
C. Battisti, Analisi delle minacce antropogene in aree umide del litorale romano

Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Reti di calcolatori
Rilevazione delle anomalie sulla rete utilizzando il Cloud e tecniche di Machine Learning Anno Accademico 2017/2018 Candidato: Nicola Ambrosone matr. N46/3129

Indice Indice ................................................................................................................................................... IIIndice figure ....................................................................................................................................... IIIIntroduzione ......................................................................................................................................... 4Capitolo 1: Strumenti base ................................................................................................................... 6
1.1 Intrusion Detection System ........................................................................................................ 71.2 Cloud Computing ..................................................................................................................... 121.3 Machine Learning .................................................................................................................... 16
1.3.1 Approcci di machine learning .......................................................................................... 171.4 Big Data ................................................................................................................................... 19
Capitolo 2: Cloud-based Detection .................................................................................................... 222.1 SIEM as a Service .................................................................................................................... 222.2 Cloud-based IDS (CBIDS) ....................................................................................................... 25
Capitolo 3: Machine Learning Detection ........................................................................................... 30Conclusioni ........................................................................................................................................ 36Bibliografia ........................................................................................................................................ 38

Indice figure
Figura 1.1.1 : Falsi positivi e falsi negativi ................................................................................ 8Figura 1.1.2 : Metodi di detection ............................................................................................ 11Figura 1.2.1 : Modelli di servizio del cloud computing .......................................................... 14Figura 1.3.1 : Deep Learnig as a brain .................................................................................... 17Figura 1.4.1 : “Le 5 V”. Caratteristiche principali dei Big Data ............................................. 20Figura 1.4.2 : (a) Anomalie nei dati, (b) Anomalie rilevate dal metodo proposto .................. 21Figura 2.2.1 : Cloud-based Intrusion Detection Service Framework ...................................... 25Figura 2.2.2: Architettura CBIDS ............................................................................................ 27Figura 2.2.3: Architettura modello distribuito di intrusion detection ...................................... 28Figura 2.2.4: Algoritmo modello distribuito di intrusion detection ........................................ 28Figura 2.2.5: Procedura di aggregazione dei dati nel sottosistema Data Aggregation ............ 29Figura 3.1.1 : Modello Fully Conncted Neural Network ......................................................... 30Figura 3.1.2 : Risultati sperimentali con NSL-KDD dataset usando il modello FNC ............. 31Figura 3.1.3 : (a) Numero di feature rispetto al tempo relativo di apprendimento. (b) Numero
di feature rispetto al tasso di errore ................................................................... 32Figura 3.1.4 : Risultati sperimentali anomaly detection con tecniche di regressione lineare
(LR) e di foresta casuale (RF) ........................................................................... 33Figura 3.1.5 : Algoritmo di classificazione degli attacchi ........................................................ 34

4
Introduzione
La rapida evoluzione tecnologica negli anni ha provocato non solo un crescente sviluppo
della società, dato sicuramente positivo, ma ha generato anche una serie di timori
nell’essere umano circa la robotica, l’automazione e la crescente diminuzione della
“scelta” umana; invece nell’ambito della sicurezza in internet, ancora non sono ben
conosciuti agli utenti i reali rischi che si possono correre nell’utilizzo quotidiano dei
sistemi informatici.
La scarsa preparazione della massa degli utilizzatori potrebbe essere una delle ragioni per
cui sono aumentate anche le minacce e le vulnerabilità a tutti i livelli.
In questo scenario di rischio i bersagli principali sono rappresentati dalle persone, che
spesso appartengono a organizzazioni o aziende, target “facili” per furti d’informazioni
sensibili.
Considerando i grandi numeri che sono coinvolti globalmente, in ogni città, paese o
continente, si può immaginare come aumentino i tentativi e le possibilità di successo per
un “attaccante”.
Quindi, elementi molto importanti per le aziende diventano i dispositivi di sicurezza, che
sono basati o su modelli che stabiliscono un perimetro della rete o su modelli di sicurezza
distribuita o entrambi.

5
La necessità di rilevare prontamente anomalie, come minacce di attacco o tentativi di
accesso non autorizzato in aree informatiche off-limits dell’azienda, rende indispensabile
l’utilizzo di sistemi di sicurezza che consentano di analizzare e monitorare gli eventi sulla
rete, che vengono analizzati con diverse tecniche, come Big Data o Machine Learning.
In questo elaborato si focalizzerà l’attenzione sulle tecnologie di rilevazione di anomalie,
basate su cloud e tecniche di machine learning.
Un ambiente cloud permette un supporto efficace per realizzare architetture scalabili e per
analizzare il crescente volume d’informazioni, prendendo decisioni real-time e sfruttando
elevate capacità computazionali di diverse macchine virtuali poste nella rete.
Inoltre essendo le anomalie eventi inattesi ed in continuo sviluppo, per poterle
discriminare dagli eventi normali, sono necessari dei sistemi di apprendimento automatico
che consentano di ridurre i tempi di ricerca e di creare modelli di dati che prevedano
eventi futuri.
Ad oggi i cloud provider (Amazon, Google, etc…) sono in grado di fornire servizi di
sicurezza completi sfruttando una vasta scala di dati provenienti da archivi aziendali,
ambienti ibridi e cloud, applicando anche algoritmi di machine learning per imparare,
adattarsi e scoprire nuovi modelli al fine di rilevare comportamenti anomali in tempo
reale.

6
Capitolo 1: Strumenti base
L’utente “medio” di Internet rende fruibili la maggior parte delle informazioni personali,
anche sensibili, e preferenze, facendo sì che, inconsapevolmente, possano essere reperite
in rete.
Il rischio reale riguarda l’opportunità, anche a scopo malevolo, di utilizzare tali dati da
parte di soggetti non autorizzati.
Diventa necessario adottare quindi, per non correre questo rischio, misure di sicurezza per
evitare intrusioni, furti di dati o frodi.
Di fondamentale importanza è la rilevazione tempestiva ed efficace delle anomalie per
garantire un buon livello di sicurezza della rete.
Un’anomalia è un tentativo di accesso non autorizzato a un sistema, che può
compromettere la sua integrità, renderlo inutilizzabile, sfruttando vulnerabilità interne,
cioè falle e punti deboli del sistema.
Le intrusioni, che di fatto sono rilevate come anomalie, sono definite tali rispetto a policy
di sicurezza, che chiariscono cosa è consentito e cosa è proibito in un sistema, senza cui è
impossibile capire se si è verificata una anomalia.

7
1.1 Intrusion Detection System
L’individuazione delle anomalie avviene a livello di rete, di trasporto o di applicazione
utilizzando strumenti informatici chiamati Intrusion Detection System (IDS).
Gli IDS sono detti Host-Based (HIDS), se effettuano un’analisi dei log del sistema
operativo e delle applicazioni ed attivano strumenti di monitoraggio interni al sistema;
altrimenti, si indicano come Network Intrusion Detection System (NIDS) se utilizzano
strumenti di monitoraggio del traffico dell’intera rete.
In un sistema NIDS, è possibile individuare tre blocchi fondamentali:
- il sensore che raccoglie informazioni dalle sorgenti e le invia all’analizzatore;
- l’analizzatore che osserva i dati raccolti dal sensore, cercando segni sospetti;
- il gestore, manager che coordina gli altri componenti del IDS.
Due invece sono i partecipanti principali:
- l’operatore, principale utilizzatore del gestore, che crea la configurazione iniziale del
IDS, controlla l’uscita del sistema di intrusion detection e eventualmente intraprende
adeguate contromisure in caso di anomalie;
- l’amministratore che è responsabile della configurazione dell’IDS e della realizzazione
delle politiche di sicurezza, su cui si fonda l’intero processo.
L’analisi dei dati raccolti può essere sviluppata seguendo due tipi di approccio:
Anomaly Detection
Le tecniche di rilevamento d’intrusione basate su anomalie ricercano eventi che vengono
classificati come anomali se presentano una elevata deviazione rispetto ai “normali”
pattern comportamentali del sistema.
Un normale comportamento di un sistema può essere definito utilizzando o algoritmi di
apprendimento, che permettono di classificare il flusso di rete distinguendo comportamenti
sospetti o creando un modello matematico che permette di analizzare le relazioni e le
differenze tra le attività implicate.

