
Decision trees - - Università degli Studi di Cassino · In ottica decisionale, un DT si utilizza...
27
Decision trees A. Iodice Decision trees Analisi statistica e matematico-finanziaria II Alfonso Iodice D’Enza [email protected] Universit` a degli studi di Cassino e del Lazio Meridionale
Transcript of Decision trees - - Università degli Studi di Cassino · In ottica decisionale, un DT si utilizza...

Decision trees
A. Iodice
Decision treesAnalisi statistica e matematico-finanziaria II
Alfonso Iodice D’[email protected]
Universita degli studi di Cassino e del Lazio Meridionale

Decision trees
A. IodiceOutline

Decision trees
A. Iodice
Decision trees (DT)
DT rappresentano un metodo supervisionato per la costruzione diun modello che mira alla previsione del valore di una variabile dirisposta (target) in funzione di un insieme di variabili indipendenti(input). Il modello e strutturato secondo un diagramma ad albero.A seconda della natura della variabile target, i DT sono definiti:
alberi di classificazione: la variabile target e qualitativa
alberi di regressione: la variabile target e quantitativa
le variabili in input possono essere sia quantitative chequalitative

Decision trees
A. Iodice
Che cos’e un diagramma ad albero?Un diagramma ad albero e un insieme di nodi collegati tra loroattraverso dei rami, che formano un grafo orientato in senso discendenteche parte da un unico nodo radice e termina in una serie di nodi foglia
Partendo dal nodo radice, le osservazioni vengono attribuite ai nodisuccessivi sulla base di una regola di ripartizione basata sulle variabiliinput, con l’obiettivo di determinare nodi progressivamente piuomogenei rispetto alla variabile target.
Ogni ramo conduce ad un nodo successivo che viene ulteriormenteripartito o ad un nodo foglia
Decision trees
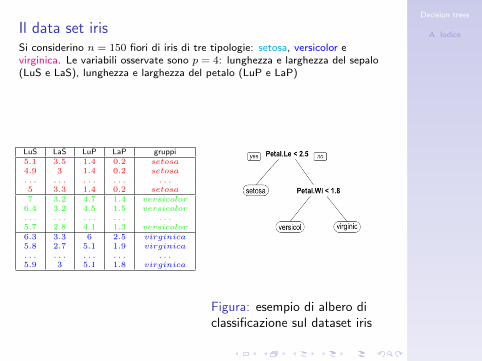
A. IodiceIl data set irisSi considerino n = 150 fiori di iris di tre tipologie: setosa, versicolor evirginica. Le variabili osservate sono p = 4: lunghezza e larghezza del sepalo(LuS e LaS), lunghezza e larghezza del petalo (LuP e LaP)
LuS LaS LuP LaP gruppi5.1 3.5 1.4 0.2 setosa4.9 3 1.4 0.2 setosa. . . . . . . . . . . . . . .5 3.3 1.4 0.2 setosa7 3.2 4.7 1.4 versicolor6.4 3.2 4.5 1.5 versicolor. . . . . . . . . . . . . . .5.7 2.8 4.1 1.3 versicolor6.3 3.3 6 2.5 virginica5.8 2.7 5.1 1.9 virginica. . . . . . . . . . . . . . .5.9 3 5.1 1.8 virginica
Figura: esempio di albero diclassificazione sul dataset iris

Decision trees
A. Iodice
Decision trees: esempi di applicazionevalutazione del rischio di credito: decidere se la banca debba concedereo meno un prestito ad un cliente sulla base delle caratteristiche diquest’ultimo
etichettare o meno una e-mail come spam sulla base delle parole checontiene
a patient’s length of stay in a hospital on the basis of his characteristics

Decision trees
A. Iodice
Partizione ricorsivaL’albero di decisione e dunque costruito attraverso un bipartizione ricorsivadelle osservazioni, che vengono suddivise in sottogruppi via via piu omogeneiinternamente. Il criterio di divisione (spilt) si basa sulle variabili input, mentreil grado di omogeneita interna ai gruppi e misurato sulla variabile target.Inoltre
I nodi terminali (o foglia) degli alberi di classificazione sono ’etichettati’da una modalita della variabile di risposta (target) qualitativa
I nodi terminali (o foglia) degli alberi di regressione sono ’etichettati’ daun intervallo di valori della variabile di risposta (target) quantitativa

