
Ingegneria della Conoscenza e Sistemi Esperti · In matematica un sistema assiomatico è un insieme...
59
Ingegneria della Conoscenza e Sistemi Esperti 1) Introduzione all'IA Con il termine intelligenza artificiale o IA si intende generalmente l'abilità di un computer di svolgere funzioni e ragionamenti tipici della mente umana. Come disciplina è al centro del dibattito tra scienziati e filosofi e comprende (in particolare nel suo aspetto puramente informatico) la teoria e le tecniche per lo sviluppo di algoritmi che consentano alle macchine di mostrare abilità/attività intelligenti, almeno in domini specifici. Secondo le parole di Marvin Minsky, uno dei pionieri della IA, lo scopo di questa nuova disciplina sarebbe stato quello di "far fare alle macchine delle cose che richiederebbero l'intelligenza se fossero fatte dagli uomini". Uno dei problemi principali dell'IA è di dare una definizione formale delle funzioni sintetiche/astratte di ragionamento e apprendimento dell'uomo, al fine di poter costruire modelli computazionali che le realizzano: l'IA si occupa quindi di studiare una appropriata descrizione dei problemi da risolvere (modellizzazione) e delle procedure effettive per la risoluzione di tali problemi (algoritmi). La domanda al centro del dibattito sull'IA è fondamentalmente una sola: i computer possono pensare? Una risposta univoca a questa domanda non esiste perchè ancora non esiste una definizione universalmente condivisa di “intelligenza”. Secondo lo psicologo francese Alfred Binet, l'intelligenza è “giudicare bene, comprendere bene e ragionare bene”, secondo lo psicologo inglese Charles Edward Spearman invece “l’intelligenza è la capacità di rapportarsi ad altre macchine”, ... In realtà le definizioni convenzionali di intelligenza fin qui indicate sono troppo astratte per essere utili in campo informatico e oggi si dispone di definizioni più pratiche, tra le quali spicca quella del matematico inglese Alan Turing, che definisce una macchina intelligente sostanzialmente una macchina in grado, dietro un paravento e attraverso una opportuna interfaccia di comunicazione, di far passare se stessa - in conversazione con un altro essere umano - per un essere umano: una formulazione rigorosa di questa definizione va sotto il nome di Test di Turing. Altro metodo oggi considerato valido per saggiare l'intelligenza è basato sui cosiddetti Test di Bongard, dal nome dello psicologo e cibernetico sovietico Mikhail Bongard che li ideò, il cui scopo è trovare due proprietà applicabili a due insiemi di figure (una vera per l’insieme a sinistra e falsa per quello di destra, l’altra vera per quello a destra e falsa per quello di sinistra). In ogni caso, l'assenza di una definizione univoca di “intelligenza” non consente di rispondere alla domanda iniziale in modo definitivo, per questo lo studio dell'IA si divide in due correnti: la prima, detta IA forte o tesi forte dell'IA ritiene che una macchina correttamente programmata possa essere dotata di intelligenza pura non distinguibile in nessun senso dall'intelligenza umana; la seconda, detta IA debole o tesi debole dell'IA, sostiene che un computer non sarà mai in grado di eguagliare la mente umana pur potendone simulare alcuni processi cognitivi, senza comunque riuscire a riprodurli nella loro totale complessità. In contrapposizione alla teoria della programmazione classica, il concetto chiave dell'IA è l' assenza di un algoritmo per la risoluzione di un problema: la macchina non deve semplicemente eseguire un algoritmo ma deve essere capace di creare l'algoritmo a partire dall'osservazione del problema. Gli approcci dell'IA, come detto, sono sostanzialmente due, tesi forte e tesi debole. Alla base della tesi forte si pongono i seguenti obiettivi: simulazione dei meccanismi cognitivi umani e, poichè nessuna conoscenza pregressa è disponibile, il sistema che si vuol realizzare deve apprendere per esempi (la conoscenza interna è rappresentata da matrici di numeri reali ) e poter operare in una fase di apprendimento e in una fase di funzionamento (o di decisione). Il principale vantaggio di un sistema siffatto è che non è necessario fornirgli esplicitamente la conoscenza (opportunamente formalizzata) ed è quindi semplice da realizzare ed è veloce nella fase di funzionamento; il principale svantaggio è relativo invece al limitato campo di applicazioni: data la lentezza della fase di apprendimento (per problemi anche piccoli le reti generate possono essere molto grandi) tale approccio è applicabile solo alla risoluzione di problemi di piccola complessità. Alla base della tesi debole si pongono invece i seguenti differenti obiettivi: scalamento della complessità del problema, formalizzazione da parte di esperti del dominio applicativo di una opportuna base di conoscenza (Knowledge Base o KB), inserita poi manualmente nel sistema, verificata e a regime utilizzata per la risoluzione di tutti e soli i problemi che coinvolgono la conoscenza in essa presente, eventualmente insieme alle relative spiegazioni. 2) Teoria dei programmi logici In matematica un sistema assiomatico è un insieme di assiomi (proposizioni o principi assunti come veri perché ritenuti evidenti o perché forniscono punti di partenza di un quadro teorico di riferimento) che possono essere usati per dimostrare teoremi. Un sistema formale (SF) è una formalizzazione rigorosa della nozione di sistema assiomatico, costituita da un alfabeto (ovvero un 1
Transcript of Ingegneria della Conoscenza e Sistemi Esperti · In matematica un sistema assiomatico è un insieme...

Ingegneria della Conoscenza e Sistemi Esperti
1) Introduzione all'IACon il termine intelligenza artificiale o IA si intende generalmente l'abilità di un computer di svolgere funzioni e
ragionamenti tipici della mente umana. Come disciplina è al centro del dibattito tra scienziati e filosofi e comprende (in particolare nel suo aspetto puramente informatico) la teoria e le tecniche per lo sviluppo di algoritmi che consentano alle macchine di mostrare abilità/attività intelligenti, almeno in domini specifici. Secondo le parole di Marvin Minsky, uno dei pionieri della IA, lo scopo di questa nuova disciplina sarebbe stato quello di "far fare alle macchine delle cose che richiederebbero l'intelligenza se fossero fatte dagli uomini". Uno dei problemi principali dell'IA è di dare una definizione formale delle funzioni sintetiche/astratte di ragionamento e apprendimento dell'uomo, al fine di poter costruire modelli computazionali che le realizzano: l'IA si occupa quindi di studiare una appropriata descrizione dei problemi da risolvere (modellizzazione) e delle procedure effettive per la risoluzione di tali problemi (algoritmi).
La domanda al centro del dibattito sull'IA è fondamentalmente una sola: i computer possono pensare? Una risposta univoca a questa domanda non esiste perchè ancora non esiste una definizione universalmente condivisa di “intelligenza”. Secondo lo psicologo francese Alfred Binet, l'intelligenza è “giudicare bene, comprendere bene e ragionare bene”, secondo lo psicologo inglese Charles Edward Spearman invece “l’intelligenza è la capacità di rapportarsi ad altre macchine”, ... In realtà le definizioni convenzionali di intelligenza fin qui indicate sono troppo astratte per essere utili in campo informatico e oggi si dispone di definizioni più pratiche, tra le quali spicca quella del matematico inglese Alan Turing, che definisce una macchina intelligente sostanzialmente una macchina in grado, dietro un paravento e attraverso una opportuna interfaccia di comunicazione, di far passare se stessa - in conversazione con un altro essere umano - per un essere umano: una formulazione rigorosa di questa definizione va sotto il nome di Test di Turing. Altro metodo oggi considerato valido per saggiare l'intelligenza è basato sui cosiddetti Test di Bongard, dal nome dello psicologo e cibernetico sovietico Mikhail Bongard che li ideò, il cui scopo è trovare due proprietà applicabili a due insiemi di figure (una vera per l’insieme a sinistra e falsa per quello di destra, l’altra vera per quello a destra e falsa per quello di sinistra). In ogni caso, l'assenza di una definizione univoca di “intelligenza” non consente di rispondere alla domanda iniziale in modo definitivo, per questo lo studio dell'IA si divide in due correnti: la prima, detta IA forte o tesi forte dell'IA ritiene che una macchina correttamente programmata possa essere dotata di intelligenza pura non distinguibile in nessun senso dall'intelligenza umana; la seconda, detta IA debole o tesi debole dell'IA, sostiene che un computer non sarà mai in grado di eguagliare la mente umana pur potendone simulare alcuni processi cognitivi, senza comunque riuscire a riprodurli nella loro totale complessità.
In contrapposizione alla teoria della programmazione classica, il concetto chiave dell'IA è l'assenza di un algoritmo per la risoluzione di un problema: la macchina non deve semplicemente eseguire un algoritmo ma deve essere capace di creare l'algoritmo a partire dall'osservazione del problema. Gli approcci dell'IA, come detto, sono sostanzialmente due, tesi forte e tesi debole. Alla base della tesi forte si pongono i seguenti obiettivi: simulazione dei meccanismi cognitivi umani e, poichè nessuna conoscenza pregressa è disponibile, il sistema che si vuol realizzare deve apprendere per esempi (la conoscenza interna è rappresentata da matrici di numeri reali) e poter operare in una fase di apprendimento e in una fase di funzionamento (o di decisione). Il principale vantaggio di un sistema siffatto è che non è necessario fornirgli esplicitamente la conoscenza (opportunamente formalizzata) ed è quindi semplice da realizzare ed è veloce nella fase di funzionamento; il principale svantaggio è relativo invece al limitato campo di applicazioni: data la lentezza della fase di apprendimento (per problemi anche piccoli le reti generate possono essere molto grandi) tale approccio è applicabile solo alla risoluzione di problemi di piccola complessità. Alla base della tesi debole si pongono invece i seguenti differenti obiettivi: scalamento della complessità del problema, formalizzazione da parte di esperti del dominio applicativo di una opportuna base di conoscenza (Knowledge Base o KB), inserita poi manualmente nel sistema, verificata e a regime utilizzata per la risoluzione di tutti e soli i problemi che coinvolgono la conoscenza in essa presente, eventualmente insieme alle relative spiegazioni.
2) Teoria dei programmi logiciIn matematica un sistema assiomatico è un insieme di assiomi (proposizioni o principi assunti come veri perché ritenuti evidenti
o perché forniscono punti di partenza di un quadro teorico di riferimento) che possono essere usati per dimostrare teoremi. Un sistema formale (SF) è una formalizzazione rigorosa della nozione di sistema assiomatico, costituita da un alfabeto (ovvero un
1

insieme) finito o numerabile di simboli, una grammatica che specifichi quali sequenze finite di questi simboli sono formule ben formate (cioè sintatticamente corrette), un insieme di assiomi (un sottoinsieme dell'insieme delle formule ben formate) e un insieme di regole di derivazione o di inferenza che consentano di associare n formule ben formate (premesse) ad un'altra formula ben formata (conseguenza). Dato un sistema formale sono teoremi tutte le formule ben formate che sono assiomi o che possono essere ottenute mediante regole di inferenza da assiomi o altri teoremi. Intuitivamente, le formule ben formate rappresentano affermazioni che hanno un senso, e gli assiomi sono affermazioni da considerare vere: se si suppone che le regole di inferenza facciano derivare affermazioni vere da altre affermazioni vere, allora tutti i teoremi sono veri (comunque, la definizione di sistema formale e di dimostrazione può essere data indipendentemente dalla nozione di verità).
Un SF nasce con l'obiettivo di descrivere un dominio (parte del mondo reale) nel quale si ha interesse a risolvere un problema. Al SF viene associata una opportuna interpretazione, ovvero un isomorfismo che realizza l'associazione tra oggetti, verità, relazioni e proposizioni dimostrabili del mondo reale e simboli (variabili e/o costanti), assiomi, regole di inferenza e teoremi del SF: l'isomorfismo assegna quindi un “significato” ai simboli e agli altri elementi del SF. La dimostrazione di un particolare teorema obiettivo nell'ambito del SF (problem solving) si basa sull'applicazione iterativa delle regole di inferenza per derivarlo dagli assiomi ed eventualmente da altri teoremi (procedura di espansione o di derivazione). Si osservi, per inciso, che l'applicabilità diretta di una regola di inferenza ad un assioma/teorema è sempre subordinata all'unificazione (in pratica, la verifica di sovrapponibilità o di compatibilità in presenza di variabili) tra l'assioma/teorema e la precondizione della regola: se l'unificazione fallisce, la regola non è applicabile. A valle della procedura di espansione, l'isomorfismo applicato al contrario (tra il SF e la realtà) consente di assegnare significato ai teoremi derivati dal SF per ottenere delle proposizioni vere nel mondo reale.
Esempio: Sistema PGSimboli: P, G, *Assiomi (infiniti): per ogni X stringa di *, X P * G X * Regole di inferenza (unica): per X, Y e Z stringhe di *, X P Y G Z ⇒ X P Y * G Z * Possibile isomorfismo: P, G, *, **, *** ... ↔ +, =, 1, 2, 3 ...Significato del generico assioma: se X è un numero ⇒ X+1 è ancora un numero Significato della regola di inferenza: se X + Y = Z ⇒ X + (Y+1) = (Z+1)
Un qualunque assioma verifica l'unificazione con la precondizione dell'unica regola (ponendo X stringa di asterischi, Y singolo asterisco e Z proprio pari a X+1), che pertanto è applicabile: dopo N applicazioni il teorema ottenuto X + (N+1) = X+N+1, consente di generalizzare la somma (corretta) tra due addendi qualsiasi. Si osservi che tutte le somme non corrette tra due addendi, come ad esempio
*** + ***** = **pur essendo formule ben formate (in quanto grammaticalmente corrette) non sono teoremi; analogamente, tutte le somme a più di due addendi (corrette oppure no) non sono nemmeno formule ben formate.
Esempio: Gioco MUSimboli: qualsiasi carattereAssiomi (unico): M IRegole di inferenza (1): per X stringa, X I ⇒ X I URegole di inferenza (2): per X, Y stringhe, X Y ⇒ X Y YRegole di inferenza (3): per X, Y stringhe, X I I I Y ⇒ X U YRegole di inferenza (4): per X, Y stringhe, X U U U Y ⇒ X U YPossibili isomorfismi: reazioni redox, catene di DNA, ...Teorema obiettivo: M U
Lo scopo del gioco è ottenere una stringa a partire da un’altra utilizzando opportune regole di trasformazione: è possibile ottenere MU a partire da MI?
Il “ragionamento” su un SF si dice interno quando si utilizzano solo le regole esplicitamente definite dal SF, viceversa si dice esterno quando si ragiona anche sulle regole, valutandone criticamente gli effetti (con riferimento al gioco
2

MU nessuna regola consente di eliminare la M, le prime due regole allungano la stringa, le ultime due accorciano la stringa, ...): il ragionamento esterno permette di affrontare in modo più efficace il problem solving dacché consente di affiancare alle regole interne del SF altre regole esterne, che fungono da vere e proprie metaregole (regole in base alle quali applicare altre regole).
Un SF con la sua interpretazione si dice coerente se ogni teorema da esso derivato, interpretato mediante l'isomorfismo, esprime una proposizione vera del mondo reale, mentre si dice completo se ogni proposizione vera del mondo reale è espressa da un teorema derivato dal sistema formale. Un SF con la sua interpretazione che sia coerente ma non completo è credibile solo quando risponde “Sì”, poichè la soluzione potrebbe esistere nel mondo reale pur non essendo formalizzata nel SF, d'altra parte un SF con la sua interpretazione che sia completo ma non coerente è credibile solo quando risponde “No”, poichè la soluzione potrebbe essere formalizzata nel SF pur non esistendo nel mondo reale. Un SF è credibile in tutti i casi se e solo se è coerente e completo.
Nell'ambito di un SF, si parla di teorematicità di una proposizione quando di essa è possibile la riduzione a teoremi già dimostrati nel SF: per affermare la completezza di un SF (e quindi la possibilità per esso di esprimere tutte le proposizioni vere), occorre formulare delle regole di teorematicità alla base di un criterio di teorematicità che consenta di affermare (o al limite negare) che una generica proposizione è un teorema (quindi ben formata e derivabile, attraverso l'applicazione in sequenza ordinata delle regole di inferenza, direttamente dagli assiomi del SF considerato). Si osservi che un generico criterio di teorematicità può rispondere in un tempo infinito, ma se esiste un criterio di teorematicità la cui applicazione dura un lasso di tempo finito esso prende il nome di procedura di decisione: la procedura di decisione (strettamente dipendente dal SF) va aggiunta a completamento della procedura di derivazione dei teoremi ed è facile convincersi che la sua assenza compromette la realizzazione di un sistema automatico di problem solving per il SF considerato. Nel 1931 una dimostrazione di Kurt Gödel stabiliva che non di tutte le formule si può stabilire la teorematicità e una procedura di decisione, cioè che tutte le assiomatizzazioni coerenti contengono proposizioni indecidibili, o in altri termini: se si vuole costruire un SF in cui tutti i teoremi corrispondano a verità nel mondo reale (coerente), tale SF conterrà necessariamente anche proposizioni indecidibili, cioè proposizioni di cui non è possibile affermare che siano teoremi nè stabilirne la non teorematicità; se si vuole, viceversa, costruire un SF che non contenga proposizioni indecidibili, tale SF conterrà necessariamente teoremi ai quali corrisponderanno falsità nel mondo reale (incoerente).
Un sistema esperto è un sistema software basato sulla tesi debole dell'AI il cui scopo è emulare le competenze e le abilità di uno o più esperti umani in uno specifico dominio di problemi. Tipicamente si definisce un SF per descrivere il dominio di interesse, si associa ad esso un opportuno isomorfismo, dopodiché si aggiunge un motore inferenziale (MI o inference engine), ovvero un programma appositamente progettato per “ragionare” su un SF (si può definire il “cervello” di un sistema esperto) e derivare da esso nuovi teoremi (e alla luce dell'isomorfismo nuove verità nel dominio) attraverso la già descritta procedura di espansione.
In generale, al MI (che è unico per tutti i problemi) viene sottoposta una domanda sotto forma di predicato obiettivo di cui si desidera appurare la verità/falsità (teorematicità). Il MI procede inizialmente (riconoscimento) tentando l'unificazione di ogni assioma (con riferimento al gioco MU, la stringa MI) con le precondizioni di ogni regola di inferenza disponibile, applicandola se possibile (attivazione) e generando così nuovi teoremi, sui quali opera poi iterativamente allo stesso modo: di volta in volta, se il risultato ottenuto non è un teorema obiettivo (si dice “un” e non “il” perchè potrebbe essercene più d'uno), ovvero non fornisce la risposta alla domanda posta, il procedimento di espansione va avanti. L'albero dei teoremi generati dal MI è più in generale un grafo, in quanto uno stesso teorema può essere ottenuto per vie diverse, e il MI si ferma solo quando ha espanso tutti i nodi e non sono più possibili ulteriori espansioni. Nel caso in cui almeno una delle regole (con riferimento al gioco MU, la regola R2) sia sempre applicabile, il grafo generato è di profondità infinita oppure è ciclico e in tali ipotesi, se il teorema obiettivo (con riferimento al gioco MU, la stringa MU) non è ricavabile dagli assiomi di partenza, il sistema non si arresta mai e non fornisce mai alcuna risposta definitiva, nè affermativa (perchè la soluzione non viene mai trovata) nè negativa (in quanto non si smette di cercarla “più avanti” nel grafo infinito o ciclico): si parla di problema non decidibile, laddove con “problema” si intende non il problema nella sua generalità ma lo specifico quesito che lo rende indecidibile (in questo caso “trovare MU a partire da MI”). Si osservi comunque che l'attività svolta dal MI è puramente “meccanica”, non dipende in alcun modo dal particolare isomorfismo (necessario in verità solo per la mente umana, incapace di ragionare agevolmente su un SF totalmente astratto) scelto ed è quindi “stupida”, cioè senza alcuna coscienza del significato effettivo della dimostrazione: alla ricerca di una soluzione, il MI non fa altro che generarle tutte finchè non trova quella desiderata.
Una base di conoscenza (Knowledge Base e KB) è un tipo speciale di database per la gestione della conoscenza per scopi aziendali, culturali o didattici. Un sistema Knowledge Based è nei fatti un sistema esperto schematizzabile come costituito da tre blocchi funzionali tra loro correlati... Con Problem Formalization si intende la definizione del SF, la scelta del linguaggio formale con cui definirlo e l'isomorfismo da associare ad esso: oggigiorno la scelta più frequente del linguaggio formale ricade sulla logica proposizionale, la cui semplice struttura sintattica è basata su proposizioni elementari, dette atomi, e su connettivi logici che restituiscono il valore di verità di una proposizione in base al valore di verità delle proposizioni connesse (l'alfabeto della logica proposizionale è costituito da un insieme numerabile di proposizioni p, q, r, etc., dai simboli dei connettivi logici ¬ (NOT), ∧ (AND), ∨ (OR), → (implicazione), ↔ (doppia implicazione) e dalle parentesi, quest'ultime perlopiù con lo scopo di
3

disambiguare il linguaggio), e su cui si basano linguaggi di programmazione simbolici come il Prolog, alternativi ai linguaggi classici (che manipolano numeri anzichè simboli). Il blocco Control Strategy contiene il MI, di norma messo a disposizione dallo specifico linguaggio simbolico adottato, ed eventualmente appositi tools, detti moduli di spiegazione, che affiancano al processo di ricerca della soluzione descrizioni supplementari del “ragionamento” usato dal MI per arrivare alla soluzione. Infine, il Dynamic Database può essere descritto come una lavagna virtuale su cui il processo inferenziale viene progressivamente memorizzato: inizialmente essa contiene solo gli assiomi della KB e le domande poste dal problema, poi iterativamente vi si aggiungono i teoremi derivati mediante il processo di
espansione e le regole applicate per ottenerli. In maniera un po' forzata è possibile ricondurre questo schema alla programmazione classica: il problem formalization corrisponde alla scelta del linguaggio (Pascal, C, Java, ...), il control strategy contiene il compilatore e il dynamic database corrisponde alle memoria contenente i risultati dell'elaborazione.
Esistono sostanzialmente due modi per rappresentare una KB attraverso un SF: la rappresentazione nello spazio degli stati (o State Space Representation o SSR) e la decomposizione in sottoproblemi (Problem Reduction o PR).
2.1) State Space Representation o SSRNella SSR un problema viene descritto mediante un insieme S di stati che ne rappresentano le soluzioni parziali: in
pratica gli stati sono strutture dati in grado di descrivere la condizione “istantanea” del problema durante il processo inferenziale, lo stato iniziale S0 è la rappresentazione della conoscenza iniziale del problema (assiomi), gli operatori (o funzioni) di transizione consentono di generare stati successori (teoremi) di altri stati precursori (assiomi o teoremi) e di “navigare” nell'albero/grafo (eventualmente infinito e/o ciclico) così progressivamente costruito, lo stato obiettivo o goal SG (che al pari del teorema obiettivo può non essere unico) corrisponde infine alla soluzione del problema.
Esempio: Gioco del 15-puzzle→ Problem FormalizationStato: configurazione del puzzle come matrice 4x4Stato iniziale: una prefissata configurazione del puzzle (si noti che non tutte le configurazioni iniziali consentono di risolvere il gioco)Operatori di transizione: “spostamento” della casella vuota a
Ovest (se non si trova sulla prima colonna),Est (se non si trova sull'ultima colonna),Nord (se non si trova sulla prima riga),Sud (se non si trova sull'ultima riga).
Stato finale: configurazione ordinata del puzzle→ Dynamic DatabaseContiene via via parte del grafo di tutti i possibili stati, collegati tra loro da archi orientati (operatori di transizione).→ Control StrategyLa macchina non fa altro che provare tutte le possibili combinazioni di mosse fino ad arrivare alla soluzione desiderata.
Esempio: Scacchi→ Problem FormalizationStato: configurazione corrente della scacchiera (posizione dei pezzi, pezzi mangiati, prossimo giocatore che muove, ...)Stato iniziale: una prefissata configurazione della scacchieraOperatori di transizione: spostamento dei pezzi e loro valore (assoluto e contestuale)Stato finale: obiettivo (vittoria, scacco, stallo) o sottobiettivo (cattura di un pezzo avversario, raggiungimento di una casella, ...)
→ Dynamic DatabaseCome sopra, contiene via via parte del grafo di tutti i possibili stati, collegati tra loro da archi orientati (operatori di transizione).→ Control StrategySulla base del prossimo sottobiettivo, dello stato corrente e delle regole applicabili determina la mossa più conveniente.
Esempio: Integrazione simbolica→ Problem FormalizationStato: espressione analitica della funzione al passo attuale del processo di integrazioneStato iniziale: funzione da integrareOperatori di transizione: inverso delle regole di calcolo analitico (differenziazione, derivazione, ...),
regole di integrazione (sostituzione, per parti, integrali notevoli ricorrenti).
4

Stato finale: integrale indefinito della funzione di partenza→ Dynamic DatabaseContiene via via parte del grafo di tutti i possibili stati, collegati tra loro da archi orientati (operatori di transizione).→ Control StrategySulla base della funzione ottenuta al passo precedente di integrazione e sulla base delle regole di integrazione applicabili determina i nuovi sottoproblemi di integrazione da risolvere.
In sostanza, dato un generico problema opportunamente formalizzato mediante un SF, la KB associata può essere posta sotto forma di un albero/grafo di stati nel quale il MI deve “navigare” partendo da S0 fino ad uno stato SG che soddisfi il predicato obiettivo. A costituire il cuore del MI sono gli algoritmi in grado di determinare tale percorso, diversamente classificabili a seconda della diversa strategia adottata: forward search vs backward search, ricerca cieca vs ricerca informata.
Una prima classificazione riguarda la direzione della ricerca... Un algoritmo di forward search (o data driven) o FS procede in modo “naturale” da S0 fino ad uno stato SG, applicando in senso diretto le regole di inferenza, viceversa un algoritmo backward search (o goal driven) o BS procede a ritroso da uno stato SG fino a S0, applicando in senso inverso le regole di inferenza. Supponendo che le regole applicabili ad ogni stato siano al massimo N, per ogni stato “visitato” un algoritmo FS deve prendere in considerazione al massimo N stati sucessori e immaginando di trovarci sempre nel worst case (caso peggiore) le alternative diventano al Nk al k-esimo livello, ovvero crescono in modo esponenziale con la profondità dell'albero. Nelle medesime ipotesi, al contrario, un algoritmo BS risale dal singolo stato successore all'unico stato predecessore applicando a ritroso una sola regola, cioè il numero di passi richiesti per giungere a S0 è semplicemente proporzionale alla profondità dell'albero. Nella pratica, sebbene apparentemente la BS sia nettamente preferibile alla FS, diversi fattori possono limitare in modo drastico la sua applicabilità: (1) se l'albero è in realtà un grafo lo stato predecessore non è unico, (2) l'inversione delle regole (quando possibile) può richiedere tempi proibitivi, (3) mentre è facile riconoscere la compatibilità di uno stato con il predicato obiettivo viceversa determinare lo stato SG in modo diretto può essere difficile o impossibile e infine (4) se lo stato SG è semplicemente non unico, in presenza di una molteplicità di SG, sorge il problema del “da dove” iniziare la ricerca... in tutti questi casi la FS è una scelta obbligata. Vi sono comunque dei casi nei quali è possibile adottare una strategia ibrida FS/BS, procedendo contemporaneamente da S0 e da SG fino ad uno stato intermedio comune ai due percorsi. Si noti in ogni caso che gli algoritmi analizzati durante il corso sono sempre di tipo FS (viceversa il Prolog utilizza la BS).
Una seconda classificazione riguarda invece l'approccio più o meno informato alla ricerca... Un algoritmo di ricerca cieca (o bruta) (che può essere sia FS che BS) su un grafo degli stati non contiene alcuna conoscenza del problema rappresentato dal grafo stesso e si limita a “percorrerlo” finchè non trova (se la trova) una soluzione: quest'approccio consente all'ingegnere della conoscenza di limitarsi a costruire la SSR, tuttavia la sua stessa semplicità ne costituisce il limite principale, dacché il grafo alla base della SSR può essere molto esteso, il che rende onerosa in temini computazionali la ricerca. Un algoritmo di ricerca informata (o euristica) (che può essere sia FS che BS) su un grafo degli stati, viceversa, sfrutta la conoscenza sulla natura del problema per “indirizzare” in modo mirato la ricerca: in questo caso, oltre a formalizzare il problema mediante un opportuno SF, l'ingegnere della conoscenza deve fornire al MI la conoscenza sufficiente a guidare la ricerca, il che è controbilanciato dall'abbreviarsi (anche notevole) dei tempi di ricerca.
Analizziamo prima di tutti gli algoritmi di ricerca cieca...Assumendo inizialmente (ipotesi che sarà rimossa successivamente) che lo spazio degli stati sia un albero (come quello rappresentato qui a lato), un algoritmo di ricerca cieca può essere schematizzato attraverso un diagramma di flusso (come quello mostrato qui sotto): in pratica si opera
sull'insieme di stati OPEN (contenente gli stati aperti) in cui c'è inizialmente solo S0 ed iterativamente, fino a che OPEN non risulti vuoto, si preleva da esso uno stato S, si tenta il matching con il predicato obiettivo e in caso di insuccesso viene espanso, ricavandone i successori da inserire a loro volta in OPEN. Si noti che la scelta del modo con cui deve avvenire il prelievo di S non è banale perchè ha effetto sulla decidibilità del SF e dei quesiti su di esso formulati.
Una prima possibilità consiste nello gestire OPEN come una coda adottando una politica FIFO, secondo la quale viene prelevato (ed espanso) lo stato presente da più tempo: in questa strategia, detta Breadth First Search (o BFS) gli stati di un livello vengono esplorati solo dopo tutti quelli del livello precedente (la ricerca procede quindi in ampiezza, come nell'albero qui sopra)
Una seconda possibilità consiste nello gestire OPEN come una pila adottando una politica LIFO, secondo la quale viene prelevato (ed espanso) l'ultimo stato inserito in OPEN: in questa strategia, detta Depth First Search (o DFS), quando l'algoritmo esamina un nodo esso esaurisce sempre tutti i suoi successori e soltanto dopo passa ad esaminare i nodi dello stesso livello del nodo di
partenza (la ricerca procede quindi in profondità, come nell'albero mostrato nella prossima figura).
5

