
Seminari Operativi sull’Analisi di Serie Temporalibarbier/files/sem05.pdf · Informazione e...
70
Introduzione all’econofisica Mondo del Lavoro 2, Prof. Francesco Mainardi Seminari Operativi sull’Analisi di Serie Temporali a cura di Davide Barbieri Marzo - Aprile 2005 1
Transcript of Seminari Operativi sull’Analisi di Serie Temporalibarbier/files/sem05.pdf · Informazione e...

Introduzione all’econofisica
Mondo del Lavoro 2, Prof. Francesco Mainardi
Seminari Operativi
sull’Analisi di Serie Temporali
a cura di Davide Barbieri
Marzo - Aprile 2005
1

Tematiche:
• Matlab, Programmazione e Grafici
• Analisi dei Segnali
Informazione e Campionamento
Modulazione di Frequenza
• Probabilita e Statistica
• Rumore e Processi Stocastici
Applicazioni (numeriche):
• Musica
• Dati Meteorologici dal 1814
• Inquinamento Ambientale a Bologna
• Mercati Finanziari
2

Programma (∼approssimato∼) delle giornate.
(03/03) Introduzione a Matlab e trasformata di Fourier.
- Per cominciare con Matlab: plot/fplot, operazioni
su matrici, m-files.
- Campionamento dei segnali: Limite di Shannon,
Informazione e Frequenza di Nyquist. Aliasing.
- Analisi in frequenza: serie di Fourier.
0 0.5 1 1.5 2 2.5 3 3.5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
3
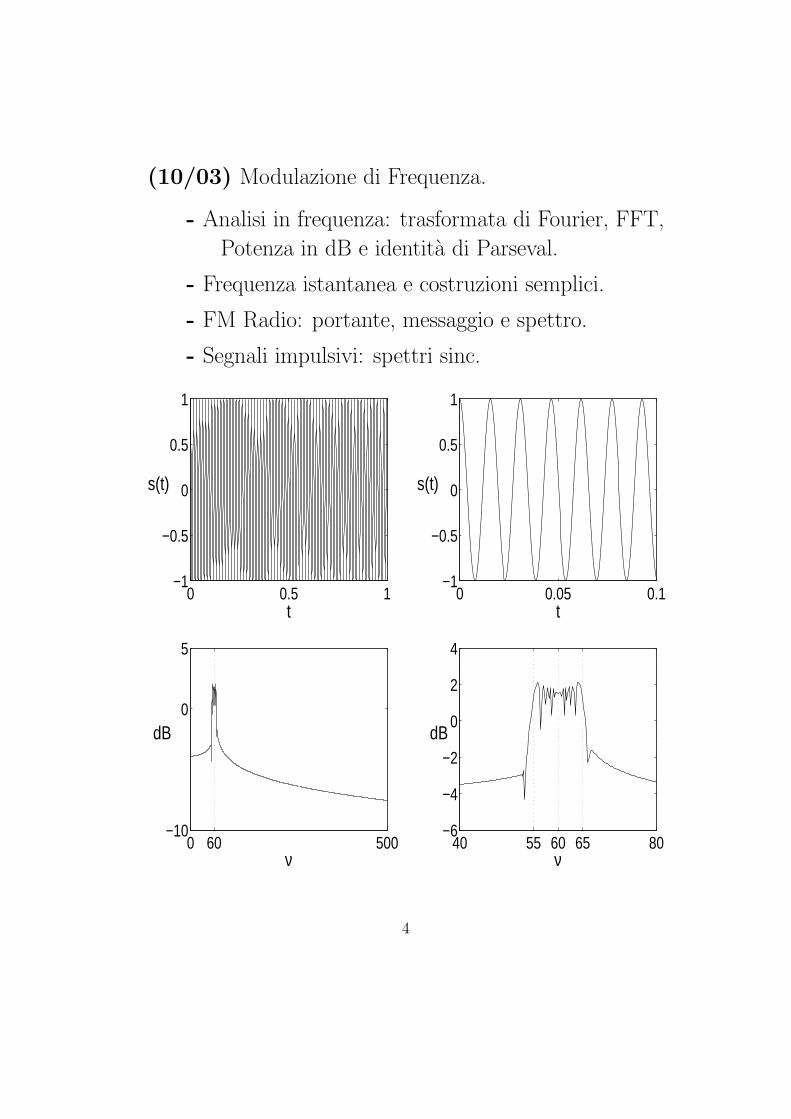
(10/03) Modulazione di Frequenza.
- Analisi in frequenza: trasformata di Fourier, FFT,
Potenza in dB e identita di Parseval.
- Frequenza istantanea e costruzioni semplici.
- FM Radio: portante, messaggio e spettro.
- Segnali impulsivi: spettri sinc.
0 0.5 1−1
−0.5
0
0.5
1
t
s(t)
0 0.05 0.1−1
−0.5
0
0.5
1
t
s(t)
0 60 500−10
0
5
ν
dB
40 55 60 65 80−6
−4
−2
0
2
4
ν
dB
4

(17/03) Analisi in Tempo-Frequenza.
- Windowed Fourier Transform.
- Osservazioni sulle finestre.
- Bach e Petrucciani: l’algoritmo del pentagramma.
- Un semplice Filtro sulle Frequenze.
0 0.1 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 −0.3
0
0.3
t (sec)
s(t
)
t (sec)
Fre
qu
en
ze
(H
z)
0 0.1 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 0
1000
2000
3000
5

(31/03) + (07/04) Probabilita e Statistica.
- Variabili Random: costruire con Matlab variabili
gaussiane e non (metodo del rigetto). Istogrammi
e densita di probabilita.
- Media e Varianza campionaria: funzionamento degli
stimatori e convergenza in probabilita. Efficienza
statistica e informazione di Fisher.
- Correlazione: interdipendenza statistica fra serie di
dati (al 2o ordine) e indipendenza aleatoria.
- Applicazioni: gioco d’azzardo e dati correlati.
0 200 400 600 800 1000 1200 1400 1600 1800 2000 2200−50
0
50
−20 −15 −10 −5 0 5 10 15 200
0.1
0.2
0.3
6

(14/04) Evoluzione della Probabilita nel Tempo:
i Processi Stocastici I.
- Il Moto Browniano: Einstein, Wiener, Markov, i
processi di Levy gaussiani e la diffusione normale
nell’equazione Xt+1 = Xt + Zt.
- Le forzanti stocastiche: il Rumore Bianco (WN),
la δ-correlazione e il caos molecolare.
- Random Walk, Efficienza dei mercati finanziari e
nottolino di Feynman.
- Per cominciare con i Processi Stocastici: AR(1).
- Autocorrelazione e Power Spectrum. Stazionarieta.
0 500 1000 1500 2000 2500 3000−100
−80
−60
−40
−20
0
20
40
60
80
100
7
Davide
Cross-Out
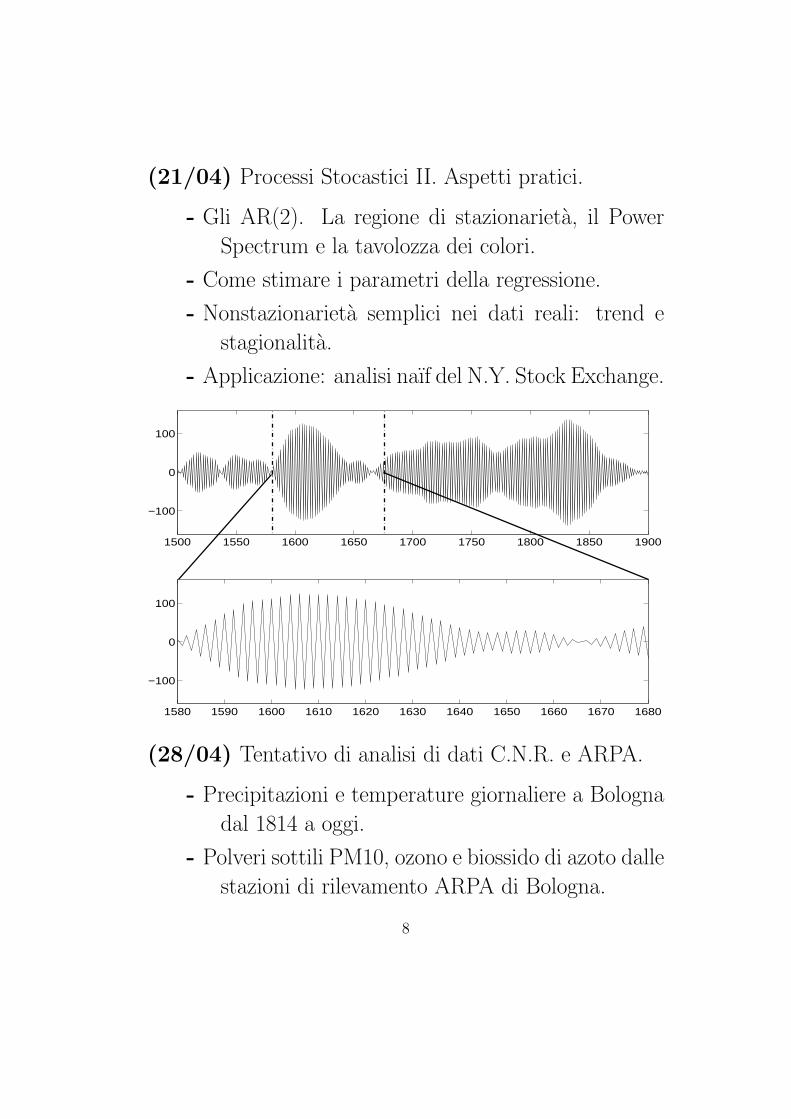
(21/04) Processi Stocastici II. Aspetti pratici.
- Gli AR(2). La regione di stazionarieta, il Power
Spectrum e la tavolozza dei colori.
- Come stimare i parametri della regressione.
- Nonstazionarieta semplici nei dati reali: trend e
stagionalita.
- Applicazione: analisi naıf del N.Y. Stock Exchange.
1500 1550 1600 1650 1700 1750 1800 1850 1900
−100
0
100
1580 1590 1600 1610 1620 1630 1640 1650 1660 1670 1680
−100
0
100
(28/04) Tentativo di analisi di dati C.N.R. e ARPA.
- Precipitazioni e temperature giornaliere a Bologna
dal 1814 a oggi.
- Polveri sottili PM10, ozono e biossido di azoto dalle
stazioni di rilevamento ARPA di Bologna.
8
Davide
Cross-Out
Davide
Cross-Out

