
Matteo Gallone - spiro.fisica.unipd.itgallone/Analisi2.pdf ·...
57
Matteo Gallone Appunti di Analisi Matematica II
Transcript of Matteo Gallone - spiro.fisica.unipd.itgallone/Analisi2.pdf ·...

Matteo Gallone
Appunti di Analisi Matematica II

Questo testo è distribuito con la licenza Creative Commons: Attribuzione - Non commerciale - Con-dividi allo stesso modo 3.0, ovvero tu sei libero di di riprodurre, distribuire, comunicare al pubblico,esporre in pubblico, rappresentare, eseguire e recitare quest’opera di modificare quest’opera alle seguenticondizioni: a) Attribuzione — Devi attribuire la paternità dell’opera nei modi indicati dall’autore o dachi ti ha dato l’opera in licenza e in modo tale da non suggerire che essi avallino te o il modo in cui tuusi l’opera. b) Non commerciale — Non puoi usare quest’opera per fini commerciali. c) Condividi allostesso modo — Se alteri o trasformi quest’opera, o se la usi per crearne un’altra, puoi distribuire l’operarisultante solo con una licenza identica o equivalente a questa.
Per il resto questa risulta essere una raccolta di appunti del corso di Analisi Matematica II tenutodal prof. Roberto Monti nell’AA 2010/2011 per il corso di laurea in Fisica nell’università di Padova.Tuttavia, per approfondire meglio alcune parti ho deciso di aggiungere (poco) leggendo dalle dispensedel corso di Analisi Matematica II tenuto dal Dott. Corrado Marastoni nell’AA 2008/2009. Ulterioriinformazioni sono state tratte dal libro di testo “P. MARCELLINI - C. SBORDONE, Elementi di AnalisiMatematica II ”.
È inoltre impossibile scrivere qualcosa di così impegnativo senza commettere errori o dimenticanze.Ringrazio pertanto tutti quelli che mi hanno suggerito correzioni o aggiunte nel testo.
Questa versione degli appunti è stata compilata il 23 luglio 2012.

Indice
1 Integrali generalizzati 51.1 Integrali impropri su intervallo illimitato . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2 Convergenza assoluta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3 Integrali oscillatori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.4 Integrali impropri di funzioni non limitate . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Equazioni differenziali: primi elementi 112.1 Nozioni generali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2 Equazioni lineari del primo ordine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.3 Equazioni a variabili separabili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.4 Equazioni lineari del secondo ordine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.5 Metodo della variazione delle costanti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.6 Equazioni a coefficenti costanti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 Curve in Rn 213.1 Definizioni di base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2 Lunghezza di una curva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.3 Ascissa curvilinea e integrale curvilineo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4 Spazi metrici e normati 294.1 Definizioni ed esempi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.2 Successioni in uno spazio metrico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304.3 Funzioni continue tra spazi metrici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.4 Spazi metrici completi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.5 Convergenza puntuale e uniforme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.6 Teorema delle contrazioni di Banach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.7 Topologia di uno spazio metrico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.8 Spazi metrici compatti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 364.9 Insiemi connessi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5 Calcolo differenziale in Rn 395.1 Limiti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395.2 Derivate parziali e differenziabilità . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405.3 Funzioni composte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 445.4 Teoremi del valor medio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 455.5 Derivate successive e Formula di Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . 465.6 Estremi relativi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
6 Ultimi teoremi 516.1 Teorema dell’invertibilità locale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 516.2 Teorema sulla funzione implicita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 526.3 Estremi locali vincolati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 536.4 Sottovarietà di Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546.5 Spazio normale e spazio tangente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
Matteo Gallone - Analisi Matematica II


CAPITOLO 1
Integrali generalizzati
1.1 Integrali impropri su intervallo illimitato
Definizione 1.1.1. Siano a ∈ R ed f : [a,∞) → R una funzione tale che la restrizionef : [a,M ] → R sia limitata e Riemann-integrabile per ogni a ≤ M < ∞. Diciamo che fè integrabile in senso improprio su [a,∞) se esiste finito il limite
I = limM→∞
∫ M
a
f(x) dx (1.1)
In questo caso si il numero reale I si chiamerà integrale improprio di f su [a,∞). Sidirà inoltre che l’integrale converge se il limite esiste ed è un numero reale; mentre si diràche l’integrale diverge se il limite non esiste oppure esiste ma è infinito.
L’integrale in senso improprio eredita dall’integrale di Riemann le proprietà di linearità(∫∞a
(f(x)+g(x)) dx =∫∞af(x) dx+
∫∞ag(x) dx), di monotonia (ovvero date due funzioni
f, g tali che f(x) > g(x) in tutto [a,∞) allora anche∫∞af(x) dx >
∫∞ag(x) dx), e
di decomposizione del dominio (ovvero, dato b ∈ R tale che a < b < ∞ si ha che∫∞af(x) dx =
∫ baf(x) dx+
∫∞bf(x) dx).
Esempio. Si studi la convergenza dell’integrale ∫ ∞1
1
xαdx
al variare del parametro reale α > 0.
Per prima cosa si calcola l’integrale da 1 a M della funzione integranda:∫Ma
1xα
dx. L’integrale è immediato per
qualsiasi α ∈ R, e vale[x−α+1
−α+1
]x=M
x=1= M1−α−1
1−α se α 6= 1 mentre vale [log(x)]x=Mx=1 = log(M)− log(1) per α = 1.
Secondariamente si calcola il limite di questa quantità per M → ∞. Nel primo caso avremo limM→∞M1−α−1
1−α il cuivalore dipende dal parametro α. Se α > 1 allora il limite vale 1
α−1∈ R e quindi l’integrale converge; se α < 1 allora il limite
va all’infinito e l’integrale diverge. Per il caso α = 1 bisogna calcolare il limite limM → ∞ logM = ∞, e quindi l’integralediverge.
In definitiva possiamo scrivere che ∫ ∞1
1
xαdx =
{ 1α−1
α > 1
∞ α ≤ 1
Teorema 1.1.2 (Criterio del confronto). Siano f, g : [a,∞) → R (con a ∈ R) duefunzioni Riemann-integrabili su ogni intervallo [a,M ] ⊂ R con a ≤M <∞. Supponiamo
Matteo Gallone - Analisi Matematica II

6 Integrali generalizzatiConvergenza assoluta 1.2
che esista x ≥ a tale che 0 ≤ f(x) ≤ g(x) definitivamente[1]. Allora
a)∫ ∞a
g(x) dx <∞⇒∫ ∞a
f(x) dx <∞
b)∫ ∞a
f(x) dx =∞⇒∫ ∞a
g(x) dx =∞(1.2)
Dimostrazione. Senza perdere generalità si può porre x = a. Infatti, per la proprietà di decomposizione del dominio,l’integrabilità delle funzioni dipende dall’integrabilità nell’intervallo [x,∞).[2] Per la monotonia dell’integrale di Riemannsi ha, per ogni M ≥ a
∫Ma f(x) dx ≤
∫Ma g(x) dx. Da cui, passando al limite[3] per M → ∞ si ottengono le affermazioni
a) e b). Infatti se F (M) ≤ G(M) allora anche limM→∞ F (M) ≤ limM→∞G(M). Quindi se limM→∞ F (M) = ∞ alloraanche limM→∞G(M) = ∞ mentre se limM→∞G(M) = ` ∈ R allora limM→∞ F (M) = `′ ≤ ` con `′ ∈ R. Ma il che èesattamente come dire che se l’integrale di f diverge allora diverge anche quello di g, mentre se l’integrale di g convergeallora converge anche quello di f .
Teorema 1.1.3 (Criterio del confronto asintotico). Siano f, g : [a,∞) → R (con a ∈R) due funzioni Riemann-integrabili su ogni intervallo [a,M ] ⊂ R con a ≤ M < ∞.Supponiamo che risulti g(x) > 0 per ogni x ≥ a e che esista finito e diverso da zero illimite
L = limx→∞
f(x)
g(x)6= 0
allora ∫ ∞a
f(x) dx converge ⇔∫ ∞a
g(x) dx converge
Dimostrazione. Si ha per ipotesi che L ∈ R\{0}, quindi possiamo supporre anche che L > 0. Allora per il teorema dellapermanenza del segno[4] esiste x ≥ a tale che per ogni x ≥ x e per la definizione di limite[5] si ha che: L
2≤ f(x)
g(x)≤ 2L.
Siccome g(x) > 0 allora si può riordinare la disuguaglianza ottenendo L2g(x) ≤ f(x) ≤ 2Lg(x). La tesi segue per il Teorema
1.1.2 (del confronto). Infatti, poichè L2g(x) ≤ f(x) ≤ 2Lg(x) allora se
∫∞a
L2g(x) dx = L
2
∫∞a g(x) dx diverge diverge anche∫∞
a f(x) dx, mentre se∫∞a 2Lg(x) dx = 2L
∫∞a g(x) dx converge, allora converge anche
∫∞a f(x) dx.
Esercizio 1.1. Si studi, al variare del parametro α ∈ R la convergenza dell’integraleimproprio ∫ ∞
1
xα+1
x+ 1log
(1 +
1
x
)dx
Soluzione. Sviluppando il logaritmo in serie di Taylor a ∞ si ha che f(x) = xα+1
x+1log(1 + 1
x
)= xα+1
x+1
(1x
+ o∞(
1x
))=
xα
x+1+ xα+1
x+1o∞(
1x
)= xα
x+1
(1 + x o∞
(1x
))= xα
x+1(1 + o∞(1)) = xα
x1
1+ 1x
(1 + o∞(1)) = 1x1−α (1 + o(1)). La funzione di
confronto sarà quindi g(x) = 1x1−α . Risulta g(x) > 0 per x > 0 e inoltre limx→∞
f(x)g(x)
= 1 6= 0. Siccome l’integrale∫∞1
1x1−α dx converge se e solo se α < 0, allora anche l’integrale in esame converge se e solo se α < 0.
1.2 Convergenza assoluta
Definizione 1.2.1. Siano a ∈ R ed f : [a,∞) → R una funzione tale che la restrizionef : [a,M ] → R sia limitata e Riemann-integrabile per ogni a ≤ M < ∞. Diciamo che fè assolutamente integrabile su [a,∞) se converge l’integrale improprio∫ ∞
a
|f(x)| dx (1.3)
[1]Ricordiamo che definitivamente vuol dire ∀x ≥ x.[2]Visto che per ipotesi si ha che f e g sono integrabili su [a,M ] per ogni M > a, allora basta porre M = x e si ha che∫∞
a f(x) dx =∫ xa f(x) dx+
∫∞x f(x) dx la cui integrabilità dipende solo da
∫∞x f(x) dx. Analogo discorso vale anche per
la g.[3]Bisogna discutere prima l’esistenza del limite. Tuttavia è semplice notando che la funzione ϕ : [a;∞) → R definita
come ϕ(M) =∫Ma f(x) dx è monotona crescente. Quindi esiste sicuramente il limite limM→∞ ϕ(M).
[4]Sia f : X → R una funzione continua definita su un intervallo aperto di reali che ha limite limx→x0 f(x) = ` > 0.Allora esiste un intorno U di x0 tale che f(x) > 0 per ogni x ∈ U ∩X diverso da x0.
[5]Per la definizione di limite, se limx→∞ f(x) = ` ∈ R deve esistere ε > 0 tale per cui `−ε < f(x) < `+ε definitivamente.
Matteo Gallone - Analisi Matematica II

1.3 Integrali generalizzatiIntegrali oscillatori
7
In questo caso diciamo che l’integrale improprio∫∞a|f(x)| dx converge assolutamente.
Teorema 1.2.2. Sia f : [a,∞)→ R una funzione limitata e Riemann-integrabile su ogniintervallo della forma [a,M ] con M ≥ a. Se f è assolutamente integrabile su [a,∞) alloraè integrabile in senso improprio su [a,∞) e inoltre∣∣∣∣∫ ∞
a
f(x) dx
∣∣∣∣ ≤ ∫ ∞a
|f(x)| dx (1.4)
Dimostrazione. Definiamo le funzioni f+ (parte positiva) e f− (parte negativa), f+, f− : [a,∞) → [0,∞) come: f+(x) =max{f(x), 0} e f−(x) = max{−f(x), 0}. Con questa definizione si ha che f(x) = f+(x)−f−(x) e |f(x)| = f+(x)+f−(x) perogni x ≥ a. È noto, inoltre, che le funzioni f+ e f− sono Riemann-integrabili su ogni intervallo [a,M ]. Per il teorema Teorema1.1.2 (del confronto) gli integrali impropri
∫∞a f+(x) dx e
∫∞a f−(x) dx convergono[6]. Passando al limite per M → ∞
nell’identità∫Ma f(x) dx =
∫Ma (f+(x)− f−(x)) dx =
∫Ma f+(x) dx−
∫Ma f−(x) dx si ottiene la convergenza dell’integrale
improprio di f su [a,∞). Passando al limite nella disuguaglianza∣∣∣∫Ma f(x) dx
∣∣∣ =∣∣∣∫Ma f+(x) dx+
∫Ma −f
−(x) dx∣∣∣ ≤∫M
a |f+(x)| dx+
∫Ma | − f
−(x)| dx =∫Ma |f(x)| dx si ottiene l’equazione (1.4).
1.3 Integrali oscillatori
Data una funzione f : [a,∞) → R con segno oscillante[7] attorno a ∞, come per le seriea segno alterno la prima cosa da fare sarà controllare la assoluta convergenza dell’inte-grale. Infatti per il Teorema 1.2.2 se una funzione è assolutamente integrabile allora èanche integrabile. Se la funzione non è assolutamente integrabile va ricordato il seguenteteorema, assimilabile al criterio di Leibnitz per le serie numeriche.
Teorema 1.3.1 (Abel - Dirichlet). Siano f ∈ C([a,∞)) e g ∈ C1([a,∞)) con a ∈ R, duefunzioni con le seguenti proprietà:
i) f = F ′ con primitiva F ∈ C1([a,∞)) limitata;ii) g′(x) ≤ 0 e limx→∞ g(x) = 0.
Allora converge l’integrale improprio∫ ∞a
f(x)g(x) dx.
Dimostrazione. Dato l’integrale∫Ma f(x)g(x) dx, integrando per parti, [F (x)g(x)]x=M
x=a −∫Ma F (x)g′(x) dx = F (M)g(M)−
F (a)g(a)−∫Ma F (x)g′(x) dx. Siccome F è limitata e g infinitesima perM →∞ si ha che limM→∞ F (M)g(M) = 0. Quindi il
primo dei tre addendi tenderà a 0. D’altra parte, siccome F (x) è limitata per ipotesi allora si ha |F (x)| ≤ supx∈[a,∞) |F (x)|,quindi si arriva alla maggiorazione
∫Ma |F (x)g′(x)| dx ≤ supx∈[a,∞) |F (x)|
∫Ma |g
′(x)| dx. Siccome g′(x) ≤ 0 si trova
che supx∈[a,∞) |F (x)|∫Ma |g
′(x)| dx = − supx∈[a,∞) |F (x)|∫Ma g′(x) dx = supx∈[a,∞) |F (x)| (g(a) − g(M)). Poichè g è
infinitesima allora limM→∞ g(M) = 0, quindi∫∞a |F (x)g′(x)| dx ≤ g(a) supx∈[a,∞) |F (x)|. Ma F (x) è limitata, quindi
supx∈[a,∞) |F (x)| ∈ R e g(a) ∈ R e quindi∫∞a |F (x)g′(x)| dx converge. La tesi è dimostrata.
Esercizio 1.2. Per ogni α ≥ 0 discutere la convergenza semplice e assoluta del seguenteintegrale improprio: ∫ ∞
1
sinx log x
xαdx
Soluzione. Si studi innanzi tutto la convergenza assoluta. Poichè | sinx| ≤ 1 sempre allora per il teorema del confronto∫∞1
∣∣∣ sin x log xxα
∣∣∣ dx ≤∫∞1
∣∣∣ log xxα
∣∣∣ dx. Per il dominio di integrazione scelto il modulo è privo di senso. Quindi lo studio della
convergenza assoluta equivale allo studio della convergenza dell’integrale∫∞1
log xxα
dx.Osservo ora che per ogni ε > 0 il limite limx→∞
log xxε
= 0, dunque per ogni ε > 0 esiste x tale che ∀x ≤ x si halog xxε≤ 1, quindi
∫∞1
log xxα
dx ≤∫∞1 xε−α dx. Quindi per α − ε > 1 l’integrale converge, quindi per α > 1 l’intgrale
converge assolutamente e quindi c’è anche convergenza semplice.Studiamo ora la convergenza assoluta per 0 ≤ α ≤ 1. Confronto ora la funzione con una serie (vedi figura sot-
to). Cosidero l’insieme Ik =[kπ + π
4, kπ + 3
4π]con k ∈ Z in modo tale che ∀x ∈ Ik si ha | sinx| ≥
√2
2, log x ≥
[6]In quanto |f(x)| converge per ipotesi e si ha che |f(x)| ≥ f+(x) e |f(x)| ≥ f−(x).[7]Sarà d’uopo definire cosa si intende per funzione oscillante; viene enunciata la seguente. Definizione. Una funzione
si dice oscillante attorno ad un punto x0 se non esiste alcun intorno di x0 in cui la funzione ha segno costante.
Matteo Gallone - Analisi Matematica II

8 Integrali generalizzatiIntegrali impropri di funzioni non limitate 1.4
log(x+ π
4
)≥ log
(54π)e 1xα≥ 1
(kπ+ 34π)α
. Quindi, usiamo il teorema del confronto come sopra:∫∞1
sin x log xxα
dx ≥∑∞k=1
√2
2log(
54π)
1
(kπ+ 34π)α
π2
=√
22
log(
54π)π2
∑∞k=1
1
(kπ+ 34π)α
. Quest’ultima serie diverge per 0 ≤ α ≤ 1, quindi non
c’è convergenza assoluta dell’integrale per 0 ≤ α ≤ 1.
Figura 1.1: L’idea che stà alla base del confronto con una serie
Verifichiamo se esiste convergenza semplice in quell’intervallo. È facile utilizzando il teorema sugli integrali oscillatori(Abel-Dirichlet), in quanto la funzione oscillante è sinx e la funzione infinitesima è log x
xαper α > 0. Quindi in questo
intervallo l’integrale converge ma non assolutamente.Resta da studiare il caso α = 0. In questo caso l’integrale da studiare è
∫∞1 sinx log x dx, ovvero resta da vedere se esiste
ed ha un valore finito il limite limM→∞∫M1 log x sinx dx = limM→∞ [− cosx log x]x=M
x=1 +∫M1
cos xx
dx. Per Abel-Dirichletil secondo addendo è un integrale convergente, mentre il primo addendo non ha limite, quindi questo limite non esiste equindi non si ha convergenza semplice.
Ricapitolando: α = 0 non c’è convergenza; α > 0 c’è convergenza semplice e α > 1 c’è convergenza assoluta.
1.4 Integrali impropri di funzioni non limitate
Finora ci siamo occupati dell’integrabilità di funzioni solo a ∞. Tuttavia ci è noto dalcorso di analisi I che alcune funzioni, in particolari punti ai limiti del loro dominio, tendonoa∞. Un esempio classico è la funzione y = 1
xall’intorno del punto x = 0. Dovremo quindi
definire cosa si intende per integrabilità in senso improprio di queste funzioni.
Definizione 1.4.1. Sia f : (a, b] → R con −∞ < a < b < ∞ una funzione limitata eRiemann-integrabile su ogni intervallo della forma [a + ε, b] con 0 < ε < b − a. Diciamoche f è integrabile in senso improprio su (a, b] se esiste finito il limite
I = limε→0+
∫ b
a+ε
f(x) dx (1.5)
In questo caso diciamo che l’integrale improprio di f su (a, b] converge e poniamo∫ baf(x) dx = I.Lo studio degli integrali impropri di funzione, così come sono stati appena definiti,
si può ricondurre allo studio fatto per le funzioni in ∞ tramite un cambio di variabilet = b−a
x−a che porta alla trasformazione formale di integrali:∫ b
a
f(x) dx = (b− a)
∫ ∞1
f
(a+
b− at
)dt
t2
Esempio. Al variare del parametro reale α > 0 studiamo ora la convergenza dell’integrale∫ 1
0
1
xαdx
Definiamo per semplicità c = 0 + ε. E calcoliamo la primitiva di 1xα
nell’intervallo [c, 1]. Per α 6= 1 si ha che∫ bc
1xα
dx =[x−α+1
−α+1
]x=1
x=c= 1− c−α+1
−α+1. Per α = 1 si ha invece che
∫ bc
1xα
dx = [log x]x=1x=c = 0− log c.
Matteo Gallone - Analisi Matematica II

1.4 Integrali generalizzatiIntegrali impropri di funzioni non limitate
9
Passando al limite per c→ 0+ si ha che limc→0+ 1− c−α+1
−α+1dipende dal parametro α. In particolare, se α > 1 l’integrale
diverge, se α < 1 l’integrale converge. Per studiare il caso α = 1 bisogna calcolare il limite limc→0+ log c = −∞, quindil’integrale diverge.
Infine possiamo riassumere quanto detto finora:∫ 1
0
1
xαdx =
{converge α < 1diverge α ≥ 1
Viene enunciato ora, senza dimostrazione, un teorema del confronto asintotico per gliintegrali di funzioni non limitate.
Teorema 1.4.2 (Confronto asintotico per funzioni non limitate). Siano f, g : (a, b]→ Rcon −∞ < a < b < ∞, due funzioni limitate e Riemann-integrabili su ogni intervallodella forma [a+ ε, b] con 0 < ε < b− a. Supponiamo che
i) limx→a+ g(x) =∞;ii) il limite limx→a+
f(x)g(x)
esiste finito ed è diverso da zero.
Allora ∫ b
a
f(x) dx converge⇔∫ b
a
g(x) dx converge
Esercizio 1.3. Al variare di α ∈ R>0 studiare la convergenza semplice dell’integrale∫ 1
0
sin(xα)
log(1 + x)dx
Soluzione. Notiamo che per x = 1 la funzione è ben definita, mentre crea problemi per x = 0. Sviluppiamo quindi inserie di Taylor il logaritmo e il seno in un intorno di 0: log(1 + x) = x + o0(x), sin(xα) = xα + o0(xα). Si ha quindi chesin(xα)
log(1+x)∼0
xα+o0(xα)x+o0(x)
. Ovvero se converge∫ 10xα+o0(xα)x+o0(x)
dx allora converge anche∫ 10
sin(xα)log(1+x)
dx per il teorema appenaenunciato.
Lavoriamo su∫ 10xα+o0(xα)x+o0(x)
dx, raccogliamo i termini di grado massimo a numeratore e denominatore e otteniamo∫ 10xα
x1+o(xα)1+o(x)
dx ∼∫ 10
1x1−α dx che converge se e solo se 1 − α < 1, ovvero se α > 0. Quindi l’integrale
∫ 10
sin(xα)log(1+x)
dx
converge per α > 0.
Esercizio 1.4. Si studi, al variare del parametro α ∈ R la convergenza dell’integraleimproprio ∫ ∞
0
tα−1e−t dt
Soluzione. L’integrale va studiato sia in 0 sia in ∞. Quindi si spezza l’integrale in∫ 10 t
α−1e−t dt e∫∞1 tα−1e−t dt.
L’integrale di partenza convergerà se e solo se convergeranno tutti e due gli integrali. Studiamoli separatamente.In un intorno di 0 la funzione integranda è asintotica a tα−1e−t ∼∗0 tα−1, il cui integrale
∫ 10 t
α−1 dt =[
1αtα]10(se
α 6= 0) converge per α > 0. Il caso α = 0 è semplice in quanto∫ 10
1t
dt = limε→0[0 − log ε] = ∞ non converge. Quindi ilprimo integrale converge per α > 0.
Studiamo il secondo integrale. Per semplicità dividiamo lo studio in 3 casi: α > 1, α = 1 e α < 1. Sapendo chedefinitivamente si ha e
12t > tα−1, allora si ha anche tα−1e−t < e
t2 e−t = e−
t2 il cui integrale da 1 a∞ si calcola direttamente∫∞
1 e−t2 dt = limM→∞−2
[−e−
t2
]M1
= −2√
1e∈ R converge, quindi per confronto anche l’integrale di partenza converge
per α > 1. Il caso α = 1 si calcola direttamente∫∞1 e−t dt = limM→∞
[−e−t
]M1
= 1e∈ R, quindi l’integrale converge.
Il caso α < 1 si risolve notando che tα−1 è infinitesima, quindi sicuramente minore di 1. Ma allora l’integrale converge see solo se converge
∫∞1 e−t dt che (come abbiamo visto analizzando il caso α = 0) converge. Quindi il secondo integrale
converge per ogni α ∈ R.In conclusione l’integrale proposto nell’esercizio converge se α > 0.
Matteo Gallone - Analisi Matematica II

10 Integrali generalizzatiIntegrali impropri di funzioni non limitate 1.4
Matteo Gallone - Analisi Matematica II

CAPITOLO 2
Equazioni differenziali: primi elementi
2.1 Nozioni generali
Un’equazione differenziale ordinaria scalare è un problema in cui si chiede di determinareuna funzione y(x) : I → C, definita su un intervallo aperto I ⊂ R, a partire da unarelazione in cui possono comparire le sue derivate (può comparire anche la stessa funzioney(x) vista come derivata di ordine 0) e la variabile x.
Da un certo punto di vista si tratta della generalizzazione del problema dell’integra-zione, ove l’integrazione è vista come una semplice equazione differenziale nella formay′ = f(x).
Un’equazione differenziale è detta ordinaria se la funzione incognita y(x) dipende dallasola variabile x (o quantomento che nell’equazione compaiono solo derivate rispetto ax). Un’equazione differenziale è detta scalare se la funzione incognita y(x) ha valoriin C e non in Cn con n ≥ 2. L’insieme delle soluzioni di un’equazione differenzialeè detto integrale generale dell’equazione e solitamente esso ha infiniti elementi (anchel’integrazione semplice fornisce un insieme infinito di elementi:
∫f(x) dx = F (x) + k).
L’ordine di un’equazione differenziale è il massimo ordine della derivata presente. Inparticolare, un’equazione differenziale di ordine n si dirà in forma autonoma se in essa laderivata di ordine massimo y(n) appare esplicitata rispetto a quelle di ordine inferiore; sidirà lineare se essa appare come polinomio di primo grado nelle derivate y(0), y(1), . . . , y(n)
della funzione incognita y(x); si dirà invece autonoma se la variabile indipendente x nonappare direttamente nell’equazione.
Spesso alle equazioni differenziali sono associate alcune condizioni iniziali. Se x0 ∈ I ele condizioni iniziali sono gli n valori che devono assumere le derivate di y(x) fino all’ordinen− 1 nel punto x0 (ovvero sono del tipo y(x0) = y0, y′(x0) = y′0, . . . , y(n−1)(x0) = y
(n−1)0 )
si parla di problema di Cauchy. Spesso, nei casi standard quasi sempre, il problema diCauchy ha un’unica soluzione.
2.2 Equazioni lineari del primo ordine
Sia I ⊂ R un intervallo aperto e siano a, b ∈ C(I) due funzioni continue. Un’equazionedifferenziale nella forma
y′ + a(x)y = b(x), x ∈ I (2.1)si dice equazione lineare del primo ordine. Il problema di Cauchy relativo a questo tipo diequazioni differenziali si ha fissando un punto x0 ∈ I e un numero y0 ∈ R ed imponendoche y(x0) = y0.
Matteo Gallone - Analisi Matematica II

12 Equazioni differenziali: primi elementiEquazioni lineari del primo ordine 2.2
Dedurremo la formula risolutiva dell’equazione differenziale, e più in generale del pro-blema di Cauchy, con un argomento euristico. Consideriamo preliminarmente il caso incui b(x) = 0, ovvero il caso dell’equazione omogenea:
y′ + a(x)y = 0 (2.2)
Una soluzione banale di questa equazione è y = 0. Cerchiamo ora le altre soluzioni. Im-poniamo quindi y 6= 0, allora la (2.2) si può riscrivere nella forma y′
y= −a(x). Integrando
ambedue i membri rispetto ad x si ha che log |y| = −A(x) + d, ove d ∈ R è la costante diintegrazione e A(x) è una funzione tale che A′(x) = a(x).
Esponenzializzando il tutto si ha che y = ±e−A(x)+d, e quindi, ponendo C = ±e−d
troviamo la soluzione generica dell’equazione omogenea:
y = Ce−A(x) (2.3)
Questa funzione risolve l’equazione omogenea per ogni C ∈ R. La soluzione dell’equazionenon omogenea, ovvero quella per l’equazione (2.1), sarà nella forma (2.3) dove ora C nonsarà più un numero reale, ma una funzione C ∈ C1(I) che deve essere determinata. Questometodo si chiama metodo della variazione delle costanti .
Calcoliamo la derivata della soluzione, ovvero y′ = C ′e−A(x) − a(x)Ce−A(x) ed inseria-mola nella (2.1). Otteniamo una nuova equazione differenziale nell’incognita C ′, ovveroC ′e−A(x) = b(x) che riscritta meglio è C ′ = b(x)eA(x). Integrando tale equazione in unintervallo (x0, x) ⊂ I otteniamo C(x) = C(x0) +
∫ xx0b(t)eA(t) dt. Abbiamo quindi deter-
minato la funzione incognita C. La sostituiamo nella (2.3) e troviamo l’integrale generaleper le equazioni lineari del primo ordine non omogenee:
y(x) =
(c(x0) +
∫ x
x0
b(t)eA(t) dt
)e−A(x), x ∈ I (2.4)
dove c(x0) ∈ R è un numero reale. Per ogni scelta di tale numero la funzione (2.4) verifical’equazione differenziale (2.1).
Il numero c(x0) si può determinare imponendo che l’integrale generale y verifichi lacondizione iniziale y(x0) = y0. Se calcoliamo la (2.4) in x0 vediamo che vale y(x0) =c(x0)e−A(x). Da cui, imponendo la condizione iniziale si ottiene c(x0) = y0eA(x). Laformula di rappresentazione per la soluzione del problema di Cauchy sarà quindi:
y(x) =
(y0eA(x0) +
∫ x
x0
b(t)eA(t) dt
)e−A(x), x ∈ I (2.5)
Il seguente teorema prova che questa soluzione è l’unica.
Teorema 2.2.1. Siano I ⊂ R un intervallo aperto, x0 ∈ I, a, b ∈ C(I) e y0 ∈ R. Allorala funzione (2.5) risolve in modo unico il problema di Cauchy{
y′ + a(x)y = b(x)y(x0) = y0
Dimostrazione. Sia z ∈ C1(I) una soluzione dell’equazione differenziale (2.1) e consideriamo la funzione ausiliaria w(x) =eA(x)z(x) −
∫ xx0b(t)eA(t) dt dove A(x) è, come di consueto, una primitiva di a(x). Dal momento che sull’intervallo I
risulta w′ = (az + z′)eA − beA = (z′ + az − b)eA = 0 allora per il teorerma di Lagrange[1] la funzione w è costantesu tutto I. Ciò significa che esiste k ∈ R tale che w(x) = k ∈ R per ogni x ∈ I. Ricaviamoci quindi l’espressioneesplicita di z(x) in funzione di w(x), z(x) =
(w(x) +
∫ xx0b(t)eA(t) dt
)e−A(x). Aggiungendo l’informazione che w(x) = k
otteniamo z(x) =(k +
∫ xx0b(t)eA(t) dt
)e−A(x) da cui si vede che perchè z(x) soddisfi alla condizione z(x0) = y0 serve che
k = y0eA(x0). Quindi l’espressione trovata per z corrisponde a (2.5) e risulta così dimostrata l’unicità della soluzione.
[1]Sia f : [a, b]→ R una funzione continua in [a, b] e derivabile in (a, b), allora esiste c ∈ (a, b) tale che f ′(c) =f(b)−f(a)
b−a .Noi qui utilizziamo un corollario. Infatti se f ′(x) = 0 allora f(a) = f(b) per ogni scelta di a, b ∈ I.
Matteo Gallone - Analisi Matematica II