8
Aspetti positivi di questo approccio riguardano il fatto di potersi adattare facilmente a
nuovi schemi di attacco e il rilevamento avviene in real-time; tuttavia perdono in termini
di accuratezza poiché l’IDS non può conoscere tutti i possibili utilizzi consentiti del
sistema.
Quindi possono essere generati dei falsi positivi, cioè attività anomale non intrusive ma
che sono rilevate come tali e dei falsi negativi, cioè attività intrusive non anomale ma che
non vengono rilevate.
L’obiettivo dell’anomaly detection è quello di ottenere una buona accuratezza,
minimizzando il numero di falsi positivi e di falsi negativi.
[ Figura 1.1.1 : Falsi positivi e falsi negativi
Misuse Detection
Questa tecnica si basa sul fatto che si possono identificare anomalie all’interno del sistema
sotto forma di tracce (signature) già note, confrontandole con i dati raccolti.
Si ricercano pattern noti nel traffico di rete o nei dati delle applicazioni attraverso file di
log.
Disagevole risulta che i pattern conosciuti devono essere inseriti manualmente e inoltre
non è possibile rilevare nuove tipologie d’intrusione se non sono già presenti all’interno
del sistema.
In compenso questo approccio è affidabile e veloce e genera un numero di falsi positivi
abbastanza basso.

9
Essendo le misuse e le anomaly detection caratterizzate da una serie di limitazioni, sono
stati messi a punto dei Sistemi ibridi , che prendono decisioni considerando entrambi gli
approcci, studiando sia il comportamento normale del sistema sia quello atteso da parte
dell’attaccante.
I sistemi ibridi riescono con una probabilità maggiore a identificare gli attacchi e sono in
grado di evitare situazioni in cui tentativi di attacco, spezzettati nel tempo, possano essere
considerati come normali, essendo “adattivi”.
Spesso gli algoritmi di detection mediante meccanismi di auto-apprendimento, utilizzano i
dati raccolti per costruire modelli che consentano di adattarsi alle possibili situazioni in cui
dovranno operare, ipotizzando attività consentite che verranno usate per future valutazioni
di comportamenti.
I parametri per valutare l’efficienza di un Intrusion Detection System sono:
- Accuratezza: calcolata in base alla capacità di rilevare correttamente anomalie e di
limitare il numero di falsi positivi;
- Elasticità: un buon IDS deve resistere agli attacchi e supportare errori parziali;
- Performance: che deve essere elevata dovendo lavorare in real-time, in termini di
velocità di processazione dei rilevamenti.
Per testare e sviluppare algoritmi ed ambienti di detection sono state definiti vari tipi di
dataset fra cui :
- KDD Cup 1999 nato per scopi militari atti a rilevare minacce e attacchi informatici,
che fornisce un elevato numero d’intrusioni simulate, circa 4.900.000 di record,
etichettati come normali o come attacco, ognuno dei quali con 41 funzionalità.
Le etichette assegnate ai record rientrano in una di queste categorie:
denial of service, user to root attack, remote to local attack e probing;

10
- NSL-KDD nuova versione del dataset precedente, introdotta per risolvere il problema
dell’alta percentuale di record ridondanti, che causano duplicazioni sia in fase di
testing sia in fase di training.
Contiene 4 file di cui due per il training (KDDTrain+, KDDTrain_20%) e due per il
testing (KDDTest+, KDDTest_21).
- UNSW-NB15 è uno dei più recenti, pubblicato nel 2015, risulta essere il più completo.
Contiene più di 2 milioni di campioni e include nove diversi tipi di attacchi, ognuno di
quali con 49 funzionalità, comuni negli ambienti multi-cloud attuali [17].
Per quanto riguarda l’anomaly detection, in base al tipo di dataset utilizzato è possibile
distinguere 3 modalità di rilevamento (figura 1.1.2):
- Supervisionata: basata sulla definizione di un modello, creato a partire da un training
dataset, in cui sono stati classificati gli oggetti come normali o anomali, per poter
valutare un nuovo oggetto ;
- Non-supervisionata: non utilizza un particolare dataset, ma si basa sulla considerazione
che oggetti normali siano maggiori di quelli anomali.
Questa modalità nonostante sia quella più applicabile, può soffrire di un numero di
rilevazioni errate.
Esistono molti approcci di questo tipo tra cui il metodo distance-based, che distingue
gli oggetti (normali o anomali) sulla base delle distanze con gli oggetti più vicini;
- Semi-supervisionata: utilizza un training dataset, le cui istanze appartengono solo alla
classe normale.
Questo metodo è maggiormente utilizzabile rispetto al supervisionato, perché consente
una migliore rilevazione di anomalie, comprese quelle non ancora note.

11
Figura 1.1.2 : Metodi di detection

12
1.2 Cloud Computing " Cloud Computing is a model for enabling convenient, on-demand network access to a
shared pool of configurable computing resources (es., networks, servers, storage, applications, and service) that can be rapidly provisioned and released with minimal management effort or service provider interaction [8]"
La definizione data dal NIST letteralmente spiega che il cloud computing è un modello di
esecuzione elastico, che consente l’accesso alla rete su richiesta a un pool condiviso di
risorse di calcolo configurabili (es. rete, server, memorizzazione, applicazioni e servizi)
che possono essere rapidamente richieste e rilasciate con minimo sforzo gestionale e con
minime interazioni da parte del fornitore dei servizi.
Si tratta di nuove tecnologie che offrono un sistema di gestione, archiviazione e
condivisione delle risorse informatiche tramite la rete, sfruttando una politica “pay-as-you-
go”.
Nato per sostituire hardware e software con sistemi remoti più efficienti, consente notevoli
risparmi in termini di costi e migliora le prestazioni dell’ICT di aziende.
Gli attori di questo sistema sono:
- il cloud provider: colui che offre i servizi (es. Amazon, Google,…);
- il client admin: addetto alla scelta e configurazione dei servizi offerti dal fornitore;
- l’end user: che è l’utente finale che utilizza i servizi configurati dal client admin.
Esistono anche dei service provider che acquisiscono risorse e servizi di cui necessitano
dai cloud provider e li rivendono (es DropBox, Netflix,…).
Le principali caratteristiche del cloud riguardano:
- Elasticità cioè rapido rilascio delle risorse, anche in grandi quantità in qualsiasi
momento;
- Controllo che il fornitore realizza monitorando l’utilizzo del servizio per evitare un
sovraccarico di richieste e garantendo così la qualità del servizio;