Decision trees
A. Iodice
In ottica esplorativa, un DT si utilizza per descrivere quali sono i valoridelle variabili input che determinano determinati intervalli/categoriedella variabile target
In ottica decisionale, un DT si utilizza per predire il valore della variabiledi risposta da attribuire ad una osservazione di cui si conoscono i valoridelle variabili in input

Decision trees
A. Iodice
Elementi per la costruzione di un DTper ciascun nodo, valutare l’insieme di possibili split
definire il criterio di partizione
definire una regola di arresto
definire il criterio per etichettare i nodi foglia (per attribuire le modalitao gli intervalli di modalita ai nodi foglia)
valutare la regola di decisione dell’albero costruito

Decision trees
A. Iodice
Il numero di possibili split dipende dalla natura delle variabili in questione. Sem e il numero di modalita di una variabile qualitativa, ed N il numero di valoridi una variabile qualitativa (tante quante sono le osservazioni)
variabile modalita no di splitqualitativa m 2m−1 − 1
quantitativa N N − 1
Da cui bisogna scegliere lo split migliore.

Decision trees
A. Iodice
Criteri di partizione
CART: Classification And Regression Trees. Si trattadella procedura di riferimento per la costruzione dialberi di decisione.
C4.5 algorithm: procedura per la costruzione di alberi diclassificazione, utilizza la misura di entropia
CHAID: Chi-squared Automatic Interaction Detector:effettua partizioni multiple invece che bivariate
MARS: specifica per alberi di regressione

Decision trees
A. Iodice
Il CART
L’idea generale del CART e di suddividere ciascun nododell’albero in modo che i nodi generati dallo split siano piupuri del nodo originale.
purezza del nodo
negli alberi di classificazione, il nodo a e piu puro delnodo b se le la proporzione di osservazioni nel nodo ache presentano la stessa modalita della variabile dirisposta e maggiore che in b.
negli alberi di regressione, il nodo a e piu puro del nodob se la varianza di Y e piu bassa in a che in b.

Decision trees
A. Iodice
Misura di impurita
alberi di classificazione: l’impurita del nodo si misuramediante l’indice di eterogeneita di Gini (o attraversol’indice di entropia)
alberi di regressione: l’impurita del nodo si misuramediante la varianza .

Decision trees
A. Iodice
indice di eterogeneita di Ginialberi di classificazione Dato un nodo t, la sua eterogeneita e
G(t) = 1−k∑j=1
f2j
dove fj e la frequenza relativa della jth, j = 1, . . . ,m modalita della variabiledi risposta nel nodo t. is the relative frequency of the jth, j = 1, . . . ,mmodality of the response variable in node t.
La massima impurita si ha quando f1 = f2 = . . . = fm
L’assenza di impurita, (G(t) = 0) si ha quando tutte le osservazionihanno la stessa modalita della variabile di risposta.

Decision trees
A. Iodice
Decremento di impuritaIl decremento di impurita ∆G(t) che deriva dallo split del nodo t in tl e tr e
∆G(t) = G(t)− [(G(tl) ∗ p(tl | t)) + (G(tr) ∗ p(tr | t))]
dove p(tl | t) e p(tr | t) rappresentano la proporzione di osservazioni del nodo’genitore’ assegnate a ciascuno dei nodi ’figli’
Quindi lo split migliore e quello che massimizza ∆G(t).

Decision trees
A. Iodice
alberi di regressione
varianzaL’impurita del nodo t e data da
R(t) =
∑nti=1 (yi − µyt )2
nt
dove nt e il numero di osservazione nel nodo t

Decision trees
A. Iodice
decremento di impuritaIl decremento di impurita ∆R(t) che deriva dallo split del nodo t in tl e tr e
∆R(t) = R(t)−R(tl)−R(tr)
Quindi lo split migliore e quello che massimizza ∆R(t).

