UNIVERSITA DEGLI STUDI DI MILANO` - lim.di.unimi.it · attraverso l’uso del linguaggio C++. ......
46
UNIVERSIT ` A DEGLI STUDI DI MILANO FACOLT ` A DI SCIENZE E TECNOLOGIE CORSO DI LAUREA TRIENNALE IN INFORMATICA MUSICALE SVILUPPO DI UN’APPLICAZIONE PER LA CREAZIONE DI PAESAGGI SONORI BINAURALI Relatore: Prof. Luca Andrea Ludovico Correlatore: Dott. Giorgio Presti Tesi di Laurea di: Bo↵elli Lorenzo Matr. Nr. 859165 anno accademico 2016-2017
Transcript of UNIVERSITA DEGLI STUDI DI MILANO` - lim.di.unimi.it · attraverso l’uso del linguaggio C++. ......

UNIVERSITA DEGLI STUDI DI MILANOFACOLTA DI SCIENZE E TECNOLOGIE
CORSO DI LAUREA TRIENNALE IN INFORMATICA MUSICALE
SVILUPPO DI UN’APPLICAZIONE PER LA CREAZIONEDI PAESAGGI SONORI BINAURALI
Relatore: Prof. Luca Andrea LudovicoCorrelatore: Dott. Giorgio Presti
Tesi di Laurea di:Bo↵elli LorenzoMatr. Nr. 859165
anno accademico 2016-2017


Introduzione
Questa tesi a↵ronta lo sviluppo di un’applicazione per la spazializzazione binauraleattraverso l’uso del linguaggio C++.L’esperienza e le conoscenze maturate durante questi tre anni di studio sono statefondamentali per lo sviluppo questo elaborato. L’audio binaurale, difatti, per le sueparticolari caratteristiche ha bisogno di molte premesse per essere compreso ed uti-lizzato.Essendo questo tipo particolare di esperienza audio modellata sul modo in cui il no-stro corpo percepisce il suono, e necessaria una buona conoscenza dell’anatomia efisiologia dell’apparato uditivo. Inoltre, va considerato il modo in cui il nostro cer-vello ottiene ed elabora i segnali per ricavarne le informazioni di cui ha bisogno; inmodo particolare verranno studiate quelle relative alla localizzazione spaziale.La natura dell’onda, e come avviene il suo viaggio all’interno dello spazio, e un fon-damento necessario per poter trattare questa tematica.Trattandosi inoltre di utilizzo dell’audio in campo informatico, sono oltremodo neces-sarie competenze a tutto tondo a livello tecnico, che spaziano dalla digitalizzazionefino all’elaborazione dei segnali, passando per gestione accurata di bu↵er di lettura escrittura, allocazione e memorizzazione.Questo corso di laurea ha coperto in modo eccellente ognuno di questi argomenti,andando spesso oltre e suscitando anche la curiosita per molti argomenti di appro-fondimento.Uno di questi e oggi oggetto della mia tesi di laurea: l’audio binaurale.L’interesse per questo argomento e stato suscitato durante le ore in aula, a partiredal primo anno (Corso di Modelli della Percezione Musicale), e mi ha portato ad unforte approfondimento a casa.Quello che trovo interessante a riguardo di questo argomento e la forte potenzialita alivello di coinvolgimento dell’ascoltatore o utente finale, e la facilita di applicazione.L’audio binaurale permette di sorpassare la linea monodimensionale dell’audio stereo,a favore di un’esperienza tridimensionale, di per se coinvolgente e piu naturale.La facilita di applicazione deriva invece dal fatto che non c’e bisogno di innovazionia livello hardware o software; si possono infatti utilizzare tutti i tipi di architetture etecnologie progettate per l’audio stereo.

L’interesse per questo particolare argomento mi ha portato a realizzare un sistemadigitale portatile per la registrazione binaurale.La parte strutturale e composta dalla testa di un manichino, su cui sono state montatedue orecchie, ottenute tramite stampa 3D ad alta definizione. All’interno dei condot-ti uditivi sono stati posizionati i microfoni, scelti per l’approssimazione alla linearitanella loro risposta in frequenza. Questi ultimi sono stati collegati ad un registratoredigitale portatile, che opera la digitalizzazione del segnale fino a 96kHz/24bit.Ovviamente, l’approssimazione all’anatomia umana e molto abbondante, ma nono-stante tutto si possono ottenere comunque dei buoni risultati.
Organizzazione della tesi
La tesi e organizzata come segue:
• nel Capitolo 1 viene spiegato il concetto di audio binaurale e tutte le nozioninecessarie per comprendere al meglio su cosa si basa, come funziona e qualisono i suoi limiti.
• nel Capitolo 2 e descritto il dataset HRTF utilizzato per lo sviluppo dell’appli-cazione: come sono stati ottenuti e filtrati i dati per ottenere le HRTF utilizzate;a fine capitolo viene motivata la scelta del dataset utilizzato rispetto ai tantialtri disponibili.
• nel Capitolo 3 si illustra la struttura del software oggetto di questa tesi, descri-vendo le varie funzioni dell’applicazione e come esse siano state realizzate.
• nel Capitolo 4 infine vengono descritti i test a cui e stata sottoposta questaapplicazione, per testarne l’e�cenza. Questi test riguardano l’approccio utente-software, la velocita di elaborazione e l’e�cacia del dataset HRTF utilizzato.I dati raccolti sono successivamente commentati nella sezione conclusiva.

Indice
Introduzione
Ringraziamenti
1 Audio Binaurale 11.1 Localizzazione Spaziale . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Di↵erenza di livello . . . . . . . . . . . . . . . . . . . . . . . . 21.1.2 Di↵erenza di tempo . . . . . . . . . . . . . . . . . . . . . . . . 31.1.3 Filtraggio relativo alla direzione . . . . . . . . . . . . . . . . . 31.1.4 Angolo minimo di discriminazione . . . . . . . . . . . . . . . . 41.1.5 Movimenti della testa . . . . . . . . . . . . . . . . . . . . . . . 5
1.2 HRTF (Head Related Transfer Functions) . . . . . . . . . . . . . . . 51.2.1 Misurazione delle HRTF . . . . . . . . . . . . . . . . . . . . . 61.2.2 HRTF Learning . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2.3 Problemi delle HRTF . . . . . . . . . . . . . . . . . . . . . . . 7
1.3 Problemi dell’audio binaurale . . . . . . . . . . . . . . . . . . . . . . 81.3.1 Distorsione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.3.2 Ascolto in cu�a . . . . . . . . . . . . . . . . . . . . . . . . . . 81.3.3 Ascolto tramite altoparlanti . . . . . . . . . . . . . . . . . . . 91.3.4 Potenza di calcolo . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Dataset HRTF 112.1 Misurazione delle HRTF . . . . . . . . . . . . . . . . . . . . . . . . . 112.2 Estrazione dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.1 Rapporto segnale-rumore . . . . . . . . . . . . . . . . . . . . . 122.2.2 Organizzazione dei file . . . . . . . . . . . . . . . . . . . . . . 132.2.3 Filtraggio delle non-linearita . . . . . . . . . . . . . . . . . . . 13
2.3 Scelta dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13

INDICE
3 Sviluppo del Software 143.1 Interfaccia grafica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1.1 Pannello . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.1.2 Lista dei file . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.1.3 Barra delle funzioni . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Funzioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.2.1 Aggiunta ed eliminazione dei file . . . . . . . . . . . . . . . . . 163.2.2 Gestione dei progetti . . . . . . . . . . . . . . . . . . . . . . . 173.2.3 Scala grandezze . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2.4 Impostazioni . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2.5 O↵set e posizionamento . . . . . . . . . . . . . . . . . . . . . 183.2.6 Rendering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.2.7 Riproduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Elaborazione dei segnali . . . . . . . . . . . . . . . . . . . . . . . . . 203.3.1 L’oggetto SorgenteAudio . . . . . . . . . . . . . . . . . . . . . 203.3.2 Preparazione dei file . . . . . . . . . . . . . . . . . . . . . . . 213.3.3 Scelta dell’HRTF . . . . . . . . . . . . . . . . . . . . . . . . . 213.3.4 Convoluzione . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.3.5 Gestione dell’o↵set . . . . . . . . . . . . . . . . . . . . . . . . 243.3.6 Unione delle sorgenti . . . . . . . . . . . . . . . . . . . . . . . 243.3.7 Normalizzazione . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4 Utilizzo ed e�cacia dell’applicazione 274.1 Approccio utente-applicazione . . . . . . . . . . . . . . . . . . . . . . 274.2 Velocita di rendering . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.3 E�cacia delle HRTF . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.3.1 Premesse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304.3.2 Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.3.3 Descrizione del test . . . . . . . . . . . . . . . . . . . . . . . . 324.3.4 Risultati Finali . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4 Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384.4.1 Sviluppi Futuri . . . . . . . . . . . . . . . . . . . . . . . . . . 39

Capitolo 1
Audio Binaurale
L’audio binaurale e una tecnica che permette di far provare all’ascoltatore un’esperien-za uditiva tridimensionale utilizzando solamente due canali audio. Partendo infattida due punti di ascolto, simula il modo di percepire eventi uditivi nel mondo reale.[1]Vi sono due approcci possibili all’audio binaurale: registrazione o sintesi. Il primoapproccio prevede l’utilizzo di microfoni o apparecchiature di registrazione binaura-li. Queste ultime possono variare per complessita in un ventaglio che va da semplicimicrofoni disposti in direzioni opposte e opportunamente spaziati, fino a manichinicomposti da busto, testa e spalle, fabbricati per approssimare al meglio un ascoltatore(Manichino KEMAR, Figura 1).
Figura 1: Manichino KEMAR.
Vi e inoltre la possibilita di utilizzare persone al posto di manichini per realizzarele registrazioni, anche se questo puo creare problemi relativi al movimento dell’a-scoltatore; oltretutto nel condotto uditivo e molto di�cile riuscire a posizionare deimicrofoni ad alta qualita senza “invadere” troppo l’organismo umano [2].Il secondo approccio si basa sulla realizzazione di funzioni particolari, specifiche perogni posizione dello spazio: le HRTF (Head Related Transfer Functions).Queste funzioni vengono ricavate registrando la risposta all’impulso (o ad uno sweep
1

CAPITOLO 1. AUDIO BINAURALE 2
in frequenza) di un sistema di registrazione binaurale, stimolato da diverse posizioninello spazio. Maggiore e il numero dei punti di stimolo acustico, piu fine sara lacollocazione nello spazio dei suoni nella fase successiva [3].Per ”inserire” i suoni nello spazio, sara quindi necessario filtrare il suono puro se-condo la funzione relativa al punto dello spazio in cui si vuole collocare rispettoall’ascoltatore. L’operazione utilizzata per realizzare il file definitivo e la convoluzione.
1.1 Localizzazione Spaziale
L’audio binaurale si basa sul funzionamento del nostro apparato uditivo e del nostrocervello per la percezione spaziale degli eventi uditivi circostanti: per questo e im-portante conoscerne le caratteristiche principali. L’apparato uditivo umano utilizza3 metodi per localizzare le sorgenti sonore: di↵erenza di livello interaurale, di↵erenzadi tempo interaurale e filtraggio relativo alla direzione [4].I primi due sono illustrati nella Figura 2.
Figura 2: Semplificazione del meccanismo di di↵erenza interaurale di livello e tempo.
1.1.1 Di↵erenza di livello
La di↵erenza interaurale di livello corrisponde alla di↵erenza di intensita e si misurapercio in decibel (dB).Se si ha di↵erenza di livello interaurale, la sorgente dell’evento uditivo sara piu vicinaall’orecchio che percepisce un’intensita maggiore. Maggiore e la di↵erenza, piu lasorgente e spostata rispetto al centro del campo uditivo.Questo metodo funziona pero solamente per le alte frequenze (sopra 1 kHz ), per lequali la testa agisce come ostacolo, creando un’ombra acustica dovuta alla di↵razionegenerata dallo scontro delle onde con la sua superficie [5], come illustrato in Figura3.

