
Prova di martedì 24 novembre 2015 - andreadd.it · Per la minuta si utilizzino le pagine bianche...
24
Politecnico di Milano Dip. di Elettronica, Informazione e Bioingegneria prof.ssa Anna Antola prof. Luca Breveglieri prof. Roberto Negrini prof. Giuseppe Pelagatti prof.ssa Donatella Sciuto prof.ssa Cristina Silvano AXO – Architettura dei Calcolatori e Sistemi Operativi Prova di martedì 24 novembre 2015 Cognome ________________________ Nome _______________________ Matricola _____________________ Firma ___________________________ Istruzioni Si scriva solo negli spazi previsti nel testo della prova e non si separino i fogli. Per la minuta si utilizzino le pagine bianche inserite in fondo al fascicolo distribuito con il testo della pro- va. I fogli di minuta, se staccati, vanno consegnati intestandoli con nome e cognome. È vietato portare con sé libri, eserciziari e appunti, nonché cellulari e altri dispositivi mobili di calcolo o comunicazione. Chiunque fosse trovato in possesso di documentazione relativa al corso – anche se non strettamente attinente alle domande proposte – vedrà annullata la propria prova. Non è possibile lasciare l’aula conservando il tema della prova in corso. Tempo a disposizione 2 h : 00 m Valore indicativo di domande ed esercizi, voti parziali e voto finale: esercizio 1 (5 punti) _________________________ esercizio 2 (2 punti) _________________________ esercizio 3 (4 punti) _________________________ esercizio 4 (2,5 punti) _________________________ esercizio 5 (2,5 punti) _________________________ voto finale: (16 punti) ______________________ CON SOLUZIONI (in corsivo)
Transcript of Prova di martedì 24 novembre 2015 - andreadd.it · Per la minuta si utilizzino le pagine bianche...

Politecnico di Milano Dip. di Elettronica, Informazione e Bioingegneriaprof.ssa Anna Antola prof. Luca Breveglieri prof. Roberto Negrini
prof. Giuseppe Pelagatti prof.ssa Donatella Sciuto prof.ssa Cristina Silvano
AXO – Architettura dei Calcolatori e Sistemi Operativi
Prova di martedì 24 novembre 2015
Cognome ________________________ Nome _______________________
Matricola _____________________ Firma ___________________________
Istruzioni Si scriva solo negli spazi previsti nel testo della prova e non si separino i fogli.
Per la minuta si utilizzino le pagine bianche inserite in fondo al fascicolo distribuito con il testo della pro-va. I fogli di minuta, se staccati, vanno consegnati intestandoli con nome e cognome.
È vietato portare con sé libri, eserciziari e appunti, nonché cellulari e altri dispositivi mobili di calcolo o comunicazione. Chiunque fosse trovato in possesso di documentazione relativa al corso – anche se non strettamente attinente alle domande proposte – vedrà annullata la propria prova.
Non è possibile lasciare l’aula conservando il tema della prova in corso.
Tempo a disposizione 2 h : 00 m
Valore indicativo di domande ed esercizi, voti parziali e voto finale:
esercizio 1 (5 punti) _________________________
esercizio 2 (2 punti) _________________________
esercizio 3 (4 punti) _________________________
esercizio 4 (2,5 punti) _________________________
esercizio 5 (2,5 punti) _________________________
voto finale: (16 punti) ______________________
CON SOLUZIONI (in corsivo)

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 2 di 24
esercizio n. 1 – traduzione da C ad assembler
Si deve tradurre in linguaggio macchina simbolico (assemblatore) MIPS il frammento di programma C ripor-tato sotto. Il modello di memoria è quello standard MIPS e le variabili intere sono da 32 bit. Non si tenti di accorpare od ottimizzare insieme istruzioni C indipendenti. Si facciano le ipotesi seguenti:
il registro “frame pointer” fp non è in uso
le variabili locali sono allocate nei registri, se possibile
vanno salvati (a cura del chiamante o del chiamato, secondo il caso) solo i registri necessari
Si chiede di svolgere i cinque punti seguenti (usando le varie tabelle predisposte nel seguito):
1. Si descriva il segmento dei dati statici, dando anche gli spiazzamenti delle variabili globali rispetto al re-gistro global pointer gp, e si traducano in linguaggio macchina le dichiarazioni delle variabili globali.
2. Si traduca in linguaggio macchina il codice del programma principale main. 3. Si descrivano l’area di attivazione della funzione search e l’allocazione delle variabili locali di search nei
registri. 4. Si traduca in linguaggio macchina il codice della funzione search. 5. Supponendo che il vettore num sia inizializzato con gli elementi num [0] = 5, num [1] = 6, num [2] = 5
e num [3] = 7, si descriva la struttura della pila, indicando gli indirizzi e i valori (se possibile) delle varie celle di pila, nonché il contenuto dei registri indicati e il loro significato simbolico, subito prima dell’esecuzione dell’istruzione macchina jal RECODE (ossia la chiamata alla funzione recode) nella prima iterazione del ciclo for della funzione search.
/ sezione dichiarativa variabili globali /
#define N 4 int res = 100; int pos = NULL; int num [N];
int recode (int cod); / testata funzione recode /
int search (int val) / funzione search / int i;
int p; p = &pos;
for (i = N 1; i >= 0; i)
p = recode (num [i]); / for / return (i + val);
/ search /
void main ( ) / programma principale /
res = num [1] search (num [0]) + 20; / main /
AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 3 di 24
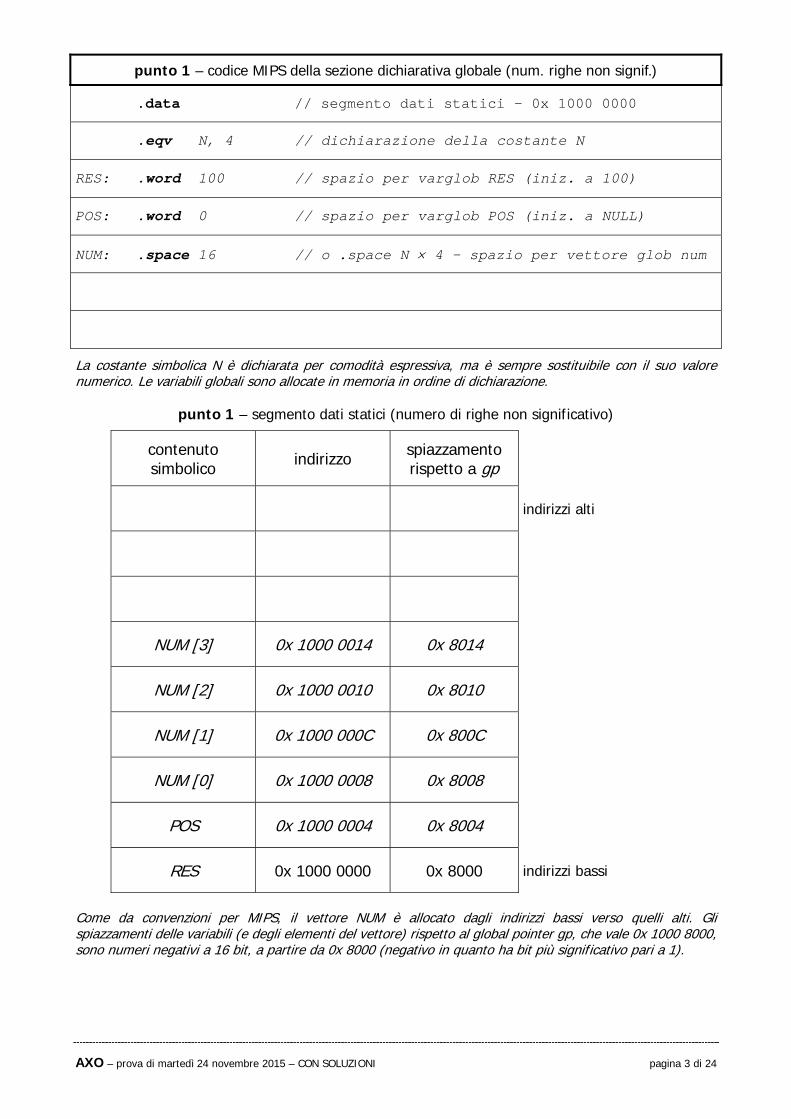
punto 1 – codice MIPS della sezione dichiarativa globale (num. righe non signif.)
.data // segmento dati statici – 0x 1000 0000
.eqv N, 4 // dichiarazione della costante N
RES: .word 100 // spazio per varglob RES (iniz. a 100)
POS: .word 0 // spazio per varglob POS (iniz. a NULL)
NUM: .space 16 // o .space N 4 – spazio per vettore glob num
La costante simbolica N è dichiarata per comodità espressiva, ma è sempre sostituibile con il suo valore numerico. Le variabili globali sono allocate in memoria in ordine di dichiarazione.
punto 1 – segmento dati statici (numero di righe non significativo)
contenuto simbolico indirizzo spiazzamento
rispetto a gp
indirizzi alti
NUM [3] 0x 1000 0014 0x 8014
NUM [2] 0x 1000 0010 0x 8010
NUM [1] 0x 1000 000C 0x 800C
NUM [0] 0x 1000 0008 0x 8008
POS 0x 1000 0004 0x 8004
RES 0x 1000 0000 0x 8000 indirizzi bassi
Come da convenzioni per MIPS, il vettore NUM è allocato dagli indirizzi bassi verso quelli alti. Gli spiazzamenti delle variabili (e degli elementi del vettore) rispetto al global pointer gp, che vale 0x 1000 8000, sono numeri negativi a 16 bit, a partire da 0x 8000 (negativo in quanto ha bit più significativo pari a 1).

