
Valutazione di descrittori per il rilevamento automatico di nuclei cellulari in immagini di...
122
Anno Accademico 2011-2012 UNIVERSITÀ DEGLI STUDI DI TRIESTE FACOLTÀ DI INGEGNERIA CORSO DI LAUREA SPECIALISTICA IN INGEGNERIA INFORMATICA Tesi di laurea "VALUTAZIONE DI DESCRITTORI PER IL RILEVAMENTO AUTOMATICO DI NUCLEI CELLULARI IN IMMAGINI DI MICROSCOPIA A FLUORESCENZA" Laureando: Relatore: Paolo Fabris Felice Andrea Pellegrino Correlatore: Walter Vanzella
Transcript of Valutazione di descrittori per il rilevamento automatico di nuclei cellulari in immagini di...

Anno Accademico 2011-2012
UNIVERSITÀ DEGLI STUDI DI TRIESTE
FACOLTÀ DI INGEGNERIA
CORSO DI LAUREA SPECIALISTICA IN INGEGNERIA INFORMATICA
Tesi di laurea
"VALUTAZIONE DI DESCRITTORI PER IL RILEVAMENTO
AUTOMATICO DI NUCLEI CELLULARI IN IMMAGINI DI
MICROSCOPIA A FLUORESCENZA"
Laureando: Relatore:
Paolo Fabris Felice Andrea Pellegrino
Correlatore:
Walter Vanzella

2 Sommario
Ai miei amici,
a tutti coloro che mi vogliono bene
a tutti quelli che mi hanno supportato per tutto questo tempo
ai miei carissimi genitori che mi sono sempre stati vicino

3 Sommario
Sommario SOMMARIO ..................................................................................................................................................... 3
INDICE DELLE FIGURE ....................................................................................................................................... 7
RINGRAZIAMENTI ............................................................................................................................................ 9
1. INTRODUZIONE .................................................................................................................................... 10
1.1. OBBIETTIVI DEL PROGETTO ....................................................................................................................... 10
1.2. L’ALGORITMO ........................................................................................................................................ 11
1.3. MICROSCOPIA A FLUORESCENZA ................................................................................................................ 11
2. REGIONI D’INTERESSE ........................................................................................................................... 14
2.1. INTRODUZIONE....................................................................................................................................... 14
2.2. NORMALIZZAZIONE DELLE IMMAGINI .......................................................................................................... 14
2.3. ESTRAZIONE DEI PUNTI D’INTERESSE ........................................................................................................... 18
2.4. RICERCA DEI PARAMETRI PER IL FILTRO DOG ................................................................................................ 28
2.5. ESTRAZIONE DELLE REGIONI D’INTERESSE ..................................................................................................... 29
2.6. ASSEGNAZIONE DELLE ROI ALLA CLASSE DI APPARTENENZA ............................................................................. 33
3. FEATURE ............................................................................................................................................... 34
3.1. INTRODUZIONE....................................................................................................................................... 34
3.2. PROPRIETÀ DELLE FEATURE ....................................................................................................................... 34
3.3. SHAPEINTENSITY..................................................................................................................................... 37
3.4. ZERNIKE ................................................................................................................................................ 39
3.5. TRASFORMATA DI FOURIER-MELLIN, AFMT, DAFMT E FAFMT .................................................................... 42
3.6. TRASFORMATA DCT................................................................................................................................ 46
4. MACCHINA A VETTORI DI SUPPORTO ................................................................................................... 48
4.1. INTRODUZIONE....................................................................................................................................... 48
4.2. LA MACCHINA ........................................................................................................................................ 48
4.2.1. Classificatore lineare su dati linearmente separabili .................................................................... 50
4.2.2. Classificatore lineare su dati non linearmente separabili ............................................................. 53

4 Sommario
4.2.3. Classificatore non lineare .............................................................................................................. 54
4.2.4. Cross-validation ............................................................................................................................ 55
5. RECEIVER OPERATING CHARACTERISTIC ............................................................................................... 57
5.1. INTRODUZIONE....................................................................................................................................... 57
5.2. SPAZIO ROC .......................................................................................................................................... 57
5.3. GENERAZIONE EFFICIENTE DEI PUNTI DI UNA CURVA ROC ............................................................................... 60
5.4. AUC .................................................................................................................................................... 62
6. NVIDIA CUDA, ARCHITETTURA E MODELLO DI PROGRAMMAZIONE ..................................................... 63
6.1. INTRODUZIONE....................................................................................................................................... 63
6.2. GPU COME COMPUTER PARALLELO ............................................................................................................ 65
6.3. ARCHITETTURA NVIDIA FERMI GF110 ...................................................................................................... 69
6.3.1. Host Interface ............................................................................................................................... 70
6.3.2. Memory Controller ........................................................................................................................ 70
6.3.3. Gerarchia memoria ....................................................................................................................... 71
6.3.4. GDDR5 ........................................................................................................................................... 72
6.3.5. GigaThread Engine ........................................................................................................................ 72
6.3.6. Streaming Multiprocessor ............................................................................................................. 73
6.3.7. Instruction cache ........................................................................................................................... 74
6.3.8. Dual warp scheduler e dispatch unit ............................................................................................. 74
6.3.9. Register file ................................................................................................................................... 76
6.3.10. LD/ST ........................................................................................................................................ 76
6.3.11. SFU ........................................................................................................................................... 76
6.3.12. Texture Unit ............................................................................................................................. 76
6.3.13. CUDA Core ................................................................................................................................ 77
6.4. INTERFACCIA CUDA ................................................................................................................................ 79
6.4.1. Architettura ................................................................................................................................... 79
6.4.2. SIMT .............................................................................................................................................. 82
6.4.3. Organizzazione thread .................................................................................................................. 82
6.4.4. Organizzazione della memoria ..................................................................................................... 84

5 Sommario
6.5. LIBRERIE ............................................................................................................................................... 85
6.6. VELOCITÀ DI ELABORAZIONE...................................................................................................................... 86
7. BENCHMARK ........................................................................................................................................ 87
7.1. INTRODUZIONE....................................................................................................................................... 87
7.2. HARDWARE E SOFTWARE IMPIEGATI ........................................................................................................... 88
7.3. VALUTAZIONE DELLE CLASSIFICAZIONI MANUALI EFFETTUATE DAGLI ESPERTI ........................................................ 90
7.4. VALUTAZIONE DEI PARAMETRI DELLA DOG .................................................................................................. 91
7.5. VALUTAZIONE DELLE PRESTAZIONI IN FASE DI ADDESTRAMENTO ....................................................................... 92
7.6. VALUTAZIONE DELLE PRESTAZIONI IN CLASSIFICAZIONE ................................................................................... 98
7.7. VALUTAZIONE DELLA VELOCITÀ DI ELABORAZIONE .......................................................................................... 99
8. CONCLUSIONI ..................................................................................................................................... 101
BIBLIOGRAFIA .............................................................................................................................................. 104
APPENDICE A ............................................................................................................................................... 105
A.1. DIRECTX 11 SU HARDWARE DIRECTX 10 E DIRECTX 9.0C .................................................................................... 105
A.1. SHADER MODEL 5 ........................................................................................................................................ 105
A.2. VERTEX E INDEX BUFFER ................................................................................................................................ 106
A.3. PRIMITIVE .................................................................................................................................................. 106
A.4. INPUT ASSEMBLER ........................................................................................................................................ 108
A.4. RASTERIZATION ........................................................................................................................................... 108
A.5. PIPELINE GRAFICA DIRECTX 11 ....................................................................................................................... 108
A.5.1. Architettura shader model unificata ............................................................................................... 108
A.5.2. Tessellation ..................................................................................................................................... 109
A.5.3. Schema logico della pipeline grafica DirectX 11 ............................................................................. 112
A.6. SPAZI IN UNA SCENA 3D ................................................................................................................................ 115
A.6.1. OBJECT E WORLD SPACE ............................................................................................................................. 115
A.6.2. VIEW E CLIP SPACE .................................................................................................................................... 116
A.6.3. SCREEN SPACE E HSR ................................................................................................................................ 117
A.7. NVIDIA APPROFONDIMENTI .......................................................................................................................... 118
A.7.1. ROP ................................................................................................................................................. 118
A.7.2. Tessellation ..................................................................................................................................... 118

6 Sommario
A.7.3 CUDA ................................................................................................................................................ 119
APPENDICE B ............................................................................................................................................... 121
B.1. SVILUPPARE MEX IN VISUAL STUDIO 2010 PROFESSIONAL ................................................................................... 121
B.2. SVILUPPARE CUDA KERNEL IN VISUAL STUDIO 2010 PROFESSIONAL ..................................................................... 121
APPENDICE C ............................................................................................................................................... 122
C.1. LIBSVM ...................................................................................................................................................... 122

7 Indice delle figure
Indice delle figure FIGURA 1 IMMAGINE CAMPIONE DI MICROSCOPIA A FLUORESCENZA .................................................................................... 12
FIGURA 2 CLASSIFICAZIONE MANUALE DA PARTE DI UN ESPERTO ......................................................................................... 13
FIGURA 3 ZOOM IN UNA REGIONE CLASSIFICATA MANUALMENTE DA UN ESPERTO ................................................................... 13
FIGURA 4 IMMAGINE NORMALIZZATA ............................................................................................................................ 14
FIGURA 5 RAPPRESENTAZIONE A COLORI ........................................................................................................................ 15
FIGURA 6 VARIAZIONE DI LUMINOSITÀ A COLORI .............................................................................................................. 15
FIGURA 7 IMMAGINE FLATTED ...................................................................................................................................... 16
FIGURA 8 NORMALIZZAZIONE CHE SFRUTTA LA MEDIANA SU IMMAGINE CON LUMINOSITÀ UNIFORME ........................................ 17
FIGURA 9 FUNZIONE GAUSSIANA MONODIMENSIONALE CON MEDIA NULLA ........................................................................... 19
FIGURA 10 FUNZIONE GAUSSIANA BIDIMENSIONALE CENTRATA .......................................................................................... 20
FIGURA 11 FILTRAGGIO DOG ...................................................................................................................................... 21
FIGURA 12 RICERCA DEI MASSIMI LOCALI ....................................................................................................................... 22
FIGURA 13 SOGLIATURA DI OTSU E RIDLER CALVARD........................................................................................................ 25
FIGURA 14 SOGLIATURA DI OTSU E DI RIDLER CALVARD SU DOG ........................................................................................ 26
FIGURA 15 CORREZIONE NELLA GENERAZIONE DEI PUNTI D’INTERESSE IN CONDIZIONI NON OTTIMALI ......................................... 28
FIGURA 16 IMMAGINE BINARIA DALLA DOG ................................................................................................................... 29
FIGURA 17 FILTRAGGIO DOG AL NEGATIVO CON IMPOSTAZIONE DEI PUNTI D'INTERESSE A ZERO ............................................... 30
FIGURA 18 BACINI WATERSHED .................................................................................................................................... 31
FIGURA 19 BLOB GENERATI DAI BACINI WATERSHED ......................................................................................................... 31
FIGURA 20 BLOB CHE CONTENGONO UN PUNTO D’INTERESSE ............................................................................................. 32
FIGURA 21 ESTRAZIONE ROI CON TRASLAZIONE DEL CENTRO DI MASSA ................................................................................ 32
FIGURA 22 FILTRAGGIO DELLA ROI CON FUNZIONE SIGMOIDALE ......................................................................................... 33
FIGURA 23 PIANO CARTESIANO .................................................................................................................................... 36
FIGURA 25 RICOSTRUZIONI DELLA ROI CON DIVERSI GRADI PER ZERNIKE .............................................................................. 41
FIGURA 26 CAMPIONAMENTO CON COORDINATE POLARI .................................................................................................. 44
FIGURA 27 CAMPIONAMENTO CON COORDINATE LOG-POLAR ............................................................................................. 45
FIGURA 28 ENERGIA DELLA DCT .................................................................................................................................. 47
FIGURA 29 RICOSTRUZIONE DI UNA ROI DAI COEFFICIENTI DCT ......................................................................................... 47
FIGURA 30 CLASSIFICATORE LINEARE ............................................................................................................................. 50
FIGURA 31 DIFFERENZA FRA MARGINI SVM ................................................................................................................... 51
FIGURA 32 DATI NON LINEARMENTE SEPARABILI .............................................................................................................. 53
FIGURA 33 SPAIO D’INPUT E DELLE FEATURE ................................................................................................................... 54
FIGURA 34 CUT-OFF .................................................................................................................................................. 58
FIGURA 35 GENERAZIONE ROC ................................................................................................................................... 61
FIGURA 36 GPU VS CPU FLOATING-POINT ..................................................................................................................... 66
FIGURA 37 GPU VS CPU BANDA DI MEMORIA ................................................................................................................ 67
FIGURA 38 ARCHITETTURA GF110 ............................................................................................................................... 69
FIGURA 39 GERARCHIA MEMORIA ................................................................................................................................ 71
FIGURA 40 CACHE L2 UNIFICATA .................................................................................................................................. 72
FIGURA 41 STREAMING PROCESSOR .............................................................................................................................. 73
FIGURA 42 ESECUZIONE KERNEL SU G80/GT200 E GF110 .............................................................................................. 74
FIGURA 43 GESTIONE THREAD NELLE ARCHITETTURE CUDA............................................................................................... 75

8 Indice delle figure
FIGURA 44 OPS PER CLOCK PER LE ISTRUZIONI ESEGUIBILI DA UNO SM ................................................................................. 75
FIGURA 45 DISTRIBUZIONE DELLE ISTRUZIONI ALL'INTERNO DI UNO SM ................................................................................ 76
FIGURA 46 CUDA CORE ............................................................................................................................................. 77
FIGURA 47 FMA VS MAD .......................................................................................................................................... 78
FIGURA 48 ARCHITETTURA MODELLO DI PROGRAMMAZIONE CUDA .................................................................................... 79
FIGURA 49 CAPACITÀ DI CALCOLO CUDA ....................................................................................................................... 81
FIGURA 50 COMPUTE CAPABILITY FEATURE CUDA........................................................................................................... 81
FIGURA 51 BLOCCHI DI THREAD .................................................................................................................................... 83
FIGURA 52 GERARCHIA MEMORIA ................................................................................................................................ 84
FIGURA 53 CALIBRATURA DOG ................................................................................................................................... 92
FIGURA 54 PERCENTUALE DI REGIONI D'INTERESSE SCARTATE NELLA FASE DI ADDESTRAMENTO DELLA MACCHINA A VETTORI DI
SUPPORTO ....................................................................................................................................................... 93
FIGURA 55 NUMERO DI COEFFICIENTI SELEZIONATI PER LA DCT .......................................................................................... 93
FIGURA 56 KERNEL POLINOMIALE ................................................................................................................................. 94
FIGURA 57 CURVA ROC KERNEL POLINOMIALE CON SHAPEINTENSITY .................................................................................. 95
FIGURA 58 KERNEL RBF ............................................................................................................................................. 95
FIGURA 59 CURVA ROC PER KERNEL RBF CON FEATURE FAFMT ....................................................................................... 96
FIGURA 60 KERNEL SIGMOIDALE ................................................................................................................................... 97
FIGURA 61 CURVA ROC PER KERNEL SIGMOIDALE CON SHAPEINTENSITY .............................................................................. 97
FIGURA 62 MIGLIORI FEATURE E KERNEL ........................................................................................................................ 98
FIGURA 63 VALUTAZIONE DEL CONTEGGIO ..................................................................................................................... 98
FIGURA 64 INCREMENTO PRESTAZIONALE SU GPU ......................................................................................................... 100
FIGURA 65 QUADRATO INDICIZZATO ........................................................................................................................... 106
FIGURA 66 VERTEX INDEX BUFFER .............................................................................................................................. 106
FIGURA 67 PRIMITIVE .............................................................................................................................................. 107
FIGURA 68 PRIMITIVA PATCH ..................................................................................................................................... 107
FIGURA 69 PIPELINE GRAFICA DIRECTX 9.0C ................................................................................................................ 108
FIGURA 70 WORKLOAD DEGLI SHADER DEDICATI ............................................................................................................ 108
FIGURA 71 PIPELINE GRAFICA DIRECTX 10 ................................................................................................................... 109
FIGURA 72 PATCH PER LA TESSELLATOR UNIT ................................................................................................................ 110
FIGURA 73 TESSELLATION REGOLARE ........................................................................................................................... 111
FIGURA 74 TESSELLATION SEMI-REGOLARE ................................................................................................................... 111
FIGURA 75 FIGURA INIZIALE PER L'EDGE FACTOR DELLA TESSELLATION ................................................................................ 111
FIGURA 76 RISULTATO DELL'EDGE FACTOR PER LA TESSELLATION ....................................................................................... 111
FIGURA 77 PIPELINE GRAFICA DIRECTX 11 ................................................................................................................... 112
FIGURA 78 SCHEMA A BLOCCHI INPUT ASSEMBLER, VERTEX SHADER, HULL SHADER, TESSELLATOR ......................................... 113
FIGURA 79 SECONDO PARTE DELLA PIPELINE GPU CON TESSELLATOR ................................................................................. 114
FIGURA 80 SPAZI IN UNA SCENA 3D ............................................................................................................................ 115
FIGURA 81 COORDINATE NEL WORLD SPACE ................................................................................................................. 116
FIGURA 82 VIEW FRUSTRUM ..................................................................................................................................... 116
FIGURA 83 PROIEZIONE DEGLI OGGETTI DAL CLIPPING SPACE AL CUBO ................................................................................ 117
FIGURA 84 POLYMORPH ENGINE ............................................................................................................................... 118
FIGURA 85 RASTER ENGINE ....................................................................................................................................... 119

9 Ringraziamenti
Ringraziamenti Uno speciale ringraziamento ad Felice Andrea Pellegrino e Walter Vanzella che mi hanno
consigliato e guidato durante il periodo di tirocinio e tesi presso la Glance Vision
Technologies Srl; mi hanno fatto apprezzare il ramo informatico dedicato all’image
processing.
Un grande grazie a Jack.
Ultimo, ma non per questo meno importante, un sentito ringraziamento agli amici e ai
parenti che mi hanno dato sostegno quando ne ho avuto bisogno.

10 Introduzione
1. Introduzione
1.1. Obbiettivi del progetto
Il progetto di questa tesi è stato sviluppato presso la Glance Vision Technologies Srl
http://www.gvt.it/; questo lavoro deriva dall’osservazione che presso la SISSA (Scuola
Internazionale Superiore Di Studi Avanzati di Trieste) gli esperti di classificazione cellulare
svolgevano in modo manuale la ricerca dei nuclei di neuroni in immagini di microscopia a
fluorescenza. L’obbiettivo che ci si prefigge è quello di automatizzare tale analisi con
conseguente raggiungimento dei seguenti benefici:
Riduzione del tempo richiesto per portare a termine le indagini;
L’esperto può concentrarsi esclusivamente sull’analisi dei risultati forniti
dall’algoritmo senza dover selezionare manualmente le regioni d’interesse valide (i
set d’immagini possono avere da 500 a 5000 regioni d’interesse valide);
L’algoritmo genera automaticamente le regioni d’interesse classificate che possono
essere usate successivamente per eseguire altre analisi (tipicamente in ambito
statistico);
Oggettività dei criteri e la conseguente ripetibilità dei risultati che non dipende da chi
svolge l’analisi.
Tutte le immagini da esaminare sono ottenute tramite la microscopia a fluorescenza che
riveste un ruolo fondamentale nell’analisi di culture cellulari. Infatti, è in grado di mettere in
risalto aspetti salienti delle cellule come la localizzazione di DNA, RNA, mitocondri e nuclei.
Le analisi di questo tipo d’immagini sono fondamentali per studiare patologie, verificare
l’evoluzione nel tempo di una malattia, analisi statistiche sulla popolazione cellulare ecc.
La strategia di fondo seguita nell’algoritmo è:
Eseguire un’analisi preliminare delle immagini per eliminare l’illuminazione non
uniforme;
Individuare le regioni d’interesse (ROI);
Rappresentare ogni ROI con opportuni descrittori (detti feature);
Usare un algoritmo d’apprendimento per affrontare il problema di
addestramento/classificazione delle ROI (rappresentate dalle corrispondenti
feature).
Nei seguenti capitoli si affrontano diverse tematiche che riguardano la classificazione binaria
delle ROI, in particolare:
Nel secondo capitolo si descrive la procedura seguita per rendere le immagini più
robuste alla luminosità non uniforme la quale può compromettere le prestazioni

11 Introduzione
dell’algoritmo in addestramento/classificazione. Successivamente si descrive
l’approccio seguito per l’estrazione delle regioni d’interesse;
Il terzo è dedicato alla rappresentazione delle ROI tramite opportuni descrittori detti
feature e si descrivono le tecniche per garantire l’invarianza per rotazione, invarianza
per traslazione e varianza per scala;
Il quarto descrive l’algoritmo d’apprendimento ossia la macchina a vettori di
supporto;
Nel quinto capitolo si presenta la descrizione delle curve ROC (Receiver Operating
Characteristic) per la caratterizzazione statistica dei risultati in classificazione binaria.
La scelta dei parametri dell’algoritmo e la valutazione delle prestazioni del medesimo
sono effettuate in base all’analisi delle curve ROC;
Il sesto tratta l’architettura NVIDIA CUDA impiegata per accelerare alcune
elaborazioni su GPU;
Il settimo presenta i risultati ottenuti;
L’ottavo riguarda le conclusioni;
Infine, l’appendice A descrive argomenti supplementari riguardanti l’elaborazione su
GPU, B illustra quali sono i passi da seguire per sviluppare in Visual Studio 2010 le
mex e i CUDA Kernel, C descrive i parametri della libreria libsvm.
1.2. L’algoritmo
Per sviluppare l’algoritmo si è scelto di usare l’ambiente MATLAB dato che mette a
disposizione una serie di strumenti che semplificano l’implementazione e quindi riducono il
tempo di sviluppo; il linguaggio MATLAB è interpretato e questo comporta lo svantaggio che
la velocità di elaborazione non è elevata. Per superare parzialmente questo inconveniente,
che influenza notevolmente il tempo totale di elaborazione, si è deciso di riscrivere una
parte della macchina a vettori di supporto con OpenMP in C/C++ (accelera l’elaborazione su
CPU multicore) e una parte degli script MATLAB in CUDA C sfruttando la programmazione
ibrida (CPU/GPU). E’ importante osservare che il wrapping fatto tramite le mex per eseguire
l’elaborazione in CUDA introduce overhead non eliminabile; in particolare la velocità di
trasferimento dei dati tra CPU e GPU è dimezzata rispetto a quanto sarebbe stato possibile
ottenere dato che le variabili nello spazio di lavoro MATLAB non sono memorizzate nella
pinned memory. Le mex sono funzioni richiamabile dall’ambiente MATLAB sviluppate in
linguaggio C/C++.
L’intero algoritmo è strutturato in modo che l’utente debba inserire solo un numero ridotto
di parametri.
1.3. Microscopia a fluorescenza
L’intero lavoro si basa sull’elaborazione d’immagini di microscopia a fluorescenza; queste
sono ottenute impiegando un microscopio a fluorescenza tipicamente usato nei laboratori
di biologia per analizzare campioni organici sfruttando i fenomeni della fluorescenza e

12 Introduzione
fosforescenza. D’ora in poi si considera soltanto il caso in cui si vogliono evidenziare i nuclei
cellulari di neuroni che è la situazione trattata in questo progetto.
Le procedure per ottenere le immagini consistono nel marcare i campioni d’interesse con
molecole fluorescenti, ossia il fluorocromo, e successivamente il tutto è illuminato con un
fascio di luce a una specifica lunghezza d’onda; il fascio luminoso è assorbito dal
fluorocromo che provoca l’emissione di luce a lunghezza d’onda maggiore e questo
permette di generare un colore diverso da quello della luce assorbita. Tramite un filtro si
separano i due tipi di luce e si considera soltanto quella generata dal fluorocromo; una tipica
immagine ottenuta con questa tecnica è riportata di seguito.
Figura 1 Immagine campione di microscopia a fluorescenza
Su immagini come quella di sopra, gli esperti di classificazione eseguono delle analisi per
separare i nuclei delle cellule da altri corpi estranei; di seguito si riporta una tipica
classificazione manuale.

13 Introduzione
Figura 2 Classificazione manuale da parte di un esperto
Figura 3 Zoom in una regione classificata manualmente da un esperto
I punti d’interesse inseriti dall’esperto marcano le regioni d’interesse valide, le ROI non
segnate sono da considerarsi come non valide.

14 Regioni d’interesse
2. Regioni d’interesse
2.1. Introduzione
L’estrazione delle regioni d’interesse presenti in un’immagine è il primo problema da
affrontare; le regioni d’interesse (ROI) sono porzioni rilevanti dell’immagine che possono
contenere i nuclei cellulari da identificare. Lo scopo è di generare una ROI per ogni oggetto
che può rappresentare un nucleo cellulare.
2.2. Normalizzazione delle immagini
Prima di poter elaborare un’immagine di microscopia a fluorescenza è necessario eseguire
una normalizzazione della stessa per renderla visibile a un operatore umano e al tempo
stesso ridurre l’influenza della variazione di luminosità che può compromettere l’estrazione
delle regioni d’interesse.
La luminosità non uniforme ha i seguenti effetti indesiderati:
C’è la possibilità che una porzione dello sfondo sia estratta come ROI quando in
realtà questa non dà alcun contributo informativo per individuare i nuclei delle
cellule;
Compromette la reale distribuzione dell’intensità del potenziale nucleo.
Il primo passo quindi consiste nell’eseguire la normalizzazione dell’immagine da elaborare
tra zero e uno. Il risultato è riportato in figura.
Figura 4 Immagine normalizzata
Dall’immagine in tonalità di grigio non si riesce ad apprezzare completamente la variazione
di luminosità; se si usa una rappresentazione in cui l’intensità segue il seguente schema di
colori (dove l’intensità più bassa è posta a sinistra e quella più alta a destra)

15 Regioni d’interesse
Figura 5 Rappresentazione a colori
si ottiene
Figura 6 Variazione di luminosità a colori
Da questa è possibile notare che la luminosità non è uniforme nell’immagine ed ha la
tendenza a essere più intensa nell’angolo in basso a destra. Per rendere l’immagine a
luminosità uniforme si dovrebbe avere a disposizione un’immagine con solo sfondo
(ottenuta nelle stesse condizioni di quella da analizzare) e combinarla con quella avente le
cellule tramite la seguente formula
dove è l’immagine con le cellule, è l’immagine con solo sfondo (chiamata
anche immagine flatted) e è l’immagine con luminosità uniforme. Il problema è che
non è disponibile direttamente e quindi è necessario ricavarla dall’immagine iniziale
estraendo solo lo sfondo; per fare questo si è deciso di sfruttare un filtro che fa la media
dato che è semplice da implementare e se la finestra di applicazione del filtro non è troppo
ampia si eseguono i calcoli velocemente. Si è scelta come dimensione della finestra di
filtraggio una abbastanza ampia da cancellare le cellule dall’immagine e allo stesso tempo
abbastanza ridotta da fare i calcoli velocemente; il risultato dell’estrazione dell’immagine
da nell’esempio considerato è

16 Regioni d’interesse
Figura 7 Immagine flatted
Da questa si nota in dettaglio la distribuzione della luminosità. Da osservare che prima
dell’applicazione del filtro si applica del padding verticale e orizzontale in modo da evitare in
prossimità dei bordi dell’immagine che la media sia fatta con dei pixel zero (che stanno fuori
dai bordi); successivamente si esegue un ritaglio in modo da estrarre la parte senza padding.
A questo punto si ha a disposizione un’immagine con distribuzione uniforme della
luminosità; si può inoltre notare che in tutte le immagini a disposizione, il 50% + 1 dei pixel è
sfondo, quindi è possibile sfruttare la mediana per cancellare quasi completamente il
rumore presente sullo sfondo con le seguenti operazioni eseguite in sequenza:
dove è la mediana di e è l’immagine normalizzata a luminosità
uniforme dopo la sottrazione con la mediana.
Il risultato finale è riportato di seguito, da cui si può notare che l’effetto della luminosità è
stato completamente cancellato.

