
Strumenti di gestione per container- based virtualization ... · perché rappresentano il cuore...
37
Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Sistemi Operativi Strumenti di gestione per container- based virtualization: Docker Swarm Anno Accademico 2015/2016 Candidato: Raffaele Giordano matr. N46/002107
-
Upload
nguyendiep -
Category
Documents
-
view
220 -
download
0
Transcript of Strumenti di gestione per container- based virtualization ... · perché rappresentano il cuore...

Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica
Elaborato finale in Sistemi Operativi
Strumenti di gestione per container-
based virtualization: Docker Swarm
Anno Accademico 2015/2016
Candidato: Raffaele Giordano matr. N46/002107

[Dedica]

3
Indice
Introduzione ........................................................................................................................... 4
Capitolo 1: Cos’è un data center ............................................................................................ 6
1.1 Monitoraggio e gestione della capacità dei data-center ............................................... 6
1.2 Scheduling in un data center ........................................................................................ 9
1.2.1 ECMP ................................................................................................................... 9
1.2.2 Global First Fit ................................................................................................... 10
1.2.3 Simulated Annealing .......................................................................................... 11
Capitolo 2: Docker Swarm .................................................................................................. 13
2.1 Virtualizzazione container-based ............................................................................... 13
2.2 Cos’è Docker Swarm ................................................................................................. 14
2.3 Architettura di Docker Swarm ................................................................................... 15
2.3.1 Artifact Repository ........................................................................................... 16
2.3.2 Union File System ............................................................................................ 17
2.4 Gestione delle risorse con Docker ............................................................................. 18
2.4.1 Container Scheduling ........................................................................................ 19
2.4.2 Networking avanzato ........................................................................................ 24
2.4.3 Sicurezza ........................................................................................................... 25
2.4.4 Monitoraggio .................................................................................................... 29
2.4.5 Quote e misurazioni .......................................................................................... 29
Capitolo 3: Esempio di Applicazione Hadoop .................................................................... 31
3.1 Architettura di Hadoop su Docker ............................................................................. 31
3.2 Esecuzione di Hadoop su Docker .............................................................................. 32
3.2.1 Download e importazione di Hadoop in Docker .............................................. 32
3.2.2 Esecuzione di Hadoop sui container Docker .................................................... 33
3.2.3 SSH e esecuzione di Pivotal Hadoop sul Cluster Docker ................................. 33
3.2.4 Test HDFS e MapReduce per Hadoop su Docker ............................................ 34
3.2.5 Esecuzione di HAWQ-SQL su Hadoop ............................................................ 35
3.2.6 Test HAWQ-SQL su Hadoop ........................................................................... 35
Conclusioni .......................................................................................................................... 37
Bibliografia .......................................................................................................................... 38

4
Introduzione
Negli ultimi anni c’è stato un grande sviluppo nell’utilizzo dei data center per la gestione
dei dati da parte delle aziende. Ospitando i sistemi più critici di un’azienda, la sicurezza e
l’affidabilità dei data center e delle relative informazioni sono una delle principali priorità
delle aziende. I data center possono avere un impatto significativo sui profitti di un’azienda
perché rappresentano il cuore infrastrutturale attraverso il quale l’IT eroga servizi di valore
in grado di aiutare gli utenti a svolgere meglio e con maggior produttività il proprio lavoro,
oltre a rappresentare l’elemento cardine dei servizi esterni resi ai clienti e ai partner/fornitori.
Se ciò è vero ‘sulla carta’, la realtà dei fatti è ben diversa, dato che la maggior parte dei data
center aziendali risulta oggi spesso obsoleto, inefficiente sotto il profilo energetico,
organizzato ‘a solos’ tecnologici complessi da gestire e con costi operativi e di
manutenzione molto elevati, poiché anche quando non eseguono applicazioni e lavoro
consumano energia di alimentazione e richiedono energia per il loro raffreddamento, e sotto
il profilo dell’utilizzo dell’hardware, sottoutilizzato, con un utilizzo medio del 10-15%
rispetto alla capacità reale. Anche la gestione e protezione delle postazioni desktop diventa
sempre più complessa, per via della costante necessità di applicare aggiornamenti e patch di
riparazione delle vulnerabilità. Un quadro che sta tuttavia mutando grazie alle innovazioni
introdotte dalla virtualizzazione e dal cloud che spingono le organizzazioni a rivedere le
proprie architetture infrastrutturali in un'ottica di maggior dinamicità e flessibilità
nell’allocazione e gestione delle risorse; il tutto a sostegno di servizi IT sempre più orientati
verso la mobilità, il social business, l’analisi in real-time dei big data.
In particolare, l’evoluzione è rappresentata dall’utilizzo di nuove logiche di gestione
all’insegna dell’ottimizzazione secondo i nuovi approcci dell’as service e del pay per use.
Il consolidamento di questi server attraverso la virtualizzazione consente di recuperare
efficienza, ottimizzando l’utilizzo dell’hardware, riducendo i consumi e semplificando la
gestione. Così facendo, infatti, il consolidamento all’interno delle macchine server fisiche
di numerose macchine server virtuali, configurabili via software, permette di ridurre
l’infrastruttura hardware. Lo stadio e il miglioramento successivo rispetto alla

5
virtualizzazione delle risorse hardware consiste nella transizione verso un’architettura IT
cloud-enabled; una nuova piattaforma capace di fornire via software tutte le risorse (CPU,
memoria, storage, ecc.) in modalità di servizio. Il punto di arrivo di questo percorso è il
Software-Defined Data Center (SDDC), in cui tutta l’infrastruttura IT è completamente
virtualizzata: dai server fisici agli apparati di rete, dai dispositivi di storage alle applicazioni.
Questo testo si propone l’obiettivo di illustrare in una prima parte come i data center
tradizionali vengono monitorati e gestiti, per poi entrare nel dettaglio della
virtualizzazione container-based degli stessi. In particolare verrà illustrato lo strumento di
gestione Docker, mostrandone l’architettura, la gestione delle risorse e il funzionamento
con un esempio di applicazione basata su Hadoop, tool per la gestione di dati.

6
Capitolo 1: Cos’è un data center
In sostanza, un data center è la sala macchine che ospita server, storage, gruppi di continuità
e tutte le apparecchiature necessarie che consentono di governare i processi, le
comunicazioni così come i servizi che supportano qualsiasi attività aziendale, 24 ore al
giorno, tutti i giorni dell’anno, di qualsiasi sistema informativo. Anche noto come CED
(Centro di Elaborazione Dati), il data center oggi rappresenta il cuore pulsante del business
perché fornisce anche tutta la consulenza tecnico-scientifica alle diverse strutture in materia
di digitalizzazione dei processi, elaborazione elettronica dei dati, definizione delle reti di
calcolo, progettazione e/o implementazione dei sistemi informativi, includendo tutte le
applicazioni di supporto, oltre all’integrazione e all’interfacciamento con i sistemi esterni
all’organizzazione.
1.1 Monitoraggio e gestione della capacità dei data-center
La gestione della capacità dell’infrastruttura fisica dei Data Center è definita come l’azione
o il processo per garantire che l’alimentazione, il raffreddamento e lo spazio vengano forniti
in modo efficiente al momento giusto e nella quantità corretta per supportare carichi e
processi IT.
Le comuni tecniche attualmente utilizzate per il monitoraggio dell’ambiente del Data Center
risalgono ai tempi dei mainframe centralizzati e includono operazioni quali recarsi nelle
varie aree portando con sé dei termometri e affidarsi al personale IT per controllare la
temperatura della sala, operazione considerata obsoleta dato il notevole sviluppo avuto in
questo campo negli ultimi anni. Infatti, con la continua evoluzione del Data Center grazie
all’elaborazione distribuita e a tecnologie server che accrescono le esigenze in termini di
raffreddamento e alimentazione, l’ambiente deve essere monitorato più attentamente. I due
principali fattori che stanno “forzando” alcuni cambiamenti della metodologia di
monitoraggio sono rappresentati dall’aumento della densità di alimentazione e dalle
variazioni dinamiche dell’alimentazione, la cui potenza assorbita, e di conseguenza la
dissipazione del calore, ora varia in base al carico di elaborazione. Sebbene sia ormai prassi
comune disporre di sofisticate funzionalità di monitoraggio e segnalazione in

