Datawarehouse Architetture, strumenti ETL, modelli dei dati Giovanni Laboccetta.
Upload
massimo-cenciCategory
view
101download
3
TECNICHE DI PROGETTAZIONE
DELLA STAGING AREAIl caricamento di un file di dati sembra un’attività a basso costo. Scopriamo perchè non è così semplice come appare.
MASSIMO CENCI

INTRODUZIONE
L’obiettivo di questo articolo è quello di mostrare le complessità che si nascondono nella fase di caricamento della Staging Area di un processo ETL. Nonostante questa fase sia spesso considerata secondaria, è invece di straordinaria importanza perché costituisce le fondamenta delle fasi successive.
Errori, dimenticanze, scarsa attenzione e, soprattutto, la mancanza di una visione globale del risultato finale e delle strutture successive, porteranno a una progettazione della Staging Area che potrebbe pregiudicare il successo dell’intero Data Warehouse.
Come sappiamo, la Staging Area è il punto di accesso di tutti i file di dati che giungono dai sistemi alimentanti. In situazioni di particolare complessità, come gli Enterprise Data Warehouse, parliamo di centinaia di flussi che giungono da numerosi sistemi diversi.
A parte la numerosità e la eterogeneità dei sistemi di alimentazione, il caricamento di un file di dati sembra un’operazione abbastanza semplice. Il file di dati, il modulo di caricamento, la tabella di Staging Area: questi gli elementi in gioco. Scopriamo perchè non è così semplice come appare.
2Micro ETL Foundation

IL PUNTO DI PARTENZA
Il caricamento di un flusso lo possiamo rappresentare con il grafico della figura 1. Quasi tutte le presentazioni di un progetto di Data Warehouse e Business Intelligence, conterranno un grafico di quel tipo. Magari sarà più generalizzato indicando un insieme di flussi, un processo elaborativo e numerose tabelle finali di Staging Area. Comunque lo si voglia rappresentare, è una piccola componente del processo ETL di caricamento di un DWH.
Se lo osservate bene sembra banale: c’è un flusso dati indicato come XXX.TXT ( un’estensione TXT
ci indica facilmente che è un flusso in formato testo). C’è una tabella di Staging Area indicata come XXX_STT. E c’è la procedura P1 che si occuperà di
caricare i dati del flusso di input nella tabella di Staging Area. Ricordiamo che il caricamento della Staging Area dovrebbe essere il primo passo nella costruzione di un DWH. Non pensate a soluzioni alternative che bypassino questa fase.
3Micro ETL Foundation

IL PUNTO DI PARTENZA
Il caricamento di questo data file sarà sicuramente presente nel Gantt di progetto con associato un numero di giorni previsto. Quel numero di giorni moltiplicato per il numero complessivo di data file darà una stima approssimativa dell’effort necessario per il caricamento della Staging Area.
La stima unitaria probabilmente sarà un numero piccolo: in fondo stiamo parlando di creare una tabella e scrivere una procedura che la carica. Se pensiamo di utlizzare un tool commerciale per il caricamento ETL, la logica non cambia, anche se la possiamo rappresentiamo graficamente. Il tool creerà per noi la tabella, e sulla base del mapping sulle colonne che configuriamo, creerà in automatico la procedura di caricamento secondo il linguaggio interno del database.
Adesso però usciamo dal mondo ideale delle presentazioni tipico dell’ambito commerciale, ed entriamo nella realtà dei dati per scoprire perché la stima che abbiamo previsto è sicuramente sbagliata.
Alla fine di questo processo di approfondimento, non saranno più un flusso, una procedura e una tabella, e dovremo stimare i tempi di qualcosa di molto più complesso. Lo faremo a piccoli step successivi, entrando sempre di più in profondità nella conoscenza delle strutture coinvolte e dei problemi nascosti.
Lo faremo ipotizzando di non avere un budget sufficiente per comprare un tool di ETL. In questo modo, vedremo più chiaramente cosa si cela dietro le quinte di un caricamento.
4Micro ETL Foundation
KNOWLEDGE DRILL 1
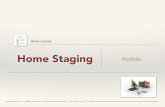
In questo primo drill sulla conoscenza, utilizzerò il concetto di external table, cioè di una struttura dati che “ vede” un flusso di testo come fosse una tabella. Quasi tutti i moderni database hanno concetti simili o riconducibili ad esso.
In questa figura notiamo la presenza della external table XXX_FXT. L’utilizzo di una external table ci permette di definire la struttura del file di dati come fosse una tabella, quindi più facile da gestire con il normale linguaggio SQL.
Diversamente avremmo dovuto scrivere una procedura che leggeva ogni riga del file di dati, con la difficoltà di identificare a programma i vari campi che costituiscono il record.
Quindi è necessario creare questa nuova struttura affinché la procedura di caricamento possa caricare la tabella di Staging Area.
La tabella esterna è un concetto logico, non occupa spazio fisico, e deve essere costruita sulla base della struttura del flusso dati di input.
