


INFORMATICA 06-Data base - Trapani Marco's BlogMARCO TRAPANI - [email protected] 9...
23
06-Data Base MARCO TRAPANI - [email protected] 1 INFORMATICA 06-Data base Marco Trapani [email protected]
Transcript of INFORMATICA 06-Data base - Trapani Marco's BlogMARCO TRAPANI - [email protected] 9...

06-Data Base
MARCO TRAPANI [email protected] 2
Record�Esempio:
�Anagrafica LIBRI� Cd libro, titolo, autore…
�Anagrafica UTENTI� Cd utente, nome, …
�Registrazione PRESTITO� Cd libro, Cd utente, data prestito…

06-Data Base
MARCO TRAPANI [email protected] 4
Storia� Inizialmente i dati erano organizzati in
modo molto semplice�Schede
� “pacchi”�FILE con accesso sequenziale
�Dischi�Accesso “random”
All’inizio i dati erano mantenuti su supporti di tipo “sequenziale”
• Schede e/o nastri magnetici in bobina
• accesso sempre dalla prima scheda in avanti,
• lettura (ed elaborazione) di tutte le schede;
• impossibilità di accesso ad una particolare scheda.
Solo con l’invenzione dei dischi è stato possibile prevedere un accesso “random”
• Stesse funzionalità delle schede
• Accesso “casuale” ad un particolare record (conoscendo il numero di record)

06-Data Base
MARCO TRAPANI [email protected] 5
Modelli�Sistemi gerarchici
�Schede “master”�Schede “figlie”�Concatenamenti
I primi sistemi di gestione denominabili come “data base” avevano una struttura molto complessa.
Ad una scheda “master” venivano “legate” le schede figlie tramite un complesso sistema di concatenamenti
In pratica
• sulla scheda “master” veniva riportato il “numero relativo di record” della prima scheda figlia.
• su ogni scheda “figlia” veniva registrato il “numero relativo di record” della successiva scheda figlia
• Sull’ultima scheda “figlia” nella posizione del “numero relativo di record prossima scheda” c’era un valore convenzionale (zero o 9999999)
Questa gestione era completamente a carico
• Inizialmente del programmatore
• Successivamente di “routine standard di gestione concatenamenti”
• Successivamente di un “sistema di gestione data base gerarchico” con cui i programmi interagivano per “leggere/scrivere” schede.

06-Data Base
MARCO TRAPANI [email protected] 6
Modelli�Sistemi reticolari
�Schede “master”�Schede “figlie”�File di “concatenazione” separati�Possibilità di più concatenamenti
(reticolo)
Il passo successivo fu di separare i dati relativi ai concatenamenti e metterli in file appositi, con la possibilità di creare più concatenamenti diversi (creando un “reticolo” tra i file, in base alle esigenze applicative)

06-Data Base
MARCO TRAPANI [email protected] 7
Modelli�Sistema relazionale
�CODD (un ricercatore IBM) presentò un “modello relazionale” (anni ’70)
�Solo alla fine degli anni ’70 si vedono le prime implementazioni reali (S/38)
�Oggi è l’unico modello usato
Il sistema relazionale permette di:
• Definire i dati in base alle esigenze applicative
• Tenere separata dai programmi applicativi tutta la logica di “indirizzamento” e “accesso” ai dati
• Creare modelli logici che sono indipendenti dalla struttura fisica dei dati

06-Data Base
MARCO TRAPANI [email protected] 8
Data base�Caratteristiche
�Organizzati�Normalizzati�Gestibili�Accessibili�Performanti
Il “Data BASE” è semplicemente un insieme di dati che rispondono a certi requisiti:
1. Organizzati
• Ovviamente dei dati devono essere organizzati, ossia rispondere a precisi requisiti di “ordine”; un insieme sconclusionato di numeri e lettere non ha alcun significato; anche dei dati relativi a dei nominativi devono essere “organizzati”
2. Normalizzati
• Per “normalizzazione” si intende una operazione tesa a ridurre la ridondanza (presenza di dati inutili) in un insieme di informazioni; la normalizzazione risponde a requisiti sia di occupazione spazio sia, oggi prevalentemente, per facilitare operazioni di aggiornamento
3. Gestibili
• I dati devono essere in un formato utile per essere gestiti nel modo piùefficiente ed efficace possibile
4. Accessibili
• Dei dati non accessibili, o che non hanno un criterio di accesso “facile”, rischiano di essere poco gestibili
5. Performanti
• Può sembrare poco importante, ma l’ottimizzazione delle performance di elaborazione, nonostante l’enorme aumento di potenza dei computer anno dopo anno, resta un requisito fondamentale; per il semplicemotivo che aumentano esponenzialmente anche il numero di dati dagestire…