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 4 di 24
punto 2 – codice MIPS di main (num. righe non signif.)
.text // segmento testo – 0x 0040 0000
MAIN: la $t0, NUM // carica indirizzo vettore NUM
lw $t1, 4($t0) // carica elem NUM [1] per calcolo espr.
la $t0, NUM // (ri)carica indirizzo vettore NUM
lw $a0, 0($t0) // carica elem NUM [0] come arg di SEARCH
addiu $sp, $sp, -4 // inizia push
sw $t1, ($sp) // push t1 (per poi continuare calcolo espr.)
jal SEARCH // chiama funz SEARCH
lw $t1, ($sp) // pop t1 (per riprendere calcolo espr.)
addiu $sp, $sp, 4 // finisci pop
sub $t1, $t1, $v0 // calcola differenza NUM[1] – search(NUM[0])
li $t2, 20 // carica cost 20
add $t1, $t1, $t2 // calcola somma ... + 20
sw $t1, RES // aggiorna varglob RES
syscall // chiamata al SO per exit
Ecco alcune ottimizzazioni possibili:
Evita di ripetere la $t0, NUM per calcolare ind di elem NUM [0].
Ottimizzazione di li $t2, 20 e add $t1, $t1, $t2:
addi $t1, $t1, 20 // calcola somma
poiché la costante 20 è codificabile in 16 bit (reg t2 non serve più).
Nota: sw $t1, RES è una pseudo-istruzione per sw $t1, RES($gp);
il collegatore (linker) risolverà il simbolo RES come spiazzamento a 16
bit della varglob RES rispetto al registro $gp (vedi punto 1).

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 5 di 24
Il MAIN non ha variabili locali, pertanto non usa i registri di tipo “s” (callee-saved), che nel modello di traduzione da C ad assemblatore illustrato a lezione sono riservati appunto per eventuali variabili locali.
Si usano tre registri di tipo “t” (temporary o caller-saved): t0 per accedere agli elementi del vettore NUM, t1 e t2 per calcolare l’espressione. Poiché gli accessi agli elementi del vettore NUM sono tutti con indice costante (NUM [0] e NUM [1]), si usa il registro t0 come puntatore con spiazzamento opportunamente allineato (ossia si moltiplica l’indice costante per 4 e si hanno gli spiazzamenti 0 e 4, rispettivamente). Naturalmente, dato che l’espressione chiama la funzione SEARCH, a un certo punto nel calcolo entra anche il registro v0 riservato per il valore in uscita alla funzione.
L’espressione è calcolata da sinistra verso destra tramite l’algoritmo illustrato a lezione, caricando variabili e costanti nei registri di tipo “t” quando esse vengono usate. Pertanto il registro t1 viene salvato prima di chiamare la funzione SEARCH, per riaverlo inalterato al rientro e così continuare il calcolo dell’espressione (vedi algoritmo di calcolo delle espressioni), non sapendosi al momento della generazione del codice di MAIN se le funzioni che MAIN chiamerà (SEARCH e all’interno di questa RECODE) andranno poi a modificarlo, e d’altra parte avendone MAIN bisogno più avanti per portare a termine il calcolo dell’espressione.
Si noti che la codifica data poi di SEARCH in effetti usa il registro t1 per allineare l’indice I (si veda il punto 4), per cui il salvataggio di t1 effettuato da parte di MAIN prima di chiamare SEARCH è davvero necessario. Invece, a MAIN non occorre salvare il registro t0 poiché non lo usa più dopo il rientro da SEARCH.
Si osservi l’istruzione “sw” finale, qui usata come pseudo-istruzione in quanto si sottintende che l’argomento RES sia lo spiazzamento della variabile globale RES rispetto al global pointer gp. Sono usate anche la pseudo-istruzione “la”. (load address), per caricare l’indirizzo iniziale (a 32 bit) del vettore NUM, e la pseudo-istruzione “li” (load immediate), per caricare la costante 20 (a 32 bit).
Si può ottimizzare un po’, come indicato nella tabella. Ecco qui di seguito il codice ottimizzato: oltre alle ottimizzazioni indicate prima, tutte le pseudo-istruzioni rimaste sono espanse in istruzioni native.
punto 2 – codice MIPS di main (num. righe non signif.) - OTTIMIZZATO
.text // segmento testo – 0x 0040 0000
MAIN: lui $t0, NUM // carica ind vet NUM (16 bit più signif.)
addiu $t0, $t0, NUM // carica ind vet NUM (16 bit meno signif.)
lw $t1, 4($t0) // carica elem NUM [1] per calcolo espr.
lw $a0, 0($t0) // carica elem NUM [0] come arg di SEARCH
addiu $sp, $sp, -4 // inizia push
sw $t1, ($sp) // push t1 (per poi continuare calcolo espr.)
jal SEARCH // chiama funz SEARCH
lw $t1, ($sp) // pop t1 (per riprendere calcolo espr.)
addiu $sp, $sp, 4 // finisci pop
sub $t1, $t1, $v0 // calcola differenza NUM[1] – search(NUM[0])
addi $t1, $t1, 20 // calcola somma ... + 20
sw $t1, RES($gp) // aggiorna varglob RES
syscall // chiamata al SO per exit

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 6 di 24
Un’ultima osservazione, marginale: se invece di usare il registro temporaneo t1 (caller-saved), si usasse il registro s0 (callee-saved), non occorrerebbe salvare questo registro s0 in pila prima di chiamare la funzione SEARCH, poiché, secondo il modello di traduzione C-assembler illustrato a lezione, lo farebbe la funzione stessa, se usasse tale registro per una sua variabile locale (come in effetti poi fa). Ecco dunque il risultato di questa ottimizzazione:
punto 2 – codice MIPS di main (num. righe non signif.) - SUPEROTTIMIZZATO
.text // segmento testo – 0x 0040 0000
MAIN: lui $t0, NUM // carica ind vet NUM (16 bit più signif.)
addiu $t0, $t0, NUM // carica ind vet NUM (16 bit meno signif.)
lw $s0, 4($t0) // carica elem NUM [1] per calcolo espr.
lw $a0, 0($t0) // carica elem NUM [0] come arg di SEARCH
jal SEARCH // chiama funz SEARCH
sub $s0, $s0, $v0 // calcola differenza NUM[1] – search(NUM[0])
addi $s0, $s0, 20 // calcola somma ... + 20
sw $s0, RES($gp) // aggiorna varglob RES
syscall // chiamata al SO per exit
Tuttavia, così facendo, rispetto al modello di traduzione da C-assembler illustrato a lezione, si suppone di avere modificato il codice C del programma MAIN, dotandolo di una variabile locale “espr” di tipo intero allocata nel registro s0, per spezzare il calcolo dell’assegnamento “res = NUM [1] + search (NUM [0]) – 20”:
void main ( )
int espr;
espr = NUM[1];
espr = espr – search (NUM [0]);
espr = espr + 20
res = espr;
Una simile ottimizzazione opera addirittura sul programma MAIN ad alto livello. Comunque essa è corretta ed è alla portata di certi compilatori C fortemente ottimizzanti e specificamente orientati a linguaggi macchina di tipo MIPS, ma esula degli interessi del corso AXO.

