
A cura di Alberto Mucci LE MACCHINE CHE PARLANO I · umanistica. Un laureato in ... per il segnale...
30
I quaderni di A cura di Alberto Mucci I l robot che parla, che risponde alle sollecitazioni della persona, che la sostituisce in molti servizi e in tante incombenze, è un’idea che da sempre avvince e esalta. Un tempo mito, quello della statua parlante, come ci tramanda la storia degli egizi; poi esperimento di volta in volta più concreto. Oggi applicazione che sta prendendo sostanza. Fino a 10 anni fa le macchine in grado di “parlare”, cioè di rispondere automaticamente, erano del tutto sperimentali. Altrettanto si può dire per le macchine che ascoltano, che capiscono e che poi sanno rispondere. Negli ultimi tempi queste macchine stanno entrando nell’uso comune. Diventano uno strumento operativo normale. Gli esempi sono nella vita quotidiana. Per consultare un orario ferroviario posso oggi servirmi di un telefono e comporre un numero verde. La risposta, sulla base delle informazioni via via fornite (città di partenza, città di destinazione, percorso, ecc.) sarà automatica, vocale. La macchina parlerà… E così il telefonino che utilizziamo quotidianamente può essere preparato per “riconoscere” la voce dell’utente. Il robot alternativo a Internet? No. Gli strumenti per comunicare si moltiplicano costantemente lungo la strada della “Grande Mutazione”, come illustriamo in questo “Quaderno” e come documenteremo nel prossimo dedicato in particolare alla elaborazione dei testi. Con una prospettiva a breve: quella di Internet che si sposa con la voce, che la cattura nel Pc e la utilizza per ampliare la sua capillarità, per aggiungere servizio a servizio, in questa società dell’informazione dagli scenari in continua evoluzione. SUPPLEMENTO AL NUMERO DI GIUGNO N. 207 DI MEDIA DUEMILA L E MACCHINE CHE PARLANO
Transcript of A cura di Alberto Mucci LE MACCHINE CHE PARLANO I · umanistica. Un laureato in ... per il segnale...

I quaderni diA cura di Alberto Mucci
Il robot che parla, che risponde alle sollecitazioni della persona, che la
sostituisce in molti servizi e in tante incombenze, è un’idea che da sempre
avvince e esalta. Un tempo mito, quello della statua parlante, come ci
tramanda la storia degli egizi; poi esperimento di volta in volta più
concreto. Oggi applicazione che sta prendendo sostanza.
Fino a 10 anni fa le macchine in grado di “parlare”, cioè di rispondere
automaticamente, erano del tutto sperimentali. Altrettanto si può dire per le
macchine che ascoltano, che capiscono e che poi sanno rispondere.
Negli ultimi tempi queste macchine stanno entrando nell’uso comune.
Diventano uno strumento operativo normale.
Gli esempi sono nella vita quotidiana. Per consultare un orario ferroviario
posso oggi servirmi di un telefono e comporre un numero verde. La risposta,
sulla base delle informazioni via via fornite (città di partenza, città di
destinazione, percorso, ecc.) sarà automatica, vocale. La macchina parlerà… E
così il telefonino che utilizziamo quotidianamente può essere preparato per
“riconoscere” la voce dell’utente.
Il robot alternativo a Internet? No. Gli strumenti per comunicare si moltiplicano
costantemente lungo la strada della “Grande Mutazione”, come illustriamo in
questo “Quaderno” e come documenteremo nel prossimo dedicato in
particolare alla elaborazione dei testi. Con una prospettiva a breve: quella di
Internet che si sposa con la voce, che la cattura nel Pc e la utilizza per ampliare
la sua capillarità, per aggiungere servizio a servizio, in questa società
dell’informazione dagli scenari in continua evoluzione.
SUPPLEMENTO AL NUMERO DI GIUGNO N. 207 DI MEDIA DUEMILA
LE MACCHINE CHE PARLANO

INDICE
IL CALCOLATORE NEGLI STUDI LINGUISTICI
SINTESI DELLA VOCE E AGENTI PARLANTI
DESKTOP SPEECH RECOGNITION: TECNOLOGIA, APPLICAZIONI E FUTURO
UN’APPLICAZIONE IN CAMPO MEDICO: PHONEMA-MED
LA CONVERSAZIONE CON IL CALCOLATORE
TECNOLOGIE VOCALI PER IL MONDO DEI DISABILI
L’E-LEARNING E I CORSI DI ITALIANO PER STRANIERI
69
74
79
82
85
90
94
Il Quaderno è stato realizzato dalla Fondazione Ugo Bordoni
(Presidente il Prof. Giordano Bruno Guerri, Direttore Generale
il Consigliere Guido Salerno). Coordinatore del Quaderno
il prof. Andrea Paoloni. Hanno collaborato: Piero Cosi, CNR;
Alessandro Tescari, Gruppo Soluzioni Tecnologiche;
Roberto Garigliano, Cirte; Giuseppe Castagneri, Loquendo;
Paolo Parlavecchia, E-Biscom.
Le facce parlanti.

- 69 -
LE MACCHINE CHE PARLANO
La tradizione italiana vuole che la veracultura, quella con la C maiuscola, siaumanistica. Un laureato in ingegneriao in fisica è un tecnico, poco più che
un operaio specializzato e non può occuparsidei fenomeni culturali. Il progresso tuttavia staspostando la bilancia in un’altra dire-zione e la tecnologia sta assumendoun ruolo da protagonista. Il termine“digital divide” fa riferimento agli o-stacoli originati dall’ignoranza neiconfronti dell’informatica nelle suemille applicazioni quotidiane e col-pisce anche, ahimè, molti dotti uma-nisti. L’impostazione tradizionale ri-schia di essere un ostacolo per il si-stema paese; è anche in questo l’im-portanza di una disciplina comequella del Trattamento Automaticodel Linguaggio (TAL) che si pone co-me ponte tra due culture e, forse, tradue diverse visioni del mondo.
Ma questo aspetto culturale non èil vero obiettivo della ricerca sul TAL: questa di-sciplina fornisce nuove possibilità di lavoro perquei laureati delle facoltà umanistiche che sap-piano comprendere che l’informatica, in quan-to opera su linguaggi artificiali, non è poi cosìdistante dai loro studi sui linguaggi naturali;contribuisce significativamente allo sviluppodell’industria dell’immateriale, ovvero delsoftware e dei servizi, che è destinata ad essereil primo motore di sviluppo, e in cui l’Italia è si-gnificativamente sotto la media europea e, infi-ne, è supporto indispensabile alla promozionedell’uso della lingua italiana in Italia e all’estero.
Verrà illustrato nel seguito di cosa si occupiil TAL è tuttavia opportuno dire che con taletermine si designano quei programmi applica-tivi e quei sistemi che, attraverso l’elaborazio-ne del segnale vocale o del testo scritto, trag-gono informazioni utili a comprendere le ri-chieste dell’utente. Ad esempio un interfacciabasata sulle tecnologie del TAL è in grado dicomprendere il significato di una domandaformulata verbalmente (Quando parte il pros-simo treno Roma Foggia?) e provvedere a for-nire una risposta, sempre verbalmente (il pros-simo treno Roma Foggia parte da Roma Termi-ni alle ore… e arriva a Foggia alle ore…) op-pure di tradurre un testo in una altra lingua.
Negli esempi ora proposti abbiamo esempli-ficato due applicazioni relative alle due grandi
aree in cui si divide il TAL, il parlato e lo scritto.Questa separazione ha origine soprattutto dallediverse aree scientifiche che tradizionalmentehanno svolto ricerche in questa area: l’acusticaper il segnale di parola e l’informatica per quel-lo che viene denominato Natural Language
Processing (NLP). Questa separazio-ne, a parere di molti, può costituireun ostacolo per lo sviluppo del TAL.La divisione tra studi sul parlato estudi sullo scritto non risponde aduna reale esigenza, ma trova spiega-zione nel tentativo di due diversecomunità scientifiche di avere piùattenzione e più fondi; la comunica-zione in linguaggio naturale integrain sé le due componenti con il fineultimo di trasmettere un messaggioe pertanto sarebbe auspicabile unamaggiore integrazione degli studi.La combinazione dell’elaborazionedel parlato con la tecnologia NLPfornisce un potente strumento per
migliorare i sistemi di interazione uomo com-puter e tra gli uomini attraverso il computer.
LA RICERCA SUL TEMA IN EUROPA
Negli ultimi anni le tecnologie del TAL sonopassate dalla ricerca di base alle applicazioninella vita quotidiana, tuttavia per gli standardcontemporanei in un ambiente dove i cicli di in-novazione tecnologica sono misurati in mesi enon più in anni, la crescita delle tecnologie lin-guistiche potrebbe sembrare deludente. Mal’impressione di una stasi tecnologica è, a nostroavviso errata. La ricerca di base ha circa 50 anni.Dopo alcune decadi le ricerche hanno fornito iprimi prodotti negli anni 90 e da allora i progres-si compiuti sono stati continui. Per molto tempola complessità del calcolo era superiore alla di-sponibilità degli elaboratori, oggi questa barrie-ra è caduta e la tecnologia del computer mette adisposizione una sufficiente capacità elaborati-va. In cambio la tecnologia del TAL fornisce aglielaboratori le interfacce uomo-macchina di cuiabbisognano per aumentare la loro penetrazio-ne nella società. Particolarmente significativo èil ruolo del TAL nell’ambito della realtà europea,caratterizzata dalla presenza di 11 lingue ufficialidestinate a divenire presto 20 con il previsto in-gresso delle nazioni dell’est. Inoltre vi sono altrelingue ufficiali quali il Basco o il Catalano e le
IL CALCOLATORE NEGLI STUDI LINGUISTICI
Fig. 1. Un art icolodell’‘86, pubbblicato daPanorama, mostra le a-spettative sull’utilizzo delriconoscimento vocale.
- 70 -
lingue degli immigrati come l’Urdu in Gran Bre-tagna, l’arabo magrebino in Francia il Turco inGermania e l’Albanese in Italia. La possibilità diusare ciascuna di queste lingue nella vita quoti-diana è una crescente esigenza nelle attività la-vorative e di svago nella civiltà europea. Questoriflette l’ambizione di un Europa che vuole inte-grarsi rispettando al meglio le singole individua-lità; perché ciascun cittadino possa partecipareliberamente all’offerta culturale è necessario unsupporto alle diversità linguistiche così che aciascuno sia consentito di esprimersi nella pro-pria lingua, che riflette la propria cultura. I pro-dotti e servizi devono essere disponibili in tuttele lingue dell’unione. La sfida di produrresoftware per il Tal in tutte le numerose lingueeuropee dà ai ricercatori e all’industria europeadella lingua un vantaggio indubbio.
Benché il TAL, in termini di mercato rivestaun importanza limitata, il suo impatto in ter-mini di accessibilità, innovazione e integra-zione è molto significativo e altrettanto signi-ficativo il suo ruolo nello sviluppo delle tec-nologie informatiche in europa (eEurope).
Quanto alla posizione italiana, in confron-to alle altre realtà d’europa, purtroppo essa siallinea con la scarsa presenza nell’industriainformatica della quale abbiamo già parlato.
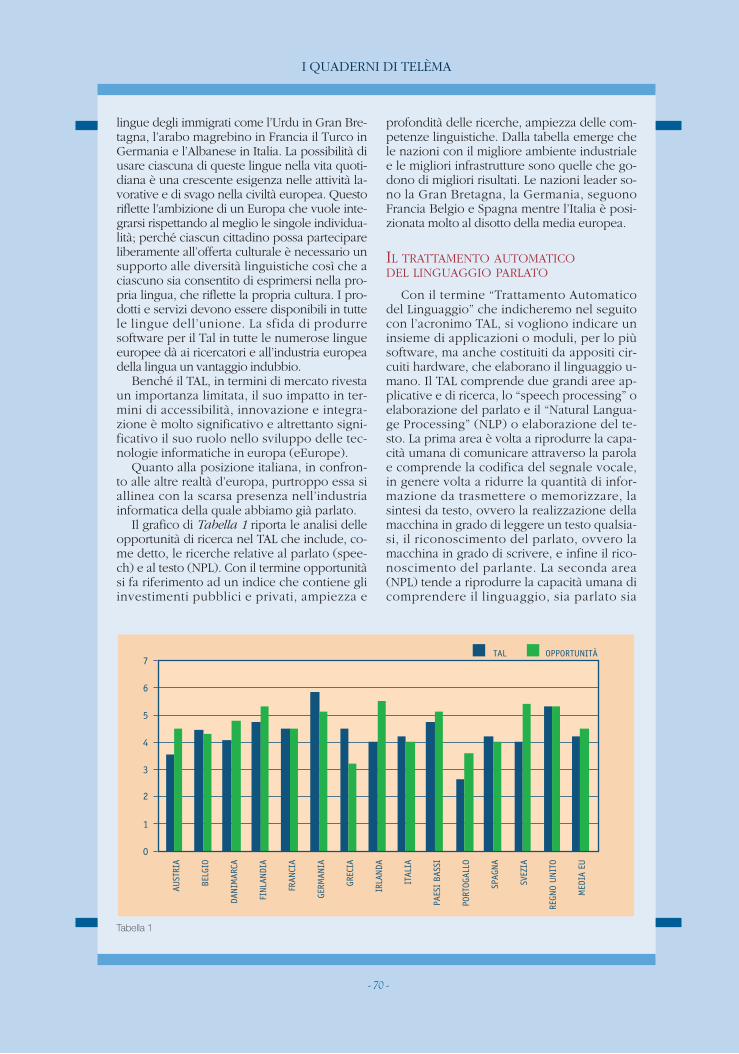
Il grafico di Tabella 1 riporta le analisi delleopportunità di ricerca nel TAL che include, co-me detto, le ricerche relative al parlato (spee-ch) e al testo (NPL). Con il termine opportunitàsi fa riferimento ad un indice che contiene gliinvestimenti pubblici e privati, ampiezza e
profondità delle ricerche, ampiezza delle com-petenze linguistiche. Dalla tabella emerge chele nazioni con il migliore ambiente industrialee le migliori infrastrutture sono quelle che go-dono di migliori risultati. Le nazioni leader so-no la Gran Bretagna, la Germania, seguonoFrancia Belgio e Spagna mentre l’Italia è posi-zionata molto al disotto della media europea.
IL TRATTAMENTO AUTOMATICODEL LINGUAGGIO PARLATO
Con il termine “Trattamento Automaticodel Linguaggio” che indicheremo nel seguitocon l’acronimo TAL, si vogliono indicare uninsieme di applicazioni o moduli, per lo piùsoftware, ma anche costituiti da appositi cir-cuiti hardware, che elaborano il linguaggio u-mano. Il TAL comprende due grandi aree ap-plicative e di ricerca, lo “speech processing” oelaborazione del parlato e il “Natural Langua-ge Processing” (NLP) o elaborazione del te-sto. La prima area è volta a riprodurre la capa-cità umana di comunicare attraverso la parolae comprende la codifica del segnale vocale,in genere volta a ridurre la quantità di infor-mazione da trasmettere o memorizzare, lasintesi da testo, ovvero la realizzazione dellamacchina in grado di leggere un testo qualsia-si, il riconoscimento del parlato, ovvero lamacchina in grado di scrivere, e infine il rico-noscimento del parlante. La seconda area(NPL) tende a riprodurre la capacità umana dicomprendere il linguaggio, sia parlato sia
I QUADERNI DI TELÈMA
AUST
RIA
TAL OPPORTUNITÀ
0
1
2
3
4
5
6
7
BELG
IO
DANI
MAR
CA
FINL
ANDI
A
FRAN
CIA
GERM
ANIA
GREC
IA
IRLA
NDA
ITAL
IA
PAES
I BA
SSI
PORT
OGAL
LO
SPAG
NA
SVEZ
IA
REGN
O UN
ITO
MED
IA E
U
Tabella 1