La figura 1 quindi, si è un po’ complicata. Poca cosa, comunque, soltanto una struttura in più da prendere in considerazione.
5Micro ETL Foundation

KNOWLEDGE DRILL 1
Teoricamente, a questo punto, la procedura P1 può contenere un banale statement di inserimento del tipo:
insert into XXX_STT select * from XXX_FXT
Questo ci risolve il problema del caricamento. Nella pratica, non sarà quasi mai così: iniziamo a
vedere ora perché anche questo disegno è incompleto.
6Micro ETL Foundation
KNOWLEDGE DRILL 2
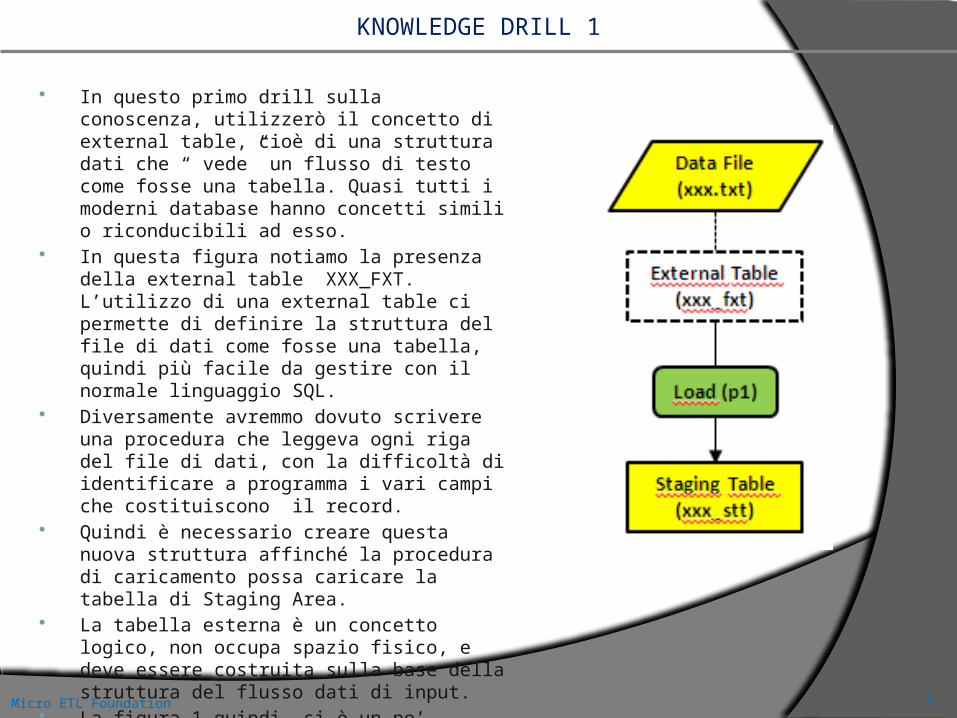
Non è usuale che il flusso dati visto dalla external table possa essere caricato direttamente, senza alcun ulteriore intervento, nella tabella finale.
Forse può accadere per qualche semplice tabella descrittiva di poche colonne, ma in genere, tutti i flussi di alimentazione importanti (per intenderci, quelli che diventeranno tabelle dimensionali o tabelle dei fatti) avranno bisogno di qualche intervento aggiuntivo.
Ecco perché è necessaria, una nuova struttura XXX_FXV. In pratica aggiungiamo una vista che adatterà i dati secondo le regole e gli standard interni del Data Warehouse.
Un esempio semplice sono il formato delle date. Io consiglio che tutte le date siano sempre strutturate secondo un unico standard che faciliti l’ordinamento, cioè nel formato YYYYMMDD.
Nei flussi di input, difficilmente sarà presente un formato di quel tipo. E’ molto più probabile che le date siano in altri formati, per esempio DD-MM-YYYY, DD/MM/YYYY o YYYY-MON-DD: in questi casi la vista effettuerà le trasformazioni necessarie.
7Micro ETL Foundation

KNOWLEDGE DRILL 2
Un altro esempio può essere il formato di un codice, che nel flusso di input è un numero, ma nelle tabelle del Data Warehouse diventa, per esempio, un codice alfanumerico preceduto da tanti zeri secondo una lunghezza massima prestabilita.
Queste piccole trasformazioni possono essere numerose, non tutte supportate nativamente dalla sintassi di creazione delle external tables, e la vista è un ottimo strumento per effettuarle, in quanto è anch’essa una struttura logica (come la external table) e quindi non occupa spazio fisico.
Se siamo fortunati la figura precedente potrebbe essere quello definitiva, ma nella maggior parte dei casi anche essa sarà incompleta. Procediamo quindi con l’analisi.
