
lezione 11 4 2012 - GulisanoLab · sintetizzata sulla base di uno STAMPO sul DNA e lʼinformazione...
19
Il Codice Gene,co Il dogma centrale, il flusso dell’informazione genica e la decifrazione della informazione del DNA Corso di Laurea in Chimica e Tecnologie Farmaceu,che a.a. 20112012 Università di Catania Stefano Forte
Transcript of lezione 11 4 2012 - GulisanoLab · sintetizzata sulla base di uno STAMPO sul DNA e lʼinformazione...

Il Codice Gene,co
Il dogma centrale, il flusso dell’informazione genica e la
decifrazione della informazione del DNA
Corso di Laurea in Chimica e Tecnologie Farmaceu,che a.a. 2011-‐2012
Università di Catania
Stefano Forte

Il dogma centrale e le prime ipotesi sul codice gene,co
• Le funzioni del materiale gene,co – Deve potersi replicare – Deve potersi esprimere
• Come avviene l’espressione? • Negli eucario, in DNA non abbandona il nucleo • Il DNA lo stesso in tuJe le cellule di un organismo • Il DNA rimane costante nel tempo • Nel 1945 Beadle: un gene -‐> un enzima • Linearità geni e sequenze proteiche

Il dogma centrale e le prime ipotesi sul codice gene,co
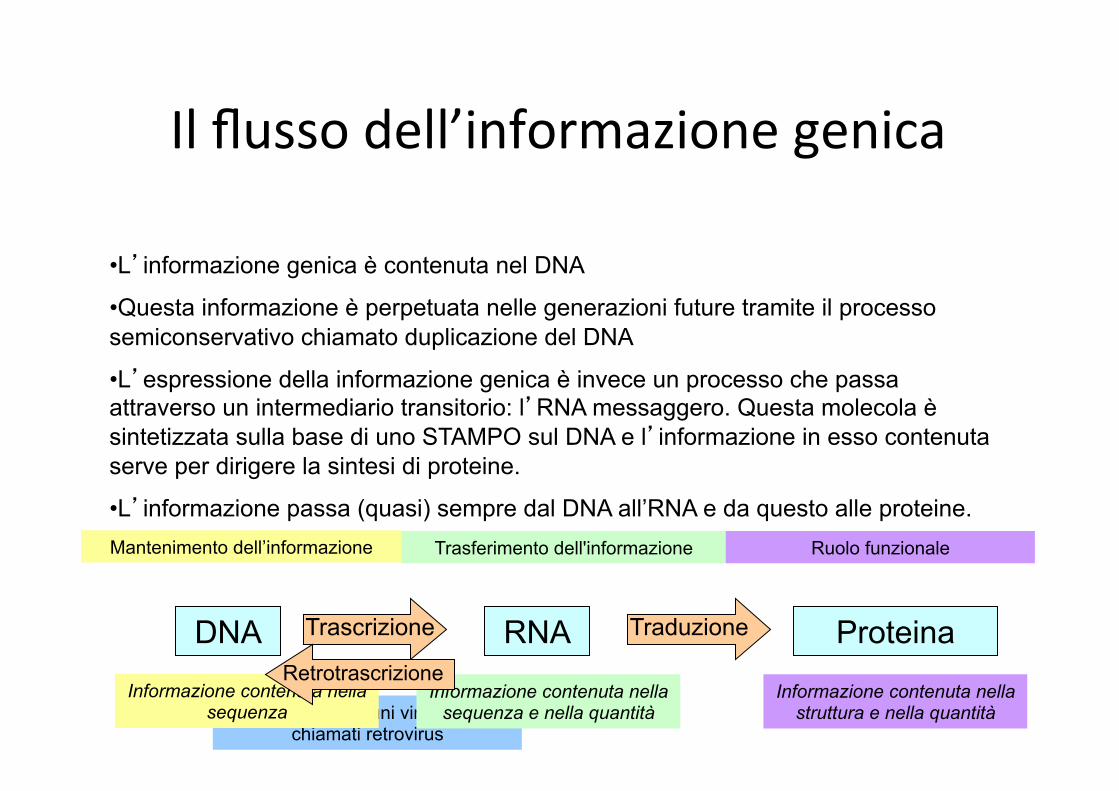
Effettuata da alcuni virus a RNA chiamati retrovirus
Il flusso dell’informazione genica
• L’informazione genica è contenuta nel DNA
• Questa informazione è perpetuata nelle generazioni future tramite il processo semiconservativo chiamato duplicazione del DNA
• L’espressione della informazione genica è invece un processo che passa attraverso un intermediario transitorio: l’RNA messaggero. Questa molecola è sintetizzata sulla base di uno STAMPO sul DNA e l’informazione in esso contenuta serve per dirigere la sintesi di proteine.
• L’informazione passa (quasi) sempre dal DNA all’RNA e da questo alle proteine.
DNA RNA Proteina Trascrizione Traduzione
Mantenimento dell’informazione Trasferimento dell'informazione Ruolo funzionale
Informazione contenuta nella sequenza
Informazione contenuta nella sequenza e nella quantità
Informazione contenuta nella struttura e nella quantità
Retrotrascrizione

