
Scripting e DataWarehouse sui Big Data. Luca Pireddu (CRS4)
124
Scripting on Big Data Pig Per il corso “Big Data Management” Luca Pireddu
-
Upload
crs4-research-center-in-sardinia -
Category
Science
-
view
114 -
download
3
Transcript of Scripting e DataWarehouse sui Big Data. Luca Pireddu (CRS4)

Scripting on Big Data
Pig
Per il corso “Big Data Management”
Luca Pireddu

2
Pig
Perché Pig e Hive? Perché MR non è perfetto
● Hadoop MapReduce → programmazione a livello relativamente basso
● Java (linguaggio da compilare) oppure Python
● Parecchio codice necessario anche solo per avviare il programma
● Opera a livello di dato, non di data set
● Modello MapReduce: map, shuffle-sort, reduce
● Spesso non è banale esprimere la funzionalità desiderata secondo questo
paradigma;
● MapReduce ha un ciclo di sviluppo lungo!
● Idea → codice → compila → debug → compila → debug → … → risultato!
● Zero interattività; difficile esplorare i dati
Quindi MapReduce è costoso in termini di sviluppo, manutenzione

3
Pig
Perché Pig e Hive? Perché MR non è perfetto
● Pig e Hive sono dei linguaggi ad alto livello
● Permettono di esprimere operazioni in maniera astratta
● I comandi poi vengono tradotti in sequenze di job per Hadoop
● Ereditano la scalabilità dei sistema
● Sono complementari, ognuno col suo posto in una data warehouse

Pig
Pig image courtesy of Hortonworks

5
Pig
Cosa è Pig ?
Pig è una piattaforma per l'elaborazione parallela di grandi quantità di dati
Gli elementi principali:
● un linguaggio di alto livello Pig Latin
● un interprete che traduce un programma Pig in sequenze
di Job MapReduce
● un'infrastruttura per l'esecuzione e la gestione dei Job
● una shell per l'esecuzione interattiva di comandi Pig Latin

6
Pig
Pig-Latin: un dataflow language
● Pig pone rimedio ad alcuni limiti di MR
● Linguaggio utilizzabile anche da non-programmatori esperti sui dati
Pig-Latin si ispira ai linguaggi funzionali e come tale
esprime le trasformazioni da eseguire sui dati ma senza dettagliare
come eseguirle
Le trasformazioni sono espresse mediante operatori ispirati all'SQL
● Join
● Order
● Filter
● Group by
● Ecc...

7
Pig
Pig-Latin: un dataflow language
Un piccolo esempio
● Carichiamo il dataset “NYSE_dividends”
● Composto da quattro colonne
● Escludiamo tutti i record senza dividendi
● Ordiniamo per dividendo decrescente
● Teniamo i primi 10 poi scriviamo a disco
A = load 'NYSE_dividends' as (exchange, symbol, date, dividends);
B = filter A by dividends > 0;
C = order B by dividends desc;
D = limit C 10;
store D into 'dividend_payers';

8
Pig
Pig-Latin: un dataflow language
● Il programma rappresenta un dataflow graph
● Flusso di dati tra operatori
● Il linguaggio lascia libertà al compilatore di decidere i dettagli dell'esecuzione
● E.g., non specifica neanche l'ordine delle operazioni!
● Viene trasformato dal compilatore in una sequenza di job MR
● Il programma quindi usa il cluster Hadoop per l'esecuzione in parallelo
A = load 'NYSE_dividends' as (exchange, symbol, date, dividends);
B = filter A by dividends > 0;
C = order B by dividends desc;
D = limit C 10;
store D into 'dividend_payers';

9
Pig
Origini
● Pig è nato come progetto di ricerca a Yahoo! Nel 2006
● Stessa azienda che ha dato vita a Hadoop
● Diventato un progetto Apache Incubator già nel 2007
● Ha rapidamente preso piede all'interno dell'azienda
● In quel periodo si riporta che 30% dei job Hadoop presso Yahoo! fossero
programmi Pig
● Migliaia di job al giorno!
10
Pig
Dove trovarlo
● Potete trovare la versione ufficiale sul sito Apache
● https://pig.apache.org/releases.html#Download
● Se usate Apache Hadoop, l'installazione è banale:
1)Scaricare l'archivio
2)Estrane i contenuti
3)Impostare PIG_HOME al path di installazione
● Pig è anche impacchettato e distribuito dai vari rivenditori di Hadoop
● Clodera
● Hortonworks
● Ecc.
● In tal caso date un'occhiata alle istruzioni specifiche
11
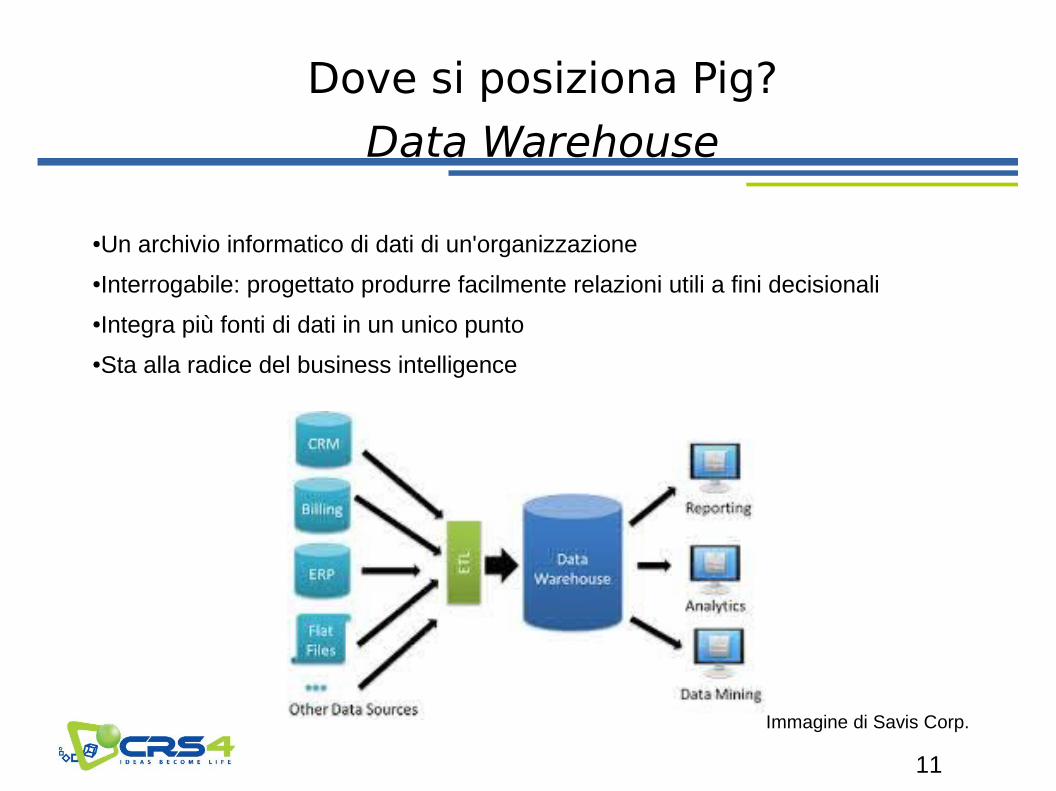
Dove si posiziona Pig?
Data Warehouse
●Un archivio informatico di dati di un'organizzazione
●Interrogabile: progettato produrre facilmente relazioni utili a fini decisionali
●Integra più fonti di dati in un unico punto
●Sta alla radice del business intelligence
Immagine di Savis Corp.

12
Pig
Dove si posiziona nel panorama BigData?
● Raccolta: raccolta e riformattazione di dati acquisiti da sorgenti diverse, sia batch
che real-time o near real-time;
● Elaborazione: molto utile per gestire dati eterogenei e grezzi. E.g.,
● filtrare i dati spuri
● creare dei metadati per meglio capire il contenuto dei dati stessi
● categorizzare, classificare
● strutturare i dati in preparazione per l'integrazione con altri sistemi
● Esplorazione: semplice analitica su grossi dataset
● campionamento e aggregazioni
● Possibile applicare funzioni più avanzate integrando librerie utente
13
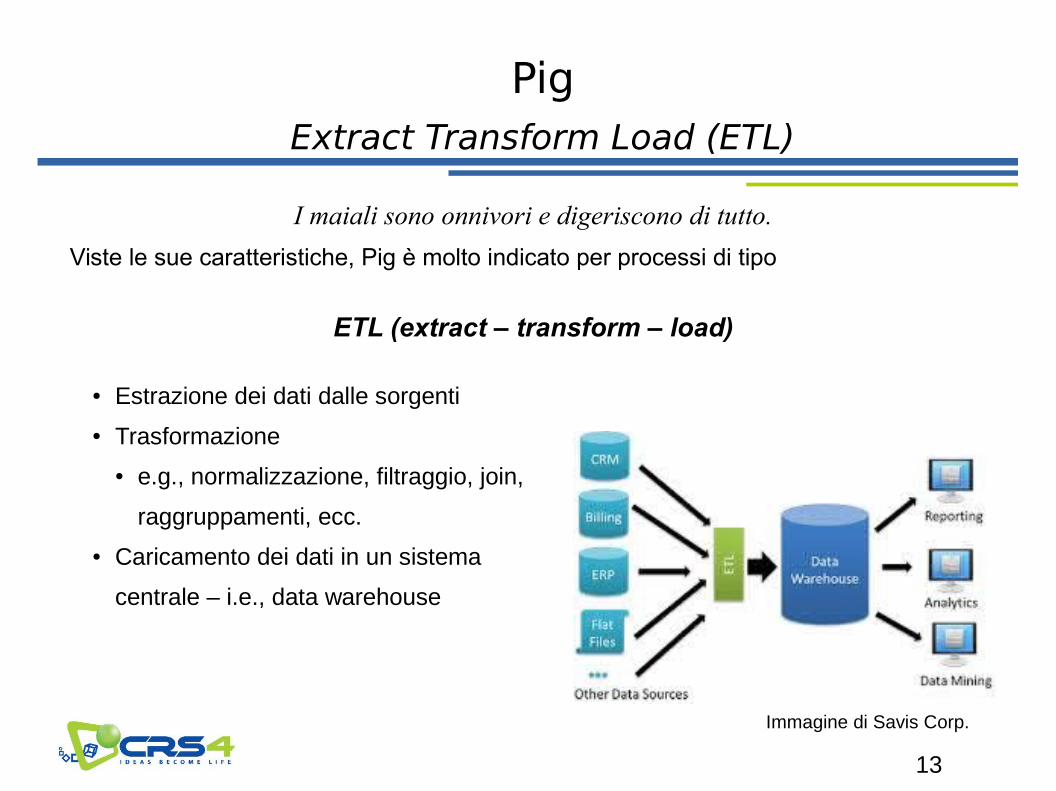
Pig
Extract Transform Load (ETL)
I maiali sono onnivori e digeriscono di tutto.
Viste le sue caratteristiche, Pig è molto indicato per processi di tipo
ETL (extract – transform – load)
● Estrazione dei dati dalle sorgenti
● Trasformazione
● e.g., normalizzazione, filtraggio, join,
raggruppamenti, ecc.
● Caricamento dei dati in un sistema
centrale – i.e., data warehouse
Immagine di Savis Corp.