7
apparecchiature fisiche quali UPS, CRAC (condizionatori d’aria per sale computer) e
sistemi antincendio, altri aspetti degli ambienti fisici vengono spesso ignorati. Con
l’introduzione di postazioni di rete automatizzate, gli amministratori IT devono disporre di
sistemi affidabili che permettano loro di rimanere sempre aggiornati sulla situazione. Grazie
alle più moderne tecnologie, i sistemi di monitoraggio possono essere configurati ad un
livello di precisione tale da soddisfare le esigenze di sicurezza e ambientali specifiche del
Data Center, considerando ogni rack come un “Data Center” in miniatura in modo tale da
adottare strategie di monitoraggio specifiche per soddisfare requisiti specifici, raccogliendo
i dati in punta di raccolta dati multipli.
Le minacce per il Data Center possono essere classificate in due categorie principali, a
seconda se siano nel campo del software o delle reti IT (minacce digitali) o nel campo delle
infrastrutture di supporto fisico del Data Center (minacce fisiche).
Le minacce digitali sono rappresentate da hacker, virus, colli di bottiglia in rete e altre
violazioni accidentali o intenzionali alla sicurezza o al flusso di dati. Le minacce digitali
vengono considerate di alto profilo dal settore IT e dalla stampa; per difendersi da queste
minacce, la maggior parte dei Data Center è dotata di sistemi affidabili e sottoposti a una
manutenzione continua, quali firewall e programmi antivirus.
Le minacce fisiche distribuite più diffuse e problematiche rientrano nelle seguenti
categorie generali:
Minacce relative alla qualità dell’aria delle apparecchiature IT (temperatura,
umidità)
Perdite di liquidi
Presenza umana o attività inusuali
Minacce per il personale derivanti dalla qualità dell’aria (sostanze estranee
trasportate dall’aria)
Fumo e pericolo d’incendio nei Data Center
Vari tipi di sensori possono essere utilizzati per individuare e notificare tempestivamente
eventuali problemi derivanti dalle minacce descritte sopra. Se il tipo e il numero specifico

8
di sensori può variare a seconda del budget, dei potenziali rischi dovuti alle minacce e dei
costi aziendali delle violazioni, bisogna adottare delle contromisure minime, usando i
sensori del set di base: sensori di temperatura, sensori di umidità, sensori di perdite cablati,
sensori di perdita a zona, videocamere digitali e interruttori per sale.
La seguente tabella illustra nel dettaglio i sensori da utilizzare per ogni minaccia fisica.
Dopo aver selezionato e disposto i sensori, la fase successiva prevede la raccolta e l’analisi
dei dati ricevuti dai sensori. Al fine di eliminare il rischio di singoli punti di guasto e per
dare la possibilità di supportare il monitoraggio nei punti di utilizzo delle sale server
remote, anziché inviare tutti i dati dei sensori ad un punto di raccolta centrale, solitamente
è preferibile disporre di punti di aggregazione distribuiti e assegnati ad aree fisiche
circoscritte nel Data Center, con funzioni di avviso e notifica in ogni punto di
aggregazione. Tali aggregatori interpretano i dati provenienti dai sensori e inviano avvisi
al sistema centrale e/o direttamente all’elenco notifiche tramite la rete IP, diminuendo così
la complessità di cablaggio dei sensori, nonché i costi generali del sistema e il carico di
gestione.

9
1.2 Scheduling in un data center
Uno scheduler centrale, possibilmente replicato per tolleranza ai guasti e scalabilità,
manipola le tabelle di inoltro degli edge e degli switch di aggregazione dinamicamente,
basandosi su regolari aggiornamenti delle richieste correnti della comunicazione su tutta la
rete.
Lo scheduler ha lo scopo di assegnare flussi a percorsi senza conflitti; più
specificatamente, prova a non assegnare flussi multipli a un link che non può soddisfare le
loro esigenze di larghezza di banda. In questo modello, ogni qual volta un flusso persiste
per un certo tempo e la sua larghezza di banda cresce oltre un limite ben definito, gli verrà
assegnato un percorso usando uno degli algoritmi di scheduling usati nei CED. A seconda
del percorso scelto, lo scheduler inserisce ingressi di flusso negli edge e negli switch di
aggregazione della sorgente per questo flusso, questi ingressi si spengono dopo un certo
timeout, una volta terminato il flusso. Si noti che lo stato tenuto dallo scheduler è solo un
soft-state e non ha necessità di essere sincronizzato con tutte le repliche per rilevare e
correggere i guasti. Lo stato dello scheduler non è richiesto per la connettività, piuttosto
esso aiuta l’ottimizzazione delle prestazioni.
Ovviamente, la scelta dello specifico algoritmo di scheduling è ampia. In questo caso,
analizzeremo tre algoritmi: ECMP, Global First Fit e Simulated Annealing. Gli ultimi
due cercano di mappare flussi con l’obiettivo di aumentare la bisezione della larghezza di
banda per i correnti modelli di comunicazione, integrando l’ECMP di default, con un
supporto per i grandi flussi.
1.2.1 ECMP
Per trarre vantaggi dai percorsi multipli nelle topologie dei Data Center, attualmente si usa
l’algoritmo di inoltro Equal-Cost Multi-Path, ECMP. Gli switch con ECMP abilitato sono
configurati con diversi possibili percorsi d’inoltro per una determinata sottorete. Quando
un pacchetto con più percorsi candidati arriva, viene inoltrato su uno di quelli che
corrisponde a una funzione hash di campi selezionati dagli header di questo pacchetto,
modulo il numero di percorsi. In questo modo, i pacchetti di un flusso seguono lo stesso

10
percorso, e il loro ordine di arrivo è mantenuto. Una delle principali limitazioni di ECMP
è che due o più larghi e longevi flussi possono collidere sulla loro funzione hash e finire
sulla stessa porta di output, creando un evitabile collo di bottiglia.
Notiamo che le performance di ECMP dipendono intrinsecamente dalla grandezza e dal
numero di flussi per host. L’inoltro basato sull’hash funziona bene nei casi in cui gli host
nella rete eseguono tutte le comunicazioni tra gli uni e gli altri simultaneamente, o con
flussi individuali che durano solo pochi Round Trip Time. Modelli di comunicazione non
uniformi, specialmente quelli che includono trasferimenti di grandi blocchi di dati,
richiedono uno scheduling dei flussi molto più attento per evitare colli di bottiglia in rete.
1.2.2 Global First Fit
In una topologia ad albero multi-rooted, ci sono diversi possibili percorsi di uguale costo
tra una qualsiasi coppia di host sorgente e destinazione. Quando un nuovo grande flusso è
rilevato, lo scheduler cerca linearmente tutti i possibili percorsi per trovarne uno i cui
componenti di collegamento possono permettere questo flusso. Se tale percorso viene
trovato, allora il flusso viene indirizzato su questo percorso: innanzitutto, viene riservata
una capacità per il flusso sui collegamenti corrispondenti al percorso; poi, lo scheduler
crea ingressi di inoltro nei bordi corrispondenti e negli switch di aggregazione. Per fare
questo, lo scheduler mantiene la capacità riservata su tutti i link della rete e la usa per
determinare quali percorsi sono a disposizione per trasportare nuovi flussi. Le capacità
riservate vengono rilasciate quando il flusso termina. Notiamo che questo corrisponde a un
algoritmo first fit; un flusso è “avidamente” assegnato al primo percorso che può
supportarlo. Quando la rete è leggermente caricata, trovare un tale percorso tra tutti i
possibili è probabile che sia facile; tuttavia, quando il carico della rete aumenta e i
collegamenti diventano saturi, questa scelta diventa più difficile. Global First Fit non
garantisce che tutti i flussi siano soddisfatti, ma questo algoritmo funziona relativamente
bene nella pratica.