8Micro ETL Foundation
KNOWLEDGE DRILL 3
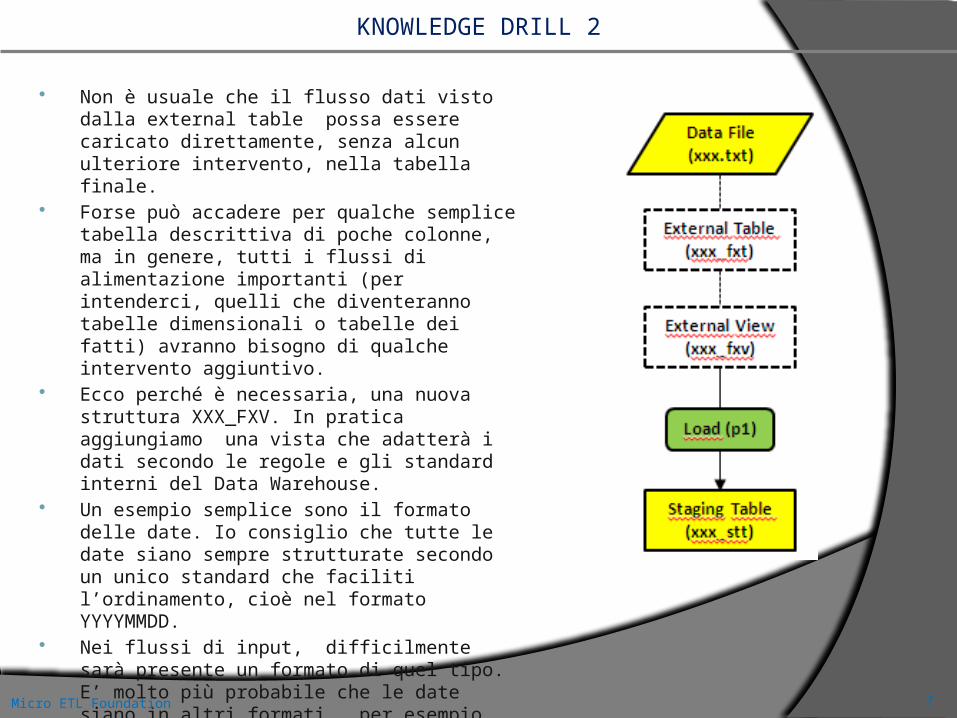
Molto spesso le informazioni presenti nel flusso di input non sono sufficienti per ottenere un dato utilizzabile. Facciamo qualche esempio.
Supponiamo che alcune informazioni sul cliente siano presenti su un’ altra tabella T1 gestita on-line o su un altro flusso che giunge da un diverso sistema alimentante. Poiché desideriamo che siano presenti anche queste informazioni aggiuntive dentro la tabella di Staging Area che raccoglie le informazioni principali dei clienti, (in modo che tutte insieme confluiscano nella dimensione cliente) sarà necessario costruire una ulteriore vista che metta in collegamento la vista precedente con la tabella T1 (o con tutte le altre tabelle necessarie).
Un altro esempio tipico è la presenza di un codice esterno diverso dal codice interno di riferimento nel Data Warehouse .
9Micro ETL Foundation

KNOWLEDGE DRILL 3
Prendiamo un codice di titolo finanziario. Spesso in una banca si utilizzano dei codici interni come riferimento titolo, ma il flusso di alimentazione, che magari arriva da una società di fondi, utilizza un codice internazionale (ISIN).
Anche in questo caso sarà necessario, per mezzo della vista, recuperare il codice interno da qualche altra tabella di mapping, prima di caricare la tabella di Staging Area. Queste trasformazioni, che ho definito come “arricchimento in un mio articolo [1] possono anche essere numerose, complicando non poco la costruzione della vista finale.
Come potete vedere, al terzo passo di approfondimento, la prima figura si è sicuramente complicata: sono presenti più strutture e più elementi da considerare. La prima vista permetteva di definire delle piccole trasformazioni “sintattiche”, la seconda vista permette di aggiungere altre informazioni “logiche”.
Si entra di più nella logica semantica dell’informazione e si orienta la struttura delle tabelle di Staging Area verso quelle che saranno le strutture dimensionali finali.