2.3 Equazioni differenziali: primi elementiEquazioni a variabili separabili
13
Esercizio 2.1. Si trovino le soluzioni generali dell’equazione differenziale
y′ = 2xex2
y
Soluzione. Per prima cosa si dividano tutti e due i membri per y (che quindi dovrà necessariamente essere diversa da 0).[2]
Si otterrà: y′
y= 2xex
2. Si integrino ora ambedue i membri rispetto alla variabile x:
∫ y′
ydx =
∫2xex
2dx. Si noti ora che
y′ dx = dy e si sostituisca∫ dy
y=∫
2xex2dx. A questo punto si possono calcolare gli integrali, e risulta log |y| = ex
2+ c.
esponenzializzando si ottiene y = eex2
+c = Ceex2
, che è proprio la soluzione generale dell’equazione differenziale cercata[3].
Esercizio 2.2. Si trovino le soluzioni generali della seguente equazione differenziale omo-genea:
y′ = arctanx y
Soluzione. Si operi come prima, ovvero si dividano ambedue i membri per y, sempre ricordando che y = 0 è soluzionebanale dell’equazione differenziale y′
y= arctanx. Si integrino ora tutti e due i membri e si trovi il dy come fatto sopra:∫ dy
y=∫
arctanx dx. Si risolvano ora i due integrali[4] e si otterrà: log |y| = x arctanx − 12
log(1 + x2) + k da cui,
esponenzializzando il tutto[5] si ottiene y = Cex arctanx√1+x2
, che è la soluzione generale dell’equazione cercata.
2.3 Equazioni a variabili separabili
Siano I, J ⊂ R due intervalli aperti e siano f ∈ C1(I) e g ∈ C(J) due funzioni continue.Si cercano le soluzioni dell’equazione differenziale del primo ordine
y′ = f(x)g(y), x ∈ I (2.6)
per qualche intervallo I1 ⊂ I. Una equazione scritta nella forma (2.6) è detta equazionedifferenziale a variabili separabili. Eventualmente, fissato un punto x0 ∈ I e un valorey0 ∈ J si può prescrivere la condizione iniziale y(x0) = y0 e costruire così un problema diCauchy.
Osserviamo che se g(y0) = 0 allora la funzione costante y(x) = y0 con x ∈ I è certa-mente una soluzione dell’equazione differenziale che soddisfa alla condizione iniziale; inaltre parole è soluzione del problema di Cauchy.
Altre soluzioni si trovano imponendo g(y0) 6= 0. Quindi, poichè g è una funzionecontinua, allora per il teorema della permanenza del segno esiste un intervallo apertoJ1 ⊂ J tale che y0 ∈ J1 in cui g 6= 0. Possiamo allora dividere ambedue i membri per g(y)e separare le variabili. Riscriviamo quindi l’equazione differenziale nel seguente modo:
y′(x)
g(y(x))= f(x) (2.7)
dove x varia in un intorno I1 ⊂ I del punto x0 tale che y(x) ∈ J1 per ogni x ∈ I1.Possiamo integrare ora ambedue i membri della (2.7) rispetto a x, ottenendo
∫ xx0
y′(t)g(y(t))
dt =∫ xx0f(t) dt. Operando un cambio di variabile η(t) = y(t) e notando che η′(t) dt = dη
allora l’integrale diventa∫ yy0
dηg(η(t))
=∫ xx0f(t) dt.
Sia ora G ∈ C1(J1) una primitiva di 1g(y)
(nella variabile y) definita nell’intervallo J1
dove risulta g 6= 0. La funzione G è strettamente monotona perchè G′(y) = g(y) 6= 0,quindi G risulta invertibile.
[2]Si noti che y(x) = 0 è una soluzione dell’equazione sovraindicata.[3]Ogni soluzione è determinata da un particolare valore del parametro C ∈ R. D’ora in poi C indicherà questo parametro,
da scegliere in R salvo precisazioni contrarie.[4]L’integrale dell’arcotangente va risolto per parti:
∫arctanx dx = xarctanx −
∫x
1+x2 dx = xarctanx − 12
∫2x
1+x2 dx =
xarctanx− 12
log(1 + x2) + k.[5]Si ricordi la proprietà dei logaritmi per cui α log(x) = log(xα). In cui α ∈ R.
Matteo Gallone - Analisi Matematica II

14 Equazioni differenziali: primi elementiEquazioni a variabili separabili 2.3
Sia poi F ∈ C1(I1) una primitiva di f . Integrando l’equazione differenziale (2.7) risultaG(y(x)) = F (x) + C dove C ∈ R è una costante che può essere determinata tramite lacondizione iniziale, e precisamente[6] vale C = G(y0)− F (x0).
Detta G−1 : G(J1) → J1 la funzione inversa di G, l’integrale generale dell’equazionedifferenziale assume la forma
y(x) = G−1(F (x) + C) (2.8)
E la soluzione del problema di Cauchy è
y(x) = G−1(F (x) +G(y0)− F (x0)) (2.9)
Si vuole far notare che questa soluzione è buona nell’intorno I1 ⊂ I di x0 che è, in generale,più piccolo di I.
Quanto trattato finora rileva due tipi di soluzioni per le equazioni differenziali nellaforma (2.6): le soluzioni costanti e le soluzioni per cui g(y0) 6= 0. Potrebbero, tuttavia,esserci delle altre soluzioni. Se g 6= 0 su J , l’argomentazione portata fino a qui provache la soluzione è necessariamente nella forma (2.8). Per quanto riguarda il problema diCauchy associato:
Teorema 2.3.1. Siano I, J ⊂ R due intervalli aperti tali che x0 ∈ I e y0 ∈ J , e sianof ∈ C(I), g ∈ C(J) tali che g 6= 0 su J . Allora il problema di Cauchy{
y′ = f(x)g(y)y(x0) = y0
ha una soluzione unica y ∈ C1(I1) data dalla formula (2.9), per qualche intervallo I1 ⊂ Icontenente x0.
Esercizio 2.3. Calcolare in forma esplicita la soluzione del seguente problema di Cauchy{y′ = 1+2x
cos y
y(0) = π
Soluzione. Per prima cosa controlliamo il dominio del problema di Cauchy, ovvero f(x) = 2x+ 1 ha come dominio Df = Re g(y) = 1
cos yha come dominio Dy = R \ {π
2+ 2kπ} con k ∈ Z.
Calcoliamo allora l’integrale generale dell’equazione differenziale (a variabili separabili) y′ cos y = 1 + 2x, risolviamoseparatamente i due integrali:
∫cos yy′ =
∫cos y dy = sin y + c1;
∫(1 + 2x) dx = x + x2 + c2. Quindi eguagliandoli
sin y = x+ x2 + c (dove c = c2 − c1 ∈ R).Determiniamo il valore di c. Per il problema di Cauchy si ha che f(0) = π, ovvero che sin(y(0)) − c = sin(π) − c = 0,
ovvero che c = 0.Determinato c scriviamo la soluzione del problema di Cauchy sin(y) = x2 + x, invertiamo la funzione seno e otteniamo
y = arcsin(x2+x) che non è la soluzione del problema di Cauchy, in quanto arcsin(0) = 0 6= π. Infatti ci siamo dimenticati diconsiderare che l’arcoseno inverte il seno solo nell’intervallo ]− π
2; π
2[, mentre la nostra soluzione dovrebbe stare nell’intervallo
]π2
; 3π2
[, quindi la soluzione del problema di Cauchy è y = arcsin(x2 + x) + π.
Esercizio 2.4. Calcolare la soluzione del seguente problema di Cauchy{y′ = tan(x)y + x2
y(0) = 0
Soluzione. Come prima consideriamo prima i domini delle funzioni in gioco. L’unico che crea problemi è quello dellatangente, infatti tanx esiste solo se x 6= π
2+ kπ con k ∈ Z.
Data la condizione di Cauchy y(0) = 0, allora l’intervallo della soluzione deve essere I =]− π2, π
2[.
Calcoliamo quindi la soluzione dell’equazione differenziale, partendo dall’omogenea associata y′ = tan(x)y, y′
y= tan(x),
y′
y= sin x
cos x; quindi, integrando ambo i membri,
∫ dyy
=∫
sin xcos x
dx si ottiene log |y| = − log | cosx| + c da cui, per le noteproprietà del logaritmo ed esponenzializzando tutto, si ottiene y = c
cos x.
[6]È facile ricavare il risultato espresso qui se anzichè svolgere gli integrali come indefini, si svolgono gli integrali definiti.Infatti
∫ yy0
dηg(η(t))
=∫ xx0f(t) dt = G(y) − G(y0) = F (x) − F (x0) da cui G(x) = F (x) + G(y0) + F (x0) e quindi C =
G(y0)− F (x0).
Matteo Gallone - Analisi Matematica II

2.4 Equazioni differenziali: primi elementiEquazioni lineari del secondo ordine
15
Cerchiamo ora la soluzione dell’equazione differenziale (finora abbiamo trattato l’omogenea), sapendo che la soluzione èdella forma y(x) =
c(x)cos x
(si usa il metodo della variazione delle costanti), basta determinare c(x)[7]. Sapendo che y = ccos x
si ha che y′ = c′ cos x+c sin xcos2 x
. Sostituendo y e y′ nell’equazione differenziale si ottiene c′
cos(x)+ c tan x
cos x= tan(x) c
cos x+ x2,
ovvero eliminando i termini uguali c′ = x2 cosx. Integrando ambedue i membri[8] si ottiene che la soluzione del problemadi Cauchy è y = (x2 − 2) tanx+ 2x.
Esercizio 2.5. Al variare di α ∈ R studiare l’esistenza e l’unicità della soluzione delseguente problema di Cauchy: {
x3y′ − y + 1 = 0y(0) = α
Soluzione. Si potrebbe supporre x3 6= 0 ⇒ x 6= 0 ma y è calcolata in 0 quindi supporre ciò è pericoloso. Tuttavia lofacciamo comunque sperando che non dia problemi nella soluzione. Dividiamo quindi ambedue i membri per x3, otteniamoy′ − y
x3 + 1x3 = 0. Risolviamo quindi l’omogenea y′ = y
x3 , che, separando le variabili, diventa y′
y= 1
x3 . Integriamo
ambedue i membri e otteniamo log |y| = − 12x2 + D. Esponenzializzando si ottiene y = ce
− 12x2 . Quindi la soluzione
dell’equazione non omogenea sarà della forma y = c(x)e− 1
2x2 . D’ora in poi scriveremo c al posto di c(x) per leggerezza di
scrittura. Calcoliamo quindi y′ = c′e− 1
2x2 + ce− 1
2x2
x3 . Sostituendo y e y′ nell’equazione differenziale non omogenea ottengo
c′e− 1
2x2 + ce− 1
2x2
x3 − ce− 1
2x2
x3 + 1x3 = 0. Eliminando i termini uguali e isolando c′ si ottiene c′ = − e
12x
x3 . Integro tutti edue i membri di questa equazione in un intervallo (x0, x) con x e x0 concordi (ovvero tali che xx0 > 0). Ottengo quindi
c(x)−c(x0) = −∫ xx0
e1
2t2
t3dt, ovvero c(x) = c(x0)+[e
12t2 ]xx0
= c(x0)+e1
2x2 −e1
2x20 . Abbiamo trovato quindi c(x) = e
12x2 +k
con k = c(x0) + e1
2x20 ∈ R. Poichè tra le ipotesi entro cui ho integrato c’è la concordanza dei due estremi di integrazione
allora, avrò in generale funzioni diverse in base all’intervallo di integrazione. Quindi la generica y(x) sarà
y(x) =
{e− 1
2x2 (k1 + e1
2x2 ) x > 0
e− 1
2x2 (k2 + e1
2x2 ) x < 0
ovvero y1 = k1e1
2x2 + 1 e y2 = k2e1
2x2 + 1. Calcoliamo ora i limiti limx→0− y2 = 1 e limx→0+ y1 = 1.[9] Ovvero le funzioniraccordano in 0 se e solo se α = 1. Quindi si avranno soluzioni solo per α = 1.
2.4 Equazioni lineari del secondo ordine
Sia I ⊂ R un intervallo aperto e siano a, b, f ∈ C(I) funzioni continue. Studiamol’equazione differenziale del secondo ordine
y′′ + a(x)y′ + b(x)y = f(x), x ∈ I (2.10)
L’incognita è una funzione y ∈ C2(I). L’equazione differenziale si dice lineare perchèl’operatore differenziale L : C2(I) → C(I), L(y) = y′′ + a(x)y′ + b(x)y è un operatorelineare. Il seguente teorema di esistenza e unicità della soluzione per il relativo problemadi Cauchy è il corollario di un teorema più generale di cui non forniamo ne enunciato nedimostrazione.
Teorema 2.4.1. Siano I ∈ R un intervallo aperto, x0 ∈ I e y0, y′0 ∈ R, e a, b, f ∈ C(I)
funzioni continue. Allora il problema di Cauchy y′′ + a(x)y′ + b(x)y = f(x) x ∈ Iy(x0) = y0
y′(x0) = y′0
(2.11)
ha un’unica soluzione y ∈ C2(I).[7]Per leggerezza di scrittura si scriverà c al posto di c(x).[8]Vengono svolti qui i calcoli in dettaglio. Da c′ = x2 cosx, integrando ambedue i membri si ha C =
∫x2 cosx dx
che si svolge per parti due volte. Si deriva la potenza di x e si integra la funzione trigonometrica: C =∫x2 cosx dx =
x2 sinx +∫
2x sinx dx = x2 sinx + 2x cosx −∫
2 cosx dx = (x2 − 2) sinx + 2x cosx. Sostituendo ora C nell’equazione
differenziale si ha y(x) =c(x)cos x
=(x2−2) sin x+2x cos x
cos x= (x2 − 2) tanx+ 2x, che è la soluzione dell’equazione cercata.
[9]Il limite vale 1 perchè e− 1
2x2 tende a 0. Inoltre i limiti vengono fatti solo tendendo da sinistra o da destra per via deldominio delle y1 e y2.
Matteo Gallone - Analisi Matematica II

16 Equazioni differenziali: primi elementiEquazioni lineari del secondo ordine 2.5
Studiamo il caso omogeneo f = 0. Consideriamo l’insieme delle soluzioni dell’equa-zione omogenea S = {y ∈ C2(I) : y′′(x) + a(x)y′(x) + b(x)y(x) = 0, x ∈ I}. Dal teoremaprecedente discende il seguente fatto:
Proposizione 2.4.2. Detto S = {y ∈ C2(I) : y′′(x) + a(x)y′(x) + b(x)y(x) = 0} l’insiemenon vuoto delle soluzioni dell’equazione differenziale, esso è uno spazio vettoriale su uncampo reale di dimensione 2.Dimostrazione. Sia S uno spazio vettoriale e L : y′′ + a(x)y′ + b(x)y = 0; per ogni coppia di costanti α, β ∈ R e y1, y2 ∈ Ssoluzioni per l’equazione differenziale, ovvero tali che L(y1) = L(y2) = 0, risulta L(αy1 + βy2) = αL(y1) + βL(y2) = 0, equindi αy1 + βy2 ∈ S.
Dimostriamo ora che S ha dimensione esattamente 2. Fissato un punto x0 ∈ I, definiamo la trasformazione T : S → R2
definita nel seguente modo: T (y) = (y(x0), y′(x0)). La trasformazione T è lineare. Se è anche biiettiva allora segurià che Sed R2 sono linearmente isomorfi e dunque dim(S) = dim(R2) = 2.
Dimostriamo l’iniettività. Se T (y) = T (z) con y, z ∈ S allora y e z risolvono lo stesso problema di Cauchy (2.11) (conf = 0). Siccome per il Teorema 2.4.1 la soluzione del problema è unica, allora si deve avere necessariamente y = z.
Dimostriamo la suriettività. Dati (y0, y′0) ∈ R2, dal teorema Teorema 2.4.1 segue l’esistenza di y ∈ S tale che T (y) =(y0, y′0). Quindi T è biiettiva ed abbiamo dimostrato che S ha dimensione 2.
Lo spazio vettoriale S delle soluzioni è di dimensione 2, quindi ammette una basecomposta da due soluzioni. Consideriamo due soluzioni y1, y2 ∈ S (non necessariamentelinearmente indipendenti) e formiamo la matrice Wronskiana
Wy1,y2(x) =
(y1(x) y2(x)y′1(x) y′2(x)
)a cui è associato un determinante Wronskiano
w(x) = det
(y1(x) y2(x)y′1(x) y′2(x)
)= y1(x)y′2(x)− y2(x)y′1(x)
Chiaramente risulta w ∈ C1(I) e inoltre w′ = y′1y′2 − y′1y
′2 + y1y
′′2 − y2y
′′1 . I primi due
addenti si annullano e si ricava poi dalla (2.10) y′′ si ha y′′ = −a(x)y′ − b(x)y. Quindisostituiamo quanto ottenuto ed abbiamo w′ = y1(−a(x)y′2−b(x)y2)−y2(−a(x)y1−b(x)y1).Sviluppando i calcoli[10] si ottiene w′(x) = −a(x)w(x).
Integrando l’equazione differenziale così ottenuta scopriamo che il determinante Wron-skiano ha la forma
w(x) = w(x0)e−∫ xx0a(t) dt
, x ∈ INotiamo, in particolare, che se w(x0) = 0 in un punto x0 ∈ I allora w = 0 in tutti i
punti.
Proposizione 2.4.3. Siano y1, y2 ∈ S soluzioni dell’equazione omogenea e sia w =detWy1,y2 il corrispondente determinante Wronskiano. Allora
A) y1, y2 sono linearmente dipendenti se e solo se esiste x0 ∈ I tale che w(x0) = 0,ovvero se e solo se w = 0 su I;
B) y1, y2 sono linearmente indipendenti se e solo se esiste x1 ∈ I tale che w(x1) 6= 0,ovvero se e solo se w 6= 0 su I.
Dimostrazione. Proviamo A). Se y1, y2 sono linearmente dipendenti allora esistono (α, β) 6= (0, 0) (con (α, β) ∈ R2) tali cheαy1 + βy2 = 0 su I. Derivando vale anche αy′1 + βy′2 = 0 su I, e dunque(
y1 y2
y′1 y′2
)(αβ
)=
(00
)Segue che w = 0 su tutto I.
Dimostriamo ora l’implicazione inversa. Supponiamo ora che w(x0) = 0 in un punto x0 ∈ I. Allora esistono (α, β) 6=(0, 0) tali che (
y1(x0) y2(x0)y′1(x0) y′2(x0)
)(αβ
)=
(00
)La funzione z = αy1 + βy2 è in S e verifica z(x0) = 0 e z′(x0) = 0. Dall’unicità della soluzione per il problema di
Cauchy segue che z = 0 e quindi y1, y2 sono linearmente dipendenti.L’affermazione B) segue da A) per negazione.
[10]Semplicemente applicando la proprietà distributiva w′(x) = −a(x)y1y′2 − b(x)y1y2 + a(x)y′1y2 + b(x)y1y2. Il secondoe il quarto addendo sono opposti, quindi la loro somma è 0; w′(x) = −a(x)y1y′2 + a(x)y′1y2. Raccogliendo −a(x) si ottienew′(x) = −a(x)(y1y′2 − y′1y2). Ma y1y′2 − y′1y2 = w, quindi w′(x) = −a(x)w(x).
Matteo Gallone - Analisi Matematica II

2.6 Equazioni differenziali: primi elementiMetodo della variazione delle costanti
17
2.5 Metodo della variazione delle costanti
Una volta trovate le soluzioni dell’equazione omogenea possiamo calcolare una soluzionedell’equazione non omogenea (2.10).
Sia y1, y2 una base di soluzioni per l’equazione omogenea associata. Cerchiamo unasoluzione del tipo
y = c1y1 + c2y2 (2.12)
dove c1, c2 : I → R sono funzioni da determinare. Derivando la relazione si ottieney′ = c′1y1 + c1y
′1 + c′2y2 + c2y
′2 e, imponendo la condizione c′1y1 + c′2y2 = 0 l’espressione
precedente si riduce alla seguente
y′ = c1y′1 + c2y
′2 (2.13)
Derivando nuovamente si ottiene
y′′ = c′1y′1 + c1y
′′1 + c′2y
′2 + c2y
′′2 (2.14)
Sostituendo la (2.13) e la (2.14) nella (2.10), dopo alcuni calcoli[11] si ottiene la secondacondizione
c′1y′1 + c′2y
′2 = f (2.15)
Mettendo insieme le condizioni si arriva al sistema{c′1y1 + c′2y2 = 0c′1y′1 + c′2y
′2 = f
che, scritto in forma matriciale, assume la forma(y1 y2
y′1 y′2
)(c′1c′2
)=
(0f
)Si noti che è apparsa la matrice Wronskiana di y1, y2. Per la Proposizione 2.4.3 questamatrice è invertibile in ogni punto x ∈ I. Questo permette di risolvere il sistema in c′1 ec′2: (
c′1c′2
)=
(y1 y2
y′1 y′2
)−1(0f
)(2.16)
Le due equazioni del sistema possono essere integrate. Questo procedimento determina c1
e c2 a meno di due costanti additive che appaiono nel processo di integrazione. Il valoredi queste due costanti può essere determinato dalle condizioni iniziali.
2.6 Equazioni a coefficenti costanti
Le equazioni differenziali del secondo ordine a coefficenti costanti sono equazioni differen-ziali del tipo
y′′ + ay′ + by = f(x) (2.17)
dove a, b ∈ R sono costanti. Le soluzioni sono nella forma y(x) = eλx dove λ ∈ C èun parametro complesso. Sostituendo le derivate y′ = λeλx e y′′ = λ2eλx nell’equazionedifferenziale si ottiene
eλx(λ2 + aλ+ b) = 0
[11]Si parte dall’equazione y′′ + ay′ + by = f (per leggerezza di scrittura a = a(x), b = b(x), . . . ) e si sostituisce quantotrovato in (2.13) e (2.14): c′1y
′1 + c1y′′1 + c′2y
′2 + c2y′′2 + a(c1y′1 + c2y′2) + b(c1y1 + c2y2) = f . Svolgendo le parentesi tonde
c′1y′1 + c1y′′1 + c′2y
′2 + c2y′′2 + ac1y′1 + ac2y′2 + bc1y1 + bc2y2 = f , raccogliendo c1 e c2 infine si ottiene c1(y′′1 + ay′1 + by1) +
c2(y′′2 +ay′2 + by2)+ c′1y′1 + c′2y
′2 = f . Usando ora il fatto che y1 e y2 risolvono l’equazione omogenea si ottiene la condizione
c′1y′1 + c′2y
′2 = f .
Matteo Gallone - Analisi Matematica II

18 Equazioni differenziali: primi elementiEquazioni a coefficenti costanti 2.6
Siccome eλx 6= 0, tale equazione è verificata se e solo se λ verifica l’equazione caratteristica:
λ2 + aλ+ b = 0
Sia ora ∆ = a2−4b il discriminante dell’equazione. Si possono presentare tre casi: ∆ > 0,∆ = 0, ∆ < 0.
∆ > 0. L’equazione caratteristica ha due soluzioni reali distinte:
λ1 =−a−
√∆
2e λ2 =
−a+√
∆
2
In questo caso la soluzione generale della (2.17) è una combinazione lineare delle soluzioniy1(x) = eλ1x e y2(x) = eλ2x, che sono linearmente indipendenti:
y(x) = c1eλ1x + c2eλ2x (2.18)
∆ < 0. L’equazione caratteristica ha due soluzioni complesse coniugate
λ1 =−a− i
√−∆
2= α + iβ e λ2 =
−a+ i√−∆
2= α− iβ
Dove si è posto α = −a2e β =
√−∆2
. Le funzioni
z1(x) = e(α+iβ)x = eαxeiβx = eαx(cos βx+ i sin βx)
z2(x) = e(α−iβ)x = eαxe−iβx = eαx(cos βx− i sin βx)
sono soluzioni a valori complessi dell’equazione differenziale. Nell’ultima eguaglianza èstata usata la formula di Eulero[12]. Le funzioni
y1(x) =z1(x) + z2(x)
2= eαx cos βx
y2(x) =z1(x)− z2(x)
2i= eαx sin βx
sono soluzioni a valori reali dell’equazione differenziale. Più in generale, le funzioni y1 ey2 sono linearmente indipendenti e quindi sono una base di soluzioni per tale equazione.la soluzione generale sarà combinazione lineare di y1 e y2 ed assumerà la forma
y(x) = eαx(c1 cos βx+ c2 sin βx) (2.19)
∆ = 0. L’equazione caratteristica ha una sola soluzione reale λ = −a2con molteplicità
2. In questo caso il metodo produce una sola soluzione y1(x) = eλx. Un calcolo direttomostra che anche la funzione y2(x) = xeλx è una soluzione[13] linearmente indipendentedalla precedente.
La soluzione generale dell’equazione è dunque una combinazione lineare delle due
y(x) = (c1 + c2x)eλx, c1, c2 ∈ R (2.20)
Esercizio 2.6. Trovare le soluzioni dell’equazione differenziale omogenea del secondoordine a coefficenti costanti:
y′′ − 5y′ + 4y = 0
[12]Ovvero eix = cosx+ i sinx.[13]Partiamo dall’equazione y′′ + ay′ + by = 0. Sostituiamo y = xeλx, y′ = eλx + λxeλx, y′′ = λeλx + λ(eλx + λxeλx) =
2λeλx + λ2xeλx ed otteniamo 2λeλx + λ2xeλx + a(eλx + λxeλx) + bxeλx = 0. Raccogliendo xeλx e eλx otteniamo:(λ2 +aλ+ b)xeλx+ (2λ+a)eλx = 0. Nell’ultimo passaggio si è usato il fatto che λ risolve l’equazione caratteristica e quindiλ2 + aλ+ b = 0 e che λ = −a
2, e quindi 2λ− a = a− a = 0.
Matteo Gallone - Analisi Matematica II

2.6 Equazioni differenziali: primi elementiEquazioni a coefficenti costanti
19
Soluzione. L’equazione caratteristica è λ2 − 5λ + 4 = 0 che ha come soluzioni λ1 = 4 e λ2 = 1. Ovvero due soluzionilinearmente indipendenti saranno le y1 = eλ1x = e4x e y2 = eλ2x = ex. Quindi la soluzione generale sarà combinazionelineare delle due, ovvero y = C1e4x + C2ex.
Esercizio 2.7. Trovare le soluzioni dell’equazione differenziale omogenea del secondoordine a coefficenti costanti:
y′′ + 4y′ + 13 = 0Soluzione. L’equazione caratteristica è λ2 + 4λ + 13 = 0, che ha come soluzione[14] λ = −2 ±
√4− 13 = −2 ±
√−9 =
−2 ± 3i. A questo punto saranno soluzioni dell’equazione differenziale le funzioni g1 e g2 così definite: g1 = eλ1x =e(−2+3i)x = e−2xe3ix = e−2x(cos(3x) + i sin(3x)), e g2 = eλ2x = e(−2−3i)x = e−2xe−3ix = e−2x(cos(−3x) + i sin(−3x)) =e−2x(cos(3x) − i sin(3x)) (negli ultimi passaggi si è usata la formula di Eulero[12] per scrivere l’esponenziale comples-so in forma di seni e coseni, e parità / disparità di coseno / seno per portare fuori il segno - dalle rispettive funzio-ni). Le g1 e g2 saranno quindi una base di soluzioni per l’equazione differenziale data, quindi la anche la loro som-ma e la loro differenza saranno base di soluzioni per l’equazione differenziale data; in particolare saranno una base disoluzioni y1 e y2 definite così: y1 = g1+g2
2= e−2x cos(3x)+i sin(3x)+cos(3x)−i sin(3x)
2= e−2x cos(3x) e y2 = g1−g2
2i=
e−2x cos(3x)+i sin(3x)−cos(3x)+i sin(3x)2i
= e−2x sin(3x). La generica soluzione sarà quindi una combinazione lineare dei dueelementi della base, ovvero y = e−2x(C1 cos(3x) + C2 sin(3x)).
Esercizio 2.8. Risolvere l’equazione differenziale di secondo ordine non omogenea acoefficenti costanti:
y′′ + y′ − 6y = xe2x
Soluzione. Per prima cosa bisogna risolvere l’equazione omogenea associata y′′ + y′ − 6y = 0.Risolviamo quindi l’omogenea associata. L’equazione caratteristica è λ2 + λ − 6 = 0 che ha come soluzioni λ1 = 2 e
λ2 = −3. Dunque due soluzioni linearmente indipendenti dell’equazione omogenea associata saranno g1 = e2x e g2 = e−3x.La soluzione generica sarà g = c1e2x + c2e−3x.
Per risolvere l’equazione non omogenea, ora bisogna usare il metodo della variazione delle costanti per cui inserendo g1,g2, g′1 e g′2 nel sistema wronskiano si ottiene{
c′1g1 + c′2g2 = 0c′1g′1 + c′2g
′2 = f
=
{c′1e2x + c′2e−3x = 02c′1e2x − 3c′2e−3x = xe2x
Dalla prima equazione si ricava c′2 = −c′1e5x, si sostituisce ora c′2 nella seconda equazione ottenendo 2c′1e2x−3c′1e2x = xe2x
è chiaro che ora si possono moltiplicare ambedue i membri dell’ equazione per e−2x ottenendo −c′1 = x, ovvero c′1 = −x. Ilsistema wronskiano diventa quindi, sostituendo questo risultato nella prima equazione:{
c′2 = −xe5x
c′1 = −x
Si tratta quindi di due equazioni differenziali banali del primo ordine che danno per soluzione c1 = x2
2+k1 e c2 =
∫xe5x dx =
15
(xe5x −
∫e5x dx
)= 1
5xe5x − 1
25e5x + k2.
La soluzione generale dell’equazione differenziale sarà allora y =(x2
2+ k1
)e2x+
(15xe5x − 1
25e5x + k2
)e−3x e, notiamo,
che è definita sempre a meno di due costanti.
Esercizio 2.9. Risolvere il seguente problema di Cauchy y′′ − 5y′ + 4y = 0y(0) = 5y′(0) = 8
Soluzione. L’equazione differenziale è stata svolta precedentemente nell’Esercizio 2.6 ed ha come soluzione generica y =C1e4x + C2ex. Risolvere il problema di Cauchy significa fare in modo che siano verificate dalla soluzione le condizioniy(0) = 5 e y′(0) = 8. Per farlo calcoliamo la generica y′(x) = 4C1e4x + C2ex. Risolvere il problema di Cauchy significarisolvere {
y(0) = C1 + C2 = 5y′(0) = 4C1 + C2 = 8
L’unica soluzione del sistema è C1 = 1 e C2 = 4 da cui si ricava che l’unica soluzione del problema di Cauchy è y = e4x+4ex.
Esercizio 2.10. (Applicazione alla fisica) Si consideri un disco di raggio R = 1m cheruota con velocità angolare ω = 10rad/s attorno ad un asse verticale passante per il suocentro. Lungo un diametro del disco è realizzata una scanalatura dove può scorrere senzaattrito una pallina di massa m = 0.1kg, collegata al centro O del disco da una molla dicostante elastica k = 5N/m e lunghezza a riposo nulla. Se inizialmente la pallina è tenutain quiete rispetto al disco, alla distanza di 50cm da O, determinare la sua velocità radialequando sta per uscire dalla scanalatura.[14]Si usa la formula ridotta. Data un’equazione di secondo grado nell’incognita λ, la sua forma generale è aλ2 +bλ+c = 0,
la formula ridotta che ne fornisce le soluzioni è λ =− b
2±√
( b2 )2−aca
.
Matteo Gallone - Analisi Matematica II