17 Regioni d’interesse
Figura 8 Normalizzazione che sfrutta la mediana su immagine con luminosità uniforme
Con questa procedura si ha che le immagini sono sempre rappresentate tra zero e uno e i
pixel risentono meno l’influenza della luminosità non uniforme che può essere diversa tra le
immagini; in questo modo le ROI e quindi le feature possono essere calcolate in condizioni
pressoché identiche tra un’immagine e l’altra.
Altra osservazione da fare è che nelle immagini spesso si presenta la situazione in cui alcuni
blob, gli agglomerati di pixel che formano un oggetto da analizzare, sono a contatto con i
bordi dell’immagine e risultano “tagliati”; per evitare di compromettere il comportamento
dell’algoritmo d’apprendimento si è deciso di non considerare i blob vicini ai bordi, il che è
anche una strategia tipica utilizzata nella classificazione manuale delle cellule.

18 Regioni d’interesse
2.3. Estrazione dei punti d’interesse
Dopo aver normalizzato l’immagine e aver eliminato gli effetti della luminosità non uniforme
è necessario procedere all’individuazione delle regioni d’interesse; si può notare che gli
oggetti presenti nelle immagini sono per lo più ovali e tipicamente l’intensità è concentrata
al centro dei medesimi, per questo motivo si è fatta la scelta di sfruttare una tecnica basata
sul Laplaciano per individuare i punti in cui si hanno le maggiori variazioni d’intensità. Da
notare che in questo modo, oltre a mettere in risalto i centri dei potenziali nuclei, si
mettono in risalto anche i bordi degli oggetti che devono essere cancellati. Una volta che i
punti d’interesse sono a disposizione, l’algoritmo li sfrutta come seme per costruire le
regioni d’interesse.
Di solito nell’ambito dell’image processing, per applicare il Laplaciano a un’immagine, si usa
una delle due seguenti tecniche:
LOG (Laplacian of Gaussian);
DOG (Difference of Gaussian).
La tecnica impiegata per applicare il laplaciano in questo lavoro si basa sulla DOG dato che
dal punto di vista computazionale è più veloce e semplice da implementare rispetto alla LOG
di cui è una buona approssimazione. Come si vedrà successivamente, entrambe le tecniche
richiedono l’uso di filtri gaussiani; prima di procedere con la trattazione è necessario
descrivere quest’ultimo filtro.
Un filtro gaussiano monodimensionale con deviazione standard e media nulla si ottiene
dalla seguente funzione
Siccome questa non si annulla con in , il supporto del filtro è teoricamente
infinito. Però per valori di fuori da , la funzione può essere considerata nulla
dato che il 99.7% dell’area sottesa della gaussiana risiede nell’intervallo suddetto.
Di seguito si riporta il profilo del filtro con .

19 Regioni d’interesse
Figura 9 Funzione gaussiana monodimensionale con media nulla
Nel caso bidimensionale si ha che il kernel del filtro con deviazione standard è
dove e rappresentano le coordinate; come nel caso precedente si ha che il 99.7% del
contributo è dato per e nell’intervallo . La finestra del kernel gaussiano
bidimensionale può quindi essere approssimata tramite una finestra quadrata di dimensioni
x ; questo filtro è di tipo passa basso.
Di seguito si rappresenta la distribuzione nello spazio con e media nulla:

20 Regioni d’interesse
Figura 10 Funzione gaussiana bidimensionale centrata
Tornando al filtro LOG si ha che
dove con s’indica la funzione che rappresenta un’immagine continua, il laplaciano
e il risultato del filtraggio che si può calcolare tramite la convoluzione; poiché
l’immagine è rappresentata da un insieme discreto di pixel, è necessario individuare un
kernel che approssimi la derivata seconda nella definizione del laplaciano. Due tipici kernel
approssimati sono riportati di seguito (il primo per intorni 4-connessi e il secondo per 8-
connessi):
L’inconveniente nell’usare la convoluzione dell’immagine con uno di questi due filtri
approssimati consiste nel fatto che sono molto sensibili al rumore (alte frequenze); per
attenuarlo, si filtra l’immagine con un filtro gaussiano. L’operazione di convoluzione è
associativa, quindi è possibile costruire prima un filtro ibrido dato dalla combinazione di
quello gaussiano con quello laplaciano e successivamente convolvere questo con
l’immagine. Tutto ciò porta a due vantaggi:
Siccome i kernel del filtro gaussiano e laplaciano sono molto più piccoli
dell’immagine da considerare, questo metodo richiede poche operazioni
aritmetiche;
Si può precalcolare il kernel e quindi fare solo la convoluzione durante
l’elaborazione.
La funzione 2-D LOG centrata nello zero con deviazione standard della gaussiana è data da
Il secondo filtro che si presenta sfrutta il kernel della DOG che è dato da

21 Regioni d’interesse
dove < sono rispettivamente le deviazioni standard della prima e seconda gaussiana.
La DOG quindi consiste nel fare la differenza tra due immagini ottenute dal filtraggio
gaussiano delle medesima ma con deviazioni standard differenti; il filtro gaussiano con
deviazione standard maggiore ha un effetto di filtraggio più accentuato.
I vantaggi del filtraggio DOG su quello di tipo LOG sono:
Semplicità d’implementazione;
Velocità di computazione maggiore (il kernel del filtro gaussiano 2D è separabile,
quindi il kernel della DOG può essere calcolato come il contributo di due kernel
gaussiani separabili);
Buona approssimazione della LOG con
.
Per i vantaggi elencati, si è deciso di impiegare il filtro DOG in luogo di LOG.
L’algoritmo, una volta a disposizione l’immagine normalizzata con luminosità non uniforme
cancellata, applica la DOG; a questo punto si passa alla ricerca dei massimi locali. Si
riportano il risultato del filtraggio e relativa ricerca dei massimi.
Figura 11 Filtraggio DOG

22 Regioni d’interesse
Figura 12 Ricerca dei massimi locali
Si può notare che in questo caso ci sono tanti punti d’interesse vicini generati in
corrispondenza delle zone poche “stabili”, cioè lì dove ci sono delle continue variazioni
d’intensità (anche se d’entità molto ridotta) causa rumore residuo. Siccome ci sono delle
zone in cui i punti d’interesse sono molto vicini fra loro (le aree nere), queste vanno a
compromettere l’estrazione delle ROI (si rischia di generare tantissime ROI vuote causa il
filtraggio circolare che sarà descritto durante la fase di estrazione delle medesime) oltre che
a ridurre di molto la velocità di elaborazione complessiva delle successive fasi. Per evitare
questi effetti indesiderati si può quindi applicare all’immagine filtrata con la DOG una
sogliatura globale in modo da cancellare queste zone. Per sogliatura globale s’intende
l’individuazione di un valore d’intensità in modo tale che tutti i pixel sotto a questo siano
considerati sfondo (e quindi è possibile porli a zero). Esistono diverse tecniche di sogliatura
in letteratura, molte delle quali si basano sull’analisi dell’istogramma di un’immagine; i
vantaggi principali di questi approcci consistono nella semplicità d’implementazione
dell’algoritmo ed efficienza computazionale. Ci sono però degli svantaggi da tenere in
considerazione che sono dovuti al fatto che il valore di soglia dipende da:
Distanza tra i picchi nell’istogramma;
Rumore nell’immagine;
Dimensione dei blob rispetto allo sfondo;
Luminosità nell’immagine.
Da notare che queste dipendenze sono notevolmente ridotte in questa fase di ricerca dei
massimi locali, infatti:
Il rumore è ridotto notevolmente grazie all’impiego del filtraggio DOG (che funge da
filtro passa banda);

23 Regioni d’interesse
Gli effetti della luminosità non uniforme sono stati eliminati durante la
normalizzazione dell’immagine;
Il 50% + 1 dei pixel sono sfondo quindi nell’istogramma è garantito che ci siano due
picchi distanti (uno relativo allo sfondo e uno all’intensità delle cellule che in questa
fase, dopo il filtraggio con DOG, hanno intensità pressoché identica e uniforme).
Da tutto ciò si deduce che la sogliatura globale in questo contesto è un buon approccio per
ridurre la generazione di punti d’interesse indesiderati.
Ci sono molti ricercatori nell’ambito dell’elaborazione digitale d’immagini ad aver proposto
diverse procedure per eseguire la sogliatura, una delle più usate prende il nome di
sogliatura di Otsu.
La sogliatura di Otsu si basa sul metodo del discriminante; i pixel dell’immagine sono
associati a due classi differenti: e ; dove
rappresenta il livello di sogliatura, valore in tonalità di grigio e il numero di livelli di grigio
nell’immagine considerata. L’algoritmo valuta le varianze delle due classi e quella totale, la
soglia ottima è scelta massimizzando la varianza inter-classe. Per utilizzare questa tecnica in
modo efficiente è necessario che sia soddisfatta l’ipotesi in cui l’istogramma contiene due
mode dominanti; in questo caso il valore di soglia è quello che separa le due mode.
Si consideri un’immagine di dimensioni con livelli d’intensità in tonalità di grigio e
con il numero totale di pixel di livello i-esimo, allora l’istogramma normalizzato ha come
componenti
Si seleziona una soglia con e si definiscono due classi:
con tutti i pixel d’intensità tra e ;
con tutti i pixel d’intensità tra e .
La probabilità di assegnamento di un pixel alla classe è pari a
mentre per la classe
Il valore medio d’intensità dei pixel che appartengono a è

24 Regioni d’interesse
invece per la classe
La media cumulativa di livello k è pari a
mentre la media sull’immagine è
Per valutare la bontà della soglia si sfrutta la seguente formula
dove rappresenta la varianza globale dei pixel dell’immagine
e la varianza inter-classe
Più distanti sono le due medie e più la varianza inter-classe è elevata, la soglia è quella
che massimizza questa varianza; si ha
L’inconveniente di questo sogliatura è che ha la tendenza a generare una soglia troppo
aggressiva, nel senso che la soglia è in genere troppo alta in questo contesto e ciò comporta
la cancellazione di pixel che invece potrebbero dare un contributo informativo per la
generazione di punti d’interesse in prossimità di oggetti che potrebbero essere nuclei
cellulari. Per risolvere questo inconveniente è possibile usare un’altra sogliatura globale
ossia quella proposta da Ridler e Calvard che permette di calcolare un valore di soglia più

25 Regioni d’interesse
conservativo e quindi di considerare più blob. Questa procedura sfrutta il metodo di Otsu
per calcolare una soglia iniziale e successivamente in modo iterativo individua la media
sopra e sotto tale soglia; la nuova soglia è individuata come la media delle due medie
calcolate precedentemente. Il procedimento continua fino a quando la differenza tra la
nuova soglia e quella al passo precedente è inferiore a un valore prestabilito.
Di seguito si riporta il confronto tra i risultati della ricerca dei massimi locali dopo
l’applicazione della soglia di Otsu e Ridler Calvard.
Figura 13 Sogliatura di Otsu e Ridler Calvard

26 Regioni d’interesse
Figura 14 Sogliatura di Otsu e di Ridler Calvard su DOG
Da sopra si nota che conviene sfruttare la procedura di Ridler Calvard che garantisce una
soglia più conservativa rispetto a quella di Otsu e ciò comporta in genere risultati più
accurati, anche se questo ha l’inconveniente di non cancellare tutte le regioni indesiderate
afflitte da rumore. Da notare comunque che le zone affette da rumore non cancellate dopo
la sogliatura di Ridler Calvard sono in genere molto poche e quindi non compromettono la
ricerca dei nuclei cellulari infatti:
Molto probabilmente le regioni indesiderate saranno cancellate dall’algoritmo
durante la fase di estrazione delle ROI per garantire l’invarianza per rotazione (come
sarà chiarito in seguito);

27 Regioni d’interesse
Nel caso in cui le regioni indesiderate non fossero scartate dopo l’estrazione delle
ROI, queste sarebbero comunque marcate come non valide durante l’addestramento
della macchina a vettori di supporto senza compromettere la ricerca dei nuclei
cellulari.
Per ottenere i punti d’interesse correttamente è necessario impostare opportunamente i
parametri della DOG; questi parametri sono fissi per ogni immagine, quello che può
accadere è che questi non vanno bene in certe situazioni e si può avere uno dei seguenti
scenari:
I punti d’interesse generati sono troppo pochi;
I punti d’interesse generati sono molti e sono troppo vicini fra loro (se sono troppo
vicini, allora questo può compromettere l’estrazione delle ROI perché rischiano di
essere vuote).
Per il primo caso, l’unico modo per risolvere il problema è di impostare altri valori per i
parametri della DOG in modo da aumentare il numero di punti d’interesse; questo non è
attuabile perché non è possibile sapere a priori quali siano i parametri ottimali senza aver a
disposizione la classificazione fatta da un esperto (non si può sfruttare una procedura
automatizzata). Per il secondo problema si è scelto di usare un algoritmo in grado di
localizzare le situazioni in cui i punti d’interesse sono troppo vicini; i parametri da impostare
sono raggio massimo e minimo che un intorno associato a un punto d’interesse può avere:
1) Si associa a ogni punto d’interesse un intorno il cui raggio è la metà della distanza dal
punto d’interesse più vicino, se viene superato il raggio massima allora è impostato a
quest’ultimo valore;
2) Per tutti gli intorni con raggio inferiore a quello minimo consentito, si procede come
di seguito:
a. Si seleziona l’intorno con raggio più piccolo e lo si marca come analizzato;
b. I punti d’interesse che distano dal centro dell’intorno selezionato di un valore
inferiore al doppio del raggio minimo consentito sono cancellati assieme ai
relativi intorni associati;
c. Si riparte da a. fino a quando tutti gli intorni sono stati analizzati.
Il raggio dell’intorno associato a ogni punto d’interesse è impiegato per rilevare la situazione
in cui i seed sono troppo vicini. Da notare che questa situazione indesiderata si verifica di
rado; questa procedura è in grado di migliorare un po’ l’estrazione delle ROI nella
condizione suddetta. Ad esempio, forzando l’algoritmo a operare con parametri che si
scostano da quelli ottimali (per simulare la situazione descritta sopra), si ottiene (a sinistra
senza l’ottimizzazione e a destra con l’algoritmo descritto):

28 Regioni d’interesse
Figura 15 Correzione nella generazione dei punti d’interesse in condizioni non ottimali
2.4. Ricerca dei parametri per il filtro DOG
Uno degli aspetti più importanti per usare correttamente la DOG riguarda l’impostazione dei
parametri del filtro DOG ossia le deviazioni standard delle due gaussiane
un’impostazione errata può compromettere drasticamente l’estrazione delle regioni
d’interesse. La procedura seguita fa riferimento a com’è stata fatta la classificazione
manuale da parte di un esperto:
1) Imposta una coppia di deviazioni standard da un insieme prestabilito in modo che
;
2) Genera i punti d’interesse per tutte le immagini classificate manualmente
dall’esperto;
3) In ogni immagine classificata manualmente dall’esperto ci sono dei marcatori che
rappresentano i centri dei nuclei, questi sono usati per costruire un intorno in modo
che il diametro massimo sia pari a quello impostato dall’utente (scelto a priori). Nel
caso di sovrapposizioni tra intorni si ha che il diametro di questi è pari alla distanza
dal centro dell’intorno più vicino (si può osservare che i nuclei sono ovali, quindi
risulta ragionevole considerare intorni di forma circolare);
4) Per ogni intorno costruito si verifica quanti punti d’interesse generati dalla DOG sono
situati all’interno di questo. Si calcolano tre quantità che saranno usate
successivamente per stabilire quali sono i parametri migliori:
a. Validi. Numero di marcatori che hanno nell’intorno un solo punto d’interesse
generato dalla DOG;
b. Sovrannumero. Numero di marcatori che hanno nell’intorno più di un punto
d’interesse;
c. Sovra raggio. Numero di marcatori che inizialmente avevano un intorno senza
punti d’interesse ma aumentando il raggio del doppio c’è almeno un punto
d’interesse nell’intorno (è ragionevole procedere in questo modo perché i
marcatori inseriti dall’esperto possono essere posizionati anche sui bordi dei
nuclei e quindi la distanza tra centro dell’intorno e punto d’interesse può
essere maggiore del raggio dell’intorno iniziale);

29 Regioni d’interesse
5) Si riparte dal passo uno fino a esaurire tutte le coppie di deviazioni standard a
disposizione.
La coppia di deviazioni standard ottima è quella che massimizza la quantità data dalla
somma dei marcatori validi con quelli in sovra raggio, questa è un indice che descrive
quanto l’algoritmo si “avvicina” nella generazione dei punti d’interesse ai marcatori
dell’esperto. Non si prende in considerazione il sovrannumero nella ricerca dei parametri
migliori perché se la DOG generasse molti punti d’interesse, allora ci sarebbero tanti
marcatori individuati per sovrannumero (quindi non è un valore discriminante nella scelta
dei parametri).
2.5. Estrazione delle regioni d’interesse
I punti d’interesse generati servono come seme per la costruzione delle regioni d’interesse
(dette ROI, Region of Interest); queste sono tutte quelle porzioni dell’immagine in analisi che
potrebbero contenere uno o più nuclei cellulari. Lo scopo è quindi di creare delle regioni che
descrivono i dettagli degli oggetti senza compromettere il contenuto informativo (bordi,
distribuzione d’intensità ecc.).
La soluzione proposta si basa sulla segmentazione dell’immagine sfruttando i punti
d’interesse generati dalla DOG e successivamente si applica un filtraggio per cancellare gli
oggetti indesiderati all’interno delle ROI; si è fatta questa scelta perché porta il notevole
vantaggio di non compromettere il contenuto informativo e di sfruttare delle tecniche
ampiamente usate e testate nell’ambito dell’image processing.
Si converte l’immagine filtrata dalla DOG in binario.
Figura 16 Immagine binaria dalla DOG
Ora è necessario calcolare il negativo dell’immagine filtrata mediante la DOG e ogni pixel
associato a un punto d’interesse si pone a valore zero. La conversione al negativo serve per

30 Regioni d’interesse
applicare la procedura watershed (descritta successivamente) e l’impostazione dei pixel a
zero in corrispondenza dei punti d’interesse serve invece a garantire che i blob che saranno
generati saranno strettamente legati ai punti d’interesse.
Figura 17 Filtraggio DOG al negativo con impostazione dei punti d'interesse a zero
A questo punto è possibile applicare la procedura watershed sull’immagine generata dal
passo precedente che è basata sul digital elevation model: i valori di un blocco di dati sono
interpretati come altitudini. Ai minimi locali si associano gli elementi dell’intorno che sono
collegati a essi da un percorso in discesa; s’individuano così i catchment basin separati da
linee chiamate watershed. Si simula il riempimento con acqua dei bacini catchment; la
crescita delle regioni nelle varie direzioni è arrestata quando più bacini si fondono. Per dare
una forma ai blob che seguono il profilo degli oggetti, è necessario moltiplicare il risultato
che si ottiene da questa procedura con l’immagine binaria calcolata in precedenza; a questo
punto si procede con l’assegnamento delle etichette ai blob ottenuti, si cancellano i blob in
prossimità dei bordi dell’immagine (dato che non devono essere considerati
nell’elaborazione) e quelli che non contengono nessun punto d’interesse.
Da notare che a ogni punto d’interesse è associato un blob grazie all’impostazione dei
relativi pixel a zero nell’immagine al negativo.

31 Regioni d’interesse
Figura 18 Bacini watershed
Figura 19 Blob generati dai bacini watershed

32 Regioni d’interesse
Figura 20 Blob che contengono un punto d’interesse
L’utente deve impostare come parametro d’ingresso dell’algoritmo il diametro massimo che
una cellula può avere; questo è usato per estrarre regioni d’interesse quadrate centrate nei
relativi punti d’interesse, la ROI ha come lunghezza dei propri lati il diametro impostato. I
blob calcolati in precedenza servono per individuare i relativi centri di massa che sono
sfruttati per traslare il blob da analizzare nel centro della ROI. Questo passo serve per
rafforzare l’invarianza per traslazione durante il calcolo delle feature che è una delle
condizioni fondamentali da garantire per rappresentare opportunamente una ROI (il
discorso è ripreso nel capitolo relativo ai descrittori delle ROI).
Figura 21 Estrazione ROI con traslazione del centro di massa
Ora si cancellano eventuali oggetti indesiderati all’interno della ROI che possono
compromettere la fase di addestramento della macchina a vettori di supporto dato che si è
interessati ad analizzare un oggetto per volta; questa situazione si può presentare quando ci
sono oggetti vicini che hanno blob di diametro inferiore a quello impostato dall’utente. La
strategia impiegata consiste nel calcolare una matrice che ha le medesime dimensioni della
ROI che deve essere moltiplicata elemento per elemento con quest’ultima; questa matrice si
ottiene sfruttando la funzione sigmoidale come riportato di seguito:

33 Regioni d’interesse
Dove è la matrice che deve essere moltiplicata elemento per elemento con i pixel
della ROI, è il raggio del blob associato alla ROI (si calcola come la metà dell’asse maggiore
dell’elisse che contiene il blob) e è la distanza dal centro della ROI.
Figura 22 Filtraggio della ROI con funzione sigmoidale
E’ importante notare che in questo modo gran parte degli oggetti indesiderati all’interno
della ROI sono cancellati; non conviene sfruttare direttamente i blob individuati
precedentemente perché si rischia di compromettere la forma degli oggetti da analizzare. Il
principale svantaggio però è legato al fatto che in questo modo non sempre è possibile
cancellare con accuratezza i blob indesiderati, quindi la macchina a vettori di supporto dovrà
gestire le situazioni in cui le ROI contengono anche parti di oggetti indesiderati e non solo
quello effettivamente da analizzare.
2.6. Assegnazione delle ROI alla classe di appartenenza
Per l’addestramento della macchina a vettori di supporto è necessario stabilire quali ROI
devono essere considerate come positive e quali negative; è indispensabile avere a
disposizione il risultato di classificazione manuale di un esperto. Per stabilire la classe di
appartenenza di una ROI si sfruttano i blob associati a ogni regione e si verifica se il blob
contiene almeno un marcatore inserito dall’esperto di classificazione; nel caso sia presente
un marcatore, allora la ROI dovrà essere considerata come positiva, altrimenti negativa.
L’approccio considerato è migliore rispetto a quello basato sulla ricerca di marcatori
all’interno di un intorno centrato nei punti d’interesse perché ci sono varie situazioni in cui
questi punti sono molto distanti dai marcatori inseriti dagli esperti (ciò andrebbe a
compromettere l’associazione della ROI alla corretta classe di appartenenza). Invece, con
l’approccio basato sui blob, si prende in considerazione la forma degli oggetti e quindi si
aumenta la probabilità di individuare i marcatori inseriti dall’esperto; lo svantaggio è che se
l’esperto ha inserito i marcatori in prossimità dei bordi delle cellule allora questa soluzione
potrebbe non rilevare tali marcatori (di solito i marcatori sono posti nel centro delle cellule,
quindi il problema è quasi sempre trascurabile).

34 Feature
3. Feature
3.1. Introduzione
Dopo aver descritto come si estraggono le regioni d’interesse, ora è necessario stabilire
come rappresentarle prima di inoltrarle all’algoritmo d’apprendimento Support Vector
Machine (SVM); la rappresentazione fa riferimento a dei descrittori che prendono il nome di
feature. Il problema da affrontare consiste quindi nell’individuare delle feature in grado di
descrivere in modo efficiente le regioni d’interesse; per efficienza s’intende che con un
numero ridotto di descrittori si è in grado di rappresentare le caratteristiche salienti degli
oggetti. Si può osservare che spesso gli oggetti che rappresentano nuclei cellulari sono di
forma ovale oppure hanno forme meno regolari e le texture degli oggetti non validi sono
abbastanza simili fra loro (dato che spesso rappresentano rumore o porzioni di cellule a
intensità pressoché uniforme); quindi, conviene usare dei descrittori in grado di mettere in
risalto le forme degli oggetti ma anche la loro texture interna.
Per costruire della feature con alto contenuto informativo per la SVM, cioè affinché questa
sia in grado di discriminare correttamente gli oggetti presenti nelle immagini, è necessario
garantire tre proprietà:
Invarianza per traslazione, ossia la posizione dell’oggetto da analizzare all’interno di
un’immagine non deve influenzare il calcolo delle feature;
Invarianza per rotazione, cioè due oggetti uguali ma ruotati devono generare le
medesime feature;
Varianza per scala, le feature devono essere strettamente legate alla scala
dell’oggetto.
Garantire le caratteristiche suddette è uno dei principali problemi da affrontare prima del
calcolo delle feature e dell’addestramento dell’algoritmo di apprendimento.
In questo lavoro si presentano come tipologie di feature ShapeIntensity, Zernike, DCT, FMT
(distinte in FAFMT e DAFMT).
3.2. Proprietà delle feature
L’invarianza per traslazione è garantita dalla fase di traslazione del centro di massa del blob
d’interesse nel centro della ROI come descritto nel capitolo precedente.
La varianza per scala dipende unicamente dal tipo di feature, quindi queste devono essere
scelte in modo da renderle dipendenti dalla scala degli oggetti da analizzare.
L’invarianza per rotazione la si può ottenere in quattro modi diversi:
Ruotare le ROI e per ogni rotazione calcolare le feature da passare alla SVM;
Agire direttamente sulle feature in modo che sia garantita questa proprietà;

35 Feature
Ruotare i vettori di supporto della SVM;
Rendere direttamente le ROI invarianti per rotazione.
La prima soluzione richiede di ruotare (per un numero finito di volte) tutte le ROI, calcolare
per ogni rotazione le relative feature e passarle alla SVM; l’inconveniente è che deve essere
la SVM ad “apprendere” che le ROI sono ruotate in base a quanto descritto dalle feature, ciò
non garantisce l’invarianza per rotazione in tutti le possibili situazioni (la macchina a vettori
di supporto può sbagliare nella classificazione). Altro inconveniente è che il tempo di
elaborazione richiesto è elevato dato che sono coinvolte molte operazioni.
La seconda soluzione non sempre è attuabile dato che dipende dalle formule impiegate per
calcolare le feature.
La soluzione basata sulla rotazione dei vettori di supporto ha l’inconveniente di complicare
l’elaborazione perché è necessario mantenere l’associazione tra vettori di supporto e
corrispondenti regioni d’interesse; altro svantaggio sta nel fatto che è necessario ruotare le
ROI e poi ricalcolare le feature, ma le rotazioni non possono essere continue (altrimenti si
avrebbero infiniti vettori di supporto che su calcolatore non è possibile rappresentare). Altro
svantaggio è che è necessario stabilire in modo empirico il numero di rotazioni da
impiegare.
La quarta soluzione è migliore rispetto alle altre perché rende direttamente le ROI invarianti
per rotazione; la soluzione che si propone si basa su una tecnica che sfrutta il gradiente sulle
regioni d’interesse da analizzare. In questo caso, prima di procedere al calcolo
dell’orientazione delle ROI, si applica un filtro gaussiano sulle ROI per ridurre il rumore. Sulle
ROI così ottenute si procede con il calcolo del gradiente
dove è il gradiente della ROI , è il versore lungo l’asse , è il versore
lungo l’asse , è la componente del gradiente lungo la direzione e lungo
l’asse .
Per risalire all’orientazione della ROI si calcola il gradiente in corrispondenza del centro
dell’oggetto in analisi; per fare questo, s’individuano i valori dei centri di e .
36 Feature
dove sono le coordinate del centro della ROI e quindi anche delle matrici e
. Sfruttando la funzione arcotangente si risale all’orientazione del centro della ROI e
quindi della ROI medesima
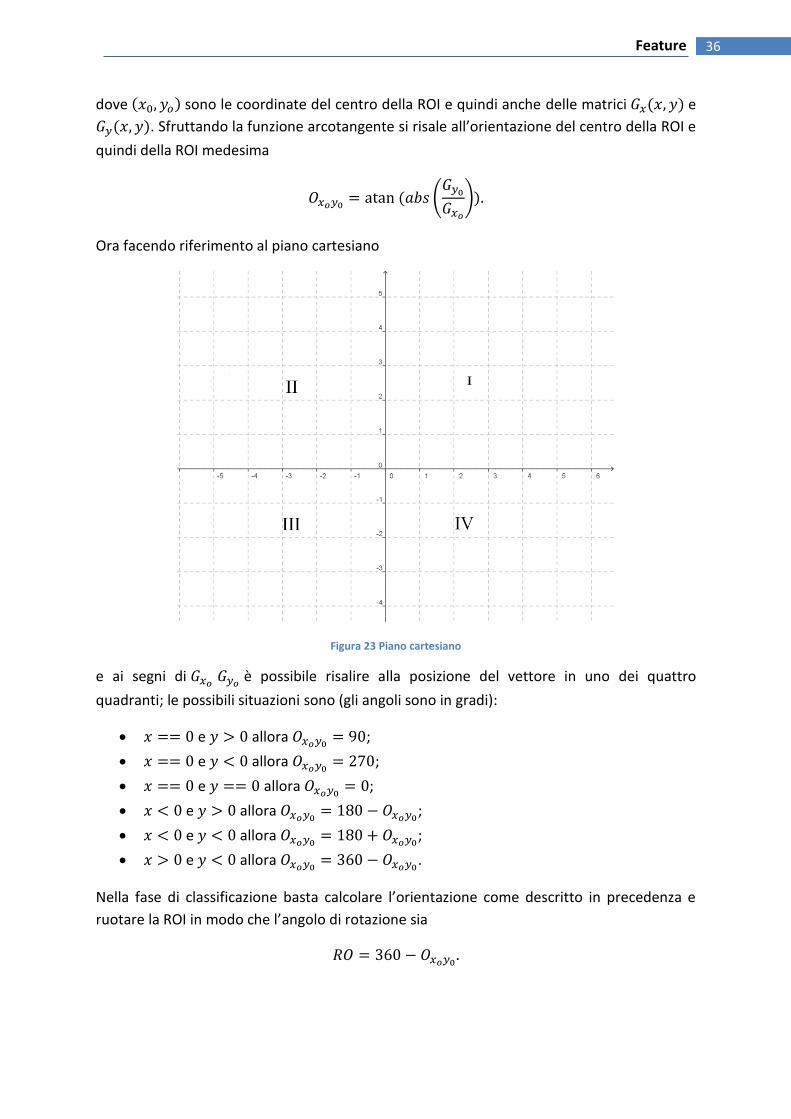
Ora facendo riferimento al piano cartesiano
Figura 23 Piano cartesiano
e ai segni di è possibile risalire alla posizione del vettore in uno dei quattro
quadranti; le possibili situazioni sono (gli angoli sono in gradi):
e allora ;
e allora ;
e allora ;
e allora ;
e allora ;
e allora .
Nella fase di classificazione basta calcolare l’orientazione come descritto in precedenza e
ruotare la ROI in modo che l’angolo di rotazione sia

