TEMPUS PECUNIA EST - Aracne editrice · Giuseppe Arca Università degli Studi di Cagliari. TEMPUS...
20
TEMPUS PECUNIA EST COLLANA DI MATEMATICA PER LE SCIENZE ECONOMICHE FINANZIARIE E AZIENDALI
Transcript of TEMPUS PECUNIA EST - Aracne editrice · Giuseppe Arca Università degli Studi di Cagliari. TEMPUS...

TEMPUS PECUNIA EST
COLLANA DI MATEMATICA PER LE SCIENZE ECONOMICHEFINANZIARIE E AZIENDALI

Direttore
Beatrice VUniversità degli Studi di Cagliari
Comitato scientifico
Umberto NUniversity of Maryland
Russel Allan JUniversità degli Studi di Firenze
Gian Italo BUniversità degli Studi di Urbino
Giuseppe AUniversità degli Studi di Cagliari

TEMPUS PECUNIA EST
COLLANA DI MATEMATICA PER LE SCIENZE ECONOMICHEFINANZIARIE E AZIENDALI
Al suo livello più profondo la realtà è la matematica della natura.
P
Questa collana nasce dall’esigenza di offrire al lettore dei trattati cheaiutino la comprensione e l’approfondimento dei concetti matema-tici che caratterizzano le discipline dei corsi proposti nelle facoltà diScienze economiche, finanziarie e aziendali.


Claudio Giorgio Giancaterino
Dai modelli lineari ai modelli linearigeneralizzati ai modelli additivi generalizzati
Con esempi mediante l’applicativo R

Copyright © MMXVAracne editrice int.le S.r.l.
via Quarto Negroni, Ariccia (RM)
()
----
I diritti di traduzione, di memorizzazione elettronica,di riproduzione e di adattamento anche parziale,
con qualsiasi mezzo, sono riservati per tutti i Paesi.
Non sono assolutamente consentite le fotocopiesenza il permesso scritto dell’Editore.
I edizione: giugno

A Diego Zappa che mi ha dato l’opportunità di uscire dalla solita monotonia


9
Indice
11 Introduzione
13 Capitolo I Statistica ed R
1.1. Analisi descrittiva dei dati, 13 – 1.2. Variabili alea-torie, 18 – 1.3. Modelli statistici, 24 – 1.4. Analisi infe-renziale dei dati, 26 – 1.5. Verifica d’ipotesi, 31
35 Capitolo II La regressione parametrica: il modello lineare e i mo-delli lineari generalizzati
2.1. Il modello lineare, 35 – 2.2. I modelli lineari gene-ralizzati, 39 – 2.3. La stima dei parametri, 47 – 2.4. In-ferenza sui modelli, 58
63 Capitolo III La regressione non parametrica e le funzioni di smoo-thing
3.1. La regressione locale, 64 – 3.2. Funzioni spline, 72

10 Indice
91 Capitolo IV La regressione semi-parametrica: i modelli additivi ge-neralizzati (GAM)
4.1. I modelli additivi generalizzati, 91 – 4.2. La stima dei parametri, 94 – 4.3. Algoritmi di stima del parame-tro di penalizzazione, 96 – 4.4 Verifica della bontà di adattamento del modello, 100 – 4.5. Un confronto nell’applicazione dei tre approcci (GAM, GLM e LM) nella misura del numero dei sinistri e del costo dei sini-stri, 102
125 Conclusioni 127 Bibliografia