E' interessante porre a confronto le strategie BFS e DFS...La BFS procede un livello alla volta, in ciascun livello vengono generati tutti i successori (stati del livello successivo) fino ad esaurimento del livello corrente ed inseriti in OPEN: se ad ogni espansione è possibile generare N successori (dall'applicazione di N regole), il numero degli stati in OPEN vale Nk al livello k-esimo e cresce esponenzialmente (così la memoria richiesta per memorizzare OPEN, il che è molto problematico); la DFS viceversa procede espandendo l'ultimo nodo del livello corrente fino ad espandere tutti i suoi successori (stati a qualunque livello) che vengono inseriti in OPEN: nelle stesse ipotesi di prima (N regole), il numero degli stati in OPEN vale k(N-1) +1 al livello k-esimo e cresce quindi in modo soltanto proporzionale alla profondità; relativamente all'occupazione di memoria quindi DFS è largamente preferibile a BFS. D'altra parte, è facile accorgersi dei limiti della DFS osservando (con riferimento all'albero raffigurato qui a lato) che, se SG ≡ S2 ma l'albero che ha per radice S3 ha profondità infinita, l'algoritmo DFS rimarrà impantanato nell'analisi di tutti gli infiniti discendenti (diretti e indiretti) di S3 senza visitare mai S2 e quindi senza mai giungere alla soluzione. In generale, se la soluzione non esiste ambedue sia BFS che DFS procedono all'infinito (problema indecidibile), ma se esiste BFS (procedendo per livelli) presto o tardi la troverà mentre DFS potrebbe girare all'infinito senza trovarla mai: la ricerca in ampiezza determina quindi una occupazione di memoria notevole ma garantisce di trovare la soluzione se questa esiste, viceversa la ricerca in profondità richiede poca memoria (ed è facile da implementare mediante la ricorsione) ma può rendere il problema indecidibile anche quando la soluzione esiste. Una prima modifica al DFS che si può apportare consiste nel fissare il limite massimo di profondità Kmax dell'albero, raggiunto il quale la ricerca in profondità si deve arrestare (con riferimento all'albero raffigurato qui sopra, si può ad esempio porre Kmax = 4 in modo da visitare al massimo gli ultimi nodi in basso nella figura), il che elimina l'indecidibilità ma introduce il nuovo problema dell'orizzonte: il SF considerato diviene decidibile (per ogni quesito) ma perde la completezza laddove almeno una delle soluzioni (ad un qualunque quesito) si trovi più in profondità del livello massimo fissato, per cui occorre scegliere il Kmax in modo opportuno, affinché sia nè troppo alto da pregiudicare l'efficienza dell'algoritmo nè troppo basso da far perdere soluzioni. Una seconda modifica al DFS che risolve il problema dell'orizzonte implementa una ricerca in profondità con approfondimenti successivi (iterative deepening DFS), che consiste nel fissare inizialmente il Kmax e (in caso di ricerca infruttuosa) aumentarne progressivamente il valore, spostando “sempre più in là” l'orizzonte di ricerca, il che garantisce la decidibilità (nel caso la soluzione esista) a patto di incrementare Kmax a sufficienza: avendo l'accortezza di memorizzare gli stati a profondità Kmax, è possibile (ad ogni incremento del Kmax) processare solo i nuovi stati successori mai visitati prima (senza ricominciare tutto daccapo) risparmiando tempo e risorse.
Rimuoviamo ora l'ipotesi che lo spazio degli stati sia un albero e assumiamo che esso sia propriamente un grafo...
Applicati ad un grafo (come quello indicato nella figura qui sopra) sia BFS che DFS dimostrano di funzionare ancora, sebbene in maniera non ottimale: in pratica viene costruito un albero ridondante in cui gli stati con più di un predecessore vengono duplicati via via, con conseguente aumento esponenziale della memoria occupata e del tempo richiesto per la ricerca. Particolarmente critico per DFS risulta inoltre il caso di grafo ciclico: immaginando un arco orientato da S6 a S0, quand'anche il grafo sia finito (cioè termini con S6) la soluzione S4 non verrà mai trovata, e ciò nonostante l'algoritmo costruirà un albero ridondante di estensione infinita (saturando in breve tempo la memoria, quantunque essa sia grande). La soluzione consiste nel modificare l'algoritmo con l'aggiunta dell'insieme CLOSED (contenente gli stati già esplorati) lasciando sostanzialmente inalterato il diagramma di flusso, con l'accortezza però di controllare (durante la fase di prelievo) lo stato prelevato da OPEN non sia già presente in CLOSED (in caso contrario va semplicemente “cestinato”) e che (durante la fase di espansione) in OPEN non siano inseriti stati duplicati: grazie a queste modifiche il grafo di partenza viene trasformato in un albero non ridondante, e anche in presenza di cicli se il grafo di partenza è finito anche l'albero non ridondante si conserva finito consentendo al DFS di esplorarlo in modo esaustivo ed efficiente. In realtà, per funzionare bene, questo DFS modificato per i grafi richiede che OPEN e CLOSED non siano strutturati come semplici liste ma piuttosto come
6

tabelle hash o alberi binari in modo da poter agevolmente eseguire la verifica di appartenenza (o non) di un generico stato a ciascuno di questi insiemi. Si noti comunque che, nonostante tutto, dal momento che CLOSED contiene tutti gli stati già esplorati e l'occupazione di memoria non è più (come nel DFS originale) proporzionale al numero di livelli, il vantaggio in termini di efficienza computazionale offerto dall'uso di un algoritmo DFS in pratica decade: per questo, piuttosto che usare il DFS modificato direttamente su un grafo, si preferisce convertire prima il grafo in albero ogni volta che sia possibile.
Un algoritmo di ricerca informata dispone di informazioni supplementari per “navigare” nel SSR...Assumiamo innanzitutto che ad ogni regola di inferenza sia associato un costo, un valore Ci strettamente positivo: ad ogni stato S corrisponde un costo pari alla somma dei Ci associati alle regole che (in sequenza ordinata) consentono di raggiungerlo partendo da S0. Nella figura i tondini in grassetto sono stati soluzione, i numeri sugli archi rappresentano i Ci e si può facilmente verificare che il primo numero indicato nel riquadro associato a ciascuno stato è il costo dello stato (per il momento trascuriamo il secondo numero) e quindi anche alle soluzioni è associato un costo. Si osservi che il costo di uno stato può non essere unico se esso ha più di un stato predecessore, e quindi se esistono percorsi alternativi che conducono ad esso: ad esempio S8 ha costo 4 se si passa per S2 e costo 7 se si passa per S3 (nel riquadro è stato indicato il minore fra essi).
Un algoritmo di ricerca informata, in presenza di più soluzioni, tenta sostanzialmente di raggiungere quella a costo minimo (nella figura S11). E' a tale scopo tra l'altro che deve essere Ci>0, infatti se fosse anche Ci<0 l'algoritmo potrebbe rimanere intrappolato in un percorso ciclico il cui costo tende a -∞ e sarebbe impossibile determinare la soluzione a costo minimo, così come analogamente se all'interno di un ciclo la somma dei costi fosse nulla l'algoritmo non potrebbe “accorgersi” della ripetizione infinita del ciclo non rilevando nessun aumento del costo totale (in assenza di cicli nulla vieta di usare Ci<0 ma di solito non si fa ugualmente).
Assumiamo inizialmente (ipotesi che sarà rimossa successivamente) che lo spazio degli stati sia un albero (si ignori l'arco S3 → S8), in modo che ad ogni stato sia possibile associare un costo univoco (per convenzione ad S0 si associa costo nullo). Il più semplice algoritmo di ricerca informata che possiamo analizzare, l'algoritmo di ricerca a costo uniforme, può essere schematizzato attraverso un diagramma di flusso (quello mostrato qui a fianco) del tutto simile a quelli già visti per BFS e DFS, con l'unica differenza che (piuttosto che adottare una strategia strettamente FIFO o strettamente LIFO) lo stato S prelevato di volta in volta da OPEN è quello a costo minimo (è conveniente che OPEN sia strutturato come lista ordinata): si può dimostrare che un tale algoritmo converge effettivamente alla soluzione a costo minimo (per l'albero in figura S11) sebbene in modo non sempre efficiente (per l'albero in figura saranno valutati nell'ordine gli stati 1, 6, 4, 5, 2, 7, 8, 3 e infine 11 con l'arresto della ricerca). L'algoritmo è detto a costo uniforme perchè se in OPEN ci sono stati a pari costo, vengono esplorati tutti prima di passare all'analisi degli stati a costo maggiore: in molte applicazioni il costo di uno stato coincide col numero di passi necessari per ottenerlo (tutte le regole hanno costo unitario) cosicchè stati a pari costo sono stati di pari livello sull'albero, e in tali casi l'algoritmo a costo uniforme si riduce al BFS. Nel caso più generale in cui lo spazio degli stati sia un grafo (ad S8 sono associati due distinti costi) l'algoritmo va modificato osservando che uno stato che sia successore di più stati (e che derivi quindi dall'espansione di più stati) potrebbe comparire in OPEN più volte con costi diversi: se a valle di una espansione si genera uno stato già presente in
OPEN, sarà inserita in OPEN solo la versione a costo minimo, rimuovendo l'altra. Per quanto efficace comunque, l'algoritmo a costo uniforme è incapace di “evitare attivamente” zone del grafo inutili da esplorare, ovvero di realizzare una “potatura“ del grafo.
Gli algoritmi di ricerca informata che consentono di realizzare una potatura selettiva dello spazio degli stati si dicono euristici. Per comprenderne il funzionamento, supponiamo inizialmente di trovarci in una situazione ideale nella quale, per ogni stato S, siano note le due funzioni g(S), che restituisce il costo (minimo) dello stato S inteso come somma dei Ci relativi al percorso che ad S conduce, ed h(S), che restituisce invece il costo associato al percorso che da S conduce alla più vicina soluzione (nel caso in cui S non sia collegato ad alcuna soluzione, tale valore è infinito), dalle quali sia possibile ricavare la funzione di valutazione f(S) = g(S) + h(S) (indicata nei riquadri della figura in alto): si può dimostrare che un algoritmo di ricerca a costo uniforme che utilizzi la f(S), anzichè la g(S), converge “a colpo sicuro” alla soluzione a costo minimo, senza esaminare nodi inutili (ai fini del percorso che conduce alla soluzione) e potando i rami “morti” (che non portano ad alcuna soluzione).
7

Va detto che in generale l'ipotesi che h(S) sia nota può apparire paradossale perchè, se effettivamente sapessimo dov'è la soluzione richiesta, non avrebbe neanche senso cercarla (anche se esistono casi particolari in cui è possibile conoscere a priori il costo del percorso senza che sia possibile conoscere il percorso stesso); in molti contesti, pur non essendo nota la h(S) ideale (denotiamola con h*(S)), è possibile comunque definire una h(S) approssimata che sotto opportune condizioni garantisca ancora la convergenza dell'algoritmo di ricerca alla soluzione cercata (chiaramente lo svantaggio nell'uso di una h(S) non ideale rispetto alla h*(S) è che la potatura non sarà ottimale così come il tempo di ricerca non sarà minimo): una funzione euristica h(S) permette di far convergere l'algoritmo alla soluzione ottima se verifica la condizione di ammissibilità
∀S 0 ≤ h(S) ≤ h*(S) ovvero se si può dimostrare che h(S) è una stima per difetto della h*(S); naturalmente la più semplice h(S) è proprio la funzione nulla, con la quale un algoritmo euristico finisce per coincidere con l'algoritmo di ricerca a costo uniforme, sicchè nessuna potatura viene prodotta; inoltre in presenza di due euristiche h'(S) e h”(S) ambedue ammissibili, la maggiore potatura dello spazio degli stati è data dalla h(S) = max { h'(S), h”(S) } e se ∀S 0 ≤ h'(S) ≤ h”(S) si dice che h”(S) è più informata di h'(S). Un metodo comune per costruire una buona approssimazione della h*(S) è quello di rimuovere alcuni vincoli del problema originario (rilassamento dei vincoli): il costo della soluzione ottima del problema “semplificato” può essere considerato un limite inferiore del costo della soluzione del problema originario.
A titolo di esempio si consideri il gioco del 15-puzzle visto in precedenza. Un rilassamento dei vincoli del problema può consistere nel supporre che “se una tessera è fuori posto è sufficiente una sola mossa per metterla a posto”, indipendentemente da come le tessere sono incastrate tra loro: una prima h(S) quindi è associata al numero di passi necessario (alle condizini descritte) a rimettere a posto tutte le tessere, ovvero è pari di volta in volta al numero assoluto di tessere fuori posto; una seconda h(S), più informata della prima, può essere associata alla somma delle distanze (misurate in caselle orizzontali e verticali che separano ciascuna casella fuori posto dalla sua posizione ideale) di tutte le caselle fuori posto e consente di garantire una migliore potatura; e così via... Va detto comunque, in generale, che la bontà di una euristica si misura non solo sulla base di quanto è informata ma anche sulla base del suo costo computazionale, ovvero h(S) deve essere sufficientemente semplice da calcolare (una euristica meno informata è preferibile ad una più informata se quest'ultima richiede per il suo calcolo uno sforzo computazionale tale da vanificare il guadagno di tempo prodotto dalla migliore potatura).
Esempio: Commesso viaggiatoreInteressante problema combinatoriale (classico nell'ambito della Ricerca Operativa) che prevede una soluzione a costo minimo è quello del commesso viaggiatore, che consiste nel trovare il cammino a costo minimo che contenga una volta soltanto tutti i
nodi di una rete (parzialmente o completamente connessa). L'approccio IA con SSR prevede che ogni stato sia una lista ordinata di città già visitate, che lo stato iniziale sia costituito dalla sola città di partenza, che l'operatore di transizione produca dalla lista XYZ tutte le liste XYZK con la città K raggiungibile dalla città Z: lo stato obiettivo deve contenere tutte le città una volta sola ed essere a costo minimo (ogni ramo della rete che congiunge due nodi, ovvero due città, avrà un costo non negativo).
2.2) Problem Reduction o PRLa SSR costituisce certamente la metodologia più semplice per la rappresentazione di una KB, ma non sempre
essa è anche la più efficace. In primo luogo si presenta il problema della decidibilità: occorre prevenire la possibilità che la macchina esplori una KB infinita e occorre perciò definire meccanismi d'azione in grado di “potare” i suoi rami infiniti (pensando ad esempio al gioco del 15-puzzle, occorre evitare che il MI rimanga bloccato all'infinito su sequenze cicliche di mosse del tipo N → S → N oppure E → W → E, e così via). In secondo luogo esiste il problema delle prestazioni limitate (computazionali e di memorizzazione) dell'elaboratore: in mancanza di strategie suggerite dall'esterno, il MI semplicemente tenta tutte le strade possibili con un aumento esponenziale delle inferenze necessarie, e non è infrequente il caso in cui l'applicazione di un elevato numero di regole faccia letteralmente esplodere il numero di soluzioni intermedie rendendo il problema non calcolabile in tempi accettabili anche con il più veloce degli elaboratori (pensando ad esempio al gioco degli scacchi, l'elevato numero di mosse possibili per ciascun pezzo comporta che la KB sebbene finita sia talmente grande da non poter essere esplorata esaustivamente, e nemmeno memorizzata per intero, se non imponendo un ragionevole limite al look-ahead). Dalle due problematiche evidenziate deriva la necessità di limitare le inferenze alle sole soluzioni intermedie utili, introducendo ulteriori regole che (benché non strettamente necessarie) possono indirizzare il MI verso la strada più vicina alla soluzione: in pratica, le regole esterne cui in precedenza abbiamo fatto riferimento. Con riferimento al gioco degli scacchi possiamo procedere definendo all'interno della KB le regole di base (come le mosse dei pezzi) ma anche regole esterne che indichino come comportarsi in determinate situazioni (ad esempio una regola che riconosca da parte dell'avversario la mossa del barbiere ed attui l'opportuna contromossa). Questo tipo di approccio costituisce una modifica concettuale al procedimento di risoluzione di un problema visto fin qui, nel senso che ci si allontana sempre più dalla condizione di “conoscenza zero” (cioè quella minima, propria di un SSR) e si “travasa conoscenza” dall'esterno: all'estremo opposto, la condizione di “conoscenza massima” è rappresentata dall'algoritmo che in modo deterministico stabilisce quale mossa eseguire in risposta ad ogni possibile configurazione del problema, il che è equivalente a fornire come assiomi tutti i casi possibili.
Una via di mezzo tra la conoscenza minima (adatta a calcolatori di elevate prestazioni o in mancanza di un algoritmo) e quella massima (unica strada percorribile per calcolatori di basse prestazioni) è costituita dalla riduzione a sottoproblemi: il problema originario va suddiviso in sottoproblemi più semplici, essendo nota la correlazione tra le soluzioni dei problemi figli e la soluzione del problema padre che si vuol determinare; se inoltre i problemi figli sono dello stesso tipo del problema padre si parla di ricorsione (per la ricorsione in Prolog leggi → 3.3). Con riferimento al gioco degli scacchi è possibile definire una
8

strategia di gioco che fissi a breve termine dei sottobiettivi più specifici rispetto alla vittoria finale (per esempio la cattura di uno specifico pezzo avversario o lo scacco). Con riferimento al problema dell'integrazione simbolica le regole di integrazione per sostituzione, per parti e per formule ricorrenti consentono di risolvere specifiche soluzioni intermedie (sottoproblemi) in modo predeterminato, senza quindi procedere per tentativi.
Esempio: Analizzatore sintattico (parser)Altro problema comune è connesso alla realizzazione di un analizzatore sintattico, modulo fondamentale di ogni compilatore, necessario a verificare la correttezza formale delle frasi inserite (sequenze di keyword) rispetto ad un set di mappe sintattiche preimpostate che costituiscono la descrizione formale dello specifico linguaggio. L'analizzatore sintattico accetta in ingresso una frase e verifica che sia “sintatticamente corretta” cercando di riconoscerla come composta da frasi più semplici anch'esse corrette (riduzione a sottoproblemi di tipo ricorsivo): il processo di riduzione termina non appena si arriva ad uno stato con una singola S (ovvero solo se la frase nella sua interezza “appartiene” al linguaggio) e l'analizzatore restituisce la sequenza di regole in accordo alle quali tale frase può essere generata. Si osservi che di fatto i nuovi linguaggi di programmazione costruiscono gli analizzatori sintattici esattamente nel modo descritto, cioè solo ponendo le regole sintattiche del linguaggio (in figura sono quelle in alto a sinistra, ovvero “ab” è una sequenza corretta, se “a” precede una sequenza corretta la loro concatenazione è ancora una sequenza corretta, e così via...) come base di conoscenza di un SF (leggi anche → 3.6).
In generale, dato un problema P: se di P si conosce la soluzione, allora si può assumere P risolto; se P è invece troppo complesso, si tenta di scomporlo in un certo numero di sottoproblemi P1, P2, ... Pk più semplici, mediante le soluzioni dei quali si costruisce la soluzione di P. Nell'ambito della PR (analogamente a quanto visto per gli stati) è possibile
costruire uno “spazio dei problemi” e rappresentarlo mediante un grafo AND-OR: ad ogni problema P corrisponde un nodo del grafo; un problema P elementare o non decomponibile è una foglia del grafo; un problema P decomponibile in n modi alternativi ha n successori in OR; un problema P decomposto in m
sottoproblemi ha m successori in AND. Tipicamente, data una classe di problemi, saranno note regole generali di scomposizione. Per esempio, una regola generale di scomposizione per un problema basato sulla “pianificazione di viaggi” potrebbe avere una forma del tipo “P(da X a Y passando per Z) → P'(da X a W p.p. Z) AND P''(da W a Y p.p. Z)” (si noti che in questo caso si riscontrano dipendenze tra sottoproblemi).
Il processo di risoluzione di un problema P corrisponde alla ricerca nel grafo AND/OR (che ne rappresenta la scomposizione e che viene, al solito, costruito durante il processo di ricerca... possono essere utilizzate strategie in profondità, in ampiezza o euristiche) di un sottografo che consenta di etichettare come “risolto” il nodo P, secondo le seguenti regole: un nodo foglia è risolto se corrisponde a un problema elementare (di cui perciò è nota la soluzione), irrisolvibile se corrisponde a un problema non elementare/decomponibile; un nodo con successori in OR è risolto se almeno uno di essi è risolto, altrimenti è irrisolvibile; un nodo con successori in AND è risolto se essi sono tutti risolti, altrimenti è irrisolvibile.
La PR può essere applicata con successo nell'ambito della teoria dei giochi, in particolare i giochi (come dama, scacchi, filetto, grundy...) definiti a due persone (due giocatori che muovono a turno) e ad informazione completa (i giocatori conoscono lo storico completo delle mosse già eseguite e le possibili mosse proprie e dell'avversario): la PR consente di trovare una strategia vincente attraverso la dimostrazione che il gioco può essere vinto. Supponendo di chiamare i due giocatori “più” e “meno”, definendo X+ una configurazione in cui la prossima mossa spetta a “+” e X- una in cui la prossima mossa spetta a “-”, vorremmo dimostrare che “+” può vincere partendo da una certa configurazione Xt... in simboli W+(Xt). Le mosse ammesse nel gioco forniscono lo schema di riduzione del problema in sottoproblemi: se nella configurazione X+ (in cui quindi tocca a “+” muovere) ci sono n mosse legali che conducono alle configurazioni X-
1, X-2, ... X-
n, per dimostrare W+(X+) bisogna dimostrare almeno uno dei W+(X-
i); d’altra parte, se nella configurazione X- (in cui quindi tocca a “-” muovere) ci sono m mosse legali che conducono alle configurazioni X+
1, X+2, ... X+
N, per dimostrare W+(X-) bisogna dimostrare tutti i W+(X+
i).
Esempio: Gioco del GrundyNel Grundy due giocatori sono dinanzi ad una pila di 7 monete: il primo giocatore deve dividere la pila in due pile diseguali, in seguito - a turno – ogni giocatore deve fare altrettanto con una delle pile risultanti... il primo che si trova di fronte pile con al più 2
9
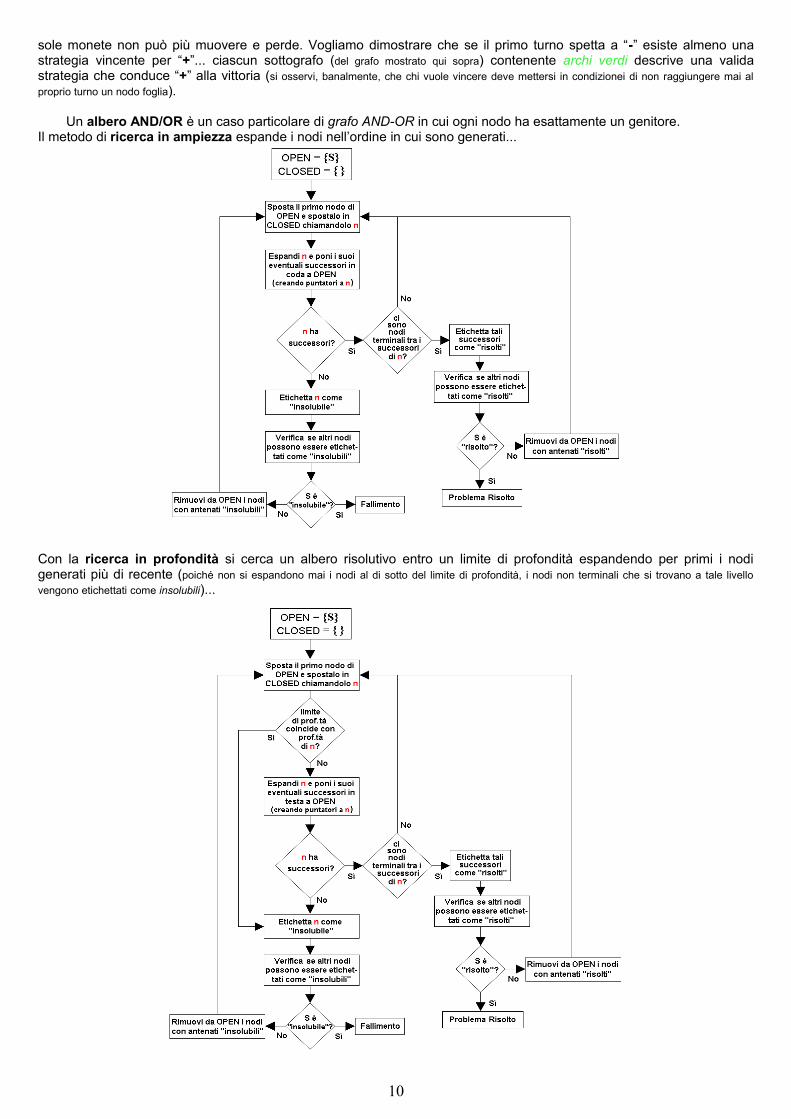
sole monete non può più muovere e perde. Vogliamo dimostrare che se il primo turno spetta a “-” esiste almeno una strategia vincente per “+”... ciascun sottografo (del grafo mostrato qui sopra) contenente archi verdi descrive una valida strategia che conduce “+” alla vittoria (si osservi, banalmente, che chi vuole vincere deve mettersi in condizionei di non raggiungere mai al proprio turno un nodo foglia).
Un albero AND/OR è un caso particolare di grafo AND-OR in cui ogni nodo ha esattamente un genitore.Il metodo di ricerca in ampiezza espande i nodi nell’ordine in cui sono generati...
Con la ricerca in profondità si cerca un albero risolutivo entro un limite di profondità espandendo per primi i nodi generati più di recente (poiché non si espandono mai i nodi al di sotto del limite di profondità, i nodi non terminali che si trovano a tale livello vengono etichettati come insolubili)...
10

Nel tentativo di definire una procedura di ricerca per i grafi AND-OR sorgono almeno due complicazioni. Prima di tutto, una definizione ragionevole della procedura di ricerca in ampiezza comporta la scelta di espandere in OPEN il nodo a minima profondità, tuttavia la definizione di profondità è più complessa rispetto agli alberi (in generale si pone la profondità del nodo di partenza uguale a 0, la profondità di ogni altro nodo pari invece alla minima fra le profondità dei genitori +1). In secondo luogo è necessario disporre di tutti i puntatori da un nodo ai suoi molteplici genitori, giacchè ciascuno di essi potrebbe risultare necessario per la definizione di un grafo risolutivo (ad esempio, in figura, i puntatori 1→2 e 6→2 sono ambedue necessari, perchè il nodo 2 è successore in AND sia di 1 che di 6), così come d’altra parte alcuni puntatori multipli potrebbero non essere necessari alla soluzione (ad esempio, sempre in figura, il puntatore 3→4): un processo di ricerca per i grafi AND-OR deve quindi essere capace, alla terminazione, di analizzare la struttura dei puntatori per scartare quelli superflui conservando solo quelli necessari a definire il grafo risolutivo; naturalmente, man mano che i successori vengono generati bisogna controllare se alcuni di essi sono già contenuti in CLOSED e come sono stati etichettati, risolti o insolubili. Fatte queste considerazioni, risulta semplice la generalizzazione degli algoritmi di ricerca negli alberi AND-OR al caso dei grafi AND-OR.
Molti giochi semplici si possono trattare con una ricerca su un albero AND-OR perché la dimostrazione della vittoria si lascia trovare senza che si debba generare un albero di ricerca eccessivamente profondo: il Grundy è stato già trattato (con riferimento al grafo, le posizioni risultanti da una mossa di “+” si rappresentano mediante nodi in OR, quelle risultanti da una mossa di “-” mediante nodi in AND... i successori di nodi AND sono quindi nodi OR e viceversa: i nodi terminali, nodi t, danno la vittoria a “+”), mentre (per fare un altro esempio) con il Filetto abbiamo un ordine di grandezza di 9! = 362'880 che è ancora tutto sommato una grandezza ragionevole. D'altra parte, giochi complessi come la Dama (~1040 nodi) o gli Scacchi (~10120 nodi) rendono del tutto proibitiva una ricerca esaustiva sull'albero AND-OR, per cui dimostrare la possibilità di vittoria è del tutto fuori questione e occorre limitarsi a cercare – ad ogni turno - una “buona” mossa: la ricerca sull'albero AND-OR può essere condotta nel modo convenzionale, a patto però di impostare una differente condizione di terminazione, come un limite di tempo, un limite di memoria utilizzata o un limite di livello dell’albero oggetto della ricerca.
La procedura del Minimax consente di trovare questa buona mossa mediante un'opportuna funzione di valutazione statistica che, applicata ad un nodo foglia, fornisca una stima del “valore” associabile alla configurazione di gioco corrispondente, sulla base di tutta una serie di parametri dipendenti dal gioco stesso e dalle sue regole (per esempio, negli scacchi, numero e tipo dei pezzi, controllo del centro, e così via...). Convenzionalmente si associa alla funzione un valore positivo nelle posizioni favorevoli a “+” e negativo nelle posizioni favorevoli a “-”, mentre ad una posizione considerata non particolarmente favorevole nè per l'uno né per l'altro si associa un valore prossimo a zero; dal momento che se “+” dovesse scegliere tra le foglie sceglierebbe quella con valutazione massima, e viceversa “-” sceglierebbe al suo turno la foglia con valutazione minima, si può associare ai genitori delle foglie un valore sintetico nel modo seguente: ad un nodo OR si assegna la massima valutazione delle sue foglie, ad un nodo AND la minima valutazione delle sue foglie; processati i genitori delle foglie, si procede quindi verso l'alto processando allo stesso modo i loro genitori, e continuando a sintetizzare i valori dei nodi, livello per livello, finché non vengano assegnati valori sintetici ai successori del nodo relativo alla configurazione di gioco corrente: a questo punto, la mossa “migliore” per il giocatore che ha diritto ad eseguirla è quella relativa al successore del nodo corrente con valore sintetico più alto in modulo (procedura questa che trae la sua validità dall'ipotesi che i valori sintetici associati ai successori del nodo di partenza forniscano una misura del valore delle posizioni corrispondenti migliore rispetto a quella fornita dall’applicazione diretta a tali posizioni della funzione di valutazione statistica), positivo per “+”, negativo per “-”.
Esempio: Gioco del FilettoSupponiamo che “+” serva delle croci (X) e “-” dei cerchi (O) e che la prima mossa spetti a “+”. Si può condurre una ricerca in ampiezza, fino a generare tutti i nodi al livello 2, e applicare poi una funzione di valutazione statistica alle posizioni corrispondenti: se p non è una posizione vincente, e(p) è pari al numero di {righe, colonne, diagonali} ancora aperte a “+” da cui sottrarre il numero di {righe, colonne, diagonali} ancora aperte a “-”, inoltre e(p) vale +∞ se p è una posizione vincente per “+” e -∞ se è una posizione vincente per “-”.
2.3) Rappresentazione della conoscenzaLa differenza che passa tra rappresentazione di un problema e rappresentazione della conoscenza è simile a
quella tra algoritmo e corrispondente programma: se un problema può essere visto come un insieme di stati e la sua risoluzione una sequenza di transizioni tra stati, la conoscenza contenuta in un SF può analogamente essere rappresentata scegliendo un opportuno formalismo (linguaggio).
Analizziamo brevemente alcuni paradigmi linguistici (modelli per la rappresentazione della conoscenza contenuta in un SF): rule based, frame based, logic based, procedure oriented, object oriented e access oriented. Nei sistemi rule based (storicamente i primi) la conoscenza su un certo dominio viene rappresentata attraverso delle regole del tipo if A then B (con
A detta testa o precondizione e B coda o postcondizione), alle quali è possibile applicare sia le tecniche forward chain (la regola si applica in senso diretto, ovvero si unifica con la precondizione e si ricava la postcondizione) sia quelle backward chain (la regola si applica in senso inverso, ovvero si unifica con la postcondizione e si ricava la precondizione). Nei sistemi frame based (apparsi all'inizio degli anni '80) si introduce una conoscenza tassonomica, cioè il principio di base è che tutte le entità del SF possono essere rappresentate in forma gerarchica e la gerarchia di per sé ne semplifica la rappresentazione: all'interno di un SF nel quale siano previste regole di tipo if...then, vengono introdotte ulteriori parole chiave finalizzate a definire una gerarchia, ed
11

ogni entità gerarchicamente subordinata ad un'altra ne eredita le regole. Nei sistemi logic based la rappresentazione della conoscenza è poco più sofisticata che nei sistemi rule based (ai quali possono essere assimilati) e si adotta un formalismo preso a prestito dalla logica matematica (che può essere considerato un'estensione del formalismo dei sistemi rule based) basato su clausole (espresse coi connettivi logici AND, OR e NOT) di cui è possibile dimostrare la verità o la falsità: il Prolog è il rappresentante più noto di questa famiglia di linguaggi. Nei sistemi object oriented compaiono gli oggetti, entità in cui sono incapsulati sia i dati che i metodi per manipolarli (fondamentale per il “riuso” razionale del codice), all'occorrenza “imparentate” tra loro in modo da condividere o ereditare determinate proprietà (ereditarietà). I sistemi procedure based e access based non vanno, infine, considerati del tutto autonomi dal punto di vista IA, bensì estensioni dei già citati sistemi rule based e logic based: nell'ottica dell'IA, essi possono essere usati quando in un determinato problema intervengono sottoproblemi per i quali sia disponibile una conoscenza algoritmica (che viene quindi richiamata).
Per riassumere, una volta scelto il paradigma linguistico per rappresentare la KB (problem fomalization), il MI (control strategy) si occupa di applicare ad essa le regole, servendosi eventualmente di opportune metaregole, cioè regole più generali su cui si basano le strategie di selezione (o esclusione) delle regole comuni, da applicare a seconda dei casi, e i risultati parziali e finali vengono memorizzati in una lavagna virtuale (dynamic database) in continuo aggiornamento. Un sistema esperto offre inoltre, in generale, un ambiente integrato (shell) con tools utili a rappresentare la conoscenza usata dal MI, nella fattispecie Linguaggi di programmazione ospiti (C, PROLOG, ...), Linguaggi per l’ingegneria della conoscenza (RULE BASED, FRAME BASED, ...), Tools di ausilio alla costruzione del sistema (acquisizione della conoscenza, tool di progettazione, ...) e Ambienti di supporto alla programmazione (Editor, Debugging, Interfaccia di SO, ...); in particolare il tool delle spiegazioni tiene traccia dell'intero processo inferenziale ed è in grado di spiegare (tipicamente in linguaggio naturale) all'utente le motivazioni che stanno alla base di ogni singolo passo.
3) Prolog (www.swi-prolog.org)Un linguaggio di programmazione è un linguaggio formale dotato di una sintassi e di una semantica ben definite,
utilizzato per il controllo del comportamento di un calcolatore elettronico. In un linguaggio logico (o dichiarativo) l'istruzione è una clausola che descrive una relazione ennaria tra oggetti, espressa tramite strutture dette predicati: il programmatore non specifica in nessun punto come risolvere un problema, semplicemente lo esprime in forma logica enunciando assiomi e regole (due tipi di predicati) utilizzate poi dal sistema per determinare la verità/falsità di un obiettivo (goal); non c'è un ordine prestabilito di esecuzione delle varie clausole, è compito dell'interprete trovare l'ordine giusto; le variabili ricevono il loro valore per istanziazione o da altre variabili già assegnate nella clausola (unificazione) e quasi mai per assegnamento, che è usato solo in caso di calcolo diretto di espressioni numeriche; inoltre, affinché sia possibile usarli in un programma dichiarativo, tutti i normali algoritmi devono essere riformulati in termini di ricorsione. Un linguaggio logico si definisce del I ordine se i predicati si riferiscono solo ad oggetti che non sono a loro volta predicati, mentre si definisce del II ordine se i predicati si riferiscono anche a predicati che a loro volta si riferiscono ad oggetti non ulteriormente definibili (ovvero non predicati); in teoria è possibile definire linguaggi logici di ordine N arbitrariamente elevato. Le applicazioni in cui l'utilizzo di un linguaggio logico si rivela vantaggioso sono le query su database, la dimostrazione automatica di teoremi, la realizzazione di parser (programma che esegue l'analisi sintattica di uno stream di caratterit in input, leggi anche → 3.6) e il calcolo simbolico (per esempio la “derivazione”).
Il Prolog (PROgramming in LOGic) è un linguaggio di programmazione ideato negli anni '70 (Kowalski, Van Emdem e Colmerauer) che adotta, per l'appunto, il paradigma linguistico logic based, ovvero è un linguaggio logico basato sul calcolo dei predicati (o logica predicativa) del I ordine.
Il Prolog ha una sintassi molto semplice limitata alle clausole di Horn, un particolare sottoinsieme dei possibili predicati del I ordine, ovvero formule composte da disgiunzioni di letterali del I ordine quantificate universalmente con al massimo un letterale positivo: il rispetto di quest'ultima condizione consente di scrivere la clausola sotto forma di implicazione; se il numero di letterali positivi è esattamente uno (ad esempio ¬A ∨ ¬B ∨ C, che applicando De Morgan diventa ¬(A ∧ B) ∨ C, equivalente a (A ∧ B) ⇒ C) si parla di clausole di Horn definite, la cui premessa (corpo) è una congiunzione di letterali positivi e la cui conclusione (testa) è il singolo letterale originariamente positivo; una clausola di Horn senza letterali negativi può essere vista come una clausola di Horn definita che si limita ad asserire una determinata proposizione, può essere scritta come una implicazione la cui conclusione vale “Falso” e viene a volte chiamata fatto (ad esempio ¬A ∨ ¬B ∨ ¬C, che applicando De Morgan diventa ¬(A ∧ B ∧ C), equivalente a ¬(A ∧ B ∧ C) ∨ Falso e quindi a (A ∧ B ∧ C) ⇒ Falso... nel campo dei database formule di questo tipo sono dette vincoli di integrità). Nel Prolog, le clausole di Horn vengono inserite direttamente nella forma
indicata qui a sinistra, con il simbolo “:-” al posto del “←”; in particolare, gli assiomi hanno il corpo (alla destra del simbolo “←”) implicitamente rappresentato da “TRUE” e quindi esprimono fatti sempre veri. Si noti, per concludere, che le clausole di Horn si rivelano particolarmente interessanti per un motivo preciso: il problema della Soddisfacibilità di una formula booleana (determinare se le
variabili di una formula booleana possano essere assegnate in modo che la formula sia valutata "Vero", oppure determinare che tale assegnamento non esiste concludendo quindi che la funzione espressa dalla formula è identicamente "Falso" per tutti i possibili assegnamenti delle sue variabili; nel primo caso si dice che la funzione è soddisfacibile, altrimenti insoddisfacibile), nel caso particolare in cui le clausole della formula siano tutte clausole di Horn (si parla di problema della Horn-Soddisfacibilità), si dimostra avere complessità polinomiale.
Da un punto di vista sintattico, in Prolog i predicati, assiomi (o fatti) e regole (di inferenza), hanno un nome (che li identifica, e che tipicamente ne richiama sinteticamente il significato) e degli oggetti (ovvero degli argomenti) separati da virgole. In particolare un assioma è costituito da un semplice predicato seguito dal punto, mentre una regola è costituita da un predicato (detto postcondizione o conseguente) seguito da “:-” e da uno o più predicati (detti precondizioni o antecedenti) separati dalla virgola (che ha valore di AND) e infine dal punto; se si desidera scrivere una regola con più di una postcondizione oppure con più precondizioni legate dall'OR è necessario scrivere più regole distinte.
Scrivere un programma in Prolog equivale a definire un SF, ovvero una serie di assiomi - con i quali si intende 12

