
Un sistema per l'integrazione di varianti di una stessa ontologia
112
Alma Mater Studiorum - Università di Bologna FACOLTÀ DI SCIENZE MATEMATICHE FISICHE NATURALI Corso di laurea in Informatica Un Sistema per l’integrazione di varianti di una medesima Ontologia Tesi di laurea in Tecnologie Web Relatore Presentata 1
-
Upload
marco-righi -
Category
Documents
-
view
46 -
download
0
Transcript of Un sistema per l'integrazione di varianti di una stessa ontologia

Alma Mater Studiorum - Università di Bologna
FACOLTÀ DI SCIENZE MATEMATICHE FISICHE NATURALI
Corso di laurea in Informatica
Un Sistema per l’integrazione
di varianti
di una medesima Ontologia
Tesi di laurea in Tecnologie Web
Relatore Presentata
Chiar.mo prof. Fabio Vitali da Marco Righi
Correlatore
Dott. Antonio Angelo Feliziani
Sessione III
Anno Accademico 2005/2006
1

Dedicato a mia madre Silvana e alla mia ragazza Michela
2

INDICE
1 Introduzione 5
2 Integrazione tra ontologie 11
2.1 Ontologie e applicazioni in campo informatico 11
2.1.1 L’origine del concetto di ontologia 11
2.1.2 Le ontologie in campo informatico 13
2.1.3 Tipizzazione delle ontologie informatiche 14
2.2 L’importanza dell’Integrazione tra ontologie 14
2.2.1 Le ontologie nell’information flow 15
2.2.2 l’importanza dell’integrazione 17
2.3 Metodologie di Integrazione 18
2.3.1 Alcune definizioni 18
2.3.2 Il processo di integrazione 19
2.3.3 Problemi nel processo di integrazione 20
2.3.4 La relazione tra le versioni 23
2.3.5 Il problema del versionamento 26
2.3.6 Un framework per il versionamento 28
2.4 Conclusioni 28
3 Metadata Integrator 31
3.1 Metadata for Document Exchange 31
3.1.1 Il progetto Metadata for Document Exchange 31
3.1.2 L’architettura 32
3.1.3 Metadata tools 33
3.2 Integreted Metadata Editor 34
3.2.1 Integrazione con Word 35
3.2.2 L’interfaccia principale 35
3.2.3 L’interfaccia secondaria 37
3.2.4 Selezione degli elementi ontologici 38
3.2.5 Modifica degli elementi ontologici 39
3.2.6 C# 40
3.2.7 RDF 42
3

3.3 Metadata Integrator 43
3.3.1 Architettura degli aggiornamenti 43
3.3.2 Principali funzionalità 44
3.3.3 Accessibilità alla nuova funzionalità 45
3.3.4 L’interfaccia principale 46
3.3.5 Il trattamento dei conflitti 48
3.4 Conclusioni 49
4 Architettura di Metadata Integrator 51
4.1 Requisiti d’installazione 51
4.2 Accenni sull’architettura Windows 52
4.3 Introduzione all’architettura di IME 52
4.3.1 Organizzazione del codice 53
4.3.2 Lo schema ontologico 53
4.3.3 Le classi ontologiche 54
4.3.4 DsoFile.dll 55
4.3.5 Drive.dll 56
4.4 Metadata Integrator 56
4.4.1 Fasi dell’implementazione 56
4.4.2 Organizzazione del codice 57
4.4.3 La classe MergeableItem 59
4.4.4 La classe MergeableElement 62
4.4.5 La classe MergeableClass 63
4.4.6 Il processo di integrazione 64
4.4.7 Installazione di IME 67
5 Conclusioni 69
6 Bibliografia 71
4

1 INTRODUZIONE
Scopo di questa dissertazione è illustrare al lettore i vantaggi che derivano
dall’adozione di software basati su ontologie nell’ambito dell’information flow e
la necessità che hanno tali software di un meccanismo di integrazione ontologica.
In questo contesto andremo anche a mostrare un esempio concreto di software
per l’integrazione ontologica che ho avuto modo di sviluppare, ovvero il
Metadata Integrator.
Il concetto di ontologia nasce nella Grecia antica come lo studio dell’essere in
quanto tale, e subito diviene un mezzo per classificare tutto ciò che esiste in
categorie.
In informatica si suole chiamare ontologia lo schema concettuale di un dato
dominio[GRU93]. Normalmente si tratta di un vocabolario che descrive un certo
dominio, e di un insieme di assunzioni esplicite che vincolano l’interpretazione
dei termini del vocabolario. Gli ambiti in cui le ontologie si sono rivelate utili
sono molteplici, e vanno dall’ingegneria del software all’ingegneria della
conoscenza. Un importante ambito di ricerca, che noi tratteremo con particolare
riguardo, è l’information flow all’interno degli elementi di un’organizzazione
estesa.
Sappiamo bene come al giorno d’oggi gran parte dei dipendenti di un’azienda
basa il proprio lavoro sull’uso del computer, e come le aziende investano sempre
maggiori risorse nell’archiviazione di documenti elettronici. Tuttavia gli
strumenti esistenti oggi per l’archiviazione, la ricerca e la condivisione di tali
documenti risultano ancora molto inadeguati, e sono alla causa di alcuni problemi
come il fraintendimento o la perdita di documenti.
Per fare un esempio basta pensare ad i motori di ricerca per il web, mediamente il
50% delle risorse estratte da questi strumenti sono irrilevanti, per di più solo il
20% delle risorse rilevanti è individuato correttamente. Alla base di questi
malfunzionamenti sta il fatto che i software non sono in gradi capire il contenuto
dei documenti, essi basano la ricerca su di una semplice corrispondenza sintattica
tra le parole della query dell’utente e le parole nel documento.
5

È facile intuire come tale meccanismo sia approssimativo ad esempio vi sono
molte parole per esprimere lo stesso concetto e molti modi diversi di descrivere
lo stesso fenomeno.
Uno strumento che può venirci in aiuto per superare i problemi dei software
attuali sono i metadati o metainformazioni. I metadati sono un insieme di
informazioni strutturate che descrivono alcune caratteristiche o relazioni del
documento per aiutarci ad interpretarne il contenuto. I metadati sono strettamente
legati al concetto di ontologia, infatti per essere efficaci le informazioni che sono
aggiunte al documento devono essere estratte da un vocabolario che non dia adito
a fraintendimenti, appunto un’ontologia.
I metadati già esistevano molto prima dell’avvento dei computer, basti pensare
alle schede sui libri di una biblioteca per la catalogazione, ma stanno assumendo
un importanza cruciale proprio grazie alle nuove tecnologie.
Un aspetto fondamentale dei metadati è che essi per funzionare al meglio devono
essere inseriti dall’autore del documento al momento della creazione dello stesso.
Infatti pensiamo se l’autore andasse ad inserirli in un momento successivo,
rischierebbe di dimenticare parte del contenuto o il senso generale dello scritto,
dando origine cosi a metainformazioni incomplete o peggio errate. Se fosse una
terza persona ad aggiungere i metadati invece si avrebbe un doppio svantaggio
infatti egli dovrebbe prima leggere attentamente il documento, investendo cosi
molto del suo tempo, e rischiando in ogni caso di fraintendere parte o tutto il
contenuto del documento, originando di nuovo metainformazioni errate o
incomplete.
In questo scenario appare vantaggioso fornire a ogni strumento per la creazione
di documenti un meccanismo per aggiungere le metainformazioni e un’ontologia
da cui trarle.
Le diverse ontologie sparse nel sistema devono tuttavia essere allineate ed in
mutuo accordo tra loro, altrimenti rischieremmo di tornare al punto di partenza.
6

Queste sono alcune tra ragioni che introducono l’esigenza di un meccanismo
efficiente per allineare le ontologie e portarle in mutuo accordo sul significato dei
termini che descrivo, in una parola per integrarle.
Il problema dell’integrazione ontologica è uno degli ambiti di ricerca più attivi
nel campo delle ontologie informatiche. Infatti non è affatto un problema di facile
soluzione, e vi sono numerosi aspetti di cui è necessario tenere conto.
Le ontologie non sono oggetti statici ma hanno la tendenza ad evolvere nel tempo
a seguito di molteplici fattori. Alcuni di questi fattori possono essere identificati
con cambiamenti del dominio descritto a cui l’ontologia deve necessariamente
adeguarsi. Altre cause possono essere la necessità di descrivere un fenomeno da
un punto di vista differente, oppure un nuovo accordo sul significato di un
termine ecc...
Metadata Integrator (MI) è un progetto che ho avuto la possibilità di sviluppare,
esso è in grado di integrare diverse varianti di una medesima ontologia. MI si
inserisce all’interno di un progetto più ampio chiamato Metadata For Document
Exchange.
Metadata For Document Exchange (MFDE) è un progetto elaborato per favorire
l’interscambio di documenti tra i diversi membri di una grande azienda. Il
progetto inoltre è in grado agevolare notevolmente tutti i processi che riguardano
l’archiviazione, la ricerca, l’integrazione, il riuso dei documenti, senza per questo
stravolgere le metodologie di lavoro a cui gli utenti sono abituati.
Il meccanismo si basa sull’adozione di un’ontologia comune, e di un certo
numero di metainformazioni strutturate che sono aggiunte ad ogni documento,
per fare sì che esso sia in grado dai autodescriversi.
Il progetto è composto di tre elementi principali, i metadati e l’ontologia cui sono
riferiti, l’architettura di sistema che deve essere messa in atto per permettere al
sistema di funzionare, e gli strumenti necessari per manipolare i metadati in
modo efficiente.
7

Tra gli strumenti necessari alla messa in opera di MFDE ve ne è uno in
particolare di nostro interesse, l’Integrated Metadata Editor (IME). Questo ci
interessa perché è proprio al suo interno che è stato inserito Metadata Integrator.
IME è un plug-in di Microsoft Word che permette l’inserimento e la modifica dei
metadati associati al documento. I plug-in sono applicativi in grado di integrarsi
ad un programma principale ed in grado di estenderne le funzionalità.
IME si attiva in modo automatico ogni volta che l’utente procede al salvataggio
del documento e lo guida nell’inserimento dei metadati necessari all’information
flow così come previsto dal progetto MFDE.
Per ricercare le metainformazioni più adatte al documento l’utente è messo in
grado di navigare attraverso gli elementi esistenti all’interno della propria
ontologia. Quando all’interno dell’ontologia non vi sono ancora i termini più
corretti l’utente è anche libero di inserirne di nuovi o di modificare quelli presenti
per aggiornarli o adattarli. Naturalmente l’utente ha anche la possibilità di
eliminare gli elementi obsoleti così da rendere più facile la ricerca.
Quello che mancava ad IME fino a questo momento era invece un meccanismo in
grado di confrontare le modifiche avvenute su due istanze indipendenti
dell’ontologia per integrarle.
Questo meccanismo è appunto Metadata Integrator. Come abbiamo detto, MI è in
grado di integrare l’ontologia locale con un'altra che si trova tra le risorse locali,
di rete, o sul web.
Il risultato di tale integrazione è una nuova ontologia che compone gli elementi
delle due in maniera opportuna. Ciò significa che il programma è in grado di
individuare gli elementi nuovi, quelli eliminati, e quelli modificati e riportare
tutte queste modifiche nell’ontologia risultante.
8

Il programma è in grado di svolgere l’integrazione in maniera semi-automatica.
Questo è possibile grazie al fatto che l’ontologia è stata modificata per contenere
alcune meta-informazioni aggiuntive sugli elementi dell’ontologia stessa.
Nel corso dell’integrazione MI è anche in grado di gestire in maniera autonoma
eventuali situazioni di conflitto che possono venirsi a creare tra le diverse varianti
ontologiche. In particolare con il termine conflitto intendiamo situazioni nelle
quali uno stesso elemento subisce, in ontologie diverse, operazioni che sono tra
loro incompatibili, per esempio cancellazione inserimento. La logica utilizzata
per risolvere queste situazioni è semplice: il programma presume che
l’operazione avvenuta in tempi più recenti sia quella corretta. Di conseguenza
tutte le altre operazioni che sarebbero incompatibili vengono ignorate.
Per implementare questo meccanismo di risoluzione automatica dei conflitti tra i
nuovi metadati aggiunti all’ontologia vi è anche un’etichetta temporale associata
ad ognuna delle operazioni che avvengono sugli elementi dell’ontologia stessa.
Alla fine del processo di integrazione l’utente viene informato per mezzo di un
report riepilogativo e a questo punto l’ontologia locale viene sostituita con il
risultato dell’integrazione.
9

10

2 INTEGRAZIONE TRA ONTOLOGIE
In questo capitolo parleremo in generale del concetto di ontologia, dalla nascita
del termine fino alle più moderne applicazioni in campo scientifico con
particolare attenzione al settore informatico. In seguito proporremo alcuni scenari
per mostrare al lettore l’importanza e l’attualità delle ontologie nel campo
dell’information flow all’interno di aziende di una certa dimensione, e con essi
mostreremo anche l’importanza di disporre di un meccanismo di integrazione tra
le ontologie quando si lavora con esse.
In fine nell’ultima parte del capitolo tratteremo il problema dell’integrazione di
ontologie da un punto di vista prettamente tecnico. Mostreremo i problemi da
considerare al momento in cui si intraprende un processo di integrazione nel
tentativo di fornire al lettore un insieme di strumenti necessari per afrontare
questo tipo di problemi.
2.1 Ontologie e applicazioni in campo informatico
In questa sezione intendiamo dare al lettore alcune nozioni generali sul concetto
d’ontologia. Partiremo analizzando origini del concetto d’ontologia legate
all’ambito filosofico e risalente all’epoca dei filosofi presocratici. Analizzeremo
poi gli sviluppi pratici seguiti a tali studi concentrandoci in maniera particolare
sugli ambiti d’utilizzo d’ontologie in campo informatico.
Termineremo fornendo alcuni modelli di ontologie applicabili in campo
informatico e analizzando come esse si adattino ai diversi utilizzi.
2.1.1 L’origine dell’ontologia
Il termine ontologia [WIK06] deriva dal greco, "eon" e "logos", e significa
letteralmente "discorso sull'ente". L'ontologia è lo studio dell'essere, ovvero
di ciò che è, esiste, è pensabile.
11