13
- On-demand self-service attraverso cui il cliente può sfruttare autonomamente i servizi
offerti senza interazione diretta con il fornitore;
- Accesso a banda larga delle risorse che devono essere accessibili attraverso l’utilizzo
di piattaforme client, come smartphone, tablet, portable pc;
- Risorse comuni, assegnate dinamicamente per consentire l’utilizzo da parte di più
clienti contemporaneamente.
In base al tipo di servizio richiesto e alle esigenze del cliente, si possono distinguere vari
modelli di servizio:
Esiste il Software as a Service (SaaS) in cui le risorse sono ospitate nel Cloud e sono
accessibili tramite interfaccia web. Così si evitano installazioni e esecuzioni tramite
sistema operativo; l’utilizzo è paragonabile a un noleggio del servizio corrisposto tramite
un pagamento (abbonamento);
Il Platform as a Service (PaaS), invece, è un’evoluzione del SaaS, da cui differisce perché
l’utente può utilizzare il servizio a consumo, pagando in base all’utilizzo, alla dimensione
dell’hardware e alle elaborazioni eseguite; sono disponibili per il cliente tutte le
applicazioni di cui necessita, senza il bisogno di installare hardware e software diversi per
eseguirle. I consumatori possono arricchire il cloud con proprie applicazioni;
Ancora l’Infrastucture as a Service (IaaS) fornisce l’accesso a veri e propri data center
remoti, corrispondenti a edifici dove sono localizzate le risorse hardware e le macchine
virtuali; un gestore software chiamato hypervisor, tramite le macchine virtuali, può
dirigere il traffico dei servizi a seconda delle richieste del cliente; il cliente paga solo per
la durata del tempo di utilizzo del servizio e deve solo occuparsi di installare e manutenere
le macchine virtuali e gli applicativi che utilizza.

14
Figura 1.2.1 : Modelli di servizio del cloud computing
Sono 4 i tipi di modelli di deployment del cloud:
- Public Cloud
in cui l’accesso da parte dei clienti avviene tramite web browser, l’infrastruttura è pubblica
e chiunque, può utilizzare i servizi offerti dal cloud provider; chiaramente questo metodo
risulta essere il meno sicuro;
- Private Cloud
dove l’infrastruttura è limitata ai confini di una azienda, può essere interna o gestita da
terzi. Quindi i servizi sono accessibili solo agli utenti appartenenti alla rete aziendale e
risorse, sicurezza e manutenzione sono gestite dall’organizzazione stessa; i costi
d’implementazione per l’azienda sono elevati;
- Community Cloud
prevede che l’infrastruttura possa essere utilizzata solo da una specifica comunità di utenti
con interessi comuni, può essere interna o gestita da terzi e il costo per ogni utente è
maggiore rispetto a un public cloud;
- Hybrid Cloud:
realizza l’infrastruttura mescolando due o più tipi di cloud e permettendo, ad esempio, di
tenere pubbliche alcune parti di servizi e applicazioni, rendendone private altre.

15
Tra i vantaggi dell’utilizzo del cloud da parte dell’utente finale si ha sicuramente un
abbattimento dei costi di manutenzione delle infrastrutture IT, che sono gestititi dai cloud
provider, pagando solo quello di cui si usufruisce. Inoltre in caso di esigenza di maggior
potenza di calcolo non si dovranno effettuare nuovi investimenti gravosi; le risorse
potranno essere raggiunte facilmente tramite la rete da qualunque parte nel mondo. Le
aziende non dovranno acquistare risorse di calcolo, che invece verranno modulate secondo
richieste on-demand (scalabilità). Da apprezzare la riduzione dei tempi di realizzazione,
installazione e configurazione e la difficile interruzione del servizio, che continuerà anche
in caso di guasti di qualche nodo. Infine un’interfaccia user friendly consente un facile
utilizzo.
Oltre ai molti vantaggi ci sono anche aspetti negativi: in primo luogo la privacy, perché
avendo a che fare con provider che utilizzano meccanismi di virtualizzazione, i dati
potrebbero non rimanere nello stesso sistema o persino nello stesso cloud perdendone il
controllo da parte del reale proprietario.
Sono quindi necessarie, da parte dei provider, politiche di protezione dei dati e criptazione;
anche la gestione della rete può diventare problematica a causa delle molte richieste da
gestire contemporaneamente con il rischio di problemi di accesso, ma anche di perdita di
pacchetti durante il trasferimento.
Tra l’altro in caso di migrazione verso un altro cloud si potrebbero verificare delle
incompatibilità dovute alla mancanza di una modalità standard.
Infine i servizi offerti potrebbero essere utilizzati per scopi illegali, poiché i provider non
sono a conoscenza delle attività di tutti i propri utenti per motivi di privacy.

16
1.3 Machine Learning
Un approccio per rilevare le deviazioni dai comportamenti normali è quello basato
sull’apprendimento, che permette di analizzare le attività del sistema per ottenere, in
maniera automatica, una rappresentazione comportamentale “normale”.
L’obiettivo dell’apprendimento automatico è quello di realizzare sistemi in grado di
imparare, in maniera autonoma, a riconoscere pattern complessi ed eseguire future scelte
intelligenti basandosi su dati già analizzati [1].
Quindi si ottiene una classificazione, cioè l’identificare la classe di un nuovo obiettivo
sulla base di conoscenza estratta da un training set.
Un sistema “classificatore” estrae dal dataset un modello, lo utilizza e poi classifica le
nuove istanze.
Anche gli algoritmi di machine learning tipicamente vengono classificati in quattro
principali categorie, in base al tipo di apprendimento:
- Supervisionato in cui il sistema viene addestrato in due fasi: tramite un training set,
un insieme di attributi relativi ad un input, ai quali viene associata una etichetta che
indica l’output; per individuare il modello migliore possibile si insegna al sistema una
regola generale per mappare l’andamento degli attributi in input al determinato output
(fase di training);
successivamente (fase di testing), l’algorimo utilizza il modello su un dataset di prova
per poter calcolare delle stime su questi dati.
- Non Supervisionato: non vengono utilizzate etichette come indicazione all’algoritmo
su cosa cercare, ma si confrontano i dati di input cercando analogie e differenze,
riorganizzandoli in base a ragionamenti e previsioni su dati successivi.
- Per rinforzo: il comportamento del sistema è determinato da una routine di
apprendimento basata su ricompensa e punizione. L’algoritmo interagisce con un
ambiente dinamico, che gli consente di avere dati di input e raggiungere un obiettivo
“ricevendo una ricompensa”, imparando anche dagli errori (punizioni).

17
- Semi-supervisionato: è un modello ibrido, in cui per l’addestramento e
l’apprendimento viene fornito al sistema un dataset incompleto, cioè alcuni input sono
dotati dei rispettivi esempi di output (apprendimento supervisionato) e altri non lo
sono (apprendimento non supervisionato).
Esistono molte tecniche per costruire un classificatore, come alberi di decisione, reti
neurali, deep learning, reti Bayesiane, algoritmi genetici, clustering, etc.
In questo elaborato si focalizzerà l’attenzione su tecniche di deep learning e reti neurali,
tecniche supervisionate (regressione lineare e random forest) e tecniche non
supervisionate di clustering.
1.3.1 Approcci di machine learning
Il Deep Learning è un ramo del Machine Learning, che crea un modello di apprendimento
automatico su più livelli, in cui i livelli inferiori prendono in input le uscite dei livelli
immediatamente superiori e si diramano sempre di più [2].
Ogni layer rappresenta un diverso livello di astrazione, con caratteristiche più astratte nei
livelli inferiori. Da ciò prende il nome “deep” l’intero processo. Alla base di questo
principio c’è il metodo con cui il cervello umano processa le informazioni e apprende:
ogni livello corrisponde a un’area della corteccia celebrale che riceve segnali in ingresso,
li elabora e li apprende dall’esperienza attivando nuovi neuroni.
Figura 1.3.1 : Deep Learnig as a brain

