![UNIVERSITA’ DEGLI STUDI DI PISA FACOLTA’ DI MEDICINA E ... · regioni: Upstream Regulatory Region [URR], Early region [ER] e Late region [LR]. La URR ha funzione di regolazione](https://static.fdocumenti.com/doc/165x107/5c6589f309d3f2876e8cca75/universita-degli-studi-di-pisa-facolta-di-medicina-e-regioni-upstream.jpg)
UNIVERSITA’ DEGLI S P - cs.unipr.it · ricerca scientifica è svolta da comunità di ricercatori...
77
UNIVERSITA’ DEGLI STUDI DI PARMA Dipartimento di Matematiche e Informatica Corso di Laurea in INFORMATICA Tesi di Laurea in RETI DEI CALCOLATORI L’AUTENTICAZIONE NEL CLOUD COMPUTING Candidato: Relatore: Francesco Pesare Chiar.mo Prof. Roberto Alfieri Anno Accademico 2013/2014
-
Upload
trinhnguyet -
Category
Documents
-
view
212 -
download
0
Transcript of UNIVERSITA’ DEGLI S P - cs.unipr.it · ricerca scientifica è svolta da comunità di ricercatori...

UNIVERSITA’ DEGLI STUDI DI PARMA
Dipartimento di Matematiche e Informatica
Corso di Laurea in INFORMATICA
Tesi di Laurea in RETI DEI CALCOLATORI
L’AUTENTICAZIONE NEL CLOUD
COMPUTING
Candidato: Relatore:
Francesco Pesare Chiar.mo Prof. Roberto Alfieri
Anno Accademico 2013/2014


i
Indice Introduzione ........................................................................................................................................... 1
1. Cloud in generale ............................................................................................................................ 5
1.1 Caratteristiche ............................................................................................................................ 5
1.2 Modelli di servizio ...................................................................................................................... 6
1.3 Modelli di sviluppo .................................................................................................................... 7
1.3.1 Private cloud ................................................................................................................... 7
1.3.2 Public cloud .................................................................................................................... 7
1.3.3 Hybrid cloud ................................................................................................................... 8
1.3.4 Community cloud ........................................................................................................... 9
1.4 Virtualizzazione .......................................................................................................................... 9
1.4.1 KVM .............................................................................................................................. 11
1.4.2 Virtualizzazione vs Cloud .............................................................................................. 11
1.5 Vantaggi del cloud ................................................................................................................... 12
1.5.1 Aspetti Economici ......................................................................................................... 12
1.5.2 Aspetti Tecnici .............................................................................................................. 13
1.6 Problematiche del cloud .......................................................................................................... 13
1.6.1 Sicurezza dei dati .......................................................................................................... 13
1.6.2 Geo localizzazione dei dati ........................................................................................... 14
1.6.3 Homomorphic Encription ............................................................................................. 15
1.6.4 Banda Larga .................................................................................................................. 16
1.7 Sicurezza degli account e dell’accesso alle risorse .................................................................. 18
1.8 Piattaforme di sviluppo del cloud ........................................................................................... 20
2. Piattaforma per lo sviluppo di una infrastruttura cloud: OPENSTACK ....................................... 22
2.1 Componenti ............................................................................................................................. 24
2.1.1 Keystone – Identity Service .......................................................................................... 24
2.1.2 Nova – Compute Service .............................................................................................. 26
2.1.3 Glance – Image Service ................................................................................................. 27
2.1.4 Cinder – Block Storage.................................................................................................. 28
2.1.5 Swift – Object Storage .................................................................................................. 28
2.1.6 Horizon – Dashboard .................................................................................................... 29
2.1.7 Neutron – Networking .................................................................................................. 30

ii
2.1.8 VPN as a Service ........................................................................................................... 31
2.1.9 Firewall as a Service ...................................................................................................... 32
3. OpenStack: Installazione e test .................................................................................................... 33
3.1 Preliminari ............................................................................................................................... 33
3.2 Preparazione e configurazione della rete per OpenStack ....................................................... 34
3.3 Installazione servizi .................................................................................................................. 38
3.3.1 Keystone - Installazione e configurazione .................................................................... 39
3.3.1.1 Creazione utenti, tenants e ruoli .......................................................................... 41
3.3.1.2 Creazione servizio e API ........................................................................................ 42
3.3.1.3 Verifica .................................................................................................................. 42
3.3.1.4 Esempio keystone.conf ......................................................................................... 43
3.3.2 Glance ........................................................................................................................... 44
3.3.3 Cinder ........................................................................................................................... 45
3.3.4 Nova .............................................................................................................................. 46
3.3.5 Neutron ........................................................................................................................ 46
3.3.6 Horizon ......................................................................................................................... 48
4. Caso d’uso: Il cloud Multi-Region dell’ INFN ............................................................................... 49
4.1 Presentazione del cloud Multi-Region .................................................................................... 49
4.1.1 Scelte Implementative ............................................................................................. 50
4.1.2 Limitazioni ................................................................................................................ 51
5. Autenticazione e Strong Authentication: Dalla teoria alla pratica ............................................. 52
5.1 Autenticazione ......................................................................................................................... 52
5.1.1 Autenticazione Federata.......................................................................................... 52
5.1.2 Integrazione dell’autenticazione federata in OpenStack ........................................ 54
5.2 Strong Authentication ............................................................................................................. 58
5.2.1 Politiche di autenticazione e password ................................................................... 59
5.2.2 OTP – One Time Password ........................................................................................ 61
5.2.3 Test integrativo dell’ OTP nell’ ambiente di test ..................................................... 62
5.2.4 Stato dell’arte globale e il “The Fappening” ............................................................ 65

iii
6. Conclusioni ed eventuali sviluppi ................................................................................................. 67
6.1 Risultati raggiunti ..................................................................................................................... 67
6.2 Sviluppi futuri .......................................................................................................................... 67
Bibliografia ....................................................................................................................................... 69
Ringraziamenti .............................................................................................................................. 73

1
Introduzione
Oggigiorno una moltitudine di vendor offrono servizi di storage per dati
multimediali personali, esaltandone la comodità e facilità d’accesso. Tuttavia, il
cloud non è la panacea che risolve tutti i mali e purtroppo non comporta solo
vantaggi.
Con il termine cloud si fa riferimento alla convergenza di una serie di tecnologie
sviluppatesi negli ultimi trent’anni. Tali sviluppi sono il risultato della stretta
interconnessione tra tecnologia informatica e ricerca scientifica. Da sempre la
ricerca scientifica è svolta da comunità di ricercatori geograficamente distribuiti sul
territorio mondiale e caratterizzati da un’eterogeneità di risorse (quali sistemi di
calcolo, strumenti scientifici, banche dati, reti); i migliori risultati scientifici
perseguiti, sono la conseguenza delle molteplici collaborazioni che hanno portato la
scienza a far progredire l’informatica e l’informatica a far raggiungere nuovi
traguardi scientifici.
Tale interconnessione ha dato vita all’e-science, ovvero ricerca scientifica che
utilizza una grande quantità di risorse di calcolo e grandi quantità di dati
geograficamente distribuiti.
Questo ci porta al concetto di Grid Computing. Esso è emerso come uno dei
principali paradigmi di calcolo che consentono la creazione e la gestione di
infrastrutture basate su internet per la realizzazione di e-Science ed e–Business a
livello globale.

2
I campi di applicazione dell’informatica alla scienza sono innumerevoli. Il problema
principale, nonché sfida tecnologica, nasce nel riuscire a far convergere i dati
provenienti da diversi campi scientifici su un unico computer, in particolar modo in
quelle discipline che sono al confine tra due settori. Questo spiega perché i centri di
ricerca scientifica più importanti del mondo abbiano affiancato alla determinazione
di conseguire i propri obiettivi, la necessità di migliorare i propri sistemi informatici,
troppo poco adeguati a causa del ridotto budget disponibile.
Inoltre, l’obiettivo che si vuole raggiungere è quello di riuscire a realizzare una
virtual private cloud, consci del fatto che la potenza di calcolo dei server utilizzati
in ambito grid non è sempre quella massima esprimibile dagli stessi server; dunque
si vuole realizzare una trasformazione dagli attuali data center fisici, a dei mainframe
software, attraverso la definizione di strati software che compongono quello che ad
oggi viene comunemente chiamato virtual data center.
Il grid computing ha dalla sua, alcuni svantaggi legati alla complessità di utilizzo,
inerenti la suddivisione di un “big job” sui vari server, e alle risorse finanziarie.
Infatti, le risorse se da una parte sono condivise a livello mondiale dall’altra, sono
limitate dalla disponibilità economica di ogni ente di ricerca. A livello pratico, se si
pensa al carico produttivo medio, nelle ore giornaliere di massima produttività gli
enti appartenenti alla stessa zona del globo, hanno meno risorse da condividere tra
di loro.
Il cloud dunque basandosi sul grid computing e avvalendosi della virtualizzazione
propone di ridurre il sotto sfruttamento dei server, consentendo ai suoi utenti di
ridurre le spese hardware in particolar modo se si pensa che, quando un’azienda fa
un investimento, tende a sovradimensionare le risorse di cui ha necessità per evitare
di trovarsi in una situazione di saturazione delle risorse nei confronti dei propri
clienti. Il cloud è la soluzione a questo problema, nessuno deve comprare le proprie
risorse in funzione delle previsioni del successo del proprio business. Il punto chiave
del cloud è per l’appunto l’elasticità delle risorse e la facilità di utilizzo: la possibilità
di richiedere risorse in funzione della loro reale necessità, avendo l’illusione di
poterne aver un numero illimitato e on-demand, pagando in funzione del loro
effettivo utilizzo, senza dover avere competenze specifiche. Tutte caratteristiche che
fanno comodo a grandi enti di ricerca ma anche all’ultimo dei neo-imprenditori,
lasciando intendere come il cloud possa essere utilizzato da una vasta gamma di
utenti, in svariati settori.
Vantaggi che da un lato fanno risparmiare una quantità ingente di denaro e dall’altro
consentono a molte più aziende e a molti più utenti di poter essere competitivi sul
mercato e di poter aumentare il proprio fatturato, sia utilizzando il cloud come utenti,
sia vendendo servizi cloud come provider.

3
L’obiettivo della tesi è analizzare il cloud computing e l’autenticazione in questo
ambito, valuteremo pro e contro, affrontando le tematiche “di moda” sui problemi
che circondano il rapido sviluppo del cloud all’interno delle aziende e fornendo una
panoramica sulle vulnerabilità principali.
Inizieremo con una presentazione basilare attraverso la quale chiariremo il concetto
di cosa si intende per cloud computing, definendo le basi, le caratteristiche, i modelli
di sviluppo e i dettagli su come si può sviluppare un tale framework , argomento che
è stato anche oggetto di tirocinio.
Presenteremo OpenStack e i suoi servizi, illustreremo come questi interagiscono tra
di loro per poter dar vita a una piattaforma cloud di qualsiasi tipo e con qualsiasi
caratteristica, con l’analisi dei moduli di estensione per l’utilizzo di Firewall e VPN
all’interno del cloud per fornire sicurezza nelle comunicazioni.
Useremo questo, come trampolino di lancio per parlare del cloud multiregion,
analizzando il caso reale dell’I.N.F.N. e discutendo dei potenziali limiti presenti in
questa implementazione legati all’autenticazione.
Parleremo della problematica dell’autenticazione in ambiente cloud, e faremo un
focus sulla strong authentication considerando uno scenario in cui sarebbe servito
averla implementata.
Il lavoro di tesi sarà dunque così composto:
Capitolo 1 – Cloud in generale
Cenni sulla struttura del cloud, definizione della tecnologia e analisi dei potenziali
vantaggi e delle potenziali problematiche che girano intorno al mondo cloud.
Capitolo 2 – Piattaforma per lo sviluppo di una infrastruttura cloud:
OpenStack
Presentazione dell’open-framework OpenStack, oggetto di studio di molte
organizzazioni scientifiche e aziende leader nel settore della virtualizzazione, scelto
per l’implementazione dell’ambiente di test, che ha caratterizzato il percorso di
tirocinio e tesi.
Capitolo 3 – Openstack: Installazione e test
Presentazione del lavoro di installazione, configurazione e test dell’ambiente
utilizzato nel percorso di tirocinio e tesi.

4
Capitolo 4 – Caso d’uso: Il cloud Multi-Region dell’ INFN
Descrizione di un caso d’uso reale che coinvolge l’INFN.
Capitolo 5 – Autenticazione e Strong Authentication: Dalla teoria alla pratica
Approfondimento sul tema dell’autenticazione e sulla sicurezza delle credenziali di
accesso.
Capitolo 6 – Conclusioni ed eventuali sviluppi futuri
Conclusioni ed eventuali sviluppi futuri.

5
CAPITOLO 1
Cloud in generale
Il cloud computing è una macrostruttura distribuita di istanze di calcolo, scalabile
dinamicamente, destinata a minimizzare gli sforzi e i costi e a massimizzare
l’efficienza.
Il Cloud computing consente infatti ai clienti di condividere risorse dinamicamente
e di pagare in base all’utilizzo effettivo.
Questa tecnologia solleva però numerose preoccupazioni circa i requisiti di
sicurezza: protezione dei dati, localizzazione, identità e gestione degli accessi,
perdita di dati, web e email security, violazione gestionale, gestione degli eventi,
criptazione, segregazione dei dati, business continuity e disaster recovery sono
sicuramente di interesse per i clienti e ancor più sono una necessità per il provider
dei servizi.
I modelli di cloud computing hanno infatti tre attori:
cloud provider: colui che fornisce l’infrastruttura al cliente
service provider: colui che utilizza l’infrastruttura per fornire applicazione o
servizi agli utenti finali
service consumer: colui che utilizza i servizi sull’infrastruttura
Secondo il NIST [1] (National Institute of Standard and Technology) i modelli di
cloud computing sono caratterizzati da cinque caratteristiche fondamentali, tre
modelli di servizio e quattro modelli di sviluppo [2].
1.1 CARATTERISTICHE
1. On-demand self service: Il cliente può procurarsi le risorse di calcolo che
necessità autonomamente
2. Broad network access: le risorse accessibili sulla rete
3. Resource pooling: diverse risorse fisiche e virtuali vengono assegnate dal
provider in base alla domanda del cliente
4. Rapid elasticity: le risorse possono essere assegnate al cliente in qualsiasi
quantità e in qualunque momento
5. Measured service: Sia provider che cliente possono monitorare e controllare
l’utilizzo di risorse

6
1.2 MODELLI DI SERVIZIO
1. SaaS (Software as a Service): E’ usato dai clienti per utilizzare il software del
provider e associare ai dati in esecuzione all’infrastruttura cloud
2. PaaS (Platform as a Service): i clienti creano applicazioni attraverso questi
servizi, utilizzando strumenti supportati dal provider, ad esempio come
Force.com, Red Hat OpenShift, Google App Engine, Windows Azure e
VMware Cloud Foundry
3. IaaS (Infrastructure as a Service): Sostanzialmente risorse di calcolo fornite
al cliente per sviluppare ed eseguire software. Qualche esempio di IaaS sono
Amazon Web Services, Citrix, CloudPlatform, windows Azure, Microsoft
System Center, OpenStack, Rackspace, Savvis and VMware vCloud Suite
Figura 1. Confronto dei modelli di servizio
1.3 MODELLI DI SVILUPPO

7
Quando si offre una soluzione di cloud computing è indispensabile decidere quale
modello deve essere implementato. Ci sono quattro tipi di cloud computing:
1.3.1 Private cloud
Questa infrastruttura fornisce uso esclusivo a un singola organizzazione includendo
clienti multipli. Questa tipologia di cloud viene implementata all’interno di
un’azienda e l’approvvigionamento, la gestione e la messa in sicurezza delle risorse
fisiche è compito del personale IT.
Figura 2. Rappresentazione Private Cloud
1.3.2 Public cloud
Questa infrastruttura è per l’uso aperto e consente l’accesso degli utenti al cloud
attraverso interfacce utilizzando un browser web. Gli utenti pagano solo per il tempo
di utilizzo del servizio; tuttavia i cloud pubblici sono meno sicuri rispetto agli altri
modelli perché il mezzo utilizzato, Internet, è intrinsecamente insicuro. La maggior
parte dei problemi di sicurezza avviene in questo tipo di cloud anche perché il cliente
si rivolge a terze parti per la gestione dei propri dati, perdendone il controllo fisico.
Standard di sicurezza, accordi, licenze e suddivisione precisa di ruoli e responsabilità
deve avvenire tra cliente e provider per preservare i dati (SLA).