37 Feature
La condizione di sopra garantisce che tutte le ROI abbiano orientazione zero; calcolando le
feature sulle ROI così ottenute, si ha che queste sono invarianti per rotazione dato che le
ROI sono sempre a orientazione zero (due ROI iniziali uguali ma con orientazioni diverse
assumono la medesima orientazione dopo l’applicazione della procedura descritta sopra,
quindi le feature calcolate sono uguali).
Nel caso in cui le ROI debbano essere impiegate nella fase di addestramento della macchina
a vettori di supporto, conviene procedere in un altro modo ossia ridurre le ROI sulle quali
calcolare le feature. Infatti alcune feature non portano contenuto informativo che permetta
di definire al meglio il modello della SVM; queste ROI sono poco robuste alla rotazione causa
rumore o forme non regolari (oggetti piccoli dello sfondo), quindi si possono non
considerare nella definizione del modello della SVM (in fase di addestramento) e ciò porta ai
seguenti vantaggi:
Migliore definizione del modello della macchina a vettori di supporto dato che si
considerano esclusivamente feature molto robuste all’invarianza per rotazione;
Si aumenta la velocità di addestramento della SVM dato che si elaborano meno ROI
e quindi meno feature.
Una ROI poco robusta è individuata ruotandola di trentacinque volte di dieci gradi, per ogni
rotazione si verifica lo scostamento dell’orientazione da quella attesa; se lo scostamento
supera i cinque gradi allora la ROI viene scartata. Si è deciso di rendere molto ridotto il
margine per garantire una definizione accurata del modello della macchina a vettori di
supporto. Se la ROI risulta robusta allora si procede come descritto in precedenza, ossia si
esegue una rotazione della regione d’interesse in modo che l’orientazione sia di zero gradi
prima di calcolare le feature.
3.3. ShapeIntensity
La prima tipologia di feature che si presenta in questo lavoro serve per descrivere la forma
dei blob, la distribuzione dell’intensità e le informazioni sul profilo dell’istogramma; questi
descrittori non possono essere impiegati per ricostruire gli oggetti analizzati. La scelta di
testare questa tipologia di descrittore deriva dal fatto che permette di descrivere in modo
naturale le caratteristiche degli oggetti da analizzare.
Le feature che si calcolano per ogni oggetto da analizzare sono: area, asse maggiore, asse
minore, rapporto tra gli assi, intensità massima, intensità media, varianza, entropia, energia,
contrasto, correlazione, omogeneità, skewness e curtosi; quasi tutte le feature menzionate
appartengono ai descrittori di forma dell’istogramma del primo e secondo ordine. Oltre a
queste se ne sono aggiunte altre per migliorare le informazioni relative alla forma degli
oggetti (area, asse maggiore, asse minore, rapporto tra gli assi).
La distribuzione di probabilità del primo ordine di un’immagine quantizzata può essere
descritta da

38 Feature
dove rappresenta la quantizzazione del livello d’intensità e è il
pixel considerato nell’immagine F di coordinate . La stima di dell’istogramma del
primo ordine è
dove rappresenta il numero totale di pixel nella finestra centrata nel punto d’interesse e
il numero di pixel d’ampiezza .
Occorre osservare che la forma dell’istogramma permette di descrivere molte
caratteristiche e in questo caso le feature prendono il nome di descrittori quantitativi di
forma dell’istogramma del primo ordine:
Le feature dell’istogramma del secondo ordine sono basate sulla definizione della
distribuzione di probabilità congiunta di una coppia di pixel. Si considerano due pixel
e di coordinate rispettivamente e posti a distanza con angolo
rispetto all’asse orizzontale; quindi la distribuzione congiunta è data da
dove sono le ampiezze quantizzate. La stima della distribuzione del secondo ordine
dell’istogramma è data da

39 Feature
dove rappresenta il numero totale dei pixel nella finestra di misura e il numero di
occorrenze per = e = . I descrittori di forma dell’istogramma del
secondo ordine sono:
Dove
Oltre a queste se ne sono aggiunte altre per migliorare le prestazioni di riconoscimento dei
nuclei cellulari, ossia il valore massimo d’intensità della cellula, asse maggiore e minore
dell’ellisse che contiene il blob considerato e il loro rapporto, area del blob ottenuta tramite
la segmentazione basata sulla sogliatura di Otsu.
3.4. Zernike
La trasformata di Zernike tipicamente si usa per l’analisi di oggetti di forma circolare di un
certo raggio, quindi in questo lavoro si presta bene alla generazione di descrittori.
L’inconveniente principale è che è necessario usare un numero molto elevato di feature
(molti coefficienti) per non perdere troppe informazioni riguardanti l’oggetto da descrivere;
ciò significa che è necessario presentare alla macchina a vettori di supporto vettori con
molti elementi (le feature) ma questo non implica necessariamente una migliore definizione
del modello della SVM.

40 Feature
Le funzioni di Zernike sono calcolate come il prodotto tra i polinomi di Zernike e le funzioni
trigonometriche coseno e seno:
Dove rappresenta il raggio e ө l’angolo, l’indice è chiamato grado della
funzione o del polinomio di Zernike, mentre con pari ed è chiamato
ordine di Zernike. I polinomi sono espressi come:
Di seguito si riportano le prime dieci funzioni di Zernike tipiche che si utilizzano nelle
applicazioni pratiche:
Queste funzioni sono un’utile base per la decomposizione di funzioni complesse perché
sono ortogonali sul cerchio di raggio unitario. Utilizzando tale ortogonalità, una qualsiasi
funzione definita sul cerchio, può essere espressa come somma delle mode di
Zernike (come nel caso delle funzioni coseno e seno nella trasformata di Fourier)
Se si rappresentano i dati in questo modo, è possibile descrivere deformazioni complesse in
termini di un numero ridotto di coefficienti associati alle mode dominanti di Zernike.

41 Feature
I coefficienti (detti momenti di Zernike) possono essere calcolati dall’inversione
dell’equazione precedente se è nota la funzione :
Il numero di coefficienti dipende dal grado del polinomio di Zernike e più questo è elevato
migliore è la rappresentazione dell’oggetto in analisi. Da notare che Zernike si può calcolare
solo all’interno di un cerchio, quindi l’oggetto da analizzare deve risiedere completamente
nel cerchio inscritto nella ROI di diametro pari alla lunghezza di un lato della ROI. Occorre
osservare che non si può aumentare il grado a un valore arbitrario dato che la velocità di
calcolo diminuisce notevolmente già da grado dieci in poi.
Di seguito si riporta un esempio di oggetto sul quale si calcola un certo numero di
coefficienti di Zernike e poi la relativa ricostruzione; rispettivamente i gradi del polinomio
sono dodici (novantuno feature), venti (duecento trentuno feature) e poi trenta
(quattrocento novantasei feature).
Figura 24 Ricostruzioni della ROI con diversi gradi per Zernike
Dalle immagini di sopra si può immediatamente notare che per rappresentare con dettaglio
elevato le caratteristiche dell’oggetto in questione sono necessari molti coefficienti; il
passaggio da grado dodici a venti non produce un miglioramento descrittivo significativo,
mentre con grado trenta si ha una buona descrizione ma il problema è che il tempo di

42 Feature
elaborazione richiesto è eccessivo dato che ci sono tantissime feature da calcolare
(quattrocentonovantasei).
3.5. Trasformata di Fourier-Mellin, AFMT, DAFMT e FAFMT
Un altro tipo di feature considerato in questo lavoro di tesi si basa sulla trasformata di
Fourier-Mellin (FMT); i principali problemi della FMT classica sono legati nell’accuratezza ed
efficienza della sua approssimazione numerica, il vantaggio è che è possibile avere una
rappresentazione accurata dell’oggetto anche con pochi coefficienti.
La trasformata di Fourier–Mellin di una funzione continua è data da
e deve valere
dove è la rappresentazione dell’immagine nel piano polare ( è il raggio e
l’angolo); questa è una trasformata globale che si applica su ogni pixel dell’immagine. Per
poterla calcolare è necessario definire il centro delle coordinate; l’inconveniente principale è
legato al calcolo dell’integrale nell’espressione di cui sopra, la FMT esiste per funzioni che
sono equivalenti a nelle vicinanze dell’origine per costante e . Occorre
osservare che la funzione di rappresentazione dell’immagine non necessariamente soddisfa
tale condizione dato che nelle vicinanze del centro dell’immagine (tipicamente corrisponde
al centro di “massa” dell’oggetto considerato) non assume valore zero; come conseguenza
non è sommabile e l’integrale per il calcolo di diverge. Altra osservazione da fare
è che la FMT è invariante per rotazione e scala di (cioè scala di ROI no dell’oggetto da
analizzare).
A causa della singolarità nell’origine delle coordinate, Ghorbel [17] ha proposto di calcolare
la FMT classica sulla funzione in luogo di dove è fissato e
deve essere un numero reale strettamente positivo; in questo caso esiste sempre la
trasformata FMT e prende il nome di trasformata di Fourier–Mellin Analitica (AFMT) di . Di
seguito si riporta l’AFMT
dove . L’anti trasformata IAFMT è data da:

43 Feature
Per , dove è l’angolo di rotazione e il fattore di scala rispetto a
, si ha che i due oggetti e hanno la stessa forma quindi sono simili. L’AFMT di g è data
da
che si può anche riscrivere come
Si può osservare che l’AFMT può essere utilizzata per calcolare feature invarianti per
rotazione (basta considerare il modulo dell’AFMT); da notare che in questo lavoro è
costante dato che le feature sono calcolate sempre su finestre (ROI) della stessa
dimensione (nel caso in cui la finestra cambiasse dimensione allora la trasformata
dipenderebbe anche dal fattore ).
Ora che si è definita l’AFMT e IAFMT per funzioni reali è necessario passare alla
rappresentazione discreta. Questa, però, non esiste direttamente e per ricavarla è
necessario stimare la trasformata diretta e inversa. L’invarianza in rotazione degli oggetti è
già gestita mediante la tecnica basata sul gradiente descritta all’inizio di questo capitolo, ma
è possibile rafforzare questa condizione considerando il modulo della trasformata;
l’inconveniente è che in questo modo si perde l’informazione sulla fase e di conseguenza
non è più possibile ricostruire l’oggetto iniziale a partire dalle feature (questo non è un
problema perché non è necessario fare la ricostruzione).
Per l’approssimazione discreta della trasformata AFMT si considera con
un’immagine discreta definita su una griglia rettangolare finita; non esiste fuori dal piano
2D, la sua AFMT non è a banda limitata e richiede un numero infinito di armoniche per
descrivere l’oggetto in questione. Su calcolatore è possibile rappresentare un numero finito
di armoniche e quindi si perde una parte dell’informazione iniziale. L’AFMT discreta a
estensione finita è calcolata per e ; nel lavoro di Goh
[18] si suggerisce di utilizzare . Per funzioni reali l’AFMT è simmetrica, quindi
indicando con la linea il complesso coniugato si ha:
D’ora in poi con si denota la ricostruzione di da un numero finito di
armoniche Fourier–Mellin; per la scelta di e non ci sono delle regole predefinite,

44 Feature
tipicamente si procede in modo empirico. Di seguito si descrivono le due approssimazioni
possibili considerate.
La prima approssimazione che si considera è quella diretta di AFMT (DAFMT) e consiste nel
campionare nel piano discreto polare e stimare gli integrali di Fourier–Mellin. La
griglia polare di campionamento si costruisce dalle intersezioni tra cerchi concentrici di
raggi incrementati di un valore fissato e linee radiali generate dal centro dell’immagine. I
passi di campionamento angolari e radiali sono rispettivamente
dove rappresenta il raggio minimo del disco che è in grado di contenere l’oggetto. I punti
di campionamento quando non corrispondono alla griglia dei pixel dell’immagine sono
calcolati per interpolazione; la rappresentazione polare dell’immagine è una matrice i
cui valori corrispondono a
dove e sono rispettivamente il raggio d’indice e cerchio d’indice .
Un esempio di campionamento in coordinate polari è riportato di seguito.
Figura 25 Campionamento con coordinate polari
La trasformata diretta DAFMT è
con
La trasformata inversa della DAFMT è data da

45 Feature
con
La seconda approssimazione possibile consiste nel cambiare la variabile d’integrazione da r a
q = ln(r), quindi si può riscrivere il tutto come la trasformata di Fourier dell’oggetto
deformato . Questa trasformata prende il nome di trasformata veloce FMT
(FAFMT) ed è data da
con
La FAFMT consiste nel campionare la nel piano log-polar e stimare Fourier-Mellin; la
conversione numerica da coordinate cartesiane in log-polar avviene come nel caso
precedente eccetto che i cerchi in questo caso sono separati esponenzialmente.
Un esempio di campionamento con log-polar è riportato di seguito.
Figura 26 Campionamento con coordinate log-polar
Per calcolare l’AFMT con questo tipo d’approssimazione si utilizza la trasformata discreta 2D
con coordinate log–polar :

46 Feature
La trasformata inversa è data da
3.6. Trasformata DCT
La trasformata DCT (Discrete Cosine Transform) è tipicamente utilizzata nelle elaborazioni
delle immagini e video; la procedura di calcolo delle feature basata sulla DCT consiste nel
calcolare la DCT direttamente sulla ROI da analizzare e poi selezionare i coefficienti (le
feature) da considerare.
Se con s’indica il valore in posizione del pixel nell’immagine di dimensione
e con il coefficiente DCT della matrice delle frequenze allora sia ha:
Per l’anti trasformata:
La DCT permette di passare da una rappresentazione nel dominio spaziale a quello della
frequenza. L’elemento è il valore massimo presente nel blocco trasformato (è la
componente continua), gli altri elementi dicono quanto potere spettrale è presente. Le
componenti a bassa frequenza rendono conto dell’andamento generale della luminosità
nell’immagine, mentre quelle ad alta frequenza codificano i dettagli e il rumore.
Per stabilire il numero di coefficienti da usare come feature è conveniente fare un’analisi
preliminare di tutte le ROI in cui si calcolano le energie dei singoli coefficienti della DCT; a
questo punto è possibile individuare l’energia media complessiva delle ROI e selezionare il
numero di coefficienti in modo che la somma delle energie di questi dia come valore quello
più vicino (per eccesso) a una soglia prestabilita dall’utente.
Di seguito si riporta un esempio dell’andamento dell’energia di una ROI, si può notare che la
DCT ha la tendenza a concentrare l’energia nei coefficienti in alto a sinistra.

47 Feature
Figura 27 Energia della DCT
Si riporta un esempio di ricostruzione della ROI con una finestra dodici
(centoquarantaquattro feature), quindici (duecentoventi cinque feature), venti
(quattrocento feature) e trenta (novecento feature). Si può notare che dopo una finestra
quindici, il miglioramento nella ricostruzione della ROI è minimo.
Figura 28 Ricostruzione di una ROI dai coefficienti DCT

48 Macchina a vettori di supporto
4. Macchina a vettori di supporto
4.1. Introduzione
Dopo aver rappresentato opportunamente le ROI tramite le feature, è necessario procede
con la classificazione delle medesime; per far questo si usa un opportuno algoritmo
d’apprendimento che dopo l’addestramento sia in grado di eseguire nel miglior modo
possibile tale classificazione. Gli algoritmi d’apprendimento stanno rivestendo un ruolo
sempre più importante in tutti quei campi in cui è necessario risolvere un problema di
classificazione:
Binario, ossia ci sono solo due possibili risposte;
Multi-classe cioè l’algoritmo è in grado di fornire più di due risposte.
Allo stato attuale esistono vari classificatori binari ma si è deciso di impiegare la macchina a
vettori di supporto (questa è implementata dalla libreria open source libsvm); si è deciso di
sfruttare la SVM (Support Vector Machine) per i seguenti motivi:
Possibilità di risolvere problemi di classificazione generali con tecniche di
programmazione quadratica o lineare ben note;
Costo computazionale ridotto e nessun problema di convergenza. Le reti neurali a
singolo strato sono molto efficienti ma si possono impiegare nel caso in cui i dati
sono linearmente separabili. Le reti multistrato possono rappresentare funzioni non
lineari ma l’addestramento è complesso, inoltre le tecniche più diffuse permettono
di ottenere i pesi della rete tramite la risoluzione a un problema di ottimizzazione
che però presenta un numero indeterminato di minimi locali;
Compatta l’informazione contenuta nel data set d’input tramite i vettori di supporto;
Gestisce dati con molte caratteristiche descrittive;
La complessità del classificatore è legata ai vettori di supporto e non alla dimensione
dello spazio delle feature. Questo comporta ridotto overfitting, ossia dopo che la
macchina è stata addestrata sul training set e l’errore minimizzato, questa tende ad
associare ai nuovi dati in ingresso un errore ridotto ossia è addestrata anche per
generalizzare le nuove situazioni che a essa si presentano.
Ultima osservazione è che la SVM è adatta per risolvere problemi binari, quindi in un
problema di classificazione multi-classe è necessario costruire una rete di macchine che
richiede una gestione dell’intera struttura; nel problema che questo lavoro si prefigge di
risolvere è possibile impiegare una singola macchina dato che la classificazione cellulare in
questo caso è binaria.
4.2. La macchina
L’algoritmo della SVM fa riferimento alla teoria di apprendimento statistico di Vapnik-
Chervonenkis (VC); questa teoria caratterizza le proprietà degli algoritmi di apprendimento

49 Macchina a vettori di supporto
che dopo l’addestramento sono in grado di generalizzare. Una SVM è un classificatore
binario che apprende il confine tra esempi appartenenti a due classi diverse. Gli esempi
d’input sono proiettati in uno spazio multidimensionale e l’algoritmo individua un iperpiano
di separazione in questo spazio in modo tale da massimizzare la distanza dagli esempi di
training più vicini (questa distanza prende il nome di margine).
Per descrivere il processo d’apprendimento è necessario introdurre un insieme di funzioni di
soglia
dove è un insieme di parametri reali che definiscono la macchina, le funzioni si
chiamano ipotesi e l’insieme è lo spazio delle ipotesi . Ora si considera un
insieme di esempi già classificati presi da una distribuzione sconosciuta :
La macchina deve trovare un’ipotesi che minimizzi il rischio, questo è in funzione di
:
L’errore teorico rappresenta la misura della bontà dell’ipotesi nel predire la classe del
punto . L’insieme genera una SVM in grado di risolvere un particolare problema di
classificazione binaria; la distribuzione di probabilità non è nota quindi non è possibile
calcolare direttamente l’errore teorico ma è necessario procedere in modo diverso per
individuare .
L’errore empirico è dato da
dove è il numero delle osservazioni a disposizione; per si ha che l’errore empirico
converge in probabilità all’errore teorico.
Prima di procedere con la descrizione della classificazione mediante macchina a vettori di
supporto è necessario introdurre il concetto di dimensione VC dello spazio delle ipotesi ;
questo è un numero naturale che rappresenta il più grande numero di punti che possono
essere separati in tutti i modi possibili dall’insieme delle ipotesi . La dimensione VC è una
misura della complessità dell’insieme e in generale per un insieme d’iperpiani separatori
di dimensione è .

50 Macchina a vettori di supporto
La teoria della convergenza uniforme in probabilità sviluppata da Vapnik e Chervonenkis
fornisce un limite alla deviazione dell’errore empirico da quello teorico; fissato con
si ha:
Dove è la dimensione VC di ; da questa espressione si ha che per ottenere l’errore
teorico minimo è necessario minimizzare la somma dell’errore empirico e della confidenza.
L’algoritmo SVM risolve efficientemente il problema di classificazione binaria minimizzando
contemporaneamente sia la dimensione VC sia il numero di errori sul training set.
4.2.1. Classificatore lineare su dati linearmente separabili
In questo caso specifico si ha che l’insieme dei dati d’ingresso, quindi le osservazioni, sono
linearmente separabili. La macchina d’apprendimento deve individuare il miglior iperpiano
che li separa in questa situazione.
Un insieme di osservazioni è linearmente separabile se esiste una coppia tale che
con
con
Le seguenti funzioni quindi rappresentano lo spazio delle ipotesi
con s’indica il discriminatore binario.
Un esempio di separazione lineare è riportato di seguito:
Figura 29 Classificatore lineare
Per quanto riguarda la notazione che sarà utilizzata d’ora in poi, si ha che: lo spazio d’input è
indicato con , lo spazio d’output , ipotesi o , training set
ed errore su un dato di test .
La distanza dell’iperpiano associato alla coppia dal generico punto è

51 Macchina a vettori di supporto
cioè è funzione di
; se s’impone che allora la distanza dell’iperpiano dal punto
più vicino deve essere maggiore di
. Per ridurre il numero d’iperpiani, e quindi migliorare la
velocità di ricerca del piano ottimale, si considerano soltanto gli iperpiani che non
intersecano nessuna delle sfere di raggio
centrate nei punti dell’insieme delle osservazioni.
L’iperpiano ottimale è quello che permette di classificare correttamente il training set e ha
minima cioè massimizza il margine alle osservazioni del training set; la norma piccola
ha come conseguenza quella di tenere la dimensione VC piccola.
Di seguito si riportano due soluzioni al medesimo problema binario, però la seconda
garantisce un minor rischio di overfitting ossia ha una migliore generalizzazione (margine più
elevato):
Figura 30 Differenza fra margini SVM
Il problema della ricerca dell’iperpiano ottimo si può descrivere tramite la
con legati al vincolo

52 Macchina a vettori di supporto
e con . Questo problema si può risolvere con la tecnica dei moltiplicatori di
Lagrange in cui s’introduce un moltiplicatore per ogni vincolo
dove rappresenta il vettore dei moltiplicatori di Lagrange positivi che fanno
riferimento ai vincoli ; deve essere minimizzata rispetto a e
massimizzata rispetto a per ottenere la soluzione ottimale. Il problema può essere
riscritto come di seguito:
Dalla prima si ha che l’iperpiano è dato da
e quindi
La funzione da ottimizzare è quadratica in cui i dati appaiono all’interno di prodotti
vettoriali; a questo punto è possibile riformulare il problema in modo più semplice
In quest’ultima formulazione si ha che i vincoli ora sono rappresentati da
vincoli sui moltiplicatori e i vettori del training set appaiono come prodotti tra vettori. La
soluzione al problema riformulato permette di individuare i moltiplicatori e il classificatore
è dato da

53 Macchina a vettori di supporto
Tutti i punti per i quali il relativo moltiplicatore è sono detti vettori di supporto (e
stanno su uno dei due iperpiani ), invece gli altri hanno il relativo moltiplicatore a zero
e quindi non hanno alcuna influenza sul classificatore. I vettori di supporto sono quelli
fondamentali che stabiliscono il comportamento della macchina e sono i punti critici del
training set (cioè quelli più vicini all’iperpiano di separazione).
4.2.2. Classificatore lineare su dati non linearmente separabili
Ora si considera la situazione in cui i dati non sono linearmente separabili come
nell’esempio seguente
Figura 31 Dati non linearmente separabili
Il piano dista dall’origine
e il punto “anomalo” dista dalla sua classe
. Nei casi in
cui i dati non siano linearmente separabili, si ha che alcune osservazioni sono in posizioni
anomale rispetto alle altre della medesima classe; si prende in considerazione una costante
di scarto (variabile di slack) che assume valori tanto più grandi quanto più lontani sono gli
elementi anomali. La coppia che soddisfa il vincolo diventa
con e . In questo modo il vincolo ammette una certa
tolleranza agli errori e un’osservazione è mal classificata se il corrispondente supera
l’unità. La sommatoria è un limite superiore al numero massimo di errori possibili sul
training set. Il problema in questo caso può essere riformulato come la minimizzazione di
con insieme degli scarti e che soddisfano i vincoli
con
La costante è il soft margin che deve essere impostata a priori. Con l’introduzione di , la
macchina cerca di minimizzare e allo stesso tempo separa le osservazioni minimizzando

54 Macchina a vettori di supporto
il numero di errori. Per la soluzione al problema di ottimizzazione si procede come visto in
precedenza, quindi tramite i moltiplicatori lagrangiani
in cui i moltiplicatori e sono associati ai vincoli
; deve essere minimizzata rispetto a e massimizzata rispetto a e
.
Con si ha che si deve massimizzare
con vincoli . La soluzione è identica al caso di dati d’input separabili
linearmente con la differenza sul vincolo sui moltiplicatori che adesso sono limitati
superiormente da ; il classificatore è
4.2.3. Classificatore non lineare
Se nello spazio d’input le osservazioni non sono linearmente separabili, in questo caso è
possibile sfruttare una funzione che mappa lo spazio d’input in quello delle feature dove
le osservazioni diventano linearmente separabili
Figura 32 Spaio d’input e delle feature
Se si mappano le osservazioni non linearmente separabili dallo spazio d’input in quello delle
feature (di dimensione maggiore rispetto al primo) per rendere i dati linearmente separabili
sfruttando la funzione di mappatura , allora l’algoritmo dipende dai dati e quindi
dal prodotto delle loro immagini da in (funzioni del tipo ). La dimensione
dello spazio delle feature influenza la velocità di calcolo; maggiore è la dimensione maggiore
è il tempo di calcolo dato che la macchina deve operare con vettori di grandi dimensioni.

