della finestra αβ. Si ha

225
quindi un’istanza di ricerca prudente ed una più audace(quella con finestra iniziale più stringente); la fortuna o menodi quest’ultima è legata alla precisione con cui è statostimato il valore minimax. È noto infatti che se il valoreminimax è contenuto nella finestra iniziale, l’istanza che hainiziato la ricerca con una finestra più stringente ottiene unmaggior numero di tagli; se invece esso cade al di fuori diquella finestra l’istanza è costretta a ripetere la ricerca ed intal caso sarebbe con molta probabilità l’istanza più prudentea rivelarsi più efficiente. La qualità del gioco del giocatoreparallelo è comunque indipendente dal grado di precisionedella stima del valore minimax in quanto esso è guidato inogni caso dalla più "fortunata" delle due istanze.
6.4.2 Giocatore parallelo con istanze di ricerca ditipo selettivo
Si consideri ora il caso in cui tutte le istanze di ricerca sianobasate su algoritmi di tipo selettivo. In questo contestoappare impredicibile il miglioramento o meno della qualità digioco del giocatore parallelo rispetto a ciascuna singolaistanza.
L’unico criterio di selezione ragionevole è quello amaggioranza generalizzato con pesi costanti. Se fosse notala maggiore forza di alcune istanze rispetto ad alcune altre, ipesi dovrebbero esprimere una maggiore fiducia verso lemosse proposte da queste istanze di ricerca.
Il metodo con pesi variabili appare invece di difficileapplicazione: esso sottintende la conoscenza di una miglioreanalisi di un’istanza rispetto ad un’altra in funzione dellaposizione corrente; ciò significherebbe sapere ad esempioche un certo algoritmo selettivo tratta meglio posizionitattiche piuttosto che strategiche o viceversa. Questaconoscenza è certamente difficile da ottenere.
Un algoritmo selettivo estende soltanto le linee di gioco "piùpromettenti". La qualità di questi algoritmi dipende dallaprobabilità con cui linee di gioco "valide" venganoerroneamente scartate. Questa probabilità dipendeprincipalmente dal criterio di espansione con cui vengonoindicate le linee di gioco più promettenti. Ogni algoritmoselettivo ha un differente criterio di espansione e quindi unadiversa probabilità di fallimento. Ciò che si aspettacombinando le mosse proposte da più ricerche selettive è diottenere una riduzione della probabilità di trascurare la lineadi gioco "migliore".
Nel seguito verrà definita fallimentare un’istanza cheerroneamente considera non promettente la migliore linea digioco.

226
Per meglio comprendere l’intuizione illustrataprecedentemente si consideri il seguente esempio:siano I1, I2 ed I3 delle istanze di ricerca con algoritmi diricerca selettivi; supponiamo che il giocatore parallelo adottiun criterio di selezione a maggioranza semplice. Nellaricerca di una posizione P si immagini che l’istanza I1fallisca, mentre ciò non accade per I2 ed I3 le qualipropongono la migliore mossa; sarà quindi questa ad esseregiocata dal giocatore parallelo. In questo caso il fallimento diun’istanza non condiziona il comportamento complessivo.
Il metodo, tuttavia, ha un comportamento impredicibile (conforte probabilità di fallimento) nel caso in cui siano più di unale istanze a fallire: in questo caso il giocatore parallelotenderà a seguire le scelte delle istanze fallimentari,specialmente se in maggioranza rispetto alle altre; laprobabilità che quest’ultima eventualità si verifichi si ritienecomunque che sia molto bassa.
Lo studio dei fenomeni descritti e la verifica delle congettureformulate sembrano di particolare interesse. La verificasperimentale può essere basata su un confronto fra lemosse proposte dalle singole istanze e dal giocatoreparallelo con quella giocata dal campione del mondo.Formulato in questi termini l’esperimento può però condurrea risultati poco significativi e conclusioni frettolose. Infattisarebbe più corretto distinguere fra situazioni in cui la mossadel campione è stata poco considerata dall’algoritmoselettivo (cioè analizzata poco in profondità) da quelle in cuipur essendo stata considerata "promettente" le è statapreferita un’altra nella scelta finale.
Data la diversità di idee e di struttura alla base degli algoritmiselettivi appare difficile stabilire dei metodi generali perattuare concretamente un’analisi più attenta come quellaappena descritta.
6.4.3 Giocatore parallelo mistoDi particolare interesse è l’analisi del comportamento di ungiocatore parallelo le cui istanze di ricerca siano sia di tipoforza bruta che selettivo.
Come si può combinare con efficacia le mosse proposte daistanze di ricerca con filosofie così dissimili? Quali relazionipossono esistere fra le mosse da esse proposte?Apparentemente nessuna.
I giocatori artificiali attualmente più forti sono tutti basati suricerca con forza bruta. Gli algoritmi selettivi, seppur piùvicini all’approccio dell’uomo nella scelta della mossa, sirivelano ancora non sufficientemente "robusti" ed affidabili.Apparentemente, quindi, le istanze di ricerca selettivasembrano offrire un contributo negativo per il giocatoreparallelo rispetto a quelle con forza bruta.

227
Resta aperto il problema di individuare un criterio diselezione non banale come quello a maggioranza sempliceo a maggioranza generalizzato con attribuzione "più o meno"casuale dei pesi alle istanze.
Una possibile soluzione può essere la seguente: le istanzedi ricerca vengono suddivise in due insiemi a seconda deltipo di ricerca (forza bruta o selettiva); viene inoltre attribuitauna priorità diversa a ciascun insieme. La mossa vienescelta sempre fra quelle proposte dalle istanze dell’insieme amaggiore priorità. La funzione delle istanze dell’altro insiemeè di risolvere situazioni di eventuale incertezza fra le mosseproposte dall’insieme principale.
La qualità di questo approccio deve essere valutata siaquando l’insieme a maggiore priorità è quello degli algoritmicon forza bruta che quando lo è quello degli algoritmiselettivi.
Quello che si aspetta in questa seconda eventualità è chesia ulteriormente ridotta la probabilità di scelta fallimentareda parte del giocatore parallelo. Supponiamo ad esempioche tutte le istanze con algoritmi selettivi propongano mossediverse; tenendo conto di queste sole proposte edutilizzando un criterio di selezione con maggioranzasemplice la scelta sarebbe casuale esponendo il giocatoreparallelo al rischio di scegliere una mossa scadente, cioèfrutto di una ricerca fallimentare.
Con il nuovo criterio presentato, però, la componentecasuale è sostituita dai suggerimenti delle ricerche con forzabruta e quindi la probabilità che la scelta finale sia di unamossa poco efficace si attende sia notevolmente ridotta.
Una naturale generalizzazione di questo criterio prevede chela suddivisione delle istanze nei due insiemi segua uncriterio qualsiasi. Ad esempio, conoscendo la forza relativadelle singole istanze si potrebbero inserire nell’insieme amaggiore priorità le istanze più forti.
Le due partizioni dell’insieme delle istanze appena descritteappaiono le uniche con un fondamento logico. La qualità diqueste e di qualsiasi altro tipo di partizione deve esserecomunque verificata da esperimenti reali.
Nella presentazione di questi metodi sono stati già discussidiversi criteri di selezione. Nessuno di questi è basato sulvalore minimax ritornato dalle istanze. Non si ritiene possaessere stabilita alcuna relazione significativa fra i valoriminimax calcolati da istanze che usano algoritmi di ricercadiversi (seppure esse abbiano in comune la stessa funzionedi valutazione). Il fatto che il valore dedotto da un’istanza siamaggiore di quello ottenuto da un’altra non permette certo diconcludere che la mossa da esse proposta sia migliore.
6.5 Conclusioni