06-Data Base
MARCO TRAPANI [email protected] 9
Organizzazione�Tabelle
�Tracciato record�Chiave di accesso primaria
�Tabelle “logiche”� Proiezione� Riordinamento� Accesso per chiavi alternative
Un data base è sempre organizzato in tabelle.
Ogni tabella corrisponde ad un insieme “logico” e coerente di dati:
• Studenti
• Dipendenti
• Libri
• …
Ogni tabella è bene che abbia una chiave di accesso “primaria” (univoca) che permetta di identificare in modo univoco ogni record.
(questo non è assolutamente indispensabile, ma è molto consigliabile)
Nel data base possono essere presenti delle “tabelle logiche” (viste) corrispondenti a una sorta di “modo di vedere” i dati, che possono prevedere:
• Proiezione dei dati
• In pratica la tabella logica permette di “vedere” solo una parte dei dati (alcune colonne)
• Riordinamento
• La tabella logica può presentare i dati riordinati in un modo diverso dalla tabella primaria
• Accesso per chiavi alternative
• La tabella logica può permettere l’accesso tramite chiavi alternative alla primaria
Esempio:
06-Data Base
MARCO TRAPANI [email protected] 10
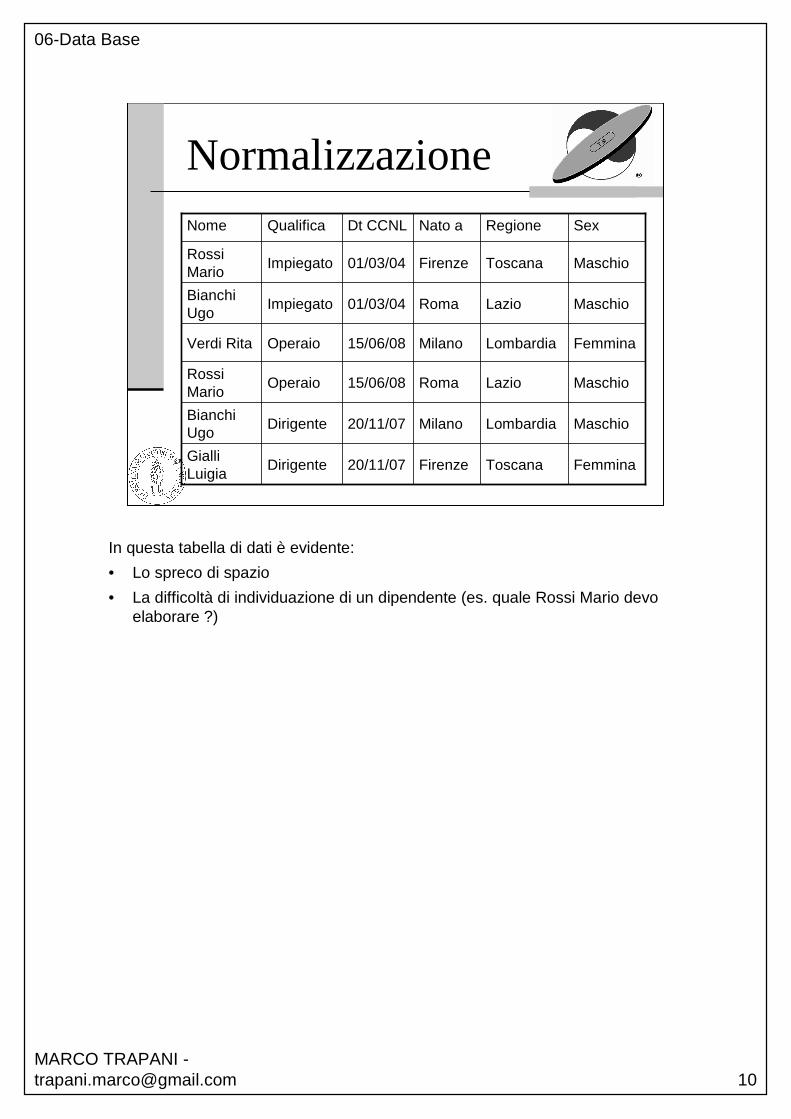
Normalizzazione
Toscana
Lombardia
Lazio
Lombardia
Lazio
Toscana
Regione
20/11/07
20/11/07
15/06/08
15/06/08
01/03/04
01/03/04
Dt CCNL
FemminaFirenzeDirigenteGialli Luigia
MaschioMilanoDirigenteBianchi Ugo
MaschioRomaOperaioRossi Mario
FemminaMilanoOperaioVerdi Rita
MaschioRomaImpiegatoBianchi Ugo
MaschioFirenzeImpiegatoRossi Mario
SexNato a QualificaNome
In questa tabella di dati è evidente:
• Lo spreco di spazio
• La difficoltà di individuazione di un dipendente (es. quale Rossi Mario devo elaborare ?)

