
Progettazione e realizzazione di un sistema di ...teca.elis.org/1132/Tesi_Romano.pdf · tecnologie...
195
UNIVERSITÀ DEGLI STUDI ROMA TRE FACOLTÀ DI I NGEGNERIA CORSO DI L AUREA IN I NGEGNERIA ELETTRONICA Tesi di Laurea Progettazione e realizzazione di un sistema di archiviazione, ricerca e gestione basata su metadati per i contenuti di un archivio televisivo digitale broadcast Candidato: Francesco Romano Relatore Chiar.mo Prof. Alessandro Neri Correlatore Chiar.mo Prof. Michele Crudele 2° Relatore Chiar.mo Prof. Alessandro Toscano Anno Accademico 2000-2001
Transcript of Progettazione e realizzazione di un sistema di ...teca.elis.org/1132/Tesi_Romano.pdf · tecnologie...

UNIVERSITÀ DEGLI STUDI ROMA TRE
FACOLTÀ DI INGEGNERIA CORSO DI LAUREA IN INGEGNERIA ELETTRONICA
Tesi di Laurea
Progettazione e realizzazione di un sistema di
archiviazione, ricerca e gestione basata su metadati
per i contenuti di un archivio televisivo digitale
broadcast
Candidato: Francesco Romano
Relatore
Chiar.mo Prof.
Alessandro Neri
Correlatore
Chiar.mo Prof.
Michele Crudele
2° Relatore
Chiar.mo Prof.
Alessandro Toscano
Anno Accademico 2000-2001

Alla Memoria di Giovanni Perrone
Corso Hyperion 1992-1995

Abstract - I
ABSTRACT
La tesi è stata svolta presso i laboratori e le strutture messe a disposizione dalla Scuola di Formazione Superiore Elis di Roma, nel contesto di sviluppo di un progetto formativo di “Vivai D’Impresa” commissionato dalla Rai Radio Televisione Italiana. Una parte del lavoro è stato svolto presso i laboratori del Centro di Ricerche e Innovazione Tecnologica (CRIT) Rai di Torino, e un’altra parte di attività si sono svolte presso le strutture della Teca Fast di Rai a Roma, che ha commissionato il prototipo.
Le necessità di Teca Fast si sono infatti concretizzate in una serie di specifiche assegnate per la realizzazione di un sistema di gestione metadati audiovisivi per l’archivio digitale televisivo interno.
Attualmente i contenuti audiovisivi della Teca Fast – memorizzati su cassette dati ad alta capacità in grandi archivi robotizzati – prevedono l’acquisizione e codifica 24 ore su 24 dei flussi audio e video trasmessi in diretta dai tre canali televisivi nazionali di Rai (RaiUno, RaiDue, RaiTre). Questi filmati, opportunamente archiviati sono accessibili per l’uso attraverso una rete intranet ad alta velocità in fibra ottica che connette alcune redazioni attrezzate per la produzione di programmi come i telegiornali. Per poter richiedere un determinato “asset”, ovvero una risorsa audiovisiva dell’archivio, è necessario conoscere il tempo assoluto di inizio e fine riferito alla trasmissione avvenuta, oltre all’identificatore del canale e della data di trasmissione. Per poter effettuare delle ricerche sulla base di informazioni di alto livello come il titolo della trasmissione o il nome di un protagonista è necessario ricorrere a strumenti esterni alla Teca. Quella di effettuare ricerche sulla base dei contenuti del palinsesto trasmesso è una delle funzionalità del Catalogo Multimediale, un prodotto sviluppato dalla divisione ICT di Rai a Torino che offre funzionalità avanzate come la possibilità di visionare tramite pagine web il contenuto di una trasmissione in maniera indicizzata, accompagnata dalla visualizzazione delle immagini chiave estratte dal programma e da un’anteprima audio delle sequenze. Tuttavia il sistema presenta delle carenze nelle possibilità di ricerca offerte, dovute in buona parte alla mancanza di una standardizzazione della struttura dei documenti di descrizione, e ad una presenza di numerosi campi descrittivi a testo libero che limitano di gran lunga l’efficacia e la puntualità delle ricerche.
Con la nascita di standard per le strutture di descrizione di risorse multimediali, come Mpeg-7, e di strumenti come dizionari o tesauri per una descrizione puntuale e non dispersiva, si prospettano nuovi orizzonti per il campo di applicazione individuato, nello specifico per il potenziamento e l’innovazione di sistemi per l’archiviazione e la ricerca.

Abstract - II
Nell’ambito della Teca si è dunque individuata l’opportunità di sviluppare un primo sistema innovativo per la descrizione e gestione basata su metadati dei contenuti audiovisivi.
Scopo delle attività oggetto di questa tesi è la realizzazione di un sistema informativo per la gestione di metadati audiovisivi per la Teca Fast, basato sulle tecnologie più innovative che si stanno imponendo in questo settore, e tralasciando in questa prima realizzazione l’uso di descrizioni non testuali.
Le tecnologie di metadati audiovisivi attualmente sono quasi tutte delle applicazioni del metalinguaggio XML (eXtensible Markup Language) e di tecnologie correlate, e alcune di esse, come Dublin Core (nell’ambito del Moving Picture Group), o Mpeg-7 propongono una serie di strumenti molto potenti per la creazione di basi di dati più accessibili, portabili e flessibili delle tradizionali tecnologie di DBMS Relazionali o ad Oggetti.
Una parte iniziale di attività sono state impiegate nello studio del Sistema Teche di Rai, per comprenderne la complessa struttura, le eterogenee modalità con cui vengono gestite le risorse audiovisive nelle varie sedi, comprenderne i processi di documentazione e di utilizzo. Questa fase è stata svolta presso le sedi di Roma per le teche Teca Master (Teca Fiction, Teca News costituite di enormi magazzini robotizzati con diversi supporti video analogici e digitali, e archivi pellicole) e la Teca Fast digitale, e presso le sedi di Torino per il Catalogo Multimediale Rai, il motore di ricerca Octopus, e i nuovi sistemi per la digitalizzazione automatica e l’editing remoto.
Una seconda fase di attività è stata impiegata nella documentazione, approfondimento e confronto delle diverse tecnologie di metadati descrittivi, e nello studio e sperimentazione di tutte le principali tecnologie XML, compreso XML Schema Language, che sono alla base dell’Mpeg-7, su cui è stata focalizzata l’attenzione, essendo lo standard più indicato applicazioni audiovisive.
Mpeg-7 è il più recente standard ISO sviluppato dal gruppo Moving Picture Expert Group (MPEG) il cui rilascio definitivo è previsto nel settembre 2001. A differenza dei precedenti standard Mpeg, Mpeg-7 non è uno standard di codifica di contenuti multimediali, ma uno standard per la creazione e gestione di descrizioni multimediali dei contenuti stessi.
In parallelo è in fase di sviluppo preliminare il successivo standard, MPEG-21, che si pone ambiziosi obiettivi nell’ambito della gestione e commercio di contenuti multimediali, come la definizione di un linguaggio per la descrizione di diritti d’autore, la standardizzazione di protocolli e linguaggi per l’interfacciamento di sistemi di archiviazione contenuti multimediali e di gestione automatica delle transazioni, tecnologie per la diffusione degli agenti intelligenti.