11
Introduzione
Nel mondo attuale, pieno di tecnologia e informazioni, diventa es-
senziale gestire i dati e darne una corretta interpretazione. Ecco che interviene la statistica col compito di aiutare il processo decisionale dell’individuo. Si sente parlare di “data scientist”, ossia uno statistico nell’era della digitalizzazione il cui compito è analizzare, interpretare, gestire i “big data”.
Questa monografia può essere considerata un utile strumento per il futuro “data scientist”; poiché, dopo una sintetica presentazione della statistica, illustra i principali modelli statistici a disposizione degli esperti del settore con l’utilizzo del linguaggio “R”; un linguaggio di programmazione dalle enormi potenzialità matematiche - statistiche - grafiche.
Nel modello lineare si assume che la relazione tra variabile risposta e covariate possa essere spiegata attraverso una funzione lineare nei parametri, quindi il valore atteso è una funzione lineare delle variabili esplicative.
Però le assunzioni di linearità possono rappresentare un’eccessiva semplificazione, ad esempio, si vuole stimare il numero di acquisti di una certa marca relativa ad un certo prodotto in un determinato arco temporale. E’ evidente che il modello lineare normale presenta dei li-miti, perché la distribuzione della variabile risposta è di tipo discreto (Poisson) e la varianza degli acquisti non è costante. I limiti del mo-dello lineare sono stati superati con i modelli lineari generalizzati (GLM) che ne rappresentano appunto una generalizzazione, perché la-vorano con funzioni di distribuzione discrete e continue (Poisson, Gamma, Normale). Il valore atteso viene trattato da una funzione di trasformazione invertibile rispetto alle covariate e la varianza è fun-zione del valore atteso. I GLM sono stati introdotti da Nelder e Wed-erburn (1972), ma la loro ampia applicazione si è diffusa a partire da metà degli anni novanta grazie ad autori inglesi.

12 Introduzione
Il loro ampio impiego li rende applicabili in numerosi ambiti della statistica con l’applicazione di software quali SAS, GLIM, JUMP ed R.
Per esempio, nell’ambito pricing danni, ulteriori problemi derivano dalla classificazione delle variabili tariffarie come l’età dell’assicurato e la potenza del motore. Sebbene l’approccio comune è quello di rag-gruppare i valori in intervalli e quindi semplificare il lavoro, dall’altra si crea il problema per quei soggetti che si trovano al confine tra un in-tervallo e l’altro. In tal caso il soggetto può pagare un premio troppo elevato, perché entra a far parte di un’altra categoria oppure un assicu-rato si trova a pagare lo stesso premio per molti anni, perché appartie-ne sempre alla stessa classe tariffaria.
Da questa evidente esigenza di una maggiore personalizzazione del premio, si è pensato di sfruttare le potenzialità della regressione non parametrica e quindi applicare una regressione polinomiale, che possa meglio descrivere il comportamento delle variabili tariffarie all’interno di ciascuna classe andando a suddividerla in sottoclassi.
Questo approccio sebbene sia più vicino alla realtà, presenta nume-rosi problemi di gestione quando aumenta eccessivamente il grado del polinomio, nonché bruschi cambiamenti della curva in un singolo in-tervallo.
Negli anni ottanta il problema di come analizzare l’effetto di varia-bili continue ha portato a numerose ricerche dando luogo allo sviluppo dei modelli additivi generalizzati (GAM) che possono essere conside-rati un’estensione dei GLM, perché il predittore lineare è specificato parzialmente come una somma di sconosciute funzioni polinomiali a tratti delle covariate. C’è un’interessante connessione tra GLM e GAM nell’utilizzo di modelli stocastici.

13
Capitolo I
Statistica ed R Prima di partire con i tre principali modelli di regressione risulta
utile fornire una spiegazione molto sintetica di quello che è il mondo statistico, all’uopo la statistica si suddivide in due principali aree: sta-tistica descrittiva e statistica inferenziale.
La statistica descrittiva estrapola dai dati della popolazione infor-mazioni come i valori medi, indici di variabilità, indici di forma, indici di relazione tra le variabili e rappresentazioni grafiche.
La statistica inferenziale invece parte da un campione della popola-zione oggetto di studio e cerca di replicarne le caratteristiche mediante stime e previsioni.
1.1. Analisi descrittiva dei dati Vengono costruiti opportuni indici statistici di sintesi con
l’obiettivo di riassumere gli aspetti essenziali della distribuzione stati-stica in esame [Thorne, Carlson, Newbold, 2010].
Tra gli indici di posizione, quello più conosciuto e semplice da uti-lizzare, è la media aritmetica, pari alla somma dei valori di tutte le os-servazioni divisa per la sua numerosità. (1.0)
Rappresenta il baricentro della distribuzione e appare adatto quan-do la distribuzione è simmetrica e non presenta outlier.
Nella pratica, quando si trattano dati raggruppati, viene applicata la media aritmetica ponderata con cui si fornisce un diverso peso a differenti modalità di un carattere esaltandone o diminuendone l’importanza: (1.1)
In ambito finanziario si utilizza la media geometrica, definita come la radice n-esima del prodotto di n valori distinti.