18
Il deep learning richiede una grande quantità di dati etichettati, ma anche una notevole
potenza di calcolo, che mediante l’utilizzo del cloud computing consente di ridurre i tempi
di apprendimento [3].
Essendo maggiormente utilizzate architetture di reti neurali si parla di reti neurali profonde
(DNN), che possono contenere circa 150 livelli nascosti rispetto alle comuni reti neurali
che ne nascondono 2-3. Una loro proprietà è che all’aumentare quantitativo e qualitativo
dei dati migliorano le prestazioni.
Il clustering è una tecnica di apprendimento non supervisionato, che consiste nel
raggruppare oggetti in classi omogenee.
Un cluster è un insieme di oggetti che hanno delle similarità, ma che presentano delle
differenze con oggetti in altri cluster.
L’input di questo approccio è costituito da un campione di elementi, invece l’output è dato
da un numero di cluster in cui gli elementi del campione sono suddivisi in base a una
misura di similarità.
Esistono due categorie di algoritmi: clustering gerarchico e partizionale.
I primi organizzano i dati in sequenze nidificate di gruppi, similmente a una struttura ad
albero; i secondi creano una partizione dei dati in modo da ridurre la dispersione
all’interno del singolo cluster e di aumentare quella tra i cluster.
Il clustering partizionale è più adatto a dataset molto grandi per i quali la costruzione
gerarchica dei cluster porterebbe a uno sforzo computazionale molto elevato.
Il random forest è un approccio costituito da un insieme di classificatori semplici (alberi
decisionali), che sono rappresentati come vettori random indipendenti e identicamente
distribuiti. Ogni albero viene costruito e addestrato a partire da un sottoinsieme casuale dei
dati presenti nel training dataset e a ogni nodo viene scelto l’attributo migliore tra un set di
attributi selezionati in maniera casuale. Il risultato restituito corrisponde alla media del
risultato numerico oppure alla classe restituita dal maggior numero di alberi in base al tipo
di output desiderato.

19
1.4 Big Data
Una delle soluzioni adottate dalle aziende per proteggere le proprie reti dalle minacce
emergenti consiste nel raccogliere i flussi di traffico IP e implementare sistemi di
rilevamento delle anomalie basati sul monitoraggio del traffico di rete [4].
I Big Data rappresentano una raccolta di dati così estesa in termini di volume, velocità e
varietà da richiedere tecnologie e metodi analitici specifici per l’estrazione dei valori [14].
Essi sono in linea con il rilevamento delle anomalie attraverso il monitoraggio del traffico
della rete, cioè approcci di tipo misuse detection.
La grande quantità di dati rende necessario l’utilizzo di strumenti e tecniche consolidate
per trovare informazioni utili nascoste nei dati grezzi. Per eseguire questo tipo di
elaborazioni si effettuano calcoli paralleli, cioè tutti contemporaneamente, sfruttando le
prestazioni di più macchine che non necessariamente sono “reali”.
Per comprendere la vastità dei dati con cui si ha a che fare definiamo come ordini di
grandezza lo Zettabyte (ZB) e lo Yottabyte (YB), che sono multipli del byte
corrispondenti a 10!" e 10!" , cioè mille miliardi di miliardi di byte e un miliardo di
biliardi di byte.
Le caratteristiche principali dei Big Data sono delineate da 5 componenti, chiamate “le 5
V”:
- volume: in termini di dimensioni, raccolgono grandi quantità di dati anche non
strutturati da varie sorgenti e applicazioni che vengono analizzati, strutturandoli, per
estrarre informazioni di interesse;
- velocità: riferita alla velocità con cui vengono prodotte e memorizzate le informazioni.
La velocità di raccolta spesso è maggiore della possibile velocità di analisi, che
obbliga all’utilizzo di nuove strategie per l’elaborazione quasi in tempo reale;
- varietà: dovuta alla provenienza dei dati che sono generati da sorgenti diverse e
arrivano in qualsiasi tipo di formato;

20
- valore: in termini di utilità ed abilità. L’utilizzo dei Big Data ha come obiettivo la
trasformazione dei dati in informazioni utili, quindi l’eliminazione di dati non
importanti per identificare ciò che è rilevante;
- veridicità: si riferisce all’affidabilità dei dati. I risultati basati sui Big Data non
possono essere provati, ad essi si può assegnare solo un valore di probabilità, vengono
quindi considerati incerti e necessitano di una fase di validazione.
Figura 1.4.1 : “Le 5 V”. Caratteristiche principali dei Big Data
I metodi tradizionali ormai non possono più fare fronte alle analisi di una così grande
quantità di dati, perciò l’utilizzo dei Big Data sta guadagnando una certa importanza,
essendo molto più rapido, scalabile e fault-tolerant.
S. Terzi e coll. [5] hanno realizzato un metodo di rilevamento delle anomalie, attraverso
l’analisi dei Big Data, di tipo non supervisionato sul cluster Apache Spark in Azure
HDInsight implementato con Netflow, tecnica di monitoraggio del flusso. Netflow utilizza
i valori in comune dei campi dell’intestazione IP dei pacchetti per identificare e catalogare
le informazioni in transito sulla rete [6], con il linguaggio di programmazione python,
ottenendo come risultato un tasso di accuratezza del 96%.
21
Per il caso di studio hanno cercato di determinare le anomalie causate da un flood attack
(inondazione) UDP proveniente da specifici IP, utilizzando il dataset CTU-13, che
comprende 13 scenari con diversi campioni di attacco, 5 ore di record e 1309791 flussi
che coprono 106352 flussi UDP DDoS [5].
Il metodo proposto è basato sul clustering, dal punto di vista dell’apprendimento
automatico, che non richiede set di dati etichettati e classi predefinite [7].
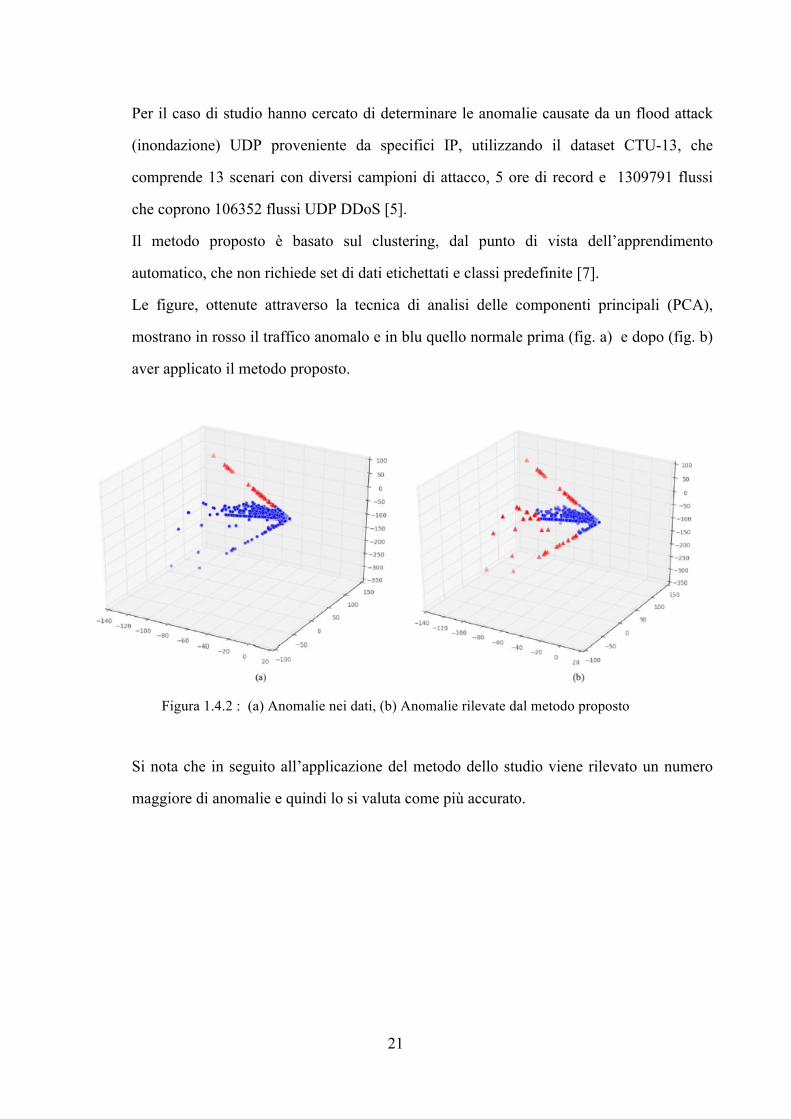
Le figure, ottenute attraverso la tecnica di analisi delle componenti principali (PCA),
mostrano in rosso il traffico anomalo e in blu quello normale prima (fig. a) e dopo (fig. b)
aver applicato il metodo proposto.
Figura 1.4.2 : (a) Anomalie nei dati, (b) Anomalie rilevate dal metodo proposto
Si nota che in seguito all’applicazione del metodo dello studio viene rilevato un numero
maggiore di anomalie e quindi lo si valuta come più accurato.