03/03/2005
1 Matrici †
>> mat=[1 2 3 ; 4 5 6 ; 7 8 9]
Ogni comando non seguito da ; restituisce un output
mat =
1 2 3
4 5 6
7 8 9
i singoli elementi sono individuabili con due indici
>> mat(2,3)
ans =
6
o con un indice solo (scorrimento per colonne)
>> mat(8)
ans =
6
e si possono sempre aggiungere elementi
>> mat(1,4)=3
mat =
1 2 3 3
4 5 6 0
7 8 9 0†Rif.: Help di Matlab.
9

I Somme
>> mat
mat =
1 2 3
4 5 6
7 8 9
Per Matlab tutte le variabili sono considerate matrici.
Es: sommare iterativamente scalari equivale a richiamare
algoritmi di somma fra matrici 1x1.
⇒ cercare sempre di ricondursi a operazioni su elementi
di una stessa matrice: piu rapide.
>> sum(mat)
ans =
12 15 18
>> sum(mat(:,1))
ans =
12
>> sum(mat(1:3,1))
ans =
12
>> sum(mat(2:3,1))
ans =
11
10

II Prodotti
La matrice trasposta si ottiene con l’apice
>> matT=mat’
matT =
1 4 7
2 5 8
3 6 9
Il prodotto matriciale e dato dall’ ∗>> mm=mat*matT
mm =
14 32 50
32 77 122
50 122 194
E ad esempio si puo usare per prodotti scalari fra vettori
>> v=[1 2 3 4]; u=[4 3 2 1];
uT=u’;
vu=v*uT
vu =
20
prodotti matriciali⇒ trasporre il vettore dx e essenziale:
>> w=v*u
??? Error using ==> *
Inner matrix dimensions must agree.
11

e ... attenzione all’ordine !
>> w=uT*v
w =
4 8 12 16
3 6 9 12
2 4 6 8
1 2 3 4
E inoltre possibile gestire operazioni termine a termine†:
>> v3=v*3
v3 =
3 6 9 12
>> uv=u.*v
uv =
4 6 6 4
notare come l’ultima operazione (.∗) usi u e non uT .
NOTA: un operatore fondamentale, gia usato per somme,
e il “due punti”. Un altro dei suoi usi piu frequenti e
quello di costruire griglie
>> Dt=[0:2:10]
Dt =
0 2 4 6 8 10
†La sintassi .* ha un corrispondente anche per la divisione termine a termine (./) el’elevamento a potenza delle componenti dei vettori (.^).
12

2 Grafici †
Con Matlab e possibile graficare (quasi) ogni cosa: fun-
zioni in una o piu variabili, serie di dati, matrici, curve di
livello ecc., in due o tre dimensioni e con scale di colori.
Qui useremo solo funzioni e dati in una variabile.
Per plottare funzioni si usa il comando fplot, con il quale
e possibile anche specificare tipo di linea, colore, etc.
fplot(‘forma funzionale’,
[intervallo del dominio])
fplot(’sin(x)/x’,[-50,50])
−50 −40 −30 −20 −10 0 10 20 30 40 50−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Per regolare gli assi su un plot si usa il comando axis:
axis([xm xM ym yM])
fplot(’..f(x)..’,[-10,10])
axis([-5 5 -2.8 0.6])
−5 −4 −3 −2 −1 0 1 2 3 4 5
−2.5
−2
−1.5
−1
−0.5
0
0.5
†Rif.: Help di Matlab.
13

Quando si hanno dati su un vettore y da plottare come
se fossero i valori assunti da una funzione si usa plot.
Di default i valori delle x sono i naturali: per specificarli
occorre un vettore x con la stessa lunghezza di y.
Esempio: si vogliono plottare i dati di inflazione FOI
(% mensili sul mese dell’anno precedente dei prezzi al
consumo per le Famiglie di Operai e Impiegati).
Disponibili i dati mensili da ottobre 1978 a gennaio 2005
(316 mesi) su un file di testo, li si trasferisce in memoria
con il comando load e si costruisce il vettore dei tempi.
>> x=load(’FOI_05_dati.txt’);
>> Dt=[1978+3/4:1/12:2005];
>> plot(Dt,x)
>> axis([1978 2005 0 22])
1980 1985 1990 1995 2000 20050
2
4
6
8
10
12
14
16
18
20
22
14

3 Campionamento dei segnali †
Un segnale f (t) viene misurato a tempi discretitjN
j=1,
dunque si presenta come una successioneftj
N
j=1.
Se gli intervalli temporali sono regolari tj+1 − tj = ∆t,
allora νc = 1/∆t e detta “frequenza di campionamento”.
Un segnale campionato si puo scrivere utilizzando la
delta di Dirac: passaggio dal discreto al continuo
f (t) =
N∑n=0
fn δ(t− n∆t)
Analisi in frequenza = scomposizione del segnale in
oscillazioni elementari:
i Per fare questo si usa la trasformata di Fourier
f (ν) =
∫ +∞
−∞ei2πνtf (t)dt
che si inverte con
f (t) =
∫ +∞
−∞e−i2πνtf (ν)dν
ii Per segnali campionati questa si riduce alla serie
f (ν) =
N∑n=0
ei2π(ν/νc)nfn
†Rif.: G.Kaiser, “A friendly guide to wavelets”, 1994 Birkhauser; C.Chatfield, “Theanalysis of time series”, 2004 Chapman & Hall; Numerical Recipes, http://www.nr.com/
15

La massima frequenza contenuta nel segnale e νc: tutto
cio che avviene in tempi minori di ∆t non e rilevato.
Questo e scritto anche nella serie di Fourier del segnale:
ν = νc + α ⇒ ei2π(ν/νc)n = ei2πnei2π(α/νc)n = ei2π(α/νc)n
dunque f (νc+α) = f (α): la rappresentazione del segnale
f (t) in frequenza e tutta contenuta nella banda [−νc, νc].
In realta si ha di piu: l’informazione del segnale e
contenuta in un intervallo di frequenze piu piccolo:
a) Una serie di dati distanziati di ∆t non puo con-
tenere informazioni su oscillazioni di periodo inferi-
ore a 2∆t: ad esempio dati di temperatura con una
misura alle 12:00 ed una alle 24:00 riescono a risolvere
fluttuazioni giornaliere, ma non danno informazioni
su cio che accade nell’arco della mattinata.
Si definisce quindi una frequenza di taglio analoga
alla frequenza di Debye per il solido cristallino: la
frequenza di Nyquist νN =νc
2.
b) Per quanto visto, un segnale campionato non risolve
frequenze piu acute di quella di Nyquist.
Per un campionamento che non perda informazioni
occorre quindi scegliere una νc che sia almeno doppia
della massima frequenza di oscillazione del segnale (se
questa massima frequenza esiste ...).
16

Esempio: campionamento della funzione seno
>> nuc = ...
>> nu = 1;
>> t = [0:1/nuc:10];
>> y = sin(2*pi*nu*t);
>> plot(t,y)
0 1 2 3 4 5 6 7 8 9 10−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
0 1 2 3 4 5 6 7 8 9 10−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
0 1 2 3 4 5 6 7 8 9 10−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Figura : Campionamento (da sinistra a destra) con νc = 50, 2.18, 1.7
Come si puo notare, nella prima figura νc À ν ed il
seno e risolto con precisione. Nella seconda νc & 2ν, ma
nonostante la bassa definizione si distinguono i 10 picchi.
Nella terza figura ν < νc < 2ν e si perde l’informazione
contenuta nel segnale (la sua frequenza).
Il limite dato dalla frequenza di Nyquist e anche detto
limite di Shannon : il suo teorema del campionamento
afferma infatti che una funzione la cui trasformata di
Fourier si annulla per frequenze superiori a Ω puo essere
ricostruita interamente (senza perdere informazione) a
partire da un campionamento a frequenza νc ≥ 2Ω.
17

Un segnale campionato sotto il limite di Shannon viene
detto “sottocampionato”, ed il fenomeno di distorsione
dell’informazione associato e chiamato aliasing.
Un esempio di aliasing e l’impressione di veder girare in
senso opposto una ruota in rapida rotazione: la durata di
una impressione retinica, di circa 1/25 di secondo, agisce
infatti come un tempo di campionamento:
nu=7;
nuc=200;
t=[0:1/nuc:3.5];
y=sin(2*pi*nu*t);
plot(t,y,’r’)
hold on
nuc=8;
t=[0:1/nuc:3.5];
y=sin(2*pi*nu*t);
plot(t,y,’black’)
plot(t,y,’ob’) 0 0.5 1 1.5 2 2.5 3 3.5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
In generale l’aliasing e causa di uno sparpagliamento delle
frequenze superiori a νN fra le frequenze “buone”, che
provoca una distorsione nel segnale campionato a danno
di queste ultime: nell’intervallo di Shannon compaiono
frequenze fittizie che confondono l’informazione.
18

10/03/2005
1 Osservazioni sulla Trasformata di Fourier †
a) Spettro di Potenza
Con “Energia Totale” contenuta in un segnale si intende
l’integrale nel tempo della “Potenza Istantanea” |f (t)|2.Il Teorema di Parseval afferma che l’energia totale di
un segnale non cambia se misurata sulle frequenze:∫ +∞
−∞
∣∣∣f (t)∣∣∣2
dt =
∫ +∞
−∞
∣∣∣f (ν)∣∣∣2
dν
e la “potenza associata alle frequenze” [ Ω− , Ω+ ] e ‡
∫ Ω+
Ω−P (ν)dν =
∫ Ω+
Ω−
∣∣∣f (ν)∣∣∣2
dν
b) Simmetrie
I segnali (campionati) reali hanno particolari simmetrie:
i f (t) ∈ R⇒ f (−ν) = f ∗(ν)
ii f (νc + α) = f (α) ⇒ f (−νN + α) = f (νN + α)
dunque |f |2 puo essere studiata solo nell’intervallo di
frequenze [ 0, νN ], essendo pari e periodica.
†Rif.: A.Papoulis, “The Fourier integral and its applications”; Numerical Recipes,Chapter 12 “Fast Fourier Transform” http://www.nr.com/
‡La potenza e comunemente espressa in scala logaritmica: i decibel (dB).
19

c) Fast Fourier Transform
La trasformata di un segnale discreto a N punti si calcola
su N valori di frequenza νk =kνN
N:
fk =
N∑n=0
eiπ(k/N)nfn , k = 0, . . . , N
Un algoritmo che implementa in modo diretto questa
trasformata di Fourier discreta richiede N 2 iterazioni.
L’algoritmo FFT riduce drasticamente le iterazioni a
Nlg2N grazie ad una semplice osservazione: la somma di
lunghezza N si puo scrivere come 2 somme di lunghezza
N/2, e se N = 2n questa scomposizione si puo ripetere
n volte, riducendo la computazione ad N valutazioni di
n “trasformate ad 1 punto”. †
La routine Matlab che realizza la FFT si richiama con
F = fft(f,M)
dove f rappresenta il segnale, F la sua trasformata, M
il numero di punti su cui viene fatto girare l’algoritmo.
Non e necessario che M sia uguale ad N : se M > N al
segnale vengono aggiunti M−N zeri, mentre se M < N
il segnale viene troncato. In questo modo si puo sempre
scegliere (vivamente consigliato) M come potenza di 2.†NOTA: se N = 104, allora N2 = 108, mentre Nlg2N = 1.33× 105.
20