Decision trees
A. Iodice
Valutazione della regola di decisioneIn generale, la qualita della regola di decisione d e Per valutare la regola di decisione si ricorre alleseguenti misure
R(d) =∑
(h∈HT )
r(h)p(h)
dove p(h) =N(h)N
e la proporzione di osservazioni presenti nel nodo-foglia h dell’albero caratterizzatoda HT .A seconda della natura dell’albero, r(h) viene definito
alberi di classificazione: tasso di errata classificazione: e il rapporto tra il numero di osservazioni’etichettate’ correttamente e il totale delle osservazioni
r(h) =1
Nh
Nh∑i=1
I [d(xi)]
dove I [·] = 1 se l’espressione contenuta e vera (se l’osservazione xi e stata classificatacorrettamente), 0 altrimenti.
alberi di regressione: errore di previsione
r(h) =1
Nh
∑(h∈HT )
(yi − yi)2

Decision trees
A. Iodice
Metodi per stimare la qualita della regolaIl calcolo del tasso di errata classificazione o l’errore di previsione si basa suosservazioni che non siano state utilizzate per la costruzione dell’albero. I datia disposizione vengono dunque suddivisi in
campione di apprendimento Sbase: osservazioni utilizzate per costruirel’albero
campione test Stest: osservazioni utilizzate per valutare la regola didecisione (albero)

Decision trees
A. Iodice
Quando il numero di osservazioni non e elevato e non consente la divisione delcampione in test e apprendimento, si ricorre alla stima cross-validation.
La procedura di cross-validationSi partizioni il campione S delle osservazioni in V sottocampioni Sv diuguali dimensioni
si costruiscono V alberi di decisione utilizzando il campione S − Sv ,v = 1, . . . , V , per l’apprendimento e Sv come campione test
valutare gli alberi ottenuti (calcolando il tasso di errata classificazione oprevisione, Rtest(Sv))
fare la media dei V valori ottenuti per ottenere la stima cross-validationdella regola di decisione, formalmente
Rcross =1
V
V∑j=1
Rtest(Sv)

Decision trees
A. Iodice
Proprieta e limitazioni degli alberi di decisionevantaggi:
possono gestire data set di grandi dimensionipossono gestire predittori di diversa natura (quantitativie qualitativi)consentono di trattare variabili ridondanti e valorimancantifacilita di interpretazione di alberi di dimensionicontenute
svantaggi:
difficolta di interpretazione di alberi di grandi dimensionirispetto ad altri metodi, le performance di previsionesono talora peggiori

Decision trees
A. Iodice
ridurre le dimensioni dell’albero di decisione(pruning/potatura)La scelta dell’albero migliore dipende sia dall’accuratezza che dalla taglia diquest’ultimo:
Rα(T ) = R(T ) + α|T |
dove R(T ) e il tasso di errata classificazione o previsione, |T | e il numero difoglie (nodi terminali) dell’albero e α e il parametro di complessita.La procedura di pruning del CART consiste nei seguenti step:
creare l’albero di dimensioni massime
creare una sequenza di sotto-alberi
scegliere l’albero finale

Decision trees
A. Iodice
Il parametro α misura la complessita dell’albero in base al numero di noditerminali. Sia Tα il sottoalbero dell’albero Tmax che minimizza Rα(T )
R(Tα) = minT⊂Tmax
Rα(T )
Piu elevato e il valore di α, piu piccola sara la taglia dell’albero migliore.
jump pointsAd ogni valore di α corrisponde un sottoalbero ottimale Tα cheminimizza Rα(T ), anche se valori prossimi di α possono portare allostesso sottoalbero ottimale Tα
si definisce jump point quel valore di α che determina un cambio in Tα
All’aumentare di α, ogni jump point successivo determinera un albero didimensioni inferiori Tα: l’albero si riduce perche il ’ramo’ piu deboleviene ’potato’. Un ramo e considerato debole, se la sua rimozione nondetermina una sostanziale riduzione nell’accuratezza della regola didecisione.