22
Capitolo 2: Cloud-based Detection
Un modello cloud-based per il rilevamento delle anomalie su gli end-user, sfruttando
servizi di sicurezza offerti da sistemi cloud, consente di effettuare un’analisi più
approfondita, garantendo una migliore individuazione delle criticità.
Questo tipo di sistema cloud-based detection consiste nel utilizzare i singoli utenti per
eseguire processi leggeri al fine di rilevare nuove possibili minacce, per poi inviarle a
data-center remoti, che stabiliscano, in seguito ad un’analisi, se consentire l’accesso o se
segnalarli come anormali.
In questo modo gli strumenti di analisi nel cloud risulteranno sempre aggiornati, poiché
apprenderanno continuamente dagli eventi ricevuti, troveranno anche anomalie ancora
sconosciute, miglioreranno il tasso di rilevamento globale utilizzando più motori di
rilevamento e ridurranno i tempi di elaborazione.
2.1 SIEM as a Service
Un Security Information and Event Managment (SIEM) è un insieme di pacchetti di
software e servizi che unisce capacità di Security Information Managment (SIM) e di
Security Event Managment (SEM).
Un SIM si occupa di attività di raccolta e analisi dei Log (non in real-time) e produzione di
report, mentre un SEM si occupa del monitoraggio in real-time degli eventi che
avvengono sulla rete.

23
Quindi un SIEM è un elemento importante dell’infrastruttura di una rete, per la raccolta,
l’aggregazione, l’analisi, la normalizzazione, l’archiviazione, la gestione di enormi registri
di eventi e mette in correlazione i dati di sistemi di sicurezza tradizionali come firewall,
sistemi di intrusion detection e prevention, sistemi anti-malware [9].
Il cloud computing ha aperto la strada al concetto di Security as a Service (SECaaS), cioè
la capacità di sviluppare servizi software riutilizzabili che possono essere composti da
servizi cloud standard per offrire elevate prestazioni di sicurezza.
La Cloud Security Alliance (CSA), organizzazione senza scopo di lucro che mira a
promuovere l’uso delle migliori pratiche per garantire la sicurezza nell’ambito del cloud
computing, ha identificato le principali categorie di servizio [10]:
- Identity and Access Management (IAM)
include persone, processi e sistemi utilizzati per gestire l'accesso alle risorse aziendali,
assicurando il corretto utilizzo della risorsa protetta, solamente alle identità verificate.
- Data Loss Prevention (DLP)
responsabile di garantire la sicurezza, la protezione e il monitoraggio dei dati scambiati
applicando policy di sicurezza specifiche sui dati, come la crittografia;
- Web Security (WS)
si occupa della protezione in tempo reale applicando le policy al traffico Web evitando
così l'introduzione di malware;
- EMail Security (EMS)
fornisce il controllo della posta elettronica in ingresso e in uscita, proteggendo
l'organizzazione da phishing e allegati dannosi, rafforzando le politiche aziendali come
l'uso consentito e la prevenzione dello spam;

24
- Intrusion Management (IM)
utilizza il riconoscimento di pattern per rilevare e reagire a eventi inusuali, riconfigurando,
se necessario, i sistemi interessati dall'intrusione, in modo da bloccare gli attacchi;
- Business Continuity and Disaster Recovery (BCDR)
è incaricato di garantire la “resistenza” quando si verifica un evento particolare che causa
l'interruzione di un servizio;
- Network Security (NS)
consiste in servizi specifici, a livello di rete, utilizzati per disciplinare l'accesso,
l'implementazione, il monitoraggio e la protezione delle risorse di rete;
- Security Assessment (SA)
si confronta con aspetti relativi al supporto delle decisioni e dei processi aziendali,
garantendo la conformità con i requisiti legali, normativi e statutari, per garantire
riservatezza, integrità e disponibilità delle risorse informative, fornendo e supportando la
sicurezza.
Infine il SIEM che raccoglie servizi, dati di log ed eventi di rete, da applicazioni e sistemi
virtuali e reali. Qui le informazioni vengono analizzate per fornire report e avvisi in tempo
reale su eventi che potrebbero richiedere un intervento.
In questo scenario, la sicurezza viene fornita come un servizio erogato in modalità cloud
[11] senza la necessità di hardware e ingenti spese, aggirando la necessità di costosi
investimenti personali o aziendali.

25
2.2 Cloud-based IDS (CBIDS)
Nel 2012 W. Yassin e N.I. Udzir [12] hanno presentato un nuovo framework chiamato
Cloud-based Intrusion Detection Service (CBIDS) che consente di identificare attività
dannose provenienti da diversi punti nella rete in modo migliore rispetto al classico IDS.
Figura 2.2.1 : Cloud-based Intrusion Detection Service Framework
Il CBIDS è costituito da 3 componenti principali (figura 2.2.1):
- User Data Collector (UDC)
che è un server integrato in User Cloud basato sulle esigenze dell’utente per proteggere
efficientemente l’intera rete. Si occupa di standardizzare e filtrare l’informazione dei
pacchetti raccolti prima di essere mandati al Cloud IDS attraverso una rete VPN sicura.
La comunicazione tra UDC e CSC è crittografata poiché contiene informazioni riservate.

26
- Cloud Service Component (CSC)
ha il compito di analizzare e convalidare le informazioni ricevute dall’UDC per
individuare intrusioni esterne, prima di decidere se eliminare queste informazioni oppure,
dopo averle tradotte in un formato comprensibile, inoltrarle al CIDC.
- Cloud Intrusion Detection Component (CIDC)
che è il reale componente per il rilevamento delle intrusioni ed è composto da:
analysis engine, service console, signature database e user database.
L’Analysis Engine (AE), componente indipendente, che può essere un qualsiasi IDS
come Snort, analizza i dati ottenuti in ingresso e li accoppia con pattern memorizzati in un
database di firme, identificando così le attività anomale e generando avvisi tramite
interfaccia video.
Il Service Console (SC) è il servizio di controllo preferito dall’utente remoto. Il CIDC può
essere configurato per fine-tuning (regolazioni), in base alle esigenze dell’utente,
attraverso questo componente (SC). Gestisce anche l’autenticazione dell’utente che ha i
privilegi, segnalandogli eventuali attività dannose attraverso alert nel formato standard
IDMEF (Intrusion Detection Message Exchange Format).
Il Signature Database (SD), contiene tutte le firme (signature), aggiornate, di attacchi
conosciuti.
L’User Database (UD) contiene tutte le informazioni utente come informazioni di
accesso, attività utente, etc…
Gli autori hanno poi simulato una situazione di funzionamento basato sul framework
CBIDS (figura 2.2.2), considerando come utente una piccola impresa, costruita utilizzando
degli host virtuali collegati attraverso switch virtuali che supportano la funzionalità di
Switchport Analyzer (SPAN).