11
1.2.3 Simulated Annealing
Descriveremo ora lo scheduler Simulated Annealing, che esegue una ricerca probabilistica
per calcolare efficientemente i percorsi per i flussi. L’intuizione fondamentale di questo
approccio è assegnare un singolo core switch per ogni host di destinazione anziché un core
switch per ogni flusso. Questo riduce lo spazio di ricerca in modo significativo. Simulated
Annealing inoltra tutti i flussi destinati a un particolare host A attraverso il core switch
designato per l’host A. L’input dell’algoritmo è l’insieme di tutti i grandi flussi da dover
indirizzare, e le loro richieste di flusso stimate dal Demand Estimator. L’algoritmo cerca
attraverso uno spazio di soluzioni per trovare una soluzione quasi ottimale. Una funzione
E definisce l’energia nello stato corrente. Ad ogni iterazione, ci muoviamo verso uno stato
vicino con una certa probabilità di accettazione P, dipendente dall’energia corrente negli
stati vicini e la corrente temperatura T. La temperatura viene diminuita a ogni iterazione
dell’algoritmo e le iterazioni si fermano quando la temperatura è zero. Consentire la
soluzione per passare a una maggiore energia di stato ci permette di evitare minimi locali.
1. Stati s: un insieme di mappature dagli host di destinazione ai core switch. Ogni
host in un pod è assegnato a un particolare core switch dal quale riceve traffico.
2. Funzione di energia E: La capacità totale superata sopra tutti i collegamenti nello
stato corrente. Ogni stato assegna un unico percorso a ogni flusso. Usiamo questa
informazione per trovare i collegamenti per i quali la capacità totale è superata e
riassume la richiesta superata su questi collegamenti.
3. Temperatura T: il restante numero di iterazioni prima della fine.
4. Probabilità di accettazione P per la transizione dallo stato s al vicino stato sn , con
energie E e En .
Dove c è un parametro che può essere modificato. Empiricamente è stato
determinato che c=0,5xT0 dà i migliori risultati per un cluster di 16 host e
c=1000xT0 è migliore per data center più grandi.

12
5. Funzione generatrice di vicini NEIGHBOR(): scambia gli switch core assegnati a
una coppia di host in uno qualsiasi dei pod nel corrente stato s.
L’obiettivo è ottimizzare per ridurre in modo significativo lo spazio di ricerca e la scelta di
appropriate funzioni di energia e di scelta dei vicini per assicurare una rapida convergenza
a una quasi ottimale schedulazione. L’approccio lineare sarebbe quello di assegnare un
core per ogni flusso individualmente e eseguire l’algoritmo. Tuttavia questo provoca un
grande spazio di ricerca limitando l’efficacia del simulated annealing. Il diametro dello
spazio di ricerca con questo approccio è uguale al numero di flussi nel sistema. La tecnica
di assegnare core switch agli host di destinazione riduce il diametro dello spazio di ricerca
al minimo tra il numero di flussi e il numero di host nel data center. Con l’approccio
lineare, il tempo di esecuzione dell’algoritmo è proporzionale al numero dei flussi e al
numero di iterazioni mentre con questa tecnica il tempo di esecuzione dipende solo dal
numero di iterazioni.
Tuttavia, ci sono dei modelli di comunicazione in cui una soluzione ottimale richiede
necessariamente un singolo host destinazione per ricevere traffico attraverso core switch
multipli. Notiamo che tutti i modelli di comunicazione possono gestiti se:
i. Il massimo numero di grandi flussi verso o da un host è al massimo uguale a k/2,
dove k è il numero dei porti negli switch di rete.
ii. La soglia minima di ogni grande flusso è settata a 2/k della capacità del link.
Dato che nella pratica i data center sono come se costruiti da switch relativamente grandi,
ad esempio k=32, l’ottimizzazione dello spazio di ricerca è improbabile eliminare il
potenziale per localizzare l’assegnamento ottimale per il flusso nella pratica.

13
Capitolo 2: Docker Swarm
In questo capitolo introdurremo lo strumento di gestione per la virtualizzazione Docker
Swarm, partendo dal concetto di virtualizzazione container-based per poi arrivare
all’architettura di tale strumento.
2.1 Virtualizzazione container-based
Si può dire che l’idea di virtualizzazione container-based sia partita ponendosi questa
domanda: perché virtualizzare un’intera macchina, quando sarebbe possibile virtualizzare
solamente una piccola parte di essa? Questo quesito ha invogliato gli sviluppatori a
trovare delle strade alternative alla virtualizzazione completa. I primi a trovare una
soluzione a questo problema furono gli sviluppatori di Google, sviluppando cgroups, sigla
di “Control Groups” (gruppi di controllo), un’aggiunta al kernel Linux, riuscendo a creare
un contesto di esecuzione isolato, con un alto livello di astrazione, tanto da imporsi come
una sorta di sistema operativo semplificato e virtualizzato. Questa soluzione prevede un
sistema operativo host centrale condiviso, su cui si appoggiano i sistemi operativi guest,
chiamati anche containers o virtual private servers (VPS), che devono essere
necessariamente dello stesso tipo dell’host. Le funzionalità sono, quindi, semplicemente
replicate senza il bisogno di effettuare onerose chiamate di sistema tra i diversi strati di
astrazione. La contenierizzazione, quindi, può essere considerata figlia della
virtualizzazione, da cui si evolve in una nuova generazione che introduce cambiamenti
migliorativi molto significativi.
Infatti, rispetto a un’intera macchina virtualizzata, un container è capace di offrire:
Un deployment semplificato: impacchettando un’applicazione in un singolo
componente distribuibile e configurabile con una sola linea di comando, la
tecnologia a container permette di semplificare il deployment di qualsiasi
applicazione, togliendo allo sviluppatore la preoccupazione di dover configurare
l’ambiente di esecuzione.
Una disponibilità rapida: a differenza delle macchine virtuali, astraendo solo il
sistema operativo e le componenti necessarie all’esecuzione dell’applicazione,

14
l’intero package si avvia in appena un ventesimo di secondo, molto meno
rispetto ai tempi di avvio di una VM.
Un controllo più granulare: suddividendo ulteriormente le risorse computazionali
in microservizi, si ha la garanzia di un controllo superiore sull’eseguibilità delle
applicazioni e un miglioramento delle prestazioni dell’intero sistema.
2.2 Cos’è Docker Swarm
Dopo pochi anni dallo sviluppo di cgroups da parte di Google, la volontà di rendere questa
tecnologia uno standard, ha condotto il team di Docker a sviluppare un formato di
contenierizzazione interoperabile, capace di rendere le applicazioni eseguibili in
qualsiasi ambiente di esecuzione, senza dar conto alle condizioni di eseguibilità.
Docker è una piattaforma open source per lo sviluppo, il trasporto e l’esecuzione di
applicazioni ed è progettata per fornire applicazioni più velocemente. Con Docker è
possibile separare le applicazioni dall’infrastruttura e curare l’infrastruttura come
un’applicazione gestita. Esso, infatti, aiuta a condividere, implementare e testare codice
molto più velocemente e, quindi, ad abbreviare il ciclo tra la scrittura e l’esecuzione dello
stesso.
Tutto ciò è reso possibile combinando una piattaforma container di virtualizzazione
leggera con i flussi di lavoro e i tools che consentono di gestire e distribuire le
applicazioni. Infatti, fornendo al suo interno dei metodi specifici, è possibile eseguire
quasi tutte le applicazioni in modo sicuro ed isolato all’interno del contenitore.
L’isolamento e la sicurezza consentono di eseguire molti contenitori contemporaneamente
sul sistema ospitante mentre la leggerezza dei contenitori, eseguiti senza il carico extra di
un hypervisor, permette di ottenere performance migliori dal proprio hardware.
Attorno alla virtualizzazione basata su container vi sono dei tools e una piattaforma che
può aiutare l’utente in diversi modi:
Ottenimento delle applicazioni (e dei componenti di supporto) in container Docker
Distribuzione e trasporto di tali container per i team di sviluppo per un ulteriore
sviluppo e test