Esempio 1. Frequenza che varia in modo continuo.
N = 8192; nuc = 256;
L = N/nuc;
t = [0:1/nuc:L];
x = cos(pi*t.*t);
subplot(2,1,1)
plot(t,x,’r’)
axis([0 10 -1 1])
Y = fft(x,N);
P = log10(Y.*conj(Y)/N);
f = nuc*(0:N-1)/N;
subplot(2,1,2); plot(f,P);
fm = min(P); fM = max(P);
Df = 0.1*(fM-fm);
axis([0 nuc fm-Df fM+Df])
0 1 2 3 4 5 6 7 8 9 10−1
−0.5
0
0.5
1
0 50 100 150 200 250−15
−10
−5
0
In questo segnale vi sono tutte le frequenze comprese nel-
l’intervallo [0, 32] (Hz). Il segnale e ben campionato, e si
osserva la simmetria dello spettro di potenza intorno alla
frequenza di Nyquist. Il plateau nello spettro si allarga
con l’aumentare del tempo totale L. A cosa e dovuta
questa dipendenza? Ponendo “a mano” una lunghezza
oltre L = 32 non si vede uno stesso cambimento, perche
si trasforma a N = 8196: il segnale viene troncato.
21

Esempio 2. Aliasing.
In presenza di piu frequenze, con alcune al di sopra del-
la frequenza di Nyquist del campionamento, si verifica
una ricombinazione della potenza dello spettro, con una
persistenza di frequenze fittizie derivanti dalle oscillazioni
sottocampionate, che sporca le frequenze ben campionate.
nu1=4.5; nu2=8.5; nu3=18;
nuc=300; t=[0:1/nuc:500]; phi=2*pi*t;
x=sin(phi*nu1)+sin(phi*nu2)+sin(phi*nu3);
subplot(2,1,1); plot(t,x); axis([0 3 -3 3])
Y = fft(x,4096); P=log(Y.*conj(Y)/4096);
f = nuc*(0:2048)/4096;
subplot(2,1,2); plot(f,P(1:2049));
axis([0 25 -10 10])
figure
x=sin(2*pi*nu1*t);
subplot(2,1,1); plot(t,x,’c’)
nuc=11; t=[0:1/nuc:500]; phi=2*pi*t;
x=sin(phi*nu1)+sin(phi*nu2)+sin(phi*nu3);
hold on; plot(t,x,’black’); plot(t,x,’ob’)
axis([0 5 -3 3])
Y = fft(x,4096); P=log(Y.*conj(Y)/4096);
f = nuc*(0:2048)/4096;
subplot(2,1,2); plot(f,P(1:2049));
axis([0 5.5 -10 10])
22

0 0.5 1 1.5 2 2.5 3−3
−2
−1
0
1
2
3
0 5 10 15 20 25−10
−5
0
5
10
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−3
−2
−1
0
1
2
3
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5−10
−5
0
5
10
Figura : Frequenze spurie in sottocampionamento.
Le tre frequenze contenute nel segnale sono 4.5, 8.5 e 18,
ma con il secondo campionamento, a νc = 11, soltanto la
prima rimane individuabile. In alto si vede il segnale reale
(sinistra) e campionato (destra). Nelle figure in basso vi
sono invee lo spettro reale e quello ottenuto dal segnale
campionato. Come si puo vedere nella figura di destra,
le due frequenze sottocampionate compaiono con valori
Ω2 = 2.5 (corrispondente di ν2 = 8.5: Ω2 = νc − ν2) e
Ω3 = 4 (corrispondente di ν3 = 18: Ω3 = 2νc − ν3).
23

2 Segnali oscillanti
s(t) = A(t)cos [φ(t)]
à Ampiezza = A(t)
à Fase = φ(t)
à Frequenza media
= ‘N o medio di rivoluzioni di 2π su un dato tempo’
=multipli di 2π percorsi da φ(t) nel tempo ∆t
∆t
=1
2π
φ(t + ∆t)− φ(t)
∆t
à Frequenza istantanea ft =1
2π
dφ
dt
ESEMPI
a. s(t) = cos [2π (νt− 0.25)]
shift di fase: φ0 = −π
2; frequenza: f = ν
0 1 2 3 4−1
−0.5
0
0.5
1φ
0 = − π / 2
φ0 = 0
24

b. s(t) + (2π)2 s(t) = 4πcos(2πt) : risonante
s(t) = t cos [2π(t− 0.25)] ; ampiezza: A(t) = t
0 1 2 3 4 5 6−6
−4
−2
0
2
4
6
s(t)
0 1 2 3 4 5 60
2
4
6
A(t)
c. s(t) = cos[πt2
]: segnale chirp
fase: φ(t) = πt2; frequenza: ft =1
2π
dφ
dt= t
0 1 2 3 4 5 6 7 8 9 100
2
4
6
8
10
m(t)
0 1 2 3 4 5 6 7 8 9 10−1
−0.5
0
0.5
1
s(t)
25

3 FM
Modulazione in frequenza = informazione in ft
s(t) = Acos
[ωpt + 2π
∫ t
0
m(t′)dt′]
La frequenza portante νp =ωp
2πviene modulata dal
messaggio m(t) (e.g. per le radio maxt
|m(t)| ¿ νp)
ft = νp + m(t)
ESEMPI
a. s(t) = cos[2π
(3sin
[π
2t])]
, ft =3π
2cos
[π
2t]
0 1 2 3 4 5 6−1
−0.5
0
0.5
1
s(t)
0 1 2 3 4 5 6−5
0
5
m(t)
26
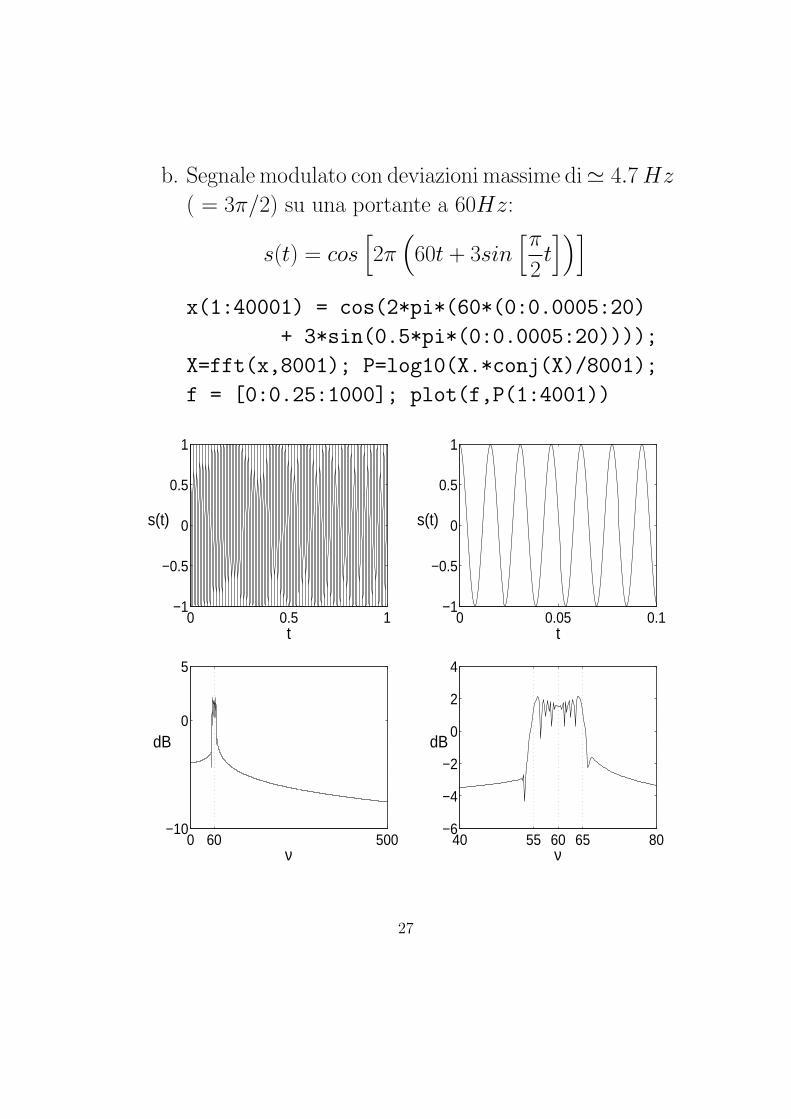
b. Segnale modulato con deviazioni massime di' 4.7 Hz
( = 3π/2) su una portante a 60Hz:
s(t) = cos[2π
(60t + 3sin
[π
2t])]
x(1:40001) = cos(2*pi*(60*(0:0.0005:20)
+ 3*sin(0.5*pi*(0:0.0005:20))));
X=fft(x,8001); P=log10(X.*conj(X)/8001);
f = [0:0.25:1000]; plot(f,P(1:4001))
0 0.5 1−1
−0.5
0
0.5
1
t
s(t)
0 0.05 0.1−1
−0.5
0
0.5
1
t
s(t)
0 60 500−10
0
5
ν
dB
40 55 60 65 80−6
−4
−2
0
2
4
ν
dB
27

4 Modulazione a impulsi: spettri SINC
∫
Re−ikxχ[−1,1](x)
dx√2π
=
√2
π
sin(k)
k
−10 −8 −6 −4 −2 0 2 4 6 8 100
0.2
0.4
0.6
0.8
1
χ [−
1,1
]
0 5 10 15 20 25−5
−4
−3
−2
−1
0
1
ν
dB
(S
INC
)
Segnale modulato da impulsi sulla frequenza
Frequenza costante a tratti
Spettro SINC
28