06-Data Base
MARCO TRAPANI [email protected] 11
Normalizzazione
6
5
4
3
2
1
Cd
FFIDGialli Luigia
MMIDBianchi Ugo
MRMORossi Mario
FMIOVerdi Rita
MRMIBianchi Ugo
MFIIRossi Mario
SexNato a QualNome
20/11/0715/06/0801/03/04Dt CCNL
DirigenteDOperaioOImpiegatoIDecodificaQual
FemminaF
MaschioM
DecodificaSex
LombardiaLazioToscanaRegione
MilanoMIRomaRMFirenzeFIDecodificaCittà
Attraverso la normalizzazione si prevede:
1. Assegnare una chiave “univoca” (in questo caso un semplice codice “bruto” )
2. Estrarre dalla tabella principale i dati che sono ripetuti, e metterli in tabelle separate
La “data rinnovo CCNL” adesso non è più “disseminata” in tutte le righe della tabella principale ma è collegata solo alla riga della qualifica. Lo stesso vale per la regione in cui è la città di nascita.
Questo, ovviamente, oltre a rappresentare un risparmio di spazio, semplifica molto le operazioni di aggiornamento.

06-Data Base
MARCO TRAPANI [email protected] 12
SQL�Structured Query Language
� Adottato come standard per la gestione di data base relazionali
� Esiste uno standard, ma molti “dialetti”
� Formato:� CMD Oper clausola,clausola
Lo Structured Query language nasce nel 1974 in un laboratorio IBM; successivamente adottato come standard ANSI (1982) e poi ISO (1987)
Non è solo un linguaggio di interrogazione (come il nome farebbe credere) ma èstato esteso per avere tutte le istruzioni necessarie e sufficienti per la manipolazione di basi di dati.
La sintassi è molto semplice ma molto rigorosa; esistono alcune decine di COMANDI; ogni comando può eseguire una operazione e prevede varie clausole di esecuzione.
Vedremo solo i comandi principali, e non addentrandosi in dettagli eccessivi.

06-Data Base
MARCO TRAPANI [email protected] 13
CreazioneCREATE TABLE IMPIEGATI
(CODICE INT NOT NULL ,
NOME VARCHAR(30) NOT NULL ,
QUALIFICA CHAR(1),NATOA CHAR(2),SEX CHAR(1),PRIMARY KEY(CODICE) )
Per creare una nuova tabella esiste il comando
CREATE TABLE
Notare;
Il nome della tabella che vogliamo creare (Impiegati)
Le clausole (in questo caso racchiuse tra parentesi e separate da virgole)
Ogni clausola comprende:
Nome della colonna (codice, nome, qualifica, natoa, sex)
Tipo di dati (INT, VARCHAR, CHAR)
Clausole speciali (NOTNULL)
Una clausola particolare che indica quale è la colonna “chiave primaria”
Ovviamente questo è un esempio “minimale”; in realtà il comando CREATE TABLE è molto più ricco e complesso.

