
RICCHEZZA E ISTRUZIONE (NEL MONDO)studiostat.unibocconi.it/uni/docs/Ricchezza e...
27
RICCHEZZA E ISTRUZIONE (NEL MONDO) Descrizione della base dati Il dataste considerato è tratto dal report annuale dell’UNESCO, relativo a 102 Stati, sui quali sono rilevate un certo numero di caratteristiche, alcune delle quali di natura socio-economica (ad esempio, prodotto nazionale lordo, speranze di vita, tassi di natalità e mortalità, mortalità infantile, tassi di urbanizzazione), altre relative al sistema istruzione del Paese (tra esse, la spesa pubblica per l’istruzione, il numero di individui che accedono all’istruzione superiore, la percentuale di donne nell’ambito del personale docente). Le variabili rilevate sono le seguenti: I GRUPPO (indicatori socio-economici e demografici) MACROAREA (gruppo o area socio-economica di appartenenza) POPOLAZIONE (espressa in migliaia di abitanti) DENSITA’ DI POPOLAZIONE (espressa in abitanti per chilometro quadrato) TASSO DI CRESCITA (espresso in aumento annuo percentuale della popolazione) TASSO DI NATALITA’ (espresso in nascite per 1000 abitanti) TASSO DI MORTALITA’ (espresso in morti per 1000 abitanti) TASSO DI FECONDITA’ (espresso in numero medio di figli per donna) TASSO DI URBANIZZAZIONE (espresso in percentuale degli abitanti che vivono in città) SPERANZA DI VITA MASCHILE SPERANZA DI VITA FEMMINILE MORTALITA’ INFANTILE (espresso in numero di bambini morti per 1000 nati vivi) PRODOTTO INTERNO LORDO PRO CAPITE (in dollari) II GRUPPO (indicatori istruzione ed università) TASSO DI ALFABETIZZAZIONE (espresso in percentuale di abitanti che sanno leggere e scrivere) TASSO DI ALFABETIZZAZIONE MASCHILE TASSO DI ALFABETIZZAZIONE FEMMINILE TASSO DI ISTRUZIONE SUPERIORE (espresso in iscritti a corsi universitari per 1000 abitanti) SPESE PUBBLICHE PER ISTRUZIONE (percentuale del PIL destinato a spese per istruzione) RAPPORTO STUDENTI-DOCENTI (numero di studenti per docente) PRESENZA FEMMINILE NELL’INSEGNAMENTO (percentuale di femmine tra i docenti) PATRIMONIO LIBRARIO UNIVERSITARIO (numero testi posseduti dalle biblioteche universitarie) BIBLIOTECHE UNIVERSITARIE (numero delle biblioteche universitarie) Intenti dell’analisi Ci si propone di analizzare questi dati, con l’obiettivo di investigare diversi aspetti, con particolare riguardo alle interazioni tra parametri socio-economici e culturali. L’obiettivo è duplice. Da una parte ci si propone di comprendere come le condizioni socio-economiche e demografiche di un Paese possano variare in contesti differenti e essere tra loro legate. Ad esempio, con riferimento al primo gruppo di caratteristiche, ci si chiede quanto la ricchezza sia distribuita equamente tra gli Stati in esame e all’interno di macroaree definite, e quanto il PIL, indicatore globale di ricchezza, sia legato ad alcune caratteristiche demografiche. Inoltre, è interessante comprendere quali differenze sussistano relativamente alle condizioni di vita di maschi e femmine, e come queste differenze varino al variare del gruppo di appartenenza dello Stato. Oppure, come variabili che indicano il livello di salute di uno Stato (quali la speranza di vita e la mortalità infantile) sono legate ad indicatori globali di ricchezza. i
Transcript of RICCHEZZA E ISTRUZIONE (NEL MONDO)studiostat.unibocconi.it/uni/docs/Ricchezza e...

RICCHEZZA E ISTRUZIONE (NEL MONDO) Descrizione della base dati Il dataste considerato è tratto dal report annuale dell’UNESCO, relativo a 102 Stati, sui quali sono rilevate un certo numero di caratteristiche, alcune delle quali di natura socio-economica (ad esempio, prodotto nazionale lordo, speranze di vita, tassi di natalità e mortalità, mortalità infantile, tassi di urbanizzazione), altre relative al sistema istruzione del Paese (tra esse, la spesa pubblica per l’istruzione, il numero di individui che accedono all’istruzione superiore, la percentuale di donne nell’ambito del personale docente). Le variabili rilevate sono le seguenti: I GRUPPO (indicatori socio-economici e demografici) MACROAREA (gruppo o area socio-economica di appartenenza) POPOLAZIONE (espressa in migliaia di abitanti) DENSITA’ DI POPOLAZIONE (espressa in abitanti per chilometro quadrato) TASSO DI CRESCITA (espresso in aumento annuo percentuale della popolazione) TASSO DI NATALITA’ (espresso in nascite per 1000 abitanti) TASSO DI MORTALITA’ (espresso in morti per 1000 abitanti) TASSO DI FECONDITA’ (espresso in numero medio di figli per donna) TASSO DI URBANIZZAZIONE (espresso in percentuale degli abitanti che vivono in città) SPERANZA DI VITA MASCHILE SPERANZA DI VITA FEMMINILE MORTALITA’ INFANTILE (espresso in numero di bambini morti per 1000 nati vivi) PRODOTTO INTERNO LORDO PRO CAPITE (in dollari) II GRUPPO (indicatori istruzione ed università) TASSO DI ALFABETIZZAZIONE (espresso in percentuale di abitanti che sanno leggere e scrivere) TASSO DI ALFABETIZZAZIONE MASCHILE TASSO DI ALFABETIZZAZIONE FEMMINILE TASSO DI ISTRUZIONE SUPERIORE (espresso in iscritti a corsi universitari per 1000 abitanti) SPESE PUBBLICHE PER ISTRUZIONE (percentuale del PIL destinato a spese per istruzione) RAPPORTO STUDENTI-DOCENTI (numero di studenti per docente) PRESENZA FEMMINILE NELL’INSEGNAMENTO (percentuale di femmine tra i docenti) PATRIMONIO LIBRARIO UNIVERSITARIO (numero testi posseduti dalle biblioteche universitarie) BIBLIOTECHE UNIVERSITARIE (numero delle biblioteche universitarie) Intenti dell’analisi Ci si propone di analizzare questi dati, con l’obiettivo di investigare diversi aspetti, con particolare riguardo alle interazioni tra parametri socio-economici e culturali. L’obiettivo è duplice. Da una parte ci si propone di comprendere come le condizioni socio-economiche e demografiche di un Paese possano variare in contesti differenti e essere tra loro legate. Ad esempio, con riferimento al primo gruppo di caratteristiche, ci si chiede quanto la ricchezza sia distribuita equamente tra gli Stati in esame e all’interno di macroaree definite, e quanto il PIL, indicatore globale di ricchezza, sia legato ad alcune caratteristiche demografiche. Inoltre, è interessante comprendere quali differenze sussistano relativamente alle condizioni di vita di maschi e femmine, e come queste differenze varino al variare del gruppo di appartenenza dello Stato. Oppure, come variabili che indicano il livello di salute di uno Stato (quali la speranza di vita e la mortalità infantile) sono legate ad indicatori globali di ricchezza.
i

Per ciò che riguarda il secondo gruppo di variabili, si è interessati a valutare se e come l’accesso e la qualità dell’istruzione siano legati ad indicatori di ricchezza o ad altre variabili di tipo socio-economico o demografico. In particolare, il numero di studenti per docente può essere interpretato come indicatore di efficienza del sistema istruzione e di buone condizioni sociali? La presenza femminile nell’insegnamento è legata ad altri indicatori della condizione femminile nel Paese? In particolare proponiamo una serie di domande, alcune delle quali saranno analizzate nel seguito. L’obiettivo è quello di rispondere ad esse traducendo la questione in termini statistici, usando gli strumenti più idonei, rilevando problemi o difficoltà di interpretazione nei risultati.
1. Com’è distribuita la ricchezza tra i vari paesi? Come varia la distribuzione della ricchezza tra le diverse macroaree?
Per rispondere a questa domanda, si possono in primo luogo determinare rappresentazioni grafiche opportune per il PIL, quindi calcolare indicatori di variabilità e concentrazione per lo stesso carattere. Inoltre, un’analisi stratificata, per macroarea, si può effettuare utilizzando le distribuzioni subordinate e le corrispondenti misure di sintesi. Concetti richiamati e strumenti statistici utilizzati: Misure di sintesi (posizione e dispersione). Rappresentazioni grafiche: box-plot; istogramma (scelta delle classi); curva di concentrazione, indice di concentrazione di Gini. Analisi stratificata per macroarea: box-plot affiancati, misure di sintesi subordinate. I valori estremi
2. Come varia tra i Paesi la speranza di vita alla nascita? Ci sono caratteristiche diverse tra le distribuzioni delle speranze di vita dei maschi e delle femmine?
Anche in questo caso, è opportuno determinare e confrontare indicatori di sintesi per le due variabili in esame, anche nell’ambito di ciascuna macroarea. Concetti richiamati e strumenti statistici utilizzati: Misure di sintesi (posizione e dispersione). Analisi delle relazioni tra due caratteri: diagramma di dispersione; coefficiente di correlazione (non-robustezza). Analisi stratificata per macroarea: medie condizionate; coefficiente di variazione condizionati
3. I tassi di natalità e mortalità sono tra loro associati? In che modo? A quali altre variabili sono significativamente legati?
Per valutare l’associazione tra le due variabili, si possono determinare opportuni indici (coefficiente di correlazione lineare) e riportare il grafico di dispersione. Inoltre, si può discutere la scelta della curva che meglio descrive la dipendenza tra le due variabili. Concetti richiamati e strumenti statistici utilizzati: Analisi delle relazioni tra due caratteri: diagramma di dispersione; coefficiente di correlazione (non-robustezza); misure di concordanza – tau di Kendall e indice di Spearman. Interpolazione di una nuovola di punti (previsione/spiegazione di un carattere in funzione di un altro): retta di regressione, indice di determinazione, funzioni polinomiali
4. Come cresce (o decresce) la popolazione? Come variano gli indicatori d’incremento demografico nelle diverse macroaree?
Oltre ad analizzare singolarmente, mediante la determinazione di misure di sintesi e grafici, le variabili “Tasso d’incremento demografico” e “Tasso di fecondità”, si possono effettuare analisi di associazione tra esse e discutere la regressione di queste variabili sul PIL. Concetti richiamati e strumenti statistici utilizzati: Analisi stratificata per macroarea: medie e mediane condizionate. Interpolazione di una nuovola di punti (previsione/spiegazione di un carattere in funzione di un altro): retta di regressione, indice di determinazione, funzioni polinomiali; valutazione dell’impatto della variabile esplicativa.
ii

5. L’accesso all’istruzione è simile nelle varie macroaree? A quali altre variabili socio-economiche sono legati indicatori quali tassi di alfabetizzazione e accesso all’istruzione superiore? Sono tra loro associati questi due indicatori? In che modo? Vi sono differenze rilevanti tra maschi e femmine?
Concetti richiamati e strumenti statistici utilizzati: Misure di sintesi (posizione e dispersione). Valori mancanti. Analisi stratificata per macroarea: medie condizionate. Analisi delle relazioni tra due caratteri: diagramma di dispersione; coefficiente di correlazione (non-robustezza); misure di concordanza – tau di Kendall e indice di Spearman. Interpolazione di una nuovola di punti (previsione/spiegazione di un carattere in funzione di un altro): retta di regressione, indice di determinazione, funzioni esponenziali. Analisi stratificata per macroarea dei coefficienti di correlazione
6. Cosa si può dire, in generale, sulla differenza tra condizione maschile e condizione femminile rispetto ai diversi aspetti considerati nell’analisi?
Le differenze tra tassi di alfabetizzazione e tra attese di vita forniscono indicazioni sulla condizione femminile. La variazione di queste differenze al variare del PIL ed al variare della macroarea informano su quanto la condizione femminile sia legata al livello di benessere complessivo del paese. Concetti richiamati e strumenti statistici utilizzati: Misure di sintesi (posizione e dispersione). Valori mancanti. Rappresentazioni grafiche: box-plot. Analisi delle relazioni tra due caratteri: diagramma di dispersione; coefficiente di correlazione (non-robustezza); misure di concordanza – tau di Kendall e indice di Spearman. Interpolazione di una nuovola di punti (previsione/spiegazione di un carattere in funzione di un altro): retta di regressione, indice di determinazione, split del modello
7. Le spese che lo Stato destina all’istruzione (spesa in percentuale sul PIL) sono positivamente associate alla ricchezza del Paese (descritta dallo stesso PIL)? Il tipo e grado di associazione è diverso nelle varie macroaree?
L’analisi, anche stratificata, della distribuzione della spesa destinata all’istruzione è il primo passo. Anche in questo caso, la regressione di questa variabile su altre variabili relative alla situazione complessiva di benessere del paese, come il PIL, forniscono informazioni sull’interdipendenza di istruzione e benessere. Concetti richiamati e strumenti statistici utilizzati: Misure di sintesi (posizione e dispersione). Valori mancanti. Rappresentazioni grafiche: box-plot, istogramma. Analisi stratificata per macroarea: box plot affiancati. Interpolazione di una nuovola di punti (previsione/spiegazione di un carattere in funzione di un altro): retta di regressione, indice di determinazione
Altre domande di interesse:
Il tasso di urbanizzazione varia significativamente nelle diverse macroaree? E’ direttamente legato ad altre caratteristiche socio-economiche? Come varia al variare della popolazione?
La percentuale di docenti di sesso femminile è legata ad altri indicatori della condizione femminile, già descritti in precedenza? Come ed in che misura?
Un indicatore di efficienza del sistema istruzione potrebbe essere fornito dal legame tra spese pubbliche per istruzione e numero di studenti che usufruiscono dell’istruzione terziaria. E’ effettivamente così? Cosa si può dedurre da questa analisi?
Il numero di studenti per docente è, a sua volta, un indicatore di efficienza e bontà del sistema istruzione? Perché ed in che misura?
iii

Alcune indicazioni per la lettura di questo documento: - breve spiegazione se una parola è evidenziata in verde, questo simbolo alla fine o all’inizio della riga in cui si trova la parola contiene una brevissima spiegazione del concetto statistico. Per leggere il contenuto del commento basta toccare il simbolo con il mouse. - [Commento o descrizione più dettagliata di una tecnica] una frase evidenziata in giallo rimanda ad un documento che contiene alcune considerazioni o metodologiche o sulle modalità di utilizzo e di interpretazione degli strumenti statistici cui si fa riferimento. Per aprire il documento, selezionate la
nella barra del menu di Adobe:
Cliccando con il mouse sulla frase, si aprirà il documento. NB: i richiami metodologici cui si rimanda nel testo (ordinati per argomento) sono tutti contenuti in questo documenti [Richiami metodologici]
iv

1. Come è distribuita la ricchezza tra i vari paesi? Come varia la distribuzione della ricchezza tra le diverse macroaree? La variabile più idonea a descrivere la ricchezza di un Paese è ovviamente il Prodotto Interno Lordo (pro capite). Una prima analisi elementare1 per comprendere come la ricchezza sia distribuita nel mondo si può effettuare rilevando alcuni indicatori sintetici (di posizione e variabilità) di questa variabile, quali media aritmetica, mediana e quartili, massimo e minimo, scarto quadratico medio (o deviazione standard).
Media 6006,108 Mediana 2912 Moda 1500 Varianza 43852813 Deviazione standard 6622,146 Minimo 122 Massimo 23474 Somma 612623 Conteggio 102
Dalla tabella (ottenuta con EXCEL) si evince che il prodotto interno lordo pro capite è, in media, 6006.11 dollari, mentre la sua mediana è pari a 2912 dollari; osservando anche i valori dei quartili e del minimo e massimo, si può concludere che la distribuzione del prodotto interno lordo è asimmetrica, più precisamente obliqua destra. Questi valori sono riassunti in un grafico, il boxplot, che, fornendo una rappresentazione sintetica della forma della distribuzione [Box plot: una rappresentazione sintetica della distribuzione] conferma le considerazioni che su essi si basano. Il boxplot2 ha l’aspetto seguente:
0
5000
10000
15000
20000
25000
PIL
Massimo3° QuartileMediana1° QuartileMinimo
Se il box-plot riesce a dare una rappresentazione sintetica della distribuzione, l’istogramma permette invece un maggior dettaglio. Uno dei problemi principali nel costruire questo tipo di grafico è però la scelta delle classi da utilizzare nella rappresentazione, sia per quanto riguarda il numero di classi sia per quanto riguarda gli estremi delle classi stesse. Un semplice criterio consiste nell’utilizzare classi di uguale ampiezza. In questo caso però, il box plot evidenzia una distribuzione fortemente asimmetrica, e la scelta di questo tipo di classi non è indicata.
1 Risultato ottenuto utilizzando Excel (Stumenti, Analisi dei dati, Statistica descrittiva). 2 Risultato ottenuto utilizzando EXCEL (macro Stat4038).
1
Università Luigi Bocconi
Quartili: sono 3 indicatori, calcolabili per dati quantitativi o qualitativi ordinali. Considerata la successione dei valori osservati disposti in ordine crescente, i quartili indicano i tre punti che dividono la distribuzione in quattro parti uguali. Ad esempio il 1° quartile tale che il 25% della popolazione presenta un valore al di sotto e il restante 75% al di sopra di esso. Il 2° quartile è la mediana.
Università Luigi Bocconi
Media: indicatore di tendenza centrale, per dati quantitativi. Nota anche come centro di ordine 2, essendo il punto più “vicino” ai dati, rispetto alla distanza quadratica. Molto sensibile a valori estremi, è quindi da usare con cautela nel caso in cui vi siano, per il carattere considerato, valori isolati molto elevati o molto bassi.
Università Luigi Bocconi
Mediana: indicatore tendenza (o posizione) centrale, per dati quantitativi oppure qualitativi ordinali. E’ il valore che, nella successione ordinata dei dati occupa la posizione centrale. Quindi il 50% delle osservazioni hanno un valore inferiore e il 50% un valore superiore alla mediana. Quando utilizzata per dati quantitativi, è nota anche come centro di ordine 1, in quanto risulta il punto più “vicino” ai dati, rispetto alla distanza usuale (euclidea). E’ un indicatore di posizione centrale “robusto” rispetto alla presenza di dati eccezionali, ovvero risente poco della presenza di valori anomali. Per questo motivo è preferibile alla media aritmetica per indicare la tendenza centrale di distribuzioni con queste caratteristiche.