20 Equazioni differenziali: primi elementiEquazioni a coefficenti costanti 2.6
Soluzione. Si scelga come riferimento un sistema solidale al disco (quindi un sistema non inerziale), con un unico asse xorientato secondo la scanalatura del disco. Si scelga come verso positivo il verso uscente dal disco in direzione della posizioneall istante t0 della pallina.
Fatto ciò si scriva l’equazione delle forze agenti sulla pallina:
F = Felastica + Fcentrifuga
Si ricordino ora le espressioni delle rispettive forze, ovvero:
Felastica = −kx
Fcentrifuga = ω2rm
Si sostituiscano le espressioni trovate per le forze nella prima equazione e ricordando il secondo principio della dinamica,ovvero F = ma. Si potrà allora scrivere:
F = ma = −kx+ ω2rm
Ricordiamo ora la definizione di accelerazione (a = d2xdt2
) e sostituiamola nella quarta equazione:
md2x
dt2= −kx+ ω2rm
Ricordando che il raggio utilizzato nella forza centrifuga è variabile nel tempo, e anzi, è proprio uguale ad x allora possiamoscrivere r = x. Portiamo tutto al primo membro e dividiamo ambedue i membri della (5) per m, otteniamo:
d2x
dt2+
k
mx− ω2x = 0
Come si può facilmente notare, quella appena scritta è un’equazione differenziale del secondo ordine lineare e omogenea, acoefficenti costanti. La soluzione è quindi:
x(t) = c1e
√ω2− k
mt
+ c2e−√ω2− k
mt
Per determinare il valore delle costanti c1 e c2 serve derivare la soluzione generale rispetto al tempo. La derivazione nonpresenta particolari problemi e dà come risultato:
v(t) =
√ω2 −
k
m
(c1e
√ω2− k
mt − c2e−
√ω2− k
mt)
Mettendo a sistema la solzione generale e la sua derivata, e imponendo le condizioni iniziali del problema (x0 = 0.5m ev0 = 0m
s) evince che c1 = c2 = 0.25 m.
A questo punto, riscrivendo la soluzione generale, con c1 = c2 = c si avrà:
x(t) = ce
√ω2− k
mt
+ ce−√ω2− k
mt
Riconoscendo in ce√ω2− k
mt
+ ce−√ω2− k
mt la scrittura del coseno iperbolico, allora possiamo riscrivere la x(t) come:
x(t) = 2c · cosh
(√ω2 −
k
mt
)Derivando questa si ottiene un’espressione per la velocità dipendente dal tempo:
v(t) = 2c
√ω2 −
k
m· sinh
(√ω2 −
k
mt
)Per trovarci la velocità in uscita (ovvero quando r = x = 1m) si ricava dalla funzione trovata per x(t) un’ espressione peril tempo sostituendo a x(t) = 1. Si otterrà:
t =settcosh
(x2c
)√ω2 − k
m
Si sostituisca l’espressione appena ottenuta nella funzione trovata per la velocità. Si otterrà:
v(t) = 2c
√ω2 −
k
msinh
(settcosh
( x2c
))= 6.12
m
s
Matteo Gallone - Analisi Matematica II

CAPITOLO 3
Curve in Rn
3.1 Definizioni di base
Vengono innanzi tutto introdotte alcune notazioni e definizioni che useremo in seguito.Il nostro spazio di lavoro sarà Rn, ovvero R× · · · × R︸ ︷︷ ︸
n volte
; un suo elemento generico sarà
x ∈ Rn; x = (x1, . . . , xn), ove le x1, . . . , xn sono dette coordinate di x.
Definizione 3.1.1. Definiamo norma (euclidea)[1] di un vettore generico (x1, . . . , xn) lafunzione ‖ · ‖ : Rn → R definita così:
‖x‖ =√x2
1 + · · ·+ x2n
Definizione 3.1.2. Si dice curva parametrizzata in Rn una funzione continua ϕ : I → Rn
con I ⊆ R intervallo; sia poi ϕ(t) = (ϕ1(t), . . . , ϕn(t)), diremo (ϕ1(t), . . . , ϕn(t)) insiemedelle coordinate di una curva, e le sue equazioni
x1 = ϕ1(t)...
xn = ϕn(t)
si dicono equazioni parametriche della curva.
Definizione 3.1.3. Sia S = ϕ(I) = {ϕ(t) ∈ Rn : t ∈ I} un insieme; tale insieme S vienedetto supporto o sostegno della curva ϕ.
Esempio. Le curve ϕ1 : [0, 2π]→ R2 e ϕ2 : [0, 4π]→ R2 di equazioni parametriche:
ϕ1 =
{xt(t) = cos tyt(t) = sin t
t ∈ [0, 2π] ϕ2 =
{xt(t) = cos tyt(t) = sin t
t ∈ [0, 4π]
pur avendo il medesimo sostegno (la circonferenza centrata sull’origine di raggio 1) sono due curve distinte. Infatti ϕ1
rappresenta il moto di una particella che compie un giro completo sulla circonferenza ruotando in senso antiorario, mentreϕ2 rappresenta il moto di una particella che compie due giri completi ruotando nello stesso senso.
Esempio. La curva ϕ : [0, π/2] → R2 di equazioni parametriche ϕ(t) = (a cos t, b sin t) con a, b > 0 rappresenta l’arco diellisse di equazione x2
a2 + y2
b2= 1 contenuto nel primo quadrante, percorso in senso antiorario.
Esempio. La curva di equazioni parametriche
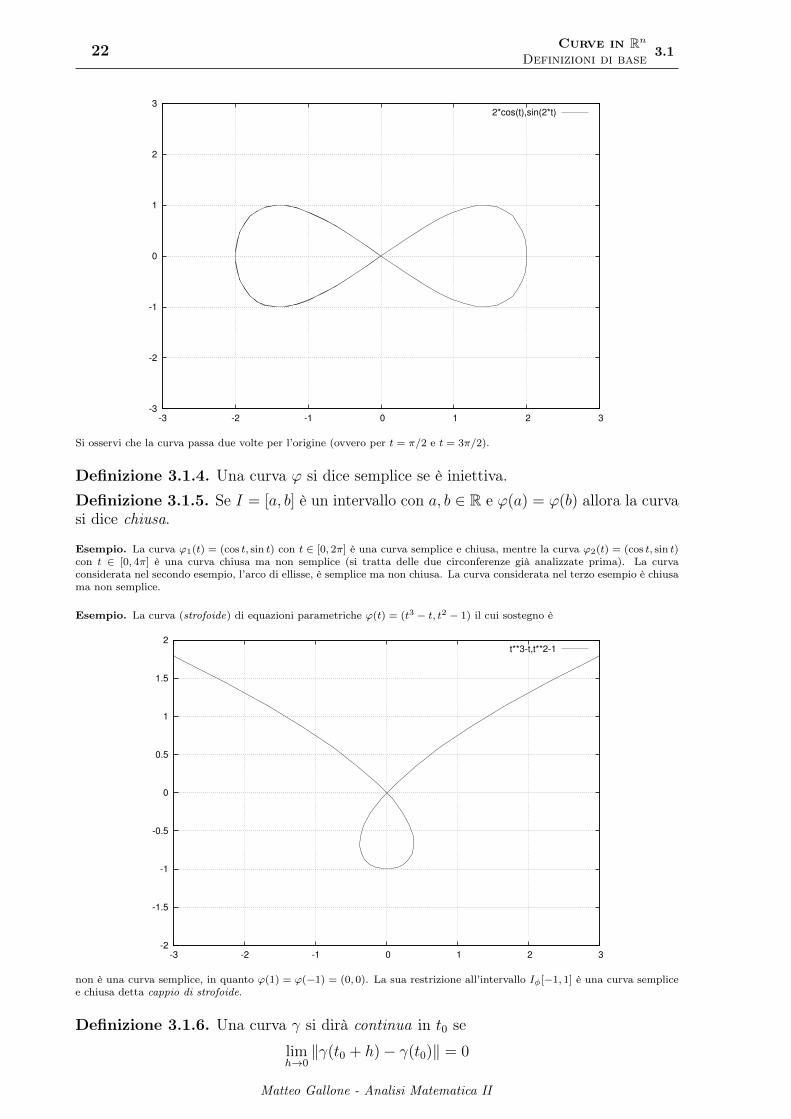
ϕ(t) =
{x = 2 cos ty = sin 2t
t ∈ [0, 2π]
ha come sostegno:
[1]Per una definizione più generale e rigorosa di norma si rimanda a Definizione 4.1.2.
Matteo Gallone - Analisi Matematica II
22 Curve in Rn
Definizioni di base 3.1
-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3
2*cos(t),sin(2*t)
Si osservi che la curva passa due volte per l’origine (ovvero per t = π/2 e t = 3π/2).
Definizione 3.1.4. Una curva ϕ si dice semplice se è iniettiva.Definizione 3.1.5. Se I = [a, b] è un intervallo con a, b ∈ R e ϕ(a) = ϕ(b) allora la curvasi dice chiusa.
Esempio. La curva ϕ1(t) = (cos t, sin t) con t ∈ [0, 2π] è una curva semplice e chiusa, mentre la curva ϕ2(t) = (cos t, sin t)con t ∈ [0, 4π] è una curva chiusa ma non semplice (si tratta delle due circonferenze già analizzate prima). La curvaconsiderata nel secondo esempio, l’arco di ellisse, è semplice ma non chiusa. La curva considerata nel terzo esempio è chiusama non semplice.
Esempio. La curva (strofoide) di equazioni parametriche ϕ(t) = (t3 − t, t2 − 1) il cui sostegno è
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
-3 -2 -1 0 1 2 3
t**3-t,t**2-1
non è una curva semplice, in quanto ϕ(1) = ϕ(−1) = (0, 0). La sua restrizione all’intervallo Iφ[−1, 1] è una curva semplicee chiusa detta cappio di strofoide.
Definizione 3.1.6. Una curva γ si dirà continua in t0 se
limh→0‖γ(t0 + h)− γ(t0)‖ = 0
Matteo Gallone - Analisi Matematica II

3.1 Curve in Rn
Definizioni di base23
Definizione 3.1.7. Una curva γ si dice derivabile in t0 se esiste un vettore v ∈ Rn taleche
limh→0
∥∥∥∥γ(t0 + h)− γ(t0)
h− v∥∥∥∥ = 0 (3.1)
tale vettore, se esiste, è unico ed è detto derivata o vettore derivata di γ in t0. Esso vieneusualmente denotato con γ′(t0).
Proposizione 3.1.8. Una curva γ è continua se e solo se sono continue tutte le suecomponenti.Dimostrazione. L’implicazione ⇒ è banale in quanto se vale limh→0 ‖γ(t0 + h) − γ(t0)‖ = 0 allora, poichè ‖γi(t0 + h) −γi(t0)‖ ≤ ‖γ(t0 + h)− γ(t0)‖ allora si ha necessariamente che limh→0 ‖γi(t0 + h)− γi(t0)‖ = 0 per ogni i.
L’implicazione inversa invece viene dedotta dalla disuguaglianza triangolare (vedi Definizione 4.1.2). Infatti selimh→0 ‖γi(t0 + h)− γi(t0)‖ = 0 allora anche
∑ni=1 limh→0 ‖γi(t0 + h)− γi(t0)‖ = 0. Ma per la disuguaglianza triangolare
‖γ(t0 + h)− γ(t0)‖ ≤∑ni=1 ‖γi(t0 + h)− γi(t0)‖ e quindi, per confronto γ è continua.
Proposizione 3.1.9. Una curva γ è derivabile se e solo se sono derivabili tutte le suecomponenti.Dimostrazione. È sostanzialmente identica a quella della proposizione precedente. Infatti, per la disuguaglianza triangolare(vedi Definizione 4.1.2) si ha ‖ γi(t0+h)−γi(t0)
h− vi‖ ≤ ‖ γ(t0+h)−γ(t0)
h− v‖ ≤
∑ni=1 ‖
γi(t0+h)−γi(t0)h
− vi‖. Quindi l’im-plicazione⇒ segue dalla disuguaglianza tra il primo e il secondo termine, mentre l’implicazione⇐ segue dalla disuguaglianzatra il secondo e il terzo termine.
Proposizione 3.1.10. Se una curva γ è derivabile allora è anche continua.Dimostrazione. Se γ è derivabile in t0 allora ‖γ(t0+h)−γ(t0)‖ = |h|‖ γ(t0+h)−γ(t0)
h‖ = |h|‖ γ(t0+h)−γ(t0)
h−γ′(t0)+γ′(t0)‖ ≤
|h|‖ γ(t0+h)−γ(t0)h
− γ′(t0)‖+ |h|‖γ′(t0)‖ che tende a 0 per h→ 0, ovvero γ è continua.
Definizione 3.1.11. Una curva si dice regolare se ϕ′(t) 6= 0 ∀t ∈ I.
Esempio. Il cappio di strofoide è una curva regolare. Infatti le derivate x′(t) = 3t2 − 1 e y′(t) = 2t non si annullano maicontemporaneamente. Si noti che nel punto di coordinate (0,−1), corrispondente al valore t = 0 del parametro, risultay′(0) = 0. La tangente in quel punto è quindi orizzontale. Analogamente, essendo x′(
√3/3) = x′(−
√3/3) = 0, la curva nei
punti t = ±√
3/3 ha tangente verticale.
Esempio. Si consideri la (già considerata precedentemente) curva ϕ(t) = (2 cos t, sin 2t). In questo caso ϕ′(t) = (−2 sin t, 2 cos 2t),si verifica facilmente che (x′(t))2 + (y′(t))2 > 0 per ogni t ∈ (0, 2π).
Abbiamo già osservato che la curva passa nell’origine in corrispondenza dei valori del parametro t = π/2 e t = 3π/2.Calcolando le derivate nel punto si ha che le rette tangenti sono y = x e y = −x.
Esempio. La curva di equazioni parametriche ϕ(t) = (t3, t2) definita in [−1, 1] non è una curva regolare in quanto ϕ′(0) = 0.
-0.5
0
0.5
1
1.5
-1 -0.5 0 0.5 1
t**3,t**2
Matteo Gallone - Analisi Matematica II

24 Curve in Rn
Lunghezza di una curva 3.2
Infatti si può vedere che nel punto (0, 0) la curva presenta una cuspide. Consideriamo ora la curva come unione di duecurve regolari ϕ+ (con sostegno nel primo quadrante) e ϕ− con sostegno nel secondo quadrante. Le due curve, che hannoin comune l’origine degli assi, sono regolari.
Definizione 3.1.12. Sia ϕ una curva regolare. Si definisce il versore tangente alla curvanel punto ϕ(t), il versore T (t) = ϕ′(t)
‖ϕ′(t)‖ .
Definizione 3.1.13. Siano ϕ ∈ C1(I,Rn) regolare e t0 ∈ I fissato; la retta di equazioniparametriche x(t) = (t− t0)ϕ′(t0) +ϕ(t0) si dice retta tangente alla curva nel punto ϕ(t0).
Definizione 3.1.14. Data f : I → R una funzione continua; allora la curva ϕ : I → Rtale che ϕ(x) = (x, f(x)) con x ∈ I si dice data in forma cartesiana oppure in forma digrafico cartesiano.
Osservazione 3.1.15. Se f ∈ C1 allora ϕ è sempre regolare.
Definizione 3.1.16. Sia ρ : I → [0,∞) una funzione continua. Una curva piana ϕ : I →R2 si dice data in coordinate polari se è scritta nella forma ϕ(ϑ) = (ρ(ϑ) cos(ϑ), ρ(ϑ) sin(ϑ)).L’equazione ρ = ρ(ϑ) si dice equazione polare della curva.
Supponiamo ora le stesse ipotesi della definizione precedente, ovvero sia ρ : I → [0,∞)una funzione continua e sia ϕ : I → R2 una curva piana. Calcoliamo una semplice formulaper il modulo della derivata prima di ϕ(ϑ) nel caso in cui ρ ∈ C1. Per come è stata definita,la curva ha equazioni ϕ(ϑ) = (ρ cos(ϑ), ρ sin(ϑ)). Derivando, e applicando la regola diLeibnitz[2] otteniamo ϕ′(ϑ) = (ρ′ cos(ϑ)− ρ sin(ϑ), ρ′ sin(ϑ) + ρ cos(ϑ)). Facciamo ora lanorma euclidea ‖ϕ′(ϑ)‖ e dopo qualche calcolo[3] si ottiene:
‖ϕ′(ϑ)‖ =√
(ρ′)2 + ρ2 (3.2)
Definizione 3.1.17. Dati gli intervalli I, J ∈ R, una funzione g ∈ C1(I, J) si dice cam-biamento di parametro ammissibile (C.P.A.) se la sua derivata prima non è mai nulla[4] ese è biiettiva.
Definizione 3.1.18. Due curve ϕ : I → Rn e ψ : J → Rn si dicono equivalenti se esisteg ∈ C1(I, J) cambiamento di parametro ammissibile tale che ϕ = ψ ◦ g, ovvero
ϕ = ψ(g(t)) ∀t ∈ I
In questo caso definiremo ψ come riparametrizzazione di ϕ.
Se ϕ e ψ sono equivalenti nel senso appena detto scriveremo ϕ ∼ ψ.[5]
Definizione 3.1.19. Siano ϕ ∈ C1(I,Rn) e ψ ∈ C1(I,Rn) due curve equivalenti. Allorase g′(t) > 0 su I diremo che le due curve sono equiorientate, se invece g′(t) < 0 su I ledue curve avranno orientazione opposta.[6]
3.2 Lunghezza di una curva
Definizione 3.2.1. Sia I = [a, b] con −∞ < a < b < ∞ un intervallo. Definiamopartizione di I l’insieme
P = {ti ∈ I : i = 0, 1, . . . , N ; a = t0 < t1 < · · · < tN = b}[2]La regola di derivazione del prodotto per cui d
dx(f(x)g(x)) = df
dx(x)g(x) + dg
dx(x)f(x).
[3]‖ϕ′(ϑ)‖ =√
(ρ′ cos(ϑ)− ρ sin(ϑ))2 + (ρ′ sin(ϑ) + ρ cos(ϑ))2. Svolgiamo ora i calcoli dentro la radice quadrata:
(ρ′ cos(ϑ)− ρ sin(ϑ))2 + (ρ′ sin(ϑ) + ρ cos(ϑ))2 = (ρ′)2 cos2(ϑ) +ρ2 sin2(ϑ)− 2ρρ′ sin(ϑ) cos(ϑ) + (ρ′)2 cos2(ϑ) +ρ2 sin2(ϑ) +2ρρ′ cos(ϑ) sin(ϑ). Raccogliamo ρ2, raccogliamo (ρ′)2 e ρρ′. Otteniamo l’espressione ρ2(sin2(ϑ) + cos2(ϑ)) + (ρ′)2(sin2(ϑ) +cos2(ϑ))+ρρ′(sin(ϑ) cos(ϑ)−sin(ϑ) cos(ϑ)). Per la nota uguaglianza trigonometrica sin2(ϑ)+cos2(ϑ) = 1, e inoltre notiamoche il terzo termine è nullo. Quindi scriviamo l’espressione equivalente (ρ′)2 + ρ2.
[4]Ovvero ∀t ∈ I si ha g′(t) 6= 0. Ovvero si ha g′(t) > 0 oppure g′(t) < 0.[5]La relazione ∼ è di equivalenza.[6]Il caso g′(t) = 0 non può essere per definizione di cambiamento di parametro ammissibile (vedi Definizione 3.1.17).
Matteo Gallone - Analisi Matematica II

3.2 Curve in Rn
Lunghezza di una curva25
Definizione 3.2.2. Data una curva ϕ : I → Rn, la sua partizione P definisce una curvapoligonale P : I → Rn inscritta in ϕ tale che:
P =ti − tti − ti−1
ϕ(ti−1) +t− ti−1
ti − ti−1
ϕ(ti)
con t ∈ [ti−1, ti] ∀i = 1, . . . , N .
Definizione 3.2.3. Definiamo la lunghezza di una poligonale P che si indica con `(P):
`(P) =N∑i=1
‖ϕ(ti)− ϕ(ti−1)‖
Definizione 3.2.4. La lunghezza di una generica curva L(ϕ) è definita come
L(ϕ) = sup{`(P)}
ove `(P) è la lunghezza della poligonale inscritta in ϕ e il sup si intende al variare di P .
Definizione 3.2.5. Una curva ϕ si dice rettificabile nel caso in cui L(ϕ) <∞.
Esempio. (1). Si prenda curva γ(t) : [0, 1]→ R2 definita come γ(t) = (r cos(2πt), r sin(2πt)) (si tratta della circonferenzadi raggio r percorsa in senso antiorario una volta sola). Cominciamo a costruire delle poligonali. La prima sarà un quadratoche avrà quindi lato r
√2. La lunghezza di questa poligonale è `(P1) = 4r
√2. Più in generale un poligono inscritto con 2n
lati avrà (per il teorema dei seni[7]) lato uguale a
l = rsin(
π2n−1
)sin(π2
(1− 1
2n−1
))Quindi la lunghezza della poligonale sarà `(Pn) = 2nl. Facendo tendere n all’infinito si arriva ad approssimare sempremeglio la circonferenza e, calcolando il limite della lunghezza della poligonale si ottiene
L(γ) = sup{`(P)} = limn→∞
2nrsin(
π2n−1
)sin(π2
(1− 1
2n−1
)) = limn→∞
2nrπ
2n−1= 2πr
(dove nel penultimo passaggio si è usato lo sviluppo in serie di Taylor al primo ordine dei due seni).(2). (curva non rettificabile). Si prenda la curva γ(t) : [0, 1] → R2 definita come γ(t) =
(t, t cos
(πt
))per t 6= 0
mentre γ(t) = (0, 0) per t = 0. Inscriviamo ora una poligonale che per i primi m elementi prenda i massimi locali dellafunzione t cos
(1t
)e poi si colleghi allo zero. Avremo quindi una suddivisione Sm =
{0, 1m, . . . , 1
2, 1}. Notiamo inoltre
che la lunghezza di ogni pezzetto di poligonale così costruita è maggiore della lunghezza della sua proiezione sull’asse y.Dimostriamo quindi che non esiste il sup della somma della proiezione dei pezzi di poligonali sull’asse y. Per farlo, innanzitutto calcoliamo esplicitamente gli estremi del k−esimo segmento della poligonale. Essi sono quei punti in cui cos
(πt
)= ±1,
ovvero πt
= kπ da cui t = 1k. Quindi gli estremi del segmento saranno ( 1
k,± 1
k) e ( 1
k+1,∓ 1
k+1) per cui la proiezione sull’asse
y risulta avere lunghezza 1k
+ 1k+1
. La lunghezza che cerchiamo è quella della somma di ogni singola proiezione:
Lp =
m∑k=1
1
k+
1
k + 1>
m∑k=1
1
k
un eventuale sup dovrà essere fatto su tutti i massimi della funzione, ovvero facendo tendere m ad infinito ma
Lp =∞∑k=1
1
k+
1
k + 1>∞∑k=1
1
k=∞
quindi il sup non esiste e la curva non è rettificabile.
Definizione 3.2.6. Sia γ = (γ1, . . . , γn) una curva. Se le sue componenti sono localmenteintegrabili allora si definisce l’integrale vettoriale di γ come il vettore
∫ b
a
γ(t) dt =
∫ baγ1(t) dt...∫ b
aγn(t) dt
∈ Rn (3.3)
[7]Ovvero in ogni triangolo indicati con a, b, c i tre lati e con α, β, γ i tre angoli opposti ad ogni lato si ha asinα
= bsin β
=c
sin γ.
Matteo Gallone - Analisi Matematica II
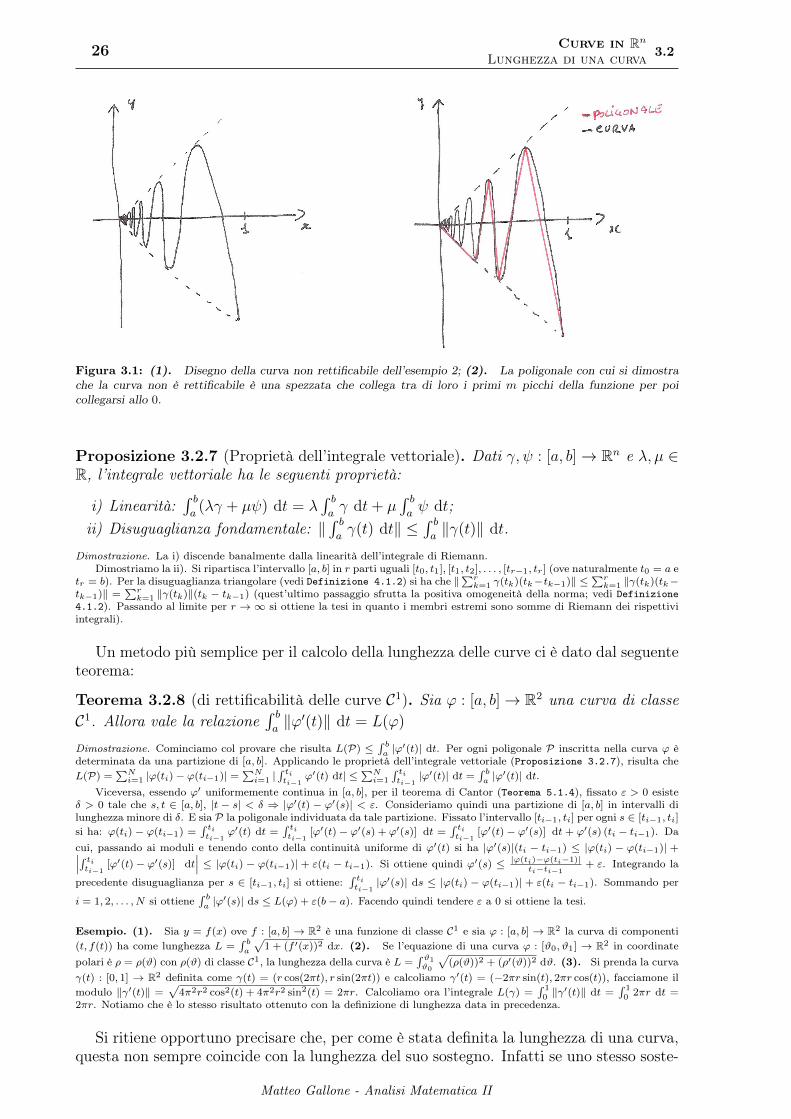
26 Curve in Rn
Lunghezza di una curva 3.2
Figura 3.1: (1). Disegno della curva non rettificabile dell’esempio 2; (2). La poligonale con cui si dimostrache la curva non è rettificabile è una spezzata che collega tra di loro i primi m picchi della funzione per poicollegarsi allo 0.
Proposizione 3.2.7 (Proprietà dell’integrale vettoriale). Dati γ, ψ : [a, b]→ Rn e λ, µ ∈R, l’integrale vettoriale ha le seguenti proprietà:
i) Linearità:∫ ba(λγ + µψ) dt = λ
∫ baγ dt+ µ
∫ baψ dt;
ii) Disuguaglianza fondamentale: ‖∫ baγ(t) dt‖ ≤
∫ ba‖γ(t)‖ dt.
Dimostrazione. La i) discende banalmente dalla linearità dell’integrale di Riemann.Dimostriamo la ii). Si ripartisca l’intervallo [a, b] in r parti uguali [t0, t1], [t1, t2], . . . , [tr−1, tr] (ove naturalmente t0 = a e
tr = b). Per la disuguaglianza triangolare (vedi Definizione 4.1.2) si ha che ‖∑rk=1 γ(tk)(tk−tk−1)‖ ≤
∑rk=1 ‖γ(tk)(tk−
tk−1)‖ =∑rk=1 ‖γ(tk)‖(tk − tk−1) (quest’ultimo passaggio sfrutta la positiva omogeneità della norma; vedi Definizione
4.1.2). Passando al limite per r → ∞ si ottiene la tesi in quanto i membri estremi sono somme di Riemann dei rispettiviintegrali).
Un metodo più semplice per il calcolo della lunghezza delle curve ci è dato dal seguenteteorema:
Teorema 3.2.8 (di rettificabilità delle curve C1). Sia ϕ : [a, b]→ R2 una curva di classeC1. Allora vale la relazione
∫ ba‖ϕ′(t)‖ dt = L(ϕ)
Dimostrazione. Cominciamo col provare che risulta L(P) ≤∫ ba |ϕ
′(t)| dt. Per ogni poligonale P inscritta nella curva ϕ èdeterminata da una partizione di [a, b]. Applicando le proprietà dell’integrale vettoriale (Proposizione 3.2.7), risulta cheL(P) =
∑Ni=1 |ϕ(ti)− ϕ(ti−1)| =
∑Ni=1 |
∫ titi−1
ϕ′(t) dt| ≤∑Ni=1
∫ titi−1|ϕ′(t)| dt =
∫ ba |ϕ
′(t)| dt.Viceversa, essendo ϕ′ uniformemente continua in [a, b], per il teorema di Cantor (Teorema 5.1.4), fissato ε > 0 esiste
δ > 0 tale che s, t ∈ [a, b], |t − s| < δ ⇒ |ϕ′(t) − ϕ′(s)| < ε. Consideriamo quindi una partizione di [a, b] in intervalli dilunghezza minore di δ. E sia P la poligonale individuata da tale partizione. Fissato l’intervallo [ti−1, ti] per ogni s ∈ [ti−1, ti]
si ha: ϕ(ti) − ϕ(ti−1) =∫ titi−1
ϕ′(t) dt =∫ titi−1
[ϕ′(t)− ϕ′(s) + ϕ′(s)] dt =∫ titi−1
[ϕ′(t)− ϕ′(s)] dt + ϕ′(s) (ti − ti−1). Dacui, passando ai moduli e tenendo conto della continuità uniforme di ϕ′(t) si ha |ϕ′(s)|(ti − ti−1) ≤ |ϕ(ti) − ϕ(ti−1)| +∣∣∣∫ titi−1
[ϕ′(t)− ϕ′(s)] dt∣∣∣ ≤ |ϕ(ti) − ϕ(ti−1)| + ε(ti − ti−1). Si ottiene quindi ϕ′(s) ≤ |ϕ(ti)−ϕ(ti−1)|
ti−ti−1+ ε. Integrando la
precedente disuguaglianza per s ∈ [ti−1, ti] si ottiene:∫ titi−1|ϕ′(s)| ds ≤ |ϕ(ti) − ϕ(ti−1)| + ε(ti − ti−1). Sommando per
i = 1, 2, . . . , N si ottiene∫ ba |ϕ
′(s)| ds ≤ L(ϕ) + ε(b− a). Facendo quindi tendere ε a 0 si ottiene la tesi.
Esempio. (1). Sia y = f(x) ove f : [a, b] → R2 è una funzione di classe C1 e sia ϕ : [a, b] → R2 la curva di componenti(t, f(t)) ha come lunghezza L =
∫ ba
√1 + (f ′(x))2 dx. (2). Se l’equazione di una curva ϕ : [ϑ0, ϑ1] → R2 in coordinate
polari è ρ = ρ(ϑ) con ρ(ϑ) di classe C1, la lunghezza della curva è L =∫ ϑ1ϑ0
√(ρ(ϑ))2 + (ρ′(ϑ))2 dϑ. (3). Si prenda la curva
γ(t) : [0, 1] → R2 definita come γ(t) = (r cos(2πt), r sin(2πt)) e calcoliamo γ′(t) = (−2πr sin(t), 2πr cos(t)), facciamone ilmodulo ‖γ′(t)‖ =
√4π2r2 cos2(t) + 4π2r2 sin2(t) = 2πr. Calcoliamo ora l’integrale L(γ) =
∫ 10 ‖γ
′(t)‖ dt =∫ 10 2πr dt =
2πr. Notiamo che è lo stesso risultato ottenuto con la definizione di lunghezza data in precedenza.
Si ritiene opportuno precisare che, per come è stata definita la lunghezza di una curva,questa non sempre coincide con la lunghezza del suo sostegno. Infatti se uno stesso soste-
Matteo Gallone - Analisi Matematica II