27
Le informazioni riservate per il traffico in entrata e il traffico in uscita di ogni host virtuale
prima vengono copiate e inoltrate al UDC (proxy), successivamente, tramite una rete VPN
sicura, vengono passate al CSC che risiede nel Cloud IDS.
Il cloud IDS è in grado di fornire un meccanismo difensivo globale completo e di rilevare,
in base alle informazioni inoltrate dall’utente, attacchi in tempo reale.
Il CSC ricevuti i pacchetti, verifica e filtra le informazioni, inoltrando all’AE solo quelle
utili, che vengono accoppiate con le firme di attacco memorizzate nel SD. Dopo il
processo di analisi viene prodotto un report o un evento sull’UC per attirare l’attenzione
dell’utente e per svolgere eventuali azioni.
Figura 2.2.2: Architettura CBIDS
In questo studio la struttura proposta ha una valenza fondamentalmente teorica e affidata
alla successiva ricerca per renderla applicabile e perfezionabile.
Han Li e Qiuxin Wu sempre nel 2012 propongono un modello di intrusion detection
distribuito adoperando le proprietà del cloud, che prevede, rispetto al sistema di
rilevamento delle intrusioni unico e centralizzato, diversi sottosistemi chiamati ID agent e
un sottosistema data aggregation [16].

28
Ogni ID agent distingue se un determinato record è anormale e in questo caso lo invia al
data aggregation per l’analisi globale, questo restituisce al ID agent corrispondente un
avviso di intrusione.
Figura 2.2.3: Architettura modello distribuito di intrusion detection
Il data aggregation registra in una tabella il valore del peso di ogni intrusione sospetta, che
viene assegnato in base alla posizione del ID agent nella rete, cioè se l’evento avviene al
confine della rete, la possibilità che esso sia un’anomalia è maggiore e se il valore di peso
risulta essere maggiore di una certa soglia di decisone stabilita; quindi viene inviato
l’allarme al ID agent interessato.
Figura 2.2.4: Algoritmo modello distribuito di intrusion detection
29
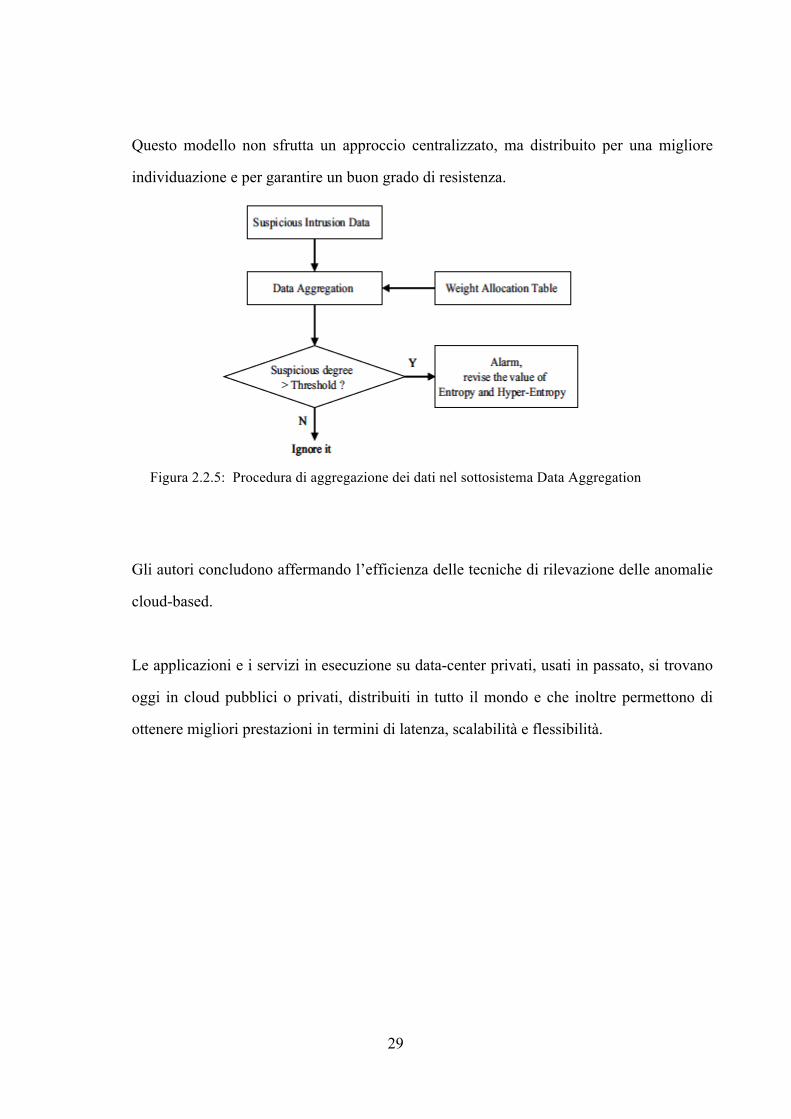
Questo modello non sfrutta un approccio centralizzato, ma distribuito per una migliore
individuazione e per garantire un buon grado di resistenza.
Figura 2.2.5: Procedura di aggregazione dei dati nel sottosistema Data Aggregation
Gli autori concludono affermando l’efficienza delle tecniche di rilevazione delle anomalie
cloud-based.
Le applicazioni e i servizi in esecuzione su data-center privati, usati in passato, si trovano
oggi in cloud pubblici o privati, distribuiti in tutto il mondo e che inoltre permettono di
ottenere migliori prestazioni in termini di latenza, scalabilità e flessibilità.

30
Capitolo 3: Machine Learning Detection
I progressi nelle tecniche di apprendimento automatico hanno attirato l’attenzione della
comunità di ricerca, per la creazione di nuovi sistemi di rilevamento delle anomalie [17].
Il machine learning consentirebbe un addestramento più sofisticato dei modelli di
sicurezza per elaborare una grande quantità di dati complessi e sempre in evoluzione,
utilizzando dataset più completi.
Un modello addestrato a tipi di attacco “completi” migliorerebbe significativamente
l’efficienza di rilevamento delle anomalie con un costo e una complessità ragionevoli [18].
In linea con quanto premesso nel paragrafo 1.3.1 si osserva lo studio del 2017 di
K.Donghwoon e coll. [3] che hanno discusso l’efficacia del deep learning per il
rilevamento delle anomalie nella rete utilizzando un modello Fully Connected Network
(FCN).
Figura 3.1.1 : Modello Fully Conncted Neural Network

