
Progettazione e sviluppo di un sistema integrato per la ...
235
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica tesi di laurea magistrale Progettazione e sviluppo di un sistema integrato per la rilevazione di eventi anomali in scenari di sicurezza Anno Accademico 2011/12 relatore Ch.mo prof. Stefano Russo correlatori Ch.mo prof. Marcello Cinque Ch.mo ing. Fabio Cornevilli candidato Raffaele Della Corte matr. M63/237
Transcript of Progettazione e sviluppo di un sistema integrato per la ...

Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica
tesi di laurea magistrale
Progettazione e sviluppo di un sistema integrato per la rilevazione di eventi anomali in scenari di sicurezza Anno Accademico 2011/12 relatore Ch.mo prof. Stefano Russo correlatori Ch.mo prof. Marcello Cinque Ch.mo ing. Fabio Cornevilli candidato Raffaele Della Corte matr. M63/237

Alla mia principessa e a tutta la mia famiglia

Ringraziamenti
Giunto a questo secondo, e più importante, traguardo della mia carriera universitaria, vorrei
ringraziare tutti coloro che, in qualsiasi modo, mi hanno aiutato in questi anni.
Innanzitutto vorrei ringraziare il professore Stefano Russo che mi ha dato una grande
opportunità, concedendomi la possibilità di realizzare un’attività di tesi davvero molto
interessante.
Un ringraziamento va anche al mio correlatore, il professore Marcello Cinque che mi ha
guidato in questo percorso, dedicandosi con santa pazienza a rispondere alle mie
innumerevoli e-mail, nonché all’ingegner Antonio Pecchia, che, insieme a lui, mi ha aiutato
a tirar su questo lavoro di tesi.
Un altro ringraziamento va anche al mio secondo correlatore, nonché tutor aziendale,
l’ingegner Fabio Cornevilli il quale, nonostante gli innumerevoli impegni, è stato sempre
disponibile quando necessario.
Voglio poi ringraziare colei che poco più di tre anni fa è entrata a far parte della mia vita,
trasformandola giorno dopo giorno nello splendore che è oggi, insegnandomi cosa significa
realmente amare ed essere amati con tutte le proprie forze, e condividendo insieme a me
tutto sempre, parlo della mia principessa, Emilia, che in questi anni è sempre stata al mio
fianco e non ha mai smesso di sostenermi ed aiutarmi, nello studio e nella vita, riuscendo
come nessuno a darmi forza e consigli per affrontare e superare ogni ostacolo. Sei il mio
punto di riferimento, il centro di tutto il mio mondo…TI AMO!!!
Un grazie anche ai miei genitori e a mia sorella, per avermi dato la possibilità di
intraprendere questo cammino, ma soprattutto per il loro enorme affetto e per la costanza
con cui mi hanno sempre spronato al raggiungimento di questo traguardo, in primis mia
mamma che si è sempre impegnata ad evitare qualsiasi fonte di disturbo durante lo studio ed
ha avuto la fermezza di svegliarmi ogni mattina alle 7:30.
Un grazie anche ai miei nonni, in particolare a nonna Rosa per le risate che mi fa fare, lei e

il “vecchio”, ogniqualvolta passa a salutarmi e per aver continuato a riempire la mia stanza
di nuovi amichetti.
Un caloroso grazie anche ai miei suoceri, la signora Tina e il signor Pasquale, e a Enzo per
la grande disponibilità dimostrata sempre, in ogni situazione, soprattutto quando si trattava
di ospitarmi per facilitare il raggiungimento della sede del tirocinio, per aver fatto di tutto
per permettermi di studiare al meglio quando ero da voi (anche con fiumi di panna), e per
avermi fatto sentire sempre parte della famiglia.
Un grazie anche a Marco per avermi gentilmente donato negli ultimi mesi un suo
smartphone…anche se l’ho sfortunatamente già distrutto.
Non può mancare anche un grazie a Luigi, Fulvia, Salvatore, Mario, Teresa, il piccolo Ciro,
Davide, Miriam, Giovanni, Paola, Fabio e Giovanna per esserci sempre e comunque anche
se non ci vediamo spesso, ma anche a Raffaella, Maria, Manuela, Emanuele, Anna e
Salvatore per i momenti trascorsi insieme.
Un sentito grazie anche a Luigi e Vincenzo, compagni di mille avventure universitarie, con
cui ho condiviso gioie e dolori di questa vita.
Un grazie anche a Giovanni, Giuseppe e Ciccio, che, nonostante le nostre strade si siano
divise, continuano…ad organizzare i Panuozzo Day.
In ambito aziendale, un grazie va a Vincenzo, Emanuela, Giancarlo e Nicola per tutto l’aiuto
che mi hanno offerto durante l’intero percorso di tirocinio.
Infine, un grazie va anche a colui che da lassù ha sempre fatto si che le cose andassero per il
verso giusto, facendo avvertire la sua mano sempre, esame dopo esame.
A voi tutti, e anche a coloro che avrò sicuramente dimenticato di citare,…
GRAZIE DI VERO CUORE!!

V
Indice Introduzione 8 Capitolo 1. Il Complex Event Processing 11 1.1 Le origini 11 1.2 Event ed Event Processing 16 1.2.1 Event Processing e programmazione Event-Based 20 1.3 Architettura di Event Processing 21 1.4 CEP ed Event Stream Processing 22 1.4.1 Regole alla base dell’ESP 24 1.5 CEP Engine 27 1.5.1 Tecniche di correlazione 32 1.5.1.1 Correlazione basata su macchine a stati finiti 33 1.5.1.2 Correlazione Rule-Based 35 1.5.1.3 Correlazione Case-Based 37 1.5.2 Proprietà di un CEP Engine 38 1.6 Il CEP nelle infrastrutture IT di sicurezza 40 Capitolo 2. Un sistema CEP in scenari di sicurezza 44 2.1 Introduzione 44 2.2 Requisiti di alto livello 48 2.2.1 Requisiti funzionali 51 2.2.2 Requisiti non funzionali 52 2.3 Scenari applicativi: Building Security 53 2.3.1 Casi d’uso: Rilevamento di un falso positivo per Camera Tampering 56 2.3.2 Casi d’uso: Rilevamento di un accesso non autorizzato 58 2.4 Scenari applicativi: Network Security 60 2.4.1 Casi d’uso: Rilevamento di una intrusione con credenziali rubate 63 2.4.2 Casi d’uso: Rilevamento di un attacco TCP Gender Changer 65 Capitolo 3. Il CEP Engine Esper 68 3.1 Introduzione 68 3.2 Rappresentazione degli eventi 70 3.2.1 Plain-Old Java Object 71 3.2.2 Map Event 72

VI
3.2.3 Object-array Event 73 3.2.4 XML Event 73 3.2.5 Confronto tra i tipi 75 3.3 Modello di elaborazione 75 3.3.1 Insert Stream 76 3.3.2 Remove Stream e Length Window 78 3.3.3 Time Window 79 3.3.4 Batch Window 80 3.4 Il linguaggio EPL 82 3.4.1 Sintassi 82 3.4.2 Accesso ad un database e supporto ai linguaggi di script 89 3.4.3 Event Pattern 91 3.5 Esper API 93 3.5.1 Service Provider Interface 94 3.5.2 Administrative Interface 94 3.5.3 Runtime Interface 95 3.6 Configurazione 96 3.7 Integrazione ed Estensione 97 3.7.1 Derived-Value and Data Window View 102 3.7.1.1 Implementazione della classe View Factory 103 3.7.1.2 Implementazione della classe View 105 3.7.1.3 Configurazione della View 107 Capitolo 4. Architettura e mapping tecnologico del sistema CEP 108 4.1 Event Driven Architecture 108 4.2 Componenti logici 111 4.3 Architettura 113 4.3.1 Dispositivi sorgenti 117 4.3.1.1 L’IDS: Snort 118 4.3.1.2 Rsyslog 120 4.3.1.3 Sensori BACnet 121 4.3.1.3.1 BACnet e BACnet4J 122 4.3.1.3.2 Struttura e logica applicativa 127 4.3.2 L’Enterprise Service Bus 130 4.3.2.1 Java Message Service 131 4.3.2.2 Apache ActiveMQ 137 4.3.2.3 Logica applicativa 140 4.3.3 Mediator 142 4.3.3.1 Struttura e logica applicativa 143 4.3.4 Prefiltering-Aggregation 155 4.3.4.1 Struttura e logica applicativa 156 4.3.5 CEP Engine 159 4.3.5.1 Struttura 160 4.3.5.2 Logica applicativa 166 4.3.5.3 Regole EPL 171 Capitolo 5. Verifica del funzionamento del sistema CEP 177 5.1 Introduzione 177

VII
5.2 Sistema di riferimento 178 5.3 Casi d’uso simulati: Rilevamento di una intrusione con credenziali rubate 180 5.3.1 Comportamento del sistema 181 5.3.1.1 Wrapper Syslog 181 5.3.1.2 Wrapper IDS 184 5.3.1.3 Enterprise Service Bus 187 5.3.1.4 Prefiltering-Aggregation 189 5.3.1.5 CEP Engine 192 5.4 Casi d’uso simulati: Rilevamento di un accesso non autorizzato 200 5.4.1 Comportamento del sistema 201 5.4.1.1 BACnet Device 202 5.4.1.2 Wrapper BACnet 203 5.4.1.3 Enterprise Service Bus 209 5.4.1.4 CEP Engine 210 5.5 Considerazioni 215 Capitolo 6. Risultati sperimentali 217 6.1 Introduzione 217 6.2 Valutazione del sistema con una distribuzione reale di traffico 218 6.2.1 Descrizione 218 6.2.2 Risultati ottenuti 222 6.3 Valutazione al variare del traffico 224 6.3.1 Descrizione 225 6.3.2 Risultati ottenuti 226 Conclusioni e Sviluppi futuri 231 Bibliografia 234

8
Introduzione
La sicurezza è un problema che assume grande rilevanza in un ampio spettro di contesti
applicativi. Basti pensare ad esempio alla necessità di monitorare una rete informatica al
fine di rilevare/evitare attacchi, ma anche la necessità di controllare e supervisionare
ambienti, pubblici o privati, al fine di garantire la sicurezza di cose e/o persone presenti in
essi. L’importanza di tale problema ha portato negli ultimi anni ad un considerevole
aumento delle componenti dei centri servizi di controllo, sia interni a realtà aziendali che
non, i quali sono diventati negli anni sempre più sofisticati. Proprio l’incremento di queste
componenti, unito anche alla loro elevata eterogeneità, ha portato da un lato ad un
potenziamento dei sistemi di sicurezza, ma dall’altro alla necessità di gestire ed elaborare
grandi quantità di dati in real-time o near real-time. Tale onere ricade ovviamente su un
operatore umano, in quanto i molteplici sistemi di controllo e gestione sono caratterizzati,
molto spesso, da scarsa integrazione e ridotta capacità di correlazione ed analisi degli
eventi rilevati dalle varie fonti. Da quì la necessità di dotare tali sistemi di soluzioni che
consentano l’interoperabilità tra i vari sottosistemi, così da alleggerire il carico di lavoro
adibito ad uno o più operatori umani, ed ottenere da un lato una netta riduzione dei tempi
di risposta, e dall’altro una maggiore consapevolezza delle attività in atto nell’ambiente
monitorato.
A tal proposito, l'integrazione di soluzioni di Complex Event Processing rappresenta
un'ottima base sulla quale costruire proprio questa interoperabilità tra i sottosistemi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
9
coinvolti. Tale tecnologia, infatti, prevede l'elaborazione e combinazione di eventi
provenienti da più fonti per dedurre eventi o modelli che suggeriscono circostanze più
complicate. Essa è alla base di molti motori di regole che consentono di effettuare
operazioni di filtraggio, aggregazione e correlazione di eventi generati da applicazioni,
database, sistemi di building e network security, in tempo reale, al fine di ottenere
informazioni più dettagliate, definite come eventi complessi, che aiutino a comprendere al
meglio ciò che sta accadendo, così da poter prendere decisioni nel miglior modo possibile,
ma soprattutto nel minor tempo possibile.
Proprio l’adozione del Complex Event Processing nell’ambito della sicurezza è una delle
tematiche alla base di questo lavoro di tesi, il cui obiettivo è quello di progettare e
implementare un sistema integrato per la rilevazione di eventi anomali in scenari di
sicurezza. Tale lavoro è stato svolto nell’ambito di un progetto di ricerca avviato dalla
System Management s.r.l. [1], azienda presso la quale ho svolto la mia attività di tirocinio,
in collaborazione con il Laboratorio Nazionale CINI ITEM “C. Savy” [2].
Il progetto su menzionato è denominato CEvOS (Complex Event processing &
management for security & Operation Support) ed è stato avviato con lo scopo di
realizzare una piattaforma sperimentale di operational intelligence dove l'analisi, la
correlazione e la fusione di eventi provenienti da sistemi tradizionali di sicurezza logica e
fisica vengono utilizzati per generare allarmi e stimolare interventi, con tecniche di
intelligenza artificiale, in situazioni di emergenza che derivano sia da scenari previsti, che
da scenari non previsti e non convenzionali.
Nell’ambito di questo progetto, il mio lavoro si è incentrato principalmente sulla
progettazione, e successiva implementazione, di una prima versione di CEvOS, dotata
delle principali componenti alla base della piattaforma, e la quale fosse in grado di
soddisfare parte dei requisiti previsti all’avvio del progetto. In particolare, il sistema
progettato è basato su un’architettura a componenti che rispecchia il pattern Event Driven
Architecture, in cui la comunicazione tra le varie parti è realizzata attraverso un apposito

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
10
bus, che sfrutta il paradigma publish/subscribe. Le componenti implementate, come
vedremo, sono cinque, e sono:
• Simulatori di sensori di Building Security: atti a generare gli eventi di alcuni sensori
hardware come telecamere e badge reader
• Mediator: si preoccupa di trasformare gli eventi provenienti dai sensori in un
formato intermedio, da poter immettere sul bus
• Enterprise Service Bus: rappresenta il bus di comunicazione tra i vari componenti
• Prefiltering-Aggregation: realizza un’operazione di filtraggio sugli eventi
• CEP Engine: si preoccupa di correlare gli eventi ricevuti attraverso il bus, al fine di
generati eventi complessi utilizzando la tecnologia CEP.
Proprio i CEP saranno l’argomento discusso nel Capitolo 1, nel quale si fornirà una
panoramica su tali sistemi e su tutti i concetti ad essi correlati.
Il Capitolo 2, invece, è dedicato alla descrizione dei requisiti che il sistema da sviluppare
dovrà soddisfare, nonché degli scenari applicativi, e dei relativi casi d’uso, nell’abito dei
quali sarà utilizzato.
Argomento principale del Capitolo 3 sarà la descrizione dettagliata del CEP Engine Esper,
utilizzato nell’abito di questo lavoro di tesi, e delle sue funzionalità, mentre nel Capitolo 4
si approfondirà l’architettura, sia generale che in dettaglio, del sistema CEP implementato
e delle scelte tecnologiche effettuate per i singoli componenti che lo costituiscono.
Nel Capitolo 5 è proposta, invece, una descrizione del funzionamento della piattaforma,
nonché una sua valutazione al fine di verificare il soddisfacimento dei requisiti previsti.
Infine, nel Capitolo 6 si discuteranno i risultati sperimentali ottenuti.

11
Capitolo 1
Il Complex Event Processing
1.1 Le origini
Il concetto di event processing nasce negli anni Cinquanta con la simulazione ad eventi
discreti. L'idea principale era che il comportamento di un sistema, sia esso un dispositivo
hardware, un sistema di controllo, una catena di produzione di una fabbrica o un
fenomeno naturale come il meteo, potesse essere studiato tramite un programma per
computer scritto in un “linguaggio di simulazione”. Presi dei dati in input, il programma
avrebbe dovuto generare eventi che riproducevano le interazioni tra i componenti del
sistema. Ogni evento doveva registrarsi in un preciso istante temporale fissato da un timer,
e, ovviamente, alcuni eventi potevano verificarsi nello stesso istante. Il simulatore, quindi,
doveva registrare il flusso di eventi generati dai vari componenti, la loro esecuzione e lo
scorrere del tempo, simulato dal timer attraverso “ticks” discreti. Le simulazioni ad eventi
discreti rappresenta certamente il primo esempio di event processing e i modelli, infatti,
erano architetture event-driven.
Oltre alla simulazione ad eventi discreti, l’event processing ha interessato anche lo
sviluppo delle reti di computer, come mostrato in figura 1.1 [3], dove sono definite le
quattro principali aree da esso interessate. Tale sviluppo ha avuto inizio verso la fine degli
anni Sessanta, con la rete ARPANET. L'obiettivo era realizzare una comunicazione
affidabile tra computer attraverso reti, tramite l'uso di eventi contenenti sequenze di dati

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
12
binari, i cosiddetti pacchetti. Trasmettere o ricevere un pacchetto corrispondeva ad un
evento.
Figura 1.1: Le quattro maggiori aree interessate dall'Event Processing negli ultimi cinquant'anni
Verso la fine degli anni Ottanta, invece, ebbe inizio lo sviluppo della tecnologia inerente ai
cosiddetti “active database”, i quali rappresentavano un miglioramento dei database
tradizionali al fine di soddisfare le esigenze di elaborazione in real time. Essi furono estesi
con capacità di event processing che permettevano loro di invocare applicazioni in risposta
ad eventi. Per fare ciò, un livello di event processing fu implementato al di sopra di ogni
database tradizionale: questo permetteva la definizione di eventi e di semplici tipi di
schemi di eventi che potevano essere utilizzati come trigger per le regole reattive, anche
chiamate regole ECA (Event - Condition - Action).
Il Complex Event Processing è il passo logico successivo nello sviluppo relativo
all’elaborazione degli eventi. Causa principale di questo passaggio è stato l’incremento del

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
13
traffico basato su eventi manifestatosi nel corso degli ultimi quarant’anni. Basti pensare
all’esplosione del networking negli anni Settanta, nonché all’aumento esponenziale
dell'uso del messagging a livello di gestione nelle attività quotidiane delle imprese,
avvenuto agli inizi degli Ottanta. Ciò ha creato una nuova serie di richieste, in quanto a
quei tempi l'unica analisi del traffico era in termini di carichi di rete e flussi.
Verso la fine degli anni Ottanta, infatti, ogni grande azienda aveva messo in
comunicazione le sue applicazioni attraverso l’utilizzo delle reti, ogni ufficio era collegato
a tutti gli altri, anche se dislocati in nazioni differenti. Così facendo, il livello IT aziendale
si trovò ben presto ad essere sommerso da eventi di ogni genere, da quelli di livello
commerciale a quelli di gestione (ad es. proposte di negoziazione, programmi di
pianificazione, semplici e-mail, etc.), provenienti da tutti gli angoli del globo, sia da fonti
esterne che dai propri uffici interni. A ciò si aggiunse anche la grande quantità di formati
differenti utilizzati dalle varie applicazioni [4].
Di conseguenza, ora non c’era più la sola necessità di garantire il corretto funzionamento
dell’IT layer aziendale, ma anche quella di capire cosa stesse accadendo in esso. Gli eventi
ricevuti, infatti, contenevano una gran quantità di informazioni (denominate business
intelligence) che sono di grande utilità nella gestione dell'impresa. Era necessario quindi
riuscire ad estrarre quante più informazioni possibili dall’insieme di eventi ricevuti, molto
spesso definitivo anche come “Event Cloud”, e farlo nel più breve tempo possibile.
Tali necessità hanno portato alla nascita del Complex Event Processing.
Precisamente, la nascita di tale tecnologia si deve a David Luckham, research professor in
Ingegneria Elettronica presso la Stanford University, il quale ha esteso il modello
“Complex Adaptive Systems” (CAS) sviluppato da John Holland nel 1976 per la
modellazione dell’adattamento della conoscenza all’ambiente organizzativo.
In particolare tale modello stabilisce che una organizzazione è un sistema complesso
avente la capacità di cambiare le proprie regole in relazione all’esperienza maturata. Il
termine adaptive, infatti, si riferisce alla necessità da parte di un sistema di evolvere
facilmente il proprio stato determinando, come conseguenza, continui cambiamenti,

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
14
modifiche, aggiunte e non ultimo il riordino dei propri componenti. Il sistema è quindi
migliorato se è in grado di imparare dall’esperienza e di adattare il proprio comportamento
dinamicamente [5].
Precisamente, la definizione data da Holland relativamente al modello CAS è la seguente:
“Un complex adaptive system non ha alla base un’unica equazione o regola che lo
controlla. Esso ha, al contrario, molte parti interagenti, distribuite, con poche o
nessuna che effettuano un controllo centrale. Tuttavia ciascuna delle parti è
disciplinata da proprie regole. A sua volta, ognuna di queste regole potrebbe
partecipare al conseguimento di un risultato, e ciascuna potrebbe influenzare le
azioni di altre parti del sistema” [6].
Le proprietà principali di cui gode un sistema basato sul modello CAS sono le seguenti:
• Complessità
• Eterogeneità
• Comportamento aggregato
• Anticipazione
• Evoluzione
• Non linearità
Tra queste, Holland pone maggiormente l’attenzione sulla non linearità dei sistemi, ossia
l’imprevedibilità del loro comportamento, in quanto rappresentano la maggior parte degli
scenari reali. Infatti, ad esempio, il flusso di traffico malevolo (ad es. virus, trojan, etc.) in
Internet è senza dubbio un fenomeno non lineare e non predicibile, così come anche il
fenomeno della “previsione delle entrate” in un sistema finanziario.
Un sistema basato sul un modello CAS riceve in ingresso degli input e, attraverso la
definizione di opportune regole che ne determinano il comportamento, presenta in uscita
degli output. L’adattamento della conoscenza viene opportunamente realizzato attraverso

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
15
un controllo sia degli ingressi, attraverso operazioni di feedback, sia dello stato interno del
sistema stesso. Adoperando un tale approccio, è possibile tener conto anche dei possibili
cambiamenti non solo degli input del sistema, ma anche dell’eventuale cambiamento
dell’ambiente esterno, al fine di garantire al sistema stesso l’insieme di tutte le proprietà
precedentemente definite.
Una caratteristica fondamentale per un CAS è quella, dunque, di poter essere usato per
stimare “conseguenze future di azioni correnti” [6], avendo anche la possibilità di
modificare il modello dinamicamente, durante il ciclo di vita del sistema, a seconda dei
risultati ottenuti con le regole inizialmente definite.
Figura 1.2: Complex Adaptive System Model
L’insieme dei concetti discussi intorno alla teoria del Complex Adaptive Systems
consentono di approcciare al problema, in generale, del Complex Event Processing come
componente per la realizzazione dei sistemi distribuiti IT, event driven, i quali possono
essere modellati in base a tali concetti.
In particolare, la tecnologia CEP applica la teoria del CAS allo studio dei processi di
business definendo metodi e regole per interpretare gli eventi, al fine di risolvere problemi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
16
di business, ma non solo. Essa infatti col passare del tempo ha trovato utilizzo negli ambiti
più disparati, tra cui, come vedremo, quello della sicurezza.
Tale tecnologia è alla base di molti motori di regole che consentono di effettuare
operazioni di filtraggio, aggregazione e correlazione di eventi generati da applicazioni,
database e sistemi di messaging, in tempo reale.
Precisamente un'applicazione CEP opera in genere su più eventi osservati in arrivo, spesso
anche migliaia al secondo, per ricavare un numero molto inferiore di eventi più
significativi, che riassumono i dati presenti in quelli di livello inferiore. Tali eventi
prendono il nome di “eventi complessi”. Ciò consente di comprendere al meglio le
condizioni attuali dell’ambiente osservato e prendere decisioni relativamente alle azioni da
intraprendere in pochi millisecondi, secondi o minuti dalla ricezione degli eventi.
Pertanto spesso si definisce il CEP come un supporto al miglioramento della cosiddetta
“situation (o situational) awareness”, che è definita come "sapere ciò che sta accadendo in
modo da poter decidere cosa fare".
Il CEP si basa su due concetti fondamentali:
• Evento
• Event Processing
La loro descrizione sarà oggetto del prossimo paragrafo.
1.2 Event ed Event Processing
Luckham definisce un evento come un oggetto che rappresenta un’occorrenza di
un'attività in un sistema o dominio: esso è qualcosa che è avvenuto, o che si prevede che
possa avvenire in quel dominio. La parola evento, inoltre, è usata per rappresentare in un
sistema computazionale l'occorrenza di una specifica entità di programmazione, come, ad
esempio, la pressione di un pulsante all'interno di un'applicazione può portare allo

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
17
scatenarsi dell'evento “mouse clicked”.
Gli eventi sono legati, molto spesso, ad altri eventi dal tempo, causalità e/o aggregazione.
Il tempo è una proprietà di un evento, ed è di solito indicata sotto forma di un timestamp.
Molto utilizzata è la notazione A → B, attraverso la quale si è soliti indicare che l'evento
A ha causato B, vale a dire, A doveva accadere prima di B, o B dipende da A.
L’assioma Causa-Tempo di Luckham lega il concetto di causalità a quello di timestamp,
infatti afferma che se l'evento A ha causato l’evento B nel sistema S, allora nessun clock in
S darà a B un timestamp precedente a quello dato ad A. [7]
Ad un livello superiore un evento può essere visto come una astrazione costituita da un
insieme di più eventi semplici che sono suoi membri. Tale astrazione prende il nome di
evento complesso (Complex Event).
Figura 1.3: Complex Event [5]
Nella figura 1.3 è mostrato un esempio di evento complesso ottenuto a partire da un
insieme finito di eventi atomici, in cui si evince in maniera precisa che un evento
complesso contiene un riferimento a tutti gli eventi dai quali è possibile astrarre un
determinato pattern. Esempi potrebbero essere:
• L’acquisto di un prodotto effettuato con successo, ossia l’astrazione di eventi in una
transazione

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
18
• Rilevamento di una situazione anomala in un certo contesto: ad esempio fraud
detection
Oltre ai Complex Event, alti eventi di particolare importanza sono gli event stream ed
event cloud.
Un event stream è una sequenza di eventi (potenzialmente infinita) ordinati in base ad un
certo criterio, solitamente di tipo temporale. In questo caso, l’ordinamento può essere
realizzato o in base all’istante di tempo in cui essi si verificano, oppure in base all’istante
di tempo in cui sono ricevuti. Formalmente, potremmo dire che un flusso di eventi è
costituito da una coppia ordinata (S,∆), dove:
• S: sequenza di eventi
• ∆: sequenza degli intervalli di tempo relativi agli eventi; è un numero razionale o
reale strettamente positivo, cioè ∆i>0 ∀i
Per quanto riguarda un event cloud invece, esso è un insieme parzialmente ordinato di
eventi. L’ordinamento parziale degli eventi è imposto principalmente da relazioni causali e
da altre relazioni tra gli eventi stessi. Un event cloud, tipicamente, è costituito da un
insieme di eventi prodotti da uno o più sistemi distribuiti.
Si comprende che un flusso di eventi è un caso particolare di event cloud, in cui gli eventi
sono necessariamente ordinati in base ad un criterio. Quindi un event cloud potrebbe
contenere uno o più event stream, ma non vale il contrario.
Un altro concetto fondamentale relativo agli eventi è sicuramente quello di tipo. Gli eventi
infatti, al variare del contesto o anche al variare della sorgente che li ha generati, possono
contenere informazioni totalmente differenti l’uno dall’altro, pertanto è necessario definire
un concetto di event type. Definiamo innanzitutto come insieme di tipi di eventi l’insieme
∑E ={E1,E2,…,En}, n≥0 costituito da tutti i tipi di eventi ammissibili per un certo dominio.
Un event type è, dunque, una coppia E= (id,a) in cui:
• id: identifica univocamente un evento

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
19
• a = {a1,a2,…,an}, n≥0: è un vettore costituito da un insieme finito di attributi che
caratterizzano un evento
Dall’univocità dell’identificativo si deduce che ∀Ei, Ej∈∑E, i≠j : Ei.id ≠ Ej.id, e cioè che
non possono esistere due eventi che presentino lo stesso id.
Esistono eventi che si potrebbero definire come rumore di fondo e che, quindi, non
richiedono alcuna reazione. Gli eventi che, invece, ne richiedono vengono spesso chiamati
situazioni. Si definisce quindi una situazione come l'occorrenza di un evento che potrebbe
richiedere una reazione.
Una delle tematiche principali legate all'event processing è l'identificazione e il riscontro
di situazioni, a seguito delle quali possano essere stabilite, se necessario, le opportune
azioni da intraprendere. Un’azione potrebbe essere, semplicemente, rispondere al telefono
o aggiungere un oggetto alla lista della spesa, oppure potrebbe consistere in qualcosa di
più complesso: nel caso in cui una persona perda l'aereo, ad esempio, esistono svariate
alternative di azione a seconda dell'ora e del giorno, dell'aeroporto in cui si trova, delle
regole della compagnia e del numero di altri passeggeri nelle sue stesse condizioni.
L'event processing è un processo computazionale che compie operazioni su eventi. Le più
comuni sono l'analisi, la creazione, la trasformazione e la cancellazione. Esistono due
tematiche principali all'interno di quest'area:
• Il design, cioè la struttura del codice e il funzionamento delle applicazioni che
utilizzano gli eventi, sia direttamente che indirettamente. Ci si riferisce a ciò come
programmazione event-based, sebbene più spesso viene utilizzata la dicitura
architettura event-driven.
• Le operazioni di elaborazione che è possibile eseguire su eventi come parti di una
certa applicazione. Questo include il filtraggio di certi tipi di eventi, il cambiare
l'istanza di un evento da un tipo ad un altro ed esaminare un insieme di eventi al
fine di riscontrare un modello specifico. Queste operazioni spesso fanno sì che
nuove istanze di eventi vengano generate.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
20
1.2.1 Event Processing e programmazione Event-Based
È possibile, ovviamente, scrivere programmi event-based senza ricorrere esplicitamente ad
operazioni di event processing. Le tre principali differenze che distinguono l'event
processing dalla semplice programmazione event-based, e che aprono ad un ricco insieme
di possibilità, sono:
• Astrazione: Le operazioni che compongono la logica dell'event processing possono
essere separate dalla logica applicativa, permettendone così la modifica senza
toccare le applicazioni che producono e consumano gli eventi.
• Disaccoppiamento: Gli eventi riscontrati e prodotti da una specifica applicazione
possono essere utilizzati e consumati da applicazioni totalmente differenti. Non c'è
alcun bisogno per le applicazioni che producono e quelle che consumano eventi di
essere a conoscenza ognuna dell'esistenza dell'altra; non a caso esse possono essere
dislocate in qualunque parte del mondo. Un evento emesso da una singola
applicazione produttrice può essere utilizzato da più macchine consumatrici di
eventi e, viceversa, si può far sì che una applicazione consumi eventi prodotti da
più applicazioni generatrici di eventi.
• Obiettivo incentrato sul mondo reale: L'event processing ha spesso a che fare con
eventi che si verificano, o che dovrebbero verificarsi, nel mondo reale. La
relazione dell'event processing con il mondo può avvenire in due modi: in maniera
deterministica, ovvero tramite un perfetto mapping tra la situazione del mondo
reale e la sua implementazione nel sistema di event processing, considerando
quindi tutte gli aspetti e le variabili in gioco di quella determinata situazione,
oppure in maniera approssimata, dove, appunto, viene considerata
un’approssimazione della situazione reale, contenete le sole variabili rilevanti.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
21
1.3 Architettura di Event Processing
Non tutte le applicazioni di event processing sono uguali tra di loro, ovviamente, ma la
maggior parte di queste hanno una struttura riconducibile alla figura sottostante.
Figura 1.4: Architettura generale di event processing
Un'applicazione può contenere uno o più generatori di eventi, anche chiamati event
producer. Essi possono apparire in una vasta gamma di forme e dimensioni: per esempio,
possono essere sensori hardware che producono eventi quando rilevano un certo tipo di
occorrenza, ma anche semplici bit di strumentazione software che produce eventi quando
alcune condizioni di errore vengono segnalate o, ancora, bit di controllo di una
applicazione.
La controparte degli event producer sono gli event consumer. Questi componenti sono
coloro che ricevono gli eventi e, tipicamente, agiscono su di essi. Le loro funzionalità
possono variare: essi sono in grado, ad esempio, di immagazzinare gli eventi per un uso
futuro, mostrarli in una interfaccia utente, o decidere eventuali comportamenti reattivi
dopo averli ricevuti.
Gli event producer e gli event consumer sono collegati a meccanismi di distribuzione degli
eventi e, solitamente, qualche meccanismo di event processing intermedio viene posto tra i
suddetti. La distribuzione è garantita mediante l'uso di una tecnologia di instradamento dei
messaggi asincrona; per questo motivo, spesso con un leggero abuso di notazione, si parla

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
22
di un producer che invia un evento o di un consumer che riceve un evento.
Il meccanismo di distribuzione degli eventi è solitamente one-to-many per far sì che ogni
evento, dopo essere stato inviato, possa essere ricevuto da più event consumer.
Per quel che riguarda i sistemi di event processing intermedi, nei casi più semplici il
processing può semplicemente essere ricondotto ad una attività di routing con o senza
filtraggio, ma in realtà essi sono solitamente in grado di generare eventi addizionali. Tali
eventi possono essere distribuiti ai vari event consumer, ma possono anche essere anche
soggetti ad ulteriori sistemi di event processing.
È importante notare il disaccoppiamento tra gli event producer e gli event consumer. Gli
eventi sono il centro dell'attenzione di tutto il sistema. L'event producer ha una relazione
con ogni evento che produce, invece di una relazione con gli event consumer. Non è
importante per esso sapere quanti event consumer ci sono per i suoi eventi, e non gli
interessano nemmeno le azioni che questi ultimi potrebbero prendere una volta ricevuti gli
eventi. Allo stesso modo gli event consumer reagiscono all'evento in sé, e non all'atto della
ricezione di un evento da uno specifico event producer, anche se in alcuni casi tale
informazione può rivelarsi fondamentale per la corretta reazione del componente.
Per quanto riguarda, invece, l’event processing agent, invece, essi si possono definire
come un modulo software che compie operazioni sugli eventi. Esso riceve e invia eventi, o
può generarne degli altri, perciò, ad un certo modo, si può dire che produce e consuma
eventi [8].
1.4 CEP ed Event Stream Processing
Mentre il CEP era in fase di sviluppo era in corso una ricerca parallela che aveva come
obbiettivo principale quello di realizzare l’analisi degli eventi in tempo reale. Tale ricerca
ebbe inizio a metà degli anni Novanta, quando ci si rese conto che i database erano troppo
lenti per fare analisi di questo tipo.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
23
L’idea di partenza era quella di eseguire query continue su flussi di dati, e sfruttare il
concetto delle finestre temporali al fine di velocizzarne l’esecuzione. Tale concetto, infatti,
prevede che una risposta ad una determinata query sia ritenuta valida solo nel corso della
finestra temporale corrente, cioè quella in cui si sono verificati gli eventi a partire dai quali
è stata determinata tale risposta. Ovviamente all’avanzare della finestra temporale, anche
la risposta dovrà essere aggiornata così da includere i nuovi eventi ed escludere quelli
fuori finestra. Questa ricerca fu denominata Data Streams Management (DSM) e ha
portato alla nascita di quello che oggi prende il nome di Event Stream Processing.
Nel caso della tecnologia CEP, invece, non ci si riferisce ad uno stream, bensì ad un event
cloud (§ 1.2), in cui gli eventi che lo compongono sono legati da relazioni complesse,
attraverso le quali è possibile rilevare situazioni significative in un certo contesto.
Si può comprendere quindi che c’è una differenza fondamentale tra CEP ed ESP, la quale
può tradursi nella differenza esistente tra un event stream e un event cloud, già
parzialmente affrontata nel paragrafo precedente.
Un flusso di eventi è una sequenza di eventi ordinata cronologicamente, come ad esempio
l’andamento della borsa; un event cloud, invece, può essere visto come un insieme
di eventi generati dalle varie attività/applicazioni che sono in esecuzione all’interno di un
sistema IT. È facile intuire che all’interno di un event cloud possano esserci uno o più
event stream, il che porta alla conclusione che questi ultimi rappresentino un caso
particolare dei primi.
Nell’ambito dell’ESP, l'ipotesi che si sta elaborando un flusso di eventi nel loro ordine di
arrivo ha i suoi vantaggi. Essa infatti consente di progettare algoritmi per l'elaborazione di
eventi che richiedano poca memoria, in quanto non vi è la necessità di ricordare molti
eventi, e che possano essere molto veloci. Tali algoritmi infatti non devono fare altro che
elaborare gli eventi dello stream al loro arrivo, trasmettere i risultati ottenuti
all’elaborazione successiva e poi dimenticare quegli eventi.
Nell’ambito invece del CEP, dato che si sta elaborando un event cloud, non si può
assumere che gli eventi arrivano in ordine cronologico. Di conseguenza, ci si concentra di

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
24
solito sulla ricerca di serie di eventi che hanno una qualche relazione complessa, per
esempio, il riconoscimento di un attacco informatico a partire dagli eventi che lo hanno
preceduto. Si comprende che potrebbe essere necessario memorizzare una grande quantità
di eventi prima di trovare quelli che si sta cercando. In questo caso è fondamentale
conoscere quali eventi causano altri eventi, il che richiede più memoria, e ovviamente più
tempo. Nonostante questo però, questo tipo di elaborazione ha l’indubbio vantaggio di
poter essere utilizzata in un insieme più ricco di problemi e scenari, non solo
nell'elaborazione di eventi, ma anche ad esempio nella gestione di processi aziendali.
In definitiva, mentre l’ESP consiste in una elaborazione di basso livello di flussi di eventi,
il CEP include invece da un lato anche l’analisi di eventi, ma pone maggiormente l’enfasi
sul riconoscimento di pattern di eventi dedotti da relazioni di causalità fra essi, in modo da
consentire una elaborazione di più alto livello, utile ad esempio per quanto concerne il
Business Process Management (BPM).
Ciò porta alla conclusione che, pur essendo entrambi due approcci differenti alla
elaborazione degli eventi, l'ESP può essere visto come un sottoinsieme della tecnologia
CEP. Pertanto, vediamo alcune delle regole alla base dell’Event Stream Processing.
1.4.1 Regole alla base dell’ESP
Come già accennato nel paragrafo precedente, il concetto di CEP vede nell’Event Stream
Processing un suo sottoinsieme. Tale tecnologia rappresenta un approccio evolutivo, in
una nuova classe di infrastrutture software, che risponde alle richieste sempre più
stringenti di elaborazioni di flussi di eventi in tempo reale e con bassa latenza, come ad
esempio accade nell’ambito del commercio elettronico, del monitoraggio di reti per la
prevenzione da attacchi di tipo DoS (denial of service) o altri tipi di attacchi, etc.
Le regole fondamentali per realizzare in maniera efficiente ed efficace il processing di
flussi di dati sono le seguenti:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
25
• Intercettare i dati nei flussi
• Interrogare lo stream utilizzando appositi linguaggi SQL like
• Integrare dati memorizzati e flussi di dati
• Garantire la sicurezza e la disponibilità dei dati
• Dividere e scalare le applicazioni
Vediamole più nel dettaglio.
Intercettare i dati nei flussi
Riuscire ad analizzare i dati presenti all’interno degli event stream in ingresso, è una delle
caratteristiche principali di cui deve essere dotato un buon sistema ESP. Infatti, solo in
questo modo si è grado di garantire una bassa latenza, in quanto non è possibile procedere
prima alla memorizzazione dei dati e successivamente al loro recupero. Un approccio di
questo tipo comporterebbe un overhead inaccettabile per molte applicazioni stream-based
che devono rispondere in real-time allo stream di dati in input.
Interrogare lo stream utilizzando linguaggi SQL like
Questa regola è strettamente legata alla precedente, infatti la necessità di dover analizzare
il flusso di eventi direttamente dagli stream in ingresso porta all’ulteriore necessità di
dover elaborare questi stream in tempo reale, al fine di individuare eventi significativi.
Un’idea potrebbe essere quella di utilizzare applicazioni e/o tool realizzati ad hoc con un
comune linguaggio di programmazione di alto livello (C++ , Java, etc), ma una tale
soluzione risulterebbe poco performante e richiederebbe costi molto elevati sia di sviluppo
che di manutenzione.
Per elaborare dati in tempo reale, invece, risulta essere molto più efficiente utilizzare un
linguaggio, anch’esso di alto livello, simile all’SQL. Quest’ultimo infatti è caratterizzato
da una grande espressività, ed è basato su potenti primitive per l’elaborazione dei dati che
consentono di effettuare filtraggio, fusione, correlazione ed aggregazione.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
26
È necessario, dunque, un linguaggio che si potrebbe definire “SQL like”, inteso come
estensione semantica dello standard SQL, che lavora su flussi continui di dati.
Il linguaggio cosi definito da un lato conserva tutte le capacità dell’SQL, dall’altro ne
aggiunge di nuove come la possibilità di definire finestre temporali, memorizzare dati e
flussi di dati e di estendere le primitive già esistenti per includere funzioni logiche ed
aritmetiche. Un linguaggio così definito rappresenta il punto logico di partenza per la
realizzazione di uno stream processing engine.
Integrare dati memorizzati e flussi di dati
Molto spesso accade che in alcuni contesti gli eventi di particolare interesse dipendono in
parte da informazioni correnti e in parte da informazioni precedenti, le quali rientrano nei
cosiddetti dati storici. Di conseguenza si comprende che un’altra regola fondamentale per
le applicazioni ESP è sicuramente quella relativa alla capacità di memorizzare le
informazioni correnti. Così facendo, infatti, si ha la possibilità di renderle nuovamente
disponibili per le successive elaborazioni, realizzando di fatto un’integrazione di
informazioni legate sia ai dati provenienti da flussi continui sia ai dati memorizzati
persistentemente. Ovviamente bisognerà garantire che l’accesso a tali dati possa avvenire
sempre attraverso lo stesso linguaggio “SQL like”.
Per applicazioni con requisiti di bassa latenza ed overhead, l’approccio più corretto per
soddisfare la regola enunciata è di avere un’infrastruttura per lo stream processing che
disponga di un DBMS embedded.
Garantire la sicurezza e la disponibilità dei dati
Altri requisiti fondamentali per le applicazioni stream-based sono sicuramente la sicurezza
e la disponibilità dei dati. Infatti la consistenza dell’informazione trasportata da uno
stream è tale se legata in maniera indissolubile all’istante di tempo in cui quest’ultimo è
ricevuto. Il verificarsi di un malfunzionamento in un’applicazione potrebbe comportare
l’interruzione di un eventuale flusso di dati che necessita di essere elaborato o, più

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
27
semplicemente, l’impossibilità a reagire sebbene siano state individuate situazioni per cui
è necessario produrre in uscita un allarme o compiere una particolare azione.
Il ripristino da un malfunzionamento precluderebbe la possibilità di elaborare in real-time
i dati, oltre a comportare un ritardo inaccettabile nell’attesa del riavvio dell’applicazione
per la quale è occorso un guasto.
Dividere e scalare le applicazioni
In un contesto distribuito, le applicazioni stream-based elaborano grandi quantità di flussi
provenienti da sorgenti diverse e in formati diversi. All’aumentare del volume di questi
flussi di dati, nonché della complessità della singola elaborazione, è opportuno dividere
su più macchine l’insieme delle operazioni svolte da un’applicazione.
Quindi un requisito fondamentale è senza dubbio la scalabilità. Per quanto riguarda il
processo di elaborazione di uno stream, l’applicazione deve anche supportare il multi-
threaded, in modo tale da sfruttare i vantaggi derivanti dalle moderne macchine multi-
processore (e multi-core) [9].
1.5 CEP Engine
L’elemento centrale di un’architettura basata sul Complex Event Processing è il motore,
ossia l’entità che effettua sugli event object l’insieme delle operazioni necessarie ad
elaborarli: creazione, lettura, trasformazione, aggregazione, correlazione, pattern detection
e rimozione.
Precisamente il suo ruolo è quello di interpretare, filtrare, combinare eventi primitivi ed
individuare gli eventi compositi sulla base di regole specifiche, al fine di notificarne
l'occorrenza ai componenti "reattivi", cioè quei componenti il cui compito è quello di
attuare determinate operazioni in risposta a determinate situazioni rilevate.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
28
Figura 1.5: Modello di riferimento per il CEP Engine [5]
Il modello di riferimento per il CEP engine è mostrato nella figura 1.5. Come si può
notare, il motore riceve in ingresso tutte le informazioni necessarie ad elaborare il flusso,
quali eventi dati, eventi di controllo e in generale tutti i tipi di eventi significativi nel
particolare contesto preso in considerazione.
La prima operazione che effettua un motore CEP è il filtraggio, ossia la rimozione degli
eventi da uno stream in base alle loro proprietà (o attributi).
Esempi di filtraggio possono essere i seguenti:
• Prendere in considerazione tutto il traffico relativo ad un determinato protocollo, ad
es. SSH, HTTP, etc
• Considerare tutti e soli i dati forniti dai sensori i cui valori sono compresi in un
range prefissato
Attraverso tale fase, il CEP engine è in grado di effettuare una selezione degli eventi di
interesse, tagliando fuori tutti quelli privi di significato e non appartenenti dunque al
dominio del problema.
La scelta dell'algoritmo di filtering deve essere operata in base ai requisiti specifici della
particolare applicazione e contesto nel quale si opera. Tali requisiti sono determinati,
principalmente, dai due seguenti fattori:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
29
• Velocità di filtering e di riconoscimento della singola sequenza di eventi:
In quanto nella maggior parte degli scenari di lavoro di un CEP, si prevede la
generazione di una ingente quantità di notifiche che, per essere utili al fine ad
esempio di generare un alert, devono essere elaborate in tempi congrui
• Quantità di memoria adoperata per tener traccia degli eventi primitivi:
In quanto un evento complesso è una combinazione di eventi primitivi, generati
anche molti istanti prima. Di conseguenza è necessario tener traccia di tali eventi,
ma allo stesso tempo è necessario anche non saturare le risorse disponibili in
termini di memoria.
Un concetto molto importante su cui i CEP engine basano l’event processing è quello di
sliding window. Una finestra è un oggetto che mantiene in memoria, in un certo istante di
tempo, un insieme finito di eventi appartenenti ad uno stream.
In generale, è possibile distinguere tra due tipi di finestre:
• Time-based window: contengono tutti gli eventi che si verificano in un determinato
intervallo temporale
• Count-based window: contengono una fissata cardinalità di eventi
L’utilizzo delle finestre consente al motore di effettuare operazioni fondamentali per
l’elaborazione degli eventi, quali ad esempio l’aggregazione.
Questa operazione consiste nell’aggregare molteplici eventi in un singolo evento,
attraverso l’applicazione, allo stream di eventi ricevuto in input, di funzioni aritmetiche
sui loro attributi (somma, conteggio occorrenze, etc.), statistiche (valor minimo, massimo,
medio, deviazione standard, etc.), estraendo in tal modo informazioni “aggregate” atte a
rilevare eventuali “scenari” significativi.
Riprendendo gli esempi proposti nel caso del filtraggio, è semplice comprendere l’utilità
di tale funzione. Ad esempio, nel caso del monitoraggio in rete, potrebbe essere utile
catturare, in un intervallo di tempo prefissato, tutto il traffico generato con un certo

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
30
protocollo, ricavando informazioni quali il traffico medio in quell’intervallo, il valore
massimo del rate di un particolare router, etc.
L’operazione più importante per un CEP engine, oltre a quelle finora presentate, è
sicuramente la correlazione. L’elaborazione contemporanea di flussi multipli di eventi
consente al motore di correlare dati appartenenti a flussi diversi e “apparentemente”
indipendenti tra loro.
La possibilità di trovare relazioni temporali, causali, topologiche tra eventi non solo dello
stesso tipo, ma soprattutto di natura diversa, rappresenta il punto di forza di un CEP
engine. Infatti riuscire a correlare informazioni semplici ed aggregate in un event cloud
vuol dire poter rilevare situazioni significative all’interno di un determinato contesto.
Riprendendo ancora una volta l’esempio precedente relativo al monitoraggio di una rete,
l’event correlation permette di rilevare efficacemente comportamenti anomali quali un
attacco di tipo TCP Gender Changer (che come vedremo sarà uno dei casi d’uso presi in
considerazione nell’ambito di questo lavoro di tesi) oppure un malfunzionamento di uno o
più dispositivi di rete (router, switch, etc.).
Nel caso, invece, di una rete di sensori predisposta per controllare e monitorare, ad
esempio, un ambiente critico da un punto di vista della sicurezza, grazie alla correlazione
di dati letti dai sensori e inviati al motore, è possibile identificare situazioni di pericolo
quali intrusioni non autorizzate.
La fase di event correlation è dunque indispensabile, e permette inoltre di evitare il rischio
di sottoporre all’applicazione eventuali informazioni irrilevanti (es. malfunzionamento di
un dispositivo di rete che invia sempre gli stessi pacchetti) o, al contrario, di trascurare
importanti segnali di pericolo (es. sensori di una stessa zona che forniscono valori critici di
temperatura).
Sebbene la correlazione sia fondamentale nell’individuare scenari significativi per il
dominio del problema, essa non consente però facilmente di stabilire relazioni temporali e
causali tra eventi. Si rende necessario, quindi, la capacità da parte di un CEP engine di
legare gli eventi da un punto di vista logico, causale e temporale, al fine di poter realizzare

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
31
la cosiddetta pattern detection.
A tale fine, i CEP engine si affidano di solito ad un linguaggio “SQL-like” (a cui si è già
accennato nell’ambito dell’ESP), il quale consente di esprimere facilmente tutte le
relazioni necessarie all’individuazione di eventi complessi.
In particolare, è possibile esprimere in maniera molto compatta ed efficiente sia relazioni
logiche tra eventi (AND, OR, NOT, etc.), sia relazioni causali (un evento ne precede un
altro, etc.).
Questa fase può essere vista in realtà come l’applicazione di tutte le altre fasi finora
descritte (filtering, aggregation e correlation), e permette di effettuare un’elaborazione di
più alto livello dell’insieme di tutti gli stream in ingresso al motore, riconoscendo
pattern complessi nel dominio di interesse [9].
Un CEP engine, come già più volte detto, utilizza un linguaggio molto simile all’SQL, che
consente di elaborare efficacemente ed efficientemente molteplici flussi di eventi.
Il filtraggio e la correlazione vengono realizzati infatti adoperando le stesse primitive
utilizzate per l’interrogazione di un database (clausole where, join, etc.), con l’aggiunta di
costrutti specifici per l’event processing (sliding windows, etc.). Tuttavia, un motore per il
complex event processing presenta alcune differenze sostanziali rispetto ad un DBMS
relazionale.
Figura 1.6: Relazione tra CEP engine e RDBMS
La figura 1.6 mostra in maniera grafica una prima differenza, la quale è relativa alla