Padre e fondatore dell'ontologia, è Parmenide, 505-504 AC, appartenente ai
presocratici. Parmenide fu il primo a porsi la questione dell'essere nella sua
totalità, dunque a porsi il problema, ancora alla sua genesi, dell'ambiguità tra
i piani logico, ontologico e linguistico. Platone, Aristotele e a seguire tutta la
filosofia greca, elaborò progressivamente questo ed altri temi.
In particolare Aristotele descrisse l'ontologia (pur senza usare questo termine)
come "la scienza dell'essere in quanto essere". L’espressione 'in quanto' vuol
dire 'riguardo all'aspetto di'. Secondo questa teoria, quindi, l'ontologia è la
scienza dell'essere riguardo all'aspetto dell'essere, o lo studio degli esseri
nella misura in cui questi esistono.
Nelle “Categorie” Aristotele mostra come tutto ciò che esiste possa essere
classificato in categorie, In figura 1 ne abbiamo una rappresentazione.
Figura 1 Categorie di Aristotele.
Dopo di lui in molti riproposero il problema, che in verità è trattato in modo
più o meno indiretto in ogni filosofia.
Il termine ontologia "fu coniato soltanto agli inizi del XVII secolo da Rudolf
Göckel per il suo “Lessico filosofico” e, autonomamente, da Jacob Lorhard
per la sua Ogdoas Scolastica[WIK06].
Nonostante la sua tradizione sia eminentemente teoretica, l'ontologia si sta
dimostrando in tempi recenti particolarmente feconda nei suoi risvolti pratici:
12

alcune questioni ontologiche hanno avuto impatto sulla fisica delle particelle
e diffuse sono le applicazioni di ontologie in campo informatico.
2.1.2 Le ontologie in campo informatico
In termini molto generali, in informatica si suole chiamare ontologia lo
schema concettuale di un dato dominio. Tale schema può assumere forme
molto diverse, a partire da una semplice tassonomia (classificazione
gerarchica di concetti) fino ad arrivare ad una vera e propria teoria logica.
Normalmente si tratta di una gerarchia di concetti correlati attraverso
relazioni semantiche, ma le ontologie più elaborate forniscono anche regole
(come assiomi o teoremi) che aiutano a specificare com’è strutturato il
dominio. Siamo quindi di fronte ad opere ingegneristiche costituite da un
vocabolario, che descrive un dato dominio, ed un insieme di assunzioni
esplicite, che vincolano l’interpretazione dei termini del vocabolario.
Barry Smith e Christopher Welty [SMI01] individuano tre grandi aree
d’applicazione delle ontologie nei sistemi informatici: l’ingegneria della
conoscenza, che concerne la progettazione di basi di conoscenza e i sistemi su
di esse basati; la modellazione concettuale, che riguarda le fasi iniziali della
progettazione di basi di dati; e l’ingegneria del software, soprattutto
relativamente ai cosiddetti ‘ linguaggi orientati agli oggetti ’.
In ognuno di questi settori, si è seguito fino a poco tempo fa, un approccio
alla progettazione che privilegiava soltanto esigenze interne al sistema da
realizzare.
Con l’avvento della rete, il problema dell’interazione e della comunicazione
tra sistemi diversi (anche distribuiti) è divenuto fondamentale
13

2.1.3 Tipizzazione delle ontologie Informatiche
È possibile tracciare alcune distinzioni tra diversi tipi di ontologie a seconda
dello scopo per il quale sono sviluppate. Un esempio può essere la distinzione
tra ontologie di applicazione, che offrono servizi terminologici, ontologie di
dominio, costruite ad hoc per uno specifico dominio, e ontologie di
riferimento, che offrono invece un alto grado d’espressività. Le ontologie di
riferimento vengono spesso utilizzate per creare consenso sui termini, o tra
ontologie d’alto livello, costituite da categorie molto generali.
Una distinzione di rilievo e che vale la pena sottolineare, poiché individua
entità di carattere abbastanza dissimile, è quella tra ontologie ``light weight'' e
ontologie fondazionali. Le ontologie ``light weigth'' sono artefatti sviluppati
specificamente per l'applicazione a domini definiti e ristretti o per compiti
molto specifici; sono strutture tassonomiche che contengono termini primitivi
e compositi con le loro definizioni, connessi da relazioni semplici e sono
normalmente utilizzate in comunità stabilizzate, in cui il significato inteso dei
termini è più o meno conosciuto e condiviso da tutti i membri. D'altro canto,
le ontologie fondazionali sono schemi più generali, non strettamente connessi
a domini particolari ma piuttosto adattabili in maniera generale e quindi più
adatti alla comunicazione dell'informazione attraverso domini e comunità
diversi.
2.2 L’importanza dell’integrazione delle ontologie
In questa parte introdurremo il ruolo che le ontologie ricoprono all’interno del
processo di information flow in organizzazioni di una certa dimensione e
valuteremo i vantaggi che seguono all’adozione di tecniche di storage delle
informazioni basate su esse. Concluderemo la nostra analisi valutando in uno
scenario come quello introdotto il ruolo indispensabile di task in grado di
allineare e coordinare tra loro le ontologie esistenti.
14

2.2.1 Le ontologie nell’information flow
Un importante ambito di ricerca, che sta prendendo piede negli ultimi anni,
riguarda l’information flow all’interno degli elementi di un’organizzazione
estesa. Sappiamo come ormai la maggior parte dei dipendenti di
un’organizzazione basi quasi completamente il proprio lavoro sul computer e
come le compagnie investano sempre di più per l’immagazzinamento
efficiente dei documenti elettronici. Gli strumenti più diffusi tra gli utenti
sono senza dubbio e-mail, web browser e search engine; l’inadeguatezza di
questi strumenti a supportare i processi di storage delle organizzazioni è alla
base di problemi quali la perdita, il fraintendimento, il salvataggio in posti
non adeguati dei documenti prodotti.
Ad esempio i search engine, nonostante siano cresciuti notevolmente sia per
diffusione che per sofisticatezza negli ultimi anni, restano molto lontani dalla
perfezione. Basti pensare ai search engine per il web, nei quali circa il 50%
dei risultati ottenuti risultano irrilevanti, e soltanto il 20% delle informazioni
rilevanti è catturato. Alla base della perdita delle informazioni sta il fatto che
uno stesso concetto può essere descritto in molti modi diversi. Gli engine
basano la propria ricerca su un confronto sintattico tra la parola nella query
dell’utente e la parola nel documento; ne consegue che se l’autore usa una
parola diversa per esprimere lo stesso concetto la ricerca sarà destinata a
fallire.
Una possibile soluzione a questo disagio potrebbe essere quella di aggiungere
ai documenti alcune parole ricavate da un vocabolario non ambiguo per
descrivere alcuni aspetti del documento. La ricerca di tali parole potrebbe
dare dei risultati praticamente perfetti. Le parole aggiunte sono dette dati
riguardanti i dati o metadati.
15

I metadati sono un insieme di informazioni strutturate che descrivono fatti o
relazioni relative al documento per aiutare a dare un significato al contenuto
dello stesso.
Metadati e ontologie sono concetti strettamente legati, infatti per essere
efficaci i metadati devono essere ricavati da un vocabolario non ambiguo che
fornisca un’interpretazione del termine; tale vocabolario è appunto
un’ontologia.
Già prima dell’avvento dei computer i metadati sono stati impiegati nella
catalogazione di ampie collezioni di libri o documenti:
Nelle biblioteche: per agevolare il meccanismo di catalogazione dei libri.
In database di pubblicazioni: per aiutare la ricerca bibliografica.
Nella pubblicazione di libri: si usa organizzare nel retro del libro un
indice delle informazioni.
I dati che non sono accompagnati da metadati sono spesso difficili da trovare
e da accedere, problematici da interpretare e integrare, perdendo in questo
modo il loro valore.
Tra i vantaggi dell’uso dei metadati troviamo:
Facilità di ricerca: gli engine possono usare i termini dell’ontologia per
ottenere i risultati rilevanti.
Supporto per il workflow: dalle metainformazioni un utente può sapere
quanto è vecchio un documento, chi è l’autore, ecc…
Supporto interdipartimentale: se tutti i dipartimenti utilizzano la stessa
ontologia e le stesse regole per l’impiego dei metadati la consistenza delle
informazioni è automatica.
16

Memoria dell’organizzazione a lungo termine: i documenti non perdono
di valore nel tempo.
2.2.2 L’importanza dell’integrazione
È importante sottolineare che i metadati per essere efficaci devono essere
inseriti dall’autore del documento al momento della creazione o della
modifica dello stesso e non in un momento successivo o da altre persone o
assistenti. Infatti se l’autore inserisse i metadati in un momento successivo
alla creazione del documento il pericolo di dimenticare una parte o tutto il
contenuto sarebbe concreto. Di conseguenza anche i metadati risulterebbero
incompleti i errati.
Ancora più grande è il rischio di avere metadati errati se l’autore dei metadati
è diverso dall’autore del documento. Un autore diverso infatti dovrebbe
leggere con attenzione il documento, perdendo cosi il proprio tempo e
rischiando in ogni caso di interpretare in maniera scorretta alcuni elementi
dello stesso.
In uno scenario come quello descritto al punto precedente risulta evidente
come può essere utile che ogni utente possegga una versione locale
dell’ontologia comune, per permettergli di lavorare anche quando si trova off-
line o fuori della sede di lavoro.
Le ontologie spesso sono soggette a variazioni per vari motivi quali ad
esempio il cambiamento del dominio descritto o la modellazione di un
fenomeno da un diverso punto di vista ecc…
È fondamentale che le varie istanze esistenti nel sistema siano sempre
allineate, ovvero non siano in contraddizione tra loro e siano coerenti
nell’attribuzione del significato ai termini, altrimenti molti dei vantaggi dei
metadati sopra descritti svanirebbero.
17

Il processo tramite il quale le diverse varianti di un’ontologia possono essere
coordinate è un problema molto attuale nel campo della ricerca sulle
ontologie ed è detto integrazione ontologica.
2.3 Metodologie di Integrazione
Con questo capitolo intendiamo fornire al lettore alcuni strumenti per
affrontare il problema dell’integrazione di ontologie da diversi punti di vista.
In primo luogo introdurremo il processo di integrazione che permette di
creare una nuova ontologia da due esistenti; di seguito mostreremo
brevemente i principali problemi da affrontare in un processo di questo tipo.
Analizzeremo quindi la relazione di versione, relazione che intercorre tra le
versioni di una stessa ontologia. Anche per questa introdurremo brevemente i
punti critici, fornendo quindi alcuni strumenti atti a creare una sorta di
framework per esprimere in modo corretto la relazione.
2.3.1 Alcune definizioni
Prima di procedere è bene dare alcune definizioni dei termini che andremo ad
utilizzare nel corso dei seguenti capitoli, poiché esistono in letteratura
svariate sfumature di significato attribuite ad essi [KLE01a].
Mappatura ontologica: processo in grado di mettere in relazione concetti
o relazioni simili provenienti da fonti diverse.
Unione o integrazione di ontologie: il processo atto a creare una nuova
ontologia a partire da due o più ontologie esistenti con degli elementi
sovrapposti.
Allineamento: Il processo in grado di portare due ontologie in mutuo
accordo.
18

Traduzione: cambiare la rappresentazione formale di un’ontologia
preservandone i concetti semantici.
Versione: l’ontologia risultante dopo avere applicato una o più variazioni
ad un’ontologia.
Versionamento: Un metodo in grado di esprimere le relazioni esistenti tra
un’ontologia e tutte le versioni esistenti di essa.
2.3.2 Il processo di integrazione
Il problema dell’Integrazione delle ontologie è a tutt’oggi uno dei maggiori
ambiti di ricerca in campo ontologico e presenta diverse questioni aperte.
Quando qualcuno si appresta a riutilizzare due o più ontologie esse devono
essere in qualche modo combinate insieme; questo può essere fatto tramite il
processo d’integrazione [PIN99].
Possiamo pensare il processo d’integrazione composto dei seguenti passaggi
[MC00]:
rilevare le zone delle ontologie sovrapposte (mappatura);
mettere in relazione i concetti che sono semanticamente vicini
(allineamento ed integrazione);
controllare la correttezza e la non ridondanza del risultato.
19