55 Macchina a vettori di supporto
Per risolvere il problema descritto sopra, la SVM sfrutta una funzione kernel che restituisce il
valore del prodotto interno fra le immagini ; a questo punto è
possibile usare nell’algoritmo per ignorare la forma diretta di In questo caso si sfrutta
una rappresentazione matriciale della funzione di kernel i cui argomenti ovviamente sono i
vettori di apprendimento. Tramite la tecnica basata sul kernel, si genera una macchina che
opera in ed esegue le elaborazioni nella stessa quantità di tempo che impiegherebbe se
lavorasse con i dati originali non mappati; quello che accade è che si costruisce un
classificatore lineare ma in uno spazio differente. In dettaglio si ha che un punto d’ingresso
generico è mappato in un vettore nello spazio delle feature tramite la funzione
, dove gli sono numeri reali e le sono funzioni reali. Ora
si procede come nel caso di osservazioni non linearmente separabili, però si sostituisce la
variabile con il vettore quindi si ha che la funzione di decisione è data da
Si sostituiscono i prodotti con il kernel
Esistono vari tipi di kernel, quelli comunemente utilizzati sono:
Lineare ;
Polinomiale ;
Radial Basis Function ;
Sigmoidale .
Da osservare che i dati d’ingresso devono essere normalizzati (ad esempio tra zero e uno )
prima di essere passati alla macchina; quindi è necessario salvare i coefficienti di
normalizzazione prima dell’addestramento (uno per ogni feature) per impiegarli
successivamente nella fase di classificazione per normalizzare le osservazioni.
4.2.4. Cross-validation
Questa è una tecnica statistica che è utilizzata per addestrare opportunamente la macchina
e permette di verificare l’overfitting ossia la bontà della generalizzazione in base ai
parametri impostati (uno per il kernel e uno che rappresenta il soft margin). L’insieme delle
osservazioni è suddiviso in porzioni e a ogni passo la parte rappresenta
l’insieme di validazione ossia il sottoinsieme delle osservazioni su cui si testa la macchina
addestrata; le parti restanti rappresentano il training set su cui si addestra la
macchina. Su ogni insieme di validazione si calcola l’AUC, cioè l’area sottesa alla curva ROC
(queste curve sono descritte in dettaglio nel prossimo capitolo) e si fa la media delle curve
ROC ottenute per ricavare la ROC e quindi l’AUC finale. A questo punto si salvano i

56 Macchina a vettori di supporto
parametri della macchina e si procede nuovamente dall’inizio con dei nuovi; quando i valori
prefissati dei parametri sono stati tutti considerati, allora si scelgono come parametri ottimi
quelli che massimizzano l’AUC e con questi parametri si procede all’addestramento della
macchina su tutto il training set a disposizione. Tale procedura permette di verificare
l’overfitting e allevia il problema del campionamento asimmetrico tipico della suddivisione
degli esempi a disposizione in due sole parti (ossia training set e validation set).

57 Receiver Operating Characteristic
5. Receiver Operating Characteristic
5.1. Introduzione
Dopo aver descritto il classificatore binario, è necessario considerare il criterio per la
valutazione delle prestazioni. In questo progetto si considera esclusivamente la
classificazione binaria dato che lo scopo è di stabilire se una ROI rappresenta un nucleo di un
neurone (ROI positiva) o meno (ROI negativa); in letteratura esistono varie tecniche per
valutare le prestazioni di un classificatore binario ma in questo lavoro si considera
unicamente quella basata sulle curve ROC (Receiver Operating Characteristic). Questa scelta
deriva dal fatto che le curve ROC hanno una proprietà molto importante ossia sono
indipendenti alle variazioni delle distribuzioni delle due classi (positivi e negativi); ciò
significa che se le proporzioni tra positivi e negativi nel test cambiano ma le prestazioni
effettive del classificatore sono le medesime (veri positivi e falsi positivi non sono cambiati
in numero) allora le curve ROC non subiscono modifiche. Quest’aspetto è molto rilevante,
infatti, garantisce che a classificatori con prestazioni uguali corrispondono curve ROC
identiche indipendentemente dalle proporzioni tra positivi e negativi. Tale proprietà non
vale per tecniche che usano metriche quali accuratezza, precisione (Precision and Recall) e
funzioni di F score cioè le curve cambiano al variare delle proporzioni tra positivi e negativi
anche se le prestazioni effettive non cambiano; da ciò si evince che la tecnica di valutazione
delle prestazioni di un classificatore binario basata su curve ROC descrive al meglio le
prestazioni del medesimo. Questa particolarità delle curve ROC deriva dal fatto che lo spazio
ROC fa riferimento esclusivamente al false positive rate e true positive rate che sono
indipendenti dalle distribuzioni delle classi.
5.2. Spazio ROC
Per verificare un’ipotesi esistono molte procedure della più svariata natura che prendono il
nome di test. I test sono classificati in due categorie in base al tipo di output:
Test qualitativi, restituiscono una risposta dicotomica ossia risultato
positivo/negativo, vero/falso ecc.;
Test quantitativi, forniscono risultati in forma di variabili numeriche discrete o
continue.
Nei test quantitativi è necessario individuare un valore di soglia detto cut-off che discrimini
al meglio le due classi di positivi e negativi; i problemi principali nell’interpretazione di un
test risiedono nel fatto che esiste spesso una sovrapposizione fra i risultati ottenuti, cioè il
test non è in grado di separare correttamente le due classi da discriminare e quindi i risultati
si discostano da quelli veri. Nel caso in cui non ci fosse tale sovrapposizione, allora il cut-off
sarebbe in grado di discriminare con precisione assoluta le due popolazioni di positivi e
negativi; in pratica quello che accade è che quasi sempre esistono queste sovrapposizioni
tra le distribuzioni.
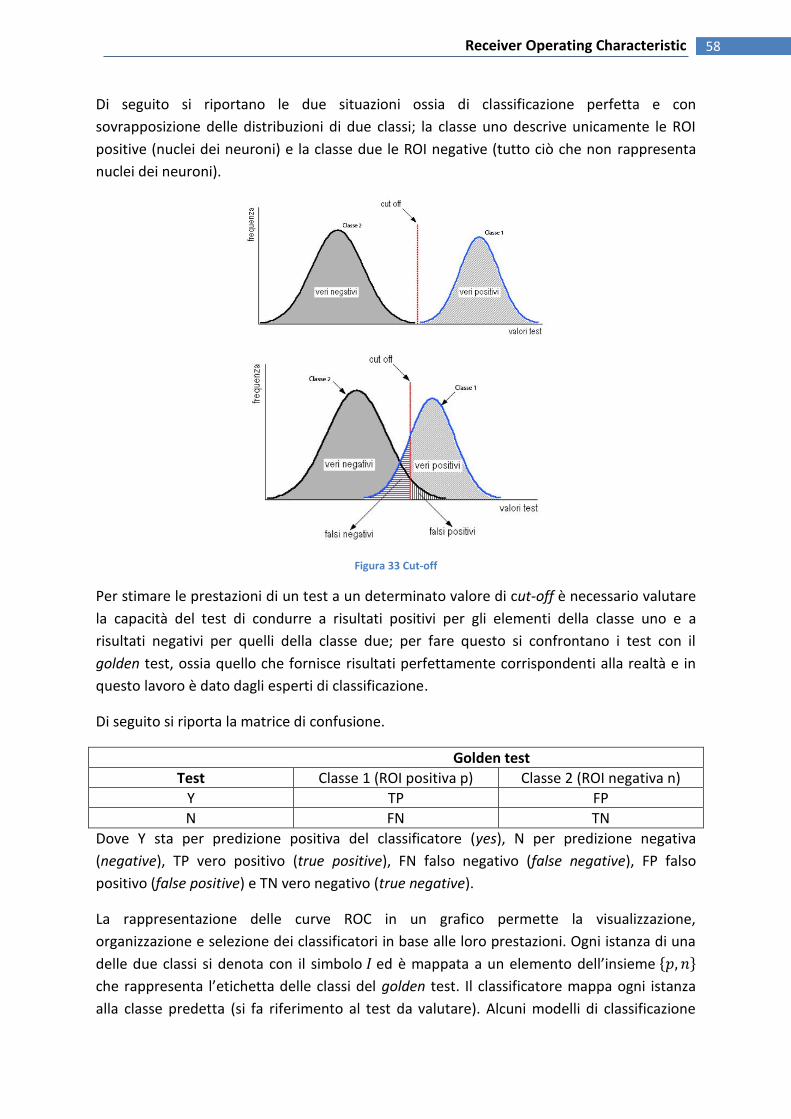
58 Receiver Operating Characteristic
Di seguito si riportano le due situazioni ossia di classificazione perfetta e con
sovrapposizione delle distribuzioni di due classi; la classe uno descrive unicamente le ROI
positive (nuclei dei neuroni) e la classe due le ROI negative (tutto ciò che non rappresenta
nuclei dei neuroni).
Figura 33 Cut-off
Per stimare le prestazioni di un test a un determinato valore di cut-off è necessario valutare
la capacità del test di condurre a risultati positivi per gli elementi della classe uno e a
risultati negativi per quelli della classe due; per fare questo si confrontano i test con il
golden test, ossia quello che fornisce risultati perfettamente corrispondenti alla realtà e in
questo lavoro è dato dagli esperti di classificazione.
Di seguito si riporta la matrice di confusione.
Golden test
Test Classe 1 (ROI positiva p) Classe 2 (ROI negativa n)
Y TP FP
N FN TN
Dove Y sta per predizione positiva del classificatore (yes), N per predizione negativa
(negative), TP vero positivo (true positive), FN falso negativo (false negative), FP falso
positivo (false positive) e TN vero negativo (true negative).
La rappresentazione delle curve ROC in un grafico permette la visualizzazione,
organizzazione e selezione dei classificatori in base alle loro prestazioni. Ogni istanza di una
delle due classi si denota con il simbolo ed è mappata a un elemento dell’insieme
che rappresenta l’etichetta delle classi del golden test. Il classificatore mappa ogni istanza
alla classe predetta (si fa riferimento al test da valutare). Alcuni modelli di classificazione

59 Receiver Operating Characteristic
generano un’uscita continua e tramite determinati valori di soglia è possibile stabilire
l’appartenenza a una classe, altri modelli producono uscite discrete ossia le etichette di
appartenenza a una specifica classe; le label predette dal classificatore binario s’indicano
con . A questo punto, dato un classificatore e un’istanza , ci sono quattro possibili
casi:
L’istanza è positiva ed è classificata come positiva, corrisponde a un TP;
L’istanza è positiva ma è classificata come negativa, quindi si è nel caso di FN;
L’istanza è negativa ed è classificata negativa, allora si ha un TN;
L’istanza è negativa ma è classificata positiva, quindi FP.
Dato un classificatore e un insieme d’istanze, si ottiene la matrice di confusione riportata
sopra; molte tecniche di valutazione delle prestazioni di un classificatore binario fanno
riferimento a questa che rappresenta la base per la costruzione di varie metriche comuni
quali:
;
;
;
.
Alle curve ROC sono associati i termini , ma anche sensitività che è la recall,
specificità che è data da
e valore predittivo positivo che è la precision.
I grafici ROC si rappresentano in un grafico a due assi, l’asse delle ascisse fa riferimento ai
e quello delle ordinate ai ; le curve ROC descrivono il compromesso tra
benefici (TP) e costi (FP).
Un classificatore discreto genera come uscite delle etichette associate alle due classi di
appartenenza, quindi a ogni classificatore corrisponde una coppia che
individua un punto nello spazio ROC. Nello spazio ROC ci sono tre punti rilevanti di
coordinate:
descrive la situazione in cui non ci sono elementi classificati come positivi,
quindi il classificatore non genera falsi positivi ma neanche veri positivi;
descrive la situazione di classificazione perfetta ossia non sono generati falsi
positivi ma soltanto i veri positivi;
si è nella situazione in cui ogni esempio è classificato come positivo.

60 Receiver Operating Characteristic
I punti sulla diagonale nello spazio ROC descrivono la situazione in cui la classificazione è
casuale; ad esempio per il punto ci si attende un 70% di veri positivi ma anche
un 70% di falsi positivi, quindi la probabilità che un elemento classificato positivo sia
effettivamente corretto è 0.5 (come nel lancio casuale di una moneta). Lo stesso discorso
vale anche per tutti gli altri punti della diagonale. Ciò implica che la regione dello spazio ROC
da considerare è data dal triangolo equilatero di coordinate e la regione
sotto questo triangolo usualmente è vuota. Se si nega il risultato fornito da un classificatore,
allora i veri positivi diventano falsi negativi (errori) e i falsi positivi diventano veri negativi;
ciò significa che se si ha un punto nel triangolo in basso a destra, questo può essere negato
per ottenere un punto nel triangolo in alto a sinistra (ad esempio la negazione di è ). Da
queste osservazioni si deduce che i punti sulla diagonale non portano informazione utile
sulla classe di appartenenza e quelli nel triangolo in basso a destra hanno informazione utile
grazie alla negazione ma risulta applicata in modo incorretto.
5.3. Generazione efficiente dei punti di una curva ROC
I classificatori si possono distinguere in due categorie:
Classificatori discreti, cioè stabiliscono l’appartenenza a una specifica classe (ad
esempio nel caso di classificatori binari associano a ogni istanza o l’etichetta o );
Classificatori probabilistici, ossia quelli che generano un numero per ogni istanza
che descrive il grado di appartenenza di un’istanza a una classe. In questo caso i
numeri generati possono essere direttamente le probabilità di appartenenza a una
classe o fanno riferimento a una funzione di score che ha la proprietà che a valori
elevati corrisponde probabilità elevate (i numeri non sono direttamente i valori della
probabilità).
Se il classificatore usa una funzione di score, è possibile sfruttare un valore di soglia per
generare una classificazione discreta binaria; cioè se l’uscita del classificatore è sopra la

61 Receiver Operating Characteristic
soglia, allora produce etichetta altrimenti . A ogni valore di soglia corrisponde un punto
nello spazio; concettualmente, si può immaginare di variare la soglia da a e
tracciare in questo modo una curva nello spazio ROC. Quest’ultima tecnica è poco efficiente
dal punto di vista della velocità di calcolo, successivamente sarà presentato un algoritmo
molto più efficiente.
Una curva ROC generata da un insieme finito d’istanze è rappresentata da una funzione a
gradini; per ottenere effettivamente una curva sarebbe necessario considerare un’infinità
d’istanze. Prima di procedere a tracciare una curva ROC è necessario avere a disposizione
una funzione di score usata dal modello del classificatore; nel caso della macchina a vettori
di supporto implementata nella libreria libsvm, si ha a disposizione direttamente questa
funzione. I valori di questa funzione fanno riferimento unicamente ai risultati positivi del
golden test, rappresentano la probabilità assegnata dalla macchina che gli esempi classificati
dalla SVM siano positivi.
Di seguito si riporta l’algoritmo adottato per tracciare una curva ROC.
Figura 34 Generazione ROC
L’input dell’algoritmo è cioè l’insieme degli esempi positivi del golden test classificati dalla
SVM, l’output è ossia l’insieme dei punti della curva ROC. Tramite la funzione di score si
ordina in modo decrescente e si ottiene ; poi s’inizializzano le variabili:

62 Receiver Operating Characteristic
a zero che rappresenta i veri positivi;
a zero che è il descrittore dei falsi positivi;
a che indica il valore di score associato all’esempio precedente
analizzato;
a 1 che indica l’indice dell’esempio da analizzare.
Fino a quando non ha raggiunto il numero di esempi presenti in si verifica se il valore di
score associato all’esempio di indice è diverso da quello di indice precedente; in caso
affermativo si genera il punto della curva ROC di coordinate
e si salva il risultato in
e si imposta , in caso contrario non si genera alcun punto. Ora si verifica se
l’esempio all’indice corrente è positivo, in caso affermativo si aggiorna
altrimenti si aggiorna . Alla fine s’incrementa l’indice di uno per analizzare il
successivo esempio e si riparte dall’inizio; se l’indice ha raggiunto il limite massimo (numero
di esempi in ) allora si genera il punto
e lo si salva in .
5.4. AUC
Una curva ROC fa riferimento a un sistema cartesiano a due assi; per confrontare le
prestazioni descritte dalle curve ROC di vari classificatori, è possibile sfruttare un singolo
valore scalare associato a ogni curva che prende il nome di AUC (Area Under the ROC Curve).
Poiché l’AUC è una porzione dell’area del quadrato nello spazio ROC (ogni lato ha lunghezza
unitaria) allora può assumere valori tra zero e uno; tuttavia, è necessario osservare che un
classificatore realistico non ha una curva ROC sotto la diagonale dello spazio ROC, quindi
l’area non sarà mai inferiore a 0.5.
L’AUC ha un’importante proprietà statistica: l’AUC di un classificatore è equivalente alla
probabilità che il risultato di un’istanza su un elemento estratto a caso dalla classe uno (dei
positivi) sia superiore a quello di un estratto a caso dalla classe due (dei negativi). Per
calcolare l’AUC si può usare la tecnica dei trapezoidi.
Per l’interpretazione dell’AUC si può tenere presente la classificazione della capacità
discriminante di un test proposta da Swets nel 1998 [15]:
test non informativo;
test poco accurato;
test moderatamente accurato;
test altamente accurato;
test perfetto.

63 NVIDIA CUDA, architettura e modello di programmazione
6. NVIDIA CUDA, architettura e modello di programmazione
6.1. Introduzione
L’inconveniente di sviluppare in linguaggio MATLAB consiste che questo è interpretato e
quindi la velocità di elaborazione non è elevata; per ridurre i tempi di test dell’algoritmo,
soprattutto nella fase di addestramento, si è reso necessario fare delle ottimizzazioni per
velocizzare i calcoli. Da osservare che dalla fase di caricamento delle immagini
all’addestramento della macchina a vettori di supporto sulle ROI ricavate sono richieste
diverse ore di elaborazione (per testare solo una feature); questo comporta che se si fa una
modifica a una o più fasi che precedono l’addestramento è necessario rifare tutti i calcoli da
capo e quindi ciò rende impraticabile la possibilità di verificare velocemente eventuali
aggiunte per migliorare il comportamento dell’algoritmo. Come conseguenza si hanno tempi
elevati di sviluppo del software (ogni modifica deve essere testata e richiede ore per la
verifica) e tempi lunghi per la correzione di bug; per risolvere questo inconveniente, che
compromette lo sviluppo veloce del software, una parte del codice degli script MATLAB è
stata riscritta tramite delle mex. Una mex non è altro che una funzione richiamabile dal
MATLAB ma sviluppata in C/C++; questo permette alla mex di sfruttare qualunque
tecnologia compatibile con i linguaggi C/C++. Le unità di elaborazione disponibili in un
moderno calcolatore sono le CPU e GPU; per la SVM si è deciso di sfruttare le mex della
libreria libsvm e di riscrivere alcune parti di codice degli script MATLAB (che tipicamente non
subiscono modifiche durante eventuali tentativi di miglioramento) sfruttando la tecnologia
CUDA su GPU. L’inconveniente della libreria libsvm è che è in grado di sfruttare un solo core
della CPU, per questo motivo si è deciso di riscrivere alcuni loop for delle mex tramite
OpenMP e ciò permette di sfruttare tutti i core durante la fase di addestramento e
classificazione della macchina. Le mex che sfruttano la tecnologia CUDA, lo possono fare
perché CUDA C è un’estensione del linguaggio C; lo svantaggio è che il MATLAB non
permette di rappresentare le variabili passate alle mex nella pinned memory e ciò comporta
un dimezzamento della velocità di scambio dei dati tra CPU e GPU. Per ridurre il più
quest’ultimo inconveniente, sono stati ridotti il più possibile le allocazioni in memoria di
variabili e trasferimento dei dati tra CPU e GPU. Altro inconveniente causato
dall’impossibilità di sfruttare la pinned memory (detta anche free page locked memory) è
che non si può sfruttare nemmeno l’overlap cioè trasferire dati tra host e device e
contemporaneamente eseguire l’elaborazione del kernel.
Si è scelto di sfruttare l’elaborazione su GPU perché questa è estremamente più
performante di una qualunque CPU di ultima generazione quando è necessario elaborare
migliaia di thread (com’è possibile fare in questo lavoro di tesi).

64 NVIDIA CUDA, architettura e modello di programmazione
Sul mercato esistono delle alternative a CUDA dal punto di vista architetturale e modello di
programmazione per quanto riguarda l’elaborazione lato GPU:
ATI Stream è una tecnologia introdotta da AMD / ATI per l’elaborazione di tipo
GPGPU, al momento attuale le feature implementate e le prestazioni sono inferiori
rispetto a CUDA, inoltre la programmazione è più complessa rispetto al modello
utilizzato in CUDA C;
OpenCL è uno standard per l’elaborazione generica su GPU alla cui definizione
partecipa la stessa NVIDIA, esistono molte analogie con CUDA ma allo stato attuale
la programmazione è più complessa, le prestazioni sono nettamente inferiori a
un’applicazione CUDA e le feature limitate (non è possibile accedere a determinate
caratteristiche dell’hardware come ad esempio la cache dedicata partizionabile in
cache condivisa e di livello uno);
DirectXCompute è l’API DirectX undici dedicata per il GPGPU, allo stato attuale ha le
medesime limitazioni di OpenCL (programmazione complessa, prestazioni inferiori a
un’applicazione CUDA, feature limitate) e inoltre può essere impiegata
esclusivamente su sistemi operativi Microsoft.
Se si vuole realizzare un’applicazione di calcolo intensivo in grado di sfruttare al massimo la
potenza di elaborazione delle GPU è quindi necessario impiegare la tecnologia CUDA; se
invece si vuole la piena compatibilità con tutte le GPU pur accettando di perdere efficienza
di calcolo dal punto di vista velocistico allora è necessario utilizzare OpenCL
(DirectXCompute se si vuole eseguire l’applicazione solo su sistemi operativi Windows).
E’ necessario fare altre osservazioni:
CUDA fa riferimento al mercato delle workstation professionali di cui quasi il 93%
(nel 2010) appartiene a NVIDIA, quindi non ci sono problemi di diffusione di
applicazioni CUDA (tutte le schede video NVIDIA professionali dal 2007 supportano
CUDA);
Più del 50% del fatturato di NVIDIA deriva dal mercato delle workstation
professionali, per questo motivo l’azienda sta investendo molto di più in ambito
professionale anziché consumer (AMD / ATI sta facendo l’opposto). Il risultato è che
l’architettura da generazione a generazione diventa sempre più efficiente per i
calcoli generici e tutto ciò ha comportato la diffusione di applicazioni professionali
che sfruttano CUDA come ad esempio Autodesk 3ds Max 2011 (con NVIDIA PhysX),
AutoCAD, ambito militare;
NVIDIA non ha una licenza per progettare e distribuire processori x86, quindi non è
in grado di contrastare direttamente le soluzioni dell’Intel e AMD correnti con GPU
sullo stesso die della CPU. Questo significa che l’unica strada percorribile da NVIDIA
per rimanere nel mercato delle GPU è di introdurre alternative valide per
l’elaborazione di tipo general purpose;

65 NVIDIA CUDA, architettura e modello di programmazione
Occorre osservare che esiste anche un compilatore CUDA x86, in questo modo è
possibile utilizzare lo stesso modello di programmazione CUDA non solo su GPU ma
anche su CPU x86. Questo significa che se la macchina sulla quale è necessario
eseguire l’elaborazione mediante CUDA non è dotata di una GPU NVIDIA, allora è
possibile eseguire il medesimo codice su CPU ovviamente con una riduzione di
prestazioni dato che il numero di core è ridotto rispetto alle GPU.
In questo lavoro si presenterà l’architettura delle GPU NVIDIA e il modello di
programmazione CUDA. In appendice A e B sono riportati i concetti fondamentali
dell’elaborazione grafica che fanno riferimento alle specifiche DirectX undici, questi sono di
fondamentale importanza per capire le elaborazioni eseguite dalle unità presenti
nell’architettura della GPU in questione (e in generale per tutte le GPU).
6.2. GPU come computer parallelo
Fino al 2003 i microprocessori erano basati su una singola unità centrale di elaborazione
(CPU) come ad esempio i prodotti dell’Intel Pentium e AMD Opteron; da una generazione
all'altra c’era un incremento prestazionale che seguiva la legge di Moore. Le prestazioni in
ambito desktop erano arrivate fino a qualche giga di operazioni in floating-point per
secondo (GFLOPS) e per i cluster di server fino a centinaia di GFLOPS. Grazie al
miglioramento delle prestazioni delle CPU da una generazione all’altra, gli sviluppatori
software erano stati in grado di aggiungere nuove funzionalità alle proprie applicazioni
(miglioramento della GUI, implementazione di algoritmi complessi in ambito scientifico per
simulazioni ecc.) e queste potevano beneficiare di un incremento prestazionale dal punto di
vista della velocità di elaborazione con il passaggio da una generazione di CPU a un’altra.
Gran parte del software in commercio era sviluppato secondo la logica sequenziale descritta
da Von Neumann 1945, solo poche applicazioni erano sviluppate specificatamente per
l’elaborazione parallela (tipicamente in ambito scientifico); dal 2003 i produttori di CPU non
potevano più aumentare le prestazioni delle proprie architetture semplicemente
incrementando la frequenza di clock a causa del consumo energetico e dissipazione
eccessiva, l’unico modo per migliorare la velocità di calcolo era di aumentare il numero di
unità di elaborazione (oltre che rendere più ottimizzate le architetture e aumentare la
cache). Da allora i produttori software sono migrati dalla programmazione sequenziale a
quella parallela, attualmente esistono molti applicativi che sono sviluppati per le nuove
architetture multicore delle CPU e quindi che sono in grado di beneficiare della potenza di
calcolo a disposizione. Oltre alle CPU, nelle workstation moderne, esistono altre unità di
elaborazioni sofisticate ossia le GPU che sono nettamente superiori nell’ambito
dell’elaborazioni multithreading intensive nel calcolo numerico rispetto alle CPU.
Le CPU attuali hanno diversi core per eseguire le computazioni (ad esempio dodici per gli
ultimi AMD Opteron), oltre a queste architetture ne esistono altre che hanno molte più
unità di elaborazione ossia le GPU (Graphics Processing Unit); nell’architettura Fermi si ha
un massimo di 512 CUDA core. Oltre alla notevole differenza nel numero di unità di

66 NVIDIA CUDA, architettura e modello di programmazione
elaborazione tra CPU e GPU è necessario osservare che esiste anche un notevole divario
prestazionale nell’elaborazione in floating-point che si assesta a cento GFLOPS e un TFLOPS
rispettivamente per CPU e GPU. Di seguito si riporta l’evoluzione prestazionale
nell’elaborazione in floating-point negli anni:
Figura 35 GPU vs CPU floating-point
L’architettura tra questi due dispositivi di elaborazione è notevolmente differente:
I core delle CPU sono progettati per eseguire una serie di operazioni su uno stream di
dati (in modo sequenziale);
I core delle GPU sono ottimizzati per eseguire elaborazioni in parallelo su molti flussi
di dati e no su uno solo;
Nelle CPU i transistor sono utilizzati per le feature hardware come predizione delle
ramificazioni nell’esecuzione d’istruzioni di un applicativo, cache e inoltre il singolo
core è ottimizzato per l’esecuzione di un solo thread nel caso di AMD invece per Intel
due o quattro thread (dipende dal modello di CPU, in questo caso si parla di
processori virtuali che sfruttano la tecnologia Hyperthreading);
I transistor nelle GPU sono utilizzati per realizzare gli array di processori, gestire via
hardware decine di migliaia di thread in modo concorrente, FPU (Floating Point
Unit), memoria condivisa e controller di memoria;
La latenza della memoria di sistema è mascherata da CPU mediante una cache
grande e hardware di branch prediction;
La latenza della memoria nelle GPU è mascherata con il fatto che è possibile eseguire
in modo concorrente molti thread e se i thread sono in attesa per l’accesso alla
memoria, allora la GPU può eseguire lo switch verso un altro insieme di thread senza
penalità (nel caso della CPU sono necessari diversi cicli di clock). Soltanto quando la
strategia descritta non si può usare allora la GPU sfrutta la cache per mascherare la
latenza;