CAPITOLO 1. AUDIO BINAURALE 3
Figura 3: Di↵erenza di livello interaurale a diverse frequenze e angoli di incidenza.
1.1.2 Di↵erenza di tempo
La di↵erenza interaurale di tempo rappresenta il ritardo di percezione di un eventouditivo tra le due orecchie, che puo arrivare ad un massimo di 0.65 ms, dovuta almaggiore percorso che l’onda sonora deve compiere nello spazio.Il ritardo di percezione di un orecchio rispetto all’altro fa comprendere l’ascoltatoreche la sorgente e posizionata verso l’orecchio che ha ricevuto l’onda sonora prima del-l’altro; in base all’entita del ritardo si stabilisce l’angolo di inclinazione della sorgenterispetto al nostro fronte (vedi Figura 4).In realta il nostro cervello non lavora sul ritardo dei transienti, ma sulle di↵erenze difase dei segnali distinti che giungono ad entrambe le orecchie. Avendo queste ultimeuna distanza fissa fra loro, calcolata la di↵erenza di fase, si puo facilmente risalireall’angolo di incidenza [2].In maniera complementare alla di↵erenza di livello interaurale, la di↵erenza di tempoagisce sulle frequenze basse, al di sotto di 1 kHz.
1.1.3 Filtraggio relativo alla direzione
Nonostante entrambi i metodi precedenti vengano utilizzati nel nostro apparato udi-tivo, ed agiscano su range complementari di frequenze, non sono capaci di dare unalocalizzazione fine delle sorgenti nello spazio. Infatti essi possono stabilire l’angolo diincidenza, ma non se rispetto al fronte o al retro, e non possono stabilire alcun angolodi elevazione [6].Interviene quindi il filtraggio relativo alla direzione, operato dal padiglione auricolaree dal condotto uditivo. In base alla direzione da cui il suono proviene, esso viene
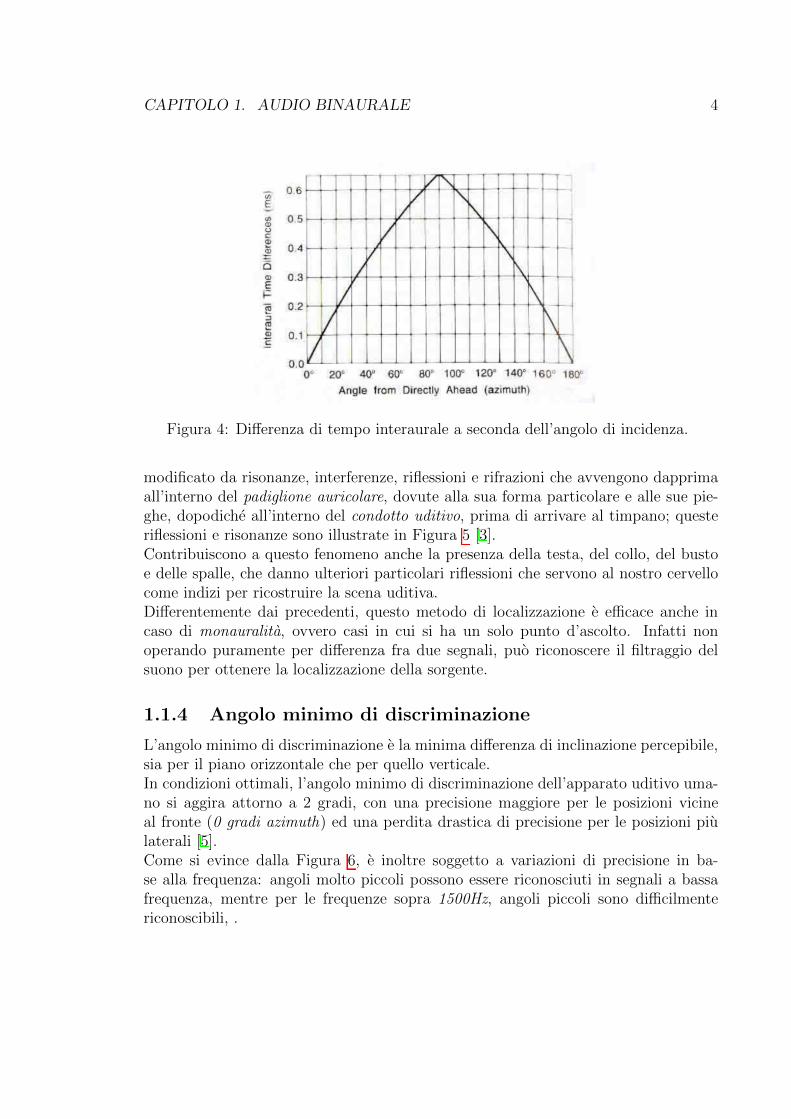
CAPITOLO 1. AUDIO BINAURALE 4
Figura 4: Di↵erenza di tempo interaurale a seconda dell’angolo di incidenza.
modificato da risonanze, interferenze, riflessioni e rifrazioni che avvengono dapprimaall’interno del padiglione auricolare, dovute alla sua forma particolare e alle sue pie-ghe, dopodiche all’interno del condotto uditivo, prima di arrivare al timpano; questeriflessioni e risonanze sono illustrate in Figura 5 [3].Contribuiscono a questo fenomeno anche la presenza della testa, del collo, del bustoe delle spalle, che danno ulteriori particolari riflessioni che servono al nostro cervellocome indizi per ricostruire la scena uditiva.Di↵erentemente dai precedenti, questo metodo di localizzazione e e�cace anche incaso di monauralita, ovvero casi in cui si ha un solo punto d’ascolto. Infatti nonoperando puramente per di↵erenza fra due segnali, puo riconoscere il filtraggio delsuono per ottenere la localizzazione della sorgente.
1.1.4 Angolo minimo di discriminazione
L’angolo minimo di discriminazione e la minima di↵erenza di inclinazione percepibile,sia per il piano orizzontale che per quello verticale.In condizioni ottimali, l’angolo minimo di discriminazione dell’apparato uditivo uma-no si aggira attorno a 2 gradi, con una precisione maggiore per le posizioni vicineal fronte (0 gradi azimuth) ed una perdita drastica di precisione per le posizioni piulaterali [5].Come si evince dalla Figura 6, e inoltre soggetto a variazioni di precisione in ba-se alla frequenza: angoli molto piccoli possono essere riconosciuti in segnali a bassafrequenza, mentre per le frequenze sopra 1500Hz, angoli piccoli sono di�cilmentericonoscibili, .

CAPITOLO 1. AUDIO BINAURALE 5
Figura 5: Distribuzione della pressione sonora nell’orecchio esterno a diversefrequenze. Le linee tratteggiate indicano i punti nodali.
1.1.5 Movimenti della testa
Per quanto possano non fare parte dell’apparato uditivo, i movimenti della testa(illustrati in Figura 7) hanno un compito critico nei meccanismi di localizzazione dellesorgenti, perche permettono di comprendere la direzione da cui un evento uditivoproviene, anche in caso di ambiguita nella rilevazione dei sistemi di localizzazione.Girare la testa, infatti, comporta delle variazioni di livello e fase nelle basse frequenzedel segnale, dando possibilita all’apparato uditivo di ascoltare da piu punti di vistadi↵erenti, e di localizzare secondo gli strumenti a disposizione [7].
1.2 HRTF (Head Related Transfer Functions)
La somma dei tre metodi utilizzati per la localizzazione delle sorgenti da come risulta-to un’unica HRTF. Questa e definita come la funzione che descrive come un orecchioriceve il suono da un punto nello spazio.Queste funzioni vanno a modificare lo spettro naturale delle sorgenti; aggiungono cioeinformazioni allo spettro originale per poter dare al cervello la possibilita di localiz-zare il suono nello spazio [3].Sono funzioni di trasferimento perche descrivono come il suono arrivera all’orecchio
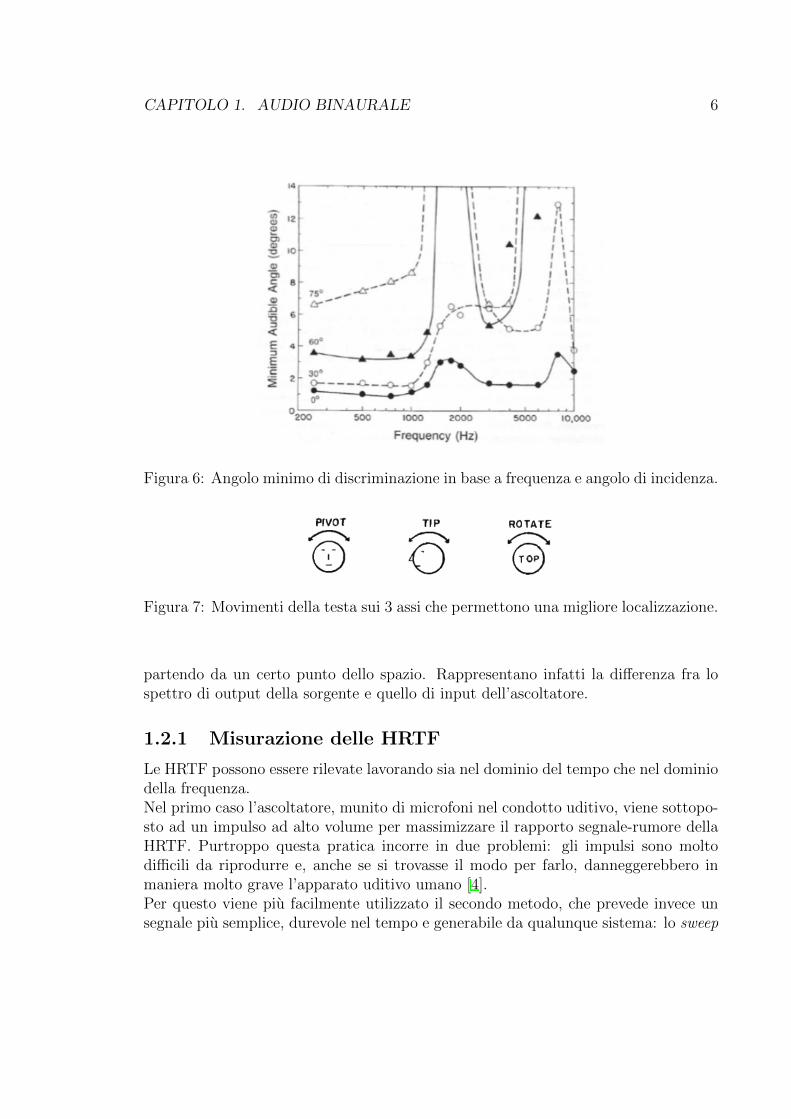
CAPITOLO 1. AUDIO BINAURALE 6
Figura 6: Angolo minimo di discriminazione in base a frequenza e angolo di incidenza.
Figura 7: Movimenti della testa sui 3 assi che permettono una migliore localizzazione.
partendo da un certo punto dello spazio. Rappresentano infatti la di↵erenza fra lospettro di output della sorgente e quello di input dell’ascoltatore.
1.2.1 Misurazione delle HRTF
Le HRTF possono essere rilevate lavorando sia nel dominio del tempo che nel dominiodella frequenza.Nel primo caso l’ascoltatore, munito di microfoni nel condotto uditivo, viene sottopo-sto ad un impulso ad alto volume per massimizzare il rapporto segnale-rumore dellaHRTF. Purtroppo questa pratica incorre in due problemi: gli impulsi sono moltodi�cili da riprodurre e, anche se si trovasse il modo per farlo, danneggerebbero inmaniera molto grave l’apparato uditivo umano [4].Per questo viene piu facilmente utilizzato il secondo metodo, che prevede invece unsegnale piu semplice, durevole nel tempo e generabile da qualunque sistema: lo sweep

CAPITOLO 1. AUDIO BINAURALE 7
in frequenza.Si tratta di un’onda sinusoidale che, partendo al limite con gli infrasuoni, cresce manmano in frequenza fino a raggiungere il limite con gli ultrasuoni, coprendo quindi latotalita dello spettro udibile [8].Avremo quindi la possibilita, una volta registrato, di condensare i dati ed ottenereuna risposta in frequenza generale su tutta la gamma delle frequenze udibili.
1.2.2 HRTF Learning
Possiamo istruire il nostro cervello a riconoscere nuove HRTF, senza pero perderequelle gia acquisite, che vengono memorizzate con la possibilita di essere riutilizzate.E’ stato dimostrato in uno studio scientifico [9] che, dopo una prima fase di trainingcondotta dando agli ascoltatori anche indizi visivi, essi riescono a localizzare le sor-genti ottenendo dei buoni risultati, di↵erentemente dalla fase precedente il training.Gli ascoltatori, richiamati dopo 5 mesi, sono ancora in grado di localizzare quasicorrettamente la provenienza del suono, e, dopo una seconda fase di training, lalocalizzazione avviene in maniera ottima. I risultati sono illustrati in Figura 7.
Figura 8: Risultati del test di Klein e Werner, prima e dopo il primo e il secondotraining.
1.2.3 Problemi delle HRTF
Le HRTF sono particolarmente legate alle caratteristiche fisiche del sistema tramitecui vengono modellate, proprio perche sono le parti anatomiche del corpo (spalle,

CAPITOLO 1. AUDIO BINAURALE 8
testa, padiglione, condotto uditivo, ...) a filtrare opportunamente i suoni per daremaggiori informazioni al cervello riguardo la localizzazione.Ognuno possiede una propria HRTF relativa alla propria anatomia, ma misurareHRTF per tutti sarebbe impraticabile, poiche sono necessari strumenti ad alta preci-sione, camere anecoiche e tempi lunghi di raccolta dei dati [6].Si utilizzano quindi HRTF generiche, misurate attraverso manichini che hanno misureanatomiche di media: queste permettono di avere delle HRTF approssimate, similialle funzioni di un vasto gruppo, anche se non specifiche per i singoli individui.Il problema e appunto che queste funzioni, non corrispondendo con il singolo ascol-tatore, possono causare errori grossolani di localizzazione nell’ascoltatore, che perdecosı il senso tridimensionale della percezione acustica.
1.3 Problemi dell’audio binaurale
Uno dei motivi per cui l’audio binaurale, anche se studiato da molto tempo, e pocodi↵uso sul mercato e legato alla sua di�colta di implementazione nelle situazioni diascolto quotidiano.Esso richiede infatti una serie di accorgimenti per poter essere sperimentato, che dif-ficilmente possono essere attuati in ambienti comuni con poche e semplici operazioni.Di seguito sono elencati i principali problemi dell’audio binaurale. [1]
1.3.1 Distorsione
Le HRTF dell’audio binaurale, come annunciato precedentemente, modificano lo spet-tro dei suoni naturali per aggiungere informazioni relative alla localizzazione da fornireal cervello.Questa e una distorsione del contenuto spettrale della sorgente necessaria per intro-durre la spazializzazione del suono. Avviene sia nel caso della sintesi con HRTF, sianel caso di registrazione binaurale, ed e una sua caratteristica intrinseca.Alla distorsione del contenuto spettrale della sorgente, nel caso della sintesi tramiteconvoluzione, va inserito il problema del possibile clipping.E’ possibile infatti che la convoluzione dei campioni possa restituire valori superiori allimite di ampiezza digitale, che risulterebbero in una distorsione digitale del segnale.Questa distorsione e facilmente evitabile tramite processi preventivi, o tramite nor-malizzazione dell’audio in uscita.
1.3.2 Ascolto in cu�a
Viene fortemente consigliato l’ascolto in cu�a per quanto riguarda l’audio binaurale.Questa scelta e motivata principalmente da tre caratteristiche dell’ascolto in cu�a:

CAPITOLO 1. AUDIO BINAURALE 9
l’ascolto a 180 gradi, l’assenza di riverbero e di cross-talk.Mentre l’ascolto con altoparlanti ha solitamente due sorgenti frontali spaziate fra loro,l’ascolto in cu�a e basato su due sorgenti laterali, direttamente collegate ognuna conciascun orecchio.Essendo direttamente appoggiate alle orecchie, le cu�e creano uno spazio acusti-camente isolato dal resto degli ambienti in cui si trova l’ascoltatore, e per questol’ambiente non influisce sull’ascolto.Le cu�e hanno la possibilita di fornire segnali di↵erenti alle due orecchie, senza chevi sia alcuna interazione fra essi.Nell’ascolto normale questa particolare caratteristica puo comportare un problema,poiche ci si trova in una situazione particolarmente irrealistica per l’apparato uditivo;tuttavia nel caso dell’audio binaurale questo permette di mandare segnali di↵erenti,filtrati secondo le HRTF misurate orecchio per orecchio, senza che interagiscano fraloro (Figura 9).
Figura 9: Acquisizione e uso delle HRTF in cu�a.
1.3.3 Ascolto tramite altoparlanti
Nell’ascolto con altoparlanti la situazione si modifica in maniera significativa. Sihanno infatti due sorgenti frontali, spaziate fra loro, che liberano onde sonore nellospazio per poi essere percepite dall’ascoltatore.L’ambiente in cui avviene l’ascolto influenza in maniera importante la percezione delsuono, modificando il contenuto del segnale sia nel dominio del tempo che in quellodella frequenza.Un altro di�cile aspetto dell’ascolto tramite altoparlanti e la presenza del cross-talk.Questo fenomeno prevede che ad ogni orecchio arrivi sia il segnale dell’altoparlantepiu vicino, sia il segnale dell’altoparlante piu lontano, seppur in ritardo e diminuitoin intensita.

CAPITOLO 1. AUDIO BINAURALE 10
Chiaramente questo influisce sull’uso dell’audio binaurale che ha bisogno di poterstimolare le due orecchie con segnali di↵erenti, senza che interferiscano fra loro.Per ottenere quindi un ascolto binaurale con gli altoparlanti si e provato ad utilizzaresistemi di cancellazione del cross-talk, basati sulla cancellazione di fase. Questi sistemimandano all’altro altoparlante parte del proprio segnale, che viene opportunamenteinvertito e riprodotto, come in Figura 10.Con questo accorgimento e l’ascolto in un ambiente controllato si puo ottenere l’audiobinaurale anche tramite altoparlanti, ma lo sweet spot, ovvero il punto in cui i segnaliinterferiscono tra loro in maniera perfetta, ha un’area molto ridotta, non permettendoquindi l’ascolto in gruppo.
Figura 10: Ascolto con altoparlanti normale (a sinistra) e con cancellazione del cross-talk.
1.3.4 Potenza di calcolo
La convoluzione e un’operazione complessa che richiede molto potere computazionale,e quindi un generoso tempo di elaborazione a meno che si disponga di un’architetturaDSP (Digital Signal Processing) dedicata.I tempi quindi dell’elaborazione sono di�cili da integrare con l’esigenza di una ripro-duzione real-time. Per ovviare a questo problema, si puo e↵ettuare la convoluzioneprima della riproduzione, salvando il file ottenuto in uno qualsiasi dei formati validiper l’audio stereo.Infatti, l’audio binaurale non ha bisogno di formati e schede audio particolari. Aven-do due canali, si puo adattare alle tecnologie sviluppate per l’audio stereo; la naturabinaurale dell’audio sta infatti nello spettro del segnale stesso.

Capitolo 2
Dataset HRTF
In questo capitolo verra descritta la componente che permette la sintesi binauralenell’applicazione di spazializzazione: il dataset HRTF.Il dataset utilizzato e ”HRTF Measurements of a KEMAR Dummy Head Micropho-ne”, sviluppato da B. Gardner e K. Martin al MIT Media Lab nel 1994.
2.1 Misurazione delle HRTF
Le HRTF sono state misurate utilizzando un manichino KEMAR, dotato di due pa-diglioni di↵erenti (DB-061 small pinna e DB-065 large red pinna).Per la registrazione sono stati utilizzati i microfoni Etymotic ER-11 con relativi pre-amplificatori, il cui output e stato collegato ad una scheda audio Audiomedia II DSPdi un Macintosh Quadra, che opera una conversione da analogico a digitale con quan-tizzazione a 16 bit e frequenza di campionamento 44.1 kHz.Le misurazioni sono state e↵ettuate nella camera anecoica del MIT, nella quale sonostati posizionati il manichino KEMAR ed un altoparlante Optimus Pro 7. Per poterruotare facilmente e in maniera precisa il manichino, esso e stato posizionato soprauna piattaforma rotante a controllo numerico, mentre l’altoparlante e stato montatoa 1,4 metri di distanza su un’asta telescopica, in modo da poter permettere un posi-zionamento verticale di precisione.L’Optimus Pro 7 e un altoparlante passivo a 2 vie, dotato di un woofer da 4 pollici eun tweeter da 1. Per via delle sue piccole dimensioni, e molto semplice da posizionareaccuratamente nello spazio. La precisione del sistema e infatti di 0,5 gradi.Gli angoli di elevazione considerati vanno da -40 a 90 gradi, con un intervallo di 10gradi. Per ogni angolo di elevazione e stata fatta una misura a 360 gradi sull’azi-muth, seppur con intervalli di misurazione non fissi, ma che variano da 5 a 30 in baseall’elevazione. Gli intervalli di misurazione sono specificati nella Tabella 1.
11
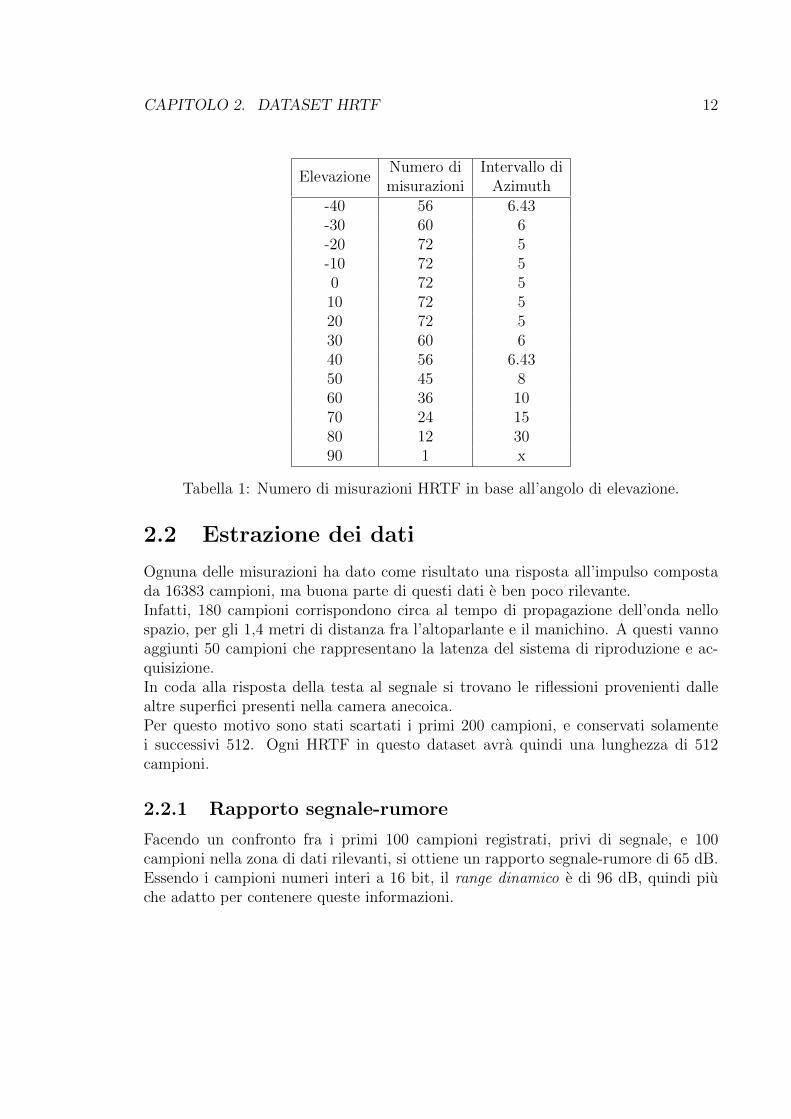
CAPITOLO 2. DATASET HRTF 12
ElevazioneNumero dimisurazioni
Intervallo diAzimuth
-40 56 6.43-30 60 6-20 72 5-10 72 50 72 510 72 520 72 530 60 640 56 6.4350 45 860 36 1070 24 1580 12 3090 1 x
Tabella 1: Numero di misurazioni HRTF in base all’angolo di elevazione.
2.2 Estrazione dei dati
Ognuna delle misurazioni ha dato come risultato una risposta all’impulso compostada 16383 campioni, ma buona parte di questi dati e ben poco rilevante.Infatti, 180 campioni corrispondono circa al tempo di propagazione dell’onda nellospazio, per gli 1,4 metri di distanza fra l’altoparlante e il manichino. A questi vannoaggiunti 50 campioni che rappresentano la latenza del sistema di riproduzione e ac-quisizione.In coda alla risposta della testa al segnale si trovano le riflessioni provenienti dallealtre superfici presenti nella camera anecoica.Per questo motivo sono stati scartati i primi 200 campioni, e conservati solamentei successivi 512. Ogni HRTF in questo dataset avra quindi una lunghezza di 512campioni.
2.2.1 Rapporto segnale-rumore
Facendo un confronto fra i primi 100 campioni registrati, privi di segnale, e 100campioni nella zona di dati rilevanti, si ottiene un rapporto segnale-rumore di 65 dB.Essendo i campioni numeri interi a 16 bit, il range dinamico e di 96 dB, quindi piuche adatto per contenere queste informazioni.

CAPITOLO 2. DATASET HRTF 13
2.2.2 Organizzazione dei file
Le HRTF cosı ottenute sono salvate in file .dat, e rinominate secondo un codicespecifico, che permette di identificare a quale orecchio e con quali angoli di elevazionee azimuth ci si riferisca.La posizione ad azimuth ed elevazione 0 corrisponde al fronte del manichino, mentrel’angolo di azimuth viene misurato in senso orario dall’alto, per cui un azimuth di 90gradi corrisponde a una posizione accostata all’orecchio destro.
2.2.3 Filtraggio delle non-linearita
I dati estratti e cosı organizzati non sono pero pronti per essere utilizzati: contengonoancora il filtraggio operato dal sistema di riproduzione che, non avendo una rispostain frequenza piatta, cambia il suono sorgente.Viene quindi misurata la risposta all’impulso del sistema di riproduzione, in modo dapoter ottenere un filtro inverso che, applicato alle funzioni ricavate, possa restituiredelle HRTF pure.Il filtro inverso viene ottenuto applicando la trasformata discreta di Fourier (DFT ),invertendo la fase e l’ampiezza dello spettro ottenuto, per poi applicare la trasformatainversa e ottenere nuovamente un segnale nel dominio del tempo.
2.3 Scelta dei dati
Allo scopo di realizzare un’applicazione per la spazializzazione binaurale per la miatesi, e stato scelto questo dataset per due motivi principali: l’utilizzo del manichinoKEMAR e la sua longevita ed a�dabilita.L’utilizzo del manichino KEMAR o↵re un ottimo grado di approssimazione di HRTFumane, un compromesso che permette l’utilizzo da parte di un pubblico molto va-sto. Se fossero state scelte HRTF ricavate da ascoltatori umani avremmo avuto dellefunzioni molto dettagliate, ma inutilizzabili perche completamente estranee a buonaparte del pubblico.La longevita di questa libreria e l’assenza di grossi aggiornamenti sono garanti dellaqualita ed utilizzabilita di queste funzioni, oltre ad essere una pietra miliare per iricercatori in questo campo.Nello specifico, sono state scelte le HRTF rilevate con il padiglione di tipo large pinna,poiche si ritiene piu simile alla maggior parte del pubblico, e quindi piu facilmenterecepibile dal cervello.