3.3 Curve in Rn
Ascissa curvilinea e integrale curvilineo27
gno viene percorso diverse volte anche la lunghezza della curva sarà aumentata rispettoa quella del sostegno.
3.3 Ascissa curvilinea e integrale curvilineo
Sia ϕ : [a, b] → Rn con n ≥ 1 una curva C1([a, b]) regolare tale che ‖ϕ′‖ 6= 0. Vogliocercare una riparametrizzazione γ ∈ C1([a, b]) di ϕ tale che ‖γ′(s)‖ = 1 per ogni s ∈ [0, L]e g : [a, b]→ [0, L].
Per il Teorema 3.2.8 abbiamo che ∀s1, s2 ∈ [0, L] con s1 < s2 la lunghezza della curvaL(γ|[s1,s2]) =
∫ s2s1‖γ′(s)‖ ds = s2 − s1. Scegliamo quindi L =
∫ ba‖γ′(t)‖ dt e definiamo
g : [a, b]→ [0, L] : g(t) =
∫ t
a
‖γ′(τ)‖ dτ
Definita la g in questo modo essa risulta avere le seguenti proprietà:
• 0 < ‖ϕ′(t)‖ = γ′(t) per ogni t ∈ [a, b], e, in particolare g ∈ C1([a, b]);• g è iniettiva e suriettiva, ovvero biiettiva.
Pertanto g così definita risulta essere un cambiamento ammissibile di parametro. Inoltreesiste f = g−1 : [0, L]→ [a, b] e f ∈ C1([0, L]), in altri termini
f ′(s) =1
g′(f(s))=
1
‖ϕ′(f(s))‖
per ogni s ∈ [0, L]. Definiamo quindi γ : [0, L] → Rn con γ ∈ C1([0, L]) e γ(s) = ϕ(f(s))riparametrizzazione di ϕ, ricordando che
γ′(s) = ϕ′(f(s))f ′(s) =ϕ′(f(s))
‖ϕ′(f(s))‖
Definizione 3.3.1. Data la curva γ : C1([a, b],Rn) e il suo sostegno Γ = γ([a, b]) ef : Γ → R funzione continua tale che t → f(γ(t)) con t ∈ [a, b] e f(γ(t)) ∈ R, definiamointegrale curvilineo l’integrale di Riemann∫
γ
f(s) ds =
∫ b
a
f(γ(t))‖γ′(t)‖ dt
Prima di vedere le proprietà dell’integrale curvilineo serve introdurre le nozioni di curvacontinua a tratti e concatenazione di curve.
Definizione 3.3.2. Una curva ϕ : [a, b]→ R continua è di classe C1 a tratti se esiste unapartizione P di [a, b], P = {a = t0 < t1 < · · · < tn = b} tale che ϕ ∈ C1([ti−1, ti]) perqualsiasi valore di i.
Osservazione 3.3.3. Nel caso in cui una curva sia di classe C1 a tratti allora risultarettificabile ed è possibile calcolarne l’integrale curvilineo.
Definizione 3.3.4. Date due curve γ1 : [a1, b1]→ Rn e γ2 : [a2, b2]→ Rn tali che γ1(b1) =γ2(a2). Definiamo la somma o concatenazione la curva γ1 + γ2 : [a1, b1 + b2− a2]→ Rn lacurva:
(γ1 + γ2)(t) =
{γ1(t) t ∈ [a1, b1]γ2(t− b1 + a2) t ∈ [a1, b1 + b2 − a2]
Proposizione 3.3.5 (Proprietà dell’integrale curvilineo). L’integrale curvilineo gode delleseguenti proprietà:
i) La definizione dell’integrale non dipende dalla parametrizzazione della curva;
Matteo Gallone - Analisi Matematica II

28 Curve in Rn
Ascissa curvilinea e integrale curvilineo 3.3
ii) Se f, g : Γ → R sono funzioni continue (con Γ sostegno della curva γ), α, β ∈ Rallora vale
∫γ(αf(s) + βg(s)) ds = α
∫γf(s) ds+ β
∫γg(s) ds;
iii) Con le stesse ipotesi dei punti precedenti risulta: f(s) ≤ g(s) su Γ allora∫γf(s) ds ≤∫
γg(s) ds;
iv) Se γ1 e γ2 sono funzioni continue a tratti e f : Γ1 ∪ Γ2 → R continua con Γi =γi(ai, bi).
Dimostrazione. i) Suppongo che γ(t) = ψ(g(t)) con le seguenti ipotesi: t ∈ [a, b]; g(t) : [a, b] → [c, d]; g ∈ C1 ecambiamento ammissibile di parametro; ψ : [c, d] → Rn e γ ∼ ψ. Per la definizione di integrale curvilineo allora∫ψ f(s) ds =
∫ dc f(ψ(s))‖ψ′(s)‖ ds. Applico la sostituzione s = g(t), ovvero ds = g′(t) dt. L’integrale appena scritto diventa∫ b
a f(ψ(g(t)))‖ψ′(g(t))‖g′(t) dt. Ora abbiamo due casi: g′(t) > 0 e g′(t) < 0. Nel primo caso si ha∫ ba f(ψ(g(t)))‖ψ′(g(t))‖g′(t) dt =∫ b
a f(ψ(g(t)))‖ψ′(g(t))g′(t)‖ dt =∫γ f(s) ds. Nel secondo caso si ha
∫ ba f(ψ(g(t)))‖ψ′(g(t))‖g′(t) dt =
∫ ba f(ψ(g(t)))‖ −
ψ′(g(t))g′(t)‖ dt =∫γ f(s) ds. La dimostrazione è terminata.
La ii) e la iii) discendono dalla liearità e dalla monotonia dell’integrale di Riemann, mentre la iv) discende dallaproprietà di decomposizione del dominio dell’integrale di Riemann.
Matteo Gallone - Analisi Matematica II

CAPITOLO 4
Spazi metrici e normati
4.1 Definizioni ed esempi
Definizione 4.1.1. Uno spazio metrico è una coppia (X, d) dove X è un insieme e d :X × X → [0,∞) è una funzione detta metrica o distanza, che per ogni (x, y) ∈ X × Xverifica le seguenti proprietà:
1. d(x, y) ≥ 0 e d(x, y) = 0 se e solo se x = y;2. d(x, y) = d(y, x) (simmetria);3. d(x, y) ≤ d(x, z) + d(z, y) (disuguaglianza triangolare).
Definizione 4.1.2. Uno spazio normato (reale) è una coppia (V, ‖ · ‖) dove V è unospazio vettoriale reale e ‖ · ‖ : V → [0,∞) è una funzione, detta norma, che per ogni(x, y) ∈ V × V e per ogni λ ∈ R verifica le seguenti proprietà:
1. ‖x‖ ≥ 0 e ‖x‖ = 0 se e solo se x = 0;2. ‖λx‖ = |λ|‖x‖ (omogeneità);3. ‖x+ y‖ ≤ ‖x‖+ ‖y‖ (subadditività o disuguaglianza triangolare).
Fissato un raggio r ≥ 0 e x ∈ X l’insieme B(x, r) = {y ∈ X : d(x, y) < r} si dice palla(aperta) di centro x e raggio r. Utilizzando le palle aperte saremo in grado di definireuna topologia su uno spazio metrico.
Una norma ‖ · ‖ su uno spazio vettoriale V induce canonicamente una distanza d su Vdefinita nel seguente modo
d(x, y) = ‖x− y‖, x, y ∈ V (4.1)
La disuguaglianza triangolare per la distanza d deriva dalla subadittività della norma ‖·‖.Infatti, per ogni x, y ∈ V si ha:
d(x, y) = ‖x− y‖ = ‖x− z + z − y‖ ≤ ‖x− z‖ − ‖z − y‖ = d(x, z) + d(z, y)
Esempio. Lo spazio metrico euclideo. La funzione | · | : Rn → [0,∞), n ≥ 1 così definita
|x| =(
n∑i=1
x2i
)1/2
, x = (x1, . . . , xn) ∈ Rn (4.2)
è una norma su Rn, detta norma euclidea. Lo spazio metrico corrispondente (Rn, d), dove d(x, y) = |x − y|, si dice spaziometrico Euclideo. L’insieme B(x, r) = {y ∈ Rn : |x − y| < r} è la palla euclidea di raggio r ≥ 0 centrata in x ∈ Rn. Conla notazione 〈x, y〉 = x1y1 + x2y2 + · · · + xnyn si indica il prodotto scalare standard di Rn. Introdotta questa notazionepossiamo esprimere la norma euclidea nel modo: |x| =
√〈x, x〉.
La verifica delle proprietà 1) e 2) per la norma euclidea è elementare. Per verificare la subadditività occorre ladisuguaglianza di Cauchy-Schwarz.
Matteo Gallone - Analisi Matematica II

30 Spazi metrici e normatiSuccessioni in uno spazio metrico 4.3
Proposizione 4.1.3 (Disuguaglianza di Cauchy-Schwarz). Per ogni x, y ∈ Rn vale ladisuguaglianza
|〈x, y〉| ≤ |x||y| (4.3)
Dimostrazione. Il polinomio reale nella variabile t ∈ R, P (t) = |x+ ty|2 = |x|2 + 2t〈x, y〉+ t2|y|2 non è mai negativo, ovveroP (t) ≥ 0 per ogni t ∈ R. Dunque il suo discriminante ∆ ≤ 0, e quindi 4〈x, y〉2−4|x|2|y|2 ≤ 0, ovvero, dividendo per quattroambedue i membri e portando il secondo addendo del primo membro a destra si ottiene 〈x, y〉2 ≤ |x|2|y|2. Estraendo leradici quadrate si ottiene la tesi.
Esempio. Possiamo ora dimostrare la subadditività della norma euclidea. Dobbiamo dimostrare che |x + y| ≤ |x| + |y|.Consideriamo solo il primo membro ed eleviamolo al quadrato: |x + y|2 = |x|2 + 〈x, y〉 + |y|2. Per la disuguaglianza diCauchy-Schwarz (Proposizione 4.1.3) si ha che 〈x, y〉 ≤ |x||y|, quindi |x|2 +〈x, y〉+ |y|2 ≤ |x|2 +2|x||y|+ |y|2 = (|x|+ |y|)2.Abbiamo appena dimostrato che |x+ y|2 ≤ (|x|+ |y|)2. Estraendo le radici quadrate abbiamo dimostrato la subadditivitàdella norma euclidea.
Esempio. Norma della convergenza uniforme. Consideriamo l’insieme V = C([0, 1];Rn) delle funzioni continue avalori in Rn, n ≥ 1, definite su un intervallo [0, 1] ⊂ R. Queste sono funzioni con n componenti f = (f1, f2, . . . , fn)e ciascuna componente è una funzione continua a valori reali. L’insieme V è uno spazio vettoriale reale. La funzione‖ · ‖∞ : V → [0,∞) definita come
‖f‖∞ = supx∈[0,1]
|f(x)| = maxx∈[0,1]
|f(x)| (4.4)
è detta norma della convergenza uniforme o norma del sup. L’estremo superiore è il massimo per il teorema di Weier-strass[1]. Le proprietà 1) e 2) sono di facile verifica. Verifichiamo la disuguaglianza triangolare per f, g ∈ V : ‖f + g‖∞ =supx∈[0,1] |f(x) + g(x)| ≤ supx∈[0,1](|f(x)|+ g|(x)|) perchè la norma euclidea soddisfa la disuguaglianza triangolare. Inoltresi ha anche supx∈[0,1](|f(x)|+ g|(x)|) ≤ supx∈[0,1] |f(x)|+ supx∈[0,1] g|(x)| = ‖f‖∞ + ‖g‖∞. la disuguaglianza triangolareè quindi verificata.
Esempio. Norma integrale. Consideriamo l’insieme V = C([0, 1]) delle funzioni continue a valori reali definite sull’inter-vallo [0, 1] ∈ R. La funzione ‖ · ‖1 : V → [0,∞)
‖f‖1 =
∫ 1
0|f(x)| dx (4.5)
è la norma della convergenza L1([0, 1]). Le proprietà 1) e 2) si verificano in modo banale. Verifichiamo la subadittività per‖ · ‖1. Date f, g ∈ V si ha
‖f + g‖ =
∫ 1
0|f(x) + g(x)| dx ≤
∫ 1
0(|f(x)|+ |g(x)|) dx =
∫ 1
0|f(x)| dx+
∫ 1
0|g(x)| dx
La disuguaglianza è dovuta alla proprietà del modulo[2] e la successiva uguaglianza è legata alla linearità dell’integrale.Quindi si è dimostrato che ‖f + g‖1 ≤ ‖f‖1 + ‖g‖1.
4.2 Successioni in uno spazio metrico
Una successione in uno spazio metrico (X, d) è una funzione x : N→ X. Si usa la seguentenotazione xn = x(n) per ogni n ∈ N e la successione si indica con (xn)n∈N.
Definizione 4.2.1. Una successione (xn)n∈N converge ad un punto x ∈ X nello spaziometrico (X, d) se
limx→∞
d(xn, x) = 0 ovvero ∀ε > 0, ∃n ∈ N, ∀n ≥ n : d(xn, x) ≤ ε (4.6)
In questo caso si scrive anche xn → x per n→∞ in (X, d) oppure anche limn→∞ xn = x,e si dice che la successione è convergente, ovvero che x è il limite della successione.
Proposizione 4.2.2. Se il limite di una successione esiste allora è unico.Dimostrazione. Prendiamo infatti x, y ∈ X e supponiamo che siano entrambi limiti di (xn)n∈N, allora risulta per ladisuguaglianza triangolare d(x, y) ≤ d(x, xn) + d(y, xn). Per definizione inoltre d(x, y) ≥ 0, quindi 0 ≤ d(x, y) ≤ d(x, xn) +d(y, xn). Ma per x→∞ l’ultimo termine dell’uguaglianza tende a 0, quindi per il teorema dei carabinieri anche d(x, y) = 0.Ma ciò implica proprio che x = y.
[1]Sia f : [a, b]→ R una funzione continua e sia [a, b] un compatto. Allora f(x) assume massimo e minimo nell’intervallo[a, b].
[2]|a+ b| ≤ |a|+ |b|.
Matteo Gallone - Analisi Matematica II

4.3 Spazi metrici e normatiFunzioni continue tra spazi metrici
31
4.3 Funzioni continue tra spazi metrici
Definizione 4.3.1. Siano (X, dX) e (Y, dY ) due spazi metrici e sia x0 ∈ X. Una funzionef : X → Y si dice continua nel punto x0 ∈ X se per ogni ε > 0 esiste δ > 0 tale che perogni x ∈ X vale
d(x, x0) < δ ⇒ d(f(x), f(x0)) < ε
La funzione si dice continua se è continua in tutti i punti di X.
Definizione 4.3.2. Data una funzione f : X → Y e un punto x0 ∈ X, f è sequenzialmentecontinua in x0 se per ogni successione (xn)n∈N ∈ X allora limxn = x0 ∈ X ⇒ lim f(xn) =f(x) ∈ Y .
Teorema 4.3.3. Negli spazi metrici la continuità è equivalente alla continuità sequenziale.Dimostrazione. Sia f : X → Y una funzione e sia x0 il punto di cui vogliamo studiare la continuità. Siano inoltre (X, dX)e (Y, dY ) due spazi metrici.
Dimostriamo che la continuità implica la continuità sequenziale. Fissato ε > 0, poichè f è continua allora esiste δ > 0tale che per ogni x ∈ X vale dX(x, x0) < δ ⇒ dY (f(x), f(x0)) < ε. Dalla convergenza della successione segue l’esistenza din ∈ N tale che per n ≥ n si ha dX(xn, x0) < δ. Quindi per tali n ≥ n deve essere dY (f(xn), f(x0)) < ε. Il che è esattamentecome dire che f è sequenzialmente continua.
Dimostriamo che la continuità sequenziale implica la continuità. Supponiamo per assurdo che f non sia continua in x0 ∈X. Allora esiste ε > 0 tale che per ogni n ∈ N esistono dei punti xn ∈ X tali che dX(xn, x0) < 1
nma dY (f(xn), f(x0)) ≥ ε.
Poichè f è sequenzialmente continua allora una qualsiasi successione (xn)n∈N che ha limite limxn = x0 dovrebbe implicare ilfatto che lim f(xn) = f(x0). Ma ciò è esattamente come dire che per n→∞ si ha dY (f(xn), f(x0)) < ε. Il che contraddicel’ipotesi che la funzione possa essere non continua.
Per funzioni f : X → R a valori reali si possono definire in modo naturale le opera-zioni di somma, moltiplicazione e reciproco. Queste funzioni ereditano la continuità dellefunzioni da cui sono composte.
Teorema 4.3.4. Sia (X, dX) uno spazio metrico e sia R munito della distanza Euclidea.Siano f, g : X → R funzioni continue in un punto x0 ∈ X allora:
1. La funzione somma f + g : X → R è continua nel punto x0;2. La funzione prodotto f · g : X → R è continua nel punto x0;3. Se f 6= 0 su X, allora la funzione reciproca 1/f : X → R è continua in x0.
Dimostrazione. La dimostrazione discende dalle analoghe proprietà dei limiti. Infatti dimostriamo la 1). Per ipotesiesistono finiti i limiti limx→x0 f(x) = f(x0) e limx→x0 g(x) = g(x0). Allora esiste finito il limite limx→x0 (f(x) + g(x)) =limx→x0 f(x) + limx→x0 g(x) = f(x0) + g(x0). Ma questo è esattamente come dire che la funzione somma è continua.
Dimostriamo la 2). Sempre per ipotesi esistono i limiti di prima. Quindi esiste finito il limite limx→x0 (f(x) · g(x)) =limx→x0 f(x) limx→x0 g(x) = f(x0)g(x0). Quindi anche il prodotto di funzioni continue è una funzione continua.
La 3) è vera perché se limx→x0 f(x) = f(x0) 6= 0 allora limx→x01
f(x)= 1
f(x0).
Inoltriamoci ora sul caso multidimensionale, nel caso in cui X = Rn e Y = Rm conn,m ≥ 1, entrambi muniti della rispettiva distanza euclidea.
Più precisamente, dato un insieme A ⊂ Rn consideriamo lo spazio metrico (A, d) doved è la distanza Euclidea su A ereditata dallo spazio ambiente.
Teorema 4.3.5. Sia f : A → Rm una funzione f = (f1, . . . , fm), e sia x0 ∈ A ⊂ Rm unpunto fissato. Sono equivalenti:
A) f è continua in x0;B) le funzioni coordinate f1, . . . , fm : A→ R sono continue in x0.
Dimostrazione. Dimostriamo l’implicazione A) ⇒ B). Poichè f è continua allora se |x − x0| < δ esiste un ε > 0 tale che|f(x)− f(x0)| < ε. Poichè però f(x) = |f1(x) + f2(x) + · · ·+ fm(x)| allora si deve avere, per ogni i = 1, . . . ,m e per ognix ∈ A, che |fi(x)− fi(x0)| ≤ |f(x)− f(x0)| < ε. Che è esattamente come dire che ogni fi è continua.
L’implicazione B) ⇒ A) si verifica così. Fissato ε > 0, per ogni i = 1, . . . ,m esiste δi > 0 tale che |x − x0| < δi ⇒|fi(x) − fi(x0)| < ε. Con la scelta δ = min{δ1, . . . , δm} vale allora l’implicazione |x − x0| < δ ⇒ |f(x) − f(x0)| <
√mε.
Che è come dire che la f è continua in x0.
Matteo Gallone - Analisi Matematica II

32 Spazi metrici e normatiSpazi metrici completi 4.4
Esercizio 4.1. Al variare di α, β ∈ R≥0 studiare la continuità in (0, 0) ∈ R2 della seguentefunzione f : R2 → R
f(x, y) =
{|x|α|y|βx2+y2 (x, y) 6= (0, 0)
0 (x, y) = (0, 0)
Soluzione. Restringo la funzione sulle rette y = mx (con m ∈ R, parametro) per vedere dove il limite non esiste.[3]
Quindi chiamo la funzione ristretta ϕ(x) = f(x,mx) =|x|α|mx|βx2+m2x2 =
|x|α+β |m|βx2(1+m2)
= |x|α+β−2 mβ
1+m2 . Calcoliamo ora il
limite limx→0 ϕ(x) = limx→0 |x|α+β−2 |m|β1+m2 =
|m|β1+m2 limx→0 |x|α+β−2. Perchè la nostra funzione sia continua serve che il
limx→0 ϕ(x) = 0, ovvero che il limite limx→0 |x|α+β−2 = 0. Ma questo è vero solo se α+ β > 2.Tuttavia finora abbiamo dimostrato solo che se α+ β ≤ 2 allora il limite non esiste. Per dimostrare che il limite esiste
si rimanda al prossimo capitolo.
Esercizio 4.2. Dimostrare che in (0, 0) la funzione
f(x, y) =
{x2yx4+y2 (x, y) 6= (0, 0)
0 (x, y) = (0, 0)
non è continua.Soluzione. Restringo la funzione alle curve del tipo y = ax2. La funzione ristretta a tali curve è ϕ(x) = f(x,mx2) =x2 ax2
x4+a2x4 = m1+m2 . Il limite per x → 0 di questa funzione dipende palesemente dalla scelta di m, quindi f non è continua
in (0, 0).
Osservazione 4.3.6. La funzione dello scorso esercizio è un esempio di funzione conqueste proprietà:
i) x→ f(x, y) è continua in x per y fissata;ii) y → f(x, y) è continua in y per x fissato;iii) (x, y)→ f(x, y) non è continua.
4.4 Spazi metrici completi
Definizione 4.4.1. Una successione (xn)n∈N in uno spazio metrico (X, d) si dice succes-sione di Cauchy se per ogni ε > 0 esiste n ∈ N tale che per
d(xn, xm) ≤ ε (4.7)
a patto di scegliere m,n ≥ n con n ∈ N sufficientemente grandi.
Gli spazi metrici in cui tutte le successioni di Cauchy sono convergenti hanno proprietàparticolari.
Definizione 4.4.2. Uno spazio metrico (X, d) si dice completo se ogni successione diCauchy in (X, d) è convergente ad un elemento di X.
Definizione 4.4.3. Uno spazio di Banach (reale) è uno spazio normato (reale) (V, ‖ · ‖)che è completo rispetto alla metrica indotta dalla norma.
Teorema 4.4.4. I numeri reali R con la distanza euclidea formano uno spazio metricocompleto.Dimostrazione. Sia (xn)n∈N una successione di Cauchy in R. Proviamo preliminarmente che la successione è limitata.Infatti, scelto ε = 1 esiste n ∈ N tale che |xn − xm| < 1 per m,n ≥ n, e in particolare per n ≥ n si ha[4] |xn| ≤|xn|+ |xn−xn| ≤ 1+ |xn|. Dunque per n ∈ N si ha la maggiorazione: |xn| ≤ max{|x1|, . . . , |xn−1|, 1+ |xn|}. Per il teorema
[3]Per dimostrare dove non esiste il limite, si usa restringere la funzione ad una famiglia di curve. Si utilizza poi laseguente Proposizione (Limiti e limiti di restrizioni) Siano E ⊂ A ⊂ Rn, f : A → Rm una funzione e x ∈ Rn un puntodi accumulazione per E (dunque anche per A). Se esiste limx→p f(x) allora esiste, ed è uguale limx→p(f |E)(x). Per cuise il limite di due restrizioni è diverso allora il limite non esiste.
[4]Si ponga xm = xn.
Matteo Gallone - Analisi Matematica II

4.5 Spazi metrici e normatiConvergenza puntuale e uniforme
33
di Bolzano-Weierstrass[5] compatto , dalla successione limitata (xn)n∈N si può estrarre una sottosuccessione convergente(xnj )j∈N. Ovvero esiste x ∈ R tale che xnj → x per j →∞.
Proviamo che xn → x per n→∞. Fissato ε > 0 sia n ∈ N data dalla condizione di Cauchy e scegliamo j ∈ N tale chenj ≥ n e |x− xnj | < ε. Allora per n ≥ n risulta |xn − x| ≤ |xn − xnj |+ |xnj − x| ≤ 2ε.
Esempio. I numeri razionali Q ⊂ R con la distanza euclidea non sono uno spazio metrico completo. Infatti la successionexn =
(1 + 1
n
)n ∈ Q, n ∈ N, è di Cauchy, in quanto converge (in R) al numero e ∈ Q, e il limite non è in Q.
Esempio. Lo spazio k-dimensionale Rk, k ∈ N, con la norma euclidea è uno spazio di Banach. Infatti se (xn)n∈N è unasuccessione di Cauchy in Rk, allora indicando con xin la coordinata i-esima di xn, i = 1, . . . , k, la successione (xin)n∈N avalori reali è di Cauchy in R e dunque converge xin → xi ∈ R. Posto x = (x1, . . . , xk) ∈ Rk, da questo segue che xn → x in
Rk: limn→∞ |xn − x| = limn→∞(∑k
i=1(xin − xi)2) 1
2= 0.
Esempio. Lo spazio X = C([0, 1]) con la distanza data dalla norma integrale d(f, g) =∫ 10 |f(x)− g(x)| dx non è completo.
Per n ∈ N sia fn ∈ C([0, 1]) la funzione così definita
fn(x) =
0 x ∈ [0, 1/2]n(x− 1/2) x ∈ [1/2, 1/2 + 1/n]1 x ∈ [1/2 + 1/n, 1]
La successione (fn)n∈N è di Cauchy. Infatti, dati m,n ∈ N con m ≥ n risulta d(fm, fn) =∫ 10 |fn − fm| dx ≤
∫ 12
+ 1n
12
(|fn|+
|fm|) dx ≤ 2n.
La candidata funzione limite è la f(x) così definita
f(x) =
{0 x ∈ [0, 1/2]1 x ∈ (1/2, 1]
In effetti, la funzione f è Riemann-integrabile su [0, 1] e risulta limn→∞∫ 10 |(fn(x)− f(x)| dx = 0. La funzione f non è in
C([0, 1]) perchè ha un punto di discontinuità. Dunque la successione (fn)n∈N non converge ad un elemento di X = C([0, 1]).
Teorema 4.4.5. Lo spazio X = C([0, 1];Rk),k ≥ 1, con la norma della convergenzauniforme:
‖f‖∞ = supx∈[0,1]
|f(x)|
è uno spazio di Banach.Dimostrazione. Sia (fn)n∈N una successione di Cauchy in X. Per ogni x ∈ [0, 1] fissato, la successione (fn(x))n∈N è unasuccessione di Cauchy in Rk e quindi è convergente. Esiste quindi il limite di questa successione, ovvero un punto chechiamiamo f(x) ∈ Rk tale che fn(x) → f(x) per n → ∞. Risulta definita una funzione f : [0, 1] → Rk tale che per ognix ∈ [0, 1] allora lim fn(x) = f(x).
Dobbiamo quindi provare che f sia limite di fn, ovvero che lim ‖fn − f‖∞ = 0. Per ogni ε > 0 fissato, esiste n ∈ N taleche per ogni x ∈ [0, 1] vale |fn(x) − fm(x)| < ε (per m,n ≥ n) poichè fn è una successione di Cauchy. Facendo tenderem → ∞ e usando la convergenza fm(x) → f(x) si ottiene, per ogni x ∈ [0, 1] |fn(x) − f(x)| < ε. Ma il che è esattamentecome dire che f(x) è limite di fn(x).
Rimane da dimostrare che f ∈ X, ovvero che f : [0, 1]→ Rk è continua. Verifichiamolo in un generico punto x0 ∈ [0, 1].Fissato ε > 0 scegliamo un n ≥ n a nostro piacere. Siccome la funzione fn è continua in x0 allora esiste un δ > 0 tale cheper ogni x ∈ [0, 1] si ha |x − x0| < δ ⇒ |fn(x) − fn(x0)| < ε. Dunque, per |x − x0| < δ si ottiene, per la disuguaglianzatriangolare, |f(x)− f(x0)| ≤ |f(x)− fn(x)|+ |fn(x)− fn(x0)|+ |fn(x0) + f(x0)| ≤ 3ε. Si è così provata la continuità di f ,e di conseguenza la sua appartenenza a X. X è uno spazio di Banach.
4.5 Convergenza puntuale e uniforme
Per le definizioni seguenti siano A ∈ Rk un insieme e f, fn : A→ R (con n ∈ N), funzioni.
Definizione 4.5.1. Diciamo che la successione (fn)n∈N converge puntualmente ad f suA se per ogni x ∈ A risulta
limn→∞
|fn(x)− f(x)| = 0 (4.8)
Definizione 4.5.2. Diciamo che la successione (fn)n∈N converge uniformemente ad f suA se per ogni x ∈ A risulta
limn→∞
supx∈A|fn(x)− f(x)| = 0 (4.9)
[5]In uno spazio euclideo di dimensione finita (Rn) ogni successione limitata ammette almeno una sottosuccessioneconvergente.
Matteo Gallone - Analisi Matematica II