associare a delle espressioni formali dei “fatti” veri nel mondo reale - e una serie di regole - mediante le quali sarà possibile espandere la base di conoscenza (KB) iniziale attraverso le inferenze. L'interpretazione del SF (isomorfismo associato) viene tipicamente data all'inizio del programma specificando con dei commenti (righe che cominciano con il simbolo percentuale) il significato di ciascuna relazione. La KB deve essere collocata all'interno di un documento di testo (per esempio “programma.pl” nella directory “C:\prolfiles”) e, avviato l'interprete Prolog, al prompt “?-” basterà digitare (per esempio)
?- ['C:\prolfiles\programma.pl']. oppure ?- consult('C:\prolfiles\programma.pl').
e la KB verrà incorporata nella memoria interna del MI, dove subirà una “compilazione” (non si tratta di una compilazione nel senso classico del termine, dal momento che il Prolog è un linguaggio interpretato), ovvero i nomi dei predicati e degli oggetti saranno modificati (verrà assegnato loro un codice hash) in modo da massimizzare l'efficienza delle ricerche, intensive, che su di essi il MI dovrà operare: alla fine della compilazione l'interprete risponderà
Yes.
per confermare il successo dell'operazione. Si consideri a titolo di esempio il seguente listato...
%femmina(X) se X è femmina%maschio(X) se X è maschio%coniuge(X,Y) se X è coniuge di Y%padre(X,Y) se X è padre di Y
femmina(angela).femmina(giulia).femmina(manuela).femmina(sandra).maschio(mario).maschio(brunosenior).coniuge(mario,sandra).coniuge(brunosenior,angela).padre(mario,manuela).padre(mario,giulia).
%se X è padre di Y, allora X è genitore di Ygenitore(X,Y):-
padre(X,Y).
%se esiste un Z coniuge di X AND padre di Y, allora X è madre di Ymadre(X,Y):-
coniuge(Z,X),padre(Z,Y).
Si noti che la rappresentazione della conoscenza è la stessa del modello relazionale, un modello logico di rappresentazione dei dati implementato sui DBMS (detti perciò DBMS relazionali): l'assunto fondamentale del modello relazionale è che tutti i dati sono rappresentati come relazioni (dette anche tabelle) e manipolati con gli operatori dell'algebra relazionale (Selezione, Proiezione, Ridenominazione, Prodotto Cartesiano, Unione, Differenza, Intersezione, Join, Divisione), il che consente al progettista di database di creare una rappresentazione consistente (inserendo appropriati vincoli) e logica dell'informazione.
Con riferimento al listato considerato, introduciamo ulteriori dettagli sulla sintassi e sulla semantica del Prolog...Le stringhe alfanumeriche identificano costanti se iniziano con lettera minuscola, variabili se iniziano con lettera maiuscola: in particolare quest'ultime rappresentano entità non specificate e in Prolog sono non tipate. Se l'argomento di un predicato è una variabile, per esempio
%X è padre di Ypadre(X,Y).
si parla di sostituzione quando si inserisce una costante al posto di una variabile: in generale si dice che il predicato B è una istanza di un predicato A se è stato ottenuto da esso per sostituzione...
%Fatto %Possibili istanzepadre(marco,Y). padre(marco,andrea).
padre(marco,mario).
Si parla invece di unificazione quando una sostituzione rende identici due predicati, per esempio la sostituzione “Y = andrea” unifica i predicati
padre(marco,Y).padre(marco,andrea).
e in generale due costanti unificano solo se sono uguali, una costante e una variabile unificano sempre (la variabile assume il valore della costante) così come due variabili. Il Prolog consente anche di utilizzare variabili anonime (il cui nome inizia con un underscore, “_”) per le quali una vera e propria sostituzione (durante una unificazione) non è necessaria e quindi non
13

avviene, per esempio
%un cibo è qualsiasi cosa qualcuno mangicibo(X) :- mangia(Y,X).
consultando tale clausola, l'interprete segnala un “warning” sulla variabile singleton “Y”, ovvero nel tentativo di soddisfare un goal alla variabile “Y” verrà assegnato un valore che poi sarà semplicemente ignorato: per eliminare questo warning, ossia per indicare che non interessa sapere l'unificazione della variabile “Y”, si può riscrivere la clausola come
%un cibo è qualsiasi cosa qualcuno mangicibo(X) :- mangia(_Y,X).
Si consideri il problema del commesso viaggiatore o TSP (Traveling Salesman Problem), formalizzabile come un insieme di relazioni binarie, ciascuna delle quali esprime un collegamento diretto ed unidirezionale tra due città...
%coll(X,Y) se tra X e Y esiste un collegamento unidirezionale X → Y
coll(na,roma).coll(na,rc).coll(roma,ba).coll(ba,rc).
Una volta formalizzata la KB, il MI si mette in attesa che l'utente formuli una domanda, una query (interrogazione di un database), usa lo stesso formalismo adottato per i predicati...
?- coll(na,rc).
Il MI tenta di unificare la query con i predicati contenuti nella KB, e in caso di esito positivo risponde
Yes.
Chiaramente, se stiamo considerando collegamenti unidirezionali il SF da noi formalizzato è coerente e completo, viceversa se si intende rappresentare collegamenti bidirezionali, alla domanda
?- coll(rc,na).
il MI risponderà “No.” anche se ci si aspetterebbe il “Yes.”, quindi il SF è ancora coerente ma non è più completo, dal momento che mancano i predicati inversi...
coll(roma,na).coll(rc,na).coll(ba,roma).coll(rc,ba).
Per rendere quindi completo il sistema con i collegamenti bidirezionali è possibile aggiungere i predicati mancanti oppure aggiungere una regola di inferenza...
%se esiste un collegamento Y → X, esiste anche un collegamento X → Ycoll(X,Y):-
coll(Y,X).
Per comprendere in che modo questa regola venga applicata, occorre capire, in generale, in che modo il Prolog gestisce la quantificazione delle variabili. Solo per fissare le idee, si consideri a titolo d'esempio la regola seguente
%se Roma è collegata ad almeno una città, allora Napoli è collegata ad ogni cittàcoll(na,Y):-
coll(roma,X).
In generale, nel Prolog le variabili che compaiono solo nelle precondizioni sono quantificate esistenzialmente (se ∃ X : coll(roma,X)) mentre le variabili che compaiono solo nella postcondizione sono quantificate universalmente (allora ∀ Y : coll(na,Y)). Si noti inoltre che un assioma (o fatto) è semplicemente una regola con precondizione sempre vera (:- true) quindi negli assiomi la quantificazione delle variabili è sempre universale. Nell'ipotesi, peraltro, in cui una variabile compaia contemporaneamente in almeno una delle precondizioni e nella postcondizione, la sua quantificazione è esistenziale. Infine, nelle query la quantificazione delle variabili è sempre esistenziale.
Con riferimento dunque alla regola del programma fin qui composto (4 assiomi e 1 regola)...
coll(na,roma).coll(na,rc).coll(roma,ba).coll(ba,rc).
14

coll(X,Y):-coll(Y,X).
la quantificazione va intesa nel senso che “Se ∃ X,Y : coll(Y,X) ⇒ coll(X,Y) per quelle stesse istanze di X,Y di cui si è appurata l'esistenza”. Formulando a questo punto la query
?- coll(roma,na).
il MI tenta l'unificazione con i 4 assiomi, senza successo, e poi unifica con la postcondizione della regola, unificando “X” con “roma“ e “Y“ con “na“, e sostituisce il suo goal (predicato obiettivo) attuale “coll(roma,na)“ con la precondizione della regola conservando i valori della variabili che hanno consentito l'unificazione, cioè “coll(na,roma)“, tentando di verificarlo: la risposta del MI è ovviamente ”Yes.“ in quanto “coll(na,roma)“ è tra gli assiomi.
Se la query è
?- coll(na,X).
ovvero se si chiede di verificare ed elencare tutte le città a cui “na” è collegata, il MI restituisce ancora “Yes.” ma stavolta elenca infinite risposte, a causa della applicazione ricorsiva (vedi anche più avanti → ricorsione) dell'unica regola presente, che in effetti richiama infinite volte se stessa invertendo ad ogni applicazione il ruolo dei due argomenti. Inoltre, se la query è
?- coll(fi,ge).
il MI si comporta come nel caso precedente ma, non esistendo alcun collegamento (né diretto né inverso) tra le città di “fi” e “ge”, esso non restituisce alcuna risposta: il problema posto, dato il SF fin qui descritto, risulta indecidibile. Gli inconvenienti riscontrati con le ultime due query possono essere risolti nel modo seguente...
coll1(na,roma).coll1(na,rc).coll1(roma,ba).coll1(ba,rc).
coll(X,Y):-coll1(X,Y).
coll(X,Y):-coll1(Y,X).
così si evita la chiamata ricorsiva delle regole e si impedisce che il MI vada in loop.
In generale quando l'utente formula una query, il MI del Prolog utilizza un approccio goal driven: il primo passo è tentare l'unificazione del goal con uno degli assiomi della KB; se tale unificazione non riesce, allora si applica una delle regole al goal (deve avere successo l'unificazione con la postcondizione) e un nuovo goal (la precondizione) diviene il goal corrente, e il procedimento ricomincia... sospendendosi o alla prima unificazione o quando si è tentata senza successo l'applicazione di tutte le possibili regole presenti nella KB. Il MI tenta inoltre di unificare il goal procedendo in profondità (si tenga presente la DFS) lungo l'albero di ricerca, percorrendo un ramo finchè trova una soluzione o raggiunge uno stato senza successori; naturalmente, al fine di poter esplorare tutto l'albero di ricerca, il MI deve essere in grado, in
qualunque nodo si trovi, di risalire di un livello e di ridiscendere lungo un altro ramo: tale operazione è chiamata backtracking. Il MI dunque risponde affermativamente alle interrogazioni se è possibile ricavarne la risposta utilizzando i fatti e le regole presenti nella KB: se tutti i tentativi di unificazione falliscono la risposta è negativa.
Si osservi che in Prolog (essendo un linguaggio logico di I ordine) i predicati non possono essere oggetto di altri predicati ed inoltre la quantificazione delle variabili è prefissata e dipende rigidamente dal contesto: tutte queste limitazioni imposte dal Prolog nella formulazione del SF si ripercuotono in realtà positivamente sull'efficienza del MI, che è infatti semplice da progettare e realizzare.
3.1) TraceE' possibile analizzare il comportamento del MI più in dettaglio, facendo riferimento ad una versione più sofisticata
del programma appena visto, per esempio la seguente...
%coll1(X,Y,C) se la città X è collegata a Y con costo Ccoll1(na,roma,220).coll1(roma,fi,200).coll1(fi,bo,100).coll1(na,sa,60).
15

coll1(sa,roma,280).
coll(X,Y,C):-coll1(X,Y,C).
coll(X,Y,C):-coll1(Y,X,C).
nella quale è stato introdotto il costo di collegamento bidirezionale tre le città. Testando la KB con la query
?- coll(na,sa,X).
la variabile X viene quantificata esistenzialmente e il MI risponde
X=60
A questo punto, premendo “Invio” il MI si arresta alla prima soluzione trovata, altrimenti premendo “;” ne cerca un’altra (in generale, per sospendere la ricerca in una fase qualunque basta premere “a”). Nel caso in esame, premendo “;” il MI risponde No.
in quanto la soluzione visualizzata è unica e non ce ne sono altre. Con un'altra query
?- coll(X,na,C1),coll(X,roma,C2).
il MI visualizza la soluzione corretta
X=saC1=60C2=280 [;]
No.
che anche adesso è unica. Infine, con la query
?- coll(na,ba,C).
il MI risponde semplicemente
No.
Verifichiamo quindi che le modifiche fatte al codice (sdoppiamento dell'unica regola “coll(X,Y,C):-coll(Y,X,C).” e ridenominazione degli assiomi e delle precondizioni delle regole da “coll” in “coll1”) hanno reso razionali e corrette le risposte del MI: senza queste modifiche, alla prima query il MI risponde correttamente “X=60” ma poi ripropone indefinitamente sempre la stessa soluzione, alle altre due invece non fornisce alcuna risposta, addirittura si blocca ed occorre premere “Ctrl-C” per riprendere il controllo dell'interprete; in tutti i casi, la presenza di una regola ricorsiva, rende infinito/ciclico lo spazio degli stati ed evidentemente il MI incappa in un ciclo o in un ramo di profondità infinita, il che rende sbagliata la soluzione del primo problema ed indecidibili gli altri due.
Per visualizzare nel dettaglio il funzionamento del MI, è possibile digitare, prima di lanciare l'ultima query “coll(na,ba,C).”, i comandi
?- leash(full). (Abilita la visualizzazione di tutte le modalità di entrata/uscita dai goal)?- trace. (Visualizza tutti i passi del MI)
con il seguente risultato
Call: ( 6) coll(na,ba,G672) ? [Invio] creep (“creep” sta per “vai avanti”)Call: ( 7) coll1(na,ba,G672) ? [Invio] creepFail: ( 7) coll1(na,ba,G672) ? [Invio] creepRedo: ( 6) coll(na,ba,G672) ? [Invio] creepCall: ( 7) coll1(ba,na,G672) ? [Invio] creepFail: ( 7) coll1(ba,na,G672) ? [Invio] creepRedo: ( 6) coll(na,ba,G672) ? [Invio] creepFail: ( 6) coll(na,ba,G672) ? [Invio] creepNo.
Si osservi preliminarmente che la variabile “C“ è stata sostituita dal MI con una sigla alfanumerica: è il risultato della “compilazione”. Il modello adoperato dal MI è detto “a porte”, cioè ogni goal (predicato obiettivo) da verificare può essere, al pari di una “scatola”, acceduto in tre modalità differenti. In modalità Call, il MI tenta per la prima volta l'unificazione di un nuovo goal con uno dei predicati della KB, ovvero percorre ordinatamente tutta la KB nel tentativo di verificare
16

l'unificazione o con un assioma o con la postcondizione di qualche regola; nel caso in esame, l'unificazione con ciascuno dei 5 assiomi è impossibile ma ha successo quella con la prima regola (livello 6), che viene infatti applicata generando un nuovo goal (livello 7), anch'esso acceduto in modalità Call: ogni tentativo di unificazione fallisce, sia con gli assiomi che con le regole, e quindi viene abbandonato, in modalità Fail, che indica un fallimento. Ne segue un backtracking, ovvero un ritorno all'indietro all'ultimo goal che ha verificato con successo una qualche unificazione, acceduto in modalità Redo, ovvero la modalità in cui si prova il goal per ogni accesso succesivo al primo: l'unificazione ha nuovamente successo con la seconda regola (livello 6), che viene applicata generando un ulteriore goal (livello 7), anch'esso acceduto in modalità Call: anche qui si esce con Fail. Segue ancora un backtracking, un tentativo di unificazione, ma poiché i predicati con cui tentare l'unificazione sono terminati si esce dal goal originario in modalità Fail, e il MI restituisce il verdetto: nessuna soluzione per il problema posto.
Analizziamo un nuovo problema, la derivazione simbolica...
%deriva(F,G,X) con F funzione da derivare, G funzione derivata, X variabile di derivazione
deriva(sin(X),cos(X),X).deriva(cos(X),-sin(X),X).
deriva(F+G,DF+DG,X):-deriva(F,DF,X),deriva(G,DG,X).
deriva(F-G,DF-DG,X):-deriva(F,DF,X),deriva(G,DG,X).
deriva(F*G,DF*G+F*DG,X):-deriva(F,DF,X),deriva(G,DG,X).
deriva(F/G,(DF*G-F*DG)/(G*G),X):-deriva(F,DF,X),deriva(G,DG,X).
Prima di tutto, si noti che gli operatori (+,*,-,/) sono simboli già presenti in Prolog ed hanno le stesse precedenze che hanno in matematica, nondimeno però essi sono solo simboli privi di semantica e non rivestono lo stesso significato che hanno nei normali linguaggi di programmazione: operatori aritmetici o che permettano confronti relazionali non sono inclusi nel Prolog (versione base), dal momento che costruire un SF significa anche definirne gli operatori (le precedenze, l'associatività, ...) e non avrebbe senso implementare operatori predefiniti (per la definizione di operatori in Prolog leggi → 3.4).
Dando i comandi necessari al tracing e provando a calcolare la derivata di una funzione eseguendo una query?- leash(full).?- trace.?- deriva(sin(x)+cos(x)*cos(x),H,x).
si ottiene il seguente risultato
Call: ( 6) deriva(sin(x)+cos(x)*cos(x),G1172,x) ? [Invio] creepCall: ( 7) deriva(sin(x),G1664,x) ? [Invio] creepExit: ( 7) deriva(sin(x),cos(x),x) ? [Invio] creepCall: ( 7) deriva(cos(x)*cos(x),G1668,x) ? [Invio] creepCall: ( 8) deriva(cos(x),G1696,x) ? [Invio] creepExit: ( 8) deriva(cos(x),-sin(x),x) ? [Invio] creepCall: ( 8) deriva(cos(x),G1708,x) ? [Invio] creepExit: ( 8) deriva(cos(x),-sin(x),x) ? [Invio] creepExit: ( 7) deriva(cos(x)*cos(x),(-sin(x))*cos(x)+(-sin(x))*cos(x),x) ? [Invio] creepExit: ( 6) deriva(sin(x)+cos(x)*cos(x),cos(x)+((-sin(x))*cos(x)+(-sin(x))*cos(x)),x) ? [Invio]H=cos(x)+((-sin(x))*cos(x)+(-sin(x))*cos(x))
Con “H” contenente il valore della corretta derivata.
3.2) ListeNel Prolog esiste una sola struttura dati vera e propria (le altre non lo sono), la lista, una sequenza di elementi separati
da virgole e racchiusi tra parentesi quadre. Una lista è chiusa quando viene determinata per enumerazione di una sequenza finita di oggetti
[a, 1, b, pippo, ...] [a, X, 1, pippo, ...]
i quali oggetti vanno interpretati come costanti puramente simboliche, non tipate e prive di qualsivoglia semantica; in una lista possono essere inserite anche delle variabili (esempio di lista a destra). Una lista aperta viene introdotta per rappresentare una lista di cui ancora non si conoscono tutti gli elementi (ad esempio, nel problema del TSP – ripreso più avanti - vengono memorizzate liste solo parzialmente specificate nel corso del processo inferenziale), e si presenta nel formato
[e1, e2, ..., ek | Y] o più comunemente [X | Y]
17

ovvero il numero dei suoi elementi non è specificato in partenza ed essa viene rappresentata in funzione di una lista detta testa, che può essere anche una variabile X (che si assume rappresentativa di un unico oggetto), e di una lista Y, detta coda, che si assume di cardinalità indefinita.
Il MI gestisce le liste mediante la tecnica dell'unificazione. L'unificazione di una costante con una lista chiusa
pippo ↔ [e1, e2, ..., ek] NO
non è mai possibile; l'unificazione di una variabile con una lista chiusa
X ↔ [e1, e2, ..., ek] SI
è sempre possibile; l'unificazione di una lista chiusa con un'altra lista chiusa è possibile solo se le due liste hanno la stessa cardinalità e gli elementi delle due liste sono ordinatamente unificabili, per esempio...
[X, pippo, 3] ↔ [papa, Y, 3] SI con X=papa, Y=pippo[X, pippo, 3] ↔ [papa, X, 3] NO perchè altrimenti X=papa=pippo
Nota: in seguito alla prima unificazioneX=papa la “X” diventa una variabile“Bind”, cioè legata e non ammetteulteriori unificazioni, come X=pippo.
[X, pippo, 3] ↔ [[1,2], Y, 3] SI con X=[1,2], Y=pippo[X, pippo, 3] ↔ [1, 2, Y, 3] NO perchè la cardinalità è diversa[X, pippo, 3] ↔ [[Y,5], Y, 3] SI con Y=pippo, X=[pippo,5]
L'unificazione di una lista chiusa con una lista aperta è possibile solo se la cardinalità della lista chiusa è almeno pari (ma può essere maggiore) alla cardinalità della testa della lista aperta, per esempio...
[pippo, 3, pluto] ↔ [X | Y] SI con X=pippo, Y=[3, pluto][pippo, 3, pluto] ↔ [X, Y | Z] SI con X=pippo, Y=3, Z=pluto[[pippo, 3], pluto] ↔ [X, Y | Z] SI con X=[pippo,3], Y=pluto, Z=[] (lista vuota)[pippo] ↔ [X | Y] SI con X=pippo, Y=[][pippo] ↔ [X, Y | Z] NO
3.3) RicorsioneSupponiamo che un problema P, sufficientemente complesso, ammetta una decomposizione in problemi P1, P2, ... Pn
più semplici: il task iniziale può venire quindi ricondotto all'elaborazione di una serie di task elementari ed autonomi, eseguiti in un certo ordine. La decomposizione in sottoproblemi come quella illustrata, nella quale in particolare i problemi figli siano dello stesso tipo del problema padre, è detta ricorsione.
Viene detto ricorsivo un algoritmo espresso in termini di sé stesso, la cui esecuzione su un insieme di dati comporta la semplificazione o suddivisione dell'insieme di dati stesso e l'applicazione del medesimo algoritmo agli insiemi di dati così ottenuti: l'algoritmo richiama sé stesso generando una sequenza di chiamate che ha termine al verificarsi di una condizione particolare, detta condizione di terminazione, che in genere si ha con particolari valori di input. L'approccio ricorsivo, che deve molto all'IA, permette di scrivere algoritmi eleganti e sintetici per molti tipi di problemi comuni, anche se non sempre le soluzioni ricorsive sono le più efficenti.
Si osservi che perchè un algoritmo possa essere espresso in forma ricorsiva deve verificare alcuni requisiti: (1) deve esistere la possibilità di formulare l'algoritmo in funzione di sé stesso, e la regola che descrive tale possibilità è solitamente chiamata passo (per esempio, nel fattoriale è n!=n x (n-1)!); (2) non deve mai verificarsi un ciclo infinito ed è necessario che, in qualche modo, l'applicazione del processo riesca sempre a terminare, deve quindi esistere una condizione di terminazione (o di chiusura, o base), ovvero almeno una istanza del processo che non richiede di essere scomposta in ulteriori istanze più semplici (per esempio, nel fattoriale è 1! o 0!), inoltre non deve esistere un valore di ingresso che renda impossibile la terminazione dell'esecuzione (per esempio, nel fattoriale è un qualsiasi numero negativo... il problema si risolve applicando un vincolo sull'ingresso o usando un tipo unsigned); (3) deve esserci convergenza insiemistica, ovvero - in termini semplici – i sottoinsiemi di dati prodotti nel corso dell'applicazione devono convergere alla base.
La ricorsione presenta il grande vantaggio di essere facilmente esprimibile in termini formali, mediante il principio di induzione: assegnata una successione { xn } e una proprietà P verificabile su ciascun termine xi, se P(xo) è vera e si può dimostrare che, per un arbitrario k, P(xk) vera ⇒ P(xk+1) vera allora risulta che P(xi) è vera ∀i. Tornando alla ricorsione, P(xi) può essere pensato (piuttosto che come la verifica di una proprietà) come la computazione eseguita sul dato i-esimo scelto tra un set di dati di ingresso, con “i” crescente a mano a mano che dai sottoproblemi “figli” più semplici si risale (attraverso i sottoproblemi intermedi “padre” che li hanno via via generati) verso il problema originario a maggiore complessità P(xn): se P(xo) è nota (e corretta) ed esiste una regola con la quale, per un arbitrario k, P(xk) nota ⇒ P(xk+1) nota allora risulta che P(xi) è nota ∀i; in altre parole, se si conoscono le soluzioni dei sottoproblemi e si conosce il modo di mettere in relazione tali soluzioni con quella del problema “padre”, siamo in grado di risolvere qualsiasi problema “padre” con un algoritmo ricorsivo.
Un classico esempio di problema che ammette un'elegante soluzione ricorsiva è il problema delle Torri di Hanoi...18

Utilizzando il formalismo descritto in figura, ovvero HACB(n), con A piolo di partenza B piolo intermedio e C piolo di arrivo
secondo le regole del gioco (non è possibile spostare un disco su uno più piccolo), occorre individuare una regola che consenta di dividere il problema in sottoproblemi più semplici dello stesso tipo. Fondamentale è conoscere la condizione di chiusura, ovvero HXZ
Y(1), che consiste semplicemente nel prendere un singolo disco e spostarlo da piolo X-esimo al piolo Z-esimo. La risoluzione del problema dato richiede tre fasi ad ogni livello (per fissare le idee, ragioniamo sul livello iniziale, il livello 4): nella fase di “divide”, il problema in esame va scomposto in sottoproblemi più semplici, ovvero HAC
B(4) → HABC(3) + HAC
B(1) + HBC
A(3); nella fase di “impera”, si assume nota la soluzione di quei sottoproblemi (quella del passo base è effettivamente nota); nella fase di “combina”, infine, occorre trovare la relazione che lega la conoscenza delle soluzioni dei sottoproblemi così individuati alla soluzione del problema “padre”, in modo da verificare le ipotesi del principio di induzione che, pertanto, può essere applicato. A questo punto non resta che riapplicare il procedimento ai sottoproblemi di ordine inferiore trovati, ovvero HAB
C(3) e HBCA(3), e di cui si è solo supposto di conoscere la soluzione, e procedere nel modo indicato fino a che
non si ottengono (livello 1) solo problemi banalmente risolvibili grazie alla condizione di chiusura. Il problema finale si risolve combinando ordinatamente tutte le soluzioni trovate (le operazioni da eseguire costituiranno i nodi foglia dell'albero che si è generato). Una possibile implementazione in Prolog è la seguente...
hanoi(1,A,B,C):-write('Muovi il disco in cima alla pila'),write(A),write('sulla pila'),write(C),nl. “nl” sta per “new line”
hanoi(N,A,B,C):-N>1,M is N-1, “is” è un operatore extralogicohanoi(M,A,C,B), equivalente a “=”...hanoi(1,A,B,C),hanoi(M,B,A,C).
Esempio di query...
?- hanoi(3,sinistra,centrale,destra).
Muovi il disco in cima alla pila sinistra sulla pila destraMuovi il disco in cima alla pila sinistra sulla pila centraleMuovi il disco in cima alla pila destra sulla pila centraleMuovi il disco in cima alla pila sinistra sulla pila destraMuovi il disco in cima alla pila centrale sulla pila sinistraMuovi il disco in cima alla pila centrale sulla pila destraMuovi il disco in cima alla pila sinistra sulla pila destra
Altro esempio significativo è il calcolo del determinante di una matrice, per il quale la procedura ricorsiva è dettata dalla definizione stessa di determinante per una matrice quadrata di ordine N, come combinazione lineare di minori (cioè ancora determinanti) di ordine N-1.
Dal momento che il Prolog è privo dei tipici costrutti della programmazione iterativa (for, while, repeat) di fatto esso “costringe” alla programmazione ricorsiva anche per operazioni che sembra naturale risolvere in modo iterativo, come la verifica di appartenenza di un elemento ad una lista: in Prolog questa operazione richiede un algoritmo ricorsivo. Per prima cosa conviene individuare la condizione di chiusura, ovvero un caso in cui il problema è risolvibile banalmente: quando l'elemento cercato è in testa alla lista sicuramente è facile verificarne l'appartenenza grazie ad un predicato del tipo seguente
%Se A è in testa alla lista allora le appartienemember(A,[A|B]).
regola che può essere scritta anche (ma non necessariamente) nella forma
%Se A=X, posto che X è la testa della lista [X|B], allora A appartiene alla listamember(A,[X|B]):-A=X.
19

Il passo ricorsivo (o induttivo) può essere invece formalizzato nel modo seguente
%Se A appartiene alla coda della lista allora le appartienemember(A,[B|C]):-
member(A,C)
Sottoponendo al MI alcune query, anche complicate...
?- member(2,[4,5,3,5]). No.?- member([3],[[1,2],[3],[1,b]]). Yes.?- member([[1],[2,3],[4,5]],[[[]],[[1],[2,3],[4,5]]]). Yes.
si ottengono risposte corrette, anche quando gli oggetti sono liste di liste, e questo perchè i simboli vengono manipolati in modo del tutto generale indipendentemente dal loro tipo. Se nelle query ci sono delle variabili, osserviamo che
?- member(X,[1,2,3]). X=1 [;]X=2 [;]X=3 [;]No.
l'appartenenza di una variabile ad una lista è verificata per ciascuno dei suoi elementi, mentre
?- member(1,X). X=[1|G880] [;]X=[G876,1|G892] [;]X=[G876,G888,1|G904] [;]...
l'appartenenza di una costante ad una variabile (intesa come lista) ammette infinite soluzioni, cioè qualunque lista composta da un numero arbitrario di variabili e dalla costante indicata (in qualunque posizione essa si trovi) verifica la query.
Determinare la lunghezza di una lista è altresì una operazione che si può definire in modo ricorsivo. La condizione di chiusura può essere formalizzata banalmente con
%La lunghezza di una lista vuota è 0length([],0).
così come il passo induttivo è dato da
%La lunghezza di una lista è data dalla lunghezza della sua coda + 1length([A|B],N):-
length(B,M),N is M+1.
Altro problema interessante è la verifica di concatenazione tra liste, ovvero un predicato che risulti vero quando una lista risulta essere la concatenazione di altre due liste. La condizione di chiusura può essere formalizzata con
%La concatenazione della lista vuota e della lista A coincide con la lista Aappend([],A,A).
mentre non è difficile convincersi che
%[A|B] concatenato a C dà [A|D] solo se D è effettivamente la concatenazione di B e Cappend([A|B],C,[A|D]):-
append(B,C,D).
costituisce un valido passo induttivo. Sottoponendo al MI alcune query...
?- append([1,2],[3,4],C). C=[1,2,3,4]?- append([1,2],X,[1,2,3,4,5]). X=[3,4,5] ?- append(Y,X,[1,2,3,4,5]). Y=[] X=[1,2,3,4,5] [;]
Y=[1] X=[2,3,4,5] [;]Y=[1,2] X=[3,4,5] [;]Y=[1,2,3] X=[4,5] [;]Y=[1,2,3,4] X=[5] [;]Y=[1,2,3,4,5] X=[] [;]No.
?- append([1|Y],[5],[1,2,3,4,5]). Y=[2,3,4]?- append([1|Y],[4|Z],[1,2,4,3,4,5]). Y=[2] Z=[3,4,5] [;]
Y=[2,4,3] Z=[5] [;]No.
?- append([1|Y],[4|Z],V). Y=[] Z=G164 V=[1,4|G164] [;]Y=[G257] Z=G164 V=[1,G257,4|G164] [;]...
20

il sistema restituisce risultati corretti e, laddove si inseriscano variabili nelle liste di input ed anche nella lista di output esso restituisce chiaramente infinite soluzioni. In realtà, pur funzionando perfettamente, la formulazione ricorsiva di tale predicato
append([],A,A).append([A|B],C,[A|D]):-
append(B,C,D).
presenta una complessità computazionale elevata (peraltro, come ogni formulazione ricorsiva di un problema!), in quanto obbliga ad un numero di passaggi N pari a quello degli elementi della prima lista. Un'alternativa consiste nell'utilizzare una struttura dati alternativa per la rappresentazione delle liste messa a disposizione dal Prolog, la difference list. Una qualsiasi lista “L”, dal punto di vista logico, può essere vista come differenza tra una lista aperta “L|C”, che ha come primi elementi quelli di “L”, e la sua coda “C”, per esempio
[1,2,3] ⇔ [1,2,3|C]\C
Un’applicazione immediata delle difference list è proprio la funzione append, che può essere definita semplicemente
append(A\B,B\C,A\C).
ed ha il pregio di avere una complessità costante (indipendente dalla cardinalità delle liste coinvolte).
In effetti le operazioni possibili sulle liste sono molteplici, e vanno tutte implementate allo stesso modo, sfruttando la ricorsione. Possiamo indicarne brevemente alcune altre in maniera sintetica (presupponendo che il ragionamento che sta alla base della loro definizione sia in sostanza sempre lo stesso)...
→ Inversione (complessità O(n2))%L'inversione della lista vuota è ancora la lista vuotainverti([],[]).
%Passo induttivoinverti([A|B],C):-
inverti(B,X),append(X,[A],C).
→ Inversione (usando una lista d'appoggio, nascosta all'utente al fine di ridurre la complessità a O(n))%Interfaccia semplificato che “richiama” il predicato che fa uso della lista d'appoggio... il%secondo parametro di “inverti(X,[],Y)” è infatti una lista d'appoggio, inizialmente vuota, che si%assume ad ogni passaggio “già invertita”; in pratica l'idea è quella di sfruttare tale lista%come accumulatore, inserendole in testa gli elementi che si prelevano dalla testa della lista da%invertire: inizialmente l'accumulatore è vuoto, alla fine conterrà la lista originaria invertita.inverti(X,Y):-
inverti(X,[],Y).
%L'inversione della lista vuota è ancora la lista vuota (concatenata alla lista accumulatore)inverti([],L,L).
%Passo induttivoinverti([A|B],L,C):-
inverti(B,[A|L],C).
→ Inserimento ordinato (di un elemento in una lista ordinata)%L'inserimento di un elemento X in una lista vuota è una lista che contiene solo Xinsert(X,[],[X]).
%L'inserimento di un elemento X minimoinsert(X,[T|C],[X,T|C]):-
X=<T.
%Passo induttivoinsert(X,[T|C],[T|L]):-
X>T,insert(X,C,L).
→ Fusione (di due liste ordinate in una lista ancora ordinata)%La fusione di una lista L con una lista vuota è ancora la sola lista L%(qualunque sia l'ordine di fusione)fusione(L,[],L).fusione([],L,L).
%Passo induttivofusione([T1|C1],[T2|C2],[T1|M]):-
21

