
Modelli Probabilistici per la Computazione Affettiva ...
30
Modelli Probabilistici per la Computazione Affettiva: Inferenza con Belief Propagation su Cluster Graph Corso di Modelli di Computazione Affettiva Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano [email protected] [email protected] http://boccignone.di.unimi.it/CompAff2015.html • Possibili algoritmi: • Push delle somme • Eliminazione variabili (VE, Variable Elimination, programmazione dinamica) • Message passing sul grafo • Belief propagation • Approssimazioni variazionali • Algoritmi stocastici: • Markov Chain Monte Carlo (MCMC) • Importance sampling Inferenza esatta //La forma Somma-Prodotto (Sum-Product)
Transcript of Modelli Probabilistici per la Computazione Affettiva ...

Modelli Probabilistici per la Computazione Affettiva:
Inferenza con Belief Propagation su Cluster Graph
Corso di Modelli di Computazione Affettiva
Prof. Giuseppe Boccignone
Dipartimento di InformaticaUniversità di Milano
[email protected]@unimi.it
http://boccignone.di.unimi.it/CompAff2015.html
• Possibili algoritmi:
• Push delle somme
• Eliminazione variabili (VE, Variable Elimination, programmazione dinamica)
• Message passing sul grafo
• Belief propagation
• Approssimazioni variazionali
• Algoritmi stocastici:
• Markov Chain Monte Carlo (MCMC)
• Importance sampling
Inferenza esatta //La forma Somma-Prodotto (Sum-Product)
