CGCTTCGGACGAAATCGCATCAGCATACGATCGCATGCCGGGCGGGATAAC ...patti/teaching/InfoAndBio.pdf · usato...
33
1 Informatica e biotecnologie Ricerca di informazioni e analisi di sequenze CGCTTCGGACGAAATCGCATCAGCATACGATCGCATGCCGGGCGGGATAAC ||||||||||||||||||||||||||||| CGAAATCGCATCAGCATACGATCGCATGC Informatica e biotecnologie Strumenti per raccogliere e organizzare le informazioni sui dati biologici ricerca delle informazioni visualizzazione analisi ...
Transcript of CGCTTCGGACGAAATCGCATCAGCATACGATCGCATGCCGGGCGGGATAAC ...patti/teaching/InfoAndBio.pdf · usato...

1
Informatica e biotecnologie
Ricerca di informazionie analisi di sequenze
CGCTTCGGACGAAATCGCATCAGCATACGATCGCATGCCGGGCGGGATAAC|||||||||||||||||||||||||||||CGAAATCGCATCAGCATACGATCGCATGC
Informatica e biotecnologie
Strumenti per
raccogliere e organizzare le informazioni sui dati biologiciricerca delle informazionivisualizzazioneanalisi
...

2
Banche dati biologiche
Banca dati biologica: raccoglie informazioni e dati su dati biologici. L’informazione proviene da
Letteratura specializzata sull’argomentoAnalisi effettuate in laboratorio (in vitro e in vivo)Analisi bioinformatiche (in silico)
NCBINational Center for Biotechnology Information: centro di raccolta di risorse di vario tipo
http://www.ncbi.nlm.nih.gov/accesso alla National Library of Medicine e al National Institutes of Healthaccesso a vari database attraverso Entrez
PubMed (data base della letteratura biomedica)GenBank…
accesso a software per riconoscimento e allineamento di sequenze

3
NCBI
Banche dati biologiche
Quali dati? Sequenze di caratteri (nucleotidi del DNA, amminoacidi delle proteine) GenBank
Banca del genoma dell’ NIH accessibile da ncbi78000 sequenze di DNA in GenBank nel 1992, ora le dimensioni raddoppiano ogni 6-8 mesi
formato ANS.1 standard per dati di sequenze per DB relazionali (Abstract Syntax Notation One)Humane Genome Projectgenomi completi o parziali di 900 specie
4
GenBank
Entry
Ogni banca dati è caratterizzata da un elemento biologico centrale (entry):
es: banche dati di sequenze di acidi nucleicielemento centrale: sequenza nucleotidica di DNA o RNAfatta la query (interrogata la banca dati), vengono associate le annotazioni che classificano quell’elemento: nome della specie, funzione, referenze bibliografiche -> attributi dell’elemento centrale

5
Banche dati distribuite
Problema dell’accesso a banche dati distribuite su diversi siti e con strutture eterogenee
cross referencing rilascio della banca dati in formato XML: oltre ai dati viene fornita sia la struttura logica che la struttura fisica della banca dati
Ricerca dei dati
Modalità di ricerca dei dati attraverso “motori di ricerca su banche dati biologiche”
campo “text search” o form per l’immissione del dato cercato (querysemplice)Specifica di criteri di ricerca mediante operatori booleani: AND, OR, BUT NOT (specializzazione della query)History: combino più query già fatte

6
Formato dei datiDiversi formati usati
sia per visualizzare, dare in output i dati risultato di ricerca,sia per l'inserimento dati quando si vuole intraprendere una ricerca o un'analisi
certi software di analisi per dati biologici chiederanno in input la (le) sequenze in un determinato formato -> sono in grado di decodificare l'informazione biologica e di elaborarla quando è presentata in quel formatoquali formati abbiamo a disposizione quando andiamo a prenderci un dato biologico in una banca dati, su cui magari poi vogliamo fare delle analisi?
Banche dati biologiche
Esempio di elemento di GenBankDalla ricerca in categoria Nucleotide (sequenze di acidi nucleici) parola chiave Arabidopsis thaliana
Seleziono una entry
formato di visualizzazione
salva il risultato

7
Entry GenBank
•Nome dell'organismo•codice di identificazioneall'interno della base di dati•riferimenti alla letteratura scientifica•cross references -> link a informazioni presenti in altrebanche dati•sequenza
Esempio di file di GenBank
Formati:Formato ASN.1
adatto allo scambio via swFormato XML
per manipolazione e presentazione sul WebFormato FASTA
semplice sequenza
Banche dati biologiche