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 7 di 24
punto 3 – area e registri di search (numero di righe non significativo)
area di attivazione di search
contenuto simbolico spiazz. rispettoa stack pointer
ra 8 indirizzi alti
s0 (reg di MAIN salvato da SEARCH) 4
s1 (reg di MAIN salvato da SEARCH) 0 sp a0 (argomento VAL di SEARCH salvato
subito prima di chiamare RECODE) max estensione della pila in SEARCH
indirizzi bassi
Dato che la funzione SEARCH non è di tipo foglia (infatti chiama la funzione RECODE), il registro ra (return address) va salvato nell’area di attivazione di SEARCH come primo elemento.
I valori dei registri s0 e s1 nel contesto del programma chiamante MAIN vanno salvati nell’area di attivazione della funzione chiamata SEARCH a cura di SEARCH stessa, pertanto i loro valori salvati hanno spazio nell’area. Le variabili locali I e P di SEARCH sono allocate nei registri s0 e s1, poiché sono rispettivamente di tipo scalare e puntatore (cioè non sono strutturate) e non vengono riferite per indirizzo (a nessuna delle due è mai applicato l’operatore di indirizzo “&”); pertanto esse NON hanno spazio riservato nell’area.
Come si vedrà poi dal codice, la funzione SEARCH dovrà salvare in pila il registro a0, contenente il suo argomento VAL, prima di chiamare la funzione RECODE, e ripristinarlo subito dopo il rientro da RECODE, poiché utilizza il suo argomento VAL dopo essere rientrata da RECODE. Il registro a0 verrà dunque messo sulla pila in cima all’area di attivazione di SEARCH, ma non fa parte dell’area, la quale comprende soltanto i tre elementi ra, s0 e s1. Nella figura sopra l’elemento a0 è mostrato solo per chiarezza.
allocazione delle variabili locali di search nei registri
variabile locale registro
I (tipo intero) s0
P (tipo puntatore) s1
La funzione SEARCH utilizza i due registri “callee-saved” s0 e s1 per le sue due varloc I e P, rispettivamente di tipo scalare e puntatore, e dunque deve salvare in pila questi due registri all’inizio e ripristinarli alla fine.
La funzione SEARCH non deve salvare gli altri registri del blocco “s”, poiché non ne fa alcun uso.
AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 8 di 24
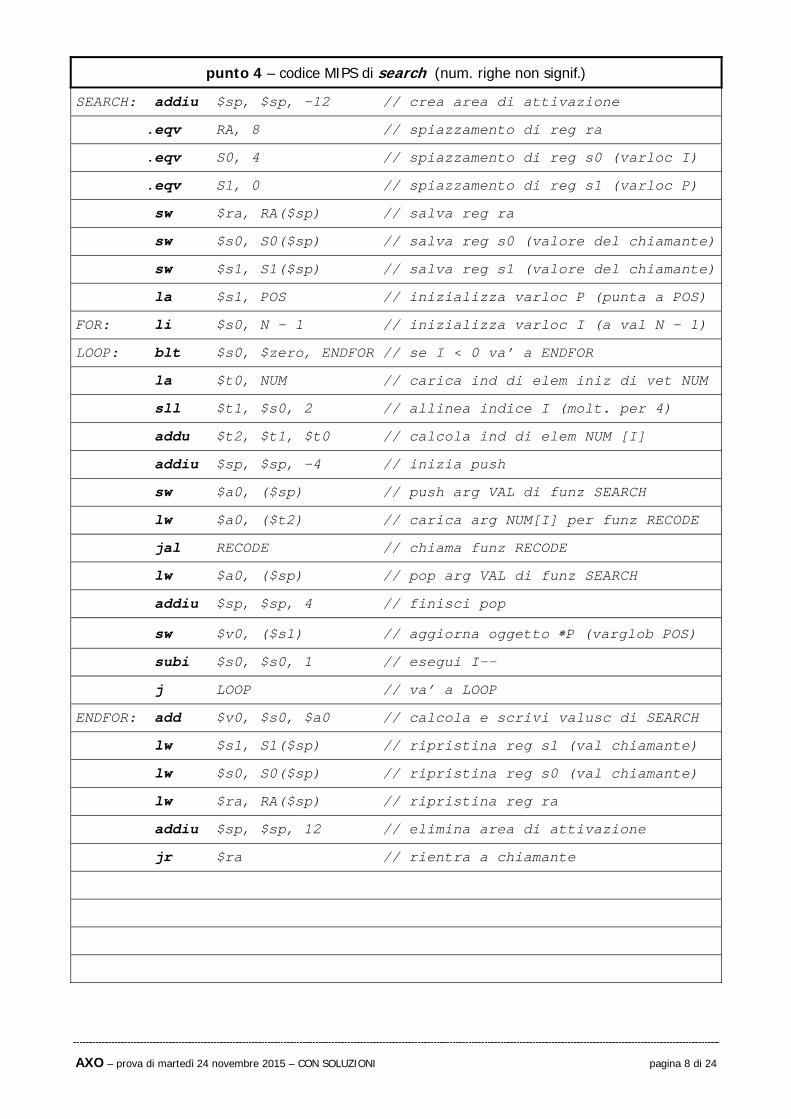
punto 4 – codice MIPS di search (num. righe non signif.)
SEARCH: addiu $sp, $sp, -12 // crea area di attivazione
.eqv RA, 8 // spiazzamento di reg ra
.eqv S0, 4 // spiazzamento di reg s0 (varloc I)
.eqv S1, 0 // spiazzamento di reg s1 (varloc P)
sw $ra, RA($sp) // salva reg ra
sw $s0, S0($sp) // salva reg s0 (valore del chiamante)
sw $s1, S1($sp) // salva reg s1 (valore del chiamante)
la $s1, POS // inizializza varloc P (punta a POS)
FOR: li $s0, N – 1 // inizializza varloc I (a val N – 1)
LOOP: blt $s0, $zero, ENDFOR // se I < 0 va’ a ENDFOR
la $t0, NUM // carica ind di elem iniz di vet NUM
sll $t1, $s0, 2 // allinea indice I (molt. per 4)
addu $t2, $t1, $t0 // calcola ind di elem NUM [I]
addiu $sp, $sp, -4 // inizia push
sw $a0, ($sp) // push arg VAL di funz SEARCH
lw $a0, ($t2) // carica arg NUM[I] per funz RECODE
jal RECODE // chiama funz RECODE
lw $a0, ($sp) // pop arg VAL di funz SEARCH
addiu $sp, $sp, 4 // finisci pop
sw $v0, ($s1) // aggiorna oggetto P (varglob POS)
subi $s0, $s0, 1 // esegui I--
j LOOP // va’ a LOOP
ENDFOR: add $v0, $s0, $a0 // calcola e scrivi valusc di SEARCH
lw $s1, S1($sp) // ripristina reg s1 (val chiamante)
lw $s0, S0($sp) // ripristina reg s0 (val chiamante)
lw $ra, RA($sp) // ripristina reg ra
addiu $sp, $sp, 12 // elimina area di attivazione
jr $ra // rientra a chiamante

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 9 di 24
Si dichiarano le tre costanti di spiazzamento degli elementi dell’area di attivazione di SEARCH: RA, S0 e S1 (si veda il punto 3). I registri s0 e s1 “callee-saved”, dopo l’avvenuto salvataggio, contengono le varloc I e P, rispettivamente.
Si usano tre registri temporanei “caller-saved”: t0, t1 e t2. Il registro t0 è usato come puntatore al (primo elemento del) vettore NUM; il registro t1 è usato per elaborare la varloc I (in particolare per l’allineamento dell’indice); e il registro t2 è usato come puntatore all’elemento NUM [I] del vettore.
Il registro a0 contiene l’argomento VAL della funzione SEARCH. Nel corso di SEARCH il registro a0 viene usato anche per l’argomento della funzione RECODE. L’argomento VAL di SEARCH è usato dopo il rientro dalla chiamata a RECODE, pertanto il registro a0 va salvato in pila (così estendendo la pila oltre l’area di SEARCH) prima di chiamare la funzione RECODE (ossia prima di scrivere in a0 quello che sarà l’argomento passato a RECODE), e va ripristinato subito dopo il rientro da RECODE.
Per elaborare gli indirizzi si usa l’aritmetica di tipo unsigned (dunque le istruzioni con il suffisso u), mentre per elaborare le variabili o gli elementi di tipo intero si usa l’aritmetica di tipo signed (dunque le istruzioni senza il suffisso u).
Si noti che l’espressione “N – 1” nella pseudo-istruzione “li $s0, N – 1” è statica, cioè l’assemblatore la può risolvere direttamente in fase di assemblaggio (prima del collegamento) dandole valore 3. In pratica la pseudo-istruzione in questione viene espansa subito come “li, $s0, 3”. Al riguardo, si ricordi che dichiarare in assemblatore una costante con la direttiva “.eqv” è del tutto analogo a definire in C una costante con “#define”.
Qua e là sono usate anche pseudo-istruzioni: “li” (load immediate), “la” (load address), “blt” (branch less than) e “subi” (subtract immediate).

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 10 di 24
A titolo puramente informativo, ecco una versione ottimizzata della funzione SEARCH, estraendo dal ciclo FOR istruzioni che non necessitano di essere ripetute, e senza direttive e pseudo-istruzioni.
punto 4 – codice MIPS di search (num. righe non signif.) - OTTIMIZZATO
SEARCH: addiu $sp, $sp, -12 // crea area di attivazione
sw $ra, 8($sp) // salva reg ra
sw $s0, 4($sp) // salva reg s0 (valore del chiamante)
sw $s1, 0($sp) // salva reg s1 (valore del chiamante)
lui $s1, POS // iniz varloc P (16 bit più signif.)
addi $s1, $s1, POS // iniz varloc P (16 bit meno signif.)
FOR: addi $s0, $zero, N – 1 // inizializza varloc I (a val N – 1)
lui $t0, NUM // carica ind vet NUM (16 bit più...)
addi $t0, $t0, NUM // carica ind vet NUM (16 bit meno...)
addiu $sp, $sp, -4 // inizia push
sw $a0, ($sp) // push arg VAL di funz SEARCH
LOOP: slt $at, $s0, $zero // se I < 0 at = 1 altrimenti at = 0
bne $at, $zero, ENDFOR // se I < 0 va’ a ENDFOR
sll $t1, $s0, 2 // allinea indice I (molt. per 4)
addu $t2, $t1, $t0 // calcola ind di elem NUM [I]
lw $a0, ($t2) // carica arg NUM[I] per funz RECODE
jal RECODE // chiama funz RECODE
sw $v0, ($s1) // aggiorna oggetto P (varglob POS)
addi $s0, $s0, -1 // esegui I--
j LOOP // va’ a LOOP
lw $a0, ($sp) // pop arg VAL di funz SEARCH
addiu $sp, $sp, 4 // finisci pop
ENDFOR: add $v0, $s0, $a0 // calcola e scrivi valusc di SEARCH
lw $s1, 0($sp) // ripristina reg s1 (val chiamante)
lw $s0, 4($sp) // ripristina reg s0 (val chiamante)
lw $ra, 8($sp) // ripristina reg ra
addiu $sp, $sp, 12 // elimina area di attivazione
jr $ra // rientra a chiamante