%% Tempi a cui accendere e spegnere gli impulsi (messaggio)
a(1)=3; a(2)=1; a(3)=4; a(4)=2; a(5)=2; a(6)=1; a(7)=2;
a(8)=5; a(9)=3; a(10)=1; a(11)=1; a(12)=3; a(13)=2;
w0=2; dw=3; vM=100; t(1) = 1/vM; w(1) = w0;
%% Costruzione del messaggio
T = 1;
for k=1:13,
for i=T+1:T+a(k)*vM,
t(i) = i/vM;
w(i) = w0+0.5*(((-1)^k)+1)*dw;
end
T=i;
end
%% Segnale modulato
for i=1:T;
x(i)=cos(2*pi*w(i)*t(i));
end
%% Spettro(dB): |fft segnale|^2 in scala semilog
X = fft(x,3000);
P = log10(X.* conj(X) / 3000);
f = [0:50/1500:50];
%% GRAFICI. 3 plot affiancati verticalmente.
%% E’ indicata la SINTASSI MANUALE PER I PLOT.
%% Grafico 1: Messaggio.
subplot(3,1,1);
plot(t,w,’b’); axis([0 30 1 6])
set(gca,’xtick’,[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,
16,17,18,19,20,21,22,23,24,25,26,27,28,29,30])
set(gca,’xticklabel’,’0’,’’,’’,’’,’’,’’,’’,’’,’’,’’,
’10’,’’,’’,’’,’’,’’,’’,’’,’’,’’,
’20’,’’,’’,’’,’’,’’,’’,’’,’’,’’,’30’,’Fontsize’,18)
set(gca,’ytick’,[1, 2, 3, 4, 5, 6])
set(gca,’yticklabel’,’’,’ 2’,’’,’’,’ 5’,’’,’Fontsize’,18)
ylabel(’m(t)’,’Fontsize’,20)
29

%% Grafico 2: Segnale.
subplot(3,1,2);
plot(t,x,’k’); axis([0 30 -1 1])
set(gca,’xtick’,[0, 5, 10, 15, 20, 25, 30])
set(gca,’xticklabel’,
’0’,’’,’10’,’’,’20’,’’,’30’,’Fontsize’,18)
set(gca,’ytick’,[-1, 0, 1])
set(gca,’yticklabel’,’-1’,’0’,’1’,’Fontsize’,18)
ylabel(’s(t)’,’Fontsize’,20)
%% Grafico 3: Spettro. Si osservano 2 frequenze
%% principali e l’assenza delle loro armoniche.
subplot(3,1,3);
plot(f,P(1:1501),’r’); axis([0 15 -5 3])
set(gca,’xtick’,[0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
10, 11, 12, 13, 14, 15])
set(gca,’xticklabel’,
’0’,’’,’2’,’’,’’,’5’,’’,’’,’’,’’,’10’,
’’,’’,’’,’’,’15’,’Fontsize’,18)
set(gca,’ytick’,[-5, -4, -3, -2, -1, 0, 1, 2, 3])
set(gca,’yticklabel’,
’-5’,’’,’’,’’,’’,’0’,’’,’’,’3’,’Fontsize’,18)
text(1.75,-3.5,’frequenze di picco’,’Fontsize’,18)
text(w0-0.2,-2,’\uparrow’,’Fontsize’,28)
text(w0+dw-0.2,-2,’\uparrow’,’Fontsize’,28)
text(8.75,1.2,’armoniche assenti’,’Fontsize’,18)
text(8-0.2,-1.2,’\downarrow’,’Fontsize’,28)
text(9-0.2,-1.2,’\downarrow’,’Fontsize’,28)
text(10-0.2,-1.2,’\downarrow’,’Fontsize’,28)
text(11-0.2,-1.2,’\downarrow’,’Fontsize’,28)
text(12-0.2,-1.2,’\downarrow’,’Fontsize’,28)
text(13-0.2,-1.2,’\downarrow’,’Fontsize’,28)
ylabel(’|f(\nu)|^2 (dB)’,’Fontsize’,20)
%% Per stampare su file in formato eps standard:
%% -depsc2 = eps colore ; -deps2 = eps b/w
orient landscape; print -depsc2 ’impulsi.eps’
30

010
2030
2 5 m(t)
010
2030
−101
s(t)
02
510
15−503
frequ
enze
di p
icco
↑↑
arm
onic
he a
ssen
ti
↓↓
↓↓
↓↓
|f(ν)|2 (dB)
31

17/03/2005
1 Timbrica di una corda vibrante †
Le vibrazioni in una corda elastica (lunga L) ad estremi
fissi sono in forma di onde stazionarie di lunghezza
λn =2L
nLa velocita delle onde trasverse dipende dalla tensione e
dalla densita lineare come v =√
T/d. Detta f1 =v
2L,
frequenza fondamentale, si ha cosı la quantizzazione
fn = nf1 “armoniche”
Le onde stazionarie sono cioe vibrazioni nelle frequenze
multiple intere della frequenza fondamentale, e questa
dipende solo dalle proprieta della corda.
L’orecchio risponde in maniera logaritmica alle frequenze.
Questo fa sı che gli intervalli musicali corrispondano a
rapporti fra frequenze, non a differenze‡: due frequenze
distano un’ottava se sono l’una doppia dell’altra, una
quinta se sono in rapporto 3 : 2, una terza maggiore
se sono in rapporto 5 : 4. Nelle prime cinque armoniche
si ritrova dunque la triade maggiore, riferimento chiave
per la musica tonale.†Rif.: J.Roederer, “The Physics and Psychophysics of Music”‡Nell’orecchio i suoni (onde di pressione) diventano vibrazioni di una membrana con
costante elastica (rigidita) diversa da punto a punto. Ogni frequenza ne mette dunque inrisonanza posizioni x diverse, secondo la relazione logaritmica x(ν)− x(2ν) ' 3.5 mm.
32

Analisi di Fourier delle oscillazioni di una corda pizzicata:
a seconda della deformazione iniziale le armoniche hanno
piu o meno peso nella timbrica uscente dalla corda†.
Profilo iniziale: f (x) ∈ L2([0, L]), dunque
f (x) =
+∞∑n=−∞
cnbn(x) serie di Fourier
bn(x) = ei2πnx/L ; cn =1
L
∫ L
0
e−i2πnx/Lf (x)dx
Estremi fissi: f (0) = f (L) = 0. La serie si riduce alla
f (x) =
+∞∑n=1
Ansen(πnx
L
); An =
2
L
∫ L
0
sen(πnx
L
)f (x)dx
0 L−1
0
1
ν 1
0 L/2 L−1
0
1
ν 2
0 L/3 2L/3 L−1
0
1
ν 3
0 L/4 L/2 3L/4 L−1
0
1
ν 4
0 L/5 2L/5 3L/5 4L/5 L−1
0
1
ν 5
†Queste si trasmettono poi alla cassa di risonanza, che le amplifica in manieracaratteristica per il suono dello strumento.
33

Esempio:
f (x) =
x
αL0 ≤ x ≤ αL
x− L
(α− 1)LαL ≤ x ≤ L
0 0.7 L L0
1
An =2
L
∫ αL
0
sen(πnx
L
) x
αLdx +
∫ L
αL
sen(πnx
L
) x− L
(α− 1)Ldx
=2
α(1− α)
sen(πnα)
(πn)2
Queste armoniche vengono propagate come onde †
∂2g(x, t)
∂t2= v2 ∂2g(x, t)
∂x2
con condizioni iniziali
g(0, t) = g(L, t) = 0 ; g(x, 0) = f (x) , gt(x, 0) = 0
dando origine a vibrazioni ‡
g(x, t) =
∞∑n=1
Ansen(πnx
L
)cos
(πnvt
L
)
†Le vibrazioni elastiche sono una approssimazione: l’amplificazione ad opera della cassadi risonanza avviene per trasmissione di energia dalle vibrazioni, che viene cosı dissipata.
‡Osservare che, nell’esempio, se α = p/q ∈ Q, mancano tutte le armoniche n = kq.
34

2 Analisi in tempo-frequenza †
La modulazione di frequenza viene usata per trasmettere
informazioni codificate: uno strumento di analisi adeguato
per questi segnali deve quindi riuscire a decodificare il
messaggio. La trasformata di Fourier puo al piu definire
l’intervallo di modulazione: il suo scopo e infatti quello
di valutare il peso delle varie componenti in frequenza
sull’intero segnale. Per cogliere la (o le) frequenze che
“istantaneamente” definiscono il messaggio occorre uno
strumento di analisi locale, che al tempo t fornisca il peso
che ha la frequenza ν nel segnale.
Uno strumento di questo tipo e dato dalla WFT:
Windowed Fourier Transform
Sia g(u) a supporto compatto, supp[g(u)
]=
[−T
2,T
2
]
diciamo ft(u) = g(u− t)f (u).
La WFT di f (t) si definisce come FT di ft(u)
[WFT f (t)
]T(ν, t) =
∫ +∞
−∞e−iνuft(u)du
g(u) e detta finestra: seleziona una porzione di segnale
sulla quale identificare il peso delle varie frequenze
attraverso FT Ã composizione locale di frequenze.
†Rif.: G.Kaiser, “A friendly guide to wavelets”
35