14
Pig
Interagire con Pig
Pig prevede due modalità di esecuzione:
● interattiva: attraverso una shell dedicata, per l'esplorazione dei dataset e la
progettazione degli script;
● batch : per l'esecuzione autonoma degli script;
Tipicamente Pig esegue i programmi su un cluster Hadoop
● Può eseguire programmi anche in modalità local
● Tutto gira sulla macchina locale
● Utile per sviluppare e fare semplici esperimenti in locale

15
Pig
Grunt: la shell
La shell di Pig si chiama grunt:
grunt>
Grunt offre alcune funzionalità di una shell tradizionale:
● tab-completion sui comandi
● storico dei comandi eseguiti
● semplice supporto all'editing
Per uscire dalla shell è sufficiente dare il comando quit o digitare CTRL+D

16
Pig
Grunt: la shell
● Pig lavora nativamente con l'HDFS
● Grunt ne da accesso diretto col comando fs
● opzioni sono le stesse offerte dal comando hadoop fs
● Molto semplice interagire con HDFS direttamente dalla shell o all'interno degli
script
mkdir cp du
ls cat rm
put Ecc....

17
Pig
Grunt: la shell
● Con grunt si lavora in modalità interattiva, inserendo comandi Pig Latin
● Può essere utile per:
● esplorare un nuovo dataset
● scrivere il prototipo di un nuovo script
● sperimentare diverse pipeline alla ricerca di ottimizzazioni
● Notate che i comandi non vengono eseguiti immediatamente
● In modalità interattiva, solo in seguito ad un comando che genera un output (i.e.,
dump o store)
● Permette al compilatore di “capire” il flusso di dati prima dell'esecuzione
● Inoltre rende la shell più interattiva
ps: in modalità batch, l'intero script viene analizzato prima dell'esecuzione

18
Pig
Grunt: controllo dei job
Grunt offre inoltre alcune semplici funzioni di controllo per l'esecuzione del codice,
attraverso i tre comandi:
● kill <jobid>: consente di terminare un particolare job
● run e exec <script>: consentono di eseguire uno script
Gli ultimi due si differenziano per il fatto che
● exec esegue lo script esternamente alla shell e mostra solo il risultato finale;
● run esegue lo script come se i comandi fossero digitati in modalità interattiva
● al termine saranno disponibili anche i dati intermedi.

19
Pig
Strumenti di sviluppo
● Grunt è ottimo per esplorare dataset e sperimentare con nuovo codice
● Invece, per sviluppare codice occorre attrezzarsi di un editor
● esistono plugin per molti editor (e.g., Vim, TextMate, Emacs, Eclipse)
● forniscono tipiche funzionalità di sviluppo, come syntax-higlighting e l'auto
completamento
● Esiste anche un'interfaccia web integrata in Hue (http://gethue.com/)
● Permette di editare, lanciare e monitorare i job Pig che girano su un determinato
cluster Hadoop

20
Pig-Latin
Introduzione al Linguaggio

21
Pig-Latin
Un dataflow language
● Pig è un dataflow language
● Simile ai linguaggi funzionali
Non si specifica come eseguire le elaborazioni!
Invece,
Si specificano solamente quali elaborazioni eseguire

22
Pig-Latin
Imperativo vs funzionale
Per rendere l'idea, confrontiamo come sommare gli elementi di una lista
● Tutto pseudo-codice
● L'imperativo richiede “dettagli” quali l'accumulatore e il modo di iterazione
● Il funzionale è più ricco di funzioni (particolarmente di ordine superiore)
● Reduce: riduce il vettore di una dimensione, usando l'operazione specificata
● Non specifichiamo l'accumulatore, ne il modo di iterazione
● L'implementazione è libera di scegliere per noi!
Imperativo (e.g., C, C++, Java, …)
int sum(list) {int s = 0;for (int i = 0; i < list.len; ++i)
s += list[i];return s;
}
Funzionale (e.g., Lisp, Erlang, …)
int sum(list):return reduce(+, list)

23
Pig-Latin
Imperativo vs funzionale
● Nell'esempio, il compilatore o interprete può scegliere l'implementazione più adatta
alla situazione
● e.g., quello stesso codice potrebbe risultare in:
● istruzioni per una CPU embedded per sommare una manciata di numeri
● Un job MapReduce per sommarne miliardi usando un cluster
● Infatti, il paradigma funzionale è parecchio usato per codici altamente parallelizzati
● Nasconde lo stato condiviso tra processori
● Semplifica la sincronizzazione

24
Pig-Latin
Istruzione base
Torniamo a Pig!
L'istruzione base (statement):
nome = operatore { parametri_op }
Esempio:
input = load 'data'
● Carica un dataset da una cartella “data”; assegna la “variabile” input
● In Pig-Latin ogni istruzione rappresenta un dataset o relazione
● concettualmente equivalente ad una tabella SQL contenente tanti record

25
Pig-Latin
Case-sensitivity
Case-sensitivity
● Le keywords di Pig non sono case-sensitive
● Queste due istruzioni fanno la stessa cosa:
input = load 'data'input = LOAD 'data'
● Però, tutto il resto è case-sensitive! Quindi le istruzioni
INPUT = load 'data'input = load 'data'
creano due alias distinti
Consideratelo un linguaggio case-sensitive

26
Pig-Latin
Introduzione al linguaggio
Nomi
● iniziano con un carattere alfabetico, seguito alfanumerici o underscore
Commenti
● multilinea stile C / C++ / Java /* … */
● riga singola stile SQL '--' (doppio meno)

27
Pig-Latin
Il modello dati
● Categorie di tipi: null, scalari e complessi
● Null → come in SQL; denota l'assenza di un valore
● I tipi scalari:
{ int, long, float, double }
chararray → String
bytearray → byte[] (in Java) , Blob (in SQL)
● I tipi complessi sono tre:
map, tuple, bag
● richiedono una descrizione più dettagliata...

28
Pig-Latin
Il tipo Map
● Tipica associazione chiave-valore
● Analoga al tipo map trovato in altri linguaggi (e.g, Java, Python, C++, ecc.)
● Però, la chiave deve essere un chararray
● Il valore può essere di qualunque tipo, scalare o complesso
Sintassi:
['chiave' # 'valore', 'name' # 'bob' , 'age' # 25]
● Se non viene specificato un tipo al valore, Pig assegna il tipo bytearray
● i valori della stessa map possono avere tipi diversi

29
Pig-Latin
Il tipo Tuple
● Tuple: una sequenza ordinata di campi
Sintassi:
( 'bob', 55 )
● Equivalente ad un record SQL
● i campi corrispondono alle colonne di una tabella
● I campi di una tupla possono contenere qualsiasi tipo supportati da Pig
● I campi della stessa tupla possono essere di tipo diverso

30
Pig-Latin
Il tipo Tuple
Accedere ai campi di una tupla
● Per posizione
● $N dove N è la posizione del campo nella tupla (N inizia da 0)
● Si può accedere anche col nome del campo, quando disponibile
● Il nome è disponibile solo se specificato da uno schema (vedremo più tardi)
Esempio:
Carichiamo dei numeri e incrementiamoli di 1
> input = LOAD 'numbers';> plus_one = FOREACH input GENERATE $0 + 1;

31
Pig-Latin
Il tipo Bag
● Bag: una collezione ordinata di tuple
Sintassi:
{ ('bob', 55) , ('sally', 52), ('john', 25) }
● La più generale delle collezioni supportate in Pig
● Potrebbe essere vista come una tabella SQL...
● Però una bag può essere contenuta da altri tipi complessi (e.g., una tupla)
● Non è possibile accedere ai contenuti per posizione
● Si applicano operatori all'intero contenuto

32
Pig-Latin
Relazioni
● Le bag sono denominati esterne ed interne (inner e outer)
● Interne: annidate all'interno di un'altra bag, a qualche livello
● Una bag è una collezione di tuple, ma la tupla può contenere una bag
● Esterne: sono la relazione a cui ci riferiamo con l'alias
input = LOAD 'data'
● input → una bag esterna
● Per analogia ad SQL, la bag esterna corrisponde ad una tabella/relazione
● Può essere salvata su file in maniera automatica
● gli altri tipi complessi invece no

33
Pig-Latin
Schemi
Schema: in Pig, è la descrizione di una struttura dati
● Specifica la struttura di un dataset, i.e.,
● Tipo collezione (tipo complesso, come un Bag)
● Tipi dei campi
● Nomi dei campi
● Fin'ora abbiamo sorvolato la necessità di descrivere i dati manipolati
● ...anche perché non è strettamente necessario farlo!
● Senza schema, Pig supporrà la tipologia dei dati in base alle operazioni richieste

34
Pig-Latin
Schemi
● Specificare gli schemi ha vantaggi
● Controllo degli errori (eventuali errori di tipo saranno rilevati dal parser)
● Ottimizzazioni delle operazioni
● Come impostare uno schema?
● Il modo più semplice: definirlo al caricamento dei dati
● Aggiungiamo al comando load la clausola as

35
Pig-Latin
Schemi
dividends = load 'NYSE_dividends' as
(exchange: chararray, symbol: chararray,
date:chararray, dividend: float);
● Sintassi per tipi semplici: nome: tipo
Quindi, abbiamo definito un dataset di record coi campi:
● exchange, tipo chararray
● symbol, tipo chararray
● date, tipo chararray
● dividend, tipo float