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 11 di 24
Le due ottimizzazioni più importanti riducono la lunghezza del corpo del ciclo, e tale modo lo accelerano. Dal ciclo sono stati estratti: il caricamento dell’indirizzo iniziale del vettore NUM, e le operazioni di push e pop dell’argomento VAL di SEARCH contenuto nel registro a0, da effettuare perché la funzione SEARCH usa il suo argomento VAL dopo il rientro dalla funzione RECODE (si vedano le discussioni ai punti precedenti).
Si badi bene che estrarre dal ciclo FOR le operazioni push e pop dette prima, significa allontanarle dal punto di chiamata alla funzione RECODE (l’istruzione “jal RECODE”). È un’operazione potenzialmente distruttiva, da valutare con MOLTA attenzione. Infatti push e pop modificano il registro sp, che così non punta più alla vera cima dell’area di attivazione di SEARCH, e dunque INVALIDANO l’uso degli spiazzamenti definiti in fase di progetto dell’area stessa. Insomma le eventuali istruzioni interposte tra push/pop e “jal RECODE”, che accedessero agli elementi dell’area di attivazione tramite il registro sp e i loro spiazzamenti, ne potrebbero soffrire. Qui l’estrazione di push e pop è resa possibile dal fatto che il corpo del ciclo NON accede a elementi dell’area, e dunque si può consentire senza danno di modificare temporaneamente il registro sp. In altre circostanze tale estrazione, seppure magari utile, non sarebbe possibile, o sarebbe assai difficoltosa.
Commento: simili considerazioni riguardano le operazioni push e pop di tutti i registri “caller-saved”, (di tipo “t”, “a” e “v”) che si potrebbero trovare subito prima e subito dopo la chiamata a una funzione. Allontanare queste push e pop dal punto di chiamata, impatta sul registro sp e potenzialmente danneggia le istruzioni interposte. In tali casi si potrebbe valutare l’uso del registro fp (frame pointer) come riferimento fisso all’area di attivazione. Tuttavia simili ottimizzazioni complicate esulano degli interessi del corso AXO.
La costante N – 1 è data come espressione statica immediatamente risolubile in fase di assemblaggio (senza aspettare il collegamento), e poiché vale 3, è codificabile con solo 16 bit; pertanto viene caricata con l’istruzione “addi” (che ha operando immediato da 16 bit) invece che con la pseudo-istruzione “li” (costanti a 32 bit). Invece gli indirizzi POS e NUM sono trattati a 32 bit come noto, dato che il collegatore (linker) li potrebbe rilocare, con la nota coppia di istruzioni native “lui” e “addi” (o anche “ori”).
Si noti l’espansione della pseudo-istruzione “blt”, ottenuta con la coppia di istruzioni native “slt” e “bne”, che si scambiano informazione (cioè l’esito del confronto) mediante il registro at. Nell’espansione di pseudo-istruzioni si fa uso del registro at (assembler temporary), riservato appunto come registro temporaneo utile per espandere certe pseudo-istruzioni. Il valore di at è significativo solo per la sequenza di istruzioni native che espande una pseudo-istruzione. Fuori da tale sequenza il registro at non è significativo, e non ci si aspetta che il suo valore venga preservato. Tale registro è usato solo per l’espansione di (certe) pseudo-istruzioni, e ogni altro uso diverso da questo è vietato o fortemente sconsigliato.
AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 12 di 24
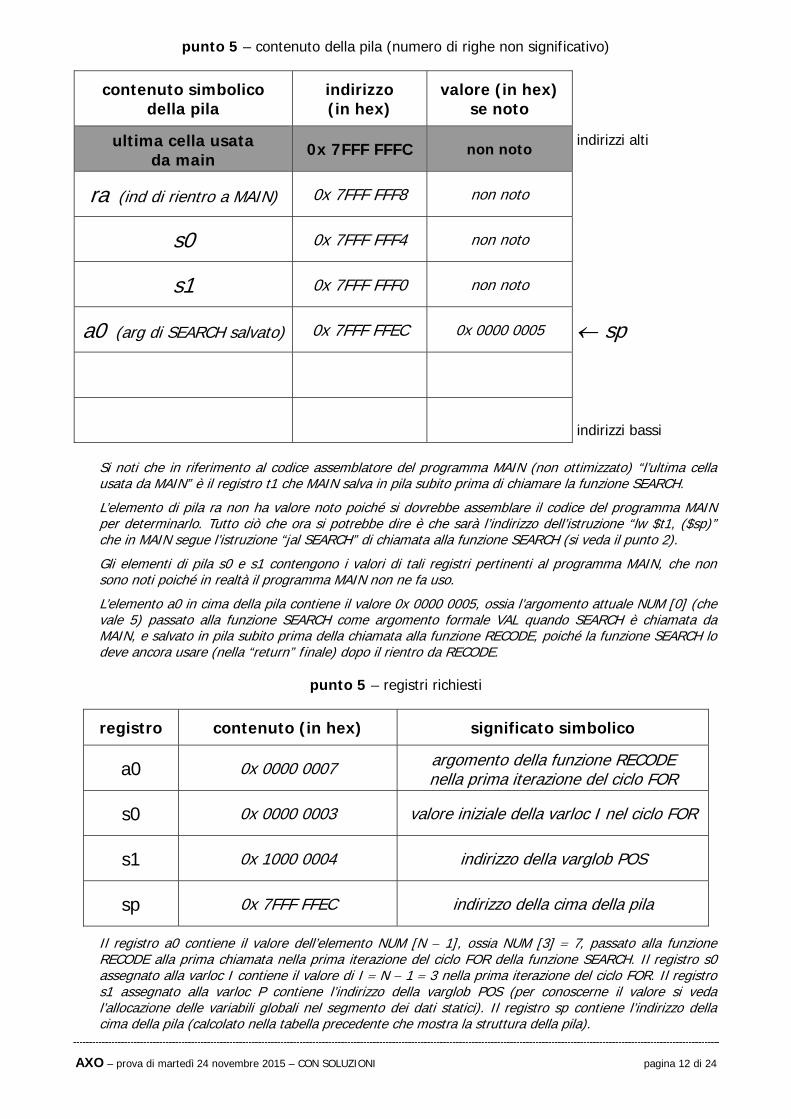
punto 5 – contenuto della pila (numero di righe non significativo)
contenuto simbolico della pila
indirizzo (in hex)
valore (in hex) se noto
ultima cella usata da main
0x 7FFF FFFC non noto indirizzi alti
ra (ind di rientro a MAIN) 0x 7FFF FFF8 non noto
s0 0x 7FFF FFF4 non noto
s1 0x 7FFF FFF0 non noto
a0 (arg di SEARCH salvato) 0x 7FFF FFEC 0x 0000 0005 sp
indirizzi bassi
Si noti che in riferimento al codice assemblatore del programma MAIN (non ottimizzato) “l’ultima cella usata da MAIN” è il registro t1 che MAIN salva in pila subito prima di chiamare la funzione SEARCH.
L’elemento di pila ra non ha valore noto poiché si dovrebbe assemblare il codice del programma MAIN per determinarlo. Tutto ciò che ora si potrebbe dire è che sarà l’indirizzo dell’istruzione “lw $t1, ($sp)” che in MAIN segue l’istruzione “jal SEARCH” di chiamata alla funzione SEARCH (si veda il punto 2).
Gli elementi di pila s0 e s1 contengono i valori di tali registri pertinenti al programma MAIN, che non sono noti poiché in realtà il programma MAIN non ne fa uso.
L’elemento a0 in cima della pila contiene il valore 0x 0000 0005, ossia l’argomento attuale NUM [0] (che vale 5) passato alla funzione SEARCH come argomento formale VAL quando SEARCH è chiamata da MAIN, e salvato in pila subito prima della chiamata alla funzione RECODE, poiché la funzione SEARCH lo deve ancora usare (nella “return” finale) dopo il rientro da RECODE.
punto 5 – registri richiesti
registro contenuto (in hex) significato simbolico
a0 0x 0000 0007 argomento della funzione RECODE nella prima iterazione del ciclo FOR
s0 0x 0000 0003 valore iniziale della varloc I nel ciclo FOR
s1 0x 1000 0004 indirizzo della varglob POS
sp 0x 7FFF FFEC indirizzo della cima della pila
Il registro a0 contiene il valore dell’elemento NUM [N 1], ossia NUM [3] 7, passato alla funzione RECODE alla prima chiamata nella prima iterazione del ciclo FOR della funzione SEARCH. Il registro s0 assegnato alla varloc I contiene il valore di I N 1 3 nella prima iterazione del ciclo FOR. Il registro s1 assegnato alla varloc P contiene l’indirizzo della varglob POS (per conoscerne il valore si veda l’allocazione delle variabili globali nel segmento dei dati statici). Il registro sp contiene l’indirizzo della cima della pila (calcolato nella tabella precedente che mostra la struttura della pila).