228
In questo capitolo abbiamo discusso vari aspetti di un nuovoapproccio al progetto di giocatori artificiali basato sul concetto di"distribuzione della conoscenza".
Sulla base della classificazione della conoscenza in terminale edirigente [Ber82] abbiamo decomposto in due parti il problema dellasua distribuzione, cioè della cooperazione di più giocatori artificialicaratterizzati, appunto, da diversa conoscenza del dominio diapplicazione.
Abbiamo individuato alcune caratteristiche generali del problemaed in particolare due tipi di criterio che sono alla base dellagenerazione dei giocatori paralleli in analisi:
• il criterio di distribuzione, cioè l’insieme di regole che guidano, apartire da una conoscenza di base del dominio, l’attribuzione diporzioni di essa ai giocatori sequenziali che si intende farcooperare;
• il criterio di selezione, cioè il principio che governa la scelta di unafra le mosse proposte da ciascun giocatore sequenziale.In particolare abbiamo approfondito il problema della distribuzionedella conoscenza terminale. A riguardo si è cercato di sviluppare uninsieme di metodi e criteri indipendenti dal dominio di applicazione.
La sperimentazione (nel dominio degli scacchi) delle idee emersenel corso della discussione ha evidenziato la validità dell’approccio:il giocatore sequenziale GnuChess è stato sconfitto da moltigiocatori paralleli ottenuti dalla distribuzione della sua stessaconoscenza terminale.
L’evidenza sperimentale ha dimostrato una curiosa anomalia deimetodi di distribuzione della conoscenza terminale: non sempre ladisponibilità di un maggior numero di risorse di elaborazione èsinonimo di migliori prestazioni. La motivazione di tale anomalia èin parte dovuta ad alcune proprietà della conoscenza terminale, giàindividuate in [Sch86], e confermate dai nostri esperimenti:
• esiste un ordinamento per importanza relativa delle categorie diconoscenza terminale;• esistono categorie di conoscenza terminale la cui efficaciadipende dalla presenza o meno di altre categorie.Chiaramente la disponibilità di un maggior numero di giocatorisequenziali può favorire la presenza di combinazioni non efficacidelle categorie di conoscenza, determinando così un apportonegativo (e determinante) da parte di alcuni di essi.
La sperimentazione dei giocatori con conoscenza distribuita su uninsieme di posizioni di test ha permesso di indagare in profondità leproprietà dei criteri di distribuzione e di selezione.
In generale è emersa l’esigenza di scelte guidate (almeno in parte)dal dominio di applicazione: data l’inerente dipendenza del concettodi conoscenza dal dominio applicativo, un approccio alla suadistribuzione completamente indipendente dal dominio difficilmentepuò garantire prestazioni ottimali.

229
L’esigenza appena denunciata si rivela particolarmente necessarianella definizione dei criteri di selezione. Il principale problema deicriteri suggeriti in questo lavoro è la loro eccessiva semplicità edincapacità di individuare la reale importanza relativa che deveessere attribuita alle proposte dei singoli giocatori sequenziali. Inparticolare è apparsa evidente la necessità di criteri di selezionedinamici, cioè capaci di adeguarsi alle caratteristiche dello statocorrente del gioco: lo sviluppo di criteri di questa natura richiedeforzatamente che essi incorporino una qualche conoscenza deldominio.
I risultati sperimentali hanno tuttavia sottolineato l’enormepotenzialità di questo nuovo approccio: nel 28.8% delle 500posizioni di test almeno una delle istanze del giocatore sequenzialeoriginario (GnuChess), pur disponendo di minore conoscenzaterminale, ha operato una scelta di migliore qualità rispetto aquest’ultimo. Rimane tuttavia aperto il problema, legato al criterio diselezione, di come far emergere tali migliori suggerimenti.

93

227
Capitolo 7Conclusioni e lavori futuri
I sistemi di reti di calcolatori autonomi, ognuno con la propria memoriaprivata, sono ormai uno strumento diffuso di elaborazione in virtù del loroeccellente rapporto prezzo/prestazioni; tuttavia, il problema dellaprogrammazione di singole applicazioni basate su questi sistemi è ancoraaperto [Bal90].
Il principale contributo offerto dal presente lavoro è stato quello di avereimpegnato un nuovo modello di programmazione distribuita (Linda) in uncampo reale di applicazione (il dominio dei giochi) nel tentativo dievidenziare le principali proprietà di tale modello.
Il dominio dei giochi (ed in particolare degli scacchi) si è rivelato unostrumento di analisi completo:• la realizzazione di alcuni degli algoritmi classici di visita parallela di alberidi gioco ha permesso di risolvere problemi con differente granularità delparallelismo (Capitolo 5);
• la parallelizzazione di un giocatore sequenziale reale (GnuChess) hafavorito un esame delle capacità del linguaggio di coordinamento Linda disostenere il riuso di moduli sequenziali nello sviluppo di programmiparalleli (Capitolo 6).
Obbiettivo non meno importante di questo lavoro era quello di fornire unapporto alla ricerca nel campo dei sistemi "intelligenti" attraverso:• la sperimentazione in ambiente distribuito di algoritmi paralleli di ricercasu alberi di gioco;• il progetto e la realizzazione di un giocatore basato sul nuovo concetto didistribuzione della conoscenza.Di seguito sarà valutato il raggiungimento degli obbiettivi prefissi, tracciatealcune conclusioni ed infine proiettato lo sguardo verso gli sviluppi futuridella ricerca.
7.1 Valutazione del raggiungimento degli obbiettivi econclusioni
7.1.1 LindaEspressività ed efficienza sono alcune delle principaliproprietà di un linguaggio di programmazione distribuita: lavalutazione di Linda che emerge dal presente lavoro è inriferimento proprio a tali caratteristiche.
Per espressività di un linguaggio distribuito si intende lafacilità offerta al programmatore di esprimere il parallelismo,la comunicazione e la sincronizzazione.
Il parallelismo in Linda è basato sulla creazione esplicita deiprocessi. Ciò consente estrema flessibilità nella costruzionedell’architettura logica di comunicazione. Nel Capitolo 5 sonostate sperimentati due tipi di architettura (relativamentesimili) basati rispettivamente sui concetti di cooperazionemaster-worker (cfr. 5.2.1.1.1) e alla pari (cfr. 5.2.1.2.2): un

228
processo master distribuisce lavoro che è eseguito da uninsieme di processi worker indistinguibili. La differenza fra idue approcci sta nel fatto che nel primo caso la distribuzionedel lavoro è dinamica, mentre nel modello alla pari il lavoroche deve essere distribuito è determinato prima dellacreazione dei worker.
Il modello di comunicazione in Linda, basatosull’implementazione di strutture dati distribuite su unospazio di tuple, ha permesso in modo molto naturale larealizzazione di tali forme di cooperazione in cui i processiinteragiscono anonimamente attraverso un’area logicacomune.
Non sempre la condivisione di strutture distribuite ènecessaria: per alcune applicazioni il modello a scambio dimessaggi, ad esempio, sarebbe la soluzione migliore;tuttavia, quando richiesto, lo scambio di messaggi in Lindapuò essere simulato attraverso il passaggio di tuple (ciò è inparte avvenuto nel progetto del giocatore con conoscenzadistribuita: cfr. 6.3.1).
Le condizioni di sincronizzazione sono espresse attraversogli stessi operatori di lettura in e rd i quali hanno la proprietàdi essere bloccanti, cioè di sospendere il processo fino alverificarsi di un evento (manifestato dalla inserzione nellospazio delle tuple della tupla attesa). Grazie a questaproprietà del linguaggio la programmazione della maggiorparte delle sincronizzazioni è molto facile perché implicitanella descrizione dell’azione che consegue al verificarsidell’evento: ad esempio un processo worker si sincronizzacon il master semplicemente "tentando" di prelevare unnuovo lavoro. Vi sono tuttavia situazioni frequenti in cui lasincronizzazione deve essere programmata esplicitamente,ad esempio nella definizione delle barriere disincronizzazione (cfr. 3.4.2.2); la descrizione di questesituazioni (cfr. 5.2.1.1.2; 5.2.1.4.2; 5.2.2.1; 6.3.1) è risultatanel corso dello sviluppo dei programmi spesso origine dierrori di programmazione, sintomo questo che le primitiveLinda forse costituiscono strumenti troppo a "basso livello"per questi scopi.
Una proprietà espressiva molto rilevante di Linda è chel’indivisibilità delle sue primitive ha reso trasparente lasincronizzazione dei processi per l’accesso in mutuaesclusione alle strutture dati distribuite. Una lacuna dellinguaggio è tuttavia l’assenza di meccanismi chegarantiscano implicitamente l’indivisibilità nell’accesso aduna molteplicità di strutture dati distribuite. Questa situazionesi è verificata, ad esempio, nella implementazionedell’algoritmo base con condivisione dello score (cfr.5.2.1.4.1): l’aggiornamento dello score e della mossa