Università Luigi Bocconi
Varianza: misura la dispersione di dati quantitativi intorno alla loro media. E’ la media degli scarti quadratici dalla media aritmetica. E’ nulla se e solo se i dati sono tutti coincidenti, altrimenti è positiva, tanto più grande quanto più i dati sono dispersi. Ha come unità di misura il quadrato dell’unità di misura del carattere e, anche per questo motivo, non è opportuno utilizzarla per confrontare la variabilità tra caratteri con unità di misura differente. E’ una misura poco robusta: tende ad accentuare gli scarti elevati dalla media. Lo scarto quadratico medio, detto anche deviazione standard, è la radice quadrata della varianza.
Piccarreta
Note
Moda: è la modalità cui compete la più elevata frequenza relativa. E’ quindi la modalità che caratterizza la maggior parte delle unità statistiche. E’ una sintesi efficace quando la frequenza che le compete è elevata. E’ sensato calcolarla solo per caratteri che assumono un numero contenuto di modalità (quindi, non per caratteri continui, per i quali ogni unità statistica presenta una modalità diversa da tutte le altre).
Piccarreta
Note
Istogramma: grafico che riporta la distribuzione delle frequenze di un carattere quantitativo raggruppando le modalità in intervalli adiacenti. Nella sua costruzione è fondamentale la scelta degli intervalli (il loro numero, i loro estremi). Scelte semplici e convenzionali, ma non necessariamente ottimali per evidenziare le caratteristiche salienti della distribuzione, sono intervalli di uguale ampiezza oppure intervalli di uguale frequenza (con ampiezze generalmente diverse). Scelte diverse possono portare per gli stessi dati a istogrammi con caratteristiche anche molto diverse. Per la scelta del numero degli intervalli, occorre un compromesso tra sintesi e dettaglio: un numero troppo elevato di intervalli fornisce ovviamente maggiore dettaglio ma sintetizza meno la distribuzione, al contrario di ciò che accade se si sceglie un numero ridotto di intervalli.
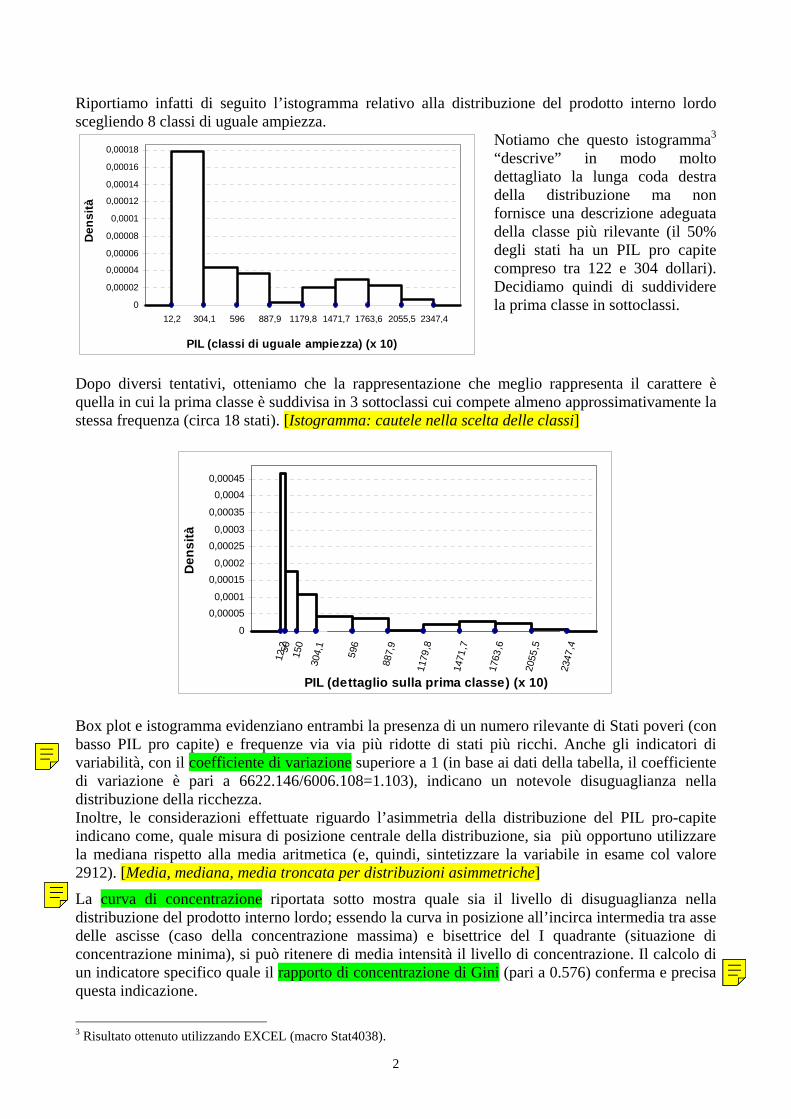
Riportiamo infatti di seguito l’istogramma relativo alla distribuzione del prodotto interno lordo scegliendo 8 classi di uguale ampiezza.
12,2 304,1 596 887,9 1179,8 1471,7 1763,6 2055,5 2347,40
0,00002
0,00004
0,00006
0,00008
0,0001
0,00012
0,00014
0,00016
0,00018
PIL (classi di uguale ampiezza) (x 10)
Den
sità
Notiamo che questo istogramma3 “descrive” in modo molto dettagliato la lunga coda destra della distribuzione ma non fornisce una descrizione adeguata della classe più rilevante (il 50% degli stati ha un PIL pro capite compreso tra 122 e 304 dollari). Decidiamo quindi di suddividere la prima classe in sottoclassi.
Dopo diversi tentativi, otteniamo che la rappresentazione che meglio rappresenta il carattere è quella in cui la prima classe è suddivisa in 3 sottoclassi cui compete almeno approssimativamente la stessa frequenza (circa 18 stati). [Istogramma: cautele nella scelta delle classi]
12,2 50 150
304,
1
596
887,
9
1179
,8
1471
,7
1763
,6
2055
,5
2347
,4
0
0,000050,0001
0,000150,0002
0,000250,0003
0,00035
0,00040,00045
PIL (dettaglio sulla prima classe) (x 10)
Den
sità
Box plot e istogramma evidenziano entrambi la presenza di un numero rilevante di Stati poveri (con basso PIL pro capite) e frequenze via via più ridotte di stati più ricchi. Anche gli indicatori di variabilità, con il coefficiente di variazione superiore a 1 (in base ai dati della tabella, il coefficiente di variazione è pari a 6622.146/6006.108=1.103), indicano un notevole disuguaglianza nella distribuzione della ricchezza. Inoltre, le considerazioni effettuate riguardo l’asimmetria della distribuzione del PIL pro-capite indicano come, quale misura di posizione centrale della distribuzione, sia più opportuno utilizzare la mediana rispetto alla media aritmetica (e, quindi, sintetizzare la variabile in esame col valore 2912). [Media, mediana, media troncata per distribuzioni asimmetriche]
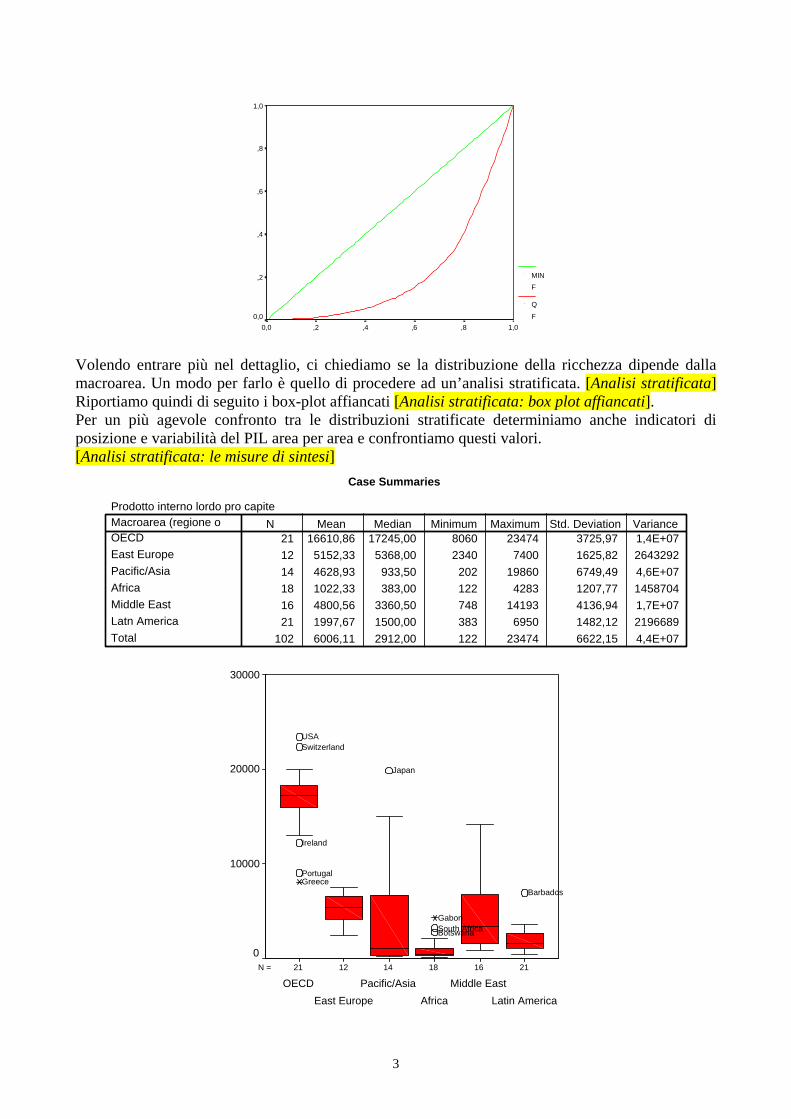
La curva di concentrazione riportata sotto mostra quale sia il livello di disuguaglianza nella distribuzione del prodotto interno lordo; essendo la curva in posizione all’incirca intermedia tra asse delle ascisse (caso della concentrazione massima) e bisettrice del I quadrante (situazione di concentrazione minima), si può ritenere di media intensità il livello di concentrazione. Il calcolo di un indicatore specifico quale il rapporto di concentrazione di Gini (pari a 0.576) conferma e precisa questa indicazione.
3 Risultato ottenuto utilizzando EXCEL (macro Stat4038).
2
Università Luigi Bocconi
Coefficiente di variazione: è ottenuto dividendo lo scarto quadratico medio (o deviazione standard) per la media della distribuzione. Tale operazione viene effettuata per depurare la deviazione standard dall’unità di misura.
Università Luigi Bocconi
Curva di concentrazione: grafico che descrive la concentrazione di un carattere trasferibile e con modalità non negative. La curva di concentrazione è sempre contenuta nella porzione di piano delimitata in basso dal segmento corrispondente all’intervallo [0,1] dell’asse delle ascisse ed in alto dalla bisettrice del I quadrante, è sempre convessa e non decrescente. Nel caso di minima concentrazione o equidistribuzione (tutte le unità hanno la stessa quantità di carattere) la curva coincide con la bisettrice, nel caso di massima concentrazione (l’intero ammontare del carattere è detenuto da un’unica unità) coincide con il segmento descritto sopra. Tanto più la curva è vicina alla bisettrice, tanto più la concentrazione è bassa.
Università Luigi Bocconi
Rapporto di Gini: è un indicatore sintetico del livello della concentrazione di un carattere trasferibile e con modalità non negative. Può assumere valori compresi tra 0 ed 1, estremi inclusi. Vale 0 se e solo se la concentrazione è nulla, ovvero vi è equidistribuzione (tutte le unità della popolazione hanno la stessa quantità di carattere), mentre vale 1 nel caso di concentrazione massima (un’unica unità detiene l’intero ammontare del carattere).
1,0,8,6,4,20,0
1,0
,8
,6
,4
,2
0,0
MINF
Q
F
Volendo entrare più nel dettaglio, ci chiediamo se la distribuzione della ricchezza dipende dalla macroarea. Un modo per farlo è quello di procedere ad un’analisi stratificata. [Analisi stratificata] Riportiamo quindi di seguito i box-plot affiancati [Analisi stratificata: box plot affiancati]. Per un più agevole confronto tra le distribuzioni stratificate determiniamo anche indicatori di posizione e variabilità del PIL area per area e confrontiamo questi valori. [Analisi stratificata: le misure di sintesi]
Case Summaries
Prodotto interno lordo pro capite
21 16610,86 17245,00 8060 23474 3725,97 1,4E+0712 5152,33 5368,00 2340 7400 1625,82 264329214 4628,93 933,50 202 19860 6749,49 4,6E+0718 1022,33 383,00 122 4283 1207,77 145870416 4800,56 3360,50 748 14193 4136,94 1,7E+0721 1997,67 1500,00 383 6950 1482,12 2196689
102 6006,11 2912,00 122 23474 6622,15 4,4E+07
Macroarea (regione oOECDEast EuropePacific/AsiaAfricaMiddle EastLatn AmericaTotal
N Mean Median Minimum Maximum Std. Deviation Variance
211618141221N =
Latin AmericaMiddle East
AfricaPacific/Asia
East EuropeOECD
30000
20000
10000
0
Barbados
BotswanaSouth AfricaGabon
Japan
Ireland
PortugalGreece
SwitzerlandUSA
3

La tabella ed il grafico mettono in luce alcune caratteristiche interessanti; in primo luogo, ovviamente, si osserva come i Paesi dell’OECD (ovvero, i paesi dell’Europa occidentale, del nord America, l’Australia e la Nuova Zelanda) abbiano livelli di ricchezza nettamente superiori a quelli degli altri 5 gruppi (le medie e mediane lo indicano chiaramente). In particolare, i valori più bassi del PIL pro capite per i paesi di questa area (osservati per Grecia, Portogallo e Irlanda) risultano comunque superiori ai valori massimi osservati per altre macroaree (Europa dell’est, Africa e America Latina). Inoltre, la distribuzione del PIL è omogenea (scarsamente variabile) e sostanzialmente simmetrica in alcuni gruppi, mentre in altri no. Ad esempio, nel primo gruppo (paesi OECD) c’è una sostanziale simmetria (lo si evince dai valori di media, mediana, quartili e dal boxplot) ed una non elevata variabilità (il coefficiente di variazione, pari a 3725.9/16610.86=0.224, è di molto inferiore a quello generale che, come già osservato, vale 1.103), il che indica buona omogeneità, rispetto alla ricchezza, dei paesi di questo gruppo. [Coefficiente di variazione e scarto quadratico medio] Al contrario, il terzo gruppo (Asia-Pacifico) presenta forte variabilità e forte asimmetria (verso destra): in un gruppo con la gran parte dei paesi sostanzialmente poveri, vi sono pochi stati con PIL elevato (in particolare, il Giappone viene identificato come outlier nel grafico). [Valori estremi e outliers]
4

2. Come varia tra i Paesi la speranza di vita alla nascita? Ci sono caratteristiche diverse tra le distribuzioni delle speranze di vita dei maschi e delle femmine? La speranza di vita alla nascita indica sostanzialmente quanti anni un nato può attendersi di vivere, se le condizioni socio-economiche e di benessere sanitario rimanessero invariate.
Iniziamo col fornire indicatori di sintesi per le variabili d’interesse (in questo caso le speranze di vita dei maschi e delle femmine):
SPERANZA FEMMINE SPERANZA MASCHI Media 70,55882 65,20588 Mediana 74 67 Moda 75 73 Varianza 103,1599 81,80868 Deviazione standard 10,15676 9,044815 Minimo 43 41 Massimo 82 76 Somma 7197 6651
Le tabelle evidenziano come, mediamente, le speranze di vita siano superiori per le femmine che per i maschi, e che, allo stesso tempo, ci sia una certa variabilità tra Paesi. Se a questo punto rappresentiamo in un grafico di dispersione i valori di speranza di vita per i maschi e femmine per i Paesi osservati, ecco che altri elementi vengono in luce.
20
30
40
50
60
70
80
90
20 30 40 50 60 70 80 90
AVF
AVM
Innanzi tutto, vediamo che le coppie di valori osservati giacciono tutti sotto la bisettrice del primo quadrante: il fatto che la speranza di vita delle femmine sia più alta della speranza di vita dei maschi non è vero solo “in media”, ma vale per tutti i paesi osservati. i due caratteri sono associati in modo diretto (concordante) e quasi perfettamente lineare: la cosa è confermata dal calcolo del coefficiente di correlazione lineare, il cui valore, come si vede dalla tabella che segue, è 0.981.
AVM AVF AVM 1 AVF 0,98144 1
Si osservi che l’assenza di outliers nella distribuzione congiunta delle variabili AVM e AVF e le caratteristiche del grafico (che mostra, come già detto, una quasi perfetta linearità) indicano quanto il valore del coefficiente di correlazione lineare sia affidabile. [Cautele nella valutazione del coefficiente di correlazione lineare e di determinazione] Questa sostanziale concordanza tra le speranze di vita maschili e femminili è assolutamente comprensibile (e ce l’aspettavamo!): la speranza di vita è in un certo senso un indicatore delle
5
Università Luigi Bocconi
Diagramma di dispersione: noto anche come “scatterplot”, è una rappresentazione grafica per coppie di caratteri quantitativi, costruita semplicemente riportando in un piano cartesiano tutte le coppie di modalità (la prima, relativa al primo carattere, in ascissa, la seconda in ordinata) rilevate sulle varie unità del collettivo in esame; appare quindi come una “nuvola” di punti. Rappresenta una prima, ma fondamentale, descrizione di come sono congiuntamente distribuiti i due caratteri e quindi, in particolare, di quale sia il tipo ed il grado di associazione tra essi. Ad esempio, è immediato rilevare l’eventuale linearità nella associazione (i punti si distribuiscono attorno ad una retta obliqua del piano), oppure un’associazione di tipo non lineare (la nuvola di punti ha forma di curva, ad esempio logaritmica o polinomiale). Al contrario, nuvole di punti senza alcun andamento particolare (distribuiti in maniera “casuale” nel piano) indicano scarsa associazione tra i caratteri. Inoltre, il grafico di dispersione permette di rilevare facilmente ( ed eventualmente di identificare) eventuali outliers (osservazioni eccezionali).