- 71 -
LE MACCHINE CHE PARLANO
scritto e, dal punto di vista dei moduli algorit-mici utilizzati, prevede analizzatori sintattici esemantici, modelli di rappresentazione delmondo basati su dizionari o enciclopedie,mentre dal punto di vista delle applicazioni,citeremo la traduzione automatica, che rivesteimportanza particolare nell’Europa dalle mol-te lingue, la produzione di sommari e le tecni-che di annotazione che sono il punto di par-tenza per il reperimento dell’informazione inun mondo, quale quello attuale dove le infor-mazioni disponibili crescono a ritmo espo-nenziale. Il presente quaderno è dedicato alprimo dei due temi del TAL ovvero all’elabo-razione del parlato, in quanto l’elaborazionedel linguaggio naturale sarà oggetto di un al-tro ulteriore quaderno di Telèma.
LE TECNOLOGIE
Riprendiamo ora il tema dell’elaborazionedel parlato esaminando singolarmente le tec-nologie in cui si divide. Possiamo dapprimasuddividere l’area in due grandi temi ovverola generazione della voce, sintesi e/o codificae la percezione del parlato, riconoscimentodel parlato e/o del parlante.
Sintesi. La generazione della voce ha unastoria molto antica: si narra di statue parlantipresso i Caldei, nel VII secolo A.C., tuttavia sipuò parlare di sistemi effettivamente in gradodi generare il parlato solo dopo l’introduzio-ne dei calcolatori numerici. Gli obiettivi dellaparametrizzazione del segnale vocale sonodue: il più importante dal punto di vista appli-cativo e commerciale è la codifica del segna-le, con l’obiettivo di ridurre la occupazione dibanda di una singola comunicazione vocale,il più interessante dal punto di vista scientifi-co è la generazione della voce a partire dalconcetto da esprimere o, almeno, da un testoscritto, l’obiettivo insomma è una macchina ingrado di leggere.
Codifica. La codifica del segnale vocale partedalla constatazione che la banda acustica per-cepita dall’orecchio umano ha una dimensio-ne di circa 700.000 bit/s e, limitatamente al se-gnale vocale, di circa 128.000 bit/s, mentre ilcontenuto informativo di un massaggio scritto(supponendo una lettura al ritmo di una paro-la al secondo) è di circa 10 bit/s; dal confron-to risulta evidente che le informazioni acces-sorie, legate alla particolare voce del parlante,all’ambiente acustico, etc. occupano una ban-da molto significativa ed è pertanto ragione-
vole cercare strade che consentano di ridurrele “ridondanza” del segnale trasmesso.
A tal fine vengono progettati codificatoriche possono essere caraterizzati sulla base diquattro parametri: la velocità di cifra (bit-ra-te), la complessità, il ritardo e la qualità. Coltermine velocità di cifra ci si riferisce alla lar-ghezza di banda occupata dal segnale, con iltermine complessità si fa riferimento agli al-goritmi che dovranno essere implementati,con il termine ritardo, il ritardo provocato dal-la codifica che deve essere minimo per noncreare problemi nella comunicazione (echi) econ il termine qualità, infine, si fa riferimentoad un insieme di caratteristiche legate al gra-dimento del segnale codificato. Vari sono ipercorsi che vengono seguiti per codificare ilsegnale vocale, uno si basa sulle caratteristi-che statistiche del segnale e cerca di adattarela codifica a queste ultime. Ad esempio puòessere inviata, in luogo del valore di un cam-pione, la differenza tra tale valore dal valoredel campione precedente.
Un’altra via è basata sulle caratteristichepercettive del nostro orecchio e l’obiettivo ètrasmettere solo ciò che può essere percepito.Una metodica applicativa di questo approccioconsiste nel suddividere la banda acustica inun certo numero di sottobande, per ciascunadelle quali è utilizzata la codifica minima ac-cettata dal nostro orecchio.
Infine un’ulteriore via per migliorare la co-difica è quella denominata “quantizzazionevettoriale”, che consiste nel codificare simul-taneamente un “vettore” di coefficienti. Inpratica ciascuna comparazione o misura dicampioni viene trasmessa come “nome” di unvetore di un appostito insieme di vettori (co-debook) che lo rappresenta.
Con le tecniche di codifica sopra descrittesono stati realizzati vari sistemi, la cui diffu-sione è molto grande: si pensi che gli attualitelefoni cellulari fanno uso delle sopraddettetecniche e trasmettono ad una velocità di cifracompresa tra 13 e 6 Kb/s.
Riconoscimento. Il riconoscimento del par-lato consiste, in senso stretto, nel convertireil parlato in un testo scritto. Ciò richiede lasua conversione in unità, come i fonemi o leparole, e l’interpretazione di tale sequenzaper poter correggere le unità riconosciute inmodo errato o, nel caso sia necessario, com-prendere il parlato per effettuarne la inter-pretazione.
Le ricerche sul riconoscimento del parlatoiniziarono negli anni ‘50, quando nei labora-
- 72 -
tori della Bell fu costruito un sistema per rico-noscere i numeri pronunciati da un determi-nato parlatore. Il sistema funzionava misuran-do le risonanze dello spettro durante i trattivocalici di ciascun numero.
Negli anni ‘60 molte idee fondamentali peril riconoscimento del parlato vennero pubbli-cate ed entrarono nella competizione nume-rosi laboratori giapponesi. Uno dei primi pro-dotti, provenienti dal Giappone, fu unhardware per riconoscere i numeri che utiliz-zava un eleborato banco di filtri.
I PROGETTI DI RICERCA
Tra i progetti di ricerca di maggior rilievo ri-cordiamo quello sviluppato presso l’RCA, voltoa risolvere il problema della non uniformità del-la durata temporale degli eventi del parlato. Ilprogettista sviluppò una serie di metodi di nor-malizzazione basati sulla corretta identificazio-ne dell’inizio e fine del tratto sonoro. All’incirca
nello stesso periodo, in Unione Sovietica Vint-syuk propose l’uso della programmazione dina-mica per allineare tra loro le coppie di fonemi.
Infine, le ricerche di Reddy, portarono, nel‘73, alla realizzazione del primo sistema dimo-strativo sul riconoscimento del parlato continuopresso la Carnegie Mellon University. Si trattadel famoso HEARSAY I che utilizzava informa-zioni semantiche per ridurre il numero di alter-native che il riconoscitore doveva analizzare.Nel sistema per il gioco degli scacchi realizzatocon HEARSAY I, il numero di frasi alternativeche potevano essere dette in un dato punto, eralimitato dalle possibili mosse. Appare fonda-mentale per il funzionamento dei sistemi di ri-conoscimento del parlato utilizzare la sintassi,la semantica e la conoscenza del contesto perridurre il numero delle alternative possibili.
Negli anni ‘70 la ricerca raggiunse i primiimportanti risultati nel riconoscimento delleparole isolate, utilizzando la tecnica del pat-tern recognition e della programmazione di-
I QUADERNI DI TELÈMA
controllo di sistema
dialogo tra due
conversazione naturale
word spotting trascrizione
dettaturacompilazione modulo
verifica del parlato
comandi vocali
elenco abbonati
agentistringhe di numeri chiamato con
2 20 200 2000 20000 illimitato
Dimensione
STIL
I DI
PAR
LATO
(numero di parole)
parlato spontaneo
parlato fluente
Parlato letto
parole connesse
parole isolate
Tecnologia per il riconoscimento del parlato/parlante
Complessità delle applicazioni del riconoscimento del parlato in funzione dello stile e del vocabolario

- 73 -
LE MACCHINE CHE PARLANO
namica. Un’altra ricerca avviata negli anni ’70,da parte dell’IBM, fu quella sui grandi voca-bolari che portartò alla realizzazione del siste-ma chiamato TANGORA.
Negli stessi anni presso i laboratori Bell si spe-rimentarono sistemi completamente indipenden-ti dal parlante per applicazioni in telefonia.
Mentre il riconoscimento per parole isolatefu l’obiettivo degli anni ‘60, negli anni ‘70 l’o-biettivo divenne il riconoscimento delle paroleconnesse. Era necessario creare un sistema ro-busto capace di riconoscere una serie di parolepronunciate in maniera fluente. A questo finefurono formulati numerosi algoritmi tra i quali laprogrammazione dinamica a due livelli, svilup-pata presso la NEC in Giappone, il metodo “onepass” sviluppato in Inghilterra e gli algoritmi svi-luppati presso i Bell Laboratories da Rabiner.
Il tema che ha caratterizzato gli anni ‘80 è sta-to il passaggio dalle tecnologie basate sul con-fronto di maschere ai modelli statistici, in parti-colare il modello denominato “Hidden MarkovModel”, utilizzato nei laboratori dell’IBM. Tra i si-stemi basati sugli HMM citeremo lo SPHINX, del-la Carnegie Mellon, e BIBLOS, della BBN.
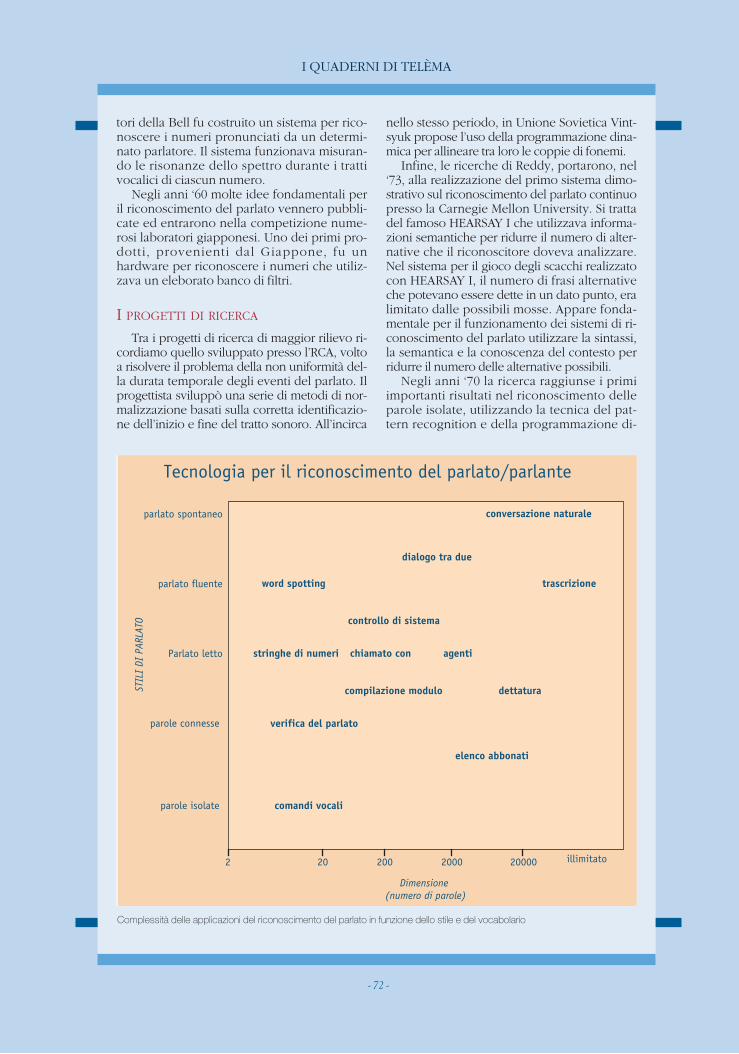
Nella figura di pagina 72 si vedono le varieapplicazioni delle tecnologie del riconoscimen-to del parlato in funzione delle dimensioni delvocabolario e del modo di parlare. Il livello didifficoltà aumenta all’aumentare della velocitàdel parlato e della dimensione del vocabolario.
Non riteniamo opportuno descrivere in det-taglio quali siano gli algoritmi utilizzati per il ri-conoscimento del parlato, tuttavia vorremmofar comprendere che l’informazione acustica,da sola, non è sufficiente a permettere la tra-scrizione di un testo, ma è necessaria una qual-che forma di comprensione. Questa compren-sione deve essere portata avanti da un compo-nente linguistico che segue il componente acu-stico nel sistema di riconoscimento.
Le due differenti aree applicative dei siste-mi di riconoscimento del parlato attualmenteesistenti sul mercato, si distinguono per il di-verso componente linguistico. Il modulo usa-to per la dettatura dei testi prevede l’uso di unvocabolario molto grande e cerca di migliora-re il contributo del modulo acustico, quelloche trasforma il segnale in ipotesi fonemi, uti-lizzando particolari interfacce che riducano ilrumore e addestrando il modulo acustico conla particolare voce di colui che detterà i testi.
I sistemi per la telefonia, che vengono usatiin rete e quindi non possono utilizzare parti-colari accortezze nel ridurre il rumore e peraddestrare il sistema, hanno il vantaggio di o-perare su un vocabolario molto più limitato,
come più limitato è il numero di frasi accetta-bili. Il modulo linguistico è pertanto affianca-to da un modulo di gestione del dialogo cheper ogni momento del colloquio propone unnumero limitato di frasi da riconoscere.
Una più completa descrizione delle carat-teristiche di queste due tipologie di riconosci-tore è proposta in due diversi articoli di que-sto quaderno.
Identificazione e verifica del chiamante.Nell’ambito del riconoscimento vocale o me-glio nell’ambito delle macchine che ascoltanoe comprendono viene molto spesso cataloga-to il processo dell’identificazione del chia-mante a partire dalla sua voce. Tradizional-mente questa tecnologia viene classificata indue diverse aree applicative: la verifica dell’i-dentità, quando l’utente si identifica e il siste-ma deve confermare o meno la identità di-chiarata, e il riconoscimento, quando la vocenon dichiara la sua identità e pertanto si trattadi attribuirla ad un parlatore all’interno di uninsieme di canali dati. In quest’ultimo caso ladifficoltà del compito cresce all’aumentaredella dimensione dell’insieme e per insiemi a-perti si ritorna alle condizioni di verifiche ri-petute. Le applicazioni di questa tecnica so-no, per la prima, i sistemi biometrici di identi-ficazione della persona, per la seconda il rico-noscimento a scopo identificativo o forense.
PROSPETTIVE FUTURE
Per ovvie ragioni, la ricerca sul Tal è storica-mente evoluta per ciascuna nazione nella pro-pria lingua. Queste tecnologie non possono es-sere semplicemente acquistate, come un com-puter o un’automobile, ma richiedono una at-tenta opera di progettazione per “funzionare”in una determinata lingua. Tuttavia è semprepiù comune trovare sistemi multilingua neimaggiori laboratori e centri di ricerca in quantosi va verso uno sviluppo sempre più globale ele conoscenze linguistiche migrano, insieme aiparlanti, nell’intera europa. La ricerca divienesempre più integrata e le conoscenze linguisti-che migliorano mentre cresce il numero di dativocali disponibili (basi di dati vocali e lessici).
La ricerca nell’area richiede un importantesupporto pubblico come è avvenuto in Euro-pa grazie ai finanziamenti CEE. È importanteche questo supporto prosegua in quanto lesole forze del mercato non possono produrreda sole il necessario sforzo finanziario.
Queste considerazioni valgono in particolareper l’Italia, dove è indispensabile superare l’at-