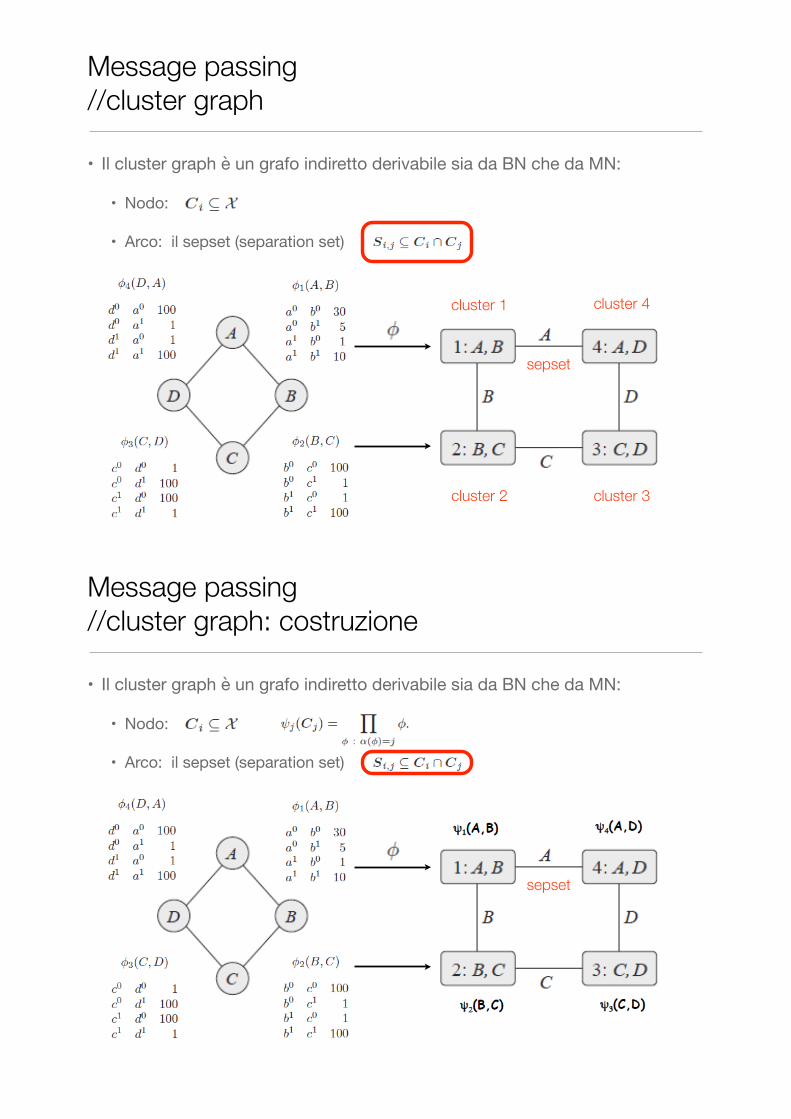
Message passing //cluster graph
• Il cluster graph è un grafo indiretto derivabile sia da BN che da MN:
• Nodo:
• Arco: il sepset (separation set)
cluster 1
cluster 2 cluster 3
cluster 4
sepset
Message passing //cluster graph: costruzione
• Il cluster graph è un grafo indiretto derivabile sia da BN che da MN:
• Nodo:
• Arco: il sepset (separation set)
sepset
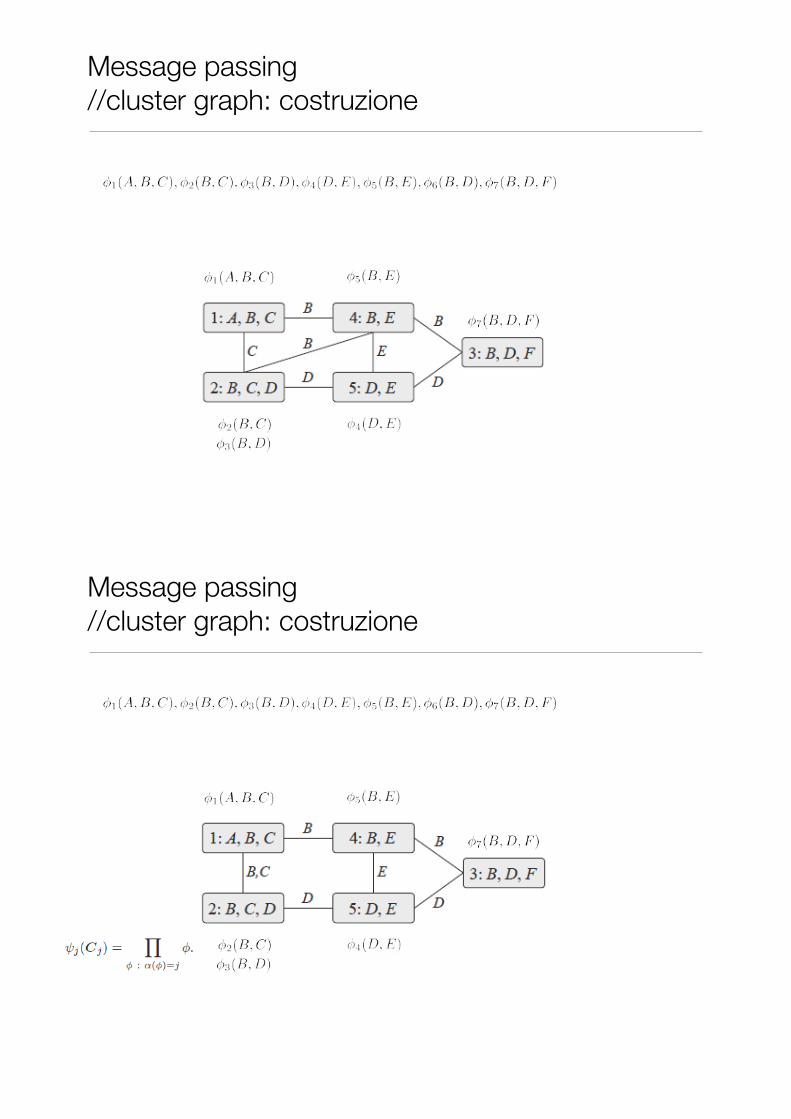
Message passing //cluster graph: costruzione
Message passing //cluster graph: costruzione

• 1. Family preservation: per ogni fattore ci deve essere un cluster in grado di contenerlo
Message passing //Proprietà dei cluster graph
Message passing //Proprietà dei cluster graph
• 2. Running Intersection Property (RIP): per ogni coppia di cluster che contengono una stessa variabile , deve esistere un cammino che unisce i due cluster dove (sepset) su tutti gli edge del cammino. Tale cammino è unico
unicità esistenza
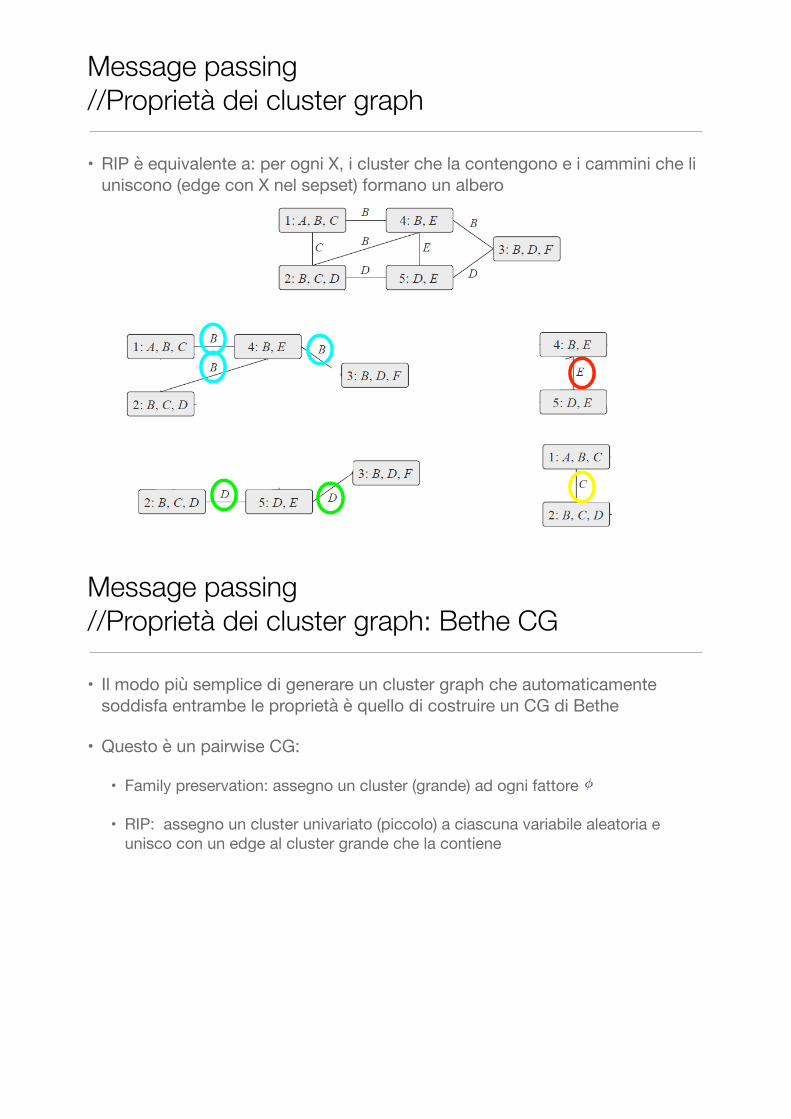
• RIP è equivalente a: per ogni X, i cluster che la contengono e i cammini che li uniscono (edge con X nel sepset) formano un albero
Message passing //Proprietà dei cluster graph
Message passing //Proprietà dei cluster graph: Bethe CG
• Il modo più semplice di generare un cluster graph che automaticamente soddisfa entrambe le proprietà è quello di costruire un CG di Bethe