Università Luigi Bocconi
Coefficiente di correlazione lineare: indicatore (relativo) del livello e del verso dell’associazione lineare tra due caratteri quantitativi. Può assumere valori compresi tra –1 e 1 (estremi inclusi). Valori positivi indicano relazione diretta (le coppie di modalità dei due caratteri tendono a concentrarsi intorno ad una retta di pendenza positiva), valori negativi associazione relazione inversa. Quanto più il coefficiente di correlazione lineare, in valore assoluto, è vicino a 1, tanto più è elevato il grado di associazione lineare; nel caso in cui il suo valore è 1 (–1), l’associazione lineare è perfetta e i punti del grafico di dispersione corrispondente sono tutti allineati su una retta con coefficiente angolare positivo (rispettivamente negativo). Un valore del coefficiente di correlazione lineare pari a 0 non indica mancanza di associazione tra i due caratteri, ma mancanza di associazione lineare; potrebbero cioè essere presenti altri tipi di legame. E’ un indicatore particolarmente sensibile alla presenza di coppie di valori anomali
Piccarreta
Note
Media: indicatore di tendenza centrale, per dati quantitativi. Nota anche come centro di ordine 2, essendo il punto più “vicino” ai dati, rispetto alla distanza quadratica. Molto sensibile a valori estremi, è quindi da usare con cautela nel caso in cui vi siano, per il carattere considerato, valori isolati molto elevati o molto bassi.
Piccarreta
Note
Mediana: indicatore di tendenza (o posizione) centrale, per dati quantitativi oppure qualitativi ordinali. E’ il valore che, nella successione ordinata dei dati occupa la posizione centrale. Quindi il 50% delle osservazioni hanno un valore inferiore e il 50% un valore superiore alla mediana. Quando utilizzata per dati quantitativi, è nota anche come centro di ordine 1, in quanto risulta il punto più “vicino” ai dati, rispetto alla distanza usuale (euclidea). E’ un indicatore di posizione centrale “robusto” rispetto alla presenza di dati eccezionali, ovvero risente poco della presenza di valori anomali. Per questo motivo è preferibile alla media aritmetica per indicare la tendenza centrale di distribuzioni con queste caratteristiche.
Piccarreta
Note
Moda: è la modalità cui compete la più elevata frequenza relativa. E’ quindi la modalità che caratterizza la maggior parte delle unità statistiche. E’ una sintesi efficace quando la frequenza che le compete è elevata. E’ sensato calcolarla solo per caratteri che assumono un numero contenuto di modalità (quindi, non per caratteri continui, per i quali ogni unità statistica presenta una modalità diversa da tutte le altre).
Piccarreta
Note
Varianza: misura la dispersione di dati quantitativi intorno alla loro media. E’ la media degli scarti quadratici dalla media aritmetica. E’ nulla se e solo se i dati sono tutti coincidenti, altrimenti è positiva, tanto più grande quanto più i dati sono dispersi. Ha come unità di misura il quadrato dell’unità di misura del carattere e, anche per questo motivo, non è opportuno utilizzarla per confrontare la variabilità tra caratteri con unità di misura differente. E’ una misura poco robusta: tende ad accentuare gli scarti elevati dalla media. Lo scarto quadratico medio, detto anche deviazione standard, è la radice quadrata della varianza.
Piccarreta
Note
Deviazione standard: Lo scarto quadratico medio, detto anche deviazione standard, è la radice quadrata della varianza.
Piccarreta
Note
outliers (o valori anomali): Nel caso bivariato definiamo anomala un’osservazione che presenta una coppia di modalità che nel diagramma di dispersione è in una posizione poco coerente con l’andamento generale della nuvola dei punti. Non è detto che una coppia anomala di modalità sia caratterizzata da due modalità anomale a livello marginale.
condizioni di vita del Paese. Quindi, ci possiamo attendere che dove le condizioni di vita peggiorano per i maschi, questo avvenga anche per le femmine e viceversa.
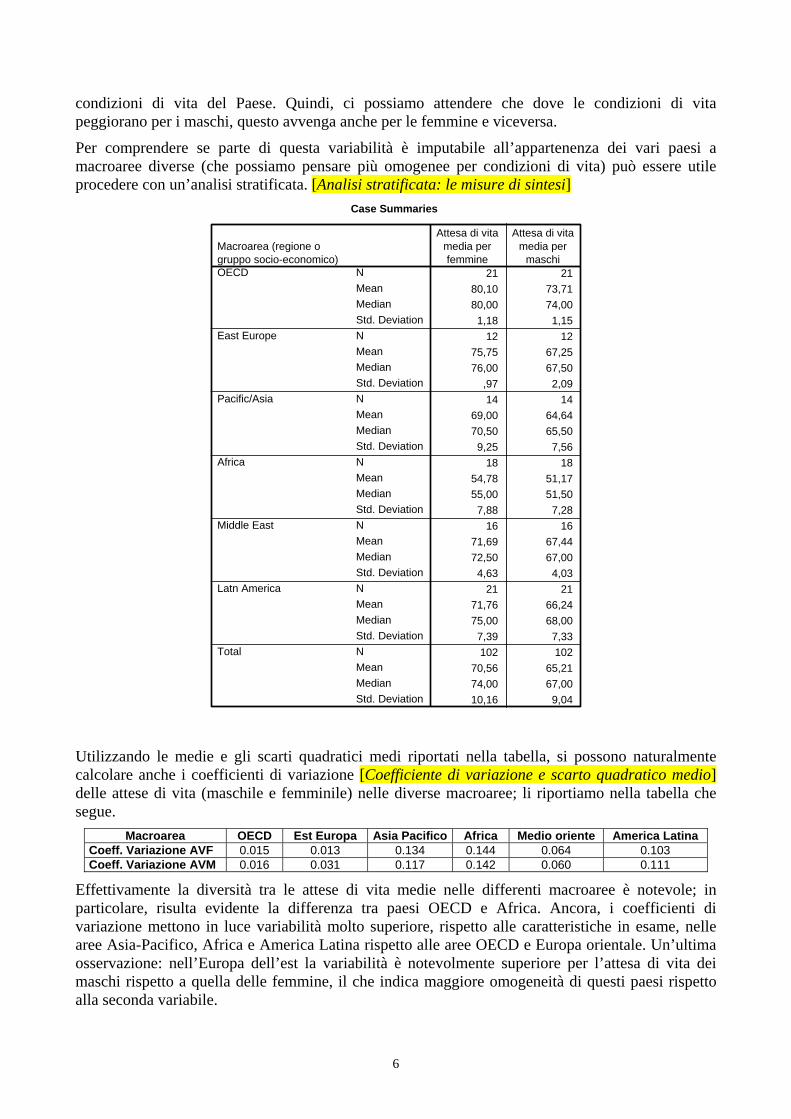
Per comprendere se parte di questa variabilità è imputabile all’appartenenza dei vari paesi a macroaree diverse (che possiamo pensare più omogenee per condizioni di vita) può essere utile procedere con un’analisi stratificata. [Analisi stratificata: le misure di sintesi]
Case Summaries
21 2180,10 73,7180,00 74,001,18 1,15
12 1275,75 67,2576,00 67,50
,97 2,0914 14
69,00 64,6470,50 65,509,25 7,56
18 1854,78 51,1755,00 51,507,88 7,28
16 1671,69 67,4472,50 67,004,63 4,03
21 2171,76 66,2475,00 68,007,39 7,33102 102
70,56 65,2174,00 67,0010,16 9,04
NMeanMedianStd. DeviationNMeanMedianStd. DeviationNMeanMedianStd. DeviationNMeanMedianStd. DeviationNMeanMedianStd. DeviationNMeanMedianStd. DeviationNMeanMedianStd. Deviation
Macroarea (regione ogruppo socio-economico)OECD
East Europe
Pacific/Asia
Africa
Middle East
Latn America
Total
Attesa di vitamedia perfemmine
Attesa di vitamedia per
maschi
Utilizzando le medie e gli scarti quadratici medi riportati nella tabella, si possono naturalmente calcolare anche i coefficienti di variazione [Coefficiente di variazione e scarto quadratico medio] delle attese di vita (maschile e femminile) nelle diverse macroaree; li riportiamo nella tabella che segue.
Macroarea OECD Est Europa Asia Pacifico Africa Medio oriente America Latina Coeff. Variazione AVF 0.015 0.013 0.134 0.144 0.064 0.103 Coeff. Variazione AVM 0.016 0.031 0.117 0.142 0.060 0.111
Effettivamente la diversità tra le attese di vita medie nelle differenti macroaree è notevole; in particolare, risulta evidente la differenza tra paesi OECD e Africa. Ancora, i coefficienti di variazione mettono in luce variabilità molto superiore, rispetto alle caratteristiche in esame, nelle aree Asia-Pacifico, Africa e America Latina rispetto alle aree OECD e Europa orientale. Un’ultima osservazione: nell’Europa dell’est la variabilità è notevolmente superiore per l’attesa di vita dei maschi rispetto a quella delle femmine, il che indica maggiore omogeneità di questi paesi rispetto alla seconda variabile.
6
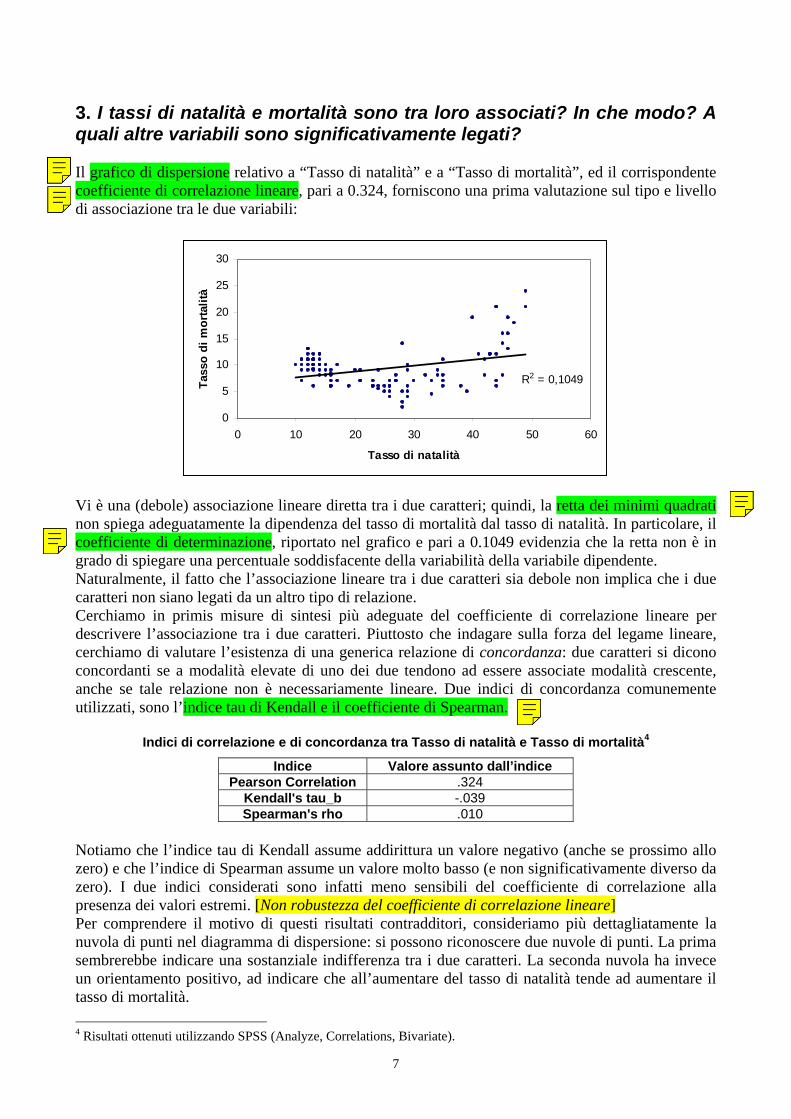
3. I tassi di natalità e mortalità sono tra loro associati? In che modo? A quali altre variabili sono significativamente legati? Il grafico di dispersione relativo a “Tasso di natalità” e a “Tasso di mortalità”, ed il corrispondente coefficiente di correlazione lineare, pari a 0.324, forniscono una prima valutazione sul tipo e livello di associazione tra le due variabili:
R2 = 0,1049
0
5
10
15
20
25
30
0 10 20 30 40 50 6
Tasso di natalità
Tass
o di
mor
talit
à
0
Vi è una (debole) associazione lineare diretta tra i due caratteri; quindi, la retta dei minimi quadrati non spiega adeguatamente la dipendenza del tasso di mortalità dal tasso di natalità. In particolare, il coefficiente di determinazione, riportato nel grafico e pari a 0.1049 evidenzia che la retta non è in grado di spiegare una percentuale soddisfacente della variabilità della variabile dipendente. Naturalmente, il fatto che l’associazione lineare tra i due caratteri sia debole non implica che i due caratteri non siano legati da un altro tipo di relazione. Cerchiamo in primis misure di sintesi più adeguate del coefficiente di correlazione lineare per descrivere l’associazione tra i due caratteri. Piuttosto che indagare sulla forza del legame lineare, cerchiamo di valutare l’esistenza di una generica relazione di concordanza: due caratteri si dicono concordanti se a modalità elevate di uno dei due tendono ad essere associate modalità crescente, anche se tale relazione non è necessariamente lineare. Due indici di concordanza comunemente utilizzati, sono l’indice tau di Kendall e il coefficiente di Spearman.
Indici di correlazione e di concordanza tra Tasso di natalità e Tasso di mortalità4
Indice Valore assunto dall’indice Pearson Correlation .324
Kendall's tau_b -.039 Spearman's rho .010
Notiamo che l’indice tau di Kendall assume addirittura un valore negativo (anche se prossimo allo zero) e che l’indice di Spearman assume un valore molto basso (e non significativamente diverso da zero). I due indici considerati sono infatti meno sensibili del coefficiente di correlazione alla presenza dei valori estremi. [Non robustezza del coefficiente di correlazione lineare] Per comprendere il motivo di questi risultati contradditori, consideriamo più dettagliatamente la nuvola di punti nel diagramma di dispersione: si possono riconoscere due nuvole di punti. La prima sembrerebbe indicare una sostanziale indifferenza tra i due caratteri. La seconda nuvola ha invece un orientamento positivo, ad indicare che all’aumentare del tasso di natalità tende ad aumentare il tasso di mortalità. 4 Risultati ottenuti utilizzando SPSS (Analyze, Correlations, Bivariate).
7
Università Luigi Bocconi
Diagramma di dispersione: noto anche come “scatterplot”, è una rappresentazione grafica per coppie di caratteri quantitativi, costruita riportando in un piano cartesiano tutte le coppie di modalità (la prima, relativa al primo carattere, in ascissa, la seconda in ordinata) rilevate sulle varie unità del collettivo in esame; appare quindi come una “nuvola” di punti. Rappresenta una prima, ma fondamentale, descrizione di come sono congiuntamente distribuiti i due caratteri e quindi, in particolare, di quale sia il tipo ed il grado di associazione tra essi. Ad esempio, è immediato rilevare l’eventuale linearità nella associazione (i punti si distribuiscono attorno ad una retta), oppure un’associazione di tipo non lineare (la nuvola di punti ha forma di curva, ad esempio logaritmica o polinomiale). Al contrario, nuvole di punti (distribuiti in maniera “casuale” nel piano) indicano scarsa associazione. Il grafico di dispersione permette di rilevare facilmente eventuali outliers.
Università Luigi Bocconi
Coefficiente di correlazione, (: indicatore (relativo) del livello e del verso dell’associazione lineare tra due caratteri quantitativi. Può assumere valori compresi tra –1 e 1 (estremi inclusi). Valori positivi indicano relazione diretta (coppie di modalità concentrate intorno ad una retta di pendenza positiva), valori negativi associazione relazione inversa. Quanto più |(| è vicino a 1, tanto più è elevato il grado di associazione lineare; nel caso in cui |(| = 1, l’associazione lineare è perfetta e i punti nel grafico di dispersione sono tutti allineati su una retta con coefficiente angolare positivo (risp. negativo). Se ( = 0 ciò non indica mancanza di associazione, ma mancanza di associazione lineare; potrebbero cioè essere presenti altri tipi di legame. E’ un indicatore particolarmente sensibile alla presenza di coppie di valori anomali
Piccarreta
Note
Retta dei minimi quadrati: E’ la retta che interpola al meglio la nuvola di punti. E’ quindi la funzione lineare che massimizza il coefficiente di determinazione R2 (nella famiglia di tutte le funzioni lineari della variabile esplicativa).
Piccarreta
Note
Coefficiente di determinazione: In questo caso è un indicatore relativo della bontà della previsione di una variabile Y sulla base di una funzione lineare della variabile esplicativa, e coincide con il quadrato del coefficiente di correlazione lineare. R2 assume valori compresi tra 0 e 1, inclusi gli estremi. Il valore 1 corrisponde ad un errore di previsione nullo (i punti del grafico di dispersione giacciono tutti su una retta); il valore 0 corrisponde ad una previsione costante (effettuata senza tener conto della variabile esplicativa). R2 è dato dal rapporto tra la varianza spiegata dalla funzione lineare utilizzata per prevedere Y e la varianza di Y.
Piccarreta
Note
Tau di Kendall e coefficiente di Spearman: Indicatori di concordanza per distribuzioni doppie, per dati qualitativi ordinali o quantitativi, basati sui ranghi. Le modalità di ognuno dei due caratteri vengono ordinate in modo crescente; ad ogni osservazione è assegnata la posizione occupata in ciascuna delle due sequenze ordinate. Vengono sostanzialmente create due graduatorie, una per ogni carattere. Si valuta quindi se le graduatorie sono concordanti (osservazioni che occupano le posizioni più elevate in una graduatoria occupano posizioni elevate anche nell’altra) o discordanti (osservazioni che occupano le posizioni più elevate in una graduatoria occupano posizioni basse nell’altra). Gli indici di concordanza assumono valori tra -1 e 1 (estremi inclusi). Il valore 1 indica che le due graduatorie sono perfettamente concordanti, mentre il valore -1 indica che le graduatorie sono perfettamente discordanti. Se utilizzati con riferimento a caratteri quantitativi, questi indicatori di concordanza risultano robusti, cioè piuttosto insensibili a valori estremi. Questo perché non si tiene conto dei valori effettivi, ma solo delle loro posizioni.
