
UNIVERSITA’ DEGLI STUDI DI SASSARI - sardegnalavoro.it · Tuttavia, creare un modello di...
56
UNIVERSITA’ DEGLI STUDI DI SASSARI FACOLTA’ DI SCIENZE POLITICHE MASTER IN STATISTICA APPLICATA L’approccio time series per l’analisi e la previsione della disoccupazione sarda Relatore: Tesi di Master di: Prof. Paolo Mattana Dott. Davide Crobu Anno Accademico 2002 - 2003
-
Upload
trinhtuong -
Category
Documents
-
view
216 -
download
0
Transcript of UNIVERSITA’ DEGLI STUDI DI SASSARI - sardegnalavoro.it · Tuttavia, creare un modello di...

UNIVERSITA’ DEGLI STUDI DI SASSARI
FACOLTA’ DI SCIENZE POLITICHE
MASTER IN STATISTICA APPLICATA
L’approccio time series per l’analisi e la previsione della disoccupazione sarda
Relatore: Tesi di Master di: Prof. Paolo Mattana Dott. Davide Crobu
Anno Accademico 2002 - 2003

Indice Premessa ............................................................................................................................ 2
1. Parte teorica: Metodi di analisi delle serie storiche. ...................................................... 6
1.1 Tipi di dati ...............................................................................................................6
1.2 Diversi approcci allo studio delle serie storiche ......................................................8
1.2.1 Approccio classico............................................................................................8
1.2.2 Approccio statistico ........................................................................................10
1.3 Caratteristiche di un processo stocastico ...............................................................15
1.3.1 Stazionarietà ...................................................................................................16
1.3.2 Ergodicità .......................................................................................................21
1.3.3 Invertibilità .....................................................................................................21
1.4 Caratteristiche di una serie temporale: l’autocorrelazione ....................................22
1.4.1 Una rappresentazione grafica dell’autocorrelazione: il correlogramma ........23
1.5 I modelli AR ..........................................................................................................25
1.6 I modelli MA.........................................................................................................27
1.7 I modelli ARMA....................................................................................................28
1.8 I modelli integrati ..................................................................................................29
2. Parte sperimentale: specificazione di un modello autoregressivo applicato al tasso di
disoccupazione sardo. ...................................................................................................... 32
2.1 Premessa sulla costruzione del dataset e sulla metodologia..................................32
2.2 Costruzione del modello e ricerca della stazionarietà ...........................................33
2.3 La previsione del tasso di disoccupazione .............................................................44
3 Conclusioni................................................................................................................... 52
Bibliografia ...................................................................................................................... 53
Allegato statistico ............................................................................................................ 55

2
Premessa
Il lavoro di questa tesina nasce da una riflessione maturata durante la frequenza del
Master di statistica applicata, ma anche grazie all’esperienza maturata all’interno
dell’Agenzia Regionale del Lavoro presso la quale presto servizio da circa 6 anni.
Infatti, in tutti questi anni ho portato avanti un lavoro di raccolta di dati dell’economia
sarda e, in particolare, relativi al mercato del lavoro sardo. Il lavoro portato avanti in
seno al settore dell’Osservatorio del mercato del lavoro è ormai standardizzato e porta
alla pubblicazione di un bollettino statistico trimestrale denominato “Trend Lavoro”.
Oggi, dopo che si è portato a regime il lavoro, mi sono reso conto che si può e si deve
fare di più: capire quali sono le dinamiche e i flussi del mercato del lavoro in un
determinato periodo è importante non solo per poter progettare e governare politiche del
lavoro efficaci ed efficienti in termini di spesa, ma è importante anche per dare una
risposta a chi è coinvolto direttamente nei processi economici, politici e sociali della
nostra isola.
Nell’ambito del Master ho avuto la possibilità di imparare le tecniche statistiche
applicate all’economia, argomenti che rientrano nell’ambito della disciplina denominata
econometria, una materia ostica per alcuni aspetti, ma di fondamentale importanza nella
formazione di un ricercatore, o una persona che è chiamata a svolgere all’interno della
propria organizzazione compiti di analisi di dati socio economici e di valutazione delle
politiche.
Inizialmente avevo scelto quale argomento da approfondire in sede di tesi la relazione
esistente fra l’andamento del prodotto interno lordo regionale (o un’altra variabile
simile come, ad esempio, il valore aggiunto) e la crescita occupazionale, dato che,
secondo un ragionamento razionale, si sarebbe portati a pensare che esista una relazione
diretta fra queste due grandezze. Questo argomento si sposava perfettamente anche con
le esigenze da più parti manifestate di fare delle analisi qualitative oltre che quantitative
del fenomeno dell’occupazione e della disoccupazione sarda. In realtà, da una rapida
analisi dei dati ho notato che le due grandezze non seguono nel tempo un andamento dal
quale possano riscontrarsi delle regolarità, pertanto, è molto difficile studiare il
comportamento e le cause che muovono una grandezza per poter inferire sull’altra.
Infatti, le dimensioni ridotte del prodotto regionale e la dipendenza dello stesso da
poche grandi realtà mi hanno fatto capire che stimare una relazione di questo tipo al fine
di fare analisi e previsioni sulla variabile dipendente, è molto difficile perché la
variazione del prodotto regionale dipende maggiormente da variabili connesse a realtà

3
specifiche di alcuni settori o, addirittura, di alcune aziende e, pertanto, non segue
l’andamento del mercato del lavoro, che al contrario ha un andamento più fluido nel
tempo. Inoltre, bisogna osservare che:
• Il fattore umano potrebbe essere sostituito da altri fattori produttivi. Potrebbe
capitare che a seconda della convenienza economica sia possibile sostituire il
fattore capitale col fattore umano e, pertanto, sia possibile ottenere lo stesso
prodotto con un minor numero di addetti, o un prodotto maggiore con lo stesso
numero di addetti;
• La produttività del fattore umano non è lo stesso a seconda del settore di attività
economica;
• La produttività del fattore umano cambia con il trascorrere del tempo.
D’altra parte anche la teoria economica non ha elaborato una teoria precisa sulla
relazione fra queste due grandezze, anche perchè in letteratura esistono opinioni
contrastanti. L’unica regola empirica che è stata riscontrata nella realtà è conosciuta
come legge di Okun. L’economista intorno agli anni settanta aveva riscontrato mettendo
in relazione i dati del prodotto interno lordo americano con il tasso di disoccupazione
che esisteva una relazione inversa fra le due grandezze. In particolare per ridurre il tasso
di disoccupazione di 1 punto percentuale occorreva uno shock nella variazione del
prodotto interno lordo di almeno il 3%. Okun aveva individuato questa relazione
utilizzando i dati americani dalla seconda guerra mondiale agli anni sessanta.
Utilizzando i dati di periodi successivi questa regola non è più riscontrabile. Pertanto, la
stessa regola è stata messa anche in discussione. Probabilmente l’economia sulla quale
Okun aveva individuato la regola dipendeva in maniera forte da settori industriali in cui
vi era una certa relazione fra il fattore umano e il prodotto, e, pertanto, per incrementare
il prodotto di una nazione occorreva effettivamente un maggior numero di addetti. Nel
momento in cui l’innovazione tecnologica introduce nuovi paradigmi produttivi viene a
cambiare la struttura dell’economia e la regola individuata da Okun non è più
riscontrabile nella realtà.
Dopo questa esperienza ho riflettuto con il Prof. Giorgio Garau, docente di statistica
economica all’Università di Sassari, il quale mi ha consigliato di lavorare seguendo
un’altra strategia. Infatti considerata la difficoltà di costruire un modello che possa
spiegare il fenomeno dell’occupazione e della disoccupazione, anche perché i due
fenomeni non seguono affatto comportamenti fra loro dipendenti come al contrario si
potrebbe pensare, si è pensato di studiare una serie dal punto di vista statistico per poi

4
risalire alla spiegazione economiche che possono aver influito sulla variazione della
serie studiata e quindi sull’altra.
Quindi, per fare questo ho integrato il programma di studio del master con le tecniche
statistiche proprie delle serie temporali. Tali tecniche prescindono dalla teoria
economica e sono state utilizzate per la prima volta dagli studiosi Box e Jenkins, dai
quali questo approccio prende anche il nome. Tale metodologia è impiegata soprattutto
in quei campi di analisi in cui si devono effettuare delle previsioni a breve termine e si
vuole prescindere dalle motivazioni di carattere economico che possono aver indotto
sulla variabile dipendente. Le motivazioni di tale scelta sono di diversa natura:
• Natura economica, connessa, ad esempio, alla molteplicità di fattori che
intervengono sulla variabile ed alla difficoltà a reperire gli stessi dati;
• Natura statistica, relativamente al fatto che sia difficile individuare o costruire un
indicatore che dia informazioni di un certo comportamento, o anche per la
semplice scarsità di informazioni.
Tutte queste problematiche si presentano soprattutto in campo finanziario dove occorre
fare delle stime di previsione sui prezzi di una qualsiasi attività finanziaria, o su un
indice rappresentativo di un mercato, al fine della riduzione del rischio di investimento
o, semplicemente, a fini speculativi. Tuttavia, creare un modello di funzionamento di un
mercato è molto complesso, sia a causa della molteplicità di fattori che intervengono
nella formazione del prezzo dell’attività finanziaria, sia per la penuria di informazioni.
Pertanto si utilizzano delle tecniche che prescindono dalle determinanti che
intervengono sulla formazione del prezzo in quanto si presume che tali determinanti
siano incorporati nei prezzi.
Quindi, pur consapevoli del fatto che l’approccio delle serie temporali (time series) è
nata per risolvere delle problematiche in altri campi di ricerca, ci si è resi conto che le
caratteristiche del fenomeno da modellare erano simili a quelle che si presentano in
campo finanziario. Pertanto si è scelto di utilizzare le stesse tecniche consapevoli del
fatto che le finalità per le quali vengono utilizzate in campo finanziario hanno un
maggior senso quando vengono applicate in questo campo di analisi, mentre hanno
scarso significato quando vengono applicate al mercato del lavoro con la semplice
finalità di prevedere una componente della domanda di lavoro nel breve periodo. Infatti,
mentre in campo finanziario effettuare una previsione corretta di un’attività finanziaria
potrebbe portare ad un profitto, nessun vantaggio di carattere economico si riesce a
trarre dalla esatta previsione del tasso di disoccupazione.

5
Di conseguenza si è ristretto il campo di analisi ad una serie storica, si è trovato un
modello che cercasse di spiegare il comportamento della variabile, e successivamente
sono state fatte le analisi e le previsioni. Più specificatamente, si è ristretto il campo di
analisi alla serie del tasso di disoccupazione, alla quale sono state applicate le tecniche
statistiche proprie delle time series, dalle quali è stato poi possibile spiegare alcuni
comportamenti e verificare la bontà del modello per fini previsionali di breve termine.
Tengo a precisare che questo lavoro va inserito nel contesto dal quale lo stesso nasce,
ossia al completamento di un percorso formativo, sicuramente di alto livello, ma non ha
assolutamente la presunzione di essere un punto di riferimento in questo campo di
ricerca.
Colgo l’occasione per ringraziare tutte le persone che hanno contribuito direttamente e
indirettamente alla realizzazione di questo lavoro e, in particolare, il direttore
dell’Agenzia Regionale del Lavoro, Luciano Uras, l’Assessore regionale del Lavoro,
Matteo Luridiana, tutti i professori, e, in particolare Prof. Giorgio Garau e Prof. Paolo
Mattana, e i colleghi del Master che mi hanno aiutato lungo tutto questo percorso
formativo, sia a risolvere problemi legati alla materia oggetto di studio, sia a superare
quei momenti di difficoltà che ben conosce chi fa ricerca in questo campo.
Davide Crobu
6
1. Parte teorica: Metodi di analisi delle serie storiche.
1.1 Tipi di dati I dati statistici possono essere di tre tipi:
1. sezionali (cross section);
2. temporali (time series);
3. longitudinali (data panel).
I dati sezionali sono delle osservazioni riferite ad un individuo o, più in generale, ad una
unità statistica rilevati nello stesso istante di tempo. In questi dati la variabile tempo non
ha alcuna rilevanza.
Tabella n.1: esempio di data set di tipo cross section
Individuo Reddito livello di studio esperienza
1 13.580,00 11 2 2 12.587,00 12 22 3 14.780,00 11 2 4 13.564,00 8 44 5 14.985,00 12 7 6 12.458,00 16 9 7 15.849,00 18 15 8 14.457,00 12 5 9 13.398,00 12 26 10 12.598,00 17 22 I dati temporali invece costituiscono rilevazioni riferite ad un individuo, o ad una entità
statistica, effettuate in periodi di tempo definiti ed equidistanti. Nelle serie temporali la
variabile osservata viene “agganciata” al tempo in cui viene rilevata.
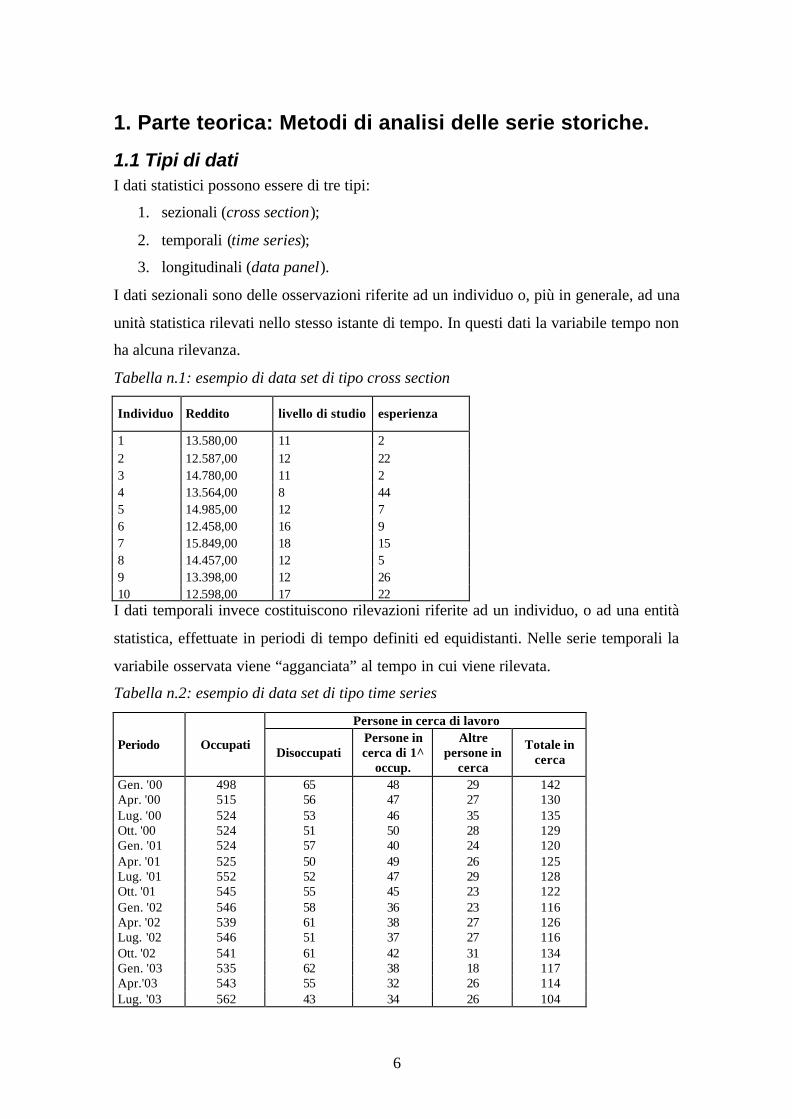
Tabella n.2: esempio di data set di tipo time series
Persone in cerca di lavoro
Periodo Occupati Disoccupati
Persone in cerca di 1^
occup.
Altre persone in
cerca
Totale in cerca
Gen. '00 498 65 48 29 142 Apr. '00 515 56 47 27 130 Lug. '00 524 53 46 35 135 Ott. '00 524 51 50 28 129 Gen. '01 524 57 40 24 120 Apr. '01 525 50 49 26 125 Lug. '01 552 52 47 29 128 Ott. '01 545 55 45 23 122 Gen. '02 546 58 36 23 116 Apr. '02 539 61 38 27 126 Lug. '02 546 51 37 27 116 Ott. '02 541 61 42 31 134 Gen. '03 535 62 38 18 117 Apr.'03 543 55 32 26 114 Lug. '03 562 43 34 26 104