Il contenuto informa,vo del DNA
La struttura del DNA è costante. Il DNA è sempre una doppia elica INDIPENDENTEMENTE dalla sequenza di nucleotidi che lo compone. L’ossatura di zucchero e fosfato è costante. La parte variabile, e quindi più informativa, è rappresentata dalla sequenza di BASI AZOTATE. Per questo motivo è possibile rappresentare l’informazione contenuta nel DNA con una lunga sequenza composta da un alternanza 4 caratteri che rappresentano le basi azotate del DNA. GCGGCGGCGGGCGGGTACTGGCTTCTGGGGCCAGGGGCCAGGGGCGGTGGGCGCCGGGACCGCGGAGCTGAGGAGCGGGGCCCGGCCAGGGCTGGAGACTTTGCGCCCGGGGGCACCGGGGCTGCGCGCGGTCGCACACATCCACCGGCGCGGCTTCCCTCGGCGGCCCGGGCTCCGCTCATCCTGCGGCGGGCGGCGCCGCTCAGGGGCGGGAAGAGGAGGCGGTAGACGCGACCACAGAAGATGTCGGGCCAAACGCTCACGGATCGGATCGCCGCCGCTCAGTACAGCGTTACAGGCTCTGCTGTAGCAAGAGCGGTCTGCAAAGCCACTACTCATGAAGTAATGGGCCCCAAGAAAAAGCACCTGGACTATTTGATCCAGGCTACCAACGAGACCAATGTTAATATTCCTCAGATGGCCGACACTCTCTTTGAGCGGGCAACAAACAGTAGCTGGGTGGTTGTGTTTAAGGCTTTAGTGACAACACATCATCTCATGGTGCATGGAAATGAGAGATTTATTCAATATTTGGCTTCTAGAAATACACTATTCAATCTCAGCAATTTTTTGGACAAAAGTGGATCCCATGGTTATGATATGTCTACCTTCATAA

Le proteine: natura ed informazione • Le proteine sono macromolecole polimeriche. I costituenti delle
proteine sono gli aminoacidi. • Gli aminoacidi sono molecole caratterizzate dalla presenza di
un gruppo aminico (basico) ed un gruppo acido che costituiscono la parte costante della molecola e da un “residuo” variabile che conferisce ad ogni aminoacido caratteristiche diverse.
• Il gruppo acido di un aminoacido ed il gruppo basico dell’aminoacido successivo si uniscono tra loro tramite un legame covalente forte chiamato legame peptidico. La ripetizione lineare di questi legami peptidici costituisce lo “scheletro” della catena polipeptidica.
• I “residui”, che costituiscono la parte variabile, possono interagire tra loro. Residui apprtenenti ad aminoacidi distanti tra loro possono interagire tramite legami deboli portando ad un “ripiegamento” della catena lineare della proteina. Queste interazioni sono alla base della struttura 3d della proteina.

Le proteine: natura ed informazione Gli aminoacidi Esistono 20 diversi aminoacidi che combina, tra loro cos,tuiscono tuJe le proteine contenute negli organismi viven,. Ques, aminoacidi hanno struJura chimica e proprietà diverse.