ESEMPIO: finestra campione
g(T )(u) =
1 + cos
(2πuT
) −T2 6 u 6 T
2
0 altrove
function g=window(u,T);
g = 0;
if (u > -0.5*T) & (u < 0.5*T)
g = 1 + cos(2*pi*u/T);
end;
−5 −4 −3 −2 −1 0 1 2 3 4 5
0
1
2
g(4) (u
)
Supporto(centrato in 0)
Localizzazione
t = 1 t = −1
Amplificato
Attenuato
36
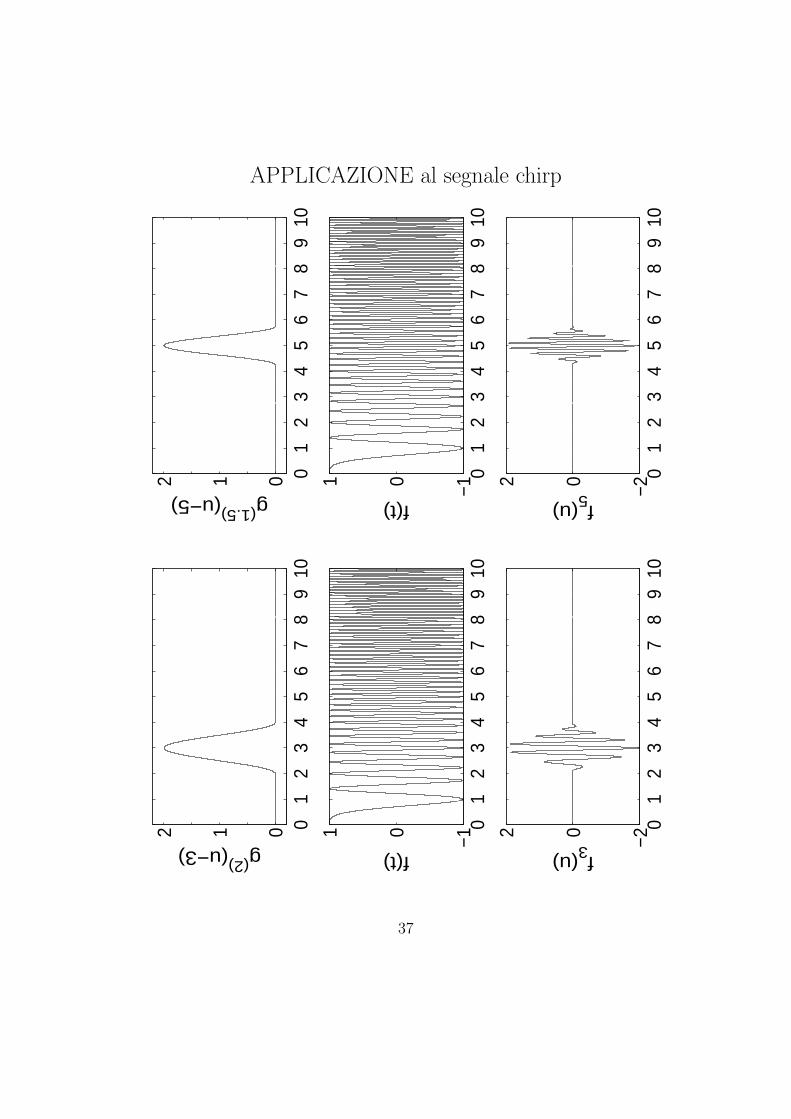
APPLICAZIONE al segnale chirp
01
23
45
67
89
10 0 1 2 g
(2)(u−3)
01
23
45
67
89
10 −
1 0 1 f(t)
01
23
45
67
89
10 −
2 0 2 f3(u)
01
23
45
67
89
10 0 1 2 g
(1.5)(u−5)
01
23
45
67
89
10 −
1 0 1 f(t)
01
23
45
67
89
10 −
2 0 2 f5(u)
37

function M=wft(x,T,nt,nnu,dB);
% x = segnale da analizzare
% T = dimensione della finestra
% nt = punti di t-risoluzione. al piu’ size(x)-T
% nnu = punti di nu-risoluzione.
si = size(x); n = si(2); dt = (n-0.5*T)/nt; t = 0.5*T;
for j = 1:nt,
% inizializzazione finestra
g(1:n)=0;
% trova i numeri corrispondenti al t-supporto fra quelli in (1:n)
k = find(-0.5*T + t <= (1:n) & (1:n) <= 0.5*T + t);
% quanti sono: l e’ un vettore = (1,Nsupp).
% se ne usera’ la seconda componente.
l = size(k);
% funzione finestra sui punti di supporto.
g(k(1):k(l(2))) = 1 + cos(2*pi*((k(1):k(l(2)))-t)/T);
% t-windowed signal
ft(1:n) = x(1:n).*g(1:n);
% fft solo sul supporto
y = fft(ft(k(1):k(l(2))),nnu);
% potenza spettrale
P = log10(y.*conj(y)/nnu);
% pulizia dal rumore a partire da -dB
k = find(P < -dB);
l = size(k);
P(k(1:l(2))) = -dB-1;
M(j,:) = P(1:nnu/2);
t = t+dt;
end;
38

39

31/03/2005 + 07/04/2005
1 Probabilita - Valori Medi †
Il paradosso di S. Pietroburgo
Un gioco di lanci di una moneta. Il giocatore G paga d $
per giocare e sceglie una faccia (testa), il banco B lancia.
Se testa esce dopo n lanci, B paga a G 2n $. Questa e una
mano (partita): una volta che G e B hanno concordato
d, si continua a giocare fino a quando G non dice basta.
Quanto puo essere disposto a pagare G per ogni mano?
d = 2 $ : se T esce al primo lancio, B da a G 2 $,
altrimenti gli da di piu. G guadagna o va in pareggio.
d > 2 $ : ?
Schema di una partita:
1 2 3
T
C
T
T
T
T
C
C
C
C C
T
C
T
1/2
1/4
1/8
pn =1
2n
probabilita che una
mano finisca in n lanci
= probabilita che T
esca solo al lancio n
†Per la teoria della probabilita esestono molti ottimi testi. Uno per tutti a cui riferirsie: William Feller “An Introduction to Probability Theory and its Applications”
40

Risultato di una mano: numero di lanci per far uscire T.
⇒ giocando N partite, se ne possono scrivere i risultati
come successione numerica (in N)xj
N
j=1xj = risultato della j-esima mano
Queste sono realizzazioni indipendenti di una variabile
random ξ discreta (a valori in N): un suo campione.
La distribuzione di probabilita di ξ e data da pn = 1/2n:∞∑
n=1
pn =
∞∑n=0
1
2n− 1 =
1
1− 1/2− 1 = 1
Dopo quanti lanci, in media, si concludera la partita?
µ =
∞∑n=1
n pn valor medio di ξ
xN =1
N
N∑j=1
xj media campionaria
Osservazione: xN dipende dal campione, che a sua volta
e il risultato di un fenomeno aleatorio. Dunque anche
xN e una variabile random: giocando altre N partite si
puo ottenere una media campionaria differente. Questa
variabile random serve pero come stima di µ, e per questo
si dice stimatore. La sua proprieta fondamentale e che
converge in probabilita a µ per N grande †.†Questo risultato e anche noto come “Legge dei Grandi Numeri”.
41

%% Paradosso di S. Pietroburgo
T = 5000; %% numero di partite
d = 12; %% posta: costo di una partita
win(1) = 0; %% soldi di partenza
%% N = numero di lanci prima che esca testa
%% win = soldi precedenti + vincita - posta
for i=1:T;
flag = 0;
N(i) = 0;
while (flag < 1)
z=rand(1,1);
N(i) = N(i)+1;
if z < 0.5
flag = 1;
end
end
win(i+1) = win(i) + 2^N(i) - d;
end
M = max(N);
%% media teorica
avT = sum((1:100)./(2.^(1:100)));
%% media campionaria
avN = sum(N(1:T))/T;
% %% Processo del capitale in possesso
% subplot(2,1,1); plot(N(1:T),’.’)
% axis([1 T M-4.5 M+0.5])
% ylabel(’N’,’Fontsize’,20); set(gca,’Fontsize’,18)
% subplot(2,1,2); plot(win(1:T))
% ylabel(’$’,’Fontsize’,20); set(gca,’Fontsize’,18)
%% Istogramma degli N: distribuzione 1/2^n
h=hist(N,M); h=h/(2*h(1));
plot(h,’.’); axis([0.5 M+0.5 0 0.55])
clear z flag d i T M %% eliminazione dal workspace
42
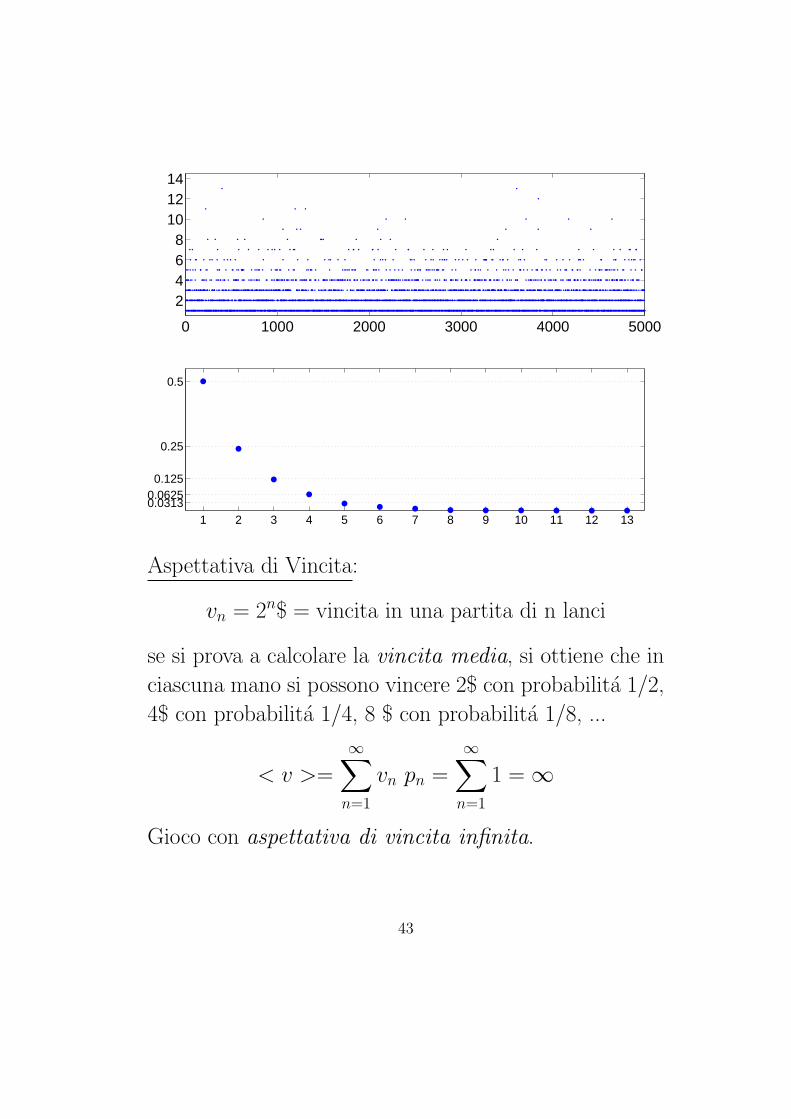
0 1000 2000 3000 4000 5000
2468
101214
1 2 3 4 5 6 7 8 9 10 11 12 130.03130.0625
0.125
0.25
0.5
Aspettativa di Vincita:
vn = 2n$ = vincita in una partita di n lanci
se si prova a calcolare la vincita media, si ottiene che in
ciascuna mano si possono vincere 2$ con probabilita 1/2,
4$ con probabilita 1/4, 8 $ con probabilita 1/8, ...
< v >=
∞∑n=1
vn pn =
∞∑n=1
1 = ∞
Gioco con aspettativa di vincita infinita.
43