T1=<T2,fusione(C1,[T2|C2],M).
fusione([T1|C1],[T2|C2],[T2|M]):-T1>T2,fusione([T1,C1],C2,M).
→ Split (di una lista in due sottoliste, contenente l'una gli elementi di posto dispari e l'altra quelli di posto pari)%Lo split di una lista vuota produce due sottoliste vuotesplit([],[],[]).
%Lo split di una lista con un solo elemento, rende non vuota solo la prima sottolistasplit([A],[A],[]).
%Passo induttivosplit([A,B|C],[A|X],[B|Y]):-
split(C,X,Y).
→ Ordinamento (con algoritmo MergeSort)%Una lista con al più un solo elemento è già ordinatamergesort([],[]).mergesort([A],[A]).
%Passo induttivomergesort([A,B|C],L):-
split([A,B|C],X1,X2),mergesort(X1,Y1),mergesort(X2,Y2),fusione(Y1,Y2,L).
→ Eliminazione (di ogni istanza di un elemento X da una lista)%L'eliminazione di X da una lista vuota produce la lista vuota stessacancella(X,[],[]).
%Passo induttivocancella(X,[X|C],L):-
cancella(X,C,L).
cancella(X,[T|C],[T|L]):-cancella(X,C,L).
3.4) Definizione di operatoriTornando al problema della derivazione simbolica, è possibile sfruttare la ricorsione per generalizzare il programma
precedentemente definito in modo che realizzi la derivazione di funzioni composte. E' sufficiente sostituire le regole
deriva(sin(X),cos(X),X).deriva(cos(X),-sin(X),X).
con le nuove
deriva(X,1,X).deriva(sin(X),cos(X)*DX,Y):-
deriva(X,DX,Y).deriva(cos(X),-sin(X)*DX,Y):-
deriva(X,DX,Y).
laddove la prima di esse (la derivazione di una variabile semplice) è facilmente identificabile come condizione di chiusura.
Il Prolog offre la possibilità di definire, tramite delle direttive poste all'inizio del programma, degli operatori infissi, postfissi e prefissi, il che consente all'utente di svincolarsi dall'uso obbligato delle parentesi... scrivere “2+5*3” è senz'altro più semplice ed intuitivo che scrivere “somma(2,prodotto(5,3))”. La definizione di un operatore avviene mediante una direttiva del tipo
:- op(priorità, tipologia, simbolo dell'operatore).
Il terzo argomento contiene banalmente il simbolo dell'operatore o una lista di simboli (in tal caso verrà definito più di un operatore con le stesse caratteristiche), “priorità“ indica un numero (tra 0 e 1200) determinante la priorità dell'operatore che si sta definendo (più è alto il numero più è bassa la priorità) mentre “tipologia“ è una stringa che indica il tipo e l'associatività dell'operatore secondo le seguenti regole
xfx → binario infisso (nessuna associatività)xfy → binario infisso, associativo a destra
:- op(..., xfy, bum) ⇒ (a bum b bum c) ⇔ bum(a,bum(b,c))22

yfx → binario infisso, associativo a sinistra:- op(..., yfx, bum) ⇒ (a bum b bum c) ⇔ bum(bum(a,b),c)
fx → unario prefissofy → unario prefisso, associativoxf → unario postfissoyf → unario postfisso, associativo
Alcuni degli operatori già predefiniti in Prolog sarebbero definiti da direttive come queste:- op(500, yfx, [+,-]).:- op(400, yfx, [*,/,mod,rem]).:- op(200, xfx, [**]).:- op(200, fy, [+,-]).
E' possibile pertanto, a titolo di esempio, definire un operatore di elevazione a potenza del tipo
:- op(200, xfy, [^]).
in modo da riformulare la regola sulla derivazione di un rapporto di funzioni nel modo seguente
deriva(F/G,(DF*G-F*DG)/G^2,X):-deriva(F,DF,X),deriva(G,DG,X).
Se vogliamo definire la regola di derivazione di una potenza a esponente intero, è opportuno prima definire in qualche modo i numeri interi dentro il Prolog: una possibilità consiste nel definire implicitamente un insieme infinito di termini, dove di ciascuno l'operatore “s” restituisca il successore (nell'interpretazione che l'utente ne dà... ma si badi che il comportamento del MI è coerente nell'uso dell'operatore “s” qualunque sia l'interpretazione ad esso arbitrariamente assegnata), e tale che il primo di essi, ovvero “0”, e tutti i suoi successori siano da considerarsi interi...
:- op(100, fy, s).
is_integer(0).is_integer(s(N)):-
is_integer(N).
in pratica, si sta introducendo un isomorfismo tra l'insieme dei naturali e un'opportuna successione di simboli secondo la seguente tabella
0 01 s(0)2 s(s(0))... ...n s(s(...s(0))))...)
e per passare dal dominio simbolico a quello numerico si può utilizzare la trasformazione ricorsiva “sim2num” che utilizza l'operatore extralogico “is”...
sim2num(0,0).sim2num(s(X),N):-
N is M+1,sim2num(X,M).
(si noti comunque, a onor del vero, che il Prolog mette già a disposizione l'operatore “integer(X)” che restituisce TRUE se “X” è numero intero). A questo punto, la regola di derivazione di una potenza a esponente intero può essere così definita
deriva(X^s(N),s(N)*X^N*DX,Y):-is_integer(N),deriva(X,DX,Y).
Fermo restando che è possibile aggiungere tutte le funzioni che si desidera (oltre a quelle trigonometriche elencate), l'unica questione irrisolta rimane la regola per la derivazione di una costante che dovrebbe avere una forma del tipo
deriva(X,0,Y):- ...
Una possibile soluzione potrebbe essere quella di scrivere tante regole quante sono le possibili costanti numeriche ma èchiaramente da scartare. Per la verità una soluzione razionale esiste e richiede l'introduzione di strumenti offerti dal Prolog che esula dagli scopi di questo corso, per cui ci si limita a presentarla
%l'operatore “atomic” restituisce TRUE se il suo argomento è una costante o un numeroderiva(X,0,Y):-
atomic(X).23

3.5) Operatori extralogiciLa loro funzionalità è esterna al modello di programmazione logica del I ordine alla base del Prolog: in effetti sono
predicati il cui argomento è ancora un predicato e il loro uso altera il comportamento classico del MI. Quelli presi in esame qui sono tre: CUT (simbolo “!”), NOT (operatore del II ordine) e FAIL.
Il CUT è sicuramente il più complesso dei tre. Per comprenderne appieno la funzione è necessario capire bene la strategia goal driven in profondità seguita dal MI del Prolog, analizzando ad esempio il seguente frammento di SF...
b:- a1(X,Y), a2(X,Z,J), ... an.b:- c1, c2, ... cm. Nota: Per b, ci e di indicare le variabili non èb:- d1, d2, ... ds. necessario ai fini dell'analisi di questo esempio
e sottoponiamo al MI la query
?- b.
Il MI cerca di unificare il goal “b” con la postcondizione della prima regola e se l'unificazione ha successo (come in questo caso) il nuovo goal corrente diventa “a1“ e il MI tenta di unificare “a1“ con un qualche assioma o con la postcondizione di una delle regole della KB. Supponendo che i predicati disponibili siano
a1(3,W).a1(4,W).a2(K,5,J):- ...a2(K,7,J):- ...
il MI scorre la KB e incontra “a1(3,W)” (la cui precondizione è banalmente vera, trattandosi di un fatto) per cui realizza l'unificazione “a1(X,W) ↔ a1(3,W)” e perfeziona quindi il binding di “X” con “3”, dopodichè “trasporta” questo binding a tutti i goal successivi a quello in esame presenti nella lista delle precondizioni di “b”; il prossimo goal attivo diviene quindi “a2“ e il MI tenta di unificare “a2“ con un qualche assioma o con la postcondizione di una delle regole della KB: il MI scorrendo la KB incontra la regola “a2(K,5,J):-...“ compatibile con “a2(3,Z,J)” e realizza l'unificazione “a2(X,Z,J) ↔ a2(3,5,J)” perfezionando il nuovo binding di “Z” con “5”, dopodichè assume come nuovo goal attivo la precondizione di “a2(K,5,J)“ in accordo con la strategia DFS. Supponiamo a questo punto che la verifica di tale/i precondizione/i non abbia successo (uscita in modalità Fail): il MI rilascia tutti i binding (Z ↔ 5) realizzati nell'analisi del goal corrente (a2(3,Z,J)) e vi riaccede in modalità Redo, scorrendo la KB alla ricerca di un nuovo predicato con la cui postcondizione sia possibile l'unificazione; il MI incontra quindi la regola “a2(K,7,J):-...“ compatibile ancora una volta con “a2(3,Z,J)” e realizza l'unificazione “a2(X,Z,J) ↔ a2(3,7,J)” perfezionando il binding di “Z” stavolta con “7”, dopodichè assume come nuovo goal attivo la precondizione di “a2(K,7,J)“. Supponiamo, anche stavolta, che la verifica di tale/i precondizione/i non abbia successo (uscita in modalità Fail): il MI rilascia tutti i binding (Z ↔ 7) realizzati nell'analisi del goal corrente (a2(3,Z,J)) e – come prima – riaccede al goal (a2(3,Z,J)) in modalità Redo, tuttavia, essendo terminati nella KB i predicati potenzialmente unificabili, ne esce nuovamente in modalità Fail e qui si realizza il backtracking, cioè – visivamente – il MI risale il grafo degli stati da quello corrente “a2(3,Z,J)“, la cui validazione è fallita per ogni possibile binding di “Z” e “J”, a quello immediatamente precedente, cioè “a1(3,W)”, cui accede in modalità Redo, rilasciando pertanto il binding (X ↔ 3) nel tentativo di realizzarne uno diverso: il MI scorre la KB e incontra “a1(4,W)” (la cui precondizione è banalmente vera, trattandosi di un fatto) per cui realizza l'unificazione “a1(X,W) ↔ a1(4,W)” e perfeziona quindi il binding di “X” con “4”, dopodichè “trasporta” nuovamente questo binding a tutti i goal successivi a quello in esame presenti nella lista delle precondizioni di “b”, a cominciare da “a2“... e il tutto ricomincia nel modo descritto. Se non riuscisse a verificare l'AND logico tra le precondizioni “ai” per nessuna configurazione di valori delle variabili, la verifica di “b:- a1(X,Y), a2(X,Z,J), ... an.” risulterebbe definitivamente fallita e il MI passerebbe all'analisi (con la stessa strategia) di “b:- c1, c2, ... cm.“ e così via di seguito.
Relativamente all'aspetto che più ci interessa (la gestione dei binding), si osservi che ogni volta che a seguito di un Call o di un Redo su un goal X si realizza un'unificazione con un predicato compatibile, una o più variabili vengono assegnate e si realizza un binding che viene ereditato da tutti i goal successivi: in caso di Fail immediato dopo un Redo (su uno di questi goal successivi), dopo il backtracking che riporta il MI ad analizzare il goal X - cui si riaccede in modalità Redo - il binding viene rimesso in discussione e si tentano nuove unificazioni. In nessun caso, però, vengono rilasciati binding prodotti nell'analisi di un goal di livello precedente.
L'operatore CUT serve ad introdurre una forma di controllo sul meccanismo automatico del backtracking...
b:- a1, a2, ... ak-1, !, ak, ... an.b:- c1, c2, ... cm.b:- d1, d2, ... ds.
Il “!” non altera il funzionamento del MI fino a quando non viene incontrato: la prima volta che il MI trova il CUT, essoviene assimilato ad un goal che ha successo, e l'analisi procede normalmente applicando Redo e backtracking nella maniera tradizionale. Nel momento in cui, però, si rende necessario il backtracking “ak → ! → ak-1“ tale operazione non viene consentita e provoca il fallimento del goal corrente “b”, qualunque sia il valore delle sue eventuali variabili, e – di più – provoca il fallimento di tutte le altre regole che hanno “b” come postcondizione. Praticamente, il CUT taglia l'albero di ricerca delle soluzioni, tendendo quindi a conservare la coerenza del SF, sebbene non sia facile prevedere l'effetto di questo taglio: potrebbe potare un ramo infinito che non contiene soluzioni a tutto vantaggio della decidibilità, ma
24

potrebbe anche tagliare il ramo in cui è presente l'unica soluzione rendendo quindi incompleto un SF che in origine lo era. Da un punto di vista operativo, esso “costringe” il programmatore a preoccuparsi anche del funzionamento del MI, piuttosto che concentrarsi solo sulla pura formalizzazione logica del problema: normalmente, l'ordine in cui vengono scritte le regole in Prolog è ininfluente sul corretto funzionamento del programma (semplicemente può alterare l'ordine nel quale le soluzioni vengono trovate) mentre il CUT rende tale ordine importante perchè può far fallire la verifica di tutte le regole successive a quella in cui viene inserito.
Il modo corretto di usare il CUT cosiddetto “rosso” (cioè quello appena visto nell'esempio precedente... l'aggettivo “rosso” indica la criticità del suo uso, criticità legata al fatto che taglia rami dell'albero delle soluzioni che potenzialmente contengono soluzioni ancora non trovate) è introdurlo tra “ak-1” e “ak” solo nel caso in cui si sappia per certo che tutte le soluzioni possibili, che provino la verità di “b”, sono assoggettate alla verità di “a1, a2, ... ak-1“ ovvero, trovata una qualunque sostituzione di variabili che renda vera la (k-1)pla di predicati considerati, la soluzione o esiste oppure non esiste: se non si riesce a verificare il predicato “ak“ e si effettua un backtracking significa che non esiste e quindi è corretto abortire l'analisi.
Anche se in generale l'uso del CUT ha effetti imprevedibili, esistono situazioni in cui si parla di CUT “verde” (il suo uso è innocuo perchè non fa perdere soluzioni, e anzi è opportuno nella misura in cui evita esplorazioni semplicemente inutili), come nel caso seguente...
member(A,[A|B]).member(A,[B|C]):-
member(A,C).
A seguito della query
?- member(1,[2,1,3,1,4]).
il MI fornirebbe due soluzioni, mentre invece ci aspetteremmo che un predicato “member” fornisca un'unica risposta, “Yes” o “No” a prescindere da quante volte un dato oggetto occorra in una lista. Modificando quindi il listato nel modo seguente
member(A,[A|B]):-!.member(A,[B|C]):-
member(A,C).
si assume che una volta verificata la prima regola (direttamente o indirettamente, come precondizione della seconda) il MI abortisca la ricerca di ogni altra soluzione: infatti dopo aver banalmente verificato la precondizione implicita “true” ed aver superato il CUT, il backtracking sulla “true” generato dal Redo (a sua volta prodotto dalla pressione del “;” da parte dell'utente) fa innescare il CUT che blocca l'elaborazione.
Sempre di CUT verde si tratta nell'esempio seguente...
leggival(N):- N is 0,!,write('Hai inserito 0').leggival(N):- N is 1,!,write('Hai inserito 1').leggival(N):- write('Hai inserito un valore numerico non booleano').
che è di banale interpretazione. Così come è ancora CUT verde quello usato nel seguente programma di eliminazione da una lista leggermente modificato...
cancella(X,[],[]).cancella(X,[X|C],L):- !,cancella(X,C,L).cancella(X,[T|C],[T|L]):- cancella(X,C,L).
dove l'inserimento del CUT evita la possibilità di unificazioni successive alla prima laddove “X” venga trovato in testa alla lista (e si sia sicuri, però, che non vi siano altre istanze di “X“ anche nella coda della lista stessa).
L'operatore extralogico NOT differisce dall'omonimo booleano di negazione...
notmember(X,T):-not member(X,T).
La quantificazione delle variabili nella regola “notmember” è esistenziale, e tale regola risulta verificata se non esiste alcuna coppia “(X,T)” tale che “member(X,T)” sia vera: se esiste almeno una soluzione che renda vero “member(X,T)” allora “notmember” risulta falso, ma se “notmember” risulta vero significa che sono stati scatenati tutti ipossibili backtracking su “member” e non è stata trovata alcuna soluzione.
Tornando al problema del commesso viaggiatore, volendo scrivere un predicato che consenta di trovare tutti i cammini possibili tra due città di una mappa geografica...
%coll1(X,Y,C) se esiste un collegamento tra X e Y con costo Ccoll1(na,roma,220).coll1(roma,fi,200).coll1(fi,bo,200).coll1(roma,mi,400).coll1(mi,bo,150).
25

coll1(na,sa,60).coll1(sa,roma,280).coll1(sa,fi,599).coll(X,Y,C):-
coll1(X,Y,C).coll(X,Y,C):-
coll1(Y,X,C).
può essere impostato ricorsivamente con le liste e usando il NOT. La condizione di chiusura può essere formalizzata con
%collegamento(Ci,Cf,Lp,Lc,C) dove Ci = città di partenza Input% Cf = città di arrivo Input% Lp = città proibite Input% Lc = città “toccate” Output% C = costo Outputcollegamento(Ci,Cf,Lp,[Ci,Cf],C):-
coll(Ci,Cf,C),not member(Ci,Lp),not member(Cf,Lp).
ovvero esiste un collegamento tra “Ci” e “Cf” se esiste tra loro un collegamento diretto (verificando che nessuno dei due nodi appartenga alla lista delle città proibite) mentre il passo induttivo è
collegamento(Ci,Cf,Lp,[Ci|L],C):-coll(Ci,Cint,C1),collegamento(Cint,Cf,[Ci|Lp],L,C2),not member(Ci,Lp),not member(Cint,Lp),C is C1+C2.
ovvero esiste un collegamento tra “Ci” e “Cf” se esiste un collegamento diretto tra “Ci” e “Cint” e un collegamento (qui interviene la ricorsione) tra “Cint” e “Cf”, avendo l'accortezza di aggiungere alla lista delle città proibite anche “Ci” (per evitare di ripassare per le stesse città): chiaramente il listato su scritto non “risolve” il problema TPS ma si limita a produrre tutti i possibili cammini da una città ad un'altra in modo da poter scegliere, alla fine, quello con costo minore; si noti inoltre che nessun backtracking può essere effettuato sul “not”.
Infine, l'operatore extralogico FAIL è tale che, una volta raggiunto, determina sempre un fallimento, consentendo al backtracking di seguire un nuovo ramo. E' interessante notare che l'operatore NOT può essere definito a partire dagli altri due...
not(A):-A, !, fail.
not(A).
Nel tentativo di unificare infatti “not(A)” scateniamo il goal “A”: se esiste una soluzione (cioè se “A” è vero), viene percorso il CUT (vero) e quindi il FAIL che provoca il backtracking sul CUT facendo fallire la postcondizione, per cui “not(A)” risulta falso; se invece non esiste una soluzione (cioè se “A” è falso), viene fatto backtracking su “not(A)” e viene incontrato il fatto “not(A).”, per cui “not(A)” risulta vero.
Infine, per concludere, combinando opportunamente gli operatori extralogici è possibile riprodurre il funzionamento dei cicli iterativi (for, while, repeat) della programmazione classica (senz'altro svantaggioso da un punto di vista didattico, ma utile da sapere). Il costrutto fondamentale sul quale tutti i cicli iterativi si basano è l' “if then else”, realizzabile mediante il CUT...
%IF P THEN QS :- P,!,Q.
%ELSE RS :- R.
Si noti che la non unificazione di Q equivale all'esecuzione di un “break” nel flusso di controllo dell' “if then else”.
3.6) Realizzazione di un analizzatore sintattico (parser)Il Prolog, grazie alle sue caratteristiche di interprete simbolico, si presta specificamente alle elaborazioni di strutture
sintattiche come quelle dei linguaggi naturali e di programmazione (per esempio il C): si capisce perciò per quale motivo, in diversi casi, gli analizzatori sintattici dei compilatori vengano realizzati proprio in Prolog. Per gli stessi motivi, il Prolog può essere un utile strumento anche per la realizzazione dei cosiddetti CASE (Computer-aided software engineering), pacchetti software che permettono di ottenere direttamente il codice dei programmi assegnando le sole specifiche di progetto.
Qui ci interessa trattare il problema di analizzare sequenze di caratteri allo scopo di verificare se corrispondano a frasi di senso compiuto. Consideriamo un linguaggio che abbia una struttura sintattica simile all'Inglese: occorre definire delle regole (determinate sulla base della grammatica del linguaggio utilizzato), formalizzate sfruttando il seguente isomorfismo
26

frase → nominale, verbalenominale → determinativo, nominale2nominale → nominale2nominale2 → aggettivo, nominale2nominale2 → soggettoverbale → verbo, nominaleverbale → verbo
e dei fatti (voci del vocabolaro) da inserire altresì nella KB
verbo → [eat]verbo → [sleep]soggetto → [cat]soggetto → [mouse]aggettivo → [gray]...
Interpretando una frase come lista di elementi è possibile verificarne la conformità ad una certa grammatica, qui implementata mediante un esemplificativo SF, listato interamente...
%REGOLE%frase → nominale, verbale%nominale → determinativo, nominale2%nominale → nominale2%nominale2 → aggettivo, nominale2%nominale2 → soggetto%verbale → verbo, nominale%verbale → verbo
append([],A,A).append([A|B],C,[A|D]):-
append(B,C,D).
frase(S):-append(S1,S2,S),frase(S1),frase(S2).
frase(S):-append(S1,S2,S),nominale(S1),
verbale(S2).nominale(S):-
append(S1,S2,S),determinativo(S1),
nominale2(S2).nominale(S):-
nominale2(S).nominale2(S):-
append(S1,S2,S),aggettivo(S1),
nominale2(S2).nominale2(S):-
soggetto(S).verbale(S):-
append(S1,S2,S),verbo(S1),nominale(S2).
verbale(S):-verbo(S).
%VOCABOLARIO%determinativo → the%determinativo → a%aggettivo → beautiful%aggettivo → hungry%aggettivo → speedy%aggettivo → white%soggetto → cat%soggetto → mouse%soggetto → dog%verbo → catch%verbo → eat%verbo → run
determinativo([the]).
27

determinativo([a]).aggettivo([beautiful]).aggettivo([hungry]).aggettivo([speedy]).aggettivo([white]).soggetto([cat]).soggetto([mouse]).soggetto([dog]).verbo([catch]).verbo([eat]).verbo([run]).
Anche in tal caso è possibile l’utilizzo delle difference list, nella forma
%REGOLEfrase(S\S0):-
frase(S\S1), frase(S1\S0).frase(S\S0):-
nominale(S\S1), verbale(S1\S0).nominale(S\S0):-
determinativo(S\S1), nominale2(S1\S0).nominale(S\S0):-
nominale2(S\S0).nominale2(S\S0):-
aggettivo(S\S1), nominale2(S1\S0).nominale2(S\S0):-
soggetto(S\S0).verbale(S\S0):-
verbo(S\S1),nominale(S1\S0).
verbale(S\S0):-verbo(S\S0).
%VOCABOLARIOdeterminativo([the]\[]).determinativo([a]).aggettivo([beautiful]\[]).aggettivo([hungry]\[]).aggettivo([speedy]\[]).aggettivo([white]\[]).soggetto([cat]\[]).soggetto([mouse]\[]).soggetto([dog]\[]).verbo([catch]\[]).verbo([eat]\[]).verbo([run]\[]).
4) Reti neurali (artificiali)Una rete neurale artificiale (ANN "Artificial Neural Network" in inglese, normalmente chiamata solo "rete neurale", NN "Neural Network"...
nel seguito RN), secondo la definizione formale di Hecht-Nielsen, è una “struttura parallela che processa informazioni distribuite” e consta di elementi di processazione, PEs o neuroni, che possono avere una memoria locale, in grado di processare localmente informazioni e interconnessi tra loro mediante canali, detti connessioni, che trasmettono segnali unidirezionali: ogni neurone ha una singola connessione di uscita che si dirama in un certo numero di connessioni collaterali, ognuna della quali trasporta lo stesso segnale d'uscita del neurone (che può essere di qualunque tipo matematico), inoltre la computazione eseguita all'interno di ciascun neurone può essere arbitrariamente definita con l'unica restrizione che deve essere completamente locale, ovvero deve dipendere solo dai valori correnti dei segnali di ingresso che arrivano al neurone tramite opportune connessioni e dai valori immagazzinati nella memoria locale del neurone.
Le RN fanno capo alla tesi forte dell'IA: l'obiettivo è realizzare un sistema in grado di risolvere problemi su un determinato dominio senza che vi sia alcuna conoscenza pregressa su tale dominio. Nella tesi debole il problema principale è il trasferimento al sistema della conoscenza in possesso degli esperti mediante una opportuna formalizzazione, e gli esperti non sono necessariamente idonei a tale compito (al pari degli informatici): nella tesi forte tale punto critico decade perchè il sistema - che si comporta come una black box che ad un vettore di input X risponde con un vettore di output Y - non parte da un predeterminato algoritmo risolutivo ma si pone l'obiettivo di apprendere per esempi (learning for examples); solo in una fase successiva, terminato l'apprendimento, esso opera in accordo alla conoscenza acquisita, generalizzando gli esempi forniti ed estrapolandone un modello sulla base del quale è in grado verosimilmente di effettuare una “previsione”, ovvero rispondere un Y adeguato ad un X che non gli è mai stato presentato prima come ingresso. Come si vedrà, alla base del funzionamento delle RN ci sono fondamenta matematiche molto rigorose (la cui conoscenza non è però strettamente necessaria dal punto di vista dell'utente), comunque l'idea di fondo è di immediata ed intuitiva comprensione: si tratta di
28
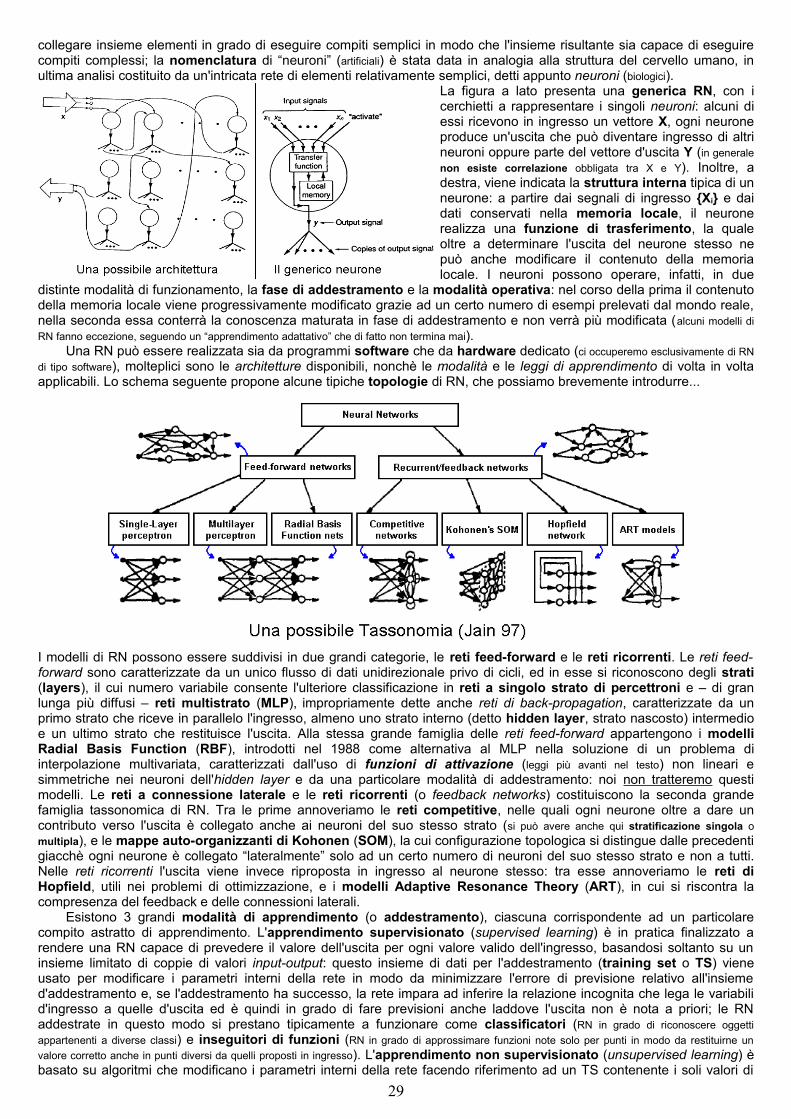
collegare insieme elementi in grado di eseguire compiti semplici in modo che l'insieme risultante sia capace di eseguire compiti complessi; la nomenclatura di “neuroni” (artificiali) è stata data in analogia alla struttura del cervello umano, in ultima analisi costituito da un'intricata rete di elementi relativamente semplici, detti appunto neuroni (biologici).
La figura a lato presenta una generica RN, con i cerchietti a rappresentare i singoli neuroni: alcuni di essi ricevono in ingresso un vettore X, ogni neurone produce un'uscita che può diventare ingresso di altri neuroni oppure parte del vettore d'uscita Y (in generale non esiste correlazione obbligata tra X e Y). Inoltre, a destra, viene indicata la struttura interna tipica di un neurone: a partire dai segnali di ingresso {Xi} e dai dati conservati nella memoria locale, il neurone realizza una funzione di trasferimento, la quale oltre a determinare l'uscita del neurone stesso ne può anche modificare il contenuto della memoria locale. I neuroni possono operare, infatti, in due
distinte modalità di funzionamento, la fase di addestramento e la modalità operativa: nel corso della prima il contenuto della memoria locale viene progressivamente modificato grazie ad un certo numero di esempi prelevati dal mondo reale, nella seconda essa conterrà la conoscenza maturata in fase di addestramento e non verrà più modificata (alcuni modelli di RN fanno eccezione, seguendo un “apprendimento adattativo” che di fatto non termina mai).
Una RN può essere realizzata sia da programmi software che da hardware dedicato (ci occuperemo esclusivamente di RN di tipo software), molteplici sono le architetture disponibili, nonchè le modalità e le leggi di apprendimento di volta in volta applicabili. Lo schema seguente propone alcune tipiche topologie di RN, che possiamo brevemente introdurre...
I modelli di RN possono essere suddivisi in due grandi categorie, le reti feed-forward e le reti ricorrenti. Le reti feed-forward sono caratterizzate da un unico flusso di dati unidirezionale privo di cicli, ed in esse si riconoscono degli strati (layers), il cui numero variabile consente l'ulteriore classificazione in reti a singolo strato di percettroni e – di gran lunga più diffusi – reti multistrato (MLP), impropriamente dette anche reti di back-propagation, caratterizzate da un primo strato che riceve in parallelo l'ingresso, almeno uno strato interno (detto hidden layer, strato nascosto) intermedio e un ultimo strato che restituisce l'uscita. Alla stessa grande famiglia delle reti feed-forward appartengono i modelli Radial Basis Function (RBF), introdotti nel 1988 come alternativa al MLP nella soluzione di un problema di interpolazione multivariata, caratterizzati dall'uso di funzioni di attivazione (leggi più avanti nel testo) non lineari e simmetriche nei neuroni dell'hidden layer e da una particolare modalità di addestramento: noi non tratteremo questi modelli. Le reti a connessione laterale e le reti ricorrenti (o feedback networks) costituiscono la seconda grande famiglia tassonomica di RN. Tra le prime annoveriamo le reti competitive, nelle quali ogni neurone oltre a dare un contributo verso l'uscita è collegato anche ai neuroni del suo stesso strato (si può avere anche qui stratificazione singola o multipla), e le mappe auto-organizzanti di Kohonen (SOM), la cui configurazione topologica si distingue dalle precedenti giacchè ogni neurone è collegato “lateralmente” solo ad un certo numero di neuroni del suo stesso strato e non a tutti. Nelle reti ricorrenti l'uscita viene invece riproposta in ingresso al neurone stesso: tra esse annoveriamo le reti di Hopfield, utili nei problemi di ottimizzazione, e i modelli Adaptive Resonance Theory (ART), in cui si riscontra la compresenza del feedback e delle connessioni laterali.
Esistono 3 grandi modalità di apprendimento (o addestramento), ciascuna corrispondente ad un particolare compito astratto di apprendimento. L'apprendimento supervisionato (supervised learning) è in pratica finalizzato a rendere una RN capace di prevedere il valore dell'uscita per ogni valore valido dell'ingresso, basandosi soltanto su un insieme limitato di coppie di valori input-output: questo insieme di dati per l'addestramento (training set o TS) viene usato per modificare i parametri interni della rete in modo da minimizzare l'errore di previsione relativo all'insieme d'addestramento e, se l'addestramento ha successo, la rete impara ad inferire la relazione incognita che lega le variabili d'ingresso a quelle d'uscita ed è quindi in grado di fare previsioni anche laddove l'uscita non è nota a priori; le RN addestrate in questo modo si prestano tipicamente a funzionare come classificatori (RN in grado di riconoscere oggetti appartenenti a diverse classi) e inseguitori di funzioni (RN in grado di approssimare funzioni note solo per punti in modo da restituirne un valore corretto anche in punti diversi da quelli proposti in ingresso). L'apprendimento non supervisionato (unsupervised learning) è basato su algoritmi che modificano i parametri interni della rete facendo riferimento ad un TS contenente i soli valori di
29

input, senza precisare le corrispondenti uscite: l'obiettivo è tentare di raggruppare i dati d'ingresso in opportuni cluster (in pratica classi) che globalmente siano rappresentativi dell'intero insieme dei dati immessi; l'apprendimento non supervisionato è anche impiegato per sviluppare tecniche di compressione dei dati. L'apprendimento per rinforzo (graded o reinforcement learning) può essere visto, in sostanza, come una sintesi tra le due modalità precedenti, ovvero la rete evolve in maniera autonoma come nella modalità non supervisionata, cui però si affianca ciclicamente una modalità supervisionata: noi non tratteremo questa modalità di apprendimento.
Esistono inoltre 5 categorie fondamentali di leggi di apprendimento. Nel performance learning (adottato tipicamente dalle reti a percettroni) l'obiettivo è massimizzare/minimizzare un certo indice prestazionale e tutti i neuroni partecipano in egual misura all'addestramento. Nel competitive learning (adottato ad esempio dalle SOM di Kohonen) si genera invece una competizione tra i diversi neuroni e, ad ogni passo dell'addestramento, solo una parte di essi modifica i suoi parametri interni. Ci sono anche coincidence learning, filter learning e spatiotemporal learning: noi non tratteremo queste categorie. Si noti che non esiste perfetta ortogonalità tra modalità di addestramento e leggi di apprendimento: in molti casi alle leggi di apprendimento possono essere applicate sia modalità di addestramento supervisionata che non, in altri casi (per esempio per l'algoritmo di backpropagation... vedi più avanti) la sola modalità supervisionata.
Nell'analisi dell'ampia varietà di RN fino ad oggi disponibili non si può non citare un progenitore delle RN, il primitivo neurone artificiale proposto da McCulloch-Pitts nel famoso lavoro “A logical calculus of the ideas immanent in nervous
activity" (1943), che schematizza un combinatore lineare a soglia, con dati binari multipli in entrata e un singolo dato binario in uscita, di cui un esempio è rappresentato nella figura a lato: un numero opportuno di tali elementi, connessi in modo da formare una rete, è in grado di calcolare semplici funzioni booleane. In realtà, mancando qualsiasi forma di addestramento, a rigore non si dovrebbe parlare nè di “neurone” nè tantomeno di “rete neurale”.
Un primo vero e proprio modello di RN viene schematizzato da Rosenblatt nel suo libro "Psychological review" (1957), nel quale, allo scopo di fornire un'interpretazione dell'organizzazione generale dei sistemi biologici, egli introduce il percettrone (perceptron), antesignano delle attuali RN e schematicamente rappresentato nella figura a destra: il modello probabilistico di Rosenblatt mira all'analisi in forma matematica di funzioni legate all'immagazzinamento delle informazioni e al riconoscimento di patterns, e costituisce un progresso decisivo rispetto al modello binario di McCulloch-Pitts, dal momento che il suo percettrone ha pesi sinaptici variabili ed è quindi in grado di apprendere. La memoria locale del percettrone è rappresentata dai valori reali Wi detti pesi, ciascuno associato ad un ingresso Xi (X0 è un ingresso unitario fittizio, ed è detta Bias Unit). La funzione di trasferimento è una semplice somma pesata degli ingressi (una combinazione lineare degli ingressi secondo i pesi), in pratica un prodotto scalare tra i vettori W e X, mentre l'uscita binaria vale 1 se il prodotto scalare è non negativo, 0 altrimenti (il percettrone si presta pertanto ad essere usato come classificatore a due sole classi o per approssimare funzioni con uscite binarie). Si può dare una interpretazione geometrica della funzione di trasferimento del percettrone osservando il grafico qui sotto (bidimensionale solo per chiarezza): essa descrive un iperpiano (nel caso bidimensionale, W0 + W1 X1 + W2 X2 = 0, una retta) che delimita le regioni di decisione
del percettrone, laddove l'iperpiano stesso è il luogo geometrico dei punti per i quali il prodotto scalare calcolato è nullo, per cui il percettrone non fa altro che operare una separazione lineare dei punti dello spazio (in 2D una retta che divide un piano, in 3D un piano che divide uno spazio, ...), definendo in tal modo due distinte classi. Nella fase di addestramento, supervisionata, vengono sottoposti al percettrone degli ingressi e le relative uscite, e in base a questi esso modifica i pesi, in accordo alla legge di apprendimento, producendo ad ogni modifica una rotazione (agendo su Wi con i≥1) e/o una traslazione (agendo su W0) dell'iperpiano, che quindi non è strettamente vincolato a passare per l'origine; la legge di apprendimento W new = W old + (y-y') x (che per il momento non giustifichiamo) prescrive che il nuovo valore del vettore W si ottenga dal precedente sommandogli il prodotto tra il vettore d'ingresso e la differenza tra l'uscita desiderata (y) e l'uscita prodotta dal percettrone (y'), ambedue naturalmente binarie: se le uscite coincidono W rimane immutato (coerentemente col fatto che non è necessario aggiungere conoscenza al percettrone) altrimenti viene modificato.A titolo di esempio possiamo far “imparare” al percettrone
la semplice funzione logica OR inclusivo (di cui si riporta a lato la tabella di verità). Prima di tutto, ogni legge di apprendimento parte da una condizione iniziale, cioè i pesi devono possedere un valore di partenza, e noi fissiamo (per il momento senza giustificare) il vettore di partenza dei pesi a [0.5, 0, 0], dopodichè si procede sottoponendo alla funzione di trasferimento del percettrone ogni possibile configurazione degli ingressi: se il valore calcolato coincide con quello atteso si procede con la configurazione successiva, altrimenti il vettore W viene modificato coerentemente con la legge di apprendimento...
W0 [ 0.5, 0, 0] ∙ X [1, 0, 0] → y' = 1 ≠ 0 = y applico legge di app.to30