Le proteine: natura ed informazione
HQVKVQGCWGRWRWQEFENAEGDEYAADLAQGSPATAAQNGPDVYVLPLTEVSLPMAKQPGRSVQLLKSTDVGRHSLLYLKEIGRGWFGKVFLGEVNSGISSAQVVVKELQASASVQEQMQFLEEVQPYRALKHSNLLQCLAQCAEVTPYLLVMEFCPLGDLKGYLRSCRVAESMAPDPRTLQRMACEVACGVLHLHRNNFVHSDLALRNCLLTADLTVKIGDYGLAHCKYREDYFVTADQLWVPLRWIAPELVDEVHSNLLVVDQTKSGNVWSLGVTIWELFELGTQPYPQHSDQQVLAYTVREQQLKLPKPQLQLTLSDRWYEVMQFCWLQPEQRPTAEEVHLLLSYLCAKGATEAEEEFERRWRSLRPGGGGVGPGPGAAGPMLGGVVELAAASSFPLLEQFAGDGFHADGDDVLTVTETSRGLNFEYKWEAGRGAEAFPATLSPGRTARLQELCAPDGAPPGVVPVLSAHSPSLGSEYFIRLEEAAPAAGHDPDCAGCAPSPPATADQDDDSDGSTAASLAMEPLLGHGPPVDVPWGRGDHYPRRSLARDPLCPSRSPSPSAGPLSLAEGGAEDADWGVAAFCPAFFEDPLGTSPLGSSGAPPLPLTGEDELEEVGARRAAQRGHWRSNVSANNNSGSRCPESWDPVSAGCHAEGCPSPKQTPRASPEPGYPGEPLLGLQAASAQEPGCCPGLPHLCSAQGLAPAPCLVTPSWTETASSGGDHPQAEPKLATEAEGTTGPRLPLPSVPSPSQEGAPLPSEEASAPDAPDALPDSPTPATGGEVSAIKLASALNGSSSSPEVEAPSSEDEDTAEATSGIFTDTSSDGLQARRPDVVPAFRSLQKQVGTPDSLDSLDIPSSASDGGYEVFSPSATGPSGGQPRALDSGYDTENYESPEFVLKEAQEGCEPQAFAELASEGEGPGPETRLSTSLSGLNEKNPYRDSAYFSDLEAEAEATSGPEKKCGGDRAPGPELGLPSTGQPSEQVCLRPGVSGEAQGSGPGEVLPPLLQLEGSSPEPSTCPSGLVPEPPEPQGPAKVRPGPSPSCSQFFLLTPVPLRSEGNSSEFQGPPGLLSGPAPQKRMGGPGTPRAPLRLALPGLPAALEGRPEEEEEDSEDSDESDEELRCYSVQEPSEDSEEEAPAVPVVVAESQSARNLRSLLKMPSLLSETFCEDL
Così come già visto per le sequenze di DNA o RNA, che vengono rappresentate come stringhe composte dal susseguirsi di 4 possibili caraJeri che corrispondono ai 4 possibili nucleo,di, anche le sequenze proteiche possono essere rappresentate da stringhe. In questo caso i possibili aminoacidi sono 20 e di conseguenza anche l’alfabeto u,lizzato nelle sequenze proteiche è cos,tuito da (almeno) 20 caraJeri.

• L’informazione genica passa del DNA all’RNA. L’informazione
contenuta in queste molecole è simile, ed il meccanismo di trasmissione dell’informazione (la complementarietà delle basi) permette di copiare l’informazione del DNA sull’RNA utilizzando lo stesso alfabeto (con l’eccezione dell’utilizzo dell’U al posto della T)
• Nel passaggio da RNA a proteina il tipo di informazione cambia notevolmente. Si deve passare da un alfabeto chimico basato su 4 diversi nucleotidi ad un alfabeto chimico basato su 20 diverse aminoacidi.
• L’impossibilità di mantenere una corrispondenza univoca tra nucleotide ed aminoacido impone l’utilizzo di una codifica
AATGTATTC TTACATAAG TTACATAAG
AAUGUAUUC
La necessità di codificare l’informazione