34 Spazi metrici e normatiTeorema delle contrazioni di Banach 4.6
La convergenza uniforme implica la convergenza puntuale ma il viceversa è falso.
Esempio. Sia fn : [0, 1]→ R, n ∈ N la funzione fn(x) = xn. Per x ∈ [0, 1] si ha il limite puntuale limn→∞ fn(x) = f(x) ={0 se 0 ≤ x < 11 se x = 1
. D’altra parte la convergenza non è uniforme in quanto, per ogni n ∈ N si ha supx∈[0,1] |fn(x)−f(x)| =
supx∈[0,1] |fn(x)| = 1. Questo perchè, definita f(x) come sopra, si ha che il supx∈A |fn(x)−f(x)| è il limx→1(fn(x)−f(x)) =
limx→1(fn(x))− limx→1(f(x)). Il primo limite vale 1 e il secondo vale 0. Quindi abbiamo che supx∈A |fn(x)− f(x)| = 1.Da cui è semplice dedurre che limn→∞ |fn(x)− f(x)| = limn→∞ 1 = 1 6= 0. Non si ha quindi la convergenza uniforme.
Esercizio 4.3. Sia fn : [−1, 1] → R, n ∈ N la funzione fn(x) = e−nx2. Dire se la serie
converge puntualmente e uniformemente.
Soluzione. La funzione candidata limite è ovviamente la δ(x) =
{0 x 6= 01 x = 0
. Per provare che c’è convergenza puntuale
si calcoli il limite limn→∞ |fn(x)− f(x)| = limn→∞ |e−nx2 − f(x)| = 0. Quindi cè convergenza puntuale.
Per vedere se c’è convergenza uniforme bisogna controllare che limn→∞ supx∈[−1,1] |fn(x) − f(x)| = 0, che equivale achiedere che se x0 è l’ascissa di un punto di estremo allora si ha fn(x0) → limx→ x0f(x). Si calcola quindi la derivataprima f ′n(x) = −2nxe−nx
2, si calcoli quali sono gli estremanti, ovvero f ′n(x) = 0, −2nxe−nx
2= 0 che equivale a x = 0.
Vediamo dunque cosa succede per x = 0. Si ha limn→∞ e−n(0)2 = 1 6= 0. Quindi non c’è convergenza uniforme.
Esercizio 4.4. Sia fn : (−∞,+∞)→ R, n ∈ N la funzione
fn(x) =(n+ 1)x+ n2x3
1 + n2x2
dire se c’è convergenza puntuale e/o uniforme.Soluzione. C’è convergenza puntualmente alla funzione f(x) = x. Cerchiamo ora su quali intervalli la successione converge
uniformemente. Dobbiamo vedere quale sia quindi il limn→∞ supx∈R ‖fn(x)−f(x)‖ = limn→∞ supx∈R ‖(n+1)x+n2x3
1+n2x2 −x‖.
Detto questo, facciamo la derivata prima di ddx
(fn − f) = n−n3x2
1+n2x2 che si annulla per x = ± 1n. Sostituendo questo valore
in fn − f si ottiene fn( 1n
)− f( 1n
) =1± 1
n2
. Se facciamo il limite di questa quantità per n→∞ otteniamo 126= 0, quindi la
successione convergerà uniformemente in intervalli del tipo (−∞,−ε) e (ε,∞).
Teorema 4.5.3 (dello scambio dei limiti). Siano A ⊂ Rk, k ≥ 1, fn ∈ C(A,R) funzionicontinue ed f : A → R. Se fn → f per n → ∞ uniformemente su A allora f ∈ C(A,R)e, per ogni x0 ∈ A vale il teorema sullo scambio dei limiti:
limn→∞
limx→x0
fn(x) = limx→x0
limn→∞
fn(x) (4.10)
4.6 Teorema delle contrazioni di Banach
Definizione 4.6.1. Sia X un insieme e sia T : X → X una funzione da X in sè stesso.Siamo interessati all’esistenza di soluzioni x ∈ X dell’equazione T (x) = x. Un simileelemento x ∈ X si dice punto fisso di T .
Definizione 4.6.2. Sia (X, d) uno spazio metrico. Un’applicazione T : X → X è unacontrazione se esiste un numero 0 < λ < 1 tale che d(T (x), T (y)) ≤ λd(x, y) per ognix, y ∈ X.
Teorema 4.6.3 (delle contrazioni di Banach). Sia (X, d) uno spazio metrico completo esia T : X → X una contrazione. Allora esiste un unico punto x ∈ X tale che x = T (x).Dimostrazione. Sia x0 ∈ X un qualsiasi punto e si definisca la successione xn = Tn(x0) = T ◦ · · · ◦ T (x0), n-volte.Proviamo che la successione (xn)n∈N è di Cauchy. Per farlo si usa la disuguaglianza triangolare per cui si ha: d(xn+k, xn) ≤∑kh=1 d(xn+h, xn+h−1). Poichè Tn è definita come Tn = xn allora
∑kh=1 d(xn+h, xn+h−1) =
∑kh=1 d(Tn+h, Tn+h−1).
Poichè T è una contrazione si ha inoltre che d(Tn+h, Tn+h−1) ≤ d(T (x0), x0)∑kh=1 λ
n+h−1 = λnd(T (x0), x0)∑kh=1 λ
h−1.Cambiando l’estremo della sommatoria a ∞ si ottiene una quantità ancora maggiore, quindi λnd(T (x0), x0)
∑kh=1 λ
h−1 ≤λnd(T (x0), x0)
∑∞h=1 λ
h−1. La serie∑∞h=1 λ
h−1 converge[6] e λn → 0 per n → ∞ poichè λ < 1. Poichè inoltre X, perdefinizione, è completo esiste un punto x ∈ X tale che x = limn→∞ Tn(x0).
Proviamo ora che x = T (x). Per come è definito x si ha che x = limn→∞ Tn(x0), inoltre per come è definito Tn,Tn = T (Tn−1(x0)). Poichè T è continua, inoltre, si ha anche che limT (f(x)) = T (lim f(x)). Quindi x = limn→∞ T (x) =
[6]Lo si può facilmente verificare per confronto con la serie geometrica con q < 1.
Matteo Gallone - Analisi Matematica II

4.7 Spazi metrici e normatiTopologia di uno spazio metrico
35
x = limn→∞(Tn(x)) = T (limn→∞ Tn−1(x)) = T (x). Eguagliando il primo e l’ultimo termine abbiamo dimostrato chex = T (x).
Dobbiamo infine dimostrare l’unicità del punto fisso. Supponiamo quindi che x′ ∈ X sia punto unito, ovvero siax′ = T (x′). Allora abbiamo d(x, x′) = d(T (x), T (x′)). Ma per definizione di contrazione d(T (x), T (x′)) ≤ λd(x, x′). Quindid(x, x′) ≤ λd(x, x′). Se d(x, x′) 6= 0 allora posso dividere ambedue i membri per d(x, x′), e ciò mi porta a dire che λ ≥ 1che è assurdo perchè λ è per definizione λ < 1. Quindi si deve avere per forza che d(x, x′) = 0, ovvero che x = x′.
4.7 Topologia di uno spazio metrico
Definizione 4.7.1. Sia (X, d) uno spazio metrico. Un insieme A ⊂ X si dice aperto seper ogni x ∈ A esiste ε > 0 tale che B(x, ε) ⊂ A.
Definizione 4.7.2. Sia (X, d) uno spazio metrico. Un insieme C ⊂ X si dice chiuso seX \ C è aperto.
Proposizione 4.7.3. Sia dato un generico spazio metrico (X, d); le palle B(x, r) sonoaperte ∀x ∈ X e ∀r > 0 con B(x, r) = {y ∈ X : d(x, y) < r}.Dimostrazione. Dato un y ∈ B(x, r), ovvero tale che d(x, y) < r posso scegliere ε > 0 tale che ε+ s < r, ossia ε < r − s.
Esempio. (1). Gli insiemi ∅ e X sono contemporaneamente aperti e chiusi. (2). In X = R con la distanzad(x, y) = |x − y| valgono i seguenti fatti: 1) gli intervalli (a, b) con −∞ ≤ a, b ≤ ∞ sono aperti; 2) gli intervalli [a, b] con−∞ < a < b <∞ sono chiusi; 3) gli intervalli [a,∞) e (−∞, b] con −∞ < a, b <∞ sono chiusi; 4) gli intervalli (a, b] e [a, b)con −∞ < a, b <∞ non sono nè aperti nè chiusi. (3). In X = R2 con la distanza euclidea 1) il cerchio {x ∈ R2 : |x| < 1}è aperto; 2) il cerchio {x ∈ R2 : |x| ≤ 1} è chiuso. (4). In uno spazio metrico generico (X, d) le palle B(x, r) con x ∈ X er > 0 sono aperte. Sia infatti y ∈ B(x, r, ovvero s := d(x, y) < r. Scegliamo ε > 0 tale che s+ ε < r. Se z ∈ B(y, ε) alloradalla disuguaglianza triangolare segue che d(z, x) ≤ d(z, y) + d(y, x) < ε+ s < r e quindi B(y, ε) ⊂ B(x, r).
Definizione 4.7.4. Sia A ⊂ X un insieme.
• Un punto x ∈ X si dice punto interno di A se esiste ε > 0 tale che B(x, ε) ⊂ A.• L’interno di A è l’insieme A◦ = {x ∈ X : x è un punto interno di A}.• Un punto x ∈ X si dice punto di chiusura di A se per ogni ε > 0 risulta B(x, ε)∩A 6=∅.• La chiusura di A, è l’iniseme A = {x ∈ A : x è un punto di chiusura per A}• La frontiera di A è l’insieme ∂A = {x ∈ X : B(x, r) ∪ A 6= ∅ e B(x, r) ∩ (X \ A) 6=
0 ∀r > 0}. In altri termini ∂A = A ∩X \ A.
Proposizione 4.7.5. Siano A ⊂ X un insieme e x ∈ X. Sono equivalenti:
a) x ∈ A;b) Esiste una successione (xn)n∈N con xn ∈ A per ogni n ∈ N tale che xn → x pern→∞.
Dimostrazione. Dimostriamo che a)⇒ b). Se x ∈ A allora per ogni r > 0 risulta B(r, x) ∩ A 6= ∅. In particolare, per ognin ∈ N esiste xn ∈ A ∩B1/n(x). La successione (xn)n∈N è contenuta in A e converge ad x in quanto d(xn, x) < 1
n.
Dimostriamo ora che b)⇒ a). Proviamo che la negazione di a) implica la negazione di b). Se x /∈ A allora esiste ε > 0tale che B(x, ε) ∩A = ∅ e quindi non può esistere una successione contenuta in A e convergente a x.
Teorema 4.7.6. Sia (X, d) uno spazio metrico e sia A ⊂ X. Allora:
a) A è aperto se e solo se A = Ao;b) A è chiuso se e solo se A = A.
Dimostrazione. Proviamo a). Se A = Ao allora A è aperto (perchè Ao è aperto per definizione). Se invece A è aperto allora∀x ∈ A ∃ε > 0 tale che B(x, ε) ⊂ A, ma quindi x deve essere un punto interno, e A è formato da punti interni, ed Ao èproprio l’insieme dei punti interni di A. Quindi, per come è definito Ao si ha che A = Ao.
Proviamo ora b). Se A è chiuso allora X \ A è aperto. È sufficente provare che A ⊂ A, perchè l’inclusione A ⊂ A èsempre verificata. Sia x ∈ A. Se per assurdo fosse x ∈ X \ A allora esisterebbe un ε > 0 tale che B(x, ε) ∩ A = ∅ e non cisarebbe una successione (xn)n∈N contenuta in A tale che xn → x per n→∞. Dunque deve essere x ∈ A.
Supponiamo ora che sia A = A e proviamo che A è chiuso, ovvero che il complementare X \ A = X \ A è aperto. Siax ∈ X \A un punto che non è di chiusura per A. Allora esiste ε > 0 tale che B(x, ε) ∩A = ∅. Se così non fosse ci sarebbeuna successione in A che converge ad x. Ma allora B(x, ε) ⊂ X \A, che dunque è aperto.
Matteo Gallone - Analisi Matematica II

36 Spazi metrici e normatiSpazi metrici compatti 4.8
Definizione 4.7.7. Sia (X, d) uno spazio metrico. La famiglia di insiemi
τ(X) = {A ⊂ X : A è aperto in X}
si dice topologia di X.
Teorema 4.7.8. La topologia di uno spazio metrico X verifica le seguenti proprietà
(A1) ∅, X ∈ τ(X);(A2) Se A1, A2 ∈ τ(X) allora A1 ∩ A2 ∈ τ(X);(A3) Per ogni famiglia di indici A risulta
Aα ∈ τ(X) per ogni α ∈ A ⇒⋃α∈A
Aα ∈ τ(X)
Osservazione 4.7.9. In modo duale la famiglia dei chiusi di uno spazio metrico verificale seguenti proprietà:
(C1) ∅, X sono chiusi;(C2) Se C1, C2 sono chiusi allora C1 ∪ C2 è chiuso;(C3) Per ogni famiglia di indici A risulta
Aα è chiuso per ogni α ∈ A ⇒⋂α∈A
Aα è chiuso
Teorema 4.7.10 (Caratterizzazione topologica della continuità). Siano (X, dX) e (Y, dY )due spazi metrici e sia f : X → Y una funzione. Sono equivalenti le seguenti affermazioni:
1. f è continua;2. f−1(A) ⊂ X è aperto in X per ogni aperto A ⊂ Y ;3. f−1(C) ⊂ X è chiuso in X per ogni chiuso C ⊂ Y
Dimostrazione. Proviamo l’implicazione 1)⇒ 2). Verifichiamo che ogni punto x0 ∈ f−1(A) è un punto interno di f−1(A).Siccome A è aperto e f(x0) ∈ A, esiste ε > 0 tale che BY (f(x0), ε) ⊂ A. Per la continuità di f esiste δ > 0 taleche dX(x, x0) < δ implica dY (f(x), f(x0)) < ε. In altre parole, si ha f(BX(x0, δ)) ⊂ BY (f(x0), ε). Allora si concludeche BX(x0, δ) ⊂ f−1(f(BX(x0, δ)) ⊂ f−1(BY (f(x0), ε)) ⊂ f−1(A) (Notare che l’inclusione a sinistra in generale non èun’uguaglianza.)
Proviamo ora l’implicazione 2)⇒ 1). Controlliamo che f sia continua in un generico punto x0 ∈ X. Fissato ε > 0, l’insie-me BY (f(x0), ε) è aperto e quindi l’antimmagine f−1(BY (f(x0), ε)) è aperta. Siccome x0 ∈ f−1(BY (f(x0), ε)), esiste δ > 0tale che BX(x0, δ) ⊂ f−1(BY (f(x0), ε)), da cui, passando alle immagini, segue che f(BX(x0, δ)) ⊂ f(f−1(BY (f(x0), ε))) ⊂BY (f(x0), ε). (Notare anche qui che l’ultima inclusione in generale non è un’uguaglianza). La catena di inclusioni provatamostra che se dX(x, x0) < δ allora dY (f(x), f(x0)) < ε, che è la continuità di f in x0.
Per provare l’equivalenza 2) ⇔ 3) si usa la seguente relazione insiemistica valida per ogni B ⊂ Y : X \ f−1(B) =f−1(Y \B). Verifichiamo 2)⇒ 3). Sia C ⊂ Y chiuso. Allora A = Y \C è aperto e quindi f−1(A) = f−1(Y \C) = X\f−1(C)è aperto. Ovvero, f−1(C) è chiuso.
Verifichiamo ora 3)⇒ 2). Sia A ⊂ Y aperto. Allora C = Y \ A è chiuso e quindi f−1(C) = f−1(T \ A) = X \ f−1(C)è chiuso. Ovvero, f−1(A) è aperto.
Teorema 4.7.11. Siano (X, dX), (Y, dY ), (Z, dZ) spazi metrici e siano f : X → Y eg : Y → Z funzioni continue. Allora la composizione g ◦ f : X → Z è continua.Dimostrazione. Usiamo la caratterizzazione di continuità del teorema precedente (Teorema 4.7.10), ovvero che una funzionecontinua manda aperti in aperti. Se A ⊂ Z è un aperto allora g−1(A) ⊂ Y è un aperto, e dunque (g ◦ f)−1(A) =f−1(g−1(A)) ⊂ X è un aperto. Quindi la funzione g ◦ f è continua.
4.8 Spazi metrici compatti
Definizione 4.8.1. Uno spazio metrico (X, d) si dice sequenzialmente compatto se ognisuccessione di punti (xn)n∈N in K ⊂ X ha una sottosuccessione che converge ad unelemento di K.
Definizione 4.8.2. Un insieme K nello spazio metrico (X, d) si dice limitato se per ognipunto x0 ∈ X esiste R > 0 tale che K ⊂ B(x0, R).
Matteo Gallone - Analisi Matematica II

4.9 Spazi metrici e normatiInsiemi connessi
37
Proposizione 4.8.3. Sia (X, d) uno spazio metrico e sia K ⊂ X un sottoinsiemecompatto. Allora K è chiuso e limitato.Dimostrazione. Proviamo che K = K. Per ogni x ∈ K esiste una successione (xn)n∈N in K che converge ad x. Questasuccessione ha una sottosuccessione (xnj )j∈N che converge ad un elemento di K. Ma questo elemento deve essere x, chequindi appartiene a K.
Supponiamo per assurdo che K non sia limitato. Allora esiste un punto x0 ∈ X tale che K ∩ (X \ B(x0, R)) 6= ∅per ogni R > 0. In particolare, con la scelta R = n ∈ N esistono punti xn ∈ K tali che d(xn, x0) ≥ n. La successione(xn)n∈N è in K. Quindi esiste una sottosuccessione (xnj )j∈N convergente ad un elemento x ∈ K. Ma allora d(x, x0) ≥d(x0, xnj ) − d(xnj , x) ≥ nj − d(xnj , x) → ∞ per j → ∞. Ma questo è assurdo perchè d(x, x0) < ∞ per definizione didistanza.
Teorema 4.8.4 (Heine-Borel). Sia Rm con m ≥ 1 munito della distanza euclidea e siaK ⊂ Rn un insieme. Sono equivalenti le seguenti affermazioni.
i) K è compatto;ii) K è chiuso e limitato.
Dimostrazione. L’implicazione i)⇒ ii) è banale per Proposizione 4.8.3.Proviamo quindi l’implicazione ii) ⇒ i). Sia (xn)n∈N una successione di punti in K. Scriviamo le coordinate xn =
(x1n, . . . , x
mn ). La successione reale (x1
n)n∈N è limitata e dunque ha una sottosuccessione (x1nj
)j∈N convergente ad un numerox1 ∈ R. La successione (x2
nj)j∈N è limitata e quindi ha una sottosuccessione convergente ad un numero x2 ∈ R. Si ripete
tale procedimento di sottoselezione m volte. Dopo m sottoselezioni successive si trova una scelta di indici j → kj tale checiascuna successione di coordinate (xikj
)j∈N converge ad un numero xi ∈ R, i = 1, . . . ,m. Ma allora (xkj )j∈N converge a
x = (x1, . . . , xm) ∈ Rm. Siccome K è chiuso deve essere x ∈ K.
Teorema 4.8.5. Siano (X, dX) e (Y, dY ) spazi metrici e sia f : X → Y continua. Se Xè compatto allora f(X) ∈ Y è compatto in Y .Dimostrazione. Sia (yn)n∈N una successione in f(X). Esistono punti xn ∈ X tali che f(xn) = yn con n ∈ N. Lasuccessione (xn)n∈N ha una sottosuccessione (xnj )j∈N che converge ad un punto x0 ∈ X. Siccome f è continua si halimj→∞ f(xnj ) = f(x0). In altri termini, ynj → f(x0) ∈ f(X) per j →∞.
Corollario 4.8.6 (Weierstrass). Sia (X, d) uno spazio metrico compatto e sia f : X → Runa funzione continua. Allora esistono x0, x1 ∈ X tali che
f(x0) = maxx∈X
f(x) e f(x1) = minx∈X
f(x)
Dimostrazione. Poichè X è un compatto ed f è continua allora anche f(X) ⊂ R è compatto. In particolare f(X) è chiusoe limitato e quindi ammette massimo e minimo.
4.9 Insiemi connessi
Definizione 4.9.1. Uno spazio metrico (X, d) si dice connesso se X = A1∪A2 con A1, A2
aperti tali che A1 ∩ A2 = ∅ implica che A1 = ∅ oppure A2 = ∅.[7]
Se un insieme X dotato della distanza dX non è connesso, allora esistono due insiemiaperti disgiunti e non vuoti A1 e A2 tali che X = A1 ∪ A2. Quindi A1 = X \ A2 eA2 = X \ A1 sono contemporaneamente aperti e chiusi. Se invece X è connesso allora ∅e X sono gli unici insiemi ad essere sia aperti e sia chiusi.
Definizione 4.9.2. Sia (X, d) uno spazio metrico e sia Y ⊂ X un suo sottoinsieme.Allora (Y, d) è uno spazio metrico che avrà la sua topologia τ(Y ), detta topologia indotta(o topologia relativa) da X su Y .
Definizione 4.9.3. Sia (X, d) uno spazio metrico. Un sottoinsieme Y ⊂ X si diceconnesso se è connesso rispetto alla topologia indotta. Precisamente, se Y = (Y ∩ A1) ∪(Y ∩A2) con A1, A2 aperti di X e unione disgiunta, allora Y ∩A1 = ∅ oppure Y ∩A2 = ∅.
Proposizione 4.9.4. L’intervallo I = [0, 1] ∈ R è connesso.[7]Ovvero un insieme K si dice connesso se non esistono A1, A2 aperti tali che X = A1 ∪A2 e A1 ∩A2 6= ∅.
Matteo Gallone - Analisi Matematica II

38 Spazi metrici e normatiInsiemi connessi 4.9
Dimostrazione. Siano A1, A2 due insiemi non vuoti tali che A1 ∩ A2 = ∅ e I = (I ∩ A1) ∪ (I ∩ A2). Supponiamo, adesempio 0 ∈ A1. Definiamo allora x = sup{x ∈ [0, 1]|[0, x) ⊂ I ∩A1}, ovvero x è l’estremo superiore di I ∩A1. Supponiamoora per assurdo che x ∈ A2. Allora, per definizione di estremo superiore, si ha che per qualche ε > 0, x − ε ∈ A1. Ma ciòimplica I ∩ A1 ∩ A2 6= ∅. Quindi si deve avere necessariamente x /∈ A2. Supponiamo ora che x < 1. Allora si avrebbe che∃δ > 0 tale che x + δ ∈ A1, assurdo per la definizione di estremo superiore. Si deve allora avere per forza x = 1 e quindiA2 = ∅. Il che è come dire che I è connesso.
Teorema 4.9.5. Siano (X, dX) e (Y, dY ) due spazi metrici e sia f : X → Y continua.Allora se X è connesso anche f(X) ⊂ Y è connesso.Dimostrazione. Siano A1, A2 ⊂ Y aperti tali che f(X) = (f(X) ∩ A1) ∪ (f(X) ∩ A2) con unione disgiunta. AlloraX = f−1(f(X)) = f−1((f(X)∩A1)∪(f(X)∩A2)) = f−1(f(X)∩(A1))∪f−1(f(X)∩A2) = (X∩f−1(A1))∪(X∩f−1(A2)) =f−1(A1)∪ f−1(A2). Il primo passaggio è dovuto al fatto che f è definita su X, mentre l’ultimo passaggio è dovuto al fattoche f−1(A1) ⊂ X, quindi X ∩ f−1(A1) = f−1(A1), e per la stessa ragione X ∩ f−1(A2) = f−1(A2). L’ultima unione èdisgiunta e gli insiemi f−1(A1), f−1(A2) sono aperti. Siccome X è connesso deve essere f−1(A1) = ∅ oppure f−1(A2) = ∅.Dunque, si ha f(X) ∩A1 = ∅ oppure f(X) ∩A2 = ∅. E quindi anche f(X) è connesso.
Definizione 4.9.6. Uno spazio metrico (X, d) si dice connesso per archi se per ognicoppia di punti x, y ∈ X esiste una curva continua γ : [0, 1] → X tale che γ(0) = x eγ(1) = y.
Teorema 4.9.7. Se uno spazio metrico (X, d) è connesso per archi allora è connesso.Dimostrazione. Supponiamo per assurdo che X non sia connesso. Allora esistono due aperti A1, A2 disgiunti e non vuotitali che X = A1 ∪ A2. Siano x ∈ A1 e y ∈ A2, e sia γ : [0, 1] → X una curva continua tale che γ(0) = x e γ(1) = y. Maallora [0, 1] = ([0, 1] ∩ γ−1(A1)) ∪ ([0, 1] ∩ γ−1(A2)) con unione disgiunta e γ−1(A1)) e γ−1(A2)) aperti non vuoti in [0, 1].Ma ciò è assurdo in quanto per la Proposizione 4.9.4 [0, 1] è connesso.
Teorema 4.9.8. Sia A ∈ Rn un aperto connesso e non vuoto. Allora A è connesso perarchi.Dimostrazione. Dimostreremo un’affermazione più precisa, ovvero che A è connesso per curve poligonali. Sia x0 ∈ A un pun-to scelto a nostro piacere. Definiamo l’insieme A1 = {x ∈ A : x si connette a x0 con una curva poligonale contenuta in A}.
Proviamo che A1 è aperto. Infatti, se x ∈ A1 ⊂ A allora esiste ε > 0 tale che B(x, ε) ⊂ A, in quanto A è aperto.Ogni punto di y ∈ B(x, ε) si collega al centro x con un segmento contenuto in A. Dunque y si collega a x0 con una curvapoligonale contenuta in A, ovvero B(x, ε) ∈ A1.
Sia A2 = A \ A1. Proviamo che anche A2 è aperto. Se x ∈ A2 ⊂ A allora esiste ε > 0 tale che B(x, ε) ⊂ A2. Se cosìnon fosse troveremmo y ∈ B(x, ε) ∩ A1. Il punto x0 si collega a y con una curva poligonale in A ed y si collega ad x conun segmento contenuto in A. Quindi x ∈ A1 che non è possibile perchè per ipotesi x ∈ A2 e A1 ∩ A2 = ∅. A2 quindi èaperto. Allora abbiamo X = A1 ∪ A2 con A1 e A2 aperti ed in unione disgiunta. Siccome X è connesso, uno degli apertideve essere vuoto. Siccome A1 6= ∅ allora A2 = ∅. Questo termina la dimostrazione.
Teorema 4.9.9 (dei valori intermedi). Sia A ⊂ Rn un aperto connesso e sia f : A→ Runa funzione continua. Allora per ogni t ∈ (infA f, supA f) esiste un punto x ∈ A tale chef(x) = t.Dimostrazione. Siano x0, x1 ∈ A tali che f(x0) < t < f(x1). Sia γ : [0, 1] → A una curva continua tale che γ(0) = x0 eγ(1) = x1. La composizione ϕ(s) = f(γ(s)) con s ∈ [0, 1], tale che ϕ(s) = t. Il punto x = γ(s) ∈ A verifica la tesi delteorema.
Matteo Gallone - Analisi Matematica II

CAPITOLO 5
Calcolo differenziale in Rn
In questo capitolo, per distinguere gli elementi appartenenti a Rn con n ≥ 2 dagli elementiappartenenti a R si usano le seguenti notazioni: ~x ∈ Rn e x ∈ R. Generalmente unelemento ~x ∈ Rn avrà n componenti che saranno degli scalari, ovvero si scriverà ~x =(x1, . . . , xi, . . . , xn). Non verrà fatta invece, alcuna differenza nella scrittura tra funzioniscalari e funzioni vettoriali.
5.1 Limiti
La definizione di limite per funzioni in una variabile reale si estende facilmente alle funzionidi due o più variabili reali. A tale scopo consideriamo un sottoinsieme A ⊂ Rn ed unafunzione A→ R, cioè z = f(~x). Sia inoltre (~x0) un punto di accumulazione per l’insiemeA.
Consideriamo innanzi tutto il caso in cui ` sia finito, cioè ` ∈ R. Si dice che f(~x) tendea ` per (~x) che tende a (~x0) se, qualunque sia ε > 0, esiste δ > 0 tale che
|f(~x)− `| < ε (5.1)
per ogni ~x ∈ A, ~x 6= ~x0 e |~x− ~x0| < δ.I due casi di limite infinito (` = ∞ e ` = −∞) si trattano in modo analogo fra loro.
Di seguito consideriamo il solo caso ` =∞.Si dice che f(~x) tende a ∞ per ~x che tende a ~x0 se, qualunque sia M > 0 esiste δ > 0
tale chef(~x) > M (5.2)
per ogni ~x ∈ A, ~x 6= ~x0 e |~x− ~x0| < δ.
Osservazione 5.1.1. Sia f : A → Rm una funzione con A ⊂ Rn. Si dice che f =
(f1, . . . , fm) tende a ~ se ogni funzione coordinata fi : A → R tende a `i ∈ R, coni = 1, . . . ,m.
Definizione 5.1.2. Sia f : A→ Rm una funzione definita in un insieme A ⊂ Rn e sia ~x0
un punto di A. Si dice che la funzione f è continua su A se per ogni ε > 0 esiste δ > 0tale che
|f(~x)− f(~x0)| < ε (5.3)
per ogni ~x ∈ A e |~x−~x0| < δ. Si dice inoltre che f è continua nell’insieme A se è continuain ogni punto ~x0 di A.
Matteo Gallone - Analisi Matematica II