8
Figura 3. Rappresentazione Public Cloud
1.3.3 Hybrid cloud
E’ la composizione di 2 o più distinti modelli di sviluppo, che congiunti posso offrire
la sicurezza di una cloud privata, senza rinunciare alla possibilità di espandere in
maniera “illimitata” le risorse in caso di necessità, senza preoccuparsi del carico di
lavoro della struttura fisica.
Questa tipologia di cloud, tuttavia va attuata tenendo in considerazione che allo stato
attuale, non esistono ancora degli standard di sviluppo per le implementazioni cloud:
dunque per essere realmente scalabile è consigliato che nella cloud privata, vengano

9
rispecchiate le caratteristiche e le varie estensioni che sono supportate, ad esempio
da servizi come Amazon Web Service [3].
Figura 4. Rappresentazione Hybrid Cloud
1.3.4 Community cloud
E’ una tipologia di cloud condivisa tra determinati gruppi di utenti appartenenti ad
un’organizzazione o comunità, che hanno interessi in comune. L’ implementazione
di questa tipologia può essere gestita internamente o da terze parti, ospitata
internamente o esternamente.
1.4 VIRTUALIZZAZIONE
L'obiettivo delle tecnologie di virtualizzazione è astrarre tutte le componenti
hardware di una macchina fisica al fine di renderle disponibili come risorse logiche
a diverse istanze di sistemi operativi eseguiti parallelamente. La gestione

10
dell'hardware e quindi delle relative componenti virtualizzate è demandata ad uno
strato software chiamato Hypervisor posizionato ad uno dei livelli più bassi della
pila delle componenti che formano un sistema virtualizzato.
L'Hypervisor viene eseguito su una macchina fisica denominata “host” e il suo ruolo
principale è intercettare e tradurre le chiamate di sistema effettuate dai sistemi
operativi “ospiti” (guest), affinché vengano correttamente eseguite dalla CPU anche
nel caso in cui esistano più guest in esecuzione in maniera concorrente.
Esistono differenti implementazioni degli hypervisor, categorizzate a seconda della
tipologia di virtualizzazione che rispettivamente gestiscono:
Virtualizzazione Completa: È la tipologia di virtualizzazione che permette ai sistemi
operativi guest di essere eseguiti senza essere a conoscenza di trovarsi, in realtà, in
un ambiente virtualizzato. Con questa tipologia di virtualizzazione, qualunque
sistema operativo che funzionerebbe sull'hardware host, funzionerà nell'ambiente
virtualizzato e sarà compito dell'hypervisor gestire e allocare le risorse ai singoli
guest, fornendo una rappresentazione logica di tutte le periferiche e le componenti
hardware. Questa tipologia di hypervisor può essere implementata in due modalità
differenti:
- Bare metal, chiamata anche Type 1 è l'implementazione dell'hypervisor
direttamente sul hardware host; è l'implementazione che offre le migliori
prestazioni in quanto, permette ai guest di trovarsi solo un livello sopra
l'hypervisor. Esempi di questa tipologia di hypervisor sono VMware ESX,
Xen e KVM.
- Hosted, chiamata anche Type 2 è l'implementazione dell'hypervisor su un
sistema operativo preesistente. In questa implementazione l'hypervisor per
funzionare si basa sulle risorse messe a disposizione dal sistema operativo in
esecuzione. Esempi di questo hypervisor sono VirtualBox e VMware Server.
Para Virtualization: È la tipologia di virtualizzazione che necessita che il sistema
operativo guest sia modificato in maniera opportuna. In tale tipologia l'hypervisor
mette a disposizione ai sistemi operativi guest un'interfaccia software con la quale
le macchine virtuali comunicano, utilizzando specifiche chiamate di sistema. Grazie
a questa tecnica le macchine virtuali possono delegare l'hypervisor a eseguire
determinate operazioni direttamente sull'hardware, evitando di eseguirle in un
contesto virtuale, computazionalmente più costoso. Un esempio di questo hypervisor
è Xen.

11
Virtualizzazione a livello di Sistema Operativo: Tipologia che si distacca molto dalla
precedenti, nella quale non viene implementato un vero e proprio hypervisor, ma il
kernel del Sistema Operativo offre la possibilità di generare contesti multipli in user-
space, altamente isolati fra di loro. Questo tipo di virtualizzazione non crea quasi
alcun overhead, non dovendo virtualizzare alcun componente; ma è poco flessibile,
in quanto tutte le istanze gireranno utilizzando il medesimo kernel. Esempi di tale
tipologia di virtualizzazione sono, il meccanismo Linux-V Server incluso nel kernel
Linux e OpenVZ.
1.4.1 KVM
La schematizzazione spiegata nel paragrafo precedente, permette di definire a grandi
linee il funzionamento degli hypervisor, ma non sempre è possibile associare un
determinato hypervisor entro i confini di una singola categoria. Un esempio pratico
è rappresentato da KVM (Kernel-based Virtual Machine) che è nato come modulo
del kernel Linux e quindi, per quanto sia implementato come un hypervisor Type 1
necessita di un sistema operativo Linux-based per essere utilizzato, entrando nei
confini della categoria Type 2.
Per funzionare KVM utilizza un set di istruzioni aggiuntivo delle CPU x86 ma
esistono versioni modificate per fornire servizi di virtualizzazione anche su
architetture differenti, come i processori ARM, utilizzando tecniche simili alla
paravirtualizzazione di XEN.
1.4.2 Virtualizzazione vs Cloud
Per far chiarezza tra le differenze sostanziali che ci sono tra la tecnica di
virtualizzazione e sistemi cloud basta far riferimento a quando dichiarato dal NIST
nella definizione delle due tecnologie [2] [4].
La virtualizzazione nell’ IT ha il significato di isolare le risorse di calcolo in maniera
tale che un oggetto in uno strato possa essere eventualmente impiegato senza avere
la preoccupazione di modifiche apportate negli strati sottostanti. La virtualizzazione
isola le risorse di calcolo, offre dunque l’opportunità di riposizionare e consolidare
le risorse isolate per un miglior utilizzo e una maggiore efficienza.
Il cloud computing è invece la capacità di rendere le risorse disponibili su richiesta:
dunque alta accessibilità e disponibilità in qualsiasi momento. Nel cloud computing
un servizio identifica qualcosa, disponibile on-demand e self-service. Così si intende

12
il software SaaS, ossia un software la cui offerta è disponibile su richiesta e
l’attenzione è riposta sulle funzioni disponibili entro e non oltre l’applicazione. PaaS
fornisce un ambiente di runtime on-demand e la portata di questo servizio è costituita
da tutto l’insieme di funzionalità disponibili on-demand, per le applicazioni
distribuite in questo ambiente runtime. IaaS è invece la capacità di implementare
macchine virtuali on-demand.
Sostanzialmente, la maggior parte delle cose che si possono fare in ambito cloud
potrebbero essere fatte sfruttando anche alcune estensioni dei più noti sistemi di
virtualizzazione come ad esempio virtualizzare un intero ambiente virtuale, aver
accesso da remoto, avere self-servering di risorse, ma nella virtualizzazione il self-
servering ad esempio non è una componente né necessaria né sufficiente, al contrario
del cloud.
1.5 VANTAGGI DEL CLOUD
I vantaggi del cloud computing [5] sono numerosi e posso essere raggruppati in due
categorie analizzando l’aspetto economico, legato dunque ai costi infrastrutturali e
di mantenimento, e l’aspetto tecnico.
1.5.1 Aspetti economici
Abbattimento dei costi fissi iniziali: risparmio per i non più necessari
investimenti, iniziali e successivi, sul software e hardware (acquisto,
configurazione, installazione, manutenzione e dismissione di hardware e
software). Non è necessario possedere computer di fascia alta per accedere ai
servizi cloud online: i programmi e i dati risiedono nell'infrastruttura cloud,
gestita da personale (teoricamente) molto esperto e qualificato;
Maggiore flessibilità: la possibilità di un facile e tempestivo adeguamento
delle condizioni contrattuali in funzione delle maggiori o minori esigenze;
Maggiore attenzione al proprio core business: vengono liberate energie umane
prima completamente dedite alla gestione dell'infrastruttura; la gestione di
tutta l'architettura informatica è demandata al provider.
1.5.2 Aspetti tecnici
Maggiore scalabilità: di fronte alla necessità di maggiori o minori risorse, il
gestore può espandere o limitare con estrema flessibilità l'infrastruttura;
Accesso al cloud in mobilità: la connessione ai dati può avvenire da qualsiasi
posto e in qualsiasi momento, anche attraverso smartphone, netbook, portatili
o pc desktop, smart-tv;

13
Sicurezza del sistema: possibilità di mettere in atto un sistema di sicurezza
volto a proteggere i dati e le reti con servizi sempre presidiati da backup, senza
costi per l’eventuale infrastruttura
Indipendenza dalle periferiche: trattandosi di programmi e dati online, non si
è vincolati ad utilizzare particolari hardware o determinate configurazioni di
reti ma è appena sufficiente qualsiasi dispositivo fisso o mobile capace di
collegamento internet attraverso un browser qualsiasi.
Continuità di servizio: il cloud computing in quanto servizio, permette di non
fare investimenti in soluzioni hardware/software ridondanti. In questo modo
si ha la possibilità di ridurre i costi, ma di aumentare la continuità di servizio.
Infatti in caso di un problema o di un upgrade al server del cloud dove sta
girando una istanza, tale istanza viene spostata interamente su un altro server.
1.6 PROBLEMATICHE DEL CLOUD
Una domanda che ci si pone spesso è: quanto è sicuro il cloud?
Ci sono molti aspetti legati alla sicurezza e molti fattori da valutare: sicurezza delle
informazioni immagazzinate, sicurezza delle informazioni in transito, accesso alla
cloud etc…
Secondo un’indagine statistica sembra essere il problema principale di molti team di
IT. [6]
1.6.1 Sicurezza dei dati
La sicurezza dei dati è un argomento estremamente delicato in ambiente cloud.
Esso infatti riguarda molti aspetti legati non solo a un aspetto tecnico ma anche alle
norme vigenti sulla riservatezza dei dati in termini di privacy e responsabilità.
Hp ha inserito all'interno della propria offerta di soluzioni HP Atalla [7] una
tecnologia di cifratura in attesa di brevetto che garantisce la cifratura dei dati nel
cloud sia in condizione di riposo sia mentre sono in uso, che protegge le chiavi di
cifratura mentre sono in uso e persino nel caso di violazione.
Con HP Atalla Cloud Encryption ogni oggetto legato ai dati (per esempio un disco)
è memorizzato in un dispositivo virtuale sicuro e viene crittografato utilizzando un
metodo di crittografia a chiave separata in due.
La prima parte, la cosiddetta Master Key, è uguale per tutti i "data object"
nell'applicazione e rimane in possesso solo del proprietario dell'applicazione e non

14
viene mai memorizzata in forma aperta né sull'account cloud dell'utente né sul
servizio di gestione chiavi di HP (HP Key Management Service).
La seconda parte della chiave è differente per ogni "data object" e viene generata
dall'appliance virtuale sicura all'interno del servizio di gestione delle chiavi di HP e
memorizzata dopo averla ulteriormente cifrata con una chiave privata RSA.
Sintentizzando:
In ambito cloud, gli hard disk virtuali risiedono su hard disk fisici condivisi ed è
perciò opportuno averli criptati.
1.6.2 Geo localizzazione dei dati
Per quanto concerne le cloud private, il problema di geo localizzare i propri dati può
essere influente in quanto la possibilità di implementare un data storage locale, è
solo una scelta implementativa.
Per le hybrid cloud e le public cloud, la necessità di geo localizzare i propri dati può
essere un problema.
Nel Public cloud i servizi IT, siano essi di tipo applicativo o di tipo elaborativo, di
storage e di sicurezza, vengono acquisiti presso provider esterni. I dati vengono
ospitati fuori dall’azienda; ciò necessità di un adeguato livello di attenzione per
l’esternalizzazione di servizi da parte di aziende o amministrazioni pubbliche che
adottano soluzioni di cloud computing. Infatti, non sono esenti da responsabilità
legali [8] in merito, per esempio, al trattamento o alla diffusione di dati sensibili
personali.
Per garantire il livello di protezione sono state messe a punto sofisticate soluzioni di
cifratura e gestione delle chiavi, tool per garantire la conformità, sistemi di gestione
dell’accesso sicuro e operanti all’interno di strutture federate sicure.
Il Garante della Privacy ha affrontato il tema della riservatezza e confidenzialità
delle informazioni collocate in ambiente public cloud e ha messo in evidenza alcuni
aspetti che vanno considerati per un utilizzo consapevole, che si possono riassumere
in questi punti:
verifica dell’affidabilità e competenze del fornitore;
attenta selezione dei dati gestiti in modalità cloud;
controllo dell’effettiva allocazione fisica dei dati;
utilizzo di servizi che favoriscono la portabilità dei dati e la loro disponibilità
in caso di necessità;

15
esigere dal fornitore opportune garanzie in merito alla sicurezza dei dati e
delle tecniche di trasmissione oltre alla gestione di situazioni critiche che
possono comprometterne la corretta conservazione;
stabilire in fase contrattuale i Service Level Agreement a cui riferirsi, le
penali previste e i tempi di conservazione dei dati dopo la scadenza del
contratto.
1.6.3 Homomorphic Encription
La crittografia omomorfica [9] è un tipo di crittografia basata su tecniche che
permettono la manipolazione di dati cifrati. Ad esempio, avendo due numeri X e Y
(cifrati con lo stesso algoritmo omomorfico a partire da due numeri A e B) è
possibile calcolare la cifratura della somma di A e B sommando direttamente X e Y,
senza bisogno di effettuare la decifratura.
Questa proprietà della crittografia omomorfica è molto importante oggi, soprattutto
con l'avvento del cloud computing: attualmente, infatti, i dati presenti su una
piattaforma di cloud non sono totalmente sicuri, soprattutto se bisogna effettuare
delle operazioni su di essi, poiché per manipolarli c'è bisogno di decifrarli. La
crittografia omomorfica, invece, può risolvere questo problema e fare in modo che
le informazioni memorizzate nel cloud non debbano mai essere decifrate (e che
quindi siano sempre al sicuro).
Esistono due tipi di crittografia omomorfica: crittografia omomorfica totale, in grado
di criptare qualsiasi tipo di dato e crittografia omomorfica parziale, specializzata per
determinate applicazioni.
I costi computazionali della crittografia omomorfica totale risultano essere tutt’ora
elevati, ma se si riuscissero ad abbassare i costi, troverebbe il suo impiego maggiore
negli ambienti cloud.
1.6.4 Banda Larga
Uno dei principali svantaggi del cloud è la necessità di utilizzare una connessione
internet veloce: in Italia siamo messi male. Nel tempo, soltanto due compagnie
italiane si sono affacciate a questa tecnologia, e sono, Telecom Italia e Fastweb. Nel
2012, Telecom Italia e Fastweb, hanno annunciato una collaborazione nell'utilizzo