10Micro ETL Foundation
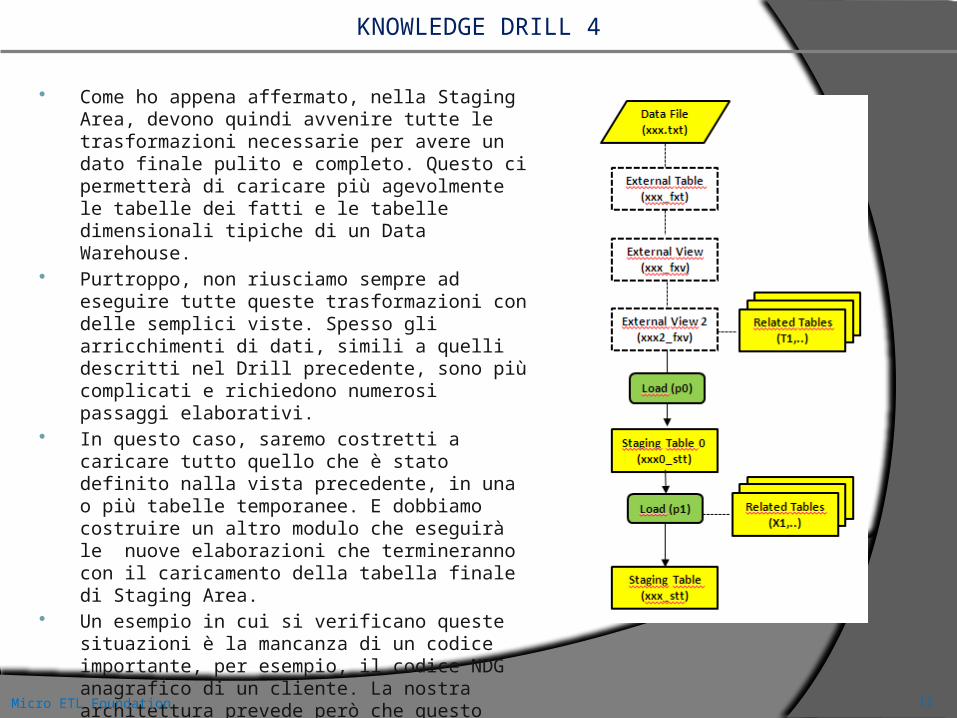
KNOWLEDGE DRILL 4
Come ho appena affermato, nella Staging Area, devono quindi avvenire tutte le trasformazioni necessarie per avere un dato finale pulito e completo. Questo ci permetterà di caricare più agevolmente le tabelle dei fatti e le tabelle dimensionali tipiche di un Data Warehouse.
Purtroppo, non riusciamo sempre ad eseguire tutte queste trasformazioni con delle semplici viste. Spesso gli arricchimenti di dati, simili a quelli descritti nel Drill precedente, sono più complicati e richiedono numerosi passaggi elaborativi.
In questo caso, saremo costretti a caricare tutto quello che è stato definito nalla vista precedente, in una o più tabelle temporanee. E dobbiamo costruire un altro modulo che eseguirà le nuove elaborazioni che termineranno con il caricamento della tabella finale di Staging Area.
Un esempio in cui si verificano queste situazioni è la mancanza di un codice importante, per esempio, il codice NDG anagrafico di un cliente. La nostra architettura prevede però che questo codice debba essere presente nella tabella dei fatti. In questi casi sono necessarie elaborazioni particolari per desumere quel codice dagli altri codici presenti nel flusso o altrove, e inserirlo nella tabella temporanea.
11Micro ETL Foundation

KNOWLEDGE DRILL 4
Tipico è il caso del flusso di saldo dei conti correnti, in cui sono presenti degli importi numerici e il codice conto, ma il codice del cliente intestatario del conto non è presente e deve essere cercato altrove. Queste considerazioni hanno come conseguenza lo sdoppiamento della procedura di caricamento. La prima salva il risultato di tutti gli arricchimenti “light” in una tabella di appoggio temporanea. La seconda esegue gli arricchimenti più “hard” e caricherà la tabella finale di Staging Area.
E’ vero che non tutti i flussi necessitano di elaborazioni così complesse, ma è anche vero che la necessità di post-elaborazioni di solito emerge solo dopo avere fatto le stime di progetto, cioè dopo avere verificato nel dettaglio la qualità dei dati di input.
Per cui è sempre meglio essere pessimisti e considerare sempre una o due procedure di caricamento aggiuntive.
Se osserviamo la figura 5 attentamente, siamo sicuri di non avere dimenticato qualcosa ? La risposta è no. Abbiamo dimenticato di rappresentare nel disegno, la parte più importante del processo, cioè le strutture dati necessarie per la configurazione e il controllo della elaborazione dei file di dati.
12Micro ETL Foundation
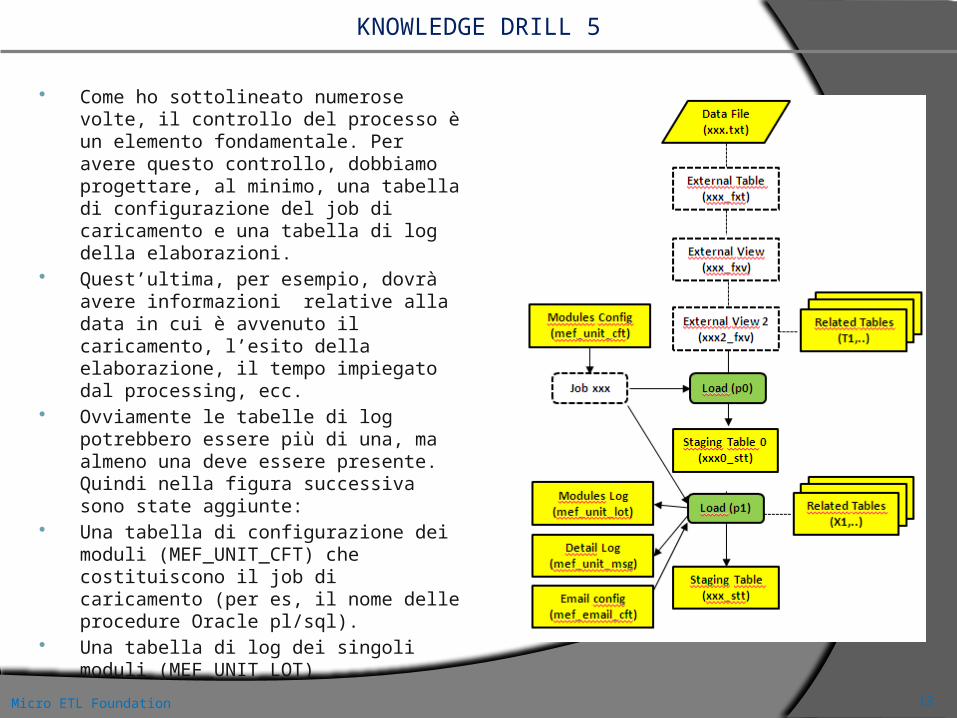
KNOWLEDGE DRILL 5
Come ho sottolineato numerose volte, il controllo del processo è un elemento fondamentale. Per avere questo controllo, dobbiamo progettare, al minimo, una tabella di configurazione del job di caricamento e una tabella di log della elaborazioni.