31
Gli esperimenti sono stati effettuati utilizzando la libreria opensource Python
TensorFlow, basata su algoritmi percettivi mediante apprendimento automatico, fornita
dalla piattaforma Google Cloud.
Il primo passo ha previsto la pre-elaborazione e trasformazione dei dati, normalizzandoli,
poiché si ha avuto a che fare con il dataset NSL-KDD, che è composto da valori numerici
e categorici (codificati come numerici).
Successivamente i dati normalizzati e trasformati sono stati passati alla rete FCN, in cui si
è eseguito l’addestramento, configurando prima alcuni iper-parametri per inizializzare il
modello: numero di unità, numero di livelli nascosti, periodo di tempo e tasso di
apprendimento.
Il modello FCN esegue l’addestramento trovando la migliore ottimizzazione e da esso
vengono prodotti i valori di restituzione.
I risultati sperimentali ottenuti mostrano come con un modello FCN ci sia un notevole
miglioramento in termini di accuratezza tra 83% e 90,4% (figura 3.1.2) rispetto a tecniche
di apprendimento automatico convenzionali come SVM, che restituiscono valori compresi
tra 50,3% e 82,5%.
Figura 3.1.2 : Risultati sperimentali con NSL-KDD dataset usando il modello FNC
Confrontando le percentuali di accuratezza del modello FCN, basato sulle reti neurali, con
quelle evidenziate nel paragrafo 1.4, della tecnica non supervisionata di clustering
mediante l’analisi dei Big Data [5], si evince una performance migliore di quest’ultima.
Tuttavia entrambi i modelli esaminati prevedono l’apprendimento automatico.
32
Lavori di ricerca contemporanea in tale ambito si orientano a proporre modelli che mirano
a raggiungere livelli di prestazioni ancora superiori alle percentuali viste prima.
A.Erbad e coll. [17], hanno esaminato sia la rilevazione che la classificazione delle
anomalie, piuttosto che la semplice rilevazione, sostenendo che la classificazione è
fondamentale per identificare le vulnerabilità ed attuare eventuali contromisure.
Hanno adoperato, sia per la rilevazione che per la classificazione, il dataset UNSW e due
tecniche di apprendimento automatico supervisionato: regressione lineare (LR) e foresta
casuale (RF).
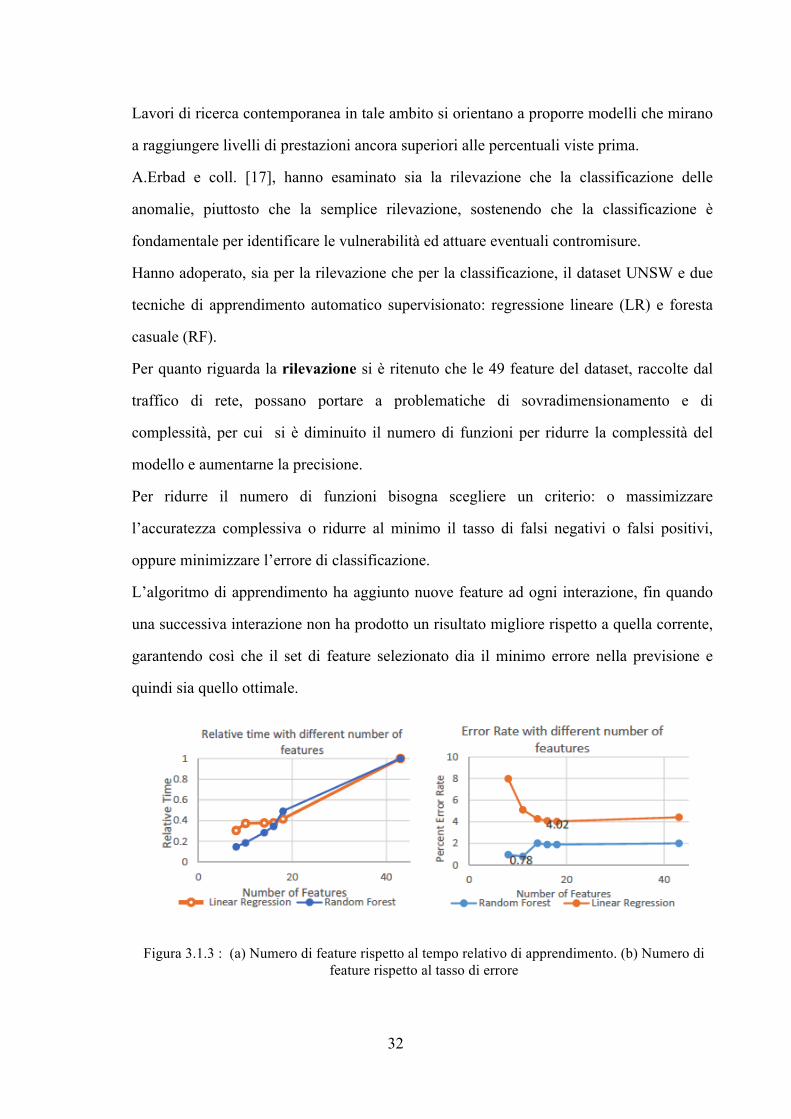
Per quanto riguarda la rilevazione si è ritenuto che le 49 feature del dataset, raccolte dal
traffico di rete, possano portare a problematiche di sovradimensionamento e di
complessità, per cui si è diminuito il numero di funzioni per ridurre la complessità del
modello e aumentarne la precisione.
Per ridurre il numero di funzioni bisogna scegliere un criterio: o massimizzare
l’accuratezza complessiva o ridurre al minimo il tasso di falsi negativi o falsi positivi,
oppure minimizzare l’errore di classificazione.
L’algoritmo di apprendimento ha aggiunto nuove feature ad ogni interazione, fin quando
una successiva interazione non ha prodotto un risultato migliore rispetto a quella corrente,
garantendo così che il set di feature selezionato dia il minimo errore nella previsione e
quindi sia quello ottimale.
Figura 3.1.3 : (a) Numero di feature rispetto al tempo relativo di apprendimento. (b) Numero di
feature rispetto al tasso di errore

33
La figura 3.1.3 di sinistra mostra l’errore di test minimo utilizzando entrambe le tecniche
di apprendimento LR e RF, ed evidenzia che il tempo relativo può essere ridotto a metà se
il numero di funzioni è ridotto a 20.
Invece la figura 3.1.3 di destra mostra il tasso di errore al variare del numero di funzioni,
evidenziando che si possono ottenere prestazioni ottimali con solo 18 caratteristiche
mediante il modello LR e con solo 11 caratteristiche usando RF.
Il numero crescente di funzioni migliora la precisione fino a raggiungere una prestazione
ottimale.
Figura 3.1.4 : Risultati sperimentali anomaly detection con tecniche di regressione lineare (LR) e di
foresta casuale (RF)
I risultati sperimentali ottenuti (figura 3.1.4) mostrano che il tasso di errore di rilevamento
delle anomalie è inferiore al 1% con 11 caratteristiche delle tecniche RF, mentre è il 4,5%
con 18 caratteristiche ottimali di LR. Tuttavia il tasso complessivo non è sufficiente per
determinare le prestazioni di qualunque schema di rilevamento di anomalie.
Infatti bisogna valutare anche la percentuale di traffico normale che è stato classificato
erroneamente come anomalo (FAR) e la percentuale di traffico che rappresenta
un’anomalia ma che viene classificata erroneamente (UND):

34
L’errore generale e la precisione sono dati da:
Dalla figura 3.1.4 si può inoltre evidenziare che l’RF funziona meglio di LR in tutte le
situazioni, nonostante questa tecnica generi risultati ottimali con soli 11 funzioni.
Invece per la classificazione delle anomalie è stato utilizzato ancora il dataset UNSW, che
permette di ottenere un errore di errata classificazione relativamente basso, a differenza
del KDD che dà un tasso di errore del 20%,
L’algoritmo proposto dagli autori, non distingue le anomalie dal traffico normale, ma
addestra il modello di apprendimento RF a distinguere una particolare anomalia da altre.
Esso effettua prima una analisi mediante una classificazione binaria di pacchetti normali e
anomali, poi iterativamente li categorizza in attacchi generici o altro tipo di attacchi.
Nel caso di somiglianze con altre anomalie, il flusso di dati viene ulteriormente analizzato,
fino al riconoscimento differenziale di una determinata anomalia.
Figura 3.1.5 : Algoritmo di classificazione degli attacchi