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 13 di 24
esercizio n. 2 – logica sequenziale
Sia dato il circuito sequenziale con un ingresso I e due uscite Z1 e Z2, descritto dalle equazioni logiche seguenti:
D I xor Q
Z1 not Q
Z2 Q and D
Il circuito sequenziale è composto da un bistabile master-slave di tipo D (D, Q), dove D è l’ingresso del bistabile e Q è lo stato / uscita del bistabile.
Si chiede di completare il diagramma temporale riportato qui sotto. Si noti che:
si devono trascurare completamente i ritardi di propagazione delle porte logiche AND e OR, e i ritardi di commutazione dei bistabili
il bistabile è il tipo master-slave la cui struttura è stata trattata a lezione, con uscita che commuta sul fronte di discesa del clock
diagramma temporale da completare
1
I
D
Q 0
Z1
Z2
CLK

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 14 di 24
soluzione Poiché vale la relazione D = (I xor Q) ne segue che il segnale D è la negazione del segnale Q quando si ha I = 1; e invece è uguale a Q quando si ha I = 0.
Il segnale Q è costante per tutto un intervallo e ha il valore che il segnale D aveva immediatamente prima del fronte di discesa del clock all’inizio dell’intervallo.
Ecco il procedimento di calcolo dei valori in un intervallo:
per tutto l’intervallo corrente si pone il segnale Q uguale al valore di D verso la fine dell’intervallo precedente
si calcola il segnale D nell’intervallo corrente, istante per istante, in funzione di I e Q
Poi si passa all’intervallo successivo, e così via fino al termine. Ovviamente nel primo intervallo il segnale Q è già dato (è lo stato iniziale, non calcolabile perché non è noto l’intervallo precedente).
Infine, in tutti gli intervalli si pone il segnale Z1 uguale a (not Q), e il segnale Z2 uguale a (Q and D).
Pertanto ricavare il diagramma temporale è semplice e rapido. Eccolo:
1
I
1
D
Q 0
1
Z1
Z2 0
CLK
Osservando il comportamento del circuito, si potrebbe dire che il circuito è un “divisore di frequenza” comandabile:
a) quando si ha I = 1 si genera su Z1 un’onda quadra sincrona con il clock, ma di periodo doppio rispetto al clock (cioè a frequenza dimezzata: ecco perché “divisore di frequenza”)
nel contempo il segnale Z2 è sempre a 0
b) quando si ha I = 0 ne segue che sia ha D = Q, quindi il bistabile si blocca al valore che il segnale D aveva nell’intervallo precedente (cioè al nuovo valore memorizzato nel bistabile) e il segnale Z1 rimane bloccato.
In questo caso, poiché vale Z2 = Q and D, il segnale Z2 vale 1 soltanto quando il bistabile è bloccato a 1. Si potrebbe dire che il segnale Z2, quando vale 1, indica che l’oscillatore è bloccato, e in particolare bloccato a 1 e non a 0 (e che quindi il segnale Z1 è bloccato a 0).

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 15 di 24
esercizio n. 3 – processore pipeline e segnali di controllo
Riferimento: processore pipeline e campi registri interstadio.
Sono dati il seguente frammento di codice macchina MIPS (simbolico), che comincia l’esecuzione all’indirizzo indicato, i valori iniziali specificati per alcuni registri, e il contenuto (e relativo indirizzo) di alcune parole della memoria dati.
indirizzo codice assemblatore
registro contenuto iniziale
0x 0000 0400 add $t0, $t0, $t2 $t0 0x 000F E261
and $a0, $t1, $t2 $t1 0x 001F C4C2
lw $t2, 0x000E($t1) $t2 0x 000F E261
beq $t0, $t1, 64 $a0 0x 0000 0510
or $t0, $t0, $zero $s2 0x 0020 0000
sw $a0, ($s2)
memoria dati
indirizzo parola 0x 001F C4CC 0x AAAA 2001 0x 001F C4D0 0x FFFF 0001 0x 0020 0000 0x FFFF 1000 0x 0020 0004 0x AAAA FFFF
Si consideri il ciclo di clock in cui l’esecuzione delle istruzioni nei vari stadi è la seguente:
IF sw $a0, ($s2) ID or $t0, $t0, $zero EX beq $t0, $t1, 64
MEM lw $t2, 0x000E($t1)
WB and $a0, $t1, $t2
1) Indicare qual è il ciclo di clock considerato: 6 (sesto ciclo) ____________________________
2) Calcolare il valore di (t0) (t2): 0x 000F E261 0x 000F E261 0x 001F C4C2 ________
3) Calcolare il valore di (t1) and (t2): 0x 001F C4C2 and 0x 000F E261 0x 000F C040 ____
4) Indicare se la condizione dell’istruzione beq è verificata: t0 dopo “add” risulta uguale a t1 dunque SÌ
5) Completare le tabelle della pagina seguente:
AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 16 di 24
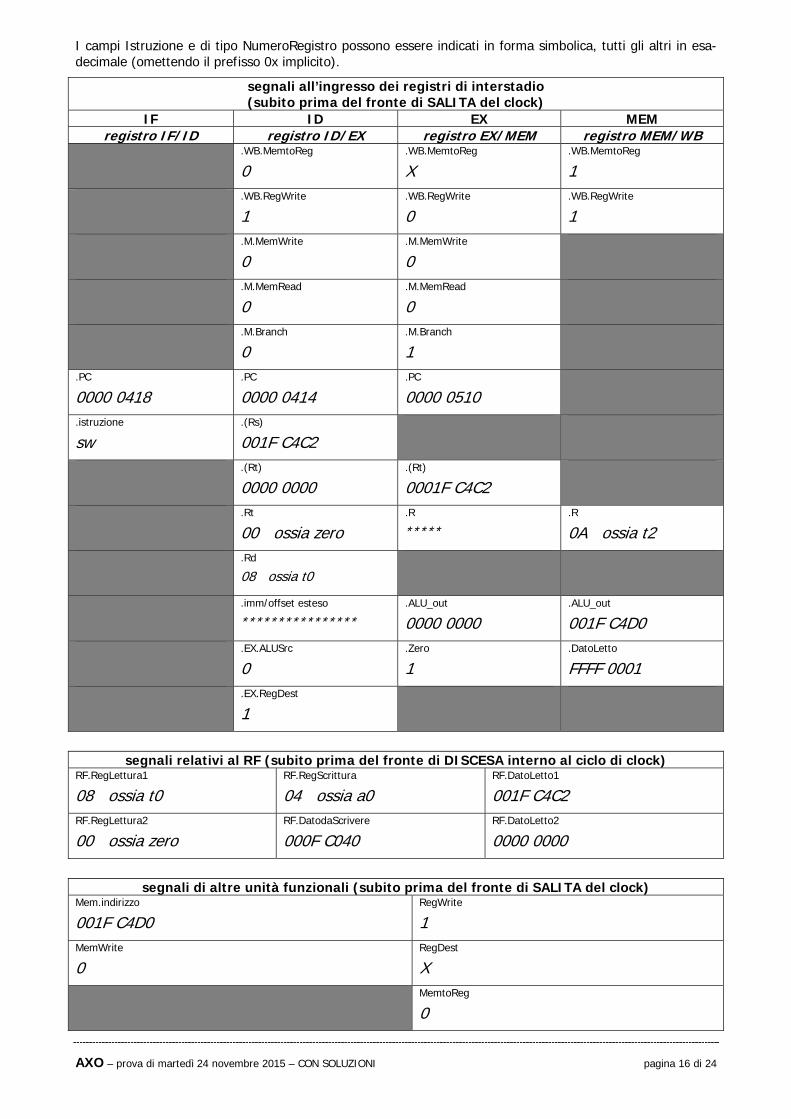
I campi Istruzione e di tipo NumeroRegistro possono essere indicati in forma simbolica, tutti gli altri in esa-decimale (omettendo il prefisso 0x implicito).
segnali all’ingresso dei registri di interstadio(subito prima del fronte di SALITA del clock)
IF ID EX MEMregistro IF/ID registro ID/EX registro EX/MEM registro MEM/WB
.WB.MemtoReg
0 .WB.MemtoReg
X .WB.MemtoReg
1 .WB.RegWrite
1 .WB.RegWrite
0 .WB.RegWrite
1 .M.MemWrite
0 .M.MemWrite
0
.M.MemRead
0 .M.MemRead
0
.M.Branch
0 .M.Branch
1
.PC
0000 0418 .PC
0000 0414 .PC
0000 0510
.istruzione
sw .(Rs)
001F C4C2
.(Rt)
0000 0000 .(Rt)
0001F C4C2
.Rt
00 ossia zero .R
***** .R
0A ossia t2 .Rd
08 ossia t0
.imm/offset esteso
**************** .ALU_out
0000 0000 .ALU_out
001F C4D0 .EX.ALUSrc
0 .Zero
1 .DatoLetto
FFFF 0001 .EX.RegDest
1
segnali relativi al RF (subito prima del fronte di DISCESA interno al ciclo di clock)
RF.RegLettura1
08 ossia t0 RF.RegScrittura
04 ossia a0 RF.DatoLetto1
001F C4C2 RF.RegLettura2
00 ossia zero RF.DatodaScrivere
000F C040 RF.DatoLetto2
0000 0000
segnali di altre unità funzionali (subito prima del fronte di SALITA del clock)
Mem.indirizzo
001F C4D0 RegWrite
1 MemWrite
0 RegDest
X
MemtoReg
0