40 Calcolo differenziale in Rn
Derivate parziali e differenziabilità 5.2
Definizione 5.1.3. Dati due spazi metrici (X, dX) e (Y, dY ) si dice che una funzionef : X → Y è uniformemente continua se ∀ε > 0 ∃δ > 0 tale che ∀x1, x2 ∈ X si hadX(x1, x2) < δ ⇒ dY (f(x1), f(x2)) < ε.
Teorema 5.1.4 (di Cantor[1]). Siano (X, dX) e (Y, dY ) spazi metrici e f : X → Y unafunzione continua. Se X è compatto allora f è uniformemente continua.
5.2 Derivate parziali e differenziabilità
Definizione 5.2.1. Sia A un insieme aperto di Rn e f : A→ R una funzione definita suA. Sia inoltre ~x0 un punto fissato di A. La derivata parziale di f rispetto alla componentexi di ~x nel punto ~x0 è (se esiste ed è finito) il limite
limh→0
f(~x0 + h~ei)− f(~x0)
h(5.4)
Dove ~ei è il vettore di tutti zeri tranne l’i -esima componente che è uguale a 1.
Per la derivata parziale di f rispetto ad x si usano i simboli ∂f∂x, fx, Dxf .
La definizione di derivata parziale è stata data per ogni punto interno ad A. Non èinvece possibile, in generale, considerare il rapporto incrementale nei punti di frontiera.In questi casi, non si procede con il rapporto incrementale, ma nel modo seguente: sisuppone che D sia un dominio di Rn, cioè D è la chiusura dell’insieme aperto. Si supponeche esistano le derivate parziali in ogni punto ~x ∈ D e si considerano i limiti
lim~x→~x0
fx1(~x) . . . lim~x→~x0
fxn(~x) (5.5)
e allora, per l’ipotesi di continuità i limiti sono uguali rispettivamente a fx1(~x0), . . . , efxn(~x0) se il punto ~x0 è interno all’insieme, mentre vengono assunti come valore delle nderivate se ~x0 è un punto di frontiera per l’insieme.
Le due derivate parziali vengono quindi prolungate per continuità. Tuttavia non èdetto che tale limite esista sempre finito. Nei casi in cui il limite non esista oppure nonsia finito si dice che la funzione non è derivabile in ~x0.
Interpretazione geometrica della derivata parziale Prendiamo ad esempio il caso dellafunzione f : A→ R con A ⊂ R2; un suo generico punto sarà della forma (x, y, f(x, y)) ∈R3.
Considero la derivata parziale rispetto ad una componente come la curva descritta dallaf ristretta a tale componente, quindi può essere vista come costituita da un vettore varia-bile per ciascuna componente del dominio. Nel nostro caso avremo ~v1 =
(1, 0, ∂f
∂x(x, y)
)e
~v2 =(
0, 1, ∂f∂y
(x, y))con ~v1, ~v2 ∈ R3. Tali vettori formano il cosiddetto piano tangente [2]
al grafico di f nel punto (x, y, f(x, y)), ed esso sarà
{α~v1 + β~v2 ∈ R3 : α, β ∈ R}
Definizione 5.2.2. Una funzione f si dice derivabile in un punto ~x0 se nel punto ~x0
esistono tutte le derivate parziali.
Definizione 5.2.3. Sia f una funzione derivabile in un punto ~x di un aperto A ⊆ Rn;cioè esistano in ~x le derivate parziali (fx1 , . . . , fxn) di f . Il gradiente di f nel punto ~x è per
[1]Il teorema è meglio noto come Teorema di Heine-Cantor.[2]Verrà precisato più avanti che l’esistenza del piano tangente in un punto è legata all’esistenza del differenziale in quel
punto. La sola derivabilità non basta per dire che in un punto esiste il piano tangente.
Matteo Gallone - Analisi Matematica II

5.2 Calcolo differenziale in Rn
Derivate parziali e differenziabilità41
definizione il vettore ∇f ∈ Rn le cui componenti sono le derivate parziali di f . Ovvero:
∇f(~x) =
∂f∂x1
(x)...
∂f∂xn
(x)
Per il gradiente si usano i simboli Df , gradf , ∇f .Una generalizzazione del concetto di gradiente è quello di matrice Jacobiana.
Definizione 5.2.4. Sia f una funzione da Rn a Rm, derivabile in un punto ~x = (x1, x2, . . . , xn).La matrice Jacobiana di f è una matrice m× n costruita così
Jf (x1, x2, . . . , xn) =
∂f1
∂x1· · · ∂f1
∂xn... . . . ...∂fm∂x1
· · · ∂fm∂xn
(5.6)
Sia ora f(x, y) una funzione in due variabili reali, derivabile in un aperto A ⊆ R2,allora le due derivate possono a loro volta essere derivabili. Se ciò si verifica si parla alloradi derivate seconde e si indicano con i simboli ∂
2f∂x2 , ∂2f
∂x∂y, fxx, fxy, ∂fx∂x ,
∂fx∂y
.Spesso le quattro derivate parziali seconde si dispongono in una matrice 2 × 2 detta
matrice Hessiana e si denota con il simbolo Hf o ∇2f
Hf = ∇2f =
(∂fx∂x
∂fx∂y
∂fy∂x
∂fy∂y
)(5.7)
Se esistono le quattro derivate parziali di f nel punto (x0, y0), cioè se è definita la matriceHessiana in quel punto, allora si dice che f è derivabile due volte in (x0, y0). Se ciò siverifica in tutti i punti di un aperto A ⊆ R2 allora si dice che f è derivabile due volte inA.
Il seguente teorema viene enunciato e dimostrato solo per le funzioni f : R2 → R.Il teorema si generalizza ad una funzione g : Rn → R prendendo in considerazione elderivate miste gxixj e gxjxi . Considerando solo queste due derivate parziali tuttavia siintende tenere tutte le altre variabili come costanti e quindi ci si riconduce sempre ad unproblema in R2. Il teorema seguente ha quindi validità generale.
Teorema 5.2.5 (di Schwarz). Sia A un aperto di R2, (x0, y0) ∈ A e f(x, y) una funzionederivabile due volte in A. Se le derivate seconde miste fxy(x, y) e fyx(x, y) sono continuenel punto (x0, y0) allora risulta fxy(x0, y0) = fyx(x0, y0).Dimostrazione. Sia (x, y) un punto generico dell’insieme A, con x 6= x0 e y 6= y0, e si considerino poi anche i punti (x0, y) e(x, y0). Calcoliamo la funzione f in corrispondenza dei quattro punti (x, y), (x0, y0), (x0, y) e (x, y0). Definiamo le seguentifunzioni in una variabile reale F (x) = f(x, y) − f(x, y0) e G(y) = f(x, y) − f(x0, y). Si applica il teorema di Lagrange aF (x) − F (x0) = F ′(x1)(x − x0) = (fx(x1, y) − fx(x1, y0))(x − x0). Si applica ancora una volta Lagrange a quest’ultimaquantità: (fx(x1, y)− fx(x1, y0))(x−x0) = fxy(x1, y1)(x−x0)(y− y0). Procedendo in modo analogo per la funzione G(y),determineremo l’esistenza di x2 ∈ [x0, x] e y2 ∈ [y0, y] tali che G(y)−G(y0) = fyx(x2, y2)(x− x0)(y − y0).
Da verifica diretta risulta poi F (x) − F (x0) = G(y) − G(y0)[3] , quindi fxy(x1, y1)(x − x0)(y − y0) = fyx(x2, y2)(x −x0)(y − y0) e quindi fxy(x1, y1) = fyx(x2, y2). Passando al limite per (x, y) → (x0, y0) anche (x1, y1) → (x0, y0) e(x2, y2)→ (x0, y0). Quindi, applicando l’ipotesi di continuità per le derivate seconde di f si ottiene fxy(x0, y0) = fyx(x0, y0).
Una generalizzazione del concetto di derivata parziale, si ha nella derivata direzionale.
Definizione 5.2.6. Un vettore di modulo uguale a 1 si chiama direzione.
[3]Infatti G(y) = f(x, y)−f(x0, y), G(y0) = f(x, y0)−f(x0, y0), F (x) = f(x, y)−f(x, y0) e F (x0) = f(x0, y)−f(x0, y0).Sostituendo si ottiene G(y)−G(y0) = f(x, y)− f(x0, y)− f(x, y0) + f(x0, y0) = f(x, y)− f(x, y0)− f(x0, y) + f(x0, y0) =[f(x, y)− f(x, y0)]− [f(x0, y)− f(x0, y0)] = F (x)− F (x0).
Matteo Gallone - Analisi Matematica II

42 Calcolo differenziale in Rn
Derivate parziali e differenziabilità 5.2
Definizione 5.2.7. Sia A un aperto di Rn ed f(~x) una funzione definita su A. Fissata unadirezione su Rn, ovvero un vettore ~λ ∈ Rn con |~λ| = 1, si definisce la derivata direzionaledella funzione f nel punto ~x e nella direzione ~λ, il limite
limt→0
f(~x+ t~λ)− f(~x)
t(5.8)
purchè il limite esista e sia finito.
La derivata direzionale si indica con uno dei simboli ∂f∂λ, Dλf .
Una condizione più forte della derivabilità in uno spazio n-dimensionale è la differen-ziabilità. Mentre, infatti, la derivabilità non implica la continuità più avanti si vedrà chela differenziabilità implica la continuità.
Definizione 5.2.8. Siano A un aperto di Rn e ~x0 ∈ A. Una funzione f : A → Rm,derivabile nel punto ~x0, si dice differenziabile nel punto ~x0 se esiste T ∈ L(Rn,Rm) taleche
lim(~x→~x0)
fi(~x)− fi(~x0)− T (~x− ~x0)
‖~x− ~x0‖= 0 (5.9)
per tutte le m componenti. La trasformazione T si dice differenziale di f in ~x0 e si indicaT = df(~x0).
Analogamente alla continuità e alla derivabilità, se f è differenziabile in ogni punto diA allora si dice che f è differenziabile in A.
Una formula particolarmente significativa per la differenziabilità di una funzione siottiene utilizzando il simbolo di “o piccolo” [4]. Con tale notazione la funzione f è diffe-renziabile nel punto ~x0 ∈ A se è derivabile in ~x0 e se
f(~x0 + ~v) = f(~x0) + T (~x− ~x0)~v + o(‖~v‖). (5.10)
Geometricamente la differenziabilità di una funzione è legata all’esistenza del pianotangente al grafico della funzione nel punto.
Per generalizzare facilmente il concetto di differenziabilità di funzioni in più variabilisi può usare la notazione vettoriale. Oltre all’ormai noto vettore ~x, si definisce il vettore~v = (h1, h2, . . . , hn) e, dato che il prodotto scalare 〈∇f(~x), ~v〉 = ∂f
∂x1(~x)h1 + ∂f
∂x2(~x)h2 +
· · ·+ ∂f∂xn
(~x)hn, si dice che una funzione è differenziabile se vale la relazione di limite:
lim~v→~0
f(~x+ ~v)− f(~x)− 〈∇f(~x), ~v〉‖v‖
= 0 (5.11)
oppure, utilizzando la notazione di “o piccolo”, la funzione f è differenziabile se
f(~x+ ~v) = f(~x) + 〈∇f(~x), ~v〉+ o(‖~v‖) (5.12)
I prossimi teoremi dimostrano che è equivalente utilizzare una di queste tre notazionie, inoltre, che se una funzione è differenziabile allora è continua.
Teorema 5.2.9. Sia f : A → Rm e ~x0 ∈ A; allora f è differenziabile in ~x0 se e solose f(~x) = f(~x0) + T (~x − ~x0) + E(~x, ~x0) dove T ∈ L(Rn,Rm) e E è un errore tale chelim~x→~x0
E(~x,~x0)‖~x−~x0‖ = 0.
Dimostrazione. Definiamo la funzione R(~x, ~x0) =f(~x)−f(~x0)−T (~x−~x0)
‖~x−~x0‖. Da questa relazione ricavo f(~x). Risulta f(~x) =
f(~x0) + T (~x− ~x0) + ‖~x− ~x0‖R(~x, ~x0). Il termine ‖~x− ~x0‖R(~x, ~x0) è il nostro errore. Infatti E(~x, ~x0) = ‖~x− ~x0‖R(~x, ~x0),si dividano ambedue i membri per ‖~x − ~x0‖ e si ottiene R(~x, ~x0) =
E(~x,~x0)‖~x−~x0‖
. Infatti per ~x → ~x0 si ha che R(~x, ~x0) → 0.Quindi effettivamente si tratta di un errore.
[4]Si dice che una funzione f1(~x) è “o piccolo” di un’altra funzione f2(~x) e si scrive f1(~x) = o(f2(~x)) se f2(~x) → 0 per~x→ ~0 e se è vera la relazione di limite lim~x→~0
f1(~x)f2(~x)
= 0.
Matteo Gallone - Analisi Matematica II

5.2 Calcolo differenziale in Rn
Derivate parziali e differenziabilità43
Per dimostrare l’implicazione inversa ricavo E(~x, ~x0) da f(~x) = f(~x0) + T (~x − ~x0) + E(~x, ~x0). Ottengo E(~x, ~x0) =f(~x) − f(~x0) − T (~x − ~x0). Divido ambedue i membri per ‖~x − ~x0‖ e ne faccio il limite per ~x → ~x0. Allora si ottienelim~x→~x0
E(~x,~x0)‖~x−~x0‖
= lim~x→~x0
f(~x)−f(~x0)−T (~x−~x0)‖~x−~x0‖
. Ma per la definizione di errore, il primo membro dell’uguaglianza tende
a 0. Quindi si ottiene lim~x→~x0
f(~x)−f(~x0)−T (~x−~x0)‖~x−~x0‖
= 0 che è esattamente come dire che la funzione è differenziabile.
Teorema 5.2.10. Siano f : A → Rm e ~x0 ∈ A, se f è differenziabile in ~x0 allora f ècontinua in ~x0.Dimostrazione. Discende dalla linearità del limite. Infatti se f è differenziabile allora f(~x) = f(~x0) + T (~x− ~x0) +E(~x, ~x0).Facendo il limite dell’uguaglianza per ~x → ~x0 si ottiene: lim~x→~x0
f(~x) = lim~x→~x0(f(~x0) + T (~x− ~x0) + E(~x, ~x0)) =
f(~x0) + lim~x→~x0T (~x − ~x0) + lim~x→~x0
E(~x, ~x0) = f(~x0). Scriviamo vicini il primo e l’ultimo membro dell’uguaglianza:lim~x→~x0
f(~x) = f(~x0). Quindi la funzione è continua.
Teorema 5.2.11. Siano f : A→ Rm e ~x0 ∈ A, se f è differenziabile allora ∂f∂~v
(~x0) = T~v.
Dimostrazione. La definizione di derivata direzionale è ∂f∂~v
(~x0) = limt→0f(~x0+t~v)−f(~x0)
tdove t è l’incremento infinite-
simo e ~v è una direzione. Applico ora le sostituzioni f(~x0) = f(~x) − T (~x − ~x0) + E(~x, ~x0) e ~x0 = ~x − t~v (ovvero~x− ~x0 = t~v) a limt→0
f(~x0+t~v)−f(~x0)t
= limt→0f(~x−t~v+t~v)−f(~x)+T (~x−~x0)−E(~x,~x0)
t= limt→0
T (t~v)−E(~x0+t~v,~x0)t
. Poichè T
è lineare allora posso scrivere T (t~v) = tT (~v), quindi limt→0tT (~v)t
= T (~v), e per definizione di errore limt→0E(~x0+t~v,~x0)
t=
limt→0 ‖~v‖E(~x0+t~v,~x0)t‖~v‖ = ‖~v‖ limt→0
E(~x0+t~v,~x0)‖~v‖t = 0. Quindi in definitiva si è dimostrata la tesi.
Grazie a quest’ultimo teorema siamo in grado di definire cosa sia esattamente T =df(~x0). Sia quindi T la matrice relativa a tale funzione. Sappiamo che Tij = 〈T~ej , ~ei〉 =
〈 ∂f∂xj
(~xj), ~ei〉 = ∂fi∂xj
(~x0). Si ritiene opportuno ricordare che j = 1, . . . ,m sono le colonnedella matrice mentre i = 1, . . . , n sono le righe. Risulta quindi che:
T = df(~x0) = Jfi(~x0) (5.13)
Nel caso in cui m = 1 allora si ha che df(~x0) = ∇f(~x0).
Osservazione 5.2.12. Sia f : A→ R una funzione differenziabile nel punto ~x0 ∈ A ⊂ Rn
(con A insieme aperto); possiamo quindi considerare la funzione (affine) ϕ : Rn → R taleche ϕ(~x) = f(~x0) + 〈∇f(~x0), ~x− ~x0〉. Allora possiamo scrivere
f(~x) = ϕ(~x) + E(~x, ~x0) (5.14)
dove E è il solito errore. Questo significa che ϕ approssima f vicino a ~x0 con un erroremolto più piccolo della distanza ‖~x− ~x0‖. Il piano affine che costituisce il grafico di ϕ
gr(ϕ) ={
(~x, ϕ(~x)) ∈ Rn+1 : ~x ∈ Rn}
si dice tangente al grafico di f nel punto (~x, f(~x). L’equazione cartesiana di tale pianorisulta essere
xn+1 = f(~x0) + 〈∇f(~x0), ~x− ~x0〉
Definizione 5.2.13. Dato un insieme A ⊂ Rn aperto, definiamo l’insieme delle funzioniderivabili con derivate parziali continue C1(A,Rm). Quindi una funzione si dice di classeC1(A,Rm) nel caso in cui f ∈ C1(A,Rm).
Teorema 5.2.14 (del differenziale totale). Sia f : A → Rm una funzione derivabile inun aperto A ⊆ Rn. Se f ∈ C1(A) allora f è differenziabile in A.[5]
Dimostrazione. Per semplicità consideriamo il caso f : R2 → R. Consideriamo la quantità f(x + h, y + k) − f(x, y) =[f(x+ h, y + k)− f(x, y + k) + f(x, y + k)− f(x, y)] = [f(x+ h, y + k)− f(x, y + k)] + [f(x, y + k)− f(x, y)]. Applicandoil teorema di Lagrange, esistono x1 ∈ [x, x + h] e y1 ∈ [y, y + k] tali che [f(x + h, y + k) − f(x, y + k)] + [f(x, y + k) −
f(x, y)] = fx(x1, y+k)h+fy(x, y1)k. Usando tale relazione calcoliamo la quantità∣∣∣∣ f(x+h,y+k)−f(x,y)−fx(x,y)h−fy(x,y)k√
h2+k2
∣∣∣∣ =∣∣∣∣ fx(x1,y+k)h+fy(x,y1)k−fx(x,y)h−fy(x,y)k√h2+k2
∣∣∣∣. Raccogliendo h e k al numeratore si ha∣∣∣∣h(fx(x1,y+k)−fx(x,y))+k(fy(x,y1)−fy(x,y))√
h2+k2
∣∣∣∣.Per le proprietà del modulo, si ha
∣∣∣∣h(fx(x1,y+k)−fx(x,y))+k(fy(x,y1)−fy(x,y))√h2+k2
∣∣∣∣ ≤ |h||fx(x1,y+k)−fx(x,y)|+|k||fy(x,y1)−fy(x,y)|√h2+k2
=
[5]Ovvero, più scorrevolmente, Se f è derivabile in x0 ∈ A e in quel punto le sue derivate sono continue allora f èdifferenziabile.
Matteo Gallone - Analisi Matematica II

44 Calcolo differenziale in Rn
Funzioni composte 5.3
|h|√h2+k2
|fx(x1, y+ k)− fx(x, y)|+ |k|√h2+k2
|fy(x, y1)− fy(x, y)|. Le quantità |h|√h2+k2
e |k|√h2+k2
sono minori o uguali a 1.
Quindi vale anche la relazione |h|√h2+k2
|fx(x1, y+k)− fx(x, y)|+ |k|√h2+k2
|fy(x, y1)− fy(x, y)| ≤ |fx(x1, y+k)− fx(x, y)|+
|fy(x, y1) − fy(x, y)|. In definitiva vale la relazione∣∣∣∣ f(x+h,y+k)−f(x,y)−fx(x,y)h−fy(x,y)k√
h2+k2
∣∣∣∣ ≤ |fx(x1, y + k) − fx(x, y)| +
|fy(x, y1)− fy(x, y)|.Calcoliamo il limite per (h, k) → (0, 0). x1 converge a x e y1 converge a y. Per l’ipotesi di continuità delle derivate
parziali si ha che lim(h,k)→(0,0)[|fx(x1, y + k) − fx(x, y)| + |fy(x, y1) − fy(x, y)|] = 0. Quindi per confronto la funzione èdifferenziabile.
5.3 Funzioni composte
Proposizione 5.3.1. Siano f, g : A → Rm funzioni differenziabili nel punto ~x0 ∈ A conA ⊂ Rn; allora la funzione f + g : A → Rm è anch’essa differenziabile nel punto ~x0 einoltre vale
d(f + g)(~x0) = df(~x0) + dg(~x0)
o in alternativa si può dire anche Jf+g(~x0) = Jf (~x0) + Jg(~x0).
Teorema 5.3.2 (Differenziale della funzione composta). Sia f : A → Rm una funzionedifferenziabile nel punto ~x0 ∈ A con A ⊂ Rn, e g : B → Rk una funzione differenziabilein f(~x0) ∈ B, con B ⊂ Rm insieme aperto; allora la composizione g ◦ f : A → Rk èdifferenziabile, e inoltre risulta
d(g ◦ f)(~x0) = dg(f(~x0)) · df(~x0)
o equivalentemente Jg◦f (~x0) = Jg(f(~x0))Jf (~x0). Ove d(f ◦g)(~x0) ∈ L(Rn,Rk), dg(f(~x0)) ∈L(Rm,Rk) e df(~x0) ∈ L(Rn,Rm).Dimostrazione. Sia ~x0 ∈ A un punto con A ⊂ Rn insieme aperto, e siano T = df(~x0) ∈ L(Rn,Rm) e S = dg(~y0) ∈L(Rm,Rk) funzioni differenziali tali che f(~x) = f(~x0) + T (~x − ~x0) + ‖~x − ~x0‖ω(~x, ~x0) con ω(~x, ~x0) errore, e g(~y) =g(~y0) + S(~y − ~y0) + ‖~y − ~y0‖ϑ(~y, ~y0) con ϑ errore. Poniamo quindi ~y = f(~x) e ~y0 = f(~x0) e otteniamo g(f(~x)) =g(f(~x0))+S(f(~x)−f(~x0))+‖f(~x)−f(~x0)‖ϑ(f(~x), f(~x0)). Si sostituisce ora a f(~x) la sua espressione ottenendo: g(f(~x)) =g(f(~x0))+S(f(~x0)+T (~x−~x0)+‖~x− ~x0‖ω(~x, ~x0)−f(~x0))+‖f(~x0)+T (~x−~x0)+‖~x−~x0‖ω(~x, ~x0)−f(~x0)‖ϑ(f(~x), f(~x0)) =g(f(~x0)) + S(T (~x − ~x0) + ‖~x − ~x0‖ω(~x, ~x0)) + ‖T (~x − ~x0) + ‖~x − ~x0‖ω(~x, ~x0)‖ϑ(f(~x), f(~x0)). Ora per la linearità di Ssi ha che S(T (~x − ~x0) + ‖~x − ~x0‖ω(~x, ~x0)) = S(T (~x − ~x0)) + ‖~x − ~x0‖S(ω(~x, ~x0)). Raccolgo quindi ‖~x − ~x0‖ ottenendo:g(f(~x0))+S(T (~x−~x0))+‖~x−~x0‖
[S(ω(~x, ~x0)) +
∥∥∥T (~x−~x0)‖~x−~x0‖
+ ω(~x, ~x0)∥∥∥ϑ(f(~x), f(~x0))
]. Per trovare la tesi non devo fare altro
che dimostrare che la quantità tra parentesi quadre è infinitesima. Osservo quindi che il termine S(ω(~x, ~x0)) è infinitesimoper l’ipotesi di linearità di S, osservo poi che ϑ(f(~x, ~x0)) è infinitesimo perchè f è continua[6] e perchè ϑ(~y, ~y0)→ 0 quando~y → ~y0. Resta quindi da dimostrare che
∥∥∥T (~x−~x0)‖~x−~x0‖
+ ω(~x, ~x0)∥∥∥ è una quantità limitata. Per la disuguaglianza triangolare si
ha∥∥∥T (~x−~x0)‖~x−~x0‖
+ ω(~x, ~x0)∥∥∥ ≤ ∥∥∥T (~x−~x0)
‖~x−~x0‖
∥∥∥+‖ω(~x, ~x0)‖. Ora ‖ω(~x, ~x0)‖ tende a 0. Per quanto riguarda la quantità∥∥∥T (~x−~x0)‖~x−~x0‖
∥∥∥,consideriamo l’insieme compatto K = {~x ∈ Rn : ‖~x‖ = 1} e la funzione ϕ.K → R continua tale che ϕ(~x) = ‖T (~x)‖. Per ilteorema di Weierstrass ϕ(~x) assume massimo su quel compatto, esiste quindi ~x′ tale che ϕ(~x) ≤ ϕ(~x′) = M . Dimostrandoche questa quantità è limitata la dimostrazione è terminata.
Corollario 5.3.3 (Derivata di una funzione composta con una curva). Siano γ : [0, 1]→Rn di classe C1 e una funzione f : Rn → R differenziabile in Rn. Allora si ha che
d
dtf(γ(t)) = 〈∇f(γ(t)), γ′(t)〉
Dimostrazione. Definiamo ϕ(t) = f(γ(t)), t ∈ [0, 1] che è differenziabile per il teorema precedente. Inoltre si ha ϕ′(t) =
dϕ(t) = df(γ(t)) ◦ γ′(t) = Jf (γ(t))Jγ(t) =∑ni=1
∂f∂xi
(γ(t))γi(t) = 〈∇f(γ(t)), γ′(t)〉.
Esempio. Calcolare tutte le funzioni u(x, y) ∈ C1(R2) che risolvono l’equazione
∂u
∂x+∂u
∂y= 0
Soluzione. Notiamo che ∂u∂x
+ ∂u∂y
= 〈∇u, (1, 1)〉, ove (1, 1) potrebbe essere la derivata prima di una curva del tipo γ(t) =
(x0, 0) + t(1, 1), ovvero γ(t) =
{x0 + tt
. Risolvendo quindi in R2 l’equazione ddtu(γ(t)) = 〈∇u(γ(t)), γ(t)〉 = 0 si ottiene
ddtu(γ(t)) = 0, ovvero
∫ t0 du(γ(τ)) = 0 che implica appunto u(γ(t)) − u(γ(0)) = 0. Ma, per come è definita γ si ha che
[6]Detto grossolanamente, se una funzione è continua allora ad una piccola variazione delle x corrisponde una piccolavariazione delle y.
Matteo Gallone - Analisi Matematica II