Abstract - III
Mpeg-7 è uno standard molto complesso, e viene presentato in diverse parti separate, alcune delle quali definiscono le modalità e le tecnologie di codifica e trasporto delle descrizioni, altre invece sono focalizzate sulle applicazioni di riconoscimento ed estrazione di caratteristiche audiovisive dai contenuti multimediali.
La parte di Mpeg-7 di interesse per la nostra applicazione è la parte 5, intitolata Multimedia Description Schemes (MDS), secondo la sua definizione presente nel documento Final Committe Draft (FCD).
MDS definisce gli strumenti per la descrizione dei contenuti multimediali (definisce i tipi di dati dei descrittori, e gli schemi di descrizione) attraverso l’uso di documenti XML basati sul Description Definition Language (DDL), un’estensione di XML Schema Language.
In collaborazione con il CRIT Rai di Torino si è lavorato alla definizione di un profilo applicativo ad hoc per l’implementazione delle strutture dati definite da Mpeg-7 MDS alle caratteristiche dei contenuti televisivi archiviati nella Teca Fast.
Con questa fase di sviluppo e sperimentazione si è prodotto un modello di documento per la risorsa “programma televisivo” (inteso come puntata di programma) conforme allo schema di descrizione Mpeg-7, e destinato a fare da contenitore per i metadati di descrizione.
Data l’estrema complessità e dettaglio dell’MDS Schema di Mpeg-7, si è scelto di costruire, a partire dal modello generico di documento di archivio individuato, una Document Type Definition ad hoc per la definizione generica della sua struttura, fondamentale anche per un’efficiente implementazione in un Database Management System (DBMS) in grado di elaborare e archiviare documenti XML.
Successivamente si è passati all’implementazione delle strutture dati e del modello di documento in un Data Base Management System XML nativo.
Si è scelto di utilizzare un DBMS XML per il tipo di documenti da gestire, poiché le descrizioni Mpeg-7 generano effettivamente dei documenti XML complessi; in questo caso l’uso di un server XML porta grandi vantaggi, in quanto la struttura dei documenti può essere modificata con relativa semplicità, e risultano più efficienti le operazioni di modifica o ricerca nei dati conservati in formato XML senza subire trasformazioni onerose dal punto di vista del carico elaborativo.
La piattaforma software prescelta per l’implementazione del prototipo è Tamino XML DB di Software AG. Su questa piattaforma è stato possibile creare il DataBase del prototipo, inserendo nella mappa dei dati la definizione di documento derivata dal documento di descrizione della risorsa di teca secondo le

Abstract - IV
specifiche Mpeg-7 per una efficiente indicizzazione degli elementi descrittivi. Inoltre questa piattaforma consente l’interfacciamento con numerosi DBMS tradizionali, compreso il SQL Server Microsoft utilizzato dal sistema di gestione asset di Teca Fast. Col server XML sono stati configurati un Web Server Apache e il Java Servlet Apache Jserv, rispettivamente per la gestione delle risorse completamente tramite interfaccia di comunicazione http standard e per l’elaborazione delle pagine di risposta XML in processi residenti sul server.
Sulla base del DataBase realizzato, si sono progettate, programmate e sperimentate le interfacce per l’inserimento dei documenti xml di descrizione e di definizione tipi di dato attraverso un browser web.
Utilizzando funzioni Javascript, e oggetti ActiveX di interfaccia standard DOM (Document Object Model del W3C) si sono realizzate delle applicazioni web per l’interrogazione del DBMS, con funzionalità di ricerca avanzate (come la possibilità di cercare un dato nome solo nel campo degli autori o in quello dei partecipanti, quindi di effettuare ricerche puntuali nella struttura dei documenti di descrizione).
Tramite queste interfacce web sono state poi implementate funzionalità di trasformazione dei risultati delle interrogazioni sul database e loro restituzione in pagine HTML standard (implementando fogli di stile XSL appositamente realizzati per la sperimentazione).
Si sono utilizzate le informazioni di documentazione riguardanti la programmazione televisiva di uno dei canali nazionali, con informazioni tipiche contenute in parte nel Catalogo Multimediale e parte nel Server SQL di Teca Fast, per poter effettuare un primo test dimostrativo delle funzionalità del sistema, a cui è stato dato il nome di Mpeg-7 Metadata eXperimental Repository.
Grazie all’approccio seguito ed all’implementazione di tecnologie XML ed MPEG-7, il sistema sviluppato si propone come importante esempio di applicazione di standard aperti per la riorganizzazione dei sistemi di gestione e ricerca delle teche multimediali.

Tavola dei contenuti - V
Tavola dei contenuti: I ° Capitolo - Mercato ICT, nuovi media e archivi multimediali..................................................1
I.1 Mercato ICT .......................................................................................................................................1
I.1.1 Risultati e previsioni nel mercato ICT ...................................................................................2
II ° Capitolo - I metadati, gli standard MPEG, le tecnologie XML e l’integrazione con i Database .......................................................................................................................................................5
II.1 I Metadati...........................................................................................................................................5
II.1.1 Metadati in generale e metadati audiovisivi ........................................................................5 II.1.2 L'interoperabilità delle informazioni di descrizione...........................................................6 II.1.3 I limiti della tecnologia: necessità di identificatori unici...................................................7 II.1.4 I metadati nel settore audiovisivo..........................................................................................8 II.1.5 Tendenze, sovrapposizioni e mancanze nell’ambito dei metadati audiovisivi............10
II.2 Gli standard della famiglia MPEG ..............................................................................................11
II.2.1 Gli agenti intelligenti e i nuovi standard Mpeg.................................................................12 II.2.2 MPEG e la protezione dei contenuti ...................................................................................13
II.3 XML, XHTML e HTML e la nuova generazione del web .....................................................15
II.3.2 Il modello relazionale e il modello XML a confronto .....................................................17 II.3.3 Come effettuare Query in XML...........................................................................................19 II.3.4 Implementazione di XML nel web......................................................................................21 II.3.5 Il modello dei dati XML........................................................................................................24 II.3.6 Il linguaggio XPath ................................................................................................................25 II.3.7 Espressione di vincoli sui dati e le carenze della DTD....................................................28 II.3.8 XML Schema ..........................................................................................................................30 II.3.9 Tipi di dato definiti dagli utenti in XML Schema .............................................................32 II.3.10 Unicità e chiavi in XML Schema ......................................................................................34 II.3.11 Meccanismi di riuso in XML Schema ..............................................................................35 II.3.12 Visualizzazione di documenti XML: la terna di XSL....................................................36
II.4 Programmare con XML................................................................................................................41
II.4.1 Parsers standard ......................................................................................................................42 II.4.2 Costruire applicazioni XML con Document Object Model di Microsoft .....................44 II.4.3 Implementare le tecnologie nel prototipo per Teca Fast..................................................47
III ° Capitolo: Studio sui sistemi di archivio di Teche RAI e Teca Fast digitale ................... 48
III.1 Il sistema teche RAI: patrimonio, architetture, sistemi informativi.....................................48 III.1.1 Dettagli sugli archivi principali e il Catalogo Multimediale .........................................51 III.1.2 Organizzazione del Catalogo Multimediale .....................................................................53 III.1.3 Il catalogo di documentazione e l’acquisizione dei documenti multimediali. ............53 III.1.4 Il Catalogo delle pubblicazioni e il trasferimento degli item di programma ..............56
III.2 Altri archivi audiovisivi in Italia ................................................................................................59
III.3 L’ambiente applicativo: la TECA FAST Rai...........................................................................60
III.3.1 Architettura di rete e software dell’archivio Teca Fast ..................................................64

Tavola dei contenuti - VI
IV ° Capitolo: Mpeg-7 MDS e costruzione di un profilo applicativo per la descrizione di archivi audiovisivi basata su metadati – Caso di Teca Fast Rai ................................................ 66
IV.1 Considerazioni preliminari su Mpeg-7 e l’uso dei metadati audiovisivi ............................66
IV.1.1 Prima di MPEG-7: proposte per descrizione risorse audiovisive.................................66 IV.1.2 Gli strumenti di MPEG-7 ....................................................................................................69 IV.1.3 Possibili applicazioni di MPEG-7......................................................................................72 IV.1.4 Lo sviluppo dello standard MPEG-7.................................................................................73
IV.2 Le necessità di progetto...............................................................................................................73
IV.2.1 Struttura dei Multimedia Description Schemes...............................................................74 IV.2.2 Una breve carrellata degli strumenti di descrizione........................................................76 IV.2.3 Impiego del Multimedia Description Schemes (MDS) Mpeg-7...................................77
IV.3 La struttura dati Mpeg-7 creata per il prototipo......................................................................95
IV.3.1 Identificazione e localizzazione del media: MediaInformation DS ...........................100 IV.3.2 L’elemento CreationInformation: aspetti di creazione e classificazione. .................110 IV.3.3 L’elemento UsageInformation: aspetti riguardanti l’uso del contenuto audiovisivo............................................................................................................................................................121 IV.3.4 La localizzazione temporale dell’audiovisivo: l’elemento MediaTime ....................125 IV.3.5 La struttura dati progettata per il prototipo di descrizione metadati audiovisivi secondo Mpeg-7 ..............................................................................................................................129
V ° Capitolo – Realizzazione del prototipo di sistema Mpeg-7 Metadata eXperimental Repository su DBMS Server XML nativo ......................................................................................130
V.1 Le specifiche di progetto: la ricerca, lo sviluppo e l’applicazione di nuove tecnologie Mpeg-7 nella realizzazione di un sistema di gestione metadati audiovisivi. ............................130
V.1.1 Considerazioni di opportunità della scelta di un DBMS XML nativo rispetto ai DBMS tradizionali ..........................................................................................................................130 V.1.2 Configurazioni hardware e software per il prototipo server e i client.........................136 V.1.3 L’elaborazione dei documenti xml: X-Machine .............................................................138 V.1.4 La piattaforma basata sul web: web server e componenti di rete ................................140 V.1.5 L’amministratore del server e il System Management HUB........................................141 V.1.6 Configurazione del DBMS XML e procedura di creazione DB prototipo.................141
V.2 La struttura dati: costruzione dello schema del documento Mpeg-7 creato ......................142
V.2.1 Definizione della gerarchia di Collezione e del DocType nel DB...............................143
V.3 Implementazione delle interfacce web di interazione con il DB XML del prototipo......147 V.3.1 Costruzione dell’interfaccia interattiva di inserimento documenti nel DB................148 V.3.2 Costruzione dell’interfaccia interattiva di eliminazione documenti nel DB..............150 V.3.3 Costruzione dell’interfaccia interattiva di definizione Doctype dei documenti nel DB............................................................................................................................................................152 V.3.4 Preparazione dei documenti di descrizione dei programmi televisivi di test.............154 V.3.5 Costruzione interfaccia per la restituzione di tutti i documenti di test nel DB..........155 V.3.6 Operazioni di query in rete tramite URL e XQuery/Xpath nel DB popolato............157 V.3.7 Costruzione di una prima applicazione web per le query .............................................159 V.3.8 Realizzazione di un’interfaccia di query con oggetti DOM e fogli di stile XSL......162 V.3.9 L’interfaccia avanzata di ricerca con elaborazione lato server dei fogli di stile XSL............................................................................................................................................................166 V.3.10 Sviluppi previsti del progetto e di progetti similari di gestione di database multimediali .....................................................................................................................................172
VI ° Capitolo – Bibliografia, risorse in rete ...................................................................................174