Capitolo 3
Sviluppo del Software
Note le informazioni presenti al capitolo 1, e scelto il dataset descritto nel capitolo 2,si puo finalmente passare alla fase di sviluppo del software.Questo verra illustrato partendo dalla sua interfaccia grafica, ovvero da come l’uten-te vede esternamente l’applicazione, per poi addentrarsi nel “cuore” del codice dellefunzioni di cui e composto.Il linguaggio scelto per la programmazione di questa applicazione e il C++, che per-mette di creare oggetti secondo le proprie esigenze, raggiungendo un alto grado disintesi ed utilita.
3.1 Interfaccia grafica
Eseguendo l’elaborato, l’utente si trova di fronte un’interfaccia grafica molto semplice(Figura 11), composta da una finestra rettangolare. All’interno di questa si possonoriconoscere facilmente gli elementi principali: una barra delle funzioni, una lista edun pannello, che contiene al suo interno un’immagine.
3.1.1 Pannello
Il pannello presente in basso a sinistra permettera all’utente di visualizzare le sorgentinello spazio e di modificarne la posizione.L’immagine presente nel pannello ra�gura infatti lo spazio visto dall’alto, diviso insettori dagli assi X e Y e da due circonferenze che consentono di approssimare ladistanza dal centro.Al centro dell’immagine si trova una testa umana stilizzata, che rappresenta l’ascol-tatore.Le sorgenti audio saranno inserite nel pannello sotto forma di punti bianchi; passando
14

CAPITOLO 3. SVILUPPO DEL SOFTWARE 15
Figura 11: Interfaccia grafica all’apertura.
il mouse sopra ognuno di essi, verra visualizzato il nome del file, rendendo identificabilidall’utente le sorgenti l’una dall’altra (Figura 12).
3.1.2 Lista dei file
La lista presente a destra del pannello raccogliera tutti i file che verranno combinatinel file di output, e mostrera di essi le seguenti informazioni: nome del file, o↵set,asse X, asse Y, asse Z e percorso del file.Le informazioni presenti all’interno della lista riguardanti l’o↵set e l’asse Z possonoessere modificate cliccandoci sopra ed inserendo il valore desiderato. I valori per gliassi X e Y possono essere modificati trascinando il punto bianco presente all’internodel pannello, mentre i valori di nome e percorso non possono essere ovviamente mo-dificati. Il doppio clic sopra questi valori riproduce invece il file desiderato.Questo insieme di dati funge da riepilogo per l’utente, che ha sempre sott’occhio tuttele informazioni importanti legate ad ogni singolo file.
3.1.3 Barra delle funzioni
Sopra le due componenti gia illustrate si trova la barra delle funzioni. Essa raccoglieal suo interno tutte le funzioni del software, utilizzabili facilmente dall’utente tramitei relativi pulsanti.I tasti sono posizionati per raggruppamenti tematici, in modo da rendere piu facileed intellegibile l’accesso all’utente.Le funzioni collegate ai pulsanti possono essere identificate tramite il disegno, oppure

CAPITOLO 3. SVILUPPO DEL SOFTWARE 16
Figura 12: Interfaccia grafica durante l’uso.
dal testo che viene visualizzato passando il puntatore del mouse sopra l’icona, comeavviene in Figura 13.
Figura 13: Barra degli strumenti e riconoscimento pulsanti.
3.2 Funzioni
In questo testo, vengono considerate funzioni tutti i servizi che l’applicazione mettea disposizione dell’utente, che sono di due tipi: opportunita di modifica dell’audio inoutput e personalizzazioni per l’utente.Le funzioni presenti all’interno dell’applicazione sono le seguenti, in ordine progressi-vo: aggiungi file, elimina file, render, riproduci, impostazioni, scala grandezze, salvaprogetto, apri progetto e nuovo progetto, a cui vanno aggiunte le opportunita dimodifica di posizione e o↵set per ogni sorgente.
3.2.1 Aggiunta ed eliminazione dei file
L’aggiunta ed eliminazione dei file riguarda solamente l’inserimento o esclusione del-l’audio dal file di output.

CAPITOLO 3. SVILUPPO DEL SOFTWARE 17
Il file audio selezionato infatti, viene aggiunto o eliminato dalla lista dei file; essacontiene tutti i dati necessari per generare correttamente l’audio in uscita.Il pulsante di aggiunta file apre una finestra di dialogo tramite la quale l’utente puonavigare nel proprio file system e selezionare un file con estensione .wav. Al click diconferma, il file viene aggiunto alla lista, e i suoi valori di o↵set e di posizionamento(asse x, y, z) vengono automaticamente impostati a 0.I file aggiunti non vengono caricati in memoria, bensı vengono acquisite le loro infor-mazioni per poterli trovare ed elaborare successivamente.Le sorgenti rappresentate nel pannello si adeguano alle operazioni e↵ettuate sullalista, aggiungendo un nuovo puntino bianco o rimuovendo quello relativo al file dalpannello.
3.2.2 Gestione dei progetti
I progetti permettono di salvare una sessione per poterla richiamare successivamente.Il salvataggio di un progetto prevede una prima fase in cui, tramite una finestra didialogo, l’utente sceglie il percorso ed il nome del progetto da salvare. Viene creatoquindi un file di testo, all’interno del quale vengono salvati i dati contenuti all’internodella lista dei file, riga per riga.I valori contenuti nelle varie colonne sono intervallati da un separatore, nel nostrocaso il carattere “|”.
Codice 3.1: Contenuto di un file di progetto.
okay -1. wav |0|52|62|40|\\ Mac\Home\Desktop\Tesi\Audio\okay -1. wav|over -here -1. wav |0 ,5| -74|32| -20|\\ Mac\Home\Desktop\Tesi\Audio\over -here -1. wav|
La presenza del separatore permette infatti una lettura del file di progetto semplicee priva di errori: una volta che l’utente ha localizzato il file .txt da aprire, esso vieneletto riga per riga; la stringa generata viene separata ad ogni occorrenza del carattereseparatore, creando delle sotto-stringhe che possono essere direttamente inserite nellalista dei file.Per ogni file del progetto aperto viene creato e posizionato un puntino bianco nelpannello, a rappresentare la sorgente con i suoi valori per l’asse x ed y.Il file di progetto non contiene al suo interno i file audio a cui i dati si riferiscono, percui nel caso in cui il percorso dei file presenti nel progetto cambiasse, non sarebbe piupossibile per l’applicazione recuperarli.La gestione dei progetti rende necessario creare una funzione per creare un nuovoprogetto, partendo da zero, eliminando quindi tutti i file presenti nella lista dei file.La funzione nuovo progetto e apri progetto chiedono all’utente, nel caso in cui cisiano file nella lista, se intende salvare il progetto corrente prima di aprirne unonuovo, evitando di perdere dati per disattenzione.

CAPITOLO 3. SVILUPPO DEL SOFTWARE 18
3.2.3 Scala grandezze
Nell’applicazione e prevista la possibilita di utilizzare due grandezze di↵erenti perposizionare le sorgenti nello spazio.Il guadagno di ogni sorgente e infatti relativo alla distanza dall’ascoltatore. Facendoclic su questo pulsante, infatti si passa da una scala ad alta precisione, con valori finoa 50 centimetri, ad una a bassa precisione, in cui e possibile posizionare le sorgenti apiu di 15 metri.Per riconoscere facilmente la scala che stiamo utilizzando, il pannello cambia a secon-da della precisione utilizzata, come visibile in Figura 14.Il guadagno relativo al raggio permette un miglior grado di approssimazione allaspazializzazione in campo aperto, dando ulteriori opzioni all’utente per la personaliz-zazione del proprio paesaggio sonoro.
Figura 14: Le due di↵erenti modalita per la spazializzazione.
3.2.4 Impostazioni
Il bottone “impostazioni” permette, per ora, solamente di poter scegliere il percorsoin cui salvare il file di output.Se questo non viene specificato, infatti, l’output verra salvato in una cartella di filetemporanei, creata automaticamente dall’applicazione.
3.2.5 O↵set e posizionamento
I valori di o↵set e posizionamento vengono inseriti dall’utente in due modalita: tra-mite doppio clic sul valore nella lista dei file, o per trascinamento della sorgente nelpannello.Questi valori permettono all’utente la creazione del proprio paesaggio sonoro, deci-dendo da dove e quando ogni sorgente deve intervenire.

CAPITOLO 3. SVILUPPO DEL SOFTWARE 19
3.2.6 Rendering
La funzione di rendering e la piu complessa, ed e il “cuore” dell’applicazione stessa.Verra introdotta in questo paragrafo, per poi essere spiegata nel dettaglio nella sezio-ne 3.3 di questo capitolo.Il rendering avviene in due fasi: nella prima si elabora ogni file presente nella listasingolarmente, mentre nella seconda tutti i file elaborati vengono uniti per formareun singolo file di output.Nella prima fase innanzitutto viene controllato che il file .wav sia idoneo, poiche ven-gono accettati solamente file stereo con frequenza di campionamento a 44.1 kHz.Successivamente, se il file rispetta i criteri predefiniti, vengono acquisite le informa-zioni relative al suo posizionamento ed o↵set dalla lista dei file. Le informazioni sulposizionamento vengono utilizzate per trovare la funzione HRTF piu adatta all’inter-no del dataset, che tramite la convoluzione dei segnali, permette di applicare al filedi input il filtraggio voluto.Una volta ottenuto il file risultato della convoluzione, qualora sia indicato un valoredi o↵set, esso viene elaborato aggiungendo un periodo di silenzio all’inizio del file,tramite l’inserimento di campioni audio con valore 0, per il valore inserito dall’utente.Questo permette di spaziare temporalmente i file, facendo intervenire l’audio conte-nuto in essi in un momento preciso.Finiti questi passaggi per tutti i file, essi sono pronti per essere sommati e formarequindi il file di output.La somma dei segnali ottenuti avviene tramite bu↵er, ovvero spezzettando i file inframmenti di lunghezza fissa. Questo procedimento viene e↵ettuato per rendere piuveloce la somma ed evitare di intasare la memoria.Alla fine del processo di rendering viene e↵ettuato il controllo anti-clipping. Se cisono infatti dei campioni con valore superiore a 1, che causerebbero una distorsioneclipping in riproduzione, il file viene normalizzato, dividendo tutti i suoi campioniper il valore piu alto contenuto all’interno.
3.2.7 Riproduzione
Il pulsante di riproduzione permette all’utente di sentire il file di output generatodalla fase di rendering.Viene cercato il file nel percorso specificato dall’utente, oppure nella cartella di filetemporanei del programma, e viene creato uno stream di dati che viene assegnato allostrumento Soundplayer del sistema operativo.La riproduzione e una fase critica, poiche e l’unico modo per l’utente di verificarel’e�cacia delle HRTF sul proprio apparato uditivo, oltre che essere lo scopo principaledi questa applicazione. Per questo sono necessari un processo di codifica a�dabile,

CAPITOLO 3. SVILUPPO DEL SOFTWARE 20
delegato dunque al sistema operativo, ed una scheda audio di buona qualita, perpermettere una giusta conversione del segnale da digitale ad analogico.
3.3 Elaborazione dei segnali
L’elaborazione dei segnali in questa applicazione avviene principalmente nella fase direndering del paesaggio sonoro, precedentemente delineata nel paragrafo 3.2.6.Entrando nello specifico, sono state adottate particolari soluzioni, sfruttando le op-zioni messe a disposizione dal linguaggio e dalla libreria scelta, per permettere lacorretta elaborazione dei segnali in maniera quanto piu scorrevole possibile.
3.3.1 L’oggetto SorgenteAudio
Utilizzando il linguaggio C++ e stato possibile definire un oggetto che raccogliessetutte le informazioni utili alla fase di rendering: coordinate cartesiane degli assi, valoredi o↵set, contatore di lettura, coordinate sferiche, alle quali si aggiungono ovviamen-te il file audio e le sue informazioni, memorizzate tramite le strutture SNDFILE eSF INFO messe a disposizione dalla libreria libsndfile.All’interno dell’oggetto sono inoltre contenute le funzioni che permettono di ricavarele coordinate sferiche (azimuth, elevazione, raggio) dalle coordinate cartesiane (x, y,z ) fornite dall’utente.
Codice 3.2: Header dell’oggetto SorgenteAudio.
public ref class SorgenteAudio{public:
double x,y,z;double offset;int readcount;int azimuth;int elevation;int radius;SNDFILE *audioFile;SF_INFO *audioInfo;SorgenteAudio ();~SorgenteAudio ();double calcRadius(double x, double y, double z);int calcAzimuth(double x, double y);int calcElevation(double x, double y, double z);
};
La conversione da coordinate cartesiane a sferiche converte anche il valore dellestesse da variabili double a int, ovvero da numeri reali ad interi, non essendo necessariauna precisione cosı alta.