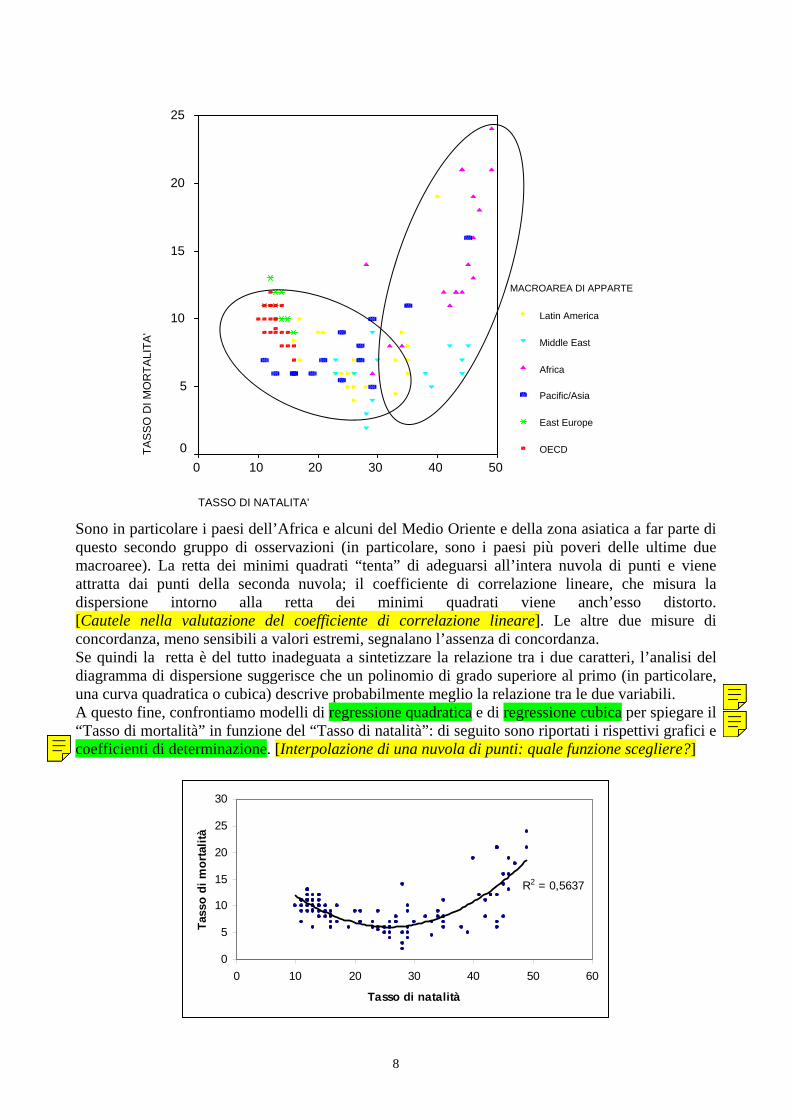
TASSO DI NATALITA'
50403020100
TAS
SO
DI M
OR
TALI
TA'
25
20
15
10
5
0
MACROAREA DI APPARTE
Latin America
Middle East
Africa
Pacific/Asia
East Europe
OECD
Sono in particolare i paesi dell’Africa e alcuni del Medio Oriente e della zona asiatica a far parte di questo secondo gruppo di osservazioni (in particolare, sono i paesi più poveri delle ultime due macroaree). La retta dei minimi quadrati “tenta” di adeguarsi all’intera nuvola di punti e viene attratta dai punti della seconda nuvola; il coefficiente di correlazione lineare, che misura la dispersione intorno alla retta dei minimi quadrati viene anch’esso distorto. [Cautele nella valutazione del coefficiente di correlazione lineare]. Le altre due misure di concordanza, meno sensibili a valori estremi, segnalano l’assenza di concordanza. Se quindi la retta è del tutto inadeguata a sintetizzare la relazione tra i due caratteri, l’analisi del diagramma di dispersione suggerisce che un polinomio di grado superiore al primo (in particolare, una curva quadratica o cubica) descrive probabilmente meglio la relazione tra le due variabili. A questo fine, confrontiamo modelli di regressione quadratica e di regressione cubica per spiegare il “Tasso di mortalità” in funzione del “Tasso di natalità”: di seguito sono riportati i rispettivi grafici e coefficienti di determinazione. [Interpolazione di una nuvola di punti: quale funzione scegliere?]
R2 = 0,5637
0
5
10
15
20
25
30
0 10 20 30 40 50 6
Tasso di natalità
Tass
o di
mor
talit
à
0
8
Università Luigi Bocconi
Regressione quadratica: è il polinomio di grado 2 della variabile esplicativa, a + bx + cx2 che interpola al meglio la nuvola di punti. E’ quindi la funzione quadratica che massimizza il coefficiente di determinazione R2 (nella famiglia di tutti i polinomi di grado 2 della variabile esplicativa). Ciò significa che minimizza la somma dei quadrati degli errori tra le modalità osservate della variabile dipendente e quelle previste utilizzando il polinomio.
Università Luigi Bocconi
Regressione cubica: è il polinomio di grado 3 della variabile esplicativa, a + bx + cx2 + dx3 che interpola al meglio la nuvola di punti. E’ quindi la funzione cubica che massimizza il coefficiente di determinazione R2 (nella famiglia di tutti i polinomi di grado 3 della variabile esplicativa). Ciò significa che minimizza la somma dei quadrati degli errori tra le modalità osservate della variabile dipendente e quelle previste utilizzando il polinomio.
Università Luigi Bocconi
Coefficiente di determinazione: Indicatore relativo della bontà della previsione di una variabile Y sulla base di una funzione della variabile esplicativa (non necessariamente lineare). Assume valori compresi tra 0 e 1, inclusi gli estremi. La funzione utilizzata per la previsione è rappresentata da una curva nel piano. Il valore 1 corrisponde ad un errore di previsione nullo (ovvero, i punti del grafico di dispersione giacciono tutti sulla curva); il valore 0 corrisponde ad una previsione costante (ovvero, effettuata senza tener conto della variabile esplicativa). Il coefficiente di determinazione si ottiene come rapporto tra la varianza (o devianza) spiegata dalla funzione utilizzata per prevedere Y e quella totale. E’ utile confrontare i coefficienti di determinazione relativi a previsioni effettuate sulla base di variabili esplicative diverse, oppure relativi a funzioni diverse (lineari, quadratiche, logaritmiche, ecc.) della stessa variabile esplicativa. La scelta, a parità di altre condizioni, cadrà sulla previsione con coefficiente di determinazione maggiore.
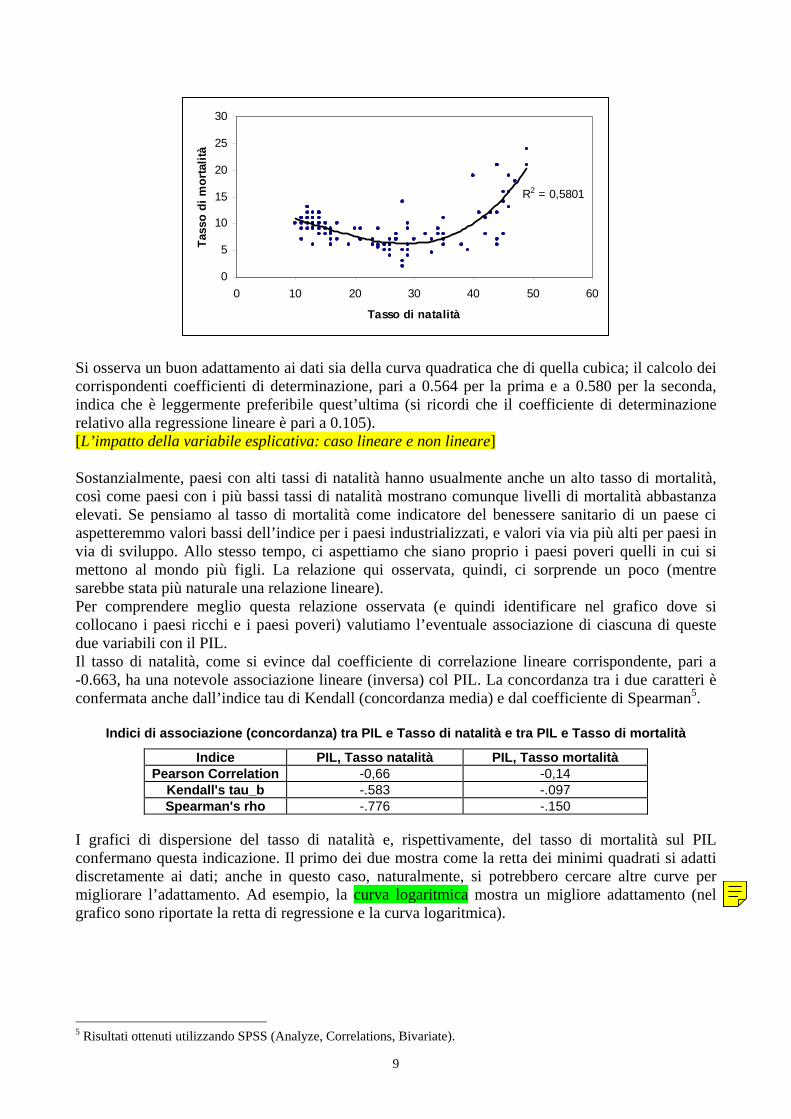
R2 = 0,5801
0
5
10
15
20
25
30
0 10 20 30 40 50 6
Tasso di natalità
Tass
o di
mor
talit
à
0
Si osserva un buon adattamento ai dati sia della curva quadratica che di quella cubica; il calcolo dei corrispondenti coefficienti di determinazione, pari a 0.564 per la prima e a 0.580 per la seconda, indica che è leggermente preferibile quest’ultima (si ricordi che il coefficiente di determinazione relativo alla regressione lineare è pari a 0.105). [L’impatto della variabile esplicativa: caso lineare e non lineare] Sostanzialmente, paesi con alti tassi di natalità hanno usualmente anche un alto tasso di mortalità, così come paesi con i più bassi tassi di natalità mostrano comunque livelli di mortalità abbastanza elevati. Se pensiamo al tasso di mortalità come indicatore del benessere sanitario di un paese ci aspetteremmo valori bassi dell’indice per i paesi industrializzati, e valori via via più alti per paesi in via di sviluppo. Allo stesso tempo, ci aspettiamo che siano proprio i paesi poveri quelli in cui si mettono al mondo più figli. La relazione qui osservata, quindi, ci sorprende un poco (mentre sarebbe stata più naturale una relazione lineare). Per comprendere meglio questa relazione osservata (e quindi identificare nel grafico dove si collocano i paesi ricchi e i paesi poveri) valutiamo l’eventuale associazione di ciascuna di queste due variabili con il PIL. Il tasso di natalità, come si evince dal coefficiente di correlazione lineare corrispondente, pari a -0.663, ha una notevole associazione lineare (inversa) col PIL. La concordanza tra i due caratteri è confermata anche dall’indice tau di Kendall (concordanza media) e dal coefficiente di Spearman5.
Indici di associazione (concordanza) tra PIL e Tasso di natalità e tra PIL e Tasso di mortalità
Indice PIL, Tasso natalità PIL, Tasso mortalità Pearson Correlation -0,66 -0,14
Kendall's tau_b -.583 -.097 Spearman's rho -.776 -.150
I grafici di dispersione del tasso di natalità e, rispettivamente, del tasso di mortalità sul PIL confermano questa indicazione. Il primo dei due mostra come la retta dei minimi quadrati si adatti discretamente ai dati; anche in questo caso, naturalmente, si potrebbero cercare altre curve per migliorare l’adattamento. Ad esempio, la curva logaritmica mostra un migliore adattamento (nel grafico sono riportate la retta di regressione e la curva logaritmica).
5 Risultati ottenuti utilizzando SPSS (Analyze, Correlations, Bivariate).
9
Università Luigi Bocconi
Curva logaritmica: per spiegare una variabile dipendente in funzione di una variabile esplicativa, X, si considera una funzione lineare non di X – come nel caso della retta dei minimi quadrati – ma del logaritmo naturale di X: a + b ln(x). La curva logaritmica è quella che interpola al meglio la nuvola di punti. E’ quindi la funzione logaritmica che massimizza il coefficiente di determinazione R2 (nella famiglia di tutti le curve logaritmiche della variabile esplicativa). Ciò significa che minimizza la somma dei quadrati degli errori tra le modalità osservate della variabile dipendente e quelle previste utilizzando la curva.
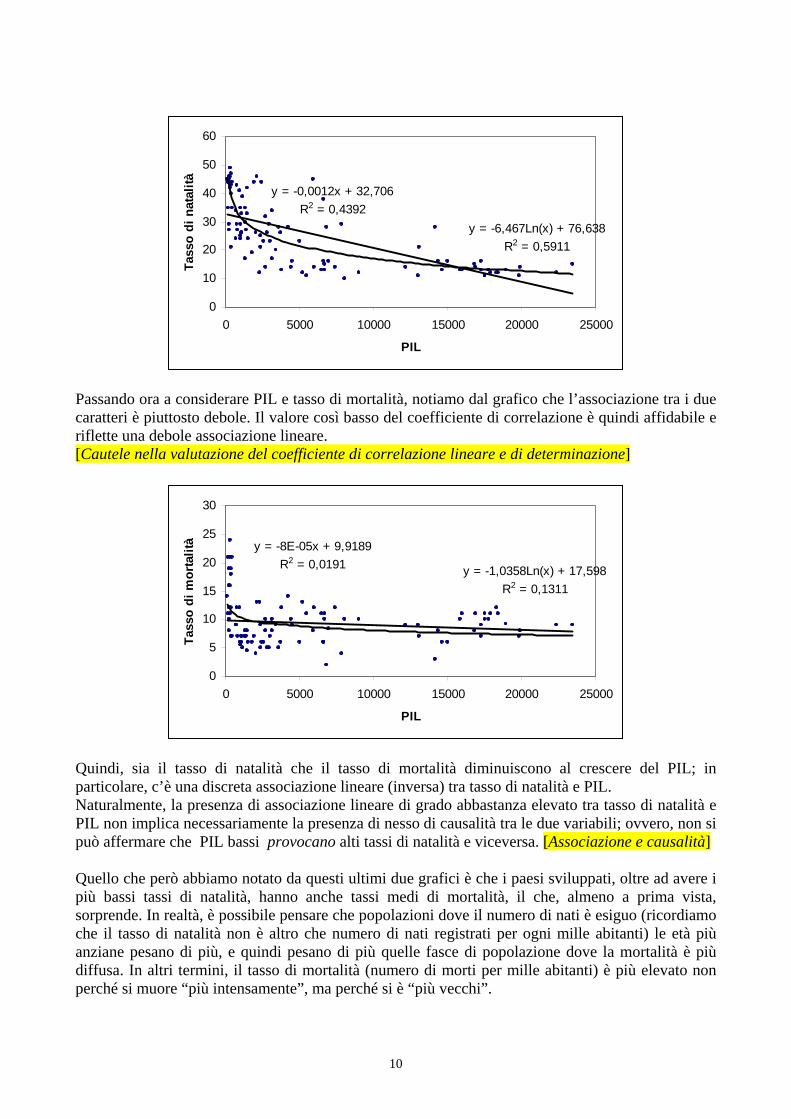
y = -6,467Ln(x) + 76,638R2 = 0,5911
y = -0,0012x + 32,706R2 = 0,4392
0
10
20
30
40
50
60
0 5000 10000 15000 20000 25000
PIL
Tass
o di
nat
alità
Passando ora a considerare PIL e tasso di mortalità, notiamo dal grafico che l’associazione tra i due caratteri è piuttosto debole. Il valore così basso del coefficiente di correlazione è quindi affidabile e riflette una debole associazione lineare. [Cautele nella valutazione del coefficiente di correlazione lineare e di determinazione]
y = -1,0358Ln(x) + 17,598R2 = 0,1311
y = -8E-05x + 9,9189R2 = 0,0191
0
5
10
15
20
25
30
0 5000 10000 15000 20000 25000
PIL
Tass
o di
mor
talit
à
Quindi, sia il tasso di natalità che il tasso di mortalità diminuiscono al crescere del PIL; in particolare, c’è una discreta associazione lineare (inversa) tra tasso di natalità e PIL. Naturalmente, la presenza di associazione lineare di grado abbastanza elevato tra tasso di natalità e PIL non implica necessariamente la presenza di nesso di causalità tra le due variabili; ovvero, non si può affermare che PIL bassi provocano alti tassi di natalità e viceversa. [Associazione e causalità] Quello che però abbiamo notato da questi ultimi due grafici è che i paesi sviluppati, oltre ad avere i più bassi tassi di natalità, hanno anche tassi medi di mortalità, il che, almeno a prima vista, sorprende. In realtà, è possibile pensare che popolazioni dove il numero di nati è esiguo (ricordiamo che il tasso di natalità non è altro che numero di nati registrati per ogni mille abitanti) le età più anziane pesano di più, e quindi pesano di più quelle fasce di popolazione dove la mortalità è più diffusa. In altri termini, il tasso di mortalità (numero di morti per mille abitanti) è più elevato non perché si muore “più intensamente”, ma perché si è “più vecchi”.