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 17 di 24
Calcolo degli ingressi dei registri di inter-stadio (campi a 32 bit):
IF.PC indirizzo dell’istr. consecutiva all’istr. in stadio IF (non nota) 0x 0000 0414 4 0x 0000 0418 IF.istruzione istruzione in stadio IF “sw” ID.PC ind. dell’istr. consecutiva all’istr. in stadio ID, che è “or” (cioè “sw”) 0x 0000 0410 4 0x 0000 0414 ID.(Rs) valore dell’arg. Rs (1° sorgente) dell’istr. in stadio ID (cioè “or”) (t0) dopo “add” 0x 000F E261 0x 000F E261 0x 001F C4C2 ID.(Rt) valore dell’arg. Rt (2° sorgente) dell’istr. in stadio ID (cioè “or”) (zero) 0x 0000 0000 EX.PC ind. della dest. di salto dell’istr. in stadio EX (cioè “beq”) ind. dell’istr. consecutiva a “beq” (cioè “or”) dist. di salto in “beq” (cioè 64) × 4 0x 0000 0410 0x 0000 0040 × 4 0x 0000 0410 0x 0000 0100 0x 0000 0510 EX.(Rt) valore dell’arg. Rt (2° sorgente) dell’istr. in stadio EX “(cioè beq”) (t1) 0x 001F C4C2 EX.ALU_out sottrazione per calcolare il confronto in dell’istr. in stadio EX (cioè “beq”) (t0) dopo “add” (t1) 0x 001F C4C2 0x 001F C4C2 0x 0000 0000 MEM.ALU_out calcolo dell’ind. effettivo di lettura in memoria dell’istr. in stadio MEM (cioè “lw”) (t1) 0x 000E 0x 001F C4C2 0x 0000 000E 0x 001F C4D0
MEM.DatoLetto memoria (0x 001F C4D0) 0x FFFF 0001
Calcolo degli ingressi dei registri di inter-stadio (campi a 5 bit):
ID.Rt numero dell’arg. Rt (2° sorgente) dell’istr. in stadio ID (cioè “or”) registro zero 00 ID.Rd numero dell’arg. Rd (destinazione) dell’istr. in stadio ID (cioè “or”) registro t0 08 MEM.R numero dell’arg. R (destinazione) dell’istr. in stadio MEM (cioè “lw”) registro t2 0A
Calcolo dei comandi in ingresso dei registri di inter-stadio (a 1 bit):
per il registro ID i comandi caratteristici di “or”, cioè di un’istr. di classe aritmetico-logica per il registro EX i comandi caratteristici di “beq”, cioè di un’istr. di classe salto condizionato per il registro MEM i comandi caratteristici di “lw”, cioè di un’istr. di classe trasferimento di memoria, in particolare di lettura da memoria
Inoltre si ha: EX.zero condizione dell’istr. in stadio EX (cioè “beq”) verificata (il salto è preso) 1
Calcolo dei segnali delle unità funzionali (a 32 bit):
RF.DatodaScrivere risultato dell’istr. in stadio WB (cioè “and”) (t1) and (t2) iniziale 0x 001F C4C2 and 0x 000F E261 0x 000F C040 RF.DatoLetto1 valore dell’arg. Rs (1° sorgente) dell’istr. in stadio ID (cioè “or”) (t0) dopo “add” 0x 001F C4C2 RF.DatoLetto2 valore dell’arg. Rt (2° sorgente) dell’istr. in stadio ID (cioè “or”) (zero) 0x 0000 0000 Mem.indirizzo indirizzo effettivo di lettura in memoria dell’istruzione in stadio MEM (cioè “lw”) (t1) 0x 000E 0x 001F C4C2 0x 0000 000E 0x 001F C4D0 Nota bene: il DatoLetto1 e il Dato Letto2 sono chiesti prima del fronte di discesa interno al ciclo, ossia prima che nello RF venga fatta l’eventuale scrittura; peraltro, nel 6° ciclo chi scrive in RF è l’istruzione “and” in stadio WB, la cui destinazione è il registro a0, e dunque non interferirebbe con i dati letti.
Calcolo dei segnali delle unità funzionali (a 5 bit):
RF.RegLettura1 numero dell’arg. Rs (1° sorgente) dell’istr. in stadio ID (cioè “or”) registro t0 08 RF.RegLettura2 numero dell’arg. Rt (2° sorgente) dell’istr. in stadio ID (cioè “or”) registro zero 00 RF.RegScrittura numero dell’arg. Rd (1° sorgente) dell’istr. in stadio WB (cioè “and”) registro a0 04
Altri comandi di unità funzionali (a 1 bit):
MemWrite 0, poiché “lw” non scrive in memoria; RegWrite 1, poiché “and” scrive nello RF; RegDest X, poiché “beq” non ha un registro destinazione, dunque indifferente; MemtoReg 0, poiché “and” non legge in memoria.
Commento finale: il salto condizionato “beq” verrà preso, ma poiché la pipeline non ha trattamento di stalli o percorsi di anticipo, ciò non impatta sulle due istruzioni consecutive al salto, già entrate in pipeline.
AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 18 di 24
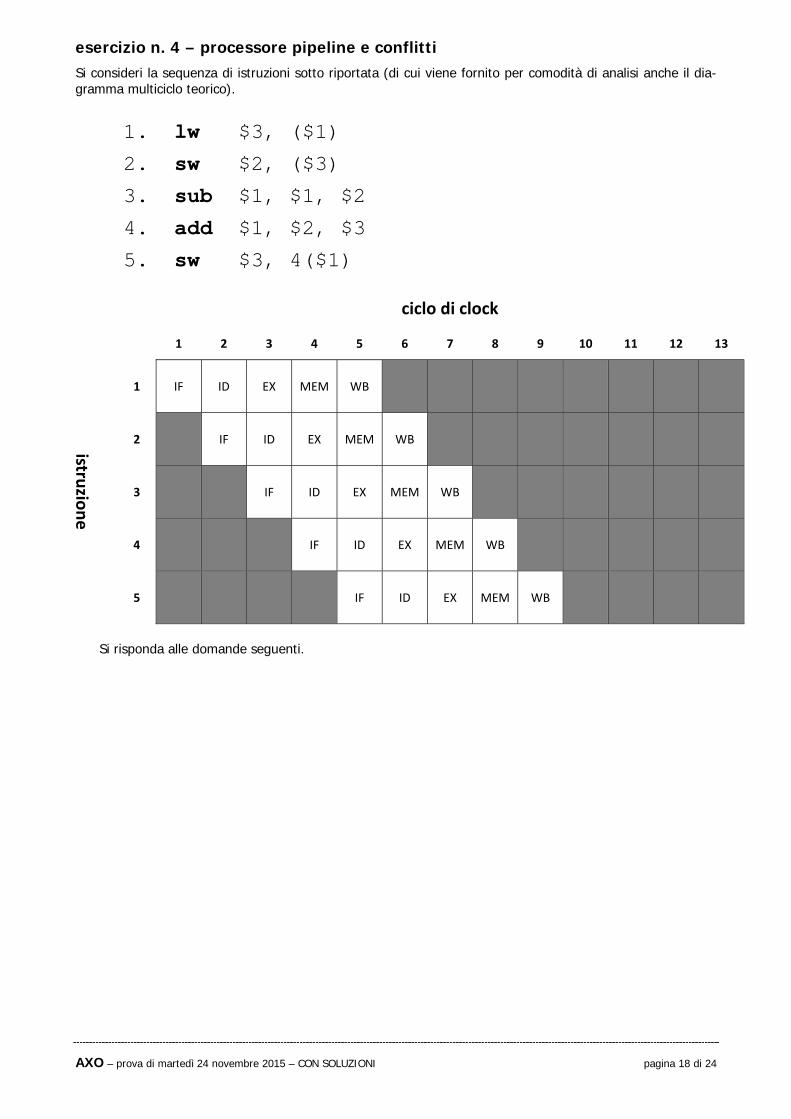
esercizio n. 4 – processore pipeline e conflitti Si consideri la sequenza di istruzioni sotto riportata (di cui viene fornito per comodità di analisi anche il dia-gramma multiciclo teorico).
1. lw $3, ($1)
2. sw $2, ($3)
3. sub $1, $1, $2
4. add $1, $2, $3
5. sw $3, 4($1)
ciclo di clock
1 2 3 4 5 6 7 8 9 10 11 12 13
istruzio
ne
1 IF ID EX MEM WB
2 IF ID EX MEM WB
3 IF ID EX MEM WB
4 IF ID EX MEM WB
5 IF ID EX MEM WB
Si risponda alle domande seguenti.