16
della VDSL2 attraverso l'architettura FTTC [10], che dovrebbe portare una copertura
internet teorica fino a 400 Mbits in 100 città italiane entro il 2014.
Dal 5 dicembre 2012, Telecom Italia ha iniziato la vendita della tecnologia in alcune
città italiane offrendo un unico profilo, con velocità di 30/3 Mbit/s.
Il 5 marzo 2013, Fastweb ha lanciato il suo servizio basato su VDSL2 col quale i
clienti potranno usufruire di velocità di 20Mbit di download e 10 Mbit di upload,
migliorabili fino a 100 in download pagando un piccolo contributo mensile.
Contrariamente a quanto avviene in Italia, a marzo del 2014 la tecnologia VDSL2 è
utilizzata in molti paesi europei:
in Slovenia, dove l'operatore telefonico "AMIS" sta fornendo VDSL2 alla
clientela Corporate dal 2013, "TušTelekom" alle imprese ,"Telekom
Slovenije" dal 5 marzo 2007 ai suoi clienti e la compagnia locale "T-2"
fornisce VDSL2 ai clienti dal maggio 2007 offrendo loro una velocità fino a
60/25 Mbps su linee telefoniche in rame e in fibra ottica vari pacchetti da
10/10 Mbps fino a 1000/1000 Mbps.
in Belgio, dove la compagnia locale Belgacom la utilizza per fornire agli
abbonati il servizio Internet e IPTV.
in Francia, gli operatori Orange, SFR, Bouygues Telecom e Free hanno offerte
dai 50Mbit/s ai 100Mbit/s con prezzi che variano da 29,9€ ai 37,9€ al mese,
incluse telefonate e televisione[5]
in Spagna, gli operatori Jazztel, Movistar e Vodafone, hanno offerte dai
30Mbit/s ai 35Mbit/s con prezzi che variano da 35€ ai 53€ al mese, [6]
in Germania, gli operatori EWE, OsnaTEL, SWB, Deutsche Telecom,
Vodafone, MDCC, hanno offerte dai 50Mbit/s ai 128Mbit/s con prezzi che
variano da 25€ ai 56€ al mese, televisione e spesso telefonate incluse [7]
in Svizzera, dove l'operatore Swisscom la utilizza per fornire agli abbonati il
servizio Internet e IPTV, offrendo loro una velocità fino a 50 Mbps su rame e
100 Mbps in fibra ottica.
a Malta Go Plc offre connessioni VdSL2 (profilo ITU-T G.993.2 Annex B)
con una velocità di 35 Mbps in download e 2 Mbps in upload. La portante,
qualora l'utente si trovi vicinissimo al cabinet di strada, può arrivare a valori
di 34.999/2.000. Attualmente, 8 Maggio 2014, la connessione è offerta senza
limiti di download.
A marzo del 2014, questi paesi hanno una velocità media nazionale di connessione
ad internet tra i 20Mbit/s e i 29Mbit/s, mentre l'Italia ne ha meno di 8Mbit/s, secondo
netindex.com
A marzo del 2014, l'Italia ha meno di 8 Mbit/s di velocità media nazionale di
connessione ad internet secondo explorer.netindex.com. Facendo un confronto con

17
i dati storici di netindex.com, il ritardo italiano nella diffusione della banda larga
corrisponde, per gli altri più avanzati paesi europei, ad un salto indietro nel tempo,
come di seguito:
7 anni di salto indietro nel tempo per la Francia (che aveva una media
nazionale inferiore a 8 Mbit/s a marzo del 2008)
6 anni di salto indietro nel tempo per la Germania (che aveva una media
nazionale inferiore a 8 Mbit/s a maggio del 2008)
5 anni di salto indietro nel tempo per la Slovenia (che aveva una media
nazionale inferiore a 8 Mbit/s ad agosto del 2009)
4 anni di salto indietro nel tempo per il Regno Unito (che aveva una media
nazionale inferiore a 8 Mbit/s ad agosto del 2010)
4 anni di salto indietro nel tempo per la Spagna (che aveva una media
nazionale inferiore a 8 Mbit/s ad agosto del 2010)
Nei confronti di questi paesi di PIL paragonabile a quello italiano, l'Italia ha circa da
4 a 7 anni di ritardo tecnologico.
Ad oggi la banda media italiana è leggermente aumentata, nonostante tutto siamo
ancora abbastanza indietro

18
Figura 5. Statistica mondiale sulle velocità medie di connessione a internet in download (a sinistra) e in upload (a destra) [11]
1.7 SICUREZZA DEGLI ACCOUNT E DELL’ACCESSO ALLE
RISORSE
Nella realizzazione di sistemi distribuiti in genere e dei sistemi cloud in particolare,
sorge l’esigenza di verificare che il proprio interlocutore sia effettivamente chi
dichiara di essere prima di poter avere accesso a determinate risorse.
Per proteggere una risorsa, in generale, si deve passare attraverso due fasi:
Autenticazione: è il processo che verifica l’identità, ovvero risponde alla domanda:
“l’utente è chi dice di essere?”
Autorizzazione: è il processo che consente l'accesso alle risorse solamente a coloro
che hanno i diritti di usarle.

19
I metodi attraverso i quali si può autenticare una persona, sono divisi in tre classi:
- qualcosa che si è: per esempio impronte digitali, impronta vocale,
struttura retina o altri identificatori biometrici;
- qualcosa che si ha: tesserino identificativo, certificato, token;
- qualcosa che si conosce: password, numero d’identificazione personale
(PIN).
Per l'autenticazione in rete è normalmente usata la terza classe, che non richiede né
l'utilizzo di hardware speciali né la presenza dell'utente.
Per ragioni di sicurezza, la password scelta dall'utente, o a lui assegnata, deve
soddisfare certi requisiti ed essere:
- non ovvia e di lunghezza minima data;
- non comunicata in chiaro;
- cambiata con una certa frequenza.
L’autenticazione tramite password è oggi il sistema più utilizzato per l’accesso ai
vari servizi della rete. Ma come vedremo in seguito, più usato è ben diverso di più
sicuro.
Questo modo di procedere causa però alcuni disagi, sia agli utenti che usufruiscono
del servizio stesso, sia a chi li fornisce. Infatti gli utenti si trovano spesso a dover
gestire diverse credenziali di accesso;
Considerando che la password dovrebbe essere cambiata spesso, e che un utente
difficilmente ha un solo account da ricordare, ne discende che per l'utente può
diventare gravoso ricordare una coppia username/password. Questo può portare a
errori comuni, come la trascrizione in chiaro delle password in email, cellulare, post-
it, o sfruttare dei key-manager per lo storage cifrato delle proprie password.
Tali sistemi in realtà non risolvono il problema della sicurezza degli account, in
quanto per poter poi accedere a tutte le proprie password al momento del bisogno,
ne basterà solamente una…
Perciò, recentemente si tende a sviluppare sistemi di autenticazione che possano
essere riutilizzabili per varie funzioni, o servizi. In alcuni casi, tali sistemi si
occupano di gestire un'unica coppia username/password associata a un utente, che
deve comunque essere fornita per ciascun servizio che si intende utilizzare.
In altri casi, almeno per quanto riguarda servizi diversi accessibili all'interno di
un'unica università/azienda, esistono dei veri e propri sistemi di Single Sign On, in
cui un utente si autentica una volta soltanto e accede poi liberamente a tutti i servizi
per cui possiede l'accesso.

20
Meno password da ricordare, più accesso alle risorse…
1.8 PIATTAFORME DI SVILUPPO DEL CLOUD Esistono diverse compagnie che investono nel cloud computing le loro risorse, non
solo come provider di servizi cloud, ma che fornisco anche supporto per lo sviluppo
di questa tecnologia attraverso la loro idea di cloud e i loro framework di sviluppo.
Figura 6. Top Cloud Companies [12]
Amazon è sicuramente la prima che è riuscita a offrire un servizio pubblico di IaaS:
la sua offerta varia dalla vendita low-cost di servizi di storage alla vendita di servizi
di computazione da 5000$ per ora.
VMware, azienda leader nel settore della virtualizzazione, non è stata di certo a
guardare. In un primo momento, con vCloud offrivano la piattaforma per lo sviluppo
di cloud, ed è solo da circa un anno che hanno cambiato idea decidendo immettere
sul mercato i servizi di una loro implementazione di cloud pubblico.
Altre compagnie come Microsoft e Google offrono servizi come Windows Azure
(Iaas e PaaS, non rinnegando Linux) e Microsoft Office 365 (SaaS) e rispettivamente
Chrome Os (PaaS) e Google Apps (SaaS), Google Engine (PaaS) e Google Drive
per lo storage.
Tuttavia, quello che è veramente importante per la ricerca e lo sviluppo lo stanno
facendo Rackspace e IBM: hanno sposato OpenStack, “LA” piattaforma open source
con la più grande community oggi esistente per il cloud libero. Nata con l’idea di

21
non voler comprare software che non si può controllare, Rackspace ha collaborato
con la NASA per lo sviluppo e IBM da parte sua, punta molto su questa piattaforma,
dichiarando che utilizzerà OpenStack, per tutte le cloud che stanno sviluppando. Il
lavoro fatto da IBM dunque, pone OpenStack come diretto concorrente per VMware.
Dunque, è proprio per questo che abbiamo deciso di adottare anche noi OpenStack
per la nostra installazione di test, stimolati dal suo potenziale e incuriositi dall’ampia
community che ha alle spalle.

22
CAPITOLO 2
Piattaforma per lo sviluppo di una
infrastruttura di Cloud Computing:
OpenStack
OpenStack [13] è un insieme di software open source rilasciato, sotto licenza
Apache che integra il codice dalla piattaforma della NASA Nebula e dalla
piattaforma Rackspace, con lo scopo di fornire infrastruttura cloud pubbliche o
private, largamente scalabili
OpenStack è un progetto IaaS cloud computing di Rackspace Cloud e NASA
fondato nel 2010 e sviluppato principalmente in python. A oggi oltre 200 società si
sono unite al progetto tra cui Arista Networks, AT&T,AMD, Brocade
Communications Systems, Canonical, Cisco, Dell, EMC, Ericsson, F5 Networks,
Groupe Bull, Hewlett-Packard, IBM, Inktank, Intel, NEC, NetApp, Nexenta,
Rackspace Hosting, Red Hat, SUSE Linux, VMware, Oracle e Yahoo!.
Dal 2010 OpenStack è in forte ascesa, e il suo sviluppo è globale: come si può vedere
dalle statistiche di Google Trends, OpenStack risulta essere un termine molto
ricercato sul motore di ricerca, soprattutto se confrontato con le altre due piattaforme
di sviluppo open source, che nel corso degli anni non sembrano aver suscitato un
forte interesse in confronto.
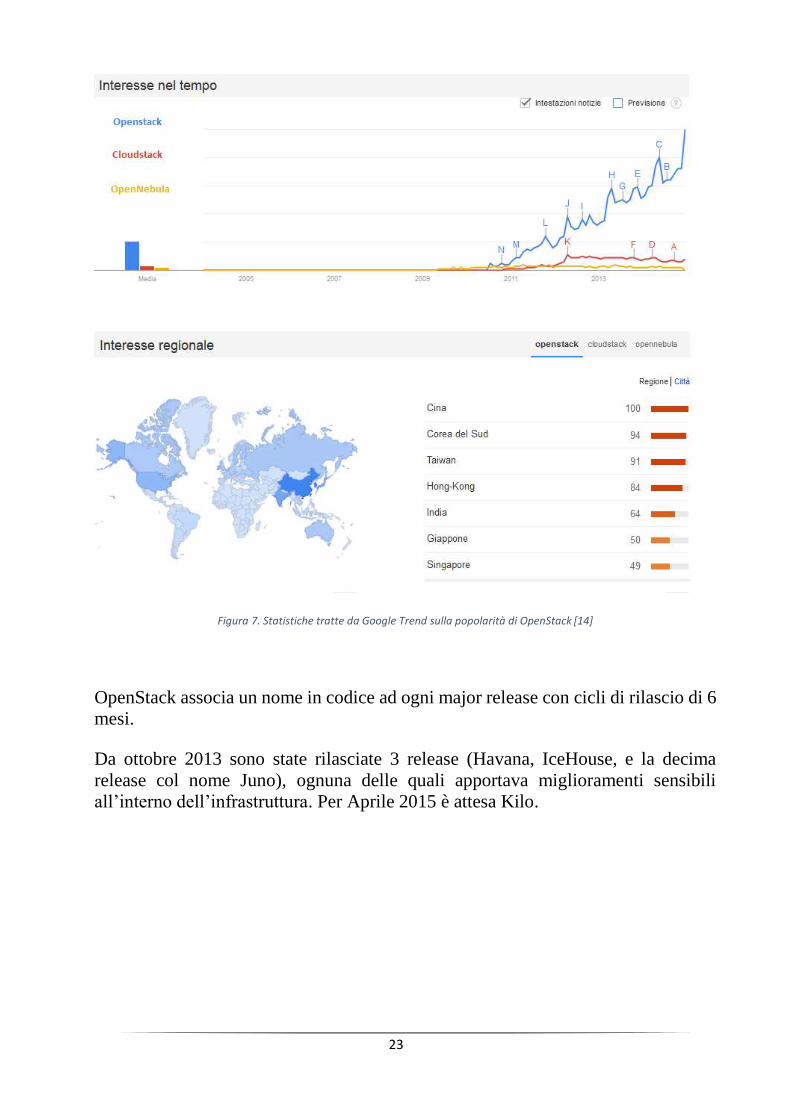
23
Figura 7. Statistiche tratte da Google Trend sulla popolarità di OpenStack [14]
OpenStack associa un nome in codice ad ogni major release con cicli di rilascio di 6
mesi.
Da ottobre 2013 sono state rilasciate 3 release (Havana, IceHouse, e la decima
release col nome Juno), ognuna delle quali apportava miglioramenti sensibili
all’interno dell’infrastruttura. Per Aprile 2015 è attesa Kilo.

24
2.1 COMPONENTI
Figura 8. Modularità di OpenStack
Come abbiamo detto OpenStack è un insieme di software ed ogni componente ha
un nome in codice che lo identifica:
Servizi Nome in codice
OpenStack Identity Keystone
OpenStack Compute Nova
OpenStack Networking Neutron
OpenStack Image Service Glance
OpenStack Block Storage Cinder
OpenStack Object Storage Swift
OpenStack Dashboard Horizon
2.1.1 Keystone – Identity service
Keystone è il servizio che si occupa di gestire autenticazione e autorizzazione
all’interno di OpenStack e funge anche da service catalog. In particolare si occupa
della validazione delle credenziali per gli utenti, validazione e gestione dei token per
l’autenticazione una volta che le credenziali siano state verificate, gestisce il
catalogo dei servizi con le informazioni relative agli endpoit di ogni servizio e le
policy ti autorizzazione.