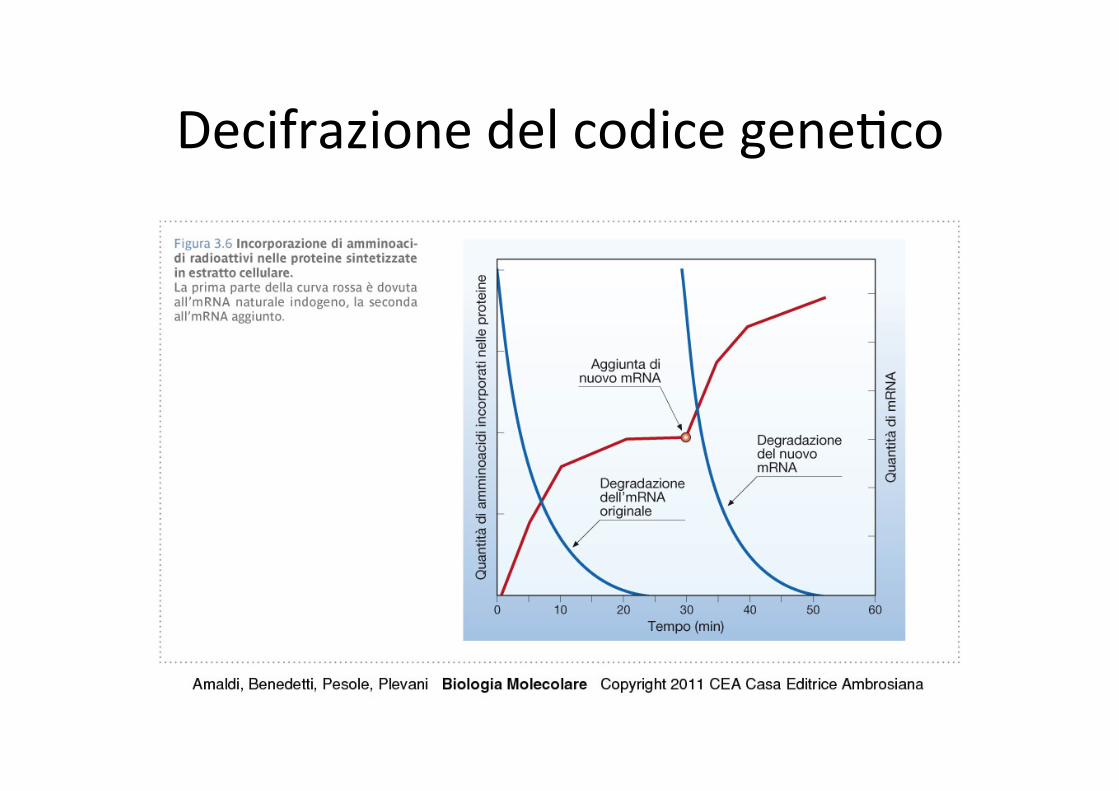
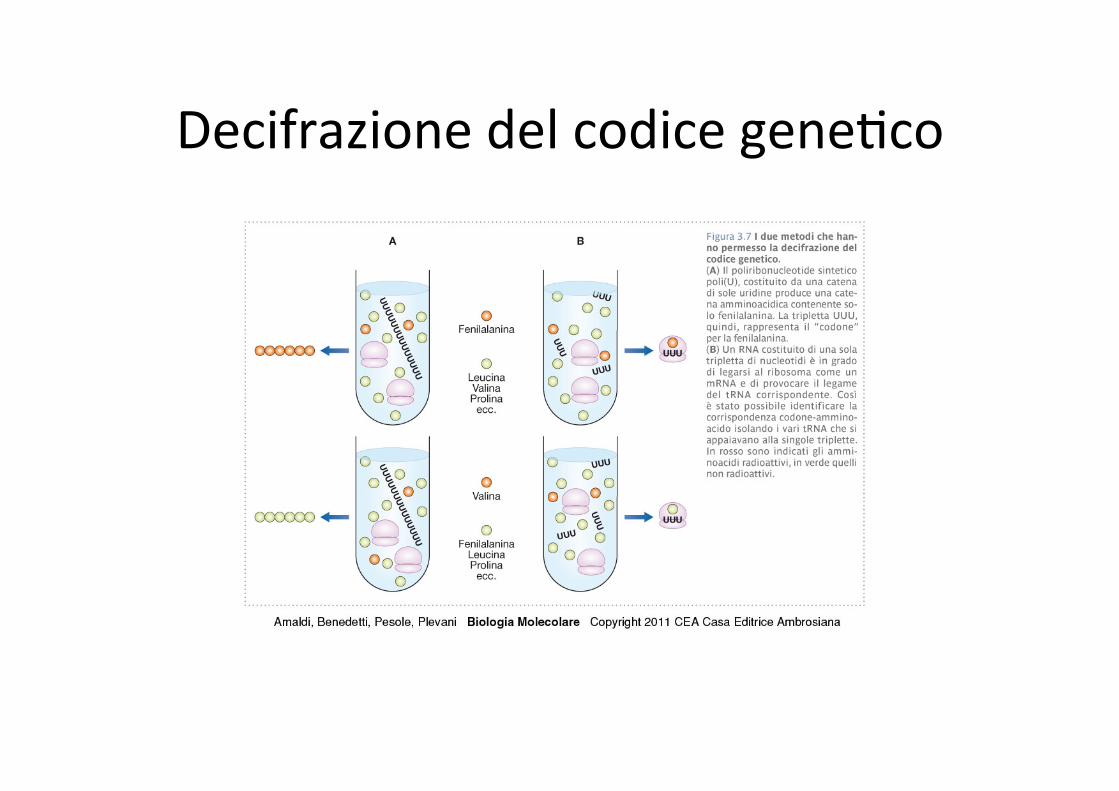
Decifrazione del codice gene,co
• Quan,tà e densità di informazione • Coppie? TripleJe? Quadruple? Tuple?
a. Un gruppo di tre basi codifica per un aminoacido b. Il codice non è sovrapposto c. La sequenza di basi viene leJa a par,re da un
punto di inizio fisso e non c’è par,colare punteggiatura