CAPITOLO 3. SVILUPPO DEL SOFTWARE 21
Il valore di o↵set e di tipo double, mentre il contatore di lettura del file e int, poicherappresenta il numero di campioni letti dal file audio.Nella struttura SF INFO sono memorizzate le informazioni relative al file audio, quali:il numero di canali, il formato del file, la frequenza di campionamento ed il numerodei frames, che corrisponde al numero dei campioni diviso per il numero di canali.
3.3.2 Preparazione dei file
La preparazione alla fase di rendering prevede la creazione di una lista di oggettiSorgenteAudio, uno per ogni riga presente all’interno della lista dei file.Ogni oggetto SorgenteAudio viene riempito con le informazioni presenti nella rigarelativa al file, dopodiche vengono preparate le strutture SNDFILE e SF INFO graziealla funzione sf open presente all’interno della libreria.Qui viene controllato che i file inseriti abbiano frequenza di campionamento a 44.1kHz e siano file stereo, dotati quindi di due canali audio.In questa fase inoltre viene controllata la scala di grandezze scelta dall’utente.
3.3.3 Scelta dell’HRTF
Le HRTF sono situate in una cartella all’interno dei file del programma. Per permet-tere la scelta della giusta risposta all’impulso, i file che contengono le HRTF hannonomi che rispettano un codice specifico, che permette di identificare l’angolo di ele-vazione e di azimuth (Hxxxeyyya, dove xxx rappresenta l’angolo di elevazione e yyyquello di azimuth). I file sono stereo, quindi racchiudono al loro interno le due di↵e-renti funzioni per l’orecchio destro e sinistro.Le coordinate devono essere convertite da cartesiane a sferiche, chiamando le apposi-te funzioni presenti nell’oggetto SorgenteAudio. Una volta ottenuti i valori di raggio,azimuth ed elevazione, bisogna pero adattarli agli angoli considerati nella misurazionedelle HRTF nel dataset: viene per prima approssimata l’elevazione, che ha funzioniogni 10 gradi, da -40 a 90, dopodiche in base all’angolo di elevazione si approssimala misura dell’azimuth in base alla tabella di misurazione (Tabella 1), grazie ad uncostrutto switch-case.
Codice 3.3: Costrutto per la scelta della corretta HRTF
int elev40 [57] = { 0, 6, 13, 19, 26, 32, 39, 45, 51, 58, 64, 71, 77,84, 90, 96, 103, 109, 116, 122, 129, 135, 141, 148, 154, 161, 167, 174,180, 186, 193, 199, 206, 212, 219, 225, 231, 238, 244, 251, 257, 264, 270,276, 283, 289, 296, 302, 309, 315, 321, 328, 334, 341, 347, 354, 360 };
int el = round(( float)fileAudio[i]->elevation / 10) * 10;if (el < -40)
el = -40;int az;

CAPITOLO 3. SVILUPPO DEL SOFTWARE 22
switch (el) {case 30:case -30:
az = round(( float)fileAudio[i]->azimuth / 6) * 6;break;
case 40:case -40:
if (fileAudio[i]->azimuth == 360)fileAudio[i]->azimuth = 0;
while (elev40[j] < fileAudio[i]->azimuth)j++;
if (fileAudio[i]->azimuth - elev40[j] >elev40[j + 1] - fileAudio[i]->azimuth)
az = elev40[j + 1];else
az = elev40[j];break;
case 50:az = round(( float)fileAudio[i]->azimuth / 8) * 8;break;
case 60:az = round(( float)fileAudio[i]->azimuth / 10) * 10;break;
case 70:az = round(( float)fileAudio[i]->azimuth / 15) * 15;break;
case 80:az = round(( float)fileAudio[i]->azimuth / 30) * 30;break;
case 90:az = 0;break;
default:az = round(( float)fileAudio[i]->azimuth / 5) * 5;
}
Tramite la concatenazione di stringhe viene successivamente generato il percorsoed il nome corretto del file, che viene poi caricato in una struttura SNDFILE, con lesue caratteristiche memorizzate in SF INFO.Il raggio viene moltiplicato per la scala di grandezza utilizzata, di modo da rispettareil grado di attenuazione voluto.
3.3.4 Convoluzione
La convoluzione avviene tramite una funzione esterna, chiamata dalla routine princi-pale, a cui vengono passati il file audio di input e la risposta all’impulso, insieme allerelative informazioni e il numero del file nella lista.

CAPITOLO 3. SVILUPPO DEL SOFTWARE 23
I campioni dei file audio vengono caricati in vettori monodimensionali, e sono perciofile stereo interlacciati, con campioni alternati per canale destro e sinistro. Per questovengono de-interlacciati e salvati su ulteriori array, che conterranno ognuno un solocanale.Viene quindi calcolata la lunghezza del file risultato della convoluzione, per creare ivettori dei due canali del file di output della funzione.Siamo quindi pronti per l’operazione di convoluzione, che sara eseguita separatamenteper ogni canale. Nel processamento di ognuno dei canali, viene presa in considera-zione prima la seconda parte del file (dalla fine della risposta all’impulso), per poirecuperare la parte iniziale, avendo esse algoritmi di↵erenti.Nel processamento della seconda parte infatti, per ricavare ogni campione del file dioutput viene moltiplicata ai campioni dell’input tutta la risposta all’impulso; al con-trario, per la prima frazione ne viene utilizzata solo una parte, che cresce di grandezzaal crescere del numero del campione di output da ricavare.
Codice 3.4: Convoluzione del canale sinistro
// convoluzione da out[iirInfo ->frames -1] a finefor (i = iirInfo ->frames - 1; i < dataSize /2; ++i){
outdataL[i] = 0;
for (j = i, k = 0; k < iirInfo ->frames; --j, ++k)outdataL[i] += indataL[j] * iirdataL[k];
}// convoluzione da inzio ad out[iirInfo ->frames -2]for (i = 0; i < iirInfo ->frames - 1; ++i){
outdataL[i] = 0;
for (j = i, k = 0; j >= 0; --j, ++k)outdataL[i] += indataL[j] * iirdataL[k];
}
Finito il complesso processo di convoluzione per entrambi i canali, essi devonoessere re-interlacciati in un vettore di lunghezza doppia rispetto al risultato dellaconvoluzione.Alternati nuovamente i campioni dei canali, il vettore viene caricato in una strutturaSNDFILE per essere salvato come file .wav nella cartella dei file temporanei delprogramma. Per permettere il riconoscimento dei file alla routine principale, alla finedel nome viene inserito il numero del file nella lista.La funzione quindi termina, e la routine principale puo caricare il file risultato dallacartella indicata, sostituendolo al file di input.

CAPITOLO 3. SVILUPPO DEL SOFTWARE 24
3.3.5 Gestione dell’o↵set
Anche per la gestione dell’o↵set viene chiamata una funzione esterna, a cui vienepassato pero solamente il file di input, le sue informazioni, il valore dell’o↵set incampioni e il numero del file nella lista.La conversione dell’o↵set da secondi in campioni audio e banale: lavorando sempre a44.1 kHz infatti, bastera moltiplicare il valore di o↵set per 44100 e per il numero dicanali, che nel nostro caso sono 2.La funzione esterna, ricevuti i valori in ingresso, carica il file di input interamente sudi un vettore e calcola la lunghezza del vettore di uscita, sommando ai campioni delfile di input il valore di o↵set. Questo vettore viene riempito di valori 0 fino al valoredi o↵set desiderato, dopodiche vengono copiati all’interno i valori dal file di input.
Codice 3.5: Estratto dalla funzione esterna per la creazione dell’o↵set.
offset = offset *44100;int framesOut = sfinfo ->frames + offset;double *data = new double[framesOut *2];double *indata = new double[sfinfo ->frames * 2];// leggo file su arraysf_read_double(sndfile , indata , sfinfo ->frames * 2);// aggiungo 0 all’inizioint i;for (i = 0; i < offset *2; i++)
data[i] = 0;for (int j = 0; j < sfinfo ->frames * 2; j++)
data[i + j] = indata[j];sf_write_double(out , data , framesOut * 2);
Il vettore viene caricato poi in una struttura SNDFILE per essere salvato come file.wav nella cartella dei file temporanei. Viene adottato il metodo visto nel paragrafo3.3.4 per il riconoscimento dei file da parte della routine principale che, una voltaterminata la funzione, carica nuovamente il file risultato della funzione sostituendo ilprecedente.
3.3.6 Unione delle sorgenti
Ottenuti tutti i file correttamente spazializzati, e con l’o↵set richiesto dall’utente, sipassa all’unione di essi per poter ottenere il file finale di output.E’ necessario quindi identificare il file contenente il maggior numero di campioni, peruna corretta scansione degli stessi; questa procedura viene e↵ettuata tramite un cicloed una variabile in cui memorizzare il valore massimo. Ottenuto questo valore si puoinizializzare la struttura SNDFILE per il file di output.L’unione dei file viene e↵ettuata tramite bu↵er, ovvero piccoli vettori che scandisconoi file progressivamente, evitando quindi di intasare la memoria nel caso in cui fossero

CAPITOLO 3. SVILUPPO DEL SOFTWARE 25
presenti in ingresso grandi quantita di file, oppure file di grandi dimensioni. La di-mensione del bu↵er utilizzata e di 1024 frame, che nell’audio stereo corrispondono a2048 campioni.Viene calcolato, in base al raggio, il coe�ciente di guadagno per ognuno dei file, ememorizzato in un vettore con la stessa lunghezza della lista dei file, in modo dapermettere l’attenuazione del volume in base alla distanza virtuale della sorgente dal-l’ascoltatore.I file di input vengono volta per volta caricati in un vettore bidimensionale contenentei bu↵er per ognuno dei file presenti nella lista, elaborati secondo le funzioni preceden-ti.I campioni presenti in ognuno dei bu↵er di input vengono scanditi e sommati ai cam-pioni gia presenti nel bu↵er di output. Ogni campione, precedentemente alla sommacon il campione presente nel bu↵er di output, viene moltiplicato per il coe�ciente diguadagno relativo al proprio file.Una volta ottenuto il bu↵er di output, i dati presenti al suo interno vengono ripor-tati nella struttura SNDFILE, e il bu↵er viene liberato, settando il valore di tutti icampioni a 0.Le operazioni precedenti vengono ripetute per ogni avanzamento del bu↵er, fino alraggiungimento del valore di lunghezza massima del file, calcolato precedentemente.Il file di output viene infine scritto nella cartella specificata dall’utente, come file .wavstereo interlacciato.
Codice 3.6: Somma sequenziale dei bu↵er
while (outCount < maxLen) {for (int i = 0; i < BUFFER_LEN * 2; i++)
OutData[i] = 0;for (int i = 0; i < fileAudio ->Length; i++) {
fileAudio[i]->readcount =sf_readf_double(fileAudio[i]->audioFile , indata[i], BUFFER_LEN );
}for (int i = 0; i < fileAudio ->Length; i++) {
for (int j = 0; j < BUFFER_LEN * 2; j++) {outData[j] = (ampCoeff[i] * indata[i][j] + outData[j]);
}}for (int j = 0; j < BUFFER_LEN * 2; j++)
if (abs(outData[j]) > maxVal)maxVal = abs(outData[j]);
sf_writef_double(outFile , outData , BUFFER_LEN );outCount += BUFFER_LEN;
}
CAPITOLO 3. SVILUPPO DEL SOFTWARE 26
3.3.7 Normalizzazione
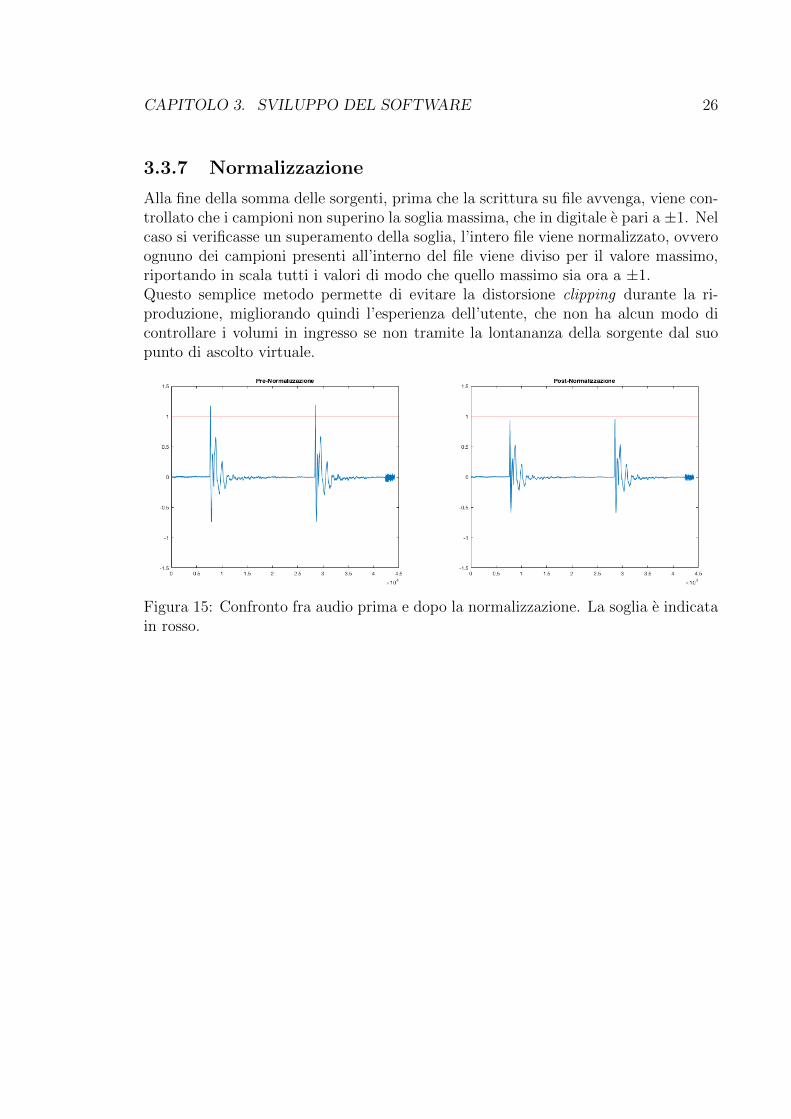
Alla fine della somma delle sorgenti, prima che la scrittura su file avvenga, viene con-trollato che i campioni non superino la soglia massima, che in digitale e pari a ±1. Nelcaso si verificasse un superamento della soglia, l’intero file viene normalizzato, ovveroognuno dei campioni presenti all’interno del file viene diviso per il valore massimo,riportando in scala tutti i valori di modo che quello massimo sia ora a ±1.Questo semplice metodo permette di evitare la distorsione clipping durante la ri-produzione, migliorando quindi l’esperienza dell’utente, che non ha alcun modo dicontrollare i volumi in ingresso se non tramite la lontananza della sorgente dal suopunto di ascolto virtuale.
Figura 15: Confronto fra audio prima e dopo la normalizzazione. La soglia e indicatain rosso.