14 Dai LM ai GLM ai GAM. Con esempi mediante l’applicativo R
(1.2) Per essere impiegata in maniera adeguata è necessario che tutte le
osservazioni siano strettamente positive. Altro indice di tendenza centrale è la mediana, ossia la modalità
che occupa il posto centrale nella successione ordinata delle n osser-vazioni individuali; pertanto suddivide a metà la distribuzione. Una propriètà che gode la mediana rispetto alla media è la robustezza; os-sia non risente di valori anomali.
La moda è la modalità che nell’insieme delle osservazioni si pre-senta con la massima frequenza.
Dato che il valor medio non è sufficiente a spiegare da solo la di-stribuzione dei dati, è necessario un indicatore che fornisca una misura sintetica della diversità tra le unità statistiche: indici di variabilità ba-sati sullo scostamento da una media e intervalli di variabilità.
Il primo è rappresentato dalla varianza, ossia la media quadratica degli scostamenti dei valori osservati dalla loro media. (1.3)
La radice quadrata della varianza rappresenta lo scarto quadratico medio (deviazione standard) ed è l’errore in media che si commette sostituendo ai dati la media aritmetica. E’ un indice di posizione con la stessa unità di misura dei valori osservati.
L’importanza di questo indice di dispersione si capisce dalla regola
empirica in base alla quale, la valutazione approssimata delle osserva-zioni il cui scostamento, in più o in meno dalla media, è pari al mas-simo a una, due o tre volte lo scarto quadratico medio.
-Il 68% circa delle osservazioni sono nell’intervallo ; -il 95% circa delle osservazioni sono nell’intervallo ; -il 99,73% di tutte le osservazioni sono nell’intervallo . Il numeratore della varianza è la devianza e viene impiegato per
esprimere la bontà dei modelli statistici. Mentre il rapporto tra lo scar-to quadratico medio e il valore medio esprime il coefficiente di varia-zione, ossia la dispersione dei dati come percentuale della media (vie-ne normalmente usato quando tutti i valori della distribuzione sono positivi) e pertanto è un indice di misura relativa. (1.4)

I. Statistica ed R 15
Un indice di dispersione che racchiude il 50% delle variazioni rife-rite ai dati centrali è il range interquartile (IQR) o differenza interquar-tile, ottenuta come la differenza tra il terzo quartile e il primo quartile.
I quartili suddividono la successione delle osservazioni in quattro categorie di osservazioni non decrescenti. Nella prima categoria, il primo quartile , si trova il 25% delle osservazioni; nella terza cate-goria, il terzo quartile , si trovano il 75% delle osservazioni. Il se-condo quartile corrisponde alla mediana, il quartile zero è il valore minimo della distribuzione e il quarto quartile è il valore massimo.
Questi numeri vengono impiegati come numeri di sintesi e utilizza-ti per rappresentare il box-plot.
Per la rappresentazione grafica dei dati, oltre all’utilizzo di dia-
grammi a torta, istogrammi, molto utile è il box-plot perché fornisce informazioni sulla forma della distribuzione; infatti è caratterizzato da tre elementi principali:
1) Una linea che indica la posizione della mediana della distribu-zione;
2) Un rettangolo la cui altezza indica la variabilità dei valori pros-simi alla mediana (gli estremi sono il primo e terzo quartile);
3) Due segmenti che partono dai lati maggiori del rettangolo e i cui estremi sono determinati in base ai valori estremi della di-stribuzione (minimo e massimo e outliers).
Per completare la descrizione di una distribuzione di frequenze so-no impiegati gli indici di forma, tra cui l’indice di asimmetria. Una di-stribuzione si definisce asimmetrica se non è possibile individuare un asse verticale in grado di dividere il suo grafico in due parti esatta-mente speculari. (1.5)
Si parla di asimmetria positiva se si verifica un maggior addensa-mento delle osservazioni in corrispondenza dei valori più bassi, ossia la distribuzione è obliqua a destra, (ha una coda destra lunga) poiché la media dei cubi delle differenze rispetto alla media è positiva.
Si parla di asimmetria negativa se si verifica un maggior addensa-mento delle osservazioni in corrispondenza dei valori più grandi, ossia la distribuzione è obliqua a sinistra, (ha una coda sinistra lunga) poi-ché assumerà valori al di sotto della media con maggior probabilità ri-spetto ai valori al di sopra della media.