36
Pig-Latin
Schemi
Se si definisce uno schema i dati gli saranno adattati
● attraverso dei cast
● inserendo dei null se mancano i dati
● scartando eventuali campi in eccesso
Se dallo schema si omettono i tipi dei dati, e.g.,
divs = load 'NYSE_divs' as (exchange, symbol, date, dividend);
● I campi avranno tipo bytearray
● Successivamente saranno convertiti dinamicamente in base all'uso

37
Pig-Latin
Schemi
Per vedere lo schema associato ad una relazione: describe
grunt> divs = load 'NYSE_divs' as (exchange, symbol, date, dividend);
grunt> describe divs
divs: {exchange: bytearray,symbol: bytearray,date: bytearray,dividend:
bytearray}
grunt>
● Notiamo le “{“ indicando che divs riferisce ad una Bag
● Le tuple interne invece sono implicite
38
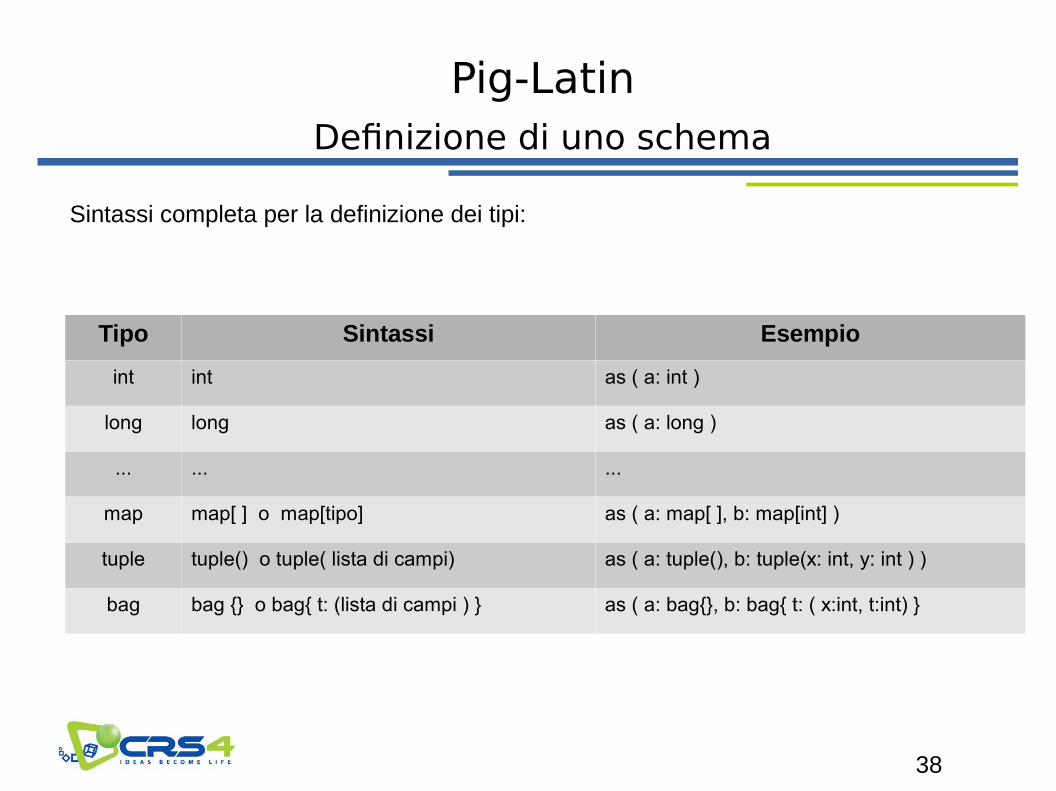
Pig-Latin
Definizione di uno schema
Sintassi completa per la definizione dei tipi:
Tipo Sintassi Esempio
int int as ( a: int )
long long as ( a: long )
... ... ...
map map[ ] o map[tipo] as ( a: map[ ], b: map[int] )
tuple tuple() o tuple( lista di campi) as ( a: tuple(), b: tuple(x: int, y: int ) )
bag bag {} o bag{ t: (lista di campi ) } as ( a: bag{}, b: bag{ t: ( x:int, t:int) }

39
Pig-Latin
Repository di schemi
● Utilizzate lo stesso schema spesso o in più script?
● Schemi troppo complessi per essere digitati spesso?
● Gli schemi possono essere memorizzati
● Usando file format su disco che li conservino coi dati (e.g., Avro)
● Usando sistemi dedicati, come Hcatalog
dividends = load 'NYSE_dividends' using HCatLoader();

40
Pig-Latin
Deduzione di uno schema
Esempio di schema dedotto da Pig
daily = load 'NYSE_daily';
calcs = foreach daily generate $7/1000, $3*100.0, SUBSTRING($0,
0,1), $3 - $6;
Pur non essendo stato fornito uno schema Pig può assumere che
● $7 sia un intero perché diviso per un intero
● $3 sia un double perché moltiplicato per un double
● $0 sia un chararray perché si estrae una sottostringa
● $6 sia un numero perché utilizzato in una sottrazione, ma non può essere di sicuro
del tipo di numero, quindi va per la scelta più prudente: double
In questo modo Pig è in grado di associare uno schema alla nuova relazione calcs.

41
Pig-Latin
Cast
● Un altro modo per associare uno schema ad una relazione è l'uso del cast.
● analogo a quello in Java, segue la stessa sintassi e quasi le stesse regole
daily = load 'NYSE_daily';
calcs = foreach daily generate
(int)$7 /1000, (double)$3 * 100.0,
(chararray)SUBSTRING($0, 0,1), (double)$6 – (double)$3;
● È possibile eseguire un cast automatico dal tipo più piccolo a quello più grande
● Il cast inverso grande → piccolo deve essere esplicito e può causare troncamenti
● Si può fare il cast da chararray a un tipo numerico ma se la stringa non ha un
formato corretto il risultato sarà un null

42
Pig-Latin
Comandi Base

43
Pig-Latin
Comandi Base
● Qualunque flusso (potenzialmente utile) di dati ha degli input e degli output
● Pig latin offre tre comandi per la loro definizione:
● load per la definizione delle sorgenti di input
● store per la definizione dei file di output
● dump per scrivere i risultati alla console

44
Pig-Latin
Load
● Load: già visto negli esempi
input = load 'data';
● Per default lavora su HDFS, partendo dalla cartella /user/${user.name}
● Accetta path assoluti e relativi, o anche URI
● e.g., hdfs://my.namenode.org/data/
● Input format di default: file testuali separati da tabulazioni
● viene usata la funzione di lettura PigStorage

45
Pig-Latin
Load
E' possibile possibile specificare diverse opzioni di lettura attraverso la clausola using
/* comma separated values */
input = load 'data' using PigStorage(',');
● Esistono altre funzioni di I/O: JsonStorage, AvroStorage, ...
Sorgenti diverse dall'HDFS, e.g., HBase
input = load 'data' using HbaseStorage();
Possiamo anche specificare lo schema per la nuova relazione con as:
input = load 'data' as ( exchange: chararray, symbol: chararray,
date: chararray, dividends: float);

46
Pig-Latin
Load: globs
● Load accetta un'intera cartella come input
● Il contenuto di tutti i file sarà accorpato in un'unica relazione.
● E' possibile anche usare delle regular expressions semplificate (globs)
Glob Significato
? match con ogni singolo carattere
* match con zero o più caratteri
[abc] match con un singolo carattere tra quelli specificati
[a-z] match con un singolo carattere tra quelli specificati dall'intervallo (estremi inclusi)
[^abc] match con un singolo carattere che non sia tra quelli specificati
[^a-z] match con un singolo carattere che non sia nell'intervallo (estremi inclusi)
\c Rimuove ( escapes ) ogni significato speciale del carattere c
{aa, bb} match con una delle stringhe indicate nell'elenco

47
Pig-Latin
store
● store: scrive una relazione allo storage
● segue le stesse regole del comando load
L'utilizzo standard di store è:
store NomeRelazione into 'nome_file';
● Anche store accetta la clausola using per modificare la funzione di scrittura
● Per default, PigStorage('\t')
store NomeRelazione into 'nome_file' using HBaseStorage();

48
Pig-Latin
dump
● dump: scrive il contenuto di una relazione a stdout
● Utile in modalità interattiva
● Possibilmente lavorando con una quantità limitata di dati!
Si usa così:
dump NomeRelazione;
● Come store, dump forza l'esecuzione di tutti i comandi per generare la relazione
specificata

49
Pig-Latin
Supporto allo sviluppo

50
Pig-Latin
Supporto allo sviluppo
Pig-Latin include comandi agevolare lo sviluppo di script e non solo
● describe → descrive lo schema associato ad una relazione
● sample → campiona il dataset creandone una versione di dimensione ridotta
● limit → selezione i primi N record di un dataset
● illustrate → mostra alcuni record rappresentativi del dataset
● explain → mostra la strategia di esecuzione dello script

51
Pig-Latin
describe● Abbiamo visto describe in precedenza; ecco un esempio più complesso
divs = load 'NYSE_dividends'
as (exchange, symbol, date, dividends:float);
projected = foreach divs generate symbol, dividends;
grouped = group projected by symbol;
avgdiv = foreach grouped generate
group, AVG(projected.dividends);
describe projected; describe grouped; describe avgdiv;
projected: {symbol: bytearray,dividends: double}
grouped: {group: bytearray,projected: {(symbol: bytearray,dividends: double)}}
avgdiv: {group: bytearray,double}

52
Pig-Latin
sample / limit
sample alias N
● Uno può voler applicare un'analisi o procedura ad un sottoinsieme dei dati
disponibili, e.g.,
● Provare uno script il cui comportamento dipende dalla natura dei dati
● Test statistico che non ha bisogno di 3 PB di dati
limit alias N
● Limit semplicemente restituisce i primi N record di alias
● Analogo al limit di qualche DBMS (e.g, MySQL, PostgreSQL, ...)

53
Pig-Latin
sample / limit
--sample.pig
divs = load 'NYSE_dividends';
some = sample divs 0.1;
some conterrà circa il 10% dei record presenti in divs.
--limit.pig
divs = load 'NYSE_dividends';
first10 = limit divs 10;
first10 conterrà i primi 10 record presenti in divs.