15
Distribuzione di tali applicazioni nell’ambiente di produzione, sia che si tratti di un
centro di dati locali sia che si tratti di un centro di dati in Cloud
2.3 Architettura di Docker Swarm
Docker implementa un’architettura client-server. Il client è un semplice strumento a linea
di comando che invia comandi al server utilizzando servizi REST, cioè servizi che
rispettano i seguenti principi: identificazione delle risorse, utilizzo esplicito dei metodi
HTTP, risorse autodescrittive, collegamenti tra risorse, comunicazione senza stato. Ciò
implica che chiunque potrebbe costruire client differenti. Il server è un daemon Linux,
cioè un programma che resta in attesa su una porta del sistema in attesa che qualcuno o
qualcosa richieda una connessione, in grado di costruire ed eseguire container sulla base di
un’immagine preesistente.
Per capire internamente Docker bisogna conoscere 3 componenti:
Le immagini Docker
I registri Docker
I container (contenitori) Docker
Un’immagine Docker è un modello di sola lettura. Ad esempio, essa può contenere un
sistema operativo Ubuntu con Apache e un’applicazione web installata. Le immagini
vengono usate per creare i container Docker. Docker fornisce un modo semplice per creare

16
nuove immagini o aggiornare le immagini esistenti, che sono la componente di
costruzione di Docker.
I registri Docker sono la componente di distribuzione di Docker, archivi, pubblici o
privati, contenenti immagini scaricabili. Il registro pubblico è fornito dal Docker Hub e
contiene una vasta collezione di immagini esistenti e pronte per l’uso che possono essere
create da noi e caricate nel registro o create in precedenza da altri utenti.
I container Docker sono la componente di esecuzione di Docker, simili alle directory,
contengono tutto ciò che è indispensabile per eseguire un’applicazione e alla base hanno
immagini Docker. Essi possono essere eseguiti, inizializzati, messi in pausa, spostati e
cancellati e ognuno di essi è una piattaforma applicativa isolata e sicura.
I container possono essere costruiti interattivamente utilizzando un file di configurazione.
La costruzione interattiva dei container andrebbe fatta “sperimentando” più soluzioni
perché consente di lanciare alcuni comandi che creano diversi cambiamenti all’interno di
un container. Modifiche che poi possono essere rese definitive con un commit verso una
nuova immagine di container. Tali container vengono spesso utilizzati nella costruzione di
processi automatizzati.
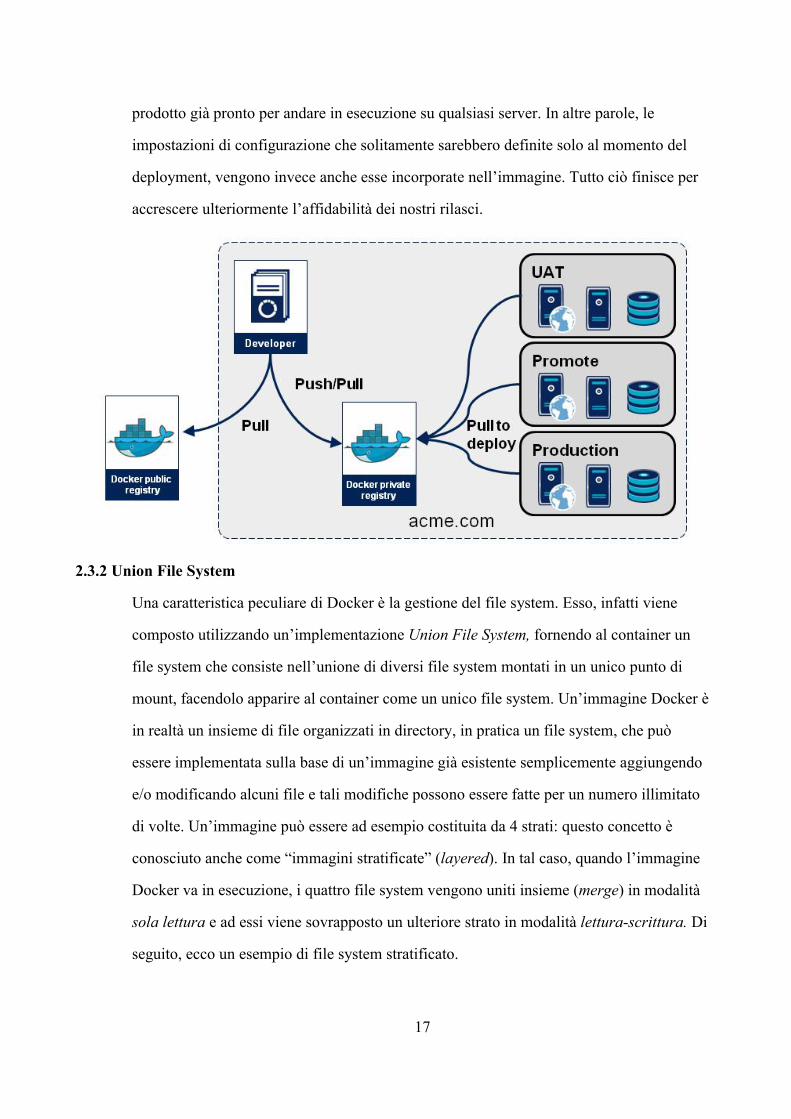
Le immagini Docker possono essere immagazzinate in un repository per facilitarne la
condivisione, attraverso ad esempio un prodotto chiamato Docker Trusted Registry,
offerto da Docker, installabile in locale. Altro prodotto disponibile per l’archiviazione e la
condivisione di immagini Docker è Artifactory.
2.3.1 Artifact Repository
Il concetto di artifact repository, una sorta di “deposito di manufatti”, non è nuovo. Molti
sistemi di build con gestione automatizzata delle dipendenze si basano su questi strumenti,
ma Docker spinge ancora più avanti i limiti della questione. Infatti, solitamente con un
artifact repository si immagazzinano i risultati di una build, magari dopo l’esecuzione di
una suite di test di integrazione automatizzati.
Ora, con Docker, è possibile immagazzinare nel repository un’immagine di container con
un’applicazione di cui già è stato effettuato il deployment, mettendo così a disposizione un
17
prodotto già pronto per andare in esecuzione su qualsiasi server. In altre parole, le
impostazioni di configurazione che solitamente sarebbero definite solo al momento del
deployment, vengono invece anche esse incorporate nell’immagine. Tutto ciò finisce per
accrescere ulteriormente l’affidabilità dei nostri rilasci.
2.3.2 Union File System
Una caratteristica peculiare di Docker è la gestione del file system. Esso, infatti viene
composto utilizzando un’implementazione Union File System, fornendo al container un
file system che consiste nell’unione di diversi file system montati in un unico punto di
mount, facendolo apparire al container come un unico file system. Un’immagine Docker è
in realtà un insieme di file organizzati in directory, in pratica un file system, che può
essere implementata sulla base di un’immagine già esistente semplicemente aggiungendo
e/o modificando alcuni file e tali modifiche possono essere fatte per un numero illimitato
di volte. Un’immagine può essere ad esempio costituita da 4 strati: questo concetto è
conosciuto anche come “immagini stratificate” (layered). In tal caso, quando l’immagine
Docker va in esecuzione, i quattro file system vengono uniti insieme (merge) in modalità
sola lettura e ad essi viene sovrapposto un ulteriore strato in modalità lettura-scrittura. Di
seguito, ecco un esempio di file system stratificato.