• Questo è un pairwise CG:
• Family preservation: assegno un cluster (grande) ad ogni fattore
• RIP: assegno un cluster univariato (piccolo) a ciascuna variabile aleatoria e unisco con un edge al cluster grande che la contiene
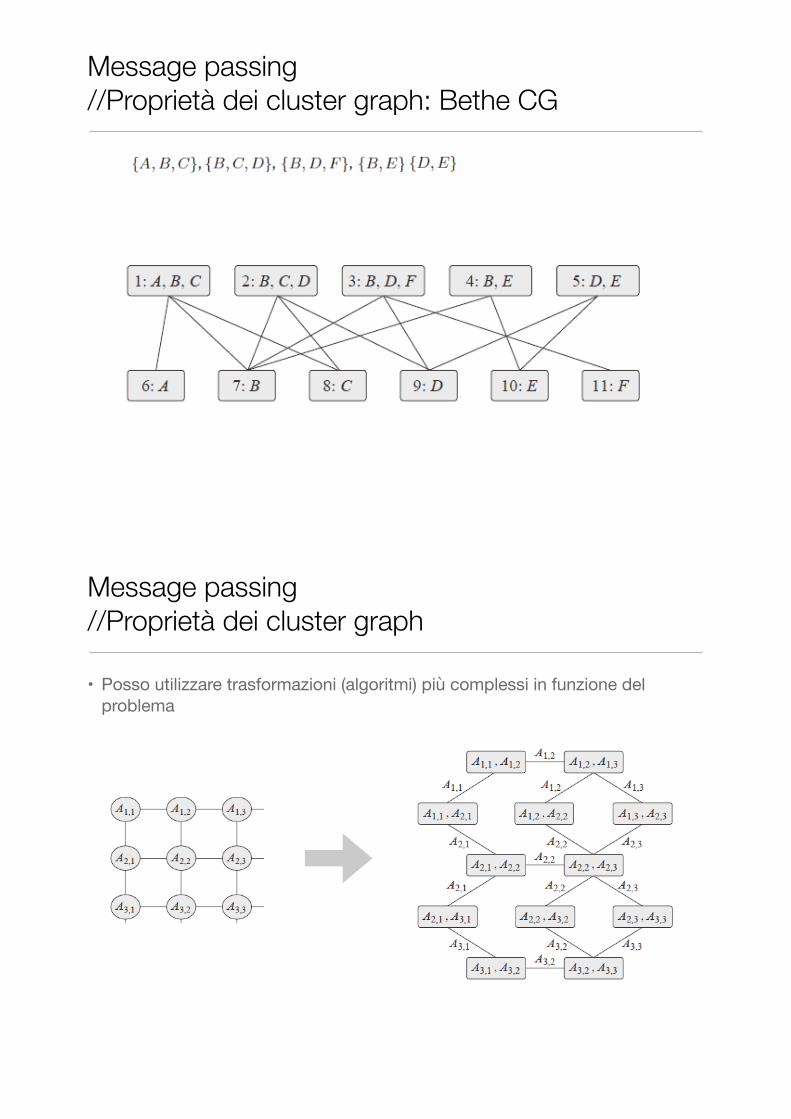
Message passing //Proprietà dei cluster graph: Bethe CG
Message passing //Proprietà dei cluster graph
• Posso utilizzare trasformazioni (algoritmi) più complessi in funzione del problema
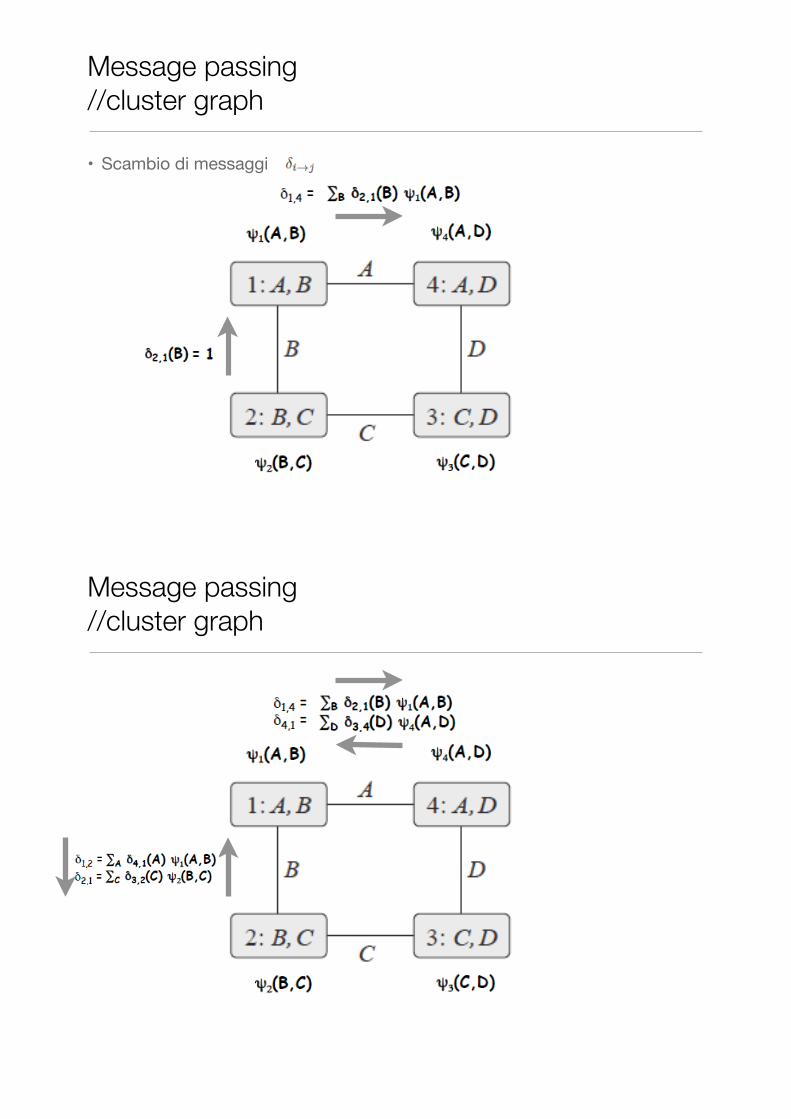
Message passing //cluster graph
• Scambio di messaggi
Message passing //cluster graph
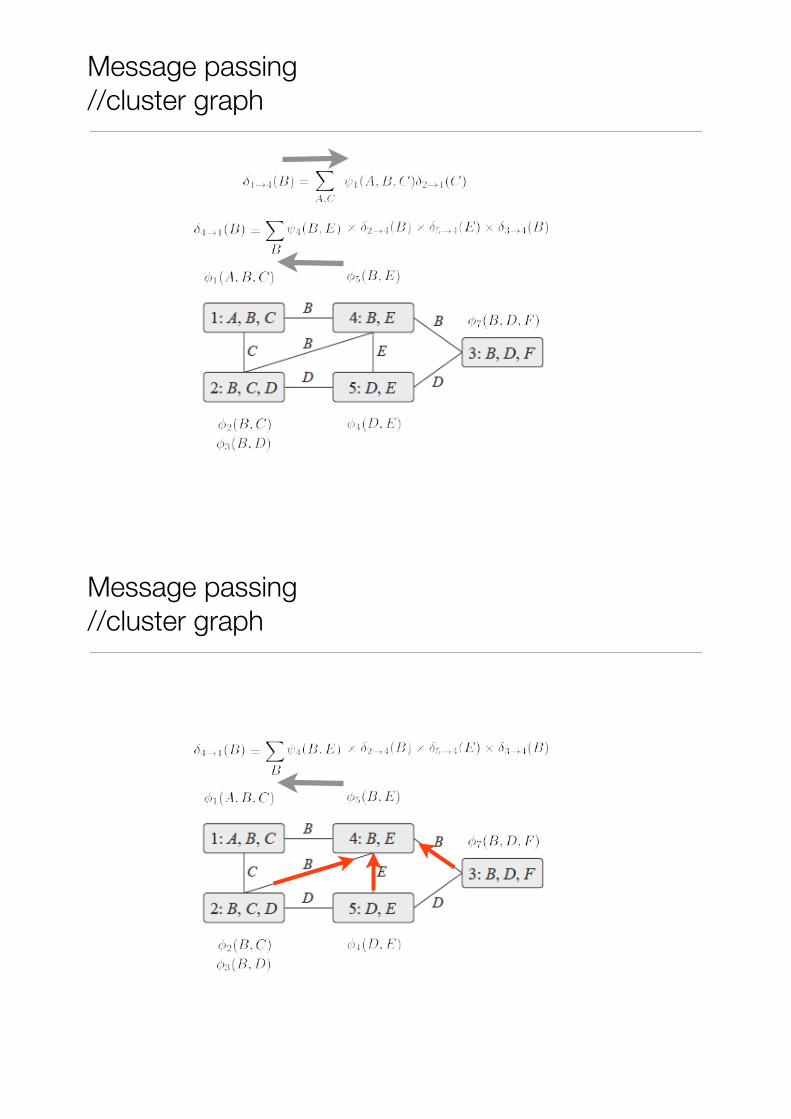
Message passing //cluster graph
Message passing //cluster graph
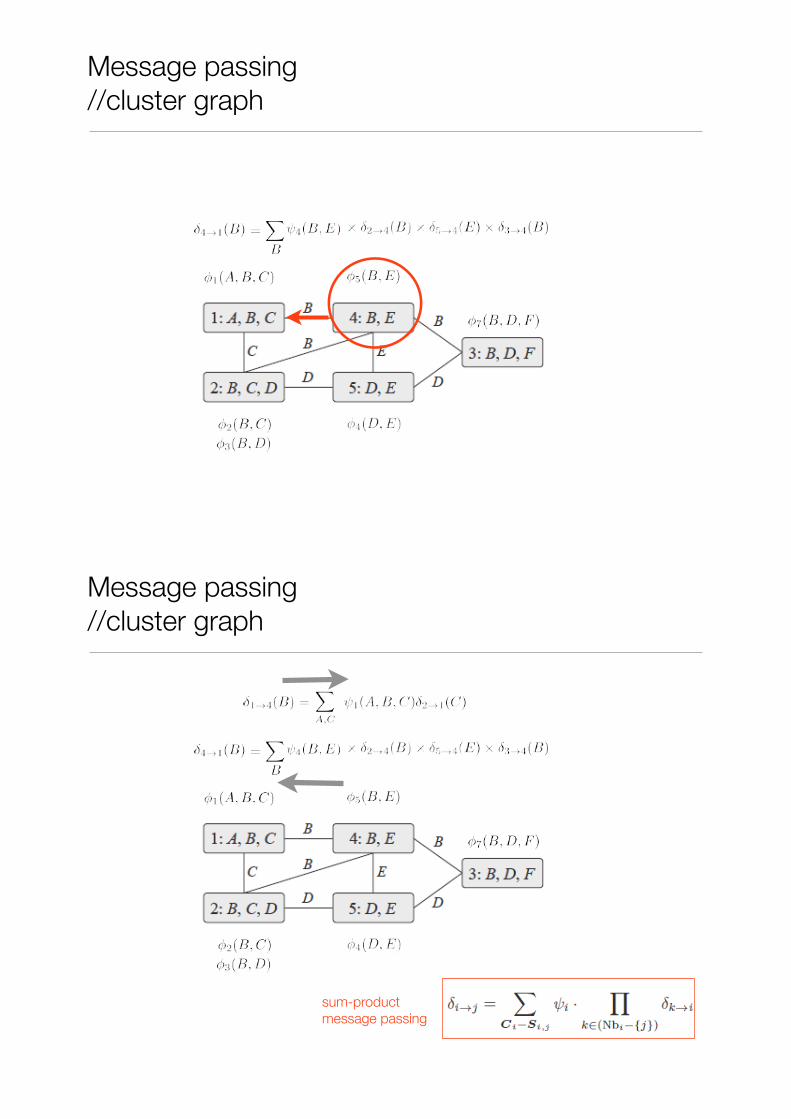
Message passing //cluster graph
sum-product message passing
Message passing //cluster graph

Message passing //cluster graph
• Quando la propagazione di messaggi è conclusa, in ciascun cluster posso calcolare il belief (una pseudo-marginale)
Message passing //Belief propagation su cluster graph
• Algoritmo
• Assegna i fattori al cluster e calcola i fattori iniziali
• Inizializza tutti i messaggi a 1 per tutti gli edge (i,j)
• Repeat...
• seleziona l’edge (i,j) e passa il messaggio
• A convergenza, calcola i belief in ciascun cluster
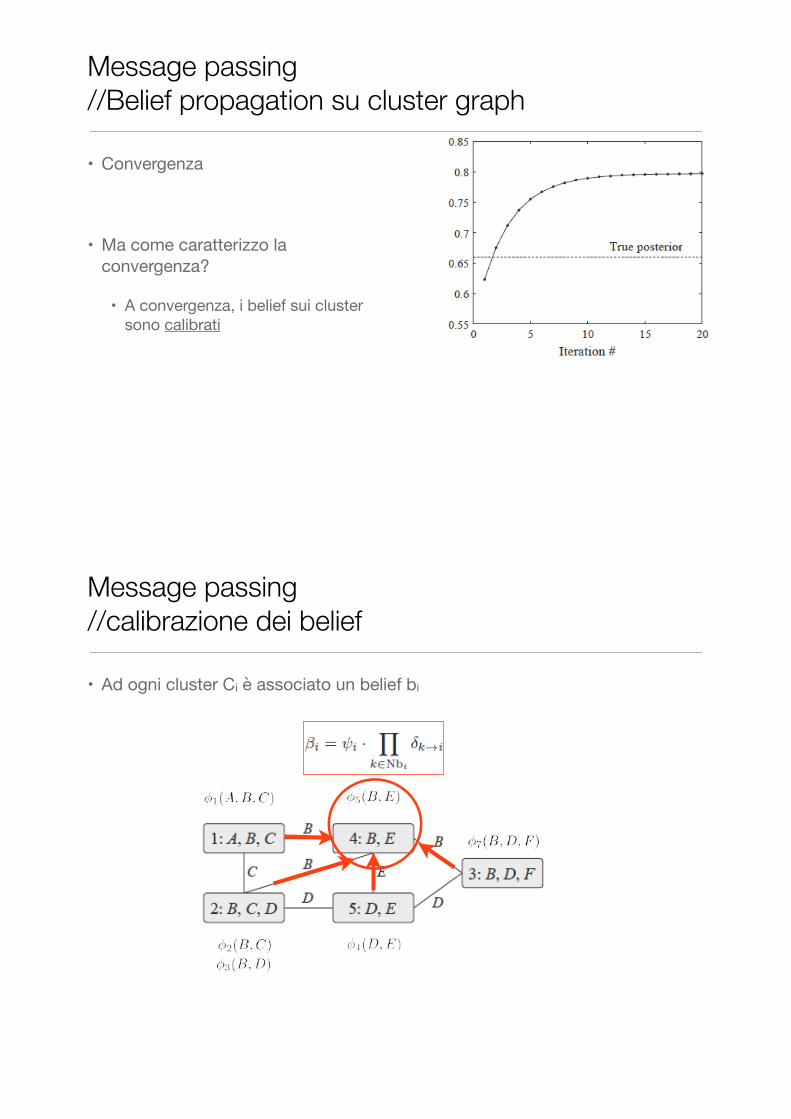
• Convergenza
• Ma come caratterizzo la convergenza?