Quest’ultima, per esempio, dovrà avere informazioni relative alla data in cui è avvenuto il caricamento, l’esito della elaborazione, il tempo impiegato dal processing, ecc.
Ovviamente le tabelle di log potrebbero essere più di una, ma almeno una deve essere presente. Quindi nella figura successiva sono state aggiunte:
Una tabella di configurazione dei moduli (MEF_UNIT_CFT) che costituiscono il job di caricamento (per es, il nome delle procedure Oracle pl/sql).
Una tabella di log dei singoli moduli (MEF_UNIT_LOT)
13Micro ETL Foundation

KNOWLEDGE DRILL 5
Una tabella di log di estremo dettaglio (MEF_MSG_LOT) che fornisce informazioni sulle singole operazioni (statement di manipolazione dati, informazioni di controllo) che sono contenute all’interno dei moduli.
Una tabella di configurazione degli indirizzi di posta (MEF_EMAIL_CFT) a cui inviare gli alert relativi ai problemi di caricamento.
Sono quattro tabelle di metadati molto importanti per la gestione del processo e si possono trovare degli esempi del loro utilizzo, in due mie presentazioni già pubblicate su Slideshare [7], [9].
Per comodità, nel disegno, queste tabelle sono state associate solo al modulo P1, ma ovviamente tutti i moduli devono essere in grado di utilizzarle.Abbiamo finalmente ottenuto il disegno conclusivo ? Ora abbiamo tutti gli elementi per stimare con più attenzione il tempo necessario a costruire tutte le strutture e le componenti elaborative della figura ? Anche in questo caso la risposta è nuovamente no.
14Micro ETL Foundation
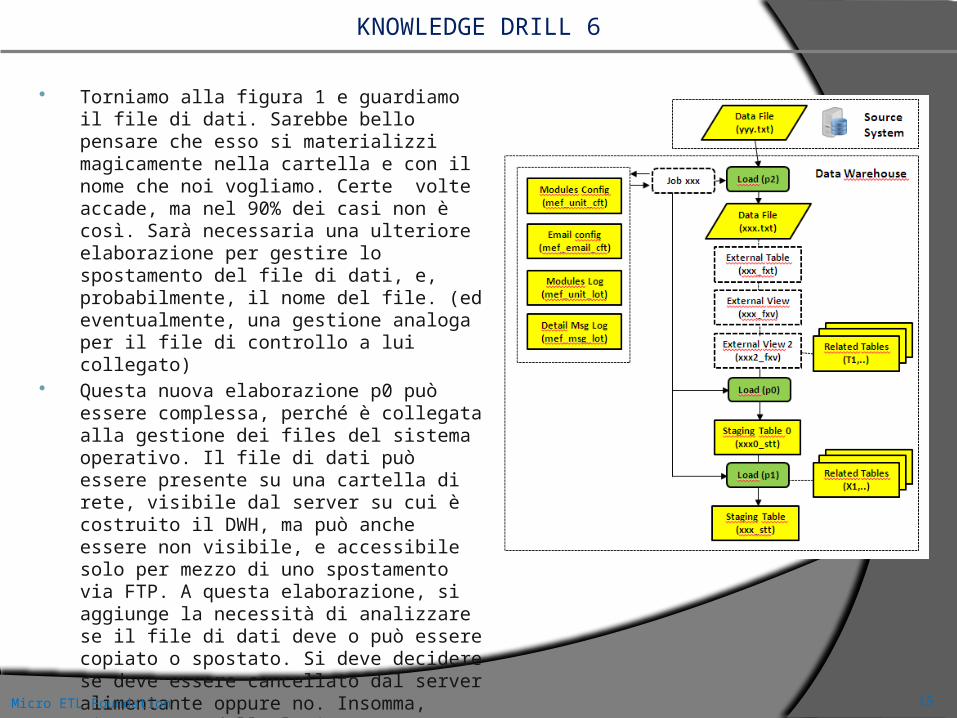
KNOWLEDGE DRILL 6
Torniamo alla figura 1 e guardiamo il file di dati. Sarebbe bello pensare che esso si materializzi magicamente nella cartella e con il nome che noi vogliamo. Certe volte accade, ma nel 90% dei casi non è così. Sarà necessaria una ulteriore elaborazione per gestire lo spostamento del file di dati, e, probabilmente, il nome del file. (ed eventualmente, una gestione analoga per il file di controllo a lui collegato)
Questa nuova elaborazione p0 può essere complessa, perché è collegata alla gestione dei files del sistema operativo. Il file di dati può essere presente su una cartella di rete, visibile dal server su cui è costruito il DWH, ma può anche essere non visibile, e accessibile solo per mezzo di uno spostamento via FTP. A questa elaborazione, si aggiunge la necessità di analizzare se il file di dati deve o può essere copiato o spostato. Si deve decidere se deve essere cancellato dal server alimentante oppure no. Insomma, sicuramente della logica non tanto semplice, da implementare in un nuovo modulo di spostamento. Ecco quindi come si trasforma la figura.