18
Se due container condividono parte degli strati dell’immagine, tali layer non dovranno
essere replicati nel file system ospitante, poiché sono montati in modalità sola lettura.
Questo può comportare significativi risparmi soprattutto se un’azienda si dà una certa
disciplina riguardo la creazione di immagini: potrebbe essere il caso, ad esempio, di
stabilire che tutte le immagini debbano derivare da una base comune.
In questo caso, poiché la base comune sarà probabilmente lo strato che occupa la maggior
parte dello spazio su disco e gli altri layer dovranno aggiungere installazioni o modificare
configurazioni minori, tale semplice linea guida potrebbe far risparmiare grandi quantità di
spazio su disco.
2.4 Gestione delle risorse con Docker
Il progetto Docker è nato con l’intenzione di semplificare la creazione e la gestione di
container, svolgendo tali compiti in modo molto efficace si può dire che Docker sia di

19
fondamentale importanza per costruire sistemi cloud basati su container, il che vuol dire
dover tenere molto a mente alcune aree tematiche principali di questi ambienti:
Container scheduling
Networking avanzato
Sicurezza
Monitoraggio
Quote e misurazioni
2.4.1 Container Scheduling
Il container scheduling è la possibilità di definire e attivare un ambiente potenzialmente
composto di diversi container, definendo la corretta sequenza di attivazione dei container,
la dimensione del cluster di container che è necessario creare e la qualità del servizio dei
container: per esempio, un’applicazione potrebbe richiedere un minimo garantito di
memoria e di accessi al disco.
Tool avanzati per lo scheduling devono garantire anche che un determinato ambiente
rifletta lo stato desiderato dopo essere stato creato, cioè con questi questi strumenti di
scheduling è possibile anche svolgere un certo grado di monitoraggio ed effettuare,
almeno in parte, un’autoriparazione nel caso lo stato dell’ambiente non sia quello stabilito
in fase di configurazione.
Un’altra importante caratteristica comune a molti scheduler per container è la capacità di
definire un livello di astrazione intorno a un cluster di container uguali, in maniera tale che
essi siano visti come servizio, cioè aventi un indirizzo Ip e una porta. Questo risultato è
ottenuto collegando, tramite lo scheduler. un load balancer al cluster di container
impostando anche le regole di indirizzamento necessarie.
In effetti, ciò che deve fare bene un container scheduler, è risolvere il problema principale
di massimizzare l’utilizzo delle risorse fisiche che si trova a gestire, soddisfacendo allo
stesso tempo i vincoli che possiede ciascuna applicazione.
Esempi di tali vincoli sono:

20
Necessità tecniche: quantità di RAM disponibile, tipo di CPU, necessità in termini
di I/O, presenza di processori GPU, tipo di sistema operativo.
Vincoli topologici: per ragioni di disponibilità, vogliamo che i componenti di un
cluster non siano collocati sullo stesso host, o rack, o addirittura proprio non siano
nello stesso Data Center. D’altro canto, desideriamo che alcuni container siano
collocati insieme sullo stesso host
Tipologia di caricamento: priorità del load, load batch vs load online.
Questi vincoli rappresentano una variante del cosiddetto “problema dello zaino”, nel quale
occorre cercare il modo migliore per inserire oggetti di forme e pesi differenti all’interno
di zaini di forma e dimensione diverse. Il problema dello zaino è di tipo NP-completo,
cioè problemi non deterministici in tempo polinomiale, e quindi non c’è modo di avere
una soluzione che sia al tempo stesso veloce e ottimale. Occorre pertanto avere un
programma per risolvere questo problema specialmente in un cluster con un grande
numero di nodi.
Una ricerca fatta da Google mostra che miscelare diversi tipi di carico aiuta a
massimizzare l’utilizzo delle risorse, cosa abbastanza prevedibile, al contrario la sorpresa
sta nel fatto che un impegno delle risorse al limite (over-commitment) è una buona
strategia di allocazione.
Nell’ambito del container scheduling, alcuni degli strumenti disponibili sono Kubernetes e
Docker Compose.
Kubernetes è un container scheduler reso disponibile come open source da Google,
introducendo il concetto di pod, una serie di container collocati insieme all’interno dello
stesso host. Esistono diverse situazioni o modelli ricorrenti in cui una funzione come
questa può essere molto utile: per esempio, in un’applicazione in cui c’è bisogno di
un’altra applicazione “di accompagnamento” che si occupi di inviare i log.
Kubernetes introduce inoltre il concetto di “controller di replicazione”. Il compito di
replication controller consiste nel garantire che tutti i pod di un cluster siano “in salute”,
cioè regolarmente funzionanti, in caso contrario, se un pod è giù o non sta fornendo le

21
prestazioni attese, il replication controller lo rimuoverà dal cluster e creerà un nuovo pod
replicando, appunto, quello rimosso.
Oltre a questo, Kubernetes cerca di essere portabile tra implementazioni private di Docker
e implementazioni cloud pubbliche, grazie all’uso di un’architettura a plugin. La
configurazione del load balancer necessaria per la definizione di un servizio attiverà un
plugin differente in base a dove il deploy del progetto sia effettuato, ad esempio in Google
Cloud invece che in Amazon Web Service. L’intenzione è quella di aggiungere plugin per
collegarsi a diversi tipi di storage, per effettuare diverse tipologie di deployment, per
utilizzare fornitori di sicurezza diversi e così via.
L’intenzione è, quindi, quella di avere un sistema di gestione di container che garantisca
scalabilità e tolleranza ai guasti. A tal proposito vedremo ora l’architettura di Kubernetes.
Le principali
componenti dell’architettura di un cluster Kubernetes sono:
Kubernetes Master Services: questi servizi centralizzati (eseguibili in Container
Docker) forniscono un API, memorizzano lo stato corrente del cluster e assegnano

22
i pod ai nodi. La maggior parte degli utenti interagiranno sempre e solo con il
Master API, permettendo una vista unificata di tutto il cluster.
Master Storage: attualmente tutti gli stati persistenti di Kubernetes sono
memorizzati negli etcd. E’ probabile che verranno costruiti nuovi motori di storage
nel tempo.
Kubelet: è un agente che viene eseguito su ogni nodo ed è il responsabile per la
guida di Docker, riportando gli stati al Master e settando le risorse al livello dei
nodi.
Kubernetes Proxy: questo proxy è eseguito su ogni nodo e fornisce ai containers
locali un singolo endpoint di rete per raggiungere un array di pods.
Il flusso generico di come il lavoro viene eseguito con Kubernetes può essere suddiviso in
4 fasi:
1. Attraverso il tool kubectl e le API Kubernetes, l’utente crea una specifica per un
Replication Controller con un Template di Pod e un calcolo per il numero delle
repliche desiderate.
2. Kubernetes usa il template nel Replication Controller per creare un certo numero di
pods.
3. Lo scheduler Kubernetes guarda lo stato corrente del cluster (cioè quali nodi sono
disponibili e quali risorse sono disponibili su tali nodi) e collega un pod a uno
specifico nodo.
4. Il Kubelet su quel nodo controlla se ci sono cambiamenti nel set dei pods assegnati
al nodo su cui sta eseguendo, per poi far partire o arrestare i pods a seconda delle
necessità. Questo lavoro include la configurazione di qualsiasi volume di storage,
scaricando l’immagine Docker su quello specifico nodo e chiamando l’API Docker
per eseguire/arrestare i singoli containers.
La tolleranza ai guasti è implementata su livelli multipli. I singoli container inseriti in un
pod possono essere controllati e monitorati dal Kubelet locale, se si guastassero,
verrebbero riaccesi automaticamente. Se, invece, è il nodo intero a essere soggetto a