10
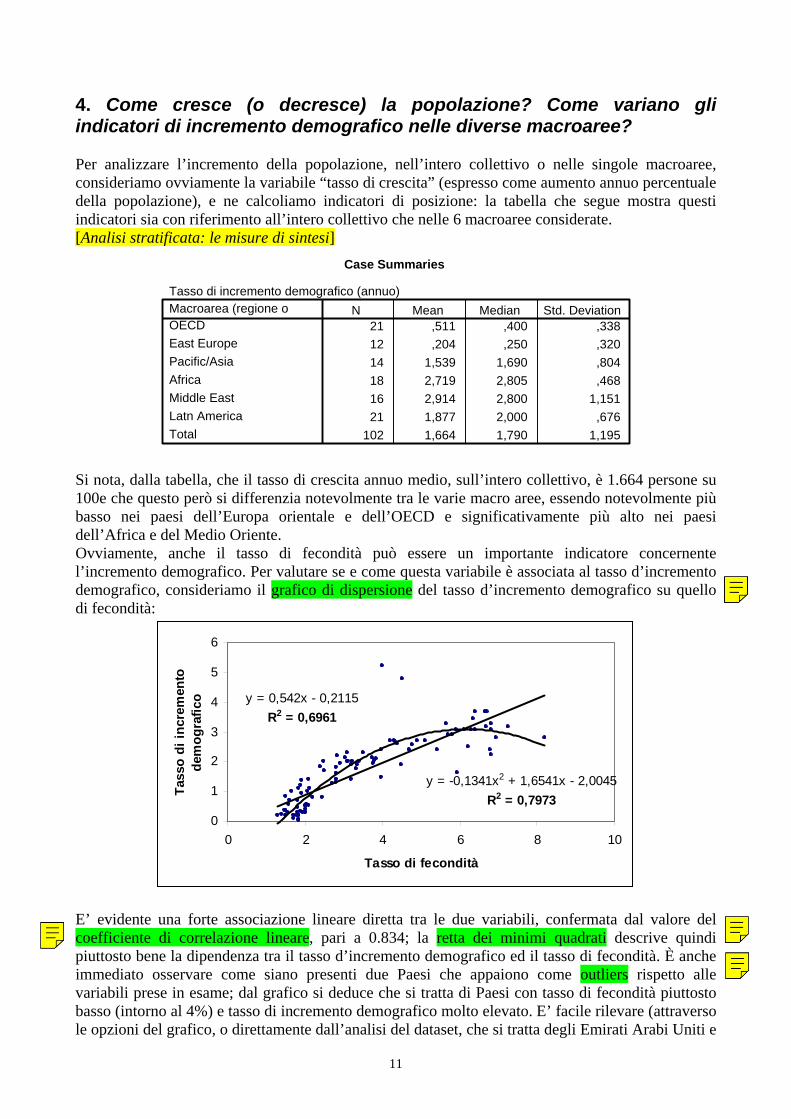
4. Come cresce (o decresce) la popolazione? Come variano gli indicatori di incremento demografico nelle diverse macroaree? Per analizzare l’incremento della popolazione, nell’intero collettivo o nelle singole macroaree, consideriamo ovviamente la variabile “tasso di crescita” (espresso come aumento annuo percentuale della popolazione), e ne calcoliamo indicatori di posizione: la tabella che segue mostra questi indicatori sia con riferimento all’intero collettivo che nelle 6 macroaree considerate. [Analisi stratificata: le misure di sintesi]
Case Summaries
Tasso di incremento demografico (annuo)
21 ,511 ,400 ,33812 ,204 ,250 ,32014 1,539 1,690 ,80418 2,719 2,805 ,46816 2,914 2,800 1,15121 1,877 2,000 ,676
102 1,664 1,790 1,195
Macroarea (regione oOECDEast EuropePacific/AsiaAfricaMiddle EastLatn AmericaTotal
N Mean Median Std. Deviation
Si nota, dalla tabella, che il tasso di crescita annuo medio, sull’intero collettivo, è 1.664 persone su 100e che questo però si differenzia notevolmente tra le varie macro aree, essendo notevolmente più basso nei paesi dell’Europa orientale e dell’OECD e significativamente più alto nei paesi dell’Africa e del Medio Oriente. Ovviamente, anche il tasso di fecondità può essere un importante indicatore concernente l’incremento demografico. Per valutare se e come questa variabile è associata al tasso d’incremento demografico, consideriamo il grafico di dispersione del tasso d’incremento demografico su quello di fecondità:
y = -0,1341x2 + 1,6541x - 2,0045R2 = 0,7973
y = 0,542x - 0,2115R2 = 0,6961
0
1
2
3
4
5
6
0 2 4 6 8
Tasso di fecondità
Tass
o di
incr
emen
to
dem
ogra
fico
10
E’ evidente una forte associazione lineare diretta tra le due variabili, confermata dal valore del coefficiente di correlazione lineare, pari a 0.834; la retta dei minimi quadrati descrive quindi piuttosto bene la dipendenza tra il tasso d’incremento demografico ed il tasso di fecondità. È anche immediato osservare come siano presenti due Paesi che appaiono come outliers rispetto alle variabili prese in esame; dal grafico si deduce che si tratta di Paesi con tasso di fecondità piuttosto basso (intorno al 4%) e tasso di incremento demografico molto elevato. E’ facile rilevare (attraverso le opzioni del grafico, o direttamente dall’analisi del dataset, che si tratta degli Emirati Arabi Uniti e
11
Università Luigi Bocconi
Diagramma di dispersione: noto anche come “scatterplot”, è una rappresentazione grafica per coppie di caratteri quantitativi, costruita semplicemente riportando in un piano cartesiano tutte le coppie di modalità (la prima, relativa al primo carattere, in ascissa, la seconda in ordinata) rilevate sulle varie unità del collettivo in esame; appare quindi come una “nuvola” di punti. Fornisce una prima, fondamentale, descrizione della distribuzione congiunta dei due caratteri e quindi, in particolare, di quale sia il tipo ed il grado di associazione tra essi. Ad esempio, è immediato rilevare l’eventuale linearità nella associazione (punti distribuiti attorno ad una retta obliqua del piano), oppure un’associazione di tipo non lineare (la nuvola di punti ha forma di curva, ad esempio logaritmica o polinomiale). Al contrario, nuvole di punti senza alcun andamento particolare (distribuiti in maniera “casuale” nel piano) indicano scarsa associazione tra i caratteri. Il grafico di dispersione permette di rilevare facilmente eventuali outliers (osservazioni eccezionali).
Università Luigi Bocconi
Coefficiente di correlazione lineare, (: indice relativo del livello e del verso della relazione lineare tra due caratteri quantitativi. Può assumere valori compresi tra –1 e 1 (estremi inclusi). Valori positivi indicano relazione diretta (coppie di modalità concentrate intorno ad una retta di pendenza positiva), valori negativi associazione relazione inversa. Quanto più |(| è vicino a 1, tanto più è forte la relazione lineare; nel caso in cui |(| = 1, la relazione lineare è perfetta e i punti nel grafico di dispersione sono tutti allineati su una retta con pendenza positiva (risp. negativa). Se ( = 0 ciò non indica mancanza di associazione, ma mancanza di associazione lineare; potrebbero cioè essere presenti altri tipi di legame. E’ particolarmente sensibile alla presenza di coppie di valori anomali
Università Luigi Bocconi
Retta dei minimi quadrati: è’ la retta che interpola al meglio la nuvola di punti. E’ quindi la funzione lineare che massimizza l’R2 (nella famiglia di tutte le funzioni lineari della variabile esplicativa).
Piccarreta
Note
outliers (Valori anomali): nel caso bivariato definiamo anomala un’osservazione che presenta una coppia di modalità che nel diagramma di dispersione è in una posizione poco coerente con l’andamento generale della nuvola dei punti. Non è detto che una coppia anomala di modalità sia caratterizzata da due modalità anomale a livello marginale.
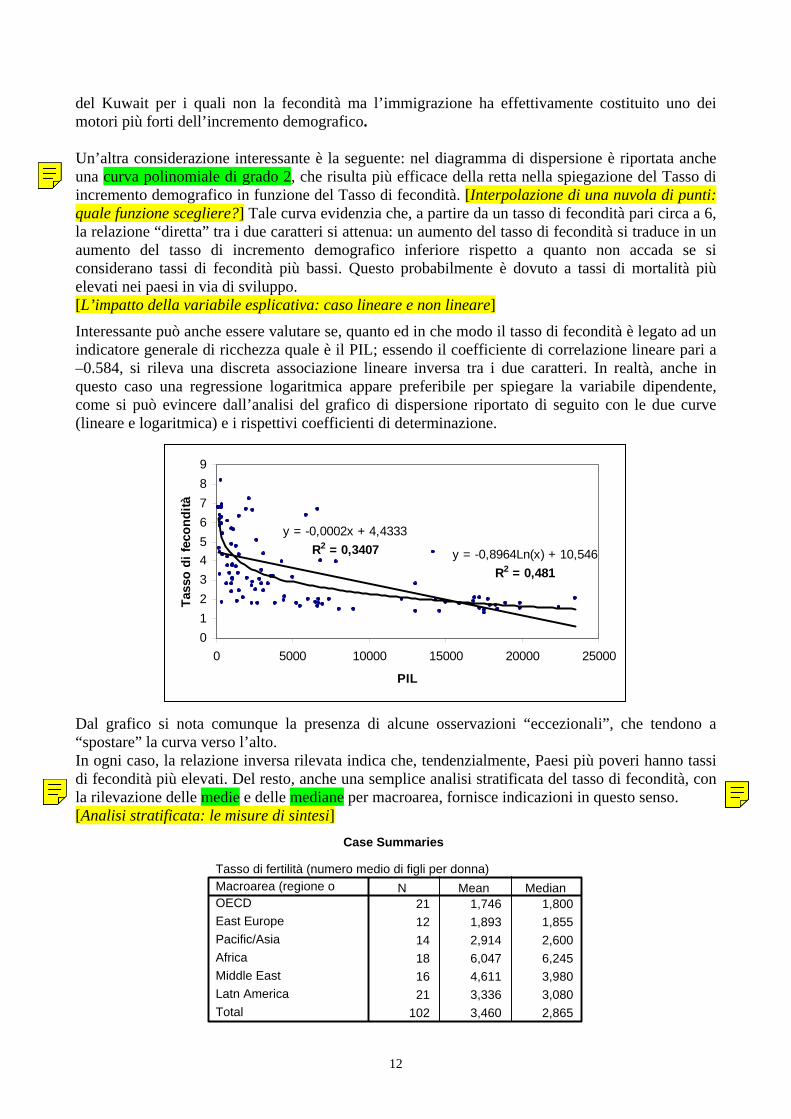
del Kuwait per i quali non la fecondità ma l’immigrazione ha effettivamente costituito uno dei motori più forti dell’incremento demografico. Un’altra considerazione interessante è la seguente: nel diagramma di dispersione è riportata anche una curva polinomiale di grado 2, che risulta più efficace della retta nella spiegazione del Tasso di incremento demografico in funzione del Tasso di fecondità. [Interpolazione di una nuvola di punti: quale funzione scegliere?] Tale curva evidenzia che, a partire da un tasso di fecondità pari circa a 6, la relazione “diretta” tra i due caratteri si attenua: un aumento del tasso di fecondità si traduce in un aumento del tasso di incremento demografico inferiore rispetto a quanto non accada se si considerano tassi di fecondità più bassi. Questo probabilmente è dovuto a tassi di mortalità più elevati nei paesi in via di sviluppo. [L’impatto della variabile esplicativa: caso lineare e non lineare]
Interessante può anche essere valutare se, quanto ed in che modo il tasso di fecondità è legato ad un indicatore generale di ricchezza quale è il PIL; essendo il coefficiente di correlazione lineare pari a –0.584, si rileva una discreta associazione lineare inversa tra i due caratteri. In realtà, anche in questo caso una regressione logaritmica appare preferibile per spiegare la variabile dipendente, come si può evincere dall’analisi del grafico di dispersione riportato di seguito con le due curve (lineare e logaritmica) e i rispettivi coefficienti di determinazione.
y = -0,0002x + 4,4333R2 = 0,3407 y = -0,8964Ln(x) + 10,546
R2 = 0,481
0123456789
0 5000 10000 15000 20000 25000
PIL
Tass
o di
feco
ndità
Dal grafico si nota comunque la presenza di alcune osservazioni “eccezionali”, che tendono a “spostare” la curva verso l’alto. In ogni caso, la relazione inversa rilevata indica che, tendenzialmente, Paesi più poveri hanno tassi di fecondità più elevati. Del resto, anche una semplice analisi stratificata del tasso di fecondità, con la rilevazione delle medie e delle mediane per macroarea, fornisce indicazioni in questo senso. [Analisi stratificata: le misure di sintesi]
Case Summaries
Tasso di fertilità (numero medio di figli per donna)
21 1,746 1,80012 1,893 1,85514 2,914 2,60018 6,047 6,24516 4,611 3,98021 3,336 3,080
102 3,460 2,865
Macroarea (regione oOECDEast EuropePacific/AsiaAfricaMiddle EastLatn AmericaTotal
N Mean Median
12
Università Luigi Bocconi
Regressione quadratica: è il polinomio di grado 2 della variabile esplicativa, a + bx + cx2 che interpola al meglio la nuvola di punti. E’ quindi la funzione quadratica che massimizza il coefficiente di determinazione R2 (nella famiglia di tutti i polinomi di grado 2 della variabile esplicativa). Ciò significa che minimizza la somma dei quadrati degli errori tra le modalità osservate della variabile dipendente e quelle previste utilizzando il polinomio.
Università Luigi Bocconi
Media: indicatore di tendenza centrale, per dati quantitativi. Nota anche come centro di ordine 2, essendo il punto più “vicino” ai dati, rispetto alla distanza quadratica. Molto sensibile a valori estremi, è quindi da usare con cautela nel caso in cui vi siano, per il carattere considerato, valori isolati molto elevati o molto bassi.
Università Luigi Bocconi
Mediana: indicatore tendenza (o posizione) centrale, per dati quantitativi oppure qualitativi ordinali. E’ il valore che, nella successione ordinata dei dati occupa la posizione centrale. Quindi il 50% delle osservazioni hanno un valore inferiore e il 50% un valore superiore alla mediana. Quando utilizzata per dati quantitativi, è nota anche come centro di ordine 1, in quanto risulta il punto più “vicino” ai dati, rispetto alla distanza usuale (euclidea). E’ un indicatore di posizione centrale “robusto” rispetto alla presenza di dati eccezionali, ovvero risente poco della presenza di valori anomali. Per questo motivo è preferibile alla media aritmetica per indicare la tendenza centrale di distribuzioni con queste caratteristiche.
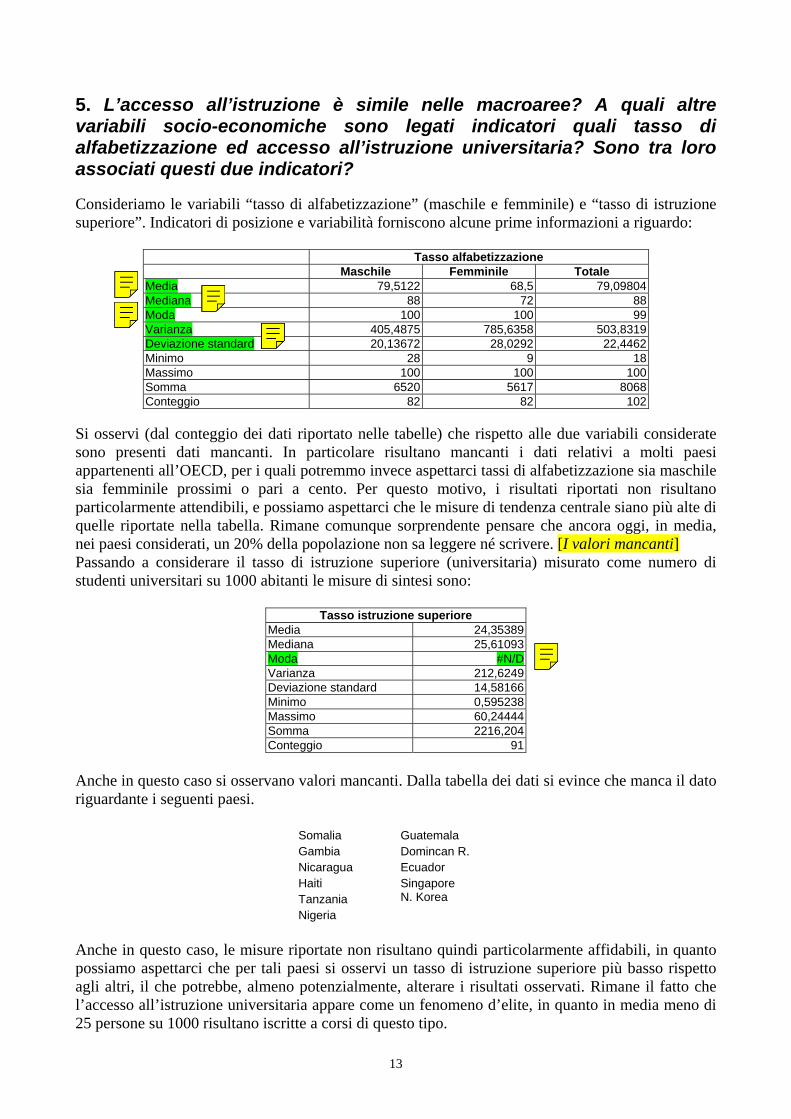
5. L’accesso all’istruzione è simile nelle macroaree? A quali altre variabili socio-economiche sono legati indicatori quali tasso di alfabetizzazione ed accesso all’istruzione universitaria? Sono tra loro associati questi due indicatori? Consideriamo le variabili “tasso di alfabetizzazione” (maschile e femminile) e “tasso di istruzione superiore”. Indicatori di posizione e variabilità forniscono alcune prime informazioni a riguardo:
Tasso alfabetizzazione Maschile Femminile Totale Media 79,5122 68,5 79,09804 Mediana 88 72 88 Moda 100 100 99 Varianza 405,4875 785,6358 503,8319 Deviazione standard 20,13672 28,0292 22,4462 Minimo 28 9 18 Massimo 100 100 100 Somma 6520 5617 8068 Conteggio 82 82 102
Si osservi (dal conteggio dei dati riportato nelle tabelle) che rispetto alle due variabili considerate sono presenti dati mancanti. In particolare risultano mancanti i dati relativi a molti paesi appartenenti all’OECD, per i quali potremmo invece aspettarci tassi di alfabetizzazione sia maschile sia femminile prossimi o pari a cento. Per questo motivo, i risultati riportati non risultano particolarmente attendibili, e possiamo aspettarci che le misure di tendenza centrale siano più alte di quelle riportate nella tabella. Rimane comunque sorprendente pensare che ancora oggi, in media, nei paesi considerati, un 20% della popolazione non sa leggere né scrivere. [I valori mancanti] Passando a considerare il tasso di istruzione superiore (universitaria) misurato come numero di studenti universitari su 1000 abitanti le misure di sintesi sono:
Tasso istruzione superiore Media 24,35389Mediana 25,61093Moda #N/DVarianza 212,6249Deviazione standard 14,58166Minimo 0,595238Massimo 60,24444Somma 2216,204Conteggio 91
Anche in questo caso si osservano valori mancanti. Dalla tabella dei dati si evince che manca il dato riguardante i seguenti paesi.
Somalia Guatemala Gambia Domincan R. Nicaragua Ecuador Haiti Singapore Tanzania N. Korea Nigeria
Anche in questo caso, le misure riportate non risultano quindi particolarmente affidabili, in quanto possiamo aspettarci che per tali paesi si osservi un tasso di istruzione superiore più basso rispetto agli altri, il che potrebbe, almeno potenzialmente, alterare i risultati osservati. Rimane il fatto che l’accesso all’istruzione universitaria appare come un fenomeno d’elite, in quanto in media meno di 25 persone su 1000 risultano iscritte a corsi di questo tipo.