54
Pig-Latin
illustrate
● In alcuni casi, fare test un semplice campionamento di dati non funziona bene
● e.g., operazioni selettive (filter, join, …) possono generare risultati vuoti
● illustrate cerca di selezionare il minimo necessario, ma sufficiente, per
illustrare il funzionamento dello script
● si assicura di selezionare dei record che arrivino al termine della trasformazione.
● e.g., se lo script esegue un join cercherà di trovare record con la stessa chiave
per evitare una relazione vuota.

55
Pig-Latin
illustrate
divs = load 'NYSE_dividends'
as (e:chararray, s:chararray, d:chararray, div:float);
recent = filter divs by d > '2009-01-01';
trimmd = foreach recent generate s, div;
grpd = group trimmd by s;
avgdiv = foreach grpd generate group, AVG(trimmd.div);
illustrate avgdiv;

56
Pig-Latin
illustrate

57
Pig-Latin
explain
● explain mostra come Pig eseguirà le operazioni richieste
● In termini di job MapReduce o altro
● Utile specialmente per ottimizzare le prestazioni di uno script
● L'output di explain non è molto intuitivo!
● Rappresenta in ASCII l'albero delle operazioni da eseguire
● Può esser utilizzato in due modi:
● su un alias: mostra il dataflow per generare i dati della relazione
● su uno script: mostra l'intero dataflow dello script
● Non approfondiremo

58
Pig-Latin
Operatori Relazionali

59
Pig-Latin
Operatori Relazionali
● Il punto di forza di Pig-Latin: gli operatori relazionali
● Simili agli equivalenti SQL
● I principali sono:
● foreach: applica un'espressione a ciascun record di una relazione
● filter: filtra, eliminando record che non soddisfano un'espressione
● group: accorpa i dati secondo i valori di uno o più campi o espressioni
● order by: ordina i record di una relazione
● join: unifica due relazioni usando campi con valori in comune

60
Pig-Latin
foreach
L'operatore foreach:
● Probabilmente l'operatore più importante di Pig
● Itera per ogni tupla di una relazione
● Esegue l'espressione (la clausola GENERATE)
● Raccoglie il risultato di ogni esecuzione in una nuova relazione
● In generale, ci permette di trasformare gli elementi di una relazione

61
Pig-Latin
foreach
Il suo formato base è piuttosto semplice
A = load 'input' as
(user: chararray, id: long, address: chararray,
phone: chararray, preferences: map[]);
B = foreach A generate user, id;
● Nell'esempio si proietta A, estraendo i campi user e id, e si genera la relazione B
● B consiste in una bag di tuple (user, id)

62
Pig-Latin
foreach
E' possibile specificare gruppi di campi attraverso i simboli
● * per indicare tutti i campi
● .. per indicare un intervallo di campi
prices = load 'NYSE_daily' as
(exchange, symbol, date, open, high, low, close, volume, adj_close);
beginning = foreach prices generate ..open;
-- produces exchange, symbol, date, open
middle = foreach prices generate open..close;
-- produces open, high, low, close
end = foreach prices generate volume..;
-- produces volume, adj_close

63
Pig-Latin
foreach
● Con foreach si possono applicare espressioni sui campi di una relazione
prices = load 'NYSE_daily' as (exchange, symbol, date, open, close);
gain = foreach prices generate close - open;
gain2 = foreach prices generate $6 - $3;
Le due relazioni gain e gain2 avranno gli stessi valori

64
Pig-Latin
foreach
● Sono disponibili le operazioni standard tra numeri
+ - * / %
● L'operatore ternario ? equivalente all' if-then-else
● i due valori restituiti devono essere dello stesso tipo
● Bene prestare attenzione ai null
● qualunque operazione aritmetica con un null ha come risultato null.
2 == 2 ? 1 : 4 --returns 1
2 == 3 ? 1 : 4 --returns 4
null == 2 ? 1 : 4 -- returns null
2 == 2 ? 1 : 'fred' -- type error; both values must be of the same type

65
Pig-Latin
foreach
● Esistono operatori per estrarre informazioni annidate all'interno di tipi complessi
● # per le map
● . per le tuple
A = load 'baseball' as (name:chararray, team:chararray,
position:bag{t:(p:chararray)}, bat:map[]);
avg = foreach A generate bat#'batting_average';
● Estrae il valore associato a “batting_average” nel map bat
B = load 'input' as (point:tuple(x:int, y:int));
Xs = foreach B generate point.x;
● Estrae le 'x' dei punti

66
Pig-Latin
filter
● L'operatore filter seleziona i record da tenere
● Seleziona secondo un'espressione booleana
● Passano il filtro i record per cui il predicato risulta vero
● Pig è ricco di funzioni per fare test su stringhe – e.g., support le espressioni regolari
divs = load 'NYSE_dividends'
as (exchange:chararray, symbol: chararray,
date:chararray, dividends:float);
startsWithCM = filter divs by symbol matches 'CM.*';
Come in SQL, per gestire i null è bene utilizzare is null e/o is not null

67
Pig-Latin
group by
● group raggruppa tutti i record accomunati da una stessa chiave
● Concettualmente “group by” in SQL
● I record risultanti dall'espressione group sono composti da due elementi:
● i campi chiave, denominati group
● un bag con il nome dell'alias su cui si è effettuato il raggruppamento contenente i
record raccolti
daily = load 'NYSE_daily' as (exchange, stock, date, dividends);
grpd = group daily by (exchange, stock);
describe grpd;
grpd: {group: (exchange: bytearray, stock: bytearray),
daily: {exchange:bytearray, stock:bytearray, date: bytearray,
dividends:bytearray}}

68
Pig-Latin
order by
● order by ordina i record secondo il criterio specificato
● Come in SQL
daily = load 'NYSE_daily' as (exchange:chararray, symbol:chararray,
date:chararray, open:float, high:float, low:float, close:float,
volume:int, adj_close:float);
bydate = order daily by date;
bydatensymbol = order daily by date, symbol;
byclose = order daily by close desc, open;

69
Pig-Latin
distinct
● distinct: elimina i record duplicati
● funziona solo su record interi non su singoli campi
daily = load 'NYSE_daily' as (exchange:chararray, symbol:chararray);
uniq = distinct daily;

70
Pig-Latin
join
● join: combina i record di due relazioni accomunati da una stessa chiave
● I record per cui non viene trovata una corrispondenza vengono scartati.
● Come in SQL!
daily = load 'NYSE_daily' as (exchange, symbol, date, open, high, low,
close, volume, adj_close);
divs = load 'NYSE_dividends' as (exchange, symbol, date, dividends);
jnd = join daily by symbol, divs by symbol;

71
Pig-Latin
join
● join conserva i nomi dei campi delle relazioni di input
● antepone il nome della relazione di provenienza per evitare conflitti
Il risultato del join precedente sarebbe
describe jnd;
jnd: {daily::exchange:bytearray, daily::symbol:bytearray,
daily::date:bytearray, daily::open:bytearray, daily::high:bytearray,
daily::low:bytearray, daily::close:bytearray, daily::volume:bytearray,
daily::adj_close:bytearray,
divs::exchange:bytearray, divs::symbol:bytearray, divs::date:bytearray,
divs::dividends:bytearray}
● Notare i “daily::” e “divs::”

72
Pig-Latin
join
● È possibile fare il join con più chiavi
● i campi di unione delle due relazioni devono avere tipi compatibili
● Stesso tipo oppure un cast implicito ammissibile
jnd = join daily by (symbol, date), divs by (symbol, date);

73
Pig-Latin
outer join
● Pig supporta anche l'outer join
● A differenza del join, non scarta i record senza corrispondenza tra le relazioni
● sostituisce la parte mancante con dei null
Come in SQL, gli outer join possono essere di tre tipi:
● left → vengono inclusi i record della relazione a sinistra
● right → vengono inclusi i record della relazione a destra
● full → vengono inclusi i record di entrambe le relazioni
jnd = join daily by (symbol, date) left outer, divs by (symbol, date);

74
Pig-Latin
union
● union: concatena due relazioni, eliminando i duplicati
● Come la tipica unione di insiemi, e anche come SQL
Ad esempio avendo due file distinti che non possono essere accorpati con un glob:
A = load '/user/me/data/files/input1';
B = load '/user/other/info/input2';
C = union A, B;
● Pig è meno rigido dell'equivalente SQL
● non è richiesto che le relazioni abbiano lo stesso schema

75
Pig-Latin
union
In caso di schemi diversi:
● Se sono diversi ma compatibili (cast impliciti) il risultato avrà lo schema più
“permissivo”
● Se sono incompatibili la relazione risultante non avrà schema
● ovvero record diversi avranno campi diversi

76
Pig-Latin
Funzionalità avanzate

77
Pig-Latin
User Defined Functions
● Pig permette di usare funzioni definite esternamente nelle normali espressioni
● possono essere scritte in
● Java
● Python e Jython
● JavaScript
● Ruby
● Groovy
● Esistono molte già UDFs che potete usare nei vostri programmi
● e.g., per l'elaborazione di stringhe (concat, substring...) e l'esecuzione di calcoli
matematici
● Una libreria di UDFs molto usata è PiggyBank

78
Pig-Latin
User Defined Functions
● Per utilizzare le UDF: registrare l'archivio che le contiene
● Si può anche definire un alias per evitare di usare il fully-qualified-name
register 'your_path_to_piggybank/piggybank.jar';
define reverse org.apache.pig.piggybank.evaluation.string.Reverse();
divs = load 'NYSE_dividends' as (exchange:chararray, symbol:chararray,
date:chararray, dividends:float);
backwards = foreach divs generate reverse(symbol);

79
Pig-Latin
User Defined Functions
● È possibile accorpare più register e definizioni di alias in un unico script
● Lo script può essere “sourced” (come in una shell) con import
import '../myProject/imports_and_definitions.pig';
● Register accetta anche path su HDFS e i globs
register 'hdfs://user/jar/acme.jar';
register '/usr/local/share/pig/udfs/*.jar';

80
Pig-Latin
foreach - UDFs
● Con foreach, una UDF può essere applicata ad un'intera bag
● Il risultato costituirà una nuova relazione
divs = load 'NYSE_dividends' as (exchange, symbol, date, dividends);
--make sure all strings are uppercase
upped = foreach divs generate UPPER(symbol) as symbol, dividends;
grpd = group upped by symbol;
--output a bag upped for each value of symbol
--take a bag of integers, produce one result for each group
sums = foreach grpd generate group, SUM(upped.dividends);

81
Riassumendo...
● Pig può semplificare la creazioni di programmi scalabili, per Hadoop
● Molti suoi operatori sono ispirati a SQL; però non è un sostituto
● Non è un "query language"
● Invece, permette l'elaborazione scalabile di dati
● Anche grezzi
● Anche disuniformi
● Infatti è un ottimo strumento per "pulire" e preparare i dati per le data warehouse
● Uno dei tanti strumenti nell'ecosistema Hadoop
82
Pig
That's enough for Pig!