23
guasti, il Master lo ravviserà e aggiornerà il suo stato per tenerlo presente. A questo punto
il Replication Controller creerà rimpiazzi per i pods che erano in quel nodo. Un
monitoraggio su più livelli aiuta a mantenere le applicazioni in esecuzione anche quando il
cluster sta subendo guasti, che siano a livello software o a livello hardware.
Docker Compose è un’aggiunta recente all’insieme delle soluzioni Docker e non può
essere considerato ancora pronto per la produzione e non è neanche ben integrato con
Docker Swarm, lo strumento di gestione dei cluster targato Docker, essendo, al momento,
solo in grado di controllare il ciclo di vita di un’applicazione composta di container
multipli che sono in esecuzione sullo stesso host. Attraverso un Compose file vengono
configurati i servizi dell’applicazione, poi, usando un singolo comando, vengono creati ed
eseguiti tutti i servizi della tua configurazione.
Compose è molto utile per lo sviluppo e il testing, così come il flusso di lavoro.
L’utilizzo di Compose consiste sostanzialmente di un processo di tre fasi:
1. Definizione dell’ambiente di sviluppo dell’applicazione con un file Docker così
che esso possa essere riprodotto ovunque
2. Definizione dei servizi che compongono l’applicazione in un file Compose così
che possano essere eseguiti insieme in un ambiente isolato
3. Infine, esecuzione di Compose che farà eseguire l’applicazione secondo la
configurazione data nei precedenti passaggi
Compose usa un nome di progetto per isolare gli ambienti l’uno dall’altro. Si può fare uso
di questo nome di progetto in diversi contesti:
Su un host di sviluppo, per creare varie copie di un singolo ambiente
Su un server CI, per evitare che le costruzioni interferiscano tra loro, si può settare
il nome di progetto per un fissato numero di costruzioni
Su un host condiviso o host di sviluppo, per evitare che diversi progetti, che
potrebbero usare gli stessi servizi, interferiscano tra loro

24
Compose preserva tutti i volumi usati dai servizi, infatti, se in fase di esecuzione trova
qualche container già eseguito in precedenza, copia il volume dal vecchio container al
nuovo, assicurando, così, che ogni dato creato in un volume non viene perso.
Inoltre, memorizza la configurazione usata per creare un container e quando è riavviato un
servizio che non è stato modificato, esso riusa il container esistente. Riusando i containers
si ha la possibilità di apportare modifiche all’ambiente molto velocemente.
Nei file Compose è supportato l’utilizzo delle variabili, utili per personalizzare la
composizione per diversi ambienti o differenti utenti.
2.4.2 Networking avanzato
Docker mette a disposizione un “interruttore virtuale” per consentire comunicazione di
rete tra i container stessi o con il resto del mondo. Non c’è supporto in Docker per i
firewall, per il reverse proxy, per il load balancing e per le reti virtuali di container, utile
nelle implementazioni multi-tenant o nel caso sia richiesto un isolamento della rete.
Queste funzionalità sono fondamentali quando si debbano effettuare dei deployments nella
realtà produttiva, e Docker non intende affrontarli. Come abbiamo visto, i container
scheduler tentano di superare questo ostacolo, concentrandosi in special modo sulle
funzionalità di firewall e load balancing, non risolvendo però il problema del tutto, e
soprattutto non in maniera portabile, cioè in maniera diffusa tra le diverse
implementazioni di cluster Docker.
Ci sono però degli strumenti che stanno tentando di colmare tale lacuna, come ad esempio
Flannel e Weave, che affrontano il problema di creare delle reti virtuali tra i container.
Funzionano entrambi aggiungendo un router virtuale a cascata con il virtual switch di
Docker, affiancando un agente per gestire la configurazione del virtual router.
In entrambi i casi, la mancanza di una piena integrazione con Docker o con un container
scheduler finisce per introdurre alcuni passaggi di configurazione manuale, il che sembra
essere una limitazione, pertanto probabilmente tool come questi saranno presto “inglobati”
nel container scheduler.

25
Al momento, non esiste una soluzione chiara per quanto concerne le capacità di reverse
proxy, e pertanto sarà necessario che tale funzione sia svolta da un software apposito, che
magari sia in esecuzione all’interno di un container.
2.4.3 Sicurezza
Docker si interessa di alcuni aspetti legati alla sicurezza, come ad esempio l’isolamento
dei container, ma altri aspetti restano a cura dell’implementatore del cluster. In particolare,
soprattutto in un’implementazione Docker multi-tenant, l’implementatore deve fornire
sicurezza intorno al demone Docker.
Gli scheduler per container analizzati in precedenza posseggono delle implementazioni
basilari di sicurezza che possono essere integrate con altri sistemi di sicurezza a livello
enterprise.
Per approfondire l’analisi di sicurezza di Docker ci sono alcune aree principali da prendere
in considerazione:
La sicurezza intrinseca del kernel e il suo supporto per i namespaces e cgroups
Attacchi al livello di sicurezza del demone Docker
Le scappatoie nel profilo di configurazione del contenitore, sia quando è nella sua
impostazione predefinita sia quando è impostato dall’utente
L’irrobustimento delle caratteristiche di sicurezza del kernel e la loro interazione
con i contenitori
Quando si esegue un container con il comando docker run, Docker crea una serie di
namespaces e gruppi di controllo per il contenitore in esecuzione.
I namespaces forniscono la prima e più semplice forma di isolamento: i processi in
esecuzione all’interno di un contenitore non possono vedere i processi in esecuzione in un
altro contenitore oppure nel sistema host.
Ad ogni container, sempre all’atto dell’esecuzione, è assegnato anche un proprio stack di
rete, ciò significa che un container non può mai accedere alle socket o alle interfacce di un
altro container in esecuzione sulla macchina.

26
I kernel namespaces sono stati introdotti tra le versioni del kernel 2.6.15 e 2.6.26,
rilasciata nel luglio del 2008, e quindi sono stati eseguiti ed esaminati su un gran numero
di sistemi di produzione, rendendolo quindi un metodo abbastanza sicuro allo stato attuale.
Altro componente chiave dei container sono i gruppi di controllo, addetti
all’implementazione della gestione e della limitazione delle risorse fornendo parametri
utili aiutando a gestirle in modo che ciascun contenitore ottenga la giusta quota di
memoria, CPU, disco, I/O e soprattutto che un singolo container non esaurisca tutte le
risorse di un sistema.
Così facendo, pur non giocando alcun ruolo nella prevenzione all’accesso o alla modifica
dei dati da parte di un altro container, essi risultano essenziali per respingere alcuni
attacchi di tipo denial-of-service, in particolar modo sulle piattaforme multi-tenant come
Paas pubbliche e private, ove garantiscono un uptime costante e performante anche
quando alcune applicazioni iniziano a malfunzionare.
I container in esecuzione con Docker implicano l’esecuzione del demone Docker che
richiede i privilegi di root, dobbiamo essere, quindi, a conoscenza di alcuni dettagli
importanti.
Innanzitutto, solo gli utenti attendibili dovrebbero essere autorizzati a controllare il
demone Docker, conseguenza diretta di alcune potenti funzioni di Docker. In particolare,
esso consente di condividere una cartella tra l’host Docker e un container ospite, senza
limitare i diritti di accesso del container. Ciò significa che è possibile avviare un container
in cui la directory “/host” sarà la directory “/” sul proprio host e che sarà in grado di
modificare il file system ospitante senza alcuna restrizione, similmente a come i sistemi di
virtualizzazione consentono la condivisione delle risorse del file system di root con una
macchina virtuale.
Ciò ha, ovviamente, una forte implicazione nel campo della sicurezza: per esempio, se si
utilizzasse Docker da un server web per avere container attraverso un’API bisognerebbe
prestare ancor più attenzione al controllo dei parametri per evitare che un utente