229
migliore devono avvenire in un’unica sezione critica. Anchela descrizione di queste situazioni può originare errori diprogrammazione (generalmente risultanti a tempo diesecuzione nello stallo dei processi); la soluzione generaledi questo problema è delimitare la sezione critica contuple-semaforo (cfr. 3.4.1.1).
Il progetto del giocatore parallelo basato sulla distribuzionedella conoscenza (cfr. 6.3.1) ha messo in evidenza lanotevole espressività di Linda quando impegnato nelcoordinamento di moduli sequenziali predefiniti; il numero dilinee di codice C-Linda, estremamente esiguo rispetto aquello del programma sequenziale originario (GnuChess),sottolinea questa proprietà. In questo senso Linda si rivelauno strumento di programmazione di straordinaria efficacia.Il tipo di approccio alla programmazione parallela chescaturisce da queste considerazioni è decisamentevantaggioso: il programmatore riduce la sua attività alla soladescrizione del coordinamento fra i processi ed è esoneratodalla definizione della loro parte sequenziale.
Il riuso del software sequenziale è risultato difficoltoso nellarealizzazione degli algoritmi paralleli discussi nel Capitolo 5.Il motivo di tale complicazione non deve essere comunqueattribuito alla espressività del linguaggio di coordinamento,ma ad una non completa modularità del programmasequenziale di partenza (GnuChess). Questo programma,infatti, non è una libreria di funzioni (come in realtà è statoutilizzato in questa fase del lavoro): le sue scelte di progettosono mirate alla massimizzazione delle prestazioni insacrificio, talvolta, della modularità del programma.
Si deve quindi concludere che un requisito fondamentaleaffinché risulti vantaggioso il riuso dei programmi sequenzialiè la loro modularità. In generale questo requisito è tanto piùnecessario quanto più fine è la granularità dell’applicazioneparallela che si intende realizzare: la non completamodularità di GnuChess non ha infatti "disturbato" il progettodel giocatore con conoscenza distribuita (caratterizzato dagranularità del parallelismo estremamente grossa), maapplicazioni a grana più fine quali sono gli algoritmi didecomposizione discussi nel Capitolo 5.
Le critiche più pesanti formulate in letteratura nei confronti diLinda riguardano l’efficienza: l’indirizzamento associativodelle tuple e la visibilità globale dello spazio omonimo hannoindotto molti studiosi a ritenere che Linda non possa essereimplementato efficientemente [Bal92]. Questo lavoro ha inparte confutato questa convinzione: la sperimentazione dialcuni degli algoritmi di decomposizione ha prodotto notevolispeedup rivelando che una programmazione accorta, chetenga conto delle proprietà del linguaggio, può mantenere le

230
prestazioni delle applicazioni parallele al di sopra di limiti giàsoddisfacenti (cfr. 5.3).Questo lavoro ha evidenziato la notevole influenza che ha laparticolare implementazione dello spazio delle tuple sulleperformance dei programmi:
• l’implementazione con "out distribuita" favorisce leprestazioni delle applicazioni con infrequenti aggiornamentidelle strutture dati distribuite rispetto al numero delle loroletture;
• l’implementazione con "in distribuita", invece, riducel’overhead determinato dalla generazione di nuove tuple, marende lineare nel numero di processi il costo della lorolettura.
L’implementazione di Network C-Linda, l’istanza del modelloLinda utilizzata in questo lavoro, è basata sullo schema con"in distribuita". Ciò non ha certo favorito l’efficienza deglialgoritmi di decomposizione i quali, per loro natura,prevedono un occasionale aggiornamento delle strutturecondivise (finestra αβ) contro una loro frequente lettura;tuttavia in 5.2.1.4.1 è stata presentata una tecnica diprogrammazione (uso di tuple "private") che ha permesso dilimitare l’overhead determinato dagli accessi in lettura allospazio delle tuple.
La programmazione in Linda di applicazioni che rispettino ilrequisito di efficienza non può quindi prescindere dallaconoscenza dell’implementazione dei costrutti dellinguaggio. Questa realtà limita la libertà del programmatoreil quale è costretto ad utilizzare uno stile di programmazionenon trasparente rispetto ai livelli inferiori dell’architettura delsistema.
Questo lavoro ha dimostrato che Linda è uno strumentoefficace per la realizzazione efficiente di applicazioni congrossa e media granularità del parallelismo.L’implementazione dell’algoritmo generale didecomposizione dinamica (cfr. 5.2.2.2), caratterizzato dauna grana più fine del parallelismo, ha rivelato che NetworkC-Linda non è adatto alla programmazione di questa classedi applicazioni a causa dell’eccessivo overhead dellecomunicazioni.
Alcune considerazioni sono infine necessarie riguardol’overhead determinato dalla creazione dei processi: questaattività si è rivelata molto costosa nel sistema usato inquesto lavoro. In 5.2.1.1.2 è stata discussa la conseguenteesigenza di limitare il numero di tali operazioni attraverso ladefinizione di una struttura di processi con funzionalitàgenerali, capaci di specializzarsi qualora venga loro richiestauna modifica dinamica delle proprie funzioni.
7.1.2 La distribuzione della ricerca