25
Supporta diversi tipologie di back-end come identity provider. Di default utilizza
MySQL ma è anche possibile utilizzare LDAP o può essere esteso con meccanismi
di autenticazione federata di tipo single sign-on.
Quando un utente fa un richiesta a Keystone se l’autenticazione ha esito positivo
allora ottiene un token da poter utilizzare per effettuare le varie richieste.
Quando un servizio, riceve una richiesta da un altro servizio, effettua una chiamata
a Keystone passandogli il token del richiedente: se l’autenticazione ha esisto positivo
allora la richiesta può essere consumata altrimenti viene rigettata.
Figura 9. Diagramma funzionale per l'autenticazione
Per installazioni di testing, questo tipo di approccio è più che valido, ma in ambienti
enterprise è possibile apportare delle migliorie: ad esempio se si pensa a dover
garantire l’accesso alla cloud a una vasta comunità di persone, usare un back-end di
tipo MySQL comporterebbe sicuramente del lavoro sia per l’aggiunta delle nuove
credenziali sia per estrapolare le informazioni dal database della community
successivamente da importare all’interno del back-end di Keystone. E se si pensa

26
alla possibilità che la cloud possa essere utilizzata da più community, non è difficile
immaginare l’ammontare del lavoro che ci sarebbe da fare: in tal caso il supporto
per il SSO di Keystone, chiamato OS_Federation è sicuramente una scelta obbligata.
Inoltre ipotizzando che la cloud possa essere utilizzata simultaneamente da diverse
entità, come si vede dall’immagine precedente, ogni richiesta fatta a un servizio della
cloud comporta la verifica da parte del servizio di un token. Tale verifica, viene
eseguita interrogando Keystone e inviandoli il token in questione e questo comporta
sicuramente un overhead di rete evitabile se si decidesse di utilizzare token di tipo
PKI, i quali verrebbero verificati in loco da ogni servizio sfruttando i certificati x.509
2.1.2 Nova – Compute service
OpenStack Compute (Nova) è un controller per il cloud computing (la parte
principale di un sistema IaaS).
L'architettura di Compute è progettata per scalare orizzontalmente su hardware
standard senza particolari requisiti software o hardware proprietari e tecnologie di
terze parti. È stato progettato per gestire e automatizzare il pool di risorse del
computer e può funzionare con tecnologie di virtualizzazione ampiamente utilizzate,
come pure in configurazioni bare-metal e high-performance computing (HPC). Ad
esempio KVM, XenServer, Hyper-V sono scelte disponibili come hypervisor.
Utilizza un database (generalmente MySQL) per la memorizzazione delle
configurazione e degli stati a run-time dell’infrastruttura, ad esempio quali tipi di
istanza sono disponibili, quali istanze sono in uso, di chi sono quelle istanze, gli
utente le reti etc.
I servizi di nova si suddividono in:
Nova-api: accetta e risponde alle richieste di computazione da parte degli
utenti
Nova-scheduler: prende da un coda una richiesta di creazione di una macchina
virtuale e determina su quale host fisico deve essere eseguita
Nova-compute: è il servizio principale che si occupa della creazione e
terminazione delle istanze attraverso le APPI dell’Hypervisor
Nova-console, nova-vncproxy, nova-consoleauth sono invece i servizio che si
occupano dell’accesso alle console delle macchine virtuali

27
Figura 10. Raffigurazione grafica Nova
2.1.3 Glance – Image Service
Image Service è un servizio centrale per la tipologia Infrastructure-as-a-Service
(IaaS) consente agli utenti di scoprire, registrare e recuperare le immagini delle
macchine virtuali.
Il servizio offre una REST API che consente di interrogare i metadati dell’immagine
della macchina virtuale e recuperare un immagine. È possibile memorizzare le
immagini per le macchine virtuali, messi a disposizione tramite l’Image Service, in
una varietà di locazioni; da semplici file sull’ hard drive ad opportuni sistemi di
archiviazione come ad esempio il servizio di OpenStack Object Storage.
Un certo numero di processi periodici eseguiti su OpenStack Image Service
supportano la cache. Servizi di replica garantiscono la coerenza e la disponibilità
attraverso il cluster ed altri processi periodici consentono di revisionare, aggiornare
e fixare il sistema.
Glance include i seguenti componenti:

28
glance-api: accetta chiamate API per l'individuazione di immagini, il recupero
e memorizzazione
glance-registry: immagazzina, processa, e recupera i metadati (informazioni
come ad esempio la dimensione e il tipo) relativi alle immagini
2.1.4 Cinder – Block Storage
Il servizio di OpenStack Block Storage aggiunge storage permanente per una
macchina virtuale. Block Storage fornisce un'infrastruttura per la gestione dei
volumi, e interagisce con OpenStack Compute per fornire i volumi alle istanze. Il
servizio consente inoltre la gestione degli snapshot di volume, e tipi di volume.
Il servizio Block storage è costituito dai seguenti componenti:
cinder-api: accetta richieste API, e li indirizza verso il cinder-volume
cinder-volume: interagisce direttamente con il servizio di block storage, e con
processi come cinder-scheduler. Inoltre interagisce anche con questi processi
attraverso una coda di messaggi. Il servizio di cinder-volume risponde per
leggere e scrivere le richieste inviate al servizio di Block Storage per
mantenere lo stato. Può interagire con una varietà di fornitori di storage
attraverso un'architettura a driver
cinder-scheduler: seleziona il nodo di archiviazione ottimale su cui creare il
volume. Un componente simile alla nova-scheduler
2.1.5 Swift – Object Storage
Analogamente, anche il servizio di OpenStack Object Store (Swift) gestisce via
software grandi quantità di spazio disco, potenzialmente scalabile fino a diverse
centinaia di petabyte. Swift non offre solo un servizio di object storage ma integra
nativamente funzionalità di Content Delivery Network, e quindi di replica
geografica con accesso al medesimo dato da punti differenti in base alla latenza
minore.
Ogni “oggetto” viene memorizzato utilizzando un path derivato dall'hash del file e
dal timestamp dell'operazione, così da assicurare che verrà servita sempre l'ultima
versione disponibile. Tutti gli oggetti vengono raggruppati in strutture logiche
denominate “ring”, che si occupano di mappare i singoli oggetti alla loro posizione
fisica, utilizzando come coordinate le zone, i dispositivi, le partizioni e le repliche.
Il concetto di partizione serve ad assicurare una equa distribuzione dei dati, in quanto

29
ogni partizione sarà distribuita tra tutti i dispositivi che fanno parte dell'installazione;
mentre il concetto di zona serve ad assicurare la replicazione dei dati, in quanto il
sistema assicura una replica delle partizioni per ogni zona presente, dove la zona può
rappresentare un disco, un server o anche un datacenter.
Particolare attenzione merita la possibilità di associare un “peso” ai dispositivi fisici
dell'infrastruttura, funzionalità che permette di avere una distribuzione dei dati
bilanciata equamente anche quando vengono utilizzati dischi di differenti
dimensioni.
L'elenco degli oggetti presenti sullo storage è mantenuto da un servizio chiamato
Container Server, che non è a conoscenza di dove fisicamente risiede un singolo
oggetto ma semplicemente associa gli oggetti ai relativi Container.
Così come i Container Server associano gli oggetti ai Container, l'elenco di questi
ultimi è mantenuto da uno o più Account Server, che si occupano, quindi, di
associare i Container ai relativi Account. Tutta la complessità dell'architettura di
storage viene celata all'esterno dal servizio Proxy Server, che esponendo
pubblicamente delle API, per ogni richiesta ricevuta ricercherà la posizione
dell'account, del container o dell'oggetto, ridirigendo la richiesta al server opportuno.
La sicurezza del dato, a livello di singolo disco fisico, è garantita da un filesystem
cifrato basato su tecnologia LUKS. Ai livelli superiori, la scelta del metodo di
cifratura è lasciato all’utente: nel caso del block storage è l’utente che formatta il
proprio volume, mentre nel caso dell’object storage possono essere utilizzati
software di terze parti che cifrano gli oggetti prima di scriverli su Swift. Tutte le
comunicazioni di tipo storage che attraversano reti non sicure sono cifrate con SSL.
2.1.6 Horizon - Dashboard
La dashboard di OpenStack, nota anche come Horizon, è un'interfaccia Web che
consente agli amministratori di cloud e agli utenti di gestire le varie risorse e servizi
di OpenStack.
La dashboard consente interazioni web-based con la cloud OpenStack attraverso le
API. E’ utilizzabile per la gran parte delle operazioni di base, ma non offre la
possibilità di eseguire in modo esaustivo tutti i comandi disponibili da shell.
2.1.7 Neutron – Network service
OpenStack Networking è un sistema per la gestione delle reti e degli indirizzi IP.
OpenStack Networking assicura che la rete non sarà il collo di bottiglia o fattore
limitante in una cloud e offre agli utenti una reale gestione self-service anche delle
loro configurazioni di rete.

30
OpenStack Networking fornisce differenti modelli di rete per le diverse applicazioni
o i gruppi utente. I modelli standard includono flat networks o VLAN per la
separazione del traffico. OpenStack Networking gestisce gli indirizzi IP,
consentendo l'assegnazione di indirizzi IP statici dedicati oppure tramite DHCP.
All’interno di ogni progetto gli utenti possono creare una o più reti private e uno o
più apparti di rete con cui connettere le reti in vario modo, indipendentemente da
come il proprio vicino di tenant abbia configurato la propria rete e questo è possibile
grazie all’utilizzo dei NAMESPACE di linux [15].
I floating IP sono indirizzi che consentono di reindirizzare il traffico in modo
dinamico a qualsiasi risorsa di calcolo gestita da OpenStack, questa caratteristica
può essere utile in caso di manutenzione programmata o in caso di guasto. Gli utenti
possono creare le proprie reti, controllare il traffico e collegare server e dispositivi
per una o più reti.
Un’altra tipologia di rete è denominata shared network, attraverso la quale si mette
a disposizione dell’infrastruttura OpenStack, una rete esistente nel centro di calcolo
per poter creare delle VM sulla rete stessa, in modo da poter usufruire di servizi di
rete presenti. In questa tipologia di rete le policy della rete non sono gestite da
OpenStack e alle varie istanze viene fornito un indirizzo ip direttamente dal server
DHCP della rete alla quale ci si connette.
Gli amministratori possono sfruttare la tecnologia SDN come OpenFlow per
consentire elevati livelli di multi-tenancy e massive scale. OpenStack Networking
ha un extension framework che consente la messa in campo e la gestione di servizi
di rete aggiuntivi, come IDS, bilanciamento del carico, firewall e VPN. Gli
utenti finali posso interagire con i servizi di Neutron o attraverso Horizon, oppure
attraverso API specifiche di ogni servizio, utilizzate tra l’altro per lo scambio di
informazioni tra i vari servizi.
Oltre ai servizi sopra citati, esistono delle estensioni per Neutron, degni di nota:
FWaaS e VPNaaS.
Queste estensioni forniscono funzioni ausiliare, deducibili dai nomi (Firewall e
VPN), per apportare maggiore sicurezza all’interno delle istanze.
2.1.8 VPN as a Service
VPN as a Service è un’estensione della suite di OpenStack che offre la possibilità di
connettere reti private, appartenenti a tenant diversi, tra di loro e/o con la rete
pubblica attraverso una connessione sicura

31
Inoltre offre la possibilità di connessione anche fra siti distribuiti geograficamente
(Hybrid Cluod, Cloud Multiregion – il caso dell’ INFN [16] [17])
Figura 11. VPNaaS - Site to Site
Il VPNaaS fornisce alle tenants di OpenStack la possibilità di estendere le proprie
reti privati attraverso l’infrastruttura pubblica. Le funzionalità offerte da questa
implementazione iniziale di VPNaaS sono:
connessioni Site-to-Site tra due reti privati
Supporto IKEv1(Internet Key Exchange ) policy con 3des, aes-128/192/256
Supporto IPSec (Internet Procotol Security) con 3des, aes-128/192/256, sha1
authentication, ESP, AH, AH-ESP transform protocol e incapsulamento
tunnel or transport mode
Deed-Peer-Detection
Questa estensione introduce nuove risorse:
IKE Policy - Internet Key Exchange Policy: Identifica gli algoritmi di
autenticazione e crittografia usati
durante le fasi 1 e 2 della negoziazione di una connessione VPN
IPSec Policy - IP Security Policy: Identifica gli algoritmi di autenticazione e
crittografia e il metodo di incapsulamento usati a connessione VPN stabilita
VPN Service - Virtual Private Network Service: Associa la VPN con un router
e una subnet specifici
IPSec Site Connection: Specifica i dettagli della connessione site-to-site
2.1.9 Firewall as a Service
L'estensione FWaaS fornisce agli utenti di OpenStack la possibilità di utilizzare
firewall come servizio della cloud per proteggere le loro reti. L'estensione FWaaS in
particolare consente di:
Applicare regole firewall sul traffico in entrata e uscita per le tenant networks.

32
Supporto per l'applicazione di TCP, UDP, ICMP, creazione e condivisione
delle politiche del firewall che tengono un insieme ordinato di regole.
Questa estensione introduce dei nuovi concetti/risorse quali:
firewall: rappresenta una risorsa logica, firewall, che una tenant può istanziare
e gestire. Un firewall è associato a una firewall_policy.
firewall_policy: è un insieme ordinato di firewall_rules. Una firewall_policy
può essere condivisa tra più tenant.
firewall_rule: rappresenta un insieme di attributi come porte, indirizzi IP che
definiscono criteri di corrispondenza e di azione (consentire, o negare) che
devono essere prese sul traffico dati abbinato
Il plug-in Firewall-as-a-Service (FWaaS) aggiunge un firewall di perimetro per
filtrare il traffico al neutron router, mentre le security groups sono attive a livello di
istanza.
Figura 12. Posizionamento logico di FWaaS in OpenStack

33
CAPITOLO 3
OpenStack: Installazione e test
3.1 PRELIMINARI
Per l’installazione di OpenStack si è fatto riferimento alla guida fornita [18], in
particolare per gli aspetti riguardanti la configurazione delle varie macchine e la
suddivisione dei vari servizi della cloud. Prima di procedere dobbiamo definire
alcune parole chiave:
Controller Node: è la macchina che orchestra e gestisce i vari servizi
Network Node: è la macchina che si occupa di tutto ciò che concerne la rete di
OpenStack, ovvero che isola le varie istanze virtuali e che fornisce connettività a
internet all’interno dell’infrastruttura
Compute Node: è necessario che ci sia almeno un compute node per ogni
installazione. E’ la macchina che si occupa di eseguire le istanze virtuali istanziate
all’interno del cloud
Block Storage Node: il block storage node è la macchina a cui sono delegati i servizi
di storage, intesi come volumi logici da associare all’istanze
Object Storage Node: è la macchina che si occupa di conservare dati in modo
permanente, indipendentemente dall’ istanza
Tutte queste macchine cooperano tra di loro attraverso un’infrastruttura di rete e per
ottimizzare la velocità di iterazione tra i vari servizi, viene suggerito di creare per
ogni servizio un host e per i servizi di storage si consiglia l’utilizzo di un bus
dedicato, in modo che un traffico di dati elevato sulla rete di storage, non influenzi
negativamente il lavoro con il resto del cloud.
A tale scopo, l’intera infrastruttura di OpenStack sfrutta più reti
contemporaneamente ognuna con un ruolo prefissato: se per le reti di storage non
c’è bisogno di dare molte spiegazioni, diverso è il discorso per le reti di management,
external network e tunnel.
La rete di management si occupa dell’iterazione dei servizi all’interno della cloud,
dunque viaggiano esclusivamente richieste interne all’infrastruttura.
L’ external network è l’interfaccia di rete che fornisce connettività internet all’intera
cloud. Tale interfaccia è presente esclusivamente sul network node.
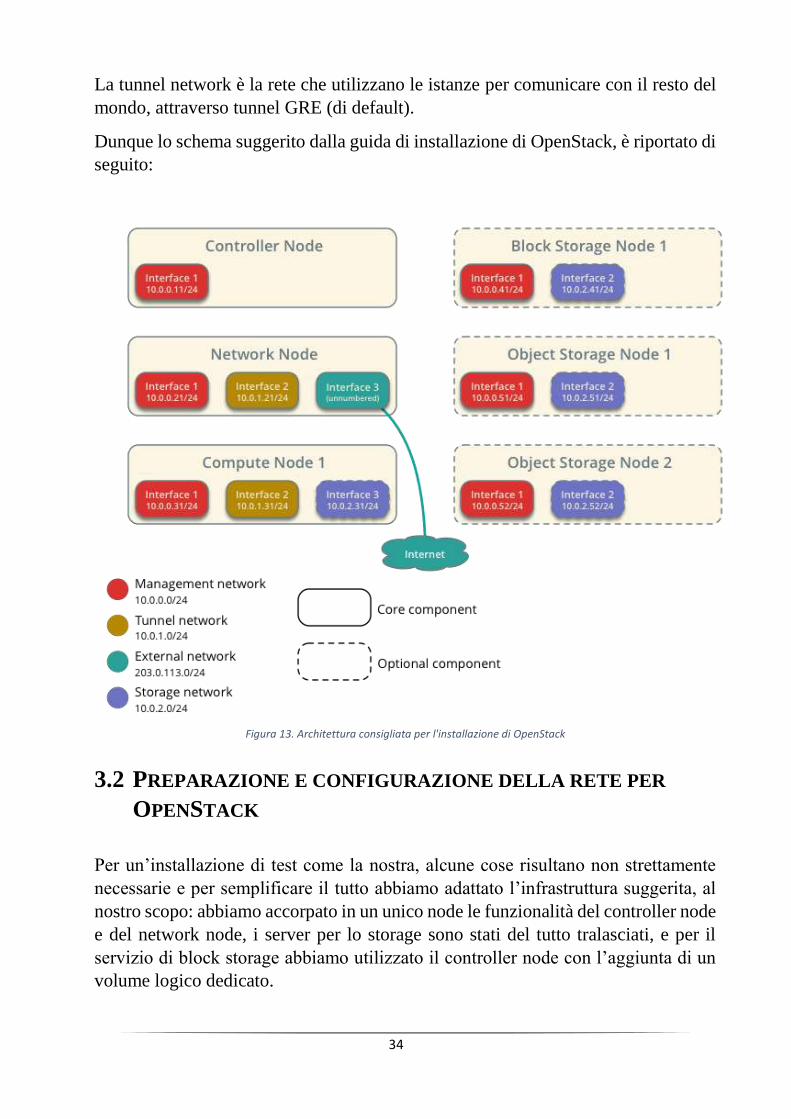
34
La tunnel network è la rete che utilizzano le istanze per comunicare con il resto del
mondo, attraverso tunnel GRE (di default).
Dunque lo schema suggerito dalla guida di installazione di OpenStack, è riportato di
seguito:
Figura 13. Architettura consigliata per l'installazione di OpenStack
3.2 PREPARAZIONE E CONFIGURAZIONE DELLA RETE PER
OPENSTACK
Per un’installazione di test come la nostra, alcune cose risultano non strettamente
necessarie e per semplificare il tutto abbiamo adattato l’infrastruttura suggerita, al
nostro scopo: abbiamo accorpato in un unico node le funzionalità del controller node
e del network node, i server per lo storage sono stati del tutto tralasciati, e per il
servizio di block storage abbiamo utilizzato il controller node con l’aggiunta di un
volume logico dedicato.