- 74 -
tuale ritardo in questa area tecnologica. Obietti-vo principale è rendere disponibili le competen-ze e i moduli di analisi, ad esempio le interfaccevocali, i motori di ricerca, le tecnologie della co-noscenza, per ogni lingua europea nella convin-zione che il motore commerciale prodotto dalTAL sia essenziale nello sviluppo delle tecnolo-gie dell’informatica e della comunicazione.
La riduzione del divario prodotto dal “digitaldivide” passa anche dalla facilità di colloquiocon i sistemi elettronici che la tecnologia attua-le rende disponibili. In particolare la televisionedigitale interattiva, che sarà pronta nel 2006 se-
condo i programmi del governo, dovrà dispor-re di un sistema di interazione efficiente basatosulla comunicazione vocale. A nostro avviso l’I-talia, seguendo l’esempio di altre nazioni, si do-vrebbe dotare di strutture dedicate a promuo-vere la ricerca e lo sviluppo questa tecnologia.
La costituzione, presso il Ministero delleComunicazioni, di un “forum permanente sulTAL” costituirebbe, a nostro avviso, un passofondamentale nella giusta direzione.
Ing. Andrea PaoloniFondazione Ugo Bordoni
I QUADERNI DI TELÈMA
SINTESI DELLA VOCE E AGENTI PARLANTI
Chi non ricorda la voce di HAL 9000, ilcomputer di bordo della navicellaspaziale Discovery, “protagonista” delfamoso film di Stanley Kubrik “2001
Odissea nello Spazio”. Era il 1968 e, a distanzadi 35 anni, si può forse dire che le previsionicontenute in un film di fantascienza, almenoper quanto riguarda la qualità della voce di unsintetizzatore vocale,si sono avverate.
La qualità dei migliori sintetizzatori vocalida testo scritto (spiegare) (TTS, Text to Spee-ch Synthesis) attualmente disponibili non solosul mercato ma anche nei laboratori di ricercapiù avanzati, è sicuramente paragonabile aquella di HAL.
Si deve ricordare però che non tutti i pro-blemi sono stati risolti. Confrontando, infatti,la capacità emotivo/espressiva di un attualesintetizzatore vocale con quella di HAL ci sirende immediatamente conto del gap ancoranon risolto e che ancora qualche anno dovràpassare prima di poter ottenere una sintesi af-fidabile anche da questo punto di vista.
Possiamo però senz’altro dire che la qualitàdella sintesi della voce ha assunto un livellotale da poter ormai essere utilizzata in moltis-sime applicazioni.
La lettura di messaggi, memorizzati in siste-mi di posta vocale, e-mail e fax all’interno diuna mail box unificata, accessibile attraversostandard e-mail-clients, tramite web o telefo-no, la lettura di pagine web, gli avvisi di parti-colari emergenze, i servizi clienti delle azien-de telefoniche ad esempio per l’inoltro dellechiamate, la consultazione interattiva ed ami-chevole di fonti di informazione elettroniche,gli ausili di lettura per i portatori di disabilitàvisive e molti altri ancora sono solo alcuni dei
possibili esempi di applicazione attualmentesperimentati con successo.
Bisogna inoltre ricordare che parlando disistemi di sintesi o TTS. negli ultimi anni, nonsi considerano soltanto quei sistemi in gradodi sintetizzare file audio, ma anche video, co-me ad esempio nella realizzazione delle co-siddette “Talking Heads” o agenti parlanti, si-stemi in grado di simulare virtualmente unapersona umana che parla.
UN PO’ DI STORIA
Gli studi passati hanno portato alla conoscen-za fondamentale della dinamica alla base dellagenerazione della voce umana. Quando parlia-mo, un suono base, prodotto dal flusso d’aria ge-nerato dai polmoni e passante attraverso le cor-de vocali, viene modulato dalla cavità orale, dalnaso e dalla bocca ed è la posizione delle diver-se parti della lingua e la posizione delle labbrache sono responsabili dei diversi suoni compo-nenti il segnale verbale, ed è questo meccani-smo complesso che si deve essere imitato perrealizzare sistemi di sintesi vocale. Possiamosenz’altro affermare che la storia di questa tecno-logia ha inizio nel 1939 presso i Bell Laboratoriesdove venne presentato per la prima volta il VO-DER (Voice Operating DEmonstratoR), VODERera una sorta di strumento musicale dove unabarra vibrante generava le frequenze fondamen-tali, variabili attraverso un meccanismo a pedaleed il suono prodotto veniva modulato utilizzan-do dei filtri acustici, controllati con le mani. Laqualità della voce era ovviamente molto scaden-te ma un simile meccanismo era la prova dellarealizzabilità di una voce sintetica. A metà delventesimo secolo negli Stati Uniti nei laboratori

- 75 -
LE MACCHINE CHE PARLANO
Haskins è stato poi presentato il Pattern Play-back, uno strumento ottico/elettronico capace disintetizzare suoni vocali a partire da una lororappresentazione acustica. Vi sono anche esem-pi di sintesi vocale sin dall’antichità. Ad esempio,nel 1779, a San Pietroburgo, il professore russoKratzenstein costruì dei risuonatori acustici ca-paci di produrre i suoni delle cinque vocali.
Tornando a tempi più recenti, la vera svoltanel campo della sintesi vocale fu l’arrivo dellatecnologia digitale che, associata agli enormiprogressi nello studio del meccanismo di pro-duzione della voce, rese possibile intorno aglianni settanta, la realizzazione dei primi sistemiper la sintesi della voce da testo scritto.
I SISTEMI DI SINTESI VOCALI
Esistono molte strategie, fra loro differenti,per sintetizzare il parlato, ma in termini gene-rali si possono dividere essenzialmente in duegrandi categorie denominate system-modelse signal-models.
1) Modello del Sistema di Produzione (system-model) (sintesi articolatoria)
Il segnale acustico è il risultato della model-lizzazione e simulazione del meccanismo fisicodi produzione del suono. Questo approccio èanche conosciuto come sintesi articolatoria. Lasintesi articolatoria si prefigge di generare il se-gnale vocale mediante una corretta modellizza-zione dell’apparato orale umano. Questo meto-do di sintesi utilizza in pratica dei modelli com-putazionali biomeccanici per la riproduzionedel parlato simulando il comportamento degliarticolatori interessati nella fonazione e le cor-de vocali. I modelli degli articolatori sono gui-dati nel tempo in modo da riprodurre le confi-gurazioni caratteristiche di ogni fonema utiliz-zando delle regole che riflettono i vincoli dina-mici imposti dalle articolazioni. Per generare ilsegnale vocale, la forma del condotto orale, de-finita dalla posizione degli articolatori, vieneconvertita in una funzione di trasferimento, cheutilizza come ingresso un segnale di eccitazio-ne generato tramite un modello delle corde vo-cali. Il problema è quindi ricondotto alla deter-minazione dei punti di articolazione caratteristi-ci di ogni fonema e delle transizioni tra fonemi.Per determinarli sono spesso utilizzati dati presida radiografie o risonanze magnetiche dinami-che. Nonostante il suo notevole valore scientifi-co questo tipo di sintesi non ha ricevuto grandeattenzione, a causa della scarsa competitività intermini di qualità con altri sistemi di sintesi e
della elevata complessità indispensabile per ot-tenere buoni risultati in termini di naturalezza.
2) Modello del Segnale (signal-model)
Con tale approccio si vuole rappresentareil suono che arriva al nostro apparato uditivo,senza fare un esplicito riferimento al meccani-smo articolatorio che genera il suono stesso,ma esclusivamente al meccanismo fisico/acu-stico responsabile della produzione della vo-ce intesa come onda sonora di pressione. Inquesto approccio sono rappresentati a lorovolta i metodi di sintesi per formanti e di sin-tesi per concatenazione.
3) Sintesi per formanti
Anche se si basa su una elaborazione del se-gnale che viene prodotto dall’apparato fono-ar-ticolatorio, la sintesi per formanti, in realtà nonignora del tutto il meccanismo di fonazione u-mana. Infatti si basa sulla teoria sorgente-filtrodella fonazione, assai ben descritto ad esempioda Gunnar Fant nel suo famoso libro “SpeechSounds and Features” (1973, MIT Press). La sin-tesi per formanti utilizza, infatti, un modello delcondotto vocale realizzato mediante un filtrocomposto da un numero limitato di risonanze(con 4 si riesce ad esempio ottenere una vocedi buona qualità), con frequenza, ampiezza, ebanda di risonanza variabili. Modelli più elabo-rati utilizzano ulteriori risonanze e antirisonan-ze per i suoni nasali, con associato anche delrumore ad alta frequenza utile ad esempio nel-la simulazione delle consonanti fricative e oc-clusive. Il segnale d’ingresso è sempre generatotramite un modello più o meno approssimatodelle corde vocali. Una sorgente molto stilizza-ta ma funzionante consiste in un treno di im-pulsi per i tratti di voce vocalizzati o in un ru-more bianco per le parti non vocalizzate (si ve-da Figura 3). Questo modello utilizza delle no-tevoli semplificazioni rispetto alla realtà. Ad e-sempio il presupposto che la sorgente di eccita-zione sia completamente indipendente dal fil-tro è assolutamente improbabile.
parametritratto vocale
filtro digitaletempo-variante
e(n)
G
vocalizzato/non-vocalizzato
s(n)
generatorerumore bianco
generatore
treno di impulsi
x
Figura 3. Modello di sintesi filtro-sorgente.

- 76 -
Con questo metodo, al fine di sintetizzareuna frase, per ogni fonema e per ogni suatransizione, bisogna determinare i parametridi controllo dei filtri e della sorgente di eccita-zione variabili nel tempo. Questo tipo di sin-tesi genera un parlato altamente intelleggibilema non completamente naturale; presenta,comunque, il vantaggio di una bassa richiestadi risorse di memoria edi calcolo.
4) sintesi per concatenazione
Questo tipo di sintesi unisce, modificandolicon appropriati algoritmi, piccoli frammenti (u-nità elementari) di segnale vocale, al fine di sin-tetizzare un intera frase. Questi metodi evitanole difficoltà di simulare l’atto di fonazione uma-na mediante specifici modelli, tuttavia introdu-cono atri problemi, quali ad esempio la diffi-coltà di concatenazione omogenea delle unitàacustiche registrate in diversi contesti e la modi-fica della prosodia intesa come variazione di in-tonazione e durata. A tal fine vengono utilizzatespecifiche tecniche di elaborazione del segnale(signal processing): fra le più comuni ricordia-mo quelle denominate Predizione Lineare ePSOLA, la prima basata sulla teoria del modellosorgente-filtro precedentemente introdotta, laseconda esclusivamente su tecniche di elabora-zione del segnale, al di fuori quindi di un mo-dello del fenomeno di produzione della voce.
Per questa modalità di sintesi possiamo fareun’ulteriore suddivisione delle strategie in basealle unità fondamentali utilizzate per la concate-nazione. Si possono infatti distinguere la sintesiper difoni (generalmente definiti come la por-
zione del segnale vocale che và da metà di un fo-nema alla metà del fonema1 successivo), trifoni,metà-sillabe, ecc. fino ad arrivare all’estensionedi unità variabili utilizzate nei sistemi di sintesipiù recenti che utilizzano algoritmi denominati“Automatic Unit Selection”.Questo tipo di sin-tesi concatena le unità selezionate da un databa-se vocale e, dopo una decodifica opzionale, in-via in uscita il segnale vocale risultante. Poiché isistemi di questo tipo usano frammenti di un di-scorso registrato risultano più naturali.
SISTEMI DI SINTESIPER CONCATENAZIONE
Questi sistemi consentono di ottenere unasintesi da testo di assoluta generalità, combi-nando frammenti di voce molto piccoli. Le u-nità elementari sicuramente più utilizzate so-no i difoni, precedentemente introdotti. Perconsentire la sintesi, sono necessari i difonicorrispondenti a tutte le coppie di fonemi diuna determinata lingua. Generalmente i siste-mi di questo tipo utilizzano poco più di unmigliaio di difoni, ricavati da parole, in gene-re sequenze di sillabe senza significato, regi-strate da un parlatore umano con intonazionemonotona. Queste unità vengono poi conca-tenate per formare le frasi desiderate su cui a-giscono sofisticati algoritmi in grado di variar-ne la durata e la frequenza fondamentale inmodo da ottenere i valori più adatti al testo.
I QUADERNI DI TELÈMA
Figura 4. Architettura generale di un sistema di sintesi da testo scritto per concatenazione di difoni.
1Con il termine fonema si intende il più piccolo suonoche compone la parola come ad esempio una vocale /a/o una consonante /s/.

- 77 -
LE MACCHINE CHE PARLANO
Un diagramma a blocchi di un tipico sistemadi sintesi per concatenazione, che, nella suaparte di analisi testuale può considerarsi comu-ne a tutti gli altri metodi, è illustrato in Figura 4.
Il primo blocco (Moduli Linguistici), comuneessenzialmente a tutte le tipologie dei sistemi disintesi, è il modulo di analisi che acquisisce ilmessaggio testuale in ASCII e lo converte in unaserie di simboli fonetici e targets metrici (fre-quenza fondamentale, durata, ampiezza). Talemodulo consiste di una serie di ‘sotto-moduli’con funzioni distinte, ma in molti casi collegate:il testo di input è prima analizzato e i numeri, isimboli non alfabetici e le abbreviazioni sono e-spanse in parole (per esempio l’abbreviazione‘Ing.’ è trascritta come ‘Ingegnere’, ‘222’ come‘duecentoventidue’). Tutte le altre parole, se nonsono parole-funzione o parole già presenti in unlessico di riferimento, vengono accentate, tra-scritte foneticamente, sillabificate e opzional-mente analizzate mediante un parser sintatticoche, riconoscendo parte del discorso per ogniparola nella frase, è utilizzato per ‘etichettare’ iltesto. Il suo compito inoltre è togliere l’ambi-guità a parti costituenti la frase per generare unacorretta stringa di suoni, ad esempio per disam-biguare parole scritte allo stesso modo ma consignificato o accento diverso (àncora, ancòra).
Il secondo blocco (Moduli Fonetico-Acu-stici) assembla le unità in base alla lista di tar-gets ed è principalmente responsabile dellaqualità acustica e della naturalezza della sin-tesi. Le unità selezionate sono infine inseritein un sintetizzatore in grado di generare leforme d’ondadel segnale vocale.
In particolare l’analisi prosodico-intonativa,intesa come determinazione della durata e del-l’intonazione (frequenza fondamentale) in corri-spondenza delle unità da sintetizzare, è sicura-mente la parte più importante di ogni sistema disintesi ed viene elaborata, o per regole esplicite,caratterizzate e studiate in dettaglio per ogni lin-gua, oppure mediante un approccio statistico(ad esempio basato su CART, Classification andRegression Trees) in grado di apprendere da uncorpus di esempi le caratteristiche prosodiche diuna determinata lingua. Entrambe i metodi sonoovviamente ottimizzati a diversi livelli principal-mente a seconda della bontà dell’analisi testuale,fonetica e sintattica precedentemente illustrata.
SISTEMI DI SINTESI A SELEZIONEDI UNITÀ (UNIT SELECTION)
Negli ultimi anni si stanno imponendo i si-stemi corpus-based o unit selection la cui ca-ratteristica fondamentale è quella di non aver
bisogno di limitare il numero, e la dimensionedei frammenti da concatenare. Questo tipo disintesi è caratterizzato dalla memorizzazione,la selezione e la concatenazione di segmentidi discorso di dimensioni variabile. Questisegmenti vengono estratti, mediante specificialgoritmi basati su tecniche statistiche, dagrandi corpora di materiale vocale pre-regi-strato, naturale e fluente.
Questa strategia di sintesi mira, non più amodificare gli attributi metrici, come durata delsuono o frequenza fondamentale di piccole u-nità fondamentali di eguale durata, ma a modi-ficare il segnale originale solo quando è indi-spensabile, ottenendo risultati ottimi per quan-to concerne la naturalezza timbrica della vocesintetica. I frammenti acustici diventano quindipiù lunghi, anche sequenze di molti fonemi,parole o addirittura frasi intere, in modo da ri-durre i punti di giunzione. Queste unità sono i-noltre disponibili in più esemplari, corrispon-denti ad esempio a contesti e ad intonazionidiverse. La dimensione del dizionario acusticopuò, infatti, raggiungere una dimensione an-che 50 volte superiore a quella dei sistemi adifoni. Questa, che in passato era una difficoltàinsormontabile, è stata ampiamente superatacon l’avvento degli attuali computer dotati dienorme capacità di calcolo e di memoria.
LE APPLICAZIONI
Sono numerose le possibili applicazioni deisistemi di sintesi da testo scritto “naturali” e diqualità paragonabile a quella umana. La diffu-sione capillare dell’utilizzo del computer saràinfatti senz’altro facilitata da un’interfaccia concui si possa interagire con tutte le fonti diinformazione in linguaggio naturale e non piùsecondo modalità non a tutti congeniali.
Fra le molteplici applicazioni si possono ri-cordare:– la lettura di messaggi, memorizzati in siste-
mi di posta vocale, e-mail e fax all’internodi una mail box unificata, accessibile trami-te web o telefono;
– la lettura di pagine web;– gli avvisi di particolari emergenze– i servizi clienti delle aziende telefoniche,
ad esempio per l’inoltro delle chiamate;– la consultazione interattiva ed amichevole
di fonti di informazione elettroniche;– gli ausili di lettura per i portatori di disabi-
lità visive come ad esempio i lettori dischermo (Screen Reader) che altro non so-no che accessori del computer per ripro-durre in voce qualsiasi cosa appaia sullo