7
Quando un insieme di caratteristiche riferite a più individui, o a più entità statistiche,
sono rilevate in diversi istanti di tempo si realizza una base di dati di tipo longitudinale.
Inoltre, si definisce data set l’insieme dei dati memorizzati in forma elettronica relativi
ad una indagine o ad un fenomeno osservato.
Un esempio di data set longitudinale può essere rappresentato dai dati che scaturiscono
dall’indagine condotta dall’Istat sul paniere di beni per il calcolo dell’indice sul costo
della vita: l’insieme dei prezzi dei beni che costituiscono il paniere rilevati in un dato
istante costituisce una cross section, quando però si considera lo stesso paniere in
relazione al tempo si ottiene un data panel.
Esiste una differenza importante fra dati sezionali e dati temporali. Infatti, mentre nelle
time series assume rilevanza l’ordine imposto dal tempo relativo al momento in cui il
fenomeno viene osservato, nelle cross section tale ordine non ha alcuna rilevanza.
Cosicché, mentre per questi ultimi è possibile studiare le caratteristiche del data set a
prescindere dall’ordine che gli viene dato, nelle time series prima di fare un’analisi
descrittiva è fondamentale ordinare i dati in base al tempo. Inoltre, mentre nei dati cross
section è immaginabile pensare che i dati osservati siano fra loro indipendenti, nelle
time series invece, la variabile osservata ad un dato istante dipende anche dalle
osservazioni precedenti, e pertanto, non è possibile assumere che le osservazioni siano
fra loro indipendenti. Tale caratteristica è nota come autocovarianza, di cui si dirà in
seguito.
Gli obiettivi dell’analisi delle serie storiche sono di diversa natura: spesso viene fatta
per descrivere un fenomeno o trovare delle spiegazioni attraverso i comportamenti che
ha avuto nel passato la variabile oggetto di osservazione; ma viene fatta, sempre più
spesso, al fine di effettuare previsioni per il futuro. Infatti, attraverso la comprensione
della storia del fenomeno oggetto di osservazione è possibile creare un modello capace
di descrivere il comportamento che assume il fenomeno in relazione al tempo e fare
affermazioni sulle possibili, o più probabili, realizzazioni che la serie avrà in futuro.
Da sempre la previsione ha suscitato nell’uomo un fascino particolare, sia quando
questa viene applicato alle scienze fisiche e naturali, sia quando ci si trova nel campo
dell’economia, della politica e della finanza, dove risulta ancor più difficile trovare
spiegazioni a determinati fenomeni. Determinati fenomeni che in passato risultavano
imprevedibili, oggi attraverso l’analisi delle serie storiche e delle relazioni fra diverse
variabili è possibile effettuare delle previsioni con un basso margine di errore. Tuttavia,
bisogna fare una distinzione fra l’analisi delle serie storiche in senso statistico e la

8
branca della statistica che studia le relazioni fra variabili, cioè all’econometria quando
l’oggetto di studio è la materia economica. Infatti, mentre quest’ultima studia le
tecniche statistiche relative alle relazioni che esistono fra una certa variabile dipendente
(esogena) e una serie di altre variabili indipendenti (endogene) che hanno una relazione
con il fenomeno oggetto di osservazione, l’analisi delle serie storiche studia invece la
storia della sola variabile osservata, al fine di trovare un modello teorico di riferimento
che sia in grado di generare la serie oggetto di analisi e fare previsioni sulle future
realizzazioni della serie.
Oggetto di questa trattazione è l’analisi statistica delle serie storiche della domanda di
lavoro sarda, in particolare per quanto attiene al tasso di disoccupazione al fine di
trovare un modello rappresentativo dell’andamento della variabile e di effettuare delle
previsioni a breve termine. Non sono oggetto di questa trattazione lo studio delle
variabili che hanno generato l’andamento della disoccupazione e dell’occupazione in
Sardegna.
1.2 Diversi approcci allo studio delle serie storiche Le serie storiche possono essere analizzate seguendo due approcci: il primo, cosiddetto
classico, consiste nella descrizione delle caratteristiche della serie storica con strumenti
propri della statistica, quali medie mobili, regressioni e interpolazioni. Il secondo
approccio, più moderno, detto anche stocastico, consiste nella determinazione di un
modello teorico di riferimento in grado di generare una serie “simile” a quella oggetto di
analisi e di studio e fare inferenza su di essa. Infatti, mentre l’approccio classico ha
carattere prevalentemente descrittivo, l’approccio statistico si pone soprattutto finalità di
tipo previsionale. Di seguito si analizzeranno i fondamenti teorici di entrambi i metodi
focalizzando l’attenzione sull’approccio statistico, oggetto di questa trattazione.
1.2.1 Approccio classico
Nell’approccio classico l’analisi della serie storica si realizza attraverso la
scomposizione della serie nelle componenti di tendenza, ciclo e stagionalità, e la
successiva determinazione delle diversi componenti della serie. Per questo motivo
questa metodologia viene spesso denominata anche analisi delle componenti.
Nell’approccio classico la previsione si realizza attraverso la determinazione di una
funzione matematica (lineare, parabolica, iperbolica, ecc), spesso stimata con il metodo
dei minimi quadrati. I valori futuri della serie vengono poi estrapolati dalla funzione
matematica ed aggiustati dalle altre componenti di ciclo e stagionalità. Tale metodologia

9
viene usata più per finalità descrittive che non per finalità previsionali in quanto,
prevedendo solo la componente di tendenza del fenomeno, non è in grado di pervenire a
buone previsioni.
Il modello può essere sintetizzato nel seguente modo:
),,,( ttttt ASCTx ϕ=
dove xt è la variabile osservata al tempo t, Tt, Ct, St, e At, sono le componenti
sistematiche osservate nello stesso istante di tempo. Più in particolare:
• Tt rappresenta la componente di trend, cioè la tendenza generale della serie
storica, l’andamento di lungo periodo che la variabile oggetto di osservazione ha
avuto nell’arco di un tempo molto esteso (in genere cinquant’anni o anche un
secolo).
• Ct è la componente ciclica, cioè l’alternanza registrata dalla serie nel corso di più
anni, in genere in un periodo variabile fra i 5 e i 15-20 anni, a seconda della
variabile oggetto di osservazione.
• St è la componente stagionale, legata cioè al diverso andamento che registra la
serie nel corso di un anno solare, dovuto quindi a cause direttamente connesse al
succedersi delle stagioni naturali.
• At rappresenta la componente accidentale, o di errore.
Mentre le cause della variabilità nel tempo delle componenti di tendenza, di ciclo e di
stagionalità sono direttamente connesse al fenomeno oggetto di osservazione, la
componente accidentale è spesso dovuta a shock esterni al fenomeno, o ad eventi di
natura puramente aleatoria, difficili da prevedere in quanto privi di una certa regolarità
nel tempo.
Del modello classico sono state proposte varie specificazioni a seconda di come
interferiscono le diverse componenti sulla variabile osservata. In particolare, dalla teoria
sono stati proposti i seguenti modelli funzionali:
1) modello additivo:
ttttt ASCTx +++=
2) modello moltiplicativo:
ttttt ASCTx ⋅⋅⋅=
che può essere ricondotto attraverso una trasformazione logaritmica al seguente
modello:
ttttt LogALogSLogCLogTLogx +++=

10
3) modello misto:
ttttt ASCTx +⋅⋅= oppure ttttt ASCTx ++⋅= quando il trend e il ciclo
vengono attribuite ad un’unica componente.
Da notare che nel modello additivo le componenti sono espresse nella stessa unità di
misura della variabile osservata e ciascuna determinante è stimata in maniera autonoma
e indipendente dalle altre. Il modello moltiplicativo, di solito più usato per la
rappresentazione dei fenomeni economici, ha solo la componente di tendenza espressa
nell’unità di misura della variabile osservata. Le altre componenti sono rappresentati da
coefficienti che amplificano o riducono l’effetto della componente di tendenza a
seconda di come vadano ad influire in quel dato istante le componenti cicliche,
stagionali ed accidentali.
1.2.2 Approccio statistico
Come visto in precedenza nell’approccio statistico l’analisi delle serie temporali avviene
attraverso la specificazione di un modello teorico di riferimento che è in grado di
generare, in base a dei coefficienti stimati, una serie temporale quanto più possibile
vicina a quella oggetto di analisi e previsione. L’analisi e la successiva previsione viene
poi effettuata sul modello teorico costruito.
L’analisi statistica applicata alle serie di variabili economiche può essere considerata
anche come una metodologia capace di modellare una qualsiasi serie a prescindere dalle
leggi che la teoria economica ha elaborato. Questa esigenza si presenta in tutti i quegli
ambiti di ricerca in cui si è interessati a fare delle previsioni di breve termine di una
qualsiasi variabile economica come ad esempio, il PIL, il valore aggiunto, la
disoccupazione e l’occupazione, variabili difficilmente modellabili dal punto di vista
teorico. Questo approccio risulta essere utile anche in tutti quei contesti in cui sia
difficile reperire i dati sulle variabili che spiegano un determinato fenomeno, quando
cioè vi è scarsità di informazioni.
Non c’è dubbio che l’approccio statistico può sembrare “la via più comoda” da
intraprendere ma spesso risulta essere anche la strada più affidabile1.
Alla base dell’approccio statistico sta la teoria dei processi stocastici, intesi come una
sequenza di variabili casuali ordinate nel tempo. Infatti nell’approccio statistico si pone
l’obiettivo di capire la natura e le caratteristiche del processo stocastico che genera la
serie storica osservata, in altri termini il problema da risolvere è di “risalire dai dati alla
1 R. Golinelli, Analisi statistica delle serie storiche stazionarie, Appunti dalle lezioni, lezione 17, pag.1

11
scatola nera”2. Per fare questo è necessario studiare il comportamento della variabile
osservata per trovare il processo stocastico che più di ogni altro è in grado di generare la
serie che si vuole studiare e prevedere. La statistica economica e l’econometria hanno
elaborato una serie di modelli stocastici per studiare il comportamento di alcune
variabili economiche e finanziarie e sono stati fatti studi e verifiche empiriche sulla
capacità di alcuni modelli di descrivere meglio certe variabili. Fra i modelli che la teoria
ha elaborato si evidenziano:
• i modelli autoregressivi, indicati con la sigla AR. Sono dei modelli univariati
caratterizzati cioè dal fatto che il comportamento della variabile osservata yt
dipende esclusivamente dai suoi valori passati, a meno di uno shock casuale (et).
Questo modello è capace di descrivere e prevedere con un accettabile margine
di errore quei fenomeni che hanno un andamento nel tempo approssimabile ad
una retta, e anche quelli che presentano delle oscillazioni dovute alla
stagionalità.
• i modelli a media mobile detti anche mooving everage dallo loro traduzione in
lingua inglese, e indicati con la sigla MA. Sono dei processi stocastici univariati
caratterizzati dal fatto che il comportamento della variabile osservata e
modellata (yt) dipende solo dai valori presenti e passati degli shock che la stessa
variabile ha subito nel tempo. Il termine mooving average deriva dal fatto che la
variabile yt è una somma ponderata dei valori più recedenti degli shock;
• i modelli ARMA nascono dall’unione del modello autoregressivo e a media
mobile. Sono quelli più utilizzati su serie temporali che non presentano
stagionalità, quindi su serie temporali di dati annuali (ad esempio per le serie
del PIL di un paese), sulle quali si devono compiere operazioni di medie mobili
e di regressione per raggiungere la stazionarietà della serie, condizione
necessaria per fare analisi e previsioni e di cui si parlerà in seguito. In pratica i
modelli ARIMA si utilizzano per tutte quelle serie temporali stazionarie intorno
a un trend (Trend Stationary, indicati con la sigla TS).
• I modelli ARIMA sono altri modelli univariati che presentano sia componenti
autoregressive sia a media mobile come i modelli ARMA, ma, a differenza di
questi ultimi, la serie di origine sulla quale viene fatta l’analisi è costituit a dalle
differenze fra un valore della serie e il precedente. Infatti la lettera I sta
“Integrated“ (integrato) per ritornare alla serie originale si deve compiere
2 L. Stanca, Appunti per il corso di econometria B, Aprile 2003, pag.6.