13
Università Luigi Bocconi
Media: indicatore di tendenza (o posizione) centrale, per dati quantitativi. E’ nota anche come centro di ordine 2, in quanto è il punto più “vicino” ai dati, rispetto alla distanza quadratica. Particolarmente sensibile ad eventuali valori estremi, è quindi da usare con cautela nel caso in cui vi siano, per il carattere considerato, valori isolati molto elevati o molto bassi.
Università Luigi Bocconi
Mediana: indicatore di tendenza (o posizione) centrale, per dati quantitativi oppure qualitativi ordinali. E’ il valore che, nella successione ordinata dei dati occupa la posizione centrale. Quindi il 50% delle osservazioni hanno un valore inferiore e il 50% un valore superiore alla mediana. Quando utilizzata per dati quantitativi, è nota anche come centro di ordine 1, in quanto risulta il punto più “vicino” ai dati, rispetto alla distanza usuale (euclidea). E’ un indicatore di posizione centrale “robusto” rispetto alla presenza di dati eccezionali, ovvero risente poco della presenza di valori anomali. Per questo motivo è preferibile alla media aritmetica per indicare la tendenza centrale di distribuzioni con queste caratteristiche.
Università Luigi Bocconi
Moda è la modalità cui compete la più elevata frequenza relativa. E’ quindi la modalità che caratterizza la maggior parte delle unità statistiche. E’ una sintesi efficace quando la frequenza che le compete è elevata. E’ sensato calcolarla solo per caratteri che assumono un numero contenuto di modalità (quindi, non per caratteri continui, per i quali ogni unità statistica presenta una modalità diversa da tutte le altre).
Università Luigi Bocconi
Varianza: misura la dispersione di dati quantitativi intorno alla loro media. E’ la media degli scarti quadratici dalla media aritmetica. E’ nulla se e solo se i dati sono tutti coincidenti, altrimenti è positiva, tanto più grande quanto più i dati sono dispersi. Ha come unità di misura il quadrato dell’unità di misura del carattere e, anche per questo motivo, non è opportuno utilizzarla per confrontare la variabilità tra caratteri con unità di misura differente. E’ una misura poco robusta: tende ad accentuare gli scarti elevati dalla media. Lo scarto quadratico medio, detto anche deviazione standard, è la radice quadrata della varianza.
Piccarreta
Note
Moda (ND): In questo caso il carattere è continuo, ogni unità presenta una modalità diversa dal carattere e quindi i valori osservati sono tutti modali (caratterizzati dalla stessa frequenza assoluta, 1). La moda non ha quindi alcuna capacità di sintesi.

E’ quindi più opportuno procedere a condurre l’analisi condizionatamente alla “Macroarea di appartenenza”, calcolando le medie subordinate. [Analisi stratificata: le misure di sintesi]
Case Summaries
6 6 2196,5000 92,8333 38,0185
9 9 1299,6667 99,3333 29,2844
13 13 1282,7692 69,0769 20,0473
17 17 1452,5882 30,1176 4,6723
16 16 1680,4375 66,4375 23,2363
21 21 1685,0952 80,6190 24,2902
82 82 9179,5122 68,5000 24,3539
NMeanNMeanNMeanNMeanNMeanNMeanNMean
MACROAREAOECD
EST EUROPA
ASIA-PACIFICO
AFRICA
MEDIOORIENTE
AMERICALATINA
TOTALE
ALFAB.MAS. ALFAB. FEM. ISTRUZ. SUP
Alcune osservazioni seguono immediatamente dalla lettura della tabella; in primo luogo, ovviamente, si rileva come il tasso di alfabetizzazione (sia maschile che femminile) varia molto tra le diverse macroaree, risultando molto elevato nelle prime due ed estremamente basso, in particolare, in Africa. Inoltre, le differenze, riguardo all’alfabetizzazione, tra maschi e femmine appaiono più o meno accentuate (sempre indicando valori superiori per i maschi) a seconda del gruppo di appartenenza dello Stato. In generale, si nota che più sono bassi questi tassi, più aumenta anche la differenza tra situazione maschile e femminile: più l’istruzione è un bene raro, più a goderne sono solo i maschi, mentre dove essa risulta estremamente diffusa, i differenziali tra maschi e femmine sono ridotti. Valutiamo ora l’associazione tra tasso di alfabetizzazione e tasso di istruzione superiore. Nell’intero collettivo, tasso di alfabetizzazione e tasso di istruzione superiore appaiono positivamente associati, come indicato dal grafico di dispersione e dal coefficiente di correlazione lineare, pari a 0.663..
y = 0,4558x - 12,694R2 = 0,4396 y = 0,804e0,0379x
R2 = 0,604300
10
20
30
40
50
60
70
0 20 40 60 80 100 120
Tasso di alfabetizzazione
Tass
o di
istru
zion
e su
perio
re
14
Università Luigi Bocconi
Diagramma di dispersione: noto anche come “scatterplot”, è una rappresentazione grafica per coppie di caratteri quantitativi, costruita semplicemente riportando in un piano cartesiano tutte le coppie di modalità (la prima, relativa al primo carattere, in ascissa, la seconda in ordinata) rilevate sulle varie unità del collettivo in esame; appare quindi come una “nuvola” di punti. Fornisce una prima, fondamentale, descrizione della distribuzione congiunta dei due caratteri e quindi, in particolare, di quale sia il tipo ed il grado di associazione tra essi. Ad esempio, è immediato rilevare l’eventuale linearità nella associazione (punti distribuiti attorno ad una retta obliqua del piano), oppure un’associazione di tipo non lineare (la nuvola di punti ha forma di curva, ad esempio logaritmica o polinomiale). Al contrario, nuvole di punti senza alcun andamento particolare (distribuiti in maniera “casuale” nel piano) indicano scarsa associazione tra i caratteri. Il grafico di dispersione permette di rilevare facilmente eventuali outliers (osservazioni eccezionali).
Università Luigi Bocconi
Coefficiente di correlazione lineare (: indice relativo del livello e del verso della relazione lineare tra due caratteri quantitativi. Può assumere valori compresi tra –1 e 1 (estremi inclusi). Valori positivi indicano relazione diretta (coppie di modalità concentrate intorno ad una retta di pendenza positiva), valori negativi associazione relazione inversa. Quanto più |(| è vicino a 1, tanto più è forte la relazione lineare; nel caso in cui |(| = 1, la relazione lineare è perfetta e i punti nel grafico di dispersione sono tutti allineati su una retta con pendenza positiva (risp. negativa). Se ( = 0 ciò non indica mancanza di associazione, ma mancanza di associazione lineare; potrebbero cioè essere presenti altri tipi di legame. E’ particolarmente sensibile alla presenza di coppie di valori anomali

Il grafico evidenzia la presenza di alcuni outliers, che attirano verso l’alto la retta di regressione, e, quindi, una certa inaffidabilità del coefficiente di correlazione lineare quale indicatore di associazione. [Cautele nalla valutazione del coefficiente di correlazione lineare] Inoltre, si può rilevare come una regressione esponenziale sia più adatta a spiegare la dipendenza in esame, anche se anche tale curva è attratta verso l’alto da queste osservazioni anomale; in ogni caso, anche i coefficienti di determinazione, pari a 0.439 per la regressione lineare ed a 0.604 per quella esponenziale, confermano la maggiore adeguatezza della regressione esponenziale. [Interpolazione di una nuvola di punti: quale funzione scegliere?] Per un’analisi più dettagliata della relazione tra il tasso di alfabetizzazione ed il tasso di istruzione superiore, riportiamo nella tabella di seguito i coefficienti di correlazione lineare e gli indici di concordanza, l’indice tau di Kendall e il coefficiente di Spearman, tra i due caratteri per macroarea.
Correlazioni tra Tasso di istruzione superiore Tasso di alfabetizzazione
MACROAREA Pearson Correlation Kendall's tau_b Spearman's rho OECD .037 .051 .056
East Europe .291 .304 .350 Pacific/Asia .697 .698 .833
Africa .375 .313 .461 Middle East -.086 .059 .078
Latin America .275 .153 .236 I tre indici forniscono le stesse informazioni sulla relazione tra i due caratteri. Si osserva come la associazione tra i due caratteri sia piuttosto diversa nelle differenti macroaree: elevata (e positiva) nell’area Asia-Pacifico, sostanzialmente nulla (leggermente positiva o negativa) nei Paesi OECD e nel Medio Oriente. Quindi, a seconda delle caratteristiche socio-economiche complessive (indicate dalle macroaree), i due caratteri in esame mostrano legami sostanzialmente differenti. Consideriamo in particolare due aree: Asia-Pacifico e Medio Oriente. Nell’area asiatica il coefficiente di correlazione lineare è 0.697. Ciò suggerisce la presenza di una forte associazione lineare positiva tra le due variabili. Per verificare se tale coefficiente è affidabile o meno, consideriamo il grafico di dispersione.
MACROAREA: ASIA-PACIFICO
TASSO ALFABETIZZAZIONE
10090807060504030
TAS
SO
ISTR
UZI
ON
E S
UP
ER
IOR
E
70
60
50
40
30
20
10
0
MACROAREA: MEDIO ORIENTE
TASSO ALFABETIZZAZIONE
100908070605040
TAS
SO
ISTR
UZI
ON
E S
UP
ER
IOR
E
60
50
40
30
20
10
0
Nel grafico si nota la presenza di un’osservazione anomala che porta la retta di regressione verso l’alto; in effetti, una curva esponenziale appare più idonea a descrivere la relazione tra le variabili in esame che, in ogni caso, appaiono decisamente positivamente associate. Al contrario, nell’area del Medio Oriente, il coefficiente di correlazione è negativo, anche se molto
15
Università Luigi Bocconi
Retta di regressione: E’ la retta che interpola al meglio la nuvola di punti. E’ quindi la funzione lineare che massimizza l’indica di determinazione R2 (nella famiglia di tutte le funzioni lineari della variabile esplicativa).
Università Luigi Bocconi
Regressione esponenziale: per spiegare una variabile dipendente in funzione di una variabile esplicativa, X, si considera una funzione lineare non di X – come nel caso della retta dei minimi quadrati – ma della funzione esponenziale applicata ad X: a e(bx). La curva di regressione esponenziale è quella che interpola al meglio la nuvola di punti. E’ quindi la funzione che massimizza il coefficiente di determinazione R2 (nella famiglia di tutti le curve esponenziali della variabile esplicativa). Ciò significa che minimizza la somma dei quadrati degli errori tra le modalità osservate della variabile dipendente e quelle previste utilizzando la curva.
Università Luigi Bocconi
Coefficiente di determinazione: Indicatore relativo della bontà della previsione di una variabile Y sulla base di una funzione della variabile esplicativa (non necessariamente lineare). Assume valori compresi tra 0 e 1, inclusi gli estremi. La funzione utilizzata per la previsione è rappresentata da una curva nel piano. Il valore 1 corrisponde ad un errore di previsione nullo (ovvero, i punti del grafico di dispersione giacciono tutti sulla curva); il valore 0 corrisponde ad una previsione costante (ovvero, effettuata senza tener conto della variabile esplicativa). Il coefficiente di determinazione si ottiene come rapporto tra la varianza (o devianza) spiegata dalla funzione utilizzata per prevedere Y e quella totale. E’ utile confrontare i coefficienti di determinazione relativi a previsioni effettuate sulla base di variabili esplicative diverse, oppure relativi a funzioni diverse (lineari, quadratiche, logaritmiche, ecc.) della stessa variabile esplicativa. La scelta, a parità di altre condizioni, cadrà sulla previsione con coefficiente di determinazione maggiore.
Piccarreta
Note
Outlier (osservazione anomala): nel caso bivariato definiamo anomala un’osservazione che presenta una coppia di modalità che nel diagramma di dispersione è in una posizione poco coerente con l’andamento generale della nuvola dei punti. Non è detto che una coppia anomala di modalità sia caratterizzata da due modalità anomale a livello marginale.
Piccarreta
Note
Tau di Kendall e coefficiente di Spearman: Indicatori di concordanza per distribuzioni doppie, per dati qualitativi ordinali o quantitativi, basati sui ranghi. Le modalità di ognuno dei due caratteri vengono ordinate in modo crescente; ad ogni osservazione è assegnata la posizione occupata in ciascuna delle due sequenze ordinate. Vengono sostanzialmente create due graduatorie, una per ogni carattere. Si valuta quindi se le graduatorie sono concordanti (osservazioni che occupano le posizioni più elevate in una graduatoria occupano posizioni elevate anche nell’altra) o discordanti (osservazioni che occupano le posizioni più elevate in una graduatoria occupano posizioni basse nell’altra). Gli indici di concordanza assumono valori tra -1 e 1 (estremi inclusi). Il valore 1 indica che le due graduatorie sono perfettamente concordanti, mentre il valore -1 indica che le graduatorie sono perfettamente discordanti. Se utilizzati con riferimento a caratteri quantitativi, questi indicatori di concordanza risultano robusti, cioè piuttosto insensibili a valori estremi. Questo perché non si tiene conto dei valori effettivi, ma solo delle loro posizioni.

vicino allo 0. L’analisi del grafico di dispersione consente in questo caso di confermare che i due caratteri non sono associati linearmente. Anche se un coefficiente di correlazione prossimo allo zero e una retta di regressione con pendenza quasi nulla non consentono di concludere che tra i due caratteri non esista un altro tipo di associazione – non lineare – in questo caso si osserva che i due caratteri non sembrano associati.
Sembra doveroso a questo punto sottolineare che tutte le considerazioni fatte in merito al tasso di istruzione superiore vanno trattate con una certa cautela. Infatti, il carattere scelto per misurare il fenomeno di interesse è il numero di studenti universitari ogni 1000 abitanti. In sostanza, è una percentuale valutata sulla totalità della popolazione. Tale percentuale dipenderà necessariamente anche dalla struttura per età della popolazione. In particolare, se in una popolazione sono le fasce di età più elevate quelle prevalenti, un tasso di istruzione universitaria molto basso sarebbe “inevitabile” (gli studenti universitari sono pochi perché sono pochi i “giovani”). Un indicatore più sensato sarebbe probabilmente dato dal numero di studenti universitari sul numero totale di soggetti che potrebbero almeno virtualmente iscriversi all’università.
16
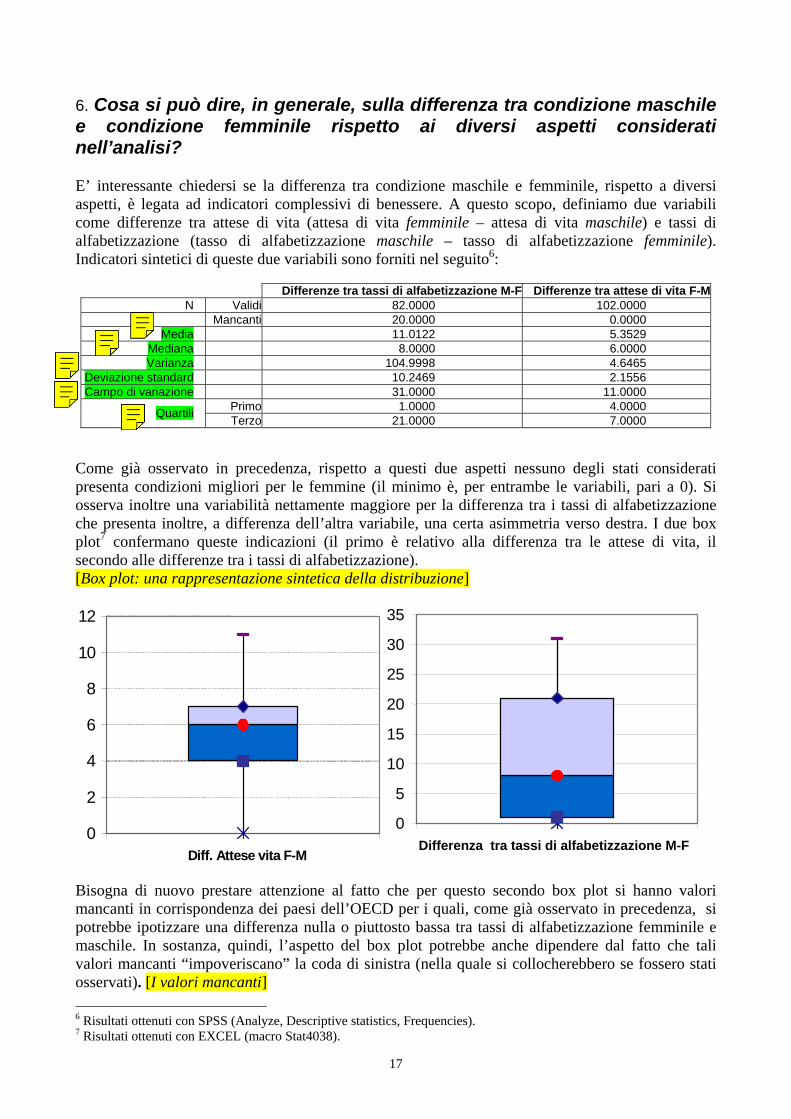
6. Cosa si può dire, in generale, sulla differenza tra condizione maschile e condizione femminile rispetto ai diversi aspetti considerati nell’analisi? E’ interessante chiedersi se la differenza tra condizione maschile e femminile, rispetto a diversi aspetti, è legata ad indicatori complessivi di benessere. A questo scopo, definiamo due variabili come differenze tra attese di vita (attesa di vita femminile – attesa di vita maschile) e tassi di alfabetizzazione (tasso di alfabetizzazione maschile – tasso di alfabetizzazione femminile). Indicatori sintetici di queste due variabili sono forniti nel seguito6:
Differenze tra tassi di alfabetizzazione M-F Differenze tra attese di vita F-MN Validi 82.0000 102.0000
Mancanti 20.0000 0.0000 Media 11.0122 5.3529
Mediana 8.0000 6.0000 Varianza 104.9998 4.6465
Deviazione standard 10.2469 2.1556 Campo di variazione 31.0000 11.0000
Primo 1.0000 4.0000 Quartili Terzo 21.0000 7.0000
Come già osservato in precedenza, rispetto a questi due aspetti nessuno degli stati considerati presenta condizioni migliori per le femmine (il minimo è, per entrambe le variabili, pari a 0). Si osserva inoltre una variabilità nettamente maggiore per la differenza tra i tassi di alfabetizzazione che presenta inoltre, a differenza dell’altra variabile, una certa asimmetria verso destra. I due box plot7 confermano queste indicazioni (il primo è relativo alla differenza tra le attese di vita, il secondo alle differenze tra i tassi di alfabetizzazione). [Box plot: una rappresentazione sintetica della distribuzione] 35
Bisogna di nuovo prestare attenzione al fatto che per questo secondo box plot si hanno valori mancanti in corrispondenza dei paesi dell’OECD per i quali, come già osservato in precedenza, si potrebbe ipotizzare una differenza nulla o piuttosto bassa tra tassi di alfabetizzazione femminile e maschile. In sostanza, quindi, l’aspetto del box plot potrebbe anche dipendere dal fatto che tali valori mancanti “impoveriscano” la coda di sinistra (nella quale si collocherebbero se fossero stati osservati). [I valori mancanti]
6 Risultati ottenuti con SPSS (Analyze, Descriptive statistics, Frequencies). 7 Risultati ottenuti con EXCEL (macro Stat4038).