15Micro ETL Foundation

KNOWLEDGE DRILL 7
Possiamo considerare i metadati aggiunti nel Drill precedente, come metadati legati al processo. Mancano ancora i metadati legati alle strutture, cioè alla composizione dei file di dati.
Ritengo molto importante avere la struttura dei file di dati in una tabella, perché ci permette di costruire in modo dinamico gli statement di creazione delle strutture di supporto e di inserzione dei dati. Non sarà necessario costruire uno statement specifico per ogni flusso alimentante: sarà sufficiente chiamare una unica procedura che prende in input il codice flusso e genera lo statement di insert.
In questo modo, se arriva la richiesta di documentare la struttura di tutti i file di dati, sarà sufficiente fare un SQL che estrae queste informazioni dalle tabelle dei metadati.
E saremo sicuri che queste informazioni saranno sempre aggiornate, perché è su di esse che si basa il processo di caricamento dinamico.
Provate a pensare di avere queste informazioni in un documento Word o Excel (come quasi sempre succede). Questo documento diventerà obsoleto dopo i primi giorni di test, in cui ci accorgeremo di dovere fare delle modifiche che agiranno, per problemi di tempo, direttamente sui programmi e quasi mai sulla documentazione.
Inoltre il file di dati, a prescindere che sia con colonne a lunghezza fissa o con terminatore di colonna, può avere una intestazione e/o un record di coda contenente il numero di righe presenti nel flusso (che deve essere controllato in qualche modo). A volte il numero di righe viene fornito in un flusso separato. Senza contare le situazioni in cui il giorno di riferimento dei dati è presente nel nome del file di dati stesso o in una riga dell’intestazione e non come campo del flusso. Una trattazione completa di questi casi la potete leggere in [4,5]. Anche tutte queste informazioni devono essere gestite per mezzo di tabelle di metadati. Le possiamo vedere nella figura seguente.
16Micro ETL Foundation
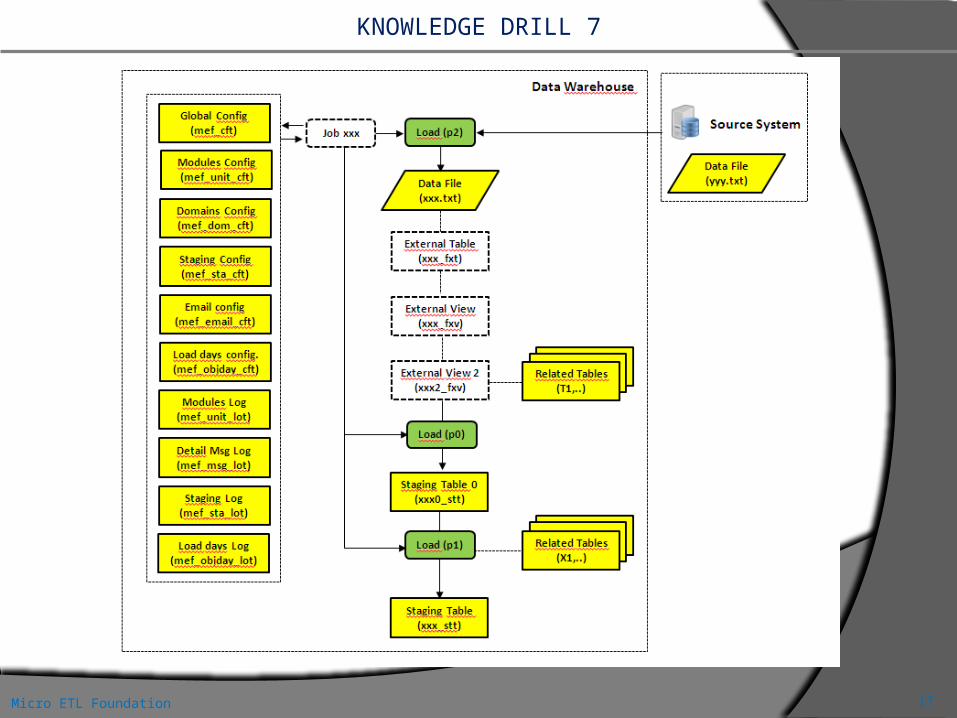
KNOWLEDGE DRILL 7
17Micro ETL Foundation

KNOWLEDGE DRILL 7
L’ultima figura ottenuta però non è ancora completa.In essa, per una gestione ottimale della Staging Area, abbiamo considerato:
Una tabella di configurazione globale (MEF_CFT) in cui inserire tutte le informazioni utili a tutto il processo di caricamento. Per esempio il formato unico di trattamento dei campi data, i valori di default nei casi di dati “null”, la lingua di default delle descrizioni, ecc.