Tavola dei contenuti - VII
VI.1 Capitolo I: Mercato ICT, nuovi media e archivi multimediali ...........................................174 VI.2 Capitolo II: Metadati, standard MPEG, tecnologie XML e integrazione con i Database................................................................................................................................................................174
VI.2.1 Paragrafo 1: I Metadati: .....................................................................................................174 VI.2.2 Paragrafo 2: La famiglia di standard MPEG..................................................................175 VI.2.3 Paragrafo 3 e 4: Tecnologie XML e DB e programmare XML..................................176
VI.3 Capitolo III: Il Sistema Teche RAI e la Teca Fast................................................................176 VI.4 Capitolo IV: Creazione di un profilo applicativo di Mpeg-7 MDS ...................................176 VI.5 Capitolo V: Il prototipo di Mpeg-7 Metadata eXperimental Repository e le interfacce 177
VII ° Capitolo: Appendici...................................................................................................................178
VII.1 Appendice A: Terminologia e abbreviazioni .......................................................................178 VII.2 Appendice B: Listato del documento descrittivo realizzato secondo Mpeg-7 MDS ....179 VII.3 Appendice C: Document Type Definition del documento di descrizione metadati ......182
Ringraziamenti………………………………………………………………………..…....185

Risultati e previsioni nel mercato ICT – 1
I° Capitolo - Mercato ICT, nuovi media e archivi multimediali
I.1 Mercato ICT
Il settore ICT nasce dalla convergenza del mondo delle Telecomunicazioni e dell’Informatica, caratterizzato da un mercato a competitività crescente e da una continua diminuzione del costo delle tecnologie di base (microprocessori, memorie, larghezza di banda delle connessioni). Tale settore e si sta evolvendo dal coprire i tradizionali aspetti applicativi volti alla produttività (i grandi sistemi informativi aziendali ‘chiusi’) al nuovo ambiente Web-Oriented, rivolto al business elettronico. Il fenomeno Internet è l’elemento trainante in questa rivoluzione che rende di fatto possibile accedere alle informazioni da qualsiasi posto in qualsiasi momento. Le nuove tecnologie dell’informazione e della comunicazione, soddisfacendo necessità esistenti ed emergenti sia degli individui, sia delle organizzazioni, risultano più pervasive e trasversali di ogni altra tecnologia. Per molti oggi Internet è divenuto il veicolo primario d’accesso alle informazioni e domani sarà il veicolo per creare nuovi modi d’interagire nel mercato (con l’avvento dei primi servizi di e-commerce B2C – Business To Consumer - vale a dire servizi verso i consumatori o utenti finali , e il raggiungimento per i servizi B2B – Business To Business servizi di commercio elettronico rivolti al mercato delle imprese – di una fase di maturità). Per affrontare in modo adeguato le necessità di comunicazione interna ed esterna oramai tutte le grandi aziende ricorrono a reti Intranet, come sempre più spesso vi ricorrono per la gestione dei contatti con il mondo esterno (extranet e internet).
La convergenza ha creato nuove opportunità nel campo della struttura delle reti, basti pensare alle rivoluzioni della telefonia mobile e della telefonia su reti IP o alla televisione su Internet, e parallelamente anche nel settore delle applicazioni come il commercio elettronico. Oggi si dispone di un ambiente di rete distribuito capillarmente a livello aziendale e domestico, in grado di supportare lo sviluppo e promozione dei servizi multimediali interattivi come il telelavoro, l’e-learning, le reti tra università e centri di ricerca, i servizi telematici per le PMI, il monitoraggio ambientale, i servizi in rete per la Pubblica Amministrazione, la telemedicina, la telediagnosi, sono solo alcune delle tecnologie che possono divenire elemento trainante per l’intero tessuto sociale e, al tempo stesso, stimolare la crescita, la competitività e l’occupazione.
• Più in particolare l’industria informatica sta entrando in una nuova fase. Internet ed il network computing hanno un serio impatto sia sull’hardware (era post-pc, internet appliances e mobile internet) che sul software, imponendo nuovi ambienti di sviluppo ed architetture di sistema molto più flessibili,

Risultati e previsioni nel mercato ICT – 2
integrabili e manutenibili per tendere al concetto di disponibilità delle informazioni ‘sempre e ovunque’.
I.1.1 Risultati e previsioni nel mercato ICT
Alcune previsioni sono desunte dai report del programma decennale Media Futures di SRI Consulting offrono dati di proiezione a medio (2003) e a lungo termine (2010) inerenti alcune delle tecnologie e servizi ICT a maggior richiesta:
• Riguardo l’ampiezza di banda: il modem via cavo e la tecnologia Dsl (Digital Subscriber Line) offrono da tempi piuttosto recenti la possibilità di connettere a larga banda le residenze domestiche, per le quali il successo commerciale si prevede arrivi entro il 2003. Rimane infatti da risolvere commercialmente il problema dell’ultimo miglio che comporta ad oggi quelle difficoltà di intervento nella abilitazione all’accesso DSL che limitano lo sviluppo del mercato (costi ancora alti).
• La telefonia cellulare integrata al Web grazie alle nuove versioni del protocollo WAP (Wireless Application Protocol), con 300 milioni di possessori di cellulari e PDA calcolati nel gennaio scorso e la previsione di raggiungere quota 1,7 miliardi di cellulari di prossima generazione nel mercato mondiale nel lungo termine (2010). La telefonia cellulare raggiunge per numero di abbonamenti il 30% degli abbonamenti telefonici, in continua crescita.
• Internet via Tv e Televisione Digitale via etere: si moltiplicano i servizi di accesso a Internet tramite televisore grazie alle nuove apparecchiature set-top box digitali. Più di un milione di residenze negli Usa e in UK connesse con set-top box per Tv via cavo. In Italia con l’avvento della rete televisiva digitale via etere, che porterà alla riassegnazione progressiva delle frequenze entro il 2006, si prevede l’installazione di milioni di set-top-box di decodifica, che possono essere abilitati al funzionalità di accesso alla rete internet. Contenuti di intrattenimento e servizi a basso costo di messaggistica personale sono le chiavi di successo. La facilità d’uso è l’altra condizione, sondaggi e ricerche mettono in evidenza le richieste da parte dei potenziali utenti di interfacce semplici e orientate al consumo di contenuti ‘da salotto’ che prevede un approccio molto differente da quello necessario per l’uso di Internet dal PC. Inoltre l’utente medio non è disposto ad accettare i problemi di ‘crash’ diffusi nel mondo dei PC per il proprio televisore. Le previsioni affermano che per il 2009, 470 milioni di residenze accederanno a contenuti televisivi in formato digitale con il proprio televisore o Pc o altro terminale mobile o fisso: 170 milioni di residenze via satellite, 160 milioni via etere, 120 milioni di residenze via cavo.