Questo gioco e basato su eventi rari: quasi sempre una
partita da un risultato basso, e piu la posta d e alta, piu
saranno rare le partite in cui G vince su B. I risultati alti,
pero, giocando molte partite ripagano tutte le perdite.
Con “raro” si intende il fatto che la distribuzione di base
e esponenziale, dunque ad esempio la probabilita che una
partita si concluda con piu di n∗ lanci e
q(n∗) =1
2n∗ +1
2n∗+1+
1
2n∗+2+ . . . =
∞∑
n=n∗
1
2n
= 1−n∗−1∑n=1
1
2n=
1
2n∗−1
Fissato d, quindi, per “vincere” occorre terminare una
partita con un numero n di lanci tale che vn ≥ d, ovvero
n ≥ [log2d
]+ 1, e cio avviene con probabilita 1/2
[log2d
]
cioe circa 1 volta su d partite†.
Nella pratica, la successione numerica che interessa e
quella dei soldi che si hanno in tasca partita dopo partita,
che puo essere descritta dawj
N
j=1wj+1 = wj + 2xj+1 − d
Nei seguenti grafici vi sono esempi di come puo andare
un gioco di 5000 partite, con d=12 $, e di quanto siano
gli eventi rari a dominarne gli esiti.†Con le parentesi quadre si intende qui la parte intera del numero reale.
44
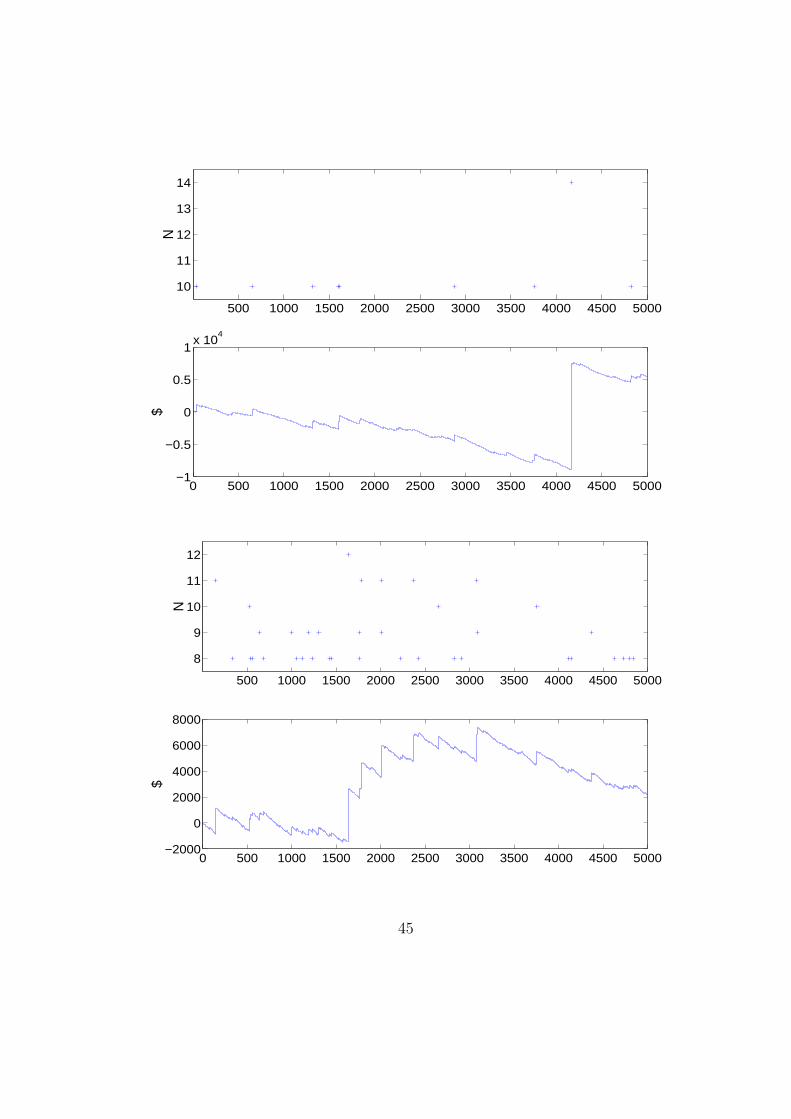
500 1000 1500 2000 2500 3000 3500 4000 4500 5000
10
11
12
13
14N
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−1
−0.5
0
0.5
1x 10
4
$
500 1000 1500 2000 2500 3000 3500 4000 4500 5000
8
9
10
11
12
N
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−2000
0
2000
4000
6000
8000
$
45

500 1000 1500 2000 2500 3000 3500 4000 4500 5000
9
10
11
12
13
N
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−1
0
1
2
3x 10
4
$
500 1000 1500 2000 2500 3000 3500 4000 4500 5000
10
11
12
13
14
N
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−1
0
1
2
3
4x 10
4
$
46

500 1000 1500 2000 2500 3000 3500 4000 4500 5000
9
10
11
12
13N
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−8000
−6000
−4000
−2000
0
2000
$
500 1000 1500 2000 2500 3000 3500 4000 4500 5000
8
9
10
11
12
N
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−2000
0
2000
4000
6000
8000
$
47

500 1000 1500 2000 2500 3000 3500 4000 4500 5000
11
12
13
14
15
N
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−1
0
1
2
3
4x 10
4
$
500 1000 1500 2000 2500 3000 3500 4000 4500 5000
9
10
11
12
13
N
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−1
0
1
2
3
4x 10
4
$
48
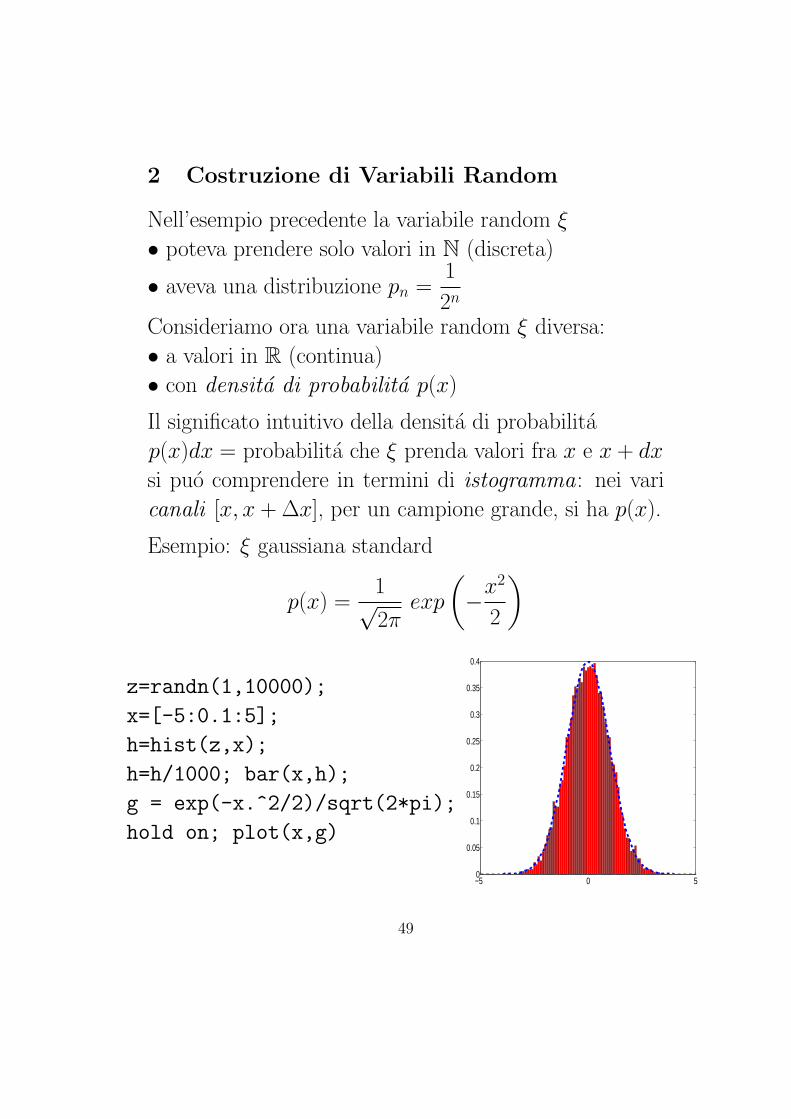
2 Costruzione di Variabili Random
Nell’esempio precedente la variabile random ξ
• poteva prendere solo valori in N (discreta)
• aveva una distribuzione pn =1
2n
Consideriamo ora una variabile random ξ diversa:
• a valori in R (continua)
• con densita di probabilita p(x)
Il significato intuitivo della densita di probabilita
p(x)dx = probabilita che ξ prenda valori fra x e x + dx
si puo comprendere in termini di istogramma: nei vari
canali [x, x + ∆x], per un campione grande, si ha p(x).
Esempio: ξ gaussiana standard
p(x) =1√2π
exp
(−x2
2
)
z=randn(1,10000);
x=[-5:0.1:5];
h=hist(z,x);
h=h/1000; bar(x,h);
g = exp(-x.^2/2)/sqrt(2*pi);
hold on; plot(x,g)
−5 0 50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
49

Matlab dispone di due generatori random: uno normale
standard (randn) ed uno uniforme fra 0 ed 1 (rand).
Con quest’ultimo e possibile costruire variabili random
aventi qualsiasi distribuzione di probabilita, attraverso
il metodo del rigetto: si estraggono coppie (x, y) con x
nell’intervallo di dominio desiderato ed y ∈ [0, pMAX ],
accettando x solo se y < p(x). Cosı entrano a far parte
del campione di ξ, in un dato intervallo, tante occorrenze
quanta e la probabilita di averne. Esempio: Cauchy
p(x) =1
π
1
1 + x2
function x=cauchy(n)
j=1; z1=rand(1,n); z2=rand(1,n);
for i=1:n,
a1=1400*z1(i)-700; a2=z2(i)/pi;
if a2*pi*(1+a1*a1)<1
x(j)=a1; j=j+1;
end;
end;
funzione richiamata da
Yc=cauchy(1000000); x = -20:.2:20;
div=.2*length(Yc); h=hist(Yc,x)/div;
bar(x,h,’b’); axis([-21 21 0 0.35]);
50

La proprieta cruciale della distribuzione di Cauchy e la
varianza infinita. L’integrale∫
Rx2p(x)dx
infatti diverge. La ragione sta nella lenta decrescita delle
code della distribuzione, che hanno un comportamento
di potenza. Queste “code grasse” causano una statistica
molto diversa da quella dell’esempio pn = 1/2n: qui
gli eventi rari non sono cosı rari. E sufficiente guardare
un’istogramma per accorgersi che le code impiegano molto
a spegnersi: sono frequenti eventi anche molto intensi
0 200 400 600 800 1000 1200 1400 1600 1800 2000 2200−50
0
50
−20 −15 −10 −5 0 5 10 15 200
0.1
0.2
0.3
51