83
HIVE
84
Hive
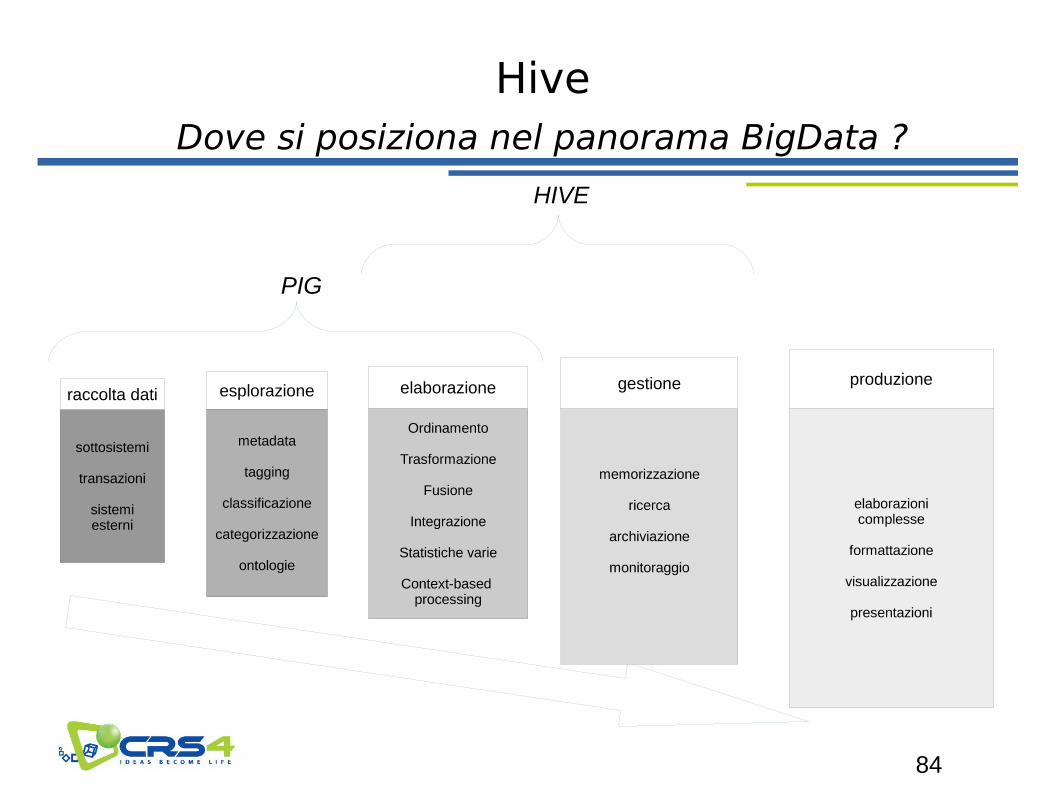
Dove si posiziona nel panorama BigData ?
HIVE
PIG

Data WareHouse
in Hadoop: Hive
● Con Hadoop MapReduce è possibile affrontare problemi di Data WareHouse
● Però, implementare processi/interrogazioni complesse con MapReduce è laborioso
e difficile
● Tempo necessario per andare dal quesito alla risposta è troppo lungo
● Molto più agevole (e comune) affrontare questi problemi con linguaggi di query
come SQL

Data WareHouse
in Hadoop: Hive
Hive è un'infrastruttura per il data warehousing basato su Hadoop
● Fornisce uno strumento per l'interrogazione e la gestione di dati non strutturati
● Fornisce un approccio simile ad SQL
● Esegue le sue elaborazioni in job Hadoop
● Riesce a gestire efficacemente grandi quantità di dati

Hive
Origini
Per la gestione dei dati in Facebook si usava abitualmente Hadoop
L'uso continuativo aveva però evidenziato alcune criticità del sistema:
- codice scarsamente riutilizzabile
- propensione agli errori
- complesse sequenze di job MR
L'idea fu quindi quella di realizzare un tool per:
- poter gestire dati non strutturati come fossero delle tabelle
- permettere di esprimere query in simil-SQL agendo direttamente su queste tabelle
- generare automaticamente catene di job se necessario

Hive
Un esempio pratico: WordCount
CREATE TABLE docs (line STRING);
LOAD DATA INPATH 'ebook' OVERWRITE INTO TABLE docs;
CREATE TABLE word_counts AS
SELECT word, count(1) AS count FROM(SELECT explode(split(line, '\s')) AS word FROM docs)
GROUP BY wordORDER BY word;

Hive
HQL
● Hive implementa un linguaggio di query molto simile ad SQL
● Di fatto, è relativamente vicino a SQL-92
● Ultime versioni supportano addirittura transazioni
● Quindi, per fare query con Hive, scrivete SQL!
● Oltre allo standard, HQL fornisce parecchie funzionalità/operatori/data type
● Funzioni per gestire i suoi tipi specifici
● Funzioni matematiche
● Tutto documentato nel wiki:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF

Hive
Primitive Data Types
I tipi primitivi di Hive:
TINYINT, dimensione 1 byte, signed integer
SMALLINT, dimensione 2 byte, signed integer
INT, dimensione 4 byte, signed integer
BIGINT, dimensione 8 byte, signed integer
BOOLEAN
FLOAT, single precision floating point
DOUBLE, double precision floating point
STRING, sequenza di caratteri (specificata con apici singoli o doppi)
TIMESTAMP, Integer, float, or string
BINARY, array di bytes

Hive
Collection Data Types: Struct
Uno struct: l'analogo di una struct C
● un “oggetto” privo di metodi
Per definire una struttura chiamata date di tipo STRUCT:
date STRUCT<year:INT, month:INT, day:INT>,
Per accedere ai campi si utilizza la tipica notazione “punto”: date.year

Hive
Collection Data Types: Array
Array: sequenze ordinate di dati aventi lo stesso tipo
● Possiamo accedere ai singoli elementi utilizzando degli interi
Per definire un campo chiamato volume di tipo ARRAY:
volume ARRAY<INT>
Ipotizzando che essa contenga:
['31', '28']
Potremo accedere al secondo elemento con volume[1]