- 78 -
schermo, oppure i lettori di libri in grado dileggere autonomamente testi a stampa
– i corsi avanzati per l’apprendimento – i portali vocali;
COSA MANCA?La caratterizzazione di un segnale vocale in
un dato stato emotivo deve essere definita tra-mite la misura dei correlati acustici ad esso as-sociati, che a loro volta derivano dai vincoli fi-siologici. Per esempio, quando una persona èin uno stato di paura o gioia, il battito del cuo-re e la pressione del sangue aumentano, labocca diventa secca e ci sono occasionali tre-mori muscolari. La voce aumenta di intensità,di velocità, e nello spettro vi sono forti com-ponenti in alta frequenza. I principali correlatiacustici delle emozioni, studiati in letteraturasono: f0, durata, intensità, e una serie di carat-teristiche del timbro quali la distribuzione del-l’energia spettrale, il rapporto segnale-distur-bo (HNR, harmonic-to-noise ratio) e alcuni in-dici di qualità della voce (voice quality).
Quest’ultima proprietà distingue le moda-lità con cui viene prodotto il segnale glottale(voce aspirata, soffiata, tesa, ecc.. Pochissimisistemi di sintesi includono queste diversemodalità espressive e sicuramente nessuno diquelli attualmente commercializzati: se si de-ve quindi leggere una fiaba ad un bambino ole “notizie ansa” in un servizio informativo lemodalità espressive sono identiche. Pur tutta-via vi sono esempi in letteratura che hannostudiato questo problema cercando di elabo-rare alcuni modelli computazionali per rende-re conto di queste caratteristiche espressivenei futuri sistemi di sintesi.
I primi esperimenti hanno utilizzato la sin-tesi per formanti, principalmente perché que-sti sistemi permettono un ricco controllo del
segnale. Purtroppo però la qualità del segnaleprodotto con tali strategie spesso non è sod-disfacente per valutare in dettaglio l’influenzaemotiva dell’uscita vocale. Utilizzando invecemetodi di sintesi concatenativa, i parametri dicontrollo solitamente sono solo la frequenzafondamentale e la durata. Con tali strategie sipossono adottare due possibili soluzioni aquesto problema. Ad esempio mediante l’uti-lizzo di un corpus di unità acustiche per ogniemozione dal quale selezionare le unità daconcatenare oppure utilizzando esclusiva-mente tecniche di elaborazione del segnale alfine di variare i correlati acustici emotivi legatial timbro della voce direttamente sulla formad’onda del segnale vocale stesso.
Nonostante gli sforzi compiuti in questo fi-lone di studio siamo però ancora distanti daun’effettiva commercializzazione di un pro-dotto in grado di risolvere e queste difficoltà.
IL FUTURO
A parte le difficoltà di una sintesi emotivaed espressiva ancora non adeguatamente af-frontata, il futuro della sintesi vocale risiedeanche nelle nuove tecnologie di animazionefacciale ad essa associata che stanno portan-do negli ultimi anni alla progettazione e allarealizzazione di agenti parlanti (Talking A-gents) in grado di rendere estremamente piùappetibili moltissime applicazioni interattive(si veda Figura 5) di cui le potenzialità offertedalle nuove tecnologie di comunicazione del-l’informazione fornite dai telefonini di nuovagenerazione, basati sulla tecnologia UMTS,sono solo un semplice e chiaro esempio.
Ing. Piero CosiIstituto di Scienze e Tecnologie della Cognizione
Sezione di Fonetica e Dialettologia del CNR
I QUADERNI DI TELÈMA
Figura 5. Illustrazione di alcune “facce parlanti” apparse recentemente “alla ribalta”:� Baldi (UCSC Perceptual Sciences Laboratory,mambo.ucsc.edu),� Ananova (www.ananova.com),� Lucia (ISTC-SPFD CNR, www.csrf.pd.cnr.it/Lucia/index.htm),� Anja (Telecom Lab Italia, multimedia.telecomitalialab.com/virtual_life.htm,� Greta (Catherine Pelachaud, www.iut.univ-paris8.fr/~pelachaud/),� Sarah (DSP.Lab Dist Genova, www.dsp.dist.unige.it/~pok/RESEARCH/index.htm).
- 79 -
LE MACCHINE CHE PARLANO
Alla metà degli anni novanta, due tec-nologie sembravano destinate ad unpromettente successo su scala pla-netaria: il WWW (WorldWide Web) e
l’ASR (Automatic Speech Recognition).Come si sia sviluppato Internet è noto a
tutti: in pochi anni, tra luci ed ombre, è diven-tato lo strumento informatico più popolare epiù diffusamente conosciuto al mondo.
Cosa ne è stato, invece, delle tecnologie diriconoscimento vocale? Quanto sono lontanenel tempo le applicazioni che ci potrebbero
permettere di rivolgere la parola ad un com-puter come nei film della serie Star Trek? Esi-ste oggi un mercato del riconoscimento voca-le e chi sono i beneficiari di questa tecnologia?
Prima di rispondere a queste domande èopportuno premettere che, quando si parla ditecnologie vocali, si devono in realtà conside-rare diversi filoni di ricerca che si differenzia-no fra di loro in modo sensibile, in base all’o-biettivo del riconoscimento.
La seguente tabella riporta i principali settoridi ricerca nel campo delle tecnologie vocali.
DESKTOP SPEECH RECOGNITION: TECNOLOGIA, APPLICAZIONI E FUTURO
Settore di ricerca Oggetto della ricerca Ampiezza dizionario Esempi attuali
Riconoscimento vocale telefonico
Sistemi di rispostatelefonica automatica concomprensione dellarichiesta dell’utente.Esistono al riguardo piùtecniche di interfacciavocale: IVR (InteractiveVoice Response) oppureVUI (Vocal User Interface)basata su VoiceXML
Centinaia di parole:l’obiettivo è individuare ecomprendere le parole-chiave della domanda
Vari siti telefonici: si segnala quello diTrenitalia per ottenereinformazioni sugli orariferroviari.
Identificazione biometrica del parlatore
Software che identifica ilparlatore a partire dallaforma delle onde acustichedi un modello precaricato
N.A. Non risultano applicazioni note
Estrazione di parole da parlato spontaneo
Software che identifica lesingole parole, all’interno diun file audio, a partire dallaforma delle onde acustichedella parola ricercata
Qualunque parola o forma Sistemi automatici di indicizzazione diprogrammi radiotelevisivi
Riconoscimento vocale su desktop
Software di dettatura. Sistemi di dettatura e dicontrollo vocale delleapplicazioni.
Decine di migliaia di paroleo, meglio, di forme (performa si intende qualsiasiparola declinata in tutti icasi previsti dallagrammatica italiana: es.“bello” genera 4 forme:bello, bella, belli, belle)
IBM ViaVoice o ScansoftNaturally Speaking. Tra i sistemi, PhonemAsoftware specializzato per la refertazione medica.
Embedded Speech Recognition
Software montato a bordo dimicrochip per lacomprensione di una limitataserie di termini preimpostatioppure dettati dall’utente
Decine di parole Telefoni mobili(identificazione di nomi dachiamare); automobili(comandi vocali che ilconducente può impartire).
Tabella: tipologie di ricerca e di applicazioni nell’ambito delle tecnologie di riconoscimento vocale.

- 80 -
La classificazione sopra descritta ci permet-te di definire il riconoscimento vocale su de-sktop (o Desktop Speech Recognition - DSR)come una tipologia tecnologica appartenenteal più ampio campo delle tecnologie ASR(Automatic Speech Recognition). Nel seguitoapprofondiremo questa specifica tipologia, a-nalizzandone le caratteristiche tecniche e lepotenziali applicazioni; infine, cercheremo dicapire perché, ad oggi, l’utilizzo delle tecno-logie DSR non è riuscito ad assumere una po-sizione di rilievo nell’ambito delle applicazio-ni informatiche.
DESKTOP SPEECH RECOGNITION:QUALCHE NOZIONE TECNICA
Le componenti di un sistema DSR sono so-stanzialmente quattro:
- la catena di acquisizione del segnale acu-stico: microfono, cavo, scheda audio.
- il motore di riconoscimento vocale: at-tualmente sul mercato italiano ne esistonodue: IBM ViaVoice e Scansoft NaturallySpeaking
- il repository acustico: contiene i profilivocali di ogni utente. Attraverso una sessionepreliminare di adattamento, il sistema è ingrado di creare i modelli fonetici, su base di-gitale, tipici dell’utente.
- il repository testuale: contiene il modellodi linguaggio tipico di ogni utente, le paroleaggiunte nel dizionario personale, le frasi pre-definite richiamabili tramite parole chiave (ades. la chiusura di una lettera).
Il funzionamento di un sistema DSR sicompone sostanzialmente delle seguenti fasi:1. l’utente parlando emette onde acustiche
che vengono catturate dal microfono; la di-rezionalità della voce è dunque importantecosì come la trasmissione attraverso il cavoche deve avvenire al riparo di distorsioni odi campi elettromagnetici.
2. il segnale acustico arriva alla scheda audioche trasforma il segnale analogico in se-quenze digitali.
3. le sequenze digitali vengono confrontatecon i modelli fonetici digitali dell’utente e,in base ad un’analisi statistica, vengonoscelte le rappresentazioni fonetiche piùprobabili.
4. l’insieme di fonemi così individuato vieneconfrontato con il modello del linguaggiodell’utente. Con altri tipi di analisi, si indivi-dua l’insieme di parole più probabili. Taliparole sono quelle che vengono ricono-sciute dal sistema.
Dal funzionamento descritto, si capisceche un sistema di dettatura continua sbagliaperché è costretto a dare sempre un risultato.Se dettiamo:– “Servono informazioni sul treno delle quin-
dici e trenta” e alteriamo la pronuncia dellala parola “quindici”, potremmo avere risul-tati del tipo:
– “Servono informazioni sul treno delle undi-ci e trenta”
– “Servono informazioni sul treno degli indicia Trento”
– “Servono informazioni sul treno delle quidici e tenta”e così via, dove l’errore è tanto più evidente
quanto più il primo termine male interpretato siallontana dalla corretta concatenazione dettata.
Le performance raggiungibili da un siste-ma DSR si misurano in percentuale di parolecorrettamente interpretate su parole dettatetotali. I prodotti in commercio proclamanopercentuali di riconoscimento del 95% che,effettivamente, possono essere raggiunte, sudizionari non troppo ampi, con un’adeguatamanutenzione del profilo vocale. Tuttavia,quando l’utente detta una pagina di testo, e sitrova a correggere un errore per riga, ha lapercezione che il sistema funzioni male: è so-lo una percezione. Bisogna infatti considerareche se ogni riga è fatta mediamente di 20 pa-role, il 5% di errore implica effettivamente lacorrezione di un errore per riga.
Per gli utenti professionali, il limite del 95%è generalmente insostenibile e porta al rifiutodella tecnologia. È dunque necessario proget-tare sistemi DSR con un tasso di riconosci-mento superiore, possibilmente vicino al100%. Ogni punto percentuale “guadagnato”oltre la soglia del 95% comporta la diminuzio-ne del 20% degli errori da correggere ma pur-troppo costa un’attività di ottimizzazione delsistema estremamente ardua e dispendiosa.
In particolare, occorre ottimizzare ogni ele-mento del sistema DSR:�� analizzare la migliore combinazione dei
componenti della catena di acquisizionedel segnale acustico (microfono, cavo,scheda audio), tenendo anche presenti lecondizioni acustiche dell’ambiente (sogliadi rumore, grado di riflessione acustica) ele funzionalità richieste dall’utente (es. mi-crofono con pulsanti).
�� mantenere aggiornato il motore di ricono-scimento vocale in funzione dell’ambientesoftware di riferimento (spesso i DSR ven-gono aggiornati con mesi di ritardo rispettoai sistemi operativi Microsoft).
I QUADERNI DI TELÈMA

- 81 -
LE MACCHINE CHE PARLANO
�� aiutare l’utente ad effettuare correttamente lasessione di adattamento del profilo vocale.
�� mettere a disposizione dell’utente, facilistrumenti per il mantenimento del propriomodello di linguaggio.
Per ottenere la massima collaborazionedell’utente professionale durante la dettatu-ra, sarà poi necessario studiare un’interfacciaparticolarmente gradevole, dotata di ognifunzionalità opportuna per semplificare le o-perazioni di correzione e, soprattutto, sicura:operando a livelli di sistema operativo piut-tosto bassi, spesso un’interruzione del fun-zionamento vocale corrisponde ad un bloc-co di Windows con le prevedibili conse-guenze per l’utente.
Oltre alla modalità dettatura, un DSR puòessere utilizzato anche per il riconoscimentodi comandi e controlli (modalità Command &Control - C&C).
La differenza sostanziale, dal punto di vistafunzionale, della modalità C&C rispetto allamodalità per dettatura è che nello schema difunzionamento sopra descritto il confronto fi-nale non viene eseguito con il modello di lin-guaggio dell’utente ma con la parola (o ilgruppo di parole o il comando) prevista nelcontesto applicativo.
Ad esempio, se in un campo posso dettarei numeri interi dallo zero al nove, solo pro-nunciando una di queste dieci parole ottengoil riconoscimento vocale corretto. Se dico al-tre parole (specie se non sono assonanti) il si-stema rifiuta il riconoscimento e, quindi, nongenera un errore.
In modo simile, posso dare un comandovocale ad un’applicazione informatica e asso-ciarne l’interpretazione a una combinazionedi tasti che attiva un’operazione: la percezio-ne sarà quella di avere comandato a vocel’applicazione.
Il limite della modalità C&C è quello di o-perare solo su parole o gruppi di parole isola-te. Per questo motivo, è inadatta alla dettaturaa testo libero (detta anche dettatura in parlatocontinuo).
DESKTOP SPEECH RECOGNITION - LE POSSIBILI APPLICAZIONI
Sulla questione dell’applicabilità dei siste-mi DSR, esistono due correnti di pensierocontrapposte: Secondo la prima (che chiame-remo “ottimista”), la voce è il modo più natu-rale per l’uomo di comunicare e quindi, pri-ma o poi, la nostra interfaccia con il computer
sarà vocale. La seconda, quella che definire-mo “pessimista”, prevede che la voce non a-vrà mai successo - se non in ambiti molto li-mitati - in quanto non competitiva con la ve-locità con cui possono essere premuti i pul-santi di una tastiera.
Probabilmente la verità sta nel mezzo, dalmomento che le applicazioni di sistemi DSRcrescono in molti settori incontrando un cre-scente favore da parte di utenti motivati pro-fessionalmente.
Le applicazioni di sistemi DSR di cui si haconoscenza in Italia, sono:� � refertazione medica: dettatura di re-
ferti e dati del paziente. Il riconosci-mento vocale in ambito medico - gene-ralmente chiamato refertazione vocale -è diffuso sia in ambito ospedaliero pub-blico e privato sia presso studi medici especialistici. Per dare un’idea della diffu-sione della tecnologia DSR, diremo che èutilizzato anche presso alcuni studi o-dontoiatrici.
�� resocontazione di un evento assem-bleare. C’è una forte domanda del mer-cato per la trascrizione automatica diquanto pronunciato da un parlatore nel-l’ambito di una riunione (si pensi alla tra-scrizione di una seduta presso un Tribu-nale oppure al verbale di Giunta in unComune o di un Consiglio di Amministra-zione in una Società). In questi casi, l’ora-tore parla in modo spontaneo, usandoparole intercalate, inserendo balbettii espot, seguendo un filo del discorso chepuò avere concatenazioni anomale tra leparole pronunciate. Il tono del parlatoreè utilizzato per dare corpo al contenutodel discorso e non per essere collaborati-vo con un sistema di riconoscimento vo-cale. In queste condizioni, non esiste an-cora un prodotto DSR in grado di restitui-re un risultato di riconoscimento accetta-bile. Viceversa esistono esempi di succes-so riguardo alla stesura del resoconto diun evento assembleare, da parte di un o-peratore adattato e formato all’utilizzo diun sistema DSR. L’esempio più eclatanteè sicuramente il sistema “CameraVox” inuso presso la Camera dei Deputati e notoa livello internazionale.
� � preparazione di documenti. Un altro am-bito di utilizzo di sistemi DSR, superiore,per numero, a ciascuno degli esempi pre-cedenti è quello degli studi legali. Attra-verso specifici dizionari giuridici, è possi-

