
3rd 3DDRESD: DB
13
POLITECNICO DI MILANO Struttura Dati per Sistemi Embedded su FPGA D D ynamic ynamic R R econfigurability econfigurability in in E E mbedded mbedded S S ystems ystems D D esign esign Paolo Roberto Grassi: paolo.grassi @dresd.org
-
Upload
usrdresd -
Category
Technology
-
view
327 -
download
0
Transcript of 3rd 3DDRESD: DB

POLITECNICO DI MILANO
Struttura Dati per Sistemi Embedded su
FPGADDynamic ynamic RReconfigurability econfigurability
inin EEmbeddedmbedded SSystemsystems DDesignesign
Paolo Roberto Grassi: paolo.grassi @dresd.org

2
OutlineOutline
IntroduzioneContesto del LavoroMotivazione del ProgettoProblematiche
Sistemi Embedded su FPGADescrizione delle FPGAFPGA e BoardFPGA e Core
Descrizione del LavoroStruttura DatiImplementazioneRelazioni tra gli oggetti del DB
Conclusioni e Sviluppi Futuri

3
Contesto del LavoroContesto del Lavoro
L’idea di costruire una struttura dati nasce all’interno del progetto “DFDK” (DRESD Free Delevopment Kit) presso il gruppo DRESD
DFDK è un progetto che conta di creare un tool per lo sviluppo di sistemi embedded su FPGA attraverso:
Elevata automatizzazione del flusso di progettoVerifica progressiva del layoutCompletamento automatico del layout del sistema

4
Motivazione del LavoroMotivazione del Lavoro
La motivazione principale era quella di creare una struttura dati per DFDK
Ben presto ci si è accorti che non era solo DFDK a necessitare di una struttura dati
Tanti altri tools e algoritmi avevano bisogno di appoggiarsi su una struttura dati omogenea e unica al fine di potersi combinare più facilmente
5
ProblematicheProblematiche
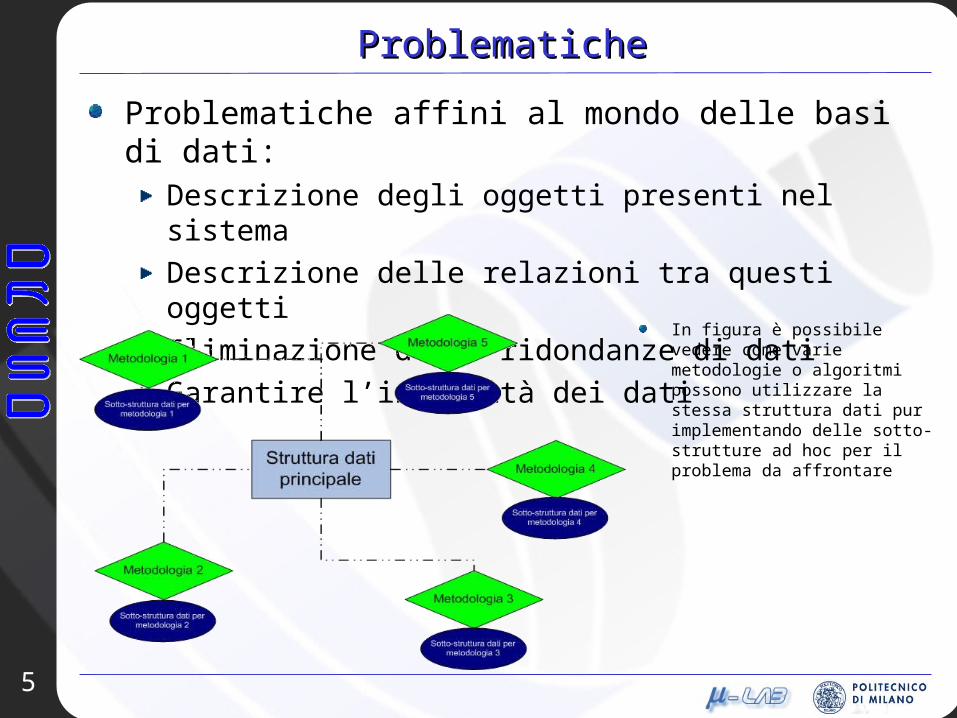
Problematiche affini al mondo delle basi di dati:Descrizione degli oggetti presenti nel sistemaDescrizione delle relazioni tra questi oggettiEliminazione delle ridondanze di datiGarantire l’integrità dei dati
In figura è possibile vedere come varie metodologie o algoritmi possono utilizzare la stessa struttura dati pur implementando delle sotto-strutture ad hoc per il problema da affrontare