W1 [-0.5, 0, 0] ∙ X [1, 0, 1] → y' = 0 ≠ 1 = y “ W2 [ 0.5, 0, 1] ∙ X [1, 1, 0] → y' = 1 = 1 = y nessuna modificaW2 [ 0.5, 0, 1] ∙ X [1, 1, 1] → y' = 1 = 1 = y “
e una volta esauriti gli ingressi si ricomincia, fino a che il vettore W non viene più modificato da nessuno degli ingressi...
W2 [ 0.5, 0, 1] ∙ X [1, 0, 0] → y' = 1 ≠ 0 = y applico legge di app.toW3 [-0.5, 0, 1] ∙ X [1, 0, 1] → y' = 1 = 1 = y nessuna modificaW3 [-0.5, 0, 1] ∙ X [1, 1, 0] → y' = 0 ≠ 1 = y applico legge di app.toW4 [ 0.5, 1, 1] ∙ X [1, 1, 1] → y' = 1 = 1 = y nessuna modificaW4 [ 0.5, 1, 1] ∙ X [1, 0, 0] → y' = 1 ≠ 0 = y applico legge di app.toW5 [-0.5, 1, 1] ∙ X [1, 0, 1] → y' = 1 = 1 = y nessuna modificaW5 [-0.5, 1, 1] ∙ X [1, 1, 0] → y' = 1 = 1 = y “ W5 [-0.5, 1, 1] ∙ X [1, 1, 1] → y' = 1 = 1 = y “ W5 [-0.5, 1, 1] ∙ X [1, 0, 0] → y' = 0 = 0 = y “
la configurazione dei pesi finale è quindi [-0.5, 1, 1] giacchè non può più essere modificata dagli ingressi, e la rete a questo punto è in grado di riconoscere correttamente la funzione OR: geometricamente si ottiene la retta X1 + X2 = 0,5 che è solo una delle possibili rette che risolvono il problema assegnato (per diverse condizioni iniziali si ottengono diverse soluzioni, equindi diverse rette).
Il percettrone di Rosenblatt calamita l'attenzione degli appassionati di IA per oltre un decennio, fino a quando nell'opera "An introduction to computational geometry" (1969) Minsky-Papert non mostrano i limiti operativi delle semplici reti a singolo strato basate sul percettrone, dimostrando l'impossibilità di risolvere per questa via tutti i problemi non caratterizzati da separabilità lineare delle soluzioni, come la semplice funzione logica XOR: geometricamente, come da figura, considerati i 4 punti corrispondenti alle configurazioni di ingresso, non esiste alcuna retta in grado di confinare in due semipiani distinti i punti in cui la XOR vale 1 da quelli in cui vale 0. Una possibile soluzione al problema arriverà solo negli anni '80 ed è rappresentata dal percettrone multilivello (leggi più avanti).
Ancora a partire dal neurone di McCulloch-Pitts, nel 1960 il professor Widrow sviluppa una nuova rete a singolo strato, denominata ADALINE (ADAptive LInear Neuron, e più tardi ADAptive LINear Element), la cui legge di apprendimento è quasi identica a quella di Rosenblatt, mentre la differenza sostanziale sta nel fatto che l'uscita (funzione di attivazione) è proprio il prodotto scalare W • X e dunque continua e non binaria, e non c'è pertanto alcuna soglia.
Dal punto di vista geometrico (figura a sinistra) l'iperpiano (una retta nello spazio bidimensionale) ha lo stesso significato del caso del percettrone (luogo geometrico dei punti in cui il prodotto scalare è nullo), solo che stavolta y' dipende linearmente dalla distanza di X dall'iperpiano (y' è tanto maggiore in modulo quanto più X si allontana dall'iperpiano).
Una classica applicazione è l'approssimazione di una funzione y a n variabili.Con riferimento all'errore commesso assumendo coincidente la funzione y e la sua approssimazione y', consideriamo la seguente espressione F(w) dell'errore quadratico medio, calcolato come media - per un numero arbitrariamente grande
di coppie (xk,yk) della funzione (è questo il senso del limite su N) – del quadrato della distanza tra i valori calcolati e i valori attesi. La funzione d'errore F(w) ha tipicamente la forma di un paraboloide (la figura rappresenta il caso bidimensionale, cioè una funzione a due variabili) per cui - salvo casi eccezionali - ha un unico punto di minimo, e affinchè l'approssimazione sia ottima, è necessario trovare questo minimo: azzerando il gradiente, si trova il vettore W* dei pesi ottimo che risolve in senso assoluto l'addestramento della nostra rete. In realtà, questa “soluzione analitica” richiede un numero N di coppie (xk,yk) (ovvero il TS) straordinariamente elevato che non sempre è disponibile, così come non è detto che l'inversa della matrice R
31
sia sempre calcolabile. L'alternativa è la legge di apprendimento di Widrow-Hoff, detta anche “Delta Rule”...
Dal punto di vista geometrico, la soluzione analitica esatta vista in precedenza si ottiene partendo da un arbitrario punto sul paraboloide (nella figura è ξ start) corrispondente ad un arbitrario valore del vettore dei pesi W, e procedendo (con la modifica dei pesi) direttamente nella direzione corrispondente alla massima pendenza e nel verso discendente, fino a raggiungere W* (cui corrisponde l'errore minimo ξ min). La legge di apprendimento che ne scaturisce (indicata qui sopra) dovrebbe modificare i pesi di una quantità proporzionale al gradiente e di segno opposto, tuttavia in questa formula compare una media statistica che ripropone il problema testé esposto: il calcolo esatto di questa media richiederebbe un TS di cardinalità infinita, cosa ovviamente non possibile. L'ostacolo viene aggirato introducendo una differenza concettuale fra training by epoch e training by pattern: nel primo caso la modifica dei pesi viene effettuata dopo ogni “epoca”, cioè dopo ogni presentazione dell'intero TS al sistema, ovvero, tenendo fermi i pesi, il sistema calcola F(W) sulla base di tutte le N terne (xk,yk,y'k) individua la direzione che minimizza l'errore ed esegue una modifica dei pesi in quella direzione secondo un opportuno learning rate η, coefficiente di apprendimento; nel secondo caso invece la modifica dei pesi avviene, al pari del percettrone, per ogni esemplare del TS, seguendo di volta in volta la direzione di un gradiente locale calcolato campione per campione e non mediato rispetto a tutto il TS. Nel caso di ADALINE a rigore si dovrebbe effettuare un training by epoch, tuttavia Widrow-Hoff hanno dimostrato che anche adottando un criterio di training by pattern si converge comunque al punto di minimo: invece di procedere direttamente verso il punto di minimo, ci si arriva con una serie di spostamenti ripetuti...
che visivamente, tra ξ start e ξ min, non procedono ortogonalmente alle curve di isoerrore (intersezioni del paraboloide con piani a quota ξ costante) nella direzione di massima pendenza e sul tragitto quindi più breve, bensì producono una traiettoria spezzata che localmente non sempre si muove nella direzione corretta, pur convergendo – a regime – alla soluzione. Si noti che il learning rate η misura la dimensione del passo, per cui la lunghezza di ciascun passo è ad esso proporzionale: un η molto piccolo causa una convergenza molto lenta, con un η troppo grande si corre invece il rischio di non riuscire a fermarsi mai sul punto di minimo, sperimentando una divergenza rispetto alla soluzione; generalmente η < 1 e con valori tipici intorno a 0,5.
Si noti che i modelli fin qui analizzati hanno oggi un valore esclusivamente didattico: a partire dagli anni '80 sono state sviluppate architetture di maggior complessità e pregio. Già nel 1974 il matematico americano Werbos getta le basi per l'addestramento del cosiddetto Percettrone Multilivello (MLP, Multi-Layers Perceptron), ma al suo lavoro non viene data molta importanza tanto è forte – ancora - l'eco della confutazione di Minsky e Papert al modello del percettrone dimostrata anni prima. Grazie agli studi di Hopfield nel 1982, l'interesse per le reti neurali cresce nuovamente e Rumhelhart-Hinton-Williams nel 1986 propongono il cosiddetto algoritmo dell'“error back-propagation” (BP), una generalizzazione dell'algoritmo di apprendimento del percettrone di Rosenblatt, alla base
32

dell'addestramento del percettrone multilivello. Un MLP si presenta come una rete a più strati o livelli (layers), per la precisione almeno 3: le componenti di un vettore di input X di cardinalità N entrano nel layer di ingresso e si propagano, attraverso gli N neuroni che compongono questo strato (il numero di ingressi della rete è quindi fissato dal problema... ad esempio per un approssimatore di funzione a 3 variabili lo strato di ingresso avrà 3 neuroni), direttamente in quello successivo senza subire alcuna modifica (non sono quindi, a rigore, neuroni in senso stretto perchè non effettuano alcuna elaborazione); esiste almeno un layer nascosto che “non vede” nè gli ingressi nè le uscite della rete; infine, il layer di uscita emette un vettore Y di cardinalità M che costituisce l'output della rete. Ciascun neurone (stiamo implicitamente escludendo quelli del primo strato) riceve un numero di ingressi pari al numero dei neuroni dello strato precedente - più naturalmente la solita Bias Unit – ed effettua il prodotto scalare tra tali ingressi e il proprio vettore dei pesi (rappresentativi della memoria locale del singolo percettrone) cui viene sommato il peso associato alla Bias Unit: tale risultato viene indicato nello schema con la notazione nets
pj dove l'apice s indica lo strato (h = hidden, nascosto e o = output, uscita), mentre i pedici p e j rispettivamente l'identificativo del campione Xp
somministrato alla rete (e a cui si riferisce la computazione) e l'identificativo del singolo neurone (che esegue la computazione); calcolata questa combinazione, ad essa viene poi applicata la funzione di attivazione producendo l'uscita effettiva del neurone pari a fs
j (netspj) (si noti che “net” sta appunto per uscita “netta”, al netto cioè della funzione di attivazione) che si propaga nella
rete esclusivamente in avanti (nessuna comunicazione laterale, quindi, tra neuroni dello stesso strato).La funzione di attivazione può essere di diversi tipi (e addirittura neuroni di strati diversi possono avere funzioni di attivazione diverse,
ovvero per esempio f hj ≠ f o
k ... benchè in generale non sia così) e non necessariamente lineare, il che costituisce il vero vantaggio del modello, dal momento che consente di risolvere anche problemi non linearmente separabili (si ricordi che nel percettrone di Rosenblatt era un gradino e in ADALINE la funzione identità)...
Per contro, il ricorso a funzioni di attivazione non lineari determina una forma diversa per la superficie di errore, che non è più necessariamente un paraboloide ma un agglomerato di monti e valli spesso molto complesso e irregolare, il che complica la ricerca del minimo soprattutto perchè in generale si hanno più minimi locali...
L'addestramento di una rete MLP avviene mediante il già citato algoritmo di back-propagation (BP), che è supervisionato e rientra nella categoria del performance learning (come per ADALINE), ovvero è finalizzato alla minimizzazione dell'errore, che può essere definito come
con Yj l'uscita attesa e Y'j quella effettiva del neurone j-esimo, con riferimento all'ingresso corrente X (la coppia (X,Y) fa ovviamente parte del TS). Il BP è strutturato come un algoritmo iterativo con due cicli innestati: nel ciclo più interno, ripetuto per ogni occorrenza del TS, ad un forward pass (passo in avanti) - nel quale si sottopone alla rete il campione r-esimo del TS e si calcola, a valle delle computazioni di tutti i neuroni di ogni strato, l'uscita della rete – e ad una valutazione puntuale dell'errore commesso (come scarto quadratico rispetto al valore atteso) con l'attuale configurazione dei pesi, segue un backward pass (passo all'indietro), in cui i pesi vengono modificati secondo la logica del “gradient descent” già vista in ADALINE, per cui a ciascun peso Wij del generico neurone j-esimo si somma
ovvero, graficamente, ci si sposta nella direzione corrispondente alla pendenza del gradiente di E nel verso discendente (in pratica, verso il centro della valle locale) secondo un opportuno learning rate; il ciclo più esterno consiste nella ripetizione di quello interno fino a che non venga verificata una opportuna condizione d'arresto, tipicamente del tipo E ≤ Emin: è stato dimostrato matematicamente che l'algoritmo converge. Naturalmente, poichè la configurazione iniziale dei pesi è indefinita e da fissare in modo casuale, si osserva che da reti diverse (con W iniziale diverso), pur sottoposte allo stesso addestramento, non si possono aspettare risultati identici ma soltanto risultati simili. Si noti inoltre che, anche se il BP appena descritto segue un training by pattern, è possibile ridefinirlo secondo la filosofia del training by epoch semplicemente spostando il backward pass all'esterno del ciclo for in modo da modificare i pesi della rete solo dopo che sia stato calcolato l'errore
33

quadratico medio sull'intero TS (tipicamente per 10'000 campioni sono sufficienti un centinaio di epoche, per un totale di un milione di passi di addestramento).
Applicando il teorema di derivazione delle funzioni composte è possibile quantificare analiticamente l'errore relativo al p-esimo campione del TS, il gradiente dell'errore e il conseguente valore della modifica da apportare al peso i-esimo del neurone j-esimo, sia per lo strato d'uscita che per lo strato nascosto: in particolare, il criterio con cui modificare i pesi dei neuroni dell'hidden layer (sebbene si necessiti, in teoria, della conoscenza delle uscite dei neuroni dello strato nascosto) può essere ricavato semplicemente esplicitando la dipendenza dell'errore finale proprio dai pesi dei neuroni di questo strato...
Si noti che, affinchè i passaggi sopra indicati abbiano un senso, è necessario che la funzione di attivazione sia differenziabile (per funzioni come il gradino o lineari a tratti si può effettuare, nei loro punti angolosi, una derivazione per continuità): a titolo di esempio si consideri la funzione sigmoidale...
limitata tra 0 e 1, presenta derivata massima intorno all'origine e asintoticamente nulla per ingressi molto grandi in modulo.
Nella figura a fianco è schematizzata una rete MLP a tre strati che schematizza la funzione XOR (si ricordi il problema riscontrato dal percettrone di Rosenblatt e la critica di Minsky), i neuroni di ingresso sono indicati coi pallini piccoli (si ricordi che essi non sono veri e propri neuroni), lo strato nascosto è costituito da due neuroni mentre il neurone di uscita è unico: i due numeri indicati in basso in ogni neurone sono i
34

i pesi Wj1 e Wj2 mentre il valore indicato con “th” (threshold, soglia) non è altro che -Wj0, ovvero il peso associato alla Bias Unit cambiato di segno; la funzione di attivazione è infatti il gradino, come per Rosenblatt, per cui se il prodotto scalare tra pesi ed input del neurone (più il Wjo naturalmente) è ≥ 0 allora l'uscita del neurone è alta: passando a secondo membro il Wj0 , si ricava banalmente che l'uscita del neurone è alta soltanto se il prodotto scalare è ≥ -Wj0 , cioè stiamo considerando una soglia di attivazione del neurone diversa da 0. Si può verificare che la struttura indicata è effettivamente in grado di risolvere problemi come quello dell'XOR.
Il MLP fin qui descritto può essere utilizzato come classificatore adottando per le uscite un “codice decodificato” (si pensi al decoder), ovvero nell'output layer si mettono tanti neuroni quante sono le classi tra le quali si necessita la discriminazione e ci si aspetta che la rete emetta un'uscita che vale 1 per il neurone relativo alla classe di appartenenza del campione presentato in input e 0 per i neuroni delle altre classi (cui ovviamente il campione non può appartenere); nella pratica, l'uscita non è binaria ma composta da numeri reali e si adotta la strategia del tipo “winner takes all”, ovvero “vince” la classe cui è associato il neurone che ha l'uscita più alta (si osservi che questa strategia può dar luogo ad incertezze se due delle uscite hanno valori prossimi tra loro). Lo schema seguente mostra il comportamento di una rete di percettroni - al variare del numero di strati – in diversi contesti applicativi...
In presenza di una rete single layer (percettrone singolo) le regioni di decisione sono semipiani limitati da un iperpiano, il che – come abbiamo visto - è insoddisfacente già per problemi semplici come l'inseguimento della XOR; una rete a due strati è in grado di generare regioni di decisione convesse ma aperte (i percettroni dell'hidden layer dividono il piano in semipiani e lo strato d'uscita li “compone”); una rete a tre strati risulta poi capace di definire regioni di decisione di forma qualunque, aperte, chiuse e persino “forate”.
In linea di principio man mano che il problema si complica dovrebbe esser necessario aumentare il numero di strati intermedi della MLP, tuttavia per il teorema di Kolmogorov è sufficiente aumentare solo il numero dei neuroni
mantenendo un unico strato intermedio: esso dimostra che una qualunque funzione
f : [0, 1]n → Rm
può essere realizzata esattamente da una RN feed-forward a 3 strati con n unità nello strato di ingresso, 2n+1 in quello nascosto (funzione di attivazione semilineare, ovvero simile ad una somma lineare pesata) e m in quello di uscita (funzione di attivazione altamente non lineare), tuttavia, poichè esso si limita a dichiarare l'esistenza di una RN siffatta ma non definisce i dettagli per la sua costruzione, la sua utilità pratica è modesta. Basato sul teorema di Kolmogorov, è utile citare anche il teorema di Hecht-Nielsen (che ha pari importanza teorica, tant'è che spesso si parla di teorema di Hecht-Nielsen-Kolmogorov): esso dimostra che, data una qualunque funzione
f : [0, 1]n → Rm
di tipo L2 (a quadrato sommabile su R secondo Lebesgue, si tratta in pratica di funzioni continue o con un numero finito di punti di discontinuità in [0,1]) e un arbitrario ε >0, esiste una RN feed-forward a 3 strati, che utilizza l'algoritmo back-propagation, che approssima la funzione con un errore quadratico medio minore di ε. Benchè non sia detto che per ogni RN esiste una funzione che ne descrive il comportamento globale, sulla base dei teoremi citati si può affermare che certamente per ogni funzione esiste una RN a 3 strati che la simula egregiamente (una relazione deterministica tra funzione e RN associata non è stata ancora formulata); in realtà, poichè all'aumentare del numero di strati la convergenza del BP diviene molto lenta, si opta (ogni volta che è possibile) per una rete a 2 soli strati con un numero adeguato di neuroni.
Come è stato già detto, la superficie di errore può essere altamente irregolare quando vengono utilizzate funzioni di attivazione non lineari, e questa sua impredicibile irregolarità è alla base di due classici problemi presentati dalle reti MLP: il problema delle flat spots (macchie piatte) e dei minimi locali. Nel primo caso una errata inizializzazione dei pesi (tipicamente valori positivi ed elevati) può portare in fase di addestramento in una zona del piano (da intendersi nel caso più generale come n-dimensionale) delle ascisse della funzione di attivazione in cui la sua derivata è praticamente nulla, il che rende nulle anche le variazioni dei pesi e “impantana” l'addestramento della rete: al fine di evitare tutto questo, generalmente il valore iniziale dei pesi si sceglie tra ±1/√ N, dove N è il numero di neuroni. Nel secondo caso invece, il problema è rappresentato dal fatto che l'addestramento può condurre alla modifica dei pesi in direzione di un minimo locale della superficie di errore e non del minimo assoluto; una possibile soluzione si ottiene modificando l'algoritmo di BP, nel senso di accelerare l'apprendimento della RN, tramite un “momentum”: al ∆ wji (n) del passo n-esimo di addestramento viene sommato il
35

termine K⋅ ∆ wji (n-1) con 0 ≤ K ≤ 1 (meglio se 0.2 ≤ K ≤ 0.8, in modo da non essere troppo vicino agli estremi) e determinato empiricamente, ovvero viene rinforzato il mutamento di ogni peso nella direzione generale di discesa lungo la superficie d'errore già emersa durante gli aggiornamenti precedenti (il “momentum” funge quindi, potremmo dire, da filtro passa-basso per l'aggiornamento dei pesi), allo scopo di annullare eventuali oscillazioni contingenti prodotte dall’algoritmo e “saltare a grandi balzi” i minimi locali incontrati lungo la discesa del gradiente. In realtà è necessario precisare che il “momentum” non elimina la possibilità teorica che la RN incorra in minimi locali, ma rappresenta comunque un utile accorgimento in fase di addestramento della rete; inoltre, si tenga presente che il “momentum” rappresenta una metodologia più che una equazione ben precisa: in letteratura si trovano molti e diversi tipi di “momentum”, ciascuno con le proprie caratteristiche,vantaggi e svantaggi.
E' utile a questo punto, prima di passare all'analisi di altri tipi di RN, approfondire il discorso sul training set (TS), che fin qui ci si è limitati a citare senza scendere nei dettagli... Come già accennato in precedenza, il TS è un insieme di N coppie di vettori (xk,yk), ovvero “esempi di ingresso” con la corrispondente uscita, estrapolati dal dominio di interesse (mondo reale) su cui si vuole addestrare la RN, e tipicamente la sua costruzione richiede grande dispendio di tempo e risorse per la raccolta delle informazioni necessarie. Caratteristiche fondamentali di un TS sono la significatività statistica (concetto isomorfo alla completezza dei SF) - cioè deve essere “in piccolo” ben rappresentativo della realtà che vuole descrivere (una scarsa significatività statistica è alla base, come si vedrà, di un addestramento della rete insoddisfacente o problematico) - e una corretta cardinalità - cioè deve essere sufficientemente ampio da coprire una significativa casistica ma non eccessivamente (o inutilmente) ampio per non appesantire la fase di addestramento.
La funzione del TS, a questo punto della trattazione, dovrebbe essere chiara: una RN finalizzata ad approssimare una certa funzione incognita y = f(x) con un'altra funzione y' = R(x,W) (dipendente anche dalla matrice W dei pesi, in pratica i parametri interni della rete, detti anche “gradi di libertà”), viene addestrata mediante esempi (learning for examples), ovvero istanze yk = f(xk) note di quella funzione, e W - inizializzata a valori casuali (generalmente non tutti uguali, nè tutti nulli) - progressivamente “tarato” nella prospettiva di rendere massima la bontà dell'approssimazione, riducendo via via lo scarto (misurato tipicamente come errore quadratico) tra valori attesi e valori effettivi. Anche se inizialmente i valori y'k forniti dalla RN sono lontanissimi dai valori yk corretti, a patto che il numero dei pesi e degli esempi sia sufficientemente elevato, è possibile costruire un'approssimazione con un grado arbitrario di accuratezza (meccanismo congruente al concetto di trasformata, per cui ogni funzione può essere ottenuta come combinazione di funzioni più semplici purchè si utilizzi un numero sufficiente di tali funzioni): è intuitivo che l'errore diminuisca all'aumentare del numero dei pesi - ad esempio, la “traiettoria” di un insieme di punti su un piano può essere approssimata da una retta (ax+b → due parametri) ma ancora meglio da una polinomio (a1xn-1 + ... + an-1x + an → n parametri) – che a sua volta dipende dal numero di neuroni (si parla di “dimensione della rete”, da intendersi come parametro di progetto); allo stesso modo, è chiaro che un numero di esempi limitato può introdurre nella rete una quantità di informazioni insufficiente al suo addestramento e va determinato accuratamente. Contrariamente alle aspettative, non esiste correlazione diretta tra
cardinalità dei pesi e cardinalità del TS, dal momento che il numero ottimale dei pesi dipende unicamente dalla funzione che si vuole approssimare: a titolo di esempio, se la funzione incognita risponde ad un modello lineare, pur avendo a disposizione un TS di migliaia di campioni è del tutto inutile avere più di due pesi (coefficiente angolare e intercetta della retta); viceversa, se la distribuzione dei punti risponde ad un modello non lineare (si pensi ad una linea curva fortemente arzigogolata, come in figura qui a fianco) il numero dei pesi necessario cresce significativamente, grande o piccolo che sia il TS. Generalmente cardinalità dei pesi e della TS sono oggetto di una
regolazione “sul campo”: si parte da un TS piccolo e da una limitata dimensione della rete, e se – osservando opportuni indicatori di funzionamento - la rete mostra di non funzionare bene si cerca di capire da quale dei due fattori ciò può dipendere e li si regola di conseguenza.
Dall'analisi delle RN condotta fin qui appare chiaro che il TS, per quanto sia ben rappresentativo del dominio di interesse, non può essere trattato come semplice database: una RN che restituisse y'k=yk in risposta a xk semplicemente consultando il contenuto del TS, commetterebbe certamente un errore nullo sul TS medesimo ma sarebbe inutile come strumento di IA, essendo incapace di generalizzare il contenuto del database per rispondere ad ingressi totalmente nuovi. D'altro canto, l'algoritmo di addestramento tipico di una RN (descritto in precedenza) non è certo costituito da molte righe di codice, e ciò nonostante lo sforzo computazionale ad esso associato non è mai banale: in corrispondenza di ogni nuovo ingresso, deve essere minimizzato non solo l'errore relativo all'ingresso attuale ma anche tutti quelli precedenti, ovvero l'apprendimento deve procedere compatibilmente con il vincolo di NON deteriorare le prestazioni della rete relative agli ingressi precedenti. Il generico termine “ingresso“ indica il singolo campione del TS se si opera secondo la strategia del training by pattern, o l'intero TS se invece si opera secondo il training by epoch: la prima strategia è più rapida ma non ricorre ad una visione d'insieme del problema, come invece fa la seconda che è più lenta ma più “prudente”.
Nel grafico (qui a fianco) è indicata una curva di apprendimento che serve per monitorare il processo di apprendimento della rete: l'errore (globale sull'intero TS) è funzione del numero di epoche di addestramento e – se l'algoritmo è ben fatto – decresce progressivamente con il numero di cicli, tende asintoticamente ad un certo valore (che può essere anche nullo), la sua derivata tende a 0 e i miglioramenti del sistema diventano via via sempre più costosi in termini computazionali. Nel caso di un algoritmo di addestramento come quello più volte descritto (si tenga presente il BP per una rete MLP) è particolarmente rilevante il ruolo assunto dalla regola di arresto (stop-learning rule) dell'algoritmo stesso: tipicamente essa prevede l'interruzione dell'addestramento quando l'errore rilevato (o la sua derivata) è inferiore ad una prefissata soglia; tuttavia l'efficienza di questa regola dipende molto da quanto il TS è effettivamente
36

rappresentativo del dominio reale di interesse, e può comportare lo sfavorevole fenomeno denominato overtraining (iperapprendimento), consistente nella possibilità che l'algoritmo individui relazioni funzionali - tra i vettori xk e yk dei campioni del TS – nella realtà inesistenti: in pratica la rete “si specializza troppo” sui campioni del TS e comincia a perdere la sua capacità di generalizzazione, consistente nel rendere basso l'errore su campioni non appartenenti al TS. Allo scopo di evitare inconvenienti di questo tipo, alcuni autori suggeriscono di utilizzare un criterio di stop-learning basato sulla Metodologia di Discesa Concorrente dell'errore (MDC), ovvero l'insieme iniziale dei dati che normalmente comporrebbero il TS viene partizionato in due, il training set propriamente detto ed il training test (o validation) set o TTS (per esempio l'80% dei campioni disponibili confluisce in TS e il restante 20% in TTS, selezionando i campioni rigorosamente a caso) e successivamente l'algoritmodi addestramento viene applicato al solo TS, finché non sia raggiunto un minimo (assoluto) dell'errore calcolato sul TTS. A regime, date le due curve d'errore misurate per il TS e il TTS, si possono avere tre alternative: (1) convergenza dei due errori, il che è segno che i campioni dei due insiemi TTS e TS hanno uguale copertura statistica (sono statisticamente omogenei); (2) l'errore commesso su TTS è mediamente più elevato, sintomo del fatto che il TTS non rappresenta adeguatamente il TS e che quindi i dati inizialmente raccolti non sono statisticamente omogenei: il TS iniziale non è ben scelto; (3) l'errore commesso su TTS prende ad aumentare, cioè da una certa epoca n* in poi diverge: questo è il caso più critico (e più frequente), sintomatico di un problema di overtraining, e richiede l'arresto del processo di addestramento nel punto di minimo per ETTS.
Nella progettazione di una RN, in generale, è auspicabile che la curva d'errore misurata sul TS tenda a 0 e che quella misurata sul TTS non sia molto peggiore. Normalmente, poichè lo scopo è definire una RN a numero ottimale di neuroni e massima efficienza, si procede in questo modo: fissato un numero iniziale di neuroni e il TS/TTS, se durante l'addestramento si ricade nel caso (3) e la distanza tra le due curve, nel punto di minimo per ETTS, appare elevata (un valore considerato soddisfacente è dell'ordine dello 0.1%) si aumenta il numero dei neuroni (si dice che il sistema necessita di un “maggior numero di gradi di libertà”) e si ripete l'addestramento; alla tornata successiva: (I) se la distanza tra le curve nel punto di minimo per ETTS è diminuita in modo soddisfacente (si dice che la rete “riesce a caratterizzare meglio la variabilità statistica”) significa che il numero di neuroni è adeguato, altrimenti occorre ulteriormente aumentarlo; (II) se le percentuali di riconoscimento della rete su TS e su TTS appaiono migliorate (o comunque sono elevate) si può dire di aver ottenuto una buona classificazione, altrimenti occorre modificare le features, cioè i parametri che discriminano le varie classi (in sostanza bisogna alterare qualitativamente - più che quantitativamente - il TS, cambiando il criterio con cui vengono selezionati dal mondo reale i campioni); (III) nel caso in cui sia la distanza tra le curve d'errore che le percentuali di riconoscimento non siano adeguate, occorre agire sia sulle features che sul numero dei neuroni.
Si osservi, per finire, che una RN addestrata deve funzionare – nella realtà - su un numero di campioni molto superiore a quello del TS, per cui è utile saggiare con cadenza periodica le prestazioni della RN su un opportuno Test Set (distinto dal TTS e dal TS): in altre parole si rende operativa la RN, monitorando periodicamente eventuali degradazioni delle percentuali di riconoscimento su campioni sempre nuovi prelevati direttamente dal mondo reale (a titolo di esempio, si pensi ad una RN per il riconoscimento delle targhe automobilistiche).
L'LVQ (Learning Vector Quantization) è un algoritmo di classificazione per RN - spesso definito una “versione supervisionata” dell'algoritmo SOM (vedi più avanti) – finalizzato a realizzare un'efficiente distribuzione in classi di campioni presentati in ingresso e viene proposto da Kohonen nel 1986: si parla di architettura LVQ con riferimento ad una RN a due strati (uno di input e uno di computazione/output, detto strato di Kohonen) che utilizza tale algoritmo. L'utilizzo tipico di una rete LVQ è come classificatore ad M classi: in fase di definizione i neuroni sono etichettati in modo da appartenere alle varie classi (tipicamente più neuroni per ciascuna classe e non necessariamente lo stesso numero di neuroni per ciascuna classe) e alla fine del
processo di apprendimento ogni neurone - più precisamente, il vettore dei pesi ad esso associato - rappresenterà un prototipo di campioni della classe cui è stato assegnato. L'algoritmo LVQ è di tipo competitive learning (quindi opera in modo differente rispetto al BP, che segue invece il paradigma performance learning), ovvero ogni ingresso X è connesso a tutti i neuroni dello strato di Kohonen, ciascuno di questi calcola la distanza (per vettori numerici si usa la metrica euclidea) tra il vettore di input e il proprio vettore dei pesi, si stabilisce quale neurone è a distanza minima (formalmente i neuroni “dialogano” tra loro per confrontare le loro distanze e quindi il modello richiede connessioni laterali – in rosso - nello strato di Kohonen... nella pratica è sufficiente un algoritmo secondario che calcoli il minimo all'interno di un vettore di distanze) e alla fine solo il neurone “vincitore” V acquisisce il diritto a modificare il proprio vettore dei pesi W, che viene “avvicinato” al vettore di ingresso X se la classe di assegnazione di V coincide con la classe di appartenenza di X (quindi se c'è stata corretta classificazione), o “allontanato” in caso contrario (quindi se c'è stata misclassificazione). Al contrario di quanto accade nelle MLP (in cui la conoscenza è distribuita su tutti i neuroni e non è possibile “giustificare” i risultati della RN), è interessante il fatto che LVQ crei prototipi che gli esperti del dominio possono facilmente riconoscere (in quanto formalmente omogenei ai
37
dati passati alla rete) il che rende semplice effettuare un postprocessing delle risposte fornite dalla rete.Sopra è schematizzato l'algoritmo LVQ1, la versione base dell'LVQ (di cui esistono molte varianti): per ognuno degli N
neuroni assegnati a ciascuna delle M classi viene calcolata la distanza di (metrica euclidea) del vettore dei pesi Wi dal vettore d'ingresso X, si calcola il minimo tra tali distanze, si verifica la congruenza tra la classe del neurone “n” vincitore e la corretta classe di attribuzione del campione di ingresso e poi si modifica Wi sommandogli algebricamente una frazione del vettore (X-Wi) in modo additivo (se la congruenza è verificata) o sottrattivo (in caso contrario). Si noti che la taratura corretta dei coefficienti α e γ deve essere fatta con cura perchè ha influenza sulla convergenza dell'algoritmo: normalmente essi non sono costanti ma variabili nel tempo secondo la formula αT = α0 (1-T/Tmax) con Tmax numero massimo di epoche e T epoca corrente (e analogamente anche per γ).
Oltre all'LVQ1 appena descritto esistono anche OLVQ1 (cioè LVQ1 ottimizzato, simile a LVQ1 ma ogni neurone ha suoi propri learning rate α e γ), LVQ2.1 (vengono selezionati i due neuroni più vicini e i loro pesi modificati solo se uno appartiene alla classe desiderata e l'altro no, e solo se la distanza dall'ingresso ricade in una predefinita finestra), LVQ3 (come il precedente ma se ambedue i neuroni vincitori appartengono alla classe corretta entrambi vengono modificati secondo uno specifico learning rate ε), OLVQ3 (cioè LVQ3 ottimizzato, simile a LVQ1 ma ogni neurone ha suoi propri learning rate α e γ), Multi-Pass LVQ (consiste nell'addestrare la rete con OLVQ1 e successivamente eseguire una “sintonia fine” dei prototipi con LVQ1, LVQ2.1 o LVQ3), e diversi altri che non tratteremo nel dettaglio.
L'algoritmo LVQ, che nella versione base è supervisionato, può essere reso non supervisionato per problemi di clustering: i neuroni non sono preassegnati alle classi (a loro volta non note a priori) e il neurone vincitore viene sistematicamente avvicinato all'ingresso (con riferimento al codice pascal-like, scompaiono quindi le righe IF ed ELSE). Nel grafico si prende in considerazione una rete con 4 neuroni, tutti inizialmente concentrati (cioè i loro vettori dei pesi) nel punto (1,0) e 4 clusters di campioni (punti) che la rete dovrebbe individuare; al primo campione del TS, dacchè tutti i neuroni sono alla medesima distanza da esso, il vincitore viene scelto a caso ed “avvicinato”; dal secondo campione in poi, però, tale neurone risulta ancora e sempre legittimamente vincitore (qualunque sia il campione in ingresso, a qualunque cluster esso appartenga e in qualunque ordine i campioni vengano presentati), si avvicina con moto oscillante e finisce per assumere una posizione equidistante da tutti e 4 i clusters, i quali vengono pertanto rappresentati tutti da un unico neurone mentre gli altri, “fermi al palo”, restano di fatto inutilizzati: tale indesiderabile fenomeno va sotto il nome di sottoutilizzo dei neuroni, e può presentarsi (sia pure con effetti meno critici) anche nel caso supervisionato.
I possibili accorgimenti utili a risolvere il problema del sottoutilizzo sono basati sull'adozione di una definizione non costante di distanza (con la quale definire il network winner, vincitore della rete) e di un meccanismo per cui i neuroni che vincono troppo vengono penalizzati. L'algoritmo FSCL (Frequency Sensitive Competitive Learning) adotta una “distanza modificata” definita come d'i = di ⋅ Fi, con di la distanza reale e Fi la frequenza relativa di vittorie del neurone i-esimo, e modifica i due neuroni più vicini anzichè uno solo, in particolare il vincitore viene “avvicinato” mentre il vice-vincitore viene “allontanato”. L'algoritmo C2L (Conscience Competitive Learning) adotta una “distanza modificata” definita come d''i = di – c ⋅ (1/N – Fi), con di ancora la distanza reale, Fi la frequenza relativa di vittorie del neurone i-esimo e c un coefficiente intero: nel caso ottimale in cui Fi valga 1/N, la “distanza modificata” coincide con la distanza reale. Nel caso supervisionato, dopo aver determinato il network winner con la distanza reale, si usa la “distanza modificata” per determinare il class winner, cioè il vincitore nella classe di appartenenza del campione d'ingresso, e i due winners vengono modificati secondo le regole
L'algoritmo LVQ1, per particolari TS, evidenzia prestazioni poco lusinghiere e, comunque si faccia variare il learning rate, esso non supera il 70% dei riconoscimenti...
Viceversa, a parità di TS, gli algoritmi FSCL e C2L raggiungono prestazioni sensibilmente migliori (FSCL addirittura tocca il 100%), sebbene le percentuali di riconoscimento misurate sul TTS siano inferiori di almeno un 5%.
La rete LVQ realizza, infine, la cosiddetta tassellazione di Voronoi (figura seguente). I numeretti indicano ciascuno la “posizione” (su un piano n-dimensionale) di un neurone e ogni linea costituisce il luogo geometrico dei punti ciascuno la
38