5.4 Calcolo differenziale in Rn
Teoremi del valor medio45
u(γ(0)) = u(x0, 0) e u(x0 + t, t) = u(x, y). Tornando alla soluzione dell’integrale si ha u(γ(t)) − u(γ(0)) = 0, ovverou(x, y) − u(x0, 0) = 0 che è esattamente come dire u(x, y) = u(x0, 0). Definiamo ora u(x0, 0) = f(x0) e vediamo che, percome è definita γ si ha x0 = x− t e y = t, quindi x0 = x− y. Quindi u(x, y) = f(x− y) per ogni f ∈ C1(R) è una soluzionedell’equazione.
Per esempio (si provi) che f(x− y) = (x− y)2 verifica l’equazione come anche g(x− y) = ex−y .
5.4 Teoremi del valor medio
Teorema 5.4.1 (Valor medio per funzioni scalari). Sia f : A→ R una funzione differen-ziabile nell’insieme A ⊂ Rn aperto; siano poi ~x, ~y ∈ A tali che
[~x, ~y] = {t~x+ (1− t)~y ∈ Rn : t ∈ [0, 1]} ⊂ A
allora esiste un punto ~z ∈ [~x, ~y] tale che f(~x)− f(~y) = ∇f(~z) · (~x− ~y).Dimostrazione. Siano γ : [0, 1] → A una curva con γ(t) = t~x + (1 − t)~y e ϕ = f(γ(t)) con t ∈ [0, 1] e ϕ derivabile in tuttii suoi punti. Per il teorema di Lagrange sappiamo che con n = 1 esiste un valore t? ∈ [0, 1] tale che ϕ(1) − ϕ(0) = ϕ′(t?).Dato quindi ~z = γ(t?) ∈ [~x, ~y] possiamo scrivere che f(~x)− f(~y) = ∇f(~z)(~x− ~y).
Teorema 5.4.2 (Valor medio per funzioni vettoriali). Sia f : A → Rm una funzionedifferenziabile nell’insieme A ⊂ Rn aperto. Siano poi ~x, ~y ∈ A tali che
[~x, ~y] = {t~x+ (1− t)~y ∈ Rn : t ∈ [0, 1]} ⊂ A
Allora per ogni ~v ∈ Rm esiste ~z ∈ [~x, ~y] tale che
(f(~x)− f(~y)) · ~v = df(~z)(~x− ~y) · ~vDimostrazione. Siano γ : [0, 1] → A con γ(t) = t~x + (1 − t)~y e sia ϕ(t) = f(γ(t)) · ~v; risulterà che ϕ(1) − ϕ(0) =f(~x) · ~v − f(~y) · ~v = (f(~x) − f(~y) · ~v. Consideriamo ora ϕ(t) = (f(γ(t)) · ~v =
∑ni=1 fi(γ(t))vi e calcoliamone la derivata
prima: ϕ′(t) = ddt
∑ni=1 fi(γ(t))vi =
∑ni=1
ddtfi(γ(t))vi = df(γ(t?))(~x − ~y) · ~v. Pertanto esisterà t? ∈ [0, 1] tale che
ϕ(1)−ϕ(0) = ϕ′(t?). Sostituendo abbiamo (f(~x)− f(~y)) ·~v = df(γ(t?))(~x− ~y) ·~v. Chiamando ~z = γ(t?) otteniamo la tesi.
Definizione 5.4.3. Sia T ∈ L(Rn,Rm) differenziale lineare, definiamo la sua norma come
‖T‖ = sup‖~x‖≤1
‖T~x‖ (5.15)
dove T~x è l’immagine del differenziale.
Proposizione 5.4.4. L’insieme L(Rn,Rm) delle funzioni lineari dotato della norma ‖ · ‖forma lo spazio normato (L(Rn,Rm), ‖ · ‖).Dimostrazione. Bisogna dimostrare che le trasformazioni lineari T, S ∈ L(Rn,Rm) verificano le proprietà dello spaziometrico normato (Definizione 4.1.2).
Dimostriamo la proprietà 1). La condizione ‖Ti‖ ≥ 0 è sempre verificata, come l’implicazione T = 0 ⇒ ‖T‖ = 0, laverifica dell’implicazione inversa (ovvero ‖T‖ = 0 ⇒ T = 0) si trova osservando che ‖T‖ = 0 ⇒ ‖T~x‖ = 0 e che ∀‖x‖ ≤ 1T~x = 0.
Dimostriamo la proprietà 2). Dato λ ∈ R risulta ‖λT‖ = sup‖~x‖≤1 ‖λT~x‖ = |λ| sup‖~x‖≤1 ‖T~x‖ = |λ|‖T~x‖.Dimostriamo ora la proprietà 3). Dimostriamo la disuguaglianza triangolare ‖T + S‖ = sup‖x‖≤1 ‖(T + S)(~x)‖. Per
linearità ora si ha che (T + S)(~x) = T~x + S~x quindi sup‖x‖≤1 ‖(T + S)(~x)‖ = sup‖x‖≤1 ‖T~x + S~x‖. Per le proprietà dellanorma euclidea si ha che ‖T~x + S~x‖ ≤ ‖T~x‖ + ‖S~x‖, quindi sup‖x‖≤1 ‖T~x + S~x‖ ≤ sup‖x‖≤1(‖T~x‖ + ‖S~x‖). Ora per leproprietà dell’estremo superiore[7] si ha che sup‖x‖≤1(‖T~x‖+‖S~x‖) ≤ sup‖~x‖≤1 ‖T~x‖+sup‖~x‖≤1 ‖S~x‖ = ‖T‖+‖S‖. Quindiè dimostrata la disuguaglianza triangolare.
Proposizione 5.4.5. Sia A ⊂ Rn un insieme aperto e f : A → Rm una funzione diffe-renziabile su tutto A; siano inoltre ~x, ~y ∈ A tali che [~x, ~y] ⊂ A. Allora esiste ~z ∈ [~x, ~y]tale che
‖f(~x)− f(~y)‖ ≤ ‖df(~z)‖‖~x− ~y‖Dimostrazione. Dal teorema Teorema 5.4.2 sappiamo che per ogni ~v ∈ Rm esiste un valore ~x ∈ [~x, ~y] tale che (f(~x) −f(~y)) · ~v = (df(~z)(~x − ~y) · ~v. Scelto quindi ~v = f(~x) − f(~y) risulta che: ‖f(~x) − f(~y)‖2 = (df(~z)(~x − ~y)) · (f(~x) − f(~y)) ≤‖df(~z)(~x−~y))·(f(~x)−f(~y))‖ ≤ ‖df(~z)(~x−~y))‖·‖(f(~x)−f(~y))‖. Or a possiamo dividere ambedue i membri per ‖f(~x)−f(~y)‖,ottengo ‖f(~x)−f(~y)‖ ≤ ‖df(~z)(~x−~y)‖. Per la disuguaglianza di Schwarz allora ‖df(~z)(~x−~y)‖ ≤ ‖df(~z)‖‖(~x−~y)‖. Quindisi ottiene la tesi.
[7]Il sup della somma è minore o uguale alla somma dei sup.
Matteo Gallone - Analisi Matematica II

46 Calcolo differenziale in Rn
Derivate successive e Formula di Taylor 5.5
Definizione 5.4.6. Sia f : A → Rm una funzione differenziabile (con A ⊂ Rn) e siasup‖~x‖≤1 ‖df(~x)‖ = L <∞; allora
‖f(~x)− f(~y)‖ ≤ L‖~x− ~y‖
∀~x, ~y ∈ A. In tale caso la funzione si dice lipschitziana.
Teorema 5.4.7. Sia A ⊂ Rn un insieme aperto e connesso e la funzione f : A → Rm
differenziabile in A con df(~x) = 0 per ogni ~x ∈ A. Allora f è costante su A.Dimostrazione. Voglio dimostrare che per ogni ~x, ~y ∈ A risulta che f(~x) = f(~y). Congiungo i punti ~x e ~y con una poligonalecontenuta in A con γ(a) = ~x e γ(b) = ~y. Allora suppongo che [a, b] ⊂ A; ma allora per la Proposizione 5.4.5 si ha:‖f(~x)− f(~y)‖ ≤ ‖df(~z)‖‖~x− ~y‖. Ma poichè df(~z) = 0 allora deve essere necessariamente f(~x) = f(~y).
5.5 Derivate successive e Formula di Taylor
Abbiamo gia introdotto i concetti di derivate seconde e di matrice Hessiana per unafunzione di due variabili reali, ovvero f : R2 → R. In questo capitolo ci si ripropone digeneralizzare questi concetti e di trovare una formula che approssimi una funzione in piùvariabili ad un punto.
Definizione 5.5.1. Sia A ⊂ Rn un insieme aperto e sia f : A → Rm una funzione taleche esistono in A le sue derivate parziali ∂f
∂xicon i = 1, . . . , n; se esse risultano derivabili,
allora possiamo definire le derivate parziali seconde come ∂∂xj
(∂f∂xi
).
Le derivate parziali seconde ∂∂xj
(∂f∂xi
)si indicano in uno dei seguenti modi: ∂2f
∂xi∂xj,
∂ijf , fij, fxixj , Dijf , ∇ijf . Nel caso in cui i = j si usa anche la notazione ∂2f∂x2i; nel caso in
cui i 6= j le derivate parziali si dicono miste.Anche per funzioni in più di due variabili vale il teorema di Schwarz (Teorema 5.2.5).
Esempio. Sia f : R2 → R la funzione così definita
f(x, y) =
{xy3
x2+y2 (x, y) 6= (0, 0)
0 (x, y) = (0, 0)
È facile dimostrare che la funzione è continua in tutto R2. Infatti in tutto R2\{(0, 0)} la funzione è continua in quanto somma
e composizione di funzioni continue ed è continua anche in (0, 0) poichè 0 ≤∣∣∣ xy3
x2+y2
∣∣∣ ≤ ∣∣∣xy(x2+y2)
x2+y2
∣∣∣ = |xy|. Calcolando
il limite lim(x,y)→(0,0) xy = 0 e quindi per il teorema dei carabinieri anche lim(x,y)→(0,0)xy3
x2+y2 = 0, quindi f è continuaanche in (0, 0). Calcoliamo ora le sue derivate prime:
∂f
∂x(x, y) =
y3(x2 + y2)− xy3(2x)
(x2 + y2)2=
y3
(x2 + y2)2(y2 − x2)
∂f
∂y(x, y) =
3y2x(x2 + y2)− xy32y
(x2 + y2)2=xy2(3x2 + y2)
(x2 + y2)2
Se calcoliamo ora i valori delle derivate parziali rispetto a x e rispetto ad y otteniamo
∂f
∂x(0, 0) = lim
h1→0
f(h1, 0)− f(0, 0)
h1= limh1→0
0− 0
h1= 0
∂f
∂y(0, 0) = lim
h2→0
f(0, h2)− f(0, 0)
h2= limh2→0
0− 0
h2= 0
Calcoliamo ora i valori delle derivate parziali seconde miste:
∂
∂y
∂f
∂x(0, 0) = lim
h2→0
∂f∂x
(0, h2)− ∂f∂x
(0, 0)
h2= limh2→0
1
h2h2 = 1
∂
∂x
∂f
∂y(0, 0) = lim
h1→0
∂f∂y
(h1, 0)− ∂f∂y
(0, 0)
h1= limh1→0
0− 0
h1= 0
Infatti questa funzione potrebbe essere presa come esempio di funzione con derivate parziali miste diverse tra loro.
Definizione 5.5.2. Si definisce l’insieme delle funzioni di classe C2(A,Rm) come l’insiemedi quelle funzioni che hanno tutte le derivate seconde continue in A. Diremo che unafunzione è di classe C2 se appartiene a questo insieme.
Matteo Gallone - Analisi Matematica II

5.5 Calcolo differenziale in Rn
Derivate successive e Formula di Taylor47
Esempio. Calcolare tutte le soluzioni u(x, y) ∈ C2(R2) che risolvono l’equazione delle onde
∂2u
∂x2−∂2u
∂y2= 0
Soluzione. Si noti che ∂2u∂x2 − ∂2u
∂y2 =(∂∂x
+ ∂∂y
)(∂∂x− ∂∂y
)u =
(∂∂x
+ ∂∂y
)(∂u∂x− ∂u
∂y
). Infatti, svolgendo i calcoli si vede
che poichè u è di classe C2 per ipotesi allora le derivate miste sono uguali, e quindi vale questa uguaglianza. Chiamiamo oraz(x, y) =
(∂u∂x− ∂u
∂y
). Quindi la nostra equazione diventa ∂z
∂x+ ∂z∂y
= 0 che sappiamo (perchè gia studiata in precedenza)
avere come soluzioni una funzione h(x − y) ∈ C1. Ma dire che h è una soluzione vuol dire che z(x, y) = h(x − y), ovverovuol dire risolvere l’equazione differenziale a derivate parziali ∂u
∂x− ∂u
∂y= h(x − y). Notiamo quindi che ∂u
∂x− ∂u
∂y=
〈∇u, (1,−1)〉. Quindi l’equazione differenziale è equivalente se scritta 〈∇u, (1,−1)〉 = h(x − y), ma anche in questo caso(−1, 1) può essere vista come la derivata prima di una curva γ(t) = (x0, 0) + t(1,−1), e quindi si ottiene la scrittura〈∇u(γ(t)), γ(t)〉 = h(γ1(t) − γ2(t)) (dove con γ1 e γ2 si intendono le due componenti della curva). Poichè per la derivatadella funzione composta si ha 〈∇u(γ(t)), γ(t)〉 = d
dtu(γ(t)). Quindi si ottiene d
dtu(γ(t)) = h(x0 + 2t) (infatti γ1(t) = x0 + t
e γ2(t) = −t, quindi γ1(t)−γ2(t) = x0−2t). Integrando ambo i membri in dt si ha∫ t0 du(γ(τ)) =
∫ t0 h(x0 + 2τ) dτ . Quindi
u(γ(t)) = u(γ(0)) +∫ t0 h(x0 + 2τ) dτ .
Ricaviamo ora x e y dall’equazione della curva. Si ha x = x0 + t e y = −t. Quindi x = x0 − y, ovvero x0 = x + y.Quindi u(γ(0)) = u(x0) = g(x + y) con g ∈ C2(R). Abbiamo quindi trovato la soluzione generale dell’equazione, che èu(x, y) = g(x + y) +
∫−y0 h(x + y + 2τ) dτ , per ogni h ∈ C1(R) e g ∈ C2(R). Detta H una primitiva di h si avrà che la
soluzione generale dell’equazione è u(x, y) = g(x+ y) +H(x− y).
Definizione 5.5.3. Sia f ∈ C2(A,Rm) con A ⊂ Rn, allora la matrice quadrata esimmetrica di ordine n× n
Hf(~x) =
∂2f∂x2
1(~x) · · · ∂2f
∂x1∂xn(~x)
... . . . ...∂2f
∂xn∂x1(~x) · · · ∂2f
∂x2n(~x)
si dice matrice Hessiana di f nel punto ~x ∈ A.Osservazione 5.5.4. Se la derivata prima fornisce una trasformazione lineare, la deri-vata seconda fornisce una forma quadratica.
Definizione 5.5.5. L’operatore differenziale in Rn
∆ =n∑i=1
∂2
∂x2i
si dice operatore di Laplace.
Definizione 5.5.6. Una funzione u ∈ C2(A) con A ⊂ Rn tale che ∆u(~x) = 0 per ognivalore di ~x ∈ A si dice armonica.
Lemma 5.5.7. Sia T ∈ L(Rn,Rm) con T = (Tij)1≤i≤m1≤j≤n
, allora
‖T‖ ≤
(m∑i=1
n∑j=1
T 2ij
) 12
Dimostrazione. Per definizione ‖T‖ = sup‖~x‖≤1 ‖T~x‖; sia ‖~x‖ ≤ 1 e ~x =∑nj=1 xjej ; risulta che T~x = T (
∑nj=1 xjej) =∑n
j=1 xjTej con Tej unico in R così come i suoi coefficenti; inoltre∑nj=1 xjTej =
∑nj=1 xj
∑mi=1 Tijei =
(∑mi=1
∑nj=1 xjTij
)ei.
Considero ora la norma in Rm di questa quantità e applico la disuguaglianza di Cauchy-Schwarz:(∑m
i=1
(∑nj=1 xjTij
)2) 1
2
≤(∑mi=1 ‖~x‖2
∑nj=1 Tij
) 12 ≤
(∑mi=1
∑nj=1 T
2ij
) 12 . Questo termina la nostra dimostrazione.
Ora che sono state date alcune definizioni, possiamo parlare della formula di Taylor delsecondo ordine. Innanzi tutto è bene ricordare e generalizzare quanto detto in precedenzanell’Osservazione 5.2.12. Infatti una funzione f : A→ Rm con A ⊂ Rn si approssimaattorno a ~x0 al primo ordine:
f(~x) = f(~x0) + 〈∇f(~x0), ~x− ~x0〉+ E(~x, ~x0)
Con il seguente teorema si va avanti con lo sviluppo fino al secondo ordine.
Matteo Gallone - Analisi Matematica II

48 Calcolo differenziale in Rn
Estremi relativi 5.6
Teorema 5.5.8 (Sviluppo di Taylor al secondo ordine). Sia A ⊂ Rn un insieme aperto,f una funzione tale che f ∈ C2(A) e ~x0 ∈ A. Allora per ogni valore ~x contenuto in A taleche [~x0, ~x] ⊂ A, esiste ~z ∈ [~x0, ~x] per cui vale
f(~x) = f(~x0) + 〈∇f(~x0), ~x− ~x0〉+1
2〈∇2f(~z)(~x− ~x0), ~x− ~x0〉
Dimostrazione. Considero la funzione F : [0, 1] → R tale che F (t) = f(~x0 + t(~x − ~x0)) con t ∈ [0, 1]. Risulta essereF ∈ C2([0, 1]), ma allora per lo sviluppo di Taylor in una dimensione e per t = 0 esiste un valore t? ∈ [0, t] per cui valel’espressione F (t) = F (0) + F ′(0)t + 1
2F ′′(t?)t2. Calcoliamo ora quanto vale F ′(t) = 〈∇f(~x0 + t(~x − ~x0)), ~x − ~x0〉 =∑n
i=1∂f∂xi
(~x0 + t~h)hi. Calcoliamo ora quanto vale F ′′(t) = ddt
∑ni=1
∂f∂xi
(~x0 − t~h)hi =∑nj=1
∑ni=1
∂∂xj
∂f∂xi
(~x0 + t~h)hihj =
〈∇2f(~x0 + t(~x − ~x0))(~x − ~x0), ~x − ~x0〉. Osserviamo ora che valgono le seguenti uguaglianze: F (1) = f(~x), F (0) = f(~x0),F ′(0) = 〈∇f(~x0), ~x−~x0〉. Pongo z = ~x0+t?(~x−~x0) ∈ [~x0, ~x]. E sostituisco tutto questo in F (t) = F (0)+F ′(0)t+ 1
2F ′′(t?)t2,
ottenendo proprio: f(~x) = f(~x0) + 〈∇f(~x0), ~x− ~x0〉+ 12〈∇2f(~z)(~x− ~x0), ~x− ~x0〉.
Corollario 5.5.9 (Resto nella forma di “o piccolo”). Se f ∈ C2(A) dove A ⊂ Rn è uninsieme aperto e ~x0 ∈ A, allora per ~x→ ~x0 si ha:
f(~x) = f(~x0) + 〈∇f(~x0), ~x− ~x0〉+1
2〈∇2f(~x0)(~x− ~x0), ~x− ~x0〉+ o(|~x− ~x0‖2)
Dimostrazione. Per lo sviluppo di Taylor e per Weierstrass sappiamo che ∀~x ∃~z ∈ [~x0, ~x] tale che f(~x) = f(~x0) +〈∇f(~x0), ~x − ~x0〉 + 1
2〈∇2f(~x0)(~x − ~x0), ~x − ~x0〉 + 1
2〈(∇2f(~z)−∇2f(~x0)
)(~x − ~x0), ~x − ~x0〉. Voglio dimostrare ora che
E(~x, ~x0) = 12〈(∇2f(~z)−∇2f(~x0)
)(~x − ~x0), ~x − ~x0〉 è un errore; o in altri termini che lim~x→~x0
E(~x,~x0)
‖~x−~x0‖2= 0. Con-
sidero pertanto ‖E(~x, ~x0)‖ e applico la disuguaglianza di Cauchy-Schwarz: ‖〈(∇2f(~z)−∇2f(~x0)
)(~x − ~x0), ~x − ~x0〉‖ ≤
‖∇2f(~z)−∇2f(~x0)‖‖~x− ~x0‖2 =(∑n
i,j=1( ∂2f∂xi∂xj
(~z)− ∂2f∂xi∂xj
(~x0))2) 1
2 ‖~x− ~x0‖2. Ma poichè f ∈ C2 abbiamo che le deri-
vate seconde sono continue, e quindi 0 ≤ lim~x→~x0
E(~x,~x0)
‖~x−~x0‖2≤ lim~x→~x0
(∑ni,j=1( ∂2f
∂xi∂xj(~z)− ∂2f
∂xi∂xj(~x0))2
) 12 ‖~x−~x0‖2 = 0.
La dimostrazione è terminata.
Definizione 5.5.10. Si definisce multiindice la quantità α ∈ Nn (con N dotato dello zero)e
α =
α1...αn
e la sua lunghezza ‖α‖ = α1 + · · ·+ αn.
Teorema 5.5.11 (Formula di Taylor). Se A è un convesso[8] e f : A→ R è di classe Ckper ogni ~x0 ∈ A si ha il seguente sviluppo (dove α è un multiindice, α! = α1! · · · · · αn!,|α| = α1 + · · ·+ αn e hα = hα1
1 · · · · · hαnn ):
f(~x0 + ~h) =∑|α|≤k
1
α!
∂|α|f
~xα(~x0)~hα + o(‖h‖k) (5.16)
5.6 Estremi relativi
Definizione 5.6.1. Siano f : A → R con A ⊂ Rn e ~x0 ∈ A; ~x0 si dice punto di minimorelativo (locale) di f se esiste δ > 0 tale che
f(~x) ≥ f(~x0)
∀~x ∈ A∩B(~x0, δ). In particolare, se f(~x) > f(~x0) per ogni ~x ∈ A∩B(~x0, δ) \ {~x0} allora~x0 si dirà punto di minimo relativo (locale) stretto.
Definizione 5.6.2. Siano f : A→ R con A ⊂ Rn e ~x0 ∈ A; ~x0 si dice punto di massimorelativo (locale) di f se esiste δ > 0 tale che
f(~x0) ≥ f(~x)
[8]Un insieme si dice convesso se, presi comunque ~x1, ~x2 ∈ A tutto il segmento [~x1, ~x2] è contenuto in A.
Matteo Gallone - Analisi Matematica II

5.6 Calcolo differenziale in Rn
Estremi relativi49
∀~x ∈ A∩B(~x0, δ). In particolare, se f(~x0) > f(~x) per ogni ~x ∈ A∩B(~x0, δ) \ {~x0} allora~x0 si dirà punto di massimo relativo (locale) stretto.
Definizione 5.6.3. Siano A ⊂ Rn un insieme aperto e ~x0 ∈ A e f ∈ C1(A). Se∇f(~x0) = 0allora ~x0 si dice punto critico di f .
Proposizione 5.6.4 (Condizione necessaria al primo ordine). Sia A ⊂ Rn un insiemeaperto e ~x0 ∈ A un suo punto, sia inoltre f ∈ C1(A); allora se ~x0 è punto di estremolocale è anche punto critico.Dimostrazione. Sia ad esempio ~x0 un punto di minimo locale; allora esiste per definizione δ > 0 tale che B(~x0, δ) ⊂ A ef(~x) ≥ f(~x0) per ogni ~x ∈ B(~x0, δ). Fissato quindi i = 1, . . . , n, calcolo in base alla definizione le derivate parziali dellafunzione in ~x0: ∂f
∂xi= limt→0±
f(~x0+t~ei)−f(~x0)t
= `. Osservo dunque che per t→ 0+ si deve avere ` ≥ 0 mentre per t→ 0−
si deve avere ` ≤ 0. Pertanto si deve avere ∂f∂xi
(~x0) = ` = 0, ovvero ~x0 è un punto critico di f .Se invece ~x0 è un massimo locale, la dimostrazione è analoga invertendo i segni delle disuguaglianze.
Definizione 5.6.5. Sia A una matrice simmetrica quadrata n× n; diciamo che:
1) A è semidefinita positiva (A ≥ 0) se e solo se 〈A~x, ~x〉 ≥ 0 per ogni ~x ∈ Rn;2) A è definita positiva (A > 0) se e solo se 〈A~x, ~x〉 > 0 per ogni ~x ∈ Rn \ {0};3) A è semidefinita negativa (A ≤ 0) se e solo se 〈A~x, ~x〉 ≤ 0 per ogni ~x ∈ Rn;4) A è definita negativa (A < 0) se e solo se 〈A~x, ~x〉 < 0 per ogni ~x ∈ Rn \ {0};5) A è indefinita negli altri casi.
Lemma 5.6.6. Se A è una matrice simmetrica quadrata n × n definita positiva, alloraesiste un m > 0 tale che 〈A~x, ~x〉 ≥ m‖~x‖2, per ogni ~x ∈ Rn.Dimostrazione. Considero la funzione ϕ : Sn−1 → R (con S = {~x ∈ Rn : ‖~x‖ = 1}), tale che ϕ(~x) = 〈A~x, ~x〉; sotto questecondizioni osservo che Sn−1 è un insieme compatto, e che ϕ è una funzione continua, pertanto sono soddisfatte le condizioniper il teorema di Weierstrass, ed esisterà un ~x0 ∈ S tale che ϕ(~x) ≥ ϕ(~x0) = 〈A~x0, ~x0〉 = m > 0 per ipotesi, in quanto Aè definita positiva. Pertanto risulta che
⟨A ~x‖~x‖ ,
~x‖~x‖
⟩= ϕ
(~x‖~x‖
)≥ m. Ovvero, moltiplicando tutto per ‖~x‖2 si ottiene la
tesi: 〈A~x, ~x〉 ≥ m‖~x‖2.
Proposizione 5.6.7 (Condizione necessaria al secondo ordine). Siano A ⊂ Rn un insiemeaperto, ~x0 un suo punto e f ∈ C2(A) una funzione. Se ~x0 è un punto di minimo localeallora deve essere[9]
∇f(~x0) = 0 Hf(~x0) ≥ 0Dimostrazione. Sia ~v ∈ Rn un vettore fissato ‖~v‖ = 1; per ipotesi esiste δ > 0 tale che B(~x0, δ) ⊂ A e f(~x) ≥ f(~x0)per ogni ~x ∈ B(~x0, δ). Allora per t < δ sarà ~x0 + t~v ∈ B(~x0, δ), e quindi dalla formula di Taylor per t → 0 ottengo0 ≤ f(~x0 + t~v)− f(~x0) = 〈∇f(~x0), t~v)〉+ 1
2t2〈∇2f(~x0~v,~v〉+ o(‖~vt2‖).
Dimostriamo che ii)⇒ i). Supponiamo nullo in quel punto per la condizione necessaria al primo ordine. Inoltre, per leproprietà della norma si ha che ‖t2~v‖ = t2‖~v‖. Ma la norma di ~v è uguale a uno, quindi o(‖t2~v‖) = o(|t2|) e dalla relazione
di prima otteniamo 0 ≤ 12t2〈∇2f(~x0)~v,~v〉+o(t2). Dividendo ambedue i membri per t2 > 0 si ha 0 ≤ 1
2〈∇2f(~x0)~v,~v〉+ o(t2)
t2
da cui, facendo il limite per t→ 0 si ottiene 〈∇2f(~x0)~v,~v〉 ≥ 0 che è come dire ∇2f(~x0) ≥ 0.
Proposizione 5.6.8 (Condizione sufficente per un minimo locale stretto). Siano A ⊂ Rn
un insieme aperto, ~x0 ∈ A un suo punto e f ∈ C2(A) una funzione. Se sono verificate lecondizioni[10]
∇f(~x0) = 0 e Hf(~x0) > 0
allora ~x0 è un minimo locale stretto.Dimostrazione. Per la formula di Taylor al secondo ordine ho f(~x) − f(~x0) = 〈∇f(~x0), ~x − ~x0〉 + 1
2〈∇2f(~x0)(~x − ~x0), ~x −
~x0〉+ o(‖~x− ~x0‖2) e inoltre, per il Lemma 5.6.6 esiste m > 0 tale che 〈∇2f(~z)(~x− ~x0), ~x− ~x0〉 ≥ m‖~x− ~x0‖2. Unendo le
due espressioni ottengo f(~x) − f(~x0) ≥ m2‖~x − ~x0‖ + o(‖~x − ~x0‖2) = ‖~x − ~x0‖2
(m2
+o(‖~x−~x0‖2)
‖~x−~x0‖2
). Quindi esiste δ > 0
tale che o(‖~x−~x0‖2)
‖~x−~x0‖2≥ m
4per ogni ~x ∈ B(~x0, δ). Allora, preso ~x ∈ B(~x0, δ) vale f(~x)− f(~x0) ≥ m
4‖~x− ~x0‖2, quindi è facile
dedurre f(x) ≥ f(~x0), ovvero che ~x0 è un punto di minimo locale.
Teorema 5.6.9. Sia A una matrice simmetrica n× n con autovalori λ1 ≤ · · · ≤ λn doveλi ∈ Rn; allora A ≥ 0 se e solo se λ1 ≥ 0 e A > 0 se e solo se λ1 > 0.
[9]Dove con Hf(~x0) ≥ 0 si intende che la matrice Hessiana calcolata in ~x0 deve essere semidefinita positiva.[10]Dove con Hf(~x0) > 0 si intende che la matrice Hessiana calcolata in ~x0 deve essere definita positiva.
Matteo Gallone - Analisi Matematica II

50 Calcolo differenziale in Rn
Estremi relativi 5.6
Osservazione 5.6.10. Esaminiamo il caso delle matrici simmetriche 2× 2: A ≥ 0 se esolo se det(A) ≥ 0 e tr(A) ≥ 0 (e A > 0 se e solo se det(A) > 0 e tr(A) > 0); A ≤ 0 see solo se det(A) ≤ 0 e tr(A) ≤ 0 (e A < 0 se e solo se det(A) < 0 e tr(A) < 0).
Definizione 5.6.11. Sia F ∈ C2(A) una funzione con A ⊂ R2 e ~x0 ∈ A; se inoltre ~x0 èun punto critico e Hf(~x0) < 0 allora diremo che ~x0 è un punto di sella.
Definizione 5.6.12. Sia A un insieme A ⊂ Rn aperto e k ∈ N definiamo l’insieme dellefunzioni di classe Ck(A) come quelle funzioni che hanno continue tutte le derivate di ordinek.
Una generica funzione appartenente a quell’insieme si dirà di classe Ck.
Definizione 5.6.13. Definiamo inoltre l’insieme C∞(A) come C∞(A) =⋂∞k=0 Ck(A).
Definizione 5.6.14. Una funzione f : Rn \ {0} → R tale che
f(λ~x) = λkf(~x)
∀~x 6= 0 e ∀λ > 0 per un certo k ∈ R si dice omogenea di grado k.
Lemma 5.6.15 (Formula di Eulero). Sia f ∈ C1(Rn \ {0}) omogenea di grado k, risultache
〈f(~x), ~x〉 = kf(~x)
Dimostrazione. Fisso ~x 6= 0 e prendo ~v = ~x. Calcolo il prodotto tra il gradiente di f e ~v: 〈∇f(~x,~v) = ∂f∂~v
(~x) =
limt→0f(~x+t~v)
t. Utilizzo ora la definizione di funzione omogenea (pongo λ = 1+t), quindi limt→0
f(~x+t~v)t
= limt→0(1+t)k−1
tf(~x) =
kf(~x) calcolando il limite notevole. Quindi si è dimostrato quanto si voleva dimostrare.
Matteo Gallone - Analisi Matematica II