3 Indipendenza e Correlazione
Il concetto di variabile random e cio che permette di
misurare eventi aleatori attraverso una mappatura dello
spazio degli eventi sull’asse reale: attraverso la densita
di probabilita (p.d.f.), l’importanza degli elementi dello
spazio degli eventi rappresentativi del fenomeno random
in questione si traduce in misura su R.
Esempio: X variabile random relativa alle dimensioni
delle foglie di un albero. La sua densita di probabilita
descrive quanto e frequente l’occorrenza dei vari eventi
(foglie di date dimensioni) pesandola su R (dimensioni).
Con la misura dµ si calcolano quindi i valori medi come
< f >=
∫
Rf (x)dµ(x) =
∫
Rf (x)p(x)dx
52

L’interdipendenza di due variabili random e legata alle
relazioni fra i rispettivi eventi di riferimento. Queste
si possono descrivere introducendo il condizionamento:
P (A|B) =P (A ∩B)
P (B)
rappresenta il condizionamento dell’evento B su A, ovvero
il peso “specifico” che B ha nell’interferire con A.
P e una misura di probabilita sullo spazio degli eventi, a
cui corrisponde univocamente una densita di probabilita
in R. Poiche P (A|B) definisce la probabilita (misura)
di A condizionata a B, gli eventi si dicono indipendenti
se P (A|B) = P (A), cioe se B non condiziona A.
Due variabili random, che mappano eventi in
intervalli di R, si dicono percio indipendenti se
i loro eventi di riferimento sono indipendenti.
53

L’indipendenza aleatoria della variabile random X da
Y indica che le realizzazioni dell’una non influiscono su
quelle dell’altra. In generale, l’azione “simultanea” di X
ed Y e regolata da una densita di probabilita congiunta
in due variabili pX,Y
(x, y), che definisce una mappatura
bidimensionale degli eventi. pX,Y
(x, y) e legata ad una
densita condizionata attraverso la formula di Bayes, che
equivale alla relazione insiemistica precedente:
pX|Y (x|y) =
pX,Y
(x, y)
pY
(y)
Per variabili random indipendenti, dunque, la densita di
probabilita congiunta fattorizza:
X,Y indipendenti ⇒ pX
(x)pY
(y)
e in questo modo non si ha condizionamento
pX|Y (x|y) = p
X(x)
In particolare, l’indipendenza di due variabili random
deve produrre l’annullamento della covarianza :
cov(X,Y ) = E[(
X − E(X))(
Y − E(Y ))]
= 0
e questo avviene proprio grazie alla fattorizzazione †.†La covarianza quantifica la somiglianza media delle fluttuazioni random di X ed Y , e
se queste sono indipendenti, in quanto affinita statistica deve annullarsi:∫
R2
(x−E(X)
)(y−E(Y )
)p
X,Y(x, y)dxdy =
∫
R
(x−E(X)
)p
X(x)dx
∫
R
(y−E(Y )
)p
Y(y)dy = 0
54

Se due variabili random X e Y sono note attraverso loro
realizzazioni, cioe si possiedono due campioni statistici
xj e yj, la covarianza si puo inferire utilizzando uno
stimatore analogo a quello di media campionaria xN : la
covarianza campionaria
cN (xj , yj) =1
N
N∑j=1
(xj − xN)(yj − yN)
La covarianza fra X e X stessa e la varianza var(X):
alla covarianza contribuiscono anche le fluttuazioni delle
singole variabili random, quindi una maniera naturale
per “normalizzare” la covarianza ed ottenere un indice
adimensionale porta alla definizione di correlazione:
corr(X, Y ) =cov(X,Y )√
var(X)var(Y )
Il cui stimatore campionario e una composizione degli
stimatori di covarianza/varianza e media campionarie:
rN (xj , yj) =
N∑j=1
(xj − xN)(yj − yN)
√√√√N∑
j=1
(xj − xN)2N∑
j=1
(yj − yN)2
55

La covarianza e la correlazione vengono spesso usate per
quantificare l’interdipendenza fra due variabili random.
Questo e possibile solo studiando la probabilita congiunta:
la valutazione di affinita aleatoria della covarianza e una
approssimazione non sempre sufficiente.
Esempio: cov(X,Y ) si annulla per X , Y indipendenti,
ma non e vero che variabili random a covarianza nulla
siano indipendenti. Se diciamo Z = XY , questa variabile
non e indipendente da X , ma se Y ha media nulla la
covarianza e comunque zero
cov(X, Z) = E(X2Y
)−E(X
)E
(XY
)= var(X)E(Y )
Occorre quindi tenere sempre presente la differenza fra
dipendenza aleatoria e covarianza. Una correlazione nulla
viene infatti considerata come “indipendenza al secondo
ordine”: la covarianza rappresenta il secondo momento
congiunto della distribuzione, e la terminologia e relativa
al fatto che da cov(X, Y ) = 0 non si hanno informazioni
sui momenti superiori (solo conoscendoli tutti e possibile
ricostruire la probabilita congiunta).
Cio nonostante si tratta comunque di uno degli strumenti
piu usati nell’analisi statistica sia per il suo significato
intuitivo che per l’efficacia degli stimatori disponibili.
56

Correlazione campionaria fra due variabili indipendenti
gaussiane generate con Matlab:
function r=correla(x,y);
n = min(length(x),length(y));
muX = mean(x); muY = mean(y);
x2 = sum((x(1:n)-muX).*(x(1:n)-muX));
y2 = sum((y(1:n)-muY).*(y(1:n)-muY));
xy = sum((x(1:n)-muX).*(y(1:n)-muY));
den = sqrt(x2*y2); r = xy/den;
confrontare il risultato ottenuto da
x = randn(2,5000); r = correla(x(1,:),x(2,:));
con quello ottenuto dalle variabili dipendenti
x = randn(1,5000); y = x.^3-x; r = correla(x,y);
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−5
0
5
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000−20
−10
0
10
20
57

Teorema del Limite Centrale
Se XiNi=1 sono variabili random i.i.d. (indipendenti e
identicamente distribuite), con media µ e varianza σ2
finite, la variabile costruita come
YN =1√N
N∑i=1
(Xi − µ)
converge in probabilita, per N → ∞, ad una variabile
gaussiana a media 0 e varianza σ2: YN ∼ N(0, σ2).
Il TLC indica la convergenza normale della somma di
variabili random a varianza finita: in questo senso la
gaussiana e un attrattore per determinate distribuzioni.
Legge dei Grandi Numeri
Se XiNi=1 sono variabili random indipendenti e identi-
camente distribuite (i.i.d.), con media µ e varianza σ2
finite, la variabile costruita come
ZN =1
N
N∑i=1
Xi
converge a µ quasi dappertutto sullo spazio degli eventi.
La LGN costruisce una variabile ZN con varianza σ2/N ,
che quindi ha limite deterministico. Questo fatto e alla
base della costruzione di molti stimatori.
58

Applicazioni Numeriche/Esercizi:
1. Calcolare la correlazione due variabili gaussiane X e
Y indipendenti. Come mai e diversa da 0? Vale la
stessa cosa per la correlazione fra X e XY ?
2. Costruire X e Y gaussiane, e Z = X + Y . Qual e
la loro correlazione? Disegnare plot(X,Z,’.’) e
plot(X,Y,’.’): che differenze ci sono? Cos’e la
densita di probabilita condizionata?
3. Per il teorema del limite centrale, preso xj un
campione a varianza finita e media nulla allora, per
N grande, il campione
zN =∑N
j=1 xj
tende ad
avere una varianza campionaria pari a N volte la
varianza di xj. Come si puo vedere con Matlab?
4. L’istogramma di un campione abbastanza grande ne
fornisce la densita di probabilita corrispondente. Cio
e assicurato dalla legge dei grandi numeri, che si puo
applicare † alla distribuzione empirica
FN(x) =#xi < x
Nche stima la distribuzione cumulativa e vi converge
(in qualche senso). Calcolarla con Matlab su un
campione gaussiano all’aumentare di N .
†Questo e il caso del Teorema di Cantelli.
59

Esercizio 1:
Lo stimatore r e una variabile random, perche dipende
dalla realizzazione del campione. In particolare, se xjNj=1
e yjNj=1 sono realizzazioni indipendenti, allora r e
una variabile random con varianza 1/N , gaussiana per N
grande: si ha quindi un 95% di probabilita che r risulti
compreso fra −2/√
N e 2/√
N (quantili gaussiani).
N = 20000; dbin = 0.002; norm = N*dbin;
for i=1:20000
x=randn(1,5000); y=randn(1,5000); z=x.*y;
r(i)=correla(x,A);
end
bin=[-0.1:0.002:0.1]; h=hist(r,bin)/norm;
bar(bin,h); axis([-0.1 0.1 0 max(h)])
Questo codice permette di istogrammare la correlazione
di X con Y o con Z = XY (A = Y o Z). Teoricamente
si ha corr(X,Z) = 0, dunque dall’analisi campionaria ci
si attende ancora “correlazione nulla”. La distribuzione
gaussiana con varianza 1/N per la correlazione si ha pero
solo fra campioni indipendenti: anche la correlazione fra
X e Z sara piccola, ma seguira una statistica differente.
Studiando questa statistica e quindi possibile rifiutare
l’ipotesi di indipendenza delle variabili †.†Ad esempio se piu del 5% delle volte si ottiene una correlazione superiore a 2/
√N .
Questo e un test che non puo venire svolto quando si dispone di un solo campione.
60
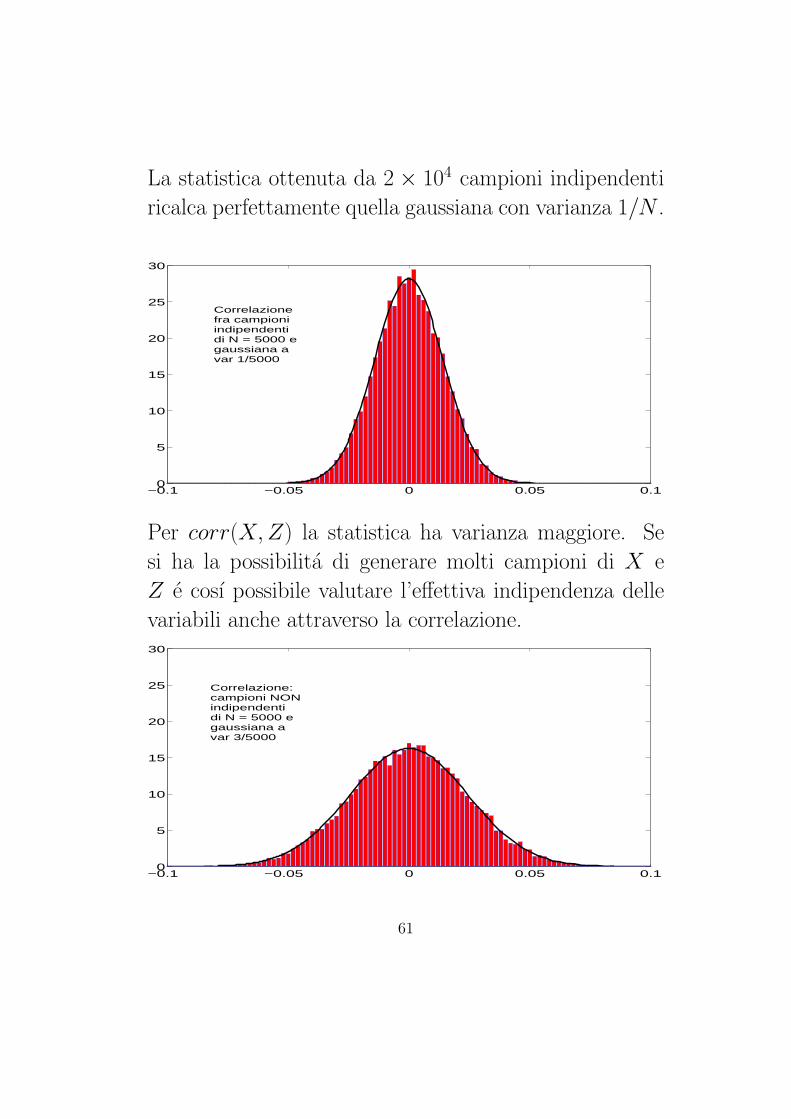
La statistica ottenuta da 2 × 104 campioni indipendenti
ricalca perfettamente quella gaussiana con varianza 1/N .
−0.1 −0.05 0 0.05 0.10
5
10
15
20
25
30
Correlazionefra campioniindipendentidi N = 5000 egaussiana a var 1/5000
Per corr(X, Z) la statistica ha varianza maggiore. Se
si ha la possibilita di generare molti campioni di X e
Z e cosı possibile valutare l’effettiva indipendenza delle
variabili anche attraverso la correlazione.
−0.1 −0.05 0 0.05 0.10
5
10
15
20
25
30
Correlazione: campioni NONindipendenti di N = 5000 egaussiana a var 3/5000
61