- 82 -
bile stendere bozze, predisporre inter-venti d’aula, preparare lettere. Anche lapreparazione di discorsi, lezioni e confe-renze può essere fatta utilizzando un si-stema DSR. Può risultare pratico, in que-ste circostanze, dettare il testo su un regi-stratore digitale portatile e scaricare ilparlato - attraverso software appositi - suun sistema DSR per l’interpretazione au-tomatica. Un’ultima “nicchia” interessanteè quella del riempimento di moduli attra-verso la voce dettando sia singoli dati (u-tilizzando la modalità C&C) sia compo-nenti testuali come osservazioni, note,descrizioni (operando in modalità a par-lato continuo).
� � simulazione di un’interazione umana. Uncaso di particolare interesse è quello dellasimulazione di interazioni vocali per la for-mazione del personale. L’esempio è quellodi un sistema per l’addestramento degli as-sistenti di volo. L’allievo dà un comandovocale ad un programma che simula il co-mandante di un aereo presente nella suazona. In base al comando ricevuto (e inter-pretato dal sistema DSR) il programma si-mula le operazioni di volo dell’aereo e l’al-lievo può verificarne l’adeguatezza.
rie di operazioni necessarie alla persona im-mobilizzata come ad esempio spostare la po-sizione del letto, accendere il televisore e viadicendo. Nel caso degli ipovedenti, si usanosistemi di dialogo come ausilio ad operazionidi routine. Un esempio a questo proposito èdato dalla rubrica telefonica vocale che per-mette di comporre numeri telefonici richia-mandoli a voce.
UN’APPLICAZIONE IN CAMPO MEDICO:PHONEMA-MED
L’impatto di un’applicazione vocale puòessere rilevante se riesce a modificare un pro-cesso produttivo semplificandolo oppure di-minuendo la necessità di risorsa umana.
È questo il caso che si manifesta tipicamen-te in Sanità quando un medico può mettere inbella copia il proprio referto in tempo realesenza dover ricorrere al personale ammini-strativo di trascrizione. Per esemplificare, par-leremo di un’applicazione specifica per la re-fertazione vocale: PhonemA.
Il metodo classico di trascrizione del re-ferto radiologico avviene attraverso l’uso deldittafono ed è sintetizzato nella figura chesegue:
I QUADERNI DI TELÈMA
TRA = tempo radiologico= TPR+TLA+TDI+TVA
TRA = tempopreparazione
esame
TLA = tempodi latenza
refertazione
TDI = tempodi latenza pertrascrizione
TVA = tempodi latenza pervalidazione
TTR = tempotrasmissione
esame
accettaz.richiestaesame
spontaneoforma delle onde
acustiche della parola ricercata
radiotelevisivi
esecuzioneesame
dettatura referto
trascrizione referto
validazione referto (firma)
trasmiss. referto al richiedente
Al di fuori delle applicazioni professionali,restano poi tutte le realizzazioni software de-stinate ai portatori di handicap. Il riconosci-mento vocale risulta di particolare ausilio perle persone affette da gravi invalidità motorie odella vista. Nel primo caso, attraverso la mo-dalità C&C, sarà possibile comandare una se-
Il processo di cui sopra richiede cinque fasioperative (ognuna delle quali introduce unalatenza) e l’attività di due risorse umane (ra-diologo e trascrittore).
Con l’introduzione del riconoscimento vo-cale, il processo di refertazione si riduce nelmodo seguente:

- 83 -
LE MACCHINE CHE PARLANO
Grazie al riconoscimento vocale, è possi-bile ottimizzare il processo di refertazioneradiologica a tre sole fasi e a una sola risorsaumana con conseguenze sia economiche(risparmio risorsa di trascrizione) sia di be-nessere del paziente: infatti, accelerando ilprocesso di cura e di dimissione diminuisceil disagio dovuto alla permanenza in ospe-dale con ulteriore recupero sui costi di de-genza (vedi Figure).
Alcune sperimentazioni si sono già occu-pate dell’argomento della refertazione voca-le, cercando di mettere in evidenza gli a-spetti di accuratezza nel riconoscimentodelle parole dettate. Tuttavia, diverse espe-rienze accumulate nel settore del refertazio-ne medica hanno dimostrato che il successodi un sistema di refertazione dipende in lar-ga misura dalla qualità e dalla semplicitàdell’interfaccia uomo-macchina, mentre il li-vello percentuale di correttezza del ricono-scimento in parlato continuo, che oggi rag-giunge (su linguaggio specialistico, ad es.medico) percentuali prossime al 100% noncostituisce più una discriminante nella scel-ta del sistema.
Dalla necessità di poter verificare i risultatinon tanto della tecnologia, quanto del siste-ma, inteso come insieme di operatori umani,di funzionalità tecnologiche e di organizza-zione è nata la sperimentazione realizzatapresso l’Azienda Ospedaliera “Umberto I” diAncona avente l’obiettivo di verificare l’im-patto derivante dall’introduzione di un siste-ma di refertazione vocale all’interno dei Servi-zi di Radiologia.
Il software di refertazione vocale “Phone-mA-Med”, che è stato utilizzato per la speri-mentazione, è stato messo a disposizione dal-la Società Gruppo Soluzioni Tecnologiche di
Trento (Gruppo AISoftw@re); la tecnologia dibase per il riconoscimento vocale - IBM Via-Voice- è stata messa a disposizione da IBM.
I risultati della sperimentazione, durata piùdi dodici mesi, hanno messo in evidenza chela refertazione vocale, quando viene usatadiffusamente, ha un impatto significativo sulprocesso di refertazione radiologica, sicura-mente avvertibile dai reparti, ed incide positi-vamente sulla durata delle degenze.
Alcune misure, verificate sperimentalmen-te, hanno dimostrato che il tempo di latenzamedio che intercorre tra la dettatura del refer-to e la sua firma viene dimezzato passandodalla dettatura tradizionale con dittafono allarefertazione vocale a computer.
Questo risultato permette l’ottenimento diimportanti risultati nell’intero flusso di cura:– il referto giunge in reparto con alcune ore
(o addirittura alcuni giorni) di anticipo;– le cure possono essere avviate prima, con
evidente vantaggio per il paziente;– la permanenza media del paziente in repar-
to diminuisce.Quest’ultimo aspetto viene verificato nella
maggioranza dei casi in cui la refertazione vo-cale viene utilizzata da almeno la metà dei ra-diologi. I recuperi per l’organizzazione ospe-daliera possono arrivare ad accorciare dimezza giornata media il ciclo di cura per ognipaziente.
Il beneficio si può estendere anche ai pa-zienti ambulatoriali, mettendo in condizioneil radiologo di produrre il referto in temporeale e di consegnarlo immediatamente alpaziente. Le specialità in regime ambulato-riale che più si avvantaggiano dall’uso dellarefertazione vocale sono quelle relative al-l’ecografia, alla mammografia e al prontosoccorso.
TRA = tempo radiologico= TPR+TLA
TPR = tempopreparazione
esame
TLA = tempodi latenza
refertazione
TTR = tempotrasmissione
esame
accettaz.richiesta
esecuzioneesame
dettatura referto
validazione referto (firma)
trasmiss. referto al richiedente

- 84 -
I vantaggi che vengono generalmente per-cepiti dai radiologi sono i seguenti:– possibilità di essere autosufficiente in qua-
lunque momento;– migliore qualità del referto prodotto, per-
ché viene controllato con l’esame ancoravisibile;
– migliore impiego del personale di video-scrittura che si può dedicare ad altre attivitàdi segreteria;
– migliore efficacia del testo scritto perché losi può immediatamente rileggere ed impa-ginare.Un vantaggio evidente per l’Amministra-
zione Ospedaliera è dato dalla riduzione del-l’attività del personale di trascrizione dei re-ferti, che può essere indirizzato a compiti piùgradevoli.
COSA MANCA AL DSR PER DIVENTAREUNA TECNOLOGIA DI SUCCESSO?
PhonemA è una delle rare storie di succes-so nel panorama del riconoscimento vocale:con più di 1500 stazioni installate in circa 300ospedali, PhonemA-Med è il leader di questanicchia di mercato e consente la produzionedi circa 9 milioni di referti medici all’anno.
I presupposti in base ai quali il prodotto èstato in grado di raggiungere questa condizio-ne di successo possono essere di ausilio perindividuare la migliore strategia per qualifica-re le tecnologie DSR e incrementarne la diffu-sione.
Innanzitutto è necessario capire se il rico-noscimento vocale è di utilità per la risoluzio-ne di un dato problema. Può sembrare unabanalità, ma quando si comincia il progetto diun’applicazione vocale, raramente si pone lanecessaria attenzione a domande quali:– esiste una tecnologia più competitiva del
vocale per questa applicazione?
– la dimensione del dizionario è troppo gran-de (in tal caso sarà difficile raggiungereperformance adeguate)?
– c’è molta ripetitività nei testi dettati (in talcaso il problema sarà risolubile con frasipredefinite)?
– i potenziali utenti sono disponibili ad usarela tecnologia? Lavorano in ambienti suffi-cientemente confortevoli? Hanno, per pro-fessione e cultura, una buona dizione?
Se l’analisi sopra descritta ha dato esito fa-vorevole, occorre lavorare su due fronti:1. Dal punto di vista tecnologico, è neces-
sario sviluppare quanto serve per puntaresubito al 99% di performance di riconosci-mento. L’utente che si rivolge al DSR è, ingenere, debole dal punto di vista informati-co e non sopporta di perdere tempo conoggetti di cui ha scarsa conoscenza e dime-stichezza. In caso di inadeguatezza del si-stema DSR alle proprie necessità, l’utentenon ha alcuno scrupolo a scegliere unmezzo di livello tecnologico inferiore mache gli rende più facile il lavoro.
2. Dal punto di vista psicologico, è oppor-tuno sviluppare interfacce coinvolgenti perl’utente, andando a verificare l’utilizzo delriconoscimento vocale all’interno del siste-ma informativo in cui si trova. Per esempli-ficare, se anche si riuscisse a fornire un si-stema DSR con performance di riconosci-mento del 100% ma tale sistema fosse inse-rito in un ambiente informativo poco gra-devole per l’utente, l’installazione del siste-ma DSR fallirebbe.
Una volta avviato il sistema DSR, sarà infi-ne necessario garantirne la manutenzione e lo
I QUADERNI DI TELÈMA

- 85 -
LE MACCHINE CHE PARLANO
continuano ad essere orientate alla venditadella sola tecnologia a bassi prezzi e non con-sentono il decollo di una classe di aziendespecializzate che producano sistemi di qualitàche possano accelerare la diffusione e l’utiliz-zo delle loro stesse tecnologie.
In attesa di un riposizionamento dei princi-pali attori del mercato DSR, nei nostri labora-tori stiamo già progettando il modello di in-terfaccia uomo-macchina del futuro. Si chia-ma PhoneidoS.
È un sistema per la refertazione radiologi-ca, che coniuga modalità di dettatura e moda-lità C&C.
Il controllo dell’applicazione è gestito, ol-tre che con la voce, anche tramite touchscreen oppure con uno speciale gamepad.
Il microfono c’è ma è invisibile: è cablato al-l’interno di una speciale mobile in materiale fo-noassorbente che contiene anche gli specialischermi per le immagini radiologiche digitali.
Mouse e tastiere sono avvertiti: ormai i lorogiorni sono contati
Alessandro TescariAmministratore Delegato
GST - Gruppo Soluzioni TecnologicheSocietà del Gruppo AISOFTW@RE
LA CONVERSAZIONE CON IL CALCOLATORE
Lo SR (Speech Recognition, o Riconosci-mento del Parlato) ha come obiettivo di-chiarato la trascrizione del parlato nelloscritto. Tale obiettivo è però troppo am-
pio e troppo ristretto al tempo stesso. Troppoampio, perché la trascrizione di tutto ciò cheviene detto, indipendentemente dal parlatore,dal mezzo di comunicazione, dalle condizioniambientali, dall’oggetto della conversazioneetc. è un obiettivo molto al di là delle possibilitàcorrenti dei sistemi di riconoscimento e, co-munque inutilmente vasto per la maggioranzadelle applicazioni pratiche (che specificanouna certa classe di parlatori, un certo insieme dicondizioni e così via). Però è anche troppo li-mitato, perché il vero fine dello SR è di produr-re una comunicazione utile tra persona e mac-china via voce, e l’utilità dell’interazione è lega-ta all’ottenimento dello scopo per cui la comu-nicazione è iniziata, indipendentemente dallaqualità tecnica dello SR impiegato nel processo.
Da questo punto di vista, lo SR si può divi-dere in due rami: da un lato, la Dettatura, in
cui il sistema rimpiazza il dattilografo (cioè ilparlatore stesso, o magari un segretario); dal-l’altro, l’Interazione, cioè i sistemi in cui il si-stema rimpiazza o collabora con un operato-re, soddisfacendo così un’esigenza del parla-tore che non è semplicemente la trascrizionedel parlato, ma la risposta al contenuto delparlato. In questa categoria ci sono sistemiche danno informazioni (e.g. elenco abbona-ti, orari ferroviari e aerei, quotazioni di borsa,informazioni sul traffico etc), che eseguonocomandi (e.g. vendite e acquisti in borsa, o-perazioni di trasferimento sul conto di banca,pagamento di bollette, organizzazione di ap-puntamenti medici etc.), che intrattengono(e.g. sistemi di simulazione di chat), che ri-chiedono operazioni da parte dell’utente (e.g.sistemi che segnalano a casa l’assenza di unoscolaro dalla scuola e chiedono ai genitori diintervenire), o sistemi ibridi (tipicamente, vo-calizzazioni di siti web che permettono navi-gazione, ottenimento di informazioni ed ese-cuzione di comandi).
sviluppo affinché il riconoscimento vocalenon venga abbandonato nel tempo.
Senza i passaggi sopra descritti, il funziona-mento di un sistema di riconoscimento vocalein un ambito professionale distribuito (e quindidi larga diffusione) è destinato all’insuccesso.
L’esperienza accumulata in oltre sette anni,ci permette di dire che, salvo rare eccezioni, latecnologia DSR acquistata da sola, senza svi-luppi mirati, ha comportato sempre esperienzefallimentari. La cosa non deve stupire. Provia-mo a pensare ad un’altra tecnologia informati-ca, ad esempio quella dei Data Base, e ponia-moci la seguente domanda: se il migliore deiData Base in commercio fosse consegnato al-l’utente finale privo di un’applicazione per ilData Entry, di quale utilità sarebbe?
Chiediamoci perché il riconoscimento vo-cale, con tutte le particolarità che abbiamodescritto in questo articolo, deve finire in ma-no a un utente che spesso lo compra per faci-litarsi l’approccio al PC e invece non riescenemmeno ad installarlo?
Quanti, degli oltre due milioni di DSR ven-duti nel mondo giacciono inutilizzati in qual-che cassetto di scrivania?
Purtroppo le strategie di distribuzione deidue leader del mercato DSR (IBM e Scansoft)