16 Dai LM ai GLM ai GAM. Con esempi mediante l’applicativo R
L’indice di curtosi fornisce una misura dello spessore delle code di una distribuzione, ossia il grado di appiattimento della curva, poiché misura l’allontanamento dalla distribuzione Normale. La curtosi di una distribuzione normale, impiegata come parametro di riferimento è pari a 3; pertanto la distribuzione risulta platicurtica, più piatta di una Normale se l’indice è negativo; al contrario risulta leptocurtica più ap-puntita di una Normale se l’indice è positivo.
Per verificare la relazione lineare tra due variabili si utilizza la co-
varianza il cui valore positivo indica una relazione diretta, mentre un valore negativo indica una relazione inversa, al contrario un valore nullo sta ad indicare assenza di correlazione. (1.7)
Rapportando la covarianza al prodotto della deviazione standard di entrambe le variabili si ottiene il coefficiente di correlazione. (1.8)
Questo coefficiente può essere maggiore di 1 allora indica una rela-zione lineare positiva; se il coefficiente è minore di 1 la relazione è negativa; se è uguale a zero allora c’è assenza di correlazione.
La rappresentazione grafica dei dati può avvenire mediante il Nor-mal Probability Plot, ossia uno strumento col quale si valuta la bontà di adattamento dei dati ad una distribuzione gaussiana.
Esempio di applicazione in R #analisi dataset diabetes# > library(faraway) > data(diabetes) > attach(diabetes) > y<-diabetes$glyhb #emoglobina glicosilata > x<-diabetes$weight #peso > mean(x, na.rm=T) #media [1] 177.592 > var(x,y=NULL, na.rm=T) #varianza [1] 1627.369 > sd(x, na.rm=T) #deviazione standard [1] 40.34067
I. Statistica ed R 17
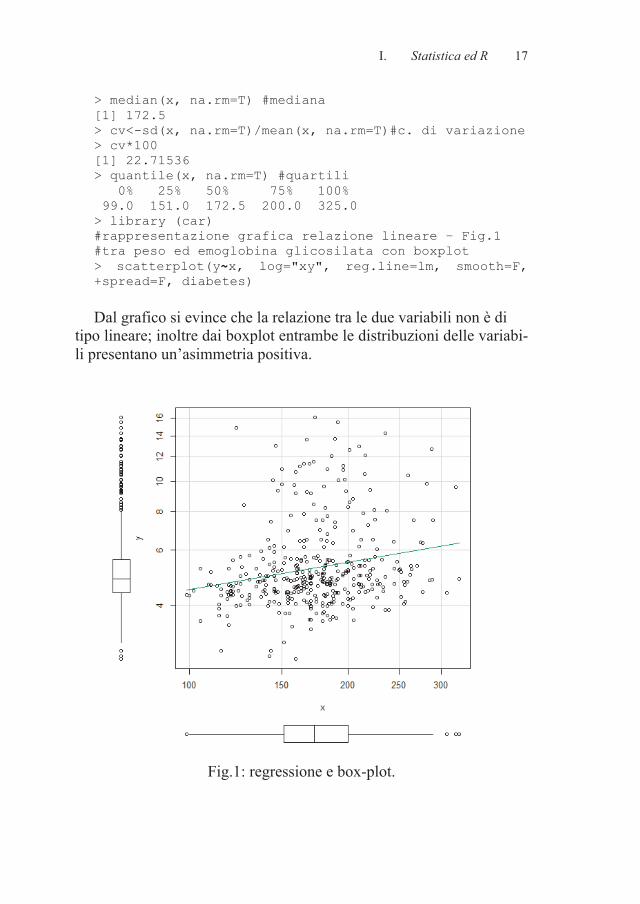
> median(x, na.rm=T) #mediana [1] 172.5 > cv<-sd(x, na.rm=T)/mean(x, na.rm=T)#c. di variazione > cv*100 [1] 22.71536 > quantile(x, na.rm=T) #quartili 0% 25% 50% 75% 100% 99.0 151.0 172.5 200.0 325.0 > library (car) #rappresentazione grafica relazione lineare – Fig.1 #tra peso ed emoglobina glicosilata con boxplot > scatterplot(y~x, log="xy", reg.line=lm, smooth=F, +spread=F, diabetes)
Dal grafico si evince che la relazione tra le due variabili non è di
tipo lineare; inoltre dai boxplot entrambe le distribuzioni delle variabi-li presentano un’asimmetria positiva.
Fig.1: regressione e box-plot.