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
32
modalità di analisi dei dati. Infatti è possibile vedere un CEP Engine come un database
“capovolto”, in quanto anziché memorizzare i dati ed effettuare query su di essi, prevede
che siano le regole ad essere memorizzate, sottoforma di query, alle quali poi saranno
sottoposti continuamente dati, ossia gli stream sottoposti ad elaborazione.
Un’altra differenza risiede nel paradigma di comunicazione. Infatti, mentre alla base di un
DBMS vi è un paradigma di tipo request/response, in cui si prevede la realizzazione di una
interrogazione al fine di ricevere un risultato, nel caso del CEP engine, invece, è di tipo
publish/subscribe, in quanto si prevede la memorizzazione di regole che definiscono il
comportamento del sistema e vengono notificati eventi complessi quando essi si
verificano.
1.5.1 Tecniche di correlazione
Come abbiamo già definito nel paragrafo precedente, lo scopo principale di un CEP
engine è quello di identificare eventi che corrispondono a pattern noti, a valle di
un’operazione di filtering, correlarli e generare un conseguente evento complesso che
descriva al meglio quanto sta accadendo nell’ambiente analizzato.
In tal modo, l'avvicendarsi degli eventi sarà più chiaro e leggibile, migliorando la
cosiddetta Situation Awareness e dando un supporto significativo al lavoro degli operatori
umani.
Il senso più profondo del concetto di correlazione risiede nell'approfondimento della
conoscenza del sistema, conseguente alla valutazione degli eventi che si verificano.
Pertanto, un motore di correlazione è uno strumento molto potente che, a seconda del
contesto in cui viene calato e del livello di astrazione delle informazioni che deve trattare,
è in grado di:
• Identificare situazioni straordinarie
• Identificare la causa che ha originato un problema

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
33
• Fare prediction sui possibili eventi futuri e scoprire trend
Oggigiorno esiste una grande varietà di soluzioni di correlazione, molte delle quali anche
estremamente differenti l’una dall’altra. Tale varietà è giustificata dalla moltitudine di
settori differenti nelle quali possono essere applicate, e per le quali costituiscono, nella
maggior parte dei casi, un valore aggiunto.
Nei prossimi paragrafi saranno descritte alcune di queste tecniche, ed in particolare le
seguenti:
• Correlazione basata su macchine a stati finiti
• Correlazione Rule-Based
• Correlazione Case-Based
1.5.1.1 Correlazione basata su macchine a stati finiti
Una delle tecniche di Event Correlation più adoperate è quella basata su macchine a stati
finiti. Un esempio del suo utilizzo è mostrato in [10]. Essa prevede l’individuazione e
successiva segnalazione di un evento considerato critico mediante due passi fondamentali:
• Costruzione del modello di sistema ad eventi
• Costruzione del protocollo diagnostico, cioè dell'insieme delle regole impiegate per
scoprire e localizzare l’evento critico
Il modello di sistemi ad eventi, strutturato come un automa a stati finiti, è costituito da un
insieme di stati, le cui transizioni sono valutate su occorrenze di eventi osservabili.
Il protocollo diagnostico riveste due specifiche funzionalità, cioè:
• La fault detection, cioè la comprensione dell'occorrenza di un evento che può
comportare la compromissione del sistema

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
34
• La localizzazione dell’evento, cioè l’individuazione del punto del sistema in cui lo
stesso è stato sollevato
In effetti, una volta modellato il sistema come una macchina a stati finiti, il correlation
engine opererà su tale formalismo, mediante un filtro, definito come un parametro
progettuale, che indicherà quali siano gli eventi da osservare e catturare.
Talvolta è auspicabile che a valle delle operazioni svolte sugli eventi, un correlation
engine restituisca più output differenti, ciascuno relativo ad uno specifico aspetto
dell’evento occorso. Per giungere a questo risultato si potrebbe, ad esempio, adoperare una
versione estesa di macchina a stati finiti, cioè una Finite State Trasducer, che consente ad
un correlatore di eventi di eseguire operazioni più complesse, senza che venga persa la
semplicità del modello sul quale si opera.
Nell'ambito della correlazione, un FTS può essere definito come una quintupla che
consiste di [11]:
• Un set di possibili input event I
• Un set di possibili output event O
• Un set di possibili stati S
• Uno stato iniziale S0 Є S;
• Una funzione di transizione di stato:
f : I x S --> S x O
che definisce lo stato successivo e il possibile output event.
Il modello prevede la possibile costruzione di un FTS per ciascuna categoria di event
pattern definita, ciascuno dei quali si riferisce ad una specifica classe di problemi
riscontrabili nell'ambito applicativo. Naturalmente, l'insieme di tutti gli FTS definiti
racchiude in sé la conoscenza del sistema complessivo.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
35
1.5.1.2 Correlazione Rule-Based
La tecnica di correlazione rule-based, di cui un esempio di utilizzo è definito in [12], è
basato su tre elementi fondamentali:
• Data repository: repository dei dati relative ai problemi riscontrati nel sistema
• Knowledge base: repository delle regole specifiche del dominio
• Engine di inferenza: che indica in corrispondenza di quali eventi (o di quali
combinazioni di questi) debbano essere applicate le regole.
Si può comprendere che la correlazione viene effettuata in maniera molto semplice, infatti
l’ engine non fa altro che valutare una regola dopo l’altra, fino a quando non viene trovata
una regola che realizzi il matching con gli eventi che sono stati osservati.
Differentemente da altre tecniche, nella correlazione rule-based il controllo e la
conoscenza sono separate. Ciò comporta un enorme vantaggio, e cioè la possibilità di
poter ampliare la knowledge base senza inficiare la struttura dell'engine, se non per
l'introduzione di nuove regole e, quindi, per la capacità di fare inferenza con un numero
più elevato di rule.
Queste regole generalmente definiscono relazioni di tipo condizione-azione, cioè essa
specifica sia una condizione (ad esempio “l’evento A si verifica almeno dieci volte in
cinque minuti”) che la relativa azione (ad esempio “invia una mail di allerta
all’operatore”).
Elemento cruciale per un corretto funzionamento di questa tecnica di correlazione è
sicuramente il linguaggio utilizzato per definire tali regole. Ad oggi esistono molti
linguaggi definiti per tale scopo e vanno da quelli proprietari, realizzati ad hoc dalle
aziende produttrici di sistemi CEP, a quelli XML based, SQL-like, etc.
Il limite principale di una correlazione rule-based è dovuto alla mancata capacità di
apprendimento dall'esperienza pregressa; pertanto, uno stesso calcolo potrà essere ripetuto
tanto frequentemente quanto frequente è l'occorrenza di uno stesso evento.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
36
Per ovviare a questo inconveniente l'unica possibilità resta l'intervento dell'operatore
umano, che dovrà inserire la nuova conoscenza acquisita nell'engine.
Questa soluzione, però, desta alcune perplessità in merito a determinati aspetti.
Un correlation engine viene applicato in contesti di diversa dimensione e complessità, ma
negli ultimi anni ci si sta spingendo maggiormente verso gli ambienti distribuiti, altamente
specializzati ed eventualmente IP-based, che mostrano più di altri caratteristiche di forte
variabilità nel tempo.
In uno scenario siffatto, un correlation engine rule-based espleterebbe i suoi compiti
richiedendo, però, un massiccio coinvolgimento da parte del personale umano.
A quest'ultimo, infatti, sarebbero richieste specifiche expertise rispetto al contesto
applicativo, in particolare: la conoscenza dello spazio degli eventi, delle loro possibili
combinazioni (che possono dar luogo ad ulteriori eventi significativi) e, naturalmente,
delle azioni da intraprendere in risposta a questi ultimi. Pertanto, in un ambiente che
coinvolge un gran numero di dispositivi, ciascuno dei quali possibile source di eventi,
dislocati in ambiente distribuito, si può facilmente intuire l'onere di conoscenza e capacità
a carico dell'esperto umano. Ancora, quando l'ambiente cambia velocemente, l'expertise
accumulata in un momento del ciclo di vita del sistema potrebbe non essere più sufficiente
per momenti successivi. Pertanto, l'evoluzione del sistema dovrebbe andare di pari passo
con l'approfondimento della competenza e della conoscenza degli operatori umani,
comportando un notevole sforzo in termini di tempo e di capacità cognitiva da parte di
questi ultimi. Tali considerazioni smantellerebbero, in ultima analisi, lo scopo principale
di un correlation engine, cioè dare supporto valido, minimizzando il lavoro ed il tempo
impiegato, al personale esperto.
Tuttavia, il principale vantaggio dell'approccio rule-based è mitigare il problema dei falsi
negativi (e non dei falsi positivi), che rappresentano una delle maggiori criticità in taluni
contesti applicativi (come quelli della sicurezza). Un ulteriore punto di forza è dato dalla
modularità dei rule pattern relativi ai vari sottosistemi, cosa che consentente agli operatori
dei singoli sottosistemi coinvolti di ottenere e concentrare la propria attenzione alle sole

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
37
informazioni a cui sono interessati.
1.5.1.3 Correlazione Case-Based
L'approccio Case Based, di cui un esempio d’uso è mostrato in [13], differisce in ampia
misura da quelli visti sino ad ora, poiché si basa sul concetto di "case".
Un case è l'insieme della definizione di un problema e della sua risoluzione, mentre si
definisce case library l'insieme di tutti i case riscontrabili in un determinato sistema. Si
comprende facilmente che quest’ultima rappresenta la base di conoscenza relativa al
dominio considerato.
Tipicamente, la case-based correlation prevede di risolvere un problema eseguendo una
determinata sequenza di operazioni, e precisamente:
• Registrazione dei dettagli dell’evento corrente
• Confronto tra i dettagli dell’evento corrente con dettagli quelli dei casi memorizzati,
al fine di identificare soluzioni adattabili all’evento problema corrente
• Selezione dei casi più simili all’evento corrente
• Applicazione della soluzione memorizzata all’evento corrente
• Se necessario, adattamento della soluzione memorizzata all’evento corrente, così da
ottenere una nuova soluzione
• Applicazione della soluzione adattata all’evento corrente e verifica del risultato
• Se la soluzione è soddisfacente, memorizzazione del nuovo caso in memoria
• Se la soluzione all’evento non è soddisfacente, esprimere la situazione di failure di
tale soluzione e proposta di una soluzione migliore.
I vantaggi più intuibili di questo approccio si intravedono principalmente nella possibilità
di riutilizzare la conoscenza di base acquisita e nella possibilità di ampliarla. Pertanto,
questo modello costituisce un supporto molto valido al lavoro degli operatori umani
addetti al controllo dello stato di sicurezza di un sistema e all’esecuzione delle

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
38
contromisure da intraprendere a fronte di eventi critici.
La pianificazione delle azioni da intraprendere per conservare lo stato corretto di un
sistema, parte dall’identificazione, laddove possibile, delle potenziali minacce a cui questo
è esposto. L’adozione del modello case-based, consente di ampliare mano a mano la
conoscenza degli eventi verificabili nel sistema e, di conseguenza, di (ri)definire le
relative contromisure. Pertanto, il processo di protezione può essere indirizzato in modo
puntuale verso la soluzione più adeguata, rispetto alla situation awareness acquisita.
1.5.2 Proprietà di un CEP Engine
Le proprietà fondamentali che caratterizzano un CEP Engine sono stette, e sono:
• Statefulness: definisce se il motore è in grado o meno di mantenere la storia degli
eventi. Di solito si preferisce utilizzare un motore che abbia questa capacità, cioè
stateful. Infatti un motore stateless, cioè che non ha memoria della storia degli
eventi, avrebbe capacità molto limitate di elaborazione di eventi complessi. In esso
infatti verrebbero a mancare concetti importanti come le sliding windows e
l’operazione di join tra stream di eventi. In tal caso sarebbe molto difficile
realizzare le operazioni di correlation e pattern detection di eventi complessi.
Gli unici vantaggi che si otterrebbe nell’utilizzare un CEP Engine stateless sono
esclusivamente la maggiore semplicità e velocità con cui è possibile realizzare le
varie operazioni. In realtà, però, tali vantaggi da soli non bastano a far preferire un
engine di questo tipo, in quanto anche un engine stateful è in grado di lavorare in
modalità stateless, così da non perdere il vantaggio di quest’ultima soluzione.
• Scalability: definisce la capacità dell’engine di essere o meno scalabile. Ovviamente
si preferisce adoperare un motore scalabile. I flussi di eventi, infatti, sono
generati, tipicamente, da applicazioni distribuite. Quindi risulta evidente il
vantaggio che si ottiene nel dividere il carico di elaborazione degli stream su più

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
39
motori. L’utilizzo di più motori riduce, però, la possibilità di sfruttare appieno le
potenzialità della correlazione, in quanto flussi multipli di eventi vengono inviati a
motori presenti su nodi diversi di elaborazione, per cui non è possibile correlarli
per rilevare eventi complessi (eccetto l’ipotesi di duplicare lo stream al fine di
inviarlo a più di un motore).
• Deployment: definisce se l’elaborazione del CEP engine è realizzata attraverso
l’ausilio di un unico motore (deployment centralizzato) o di più motori
(deployment distribuito).
• Information loss: cioè la perdita di informazioni da parte del motore. Un’operazione
di filtraggio, aggregazione o correlazione si definisce lossless se nessun evento o
informazione vengono persi durante l’operazione stessa. Un CEP engine è lossless
(senza perdita) se tutte le operazioni che effettua sono lossless. Un tale requisito
potrebbe essere richiesto nel caso in cui si debba effettuare un logging di tutti gli
eventi rilevati o, al contrario, potrebbe non essere affatto specificato, in modo tale
da consentire di preservare le risorse del sistema (memoria, CPU, etc.) su cui
risiede l’applicazione di Complex Event Processing.
• Trasparency: caratteristica fondamentale di un engine, la quale impone che siano
verificate le seguenti condizioni:
o Tutte le operazioni effettuate devono essere deterministiche
o Lo stato interno del motore e gli eventi in ingresso ad esso devono essere
noti
In questo modo il comportamento del motore, che può essere rappresentato da un
insieme di regole, risulta essere noto. In particolare, nel caso di un engine rule-
based, si ha che le regole sono sempre note e lo stato interno dipende soltanto da
un insieme limitato (temporalmente) di eventi, per cui le decisioni prese sono
deterministiche. In altri casi, invece, in cui il motore effettua un
autoapprendimento della realtà, prendere decisioni è più complesso, in quanto il

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
40
comportamento potrebbe dipendere da un insieme molto più ampio,
temporalmente, di eventi.
• Robustness: cioè la capacità di far fronte a situazioni impreviste, ossia non
contemplate dalle specifiche.
• Maintainability: cioè la capacità di apportare facilmente modifiche al motore.
Quest’ultima è una proprietà fondamentale per un CEP engine, in quanto
l’esigenza di elaborare eventi complessi si ha molto spesso in contesti in cui è
richiesta una conoscenza approfondita della realtà di interesse ed in cui l’ambiente
esterno cambia frequentemente.
1.6 Il CEP nelle infrastrutture IT di sicurezza
Il problema della sicurezza assume grande rilevanza in un ampio spettro di contesti
applicativi, dalla gestione dei processi aziendali al monitoraggio di reti; dal controllo e
supervisione di ambienti (pubblici e privati), al supporto di applicazioni per servizi
finanziari e bancari. Si effettua una breve sintesi delle varie aree:
• Business Process Management (BPM) and automation: process monitoring,
business activity monitoring (BAM), report exceptions, operational intelligence
• Finance: algorithmic trading, fraud detection, risk management
• Network monitoring: intrusion detection, SLA(service level agreement) monitoring
• Sensor network applications: RFID (radio frequency identification) reading, air
traffic control
La tecnologia CEP è in grado di fornire, per ciascuna delle aree sopra indicate, un valido
strumento di approccio al problema fondamentale che rappresenta il minimo comun
denominatore di tutte: l’elaborazione di grandi volumi di dati in real-time al fine di
rilevare eventi complessi.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
41
Le moderne infrastrutture IT, infatti, hanno la necessità di gestire grandi volumi di dati e
garantire la sicurezza, diventa ancor più un problema complesso da affrontare.
Nel corso degli ultimi anni, lo sviluppo tecnologico ha consentito l’introduzione sul
mercato di un numero elevato di dispositivi utili nell’ambito della sicurezza, come ad
esempio sensori ambientali, telecamere intelligenti, sonde per il controllo degli accessi nei
sistemi informatici, sonde per il traffico di rete, Intrusion Detection System, etc.
Tali strumenti hanno aperto nuovi scenari relativamente alla sicurezza, sia ambientale
(come ad esempio la Building Security), sia informatica.
La possibilità di monitorare un ambiente o una rete con un numero elevato di dispositivi
permette da un lato di avere una grande quantità di informazioni per poter valutare le
condizioni in cui versa attualmente il sistema monitorato, ma dall’altro pone un problema
di non poca rilevanza, e cioè gestire opportunamente tutte le informazioni di cui si
dispone, in tempo reale.
Gli scenari odierni prevedono la presenza di numerosi e spesso eterogenei sistemi di
controllo e di gestione, tutti caratterizzati da scarsa integrazione e ridotta capacità di
analisi e correlazione di eventi.
Un modello di processo valido, in linea di principio, per l’approccio ai problemi di analisi
e correlazione di eventi in ambienti complessi dovrebbe essere fondato essenzialmente su
tre fasi fondamentali, rappresentate nella figura 1.7:
• Ricezione degli eventi semplici (definiti spesso anche come Raw Event o eventi
grezzi), provenienti dalle varie sorgenti
• Analisi di tali eventi in tempo reale, attraverso l’ausilio di un CEP Engine, al fine di
identificare degli eventi complessi/situazioni, nella realtà di interesse, basandosi
sulle regole e/o pattern noti a priori
• Avvio delle azioni necessarie previste per la determinata situazione rilevata
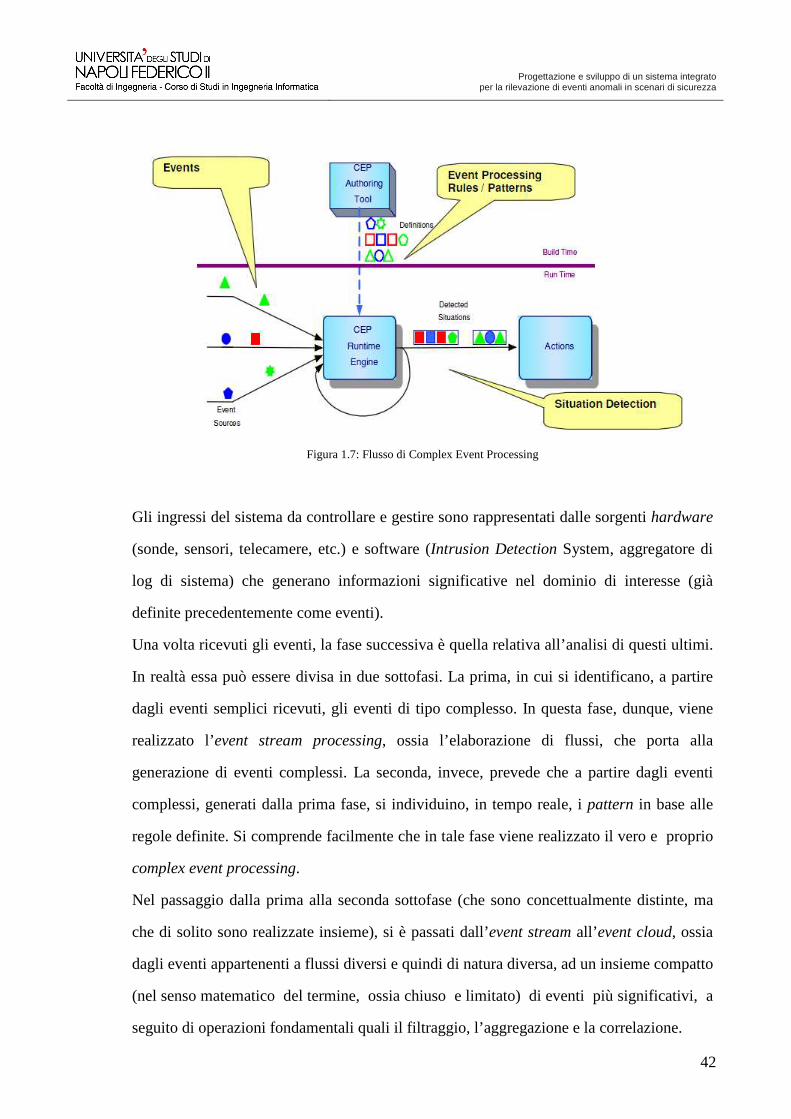
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
42
Figura 1.7: Flusso di Complex Event Processing
Gli ingressi del sistema da controllare e gestire sono rappresentati dalle sorgenti hardware
(sonde, sensori, telecamere, etc.) e software (Intrusion Detection System, aggregatore di
log di sistema) che generano informazioni significative nel dominio di interesse (già
definite precedentemente come eventi).
Una volta ricevuti gli eventi, la fase successiva è quella relativa all’analisi di questi ultimi.
In realtà essa può essere divisa in due sottofasi. La prima, in cui si identificano, a partire
dagli eventi semplici ricevuti, gli eventi di tipo complesso. In questa fase, dunque, viene
realizzato l’event stream processing, ossia l’elaborazione di flussi, che porta alla
generazione di eventi complessi. La seconda, invece, prevede che a partire dagli eventi
complessi, generati dalla prima fase, si individuino, in tempo reale, i pattern in base alle
regole definite. Si comprende facilmente che in tale fase viene realizzato il vero e proprio
complex event processing.
Nel passaggio dalla prima alla seconda sottofase (che sono concettualmente distinte, ma
che di solito sono realizzate insieme), si è passati dall’event stream all’event cloud, ossia
dagli eventi appartenenti a flussi diversi e quindi di natura diversa, ad un insieme compatto
(nel senso matematico del termine, ossia chiuso e limitato) di eventi più significativi, a
seguito di operazioni fondamentali quali il filtraggio, l’aggregazione e la correlazione.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
43
La terza ed ultima fase è quella in cui, partendo dai pattern opportunamente rilevati, si
effettuano azioni di risposta, atte a risolvere la situazione rilevata. In quest’ultima fase,
dunque, si definisce il processo decisionale in base al quale il sistema adotterà precise
politiche.
Le azioni da compiere, quando si verifica un evento complesso significativo per il dominio
del problema, variano a seconda del tipo di obiettivo da perseguire e possono essere cosi
sintetizzate:
• Gli eventi vengono notificati al fine di realizzare un monitoraggio (Business Activity
Monitoring, BAM) per fare reportistica e produzione di statistiche (dashboard), file
di log, etc.
• Al verificarsi di un evento possono scattare precise attività o processi
L’elaborazione corretta dell’insieme degli eventi prodotti, ossia la loro aggregazione,
correlazione logica, temporale e topologica, consente di rilevare, in tempo reale, situazioni
di pericolo per le quali può risultare fondamentale agire in maniera tempestiva [9].
La tecnologia CEP può rappresentare quindi un elemento fondamentale nella realizzazione
di sistemi per la gestione di eventi complessi, soprattutto per quelli in cui è molto forte
l’esigenza di elaborare in tempo reale un enorme volume di informazioni, proprio come
quelli relativi alla building e network security.

44
Capitolo 2
Un sistema CEP in scenari di sicurezza
2.1 Introduzione
La crescente complessità ed eterogeneità delle moderne infrastrutture dei sistemi di
controllo porta ad una crescita esponenziale della complessità di gestione
dell’infrastruttura e delle attività di analisi relative a situazioni di anomalia o pericolo
rilevate da tali sistemi.
Gli scenari odierni prevedono la presenza, all’interno dei centri servizi di controllo, di
numerosi, e spesso eterogenei, componenti come sistemi per la visualizzazione delle
immagini rilevate dall’infrastruttura di videosorveglianza, quadri sinottici e/o riepilogativi
utilizzati per rilevare il funzionamento e le segnalazioni dei sensori ambientali, sistemi per
il controllo degli accessi fisici, sistemi di controllo delle piattaforme IT, etc; tali scenari, se
da un lato portano al potenziamento delle funzionalità complessive del sistema, dall’altro
portano un incremento della complessità e del volume del flusso dati prodotto dai sistemi
ed un accrescimento esponenziale nelle richieste di elaborazione di tali informazioni.
Tale accrescimento della complessità e del volume dati ricade in modo diretto sulla
capacità di analisi degli scenari e sintesi degli interventi da parte del personale addetto alla
gestione e supporto delle operazioni di controllo: ogni operatore è chiamato ad analizzare,
in tempi brevi, un numero sempre crescente di eventi e/o anomalie, provenienti da un
numero sempre crescente di sistemi, dovendo correlare, filtrare ed

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
45
analizzare tali scenari al fine di rispondere in modo adeguato alle situazioni che richiedono
attenzione e risposte adeguate.
Le attuali tecnologie impiegate prevedono la presenza di molteplici sistemi di controllo e
gestione, caratterizzati da scarsa integrazione e ridotta capacità di correlazione ed analisi
degli eventi rilevati nel complesso di tali sistemi.
L’onere dell’analisi di tali eventi (spesso molto semplici e “primitivi”), al fine di ricavare
un quadro d’insieme, è demandata in modo quasi totale alla capacità ed alla preparazione
dei singoli operatori: essi devono interagire con le piattaforme di controllo in modo da
sintetizzare in maniera corretta le informazioni raccolte in tale ambiente eterogeneo, e
devono conoscere a fondo l'ambito applicativo ed ogni singolo componente del sistema.
Inoltre dovranno essere a conoscenza delle caratteristiche dell'ambiente in cui operano,
degli eventi che possono essere generati da ciascun sotto-sistema, delle conseguenze che
possono essere prodotte sul sistema e di quali siano le azioni da intraprendere a fronte di
particolari situazioni. In alcuni casi, l’elevata eterogeneità dell’ambiente, può ridurre
all’impossibilità la capacità di effettuare un’analisi accurata in tempi brevi e, di
conseguenza, fornire una risposta adeguata a tali situazioni.
In tale quadro si evidenziano in modo sintetico i principali problemi rilevati:
• Crescente volume di informazioni da analizzare e riduzione dei tempi di risposta
attesi
• Richieste crescenti di capacità di analisi e gestione da parte degli operatori in
ambienti di controllo dalla elevata complessità
• Richiesta capacità di interazione con più sistemi anche molto diversi
• Accoppiamento marcato tra la capacità di analisi e correlazione degli operatori ed il
volume di dati elaborati per supportare il processo decisionale di intervento
• Mancanza di correlazione tra le informazioni e gli eventi raccolti nel complesso dei
sistemi in campo
• Ampi margini discrezionali e di interpretazione nel processo decisionale per
intraprendere le opportune azioni correttive al verificarsi di eventi diffusi nel

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
46
complesso dei sistemi in campo
Tali problematiche rendono necessario l’utilizzo di un sistema che sia in grado di
supportare, in modo efficace, gli operatori nel processo decisionale degli interventi da
porre in essere in risposta alle sollecitazioni provenienti dall’ambiente sotto controllo.
A tal proposito, l'integrazione all'interno di tali sistemi di soluzioni di Complex Event
Processing rappresenterà un'ottima base sulla quale costruire l'interoperabilità tra i
sottosistemi coinvolti [14].
L'adozione della tecnologia CEP consentirebbe di automatizzare la maggior parte del
lavoro richiesto agli operatori umani, fornendo grossi benefici in termini di tempi, costi
ed, in definitiva, di opportunità di business [15].
Un CEP è in grado, infatti, di fornire in near real-time informazioni significative sulla
sicurezza, mostrando un quadro realistico dello stato di protezione dell'ambiente
sorvegliato. Dunque, a garanzia della situation awareness, in un CEP è possibile
esplicitare le relazioni tra i sotto-sistemi dai quali sono ricevuti i flussi di eventi,
individuando le informazioni rilevanti e trascurando quelle irrilevanti (come i falsi
positivi).
Come già accennato all’inizio di questa trattazione, la realizzazione di un tale sistema è
proprio l’obbiettivo del progetto CEvOS, nonché l’oggetto di questo lavoro di tesi.
Pertanto saranno fornite, nei paragrafi seguenti, una descrizione dei principali requisiti che
la piattaforma implementata deve necessariamente soddisfare, nonché gli scenari
applicativi, e i relativi casi d’uso, nei quali essa sarà adoperata.
Prima però è presentata una tabella comparativa, in relazione ai principali aspetti legati
alle problematiche presentate, tra le tecnologie attualmente impiegate e quella oggetto di
studio di questo lavoro di tesi:
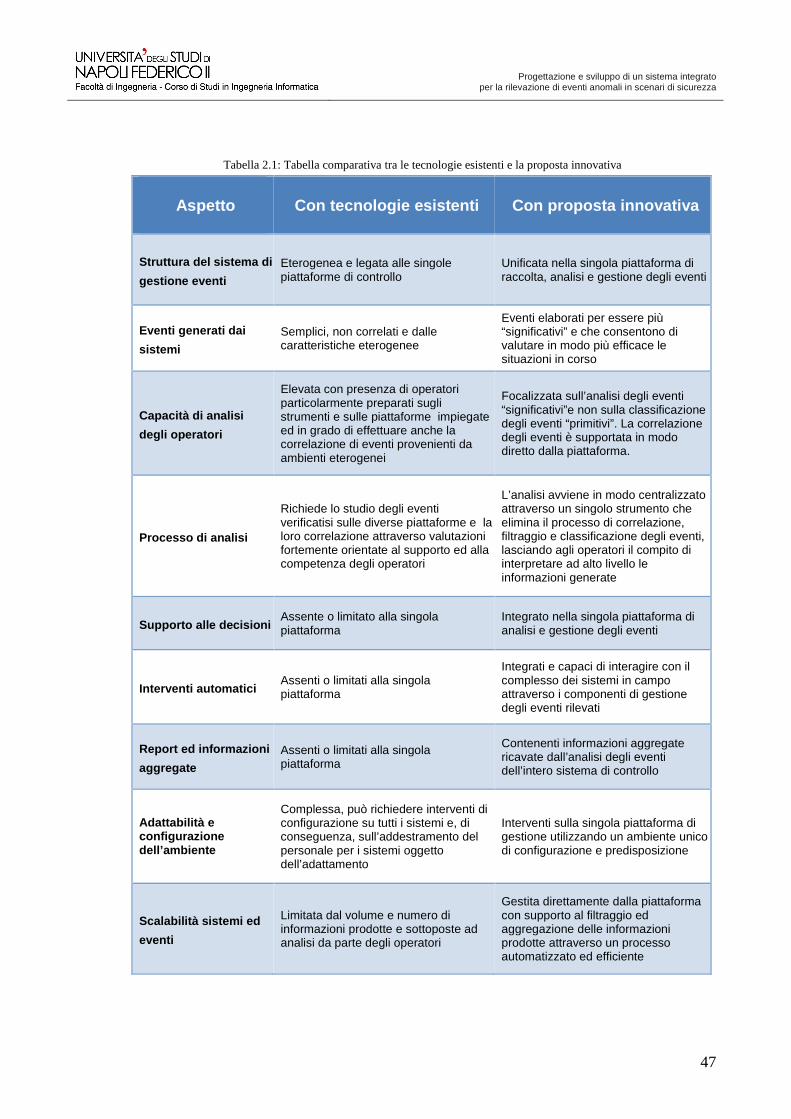
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
47
Tabella 2.1: Tabella comparativa tra le tecnologie esistenti e la proposta innovativa
Aspetto
Con tecnologie esistenti Con proposta innovativa
Struttura del sistema di
gestione eventi Eterogenea e legata alle singole piattaforme di controllo
Unificata nella singola piattaforma di raccolta, analisi e gestione degli eventi
Eventi generati dai
sistemi Semplici, non correlati e dalle caratteristiche eterogenee
Eventi elaborati per essere più “significativi” e che consentono di valutare in modo più efficace le situazioni in corso
Capacità di analisi
degli operatori
Elevata con presenza di operatori particolarmente preparati sugli strumenti e sulle piattaforme impiegate ed in grado di effettuare anche la correlazione di eventi provenienti da ambienti eterogenei
Focalizzata sull’analisi degli eventi “significativi”e non sulla classificazione degli eventi “primitivi”. La correlazione degli eventi è supportata in modo diretto dalla piattaforma.
Processo di analisi
Richiede lo studio degli eventi verificatisi sulle diverse piattaforme e la loro correlazione attraverso valutazioni fortemente orientate al supporto ed alla competenza degli operatori
L’analisi avviene in modo centralizzato attraverso un singolo strumento che elimina il processo di correlazione, filtraggio e classificazione degli eventi, lasciando agli operatori il compito di interpretare ad alto livello le informazioni generate
Supporto alle decisioni Assente o limitato alla singola piattaforma
Integrato nella singola piattaforma di analisi e gestione degli eventi
Interventi automatici Assenti o limitati alla singola piattaforma
Integrati e capaci di interagire con il complesso dei sistemi in campo attraverso i componenti di gestione degli eventi rilevati
Report ed informazioni
aggregate Assenti o limitati alla singola piattaforma
Contenenti informazioni aggregate ricavate dall’analisi degli eventi dell’intero sistema di controllo
Adattabilità e configurazione dell’ambiente
Complessa, può richiedere interventi di configurazione su tutti i sistemi e, di conseguenza, sull’addestramento del personale per i sistemi oggetto dell’adattamento
Interventi sulla singola piattaforma di gestione utilizzando un ambiente unico di configurazione e predisposizione
Scalabilità sistemi ed
eventi
Limitata dal volume e numero di informazioni prodotte e sottoposte ad analisi da parte degli operatori
Gestita direttamente dalla piattaforma con supporto al filtraggio ed aggregazione delle informazioni prodotte attraverso un processo automatizzato ed efficiente

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
48
2.2 Requisiti di alto livello
Come già accennato nel paragrafo precedente, l’obiettivo principale del progetto è quello
di realizzare una piattaforma che consenta di supportare in modo adeguato gli operatori nel
processo di analisi degli eventi e di definizione delle decisioni da selezionare in risposta a
tali eventi.
Tale obiettivo è perseguito costruendo la piattaforma in base ad una serie di linee guida
ritenute primarie ed essenziali al fine di conseguire in modo corretto le finalità del
software oggetto di questo lavoro di tesi. Tali linee guida possono essere considerate come
veri e propri requisiti funzionali di alto livello che il software da sviluppare deve
soddisfare, e sono indicati di seguito:
• La piattaforma deve essere in grado di elaborare in modo autonomo grandi quantità
di dati (eventi) generati dai sistemi presenti sul campo; l’elaborazione ha i seguenti
obiettivi:
o Rilevare e rimuovere informazioni accessorie, non significative, replicate o
deducibili da altre informazioni già in elaborazione; tale elaborazione
riduce il carico elaborativo dell’analisi e rende maggiormente focalizzata
l’attività di sintesi degli operatori
o Condensare e sintetizzare gli eventi riportando le informazioni essenziali;
tale elaborazione aiuta il processo di interpretazione degli scenari in corso
di analisi
o Aggregare e correlare informazioni ed eventi in base ad una affinità di
carattere topologico oppure in base a precisi schemi di elaborazione; tale
elaborazione effettua in modo automatico la correlazione degli eventi
sollevando l’operatore dall’onere di effettuare la correlazione in base
unicamente alla sua preparazione, esperienza ed attenzione sull’attuale
scenario in corso di valutazione
o Riportare eventi generali e maggiormente significativi creati appositamente

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
49
dal sistema di analisi a descrizione di una serie di eventi “primitivi”
elaborati in ingresso; tale elaborazione fornisce eventi artificialmente creati
dal sistema di elaborazione, partendo dagli eventi “primitivi”, che sono
maggiormente significativi per gli operatori a cui non è demandato
completamente l’onere di interpretare le informazioni
o Assorbire eventi ricavabili direttamente dall’elaborazione; tale elaborazione
evita di fornire informazioni non essenziali e ricavabili in modo automatico
o semiautomatico al fine di ridurre il carico di elaborazione delle
informazioni demandato all’operatore
• La piattaforma deve fornire strumenti per la formalizzazione, memorizzazione ed
utilizzo delle regole e degli schemi adoperati dal motore di analisi degli eventi in
modo da poter gestire in modo strutturato e deterministico il processo di
elaborazione; tale caratteristica rende affidabile il processo di elaborazione
slegandolo dalle interpretazioni e dal grado di preparazione e capacità degli
operatori
• La piattaforma deve essere in grado fornire un processo decisionale autonomo
attivato in tempi rapidi che possa rispondere in modo adeguato alle configurazioni
di eventi “significativi” forniti dal motore di elaborazione degli eventi; questo
componente ha l’obiettivo di fornire supporto al processo decisionale affidato agli
operatori che dovranno finalizzare le decisioni automatiche intraprese oppure
decidere in piena autonomia (ma correttamente supportati) le azioni da
intraprendere.
In sintesi, fornendo una piattaforma integrata dotata di strumenti avanzati, a supporto
dell’analisi degli eventi ed a supporto del processo decisionale innescato
conseguentemente, si intende ridurre e, laddove possibile, eliminare, la complessità di
analisi e correlazione degli eventi, nei complessi scenari presentati, a beneficio della
capacità di valutazione e risposta degli operatori alle situazioni che richiedono particolare

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
50
attenzione.
In raccordo con le linee guida fornite, elenchiamo la sintesi delle caratteristiche chiave
della piattaforma:
• Fornire un ambiente unico ed integrato a supporto del processo di analisi e del
processo decisionale degli operatori
• Elaborare in tempo reale gli eventi provenienti dal complesso dei sistemi in campo
in modo da fornire una sintesi di alto livello a beneficio degli operatori e del
sistema di supporto decisionale
• Capacità di sintetizzare eventi eterogenei in eventi “significativi” e maggiormente
descrittivi degli accadimenti in corso sul campo operativo oggetto del controllo da
parte dei sistemi
• Gestire un processo decisionale automatizzato con due finalità principali:
o Rispondere in modo diretto ed in tempi rapidi alle sollecitazioni provenienti
dai sistemi negli scenari gestibili in modo automatico
o Fornire un supporto agli operatori nella gestione di situazioni complesse
fornendo elaborazioni decisionali preliminari e demandando l’intervento
finale alle decisioni degli operatori
• Predisporre la piattaforma in modo che possa raccogliere le informazioni
provenienti da sistemi sul campo anche notevolmente diversi, ad esempio:
o Telecamere intelligenti
o Sistemi di rilevazione degli accessi
o Sonde per il traffico di rete
o Sonde per il controllo accessi nei sistemi informatici
• Dotare la piattaforma della capacità di interagire con i sistemi sul campo oppure con
sistemi orientati al controllo ed intervento in risposta agli scenari in corso di
valutazione; tale caratteristica permette di incrementare la quantità e qualità delle
informazioni visualizzate dagli operatori intervenendo direttamente sulla
presentazione dei dati attraverso le piattaforme di controllo pre-esistenti; in

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
51
particolare tale caratteristica consentirà di fruire di una visualizzazione in “realtà
aumentata” inserita direttamente nei sistemi di controllo basati su
videosorveglianza.
Definiamo ora in maniera più formale i requisiti della piattaforma implementata,
considerando separatamente i requisiti funzionali e quelli non funzionali.
2.2.1 Requisiti funzionali
Per quanto riguarda i requisiti funzionali, che ricordiamo sono quei requisiti che
descrivono le funzionalità del sistema, la nostra piattaforma prevede:
• Events Receiving: il sistema deve essere in grado di comunicare con più
sottosistemi, ad esempio sensori, anche molto eterogenei tra loro, al fine di ricevere
gli eventi da essi generati
• Events Filtering and Aggregation: il sistema deve essere in grado di realizzare
operazioni di filtraggio e aggregazione di eventi alla loro ricezione, al fine di
rimuove eventi non significativi e/o aggregare eventi simili
• Events Correlation: il sistema deve essere in grado di correlare eventi,
filtrati/aggregati e non, al fine di rilevare particolari situazioni di interesse
• Complex Events Generation: il sistema deve essere in grado di generare eventi
complessi che descrivano la particolare situazione di interesse rilevata, e i quali
potrebbero essere utilizzati da altri sottosistemi, ad es. sottosistemi di attuazione
• Alerts Generation: il sistema deve essere in grado di generare alert per gli operatori,
i quali saranno così avvertiti sulla situazione rilevata.
Tali requisiti funzionali possono essere riassunti nel seguente use case diagram.
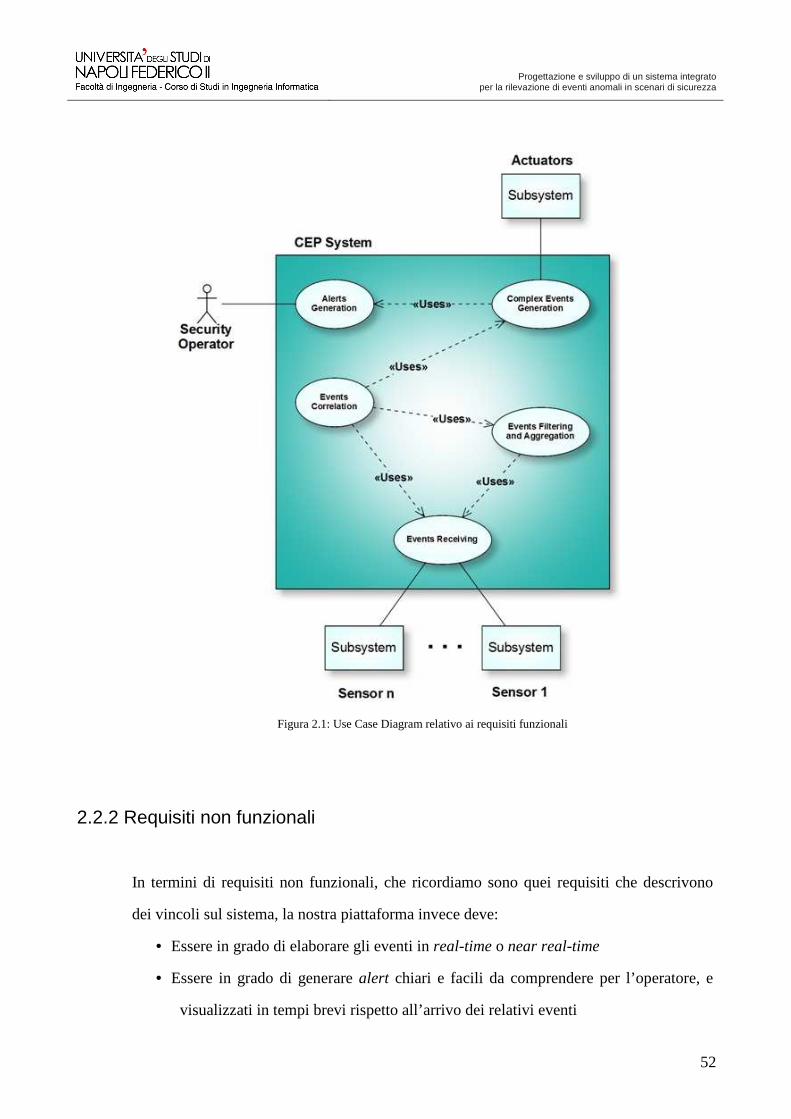
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
52
Figura 2.1: Use Case Diagram relativo ai requisiti funzionali
2.2.2 Requisiti non funzionali
In termini di requisiti non funzionali, che ricordiamo sono quei requisiti che descrivono
dei vincoli sul sistema, la nostra piattaforma invece deve:
• Essere in grado di elaborare gli eventi in real-time o near real-time
• Essere in grado di generare alert chiari e facili da comprendere per l’operatore, e
visualizzati in tempi brevi rispetto all’arrivo dei relativi eventi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
53
• Essere facilmente manutenibile, garantendo che la modifica di uno dei suoi moduli
non comporti modifiche anche agli altri
• Essere facilmente estensibile, garantendo modifiche lievi o assenti agli altri moduli
all’aggiunta di un nuovo componente
• Garantire una buona capacità di riconoscimento delle situazioni di interesse, e
precisamente deve:
o Garantire una quantità molto bassa di falsi negativi, e quindi un valore di
Recall quanto più prossimo a 1
o Garantire una quantità di falsi positivi ottimale, cioè in quantità almeno
ridotte rispetto a quelli che si avrebbero senza l’ausilio del sistema. Ciò si
traduce in un valore di Precision non necessariamente molto vicino ad 1.
• Garantire il mantenimento delle proprie prestazioni, soprattutto in termini di falsi
negativi (e quindi di Recall), all’aumentare della quantità di eventi da elaborare
Da notare che i parametri di Precision e Recall saranno definiti e approfonditi nel capitolo
6, dove saranno trattai i risultati sperimentali di questo lavoro di tesi.
Defiamo ora i requisiti di dettaglio. A tal fine saranno descritti gli scenari applicativi
nell’ambito dei quali sarà simulata l’applicazione. Precisamente i due scenari sono:
• Building Security
• Network Security
2.3 Scenari applicativi: Building Security
Lo scenario è incentrato sul garantire la building security ad una determinata
organizzazione, allo scopo di prevenire, evitare o mitigare situazioni di pericolo per
persone, ambiente e sistema.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
54
A tale scopo, la piattaforma è dotata di un insieme eterogeneo di sottosistemi ICT,
deputati, in varia misura, al monitoraggio di specifiche sezioni e/o tipologie di eventi del
contesto in cui sono calati. Tali dispositivi, al momento, non sono connessi tra loro,
dunque il sistema di sorveglianza non è adoperato in maniera ottimale.
Pertanto, l'obiettivo è quello di mettere in comunicazione i componenti deputati al
monitoring dell'area, al fine di ottenere una visione maggiormente dettagliata dello
scenario complessivo posto sotto sorveglianza. Tale conoscenza consentirà di
intraprendere azioni specifiche per prevenire/evitare/mitigare situazioni che
compromettono la sicurezza del sistema ed, in definitiva, di supportare l'ente preposto alla
sicurezza alla scelta delle azioni da intraprendere.
Figura 2.2: Data processing for alarm generation
Per quanto riguarda il sistema relativo a questo scenario, ad un elevato livello di
astrazione, i dispositivi che lo compongono sono:
• Sistema di controllo dell’impianto di illuminazione: si preoccupa di monitorare lo
stato dei componenti dell’impianto di illuminazione
• Sistema di controllo degli accessi: adoperato al fine di restringere l'accesso a
determinate aree, considerate "sensibili", a personale non autorizzato
• Sistema di monitoraggio e sorveglianza, che comprende:
o Telecamere, che monitorano diverse zone sensibili dell’organizzazione
o Centri di controllo, che ricevono le immagini dalle camere e dotati di moduli

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
55
per l'esecuzione di azioni specifiche.
Il sistema così realizzato, dovrà soddisfare una serie di requisiti, e precisamente:
• Monitoraggio del sistema di illuminazione: L'area sottoposta a videosorveglianza è
illuminata mediante fari dislocati lungo tutto il suo perimetro ed in corrispondenza
di ogni telecamera. Il sistema di controllo dovrà monitorare il corretto
funzionamento dell'impianto di illuminazione, segnalando eventi quali: mancanza
di alimentazione, anomalia o guasto di un dispositivo, etc.
• Controllo degli accessi pedonali: Il punto di accesso ad una zona sensibile sarà
dotato di un tornello, dotato di un badge reader e sbarra di accesso.
Il controllo sarà effettuato, oltre che sulle credenziali d'accesso presenti sul badge,
da una telecamera, che riprenderà 24h/24 il varco di ingresso. Tale telecamera,
dotata di un modulo di Video Analytics, al fine di consentire l'accesso all’area
riservata, eseguirà la Face Detection. Il sistema riceverà pertanto le informazioni
relativa alla persona identificata mediante il badge, e quelle relative alla persona
identificata mediante la Face Detection. L’addetto dovrà ovviamente garantire
l’accesso nel caso in cui le informazioni pervenute siano relative alla stessa
persona. Ovviamente si prevede che ciascun operatore sarà dotato di un badge
magnetico personale, contenente le credenziali di identificazione (nome, cognome,
numero operatore, società terza di afferenza, etc.) e la fototessera.
• Gestione del Tampering: Il sistema di videosorveglianza, attraverso la funzionalità
di Video Analytics, rileverà l'oscuramento di qualsiasi telecamera ubicata nella
zona sottoposta a sorveglianza. Il sistema di videosorveglianza gestirà l'evento
acquisito ed allerterà il centro di controllo, per consentire alle unità preposte di far
fronte all'evento.
• Gestione Low Light: All'interno dell'area sorvegliata, il sistema di videosorveglianza
sarà costituito da telecamere, dotate di funzionalità di Video Analytics ed
illuminate dai fari dell'impianto di illuminazione e da luce naturale. Ogni

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
56
telecamera sarà in grado di rilevare una variazione della luminosità dell'ambiente
circostante. In tal caso, il sistema individuerà e gestirà l'evento “Low Light”, ed
allerterà il centro di controllo, per consentire alle unità preposte di far fronte
all'accadimento.
Definito in maniera generale il primo scenario applicativo, e i requisiti relativi a
quest’ultimo, vediamo ora i due casi d’uso presi in considerazione, soffermandoci sia sui
requisiti richiesti al sistema CEP che si vuole realizzare, sia sugli effettivi vantaggi che
l’utilizzo di quest’ultimo porta in essi.
2.3.1 Casi d’uso: Rilevamento di un falso positivo per Camera Tampering
Il primo caso d’uso per questo scenario applicativo è relativo alla possibilità che venga
generato un falso positivo per evento di Tampering su una camera del sistema di
videosorveglianza.
Supponiamo infatti che, di notte, in un certo istante si verifica il guasto di una lampada,
che non viene tracciato. La telecamera, che è puntata nell’area illuminata da quella
lampada, interpreterà la variazione di luminosità come un evento di tampering e genererà
un allarme. Nel frattempo, l'operatore umano sarà situato nella Control Room, dalla quale
espleterà le operazioni di controllo, analisi ed interpretazione degli eventi generati dal
sistema, o meglio dai vari sotto-sistemi.
A questo punto valutiamo che cosa accade nel caso in cui sia presente o meno il nostro
sistema CEP:
• Nel caso di assenza di CEP, l'allarme relativo all'evento di tampering è stato
generato dal sistema di controllo della telecamera e perverrà all'operatore.
Nell'immediato, quest’ultimo non sarà in grado di identificare come falso allarme il
segnale di pericolo che è stato notificato, e quindi avrà una conoscenza errata dello

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
57
stato di sicurezza dell'ambiente. Ciò porterà all’attuazione di azioni non idonee alla
risoluzione del problema riscontrato. Altresì, il tempo necessario affinché
l'operatore possa chiarire le cause dell'evento potrebbe essere tale da non
consentirne una risposta tempestiva.
• Nel caso di presenza di CEP, si prevede che quest’ultimo sia stato preliminarmente
istruito sulla posizione di ciascuna lampada e sul raggio di copertura di ognuna di
esse, cioè conosce quali telecamere sono illuminate da quali lampade. Ciò fa sì che
per il sistema sarà chiara la relazione causale tra gli eventi “guasto della lampada”
ed “allarme di tampering”. Pertanto, filtrando le informazioni pervenutegli, e
precisamente riscontrando che l’evento di “tampering” per la camera è stato
preceduto dal guasto della lampada che illumina quella stessa camera, il CEP sarà
in grado di trascurare il falso allarme, notificando all'operatore il “guasto della
lampada”.
Come si può comprendere, l'integrazione di una soluzione CEP consente di aprire un varco
all'interoperabilità tra i sottosistemi, che saranno in grado di comunicare gli eventi generati
al sistema. Inoltre, l'operatore è sollevato dalla conoscenza specifica di tutti gli eventi che
possono essere originati da ciascun sottosistema, nonché delle loro relazioni di
dipendenza. Ed infatti, il CEP (se in precedenza istruito in maniera adeguata) eseguirà
automaticamente ed efficientemente le attività tipicamente a carico dell'operatore umano.
Infine, il sistema fornirà in near real-time solo le informazioni significative per il contesto
sorvegliato, allo scopo di supportare l'addetto alla sicurezza alla scelta dell'azione da
intraprendere a fronte di un problema reale.
Vediamo ora quali sono i requisiti del nostro sistema CEP per questo caso d’uso.
Precisamente abbiamo che la piattaforma deve essere in grado di:
• Interfacciarsi con sottosistemi che adoperano particolari standard (come ad es.
BACnet). In tal modo, i componenti coinvolti nel controllo della sicurezza potranno
comunicare eventi di natura diversa che, una volta correlati, consentiranno di