0
2
4
6
8
10
Diff. Attese vita F-M
12
30
25
20
15
10
5
0Differenza tra tassi di alfabetizzazione M-F
17
Università Luigi Bocconi
Media: indicatore di tendenza (o posizione) centrale, per dati quantitativi. E’ nota anche come centro di ordine 2, in quanto è il punto più “vicino” ai dati, rispetto alla distanza quadratica. Particolarmente sensibile ad eventuali valori estremi, è quindi da usare con cautela nel caso in cui vi siano, per il carattere considerato, valori isolati molto elevati o molto bassi.
Università Luigi Bocconi
Mediana: indicatore di tendenza (o posizione) centrale, per dati quantitativi oppure qualitativi ordinali. E’ il valore che, nella successione ordinata dei dati occupa la posizione centrale. Quindi il 50% delle osservazioni hanno un valore inferiore e il 50% un valore superiore alla mediana. Quando utilizzata per dati quantitativi, è nota anche come centro di ordine 1, in quanto risulta il punto più “vicino” ai dati, rispetto alla distanza usuale (euclidea). E’ un indicatore di posizione centrale “robusto” rispetto alla presenza di dati eccezionali, ovvero risente poco della presenza di valori anomali. Per questo motivo è preferibile alla media aritmetica per indicare la tendenza centrale di distribuzioni con queste caratteristiche.
Università Luigi Bocconi
Varianza: misura la dispersione di dati quantitativi intorno alla loro media. E’ la media degli scarti quadratici dalla media aritmetica. E’ nulla se e solo se i dati sono tutti coincidenti, altrimenti è positiva, tanto più grande quanto più i dati sono dispersi. Ha come unità di misura il quadrato dell’unità di misura del carattere e, anche per questo motivo, non è opportuno utilizzarla per confrontare la variabilità tra caratteri con unità di misura differente. E’ una misura poco robusta: tende ad accentuare gli scarti elevati dalla media. Lo scarto quadratico medio, detto anche deviazione standard, è la radice quadrata della varianza.
Piccarreta
Note
Quartili: sono 3 indicatori, calcolabili per dati quantitativi o qualitativi ordinali. Considerata la successione dei valori osservati disposti in ordine crescente, i quartili indicano i tre punti che dividono la distribuzione in quattro parti uguali. Ad esempio il 1° quartile è tale che il 25% della popolazione presenta un valore al di sotto e il restante 75% al di sopra di esso. Il 2° quartile è la mediana.
Piccarreta
Note
Campo di variazione: è ottenuto come differenza tra il massimo e il minimo valore osservato e rappresenta quindi la lunghezza dell’intervallo in cui cadono tutte le osservazioni relative al carattere di interesse
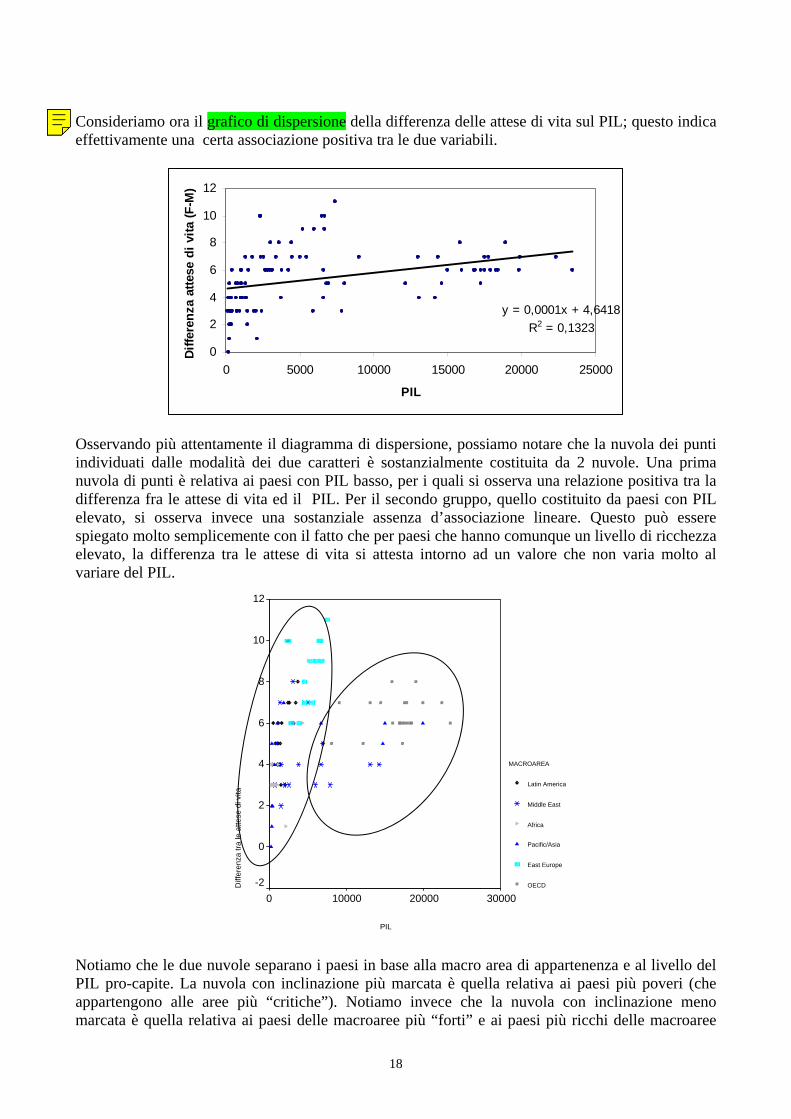
Consideriamo ora il grafico di dispersione della differenza delle attese di vita sul PIL; questo indica effettivamente una certa associazione positiva tra le due variabili.
y = 0,0001x + 4,6418R2 = 0,1323
0
2
4
6
8
10
12
0 5000 10000 15000 20000 25000
PIL
Diffe
renz
a at
tese
di v
ita (F
-M)
Osservando più attentamente il diagramma di dispersione, possiamo notare che la nuvola dei punti individuati dalle modalità dei due caratteri è sostanzialmente costituita da 2 nuvole. Una prima nuvola di punti è relativa ai paesi con PIL basso, per i quali si osserva una relazione positiva tra la differenza fra le attese di vita ed il PIL. Per il secondo gruppo, quello costituito da paesi con PIL elevato, si osserva invece una sostanziale assenza d’associazione lineare. Questo può essere spiegato molto semplicemente con il fatto che per paesi che hanno comunque un livello di ricchezza elevato, la differenza tra le attese di vita si attesta intorno ad un valore che non varia molto al variare del PIL.
PIL
3000020000100000
Diff
eren
za tr
a le
atte
se d
i vita
12
10
8
6
4
2
0
-2
MACROAREA
Latin America
Middle East
Africa
Pacific/Asia
East Europe
OECD
Notiamo che le due nuvole separano i paesi in base alla macro area di appartenenza e al livello del PIL pro-capite. La nuvola con inclinazione più marcata è quella relativa ai paesi più poveri (che appartengono alle aree più “critiche”). Notiamo invece che la nuvola con inclinazione meno marcata è quella relativa ai paesi delle macroaree più “forti” e ai paesi più ricchi delle macroaree
18
Università Luigi Bocconi
Diagramma di dispersione: noto anche come “scatterplot”, è una rappresentazione grafica per coppie di caratteri quantitativi, costruita semplicemente riportando in un piano cartesiano tutte le coppie di modalità (la prima, relativa al primo carattere, in ascissa, la seconda in ordinata) rilevate sulle varie unità del collettivo in esame; appare quindi come una “nuvola” di punti. Fornisce una prima, fondamentale, descrizione della distribuzione congiunta dei due caratteri e quindi, in particolare, di quale sia il tipo ed il grado di associazione tra essi. Ad esempio, è immediato rilevare l’eventuale linearità nella associazione (punti distribuiti attorno ad una retta obliqua del piano), oppure un’associazione di tipo non lineare (la nuvola di punti ha forma di curva, ad esempio logaritmica o polinomiale). Al contrario, nuvole di punti senza alcun andamento particolare (distribuiti in maniera “casuale” nel piano) indicano scarsa associazione tra i caratteri. Il grafico di dispersione permette di rilevare facilmente eventuali outliers (osservazioni eccezionali).

più “deboli” (ad esempio, i paesi del medio oriente che appartengono a questo secondo gruppo sono Israele ed Emirati Arabi).
y = 0,0008x + 3,3569R2 = 0,4355
0
2
4
6
8
10
12
0 1000 2000 3000 4000 5000 6000 7000 8000
y = 9E-05x + 4,651R2 = 0,0936
0
1
2
3
4
5
6
7
8
9
0 5000 10000 15000 20000 25000
Di fianco sono riportati i diagrammi di dispersione relativi ai due gruppi. Questi due grafici confermano la sensazione iniziale: nei paesi con basso PIL pro-capite una variazione del PIL porta ad una variazione abbastanza marcata della differenza tra le attese di vita. Nei paesi con PIL pro-capite elevato, questa “reazione” è molto più tenue (si noti che la capacità esplicativa della retta di regressione in questo secondo caso è decisamente bassa: il coefficiente di determinazione R2= 0.09).
Di seguito riportiamo il coefficiente di correlazione lineare e gli indici di concordanza, l’indice tau di Kendall e il coefficiente di Spearman tra il PIL e le due differenze considerate. Con riferimento alla coppia PIL, differenza tra attese di vita, il coefficiente di correlazione risulta pari a 0.364, valore non è molto significativo, dal momento che risulta dall’aggregazione di strutture diverse di associazione.
PIL Diff. attese vita F-M
Diff. tasso di alfabetizz. M-F
PIL 1 .364 -.340 Diff. attese vita F-M .364 1 -.703 Pearson Correlation
Diff. tasso di alfabetizz. M-F -.340 -.703 1 PIL 1 .415 -.351
Diff. attese vita F-M .415 1 -.566 Kendall's tau_bDiff. tasso di alfabetizz. M-F -.351 -.566 1
PIL 1.000 .577 -.487 Diff. attese vita F-M .577 1.000 -.711 Spearman's rho
Diff. tasso di alfabetizz. M-F -.487 -.711 1.000 E’ anche interessante notare come sia elevato, e di segno negativo, il coefficiente di correlazione lineare tra la differenza tra le attese di vita e la differenza tra i tassi di alfabetizzazione; in realtà, l’analisi stratificata, per macroarea, riportata nel grafico di seguito, mostra come vi sia disomogeneità tra le macroaree stesse, con riferimento ai caratteri in esame.
19
Università Luigi Bocconi
Coefficiente di determinazione: in questo caso è un indicatore relativo della bontà della previsione di una variabile Y sulla base di una funzione lineare della variabile esplicativa, e coincide con il quadrato del coefficiente di correlazione lineare. R2 assume valori compresi tra 0 e 1, inclusi gli estremi. Il valore 1 corrisponde ad un errore di previsione nullo (i punti del grafico di dispersione giacciono tutti su una retta); il valore 0 corrisponde ad una previsione costante (effettuata senza tener conto della variabile esplicativa). R2 è dato dal rapporto tra la varianza spiegata dalla funzione lineare utilizzata per prevedere Y e la varianza di Y.
Università Luigi Bocconi
Coefficiente di correlazione lineare (: indice relativo del livello e del verso della relazione lineare tra due caratteri quantitativi. Può assumere valori compresi tra –1 e 1 (estremi inclusi). Valori positivi indicano relazione diretta (coppie di modalità concentrate intorno ad una retta di pendenza positiva), valori negativi associazione relazione inversa. Quanto più |(| è vicino a 1, tanto più è forte la relazione lineare; nel caso in cui |(| = 1, la relazione lineare è perfetta e i punti nel grafico di dispersione sono tutti allineati su una retta con pendenza positiva (risp. negativa). Se ( = 0 ciò non indica mancanza di associazione, ma mancanza di associazione lineare; potrebbero cioè essere presenti altri tipi di legame. E’ particolarmente sensibile alla presenza di coppie di valori anomali
Piccarreta
Note
Tau di Kendall e coefficiente di Spearman: Indicatori di concordanza per distribuzioni doppie, per dati qualitativi ordinali o quantitativi, basati sui ranghi. Le modalità di ognuno dei due caratteri vengono ordinate in modo crescente; ad ogni osservazione è assegnata la posizione occupata in ciascuna delle due sequenze ordinate. Vengono sostanzialmente create due graduatorie, una per ogni carattere. Si valuta quindi se le graduatorie sono concordanti (osservazioni che occupano le posizioni più elevate in una graduatoria occupano posizioni elevate anche nell’altra) o discordanti (osservazioni che occupano le posizioni più elevate in una graduatoria occupano posizioni basse nell’altra). Gli indici di concordanza assumono valori tra -1 e 1 (estremi inclusi). Il valore 1 indica che le due graduatorie sono perfettamente concordanti, mentre il valore -1 indica che le graduatorie sono perfettamente discordanti. Se utilizzati con riferimento a caratteri quantitativi, questi indicatori di concordanza risultano robusti, cioè piuttosto insensibili a valori estremi. Questo perché non si tiene conto dei valori effettivi, ma solo delle loro posizioni.
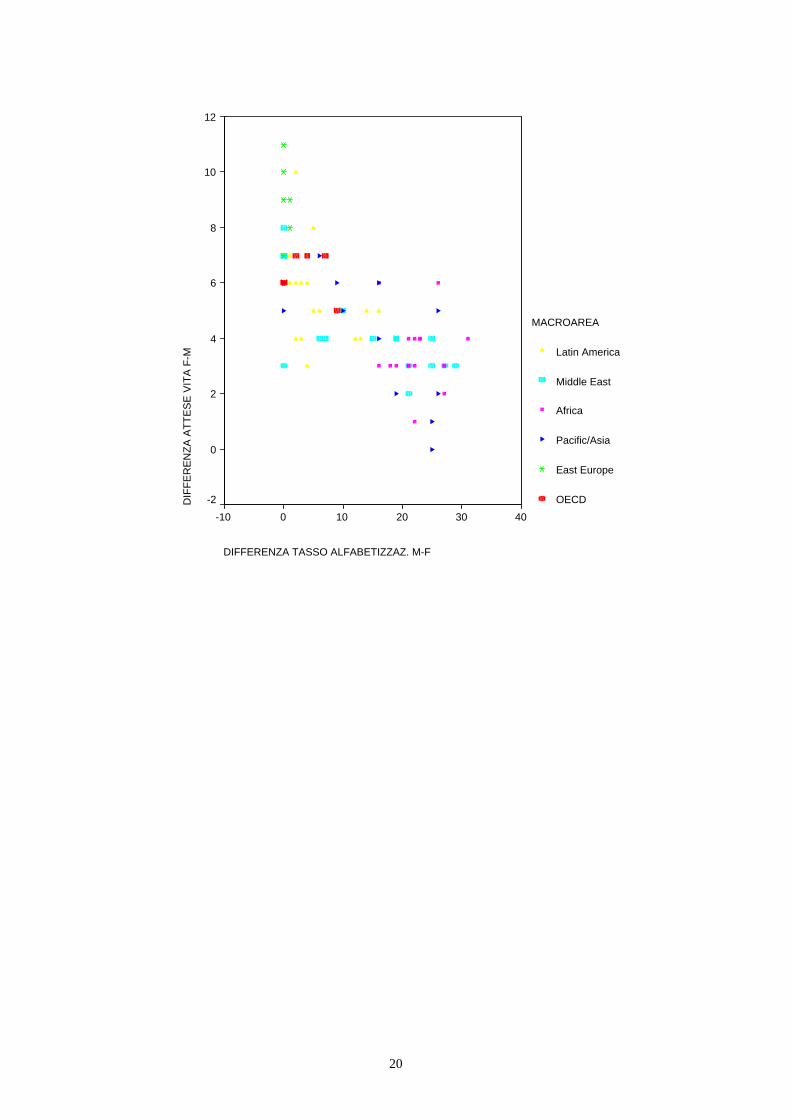
DIFFERENZA TASSO ALFABETIZZAZ. M-F
403020100-10
DIF
FER
EN
ZA A
TTE
SE
VIT
A F
-M
12
10
8
6
4
2
0
-2
MACROAREA
Latin America
Middle East
Africa
Pacific/Asia
East Europe
OECD
20
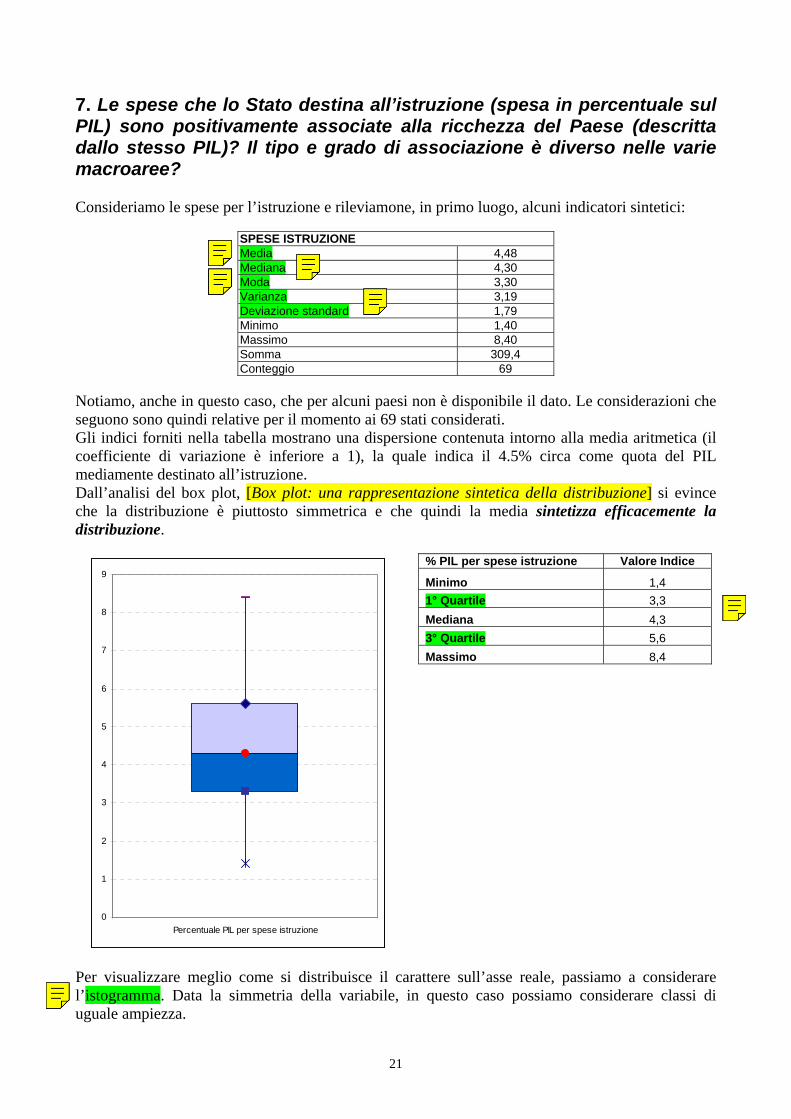
7. Le spese che lo Stato destina all’istruzione (spesa in percentuale sul PIL) sono positivamente associate alla ricchezza del Paese (descritta dallo stesso PIL)? Il tipo e grado di associazione è diverso nelle varie macroaree? Consideriamo le spese per l’istruzione e rileviamone, in primo luogo, alcuni indicatori sintetici:
SPESE ISTRUZIONE Media 4,48 Mediana 4,30 Moda 3,30 Varianza 3,19 Deviazione standard 1,79 Minimo 1,40 Massimo 8,40 Somma 309,4 Conteggio 69
Notiamo, anche in questo caso, che per alcuni paesi non è disponibile il dato. Le considerazioni che seguono sono quindi relative per il momento ai 69 stati considerati. Gli indici forniti nella tabella mostrano una dispersione contenuta intorno alla media aritmetica (il coefficiente di variazione è inferiore a 1), la quale indica il 4.5% circa come quota del PIL mediamente destinato all’istruzione. Dall’analisi del box plot, [Box plot: una rappresentazione sintetica della distribuzione] si evince che la distribuzione è piuttosto simmetrica e che quindi la media sintetizza efficacemente la distribuzione.