67 NVIDIA CUDA, architettura e modello di programmazione
SIMD vs SIMT. Le CPU moderne sfruttano anche unità SIMD (Single Instruction
Stream, Multiple Data Stream) per vector processing; le GPU impiegano SIMT (Single
Instruction Stream, Multiple Thread Stream) per scalar thread processing, SIMT non
richiede l’organizzazione dei dati in vettori come invece SIMD impone;
La banda di memoria della GPU è dieci volte superiore a quella della CPU dato che i
memory controller stanno sul die e anche per il fatto che per le CPU c’è il vincolo di
compatibilità con sistemi operativi e applicazioni legacy e accesso da parte dei
dispositivi di I/O;
Figura 36 GPU vs CPU banda di memoria
L’architettura delle GPU è modellata in base alle esigenze dell’industria dei video
giochi che richiede di eseguire un numero elevatissimo di operazioni in floating-point
per frame, questo ha contribuito a massimizzare l’area del chip dedicata alla FPU
(Floating Point Unit). Gran parte delle GPU utilizzano il formato in virgola mobile in
singola precisione, questo è un problema per le applicazioni che richiedono la doppia
precisione per l’elaborazione, solo di recente le GPU sono passate all’elaborazione in
double-precision;
Le GPU sono altamente ottimizzate per l’esecuzione in parallelo di molti thread (a
differenza delle CPU che sono in grado di gestire un thread per core per AMD o 2 – 4
thread nel caso di Intel mediante la tecnologia Hyperthreading). La logica di controllo
dei thread è molto più semplice che quella impiegata nella CPU e ciò permette di
eseguire in modo concorrente tanti thread e fare il context switch senza costo, si ha
anche a diposizione un piccolo quantitativo di cache per ogni multiprocessore in
modo tale che i thread non debbano necessariamente accedere alla GDDR DRAM.
Le applicazioni attuali, per sfruttare a pieno le potenzialità delle unità di elaborazione
presenti sul mercato, devono essere sviluppate in modo tale che la parte sequenziale di

68 NVIDIA CUDA, architettura e modello di programmazione
elaborazione sia eseguita su CPU e il calcolo numerico intensivo parallelo su GPU; da queste
osservazioni sono nati il modello di programmazione CUDA e la relativa architettura
hardware (Compute Unified Device Architecture) che permette di eseguire un’applicazione
su CPU e GPU (questo modo di eseguire elaborazioni prende il nome di elaborazione
eterogenea e riguarda l’esecuzione delle varie operazioni sul processore più adatto). In
passato, il GPGPU (General Purpose Graphics Processor Unit) richiedeva l’utilizzo di apposite
API (OpenGL o Direct3D) per accedere alle funzionalità delle GPU ma questo era un notevole
limite dato che si era legati esclusivamente alle API. L’API grafica richiede di salvare i dati
come texture, di usare specifici indirizzi dei registri, non permette di accedere a funzionalità
specifiche dell’hardware, richiede una conoscenza ampia dell’API. Con CUDA l’approccio
cambia completamente, i programmatori possono sviluppare le applicazioni direttamente in
CUDA C (estensione del C) per GPU e usare qualsiasi linguaggio lato CPU, quindi senza dover
usare apposite API grafiche. Il principale vantaggio è che tramite CUDA è possibile accedere
a delle feature hardware che tramite le API grafiche non sono accessibili, in particolare, la
cache condivisa tra i thread per ogni Streaming Multiprocessor (che permette di salvare dati
che sono usati spesso dai thread del medesimo warp), salvare i dati in qualsiasi indirizzo e
non serve tradurre il problema da risolvere in termini di concetti di elaborazione grafica
(come texture). Tutto ciò è possibile perché sul chip di silicio c’è un’apposita area dedicata
all’interfacciamento con applicazioni sviluppate tramite CUDA C.
CUDA è un modello di programmazione e architettura hardware che permette di usare molti
core della GPU per calcoli matematici general purpose. Attualmente esiste anche il
compilatore della PGI che permette di usare il medesimo modello di programmazione CUDA
anche su CPU X86; quindi è possibile eseguire codice CUDA su CPU multicore ad esempio
quando la macchina non ha a disposizione una GPU NVIDIA.
Per quanto riguarda la programmazione parallela nell’ambito delle CPU, il principale
problema è legato alla gestione dei cluster di CPU da parte dell’applicazione che deve essere
divisa in più thread da eseguire in modo concorrente sui core a disposizione; dato che le CPU
sono essenzialmente dei processori per eseguire calcoli in modo sequenziale, avere più
processori richiede la scrittura di codice in modo piuttosto complesso. Con CUDA la
programmazione è molto più semplice da gestire, questo modello prevede
l’implementazione di un algoritmo sequenziale (chiamato kernel) il quale è caricato dalla
GPU che esegue migliaia d’istanze del medesimo (ogni istanza è un thread che opera su dati
indipendenti). CUDA C è un’estensione del linguaggio di programmazione C, questo
semplifica notevolmente il porting delle applicazioni attuali C su questo tipo di architettura.
Per realizzare un’applicazione in CUDA tipicamente si seguono i seguenti passi:
S’individuano i colli di bottiglia del programma e relative porzioni di codice su CPU
che possono essere parallelizzate (sfruttando il paradigma data parallelism, ossia
ogni dato può essere elaborato in modo indipendente);
Per ogni porzione parallelizzabile s’implementa il kernel;

69 NVIDIA CUDA, architettura e modello di programmazione
Il kernel è caricato dalla GPU ed è applicato a uno specifico data set;
Per ogni elemento del data set è istanziato il kernel, ogni istanza prende il nome di
thread (formato dal program counter, registri e stato)
6.3. Architettura NVIDIA Fermi GF110
In questo paragrafo si analizzano in dettaglio gli aspetti salienti dell’architettura CUDA
GF110 (Graphics Fermi). Dall’analisi della pipeline grafica descritta in appendice A e dalle
soluzioni architetturali della NVIDIA, sarà subito chiaro che l’azienda di Santa Clara ha deciso
di introdurre dove possibile unità general purpose per rendere la GPU sempre più simile alla
CPU in contrapposizione all’AMD / ATI che invece utilizza in modo massiccio unità dedicate
soprattutto per applicare la tecnica di tessellation. La NVIDIA ha assegnato a
quest’architettura il nome di CUDA per specificare che la GPU oltre ad essere in grado si
eseguire elaborazioni grafiche è anche capace di fare calcoli intensivi generici per
applicazioni generiche.
Di seguito si riporta la figura relativa all’architettura completa di una GPU CUDA Fermi
GF110 costituita da tre miliardi di transistor con processo produttivo a quaranta nm:
Figura 37 Architettura GF110
La differenza da un modello all’altro in questa generazione di GPU sta nel numero di GPC
(Graphics Processing Clusters che rappresenta un gruppo di calcolo), di memory controller,
ROP, frequenze di clock e il numero di SM (alcuni di questi sono disattivati per motivi di resa
produttiva, quindi se ci sono degli SM non funzionanti si può comunque procedere alla
certificazione della GPU per un’altra classe).

70 NVIDIA CUDA, architettura e modello di programmazione
Di seguito si riporta la descrizione di ogni componente di quest’architettura:
Host interface. Rappresenta l’interfaccia tramite la quale l’host e device sono in
grado di comunicare fra loro (per host s’intende la CPU e per device GPU);
GigaThread Engine. E’ una nuova tecnologia introdotta dalla NVIDIA che permette di
gestire migliaia di thread da eseguire in parallelo sulla GPU (assegna i thread agli SM)
e accedere al frame buffer;
Memory controller. Sono i controller per gestire l’accesso alla memoria video;
L2 Cache. E’ la cache di secondo livello, ci sono 128 KB assegnati a ogni specifico
memory controller per un totale di 768 KB;
ROP. Render output unit o più propriamente detta raster operations pipeline è l’unità
utilizzata per eseguire uno degli ultimi passi del rendering, in GF110 ci sono 48 ROP
(riguarda unicamente l’elaborazione grafica, per dettagli vedere l’appendice A);
GPC. Graphics processing cluster è l’unità grafica di elaborazione costituita dagli SM
(4) e Raster Engine (1);
Raster Engine e Polymorph Engine. Sono le unità per gestire la tessellation (fare
riferimento all’appendice A per dettagli).
SM. Uno streaming multiprocessor è il processore utilizzato per elaborare in parallelo
molti flussi di dati (32 SM);
SP. Streaming processor, detto anche CUDA core, è l’unità di elaborazione generica
per il singolo flusso di dati (32 per ogni SM per un totale di 512 CUDA core);
Nei successivi paragrafi si andrà a descrivere in dettaglio ogni singolo componente di
quest’architettura (eccetto quelli che sono impiegati esclusivamente per l’elaborazione
grafica, in questo caso è necessario per ulteriori dettagli fare riferimento all’appendice A)
6.3.1. Host Interface
L’host interface è utilizzato per leggere i comandi inviati dalla CPU alla GPU; per ogni
comando grafico restituisce lo stato d’esecuzione ed eventuali dati di ritorno alla CPU
(quindi otre a leggere dalla memoria centrale è in grado anche di scrivere nella memoria
centrale). Si sfrutta anche durante l’elaborazione in CUDA per gestire le interazioni tra host
e device.
6.3.2. Memory Controller
Ci sono sei memory controller per l’accesso alla memoria video di tipo GDDR5 (Graphics
Double Date Rate) DRAM detta frame buffer e ognuno sfrutta un’interfaccia a 64 bit per un
totale di 384 bit di bus per l’accesso al frame buffer. La differenza tra GDDR DRAM e DDR
DRAM di sistema sta nel fatto che la prima è utilizzata come memoria per memorizzare dati
grafici o dati generici per un’applicazione CUDA, invece la seconda tipologia è utilizzata per
memorizzare dati generici non legati alla grafica. Per le applicazioni grafiche, nella GDDR
sono memorizzate le immagini video, informazioni sulle texture per il rendering 3D; invece
per CUDA è utilizzata come memoria generica con elevata banda (5 – 10 volte maggiore a
quella della DRAM di sistema utilizzata dalla CPU).

71 NVIDIA CUDA, architettura e modello di programmazione
6.3.3. Gerarchia memoria
Di seguito si descrive la gerarchia della memoria utilizzata all’interno di GF110:
Figura 38 Gerarchia memoria
La cache L1 è dedicata alle operazioni di load e store, non era presente fino all’architettura
GT200; in GF110 permette di incrementare le prestazioni soprattutto in simulazioni di fisica
e di ray tracing. La cache condivisa è invece presente in quantitativo di 16 KB dalle soluzioni
GT200. Quest’ultima è impiegata per condividere dati tra thread del medesimo warp.
In GF110 la cache dedicata è di 64 KB ed è di tipo partizionabile; le proporzioni possono
essere di 3:1 (48 KB / 16 KB) o 1:3 (16 KB / 48 KB) per memoria condivisa e cache L1.
Le unità di texture (4) hanno una cache dedicata all’interno di ogni SM in quantitativo pari a
12 KB: in questo caso il valore è rimasto invariato rispetto a quanto implementato nelle GPU
GT200.
A completare la gerarchia della cache c’è la cache L2 integrata nella GPU e condivisa tra i
vari SM; la quantità di memoria è di 768 KB cioè 128 KB dedicato a ogni memory controller.
La gerarchia della memoria segue il medesimo approccio impiegato nelle CPU multicore di
ultima generazione, ove, le strutture di cache dedicate al singolo core sono tutte raccordate
da una più ampia (solitamente di terzo livello).

72 NVIDIA CUDA, architettura e modello di programmazione
Figura 39 Cache L2 unificata
6.3.4. GDDR5
Nell’architettura Fermi il tipo di memoria che si utilizza per il frame buffer è la
GDDR5 (Graphics Double Data Rate), questa è basata sulla tecnologia double date rate
specifica per le schede video in sostituzione all’obsoleta VRAM (Video RAM). Il frame buffer
è utilizzato dalla GPU per memorizzare informazioni relative al rendering o per i dati per il
kernel sviluppato tramite CUDA C; GDDR5 è utilizzata in luogo della memoria DDR DRAM di
sistema dato che quest’ultima è più lenta di quella utilizzata nelle GPU (il requisito
fondamentale per la memoria video è un’elevata velocità in lettura e scrittura). Il bus,
nell’architettura Fermi, è di 384 bit dato che ci sono sei controller di memoria a 64 bit.
L'obiettivo delle memorie GDDR5 è di garantire un transfer rate elevatissimo, attualmente
con i chip Samsung si è raggiunto 24 GBit/s (DDR 3 arriva a 1.5 GBit/s),
contemporaneamente a un risparmio energetico maggiore del 20% rispetto alla generazione
precedente ossi alla GDDR4 grazie anche alla riduzione della tensione operativa a 1.5 V. Le
GDDR5 usano un prefetch buffer a 8 bit (il prefetch buffer serve per raccogliere i dati da
inviare alla successiva interfaccia più veloce) come le GDDR4 ma offrono alcune innovazioni:
le GDDR5 hanno due frequenze di clock ossia CK e WCK (la seconda lavora a frequenza
doppia rispetto alla prima). I comandi sono trasferiti in modalità single data rate (SDR) alla
frequenza CK quindi con trasferimento sul solo fronte di salita del clock, gli indirizzi sono
trasferiti in double data rate (DDR) alla frequenza CK, i dati invece sono trasferiti in DDR alla
frequenza WCK. Tale approccio permette di ridurre i problemi legati alla qualità del segnale
durante la trasmissione dei comandi e degli indirizzi, mentre accede a una frequenza
superiore per la trasmissione dati. Siccome a frequenze maggiori si ha una maggiore
probabilità di errore, in questo tipo di memoria è implementato anche un meccanismo di
rivelazione di tali errori al fine di garantire l'integrità dei dati trasmessi.
6.3.5. GigaThread Engine
Il GigaThread engine raccoglie i dati necessari dalla memoria di sistema e li copia nel frame
buffer passando attraverso i memory controller; a questo punto, crea blocchi di thread
chiamati warp e li invia agli SM. Il GigaThread entra in funzione anche per redistribuire i
compiti alle singole unità di elaborazione.

73 NVIDIA CUDA, architettura e modello di programmazione
Una delle caratteristiche più rilevanti del GigaThread engine di GF110 è che è in grado di
inviare kernel in parallelo anziché sfruttare l’approccio “un kernel alla volta” tipico
dell’architettura Tesla precedente; il numero massimo di kernel gestibili è pari a sedici. Tale
tecnologia ottimizza la schedulazione dei thread da gestire al fine di sfruttare al meglio le
unità d'elaborazione a disposizione. Il processore è in grado di processare fino a 24576
thread e può far eseguire più thread in parallelo all'interno di ogni SM al fine di ottimizzare
l'utilizzo dei CUDA core.
6.3.6. Streaming Multiprocessor
Lo stream processing è un paradigma di programmazione parallela che prevede l’esecuzione
di una serie di operazioni su dati organizzati in gruppi detti stream. Uno streaming
multiprocessor è un’unità in grado di elaborare contemporaneamente flussi multipli di dati
(in parallelo), uno streaming processor invece esegue l’elaborazione su un singolo stream di
dati.
Di seguito si riporta in dettaglio l’architettura di uno Streaming Multiprocessor:
Figura 40 Streaming Processor
Uno SM ha trentadue CUDA core:
A gruppi di quattro sono associati a due unità di load e store (LD/ST);
A gruppi di otto sono abbinati a un’unità di tipo special function (SFU), la quale
esegue elaborazioni in floating point con le funzioni trascendenti (tutte le funzioni di
tipo non algebrico che non utilizzano le quattro operazioni elementari dell’aritmetica
e le potenze e radici come seno, coseno, seccante, tangente ecc).

74 NVIDIA CUDA, architettura e modello di programmazione
A monte dello SM c’è la cache per le istruzioni, seguita da due warp scheduler, da due unità
per le operazioni di dispatch le quali sono collegate al registro dei file capace di gestire un
massimo di 32.768 entry a 32bit.
Per ogni streaming multiprocessor si ha una cache dedicata a 64 KB partizionabile come
memoria condivisa e come cache L1: i rapporti sono 1:3 oppure 3:1. Il rapporto è funzione
del tipo di applicazione che deve essere eseguita, nell’architettura precedente GT200 si
aveva una memoria cache da 16 KB non partizionabile.
Ogni SM integra al proprio interno quattro texture unit, per un totale quindi di 64 unità di
questo tipo; le texture unit sono dotate di una propria cache dedicata integrata all'interno
dello specifico SM che serve per accelerare le operazioni di gestione delle texture.
6.3.7. Instruction cache
La cache istruzioni è di 12 KB, serve per accelerare il prelievo delle istruzioni da eseguire;
occorre osservare che ogni warp è formato da thread che devono eseguire le medesime
operazioni però su dati differenti.
6.3.8. Dual warp scheduler e dispatch unit
Il G80 era la prima GPU in grado di supportare la tecnologia CUDA (2007), tutte le
architetture prima dell’evento del GF100/GF110 richiedono che gli SM lavorino sullo stesso
kernel (funzione/programma/loop) allo stesso istante; nelle generazioni precedenti, se il
kernel non era abbastanza grande da occupare l’esecuzione di tutto l’hardware, allora
alcune unità potevano restavano in idle con conseguente riduzione dell’efficienza
nell’utilizzo della GPU. Occorre osservare che l’architettura delle GPU permette di ottenere
notevoli vantaggi dal punto di vista della velocità d’elaborazione solo se l’utilizzo
dell’hardware è vicino al 100%.
In GF110 è possibile eseguire kernel multipli in parallelo, ciò permette alla GPU di scalare il
numero di core nel chip senza decrementare l’efficienza. Di seguito si riporta un esempio di
elaborazione prima dell'introduzione dell'architettura in GF110 (a sinistra) e quella attuale
(a destra):
Figura 41 Esecuzione kernel su G80/GT200 e GF110

75 NVIDIA CUDA, architettura e modello di programmazione
L’architettura Fermi è migliorata anche nello switch tra modalità grafica e CUDA di un fattore dieci; ora è possibile fare lo switch più volte in un frame e questo permette di sfruttare meglio la GPU ad esempio per l’accelerazione della fisica nei video giochi.
L’architettura Tesla GT200 riesce a gestire un numero enorme di thread, oltre 30000 thread al volo; con GF110, il numero è sceso a circa 24000 per ridurre la complessità dell’hardware di gestione dei thread e aumentare la memora condivisa negli SM.
Figura 42 Gestione thread nelle architetture CUDA
Ogni SM ha due warp scheduler e due unità di dispatch. I due schedulatori del GF110
selezionano due warp che sono distribuiti su trentadue CUDA core. Nel GT200 e G80, la
metà di ogni warp è distribuita su un singolo SM ed eseguita in un singolo ciclo di clock, cioè
richiede due cicli di clock per completare un warp (senza branch condition), inoltre la logica
di dispatch per la SM è strettamente legata all’hardware di esecuzione. Se un thread
richiede l’elaborazione con una SFU, allora sull’intero SM non può essere distribuita una
nuova istruzione fino a quando l’istruzione che occupa la SFU non è stata eseguita
completamente. Questo porta a una notevole riduzione d’efficienza nell’utilizzo della GPU;
questo problema è superato nell’architettura Fermi con due unità di dispatch indipendenti
in ogni SM e queste sono completamente disaccoppiate dal resto dello SM. Ogni unità di
dispatch può selezionare e distribuire metà del warp per ciclo di clock, i thread possono
provenire da differenti warp in modo da ottimizzare la possibilità di individuare operazioni
indipendenti.
L’inflessibilità della gestione dei thread nell’architettura NVIDIA consiste nel fatto che ogni
thread nel warp deve eseguire la stessa istruzione contemporaneamente, se ciò accade, si
ha il pieno utilizzo delle risorse a disposizione altrimenti alcune unità resteranno in idle
(path d’esecuzione diversi sono eseguiti in modo seriale e quindi alcuni CUDA core non sono
sfruttati).
Di seguito si riporta il numero di operazioni per clock che uno SM è in grado di eseguire:
Figura 43 Ops per clock per le istruzioni eseguibili da uno SM
Nel GF110 le SFU non bloccano l’intero SM, questo significa che se una o più SFU sono
utilizzate da mezzo warp si hanno comunque altri sedici CUDA core liberi per l’elaborazione.
Nelle architetture precedenti l’intero SM restava bloccato per otto cicli di clock per eseguire

76 NVIDIA CUDA, architettura e modello di programmazione
le istruzioni tramite le SFU (se tutte e quattro le SFU erano utilizzate). Con il nuovo
approccio è possibile eseguire molte istruzioni in modo concorrente: due istruzioni su interi,
due istruzioni su floating point o un mix d’istruzioni per interi, floating point, load, store e
SFU.
Figura 44 Distribuzione delle istruzioni all'interno di uno SM
6.3.9. Register file
Un register file è un array di registri del processore (SM) implementato tramite memoria
RAM statica con porte multiple e ogni porta è di lettura e scrittura; questi registri
organizzano i dati tra memoria e unità funzionali del chip. Il register file è visibile in fase di
programmazione.
6.3.10. LD/ST
Siccome CUDA C è un’estensione del C/C++, per utilizzare questo linguaggio di
programmazione la NVIDIA ha deciso di aggiungere delle unità per gestire le istruzioni di
load e store.
Ogni SM ha sedici unità di load/store che supportano il load e store a qualsiasi indirizzo di
cache e DRAM.
6.3.11. SFU
Ogni SM ha quattro special function unit (SFU), ogni SFU è in grado di eseguire istruzioni
trascendenti come sin, cos, esponenziale, logaritmo, reciproco, radice quadrata e anche i
calcoli d’interpolazione grafica; la pipeline SFU è disaccoppiata dal dispatch unit in modo tale
che sia possibile eseguire altre elaborazioni con i CUDA core quando la SFU è occupata. A
trarre particolare beneficio dall’hardware dedicato alle special function è l’elaborazione
intensiva attraverso shader.
6.3.12. Texture Unit
Ogni SM ha quattro unità per la gestione delle texture, ogni unità di texture calcola
l’indirizzo della texture ed esegue la fase di fetch della medesima per clock (quindi sono
gestite quattro texture per ogni ciclo clock in ogni SM). Il risultato restituito può essere
filtrato: bilineare, trilineare e anisotropico o niente.

77 NVIDIA CUDA, architettura e modello di programmazione
Il vantaggio in GF110 delle texture unit rispetto alla generazione precedente consiste nel
fatto che le texture sono gestite più velocemente perché è stata migliorata l’efficienza di
queste unità; infatti, ora, le unità di texture sono raggruppate all’interno degli SM, si ha
cache dedicata esclusivamente per la gestione delle texture e il clock delle texture unit /
texture cache è maggiore rispetto alla generazione precedente.
Inoltre è supportato il nuovo formato di compressione delle texture DirectX 11 BC6H e BC7
che permette di ridurre la memoria occupata dalle texture per la gestione HDR (High
Dynamic Range) e per il target da renderizzare.
6.3.13. CUDA Core
Di seguito si riporta la struttura completa di uno streaming processor detto anche CUDA
core:
Figura 45 CUDA Core
Uno SM ha trentadue SP, quindi in totale ci sono 512 CUDA core nell’architettura GF110.
Un CUDA core è un’unità di elaborazione in grado di eseguire una serie di operazioni su
flussi di dati multipli in modo efficiente e performante; ogni singolo CUDA core integra al
proprio interno una Dispatch Port, un’unità per la raccolta degli operandi, una FPU, un’ALU
e in fine una Result Queue.
6.3.13.1. Operand collector
L’Operand Collector è un’unità hardware che legge molti valori dai registri e li bufferizza per
un utilizzo successivo, è una sorta di cache per registri temporanei per le unità funzionali;
quindi l’Operand Collector legge gli operandi necessari per le operazioni da eseguire (ad
esempio per le SFU). Quest’unità è strettamente legata al Register File ma è anche in grado
di prelevare gli operandi da altre sorgenti ossia memoria condivisa, cache L1 e texture
cache.
6.3.13.2. FPU
In GF110 l’elaborazione in floating-point supporta i numeri subnormali via hardware e lo
standard IEEE 754-2008 con le quattro approssimazioni: nearest, zero, positive infinity e
negative infinity. I numeri subnormali sono quelli tra lo zero e il più piccolo numero

78 NVIDIA CUDA, architettura e modello di programmazione
normalizzato dato un sistema numerico floating-point. Nelle generazioni precedenti di GPU
questi numeri sono posti direttamente a zero con perdita di precisione. Tipicamente nelle
CPU il calcolo dei numeri subnormali è gestito via software e richiede migliaia di cicli di
clock, in Fermi le FPU gestiscono questi numeri via hardware senza penalità in termini di
prestazioni.
In computer grafica, algebra lineare e applicazioni scientifiche spesso si ha l’esigenza di
moltiplicare due numeri e poi sommare il risultato a un altro numero per esempio D = A x B
+ C. Prima di GF110, questa funzione era accelerata mediante l’istruzione multiply-add
(MAD) che permette di eseguire entrambe le operazioni in un singolo ciclo di clock; la MAD
esegue un’approssimazione dopo la moltiplicazione e subito dopo esegue la somma con
approssimazione nearest. Nell’architettura Fermi, si sfrutta invece l’istruzione fused
multiply-add (FMA) sia a 32 bit (single precision) sia a 64 bit (double precision) e questo
migliora l’operazione di moltiplicazione e somma dato che non c’è l’approssimazione nel
passo intermedio di moltiplicazione. Tutto ciò garantisce notevoli benefici in termini di
precisione per molti algoritmi come ad esempio: minimizza l’errore di rendering di triangoli
vicini sovrapposti, migliore precisione nel calcolo matematico iterativo, migliore
approssimazione della divisione e operazioni di radice quadrata.
Figura 46 FMA vs MAD
6.3.13.3. ALU
In Fermi si utilizza una nuova ALU con supporto completo alla precisione a 32 bit per tutte le
istruzioni ed è consistente con i requisisti dei linguaggi di programmazione standard C/C++;
inoltre l’ALU è ottimizzata anche per operazioni a 64 bit.
Le istruzioni che sono supportate sono elencate di seguito: boolean, shift, convert, bit-field
extract, bit-reverse insert e conteggio.
6.3.13.4. Result queue
Il duale dell’Operand Collector è il Result Queue, questo bufferizza l’output delle unità
funzionali prima di eseguire la scrittura nel Register File; per essere efficace è necessario che
la dimensione sia almeno pari alla dimensione di un warp cioè trentadue operandi. Occorre
osservare che non tutti i risultati calcolati richiedono di essere scritti nel Register File, alcune
operazioni richiedono esclusivamente un risultato intermedio che successivamente sarà

79 NVIDIA CUDA, architettura e modello di programmazione
utilizzato in un’altra operazione; con quest’unità si garantiscono migliori performance senza
dover ogni volta andare a prelevare i risultati dal Register File.
6.4. Interfaccia CUDA
In questo paragrafo si andrà ad analizzare in dettaglio l’interfaccia CUDA, l’organizzazione
dei thread e in fine l’organizzazione della memoria dal punto di vista del modello di
programmazione CUDA.
6.4.1. Architettura
Di seguito si riporta l’architettura completa dell’interfaccia CUDA per la programmazione
GPGPU che permette la comunicazione tra host e device:
Figura 47 Architettura modello di programmazione CUDA
Per quanto riguarda la programmazione della GPU per elaborazioni generiche sono possibili
i seguenti casi:
Nell’API DirectX undici esiste la DirectXCompute. In questo caso si utilizza come
linguaggio di programmazione HLSL compute shader (che fa parte degli shader model
cinque), il compilato è inviato all’API DirectXCompute che si occupa della
comunicazione con GPU CUDA tramite il kernel del sistema operativo;
Con le OpenGL invece è necessario utilizzare OpenCL C come linguaggio di
programmazione e inviare il kernel al driver OpenCL. Quest’approccio richiede di
comunicare con un’API chiamata CUDA driver;
Applicazione CUDA che sfrutta direttamente l’API di basso livello CUDA driver per
comunicare con la GPU;
Applicazione CUDA che sfrutta l’API C runtime for CUDA per la comunicazione con la
GPU.
Nel seguito ci si concentrerà esclusivamente su CUDA e no su OpenCL e DirectXCompute.