Figura 2 Interazione d’Ontologie.
L’allineamento delle ontologie spesso rende indispensabile apportare alcune
modifiche almeno ad una delle due. Tali modifiche generano una nuova
versione dell’ontologia stessa, introducendo il problema del versioning.
In fine va tenuto in considerazione che, se le ontologie sono espresse in
linguaggi diversi si rende necessaria una traduzione, ovvero la modifica della
rappresentazione formale dell’ontologia preservando la semantica della
stessa.
2.3.3 Problemi nel processo di integrazione
La chiave dei problemi che nascono nell’utilizzo di ontologie indipendenti sta
nelle differenze che possono esistere tra esse [KLE01a]. Per questo ora
esploreremo in che cosa due ontologie possono differire.
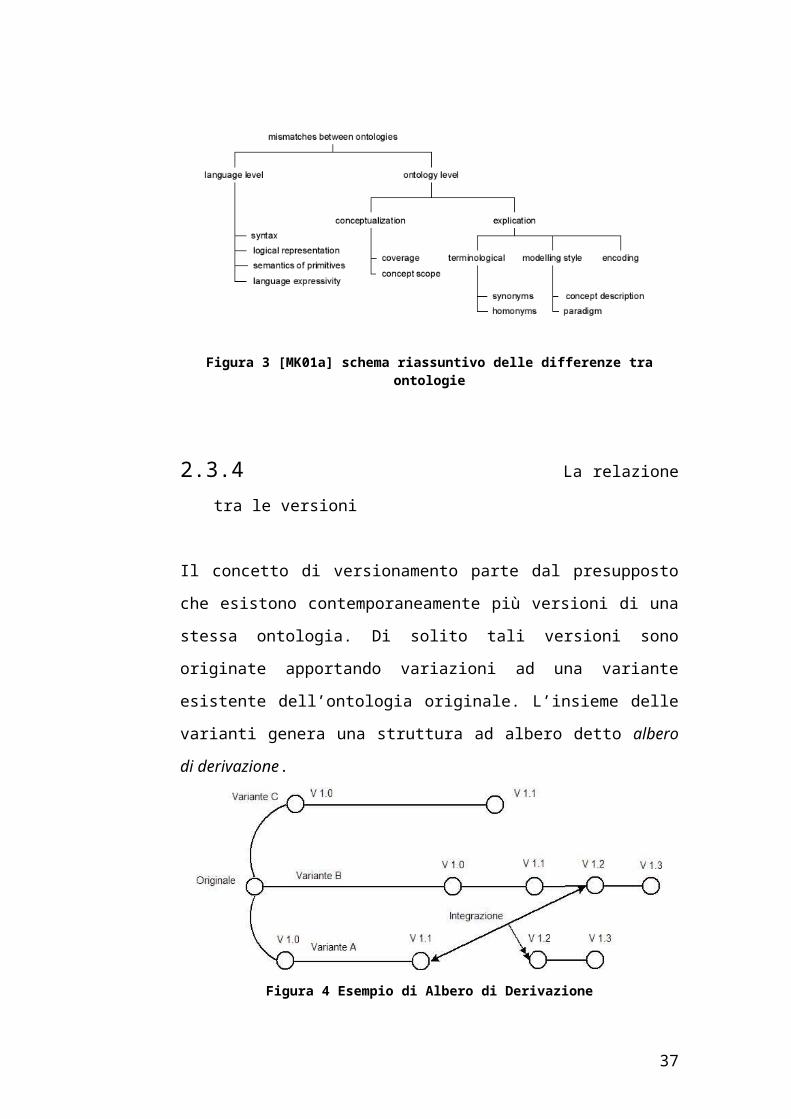
Una prima distinzione da fare è tra differenze a livello linguistico che
riguardano i meccanismi tramite i quali vengono definiti classi, relazioni, ecc,
e differenze a livello ontologico che riguardano invece il modo in cui il
dominio è modellato [VIS97].
Le differenze a livello linguistico occorrono ogni qual volta si vuole
combinare ontologie scritte in linguaggi ontologici differenti. In esse
possiamo distinguere quattro tipi di differenze [CHA00] che possono
verificarsi:
20

Sintassi: ovviamente linguaggi diversi usano una diversa sintassi. Ad
esempio per esprimere la stessa classe in RDF, un linguaggio nato per la
descrizione della conoscenza nel web, che vedremo meglio nel capitolo 3, si
utilizza l’espressione <rdfs:Class ID=”miaClasse”/> mentre in
LOOM, un linguaggio introdotto nello studio delle intelligenze artificiali,
(defconcept miaClasse). Questo tipo di differenze è tipicamente il
tipo più semplice da affrontare.
Notazione logica: si presenta quando i due linguaggi utilizzano una
notazione logica diversa per esprimere gli stessi concetti, ad esempio alcuni
linguaggi permettono di esprimere in maniera esplicita la disgiunzione tra
classi (es. disjoint A B ) mentre altri esprimono tale concetto attraverso la
negazione del concetto di sottoclasse (es. A sub-class-of (NOT B)). Le
ontologie che rientrano in questo caso non presentano alcuna differenza a
livello di concetti ontologici ma solo di come essi sono espressi logicamente.
Semantica delle primitive: va tenuto in considerazione il fatto che uno
stesso termine può presentarsi tra le parole chiave di diversi linguaggi, ma
esso può possedere una semantica diversa in base al linguaggio. Ex. ci sono
diverse interpretazioni di della funzione di eguaglianza tra classi.
Espressività del linguaggio: in fine va sempre considerato che linguaggi
diversi possono essere in possesso di capacità espressive diverse. Ex. alcuni
linguaggi posseggono il concetto di Lista e Insieme, altri ne sono sprovvisti.
21

Differenze a livello ontologico si presentano invece quando si procede
all’integrazione di due o più ontologie anche solo parzialmente sovrapposte,
indipendentemente dal linguaggio in cui esse sono espresse.
Una prima categoria di differenze ontologiche sono quelle inerenti alla
concettualizzazione del dominio.
Scope: Due classi sembrano rappresentare lo stesso concetto, ma non
posseggono la medesima specifica [VIS97]. Un esempio può essere la classe
Impiegato, amministrazioni diverse possono utilizzare tale concetto con
piccole ma significative distinzioni.
Modello e granularità: Questa differenza occorre quando parti del
dominio sovrapposte sono modellate con un livello di dettaglio diverso
[CHA00]. Ad esempio un’ontologia può fornire il concetto di auto ma non di
camion, un'altra presentare il concetto di camion in maniera superficiale, una
terza può entrare in dettaglio.
Procedendo con l’analisi delle differenze a livello ontologico incontriamo
un’altra classe che possiamo definire differenze di interpretazione: questa
riguarda lo stile di modellazione del dominio.
Paradigma: diversi paradigmi possono essere usati per esprimere
concetti come tempo, azioni, casualità ecc.
Descrizione dei concetti: vi sono alcune scelte che possono essere fatte
all’atto di modellare un concetto. Ex una differenza tra due concetti può
essere espressa introducendo un attributo qualificante o definendo una nuova
classe.
22

In fine un’ultima classe può essere descritta come differenze a livello
terminologico.
Sinonimi: lo stesso concetto può essere presentato con nomi diversi, ad
esempio un’ontologia lo può presentare con il nome di macchina mentre
un'altra sotto il nome di automobile.
Omonimi: lo stesso termine esprime concetti diversi in diversi domini, ad
esempio il termine ontologia ha un significato diverso in informatica piuttosto
che in filosofia.
Encoding: Un valore può essere fornito con encode diversi, ad esempio
una distanza può essere fornita in km, in m ecc.
Figura 3 [MK01a] schema riassuntivo delle differenze tra ontologie
2.3.4 La relazione tra le versioni
Il concetto di versionamento parte dal presupposto che esistono
contemporaneamente più versioni di una stessa ontologia. Di solito tali
versioni sono originate apportando variazioni ad una variante esistente
23

dell’ontologia originale. L’insieme delle varianti genera una struttura ad
albero detto albero di derivazione.
Figura 4 Esempio di Albero di Derivazione
Ci sono due importanti aspetti da considerare quando si parla di relazione tra
versioni, il primo è la differenza tra una relazione di versione e le relazioni
concettuali all’interno di un’ontologia.
Di solito un’ontologia è un insieme di definizioni di classi (o concetti), delle
loro proprietà e di assiomi su esse. Una variazione in un’ontologia genera una
nuova versione di essa e di conseguenza una relazione tra i concetti e le
relazioni della versione originale e gli stessi elementi della versione
modificata.
Tale relazione tuttavia è profondamente diversa dalle relazioni che legano tra
loro gli elementi dell’ontologia originale.
Figura 5 Esempio di relazione di versione [KLE02b]
La relazione di versione non è una vera e propria relazione concettuale, essa
infatti non aggiunge alcun tipo di informazione sul conto della classe quale
24

concetto appartenente al dominio, bensì fornisce metainformazioni su essa
quale elemento ontologico.
Una relazione di versione dovrebbe possedere le seguenti caratteristiche:
Trasformazioni: [BAN87] una specifica di cosa è cambiato nella
versione corrente dal punto di vista della definizione ontologica.
Relazioni concettuali: le relazioni esistenti tra i costrutti delle due
diverse versioni, ex relazioni di equivalenza o altre relazioni logiche.
Metainformazioni: quali per esempio l’autore della versione, la data,
ecc…
Scope: una descrizione del contesto all’interno del quale gli
aggiornamenti sono considerati validi. Ex può essere un contesto temporale
come una data di transizione.
Un secondo aspetto da tenere in considerazione è in quale maniera viene
concretamente espresso l’insieme dei cambiamenti avvenuti sulla versione
corrente. Possiamo distinguere due diversi aspetti che riguardano l’insieme
dei cambiamenti: il primo è la granularità dell’informazione che può andare
dal singolo attributo della classe al file intero. Il secondo riguarda invece il
metodo con il quale tali informazioni vengono espresse. Vi sono due metodi
pensabili:
Esplicito: i cambiamenti vengono espressi in maniera esplicita in forma di
un insieme di operazione (ex Add A Delete B ecc…)
Implicito: i cambiamenti vengono espressi tramite il confronto della
nuova versione con la precedente.
Naturalmente non vi è equivalenza tra i metodi, infatti essi non sono in grado
di fornire le stesse informazioni.
25

2.3.5 Il problema del versionamento
Dal punto di vista ontologico possiamo affermare che il processo di
versionamento fornisce un meccanismo agli utilizzatori delle varianti
ontologiche per eliminare le ambiguità nell’interpretazione dei concetti
presenti nell’ontologia[KLE01b]; in altre parole esplicita la compatibilità tra
le versioni. La compatibilità tra due varianti è legata alle modifiche avvenute,
di conseguenza l’impatto semantico delle modifiche dovrebbe essere
esaminato.
Per analizzare i cambiamenti che possono avvenire su un ontologia è
fondamentale che ne esaminiamo la natura. Possiamo definire un’ontologia
come la specifica di una concettualizzazione condivisa su un dominio
[GRU93]. Va da se che le modifiche possono riguardare:
Dominio: Se varia il dominio deve indiscutibilmente variare anche
l’ontologia che lo descrive. Un esempio può essere la creazione di un nuovo
reparto aziendale, o l’assunzione di un nuovo impiegato.
Concettualizzazione condivisa: La concettualizzazione di un dominio
non è un concetto statico che viene creato in fase iniziale e dimenticato, ma
un elemento dinamico che varia nel tempo in relazione ai concetti descritti e
al consenso comune sul loro significato. Inoltre una concettualizzazione può
variare in base alla prospettiva che si applica al dominio. Processi diversi
possono avere punti di vista differenti sul dominio e di conseguenza una
diversa concettualizzazione. Ex si pensi ad un’ontologia che descriva le
connessioni stradali di Venezia dal punto di vista di un pedone; se la
prospettiva viene spostata a quella di una gondola alcuni oggetti come un
26

ponte variano la propria concettualizzazione passando da elemento necessario
per attraversare un canale a ostacolo.
Specifica: Anche la specifica può variare; in questo caso otteniamo una
specie di traduzione dell’ontologia. I concetti e il dominio rimangono
invariati, ciò che varia è il meccanismo tramite il quale le informazioni sono
formalmente immagazzinate.
Il versionamento è fondamentale perché talvolta i cambiamenti ad
un’ontologia possono essere causa di incompatibilità.
Vi sono diversi oggetti che possono avere una dipendenza da un’ontologia.
Per ognuno di questi si genera un diverso tipo di incompatibilità:
Documenti conformi all’ontologia: nel semantic web ad esempio un
documento può essere creato utilizzando i termini di un ontologia. Se questa è
modificata il documento potrebbe trovarsi a contenere un’ interpretazione
diversa di un termine o un termine che non esiste.
Altre ontologie: infatti vi possono essere altre ontologie create a partire
da essa o che vi fanno riferimento e ogni cambiamento può portare
conseguenze in esse.
Software: vi possono essere applicativi che utilizzano l’ontologia. Le
applicazioni infatti spesso usano un modello interno per rappresentare
l’ontologia; variazioni nel documento originale possono portare ad
un’incompatibilità tra i due modelli.
2.3.6 Un framework per il versionamento
27