Una tabella di configurazione dei file dati (MEF_IO_CFT), con tutte le informazioni relative al tipo di file e ai suoi contenuti.
Una tabella di configurazione della struttura dei file dati (MEF_STA_CFT), con i nomi dei campi, tipo, lunghezza, formati, regole di trasformazione, ecc.
Una tabella di definizione dei domini di valori dei codici (MEF_DOM_CFT). Vedi [6] Una tabella di configurazione dei giorni di ricevimento dei file di dati (MEF_OBJDAY_CFT). Vedi [7,8] Una tabella di log (MEF_OBJDAY_LOT) di arrivo dei file di dati.
18Micro ETL Foundation

KNOWLEDGE DRILL 8
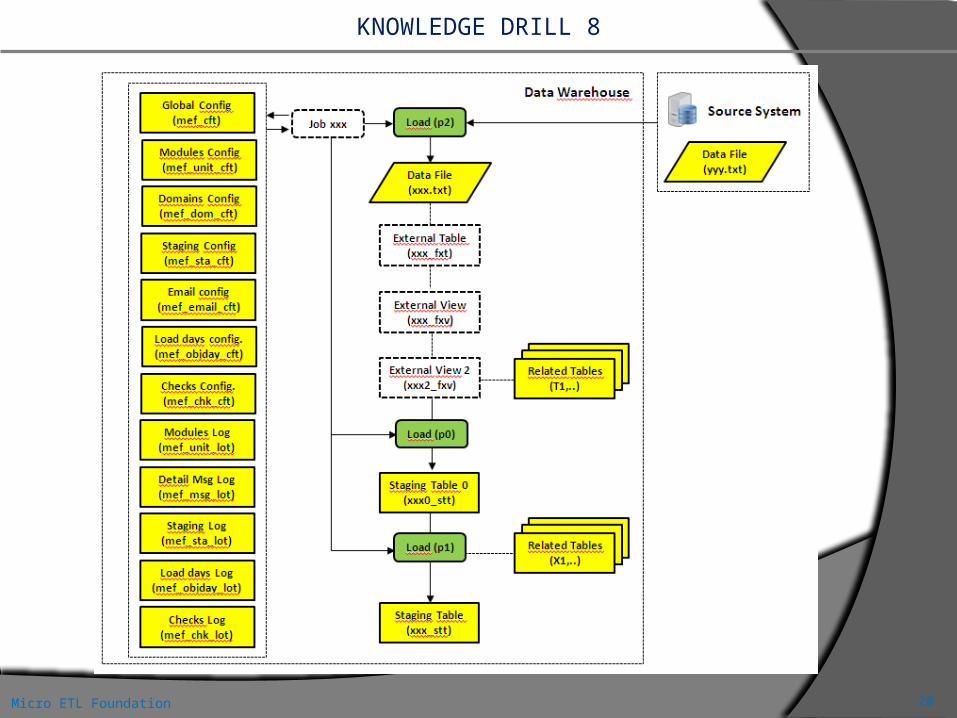
Non abbiamo ancora parlato di un altro elemento fondamentale: la qualità del dato. Tutte le strutture create fino ad ora, ci hanno permesso di gestire gran parte delle problematiche
collegate a un processo ETL. Sicuramente, le tabelle di metadati ci hanno permesso di ottimizzare e generalizzare i moduli di elaborazione e di tenere sotto controllo l’esito delle elaborazioni.
Inoltre molte di queste strutture, possono essere utilizzabili non solo per il caricamento della Staging Area, ma anche per le fasi successive del caricamento. Purtroppo però la figura semplice che abbiamo visto all’inizio, si è molto complicata. Nuove strutture e nuovi moduli di caricamento si sono aggiunti per gestire tutta quella varietà si situazioni che si verificano nella realtà.