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
58
migliorare l'efficienza del sistema di sorveglianza nella sua interezza. In
particolare, per questo caso d’uso, i sottosistemi con cui dovrà interfacciarsi la
piattaforma sono:
o Sistema di monitoraggio dell’impianto di illuminazione
o Telecamere di videosorveglianza
• Riconoscere gli alert relativi al tampering di una camera, provenienti dal sistema di
videosorveglianza
• Riconoscere gli alert relativi al guasto di una lampada, provenienti dal sistema di
monitoraggio dell’impianto di illuminazione
• Conoscere la posizione di ogni telecamera e di ogni lampada, così da quale o quali
lampade illuminano una determinata videocamera
• Correlare le informazioni provenienti dalle due fonti, al fine di riconoscere un falso
positivo per un evento di “camera tampering”
2.3.2 Casi d’uso: Rilevamento di un accesso non autorizzato
Il secondo caso d’uso per questo scenario applicativo è relativo alla possibilità che un
dipendete dell’organizzazione, o una persona esterna, acceda ad una delle aree sensibili
utilizzando un badge di un altro dipendente.
In questa ipotesi, il sistema di controllo degli accessi verifica l'identità della persona che
sta accedendo all’area riservata attraverso il badge magnetico, che è stato opportunamente
inserito nel badge reader, autorizzandolo.
Contestualmente, la videocamera posta all’ingresso dell’area effettua la Face Detection e
rileva il volto della persona che ha richiesto l'accesso, identificandolo (nel caso in cui sia
un dipendente dell’organizzazione).
A questo punto valutiamo che cosa accade nel caso in cui sia presente o meno il nostro
sistema CEP:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
59
• Nel caso di assenza di CEP, i due sottosistemi non sono in grado di comunicare;
pertanto, le operazioni di correlazione degli eventi sono completamente a carico
dell'addetto alla sicurezza. Questi dovrebbe, innanzitutto, reperire in tempo reale le
informazioni pervenute dal sistema di controllo degli accessi e da quello di
videosorveglianza, poi individuare le relazioni tra gli eventi ed, infine, ordinare il
blocco di accesso alla persona che lo ha richiesto. Ovviamente, il tempo necessario
affinché l'addetto compia in maniera efficiente tali operazioni potrebbe essere
inaccettabile. Del resto, il varco di ingresso all'area sorvegliata potrebbe presentare
più tornelli, cosa che complicherebbe molto il lavoro di un operatore umano, al
quale sarebbe richiesta un'attenzione simultanea a più sottosistemi, una notevole
capacità di correlazione degli eventi ed un tempo di risposta congruo.
• Nel caso di presenza di CEP, invece, si prevede che quest’ultimo sia stato istruito
precedentemente sugli eventi che possono essere generati dal sistema di controllo e
dal sistema di videosorveglianza; di conseguenza, sarà in grado, in tempo reale, di
correlare gli eventi occorsi (esito positivo dal primo ed esito negativo dal secondo
sottosistema), ed indicare all'addetto alla sicurezza l'azione da intraprendere, cioè il
blocco dell'ingresso all'area.
Come si può comprendere, anche in questo caso, l'integrazione di una soluzione CEP porta
a numerosi vantaggi, consentendo di sollevare l'operatore umano da operazioni talvolta
difficili, affinché possano essere intraprese azioni tempestive ed efficaci agli eventi
occorsi.
Vediamo ora quali sono i requisiti del nostro sistema CEP per questo caso d’uso.
Precisamente abbiamo che la piattaforma deve essere in grado di:
• Interfacciarsi con sottosistemi che adoperano particolari standard (come ad es.
BACnet). In tal modo, i componenti coinvolti nel controllo della sicurezza
potranno comunicare eventi di natura diversa che, una volta correlati consentiranno
di migliorare l'efficienza del sistema di sorveglianza nella sua interezza.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
60
In particolare, per questo caso d’uso, i sottosistemi con cui dovrà interfacciarsi la
piattaforma sono:
o Sistema di controllo degli accessi
o Telecamere di videosorveglianza
• Riconoscere gli eventi relativi alla lettura di un badge da parte di un badge reader,
provenienti dal sistema di controllo degli accessi
• Riconoscere gli eventi di face detection di una camera, relativi all’accesso di una
persona in un’area riservata e provenienti dal sistema di videosorveglianza
• Conoscere la posizione di ogni telecamera e di ogni badge reader, così da sapere
quale camera sorveglia l’accesso protetto da quel determinato lettore
• Correlare le informazioni provenienti dalle due fonti, al fine di riconoscere un
tentativo di accesso all’area riservata da parte di un addetto, o di una persona
esterna, con un badge differente dal proprio.
2.4 Scenari applicativi: Network Security
Lo scenario è incentrato sulla protezione di una infrastruttura IT dagli attacchi alla
sicurezza. L’infrastruttura ipotizzata rappresenta la tipica dotazione informatica di
un’organizzazione di medie dimensioni, costituita da PC aziendali, infrastrutture cloud
private e/o multi-tennant, server dedicati ad uso interno (mail-server, repository, database
server, etc.). Essa è dotata di sistemi di monitoraggio e protezione, volti alla prevenzione
e/o rilevamento in tempo utile di attacchi informatici, cioè di: firewall, intrusion detection
systems (IDS), tool per la verifica dell’integrità di sistema e tool per la raccolta di log
applicativi.
Il problema tipico di questo tipo di infrastrutture è che la co-presenza di tutti i sistemi di
monitoraggio citati non viene sfruttata in maniera adeguata.
Ed infatti, ogni sistema produce le proprie segnalazioni (allarmi) indipendentemente

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
61
dall’altro, senza sfruttare le potenzialità di un uso sinergico delle informazioni raccolte.
Eppure un uso integrato delle segnalazioni potrebbe aiutare a ridurre i falsi positivi (falsi
allarmi) dovuti a comportamenti anomali ma ritenuti leciti, e nel contempo ridurre i falsi
negativi, laddove uno dei sistemi non rilevi il perdurare di un comportamento malizioso.
D’altra parte non è pensabile intervenire sui singoli sistemi al fine di renderli consapevoli
gli uni degli altri, poiché ciò richiederebbe di rivedere le regole con cui gli allarmi sono
segnalati.
L’obiettivo che si vuole raggiungere in uno scenario siffatto consiste nell’utilizzo delle
informazioni prodotte dai sotto-sistemi di monitoraggio dell’organizzazione, al fine di
rilevare in maniera automatica la presenza di attacchi in corso, per minimizzare
l’occorrenza di falsi positivi e falsi negativi.
Il soddisfacimento di questo obiettivo richiederà di risolvere diverse problematiche, quali:
• Realizzazione di uno strato per l’interoperabilità semantica e di formato delle
informazioni raccolte
• Definizione di regole per l’individuazione di falsi positivi e falsi negativi
• Necessità di realizzare strumenti di gestione automatici
Ad un elevato livello di astrazione, si può ipotizzare che l’architettura sia costituita dai
seguenti componenti:
• Intrusion Detection System (IDS): software o hardware, utilizzato per identificare
accessi non autorizzati ai computer o alla rete locale, e soprattutto per identificare
utilizzi anomali degli host
• Strumenti per la raccolta di log applicativi e di sistema: utilizzati al fine di tener
traccia delle attività svolte su ogni host dell’organizzazione, ed in particolare gli
accessi ad essi effettuati
• Sotto-sistemi di monitoraggio ausiliari: utilizzati per mantenere lo storico delle
connessioni, e apprendere le abitudini dei singoli utenti dell’organizzazione
• Componente di adattamento/correlazione allarmi: utilizzato per uniformare gli alert

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
62
e correlarli in maniera opportuna
Figura 2.3: Componenti previsti per lo scenario di Network Security
Il sistema così realizzato, dovrà soddisfare una serie di requisiti, e precisamente:
• Rilevamento di attività maliziose che coinvolgano gli host: Il sistema IT è dotato di
un IDS, il quale, istruito con opportune regole, è in grado di rilevare attività
maliziose svolte attraverso gli host che compongono l’infrastruttura IT.
Ovviamente il tutto attraverso l’analisi del traffico di rete. Precisamente il sistema
IDS è istruito con regole che gli consentiranno di rilevare:
o Download e Upload di file sospetti, cioè con estensioni sensibili
o Tentativi multipli di stabilire una connessione TCP verso un IP esterno
• Rilevamento delle connessioni agli host: Il sistema IT è dotato di un sottosistema
per la raccolta dei log applicativi e di sistema dei singoli host, attraverso il quale si
mantiene traccia di tutte le connessioni, e le informazioni ad esse correlate, che
avvengono dai singoli host da parte dei vari utenti dell’organizzazione. Da notare
che si presuppone che gli accessi avvengano da remoto attraverso il protocollo
SSH, con l’ausilio di differenti metodi di autenticazione.
Definito in maniera generale il secondo scenario applicativo, vediamo ora i due casi d’uso
presi in considerazione, soffermandoci, anche in questo caso, sia sui requisiti richiesti al
nostro sistema, sia sugli effettivi vantaggi che l’utilizzo di quest’ultimo porta in essi.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
63
2.4.1 Casi d’uso: Rilevamento di una intrusione con credenziali rubate
Il primo caso d’uso per questo scenario applicativo è relativo alla possibilità che le
credenziali di un utente siano state rubate, e un attacker malintenzionato acceda alla rete
dell’organizzazione attraverso queste ultime.
Supponiamo che l’attacker, dopo aver effettuato l’accesso al sistema con le credenziali
rubate, effettui il download di un file sospetto da internet, ad es. il file patch.c, attraverso
un server dell’organizzazione.
A questo punto valutiamo che cosa accade nel caso in cui sia presente o meno il nostro
sistema CEP:
• Nel caso di assenza di CEP, il download è rilevato dal sistema IDS e segnalato nel
log di sistema, e sarà mostrato un allarme su un apposito terminale controllato
dagli amministratori. Questi ultimi sono allertati dalla segnalazione del download
sospetto e avviano un procedimento di ispezione al fine di determinare se il
download sospetto corrisponde ad un falso positivo, e , in caso affermativo, quale
sia l’entry-point dell’attacco per individuare le azioni di recovery da intraprendere
(riavvio di applicazioni/macchine, disattivazione di uno o più account, etc.).
Questa ispezione è condotta analizzando diversi log di sistema ed è un processo
quasi interamente manuale, e quindi soggetta ad errori, e fortemente time-
consuming. Il tempo necessario affinché gli amministratori possano determinare la
sorgente e la destinazione dell’attacco genera un ritardo nelle operazioni di
ripristino.
Figura 2.4: Data processing for alarm generation

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
64
• Nel caso di presenza di CEP, esso è stato configurato in maniera tale da
storicizzare le abitudini di ogni utente, ad es. gli IP che abitualmente utilizza per
connettersi al sistema, ed è in grado di allertarsi nel momento in cui l’utente non
rispetti queste abitudini (ad es. utilizzo di un IP diverso dai soliti utilizzati). Inoltre,
esso è in grado di ricevere gli alert generati dal sistema IDS.
Attraverso la correlazione dell’alert generato dal sistema IDS relativo al download
di un file sospetto, e dell’evento che un determinato utente non si è mai connesso
dall’IP che ha utilizzato, il CEP è in grado di allertare prontamente che tale utente
è compromesso, e che è in corso un’intrusione utilizzando le sue credenziali.
Come si può quindi notare, l’adozione del CEP introduce un enorme vantaggio,
sollevando gli amministratori del sistema di effettuare una correlazione manuale degli
eventi generati dalle due fonti, garantendo quindi una maggiore velocità di reazione e un
minor rischio di errore
.Vediamo ora quali sono i requisiti del nostro sistema CEP per questo caso d’uso.
Precisamente abbiamo che la piattaforma deve essere in grado di:
• Ricevere gli alert del sistema IDS
• Riconoscere gli alert relativi al download sospetto di un file, provenienti dall’IDS
• Ricevere gli eventi provenienti dai log di sistema delle macchine
dell’organizzazione
• Riconoscere gli eventi di accesso al sistema, provenienti dai log di sistema,
scartando tutti gli altri eventi
• Apprendere le abitudini degli utenti, e precisamente quelle relative all’IP di
connessione, al metodo di autenticazione e all’host, e deve essere in grado di
segnalare se si tratta della prima connessione di un determinato utente
• Correlare le informazioni provenienti dalle due fonti, al fine di riconoscere un
tentativo di intrusione effettuato attraverso l’utilizzo di credenziali rubate,
generando, in tal caso, un alert

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
65
2.4.2 Casi d’uso: Rilevamento di un attacco TCP Gender Changer
Il secondo caso d’uso per questo scenario applicativo è relativo alla possibilità che
l’organizzazione subisca un attacco del tipo TCP Gender Changer. Esso prevede due nodi,
uno residente all’interno della rete dell’organizzazione (Compromised Server), attraverso
il quale il malintenzionato può accedere al server desiderato (Target Server), e l’altro
residente all’esterno della rete (Attacker). Di seguito sono riportati i passi dell’attacco:
• L’ Attacker stabilisce l'accesso alla shell del Compromised Server in qualche modo,
ad esempio attraverso il protocollo ssh, ed effettua l’upload e l’avvio di un
software client sullo stesso, il quale si preoccuperà di realizzare una connessione
TCP con l’Attacker.
• Il software client tenta la connessione TCP verso l’Attacker. Al rilevamento della
connessione, l’Attacker invia una richiesta sul canale di comunicazione in modo
che il Compromised Server possa richiedere una nuova connessione dati.
• Il Compromised Server riceve il messaggio dall’Attacker e stabilisce una nuova
connessione con quest’ultimo. Inoltre, si connette al Target Server così da essere in
grado di inoltrare i dati da quest’ultimo all’Attacker e viceversa.
Figura 2.5: TCP Gender Changer
In questo scenario, l’IDS è in grado di rilevare l’upload di un file sospetto sul
Compromised Server, i continui tentativi di connessione di quest’ultimo verso l’esterno

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
66
della rete, nonché eventuali tentativi di Port Scanning verso lo stesso e notificare un alert
agli amministratori di rete.
A questo punto valutiamo che cosa accade nel caso in cui sia presente o meno il nostro
sistema CEP:
• Nel caso di assenza di CEP, gli amministratori avviano un procedimento di
ispezione al fine di determinare, se i tentativi di connessione ripetuti verso un IP
esterno alla rete corrispondono ad un falso positivo, ed, eventualmente stabilire
l’ entry-point dell’attacco per individuare le azioni di recovery da intraprendere.
L’ispezione è condotta analizzando diversi log di sistema e i vari alert generati
dall’IDS, ed è un processo quasi interamente manuale, e quindi soggetto ad errori e
fortemente time-consuming. Il tempo necessario affinché gli amministratori
possano determinare la sorgente e la destinazione dell’attacco genera un ritardo
nelle operazioni di ripristino.
• Nel caso di presenza di CEP, esso è stato configurato in maniera tale da
storicizzare le abitudini di ogni utente, ad es. gli IP che abitualmente utilizza per
connettersi al sistema, ed è in grado di allertarsi nel momento in cui l’utente non
rispetti queste abitudini (ad es. utilizzo di un IP diverso dai soliti utilizzati). Inoltre,
esso è in grado di ricevere gli alert generati dal sistema IDS.
Attraverso la correlazione degli alert generati dal sistema IDS, nella fattispecie
quello relativo all’upload di un file sospetto sul Compromised Server e quello
relativo ai tentativi di connessione ripetuti da parte di quest’ultimo verso l’esterno
della rete, con l’alert che un determinato utente X si è connesso a quel server non
rispettando le sue abitudini (ad es. non si è mai connesso da quell’indirizzo IP), il
CEP è in grado di allertare prontamente che è in corso un probabile attacco del tipo
TCP Gender Changer sfruttando l’account dell’utente X. Inoltre il CEP è in grado
di riconoscere eventuali attacchi di questo tipo sferrati senza l’ausilio di credenziali
rubate. A tale scopo effettua la correlazione tra l’alert relativo ad un Port Scanning
sul Compromised Server e quello relativo ai ripetuti tentativi di connessione,

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
67
da parte di quest’ultimo, verso l’esterno della rete.
Vediamo ora quali sono i requisiti del nostro sistema CEP per questo caso d’uso.
Precisamente abbiamo che la piattaforma deve essere in grado di:
• Ricevere gli alert del sistema IDS
• Riconoscere gli alert relativi all’upload sospetto di un file, ai tentativi multipli di
stabilire la connessione TCP verso un indirizzo IP esterno, a un tentativo di port
scanning, provenienti dall’IDS
• Ricevere gli eventi provenienti dei log di sistema delle macchine
dell’organizzazione
• Riconoscere gli eventi di accesso al sistema, provenienti dai log di sistema,
scartando tutti gli altri eventi
• Apprendere le abitudini degli utenti, e precisamente quelle relative all’IP di
connessione, al metodo di autenticazione e all’host, e deve essere in grado di
segnalare se si tratta della prima connessione di un determinato utente
Correlare le informazioni provenienti dalle due fonti, al fine di riconoscere un tentativo di
intrusione effettuato attraverso l’utilizzo di credenziali rubate, generando, in tal caso, un
alert.

68
Capitolo 3
Il CEP Engine Esper
3.1 Introduzione
Come vedremo nel prossimo capitolo, uno dei componenti fondamentali del sistema
progettato è il CEP Engine. Per la sua realizzazione, ci si è basati sull’ausilio di un motore
di correlazione molto diffuso, denominato Esper. Le motivazioni di tale scelta saranno
anche’esse approfondite nel prossimo capitolo. Ma vediamo meglio di cosa si tratta.
Esper è un componente per il Complex Event Processing (CEP), dotato anche di capacità
di Event Stream Processing, disponibile sia per Java che per .NET (Nesper), il quale
consente un rapido sviluppo di applicazioni che elaborano grandi volumi di messaggi o
eventi in real-time, o near real-time. Il motore di Esper funziona come un database
capovolto. Invece di memorizzare i dati ed eseguire query su questi ultimi, esso consente
alle applicazioni di memorizzare query ed eseguirle sui dati. Il modello di esecuzione è
continuo, infatti la risposta dell’engine è in tempo reale quando le condizioni definite
all’interno della query si verificano.
Esper fornisce due metodi principali per processare gli eventi, e sono:
• Event pattern
• Event stream query
Il primo si basa su un linguaggio che permette di specificare dei pattern expression-based

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
69
per il matching degli eventi. Questo metodo di elaborazione degli eventi, alla cui base vi è
l’implementazione di una macchina a stati, si aspetta sequenze di eventi o una loro
combinazione, e consente la loro correlazione basata sul tempo.
Il secondo metodo invece, offre la possibilità di definire query che consentono operazioni
di filtering, aggregation, correlation (attraverso gli operatori di join), nonché mettono a
disposizione funzioni di analisi per i flussi di eventi. Queste query seguono la sintassi del
linguaggio EPL (Event Processing Language) che è un linguaggio dichiarativo abbastanza
simile all’SQL, e mediante il quale è possibile definire gli statement CEP per la corretta
elaborazione degli stream.
L’ EPL differisce dall’SQL sostanzialmente in quanto utilizza il concetto di vista piuttosto
che quello di tabella. Tali viste rappresentano le varie operazioni necessarie per strutturare
e ricavare i dati in un flusso di eventi.
Da notare che una volta espresse (in EPL), le interrogazioni dovranno essere registrate
nell'engine (a runtime), in modo che Esper possa verificare i risultati delle interrogazioni
sugli eventi in ingresso ed, eventualmente, inviarli in tempo reale ad uno o più moduli
sottoscriventi (listener). Tale modo di operare consente, qualora fosse necessaria, una
modifica abbastanza semplice e veloce delle interrogazioni già registrare e offre la
possibilità di eseguire il riuso degli eventi.
Figura 3.1: ESP e CEP in Esper [16]

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
70
Un’altra grande potenzialità di Esper è la possibilità di accedere agevolmente ai maggiori
database esistenti grazie ad uno dei componenti dell’architettura, e precisamente
l’ historical data access layer. Di seguito è mostrata una vista globale dell’architettura di
Esper [16].
Figura 3.2: Vista globale dell’architettura di Esper
Dopo aver fatto una breve panoramica, approfondiamo ora alcuni aspetti di questo CEP
engine, e precisamente vediamo più in dettaglio le modalità di rappresentazione degli
eventi, il modello di elaborazione, il linguaggio EPL, nonché le API, le modalità di
configurazione e le possibilità di integrazione ed estensione del suo motore.
3.2 Rappresentazione degli eventi
In Esper un evento può essere rappresentato attraverso differenti classi java, e
precisamente come [16]:
• Un qualsiasi java POJO (plain-old java object) che segue le convenzioni JavaBean
o una qualsiasi Legacy java class che non rispetta le convenzioni JavaBean,
entrambe derivate dalla classe java.lang.Object
• Una mappa del tipo java.util.Map, dove ogni entry rappresenta una proprietà

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
71
• Un array di oggetti (Object[ ]) dove ogni elemento è una proprietà dell’evento
• Un XML Document Object Model (DOM)
• Una qualsiasi Classe Applicativa, utilizzabile attraverso la plugin rapresentation
event messa a disposizione dalle API di Esper
Il comportamento delle API per tutte le rappresentazioni di eventi è la stessa, tranne in
alcuni rari casi. Tutte le rappresentazioni hanno in comune il supporto a determinate
tipologie di proprietà, e precisamente queste possono essere:
• Semplici: proprietà che hanno un valore unico, il cui tipo può essere un tipo
primitivo del linguaggio Java (come int), un semplice oggetto (ad esempio un
java.lang.String), o un oggetto più complesso la cui classe è definita mediante il
linguaggio Java.
• Indicizzate: proprietà che memorizzano un insieme ordinato di oggetti (tutti dello
stesso tipo) a cui è possibile accedere singolarmente attraverso un indice.
• Mappate: proprietà che accettano una chiave String-valued.
• Nidificate: proprietà che vivono all’interno di un altro oggetto Java che di per se è
una proprietà di un evento. Da notare che non c’è limite alla nidificazione.
Ovviamente sono possibili delle combinazioni.
3.2.1 Plain-Old Java Object Event
I Plain-Old Java Object Event sono istanze di oggetti che espongono le proprietà di un
evento attraverso degli appositi metodi get, come definito nelle specifiche JavaBeans. In
realtà, le classi o le interfacce che rappresentano gli eventi non devono essere pienamente
compatibili con queste ultime. Cosa fondamentale però è la presenza dei metodi get che
danno la possibilità al motore di Esper di ottenere le proprietà degli eventi.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
72
Di seguito è mostrato un esempio di evento di tipo POJO.
public class NewEmployeeEvent { private String firstName; private String address; private Employee[] Subordinates; public String getFirstName(){…}; public Address getAddress(String type){…} ; public Employee getSubordinate(int index) {…}; public Employee[] getAllSubordinates(){…} ; }
Come si può notare la classe è dotata di due proprietà semplici, firstName e address, che
rappresentano rispettivamente il nome e l’indirizzo del dipendente, e una proprietà
indicizzata, Subordinates, che rappresenta i dipendenti subordinati del dipendente
considerato. Inoltre sono presenti i metodi get che permettono di recuperare le varie
proprietà.
3.2.2 Map Event
Come già detto precedentemente, gli eventi possono essere rappresentati anche da oggetti
che implementano l'interfaccia java.util.Map. In questo caso le proprietà degli eventi sono
i valori presenti nella mappa, i quali sono accessibili attraverso il metodo get esposto dalla
stessa interfaccia.
L'applicazione può aggiungere proprietà ad un evento di questo tipo utilizzando
l'operazione di configurazione updateMapEventType. Le proprietà non possono essere
aggiornate o cancellate, ma solo aggiunte. Di seguito è mostrato un esempio di Event Map.
Map<String, Object> event = new HashMap<String, Obj ect>(); event.put("carId", carId); event.put("direction", direction);

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
73
3.2.3 Object-array Event
Un evento può anche essere rappresentato da un array di oggetti. In questo caso le
proprietà degli eventi sono i valori degli elementi dell'array. Un dato evento di questo tipo
può avere solo un supertipo che deve essere anche esso un Object-array. Ovviamente,
come nel caso dei Map Event, tutte le proprietà disponibili sul supertitpo Object-array
saranno disponibili anche sul tipo stesso.
L'applicazione può aggiungere proprietà ad un evento di questo tipo a runtime utilizzando
l'operazione di configurazione updateObjectArrayEventType. Le proprietà non possono
essere aggiornate o cancellate, ma solo aggiunte.
Di seguito un esempio di Object-array Event.
String[] propertyNames = {"carId", "direction"}; Object[] propertyTypes = {String.class, int.class};
3.2.4 XML Event
Gli eventi possono essere rappresentati anche come org.w3c.dom.Node. Ovviamente, se un
XML schema (file XSD) è reso disponibile come parte della configurazione dell’engine
(tale argomento sarà discusso più avanti), allora Esper può leggere lo schema e validare gli
statement che utilizzando quel tipo di evento e le sue proprietà.
Quando nessun XML schema viene fornito, gli eventi XML possono ancora essere
interrogati, ma tutte le espressioni realizzate nei loro confronti si presumono valide, in
quanto non vi è alcuna convalida dell'espressione.
In entrambi i casi Esper permette di configurare esplicite espressioni XPath come
proprietà di un evento.
Di seguito è mostrato un esempio di XML Event.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
74
<?xml version="1.0" encoding="UTF-8"?> <Sensor xmlns="SensorSchema"> <ID>urn:epc:1:4.16.36</ID> <Observation Command="READ_PALLET_TAGS_ONLY"> <ID>00000001</ID> <Tag> <ID>urn:epc:1:2.24.400</ID> </Tag> <Tag> <ID>urn:epc:1:2.24.401</ID> </Tag> </Observation> </Sensor>
Mentre questo è l’XML schema associato:
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSche ma"> <xs:element name="Sensor"> <xs:complexType> <xs:sequence> <xs:element name="ID" type="xs:stri ng"/> <xs:element ref="Observation" /> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="Observation"> <xs:complexType> <xs:sequence> <xs:element name="ID" type="xs:string "/> <xs:element ref="Tag" maxOccurs="unbo unded" /> </xs:sequence> <xs:attribute name="Command" type="xs:str ing" use="requ ired"/> </xs:complexType> </xs:element> <xs:element name="Tag"> <xs:complexType> <xs:sequence> <xs:element name="ID" type="xs:stri ng"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
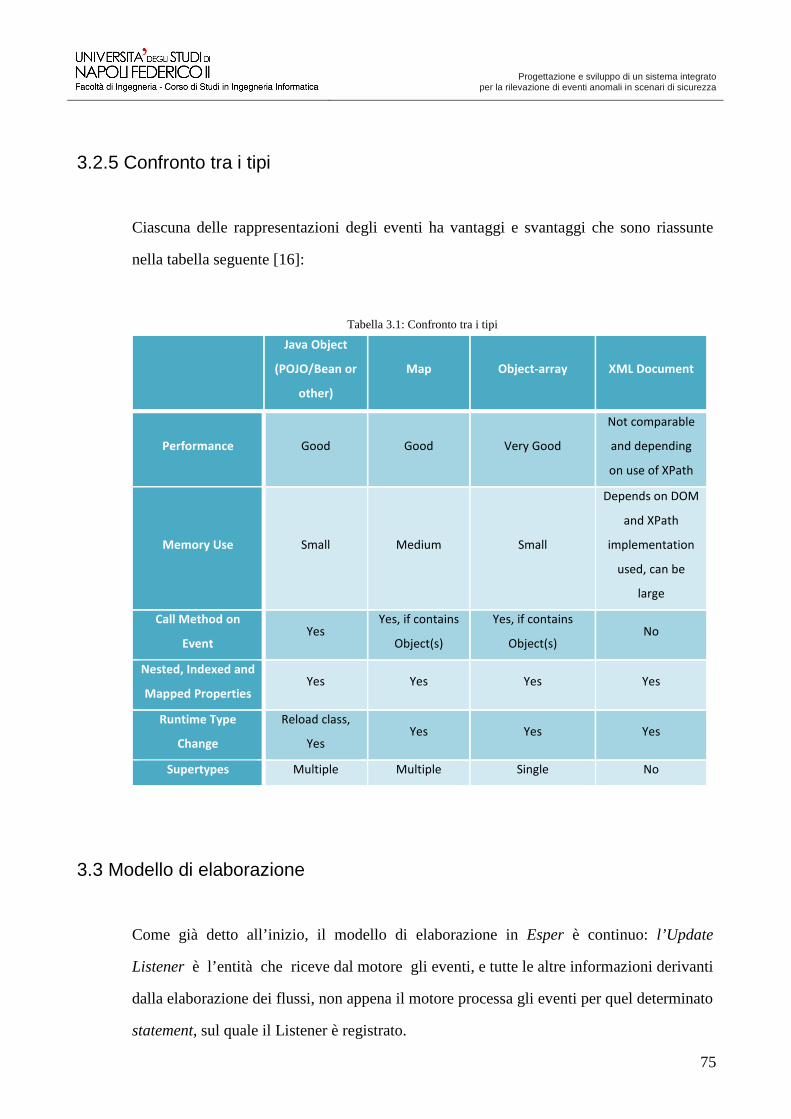
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
75
3.2.5 Confronto tra i tipi
Ciascuna delle rappresentazioni degli eventi ha vantaggi e svantaggi che sono riassunte
nella tabella seguente [16]:
Tabella 3.1: Confronto tra i tipi
Java Object
(POJO/Bean or
other)
Map Object-array XML Document
Performance Good Good Very Good
Not comparable
and depending
on use of XPath
Memory Use Small Medium Small
Depends on DOM
and XPath
implementation
used, can be
large
Call Method on
Event Yes
Yes, if contains
Object(s)
Yes, if contains
Object(s) No
Nested, Indexed and
Mapped Properties Yes Yes Yes Yes
Runtime Type
Change
Reload class,
Yes Yes Yes Yes
Supertypes Multiple Multiple Single No
3.3 Modello di elaborazione
Come già detto all’inizio, il modello di elaborazione in Esper è continuo: l’Update
Listener è l’entità che riceve dal motore gli eventi, e tutte le altre informazioni derivanti
dalla elaborazione dei flussi, non appena il motore processa gli eventi per quel determinato
statement, sul quale il Listener è registrato.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
76
La classe UpdateListener possiede un unico metodo astratto update(), come mostrato in
figura 3.3, che necessita di essere implementato.
Figura 3.3: UpdateListener
Il motore fornisce i risultati degli statement agli update listener inserendoli in oggetti
com.espertech.esper.client.EventBean. Un'implementazione tipica di un update listener
interroga le istanze EventBean tramite metodi get per ottenere i risultati generati.
Un secondo metodo per la consegna dei risultati, fortemente tipizzato, nativo e altamente
performante è l’utilizzo di un Subscriber Object, il quale rappresenta un legame diretto dei
risultati della query a un oggetto Java. L'oggetto, un POJO, riceve i risultati dello
statement tramite l’invocazione di metodi. Per poter implementare un subscriber object
non è necessario implementare ne un’interfaccia e ne estendere una classe.
Detto ciò, al fine di comprendere al meglio il modello di elaborazione di Esper,
analizziamo i concetti di Insert stream e Remove stream, nonché la capacità dell’engine di
gestire le cosiddette sliding windows, le quali sono fondamentali per l’elaborazione, nel
tempo, dei flussi di eventi. Nel fare ciò verrà mostrato anche qualche semplice esempio di
EPL.
3.3.1 Insert Stream
L’ Insert Stream indica i nuovi eventi in arrivo, cioè quelli che o rientrano in una
opportuna finestra (data window), temporale, di lunghezza o batch che sia, definita da una

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
77
opportuna regola EPL, o che vengono aggregati con altri eventi, sempre attraverso
un’opportuna regola. Supponiamo di avere il seguente statement EPL:
select * from Withdrawal
il quale seleziona tutti gli eventi di tipo Withdrawal.
Ogni volta che l’engine processa un evento di questo tipo, esso invoca tutti gli update
listener associati allo statement, consegnando a ciascuno di essi il nuovo evento, il quale
entra a far parte dell’Insert Stream.
Il diagramma seguente mostra una serie di eventi di Withdraw in arrivo nel corso del
tempo.
Figura 3.4: Insert Stream

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
78
3.3.2 Remove Stream e Length Window
A differenza dell’Insert Stream, il Remove Stream indica gli eventi che lasciano una data
window. Per comprendere tale concetto, introduciamo una prima operazione messa a
disposizione dall’engine di Esper per gestire le sliding windows, e cioè quella di
considerare finestre di lunghezza prefissata, o length windows.
Supponiamo di avere il seguente statement EPL:
select * from Withdrawal.win:length(5)
il quale fa si che il motore faccia entrare tutti gli eventi di tipo Withdrawal in arrivo (Insert
Stream) nella data window. Quando la finestra è piena, cioè sono arrivati più di cinque
eventi, l'evento più vecchio viene spinto fuori. A questo punto il motore indica ai listener
tutti gli eventi che entrano dalla finestra come nuovi eventi e tutti gli eventi che lasciano la
finestra come vecchi eventi. Questi ultimi rappresentano il Remove Stream.
Il seguente diagramma chiarisce quanto appena spiegato.
Figura 3.5: Length Windows

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
79
Come si può notare, all’arrivo dei primi 5 eventi, essi vengono inseriti nel vettore
NewEvents e, all’occorrenza di un ulteriore evento, il primo evento inserito, W1, viene
rimosso dalla finestra e inserito nel vettore OldEvents.
3.3.3 Time Window
Un’altra operazione molto importante sulle finestre è di tipo temporale, ossia time window.
In questo caso il parametro fisso non è la cardinalità della finestra, bensì il tempo. Quindi,
una finestra di lunghezza T secondi, conserva gli eventi ricevuti negli ultimi T secondi,
traslando continuamente nel tempo (finestra scorrevole nel tempo, sliding window) [16].
Figura 3.6: Time Windows
La figura 3.6 mostra un esempio di time-windows con T=4sec, in cui si nota come la
finestra contenga sempre gli eventi ricevuti negli ultimi 4 sec. Infatti, all’istante di tempo

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
80
t=5sec, in cui arriva in ingresso al motore un altro evento, la finestra è traslata “avanti nel
tempo” di 1 secondo (unità minima di tempo considerabile per il motore, avendo
specificato i secondi come unità di misura del tempo per la finestra).
All’istante t=6.5, la finestra contiene anche l’evento W3. Infine, all’istante t=8 sec, la
finestra temporale iniziale non conterrà più l’evento W1, occorso all’istante di tempo t=4.
Lo statement EPL che genera il comportamento appena descritto è il seguente:
select * from Withdrawal.win:time(4 sec)
3.3.4 Batch Window
Oltre alla possibilità di considerare finestre in base alla lunghezza e in base al tempo,
Esper consente anche di definire un batch, ossia un insieme finito, in cui si fissa il tempo o
la cardinalità del gruppo di eventi che possono eventualmente confluire in esso.
Si definisce dunque l’operazione di time-batch come l’elaborazione degli eventi che
arrivano in un intervallo di tempo prefissato, terminato il quale gli eventi memorizzati nel
vettore NewEvents vengono forniti all’UpdateListener.
A differenza dei due casi analizzati in precedenza, non si hanno finestre “scorrevoli”, in
relazione alla cardinalità N o il tempo T, ma sono fisse.
La figura 3.7 mostra un esempio di time-batch window con T=4 sec. Nei primi 4 secondi,
gli eventi W1 e W2 vengono inseriti nel batch. All’istante t=5 sec, entrambi gli eventi
vengono estratti dal batch ed inseriti nel vettore NewEvents, e il motore considera un
nuovo batch dello stesso intervallo temporale.
A differenza dei casi precedentemente esaminati, con il time-batch si hanno finestre fisse
che non traslano nel tempo, ossia tutti i batch sono indipendenti tra loro, in quanto ogni
evento può far parte di un solo batch specifico, e non può appartenere a più finestre entro
l’intervallo di tempo definito. Lo statement EPL che genera questo comportamento è il

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
81
seguente:
select * from Withdrawal.win:time_batch(4 sec)
Figura 3.7: Time-batch Windows
Oltre al time-batch, è possibile avere un batch di eventi legato soltanto alla lunghezza del
batch stesso, ed è rappresentato dalla operazione di length-batch.
Ad esempio, un batch di lunghezza N=5 consente di ricevere 5 eventi senza alcun vincolo
sull’intervallo di tempo entro cui gli eventi devono arrivare al fine di essere analizzati.
Analogamente al caso precedente, una volta “riempito” il batch, tutti gli eventi verranno
estratti da essi e passati all’UpdateListener per poter essere manipolati.
Lo statement EPL che genera questo comportamento è il seguente:
select * from Withdrawal.win:lenggth_batch(5)

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
82
Ovviamente, sono stati mostrati esempi molto semplici per gli statement EPL, i quali,
attraverso le varie clausole, permettono di effettuare operazioni molto più complesse. Per
tale motivo, nella sezione successiva approfondiamo proprio tale linguaggio.
3.4 Il linguaggio EPL
Il linguaggio EPL è un linguaggio SQL-like, dotato delle clausole SELECT, FROM,
WHERE, GROUP BY, HAVING e ORDER BY, nel quale gli stream sostituiscono le tabelle
come fonte di dati e gli eventi sostituiscono le righe come unità base dei dati. Poiché gli
eventi contengono dati, i concetti di correlazione attraverso join, filtraggio e aggregazione
previsti nell’SQL possono essere efficacemente sfruttati [16].
Gli statement EPL vengono utilizzati per ricavare informazioni aggregate da uno o più
flussi di eventi, e per unire o fondere questi ultimi, e possono contenere definizioni di una
o più viste, che, come già detto all’inizio, sono simili a tabelle in SQL, ma definiscono i
dati disponibili per l'interrogazione e il filtraggio. Alcune viste rappresentano le finestre su
un flusso di eventi, altre derivano statistiche dalle proprietà degli eventi. Le viste possono
essere inoltre concatenate al fine di costruire una catena di viste.
Vediamo ora più da vicino la sintassi, nonché le possibilità offerte dall’EPL in termini di
accesso ai database relazionali e definizione di script. Infine approfondiremo il linguaggio
per la definizione di pattern expression.
3.4.1 Sintassi
Le query EPL si basano sulla seguente sintassi:
[annotations] [expression_declarations]

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
83
[context context_name] insert [istream|rstream] into event_stream_name[(pr operty_name [,...])] select [istream | irstream | rstream] [distinct] * | expression_list ... from stream_def [.view_spec][(filter_criteria)][as name][,...] [where search_conditions] [group by grouping_expression_list] [having grouping_search_conditions] [output output_specification] [order by order_by_expression_list] [limit num_rows]
Come si può notare, le sole clausole obbligatorie sono la SELECT e la FROM, mentre le
altre sono del tutto opzionali. Vediamo ora velocemente il significato delle principali.
SELECT
La clausola select è richiesta in tutti gli statement EPL, e può essere utilizzata per
selezionare tutte le proprietà tramite il carattere *, o per specificare un elenco di
proprietà o espressioni.
Essa offre anche le parole chiave opzionali istream, irstream e rstream che consentono di
definire gli eventi di quale stream notificare agli UpdateListener.
Precisamente, la parola chiave istream, che rappresenta anche l’impostazione predefinita,
indica che l’engine Esper invia ai listener solo gli eventi dell’Insert stream, mentre quella
rstream indica al motore di erogare solo gli eventi del Remove Stream, ed infine quella
irstream indica che al motore di erogare gli eventi di entrambi gli stream.
Un’altra importante parola chiave è quella distinct, la quale permette di selezionare solo le
righe uniche a seconda della lista di colonne specificato dopo di esso.
Dio seguito è mostrato un esempio:
select symbol, price, sum(volume) as sm from StockTick.win:time(60 sec)
Questo statement prevede la selezione degli attributi symbol e price degli eventi StockTick,
e la somma del volume per gli eventi di questo tipo che ricadono in una finestra temporale

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
84
di 60 secondi.
È importante notare che all’interno della clausola select è anche possibile definire delle
espressioni, come mostrato nel seguente statement:
select volume * price from StockTick.win:time_batch(30 sec)
nel quale è selezionato il prodotto tra il volume e il prezzo.
FROM
La clausola from è obbligatoria in tutti gli statement EPL, e permette di specificare uno o
più flussi di eventi, ai quali opzionalmente può essere associato un nome attraverso la
parola chiave as.
Ovviamente la specifica di più di un flusso ha come obbiettivo la realizzazione di uno o
più join, che sono perfettamente supportati dall’EPL.
Attraverso la clausola from è anche possibile realizzare operazioni di filtraggio, il tutto
semplicemente prevedendo delle espressioni tra parentesi tonde subito dopo la definizione
del flusso di eventi. Vediamo un esempio:
select * from RfidEvent(zone=1 and category=10)
Attraverso tale statement, sono selezionati tutti gli attributi degli eventi del tipo RfidEvent,
i quali presentano l’attributo zone=1 e quello category=10.
Un’altra operazione di fondamentale importanza che può essere realizzata attraverso tale
clausola è l’utilizzo delle viste. Infatti basta semplicemente far seguire al nome dello
stream quello della vista, preceduto da un punto. Un esempio di EPL è già stato mostrato
precedentemente, ma lo riproponiamo per semplicità:
select * from Withdrawal.win:time(4 sec)
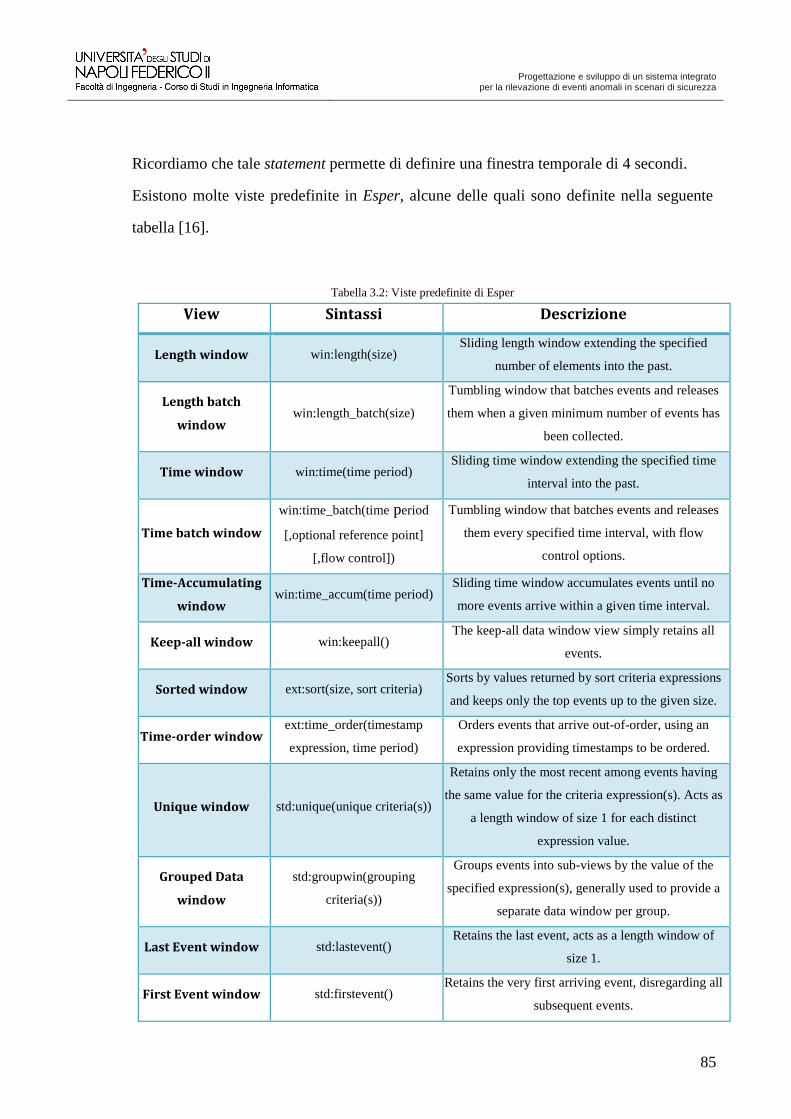
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
85
Ricordiamo che tale statement permette di definire una finestra temporale di 4 secondi.
Esistono molte viste predefinite in Esper, alcune delle quali sono definite nella seguente
tabella [16].
Tabella 3.2: Viste predefinite di Esper
View Sintassi Descrizione
Length window win:length(size) Sliding length window extending the specified
number of elements into the past.
Length batch
window win:length_batch(size)
Tumbling window that batches events and releases
them when a given minimum number of events has
been collected.
Time window win:time(time period) Sliding time window extending the specified time
interval into the past.
Time batch window
win:time_batch(time period
[,optional reference point]
[,flow control])
Tumbling window that batches events and releases
them every specified time interval, with flow
control options.
Time-Accumulating
window win:time_accum(time period)
Sliding time window accumulates events until no
more events arrive within a given time interval.
Keep-all window win:keepall() The keep-all data window view simply retains all
events.
Sorted window ext:sort(size, sort criteria) Sorts by values returned by sort criteria expressions
and keeps only the top events up to the given size.
Time-order window ext:time_order(timestamp
expression, time period)
Orders events that arrive out-of-order, using an
expression providing timestamps to be ordered.
Unique window std:unique(unique criteria(s))
Retains only the most recent among events having
the same value for the criteria expression(s). Acts as
a length window of size 1 for each distinct
expression value.
Grouped Data
window
std:groupwin(grouping
criteria(s))
Groups events into sub-views by the value of the
specified expression(s), generally used to provide a
separate data window per group.
Last Event window std:lastevent() Retains the last event, acts as a length window of
size 1.
First Event window std:firstevent() Retains the very first arriving event, disregarding all
subsequent events.
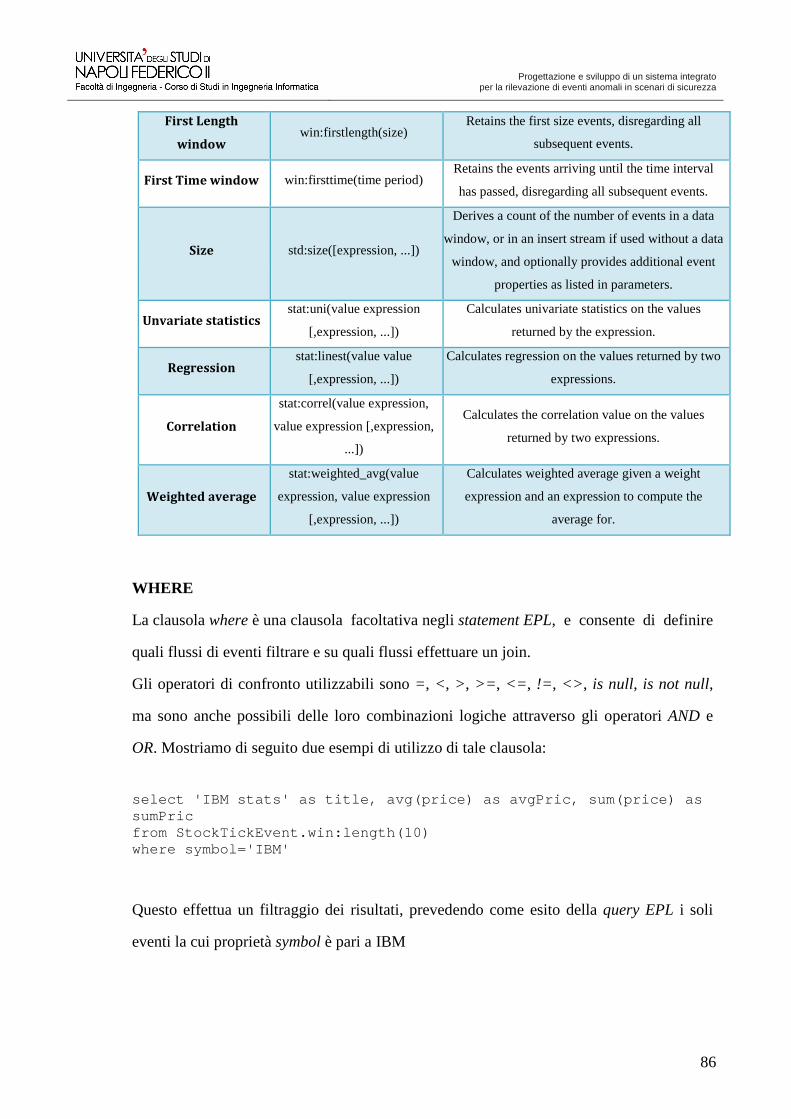
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
86
First Length
window win:firstlength(size)
Retains the first size events, disregarding all
subsequent events.
First Time window win:firsttime(time period) Retains the events arriving until the time interval
has passed, disregarding all subsequent events.
Size std:size([expression, ...])
Derives a count of the number of events in a data
window, or in an insert stream if used without a data
window, and optionally provides additional event
properties as listed in parameters.
Unvariate statistics stat:uni(value expression
[,expression, ...])
Calculates univariate statistics on the values
returned by the expression.
Regression stat:linest(value value
[,expression, ...])
Calculates regression on the values returned by two
expressions.
Correlation
stat:correl(value expression,
value expression [,expression,
...])
Calculates the correlation value on the values
returned by two expressions.
Weighted average
stat:weighted_avg(value
expression, value expression
[,expression, ...])
Calculates weighted average given a weight
expression and an expression to compute the
average for.
WHERE
La clausola where è una clausola facoltativa negli statement EPL, e consente di definire
quali flussi di eventi filtrare e su quali flussi effettuare un join.
Gli operatori di confronto utilizzabili sono = , <, > , >= , <= , != , <> , is null, is not null,
ma sono anche possibili delle loro combinazioni logiche attraverso gli operatori AND e
OR. Mostriamo di seguito due esempi di utilizzo di tale clausola:
select 'IBM stats' as title, avg(price) as avgPric, sum(price) as sumPric from StockTickEvent.win:length(10) where symbol='IBM'
Questo effettua un filtraggio dei risultati, prevedendo come esito della query EPL i soli
eventi la cui proprietà symbol è pari a IBM

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
87
select * from TickEvent.std:unique(symbol) as t, NewsEvent.std:unique(symbol)as n where t.symbol = n.symbol
Questo invece effettua un join tra i due stream TickEvent e NewsEvent, attraverso la
proprietà symbol.
GROUP BY
La clausola group by è facoltativa in uno statement EPL, e permette di suddividere l'uscita
di quest’ultimo in gruppi. È possibile raggruppare a partire da uno o più nomi di proprietà
di eventi, o dal risultato di espressioni calcolate.
Ad esempio, la dichiarazione seguente restituisce il prezzo totale per simbolo per gli
eventi del tipo StockTickEvent negli ultimi 30 secondi:
select symbol, sum (price) from StockTickEvent.win: time (30 sec) group by symbol
Esper pone le seguenti restrizioni alle espressioni sulla clausola group by:
• Le espressioni in group by non possono contenere funzioni di aggregazione
• Le proprietà degli eventi che vengono utilizzati all'interno di funzioni di
aggregazione, nella clausola select, non possono essere utilizzate anche nelle
espressioni della group by
• Quando si raggruppa un flusso non limitato, è necessario assicurarsi che
l’espressione definita in group by non restituisca un numero illimitato di valori.
HAVING
La clausola having permette di rifiutare o lasciar passare eventi definiti in group by in
maniera molto semplice, e precisamente nello stesso modo in cui nella clausola where si
definiscono le condizioni per la select, con l’eccezione che in having è possibile utilizzare