Risultati e previsioni nel mercato ICT – 3
Se vediamo i risultati economici più recenti, il contesto mondiale risulta piuttosto vivace, mosso dalla spinta generata da internet e dai servizi radiomobili, e l’Italia presenta un incremento dei flussi legati a Information technology e telecomunicazioni quasi del 13% nel passaggio dal 1999 al 2000: più esattamente, l’intero mercato è risultato pari a 108.160 miliardi di lire, raggiungendo una quota del PIL (Prodotto Interno Lordo) del 5,5%.
Figura: Il mercato dell’ITC in Italia (1999-2000) – Valori in miliardi di Lire –
Variazioni %.
Alla base della crescita la diffusione del Web ma anche i consistenti investimenti fissi in telecomunicazioni e la spesa in informatica, arrivata al 12,6%, vale a dire 2 punti percentuali sopra la media europea ed americana. Analizzando i grafici di una ricerca che Assinform (Associazione nazionale produttori tecnologie e servizi per l’informazione e la comunicazione) ha presentato nel rapporto annuale dedicato all’andamento del mercato ICT, risulta che l’utenza italiana si è accorta solo da due anni dell’importanza della rete: nel 1998 poco più dell’1% della popolazione dichiarava familiarità con Internet, mentre, con una crescita del 209%, ora gli italiani che dichiarano di utilizzare internet sono diventati più del 13% complessivo (intendendo come utente in tal caso chi abbia navigato almeno 1 volta nei tre mesi precedenti la rilevazione, non limitando quindi la categoria agli abituali utilizzatori della rete).
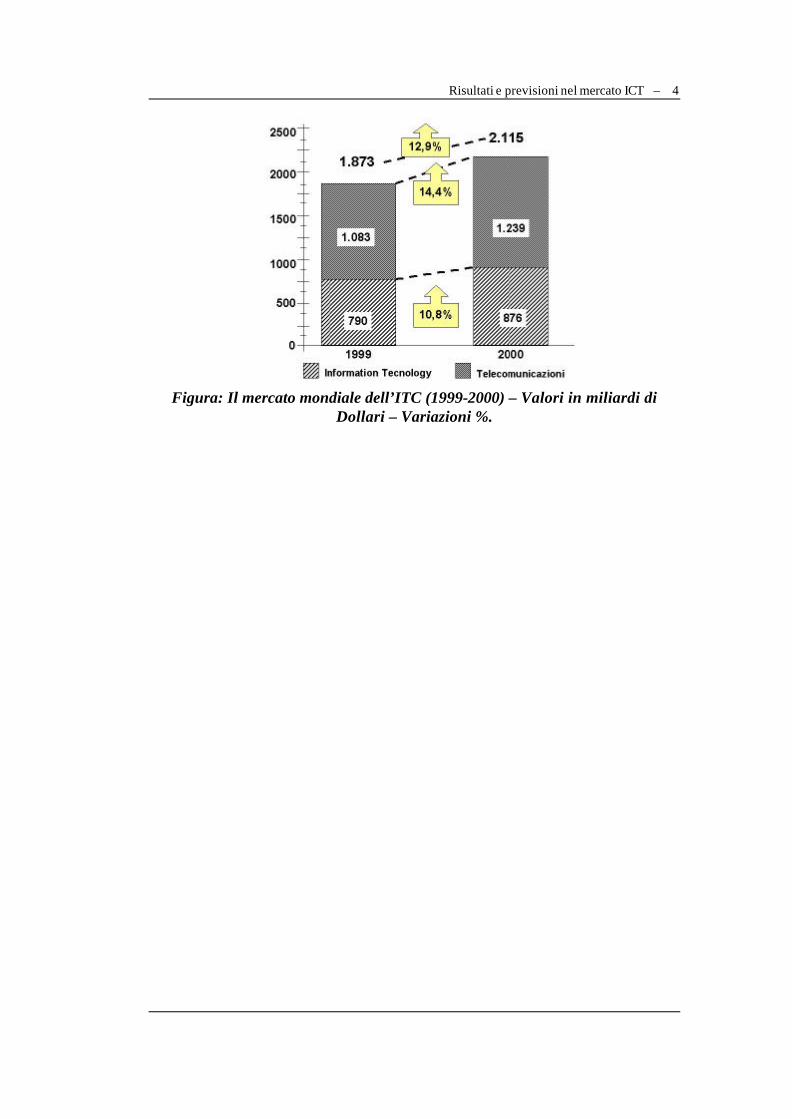
Risultati e previsioni nel mercato ICT – 4
Figura: Il mercato mondiale dell’ITC (1999-2000) – Valori in miliardi di
Dollari – Variazioni %.

Metadati in generale e metadati audiovisivi – 5
II° Capitolo - I metadati, gli standard MPEG, le tecnologie XML e l’integrazione con i Database
II.1 I Metadati
II.1.1 Metadati in generale e metadati audiovisivi
I metadati stanno assumendo un'importanza critica, quasi paragonabile a quella del contenuto che descrivono o che permettono di gestire.
Di qualunque contenuto o collezione si parli, che sia un libro o una biblioteca, un archivio di applicazioni software di pubblico dominio, i miliardi di pagine web memorizzate nei web server dislocati su tutta la rete Internet, gli stock alimentari di un grande magazzino. I metadati favoriscono la ricerca e il reperimento delle risorse, informative o materiali nel senso più stretto. Ma soprattutto lo scambio di dati e risorse, da sempre anima del commercio tradizionale e oggi anche elettronico. Proprio il commercio elettronico dipende maggiormente rispetto al commercio tradizionale dal modo con cui le cose vengono identificate (che siano merce, oggetti in genere o anche persone od organizzazioni) e dai termini in cui queste vengono descritte (i cosidetti metadati o dati sui dati).
Il commercio elettronico necessita dell'identificazione delle risorse e del loro valore. Nella vendita dei diritti d'autore sappiamo bene quanto sia importante identificare i prodotti e le autorizzazioni d'uso attraverso catene del valore complesse e dinamiche. Viene richiesta una grande affidabilità, fino ad oggi pressoché assente, ai sistemi per l'identificazione e descrizione di risorse e diritti d'uso, e con la crescita dei volumi d'affari nell'e-commerce si assiste ad un crescente interesse e ad un moltiplicarsi di iniziative per la promozione e armonizzazione di diversi modelli di descrizione basati sui metadati.
Molto spesso la risorsa in gioco (un film, un'opera multimediale, un software) presenta una certa complessità, e con essa diventa sempre più difficile identificare i diritti d'autore (ad esempio se in un film vi sono degli spezzoni presi da un archivio audiovisivo, o se in un programma tv vengono utilizzate sequenze video di diverse fonti e proprietari).
Ritrovare una particolare notizia o un brano musicale: capita comunemente una necessità del genere, ma per portare a buon fine la ricerca spesso si scoprono difficoltà tutt'altro che banali, con considerevoli dispendi di tempo.
E ancora, mentre una mela acquistata ad un supermercato rimane una singola entità fisica e può essere proprietà esclusiva di una persona, una singola opera