8
ASN.1
FASTA

9
XML
Banche dati biologiche
Formato dei dati in NCBIFASTA
leggibile da vari programmi per l’analisi delle sequenzecontiene poche informazioni collegate
GenBankformato legacy in disuso
ASN.1 (Abstract Syntax Notation.One)specifica generica dei dati, usata in tutti i DB di NCBI
Formati usati sia per dati risultato di ricerca sia per l'inserimento dati

10
Una banca dati può supportare oltre ai formati standard (FASTA, ANS.1) dei formati di dati particolari, che possono essere usati da software per l'analisi del tipo dato trattato dalla banca datiEsempio: Protein Data Bank
formato legacy di PDBusato comunemente dai software per l'analisi di proteine
mmCIF: solo il nuovo software per l'analisi delle strutture usa questo formato
Banche dati biologiche
Letteratura: PubMed: http://www.ncbi.nlm.nih.gov
Sequenze di acidi nucleici:GenBank: http://www.ncbi.nlm.nih.gov SRS: http://srs.ebi.ac.uk
Seq. del genoma:GenBank: http://www.ncbi.nlm.nih.govSwiss-Prot: http://www.expasy.ch/spro
Struttura delle proteine:Protein Data Bank: http://www.rcsb.org/pdb
Risorse Web: EBI Biocatalog: http://www.ebi.ac.uk/biocat/IUBio Archive: http://iubio.bio.indiana.edu
Banche dati biologiche

11
Sequenze
Rappresentazione dei dati biologiciL’uso di sequenze è la forma di gran lunga più diffusa per rappresentare dati biologici di varia natura:Ad esempio:
DNA genomicoProteinecDNAmRNA...
si trovano sotto forma di sequenze nel DB GenBankdel NCBI
SequenzeHanno un formato puramente testuale: sono stringhe di lettere di un certo alfabetoEsempi di sequenze biologiche:
Sequenze DNA -> formate da 4 tipi di lettere:A (adenina), C (citosina), G (guanina), T (timina)
esempio: ATGCCGTAA, TAG, TTT, …Sequenze RNA -> formate da 4 tipi di lettere:
A (adenina), C (citosina), G (guanina),U (uracile)esempio: AUCGCUAA, AUUCG, …
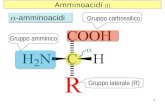
Sequenze proteiche: formate da 20 lettere corrispondenti agli amminoacidi: A, C, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y
esempio: MPIVDTGSVAPLSAAEK…

12
Sequenze DNA
La rappresentazione di una molecola di DNA come sequenza di simboli {A,T,C,G} è ovviamente un'astrazione di una struttura chimica 3DTuttavia se lo scopo è quello di usare le tecniche per l’analisi di sequenze, possiamo temporaneamente ignorare tale strutturaAnalogo vale per molecole di RNA
Sequenze di proteine
La rappresentazione di proteine come sequenze di simboli {A, C, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y} è anche detta struttura primariaA causa della maggiore complessità chimica degli
amminoacidi rispetto agli acidi nucleici è più difficile tenere separato il contenuto informativo delle sequenze dalle proprietà degli amminoacidi componenti

13
Sequenze
Vantaggipossibilità di analisi mediante tecniche consolidate: pattern matching, pattern recognitionportabilità tra vari sistemi operativicompatibilità tra diverse applicazionitrasferibilità tra computer remoti
Svantaggisoprattutto per le proteine, il tipo di informazione “sequenziale” ha un contenuto informativo parziale
Confronti fra sequenze
I confronti fra sequenze costituiscono la tecnica di analisi fondamentale per applicazioni biotecnologiche:
individuazione delle proprietà caratterizzanti famiglie di proteine, e delle funzionalità dei genidefinizione di alberi evolutividefinizione di modelli di omologiastrumento base per ricerche in DB attraverso “query” basate su sequenze