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
88
funzioni di aggregazione.
Il seguente statement è un esempio di clausola having con una funzione di aggregazione.
Esso mostra il prezzo totale per simbolo degli eventi StockTickEvent degli ultimi 30
secondi, ma solo per quelli il cui prezzo totale supera 1000. Quindi tutti quelli il cui prezzo
totale è pari o inferiore a 1000 saranno eliminati.
select symbol, sum(price) from StockTickEvent.win:time(30 sec) group by symbol having sum(price) > 1000
ORDER BY
La clausola order by è facoltativa, e viene utilizzata per ordinare gli eventi in uscita
rispetto ad alcune loro proprietà. Ad esempio, lo statement seguente restituisce gli eventi
StockTickEvent degli ultimi 60 secondi, ordinati in base al prezzo e al volume:
select symbol from StockTickEvent.win:time(60 sec) order by price, volume
Esper pone una restrizione per tale clausola, e cioè che tutte le funzioni di aggregazione
che compaiono in essa, devono apparire anche nell'espressione della select.
INSERT INTO
Anche la clausola insert into è facoltativa in Esper. Essa può essere utilizzata per rendere
disponibili i risultati di uno statement EPL come un flusso di eventi, così da poter essere
utilizzato in ulteriori statement. Tale clausola può anche essere usato per unire flussi di
eventi multipli per formare un unico flusso di eventi.
Esper pone le seguenti restrizioni alla clausola insert into:
• Il numero di elementi nella clausola select deve corrispondere al numero di elementi
nella clausola insert into, se essa specifica un elenco di nomi di proprietà degli

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
89
eventi
• Se il nome del flusso di eventi è stato già definito da uno statement precedente, e i
nomi delle proprietà degli eventi e/o i tipi non corrispondono, viene generata
un'eccezione in fase di creazione dello statement.
Il seguente esempio inserisce in un flusso di eventi, denominato CombinedEvent, il
risultato dello statement:
insert into CombinedEvent select A.customerId as custId, A.timestamp - B.time stamp as latency from EventA.win:time(30 min) A, EventB.win:time(30 min) B where A.txnId = B.txnId
Ogni evento in CombinedEvent ha due proprietà: "custid" e "latenza". Gli eventi generati
da tale statement possono essere utilizzati in ulteriori statement, come ad esempio quello
seguente:
select custId, sum(latency) from CombinedEvent.win:time(30 min) group by custId
3.4.2 Accesso ad un database e supporto ai linguaggi di script
Altre potenzialità messe a disposizione dal linguaggio EPL, sono la possibilità di accedere
ai dati relazionali presenti all’interno di un database attraverso l’utilizzo del linguaggio
SQL. A questa si aggiunge quella di poter definire al suo interno degli script, così da poter
eseguire determinate operazioni direttamente come parte dell’EPL stesso.
Per quanto riguarda l’accesso ad un database, tale operazione può essere realizzata
seguendo la seguente sintassi:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
90
sql:database_name [" parameterized_sql_query "]
Un esempio di utilizzo è il seguente:
select custId, cust_name from CustomerCallEvent, sql:MyCustomerDB [' select cust_name from Customer where cust_id = ${custId} ']
il quale presuppone che l’evento CustomerCallEvent presenti una proprietà denominata
custId. La query SQL non fa altro che selezionare il nome del customer dalla tabella
Customer, dove il cust_id presente nella tabella coincida con il custId dell’evento appena
sopraggiunto.
Relativamente invece alla possibilità di inserire script nel codice EPL, è importante
specificare che i linguaggi di scripting accettati sono quelli che supportano JSR 223 e il
MVEL. La sintassi per utilizzare questi linguaggi all’interno dell’EPL è la seguente:
expression [return_type] [dialect_identifier:] scri pt_name [ (parameters) ] [ script_body ]
Dove expression è la parola chiave per dichiarare uno script, return_type è opzionale e
rappresenta l’eventuale tipo di dato ritornato dallo script, dialect_identifier, anch’esso
opzionale, definisce il linguaggio utilizzato per lo script (es. mvel per MVEL, js per
JavaScript e python per Python). Di seguito è riportato un esempio di script che calcola il
totale di Fibonacci, e il suo utilizzo in uno statement EPL: expression double js:fib(num) [ fib(num); function fib(n) { if(n <= 1) return n; return fib(n-1) + fib(n-2); } ] select fib(intPrimitive) from SupportBean;

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
91
3.4.3 Event Pattern
Come già accennato all’inizio di questa trattazione, gli Event Pattern sono dei pattern
expression-based per il matching degli eventi. Essi sono costituiti da due elementi
fondamentali:
• Pattern atoms: sono gli elementi costitutivi dei pattern, e sono espressioni di
filtraggio, osservatori per eventi temporali e plug-in per osservatori personalizzati
che osservano gli eventi esterni, cioè quelli che non sono sotto il controllo del
motore.
• Pattern operator: controllano il ciclo di vita delle espressioni e combinano i Pattern
atom in maniera logica o temporale.
La tabella seguente descrive i diversi pattern atom disponibili [16]:
Tabella 3.3: Pattern atom disponibili degli Event Pattern
Pattern Atom Example
Filter expressions specify
an event to look for StockTick(symbol='ABC', price > 100)
Time-based event
observers specify time
intervals or time schedules.
timer:interval(10 seconds)
Custom plug-in observers
can add pattern language
syntax for observing
application-specific events.
myapplication:myobserver("http://someResource")
Per quanto riguarda, invece, gli operatori, essi sono di 4 tipi:
• Operatori che controllano la ripetizione delle sottoespressioni:
o every: indica che la pattern sub-expression deve riavviarsi dopo essere stata

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
92
valutata.
o every-distinct: come every, ma elimina i duplicati
o [num]: si attiva quando una pattern sub-expression restituisce true un
numero num di volte
o until: permette di definire fino a quando effettuare la valutazione
• Operatori logici: AND, OR, NOT
• Operatori temporali: operano sull’ordine degli eventi: -> (followed-by)
• Guards: sono where-conditions che controllano il ciclo di vita delle
sottoespressioni. Esempi sono:
o timer:within: una sorta di cronometro che, se la pattern sub-expression non
ritorna true nello specifico intervallo temporale , viene fermato e ritorna
sempre false
o timer:withinmax: simile al precedente, ma possiede anche un contatore di
match
o while-expression: seguita da una espressione che il motore di valuta per ogni
match riportato dalla guard pattern sub-expression. Quando l'espressione
restituisce false, la pattern sub-expression termina.
Le pattern expression possono essere innestate con profondità arbitraria includendo
l'espressione nidificata in parentesi tonde.
Vediamo qualche esempio. Il seguente mostra una pattern expression che effettua il match
su ogni evento ServiceMeasurement il cui valore di latency è superiore a 20 secondi o il
cui valore di success è false.
every (spike=ServiceMeasurement(latency>20000) or error=ServiceMeasurement(success=false))
Un esempio leggermente più complesso è il seguente, nel quale il pattern individua
quando 3 sensor event indicano una temperatura maggiore di 50 gradi ininterrottamente

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
93
per 90 secondi dal primo evento, considerando però gli eventi provenienti dallo stesso
sensore.
every sample=Sample(temp>50) -> ((Sample(sensor=sample.sensor, temp>50) and not Sample(sensor=sample.sensor,temp<=50))-> (Sample(sensor=sample.sensor,temp>50) and not Sample(sensor=sample.sensor, temp <= 50)))where tim er:within(90 seconds))
Un aspetto molto importante da notare è che un pattern può apparire ovunque nella
clausola from di un'istruzione EPL, e possono essere utilizzati in combinazione con le
clausole where, group by, having e insert into.
Il seguente esempio mostra la selezione del prezzo totale per cliente sulla coppia di eventi
(ServiceOrder seguito da un evento ProductOrder per lo stesso id cliente entro 1 minuto),
che si verificano nelle ultime 2 ore, in cui la somma del prezzo è maggiore di 100:
select a.custId, sum(a.price + b.price) from pattern [every a=ServiceOrder -> b=ProductOrde r(custId = a.custId) where timer:within(1 min)].win:time(2 hou r) group by a.custId having sum(a.price + b.price) > 100
3.5 Esper API
Le API di Esper sono caratterizzate da una serie di interfacce, ognuna delle quali ha uno
suo scopo ben definito. Le seguenti sono quelle considerate di primaria importanza [16]:
• Service Provider Interface
• Administrative Interface
• Runtime Interface
Vediamole più in dettaglio.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
94
3.5.1 Service Provider Interface
L'interfaccia EPServiceProvider rappresenta un'istanza del motore di Esper. Ogni istanza è
completamente indipendente dalle altre e dispone di una propria interfaccia di
amministrazione e runtime. Un’istanza del motore di Esper può essere ottenuta tramite
metodi statici sulla classe EPServiceProviderManager. Precisamente, il metodo
getDefaultProvider(String providerURI) e quello GetDefaultProvider() restituiscono
un'istanza del motore di Esper. In particolare, il primo può essere utilizzato per ottenere
più istanze del motore per valori diversi del provider URI. In questo caso
l’ EPServiceProviderManager determina se il provider URI corrisponde a istanze già
definite e restituisce quella con lo stesso provider URI, in caso contrario, si crea una nuova
istanza del motore. Una volta istanziata, tale istanza può opzionalmente essere inizializzata
attraverso il metodo initialize(), il quale ferma l’istanza, rimuove tutti gli statement ad essa
associati e resetta la sua configurazione. Inoltre un’istanza può anche essere distrutta con il
metodo destroy().
Di seguito è riportato un semplice esempio di codice.
// Obtain an engine instance EPServiceProvider epService = EPServiceProviderManager.getDefaultProvider(); // Optionally epService.initialize(); // Destroy the engine instance when no longer neede d, frees up resources epService.destroy();
3.5.2 Administrative Interface
L’interfaccia EPAdministrator è utilizzata principalmente per creare e gestire statement
EPL e pattern, nonché per effettuare una configurazione a runtime dell’istanza del motore
di Esper (tale aspetto sarà mostrato più avanti in questa trattazione).

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
95
Nello specifico, la creazione di uno statement EPL e di un pattern può essere realizzata
attraverso l’utilizzo rispettivamente dei metodi createEPL(String EPL) e
createPattern(String Pattern), i quali ritornano entrambi un oggetto EPStatement, che
rappresenta lo statement creato, il quale viene automaticamente avviato e attivato.
Sugli EPStatement generati è poi possibile associare un listener, al quale saranno passati
tutti gli eventi di cui lo statement effettua il match, attraverso il metodo addlistener().
EPServiceProvider epService = EPServiceProviderManager.getDefaultProvider(); EPAdministrator admin = epService.getEPAdministrato r(); EPStatement 10secRecurTrigger = admin.createPattern ("every timer:at(*, *, *, *, *, */10)"); EPStatement countStmt = admin.createEPL("select cou nt(*) from MarketDataBean.win:time(60 sec)"); MyListener listener = new MyListener(); countStmt.addListener(listener);
3.5.3 Runtime Interface
L'interfaccia EPRuntime viene utilizzata principalmente per inviare eventi al motore
Esper, così da poter essere elaborati dallo stesso.
Il frammento di codice seguente mostra come inviare un oggetto evento Java al motore.
EPServiceProvider epService = EPServiceProviderManager.getDefaultProvider( ); EPRuntime runtime = epService.getEPRuntime(); // Send an example event containing stock market da ta runtime.sendEvent(new MarketDataBean('IBM', 75.0));
Un altro metodo che può essere utilizzato per inviare eventi al motore è l’utilizzo
del’interfaccia EventSender, la quale consente di elaborare eventi di un determinato tipo.
Tale interfaccia mette a disposizione il metodo getEventSender(String EventTypeName)
attraverso il quale è possibile ottenere un EventSender per quel determinato tipo di evento.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
96
EventSender sender = epService.getEPRuntime().getEventSender("MyEv ent"); sender.sendEvent(myEvent);
3.6 Configurazione
Esper ha un numero molto limitato di parametri di configurazione, i quali possono essere
utilizzati per semplificare gli event pattern e gli stetment EPL, nonché per ottimizzare il
comportamento del motore per specifiche esigenze. Il motore di Esper funziona out-of-
the-box senza configurazione, essa infatti è assolutamente facoltativa.
Nel caso in cui un’applicazione abbia la necessità di configurare opportunamente il motore
di Esper, vi sono due metodi possibili per realizzarla [16]:
• Configurazione a runtime
• Configurazione attraverso file XML
La classe di riferimento per tale operazione è quella Configuration, la quale rappresenta
tutti i parametri di configurazione per l’engine.
Nel primo metodo si prevede semplicemente di istanziare un oggetto Configuration il
quale sarà opportunamente popolato con i valori di configurazione. Successivamente tale
oggetto sarà passato all’EPServiceProviderManager per ottenere un’istanza del motore
Esper configurata ad hoc.
Configuration config = new Configuration(); config.addEventType("PriceLimit", PriceLimit.class. getName()); config.addEventType("StockTick", StockTick.class.ge tName()); config.addImport("org.mycompany.mypackage.MyUtility "); config.addImport("org.mycompany.util.*"); EPServiceProvider epService = EPServiceProviderManager.getProvider("Ex",con fig);
Per quanto riguarda invece il secondo metodo, Esper è in grado di recuperare i parametri

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
97
necessari da un file xml. Ciò avviene attraverso il metodo configure() della classe
Configuration, il quale accetta un URL, o un oggetto File o String per identificare il file da
caricare. Per default tale file è esper.cfg.xml, che dovrà essere presente nella directory root
dell’applicazione.
Configuration configuration = new Configuration(); configuration.configure("myengine.esper.cfg.xml");
Un esempio di file XML di configurazione è presentato di seguito. Esso realizza la stessa
configurazione prevista nell’esempio del primo metodo.
<?xml version="1.0" encoding="UTF-8"?> <esper-configuration xmlns:xsi="http://www.w3.org/2001/XMLSchema-i nstance" xmlns="http://www.espertech.com/schema/esper" xsi:schemaLocation=" http://www.espertech.com/schema/esper http://www.espertech.com/schema/esper/esper- configuration-2.0.xsd"> <event-type name="StockTick" class="com.espertech.esper.example.st ockticker .event.StockTick"/> <event-type name="PriceLimit" class="com.espertech.esper.example.st ockticker .event.PriceLimit"/> <auto-import import- name="org.mycompany.mypackage.MyUtil ity"/> <auto-import import- name="org.mycompany.util.*"/> </esper-configuration>
3.7 Integrazione ed Estensione
Esper mette a disposizione la possibilità di integrare dati esterni e/o estendere le
funzionalità dell’engine. I principali meccanismi presenti sono:
• Virtual Data Window
• Single-Row Function

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
98
• Derived-value and Data Window View
• Aggregation Function
• Pattern Guard
• Pattern Observer
• Event Type and Event Object
• Plugin
Di questi sarà ora fornita una breve descrizione, tranne che per le Derived-value and Data
Window View, che saranno approfondite in seguito.
Virtual Data Window
Le Virtual Data Window possono essere utilizzate quando si dispone di un (grande)
archivio esterno di dati a cui si desidera accedere. L'accesso avviene in maniera
trasparente: non vi è alcuna necessità di usare una sintassi speciale o join, tutte le query
sono supportate senza problemi. Non vi è la necessità di mantenere tutti i dati o eventi in
memoria con tali finestre, l'unico requisito è che tutte le righe di dati restituiti sono istanze
della classe EventBean.
Per poter realizzare una Virtual Data Window è necessario realizzare i seguenti passi:
• Implementare_l’interfaccia
com.espertech.esper.client.hook.VirtualDataWindowFactory
• Implementare l’interfaccia com.espertech.esper.client.hook.VirtualDataWindow
• Implementare_l’interfaccia
com.espertech.esper.client.hook.VirtualDataWindowLookup
• Registrare la classe factory nella configurazione dell’engine
Una volta completati questi step, sarà possibile utilizzare la finestra all’interno di uno
statement EPL.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
99
Single-Row Function
Le Single-Row Function sono funzioni che restituiscono un solo valore per ogni singola
riga di risultato generata da uno statement. Esse possono essere utilizzate in una qualsiasi
espressione e possono ricevere in input un numero qualsiasi di parametri. Esper prevede di
default un buon numero di funzioni di questo tipo (ad es. min e max che consentono di
determinare rispettivamente il minimo e il massimo degli esiti di due o più espressioni),
ma mette anche a disposizione la possibilità di definire funzioni Single-Row
personalizzate. A tale scopo è necessario seguire i due seguenti passi:
• Implementare una classe che prevede uno o più metodi statici che accettano il
numero e il tipo di parametri richiesti
• Registrare i nomi della classe e dei metodi della single-row function, attraverso il
file di configurazione dell’engine o le API
Aggregation Function
Le funzioni di aggregazione aggregano i valori delle proprietà degli eventi o i risultati di
un’espressione, ottenuti da uno o più flussi. Esempi di funzioni di aggregazione built-in
sono count (*), sum (prezzo * volume ) o avg (distinct volume).
Anche le funzioni di aggregazione possono essere personalizzate. A tal fine basta seguire i
seguenti passaggi:
• Implementare una aggregation function factory class, implementando l'interfaccia
com.espertech.esper.client.hook.AggregationFunctionFactory.
• Implementare una funzione di aggregazione, implementando l'interfaccia
com.espertech.esper.epl.agg.AggregationMethod.
• Registrare l’aggregation function factory class, attraverso il file di configurazione
del motore o le API.
Pattern Guard
I Pattern Guard sono pattern che controllano il ciclo di vita delle sub-expression, e

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
100
possono filtrare gli eventi generati da queste ultime. Esper da la possibilità di definirne di
personalizzate attraverso i seguenti passaggi:
• Implementare una guard factory class, responsabile della creazione di istanze dei
guard object.
• Implementare una guard class.
• Registrare la classe factory, tramite il file di configurazione del motore o le API.
Pattern Observer
I Pattern Observer sono pattern object che sono eseguiti come parte di una pattern
expression e possono osservare eventi o condizioni di prova. Esempi di observer built-in
sono timer:at e timer:interval.
I seguenti passi sono necessari per sviluppare e utilizzare un Observer Object
personalizzato:
• Implementare una Observer factory class, responsabile della creazione di istanze
degli Observer Object.
• Implementare una Observer class.
• Registrare la classe factory, tramite il file di configurazione del motore o le API.
Event Type and Event Object
È possibile definire nuovi tipi di eventi in Esper sottoforma di plugin, attraverso
l'implementazione dell’interface com.espertech.esper.plugin.PlugInEventRepresentation.
Una volta implementata sarà ovviamente necessario prevedere la registrazione all’interno
della classe Configuration.
È possibile registrare più rappresentazioni di eventi sottoforma di plug-in. Ogni
rappresentazione avrà un proprio URI, il quale è utilizzato per dividere lo spazio
complessivo relativo alle diverse rappresentazioni di eventi e svolge un ruolo importante
nel risolvere i tipi di eventi.
L'implementazione dell'interfaccia PlugInEventRepresentation deve prevedere

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
101
l’implementazione di altre due interfacce: com.espertech.esper.client.EventType e
EventBean.
I metodi EventType forniscono i metadati relativi agli eventi, inclusi i nomi ei tipi delle
proprietà. Essi inoltre forniscono le istanze di EventPropertyGetter per il recupero dei
valori di tali proprietà. Ogni istanza di EventType invece, rappresenta un tipo distinto di
evento, e la sua implementazione è l'evento stesso, e incapsula l'evento sottostante.
I seguenti passi consentono l’elaborazione degli eventi definiti come plugin:
• Implementare le interfacce EventType, EventPropertyGetter e EventBean.
• Implementare le interfacce PlugInEventRepresentation, PlugInEventTypeHandler e
PlugInEventBeanFactory, e poi aggiungere il nome della classe che implementa la
prima alla configurazione dell’engine.
• Registrare il plug-in event type attraverso la configurazione.
• Ottenere un EventSender dalla EPRuntime attraverso il metodo
getEventSender(URI[]), e usarlo per l’invio degli eventi.
Plugin
Un plug-in loader è utilizzato per aggiungere all’applicazione qualsiasi tipo di task che
possa beneficare dall'essere parte di un file di configurazione di Esper e che segua il ciclo
di vita del motore.
Un plug-in loader implementa l'interfaccia com.espertech.esper.plugin.PluginLoader e
può essere inserito nella configurazione. Ogni plug-in loader configurato segue il ciclo di
vita dell'istanza motore, infatti quando un'istanza del motore è inizializzata, viene creata
un'istanza di ciascuna delle classi di implementazione dei plug-in loader elencati nella
configurazione. In più il motore richiama i metodi relativi al ciclo di vita della classe che
implementa il plug-in loader prima e dopo che il motore venga completamente
inizializzato, e prima che un'istanza dello stesso venga distrutta.
È possibile dichiarare un plug-in loader nella configurazione XML come segue:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
102
... <plugin-loader name="MyLoader" class-name="org.mypackage.MyLoader"> <init-arg name="property1" value="val1"/> </plugin-loader>
In alternativa è possibile utilizzare le API:
Configuration config = new Configuration(); Properties props = new Properties(); props.put("property1", "value1"); config.addPluginLoader("MyLoader", "org.mypackage.M yLoader", props);
Relativamente alla classe che implementa il plug-in loader, in essa è necessario
implementare il metodo init, il quale permette di ricevere i parametri di inizializzazione.
Il motore richiama questo metodo prima che il motore sia completamente inizializzato.
Altri metodi da implementare sono il postInitialize e quello destroy, i quali vengono
rispettivamente richiamati dal motore al termine dell’inizializzazione e prima della
distruzione del motore stesso.
3.7.1 Derived-Value and Data Window View
Le viste in Esper, come già accennato più volte, vengono utilizzate per ricavare
informazioni da un flusso di eventi e per realizzare delle data windows, e ne sono previste
differenti di default (v. tabella paragrafo 3.2).
I passaggi seguenti sono necessari per poter sviluppare e utilizzare una custom View con
Esper:
• Implementare una classe view factory. Le classi di questo tipo sono classi che
accettano e controllano i parametri della vista e creano un'istanza della classe view.
• Implementare una classe view. Una classe view spesso rappresenta una data
windows o deriva nuove informazioni da un flusso di eventi.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
103
• Configurare la classe view factory fornendo un view namespace e un nome al file di
configurazione dell’engine.
Vediamoli più nel dettaglio.
3.7.1.1 Implementazione della classe View factory
La classe view factory è un’estensione della classe
com.espertech.esper.view.ViewFactorySupport, ed è responsabile di una serie di compiti,
e precisamente sono:
• Accettare zero o più view parameter, che sono espressioni che la classe deve
validare e valutare
• Instanziare la classe view
• Fornire informazioni relative al tipo di eventi postati dalla view
Il primo compito è realizzato attraverso l’implementazione del metodo
setViewParameters, il quale riceve ed effettua l’analisi dei view parameter. Il seguente
codice, ad esempio, controlla il numero di parametri passati e li memorizza all’interno
della classe:
public void setViewParameters(ViewFactoryContext viewFactoryContext, List<ExprNode> viewParameter s) throws ViewParameterException { this.viewFactoryContext = viewFactoryContext; if (viewParameters.size() != 3) { throw new ViewParameterException("View requires a 3 parameters: ip, time and file name"); } this.viewParameters = viewParameters; }
Dopo che l’engine avrà fornito i view parameter alla classe factory, esso chiederà alla

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
104
vista di collegarsi alla sua parent view e di convalidare le parametr expression rispetto al
tipo di evento di quest’ultima.
A tale scopo è necessaria l’implementazione del metodo attach e l’utilizzo in esso del
metodo validate della classe ViewFactorySupport. Di seguito è riportato un esempio di
implementazione del metodo attach, nel quale avviene la convalida delle parameter
expression, nonché il controllo del tipo dei parametri.
public void attach(EventType parentEventType, StatementContext statementContext, Vi ewFactory optionalParentFactory, List<ViewFacto ry> parentViewFactory) throws ViewParameterException { ExprNode[] validatedNodes = ViewFactorySupport.validate("atta ckPV", parentEventType, statementContext , viewParameters, false); ipExpression = validatedNodes[0]; timeExpression = validatedNodes[1]; fileExpression = validatedNodes[2]; if ((ipExpression.getExprEvaluator().getType() != String.class) && (timeExpression.getExprEvaluator().getType( ) != String.class) && (fileExpression.getExprEvaluator().getType( ) != String.class)){ throw new ViewParameterException("View requires String-typed values for input parameters") ; } }
Infine, l’engine chiede alla view factory di creare un’istanza della custom view, e chiede il
tipo di eventi generati dalla stessa. Per tale motivo si prevede l’implementazione dei
metodi makeView e getEventType, di cui un esempio è riportato di seguito:
public View makeView(AgentInstanceViewFactoryChainC ontext agentInstanceViewFactoryContex t) { return new PluginView(agentInstanceViewFactoryCo ntext, ipExpression, timeExpression, fileExpression ); } public EventType getEventType() { return PluginView.getEventType(viewFactoryContext

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
105
.getEventAdapterService()); }
3.7.1.2 Implementazione della classe View
Una classe view, come già detto, rappresenta la vista personalizzata vera e propria, la quale
ricordiamo è istanziata dalla View Factory. Tale classe sarà un’estensione di quella
com.espertech.esper.view.ViewSupport, e sarà responsabile dei seguenti metodi:
• Il metodo setParent, che informa la vista del tipo di evento della parent view
• Il metodo update, che riceve gli eventi dell’insert stream e del remove stream dalla
sua parent view
• Il metodo iterator (opzionale), che fornisce un iterator per consentire ad
un'applicazione di prelevare o richiedere i risultati di un EPStatement
• Il metodo cloneView, che è necessario per creare una copia della vista per abilitare la
stessa a lavorare in un grouping context insieme ad una parent view del tipo
std:groupwin
Di questi, di fondamentale importanza è il metodo update, il quale si preoccupa
dell'elaborazione degli eventi in entrata (insert stream) e in uscita (remove stream) inviati
dalla parent view (se presente), oltre a fornire gli eventi in entrata e in uscita alle viste
figlie (child view).
Da notare che, l'implementazione della vista dovrà prevedere l’utilizzo del metodo
updateChildren, attraverso il quale effettuerà il post degli eventi dell’ insert stream e del
remove stream. Simile al metodo di update, questo metodo prende gli eventi dei due
stream come parametri.
Di seguito è mostrato un esempio di implementazione del metodo update, nonché un
esempio di utilizzo del metodo updateChildren:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
106
public void update(EventBean[] newData, EventBean[] oldData) { for (EventBean theEvent : newData){ eventsPerStream[0] = theEvent; String ip = (String)ipExpression.getExprEvaluator().ev aluate (eventsPerStream, true, agentInstanceViewFactoryContext); String time = (String)timeExpression.getExprEvaluator(). evaluate (eventsPerStream, true, agentInstanceViewFactoryContext); String file = (String)fileExpression.getExprEvaluator(). evaluate
(eventsPerStream, true, agentInstanceViewFactoryContext) ;
if(find_probability("type")<0.5) continue; this.ip = ip; this.time = time; this.type = "Illegal_Download"; this.moreInfo = "Downloaded " + file; postData(); } } private void postData(){ AttackEvent attackEvent = new AttackEvent(ip,time,type,moreInfo); EventBean outgoing = agentInstanceViewFactoryContext. getStatementContext().getEventAdapterSer vice() .adapterForBean(attackEvent); if (lastEvent == null){ this.updateChildren(new EventBean[] {ou tgoing}, null); }else{ this.updateChildren(new EventBean[] {ou tgoing}, new EventBean[] {lastEvent}); } lastEvent = outgoing; ip = null; time = null; type = null; moreInfo = null; }
Come si può notare, il metodo update riceve gli eventi dall’insert stream (newData) e dal
remove stream (oldData), realizza le sue elaborazioni sui dati presenti in essi, e
successivamente richiama, all’interno del metodo postData(), il metodo updateChildren,

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
107
con il quel effettua il post di una nuova tipologia di evento (AttackEvent), opportunamente
istanziata e popolata.
3.7.1.3 Configurazione della View
Come accade per gli altri componenti personalizzati, anche le custom view necessitano di
essere aggiunte all’interno della configurazione del motore di Esper. Precisamente è
necessario aggiungere il nome della classe view factory, il nome della classe che
implementa la custom view e il suo namespace. Ovviamente, la configurazione può
avvenire sia attraverso le API che attraverso un file XML. Di seguito è riportato un
esempio utilizzando le API, in cui si prevede la registrazione di una custom View di nome
attackPV, con namespace examples e istanziata dalla classe PluginViewFactory:
Configuration config = new Configuration(); config.addPlugInView("examples", "attackPV", PluginViewFactory.class.getName());

108
Capitolo 4
Architettura e mapping tecnologico del sistema CEP
Dopo aver trattato dei requisiti che la piattaforma, oggetto di questo lavoro di tesi, deve
essere in grado di soddisfare, nonché del CEP Engine utilizzato alla base della stessa, è
bene ora soffermarci sulla sua architettura. Pertanto, sarà dapprima fornita una panoramica
sulle sue componenti logiche, per poi scendere maggiormente nel dettaglio descrivendo la
struttura e il funzionamento di ogni sua parte.
Prima però vediamo i principi alla base dell’architettura realizzata.
4.1 Event Driven Architecture
Il concetto alla base dello sviluppo architetturale della piattaforma progettata è, ancora una
volta, quello di evento. Infatti, trattandosi di un sistema integrato rivolto alla Complex
Event Processing, gli eventi rappresentano il vero filo conduttore dell’intera architettura.
Di conseguenza, l’approccio scelto per la realizzazione di tale sistema è quello relativo al
pattern architetturale EDA (Event Driven Architecture), che supporta la produzione di
eventi e la reazione ad essi.
In particolare, EDA costituisce uno stile architetturale in cui alcuni elementi applicativi
entrano in esecuzione in risposta al verificarsi di eventi. Ovvero, un elemento decide se

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
109
agire o meno, in base all’arrivo di eventi. Un evento è, semplicemente, qualcosa che
accade. Tale pattern può essere utilizzato per la specifica e l’implementazione di
applicazioni e sistemi che trasmettono eventi tra servizi e/o componenti debolmente
accoppiati.
Un sistema orientato agli eventi, infatti, è tipicamente costituito da produttori e
consumatori di eventi. I consumatori si sottoscrivono presso un elemento intermedio,
denominato solitamente manager, e i produttori pubblicano presso di esso i propri eventi.
Quando il manager riceve un evento dal producer, lo inoltra al consumer. Se il consumer
non è disponibile, il manager può memorizzare l’evento e provare ad inoltralo in seguito.
Figura 4.1: Event Driven Architecture
Si comprende quindi che la Event Driven Architecture fornisce una modalità di
accoppiamento lasco, essa infatti è un pattern asincrono che si basa sul paradigma di
comunicazione publish/subscribe. Il publisher è completamente ignaro della presenza del
subscriber, e viceversa, il che garantisce anche una elevata indipendenza tra le due
componenti.
È possibile vedere EDA come una estensione della Service Oriented Architecture, così
come la definisce Luckham, il quale afferma che:
"Una Event Driven Architecture (EDA) è una Service Oriented Architecture (SOA)
nella quale tutte le comunicazioni sono basate su eventi e tutti i servizi sono processi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
110
in grado di reagire agli eventi (cioè, reagire ad un evento in ingresso e generare un
evento in uscita)" [5].
Da tale definizione si evince facilmente la stretta correlazione esistente tra un’architettura
orientata ai servizi ed una orientata agli eventi. Quest’ultima infatti eredita dalla SOA
alcuni dei suoi principi fondamentali, e precisamente:
• Componibilità : cioè la capacità di realizzare sistemi caratterizzati da più
componenti, i quali possano essere aggiunti e/o rimossi a seconda delle necessità, o
meglio del servizio che si intende offrire.
• Riusabilità: cioè la capacità di prevedere componenti che possano essere riutilizzati
anche per sistemi o ambiti differenti da quelli per cui erano inizialmente previsti.
• Interoperabilità : cioè la capacità di garantire che ogni componente del sistema sia
in grado di operare/comunicare con gli altri componenti, anche se estremamente
differenti.
• Accoppiamento lasco: cioè, come già detto precedentemente, la capacità di un
sistema di avere componenti che abbiano poca o nessuna conoscenza relativa agli
altri componenti del sistema.
Figura 4.2: Principi fondamentali della Service Oriented Architecture

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
111
Costruire applicazioni e sistemi basandosi sul pattern EDA permette di ottenere una
maggiore affidabilità, poiché i sistemi basati sugli eventi sono, per costruzione, più
tolleranti e flessibili rispetto ad ambienti imprevedibili ed asincroni, spesso mediante
anche l'applicazione di logiche real-time e/o predittive.
Proprio questo aspetto, insieme a quelli fin’ora citati, ci ha spinti alla realizzazione della
nostra piattaforma seguendo questo pattern, il che ci ha portato allo sviluppo di un sistema
event-driven, basato sul paradigma di comunicazione publish/subscribe.
Si è cercato di rendere il sistema quanto più modulare e componibile possibile, così da
garantire la capacità di aggiunta di nuovi elementi in maniera rapida e indolore, e di
dotarlo, inoltre, di componenti che fossero indipendenti e fortemente riutilizzabili.
4.2 Componenti logici
Prima di passare alla descrizione dell’architettura della piattaforma, come già annunciato
all’inizio di questo capitolo, diamo uno sguardo alle le componenti logiche di cui il
sistema dovrà essere dotato, così come previsto nei primi documenti di progetto di
CEvOS.
Figura 4.3: Componenti logici del sistema

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
112
Secondo tali documenti, il sistema deve essere caratterizzato, ad un elevato livello di
astrazione, dalle sei componenti mostrate in figura 4.3, le quali sono dotate delle seguenti
macrofunzionalità:
• Capture: modulo per la gestione degli stream in ingresso da cui sono elaborati gli
eventi
• Analyze: modulo che abiliterà la feature extraction dai flussi in input, per consentire
la classificazione di oggetti e metadati in essi contenuti, nonché eventuali
operazioni di filtraggio e aggregazione
• Store: modulo deputato alla gestione degli stream in input, sulla base dei quali gli
eventi sono classificati. Tale modulo si occuperà di mantenere le correlazioni sulle
feature estratte dal componente Analyze. Inoltre, è prevista l'esistenza sia di una
componente in memory, sia di una persistente che conterrà gli historical data
• Correlate: rappresenta il cuore del CEP Engine, che abiliterà la situation awareness
• Manage: componente che si occuperà di: integrare e far interagire le piattaforme di
gestione dei componenti di sorveglianza esterni; configurare i profili di accesso e
di servizio; implementare la “anomaly detection”. Tale modulo dovrà prevedere un
sottocomponente di “Control & Command”, per gestire l’esecuzione di azioni
dirette sui componenti attivi (sensori, telecamere, etc.), a valle delle rilevazioni di
allarmi/anomalie
• Search: componente che abilita le capabilities di investigazione del sistema. Infatti,
mediante l'esecuzione di query di ricerca (temporali, topologiche), il modulo
Search sarà in grado di restituire al sistema gli stream che rispondono ai criteri di
ricerca (caratterizzati da particolari feature, estratte nella fase di analisi e
storicizzate nello store). Si noti che, oltre alle funzionalità di ricerca in post-
processing, il motore di Search dovrà coadiuvare il componente di correlazione
(CEP) nella “Continous Analysis”, operazione che consiste nel verificare la
corrispondenza di un subset di eventi dell’event stream con i pattern codificati
per gli alert (e che indicheranno situazioni di pericolo). Si ricordi che tale

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
113
componente potrà affidarsi a tecniche di storicizzazione in-memory, piuttosto che a
quelle persistenti.
Da notare che non tutte queste componenti sono previste nella piattaforma implementata.
Infatti, come già accennato nell’introduzione di questa tesi, il sistema realizzato è una
prima versione di CEvOS e pertanto non prevede tutte le componenti che sono state
inizialmente pensate. Precisamente in termini di componenti logiche, non sono stai inclusi
il modulo Manage, Store e quello Search.
4.3 Architettura
Definiti i componenti logici, passiamo ora alla descrizione dell’architettura vera e propria
del sistema. Come già accennato all’inizio di questo capitolo, si è realizzata una
piattaforma modulare in cui i componenti sono indipendenti e riutilizzabili, nonché in
grado di comunicare attraverso un canale asincrono, basato sul paradigma
publish/subscribe.
La piattaforma progettata è caratterizzata da cinque componenti fondamentali, mostrati
nella figura 4.4, che sono:
• Enterprise Service Bus: rappresenta il bus di comunicazione tra i vari moduli
• Mediator: media, attraverso degli appositi wrapper, tra i sensori/dispositivi di rete e
l’ ESB, convertendo gli eventi raw, cioè gli eventi prodotti da ogni singola sorgente,
in un formato unico di rappresentazione degli eventi, così da renderli trasportabili
sul bus
• Prefiltering-Aggregation: realizza il filtraggio degli eventi raw ed un loro eventuale
arricchimento
• CEP Engine: che si preoccupa di effettuare la correlazione tra gli eventi raw,
opportunamente filtrati, al fine di generare eventi complessi relativi ai casi d’uso
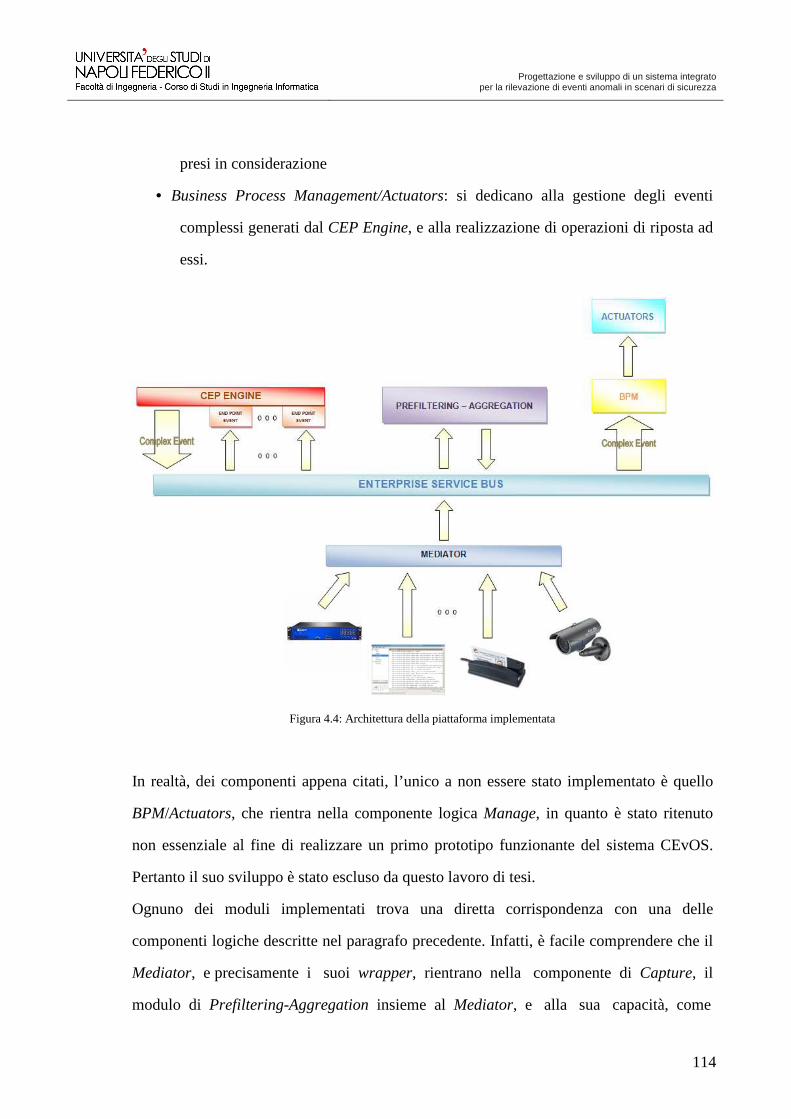
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
114
presi in considerazione
• Business Process Management/Actuators: si dedicano alla gestione degli eventi
complessi generati dal CEP Engine, e alla realizzazione di operazioni di riposta ad
essi.
Figura 4.4: Architettura della piattaforma implementata
In realtà, dei componenti appena citati, l’unico a non essere stato implementato è quello
BPM/Actuators, che rientra nella componente logica Manage, in quanto è stato ritenuto
non essenziale al fine di realizzare un primo prototipo funzionante del sistema CEvOS.
Pertanto il suo sviluppo è stato escluso da questo lavoro di tesi.
Ognuno dei moduli implementati trova una diretta corrispondenza con una delle
componenti logiche descritte nel paragrafo precedente. Infatti, è facile comprendere che il
Mediator, e precisamente i suoi wrapper, rientrano nella componente di Capture, il
modulo di Prefiltering-Aggregation insieme al Mediator, e alla sua capacità, come
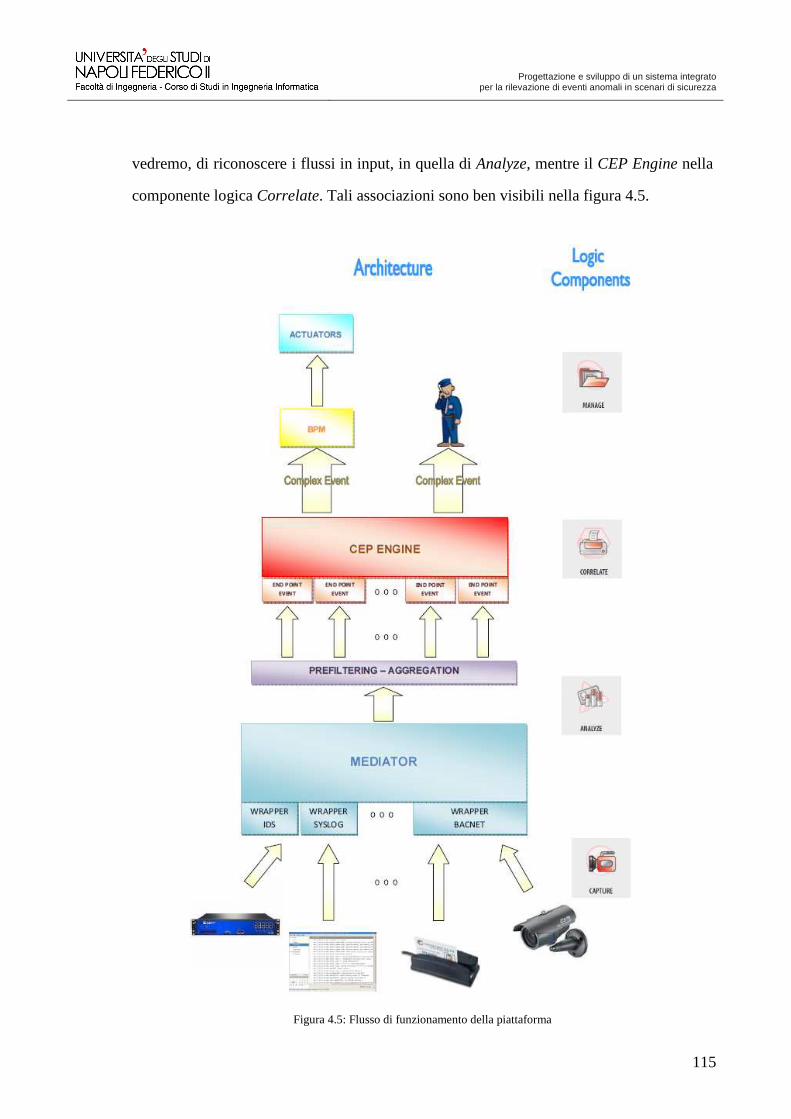
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
115
vedremo, di riconoscere i flussi in input, in quella di Analyze, mentre il CEP Engine nella
componente logica Correlate. Tali associazioni sono ben visibili nella figura 4.5.
Figura 4.5: Flusso di funzionamento della piattaforma

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
116
In tale figura, in realtà, non è mostrata la sola associazione tra le componenti reali e quelle
logiche del sistema, ma anche il flusso di funzionamento dell’intera piattaforma, così da
comprendere la reale interazione tra i vari moduli.
Come si può vedere dalla figura, tutto parte dalle sorgenti degli eventi, cioè i
sensori/software che sono disponibili (ad es. telecamere, sistemi IDS, etc.). Tali dispositivi
sono in grado di generare eventi nel momento in cui si verifica un determinato
avvenimento (ad es. per le telecamere con modulo di Face Detection può essere il
riconoscimento di un volto, per un sistema IDS può essere un tentativo di Port Scanning).
Ovviamente tali eventi conterranno informazioni atte a descrivere quanto i dispositivi
hanno rilevato.
Questi eventi, che saranno rappresentati nel formato specifico della sorgente, vengono
catturati dai wrapper del mediator, uno per ogni tipologia di sorgente, i quali si
preoccuperanno di convertire gli eventi in un formato comune di rappresentazione e di
inviarli sul Bus, dal quale saranno poi prelevati dal componente di Prefiltering-
Aggregation.
Quest’ultimo effettuerà operazioni di filtraggio, infatti scarta gli eventi non di interesse,
mentre arricchisce, eventualmente, di altre informazioni quelli considerati significativi.
Ovviamente questi ultimi saranno nuovamente immessi sul bus. In realtà, come vedremo,
l’unica operazione prevista da questo componente sarà quella di filtraggio per un
determinata tipologia di eventi.
A questo punto, gli eventi non filtrati saranno ricevuti dal CEP Engine che,
opportunamente istruito, cercherà un’eventuale correlazione, e in tal caso genererà un
evento complesso che descrive la situazione rilevata. Tale evento può essere immesso
nuovamente sul bus, così da renderlo disponibile agli strumenti di gestione BPM/Actuators
nonché agli addetti al controllo. Ovviamente, non avendo implementato i componenti
BPM/Actuators, il CEP Engine non fa altro che visualizzare su un terminale gli alert
relativi alle situazioni rilevate.
Descritto per sommi capi, il funzionamento del sistema, è bene ora scendere

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
117
maggiormente nel dettaglio, descrivendo ogni singolo componente, partendo innanzitutto
dai dispositivi sorgenti e dagli eventi che essi sono in grado di generare.
4.3.1 Dispositivi sorgenti
Come abbiamo già accennato nel paragrafo precedente, il processo di elaborazione della
piattaforma implementata parte dagli event source, rappresentati da sensori e/o software
che generano eventi in seguito alla rilevazione di determinati avvenimenti.
Sulla base degli scenari e dei casi d’uso previsti per l’utilizzo del nostro sistema (descritti
nel capitolo 2), sono stati previsti cinque sensori:
• Software IDS: il quale si preoccupa di controllare le attività che sono svolte
all’interno della rete locale sotto osservazione, generando all’occorrenza degli
opportuni alert
• Log di sistema: attraverso i quali è possibile monitorare le attività svolte sulle
singole macchine di una rete locale
• Telecamere BACnet con capacità di Face e Tampering Detection: cioè telecamere,
compatibile con il protocollo BACnet, in grado di riconoscere i volti delle persone
osservate (se noti), nonché di rilevare un attività di tampering. In entrambi i casi
esse sono in grado di generare un evento
• Sistema di controllo dell’illuminazione BACnet: cioè un sistema BACnet compliant
in grado di rilevare eventuali malfunzionamenti dell’impianto di illuminazione,
generando un evento
• Badge Reader BACnet: cioè un lettore in grado di generare un evento ogniqualvolta
un badge viene fatto passare nella fessura del lettore e anch’esso compatibile con il
protocollo BACnet.
Tali sensori, laddove possibile, sono stati utilizzati realmente. È il caso ad esempio del

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
118
software IDS e dei log di sistema, per i quali si è adoperato nel primo caso il software
SNORT [17] e per il secondo il sistema di gestione dei log di Linux, basato sul protocollo
SYSLOG [18], e precisamente RSYSLOG [19].
Per quanto riguarda gli altri sensori invece, non avendo a disposizione dispositivi reali,
sono stati realizzati appositi software che fossero in grado di simularli. Tali software sono
stati implementati facendo uso di una apposita libreria open source denominata BACnet4J,
la quale, insieme al protocollo BACnet, sarà descritta nei successivi paragrafi.
Ma vediamo più nel dettaglio ogni singola sorgente.
4.3.1.1 L’IDS: Snort
Come già annunciato, l’IDS utilizzato al fine di controllare la rete locale prevista nello
scenario della Network Security, è Snort. Quest’ultimo è un Network-based Intrusion
Detection/Prevention System open source sviluppato dalla Sourcefire Inc., e rappresenta
un vero e proprio standard de facto per i sistemi Unix-based.
Esso è in grado di eseguire il logging dei pacchetti e l’analisi, sia live che offline, del
traffico prodotto su una rete IP. Precisamente Snort esegue l’analisi di protocollo e la
ricerca/matching di contenuti all’interno dello stream di dati raccolto, il che gli permette di
realizzare sia live che offline detection, rilevando eventuali tentativi di intrusione in un
sistema tramite il confronto delle “impronte” dei pacchetti di rete in arrivo e quelle
conservate in un database (rules), nonché attraverso il rilevamento di anomalie di
protocollo.
Rilevata un’attività sospetta, Snort effettua sia la funzione di registrazione dell’accaduto
che di avviso all’amministratore, quest’ultima attraverso l’invio di appositi alert. Da
notare che tale IDS non è in grado, di default, di svolgere alcun compito di difesa attiva,
la quale sarà quindi demandata all’amministratore del sistema.
Come già accennato, la rilevazione di eventuali intrusioni viene effettuata attraverso

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
119
l’utilizzo di apposite regole, attraverso il cui matching Snort è in grado di identificare
situazioni sospette. Tali rules sono direttamente messe a disposizione dalla Sourcefire, ma
possono essere anche realizzate ad hoc dall’utente a seconda delle particolare necessità.
Ciò ci ha dato la possibilità di istruire l’IDS sulla base delle nostre esigenze, e cioè quelle
definite nell’ambito dello scenario della Network Security, e precisamente è stato
configurato in maniera tale da riconoscere:
• Il Download, da parte di un host della rete monitorata, di un file con estensione
sospetta (ad es. exe, c, sh etc.)
• L’ Upload, verso un host interno alla rete, di un file con estensione sospetta
• Un Port Scanning realizzato su uno degli host della rete
• Tentativi ripetuti di stabilire una connessione TCP da parte di un host interno alla
rete verso uno stesso indirizzo IP esterno alla rete
A tale scopo, sono state realizzate delle apposite regole che portano alla generazione di
alert che saranno poi immessi all’interno dei log di sistema, così da poter essere analizzati.
In realtà, come vedremo nel prossimo paragrafo, tali log saranno inviati su delle apposite
socket così da poterli consegnare ai wrapper del Mediator. Precisamente i log relativi agli
alert di Snort saranno inviati sulla porta 2000.
A titolo di esempio, mostriamo di seguito una delle regole implementate e il relativo alert
generato da Snort. Precisamente è mostrata la regola che permette di rilevare le
connessioni TCP multiple.
alert tcp $HOME_NET any -> !$HOME_NET any (msg:"20 or most connections to an external IP addr ess"; threshold:type both, track by_dst, count 20, second s 60; sid:9000000; rev:3; priority:3;)
La comprensione della regola è molto semplice, in quanto si sta istruendo l’IDS a generare
un messaggio di alert, cioè “20 or most connection sto an external IP address”, quando un
indirizzo IP della HOME_NET, cioè la rete osservata, tenta di stabilire per venti volte, in