La principale domanda cui dovrebbe rispondere un framework ontologico per
il versionamento è “come usare le ontologie esistenti in nuove
situazioni”[KLE01a]. Esso dovrebbe quindi tener conto da un lato della
relazione tra le versioni ontologiche, dall’altro della relazione con le
dipendenze dell’ontologia, fornendo agli utilizzatori delle varie versioni un
meccanismo per garantire la compatibilità. Per questo possiamo imporgli i
seguenti requisiti in ordine crescente di complessità:
Identificazione: un meccanismo che permetta di riconoscere in
maniera certa le definizioni contenute all’interno dell’ontologia.
Insieme dei cambiamenti: un meccanismo in grado di fornire
l’insieme dei cambiamenti avvenuti tra due diverse versioni in
maniera esplicita.
Trasparenza: l’operazione di conversione dovrebbe essere, ove
possibile, automatizzata.
2.4 Conclusioni
In questo capitolo abbiamo visto come il concetto di ontologia stia
progressivamente trovando sempre maggiori applicazioni in campo
informatico.
In molte di queste applicazioni le esigenze di avere sistemi distribuiti e
concorrenti di aggiornamento, modifica o rimpiazzamento delle ontologie
esistenti hanno introdotto la necessità di possedere un meccanismo che sia in
grado di riconoscere e gestire tutti questi cambiamenti.
Queste premesse hanno fatto nascere il problema del riuso delle ontologie,
uno dei principali problemi all’interno della ricerca che riguarda le ontologie.
Poiché il problema del riuso non è affatto un problema banale o di facile
28

soluzione, esso è stato scomposto in due distinti problemi secondo la
definizione di [KLE01a]. Ognuno dei componenti infine è stato analizzato in
dettaglio per quello che riguarda i meccanismi di funzionamento e le
criticità.
Tutti gli strumenti forniti nel corso di queste pagine hanno l’ obiettivo di
preparare il lettore ad affrontare il prossimo capitolo in cui verrà presentato
un caso concreto di riuso di ontologie in un applicazione ontology oriented,
l’Integrated Metadata Editor (IME).
29

30

3 METADATA INTEGRATOR
Nel corso di questo capitolo andremo ad analizzare l’implementazione di un
meccanismo di integrazione tra istanze di ontologie che ho avuto modo di
sviluppare.
Dal momento che tale meccanismo che ho chiamato Metadata Integrator è stato
inserito all’interno di un progetto esistente ovvero Metadata for Document
Exchange partiremo la nostra analisi con una presentazione del progetto in
generale.
In particolare il processo è stato inserito all’interno di un elemento del progetto
chiamato Integrated Metadata Editor; la nostra analisi proseguirà quindi con una
carrellata sulle principali funzionalità fornite da questo software nel corso della
quale verranno anche brevemente trattati i linguaggi di programmazione con i
quali è stato sviluppato.
In fine ci concentreremo sul progetto in se, su quali servizi in particolare sia in
grado di fornire e sul suo funzionamento generale.
3.1 Metadata for Document Exchange
3.1.1 Il progetto Metadata for Document Exchange
Metadata for document Exchange è un progetto elaborato per favorire
l’interscambio efficiente di informazioni tra i diversi membri di una grande
organizzazione.
MFDE si propone di migliorare il modo in cui gli utenti sono in grado di
modificare, scambiarsi e salvare i documenti prodotti all’interno
dell’organizzazione, senza per questo stravolgere le metodologie di lavoro. Il
sistema si basa sulla sistematica adozione di un certo numero e di un certo
tipo di metadati con il quale ogni documento è in grado di fornire
informazioni su se stesso.
Il progetto è composto di tre elementi principali, i metadati e l’ontologia cui
sono riferiti, l’architettura di sistema che deve essere messa in atto per
31

permettere al sistema di funzionare, e gli strumenti necessari per manipolare i
metadati in modo efficiente.
3.1.2 L’architettura
È importante comprendere pienamente l’architettura aziendale per la quale è
stato progettato MFDE al fine di comprendere appieno quali siano poi gli
strumenti necessari per la manipolazione dei metadati. Il contesto preso in
esame è quello di una organizzazione di grandi dimensioni, in particolare
l’OCHA (Office for the Coordination of Humanitarian Affaire presso l’UN),
e sono state seguite alcune linee guida:
La manipolazione dei metadati va fatta client-side
Devono esistere più copie dello stesso documento salvate in posizioni
diverse all’interno del sistema.
Il lavoro degli utenti deve essere influenzato il meno possibile dal
sistema.
La documentazione esistente deve essere solo marginalmente
interessata dalla nuova implementazione.
Centralrepository (NYC/GE) Local
repository
Field officer
Semi-automaticselection
Automaticupdate Shared directory
e-mail attachmente-mail message
FTPdiskette, etc.
checkpointcheckpoint
Other uses of documents
Other sources of documents
Other sources of documents
Figura 6 l'architettura proposta
32

Possiamo vedere in figura l’architettura risultante, vi è un unico central
repository che contiene una copia di tutti i documenti che esistono negli altri
luoghi e vari repository locali che contengono un sottoinsieme di questi
documenti.
In fine vi sono gli utenti che devono essere messi in grado di integrare i
metadati all’interno dei documenti che creano e di poter modificare a
piacimenti tanto i documenti quanto le relative metainformazioni.
Generalmente considereremo documenti file appartenenti al pacchetto office
(word – excell – powerpoint ), pdf, ma anche immagini quali gif o jpg ecc…
3.1.3 Metadata tools
I metadata tools sono divisi in tre grandi categorie e in accordo con
l’architettura che abbiamo appena visto troviamo:
User tool: sono installati su ogni singola macchina, usati normalmente
dagli utenti nel corso delle loro quotidiane mansioni.
Local tool: installati sul server locale questi strumenti forniscono
funzionalità di verifica, validazione e comunicazione agli altri servizi
e strumenti.
Central tool: installati solamente sul repository centrale questi
strumenti forniscono funzionalità di verifica validazione e
comunicazione con i repository locali.
Gli user tool hanno come principale obiettivo quello di permettere all’utente
di inserire e modificare i metadati corretti, secondo l'ontologia proposta,
all’interno del documento; questo, come detto, nella maniera più intuitiva
possibile. I tool che ricadono in questa categoria sono tutti editor per
metadati:
33

Internal metadata editing application: questo strumento si andrà ad
integrare con l’editor del documento e consentirà di associare le
metainformazioni ad ogni salvataggio dello stesso. I formati che
prevedono l’associazione di metadati sono quelli appartenenti al
pacchetto office ed i pdf.
External metadata editing application: questo è invece l’editor
associato a tutti i tipi di file che non prevedono la possibilità di
associare metadati (immagini, ecc…); in questo caso è l’utente a
dover ricordare di attivare la funzionalità.
Mail validator: applicativo associato al client mail dell’utente che ha il
compito di controllare se il messaggio o eventuali allegati hanno un
formato valido di metainformazioni.
3.2 Integrated Metadata Editor
Integrated Metadata Editor(IME) è un applicativo che si propone all’interno del
progetto Metadata for Document Exchange come internal editor per i documenti
di microsoft Word.
Tale progetto, sviluppato in C sharp, di cui darò alcune nozioni inseguito, è
proposto come plug-in per il programma Microsoft Word. I plug-in sono
applicativi in grado di interagire con un programma principale , nel nostro caso
microsoft Word, ed in grado di estenderne le funzionalità.
3.2.1 Integrazione con Word
34

Come detto IME estende le funzionalità di Word e gli fornisce da un lato
l’abilità di associare elementi della nostra ontologia al documento,
arricchendolo in questo modo di metainformazioni, dall’altro permette
all’utente di aggiornare l’insieme di elementi dell’ontologia.
Dopo l’installazione del programma compare tra le barre degli strumenti un
nuovo elemento denominato Integrated Metadata Editor che permette di
abilitare o disabilitare il plug-in (come mostrato in figura 7).
Figura 7 integrazione all'interno di Microsoft Word
Quando il plug-in è abilitato, ogni volta che un documento di word viene
salvato appare l’interfaccia principale del IME prima che l’operazione sia
eseguita.
3.2.2 Interfaccia principale
L’interfaccia principale abbiamo detto viene mostrata ogni volta che l’utente
decide di salvare un file di word, essa permette di compilare tutte le
metainformazioni obbligatorie al funzionamento dell’architettura.
Nel corso del normale utilizzo questa maschera è generalmente la sola con
cui l’utente si trova ad interagire.
35

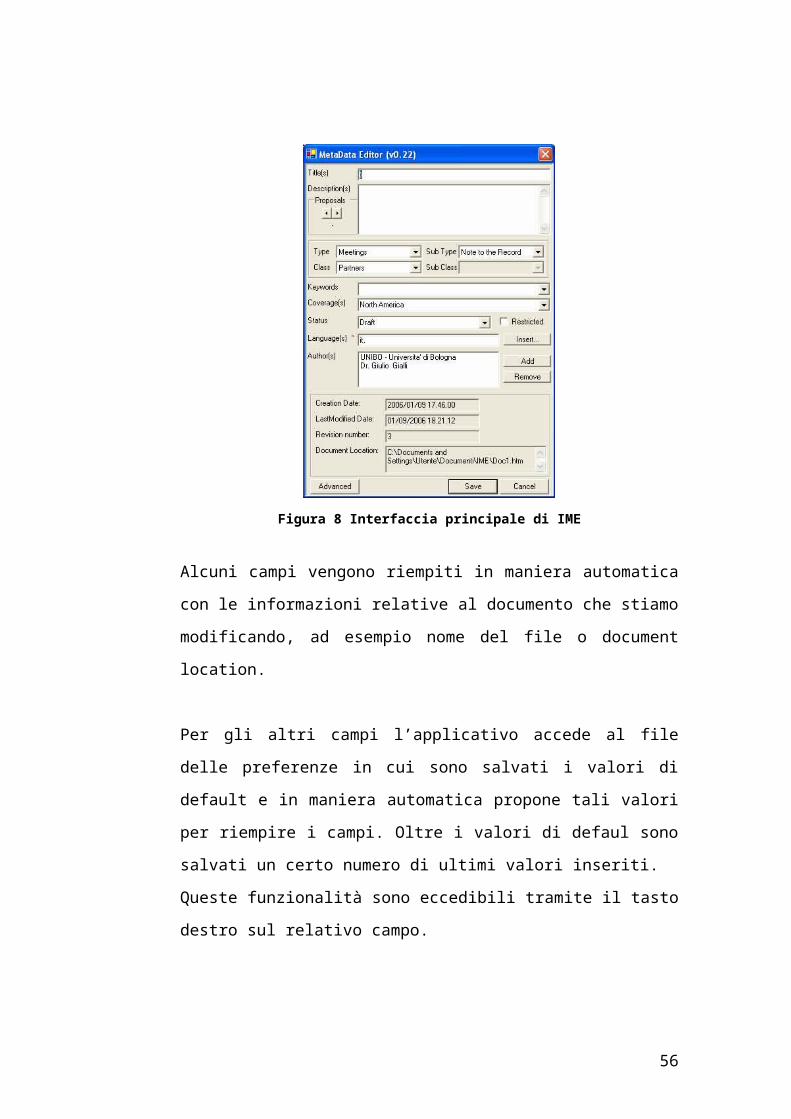
Figura 8 Interfaccia principale di IME
Alcuni campi vengono riempiti in maniera automatica con le informazioni
relative al documento che stiamo modificando, ad esempio nome del file o
document location.
Per gli altri campi l’applicativo accede al file delle preferenze in cui sono
salvati i valori di default e in maniera automatica propone tali valori per
riempire i campi. Oltre i valori di defaul sono salvati un certo numero di
ultimi valori inseriti.
Queste funzionalità sono eccedibili tramite il tasto destro sul relativo campo.
Figura 9 Funzionalità aggiuntive dell’interfaccia principale di IME
Per stabilire se il documento sia stato modificato e quindi stabilire se
aumentare o meno il numero di versione del documento il programma
effettua il checksum del documento e lo confronta con le informazioni
precedentemente salvate.
36
Dopo aver eseguito queste operazioni l’applicazione procede alla lettura
dell’ontologia per essere in grado ove richiesto di suggerire tutti i possibili
valori in essa contenuti per i vari campi previsti.
3.2.3 Interfaccia secondaria
L’interfaccia secondaria permette all’utente di inserire una serie di
informazioni che non sono strettamente necessarie al funzionamento
dell’architettura ma possono essere utili agli utenti per meglio definire alcuni
dei loro documenti.
L’interfaccia è divisa in due sezioni: optional info e details. La prima
contiene appunto informazioni opzionali per i documenti standard che
tuttavia è bene definire per alcuni tipi di documenti come ad esempio le
pubblicazioni tecniche. La seconda parte invece contiene informazioni sulle
relazioni del documento corrente con altri documenti esistenti.
Figura 10 interfaccia secondaria di IME
37