L'interoperabilità delle informazioni di descrizione – 6
audiovisiva digitale può contenere centinaia o addirittura migliaia di componenti separate ognuna identificata da proprietà intellettuale diversa. Possono esservi foto, audio registrato, filmati, grafica sintetica, testo e applicazioni software, alcune magari presenti solo in parte o in forma modificata. Ognuna di queste manifestazioni separate di proprietà intellettuale potrebbe avere dei diritti d'uso ed essere accompagnata da informazioni riguardanti l'autore, i contributori, l'organizzazione che si occupa della distribuzione, i collegamenti ad uno o più archivi dove poter trovare facilmente quel contenuto e magari acquistarlo.
Una delle caratteristiche che sono dunque necessarie per un insieme di metadati utile a descrivere risorse di archivio di questo tipo è quello della modularità. Si riconoscono delle entità di base per la descrizione di un oggetto (ad esempio le informazioni di creazione e produzione, quelle di pubblicazione, le informazioni per la gestione delle transazioni anche commerciali, o la licenza d'uso). Ognuno di questi aspetti necessita del proprio insieme di metadati.
I metadati nell'ambiente digitale possono quindi essere visti come un insieme di moduli informativi, magari anche prodotti in posti diversi e per scopi diversi, che devono anche essere facilmente riutilizzabili e connessi in qualche modo con il contenuto cui si riferiscono. In questo senso si sente parlare di una rete semantica o di una rete di metadati, dove ogni contenuto è descritto e identificato (il titolo di un film non è comune testo formattato ma è testo formattato ed etichettato in modo tale che se estratto dal documento originale rimanga riconoscibile la sua natura di titolo, ad esempio).
II.1.2 L'interoperabilità delle informazioni di descrizione
Un'altra caratteristica ritenuta fondamentale per dei set di metadati è l'interoperabilità, che consente di utilizzare le informazioni create in diversi contesti e di scambiarle nei modi il più possibile automatizzati. Nel commercio elettronico non è detto che si scambino solo soldi: in un ambiente in cui le creazioni sono create o utilizzate attraverso mezzi elettronici si potrà parlare di nuove forme di baratto delle informazioni. Comunque le informazioni che devono interoperare in questi casi sono i metadati: dati di tutti i tipi relativi alle creazioni, ai ruoli che le creano e utilizzano, e alle transazioni che supportano tali utilizzi.
L'interoperabilità nel commercio elettronico ha molti aspetti diversi. Le organizzazioni affrontano la necessità di combinare o accedere le informazioni che pervengono in una varietà di forme e da sorgenti informative eterogenee. Chi inserisce i metadati riguardo un pezzo di proprietà intellettuale (il responsabile della documentazione di un filmato di archivio per esempio) potrebbe volere la certezza che l'accuratezza e la veridicità delle informazioni allegate (spesso con costi ingenti) sopravvivano intatte attraverso varie negoziazioni.
Un approccio completo al problema richiede il supporto di almeno sei tipi differenti di interoperabilità:

I limiti della tecnologia: necessità di identificatori unici – 7
• Attraverso diversi media (come libri, suoni, audiovisivi, software, lavori concettuali, materiali visivi,etc.)
• Attraverso diverse funzioni (come la catalogazione, la ricerca, i flussi di lavoro, la gestione dei diritti)
• Attraverso diversi livelli di metadati (dai più semplici ai più complessi e dettagliati).
• Attraverso le barriere linguistiche e semantiche.
• Attraverso le barriere territoriali.
• Attraverso diverse piattaforme tecnologiche.
Lacune nell’interoperabilità in ognuna di queste dimensioni possono essere viste come barriere per il commercio, barriere che non sono ancora viste come critiche, solo perché attualmente il volume di affari dell'e-commerce riguardante la proprietà intellettuale è relativamente modesto.
Tuttavia da tempi relativamente recenti si assiste ad una vera e propria esplosione di iniziative di sviluppo proprio nel campo degli schemi di metadati. Possiamo citare alcune delle maggiori iniziative in cui più o meno corposi vocabolari, modelli, basi di dati e formati di scambio sono attualmente in sviluppo e rilasciati, per essere mostrati alle comunità in cui questi gruppi di lavoro operano o da cui si sono originati: CIDOC (musei e archivi), CIS (società di copyright), DCMS (industria discografica), Dublin Core (ambiente bibliotecario), EPICS/ONIX (industria libraria), IFLA FRBR (biblioteche), IMS (educazione), International DOI Foundation (industria dell'editoria), IEEE LOM (educazione), MPEG7 (originato nell'ambito degli audiovisivi e multimediale), MPEG21 (originato nell'ambito degli audiovisivi, multimediale e agenti intelligenti), P/META (audiovisivi), SMPTE (audiovisivi). Questi schemi, che sono stati sviluppati o ancora sono in via di sviluppo da differenti contesti applicativi, stanno tutti convergendo sui problemi del superamento delle barriere menzionate.
In un certo senso ognuna di queste iniziative sta cercando di divenire multimediale, multifunzionale, multilivello, multilingue e multipiattaforma. Col crescere dei fattori di convergenza le tradizionali divisioni settoriali perdono significato, e inevitabilmente esse necessitano di interoperare con le altre in modo sostanziale.
II.1.3 I limiti della tecnologia: necessità di identificatori unici
Strumenti nati nell'ambito del web, come il metalinguaggio XML (eXtensible Markup Language) e RDF (Resource Description Framework) e i loro derivati e successori, provvederanno solo parte della soluzione.

I metadati nel settore audiovisivo – 8
Essi non risolvono il problema dell'identità semantica. Solo con lo sviluppo di identificatori unici e l'impiego massiccio e standardizzato di metadati, si potranno superare le barriere al commercio dei contenuti, senza soffrire di antieconomici livelli di intervento e interpretazione umana in ogni singola, anche piccola, transazione. Sistemi per l'identificazione univoca delle risorse sono in via di sviluppo da parte di alcuni degli organismi sopra menzionati.
II.1.4 I metadati nel settore audiovisivo
Rispetto al settore bibliografico, lo sviluppo di dizionari di metadati e schemi di metadati per i supporti audiovisivi è un ambito applicativo relativamente giovane.
Per alcune fasi del processo di produzione di audiovisivi sono già stati sviluppati degli schemi standard specializzati e in certi casi questi sono già operativi, anche se spesso non si è raggiunto uno standard formale. Non ci sono stati sino ad oggi standard ufficiali dettagliati per l'interoperabilità di metadati nel settore degli audiovisivi (che include e integra tutti i processi di produzione digitale, di distribuzione e di archiviazione) e quelli che già esistono sono modelli non comunemente accettati nella totalità del settore audiovisivo.
E' necessario considerare due aspetti correlati per poter definire uno schema di metadati per un sistema di gestione di media per l'ambito della produzione. In primo luogo il sistema deve essere mirato a soddisfare i requisiti specifici dell'organizzazione operante nel campo audiovisivo per cui il sistema stesso dovrà operare; in secondo luogo i protocolli e gli standard necessari andrebbero modellati tenendosi il più vicino possibile agli schemi internazionali e agli standard per poter aumentare il grado di interoperabilità e facilitare lo scambio di documenti audiovisivi scala nazionale ed internazionale.
Gli schemi di metadati che sono sviluppati localmente devono dunque essere allineati con gli standard internazionali accettati o in via di accettazione. Quando possibile le definizioni locali andrebbero tradotte nello standard internazionale dall'inizio.
Per la produzione e la distribuzione di prodotti digitali televisivi e radio il dizionario dei metadati SMPTE e le funzioni guida fornite per l'ingegnerizzazione di sistemi sono un possibile punto di riferimento.
Lo stesso naturalmente si può dire per le attività del gruppo MPEG-7, oramai prossime al rilascio dello standard internazionale, e che sono state oggetto di approfondito studio per la parte riguardante i metadati nell’ambito di questo lavoro, nella fase di sviluppo di schemi per il contenuto audiovisivo in ambiente professionale. L’uso di strutture dati Mpeg-7 per metadati audiovisivi è ampiamente illustrato nel capitolo 4.

I metadati nel settore audiovisivo – 9
Per la categoria di metadati descrittivi un importante punto di riferimento sono anche le funzioni di Dublin Core.
Lo Standard Media Exchange Framework (SMEF) della BBC viene a volte utilizzato con modello di dati di riferimento per gli ambienti della produzione broadcast e per i sistemi di gestione dei media.
Nell'ambito della produzione, distribuzione e archiviazione audiovisiva schemi interoperabili sono sviluppati, come accennato, su vari livelli:
• Schemi di metadati basati su progetti:
o Progetti locali o iniziative per la produzione digitale, ad esempio per una emittente pubblica o commerciale.
o Progetti con uno scopo ampio, nazionale, etc. Un esempio è la Digital Platform dell'emittenza televisiva pubblica nei Paesi Bassi, che prepara una infrastruttura digitale con la copertura di un dizionario di metadati e un modello dei dati comune.
o I progetti europei che rientrano nel Fifth Framework, il cui obiettivo è di costituire delle libreria video digitali come il progetto European Chronicles Online (ECHO).
• Schemi di metadati sviluppati nell'industria:
o I soggetti industriali a volte sviluppano i loro propri schemi e modelli, di solito includendo parti di preesistenti standard o standard in via di sviluppo e aggiungendo i metadati e i modelli di dati richiesti dalle aziende clienti. Per i sistemi di gestione delle risorse mediali questi modelli sono tipicamente in accordo con SMPTE.
• Schemi interoperabili provenienti dalle comunità di standardizzazione:
o Per esempio P/Meta, uno dei gruppi di progetto della European Broadcasting Union (EBU) che mira all'armonizzazione dei dizionari di metadati di SMPTE, Dublin Core e MPEG-7 per favorire l'interscambio di informazioni audiovisive tra le emittenti Europee, gli archivi e i consumatori.
Generalmente uno dei problemi maggiori riscontrati in questo campo è la difficoltà di tenere di pari passo il lavoro che viene svolto dai vari organismi di standardizzazione, i progetti pilota e le altre iniziative sul piano del tempo, dei risultati e degli scopi. Attualmente non vi è uno scambio di informazioni centralizzato, sistematico e efficiente tra i vari progetti locali, internazionali e nazionali che riguardano lo sviluppo di schemi per i metadati audiovisivi. I comitati di standardizzazione lavorano lentamente e i broadcaster e i produttori