Esercizio 2:
Anche per questo punto osserviamo l’intera distribuzione
della correlazione campionaria. Questa volta il suo valore
medio (la correlazione teorica) non sara 0:
corr(X,X + Y ) =cov(X,X + Y )√
var(X)var(X + Y )
=E [X(X + Y )]√
var(X) (var(X) + var(Y ))
=1√2
Dove si e usata la media nulla delle variabili X e Y e la
loro indipendenza: E [XY ] = cov(X,Y ) = 0.
0.67 0.68 0.69 0.7 0.71 0.72 0.73 0.740
10
20
30
40
50
62

Disegnamo ora lo Scatter Plot
x=randn(1,5000); y=randn(1,5000);
z=x+y; plot(x,z,’.’)
−4 −3 −2 −1 0 1 2 3 4−6
−4
−2
0
2
4
6
X
Z
La densita di probabilita condizionata fZ|X (z|x) e una
densita per la variabile Z, pesata con il condizionamento
di X , e la si puo costruire numericamente istogrammando
lo scatter plot lungo Z considerando i punti fra x e x+dx.
In figura e messo in evidenza fZ|X (z|x = 1).
63

Un esempio ancora piu evidente di come lo scatter plot
possa essere utile per quantificare l’interdipendenza fra
variabili random e dato dai campioni dell’esercizio 1: di
X e Z = XY . Una valutazione la loro non indipendenza
attraverso la correlazione richiede di ricorrere a statistiche
su piu campioni, non sempre disponibili. Con lo scatter
plot si ottiene invece immediatamente una distribuzione
estremamente diversa da quella di variabili indipendenti.
−4 −3 −2 −1 0 1 2 3 4−4
−3
−2
−1
0
1
2
3
4
X
Y
−4 −3 −2 −1 0 1 2 3 4−8
−6
−4
−2
0
2
4
6
8
X
Z
A sinistra si osserva isotropia, carattere che corrisponde
a indipendenza, mentre a destra e ben visibile una forte
interdipendenza fra X e Z.
64

14/04/2005
1 Moto Browniano †
Einstein e la diffusione
Il lavoro di Einstein arriva dopo le molte osservazioni del
moto di particelle sospese in fluidi, ad opera di biologi e
botanici, e dopo i lavori di fine ottocento di meccanici
statistici come Boltzmann e Maxwell. La teoria cinetica
dei gas e la termodinamica dell’equilibrio erano gia state
introdotte, e ora mancava un collegamento fra questi
strumenti e quei moti irregolari : la loro comprensione
non poteva rifarsi alla meccanica, e la descrizione delle
traiettorie doveva perdere il determinismo.†Un articolo sempre interessante e “On the theory of the brownian motion”, di Ornstein
e Uhlenbeck su Phys.Rev. 36, 823-841 (1930). Di riferimento per la fisica dei processidi Markov sono invece i libri di H.Risken “The Fokker-Planck equation” e di N.G.VanKampen “Stochastic processes in physics and chemistry”.
65

Moto Browniano (Einstein, 1905)
Risultato di un fenomeno di diffusione delle particelle
sospese ad opera dei moti molecolari, determinati dalla
cinetica dell’ambiente all’equilibrio (bagno termico).
Le traiettorie sono caratterizzate dalle seguenti proprieta:
1. e possibile introdurre un intervallo di tempo τ ¿ del
tempo di osservazione, tale che i movimenti di una
particella in intervalli τ differenti siano indipendenti
2. in un intervallo τ la posizione della particella viene
incrementata di una quantita random ∆
3. in presenza di ν particelle in sospensione per unita di
volume, in ciascuna regione interessata dal moto si ha
un flusso† di particelle pari a −D∂ν
∂x, con costante di
diffusione D = kBT/γ (γ = frizione dell’ambiente).
4. la relazione fra la distribuzione degli incrementi ∆ e
la diffusione e data in termini della varianza:
σ2(∆) = 2Dτ
si ottiene cosı l’equazione per la densita di probabilita
del moto delle particelle sospese
∂p(x, t)
∂t= D
∂2p(x, t)
∂x2
†Questa e la legge di Fick della diffusione, qui relazionata alla teoria cinetica dei gas.
66

Ornstein, Uhlenbeck e i processi stocastici
Per descrivere le traiettorie e possibile anche utilizzare
una rappresentazione meccanica dell’azione dell’ambiente,
introducendo la nozione di forzante stocastica: gli urti
subiti da una particella in un bagno termico si possono
rappresentare come impulsi casuali non correlati fra
loro. Per una particella in un ambiente che induce queste
fluttuazioni e dissipa energia a causa degli attriti si puo
scrivere l’equazione di Langevin nella velocita:
dv(t)
dt= −γv(t) +
√DΓ(t)
dove Γ(t) e una famiglia di variabili aleatorie a media
nulla e non correlate a tempi diversi (impulsi random)†:
E(Γ(t)) = 0 ; corr(Γ(t), Γ(s)) = δ(t− s)
Viene definito cosı un processo stocastico: una evoluzione
le cui traiettorie sono oggetti probabilistici descritti da
una equazione di Fokker-Planck per la p.d.f. della
velocita (aleatoria) v, che evolve in t:
∂p(v, t)
∂t= D
∂2p(v, t)
∂v2+ γ
∂p(v, t)
∂vL’ipotesi di non correlazione nella forzante e quella del
“caos molecolare” e Γ viene anche detto rumore bianco.†Si considera cioe, in ciascun istante t, una variabile random i.i.d. rispetto alle
precedenti. Nell’approssimazione di Einstein questo significa considerare τ infinitesimo.
67

Random Walk gaussiano e Teorema del Limite Centrale
La proprieta 1) delle traiettorie browniane (Einstein) viene
detta degli incrementi stazionari indipendenti (Levy):
ogni salto e indipendente dai precedenti e la distribuzione
dei salti ∆ effettuati nell’intervallo τ dipende solo da τ †.
Se diciamo Xt la “posizione del processo al tempo t”,
possiamo introdurre gli incrementi, o salti, come
∆Xt = Xt+τ −Xt
e la proprieta di Levy imponendo che ∆Xt = Zt siano
variabili random i.i.d. la cui p.d.f. dipende solo da τ .
Considerando τ come intervallo unitario, si puo lavorare
a tempi discreti e definire cosı il processo operativamente:
Xt+1 = Xt + Zt
Con la condizione iniziale X0 = 0 si ottiene dunque
Xt+1 =
t∑n=0
Zt
cioe la posizione del processo al tempo t puo pensarsi
come somma di t variabili i.i.d.. Se hanno varianza σ2
finita, il moto browniano “ricade” dunque nel TLC:
Xt ∼ N(0, tσ2)
†Un processo stocastico di questo tipo e detto di Levy.
68

La gaussianita del processo e coerente con l’equazione
della diffusione, la cui soluzione e appunto
p(x, t) =1√
4πDte−x2/4Dt
e la scrittura ad incrementi si puo intendere come versione
discreta dell’equazione di Langevin.
Per visualizzare il processo risultante occorre generare
molte traiettorie Xt =∑
Zt infatti per t diversi si hanno
variabili random Xt con diversa p.d.f.. L’evoluzione della
densita di probabilita puo essere istogrammata solo con
molte realizzazioni di ciascuna Xt: per questo ciascuna
traiettoria va considerata come un unico oggetto random.
Ogni traiettoria e una realizzazione del processo.
subplot(2,1,1)
for n=1:200;
z=randn(1,500);
for i=1:500;
x(i)=sum(z(1:i));
end;
for i=1:50; y(i)=x(10*i); end;
plot(y,’.’); hold on
end
subplot(2,1,2); plot(x)
69

0 100 200 300 400 500−100
−50
0
50
100
0 100 200 300 400 500−20
−10
0
10
Nel riquadro superiore sono state plottate a punti molte
traiettorie sovrapposte, mettendo in risalto come a ciascun
t la densita di probabilita vari: in particolare si nota
l’aumento della varianza e la media sempre circa nulla.
Nel riquadro inferiore si ha una traiettoria browniana: per
ciascun t e stata scelta una realizzazione della variabile
Xt, formando cosı una realizzazione del processo stocastico.
70


