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
120
60 secondi, una connessione TCP con un indirizzo IP che non appartiene alla
HOME_NET. Al rilevamento di una tale condizione, l’alert generato sarà il seguente:
09/24-12:27:45.036332 [**] [1:9000000:3] 20 or mos t connections to an external IP address [**] [Priority: 3] {TCP} 172.16.4.53:40625 -> 62.149.140.72:80
Come si può vedere, l’IDS segnala il tipo di alert, la data e l’ora in cui è stato generato, la
priorità assegnata nonché gli indirizzi IP e porta sorgente e destinazione.
4.3.1.2 Rsyslog
Una altra sorgente di eventi, nell’ambito dello scenario della Network Security, sono i log
di sistema degli host della rete monitorata. Precisamente si è preso come riferimento
Rsyslog, una software utility open source nata nel 2004 ad opera di Rainer Gerhards, la
quale è usata su sistemi UNIX e Unix-like per l'inoltro di messaggi di log in una rete IP.
Essa implementa il protocollo di base Syslog, estendendolo attraverso l’introduzione di
filtri basati sul contenuto, di una maggiore quantità di opzioni di configurazione, nonché
aggiungendo caratteristiche importanti come l'utilizzo di TCP per il trasporto.
Proprio queste caratteristiche ci hanno spinto al suo utilizzo come sorgente di eventi
relativa ai log. Infatti, la sue capacità di filtraggio nonché di elevata configurabilità, hanno
permesso di impostare il sistema di logging secondo le necessità. Precisamente, si è
configurato il sistema in maniera tale da riconoscere i log relativi agli alert di Snort e
separarli da quelli di sistema, così da garantire un diverso trattamento per le due tipologie.
Pertanto, mentre per gli alert del sistema IDS, come già detto nel paragrafo precedente, si
è impostato l’invio dei log attraverso una socket sulla porta 2000, per i log di sistema si è
previsto l’inoltro su una porta differente, e precisamente la porta 2001.
Ovviamente, come sarà accennato quando si discuterà del Mediator, i wrapper dedicati
alla cattura di queste informazioni saranno in ascolto proprio su tali porte.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
121
Mostriamo ora di seguito due esempi di log generati da Rsyslog, uno per ogni tipologia.
Il primo è un log relativo all’alert dell’IDS mostrato nel paragrafo precedente:
Sep 24 12:27:45 SM_0 snort: [1:9000000:3] 20 or mos t connections to an external IP address[Priority: 3]: {TCP} 172.1 6.4.53:40625 -> 62.149.140.72:80
Il seguente, invece, mostra un log di sistema relativo all’accesso ad un determinato host:
Sep 24 12:34:45 SM_0 sshd[1341]: Accepted hostbased for PEL_DAV from 62.211.226.162 port 2622 ssh2
Precisamente, con esso viene segnalato che l’utente con identificativo PEL_DAV ha
effettuato l’accesso all’host SM_0 dall’indirizzo 62.211.226.162:2622 utilizzando il
protocollo SSH2 e il metodo di autenticazione hostbased.
4.3.1.3 Sensori BACnet
L’ultima tipologia di sensori utilizzata per la piattaforma implementata è quella relativa ai
sensori per la building security basati sul protocollo BACnet, i quali ricordiamo sono:
• Telecamere con capacità di Face e Tampering Detection
• Sistema di controllo dell’illuminazione
• Badge Reader
Tali sensori, come già detto nel paragrafo 4.3.1, non sono stati adoperati fisicamente, bensì
sono stati simulati attraverso degli appositi software implementati nel corso di questo
lavoro di tesi.
Ognuno dei software implementati ha lo scopo di simulare un determinato dispositivo, e
precisamente la sua logica, nonché le operazioni di comunicazione, basate sul protocollo

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
122
BACnet. Tale operazione è stata possibile attraverso l’ausilio di un’apposita libreria
software denominata BACnet4J, che ha consentito un loro sviluppo agile.
Detto ciò, prima di passare alla descrizione dei tre software realizzati, è bene soffermarci a
descrivere sia il protocollo BACnet che la libreria BACnet4J.
4.3.1.3.1 BACnet e BACnet4J
BACnet è uno standard di comunicazione, internazionale ed aperto, per la Building
Automation, il cui sviluppo è stato appoggiato dalla ASHRAE (America Society of Heating
and Ventilating Engineers) [20].
BACnet consente l'utilizzo di un'unica interfaccia per controllare tutti i dispositivi di un
sistema, realizzandone e sfruttandone le relazioni in maniera più efficiente. Ed infatti, le
informazioni tra i sotto-sistemi vengono distribuite in base a regole logiche, invece che a
vincoli strutturali; pertanto, l'applicazione dello standard semplifica la ricerca e la
manutenzione dei singoli impianti. BACnet, infatti, non definisce la configurazione
interna, le strutture dati, la logica dei controllori o dei dispositivi su cui viene eseguito il
protocollo. Piuttosto il fulcro dello standard è nelle informazioni che i dispositivi possono
scambiarsi, astraendo i dettagli implementativi.
Precisamente, il modello offre un linguaggio standard e non ambiguo, comune a tutti i
dispositivi BACnet, utilizzato per specificare le entità che partecipano alla comunicazione
e le funzionalità che si vogliono implementare. Lo standard, infatti, si basa su quattro
elementi chiave:
• BACnet Object
• BACnet Service
• BIBBs
• BACnet Media

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
123
Figura 4.6: BACnet architecture
Un oggetto rappresenta l'informazione che due dispositivi si scambiano (ad esempio il
valore di una misurazione di temperatura, un allarme), ed è caratterizzato da un
identificativo, da proprietà specifiche (obbligatorie ed opzionali) e da metodi di accesso
standardizzati. Un object è completamente descritto mediante le sue property, che devono
essere impostate al momento dell'istanziazione dell'oggetto stesso.
Al fine di soddisfare tutti i requisiti (meccanico, elettrico, servizi ausiliari, sicurezza,
incendio, controllo degli accessi, ecc.) della Building Automation, in BACnet sono definiti
venticinque oggetti standard, visibili nella figura 4.7, attraverso i quali sono rappresentate
sia le informazioni relative a dati e sistema, sia tutte le funzioni che si vogliono
implementare.
Per quanto riguarda i BACnet Service, essi rappresentano gli elementi attraverso i quali lo
standard è in grado di garantire l'affidabilità della comunicazione tra i dispositivi. Infatti
esso definisce un insieme di servizi standard, attraverso i quali i BACnet device potranno
acquisire le informazioni, inviare comandi, notificare eventi, etc. Essi quindi, in parole
povere, definiscono le regole di invio e ricezione dei messaggi lungo il media di
comunicazione. Tali servizi seguono un modello Client-Server, e sono definiti attraverso
la descrizione dei BACnet Interoperability Building Blocks (BIBBs).
Ciascun BIBB, in realtà, descrive una specifica unità funzionale, non una relazione tra
dispositivi nel suo complesso.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
124
Figura 4.7: Oggetti standard del protocollo BACnet
Essi infatti, poiché i servizi BACnet sono organizzati secondo il principio client/server,
sono espressi mediante una coppia di regole, una relativa all'attività client, l'altra
all'attività server.
Ultimo concetto alla base dello standard è quello del BACnet Media, ovvero del protocollo
di trasporto adoperato. In relazione al livello fisico utilizzato, si distinguono:
• BACnet PTP (connessione Punto-Punto)
• BACnet MSTP (connessione Token Passing)
• BACnet ARCnet (connessione ARCnet)
• BACnet Ethernet (connessione Ethernet, basata su MAC address)
• BACnet IP (connessione Ethernet basata due indirizzo IP).
Tra questi, molto utilizzato è BACnet IP, il quale indica le modalità di costruzione di una
BACnet Network over IP. La specifica definisce la BACnet/IP network, cioè una rete
virtuale costituita da un insieme di BACnet Device che comunicano utilizzando il
protocollo BACnet/IP.
Quest’ultimo lavora a livello Data Link e consente la comunicazione tra dispositivi ubicati
in sottoreti differenti, mediante l'utilizzo del BACnet Broadcast Management Device (uno
per ciascuna sottorete). Il BBMD riceve i messaggi broadcast e li distribuisce con un

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
125
messaggio diretto a BBMD di altre sottoreti. Il protocollo di trasporto adoperato è UDP/IP,
il cui port number di default è 47808 (in esadecimale X'BAC0').
Un Client BACnet può assegnare alle proprie uscite un dato livello di priorità (lo standard
definisce sedici livelli di priorità), che un gateway BACnet è in grado di gestire. Inoltre
quest’ultimo, quando opera come BACnet Server, è in grado anche di gestire il Change of
Value (COV). In pratica, un Client BACnet può fare richiesta di sottoscrizione alla notifica
di uno o più COV (di oggetti o proprietà), in maniera tale da ottenere un messaggio di
notifica ogniqualvolta l’oggetto, sulla quale si è sottoscritta la COV, subisce una modifica.
Precisamente, la sottoscrizione di una COV avviene attraverso i seguenti passi:
• Istanziazione e inizializzazione di un Device Locale (Client)
• Invio di un messaggio broadcast WHO-IS da parte del Device Locale, attraverso il
quale è grado di conoscere i dispositivi connessi alla rete
• Invio della risposta I-AM del Device Remoto al Device Locale, con la quale il device
remoto fa conoscere le proprie caratteristiche al device locale
• Invio da parte del Device Locale di una richiesta di sottoscrizione ad un oggetto, od
alle sue proprietà, mediante un messaggio di SubscribeCOVRequest verso il Device
Remoto
• Invio da parte del Device Remoto del messaggio SimpleACK verso il Device Locale
• Il Device Remoto invia una notifica al sottoscrittore ConfirmedCOVNotification, che
contiene le informazioni richieste dal Local Device, ogniqualvolta l’oggetto e/o la
proprietà sottoscritta viene modificata
• Il LocalDevice invia una SimpleAck al Dispositivo Remoto

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
126
Figura 4.8: Sottoscrizione COV
Da notare che tutti i messaggi scambiati attraverso il protocollo BACnet hanno la struttura
mostrata in figura 4.9.
Figura 4.9: Struttura di un BACnet IP message

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
127
Tutte queste caratteristiche rendono il protocollo BACnet una soluzione adottabile in
qualsiasi contesto di Building Automation ed applicabile a tutti i livelli del sistema,
indipendentemente dalla dimensione, dalla complessità dei sistemi coinvolti e dal numero
dei relativi costruttori.
Un sistema di dispositivi BACnet offre a proprietari e gestori una notevole libertà di scelta
dei dispositivi e delle tecnologie da adoperare nel contesto di interesse (soprattutto rispetto
alle tecnologie di cui già si dispone). In tal modo si potranno migliorare ed incrementare le
funzionalità/servizi offerti, aumentando il valore competitivo aziendale. In definitiva,
l'adozione della tecnologia BACnet comporta notevoli vantaggi in termini di riduzione dei
costi, aumento della flessibilità e delle performance globali del sistema. Tali
considerazioni hanno portato all’ausilio di tale protocollo, e di conseguenza alla necessità
di simulare dispositivi che lo adottassero. A tal fine si è utilizzata la libreria BACnet4J.
Tale libreria rappresenta una implementazione Java ad alte prestazioni del protocollo
BACnet IP. Essa mette a disposizione una serie di classi, attraverso le quali è in grado di
garantire il supporto a tutti i servizi BACnet.
Le principali classi previste sono:
• LocalDevice e RemoteDevice, attraverso le quali sono rappresentati device locali e
device remoti
• WhoIsRequest e SubscribeCOVRequest, attraverso le quali sono rappresentate le
richieste di Who-Is e quella di sottoscrizione di una COV
• BACnetObject e ObjectIdentifier, che rappresentano rispettivamente un oggetto
BACnet e il suo identificativo.
4.3.1.3.2 Struttura e logica applicativa
Dopo aver definito il protocollo BACnet e la libreria BACnet4J, vediamo ora come sono
stati implementati i software. Precisamente sono state realizzate tre classi, una per

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
128
dispositivo:
• BADGE_READER_Device, che simula un Badge Reader BACnet, generando
periodicamente eventi di lettura di un Badge, e quindi riconoscimento della
persona attraverso i dati presenti su di esso
• CAMERA_Device, che simula una videocamera di sorveglianza BACnet, generando
periodicamente, e in maniera alternata, eventi di Tampering e di Face Detection
• LAMP_Device, che simula un sistema di controllo dell’illuminazione BACnet,
generando periodicamente eventi di LAMP down, ovvero spegnimento e/o guasto
di una lampada del sistema.
Ognuna di queste classi è caratterizzata da un unico metodo main, che se eseguito avvia la
simulazione del dispositivo, e da una serie di attributi. Tra questi i principali sono il
LocalDevice, che rappresenta il dispositivo che si intende simulare, il BACnetObject e il
relativo ObjectIdentifier, che rappresentano l’oggetto e il suo ID, monitorato dal sensore, il
RemoteDevice, che rappresenta il getway che gestisce i dispositivi (il Mediator nell’ambito
della nostra piattaforma), nonché il LOCAL_ADDRESS e BRODCAST_ADDRESS, che
rappresentano rispettivamente l’indirizzo IP del dispositivo e quello di broadcast della rete
su cui esso è in funzione, ed infine il DEVICE_ID, che invece rappresenta l’identificativo
del dispositivo simulato.
Figura 4.10: Classi BACnet Device

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
129
Una volta avviati i dispositivi assumeranno il comportamento mostrato nel sequence
diagram di figura 4.11, dove è mostrata per brevità il comportamento del solo Device
LAMP, che però rispecchia quello degli altri device. Precisamente per prima cosa
istanzieranno un LocalDevice e un BACnetObject, per poi successivamente associare al
primo un listener, il quale si preoccuperà di gestire eventuali messaggi ricevuti in ingresso
dal sensore, ma che in questo caso è stato lasciato con l’implementazione di default non
dovendo gestire alcuna operazione in particolare. Infatti la libreria BACnet4J è in grado di
gestire autonomamente le interazioni con un server BACnet/IP, quando utilizzata per
simulare un dispositivo. Fatto ciò, si inizializza il dispositivo, il quale sarà a quel punto
operativo e potrà cominciare a modificare in maniera casuale l’oggetto monitorato,
cosicché vengano generati messaggi di COVNotification verso tutti i dispositivi che hanno
sottoscritto una COV su quell’oggetto. Nell’ambito del nostro sistema, l’unico componente
in grado di effettuare sottoscrizioni sarà il Mediator.
Figura 4.11: Sequence Diagram del LAMP_Device

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
130
4.3.2 L’Enterprise Service Bus
Un Enterprise Service Bus (ESB), può esser definito come un middleware in grado di
riunire varie tecnologie di integrazione, al fine di creare servizi ampiamente disponibili per
il riuso. Un ESB offre la migliore soluzione per venire incontro alla necessità di
integrazione di applicazioni, fornendo un’infrastruttura software che permette l’impiego di
architetture SOA/EDA. In particolare, le applicazioni non interagiscono direttamente l’un
l’altra, bensì, l’ESB si comporta come un mediatore tra essi, garantendone il
disaccoppiamento. Pertanto agisce come un bus di messaggistica, eliminando la necessità
di una comunicazione point-to-point. Infatti, quando un sistema deve comunicare con un
altro, esso deposita semplicemente un messaggio sul bus, e sarà poi compito di
quest’ultimo instradare opportunamente il messaggio al suo endpoint di destinazione.
Figura 4.12: ESB - Comunicazione indiretta
Una comunicazione di questo tipo introduce due principali vantaggi, rispetto ad una
comunicazione point-to-point:
• L’aumento del numero di applicazioni che compongono il sistema integrato non
comporta un aumento della complessità del sistema stesso. Ciò consente di poter
aggiungere senza problemi ulteriori moduli senza compromettere le funzionalità
• Ogni componente non dovrà avere n interfacce per una comunicazione completa con
gli altri n-1 componenti, bensì basterà la sola interfaccia verso l’ESB

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
131
L’integrazione tra le varie applicazioni è inoltre garantita anche dalla possibilità di far
comunicare applicazioni basate su differenti protocolli di comunicazione (ad esempio
SOAP, CORBA, JMS, FTP, POP3, HTTP, etc.), realizzando le dovute trasformazioni nel
corso della trasmissione del messaggio.
I servizi chiave forniti da un ESB includono, quindi:
• Supporto a differenti protocolli di trasporto per i messaggi
• Supporto alle trasformazioni tra i vari protocolli
• Gestione ed instradamento dei messaggi
A questi poi, molto spesso, i fornitori degli ESB aggiungono anche caratteristiche di
quality of service, come fault tolerance, failover, load balancing, message buffering, etc.
Da quanto detto, si comprende che un tale componente è di fondamentale importanza per
il sistema implementato, in quanto, come più volte menzionato, l’architettura sviluppata
deve garantire la comunicazione tra moduli differenti in modalità asincrona e
disaccoppiata, nonché una semplice espandibilità del sistema, eventualmente anche con
sistemi basati su protocolli di comunicazione differenti da quelli utilizzati internamente
alla piattaforma.
Nello specifico, il protocollo di comunicazione utilizzato nel nostro sistema è JMS (Java
Messaging Service), mentre l’ESB adoperato è Apache ActiveMQ [21].
Diamo uno sguardo a queste due tecnologie.
4.3.2.1 Java Message Service
Java Messaging Service (JMS) è un insieme di API che consentono lo scambio di
messaggi tra applicazioni Java distribuite nella rete. In sostanza esso fornisce un metodo
standard tramite il quale le applicazioni Java possono creare, inviare e ricevere i messaggi
usando un Message Oriented Middleware (ad esempio lo stesso Apache ActiveMQ).

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
132
JMS definisce, dunque, una interfaccia comune indipendente dalla specifica
implementazione del sistema di messaging. In tal modo una applicazione Java risulta
essere indipendente, oltre che dal sistema operativo, anche dalla specifica implementazione
del sistema di messaging.
Gli elementi principali che compongono questo standard sono:
• JMS Provider: sistema di messaggistica che implementa la specifica JMS e realizza
funzionalità aggiuntive per l’amministrazione e il controllo della comunicazione
attraverso messaggi
• JMS Client: programma in linguaggio Java che invia o riceve messaggi JMS
• Message: raggruppamento di dati che viene inviato da un client a un altro
• Administered objects: sono oggetti preconfigurati da un amministratore ad uso dei
client, e permettono di creare e gestire la comunicazione tra le applicazioni. Essi
incapsulano la logica specifica del JMS provider nascondendola ai client,
garantendo maggiore portabilità al sistema complessivo
• Destination (queue/topic): è un Administered object che svolge il ruolo di
“deposito” in cui i mittenti possono lasciare i messaggi che creano, e da cui i
destinatari possono recuperare i messaggi. Le destinazioni possono essere usate
contemporaneamente da più mittenti e da più destinatari. A seconda del tipo di
destinazione usato (queue o topic), la consegna dei messaggi avviene secondo
modalità diverse (point-to-point o publish/subscribe).
Come appena accennato, la consegna dei messaggi in JMS può avvenire in due modalità
diverse, e precisamente:
• Point-to-Point
• Publish/Subscribe
Nel primo caso, cioè nel modello point-to-point (PTP), un client può inviare uno o più
messaggi ad un altro client, non in maniera diretta, bensì condividendo una stessa

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
133
destinazione verso cui si inviano e da cui si prelevano i messaggi.
Tale destinazione, nel modello PTP, prende il nome di coda (o queue): più produttori e più
consumatori possono condividere la stessa coda, ma ogni messaggio ha un solo
consumatore, infatti un messaggio dalla coda può essere letto una ed una sola volta.
Questo approccio consente di fatto una comunicazione uno-a-uno.
Ovviamente, non è prevista alcuna dipendenza temporale tra produttori e consumatori,
pertanto il consumer può prelevare il messaggio dalla coda anche se non era in ascolto al
momento del suo invio, confermando l’operazione con un Acknowledge.
Figura 4.13: Modello PTP
Il secondo modello, cioè quello Publish/Subscribe, è detto anche sistema di messaging
event-driven. I client inviano messaggi ad un Topic, ossia una particolare coda in grado di
inoltrare i messaggi a più destinatari. In particolare, il sistema si prende carico di
distribuire i messaggi inviati da più publishers: tali messaggi vengono consegnati
automaticamente a tutti i subscribers che hanno effettuato la sottoscrizione ad un certo
topic, cioè che si sono dichiarati interessati alla ricezione di messaggi appartenenti a quel
topic. In questo caso la comunicazione è uno-a-molti, in quanto ogni messaggio può avere
più consumatori. È il JMS Provider che si occupa di consegnare una copia di ogni
messaggio pubblicato agli interessati. Il messaggio viene poi eliminato dal topic quando
tutti i subscribers interessati lo hanno ricevuto.
Nel modello publish/subscriber esiste una dipendenza temporale tra publisher e
subscriber, in quanto quest’ultimo può ricevere il messaggio solo dopo essersi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
134
“sottoscritto” al topic d’interesse, e dopo che il publisher abbia effettivamente inviato il
messaggio. Inoltre il subscriber deve rimanere attivo se vuole continuare a ricevere.
Le API JMS rilassano tale vincolo temporale mediante il concetto di durable
subscriptions. Queste ultime, infatti, permettono di ricevere i messaggi anche se i
subscribers non erano in ascolto al momento dell’invio del messaggio.
Figura 4.14: Modello Publish/Subscribe
La figura 4.15, mostra le principali componenti del modello di programmazione JMS.
Precisamente abbiamo:
• Connection Factory e Destination
• Connection
• Session
• Message Producer
• Message Consumer
• Message
La Connection rappresenta l’astrazione di una connessione attiva con un particolare JMS
Provider e si ottiene dalla ConnectionFactory.
La Session, invece, si ottiene dalla Connection e rappresenta il canale di comunicazione
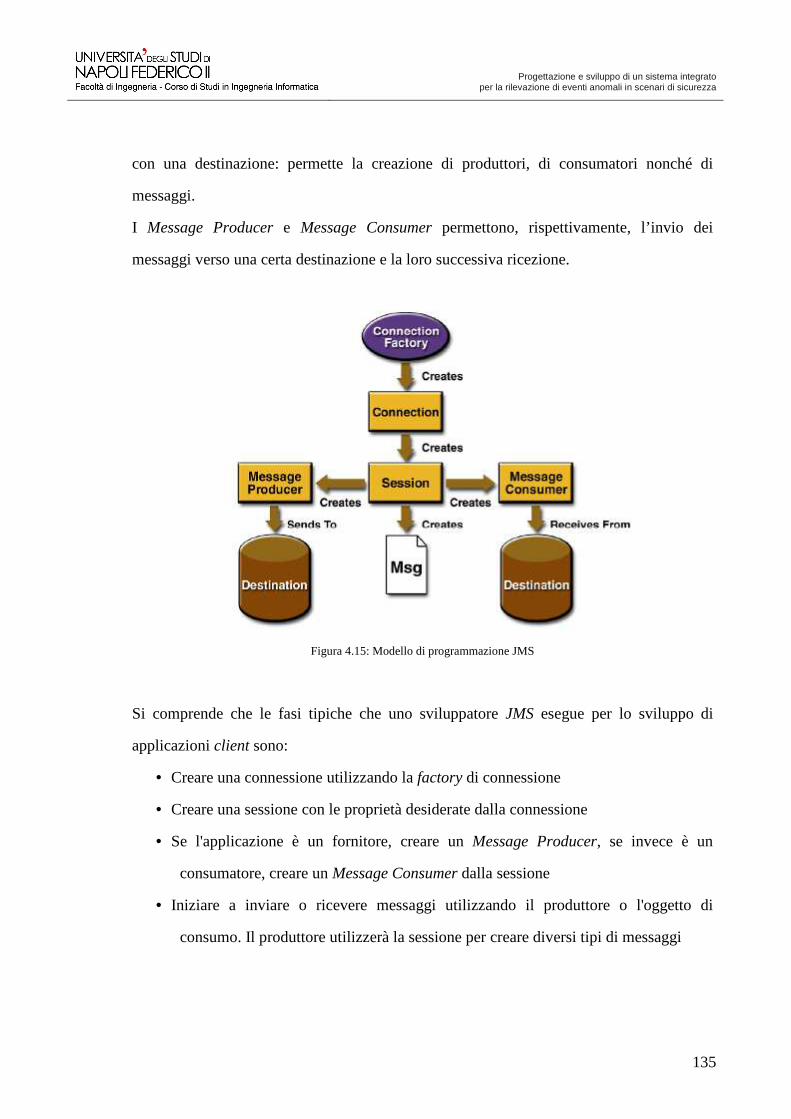
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
135
con una destinazione: permette la creazione di produttori, di consumatori nonché di
messaggi.
I Message Producer e Message Consumer permettono, rispettivamente, l’invio dei
messaggi verso una certa destinazione e la loro successiva ricezione.
Figura 4.15: Modello di programmazione JMS
Si comprende che le fasi tipiche che uno sviluppatore JMS esegue per lo sviluppo di
applicazioni client sono:
• Creare una connessione utilizzando la factory di connessione
• Creare una sessione con le proprietà desiderate dalla connessione
• Se l'applicazione è un fornitore, creare un Message Producer, se invece è un
consumatore, creare un Message Consumer dalla sessione
• Iniziare a inviare o ricevere messaggi utilizzando il produttore o l'oggetto di
consumo. Il produttore utilizzerà la sessione per creare diversi tipi di messaggi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
136
JMS supporta cinque diversi tipi di messaggi, come mostrato nella figura 4.16, i quali
vengono creati mediante i metodi dell’interfaccia Session, dalla quale estendono sia
l’interfaccia QueueSession che TopicSession.
L’interfaccia mette a disposizione i metodi create relativi ad ogni tipologia di message:
createTextMessage, createObjectMessage, createMapMessage, createBytesMessage e
create StreamMessage.
Per creare messaggi nel caso di tipologia Point-to-point è sufficiente invocare il metodo
create opportuno sulla QueueSession, mentre nel caso di Publish/Subscribe sull'oggetto
TopicConnection [9].
Figura 4.16: Tipi di messaggi
La ricezione dei messaggi in JMS può avvenire in due modi: pull o push.
Nel modello pull, un client JMS richiama un metodo per il consumatore del messaggio al
fine di ricevere un evento. Nel modello push, invece, i registri dei consumatori richiamano
un oggetto del consumatore o della sessione, ed i messaggi vengono ricevuti in modo
asincrono dalle invocazioni del metodo onMessage nell'interfaccia di callback.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
137
Ovviamente, non è possibile utilizzare contemporaneamente entrambi i metodi di
ricezione.
4.3.2.2 Apache ActiveMQ
ActiveMQ è un middleware orientato ai messaggi (MOM) [22] della Apache Software
Foundation, open source e compatibile con JMS 1.1, che fornisce elevata disponibilità,
prestazionalità, scalabilità, affidabilità e sicurezza per la messaggistica aziendale, e più in
generale per la enterprise integration.
Il lavoro di un MOM è quello di mediare eventi e messaggi tra le applicazioni distribuite,
garantendo che raggiungano i relativi destinatari. Quindi è fondamentale che esso sia
altamente performante e scalabile. L'obiettivo di ActiveMQ è quello di poter garantire un
integrazione delle applicazioni ti tipo standard-based, nonché orientata ai messaggi,
cercando di supportare quanti più linguaggi e piattaforme possibile.
Tale ESB offre una grande varietà di funzioni, alcune delle quali sono definite di seguito:
• JMS compliance: ActiveMQ è un'implementazione della specifica JMS 1.1
• Connettività: ActiveMQ fornisce una vasta gamma di opzioni di connettività, incluso
il supporto per i protocolli come HTTP/S, multicast IP, SSL, TCP, UDP, XMPP, e
altri. Il supporto per ad una gran quantità di protocolli equivale a una maggiore
flessibilità. Molti sistemi, infatti, utilizzano un particolare protocollo e non hanno
la possibilità di cambiare, per cui una piattaforma di messaggistica che supporta
molti protocolli rende possibile la loro adozione.
• Pluggable persistance and security: ActiveMQ fornisce molteplici tipi di
persistenza, tari i quali è possibile scegliere. Inoltre, la sicurezza in esso può essere
completamente personalizzata, sia in termini di autenticazione e che di
autorizzazione.
• Costruire applicazioni di messaggistica con Java: L’utilizzo più comune di

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
138
ActiveMQ è con applicazioni Java, per l'invio e la ricezione di messaggi. Questo
compito, ovviamente, implica l'uso delle API JMS.
• Client API: ActiveMQ fornisce le API client per molti linguaggi di programmazione
oltre Java, tra cui C / C ++, .NET, Perl, PHP, Python, Ruby e altri.
• Amministrazione semplificata: ActiveMQ non richiede un amministratore dedicato
perché fornisce funzioni di amministrazione potenti, ma la tempo stesso semplici
da usare.
ActiveMQ è stato pensato per essere utilizzato, così come le specifiche JMS, per le
comunicazioni remote tra le applicazioni distribuite. Esso infatti offre i vantaggi di
accoppiamento lasco, garantendo una quasi totale indipendenza trai i vari componenti,
nonché una totale asincronicità nelle comunicazioni.
Inoltre le applicazioni possono contare anche sulla capacità di ActiveMQ di garantire la
consegna dei messaggi. Questo consente di liberare lo sviluppatore dal vincolo di
preoccuparsi di come o quando il messaggio venga recapitato. Allo stesso modo, le
applicazioni che attendono la ricezione di messaggi non hanno alcun interesse a conoscere
il modo con cui siano stati inviati ad ActiveMQ. Questo è un grande beneficio in ambienti
eterogenei, permettendo ai client di essere scritti utilizzando linguaggi e protocolli diversi.
ActiveMQ funge da intermediario, permettendo l'integrazione e l'interazione eterogenea in
modo asincrono.
Ovviamente l’accoppiamento lasco garantito da tale ESB, porta numerosi vantaggi anche
nell’ambito dell’espandibilità del sistema. Infatti, a differenza di due moduli fortemente
accoppiati, per i quali la modifica di una dei due porterà inevitabilmente anche alla
modifica dell’altro, nel caso di componenti accoppiati in maniera lasca, ciò non accade.
Si comprende quindi che ActiveMQ offre ai sistemi una forte flessibilità dell'architettura
applicativa, permettendo ai concetti che circondano l’accoppiamento lasco di diventare
una realtà.
Ci sono molti scenari in cui ActiveMQ e messaggistica asincrona possono avere un impatto

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
139
significativo sull’architettura di un sistema. Ad esempio:
• Integrazione: ActiveMQ supporta differenti linguaggi di programmazione. Questo è
un vantaggio enorme se si considera come si potrebbe integrare applicazioni scritte
in linguaggi diversi su piattaforme diverse. In casi come questo, le API dei vari
client permettono l’invio e la ricezione di messaggi tramite ActiveMQ senza
preoccuparsi del linguaggio utilizzato.
• Ridurre l'accoppiamento tra le applicazioni: Come già discusso, architetture con un
elevato accoppiamento possono generare problemi per molte ragioni, soprattutto se
distribuite. Architetture debolmente accoppiate, invece, mostrano meno
dipendenze, rendendo più semplice la gestione di cambiamenti imprevisti.
• Nelle Event-Driven Architecture: Il disaccoppiamento e lo stile asincrono
dell’architettura descritta al punto precedente, conferisce al sistema una maggiore
scalabilità, nonché la capacità di gestire una quantità notevolmente maggiore di
client attraverso l’ottimizzazione, l'allocazione di memoria aggiuntiva, e così via
(noto come scalabilità verticale), anziché attraverso il solo aumento del numero di
nodi broker (noto come scalabilità orizzontale).
• Per migliorare la scalabilità delle applicazioni: Molte applicazioni utilizzano una
event-driven architecture al fine di fornire una elevata scalabilità, compresi settori
come l’e-commerce, il gioco online, etc. Attraverso la separazione di
un'applicazione lungo linee del dominio aziendale, utilizzando lo scambio
asincrono di messaggi, molte altre possibilità possono emergere. Basti pensare alla
capacità di progettare un'applicazione prevedendo un servizio per ogni specifico
compito, concetto che è alla base della SOA. Ogni servizio soddisfa una
determinata funzione e solo quella. Di conseguenza, le applicazioni sono costruite
attraverso la composizione di questi servizi, e la comunicazione tra i servizi si
ottiene utilizzando la messaggistica asincrona. Questo stile di progettazione
consente di introdurre concetti come quello del già noto Complex Event
Processing, utilizzando il quale, come sappiamo, le interazioni tra i componenti di

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
140
un sistema sono monitorati per ulteriori analisi [23].
4.3.2.3 Logica applicativa
Definite le tecnologie alla base del Bus utilizzato nella nostra architettura, è bene
riassumere le sue caratteristiche.
Come già menzionato nel paragrafo 4.3.2, l’ESB utilizzato è ActiveMQ, il quale è stato
utilizzato out of the box, cioè senza alcuna modifica o configurazione particolare. Si è
sfruttata la sua caratteristica di essere JMS compliant, così da basare l’intero processo di
comunicazione delle varie componenti del sistema sul protocollo JMS.
Precisamente, relativamente a quest’ultimo, si prevede l’utilizzo del modello di
comunicazione publish/subscribe, che consente di realizzare un meccanismo di
comunicazione uno-a-molti asincrono. Come sappiamo tale modello è basato sul concetto
di Topic, ed infatti sul BUS sono previsti proprio una serie di Topic, uno per ogni tipologia
di event source, e precisamente:
• IDS: sul quale viaggeranno gli eventi generati dal sistema IDS, sottoforma di
MapMessage
• Unfiltered_Syslog: sul quale viaggeranno gli eventi generati dai log di sistema,
sottoforma di TextMessage
• SYSLOG: sul quale viaggeranno gli eventi generati dai log di sistema, che
supereranno l’operazione di filtraggio, sottoforma di MapMessage
• LAMP: sul quale viaggeranno gli eventi generati dal sistema di controllo
dell’impianto di illuminazione, sottoforma di MapMessage
• CAMERA: sul quale viaggeranno gli eventi viaggeranno gli eventi generati dalle
videocamere di sicurezza, sottoforma di MapMessage
• BADGE_READER: sul quale viaggeranno gli eventi generati dai Badge Reader,
sottoforma di MapMessage

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
141
Di seguito è mostrata una tabella che definisce per ogni Topic quali siano i moduli del
nostro sistema che fungono da Publisher e quali da Subscriber.
Tabella 4.1: Publisher e Subscriber dei topic previsti
TOPIC PUBLISHER SUBSCRIBER
IDS Mediator (Wrapper IDS) CEP Engine
Unfiltered_Syslog Mediator (Wrapper Syslog) Prefiltering-Aggregation
SYSLOG Prefiltering-Aggregation CEP Engine
LAMP Mediator (Wrapper BACnet) CEP Engine
CAMERA Mediator (Wrapper BACnet) CEP Engine
BADGE_READER Mediator (Wrapper BACnet) CEP Engine
Si può notare che quasi tutti i topic prevedano come Publisher il Mediator. L’eccezione è
data da quello SYSLOG, in quanto, come sarà chiarito quando verrà descritto il
componente di Prefiltering-Aggregation, gli eventi presenti su questo topic sono quelli
“sopravvissuti” ad una operazione di filtraggio, realizzata allo scopo di mantenere i soli
eventi relativi a connessioni SSH sugli host monitorati. Pertanto il suo Publisher è proprio
il componente di Prefiltering-Aggregation. Ovviamente, per lo stesso motivo, il topic
Unfiltered_Syslog prevede come Subscriber proprio l’appena citato componente.
Un’ultima cosa da chiarire relativamente al BUS, è che si prevede che la consegna dei
messaggi avvenga attraverso la modalità push, che, come accennato nel paragrafo 4.3.2.1,
è caratterizzata dal fatto che i Subscriber ricevano i messaggi in modo asincrono attraverso
le invocazioni del metodo onMessage nell'interfaccia di callback.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
142
4.3.3 Mediator
Come già detto nel paragrafo 4.3, il Mediator è quel componente del sistema che media,
attraverso degli appositi wrapper, tra i sensori/dispositivi di rete e l’ESB, convertendo gli
eventi raw, cioè gli eventi prodotti da ogni singola sorgente, in un formato unico di
rappresentazione degli eventi, così da renderli trasportabili sul bus.
L’idea alla base di questo componente è quella di realizzare uno strato di adattamento:
• Completamente avulso dalla natura dei sensori, che rappresentano, come sappiamo,
la fonte di eventi della piattaforma, nonché dalle caratteristiche dei dati che
pervengono da essi
• Che sia una interfaccia comune a tutte i sensori connessi alla piattaforma
• Che sia in grado di ricevere, riconoscere e distribuire gli eventi verso l’Enterprise
Service Bus, e più precisamente verso gli appositi topic su di esso definiti.
La principale problematica relativa alla realizzazione di un componente di questo tipo è
stata sicuramente quella relativa alla natura diversa dei sensori che potessero essere
utilizzati come sorgenti di eventi.
Ogni sensore, infatti, hardware o software che sia, è in grado di produrre dati secondo un
proprio formato di rappresentazione. Ciò è dovuto, innanzitutto, alla tipologia
dell’informazione che ognuno di essi è in grado di trattare, cioè: audio, video, testo,
immagini, valori analogici, etc.. In secondo luogo, i dispositivi coinvolti sono spesso
basati su piattaforme proprietarie, magari obsolete, quindi volutamente o forzatamente non
dotate di flessibilità.
Al fine di risolvere questa problematica, si è pensato per tale componente un’architettura
basata su wrapper, uno per ciascuna tipologia di sensori. Tali wrapper non fanno altro che
ricevere gli eventi provenienti dalla tipologia di sensori a cui sono stati associati,
riconoscere gli eventi ricevuti, trasformare questi eventi in un formato intermedio
utilizzabile dal BUS, e poi inviarlo su quest’ultimo, e precisamente sul topic associato a

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
143
quella determinata tipologia di sensore. Ovviamente il formato intermedio sarà JMS, che
come abbiamo visto è supportato da ActiveMQ, e precisamente ogni evento sarà
trasformato in un MapMessage o TextMessage.
Vediamo ora più nel dettaglio come è implementato questo componente, nonché il suo
funzionamento.
4.3.3.1 Struttura e logica applicativa
Come abbiamo detto, tale componente è stato pensato e realizzato come un insieme di
wrapper, ognuno dei quali rappresenta una vera e propria interfaccia tra una specifica
tipologia di sensore e la nostra piattaforma.
Dati gli scenari previsti, nonché i relativi casi d’uso, (descritti nel capitolo 2) si è deciso di
prevedere tre wrapper:
• Wrapper_BACnet: rappresenta il wrapper per i tre dispositivi BACnet previsti
• Wrapper_IDS: rappresenta il wrapper per il sistema IDS
• Wrapper_SYS: rappresenta il wrapper per i log di sistema
Vediamoli più in dettaglio.
Wrapper_BACnet
Il diagramma delle classi per il Wrapper_BACnet, è quello di figura 4.17.
Come si può notare, la classe principale è quella denominata Wrapper_BACnet, la quale
prevede il metodo main, che consente l’avvio del wrapper nonché l’inizializzazione della
connessione con il bus, e quello bacnet_interaction, il quale si preoccupa di realizzare
l’intera logica necessaria alla comunicazione con i vari dispositivi BACnet. A tale scopo, è
stata utilizzata la libreria BACnet4J (descritta nel paragrafo 4.3.1.3.1), grazie alla quale il
wrapper funge da vero e proprio BACnet/IP Server. Esso infatti è in grado di gestire più di

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
144
un dispositivo BACnet contemporaneamente, sottoscrivendo una COV Notification per
ognuno di essi.
Figura 4.17: Wrapper_BACnet – Class Diagram
Ovviamente, per l’interazione con i dispositivi si prevede l’istanziazione di un apposito
listener, BACnet_Listener, che implementa l’interfaccia DeviceEventListener della libreria
BACnet4J. Pertanto, come si può vedere dal diagramma, tale classe prevede
un’implementazione di tutti i suoi metodi, ognuno di quali viene richiamato alla ricezione
del relativo messaggio proveniente da un dispositivo. Da notare che in realtà gli unici
metodi per cui non si è prevista l’implementazione di default sono iAmReceived e
covNotificationReceived, demandati rispettivamente alla gestione della ricezione di un
messaggio di I-AM e di una notifica COV.
Per quanto riguarda gli attributi, la classe Wrapper_BACnet prevede il LocalDevice, che
rappresenta il BACnet/IP Server, nonché il DEVICE_ID, il LOCAL_ADDRESS e il
BRODCAST_ADDRESS, che rappresentano rispettivamente l’ID del server (essendo esso

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
145
stesso visto come un device), l’indirizzo IP locale di quest’ultimo e quello di Broadcast
della rete su cui esso è in funzione. Di fondamentale importanza sono poi anche l’attributo
di tipo Session e quello BUS_ADDRESS, che invece rappresentano rispettivamente la
sessione stabilita con l’ESB e l’indirizzo IP per connettersi ad esso.
La classe BACnet_Listener prevede anch’essa una serie di attributi, tra cui ancora una
volta LocalDevice e Session, che sono passati al suo costruttore dalla classe
Wrapper_BACnet, nonché RemoteDevices, MessageProducers e Destinations, le quali
rappresentano rispettivamente una lista di RemoteDevice, con il quale il server interagisce,
una lista di MessageProducer e una lista di Destination, entrambe utilizzate per l’invio
degli eventi sui relativi topic dell’ESB. Da notare che tutte e tre le liste menzionate sono
popolate dal metodo iAmReceived alla ricezione di un messaggio di I-AM da ogni
dispositivo.
Relativamente al funzionamento delle due classi, esso è visibile nel sequence diagram di
figura 4.18, nel quale però sono mostrate solo le operazioni rilevanti.
Come si può notare da quest’ultimo, una volta avviato, il wrapper stabilisce una
connessione con l’ESB attraverso la ActiveMQConnectionFactory, alla quale viene passato
l’indirizzo del bus, e il metodo createConnection, per poi avviarla attraverso il metodo
start. Dalla connessione è poi creata una sessione con il metodo createSession.
In seguito viene istanziano un oggetto Wrapper_BACnet , sul quale viene invocato il
metodo bacnet_interaction. Tale metodo istanzia il LocalDevice, che rappresenta il
BACnet/IP Server, setta alcune proprietà con il metodo setProperty, come ad esempio il
numero di porta su cui il server è in ascolto, per poi instanziare ed associare il
BACnet_Listener al LocalDevice. Si può notare che al costruttore del listener sono passati
sia l’oggetto Session che quello LocalDevice, in quanto, come vedremo, quest’ultimo li
utilizza al fine di creare i topic e inviare su di essi gli eventi, con il primo, e per inviare le
richieste di COV ai dispositivi, con il secondo.
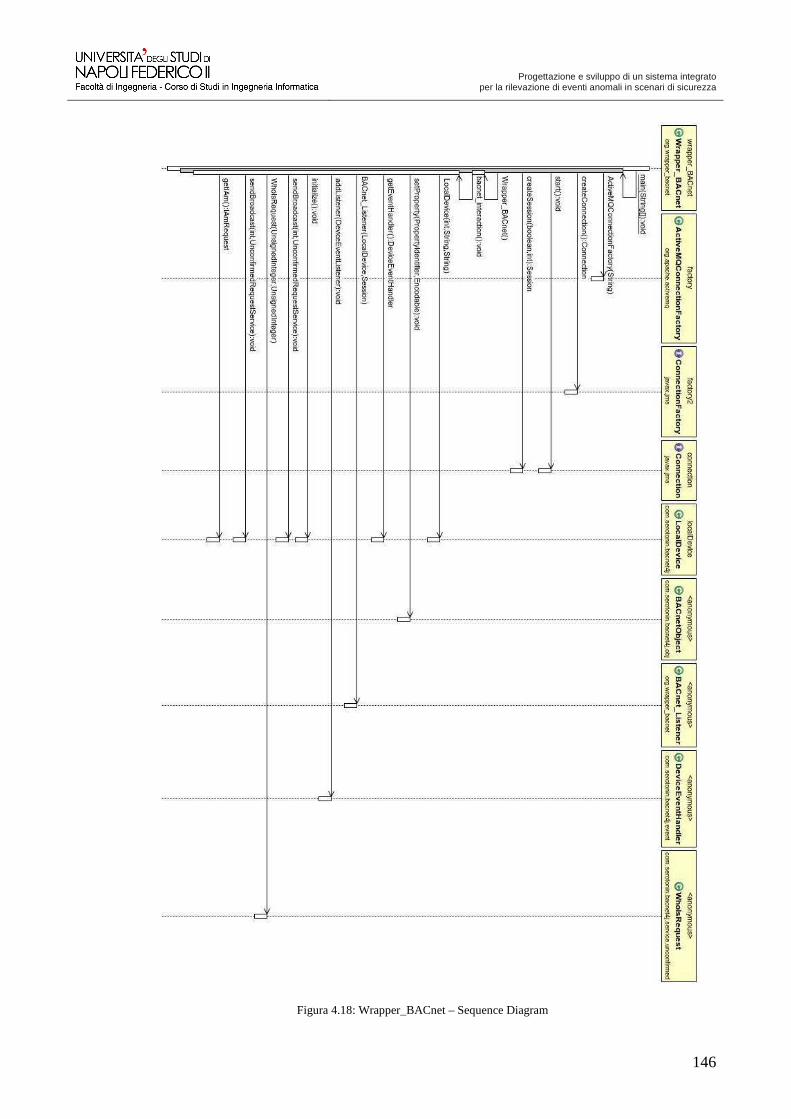
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
146
Figura 4.18: Wrapper_BACnet – Sequence Diagram

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
147
Successivamente viene inizializzato il device, attraverso il metodo initialize, e rispettando i
passi descritti nel paragrafo 4.3.1.3.1, si prevede l’invio in broadcast di un messaggio di
WHO-IS, così da conoscere i dispositivi in ascolto, i quali risponderanno con messaggio di
I-AM.
Infine si prevede l’invio, sempre in broadcast, di un messaggio di I-AM, così da garantire
ad ogni dispositivo di conoscere le informazioni relative al server.
Per quanto riguarda il BACnet_Listener, invece, il suo funzionamento è descritto dal
sequence diagram della figura 4.19. In essa viene mostrata che cosa accade nel momento
in cui viene ricevuto un messaggio di I-AM e una COV Notification da parte di un sensore.
Precisamente, nel primo caso, viene invocato il metodo iAmReceived, la cui
implementazione prevede di prelevare il Vendor ID del dispositivo, e sulla base di
quest’ultimo, e quindi del tipo di dispositivo, creare un ObjectIdentifier per l’oggetto
monitorato da quel device, nonché un’apposita Destination e MessageProducer per quella
tipologia di dispositivo. Queste ultime saranno poi aggiunte alle rispettive liste.
Ovviamente, attraverso le Destination saranno creati gli appositi topic. Di conseguenza, a
seconda che il dispositivo che abbia inviato l’I-AM sia una camera, un badge reader o il
sistema di controllo dell’illuminazione, sarà creato l’apposito topic, che potrà essere
rispettivamente CAMERA, BADGE_READER o LAMP.
Creati i topic, l’operazione successiva è l’invio della SubscribeCOVRequest verso il
dispositivo da cui si è ricevuto il messaggio di I-AM.
A questo punto, alla ricezione di una COV Notification, entra in gioco il metodo
covNotificationReceived, il quale non fa altro che creare, sulla base del tipo di device che
ha inviato la COV Notification, un MapMessage (i cui campi sono definiti nella tabella
4.2) con i dati ottenuti dalla COV, e inviare tale message sul topic relativo a quella
determinata tipologia di device. Ciò, ovviamente, dopo aver recuperato l’opportuna
Destination e MessageProducer dalla rispettive liste.
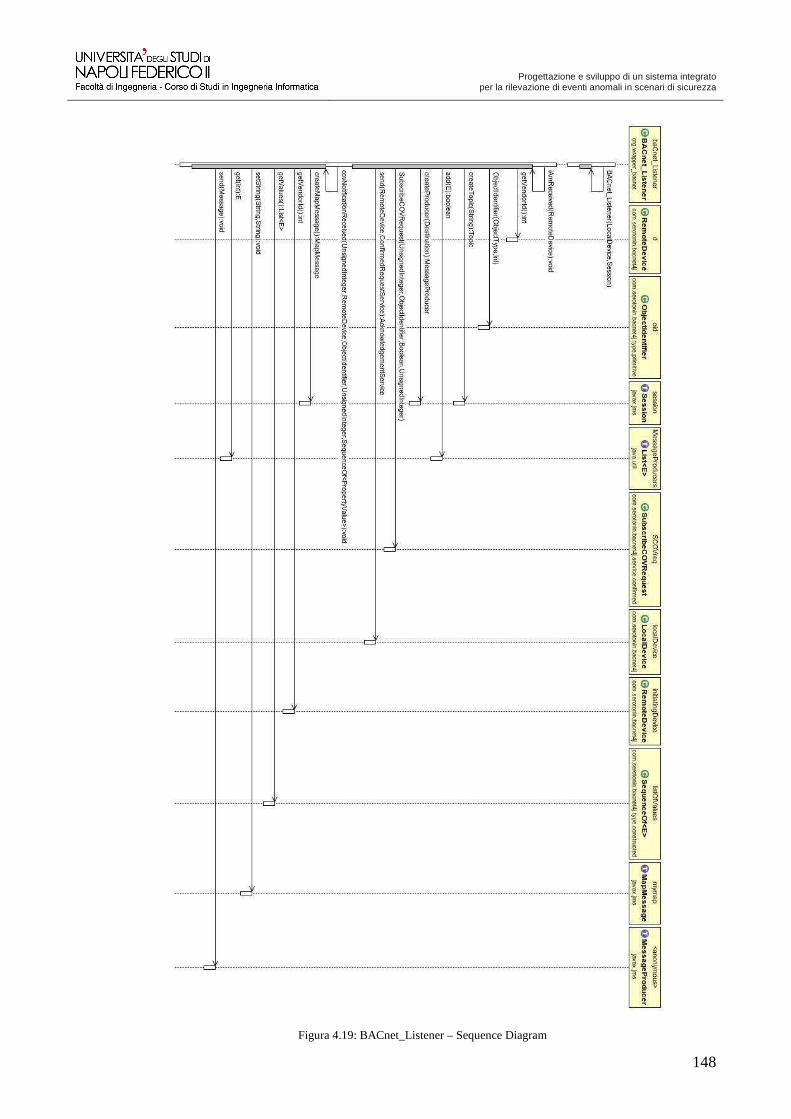
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
148
Figura 4.19: BACnet_Listener – Sequence Diagram

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
149
Tabella 4.2: Attributi MapMessage per ogni Device/Topic
DEVICE/TOPIC
ATTRIBUTI MAP MESSAGE
ATTRIBUTO DESCRIZIONE
LAMP lampID ID della lampada fuori uso
CAMERA
camID ID della camera che ha generato
l’evento
eventType Tipo do evento generato dalla camera
(0 = Tampering 1 = Face Detection)
ID_employee ID dell’impiegato riconosciuto
(nel caso di evento di Face Detection)
BADGE_READER
badgeID ID del Badge Reader
ID_employee ID dell’impiegato riconosciuto
Wrapper_IDS
Il diagramma delle classi per il Wrapper_IDS, è quello mostrato nella seguente figura.
Figura 4.20: Wrapper_IDS – Class Diagram
Come si può notare, la classe principale è quella denominata Wrapper_IDS, la quale è
dotata di un metodo main che consente l’avvio del Wrapper nonché l’inizializzazione
della connessione con il bus, del quale è noto l’indirizzo IP, definito dall’attributo
BUS_ADDRESS. Attraverso tale metodo, in realtà, questa classe istanzia anche un thread,
Thd_IDS, il quale si preoccuperà di gestire la comunicazione con il sistema IDS,