Tendenze, sovrapposizioni e mancanze nell’ambito dei metadati audiovisivi – 10
dall'altro lato - a causa del rapido avanzare delle tecnologie - hanno necessità di mettere qualcosa in atto e non possono attendere ogni nuova versione degli standard.
Un altro problema è la comunicazione tra le varie comunità che contribuiscono alla creazione degli schemi, spesso inadeguata, sia all'interno, a livello di una stessa azienda, che a livello internazionale. Problemi di comunicazione possono essere causati dalle diverse professionalità in gioco (degli ambiti tecnico, archivista, di produzione), i diversi background dei contributori che necessitano di integrare i requisiti per arrivare ad uno schema interoperabile.
Anche il cambiamento di gran parte dei modelli di produzione audiovisiva comporta dei problemi nello stabilire modelli comuni per i metadati, che possono rendere difficile standardizzare ad un livello dettagliato i vari gruppi e classi di metadati che sono necessari per i sistemi di supporto digitale al contenuto.E’ possibile riconoscere altre problematiche più specifiche:
• Armonizzare le richieste dell'utenza attraverso i vari settori della produzione audiovisiva.
• Standardizzare i processi di produzione, distribuzione e archiviazione di audiovisivi e le procedure di lavorazione.
• Standardizzare le strutture dati e i modelli dei dati, le entità e gli attributi.
• Standardizzare i campi di tipo e i valori ammessi.
• Sviluppare identificatori unici globalmente riconosciuti, per il contenuto audiovisivo da collegare al materiale immagazzinato con la relativa documentazione nel processo di produzione audiovisiva.
• Rendere gli schemi interoperabili compatibili con più lingue.
• Comprendere ed integrare le varie categorie e tipi di metadati nell'ambito dell'audiovisivo, inclusi i metadati riguardanti il processo di registrazione, i metadati tecnici, i metadati relativi alla produzione e le categorie descrittive.
• Integrare gli archivi e i cataloghi preesistenti nel settore digitale.
II.1.5 Tendenze, sovrapposizioni e mancanze nell’ambito dei
metadati audiovisivi
Ogni ambiente di produzione audiovisiva spesso possiede delle procedure e requisiti particolari e questi devono essere inclusi negli schemi e nei modelli di dati dell'azienda. Oltre a questo, le realtà possono differire nelle modalità con cui

Tendenze, sovrapposizioni e mancanze nell’ambito dei metadati audiovisivi – 11
avviene lo scambio di informazioni dal punto di vista dei diritti di copyright e dello sfruttamento commerciale.
In altri casi gli schemi ad uso interno contengono informazioni dettagliate sulle procedure aziendali interne e i processi di lavorazione e possono quindi risultare non condivisibili liberamente in altri ambienti. E' per ragioni come questa che iniziative come EBU P/Meta (di European Broadcaster Union), che lavorano per trovare una connessione ai requisiti, schemi e modelli di vari broadcaster con gli standard internazionali, sono di importanza fondamentale.
Per poter promuovere l'interoperabilità da subito, sarebbe davvero utile stabilire piattaforme professionali in cui i broadcaster e gli altri produttori di audiovisivi possano acquisire informazioni dettagliate ed obiettive su quale lavoro è già stato svolto e quali schemi sono disponibili come modello di riferimento. Attualmente gran parte dei progetti pilota che si stanno portando avanti all'interno delle emittenti includono lo sviluppo e l’uso di schemi di metadati. Spinti dalla rapida crescita della produzione digitale di materiali audiovisivi e dalla mancanza di schemi e standard comuni utilizzabili, gran parte delle compagnie televisive stanno sviluppando i propri schemi di metadati. Durante questo processo spesso queste partono dalla formulazione di specifiche locali e definiscono i processi e flussi di dati del proprio caso particolare. Successivamente devono cercare delle estensioni per poter armonizzare e mappare i propri modelli proprietari con gli standard esistenti o in via di rilascio.
Nuovi broadcaster commerciali che non posseggono archivi o cataloghi pregressi, attualmente tendono a posizionarsi in prima linea nello sviluppo dei sistemi, lavorando spesso in ambienti completamente digitali, e utilizzando modelli proprietari e dizionari di metadati. Tra broadcaster, produttori di audiovisivi, e altri soggetti nel campo degli audiovisivi cresce rapidamente la consapevolezza che l'interoperabilità tra strumenti di descrizione aziendali di questo e di altri settori sia un requisito importante. Si è registrato più volte il fallimento nell'adozione degli standard internazionali nella prima fase di sviluppo dei sistemi, ad indicare l'effettiva inadeguatezza e inefficienza dei sistemi proprietari sviluppati localmente. Adattare successivamente i sistemi sviluppati in ambito proprietario risulta un impegno intensivo e costoso e la graduale implementazione degli standard in casi come questo tende spesso a seguire più la tecnologia che le necessità dell'utente dei sistemi.
II.2 Gli standard della famiglia MPEG
MPEG è l'acronimo di Moving Picture Experts Group, un gruppo di lavoro dell'ISO/IEC nato nel 1988 e originariamente incaricato di creare degli standard internazionali per la compressione, la decompressione, il processing e la codifica di immagini in movimento, audio e relative combinazioni, utilizzabili su media del tipo CD-ROM, CD-i, CD Multi-sessione e Video CD.

Gli agenti intelligenti e i nuovi standard Mpeg – 12
Un incontro fra l'ISO (International Standards Organisation) e l'IEC (International Electrotechnical Commission) nel 1992 ebbe come risultato lo standard di codifica audio/video denominato MPEG-1. Con la costituzione del gruppo MPEG e il rilascio del primo standard è iniziato un processo che ha trasformato i servizi audiovisivi analogici in forma digitale e ha portato a una vera rivoluzione mediale.
La digitalizzazione dell'audiovisivo sta cambiando la natura delle varie forme di comunicazione e ne ha creato una nuova, quella multimediale. Il successo probabilmente risiede proprio nella capacità dimostrata non solo nella definizione degli standard ma anche nella loro divulgazione e consenso a livello globale.
La ricerca è andata avanti, e i sistemi finora ideati e realizzati, o in fase di realizzazione, sono i seguenti:
• MPEG-1, lo standard per il Video CD e in generale per la codifica di sequenze video in qualità VHS.
• MPEG-2, lo standard per la televisione digitale.
• MPEG-4 versione 1, 2, 3, lo standard per applicazioni multimediali.
• MPEG-7 esce dall’ambito della codifica audiovisiva per definire strumenti per la descrizione e ricerca di informazioni multimediali (multimedia information search), filtering, management e processing, draft standard da luglio 2001, e definitivo da settembre.
• E' inoltre iniziato il lavoro per la realizzazione di MPEG-21, l’ambizioso progetto per uno standard di multimedia framework.
II.2.1 Gli agenti intelligenti e i nuovi standard Mpeg
In realtà la vera potenzialità di un’infrastruttura multimediale sta proprio nel fornire degli automatismi e meccanismi intelligenti di elaborazione e comunicazione tra dispositivi elettronici, come nel caso dell'elaborazione intelligente delle immagini (per applicazioni di sorveglianza, visione intelligente, riconoscimento di forme), della conversione del formato dei dati (ad esempio la conversione automatica del parlato di un filmato in testo per gli audiolesi, la ricerca di informazione di vario tipo su documenti multimediali di particolare interesse per l'utente secondo un profilo, oppure operazioni di controllo e filtraggio per ricevere solo quei dati che soddisfano le scelte dell'utente). Un codice inserito in un programma televisivo può essere utilizzato da un videoregistratore per registrare in automatico, come già avviene nel sistema ShowView, oppure un sensore di immagine può far scattare un allarme quando