231
Nel corso di questo lavoro sono stati presentati moltialgoritmi di ricerca distribuita su alberi di gioco, conparticolare attenzione ai metodi di decomposizionedell’albero.
A riguardo è stata formalizzata una nuova classificazione ditali metodi e introdotta una nuova terminologia. Attraversoquesti strumenti si è raggiunto l’obbiettivo di stabilire unmaggiore ordine all’interno di questa così complessa classedi algoritmi e di fissare dei punti di riferimento perl’individuazione delle loro qualità salienti.
L’evidenza sperimentale ha confermato il valore relativo cheè attribuito in letteratura a tali algoritmi: PVSplit ed inparticolare la sua variante DPVSplit costituiscono i metodipiù efficienti di ricerca parallela αβ in presenza di un numerodi processori limitato (≤11) e di un’architettura parallela dibase di tipo rete locale. È doveroso sottolineare come Lindaabbia aiutato nello sviluppo degli algoritmi, permettendo diapplicare selettivamente o incrementalmente nuovimiglioramenti all’algoritmo (estremamente semplice) dipartenza (cfr. 5.2.1.1). Fra questi quello più sorprendente intermini di prestazioni è risultato il metodo di condivisionedello score (cioè del limite α al top-level dell’albero): talecondivisione attuata attraverso la memorizzazione delloscore in una struttura dati distribuita ha garantito unanotevole riduzione dell’overhead di ricerca con un costodelle comunicazioni trascurabile rispetto al guadagno diefficienza complessivo.
L’approccio con decomposizione dinamica si è rivelatoefficace solo in combinazione con PVSplit (da cui original’algoritmo DPVSplit). La sua finalità, infatti, è di favorire ilbilanciamento del carico di lavoro fra i processi aumentandola decomposizione dell’albero: ciò determina però unaumento del numero di comunicazioni inter-processo.Mentre in DPVSplit il vantaggio garantito dalla maggioreuniformità nell’attribuzione del carico è superioreall’overhead di comunicazione addizionale, quest’ultimodiviene insopportabile in algoritmi con maggioredecomposizione come quelli discussi ad epilogo del Capitolo5.
Gli esperimenti hanno inoltre dimostrato che, qualora siaapplicabile, il meccanismo di cooperazione alla pari èpreferibile al master-worker (ciò è almeno vero per laprogrammazione in Linda). Il primo approccio, infatti, ha ilpregio di impegnare tutte le risorse di elaborazione in attivitàproduttiva (nella fattispecie nella ricerca di sottoalberi digioco) distribuendo fra esse i compiti "gestionali". È statotuttavia spiegato che tale asserzione è vera in presenza diun’architettura con pochi processori: la differenza (in termini

232
di efficienza) fra i due approcci tende ad annullarsiall’aumentare dei processori.È stato inoltre presentato un nuovo approccio allo sviluppo dialgoritmi αβ di decomposizione strutturato in due fasiconsecutive:
• selezione del criterio di decomposizione più "promettente"• sviluppo di un algoritmo che tenga conto dellecaratteristiche del criterio di decomposizione individuatonella prima fase così da massimizzare le prestazioni.
È stato progettato e realizzato uno strumento di assistenzaalla prima delle due fasi elencate: un algoritmo generale didecomposizione dinamica parametrico rispetto al criterio didecomposizione. Tale struttura software deve essere quindiintesa come uno strumento di ricerca che consente distimare con immediatezza le prestazioni di nuovi criteri didecomposizione, senza che sia programmata ogni volta lastruttura di interazioni fra i processi.
7.1.3 La distribuzione della conoscenzaIn questo lavoro è stato presentato un approcciorelativamente nuovo al progetto di giocatori artificiali parallelidenominato "distribuzione della conoscenza". L’idea allabase dei giocatori così definiti è la cooperazione fra giocatorisequenziali con diversa conoscenza del dominio diapplicazione (la cui attribuzione è in rispetto di un criteriodetto di distribuzione): ogni giocatore propone la rispettivamigliore mossa e, dall’insieme così ottenuto di candidate,viene scelta (attraverso un criterio detto di selezione) quellache sarà effettivamente giocata.
In riferimento alla classificazione della conoscenza (dovuta aBerliner [Ber82]) in terminale e dirigente sono stati separati iconcetti di distribuzione dei due differenti tipi di conoscenza.
Il problema della distribuzione della conoscenza terminale èstato indagato in profondità, mentre relativamente alladistribuzione della conoscenza dirigente sono statesuggerite alcune interessanti soluzioni intuitive.
Alcuni esperimenti hanno confermato precedenti risultati[Sch86]:• esiste un ordinamento per importanza relativa dellecategorie di conoscenza terminale;• esistono categorie di conoscenza terminale la cui efficaciaè dipendente dalla presenza o meno di altre categorie.Nel corso del lavoro è stata generata, su base intuitiva, unarassegna di criteri di distribuzione e di selezione.Sono stati così definiti dei giocatori paralleli reali le cuiprestazioni sono state confrontate in condizioni di torneocontro un avversario comune: il giocatore sequenziale discacchi GnuChess. I risultati ottenuti sono sorprendenti: il75% dei giocatori paralleli è risultato vincente; l’obbiettivo di

233
migliorare le prestazioni di un giocatore sequenzialeutilizzando una forma di distribuzione della sua stessaconoscenza è stato quindi eccellentemente raggiunto.
Sono state inoltre definite delle metriche per la valutazioneseparata dei criteri di distribuzione e di selezione. Questavalutazione è stata applicata sulla base delle prestazioniottenute dai diversi giocatori paralleli nella esplorazione di unnotevole numero (=500) di posizioni scacchistiche di test. Leconclusioni cui conducono tali esperimenti sono chiare:
• i giocatori paralleli con conoscenza distribuita sono"potenzialmente" in grado di raddoppiare le prestazioni (suposizioni di test) del giocatore sequenziale originario. Questaasserzione è basata sulla misura della capacità, di almenouna delle istanze che compongono i giocatori paralleli, disuggerire la mossa realmente migliore in una data posizione.Si parla di prestazioni potenziali proprio perché ilsuggerimento corretto deve ancora emergere, attraversol’applicazione del criterio di selezione, come la scelta finaledel giocatore parallelo.
• il criterio di selezione è la componente più delicata deigiocatori con conoscenza distribuita. I criteri proposti hannopalesato prestazioni complessivamente deludenti che hannodenunciato la loro eccessiva semplicità ed incapacità dimodificare dinamicamente l’importanza relativa attribuita alleproposte delle istanze sequenziali.
7.2 Lavori futuri7.2.1 Linda
Sebbene vasta e circonstanziata la valutazione del modelloLinda di programmazione distribuita operata in questo lavoroha fissato tre importanti parametri: l’architettura parallela(rete locale di workstation), l’implementazione dello spaziodelle tuple ("in distribuita") ed il dominio di applicazione (igiocatori artificiali di scacchi). Sarebbe di sicuro interesseper la comunità scientifica estendere ad ampio spettro(rispetto ai parametri appena citati) l’analisi di questo nuovomodello.
Particolare attenzione dovrebbe essere rivolta all’esamedelle sue prestazioni in architetture a parallelismo massiccio.Implementazioni di Linda su ipercubo [BjCaGe89] etransputer [Zen90] sono già state realizzate; tuttavia leapplicazioni parallele sviluppate su tali sistemi sono ancorain numero troppo esiguo per poter trarre conclusioni sullavalidità del modello Linda quando basato su questearchitetture.
Nel corso di questo lavoro è stata più volte sottolineata ladipendenza delle prestazioni delle applicazioni in Linda dallaimplementazione delle sue primitive. Questa realtà è