12
l’operazione inversa della differenziazione che è detta integrazione. Per questo
motivo si dice anche che i modelli ARIMA sono stazionari in differenza
(Difference Stationary, indicati con la sigla DS).
• I modelli VAR a differenza dei precedenti sono dei modelli multivariati, dove
cioè la variabile che si vuole prevedere dipende, oltre che dalla serie storica
della variabile stessa, anche da altre variabili osservate negli stessi istanti di
tempo, o relative a un determinato periodo. Nella definizione di modelli
complessi, anche di natura economica, capita spesso di studiare dei fenomeni
che vengano spiegati da più di una variabile. In questi casi si devono utilizzare
dei vettori (da cui deriva l’acronimo della lettera V) di variabili osservate per gli
stessi istanti di tempo o relativi ad un periodo. La previsione su una data
variabile viene fatta attraverso lo studio contemporaneo di tutte le variabili. In
pratica il modello VAR costituisce la generalizzazione multivariata del processo
AR.
• I modelli a varianza condizionata indicati con la sigla ARCH e GARCH dagli
acronimi delle traduzioni di AutoRegressive Conditional Heteroskedasticity, e
Generalized AutoRegressive Conditional Heteroskedasticity che vengono
utilizzati per lo studio di variabili che presentano una variabilità della varianza
con il trascorrere del tempo. Tale caratteristica si presenta soprattutto nelle serie
storiche dei rendimenti di attività finanziarie, in cui si deve prevedere il rischio,
che è connesso alla varianza, o, come anche si dice in termini finanziari, alla
volatilità dell’attività finanziaria. Tali modelli si basano sull’assunto che per
istanti di tempo vicini le varianze della serie hanno valori simili, mentre per
istanti di tempo lontani tali varianze sono dissimili.
Dei modelli AR e MA e delle varie combinazioni ARMA e ARIMA si dirà in seguito,
mentre i modelli VAR, ARCH e GARCH non verranno analizzati nel dettaglio in
quanto non applicati alla materia oggetto di analisi e di previsione di questa trattazione.
L’approccio allo studio delle serie temporali fatto attraverso la determinazione di un
modello teorico è detto anche di Box-Jenkins, dai nomi dei due studiosi che per primi ne
hanno proposto al metodologia. Tale metodologia consiste nel procedere secondo un
percorso individuato dai due studiosi articolato in tre fasi per l’individuazione del
modello teorico di riferimento e la successiva stima dei parametri.
La prima fase consiste nell’identificazione del modello teorico di riferimento. Ciò si
realizza attraverso la trasformazione della serie oggetto di analisi al fine di renderla

13
stazionaria in media, varianza e covarianza, condizione, quest’ultima, necessaria sia per
ottenere delle stime dei parametri del modello che rispettino i requisiti della consistenza,
correttezza, ed efficienza, sia per poter fare inferenza sul modello stesso. Nelle serie
temporali di natura economica una trasformazione che spesso viene fatta consiste nella
determinazione del logaritmo dei valori della serie zt=? lnyt, che corrisponde
approssimativamente al tasso di variazione del fenomeno:
1
1
−
−−≈∆
t
ttt y
yyy
Successivamente si seleziona il modello teorico sulla base delle funzioni di
autocorrelazione globale e parziale della serie trasformata. Per fare questo viene
utilizzato uno strumento grafico denominato correlogramma. Dal confronto dei
correlogrammi delle autocorrelazione totali e parziali vengono determinati i parametri p
e q che definiscono l’ordine e il tipo di processo stocastico teorico che genera quella
determinata serie. Più specificatamente, se dal controllo dei correlogrammi risulta:
• Il parametro q è pari a 0, mentre il parametro p è un numero maggiore di 0,
allora il processo stocastico generatore sarà un AR di ordine p, e si indica con la
sigla AR(p).
• Il parametro p è pari a 0, mentre il parametro q è un numero maggiore di 0,
allora il processo stocastico generatore sarà di tipo MA di ordine q, e si indica
con la sigla MA(q).
• Sia il parametro p che il parametro q sono maggiori di zero, allora il processo
stocastico generatore è di tipo misto e si indica con la sigla ARMA(p,q).
Individuato il modello si passa alla seconda fase individuata da Box e Jenkins che
consiste nella stima dei parametri del modello. Tale stima avviene con il metodo della
massima verosomiglianza che nei processi di tipo autoregressivi, coincide al metodo dei
minimi quadrati ottenute dalla regressione dei valori della serie yt sui p valori ritardati.
Ad esempio nel caso di un modello AR(1) senza costante il parametro da stimare è dato
dalla seguente formula:
∑∑
= −
= − ⋅= T
t t
T
t tt
y
yy
2 1
2 1φ̂
Nel caso dei processi MA ed anche in quelli misti, che hanno cioè sia componenti
autoregressive sia componenti a media mobile (ARMA), la somma dei quadrati dei

14
residui è non lineare nei parametri ? e la minimizzazione utilizza algoritmi iterativi, non
esistendo una soluzione esplicita3.
Infine la terza fase consiste nella verifica dei parametri attraverso l’applicazione di
particolari test di significatività dei parametri del modello determinato e l’analisi dei
residui delle stime. In particolare in questa fase si devono verificare tre proprietà:
normalità, omoschedasticità e incorrelazione dei residui. Infatti, se i residui delle stime
dei parametri si comportano in maniera non normale, o presentano eteroschedasticità, o
esiste una correlazione dei residui, le stime sono, a seconda dei casi, distorte,
inconsistenti o inefficienti, in pratica non rispettano le proprietà degli stimatori e non
sono “B.L.U.E.” (Best, Linear, Unbiased, Estimator).
Ottenuta la stima del modello lo stesso può essere utilizzato per le finalità per le quali è
stato costruito, ovvero:
1. descrivere il comportamento della serie rispetto al tempo;
2. spiegarne il comportamento rispetto al tempo;
3. fare previsioni delle possibili realizzazioni future della serie attraverso
l’estrapolazione dal modello dei valori futuri.
L’approccio statistico viene usato soprattutto per quest’ultima finalità poi esso è in
grado di pervenire a previsioni più precise, nel senso che si sono dimostrate avere un
margine di errore minore delle altre metodologie di scomposizione della serie nelle
varie componenti di trend, ciclo e stagionalità. Pertanto, l’approccio statistico è
maggiormente utilizzato in quegli ambiti di ricerca in cui si devono effettuare
previsioni piuttosto che semplici descrizioni o spiegazioni del fenomeno.
3 T. Proietti, Econometria applicata, appunti ad uso degli studenti, pag. 39.

15
1.3 Caratteristiche di un processo stocastico Come si è visto un processo stocastico dal punto di vista statistico è un insieme di
variabili casuali ordinate nel tempo.
Per descrivere un processo stocastico è necessario conoscere tutte le distribuzioni
congiunte di probabilità delle variabili indicate con xt che compongono il processo
stesso, e poiché ciò è molto difficile, si ricorre alla determinazione di alcuni valori
sintetici che prendono il nome di momenti del processo aleatorio. Tali momenti sono:
1. la media, indicata con µt, che è pari al valore atteso E(xt);
2. la varianza, V(x t), che è pari a s 2 , che è anche uguale a E(xt - µ)2;
3. l’autocovarianza, indicata con ?k che è pari a E[(xt - µ)(xt-k – µ)] dove k è il
ritardo o, in inglese, lag.
La media è anche detta momento di ordine primo, la varianza e l’autocovarianza sono
momenti di ordine secondo. I momenti superiori al secondo, come ad esempio
l’asimmetria e la curtosi (momento terzo), non verranno esaminati in questa sede perché
non hanno rilevanza per la definizione e le finalità dei modelli stocastici illustrati in
questa trattazione.
Il fatto che per i processi stocastici sia possibile definire dei momenti è una caratteristica
dei processi stocastici in quanto strutture probabilistiche. Quando però si vuole
utilizzare queste strutture come base per fare inferenza si pongono due problemi4:
1. Se la serie che si osserva, peraltro non nella sua interezza, è una sola
realizzazione delle molte possibili, la possibilità di fare inferenza sul processo
non può essere data per scontata; infatti non è possibile dire quali caratteristiche
della serie osservata sono specifiche della realizzazione osservata e quali invece
si presenterebbero osservandone un’altra.
2. Se anche fosse possibile utilizzare una sola realizzazione per fare inferenza sulle
caratteristiche del processo, è necessario che esso sia stabile nel tempo, cioè che
i suoi connotati (media, varianza, ecc.) non cambino nel tempo, o, per lo meno,
nell’intervallo di osservazione.
Queste osservazioni fanno sì che di tutti i possibili processi stocastici soltanto su alcuni
di essi è possibile fare inferenza, e, quindi, utilizzare un modello teorico al posto di una
qualsiasi serie osservata per:
1. descriverne le caratteristiche;
2. spiegarne il comportamento rispetto al tempo; 4 R. Lucchetti, Appunti di analisi delle serie storiche, luglio 2002, pag. 3.

16
3. fare delle estrapolazioni per prevedere le possibile realizzazioni future.
I processi stocastici sui quali è possibile fare inferenza sono quelli che presentano le
seguenti caratteristiche:
1. stazionarietà;
2. ergodicità;
3. invertibilità.
Di tali caratteristiche si dirà in seguito, per il momento è importante sottolineare il fatto
che il concetto di stazionarietà non necessariamente implica l’ergodicità, in altri termini
è possibile che un processo sia stazionario ma non possedere momenti (non ergodico),
così come “la costanza nel tempo dei momenti non implica che le varie marginali
abbiano la stessa distribuzione”5. I due concetti tuttavia coincidono soltanto quando il
processo è di tipo gaussiano, cioè quando la distribuzione congiunta di un qualunque
sottoinsieme di element i del processo è una normale di Gauss. Poiché l’ipotesi di
ergodicità non è testabile attraverso dei test di fiducia, mentre la teoria ha elaborato
diversi metodi per testare la stazionarietà di un processo stocastico6, in seguito si farà
riferimento soltanto ai processi stocastici di tipo gaussiano, perché dall’esito del test
sulla stazionarietà si garantiscono entrambe le proprietà.
1.3.1 Stazionarietà Si parla di stazionarietà in due sensi:
1. stazionarietà in senso forte;
2. stazionarietà in senso debole.
Un processo stocastico è stazionario in senso forte se la distribuzione congiunta di un
insieme di n osservazioni agli istanti t1,. ….,tn è uguale alla distribuzione congiunta delle
osservazioni agli istanti t1+k,. ….,tn+k. In altri termini, un processo è stazionario in senso
forte se le caratteristiche delle distribuzioni di tutte le marginali (media, varianza,
covarianza) rimangono costanti al passare del tempo, o, come si dice, sono invarianti.
Un processo stocastico si dice stazionario in senso debole se solo i momenti primi e
secondi, cioè le medie e le varianze, sono costanti nel tempo, mentre i momenti
superiori al secondo possono dipendere dall’ampiezza temporale. In altri termini un
processo è stazionario se7:
5 R. Lucchetti, op. citata, pag.4. 6 Il test che di norma viene effettuato è il test Dickey e Fuller, di cui si dirà in seguito. 7 F. Giusti O. Vitali, Statistica Economica, Cacucci Editore, Bari, 1990, pag.72.