MPEG e la protezione dei contenuti – 13
accade un determinato evento visuale (ad esempio una telecamera attraverso un opportuno software permette di rilevare l'immagine di un soggetto estraneo e fa scattare l'allarme). Le informazioni audiovisive devono quindi essere opportunamente codificate per abilitare un dispositivo o un elaboratore ad interagire con esse. Il ruolo che tali informazioni multimediali avranno nel futuro sarà tale da dover superare la semplice rappresentazione basata su forme d'onda o fotogrammi della codifica audio video (come per gli standard MPEG-1 e MPEG-2). Sarà necessaria una forma di rappresentazione delle informazioni multimediali che possa permettere un certo grado di interpretazione sul significato delle informazioni che sono trasmesse ad un dispositivo.
Ad esempio, nella trasmissione di immagini di una telecamera intelligente i dati potranno essere rappresentati, invece che nella forma di valori campionati (valori per pixel), nella forma di oggetti con associate delle misurazioni fisiche, informazioni temporali, etc., informazioni aggiuntive che potranno essere memorizzate ed elaborate per verificare se una certa condizione programmata si è verificata ed agire di conseguenza. Un videoregistratore potrebbe ricevere le descrizioni di un'informazione audiovisiva associata ad un programma che abilita alla registrazione, ad esempio, delle sole notizie di cronaca escludendo lo sport, oppure i prodotti di una azienda potrebbero essere descritti in un modo che un dispositivo possa rispondere ad una interrogazione su determinati requisiti richiesti dall'utente. Attualmente sono in fase di sviluppo due progetti che delineano il futuro degli standard audio-video: la realizzazione dell’ MPEG-7 e MPEG-21, quest'ultimo ancora in fase di progettazione formale. Significativo il fatto che entrambi siano orientati ad una formalizzazione descrittiva dei contenuti multimediali di un flusso di dati digitali.
II.2.2 MPEG e la protezione dei contenuti
Mp3 è usato da milioni di entusiasti per comprimere file di musica letti da un cd e scambiarli su Internet: un grande risultato perché fornisce gli strumenti per superare il macchinoso sistema di distribuzione di contenuti basato sulla vendita del supporto fisico su cui il contenuto è stato fissato. Molti utenti però ritengono che i contenuti digitalizzati in forma di bit debbano essere liberi, cioè gratuiti. Questo sta mettendo in crisi tutto il mercato dei contenuti sia sui media tradizionali che sui nuovi media. E questa è anche la ragione per cui le tecnologie di protezione applicate ai contenuti in forma numerica sono destinate ad avere un ruolo importante per la futura società in rete. Una volta che non possa più essere copiato in modo indiscriminato, il contenuto riacquista il suo valore, e Internet stessa, spesso accusata di essere la causa della sua perdita di valore, diventa lo strumento mediante il quale il suo valore viene accresciuto: ognuno può esporre le proprie opere in forma protetta e ricevere una remunerazione che è diretta conseguenza del valore dell’opera.
Questo avvantaggia gli artisti perché c'è un modo più semplice e diretto per raggiungere i fan, ma anche i consumatori, perché diventa possibile acquisire il

MPEG e la protezione dei contenuti – 14
diritto di consumare un'opera in più modi di quanto sia possibile oggi: invece di comperare un cd e poterlo sentire fino a quando dura anche se l'interesse per il brano è ormai passato da anni, un consumatore può comperare il diritto a sentirlo 10 volte o per la durata di una settimana, ovviamente pagandolo di meno rispetto al caso in cui lo si acquista per sempre. Anzi potrebbe avere la musica gratis se riesce a venderla a 10 suoi amici. Un artista potrà affidarsi al valore della propria arte mettendo le proprie opere direttamente sul web e aspettando che arrivino clienti. Oppure può decidere di chiamare in soccorso un intermediario, come una possibile evoluzione delle case discografiche di oggi. O ancora potrebbe rivolgersi a uno di quegli intermediari di nuovo tipo, esempi dei quali nascono sul web ogni giorno. In un mondo in cui raggiungere le persone, ed in particolare i consumatori, diventa più semplice, ogni utente della rete può in principio assumere uno qualsiasi dei ruoli di autore, esecutore, produttore, editore, fornitore di servizio, rivenditore a valore aggiunto, consumatore etc.
Si studiano oggi le tecnologie che consentiranno di acquisire i diritti per una porzione di un'opera, del valore magari di poche lire, allo scopo di riutilizzarla a certe condizioni, attraverso il necessario utilizzo di negoziazioni e transazioni automatizzate. Da parte di iniziative come Fipa (Foundation for Intelligent Physical Agents, http://www.fipa.org) ad esempio stanno nascendo soluzioni a questo problema. Il linguaggio di comunicazione tra agenti (Acl), è una componente chiave delle specifiche Fipa perché definisce la lingua universale parlata dagli agenti intelligenti. Ma essere in grado di parlare è condizione necessaria, non sufficiente per permettere il dialogo tra agenti. In più serve la conoscenza del vocabolario di un dominio specifico, nel nostro caso i contenuti audio e video. Questo problema viene risolto ancora da MPEG con il suo standard MPEG-7.
Con MPEG-7 è possibile dare descrizioni semantiche di oggetti audio e video, ad esempio la forma di un oggetto visivo o il ritmo di una canzone. In uno scenario non troppo lontano sarà possibile chiedere al proprio agente intelligente personale di cercare la fotografia di un gabbiano sulla spiaggia con un wind-surf che sta attraversando la costa sullo sfondo, chiedendo di valutare solo le offerte di foto con un costo non superiore ad una data cifra. MPEG-7 e Fipa insieme si prefiggono di consentire al proprio agente di descrivere ai suoi colleghi agenti ciò che sta cercando e di condurre una trattativa.
Mettere insieme tutte queste tecnologie in modo tale da permetterne l'interazione è la sfida maggiore perché gli standard su cui queste si basano sono stati sviluppati da gruppi industriali diversi, che hanno lavorato basandosi ognuno sulla propria visione del mondo e sulle proprie necessità di business. Questa è la ragione per cui MPEG ha recentemente iniziato lo sviluppo di un nuovo standard chiamato MPEG-21 "Multimedia Framework". L'obiettivo dello standard può essere descritto come l'integrazione di due tecnologie cruciali: quella che consente ai consumatori di cercare ed ottenere contenuti - da soli o con l'aiuto di agenti intelligenti - e quella che consente di decodificare e consumare il contenuto secondo i diritti d'uso ad esso associati.

XML, XHTML e HTML e la nuova generazione del web – 15
II.3 XML, XHTML e HTML e la nuova generazione del web I I . 3 . 1 X M L , X H T M L e H T M L e l a n u o v a g e n e r a z i o n e d e l w e b
Affrontiamo ora le tecnologie alla base della diffusione del web e dei contenuti multimediali in rete, partendo dal nuovo standard per lo scambio di informazioni sul quale si basa anche la specifica di Mpeg-7. Parliamo di XML, l’eXtensible Markup language che ha preso origine dall’SGML (Standard Generalized Markup Language). Parlando di XML si deve affrontare anche la sua Document Type Definition (DTD) che è quasi identica alle SGML DTD. Lo standard SGML – pubblicato nel 1986 – definisce un metalinguaggio per un formato di documenti portabile e indipendente dalla piattaforma con l’enfasi posta sui documenti.
L’XML – rilasciato nel febbraio del 1998 – ha un diverso dominio di applicazione. Progettato per ovviare alle carenze di HTML, esso viene utilizzato molto spesso come lingua franca nell’ambiente Internet, come un formato comune per scambiare e immagazzinare non solo documenti ma ogni tipo di contenuto. Nel mercato del commercio elettronico in particolare, XML non ha a che fare – come SGML – principalmente con documenti destinati alla lettura da parte di esseri umani: i documenti XML devono essere leggibili e comprensibili da parte dei sistemi informatici oltre che dall’uomo.
Nella gestione elettronica della catena del valore i documenti XML che sono trasmessi da diversi partners commerciali sono generati da un sistema informatico e interpretati da un altro sistema informatico diverso dal primo. Nei mercati digitali aperti, si prevede che i cataloghi e la lista dei prezzi debbano essere presentati in una forma tale che li renda accessibili alla ricerca da parte degli agenti software. Quello che XML deve gestire in questi ambiti è una combinazione di un punto di vista del “documento” insieme ad un punto di vista dei “dati”, che è proprio dei database tradizionali.
I documenti XML hanno una sintassi semplice. Seguendo poche semplici regole sull’uso dei tag è possibile costruire documenti ben-formati, e viene richiesto ad un processore XML di processare un documento ben-formato (segnalando e rifiutando ogni documento che non lo sia). Grazie alla sua estensibilità, l’XML consente l’aggiunta di etichette – i tag – al documento che descrive il contenuto degli elementi del documento stesso. Questo consente ad esempio ai motori di ricerca di effettuare ricerche su specifici elementi, come per esempio il prezzo, la descrizione del prodotto, etc. Al contrario, i tag in HTML descrivono le modalità di presentazione di un elemento: se è grassetto o corsivo, se deve avere il carattere di testa,etc.
In XML un elemento che contiene le informazioni di prezzo può ad esempio essere etichettato con i tag <prezzo></prezzo>. Questa viene chiamata etichettatura semantica poiché i tag e i nomi degli attributi descrivono il significato di ogni elemento e attributo, che sono comprensibili anche ad un lettore umano.