35
Per quello che riguarda le reti, la nostra installazione ne ha tre: l’external network,
la management network e la tunnel network: i servizi di storage, nel nostro caso
viaggiano attraverso la rete di management.
Le macchine utilizzate per il conseguimento del nostro scopo, inizialmente erano
due: una macchina virtuale destinata alle funzionalità di controller e network node e
un server fisico dedicato alla computazione.
Le scelte sono state fatte tenendo in considerazione due problematiche:
1. durante i test, è normale sbagliare qualcosa ed è più facile utilizzare la
funzionalità di snapshot per il restore ad uno stato funzionante di una
virtual machine, invece di andare a tentativi nella speranza di fixare
l’eventuale problema
2. dato che le istanze del cloud, sono virtualiazzate ci è sembrato opportuno
avere un server fisico dedicato per ottimizzare le prestazioni delle singole
istanze del cloud, piuttosto di avere ambienti virtualizzati in ambienti
virtualizzati
Per la rete invece, utilizzavamo la rete del Dipartimento di Fisica.
Su entrambe le macchine abbiamo installato una Scientific Linux 6 e abbiamo
utilizzato la release IceHouse di OpenStack.
Ci siamo ben presto accorti che una tale implementazione era da maneggiare con
cura: il primo grosso problema che abbiamo riscontrato, era la configurazione del
servizio neutron sul controller node. Neutron, come già detto, si occupa di
virtualizzare il livello2 e il livello3, e nonostante avessimo apparentemente attuato
una configurazione corretta sulle macchine, si è tuttavia verificato uno spiacevole
inconveniente legato alla presenza di un ciclo nel controller che mandava in loop la
rete dipartimentale con un conseguente blocco di alcuni servizi dipartimentali.
Dunque, abbiamo deciso di rivedere l’infrastruttura iniziale e abbiamo optato per un
cambiamento che ci avrebbe permesso di isolare il nostro ambiente di test dalla rete
dipartimentale, in modo da prevenire ulteriori malfunzionamenti.
Abbiamo realizzato all’interno di vSphere il nostro ambiente, e inserito un Bastion
host virtuale (computer specializzato nell’isolare una rete locale da una connessione
internet pubblica, creando uno scudo che permette di proteggere la rete locale).
Inoltre abbiamo deciso di inserire nel nuovo ambiente anche un secondo compute
node: consci di quanto detto sul degrado delle prestazioni di istanze virtuali in
ambienti virtuali, il suo scopo prevedeva il semplice test della configurazione, che
solo successivamente si sarebbe riportata sul compute node fisico.

36
Non ci restava che collegare il compute node fisico all’interno del nostro ambiente
virtuale, e ripartire di nuovo con l’installazione di tutti i servizi.
Figura 14. Configurazione architetturale e dei servizi dell’installazione di test
Un altro problema che abbiamo riscontrato durante l’installazione di OpenStack
IceHouse, si è presentato durante l’installazione dei servizi di cinder: siamo
incappati in un noto bug di OpenStack, legato alla gestione delle partizioni LVM.
La soluzione era cambiare il tipo di partizione usata: varie ricerche ci suggerivano
di passare ad usare Gluster FS, ma al col tempo era uscita la nuova release di
OpenStack: Juno.
Da qui, la scelta di abbandonare IceHouse e ripartire con Juno, mantenendo
l’infrastruttura illustrata.
La nuova release necessitava di una CentOS7 e così abbiamo resettato le macchine
virtuali e installato Scientific Linux 7 anche sul compute fisico. Durante la fase di
installazione di Juno, non sono stati rilevati problemi legati a malfunzionamenti di
alcun tipo, e il processo si è concluso senza troppi problemi.

37
Figura 15. Esempio di Snapshot

38
3.3 INSTALLAZIONE SERVIZI
Illustriamo adesso i vari step, che si sono resi necessari, per l’installazione di tutti i
servizi che ci servono per raggiungere il nostro scopo. OpenStack struttura come
segue l’installazione dei vari servizi:
Figura 16. Suddivisione consigliata per l’installazione dei servizi di OpenStack
Nel nostro caso, lo schema seguente rappresenta i pacchetti necessari da installare
sulle varie macchine per erogare i servizi della cloud. Dato che abbiamo deciso di
non usare un nodo dedicato al Block Storage, sul controller abbiamo installato i
servizi di Cinder, in modo da poter associare alle istanze nella cloud almeno un
volume logico sul quale eventualmente installare il sistema operativo per le varie
istanze.

39
Figura 17. Suddivisione servizi nell'installazione di test
L’installazione dei repository di OpenStack è il primo passo che ci consente di poter
utilizzare l’utility yum per installare i pacchetti necessari e le relative dipendenze.
3.3.1 Keystone - Installazione e configurazione
L’identity service è stato installato sul controller. Di default [19] sfrutta un backend
MySQL per lo store degli utenti e il service catalog.
L’installazione ha inizio:
yum install openstack-keystone python-keystoneclient

40
Adesso si procede con la configurazione del file keystone.conf attraverso openstack-
config
openstack-config --set /etc/keystone/keystone.conf \
database connection
mysql://keystone:[email protected]/keystone
Sul controller node serve avere MySQL e al suo interno dobbiamo creare
manualmente il database per Keystone e settare i relativi previlegi
mysql -u root -p
CREATE DATABASE keystone;
GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'localhost' IDENTIFIED BY
'keystonepass';
GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'%' IDENTIFIED BY
'keystonepass';
exit
Creato il database, col seguente comando vengono opportunatamente create le
tabelle e i record necessari (di default)
su -s /bin/sh -c "keystone-manage db_sync" keystone
Attraverso openssl generiamo un token, da impostare nel keystone.conf che ci
consentirà di eseguire le query all’identity service. Seguono altri parametri di
configurazione:
Auth_token
ADMIN_TOKEN=$(openssl rand -hex 10)
echo $ADMIN_TOKEN
openstack-config --set /etc/keystone/keystone.conf DEFAULT admin_token
$ADMIN_TOKEN
keystone-manage pki_setup --keystone-user keystone --keystone-group
keystone
chown -R keystone:keystone /etc/keystone/ssl
chmod -R o-rwx /etc/keystone/ssl
service openstack-keystone start
chkconfig openstack-keystone on

41
3.3.1.1 Creazione utenti, tenants e ruoli
Keystone per fare autorizzazioni si basa sulla definizione di regole e sul concetto di
tenants. Ogni tenant ha un determinato scope, e per ogni scope vengono impostati
determinati privilegi. Di default l’installazione di test prevede l’uso di 3 gruppi:
Admin: in questo gruppo esiste solo l’utente admin, membro dell’intera
infrastruttura cloud
Service: in questo gruppo vengono registrati i vari servizi di OpenStack, in
quanto prima di comunicare tra di loro anch’essi necessitano di autenticazione
e autorizzazioni
Demo: è un gruppo creato per l’utente di test che ha solo la possibilità di
gestire il suo spazio di lavoro limitato alla sua tenant.
export OS_SERVICE_TOKEN=ADMIN_TOKEN
export OS_SERVICE_ENDPOINT=http://cloud98.fis.unipr.it:35357/v2.0
--Admin
keystone user-create --name=admin --pass=adminpass --email=ADMIN_EMAIL
keystone role-create --name=admin
keystone tenant-create --name=admin --description="Admin Tenant"
keystone user-role-add --user=admin --tenant=admin --role=admin
keystone user-role-add --user=admin --role=_member_ --tenant=admin
--Demo
keystone user-create --name=demo --pass=demopass --email=DEMO_EMAIL
keystone tenant-create --name=demo --description="Demo Tenant"
keystone user-role-add --user=demo --role=_member_ --tenant=demo
--Service Tenant
keystone tenant-create --name=service --description="Service Tenant"

42
3.3.1.2 Creazione servizio ed API
Così come tutti i servizi di OpenStack, Keystone utilizza delle REST API. Di default,
tutti gli endpoint esposti utilizzano il protocollo http, in maniera non cifrata, su
determinate porte di servizio. Per Keystone si utilizzano le porte 5000 per le richieste
pubbliche, mentre la 35357 per la parte amministrativa.
Attraverso i seguenti comandi, gli endpoint vengono memorizzati all’interno del
database MySQL
keystone service-create --name=keystone --type=identity --
description="OpenStack Identity"
keystone endpoint-create
--service-id=$(keystone service-list | awk '/ identity / {print $2}')
--publicurl=http://cloud98.fis.unipr.it:5000/v2.0
--internalurl=http://cloud98.fis.unipr.it:5000/v2.0
--adminurl=http://cloud98.fis.unipr.it:35357/v2.0
Figura 18. Screenshot della fase d'installazione
3.3.1.3 Verifica
Una semplice verifica dell’installazione di OpenStack consiste nel rimuovere le
variabili d’ambiente in cui erano immagazzinati i token e gli endpoint, per poi
eseguire una richiesta da terminale.
Precisamente vengono effettuate due richieste a Keystone: la prima riguarda la
richiesta di un token di autenticazione, rilasciato dopo aver fornito nome utente e
password, la seconda effettua la richiesta vera e propria verso il servizio target, che
identifica il richiedente attraverso il token.

43
unset OS_SERVICE_TOKEN OS_SERVICE_ENDPOINT
keystone --os-username=admin --os-password=adminpass --os-auth-url =
http://cloud98.fis.unipr.it:35357/v2.0 token-get
keystone --os-username=admin --os-password=adminpass --os-tenant-
name=admin--os-auth-url=http://cloud98.fis.unipr.it:35357/v2.0 tenant-
list
keystone --os-username=admin --os-password=adminpass --os-tenant-
name=admin --os-auth-url=http://cloud98.fis.unipr.it:35357/v2.0 user-
listd
Figura 19. Screenshot della fase d'installazione
3.3.1.4 Esempio di keystone.conf
[DEFAULT]
admin_token=cb7b539565eb2717c229
debug=true
verbose=true
[auth]
auth_protocol = https
auth_uri = https://controller:5000/v2.0
identity_uri = https://controller:35357
insecure = true
methods = password,token
[database]
connection=mysql://keystone:keystonedbpass@juno198/keystone
[token]
provider = keystone.token.providers.uuid.Provider
driver = keystone.token.backends.sql.Token

44
3.3.2 Installazione servizi - Glance
Per glance [20] è stato deciso di utilizzare lo spazio di storage a disposizione sulle
nostre macchine per immagazzinare le immagini di maggiore interesse. Ad esempio
abbiamo registrato in glance le immagini relative a una versione basilare di linux
chiamata cirrOS, che consente di testare se i servizi di nova sono configurati
correttamente. Successivamente abbiamo aggiunto delle release di Ubuntu e
Scientifc Linux per testare il loro comportamento in ambito cloud.
Figura 20. Screenshot della fase d'installazione

45
Figura 21. Screenshot della fase d'installazione
3.3.3 Installazione servizi – Cinder
Il servizio cinder offre volumi persistenti alle macchine virtuali. Dunque mette a
disposizione un’infrastruttura per la gestione di volumi e interagisce con il servizio
di compute per fornire spazio disco alle istanze.
La sua installazione [21] è suddivisa in:
Installazione cinder-api
Installazione cinder-volume
Installazione cinder-scheduler
Per semplicità, su questa installazione abbiamo utilizzato un unico disco virtuale,
realizzato tramite vSphere, partizionato con LVM, per garantire una facile scalabilità
dato che LVM riesce a utilizzare più dischi fisici, come se fossero un unico volume
logico.

46
3.3.4 Installazione servizi – Nova
Nel nostro caso, avendo un nodo fisico e uno virtuale dedicato al compute, le
configurazioni variano leggermente in quanto per l’host virtuale che non supporta
l’accelerazione hardware, bisogna configurare libvirt per utilizzare QEMU di KVM.
La sua installazione [22] è suddivisa in:
Installazione nova-api
Installazione nova-api-metadata service
Installazione nova-compute service
Installazione nova-scheduler service
Installazione di nova-scheduler module
Installazione di nova-network
Installazione di nova-consoleauth
Installazione di novncproxy
3.3.5 Installazione servizi – Neutron
L’installazione e la configurazione di neutron è sostanzialmente la parte tragica di
tutta l’infrastruttura di OpenStack.
Tale servizio si occupa di gestire la comunicazione tra le varie macchine del cloud
e le varie istanze virtuali, tutto a livello software, sfruttando plug-in tipo ML2-plugin
per la simulazione del livello 2 della pila iso/osi e L3-plugin per il livello 3 e
strumenti quali Open vSwitch.
La sua installazione [22] è suddivisa in:
Installazione neutron-server
Installazione neutron-ml2 plug-in
Installazione neutron-openvswitch
Installazione neutron-L3_agent plug-in
A fine installazione di tutti i pacchetti sulle rispettive macchine, si è proceduto poi
inizializzando la rete e suddividendo le varie interfacce per gli scopi prefissi.
Di seguito uno grafico su come neutron interagisce con le istanze per fornire
connettività:
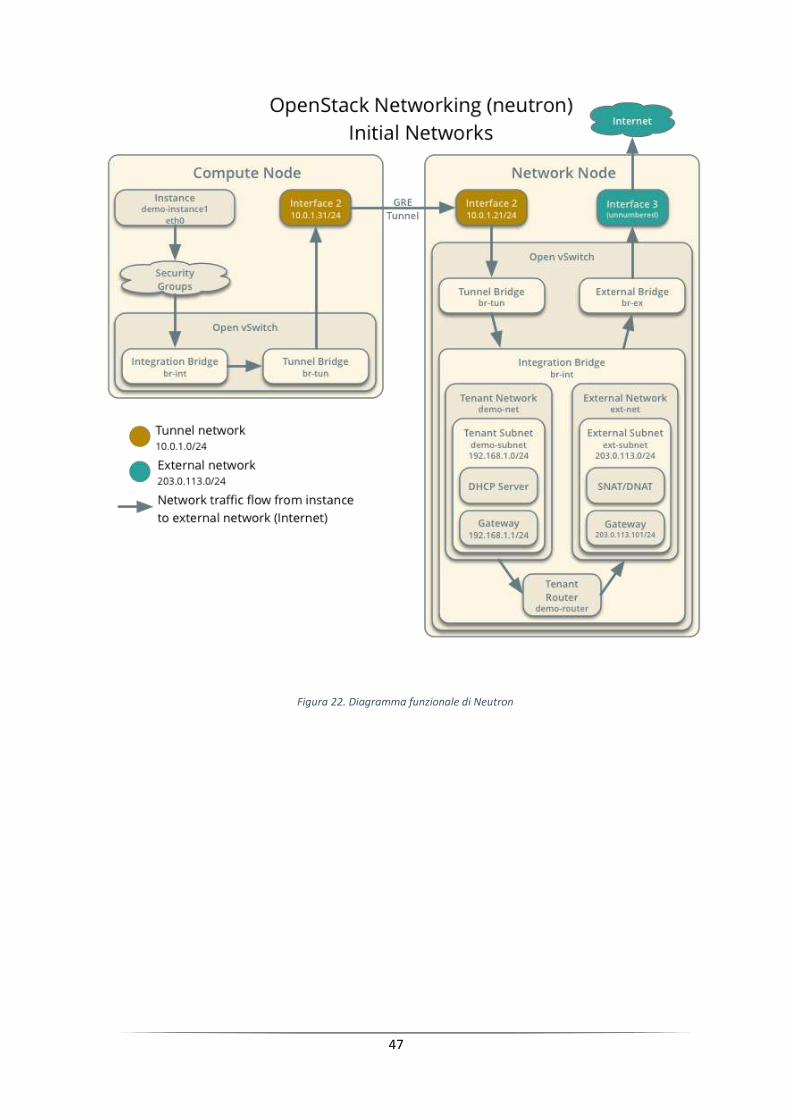
47
Figura 22. Diagramma funzionale di Neutron

48
3.3.6 Installazione servizi – Dashboard
L’installazione [23] della dashboard è abbastanza semplice, in quanto basta aver
installato apache e successivamente impostare qualche parametro, dopo di che l’url
http://controller/dashboard risulta funzionante.