17
1. il valore medio è costante al variare del tempo e il valore atteso E della variabile
casuale Xt è pari alla media µ cioè: E(Xt)=µ. Tale condizione, detta invarianza in
media, implica l’assenza di un trend nella stessa media;
2. la varianza è finita e costante al variare del tempo E(Xt-µ)2=s 2; questa è la
condizione di omoschedasticità;
3. l’autocovarianza fra Xt e Xt+k dipende soltanto dallo sfasamento temporale o
ritardo (lag);
)()()(: kXXEk ktt γµµ =−⋅− +
tale condizione esprime la connessione fra le variabili casuali al variare della
loro distanza. Per questo motivo la stazionarietà in senso debole viene anche
denominata stazionarietà in covarianza. L’autocovarianza del processo assume
un ruolo fondamentale in quanto rappresenta l’indice della relazione lineare che
esiste fra un valore del processo al tempo t e gli stessi valori al tempo t+k .
Dal punto di vista grafico una serie temprale stazionaria si presenta come nel grafico di
Figura 1.18.
Figura n.1.1: Esempio di serie stazionaria
-.20
.2.4
, D
1992q3 1995q1 1997q3 2000q1 2002q3 2005q1tempo
Esempio di serie stazionaria
Fonte: Istat – Indagine trimestrale sulle forze di lavoro
Dal grafico si deduce anche che una serie temporale è stazionaria quando vi è assenza di
trend, e quando non sono presenti anche le altre componenti di ciclo e stagionalità. In
8 Il grafico è stato ottenuto da una serie storica non stazionaria attraverso un procedimento autoregressivo. La serie temporale originale è il tasso di disoccupazione della regione sarda alla quale è stato calcolato il logaritmo e successivamente la differenza fra un termine e il precedente.

18
pratica è stazionaria quando il suo tracciato segue un’andatura irregolare fluttuando
intorno ad un valore medio.
Il processo stocastico più semplice è il cosiddetto rumore bianco (o white noise). Esso è
composto da un numero infinito di variabili casuali e media zero e varianza costante. Un
processo white noise non presenta momenti superiori al secondo e sia media che la
varianza sono costanti nel tempo, in pratica le variabili casuali non conferiscono al
processo alcune memoria di sé9.
Quanto detto può essere formalizzato nel seguente modo:
22 )()(
0)(
σεε
ε
==
=
tt
t
VE
E
?k=0 per |k|>0
dove E(et), indica il valore atteso del t-esimo elemento della serie, è pari alla media, cioè
zero, e il momento secondo, ossia la varianza, è pari a s 2.
Bisogna notare che non esiste sostanziale differenza fra le condizioni che definiscono un
processo white noise e le cosiddette ipotesi classiche sul termine di disturbo nel modello
OLS, eccezion fatta per l’incorrelazione fra regressori e disturbi, e non si commette
alcun errore se si afferma che il disturbo è un white noise incorrelato coi regressori 10.
I processi stocastici stazionari hanno un’importante proprietà che sta alla base della
costruzione di tutti i modelli stocastici. Tale proprietà nota come teorema di Wold
afferma che un processo stocastico stazionario può essere scomposto in due processi
stocastici indipendenti, uno dei quali è linearmente deterministico c(t), mentre l’altro è
una sequenza di variabili casuali incorrelate. Quanto detto può essere scritto nel
seguente modo:
....)( 2211 ++++= −− tttt tcY εψεψε
dove et rappresenta l’errore di previsione ed è pertanto un white noise, mentre il valore
c(t), cioè la parte deterministica, corrisponde alla media del processo µ.
Per verificare se un processo è di tipo white noise si deve applicare una statistica test
sulla serie in oggetto. I test che possono essere utilizzati sono:
1. Il test elaborato da Ljung e Box
2. Il test elaborato da Box e Pierce;
3. Il test di Dickey e Fuller.
9 R. Lucchetti, op. citata, pag.13. 10 R. Lucchetti, op. citata, pag.13

19
Il primo test sottopone ad ipotesi nulla che fra i dati della serie non vi sia
autocorrelazione. La statistica TL&B è calcolata nel seguente modo:
∑=
⋅−+
⋅=H
hBL h
hnn
nT1
2& )(ˆ
2ρ
Questa statistica si distribuisce secondo una T di Student con H gradi di libertà. Il test
viene rifiutato quando la statistica TL&B presenta valori elevati rispetto al corrispondente
valore di significatività del test. Pertanto, in questo caso è possibile affermare che esiste
autocorrelazione fra i dati e che tale autocorrelazione non è dovuta ad un errore di stima
ma è reale.
Il tast di Box e Pierce è analogo al precedente, nel senso che si distribuisce secondo una
T si Student e le aree di accettazione e rifiuto sono le medesime. Tuttavia, si differenzia
dal test di Ljung e Box per il diverso peso che moltiplica il quadrato di ?(h), che è n
anziché hn
nn
−+ 2
. Pertanto la formula per il calcolo della statistica è:
∑=
⋅=H
hPB hnT
1
2& )(ρ̂
Poiché la prima statistica converge più rapidamente alla sua distribuzione asintotica è
preferibile utilizzare quest’ultimo.
Infine, il test elaborato da Dickey e Fuller detto “Dickey-Fuller aumentato”, e indicato
con la sigla ADF, permette di sottoporre a test, sotto l’ipotesi nulla, che un processo non
sia stazionario, contro l’ipotesi alternativa che il processo sia stazionario. Il test è adatto
per le serie temporali in quanto permette di discriminare una serie che presenta un trend
da una serie priva di trend. Nell’impostare il test si deve scegliere il numero dei periodi
da considerare per verificare la correlazione che la serie presenta con il suo passato. In
una serie di dati trimestrali il valore i-esimo della serie potrebbe avere una correlazione
con lo stesso periodo di un anno precedente, quindi i-4. Questo per effetto della
stagionalità. Pertanto, in una serie di dati trimestrali si consiglia l’utilizzo di un ordine
pari a 5. Viceversa in una serie mensile si consiglia di utilizzare un ordine pari a 13.
Nel test ADF la variazione della variabile in questione è regredita sul valore ritardato
della variabile, sulle variazioni ritardate della variabile, su una costante e su un trend
temporale, quando la variabile da ispezionare presenta un trend. Cioè:
ttttt udxLxx ++∆+−=∆ −− 11 )(ϕθ
Dove x è la variabile da testare, d è la parte deterministica contenente la costante ed il
trend temporale e u è l’errore.

20
Sottoporre ad ipotesi nulla che la serie non sia stazionaria significa ipotizzare che il
parametro θ sia pari a 0. Il test di Dickey e Fuller si distribuisce secondo una T di
Student con un numero di gradi di libertà pari al numero delle osservazioni della serie
temporale. Se il numero di osservazioni è sufficientemente grande (in genere maggiore
di 30) allora la distribuzione è approssimabile ad una normale e la statistica test è una
z(t). Se il valore della statistica test è elevato (in valore assoluto) rispetto ai valori critici
indicati per le aree di accettazione/rifiuto allora il test rifiuta l’ipotesi nulla che il
processo non sia stazionario e, quindi, si deve accettare l’ipotesi contraria, cioè che il
processo considerato è stazionario.
Non sempre le variabili osservate relative a fenomeni economici e sociali sono
stazionarie. Infatti, tali fenomeni presentano quasi sempre un trend. Pertanto, al fine di
poterle analizzare è necessario renderle stazionarie tramite alcuni accorgimenti. La
stabilizzazione di una serie avviene attraverso la trasformazione funzionale della serie
osservata e quindi attraverso l’isolamento delle componente deterministica dalla
componente di errore. La trasformazione può essere di diverso tipo:
• trasformazione logaritmica;
• utilizzo della media mobile della serie;
• impiego delle variazioni relative fra un periodo e il precedente al posto del
valore assoluto del fenomeno osservato.
La trasformazione logaritmica viene utilizzata per stabilizzare una serie in quanto
l’operazione produce l’effetto di diminuire la variabilità della serie poiché essa cresce in
termini assoluti al crescere del trend. Ad esempio, una variabilità del 5% su valori
elevati è maggiore in termini assoluti della stessa percentuale applicata però ai valori
bassi della serie. In atri termini, mentre la serie originaria può essere pensata come il
risultato moltiplicativo di più componenti la trasformazione logaritmica rende additiva
tale relazione al trascorrere del tempo.
Anche l’utilizzo delle medie mobili ha un effetto stabilizzante. Infatti l’utilizzo di un
valore centrale degli n termini precedenti produce l’effetto di eliminare la variabilità
all’interno degli n termini scelti per il calcolo della media. Dal punto di vista grafico il
risultato dell’impiego delle medie mobili si traduce in una “smussatura” del tracciato del
grafico e uno spostamento della curva verso il centro o verso destra, a seconda che si
utilizzino rispettivamente medie mobili centrate o medie mobili degli n termini
precedenti.

21
Infine, spesso può essere utile l’utilizzo delle variazioni che il fenomeno osservato
subisce nel tempo con un periodo e il precedente, piuttosto che considerare il valore
assoluto del fenomeno. Tale trasformazione è alla base di tutti i processi integrati
illustrati nel paragrafo 1.8.
Queste trasformazioni possono essere utilizzate anche una di seguito all’altro, perché
ciascuna trasformazione funzionale risolve un particolare problema: la trasformazione
logaritmica rende lineare e costante la varianza della serie, la media mobile “smussa”
l’andamento della serie negli n periodi considerati, e infine, considerare le variazioni
assolute permette di “appiattire” il trend. Pertanto, viene consigliato dagli esperti anche
l’utilizzo combinato delle trasformazioni funzionali.
1.3.2 Ergodicità L’ergodic ità è una proprietà dei processi stocastici che assicura che le medie nel tempo
forniscano stime consistenti dei momenti (media, varianza e autocovarianza) del
processo stocastico. In sostanza l’ergodicità richiede la “memoria” del processo sia
limitata così che osservazioni molto distanti nel tempo siano fra loro non correlati. Tale
condizione viene sintetizzato nella seguente proprietà dei processi stocastici che deriva
dal teorema ergodico di Slutsky:
0),(1
lim1
=∑=
−∞→
n
kktt
nxxCov
n
Di conseguenza se un processo è ergodico è possibile usare le informazioni contenute
nella sua evoluzione nel tempo e fare inferenza sulle caratteristiche. Il “teorema
ergodigo” dice appunto che l’osservazione di una serie “abbastanza lunga” è
equivalente, ai fini inferenziali, all’osservazione di un gran numero di realizzazioni. Ad
esempio, se un processo ergodico ha valore atteso µ, allora la sua media aritmetica nel
tempo è uno stimatore consistente di µ, e quindi µ può essere stimato in modo
consistente come se si disponesse di molte realizzazioni del processo anziché di una
sola11.
1.3.3 Invertibilità L’invertibilità è una caratteristica propria dei modelli MA e consiste nella possibilità
teorica di esprimere un modello MA con un modello AR di ordine infinito. Pertanto, si
può dire che un processo stocastico si dice invertibile se per qualsiasi t, è possibile
esprimere il processo come una funzione convergente delle variabili casuali precedenti
11 R. Lucchetti, op. citata, pag.5

22
generate dal processo. Ad esempio un processo MA(1), per semplicità con media nulla,
si dice invertibile se12:
1−+= ttt uuy ϑ e 1−−= ttt uyu ϑ
Con sostituzioni successive si arriva alla seguente formula:
1)( −
∞
=
⋅−= ∑ toi
it yu ϑ
Tale condizione è verificata se soltanto se |ϑ |<1. In generale è possibile dimostrare che
condizione necessaria all’invertibilità di un processo stocastico di ordine q è che le q
soluzioni dell’equazione
0...1 1 =+++ qq xx ϑϑ
siano in modulo maggiori di 1.
1.4 Caratteristiche di una serie temporale: l’autocorrelazione Come visto in precedenza i fenomeni economici e sociali presentano una dipendenza dal
tempo in cui sono osservati. Tale caratteristica è detta autocorrelazione per il fatto che i
dati rilevati nel presente hanno una dipendenza con il passato. L’autocorrelazione può
estendersi al passato più o meno recente. In particolare, se il valore del presente è
correlato solo al valore precedente si dice che l’autocorrelazione è di ordine 1. Si parla
invece di autocorrelazione di ordine k se il valore presente della serie è correlato con k
valori precedenti. Per verificare l’esistenza di autocorrelazione si può procedere in
diversi modi:
• in maniera grafica: si rappresenta in un diagramma a dispersione il valore della
serie al tempo t e al tempo ritardato di un periodo (t-1); se si ottiene una nuvola
di punti che si dispone lungo una retta allora esiste correlazione fra il termine al
tempo t e il tempo t-1. Se la retta è inclinata positivamente la correlazione è
positiva, viceversa, se la retta è inclinata negativamente la correlazione è
negativa.
• In maniera analitica, si può procedere in due modi: una prima strada consiste nel
calcolo degli indici di correlazione sia totale che parziale, e quindi attraverso la
verifica dell’ordine di relazione k che la serie presenta con il passato.
Un’alternativa della verifica della correlazione consiste nell’effettuare la stima
del parametro di una regressione, fra il valore della serie al tempo t e il valore
della serie ritardato di un periodo. Se il t-ratio della statistica è superiore a circa
12 G.Masarotto, Analisi delle serie temporali (lucidi delle lezioni) , gennaio 2003