“posizione” (su un piano n-dimensionale) di un neurone e ogni linea costituisce il luogo geometrico dei punti equidistanti da due neuroni associati a regioni di decisione “confinanti” (essa è perpendicolare alla congiungente i due neuroni confinanti e passante per il suo punto mediano): posizionando opportunamente i neuroni è possibile ottenere configurazioni di regioni di decisione arbitrariamente complesse (al pari di quelle ottenibili con un MLP a 3 strati).
Un'altra interessante tipologia di rete è la cosiddetta mappa auto-organizzante o rete SOM (Self-Organizing Map), elaborata sempre da Kohonen, il cui algoritmo d'apprendimento rappresenta una brillante formulazione di apprendimento (sempre) non supervisionato, e ha generato un gran numero di applicazioni nell'ambito dei problemi di classificazione.
Una SOM è basata essenzialmente su un reticolo (o griglia) di neuroni i cui pesi sono continuamente adattati ai vettori d'ingresso (i campioni del relativo TS) di dimensione generica (nella maggior parte delle applicazioni piuttosto alta), mentre fornisce uscite di dimensione massima pari a 3, generando mappe bidimensionali o al più tridimensionali. Ciascun neurone occupa una precisa posizione sulla mappa (rappresentativa degli output) e compete con gli altri secondo la già citata filosofia del winner takes all, per cui il nodo con vettore dei pesi più “vicino” ad un certo input è dichiarato vincitore e i suoi pesi modificati in modo da “avvicinarlo” al vettore di ingresso; inoltre il nodo vincitore si “trascina dietro” anche i vettori dei pesi dei nodi ad esso adiacenti, i quali vengono pertanto spostati sulla griglia secondo la regola generale per cui “più un nodo è lontano dal vincitore meno marcata deve essere la variazione dei suoi pesi” (il che aggira elegantemente il problema del sottoutilizzo), precisamente secondo la formula
In particolare, si consideri un immaginario braccio a due giunti che di volta in volta (l'operazione si ripete nell'ordine delle migliaia di volte!) randomicamente “punta” ad un diverso campione di ingresso - indicato simbolicamente dalla coppia di coordinate (u,v) - e restituisce la coppia (θ,φ) di coordinate (nel caso in cui la mappa sia bidimensionale, come in figura... se invece la mappa è tridimensionale non è difficile immaginare una tripla del tipo (θ,φ,ρ)), con cui la rete realizza la corrispondenza topologica tra l'universo di input e la griglia di neuroni, peraltro disposti in un modo del tutto analogo agli elementi di una matrice (per esempio, il neurone (1,2) sarà situato nella riga 1 e nella colonna 2): una volta identificato il neurone più vicino al punto (θ,φ) sulla griglia, la rete aggiorna il vettore dei pesi Wi del generico neurone i-esimo secondo un coefficiente α decrescente con la distanza z dal neurone vincitore e con il tempo t di addestramento, per cui tutti i neuroni sufficientemente vicini (in senso geometrico... per esempio, i neuroni (1,2) e (2,2) sono a distanza 1 sul reticolo) al vincitore vengono coinvolti nello spostamento di quest'ultimo in direzione di (θ,φ); ovviamente se il neurone i-esimo coincide col vincitore, z varrà 0 e α sarà massimo, inoltre esisterà una certa distanza z* dal vincitore oltre la quale α sarà praticamente nullo e i neuroni oltre questo immaginario “limite di adiacenza” resteranno immobili, pertanto α viene definito fattore di neighbour (vicinanza).
Inizialmente tutti i neuroni (per la precisione, i vettori dei loro pesi) sono concentrati nell'origine, e all'aumentare dei cicli il reticolo tende ad espandersi. In verità, una configurazione in espansione “regolare” (come quella mostrata qui sopra), si ottiene solo se
39

anche la configurazione iniziale del reticolo denotava una coerente corrispondenza topologica (ovvero, per essere chiari, solo se il neurone (1,1) occupava l'angolo Nord-Ovest della massa iniziale, il neurone (1,N) l'angolo Nord-Est e così via...): in caso contrario ne può risultare una “maglia intrecciata” (twisted mesh). Inoltreuna SOM può essere “stimolata” con punti prelevati da uno spazio bidimensionale non necessariamente quadrato, ma anche – ad esempio – triangolare, così come sono possibili SOM lineari: in tutti i casi la rete si comporta come un gas che si espande fino
ad assumere la forma del recipiente che lo contiene.Infine una SOM, pur non essendo supervisionata, può
essere usate come classificatore. Dopo un primo addestramento non supervisionato, si sottopone alla SOM nuovamente lo stesso TS però labellato (ovvero tenendo presente l'appartenenza già nota dei singoli campioni alle diverse classi... label = etichetta), etichettando ciascun neurone sulla base delle competizioni vinte: se il neurone i-esimo (nel corso del secondo training) è risultato vincitore j volte e nella maggior parte di esse si è trattato di campioni della classe k, allora esso viene associato alla classe k; nel caso in cui non sia riconoscibile una prevalenzanetta di una classe (per esempio su j vittorie, nel 55% dei casi i campioni sono della classe k, nel restante 45% della classe h) al neurone viene associata una etichetta disambigua (nel caso precedente, kh).
Un'interessante applicazione delle SOM è lo scrittore fonetico, realizzato dallo stesso Kohonen nel 1988, la cui descrizione può chiarire ulteriormente quanto detto a proposito della SOM come classificatore. Lo strumento era un rudimentale riconoscitore vocale in grado di far comparire sullo schermo le lettere di una parola pronunciata da un utente umano: ciascuna parola veniva sottoposta a campionamento e ad essa associato un vettore di 15 elementi (uno per ogni componente frequenziale della parola stessa), la rete veniva poi sollecitata presentando in ingresso i campioni così ottenuti e ogni neurone veniva “labellato” nel modo descritto (ad esempio, tra quelli rappresentati in figura, il neurone vm è associato sia alla lettera v che alla lettera m, per cui, se in fase d'esecuzione risulta vincitore, il suono può essere tanto quello dell'una quanto dell'altra lettera). Per avere un'idea del funzionamento, in figura è rappresentata anche la sequenza di attivazione dei neuroni della SOM in risposta alla pronuncia della parola “humppila” (per la precisione, la parola pronunciata viene prima campionata nel modo descritto e poi i campioni ottenuti vengono presentati in sequenza alla rete).
Nel 1982, il fisico Hopfield pubblica un articolo fondamentale in cui presenta un modello matematico comunemente noto come rete di Hopfield: ogni sistema fisico può essere considerato un potenziale dispositivo di memoria, qualora esso disponga di un certo numero di stati stabili che fungano da attrattori per il sistema stesso, e in particolare Hopfield formula la tesi per cui la stabilità e la distribuzione di tali attrattori sono proprietà spontanee di sistemi costituiti da un elevato numero di neuroni reciprocamente interagenti.
Una rete di Hopfield è un esempio di rete ricorrente: al contrario delle reti feed forward, ogni neurone è collegato a tutti gli altri (anche a se stesso!) attraverso dei pesi e i segnali tra neuroni viaggiano in senso bidirezionale e non soltanto quindi dallo strato di input in direzione dello strato di output. In fase di apprendimento (noi non studieremo un algoritmo di addestramento) la rete memorizza un certo numero di configurazioni dette stati stabili, dopodichè in fase operativa viene presentato un vettore X che funge sia da ingresso, sia da stato della rete e sia da vettore d'uscita: lo stato viene continuamente ricalcolato sulla base dei valori attuali dei pesi secondo la seguente funzione di trasferimento
In pratica, durante ogni ciclo, ciascun neurone i-esimo verifica se è il caso di modificare il proprio stato Xi, che è binario e può assumere solo i valori ±1: se la somma pesata dello stato attuale (al primo ciclo si tratta banalmente dell'ingresso) secondo i pesi che congiungono il neurone corrente con tutti gli altri è superiore ad una certa soglia Ti il nuovo valore è 1, se è minore il nuovo valore è -1, altrimenti resta stabile. Assegnata la seguente funzione d'energia ad ogni stato della rete
si può dimostrare facilmente che se la matrice W dei pesi è simmetrica, allora H(x) è monotona non crescente con l'evolvere dello stato, ovvero H(X(t+1)) ≤ H(X(t)), infatti...
40
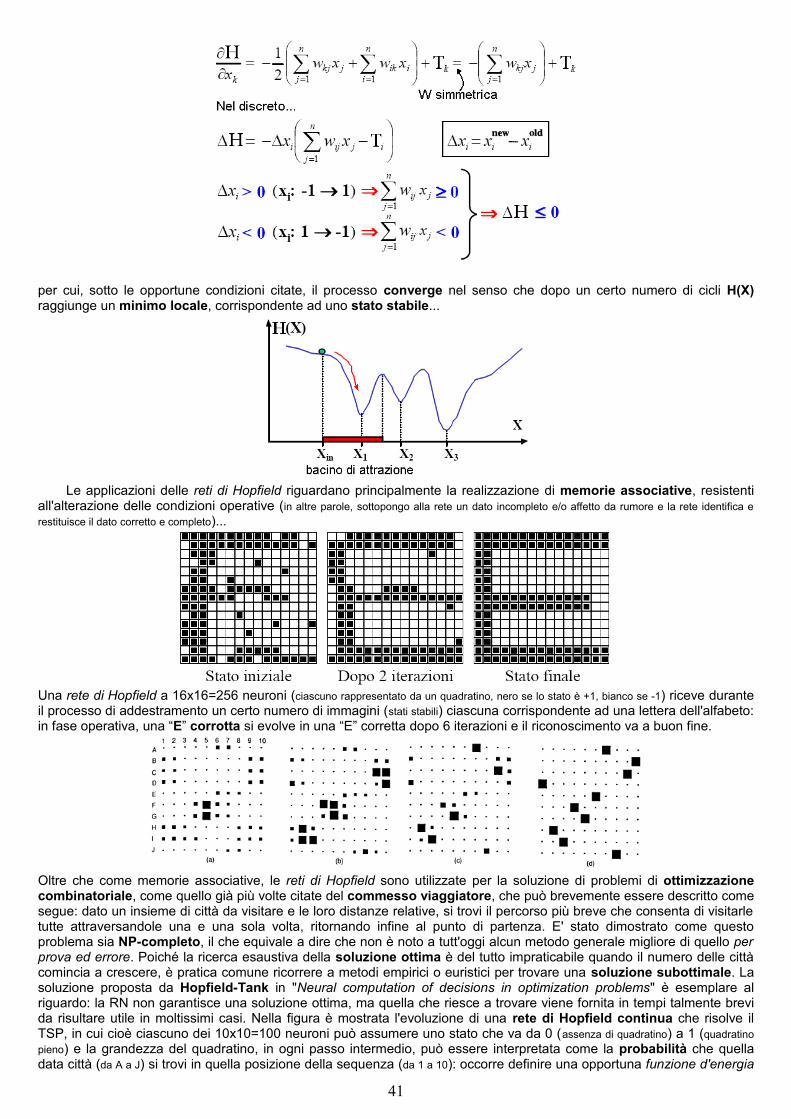
per cui, sotto le opportune condizioni citate, il processo converge nel senso che dopo un certo numero di cicli H(X) raggiunge un minimo locale, corrispondente ad uno stato stabile...
Le applicazioni delle reti di Hopfield riguardano principalmente la realizzazione di memorie associative, resistenti all'alterazione delle condizioni operative (in altre parole, sottopongo alla rete un dato incompleto e/o affetto da rumore e la rete identifica e restituisce il dato corretto e completo)...
Una rete di Hopfield a 16x16=256 neuroni (ciascuno rappresentato da un quadratino, nero se lo stato è +1, bianco se -1) riceve durante il processo di addestramento un certo numero di immagini (stati stabili) ciascuna corrispondente ad una lettera dell'alfabeto: in fase operativa, una “E” corrotta si evolve in una “E” corretta dopo 6 iterazioni e il riconoscimento va a buon fine.
Oltre che come memorie associative, le reti di Hopfield sono utilizzate per la soluzione di problemi di ottimizzazione combinatoriale, come quello già più volte citate del commesso viaggiatore, che può brevemente essere descritto come segue: dato un insieme di città da visitare e le loro distanze relative, si trovi il percorso più breve che consenta di visitarle tutte attraversandole una e una sola volta, ritornando infine al punto di partenza. E' stato dimostrato come questo problema sia NP-completo, il che equivale a dire che non è noto a tutt'oggi alcun metodo generale migliore di quello per prova ed errore. Poiché la ricerca esaustiva della soluzione ottima è del tutto impraticabile quando il numero delle città comincia a crescere, è pratica comune ricorrere a metodi empirici o euristici per trovare una soluzione subottimale. La soluzione proposta da Hopfield-Tank in "Neural computation of decisions in optimization problems" è esemplare al riguardo: la RN non garantisce una soluzione ottima, ma quella che riesce a trovare viene fornita in tempi talmente brevi da risultare utile in moltissimi casi. Nella figura è mostrata l'evoluzione di una rete di Hopfield continua che risolve il TSP, in cui cioè ciascuno dei 10x10=100 neuroni può assumere uno stato che va da 0 (assenza di quadratino) a 1 (quadratino pieno) e la grandezza del quadratino, in ogni passo intermedio, può essere interpretata come la probabilità che quella data città (da A a J) si trovi in quella posizione della sequenza (da 1 a 10): occorre definire una opportuna funzione d'energia
41

che schematizzi i vincoli del problema e attendere che la rete evolva verso uno stato che ne minimizzi il valore (si noti che per le soluzioni parziali i vincoli non sono necessariamente rispettati, si ha quindi un rilassamento dei vincoli... nei passi intermedi infatti può esserci più di un quadratino per riga e/o per colonna). Il percorso ottimo trovato dalla rete dell'esempio muove attraverso le città D-H-I-F-G-E-A-J-C-B.
Purtroppo, neanche le reti di Hopfield sono prive di inconvenienti: il principale è costituito dalle limitazioni cui soggiace il numero di pattern memorizzabili nella rete. In primo luogo, poiché l'attività di ogni neurone può assumere solo due valori, una rete da N neuroni può assumere al massimo 2N stati distinti, limite massimo teorico di pattern memorizzabili. Inoltre è naturale che, per essere discriminati, due pattern del TS devono essere sufficientemente diversi l'uno dall'altro: tale condizione può essere espressa in termini di ortogonalità dei vettori corrispondenti, e lo stesso Hopfield ha quantificato sperimentalmente in circa 0.15⋅N il numero di pattern che la rete è generalmente in grado di memorizzare in maniera corretta; quando il numero di pattern memorizzati supera determinati limiti, la rete può non riuscire a stabilizzarsi su alcuno di essi, oppure converge su un pattern diverso da tutti quelli con cui è stata addestrata (stato stabile “spurio”... fenomeno concettualmente analogo al problema dei minimi locali della funzione d'errore visto per altri tipi di RN).
A titolo puramente riepilogativo, è possibile elencare i principali campi di applicazione delle RN, nei quali esse dimostrano significative potenzialità...
Innanzitutto c'è la pattern classification (classificazione di schemi/modelli), per la quale le reti maggiormente impiegate sono quelle basate su percettroni e in generale quelle di tipo competitivo: si pensi ad una RN in grado di discriminare una serie di elettrocardiogrammi in ingresso tra normali o indicativi di una qualche patologia.
Nel clustering (raggruppamento, riunione in grappoli) l'obiettivo è analizzare un certo numero di esemplari di cui non si conosce a priori la classe di appartenenza (non è noto nemmeno il numero delle classi) e individuare proprietà comuni che consentano una classificazione a posteriori: in uno spazio bidimensionale o tridimensionale l'aggregazione (in una certa regione spaziale) di esemplari può essere indicativa del fatto che tali oggetti possiedano proprietà simili; in uno spazio n-dimensionale un banale ragionamento geometrico non è più fattibile ed è necessario usare appositi algoritmi. Poichè le classi non sono note a priori è evidente che non si può usare una rete che richieda un algoritmo di apprendimento supervisionato: la scelta d'elezione è rappresentata dalle SOM.
Esistono molti strumenti che non hanno nulla a che vedere con l'AI in grado di implementare una approssimazione di funzioni, ovvero ricavare una corrispondenza analitica per una funzione nota per punti e/o affetta da rumore: l'approccio con le RN si rivela però più efficiente soprattutto in presenza di forti non linearità.
Analogamente, a partire da N-1 osservazioni una RN si pone come valido strumento di previsione per ipotizzare il valore dell'N-esima istanza (serie storiche).
Infine, le reti ricorrenti di Hopfield (come abbiamo appena visto) sono particolarmente indicate per realizzare memorie associative, approcciare problemi di controllo e risolvere problemi di ottimizzazione (si pensi al già citato problema TSP).
5) Apprendimento simbolicoParticolari algoritmi per l'apprendimento sono quelli che operano su domini caratterizzati da una descrizione
strutturale delle informazioni. Normalmente (in informatica) un “oggetto” viene rappresentato misurandone un certo numero di caratteristiche e raccogliendo queste misure in un vettore (per esempio, un essere umano di sesso maschile alto 1,80m e di peso 70Kg può essere rappresentato dal vettore [M,180,70]). In alternativa, si può dare dell'“oggetto” una descrizione strutturale, ovvero può essere rappresentato attraverso un certo numero di componenti – dette primitive o atomi – e da una sequenza ordinata di relazioni tra esse (per esempio, un essere umano è costituito da una testa, un tronco e degli arti, congiunti a due a due in quest'ordine).
L'interesse per le descrizioni strutturali risiede sostanzialmente nella loro similarità col modo classico di descrivere proprio degli esseri umani, e in più esse consentono di contestualizzare il significato delle componenti di un “oggetto” e di dare a ciascuno una diversa interpretazione in funzione della posizione che occupa nell'”oggetto” medesimo; per contro - a fronte di una estrema semplicità concettuale della rappresentazione vettoriale – le descrizioni strutturali sono molto suscettibili al rumore e ad altre variabilità, il che può renderle facilmente affette da errore: si pensi ad un individuo rappresentato attraverso una immagine BMP... se la sua altezza reale può essere stimata misurando l'altezza in pixel della sua sagoma, è chiaro che uno o più pixel ascrivibili ad un qualche “rumore” possono incidere sulla correttezza del valore finale; analogamente, se si è interessati ad individuare un certo numero di componenti nell'immagine (vettorializzazione) anche solo un pixel pseudocasuale potrebbe collegare due componenti separate facendole apparire un tutt'uno, con effetti chiaramente indesiderabili. Ovviamente le operazioni richieste per ottenere una soddisfacente descrizione strutturale di un “oggetto” variano a seconda dell'applicazione e chiaramente a seconda dell'”oggetto”: riconoscere un volto umano è certamente cosa diversa dal riconoscere un carattere manoscritto, tuttavia anche quest'ultimo problema non è di banale soluzione...
A titolo di esempio (figura qui a destra) si consideri un'immagine BMP raffigurante un numero “6”: prima di tutto è necessario eliminare fattori inessenziali, come l'eccessivo spessore, mediante un'operazione di thinning (assottigliamento), dopodichè è opportuno trasformare questa collezione di pixel in una rappresentazione poligonale e infine sostituire i segmenti con archi di cerchio; a questo punto, la rappresentazione ottenuta (che è quanto più possibile
42

simile a quella percepita da un essere umano) può essere tradotta in un linguaggio come la logica dei predicati e, per fissare le idee, si faccia riferimento alla lettera “B” (figura qui a destra, supponendo di averla ottenuta in modo del tutto analogo a quanto visto per il numero “6”), rappresentata geometricamente da 3 archi di cerchio tra loro collegati e logicamente da 12 predicati (6 per i componenti e 6 per le relazioni): l'arco n1 ha una grande curvatura (large) ed è quasi dritto (straight), gli altri due invece sono di medie dimensioni (medium_size) e marcatamente curvi (bent), inoltre n2 intercetta n3 con una giunzione a T (tlike) ed n1 con una giunzione a V (vlike) a formare un angolo ottuso (obtuse), n3 intercetta n1 con una giunzione a T e, infine, n1 si congiunge con n3 con una giunzione a V a formare un angolo pressocchè retto (medium_angle)... il vantaggio di una rappresentazione espressa mediante un simile formalismo è che esso può essere manipolato come se descrivesse un SF e quindi si può usare un linguaggio come il Prolog.
Una rappresentazione alternativa fa uso di grafi relazionali con attributi, nei quali oltre al classico insieme di nodi (primitive) collegati da archi orientati (relazioni tra primitive) si aggiungono anche un certo numero di attributi per la descrizione sia dei componenti che delle relazioni (si parla anche di reti semantiche): i diagrammi UML o le formule chimiche di struttura sono esempi di grafi relazionali con attributi (il carattere “B” di prima, rappresentato mediante uno di questi grafi, appare come a lato)
Operazione fondamentale nei problemi che coinvolgono questi grafi è il confronto tra diverse rappresentazioni. Quando si opera con i vettori tale operazione è molto semplice da eseguire: introdotta una opportuna metrica, si lavora componente per componente, nell'ordine, senza particolari problemi. Viceversa, l'ordine con cui le informazioni sono inserite in un grafo è soggetta a variazioni, ed è proprio questa variabilità a rendere l'operazione di confronto non banale, dacchè la necessità di stabilire una corrispondenza, tra i nodi di due grafi posti a confronto, basata non sull'ordine (che può essere arbitrario e differente nei due casi) bensì sulla posizione relativa, pone un problema di complessità esponenziale (nell'esempio rappresentato nella figura qui sotto si tratta di riconoscere che, nei due grafi, il nodo
intermedio è etichettato in modo diverso, ed eseguire il matching in modo corretto): si rende pertanto necessario adottare, negli algoritmi di esplorazione di grafi come questi, delle efficienti euristiche che rendano sostenibile il tempo di computazione, fissando ad esempio un limite superiore di ordine polinomiale. Alcuni algoritmi, concepiti a questo scopo, impongono tipicamente dei vincoli nei grafi, come l'assenza di cicli o di incroci tra le relazioni: quando tali vincoli non sono rispettati, essi non garantiscono l'ottimalità della soluzione ma solo una soluzione subottimale. Altri algoritmi presentano invece un caso peggiore di ordine esponenziale ma riescono nella maggior parte dei casi a mantenere basso il tempo di computazione: sono capaci, per esempio, di riconoscere un accoppiamento tra grafi in anticipo rispetto al tempo richiesto per un esame completo, oppure, nel confrontare un singolo grafo con altri n grafi, snelliscono i tempi mediante una opportuna pre-elaborazione dei grafi, o ancora fanno uso di “firme dei grafi” (qualcosa di analogo ad un message digest ottenuto mediante una funzione hash) per scartare a priori un certo numero di accoppiamenti ritenuti non plausibili.
Nell'ambito della classificazione di oggetti rappresentati da descrizioni strutturali, il principale problema è l'addestramento del sistema, ovvero stabilire in che modo istruirlo a riconoscere se un oggetto appartiene o meno ad una classe di oggetti di interesse...
Con i vettori è possibile utilizzare le metodologie già descritte per le RN, ma per i grafi è necessario disporre di una adeguata descrizione delle classi di oggetti. Una prima possibilità consiste nel costruire un reference set o RS, ovvero si raccoglie un numero adeguato (per esempio, 1000) di esemplari (per esempio, immagini della lettera “A” scritta in svariati modi) di una certa classe A, così che quando il sistema deve riconoscere un carattere può eseguire un confronto con gli elementi del RS (della classe A e di altre classi), individuare l'esemplare più “vicino” e identificare di conseguenza la classe. In realtà, questo
43

metodo non si basa su un vero e proprio addestramento ma può risultare efficace in molti casi; il problema maggiore sta nel disporre di un RS molto ampio (che “catturi” una variabilità statistica sufficiente a consentire il riconoscimento), e anche se ciò, d'altra parte, può aumentare il tempo necessario alla computazione è possibile adottare accorgimenti computazionali basati sulla parallelizzazione (più confronti contemporanei) o sulla distanza (per ogni RS si esegue un numero ristretto di confronti con gli esemplari più significativi, assumendo che, se un dato campione dell'RS viene scartato, non vale la pena tentare il confronto con quelli molto simili ad esso). Una seconda possibilità consiste nel definire le classi attraverso descrizioni generali che tengano conto solo degli elementi essenziali degli oggetti appartenenti ad essa: un esperto umano (per esempio, in zootecnìa) può formalizzare le differenze tra classi di oggetti (equini, bovini, uccelli, ...) del dominio di interesse (regno animale) oppure - laddove non sia in grado di formalizzare in modo rigoroso le conoscenze di cui è in possesso – può procedere con una descrizione informale e successivamente adottare metodi opportuni di formalizzazione, tuttavia con questo approccio il sistema non produce conoscenza in modo autonomo e trovare un esperto con specifiche competenze e sufficienti capacità di formalizzazione non sempre è possibile: l'alternativa consiste (come per le RN) nell'automatizzare il processo di apprendimento, fornendo al sistema un certo numero di esempi da analizzare, in modo che ne individui le caratteristiche essenziali e su questa base costruisca la descrizione delle classi.
Un primo metodo, proposto da Winston nel 1970, si può definire semi-automatico in quanto richiede un operatore umano, l'oracolo, che supervisioni l'addestramento sottoponendo gli esempi al sistema in modo oculato e non casuale.
L'idea di fondo si basa sull'esperienza per cui è più facile descrivere un oggetto precisando “cosa non è” piuttosto che dire precisamente “cosa è” (così come è più facile trovare errori in una presunta soluzione piuttosto che trovarne una corretta ex-novo). Il sistema ha bisogno di controesempi del concetto da apprendere: partendo da una descrizione banale dell'esempio che “copre” anche oggetti che non appartengono alla classe da riconoscere, l'oracolo mostra al sistema la inadeguatezza della descrizione attuale sottoponendogli un controesempio (quindi non appartenente alla classe di interesse) che, pur “coperto” dalla descrizione corrente, “differisca di poco” da essa, in modo che il sistema possa modificarla (ricorrendo al numero minimo di modifiche necessarie) in una direzione tale da escludere codesto controesempio dalla “copertura”; il procedimento si ripete iterativamente fino a che si ottenga una descrizione in grado di “coprire” tutti gli esemplari della classe escludendo tutti i controesempi. L'esempio proposto da
Winston faceva uso del cosiddetto “mondo dei blocchi”, una realtà applicativa semplificata in cui gli unici oggetti sono blocchi diposti in diverse posizioni: in figura è mostrato l'insieme dei raffinamenti successivi per una descrizione della struttura “arco” - costituito da due blocchi verticali (non a contatto) e uno orizzontale (posto su di essi) – e come si vede l'ultimo controesempio induce la formulazione della descrizione corretta.
Una importante famiglia di tecniche che non richiede la presenza di un oracolo va sotto il nome di ILP (Inductive Logic Programming, termine comparso per la prima volta nel 1991) e prevede che l'apprendimento di un concetto si realizzi come costruzione di un SF da sottoporre successivamente ad un MI (come il Prolog) per riconoscere le istanze del concetto. Inizialmente l'utente fornisce al sistema un TS costituito da esempi positivi e controesempi, e l'algoritmo ILP deve costruire un SF in grado con le sue regole di riconoscere l'appartenenza di un oggetto alla classe appresa: i principali vantaggi riguardano il ricorso ai SF che rende questo tipo di descrizione facilmente comprensibile dal punto di vista umano (al contrario di ciò che accade con le RN), la possibilità di riconoscere in modo del tutto generale oggetti mai visti prima (cosa non possibile con un approccio basato su RS) e il fatto che le descrizioni ottenute sono “eseguibili” (si ottiene direttamente un programma in grado di riconoscere gli oggetti); d'altra parte, svantaggi dei metodi ILP sono il costo computazionale elevato e una certa
sensibilità al rumore (gli esemplari del TS devono essere il più possibile esenti da rumore).Si consideri l'esempio illustrato (qui a fianco) in cui il sistema deve “coprire” due classi (1), X e O, costruendo per entrambe una descrizione coerente e completa del “concetto” da ciascuna rappresentato: la prima copertura (2) è coerente ma non completa, la seconda (3) è completa ma non coerente, l'ultima infine (4), più complessa delle precedenti, rispetta ambedue i requisiti richiesti. Per raggiungere questo risultato ci sono due alternative possibili: la prima è partire da una descrizione delle classi coerente ma non completa ed eseguire un processo di generalizzazione (si parte infatti da una descrizione molto specifica che include pochi casi e si cerca di renderla più generale includendo gli altri), nell'esempio allargando i rettangoli (che possono essere più d'uno per ogni classe) fino al punto limite oltre il quale si perderebbe la coerenza; la seconda è partire da una descrizione delle classi completa ma non coerente ed eseguire un processo di specializzazione (duale di
44