Decifrazione del codice gene,co Le mutazioni per inserzione o delezione alterano tuJa la sequenza proteica a valle per frameshi\

Decifrazione del codice gene,co Mutan, del gene RII del fago T4 oJenu, mediante traJamento con acrilammide (induzione di inserzioni o delezioni)

Decifrazione del codice gene,co
Decifrazione del codice gene,co
Decifrazione del codice gene,co
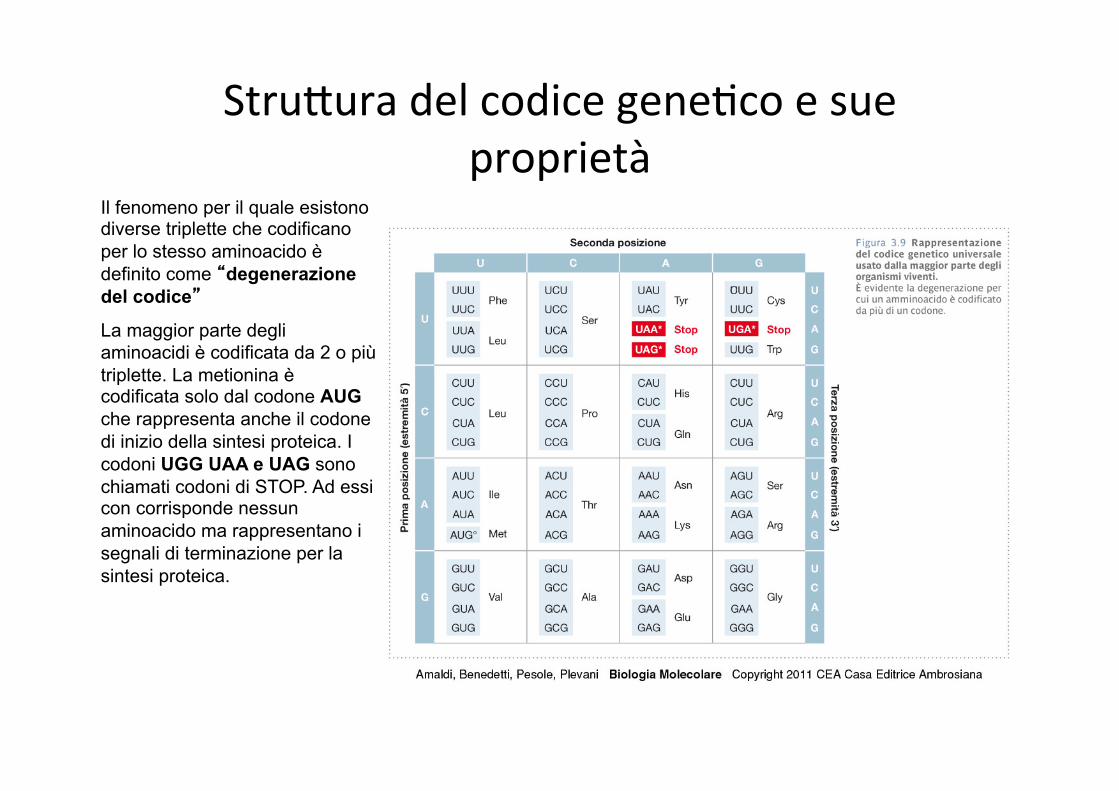
StruJura del codice gene,co e sue proprietà
Il fenomeno per il quale esistono diverse triplette che codificano per lo stesso aminoacido è definito come “degenerazione del codice”
La maggior parte degli aminoacidi è codificata da 2 o più triplette. La metionina è codificata solo dal codone AUG che rappresenta anche il codone di inizio della sintesi proteica. I codoni UGG UAA e UAG sono chiamati codoni di STOP. Ad essi con corrisponde nessun aminoacido ma rappresentano i segnali di terminazione per la sintesi proteica.