% PIL per spese istruzione Valore Indice
Minimo 1,4 1° Quartile 3,3 Mediana 4,3 3° Quartile 5,6 Massimo 8,4
0
1
2
3
4
5
6
7
8
9
Percentuale PIL per spese istruzione
Per visualizzare meglio come si distribuisce il carattere sull’asse reale, passiamo a considerare l’istogramma. Data la simmetria della variabile, in questo caso possiamo considerare classi di uguale ampiezza.
21
Università Luigi Bocconi
Media: indicatore di tendenza (o posizione) centrale, per dati quantitativi. E’ nota anche come centro di ordine 2, in quanto è il punto più “vicino” ai dati, rispetto alla distanza quadratica. Particolarmente sensibile ad eventuali valori estremi, è quindi da usare con cautela nel caso in cui vi siano, per il carattere considerato, valori isolati molto elevati o molto bassi.
Università Luigi Bocconi
Mediana: indicatore di tendenza (o posizione) centrale, per dati quantitativi oppure qualitativi ordinali. E’ il valore che, nella successione ordinata dei dati occupa la posizione centrale. Quindi il 50% delle osservazioni hanno un valore inferiore e il 50% un valore superiore alla mediana. Quando utilizzata per dati quantitativi, è nota anche come centro di ordine 1, in quanto risulta il punto più “vicino” ai dati, rispetto alla distanza usuale (euclidea). E’ un indicatore di posizione centrale “robusto” rispetto alla presenza di dati eccezionali, ovvero risente poco della presenza di valori anomali. Per questo motivo è preferibile alla media aritmetica per indicare la tendenza centrale di distribuzioni con queste caratteristiche.
Università Luigi Bocconi
Istogramma: grafico che riporta la distribuzione delle frequenze di un carattere quantitativo raggruppando le modalità in intervalli adiacenti. Nella sua costruzione è fondamentale la scelta degli intervalli (il loro numero, i loro estremi). Scelte semplici e convenzionali, ma non necessariamente ottimali per evidenziare le caratteristiche salienti della distribuzione, sono intervalli di uguale ampiezza oppure intervalli di uguale frequenza (con ampiezze generalmente diverse). Scelte diverse possono portare per gli stessi dati a istogrammi con caratteristiche anche molto diverse. Per la scelta del numero degli intervalli, occorre un compromesso tra sintesi e dettaglio: un numero troppo elevato di intervalli fornisce ovviamente maggiore dettaglio ma sintetizza meno la distribuzione, al contrario di ciò che accade se si sceglie un numero ridotto di intervalli.
Piccarreta
Note
Moda: è la modalità cui compete la più elevata frequenza relativa. E’ quindi la modalità che caratterizza la maggior parte delle unità statistiche. E’ una sintesi efficace quando la frequenza che le compete è elevata. E’ sensato calcolarla solo per caratteri che assumono un numero contenuto di modalità (quindi, non per caratteri continui, per i quali ogni unità statistica presenta una modalità diversa da tutte le altre).
Piccarreta
Note
Varianza: misura la dispersione di dati quantitativi intorno alla loro media. E’ la media degli scarti quadratici dalla media aritmetica. E’ nulla se e solo se i dati sono tutti coincidenti, altrimenti è positiva, tanto più grande quanto più i dati sono dispersi. Ha come unità di misura il quadrato dell’unità di misura del carattere e, anche per questo motivo, non è opportuno utilizzarla per confrontare la variabilità tra caratteri con unità di misura differente. E’ una misura poco robusta: tende ad accentuare gli scarti elevati dalla media. Lo scarto quadratico medio, detto anche deviazione standard, è la radice quadrata della varianza.
Piccarreta
Note
Quartili: sono 3 indicatori, calcolabili per dati quantitativi o qualitativi ordinali. Considerata la successione dei valori osservati disposti in ordine crescente, i quartili indicano i tre punti che dividono la distribuzione in quattro parti uguali. Ad esempio il 1° quartile è tale che il 25% della popolazione presenta un valore al di sotto e il restante 75% al di sopra di esso. Il 2° quartile è la mediana.
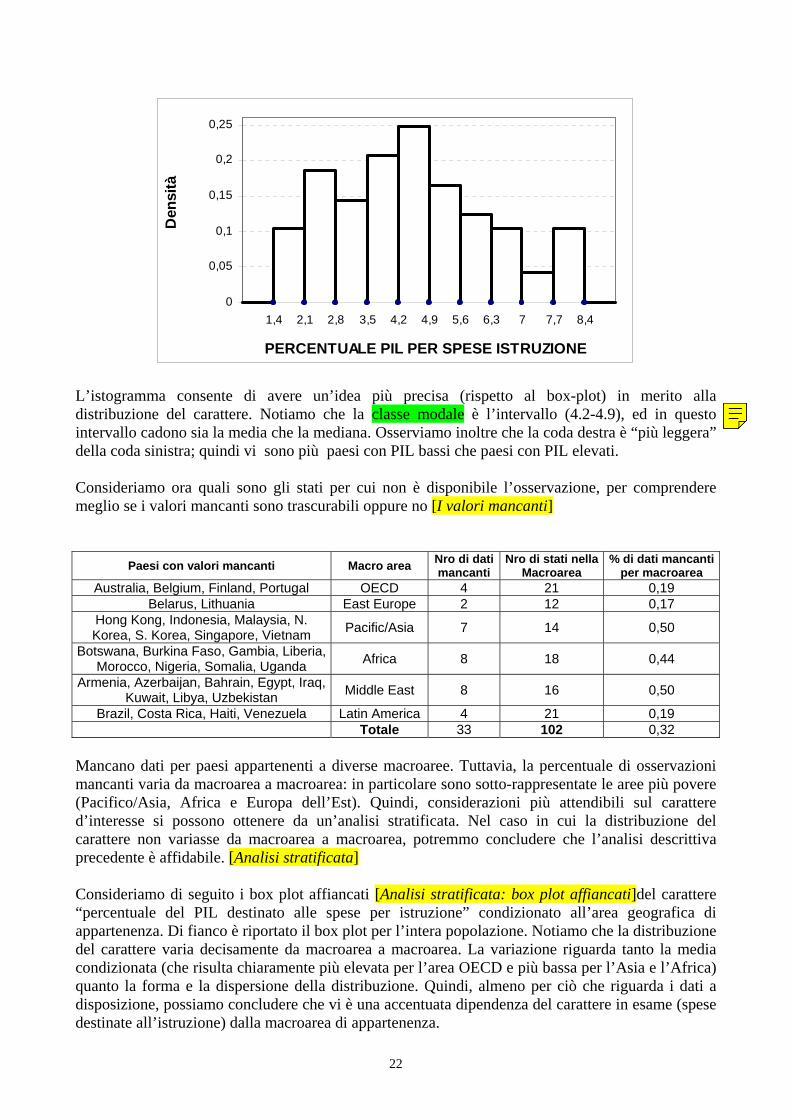
1,4 2,1 2,8 3,5 4,2 4,9 5,6 6,3 7 7,7 8,40
0,05
0,1
0,15
0,2
0,25
PERCENTUALE PIL PER SPESE ISTRUZIONE
Den
sità
L’istogramma consente di avere un’idea più precisa (rispetto al box-plot) in merito alla distribuzione del carattere. Notiamo che la classe modale è l’intervallo (4.2-4.9), ed in questo intervallo cadono sia la media che la mediana. Osserviamo inoltre che la coda destra è “più leggera” della coda sinistra; quindi vi sono più paesi con PIL bassi che paesi con PIL elevati. Consideriamo ora quali sono gli stati per cui non è disponibile l’osservazione, per comprendere meglio se i valori mancanti sono trascurabili oppure no [I valori mancanti]
Paesi con valori mancanti Macro area Nro di dati mancanti
Nro di stati nella Macroarea
% di dati mancanti per macroarea
Australia, Belgium, Finland, Portugal OECD 4 21 0,19 Belarus, Lithuania East Europe 2 12 0,17
Hong Kong, Indonesia, Malaysia, N. Korea, S. Korea, Singapore, Vietnam Pacific/Asia 7 14 0,50
Botswana, Burkina Faso, Gambia, Liberia, Morocco, Nigeria, Somalia, Uganda Africa 8 18 0,44
Armenia, Azerbaijan, Bahrain, Egypt, Iraq, Kuwait, Libya, Uzbekistan Middle East 8 16 0,50
Brazil, Costa Rica, Haiti, Venezuela Latin America 4 21 0,19 Totale 33 102 0,32
Mancano dati per paesi appartenenti a diverse macroaree. Tuttavia, la percentuale di osservazioni mancanti varia da macroarea a macroarea: in particolare sono sotto-rappresentate le aree più povere (Pacifico/Asia, Africa e Europa dell’Est). Quindi, considerazioni più attendibili sul carattere d’interesse si possono ottenere da un’analisi stratificata. Nel caso in cui la distribuzione del carattere non variasse da macroarea a macroarea, potremmo concludere che l’analisi descrittiva precedente è affidabile. [Analisi stratificata] Consideriamo di seguito i box plot affiancati [Analisi stratificata: box plot affiancati]del carattere “percentuale del PIL destinato alle spese per istruzione” condizionato all’area geografica di appartenenza. Di fianco è riportato il box plot per l’intera popolazione. Notiamo che la distribuzione del carattere varia decisamente da macroarea a macroarea. La variazione riguarda tanto la media condizionata (che risulta chiaramente più elevata per l’area OECD e più bassa per l’Asia e l’Africa) quanto la forma e la dispersione della distribuzione. Quindi, almeno per ciò che riguarda i dati a disposizione, possiamo concludere che vi è una accentuata dipendenza del carattere in esame (spese destinate all’istruzione) dalla macroarea di appartenenza.
22
Università Luigi Bocconi
Classe modale: in un istogramma è l’intervallo cui compete la massima densità di frequenza. (il rettangolo più “alto” nel grafico).
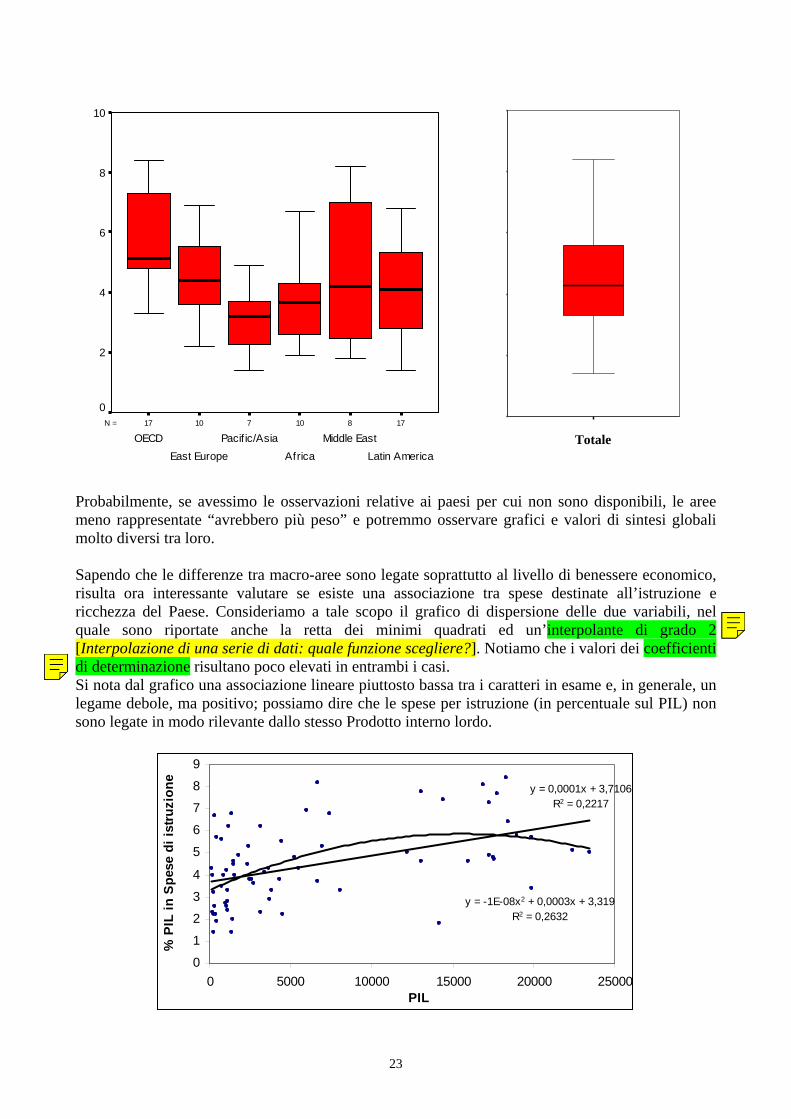
1781071017N =
Latin AmericaMiddle East
AfricaPacif ic/Asia
East EuropeOECD
10
8
6
4
2
0
Totale
Probabilmente, se avessimo le osservazioni relative ai paesi per cui non sono disponibili, le aree meno rappresentate “avrebbero più peso” e potremmo osservare grafici e valori di sintesi globali molto diversi tra loro. Sapendo che le differenze tra macro-aree sono legate soprattutto al livello di benessere economico, risulta ora interessante valutare se esiste una associazione tra spese destinate all’istruzione e ricchezza del Paese. Consideriamo a tale scopo il grafico di dispersione delle due variabili, nel quale sono riportate anche la retta dei minimi quadrati ed un’interpolante di grado 2 [Interpolazione di una serie di dati: quale funzione scegliere?]. Notiamo che i valori dei coefficienti di determinazione risultano poco elevati in entrambi i casi. Si nota dal grafico una associazione lineare piuttosto bassa tra i caratteri in esame e, in generale, un legame debole, ma positivo; possiamo dire che le spese per istruzione (in percentuale sul PIL) non sono legate in modo rilevante dallo stesso Prodotto interno lordo.
y = 0,0001x + 3,7106R2 = 0,2217
y = -1E-08x2 + 0,0003x + 3,319R2 = 0,2632
0
1
2
3
4
5
6
7
8
9
0 5000 10000 15000 20000 25000PIL
% P
IL in
Spe
se d
i ist
ruzi
one
23
Università Luigi Bocconi
Regressione quadratica: è il polinomio di grado 2 della variabile esplicativa, a + bx + cx2 che interpola al meglio la nuvola di punti. E’ quindi la funzione quadratica che massimizza il coefficiente di determinazione R2 (nella famiglia di tutti i polinomi di grado 2 della variabile esplicativa). Ciò significa che minimizza la somma dei quadrati degli errori tra le modalità osservate della variabile dipendente e quelle previste utilizzando il polinomio.
Università Luigi Bocconi
Coefficiente di determinazione: Indicatore relativo della bontà della previsione di una variabile Y sulla base di una funzione della variabile esplicativa (non necessariamente lineare). Assume valori compresi tra 0 e 1, inclusi gli estremi. La funzione utilizzata per la previsione è rappresentata da una curva nel piano. Il valore 1 corrisponde ad un errore di previsione nullo (ovvero, i punti del grafico di dispersione giacciono tutti sulla curva); il valore 0 corrisponde ad una previsione costante (ovvero, effettuata senza tener conto della variabile esplicativa). Il coefficiente di determinazione si ottiene come rapporto tra la varianza (o devianza) spiegata dalla funzione utilizzata per prevedere Y e quella totale. E’ utile confrontare i coefficienti di determinazione relativi a previsioni effettuate sulla base di variabili esplicative diverse, oppure relativi a funzioni diverse (lineari, quadratiche, logaritmiche, ecc.) della stessa variabile esplicativa. La scelta, a parità di altre condizioni, cadrà sulla previsione con coefficiente di determinazione maggiore.







![LA FRATERNITÁ EVANGELICA IN UN MONDO … · Web viewLa vita fraterna intende rispecchiare la profondità e la ricchezza di tale mistero [della Chiesa-comunione] configurandosi come](https://static.fdocumenti.com/doc/165x107/5c6be2fa09d3f2ff0e8c1857/la-fraternita-evangelica-in-un-mondo-web-viewla-vita-fraterna-intende-rispecchiare.jpg)