Hive
Collection Data Types: Map
Map: collezione di coppie chiave-valore
Per definire una MAP chiamata sellers
sellers MAP<STRING, FLOAT>
Ipotizziamo che contenga le coppie
< 'Connor' , 65367 >< 'Malley' , 92384 >< 'Burns' , 52453 >
per ricavare il valore corrispondente alla chiave Burns scriveremo:
sellers['Burns']
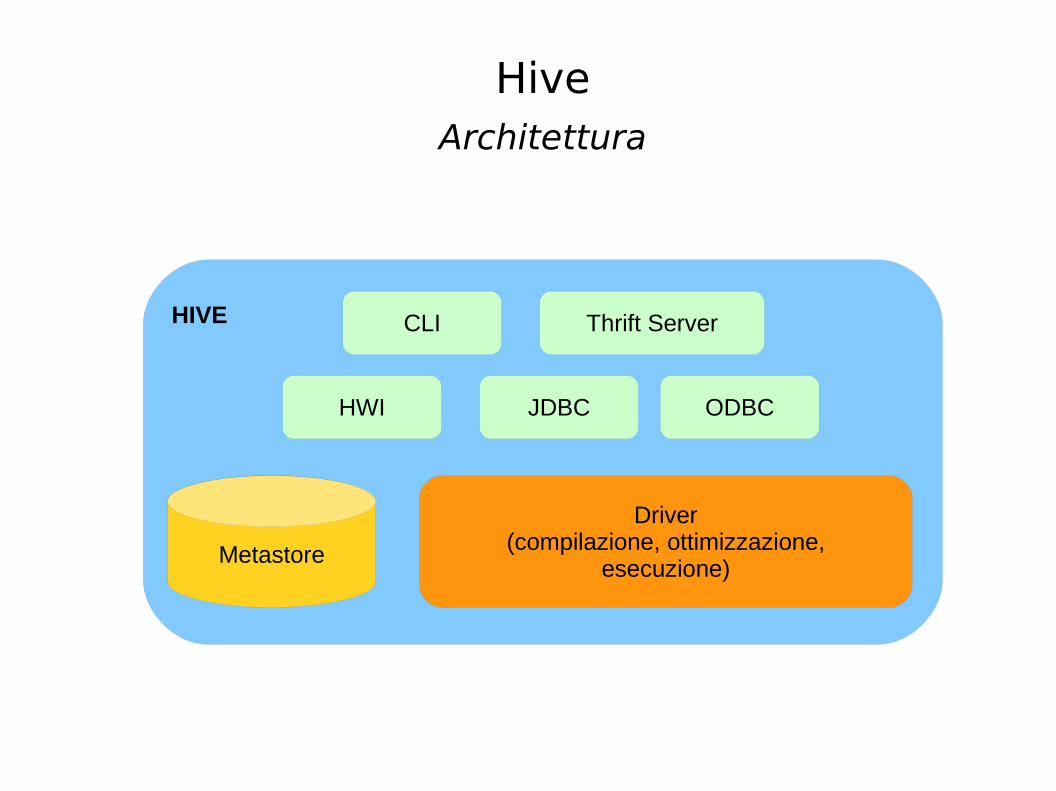
Hive
Architettura
JDBC ODBC
Thrift Server
HWI
CLI
Metastore
Driver(compilazione, ottimizzazione,
esecuzione)
HIVE
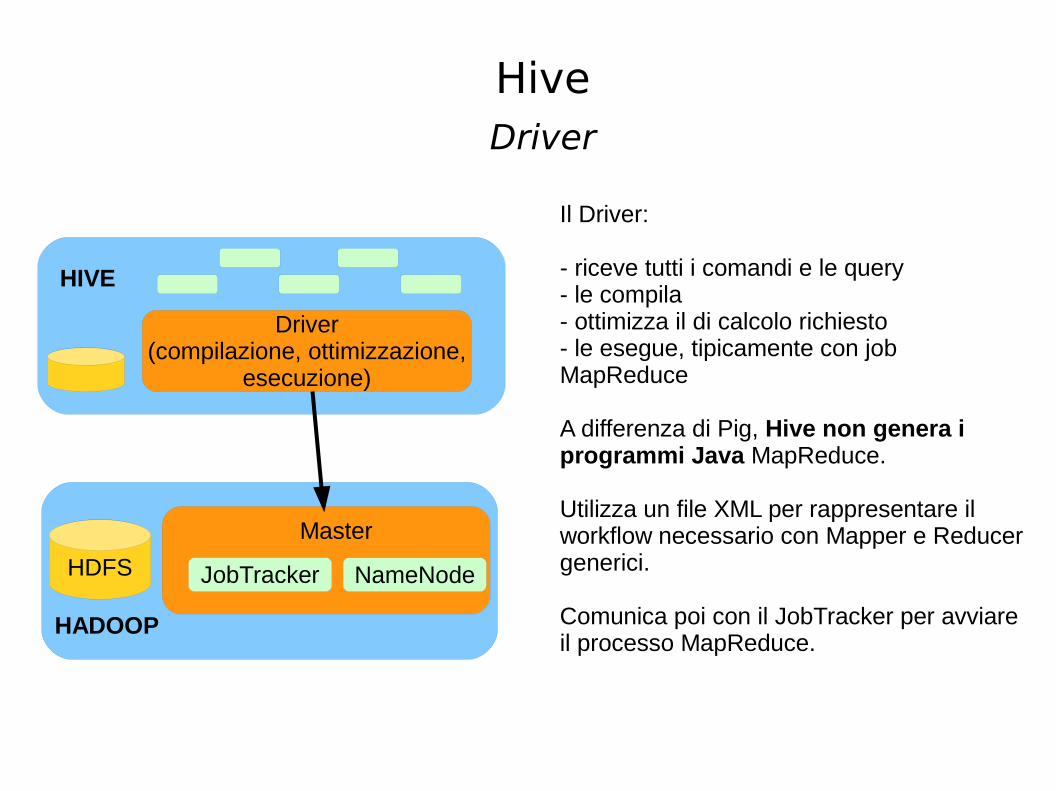
Hive
Driver
Driver(compilazione, ottimizzazione,
esecuzione)
HIVE
HDFS
HADOOP
JobTracker NameNode
Master
Il Driver:
- riceve tutti i comandi e le query- le compila- ottimizza il di calcolo richiesto- le esegue, tipicamente con job MapReduce
A differenza di Pig, Hive non genera i programmi Java MapReduce.
Utilizza un file XML per rappresentare il workflow necessario con Mapper e Reducer generici.
Comunica poi con il JobTracker per avviare il processo MapReduce.
Hive
Metastore
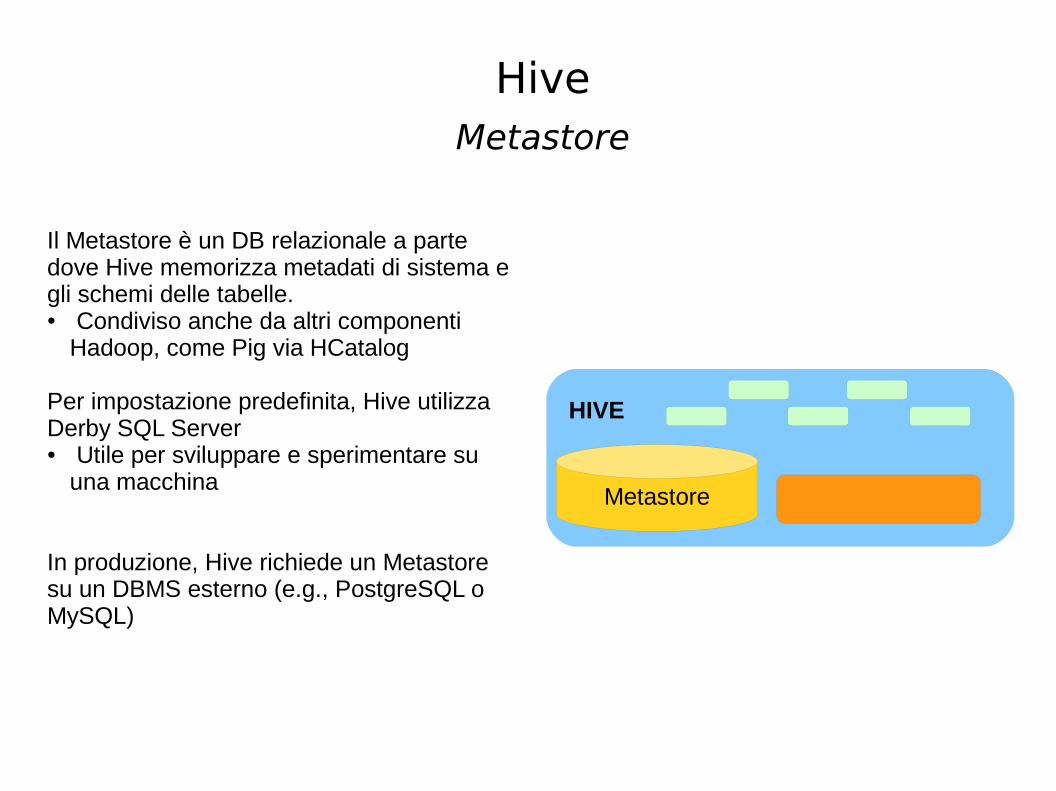
Metastore
HIVE
Il Metastore è un DB relazionale a parte dove Hive memorizza metadati di sistema e gli schemi delle tabelle.● Condiviso anche da altri componenti
Hadoop, come Pig via HCatalog
Per impostazione predefinita, Hive utilizza Derby SQL Server● Utile per sviluppare e sperimentare su
una macchina
In produzione, Hive richiede un Metastore su un DBMS esterno (e.g., PostgreSQL o MySQL)
Hive
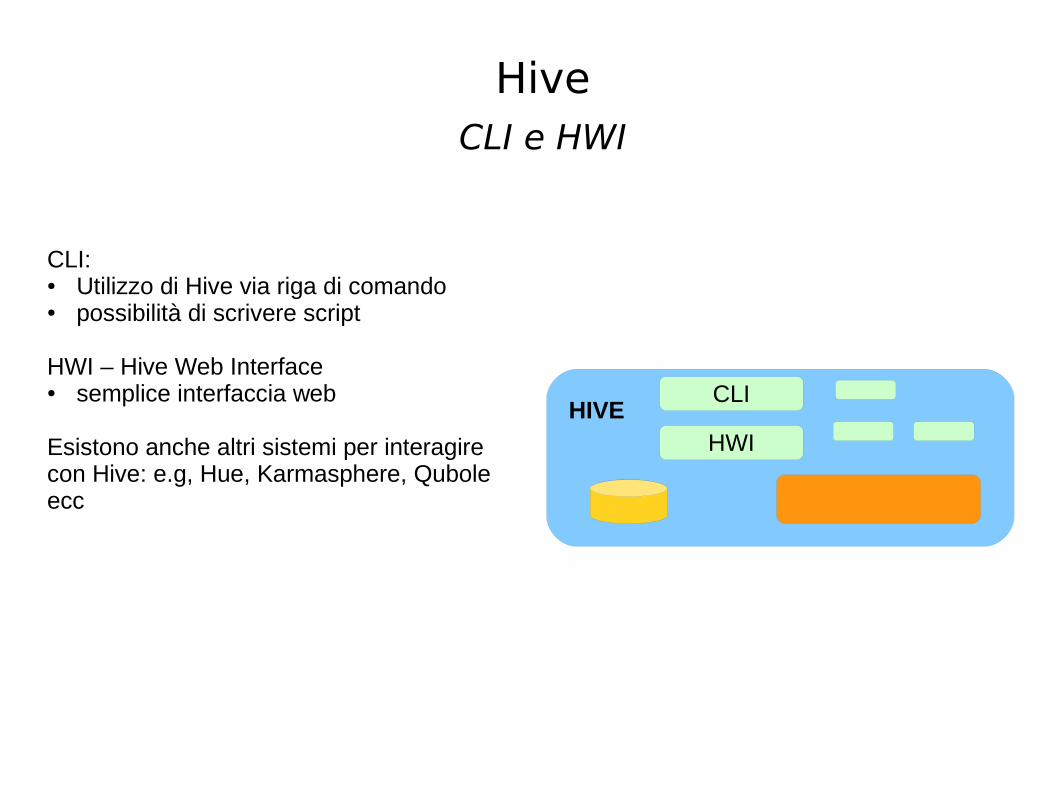
CLI e HWI
HIVE
CLI:● Utilizzo di Hive via riga di comando● possibilità di scrivere script
HWI – Hive Web Interface● semplice interfaccia web
Esistono anche altri sistemi per interagire con Hive: e.g, Hue, Karmasphere, Qubole ecc
CLI
HWI