234
conseguenza della scelta del modello Linda di renderetrasparente al programmatore la distribuzione fisica delletuple.
La sperimentazione di alcuni algoritmi paralleli di ricerca αβha dimostrato che l’utilizzo di particolari tecniche diprogrammazione (nel nostro caso "tuple private") può ridurreil degrado delle prestazioni indotto da una implementazionedel linguaggio non ottimale per il tipo di applicazione che siintende realizzare. Sarebbe desiderabile uno studio piùapprofondito di tali problemi che permetta di generaretecniche di programmazione Linda (mirate all’efficienza deiprogrammi) tali da coprire la casistica di tutte le possibiliimplementazioni del modello. Ciò favorirebbe la portabilitàdei programmi Linda: il programmatore sarebbe già in gradodi prevedere quali modifiche apportare alla sua applicazione(volendo impedire un degrado delle prestazioni) quandoessa sarà trasportata su un sistema che attua una differenteimplementazione del modello.
È tuttavia lecito porre alcuni interrogativi sulla possibilità diarricchimento del modello Linda di strumenti che risolvino apiù basso livello i problemi descritti:
• quale implicazioni (sull’implementazione del modello esull’efficienza dei programmi) avrebbe offrire alprogrammatore la possibilità di disporre del controllodell’allocazione fisica delle tuple? Un recente approccio intale direzione è quello offerto dal sistema LIPS per reti diworkstation [RotSet93]: si tratta di un sistema ispirato almodello di comunicazione Linda in cui l’invocazione dellaprimitiva out prevede che uno dei parametri specifichi ilprocessore su cui la tupla dovrà essere memorizzata.
• è ragionevole pensare ad un sistema Linda che adattidinamicamente l’implementazione delle sue primitive infunzione di statistiche raccolte a tempo di esecuzione?
Si potrebbe pensare, ad esempio, di arricchire il nucleo di unsistema Linda implementato con "in distribuita" difunzionalità che consentano comunque la "diffusione" diquelle strutture dati distribuite (tuple) accedute moltofrequentemente in lettura ed aggiornate di rado.
L’implementazione del modello master-worker haevidenziato l’esigenza, per questo tipo di cooperazione, diun controllo a livello di programma dell’allocazione deiprocessi. Allo stato dell’arte non ci risulta la presenza disistemi Linda reali che garantiscano questa funzionalità.
7.2.2 Giocatori artificiali paralleliQuesto lavoro ha affrontato molti dei temi legati alladefinizione di sistemi "intelligenti" distribuiti, cioè strutture dicalcolatori autonomi che cooperano nel prendere decisioni.Le componenti logiche di un sistema intelligente sono la

235
conoscenza del dominio di applicazione e le capacità diricerca: il problema della distribuzione di entrambe questeproprietà è stato studiato separatamente lasciando aperta ladiscussione riguardo una loro combinazione.
Data la complessità dell’argomento sono state esplorate inprofondità solo una parte delle problematiche ad essoinerenti ed in taluni casi esse non sono state esaminate inmodo esauriente.
In riferimento alla distribuzione della ricerca la discussioneha concentrato la sua attenzione sugli algoritmi didecomposizione, cioè la classe di metodi di ricercadistribuita che ha garantito nel recente passato le miglioriprestazioni; è quindi doveroso rivolgere brevemente losguardo verso il futuro delle altre forme di parallelizzazionedella ricerca su alberi di gioco.
Fra gli approcci alternativi ai metodi di decomposizionequello basato sulla ricerca con finestre parallele è quellomaggiormente studiato in passato e non sono attualmenteprevedibili ulteriori approfondimenti in questa direzione.
Deep-Thought [AnCaNo90] e HITECH [Ebe87] sono esempidi giocatori paralleli che utilizzano hardware ad hoc perl’implementazione di funzionalità (della ricerca) applicatelocalmente ad un nodo dell’albero: il calcolo della funzione divalutazione e la generazione delle mosse. Naturalmente ilprogetto di tale hardware deve essere guidato dal dominio diapplicazione. È ragionevole pensare alla definizione in unimmediato futuro di metodi generali di progetto di talicomponenti che possano essere applicati in più domini?
L’approccio alternativo forse più affascinante e che sembrapromettere le migliori prestazioni è quello che stabilisce ilmapping degli stati della ricerca nell’insieme dei processori(cfr. 4.2.4); il suo successo è legato agli sviluppi futuri dellatecnologia: l’overhead di comunicazione che esso ingenerale determina è, allo stato dell’arte, insostenibile[FeKoPo93]. Tuttavia un’auspicabile riduzione dei costi dellecomunicazioni fisiche inter-processore potrebbe fare diquesta classe di metodi la migliore soluzione per moltidomini applicativi.
Per quanto concerne gli algoritmi di decomposizionesperimentati in questo lavoro molti di essi non stati valutaticompletamente; in particolare:
• il metodo di condivisione dello score è stato applicatounicamente al top-level (dove tuttavia si attende che essomanifesti maggiormente la sua efficacia). Quali vantaggiavrebbe apportato la condivisione (in questo caso dientrambi i limiti α e β) anche ai livelli inferiori dell’albero?Fino a quale profondità i vantaggi della condivisione nonsarebbero stati vanificati dall’aumento delle comunicazioni?

236
L’estensione in profondità di tale tecnica avrà incidenzadifferente su PVSplit rispetto a quella sull’algoritmo base?• stesse considerazioni devono essere fatte per la versionedell’algoritmo base con subappalto dinamico della ricerca(cfr. 5.2.2.1), applicato anch’esso unicamente al livellosuperiore dell’albero di gioco.
• fra le euristiche di ordinamento interno dei nodi (cfr. 1.3.3)sono state sperimentate unicamente la tecnica diapprofondimento iterativo in combinazione con ilriordinamento statico (fra due iterazioni successive) dei nodial top-level (cfr. 5.2.1.3). Come noto l’incidenza di questeeuristiche sull’efficienza della ricerca è notevole [Sch86]. In4.3 è stata anticipata una discussione generale sugli effettidell’applicazione di tali tecniche in ambiente distribuito;sarebbe tuttavia interessante verificare tali intuizioni in unambiente di programmazione Linda. La totalità di questeeuristiche è basata sulla gestione di tabelle: laprogrammazione di quest’ultime come strutture datidistribuite e della loro manipolazione attraverso le primitiveLinda sarebbe immediata. Restano però perplessitàsull’efficienza della loro gestione, specialmente per la tabellahistory (8196 posizioni in GnuChess) e quella delletrasposizioni (216 posizioni in GnuChess), le quali, oltre chedi elevate dimensioni, sono accedute in corrispondenza diogni nodo interno dell’albero di gioco e quindi moltofrequentemente. Solo la sperimentazione di tali euristichepuò indicare con chiarezza se la condivisione di tali tabelle èvantaggiosa ed eventualmente per quali loro parametri(dimensione e numero di accessi). Deve essere comunquevalutata l’alternativa di una implementazione di tabelle localiai processi oppure di un approccio misto che preveda lacoesistenza di tabelle globali e locali (quest’ultimeaggiornate periodicamente).
Durante lo studio dei metodi di decomposizione dell’albero digioco è sorta l’esigenza di un loro riordinamento logico: daessa è nata la classificazione presentata in 4.2.5.1. Nelsettore della ricerca interessato allo studio di algoritmiparalleli di visita di alberi di gioco deve purtroppo esseresegnalata una certa povertà di strumenti formali: molte dellenozioni sono di natura empirica o intuitiva ed è indubbia ladifficoltà di tramutare queste in definizioni formali o inoggetto di studi analitici. Il formalismo introdotto in questolavoro è soltanto un timido approccio in questa direzione: losviluppo di strumenti formali ben più sofisticati potrebbeessere la chiave di un progresso sistematico in questosettore.
L’algoritmo generale di decomposizione dinamica propostoalla fine del capitolo 5 rappresenta un esempio di sviluppo di