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
150
ricevendo gli alert da esso generati e immettendoli poi sul relativo topic del bus.
Tale classe, essendo un’estensione della classe Thread, prevede l’implementazione del
metodo run, che realizza la sua logica applicativa. Essa inoltre è caratterizzata
dal’'attributo Session, ricevuto dalla classe Wrapper_IDS e che rappresenta la sessione
instaurata con l’ESB, nonché da quelli PORT e BUFFER_SIZE, che rappresentano
rispettivamente il numero di porta e la dimensione del buffer relativi alla socket utilizzata
dal metodo run per comunicare con l’IDS. In realtà, la comunicazione non avviene
direttamente con l’IDS, bensì con RSYSLOG. Infatti si prevede che l’IDS immetta i propri
alert nei log di sistema, e che RSYSLOG li invii, all’interno di pacchetti, all’indirizzo IP su
cui è in esecuzione il wrapper e sul numero di porta PORT, cioè 2000.
Per quanto riguarda la logica applicativa delle due classi, essa è visibile nel sequence
diagram di figura 4.21, nel quale sono mostrate le sole operazioni rilevanti.
Come si può notare, una volta avviato, il wrapper crea una connessione, e la relativa
sessione, con l’ESB e la avvia. Successivamente, istanzia il Thd_IDS e lo avvia mediante il
metodo start. Alla chiamata di tale metodo, viene eseguito il metodo run della sopra citata
classe, all’interno del quale viene generato un topic, e precisamente quello IDS, e il
relativo MessageProducer. A questo punto viene istanziata una DatagramSocket che viene
posta in ascolto sulla porta 2000, mediante il metodo receive. Alla ricezione di un
DatagramPacket dalla socket, il metodo analizza il suo contenuto al fine di definire il tipo
di alert pervenuto, e sulla base di quest’ultimo genera un apposito MapMessage (i cui
campi variano al variare del tipo di alert, e i quali sono descritti nella tabella presentata di
seguito) e lo invia sul topic IDS.
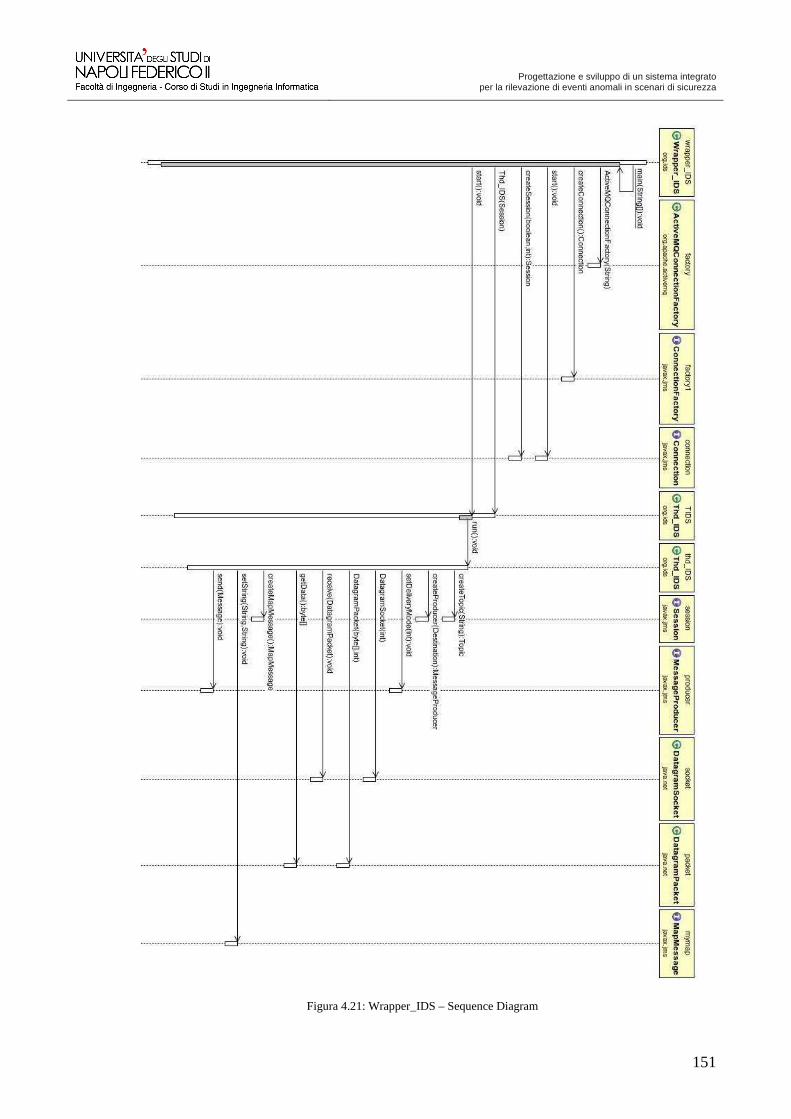
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
151
Figura 4.21: Wrapper_IDS – Sequence Diagram
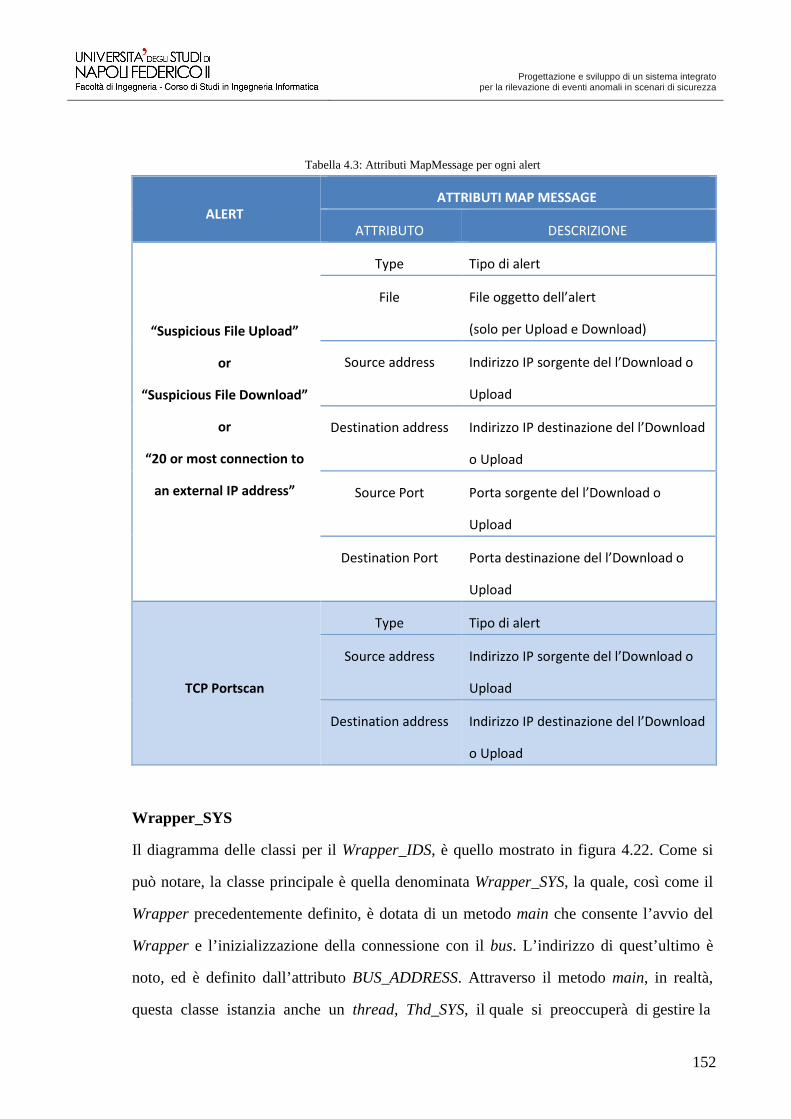
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
152
Tabella 4.3: Attributi MapMessage per ogni alert
ALERT
ATTRIBUTI MAP MESSAGE
ATTRIBUTO DESCRIZIONE
“Suspicious File Upload”
or
“Suspicious File Download”
or
“20 or most connection to
an external IP address”
Type Tipo di alert
File File oggetto dell’alert
(solo per Upload e Download)
Source address Indirizzo IP sorgente del l’Download o
Upload
Destination address Indirizzo IP destinazione del l’Download
o Upload
Source Port Porta sorgente del l’Download o
Upload
Destination Port Porta destinazione del l’Download o
Upload
TCP Portscan
Type Tipo di alert
Source address Indirizzo IP sorgente del l’Download o
Upload
Destination address Indirizzo IP destinazione del l’Download
o Upload
Wrapper_SYS
Il diagramma delle classi per il Wrapper_IDS, è quello mostrato in figura 4.22. Come si
può notare, la classe principale è quella denominata Wrapper_SYS, la quale, così come il
Wrapper precedentemente definito, è dotata di un metodo main che consente l’avvio del
Wrapper e l’inizializzazione della connessione con il bus. L’indirizzo di quest’ultimo è
noto, ed è definito dall’attributo BUS_ADDRESS. Attraverso il metodo main, in realtà,
questa classe istanzia anche un thread, Thd_SYS, il quale si preoccuperà di gestire la

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
153
comunicazione con RSYSLOG, ricevendo i log di sistema da esso gestiti e immettendoli
poi sul relativo topic del bus. Tale classe, essendo un’estensione della classe Thread,
prevede l’implementazione del metodo run, che realizza la sua logica applicativa. Essa
inoltre è caratterizzata dall’attributo Session, ricevuto dalla classe Wrapper_SYS e che
rappresenta la sessione instaurata con l’ESB, nonché da quelli PORT e BUFFER_SIZE,
che rappresentano rispettivamente il numero di porta e la dimensione del buffer relativi
alla socket utilizzata dal metodo run per comunicare con l’RSYSLOG.
Figura 4.22: Wrapper_SYS – Class Diagram
Per quanto riguarda la logica applicativa delle due classi, essa è visibile nel sequence
diagram di figura 4.23, nel quale sono mostrate le sole operazioni rilevanti.
Come si può notare, una volta avviato, il wrapper crea una connessione, e la relativa
sessione, con l’ESB e la avvia. Successivamente, istanzia il Thd_SYS e lo avvia mediante il
metodo start. Alla chiamata di tale metodo, viene eseguito il metodo run della sopra citata
classe, all’interno del quale viene generato un topic, e precisamente quello
Unfiltered_Syslog, sul bus e il relativo MessageProducer. A questo punto viene istanziata
una DatagramSocket, la quale viene posta in ascolto sulla porta 2001 mediante il metodo
receive. Alla ricezione di un DatagramPacket dalla socket, il metodo prende il suo
contenuto e lo immette all’interno di un TextMessage precedentemente creato, e lo invia
sul topic Unfiltered_Syslog.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
154
Figura 4.23: Wrapper_SYS – Sequence Diagram

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
155
Definiti i tre wrapper è bene fare una considerazione. Come si può notare dalla loro
struttura, tutti e tre sono stati implementati in maniera tale da essere indipendenti, e quindi
eseguibili su macchine differenti. Ciò consente di poter scegliere senza alcun problema la
loro migliore ubicazione nell’ambito del sistema che si sta monitorando. Ad esempio, si
potrebbe prevedere di avviare il Wrapper_SYS sulla macchina adibita al raccoglimento dei
log di sistema di tutti gli host, nonché l’avvio del Wrapper_IDS sulla macchina su cui è
installato il sistema IDS, etc. Si comprende quindi che in realtà il componente Mediator è
un componente astratto, formato da tre wrapper indipendenti.
4.3.4 Prefiltering-Aggregation
Come già definito nel paragrafo 4.3, il componente Prefiltering-Aggregation realizza il
filtraggio degli eventi raw ed un loro eventuale arricchimento.
La motivazione alla base di questo componente è quella relativa alla capacità di ogni
sensore di generare, in un breve lasso temporale, una elevata quantità di dati, non tutti
necessari alla produzione di informazioni rilevanti.
Pertanto si è reso necessaria l’implementazione di un modulo che si preoccupi di effettuare
un’analisi degli eventi provenienti dalle varie fonti, al fine di determinare quelli realmente
necessari, che saranno mantenuti ed eventualmente arricchiti, e quelli non significativi,
che invece saranno scartati.
In realtà, come vedremo nel prossimo paragrafo, nella sua implementazione finale, tale
componente si preoccuperà solo ed esclusivamente di effettuare il filtraggio dei messaggi
provenienti dal Wrapper_SYS, allo scopo di far giungere al CEP Engine i soli messaggi
relativi alle operazioni di accesso, mediante protocollo SSH, agli host della rete
monitorata. Vediamo ora più nel dettaglio come è implementato questo componente,
nonché il suo funzionamento.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
156
4.3.4.1 Struttura e logica applicativa
Il diagramma delle classi per il componente di Prefiltering-Aggregation, è mostrato nella
figura seguente.
Figura 4.24: Prefiltering-Aggregation – Class Diagram
Come si può notare, la classe principale è quella Prefiltering_Aggregation, la quale è
dotata di un metodo main che consente l’avvio del componente e l’inizializzazione della
connessione con il bus. L’indirizzo di quest’ultimo è noto, ed è definito dall’attributo
BUS_ADDRESS. In realtà, oltre a tali operazioni, tale metodo si preoccupa anche di
definire il topic del bus sul quale sarà in ascolto, e precisamente quello Unfiltered_Syslog,
nonché istanziare un apposito Listener, BusListener, mediante il quale riceverà i messaggi
che viaggiano su tale topic. Questo listener, come si può vedere dal class diagram, è
caratterizzato da un attributo di tipo Session, passato dalla classe Prefiltering-Aggregation,
e da uno di tipo MessageProducer, il quale è utilizzato nel metodo onMessage per l’invio
dei MapMessage sul bus. Infatti, tale metodo, che ricordiamo viene invocato alla ricezione
di ogni messaggio sul topic considerato, si preoccupa anche di effettuare la vera e propria
operazione di filtraggio, analizzando i TextMessage. Se questi non dovranno essere
scartati, vengono convertiti in MapMessage è immessi nuovamente sul bus, questa volta
però nel topic SYSLOG, attraverso il quale giungeranno al CEP Engine.
Di seguito è mostrato il sequence diagram relativo a questo componente.
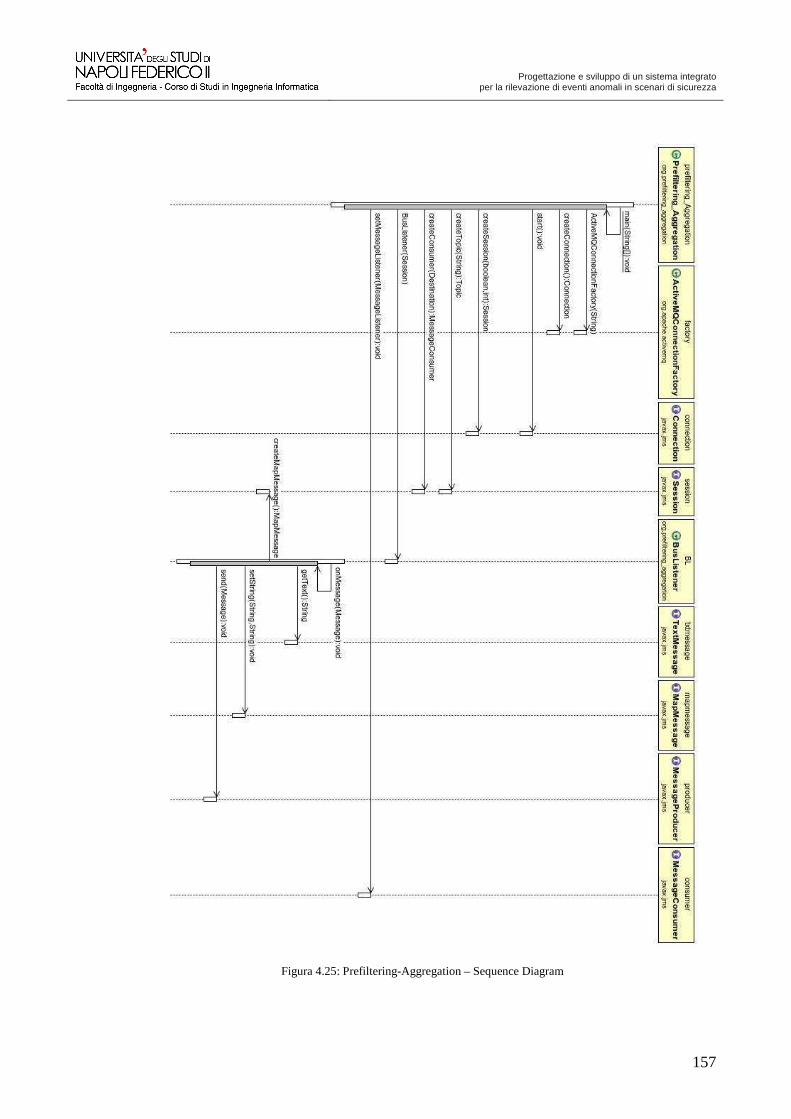
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
157
Figura 4.25: Prefiltering-Aggregation – Sequence Diagram

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
158
Ovviamente, in esso sono mostrate le sole operazioni rilevanti.
Come si può notare, una volta avviato, il componente crea una connessione, e la relativa
sessione, con l’ESB e la avvia, mediante il metodo start. Successivamente, crea il topic sul
quale intende mettersi in ascolto (Unfiltered_Syslog) e instanzia il relativo
MessageConsumer, al quale poi associa, mediante il metodo setMessageListener,
un’istanza della classe BusListener. Come già detto precedentemente, a tale classe viene
passata la sessione generata.
Per quanto riguarda proprio il listener, nel momento in cui giunge un TextMessage sul
topic Unfiltered_Syslog, viene richiamato il suo metodo onMessage, il quale non fa altro
che utilizzare il metodo getText per prelevare il contenuto del messaggio, il quale sarà
successivamente analizzato. Precisamente, se il messaggio contiene le parole chiave ssh e
Accepted, che compaiono contemporaneamente nei soli log relativi alle agli accessi con
protocollo ssh, allora il messaggio sarà convertito in un MapMessage, che sarà poi inviato
sul topic SYSLOG del bus, mediante il metodo send richiamato su un oggetto
MessageProducer precedentemente instanziato.
Tale MapMessage sarà caratterizzato dai seguenti campi:
• Host e HostIP, che contengono relativamente l’host al quale è stato effettuato
l’accesso e il suo IP. Quest’ultimo viene ricavato dal componente stesso
• ExtIP e ExtPort, che contengono rispettivamente l’indirizzo IP e la porta esterni dal
quale è stato effettuato l’accesso
• User ed Auth_method, che rappresentano rispettivamente l’username dell’utente che
ha effettuato l’accesso e il metodo di autenticazione utilizzato
Da notare che, nel caso l’analisi del messaggio non vada a buon fine, cioè il messaggio
non rappresenta un accesso tramite ssh, allora esso viene ignorato e scartato.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
159
4.3.5 CEP Engine
Il componente fondamentale di tutta l’architettura progettata è sicuramente il Complex
Event Processing Engine, il quale, come già accennato nei primi paragrafi, rappresenta il
modulo che si preoccupa di effettuare la correlazione tra gli eventi raw, generati dai
sensori ed opportunamente trasformati in MapMessage dal Mediator, nonché controllati
dal componente di prefiltering, al fine di generare eventi complessi relativi ai casi d’uso
presi in considerazione.
Precisamente questo componente deve essere in grado di:
• Ricevere gli eventi che viaggiano sui differenti topic dell’ESB
• Convertire tali eventi nel formato di rappresentazione degli eventi del motore di
correlazione utilizzato
• Correlare gli eventi convertiti, in real-time o near real-time, al fine di riconoscere i
casi d’uso presi in considerazione, e opportunamente descritti attraverso delle
regole
• Usufruire delle informazione relative alle abitudini degli utenti del sistema
dell’organizzazione monitorata, per raggiungere l’obbiettivo di cui al punto
precedente
• Generare eventi complessi al riconoscimento dei casi d’uso e stampa a video degli
alert relativi
Come già annunciato nel capitolo precedente, per la realizzazione di questo componente si
è scelto di utilizzare il CEP Engine Esper, il quale è anche stato ampiamente descritto
nello stesso. Le motivazioni principali che hanno portato alla sua scelta sono basate
sostanzialmente su alcune delle sue principali caratteristiche, e precisamente:
• È scritto in Java, e può facilmente essere integrato in applicazioni scritte con tale
linguaggio, proprio come la nostra piattaforma
• Consente l’analisi in real-time di flussi di eventi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
160
• È basato sull’EPL, un linguaggio di event stream processing SQL-like molto
intuitivo, flessibile e potente, che consente di rappresentare in maniera semplice e
veloce qualsiasi scenario possibile, dal più semplice al più complesso
• Offre differenti modi di rappresentazioni degli eventi, così da potersi adattare alle
varie necessità
• Garantisce una semplice e rapida espandibilità e configurazione
Tutti questi aspetti, già discussi nel capitolo 3, hanno portato al suo utilizzo nell’ambito
della nostra piattaforma. In realtà, però, c’è da riconoscere un limite ad Esper, e cioè
l’assenza di auto-apprendimento, e cioè la capacità di apprendere automaticamente nuove
situazioni critiche. Ciò comporta la sua incapacità di poter rilevare situazioni non previste,
cioè per le quali non sono state previste delle regole. Ma in realtà, questo è un problema
che pesa su quasi tutti i CEP Engine rule-based.
Detto ciò, passiamo ora alla descrizione della struttura di questo componente.
4.3.5.1 Struttura
Prima di procedere alla definizione dettagliata delle classi che compongono questo
modulo, è bene soffermarci su alcuni elementi fondamentali, e cioè gli eventi.
Come abbiamo detto nel paragrafo precedente, e ancor prima nel capitolo 3, Esper è in
grado di supportare differenti modalità di rappresentazione di eventi, come Java POJO,
Java Map, XML Document, etc. Ognuna di queste presenta determinati vantaggi e
svantaggi, come mostrata nella tabella 3.1. Proprio valutando tale tabella, si è dedotto che
il miglior compromesso, rispetto ai parametri valutati, è dato dalla rappresentazione basata
su Java POJO.
Come ormai è noto, gli eventi raw da rappresentare sono otto, e sono:
• Lettura di un badge da parte di un Badge Reader

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
161
• Riconoscimento di un Port Scanning da parte dell’IDS SNORT
• Face Detection da parte di una videocamera
• Tampering Detection da parte di una videocamera
• Rilevamento del guasto ad una lampada da parte del sistema di controllo
dell’impianto di illuminazione
• Riconoscimento di un Download sospetto da parte dell’IDS SNORT
• Riconoscimento di un Upload sospetto da parte dell’IDS SNORT
• Riconoscimento di ripetuti tentativi di stabilire una connessione TCP da parte di un
host interno alla rete monitorata, verso un indirizzo IP esterno, da parte dell’IDS
SNORT
La loro rappresentazione è mostrata nella seguente figura.
Figura 4.26: Eventi – Class Diagram
Come si può notare, ogni evento è rappresentato da una apposita classe la quale è dotata di
una serie di attributi, che sono quelli che caratterizzano la particolare tipologia di evento,
nonché una serie di metodi che non sono altro che getter method che l’engine Esper

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
162
utilizzerà per prelevare le informazioni dagli eventi, qualora richieste all’interno di una
regola EPL. Come si può notare, gli attributi rispecchiano fedelmente i dati presenti
all’interno dei MapMessage inviati sul Bus dal Mediator. In realtà, però, da un’analisi più
attenta della figura 4.26 è possibile anche notare che sono presenti degli attributi in più. È
il caso degli attributi time, nonché di quelli posID/placeID. Tali attributi sono popolati,
come vedremo, dalla classe che si preoccupa di recuperare i messaggi dall’ESB, e
conterranno rispettivamente l’istante di arrivo dell’evento al CEP Engine e l’ID della
posizione in cui si trova il sensore che ha generato l’evento.
Oltre agli eventi raw, però il CEP Engine deve essere anche in grado di gestire gli eventi
complessi, che sono generati a valle del riconoscimento di uno dei casi d’uso descritti
mediante le regole. Precisamente i complex event previsti sono:
• Accesso sospetto al sistema, cioè da parte di un utente che non rispetta le sue
consuete abitudini
• Accesso al sistema con credenziali rubate
• Attacco TCP Gender Changer, con upload di file sospetto
• Attacco TCP Gender Changer, con Port Scanning
• Riconoscimento di un evento di Tampering su una videocamera
• Riconoscimento di un tentativo di accesso ad un area riservata con un badge
diverso dal proprio
In realtà, non per tutti questi eventi è stato necessario prevedere la realizzazione di un Java
POJO. Ciò infatti si è reso necessario solo per il primo, dato che, come vedremo, viene ad
essere generato e popolato attraverso una apposita View, concetto di Esper già descritto
nel paragrafo precedente. Per gli altri non si è reso necessario, in quanto la loro definizione
è avvenuta direttamente all’interno dell’EPL, che sarà successivamente illustrato.
In Figura 4.27 è mostrata la rappresentazione in Esper dell’evento Accesso sospetto al
Sistema. Come si può notare, esso da attributi che descrivono l’evento e da metodi.
Precisamente gli attributi sono:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
163
• HostIp e Host: rappresentano rispettivamente l’identificativo dell’ host, al quale sta
accedendo l’utente, e il suo indirizzo IP
• ExtIp e ExtPort: rappresentano rispettivamente l’indirizzo IP e il numero di porta
esterni dal quale si sta effettuando l’accesso
• userId ed authMethod: rappresentano l’username dell’utente che ha effettuato
l’accesso e il metodo di autenticazione utilizzato
• time e motivation: rappresentano l’istante in cui è avvenuto l’accesso e la
motivazione che spiega il perché quell’accesso è ritenuto sospetto. Sostanzialmente
quest’ultimo riporta quale o quali abitudini l’utente non ha rispettato.
Figura 4.27: SuspiciousAccessSystemEvent – Class Diagram
Come questi eventi sono generati, sarà discusso in seguito, quando saranno descritte le
regole EPL utilizzate per riconoscere i vari casi d’uso.
Vediamo ora la struttura vera e propria del componente, la quale è mostrata nella figura
4.28. Da quest’ultima si può facilmente notare la presenza di un solo event raw, e
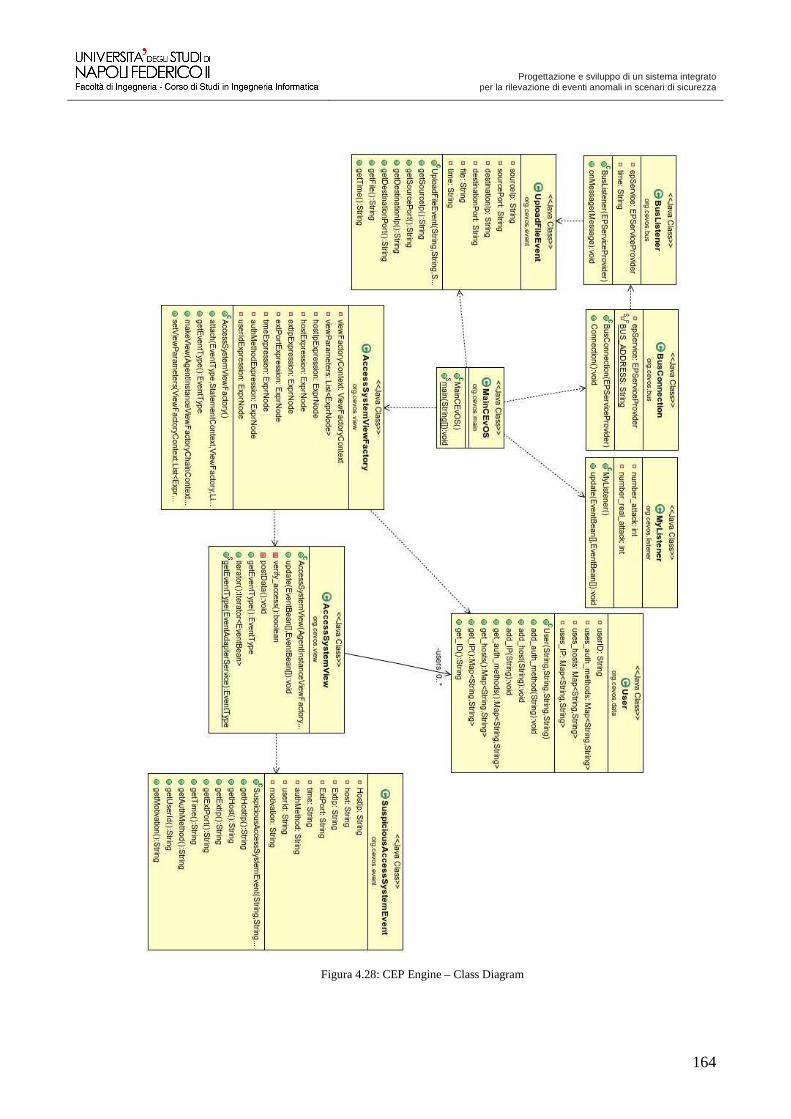
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
164
Figura 4.28: CEP Engine – Class Diagram

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
165
precisamente quello di UploadFileEvent. Ciò ovviamente è dovuto agli ovvi problemi di
ingombro, ma anche perché tutti gli altri event raw presentano le stesse relazioni visibili
per l’evento sopra citato.
La classe principale dell’intera struttura è quella MainCEvOS, la quale è dotata di un
metodo main che consente di configurare l’engine di Esper, definendo gli eventi che esso
dovrà gestire, nonché le View utilizzabili e le regole EPL da valutare all’arrivo di ogni
evento. Precisamente, al fine di definire quali eventi e view sono utilizzate, all’interno di
tale metodo è prevista una referenziazione per nome dei .class che rappresentano gli eventi
e la view. Da ciò si comprende la relazione esistente tra la classe MainCEvOS e le due
classi UploadFileEvent e AccessSystemViewFactory. Il metodo main inoltre, una volta
configurato l’engine e definite le regole, si preoccupa di istanziare un listener, MyListener,
il quale interviene ogni qualvolta viene trovato un matching con una delle regole.
Precisamente, in tale evenienza ad essere invocato è il suo metodo update, che si
preoccuperà di generare i dovuti alert.
Un’ulteriore relazione della classe MainCEvOS è quella esistente con la classe
BusConnection. Infatti, attraverso il metodo main, viene istanziato un oggetto di tale classe
che verrà utilizzato per stabilire una connessione con l’ESB, mediante il suo metodo
Connection. Tale metodo a sua volta istanzierà un oggetto della classe BusListener,
attraverso il quale riceverà i MapMessage che viaggiano sui vari topic dell’ESB, e per ogni
messaggio istanzierà un oggetto della classe che rappresenta quel determinato tipo di
evento, e lo invierà all’engine di Esper.
Per quanto riguarda la classe AccessSystemViewFactory, come sappiamo dal capitolo
precedente, essa rappresenta una classe factory per una View, di conseguenza il suo
compito è quello di accettare e controllare i parametri della vista, che in questo caso
corrispondono ai campi di un evento di tipo AccessSystemEvent, nonché di creare
un’istanza della View. In particolare tale classe istanzia la AccessSystemView, il cui
compito è verificare, attraverso i dati ricevuti, se l’evento a cui essi fanno riferimento
rappresenti o meno un accesso sospetto. A tale scopo controlla le abitudini dell’utente,

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
166
memorizzate in una HashMap composta di oggetti di tipo User e instanziata dalla factory.
Nel caso in cui dal controllo si deduce che l’accesso è sospetto, allora sarà generato un
evento del tipo SuspiciousAccessSystemEvent.
Da notare che la classe User, rappresenta un generico utente, ed è infatti caratterizzata
dall’attributo userID, che rappresenta l’ID dell’utente, nonché da quelli uses_auh_method,
uses_host e uses_IP, che sono JavaMap che contengono rispettivamente tutti i metodi di
autenticazione, gli host e gli IP esterni utilizzati da quell’utente.
Approfondiamo ora la logica applicativa di ogni singola classe.
4.3.5.2 Logica applicativa
Per quanto riguarda il funzionamento della classe MainCEvOS, esso è ben visibile dal
sequence diagram seguente, nel quale sono mostrate solo le operazioni rilevanti.
Figura 4.29: MainCEvOS – Sequence Diagram

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
167
Come si può notare, nel metodo main per prima cosa viene istanziato un oggetto
Configuration, attraverso il quale avviene la configurazione del motore di Esper.
Precisamente è prevista l’aggiunta dei tipi di eventi che esso dovrà gestire, mediante il
metodo addEventType, nonché delle view utilizzabili, mediante il metodo addPluginView.
Successivamente, dopo aver istanziato, attraverso il metodo getProvider della classe
EPServiceProviderManager, una istanza dell’engine di Esper si prevede la definizione
delle regole EPL per la correlazione (che saranno mostrate nel paragrafo successivo) e la
loro creazione, con il metodo createEPL dell’interfaccia EPAdministartor. Tale metodo
restituirà un apposito Statement, al quale sarà associato l’istanza della classe MyListener,
in maniera tale che ogni matching trovato per quella determinata regola, porterà
all’invocazione del suo metodo update.
Dopo tale operazione, si istanzia un oggetto della classe BusConnection, al quale viene
passato l’oggetto EPServiceProvider, sul quale viene poi richiamato il metodo
Connection, che si preoccuperà proprio di effettuare la connessione al Bus.
Vediamo proprio il comportamento di questa classe, il quale è mostrato nel sequence
diagram di figura 4.30. Come si può notare, il metodo Connection stabilisce una
connessione con l’ESB attraverso la ActiveMQConnectionFactory, alla quale viene
passato l’indirizzo del bus, e il metodo createConnection, per poi avviarla attraverso il
metodo start. Dalla connessione è poi creata una sessione con il metodo createSession,
attraverso la quel vengono ad essere definiti i topic sui quali mettersi in ascolto. Infatti per
ognuno di essi si definisce una Destination e un Consumer. A quest’ultimo sarà associato
l’istanza della classe BusListener, mediante il metodo setMessageListener.
Alla ricezione di un messaggio su uno dei topic definiti, verrà richiamato il metodo
onMessage del listener, il quale, sulla base del topic sul quale si è ricevuto l’evento, non
farà altro che istanziare un oggetto della classe che descrive quella determinata tipologia di
evento, per poi inviarla all’engine Esper mediante il metodo sendEvent. Ciò permetterà
Esper di elaborare quell’evento. Infatti a questo punto l’engine cercherà eventuali match
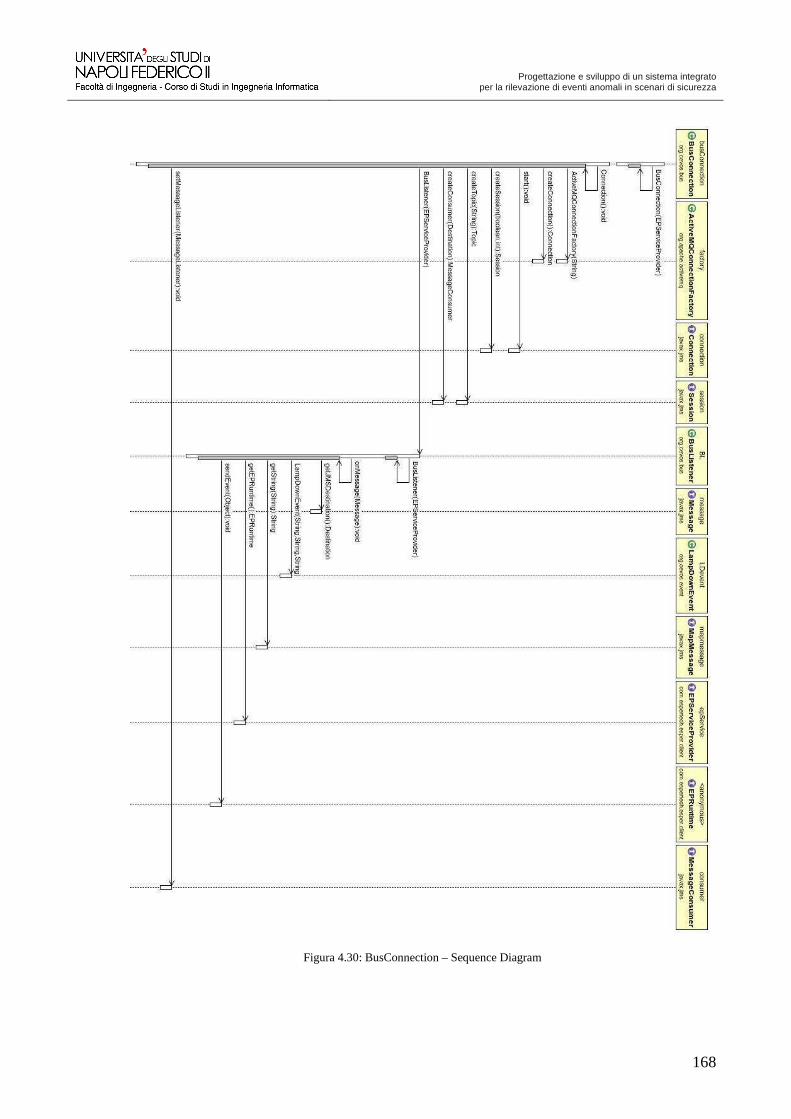
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
168
Figura 4.30: BusConnection – Sequence Diagram

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
169
con le regole definite, e in tal caso va a richiamare il metodo update della classe
MyListener. Il sequence diagram di questa classe è mostrato in figura 4.31.
Da esso è possibile notare che, quando viene invocato il metodo update, questo non faccia
altro che prendere i dati dall’evento generato, soprattutto il tipo di evento, che in questo
caso è un complex event generato a valle della correlazione, in maniera tale da generare
alert differenti proprio sulla base dell’evento complesso generato, o meglio del caso d’uso
rilevato.
Figura 4.31: MyListener – Sequence Diagram
Le ultime classi da analizzare sono quella AccessSystemViewFactory e la relativa
AccessSystemView. La prima, e precisamente il suo metodo makeView, entra in azione nel
momento in cui, all’interno di una opportuna regola EPL, viene richiesto l’utilizzo della
AccessSystemView. Tale metodo, come visibile nel sequence diagram di figura 4.32, non

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
170
Figura 4.32: AccessSystemViewFactory – Sequence Diagram

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
171
fa altro che istanziare una HashMap di oggetti di tipo User, che come già accennato
contiene le abitudini degli utenti, nonché istanzia un oggetto della classe
AccessSystemView, al quale passa tale HashMap. Alla ricezione di un evento da parte della
view, viene ad essere richiamato il suo metodo update, il quale, dopo aver valutato i
parametri ottenuti, richiama il metodo verify_access, da noi implementato, che non fa altro
che verificare se l’accesso effettuato da quel determinato utente rispetta le sue normali
abitudini. In caso affermativo, il metodo ritornerà il valore booleano false e la view
termina il suo operato. In caso negativo invece, il metodo restituirà true e
sarà invocato il metodo postData, il quale istanzierà un SuspiciuosAccessSystemEvent,
passandolo alla regola EPL che ha richiesto la view, attraverso il metodo updateChildren.
4.3.5.3 Regole EPL
Diamo ora uno sguardo, alle regole EPL implementate sia al fine di rilevare i casi d’uso
descritti nel capitolo 2, sia di generare gli eventi complessi ad essi associati.
Ma andiamo per ordine, e consideriamo ogni singolo caso d’uso.
Building Security: Rilevamento di un falso positivo per Camera Tampering
Ricordiamo che tale caso d’uso è relativo alla possibilità che venga generato un falso
positivo per evento di Tampering su una camera del sistema di videosorveglianza.
Supponiamo infatti che, di notte, in un certo istante si verifica il guasto di una lampada,
che non viene tracciato. La telecamera, che è puntata nell’area illuminata da quella
lampada, interpreterà la variazione di luminosità come un evento di tampering e genererà
un allarme, che rappresenta ovviamente un falso positivo.
La regola pensata per riconoscere una situazione del genere è basata sull’idea che un
evento di Tampering, non sia un falso positivo se esso non è preceduto, in una finestra
temporale di 10 secondi, da eventi di LampDown, relativi a lampade che si trovano nella

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
172
stessa posizione della videocamera che ha generato l’evento di Tampering. Pertanto la
regola EPL è la seguente:
insert into Scenario1Stream select TE.camID as camID, TE.posID as posID, TE.tim e as time from TamperingEvent as TE where not exists (select * from LampDownEvent.win:time(10 sec) as L DE where TE.posID=LDE.posID)
Si comprende che se la regola produce un riscontro, l’evento complesso viene inserito
nello stream Scenario1Stream, e sarà caratterizzato dagli attributi camID, posID e time.
Building Security: Rilevamento di un accesso non autorizzato
Come già descritto nel capitolo 2, tale caso d’uso è relativo alla possibilità che un
dipendete dell’organizzazione, o una persona esterna, acceda ad una delle aree sensibili
utilizzando un badge di un altro dipendente.
In questa ipotesi, il sistema di controllo degli accessi verifica l'identità della persona che
sta accedendo all’area riservata attraverso il badge magnetico, che è stato opportunamente
inserito nel badge reader, autorizzandolo.
Contestualmente, la videocamera posta all’ingresso dell’area effettua la Face Detection e
rileva il volto della persona che ha richiesto l'accesso, identificandolo (nel caso in cui sia
un dipendente dell’organizzazione). Ovviamente, al fine di riconoscere il tentativo di
accesso, è necessario correlare le due informazioni. A tale scopo, l’idea alla base è quella
che un accesso sia non autorizzato se un BadgeReaderEvent, generato da un determinato
Badge Reader, è seguito, in una finestra temporale di 6 secondi, da un
FaceDetectionEvent, proveniente dalla videocamera che riprende quel determinato lettore,
i quali però prevedono un valore differente per l’attributo ID_employee. Pertanto la regola
EPL è la seguente:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
173
insert into Scenario2Stream select BRE.ID_employee as idBadge, FDE.time as time , FDE.ID_employee as idFace, BRE.placeID as plac eID from pattern[every BRE=BadgeReaderEvent -> FDE=FaceDetectionEvent((BRE.placeID=FDE.placeID ) and (BRE.ID_employee!=FDE.ID_employee)) where timer:within(6 sec)]
Si comprende che se la regola produce un riscontro, l’evento complesso viene inserito
nello stream Scenario2Stream, e sarà caratterizzato dagli attributi idBadge, time, idFace e
placeID.
Network Security: Rilevamento di una intrusione con credenziali rubate
Ricordiamo che tale caso d’uso è relativo alla possibilità che le credenziali di un utente
siano state rubate, e un attacker malintenzionato acceda alla rete dell’organizzazione
attraverso queste ultime. Si suppone, inoltre, che l’attacker, dopo aver effettuato l’accesso
al sistema con le credenziali rubate, effettui il download di un file sospetto da internet
attraverso un server dell’organizzazione.
Per rilevare questo caso d’uso, l’idea alla base è quella di considerare che stia avvenendo
una intrusione di questo tipo se un SuspiciousAccessSystemEvent, cioè un accesso
effettuato da un utente senza rispettare la sue normali abitudini, è seguito, in una finestra
temporale di cinque minuti, da un DownloadFileEvent, cioè il download di un file
sospetto, il cui indirizzo IP di destinazione coincida con quello dell’host al quale l’utente
ha acceduto. Pertanto, in questo caso, sono necessarie due regole EPL. La prima che
verifica se un determinato AccessSystemEvent rappresenti o meno un accesso sospetto.
Ciò, in particolare, viene realizzato attraverso l’utilizzo della AccessSystemView, indicata
nella regola come accessSystemPV:
insert into SuspiciousAccessSystemEvent select * from pattern[every ASE=AccessSystemEvent].accessSystem:accessSy stemPV (ASE.hostIp, ASE.host, ASE.extIp, ASE.extPor t, ASE.time, ASE.authMethod, ASE.userId)

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
174
La seconda invece, realizza la vera e propria correlazione:
insert into ScenarioR1Stream select SASE.hostIp as hostIp, SASE.host as host, SA SE.extIp as extIp, SASE.extPort as extPort, SASE.authMethod as authMethod, SASE.userId as userId, SASE.motivation as motivatio n, SASE.time as aTime, DFE.sourceIp as sourceIp, DFE.sourcePort as sourcePort, DFE.time as dTime, DFE.file as file, DFE.destinatio nIp as destDown, DFE.destinationPort as destinationPort from pattern[every SASE=SuspiciousAccessSystemEvent -> DFE=DownloadFileEvent(SASE.hostIp=DFE.destinati onIp) where timer:within(5 min)]
Si comprende che se la regola produce un riscontro, l’evento complesso viene inserito
nello stream ScenarioR1Stream, e sarà caratterizzato dagli attributi hostIp, host, extIp,
extPort, authMethod, userId, motivation, aTime, sourceIp, sourcePort, dTime, file,
destDown e destinationPort.
Network Security: Rilevamento di un attacco TCP Gender Changer
Ricordiamo che tale caso d’uso è relativo alla possibilità che l’organizzazione monitorata
subisca un attacco del tipo TCP Gender Changer. In particolare ricordando i passi descritti
nel paragrafo 2.4.2, una delle idee per la rilevazione di tale attacco è quella di verificare
che un evento di SuspiciousAccessSystemEvent non sia seguito, in una finestra temporale
di due minuti, da un UploadFileEvent che presenti come IP destinazione l’IP dell’host
utilizzato per quel determinato accesso sospetto, e inoltre che questa sequenza non sia a
sua volta seguita, in una finestra temporale di tre minuti, da un MultyTCPconnEvent che
presenti come hostIP lo stesso dell’ SuspiciousAccessSystemEvent. Pertanto si prevedono
due regole. La prima intercetta la prima sequenza di eventi:
insert into AccSysAndUpFile select SASE.hostIp as hostIp, SASE.host as host, SA SE.extIp as aExtIp, SASE.extPort as aExtPort, SASE.authMethod a s authMethod, SASE.userId as userId, SASE.motivation as motivatio n, SASE.time as aTime, UFE.sourceIp as sourceIp, UFE.sourcePort as sourcePort, UFE.time as uTime, UFE.file as file, UFE.destinatio nIp as destUpl, UFE.destinationPort as destinationPort

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
175
from pattern[every SASE=SuspiciousAccessSystemEvent -> UFE=UploadFileEvent(SASE.hostIp=UFE.destinat ionIp) where timer:within(2 min)]
Mentre la seconda, correla la prima sequenza con gli eventi di MultyTCPconnEvent:
insert into ScenarioR2aStream select ASAUF.hostIp as hostIp, ASAUF.host as host, ASAUF.aExtIp as aExtIp, ASAUF.aExtPort as aExtPort, ASAUF.authMethod as authMethod, ASAUF.userId as use rId, ASAUF.motivation as motivation, ASAUF.aTime as aTim e, ASAUF.sourceIp as sourceUpl, ASAUF.sourcePort as so urceUplPort, ASAUF.uTime as uTime, ASAUF.file as file, ASAUF.des tUpl as destUpl, ASAUF.destinationPort as destUplPort, MTCE .hostIp as mHostIp, MTCE.hostPort as mHostPort, MTCE.extIp as mExtIp, MTCE.extPort as mExtPort, MTCE.time as mTime from pattern[every ASAUF=AccSysAndUpFile-> MTCE=MultyTcpConnEvent(ASAUF.hostIp=MTCE.hostI p) where timer:within(3 min)]
Si comprende che se la regola produce un riscontro, l’evento complesso viene inserito
nello stream ScenarioR2aStream, e sarà caratterizzato dagli attributi hostIp, host, aExtIp,
aExtPort, authMethod, userId, motivation, aTime, sourceUpl, sourceUplPort, uTime, file,
desUpl, destUplPort, mHostIp, mHostPort, mExtIp, mExtPort ed mTime.
Allo scopo poi di rilevare un attacco TCP Gender Changer, che però sia realizzato
attraverso l’ausilio di un Port Scanning, è stata realizzata un’altra regola la quale genera
un riscontro se un PortScanEvent è seguito, in una finestra temporale di 5 minuti, da un
MultyTCPconnEvent, il cui hostIP coincida con l’IP di destinazione del Port Scanning.
Pertanto la regola è:
insert into ScenarioR2bStream select MTCE.hostIp as hostIp, MTCE.hostPort as mHos tPort, MTCE.extIp as mExtIp, MTCE.extPort as mExtPort, MTC E.time as mTime, PS.sourceIp as pExtIp, PS.time as pTime from pattern[every PS=PortScanEvent-> MTCE=MultyTcp ConnEvent (PS.destinationIp=MTCE.hostIp) where timer:within(5 min)]
Si comprende che se la regola produce un riscontro, l’evento complesso viene inserito

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
176
nello stream ScenarioR2bStream, e sarà caratterizzato dagli attributi hostIp, mHostPort,
mExtIp, mExtPort, mTime, pExtIp e pTime.