CAPITOLO 6
Ultimi teoremi
6.1 Teorema dell’invertibilità locale
Sia f : Rn → Rn una funzione lineare. Fissato un vettore b ∈ Rn l’equazione f(x) = b(che è un sistema di equazioni reali) ha certamente una soluzione unica x ∈ Rn se f hadeterminante det f(x) 6= 0. In questo caso, infatti, la funzione è invertibile e la soluzionex = f−1(b).
Per generalizzare questo risultato al caso in cui f non sia una funzione lineare verrannointrodotti prima i concetti di diffeomorfismo e diffeomorfismo locale.
Definizione 6.1.1. Sia A ⊂ Rn un aperto. Una funzione f ∈ Ck(A;Rn), con 1 ≤ k <∞si dice diffeormorfismo di classe Ck se
i) f : A→ f(A) ∈ Rn è iniettiva (e suriettiva);ii) la funzione inversa verifica f−1 ∈ Ck(f(A);A); in particolare f(A) ⊂ Rn è un aperto.
Definizione 6.1.2. Sia A ⊂ Rn un aperto. Una funzione f ∈ Ck(A;Rn), k ≥ 1, si dicediffeomorfismo locale di classe Ck se:
i) f è aperta, e cioè trasforma insiemi aperti in aperti;ii) Per ogni punto x ∈ A esiste un δ > 0 tale che f : B(x, δ) → Rn è iniettiva e la
funzione inversa verifica f−1 ∈ Ck(f(B(x, δ));Rn).
Teorema 6.1.3 (Invertibilità locale). Sia A ⊂ Rn un aperto e sia f ∈ Ck(A,Rn), k ≥ 1.Sono equivalenti le seguenti affermazioni:
i) f è un diffeomorfismo locale di classe Ck;ii) det(Jf (x0)) 6= 0 in ogni punto x0 ∈ A (dove Jf è la matrice Jacobiana di f).
Dimostrazione. Dimostriamo che i)⇒ ii). Fissiamo xo ∈ A e sia δ > 0 tale che f ∈ Ck(B(x0, δ);Rn) sia un diffeomorfismodi classe Ck. Indichiamo con f−1 : f(B(x0, δ)) → B(x0, δ) la funzione inversa. Allora per ogni x ∈ B(x0, δ) si haf−1(f(x)) = x = In(x) (ove In(x) è la funzione identità In : Rn → Rn). Dal teorema del differenziale della funzionecomposta (Teorema 5.3.2) si ha che Jf−1 (x)Jf (x) = In per ogni x ∈ B(x, δ). Dal teorema sui determinanti si ottieneallora det(Jf−1 (x)Jf (x)) = det(Jf−1 (x)) det(Jf (x)) = det(In) = 1. Ciò implica det(Jf (x)) 6= 0 per ogni x ∈ B(x0; δ), e inparticolare per x = x0.
Dimostriamo che ii) ⇒ i). La dimostrazione di questa seconda implicazione è lunga e - per alcuni versi - difficile daseguire. Per uno studio più facile conviene dividerla in più parti: per dimostrare che f è un diffeomorfismo locale bisognadimostrare a) che f trasforma punti interni in punti interni; b) che f è localmente iniettiva e che f−1 è continua, infine c)che f−1 è di classe Ck. Sempre per lo stesso principio conviene dividere la prima parte in sottoparti nel seguente ordine:a-1) Definire una funzione K(x) che ci permetta di provare che f è localmente suriettiva; a-2) Dimostrare che K(x) è unacontrazione (ovvero che a-2.1) Dimostrare che K è ben definita; a-2.2) Dimostrare che esiste un λ compreso tra zero e unotale che ‖K(x)−K(y)‖ < λ‖x− y‖).
a-1) Definire una funzione K(x) che dimostri che f è localmente biiettiva. Supponiamo che sia det(Jf (x)) 6= 0in ogni punto x ∈ A. Siano x0 ∈ A ed ε > 0 piccolo a piacere tale che B(x0, ε) ⊂ A. Proveremo che esiste δ > 0tale che B(f(x0), δ) ⊂ f(B(x0, ε)). Da questo segue che f trasforma punti interni in punti interni e quindi aperti in
Matteo Gallone - Analisi Matematica II

52 Ultimi teoremiTeorema sulla funzione implicita 6.2
aperti. L’affermazione appena scritta è equivalente a ∃δ > 0 tale che ∀y ∈ B(f(x0), δ) ∃x ∈ B(x0, ε) tale che f(x) = y.Fissiamo dunque y ∈ B(f(x0), δ)) con δ > 0 da determinare e cerchiamo un punto x ∈ B(x0, δ) tale che f(x) = y. SiaT = df(x0) ∈ L(Rn;Rn) il differenziale di f in x0 e osserviamo che det(T ) = det(Jf (x0)) 6= 0. Dunque esiste l’operatorelineare inverso T−1 ∈ L(Rn,Rn). Definiamo la funzione K della variabile x come K(x) = x − T−1(f(x) − y). Vogliamoprovare che K : B(x0, ε) → B(x0, ε) è una contrazione rispetto alla distanza standard. Siccome B(x0, ε) è completo conla distanza ereditata da Rn, dal teorema del punto fisso di Banach (Teorema 4.6.3) segue che esiste un (unico) puntox ∈ B(x0, ε) tale che x = K(x). Ma allora x = K(x) = x− T−1(f(x)− y)⇔ 0 = T−1(f(x)− y)⇔ f(x)− y = 0 e quindif(x) = y, che è quel che cercavamo.
a-2) Dimostrare che K(x) è una contrazione. Dobbiamo però mostrare ora che K è una contrazione, ovvero cheK è ben definita e cioè trasforma B(x, ε) in sé stesso; e che |K(x)−K(y)| ≤ λ|x− y| con 0 < λ < 1.
a-2.1) Provare che K(x) è ben definita. Per provare che K è ben definita conviene introdurre la funzione ausiliariag(x) = x − T−1(f(x)). Osserviamo che dg(x0) = In − T−1df(x0) = 0, ovvero ∂gi(x0)
∂xj= 0 con i, j = 1, . . . , n. Siccome
g è di classe C1 (poichè f ∈ C1), pur di prendere un ε > 0 più piccolo, si può per continuità supporre che ‖dg‖ ≤ 12
∀x ∈ B(x0, ε).[1] Per il teorema del valor medio (Teorema 5.4.1) esiste z ∈ [x0, x] tale che |g(x)− g(x0)| ≤ ‖dg(x)‖|x− x0|e quindi |K(x)−x0| ≤ ‖dg(z)‖|x−x0|+‖T−1‖|f(x0)−y| ≤ 1
2ε+δ‖T−1‖. In definitiva sarà sufficiente sciegliere δ < ε
2‖T−1‖affinché K sia ben definita.
a-2.2) Provare che K(x) è una contrazione trovando il fattore contrattivo. Per ogni x, x ∈ B(x0, ε) si hacome sopra |K(x)−K(x)| = |x−T−1(f(x)− y)− x+T−1(f(x)− y)| = |x−T−1(f(x))− x+T−1(f(x))| = |g(x)− g(x)| ≤‖dg(z)‖|x− x| ≤ 1
2|x− x|. Dunque K è una contrazione con fattore contrattivo 1
2.
b) Provare che f è localmente iniettiva e che f−1 è continua. Il prossimo obiettivo è provare che esisteuna costante M > 0 tale che per ogni x, x ∈ B(x0, ε) si ha |f(x) − f(x)| ≥ M |x − x|. Tale maggiorazione, infatti,implica che f è iniettiva e che f−1 è continua. Precisamente, f−1 verifica |f−1(y) − f−1(y)| ≤ 1
M|y − y|. La verifica di
|f(x)− f(x)| ≥ M |x− x| si riconduce nuovamente alle proprietà di g. |x− x| = |g(x) + T−1(f(x))− g(x) + T−1(f(x))| ≤|g(x)− g(x)|+ ‖T−1‖|f(x)− f(x)| ≤ 1
2|x− x|+ ‖T−1‖|f(x)− f(x)|, e quindi |f(x)− f(x)| ≥ 1
2‖T−1‖ |x− x|.
c) Provare che f−1 è di classe Ck. Rimane da provare che la funzione inversa f−1 : f(B(x0, ε)) → (B(x0, ε) èdi classe Ck. Proviamo che f−1 è differenziabile con derivate parziali continue (ovvero è di classe C1). Per ipotesi si haf(x) = f(x0) + df(x0)(x − x0) + o(|x − x0|), e invertendo l’identità precedente con y = f(x) e y0 = f(x0) si ottienef−1(y) − f−1(y0) = df(x0)−1(y − y0 − o(‖|x − x0|)) = df(x0)−1(y − y0) − df(x0)−1(o|f−1(y) − f−1(y0)|). Ma poichè|f−1(y)−f−1(y0)| ≤ 1
M|y−y0| allora si deduce che df(x0)−1(o|f−1(y)−f−1(y0)|) = o(|y−y0|) e quindi f−1 è differenziabile
con differenziale df−1(y0) = df(x0). Poichè il differenziale può essere rappresentato come la matrice delle derivate parziali,da quest’ultima espressione si vede che la continuità delle derivate parziali di f−1 segue dalla continuità di quelle di f .Analogo discorso vale per la regolarità superiore.
Esempio. Si consideri il sistema di due equazioni nelle incognite x, y ∈ R:{x+ y sinx = b1x2y + sin y = b2
dove b = (b1, b2) è un vettore assegnato.Certamente, quando ~b = ~0 il sistema ha almeno la soluzione nulla x = y = 0. Ci proponiamo di dimostrare che esistono
due numeri ε > 0 e δ > 0 tali che per ogni b ∈ B(0, ε) esiste un’unica soluzione (x, y) ∈ B(0, δ) del sistema.
Sia f : R2 → R2 la funzione f(x, y) =
(x+ y sinxx2y + sin y
). Risulta f ∈ C∞(R2;R2). La matrice Jacobiana di f è
Jf (x, y) =
(1 + y cosx sinx
2xy x2 + cos y
)Nel punto (0, 0) si ha det Jf = 1 > 0 e per continuità si deduce l’esistenza di δ > 0 tale che Jf (x, y) > 0 per ogni(x, y) ∈ B(0, δ). Dunque f è un diffeomorfismo locale di classe C∞ su B(0, δ). Per il teorema dell’invertibilità locale(Teorema 6.1.3), pur di prendere un δ > 0 ancora più piccolo, f è anche aperta ed iniettiva su B(0, δ). Dunque l’insiemef(B(0, δ)) ⊂ R2 è aperto e siccome 0 = f(0) ∈ f(B(0, δ)) allora esiste ε > 0 tale che B(0, ε) ⊂ f(B(0, δ)).
Se b ∈ B(0, ε) allora esiste (x, y) ∈ B(0, δ) tale che f(x, y) = b e per l’iniettività di f il punto è unico.
6.2 Teorema sulla funzione implicita
Sia f : R2 → R una funzione e consideriamo l’equazione f(x, y) = 0 nelle variabilix, y ∈ R. Ci domandiamo quando tale equazione definisca implicitamente una funzioney = ϕ(x), ovvero una funzione ϕ : R→ R tale che il luogo degli zeri di ϕ coincida con ilgrafico di ϕ.
Il teorema del Dini fornisce una condizione sufficiente affinchè ciò avvenga localmente.Siano p, q ∈ N interi tali che p, q ≥ 1. Scomponiamo Rn = Rp × Rq, con n = p + q.
Indichiamo con x ∈ Rp la variabile di Rp e con y ∈ Rq la variabile di Rq. Data quindiuna funzione f : Rp × Rq → Rq che ha derivate parziali, definiamo le seguenti matrici
[1]Questa affermazione può essere provata partendo dalla disuguaglianza ‖dg‖ ≤(∑n
i,j=1
(∂gi(x)∂xj
)2) 1
2
, usando il fatto
che le derivate parziali sono continue.
Matteo Gallone - Analisi Matematica II

6.3 Ultimi teoremiEstremi locali vincolati
53
Jacobiane parziali
∂f
∂x=
∂f1
∂x1. . . ∂f1
∂xp... . . . ...∂fq∂x1
. . . ∂fq∂xp
matrice q × p
e analogamente
∂f
∂y=
∂f1
∂y1. . . ∂f1
∂yq... . . . ...∂fq∂y1
. . . ∂fq∂yq
matrice q × q
Teorema 6.2.1 (del Dini). Siano A ⊂ Rp × Rq un insieme aperto, (x0, y0) ∈ A e siaf ∈ C1(A;Rq) una funzione di classe C1 che verifica
f(x0, y0) = 0 det
(∂f(x0, y0)
∂y
)6= 0 (6.1)
Allora esistono due numeri η, δ > 0 ed esiste una funzione ϕ ∈ C1(B(x0, δ);B(y0, ε)) taleche:
i) B(x0, δ)×B(y0, ε) ⊂ A;ii) {(x, ϕ(x)) ∈ Rp+q : x ∈ B(x0, δ)} = {(x, y) ∈ B(x0, δ) × B(y0, ε) : f(x, y) = 0};
ovvero ϕ è il luogo degli zeri di f(x, y).iii) La funzione ϕ verifica
∂ϕ
∂x= −
(∂f(x, ϕ(x))
∂y
)−1∂f(x, ϕ(x))
∂x, x ∈ B(x0, δ) (6.2)
dove ∂ϕ∂x
indica la matrice Jacobiana di ϕ e a destra si intende il prodotto di matrici.Dimostrazione. Dimostriamo la i). Definiamo la funzione F : A → Rp × Rq come F (x, y) = (x, f(x, y)), (x, y) ∈ A.Siccome f ∈ C1(A;Rq), risulta che F ∈ C1(A;Rn). Inoltre si ha F (x0, y0) = (x0, 0). La matrice Jacobiana di F è
JF (x, y) =
(Ip 0
∂f(x,y)∂x
∂f(x,y)∂y
), e dunque nel punto (x0, y0) ∈ A si ha det(JF (x, y)) = det
(∂f(x0,y0)
∂y
)6= 0. Per il
teorema di invertibilità locale (Teorema 6.1.3) esiste η > 0 tale che F ∈ C1(B(x0, η) × B(y0, η);Rn) è un diffeomorfismosull’immagine. In particolare, l’insieme B = F (B(x0, η) × B(y0, η)) è aperto e (x0, 0) = F (x0, y0) ∈ B. Dunque esisteδ > 0 tale che B(x0, δ) × B(0, δ) ⊂ B. Indichiamo con G : A → A la funzione inversa di F , G = F−1 ∈ C1(B;A), eindichiamo con G1 e G2 le componenti di G in Rp e Rq , G = (G1, G2) ∈ (Rp,Rq). Risulta G = f(x,G2(x, y)), infatti(x, y) = F (G(x, y)) = F (G1(x, y), f(G1(x, y), G2(x, y)). Nelle coordinate (x, y), il luogo di zeri di f è dato dall’equazioney = 0. Questo suggerisce la definizione ϕ(x) = G2(x, 0) con x ∈ B(x0, δ). Risulta ϕ ∈ C1(B(x0, δ);B(y0, η)).
Proviamo l’uguaglianza insiemistica ii). Per ogni x ∈ B(x0, δ) si ha f(x, ϕ(x)) = f(x,G2(x, 0)) = 0, e quindi (x, ϕ(x)) ∈{(x, y) ∈ B(x0, δ) × B(y0, η) : f(x, y) = 0}. Questo prova l’inclusione “⊂”. Proviamo ora l’inclusione opposta. Sianox ∈ B(x0, δ) e y ∈ B(y0, η) tali che f(x, y) = 0. Allora si ha (x, y) = G(F (x, y)) = G(x, f(x, y)) = G(x, 0) = (x,G2(x, 0)) =(x, ϕ(x)), per cui si deduce y = ϕ(x).
Per provare la iii) basta derivare rispetto a x l’identità f(x, ϕ(x)) = 0. Infatti per il Teorema 5.3.2 per ogni x ∈ B(x0, δ)
si ha ∂f(x,ϕ(x))∂x
+∂f(x,ϕ(x))
∂y∂ϕ(x)∂x
= 0. Ricavando ∂ϕ∂x
dalla precedente uguaglianza si ottiene la tesi.
Esempio. Prendiamo la funzione f : R2 → R definita come f(x, y) = x2 − y2 − 1. Il luogo degli zeri di questa funzione èx2 − y2 − 1 = 0. Calcoliamo ∂f
∂y= −2y. Questo ci dice che quell’equazione definisce implicitamente una funzione per tutti
i −2y 6= 0⇒ y 6= 0. Infatti, sappiamo che questa funzione esiste ed è y =√x2 − 1 oppure y = −
√x2 − 1. Nei punti in cui
y = 0 si può tuttavia esprimere il luogo degli zeri come funzione di y in quanto ∂f∂x
(±1, 0) 6= 0, ed essa sarà x =√y2 + 1 o
x = −√y2 + 1.
Generalmente, tuttavia, non esiste un’espressione analitica per queste funzioni.
6.3 Estremi locali vincolati
Definizione 6.3.1. Siano M ⊂ Rn (con n ≥ 2) un insieme, A ⊂ Rn un insieme aperto edf : A→ R una funzione. Diciamo che un punto x0 ∈M ∩A è un punto di minimo localedi f ristretta (o vincolata) su M se esiste δ > 0 tale che B(x0, δ) ⊂ A e f(x) ≥ f(x0) perogni x ∈M ∩B(x0, δ).
Matteo Gallone - Analisi Matematica II

54 Ultimi teoremiSottovarietà di Rn 6.5
Definizione 6.3.2. Siano M ⊂ Rn (con n ≥ 2) un insieme, A ⊂ Rn un insieme aperto edf : A→ R una funzione. Diciamo che un punto x0 ∈M ∩A è un punto di massimo localedi f ristretta (o vincolata) su M se esiste δ > 0 tale che B(x0, δ) ⊂ A e f(x) ≤ f(x0) perogni x ∈M ∩B(x0, δ).
Si usa di solito chiamare vincolo l’insiemeM utilizzato nelle due precedenti definizioni.Il teorema che segue permette di trovare estremani locali di una funzione ristretta inparticolari vincoli.
Teorema 6.3.3 (Moltiplicatori di Lagrange). Siano A ⊂ Rn un insieme aperto, f ∈C1(A), ed M = {x ∈ Rn : h(x) = 0}, dove h ∈ C1(Rn) è una funzione che verifica∇h(x) 6= 0 per ogni x ∈ M . Se x ∈ M è un punto di estremo locale di f su M , alloraesiste un numero λ ∈ R, detto moltiplicatore di Lagrange, tale che ∇f(x) = λ∇h(x).
Dimostrazione. Siccome il gradiente di h è sempre diverso da 0, possiamo supporre (senza perdere di generalità) che∂h(x)∂xn
6= 0. Infatti esisterà sempre almeno una componente di ∇h diversa da 0.Introduciamo la notazione x = (x′, xn) con x′ ∈ Rn−1 e xn ∈ R. Per il Teorema 6.2.1 esistono δ, η > 0 ed esiste
una funzione ϕ ∈ C1(B(x′, δ);B(xn, η)) tale che {(x′, ϕ(x′)) ∈ Rn : x ∈ B(x′, δ)} = {x ∈ B(x′, δ) × B(xn, η) : h(x) = 0}.Ricordando poi che M sono tutti quegli x per cui h(x) = 0 allora possiamo scrivere {x ∈ B(x′, δ)×B(xn, η) : h(x) = 0} =M ∩B(x′, δ)×B(xn, η).
Quindi possiamo riscrivere M = {x ∈ Rn : h(x) = 0} = {(x′, ϕ(xn)) : h(x′, ϕ(x′)) = 0}. Inoltre f vincolata su M sipuò scrivere come f(x′, ϕ(x′)). Per ipotesi, inoltre, si ha che f ha punto di estremo locale in x′; ovvero ∇f(x′, xn) = 0.Calcolando esplicitamente: ∂f(x,ϕ(x))
∂x=
∂f(x)∂xi
+∂f(x)∂xn
∂ϕ(x′)∂xi
= 0.
Inoltre dal teorema della funzione implicita sappiamo che ∂ϕ(x′)∂x′ = −
(∂h(x)∂xn
)−1 ∂h(x)∂xi
, ovvero che ∂h(x)∂xi
+∂ϕ(x′)∂xi
∂h(x)∂xn
=
0.
Scegliamo ora il numero λ =∂f(x)∂xn∂h(x)∂xn
∈ R e sostituiamolo nell’equazione ∂f(x)∂xi
+∂f(x)∂xn
∂ϕ(x′)∂xi
= 0. Si ottiene ∂f(x)∂xi
+
λ∂h(x)∂xn
∂ϕ(x′)∂xi
= λ(
1λ∂f(x)∂xi
+∂h(x)∂xn
∂ϕ(x′)∂xi
)= 0 che implica 1
λ∂f(x)∂xi
+∂h(x)∂xn
∂ϕ(x′)∂xi
= 0 in quanto λ 6= 0. Ma poichè si ha
anche ∂h(x)∂xi
+∂ϕ(x′)∂xi
∂h(x)∂xn
= 0 allora le due espressioni si possono eguagliare: ∂h(x)∂xi
+∂ϕ(x′)∂xi
∂h(x)∂xn
= 1λ∂f(x)∂xi
+∂h(x)∂xn
∂ϕ(x′)∂xi
.
Da qui si ottiene facilmente (eliminando i termini uguali dai due membri dell’uguaglianza) che ∂f(x)∂xi
= λ∂h(x)∂xi
per qualsiasii. In notazione compatta è esattamente come dire che ∇f(x) = λ∇h(x).
6.4 Sottovarietà di Rn
Definizione 6.4.1. Un insieme M ⊂ Rn è una sottovarietà differenziabile di Rn di classeCk, k ≥ 1, e di dimensione d, con 1 ≤ d ≤ n − 1, se per ogni x ∈ M esistono δ > 0 edf ∈ Ck(B(x, δ);Rn−d) tali che:
i) B(x, δ) ∩M = {x ∈ B(x, δ) : f(x) = 0};ii) rk(Jf (x)) = n− d in ogni punto x ∈ B(x, δ). (ipotesi di rango massimo).
Definizione 6.4.2. Sia X ⊂ Rn un insieme. Una funzione ϕ : A→ Rn, A ⊂ Rd insiemeaperto, è una parametrizzazione di X di classe Ck, k ≥ 1, e rango d ∈ {1, 2, . . . , n− 1} se:
i) ϕ ∈ Ck(A;Rn);ii) ϕ : A→ X è biiettiva;iii) rk(Jϕ(ξ)) = d per ogni ξ ∈ A;iv) ϕ−1 : X → A è continua.
Diremo in questo caso che X è parametrizzato da ϕ.
Teorema 6.4.3. Siano M ⊂ Rn, k ≥ 1 e 1 ≤ d ≤ n.1. Le seguenti affermazioni sonoequivalenti:
A) M è una sottovarietà differenziabile di Rn di dimensione d e di classe Ck;B) Per ogni punto x ∈ M esiste r > 0 tale che M ∩ B(x, r) è parametrizzabile con una
parametrizzazione di classe Ck e rango d.
Matteo Gallone - Analisi Matematica II

6.5 Ultimi teoremiSpazio normale e spazio tangente
55
6.5 Spazio normale e spazio tangente
Definizione 6.5.1. Sia M una sottovarietà differenziabile di Rn di dimensione d. Lospazio tangente a M in un punto x ∈ M è l’insieme TxM costituito da tutti i vettoriv ∈ Rn tali che esiste una curva di classe C1 γ : (−δ, δ) → M tale che γ(0) = x eγ(0) = v.[2]
Teorema 6.5.2. SiaM una sottovarietà differenziabile di Rn di classe Ck e di dimensioned, sia x ∈M un punto fissato e sia TxM lo spazio tangente a M in x. Allora:
i) Se f = 0 è un’equazione locale per M in un intorno di x, allora si ha TxM =ker(df(x)) = {v ∈ Rn : df(x)v = 0}.
ii) Se ϕ : A→ Rn è una parametrizzazione locale di M , A ⊂ Rd aperto e x = ϕ(ξ) conξ ∈ A, allora TxM = im dϕ(ξ) = {dϕ(ξ)w ∈ Rn : w ∈ Rd}.
Dimostrazione. i) Proviamo che TxM ⊂ ker(df(x)). Sia v ∈ TxM e consideriamo γ : (−δ, δ) → M differenziabile tale cheγ(0) = x e γ(0) = v. Poichè f = 0 è un’equazione locale per M intorno a x, si ha f(γ(t)) = 0 per ogni t ∈ (−δ, δ). Dallaregola per la derivata della funzione composta (Corollario 5.3.3) si ottiene: 0 = d
dtf(γ(t)) = df(γ(t))γ(t) = df(γ(t))v.
Ovvero v ∈ ker(df(x)).Proviamo l’inclusione inversa, ovvero ker(df(x)) ⊂ TxM . Sia v ∈ Rn tale che df(x)v = 0. Si deve costruire una
curva di classe C1 γ : (−δ, δ) → M tale che γ(0) = x e γ(0) = v. Per ipotesi, il rango di df è n − d. Con la notazione(ξ, y) ∈ Rd × Rn−d, non è restrittivo supporre che risulti det
(∂f∂y
)6= 0 in un intorno di x = (ξ, y) ∈ M . Per il teorema
del Dini (Teorema 6.2.1) allora esiste una funzione ϕ : B(ξ, δ) → B(y, η) di classe Ck con δ, η > 0 tale che ξ → (ξ, ϕ(ξ))
parametrizza localmente M con (ξ, ϕ(ξ)) = x e Jϕ(ξ) =∂ϕ(ξ)∂ξ
= −(∂f(ξ,ϕ(ξ))
∂y
)−1 ∂f(ξ,ϕ(ξ))∂ξ
. Se v = (v1, v2) ∈ Rd×Rn−d,allora ξ + tv1 ∈ B(ξ, δ) per t ∈ (−δ, δ). La curva γ(t) = (ξ + tv1, ϕ(ξ + tv1)) verifica γ(0) = (ξ, ϕ(ξ)) = x, e inoltre
γ(0) =(v1,
∂ϕ(ξ)∂ξ
v1
). Per ipotesi df(x)v = 0 e cioè ∂f(x)
∂ξv1 +
∂f(x)∂y
v2 = 0, da cui si ricava v2 = −(∂f(x)∂y
)−1 ∂f(x)∂ξ
v1.
Questo prova che γ(0) = v. Qui termina la dimostrazione di i).[3]
Dimostriamo ii). Sia ϕ una parametrizzazione di M intorno a x = ϕ(ξ) e supponiamo che v = dϕ(x)w per un certow ∈ Rd. Si sceglia la curva γ(t) = ϕ(ξ + tw) in modo che γ(0) = ϕ(ξ) = x e γ(0) = dϕ(ξ)w = v. Questo prova cheim dϕ(ξ) ⊂ TxM .
D’altra parte dϕ(ξ) ha rango d e dunque im dϕ(ξ) è uno spazio vettoriale di dimensione d. Ma TxM ha dimensione d,e dunque deve necessariamente essere im dϕ(ξ) = TxM .
Definizione 6.5.3. Sia M = {f = 0} una ipersuperficie con f ∈ C1(Rn) e ∇f 6= 0 su M .Il vettore normalizzato
N(x) =∇f(x)
|∇f(x)|con x ∈ M si dice campo normale alla superficie ed è localmente definito in modo unicoa meno del segno.
[2]La notazione γ(0) è equivalente a dγdt
(0).[3]Da qui discende che siccome ker(df(x)) è uno spazio vettoriale, anche TxM è uno spazio vettoriale. Inoltre la sua
dimensione è dim(TxM) = dim(ker(df(x))) = dim(Rn) − dim(im df(x)) = n − (n − d) = d. Ciò vuol dire che lo spaziotangente di una varietà di dimensione 1 (ad esempio una curva) sarà una retta, di una varietà di dimensione 2 (una superficie)sarà un piano.
Matteo Gallone - Analisi Matematica II

Indice analitico
Abel-Dirichlet, 7
cambiamento di parametro ammissibile, 24caratterizzazione topologica della continuità, 36concatenazione di curve, 27condizione necessaria al primo ordine, 49condizione necessaria al secondo ordine, 49condizione sufficente per un minimo locale stretto, 49confronto asintotico, 9contrazione, 34coordinate di una curva, 21criterio del confronto, 5criterio del confronto asintotico, 6curva
chiusa, 22semplice, 22con orientazione opposta, 24continua, 22continua a tratti, 27equiorientata, 24equivalente, 24in forma cartesiana, 24parametrizzata, 21poligonale, 25regolare, 23rettificabile, 25
derivatadi una curva, 23direzionale, 41parziale, 40seconda, 41, 46
diffeomorfismo, 51diffeomorfismo locale, 51differenziale, 42direzione, 41disuguaglianza di Cauchy-Schwarz, 30
equazione delle onde, 47equazione differenziale, 11equazione polare di una curva, 24equazioni parametriche di una curva, 21equivalenza tra continuità della funzione e continuità delle
coordinate, 31equivalenza tra continuità e continuità sequenziale, 31
funzionearmonica, 47continua, 31, 39derivabile, 40differenziabile, 42lipschitziana, 46omogenea, 50sequenzialmente continua, 31uniformemente continua, 40
gradiente, 40
Heine-Borel, 37
insiemeaperto, 35chiuso, 35connesso, 37connesso per archi, 38vincolo, 54
integraleconvergente, 5, 8convergente assolutamente, 6curvilineo, 27divergente, 5generale, 11improprio, 5oscillatore, 7vettoriale, 25
la composizione di funzioni continue è continua, 36limite, 39lunghezza
di una curva, 25di una poligonale, 25
matricedefinita negativa, 49definita positiva, 49Hessiana, 41, 47Jacobiana, 41semidefinita negativa, 49semidefinita positiva, 49wronskiana, 16
moltiplicatori di Lagrange, 54multiindice, 48
norma, 29del differenziale, 45della convergenza, 30della convergenza uniforme, 30euclidea, 21integrale, 30
operatore di Laplace, 47
palla aperta, 29parametrizzazione di una sottovarietà, 54partizione di un insieme, 24punto
di chiusura, 35di frontiera, 35di massimo locale vincolato, 54di massimo relativo, 48di minimo locale vincolato, 53di minimo relativo, 48di sella, 50interno, 35
punto fisso, 34
retta tangente ad una curva, 24riparametrizzazione di una curva, 24
Matteo Gallone - Analisi Matematica II

somma di curve, 27somma, prodotto o reciproco di continue è continua, 31sostegno di una curva, 21sottovarietà differenziabile, 54spazio metrico, 29
completo, 32euclideo, 32euclideo, 29, 33limitato, 36sequenzialmente compatto, 36
spazio normale, 55spazio normato
di Banach, 32spazio tangente, 55successione, 30
convergente, 30convergente puntualmente, 33convergente uniformemente, 33di Cauchy, 32
supporto di una curva, 21Sviluppo di Taylor, 48sviluppo di Taylor al secondo ordine, 48
teorema dei valori intermedi, 38teorema del differenziale totale, 43teorema del Dini, 53teorema del valor medio (scalare), 45teorema del valor medio (vettoriale), 45teorema delle contrazioni di Banach, 34teorema dello scambio dei limiti, 34teorema di Cantor, 40teorema di inverbilità locale, 51teorema di rettificabilità delle curve C1, 26teorema di Schwarz, 41teorema di Weierstrass, 37teorema sul differenziale della funzione composta, 44topologia, 36
indotta (o relativa), 37
unicità del limite di una successione, 30unicità della soluzione del problema di Cauchy, 12, 14
variazione delle costanti, 12, 17versore tangente, 24


















![3 Calcolo Integrale - mat.uniroma2.itbraides/0405/Analisi2/filepdf/IntegT.pdf · Consideriamo infatti una funzione continua f de nita su un certo insieme [a;b] e e supponiamo di poter](https://static.fdocumenti.com/doc/165x107/5c16fccb09d3f2564e8b5e1f/3-calcolo-integrale-mat-braides0405analisi2filepdfintegtpdf-consideriamo.jpg)