• A convergenza, i belief sui cluster sono calibrati
Message passing //Belief propagation su cluster graph
Message passing //calibrazione dei belief
• Ad ogni cluster Ci è associato un belief bi
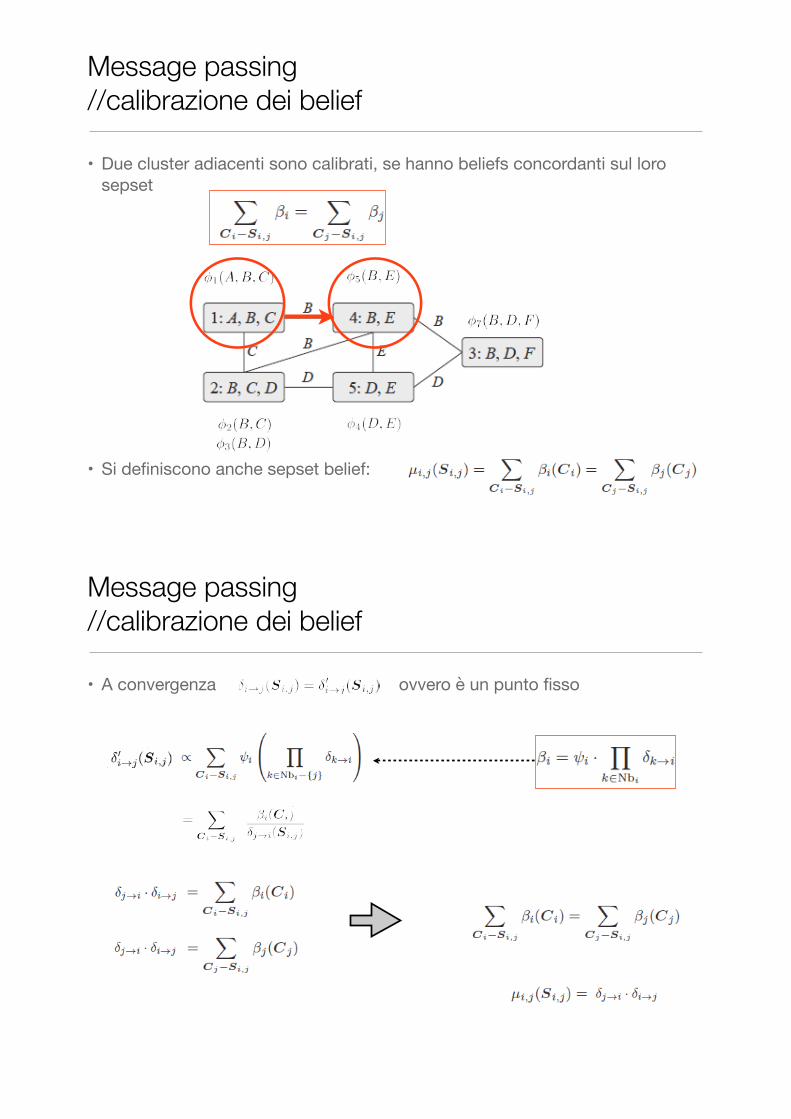
Message passing //calibrazione dei belief
• Due cluster adiacenti sono calibrati, se hanno beliefs concordanti sul loro sepset
• Si definiscono anche sepset belief:
• A convergenza ovvero è un punto fisso
Message passing //calibrazione dei belief

Message passing //calibrazione dei belief
• Ricordiamo la definizione di cluster graph
Message passing //Clique tree o junction tree
• 1. Family preservation: per ogni fattore ci deve essere un cluster in grado di contenerlo
• 2. Running Intersection Property (RIP): per ogni coppia di cluster che contengono una stessa variabile , deve esistere un cammino che unisce i due cluster dove (sepset) su tutti gli edge del cammino. Tale cammino è unico
Se non si considera la condizione
in generale sono ammessi loop su cluster
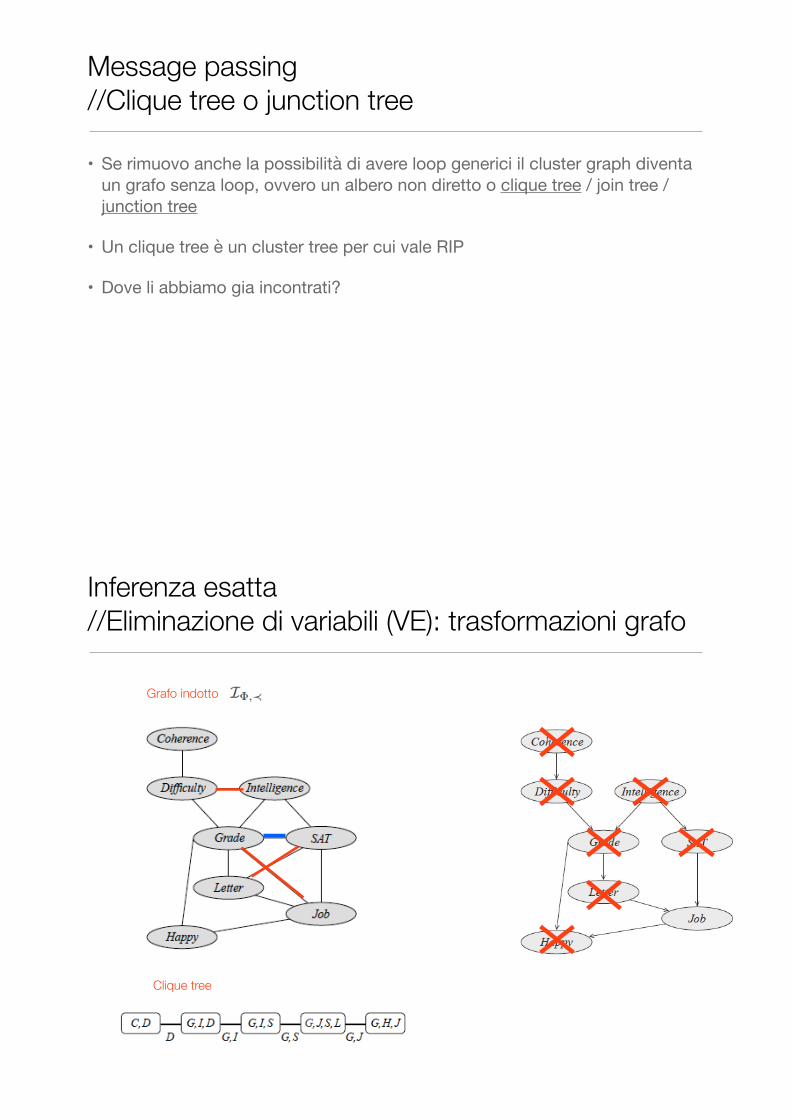
• Se rimuovo anche la possibilità di avere loop generici il cluster graph diventa un grafo senza loop, ovvero un albero non diretto o clique tree / join tree / junction tree
• Un clique tree è un cluster tree per cui vale RIP
• Dove li abbiamo gia incontrati?