49
CAPITOLO 4
Caso d’uso: Il cloud dell’INFN
Ma cosa si può fare realmente con OpenStack?
La nostra installazione di test, è nata per far fronte a necessità di studio e non per
supportare una mole di lavoro tale da poterla prendere in considerazione in un
contesto reale, né tanto meno ne rispecchia fedelmente caratteristiche e funzioni.
Guardiamo un caso reale…
4.1 PRESENTAZIONE DEL CLOUD MULTI-REGION
L’INFN (Istituto Nazione di Fisica Nucleare) è da anni ha operativo un servizio di
grid computing dedicato alla ricerca: è stato uno dei promotori con il CERN del
progetto Grid computing per Lhc (Wlcg) [24] e oggi è fortemente impegnato a
garantire la regolare gestione di numerosi aspetti relativi alla produzione,
archiviazione, sicurezza, funzionalità e management dell’infrastruttura Grid
dell’esperimento.
Ad oggi, sta lavorando a un progetto, con la collaborazione dell’IGI (Italian Grid
Infrastructure) e EGI (European Grid Initiative) che tende a rendere più facile
e flessibile l’accesso alle infrastrutture di calcolo distribuite, come la Grid, con lo
sviluppo di una nuova interfaccia web e l’uso di ambienti virtuali che permettono ad
ogni utente di acquisire e usare via Internet le risorse del tipo che vuole, quando le
vuole e per il tempo a lui strettamente necessario: questo sforzo è noto come Cloud
Computing e per raggiungerlo si basano su una cloud OpenStack con risorse
dislocate in più sedi INFN geo-distribuite.
Questa infrastruttura si appoggia ad un unico Identity Service (Keystone) distribuito
e ridondante e si avvale del concetto di regione per la suddivisione logica delle
risorse.
Si appoggia inoltre ad un servizio di object storage (Swift) anch’esso distribuito e
replicato su più sedi. In dettaglio sono coinvolte 5 sedi: Bari, Laboratorio Nazionale
del Gran Sasso, Padova Roma 2 e Roma 3.

50
Figura 23. Cloud Multi-Region
Keystone è distribuito su 3 sedi (ba lngs pd) su db Mysql nativo mentre Swift
distribuito anche lui ma su 4 sedi (ba lngs pd rm2).
4.1.1 Scelte Implementative
Perché avere Keystone distribuito?
Il servizio di identità di una infrastruttura cloud distribuita deve essere sempre
disponibile anche in caso di interruzione del collegamento ad un intero sito e deve
perciò essere dislocato in più sedi. Come già detto, questo obiettivo è stato raggiunto
realizzando un cluster di tre server Keystone in tre sedi diverse. Il database SQL
usato come back-end è replicato sui tre siti usando Percona XtraDB cluster, una
soluzione di High Availability per cluster MySQL.
Per ottimizzare le performance, poiché la replica è sincrona e per garantire la
consistenza delle transazioni si è preferito fare in modo che uno solo dei server
Keystone sia attivo in ogni istante, mentre un secondo server è pronto a prendere il
posto.

51
Il terzo server ha lo scopo di contribuire a stabilire il quorum del cluster e può
diventare il server attivo nel caso improbabile di failure dei primi due.
Come comunicano tra di loro le varie sedi?
E’ ancora in fase di test e ha bisogno di maggior tempo per maturare, ma attualmente
le varie regioni comunicano tra di loro attraverso l’estensione VPNaaS di neutron
[17].
4.1.2 Limitazioni
Un potenziale problema che si evince da questa installazione, è legata dalla presenza
di un bacino di utenze che dovranno cooperare con la cloud. In un ambiente di test
come il nostro, l’utilizzo di un backend MySQL per la gestione degli account è più
che sufficiente e avere Keystone configurato in High availability di certo va ben oltre
i nostri scopi: ma quando si ha a che fare con una vasta comunità, una valida
alternativa per l’autenticazione viene offerta dall’ autenticazione federata.
In questo modo non c’è più bisogno di dover farsi carico della gestione delle utenze,
ma basterà integrare gli IdP remoti di ogni singolo ente che appartiene alla
federazione, per poter garantire l’accesso alle risorse e poter comunque gestire le
policy di autorizzazione di Keystone.
Entrando in contatto con alcuni ricercatori dell’INFN, che si stanno occupando di
integrare nella loro installazione di OpenStack IceHouse, l’autenticazione federata,
abbiamo deciso di testare nel nostro piccolo ambiente di test l’autenticazione
federata all’interno di Juno e di analizzare alcuni aspetti che possano incrementare
il livello di sicurezza dell’autenticazione attuale.

52
CAPITOLO 5
Autenticazione e Strong Authentication:
Dalla teoria alla pratica
5.1 AUTENTICAZIONE
L'autenticazione di base è il processo mediante il quale un sistema informatico
identifica positivamente un utente, ed è generalmente richiesta per accedere in
sicurezza ai dati o entrare in una rete sicura.
Per l’identificazione è possibile utilizzare uno dei seguenti metodi:
Qualcosa che si ha (token, certificato personale)
Bisogna avere con se il token o il certificato personale
Qualcosa che si conosce (username/password, pin)
Facile da utilizzare
Qualcosa che si è (lettura biometrica retina, impronta digitale)
Efficace ma tecnologicamente costoso
Il sistema di autenticazione dominante oggi, si basa su nomi utente e password,
comunemente considerato uno dei metodi di sicurezza più deboli del computing
moderno.
Di default è il sistema utilizzato nell’ autenticazione di OpenStack dove nome utente
e password sono memorizzati in un db MySQL.
5.1.1 Autenticazione Federata
L’autenticazione federata è una tecnica di autenticazione adottabile all’interno di
una federazione e nasce per rispondere ad un bisogno di gestione decentralizzata
degli utenti consentendo ad ogni gestore federato di mantenere il controllo della
propria politica di sicurezza.
Attraverso l’autenticazione federata è possibile garantire l’accesso a risorse web (al
cloud) a utenti esterni alla propria organizzazione, appartenenti ad enti e aziende

53
diverse, che fanno tutte parte della stessa federazione, senza la necessità di dover
registrare ogni singolo nuovo utente all’interno dell’identity service della cloud,
grazie a una relazione di fiducia tra gli enti federati.
Quando si parla di autenticazione federata bisogna identificare i soggetti coinvolti
in primis IDP, SP.
Identity Service Provider
Ogni organizzazione ha un proprio database all’interno del quale memorizza le
credenziali/policy di accesso alle risorse IT per i propri utenti. Nella maggior parte
dei casi si è in presenza di una vera e proprio infrastruttura di autenticazione e
autorizzazione, più che di un semplice database. L’ IdP è il servizio al quale si fa
riferimento quando si necessita di autenticare un utente a una risorsa in un contesto
federato
Service Provider
Il service provider (letteralmente fornitore del servizio), è la risorsa che un ente
federato mette a disposizione, e alla quale un utente cerca di accedere.
Nel nostro ambiente di test, il service provider è il cloud98 che rappresenta il punto
d’accesso della risorsa, mentre come IdP abbiamo utilizzato TestSHIB per una prima
fase di test e successivamente l’IdP dell’Università degli Studi di Parma.
Il processo di autenticazione avviene, in buona sostanza, nei seguenti termini:
a) l’utente richiede la connessione ad una risorsa protetta facendo sì che il SP
intercetti la richiesta (la risorsa da proteggere è definita nei files di configurazione
del web server che la ospita);
b) il SP, basandosi sulla configurazione di cui sopra, determina a quale IdP far
riferimento e quale protocollo utilizzare attraverso un meccanismo di “scoperta”
noto come servizio WAYF (acronimo di Where Are You From): la richiesta di
autenticazione è così delegata al WAYF che la passa all’IdP selezionato dall’utente;
c) come risultato delle azioni precedenti, una richiesta di autenticazione via browser
è inviata dal SP all’IdP selezionato dall’utente: l’IdP decide se l’utente può
autenticarsi e quali attributi inviare al SP, scelta questa basata prevalentemente sulle
caratteristiche del SP che fornisce il servizio e su quelle dell’attributo principale
dell’utente;
d) l’IdP impacchetta e firma i dati che trasmette sotto forma di asserzione SAML al
SP che la spacchetta e la decodifica eseguendo poi una serie di controlli di sicurezza
per decidere infine se il richiedente abbia o meno diritto di accesso alla risorsa
desiderata;
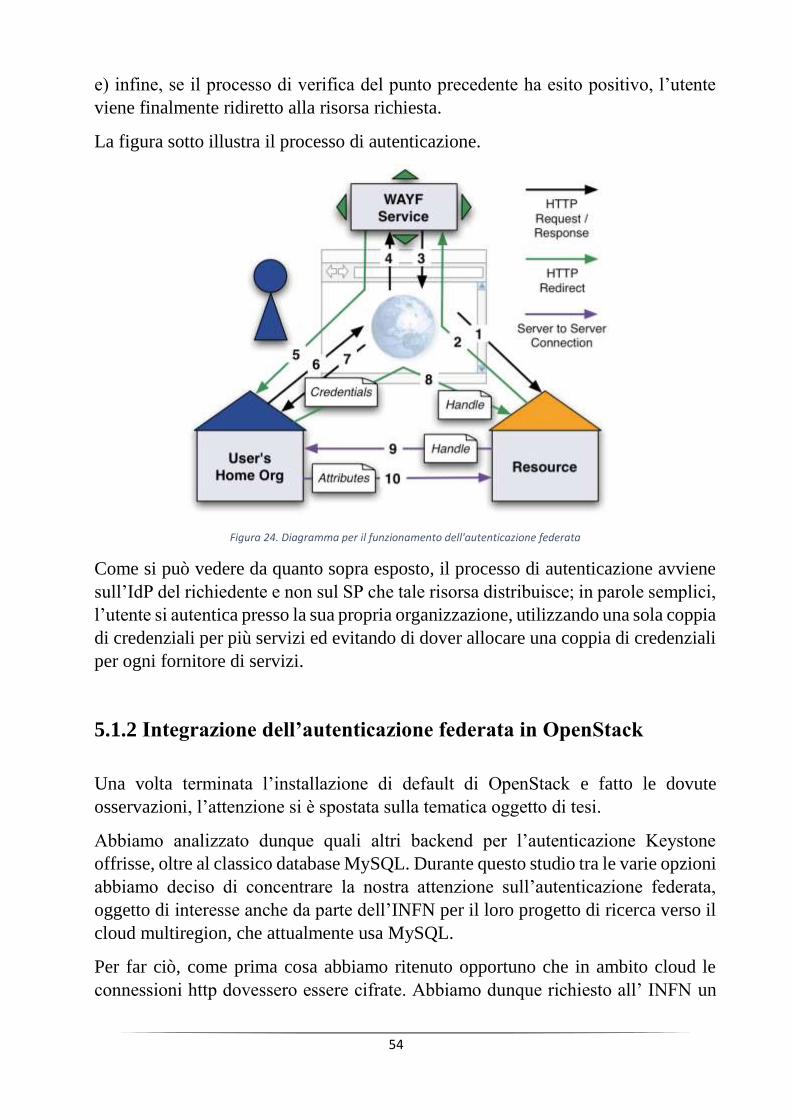
54
e) infine, se il processo di verifica del punto precedente ha esito positivo, l’utente
viene finalmente ridiretto alla risorsa richiesta.
La figura sotto illustra il processo di autenticazione.
Figura 24. Diagramma per il funzionamento dell'autenticazione federata
Come si può vedere da quanto sopra esposto, il processo di autenticazione avviene
sull’IdP del richiedente e non sul SP che tale risorsa distribuisce; in parole semplici,
l’utente si autentica presso la sua propria organizzazione, utilizzando una sola coppia
di credenziali per più servizi ed evitando di dover allocare una coppia di credenziali
per ogni fornitore di servizi.
5.1.2 Integrazione dell’autenticazione federata in OpenStack
Una volta terminata l’installazione di default di OpenStack e fatto le dovute
osservazioni, l’attenzione si è spostata sulla tematica oggetto di tesi.
Abbiamo analizzato dunque quali altri backend per l’autenticazione Keystone
offrisse, oltre al classico database MySQL. Durante questo studio tra le varie opzioni
abbiamo deciso di concentrare la nostra attenzione sull’autenticazione federata,
oggetto di interesse anche da parte dell’INFN per il loro progetto di ricerca verso il
cloud multiregion, che attualmente usa MySQL.
Per far ciò, come prima cosa abbiamo ritenuto opportuno che in ambito cloud le
connessioni http dovessero essere cifrate. Abbiamo dunque richiesto all’ INFN un

55
certificato x509 per cloud98, e lo abbiamo installato nel server di apache attraverso
mod_nss. Una volta configurato correttamente il certificato e testato il
funzionamento, abbiamo deciso di negare le richieste http per le API di Keystone in
modo da evitare la possibilità di strippare il traffico ssl e bloccare un potenziale
rischio per il furto delle credenziali.
Queste operazioni hanno portato a rivedere alcuni paramenti di default della
configurazione dei vari servizi della cloud, in particolare in quello di Keystone dove
è stato necessario inserire i certificati del server e la chiave per poter erogare
comunicazioni sicure e inoltre all’interno del database Keystone di MySQL, i vecchi
endpoint http sono stati rimpiazzati dai nuovi https.
Documentandoci su come poter implementare l’autenticazione federata in
OpenStack, abbiamo scoperto che esiste un’estensione chiamata OS_Federation [25]
che fa proprio questo.
Per poter attivare l’OS_Federation erano necessarie alcune operazioni preliminari:
dunque abbiamo messo dietro apache Keystone, in modo da farlo lavorare come
servizio web attraverso WSGI (Web Server Grafic Interface - interfaccia standard
per il web service per la programmazione in python), abilitato l’utilizzo delle
Keystone APIv3 e dell’unversion API [26], quest’ultima non prettamente necessaria,
ma forniva maggior retro compatibilità con l’APIv2.
Successivamente abbiamo installato shibboleth SP, estrapolato i metadati dalla
macchina e gli abbiamo inoltrati presso l’IdP di ateneo, che ci ha fornito i metadati
dell’IdP e i seguenti attributi:
<Attribute name="urn:oid:1.3.6.1.4.14657.1.1.3.7" id="corsolaurea"/>
<Attribute name="urn:oid:1.3.6.1.4.14657.1.1.3.5" id="matricola"/>
<Attribute name="urn:oid:1.3.6.1.4.14657.1.1.3.42" id="uniprId"/>
<Attribute name="urn:oid:1.3.6.1.4.14657.1.1.3.45" id="principal"/>
<Attribute name="urn:oid:1.3.6.1.4.14657.1.1.3.49" id="uniprStudDip"/>
Il passo successivo era mappare gli attributi forniti dall’IdP, in modo che Keystone
possa comprenderne il significato.
Per far ciò, è necessario creare dei gruppi, ad ogni gruppo vanno associati una
combinazione di attributi in modo da mappare gli attributi remoti su attributi locali.
I gruppi in questione, per ovvie ragioni, possono essere creati esclusivamente
dall’amministratore della cloud.