23
2, allora esiste una relazione fra il termine della serie al tempo t e i termini della
serie ritardati di un periodo. La strada preferibile è la prima, ma possono essere
utilizzate entrambe per verificare i risultati ottenuti con la prima.
Come si è appena detto l’autocorrelazione può essere di due tipi:
• totale;
• parziale.
L’autocorrelazione totale, indicata con la lettera ? (leggi ro), viene nel seguente modo:
)0()(
)var()var(
),cov()(
γγ
ρk
ZZ
ZZk
ktt
ktt =⋅
=+
+
dove k è il ritardo temporale, cioè il numero di periodi presi in considerazione per il
calcolo dell’indicatore a partire da quello più recedente.
L’autocorrelazione parziale, indicata con la lettera p è una misura della relazione lineare
che esiste fra il termine del processo al tempo t e il termine del processo al tempo t+k
“depurata” dalla correlazione dei valori intermedi del processo. Essa è calcolata con la
seguente formula:
)],..,(|[)](),,..,,(|[()( 111121 −++++−+++ −= kttttktktttt ZZZEZEZZZZEZcorrkπ
che definisce appunto la correlazione parziale Z(t) e Z(t+k) al netto delle altre variabili
intermedie.
1.4.1 Una rappresentazione grafica dell’autocorrelazione: il
correlogramma
I metodi visti in precedenza per la verifica dell’autocorrelazione presentano il problema
di dover calcolare più grafici di dispersione o indici di correlazione per ogni ritardo
della serie temporale. Nelle time series esiste un particolare rappresentazione grafica
che viene impiegata per visualizzare le autocorrelazioni che la serie presenta con il
passato. La rappresentazione grafica viene denominata correlogramma e consiste in un
diagramma ad “aste” (detti spike) che contiene in ascissa i ritardi, ordinati dal più
recente al più remoto e, in ordinata, i corrispondenti valori di autocorrelazione.
Per determinare l’ordine di autocorrelazione che la serie presenta con il passato è
necessario vedere quante “aste” consecutive, dalla più recente alla più remota cadono
fuori da un’area evidenziata dalle bande di confidenza.
L’analisi dei correlogrammi delle autocorrelazioni globali (ACF) e parziali (PAC) è
utile anche ai fini dell’individuazione degli ordini p e q dei modelli AR e MA che
generano la serie osservata. Infatti in un processo MA di ordine q il correlogramma

24
presenta autocorrelazioni significative fino al ritardo q, mentre la PAC dovrebbe tendere
a zero gradualmente. Viceversa in un processo AR di ordine p le stime delle PAC
dovrebbero essere significativamente diverse da zero fino al ritardo p, mentre il
correlogramma delle ACF presenta autocorrelazioni che vanno a zero gradualmente.
Infine, se sia le autocorrelazioni globali che quelle parziali vanno a zero gradualmente si
è in presenza di un processo ARMA, e gli ordini delle due componenti vanno
identificati di conseguenza13.
A titolo di esempio si riporta nella figura n.1.2 il correlogramma della serie delle
persone in cerca di occupazione in Sardegna su valori trimestrali, per il periodo
compreso fra ottobre 1992 e ottobre 2003, con un ritardo di 10 periodi.
Figura n.1.2 Correlogramma del tasso di disoccupazione sardo sulla serie trimestrale.
Fonte: Istat – Indagine trimestrale sulle forze di lavoro
Come si può, notare l’analisi della serie trimestrale delle persone in cerca di
occupazione presenta una correlazione con il passato fino a 2 periodi precedenti. Ciò è
importante quando si andrà ad impostare un modello stocastico che cerca di prevedere
le realizzazioni future della serie dall’analisi delle osservazioni passate.
Infine, alcuni software permettono di realizzare anche dei correlogrammi in una forma
grafica più stilizzata ma con i valori delle AC, PAC, le statistiche dei test Q e i
13 L. Stanca, op. citata, pag.14.

25
corrispondenti valori di probabilità riferiti a ciascun lag. Sempre a titolo di esempio si
riporta un correlogramma analitico riferito stavolta al tasso di disoccupazione sardo.
Figura n.1.3 Correlogramma della serie del tasso di disoccupazione in Sardegna.
Fonte: Istat – Indagine trimestrale sulle forze di lavoro
1.5 I modelli AR I modelli AR sono dei modelli in cui il valore della serie al tempo t è una funzione
lineare di un certo numero p di valori passati, più un errore che non è possibile stimare.
Tale errore in precedenza è stato definito rumore bianco o, anche, secondo la
terminologia anglosassone, white noise.
Il modello può essere scritto nel seguente modo14:
tptptt yyy εαα +++= −− ....11
dove (a1,.. ap) è un vettore di parametri costanti.
Come si può notare si tratta di un normale modello di regressione lineare in cui la
variabile risposta yt è il valore al tempo t del processo, mentre le variabili esplicative
sono i valori passati del processo stesso. Il termine et rappresenta l’errore di stima
assimilabile al disturbo di un modello di regressione lineare.
Il processo AR più semplice è il cosiddetto random walk (passeggiata casuale), dove il
parametro p assume valore 1, e, pertanto, viene indicato con sigla AR(1). I processi AR
possono essere sia stazionari sia non stazionari, a differenza dei processi MA che sono
sempre stazionari. Infatti il random walk è un processo stocastico non stazionario in cui
14 G. Masarotto, Analisi delle serie temporali (lucidi delle lezioni), Padova, gennaio 2003, pag.210.

26
le varianze e le k autocovarianza dipendono dal tempo t. Il modello viene specificato
nel seguente modo:
ttt yy εα += −1
Nelle time series uno strumento molto importante è l’operatore ritardo che applicato ad
Yt fornisce il valore della serie ritardato di un periodo Yt-1:
LYt=Yt-1
L’operazione ripetuta n volte per ottenere un ritardo n-esimo sul valore della serie viene
indicato con la scrittura Ln, e, quindi si ha che LnYt=Yt-n. L’operatore L è lineare nel
senso che se due numeri a e b sono costanti, si ha L(ax t+b)=aLx t+b=ax t-1+b. La
caratteristica dell’operatore ritardo è che le sue proprietà permettono di manipolarlo
algebricamente come se fosse un numero15. Questo avviene soprattutto quando si
considerano polinomi nell’operatore L, e ciò è utile quando si devono stimare i
coefficienti di un modello autoregressivo superiori ad 1.
Pertanto la formula del modello generale tramite l’operatore ritardo può essere riscritta
nel seguente modo:
ttt Lyy εα +=
e, quindi, è possibile fare alcune operazioni di raggruppamento, per ottenere la seguente
formula:
ttyL εα =− )1(
Per descrivere questo processo è fondamentale determinare i momenti primi e secondi
sotto l’ipotesi che il processo sia stazionario, per poi derivare le conseguenze di tale
ipotesi. Si supponga quindi che il processo abbia media costante µ. Quest’ipotesi
implica che:
µ=E(yt)=aE(yt-1)+E(et)=aµ
Questa espressione può essere vera in due casi:
1. quando µ =0, e, in questo caso, l’espressione è vera per qualsiasi valore di a
2. quando a=1 e, in questo caso, l’espressione è vera per qualsiasi valore di µ e la
media del processo è indeterminata. In questo caso si dice che il processo
presenta una radice unitaria.
Se si esclude il secondo caso per cui la media non può essere determinata il processo è
stazionario quando la media è nulla.
15 R. Lucchetti, op. citata, pag.9.

27
Analogamente si procede per i momenti secondi: si supponga che la componente
erratica del processo et abbia varianza pari a s 2, se si pone V la varianza di yt e si
ipotizza che essa esista e sia costante nel tempo, si avrà che:
)(2])[()( 1222
12
ttttt yEVyEyEV εασαεα −− ++=+==
Dove l’ultimo addendo è pari a 0 perché combinazione lineare di autocovarianza di un
white noise16 (tutte nulle per definizione). Se ne deduce che:
V=a2V+s2, che è apri a 2
2
1 ασ−
=V
Tale espressione dice che solo nel caso in cui | a |<1 ha senso parlare di varianza stabile
nel tempo. Tale condizione esclude dal novero dei processi AR(1) stazionari, non solo
quelli a radice unitaria, ma anche quelli a radice cosiddetta esplosiva17.
Infine, rimangono da analizzare le autocovarianza: l’autocovarianza di ordine 0 è V;
l’autocovarianza di ordine 1 è data da:
VyyEyyE ttttt αεαγ =+== −−− ])[()( 1111
e, in generale, l’autocovarianza di ordine k è data da:
11 ])[()( −−−− =+== kktttkttk yyEyyE αγεαγ
e si deduce che
2
2
1 ασ
αγ−
= kk
Le autocorrelazioni assumono in questo caso una forma molto semplice:
?k=ak
Quanto esposto può essere interpretato nel seguente modo: poiché le autocovarianze
esprimo in un certo senso la memoria del processo, le stesse sono tanto più grandi (in
valore assoluto), quando tanto più grande è a. Per questo motivo a può essere
considerato come un parametro della persistenza della memoria del processo.
1.6 I modelli MA Un processo stocastico si dice a media mobile, e si indica con la sigla MA(q), quando il
comportamento di yt dipende solo dai valori presenti e passati degli shock del processo,
vale a dire della componente di errore. Pertanto, esso può essere scritto nel seguente
modo:
yt=et+?1et-1+ ? 2et-2+……. ? qet-q
o anche: 16 R. Lucchetti, op. citata, pag.19. 17 R. Lucchetti, op. citata, pag.19.

28
∑=
− ==q
oititit Ly εθεθ )(
dove ?(L) è un polinomio di ordine q dell’operatore ritardo e et è un white noise.
Per descrivere le caratteristiche del modello MA(q) è necessario determinare i momenti
primo, secondo e le autocovarianza, come, d’altra parte visto anche per i modelli AR.
I momenti di un modello MA sono dati da18:
media: E(yt)=0
varianza(?0): E(y2t)=s 2(1+?2)
autocovarianza di ordine 1(?1) E(yt yt-1)= ? s2
autocovarianza di ordine superiore ad 1 E(yt yt-k)= 0 se k>q
La funzione di autocorrelazione di ordine 1 è pari a :
222
2
0
11 1)1( θ
θσθ
θσγγ
ρ+
=+
==
Da ciò ne consegue che i modelli MA hanno sempre media nulla e, pertanto, sono
sempre stazionari. Questa caratteristiche potrebbe far pensare ad una limitazione
dell’applicabilità dei processi MA a fenomeni reali, dato che raramente tali fenomeni
oscillano intorno al valore 0. “Tuttavia la limitazione è più apparente che reale, visto
che per ogni processo xt per cui E(x t)=µt si può sempre definire un nuovo processo yt=x t
- µt a media nulla”19. Inoltre è possibile affermare che un processo MA(q) è un processo
ottenuto come combinazione di diversi elementi di uno stesso white noise che presenta
delle caratteristiche di persistenza più pronunciate quanto più alto è il suo ordine.20
Un processo a media mobile di ordine 1, indicato con la sigla MA(1), è dato da:
11 −+= ttty εθε
e, utilizzando l’operatore ritardo visto nei modelli AR, può essere anche scritto come
segue:
tt Ly εθ )1( 1+=
1.7 I modelli ARMA I modelli ARMA nascono dalla combinazione dei modelli AR e MA e sono
caratterizzati dal fatto che il comportamento della variabile risposta yt dipende
18 Per semplicità si omette la dimostrazione. Si veda Giusti F., Vitali O., op. citata, pag.5; oppure R. Lucchetti, op. citata, pag. 13. 19 R. Lucchetti, op. citata, pag.14. 20 R. lucchetti, op. citata, pag. 15.

29
linearmente sia dai suoi valori passati, che dai valori present i e passati degli shock.
Analiticamente un processo ARMA(p,q) può essere descritto nel seguente modo:
qtqttptptt yyy −−−− ++++++= εθεθεφφ ...... 1111
dove p è l’ordine della componente autoregressiva e q è l’ordine della componente a
media mobile. La stessa espressione può essere anche scritta utilizzando l’operatore
ritardo nella seguente forma:
tt LyL εθφ )()( =
Poiché i processi MA sono sempre stazionari, la stazionarietà del processo ARMA
dipenderà dalla componente AR, mentre l’invertibilità dell’intero processo dipenderà
dalla componente a media mobile. Il modello ARMA può rappresentare anche modelli
generati dalla sola componete AR o MA per valori pari a zero rispettivamente di q e p.
1.8 I modelli integrati Come visto in precedenza, raramente i fenomeni socio-economici si presentano senza
trend. Poiché l’esistenza di un trend implica la non stazionarietà, una serie prima di
essere modellata attraverso un processo stocastico AR o MA, deve essere resa
stazionaria. I modelli integrati nascono proprio dall’esigenza di analizzare dei dati che
presentano delle tendenze. Il trend può essere eliminato facendo semplicemente la
differenza fra un termine della serie e il precedente, considerando così le variazioni
assolute che la serie subisce nel tempo. A questo punto occorre introdurre la differenza
fra dato di flusso e dato di stock. La variabile di flusso è definita come la differenza fra
una variabile al tempo t e la stessa variabile al tempo t-1. La variabile di stock invece è
il valore assoluto della variabile osservata al tempo t.
A titolo di esempio si riporta nel grafico di figura n.1.4 l’andamento delle persone in
cerca di occupazione in Sardegna nel periodo compreso fra ottobre ’92 e ottobre ’03.
Come si può notare, la variabile osservata mostra un trend a “salire” nel periodo
compreso fra ottobre ’92 e gennaio ’00, e un trend a “scendere” a partire da
quest’ultimo periodo e l’ultimo dato della serie dell’ottobre ’03.
Tuttavia, il trend non è nitido. Infatti, si può notare come all’interno di un anno solare la
crescita non sia lineare ma oscilli intorno ad un valore medio. Questa variabilità è
dovuta alla stagionalità e mostra come nel mercato del lavoro le persone che cercano
un’occupazione diminuiscono nella stagione estiva e aumentano nella stagione
invernale. La spiegazione economica della stagionalità è da ricercare nella struttura
occupazionale del mercato del lavoro sardo e nella relazione che esiste fra i diversi