237
uno strumento di assistenza per i ricercatori capace digarantire una rapida stima delle prestazioni di algoritmibasati su diversi criteri di decomposizione. La versionecorrente di tale algoritmo prevede che la specializzazionedel criterio di decomposizione sia attuata modificando ilcodice di una funzione C-Linda; un lavoro futuro è quello direndere trasparente l’aggiornamento di tale codice, adesempio definendo un meta-linguaggio che permetta didescrivere il criterio di decomposizione relativamente ad uncerto numero di parametri della ricerca.
Gli algoritmi di decomposizione dinamica si sono rivelaticomplessivamente inefficienti a causa della granularità piùfine del parallelismo la quale ha originato un insostenibileoverhead di comunicazione. Sarebbe interessante verificarel’efficienza di questi algoritmi in architetture a parallelismomassiccio dove il costo delle comunicazioni incide in minormisura sulle prestazioni dei programmi.
L’assoluta novità dei metodi di decomposizione dellaconoscenza introdotti in questo lavoro schiude le porte di unsettore finora inesplorato della ricerca e che i risultatisperimentali documentati in questa tesi rendono meritevoledi estrema attenzione.
Sono stati fornite molte indicazioni per quanto riguarda ladistribuzione della conoscenza terminale; tuttavia molte diesse sono frutto dell’applicazione di idee intuitive chemeriterebbero un’indagine più sistematica.
Per quanto concerne i criteri di distribuzione dellaconoscenza terminale, infatti, sono stati sperimentati solo 4di essi: è desiderabile fissare nuovi criteri che definiscanoaltre combinazioni significative della conoscenza all’internodelle istanze del giocatore parallelo. In particolare sidovrebbe tenere in maggiore considerazione gli effetti dellacombinazione di certe categorie di conoscenza e nonlasciare al caso la loro contemporanea presenza all’internodi una stessa istanza.
Indicazioni più complete potrebbero essere ottenuteverificando le prestazioni di giocatori risultanti dalladistribuzione della conoscenza ricavata:
• dalla funzione di valutazione di un giocatore reale diversoda GnuChess• dalla combinazione delle funzioni di valutazione di piùgiocatori reali• dalla definizione di una funzione di valutazione ad hoc(finalizzata alla sua "distribuzione").Già in sede di conclusioni è stato sottolineato il delicato ruolodel criterio di selezione; sono stati sperimentati diversi criteriindipendenti dal dominio di applicazione, che però gliesperimenti con posizioni di test hanno rivelato

238
insoddisfacenti. Lavori futuri dovranno quindi impegnareanche criteri di selezione più complessi e maggiormentelegati al dominio.
L’efficacia di un criterio di selezione è legata alla suacapacità di riconoscere, posizione per posizione,l’importanza relativa dei suggerimenti proposti dalle diverseistanze di ricerca che compongono il giocatore parallelo:sarebbe interessante incorporare il criterio di selezione in unsistema intelligente "di sostegno" al giocatore parallelo (adesempio un sistema esperto basato su regole). Il compito ditale agente è di individuare particolari caratteristiche dellaposizione corrente e in funzione di esse attribuire pesodifferente alle proposte delle istanze.
Il principale problema nell’indagine dei metodi descrittirimane tuttavia l’esplosione esponenziale del numero didifferenti giocatori paralleli che possono scaturire in funzionedi:
• numero di istanze• attribuzione di conoscenza alle istanze• attribuzione di pesi alle proposte delle diverse istanze.Lo stesso problema si verifica, con minori gradi di libertà,nell’attribuzione ottimale di pesi ai parametri di una funzionedi valutazione di un ordinario giocatore artificiale. Lesoluzioni più interessanti a tale problema sono basate sullaregolazione automatica dei pesi (auto-tuning) ottenuta perapprossimazioni successive della migliore soluzione. Ingenerale questi metodi di ottimizzazione operano attraversola ripetizione ciclica (fino al raggiungimento di una soluzionesoddisfacente) delle seguenti fasi:
1. sono verificate, attraverso un database di posizioni di test,le prestazioni di certi giocatori artificiali originati da una certaattribuzione di pesi nella rispettiva funzione di valutazione
2. sulla base dei risultati della fase 1. sono determinatenuove attribuzioni di pesi (e quindi nuovi giocatori) chesintetizzano le principali qualità manifestate dai giocatoriprecedenti; tale sintesi può essere attuata con:
• metodi analitico-statistici [Ana90]• algoritmi genetici [Ped91]• reti neurali [vTi91]3. torna alla fase 1. sperimentando i giocatori ottenuti nellafase 2.È ragionevole l’utilizzo di questi metodi di indagine nellostudio della distribuzione della conoscenza?È completamente da indagare, infine, la possibilità disviluppo di algoritmi ed euristiche di ricerca strettamentedipendenti dalle categorie di conoscenza usate nellafunzione di valutazione. Ad esempio nell’esperimento Scouts[Sch87] è utilizzata l’euristica "null move" per aumentare

239
enormemente la profondità di una ricerca αβ che valuta soloil materiale. La nostra idea è che si possa aprire un grandespazio di ricerca riguardo euristiche di ricerca specifiche, chehanno a che fare con funzioni di valutazione particolari, incontrapposizione ad euristiche di ricerca indipendenti daldominio o che fanno riferimento a funzioni di valutazione ditipo generale (come sono quelle attualmente presenti neigiocatori artificiali più forti).
Riguardo il problema della distribuzione della conoscenzadirigente devono essere ancora verificate da un’analisi piùattenta e dalla sperimentazione le idee proposte in 6.4,fondate su base assolutamente intuitiva.
È possibile confluire in un unico giocatore parallelo sia ilconcetto di distribuzione della ricerca che della conoscenza?Si potrebbe pensare, ad esempio, ad un giocatore parallelocon due livelli logici di distribuzione:• a più alto livello vi sono giocatori indipendenti con diversaconoscenza terminale i quali cooperano dopo ilcompletamento delle rispettive ricerche selezionando(attraverso un criterio di selezione) una delle mosse da essiproposte
• tali giocatori sono in realtà dotati di ricerca distribuita(distribuzione a basso livello) la quale garantisce maggioreefficienza nella visita e quindi l’esplorazione più in profonditàdell’albero di gioco.
Soluzione alternativa potrebbe essere l’applicazione incascata delle due forme di distribuzione:• nella prima fase tutte le risorse di elaborazione sonoimpegnate nella visita separata dell’albero di giocodisponendo ciascuna di differente conoscenza terminale
• nello stadio successivo il criterio di selezione diviene inrealtà l’esplorazione delle sole mosse proposte nella primafase; essa è attuata attraverso l’impiego di tutte le risorse dielaborazione guidato da un algoritmo di distribuzione dellaricerca: la mossa che emerge migliore da questa ricerca(selettiva) sarà quella realmente proposta dal giocatoreparallelo complessivo.
I due esempi appena indicati suggeriscono che lacombinazione di distribuzione della ricerca e dellaconoscenza possa essere stabilita in modo molto naturale.Riteniamo che questo lavoro abbia fornito sufficientiindicazioni riguardo la possibilità di un "incontro" fra le dueforme di distribuzione giustificando così future ricerche nelladirezione appena tracciata di una loro combinazione.

244
Bibliografia[Abr89] B. Abramson, "Control Strategies for Two-player Games", ACM
Computing Surveys, Vol.21, No.2, (Jun.1989),137-161.
[AkBaDo82] S. Akl, D. Barnard, R. Doran, "Design, Analysis, andImplementation of a Parallel Tree Search Algorithm", IEEETransactions on Pattern Analysis and Machine Intelligence,Vol. PAMI-4, No.2, (Mar.1982), 192-203.
[Alt89] I. Althöfer, "A Summary of some Results in theoretical game treesearch and dreihirn-experiment", Proc. Workshop on NewDirections in Game-Tree Search, Ed. T.A. Marsland, Edmonton,(1989), 16-32.
[Alt91] I. Althöfer, "Selective trees and majority systems: two experimentswith commercial chess computers", Advances in computer chess 6,Ed. D. Beal, (1991), 37-59.
[Ana90] T. Anantharaman, "A statistical study of selective min-max search incomputer chess", Carnegie-Mellon University, Pittsburgh, (May1990).
[AsCaGe89] C. Ashcraft, N. Carriero, D. Gelernter, "Is explicit parallelismnatural? Hybrid DB search and sparse LDLT factorization usingLinda", Yale University, New Haven, (Jan. 1989).
[BaKaLe92] H. Bal, M. Kaashoek, W. Levelt, "A comparison of two paradigmsfor distributed shared memory", Dept. of Mathematics andComputer Science, Vrije Universiteit, Amsterdam, (1992).
[BaKaTa92] H. Bal, M. Kaashoek, S. Tanenbaum, "Orca: a language for parallelprogramming of distributed systems", IEEE Transactions onSoftware Engineering, Vol. 18, No. 3, (Mar. 1992), 190-205.
[Bal91] H. Bal, "Heuristic search in PARLOG using replicated worker styleparallelism", Future Generation Computer Systems, North-Holland,6, (1991), 303-315.
[Bal92] H. Bal, "A comparative study of five parallel programminglanguages", Future Generation Computer Systems, North-Holland,8, (1992), 121-135.