56
Di seguito i passi per autenticarsi e richiedere un token e successivamente la
creazione del gruppo:
curl -k https://localhost:5000/v3/auth/tokens \
-s \
-i \
-H "Content-Type: application/json" \
-d '
{
"auth": {
"identity": {
"methods": [
"password"
],
"password": {
"user": {
"domain": {
"name": “admin"
},
"name": "admin",
"password": “adminpass"
}
}
},
"scope": {
"domain": {
"name": “admin"
}
}
}
}'
curl -k -X POST https://localhost:5000/v3/groups \
-s \
-H "X-Auth-Token: 898f8e73b78c42d5921fe237c7cbf9bf" \
-H "Content-Type: application/json" \
-d ' \
{
"group": {
"description": "Test group",
"domain_id": “00001",
"name": "Group1"
}
}’

57
Creati tutti i gruppi di cui si necessita, bisogna associarli a determinati
configurazioni di attributi forniti attraverso SAML2 dall’ IdP, come ad esempio
l’associazione di gruppi in base al corso di laurea:
curl -k -X POST https://localhost:5000/v3/groups \
-s \
-H "X-Auth-Token: 898f8e73b78c42d5921fe237c7cbf9bf" \
-H "Content-Type: application/json" \
-d ' \
{
"mapping": {
"rules": [
{
"local": [
{
"user": {
"id": "local_id"
}
}
],
"remote": [
{
"type": "uniprId"
}
]
},
{
"local": [
{
"group": {
"id": " id_local_group"
}
}
],
"remote": [
{
"type": "corsolaurea",
"any_one_of": [
"id_corso_laurea"
]
}
]
}
]
}
}

58
Figura 25. Diagramma per il funzionamento dell'autenticazione federata nell'ambiente di test
5.2 STRONG AUTHENTICATION
L’autenticazione basata su nome utente e password è soggetta ad una serie di difetti,
tra cui scelte sbagliate delle password utente, key-manager, phishing, attacchi man-
in-the-middle ecc....niente di nuovo.
Per ovviare, la soluzione più comune e convincente è l'uso di Strong Authentication,
altrimenti denominato autenticazione a due fattori.
Un sistema di autenticazione a due fattori funziona richiedendo due metodi di
autenticazione simultanee ma indipendenti comunemente indicato come "qualcosa
che si ha e qualcosa che si conosce." Normalmente, il primo fattore (qualcosa che si
ha) comporta hardware o software che fornisce all'utente un passcode generato
elettronicamente, o un certificato digitale che funge da identificatore univoco per un

59
particolare utente. È dunque accoppiato con il secondo fattore (qualcosa che si sa),
come una password e insieme costituiscono un sistema di strong authentication per
consentire l'accesso alle risorse critiche come una rete aziendale. Sistemi di
autenticazione a due fattori sono molto più sicuri del semplice “nome utente e
password” perché è molto difficile per gli utenti non legittimi poter ottenere entrambi
questi fattori.
Secondo gli esperti, l'autenticazione a due fattori riduce drasticamente l'incidenza di
furto di identità on-line, attacchi di phishing, MITM e altre frodi online, perché la
password della vittima non è più sufficiente a fornire un accesso alle loro
informazioni. Quando si trasferisce la parte IT di un’azienda nel cloud, bisognerebbe
tenerne conto.
5.2.1 Politiche di autenticazione e password
In generale, la maggior parte dei service provider hanno risposto a un numero
crescente di minacce alla sicurezza utilizzando tecnologie obsolete "rinforzate".
Oggi, un dipendente continua ad accedere alle informazioni aziendali attraverso l'uso
di una password. Quello che è cambiato è che adesso la password deve essere di
almeno otto o più caratteri, deve includere simboli e numeri, deve avere almeno un
simbolo in maiuscolo e devono essere cambiate spesso nel giro di pochi mesi o più.
Inoltre, il dipendente può avere bisogno di diverse password per accedere a diverse
aree di banche dati di informazioni-diverso, diverse aree di reti interne, ecc.
Il difetto nel richiedere ai dipendenti di memorizzare le nuove password, è evidente.
E il risultato comune è che le password sono semplicemente scritte in una email
salvata o su post-it, o se prima la password era “password” adesso per poterla
ricordare l’utente utilizzerebbe “Password1”, “Password2”, “Password3” oppure nei
miglior dei casi ci si appoggia a sistemi di key-management per immagazzinare tutte
le proprie password cifrate, ovviamente con accesso al keystore protetto da
un’ulteriore password. Non è esattamente quello che il reparto IT di qualsiasi
azienda, aveva in mente.
A supporto di quanto detto, Forrester Consulting [6] ha rilevato che il 27% delle
aziende intervistate richiede agli utenti di "ricordare" almeno 6 password e il 66%
delle aziende hanno almeno sei diverse Password policies. Il risultato è stato che l’
81% delle aziende considera i problemi di password (e in particolare la sfida per gli
utenti di gestire più password complesse con politiche sulla costruzione e scadenza)
essere la più grande lamentela per l'accesso alle informazioni.

60
Con il cloud è ora di guardare avanti e pensare a un nuovo approccio per
l’autenticazione, che consenta e semplifichi l’accesso alle risorse d’uso quotidiano
senza tralasciare la sicurezza. Il tempo per i token e gli alti costi legati alla loro
distribuzione è passato. Oggi, i telefoni cellulari sono onnipresenti e sono tutto
quello che serve per un efficace, all'avanguardia, soluzione di strong authentication.
Questo significa che gli utenti non devono portare tutto ciò che non hanno già con
se in ogni momento, e i provider di non dover sostenere costi per hardware o i costi
di distribuzione e logistica associati. Pertanto, le aziende dovrebbero cercare una
mobile-credential scaricabile per fare strong authentication in modo più conveniente
per gli utenti finali e anche più conveniente per l'impresa.
Uno dei più diffusi sistemi di mobile-credential a disposizione è Google
Authenticator [27]: è un’applicazione che implementa strong authentication
utilizzando OTP time-based che è supportato da diversi siti e applicazioni.
Sostanzialmente è un app, che può essere installata direttamente sul proprio
smartphone (indipendentemente dalla piattaforma usata) e una volta che l’utente
inserisce il proprio nome utente e password per la risorsa che necessità, produce una
OTP di sei caratteri.
Un altro fork open source è chiamato FreeOTP [28] che è stato pubblicato da
RedHAt.
Figura 26. Siti e applicazioni che supportano Google Authenticator

61
5.2.2 OTP – One Time Password
La tecnica della One Time Password non è certo una scoperta fatta di recente (cit.
Enigma [29]), ma è un argomento tornato alla ribalta come secondo metodo di
autenticazione in un contesto di 2FA. L’obiettivo dell’OTP è prevenire attacchi di
tipo replay inficiando tecniche di attacco come il MITM.
Utilizzando infatti l’OTP come secondo metodo di autenticazione, l’utente richiede
l’accesso con la sua coppia di credenziali (username e password) più l’utilizzo di un
pin OTP, che può essere usato una volta sola. Qual ora un attaccante riuscisse a
intercettare entrambi i fattori d’accesso alla risorsa, per esempio attraverso MITM,
un eventuale accesso successivo con i dati intercettati, sarebbe negato in quanto
quell’OTP risulterebbe già consumato.
La sicurezza dell’OTP si basa inoltre sulla non invertibilità delle funzioni hash: come
è noto, un hash crittografico è una funzione unidirezionale che consente di associare
un messaggio di lunghezza arbitraria a un digest di lunghezza fissa. Pertanto, una
soluzione OTP basata su hash inizia con gli input (parametro di sincronizzazione,
chiave segreta, PIN), li esegue tramite la funzione unidirezionale e produce la
password di lunghezza fissa.
Esistono diversi tipi di OTP:
TOTP – Time based
Sono algoritmi basati sulla sincronizzazione temporale, tra il server di
autenticazione e il client che fornisce la password, in cui le otp sono valide
solo per un lasso di tempo predefinito. Superato l’intervallo di validità quel
pin è bruciato e ne viene generato un altro.
Le soluzioni OTP sincronizzate in base al tempo sono largamente diffuse ma
sono soggette allo sfasamento dei segnali di clock: questo comporta che se
client/server non sono sincronizzati l’autenticazione non avverrà mai in
quanto i valori OTP lato server e lato client risulteranno differenti. La
soluzione è fornita sincronizzando lo stesso NTP server e impostando un
“linger time” sufficientemente ampio da convalidare un pin generato con una
differenza temporale minima, ma non così ampio da compromettere al
contempo la sicurezza del sistema.
HOTP – Counter based
Sono algoritmi che si basano sulla password utilizzata durante l’ultimo
accesso per generare la nuova. Una soluzione OTP sincronizzata in base al

62
contatore prevede la sincronizzazione di un contatore tra il dispositivo client
e il server. Il contatore viene incrementato ogni volta che viene richiesto un
valore OTP al dispositivo. Analogamente alle soluzioni OTP sincronizzate in
base la tempo, quando l'utente desidera eseguire l'accesso, immette il valore
OTP correntemente visualizzato sul dispositivo. Tutta via, anche questo tipo
di approccio può essere vittima di una errata sincronizzazione: il problema
risiede nella non corretta sincronizzazione dei contatori tra server e client. La
soluzione in questo caso è banale… il server conosce sempre l’ultimo counter
che è stato utilizzato per fare l’ultimo accesso e a partire da questo valore, si
calcola l’hash incrementando progressivamente i valori del counter, fino a
trovare la giusta corrispondenza.
In entrambi gli approcci è richiesto che l’utente porti con se un dispositivo hardware
o un software che viene sincronizzato con un server e che prevedono l’utilizzo di un
algoritmo per la generazione della password.
L’OTP tuttavia, va considerato comunque un sistema vulnerabile: infatti
tecnicamente è possibile che un attaccante possa intercettare tutto il pin OTP o
comunque una buona parte e dedurne la restante per poi concorrere con l’utente
legittimo all’autenticazione. Questo tipo di problema tuttavia è aggirabile se si
consente un'unica sessione di autenticazione per volta, in modo da non avere più
utenti che cercando di autenticarsi con le stesse credenziali allo stesso tempo.
Inoltre una falla nel dispositivo che genera il token, risulta fatale. Ad esempio nei
sistemi OTP che inviano il pin tramite sms può non essere così difficile, che un
attaccante possa intercettare il pin di sicurezza o se si utilizzano gli smartphone la
possibilità di intercettare schermate video o altre forme di dati, se il telefono è
collegato a internet non è fantascienza.
5.2.3 Test integrativo dell’ OTP nell’ ambiente di test
L’autenticazione federata non risolve la problematica dell'utilizzo di un singolo
fattore di autenticazione. Abbiamo dunque testato la possibilità di implementare una
versione casereccia dell'OTP che proteggesse l'accesso alla dashboard di OpenStack,
sfruttato un modulo di apache, denominato mod_authn_otp [30].
La configurazione attuata si basava sull'utilizzo di OTP con l'utilizzo di un contatore:
il server, protegge la risorsa chiedendo ad ogni accesso, delle credenziali (nome
utente, password, pin) attraverso la basic authentication del protocollo HTTP. Non
molto bello da vedere...

63
Lato server, il contatore veniva aggiornato ed incrementato ad ogni accesso, mentre
lato client, attraverso un tool potevamo generare il pin OTP, fornendo un valore al
counter. Con valori casuali (dunque counter non sincronizzati) l'accesso alla risorsa
ci veniva negato, mentre con l'utilizzo del corretto valore del counter l'accesso alla
risorsa veniva garantito.
Un altro dettaglio non irrilevante era come i pin venivano generati dal modulo: ogni
utente doveva essere presente in un file di configurazione testuale, insieme
all’ultimo pin utilizzato e alla sua chiave segreta che consentiva la generazione del
pin. Un approccio sicuramente discutibile, ma comunque funzionale.
# Example users file for mod_authn_otp
#
# Blank lines and lines starting with '#' are ignored. Fields are
whitespace-separated.
#
# Fields:
#
# 1. Token Type See below
# 2. Username User's username
# 3. PIN User's PIN, or "-" if user has no PIN, or "+"
to verify PIN via "OTPAuthPINAuthProvider"
# 4. Token Key Secret key for the token algorithm (see RFC
4226)
# 5. Counter/Offset Next expected counter value (event tokens) or
counter offset (time tokens)
# 6. Failure counter Number of consecutive wrong OTP's provided by
this users (for "OTPAuthMaxOTPFailure")
# 7. Last OTP The previous successfully used one-time
password
# 8. Time of Last OTP Local timestamp when the last OTP was generated
(in the form 2009-06-12T17:52:32L)
# 9. Last IP address IP address used during the most recent
successful attempt
#
# Fields 5 and beyond are optional. Fields 6 and beyond should be
omitted for new users.
#
# Token Type Field:
#
# This field contains a string in the format: ALGORITHM [ / COUNTERINFO
[ / DIGITS ] ]
#
# The ALGORITHM is either "HOTP" (RFC 4226) or "MOTP"
(http://motp.sourceforge.net/).
#
# The COUNTERINFO is either "E" for an event-based token, or "TNN" for
a time based token
# where "NN" is the number of seconds in one time interval. For HOTP,
the default is "E";
# for MOTP, the default is "T10".
#
# The DIGITS is the number of digits in the one-time password; the
default is six.
#

64
# Examples:
#
# HOTP - HOTP event-based token with six digit OTP
# HOTP/E - HOTP event-based token with six digit OTP
# HOTP/E/8 - HOTP event-based token with eight digit OTP
# HOTP/T30 - HOTP time-based token with 30 second interval
and six digit OTP
# HOTP/T60 - HOTP time-based token with 60 second interval
and six digit OTP
# HOTP/T60/5 - HOTP time-based token with 60 second interval
and five digit OTP
# MOTP - Mobile-OTP time-based token 10 second interval
and six digit OTP
# MOTP/E - Mobile-OTP event-based token with six digit OTP
#
# For more info see: http://code.google.com/p/mod-authn-
otp/wiki/UsersFile
#
# Some users who have logged in at least once.
HOTP barney 1234 8a2d55707a9084982649dadc04b426a06df19ab2
21 0 820658 2009-06-12T17:52:32L 192.168.1.1
HOTP fred 5678 acbd18db4cc2f85cedef654fccc4a4d8bd537891
78 0 617363 2009-06-04T21:17:03L 192.168.1.2
HOTP/T joe 999999 ef654fccdef654fccc4a4d8acbd18db4cc2f85ce -
2 2 883913 2009-06-04T21:17:03L 10.1.1.153
# Wilma and Betty are new users. Note betty does not have a PIN so "-" is
used instead as a placeholder
HOTP wilma 5678 a4d8acbddef654fccc418db4cc2f85cea6339f00
HOTP betty - 54fccc418a4d8acbddef6db4cc2f85ce99321d64
# Here is a user who's PIN is verified externally using whatever
"OTPAuthPINAuthProvider" list you have configured.
# E.g. to use an htpasswd type file, specify "OTPAuthPINAuthProvider
file" and then "AuthUserFile /some/file".
HOTP bambam + d8acbddef6db4cc254fccc418a4f85ce99321d64
In ambito enterprise, esistono già soluzioni per la two factor authentication dedicate
al cloud, una tra tutte è proposta dalla Secure-pass [31] azienda partner del GARL
[32]: perché dunque attendere oltre per iniziare a usare il cloud computing, per il
proprio e-business, in modo sicuro?