Message passing //Clique tree o junction tree
Grafo indotto
Clique tree
Inferenza esatta //Eliminazione di variabili (VE): trasformazioni grafo
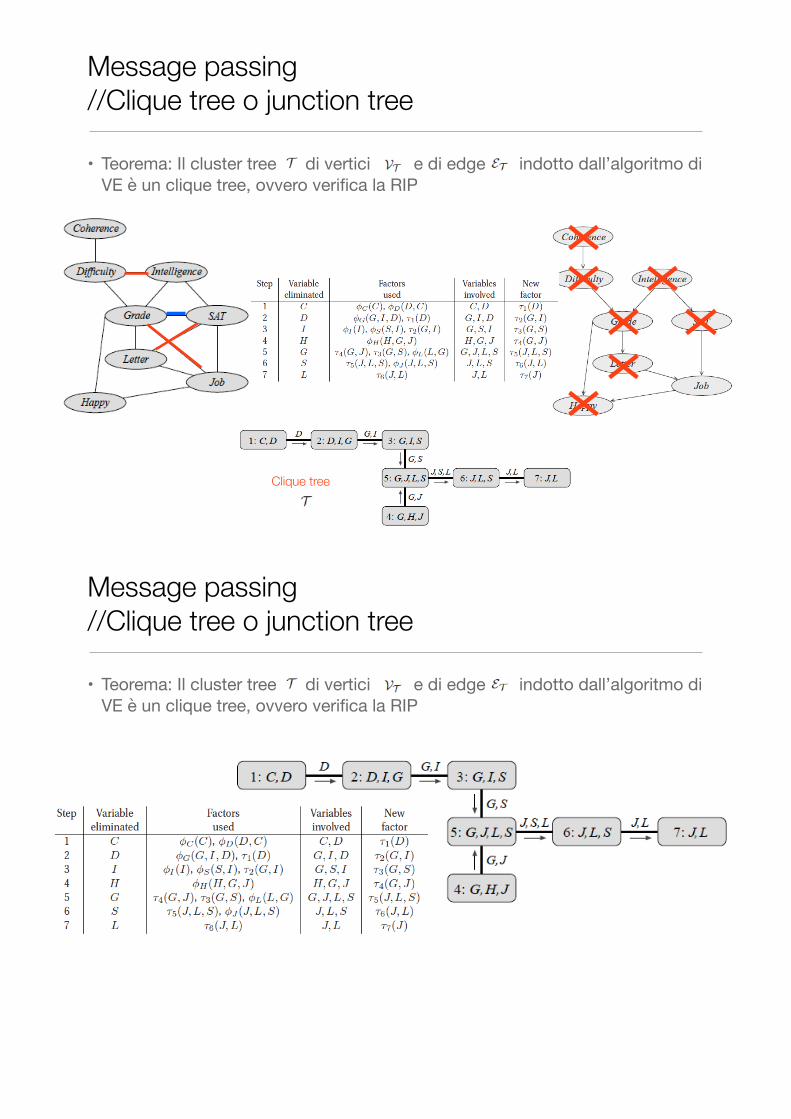
• Teorema: Il cluster tree di vertici e di edge indotto dall’algoritmo di VE è un clique tree, ovvero verifica la RIP
Message passing //Clique tree o junction tree
Clique tree
• Teorema: Il cluster tree di vertici e di edge indotto dall’algoritmo di VE è un clique tree, ovvero verifica la RIP
Message passing //Clique tree o junction tree
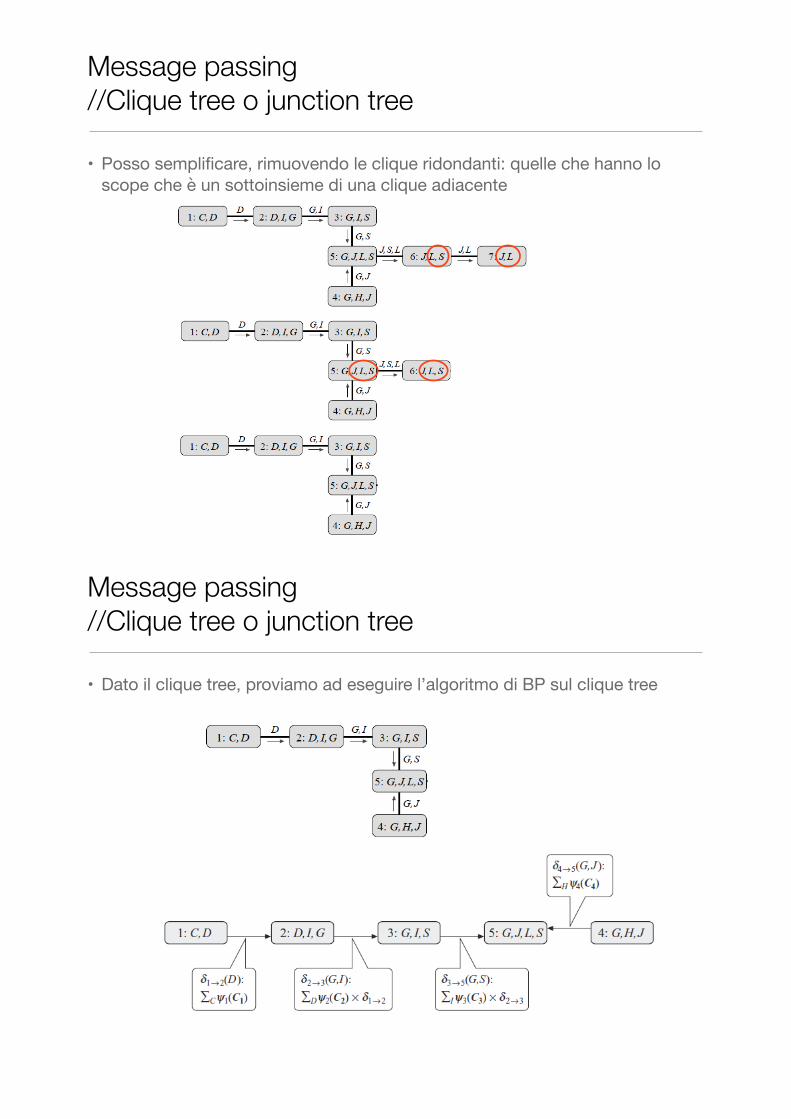
• Posso semplificare, rimuovendo le clique ridondanti: quelle che hanno lo scope che è un sottoinsieme di una clique adiacente
Message passing //Clique tree o junction tree
• Dato il clique tree, proviamo ad eseguire l’algoritmo di BP sul clique tree
Message passing //Clique tree o junction tree
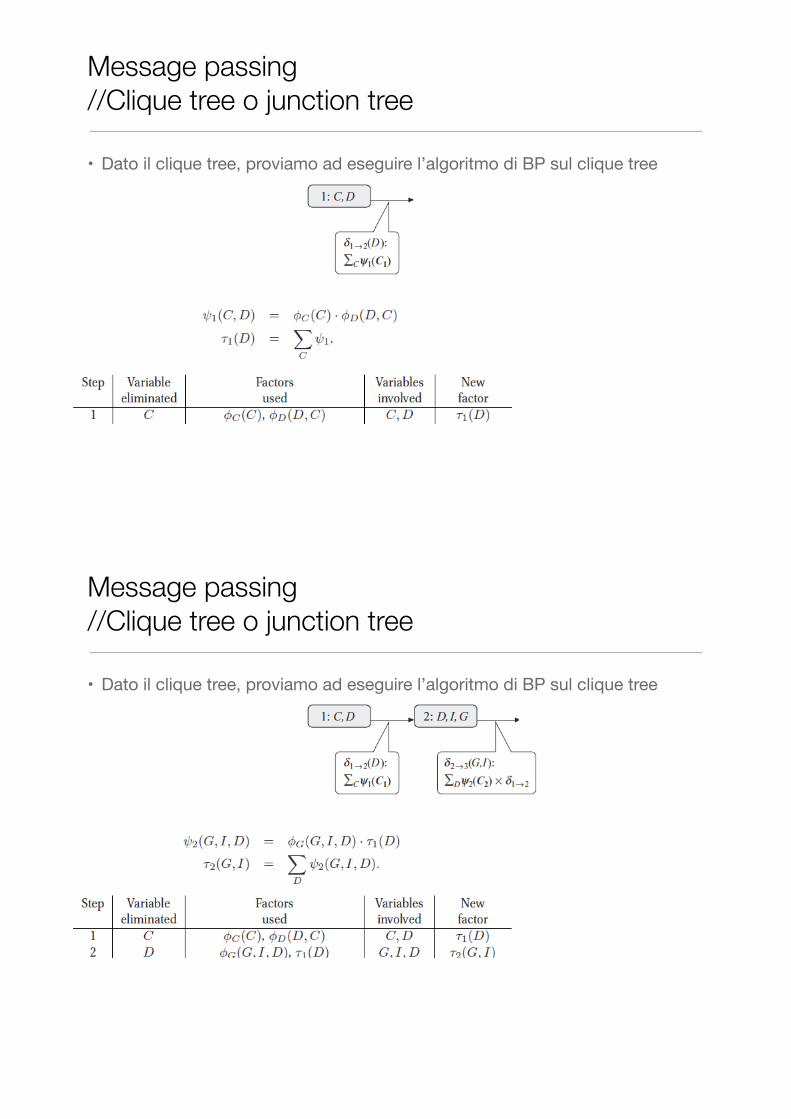
• Dato il clique tree, proviamo ad eseguire l’algoritmo di BP sul clique tree
Message passing //Clique tree o junction tree
• Dato il clique tree, proviamo ad eseguire l’algoritmo di BP sul clique tree
Message passing //Clique tree o junction tree

• Su un clique tree, l’algoritmo di BP è una variante dell’algoritmo di VE : i beliefs risultanti, sono marginali corrette
Message passing //Clique tree o junction tree
• Posso cambiare la radice dell’albero per la propagazione dei messaggi
Message passing //Clique tree o junction tree
su un clique tre siamo sempre in condizione di
message passing asincrono
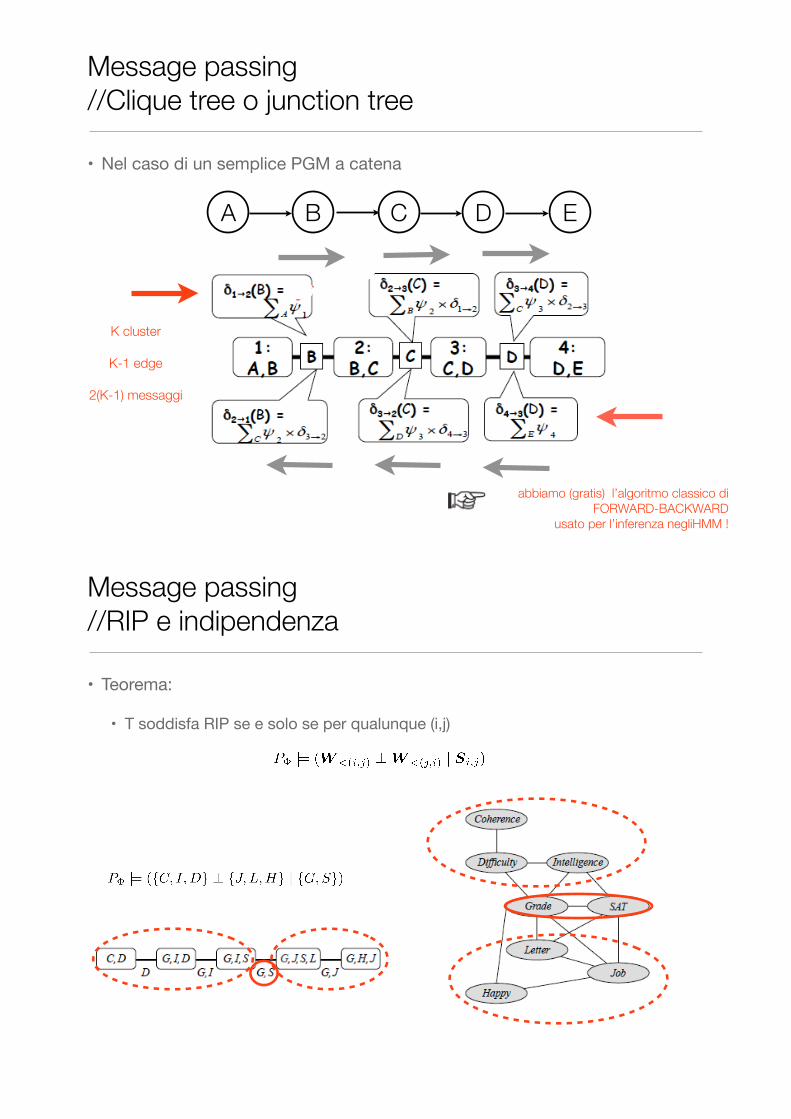
• Nel caso di un semplice PGM a catena
A B C D E
Message passing //Clique tree o junction tree
abbiamo (gratis) l’algoritmo classico di FORWARD-BACKWARD
usato per l’inferenza negliHMM !