3.2.4 Selezione degli elementi ontologici
Le restanti funzionalità dell’applicazione sono essenzialmente dedicate alla
ricerca inserimento eliminazione e modifica degli elementi ontologici
appartenenti all’ontologia. Ogni utente possiede una copia locale
dell’ontologia e ha anche la facoltà di modellarne gli elementi in qualsiasi
momento per rispondere in maniera immediata ed efficiente a esigenze
derivanti da una variazione del dominio o dalla necessità di descrivere un
elemento imprevisto fino a quel momento.
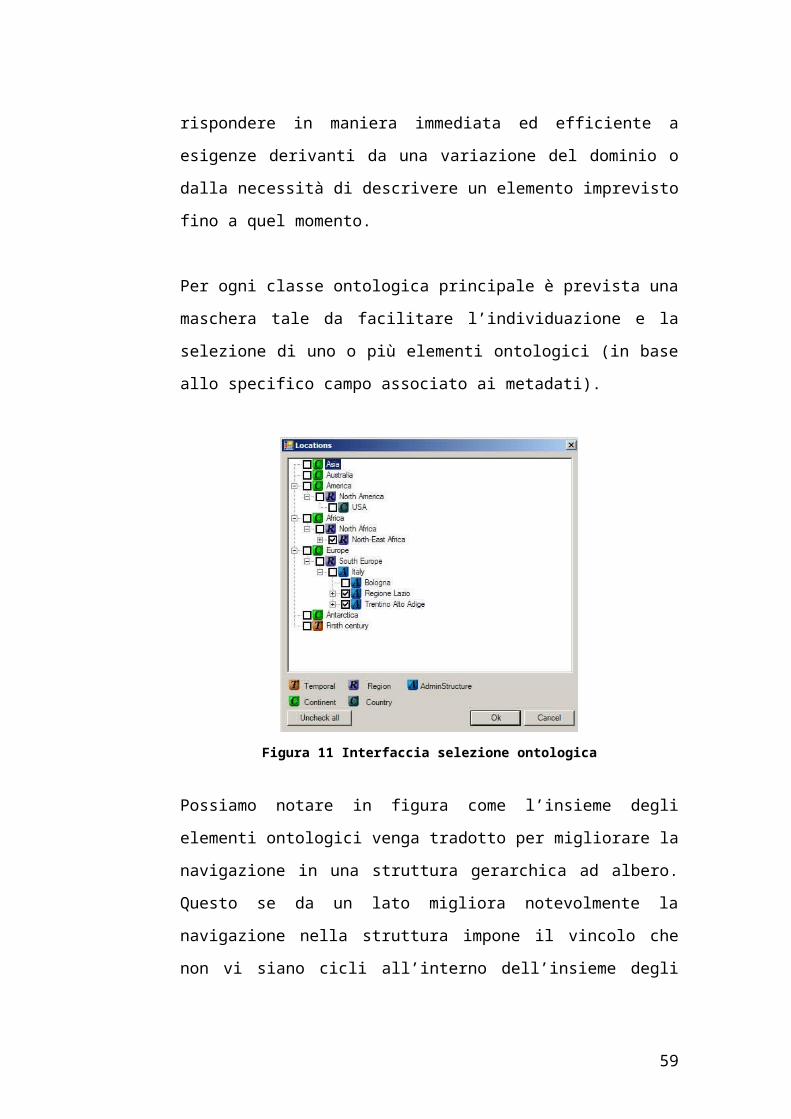
Per ogni classe ontologica principale è prevista una maschera tale da facilitare
l’individuazione e la selezione di uno o più elementi ontologici (in base allo
specifico campo associato ai metadati).
Figura 11 Interfaccia selezione ontologica
Possiamo notare in figura come l’insieme degli elementi ontologici venga
tradotto per migliorare la navigazione in una struttura gerarchica ad albero.
Questo se da un lato migliora notevolmente la navigazione nella struttura
impone il vincolo che non vi siano cicli all’interno dell’insieme degli
elementi, altrimenti la struttura non risulterebbe più assimilabile ad un albero.
38

3.2.5 Modifica degli elementi ontologici
Tramite la maschera vista al punto precedente è anche possibile accedere
all’insieme di operazioni di modifica degli elementi ontologici.
Queste funzionalità sono situate nel menu contestuale che appare premendo il
tasto destro sull’elemento o sul controllo.
Figura 12 Menu contestuale tasto destro
Come possiamo notare in figura i menu contestuali sono differenti a seconda
di quale punto del controllo viene cliccato: cliccando su un elemento potrò
accedere all’insieme delle operazioni di modifica di quel elemento; cliccando
su un punto generico potrò accedere alle operazioni di inserimento di un
elemento al top-level.
L’insieme delle operazioni messe a disposizione sono:
Inserimento di un elemento: Una nuova istanza della classe ontologica
è inserita all’interno della gerarchia. Esso può essere aggiunto al top
level oppure come figlio di un elemento già esistente. Quando si
sceglie di inserire un nuovo elemento viene visualizzata una nuova
maschera (figura 13) da compilare con le informazioni riferite al
nuovo elemento.
Cancellazione di un elemento: Un elemento nella gerarchia viene
rimosso, e con esso tutti i propri discendenti. Per questo è bene porre
una certa attenzione prima di eseguire un operazione di cancellazione,
eventuali operazioni di variazione della gerarchia vanno infatti
compiute preventivamente per evitare perdita di informazioni.
39

Modifica di un elemento: permette di modificare ognuno degli
attributi di cui è composto l’elemento. Viene mostrata una nuova
interfaccia (figura 13) che a sua volta permette di aggiungere
eliminare modificare tutti i campi di cui è composto l’elemento. Oltre
a ciò è anche possibile modificare la posizione dell’elemento
all’interno della gerarchia, portandolo ad esempio al top-level o
rendendolo figlio di un altro nodo.
Figura 13 Maschera di modifica / Inserimento
Da notare che non tutte le maschere di visualizzazione posseggono
funzionalità di modifica dell’insieme degli elementi ontologici. Le maschere
che ne sono sprovviste evidentemente fanno riferimento ad elementi che si
considerano non modificabili direttamente dall’utente (es. le lingue non sono
modificabili dall’utente).
3.2.6 C#
Il core del progetto Integrated Metadata Editor è stato sviluppato interamente
in C#.
C# (o C Sharp) è un linguaggio di programmazione orientato agli oggetti
sviluppato da Microsoft all’interno del progetto .NET ed in seguito divenuto
40

standard ed approvato da ECMA (European Computer Manufacturers
Association) ed ISO (International Organization for Standardization).
C# possiede una sintassi procedurale [WIK07b], ovvero organizzata a
blocchi, orientata agli oggetti e basata su quella di C++, ma che include
aspetti di molti altri programmi (come Delphi e Java) con una particolare
enfasi alla semplificazione.
Nella specifica ECMA a C# sono posti i seguenti obiettivi di design:
Il linguaggio e la sua implementazione devono fornire un supporto
ideale per l’ingegneria del software come una forte tipizzazione un
controllo sugli array e sulle variabili non inizializzate non che un
garbage collector automatico.
Il linguaggio deve essere inteso per lo sviluppo di componenti
software che possano essere inseriti in sistemi distribuiti.
La portabilità del codice sorgente è importante.
Il supporto per l’internazionalizzazione è importante.
Il linguaggio deve essere in grado di creare applicazioni utilizzabili
sia in sistemi hosted che embedded
Le prestazioni delle applicazioni sono importanti. Particolare
attenzione è posta all’ottimizzazione delle risorse del sistema, anche
se non è pensabile naturalmente di competere con applicativi C o
assembly.
3.2.7 RDF
41

RDF è il linguaggio che abbiamo scelto per esprimere e memorizzare la
nostra ontologia su file.
Il Resource Description Framework (RDF) è sostanzialmente un modello
formale di dati dotato di sintassi di interscambio, un sistema di schemi di tipo
ed un linguaggio d’interrogazione. Esso è stato specificatamente creato,
secondo una raccomandazione (10 Febbraio 2004) del W3C, l’organo nato
per favorire lo sviluppo degli standard nel web, per la descrizione dei
metadati relativi alle risorse.
Il modello di dati RDF è formato da risorse, proprietà e valori. Qualunque
cosa descritta da RDF è detta risorsa; ogni risorsa è identificata da un URI
(Uniform Resource Identifier). L’ URI è quindi un identificatore univoco di
risorse e può essere un URL (Uniform Resource Locator) o un URN
(Uniform Resource Name).
Le proprietà sono delle relazioni che legano tra loro risorse e valori oppure
risorse con altre risorse, e possono anch’esse essere identificate da un URI.
Un valore, invece, o è una risorsa o è un tipo di dato primitivo.
L’unità base per rappresentare un’informazione in RDF è lo statement. Uno
statement è una tripla del tipo: “Soggetto – Predicato – Oggetto” dove il
soggetto è una risorsa, il predicato è una proprietà e l’oggetto è un valore.
Un modello RDF altro non è che un insieme di statement, questo può essere
immaginato come un grafo orientato in cui i nodi sono risorse o valori,
mentre gli archi sono dati dalle proprietà.
Un grafo RDF può essere rappresentato fisicamente tramite una
rappresentazione, esistono vari tipi di serializzazione:
42

N-TRIPLE: si serializza il grafo come un insieme di triple soggetto -
predicato – oggetto
N3: si serializza il grafo descrivendo, una per volta, una risorsa e tutte
le sue proprietà
XML: l’RDF è serializzato in un file XML.
Per serializzazione si intende la possibilità di salvare dati in un formato tale
da permettere in seguito di recuperarli; in particolare la serializzazione xml
salva i dati in un file di testo tramite la sintassi XML. L'XML, acronimo di
eXtensible Markup Language è un metalinguaggio di markup creato dal
W3C.
3.3 Metadata Integrator
Come accennato nel corso di questo documento Metadata Integrator è un
processo per l’integrazione di varianti di istanze di una stessa ontologia che ho
avuto la possibilità di sviluppare e di cui ora voglio illustrare le principali
funzionalità.
Come ho gia accennato il processo è stato inserito all’interno del progetto
Metadata for Document Exchange ed in particolare all’interno di un suo
componente ovvero l’IME.
3.3.1 Architettura degli aggiornamenti
L’architettura degli aggiornamenti non è stata vincolata alla struttura del
progetto ma è stata lasciata piuttosto flessibile. Come possiamo vedere in
figura 14 infatti un utente può aggiornare la propria ontologia integrandola sia
con quella del central repository o del local server, ma anche con quella di un
altro utente del sistema.
43

Figura 14 Architettura degli aggiornamenti
Al momento dell’esecuzione il programma richiede all’utente di indicare
l’ubicazione dell’ontologia con la quale verrà eseguito il confronto. Per
agevolare il più possibile gli utenti tale ontologia si può trovare sulla
macchina locale, su una delle macchine appartenenti alla rete interna, oppure
ad un indirizzo web.
3.3.2 Principali funzionalità
Metadata Integrator si occupa di integrare ed allineare l’ontologia utilizzata
dall’utente che lo invoca con un'altra ontologia che viene indicata al processo
dall’utente.
Il processo di integrazione è composto da una serie di sotto processi più
semplici:
Inserimento: Tutti gli elementi che sono stati inseriti nell’ontologia di
confronto e non compaiono nell’ontologia corrente vengono inseriti.
L’inserimento avviene in maniera da rispettare la struttura dei dati,
oltre l’oggetto vengono inseriti anche tutti i suoi riferimenti da e per
gli altri oggetti dell’insieme.
44

Eliminazione:Tutti gli oggetti che sono stati eliminati nell’ontologia
di confronto e invece qui compaiono vengono eliminati, naturalmente
con essi viene anche aggiornata la struttura dei dati.
Confronto: per tutti gli elementi che compaiono in entrambe le
ontologie si procede al confronto tra le diverse versioni. Nel corso di
questo confronto vengono controllati tutti i campi dell’oggetto e per
ogni uno di essi si procede all’aggiornamento del valore se più recente
o all’aggiunta di nuovi valori all’interno dell’insieme dei valori del
campo se si tratta di campo a valore multiplo. Vengono inoltre
aggiornati, ove possibile, i collegamenti verso gli altri oggetti
dell’insieme.
Controllo di validità: alla fine di questi processi si esegue un controllo
di validità che accerta che la nuova struttura dati creata sia una
struttura valida.
Importante sottolineare che il processo non aggiorna entrambe le ontologie
ma solamente quella dell’utente che l’ha invocata.
Questo per semplicità poiché non sempre si posseggono i permessi per poter
scrivere sul disco di origine dell’ontologia di confronto, specialmente se essa
si trova in rete o sul web.
3.3.3 Accessibilità alla nuova funzionalità
La nuova funzionalità come abbiamo più volte detto è stata integrata
all’interno del progetto IME.
45

Figura 15 Accesso alla nuova funzionalità
Come vediamo in figura è stato inserito un nuovo bottone denominato
Ontology Integrator, nella parte inferiore dell’interfaccia principale di IME,
tramite questo è possibile accedere alla funzione Integrazione.
3.3.4 L’interfaccia principale
L’Interfaccia principale del nuovo processo è quella che permette di avere
accesso alla nuova funzionalità di integrazione.
Come possiamo vedere in figura essa è estremamente semplice ed intuitiva,
composta di pochi essenziali elementi.
L’unico input richiesto all’utente è la locazione dell’ontologia con la quale
effettuale l’integrazione, che, come abbiamo detto, può essere una risorsa
locale, di rete o web. Nei primi due casi si può usufruire dell’apposito tasto
sfoglia posto alla destra del campo di testo, mentre nel terzo è necessario
inserire manualmente l’intero indirizzo nel campo.
Il resto del processo è completamente automatico e l’utente può monitorare
l’andamento attraverso le due barre dell’interfaccia. Come avremo modo di
vedere nel prossimo capitolo l’ontologia è composta da un certo numero di
classi ontologiche, ognuna delle quali a propria volta composta da un certo
numero di istanze.
46

Figura 16 La schermata principale
Come vediamo in figura 16 le varie classi ontologiche compaiono nella lista
nella parte centrale dell’interfaccia. La barra mostra lo stato di elaborazione
della classe corrente. Una volta che l’elaborazione della classe è terminata a
lato della relativa voce dell’elenco compare una “v” e si riparte con
l’elaborazione della prossima classe.
Dopo aver terminato il processo di integrazione all’utente viene fornito un
breve documento riepilogativo delle operazioni eseguite, che per ogni classe
ontologica riporta tutti gli elementi nuovi che sono stati inseriti e tutti gli
elementi eliminati.
Figura 17 Riepilogo Integrazione
47