- 86 -
I sistemi a scopo di Interazione usano tuttiuna qualche forma di dialogo, cioè di intera-zione strutturata, dalle forme più semplici erigide a quelle più complesse e libere. In ge-nerale, più il sistema usa tecniche di gestionedel dialogo di tipo umano nell’interazione, emeglio reagisce l’utente.
I PROBLEMI DELL’INTERAZIONE
Storicamente, la Dettatura è stato il primo,ovvio obiettivo dello SR. Il lavoro di ricerca, elo sviluppo industriale/commerciale, hannoperò da tempo individuato l’Interazione comel’area più ricca e promettente per lo SR, siaper le limitazioni insite nella Dettatura (trai-ning e uso per utente specifico) sia per gli o-rizzonti di applicazione aperti all’Interazione(telefonia fissa e mobile, web, giochi etc). Èinteressante notare che, dopo alcuni test ini-ziali di Dettatura, le competizioni annuali perSR organizzate da DARPA (Defence AdvancedResearch Projects Agency, USA) si sono sem-pre più orientate su tasks di tipo Interazione,in particolare la richiesta di informazioni eprenotazioni aeree.
Per costruire sistemi di SR di tipo Intera-zione, si devono affrontare tre tipi di proble-mi. Il primo tipo è quello più strettamentelegato allo SR, si tratta cioè dei problemi diriconoscimento del parlato. Non tutto il par-lato ha però lo stesso valore all’interno diun’Interazione: per esempio, nel caso delleinformazioni aeree, vi sono parti assoluta-mente chiave (città di partenza, città di arri-vo, orario etc), parti di supporto (eg ‘vorreipartire da...’, ‘un volo per...’), parti conte-nenti segnali di dialogo necessarie ai finidell’operazione (e.g. ‘vorrei sapere se....’,‘potrei prenotare un...’) e parti utili nel dia-logo umano, ma non necessariamente inquello umano-sistema (e.g. ‘per favore...’,‘sarebbe così gentile da...’, ‘mi chiedevose...’). Dunque l’identificazione corretta deitermini più importanti è essenziale nell’ap-plicazione, così come lo è la consapevolez-za di quali parti sono state riconosciute consufficiente certezza e quali sono da control-lare o richiedere.
Il Dialogo ha a sua volta le sue problemati-che: per esempio può permettere rispostesingole, frasi libere con risposte singole, o fra-si libere con risposte multiple; può avere unastruttura lineare, ad albero, o a grafo; può es-sere costruito in base ad aspettative rigide oflessibili; in questo caso può essere basato sumodelli del task o dell’utente.
La Generazione, infine (cioè la generazio-ne del parlato con cui il sistema comunicacon l’utente) presenta problematiche sia ba-sate sulla qualitàfonica e prosodica del sinte-tizzatore (TTS, Text To Speech), sia sulla co-struzione del contenuto da sintetizzare, chepuò essere di tipo preconfezionato, generatoper template combinatoriale, o generato pervia logica-pragmatica.
LE FASI DEL RICONOSCIMENTO
Il riconoscimento in sè può avvenire at-traverso varie tecniche: statistiche, adattati-ve (e.g. reti neurali) o a base linguistica. Isistemi più recenti e più potenti, come il si-stema ARA sviluppato presso la Cirte, usa-no un approccio statistico, con un addestra-mento su un corpus molto ampio e apposi-tamente bilanciato ed annotato, che produ-ce, attraverso vari algoritmi, dei modelli alivello di trifoni (combinazioni di 3 fonemi,l’unità di suono del linguaggio), con le ap-propriate probabilitàdi entrare in uno diquesti modelli e di transitare da uno statoall’altro. Al momento del riconoscimento, ilsistema prova a far attraversare all’inputquesti modelli e sceglie quello con le mi-gliori probabilitàcomplessive. Il sistemaproduce una lista delle parole con i miglioripunteggi, che viene poi passata al resto delsistema, il quale può semplicemente sce-gliere la migliore, o fare ulteriori operazio-ni (per esempio confrontare le differenze dipunteggio, o prendere gli N migliori ed in-crociare i risultati coi risultati di una ricercasuccessiva).
I QUADERNI DI TELÈMA

- 87 -
LE MACCHINE CHE PARLANO
Nel caso delle parole singole, cioè quan-do all’utente è richiesto di dire solo l’infor-mazione richiesta (e.g. la stazione di parten-za) questo esaurisce l’aspetto di SR proprio.Questo però è un approccio poco usato neisistemi più recenti, perché obbliga l’utentead una interazione poco naturale di tipo aalbero. Più comunemente, l’utente può darel’informazione all’interno di una frase libera(e.g. ‘partenza da Napoli’). In questo caso, sipossono usare due approcci. Il primo è cer-care di prevedere le frasi che possono esse-re usate, ed inserirle all’interno di una gram-matica specializzata. Questo approccio ten-de ad essere fragile, cioè a funzionare moltobene quando la frase usata è simile a quellenella grammatica, e a funzionare male altri-menti. Un approccio alternativo è quello diusare una grammatica ‘garbage’ (letteral-mente, ‘spazzatura’), cioè una grammaticache contiene solo le parole da riconoscere(cioè, in questo esempio, le città), più unasequenza arbitraria di fonemi arbitrari. Que-sto approccio tende ad essere robusto, manon accurato quanto quello con grammaticaspecializzata. È possibile combinare i dueapprocci per ottimizzare il comportamentodel sistema.
Un’ulteriore complicazione è data dal casoin cui all’utente sia permesso fornire più datinella stessa frase (e.g. ‘vorrei andare da Napo-li a Palermo il 18 Maggio, nel pomeriggio). Inquesto caso, le possibili grammatiche specia-lizzate aumentano di complessità, le gramma-tiche garbage sono meno efficaci, ed è essen-ziale riconoscere non solo i dati principali(e.g. Napoli e Palermo), ma anche il contesto(in questo caso, partenza ed arrivo). Per otte-nere buone performance su questa classe diproblemi, specialmente su dizionari medio-grandi (e.g. le 3000 stazioni ferroviarie italia-ne), occorre che ogni componente sia otti-mizzato. È spesso necessario un training spe-cifico sulle parole, un lavoro di test in campoper catalogare le forme di frasi usate più co-munemente, una mescolanza accurata dellediverse tecniche, e delle buone strategie di re-cupero per i campi che non sono stati ricono-sciuti. Inoltre, la maggior parte dei sistemimoderni permettono il barge-in, cioè permet-tono all’utente di parlare in qualunque mo-mento, intervenendo sulla domanda, il checausa ulteriori difficoltànel determinare esat-tamente i limiti d’inizio e fine della frase, spe-cie in situazioni rumorose dove altri suonipossono essere confusi col l’input in modalitàbarge-in.
ELEMENTI DEL DIALOGO
La struttura del dialogo controlla il tipo diInterazione. Per esempio, il dialogo più sem-plice è quello in cui all’utente viene richiestauna sola informazione, da dire isolatamente(e.g. un numero di codice). In questo caso,non c’è nè progressione nè variazione. Più co-mune è la struttura in cui diverse domandevengono richieste in una sequenza stabilita(e.g. ‘nome’, ‘cognome’, ‘indirizzo’), tipica-mente in un’applicazione di directory enquiry.Questo modello è a sua volta superato dallestrutture ad albero, in cui vi sono vari punti dibiforcazione, in cui il sistema sceglie il prose-guo a seconda dell’informazione ricevuta.
Il caso tipico è quello in cui l’utente può inse-rire più dati assieme in una frase: a seconda diquali dati sono stati inseriti (e quali il sistema hariconosciuto con un grado accettabile di sicurez-za), il gestore del dialogo sceglie la continuazio-ne. Questo modello rappresenta in molti casi lapresente frontiera dei sistemi commerciali, spe-cialmente nei casi di liste di dati medio-grandi.
L’approccio successivo è quello basato suScripts, cioè su strutture (di tipo grafo) cheprevedono non solo i punti di scelta (comequelle ad albero), ma anche loops, salti, inter-ruzioni e sotto-scripts.

- 88 -
Tali sistemi di gestione del dialogo sonomolto avanzati, e al momento presenti soloin sistemi accademici o di dimostrazione. Èmolto probabile, tuttavia, che la prossimagenerazione di sistemi vocali per Interazio-ne sia basata su strutture di dialogo di tipoScripts.
TTS E GENERAZIONE
Dal punto di vista della produzione di par-lato da parte del sistema, si possono usare te-sti pre-registrati o impiegare un TTS. I testipre-registrati erano molto usati nel periodo incui i TTS non soddisfacevano, e vengono an-cora impiegati per applicazioni limitate e mol-to statiche, quali quelle per centralino telefo-nico di ditta, ma i miglioramenti recenti deiTTS e la loro flessibilitàe convenienza hannofatto sì che le applicazioni più moderne ecomplesse usino solo TTS.
I TTS presentano due caratteristiche fon-damentali, dal punto di vista dell’utente: laqualitàfonica della voce (cioè, quanto sia si-mile al suono di una voce umana appropria-ta alla transazione), e la qualitàprosodica,cioè della lettura (intonazione, volume, pau-se, velocità etc.). La qualità fonica dei mi-gliori TTS sul mercato per la lingua italiana èormai eccellente, specialmente per le appli-cazioni che usano altoparlanti, ma anche leversioni per telefono sono recentemente di-ventate molto gradevoli. La prosodia è mi-gliorata recentemente, ed è adeguata per ap-plicazioni più limitate, come la lettura di ora-ri. Per la lettura di pagine intere di testo,però (e.g. nel caso della vocalizazzione dipagina web), il ruolo della prosodia diventafondamentale, ed in questo campo vi sonoancora dei passi avanti da fare, in quanto al-cuni elementi prosodici non sono derivabilida corrispondenze statistiche, ma sembranodipendere in modo maggiore da elementilinguistici: grammaticali, ma soprattutto lega-ti all’interpretazione semantica e pragmaticadel testo.
Per quanto riguarda la generazione dalpunto di vista del contenuto, vi sono in ge-nere tre approcci. Nelle applicazioni piùsemplici, il testo è preconfezionato, cioè èstato preparato come parte del disegno del-l’applicazione, a parte gli elementi di datoda fornire (e.g., la frase ‘il numero da lei de-siderato è’ è già preparata, e al momentodell’esecuzione viene aggiunto il numero ri-chiesto). Per ottenere un dialogo di una cer-ta complessità con questo sistema (e.g. per
applicazioni di simulazione di chat, o perassistenti artificiali online), è necessario ave-re una gamma molto vasta di frasi preparate,ed un sofisticato sistema statistico per sce-gliere la più appropriata. Un approccio piùsofisticato è quello di usare templates (mo-duli), in cui la struttura della frase è pre-con-fezionata, e gli slots (campi) vengono riem-piti attraverso variazioni che si combinanoal run-time. Dato la crescita combinatorialedi queste frasi istanziate, questo metodo hail vantaggio della solidità derivante dal tem-plate e della varietà derivante dall’esplosio-ne combinatoriale.
Vi è anche un approccio logico-linguisti-co, in cui la struttura della frase è generata apartire dalla rappresentazione logica astrattadi ciò che si vuole dire (per esempio usandografi concettuali), accresciuta da elementi diteoria del dialogo e instanziata secondo re-gole linguistiche. Questo metodo ha il van-taggio di una maggiore flessibilità ed e-spressività, ma è anche al momento pocorobusto ed è solo impiegato in applicazionidimostrative. Come per gli altri elementi deisistemi ad interazione, è possibile ottenererisultati ottimizzati in una particolare appli-cazione usando una mistura dei tre metodidi generazione.
IL VOICE PORTAL CIRTE
Gli elementi principali del sistema VoicePortal Cirte sono costituiti dall’interfaccia te-lefonica, IVR (che include anche il modulo SRARA), dal modulo Browser e dai Voice Tem-plate, e dal prograama di amministrazione.
Il sistema è costituito da una serie di mo-duli applicativi che interagiscono tra loro perrealizzare le funzioni richieste. Tali moduli ri-siedono tutti sulla macchina IVR ad eccezioneeventuale dei Voice Template.
La struttura del progetto prevede così lasuddivisione dei compiti in 3 moduli:
Voice Portal IVR, espleta l’interazione te-lefonica acquisendo i comandi di navigazio-ne nelle modalità previste dalla configura-zione attraverso il sistema ARA. Invia i co-mandi di navigazione al modulo Browser. E-segue la conversione del testo da riprodurrein file di formato variabile a seconda dellaconfigurazione e comunque definiti da uninsieme finito.
Browser, questo modulo interpreta il conte-nuto dei Voice Template e fornisce il testo da
I QUADERNI DI TELÈMA

- 89 -
LE MACCHINE CHE PARLANO
riprodurre, nonché nel caso di interazione vo-cale il nome del dizionario che contiene l’in-sieme delle parole che è possibile riconosce-re. Esegue l’interazione con le pagine del sitoWeb leggendo i comandi dai Voice Template.Questi ultimi possono essere comandi di na-vigazione o script di esecuzione.
Voice Portal Manager, consente la modificadei parametri di funzionamento del sistema. Ilsignificato dei parametri è indicato dal pro-gramma stesso.
La figura di seguito mostra i vari moduli ele loro interazioni:
Il modulo IVR riceve i comandi in formavocale o tramite DTMF, attraverso la rete te-lefonica secondo le specifiche della stessa, eutilizzando per l’interfaccia una scheda Dialo-gic con gestione della segnalazione prescelta.I comandi vengono tradotti nel caso di rico-noscimento vocale e inviate al modulo Brow-ser tramite lo Shared Memory File.
Lo Shared Memory File è un file struttu-rato aperto in memoria e condiviso in lettu-ra e scrittura dai due processi IVR e Brow-ser. L’IVR scrive il comando da eseguire elegge i risultati quando il Browser ha rila-sciato l’accesso all’area condivisa (comandocompletato). Questo scambio è regolato da
un timeout che consente di determinare untempo massimo dal punto di vista del IVRper la ricezione dei valori di ritorno del co-mando impartito. Più avanti viene dettaglia-to il formato dei comandi e dello Shared Me-mori File, nonché le modalità di scambiodelle informazioni.
Il modulo Browser riceve i comandi nelformato di stringhe contenenti una parola oun codice DTMF, quindi interpreta la gram-matica (sezione ASR) del Voice Template erealizza il comando ad esso associato chepuò operare sulla pagina del sito Web cor-rente (script di esecuzione) oppure genera-re una navigazione ad una nuova pagina.Vengono quindi prelevati dal Voice Templa-te che identifica la pagina corrente del sito,il testo da riprodurre (dalla sezione TTS) edeventualmente, nel caso di interazione vo-cale, il dizionario per il riconoscimento vo-cale (sezione ASR), il Browser mantienequindi all’interno un puntatore al comandocorrente del Voice Template in esame. Que-sto puntatore viene azzerato ogni volta chesi naviga in una nuova pagina e permette diesegure più comandi in una stessa paginariportati nello stesso Voice template (sezio-ne CMD), un esempio è rappresentato dallepagine che contengono Form di inserimen-to dati.
1 2 3
4 5 6
7 8 9
* 8 #
BROWSERIVR
Manager
ReteTelefonica
Intrfaccia utente
File diconfigurazione
SharedMemory File
XML Parser
HTTP
Voice Templete