30
settori di attività economica. Infatti, l’economia sarda ha una spiccata vocazione
turistica e le attività connesse al turismo (servizi alberghieri, della ristorazione, e dei
mezzi di trasporto) si intensificano proprio nel periodo estivo. In questo periodo
l’occupazione aumenta e le persone in cerca di occupazione diminuiscono. Il fenomeno
è tanto più accentuato quanto più incide l’attività turistica sull’economia del territorio.
Figura n.1.4 Andamento delle persone in cerca di occupazione in Sardegna.
Andamento delle persone in cerca di occupazione in Sardegna dall'ottobre 1992 all'ottobre 2003Valori in migliaia di unità
50
60
70
80
90
100
110
120
130
140
150
ott-
92ge
n-93
apr-
93lu
g-93
ott-
93ge
n-94
apr-
94lu
g-94
ott-
94ge
n-95
apr-
95lu
g-95
ott-
95ge
n-96
apr-
96lu
g-96
ott-
96ge
n-97
apr-
97lu
g-97
ott-
97ge
n-98
apr-
98lu
g-98
ott-
98ge
n-99
apr-
99lu
g-99
ott-
99ge
n-00
apr-
00lu
g-00
ott-
00ge
n-01
apr-
01lu
g-01
ott-
01ge
n-02
apr-
02lu
g-02
ott-
02ge
n-03
apr-
03lu
g-03
ott-
03
Fonte: Istat – Indagine trimestrale sulle forze di lavoro
Per eliminare il trend di questa serie è possibile calcolare la variazione fra un periodo e
il precedente e tracciare l’andamento, come mostrato in figura n.1.5
Come si può notare l’andamento della serie delle differenze assolute è privo di trend,
ma perde di informazione, in quanto non si riesce a cogliere quale sia lo stock delle
persone in cerca di occupazione, ad esempio, ad ottobre 2003. Dal grafico è possibile
notare che le persone in cerca di occupazione sono soltanto aumentate di 7mila unità
rispetto al periodo precedente; nel periodo ancora precedente erano diminuite rispetto al
periodo precedente; e così via. Se si volesse conoscere lo stock delle persone in cerca di
occupazione ad ottobre 2003 occorre conoscere lo stock di occupati ad un determinato
periodo e fare le somme algebriche dei diversi periodi intermedi fino ad arrivare
all’ultimo periodo. Avendo tale informazione è possibile fare inferenza sulla serie delle

31
variazioni per poi risalire dalle variazioni allo stock di occupati aggiungendo o
sottraendo la variazione prevista dal modello.
Figura n.1.5 Variazione fra un periodo e il precedente delle persone in cerca di
occupazione in Sardegna.
Andamento delle variazioni delle persone in cerca di occupazione in Sardegna dall'ottobre 1992 all'ottobre 2003
Valori assoluti in migliaia
-30
-20
-10
0
10
20
30
40
ott-
92ge
n-93
apr-
93lu
g-93
ott-
93ge
n-94
apr-
94lu
g-94
ott-
94ge
n-95
apr-
95lu
g-95
ott-
95ge
n-96
apr-
96lu
g-96
ott-
96ge
n-97
apr-
97lu
g-97
ott-
97ge
n-98
apr-
98lu
g-98
ott-
98ge
n-99
apr-
99lu
g-99
ott-
99ge
n-00
apr-
00lu
g-00
ott-
00ge
n-01
apr-
01lu
g-01
ott-
01ge
n-02
apr-
02lu
g-02
ott-
02ge
n-03
apr-
03lu
g-03
ott-
03
Fonte: Istat – Indagine trimestrale sulle forze di lavoro
Un modello in cui si effettuano operazioni di differenza fra un valore e il precedente, si
definisce integrato, dall’inglese Integrated, e viene indicato con la lettera I(d). La lettera
d indica l’ordine di integrazione, cioè il numero di volte che l’operatore differenza viene
applicato alla serie.
Potrebbe capitare, infatti che il processo debba essere differenziato più di una volta al
fine di renderlo stazionario ed invertibile, premesse necessarie al fine di modellare la
serie con un processo stocastico del tipo visto in precedenza.

32
2. Parte sperimentale: specificazione di un modello
autoregressivo applicato al tasso di disoccupazione
sardo.
2.1 Premessa sulla costruzione del dataset e sulla metodologia Il dataset utilizzato è stato costruito presso l’Osservatorio del mercato del Lavoro
dell’Agenzia Regionale del Lavoro della regione Sardegna, che dispone di un archivio
delle rilevazioni trimestrali sulle forze di lavoro realizzate dall’Istat dall’ottobre 1992,
cioè da quando sono stati introdotti i nuovi criteri di indagine, aggiornato all’ultima
indagine disponibile (ottobre 2003). Per eventuali approfondimenti che il lettore vorrà
fare su questa materia si riportano le intere tavole Istat in un allegato statistico in calce
alla presente trattazione.
Per le finalità di questo lavoro sono state estratte dalle tavole Istat le serie delle persone
in cerca di occupazione e degli occupati e si è costruito il dataset con le seguenti
variabili:
1. anno variabile numerica che indica l’anno di riferimento dell’indagine
Istat;
2. trimestre variabile numerica che indica il trimestre;
3. occ variabile numerica relativa al numero di occupati;
4. disocc variabile numerica relativa alle persone in cerca di occupazione;
5. tempo variabile temporale definita nell’elaborazione dei dati per ordinare
i dati in relazione al tempo di riferimento
6. locc variabile numerica definita per l’analisi della serie degli occupati
e determinata facendo il logaritmo degli occupati.
7. ldisocc variabile numerica definita per l’analisi della serie delle persone
in cerca di occupazione e determinata facendo il logaritmo della stessa
grandezza.
8. var variabile numerica definita per l’analisi della serie delle persone
in cerca di occupazione e determinata facendo la differenza fra un termine della
serie e il precedente.
9. unem il tasso di disoccupazione
10. varun la variazione del tasso di disoccupazione rispetto al periodo
precedente

33
11. varun4 la variazione del tasso di disoccupazione rispetto allo stesso
periodo dell’anno precedente.
12. fdl Forze di lavoro determinate facendo la somma degli occupati e
delle persone in cerca di occupazione.
Il dataset si compone di 45 osservazioni e il programma utilizzato per le elaborazioni
statistiche è Stata, versione n.8, adottato nell’ambito del master di statistica applicata.
L’analisi è stata concentrata sulla serie del tasso di disoccupazione e la metodologia
utilizzata per l’individuazione del modello è quella proposta da Box e Jenkins.
L’intera procedura si articola nelle seguenti fasi:
1. Analisi statistica e grafica della serie del tasso di disoccupazione e delle persone
in cerca di occupazione al fine di cogliere trend e stagionalità.
2. Identificazione del modello teorico di riferimento per la quale, è necessario
procedere prima alla ricerca della stazionarietà della serie, attraverso l’uso delle
tecniche analizzate nella parte teorica.
3. Individuazione dei parametri di p e q del modello di riferimento attraverso
l’analisi delle correlazioni globali e parziali, e dei correlogrammi.
4. Analisi e valutazione del modello per fini previsionali.
2.2 Costruzione del modello e ricerca della stazionarietà Osservando il grafico del tasso di disoccupazione si osserva innanzitutto che la serie
presenta un trend inizialmente crescente, con una accelerazione nel 1993.
Andamento del tasso di disoccupazione in Sardegna dall'ottobre 1992 all'ottobre 2003 Valori percentuali
101112131415161718192021222324
ott-9
2ge
n-93
apr-
93lu
g-93
ott-9
3ge
n-94
apr-
94lu
g-94
ott-9
4ge
n-95
apr-
95lu
g-95
ott-9
5ge
n-96
apr-
96lu
g-96
ott-9
6ge
n-97
apr-
97lu
g-97
ott-9
7ge
n-98
apr-
98lu
g-98
ott-9
8ge
n-99
apr-
99lu
g-99
ott-9
9ge
n-00
apr-
00lu
g-00
ott-0
0ge
n-01
apr-
01lu
g-01
ott-0
1ge
n-02
apr-
02lu
g-02
ott-0
2ge
n-03
apr-
03lu
g-03
ott-0
3
Fonte: Istat – Indagine trimestrale sulle forze di lavoro

34
La crescita del tasso di disoccupazione rallenta nei 2 anni successivi, per poi iniziare a
calare dall’aprile 2000 fino all’ultima rilevazione.
La serie del tasso di disoccupazione presenta le seguenti caratteristiche:
Num osserv. Media Varianza Minimo Massimo
45 19.44 1.64 14.63 22.19
Come si è visto in precedenza la presenza di un trend implica l’assenza di stazionarietà,
che porta ad un modello in cui le stime non sono “B.L.U.E.”. L’esistenza di una
relazione di tipo lineare viene confermata dal diagramma a dispersione fra i punti della
serie al tempo t e al tempo t-1.
Figura n.2.1 Grafico a dispersione del tasso di disoccupazione al tempo t e al tempo t-1.
1416
1820
22T
asso
di d
isoc
cupa
zion
e ri
tard
ato
1 pe
riod
o
14 16 18 20 22Tasso di disoccupazione
Dispersione del tasso di disoccupazione al tempo t e t-1
Fonte: Istat – Indagine trimestrale sulle forze di lavoro
Anche facendo la regressione lineare fra un termine e il precedente si nota questa
relazione.

35
Infatti il p-value associato al coefficiente L1 (ritardo di 1 periodo) della regressione è
pari a 0, e il t-ratio è pari a 4.03, molto lontano dal valore 1.96 cui corrisponde una
probabilità del 95% di accettazione del test. Quindi si può rifiutare l’ipotesi nulla che
“non vi sia alcuna relazione” e, pertanto, esiste una dipendenza del tasso di
disoccupazione al tempo t e il tasso di disoccupazione al tempo precedente.
Il problema però consiste nel vedere quanto la serie del tasso di disoccupazione ha
memoria del suo passato. Lo strumento che si utilizza è il correlogramma che mette in
evidenza le correlazioni globali e le correlazioni parziali (dirette) fra un termine della
serie e il k termine precedente. Il correlogramma può essere analizzato nella sua forma
analitica o grafica.
Il correlogramma nella forma analitica riporta nella prima colonna il ritardo, nella
seconda e terza colonna i coefficienti di autocorrelazione globale (AC) e parziale
(PAC), nella quarta colonna le statistiche dei test Q e nella quinta colonna i
corrispondenti valori di probabilità. Nelle altre 2 colonna sono rappresentate le AC e le
PAC in una forma grafica più stilizzata. In questo caso si è scelto un numero di lags pari
a 20 perché è una regola pratica riscontrata empiricamente che conviene utilizzare un
ritardo massimo pari al numero di osservazioni diviso 4 (in questo caso 44/4=11), o fino
ad un ritardo massimo ci circa 4-5 anni (in questo caso 5 x 4 = 20).

36
Figura n.2.2: Correlogramma del tasso di disoccupazione fino a 20 periodi.
-0.5
00.
000.
50A
utoc
orre
latio
ns o
f un
em
0 5 10 15 20Lag
Bartlett's formula for MA(q) 95% confidence bands
Dai 2 correlogrammi, si può notare che le AC decrescono lentamente fino ad annullarsi
dopo 8 periodi. Questo significa che la memoria del processo è abbastanza persistente.
Tuttavia, soltanto i ritardi fino al secondo ordine sono significativi. Infatti, il
correlogramma grafico che mostra anche le bande di accettazione/rifiuto dei test di
significatività dei ritardi, mostra che la serie del tasso di disoccupazione ha una
memoria del processo pari a 2 periodi, poiché solo 2 aste cadono fuori dall’area di
accettazione dell’ipotesi nulla che non vi sia relazione fra un termine e il precedente.
Pertanto, l’analisi delle autocorrelazioni suggerisce che la serie del tasso di
disoccupazione possa essere modellata da un processo stocastico autoregressivo di
ordine 2.
Tuttavia, tale processo stocastico non è stazionario come dimostra anche il test Dickey-
Fuller e, pertanto, non può essere modellato, perchè in assenza di stazionarietà “non si
possono utilizzare i dati campionari per la stima dei momenti primi e secondi perché è
come se i dati fossero eterogenei (non sommabili) in quando prodotti nel tempo da
diversi processi stocastici”.21
Applicando il test ADF con le opzioni trend e regress, che permettono di analizzare una
serie in presenza di trend e di ottenere anche la stima dei parametri della regressione
21 M.E. Bontempi, La modellazione empirica delle relazioni economiche: applicazioni in Stata7, dispense ad uso degli studenti.

37
associata, si nota che soltanto quando si arriva a considerare soltanto 2 lags i t-ratio
associati ai lags sono significativi (poiché il tasso di disoccupazione è rilevato su base
trimestrale, quindi con 4 rilevazioni all’anno, la teoria suggerisce di iniziare ad
effettuare le stime prendendo in considerazione 4+1 rilevazioni precedenti).

38
La statistica porta ad accettare l’ipotesi nulla che la serie non è stazionaria poiché il
valore della statistica test, pari a –3.277, è minore (in valore assoluto) del valore critico
che porterebbe a rifiutare il test commettendo un errore del 5%. Tale valore infatti è -
3.528.

39
La serie deve essere prima resa stazionaria.
Per eliminare il trend è possibile determinare la differenza prima, data da unem(t) –
unem(t-1).
Num osserv. Media Varianza Minimo Massimo 44 -0.000101 1.557808 -3.524687 5.019882 Come si può osservare adesso la media è pari a 0 come lo dimostra anche il grafico di
figura 2.3
Figura n.2.3: Andamento delle variazioni del tasso di disoccupazione.
-4-2
02
46
Diff
eren
za 1
^ de
l tas
so d
i dis
occu
pazi
one
1992q3 1995q1 1997q3 2000q1 2002q3 2005q1tempo
Fonte: Istat – Indagine trimestrale sulle forze di lavoro
Per verificare la stazionarietà della serie si effettua il test ADF che conferma la
stazionarietà della serie poiché la statistica test con 1 lag di ritardo è pari a –5.804 che è
molto distante da –3.634 che rifiuta l’ipotesi con una probabilità del 99%.