3.3.5 Il trattamento dei conflitti
Nel corso delle operazioni di modifica che ogni utente svolge sulla propria
ontologia in maniera indipendente, è lecito aspettarsi che possano venirsi a
creare situazioni di indecisione nel trattamento degli aggiornamenti.
Ad esempio a seguito di comunicazioni che alcuni utenti ricevono e altri no o
di fraintendimento di tali comunicazioni si possono creare situazioni in cui su
uno stesso elemento vengono eseguite operazioni incompatibili quali ad
esempio inserimento e cancellazione.
Dal momento che il processo è totalmente automatico è bene spiegare quale
tecnica è utilizza per la risoluzione di tali conflitti.
Per fare questo ci serviremo di un esempio esplicativo.
Paolo ed Elena ricevono una comunicazione che il collega dell’ufficio
vendite Mario è stato licenziato, quindi entrambi procedono ad eliminare
l’elemento ontologico associato a Mario. Il giorno seguente Paolo è in
permesso quando Elena riceve la comunicazione che si è verificato un
malinteso e Mario è stato reintegrato, quindi procede al reinserimento di
Mario in ontologia; quando Paolo rientra dal permesso chiede ad Elena di
poter aggiornale la sua ontologia con quella della collega.
A questo punto il sistema di trattamento dei conflitti decide di inserire
nuovamente Mario anche nell’ontologia di Paolo.
Il criterio generale seguito dal sistema in questo caso e di conseguenza in
ogni caso di conflitto, è quello che probabilmente l’operazione svolta in
tempi più recenti è quella corretta.
48

3.4 Conclusioni
Abbiamo visto in questo capitolo un processo per l’integrazione tra varianti
ontologiche inserito all’interno di un contesto più generale di un progetto per
l’applicazione di metadati ai documenti.
Tale strumento è un esempio pratico dell’utilità dei processi di integrazione
tra ontologie che abbiamo trattato nei paragrafi precedenti.
49

50

4 ARCHITETTURA DI METADATA INTEGRATOR
Questo capitolo è rivolto a quella parte dei lettori che desiderano approfondire il
funzionamento di Metadata Integrator al fine modificarlo o di aggiungervi nuove
funzionalità.
Varranno analizzati in dettaglio molti aspetti del software, dalla sua installazione
ad una visione generale delle classi fondamentali che lo compongono.
Durante il capitolo verranno anche introdotti in maniera molto sommaria alcuni
argomenti che riguardano l’architettura di windows ed i paradigmi di
programmazione ad oggetti per fornire al lettore i necessari strumenti a
comprendere appieno i contenuti.
4.1 Requisiti d’installazione
Come detto più volte il progetto Metadata Integrator è stato inserito all’interno
del progetto Integrate Metadata Editor, di conseguenza i requisiti e la procedura
di installazione che andremo qui ad analizzare sono quelli di IME.
I sistemi operativi supportati sono: Windows 2000, Windows Server 2003
Service Pack 1 for Itanium-based Systems, Windows Server 2003 x64 editions,
Windows Vista Business, Windows Vista Enterprise, Windows Vista Home
Basic, Windows Vista Home Premium, Windows Vista Starter, Windows Vista
Ultimate, Windows XP, Windows XP Professional x64 Edition.
In oltre abbiamo detto in precedenza il programma funge da plug-in per
Microsoft Word, di conseguenza la presenza del programma principale è
indispensabile. Le versioni di Word compatibili con il nostro componente sono
Microsoft Word 2003 / 2007.
In fine l’applicativo richiede la presenza del Microsoft .NET Framework Version
1.1 Redistributable Package. Questo altro non è che un pacchetto di strumenti
necessari al corretto funzionamento delle applicazioni sviluppate con
51

tecnologia .NET di Microsoft ed è scaricabile in forma gratuita dall’apposito sito
di Microsoft.
4.2 Accenni sull’architettura Windows
Sin dalla loro nascita i sistemi della famiglia Windows presentavano una struttura
modulare, il sistema è operativo formato da una collezione di librerie ad aggancio
dinamico (DLL). Queste DLL costituiscono la cosiddetta API (Application
Program Interface) ovvero l’interfaccia fra le applicazioni e il sistema operativo.
Una dynamic link library è una libreria software, ovvero un insieme di funzioni
di uso comune, che non viene collegata in maniera statica ad un eseguibile in fase
di compilazione, ma viene caricata dinamicamente in fase di esecuzione.
I vantaggi di questo tipo di approccio sono che permette la separazione del codice
di programmi in parti concettualmente distinte, che verranno caricate solo se
effettivamente necessarie. Inoltre, una singola libreria può essere caricata in
memoria una sola volta e utilizzata da più programmi, il che permette di
risparmiare le risorse del sistema.
Il principale svantaggio è legato al fatto che una nuova versione di una DLL, se
mal progettata, potrebbe avere un comportamento diverso, interferendo in alcuni
casi addirittura con il funzionamento di alcuni programmi che usavano la
versione precedente.
4.3 Introduzione all’architettura di IME
Come abbiamo detto nel corso di questo documento il progetto Metadata
Integrator è stato inserito all’interno del progetto IME, per cui è bene prima di
approfondire l’architettura, dare un breve introduzione dell’architettura di IME
cosi da poter comprendere meglio il contesto all’interno del quale si è lavorato.
52

4.3.1 Organizzazione del codice
Normalmente un progetto in C sharp contiene almeno due tipi di file, i file cs
che possono essere form di qualche tipo, classi, interfacce ecc, oppure i file
resx utilizzati per creare e definire le risorse dell'applicazione
All’interno di un progetto C# una risorsa è costituita da dati non eseguibili
che vengono distribuiti con l'applicazione stessa. Una risorsa può essere
visualizzata in un'applicazione sotto forma di messaggi di errore o come parte
dell'interfaccia utente.
All’interno del progetto IME in fine vi sono anche file rdf, essi contengono la
materializzazione su disco della nostra ontologia in serializzazione XML.
Le classi che compongono il progetto IME si possono dividere in tre
categorie:
Grafiche: classi che forniscono da interfaccia verso l’utente.
Ontologiche: classi che forniscono una rappresentazione
dell’ontologia all’interno dell’appicazione.
Input Output: classi che forniscono un framework per acquisire e
salvare i dati nei documenti siano essi documenti del pacchetto office
oppure file rdf.
4.3.2 Lo schema ontologico
L’ontologia funge da perno attorno al quale l’intero progetto ruota, essa è
composta da due classi principali (file e document) e quattro classi secondarie
(term location organization e person).
53

Le due classi principali sono materializzate direttamente all’interno del
documento di Word, mentre le classi secondarie sono materializzate
all’interno di altrettanti file RDF.
Si può affermare che le classi secondarie forniscano in un certo qual modo la
base dati per le metainformazioni che sono allegate al documento di Word.
Figura 18 Schema dell'ontologia del progetto
Per manipolare la nostra ontologia usiamo due strumenti diversi a seconda di
dove siano le informazioni; per aggiungere metainformazioni al documento di
Word si usa DsoFile.dll, mentre per accedere alle ontologie materializzate
tramite RDF viene utilizzato Drive.dll. Entrambi i meccanismi di accesso
verranno analizzati più in dettaglio nel corso di questo capitolo.
4.3.3 Le classi ontologiche
Queste classi sono a loro volta divise in due categorie, un primo gruppo
riproduce in maniera più o meno fedele la struttura dei singoli elementi
ontologici secondari. Un secondo gruppo invece riproduce la struttura
54

dell’ontologia, funge da contenitore per le classi del primo tipo e permette le
interazioni tra esse.
Ogni istanza di una classe ontologica possiede un identificatore univoco
all’interno dell’ontologia, attraverso il quale può essere referenziata da tutti
gli altri elementi della stessa ontologia.
L’identificatore contiene informazioni sull’utente e la macchina che hanno
creato l’istanza, per cui non è possibile che due istanze create da utenti
diversi posseggano lo stesso identificatore, anche se rappresentano lo stesso
fenomeno.
4.3.4 DsoFile.dll
I documenti “OLE di archiviazione strutturata” di Microsoft posseggono la
capacità di memorizzare alcune metainformazioni in insiemi di proprietà
permanenti situate all’interno della struttura del documento.
File OLE sono ad esempio documenti di Word, cartelle di lavoro di Excel,
presentazioni PowerPoint ecc…
La libreria Dsofile.dll ,fornita in forma gratuita da Microsoft, è in grado di
accedere sia in lettura che in scrittura alle proprietà di qualsiasi file "OLE di
archiviazione strutturata".
All’interno della libreria Dsofile.dll vi è un unico oggetto che è possibile
istanziare, ovvero DSOFile.OleDocumentProperties.
L'oggetto DSOFile.OleDocumentProperties consente di accedere alle
proprietà di documenti OLE di un file che si carica utilizzando il metodo
Open. Tutte le proprietà vengono lette e salvate in cache al momento
dell'apertura. Le proprietà vengono riscritte nel file solo quando si invoca il
metodo Save. In fine il metodo Close rilascia le risorse allocate e libera i
blocchi sul documento.
55
4.3.5 Drive.dll
Drive è una libreria sviluppata in C# per il pacchetto .NET e fornita dai suoi
sviluppatori con la formula open source. Drive è un parser per documenti
RDF pienamente compatibile con la specifica di RDF fornita dal W3C.
Abbiamo avuto modo di vedere nel capitolo precedente come un grafo RDF
possa essere poi materializzato su file seguendo una delle serializzazioni
esistenti. Va aggiunto che uno stesso grafo può essere espresso in modi molto
diversi, anche se si utilizza la stessa serializzazione.
La libreria drive agevola il lavoro del programmatore acquisendo il
documento RDF e costruendo la struttura a grafo tipica del linguaggio, in
maniera indipendente dalla tecnica di rappresentazione scelta dall’autore del
documento.
La libreria Drive mette a disposizione tre classi principali:
IRdfParserFactory: permette di istanziare un nuovo parser tramite il
metodo GetRdfParser.
IRdfParser: permette di caricare un file rdf tramite il metodo
ParseRdf.
IRdfGraph: permette di navigare all’interno del grafo.
4.4 Metadata Integrator
4.4.1 Fasi dell’implementazione
L’implementazione del progetto si è svolta in due fasi fondamentali. In una
prima fase sono state analizzate le caratteristiche dell’architettura esistente e
comparate con le esigenze associate alle nuove funzionalità che si desidera
implementare. Frutto di tale analisi è stato un insieme di modiche
56

architetturali necessarie agli oggetti che si desiderino sottoporre alla funzione
di integrazione.
In una seconda fase sono stati introdotti tutti i nuovi elementi necessari al
funzionamento del sistema ed è stato quindi implementata la funzione di
integrazione.
4.4.2 Organizzazione del codice
L’organizzazione del codice è stata basata su di due paradigmi tipici della
programmazione ad oggetti, le classi astratte e l’ereditarietà tra classi.
La programmazione orientata agli oggetti è un paradigma di
programmazione, che prevede di raggruppare in un'unica entità (la classe) sia
le strutture dati che le procedure che operano su di esse, creando per l'appunto
un "oggetto" software dotato di proprietà (dati) e metodi (procedure) che
operano sui dati dell'oggetto stesso.
L' ereditarietà consente di definire una classe come sottoclasse o classe
derivata a partire da una classe preesistente detta superclasse o classe base. La
sottoclasse "eredita" implicitamente tutte le caratteristiche (proprietà e
metodi) della classe base.
Concettualmente, l'ereditarietà indica una relazione di generalizzazione: essa
corrisponde infatti all'idea che la superclasse rappresenti un concetto generale
e la sottoclasse rappresenti una variante specifica di tale concetto generale.
Una classe A dichiarata sottoclasse di un'altra classe B:
eredita (possiede implicitamente) tutte le variabili di istanza e tutti i
metodi di B;
può avere variabili o metodi aggiuntivi;
57

può ridefinire i metodi ereditati da B attraverso l'overriding, in modo tale
che essi eseguano la stessa operazione concettuale in un modo specializzato.
C# cosi come altri linguaggi di programmazione ad oggetti permette ad una
classe o ad un oggetto di modificare il modo in cui è implementata una
propria funzionalità ereditata da un'altra classe (di solito un metodo). Questa
caratteristica è chiamata "ridefinizione" (in inglese, "override").
Una classe astratta è una classe che non può essere istanziata direttamente.
Da una siffatta classe sarà possibile soltanto ereditarne proprietà e metodi
nelle classi figlie. In C#, per definire una classe astratta si utilizza la parola
riservata abstract. Ad esempio:
public abstract class FiguraGeometrica {...}
Sempre grazie alla parola riservata abstract, è possibile definire anche dei
metodi astratti all'interno delle classi astratte. Tali metodi, dovranno essere
necessariamente ridefiniti nelle classi figlie. Un possibile esempio di un
metodo astratto nella classe astratta FiguraGeometrica potrebbe essere il
seguente:
public abstract void disegna();
Ogni sottoclasse di una classe astratta deve ridefinire tutti i metodi astratti
della sua superclasse (o essere anch'essa dichiarata astratta). Se è una classe
astratta ed implementarne un'altra essa non ha tale obbligo, ma chi dovesse
implementare la classe astratta figlia dovrà implementare i metodi astratti di
entrambe.
Una classe astratta può anche contenere proprietà e metodi concreti, in tal
caso essi vengono ereditati direttamente dalle classi figlie.
58
4.4.3 La classe MergeableItem
La classe MergeableItem è una classe astratta che è stata aggiunta al progetto
per fungere da interfaccia alle classi ontologiche che rispecchiano in maniera
diretta uno delle classi secondarie dell’ontologia.
Questa classe definisce in particolare alcuni metodi astratti che sono
fondamentali per la funzione di integrazione, soprattutto per poter mettere a
confronto due diverse classi ontologiche e sapere se sono uguali o in cosa
differiscono.
Il confronto tra la classe corrente ed un'altra classe ontologica viene fatto per
mezzo del metodo equals.
Public bool Equals(object obj){…};
Il metodo equals è un metodo implementato nella classe object di C# della
quale tutte le classi sono necessariamente figlie, esso consente di determinare
se l'oggetto Object specificato è uguale all'oggetto Object corrente. Tale
metodo può tuttavia essere ridefinito nelle classi figlie, ed è proprio questo il
nostro caso, per poterne personalizzare il comportamento.
Il metodo equals non si limita a controllare se gli oggetti sono dello stesso
tipo, ma controlla che i valori associati alle proprietà dei due oggetti
corrispondano.
Si pone tuttavia il problema di scegliere in modo efficace le proprietà
pertinenti a identificare l’oggetto in quanto rappresentazione della stessa
entità concreta, che noi chiameremo proprietà identificanti.
Abbiamo visto nel corso del secondo capitolo come le ontologie siano entità
che variano nel corso del tempo, per cui abbiamo bisogno di un metodo che
sia il più possibile flessibile per specificare le proprietà identificanti.
59