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 19 di 24
Punto 1 – Definire tutte le dipendenze di dato completando la Tabella 1.
Tabella 1 (domanda 1) (numero di righe non significativo)
Tabella 2 (domanda 2.a) (num. di righe non signif.)
istruzione istruzione
da cui dipende registro coinvolto
genera conflitto (sì / no)
numero di stalli
2 sw 1 lw $3 SI 2
4 add 1 lw $3 NO 0
5 sw 1 lw $3 NO 0
5 sw 3 sub $1 SI 1
5 sw 4 add $1 SI 2
Per maggiore chiarezza qui sotto sono riportate tutte le frecce di dipendenza. Quelle conflittuali sono messe in evidenza in tratto più spesso. I registri coinvolti sono elencati nelle due tabelle qui sopra.
ciclo di clock
1 2 3 4 5 6 7 8 9 10 11 12 13
istruzio
ne
1 IF ID EX
MEM WB
2 IF ID EX MEM WB
3 IF ID EX MEM
WB
4 IF ID EX
MEM WB
5 IF ID EX MEM WB
Nel programma non ci sono altre dipendenze (conflittuali o no) oltre a quelle mostrate. Si ricordi che qui la pipeline non ha meccanismi per introdurre stalli e non dispone di percorsi di anticipo.
AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 20 di 24
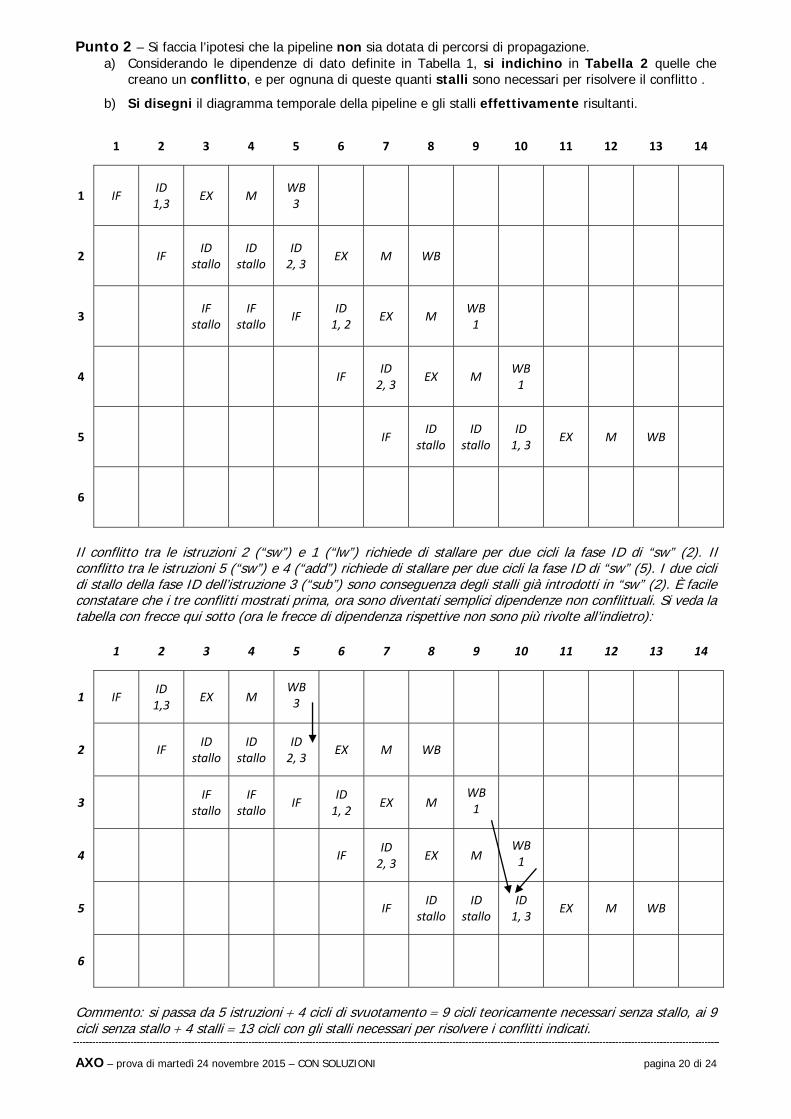
Punto 2 – Si faccia l’ipotesi che la pipeline non sia dotata di percorsi di propagazione. a) Considerando le dipendenze di dato definite in Tabella 1, si indichino in Tabella 2 quelle che
creano un conflitto, e per ognuna di queste quanti stalli sono necessari per risolvere il conflitto .
b) Si disegni il diagramma temporale della pipeline e gli stalli effettivamente risultanti.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1 IF ID 1,3
EX M WB 3
2 IF ID
stallo ID
stallo ID 2, 3
EX M WB
3 IF
stallo IF
stallo IF
ID 1, 2
EX M WB 1
4 IF ID 2, 3
EX M WB 1
5 IF ID
stallo ID
stallo ID 1, 3
EX M WB
6
Il conflitto tra le istruzioni 2 (“sw”) e 1 (“lw”) richiede di stallare per due cicli la fase ID di “sw” (2). Il conflitto tra le istruzioni 5 (“sw”) e 4 (“add”) richiede di stallare per due cicli la fase ID di “sw” (5). I due cicli di stallo della fase ID dell’istruzione 3 (“sub”) sono conseguenza degli stalli già introdotti in “sw” (2). È facile constatare che i tre conflitti mostrati prima, ora sono diventati semplici dipendenze non conflittuali. Si veda la tabella con frecce qui sotto (ora le frecce di dipendenza rispettive non sono più rivolte all’indietro):
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1 IF ID 1,3
EX M WB 3
2 IF ID
stallo ID
stallo ID 2, 3
EX M WB
3 IF
stallo IF
stallo IF
ID 1, 2
EX M WB 1
4 IF ID 2, 3
EX M WB 1
5 IF ID
stallo ID
stallo ID 1, 3
EX M WB
6
Commento: si passa da 5 istruzioni 4 cicli di svuotamento 9 cicli teoricamente necessari senza stallo, ai 9 cicli senza stallo 4 stalli 13 cicli con gli stalli necessari per risolvere i conflitti indicati.
AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 21 di 24
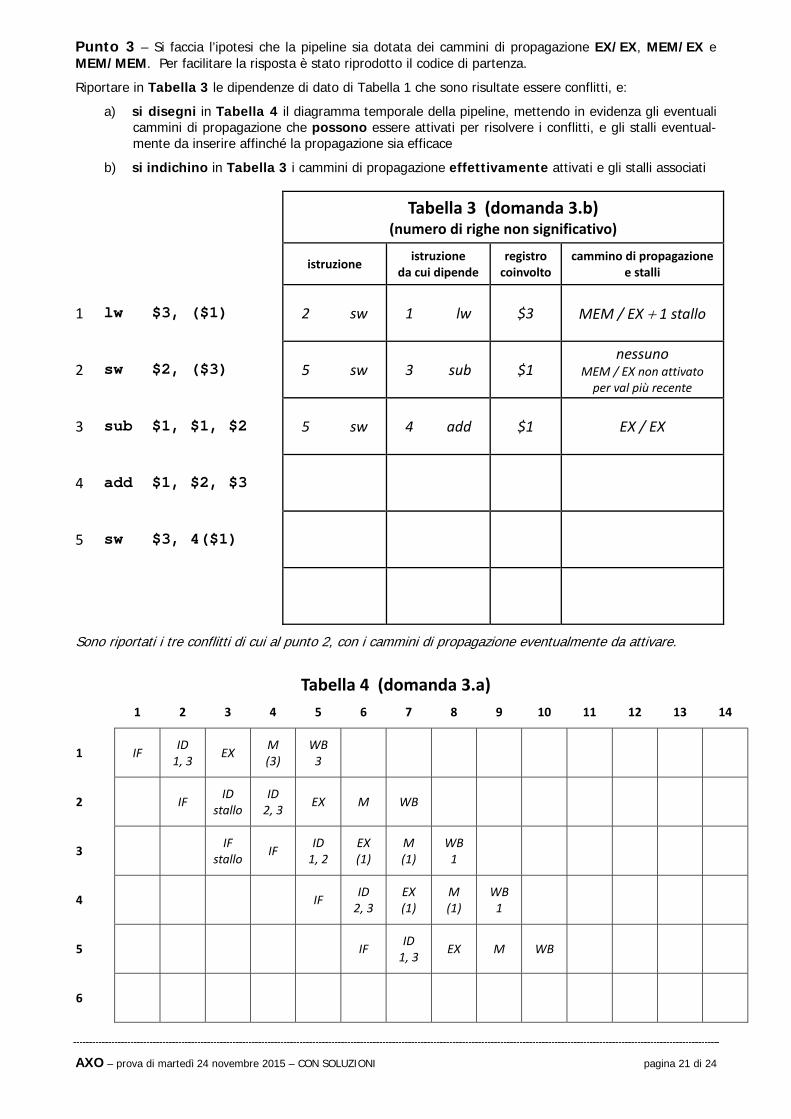
Punto 3 – Si faccia l’ipotesi che la pipeline sia dotata dei cammini di propagazione EX/EX, MEM/EX e MEM/MEM. Per facilitare la risposta è stato riprodotto il codice di partenza.
Riportare in Tabella 3 le dipendenze di dato di Tabella 1 che sono risultate essere conflitti, e:
a) si disegni in Tabella 4 il diagramma temporale della pipeline, mettendo in evidenza gli eventuali cammini di propagazione che possono essere attivati per risolvere i conflitti, e gli stalli eventual-mente da inserire affinché la propagazione sia efficace
b) si indichino in Tabella 3 i cammini di propagazione effettivamente attivati e gli stalli associati
Tabella 3 (domanda 3.b) (numero di righe non significativo)
istruzione istruzione
da cui dipende registro coinvolto
cammino di propagazionee stalli
1 lw $3, ($1) 2 sw 1 lw $3 MEM / EX 1 stallo
2 sw $2, ($3) 5 sw 3 sub $1 nessuno
MEM / EX non attivato per val più recente
3 sub $1, $1, $2 5 sw 4 add $1 EX / EX
4 add $1, $2, $3
5 sw $3, 4($1)
Sono riportati i tre conflitti di cui al punto 2, con i cammini di propagazione eventualmente da attivare.
Tabella 4 (domanda 3.a)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1 IF ID 1, 3
EX M (3)
WB 3
2 IF ID
stallo ID 2, 3
EX M WB
3 IF
stallo IF
ID 1, 2
EX (1)
M (1)
WB 1
4 IF ID 2, 3
EX (1)
M (1)
WB 1
5 IF ID 1, 3
EX M WB
6