80 NVIDIA CUDA, architettura e modello di programmazione
Quando si sfrutta il modello di programmazione CUDA, è necessario utilizzare una o
entrambe le API seguenti (tipicamente si utilizza una sola):
API di basso livello che prende il nome di CUDA driver;
API di alto livello chiamata C runtime for CUDA che è costruita sopra l’API
precedente.
C runtime for CUDA è la più utilizzata perché semplifica notevolmente la programmazione e
riduce il numero di righe di codice da scrivere dato che la gestione del device avviene
mediante inizializzazione implicita come pure la gestione del context e dei moduli. CUDA
driver API invece richiede molto più codice, aumenta la complessità della programmazione e
debugging ma offre un miglior livello di controllo; da osservare che queste due API sono
riferite all’host quindi il kernel in esecuzione sulla GPU sarà il medesimo indipendentemente
dall’API utilizzata.
Le due API sono facilmente distinguibili dato che CUDA driver è fornita dalla libreria
dinamica nvcuda.dll e le varie istruzioni hanno tutte il prefisso cu; mentre C runtime for
CUDA è fornita dalla libreria dinamica cudart.dll e tutte le istruzioni iniziano con suffisso
cuda. Da osservare che CUDA driver mette a disposizione le stesse funzionalità del C runtime
con l’aggiunta però di altre più di basso livello. D’ora in poi si farà riferimento
esclusivamente al C runtime for CUDA salvo dove indicato diversamente.
Nel CUDA driver è incluso anche il PTX ISA ossia il parallel thread execution virtual machine
instruction set architecture; PTX definisce la CUDA virtual machine e l’ISA virtuale per
l’elaborazione generica parallela tramite thread. Il compilatore CUDA genera un binario PTX
che rappresenta l’ISA virtuale per le GPU NVIDIA (codice assembler); un traslatore, che può
essere il compilatore o la macchina virtuale al runtime, esegue la traduzione da codice PTX
in codice binario per l’architettura fisica target. Nel caso in cui si sfrutti la virtual machine, il
vantaggio consiste nel fatto che al runtime è invocato il compilatore jit (just in time detto
anche jitter) per compilare e ottimizzare il codice per l’architettura della GPU che
l’applicazione CUDA utilizzerà (rende il codice PTX portabile fra GPU diverse); lo svantaggio è
che il caricamento dell’applicazione è più lento rispetto a un approccio completamente
compilato.
Ogni GPU ha un proprio compute capability che specifica le caratteristiche CUDA
supportate, il tutto è fornito con un major e minor number; le pipeline grafiche con lo stesso
major number utilizzano la medesima architettura mentre il minor number specifica
l’aggiunta di nuove feature. Di seguito si riporta la tabella del compute capability delle varie
pipeline grafiche:

81 NVIDIA CUDA, architettura e modello di programmazione
Figura 48 Capacità di calcolo CUDA
Di seguito invece si riportano le feature supportate per ogni compute capability.
Figura 49 Compute capability feature CUDA
Per sfruttare a pieno l’architettura CUDA è necessario che l’applicazione presenti un elevato
grado di data parallelism, questo significa che l’algoritmo è in grado di eseguire molte
operazioni aritmetiche in modo indipendente su ogni dato del data set. Come esempio si più
considerare il prodotto tra due matrici, la matrice prodotta è costituta da un insieme di
elementi ognuno dei quali è calcolato come prodotto tra colonna e riga della prima e
seconda matrice rispettivamente e relativa somma; ogni elemento può essere calcolato in
modo indipendente dagli altri, questo permette d’implementare un algoritmo in CUDA C
altamente ottimizzato per l’esecuzione su GPU.

82 NVIDIA CUDA, architettura e modello di programmazione
6.4.2. SIMT
L’architettura CUDA è costruita su un array scalabile di Streaming Multiprocessor; i thread
sono organizzati in blocchi e questi ultimi enumerati e distribuiti sui multiprocessori liberi. I
thread di un blocco di thread sono eseguiti in modo concorrente sul medesimo SM; quando
l’esecuzione dei blocchi su uno SM è finita, allora nuovi blocchi possono essere lanciati sullo
SM libero.
Un multiprocessore è progettato per eseguire migliaia di thread in modo concorrente; per
gestire un numero così elevato di thread, l’architettura impiegata è la SIMT (Single-
Instruction e Multiple-Thread).
I thread sono organizzati in warp, i warp a loro volta sono organizzati in blocchi di warp, ogni
warp è costituito da trentadue thread. I thread che fanno parte del medesimo warp iniziano
tutti assieme dallo stesso program address, ma ognuno ha il proprio instruction address
counter e register state e quindi sono liberi di eseguire ramificazioni di esecuzione diverse.
Metà warp può essere la prima o seconda metà di un warp, un quarte-warp può essere il
primo, secondo, terzo o quarto quarte di un warp.
Quando un multiprocessore deve eseguire blocchi di thread, i warp sono schedulati dal
warp scheduler; per la massima efficienza è necessario che i trentadue thread seguano il
medesimo path d’esecuzione. Se i thread di un medesimo warp divergono verso rami diversi
d’esecuzione, allora i vari rami sono eseguiti in modo seriale e i thread che appartengono al
medesimo ramo in parallelo; dopo aver terminato tutti i rami d’esecuzione, l’elaborazione
ricomincia di nuovo in parallelo per tutti i thread del medesimo warp. Questa divergenza si
può manifestare esclusivamente all’interno del medesimo warp dato che ognuno è
indipendente nell’esecuzione rispetto agli altri.
L’architettura SIMT è simile alla SIMD (Single-Instruction Stream Multiple-Data Stream) in
cui una singola istruzione controlla l’elaborazione su più elementi (i dati); la differenza tra le
due architetture consiste nel fatto che un’istruzione SIMD ha una dimensione massima per i
dati gestibili (pari a quattro), invece un’istruzione SIMT specifica l’esecuzione e il branching
behavior del singolo thread (non c’è un vincolo sul numero di dati).
Il contesto d’esecuzione (program counter, register, ecc.) per ogni warp elaborato dal
multiprocessore è mantenuto sul chip per tutto il ciclo di vita del warp; lo switching da un
execution context a un altro non ha alcun costo e a ogni instante d’esecuzione di
un’istruzione il warp scheduler seleziona un warp in cui i thread sono pronti per l’esecuzione
(thread attivi) e li distribuisce per la successiva istruzione da eseguire.
6.4.3. Organizzazione thread
CUDA C estende il linguaggio C permettendo al programmatore di definire delle funzioni che
prendono il nome di kernel e le quali sono eseguite su GPU; da codice il kernel è definito
come una funzione con qualificatore __global__; per istanziare il kernel, è necessario da
host utilizzare la sintassi <<<numero blocchi, numero thread per blocco, cache condivisa,

83 NVIDIA CUDA, architettura e modello di programmazione
cuda stream>>> che specifica come organizzare i thread. Le funzioni possono essere definite
anche con __device__ e __host__ che rappresentano rispettivamente funzioni eseguite e
invocate sul e dal device e host; __host__ è applicato implicitamente a tutte le funzioni
senza qualificatore. Ogni thread che esegue il kernel ha un identificatore univoco dato dalla
variabile threadIdx, questa è un vettore di tre dimensioni che permette l’identificazione
univoca del thread all’interno del blocco; ciò permette di eseguire l’elaborazione di elementi
di un data set in modo naturale ad esempio per il calcolo con vettori, matrici o volumi.
I thread sono organizzati in blocchi, questi sono ordinati in una griglia monodimensionale o
bidimensionale; il numero di thread per blocco in una griglia è individuato tipicamente dalla
dimensione dei dati da elaborare o dal numero di CUDA core nel sistema. Nell’invocazione
del kernel è possibile passare come primo parametro o int (per griglia monodimensionale) o
dim3 (per griglia bidimensionale); ogni blocco è identificato univocamente dalla variabile
blockIdx (mono o bidimensionale) e mette a disposizione la dimensione tramite blockDim
(mono o bidimensionale). I blocchi sono eseguiti in modo indipendente, questo permette di
scalare su un qualsiasi numero di processori.
Figura 50 Blocchi di thread
I CUDA thread possono accedere ai dati memorizzati in diversi spazi di memoria durante
l’esecuzione; ogni thread ha una memoria locale privata, i thread del medesimo blocco
possono salvare i dati nella memoria condivisa la quale è visibile a ogni thread dello stesso
blocco, tutti i thread possono accedere alla memoria globale (quella del device). Ci sono
ancora due spazi di memoria accessibili dai thread ma solo in lettura ossia la constant e
texture memory, questi sono ottimizzati per differenti tipi d’utilizzo e inoltre la texture

84 NVIDIA CUDA, architettura e modello di programmazione
memory permette differenti modalità d’indirizzamento come pure il filtraggio dei dati. La
global, constant e texture memory sono inoltre persistenti per tutti i lanci del kernel per la
medesima applicazione.
Figura 51 Gerarchia memoria
Occorre osservare che la memoria di sistema (quella dell’host) è separata da quella della
GPU, questo significa che è necessario un trasferimento dei dati tra memoria dell’host e
memoria del device; in CUDA C i puntatori alla memoria dell’host possono accedere
esclusivamente alle locazioni di memoria che stanno sull’host, i puntatori alla memoria del
device possono accedere esclusivamente alle locazioni che stanno sul device. Per eseguire la
comunicazione tra host e device si utilizzano opportune chiamate al C Runtime for CUDA
(tramite cudaMemcpy e simili).
6.4.4. Organizzazione della memoria
In questo paragrafo si andrà ad analizzare l’organizzazione della memoria a cui fa
riferimento un’applicazione CUDA sia per host sia per device:
Linear device memory. La linear memory è presente su device nella global memory e
utilizza uno spazio d’indirizzamento di trentadue e quaranta bit rispettivamente per
compute capability 1.x e 2.x; per l’allocamento e liberare le risorse si utilizzano le
chiamate cudaMalloc e cudaFree, per il trasferimento dei dati si utilizza
cudaMemcpy. C’è la possibilità di eseguire l’allocazione anche con altre due
chiamate al C runtime ossia cudaMallocPitch e cudaMalloc3D, queste permettono
rispettivamente di allocare vettori 2D e 3D in modo efficiente impiegando
l’allineamento in memoria. Le operazioni di copia sono eseguite in questo caso da
cudaMemcpy2D e cudaMemcpy3D;
Shared device memory. La memoria condivisa all’interno di ogni SM è molto più
veloce della memoria globale del device; la dimensione è ridotta, quindi è necessario
salvare in questa porzione di memoria i dati a cui i thread accedono più
frequentemente. L’allocazione avviene mediante __shared__;
Texture device memory. In ogni SM c’è una cache dedicata per la gestione delle
texture, questa memoria è molto più performante della memoria globale. Il kernel è
in grado di accedere a questa in lettura; l’operazione di fetch della texture avviene
mediante le funzioni che prendono il nome di texture fetch function device, il primo

85 NVIDIA CUDA, architettura e modello di programmazione
parametro di queste funzioni è un oggetto chiamato texture reference che specifica
quale parte della texture memory deve essere prelevata. Una texture reference ha
diversi attributi, in particolare si può specificare che l’accesso alla texture elemento
per elemento (ogni elemento è chiamato texel) può avvenire tramite un array a 1,2 o
3 dimensioni, il tipo di dati d’input e output della texture, interpretazione delle
coordinate e il tipo di filtraggio;
Surface device memory. La texture cache è in sola lettura, la surface cache memory è
un CUDA array in lettura e scrittura; il compute capability specifica la massima
altezza, larghezza e profondità. La funzione per allocare la surface memory è
cudaArraySrufaceLoadStore;
Pinned host memory. Pinned memory (free page-locked) sta sull’host, per allocare
questa memoria è necessario utilizzare cudaHostAlloc e cudaFreeHost. Occorre
osservare però che la quantità di memoria a disposizione è limitata e togliendo
memoria disponibile al sistema operativo per la paginazione ciò può comportare a
una riduzione delle prestazioni dell’intero sistema. Se si utilizza la chiamata al C
runtime cudaHostAlloc, la pinned memory è cacheable lato host ma si può disattivare
questa modalità tramite la chiamata a cudaHostAllocWriteCombined. In quest’ultimo
caso non si utilizzano le cache L1 e L2, le quali potranno essere utilizzate dalla CPU
per altri scopi, inoltre l’accesso diventa piuttosto lento lato host e conviene utilizzare
questa tecnica solo quando l’host deve scrive dati nella memoria e il device accede a
questa soltanto in lettura. Nel caso in cui la memoria è mappata tra host e device
allora questa è condivisa ed è necessaria la sincronizzazione per l’accesso ai dati. I
vantaggi nell’utilizzo di questa memoria sono:
o E’ possibile eseguire la copia dei dati tra pinned host memory e device in
modo concorrente con il kernel in esecuzione;
o C’è la possibilità di eseguire il mapping dello spazio d’indirizzamento della
pinned host in device memory quindi non serve eseguire la copia dei dati con
cudaMemcpy;
o Il trasferimento dei dati tra host e device è molto efficiente dato che la
memoria allocata non è paginabile (non può essere salvata dal sistema
operativo su disco) e in particolare per il fatto che si sfrutta il DMA (Direct
Memory Access) per sollevare la CPU dalla gestione del trasferimento.
6.5. Librerie
Il CUDA SDK mette a disposizione svariate librerie per facilitare la programmazione in CUDA
C:
CUBLAS è l’implementazione di BLAS (Basic Linear Algebra Subprograms) in CUDA,
permette di eseguire le classiche operazioni su matrici;
CUFFT è una libreria per eseguire la Fast Fourier Transform (FFT) su GPU;
CURAND mette a disposizione una libreria per la creazione di numeri casuali tramite
CPU o GPU;

86 NVIDIA CUDA, architettura e modello di programmazione
CUSPARSE per le tipiche operazioni su matrici sparse;
NPP è la libreria dedicata all’image e digital signal processing.
6.6. Velocità di elaborazione
La legge di Amdahl specifica qual è il massimo aumento in velocità di elaborazione che si
può ottenere mediante la parallelizzazione di una porzione di un programma seriale
dove S è l’aumento di velocità, P la frazione del tempo totale di esecuzione seriale della
porzione di codice che può essere parallelizzata e N il numero di processori per eseguire la
porzione di codice parallelizzata. Più grande è N più piccolo è il rapporto P/N, nel caso di
GPU N è molto grande e quindi il termine P/N può essere trascurato; per ottenere un
elevato incremento prestazionale dalla parallelizzazione è necessario rendere P il più grande
possibile. Da questo si deduce che per eseguire il più velocemente possibile un’applicazione
con CUDA è necessario parallelizzare la maggior parte del codice, quindi la fase di analisi e
successiva programmazione è di fondamentale importanza per ottenere il massimo del
beneficio prestazionale dall’architettura CUDA.

87 Benchmark
7. Benchmark
7.1. Introduzione
In questo capitolo si presentano i risultati ottenuti con l’algoritmo descritto; i benchmark
riguardano le prestazioni sia dal punto di vista del riconoscimento dei nuclei cellulari sia in
termini di velocità di calcolo.
Per fare i test di calibrazione del filtro DOG e addestramento dell’algoritmo si è usato un
insieme di centotrentadue immagini classificate manualmente da due esperti; dato che non
è possibile stabilire chi dei due esperti ha eseguito la migliore classificazione, si è deciso di
usare l’insieme classificato del secondo esperto come riferimento. La scelta deriva dal fatto
che il secondo esperto ha la tendenza di fornire un conteggio maggiore rispetto al primo, ciò
permette di presentare più esempi positivi all’algoritmo che “simulerà” questa tendenza. Sì
è notato che l’algoritmo ha la propensione di generare un conteggio molto inferiore rispetto
a quello dell’esperto in certi data set (a queste situazioni corrispondono i casi in cui
l’algoritmo si comporta peggio), quindi il vantaggio consiste nel fatto che in questi casi si ha
un aumento nel conteggio senza compromettere la classificazione in cui l’algoritmo non
presenta questo problema. Da notare che si poteva procedere anche con un’altra strategia
ossia considerare i soli oggetti classificati allo stesso modo dai due esperti. In quest’ultimo
caso si hanno dei notevoli svantaggi, prima di elencarli è necessario stabilire cosa s’intende
per oggetti classificati allo stesso modo; è necessario distinguere due situazioni:
Nel caso della calibrazione dei parametri per la DOG (fare riferimento al paragrafo
2.4.), un oggetto è classificato allo stesso modo dai due esperti quando l’intorno
(centrato ad esempio nel marcatore del secondo esperto) contiene un solo
marcatore dell’altro esperto. Si ha ambiguità quando l’intorno contiene più
marcatori dell’altro esperto o nessuno;
Per la procedura di assegnazione della classe di appartenenza della ROI (fare
riferimento al paragrafo 2.6.), l’oggetto è classificato allo stesso modo quando il blob
associato contiene un marcatore di entrambi gli esperti. Si ha ambiguità quando il
blob contiene due marcatori dello stesso esperto, ha un solo marcatore o ha più di
due marcatori.
Per tutte le situazioni ambigue non si definisce il comportamento dell’algoritmo dato che si
prendono in considerazione soltanto gli oggetti classificati allo stesso modo, ciò ha dei
notevoli svantaggi che compromettono irrimediabilmente il comportamento dell’intero
algoritmo visto che tali situazioni determinano circa il 10% (fare riferimento al paragrafo
7.3.) di scostamento nella classificazione fatta dai due esperti:
Non sarebbe possibile calibrare accuratamente i parametri della DOG dato che non si
stabilisce (e non si verifica) la generazione dei punti d’interesse nelle situazioni
ambigue, quindi si rischia di compromettere tutti i passi successivi di elaborazione

88 Benchmark
che determinano il comportamento dell’algoritmo (generazione ROI, calcolo feature
e conseguente comportamento della SVM);
Come già detto, si è notato che l’algoritmo ha la tendenza di generare un conteggio
molto inferiore rispetto a quello dell’esperto in certi data set (causato per parametri
DOG non ottimi e quindi aumenta la possibilità di classificazione errata), con la
tecnica descritta si passerebbero meno esempi positivi rispetto alla soluzione finale
addotta con conseguente possibile tendenza ad accentuare questo tipo di
comportamento non desiderato;
Siccome non si prenderebbero in considerazione gli oggetti ambigui, non si definisce
il modello della SVM in queste situazioni e la classificazione finale potrebbe essere
completamente diversa da quell’attesa (poiché lo scostamento è di circa 10% nella
classificazione tra i due esperti).
Da tutto ciò si deduce che non stabilire il comportamento dell’algoritmo nelle situazioni
ambigue può compromettere notevolmente la classificazione finale, è meglio definire
accuratamente i parametri della DOG e il modello della SVM facendo riferimento al secondo
esperto piuttosto che rischiare di avere comportamenti non previsti dell’algoritmo. D’ora in
poi si farà riferimento unicamente alla soluzione che impiega il secondo esperto.
Dopo la calibrazione della DOG, la scelta del miglior kernel e feature per le centotrentadue
immagini, si sono fatte le valutazioni di conteggio su dieci insiemi d’immagini per le quali si
hanno a disposizione esclusivamente i conteggi finali cioè il numero di cellule classificate
come positive senza le posizioni delle medesime (eccetto che per due insiemi che sono stati
usati anche nella fase di addestramento ossia Data1 e Data2): ctrl 30 aprile 2010, ctrl2 30
aprile 2010, Data1, Data2, dot 400 4, Dot100, dots 200nm 1, Pillar100, t9_12 DAPI 400nm e
t9_12 DAPI ctrl.
7.2. Hardware e software impiegati
La macchina utilizzata per fare i benchmark ha le seguenti caratteristiche hardware:
CPU:
o Intel Core 2 Duo T5550;
o Processo produttivo a 65 nm;
o Frequenza core 1.83 GHz;
o Frequenza bus 167 MHz;
o FSB 667 MHz ;
o L1 Cache 32 KBytes x2;
o L2 Cache 2048 KBytes
o Numero di core 2;
GPU:
o GeForce 8600m GT;
o Compute capability 1.1;

89 Benchmark
o Frequenza streaming processor 950 MHz;
o Numero di SM 4;
o Dimensione warp di 32 thread;
o Regs per blocco 8192;
o Thread per blocco 512;
o Dimensioni massime dei thread 512x512x64;
o Dimensioni massime della griglia 655535x65535x1;
o Clock della memoria a 400 MHz;
o Memoria globale di 466.625 MB;
o Cache condivisa per blocco di 16 KB;
o Pitch 2.09715 GB;
o Memoria costante di 64 KB;
o Allineamento texture di 256 bytes;
o Overlap è supportato;
o Transfer rate da host a device con pinned 1750 MB/s;
o Transfer rate da host a device pageable 1000 MB/s;
o Transfer rate da device a host pinned 1750 MB/s;
o Transfer rate da device a host pageable 1000 MB/s;
o Transfer rate da device a device 5200 MB/s;
o 32-bit floating-point 60500 Mflop/s;
o 32 –bit integer 12150 Miop/s;
o 24-bit integer 60500 Miop/s;
o Processo produttivo 80 nm;
o Dimensione bus di memoria di 128 bits.
Memoria principale:
o DDR2;
o 3072 MB;
o Dual channels;
o DC in modalità simmetrica;
o Frequenza DRAM 333 MHz.
Memoria di massa:
o SSD Corsair F60;
o Capacità di 60 GB;
o Massimo transfer rate sequenziale in lettura e scrittura 285 MB/s 275 MB/s;
o Numero di IOPS con blocchi casuali di 4 KB 50000 IOPS.
I software impiegati sono:
Windows 7 Professional x64;
Visual Studio 2010 Ultimate;
NVIDIA Parallel Nsight 2.0, NVIDIA CUDA SDK 4.0, NVIDIA Compute Visual Profile 4.0;
MATLAB 2011a.

90 Benchmark
Per eseguire il debugging del codice CUDA C si è impiegata una macchina remota con GPU
NVIDIA G82.
7.3. Valutazione delle classificazioni manuali effettuate dagli esperti
Prima di poter valutare le prestazioni dell’algoritmo è necessario avere un termine di
paragone, ossia il golden test che è dato dalla classificazione manuale degli esperti. Le
immagini classificate sono organizzate in due gruppi (Data1 e Data2) per un totale di
centotrentadue; nella fase di confronto delle classificazioni manuali, calibratura dei
parametri della DOG e valutazione delle prestazioni in addestramento si raggruppano
queste immagini in un unico gruppo. Ciò ha i seguenti vantaggi:
Avere più esempi a disposizione in addestramento significa costruire un modello
della SVM più accurato;
Avere molti esempi permette in fase di cross-validation verificare meglio la
generalizzazione dell’algoritmo d’apprendimento;
Con molti esempi è possibile valutare meglio l’errore in classificazione tra i due
esperti.
Gli esperti a disposizione (per Data1 e Data2) sono due e di seguito si riporta la tabella
riassuntiva relativa alle classificazioni manuali.
Esperto Conteggio
1 5208
2 5280
La differenza fra il numero totale di cellule è 72 mentre in percentuale è 4.6083%; da notare
che questo modo di confrontare la classificazione non è molto accurato dato che non si è in
grado di stabilire effettivamente se un oggetto è stato classificato nello stesso modo da
entrambi gli esperti. Per tale motivo si è deciso di procedere in modo diverso per
confrontare le due classificazioni, da notare che si hanno a disposizione le posizioni dei
marcatori sui nuclei delle cellule. La strategia consiste nel prendere come riferimento la
classificazione del secondo esperto e costruire un intorno riferito a ogni marcatore inserito
(gli intorni sono costruiti con la medesima logica in 2.4); all’interno di ogni intorno si verifica
se c’è un solo marcatore dell’esperto uno, in caso affermativo significa che il nucleo è
classificato nello stesso modo. L’errore finale è calcolato come
è il numero di nuclei classificati dal secondo esperto in modo diverso dal primo, è il
numero di nuclei del primo esperto che non sono stati coinvolti nella ricerca all’interno degli
intorni e è il numero totale di nuclei classificati dal secondo esperto.
D S N D + S e%
200 340 5280 540 10.2273

91 Benchmark
L’effettivo errore di scostamento è del 10.2273%, quindi per avere delle prestazioni
confrontabili con quelle degli esperti l’algoritmo non deve scostarsi troppo nei test da
questa soglia.
7.4. Valutazione dei parametri della DOG
La calibrazione dei parametri del filtro DOG è di fondamentale importanza, una calibratura
errata compromette l’intero funzionamento dell’algoritmo; per questo motivo si sfrutta una
procedura che testa varie coppie di deviazioni standard e tutto il processo richiede ore di
elaborazione prima di individuare la coppia ottima. L’utente deve inserire soltanto il
diametro massimo di una cellula; l’algoritmo segue la logica descritta in 2.4 per stabilire
quali sono i parametri ottimali.
Indice Sigma1 Sigma2 Validi% Sovrannumero% Sovra raggio%
Non individuati%
Validi% + Sovra raggio%
1 10 11 78.1277 9.6238 11.6360 0.6124 89.7637
2 11 12 79.3991 6.7382 12.1459 1.7167 91.545
3 11 13 78.8627 5.8155 12.9399 2.3820 91.8026
4 11 14 77.9614 5.1502 14.3133 2.5751 92.2747
5 11 15 76.9528 4.8069 15.0429 3.1974 91.9957
6 11 16 75.4077 4.4850 16.6953 3.4120 92.103
7 11 17 73.6052 4.1416 18.0043 4.2489 91.6095
8 11 18 65.6315 3.5197 24.2236 6.6253 89.8551
9 12 13 77.6180 5.1073 14.5279 2.7468 92.1459
10 12 14 76.3519 4.6352 15.8155 3.1974 92.1674
11 12 15 74.0773 4.3348 17.8326 3.7554 91.9099
12 12 16 71.9957 3.9914 19.1631 4.8498 91.1588
13 12 17 64.6998 3.7267 24.6377 6.9358 89.3375

92 Benchmark
Figura 52 Calibratura DOG
Indice indica il passo di ricerca dell’algoritmo, Sigma1 è la deviazione standard della prima
gaussiana, Sigma2 è la deviazione standard della seconda gaussiana, Validi% indica la
percentuale di marcatori validi, Sovrannumero% percentuale di marcatori individuati per
sovrannumero, Sovra raggio% percentuale di marcatori individuati per aumento del raggio,
No individuati% è la percentuale di marcatori non individuati dall’algoritmo (cioè non ci
sono punti d’interesse generati dalla DOG negli intorni centrati nei marcatori inseriti dagli
esperti). La combinazione migliore è quella che massimizza la somma di Validi% con Sovra
raggio% (fare riferimento al paragrafo 2.4.) che è data per indice quattro.
7.5. Valutazione delle prestazioni in fase di addestramento
Nel capitolo tre si è descritto in dettaglio come si garantisce l’invarianza per rotazione delle
regioni d’interesse; come già detto, per ridurre il numero di ROI poco significative da fornire
alla macchina a vettori di supporto nella fase di addestramento e quindi definire meglio il
modello della macchina SVM, si scartano nell’elaborazione le ROI poco robuste
nell’invarianza per rotazione (fare riferimento a 3.2). L’errore di scostamento massimo in
gradi è pari a cinque e il numero di rotazioni da verificare sono trentacinque (con incrementi
di dieci gradi). Di seguito si riporta il risultato delle ROI scartate.
89.7637
91.545
91.8026
92.2747
91.9957
92.103
91.6095
89.8551
92.1459
92.1674
91.9099
91.1588
89.3375
87 88 89 90 91 92 93
1
2
3
4
5
6
7
8
9
10
11
12
13
%
Validi% + Sovra raggio%
Validi% + Sovra raggio%

93 Benchmark
Figura 53 Percentuale di regioni d'interesse scartate nella fase di addestramento della macchina a vettori di supporto
Dopo aver scartato le ROI poco robuste all’invarianza per rotazione, è necessario stabilire il
numero di coefficienti per le varie tipologie di feature.
Il numero di coefficienti per le feature di tipo DCT è legato all’energia media minima
impostata che in questo caso è del 90% a cui corrisponde una finestra DCT 7x7 e quindi
s’impiegano quarantanove coefficienti.
Figura 54 Numero di coefficienti selezionati per la DCT
In tutti gli altri casi si procede considerando un buon compromesso tra velocità di
elaborazione e descrizione degli oggetti; per Zernike s’impiegano duecentotrentuno feature
(cioè il grado del polinomio di Zernike è impostato a venti), per FAFMT e DAFMT si sfrutta
50.3860
52.0607
49.5000 50.0000 50.5000 51.0000 51.5000 52.0000 52.5000
Esprto 2
%
Percentuale di regioni d'interesse scartate
Positivi scartati
Negativi scartati
0 10 20 30 40 50 60 70 80 90 1000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Size DCT
Energ
y (
energ
y:
0.9
2366 w
indow
: 7 )