Sono venuti in nostro aiuto ancora una volta i metadati, infatti abbiamo
inserito all’interno dell’ontologia un nuovo elemento in grado di fornirci
metainformazioni sugli elementi strutturali delle classi ontologiche.
In particolare per ogni classe sappiamo quali siano le proprietà identificanti.
Tali informazioni sono accessibili tramite il metodo statico :
public static ArrayList getMergeableItemIdentifierFields (MergeableClassesType)
che si trova all’interno della classe MergeableClass di cui parleremo in
seguito.
Alla luce di queste premesse possiamo capire il funzionamento del metodo
equals implementato nelle cassi figlie di MergeableItem. Il metodo ricava
dall’ontologia le metainformazioni sulla classe che esso rappresenta, quindi
confronta tra loro i campi significativi per valutare se l’oggetto specificato
possa essere accomunato all’oggetto corrente.
Abbiamo detto nel corso del capitolo precedente che ogni istanza ontologica è
in possesso di un identificatore univoco, usato dalle altre istanze all’interno
dell’ontologia per referenziarla.
Abbiamo anche fatto notare come tale identificatore sia diverso in base
all’utente che crea l’istanza. Si deduce che anche se due istanze
rappresentano lo stesso oggetto esse possano avere identificatori distinti in
diverse ontologie. Vista l’architettura del progetto vi possono essere vi
possono essere nel sistema innumerevoli documenti che identificano
l’oggetto con uno o l’altro identificatore indipendentemente.
Può essere quindi vantaggioso che il prodotto dell’integrazione sia in grado di
associare entrambi gli identificatori all’oggetto. A questo scopo è stato
aggiunto alla classe MergeableItem un campo di tipo collezione
alternativeIdentifiers. All’interno di alternativeIdentifiers vengono salvati di
60

volta in volta gli identificatori delle ontologie con le quali l’oggetto corrente è
stato integrato, naturalmente solo se i due non coincidono.
Questo metodo riproduce a propria volta un processo di integrazione a livello
del singolo oggetto. Esso analizza ogni singola proprietà dell’oggetto corrente
mettendola in confronto con la relativa proprietà l’oggetto specificato alla
ricerca di valori che non coincidano.
Public void Integrate(MergeleItem Item){…};
Quando viene rinvenuto un valore non coincidente modifica l’oggetto
corrente assegnando al campo in conflitto il valore più recente.
Quindi ritorno da tale metodo l’oggetto sul quale è stato invocato è stato
aggiornato, ogni campo riporta il valore più recente e le relative
metainformazioni associate.
4.4.4 La classe MergeableElement
Per applicare la politica di gestione automatica dei conflitti vista nel capitolo
precedente abbiamo necessità di avere informazioni aggiuntive su alcuni
degli elementi che compongono la nostra ontologia.
In particolare necessitiamo metainformazioni riguardanti l’ultima operazione
avvenuta sull’oggetto in questione e la data della stessa.
La classe MergeableElement fornisce un interfaccia per tutti gli oggetti che
necessitano delle nuove metainformazioni.
Oggetti che rientrano in questa categoria sono sia le istanze delle diverse
classi ontologiche, sia le proprietà delle stesse classi.
In particolare:
61
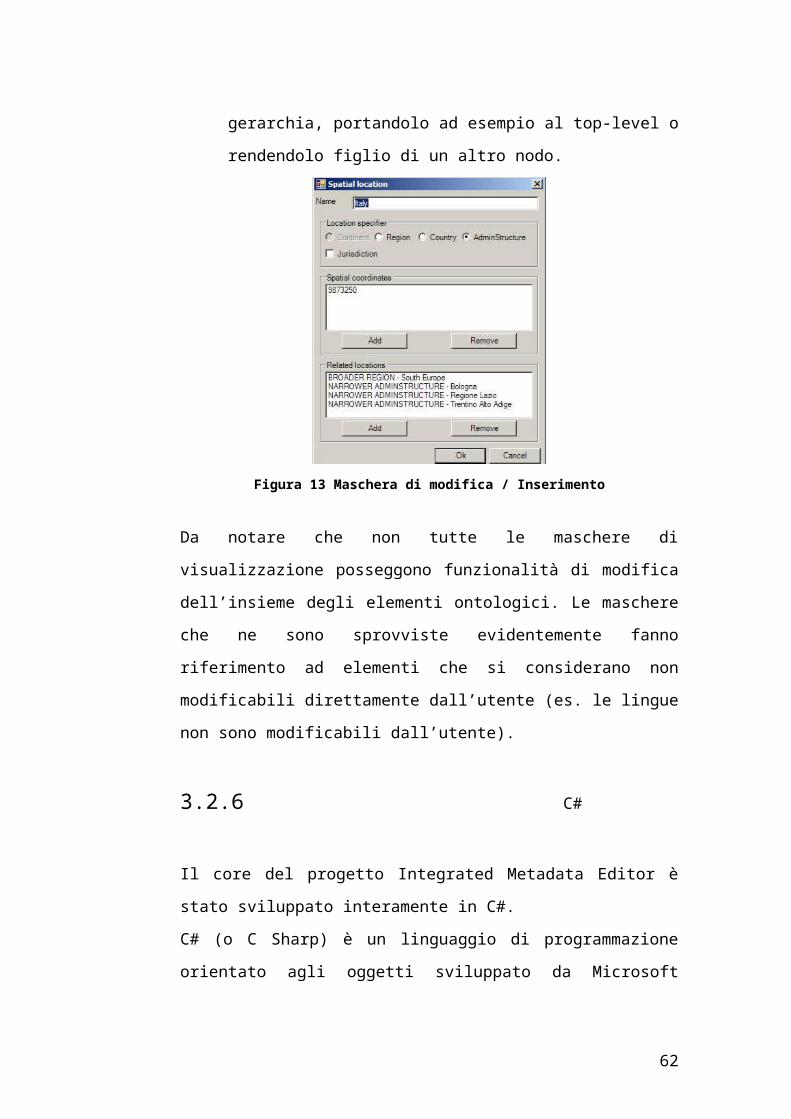
public void setOperation(operation newOperation)
public operation getOperation()
sono i metodi che permettono rispettivamente di marcare un oggetto come
modificato, e di ottenere informazioni su quale tipo di operazione sia
avvenuta.
Nel caso non sia avvenuta alcuna operazione il metodo ritornerà un valore
predefinito (Ex. Nothing).
Le uniche operazioni possibili sugli oggetti sono inserimento e cancellazione,
nel caso l’oggetto sia soggetto ad un operazione di aggiornamento, essa è resa
tramite un operazione di cancellazione del vecchio valore seguita da un
operazione di inserimento del valore aggiornato.
Anche la struttura ontologica è stata modificata leggermente per essere in
grado immagazzinare le nuove informazioni sugli oggetti.
4.4.5 La classe MergeableClass
Questa classe astratta fornisce un interfaccia comune alle classi che fungono
da collezioni di elementi ontologici.
Tra i metodi implementati troviamo meccanismi per la manipolazione degli
elementi (ex. aggiungi elimina elemento) e soprattutto metodi di confronto tra
elementi.
Il metodo getEquivalentElement consente di stabilire se la classe contiene
l’elemento specificato. In caso affermativo restituisce l’elemento
corrispondente altrimenti torna un valore nullo, che significa che non
contiene nessun oggetto concettualmente uguale all’oggetto specificato.
Per ottenere il risultato per ognuno degli elementi di cui è contenitore invoca
il metodo equals con l’oggetto specificato. Il primo degli oggetti che da un
esito positivo viene restituito.
62

public MergeableItem getEquivalentElement (MergeableItem){…}
Figura 19 Relazioni di ereditarietà legate alle classi Mergeable
4.4.6 Il processo di integrazione
Dopo aver creato le interfacce viste nella sezione precedente ed adattato gli
oggetti esistenti nel progetto affinché siano in grado di implementarle, siamo
in fine pronti per implementare il nostro processo di integrazione.
Il processo si compone di quattro fasi fondamentali:
Acquisizione delle informazioni: vengono raccolte informazioni
inerenti le classi di entrambe le ontologie, e vengono istanziate le
classi ontologiche.
Confronto degli elementi: i singoli elementi vengono confrontati tra
loro e vengono individuate le zone di sovrapposizione tra le due
ontologie.
Aggiornamento dell’ontologia corrente: vengono inseriti ,eliminati o
modificati gli elementi dell’ontologia corrente ove necessario.
63

Controllo di validità: viene verificato che il risultato dell’integrazione
sia ancora un ontologia valida.
Come abbiamo detto più volte nel corso di questo documento le ontologie
hanno la tendenza a subire variazioni nel tempo a seguito di svariati fattori.
Per assecondare tale esigenza abbiamo strutturato il meccanismo che
stabilisce quali classi debbano partecipare all’integrazione in maniera
dinamica.
Le nuove informazioni sono state inserite direttamente all’interno
dell’ontologia in un apposita sezione.
Le informazioni su quali classi ontologiche siano interessate dall’integrazione
sono accessibili all’interno dell’applicativo tramite il metodo statico:
public static ArrayList getMergeableClassList()
che si trova all’interno della classe MergeableClass.
Dopo aver acquisito tali informazioni il processo procede acquisendo gli
elementi interessati da entrambe le ontologie. La posizione dell’ontologia
locale è nota al processo, l’altra ontologia, che noi chiameremo onologia di
confronto, viene invece indicata dall’utente come abbiamo visto nel capitolo
precedente.
Una volta acquisiti i dati per ogni classe ontologica vengono istanziate una
collezione di MergeableItem, che rappresenta gli elementi dell’ontologia di
confronto, e una MergeableClass, che rappresenta gli elementi dell’ontologia
corrente, e si procede alla fase di confronto.
Il prossimo passo dell’integrazione sta nell’individuazione delle zone di
sovrapposizione delle due ontologie ovvero degli elementi presenti in
entrambe.
64

Ogni oggetto può trovarsi:
Nell’ontologia locale ma non in quella di confronto.
Nell’ontologia di confronto ma non in quella locale.
In entrambe le ontologie.
Il primo caso non è di nostro interesse, in quanto come abbiamo detto nel
corso del capitolo precedente soltanto l’ontologia locale risulta modificata al
termine del processo, e rispetto a questo caso l’ontologia locale già risulta
completa.
Il secondo caso prevede invece che l’oggetto sia aggiunto all’ontologia locale
che altrimenti risulterebbe incompleta.
In fine l’ultimo caso risulta leggermente più complesso. Infatti dopo aver
verificato che l’oggetto esiste in entrambe le ontologie è necessario in primo
luogo verificare se ha subito modifiche in uno o in entrambe le ontologie.
Se l’oggetto è stato soggetto ad un operazione in una soltanto delle ontologie,
la versione modificata diventa quella ufficiale.
Se invec l’oggetto ha subito modifiche in entrambe le ontologie, è necessario
stabilire quale versione sia più attendibile.
Come abbiamo visto nel corso del capitolo 3 questo viene fatto in base alla
data in cui la modifica è avvenuta, infatti associata ad ogni operazione si
trova come abbiamo visto un etichetta temporale che indica con esattezza il
giorno in cui l’operazione è avvenuta. Confrontando le date è semplice
ottenere quale versione sia più recente e di conseguenza più attendibile.
Dopo aver terminato questo controllo è necessario ripetere lo stesso tipo di
confronto anche per ogni proprietà dell’oggetto. Come abbiamo visto questo
65

secondo controllo viene delegato all’oggetto stesso invocando il metodo
Integrate.
Il controllo di validità viene eseguito a livello del singolo elemento.
immediatamente dopo l’inserimento o la modifica dell’oggetto stesso.
Abbiamo visto come la rappresentazione dell’ontologia interna all’IME sia
associabile ad un albero, mentre la struttura ontologia di RDF sia associabile
ad un grafo diretto. Per permetterci di convertire un grafo in un albero
tuttavia è necessaria una condizione: non ci devono essere cicli all’interno del
grafo.
Il controllo di validità ha esattamente questo scopo, verifica che l’eventuale
inserimento dell’oggetto non dia origine a conflitti simili, non generi nessun
ciclo all’interno della struttura ontologica.
4.5 Installazione di IME
L’installazione di IME è semplice ed immediata gran parte delle applicazioni in
ambiente Windows del resto.
In primo luogo è necessario procurarsi “Microsoft .NET Framework Version 1.1
Redistributable Package” se questo non è gia installato sulla macchina. Il
pacchetto può essere reperito in forma gratuita nella sezione download del sito di
Microsoft.
Una volta installato l’aggiornamento sarà sufficiente lanciare il pacchetto di
installazione di IME e seguire la procedura guidata.
Ad installazione avvenuta possiamo notare che aprendo un documento di Word si
presenta un nuovo elemento tra le barre degli strumenti del programma chiamato
“Integrated Metadata Editor Toolbar”. Questo elemento consente di abilitare /
disabilitare il nuovo plug-in.
Dopo l’installazione IME di default risulta abilitato quindi all’utente che desideri
utilizzarlo non restano altre operazioni da svolgere.
66