18 Dai LM ai GLM ai GAM. Con esempi mediante l’applicativo R
1.2. Variabili aleatorie
Il calcolo delle probabilità studia i fenomeni casuali o aleatori, os-sia i fenomeni per i quali non si possono prevedere con certezza l’esito del risultato su una scala che va da 0 ad 1.
Si utilizza il concetto di variabile casuale perché in tal modo agli eventi (che possono avere natura qualsiasi) vengono associate quantità numeriche, più agevoli da utilizzare.
La variabile aleatoria X è una funzione che associa ad ogni evento di una partizione dello spazio di probabilità ( , spazio di tutti gli esiti possibili dell’esperimento) un numero reale.
Una variabile aleatoria si dice discreta se può assumere un’infinità numerabile di valori, cioè un numero (non necessariamente finito) di probabilità e quindi di eventi diversi. Si utilizzano perché producono risposte numeriche che derivano da un processo di conteggio, per esempio, il numero di componenti di una famiglia oppure il lancio di una moneta.
Una variabile aleatoria si dice continua se può assumere un numero infinito di valori, in un dato intervallo, ognuno dei quali con probabili-tà nulla. Si utilizzano perché producono risposte che derivano da un processo di misurazione, per esempio, l’altezza o il reddito.
La distribuzione di probabilità (caso discreto) o la funzione di den-sità (caso continuo) associano ad ogni sottoinsieme dell’insieme dei possibili valori della variabile casuale le corrispondenti probabilità.
a) Variabili discrete Iniziando dalle variabili discrete [Ferrante, 2012, Pacchiarotti, 2010
e Waldner, 2005], la variabile di Bernoulli è la più semplice e più im-portante, un esempio di applicazione è il lancio della moneta. La va-riabile aleatoria assumerà il valore 1 in caso di successo con proba-bilità e il valore 0 in caso di insuccesso con probabilità 1- .
ha una distribuzione di Bernoulli con parametro ( ) con . Pertanto la media,
ossia il valore atteso sarà: . La varianza: L’estensione della variabile di Bernoulli per n prove ripetute e in-
dipendenti di un esperimento con due esiti (0,1) è la Binomiale. Tale variabile aleatoria X può essere vista come la somma di n va-
riabili indipendenti bernoulliane , ciascuna corrispondente ad una prova con parametro .