245
[Bal90] H. Bal, "Programming distributed systems", Prentice Hall, SiliconPress, (1990).
[BalvRe86] H.E. Bal, R. van Renesse, "A summary of parallel alpha-betasearch results", ICCA Journal, (Sep.1986), 146-149.
[Bau78a] G. Baudet, "The design and analysis of algorithms forasynchronous multiprocessors", Ph.D. dissertation, ComputerScience Dept., Carnegie-Mellon University, Pittsburgh, (Apr.1978).
[Bau78b] G. Baudet, "On the branching factor of the alpha-beta pruningalgorithm", Artificial Intelligence, Vol. 10, (1978), 173-199.
[Ber73] H. Berliner, "Some necessary conditions for a master chessprogram", Proceedings of the Third Intenational Joint Conferenceon Artificial Intelligence, Stanford, California, (Aug.1973), 77-85.
[Ber82] H. Berliner, "Search vs. knowledge: an analysis from the domain ofgames", Department of Computer Science, Carnegie-MellonUniversity, (1982).
[BerEbe86] H. Berliner, C. Ebeling, "The SUPREM architecture: a newintelligent paradigm", Artificial Intelligence, Vol. 28, (1986), 3-8.
[BjCaGe89] R. Byornson, N. Carriero, D. Gelernter, "The implementation andperformance of hypercube Linda", Report RR-690, Yale University,New Haven, (Mar. 1989).
[BraKop82] I. Bratko, D. Kopec, "The Bratko-Kopec experiment: a comparisonof human and computer performance in chess", Advances inComputer Chess 3, Ed. M.R.B. Clarke, Pergamon Press, (1982),57-72.
[Bru63] A.L. Brudno, "Bounds and valuations for abridging the search ofestimates", Problems of Cybernetics, Pergamon Press, Elmsford,N.Y., (1963), 225-241.
[CCCG85] N. Carriero, S. Chandran, S. Chang, D. Gelernter, "Parallelprogramming in Linda", IEEE Parallel Processing Conf., (1985).
[CaGeLe88] N. Carriero, D. Gelernter, J. Leichter, "Distributed data structures inLinda", Proceedings of the ACM Symposium on Principles ofProgramming Languages, (Jan. 1986), 13-15.

246
[CarGel88a] N. Carriero, D. Gelernter, "Applications experience with Linda", YaleUniversity, New Haven, (Jan. 1988).
[CarGel88b] N. Carriero, D. Gelernter, "How to write parallel programs: A guideto the perplexed", Yale University, New Haven, (Nov. 1988).
[CarGel89] N. Carriero, D. Gelernter, "Linda in context", Communications of theACM, (Apr. 1989), 444-458.
[CarGel90] N. Carriero, D. Gelernter, "How to write parallel programs. A firstcourse", The MIT Press, (1990).
[Cia92] P. Ciancarini, "I giocatori artificiali di scacchi", Ed. Mursia, (1992).
[CiaGas89] P. Ciancarini, M. Gaspari, "A knowledge-based system and adevelopement interface for the middle game in chess", Advances inComputer Chess 5, D.F Beal (Editor), (1989).
[CFC84] CFC, Chess federation of Canada Rating System, En Passant,(1984), 63-64.
[DanMah93] C. Daniels, A. Mahanti, "A SIMD approach to parallel heuristicsearch", Artificial Intelligence, Vol. 60, (1993), 243-282.
[dGr65] A.D. de Groot, "Thought and Choice in Chess", Mouton, TheHague, (1965).
[Ebe86] C. Ebeling, "All the Right Moves: A VLSI Architecture for Chess",The MIT Press, (1986).
[EdwHar63] D. Edwards, T. Hart, "The alpha-beta heuristic", Tech. Rep. 30, MITAI Memo, Computer Science Dept., Massachusetts Institute ofTechnology, Cambridge, (1963).
[Eli90] R.J. Elias, "Oracol, A Chess Problem Solver in Orca", Dept. ofMathematics and Computer Science, Vrije Universiteit, Amsterdam,(1990)
[FaFeGe91] M. Factor, S. Fertig, D. Gelernter, "Using Linda to build parallel AIapplications", Yale University, New Haven, (Jun. 1991).
[FacGel88] M. Factor, D. Gelernter, "The parallel process lattice as anorganizing scheme for realtime knowledge daemons", YaleUniversity, New Haven, (Mar. 1988).

247
[FerGel91] S. Fertig, D. Gelernter, "The design, implementation, andperformance of a database-driven expert system", Yale University,New Haven, (Feb. 1991).
[FeKoPo93] C. Ferguson, R. Korf, C. Powley, "Depth-first heuristic search on aSIMD machine", Artificial Intelligence, Vol. 60, (1993), 199-242.
[FeMyMo91] R. Feldmann, P. Mysliwietz, B. Monien, "A Fully Distributed ChessProgram", Advances in computer chess 6, , Ed. D. Beal, (1991),1-27.
[FeMyMo92] R. Feldmann, P. Mysliwietz, B. Monien, "Experiments with a Fully-Distributed Chess Program", Heuristic Programming in AI,Eds. J. Van Den Herik e V. Allis, Hellis Horwood, (1992), 72-87.
[FelOtt88] E.W. Felten, S.W. Otto, "A Highly Parallel Chess Program",Proceedings of the International Conference on Fifth GenerationComputer Systems, (1988), 1001-1009.
[FisFin80] J.P. Fishburn, R.A. Finkel, "Parallelism in Alpha-Beta Search onArachne", Technical Report 394, Computer Science Dept.,University of Wisconsin, Madison, (Jul.1980).
[FinFis82] J.P. Fishburn, R.A. Finkel, "Parallelism in alpha-beta search",Artificial Intelligence, Vol. 19, (1982), 89-106.
[FMMV89] R. Feldmann, P. Mysliwietz, B. Monien, O. Vornberger, "DistributedGame-Tree Search", ICCA Journal, Vol.12, No.2, (1989), 65-73.
[Gel85] D. Gelernter, "Generative communication in Linda", ACM Trans.Progr. Lang. Syst. 7, 1 (1985), 80-112
[GelKam92] D. Gelernter, D. Kaminsky, "Supercomputing out of recycledgarbage: preliminary experience with Piranha", Proceedings of theACM Int. Conf. on Supercomputing, (Jul. 1992).
[Gil72] J. Gillogly, "The technology chess program", Artificial Intelligence,Vol. 3, (1972), 145-163.
[Gil78] J. Gillogly, "Performance analysis of the technology chessprogram", Carnegie Mellon University, Pittsburgh, (Mar. 1978).