177
Capitolo 5
Verifica del funzionamento del sistema CEP
5.1 Introduzione
Dopo aver mostrato in dettaglio l’architettura e il funzionamento della piattaforma oggetto
di questo lavoro di tesi, si vuole ora focalizzare l’attenzione sul comportamento della
stessa nell’ambito della simulazione di alcuni dei casi d’uso descritti nel capitolo 2. Ciò
allo scopo di dimostrare sia il suo corretto funzionamento, nonché la sua capacità di
soddisfare i requisiti previsti in fase di progettazione.
Saranno presi in considerazioni due dei quattro casi d’uso previsti, uno per ogni scenario,
così da mettere in luce il funzionamento di ogni componente dell’architettura in situazioni
reali, in quanto non tutti sono sempre utilizzati.
Precisamente i casi d’uso simulati saranno:
• Rilevamento di una intrusione con credenziali rubate, per lo scenario relativo alla
Network Security
• Rilevamento di un accesso non autorizzato, per lo scenario relativo alla Building
Security
Per ognuno di essi sarà fornita, per semplicità, nuovamente una breve descrizione, nonché
una descrizione del comportamento di ogni singolo componente del sistema in quel
preciso caso, la quale sarà corredata da opportuni screenshot ed estratti del codice

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
178
sorgente.
Prima, però, viene definito brevemente il sistema di riferimento sul quale sono basate le
simulazioni realizzate.
5.2 Sistema di riferimento
Il sistema di riferimento pensato per la piattaforma implementata, cioè un sistema in cui
l’adozione di CEvOS può risultare utile, è quello relativo ad una generica organizzazione,
nella quale si prevede che:
• I dipendenti possano accedere agli host, durante l’orario lavorativo, attraverso
connessioni remote basate sul protocollo SSH
• Le aree sensibili e i varchi di accesso all’organizzazione siano monitorate mediate
appositi sistemi di sicurezza
• Il sistema di illuminazione sia costantemente monitorato
Precisamente, si prevede che un tale sistema sia costituito da:
• 5 macchine utente (SM_0, SM_1, SM_2, SM_3, SM_4), alle quali i dipendenti
possono connettersi in remoto
• 1 macchina (LOG_HOST) su cui sono inviati i log di sistema delle 5 macchine
utente
• 1 macchina (IDS_HOST) su cui è installato l’IDS
• 1 macchina (BACNET_HOST) su cui arrivano gli eventi generati dai sistemi di
sicurezza BACnetIP, che sono:
o 2 telecamere BACnetIP , installate in prossimità di due zone sensibili
o 2 telecamere BACnetIP con modulo di Face Detection, installate in
prossimità dei due ingressi
o 2 badge reader BACnetIP, installati in prossimità dei due ingressi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
179
o 4 sensori per il controllo dell’impianto di illuminazione BACnetIP, ognuno
installato in prossimità delle telecamere
Ovviamente tutte le macchine e i dispositivi di sicurezza sono connessi in rete tra loro
attraverso un apposito switch di rete, e in particolare i componenti di relativi alla building
security sono collegati a quest’ultimo mediante un access point WiFi. Lo switch è inoltre
connesso ad un gateway che consente l’accesso alla rete Internet.
Come si può facilmente comprendere, l’utilizzo della piattaforma implementata in un
sistema siffatto produce l’indubbio vantaggio di mettere in comunicazione le varie fonti di
informazioni, correlando i dati da esso generati, così da garantire una maggiore sicurezza
sia in termini di Network Security che di Building Security.
L’installazione di CEvOS in tale organizzazione prevede:
• Aggiunta di un host (CEVOS_HOST) su cui sarà avviato il componente CEP
Engine, nonché l’ESB Apache ActiveMQ
• Esecuzione del componente di Prefiltering-Aggregation e del Wrapper_SYS sulla
macchina LOG_HOST
• Esecuzione del Wrapper_IDS sulla macchina IDS_HOST
• Esecuzione del Wrapper_BACnet sulla macchina BACNET_HOST
Nella figura seguente è mostrato il sistema di riferimento configurato nel modo appena
descritto.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
180
Figura 5.1: Sistema di riferimento
5.3 Casi d’uso simulati: Rilevamento di una intrusione con credenziali rubate
Il primo caso d’uso simulato è quello relativo alla possibilità che le credenziali di un
utente siano state rubate, e un attacker malintenzionato acceda alla rete
dell’organizzazione attraverso queste ultime. Si suppone, come già descritto nel capitolo 2,
che l’attacker, dopo aver effettuato l’accesso al sistema, effettui il download di un file con
estensione sospetta da internet, ad es. un file con estensione .exe, utilizzando l’host
dell’organizzazione a cui si è connesso.
In questo caso, i sensori che intervengono sono due, e precisamente sono il sistema di
gestione dei log RSYSLOG, che invia i log all’apposito wrapper tramite una socket, e
l’ Intrusion Detection System SNORT, che immette i propri alert all’interno dei log di
sistema attraverso i quali arriveranno all’apposito wrapper, anch’essi tramite socket.
Ovviamente da RSYSLOG giungerà al sistema la segnalazione di accesso da parte di un

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
181
utente ad uno degli host dell’organizzazione monitorata, mentre da SNORT giungerà
l’alert relativo al download di un file sospetto.
La nostra piattaforma, attraverso la correlazione di questi due eventi, è in grado di
riconoscere il tentativo di intrusione e generare un apposito alert.
5.3.1 Comportamento del sistema
Come già annunciato nell’introduzione di questo capitolo, non tutti i moduli del sistema
implementato sono sempre utilizzati. In particolare, nello scenario appena descritto
entrano in azione cinque componenti, e precisamente:
• Il Wrapper IDS
• Il Wrapper SYSLOG
• L’ Enterprise Service Bus
• Il componente di Prefiltering-Aggregation
• Il CEP Engine
Vediamo quindi come ognuno di essi lavoro nell’ambito di questo caso d’uso.
5.3.1.1 Wrapper Syslog
Il Wrapper Syslog, come noto, è il componente dell’architettura che si preoccupa di
comunicare con il sistema di gestione dei log di sistema, nello specifico con RSYSLOG,
allo scopo di ricevere i log generati dai vari host e darli in pasto al sistema.
Come già descritto nel capitolo 4, tale componente per prima cosa effettua la connessione
al bus e successivamente instanzia un thread che rappresenta il wrapper vero e proprio.
Di seguito è mostrato un estratto di codice del metodo main della classe Wrapper_SYS.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
182
… ConnectionFactory factory= new ActiveMQConnectionFactory(BUS_ADDRESS); javax.jms.Connection connection; try { connection = factory.createConnection(); connection.start(); System.out.println("Connected to bus"); // Create a Session Session session = connection.createSession(false,Session.AUTO_ACKNOWL EDGE); //Create and start Thread Syslog Thd_Sys TSys = new Thd_Sys(session); TSys.start(); } catch (JMSException e) { e.printStackTrace(); } …
Come si può vedere, una volta istanziato, il thread viene anche lanciato. Quest’ultimo
effettua la creazione del topic Unfiltered_Syslog sul bus, genera un producer su di esso, e
instanzia una socket sul porto 2001, sul quale si pone in ascolto. Infatti proprio su tale
porto, come già anticipato nel capitolo precedente, è stato configurato l’inoltro dei log da
parte di RSYSLOG.
Nel caso d’uso simulato, si è previsto che venga effettuato un accesso dall’utente raffaele
sull’host raffaele-HP-Pavillion-dv5-Notebook-PC. Tale accesso è stato effettuato
dall’indirizzo IP 192.168.1.111 e prevede come metodo di autenticazione una password.
Pertanto alla realizzazione dell’accesso, RSYSLOG genera un apposito log, e
precisamente:
<38>Sep 30 17:38:30 raffaele-HP-Pavillion-dv5-Noteb ook-PC sshd[3462]: Accepted password for raffaele from 192 .168.1.111 port 51028 ssh2

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
183
Tale log sarà inviato sul porto 2001, e sarà quindi ricevuto dal Wrapper Syslog, come
mostrato nella figura seguente.
Figura 5.2: Output del Wrapper Syslog
Si può notare che in realtà il wrapper non riceve il solo log descritto, ma anche altri, i
quali sono stati generati allo scopo di mostrare, successivamente, le capacità di filtraggio
del componente di Prefiltering-Aggregation. Dalla figura precedente è anche possibile
vedere la successiva operazione svolta dal wrapper, il quale infatti, alla ricezione del log
sulla socket, non fa altro che generare un apposito TextMessage, popolato con l’intero log,
ed immetterlo sul topic precedentemente definito. Fatto ciò, si rimette nuovamente in
ascolto sulla socket.
Di seguito è mostrato un estratto del codice sorgente del metodo run della classe Thd_Sys
che realizza le operazioni descritte:
public synchronized void run(){
try { // Create the destination Topic Destination destination = session.createTopic("Unfiltered_Syslog");
// Create a MessageProducer MessageProducer producer = session.createProducer(destination); … DatagramSocket socket = new DatagramSocket(PORT); DatagramPacket packet = new DatagramPacket(new
byte[BUFFER_SIZE],BUFF ER_SIZE); String Sys_message = null;

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
184
TextMessage TextMess = null; while(true) {
socket.receive(packet); Sys_message = new
String(packet.getData(),0,packet.getL ength()); … TextMess = session.createTextMessage(); TextMess.setText(Sys_message); … producer.send(TextMess); } } catch (JMSException e) { e.printStackTrace(); } … }
5.3.1.2 Wrapper IDS
Come sappiamo, il Wrapper IDS è il componente dell’architettura che si preoccupa di
comunicare con il sistema di gestione dei log di sistema, nello specifico con RSYSLOG,
allo scopo di ricevere gli alert generati dall’IDS SNORT.
Come per il wrapper SYSLOG, anche tale componente prevede per prima cosa la
connessione al bus e successivamente l’istanziazione di un thread che rappresenta il
wrapper vero e proprio. Di seguito è mostrato un estratto di codice del metodo main della
classe Wrapper_IDS.
… ConnectionFactory factory= new ActiveMQConnectionFactory(BUS_ADDRESS ); javax.jms.Connection connection; try { connection = factory.createConnection(); connection.start(); System.out.println("Connected to bus"); // Create a Session Session session = connection.createSession(false,Session.AUTO_ACKNOWL EDGE);

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
185
//Create and start Thread IDS Thd_IDS TIDS = new Thd_IDS(session); TIDS.start(); } catch (JMSException e) { e.printStackTrace(); } …
Come si può vedere, una volta istanziato, il thread viene anche lanciato. Quest’ultimo
effettua la creazione del topic IDS sul bus, genera un producer su di esso, e instanzia una
socket sul porto 2000, sul quale si pone in ascolto. Infatti proprio su tale porto, come già
anticipato nel capitolo precedente, è stato configurato l’inoltro dei log relativi agli alert di
SNORT da parte di RSYSLOG.
Nel caso d’uso simulato, si è previsto che venga effettuato un download di un file con
estensione .exe dall’IP dell’host sul quale era avvenuto l’accesso da parte dell’utente
raffaele. Alla realizzazione del download viene immediatamente sollevato un alert da
parte di SNORT, il quale è stato istruito in maniera tale da intercettare download relativi a
file con estensioni sensibili, tipo i .exe. Inoltre è stato configurato in maniera tale da
immettere tali alert all’interno dei log di sistema. Di conseguenza sarà generato un
apposito log, e precisamente:
<38>Sep 30 17:38:44 raffaele-HP-Pavillion-dv5-Noteb ook-PC snort: [1:900000007:3] Suspicious File Download – extensio n.exe[Priority: 2]: {TCP} 62.149.140.72:80 -> 192.168.1.108:36574
Tale log sarà inviato sul porto 2000 da parte di RSYSLOG, e sarà quindi ricevuto dal
Wrapper IDS, come mostrato nella figura seguente.
Figura 5.3: Output del Wrapper IDS

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
186
Da tale figura è anche possibile notare la successiva operazione svolta dal wrapper, il
quale infatti, alla ricezione del log sulla socket, non fa altro che analizzarne il contenuto, al
fine di classificare l’alert ricevuto tra quelli che in grado di gestire, che ricordiamo sono:
• Suspicious File Download
• Suspicious File Upload
• 20 or most connections to an external IP address
• TCP Port scan
Dopo aver rilevato che si tratta di un alert del tipo Suspicious File Download, il wrapper
genera un apposito MapMessage, popolato con le principali informazioni contenute in
esso. La creazione di tale messaggio avviene in seguito ad un’operazione di parsing del
testo ricevuto, così da poter estrarre tutte le informazioni di interesse. Una volta generato il
messaggio, questo viene immesso sul topic precedentemente definito. Fatto ciò, il wrapper
si rimette nuovamente in ascolto sulla socket.
Di seguito è mostrato un estratto del codice sorgente del metodo run della classe Thd_IDS
che realizza le operazioni descritte:
public synchronized void run(){
try { // Create the destination Topic and Message // Producer Destination destination = session.createTopic("IDS"); MessageProducer producer = session.createProducer(destination); … DatagramSocket socket = new DatagramSocket (PORT);
DatagramPacket packet = new DatagramPacket(new byte[BUFFER_SIZE],BUFFER_S IZE); String IDS_message = null;
while(true) { socket.receive(packet); IDS_message = new String(packet.getData(),0,packet.getLeng th()); … MapMessage mymap = null; if(IDS_message.contains("Suspicious File Dow nload")){

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
187
String file = IDS_message.substring(… ); String source_address = IDS_message.subs tring(…); String source_port = IDS_message.subs tring(…); String destination_address = IDS_message.subs tring(…); String destination_port = IDS_message.subs tring(…); … mymap.setString("File", file); mymap.setString("Source_address", source_ address); mymap.setString("Source_port", source_po rt); mymap.setString("Destination_address", destination_ address); mymap.setString("Destination_port", destinati on_port); producer.send(mymap); }else if(IDS_message.contains("20 or most co nnections to an external IP address")){ … }else if(IDS_message.contains("Suspicious F ile U pload")){ … }else if(IDS_message.contains("TCP Portscan ")){ … } } } catch (JMSException e) { e.printStackTrace(); } … }
5.3.1.3 Enterprise Service Bus
Dopo che i wrapper avranno ricevuto gli eventi provenienti dalle rispettive fonti, come
abbiamo visto, l’operazione seguente è relativa alla costruzione di appositi messaggi della
specifica JMS, per poi immetterli sul bus. È qui quindi che entra in azione l’ESB utilizzato,
cioè Apache ActiveMQ. Infatti, una volta avviato, accetterà le richieste di creazione dei
topic, precisamente quello Unfiltered_Syslog e quello IDS, e si preoccuperà di gestirli

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
188
garantendo che i messaggi spediti su di essi giungano ai relativi Consumer, cioè a quei
componenti interessati alla ricezione dei messaggi su quei topic.
Precisamente, i Consumer in questo caso sono rappresentati dal modulo di Prefiltering-
Aggregation, che si sottoscrive al topic Unfiltered_Syslog, e dal CEP Engine, che si
sottoscrive al topic IDS e, come vedremo, a quello SYSLOG.
Di seguito è mostrato uno screenshot del pannello di gestione di Apache ActiveMQ, nel
quale sono visibili i topic generati, e i messaggi in transito e prelevati da essi.
Figura 5.4: Topic su Apache ActiveMQ
Come si può notare, oltre ai vari topic di gestione, sono stati generati anche i topic prima
menzionati, nonché quello SYSLOG che è stato generato dal componente di Prefiltering-
Aggregation, di cui parleremo nel prossimo paragrafo. In realtà la figura fornisce anche
altre importanti informazioni. Infatti definisce che per ogni topic vi sia un numero pari a
uno di Consumer, nonché che all’interno del topic IDS è stato immesso un solo messaggio,
in quello Unfiltered_Syslog sono stati immessi quattro messaggi, mentre in quello
SYSLOG è stato immesso un unico messaggio.
Tali informazioni sono ovviamente attese, in quanto si è visto nei paragrafi precedenti che
il wrapper IDS ha ricevuto il solo alert relativo al download sospetto dall’IDS SNORT, il
quale è stato quindi immesso sul topic IDS, mentre il wrapper SYSLOG ha ricevuto quattro

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
189
log di sistema da RSYSLOG, i quali sono quindi stati immessi sul topic Unfiltered_Syslog.
Relativamente al topic SYSLOG, rimandiamo la trattazione al prossimo paragrafo, così da
comprendere al meglio i dati presenti nella figura 5.4.
Ovviamente i messaggi, una volta messi sul bus, sono stati smistati ai rispettivi consumer.
5.3.1.4 Prefiltering-Aggregation
Come appena detto, dopo che i messaggi sono immessi sui topic dell’ESB, essi saranno
smistati ai rispettivi consumer. Uno di questi è proprio il componente di Prefiltering-
Aggregation, il quale, come sappiamo, ha lo scopo sostanziale di effettuare un filtraggio
dei messaggi che viaggiano sul topic Unfiltered_Syslog al fine di immettere su quello
SYSLOG i soli messaggi di log relativi ad operazioni di accesso ad un host.
A tal fine, dopo essersi connesso al bus, tale componete istanzia un MessageConsumer sul
topic Unfiltered_Syslog e vi associa un apposito BusListener. Di seguito è mostrato un
estratto di codice del metodo main della classe Prefiltering_Aggregation.
…
ConnectionFactory factory= new ActiveMQConnectionFactory(BUS_ADDR ESS);
javax.jms.Connection connection; try { connection = factory.createConnection(); connection.start(); System.out.println("Connected to bus"); // Create a Session Session session = connection.createSession(false, Session.AUTO_ACKN OWLEDGE); // Create the Topic, a MessageConsumer and // Set a Listener Destination destination = session.createTopic("Unfiltered_ Syslog"); MessageConsumer consumer = session.createConsumer(dest ination); BusListener BL = new BusListener(ses sion); consumer.setMessageListener(BL); } catch (JMSException e) { e.printStackTrace();}…

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
190
Una volta istanziato il listener, e dopo averlo associato al consumer, nel momento in cui
giunge un nuovo messaggio, e precisamente un TextMessage, sul topic Unfiltered_Syslog
viene immediatamente invocato il metodo onMessage dello stesso. Attraverso tale metodo,
il componente di prefiltering, realizza la vera e propria operazione di filtraggio. Infatti
esso per prima cosa verifica se il messaggio ricevuto sia o meno un TextMessage. In tal
caso, effettua l’analisi del suo contenuto al fine di verificare se si tratti di un messaggio
contenente o meno un log relativo ad un’operazione di accesso ad un host
dell’organizzazione. A tal fine verifica, come già accennato nel capitolo precedente, se
esso contenga o meno le parole sshd[ e Accepted. Se la verifica ha prodotto esito positivo,
allora effettuerà un parsing del testo del TextMessagge, così da prelevare le informazioni
rilevanti e costruire un apposito MapMessagge da immettere sul topic SYSLOG, il quale è
stato generato dal costruttore della classe BusListener.
Di seguito è mostrato un estratto del codice sorgente del costruttore e del metodo
onMessage della classe BusListener, che realizzano le operazioni descritte:
public BusListener(Session session){
Destination destination; this.session = session; try { destination = this.session.createTopic(" SYSLOG"); // Create a MessageProducer from the Session // to the Topic producer = this.session.createProducer(dest ination); … } catch (JMSException e) { e.printStackTrace(); } }
public void onMessage(Message message) { try{ if(message instanceof TextMessage){ TextMessage txtmessage = (TextMessage)messag e; … if((txtmessage.getText().contains("ss hd[")) && (txtmessage.getText().contains("Acce pted"))){ MapMessage mapmessage = session.createMapM essage();

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
191
String text = txtmessage.getText(); …
mapmessage.setString("Host", text.substring(…)); …
mapmessage.setString("HostIP",…); … mapmessage.setString("Auth_method", text.subst ring(…)); mapmessage.setString("User", text.subst ring(…)); mapmessage.setString("ExtIP", text.subst ring(…)); mapmessage.setString("ExtPort", text.subst ring(…)); producer.send(mapmessage); … }else{ System.out.println("\nNew message fil tered!"); } }else System.out.println("\nNo TextMessage rec eived!"); }catch(JMSException e){ e.printStackTrace(); } }
Si noti che, se il messaggio non contiene le parole chiave prima specificate, esso viene
scartato, come si può vedere nella figura seguente.
Figura 5.5: Output del componente di Prefiltering-Aggregation
Si vede infatti, come, tra tutti i messaggi ricevuti, l’unico a non essere scartato è quello

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
192
relativo alla connessione tramite il protocollo SSH. Di conseguenza si può comprendere il
motivo per cui nella figura 5.4, presentata nel paragrafo precedente, si indicato la presenza
di un unico messaggio all’interno del topic SYSLOG.
5.3.1.5 CEP Engine
L’ultimo componente dell’architettura ad entrare in azione è il CEP Engine. Esso infatti,
rappresenta il consumer di tutti i topic generati sul bus, tranne che per quello
Unfiltered_Syslog. Come sappiamo, il suo scopo è quello di effettuare la correlazione tra
gli eventi ricevuti in ingresso attraverso il bus, al fine di rilevare il verificarsi di un
determinato caso d’uso. In questo caso specifico, il suo obbiettivo è quello di rilevare
un’intrusione all’interno di un host attraverso l’utilizzo di credenziali rubate.
A tale scopo, come già definito nel capitolo 4, questo modulo utilizza il motore di
correlazione Esper, il quale ovviamente necessita di essere instanziato ed opportunamente
configurato. Proprio questa è la prima operazione svolta dal componente CEP Engine, il
quale infatti configura Esper definendo sia i tipi di eventi che saranno utilizzati, nonché le
eventuali View. Successivamente instanzia il motore di correlazione e lo istruisce con delle
apposite espressioni EPL, così da consentirgli il riconoscimento dei vari casi d’uso.
A partire da tali espressioni, saranno generati degli appositi statement, uno per ogni regola,
ai quali sarà associato un listener, il cui metodo update verrà richiamato in caso di
matching dei flussi di eventi ricevuti con una o più regole.
Dopo ciò, viene istanziato un oggetto BusConnection, il quale si preoccuperà di realizzare
la connessione sul bus e ricevere i messaggi che viaggiano sui topic, dopo ovviamente
aver istanziato dei MessageConsumer per ogni topic da ascoltare (IDS e SYSLOG in
questo caso) e un apposito listener.
Di seguito è mostrata una parte del codice del metodo main della classe MainCEvOS e del
metodo Connection della classe BusConnection, nei quali sono mostrate le sole istruzioni

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
193
fondamentali per questo caso d’uso.
public static void main(String[] args) throws InterruptedExcep tion{
// Configurazione engine Configuration config = new Configuration(); … config.addEventType("AccessSystemEvent", AccessSystemEven t.class); config.addEventType("DownloadFileEvent", DownloadFileEven t.class); … config.addPlugInView("accessSystem", "accessSystemPV", AccessSystemViewFactory.class.ge tName()); EPServiceProvider epService= EPServiceProviderManager.getProvider("CEvO S_Engine" , co nfig); … // Definizione EPL per Scenario reti: Accesso // sospetto e Download sospetto String expressionSR1_1 = "insert into SuspiciousAccessSystem Event …”; EPStatement stmtSR1_1 = epService.getEPAdministrator().createEPL(expression SR1_1); String expressionSR1 = "insert into ScenarioR1Stream select…”; EPStatement stmtSR1 = epService.getEPAdministrator().createEPL(expression SR1); … // Istanziazione listener MyListener listener = new MyListener(); … stmtSR1.addListener(listener); stmtSR1_1.addListener(listener); … //Connessione al bus BusConnection BC = new BusConnection(epService); BC.Connection();
} public void Connection(){
ConnectionFactory factory= new ActiveMQConnectionFactory(BUS_ADDRESS);
javax.jms.Connection connection; try { connection = factory.createConnection(); connection.start(); … // Create a Session Session session =
connection.creat eSession(false,

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
194
Session.AUT O_ACKNOWLEDGE);
// Create Topic, a MessageConsumer and Set a // Listener Destination destination = session.createTopic("I DS"); MessageConsumer consumer = session.createConsumer(destinat ion); BusListener BL = new BusListener(epServic e); consumer.setMessageListener(BL) ; destination = session.createTopic("SYSLOG "); consumer= session.createConsumer(destination) ; consumer.setMessageListener(BL); … } catch (JMSException e) { e.printStackTrace(); } }
Si noti che per brevità non sono state inserite le regole EPL (§ 4.3.5.3).
Dal codice è possibile anche notare la configurazione di Esper con gli eventi
AccessSystemEvent e DownloadFileEvent, che rappresentano rispettivamente l’evento
accesso al sistema e quello download file sospetto rappresentati sottoforma di Java POJO.
Ricordiamo che una loro descrizione accurata è stata già data nel capitolo precedente.
A questo punto, terminate le operazioni di configurazione, così come è accaduto per il
componente di Prefiltering-Aggregation, alla ricezione di un messaggio su uno dei topic
sottoscritti viene invocato il metodo onMessage della classe BusListener.
Attraverso tale metodo il CEP Engine, sulla base del topic dal quale è stato ricevuto il
MapMessage, va ad istanziare un oggetto evento. Nel caso considerato, ad esempio, alla
ricezione del MapMessage relativo all’evento accesso sul topic SYSLOG, il modulo va ad
istanziare un oggetto della classe AccessSystemEvent e a popolarlo con i dati contenuti nel
messaggio stesso. Successivamente il messaggio sarà inviato al motore di correlazione.
Stessa operazione viene svolta alla ricezione del MapMessage relativo all’evento
download sospetto. In questo caso però, dato che sul topic IDS, sul quale è stato ricevuto,
possono viaggiare differenti tipi di alert, viene effettuato un controllo sul campo Type del
messaggio. Nel caso considerato, trattandosi di un download, viene istanziato un oggetto
della classe DownloadFileEvent, il quale viene prima opportunamente popolato e poi

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
195
inoltrato al motore di correlazione.
Di seguito è mostrato un estratto di codice del metodo onMessage, dove sono mostrate le
solo istruzioni fondamentali per il caso d’uso considerato.
public void onMessage(Message message) {
try{ if(message instanceof MapMessage){ MapMessage mapmessage = (MapMessage) mes sage; if(message.getJMSDestination().toString( ) .contains ("IDS")){ time=new Date().toString(); if(mapmessage.getString("Type") .contains("Suspicious File Dow nload")){ DownloadFileEvent DFevent = new DownloadFileEvent( mapmessage.getString("Source_a ddress"),
mapmessage.getString("So urce_port"), mapmessage.getString("Destina tion_address"), mapmessage.getString("Dest ination_port"), mapmessage.getString("Fi le"),time);
epService.getEPRuntime() .sendEvent( DFevent); …
}else if(mapmessage.getString("Type"). contains( "20 or most connections to an external IP address") … }else if(mapmessage.getString("Type ") .contains("Suspicious File Upload")){ … }else if(mapmessage.getString("Type") .contains("TCP Por tscan")){ … } }else if(message.getJMSDestination().toS tring() .contains("S YSLOG")){ time=new Date().toString(); AccessSystemEvent ASevent = new AccessSystemEvent( mapmessage.getString("Host IP"), mapmessage.getString("Host "), mapmessage.getString("ExtI P"), mapmessage.getString("ExtP ort"), time,

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
196
mapmessage.getString("Auth_ method"), mapmessage.getString("User ")); epService.getEPRuntime() .sendEvent(ASevent); … }else if(message.getJMSDestination() .toString().contains("LAMP")){
… }else if(message.getJMSDestination(). toString().contains("C AMERA")){ … }else if(message.getJMSDestination() .toString().contains("BADGE_R EADER")){ …} }else System.out.println("No MapMessage receive d!"); }catch(JMSException e){ e.printStackTrace(); }
}
A questo punto, il motore di correlazione, ricevuti gli eventi cerca un eventuale matching
con le regole con le quali è stato precedentemente istruito. Nel caso in cui venga trovata
una corrispondenza, viene richiamato il metodo update della classe MyListener, di cui
un’istanza era stata associata ai vari statement relativi alle regole definite.
Con tale metodo, il listener verifica quale sia l’evento complesso generato, e sulla base di
quest’ultimo produce un alert, che sarà visualizzato a terminale. Di seguito è mostrato
parte del codice del metodo update della classe MyListener.
public void update(EventBean[] newEvents, EventBean [] oldEven ts) {
EventBean event = newEvents[0]; if(event.getEventType().getName() .compareTo("Scenario2Stream")==0){ …} if(event.getEventType().getName() .compareTo("Scenario1Stream")==0){ …} if(event.getEventType().getName() .compareTo("ScenarioR1Stream")==0){ System.out.println("\n ** ALERT: Compromised User Event caused by Suspicious Access System and File Download\n ** UserID= " +

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
197
event.get("userId") + " ---- Host= " + event.get("host") + " ---- Host IP= " + event.get("hostIp")); System.out.println(" ** Access System info:" ); System.out.println(" ** External IP= " + event.get("extIp") + ":"+event.get("ex tPort")+ " ---- Authentication Method= " + event.get("authMethod")); System.out.println(" ** Motivation= " + event.get("motivation") + " ---- Tim e= " + event.get("aTime")); System.out.println(" ** File Download info:" ); System.out.println(" ** File= " + event.get("file") + " ---- Source= " + event.get("sourceIp")+":" + event.get("sourcePort")); System.out.println(" ** Destination Port= " + event.get("destinationPort") + " Tim e= " + event.get("dTime") + "\n"); … } if(event.getEventType() .getName().compareTo("ScenarioR2aStre am")==0){ …} if(event.getEventType() .getName().compareTo("ScenarioR2bStre am")==0){ …}}
Nel caso considerato, si ha un matching sia con la regola che genera lo stream
SuspiciousAccessSystemEvent sia con quella che genera lo stream ScenarioR1Stream, che
riportiamo di seguito in versione ridotta.
insert into SuspiciousAccessSystemEvent select * from pattern[every ASE=AccessSystemEvent].accessSystem:accessSystemPV (ASE.hostIp, ASE.host, ASE.extIp, ASE.extPort, ASE. time, ASE.authMethod, ASE.userId)
insert into ScenarioR1Stream select … from pattern[every SASE=SuspiciousAccessSystemEvent -> DFE=DownloadFileEvent (SASE.hostIp=DFE.destinationIp) where timer:within(5 min)]

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
198
Ciò è avvalorato anche dall’output del modulo CEP Engine mostrato di seguito.
Figura 5.6: Output del CEP Engine
Precisamente all’arrivo del ASevent, il motore trova una corrispondenza con la prima
regola, dato che essa analizza tutti gli eventi de tipo AccessSystemEvent.
Di conseguenza, l’evento ricevuto viene passato alla View AccessSystemPV, la quale,
come già detto nel capitolo precedente, si preoccupa di verificare se l’utente che ha
effettuato l’accesso stia rispettando o meno le sue normali abitudini.
Precisamente il controllo viene effettuato sull’IP esterno utilizzato, sul metodo di
autenticazione, nonché sull’host a cui l’utente si è connesso, verificando se ognuno di essi
sia già presente in un’apposita HashMap (users nel codice) contenete la storia degli
accessi di quell’utente, proprio rispetto a questi elementi. Inoltre viene verificato anche se
si tratta della prima connessione, semplicemente controllando se l’utente sia presente o
meno nella HashMap.
Nel caso in cui uno di questi elementi non sia presente nella rispettiva HashMap, allora
sarà generato un evento del tipo SuspiciousAccessSystemEvent.
Di seguito è mostrato una parte del codice del metodo update, e dei metodi da esso
utilizzati, della classe AccessSystemView che si preoccupa di realizzare queste operazioni.
public void update(EventBean[] newData, EventBean[] oldDa ta) {
if (newData!=null) for (EventBean theEvent : newData){ // Recupero dati evento eventsPerStream[0] = theEvent; hostIp =

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
199
(String)hostIpExpression.getExprEvalu ator() .evaluate (eventsPerStream, true, agentInstanceViewFactoryContext); host = (String)… extIp = (String)… extPort = (String)… time = (String)… authMethod = (String)… userId = (String)… // Verifica l'accesso if(verify_access()) continue; // Invia i dati postData(); } } private boolean verify_access(){ boolean status_verify = true; … String motivation = ""; if(users.containsKey(userId)){ User user = (User)users.get(userId); HashMap<String,String> auth_methods = (HashMap<String,String>) user.get_auth_methods(); HashMap<String,String>hosts= (HashMap<String,String>) user.get_h osts(); HashMap<String,String>extIPused= (HashMap<String,String>)user.get_IP (); if(!auth_methods.containsKey(authMeth od)){ status_verify = false; motivation = motivation+" //Auth method nev er used"; } if(!hosts.containsKey(host)){ status_verify = false; motivation= motivation+" //Host never used "; } if(!extIPused.containsKey(extIp)){ status_verify = false; motivation=motivation+" //Ext IP never used"; } }else{ status_verify = false; motivation = "//First connection"; }
return status_verify; } private void postData(){ SuspiciousAccessSystemEvent SASE = new SuspiciousAccessSystemEvent( hostIp,host,extIp,extPort,time,authMe thod,

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
200
userId,motivation); EventBean outgoing = agentInstanceViewFactoryContext. getStatementContext().getEventAdapterSe rvice() .adapterForBean(SASE); if (lastEvent == null){ this.updateChildren(new EventBean[] {outgoing }, null); }else{ this.updateChildren(new EventBean[]{out going}, new EventBean[]{lastEvent}); } lastEvent = outgoing; … }
Nel caso in esame, il metodo verify_access restituisce il valore false, in quanto essendo
vuota la HashMap users, l’utente risulta essersi connesso per la prima volta. Di
conseguenza viene richiamato il metodo post_Data che genera l’evento.
A questo punto, tale evento insieme a quello DFevent ricevuto dal CEP Engine provoca il
matching con la seconda regola. Infatti, come è possibile notare dalla figura 5.6, i due
eventi presentano lo stesso indirizzo IP come hostIP, per l’evento accesso, e destinationIP,
per l’evento download. Inoltre il primo segue il secondo in un intervallo temporale minore
di cinque minuti. Pertanto viene generato un evento del tipo ScenarioR1Stream, che porta
alla visualizzazione da parte del listener dell’alert visibile sempre in figura 5.6.
5.4 Casi d’uso simulati: Rilevamento di un accesso non autorizzato
Il secondo caso d’uso simulato è quello relativo alla possibilità che un dipendete
dell’organizzazione monitorata, o una persona esterna, acceda ad una delle aree sensibili
utilizzando il badge di un altro dipendente.
In questa ipotesi, il sistema di controllo degli accessi verifica l'identità della persona che
sta accedendo all’area riservata attraverso il badge magnetico, che è stato opportunamente
inserito nel badge reader, autorizzandolo.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
201
Contestualmente, la videocamera posta all’ingresso dell’area effettua la Face Detection e
rileva il volto della persona che ha richiesto l'accesso, identificandolo (nel caso in cui sia
un dipendente dell’organizzazione).
Si comprende quindi che, in questo caso d’uso, i sensori che intervengono sono due, e
precisamente sono un badge reader, che invia l’evento relativo alla lettura del badge del
dipendente, e una videocamera di sicurezza con modulo di Face Detection, la quale tenta
di riconoscere la persona che sta tentando l’accesso generando un apposito evento con
l’esito.
La nostra piattaforma, attraverso la correlazione di questi due eventi, è in grado di
riconoscere il tentativo di un accesso non autorizzato, cioè un accesso effettuato da un
dipendente che sta utilizzando il badge di un altro dipendente, o addirittura da una persona
non riconosciuta che utilizza un badge aziendale. Ma vediamo come ciò avviene attraverso
l’analisi del comportamento di ogni singolo componente.
5.4.1 Comportamento del sistema
Nello scenario analizzato, non tutti i moduli del sistema progettato sono utilizzati, infatti
nell’ambito della Building Security non è previsto l’ausilio del componente di Prefiltering-
Aggregation. Precisamente i componenti chiamati in causa sono:
• I BACnet Device
• Il Wrapper BACnet
• L’ Enterprise Service Bus
• Il CEP Engine
Vediamo quindi come ognuno di essi lavoro nell’ambito di questo caso d’uso.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
202
5.4.1.1 BACnet Device
I BACnet Device, come abbiamo definito nel capitolo precedente, sono stati implementati
allo scopo di colmare l’assenza di dispositivi reali per la realizzazione di simulazioni.
Pertanto si è reso necessaria l’implementazione di software in grado di simularli.
Precisamente, per lo scenario in analisi, sono simulati i due device CAMERA e
BADGE_READER. Il loro comportamento è molto semplice, infatti i due device una volta
avviati si limitano a generare, ad intervalli di tempo regolari, delle modifiche al valore del
BACnet Object sotto osservazione, il che produce l’invio di una COVNotification agli altri
BACnet Device che hanno effettuato una sottoscrizione COV a tale oggetto. Come
vedremo nei prossimi paragrafi, e come già accennato nel capitolo 4, il dispositivo che
effettua tale sottoscrizione è il Wrapper_BACnet.
Di seguito è mostrato un estratto del codice del metodo main del device CAMERA che
realizza tali operazioni.
public static void main(String[] args) {
localDevice = new LocalDevice(DEVICE_ID, BROADCAST_ADDRESS, LOCAL_DEVICE_ ADDRESS); localDevice.setPort(0xBAC0); // Set up objects. ai0 = new BACnetObject(localDevice, new
ObjectIdentifier(ObjectType.binaryValue,0)); try { localDevice.addObject(ai0); … localDevice.initialize(); System.out.println("I'm ready"); try { Thread.sleep(20000); } catch (InterruptedException e2) { e2.printStackTrace(); } boolean ai0value = false; int i=1; while (i<10) { // Change the values. ai0value = !ai0value; ai0.setProperty(PropertyIdentifier.pres entValue, ai0value ? BinaryPV.active : BinaryPV.inactive);

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
203
System.out.println("Observed value changed...COVNotificatio n sent"); Thread.sleep(5000); i++; } } catch (BACnetServiceException e) { e.printStackTrace(); } … }
Si noti che lo stesso codice caratterizza anche il metodo main del device
BADGE_READER. Tale codice porta al seguente output.
Figura 5.7: Output del Camera Device
5.4.1.2 Wrapper BACnet
Il Wrapper BACnet, come noto, è il componente dell’architettura che si preoccupa di
comunicare con i dispositivi basati su questo protocollo, nello specifico con i due device
definiti nel capitolo precedente, allo scopo di ricevere gli eventi da essi generati.
Come già descritto nel capitolo 4, tale componente per prima cosa effettua la connessione
al bus e successivamente instanzia un oggetto del tipo Wrapper_BACnet che rappresenta il
wrapper vero e proprio. Precisamente di tale oggetto viene richiamato il metodo
bacnet_interaction, il quale si preoccupa di stabilire una connessione con i vari device, e
precisamente una sottoscrizione COV, secondo i passi illustrati nella figura 4.8. A tale
scopo istanzia anche un apposito BACnet_Listener. Di seguito è mostrato un estratto di
codice dei metodi main e bacnet_interaction della classe Wrapper_BACnet.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
204
public static void main(String[] args) {
ConnectionFactory factory= new ActiveMQConnectionFactory(BUS_ ADDRESS); javax.jms.Connection connection; try { connection = factory.createConnection(); connection.start(); System.out.println("Connected to bus"); // Create a Session session = connection.createSession(false, Session.AUTO_ACKN OWLEDGE); Wrapper_BACnet WB = new Wrapper_BACnet(); WB.bacnet_interaction(); } catch (JMSException e1) { e1.printStackTrace(); }… } private void bacnet_interaction() throws …{ // Create Local Bacnet Device localDevice = new LocalDevice(DEVICE_ID,BROADCAST _ADDRESS, LOCAL_DEVICE_ADDRESS); localDevice.setPort(0xBAC0); localDevice.getConfiguration().setProperty( PropertyIdentifier.segmentationSupporte d, Segmentation.noSegmentation); localDevice.getEventHandler().addListener(ne w BACnet_Listener(localDevice,session)); localDevice.initialize(); // Send WhoIsRequest localDevice.sendBroadcast(0xBAC0,new WhoIsRequest(nul l,null)); System.out.println("\nWhoIsRequest sent\n"); … // Wait for I-Am message Thread.sleep(15000); }
Dal codice è possibile notare che il metodo bacnet_interaction in realtà copre i soli primi
due passi della figura 4.8. Per semplicità li riportiamo di seguito:
• Istanziazione e inizializzazione di un Device Locale (Client)
• Invio di un messaggio broadcast WHO-IS da parte del Device Locale, attraverso il
quale è grado di conoscere i dispositivi connessi alla rete
• Invio della risposta I-AM del Device Remoto al Device Locale, con la quale il device
remoto fa conoscere le proprie caratteristiche al device locale

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
205
• Invio da parte del Device Locale di una richiesta di sottoscrizione ad un oggetto, od
alle sue proprietà, mediante un messaggio di SubscribeCOVRequest verso il Device
Remoto
• Invio da parte del Device Remoto del messaggio SimpleACK verso il Device Locale
• Il Device Remoto invia una notifica al sottoscrittore ConfirmedCOVNotification, che
contiene le informazioni richieste dal Local Device, ogniqualvolta l’oggetto e/o la
proprietà sottoscritta viene modificata
• Il LocalDevice invia una SimpleAck al Dispositivo Remoto
Gli altri passi infatti saranno realizzati dal BACnet_Listener. Tale classe, come abbiamo
già visto nel capitolo precedente, è dotata di tanti metodi quanti sono i tipi di messaggi che
è possibile ricevere da un device BACnet remoto. Nel nostro caso, dovendo solo gestire
messaggi di I-AM e COVNotification, si è prevista la sola implementazione dei relativi
metodi, cioè iAmReceived e covNotificationReceived.
Il primo viene invocato alla ricezione di un messaggio di I-AM, il quale è inviato in
automatico dai device prima descritti, alla ricezione del messaggio di WHO-IS. Esso
prevede per prima cosa la generazione dei topic sul bus e l’istanziazione del rispettivo
MessageProducers (che sarà anche inserito all’interno di una apposita List), sulla base del
vendorID del dispositivo mittente. Precisamente, nel caso in esame saranno generati due
topic: quello CAMERA, su cui viaggeranno gli eventi di Face Detection generati dalla
videocamera, e quello BADGE_READER, su cui viaggeranno gli eventi generati dal badge
reader. Successivamente tale metodo aggiunge il device remoto mittente in un’apposita
List, e gli invia una SubscribeCOVRequest per monitorare l’oggetto che esso gestisce.
Il metodo covNotificationReceived viene invece invocato alla ricezione di una notifica
COV da parte di uno dei dispositivi remoti con cui si è realizzata una sottoscrizione COV,
e si preoccupa di creare i MapMessage che descrivono l’evento relativo al cambiamento
del valore monitorato. Ovviamente tale operazione sarà differenziata a seconda di quale
sia il device mittente.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
206
Di seguito è mostrato parte del codice sorgente dei due metodi, contenente le sole
istruzioni fondamentali per il caso d’uso in esame.
public synchronized void iAmReceived(RemoteDevice d ) {
// I-Am received Destination destination = null; // Set name try{ switch (d.getVendorId()) { case LAMP:{ … }break;
case CAMERA:{ d.setName("CAMERA"); index_CAMERA = index; destination = session.createTopic("CAMERA "); Destinations.add(index_CAMERA,destination ); MessageProducers.add(session .createProducer(destination)); }break;
case BADGE_READER:{ d.setName("BADGE_READER"); index_BADGE_READER = index; destination = session.createTopic("BADGE_ READER"); Destinations.add(index_BADGE_READER, destination); MessageProducers.add(session .createProducer(destination )); }break; } } catch (JMSException e) { e.printStackTrace(); } index++; … remoteDevices.add(d); // Send SubscribeCOV … SubscribeCOVRequest SCOVreq = new SubscribeCOVRequest(…); try { … localDevice.send(d, SCOVreq); … } catch (BACnetException e) { e.printStackTrace(); }… }

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
207
public void covNotificationReceived(…) {
MapMessage mymap; Random rand=new Random(); try{
mymap = session.createMapMessage(); switch (initiatingDevice.getVendorId()) {
case LAMP:{ ... }break; case CAMERA:{ String camID = ""+rand.nextInt(4); String type_event = listOfValues.getValues().get( 1) .getValue().toString(); mymap.setString("camID",camID); mymap.setString("EventType", type_event); if(type_event.contains("1")){ String ID_employee = ""+rand.ne xtInt(4); mymap.setString("ID_employee", ID_e mployee); } MessageProducers.get(index_CAMERA) .send(mymap); … }break; case BADGE_READER:{ String badgeID = ""+rand.nextInt(4); String ID_employee = ""+rand.nextInt(4) ; mymap.setString("badgeID",badgeI D); mymap.setString("ID_employee", ID_e mployee); MessageProducers.get(index_BADGE_RE ADER) .sen d(mymap); … }break; } } catch (JMSException e) { e.printStackTrace(); }
}
Una cosa fondamentale da notare è che all’interno del metodo covNotificationReceived, i
dati necessari al popolamento dei MapMessage da immettere sui topic sono generati
causalmente all’interno del metodo stesso. Il motivo di tale operazione è dovuta alla
necessità di dover superare la limitazione imposta dalla libreria BACnet4J, che ricordiamo
è alla base sia dell’implementazione di questo wrapper sia dei dispositivi prima descritti.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
208
Tale limitazione in pratica prevede di poter gestire un unico oggetto quando un
LocalDevice è utilizzato come client, e soprattutto la possibilità di poter sottoscrivere COV
solo su oggetti di tipo booleano. Ciò impedisce la possibilità di poter simulare
precisamente il comportamento reale di un dispositivo, dal quale si potrebbero ricavare
senza problemi tutte le informazioni necessario. Di conseguenza l’unico valore che è
possibile ottenere è quello booleano dell’oggetto tenuto sotto osservazione dai device. In
particolare, il valore di tale oggetto viene utilizzato solo nell’ambito degli eventi generati
dalla device CAMERA, al fine di discriminare gli eventi di Face Detection da quelli di
Camera Tampering. Infatti, ricordiamo che si è presupposto che tale device generi in
maniera alternata le due tipologie di eventi.
Detto ciò, si comprende che all’avvio del wrapper, nel caso considerato, quest’ultimo
invia la propria WHO-IS Request, ricevendo in risposta i messaggi di I-AM dai due device
simulati e successivamente sottoscriverà una COV con entrambi. Di conseguenza ad ogni
modifica del valore dell’oggetto monitorato dai due dispositivi, il wrapper riceverà una
COV Notification. Precisamente è stata presa in considerazione una solo notifica per
dispositivo, delle nove generate da entrambi: una proveniente dal device CAMERA,
relativa ad un evento di Face Detection, che porta alla creazione del relativo MapMessage
sul topic CAMERA, e una dal device BADGE_READER, che porterà alla creazione del
relativo MapMessage sul topic BADGE_READER.
Di seguito è mostrato l’output del wrapper.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
209
Figura 5.8: Output del Wrapper_BACnet
5.4.1.3 Enterprise Service Bus
Come nel caso d’uso precedente, anche per questo caso Apache ActiveMQ, una volta
avviato, accetterà le richieste di creazione dei topic, precisamente quello CAMERA e
quello BADGE_READER, e si preoccuperà di gestirli garantendo che i messaggi spediti su
di essi giungano ai relativi Consumer. Precisamente, il Consumer in questo caso è unico
ed è rappresentato dal CEP Engine, il quale si sottoscrive ad entrambi i topic.
In figura 5.9 è mostrato un screenshot del pannello di gestione di Apache ActiveMQ, nel
quale sono visibili i topic generati, e i messaggi in transito e prelevati da essi.
Come si può notare, oltre ai vari topic di gestione, sono stati generati anche i topic prima
menzionati. Inoltre è possibile vedere che per ogni topic vi è un numero pari a uno di
Consumer, nonché che all’interno dei topic CAMERA e BADGE_READER sono stati
immessi, e successivamente inoltrati al consumer, nove messaggi.
Tali informazioni sono ovviamente attese, in quanto si è visto nei paragrafi precedenti che
il wrapper BACnet ha ricevuto nove eventi del device CAMERA e nove da quello
BADGE_READER.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
210
Figura 5.9: Topic su Apache ActiveMQ
5.4.1.4 CEP Engine
Essendo il consumer dei due topic considerati, il CEP Engine è l’ultimo dei componenti
dell’architettura ad entrare in azione. Il suo comportamento in questo caso d’uso è
esattamente pari a quello descritto per il caso d’uso precedente. Pertanto non saranno
descritte nuovamente tutte le singole operazioni. Ovviamente le differenze risiedono nei
differenti tipi di eventi gestiti, e nelle differenti regole EPL che questi ultimi attivano.
Vediamo pertanto parte del codice del metodo main della classe MainCEvOS e del metodo
Connection della classe BusConnection.
public static void main(String[] args) throws InterruptedExcep tion{
// Configurazione engine Configuration config = new Configuration(); … config.addEventType("BadgeReaderEvent", BadgeReaderEven t.class); config.addEventType("FaceDetectionEvent", FaceDetectionEven t.class); … EPServiceProvider epService = EPServiceProviderManager.getProvider( "CEvOS_Engine", config); … // Definizione EPL per Scenario 2: BadgeReader e // FaceDetectoin

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
211
String expressionS2 = "insert into Scenario2Stre am…"; EPStatement stmtS2 = epService.getEPAdministrator().createEPL(expre ssionS2); … // Istanziazione listener MyListener listener = new MyListener(); … stmtS2.addListener(listener); … //Connessione al bus BusConnection BC = new BusConnection(epService); BC.Connection(); }
public void Connection(){ ConnectionFactory factory= new ActiveMQConnectionFactory(BUS_ADDRESS); javax.jms.Connection connection; try { connection = factory.createConnection(); connection.start(); … // Create a Session Session session = connection.createSession(false, Session.AUTO_ACKN OWLEDGE); // Create the destination Topic, a MessageConsume r // and Set a Listener Destination destination = session.createTopic(" CAMERA"); MessageConsumer consumer = session.createConsumer(dest ination); BusListener BL = new BusListener(epService ); consumer.setMessageListener(BL); … destination = session.createTopic("BADGE_R EADER"); consumer = session.createConsumer(destinat ion); consumer.setMessageListener(BL); … } catch (JMSException e) { e.printStackTrace(); } }
Si noti che per brevità non sono state inserite le regole EPL (§ 4.3.5.3).
Dal codice è possibile anche notare la configurazione di Esper, e precisamente l’aggiunta
a quest’ultima degli eventi BadgeReaderEvent e FaceDetectionEvent, che rappresentano
rispettivamente l’evento lettura di un badge e quello di riconoscimento di un volto.
In questo caso infatti, lo scopo di questo componente è quello di rilevare un accesso non

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
212
autorizzato effettuato da un dipendente utilizzando un badge differente dal proprio.
A tale scopo, una volta ricevuti i messaggi in transito sui topic CAMERA e
BADGE_READER del bus, attraverso il metodo onMessage della classe BusListener, il
CEP Engine, proprio all’interno di tale metodo va ad istanziare un oggetto evento a
seconda del topic dal quale ha ricevuto il MapMessage. Precisamente viene istanziato un
oggetto della classe FaceDetectionEvent se il MapMessage proviene dal topic CAMERA e
presenta come valore del campo Type la stringa “1”, mentre ne viene istanziato uno della
classe BadgeReaderEvent, nel caso di MapMessage ricevuto dal topic BADGE_READER.
Una volta istanziati e popolati, tali eventi saranno inviati al motore di correlazione.
Di seguito è mostrato un estratto di codice del metodo onMessage, dove sono mostrate le
solo istruzioni fondamentali per il caso d’uso considerato.
public void onMessage(Message message) {
try{ if(message instanceof MapMessage){ MapMessage mapmessage = (MapMessage) message ; if(message.getJMSDestination() .toString().contains("C AMERA")){ if(mapmessage.getString("EventType") .contai ns("1")){ time=new Date().toString(); FaceDetectionEvent FDevent= new FaceDetectionEvent("ROS_VNC" +mapmessage.getString("ID_employee"), time, "POS_"+mapmessage.getString("camID")) ; epService.getEPRuntime().sendEvent(FDev ent); … }else{ time=new Date().toString(); TamperingEvent Tevent= new TamperingEvent("CAM_"+mapmessage. getString("camID"),"POS_" +mapmessage.getString("camID"), time) ; epService.getEPRuntime().sendEvent(Tevent); …} }else if(message.getJMSDestination().toString () .contains("BADGE_R EADER")){ time=new Date().toString(); BadgeReaderEvent BRevent= new BadgeReaderEvent("ROS_VNC" +mapmessage.getString("ID_employee" ),time, "POS_"+mapmessage.getString("badgeI D"));

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
213
epService.getEPRuntime().sendEvent(BRevent); … }else if(message.getJMSDestination().toStri ng() .contains( "LAMP")){ … }else if(message.getJMSDestination().toSt ring() .contains ("IDS")){ … }else if(message.getJMSDestination().to String() .contains("S YSLOG")){ …} }else System.out.println("No MapMessage received!" ); }catch(JMSException e){ e.printStackTrace(); }
}
A questo punto, ricevuti gli eventi, il motore di correlazione cerca un eventuale matching
con le regole con le quali è stato precedentemente istruito. Nel caso in cui venga trovata
una corrispondenza, viene richiamato il metodo update della classe MyListener, di cui
un’istanza era stata associata ai vari statement relativi alle regole definite.
Con tale metodo, il listener verifica quale sia l’evento complesso generato, e sulla base di
quest’ultimo produce un alert, che sarà visualizzato a terminale. Di seguito è mostrato
parte del codice del metodo update.
public void update(EventBean[] newEvents, EventBean [] oldEven ts) {
EventBean event = newEvents[0]; if(event.getEventType().getName() .compareTo("Scenario1Stre am")==0)} …} if(event.getEventType().getName() .compareTo("Scenario2Stre am")==0){ System.out.println("\n ** ALERT: Unauthorize d access\n ** place = " + event.get("placeID ") + "\n ** time: " + event.get("time") +"\n **”+“B adgeID: " + event.get("idBadge") + "\n ** FaceID: " + + event.get("idFace") + "\n"); … } if(event.getEventType().getName() .compareTo("ScenarioR1Stre am")==0){

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
214
…} if(event.getEventType().getName() .compareTo("ScenarioR2aStre am")==0){ …} if(event.getEventType().getName() .compareTo("ScenarioR2bStre am")==0){ …}
Nel caso considerato, si ha un matching con la regola che genera lo stream
Scenario2Stream, che riportiamo di seguito.
insert into Scenario2Stream select BRE.ID_employee as idBadge, FDE.time as time , FDE.ID_employee as idFace, BRE.placeID as placeID from pattern[every BRE=BadgeReaderEvent -> FDE=Face DetectionEvent ((BRE.placeID=FDE.placeID) and (BRE.ID_employee!=FDE.ID_employee)) where timer:within(6 sec)]
Ciò è avvalorato anche dall’output del modulo CEP Engine mostrato di seguito.
Figura 5.10: Output CEP Engine
Precisamente all’arrivo del BRevent e del successivo FDevent, il motore cerca una
corrispondenza con la regola EPL prima definita. Pertanto, osservando la figura 5.10, si
può notare che i due eventi possiedono entrambi lo stesso valore per il campo placeID,
mentre hanno valori differenti per quello ID_employee. Inoltre il BRevent segue
l’ FDevent in una finestra temporale minore di sei secondi. Si comprende quindi che tale
sequenza di eventi realizza un effettivo matching con la regola EPL considerata. Di
conseguenza viene generato un evento del tipo Scenario2Stream, che porta alla
visualizzazione da parte del listener dell’alert visibile nella stessa figura 5.10.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
215
5.5 Considerazioni
Dalle simulazioni effettuate è semplice dedurre che il sistema implementato funziona
correttamente, in quanto assume il comportamento atteso. In più, analizzando il
comportamento di ogni singolo componente, è chiara anche la sua capacità di soddisfare i
requisiti previsti nell’ambito dell’attività di progettazione. Infatti, in termini di requisiti
funzionali, il sistema soddisfa:
• Il requisito di Events Receiving, attraverso l’ausilio dei vari wrapper, che gli
consentono di ricevere gli eventi generati da più sottosistemi, anche fortemente
eterogenei
• Il requisito di Events Filtering and Aggregation, attraverso l’ausilio del componente
di Prefiltering-Aggregation, il quale gli consente di effettuare un filtraggio sugli
eventi ricevuti dai vari wrapper, prima che essi giungano al motore di correlazione
• I requisiti di Events Correlation, Complex Events Generation e Alerts Generation,
attraverso l’ausilio del componente CEP Engine, il quale è in grado di correlare gli
eventi ricevuti dai wrapper, opportunamente filtrati dal componente di
Prefiltering-Aggregation, nonché di generare eventi complessi ed opportuni alert,
nel caso in cui sia riconosciuta una particolare situazione definita in una delle
regole con cui è stato istruito
Il sistema inoltre soddisfa anche i requisiti non funzionali. Esso infatti è facilmente
manutenibile ed estensibile, grazie alla sua architettura modulare e a componenti
indipendenti, nonché consente una elaborazione dei dati in real-time. Precisamente,
relativamente a quest’ultimo requisito, pur non avendo realizzato dei veri e propri test, è
possibile vedere che il sistema fornisce delle risposte in tempi molto rapidi. Infatti, se
prendiamo in considerazione le figure 5.3 e 5.6, è possibile notare che il timestamp
relativo all’arrivo dell’evento SuspiciousFileDownload al wrapper IDS (Figura 5.3) e
quello relativo all’arrivo dello stesso evento al CEP Engine (Figura 5.6) sono

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
216
perfettamente identici. Quindi l’elaborazione realizzata dalla piattaforma avviene
nell’ambito dello stesso secondo. A ciò si aggiunge anche la capacità del sistema di
generare istantaneamente gli alert. Infatti, come è possibile vedere sempre nella figura 5.6,
l’ alert relativo ad un tentativo di intrusione con credenziali rubate viene visualizzato a
video in contemporanea con il messaggio relativo alla ricezione dell’evento di download
sospetto.
Si noti che anche il requisito funzionale relativo ad un’elevata Precision e Recall è
soddisfatto, anche se non completamente. Ciò sarà chiarito nel successivo capitolo.