I. Statistica ed R 19
La variabile casuale Binomiale trova applicazione nelle assicura-zioni sulla vita e nello specifico nelle tavole di mortalità in cui a fronte di una numerosità della popolazione si studia la probabilità di morte e di sopravvivenza.
ha una distribuzione Binomiale con parametro ( ) ed n .
(1.9) Per il calcolo del valore atteso e della varianza si sfrutta il fatto che
la Binomiale è data dalla somma di Bernoulliane.
Mentre l’asimmetria sarà definita come:
L’indice di curtosi avrà la seguente forma: La deviazione standard aumenta all’aumentare del numero delle
prove e all’approssimarsi di a 0,5. Questa distribuzione di probabilità presenta un’asimmetria positiva
e all’aumentare della media, dello scarto quadratico medio e all’approssimarsi di a 0,5 diventa più simmetrica; con >0,5 l’asimmetria diventa negativa.
Sempre all’aumentare della media e della deviazione standard la curtosi si avvicina a quella di una distribuzione Normale.
La variabile casuale di Poisson è una variabile di conteggio; infatti descrive il numero di eventi che si verificano in un determinato perio-do di tempo o spazio. Trova applicazione in numerosi fenomeni natu-rali, come per esempio il numero di persone che entrano in ufficio po-stale in un intervallo orario. Nell’ambito dell’assicurazione danni si utilizza per stimare il numero atteso di sinistri di una collettività di as-sicurati nell’arco di un periodo di tempo come un anno.
La distribuzione di Poisson può essere utilizzata come approssima-zione dalla variabile aleatoria Binomiale di parametri per grande e piccolo a sufficienza per avere che tenda ad un valore positivo finito, rappresenta il valore atteso dei successi. Per questo motivo è anche definita legge degli eventi rari o legge dei pic-coli numeri.
20 Dai LM ai GLM ai GAM. Con esempi mediante l’applicativo R
ha una distribuzione di Poisson con parametro .
Il valore atteso e la varianza di una variabile casuale di Poisson so-no entrambi uguali al parametro .
L’asimmetria e la curtosi sono le seguenti: La distribuzione di Poisson presenta un’asimmetria a destra, con
l’aumentare della media e quindi del numero di osservazioni, la varia-bile diventa sempre più simmetrica e simile ad una variabile Normale.
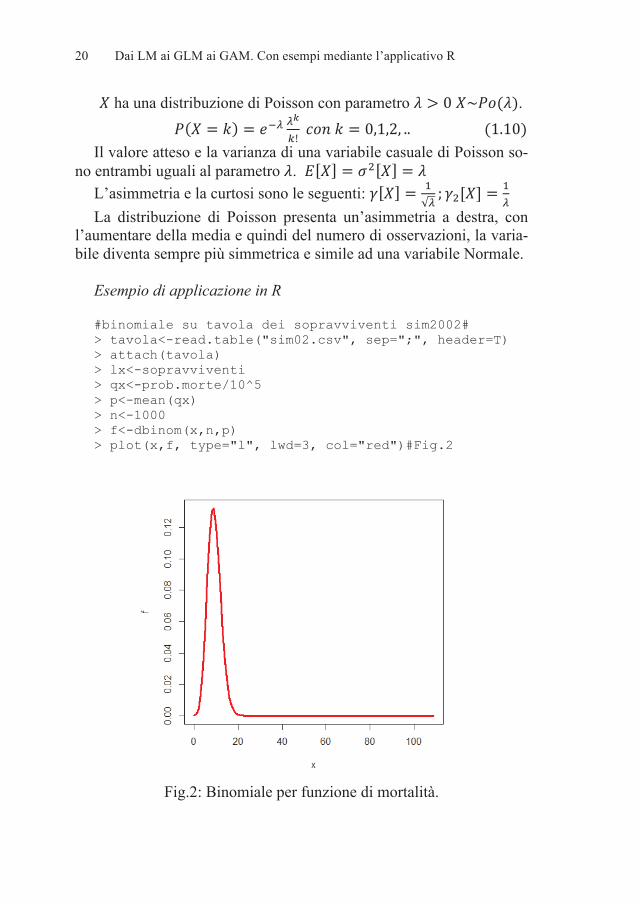
Esempio di applicazione in R #binomiale su tavola dei sopravviventi sim2002# > tavola<-read.table("sim02.csv", sep=";", header=T) > attach(tavola) > lx<-sopravviventi > qx<-prob.morte/10^5 > p<-mean(qx) > n<-1000 > f<-dbinom(x,n,p) > plot(x,f, type="l", lwd=3, col="red")#Fig.2
Fig.2: Binomiale per funzione di mortalità.