Hive
CLI
La CLI di Hive ci consente di:
- interagire con Hive con una shell simile a quella di MySql hive
- lanciare una singola queryhive -e '<comando>'
- effettuare il dump del risultato di una query hive -S -e '<comando>' > out.txt
- eseguire uno script localehive -f myScript
- eseguire uno script presente nell'hdfshive -f hdfs://<namenode>:<port>/myScript
Hive
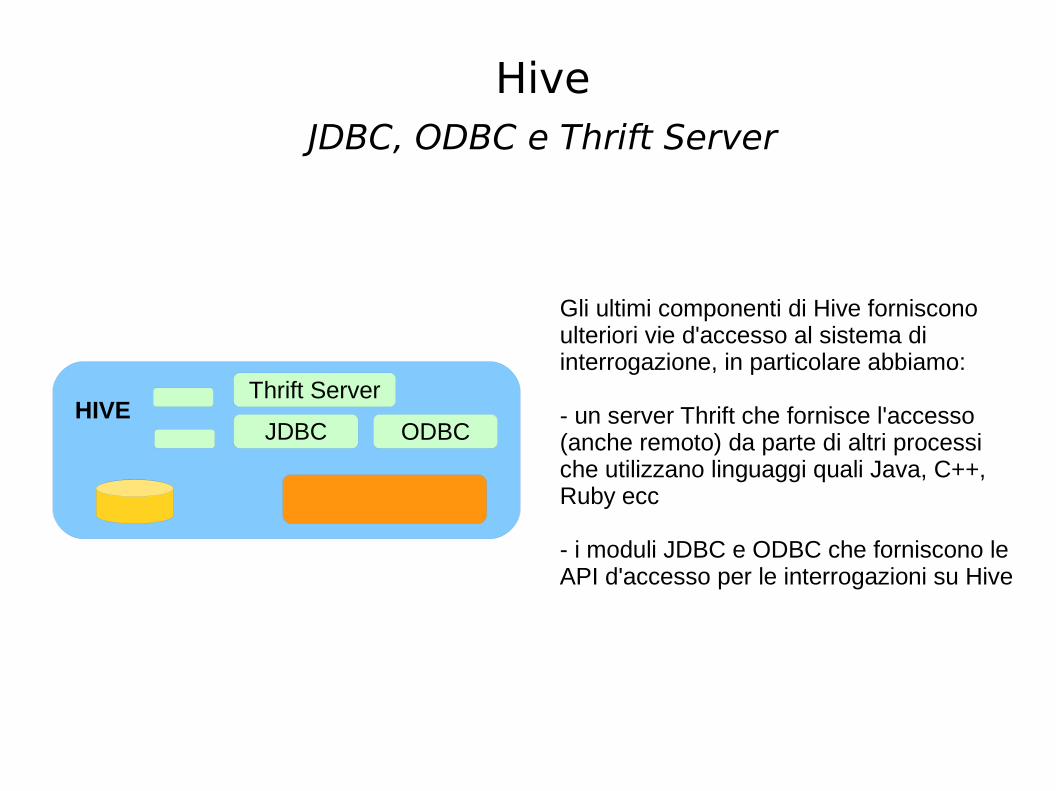
JDBC, ODBC e Thrift Server
HIVE
Gli ultimi componenti di Hive forniscono ulteriori vie d'accesso al sistema di interrogazione, in particolare abbiamo:
- un server Thrift che fornisce l'accesso (anche remoto) da parte di altri processi che utilizzano linguaggi quali Java, C++, Ruby ecc
- i moduli JDBC e ODBC che forniscono le API d'accesso per le interrogazioni su Hive
Thrift Server
ODBCJDBC
100
Hive
HiveQL
Comandidi base

Hive
Database
Per la creazione di un database in Hive usiamo il comando
CREATE DATABASE IF NOT EXISTS financials;
Possiamo anche aggiungere una serie di metadati (localizzazione dei dati, informazioni sull'autore, sulla data di creazione, commenti ecc)
Ad esempio per specificare dove scrivere i dati sull'HDFS:
LOCATION '/user/hue/financials_db';

Hive
Database
Per visualizzare le proprietà di un certo database usiamo:
DESCRIBE DATABASE financials;
Per cancellarlo invece:
DROP DATABASE financials;

Hive
Tabelle
A differenza dei tipici RDBMS, Hive tipicamente Hive legge dei dati da file di tipo testuale
● e.g., CSV o TSV
Per separare elementi, Hive utilizza dei caratteri che hanno meno probabilità di comparire nei dati
In particolare
\n → separatore di linea^A octal \001 → separatore di colonna^B octal \002 → separatore dei valori negli struct e negli array o delle coppie chiave-valore nei map^C octal \003 → separatore inserito tra la singola coppia chiave-valore all'interno del map

Hive
Text Files Encoding
Codice corrispondente alle impostazioni di default:
ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\001'COLLECTION ITEMS TERMINATED BY '\002'MAP KEYS TERMINATED BY '\003'LINES TERMINATED BY '\n'STORED AS TEXTFILE ;

Hive
Tipologia di Tabelle
La creazione delle tabelle in Hive ricorda in maniera particolare la creazione delle tabelle in SQL
Esistono due principali tipi di tabelle:
- Tabelle ordinarie (non partizionate)- Tabelle partizionate
Che a loro volta possono essere suddivise in:
- Tabelle interne- Tabelle esterne

Hive
Tabelle ordinarie: Tabelle InterneIn questo tipo di tabelle:
Hive assume di avere la “proprietà” dei dati
Quando creiamo una tabella ordinaria interna:
● Il file contenente i dati viene spostato all'interno della cartella della nostra tabella nell'HDFS
● Questo perché:- i dati importati non devono subire modifiche- copiare i dati potrebbe significare copiare petabytes di file
● La struttura della tabella viene memorizzata nel metastore di Hive

Hive
Tabelle ordinarie: Tabelle Esterne
Tabelle ordinarie esterne:● Utilizzano dati “al di fuori” dal controllo diretto di Hive● I dati sono lasciati a disposizione di altri tool (e.g., Pig)
Quando creiamo una tabella ordinaria esterna:
● Il file importato viene lasciato nella posizione originaria
● Non viene creata nello spazio Hive alcuna cartella che rappresenta la tabella da creare
● La struttura della tabella viene memorizzata nel metastore di Hive
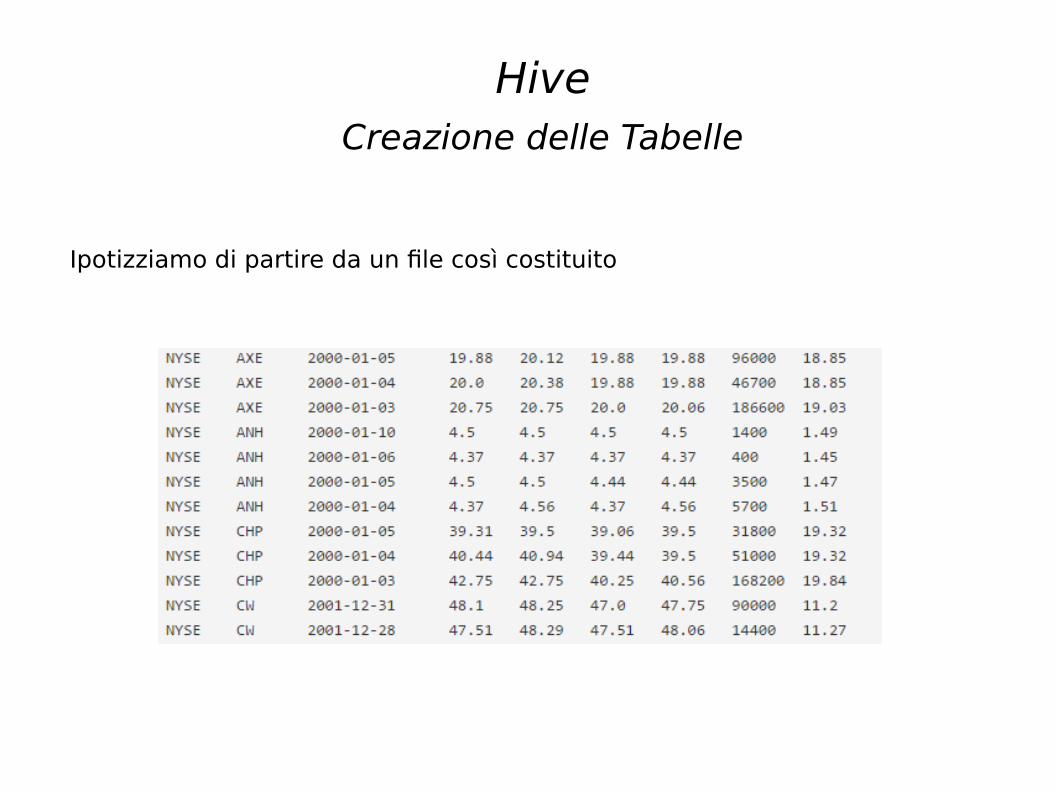
Hive
Creazione delle Tabelle
Ipotizziamo di partire da un file così costituito

Hive
Creazione della Tabella Interna
CREATE TABLE financials.nyse (exchange_col STRING,stock_symbol STRING,date STRUCT<year:INT, month:INT, day:INT>,stock_price_open FLOAT,stock_price_high FLOAT,stock_price_low FLOAT,stock_price_close FLOAT,stock_volume INT,stock_price_adj_close FLOAT
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'COLLECTION ITEMS TERMINATED BY '-'STORED AS TEXTFILE ;

Hive
Importare i dati in una Tabella Interna
Per importare i dati nella tabella interna eseguiamo:
LOAD DATA INPATH '/user/hue/nyse' OVERWRITE INTO TABLE financials.nyse;
Quindi, prima creiamo la tabella, poi inseriamo dei dati.