27
malintenzionato passi parametri predisposti che causano la creazione di contenitori
arbitrari in Docker.
E’ possibile, quindi, che in futuro il demone Docker verrà eseguito con privilegi ristretti e
le operazioni delegate a sotto-processi ben controllati ognuno con la propria (limitata)
portata delle capacità di Linux, installazione di rete virtuale, gestione del file system, ecc.
Infine, se si esegue Docker su un server si consiglia di eseguire esclusivamente Docker nel
server e spostare tutti gli altri servizi all’interno di container controllati da Docker, seppure
sia bene mantenere gli strumenti di amministrazione, così come i processi monitoraggio
esistenti.
Per impostazione predefinita, Docker inizializza container con una serie limitata di
funzionalità. I processi (come i web server) che hanno bisogno di usare una porta inferiore
a 1024 non devono essere eseguiti come root: possono anche avere in concessione solo la
capacità net_bind_service. Ci sono anche altre funzionalità, per quasi tutti i settori
specifici per cui di solito sono necessari i privilegi di root. Tutto ciò è molto importante a
livello di sicurezza: il server deve eseguire una serie di processi come root che di solito
comprendono SSH, gestione dei log, strumenti di gestione hardware, strumenti di
configurazioni di rete e molto altro. Un container è molto diverso, perché quasi tutti questi
compiti vengono gestiti dall’infrastruttura intorno al contenitore. Ciò significa che nella
maggior parte dei casi i contenitori non avranno bisogno di dare dei privilegi di root
“reali” a tutti e possono essere eseguiti con capacità ridotte, implicando che l’utente root
all’interno di un contenitore abbia molti meno privilegi rispetto alla vera “root”. Così
facendo, anche se un intruso riuscisse a creare una root all’interno di un container sarebbe
molto più difficile arrecare gravi danni all’host.
Un rischio primario con l’esecuzione di container Docker è che l’insieme predefinito di
funzionalità e supporti dato ad un container può fornire un isolamento incompleto quando
usato in combinazione con la vulnerabilità del kernel.
Docker supporta l’aggiunta e la rimozione di capacità, grazie all’uso di profili non
predefiniti, rendendo più sicura suddetta rimozione. La pratica migliore per gli utenti

28
sarebbe quella di eliminare tutte le funzionalità ad eccezione di quelle espressamente
richieste per i loro processi.
Le capacità sono solo una delle molte caratteristiche di sicurezza fornite dal kernel Linux
moderno. E’ anche possibile sfruttare i sistemi esistenti, noti come Tomoyo, AppArmor,
SELinux, grsec, ecc con Docker.
Docker attualmente, anche consentendo solo capacità, non interferisce con gli altri sistemi
e ciò significa che esistono molti modi diversi per rendere un host Docker più solido.
Eccone alcuni esempi:
E’ possibile eseguire un kernel con GRSEC e PAX. Questo aggiungerà molti
controlli di sicurezza, sia al momento della compilazione che in fase di esecuzione
e riuscirà ad evitare problemi legati alla sicurezza grazie a tecniche come
l’indirizzamento casuale. Non necessita di una configurazione specifica di Docker
in quanto tali funzioni di sicurezza si applicano a livello di sistema,
indipendentemente dai container.
Se la distribuzione ha dei template per i modelli di sicurezza per i container
Docker, essi possono essere usati al di fuori del contenitore. Ad esempio, possiamo
inviare un template che funziona con AppArmar e Red Hat e viene fornito con le
politiche SELinux per Docker. Questi template forniscono una rete di sicurezza in
più.
E’ possibile definire le proprie politiche preferite per l’utilizzo dei meccanismi dei
controlli di accesso.
Così come esistono molti strumenti di terze parti per aumentare la solidità dei contenitori
Docker con, ad esempio, le reti speciali o file system condivisi, ci si può aspettare di avere
strumenti per fortificare i container Docker esistenti senza incidere sul nucleo di Docker.
Recenti miglioramenti nei namespaces Linux permetteranno presto di eseguire contenitori
full-optional, senza privilegi di root, grazie al nuovo spazio dei nomi utente. Ciò risolverà
il problema causato dalla condivisione di file system tra host e guest, dal momento che lo

29
spazio dei nomi utente consente agli utenti all’interno di container (compreso l’utente
root) di essere mappato da altri utenti del sistema host.
Oggi Docker non supporta direttamente gli user namespaces ma essi possono essere
utilizzati dai contenitori Docker su kernel supportanti utilizzando la syscall clone o
utilizzando l’utility ‘unshare’. Ci si aspetta che Docker avrà presto supporto diretto e
nativo per gli user namespaces semplificando il processo di fortificazione della sicurezza
dei contenitori.
2.4.4 Monitoraggio
Docker e gli strumenti che funzionano con esso, come Kubernetes, sono stati costruiti,
come abbiamo visto in precedenza, con la capacità di fornire statistiche a tool di
monitoraggio. Tali strumenti possono fornire informazioni molto ricche sullo stato dei
nodi host e dei container in essi ospitati. Queste informazioni dovranno essere raccolte e
analizzate da tool “a valle” del processo, come InfluxDB, Graphite o Grafana, prodotti
open source che possono contribuire a gestire la grande mole di dati generati dai cluster
Docker e trarne delle informazioni sensate.
2.4.5 Quote e misurazioni
Come abbiamo visto, i container possono stabilire come debbano essere utilizzate le
risorse su un singolo container; in Docker, però, non c’è un buon modo per stabilire
l’utilizzazione globale delle risorse di un insieme di container, detto ambiente, creato da
un utente. Questo controllo, invece, è cruciale per evitare che una configurazione errata
fatta da un team possa far crollare un intero cluster Docker poiché ne esaurisce le risorse.
Si tratta chiaramente di un compito che dovrebbe essere eseguito dallo scheduler, e il
precedentemente analizzato Kubernetes supporta questo tipo di controllo.
Misurare l’utilizzo delle risorse è un altro aspetto importante: queste informazioni
verranno infatti usate per produrre report dell’utilizzo delle risorse, per elaborare le
politiche con cui comprendere l’utilizzo delle risorse da parte dei vari dipartimenti e/o
utilizzatori, nonché per stabilire i costi da imputare nei casi di servizi a pagamento.

30
Capitolo 3: Esempio di Applicazione Hadoop
La libreria software Hadoop di Apache è un framework che supporta i processi distribuiti
con elevati afflussi di dati attraverso cluster di computer usando semplici modelli di
programmazione. Esso è progettato per essere usato tanto per singoli server che per
migliaia di macchine, a ognuno dei quali è offerto calcolo e storage locali. Piuttosto che
fare affidamento sull’hardware per fornire alta disponibilità, la libreria stessa è progettata
per rilevare guasti a livello applicazione, e quindi anche fornire un servizio altamente
disponibile su di un cluster di computer, ognuno dei quali potrebbe essere incline a guasti.
Mentre Hadoop sta diventando sempre più mainstream, molti leader di sviluppo vogliono
aumentare la velocità e ridurre gli errori nei loro processi di sviluppo e distribuzione
usando piattaforme del tipo Platform as a Service, PaaS, e container leggeri in fase di
esecuzione. A questo punto, Docker è una nuova ma ascendente soluzione di
virtualizzazione leggera su cui applicazioni Hadoop si possono appoggiare per realizzare
applicazioni leggere e veloci.
Aziende come Pivotal, riconosciuta a livello internazionale per lo sviluppo di applicazioni
big data, si appoggiano appunto su Docker per rendere le loro applicazioni leggere e
scalabili.
Di seguito, verrà mostrato come due componenti della Pivotal Big Data Suite - la sua
distribuzione Hadoop, Pivotal HD, e la sua interfaccia SQL su Hadoop, HAWQ - possono
essere facilmente e velocemente settati ed eseguiti sul laptop di uno sviluppatore con
Docker.
3.1 Architettura di Hadoop su Docker
Il seguente diagramma spiega uno sviluppo generico di un’applicazione Hadoop attraverso
diversi container Docker. Fondamentalmente, i carichi di lavoro vengono eseguiti su un
nodo Hadoop master con alcuni nodi Hadoop e un HAWQ master con due server.