40
Trovata la stazionarietà della serie è possibile passare allo step successivo di stima e
verifica dei parametri e rappresentare il comportamento della serie mediante un modello
stocastico.
Si ricorda che la differenziazione non pone alcun problema poiché è sempre possibile
risalire dal valore di flusso al valore di stock applicando a partire dal primo valore della
serie gli incrementi o decrementi generati dal modello. Il problema sta nel verificare se
gli errori generati dal modello si mantengono stabili nel tempo o al contrario tendono ad
aumentare. In altri termini se si presenta eteroschedasticità nei residui. Pertanto
bisognerà verificare se con il trascorrere del tempo il modello teorico tende ad
allontanarsi dalla serie reale.
La stima dei parametri per un modello AR può essere calcolata con il metodo OLS
regredendo il termine della serie stazionaria al tempo t con quelle precedenti.
Scegliendo un ordine di ritardo pari a 5 si nota come i ritardi superiori al primo non
sono significativi e pertanto possono essere omessi.

41
La regressione presenta le seguenti caratteristiche :
1. Uno scarso r-quadro pari a circa il 33%. In pratica il modello che cerca di
spiegare la variabilità del tasso di disoccupazione utilizzando la variazione
precedente non riesce a spiegare molto. Ma ciò non deve allarmare poiché nei
modelli stocastici che prescindono dalla teoria economica l’r-quadro ha poco
significato. Per aumentare la significatività è necessario introdurre altre variabili
nel modello. Tali variabili devono essere necessariamente di tipo economico
visto che il modello statistico non riesce a spiegare molto. Tuttavia si entrerebbe
nel campo dei modelli VAR che esulano da questa trattazione e, pertanto, si
prende atto di tale risultato per trarre le successive conclusioni.
2. Significatività del coefficiente relativo al ritardo di un periodo.
3. Non significatività del coefficiente relativo alla costante.
Si salvano i residui della regressione e si verifica la presenza di eteroschedasticità nei
residui.
Figura n.2.4: Scatter dei residui della regressione.
-4-2
02
4R
esid
uals
1992q3 1995q1 1997q3 2000q1 2002q3 2005q1tempo

42
Graficamente già si può notare che la variabilità dei residui non aumenta con il trascorre
del tempo. Comunque per la verifica analitica si effettua il test di eteroschedasticità.
Il test sottopone ad ipotesi nulla che la varianza sia costante. Come si può vedere tale
ipotesi non può essere rifiutata perché il test non è significativo.
Si effettua anche il test per la verifica della forma funzionale.
Tale test sottopone ad ipotesi nulla che il modello non ha variabili omesse. Come si può
vedere il test non è significativo.
Infine, si verifica l’autocorrelazione dei residui sotto l’ipotesi nulla che i residui siano
white noise.
Pertanto, da tutti i test effettuati risulta che il processo stocastico del tipo trovato, cioè
AR(1)22 sulla serie differenziata del primo ordine, rappresenta un’adeguata
specificazione delle variazioni del tasso di disoccupazione sardo e pertanto può essere
utilizzato per fare analisi e previsioni.
Un modo alternativo molto più rapido per determinare l’ordine p del modello
autoregressivo più adatto per la serie oggetto di analisi, consiste nell’ispezionare il
correlogramma delle autocorrelazioni parziali. In pratica i ritardi che cadono fuori
dall’intervallo di confidenza indicano l’ordine del modello AR da utilizzare.
22 Il modello potrebbe essere anche scritto nella forma ARIMA(1,1,0) riferita però alla serie del tasso di disoccupazione.

43
Figura n.2.5: Grafico PAC delle differenze prime del tasso di disoccupazione.

44
2.3 La previsione del tasso di disoccupazione Il modello trovato può essere scritto nel seguente modo:
ttt yy εφ +∆=∆ −11
dove il coefficiente F stimato è pari a –0.565. Pertanto il modello diventa:
ttt yy ε+∆−=∆ −1565.0ˆ
e, quindi, il tasso di disoccupazione viene calcolato sommando la variazione stimata per
il periodo t al tasso di disoccupazione registrato nel periodo precedente (t-1):
tt yunemunem ˆ1 ∆+= −
Nel grafico successivo si riporta l’andamento della stima del modello a confronto con la
serie effettiva del tasso di disoccupazione.
Andamento del tasso di disoccupazione in Sardegna effettivo e previsto dall'ottobre 1992 all'ottobre 2003 e previsioni per primo trimestre 2004
14,0
15,0
16,0
17,0
18,0
19,0
20,0
21,0
22,0
23,0
ott-
92ge
n-93
apr-
93lu
g-93
ott-
93ge
n-94
apr-
94lu
g-94
ott-
94ge
n-95
apr-
95lu
g-95
ott-
95ge
n-96
apr-
96lu
g-96
ott-
96ge
n-97
apr-
97lu
g-97
ott-
97ge
n-98
apr-
98lu
g-98
ott-
98ge
n-99
apr-
99lu
g-99
ott-
99ge
n-00
apr-
00lu
g-00
ott-
00ge
n-01
apr-
01lu
g-01
ott-
01ge
n-02
apr-
02lu
g-02
ott-
02ge
n-03
apr-
03lu
g-03
ott-
03ge
n-04
Tasso di disocc Previsioni
Come si può osservare anche dalla tabella n.2.1, il modello ha fornito un errore positivo
in 22 casi su 43 e, quindi, ha fornito una stima del tasso di disoccupazione minore
rispetto a quello che si è effettivamente registrato il trimestre successivo.
Viceversa, ha fornito una stima del tasso di disoccupazione maggiore di quello che si è
realmente registrato in 21 casi su 43. La media degli errori ovviamente è pari a 0.

45
Tabella 2.1: Andamento del tasso di disoccupazione e previsione.
Periodo trimestre Tasso di disocc.
Var del tasso di disocc
Previsione della variaz.
Previsione del tasso
Errori Errore %
ott-92 4 16.8 gen-93 1 14.6 -2.13 apr-93 2 19.7 5.08 1.21 15.8 3.87 24.45 lug-93 3 18.1 -1.64 -2.87 16.8 1.23 7.31 ott-93 4 20.3 2.20 0.93 19.0 1.28 6.72 gen-94 1 19.5 -0.75 -1.24 19.0 0.49 2.58 apr-94 2 20.5 0.98 0.43 19.9 0.55 2.78 lug-94 3 19.8 -0.71 -0.55 19.9 -0.15 -0.78 ott-94 4 19.0 -0.77 0.40 20.2 -1.17 -5.78 gen-95 1 20.5 1.47 0.43 19.4 1.04 5.34 apr-95 2 20.2 -0.33 -0.83 19.7 0.51 2.57 lug-95 3 19.0 -1.12 0.18 20.3 -1.30 -6.39 ott-95 4 21.5 2.44 0.63 19.7 1.81 9.19 gen-96 1 21.0 -0.50 -1.38 20.1 0.88 4.36 apr-96 2 21.4 0.37 0.28 21.3 0.09 0.40 lug-96 3 17.8 -3.53 -0.21 21.1 -3.32 -15.71 ott-96 4 19.7 1.89 2.00 19.8 -0.10 -0.53 gen-97 1 19.7 -0.03 -1.07 18.6 1.04 5.59 apr-97 2 20.3 0.56 0.01 19.7 0.55 2.79 lug-97 3 19.4 -0.86 -0.32 19.9 -0.55 -2.74 ott-97 4 20.9 1.46 0.49 19.9 0.97 4.91 gen-98 1 21.3 0.41 -0.83 20.0 1.24 6.20 apr-98 2 20.5 -0.77 -0.23 21.0 -0.53 -2.54 lug-98 3 19.4 -1.09 0.43 20.9 -1.52 -7.28 ott-98 4 21.2 1.83 0.62 20.0 1.21 6.06 gen-99 1 20.9 -0.31 -1.03 20.2 0.72 3.58 apr-99 2 21.4 0.52 0.18 21.1 0.35 1.65 lug-99 3 21.3 -0.19 -0.30 21.2 0.11 0.50 ott-99 4 20.4 -0.88 0.11 21.4 -0.99 -4.63 gen-00 1 22.1 1.75 0.50 20.9 1.25 5.98 apr-00 2 20.2 -1.96 -0.99 21.1 -0.98 -4.62 lug-00 3 20.5 0.29 1.11 21.3 -0.82 -3.84 ott-00 4 19.8 -0.65 -0.17 20.3 -0.48 -2.39 gen-01 1 18.6 -1.17 0.37 20.2 -1.54 -7.61 apr-01 2 19.2 0.59 0.66 19.3 -0.07 -0.38 lug-01 3 18.8 -0.38 -0.33 18.9 -0.05 -0.26 ott-01 4 18.3 -0.58 0.22 19.1 -0.79 -4.15 gen-02 1 17.6 -0.70 0.33 18.6 -1.02 -5.49 apr-02 2 18.9 1.38 0.39 18.0 0.99 5.49 lug-02 3 17.5 -1.49 -0.78 18.2 -0.71 -3.88 ott-02 4 19.8 2.37 0.84 18.3 1.53 8.36 gen-03 1 17.9 -1.89 -1.34 18.5 -0.55 -2.98 apr-03 2 17.3 -0.65 1.07 19.0 -1.72 -9.04 lug-03 3 15.6 -1.70 0.37 17.7 -2.07 -11.71 ott-03 4 16.7 1.13 0.96 16.6 0.17 1.02 gen-04* 1 -0.64 16.1 Fonte: Istat – Indagine trimestrale sulle forze di lavoro. * Previsione
Il modello ha fornito degli errori elevati nei seguenti periodi:
1. aprile ’93 (24.45%)
2. luglio ’96 (-15.7%)

46
3. luglio ’03 (-11.7%)
Il primo errore (aprile ’93), in cui il modello ha previsto un tasso di disoccupazione
inferiore rispetto a quello effettivo, può essere ricondotto a motivazioni di carattere
puramente statistico.
Infatti, bisogna notare che tale previsione è stata fatta sulla base del trimestre precedente
(gennaio ’93) che può essere considerato un dato anomalo (outlier), poichè si ha una
inspiegabile riduzione del tasso di disoccupazione in un periodo in cui lo stesso dato
cresce. Inoltre non si riscontra nella realtà alcun fenomeno di natura economica che
possa avere influito positivamente sul tasso di disoccupazione rilevato nel mese di
gennaio 1993. Anzi, lo stesso registra proprio in quel periodo un’accelerazione
portandosi a livelli medi del 20% e rimanendovi fino al gennaio del 2000.
Quindi è da ritenere che il tasso di disoccupazione del 14.6% registrato nel gennaio del
1993 è connesso con molta probabilità a motivazioni di carattere statistico.
Negli altri 2 errori, registrati nelle rilevazioni del mese di luglio ’96 e di luglio ’03, il
modello aveva previsto un tasso di disoccupazione maggiore di quello che poi si è
effettivamente registrato. Tali errori sono dovuti sia a cause imputabili al modello, sia a
cause connesse alla stagionalità del mercato del lavoro sardo che, nel periodo estivo,
tendono ad amplificare l’errore.
La prima si verifica perché il modello non è in grado di prevedere per due trimestri
consecutivi una variazione dello stesso segno. Il modello ha come variabili endogene
soltanto la variazione del trimestre precedente e il coefficiente di tale variabile è
negativo. Pertanto, quando nel trimestre precedente si registra una variazione negativa
il modello prevede una variazione positiva corretta per il coefficiente. Se anche nel
trimestre successivo si registra una variazione negativa l’errore del modello aumenta.
Questo succede nei periodi in cui il tasso di disoccupazione mostra dei chiari trend in
diminuzione (aumento) e quando per due trimestri successivi si registra una variazione
dello stesso segno.
Per evitare questo inconveniente si dovrebbe estendere il modello inserendo un
maggior numero di parametri riferiti a ritardi più remoti, ma si è visto che tali parametri
non sono significativi. Pertanto, le soluzioni che si potrebbero adottare sono:
1. rendere stazionaria la serie attraverso altri procedimenti;
2. dividere la serie in due parti e analizzarle separatamente utilizzando due modelli
diversi;
3. aumentare il numero di osservazioni.