65
5.2.4 Stato dell’arte globale e il “The Fappening”
Le aziende oggi espongono sempre più informazioni critiche per estendere l'accesso
ai dati aziendali al fine di eseguire in modo più efficace le loro attività.
Ma devono trovare una soluzione per affrontare efficacemente i rischi associati a un
ambiente più aperto una soluzione che soddisfi anche i rispettivi obblighi dei partner
e i requisiti normativi vigenti. Secondo la società di ricerca Forrester Research, Inc.
[6], pochi stanno facendo così. In realtà, la maggior parte delle organizzazioni ancora
usano un semplice “nome utente e password” come unica forma di autenticazione
per i loro dipendenti e partner. Nonostante i successi ben documentati della
soluzione 2FA, solo due terzi delle imprese in Nord America e in Europa hanno
anche iniziato a garantire le informazioni attraverso l'uso di tecnologie di strong
authentication. La maggior parte di queste organizzazioni hanno implementato tale
tecnologia solo su scala limitata.
Non è quindi una sorpresa che le violazioni della sicurezza sono aumentate
rapidamente negli ultimi 12 mesi. Secondo Forrester [6], il 54% delle imprese
intervistate ha subito una violazione nell'ultimo anno, mentre un terzo degli
intervistati ha subito tre o più attacchi.
In generale, ma soprattutto nel cloud le aziende devono cominciare immediatamente
a interessarsi all'accesso alle informazioni, come un componente critico per una
strategia di sicurezza globale dell’azienda.
Two factor authentication è una tecnologia matura, il costo della tecnologia è
diminuito in modo significativo, mentre l'evoluzione delle soluzioni basate su cloud
ha notevolmente diminuito la complessità tecnica. Non è più necessario per gli utenti
utilizzare scomodi token installati nel browser e ricordare le password, ora il
semplice (e onnipresente) telefono cellulare è tutto ciò che è necessario per offrire
alle imprese una protezione da hacker, attacchi di phishing e altre forme di accesso
non autorizzato.
Un recente studio del 2010 condotto da Forrester Consulting [6] e commissionato
per conto di VeriSign Authentication Business indica chiaramente che mentre le
imprese sono consapevoli delle minacce e le considerano un problema molto reale,
non hanno tuttavia preso misure sufficienti per proteggersi.
A supporto di quanto appena detto, nel 2014 Apple è stata vittima di un attacco
informatico alla propria piattaforma iCloud, noto con il nome “The Fappening” [33].
Tale attacco, secondo diverse fonti web [34] [35], sfruttava una falla
nell’implementazione del “Find My iPhone”, per estrapolare nome utente e
password dei vari account tramite bruteforce. Con queste informazioni, gli attaccanti

66
sono stati in grado di accedere agli account di iCloud, rubare le foto dei legittimi
proprietari e renderle pubbliche sul web. Tra le vittime rese note, ci sono attrici e
modelle che avevano sul proprio account di iCloud foto e video con nudo, che
difficilmente avrebbero reso noto e che adesso faranno sempre parte del web.
Se iCloud avesse adottato policy di sicurezza sulle password, che obbligassero gli
utenti ad usare un sistema di strong authentication, nulla di tutto ciò sarebbe successo
e la privacy di oltre 500 utenti non sarebbe stata violata, indipendentemente dalla
falla presente su Find My iPhone.

67
CAPITOLO 6
Conclusioni e sviluppi futuri
6.1 RISULTATI RAGGIUNTI
In questa tesi è stata analizzata una nuova tecnologia che si presenta come una
opportunità per il futuro nell’ambito dell’e-science e dell’e-bussines. E’ stato
studiato e analizzato OpenStack, un framework open source dall’architettura
modulare, con sviluppo e supporto in forte crescita e che può costituire una
importante scelta strategica per il futuro.
Tuttavia, l’ingegnerizzazione e la configurazione di OpenStack è abbastanza
complessa a causa dei molti scenari applicativi supportati, della immaturità del
prodotto e dalla problematica che non tutto è gestibile da interfacce grafiche.
Il focus sull’autenticazione ha evidenziato come l’utilizzo di un’autenticazione
federata in ambito cloud può semplificare la gestione delle utenze e ridurre le
responsabilità per il provider del servizio, il quale delega l’autenticazione all’IdP di
appartenenza dell’utente.
Inoltre, l’introduzione di un secondo metodo di autenticazione rafforza
concretamente l’accesso alle risorse in uno scenario delicato come il cloud
computing, dove l’accesso alle risorse può avvenire da ogni parte del globo grazie
al web.
6.2 SVILUPPI FUTURI
Sviluppi futuri, in uno scenario come quello di OpenStack, di certo non mancano.
Un’ importante analisi potrebbe essere fatta, sempre in ambito dell’ autenticazione,
su come Keystone opera.
Come già detto in questo lavoro di tesi, Keystone di default rilascia all’utente
autenticato un token di tipo UUID, con il quale l’utente è libero di accedere alle
risorse. Tale operazione avviene attraverso questi passi cruciali:
a) L’utente che vuole accedere a una risorsa invia la richiesta verso l’API
del servizio di cui necessita e inoltra il token fornito.
b) Il servizio interrogato, per verificare l’utente, invia a Keystone il token

68
c) Keystone risponde fornendo le informazioni necessarie
In uno scenario ampio, tutte queste richieste alle API di Keystone creano dei
rallentamenti dovuti in parte al carico della rete ma soprattutto al carico di lavoro
che svolgono le API.
Esiste un altro scenario [36] che è rappresentato dall’utilizzo di token PKI firmati da
Keystone, che svolgerebbe il ruolo di CA.
Sfruttando dunque questa tipologia di token, ogni servizio all’interno della cloud ha
una copia della chiave pubblica di Keystone che sfrutta per validare o meno il token
ricevuto da parte di un’utente. Sostanzialmente, quando un utente si identifica a
Keystone, riceve un token PKI che utilizzerà per fare le richieste verso le API dei
vari servizi della cloud. Avremo dunque questo scenario:
a) L’ utente che vuole accedere a una risorsa, invia la richiesta verso l’API
del servizio e inoltra il token questa volta di tipo PKI
a) Il servizio interrogato, per verificare l’utente, utilizza la sua copia della
chiave pubblica dei Keystone per validare la richiesta dell’utente, in loco
Così facendo, per la validazione del token viene sfruttata la potenza di calcolo della
macchina che ospita il servizio e non viene più richiamato Keystone che è libero di
operare su nuove richieste.
Un altro sviluppo futuro potrebbe essere quello di perfezionare l'utilizzo dell'OTP e
renderlo più user-friendly, o implementando un'opportuna app mobile-credentials o
ancora integrando l'utilizzo di Google Authenticator in OpenStack.

69
BIBLIOGRAFIA
[1] NIST, «National Institute of Standards and Technology,» [Online]. Available:
http://www.nist.gov/. [Consultato il giorno 11 03 2015].
[2] T. G. Peter Mell, «NIST SP 800-145, The NIST Definition of Cloud Computing,» [Online].
Available: http://csrc.nist.gov/publications/nistpubs/800-145/SP800-145.pdf. [Consultato il
giorno 11 03 2015].
[3] Amazon , «Amazon Web Services (AWS) - Cloud Computing Services,» [Online]. Available:
http://aws.amazon.com/. [Consultato il giorno 11 03 2015].
[4] NIST, «NIST Special Publication 800-125, Guide to Security for Full Virtualization
Technologies,» [Online]. Available: http://csrc.nist.gov/publications/nistpubs/800-125/SP800-
125-final.pdf. [Consultato il giorno 11 03 2015].
[5] M. G. &. M. Salvatore, «CLOUD COMPUTING: Significato, Vantaggi, Svantaggi e Tipologie,»
[Online]. Available: http://www.infomart.it/cloud-computing#ixzz3Oz3dkqic. [Consultato il
giorno 11 03 2015].
[6] «whitepaper-strong-authentication-steps,» [Online]. Available:
http://www.verisign.com/authentication/information-center/authentication-
resources/whitepaper-strong-authentication-steps.pdf. [Consultato il giorno 11 3 2015].
[7] R. Florio, «HP Atalla Cloud Encryption: cifratura nel cloud per i dati in uso e a riposo,» 20 10
2014. [Online]. Available: http://www.tomshw.it/cont/articolo/hp-atalla-cloud-encryption-
cifratura-nel-cloud-per-i-dati-in-uso-e-a-riposo/59992/1.html. [Consultato il giorno 11 03
2015].
[8] «L'Europa in cerca di regole per il Cloud e la privacy,» [Online]. Available:
http://www.ict4executive.it/cloud/interviste/l-europa-in-cerca-di-regole-per-il-cloud-e-la-
privacy_43672151417.htm. [Consultato il giorno 11 03 2015].
[9] A. Longo, «Crittografia a prova di «cloud»,» [Online]. Available:
http://www.ilsole24ore.com/art/tecnologie/2011-09-16/crittografia-prova-cloud-
190508.shtml?uuid=AaVpZ44D. [Consultato il giorno 11 3 2015].
[10] Wikipedia, «FTTx,» [Online]. Available: http://it.wikipedia.org/wiki/Fttx. [Consultato il giorno
11 03 2015].
[11] «Global Broadband and Mobile Performance Data Compiled by Ookla | Net Index,» OOKLA,
[Online]. Available: http://www.netindex.com/. [Consultato il giorno 11 3 2015].
[12] J. Bort, «The 10 Most Important Companies In Cloud Computing,» [Online]. Available:
http://www.businessinsider.com/10-most-important-in-cloud-computing-2013-4?op=1&IR=T.
[Consultato il giorno 11 3 2015].
[13] « OpenStack Open Source Cloud Computing Software,» OpenStack, [Online]. Available:
http://www.openstack.org/. [Consultato il giorno 11 3 2015].

70
[14] «Google Trend,» Google , [Online]. Available: http://www.google.it/trends/. [Consultato il
giorno 11 3 2015].
[15] S. Orlando, «A few link, about NameSpace,» [Online]. Available:
http://pastebin.com/ruR70tH4. [Consultato il giorno 11 03 2015].
[16] «Workshop di CCR sull'Infrastruttura Cloud,» INFN , [Online]. Available:
https://agenda.infn.it/conferenceOtherViews.py?view=standard&confId=8785. [Consultato il
giorno 11 3 2015].
[17] M. Antonacci, «infn-bari-school/VPN-as-a-Service Wiki · GitHub,» [Online]. Available:
https://github.com/infn-bari-school/VPN-as-a-Service/wiki. [Consultato il giorno 11 3 2015].
[18] openstack, «Chapter 1. Architecture - OpenStack Installation Guide for Red Hat Enterprise
Linux 7, CentOS 7, and Fedora 20 - juno,» [Online]. Available:
http://docs.openstack.org/juno/install-guide/install/yum/content/ch_overview.html.
[Consultato il giorno 11 3 2015].
[19] openstack, «Chapter 3. Add the Identity service - OpenStack Installation Guide for Red Hat
Enterprise Linux 7, CentOS 7, and Fedora 20 - juno,» [Online]. Available:
http://docs.openstack.org/juno/install-guide/install/yum/content/ch_keystone.html.
[Consultato il giorno 11 3 2015].
[20] openstack, «Chapter 4. Add the Image Service - OpenStack Installation Guide for Red Hat
Enterprise Linux 7, CentOS 7, and Fedora 20 - juno,» [Online]. Available:
http://docs.openstack.org/juno/install-guide/install/yum/content/ch_glance.html.
[Consultato il giorno 11 3 2015].
[21] openstack, «Chapter 8. Add the Block Storage service - OpenStack Installation Guide for Red
Hat Enterprise Linux 7, CentOS 7, and Fedora 20 - juno,» [Online]. Available:
http://docs.openstack.org/juno/install-guide/install/yum/content/ch_cinder.html.
[Consultato il giorno 11 3 2015].
[22] openstack, «OpenStack Networking (neutron) - OpenStack Installation Guide for Red Hat
Enterprise Linux 7, CentOS 7, and Fedora 20 - juno,» [Online]. Available:
http://docs.openstack.org/juno/install-guide/install/yum/content/section_neutron-
networking.html. [Consultato il giorno 11 3 2015].
[23] openstack, «Chapter 7. Add the dashboard - OpenStack Installation Guide for Red Hat
Enterprise Linux 7, CentOS 7, and Fedora 20 - juno,» [Online]. Available:
http://docs.openstack.org/juno/install-guide/install/yum/content/ch_horizon.html.
[Consultato il giorno 11 3 2015].
[24] INFN, «GRID,» [Online]. Available:
http://www.infn.it/comunicazione/index.php?option=com_content&view=article&id=241:gri
d&catid=30&Itemid=738&lang=it. [Consultato il giorno 11 3 2015].
[25] openstack, «Enabling the Federation Extension,» [Online]. Available:
http://docs.openstack.org/developer/keystone/extensions/federation.html. [Consultato il
giorno 11 3 2015].

71
[26] openstack, «HTTP API,» [Online]. Available:
http://docs.openstack.org/developer/keystone/http-api.html#how-do-i-migrate-from-v2-0-
to-v3. [Consultato il giorno 11 3 2015].
[27] google, «google-authenticator · GitHub,» [Online]. Available:
https://github.com/google/google-authenticator/. [Consultato il giorno 11 3 2015].
[28] «FreeOTP,» [Online]. Available: https://fedorahosted.org/freeotp/. [Consultato il giorno 11 3
2015].
[29] Wikipedia, «Enigma,» [Online]. Available:
http://it.wikipedia.org/wiki/Enigma_%28crittografia%29. [Consultato il giorno 11 03 2015].
[30] « mod-authn-otp - Apache module for one-time password authentication,» [Online].
Available: https://code.google.com/p/mod-authn-otp/. [Consultato il giorno 2015 03 11].
[31] Secure-Pass, [Online]. Available: http://www.secure-pass.net/. [Consultato il giorno 11 03
2015].
[32] GARL, [Online]. Available: http://www.garl.ch/. [Consultato il giorno 11 03 2015].
[33] Wikipedia, «2014_celebrity_photo_hack,» [Online]. Available:
http://en.wikipedia.org/wiki/2014_celebrity_photo_hack. [Consultato il giorno 11 03 2015].
[34] O. Williams, «This could be the iCloud flaw that led to celebrity photos being leaked (Update:
Apple is investigating),» [Online]. Available: http://thenextweb.com/apple/2014/09/01/this-
could-be-the-apple-icloud-flaw-that-led-to-celebrity-photos-being-leaked/. [Consultato il
giorno 11 03 2015].
[35] theguardian, «Naked celebrity hack: security experts focus on iCloud backup theory,»
[Online]. Available: http://www.theguardian.com/technology/2014/sep/01/naked-celebrity-
hack-icloud-backup-jennifer-lawrence. [Consultato il giorno 11 03 2015].
[36] B. Kupidura, «Understanding OpenStack Authentication: Keystone PKI,» [Online]. Available:
https://www.mirantis.com/blog/understanding-openstack-authentication-keystone-pki/.
[Consultato il giorno 11 3 2015].
[37] openstack, «Chapter 5. Add the Compute service - OpenStack Installation Guide for Red Hat
Enterprise Linux 7, CentOS 7, and Fedora 20 - juno,» [Online]. Available:
http://docs.openstack.org/juno/install-guide/install/yum/content/ch_nova.html. [Consultato
il giorno 11 3 2015].
[38] G. Parternò. [Online]. Available: http://www.gpaterno.com/. [Consultato il giorno 11 03
2015].
[39] D. S. Namia, «Corsi di Laurea in Informatica (classe L31): Archivio Tesi Laurea Triennale,»
[Online]. Available: http://www.cs.unipr.it/Informatica/Tesi/Spartaco_Namia_20100428.pdf.
[Consultato il giorno 11 03 2015].

72
[40] D. A. Gioia, «Corsi di Laurea in Informatica (classe L31): Archivio Tesi Laurea Triennale,»
[Online]. Available: http://www.cs.unipr.it/Informatica/Tesi/Alberto_Gioia_20080326.pdf.
[Consultato il giorno 11 03 2015].
[41] G. Partenò, «Openstack: security beyond firewalls,» [Online]. Available:
http://www.slideshare.net/GARLsecurity/openstacksecuritybeyondfirewalls?qid=1092943c-
5c13-4d60-ae8a-2f74c14be99c&v=default&b=&from_search=9. [Consultato il giorno 11 03
2015].
[42] V. Salvatore Orlando, «Neutron: peeking behind the curtains,» [Online]. Available:
http://files.meetup.com/6653182/1_Salvatore%20Orlando_VMware_h14.pdf. [Consultato il
giorno 11 03 2015].


