35
La figura 3.1.5 mostra come funziona l’algoritmo di classificazione spiegato, applicato per
l’identificazione di vari tipi di attacchi informatici.
Con questo algoritmo si commette un errore di classificazione che, nell’esempio utilizzato
dagli autori applicato all’individuazione di diverse tipologie di tali attacchi, consiste nella
non distinzione tra attacchi non Exploit che vengono rilevati tutti come Exploit.
E’ necessario, quindi, trovare ulteriori caratteristiche o dati per una corretta classificazione
di questi attacchi.
Pertanto, l’errore di classificazione effettuato dall’algoritmo proposto per gli attacchi presi
in considerazione è di circa il 6,4%, dato che rappresenta un notevole miglioramento
rispetto alle tecniche di classificazione convenzionali.
I risultati da loro ottenuti hanno mostrato un’accuratezza di più del 99% per il rilevamento
e una precisione di classificazione del 93,6%, ma, non riuscendo a classificare alcuni tipi
di attacchi a causa della somiglianza fra essi, si manifesta un errore di classificazione nel
dataset UNSW. Si propone la necessità di raccogliere un numero ancora maggiore di dati
per distinguere meglio le anomalie e di applicare approcci di machine learning più
sofisticati.
Si ritiene che l’algoritmo scelto in questo studio possa essere esteso più in generale ad altri
tipi di anomalie.
Si può concludere che questi modelli di apprendimento affrontati potrebbero essere
applicati, in ambienti multi-cloud, per rilevare sempre nuove anomalie nei flussi di rete,
garantendo che i dati siano sempre aggiornati e al passo con il crescente rischio di
minacce.

36
Conclusioni
L’aumentata necessità di sicurezza informatica obbliga ormai ad un utilizzo sempre più
efficiente di strategie per assicurare soluzioni a tante problematiche che il cloud soddisfa
in maniera più performante rispetto agli approcci classici.
In particolare è stato valutato l’impiego del cloud computing applicato all’anomaly
detection, tenendo conto delle caratteristiche vantaggiose che esso offre e cioè la riduzione
dei costi, visto che il prezzo di distribuzione delle applicazioni nel cloud può essere
inferiore rispetto a quello dell’hosting in loco, a causa dei minori costi hardware derivanti
da un uso più efficace delle risorse fisiche.
Inoltre il cloud computing permette un accesso universale visto che può consentire ai
dipendenti in remoto di accedere alle applicazioni e lavorare via internet.
Un’ulteriore convenienza riguarda l’aggiornamento continuo dei software e dei servizi da
parte del cloud provider che, in ambito detection, consente di stare al passo con l’aumento
esponenziale delle minacce, che sono sempre più attive.
Ancora in termini di flessibilità il cloud offre agli utenti un’ampia scelta di applicazioni,
consentendo di scegliere la migliore soluzione in base alle proprie esigenze.
E parlando in termini commerciali, il cloud computing inoltre, consente alle aziende, che
se ne servono di accedere, adoperare e pagare solo per ciò che viene utilizzato, anche con
tempi di implementazione rapidi.
In fine, ma non da ultimo, la caratteristica di essere più ecologico e più economico [15]:
la quantità media di energia necessaria per un'azione computazionale eseguita nel cloud è
molto inferiore all'importo medio richiesto per una distribuzione in loco.

37
Questo perché diverse organizzazioni possono condividere le stesse risorse fisiche in
modo sicuro, portando a un uso più produttivo delle risorse condivise.
Sia chiaro che il cloud ha comunque in sé alcune fragilità che non sembrano influire ad
oggi sulla sua utilità applicata alla anomaly detection.
Tutte queste considerazioni fatte sul cloud insieme con le tecniche di machine learning, di
cui abbiamo esposto alcune delle caratteristiche inerenti all’anomaly detection,
autorizzano a valutare la loro forza sinergica, come reale strumento di sicurezza
informatica.
Inoltre possiamo ritenere che l’evoluzione delle tecniche di machine learning in futuro
garantiranno un livello di accuratezza sempre più completo nella ricerca delle anomalie,
restando costantemente al passo con le minacce nella rete.
Resta tuttavia necessario, condiviso dalla letteratura consultata, l’intervento umano per la
detection di comportamenti anomali, un irrinunciabile livello di sicurezza per un controllo
“intelligente“, affidabile, altamente specializzato.
In conclusione si può affermare che risulta molto conveniente per l’utenza che sfrutta la
rete, adottare sistemi di anomaly detection basati su cloud, spesso affidati a team
qualificati ed esperti.

38
Bibliografia
[1] A. Moschitti, R. Basili , “Apprendimento Automatico e IR: introduzione al Machine Learning”, Dipartimento di Informatica Sistemi e produzione Università di Roma “Tor Vergata”, MGRI a.a. 2007/8
[2] S. Cavalli, L. Ferrarotti, Corso di Intelligenza Artificiale: Deep Learning, Dipartimento di Informatica Politecnico di Torino, July 19, 2015 https://areeweb.polito.it/didattica/gcia/tesine/Tesine_2015/Cavalli_Ferrarotti/Deep_Learning.pdf
[3] Donghwoon Kwon, Hyunjoo Kim, Jinoh Kim, “A survey of deep learning-based network anomaly detection”, Springer Science+Business Media, LLC 2017
[4] Cisco Public, Network as a Security Sensor Threat Defense with Full . 2016. 1-19 [5] Duygu Sinanc Terzi, Ramazan Terzi, Seref Sagiroglu, “Big Data Analytics for
Network Anomaly Detection from Netflow Data”, In 2nd International Conference on Computer Science and Engineering, 2017
[6] Alessandro Tanasi , Monitoraggio di rete con NetFlow, http://www.tanasi.it/docs/appunti_su_netflow.pdf
[7] Liu, D., et al. Network Traffic Anomaly Detection Using Adaptive Density-Based Fuzzy Clustering. in 2014 IEEE 13th International Conference on Trust, Security and Privacy in Computing and Communications. 2014.
[8] [U.S. NIST (National Institute of Standards and Technology)]
[9] L. Jong-Hoon, K. Young Soo, “Toward the SIEM Architecture for Cloud-based
Security Services”, IEEE Conference on Communications and Network Security (CNS): IEEE CNS 2017
[10] Cloud Security Alliance, “SecaaS Implementation Guidance, Category 1: Identity
and Access Management”, September 2012

39
[11] A. Furfaro, A. Garro, Andrea Tundis, “Towards Security as a Service (SecaaS): on the modeling of Security Services for Cloud Computing”, International Carnahan Conference on Security Technology (ICCST), Rome 2014
[12] W. Yassin, N.I. Udzir, Z. Muda, A. Abdullah and M.T. Abdullah, “A Cloud-Based
Intrusion Detection Service Framework”, International Conference on Cyber Security, Cyber Warfare and Digital Forensic (CyberSec), 2012
[13] M. Hussain, H. Abdulsalam, "SECaaS: Security as a Service for Cloud-based
Applications", In 2nd Kuwait Conference o e-Services and e-Systems, pp.1-4, 2011. [14] A. De Mauro, M. Greco and M. Grimaldi. A Formai Definition of Big DataBased on
its Essential Features. [15] S. Hatem, Dr. Maged H. wafy , Dr. Mahmoud M. El-Khouly , “Malware Detection
in Cloud Computing”, (IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 5, No. 4, 2014
[16] Han Li, Qiuxin Wu, “A distribuited intrusion detection model based on cloud
theory”, IEEE 2nd International Conference on Cloud Computing and Intelligent Systems (CCIS), 2012
[17] T. Salman, D. Bhamare, A. Erbad , “Machine Learning for Anomaly Detection and
Categorization in Multi-cloud Environments”, IEEE 4th International Conference on Cyber Security and Cloud Computing, 2017
[18] C. Tsai, Y. Hsu, C. Lin, and W. Lin, “Intrusion detection by machine learning: A
review,” in Expert Systems with Applications vol. 36, no. 10, 2009, pp. 11994-12000.


