La retrotraduzione?
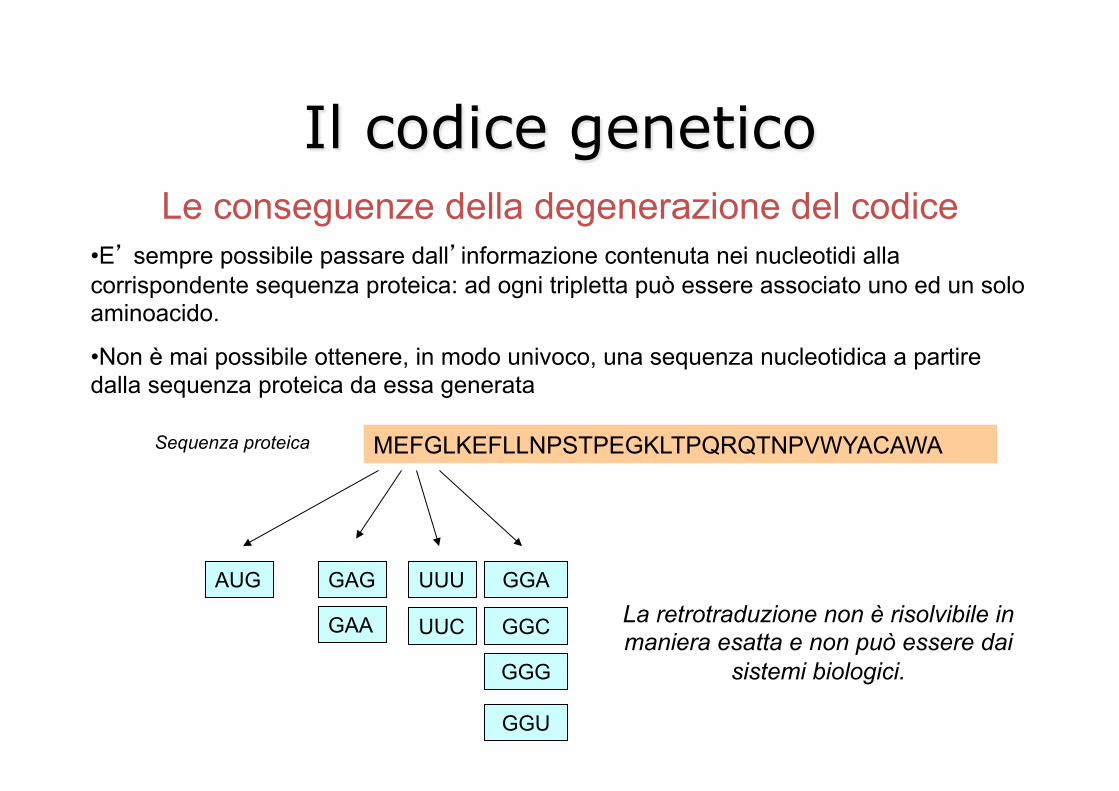
Il codice genetico Le conseguenze della degenerazione del codice
• E’ sempre possibile passare dall’informazione contenuta nei nucleotidi alla corrispondente sequenza proteica: ad ogni tripletta può essere associato uno ed un solo aminoacido.
• Non è mai possibile ottenere, in modo univoco, una sequenza nucleotidica a partire dalla sequenza proteica da essa generata
MEFGLKEFLLNPSTPEGKLTPQRQTNPVWYACAWA Sequenza proteica
AUG
GAA
GAG UUU
UUC
GGA
GGC
GGG
GGU
La retrotraduzione non è risolvibile in maniera esatta e non può essere dai
sistemi biologici.

Il codice genetico Il vacillamento della terza base
I CODONI CHE RAPPRESENTANO LO STESSO A.A., O A.A. CORRELATI, HANNO SEQUENZE SIMILI.
SPESSO LA BASE CHE OCCUPA LA TERZA POSIZIONE DEL CODONE NON E’ SIGNIFICATIVA, COME DIMOSTRA IL FATTO CHE NEI GRUPPI DI 4 CODONI CHE RAPPRESENTANO LO STESSO A.A., SOLO LA TERZA BASE E’ DIFFERENTE.


