14
Tipi di analisi sulle sequenze
1. Allineamento di sequenzeA coppie (usato ad es. per ricerche in DB a sequenze)Multiplo (usato ad es. per inferenze filogenetiche)
Osservazione: l’allineamento di sequenze a coppie è la tecnica di analisi più usata
Principale metodo per l’associazione di funzioni biologiche al genoma e per il trasferimento di tali informazioni fra genomi di organismi diversi
2. Analisi/caratterizzazione di singole sequenze3. Traduzione “DNA -> proteina”
Software di supporto all'analisiEsistono diversi “tool” specializzati che automatizzano l’analisi di sequenze:GENSCAN : individuazione di “zone di codifica” in sequenze genomicheBLAST (integrato in GenBank), FASTA :
ricerca di zone di omologia locali in coppie di sequenze;individuazione di pattern corrispondenti per ricerche in DB
ALIGN : ricerca del miglior allineamento globale (intera lunghezza) fra due sequenze Protein MachineServer (presso European Institute for Biotechnology): conversione “DNA -> Proteine” e viceversa

15
Software di supporto all'analisi
Molti di questi programmi sono integrati in web-server; alcuni possono anche essere
installati ed eseguiti localmente (spesso in ambiente Linux e con interazione a linea di
comando)
Tecniche di analisi di sequenze
Le stesse tecniche di analisi possono essere applicate a sequenze di nucleotidi (DNA, RNA) e di amminoacidi (proteine), anche se con scopi diversi

16
Allineamento di sequenzeUno dei problemi di base nell’analisi di sequenze (dinucleotidi o di amminoacidi) consiste nel determinare se due sequenze sono correlate, ossia se è plausibile che derivino da un comune antenato attraverso un processo di mutazione e selezione.I processi di mutazione considerati comprendono
sostituzioni, aggiunte e cancellazioni (delezioni)
di elementi nella sequenza. Il tipo di mutazione è influenzato dal meccanismo di selezione naturale, cosicché alcuni cambiamenti possono essere più frequenti di altri.
Allineamento di sequenzeEs: DNA: Per quanto riguarda il DNA uno degli scopi primari è la comprensione del meccanismo delle mutazioni, attraverso lo studio comparativo di sequenze
Mutazioni puntuali: sostituzioni di singoli nucleotidi (significative se all’interno di zone particolari, es. zone di codifica)Mutazioni segmentali (più significative):
sostituzioni di più nucleotidi adiacenti in punti arbitrari, inserimento o eliminazione di nuovinucleotidi, etc.

17
Allineamento di sequenze
Il problema viene affrontato cercando di individuare “similarità” fra sequenze: una delle tecniche fondamentali in BioinformaticaConcetto base: trovare l’allineamento ottimale(globale o locale) di due sequenze
Allineamento ottimale
Il criterio di ottimalità si basa sull’attribuzione di un punteggio (score) tanto più elevato quanto maggiore è la similarità delle due sequenze -> modello probabilistico per valutare tali punteggi (scoring model ).

18
Allineamento semplice
L’allineamento semplice si ottiene facendo scorrere una sequenza sull’altra un nucleotide/amminoacido alla volta
cerco il massimo numero di corrispondenze
CGCTTCGGACGAAATCGCATCAGCATACGATCGCATGCCGGGCGGGATAAC|||||||||||||||||||||||||||||CGAAATCGCATCAGCATACGATCGCATGC
Allineamento di sequenze: gap
La possibilità di avere aggiunte e cancellazioni fa sì che nell’allineamento vi possano essere dei vuoti (gap).
• A meno che le sequenze non coincidano perfettamente èmolto spesso necessario introdurre “gap” per trovare un più alto numero di corrispondenzeLa figura mostra un possibile allineamento di due catenepolipeptidiche. Legenda: la linea centrale indica con
lettere i residui identici e con un segno + i residui simili (rispetto alle proprietà chimico-fisiche)Un segno - denota i gap

19
Allineamento di sequenze
Approccio:Passo1: confrontare le sequenze (inizialmente
in modo arbitrario)Passo2: assegnare un punteggio sulla base di
criteri fissatiPasso3: ripetere l’operazione, muovendo in tutti
i modi possibili una sequenza rispetto all’altrail punteggio massimo corrisponde
all’allineamento ottimaleApproccio facilmente automatizzabile
Allineamento di sequenze
Perché sia biologicamente attendibile bisogna risolvere alcune questioni:
come stabilire il punteggio per l’allineamento?es. +1 per posizioni uguali, -1 per discrepanze
possono essere inseriti dei buchi (gap) nelle sequenze per trovare corrispondenze altrove?come valutare i gap? Quale algoritmo usare per
l’allineamento ottimale?Esistono alcune differenze fra allineamenti di sequenze DNA e allineamenti di sequenze proteiche