06-Data Base
MARCO TRAPANI [email protected] 14
LetturaSELECT Campo1, Campo2, Campo3, … [*]
FROM Nometabella
WHERE Clausola
GROUP BY CampoX
ORDER BY CampoY, Campo Z, …
La lettura (interrogazione) di dati si effettua con il comando
SELECT
Che prevede:
Elenco dei campi che si vogliono vedere (oppure * per vederli tutti)
FROM Nome della tabella che si vuole interrogare
WHERE Clausola di selezione (vedi dopo)
GROUP BY Nome del campo di “totalizzazione” (opzionale, solo se s vogliono dei totali invece del dettaglio)
ORDER BY Nome del/dei campo/i di ordinamento

06-Data Base
MARCO TRAPANI [email protected] 15
SelezioneWHERE Campo 1 COMP Valore1
AND/OR Campo2 COMP Valore2
AND/OR Campo3 COMP Valore3
Dove COMP simbolo matematico di confronto
> Maggiore
< Minore
= Uguale
<> Diverso
La clausola di selezione (WHERE) prevede un test tra coppie di valori formate da
• Un campo della tabella che si sta interrogando
• Un valore di confronto (che può essere un altro campo della tabella o una costante)
I confronti che si possono fare sono:
> Maggiore
>= Maggiore o uguale
< Minore
<= Minore o uguale
= Uguale
<> Diverso

06-Data Base
MARCO TRAPANI [email protected] 16
SelezioneTra coppie di valori si deve inserire il criterio di
relazione
ANDOR
INTERA TABELLA
Clausola 1
Clausola 2
Tra una clausola di selezione e un’altra si deve definire quale relazione vogliamo:
AND = vogliamo solo le righe che rispettano ENTRAMBE le condizioni (quindi SOLO la zona di “sovrapposizione” tra le due aree colorate)
OR = vogliamo le righe che rispettano UNA o L’ALTRA condizione (quindi tutta la zona gialla e la zona blu, compresa la zona di sovrapposizione)

06-Data Base
MARCO TRAPANI [email protected] 17
Sistemi di IR� Information Retrival
�Catalogazione elementi�Ricerca
� Tramite Keyword� Catalogazione “a faccette”� Criteri And/Or
I sistemi DB sono estremamente rigorosi, e vengono utilizzati ogni volta si debbano gestire dei dati “strutturati”.
Spesso però si vogliono catalogare dei dati “non strutturati” (es. immagini) e non si è certi di come si vorranno “ricercare” (indeterminazione dei possibili criteri di catalogazione)
Es: delle fotografie, potrebbero essere catalogate:
• In base al genere (paesaggi, palazzi, persone singole, gruppi…)
• In base al periodo (vacanze 2000, natale 2001, anno 2002…)
• In base all’evento (matrimonio Luigi, Battesimo Ugo…)
• In base alla dimensione (800x600, 1024x768…)
• In base al tipo di file (Jpeg, GIF, TIFF…)
• In base alla tecnica (B&W, Colore, Seppiata, Stilizzata….)
• In base a …….

06-Data Base
MARCO TRAPANI [email protected] 18
Problemi�Silenzio / Rumore
� In ogni ricerca si può avere: � Silenzio : quando i dati non vengono estratti
� Rumore : quando vengono estratti dati non pertinenti
Tutti i criteri di catalogazione e di ricerca devono essere attentamente studiati per diminuire le interferenze provocate da
Silenzio: otteniamo una lista di risultati, che però NON comprende alcuni elementi che sarebbero stati per noi interessanti
Rumore: nella lista di risultati sono presenti degli elementi che NON ci interessano.
Esempio molto chiaro: provate a ricercare su GOOGLE il vostro “nome e cognome”: molto probabilmente otterete una grande, grandissima quantità di RUMORE, ossia di riferimenti a pagine che niente hanno a che vedere con voi….