generalizzazione), nell'esempio restringendo i rettangoli fino a raggiungere la coerenza. Introdotto da Quinlan nel 1990, il FOIL (First Order Inductive Learner) costituisce una delle prime applicazioni dei
metodi ILP di tipo top-down al problema dell'apprendimento di regole del primo ordine, ed utilizza una funzione euristica basata su misure di entropia per scegliere la più promettente direzione di specializzazione. In generale, in un algoritmo di ricerca euristica, è presente una coda di nodi aperti dalla quale si preleva il nodo con valore della funzione obiettivo (costo + euristica) più basso, e poichè il primo nodo potrebbe risultare non ottimale l'algoritmo deve tenere memoria di tutti i nodi aperti per poter eventualmente cambiare la sua scelta, il che rende nel caso peggiore la complessità esponenziale; la strategia di Quinlan, viceversa, non consente all'algoritmo di tornare sui suoi passi: quando espande uno stato calcola la funzione obiettivo per i suoi figli e sceglie il nodo-figlio col valore migliore (strategia best-first, approccio greedy = avido), dimenticando tutti gli altri (è come se la lunghezza della coda fosse imposta pari a 1). Le ipotesi che possono essere apprese da FOIL sono rappresentabili in forma simile alle clausole di Horn, ma a differenza di queste non consentono l'uso di simboli di funzione mentre ammettono letterali negati nel corpo della clausola: ciò consente di poter costruire programmi Prolog di tipo ricorsivo. L'algoritmo è strutturato su due cicli innestati: il ciclo esterno ha l'obiettivo di apprendere una singola regola alla volta, sicchè in ogni iterazione vengono eliminati dal TS gli esempi positivi che soddisfano la nuova regola e il ciclo termina quando tutti gli esempi positivi risultano “coperti” da una delle definizioni ottenute; il ciclo interno effettua una ricerca nello spazio delle ipotesi (per spazio delle ipotesi si intende l'insieme delle possibili definizioni del concetto in esame, esprimibili nel linguaggio definito dal particolare metodo di apprendimento utilizzato) partendo da quella più generale possibile per il predicato da apprendere (del tipo, p(X1, ... ,XN) :- true. ), considera di volta in volta l'insieme ottenuto applicando all'ipotesi corrente un operatore di specializzazione (sostituzione di una variabile con un valore particolare e/o aggiunta di un predicato alle premesse di una clausola), sceglie tra le ipotesi candidate quella che presenta il migliore guadagno di informazione rispetto agli esempi positivi del TS e, infine, la nuova ipotesi così ottenuta costituisce la base per la prossima specializzazione; la ricerca termina quando tutti i controesempi risultano correttamente discriminati. Facendo un esempio preso a prestito dal riconoscimento dei caratteri, si consideri il riconoscimento della lettera “A”...A fronte di un insieme di esempi positivi e controesempi, il sistema parte da un descrizione del tutto generale: ogni oggetto è una “A” (completezza). Usando la sua euristica determina che il massimo guadagno informativo (miglioramento della coerenza) prodotto da singola specializzazione si ricava classificando come “A” tutti gli oggetti con una linea orizzontale. Al fine di scartare i restanti controesempi, il sistema aggiunge la specifica che il carattere debba avere anche una linea diagonale, ma così facendo ha specializzato troppo (si perde completezza). Non essendo previsto alcun backtracking (che consentirebbe all'algoritmo di tornare sui propri passi e scegliere una diversa specializzazione, al fine di tentare di evitare – o limitare - la perdita di coerenza occorsa...) il sistema semplicemente assume per “coperti” gli esempi positivi attualmente rappresentati dalla definizione corrente e li elimina dal TS, ricominciando tutto daccapo sui restanti campioni del TS: alla fine il sistema troverà un insieme di regole che descrive tutte e sole le “A”.
Il sistema ARG (presentato all'università Federico II) è un altro esempio di sistema di apprendimento in domini caratterizzati da descrizione strutturale, che però funziona in maniera diversa dai metodi ILP: anzichè utilizzare un MI su un SF esso opera direttamente su grafi relazionali con attributi (mediante un algoritmo di graph matching, componente fondamentale di ARG), al pari degli oggetti da classificare pure le classi
45
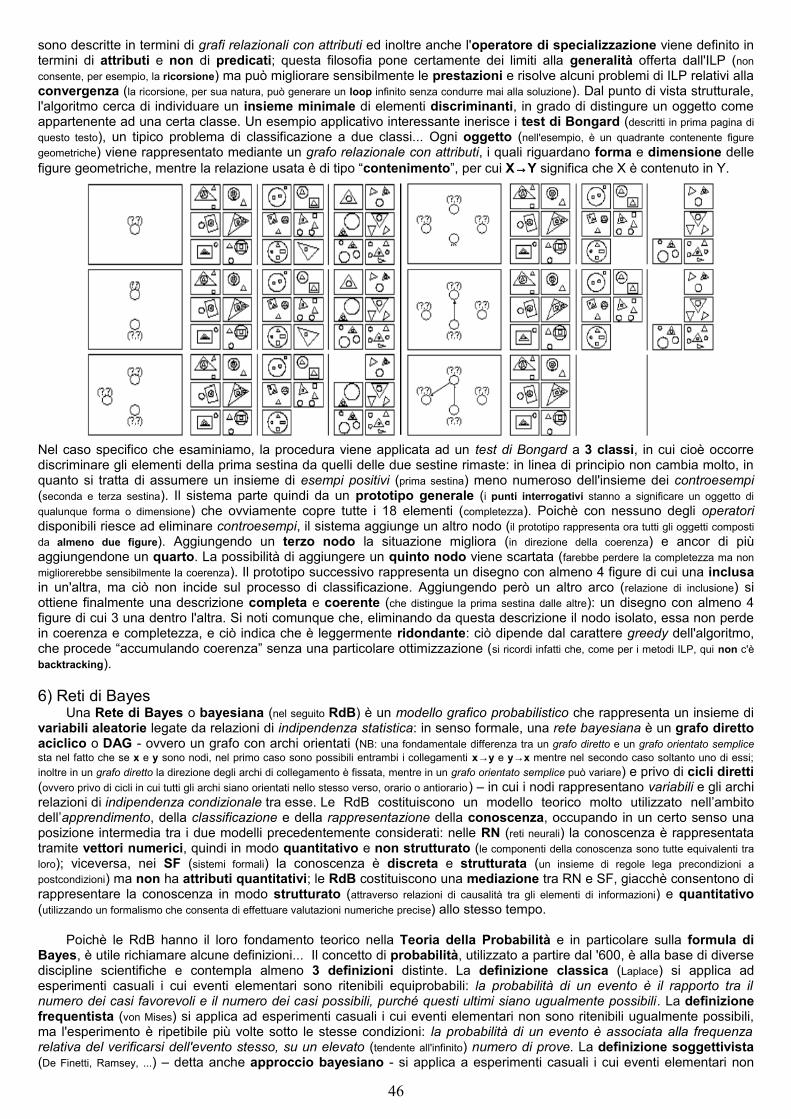
sono descritte in termini di grafi relazionali con attributi ed inoltre anche l'operatore di specializzazione viene definito in termini di attributi e non di predicati; questa filosofia pone certamente dei limiti alla generalità offerta dall'ILP (non consente, per esempio, la ricorsione) ma può migliorare sensibilmente le prestazioni e risolve alcuni problemi di ILP relativi alla convergenza (la ricorsione, per sua natura, può generare un loop infinito senza condurre mai alla soluzione). Dal punto di vista strutturale, l'algoritmo cerca di individuare un insieme minimale di elementi discriminanti, in grado di distingure un oggetto come appartenente ad una certa classe. Un esempio applicativo interessante inerisce i test di Bongard (descritti in prima pagina di questo testo), un tipico problema di classificazione a due classi... Ogni oggetto (nell'esempio, è un quadrante contenente figure geometriche) viene rappresentato mediante un grafo relazionale con attributi, i quali riguardano forma e dimensione delle figure geometriche, mentre la relazione usata è di tipo “contenimento”, per cui X→Y significa che X è contenuto in Y.
Nel caso specifico che esaminiamo, la procedura viene applicata ad un test di Bongard a 3 classi, in cui cioè occorre discriminare gli elementi della prima sestina da quelli delle due sestine rimaste: in linea di principio non cambia molto, in quanto si tratta di assumere un insieme di esempi positivi (prima sestina) meno numeroso dell'insieme dei controesempi (seconda e terza sestina). Il sistema parte quindi da un prototipo generale (i punti interrogativi stanno a significare un oggetto di qualunque forma o dimensione) che ovviamente copre tutte i 18 elementi (completezza). Poichè con nessuno degli operatori disponibili riesce ad eliminare controesempi, il sistema aggiunge un altro nodo (il prototipo rappresenta ora tutti gli oggetti composti da almeno due figure). Aggiungendo un terzo nodo la situazione migliora (in direzione della coerenza) e ancor di più aggiungendone un quarto. La possibilità di aggiungere un quinto nodo viene scartata (farebbe perdere la completezza ma non migliorerebbe sensibilmente la coerenza). Il prototipo successivo rappresenta un disegno con almeno 4 figure di cui una inclusa in un'altra, ma ciò non incide sul processo di classificazione. Aggiungendo però un altro arco (relazione di inclusione) si ottiene finalmente una descrizione completa e coerente (che distingue la prima sestina dalle altre): un disegno con almeno 4 figure di cui 3 una dentro l'altra. Si noti comunque che, eliminando da questa descrizione il nodo isolato, essa non perde in coerenza e completezza, e ciò indica che è leggermente ridondante: ciò dipende dal carattere greedy dell'algoritmo, che procede “accumulando coerenza” senza una particolare ottimizzazione (si ricordi infatti che, come per i metodi ILP, qui non c'è backtracking).
6) Reti di BayesUna Rete di Bayes o bayesiana (nel seguito RdB) è un modello grafico probabilistico che rappresenta un insieme di
variabili aleatorie legate da relazioni di indipendenza statistica: in senso formale, una rete bayesiana è un grafo diretto aciclico o DAG - ovvero un grafo con archi orientati (NB: una fondamentale differenza tra un grafo diretto e un grafo orientato semplice sta nel fatto che se x e y sono nodi, nel primo caso sono possibili entrambi i collegamenti x→y e y→x mentre nel secondo caso soltanto uno di essi; inoltre in un grafo diretto la direzione degli archi di collegamento è fissata, mentre in un grafo orientato semplice può variare) e privo di cicli diretti (ovvero privo di cicli in cui tutti gli archi siano orientati nello stesso verso, orario o antiorario) – in cui i nodi rappresentano variabili e gli archi relazioni di indipendenza condizionale tra esse. Le RdB costituiscono un modello teorico molto utilizzato nell’ambito dell’apprendimento, della classificazione e della rappresentazione della conoscenza, occupando in un certo senso una posizione intermedia tra i due modelli precedentemente considerati: nelle RN (reti neurali) la conoscenza è rappresentata tramite vettori numerici, quindi in modo quantitativo e non strutturato (le componenti della conoscenza sono tutte equivalenti tra loro); viceversa, nei SF (sistemi formali) la conoscenza è discreta e strutturata (un insieme di regole lega precondizioni a postcondizioni) ma non ha attributi quantitativi; le RdB costituiscono una mediazione tra RN e SF, giacchè consentono di rappresentare la conoscenza in modo strutturato (attraverso relazioni di causalità tra gli elementi di informazioni) e quantitativo (utilizzando un formalismo che consenta di effettuare valutazioni numeriche precise) allo stesso tempo.
Poichè le RdB hanno il loro fondamento teorico nella Teoria della Probabilità e in particolare sulla formula di Bayes, è utile richiamare alcune definizioni... Il concetto di probabilità, utilizzato a partire dal '600, è alla base di diverse discipline scientifiche e contempla almeno 3 definizioni distinte. La definizione classica (Laplace) si applica ad esperimenti casuali i cui eventi elementari sono ritenibili equiprobabili: la probabilità di un evento è il rapporto tra il numero dei casi favorevoli e il numero dei casi possibili, purché questi ultimi siano ugualmente possibili. La definizione frequentista (von Mises) si applica ad esperimenti casuali i cui eventi elementari non sono ritenibili ugualmente possibili, ma l'esperimento è ripetibile più volte sotto le stesse condizioni: la probabilità di un evento è associata alla frequenza relativa del verificarsi dell'evento stesso, su un elevato (tendente all'infinito) numero di prove. La definizione soggettivista (De Finetti, Ramsey, ...) – detta anche approccio bayesiano - si applica a esperimenti casuali i cui eventi elementari non
46

sono ritenibili ugualmente possibili e l'esperimento non è ripetibile più volte sotto le stesse condizioni: la probabilità di un evento è fornita secondo l'esperienza personale e le informazioni disponibili. In tutte le definizioni la propabilità è una funzione il cui codominio è il compatto [0,1]. Secondo la teoria classica tutti i casi sono equiprobabili, il che non sempre accade in realtà (peraltro, è interessante notare che nella definizione classica è contenuto un vizio logico: supporre che tutti i casi siano egualmente possibili implica di avere definito in precedenza la probabilità nel momento stesso in cui la si definisce!); la teoria frequentista introduce pertanto la cosiddetta legge empirica del caso o legge dei grandi numeri o teorema di Bernoulli (in parole povere, in una successione di prove effettuate nelle medesime condizioni, la frequenza di un evento si avvicina alla probabilità dell'evento stesso e l'approssimazione tende a migliorare con l'aumentare delle prove) ovvero definisce la probabilità di un evento attraverso la sperimentazione; diversamente, l'approccio bayesiano introduce il concetto di speranza matematica o valore atteso, assegnando alla definizione di probabilità connotati di soggettività. Immaginiamo che ci sia una partita di calcio (esempio formulato dal De Finetti) e che lo spazio dei 3 eventi possibili sia costituito dalla vittoria della squadra di casa, dalla vittoria della squadra ospite e dal pareggio: secondo la teoria classica i tre eventi hanno uguale probabilità 1/3, secondo la teoria frequentista ci si può dotare di un almanacco per controllare tutte le partite precedenti e calcolare la frequenza relativa di ciascun evento, oppure secondo l'approccio bayesiano ci si può documentare sullo stato attuale della forma dei giocatori, sullo stato del terreno e così via, fino ad emettere una probabilità soggettiva. Quindi, ricapitolando, al contrario della probabilità intesa in senso classico/frequentista la probabilità secondo Bayes si può intendere come una misura soggettiva associata ad un evento, e non necessariamente assoggettata agli esiti di prove ripetute: questo è molto importante per l’ingegnere della conoscenza, dal momento che spesso tratta informazioni non derivanti da esperimenti diretti sulla realtà bensì basate su considerazioni che possono essere anche soggettive (per esempio, una diagnosi medica).
Risale al 1933 l'impostazione assiomatica (Kolmogorov), adeguata a caratterizzare la probabilità indipendentemente dalle diverse scuole di pensiero: ad ogni evento casuale α corrisponde un certo numero P(α), chiamato "probabilità di α", tale che 0 ≤ P(α) ≤ 1 (assioma di non negatività); la probabilità dell'evento certo è 1 (assioma di normalizzazione); la probabilità dell'unione di un numero finito (o infinito numerabile) di eventi mutuamente esclusivi è la somma delle probabilità di questi eventi (assioma di numerabile additività). Si definisce Ω spazio campione associato ad un esperimento, l'insieme (finito o infinito) dei possibili risultati dell'esperimento (ad esempio, per il lancio di una moneta Ω = { Testa, Croce }). Si definisce Β σ-campo o campo di Borel un campo - collezione non vuota di elementi, chiusa rispetto al complemento (A∈Β ⇒ Ā∈Β) e all'unione (A,B∈Β ⇒ A U B∈Β) – che è chiuso anche rispetto all'unione numerabile, ovvero {Ai}∞
i=1 ∈Β ⇒ U∞i=1 Ai∈Β. Pertanto,
formalmente, assegnato uno spazio campione Ω e definito un σ-campo Β come Β = { tutti i sottoinsiemi di Ω, Ω incluso}, si definisce probabilità una funzione P(Β) a valori in [0,1] che soddisfa gli assiomi di Kolmogorov. Assegnato uno spazio di probabilità (Ω,Β,P), si definisce inoltre X variabile aleatoria (v.a.) una funzione
X: Ω → χ ⊆ ℜ U {+∞,-∞} tale che
I) { X ≤ x } è un evento,∀x ∈ ℜ U {+∞,-∞}II) P({X=+∞}) = P({X=+∞}) = 0
e intuitivamente può essere pensata come il risultato numerico di un esperimento soggetto al caso (ossia non deterministico), ad essa si associa la distribuzione di probabilità PX che assegna ad ogni sottoinsieme A ⊆ χ dell'insieme dei possibili valori di X la probabilità che X assuma valore in esso, ovvero PX(A) = P(X ∈ A).
In teoria della probabilità, la probabilità di un evento A condizionata ad un evento B (qualsiasi, purchè non sia l'evento impossibile) è la probabilità che si verifichi A accertato il verificarsi di B: si parla di probabilità condizionale, formalmente definita come P(A|B) = P(A∩B) / P(B) - con P(A∩B) detta probabilità congiunta (il simbolo ∩ può essere anche omesso, e talvolta è sostituito dalla virgola “,”) - ed esprime una sorta di "correzione" delle aspettative dettata dall'osservazione di B; si noti che è possibile estendere la definizione di probabilità condizionale anche al caso di più eventi condizionanti, per esempio P(A|B,C) = P(A,B,C) / P(B,C). Banalmente ricavato dal concetto di probabilità condizionale è il teorema della probabilità composta, per cui
P(AB) = P(A|B)·P(B) = P(B|A)·P(A)e la sua generalizzazione, cosiddetta regola della catena, per cui
P(A1,A2,...An)=P(A1)·P(A2|A1)·P(A3|A1,A2)...P(An|A1,A2,...An-1) (si noti che tale regola può essere applicata indipendentemente dall'ordine in cui si considerano gli eventi... quindi esisono n! modi alternativi di applicarla). Il teorema della probabilità totale o assoluta stabilisce invece che, se A1,A2,...An formano una partizione dello spazio campionario Ω di tutti gli eventi possibili e B è un evento qualunque, allora
Si parla di indipendenza stocastica (o probabilistica) tra due eventi A e B quando il verificarsi di uno non modifica la probabilità che si verifichi l'altro, ovvero quando le probabilità condizionate P(A|B) e P(B|A) sono pari rispettivamente a P(A) e P(B), il che si può sintetizzare con la formula P(A,B) = P(A)·P(B). Si parla inoltre di indipendenza condizionale se P(A|B,C) = P(A|B), ovvero se un evento A è indipendente da C sotto il condizionamento di B. Infine, banale conseguenza dei teoremi della probabilità composta e della probabilità totale è il teorema di Bayes
Comunque, per i nostri scopi è sufficiente conoscere la cosiddetta formula o regola di Bayes (conseguenza banale e diretta del solo teorema della probabilità composta)
47

secondo la quale la probabilità di un evento A condizionato ad un evento B (probabilità a posteriori) è riconducibile alla probabilità dell'evento B condizionato all'evento A (likelihood = verosimiglianza), alla probabilità non condizionata dell'evento A (probabilità a priori) e alla probabilità dell'evento condizionante B (osservazione)... Supponendo che l’evento A (ad esempio, “stanotte ha piovuto”) sia causa dell’evento B (ad esempio, “strada bagnata”), la stima della probabilità P(A|B) di A stante l’osservazione di B è il risultato di un processo di inferenza, di deduzione: questa è la probabilità della causa dato l’effettoquindi probabilità a posteriori, ovvero stimata “dopo” l’osservazione. E' utile conoscere anche la versione condizionale della formula di Bayes, in cui si aggiunge un terzo evento C da cui dipendono in qualche modo sia A che B, e che si ottiene facilmente dalla formula di Bayes e dalla regola della catena
Problemi che coinvolgono un elevato numero di v.a. diventano presto intrattabili (matematicamente e computazionalmente), ad esempio già nel caso semplice di K v.a. binomiali (discrete che descrivono una sequenza di prove dicotomiche, del tipo “successo” o “insuccesso”... come il lancio di una moneta) una distribuzione di probabilità congiunta che coinvolga tutti i possibili scenari richiederebbe 2k valori di probabilità (crescita con andamento esponenziale!): le formule che abbiamo fin qui introdotto consentono in molti casi di semplificare l'impostazione di tali problemi, principalmente nel caso in cui due o più di queste v.a. siano tra loro indipendenti. Per fissare le idee, supponendo di avere 4 v.a.
A B C(A,B) D(C) E(C) (C dipende da A e B, D ed E dipendono da C)si ha
P(A,B,C,D,E) = P(A)⋅P(B|A)⋅P(C|A,B)⋅P(D|A,B,C)⋅P(E|A,B,C,D) (regola della catena)P(A,B,C,D,E) = P(A)⋅P(B)⋅P(C|A,B)⋅P(D|C)⋅P(E|C) (indipendenza)
A valle dei necessari richiami teorici fin qui fatti, riprendiamo dunque il discorso iniziale...Una RdB è un DAG in cui ogni nodo corrisponde ad una v.a., ad ogni nodo (ad eccezione dei nodi radice) viene associata una Tabella delle Probabilità Condizionate o CPT, ed ogni arco tra nodi rappresenta una influenza diretta tra la v.a. che tali nodi rappresentano: per esempio, A → B rappresenta una influenza diretta della v.a. A sulla v.a. B, ovvero A è causa diretta di B; analogamente, dato un grafo (o sottografo) A → B → C si ha che A influenza direttamente B, la quale influenza direttamente C, mentre A non influenza direttamente C, cioè si può dire che C è indipendente da A sotto il condizionamento di B, il che comunque non equivale a dire che C sia indipendente in assoluto da A (infatti vi dipende per il tramite di B). In generale, il DAG della RdB si costruisce tracciando un arco Y → X se e solo se la v.a. Y ∈ Parents(X) delle cause dirette della v.a. X, cioè graficamente l'insieme dei predecessori (genitori) di X: con riferimento alle v.a. A,B,C,D ed E precedentemente citate la RdB ha un aspetto che ricalca lo schema seguente...
Si consideri un esempio concreto inerente le v.a. N (“è una giornata nuvolosa”), I (“gli irrigatori sono in funzione”), P (“oggi ha piovuto”) e B (“il prato è bagnato”): sicuramente N → P dal momento che la nuvolosità è precondizione per lo stato di pioggia, certamente N → I giacchè se il cielo è coperto è probabile che il giardiniere non accenda gli irrigatori, ed anche P → B poichè se piove il prato si bagna, inoltre I → B visto che gli irrigatori per definizione bagnano il prato; potrebbe esserci anche una relazione P → I ma solo se la pioggia si verifica prima di un orario preciso (se piove alle 16, ma alle 8:30 il giardiniere
48

ha già scelto se mettere in funzione gli irrigatori oppure no, è chiaro che non c'è relazione tra i due eventi) quindi in generale è possibile escluderla. La RdB corrispondente ha la forma seguente...
In essa compaiono le probabilità a priori dei nodi che non hanno predecessori (nodo N) e le probabilità condizionali dei nodi che invece li hanno (nodi I, P e B), ovvero tutti e soli questi valori consentono di calcolare qualunque distribuzione di probabilità congiunta su { N,I,P,B } attraverso la cosiddetta funzione probabilità congiunta, che nel caso in esame vale
P(N,I,P,B) = P(B|I,P)⋅P(I|N)⋅P(P|N)⋅P(N)e più in generale
espressione banalmente ottenuta dalla regola della catena e dall'indipendenza stocastica. Per fissare le idee, la probabilità che “il tempo sia nuvoloso, gli irrigatori siano spenti, piova e l'erba non si bagni” è data da
P(Nv,IF,Pv,BF) = P(¬B|IF,Pv) ⋅ P(¬I|Nv) ⋅ P(P|Nv) ⋅ P(N) = (1-0.9) x (1-0.1) x 0.4 x 0.1 = 0.36%
mentre la probabilità che “non piova e che gli irrigatori siano spenti” si ottiene da
P(IF,PF) = ΣN,B ∈{ V, F } P(N,IF,PF,B) = P(NF,IF,PF,BF) + P(NF,IF,PF,BV) + P(NV,IF,PF,BF) + P(NV,IF,PF,BV)
cioè attraverso un cosiddetto processo di marginalizzazione sulle v.a. il cui valore non è esplicitato. Appare chiaro quindi che la RdB è una rappresentazione compatta della funzione probabilità congiunta per un insieme di v.a. per le quali le dipendenze stocastiche delle probabilità congiunte siano “sparse”, ovvero non accade che ogni v.a. sia condizionata nella probabilità da tutte le altre bensì solo da un numero ristretto di esse (per esempio, memorizzare le probabilità condizionali di 10 v.a. binomiali con una tabella richiede uno spazio di 210 = 1024 elementi, ma se nessuna v.a. ha distribuzioni di probabilità dipendenti da più di 3 v.a. “predecessori”, una rappresentazione equivalente mediante RdB richiede di memorizzare al più 10⋅23 = 80 valori con evidente risparmio di memoria... nell'esempio precedente, in luogo di 24 = 16 valori è sufficiente memorizzarne solo 1+2+2+4=9).
La costruzione di una RdB richiede innanzitutto di fissare un set di v.a., di stabilirne le dipendenze ordinandole secondo un plausibile principio di causa → effetto, e individuarne le CPT: per i = 1..n si aggiunge il nodo Ai alla rete individuando il minimo insieme Parents(Ai) ⊂ { A1,A2, ... An } di v.a. per cui P(Ai | A1,A2, ... An) = P(Ai | Parents(Ai)) e compilando la corrispondente CPT che da Parents(Ai) dipende... questo algoritmo (semplice concettualmente ma oneroso computazionalmente) garantisce che la rete sia aciclica. Resta naturalmente aperto il problema della determinazione delle probabilità a priori e condizionali (la cui conoscenza si è data fin qui per scontata), che può comunque basarsi su valutazioni soggettive (esperto), oggettive (esperimenti/prove ripetute) o una combinazione delle due (ci torneremo più avanti...).
Con riferimento all'esempio precedente, si osservi che la RdB non consente soltanto di rappresentare informazioni in modo compatto, ma anche di rispondere a particolari domande come
“qual è la probabilità che stia piovendo, dato che l'erba è bagnata?”in formule
P(Pv|Bv) ?ovvero “qual è la probabilità che si sia verificato un evento considerato “causa” alla luce del fatto che un evento assimilabile a suo “effetto” è stato effettivamente osservato?”, e la risposta si ottiene applicando il teorema della probabilità composta, la funzione probabilità congiunta e la marginalizzazione...
P(Pv|Bv) = P(Pv ,Bv) / P(Bv) = ΣN,I ∈{ V, F } P(N,I,PV,BV) / ΣN,I,P ∈{ V, F } P(N,I,P,BV)
49

Per chiarire meglio il concetto, si consideri il cosiddetto problema di Monty Hall...Il concorrente di uno show ha la possibilità di vincere un premio se è sufficientemente fortunato da indovinare dietro quale delle tre porte esso è celato: le altre due nascondono una capra. Le regole del gioco sono semplici: il concorrente sceglie una delle tre porte, che non viene aperta subito; il conduttore apre una porta diversa da quella selezionata dal concorrente e dietro cui c'è una capra; il concorrente a questo punto ha la possibilità confermare la porta già scelta oppure di cambiare, scegliendo l'altra porta rimasta chiusa. Il problema a questo punto è: cosa conviene fare al concorrente? Dopo l'azione del conduttore, la probabilità di trovare il premio in una delle due porte rimanenti resta la stessa? Modelliamo tale problema con una RdB definendo le v.a. P (“porta che nasconde il premio”), G (“porta scelta inizialmente dal concorrente”) e M (“porta aperta da Monty Hall”), tutti e tre a valori in {1,2,3}: sicuramente P → M ma anche G → M, perchè il conduttore non può aprire la porta scelta dal concorrente ma neanche quella contenente il premio, per cui la RdB corrispondente è quella indicata
qui a lato. Chiaramente la presenza del premio dietro ciascuna delle 3 porte viene assunta equiprobabile (gioco non truccato), così come assumiamo equiprobabile la scelta iniziale della porta da parte del concorrente (scelta del tutto casuale), al contrario il conduttore può realmente “scegliere” una porta da aprire solo in 3 casi su 9, ovvero quando (con probabilità per l'appunto 1/3=3/9) il concorrente sceglie proprio la porta che nasconde il premio: il conduttore aprirà una delle due rimanenti al 50%; viceversa, nei restanti 6 casi su 9, aprirà l'ultima porta rimasta, ovvero quella che nasconde la capra ma non scelta dal concorrente. Per rispondere alla domanda iniziale assumiamo (senza che ciò faccia perdere di generalità al ragionamento) che il concorrente scelga inizialmente la porta 1 e che il conduttore apra quindi la porta 2 e calcoliamo come cambia, a posteriori, la probabilità P(P|G1,M2) che il premio si trovi dietro ciascuna delle 3 porte. Prima di tutto serve definire la funzione probabilità congiunta
P(P,G,M)=P(M|P,G)⋅P(P)⋅P(G)e in secondo luogo osservare che
P(PX|G1,M2) = P(PX,G1,M2) / P(G1,M2)
= P(PX,G1,M2) / ΣP∈{ 1,2,3 } P(P,G1,M2)A questo punto, per X = { 1, 2, 3 } calcoliamo P(PX|G1,M2)...
P(P1|G1,M2) = P(P1,G1,M2) / [ P(P1,G1,M2) + P(P2,G1,M2) + P(P3,G1,M2) ] = P(M2|P1,G1)⋅P(P1)⋅P(G1) / [ P(M2|P1,G1)⋅P(P1)⋅P(G1) + P(M2|P2,G1)⋅P(P2)⋅P(G1) + P(M2|P3,G1)⋅P(P3)⋅P(G1) ] = P(M2|P1,G1)⋅1/3⋅1/3 / { 1/3⋅1/3⋅ [ P(M2|P1,G1) + P(M2|P2,G1) + P(M2|P3,G1) ] }= P(M2|P1,G1) / [ P(M2|P1,G1) + P(M2|P2,G1) + P(M2|P3,G1) ]= 1/2 / [ 1/2 + 0 + 1 ] = 1/2 / 3/2 = 1/2⋅2/3 = 1/3
P(P2|G1,M2) = ... P(M2|P2,G1) / [ P(M2|P1,G1) + P(M2|P2,G1) + P(M2|P3,G1) ] = 0 / [ 1/2 + 0 + 1 ] = 0P(P3|G1,M2) = ... P(M2|P3,G1) / [ P(M2|P1,G1) + P(M2|P2,G1) + P(M2|P3,G1) ] = 1 / [ 1/2 + 0 + 1 ] = 1 / 3/2 = 2/3
in altre parole, se il concorrente mantiene la sua scelta (porta numero 1) conserva la probabilità di vittoria iniziale di 1/3, mentre se sceglie la porta rimanente (porta numero 3) la sua probabilità di vittoria raddoppia (ovviamente, ammesso che abbia senso, se scegliesse la porta aperta aperta dal conduttore vince con probabilità 0).
Il processo appena effettuato va sotto il nome di inferenza su RdB, e consiste nel calcolo della distribuzione di probabilità di un sottoinsieme di v.a. della rete (variabili di query) a partire dall'osservazione di un altro sottoinsieme (variabili di evidenza). Per un agente intelligente (l'utente) la RdB rappresenta la sua conoscenza: in base agli stimoli dell'ambiente esterno, l'agente interroga la RdB per dedurre qual è l'azione più idonea...
Ambiente ↔ Agente ↔ Rete di BayesEsistono 4 tipi possibili di interrogazione di una RdB o inferenza bayesiana... L'inferenza diagnostica è quella usata per rispondere alla domanda “qual è la probabilità che stia piovendo, dato che l'erba è bagnata?”, ovvero dalla probabilità dell'effetto risalgo alla probabilità della causa. L'inferenza causale è l'inverso della precedente e (con riferimento allo stesso esempio) consente di rispondere alla domanda “qual è la probabilità che l'erba si bagni, dato che è nuvoloso?”, ovvero dalla probabilità della
50

causa ottengo la probabilità dell'effetto. Si parla di inferenza intercausale quando, date due v.a. che sono concause di un effetto comune, si desidera conoscere in che modo esse si influenzano, per esempio “sapere che ha piovuto cambia la probabilità che gli irrigatori siano stati accesi?”. Si parla infine di inferenza mista quando si ha a che fare con una combinazione delle precedenti, per esempio con riferimento al problema di Monty Hall abbiamo considerato una combinazione di inferenza diagnostica e inferenza intercausale.
Per capire in che modo queste diverse tipologie di inferenza possano essere eseguite su una RdB, è utile considerare un esempio pratico. Data la RdB descritta qui a destra, calcoliamo la probabilità
P(B|J) (inferenza diagnostica)assumendo l'evento “J=True” come evidenza e B come v.a. di query: ci stiamo chiedendo in pratica “qual è la probabilità che ci sia un intruso dato che John telefona?”. All'interno di una RdB è utile pensare alle informazioni come ad entità che si propagano tra nodi adiacenti, “migrando” iterativamente dai nodi di evidenza ai nodi di query; più in generale è utile attenersi ad una predefinita strategia di propagazione delle informazioni da un nodo verso il suo predecessore o verso un suo successore. Nel caso in esame, consideriamo pertanto prima di tutto in che modo l'evidenza “J=True” altera la distribuzione di probabilità del nodo A. Dalla formula di Bayes, sappiamo che
P(A|J)=P(J|A)⋅P(A)/P(J)=P(J,A)/P(J)
espressione in cui, a parte P(J|A), i termini P(J,A), P(A) e P(J) non sono al momento noti (per quanto, comunque, interdipendenti). Come apparirà chiaro tra breve, è sempre conveniente in generale puntare direttamente alla costruzione di una tabella di probabilità congiunta che coinvolga il nodo in esame e i suoi predecessori ovvero, in questo frangente, la tabella P(J,A), ma poichè si ha
P(J,A)=P(J|A)⋅P(A)
occorre, prima ancora, calcolare P(A)... spostiamo quindi la nostra attenzione sul nodo predecessore. Anche qui conviene (sarà presto evidente il motivo) puntare direttamente alla costruzione di una tabella di probabilità congiunta che coinvolga il nodo in esame e i suoi predecessori ovvero, in questo passo, la tabella P(A,B,E), da ottenere applicando la corrispondente funzione probabilità congiunta
P(A,B,E)=P(A|B,E)⋅P(B)⋅P(E)
ed essendo Pa(B)=Pa(E)=∅ e note ambedue le probabilità a priori P(B) e P(E), il suo calcolo è semplice: si tratta, in pratica, di riempire la CPT di A con i valori delle probabilità a priori di B ed E ed eseguire dei prodotti, incolonnando opportunamente i risultati
Già sappiamo che, nota la funzione probabilità congiunta, è possibile da essa ricavare mediante marginalizzazione qualsiasi probabilità congiunta: ebbene, marginalizzare sulla corrispondente tabella si traduce in una semplice operazione di somma...
51

e ricavare il valore di probabilità che ci serviva, P(A), risulta pertanto banale (così come calcolare qualunque altra probabilità che coinvolga il nodo A e i suoi predecessori... dovrebbe essere chiara adesso l'utilità di una tabella siffatta) se si ha sotto mano la tabella P(A,B,E); si osservi, peraltro, che per calcolare questa tabella abbiamo utilizzato solo e soltanto le CPT fornite assieme alla RdB. A questo punto, si può fare un passo indietro, tornando al nodo J, e calcolare anche per esso (con lo stesso procedimento) la tabella di probabilità congiunta P(J,A)
da cui banalmente (marginalizzando) si ricava P(J)=0.0022648158+0.0498741769=0.0521389927. A questo punto abbiamo tutti i dati che ci occorrono per valutare
P(A|J)=P(J|A)⋅P(A)/P(J)=P(J,A)/P(J)ad esempio
P(AT|JT)=P(JT|AT)⋅P(AT)/P(JT)=0.90 x 0.002516462 / 0.0521389927=0.0434380429e allo stesso modo
P(AT|JT)=P(JT,AT)/P(JT)=0.0022648158 / 0.0521389927=0.0434380429
Tuttavia questa espressione, ricavata inizialmente dall'applicazione della formula di Bayes, è scomoda da utilizzare in quanto richiede il calcolo manuale di tutte le altre combinazioni cui potremmo essere interessati, ovvero P(AT|JF), P(AF|JT) e P(AF|JF) e rende inoltre problematica la “propagazione” dell'informazione legata all'evidenza di cui si dispone: l'alternativa consiste nell'“inglobare” l'evidenza “J=True” direttamente nella tabella P(J,A) applicando la formula
P*(J,A)=P(J,A)⋅P*(J)/P(J)
Analizziamone i termini... Il termine P*(J) rappresenta la “nuova probabilità” dell'evento associato al nodo J, alla luce dell'evidenza osservata: poichè l'evento è “J=True” banalmente P*(J)=(1,0), in quanto la probabilità che J si verifichi è 1, mentre quella che non si verifichi è banalmente 0 (essendosi già verificato!); se viceversa l'evento osservato fosse stato “J=False” analogamente avremmo posto P*(J)=(0,1). D'altronde il termine P(J) ha il significato che ci si aspetta, ovvero la probabilità dell'evento J calcolabile (e l'abbiamo già calcolata) sulla base di tutte le informazioni contenute nella RdB prima che J diventasse un nodo di evidenza, e vale P(J)=(0.0521389927,0.9478610073) dove chiaramente “0.9478610073” non è altro che P(¬ J)=1-P(J) (cioè la probabilità che J non si verifichi). La formula scritta sopra va dunque applicata in questo modo: per ogni casella della tabella P(J,A) se ne moltiplica il valore corrente per 1/0.0521389927 se la casella corrisponde al valore “J=T”, viceversa lo si moltiplica per 0/0.0521389927 se la casella corrisponde al valore “J=F”...
52

e il risultato è una nuova tabella di probabilità congiunta P*(J,A) che “contiene” l'informazione relativa all'evidenza su J. A questo punto, ricavare il P(A|JT) non è più un problema: basta marginalizzare sulla nuova tabella
e ottenere P*(A), cioè la probabilità di A alla luce dell'evidenza “J=True”. Fatto questo, il passo successivo è facile da immaginare: occorre “propagare” questa informazione relativa all'evidenza su J dal nodo J al suo predecessore A, ovvero “propagarla” da P*(J,A) verso P(A,B,E), trasformando quest'ultima in P*(A,B,E)...
e una volta aggiornata la tabella di probabilità congiunta per il nodo A, non occorre “propagare” l'informazione più in alto nella RdB: marginalizzando su P*(A,B,E) si ottiene infatti il valore desiderato per P(B|JT)=P*(B), cioè la probabilità di B alla luce dell'evidenza “J=True”. Ricapitolando per calcolare P(B|J) abbiamo eseguito i seguenti passi:
→ si parte dal nodo di evidenza J...→ calcolo di P(J,A) da CPT(J) e P(A)
→ calcolo di P(A,B,E) da CPT(A), P(B) e P(E)→ marginalizzazione su P(A,B,E) ⇒ P(A)
→ calcolo di P*(J,A) applicando l'evidenza P*(J) a P(J,A) sul nodo J... serve P(J)→ marginalizzazione su P(J,A) ⇒ P(J)
→ marginalizzazione su P*(J,A) ⇒ P*(A) = P(A|J*)→ calcolo di P*(A,B,E) applicando l'evidenza P*(A) a P(A,B,E) sul nodo A... serve P(A)→ marginalizzazione su P*(A,B,E) ⇒ P*(B) = P(B|J*)
Sempre con riferimento alla medesima RdB, supponiamo adesso di voler calcolare la probabilitàP(M|B) (inferenza causale)
assumendo l'evento “B=True” come evidenza ed M come v.a. di query: ci stiamo chiedendo in pratica “qual è la probabilità che Mary telefoni dato che c'è un intruso?”. Abbiamo già visto che è possibile, operando su tabelle, far “migrare” iterativamente tra nodi adiacenti l'informazione dai nodi di evidenza ai nodi di query; nel caso precedente abbiamo sperimentato la “migrazione” in senso ascendente, da un nodo verso i suoi predecessori: ora consideriamo quella in senso discendente, da un nodo verso un suo successore. Poichè i singoli passaggi sono stati già approfonditi, possiamo limitarci a citarli nell'ordine:
→ si parte dal nodo di evidenza B...→ ...e poichè non ha predecessori ci si sposta al suo nodo successore A...
→ calcolo di P(A,B,E) da CPT(A), P(B) e P(E)→ calcolo di P*(A,B,E) applicando l'evidenza P*(B) a P(A,B,E) sul nodo A... serve P(B)→ marginalizzazione su P*(A,B,E) ⇒ P*(A) = P(A|B*)→ calcolo di P(M,A) da CPT(M) e P(A)
→ marginalizzazione su P(A,B,E) ⇒ P(A)→ calcolo di P*(M,A) applicando l'evidenza P*(A) a P(M,A) sul nodo M... serve P(A)→ marginalizzazione su P*(M,A) ⇒ P*(M) = P(M|B*)
53