20
Allineamento: terminologia
Identità: occorrenza dello stesso elemento (base oaminoacido) nella stessa posizione delle 2 sequenzeallineate
Similarità (proteine): occorrenza di amminoacidi chimicamente simili (reciprocamente sostituibili) nella stessa posizione
Esempio: acido glutammico e acido asparticosono simili
Omologia: concetto più astratto, che indica un legame di tipo evolutivo fra 2 sequenze
Esempio: allineamento di sequenze di proteine e DNA
proteine
DNA

21
Matrici di valutazione: proteine
matrici di valutazione: scoring matrixAbbiamo detto che occorre assegnare un punteggioall'allineamento sulla base di criteri fissatistrumento per valutare con un punteggio un allineamento (è significativo? Se sì, quanto?): matrici di valutazioneCosa sono? Sono tabelle di valori che indicano la probabilità che una coppia di amminoacidi sia “allineata”Valori: parti intere di log( P{a,b}/ P{a_r}), dove
P{a,b} : probabilità di allineamento (non casuale) della coppia di amminoacidi a e b, determinata in base a statistiche tratte da allineamenti noti come validiP{a_r} : probabilità di occorrenza “random” dell'aminoacido a in una sequenza
Esempio: matrice di valutazione BLOSUM45 (proteine)

22
Matrici di valutazione (proteine)
Un valore in tabella è positivo se P{a,b}è maggiore di P{a_r}: è più probabile che l’allineamento dei due amminoacidi corrispondenti sia il risultato di un evento evolutivoSe il valore è < = a zero: è più probabile che l’allineamento dei due amminoacidi corrispondenti sia casualeIdea per assegnare un punteggio all'allineamento: i singoli valori delle matrici di valutazioni possono essere sommati, per assegnare un punteggio all’intero allineamento
Matrici di valutazione (proteine)
Valori sulla diagonale:indicano l’ordine di casualità nell’allineamento di
due amminoacidi nelle 2 sequenzedipendono dalla frequenza di occorrenza
dell’aminoacido (più raro è l’aminoacido, più grande la probabilità che l’allineamento dello stesso aminoacido nelle 2 sequenze non sia casuale)
Nota: le matrici di valutazione sono matrici triangolari

23
Struttura diagonale
Matrici di valutazione: acidi nucleici
Sono molto più semplici di quelle usate per le proteine
non si tiene conto della natura chimica (similarità)non si tiene conto della frequenza delle basiesempio BLAST: punteggio (standard) positivo per le identità, negativo per le discrepanze

24
Gap
Le sequenze di DNA possono mutare sia per sostituzioni puntuali che per inserimento o eliminazione di intere sottosequenze di nucleotidiE’ spesso necessario inserire dei buchi (gap) nelle sequenze da allineare per avere allineamenti significativiTale operazione va fatta con discrezione: si assegnano penalità (punteggi negativi) per l'inserimento di gap
Valutazione dei gap
La penalità assegnata a gap singoli è molto più grande di quella assegnata a blocchi di gap consecutivi:
E' più probabile che si verifichi una sola mutazione che coinvolge più nucleotidi adiacenti, piuttosto che si verifichino numerose mutazioni isolate che coinvolgono un unico nucleotide
Esempio: -11 per gap singoli, -1 per gap consecutivi

25
Algoritmi di allineamento (cenni)
Sono delle specializzazioni di algoritmi per la risoluzione di problemi di ottimizzazione:
vi è un numero elevato di soluzioni possibili, ma solo un sottoinsieme ristretto è ottimaleil problema originale è decomposto in sottoproblemi più semplici (di dimensioni più piccole)esiste una “sequenzialità” nella risoluzione dei sottoproblemi (si risolvono prima i sottoproblemi di dimensioni minori, poi quelli di dimensioni maggiori)
Algoritmi di allineamento (cenni)
Nel caso di allineamento di due sequenze di dati biologici l'obiettivo è:
massimizzare il numero di coppie di elementi allineati con un punteggio positivominimizzare il numero di gap e allineamenti con punteggio negativo
Il problema è decomposto nell’allineare in modo ottimale prima coppie di singoli elementi (sottoproblema di dimensione minore) e poi “sottosequenze” via via più grandi (sottoproblemi di dimensioni maggiori)