217
Capitolo 6
Risultati sperimentali
6.1 Introduzione
L’ultima attività che ha interessato questo lavoro di tesi è quella volta alla valutazione
sperimentale delle capacità del sistema implementato.
In questo capitolo ci preoccuperemo proprio di descrivere questa attività, e i risultati da
essa ottenuti.
In particolare, sarà fornita una descrizione delle due sottoattività realizzate, che sono:
• Valutazione del sistema con una distribuzione reale del traffico
• Valutazione del sistema all’aumentare del traffico
Entrambe le sottoattività sono state svolte nell’ambito dello scenario di Network Security,
ed entrambe avevano come obbiettivi sia quello di verificare ulteriormente la corretta
funzionalità del sistema, sia quello di valutare le capacità dello stesso di rilevare attacchi.
A tale scopo sono stati valutati alcuni parametri fondamentali, quali:
• Falsi Positivi
• Falsi Negativi
• Precision
• Recall
• F-Measure

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
218
Essi saranno opportunamente presentati nei paragrafi successivi, dove sarà fornita la
descrizione sia di come sono state realizzate le due sottoattività, sia dei risultati con esse
ottenuti.
6.2 Valutazione del sistema con una distribuzione reale del traffico
Come anticipato nell’introduzione, la prima sottoattività realizzata è quella di verificare il
nostro sistema nell’ambito dello scenario di Network Security, e verificare la sua
funzionalità, nonché la sua capacità di rilevare attacchi sottoponendolo ad una
distribuzione reale del traffico.
6.2.1 Descrizione
Per raggiungere lo scopo appena definito, è stata presa in considerazione una particolare
distribuzione reale di traffico. Precisamente è stata utilizzata quella definita in [24], dove,
al fine di rilevare i possibili utenti compromessi che si connettono all’interno di un sistema
reale, sono state messe in luce sia la tipologia che la quantità degli eventi a cui è
sottoposto tale sistema nell’arco di una giornata standard di utilizzo.
Precisamente, gli eventi considerati sono:
• Accesso Sospetto ad un host, considerato tale per una delle seguenti motivazioni:
o Indirizzo IP esterno mai utilizzato (AS1)
o Metodo di autenticazione mai utilizzato (AS2)
o Host mai utilizzato (AS3)
o Prima connessione al sistema (AS4)
• Download di un file con estensione sospetta da un host
• Upload di un file con estensione sospetta da un host
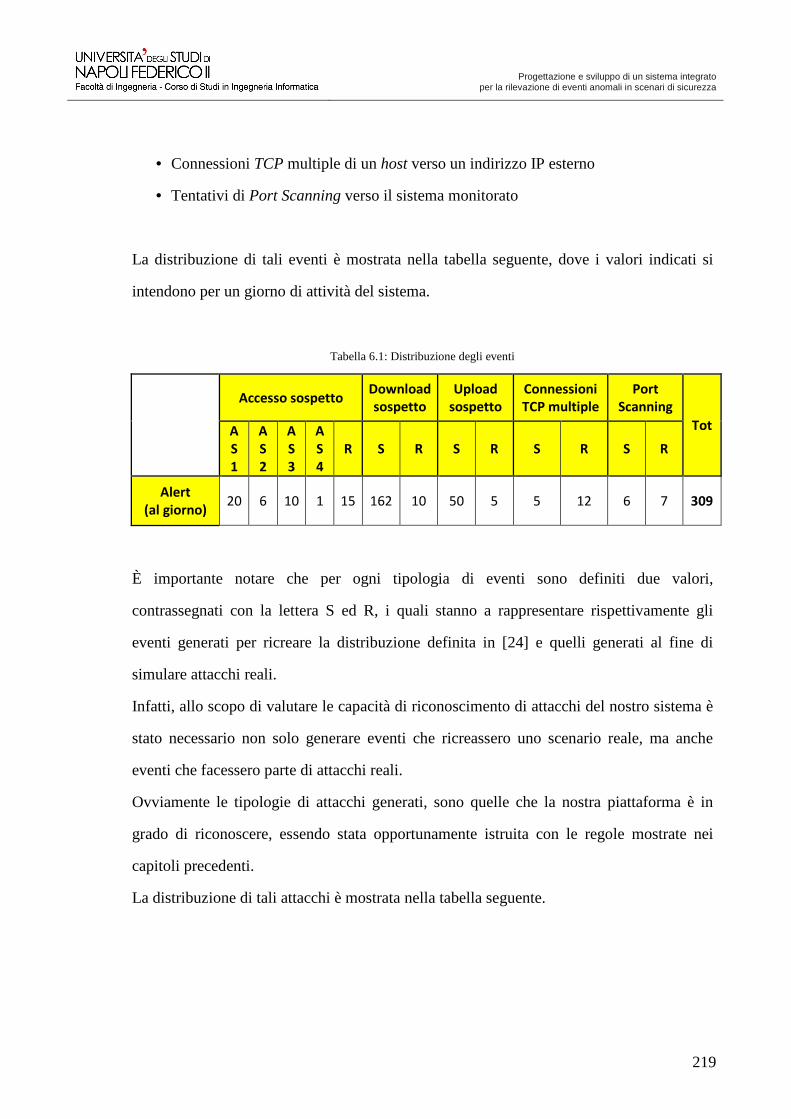
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
219
• Connessioni TCP multiple di un host verso un indirizzo IP esterno
• Tentativi di Port Scanning verso il sistema monitorato
La distribuzione di tali eventi è mostrata nella tabella seguente, dove i valori indicati si
intendono per un giorno di attività del sistema.
Tabella 6.1: Distribuzione degli eventi
È importante notare che per ogni tipologia di eventi sono definiti due valori,
contrassegnati con la lettera S ed R, i quali stanno a rappresentare rispettivamente gli
eventi generati per ricreare la distribuzione definita in [24] e quelli generati al fine di
simulare attacchi reali.
Infatti, allo scopo di valutare le capacità di riconoscimento di attacchi del nostro sistema è
stato necessario non solo generare eventi che ricreassero uno scenario reale, ma anche
eventi che facessero parte di attacchi reali.
Ovviamente le tipologie di attacchi generati, sono quelle che la nostra piattaforma è in
grado di riconoscere, essendo stata opportunamente istruita con le regole mostrate nei
capitoli precedenti.
La distribuzione di tali attacchi è mostrata nella tabella seguente.
Accesso sospetto Download
sospetto
Upload
sospetto
Connessioni
TCP multiple
Port
Scanning
Tot A
S
1
A
S
2
A
S
3
A
S
4
R S R S R S R S R
Alert
(al giorno) 20 6 10 1 15 162 10 50 5 5 12 6 7 309
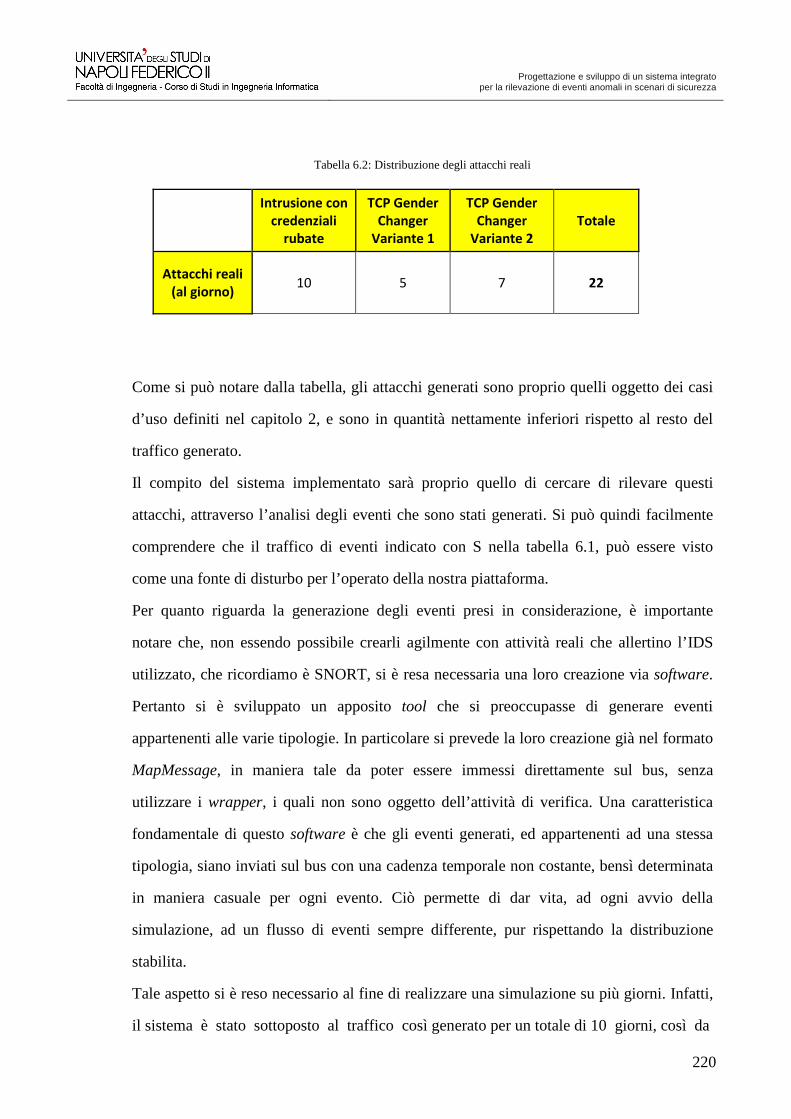
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
220
Tabella 6.2: Distribuzione degli attacchi reali
Come si può notare dalla tabella, gli attacchi generati sono proprio quelli oggetto dei casi
d’uso definiti nel capitolo 2, e sono in quantità nettamente inferiori rispetto al resto del
traffico generato.
Il compito del sistema implementato sarà proprio quello di cercare di rilevare questi
attacchi, attraverso l’analisi degli eventi che sono stati generati. Si può quindi facilmente
comprendere che il traffico di eventi indicato con S nella tabella 6.1, può essere visto
come una fonte di disturbo per l’operato della nostra piattaforma.
Per quanto riguarda la generazione degli eventi presi in considerazione, è importante
notare che, non essendo possibile crearli agilmente con attività reali che allertino l’IDS
utilizzato, che ricordiamo è SNORT, si è resa necessaria una loro creazione via software.
Pertanto si è sviluppato un apposito tool che si preoccupasse di generare eventi
appartenenti alle varie tipologie. In particolare si prevede la loro creazione già nel formato
MapMessage, in maniera tale da poter essere immessi direttamente sul bus, senza
utilizzare i wrapper, i quali non sono oggetto dell’attività di verifica. Una caratteristica
fondamentale di questo software è che gli eventi generati, ed appartenenti ad una stessa
tipologia, siano inviati sul bus con una cadenza temporale non costante, bensì determinata
in maniera casuale per ogni evento. Ciò permette di dar vita, ad ogni avvio della
simulazione, ad un flusso di eventi sempre differente, pur rispettando la distribuzione
stabilita.
Tale aspetto si è reso necessario al fine di realizzare una simulazione su più giorni. Infatti,
il sistema è stato sottoposto al traffico così generato per un totale di 10 giorni, così da
Intrusione con
credenziali
rubate
TCP Gender
Changer
Variante 1
TCP Gender
Changer
Variante 2
Totale
Attacchi reali
(al giorno) 10 5 7 22

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
221
poter valutare mediamente il suo comportamento.
Da notare però, che il tempo utilizzato per la realizzazione dell’attività di valutazione non
è quello reale. Infatti la simulazione è stata realizzata in tempo simulato, prevedendo la
trasformazione:
1 minuto reale = 1 minuto simulato
Ciò ha permesso di realizzare il tutto in maniera nettamente più agevole.
Ovviamente le regole EPL, con le quali si è istruito il CEP engine, sono state
opportunamente adattate.
Una volta generati gli eventi, essi sono stati dati in pasto al nostro sistema, e
successivamente sono valutati i suoi output, e precisamente gli alert che ha generato, al
fine di comprendere le sue capacità di rilevazione degli attacchi.
Precisamente, come già accennato all’inizio di questo capitolo, sono stati valutati una serie
di parametri, quali:
• Falsi Positivi: rappresentano gli attacchi non reali rilevati. Essi sono calcolati nel
modo seguente:
Falsi Positivi = Attacchi rilevati – Attacchi reali generati
• Falsi Negativi: rappresentano gli attacchi reali non rilevati. Essi sono calcolati nel
modo seguente:
Falsi Negativi = Attacchi reali generati – Attacchi reali rilevati
• Precision: parametro di information retrieval che valuta la capacità del sistema di
riconoscere i soli attacchi reali. Esso è calcolato nel modo seguente:

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
222
Si comprende che un valore pari a 1 di questo parametro indica che ogni attacco
rilevato dal sistema è sicuramente un attacco reale, e quindi totale assenza di falsi
positivi
• Recall: parametro di information retrieval che valuta la capacità del sistema di
riconoscere tutti gli attacchi reali. Esso è calcolato nel modo seguente:
Si comprende che un valore pari a 1 di questo parametro indica che il sistema è
stato in grado di rilevare tutti gli attacchi reali, e quindi totale assenza di falsi
negativi
• F-Measure: indice prestazionale di information retrieval ottenuto come
combinazione di precision e recall. Esso è calcolato nel modo seguente:
Si comprende che un valore pari a 1 di questo parametro indica ottime prestazioni
del sistema.
Descriviamo ora i risultati ottenuti da questa prima sottoattività.
6.2.2 Risultati ottenuti
Dalla simulazione realizzata sul nostro sistema, utilizzando come fonte di eventi il
software precedentemente descritto, sono stati ottenuti risultati interessanti, i quali sono
ottimamente riassunti nella seguente tabella.
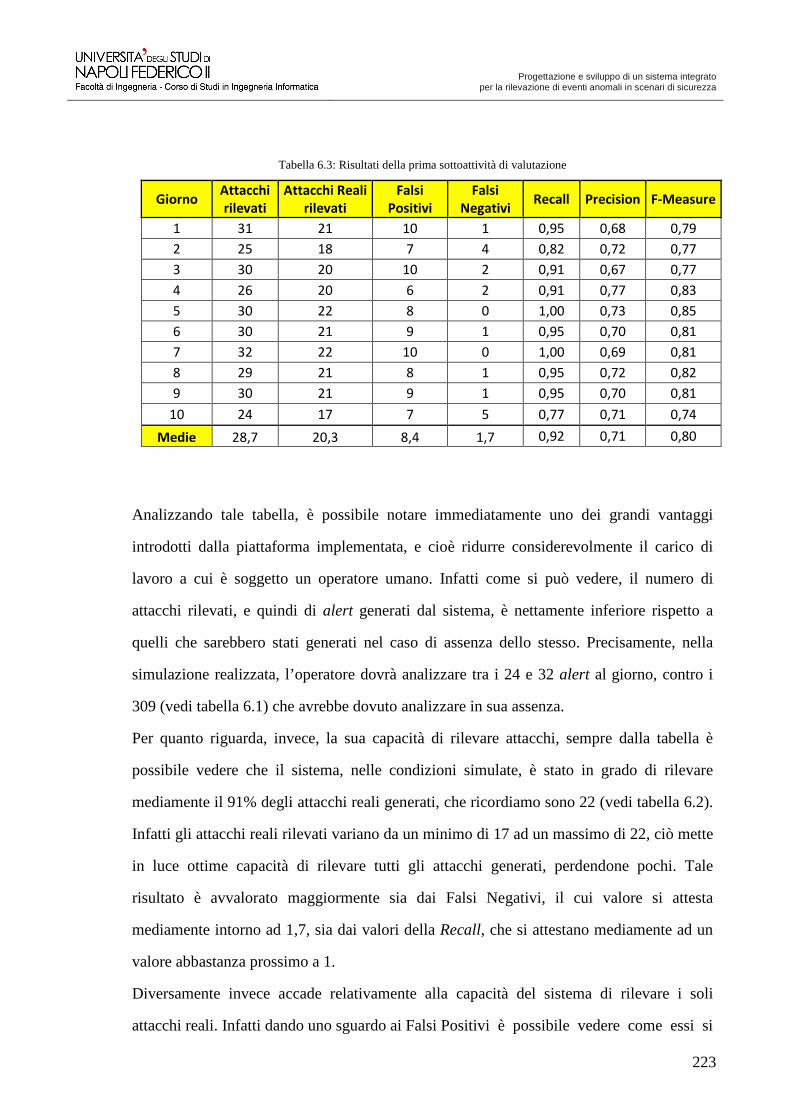
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
223
Tabella 6.3: Risultati della prima sottoattività di valutazione
Analizzando tale tabella, è possibile notare immediatamente uno dei grandi vantaggi
introdotti dalla piattaforma implementata, e cioè ridurre considerevolmente il carico di
lavoro a cui è soggetto un operatore umano. Infatti come si può vedere, il numero di
attacchi rilevati, e quindi di alert generati dal sistema, è nettamente inferiore rispetto a
quelli che sarebbero stati generati nel caso di assenza dello stesso. Precisamente, nella
simulazione realizzata, l’operatore dovrà analizzare tra i 24 e 32 alert al giorno, contro i
309 (vedi tabella 6.1) che avrebbe dovuto analizzare in sua assenza.
Per quanto riguarda, invece, la sua capacità di rilevare attacchi, sempre dalla tabella è
possibile vedere che il sistema, nelle condizioni simulate, è stato in grado di rilevare
mediamente il 91% degli attacchi reali generati, che ricordiamo sono 22 (vedi tabella 6.2).
Infatti gli attacchi reali rilevati variano da un minimo di 17 ad un massimo di 22, ciò mette
in luce ottime capacità di rilevare tutti gli attacchi generati, perdendone pochi. Tale
risultato è avvalorato maggiormente sia dai Falsi Negativi, il cui valore si attesta
mediamente intorno ad 1,7, sia dai valori della Recall, che si attestano mediamente ad un
valore abbastanza prossimo a 1.
Diversamente invece accade relativamente alla capacità del sistema di rilevare i soli
attacchi reali. Infatti dando uno sguardo ai Falsi Positivi è possibile vedere come essi si
Giorno Attacchi
rilevati
Attacchi Reali
rilevati
Falsi
Positivi
Falsi
Negativi Recall Precision F-Measure
1 31 21 10 1 0,95 0,68 0,79
2 25 18 7 4 0,82 0,72 0,77
3 30 20 10 2 0,91 0,67 0,77
4 26 20 6 2 0,91 0,77 0,83
5 30 22 8 0 1,00 0,73 0,85
6 30 21 9 1 0,95 0,70 0,81
7 32 22 10 0 1,00 0,69 0,81
8 29 21 8 1 0,95 0,72 0,82
9 30 21 9 1 0,95 0,70 0,81
10 24 17 7 5 0,77 0,71 0,74
Medie 28,7 20,3 8,4 1,7 0,92 0,71 0,80

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
224
attestino intorno ad un valore circa pari a 8, il che ci porta a comprendere che il sistema
tende a generare di falsi allarmi. Tale aspetto è comprensibile anche valutando i valori di
Precision, che si attestano ad un valore di 0,71, quindi nettamente più lontano dall’ottimo
rispetto alla Recall. Tale comportamento in realtà era prevedibile, in quanto, come
descritto nel paragrafo 1.5.1.2, esso rappresenta proprio una delle peculiarità dei sistemi di
correlazione rule-based.
In ogni caso, si tratta comunque di un risultato accettabile se paragonato all’enorme
riduzione di Falsi Positivi che il sistema introduce con il suo utilizzo, e di cui si è trattato
all’inizio di questo paragrafo.
In conclusione, quindi, le prestazioni in termini di rilevazione complessive, nell’ambito di
uno scenario reale di utilizzo, sono medio-alte, il che è suggerito anche dal valore del
parametro F-Measure, il quale si attesta intorno ad un valore di 0,8.
Da notare infine che da tale sottoattività è stato rilevato un corretto funzionamento del
sistema, il quale non ha generato alcun tipo di problema nel corso delle simulazioni
realizzate.
6.3 Valutazione al variare del traffico
Per quanto riguarda la seconda sottoattività, anch’essa è realizzata nell’ambito dello
scenario di Network Security, come già anticipato nell’introduzione di questo capitolo, ed
è incentrata sul verificare la capacità della piattaforma del sistema di rilevare attacchi,
questa volta considerando però più livelli di traffico, differenti l’uno dall’altro, e
caratterizzati da un valore sempre maggiore di eventi.
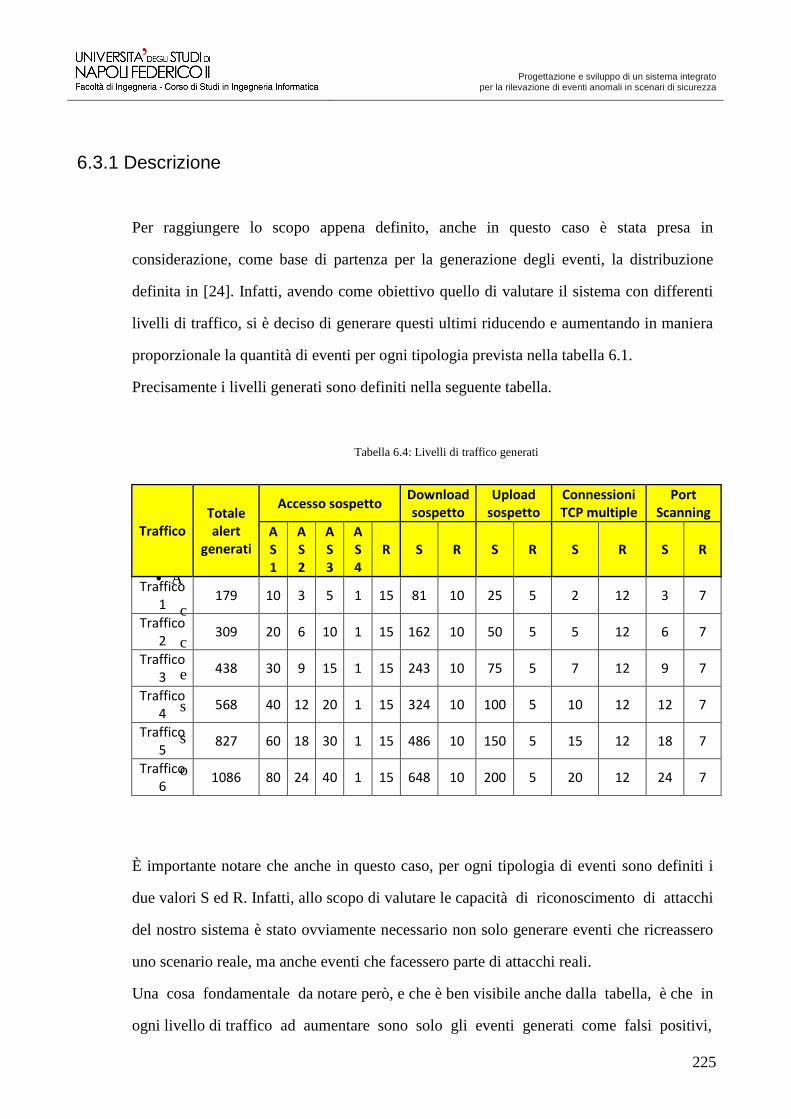
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
225
6.3.1 Descrizione
Per raggiungere lo scopo appena definito, anche in questo caso è stata presa in
considerazione, come base di partenza per la generazione degli eventi, la distribuzione
definita in [24]. Infatti, avendo come obiettivo quello di valutare il sistema con differenti
livelli di traffico, si è deciso di generare questi ultimi riducendo e aumentando in maniera
proporzionale la quantità di eventi per ogni tipologia prevista nella tabella 6.1.
Precisamente i livelli generati sono definiti nella seguente tabella.
Tabella 6.4: Livelli di traffico generati
• A
c
c
e
s
s
o
È importante notare che anche in questo caso, per ogni tipologia di eventi sono definiti i
due valori S ed R. Infatti, allo scopo di valutare le capacità di riconoscimento di attacchi
del nostro sistema è stato ovviamente necessario non solo generare eventi che ricreassero
uno scenario reale, ma anche eventi che facessero parte di attacchi reali.
Una cosa fondamentale da notare però, e che è ben visibile anche dalla tabella, è che in
ogni livello di traffico ad aumentare sono solo gli eventi generati come falsi positivi,
Traffico
Totale
alert
generati
Accesso sospetto Download
sospetto
Upload
sospetto
Connessioni
TCP multiple
Port
Scanning
A
S
1
A
S
2
A
S
3
A
S
4
R S R S R S R S R
Traffico
1 179 10 3 5 1 15 81 10 25 5 2 12 3 7
Traffico
2 309 20 6 10 1 15 162 10 50 5 5 12 6 7
Traffico
3 438 30 9 15 1 15 243 10 75 5 7 12 9 7
Traffico
4 568 40 12 20 1 15 324 10 100 5 10 12 12 7
Traffico
5 827 60 18 30 1 15 486 10 150 5 15 12 18 7
Traffico
6 1086 80 24 40 1 15 648 10 200 5 20 12 24 7

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
226
mentre rimangono invariate le quantità degli eventi generati al fine di simulare attacchi
reali, la cui distribuzione è ancora quella della figura 6.2. Si comprende quindi, che ad
aumentare del livello, crescere il traffico di disturbo per il nostro sistema.
Il compito della piattaforma implementata sarà ancora una volta, quindi, quello di cercare
di rilevare questi attacchi, all’aumentare del traffico di eventi da analizzare.
Naturalmente, anche per questa attività è stata prevista sia la generazione degli eventi
attraverso il tool implementato, di cui si è parlato nell’ambito della descrizione della
precedente sottoattività, sia la realizzazione di simulazioni baste su più giorni sfruttando il
tempo simulato. Precisamente ogni livello di traffico è stato simulato per 10 giorni.
I parametri valutati sono esattamente gli stessi presi in considerazione nella precedente
attività. Di seguito sono mostrati i risultati ottenuti da questa seconda sottoattività.
6.3.2 Risultati ottenuti
Dalla simulazione realizzata sul nostro sistema, prevedendo quanto detto nel paragrafo
precedente, sono stati ottenuti risultati ottimamente riassunti nella tabella 6.5, nella quale i
dati presenti sono da intendersi come valori medi su una simulazione di 10 giorni, in
tempo simulato.
Analizzando tale tabella, è possibile notare che anche in questa attività viene messa in luce
la capacità del sistema di ridurre considerevolmente il carico di lavoro a cui è soggetto un
operatore umano. Infatti come si può vedere, il numero di attacchi rilevati, e quindi di
alert generati dal sistema, è nettamente inferiore rispetto a quelli che sarebbero stati
generati nel caso di assenza dello stesso. Precisamente, nella simulazione realizzata,
l’operatore dovrà analizzare tra i 23 e 51 alert al giorno, contro i 179 - 1086 che avrebbe
dovuto analizzare in sua assenza, al variare del traffico.
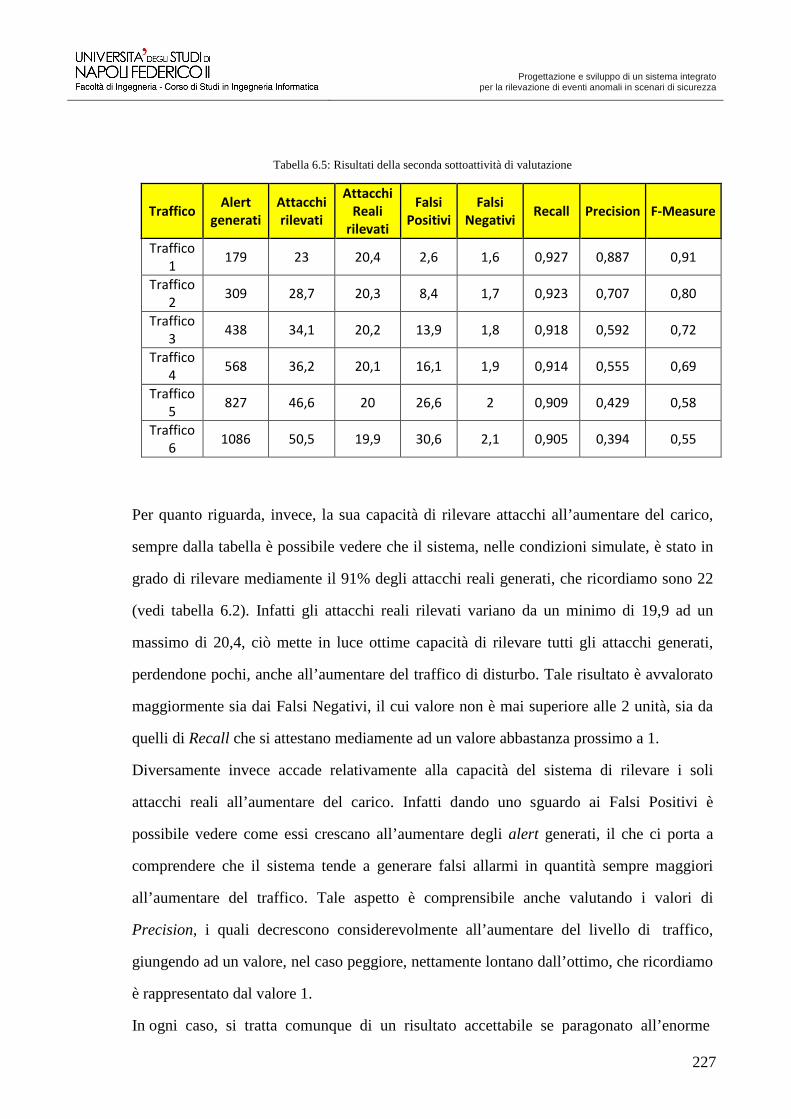
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
227
Tabella 6.5: Risultati della seconda sottoattività di valutazione
Per quanto riguarda, invece, la sua capacità di rilevare attacchi all’aumentare del carico,
sempre dalla tabella è possibile vedere che il sistema, nelle condizioni simulate, è stato in
grado di rilevare mediamente il 91% degli attacchi reali generati, che ricordiamo sono 22
(vedi tabella 6.2). Infatti gli attacchi reali rilevati variano da un minimo di 19,9 ad un
massimo di 20,4, ciò mette in luce ottime capacità di rilevare tutti gli attacchi generati,
perdendone pochi, anche all’aumentare del traffico di disturbo. Tale risultato è avvalorato
maggiormente sia dai Falsi Negativi, il cui valore non è mai superiore alle 2 unità, sia da
quelli di Recall che si attestano mediamente ad un valore abbastanza prossimo a 1.
Diversamente invece accade relativamente alla capacità del sistema di rilevare i soli
attacchi reali all’aumentare del carico. Infatti dando uno sguardo ai Falsi Positivi è
possibile vedere come essi crescano all’aumentare degli alert generati, il che ci porta a
comprendere che il sistema tende a generare falsi allarmi in quantità sempre maggiori
all’aumentare del traffico. Tale aspetto è comprensibile anche valutando i valori di
Precision, i quali decrescono considerevolmente all’aumentare del livello di traffico,
giungendo ad un valore, nel caso peggiore, nettamente lontano dall’ottimo, che ricordiamo
è rappresentato dal valore 1.
In ogni caso, si tratta comunque di un risultato accettabile se paragonato all’enorme
Traffico Alert
generati
Attacchi
rilevati
Attacchi
Reali
rilevati
Falsi
Positivi
Falsi
Negativi Recall Precision F-Measure
Traffico
1 179 23 20,4 2,6 1,6 0,927 0,887 0,91
Traffico
2 309 28,7 20,3 8,4 1,7 0,923 0,707 0,80
Traffico
3 438 34,1 20,2 13,9 1,8 0,918 0,592 0,72
Traffico
4 568 36,2 20,1 16,1 1,9 0,914 0,555 0,69
Traffico
5 827 46,6 20 26,6 2 0,909 0,429 0,58
Traffico
6 1086 50,5 19,9 30,6 2,1 0,905 0,394 0,55
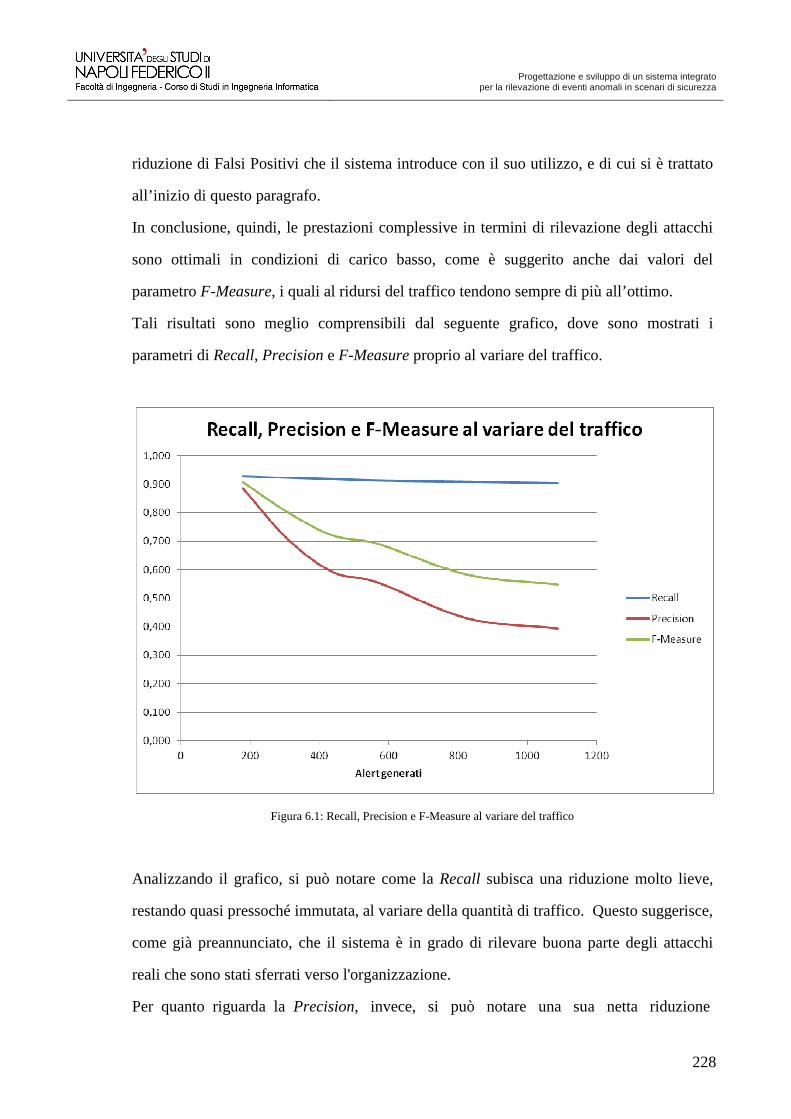
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
228
riduzione di Falsi Positivi che il sistema introduce con il suo utilizzo, e di cui si è trattato
all’inizio di questo paragrafo.
In conclusione, quindi, le prestazioni complessive in termini di rilevazione degli attacchi
sono ottimali in condizioni di carico basso, come è suggerito anche dai valori del
parametro F-Measure, i quali al ridursi del traffico tendono sempre di più all’ottimo.
Tali risultati sono meglio comprensibili dal seguente grafico, dove sono mostrati i
parametri di Recall, Precision e F-Measure proprio al variare del traffico.
Figura 6.1: Recall, Precision e F-Measure al variare del traffico
Analizzando il grafico, si può notare come la Recall subisca una riduzione molto lieve,
restando quasi pressoché immutata, al variare della quantità di traffico. Questo suggerisce,
come già preannunciato, che il sistema è in grado di rilevare buona parte degli attacchi
reali che sono stati sferrati verso l'organizzazione.
Per quanto riguarda la Precision, invece, si può notare una sua netta riduzione
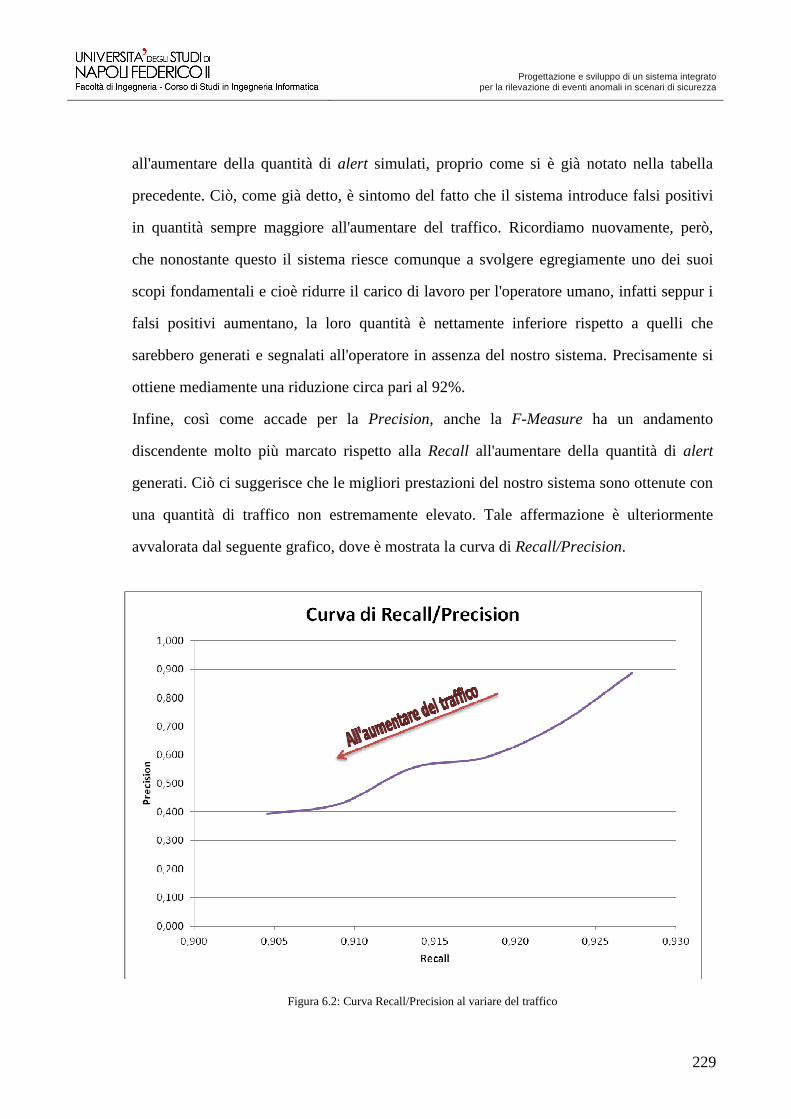
Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
229
all'aumentare della quantità di alert simulati, proprio come si è già notato nella tabella
precedente. Ciò, come già detto, è sintomo del fatto che il sistema introduce falsi positivi
in quantità sempre maggiore all'aumentare del traffico. Ricordiamo nuovamente, però,
che nonostante questo il sistema riesce comunque a svolgere egregiamente uno dei suoi
scopi fondamentali e cioè ridurre il carico di lavoro per l'operatore umano, infatti seppur i
falsi positivi aumentano, la loro quantità è nettamente inferiore rispetto a quelli che
sarebbero generati e segnalati all'operatore in assenza del nostro sistema. Precisamente si
ottiene mediamente una riduzione circa pari al 92%.
Infine, così come accade per la Precision, anche la F-Measure ha un andamento
discendente molto più marcato rispetto alla Recall all'aumentare della quantità di alert
generati. Ciò ci suggerisce che le migliori prestazioni del nostro sistema sono ottenute con
una quantità di traffico non estremamente elevato. Tale affermazione è ulteriormente
avvalorata dal seguente grafico, dove è mostrata la curva di Recall/Precision.
Figura 6.2: Curva Recall/Precision al variare del traffico

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
230
Infatti, analizzando l’andamento della curva, e sapendo che in un grafico di questo tipo la
prestazione ideale si ottiene quando più ci si avvicina al punto (1,1), si può vedere
facilmente che le prestazioni del sistema sono ottimali al diminuire degli alert generati.
Anche qui, inoltre, è possibile verificare, come ad una lieve riduzione della Recall
corrisponda una maggiore riduzione della Precision, il che convalida quanto già dedotto
precedentemente, e cioè che il nostro sistema introduce pochi falsi negativi all'aumentare
del traffico, mentre introduce maggiori falsi positivi all'aumentare di quest'ultimo.
In ultima istanza, è bene notare che anche in questa sottoattività è stato rilevato un corretto
funzionamento del sistema, il quale non ha generato alcun tipo di problema nel corso delle
simulazioni realizzate.

231
Conclusioni e Sviluppi futuri
Nell’ambito di questo lavoro di tesi è stato progettato e successivamente implementato un
sistema integrato per la rilevazione di situazioni anomale in scenari di sicurezza.
Tale sistema è nato essenzialmente allo scopo di fornire un supporto ad un operatore
umano, sia nell’ambito della Building che Network Security, in quanto i centri di controllo
sono oggi caratterizzati da una quantità sempre maggiore di dispositivi indipendenti, e
molto spesso eterogenei. Ciò ha portato ad un netto aumento della quantità di dati da
analizzare ed un conseguente aumento dei tempi di risposta da parte dell’operatore. Su di
esso infatti ricade l’intera operazione di analisi e correlazione delle informazioni rilevate,
la quale, quindi, diventa fortemente dipendente dalle sue capacità, nonché dalla sua
conoscenza del contesto monitorato e dei sistemi utilizzati.
Pertanto la piattaforma implementata si pone l’obiettivo di ridurre il carico di lavoro a cui
è soggetto l’operatore, nonché di migliorare la cosiddetta situation awareness, il tutto
attraverso l’ausilio della Complex Event Processing.
Precisamente, la piattaforma è caratterizzata da un’architettura modulare, e a componenti
indipendenti, basata sul paradigma architetturale Event Driven Architecture e su quello di
comunicazione Publish/Subscribe. Essa è dotata di quattro componenti, che sono:
• Mediator
• Enterprise Service Bus
• Prefiltering-Aggregation

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
232
• CEP Engine
Sul sistema così costituito sono state realizzate due attività di verifica, una volta a valutare
il corretto funzionamento del sistema, nonché il rispetto dei requisiti previsti durante la sua
progettazione, e l’altra volta a valutare sperimentalmente la capacità del sistema di rilevare
attacchi informatici. Precisamente, in quest’ultima le valutazioni sono state effettuate
attraverso alcuni parametri, e cioè:
• Falsi Positivi e Falsi Positivi
• Recall, Precision e F-Measure
Inoltre, essa è stata suddivisa in due sottoattività. Nella prima si è sottoposta al sistema una
distribuzione reale di traffico, mentre nella seconda sono stati sottoposti ad esso differenti
livelli di traffico, ognuno caratterizzato da una quantità crescente di eventi.
Oltre al corretto funzionamento della piattaforma, dalle due attività previste è emerso che
il sistema soddisfa i requisiti definiti in fase di progettazione, ma, soprattutto, è emersa
anche la sua capacità di generare un valore molto basso di Falsi Negativi, anche
all’aumentare del traffico. Infatti sono stati osservati valori di Recall abbastanza prossimi a
1, il che si traduce nella capacità del sistema implementato di riuscire a riconoscere tutti
gli attacchi a cui la rete monitorata è sottoposta. Oltre a ciò, è anche emersa la sua
tendenza a generare un valore crescente di Falsi Positivi all’aumentare del carico, il che si
traduce nell’incapacità di rilevare i soli attacchi reali a cui è soggetta la rete monitorata
quando la quantità di traffico aumenta. Infatti sono stati osservati valori di Precision che si
allontanano fortemente da 1 all’aumentare del livello di traffico.
In realtà, nonostante questo comportamento, il sistema riesce in ogni caso a raggiungere il
suo obiettivo di ridurre il carico di lavoro degli operatori. Dalla seconda attività, infatti, è
emerso anche che, in qualsiasi condizione di traffico, il sistema genera una quantità di
Falsi Positivi nettamente inferiore rispetto a quella a cui sarebbe sottoposto l’operatore
senza il suo utilizzo.

Progettazione e sviluppo di un sistema integrato
per la rilevazione di eventi anomali in scenari di sicurezza
233
Per quanto riguarda gli sviluppi futuri, trattandosi di una prima versione della cosiddetta
piattaforma CEvOS, il sistema implementato richiede sicuramente una serie di
ottimizzazioni. Prima tra tutte, la necessità di migliorare le regole di correlazione con il
quale è stato istruito il CEP Engine, al fine di ridurre la quantità di Falsi Positivi che sono
generati dal sistema all’aumentare del traffico a cui è sottoposto.
Oltre a questa, vi sono altre migliorie che potrebbero essere realizzate sul sistema, e che
risulterebbero di grande interesse. Tra queste abbiamo ad esempio:
• L’introduzione di tecniche di autoapprendimento, che consentano al sistema di poter
riconoscere situazioni non previste, e per le quali non è stata definita a priori
alcuna di regola
• L’introduzione di un database per la storicizzazione degli eventi, il che darebbe la
possibilità di realizzare operazioni di Historical Analysis
• L’introduzione nel sistema di più motori di correlazione, e prevedere la
combinazione dei loro esiti attraverso un sistema multi-esperto, in modo tale da
migliorare la capacità del sistema nel riconoscimento di situazioni anomale.

234
Bibliografia
[1] System Management, http://www.sysmanagement.it/
[2] Cini ITEM, http://www.consorzio-cini.it/?q=node/19
[3] D. Luckham, 2007, “A short history of complex event processing - part 1:
Beginnings”
[4] D. Luckham, 2007, “A short history of complex event processing - part 2: The rise
of CEP”
[5] D. Luckham, 2002, “The Power of Events: An introduction to Complex Event
Processing in Distribuited Systems”
[6] J. Holland, 1992, “Complex Adaptive Systems”
[7] David B. Robins, 2010, “Complex Event Processing”, University of Washington,
Redmond, WA
[8] Alessandro Miracca, 2010/2011, Tesi: “Approccio basato su Complex Event
Processing per l'adattività nei sistemi informativi”, Politecnico di Milano, Corso di
Laurea Specialistica in Ingegneria Informatica
[9] Antonio Addivinola, 2009/2010, Tesi: "Sviluppo di un’architettura software per il
“Complex Event Processing” in scenari di videosorveglianza", Università degli
studi di Napoli Federico II, corso di Laurea Specialistica in Ingegneria Informatica
[10] Peyman Kabiri, Ali A. Ghorbani, July 2007, “A Rule-Based Temporal Alert
Correlation System”, Vol.5, No.1, PP.66–72
[11] Andreas Muller, 2009, “Event Correlation Engine”, Department of Information
Technology and Electrical Engineering Swiss Federal Institute of Technology
Zurich

235
[12] Nahid Amani, Mahmood Fathi, Mehdi Dehghan, “A Case-Based Reasoning Method
For Aalarm Filtering And Correlation In Telecommunication Networks”
[13] Feng Xuewei, 2010, “Analyzing and Correlating Security Events Using State
Machine”, Nat. Key Lab. of Sci. & Technol. on Inf. Syst. Security, Beijing Inst. of
Syst. Eng., Beijing, China
[14] B. Schilling, B. Koldehofe, K. Rothermel, “Distributed heterogeneous event
processing: enhancing scalability and interoperability of CEP in an industrial
context”
[15] D. Jobst, “Modern Process Management with SOA, BAM und CEP”
[16] Esper Team and EsperTech Inc., “Esper Reference Version 4.6.0”,
http://esper.codehaus.org
[17] SNORT, www.snort.org
[18] R. Gerhards, 2009, RFC 5424: “The Syslog Protocol”
[19] RSYSLOG, http://en.wikipedia.org/wiki/Rsyslog
[20] Ashare, Ashare Standard: “BACnet - A Data Comunication Protocol for Building
Automation and Control Networks”, ANSI/ASHARE Addendum d to
ANSI/ASHARE standard 135-2001
[21] Apache ActiveMQ, http://activemq.apache.org/
[22] S. Russo, D. Cotroneo, C. Savy, A. Sergio, 2002, “Introduzione a CORBA”,
McGraw-Hill
[23] Bruce Snyder, Dejan Bosanac, Rob Davies, 2011, “ActiveMQ in Action”, Manning
Pubblications
[24] A. Pecchia, A. Sharma, Z. Kalbarczyk, D. Cotroneo, R. K. Iyer, 2011, “Identifying
Compromised Users in Shared Computing Infrastructures: a Data-Driven Bayesian
Network Approach”, Dipartimento di Informatica e Sistemistica, Università degli
Studi di Napoli Federico II, Center for Reliable and High Performance Computing,
University of Illinois at Urbana-Champaign


