Decision trees
A. Iodice
Sia T1 un sottoalbero Tmax e sia t un nodo interno di T1. La complessita di te
Rα(t) = R(t) + α
Sia Tt il ramo dell’albero che ha origine in t, dunque la complessita del ramo e
Rα(Tt) = R(Tt) + α|Tt|
Il valor di α che corresponde al jump point si ottiene risolvendo la seguentedisuguaglianza
Rα(t) ≥ Rα(Tt) then αt ≤R(t)−R(Tt)
|Tt| − 1;
Quindi la procedura CART calcola αt per tutti i sottoalberi di Tmax, quindi
si otterra una sequenza di jump points α1, . . . , αk a cui corrispondono
T1, . . . , Tk sottoalberi. Il miglior albero sara quello che, nella sequenza,
minimizza il tasso di errata classificazione o previsione.
Decision trees
A. Iodice
%
> rm(list = ls())
> gc()
%
%
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 197779 10.6 407500 21.8 350000 18.7
Vcells 316693 2.5 905753 7.0 863120 6.6
%
%
> str(iris)
%
%
’data.frame’: 150 obs. of 5 variables:
Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
%
%
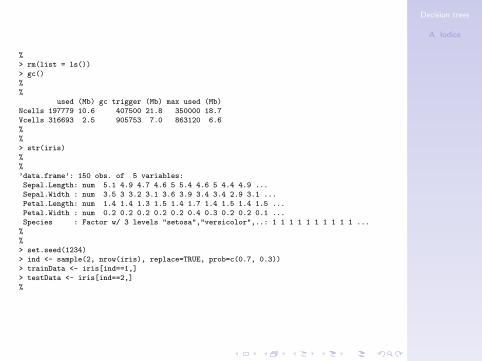
> set.seed(1234)
> ind <- sample(2, nrow(iris), replace=TRUE, prob=c(0.7, 0.3))
> trainData <- iris[ind==1,]
> testData <- iris[ind==2,]
%
Decision trees
A. Iodice
%
> #install.packages("party",dep=T)
> library(party)
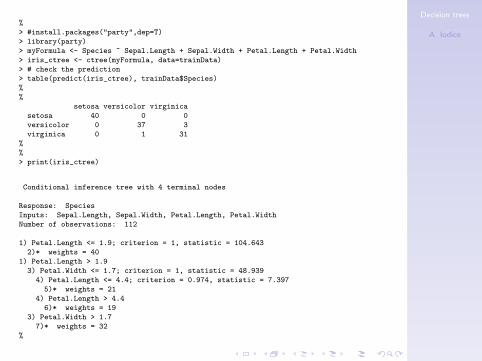
> myFormula <- Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width
> iris_ctree <- ctree(myFormula, data=trainData)
> # check the prediction
> table(predict(iris_ctree), trainData$Species)
%
%
setosa versicolor virginica
setosa 40 0 0
versicolor 0 37 3
virginica 0 1 31
%
%
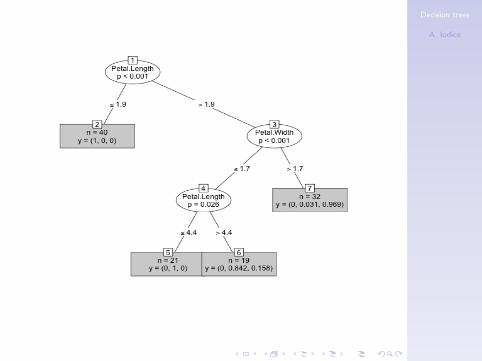
> print(iris_ctree)
Conditional inference tree with 4 terminal nodes
Response: Species
Inputs: Sepal.Length, Sepal.Width, Petal.Length, Petal.Width
Number of observations: 112
1) Petal.Length <= 1.9; criterion = 1, statistic = 104.643
2)* weights = 40
1) Petal.Length > 1.9
3) Petal.Width <= 1.7; criterion = 1, statistic = 48.939
4) Petal.Length <= 4.4; criterion = 0.974, statistic = 7.397
5)* weights = 21
4) Petal.Length > 4.4
6)* weights = 19
3) Petal.Width > 1.7
7)* weights = 32
%
Decision trees
A. Iodice














![[MIDES] Forges - SmartSmart Cities:Cities: lala ricercaricerca … · 2013. 11. 5. · (planning, crisis, decision…) living labs (planning, crisis, decision…) city government](https://static.fdocumenti.com/doc/165x107/60575f723249db74cd5de734/mides-forges-smartsmart-citiescities-lala-ricercaricerca-2013-11-5-planning.jpg)