Come possiamo garantire che il risultato finale è corretto ? Possiamo essere sicuri che, a fronte di un data file, per esempio di 23915 righe, la tabella finale di Staging Area conterrà esattamente 23915 righe ? Chi ha un minimo di esperienza, sa che tutti questi passaggi intermedi di arricchimento e di join con altre tabelle potrebbero portare alla perdita o alla duplicazione delle righe iniziali. Ecco perché è necessario aggiungere ancora alcune tabelle di controllo che ci diano questa sicurezza. Potrebbero essere utili, per esempio:
Una tabella di configurazione dei controlli di qualità (MEF_CHK_CFT ) Una tabella di log di esito dei controlli (MEF_CHK_LOT) che mostri la quadratura su tutte le strutture
coinvolte nel processo elaborativo. Un esempio della applicazione di questi controlli lo potete trovare nella slideshare [9]
19Micro ETL Foundation
KNOWLEDGE DRILL 8
20Micro ETL Foundation
CONCLUSIONE
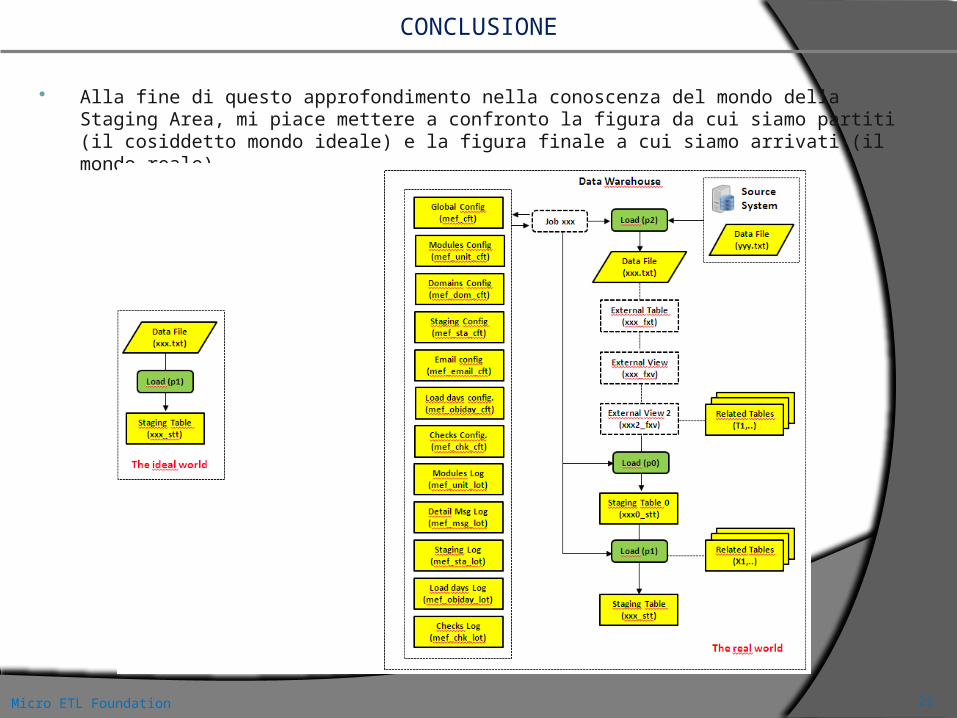
Alla fine di questo approfondimento nella conoscenza del mondo della Staging Area, mi piace mettere a confronto la figura da cui siamo partiti (il cosiddetto mondo ideale) e la figura finale a cui siamo arrivati (il mondo reale).
21Micro ETL Foundation

CONCLUSIONE
Con questo confronto desidero rendere consapevoli progettisti, capi progetto, commerciali e utenti finali, della complessità legata a un progetto di Business Intelligence, e, in particolare, al processo di caricamento della Staging Area, che, ricordiamo, è solo una componente dell’intero processo ETL di un Data Warehouse.
Il drill-down di complessità, evidenziato man mano che si prende coscienza della realtà dei fatti, a mio avviso è straordinario e inaspettato. Non sarà mai più possibile pronunciare la frase “è solo il caricamento di un flusso”
Concluderei queste riflessioni con la stessa frase (quasi) con cui Humphrey Bogart concludeva il film "L'ultima minaccia".
That's Data Warehouse, baby!
22Micro ETL Foundation

RIFERIMENTI
23Micro ETL Foundation
[1] Data Warehouse - What you know about etl process is wrong
[2] Recipes 9 of Data Warehouse and Business Intelligence - Techniques to control the processing units in the ETL process
[3] Recipes of Data Warehouse and Business Intelligence.A messaging system for Oracle Data Warehouse (part 1)
[3] Data Warehouse and Business Intelligence - Recipe 7 - A messaging system for Oracle Data Warehouse (part 2)
[4] Data Warehouse and Business Intelligence - Recipe 1 - Load a Data Source File (with header, footer and fixed lenght columns) into a Staging Area table with a click
[5] Data Warehouse and Business Intelligence - Recipe 2 - Load a Data Source File (.csv with header, rows counter in a separate file) into a Staging Area table with a click
[6] Recipes 10 of Data Warehouse and Business Intelligence - The descriptions management
[7] Data Warehouse and Business Intelligence - Recipe 4 - Staging area - how to verify the reference day
[8] Recipe 12 of Data Warehouse and Business Intelligence - How to identify and control the reference day of a data file
[9] Data Warehouse and Business Intelligence - Recipe 3 - How to check the staging area loading