K cluster
K-1 edge
2(K-1) messaggi
• Teorema:
• T soddisfa RIP se e solo se per qualunque (i,j)
Message passing //RIP e indipendenza
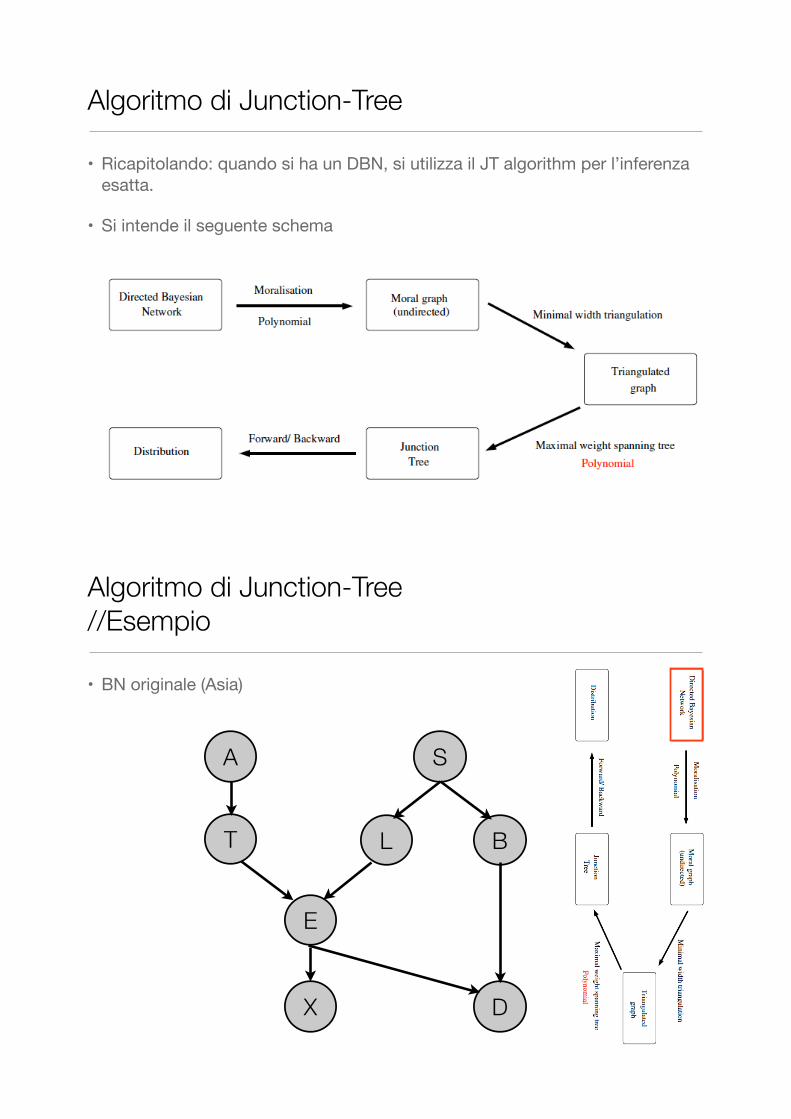
Algoritmo di Junction-Tree
• Ricapitolando: quando si ha un DBN, si utilizza il JT algorithm per l’inferenza esatta.
• Si intende il seguente schema
A S
L BT
E
X D
• BN originale (Asia)
Algoritmo di Junction-Tree //Esempio
A S
L BT
E
X D
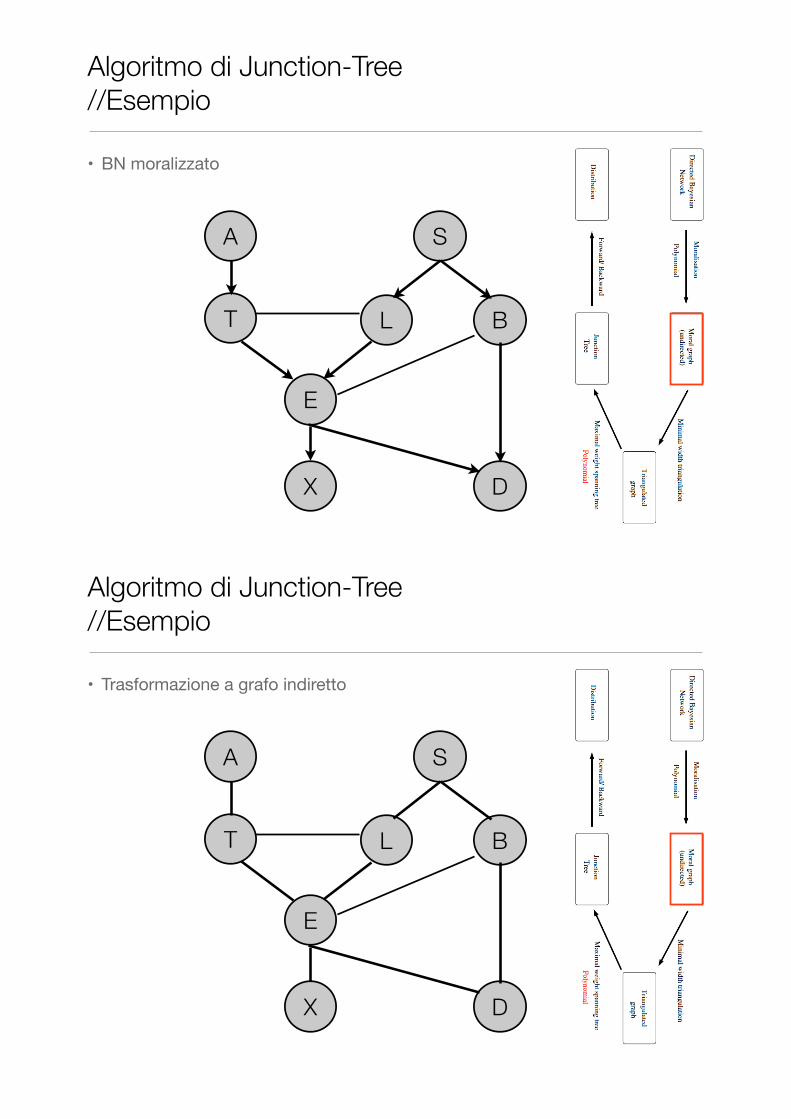
• BN moralizzato
Algoritmo di Junction-Tree //Esempio
A S
L BT
E
X D
• Trasformazione a grafo indiretto
Algoritmo di Junction-Tree //Esempio
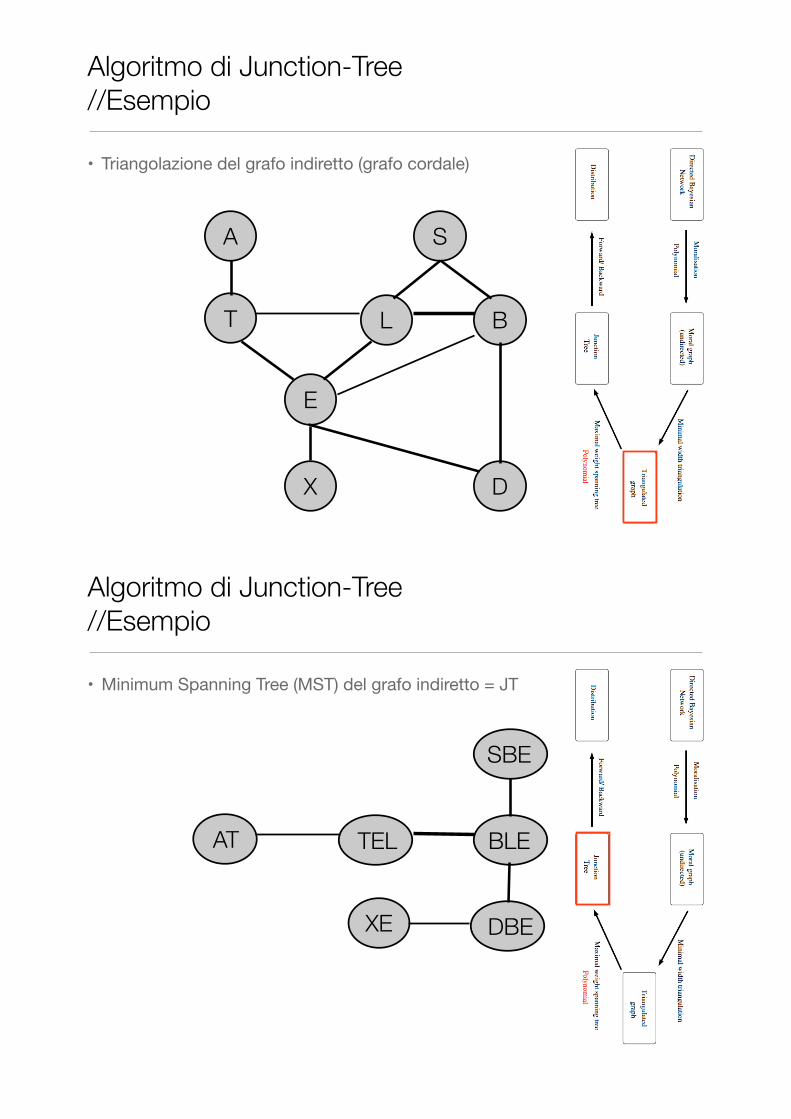
A S
L BT
E
X D
• Triangolazione del grafo indiretto (grafo cordale)
Algoritmo di Junction-Tree //Esempio
SBE
TEL BLEAT
XE DBE
• Minimum Spanning Tree (MST) del grafo indiretto = JT
Algoritmo di Junction-Tree //Esempio
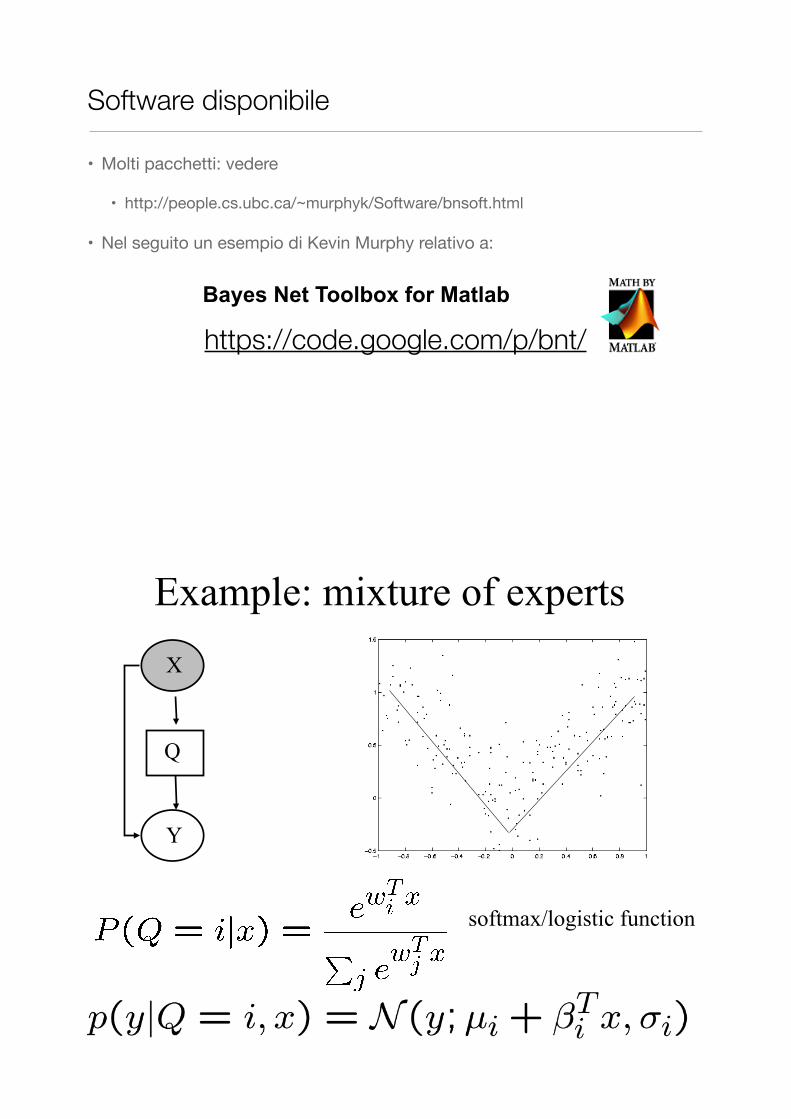
Software disponibile
• Molti pacchetti: vedere
• http://people.cs.ubc.ca/~murphyk/Software/bnsoft.html
• Nel seguito un esempio di Kevin Murphy relativo a:
Bayes Net Toolbox for Matlab
https://code.google.com/p/bnt/
Example: mixture of experts
X
Y
Q
softmax/logistic function

1. Making the graph
X
Y
Q
X = 1; Q = 2; Y = 3; dag = zeros(3,3); dag(X, [Q Y]) = 1; dag(Q, Y) = 1;
•Graphs are (sparse) adjacency matrices •GUI would be useful for creating complex graphs •Repetitive graph structure (e.g., chains, grids) is best created using a script (as above)
2. Making the model