Hive
Creazione della Tabella Esterna e Importazione dei Dati
CREATE EXTERNAL TABLE financials.stock (exchange_col STRING,stock_symbol STRING,date STRUCT<year:INT, month:INT, day:INT>,stock_price_open FLOAT,stock_price_high FLOAT,stock_price_low FLOAT,stock_price_close FLOAT,stock_volume INT,stock_price_adj_close FLOAT
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'COLLECTION ITEMS TERMINATED BY '-'LOCATION '/user/hue/data' ; ← diciamo a Hive dove sono i dati

Hive
Cancellare una tabella
Per cancellare una tabella:
DROP TABLE IF EXISTS financials.nyse;
Il comportamento è differente nel caso si tratti di una tabella interna o esterna:
- in caso di tabella interna, viene cancellato lo schema della tabella e anche tutti i dati ad essa associati
- in caso di tabella esterna, viene cancellato lo schema della tabella ma non tutti i dati associati

Hive
Tabelle Partizionate
La tabella partizionata● Record partizionati secondo il valore di uno o più campi● Assemblata durante l'import
L'utilizzo di queste tabelle comporta tre vantaggi:
● Maggior velocità delle query che coinvolgono i capi “chiave” della partizione
● Parte dei dati non viene analizzata per elaborare la query
● Gerarchia dei dati anche per altri tool (es. Pig)
● La dimensione complessiva dei dati diminuisce
● I dati finali non contengono I valori dei campi di partizionamento
Un efficiente partizionamento dipende dalla conoscenza dei dati e dalle principali query che l'utente potrebbe lanciare

Hive
Tabella Partizionata – Tabelle interne ed esterne
Anche le tabelle partizionate possono essere create come tabelle esterne.
Rispetto alle tabelle non partizionate:
● l'importazione dei dati all'interno di una tabella partizionata comporta SEMPRE la copia dei dati nella directory di riferimento per la tabella.● Che sia interna o esterna
La cancellazione invece ha il medesimo comportamento:
● la cancellazione della tabella partizionata interna comporta la perdita dei dati;
● la cancellazione della tabella partizionata esterna preserva i dati.
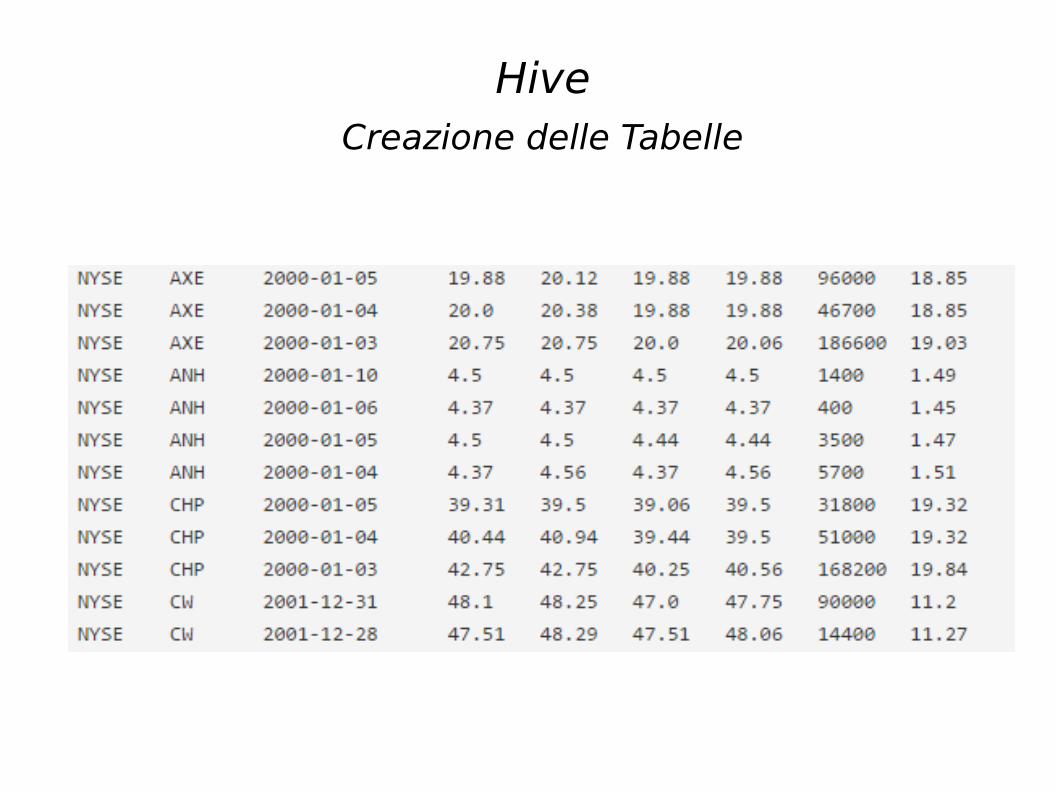
Hive
Creazione delle Tabelle

Hive
Tabella Partizionata – Dati nell'HDFS
Nel momento della scrittura dei dati Hive suddivide i dati in ingresso in un albero di cartelle su HDFS nella forma
…/ Anno / Stock Exchanges / Indice / Altri Valori
ad esempio:
…/ year=2012 / exchange_col=LSEG / stock_symbol=IBM / 000000_0...
…/ year=2013 / exchange_col=NYSE / stock_symbol=AXE / 000000_0…/ year=2013 / exchange_col=NYSE / stock_symbol=ANH / 000000_0
...
…/ year=2014 / exchange_col=NYSE / stock_symbol=ANH / 000000_0

Hive
Tabella Partizionata – Creazione
Possiamo creare la nostra nuova tabella partizionata con
CREATE TABLE financials.part (month INT,day INT,stock_price_open FLOAT,stock_price_high FLOAT,stock_price_low FLOAT,stock_price_close FLOAT,stock_volume INT,stock_price_adj_close FLOAT
)PARTITIONED BY (year INT, exchange_col STRING, stock_symbol STRING);

Hive
Tabella Partizionata – Importazione Implicita
E possiamo caricare i dati a partire dalla tabella esterna creata precedentemente e chiamata financials.stock
INSERT OVERWRITE TABLE financials.partPARTITION (year, exchange_col, stock_symbol)SELECT date.month,date.day,stock_price_open,stock_price_high,stock_price_low,stock_price_close,stock_volume,stock_price_adj_close,date.year,exchange_col,stock_symbolFROM financials.stock;
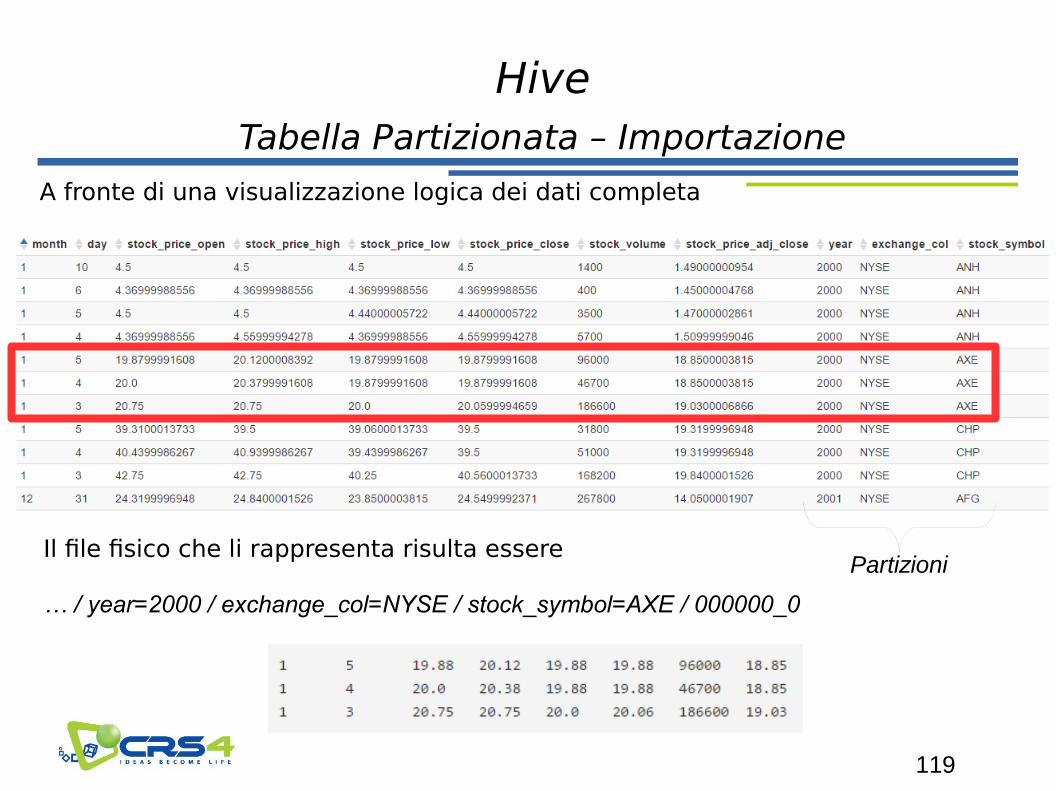
119
Hive
Tabella Partizionata – Importazione
A fronte di una visualizzazione logica dei dati completa
Il file fisico che li rappresenta risulta essere
… / year=2000 / exchange_col=NYSE / stock_symbol=AXE / 000000_0
Partizioni

Hive
Riassumendo...
● Hive di fatto è una facciata SQL posata davanti a file regolari
● Supporta select SQL, ma non è adatto per OLTP
● Particolarmente adatto per DB molto molto grandi e quasi in sola lettura
● Se I dati sono interrogabili da una singola macchina, usa un DB standard
● Lo scenario di utilizzo dev'essere:
● Accumulo di dati
● Frequentemente interrogati
● Mai, o raramente, modificati
Appunto, un data warehouse!

121
Hive
That's enough for Hive!

Pig e Hive
Conclusion
● Sia Pig che Hive facilitano l'elaborazione di dati su Hadoop
● Permettono l'espressione di operazioni ad alto livello
● Senza obbligare l'utente a specificare I dettali implementativi
● Le query girano su Hadoop
● Ereditano la sua scalabilità
● Anche la sua alta latenza
● Non ideale per query interattive, ma è nella norma per questo tipo di uso
● Sono entrambi in continuo rapido sviluppo

123
Risorse
● Vi ho inondato di informazioni!
● Se volete metterle in pratica, installate Hadoop, Pig e Hive
● Anche sulla vostra workstation o portatile
● Provate l tutorial:
● http://pig.apache.org/docs/r0.14.0/start.html#tutorial
● https://cwiki.apache.org/confluence/display/Hive/Tutorial#Tutorial-HiveTutorial
● Sono entrambi ben documentati
● Per esercitarvi, trovate dei dataset interessanti qui:
● https://github.com/hackreduce/Hackathon
● Tranquilli, non sono BigData!

124
Risorse
● Vi ho inondati di informazioni!
● Se volete metterle in pratica, installate Hadoop, Pig e Hive
● Anche sulla vostra workstation o portatile
● Provate l tutorial:
● http://pig.apache.org/docs/r0.14.0/start.html#tutorial
● https://cwiki.apache.org/confluence/display/Hive/Tutorial#Tutorial-HiveTutorial
● Sono entrambi ben documentati
● Per esercitarvi, trovate dei dataset interessanti qui:
● https://github.com/hackreduce/Hackathon
● Credits: molte di queste slide sono state preparate per il CRS4 da Maurizio Pilu e Nicola Sirena
Grazie e buon pranzo!


