248
[HLMSW92] F. Hsu, R. Levinson, J. Schaeffer, T.A. Marsland, D. Wilkins,"Panel: the role of chess in artificial intelligence research", D.E inProc. 12th Int’1 Joint Conference in Artificial Intelligence, (1992),547-552.
[Hsu90] F. Hsu, "Large scale parallelization of alpha-beta search: analgorithmic and architectural study with computer chess", Ph.D.thesis, Carnegie Mellon University, Pittsburgh, (Feb. 1990).
[KerRit78] B. Kernighan, D. Ritchie, "The C programming language",Prentice-Hall, (1978).
[KnuMoo75] D.E. Knuth, R.W. Moore, "An analysis of alpha-beta pruning",Artificial Intelligence, Vol.6, (1975), 293-326.
[Kor85] R. Korf, "Depth-first iterative-deepening: An optimal admissible treesearch", Artificial Intelligence, Vol. 27, (1985), 97-109.
[Kor90] R. Korf, "Real-time heuristic search", Artificial Intelligence, Vol. 42,(1990), 189-211.
[Kor93] R. Korf, "Linear-space best-first search", Artificial Intelligence,Vol. 62, (1993), 41-78.
[LanSmi93] K. Lang, W Smith, "A test suite for chess programs", Draft,(Jun. 1993).
[LeiWhi88] J. Leichter, R. Whiteside, "Using Linda for supercomputing on alocal area network", Yale University, New Haven, (Jun. 1986).
[Lin90] "C-Linda Reference manual", Scientific computing associates inc.,New Haven, Connecticut, (1990).
[Low89] C. Low, "Parallel game tree searching with lower and upperbounds", University of Illinois at Urbana-Champaign, (1989).
[MaBrSu91] T.A. Marsland, T. Breitkreutz, S. Sutphen, "A networkmulti-processor for experiments in parallelism", Concurrency:Practice and Experience, Vol.3, No.3, (Jun.1991), 203-219.
[MarCam82] T.A. Marsland, M. Campbell, "Parallel Search of Strongly OrderedGame Trees", ACM Computing Surveys, Vol.14, No.4, (Dec.1982),533-551.

249
[MaOlSc86] T.A. Marsland, M. Olafsson, J. Schaeffer, "Multiprocessortree-search experiments", Adavances in Computer Chess 4,Pergamon Press, (1986), 37-51.
[MarPop83a] T.A. Marsland, F. Popowich, "A multiprocessor tree-searchingsystem design", University of Alberta, Edmonton, Canada, (Jul.1983).
[MarPop83b] T.A. Marsland, F. Popowich, "Experience with a parallel chessprogram", University of Alberta, Edmonton, Canada, (Aug. 1983).
[MarPop85] T.A. Marsland, F. Popowich, "Parallel Game-Tree Search", IEEETransactions on Pattern Analysis and Machine Intelligence, Vol.7,No.4, (Jul.1985), 442-452.
[McA85] D.A. McAllester, "A New Procedure for Growing Mini-Max Trees",Technical Report, Artificial Intelligence Laboratory, MassachusettsInstitute of Technology, (1985).
[Nau82] D.S. Nau, "The last player theorem", Artificial Intelligence, Vol.18,(1982), 53-65.
[New79] M. Newborn, "Recent progress in computer chess", Advances inComputers, Academic Press, (1979), 59-117.
[New88] M. Newborn, "Unsynchronized Iteratively Deepening Parallel Alpha-Beta Search", IEEE Transactions on Pattern Analysis and MachineIntelligence, Vol.10, No.5, (Sep.1988), 687-694.
[Pea80] J. Pearl, "Asymptotic Properties of Minimax Trees and Game-Searching Procedures", Artificial Intelligence, Vol.14, No.2, (1980),113-138.
[Pea82] J. Pearl, "The solution for the branching factor of the alpha-betapruning algorithm and its optimality", Comm. of the ACM 25, 8,(1982), 559-564.
[Riv88] R. Rivest, "Game tree searching by min/max approximation",Artificial Intelligence, Vol. 34, (1988), 77-96.
[Ros81] P.S. Rosenbloom, "A world-championship-level othello program",CMU-CS-81-137, Department of Computer Science,Carnegie-Mellon University, (1981).

250
[RotSet93] R. Roth, T. Setz, "LIPS: a system for distributed processing onworkstations", Draft, (Feb. 1993).
[Sam60] A. L. Samuel, "Programming computers to play games", Advancesin Computers, Vol.1, (1960), 165-192.
[Sha50] C.E. Shannon, "Programming a computer for playing chess",Philosophical Magazine , Vol.41, (1950), 256-275.
[Sch86] J. Schaeffer, "Experiments in search and knowledge", University ofAlberta, Edmonton, Canada, (Jul. 1986).
[Sch87] J. Schaeffer, "Experiments in distributed game-tree searching",University of Alberta, Edmonton, Canada, (Jan. 1987).
[Sch89] J. Schaeffer, "Distributed Game-Tree Searching", Journal ofParallel and Distributed Computing, Vol.6, (1989), 90-114.
[Sch90] J. Schaeffer, "Conspiracy numbers", Artificial Intelligence, Vol. 43,(1990), 67-84.
[SlaDix69] J.R. Slagle, J.K. Dixon, "Experiments with some programs thatsearch trees", J. ACM, Vol.16, No.2, (Apr.1969), 189-207.
[SlaAtk77] D.J. Slate, L.R. Atkin, "Chess 4.5-the Northwestern Universitychess program, Chess Skill in Man and Machine, P.W. Frey, Ed.Springer-Verlag, New York, (1977), 82-118.
[StaWal88] C. Stanfill, D. Waltz, "Artificial intelligence related search on theconnection machine", Proc. of the Int. Conf. on Fifth GenerationComputer Systems, (1988).
[Sti89] L. Stiller, "Parallel Analysis of Certain Endgames", ICCA Journal,Vol. 12:2, (1989), 55-64.
[Sti91] L. Stiller, "Group Graphs and Computational Symmetry onMassively Parallel Architecture", The Journal of Supercomputing,Vol.5, (1991), 99-117.
[Tho82] K.Thompson, "Computer Chess Strength", Advances in ComputerChess 3, Ed. M.R.B. Clarke, Pergamon Press, (1982), 55-56.
[Thu92] F. Thuijsman, "An introduction to the theory of games", HeuristicProgramming in AI, Eds. J. Van Den Herik e V. Allis, HellisHorwood, (1992), 205-220.

251
[Tun91] W. Tunstall-Pedoe, "Genetic algorithms optimizing evaluationfunctions",ICCA Journal, Vol. 14, No. 3, (Sep. 1991), 119-128.
[vNeMor44] J. von Neumann, O. Morgenstern, "Theory of Games and EconomicBehavior", Princeton Univ. Press, Princeton, N.J., (1944).
[vTi91] A. van Tiggeken, "Neural networks as a guide to optimization. Thechess middle game explored", ICCA Journal, Vol. 14, No. 3, (Sep.1991), 115-118.
[Wil79] D.E. Wilkins, "Using patterns and plans to solve problems andcontrol search", Ph.D. thesis, Department of computer science,Stanford University, (1979).
[Wil87] W. Wilson, "Concurrent alpha-beta. A study in concurrent logicprogramming", Int. Conf. on Logic programming, S. Francisco,(1987).
[Zen90] S.E. Zenith, "Linda coordination language: Subsystem kernelarchitecture (on transputers), RR-794, Yale University, New haven,(May 1990).
Appendice APosizioni di Bratko -Kopec
1. d6-d1 2. d4-d5

241
3. f6-f5 4. e5-e6
5. a2-a4 / c3-d5 6. g5-g6
242
7. h5-f6 8. f4-f5
9. f4-f5 10. c6-e5
11. f2-f4 12. d7-f5

243
13. b2-b4 14. d1-d2 / d1-e1
15. g4x g7 16. d2-e4
17. h7-h5 18. c5-b3

244
19. e8x e4 20. g3-g4
21. f5-h6 22. b7x e4
23. f7-f6 24. f2-f4


