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 22 di 24
Per maggiore chiarezza, ecco la stessa tabella con frecce che indicano i due percorsi di propagazione attivati, e l’unico stallo residuo ancora necessario.
Tabella 4 (domanda 3.a)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1 IF ID 1, 3
EX M (3)
WB 3
2 IF ID
stallo ID 2, 3
EX M WB
3 IF
stallo IF
ID 1, 2
EX (1)
M (1)
WB 1
4 IF ID 2, 3
EX (1)
M (1)
WB 1
5 IF ID 1, 3
EX M WB
6
Si noti bene che la dipendenza tra le istruzioni 2 e 1 (cioè tra “sw” e “lw”) riguarda il registro $3, che è la destinazione di “lw” e la seconda sorgente di “sw”. L’istruzione “sw” utilizza il registro $3 in fase EX per calcolare l’indirizzo di scrittura in memoria, sommandogli lo spiazzamento (che qui vale 0 ma va comunque sommato). Pertanto il cammino di propagazione da utilizzare è MEM / EX con uno stallo in fase ID per “sw” (per posticipare di un ciclo la fase EX di “sw” rispetto alla fase MEM di “lw” – ciò induce uno stallo in fase IF per l’istruzione “sub” successiva – la bolla introdotta nella pipeline è una sola), e NON MEM / MEM. Infatti con il cammino MEM / MEM il valore di $3 letto in memoria da “lw” arriverebbe troppo tardi a “sw” per calcolare il suo indirizzo di scrittura in memoria. Un cammino MEM / MEM potrebbe servire se si avesse una coppia di istruzioni come “lw $3, ...” subito seguita da “sw $3, ...” (si veda il materiale di lezione e/o il testo).
Il cammino di propagazione EX / EX dall’istruzione 4 (“add”) all’istruzione 5 (“sw”), che coinvolge il registro $1, va regolarmente utilizzato e non abbisogna di stalli.
Invece, il cammino di propagazione MEM / EX dall’istruzione 3 (“sub”) all’istruzione 5 (“sw”) viene disattivato dal cammino da 4 a 5, per valore più recente del registro convolto $1. Si noti bene che l’istruzione “sub” produce nella sua fase EX il valore di $1 usato in “sw” pure in fase EX, ma il cammino di propagazione da usare (se non venisse disattivato), NON è non EX / EX (che distano due cicli di clock – si veda la tabella sopra), bensì MEM / EX (che distano un ciclo di clock – si veda la tabella sopra).
Commento: usando l’anticipo, complessivamente si hanno 5 istruzioni 4 cicli di svuotamento 1 stallo 10 cicli, rispetto ai 13 cicli necessari senza anticipo ricorrendo solo all’inserimento di stalli.
cammino disattivato
AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 23 di 24
esercizio n. 5 – microarchitettura di memoria
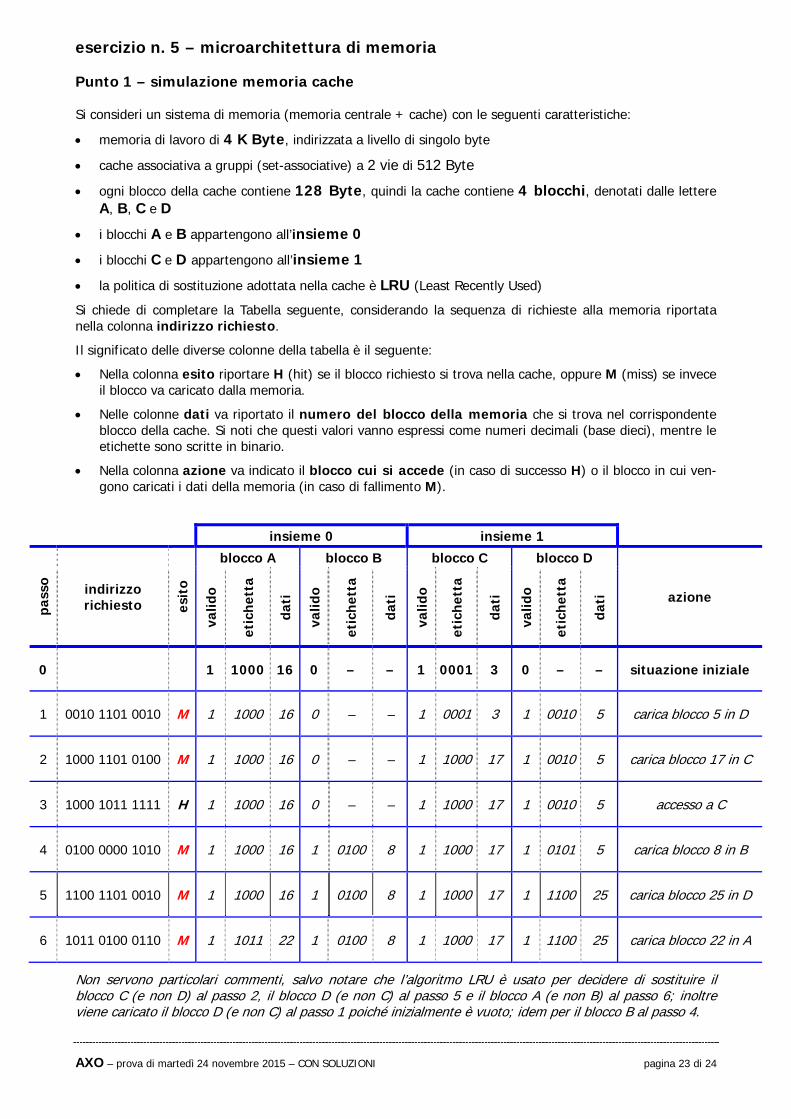
Punto 1 – simulazione memoria cache
Si consideri un sistema di memoria (memoria centrale + cache) con le seguenti caratteristiche:
memoria di lavoro di 4 K Byte, indirizzata a livello di singolo byte
cache associativa a gruppi (set-associative) a 2 vie di 512 Byte
ogni blocco della cache contiene 128 Byte, quindi la cache contiene 4 blocchi, denotati dalle lettere A, B, C e D
i blocchi A e B appartengono all’insieme 0
i blocchi C e D appartengono all’insieme 1
la politica di sostituzione adottata nella cache è LRU (Least Recently Used)
Si chiede di completare la Tabella seguente, considerando la sequenza di richieste alla memoria riportata nella colonna indirizzo richiesto.
Il significato delle diverse colonne della tabella è il seguente:
Nella colonna esito riportare H (hit) se il blocco richiesto si trova nella cache, oppure M (miss) se invece il blocco va caricato dalla memoria.
Nelle colonne dati va riportato il numero del blocco della memoria che si trova nel corrispondente blocco della cache. Si noti che questi valori vanno espressi come numeri decimali (base dieci), mentre le etichette sono scritte in binario.
Nella colonna azione va indicato il blocco cui si accede (in caso di successo H) o il blocco in cui ven-gono caricati i dati della memoria (in caso di fallimento M).
Non servono particolari commenti, salvo notare che l’algoritmo LRU è usato per decidere di sostituire il blocco C (e non D) al passo 2, il blocco D (e non C) al passo 5 e il blocco A (e non B) al passo 6; inoltre viene caricato il blocco D (e non C) al passo 1 poiché inizialmente è vuoto; idem per il blocco B al passo 4.
insieme 0 insieme 1
pass
o indirizzo richiesto es
ito
blocco A blocco B blocco C blocco D
azione
valid
o
etic
hett
a
dati
valid
o
etic
hett
a
dati
valid
o
etic
hett
a
dati
valid
o
etic
hett
a
dati
0 1 1000 16 0 – – 1 0001 3 0 – – situazione iniziale
1 0010 1101 0010 M 1 1000 16 0 – – 1 0001 3 1 0010 5 carica blocco 5 in D
2 1000 1101 0100 M 1 1000 16 0 – – 1 1000 17 1 0010 5 carica blocco 17 in C
3 1000 1011 1111 H 1 1000 16 0 – – 1 1000 17 1 0010 5 accesso a C
4 0100 0000 1010 M 1 1000 16 1 0100 8 1 1000 17 1 0101 5 carica blocco 8 in B
5 1100 1101 0010 M 1 1000 16 1 0100 8 1 1000 17 1 1100 25 carica blocco 25 in D
6 1011 0100 0110 M 1 1011 22 1 0100 8 1 1000 17 1 1100 25 carica blocco 22 in A

AXO – prova di martedì 24 novembre 2015 – CON SOLUZIONI pagina 24 di 24
Punto 2 – struttura degli indirizzi
Si consideri un sistema di memoria (memoria + cache) caratterizzato dalle dimensioni seguenti:
memoria di 1 Giga parole da 16 bit (indirizzata a livello di parola) 30 bit di indirizzo centrale
cache di 1 Mega parole da 16 bit (indirizzata a livello di parola) 20 bit di indirizzo cache
ogni blocco della cache contiene 256 parole (da 16 bit) 8 bit di spiazzamento parola
Si chiede di indicare la struttura degli indirizzi per la memoria cache nelle situazioni seguenti:
cache a indirizzamento diretto (direct mapped)
spiazzamento della parola 8 bit come visto sopra
# di blocchi in cache 220 parole / 28 parole 212 blocchi indice di blocco 12 bit
etichetta 30 bit di indirizzo centrale 12 bit indice di blocco 8 bit spiazzamento 10 bit
cache completamente associativa (fully associative)
spiazzamento della parola 8 bit come visto sopra
etichetta 30 bit di indirizzo centrale 8 bit spiazzamento 22 bit
cache associativa a gruppi (set-associative) a 4 vie
spiazzamento della parola 8 bit come visto sopra
# di gruppi in cache 220 parole / (28 parole 4 blocchi) 220 parole / 210 parole 210 gruppi indice di gruppo 10 bit
etichetta 30 bit di indirizzo centrale 10 bit indice di gruppo 8 bit spiazzamento 12 bit
Nota bene: la dimensione della parola, in questo caso 16 bit ossia 2 byte, è ininfluente per analizzare l’indirizzo di memoria, poiché si precisa che la memoria è indirizzata a livello di parola (e non di byte), cioè la minima unità di informazione trasferibile è appunto la parola da 16 bit; insomma il singolo indirizzo da 30 bit si riferisce alla parola da 16 bit e non c’è modo di indirizzare separatamente i due byte componenti la parola.


