94 Benchmark
una finestra 15x15 quindi s’impiegano duecentoventicinque feature, per ShapeIntensity si
hanno quattordici descrittori.
Per la macchina a vettori di supporto si testa il kernel polinomiale, RBF e sigmoidale con le
feature descritte nel capitolo tre; per i concetti relativi alle curve ROC fare riferimento al
capitolo cinque.
Di seguito si riporta per ogni kernel della macchina a vettori di supporto il valore , il
parametro del kernel (nel caso di kernel polinomiale corrisponde al grado, per RBF a
gamma e per sigmoidale a gamma) e ossia il soft margin. Questi parametri fanno
riferimento alla miglior macchina per feature con uno specifico kernel.
Kernel polinomiale con feature
AUC dg C
ShapeIntensity 0.9467 2 10000
Zernike 0.9165 2 10000
FAFMT 0.9325 2 10000
DAFMT 0.9295 2 10000
DCT 0.9375 3 10000
Figura 55 Kernel polinomiale
In questo caso le migliori feature con kernel polinomiale sono ShapeIntensity. Si riporta la
relativa curva ROC.
0.9467
0.9165
0.9325
0.9295
0.9375
0.9 0.91 0.92 0.93 0.94 0.95
ShapeIntensity
Zernike
FAFMT
DAFMT
DCT
AUC
Kernel polinomiale
AUC
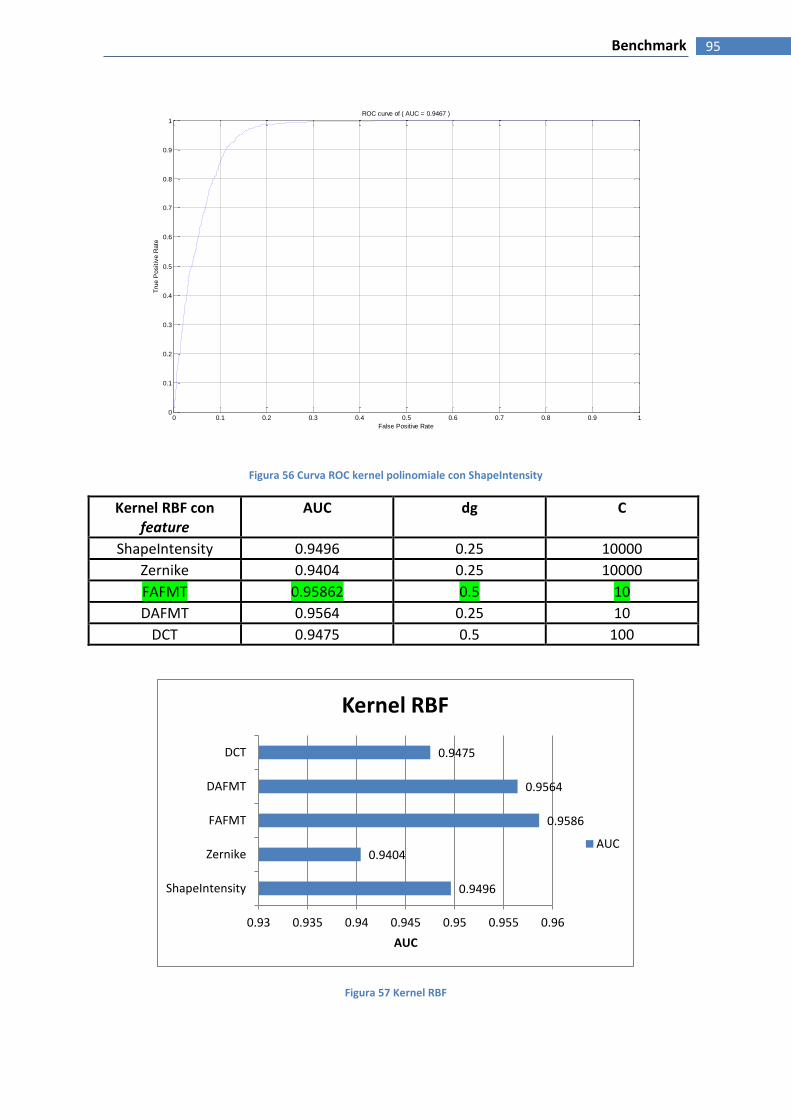
95 Benchmark
Figura 56 Curva ROC kernel polinomiale con ShapeIntensity
Kernel RBF con feature
AUC dg C
ShapeIntensity 0.9496 0.25 10000
Zernike 0.9404 0.25 10000
FAFMT 0.95862 0.5 10
DAFMT 0.9564 0.25 10
DCT 0.9475 0.5 100
Figura 57 Kernel RBF
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
False Positive Rate
Tru
e P
ositiv
e R
ate
ROC curve of ( AUC = 0.9467 )
0.9496
0.9404
0.9586
0.9564
0.9475
0.93 0.935 0.94 0.945 0.95 0.955 0.96
ShapeIntensity
Zernike
FAFMT
DAFMT
DCT
AUC
Kernel RBF
AUC
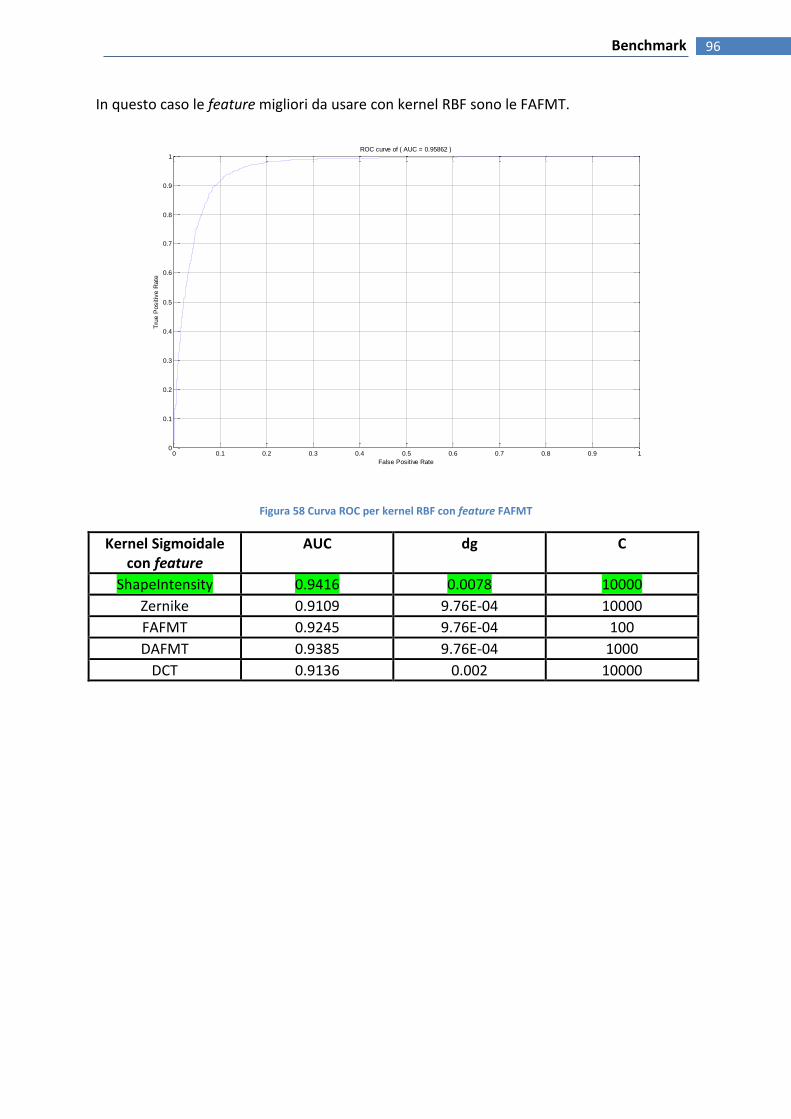
96 Benchmark
In questo caso le feature migliori da usare con kernel RBF sono le FAFMT.
Figura 58 Curva ROC per kernel RBF con feature FAFMT
Kernel Sigmoidale con feature
AUC dg C
ShapeIntensity 0.9416 0.0078 10000
Zernike 0.9109 9.76E-04 10000
FAFMT 0.9245 9.76E-04 100
DAFMT 0.9385 9.76E-04 1000
DCT 0.9136 0.002 10000
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
False Positive Rate
Tru
e P
ositiv
e R
ate
ROC curve of ( AUC = 0.95862 )

97 Benchmark
Figura 59 Kernel sigmoidale
In questo caso conviene impiegare come feature le ShapeIntensity.
Figura 60 Curva ROC per kernel sigmoidale con ShapeIntensity
Dai dati precedenti si nota che la migliore soluzione si ottiene con kernel RBF e feature
FAFMT. Di seguito si riporta il sommario dei risultati ottenuti.
Kernel Feature AUC dg C
Polinomiale ShapeIntensity 0.9467 2 10000
RBF FAFMT 0.9586 0.5 10
Sigmoidale ShapeIntensity 0.9416 0.0078 10000
0.9416
0.9109
0.9245
0.9385
0.9136
0.89 0.9 0.91 0.92 0.93 0.94 0.95
ShapeIntensity
Zernike
FAFMT
DAFMT
DCT
AUC
Kernel sigmoidale
AUC
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
False Positive Rate
Tru
e P
ositiv
e R
ate
ROC curve of ( AUC = 0.9416 )

98 Benchmark
Figura 61 Migliori feature e kernel
7.6. Valutazione delle prestazioni in classificazione
A questo punto è necessario valutare le prestazioni dell’algoritmo in classificazione con
kernel RBF e feature FAFMT; per tutti gli insiemi d’immagini (eccetto Data1 e Data2) si
hanno a disposizione esclusivamente i conteggi fatti dagli esperti , quindi, non c’è modo per
risalire alle posizioni reali dei marcatori inseriti manualmente.
Figura 62 Valutazione del conteggio
Il valore medio dell’errore (prendendo in esame gli errori in valore assoluto) è 4.1834% con
deviazione standard 2.2972%.
0.9467
0.9586
0.9416
0.93 0.935 0.94 0.945 0.95 0.955 0.96
ShapeIntensity
FAFMT
ShapeIntensity
Po
lino
mi
ale
RB
F Si
gmo
idal
e
AUC
Migliori feature e kernel
AUC
3.4142
-7.0646
1.3793
3.9033
0.6775
2.931
6.2937
3.5326
-7.5026
-5.1351
-10 -8 -6 -4 -2 0 2 4 6 8
Data1 (3544)
dot 400 4 (821)
Dot100 (1450)
dots 200nm 1 (538)
t9_12 DAPI ctrl (738)
Data2 (1160)
ctrl 30 aprile 2010 (715)
ctrl2 30 aprile 2010 (736)
t9_12 DAPI 400nm (973)
Pillar100 (2220)
%
Valutazione del conteggio
Errore nel conteggio

99 Benchmark
7.7. Valutazione della velocità di elaborazione
Per valutare la velocità di elaborazione dell’algoritmo si sono fatti cinque test per ogni
routine da testare e il tempo riportato è la media di questi; nella valutazione si considera
l’incremento della velocità di elaborazione quando s’impiega la GPU in luogo della CPU. Da
ricordare che solo una parte dell’algoritmo è implementata in CUDA C, in particolare due
funzioni sono implementate completamente in CUDA C:
mexBlob restituisce le coordinate dei punti d’interesse presenti in un blob;
mexFind restituisce le coordinate di un solo punto d’interesse specificando
l’etichetta associa.
Queste due routine sono ampiamente usate in varie porzioni di codice dell’algoritmo ed
eseguono compiti tipici riguardanti la gestione dei punti d’interesse. Si è scelto
d’implementare queste due funzionalità perché sono molto generiche e quindi non
subiscono modifiche se s’implementano nuove procedure di elaborazione dell’algoritmo
quali nuove tecniche di confronto tra le classificazioni manuali dei due esperti, filtraggi,
ricerca dei parametri della DOG, estrazione delle ROI, nuove feature, nuovi kernel per la
SVM e l’impiego di altri algoritmi d’apprendimento. Tutti i test sono effettuati sul training
set (centotrentadue immagini date da Data1 e Data2); per tenere traccia delle tempistiche
delle funzioni si sfrutta il profile del MATLAB.
Routine CPU (s) GPU (s) Incremento prestazionale su
GPU
ExtractCircularBlob 74.059 32.737 2.2622415
ExtractDOGError 1985.363 162.614 12.20905334
GetCircularSeed 56.442 18.052 3.126634168
BenchmarkUserSeeds 182.877 98.796 1.851056723
GetSeeds 283.704 154.004 1.842185917
AutomaticDOG 4975.376 2414.042 2.06101468
AutomaticDOGImproved 1054.537 629.794 1.674415761

100 Benchmark
Figura 63 Incremento prestazionale su GPU
L’incremento medio delle prestazioni su GPU è di 3.57 volte con deviazione standard 3.84.
2.26
12.21
3.13
1.85
1.84
2.06
1.67
0 2 4 6 8 10 12 14
ExtractCircularBlob
ExtractDOGError
GetCircularSeed
BenchmarkUserSeeds
GetSeeds
AutomaticDOG
AutomaticDOGImproved
Incremento
Incremento prestazionale su GPU
Incremento prestazionale su GPU

101 Conclusioni
8. Conclusioni In questo lavoro si è presentato un algoritmo efficace dal punto di vista del riconoscimento
dei nuclei cellulari e velocità di elaborazione grazie alla GPU.
Nella calibratura del filtro DOG si osserva che conviene usare la coppia di deviazioni
standard che garantisce un numero di marcatori dell’esperto
non rilevati pari a 2.5751% che è un valore abbastanza piccolo (se paragonato al 10.2273%
di differenza in classificazione manuale tra i due esperti). Questo scostamento influenza il
risultato finale di conteggio dell’algoritmo però in lieve entità.
Nella valutazione dei kernel per la SVM si nota che le feature di tipo ShpaeIntensity sono
quelle che garantiscono un miglior comportamento dell’algoritmo con kernel polinomiale e
sigmoidale; per kernel RBF conviene usare le feature di tipo FAFMT che sono migliori
rispetto alle altre. La migliore AUC si ottiene con kernel RBF e feature FAFMT che assume il
valore di 0.9586 e in base alla capacità discriminante dell’AUC proposta da Swets [15] risulta
che il test è altamente accurato. Da questi risultati si deduce che il kernel RBF con vettori di
supporto che sfruttano le feature FAFMT discrimina al meglio le osservazioni. Si può notare
che per feature FAFMT e DAFMT i risultati che si ottengono nella valutazione dei kernel sono
molto simili a dimostrazione del fatto che sono due approssimazioni della medesima
trasformata; le feature di Zernike sono poco accurate come previsto (fare riferimento a 3.3)
e sono le peggiori in tutti i casi considerati dato che nonostante un numero elevato di
coefficienti (le feature) non sono in grado di rappresentare efficacemente i dettagli degli
oggetti. Le feature di tipo ShapeIntensity garantiscono un buon comportamento, da ciò si
deduce che i descrittori scelti (quattordici) permettono una descrizione molto accurata della
forma e della distribuzione dell’intensità degli oggetti.
Si è notato che la differenza in classificazione tra i due esperti è del 10.2273% e lo scopo
dell’algoritmo è fornire un conteggio che ha un errore di scostamento non superiore a
questo valore; dalla differenza in classificazione tra i due esperti si nota che c’è un fattore
soggettivo non trascurabile che influenza la classificazione. Lo scostamento massimo che si è
ottenuto nei dieci insiemi d’immagini a disposizione è di -7.5026% (set “t9_12 DAPI ctrl” che
ha 738 nuclei cellulari classificati manualmente dall’esperto), quindi il risultato è notevole a
fronte dell’elevata soggettività in classificazione. Da osservare che ci sono molti insiemi
d’immagini per i quali l’algoritmo fornisce un errore di scostamento molto ridotto, inferiore
al 4%, questo a dimostrazione del buon comportamento dell’algoritmo. I casi peggiori hanno
un errore (in valore assoluto) di scostamento tra il 5% e 7.5%; i principali motivi che possono
portare a questi risultati sono:
Parametri del filtro DOG non sempre adatti poiché le immagini sono prelevate in
condizioni diverse (la luminosità può variare molto da un’immagine all’altra e se

102 Conclusioni
questa è particolarmente intensa in certe zone dello sfondo, allora potrebbe
accadere che in corrispondenza di queste l’algoritmo generi delle ROI indesiderate);
Modello della macchina a vettori di supporto non ben definito. Alcuni esempi
classificati positivi da un esperto potrebbero essere passati alla SVM nella fase di
addestramento come esempi negativi perché l’esperto ha inserito alcuni marcatori
sui bordi dei nuclei anziché vicino ai centri degli oggetti da analizzare. Ciò significa
che l’algoritmo potrebbe non individuare questi marcatori e impostare l’esempio
come negativo quando in realtà è positivo;
L’AUC migliore durante i test di addestramento è pari a 0.9586 (kernel RBF e feature
FAFMT) e questo significa che l’algoritmo commette degli errori, questi potrebbero
aumentare se gli esempi da analizzare sono molto diversi da quelli usati nella fase di
addestramento della macchina;
L’ipotesi di non considerare i blob a una certa distanza dai bordi dell’immagine non
sempre funziona correttamente dato che dipende dalla distanza impostata. Questa
distanza, che è fissa, potrebbe non essere efficace in alcuni casi poiché potrebbe
accadere che ci siano immagini con un elevato numero di nuclei cellulari di diametro
inferiore alla distanza limite vicini ai bordi. Questo è il principale motivo per il quale
si hanno scostamenti negativi, cioè conteggi che in numero sono inferiori a quelli
effettuati da un esperto. Infatti, in tutti questi casi, diminuendo questa distanza si ha
un notevole miglioramento nel conteggio ma un peggioramento negli altri esempi
perché i blob risultano tagliati e quindi non riconoscibili correttamente dalla SVM (da
notare che i blob tagliati non sono impiegati nel conteggio e quindi l’errore aumenta
sia perché la SVM li classifica positivi sbagliando sia perché non sono presi in
considerazione nel conteggio da parte degli esperti);
Il filtro basato sulla funzione sigmoidale per l’estrazione dell’oggetto della ROI può
non essere efficace in alcuni casi, specialmente se gli oggetti indesiderati sono molto
vicini a quello da analizzare (in questa situazione la funzione sigmoidale non è in
grado di cancellare completamente gli oggetti da non analizzare).
Per quanto riguarda le prestazioni si ha che le routine che sfruttano la tecnologia CUDA
hanno un incremento da 1.6 a 12.2 volte rispetto al medesimo algoritmo elaborato però
esclusivamente su CPU; le funzioni con incremento prestazionale massimo di circa due
eseguono poche chiamate alle routine CUDA mexBlob e mexFind, invece le altre le usano in
modo più intensivo (ExtractDOGError impiega quasi esclusivamente funzioni CUDA e ciò
permette un incremento prestazionale superiore a dodici volte) . Per migliorare le
prestazioni lato CUDA sarebbe opportuno impiegare una GPU di fascia alta, invece, nei test
effettuati si è usata una GPU di fascia bassa con varie restrizioni poiché ha compute
capability di solo 1.1.
Possibili sviluppi futuri per migliorare l’algoritmo sono:

103 Conclusioni
Usare nuove feature che permettano di migliorare ulteriormente la descrizione della
forma e texture degli oggetti da analizzare (una possibile idea sarebbe di impiegare
feature basate sui filtri di Gabor per mettere in risalto le texture);
Impiegare la libreria MKLAB libsvm per la macchina a vettori di supporto che sfrutta
la tecnologia CUDA per gestire il kernel RBF (non ha il supporto al kernel polinomiale
e sigmoideo). In questo caso è necessario implementare una mex per interagire con
il MATLAB;
Impiegare una tecnica più efficace della funzione sigmoidale per escludere gli oggetti
da non analizzare presenti nella ROI;
Eventualmente per rendere il codice per l’elaborazione su GPU indipendente dal
produttore hardware si potrebbe eseguire un’implementazione in OpenCL anziché
CUDA C.

104 Bibliografia
Bibliografia [1] Programming Massively Parallel Processors-David B. Kirk, Wen-mei W. Hwu 2010.
[2] CUDA by example An Introduction to General-Purpose GPU Programming Jason Sanders,
Edward Kandrot 2010.
[3] White Paper NVIDIA GF110 2010.
[4] White Paper NVIDIA Fermi Compute Architecture 2010.
[5] NVIDIA CUDA Architecture Introduction & Overview 2010
[6] NVIDIA CUDA C Best Practices Guide 2010.
[7] NVIDIA CUDA C Programming Guide 2010.
[8] NVIDIA PTX: Parallel Thread Execution ISA version 2.1 2010
[9] NVIDIA Fermi Tuning Guide 2010.
[10] F. Ghorbel. A complete invariant description for gray-level images by the harmonic
analysis approach. Pattern Recognition Letters, October 1994.
[11] Milan Sonka, Vaclav Hlavac, and Roger Boyle Image Processing, Analysis and Machine
Vision 2 Ed.
[12] Digital Image Processing: PIKS Inside, Third Edition. William K. Prat.
[13] Chris Stauffer, "Automatic hierarchical classification using time-based co-
occurrences", IEEE Conference on Computer Vision and Pattern Recognition (CVPR1999), pp.
333-339, June 23-25, 1999.
[14] Chih-Chung Chang and Chih-Jen Lin, LIBSVM : a library for support vector machines.
ACM Transactions on Intelligent Systems and Technology, 2:27:1--27:27, 2011. Software
available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
[15] Swets J.A. (1998) Measuring the accuracy of diagnostic systems. Science, 240, 1285-93.
[16] Schäfer H. (1989). Constructing a cut-off point for a quantitative diagnostic test.
[17] F. Ghorbel, A complete invariant description for gray-level images by the harmonic
analysis approach 1994.
[18] S. Goh. The Mellin transformation: Theory and digital filter implementation 1985.

105 Appendice A
Appendice A
A.1. DirectX 11 su hardware DirectX 10 e DirectX 9.0c
E’ possibile utilizzare l’API DirectX 11 su hardware DirectX 10 o 9.0c con il vantaggio di
sfruttare i miglioramenti prestazionali introdotti nell’API; però per utilizzare le nuove feature
è necessario sfruttare hardware DirectX 11 compatibile (tessellation, compute shader).
A.1. Shader model 5
Gli shader model servono per applicare effetti visivi ai modelli 3D in base al tipo di oggetto,
ad esempio se l’oggetto è metallico, allora è necessario utilizzare gli shader relativi alla
gestione dei metalli. Gli shader model sono suddivisi nelle seguenti categorie:
Vertex Shader (VS), descrivono la forma del modello 3D e a ogni vertex d’input
corrisponde un vertex d’output cioè è in grado di alterare la posizione e orientazione
dei vertici di un oggetto;
Geometry Shader (PolyMorph, GS), esegue operazioni di amplificazione o
deamplificazione delle geometrie permettendo l’aumento o riduzione del numero di
vertici per creare un modello finale più complesso di quello iniziale;
Pixel Shader, descrivono il valore del singolo pixel per applicare texture o effetti
come bump mapping o nebbia;
Gli Hull Shader (HS) elaborano da uno a trentadue control point del patch generato
dai vertex shader, da questi e dalle caratteristiche che definiscono la mesh, ricavano
un nuovo insieme di control point (sempre in numero massimo pari a trentadue). Nel
fare quest’operazione, gli HS possono decidere se variare il numero dei control point,
aumentandolo o diminuendolo;
Domain Shader (DS). Gli ingressi dei DS sono dati dai control point generati dagli hull
shader, tessellation factor e il patch generato dal tessellator; in questa fase si sta
operando a livello di view space. Questi shader svolgono i seguenti compiti:
o Si occupano di confrontare il risultato della tessellation con le indicazioni
fornite dai control point generati dagli HS;
o Trasformano, in base ai dati degli HS le serie di linee, triangoli e altri poligoni
generati in fase di tessellation in nuovi vertici da renderizzare;
o Controllano che i risultati ottenuti siano congruenti con il valore di LoD (Level
of Detail) impostato;
o Procedono, se necessario, a eseguire altre operazioni come ad esempio
l’applicazione del displaced mapping;
Compute Shader. E’ un nuovo tipo di shader introdotto in DirectX 11 per eseguire
calcoli di tipo generico su GPU.
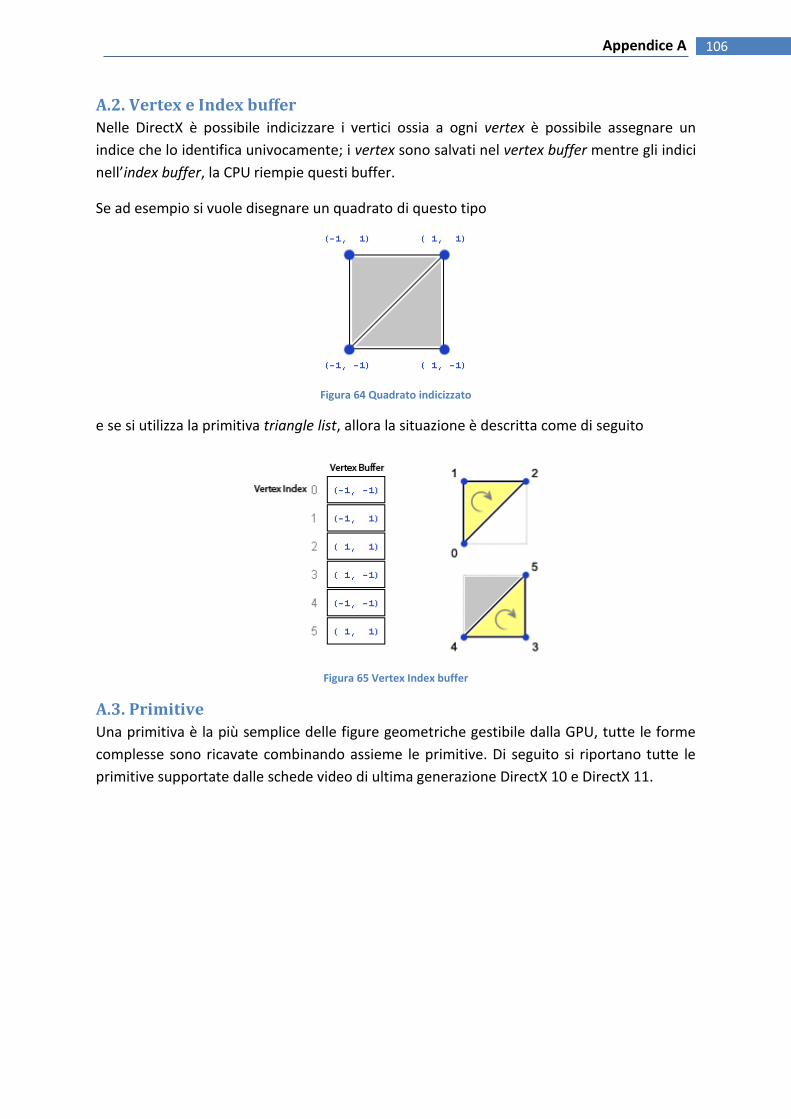
106 Appendice A
A.2. Vertex e Index buffer
Nelle DirectX è possibile indicizzare i vertici ossia a ogni vertex è possibile assegnare un
indice che lo identifica univocamente; i vertex sono salvati nel vertex buffer mentre gli indici
nell’index buffer, la CPU riempie questi buffer.
Se ad esempio si vuole disegnare un quadrato di questo tipo
Figura 64 Quadrato indicizzato
e se si utilizza la primitiva triangle list, allora la situazione è descritta come di seguito
Figura 65 Vertex Index buffer
A.3. Primitive
Una primitiva è la più semplice delle figure geometriche gestibile dalla GPU, tutte le forme
complesse sono ricavate combinando assieme le primitive. Di seguito si riportano tutte le
primitive supportate dalle schede video di ultima generazione DirectX 10 e DirectX 11.

107 Appendice A
Figura 66 Primitive
Occorre osserva che le informazioni relative alle adiacenze riguardano esclusivamente i
geometry shader.
Oltre alle nove primitive di sopra, nelle DirectX 11 è stata introdotta una nuova chiamata
patch:
Figura 67 Primitiva patch
I vari punti rappresentano i control point da inviare al tessellator, quindi questa primitiva si
utilizza esclusivamente con i tessellator e no per altri compiti.