47
La prima soluzione potrebbe essere utilizzata applicando, per esempio, prima il
logaritmo della serie e differenziando più di una volta. La seconda soluzione sarebbe
percorribile se si avesse a disposizione una serie più lunga con un maggior numero di
rilevazioni, perché 45 osservazioni non ne permettono la divisione. Infine se si
disponesse di una serie più estesa si riuscirebbe magari ad avere un numero di
parametri maggiori e ottenere delle stime migliori23.
Facendo un’analisi più dettagliata del tasso di disoccupazione degli ultimi 10 anni si
possono notare 3 periodi:
1. Un primo periodo in cui il tasso di disoccupazione cresce (ottobre 1993-aprile
1994)
2. Un secondo periodo in cui il tasso di disoccupazione si mantiene
sostanzialmente stabile oscillando intorno al valore del 20% (aprile 1994-
ottobre 2000);
3. Un terzo periodo in cui il tasso di disoccupazione diminuisce (ottobre 2000-
ottobre 2003)
Nel primo periodo l’aumento del tasso di disoccupazione su base annua è accompagnato
dalla diminuzione degli occupati. In questo periodo la serie del tasso di disoccupazione
registra probabilmente un break strutturale dovuto all’uscita dell’Italia dal sistema
monetario europeo avvenuto nel settembre del 199224. Il mercato del lavoro non
reagisce mai immediatamente ad uno shock esogeno, ma anzi tende a reagire sempre
con un certo ritardo rispetto alla causa. Questo fenomeno è detto isteresi e, dal punto di
vista economico, nel mercato del lavoro, è dovuto al sistema delle leggi di protezione
del lavoro nelle grandi imprese, le quali non possono procedere al licenziamento per il
semplice effetto della contrazione degli ordini e della produzione.
23 In uno studio analogo effettuato nell’ambito del corso di Econometria B del Prof. Luca Stanca da parte di un gruppo di studenti, viene analizzata la serie trimestrale del tasso di disoccupazione italiano dal 1960 al 1998. Il modello che si ricava dall’analisi della serie è un ARIMA(4,2,4), cioè differenziata 2 volte e con 4 componenti autoregressive e a media mobile. AA.VV., Analisi della disoccupazione italiana, Gruppo di lavoro n.5 del corso di Econometria B, Prof. Luca Stanca, 2001. In altri studi sul tasso americano si perviene a dei modelli AR(2) Randall E. Parker, Philip Rothman, The Current Depth of Recession and Unemployment Rate Forecasts, Department of Economics East Carolina University Brewster Building East Carolina University, 1997 Revised 1998. In altri studi effettuati sempre sul tasso di disoccupazione americano si perviene addirittura a dei modelli diversi quali ad esempio, TAR(2;4,2) dove la T sta per threshold (soglia) e ARCH (1,1). A. Amendola, Modelling asymmetries in unemployment rate, Università degli studi di Salerno, Discussion paper 60, lugio 2001. 24 AA.VV., Analisi della disoccupazione italiana, Gruppo di lavoro n.5 del corso di Econometria B, Prof. Luca Stanca, 2001.

48
Pertanto, le grandi aziende hanno assorbito lentamente nel tempo lo shock dovuto
all’uscita dell’Italia dal sistema monetario europeo con tutte le conseguenze ad essa
connesse.
Le piccole imprese invece si sono comportate diversamente: la contrazione delle vendite
e del fatturato ha indotto le piccole imprese a licenziare personale dipendente. Ma anche
questo fenomeno è avvenuto lentamente ne l tempo e questo spiegherebbe il calo degli
occupati che si è registrato su base annua nei trimestri a cavallo fra il 1993 e il 1994
(figura n.2.6).
Inoltre, dal lato dell’offerta, ha continuato ad affacciarsi nuova forza lavoro che non
trovava collocazione nel mercato che si aggiungeva a quella espulsa dalle aziende in
crisi. E questo spiegherebbe l’aumento del tasso di disoccupazione su base annua che si
è verificato nel periodo compreso fra ottobre 1993 e luglio 1994 (figura 2.7).
Figura n.2.6: Variazione degli occupati rispetto all’anno precedente.
Variazione percentuale degli occupati rispetto all'anno precedente
-6
-4
-2
0
2
4
6
8
ott-
92ge
n-93
apr-
93lu
g-93
ott-
93ge
n-94
apr-
94lu
g-94
ott-
94ge
n-95
apr-
95lu
g-95
ott-
95ge
n-96
apr-
96lu
g-96
ott-
96ge
n-97
apr-
97lu
g-97
ott-
97ge
n-98
apr-
98lu
g-98
ott-
98ge
n-99
apr-
99lu
g-99
ott-
99ge
n-00
apr-
00lu
g-00
ott-
00ge
n-01
apr-
01lu
g-01
ott-
01ge
n-02
apr-
02lu
g-02
ott-
02ge
n-03
apr-
03lu
g-03
ott-
03
variazione del tasso di disoccupazione

49
Figura n.2.7: Variazione del tasso di disoccupazione rispetto all’anno precedente.
Variazione del tasso di disoccupazione rispetto all'anno precedente
-4
-3
-2
-1
0
1
2
3
4
5
6
ott-9
2ge
n-93
apr-
93lu
g-93
ott-9
3ge
n-94
apr-
94lu
g-94
ott-9
4ge
n-95
apr-
95lu
g-95
ott-9
5ge
n-96
apr-
96lu
g-96
ott-9
6ge
n-97
apr-
97lu
g-97
ott-9
7ge
n-98
apr-
98lu
g-98
ott-9
8ge
n-99
apr-
99lu
g-99
ott-9
9ge
n-00
apr-
00lu
g-00
ott-0
0ge
n-01
apr-
01lu
g-01
ott-0
1ge
n-02
apr-
02lu
g-02
ott-0
2ge
n-03
apr-
03lu
g-03
ott-0
3
variazione del tasso di disoccupazione
Fonte: Istat – Indagine trimestrale sulle forze di lavoro
Il tasso di disoccupazione fa registrare la variazione record di quasi 5 punti percentuali
nel periodo gennaio ’93 – gennaio ’94. Tuttavia tale variazione è amplificata dalla
presenza del dato anomalo del gennaio ’93, come spiegato in precedenza. Il dato
importante consiste nella persistenza nel tempo della crescita della disoccupazione, che
si registra per 4 periodi consecutivi: soltanto nell’ottobre del 1994 il tasso di
disoccupazione torna a calare. Comunque, queste variazioni del tasso di disoccupazione
sono dovute principalmente a fattori stagionali.
L’effettivo inizio del trend discendente del tasso di disoccupazione si è avuto con uno
shock registrato nel gennaio 2001: in questo periodo il tasso di disoccupazione fa
registrare una variazione su base annua di oltre il 3%, ma ci sono voluti 3 anni affinché
il tatto di disoccupazione si riportasse ai valori del 1993.
Questo dimostra quanto già riscontrato in numerosi studi sul tasso di disoccupazione
americano (S.N. Neftci25, 1984), nei quali si sono scoperte significative non linearità
nelle variazioni del tasso di disoccupazione dal dopoguerra fino agli anni ’80.
Questo comportamento non lineare del tasso di disoccupazione comporta delle
asimmetrie, nel senso che il tasso di disoccupazione cresce velocemente ne i periodi di
recessione 26 e diminuisce lentamente nei periodi di espansione del ciclo economico.
25 Neftci S.N., Are Economic time series aymmetric over the Business Cycles?, Journal of Political Economy,85, 1984, 281-291.

50
La variazione del 3.5% registrata nel gennaio ’01 potrebbe essere spiegata da due eventi
di natura politica ed economica che possono aver influenzato positivamente il mercato
del lavoro:
1. l’utilizzo della moneta unica in sostituzione delle rispettive monete nazionali
negli 11 paesi aderenti all’Unione Economica e Monetaria;
2. l’entrata in vigore di diverse leggi nazionali e regionali dirette ad incentivare le
imprese che intendevano assumere personale dipendente con contratto a tempo
indeterminato a ad incremento della base occupazionale 27.
Entrambe le cause potrebbero aver influito positivamente se la diminuzione delle
persone in cerca di lavoro sia stata accompagnata da un rispettivo aumento
dell’occupazione. Infatti i due fenomeni come si potrebbe immaginare non sono
correlati. Questo lo dimostra il grafico di figura n.2.8. e la regressione effettuata fra la
variazione delle persone in cerca di occupazione e la variazione degli occupati. Se
esistesse una relazione fra le due variazioni i punti del grafico dovrebbero disporsi
lungo una retta o, per lo meno non essere così dispersi come nel grafico.
Inoltre la regressione rifiuta l’ipotesi nulla che fra le due variazioni ci sia una relazione:
il t-ratio della regressione (-1.50) è inferiore a -1.96, valore critico che permetterebbe
di accettare l’ipotesi di una relazione fra le due variazioni.
26 Nel 1993 il PIL nazionale registrò una variazione negativa dello 0,9% rispetto al prodotto interno lordo del 1992 (dati Istat sul PIL a prezzi costanti del 1995) 27 Si tratta della legge regionale n.36 del 24 dicembre 1998 e l’articolo 7 della l.338/2000, la legge finanziaria per il 2001, che aveva introdotto il sistema del credito d’imposta a favore delle imprese che effettuavano assunzioni ad incremento della base occupazionale. Tali incentivi erano cumulabili con altri benefici eventualmente concessi da altre leggi.

51
Figura n.2.8: Relazione fra la variazione degli occupati e delle persone in cerca di
occupazione. -2
0-1
00
1020
30V
aria
zion
e de
gli o
ccup
ati
-20 0 20 40Variazione dei disoccupati
Relazione fra la variazione degli occupati e dei disoccupati
In effetti fra il gennaio 2000 e il gennaio 2001 si registra un incremento degli occupati
del 5,1% che corrispondono a circa 26mila unità lavorative. Analizzando nel dettaglio
tale aumento si nota che circa 15mila sono nella posizione di dipendente e circa 11mila
in una posizione autonoma.
Pertanto è da ritenere che il sistema di incentivazione messo in campo dal governo
locale e centrale abbia sicuramente influito in maniera positiva il mercato del lavoro ma
non sia stata l’unica causa ad avere un effetto positivo sull’occupazione.
Una concausa potrebbe essere l’ingresso della moneta unica, che può aver influito sul
mercato del lavoro:
• in maniera strutturale (aumento degli scambi commerciali nell’area euro e,
quindi, aumento della produzione e dell’occupazione) i cui effetti hanno avuto
una durata più estesa nel tempo;
• in maniera congiunturale (forza lavoro aggiuntiva che è stata richiamata dalle
aziende per adeguare il sistema dei mezzi di pagamento e della contabilità dalla
lira all’euro) i cui effetti hanno avuto breve durata e limitatamente al periodo di
transizione dalla lira all’euro.

52
3 Conclusioni
A conclusione di questo lavoro posso affermare che l’approccio time series può essere
utilizzato a scopi previsionali del tasso di disoccupazione, ma il modello trovato di tipo
ARIMA(1,1,0) non è in grado di fornire una buona stima nei periodi in cui è in atto un
evidente trend del tasso di disoccupazione.
Se utilizzato a fini previsionali il modello dovrebbe essere integrato con altre variabili di
carattere economico o esteso a ritardi più remoti.
Inoltre, l’esperienza di questo studio mi ha insegnato che l’approccio time series
potrebbe essere impiegato in tutti quei campi di analisi in cui è difficile modellare il
funzionamento del fenomeno che si vuole studiare e si vuole pertanto prescindere dalle
cause che influenzano la variabile osservata.
Tale approccio potrebbe costituire una prima fase di studio del fenomeno che si sta
studiando se effettuata con le finalità di analisi e di ricerca dei fattori che possono aver
influito sull’andamento della serie oggetto di analisi. Infatti, questo approccio permette
di avere una maggiore conoscenza del fenomeno che si sta studiano e di passare alla
fase successiva di costruzione di un modello strutturale più complesso.

53
Bibliografia AA.VV., 10° rapporto sull’economia della Sardegna – Analisi strutturale e previsioni
2002-2004, CRENoS – Centro di Ricerche Economiche Nord Sud, Università di
Cagliari e Sassari, CUEC, Cagliari, maggio 2003.
AA.VV., Analisi della disoccupazione italiana, relazione a cura degli studenti nel corso
di econometria B, Università di Milano, Prof. L.Stanca, 2001.
AA.VV., Econometria. Volume I, Franco Angeli, Milano, 2000.
A. Amendola, Modelling asymmetries in unemployment rate, Università degli studi di
Salerno, Discussion paper 60, lugio 2001.
Bontempi M.E., La modellazione empirica delle relazioni economiche: applicazioni in
Stata7, Dispense delle lezioni, 2003.
Box G., Jenkins G.M., Reinsel G., Time Series Analysis: Forecasting & Control (3rd
Edition), Prantice Hall, 1994.
Chen, J., Do Financial Market Variables Predict Unemployment Rate Fluctuations?,
Department of Economics College of Arts & Science East Carolina University, M.S
Research Paper, June, 2002.
Contini B. (a cura di), Osservatorio sulla mobilità del lavoro in Italia, Il Mulino,
Bologna, 2002
Douglas Hamilton J., Time Series Analysis, Princeton Univ Pr., 1994.
Giusti F. e Vitali O., Statistica Economica, Cacucci Editore, Bari, 1990.
Golan A., Perloff, J.M., Superior Forecasts of the U.S. Unemployment Rate Using a
Nonparametric Method, Working Papers, Gennaio 2003.
John D. Johnson, An Analysis of strike and Unemployment Rates, 1951-1980, Working
Papers.
Lucchetti R., Appunti di analisi delle serie storiche, Dispense ad uso degli studenti,
luglio 2002.
Masarotto G., Analisi delle serie temporali, Lucidi delle lezioni, gennaio 2003.
Mikhail O. Eberwein C.J., Handa J., Testing and estimating persistence in Canadian
Unemployment, abstract 2003.
Piccolo D. e Vitale C., Metodi statistici per l’analisi economica, Il Mulino, Bologna,
1981.
Proietti T., Econometria applicata, Dispense ad uso degli studenti.
Rapporto Isfol 2001, Federalismo e politiche del lavoro, Franco Angeli, Milano, 2001.

54
Stanca L., Appunti per il corso di econometria B, Dispense ad uso degli studenti, Aprile
2003.
Wooldridge J.M. Introductory Econometrics, Thomson South Western, 2002.
Randall E. Parker, Philip Rothman, The Current Depth of Recession and Unemployment
Rate Forecasts, Department of Economics East Carolina University Brewster
Building East Carolina University, 1997 Revised 1998.

55
Allegato statistico
Tavole dei dati utilizzati per l’analisi statistica e la previsione.
Fonte Istat - Rilevazione trimestrale sulle forze di
lavoro.


