- 90 -
Il modulo Manager consente di modifi-care il file di configurazione a cui ha acces-so il modulo IVR. Questo file è scritto nelformato XML e contiene parametri di funzio-namento sia del IVR che del modulo Brow-ser. In particolare, alcuni parametri vengonocaricati all’avvio del modulo IVR, altri al ve-rificarsi di ogni chiamata telefonica al siste-ma, tutti i parametri sono trattati in dettaglionel Manuale Utente.
NUOVE FRONTIERE
La nuova frontiera dell’Interazione è l’usodella semantica e pragmatica direttamentenel riconoscimento. Questo vuol dire incre-mentare il modello statistico con elementiche tengono in considerazione il contestodella conversazione fino a quel momento.Per esempio, se dopo aver chiesto informa-zioni sul treno da Napoli a Palermo l’utentedice ‘e quello per Salerno, invece?’, il sistemadovrebbe rendersi conto che ci si trova difronte ad un’anafora (‘quello’ riferito a tre-no), un’ellisse (‘il treno da Napoli...’) ed una
struttura di dialogo ancora aperta (‘vorreiinformazioni su...’), per cui la frase va inter-pretata come ‘adesso vorrei informazioni sultreno da Napoli per Salerno’. Il modello didialogo a Script presume un modello dell’u-tente basato su un’attività strutturata (e.g.prenotare un biglietto aereo). Per attivitàpiùaperte (e.g. la gestione delle lamentele, gliusi per intrattenimento etc.) è necessario an-dare oltre questo modello, e usare un mo-dello basato sulle conoscenze e motivazionidell’utente, sia come classe, sia come indivi-duo. Per quest’ultimo caso, si tratta di usaresistemi adattativi (e.g. basati su reti neurali oalgoritmi genetici) che imparano il profilo diun particolare utente, o di una particolaresottoclasse. In generale, la capacità adattati-va del sistema una volta in campo apriràpossibilità di ottimizzazione anche sui ver-santi dello SR proprio e della Generazione,introducendo così una nuova generazione disistemi di SR attraverso il Dialogo.
Prof. Roberto GariglianoIdeatore del sistema di SR ARA sviluppato da Cirte e
consulente tecnico-scientifico presso Cirte
I QUADERNI DI TELÈMA
TECNOLOGIE VOCALI PER IL MONDODEI DISABILI
Dar voce a chi non ce l’ha, moltopiù che far parlare i computer, èsempre stata un’inconfessata spe-ranza di molti ricercatori che da
anni studiano le più avanzate tecnologie vo-cali. Ma non solo di questo si tratta, perchéle stesse tecnologie possono essere utilizza-te, da chi non vede, per leggere, o da chi haimpedimenti al movimento, per controllarein qualche modo l’ambiente esterno permezzo della voce.
A che punto siamo arrivati nello sviluppodi queste tecnologie? È già possibile utiliz-zarle realmente nella vita quotidiana? questoarticolo tenta di dare una risposta a questedomande, con una panoramica sui progressitecnologici e sulla disponibilità di prodotti eservizi indirizzati al mondo della disabilità,non trascurando gli aspetti normativi che,specie negli ultimi anni, stanno affrontandocon sempre maggior interesse il rapporto tratecnologia e disabilità.
Prima di inoltrarci nel complesso mondo
della disabilità, ecco una breve presentazionedelle tecnologie vocali più importanti.
LE TECNOLOGIE
Ormai assuefatti alle novità tecnologiche eincapaci di stupirci, pare ovvio che le macchi-ne si rivolgano a noi con voce umana: ci ordi-nano di ritirare il biglietto al casello dell’auto-strada, ci forniscono informazioni al telefono,annunciano la prossima fermata sul tram o ilprossimo treno alla stazione.
Ma se proviamo a curiosare dietro l’appa-rente naturalezza della tecnologia della vo-ce, scopriamo che la macchina parlante hapotuto diventare reale solo a partire dall’eradell ’elettronica. E ancora oggi, dopotrent’anni, la tecnologia vocale pone sfide edifficoltà irrisolte.
Cominciamo col dissipare il primo equivo-co: una macchina che parla non capisce ciòche dice, e legge pedissequamente ciò che èscritto (errori di ortografia compresi). In mo-

- 91 -
LE MACCHINE CHE PARLANO
do simile, un sistema di riconoscimento nonnecessariamente capisce ciò che sente. Unasemplice locuzione come “Dammelo”, ancor-ché riconosciuta correttamente, può non ge-nerare una risposta corretta da parte del siste-ma, perché esso può non capire cosa io vo-glio che mi dia.
Come in molti altri casi in cui un sistemaartificiale riproduce un comportamento uma-no, l’analogia di funzionamento tra macchinae uomo è solo superficiale; nei paragrafi suc-cessivi cercheremo di dare una panoramicaragionata delle due tecnologie vocali princi-pali: la sintesi da testo e il riconoscimento del-la voce.
Per sintetizzatore vocale, noi oggi intendia-mo generalmente un sistema digitale, costitui-to da un software che trasforma un testo in unsegnale vocale, simile a quello prodotto daun essere umano che legge. Nel processo digenerazione del segnale vocale da un testo, sipossono individuare due fasi distinte: �� l’analisi del testo, in cui si decide che cosa
pronunciare, quali suoni (fonemi) e conquale intonazione;
�� la produzione, in cui si generare il suono.
Gli sviluppi più recenti della tecnologiasi basano sulla sintesi concatenativa, meto-dologia usata per comporre nuovi messaggia partire da frammenti di voce naturale(difoni, trifoni, sequenze di molti fonemi,porzioni di parole e parole intere), che ven-gono registrati in condizioni controllate alfine di poter essere composte in modo ap-propriato, riducendo al minimo i punti digiunzione.
Per ottenere una sintesi naturale, i fram-menti di voce devono poi essere concatenatiin modo graduale e la loro prosodia, cioè ilritmo e l’intonazione con cui sono stati pro-nunciati, deve essere scelta accuratamente emodificata in modo da dare un risultato il piùsimile possibile alla voce umana.
L’elemento prosodico è di importanzachiave per comprendere le più recenti evolu-zioni della tecnologia di sintesi. Infatti, ciòche distingue i sistemi di sintesi di nuovissimagenerazione da quelli immediatamente pre-cedenti è proprio il maggior grado di natura-lezza del timbro vocale ottenuto grazie ad in-ventari di frammenti vocali molto più ampi,da cui il sistema riesce ad estrarre i più adattia realizzare il messaggio di sintesi. Il progres-so tecnologico nel campo delle memorie percomputer ha facilitato l’avvento di questi si-stemi di nuova generazione, che non hanno
bisogno di limitare il numero, e quindi la di-mensione, dei frammenti da concatenare.
RICONOSCIMENTO DELLA VOCE
Il riconoscimento della voce è una capa-cità umana che coinvolge diverse funzionidel nostro sistema nervoso: dai centri uditi-vi che raccolgono il segnale acustico, alle a-ree linguistiche del cervello che permetto-no la comprensione del significato del suo-no udito. Quando si parla di riconoscimen-to automatico della voce, si limita “automa-ticamente” il campo delle funzionalità ai li-velli più semplici del processo umano: lapercezione del suono, la classificazionedell’input in categorie finite e la sua rappre-sentazione in una sequenza simbolica chespesso, ma non necessariamente, coincidecon la trascrizione ortografica delle parole.Riprendendo il paragone della sintesi cheriproduce la funzione della lettura ad altavoce, il riconoscimento simula il processodi dettatura, con il nostro sistema nei pannidi uno scolaro diligente che trascrive ciòche sente. Anche in questo caso, però, esi-ste un’importante limitazione: il sistema diriconoscimento è in grado di trascrivere so-lo ciò che sa, ovverosia solo le parole su cuiè stato addestrato preventivamente. Ciono-nostante,il processo di riconoscimento au-tomatico può includere anche un livello diprocessing sintattico e semantico, al fine diattribuire a parole diverse lo stesso signifi-cato (“voglio andare a Milano” o “desideropartire per Milano” sono semanticamente e-quipollenti). I riconoscitori si differenzianoa livello funzionale:�� per le dimensioni del vocabolario: si va da
qualche unità (cifre, SI/NO...) a diverse mi-gliaia di parole
�� per le modalità di addestramento: dai siste-mi che devono essere addestrati per la vo-ce di ogni parlatore a quelli pre-addestratiin modo statistico, indipendententementedal parlatore
�� per le modalità di input: a parole isolate(una sola parola alla volta) piuttosto cheper il parlato continuo (più simile al lin-guaggio naturale).
Questa articolazione è spiegata dall’estre-ma difficoltà del riconoscimento della voce,dovuta alla ricchezza di suoni e parole checompongono una lingua, nonché alla gran-de varietà di pronunce di un singolo suono.A ciò si aggiungono le difficoltà grammati-

- 92 -
cali e semantiche, per cui la stessa parolapuò assumere funzioni e significati comple-tamente diversi a seconda del contesto dellafrase (i marinai non hanno ancora levatol’ancora).
TECNOLOGIE VOCALI E DISABILITÀ
Noi tutti dipendiamo dalla tecnologia; incasa e al lavoro numerosi dispositivi ci per-mettono di essere autonomi. La stessa cosavale anche per le persone portatrici di disa-bilità. È vitale riconoscere che l’utilizzo ditecnologie da parte dei disabili, se da unaparte è per loro importantissimo, non è diper se stesso una eccezione, una ulteriorediversità. Ciò è ancor più valido per le tec-nologie vocali, dal momento che tutti siamoormai abituati ad aver a che fare con mac-chine che parlano o che registrano la voce.Benché nei capitoli precedenti si stato sotto-lineato come le similitudini tra il comporta-mento umano e alcune funzionalità assicu-rate dai computer nel campo della voce sia-no spesso superficiali, vedremo come que-ste funzionalità, se usate in modo corretto,possano essere utilissime per assistere l’uo-mo in alcune funzionalità quali:– la lettura– la comunicazione– Il controllo di dispositivi– il controllo dell’ambiente esterno
Analizziamo separatamente le singole funzio-nalità correlate alle diverse tipologie di disabiltà.
LETTURA
I non vedenti e gli ipovedenti utilizzanoormai da anni i sistemi di sintesi da testo ingrado di leggere qualsiasi testo. La sintesi èinfatti l’unica alternativa al metodo di lettu-ra tattile Braille, il quale richiede però testistampati ad hoc, o dispositivi elettroniciappositi molto costosi. La grande disponi-bilità di testi in formato elettronico e la dif-fusione di Personal computer dotati di di-spositivi multimediali (schede audio, mi-crofoni, cuffie) ha favorito negli ultimi annil’utilizzo della sintesi da testo, che ha rag-giunto una qualità spesso indistinguibiledalla voce umana naturale (per provare di-versi esempi di voci di sintesi si può visita-re il sito www.loquendo.com/it/demos/de-mo_tts.htm).
Una delle applicazioni più comuni è l’ac-cesso ai siti web; tramite la sintesi della voce,è infatti possibile accedere ad internet e leg-
gere le informazioni contenute nelle singolepagine. Ciò a patto che i siti siano stati svilup-pati tenendo conto delle raccomandazionipubblicate dall’IWA sulla accessibilità dei siti(http://www.w3.org/WAI/). A questo pro-posito, in occasione dell’anno europeo del di-sabile, il parlamento italiano sta discutendouna proposta di legge per rendere obbligato-ria la certificazione sull’accessibilità per i sitidi istituzioni ed enti pubblici, come già avvie-ne in altri stati.
La lettura di informazioni non è limitataall’ambito web; sono ormai molti anni cheservizi telefonici interattivi permettono l’ac-cesso a voce a diversi tipi di informazioni u-tili. Fin dal 1998 Fs-Informa, il servizio te-lefonico automatico di Trenitalia permettel’accesso vocale all’orario dei treni 24 ore algiorno, utilizzando tecnologie vocali svilup-pate da CSELT prima e da Loquendo più re-centemente (entrambe realtà del gruppo Te-lecom Italia). Altri portali vocali sono statirecentemente sviluppati da operatori telefo-nici, e da enti pubblici quali Inps, Italgas, uf-ficio tributi del Comune di Roma, proprioper mettere a disposizione di chi non puòleggere o accedere ad internet, ma può uti-lizzare un comune telefono, le informazionied i servizi disponibili già in rete.
COMUNICAZIONE
Anche in questo campo non mancano e-sempi di applicazioni di tecnologie vocali esistemi sviluppati ad hoc o utilizzabili da disa-bili per comunicare. A questo proposito, sipossono citare i sistemi ideati nell’ambito deiprogetti finanziati dal MURST per permettereai muti di comunicare a voce tramite sistemiche sintetizzano frasi. Benché questi metodinon possano sostituire l’uso del linguaggiodei segni o della lettura labiale per la comuni-cazione diretta, possono però essere un vali-do ausilio per la comunicazione telefonica,permettendo anche a chi ha problemi di lin-guaggio di interloquire in modo diretto con ilcorrispondente.
Restano irrisolti al momento i problemi ri-guardanti i sordomuti perché, come si è vistoin precedenza, il riconoscimento del parlatolibero senza vincoli lessicali, tipico della co-municazione tra due persone, non è ancoratecnologicamente fattibile.
Un’ulteriore applicazione della sintesi datesto è il suo utilizzo quale ausilio alla Comu-nicazione Facilitata, una tecnica che ha datorisultati positivi nel trattamento di pazienti au-
I QUADERNI DI TELÈMA