108 Appendice A
A.4. Input assembler
Lo input assembler preleva i dati per le primitive dai vertex e index buffer con lo scopo di
assemblare le primitive che saranno utilizzate dagli stadi successivi della pipeline grafica.
A.4. Rasterization
Consiste nella conversione della scena 3D in immagine raster o bitmap cioè formata da
pixel; ciò server per ottenere un'immagine proiettabile sul monitor. Questo significa che è
necessario passare da una descrizione lineare a una discreta, ossia i pixel dell'immagine
raster. Questo ha comportato l’implementazione di vari algoritmi di rastering, sia per
oggetti semplici come le linee sia per più complessi come i poligoni.
A.5. Pipeline grafica DirectX 11
Per comprendere in dettagli l’architettura NVIDIA Fermi è necessario descrivere la piepeline
grafica dal punto di vista logico.
A.5.1. Architettura shader model unificata
Prima dell’evento delle DirectX 10, le unità di gestione degli shader erano dedicate e si
utilizzava una pipeline come riportata di seguito (sia per ATI sia per NVIDIA):
Figura 68 Pipeline grafica DirectX 9.0c
In uno schema di questo tipo ogni unità di calcolo è dedicata a un compito ben specifico da
eseguire e ogni blocco funzionale rimane in attesa dei dati dell’unità precedente (senza
poter eseguire elaborazioni). Con un’architettura di questo tipo non è possibile avere la
piena occupazione di tutte le unità funzionali a pieno carico, quello che tipicamente accade
è riportato di seguito:
Figura 69 Workload degli shader dedicati

109 Appendice A
Ossia quando un’unità è occupata, tutte le successive sono in idle; per sfruttare al meglio il
silicio (quindi i transistor) i progettisti hanno seguito la filosofia degli shader unificati: unità
generica per eseguire compiti differenti (per le varie tipologie di shader).
Gli shader unificati sono stati introdotti nelle DirectX 10 e comprendono vertex, geometry e
pixel shader; con le DirectX 11 sono stati aggiunti altri tre shader ossia hull, domain e
compute shader.
Il modello degli shader model unificati utilizza il medesimo instruction set per gestire i vari
tipi di shader; questo ha portato notevoli vantaggi:
Ottimizzazione del lavoro dell’intero chip e non nella maggior efficienza della singola
operazione (si sfrutta meglio l’intera architettura del chip);
Miglioramento del workload e conseguente risparmio di transistor dato che non ci
sono più unità dedicate in idle;
Programmazione più semplice dato che si sfrutta il medesimo ISA (Instruction Set
Architecture) unificato che ne semplifica la gestione;
Flessibilità nell’utilizzo dell’hardware di elaborazione, in quanto a ogni unità di
shading può essere affidata una delle tipologie di shader a disposizione; ad esempio
se un’applicazione richiede calcoli intensivi di tipo geometry shader, piuttosto che di
vertex e pixel, allora un numero maggiore di unità può essere dedicato al tipo di
elaborazione prevalente aumentando la velocità d’esecuzione complessiva.
Di seguito si riporta la pipeline grafica DirectX 10 con shader model unificati.
Figura 70 Pipeline grafica DirectX 10
A.5.2. Tessellation
Una delle principali novità nelle DirectX 11 è la tecnica di tessellation; occorre osservare che
durante l’introduzione delle DirectX 9.0c nel mercato delle GPU c’era già stato un primo
tentativo di tessellation ma successivamente abbandonato dato che era molto primitiva
come tecnica e non permetteva d’ottenere benefici consistenti nel miglioramento
dell’immagine finale. Il primo tentativo fu fatto da ATI con R200 e successivamente con la
GPU Xenos per XBOX 360, da allora fino all’evento delle DirectX 11 nessun produttore
hardware ha introdotto soluzioni significative in quest’ambito. Solo con la nuova API grafica,
la Microsoft ha introdotto tecniche di tessellation sofisticate e ha reso l’implementazione
hardware obbligatoria.

110 Appendice A
La tessellation consiste nel ripetere una figura geometrica (o un gruppo di figure) chiusa fino
a riempire un’intera superficie senza soluzione di continuità (nel caso di utilizzo di una sola
forma, si parla di tessellation pura). Prima dell’introduzione della tessellation, un
modellatore 3D creava il modello dell’oggetto d’interesse con un certo numero di poligoni,
maggiore era il numero di poligoni e maggiore era il dettaglio dell’oggetto ma questo
comportava un aumento della memoria occupata e diminuzione del frame rate. Invece con
la tessellation, che è un approccio hardware, da un modello iniziale opportunamente
elaborato è generato un finale cha ha un numero di poligoni maggiore rispetto all’originale.
Vantaggi:
Risparmio di memoria a parità di complessità poligonale;
Riduzione dei dati che la CPU deve inviare alla GPU quindi miglioramento nel
sfruttare la banda a disposizione;
Aumenta il dettaglio dell’oggetto rendendolo molto realistico;
Può genera lo skeletal animation in modo da rendere più fluide le animazioni;
Possibilità di replicazione del medesimo oggetto con notevole risparmio di memoria
(in memoria è presente un singolo oggetto e non tutte le repliche).
Svantaggi:
La tessellator unit si occupa esclusivamente della generazione dei poligoni, quindi se
si aumenta la complessità poligonale, allora si aumenta anche quella del rendering e
questo comporta a una riduzione del frame rate. Per risolvere questo problema,
almeno parzialmente, si sfrutta la tessellation adattativa;
La tessellator unit richiede come input un patch come quello riportato di seguito
Figura 71 Patch per la tessellator unit
dove sono indicati i control point i cui valori rappresentano gli input della fase di tessellation,
a ogni control point è associato un dominio; a questo punto si calcola in quante parti il
dominio dovrà essere suddiviso. Esistono due tecniche per eseguire l’operazione descritta:
tessellation regolare (poligoni regolari e congruenti) oppure semi-regolare (poligoni regolari
ma di tipo differente).

111 Appendice A
Figura 72 Tessellation regolare
Figura 73 Tessellation semi-regolare
Quello al centro è il control point, i numeri indicano il numero di lati per ogni poligono
generato.
Oltre a dover specificare il numero di suddivisioni, la tessellator unit tiene in considerazione
anche del tessellation edge factor, ossia il numero di segmenti di cui è composto un lato. Se
ad esempio la figura iniziale fosse la seguente
Figura 74 Figura iniziale per l'edge factor della tessellation
e se il risultato della tessellation fosse questo
Figura 75 Risultato dell'edge factor per la tessellation
l’edge factor per il lato superiore sarebbe uno, mentre per gli altri quattro. E’ di
fondamentale importanza osservare che i patch contigui devono avere il medesimo edge
factor sulle superfici a contatto altrimenti sarebbero generati degli artefatti.
Oltre alla scelta dei poligoni da utilizzare, è necessario stabilire come la tessellation debba
essere applicata: continua o adattativa. Nel caso di modalità continua, si usa un unico livello
di tessellation per ciascuna mesh o gruppo quindi si ha una tessellation omogenea (permette
di ottenere il miglior risultato dal punto di vista della qualità dell’immagine); al variare del
LoD (Level Of Detail) varia il livello di tessellation in modo proporzionale. Nella modalità
adattativa si hanno differenti livelli di tessellation per ogni edge o spigolo della mesh (la
tessellation non necessariamente è uniforme); in questo modo è possibile adattare il livello
di tessellation al LoD e alle superfici che risultano più visibili. Siccome l’adaptive mode

112 Appendice A
richiede un’analisi dinamica, è necessario calcolare l’edge factor per ogni frame, inoltre è
necessario stabilire un valore minimo e massimo di tessellation.
La tecnica continua ha il vantaggio di generare un modello geometrico altamente dettagliato
ma ha lo svantaggio di rendere molto lento il rendering a causa dell’elevata complessità
poligonale uniforme su tutti gli oggetti. L’adattativa ha il vantaggio di generare un modello
poligonale che dal punto di vista del dettagliato visivo è quasi come quello della tecnica
continua (leggermente inferiore) che richiede però meno tempo per eseguire il rendering (le
superfici meno visibili, lontane dall’osservatore e/o oscurate hanno una tessellation molto
ridotta); lo svantaggio è che per ogni frame è necessario riapplicare la tessellation.
A.5.3. Schema logico della pipeline grafica DirectX 11
Fare riferimento all’appendice B per approfondire i concetti di object, world, view, clip,
screen space e HSR (Hidden Surface Removal).
Dal punto di vista logico una pipeline grafica DirectX 11 è rappresentata come di seguito:
Figura 76 Pipeline grafica DirectX 11
Di seguito si descrivono in dettaglio le varie parti della pipeline grafica nel caso in cui si
sfrutta la tecnica di tessellation (se non si utilizza tale tecnica, allora l’output dei vertex
shader è inviata direttamente agli stadi dopo i domain shader). Sotto si riporta in dettaglio lo
schema a blocchi dall’Input Assembler al Tessellator:

113 Appendice A
Figura 77 Schema a blocchi Input Assembler, Vertex Shader, Hull Shader, Tessellator
Lo input assembler riceve i dati dai vertex e index buffer che sono stati riempiti dalla CPU,
questi contengono le informazioni relative alla creazione della geometria del frame. Il suo
output è costituito da primitive che possono contenere un numero di vertici variabile tra
uno e trentadue; tutta l’elaborazione avviene a livello dell’object space. Le mesh così
ottenute sono inviate ai vertex shader (VS), che possono compiere una serie di operazioni,
come cambiare le coordinate, effettuare operazioni di trasformazione sui control point per
ottenere effetti tipo skeletal animation. In questa fase avviene anche il passaggio da object a
world space; l’output dei VS, costituito dai control point del patch elaborato, diventano lo
input per il successivo stadio che, nelle DX11, è costituto dagli hull shader. Si può notare che
l’hull shader è formato da due parti ossia dalla constant function (CF) e dalla parte
programmabile; se si sfrutta la tessellation continua, allora la CF esegue una sola volta per
l’intero patch la definizione dei valori comuni a tutti i control point ossia il tessellation factor
da inviare al tessellator altrimenti con la tecnica adattativa il tessellation factor è calcolato
per ogni control point. Il tessellation factor si ricava dai valori dei control point in ingresso,
caratteristiche della mesh (superficie nascoste nell’ombra e poco visibili) e dall’algoritmo di
tessellation. Lo stadio programmabile, in base alla posizione dei control point del patch
forniti dai VS e dalla funzione di tessellation scelta, definisce un insieme di nuovi control
point.
I dati relativi ai nuovi control point (generati dagli HS) sono inviati ai domain shader, mentre
il tessellation factor (generato dalla CF) che fornisce indicazioni su quanti sono i poligoni in
cui ciascuna figura geometrica formante la mesh deve essere scomposta, diventa lo input
del tessellator vero e proprio e dei domain shader (DS).

114 Appendice A
Figura 78 Secondo parte della pipeline GPU con tessellator
Il tessellator opera su patch formato da più domini (a ogni control point corrisponde un
dominio) e il cui input è il tessellation factor e il cui output è un patch in cui ciascuno dei
domini è stato suddiviso in un determinato numero di poligoni. L’interno di un tessellator è
formato da due stadi consecutivi:
Elaborazione in floating-point a 32 bit e si occupa di gestire le approssimazioni,
decodificare e ottimizzare lo input per il successivo stadio della tessellator unit;
Calcoli in fixed-point a 16 bit per eseguire l’operazione di tessellation vera e propria,
quindi stabilire la topologia del partizionamento. L’utilizzo della notazione in virgola
fissa a 16 bit deriva dal dover soddisfare esigenze di velocità di esecuzione senza
penalizzare eccessivamente la qualità delle operazioni svolte.
L’output dei DS è dato dai nuovi vertici e primitive definite dall’operazione di tessellation ed
è inviato ai GS, tutta l’elaborazione è fatta nel view space; l’output dei GS è inviato al
Rasterizer che esegue l’elaborazione nel canonical view volume e individua i pixel da
rappresentare su schermo, i pixel così ottenuti sono inviati ai pixel shader (PS). L’output dei
GS può essere anche inviato allo stream output per salvare i dati correnti e utilizzarli
successivamente per altre elaborazioni. L’ultima parte della pipeline è formata dall’output
merger che si occupa di raccogliere tutte i dati elaborati e combinarli assieme per ottenere
specifici effetti come le ombre, in questo modo sono impostati i pixel da visualizzare su
schermo sfruttando la combinazione del z test e stencil buffer (funge da maschera per i
pixel, questi possono essere cancellati oppure cambiati di valore ad esempio per dare
l’effetto di ombra).

115 Appendice A
A.6. Spazi in una scena 3D
Un oggetto prima di essere visualizzato su schermo deve essere riportato in diversi spazi,
ognuno di questi serve per definire le caratteristiche di posizione, colore, forma,
orientazione e consistenza; questi spazi convertono le varie caratteristiche degli oggetti in
coordinate e mettono in relazione le coordinate dell’oggetto considerato con gli altri in
modo tale che possano interagire fra loro.
Di seguito si riporta lo schema completo degli spazi che si utilizzano per rappresentare gli
oggetti e relative caratteristiche:
Figura 79 Spazi in una scena 3D
A.6.1. Object e world space
Il primo passo è quello di definire l’oggetto nell’object space (talvolta detto anche model
space), in cui ogni oggetto è rappresentato con un proprio sistema di coordinate; si sceglie
un punto che rappresenta l’origine degli assi (detto pivot point o object orgigin), tipicamente
un vertice della mesh o il suo baricentro, si utilizza tale origine per definire la posizione e le
dimensioni dell’oggetto nello spazio definito. Per ogni oggetto aggiunto alla scena, si
procede come descritto precedentemente per la scelta del pivot point. A questo punto ogni
oggetto ha un proprio sistema di coordinate e un pivot assegnato tramite il quale, l’oggetto
in questione, può essere traslato, ruotato e scalato (si comporterà come un corpo rigido);
quindi si utilizzano coordinate locali e si ha una certa facilità nella modellazione 3D. In
questo spazio gli oggetti possono non essere in relazione fra loro e sono rappresentati in
forma di vettori in coordinate omogenee con le relative normali, la quaterna è data da (x, y,
z, w); in questo modo a ogni terna x, y, z corrisponderà un’infinità di elementi al variare di
w.
Gli oggetti poi devono essere posti in uno spazio comune chiamato world space in modo tale
che essi siano messi in reciproca relazione spaziale.

116 Appendice A
Figura 80 Coordinate nel World space
A questo punto sono definite le proprietà dei singoli oggetti ossia di superficie, animazione
(skeletal) e illuminazione; il vantaggio di utilizzare coordinate omogenee consiste
nell’effettuare trasformazioni di coordinata, traslazione e scala ecc. sfruttando la
moltiplicazione tra vettori e matrici.
A.6.2. View e clip space
Per definire il view space è necessario stabilire la posizione dell’osservatore, che non deve
per forza coincidere con l’origine del world space, quindi il sistema di coordinate
(tipicamente terna sinistra) è orientato in modo tale che x, y e z coincidono rispettivamente
con l’asse orizzontale, verticale e quello normale al piano xy nella sua origine; tutto ciò serve
per definire la direzione e il verso in cui l’osservatore guarda. Il campo visivo non è illimitato,
per definire i limiti s’imposta un angolo solido con vertice nella posizione dell’osservatore
inserito nel view space che si apre nella direzione e verso in cui guarda; altri limiti sono
impostati mediante due piani perpendicolari all’asse z, direzione in cui si guarda, chiamati
far clipping plane (che limita il fondo del campo visivo) e near clipping plane (che limita il
campo visivo in prossimità del punto dell’osservatore). Tutto ciò serve per limitare il campo
visivo tramite sei piani (i clipping plane) che formano un tronco di piramide di nome view
frustrum.
Figura 81 View Frustrum
Tutto ciò che risiede nel view frustrum è renderizzato per lo specifico frame. Esistono vari
algoritmi per gestire il view frustrum culling (fase di clipping culling), tipicamente si procede
tramite delle celle che contengono dei poligoni (non si esaminano direttamente i poligoni);
da un punto di vista logico l’algoritmo funziona come descritto di seguito:
Cella fuori dal view frustrum allora è culled (cella scartata);
Cella inclusa nel view frustrum allora è rendered (cella renderizzata);
Cella parzialmente nel view frustrum. Si divide la cella fino eventualmente al singolo
poligono per stabilire cosa sta all’interno del view frustrum (tutto ciò che sta
all’interno del view frustrum è renderizzato).

117 Appendice A
Ora si procede con la fase di backface culling ossia si rimuovono le superfici di un oggetto
solido coperte alla vista in quanto nascoste da altre superfici visibili dallo stesso oggetto.
Quello che si ottiene va sotto il nome di clip space, le operazioni descritte precedentemente
servono per ottimizzare il rendering.
Il monitor è rettangolare e non è adatto a uno spazio a forma di tronco piramidale, il passo
successivo consiste nel proiettare l’immagine del clip space all’interno di un altro spazio a
forma di cubo dove le coordinate x, y variano tra -1, +1 e per z da 0 (che rappresenta il near
clipping plane) a 1 (far clipping plane) per DirectX 11 e -1, 1 per OpenGL.
Figura 82 Proiezione degli oggetti dal clipping space al cubo
Lo spazio così ottenuto prende il nome di canonical view volume, la visione in prospettiva è
un’illusione che si ottiene dalla deformazione degli oggetti proiettati in questo spazio.
A.6.3. Screen space e HSR
Lo schermo è a due dimensioni e di forma rettangolare quindi è necessario creare l’illusione
che gli oggetti si sviluppino lungo un’inesistente terza dimensione; per far ciò si sfrutta lo
screen space:
Dalle quattro dimensioni dello spazio omogeneo (x, y, z, w) si passa a uno di due (x,
y);
Lo spazio tridimensionale delle figure geometriche è sostituto da uno spazio
bidimensionale in cui si opera in termini di pixel.
Si taglia il canonical view volume in una serie di piani ideali perpendicolari a z, ogni piano è
individuato da mxn punti (x, y) e a ogni punto corrisponde un valore z comune a tutto il
piano; quindi gli oggetti presenti nel canonical view volume sono rappresentati da una serie
di piani. Per ogni frame si ha che per ogni punto di un poligono si associa una coppia di
coordinate (x, y) che ne individuano la posizione nello screen space z che ne definisce la
distanza dall’osservatore.
Prima di poter eseguire il rendering in modo efficiente, le GPU attuali devono individuare le
superfici nascoste dietro superfici facenti parte di altri oggetti (fino a questo punto sono
stati rimossi gli oggetti fuori dal view frustrum e le superfici nascoste da quelle dell’oggetto
medesimo). Quest’ultima fase prima del rendering è elaborata mediante algoritmi di nome
hidden surface removal (HSR), tipicamente fanno uso di uno o più z-buffer che contengono i
valori recenti di z dei vari piani dei poligoni; la scansione può essere front to back (quando si
parte dal piano dell’osservatore) e back to front (quando si parte dal piano più lontano
dall’osservatore).

118 Appendice A
A.7. NVIDIA approfondimenti
A.7.1. ROP
La raster operation pipeline esegue una delle ultime fasi del rendering; l’unità in questione,
preleva le informazioni relative ai pixel e texel (singoli elementi di una texture) ed esegue le
elaborazioni mediante operazioni matriciali e vettoriali per ottenere il valore finale del pixel
o di profondità. Richiede l’accesso alla memoria GDDR in lettura e scrittura.
Il back-end di GF110 è organizzato in sei blocchi ROP, ognuno dei quali contiene 8 unità per
un totale di 48 ROP; ogni partizione è in grado di gestire otto pixel di tipo intero a 32 bit per
ogni ciclo di clock. Questo dato è superiore agli otto blocchi GT200 capaci di quattro pixel
per clock. In quest’architettura si mantiene un controller di memoria a 64 bit per blocco, ma
realizza un incremento generale da 32 a 48 pixel per clock.
Questa GPU è migliore rispetto all’architettura Tesla anche dal punto di vista della gestione
dell’anti-aliasing eseguita dalle ROP; esiste una nuova modalità chiamata coverage sampling
anti-aliasing 32x (CSAA). Il risultato di queste ottimizzazioni è che NVIDIA afferma di avere
un calo prestazionale inferiore al 10% passando dall'anti-aliasing multi-sampling 8x al CSAA
a 32x (quindi si ha una lieve riduzione delle prestazioni a fronte di un notevole
miglioramento dell’anti-aliasing).
A.7.2. Tessellation
La NVIDIA ha implementato nell'architettura Fermi due componenti hardware per la
gestione della tessellation cioè PolyMorph engine e Raster engine (quest’ultima può essere
utilizzata anche per rasterizzare le mesh generate dai GS senza la tessellation); non ci sono
unità dedicate di hull e domain shader in NVIDIA Fermi, queste sono emulate via software
tramite gli shader core a differenza di quanto fatto da AMD / ATI .
Ogni SM ha un PolyMorph engine dotato al proprio interno di un'unità dedicata alla
tessellation e di altre unità specifiche per l’elaborazione della geometria degli oggetti 3D. La
presenza di cache L1 e L2 integrata nel chip consente un veloce passaggio dei dati tra SP e
PolyMorph engine, oltre che tra i vari SM presenti nella GPU, velocizzando tutte le
operazioni legate alla tessellation.
Figura 83 PolyMorph Engine
Quest’unità ha cinque stadi: Vertex Fetch, Tessellator, Viewport Transform, Attribute Setup
e Stream Output; il primo passo consiste nel fare il fetch (prelievo) dei vertex dal vertex
buffer globale, questi vertici sono inviati allo SM per il vertex shading e hull shading (eseguiti

119 Appendice A
dai CUDA core). Dopo queste elaborazioni si procede con il calcolo dei tessellation factor e
sono inviati al Tessellator; l’elaborazione dei domain shader e geometry shader avviene
nuovamente tramite i CUDA core. Il terzo stadio esegue la trasformazione di viewport
(divide il canonical view volume con dei piani paralleli tra loro e normali a z) e correzione
della prospettiva; l’Attribute Setup trasforma gli attributi dei vertici calcolati nella fase di
post-processing in equazioni di piano per rendere efficiente l’elaborazione di tipo shader.
L’ultimo stadio è opzionale, serve per mettere i vertici calcolati in uno stream verso la
memoria per eventuali elaborazioni successive.
C’è un Raster Engine per ogni GPC quindi per un totale di quattro unità, la pipeline è ha tre
stadi:
Figura 84 Raster Engine
L’Edge Setup esegue il fetch dei vertici e calcola le equazioni di edge del triangolo (le
equazioni delle rette sulle quali giacciono i segmenti del triangolo); i triangoli non visibili
sono rimossi mediante la tecnica del back face cull (vedere appendice). Ogni Edge Setup è in
grado di gestire una linea, punto o triangolo per clock; questo significa che nell’architettura
GF110 è possibile processare al massimo quattro triangoli per ogni ciclo di clock. L’unità
Rasterizer preleva le equazioni calcolate dal passo precedente e calcola la copertura dei
vertici; per ogni ciclo di clock la Rasterizer è in grado di generare otto pixel quindi un totale
di trentadue pixel per clock. Z-Cull individua le superfici nascoste e le elimina in modo tale
che queste non siano renderizzate, tutto ciò per migliorare l’utilizzo della banda a
disposizione.
A.7.3 CUDA
Il numero totale di warp in un blocco è dato da:
è il numero di thread per blocco, dimensione del warp che per tutte le architetture
fino ad ora è di trentadue thread, è uguale a arrotondato al multiplo più vicino a
.
Il numero totale di registri allocati per blocco sono dati per GPU con compute capability 1.x:
.
Invece per compute capability pari a 2.x:

120 Appendice A
è la granularità di allocazione dei warp che per compute capability 1.x è pari a due dato
che ogni SM ha soltanto sedici CUDA core, è il numero di registri utilizzati dal kernel, è
la granularità d’allocazione dei thread che per compute capability 1.0 e 1.1 è pari a 256 per
1.3 e 1.4 512 e per 2.x 64.
Il totale della memoria condivisa allocata in byte per blocco è pari a:
Dove è l’ammontare della memoria condivisa in byte occupata dal kernel, è la
granularità della memoria condivisa allocata che è pari a 512 nel caso di compute capability
1.x e 256 per compute capability 2.x.

121 Appendice B
Appendice B
B.1. Sviluppare mex in Visual Studio 2010 Professional
Per compilare le librerie mex, da usare in MATLAB, direttamente in ambiente Visual Studio
2010 Professional o superiore è necessario seguire i seguenti passi:
Creare un progetto di tipo C++ class library (dll);
In Configuration Properties->General->Target Extension aggiungere mexw64;
Creare un file def nel progetto che deve contenere l’indicazione LIBRARY
“name.mexw64” ed EXPORTS mexFunction;
In C/C++->General->AdditionalIncludeDirectories aggiungere
matlabroot\extern\include come folder addizionale dove matlabroot è la directory in
cui è installato il MATLAB;
In General cambiare l’estensione del file Target Extension da .dll a .mexw64;
In Linker->General->AdditionalLibraryDirectories aggiungere
matlabroot\extern\lib\microsoft;
In Linker->Input->AdditionalDependencies aggiungere libmx.lib, libmex.lib e
libmat.lib come dipendenze addizionali;
In Linker Input properties aggiungere il modulo .def.
B.2. Sviluppare CUDA Kernel in Visual Studio 2010 Professional
E’ necessario installare il software NVIDIA Parallel Nsight 2.0, questo aggiungerà in
automatico le variabili d’ambiente e le regole di compilazione per Visual Studio 2010
Professional o superiore.
Installare il software NVIDIA Parallel Nsight Monitor 2.0 sulla macchina su cui s’intende
eseguire il debugging; occorre osservare che sono sempre necessarie due GPU, una per il
rendering e l’altra su cui fare il debugging. Se la macchina utilizzata non ha due GPU, è
possibile utilizzare tale software per fare il debugging da remoto su una macchina con GPU
NVIDIA.
Creare un progetto C++ e utilizzare la regola di compilazione CUDA dal menu Build
Customization:
In C/C++->General->AdditionalIncludeDirectories aggiungere $(CUDA_INC_PATH);
In Linker->General->AdditionalLibraryDirectories aggiungere $(CUDA_LIB_PATH);
In Linker->Input->AdditionalDependencies aggiungere cudart.lib.

122 Appendice C
Appendice C
C.1. Libsvm
Per la Support Vector Machine si è utilizzata la libreria libsvm.
Utilizzo:
svm-train [options] training_set_file [model_file].
Opzioni (precedute dal simbolo -):
s svm_type : imposta il tipo di SVM (default 0)
0 -- C-SVC
1 -- nu-SVC
2 -- one-class SVM
3 -- epsilon-SVR
4 -- nu-SVR
t kernel_type : imposta il tipo di kernel (default 2)
0 -- linear: u'*v
1 -- polynomial: (gamma*u'*v + coef0)^degree
2 -- radial basis function: exp(-gamma*|u-v|^2)
3 -- sigmoid: tanh(gamma*u'*v + coef0)
4 -- precomputed kernel (kernel caricato da file)
- d degree: imposta il grado della kernel function (default 3)
- g gamma: imposta gamma nella kernel function (default 1/num_features)
- r coef0: imposta coef0 in kernel function (default 0)
- c cost: imposta il parametro C di C-SVC, epsilon-SVR, e nu-SVR (default 1)
- n nu: imposta il parametro di nu-SVC, one-class SVM, and nu-SVR (default 0.5)
- p epsilon: imposta epsilon in loss function di epsilon-SVR (default 0.1)
- m cachesize: imposta cache memory size in MB (default 100)
- e epsilon: imposta tolleranza del criterio di stop (default 0.001)
- h shrinking: usa shrinking heuristics, 0 o 1 (default 1)
- b probability_estimates: train di una SVC o SVR model per la stima di probabilità, 0 o 1
(default 0)
- wi weight: imposta il parametro C della classe i a weight*C, for C-SVC (default 1)
- v n: n-fold cross validation mode
- q: quiet mode (no outputs)
k in -g significa numero di attributi in input.


