26
Algoritmi di allineamento (cenni)
Allineamento di coppie di elementi di due sequenze: 3 decisioni possibili1. Tenere allineati i due elementi2. Inserire un gap nella sequenza I3. Inserire un gap nella sequenza II
La decisione 1 ha un punteggio che (sulla base della “scoring matrix” usata) può essere negativo o positivo; 2 e 3 hanno un punteggio negativoSi sceglie la decisione col punteggio più alto
...and so on -> non ci addentriamo nei dettagli di come funziona l'algoritmo
Esempio di allineamento locale
L’allineamento locale (fra spezzoni di sequenze) ottimale si ottiene partendo dalla 5a posizione di SeqI, ed inserendo un gap sempre in Seq I

27
Matrice di allineamento di seq.I e II
Allineamento globale
esistono diversi tipo di allineamento globale o localeAllineamento globale:
Le sequenze sono allineate secondo la loro intera lunghezza (inserimento di gap se hanno lunghezze diverse)Si riempie la matrice M partendo dall’angolo superiore sinistro fino a quello inferiore destro -> Viene tracciato solo il cammino che corrisponde all’allineamento ottimale algoritmo Needleman-Wunsch

28
EMBOSS- Needle: Allineamento globalehttp://www.ebi.ac.uk/emboss/align/: Needleman-Wunsch global alignment from EBI - European Bioinf.Inst.
specifica dei parametri:- allineamentoglobale/locale- scoring matrix- proteine/DNA- gap penalties...
ALIGN
“Utility” del pacchetto sw FASTA per l’allineamento globale di coppie di sequenzeE' integrato in applicazioni WEB, es. SDSC Biology Workbench
http://workbench.sdsc.edu/index.htmlhttp://fasta.bioch.virginia.edu/fasta/align.htm
Se scaricate il programma è eseguibile ambiente Linux (va compilato); interfaccia a linea di comando
Accetta sequenze memorizzate in formato FASTA (lo standard più semplice)

29
ALIGN: esempio di allineamento di 2 sequenze protiche
Allinemento locale
Locale (vedi esempio diapositive precedenti)
E’ di gran lunga il più usatoNon sempre le 2 sequenze da allineare sono note: ad esempio quando si usano query a sequenze per ricerche in basi di datiSpesso si cercano analogie fra spezzoni di sequenze

30
Allineamento locale
Non richiede che il confronto di due sequenze sia svolto per la loro intera lunghezzaVariante dell’algoritmo per l’allineamento globale: algoritmo Smith-WatermanIn caso di punteggio parziale negativo, l’allineamento corrente può essere abbandonatoL’allineamento può terminare in qualsiasi punto della matriceTools: SSEARCH, LALIGN (utilities FASTA);BLAST
Query basate su sequenze
L’allineamento viene usato per cercare sequenze “similari” in DB biologiciProblema di efficienza
sequenza di query = stringa lunga fino a qualche migliaio di caratterinel DB migliaia di sequenze di dimensioni analoghe
Cercare allineamenti ottimali è in genere impraticabileSoluzione: Si usano tecniche euristiche per velocizzare le ricerche, senza garantire allineamenti ottimali -> si guadagna in efficienza ma si può sbagliare
31
BLAST
Basic Local Alignment Search Tool: è il programma ad oggi più diffuso per ricerche basate su sequenzeUsato da molti server di ricercaIntegrato in GenBank (NCBI)Molto veloce (migliaia di confronti/min): versione efficiente dell’algoritmo di allineamento localeCerca zone di similarità localihttp://www.ncbi.nlm.nih.gov/BLAST/
BLAST

32
BLAST
Implementazioni:NCBI BLAST, WU-BLAST (funzionalità aggiuntive per ricerche nelle sequenzeGenoma)Integrati entrambi in applicazioni WEBDisponibili anche come pacchetti sw free(scaricabili anche solo gli eseguibili)Ambiente LinuxInformazioni: sito del NCBI oppure
http://blast.wustl.edu
BLAST
Programmi disponibiliblastall (ricerche di tipo generali; modalità:blastp, blastn, blastx, tblastn)blastpgp (allineamenti multipli)bl2seq (allineamenti locali di due sequenze)...

33
BLAST: modi di funzionamento
Diverse modalità di funzionamento (espressecome opzioni di blastall)
blastp: query di sequenze proteine (PS) a base dati PSblastn: query di sequenze acido nucleiche (NS) a base dati NSblastx: query NS tradotta nei 6 possibiliframe PS a base dati PStblastn: query PS a base dati NS tradotta nei 6 possibili frame