06-Data Base
MARCO TRAPANI [email protected] 19
DBMS�Esistono diversi “package” DBMS
�OpenSource� MySQL
�Commerciali� MS SQLServer� Oracle� DB/2
Per la gestione dati si possono usare diversi software, fondamentalmente in base a due parametri:
• Costo
• Esigenze
Esistono dei software OPENSOUCE gratuiti, gestiti dalla comunità Open Source; il più noto e diffuso è MYSQL, un prodotto ormai molto solido e, soprattutto in ambiente Linux, molto diffuso e apprezzato.
Esistono diversi prodotti commerciali il cui costo varia da poche centinaia di euro a diverse decine se non centinaia di migliaia di EURO.
Ovviamente se dobbiamo gestire dei Data base molto grandi, dell’ordine di migliaia di tabelle con diversi milioni di record in ogni tabella, abbiamo bisogno sia di un sistema HW molto potente che di un DBMS con molte funzioni di servizio e in grado di permettere l’accesso a, potenzialmente, decine di migliaia di utenti senza creare alcun problema.
I DB commerciali più diffusi sono ormai tre:
• SQLServer, della Microsoft, considerato un “entry-level” di base
• Oracle, della Oracle Corp., uno dei DBMS più potenti e diffusi
• DB/2 della IBM, ritenuto una pietra di paragone per tutti gli altri
NB: ovviamente la diatriba tra Oracle e DB/2 è una sorta di “guerra di religione”simile a quella tra i fautori della scelta tra Windows, Apple o Linux; in realtàmolto dipende da preferenze di carattere commerciale o di assistenza.

06-Data Base
MARCO TRAPANI [email protected] 20
DBMS�Uso personale:
�MS Access� Costo� Solo su windows
�Open Office Base� Gratuito� Su Windows o Linux
Per uso personale possiamo usare :
• Microsoft Access
• Licenza che prevede un pagamento
• Esiste solo su Windows
• Open Office Base
• Licenza OpenSource Gratuita
• Esiste per Windows e Linux
Per uso personale sono praticamente equivalenti.

06-Data Base
MARCO TRAPANI [email protected] 21
DBMS�MS Access / OpenOffice Base
�Un DB = Un file (su disco)�Contiene:
� Tabelle� Viste� Maschere (per immissione)� Report (per stampa)
Se si crea un nuovo DB in realtà il sistema operativo lo vede come UN SOLO FILE
Access : estensione MDB
OpenOffice Base : Estensione ODB
Dentro il file con il DBMS si creano, nell’ordine:
Tabelle,
Query (viste),
Maschere (per l’input),
Report (per le stampe).
Altri oggetti particolari in base al tipo di DBMS adottato (es.trigger, utenti, macro, ….)
In entrambi sono disponibili dei “modelli” di data base completi, per semplici applicazioni (es. gestione libri, gestione contatti,ecc.ecc.)
E’ consigliabile crearne uno per prova e studiarne il contenuto, eseguendo alcune modifiche di prova.

06-Data Base
MARCO TRAPANI [email protected] 22
DBMS� Indipendenza dall’HW� Indipendenza dal DBMS
�DB/2 e Oracle esistono in piùversioni
�SQLServer solo su Windows�MySQL su Windows e Linux
Per la gestione di Basi dati di grande dimensione, generalmente di tipo aziendale, si utilizzano dei DBMS più “potenti” che permettono anche complesse operazioni in merito alla sicurezza (autorizzazione all’accesso) e alla “integrità” in caso di caduta di tensione o di linea.
In realtà molte applicazioni commerciali oggi vengono sviluppate sfruttando degli “strati” di software che isolano il programmatore dal DBMS sottostante, in modo da poter utilizzare diversi data base in base alle preferenze del cliente.

06-Data Base
MARCO TRAPANI [email protected] 23
Homework� Ipotizzare tutti i dati da inserire in
una ipotetica “scheda paziente”, definendone tipo, contenuti previsti, lunghezza
�Mail to: [email protected]


