31
Ci sono altri componenti importanti da menzionare:
Tar files: sono i file immagine di Docker, attualmente a disposizione solo sul
repository di Pivotal ma che verranno caricati anche sul Repository di Docker.
Container: Sono i container Docker che contengono il Pivotal Command Center (il
tool per l’orchestrazione dei cluster) e le componenti di Pivotal HD e HAWQ. Non
è necessaria l’installazione di Pivotal, è già inclusa nei file Docker.
Altre librerie: servono per settare i server DNS e SSH per lavorare per il cluster.
Questo è tutto, le immagini tar contengono tutto ciò che serve per settare l’applicazione su
un qualsiasi ambiente di sviluppo.
3.2 Esecuzione di Hadoop su Docker
Dopo aver installato Docker su un sistema operativo Linux, questi sono i passaggi da
compiere per eseguire un’applicazione Hadoop su Docker.
3.2.1 Download e importazione di Hadoop in Docker
Innanzitutto, bisogna scaricare i file tar necessari, estrarli, e iniziare a importare le
immagini in Docker. Di seguito il codice necessario per tali operazioni.
tar -xvf phd-docker.tar.gz
sudo su # Make sure you run docker command as root.
cd images

32
cat phd-master.tar | docker import - phd:master
cat phd-slave1.tar | docker import - phd:slave1
cat phd-slave2.tar | docker import - phd:slave2
3.2.2 Esecuzione di Hadoop sui container Docker
Una volta importate le immagini, è possibile eseguire Hadoop sui container. Questa parte
del processo richiede alcuni parametri, che dovrebbero funzionare su ogni ambiente di
esecuzione senza alcun problema.
# Set a variable
DOCKER_OPTION="--privileged --dns 172.17.0.2 --dns 8.8.8.8 -d -t -
i"
# Start master container
docker run ${DOCKER_OPTION} -p 5443 --name phd-master -h
master.mydomain.com phd:master bash -c "/tmp/phd-
docker/bin/start_pcc.sh"
# Start slave containers
for x in {1..2} ; do docker run ${DOCKER_OPTION} --name phd-
slave${x} -h slave${x}.mydomain.com phd:slave${x} /tmp/phd-
docker/bin/start_slave.sh ; done
Con questi semplici passaggi è stata avviata l’esecuzione sulla macchina di ben 3 nodi, o
più comunemente macchine virtuali. Precisamente sono state messi in esecuzione il
Pivotal Command Center, Pivotal HD e HAWQ.
3.2.3 SSH e esecuzione di Pivotal Hadoop sul Cluster Docker
Ora si può accedere (ssh) al container master ed eseguire il cluster Pivotal HD.

33
ssh [email protected] # Password: changeme
# Make sure all services are running. Wait a few moments if any of
them are not running yet.
service commander status
# Login as PHD admin user
su - gpadmin
# Start the cluster
icm_client start -l test
3.2.4 Test HDFS e MapReduce per Hadoop su Docker
A questo punto, Pivotal Hadoop è in esecuzione, ma HAWQ ancora no. Prima di farlo
partire, si dovrebbe verificare se Hadoop è in esecuzione.
Innanzitutto, si va all’interfaccia web-based per lo stato di Hadoop, situata all’indirizzo
http://172.17.0.2:50070/dfshealth.jsp, che visualizza lo stato di HDFS, cioè Hadoop
Distributed File System. Se sono presenti due “Live Nodes” (vedi immagine), vuol dire
che i nodi dati dei container Docker sono connessi al container master.
Dopo di che, si accede all’indirizzo http://172.17.0.2:8088/cluster, che mostra lo stato di
MapReduce, framework di programmazione utilizzato per semplificare il processamento
di massicci insiemi di dati. Di seguito un esempio di utilizzo di MapReduce con
contemporaneo controllo sull’interfaccia web mentre il processo è in esecuzione.
# Simple ls command
hadoop fs -ls /

34
# Make an input directory
hadoop fs -mkdir /tmp/test_input
# Copy a text file
hadoop fs -copyFromLocal /usr/lib/gphd/hadoop/CHANGES.txt
/tmp/test_input
# Run a wordcount MapReduce!
hadoop jar /usr/lib/gphd/hadoop-mapreduce/hadoop-mapreduce-
examples.jar wordcount /tmp/test_input /tmp/test_output
# Check the result
hadoop fs -cat /tmp/test_output/part*
3.2.5 Esecuzione di HAWQ-SQL su Hadoop
Ora che si è sicuri che Hadoop stia eseguendo correttamente su Docker, si può far partire il
cluster HAWQ. In questo esempio, hawq-master è in esecuzione sulla macchina slave1;
quindi, si deve effettuare il login sulla macchina slave1.
ssh slave1 # which is hawq master
su - gpadmin
# Source the environment variables for HAWQ.
source /usr/lib/gphd/hawq/greenplum_path.sh
# SSH keys should be set among HAWQ cluster nodes.
echo -e "slave1nslave2" > HAWQ_HOSTS.txt
gpssh-exkeys -f HAWQ_HOSTS.txt # gpadmin's password is gpadmin
# Initialize HAWQ cluster.
/etc/init.d/hawq init
3.2.6 Test HAWQ-SQL su Hadoop
Dal momento che è stato effettuato il login, HAWQ ora è in esecuzione, va verificato.

35
# On slave1, login as gpadmin and source the environment variables
if you haven’t so.
su - gpadmin
source /usr/lib/gphd/hawq/greenplum_path.sh
# Postgres shell
psql -p 5432
create table test1 (a int, b text);
# Insert a couple of records
insert into test1 values (1, 'text value1');
insert into test1 values (2, 'text value2');
# See it returns the rows.
select * from test1;
# Exit the shell and find how they are stored in HDFS.
hadoop fs -cat /hawq_data/gpseg*/*/*/* # This shows a raw hawq file
on hdfs
Ora, salvo imprevisti, Pivotal HD e HAWQ sono in esecuzione sul proprio ambiente di
sviluppo all’interno dei container Docker.

36
Conclusioni
In conclusione, abbiamo visto come Docker sia molto più che una macchina virtuale, è
un’evoluzione della tecnologia di virtualizzazione. Esso permette di gestire molti
contenitori contemporaneamente garantendone l’isolamento e l’integrità, cruciali per la
sicurezza di un sistema, sfruttando al massimo il supporto hardware a disposizione di
un’azienda. Le differenze sostanziali tra la virtualizzazione di Docker e quella di una
macchina virtuale è che, con Docker, tutti i contenitori condividono lo stesso kernel di
base, quello del sistema host. Inoltre, consente di fare un grande passo in avanti nella
scalabilità, migliorando l’implementazione del codice su diversi server in un tempo più
breve.
Vedendo come Docker venga incluso in progetti di aziende quali Red Hat, IBM, Google,
Cisco Systems e Microsoft, è chiaro che esso rappresenta il punto di svolta della
virtualizzazione e col tempo sarà sempre più diffuso il suo utilizzo.

37
Bibliografia
[1] Sébastien Goasguen, Docker Cookbook, O’Reilly, 2015
[2] Sito ufficiale Docker, https://docs.docker.com/swarm/, 12/12/2016
[3] C. Cowan C. Gaskins, White Paper 102 Rev. 3, Schneider Electric, 2012
[4] M. Al-Fares S. Radhakrishnan B. Raghavan N. Huang A. Vahdat, Hedera: Dynamic
Flow Scheduling for Data Center Networks, Department of Computer Science and
Engineering Department of Computer Science & University of California, San Diego
Williams College, 2010
[5] Container e alter nuove tecnologie nelle IT operations,
http://www.mokabyte.it/2015/12/containersoperations-2/, 09/12/2016
[6] Che cos’è un data center, https://www.paloaltonetworks.it/resources/learning-
center/what-is-a-data-center.html, 05/12/2016
[7] Guida al data center, https://www.digital4.biz/searchdatacenter/system-
management/guida-al-data-center-cos-e-come-funziona-classificazione-e-
vantaggi_43672158815.htm, 06/12/2016
[8] I container: cosa sono e come funzionano, http://www.cloudtalk.it/container-cosa-
sono-come-funzionano/, 10/12/2016
[9] 6 Easy Steps: Deploy Pivotal's Hadoop on Docker,
https://blog.pivotal.io/pivotal/products/6-easy-steps-deploy-pivotals-hadoop-on-docker,
27/12/2016
[10] Overview of Docker Compose, https://docs.docker.com/compose/overview/,
13/12/2016


