6
Descrizione delle FPGADescrizione delle FPGA
Non volendosi addentrare nei dettagli, verrà specificata solo la terminologia utilizzata
FPGA: termine autoesplicativo per indicare le FPGAGRID: questo termine, se legato alla descrizione delle FPGA, indica la suddivisione dell'FPGA in macroblocchi quali: processori, memorie, CLB,...RPM GRID: termine che indica una suddivisione a grana più ne di quella effettuata per le grid. Si usa per descrivere il collocamento dei blocchi funzionali contenuti nelle grid, quali le slice.PINOUT: termine che descrive le parti di I/O della FPGA verso il mondo esterno. Se a questo termine si affianca GLOBAL, ci si riferisce a tutta la piedinatura utilizzata per le alimentazioni o comunque riservate al dispositivo e quindi non utilizzabile dalla logica programmabile.

7
FPGA e BoardFPGA e Board
BOARD: termine autoesplicativo per identificare una specifica board
PERIPHERAL: termine che identica le periferiche presenti sulla board, le loro caratteristiche e come sono connesse alla stessa
GENERIC: termine che, se associato alle periferiche, indica i parametri cui sono settate le periferiche. Indicano, ad esempio, il baudrate, la larghezza degli ingressi, il tipo di configurazione usata,... Sono utili per conoscere come dovranno essere configurati i cores al ne di garantire il corretto funzionamento e utilizzo della periferica.
PORT: termine che indica le interfacce di comunicazione della periferica. Oltre ad indicare quali sono, indica anche, rispetto alla board desiderata, come e dove sono collegate all'FPGA presente su di essa.

8
FPGA e CoreFPGA e Core
CORE: unità funzionale descritta in un linguaggio di programmazione hardware
PORT: se associata ai core, intende un ingresso o una uscita del core
GENERIC: parametri che possono essere usati all'interno dei core per una maggiore e più facile customizzazione di parti di esso.

9
Struttura DatiStruttura Dati
BOARD_FPGA (id_board, fpga_device, fpga_package)
BOARDS (id, vendor, name, revision, short_description, long_description)
CORE (name, major_version, minor_version, description, category, role, interrupt, bandwith)
CORE_CATEGORY (name)
CORE_GENERICS (core_name, core_major_version, core_minor_version, name, type, default_value)
CORE_MASTER_SLAVE (master_name, master_major_version, master_minor_version, slave_name, slave_major_version, slave_minor_version)
CORE_PORTS (core_name, core_major_version, core_minor_version, name, direction, type, begin, end, default_value)
CORE_VHDL (core_name, core_major_version, core_minor_version, filename)
FPGA (device, package, vendor, family)
FPGA_GLOBAL_PINOUTS (device, package, pin_name, pin_type)
FPGA_GRID (device, package, rpm_x, rpm_y, oset_x, oset_y, type)
FPGA_PINOUTS (device, package, rpm_x, rpm_y, bank, pin_name, pin_type)
FPGA_RPM_GRID (device, package, rpm_x, rpm_y, type)
PERIPHERAL_GENERICS (id_board, peripheral_name, generic_name, value)
PERIPHERAL_PORTS (id_board, peripheral_name, name, ucf_loc_string, ucf_iostandard_string, ucf_period_string, initial_val)
PERIPHERALS (id_board, name, description)