node_sizes = [1 2 1]; dnodes = [2]; bnet = mk_bnet(dag, node_sizes, … ‘discrete’, dnodes);
X
Y
Q
•X is always observed input, hence only one effective value •Q is a hidden binary node •Y is a hidden scalar node •bnet is a struct, but should be an object •mk_bnet has many optional arguments, passed as string/value pairs

3. Specifying the parametersX
Y
Q
bnet.CPD{X} = root_CPD(bnet, X); bnet.CPD{Q} = softmax_CPD(bnet, Q); bnet.CPD{Y} = gaussian_CPD(bnet, Y);
•CPDs are objects which support various methods such as •Convert_from_CPD_to_potential •Maximize_params_given_expected_suff_stats
•Each CPD is created with random parameters •Each CPD constructor has many optional arguments
4. Training the modelload data –ascii; ncases = size(data, 1); cases = cell(3, ncases); observed = [X Y]; cases(observed, :) = num2cell(data’);
•Training data is stored in cell arrays (slow!), to allow for variable-sized nodes and missing values •cases{i,t} = value of node i in case t
engine = jtree_inf_engine(bnet, observed);
•Any inference engine could be used for this trivial modelbnet2 = learn_params_em(engine, cases);•We use EM since the Q nodes are hidden during training •learn_params_em is a function, but should be an object
X
Y
Q
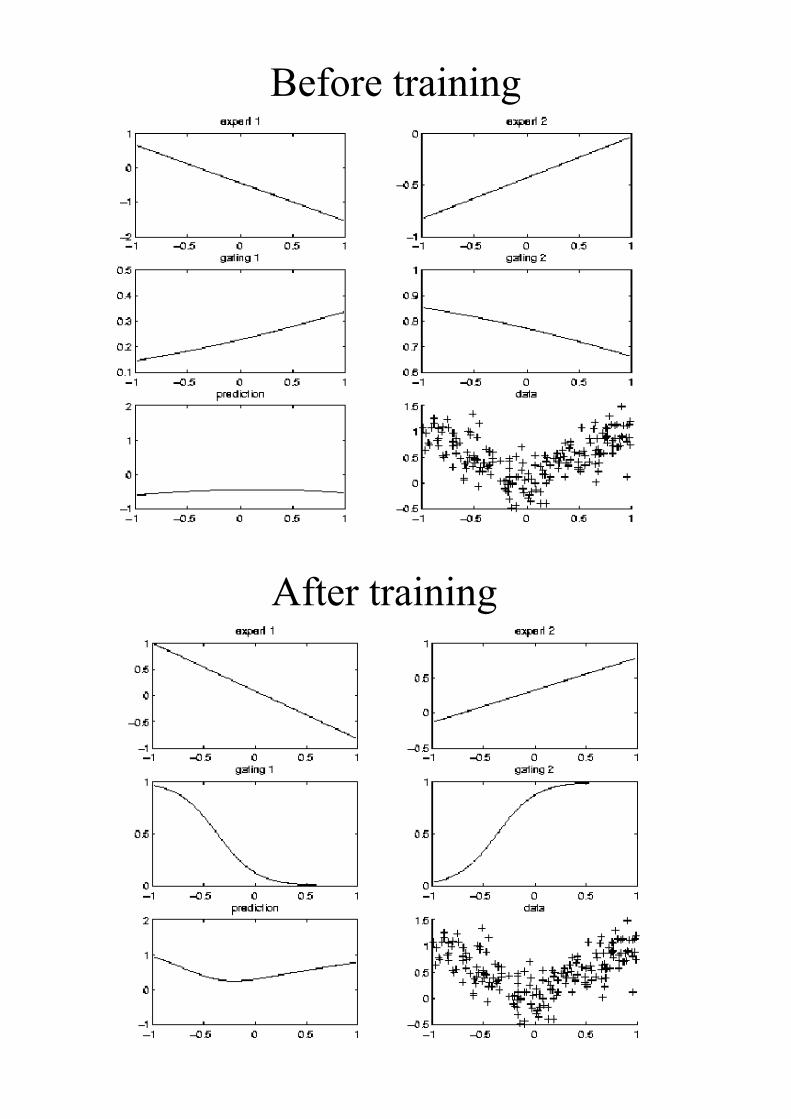
Before training
After training

5. Inference/ predictionengine = jtree_inf_engine(bnet2);
evidence = cell(1,3);
evidence{X} = 0.68; % Q and Y are hidden
engine = enter_evidence(engine, evidence);
m = marginal_nodes(engine, Y);