Ancora, supponiamo di voler calcolare la probabilitàP(E|B) (inferenza intercausale)
assumendo l'evento “B=True” come evidenza ed E come v.a. di query: ci stiamo chiedendo in pratica “qual è la probabilità che possa verificarsi un terremoto dato che c'è un intruso?”. Come prima ci limitiamo a citare i passi necessari ad eseguire l'inferenza:
→ si parte dal nodo di evidenza B...→ ...e poichè non ha predecessori ci si sposta al suo nodo successore A...
→ calcolo di P(A,B,E) da CPT(A), P(B) e P(E)→ calcolo di P*(A,B,E) applicando l'evidenza P*(B) a P(A,B,E) sul nodo A... serve P(B)→ marginalizzazione su P*(A,B,E) ⇒ P*(E) = P(E|B*)
Infine, supponiamo di voler calcolare la probabilitàP(B|A,E) (inferenza mista)
assumendo gli eventi “A=True” ed “E=True” come evidenze e B come v.a. di query: ci stiamo chiedendo in pratica “qual è la probabilità che ci sia un intruso dato che si è verificato un terremoto e l'allarme suona?”. Anche qui, sarà sufficiente elencare le operazioni da eseguire, che dovrebbero essere ormai di ovvia interpretazione:
→ si aggiunge una evidenza alla volta... partiamo dal primo nodo di evidenza, il nodo A...→ calcolo di P(A,B,E) da CPT(A), P(B) e P(E)→ calcolo di P*(A,B,E) applicando l'evidenza P*(A) a P(A,B,E) sul nodo A... serve P(A)
→ marginalizzazione su P(A,B,E) ⇒ P(A)→ marginalizzazione su P*(A,B,E) ⇒ P*(B) = P(B|A*)→ si aggiunge la seconda evidenza... partiamo stavolta dal secondo nodo di evidenza, il nodo E...
→ ...e poichè non ha predecessori ci si sposta al suo nodo successore A...→ calcolo di P**(A,B,E) applicando l'evidenza P**(E) a P*(A,B,E) sul nodo A... serve P*(E)
→ marginalizzazione su P*(A,B,E) ⇒ P*(E) (infatti P**(A,B,E)=P*(A,B,E)⋅P**(E)/P*(E), con P*(E)=P(E|A*))→ marginalizzazione su P**(A,B,E) ⇒ P**(B) = P(B|A*,E**)
In virtù di una fondazione teorica molto rigorosa, le RdB stanno soppiantando altri formalismi di rappresentazione della conoscenza, anche perchè capaci di gestire DS incompleti e rumorosi, cosa non possibile ad esempio utilizzando i SF (un assioma errato produrrà risultati errati!). Nella formulazione attuale le RdB (nonostante debbano il nome al matematico e teologo Thomas Bayes, vissuto nel XVIII secolo) sono state in realtà introdotte solo nel 1986 dall'informatico e filosofo Judea Pearl, allo scopo di rendere trattabili problemi probabilistici di qualsiasi dimensione sotto opportune condizioni, e proprio a quest'ultimo si deve un algoritmo per la risoluzione automatica delle inferenze su RdB, il cosiddetto algoritmo di inferenza di Pearl. Dall'analisi del procedimento risolutivo precedentemente illustrato si capisce che, per RdB piuttosto piccole e con poche v.a., è ancora possibile risolvere le inferenze effettuando i conti a mano, tuttavia nel caso generale di N v.a. la procedura descritta manifesta una complessità esponenziale (e questo è uno dei motivi per cui le RdB fino agli anni '80 non sono state molto popolari): l'algoritmo di Pearl consente invece di risolvere - in modo esatto - questo tipo di problemi (interrogazione di una RdB) senza esibire una complessità esponenziale, purchè la RdB sia un DAG in cui tra due nodi qualunque esista uno ed un solo cammino , in altre parole deve avere una struttura ad albero (nel caso della RdB relativa alle v.a. N,I,P e B è quindi inapplicabile, in quanto il cammino N → B non è unico!); l'idea di base è esattamente quella descritta fin qui, ovvero partire dai nodi di evidenza e da questi “propagarla” alterando il valore delle v.a. ad essi adiacenti, procedendo iterativamente - in direzione dei loro predecessori e successori - finché l’informazione non raggiunge tutti i nodi della rete (e quindi anche i nodi di query, per i quali interessa conoscere la probabilità a posteriori). Non abbiamo analizzato l’algoritmo nel dettaglio: basti sapere che ciascun nodo scambia con i suoi “vicini” l’informazione relativa alle probabilità condizionali modificate, e tali informazioni viaggiano in modo bidirezionale attraverso la rete fino che, dopo un certo numero di iterazioni l'algoritmo raggiunge la convergenza, rilasciando una RdB dal contenuto informativo “aggiornato” e in “equilibrio”. Quello di Pearl non è l'unico algoritmo esatto di questo tipo: ne esistono altri che estendono il calcolo dell’inferenza anche a DAG che non siano alberi, tuttavia la maggior parte di essi modifica comunque il DAG originale trasformandolo in un DAG più semplice da trattare, e in ogni caso la complessità di tali algoritmi si conserva esponenziale, per cui vengono utilizzati solo in casi particolari. Molto interessanti sono peraltro gli algoritmi inesatti che effettuano delle approssimazioni in modo da ridurre la complessità computazionale a polinomiale, introducendo però un errore rispetto alla soluzione ottima (questo tipo di approccio si rende a volte necessario per ridurre tempi di calcolo altrimenti proibitivi).
Si è fatto cenno, inizialmente, al problema della determinazione dei valori delle probabilità a priori e condizionali da inserire nella RdB. In teoria è possibile costruire una RdB lasciando che sia un esperto umano a codificarne la struttura e ad assegnare i valori alle distribuzioni di probabilità di interesse, tuttavia - almeno per questo secondo aspetto - la compilazione manuale risulta un processo oneroso e soggetto a errore, per cui è preferibile ricavare queste
54

informazioni quantitative direttamente dall'osservazione della realtà, attraverso un processo di apprendimento analogo a quello già visto per le RN. In particolare, ci sono 4 possibili situazioni di partenza in cui potremmo voler “integrare” informazioni (provenienti dall'osservazione della realtà) dentro una RdB attraverso un processo di apprendimento, situazioni che differiscono tra loro essenzialmente per 2 aspetti: la conoscenza a priori della struttura della rete - quindi le relazioni di causalità diretta tra le v.a. in gioco - e la possibilità di osservare o meno tutte le suddette v.a..
Il primo caso (il più semplice ma, come vedremo, di per sè non banale) è quello in cui è nota la struttura della rete e tutte le variabili sono osservabili. A titolo di esempio, con riferimento al problema iniziale {Nuvolosità,Irrigatori,Pioggia,prato Bagnato}, si conoscono a priori gli eventi e le loro relazioni di causalità, ed inoltre si conoscono un certo numero di osservazioni (nelle RN le abbiamo chiamate Training Set) per ciascuna delle quali il valore di tutte e quattro le v.a. N,I,P e B è noto (quindi, per il dato giorno X, si sa se era nuvoloso, se ha piovuto, e così via...): l'obiettivo è desumere da queste osservazioni le CPT che descrivono il modello.
Il secondo caso (più complicato) è quello in cui è nota la struttura della rete ma le osservazioni disponibili non ci forniscono i valori di tutte le v.a. in gioco. In pratica, è possibile che alcune v.a. siano osservabili solo in alcune istanze delle osservazioni, oppure che non siano osservabili affatto: in quest'ultimo caso si parla di variabili nascoste e si riscontra un problema analogo a quello già visto per le reti neurali MLP (in cui il valore dei neuroni dello strato hidden non è di facile determinazione).
Il terzo caso (ancor più complicato del precedente) è quello in cui tutte le variabili sono osservabili, ma non è nota a priori la struttura della rete. Pertanto occorre prima determinare in qualche modo (a partire dall'osservazione delle variabili) la struttura della rete e poi costruire (sempre dall'osservazione) le CPT: l'idea è quella di ricostruire (per tentativi) la topologia della rete attraverso una ricerca guidata dalla capacità di rendere conto dei dati disponibili (in ogni caso, algoritmi efficaci per risolvere sono ancora materia di ricerca).
Infine, il quarto caso (il più complicato in assoluto) è quello in cui nè la struttura della rete è nota a priori, nè si ha la possibilità di osservare tutte le variabili. Di fatto non esistono approcci veramente soddisfacenti in grado di dare una soluzione, anche approssimata, a questo problema e comunque esso è affrontabile solo quando il numero delle variabili in gioco è molto basso.
Consideriamo nel dettaglio il primo caso: la struttura della RdB è nota e si dispone di un certo insieme D di osservazioni che coinvolgono tutte le v.a. di interesse. Prima di tutto è conveniente (per semplicità) assumere che le distribuzioni di probabilità di ciascuna v.a. siano in qualche modo parametriche: se la singola v.a. è discreta occorrerà determinare la probabilità di ciascuno dei suoi possibili valori, se invece è continua è auspicabile che essa possa essere caratterizzata da un numero limitato di parametri (ad esempio, se gaussiana, basterà determinarne media e varianza). In pratica l'obiettivo è trovare i valori (delle righe) delle CPT associate ai nodi della rete, per cui se essi dipendono da un vettore (più o meno limitato) di parametri W={w1, w2, ... wp}, il problema di determinare le CPT si traduce nel problema di determinare tale vettore: il W ottimale è quello che consente di costruire un RdB capace di descrivere la realtà in modo coerente con le osservazioni di cui si dispone.
Esistono diversi modi di formalizzare questo problema, ma quello più usato è il cosiddetto approccio bayesiano, la cui idea di base consiste nel considerare ciascun parametro wk a sua volta come una v.a., tale che ogni valore xi che essa può assumere (wk = xi) corrisponda ad un preciso modello ipotetico Hi della rete; immaginando di disporre di un certo numero di queste ipotesi sulla costituzione della rete (ogni ipotesi consiste dunque in una precisa assegnazione di valori ai parametri) tutte “in competizione” tra loro (si dovrà infatti scegliere un solo modello!), per ciascuna si calcola la probabilità P(Hi|D) che essa sia il “vero” modello che la RdB dovrebbe avere per descrivere la realtà in modo quanto più possibile realistico date le osservazioni D di cui si dispone, e si sceglie poi l'ipotesi “vincente”
HMAP = arg max{Hi} P(Hi |D)secondo il cosiddetto approccio della probabilità massima a posteriori (Maximum a Posteriori mode o MAP): si cerca cioè il valore “migliore” del parametro (in questo caso Hi) in grado di massimizzare la probabilità a posteriori considerata. Naturalmente il valore di P(Hi|D) non è determinabile direttamente, ma se si applica la formula di Bayes si ottiene
P(Hi|D)=P(D| Hi)⋅P(Hi) / P(D)espressione in cui, posto che il termine P(D) non dipende da Hi e si può assumere costante (quand'anche non noto), il termine P(Hi) rappresenta la probabilità a priori dell'ipotesi Hi e in generale non è nota, tuttavia se non si hanno informazioni sulle Hi da utilizzare la scelta più opportuna è considerare tutte le ipotesi equiprobabili a priori, il che ci induce a ritenere costante (e quindi ininfluente nel processo di massimizzazione) anche il termine P(Hi); in alternativa, se si dispone di qualche informazione sulle diverse Hi conviene, in accordo al cosiddetto rasoio di Ockham (principio metodologico espresso nel XIV secolo dal frate filosofo William di Ockham), assegnare alle varie ipotesi una probabilità a priori tanto più alta quanto più il modello è semplice, anche perchè privilegiare un modello semplice rispetto ad uno (inutilmente) complesso riduce il rischio di produrre overfitting dei dati (in altre parole, specializzare troppo la RdB col rischio che essa risulti “cucita addosso” al Data Set considerato e quindi priva di ogni capacità di generalizzazione). Ricapitolando quindi, la massimizzazione della probabilità a posteriori dipende essenzialmente dalla likelihood P(D|Hi) - detta anche verosimiglianza dei dati - ovvero dalla probabilità che l'insieme di osservazioni D si realizzi nel caso in cui il modello reale che le ha generate corrisponda effettivamente al modello ipotetico descritto da Hi: per questo motivo l'approccio MAP si riduce ad una stima a massima verosimiglianza (Maximum Likelihood Estimate o MLE)
HMLE = arg max{Hi} P(D|Hi)Questa strategia può apparire di buon senso, ma non è detto che la scelta fatta secondo la MLE sia in generale la “migliore”: per fare un caso pratico, supponiamo di lanciare 4 volte una moneta e che gli esiti siano 1 testa e 3 croce; la scelta più naturale sembrerebbe allora quella di usare le frequenze di uscita come stima delle probabilità da assegnare ai due eventi testa e croce e, secondo la MLE, si dovrebbe concludere che nella realtà - che la RdB dovrebbe coerentemente descrivere - i lanci di monete producono croce 3 volte più frequentemente di testa (75% vs 25%)... il che ovviamente non è. In verità si dimostra matematicamente che la MLE produce risultati corretti solo quando le
55

osservazioni tendono ad essere infinite, dal momento che solo dopo n→ ∞ esperimenti la distribuzione di probabilità “frequentista” converge al modello reale che ha generato le evidenze: pertanto, non avendo a disposizione un Data Set infinito, l'applicazione corretta della MLE richiede almeno un numero di osservazioni significativo rispetto alla complessità del problema considerato. In pratica però, anche solo un numero di osservazioni sufficientemente elevato potrebbe non essere disponibile: ad esempio, per una moneta potrebbero andar bene 100 lanci ma, già se le v.a. diventano 2, il numero di esperimenti necessario a “catturare” la distribuzione di probabilità reale diventa 1002 (nel caso peggiore esse possono infatti essere indipendenti tra loro) e in generale all'aumentare delle v.a. il numero di osservazioni necessarie cresce esponenzialmente. Sembrerebbe pertanto che si debba rinunciare alla MLE e che si sia costretti ad utilizzare la formula completa
P(Hi|D)=P(D| Hi)⋅P(Hi) / P(D)in cui compaiono anche le probabilità a priori, ma fortunatamente si dimostra - usando una distribuzione di Dirichlet (una particolare famiglia di distribuzioni di probabilità multivariate e continue... non ci interessano altri dettagli) – che è possibile continuare ad utilizzare la MLE “iniettando”, con un artificio, probabilità a priori direttamente dentro la stima della likelihood, ovvero aggiungendo alle osservazioni reali anche osservazioni fittizie che rispecchino tale probabilità a priori: nel caso della moneta, se l'ingegnere della conoscenza ha convinzione o esperienza che, nonostante l'esito dei pochi lanci disponibili, testa e croce siano in realtà equiprobabili, allora può “integrare” la sua convinzione/esperienza aggiungendo (ad esempio) 20 lanci fittizi, e assegnare a priori a questi lanci 10 esiti con testa e 10 esiti con croce, in modo da ottenere le nuove probabilità 11/24 (invece di 1/4) e 13/24 (invece di 3/4), ambedue più vicine all'1/2 reale.
Appurato quindi che è lecito utilizzare la metodologia MLE, il problema di trovare l'ipotesi Hi che massimizzare la likelihood P(D|Hi) può essere in sè affrontato con tecniche simili a quelle viste per le RN. Infatti, se per le RN si è trattato di trovare il vettore dei pesi della rete che potesse minimizzare una funzione d'errore dipendente proprio dai pesi e dal TS, qui - mutatis mutandis - occorre trovare il vettore dei parametri della rete che possa massimizzare una funzione di likelihood dipendente allo stesso modo dai parametri e dal DS: nel caso delle RN abbiamo utilizzato la tecnica del gradiente discendente, qui occorre invece applicare alla funzione obiettivo la tecnica del gradiente ascendente (essendo richiesta una massimizzazione piuttosto che una minimizzazione), partendo da una certa configurazione iniziale dei parametri (nel caso delle RN erano pesi), magari casuale, e modificandoli poi iterativamente attraverso il gradiente (nel caso delle RN veniva cambiato di segno, qui no) della funzione obiettivo moltiplicato per un certo learning rate.
Prima di procedere conviene esplicitare nella funzione obiettivo la dipendenza dalle singole osservazioni, ovvero dalle singole istanze del DS (usato qui come TS)
P( D | Hi ) = P( D1, D2, ... DN | Hi )e possiamo supporre (come generalmente si fa) che le singole osservazioni Dj siano indipendenti ed identicamente distribuite (o IID, etichetta attribuita ad un set di v.a. che abbiano la stessa distribuzione di probabilità e siano mutuamente indipendenti l'una dall'altra), così che applicando la definizione di probabilità congiunta condizionata si ottiene
P(D| Hi) = P(D1, D2, ... DN| Hi) = P(D1 | Hi)⋅P(D2, ... DN| Hi,D1)= P(D1 | Hi)⋅P(D2 | Hi,D1)⋅P(D3, ... DN| Hi,D1,D2)= ...= P(D1 | Hi)⋅P(D2 | Hi,D1) ⋅ ... ⋅ P(DN | Hi,D1,D2, ... DN-1)
e poichè i Dj sono IID si ha
P( D | Hi) = P(D1|Hi)⋅P(D2|Hi) ⋅ ... ⋅ P(DN |Hi) = Πj=1..N P( D j | Hi )
ed esplicitando anche la dipendenza dai singoli parametri, si ottiene
P( D | Hi) = Πj=1..N P( Dj | Hi ) = Πj=1..N P( D j | w1,w2, ... wp )
Naturalmente con analogo procedimento si può mostrare anche che
P( D ) = P(D1)⋅P(D2) ⋅ ... ⋅ P(DN) = Πj=1..N P( Dj )
A questo punto possiamo calcolarne il gradiente
avendo inserito (e alla fine eliminato), come si vede, strumentalmente la funzione logaritmo (che è strettamente monotona quindi non altera la crescenza/decrescenza della funzione obiettivo), al fine di ricondurre la derivata di un prodotto alla somma di derivate:
56

possiamo passare dunque dal calcolo del gradiente di P(D | w1,w2, ... wp) al calcolo dei gradienti delle singole likelihood, ciascuna riferita alla singola osservazione. Il valore del singolo termine P(Dj | w1,w2, ... wp) potrebbe essere convertito (usando la regola della catena e assumento che le wi siano IID) nella forma
P(Dj)⋅ ... P(wi|Dj)/P(wi) ...tuttavia risulterebbe di difficile manipolazione sotto il segno di derivata; in alternativa, sotto il segno di derivata parziale, sipuò utilizzare direttamente la P(Dj) mettendo in evidenza di volta in volta la dipendenza dal singolo parametro wi.
Per semplicità consideriamo solo il caso più semplice in cui le v.a. della rete siano discrete e quindi i parametri wi
sono proprio i valori contenuti nelle CPT: la v.a. discreta associata al generico nodo X della rete può assumere un generico valore xi con una probabilità - cioè wi - condizionata alla k-pla di valori u assunti dai k predecessori del nodo X in questione, ovvero
wi = P(X=xi | Pa(X)=u)per cui si può sinteticamente porre
wi = P(xi|u)
Esplicitiamo dunque la dipendenza di P(Dj) dalla tupla (xi , u), osservando che P(Dj) può ottenersi per marginalizzazione proprio dalla probabilità congiunta P(Dj,xi,u)
P(D j) = Σ i P(D j,xi,u)applichiamo la definizione di probabilità condizionale
P(D j) = Σ i P(D j|xi,u)⋅P(xi,u)applichiamola nuovamente
P(D j) = Σ i P(D j|xi,u)⋅P(xi|u)⋅P(u)e per sostituzione dalla definizione di wi si ottiene
P(D j) = Σ i P(D j|xi,u)⋅ wi ⋅P(u)
Quindi, deriviamo su uno specifico wi (il valore di “i” è pertanto fissato) ottenendo
P(D j|xi,u)⋅P(u)da cui applicando la formula di Bayes
P(xi,u|Dj)⋅P(Dj)⋅P(u) / P(xi,u)e la definizione di probabilità congiunta
P(xi,u|Dj)⋅P(Dj) / P(xi|u)ancora dalla definizione di wi si ottiene
P(xi,u|Dj)⋅P(Dj) / wi
e infineP(xi,u|Dj) / wi
per semplificazione col termine P(Dj) presente al denominatore dell'espressione originaria. Ricapitolando, con riferimento alla j-esima componente del DS, la componente i-esima del gradiente della funzione obiettivo (cioè la sua derivata parziale rispetto al parametro wi) è un rapporto in cui al denominatore compare il valore corrente di wi - ed è quindi noto – mentre al numeratore compare il risultato di una inferenza bayesiana, che ha come variabili di query un certo nodo X e i suoi nodi predecessori e come variabili di evidenza quelle cui si riferiscono i valori del campione Dj: il risultato di questa inferenza bayesiana va calcolato con i metodi precedentemente illustrati (algoritmo di Pearl se la RdB in esame ha un DAG ad albero, altri algoritmi nel caso più generale).
Noto dunque il gradiente è possibile addestrare la RdB con i medesimi algoritmi delle RN. A questo proposito, abbiamo visto per le RN che è possibile calcolare il gradiente della funzione obiettivo sia rispetto all'intero TS (training by epoch) che al singolo elemento del TS (training by pattern), e tale scelta può essere fatta anche per le RdB: è possibile calcolare allo stesso tempo i diversi contributi del gradiente, ciascuno per la singola osservazione Dj, avendo presente la totalità D delle osservazioni disponibili, e poi fare un aggiornamento dei parametri sulla base della somma diquesti contributi (apprendimento on line), oppure man mano che “perviene” una nuova osservazione Dj si calcola il gradiente e si aggiornano i parametri in base a quel gradiente (apprendimento off line); ovviamente anche per le RdB i pro e i contra dei due approcci sono gli stessi già citati per le RN.
Si osservi comunque che, nonostante le analogie con gli algoritmi di apprendimento delle RN, l'addestramento di una RdB è molto più oneroso: in una RN il gradiente viene fuori da calcoli piuttosto semplici, viceversa in questo caso, per ogni singolo campione e per ogni singolo parametro, occorre risolvere un'inferenza bayesiana. D'altra parte, in una RN non si può attribuire un significato preciso al singolo peso in quanto la conoscenza della rete è distribuita sui singoli neuroni in modi imperscrutabili; viceversa, in una RdB ogni parametro ha un significato (è una probabilità) preciso e un esperto umano può (anche in corso d'apprendimento) “leggerli” ed interpretarli in modo da controllare se i loro valori sono ragionevoli oppure no, e se la rete è più o meno performante: proprio per questo, l'addestramento di una RdB presenta l'indubbio vantaggio - per l'ingegnere della conoscenza che la costruisce - di poter “calare” direttamente conoscenza a priori nella rete: se un esperto umano intuisce una struttura verosimile per la rete può impostare un “ragionevole” valore
57

iniziale per i parametri in modo da far convergere la rete alla sua corretta forma finale, pur se non dispone di un elevato numero di campioni per l'addestramento.
Diamo ora qualche cenno sul secondo caso: la struttura della RdB è nota ma si dispone di un insieme D di osservazioni che NON coinvolgono tutte le v.a. di interesse. Comunemente si utilizza l'algoritmo denominato Media e Massimizzazione (Expectation-Maximization o EM), utilizzato in statistica per implementare la stima a massima verosimiglianza (MLE) di uno o più parametri in modelli probabilistici (come le RdB, appunto) contenenti variabili nascoste (il cui valore non è direttamente osservabile): l'algoritmo EM alterna una passo di expectation (passo E) in cui viene calcolato in qualche modo un valore “atteso” - una media - della likelihood includendo le variabili nascoste come se esse fossero state realmente osservate, e un passo di maximization (passo M) in cui di fatto si applica la MLE alla likelihood trovata nel passo precedente per la modifica dei parametri... dopodichè i parametri delle variabili non-nascoste così trovati vengono riutilizzati per un nuovo passo E, e il procedimento si ripete fino a convergenza.
In soldoni, l'idea è semplice: data una osservazione, per una o più v.a. non è noto alcun valore, ci sono pertanto dei “buchi” nell'informazione che devo sottoporre alla rete (per esempio, nel solito problema degli irrigatori, potrei avere una o più osservazioni nelle quali il valore di N non è noto, quindi non si sa se in quei tali giorni il cielo era nuovoloso oppure no); allora, sulla base del valore corrente (non definitivo) dei parametri fin qui calcolati viene stimato un valore “atteso” per le variabili nascoste e viene loro assegnato in via provvisoria (per l'esempio di prima, il valore di N viene ricavato con una inferenza sulla base delle attuali, sebbene non definitive, distribuzioni di probabilità memorizzate nella rete), dopodichè si applica la MLE che rimodifica i parametri... e si ricomincia. Si dimostra che, sotto certe ipotesi non troppo restrittive, l'algoritmo EM converge ad un massimo locale, che non è detto che sia anche globale: quindi si può approdare ad una soluzione non ottima che potrebbe essere una buona soluzione oppure viceversa totalmente inadeguata, e il modo per aumentare la probabilità di ottenere una buona soluzione consiste, come sempre, nel introdurre conoscenza a priori nel modello (se la stima iniziale delle distribuzioni di probabilità non si discosta molto da quelle reali, l'algoritmo certamente convergerà al valore giusto... assegnare invece ai parametri valori iniziali del tutto arbitrari può produrre risultati insoddisfacenti). Senza dubbio, rispetto al primo caso, questo pone un problema più complicato in quanto ogni passo è più laborioso e per giungere al risultato finale è necessario disporre di una maggiore quantità di conoscenza a priori.
Il terzo caso è al limite della trattabilità: la struttura della RdB NON è nota sebbene si disponga di un insieme D di osservazioni che coinvolgono tutte le v.a. di interesse. Un approccio alla soluzione del problema può essere quello di procedere per tentativi: si considerano tutte le strutture possibili (tanto sono in numero finito) e per ciascuna di esse viene calcolata la migliore combinazione di parametri (fissata la struttura, si ricade nel primo caso); alla fine, si sceglie la combinazione di struttura più parametri che massimizza la probabilità di generare le osservazioni del DS. In teoria questo approccio funziona, ma nella pratica il numero di strutture possibili, assegnato un numero di nodi, cresce esponenzialmente per cui diventa presto impraticabile: di norma si usano algoritmi di ricerca che, pur precedendo per tentativi, usano delle euristiche per potare l'albero di ricerca; tipicamente non garantiscono la soluzione ottimale, ma producono molto spesso soluzioni accettabili.
Il quarto caso è il più arduo: la struttura della RdB NON è nota e si dispone di un insieme D di osservazioni che NON coinvolgono tutte le v.a. di interesse. In queste condizioni, avendo delle variabili nascoste e nessun indizio sulla struttura della rete, si potrebbe ipotizzare di applicare l'algoritmo EM per ogni struttura possibile (fissata la struttura, si ricade nel secondo caso) ma, in pratica, i tempi di calcolo estremamente lunghi necessari per giungere ad una soluzione anche solo ragionevole ne rende vano l'utilizzo: al momento non esiste nessun algoritmo praticamente utilizzabile per questa quarta tipologia di apprendimento.
***DEMO MATLAB (pag. 116,125,126,130 sansone)
A) Appendice (materiale aggiuntivo)
A.1) Somma degli elementi di un vettore – Algoritmo ricorsivo – C
//Inizializzione: i=indice iniziale, j=indice finale, v=vettoreint somma(int i, int j, int[] v) {
if (i==j) return v[i]; //CHIUSURA DELLA RICORSIONEelse {
half=(i+j)/2;int s1=somma(i,half,v); //IMPERAint s2=somma(half+1,j,v); // ”return(s1+s2); //COMBINA
}}
A.2) Minimo degli elementi di un vettore – Algoritmo ricorsivo – C
//Inizializzione: i=indice iniziale, j=indice finale, v=vettoreint minimo(int i, int j, int[] v) {
if (i==j) return v[i]; //CHIUSURA DELLA RICORSIONEelse {
minimo2=minimo(i+1,j,v); //IMPERAif (v[i]<=minimo2) return v[i]; //COMBINA
58

else return minimo2; // ”}
}
A.3) Merge di vettori ordinati – Algoritmo ricorsivo – C
//Inizializzione: i=indice iniziale, j=indice finale, v=vettore//...1 e 2 sorgenti, 3 destinazionevoid merge(int i1, int j1, int[] v1, int i2, int j2, int[] v2, int i3, int j3, int[] v3) {
if ((i1<=j1)&&(i2>j2)) { //CHIUSURA DELLA RICORSIONEv3[i3]=v2[i2];merge(i1+1,j1,v1,i2,j2,v2,i3+1,j3,v3); //2° vettore terminato
}if ((i1>j1)&&(i2<=j2)) {
v3[i3]=v2[i2];merge(i1,j1,v1,i2+1,j2,v2,i3+1,j3,v3); //1° vettore terminato
}if ((i1>j1)&&(i2>j2)) return; //entrambi terminati
if (v1[i1]<=v2[i2] { //IMPERAv3[i3]=v1[i1];merge(i1+1,j1,v1,i2,j2,v2,i3+1,j3,v3);
}if (v1[i1]>v2[i2] { // ”
v3[i3]=v2[i2];merge(i1,j1,v1,i2+1,j2,v2,i3+1,j3,v3);
}
A.4) Quick Sort di un vettore (tramite Merge) – Algoritmo ricorsivo – C
//Inizializzione: i=indice iniziale, j=indice finale, v=vettorevoid sort(int i, int j, int[] v) {
if (i==j) return; //CHIUSURA DELLA RICORSIONEif (j==i+1) { // ”
if (v[i]>v[j]) { int swap=v[i]; v[i]=v[j]; v[j]=swap;}return;
} else {half=(i+j)/2;sort(i,half,v); //IMPERAsort(half+1,j,v); // ”int[] temp;<allocazione a “temp” di j-i+1 byte>merge(i,half,v,half+1,j,v,1,j-i+1,temp); //COMBINA<ricopiatura di temp in v[i→j]>
}}
59


