10
ImplementazioneImplementazione
L’implementazione ha accoppiato un database relazionale con un linguaggio di programmazione ad oggettiNello specifico sono stati utilizzati SQL e C++Per poter sfruttare al meglio questi linguaggi, si è scelto di creare la struttura dati in SQL, gestendo facilmente tutti vincoli di integrità dei dati, e una serie di classi C++ che interrogano il DB e ne estraggono le informazioniQueste classi istanziano degli oggetti che contengono le informazioni richieste dal database
11
ImplementazioneImplementazione
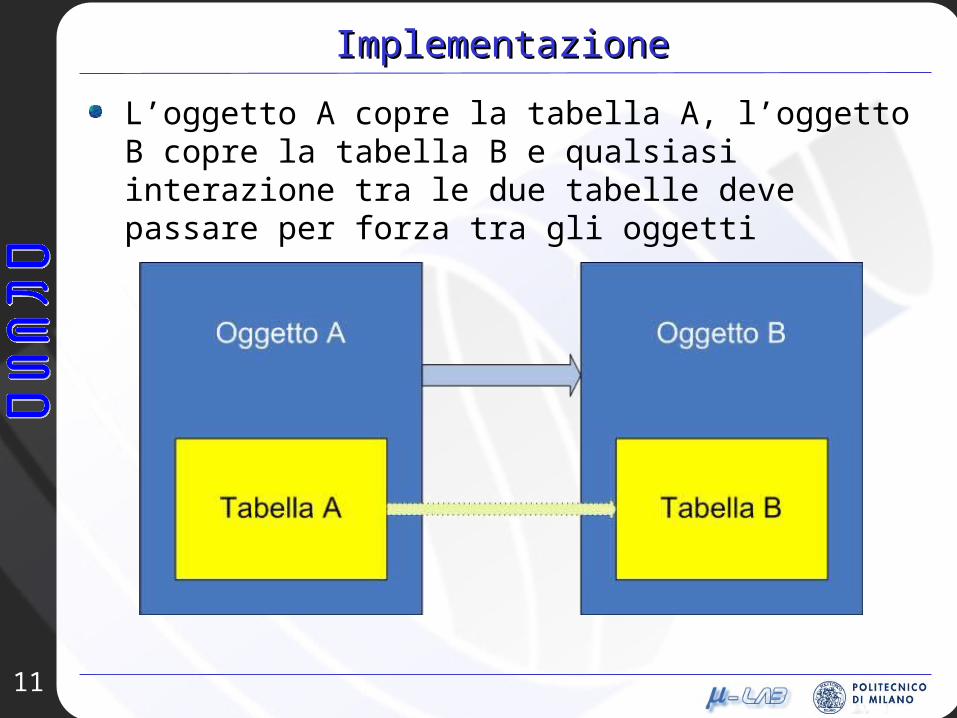
L’oggetto A copre la tabella A, l’oggetto B copre la tabella B e qualsiasi interazione tra le due tabelle deve passare per forza tra gli oggetti
12
Relazioni tra gli Oggetti del DBRelazioni tra gli Oggetti del DB
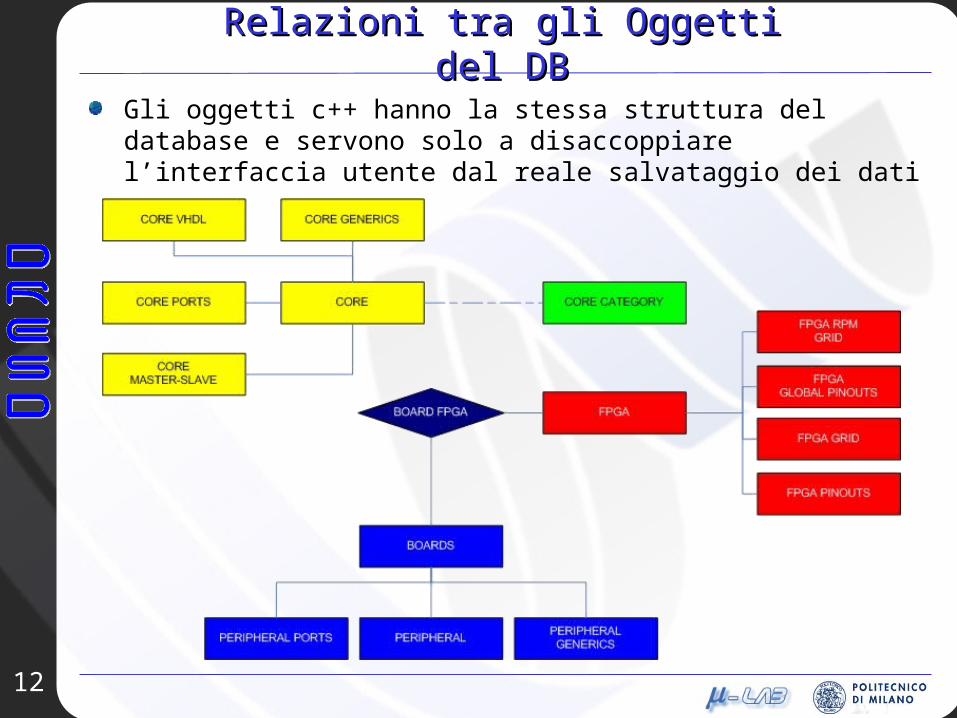
Gli oggetti c++ hanno la stessa struttura del database e servono solo a disaccoppiare l’interfaccia utente dal reale salvataggio dei dati

13
Conclusioni e Sviluppi FuturiConclusioni e Sviluppi Futuri
Il lavoro ha portato alla realizzazione di una struttura dati per progettazione di sistemi embedded su FGPA.Non si è solo fermato alla implementazione reale della struttura dati nel linguaggio scelto, ma ha dato il via ad un flusso di lavoro legato alla descrizione delle entità distinte che, se composte, formeranno il sistema embedded.Vista l'efficacia del lavoro, si sta pensando di utilizzare tale struttura per altri progetti oltre DFDK. Questa estensione avrà sicuramente bisogno di essere analizzata con cura, affrontandone razionalmente tutti gli aspetti di crescita.


