67

5 CONCLUSIONI
Da questa dissertazione emerge l’utilità e l’attualità delle ontologie in molti
ambiti, soprattutto in quello dell’information flow all’interno di organizzazione
di una certa dimensione. È anche emerso tuttavia come ad oggi gli strumenti più
diffusi tra gli utenti non siano ancora in grado di supportare queste nuove
metodologie di lavoro basate sulle ontologie e sui metadati.
In questo contesto abbiamo visto come Metadata For Document Exchange ed in
particolare Integrated Metadata Editor siano strumenti preziosi per l’utente, in
grado di integrarsi con gli strumenti di uso comune, e che con un disagio minimo
sono in grado di offrirgli tutti i vantaggi, che abbiamo visto essere molti,
derivanti dall’inserimento dei metadati all’interno dei documenti prodotti.
Proseguendo con lo sviluppo del documento abbiamo visto l’assoluta necessità,
quando si comincia a lavorare con le ontologie, di un processo in grado di
allineare le svariate varianti ontologiche esistenti in un modello come quello da
noi proposto. Proprio in questo ambito abbiamo inserito Metadata Integrator, un
processo capace di integrare diverse varianti ontologiche in maniera semi
automatica. Il nostro programma tuttavia è ancora lungi dall’essere perfetto, e di
questo tratteremo in questa sezione, a beneficio di coloro che desiderino
implementare un processo simile al nostro o che desiderino aumentarne le
funzionalità.
Sicuramente un primo punto che può essere migliorato è la gestione dei conflitti
che si possono creare tra le diverse ontologie. È importante che l’integrazione
ontologica sia per quanto possibile automatica, poiché non si possono fare
assunzioni sul grado di preparazione di un utente. Tuttavia abbiamo visto vi sono
situazioni in cui il processo si trova in difficoltà a stabilire quale versione sia la
più attendibile.
Il linguaggio RDF non mette a disposizione alcun meccanismo per il
versionamento o l’integrazione delle ontologie, per cui un programmatore che si
68

appresti ad affrontare questo problema deve prevedere di salvare in qualche
modo metainformazioni sull’ontologia stessa.
Il nostro processo prevede di registrare la quantità minima di informazioni per
essere in grado di prendere decisioni autonome sulle situazioni di conflitto. Dal
momento che le informazioni a disposizione sono minime, il meccanismo di
decisione in caso di conflitto è tutto sommato piuttosto ingenuo. Avendo a
disposizione un numero maggiore di metainformazioni sulle ontologie e le
operazioni avvenute si potrebbero prevedere meccanismo molto più raffinati.
Un altro punto che sarebbe interessante sviluppare meglio sarebbe l’interfaccia di
Metadata Integrator, con particolare riferimento al report riepilogativo delle
modifiche apportate all’ontologia. Al momento, ricordiamo, riporta solamente gli
elementi aggiunti ed eliminati dalle diverse classi. Potrebbe essere interessante
per un utente più esperto un report più dettagliato, che riporti anche gli elementi
modificati ed i campi di tali elementi che sono stati interessati.
Potrebbe anche essere interessante permettere agli utenti una volta terminata
l’integrazione di verificare i cambiamenti avvenuti e di annullare quelle che loro
ritengono non corrette.
Questo sviluppo potrebbe essere un diverso meccanismo per ridurre al minimo
gli errori dovuti all’integrazione di ontologie, anche se richiederebbe l’intervento
di un utente con un certo bagaglio di conoscenze di base.
Vorrei concludere dicendo che la possibilità di partecipare a questo progetto è
stata per me un esperienza particolarmente gratificante. In particolare sono felice
di aver concluso il mio piano di studi con esso perché mi ha dato la possibilità di
mettere in pratica buona parte delle conoscenze che ho acquisito nel corso di
questi tre anni di studio.
Ad esempio i corsi di programmazione e paradigmi di programmazione sono stati
fondamentali per comprendere l’architettura di un progetto complesso come
Integrated Metadata Editor, per giunta sviluppato in un linguaggio C# mai visto
fino a questo momento. Il corso di ingegneria del software è stato indispensabile
69

per impostare le struttura del mio progetto ed integrarla con quello gia esistente,
il corso di sistemi operativi e di reti di calcolatori sono stati preziosi per
comprendere il comportamento del mio sistema operativo.
In fine il corso di tecnologie web mi ha permesso di comprendere appieno le
grandissime potenzialità e le prospettive di applicazioni fondate su ontologie e
metadati. Tali applicazioni sono probabilmente il prossimo livello di sviluppo in
molti più ambiti di quanti si possa ad oggi immaginare.
70

6 BIBLIOGRAFIA
[BAN87] Jay Banerjee and Won Kim and Hyoung-Joo Kim and Henry F. Korth.
“Semantics and Implementation of Schema Evolution in Object-Oriented
Databases” ACM SIGMOD Record archive Volume 16 , Issue 3 (December
1987) Pages: 311 - 322 Year of Publication: 1987 ISSN:0163-5808
http://portal.acm.org/ft_gateway.cfm?
id=38748&type=pdf&coll=&dl=ACM&CFID=15151515&CFTOKEN=6184618
[CHA00] H. Chalupsky. “OntoMorph: a translation system for symbolic
knowledge”. In A.G. Cohn, F. Giunchiglia, and B. Selman, editors, Principles of
Knowledge Representation and Reasoning: Proceedings of the Seventh
International Conference (KR2000), Breckenridge, Colorado, USA, April 2000,
San Francisco, CA, 2000. Morgan Kaufmann.
http://www.isi.edu/~hans/publications/KR2000.pdf
[GRU93] Gruber, T. R. (1993). “A Translation Approach to Portable
Ontology Specifications”. Knowledge Acquisition, 5(2), 199-220, Academic
Press Ltd. London, UK
ftp://ftp.ksl.stanford.edu/pub/KSL_Reports/KSL-92-71.ps.gz
[HEF04] Heflin, J. and Hendler, J. “Dynamic Ontologies on the Web”. In:
Proceedings of the Seventeenth National Conference on Artificial Intelligence
(AAAI-2000). AAAI/MIT Press, Menlo Park, CA, 2000. pp. 443-449.
[KLE01a] Michel Klein. “Combining and relating ontologies: an analysis of
problems and solutions”. In: Workshop on Ontologies and Information Sharing,
IJCAI'01, Asuncion Gomez-Perez, Michael Gruninger, Heiner Stuckenschmidt
and Michael Uschold (eds.), Seattle, USA, August 4-5, 2001.
http://www.cs.vu.nl/~mcaklein/papers/IJCAI01-ws.pdf
71
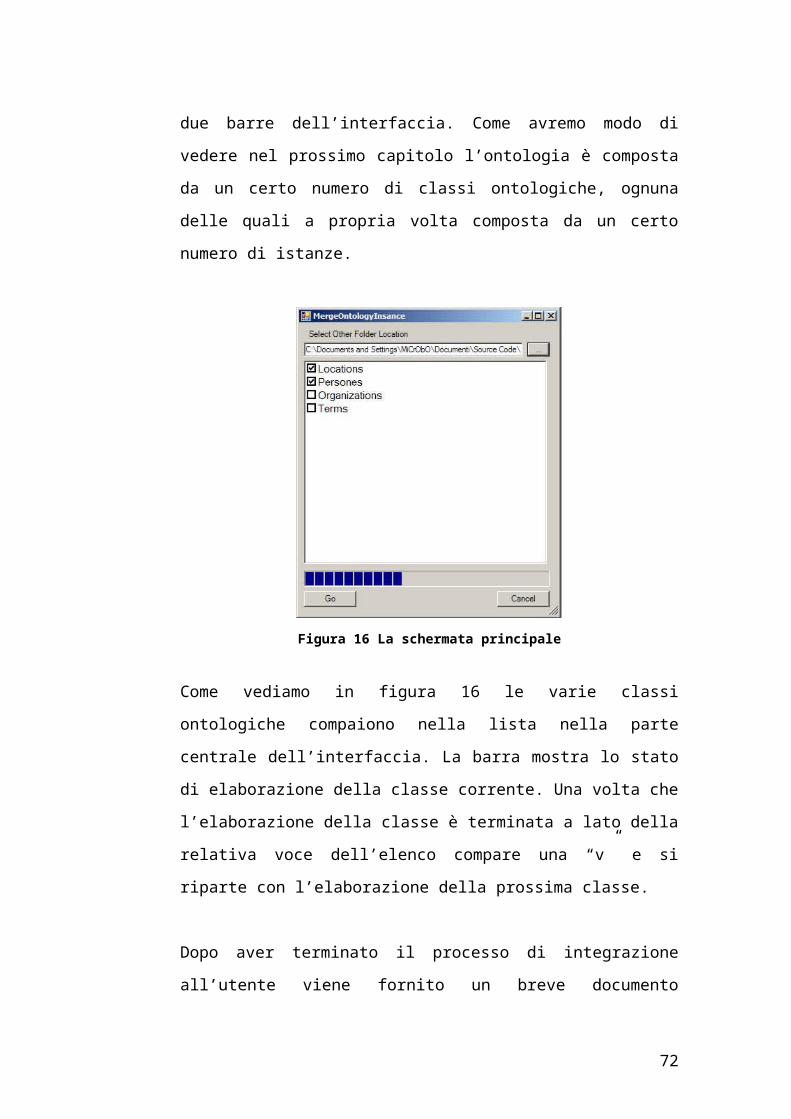
[KLE01b] Michel Klein and Dieter Fensel. “Ontology versioning for the
Semantic Web”. In: Proceedings of the First International Semantic Web
Working Symposium (SWWS), page 75-91, Stanford University, California,
USA, July 30 - August 1, 2001.
http://www.cs.vu.nl/~mcaklein/papers/SWWS01.pdf
[KLE02a] Michel Klein, Dieter Fensel, Atanas Kiryakov and Damyan
Ognyanov. “Ontology Versioning and Change Detection on the Web”. In:
13th International Conference on Knowledge Engineering and Knowledge
Management (EKAW02), LNCS no. 2473, page 197-212, Siguenza, Spain,
October 1-4, 2002.
http://www.cs.vu.nl/~mcaklein/papers/EKAW02.pdf
[KLE02b] Michel Klein, Atanas Kiryakov, Damyan Ognyanov and Dieter
Fensel. “Finding and Characterizing Changes in Ontologies.” In: Proceedings
of the 21st International Conference on Conceptual Modeling (ER2002) , LNCS
no. 2503, page 79-89, Tampere, Finland, October 7-11, 2002.
http://www.cs.vu.nl/~mcaklein/papers/ER2002.pdf
[MAS03] MASOLO Claudio, OLTRAMARI Alessandro, GANGEMI Aldo,
GUARINO Nicola, VICU Laure “La prospettiva dell'ontologia applicata”
Rivista di estetica ISSN 0035-6212 2003, vol. 43, no22, pp. 170-183
http://www.loa-cnr.it/Papers/rivest.pdf
[MC00] Deborah L. McGuinness, Richard Fikes, James Rice, and Steve Wilder.
“An Environment for Merging and Testing Large Ontologies”. In the
Proceedings of the Seventh International Conference on Principles of Knowledge
Representation and Reasoning (KR2000), Breckenridge, Colorado, USA. April
12-15, 2000.
http://dit.unitn.it/~accord/RelatedWork/Matching/McGuinnessKR.pdf
72

[PIN99]H. Sofia Pinto, Asuncion Gomez-Perez, and Joao P. Martins
“Some issues on ontology integration”. In Proceedings of The Workshopon
Ontologies and Problem Solving Methods During IJCAI-99, Stockholm, Sweden,
August 1999.
http://ftp.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-18/7-pinto.pdf
[SMI01] Barry Smith, Christopher Welty. “FOIS introduction: Ontology
towards a new synthesis” Formal Ontology in Information Systems Proceedings
of the international conference on Formal Ontology in Information Systems -
Ogunquit, Maine, USA Pages: 3 - 9
Year of Publication: 2001 ISBN:1-58113-377-4
http://www.cs.vassar.edu/faculty/welty/papers/fois-intro.pdf
[VIS97] Pepjijn R. S. Visser and Dean M. Jones and T. J. M. Bench-Capon and
M. J. R. Shave. “An Analysis of Ontological Mismatches: Heterogeneity
versus Interoperability” Working notes of the AAAI 1997 Spring Symposium
on Ontological Engineering, Stanford University, California , USA, pp.164-172.
http://www.csc.liv.ac.uk/~kraft/publications/stanf-97.ps.gz
[WIK06] WikiPedia “Ontologia” 09/02/2006
http://it.wikipedia.org/wiki/Ontologia
[WIK07a] WikiPedia “Ontologia (informatica)” 07/02/2007
http://it.wikipedia.org/wiki/Ontologia_%28informatica%29
[WIK07b] WikiPedia “C Sharp” 17/02/2007
http://en.wikipedia.org/wiki/C_Sharp
73






![Imp plescia[1] pdf libro ontologia](https://static.fdocumenti.com/doc/165x107/568cc68e1a28ab8c668b6637/imp-plescia1-pdf-libro-ontologia-5707dcfa7f8bc.jpg)