- 93 -
LE MACCHINE CHE PARLANO
tistici. In questo caso, il bambino utilizza ilcomputer, o un dispositivo apposito dotato diuna tastiera semplificata, e la sintesi della vo-ce per comporre i messaggi e comunicare conchi lo circonda.
Il computer dotato di sintetizzatore vocaleè inoltre usato come ausilio per l’apprendi-mento dai ragazzi affetti da dislessia (una pa-tologia del sistema nervoso centrale che cau-sa difficoltà/impossibilità di leggere). Ascol-tando i testi letti dal computer, essi riesconoad imparare a casa le lezioni.
Esistono infine software per la rieducazio-ne dei bambini con difficoltà di produzionedel linguaggio, che si appoggiano su algorit-mi derivati dagli studi sui sistemi di sintesi ericonoscimento. Gli esercizi vengono effet-tuati attraverso un microfono collegato allascheda audio del computer, e vengono pre-sentati ai i più piccoli sotto forma di giochi. Èprevista anche la possibilità di registrare losvolgimento degli esercizi, una opzione mol-to utile per i logopedisti e per gli esperti dellariabilitazione del linguaggio, che possono co-sì analizzare, a posteriori e con l’aiuto del cal-colatore, i progressi e le caratteristiche vocalidei loro pazienti.
CONTROLLO DI DISPOSITIVI
Il riconoscimento e la sintesi della vocepossono essere utilizzati per facilitare l’ac-cesso al PC; queste tecnologie sono integra-te in software presenti sul mercato ormai daqualche anno e che recentemente hannoraggiunto buoni livelli di funzionalità. Ben-ché questi software siano progettati per unpubblico vasto, essi hanno assunto un certointeresse anche come ausili per le personecon disabilità. Sviluppati soprattutto alloscopo di rendere ancora più veloce il lavorod’ufficio, superando i problemi di lentezzanella digitazione, questi software permetto-no, in pratica, di gestire le funzionalità dibase di un personal computer senza doverutilizzare la tastiera e si rivelano utili perquei disabili motori che hanno preservatointegra la capacità di parlare.
Vi sono esempi di utilizzo del riconosci-mento della voce per permettere il controllodel selettore di direzione e velocità delle car-rozzelle. Questi sistemi sono utilizzati da disa-bili motori gravi, per raggiungere una relativaautonomia di movimento. In questi casi si uti-lizza un sistema di riconoscimento speakerdependent, in grado di addestrarsi sulle carat-teristiche della voce dell’utilizzatore, superan-
do così anche eventuali difficoltà derivate dadifetti di pronuncia eventualmente legati alladisabilità.
CONTROLLO DELL’AMBIENTE
La domotica, l’ultima frontiera domesticadell’utilizzo del computer nel quotidiano, stariproponendo su scala commerciale idee esoluzioni emerse con scopo di aumentarel’autonomia a disabili motori nell’ambientedomestico.
Il fine ultimo è quello di poter controllare ilfunzionamento di elettrodomestici o attuatoriservocontrollati con un computer. La voce, inquesto caso, permette al disabile di comanda-re a voce i vari dispositivi, permettendogli co-si di aprire porte, accendere luci, telecoman-dare il televisore, accendere il forno e svolge-re le semplici funzionalità indispensabili pervivere in modo autonomo. Lo sviluppo recen-tissimo di reti wireless domestiche (WIFI,Bluetooth..) potrà contribuire alla realizzazio-ne di ambienti senza barriere a costi più con-tenuti, facilitando la diffusione di soluzionicontrollate vocalmente che proprio nell’altocosto di impiantistica ed attuatori, ha trovatola più grande barriera.
CONCLUSIONE
Lo studio della biologia ci ha insegnato chela differenziazione e la diversità nelle formedi vita è la vera ricchezza del nostro sistemabiologico. D’altra parte, abbiamo appena sot-tolineato come il linguaggio sia un espressio-ne così complessa e differenziata da renderedifficile anche ai più potenti sistemi di calcolocomprendere e dialogare utilizzando il lin-guaggio umano a meno di limitazioni lessicalio funzionali.
La diversità come barriera e ricchezza: que-sto è quello che si ripropone come eterno bi-nomio, ben noto alle persone disabili. Se fi-nora la diversità/disabilità è stata prevalente-mente barriera, per quanto riguarda le tecno-logie vocali è già diventata in parte ricchezzain quanto fonte di stimolo al miglioramentotecnologico e per l’individuazione di nuove a-ree applicative in cui il progresso tecnologicosia strumento di autonomia.
Ing. Giuseppe CastagneriResponsabile del gruppo di sviluppo
delle interfacce vocali LoquendoPresidente APISB

- 94 -
Le tecniche di formazione a distanza di ul-tima generazione, che chiamiamo in generalee-learning, hanno introdotto nelle situazioniformative classiche l’uso del computer sia at-traverso i supporti off line (principalmentefloppy disc e cd rom, prossimamente DVDrom) sia attraverso l’accesso alla rete internet.Lo sviluppo dell’e-learning ha tratto particola-re vigore dall’affermarsi delle teorie cognitivi-ste e costruttiviste, che pongono l’accento, fral’altro, sul carattere individuale dei percorsi diapprendimento, sul ruolo attivo del discente,sull’importanza dell’interazione con gli altridiscenti nel processo di apprendimento (col-laborative learning) e sulla necessità di inte-grare il momento della valutazione nelle variefasi di tale processo. È evidente che tutti que-sti aspetti sono presenti nelle metodologie di-dattiche basate sulle tecniche dell’e-learning:se a ciò si aggiunge il vantaggio individuale dipoter scegliere il luogo e il momento più a-datti all’apprendimento, si comprende comel’apprendimento delle lingue è oggi di granlunga l’applicazione più frequente e maggior-mente efficace.
Se la lingua inglese fa ovviamente la partedel leone, si deve notare che anche chi è inte-ressato all’apprendimento dell’italiano puòtrovare parecchie offerte in modalità e-lear-ning. Una disamina, sia pure non esaustiva,delle offerte presenti sulla rete, può essere u-tile per offrire alcuni spunti di riflessione sugliaspetti positivi e i problemi aperti.
WWW.EDSCUOLA.IT/STRANIERI.HTML - Èun sito specificamente dedicato alla didatticanella scuola, a cui si accede dal sito www.ed-scuola.it. La pagina intitolata “Educazione in-terculturale e Didattica della Lingua italianacome Seconda lingua” è articolata in numero-se voci: materiali, progetti, didattica della lin-gua, interviste e articoli, le novità editoriali,link e norme.
WWW.SOCRATES-ME-TOO.ORG - Il sito pre-senta il progetto “Me Too - Anch’io. La multi-medialità per il plurilinguismo e l’interculturanelle scuole”, che si propone l’obiettivo dipromuovere la diffusione del plurilinguismosia della seconda lingua, sia delle varie linguematerne fra gli allievi figli di lavoratori mi-granti, nelle scuole di ogni ordine e grado.
WWW.UNIVE.IT/PROGETTO ALIAS - ALIAS(Approccio Alla Lingua Italiana per AllieviStranieri) - è un progetto di studio e di infor-mazione, coordinato dall’Università Cà Fosca-ri di Venezia, sul processo di integrazione lin-guistica degli allievi stranieri e di (auto)forma-zione dei docenti di italiano come secondalingua. Contiene numerosi materiali, diretta-mente scaricabili.
WWW.LOGOS.IT - Il Gruppo Logos ha resodisponibile gratuitamente dal proprio portaleil primo dizionario multilingua per bambini. IlDizionario dei bambini comprende 50 lingue.Oltre alla traduzione della parola è possibilevederne l’illustrazione, leggerne le definizionie ascoltarne la pronuncia.
http://www.italicon.it - Il portale della lin-gua italiana, offre corsi che consentono di im-parare la lingua italiana o di migliorarne la co-noscenza. I corsi sono realizzati da docentidelle Università consorziate (Aderiscono a I-CoN le Università di Bari, Cassino, Catania, Fi-renze, Genova, Milano Statale, Padova, Par-ma, Pavia, Perugia per Stranieri, Pisa, Roma“La Sapienza”, Roma “Tor Vergata”, Roma Tre,Salerno, Siena per Stranieri, Teramo, Torino,Trento, Venezia; la Libera Università di Linguee Comunicazione IULM di Milano, l’Istituto U-niversitario Orientale di Napoli, la Scuola Su-periore di Studi Universitari “S. Anna” di Pisae il Consorzio NET.T.UNO)
I corsi prevedono diverse tipologie di ser-vizi: tutoraggio di assistenza didattica, didatti-ca modulare, possibilità di utilizzo on line eoff line, lezioni ed esercitazioni didattiche in-terattive, correzioni automatiche, materiali di-dattici multimediali (audio, immagini, testi,filmati), test di autovalutazione, forum deglistudenti
http://www.individuallearning.it/site/made_in_italy.html - Made in Italy è il corsoon line di italiano per stranieri progettatosecondo le indicazioni del Quadro ComuneEuropeo. Il corso si articola in 7 livelli di ap-prendimento: 2 livelli principiante, 2 livelliintermedio e 2 livelli avanzato. È inoltre di-sponibile un livello zero, inferiore al livelloprincipiante assoluto. Per stabilire il livellodi partenza, è disponibile il test di ingresso.
I QUADERNI DI TELÈMA
L’E-LEARNING E I CORSI DI ITALIANOPER STRANIERI

- 95 -
LE MACCHINE CHE PARLANO
A conclusione di ogni livello, è previsto untest di livello.
Ogni lezione prevede approfondimenti difonetica, grammatica, sintassi e lessico ed e-sercizi per le abilità di comprensione e produ-zione linguistica (ascolto, pronuncia, lettura,vocabolario e scrittura). In qualsiasi momen-to, lo studente può avvalersi del supporto di-dattico nella sua lingua (la prima lingua di-sponibile sarà l’inglese).
Sono inoltre disponibili schede multime-diali per far conoscere aspetti significativi del-l’Italia e degli Italiani, consultabili gratuita-mente nella versione lancio.
http://www.educational.rai.it/ioparloita-liano/corso_35_38.htm - Io parlo italiano siarticola in fasi diverse che sfruttano le oppor-tunità offerte dalla comunicazione multime-diale. Il corso è seguito dai corsisti raggruppa-ti in classi di dieci-quindici partecipanti, assi-stiti dai tutor, che dopo la lezione televisiva,continuano il percorso didattico delle classinell’ora successiva, grazie alla rete costituitadai Centri territoriali permanenti per l’educa-zione degli adulti. Le quaranta lezioni delladurata di un’ora sono trasmesse dal canale sa-tellitare tematico di Rai Educational a partiredal 22 gennaio 2001.
http ://www.cyber i ta l ian .com/cgi -local/home_visitors.cgi - Un corso in cui ilfamoso burattino italiano e altri personaggi(Dante, Leonardo e tanti altri) insegnano l’ita-liano basandosi su un’idea divertente e effica-ce. Il corso offre 30 lezioni sempre a disposi-zione attraverso il collegamento Internet, unasezione grammatica, un glossario, articoli sul-l’Italia (Gallery) e collegamenti a siti d’interes-se (Links) e l’area interattiva (Meeting rooms,Calendar e Profiles) per favorire l’interazionefra i membri di CyberItalian e incontrare elet-tronicamente il professor Pinocchio.
http://corso.italica.rai.it/livello1/percor-si/unita/unita.xml - Altro corso della RAI. IlCorso di Lingua italiana, realizzato da DIDAELS.P.A., è suddiviso in 72 lezioni divise in tre li-velli Principiante, Intermedio, Avanzato.
È possibile inoltre seguire le Lezioni delcorso seguendo i percorsi per Unità, Funzio-ni, o Ambienti. Il corso è disponibile gratuita-mente in 5 lingue: Inglese, Francese, Spagno-lo, Tedesco e Portoghese.
http://www.auralog.com/it/elearning.html - Auralog è uno dei produttori di mag-
gior successo di corsi di lingue su CD Rom.Recentemente ha arricchito la sua offertaformativa con sezioni on line dei propri cor-si, con aule virtuali caratterizzate dalla pre-senza di tutor esperti. I maggiori punti diforza sono il metodo di Riconoscimento vo-cale che permette di valutare la corretta pro-nuncia, individua automaticamente gli errori(tecnologia S.E.T.S(r)) e li corregge e le Ani-mazioni fonetiche in 3D per visualizzarel’articolazione delle parole.
Quali conclusioni si possono trarre dall’e-same di queste offerte in Internet?
Innanzitutto il target di riferimento è e-stremamente variegato, per provenienza,caratteristiche sociodemografiche, compe-tenze di base sia linguistiche sia tecnologi-che. Ma la maggiore diversità risiede nellemotivazioni all’apprendimento, quelle mo-tivazioni che costituiscono la base del “pat-to formativo” tra discente ed erogatore delcorso e che rappresentano il fondamentodell’efficacia dei corsi. Dovrebbe infatti es-sere evidente che sono molto differenti lemotivazioni di apprendimento, ad esempio,da parte di chi non risiede in Italia e fa par-te di comunità linguistiche non italiane, maè discendente di italiani da una o due gene-razioni, di chi è immigrato da poco in Italiae proviene da una comunità linguistica mol-to lontana per struttura e lessico, e di chi in-fine appartiene alla koinè delle personecolte affascinate non solo dalla lingua insenso stretto ma anche dalla cultura e dallaidentità italiana,
I livelli di interattività e multimedialità sonomolto vari: in generale essi dovrebbero esserestrettamente correlati agli scopi dell’interven-to formativo e alle caratteristiche del discente.
Istruzioni, commenti, guide passo passonella lingua madre d’origine sono essenzialisoprattutto nelle prime fasi dell’apprendimen-

- 96 -
to, anche a livello scritto e non solo orale. Sideve anche tener conto, in parecchi casi, del-la non perfetta conoscenza dei caratteri latini,e della necessità quindi di offrire “tastiere vir-tuali” con caratteri non latini, dal cirillico algiapponese.
Le piattaforme di erogazione dei corsi online sono le più varie: uno dei massimi osta-coli allo sviluppo dell’e-learning è la lentez-za con cui si diffonde lo standard interna-zionale SCORM, peraltro adottato ormai datutte le maggiori piattaforme software dicreazione autoriale, erogazione e aministra-zione dei corsi.
La presenza di aule virtuali (ed eventual-mente reali) e di momenti di collaborativelearning è ancora scarsa e poco strutturata.Ciò è un ostacolo grave, poichè ormai è am-piamente condivisa l’opinione che il successodell’e-learning è favorito da soluzioni blen-ded, in cui a momenti di autoformazione si al-ternano momenti di aula in gruppo.
I test di valutazione all’ingresso, nelle fasidi apprendimento e al termine del corso nonsi appoggiano a sistemi di valutazione suffi-cientemente standardizzati e riconosciuti. Ènoto invece che il test linguistico effettuatonelle varie fasi dell’apprendimento è parte in-tegrante del processo stesso e del patto for-mativo tra discente e insegnante: le piattafor-me di e-learning, che permettono l’autoaccer-tamento eventualmente ripetuto, semplifica-no enormemente il processo, lo rendono tra-sparente al discente e ne “sdrammatizzano”l’effettuazione. D’altro canto questi test devo-no essere concepiti da chi progetta il corso te-nendo ben presente i “syllabus” che presiedo-no al test di certificazione finale. La certifica-zione infatti non è soltanto un momento fon-
damentale di accertamento condiviso dellecompetenze linguistiche, ma è in moltissimicasi la motivazione primaria per la frequenzaai corsi.
Un discorso a parte merita l’utilizzo delletecnologie TTS text to speech (che consento-no di “far leggere” al computer con risultatisoddisfacenti testi scelti, ad esempio, su ap-positi siti internet) e soprattutto SR speech re-cognition. Quest’ultima è ampiamente pre-sente da anni in tutti i corsi di lingua su CDRom, ma non è ancora stabilmente presenteon line. È ovvia l’importanza di ST ai fini del-l’autovalutazione dell’apprendimento, poichèuna corretta pronuncia e intonazione costitui-sce un elemento fondamentale nella padro-nanza della lingua. I passi avanti sono statinotevoli. Ricordo che fino a pochi anni fa uti-lizzavo un metodo infallibile per far “fallire”tali sistemi: sottoponevo a misurazione la pro-nuncia di una mia redattrice e quella dell’in-segnante madrelingua. Invariabilmente “vin-ceva” la redattrice, ma soltanto perché di for-mazione “teatrale” e abilissima quindi nell’“i-mitare” pronuncia e intonazione del testo dipartenza. Solo con gli ultimi software a dispo-sizione questi ostacoli sono stati superati.L’integrazione dei sistemi di speech recogni-tion nelle piattaforme di erogazione dei corsion line consentirà di integrare nel sistema diautoaccertamento delle competenze acquisiteanche i test di pronuncia.
In conclusione: grazie all’e-learning oggil’apprendimento dell’italiano può essere piùsemplice, più efficace e meno costoso per lepiù diverse categorie di discenti.
Prof. Paolo ParlavecchiaE-Biscom
I QUADERNI DI TELÈMA


