Capitolo 4
Utilizzo ed e�caciadell’applicazione
L’applicazione oggetto di questa tesi, dopo la spiegazione dettagliata dello sviluppo,presente nel capitolo 3, deve essere testata per quanto riguarda la sua esecuzione ede�cacia.Saranno necessarie quindi tre valutazioni: una riguardante la facilita di approccio daparte dell’utente, una valutazione tecnica sulla velocita dei processi software ed unaterza sull’e�cacia e riconoscibilita della provenienza dei suoni, ovvero delle HRTFutilizzate.
4.1 Approccio utente-applicazione
In questa sezione verra valutata l’utilizzabilita dell’applicazione da parte dell’utente.E’ importante infatti che il software sia performante e valido, ma che sia anche ac-cessibile facilmente ad ogni utente.Per questo, un campione di persone di eta di↵erente e stato messo in condizione diinteragire col programma, con l’obiettivo di comprenderne le funzionalita e di sfrut-tarlo per i propri scopi. Ad ognuna delle persone che hanno condotto questa provae poi stato richiesto di valutare la propria esperienza in termini di qualita; venivainoltre misurata la quantita di tempo necessaria perche l’utente arrivasse alla fasefinale, ovvero quella di riproduzione del file e riconoscimento di tutte le funzionalita.Per tutti gli utenti che si sono sottoposti al test l’esperienza e stata confortevole e nonparticolarmente di�cile, ed i tempi di apprendimento rilevati sono corrispondenti aquelli attesi. La semplicita dell’applicazione, dotata di una sola barra delle funzionicon pulsanti di facile identificazione, permette l’utilizzo e l’apprendimento di tutte lefunzioni in breve tempo.
27
CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 28
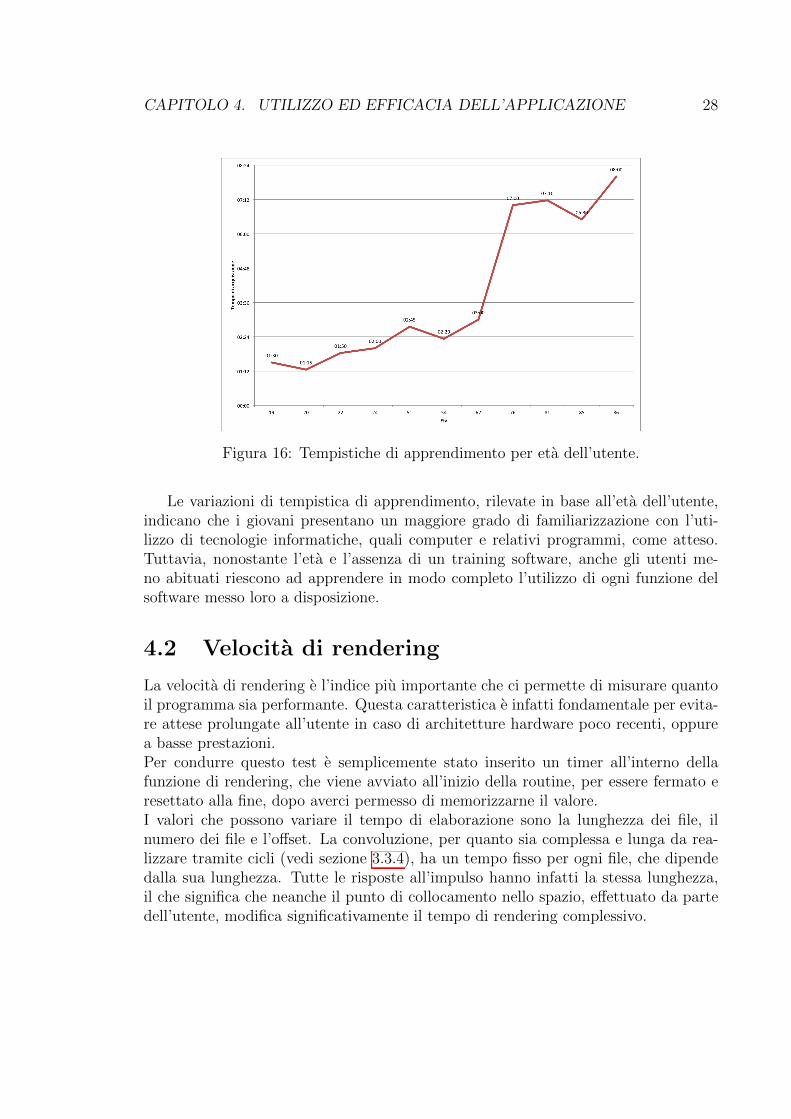
Figura 16: Tempistiche di apprendimento per eta dell’utente.
Le variazioni di tempistica di apprendimento, rilevate in base all’eta dell’utente,indicano che i giovani presentano un maggiore grado di familiarizzazione con l’uti-lizzo di tecnologie informatiche, quali computer e relativi programmi, come atteso.Tuttavia, nonostante l’eta e l’assenza di un training software, anche gli utenti me-no abituati riescono ad apprendere in modo completo l’utilizzo di ogni funzione delsoftware messo loro a disposizione.
4.2 Velocita di rendering
La velocita di rendering e l’indice piu importante che ci permette di misurare quantoil programma sia performante. Questa caratteristica e infatti fondamentale per evita-re attese prolungate all’utente in caso di architetture hardware poco recenti, oppurea basse prestazioni.Per condurre questo test e semplicemente stato inserito un timer all’interno dellafunzione di rendering, che viene avviato all’inizio della routine, per essere fermato eresettato alla fine, dopo averci permesso di memorizzarne il valore.I valori che possono variare il tempo di elaborazione sono la lunghezza dei file, ilnumero dei file e l’o↵set. La convoluzione, per quanto sia complessa e lunga da rea-lizzare tramite cicli (vedi sezione 3.3.4), ha un tempo fisso per ogni file, che dipendedalla sua lunghezza. Tutte le risposte all’impulso hanno infatti la stessa lunghezza,il che significa che neanche il punto di collocamento nello spazio, e↵ettuato da partedell’utente, modifica significativamente il tempo di rendering complessivo.

CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 29
E↵ettuati i test con diverso numero di file e con diversa lunghezza ed o↵set, i datirisultanti sono stati salvati su un file per e↵ettuare le analisi necessarie a ricavaredelle informazioni rilevanti sulle prestazioni del software.I test sono stati condotti con hardware a basse prestazioni, ovvero su una macchinavirtuale Windows, in esecuzione su un portatile MacBook Pro del 2012, dotato diprocessore dual-core Intel i5 da 2,5 GHz e 16 GB di Memoria RAM, di cui solamente4 a disposizione dalla macchina virtuale.Parte rilevante ed esplicativa dei risultati e espressa nella Tabella 2. I valori rilevatisono divisi in 4 colonne: la prima riporta il tempo di elaborazione misurato dal timer,mentre le altre i valori a cui e strettamente connesso.
Tempo (msec) Numero file Lunghezza max file (s) Somma o↵set(s)319 1 0,5 0354 1 1 0629 2 1 0683 2 1 1730 2 2 31203 4 1 01418 4 1 102281 7 2 10
Tabella 2: Tempo di elaborazione in base all’input.
Il numero dei file e la loro lunghezza influisce sul tempo poiche richiede un mag-gior numero di processi di convoluzione, o dei processi piu lunghi. Nel primo caso, lafunzione esterna che si occupa di questa operazione dovra essere chiamata piu volte,nel secondo si vedra aumentata la durata dei cicli all’interno della funzione, essendoquest’operazione condotta campione per campione.La funzione di o↵set si basa anch’essa su un ciclo, che opera campione per campionesul file di output aggiungendo dei valori 0 all’inizio del file. Per questo e rilevante lasomma di tutti gli o↵set utilizzati, ovvero per quanto e stato necessario rimanere nelciclo di o↵set durante l’intera fase di rendering.Si evince dalla tabella che il valore che modifica in maniera significativa il tempo dielaborazione e il numero di file presenti. Procedendo per esclusione infatti, si notache la presenza di o↵set nei file (righe 3-4, 6-7) non aumenta di molto il tempo dielaborazione dei dati; nelle righe 3-4, per 1 secondo di o↵set il tempo di elaborazioneaumenta di 54 msec dai 629 precedenti, mentre nelle righe 6-7 la somma degli o↵sete di 10 secondi, e ricade sul tempo di elaborazione per 215 msec, sui 1203 misuratisenza presenza di o↵set.La lunghezza dei file utilizzati, sorprendentemente, incide in maniera ancora meno

CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 30
significativa rispetto alla presenza di o↵set. Come verificabile dalle righe 1-2, il rad-doppio della lunghezza del file incide sul tempo di elaborazione per 35 msec. Nellerighe 4-5, la di↵erenza di 47 msec nell’elaborazione e causata dall’aumento dell’o↵settotale da 1 a 3 secondi, e dal raddoppio della lunghezza per uno dei file. Al raddop-pio del numero di file invece, il tempo di elaborazione quasi raddoppia, come si notafacilmente dal confronto fra le righe 2-3-6; nel primo caso si ha un aumento di 275msec su 354, nel secondo di 574 msec su 629.Questi valori vengono motivati semplicemente: il fatto che il raddoppio della lun-ghezza dei file incida in maniera scarsamente significativa rispetto al raddoppio delnumero di file e indice di lentezza nella chiamata della funzione esterna e della pre-parazione alla fase di convoluzione. Infatti, a parita di campioni da processare, glie↵etti sul tempo di elaborazione sono totalmente di↵erenti. Questo avviene perche lafunzione esterna di convoluzione richiede fasi di preparazione e di ultimazione, comela scrittura su file e la riapertura nella routine principale, che influiscono pesante-mente sul tempo di calcolo. Resta comunque da specificare che un maggior numerodi file richiede un maggior tempo di elaborazione, anche perche aumentano i processinecessari per l’apertura e la memorizzazione dei file, la scelta dell’HRTF e l’aperturadella risposta all’impulso relativa, tutte operazioni “costose” a livello di tempo.La di↵erenza che si ricava fra l’aumento della lunghezza dei file e la presenza di o↵sete inaspettato. Data la complessita dell’operazione, ci si aspetterebbe che la convo-luzione incida maggiormente sul tempo di elaborazione, mentre invece la situazionerilevata e totalmente opposta. Il motivo e invece semplice: mentre il raddoppio deicampioni di ogni file influisce significativamente solo sul tempo di ciclo all’internodella funzione di convoluzione, la presenza di o↵set rende necessaria una chiamata aduna funzione esterna, con la scrittura e riapertura del file processato.
4.3 E�cacia delle HRTF
Per misurare l’e�cacia delle HRTF utilizzate e stato necessario e↵ettuare un terzotest, nel quale l’ascoltatore, stimolato da suoni posizionati in diverse posizioni dellospazio, deve riconoscere la posizione delle sorgenti.Questo test non ha tenuto conto dell’attenuazione relativa al raggio poiche questavalutazione avrebbe influito in maniera negativa sul riconoscimento della spazializza-zione delle sorgenti, che e invece di prim’ordine per lo scopo dell’applicazione.
4.3.1 Premesse
Il test e stato e↵ettuato in ambiente controllato, acusticamente isolato dall’esterno,per permettere di dare rilevanza scientifica ai dati ed evitare di distrarre l’ascoltatoredal test. Le sedute hanno avuto infatti luogo nella stanza di ripresa di uno studio di

CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 31
registrazione, ben isolata quindi dall’esterno e dagli altri spazi interni presenti.Ogni test e stato condotto tramite delle cu�e chiuse circumaurali Audio TechnicaATH-M50, utilizzando un XR18 come scheda audio per la conversione del segnale dadigitale ad analogico. Alla persona veniva chiesto, domanda per domanda, di indicaresopra un disegno, analogo a quello presente nel pannello (Figura 14), da dove sentissearrivare il suono.
Figura 17: Risposta in frequenza delle cu�e Audio Technica ATH-M50
Le domande sono state divise in 3 sezioni: la prima richiedeva il riconoscimentosolamente dell’angolo di azimuth, la seconda solamente di quello di elevazione ed unafase finale in cui gli angoli venivano utilizzati in maniera congiunta.
4.3.2 Training
Prima di e↵ettuare il test, ogni ascoltatore e sottoposto ad una breve fase di training,in cui il suo apparato uditivo e sottoposto alle HRTF presenti nell’applicazione, pertentare di abituare il cervello alle funzioni presenti, totalmente di↵erenti da quelle inuso quotidianamente dal soggetto.Il training viene e↵ettuato puramente su angoli di azimuth ed elevazione in manieraseparata. In mancanza di apparecchiature in grado di creare stimoli visivi per l’a-scoltatore, in una fase appena precedente l’ascolto viene illustrato nello spazio dovesaranno posizionate le sorgenti, utilizzando anche un’illustrazione e degli indizi tattili.In questa fase vengono utilizzati due tipi di training per ogni angolo in esame: primane viene somministrato uno piu semplice, ovvero con angoli che hanno ampiezze rile-vanti (45� per azimuth, 30� per elevazione), ed in una fase successiva uno con angolipiu stretti, che variano di 10� alla volta. L’e�cacia di questi ultimi e pero minatadalla di�colta di rappresentazione visiva da parte dell’ascoltatore, che spesso si perde

CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 32
in un numero cosı vasto di sorgenti.Il training viene ripetuto piu volte in base alla capacita di apprendimento dell’ascol-tatore.
4.3.3 Descrizione del test
Il test e stato e↵ettuato su un campione di 40 persone di sesso ed eta misti, 26 uominie 14 donne di eta compresa fra 19 ed 85 anni.Ogni test e composto da 16 quesiti, 6 per l’angolo di azimuth ad elevazione 0, 8 perquello di elevazione ad azimuth 0 e 2 quesiti finali in cui gli angoli sono combinati. Iprimi 4 test per ogni angolo prevedono la presenza di un solo stimolo sonoro, mentrei successivi contengono 2 sorgenti.Gli angoli di spazializzazione delle sorgenti sono contenuti nella Tabella 3. Le pri-me 4 righe presentano infatti un solo angolo, mentre le successive ne hanno 2, perl’individuazione di entrambe le sorgenti. Caso particolare nella colonna dei quesiticombinati, che inizia dalla riga 5 poiche entrambi i quiz contengono due sorgenti,che hanno sia un angolo di azimuth, che un angolo di elevazione, opportunamenteseparati, per ogni sorgente, dal simbolo “:”.I file audio utilizzati nel corso del training e del test sono 4: due onde sinusoidali (440e 1000 Hz) e due campioni di voce umana, una maschile ed una femminile. I file sonostati scelti poiche hanno risposte in frequenza diverse, e rappresentano quindi segnalimolto di↵erenti, con relative risposte dell’apparato uditivo.L’angolo di azimuth considerato e completo, va da 0� a 360�, con il fronte fissato a0�, misurato in senso orario dall’alto (90� e la posizione direttamente sulla destra).L’angolo di elevazione considerato invece e di 260�, ma per mantenere il fronte a 0�,la misurazione va da -40� a 220�, dove 180� e la posizione alle spalle dell’ascoltatore.
Azimuth Elevazione Combinati (A:E)315 -40120 125195 3065 90
40/215 0/130 42:30 / 295:-20300/25 0/50 225:0 / 336:80
0/18080/-30
Tabella 3: Angoli di stimolo dell’ascoltatore.

CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 33
4.3.4 Risultati Finali
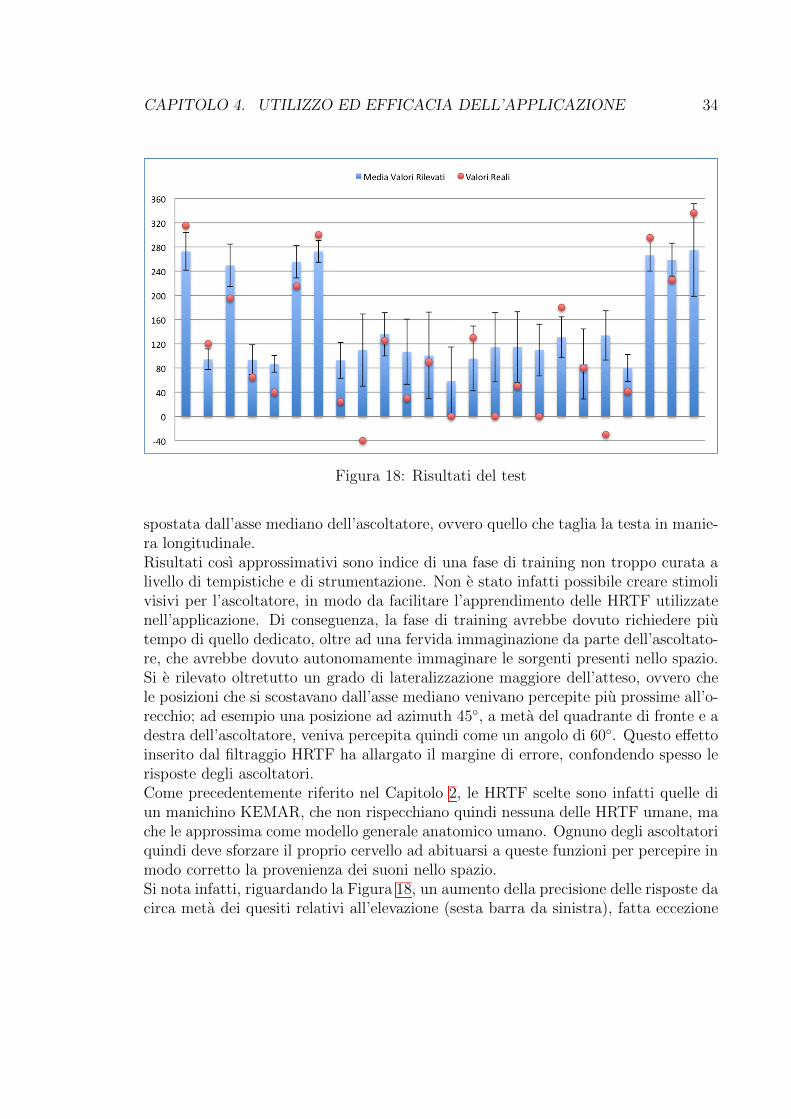
I dati rilevati dal test sono stati estratti per essere elaborati ed ottenere delle infor-mazioni rilevanti.Nel passaggio dalla carta al foglio digitale si e utilizzato un goniometro con precisionedi 1�. Questa precisione e su�ciente, poiche le HRTF utilizzate hanno sensibilita diminimo 5� (vedi Tabella 1).Nella Figura 18, possiamo vedere mostrati i risultati del test per ogni quesito. I que-siti che contenevano piu sorgenti sono stati divisi sorgente per sorgente, per questo ilnumero dei valori riportati nelle colonne e 24 e non 16; non e stato riportato inoltrel’angolo di elevazione per gli ultimi due test, poiche agli ascoltatori non e stato ri-chiesto di stimare un angolo preciso, ma solamente l’elevazione delle sorgenti rispettoal proprio punto di ascolto.Sull’asse delle ordinate sono rappresentati i valori degli angoli espressi in gradi. Inquesta rappresentazione i valori vanno da -40 a 360 per poter tenere conto contem-poraneamente sia degli intervalli di azimuth che di elevazione.In blu e rappresentata la media dei valori inseriti dagli ascoltatori, la barretta in nerorappresenta la deviazione standard dei valori, ed infine il puntino rosso indica il valorereale dell’angolo di posizionamento della sorgente.Si nota quindi facilmente che nel 70% dei casi l’angolo di stimolo e fuori dal range divalori composto dalla media e dalla deviazione standard. Questo rispecchia una scar-sa capacita di individuazione specifica della posizione della sorgente, a partire dalladiversita dei dati rilevati e della grandezza dell’intervallo di deviazione standard.
Tuttavia la percezione della spazializzazione generale rimane buona: per quan-to riguarda l’azimuth le risposte rispettano comunque il quadrante di provenienzadel suono, a dimostrazione del fatto che la distinzione fronte-retro e destra-sinistraagiscono comunque in maniera corretta. Analizzando invece l’angolo di elevazione,si ha un maggiore scostamento delle risposte dalla posizione della sorgente, dovutoalla maggiore di�colta di individuazione, forse data anche dalla stessa distanza daentrambi i punti d’ascolto.I test combinati di azimuth ed elevazione rilevano invece un piccolo aumento nel-la precisione dell’individuazione della posizione delle sorgenti. I dati qui citati sonofacilmente riscontrabili nel grafico presente in Figura 19.
Per quanto riguarda questo tipo di quesiti, in grafico sono mostrati i dati relativiallo scostamento dall’azimuth, ma anche le risposte per l’elevazione danno ottimi ri-sultati. Il 23% rileva infatti correttamente il posizionamento dell’elevazione assoluta,mentre il 70% individua in maniera corretta la di↵erenza di elevazione fra le due sor-genti.Ne consegue che sia e↵ettivamente piu facile individuare l’elevazione se la sorgente e
CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 34
Figura 18: Risultati del test
spostata dall’asse mediano dell’ascoltatore, ovvero quello che taglia la testa in manie-ra longitudinale.Risultati cosı approssimativi sono indice di una fase di training non troppo curata alivello di tempistiche e di strumentazione. Non e stato infatti possibile creare stimolivisivi per l’ascoltatore, in modo da facilitare l’apprendimento delle HRTF utilizzatenell’applicazione. Di conseguenza, la fase di training avrebbe dovuto richiedere piutempo di quello dedicato, oltre ad una fervida immaginazione da parte dell’ascoltato-re, che avrebbe dovuto autonomamente immaginare le sorgenti presenti nello spazio.Si e rilevato oltretutto un grado di lateralizzazione maggiore dell’atteso, ovvero chele posizioni che si scostavano dall’asse mediano venivano percepite piu prossime all’o-recchio; ad esempio una posizione ad azimuth 45�, a meta del quadrante di fronte e adestra dell’ascoltatore, veniva percepita quindi come un angolo di 60�. Questo e↵ettoinserito dal filtraggio HRTF ha allargato il margine di errore, confondendo spesso lerisposte degli ascoltatori.Come precedentemente riferito nel Capitolo 2, le HRTF scelte sono infatti quelle diun manichino KEMAR, che non rispecchiano quindi nessuna delle HRTF umane, mache le approssima come modello generale anatomico umano. Ognuno degli ascoltatoriquindi deve sforzare il proprio cervello ad abituarsi a queste funzioni per percepire inmodo corretto la provenienza dei suoni nello spazio.Si nota infatti, riguardando la Figura 18, un aumento della precisione delle risposte dacirca meta dei quesiti relativi all’elevazione (sesta barra da sinistra), fatta eccezione

CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 35
Figura 19: Media degli scostamenti per tipo di quesito.
per alcuni angoli particolamente critici (ventesima barra, angolo di -30� di elevazio-ne). Questo e dovuto al processo di apprendimento ed abitudine del cervello che siverifica durante il test: anche questo parametro influisce sull’aumento di precisionenegli ultimi quesiti che, dall’esterno, sembrerebbero i piu complicati.Analizzando le risposte per tipo di suono utilizzato nel quesito, si scopre una grossadi↵erenza nel rilevamento delle relative sorgenti, visibile in Figura 20.Come conseguenza dei dati visibili nel grafico presente in Figura 19, il valore discostamento medio per ognuno dei suoni utilizzati sara compreso fra il valore delloscostamento medio dell’azimuth e quello piu elevato dell’elevazione.
Mentre i suoni del parlato umano hanno valori simili, con aumento di precisionesul parlato femminile, i suoni di sintesi sinusoidali con frequenza 440Hz e 1kHz hannoun angolo di scostamento decisamente di↵erente. L’onda con frequenza 440Hz hauno scostamento medio di oltre 73�, mentre quella con frequenza 1 kHz solo di 18�,decisamente piu piccolo anche di entrambi i suoni del parlato umano.In questo caso la di↵erenza e da ricercare nello spettro sonoro di queste sorgenti: quelleumane hanno un contenuto comprendente tutte le frequenze udibili, che si attenuanoandando verso i limiti di percezione, mentre quelle di sintesi contengono al loro internosolo un valore di frequenza. Riguardando le nozioni presenti all’interno del Capitolo1, si capisce come le due frequenze di↵erenti agiscano in maniera totalmente diversasull’apparato uditivo per quanto riguarda la localizzazione, ed e per questo appuntoche sono state scelte.Inoltre, la di↵erenza delle due frequenze e anche riscontrabile nelle curve isofoniche(Figura 21), nelle quali ad 1 kHz si trova il punto di linearita utilizzato come indicedelle curve; non e stato utilizzato il punto di sensibilita massima poiche si ritenevafastidiosa un’onda sinusoidale a quella frequenza.
CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 36
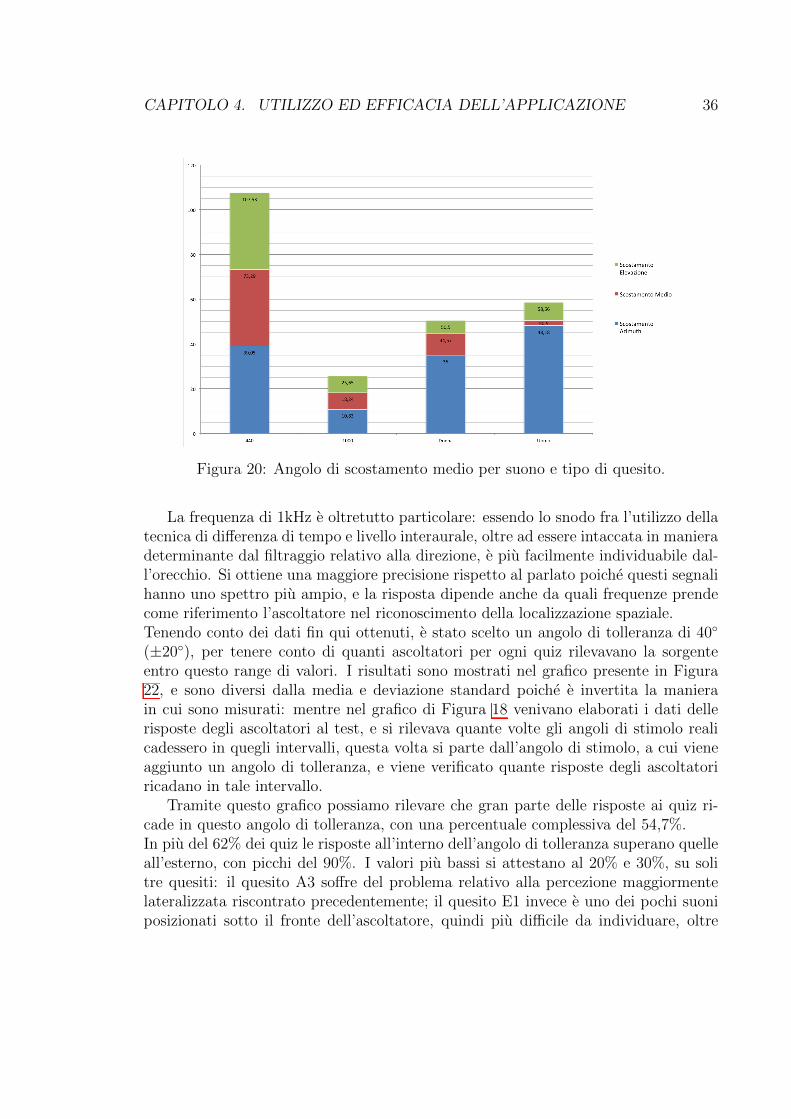
Figura 20: Angolo di scostamento medio per suono e tipo di quesito.
La frequenza di 1kHz e oltretutto particolare: essendo lo snodo fra l’utilizzo dellatecnica di di↵erenza di tempo e livello interaurale, oltre ad essere intaccata in manieradeterminante dal filtraggio relativo alla direzione, e piu facilmente individuabile dal-l’orecchio. Si ottiene una maggiore precisione rispetto al parlato poiche questi segnalihanno uno spettro piu ampio, e la risposta dipende anche da quali frequenze prendecome riferimento l’ascoltatore nel riconoscimento della localizzazione spaziale.Tenendo conto dei dati fin qui ottenuti, e stato scelto un angolo di tolleranza di 40�
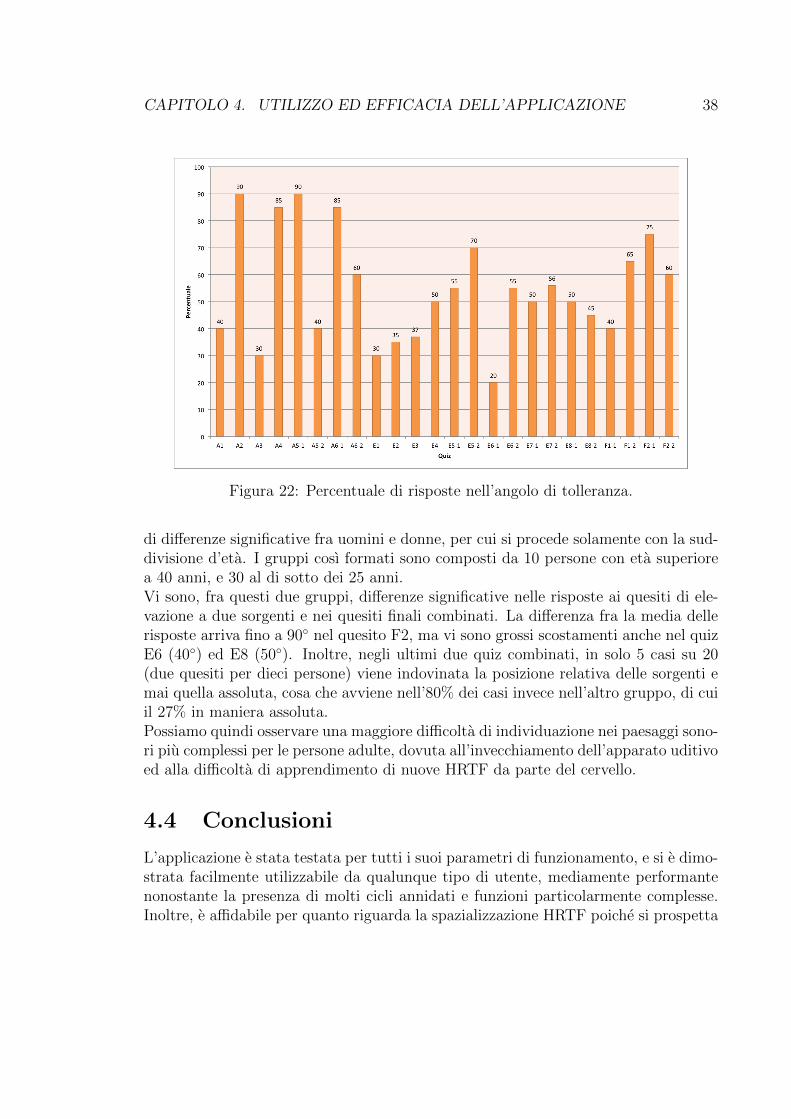
(±20�), per tenere conto di quanti ascoltatori per ogni quiz rilevavano la sorgenteentro questo range di valori. I risultati sono mostrati nel grafico presente in Figura22, e sono diversi dalla media e deviazione standard poiche e invertita la manierain cui sono misurati: mentre nel grafico di Figura 18 venivano elaborati i dati dellerisposte degli ascoltatori al test, e si rilevava quante volte gli angoli di stimolo realicadessero in quegli intervalli, questa volta si parte dall’angolo di stimolo, a cui vieneaggiunto un angolo di tolleranza, e viene verificato quante risposte degli ascoltatoriricadano in tale intervallo.
Tramite questo grafico possiamo rilevare che gran parte delle risposte ai quiz ri-cade in questo angolo di tolleranza, con una percentuale complessiva del 54,7%.In piu del 62% dei quiz le risposte all’interno dell’angolo di tolleranza superano quelleall’esterno, con picchi del 90%. I valori piu bassi si attestano al 20% e 30%, su solitre quesiti: il quesito A3 so↵re del problema relativo alla percezione maggiormentelateralizzata riscontrato precedentemente; il quesito E1 invece e uno dei pochi suoniposizionati sotto il fronte dell’ascoltatore, quindi piu di�cile da individuare, oltre

CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 37
Figura 21: Curve isofoniche
che subire il problema di localizzazione relativo al suono, che in questo quesito e lasinusoide a 440 Hz; il primo suono del quesito E6, ancora la sinusoide a 440 Hz, edi�cilmente rilevato, ma e in realta lo stesso suono posizionato nello stesso punto delquesito E5.Da considerare in questo caso e la di↵erenza fra le sorgenti che compongono un sin-golo paesaggio sonoro; nei quesiti E5 ed E6 sono infatti presenti due sorgenti: unasinusoide a 440 Hz, posizionata di fronte all’ascoltatore, ed un parlato umano, cheproviene nel primo caso da dietro e nel secondo da davanti, con inclinazione ±40�
rispetto all’asse verticale.E’ interessante notare quanta di↵erenza vi sia nella percezione dello stesso suono, po-sizionato nello stesso punto nei due di↵erenti quesiti: sicuramente l’ascoltatore, allapresenza di piu di una sorgente nel paesaggio sonoro, opera piu per di↵erenza che perassoluti, e questo ragionamento puo portarlo fuori strada o aiutarlo nel riconoscimen-to. Riferendoci infatti nuovamente al grafico possiamo notare altre situazioni in cuila di↵erenza aiuta il riconoscimento: per esempio nei quesiti A5 ed A6 la sinusoide a440 Hz viene riconosciuta in maniera piu incisiva rispetto al quesito A1, considerandoanche la piccola di↵erenza di posizionamento della sorgente tra i quesiti A1 e A6, disoli 15�.Altro dato rilevante si ottiene dalla di↵erenza delle risposte fra i quesiti E3 ed E5, incui e presente in entrambi i casi il parlato di donna, che vede impennarsi il riconosci-mento della sorgente dal 37% al 70%, aiutata molto probabilmente dalla di↵erenzacon l’altro suono.Analizzando ulteriormente i dati secondo le caratteristiche dei soggetti esaminati,possiamo creare 4 classi basate sulla di↵erenza di eta e di sesso. Si riscontra l’assenza
CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 38
Figura 22: Percentuale di risposte nell’angolo di tolleranza.
di di↵erenze significative fra uomini e donne, per cui si procede solamente con la sud-divisione d’eta. I gruppi cosı formati sono composti da 10 persone con eta superiorea 40 anni, e 30 al di sotto dei 25 anni.Vi sono, fra questi due gruppi, di↵erenze significative nelle risposte ai quesiti di ele-vazione a due sorgenti e nei quesiti finali combinati. La di↵erenza fra la media dellerisposte arriva fino a 90� nel quesito F2, ma vi sono grossi scostamenti anche nel quizE6 (40�) ed E8 (50�). Inoltre, negli ultimi due quiz combinati, in solo 5 casi su 20(due quesiti per dieci persone) viene indovinata la posizione relativa delle sorgenti emai quella assoluta, cosa che avviene nell’80% dei casi invece nell’altro gruppo, di cuiil 27% in maniera assoluta.Possiamo quindi osservare una maggiore di�colta di individuazione nei paesaggi sono-ri piu complessi per le persone adulte, dovuta all’invecchiamento dell’apparato uditivoed alla di�colta di apprendimento di nuove HRTF da parte del cervello.
4.4 Conclusioni
L’applicazione e stata testata per tutti i suoi parametri di funzionamento, e si e dimo-strata facilmente utilizzabile da qualunque tipo di utente, mediamente performantenonostante la presenza di molti cicli annidati e funzioni particolarmente complesse.Inoltre, e a�dabile per quanto riguarda la spazializzazione HRTF poiche si prospetta

CAPITOLO 4. UTILIZZO ED EFFICACIA DELL’APPLICAZIONE 39
un tasso di riconoscimento migliore e piu fine se si viene sottoposti ad un maggiortempo di training.Grazie ai dati estratti dall’ultimo test e stato inoltre possibile verificare la di↵erenzanella percezione di segnali con spettro sonoro di↵erente, mettere in luce la maggioredi�colta di percezione dell’angolo di elevazione e l’e↵etto causato dalla sovrapposizio-ne di suoni, che fa scattare il meccanismo di percezione per di↵erenza nell’ascoltatore.E’ stato inoltre possibile stimare una di↵erenza nell’apprendimento ed utilizzo di fun-zioni HRTF in base all’eta dell’ascoltatore, mentre si e riscontrato che non vi e alcu-na di↵erenza significativa fra uomo e donna, forse dovuta alle HRTF ricavate da unmanichino, e quindi neutro.
4.4.1 Sviluppi Futuri
In futuro potrebbe essere possibile l’implementazione dell’applicazione, in primo luo-go aggiungendo un breve tutorial alla prima apertura. Altre migliorie riguardano lapossibilita di includere ulteriori HRTF per avvicinarsi maggiormente a quelle dell’a-scoltatore, l’aggiunta di un pannello tridimensionale per il posizionamento per trasci-namento anche nell’asse z, l’aggiunta ed eliminazione di piu file contemporaneamente.Infine, sarebbe possibile aggiungere un controllo del volume per ogni file oltre a quel-lo relativo al raggio ed anche la possibilita di utilizzare altri formati per i file audiodi↵erenti dal .wav.Per quanto riguarda un possibile nuovo test, verra condotta la fase di training inmaniera piu prolungata, stimolando l’ascoltatore anche visivamente.Interessante inoltre potrebbe essere il prosieguo dello studio sugli e↵etti delle HRTFin base all’eta, che qui e stato trattato in maniera limitata date le dimensioni delcampione esaminato.

Bibliografia
[1] V. Lombardo, A. Valle, Audio e Multimedia, Milano, Apogeo, 2002.
[2] F. Rumsey, Spatial Audio, Oxford, Focal Press, 2001.
[3] J. Blauert, Spatial Hearing: The Psychophysics of Human Sound Localization,MIT Press, Cambridge, MA, revised edition, 1996.
[4] G. Rindi, E. Manni, Fisiologia Umana, Torino, UTET, 1980.
[5] D. Mauro, On Binaural Spatialization and the use of GPGPU for AudioProcessing, Tesi di Dottorato - Universita Degli Studi Di Milano, Milano, 2012.
[6] R. Butler, R. Humanski, A. Musicant, Binaural and Monaural Localization ofSound in Two-Dimensional Space, Perception, 1990.
[7] S. Perrett, W. Noble, The e↵ect of head rotations on vertical plane soundlocalization, The Journal of the Acoustical Society of America, 1997.
[8] C.Brown, R. Duda, A structural model for binaural sound synthesis, IEEETransactions on Speech and Audio Processing, 1998.
[9] F. Klein, S. Werner, HRTF adaptation and pattern learning, Ilmenau, 2013.
[10] B. Gardner, K. Martin, HRTF Measurements of a KEMAR Dummy Head Mi-crophone, MIT Media Lab Perceptual Computing - Technical Report 280, MITMedia Lab, 1994.
40