m.mu % E[Y|X]
m.Sigma % Cov[Y|X]X
Y
Q
• Se eseguo l’algoritmo generale su cluster graph:
• ho l’algoritmo di Loopy Belief Propagation
• potrebbe non convergere
• in genere per applicazioni pratiche converge
• l’inferenza è approssimata
• ho comunque il problema di come schedulare il message passing
Message passing //BP in generale
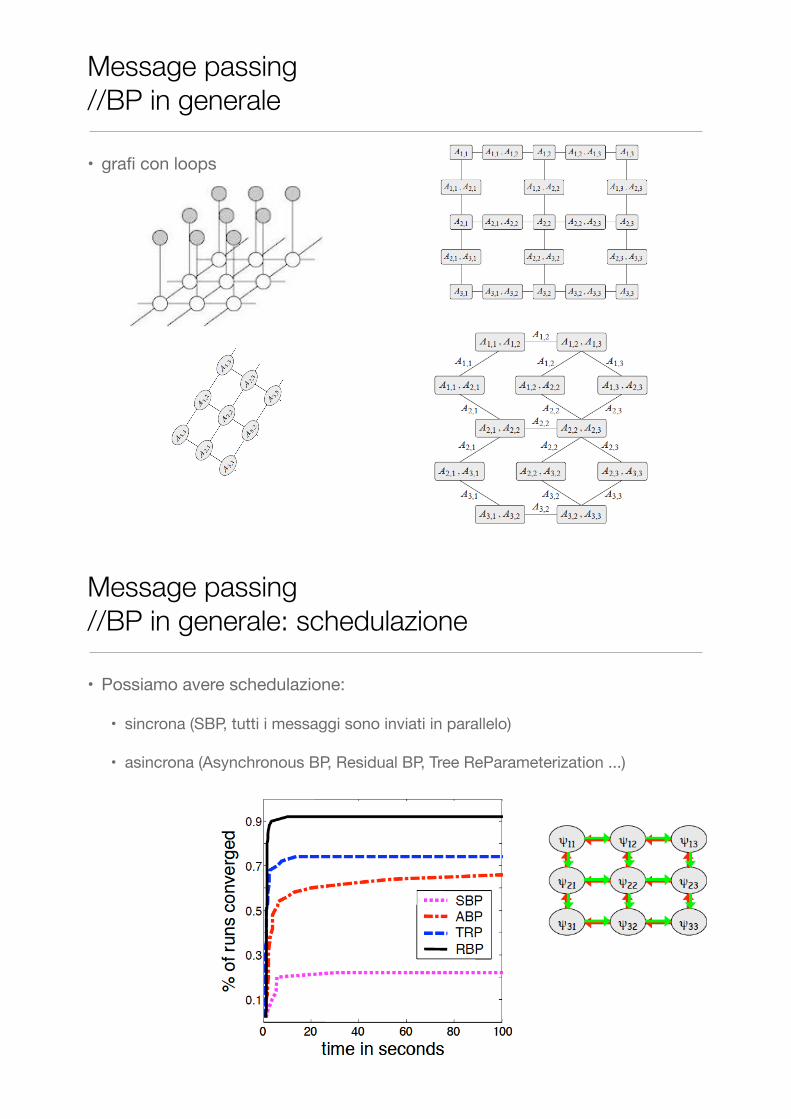
• grafi con loops
Message passing //BP in generale
• Possiamo avere schedulazione:
• sincrona (SBP, tutti i messaggi sono inviati in parallelo)
• asincrona (Asynchronous BP, Residual BP, Tree ReParameterization ...)
Message passing //BP in generale: schedulazione
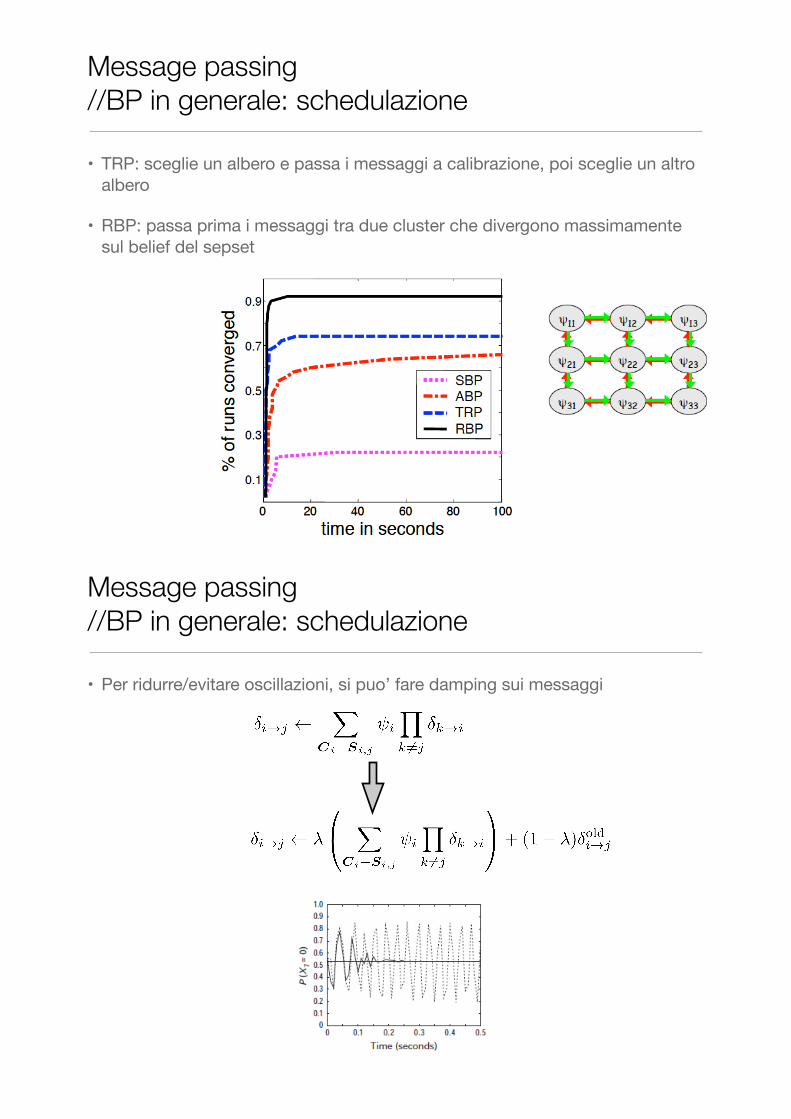
• TRP: sceglie un albero e passa i messaggi a calibrazione, poi sceglie un altro albero
• RBP: passa prima i messaggi tra due cluster che divergono massimamente sul belief del sepset
Message passing //BP in generale: schedulazione
• Per ridurre/evitare oscillazioni, si puo’ fare damping sui messaggi
Message passing //BP in generale: schedulazione

• Possibili algoritmi:
• Push delle somme
• Eliminazione variabili (VE, Variable Elimination, programmazione dinamica)
• Message passing sul grafo
• Belief propagation
• Approssimazioni variazionali
• Algoritmi stocastici:
• Markov Chain Monte Carlo (MCMC)
• Importance sampling
Inferenza esatta //La forma Somma-Prodotto (Sum-Product)
Inferenza come ottimizzazione Minimizzazione energia libera di Gibbs /Bethe (GBP)
Expectation-Propagation


