XML, XHTML e HTML e la nuova generazione del web – 16
Per un generico processore XML il nome di un tag non ha alcun significato. Un tag è solo un tag, ed un elemento di testo è solo un elemento di testo. Questo perché un generico processore XML non ha conoscenza della semantica del documento. Paradossalmente, i processori HTML come ad esempio i browser web, conoscono la semantica dei tag HTML molto bene: essi devono ad esempio sapere che il testo racchiuso tra i tag <b> </b> deve essere visualizzato in grassetto.
Attualmente l’HTML (Hyper Text Markup Language) ha la diffusione maggiore rispetto a qualunque altro formato di codifica documenti per il grande numero di documenti prodotti. Ma dopo rilascio delle specifiche HTML 4.0 non ci sono stati e non ci saranno altri aggiornamenti per HTML. Il World Wide Web Consortium (W3C) ha infatti rilasciato come raccomandazione successiva le specifiche di XHTML 1.0 (eXtensible HyperText Markup Language), che si potrebbe definire come un ponte tra il mondo HTML e quello di XML: XHTML non è altro se non un’applicazione di XML, definita attraverso una XML DTD (Document Type Definition) e un XML namespace. XHTML 1.0 ripropone le funzionalità di HTML in un modello XML. Allo stesso tempo XHTML costituisce l’inizio di un processo di convergenza per i documenti sul web. Si prevede infatti di combinare XHTML e WML (Wireless Markup Language) in un unico standard consistente. WML è il formato dei documenti utilizzati nel protocollo WAP per gli apparati cellulari, e anche quest’ultimo, come XHTML, si basa su XML.
Questo significa che tutte le tecnologie ed applicazioni XML attualmente in sviluppo, come Browsers, Parsers, software di editing, API (Application Program Interface), server Database, si rivelano utili a supportare anche XHTML e WAP. La tecnologia XML sarà dunque una tecnologia chiave della prossima generazione delle applicazioni web, su reti mobili e fisse.
Diversamente da quanto previsto da HTML, per XML la presentazione del contenuto non è l’unica applicazione (come pure nel caso della raccomandazione XHTML). Inoltre ci sono diversi standard relativi all’XML che si stanno imponendo, e l’XML è la tecnologia che ben si sposa con la ricerca di soluzioni efficaci per l’interoperabilità di sistemi per l’immagazzinamento e la gestione dei dati. Sono presenti standard come XSL per la visualizzazione dei contenuti, XPATH per la navigazione delle strutture dati, XPOINTER per la creazione di link evoluti, o XML Schema per la definizione di tipi di documenti, e rappresentano solo alcuni degli strumenti creati sulla base di XML e che ne fanno un metalinguaggio potente.
In questo capitolo vengono discussi i concetti principali riguardanti le tecnologie XML e la loro applicazione alle Basi di Dati. Le tradizionali pagine HTML sono solitamente memorizzate come in file “piani”, cosa che non è certo adeguata alle potenzialità di XML. L’accesso a parti di documento (tramite gli elementi), le ricerche su caratteristiche qualificate, la composizione dinamica da documenti originali interconnessi, tutte queste operazioni richiedono la potenza elaborativa di un DBMS (Data Base Management System).

Il modello relazionale e il modello XML a confronto – 17
I DBMS Relazionali sono lo standard di fatto nelle attuali tecnologie di database. Tuttavia, questi non rappresentano la piattaforma ideale per utilizzare documenti XML. Per comprenderlo meglio è certamente utile esplorare alcuni esempi sull’approccio XML nella gestione delle basi di dati.
II.3.2 Il modello relazionale e il modello XML a confronto
Il modello dei dati relazionale si basa sulle tabelle. Le tabelle contengono i dati relazionati, anche chiamati “Relazioni”, ed è proprio per questo che i DBMS che si basano su questa teoria si indicano con l’acronimo RDBMS (Relational DBMS). Le relazioni rappresentano le entità che si ritiene essere interessanti nel database. Ogni istanza dell'entità troverà posto in una tupla della relazione, mentre gli attributi della relazione rappresenteranno le proprietà dell'entità. Per strutturare un Database relazionale sono necessarie delle operazioni di normalizzazione delle tabelle, ad esempio per la rimozione di alcune anomalie. Ma la normalizzazione è un processo oneroso dal punto di vista della progettazione e manutenzione dello schema della base di dati, ed inoltre introduce dei problemi di integrità dei dati. Dopo la normalizzazione il RDBMS non ha informazioni riguardo la struttura dei complessi oggetti informativi originali e non può controllare la loro integrità strutturale. Gli RDBMS (Relational DataBase Management System) risolvono questo problema reintroducendo informazioni strutturali nella forma di vincoli di integrità e limitatori, che consentono al RDBMS di controllare l’integrità delle relazioni chiave mentre vengono effettuate operazioni di aggiornamento. Comunque, questo introduce un “overhead” cioè aumento della complessità elaborativa.
Affrontiamo adesso un esempio: le relazioni che descrivono la struttura di un Database per la gestione degli ordini di prodotti da parte di un insieme di fornitori.
XML può memorizzare le informazioni con la propria struttura intatta. Riportiamo qui sotto un esempio di rappresentazione di un ordine in XML:
<ORDINI_PER_FORNITORE> <CODICE_FORNITORE> 287 </CODICE_FORNITORE> <NOME> Magic </NOME> <CITTA> Torino <DIMENSIONI> Grande </DIMENSIONI> </CITTA> <ORDINI> <ORDINE> <CODICE_PRODOTTO> 807001 </CODICE_PRODOTTO> <PRODOTTO> Superottica </PRODOTTO> <QUANTITA> 20512 </QUANTITA> </ORDINE> <ORDINE>
<CODICE_PRODOTTO> 802320 </CODICE_PRODOTTO> <PRODOTTO> FishEyeLens35 </PRODOTTO> <QUANTITA> 251 </QUANTITA> </ORDINE>

Il modello relazionale e il modello XML a confronto – 18
</ORDINI> </ORDINI_PER_FORNITORE>
Si può notare che la modalità con cui XML memorizza le informazioni non richiede uno schema perché tutti gli elementi informativi hanno un loro nome. In XML i dati sono modellati come in un albero ordinato ed etichettato. I nodi dell’albero sono gli elementi informativi, i dati, ma possono anche consistere di attributi, processing information (PI), o commenti.
Gli oggetti XML sono auto descrittivi: essi contengono tutte le informazioni necessarie per le interrogazioni e per la navigazione nei singoli elementi. In tal modo XML richiede una quantità di spazio molto maggiore rispetto al modello relazionale, ma è possibile effettuare una compressione. L’uso dei “tags” comporta però grandi vantaggi quando la struttura del documento cambia. Per esempio, se dovessimo aggiungere un’informazione di prezzo ad un ordine. In XML questa operazione si effettua semplicemente aggiungendo un nuovo elemento all’oggetto: <PREZZO> 10.5 </PREZZO>.
Per un RDBMS, al contrario, si rende necessario modificare lo schema relazionale, operazione che se per l’esempio dato è ancora piuttosto semplice (richiede qualche intervento da parte dell’amministratore del database, inclusa una conversione dei preesistenti record memorizzati), nei casi più complessi comporta una onerosa reiterazione dei passi di normalizzazione e il progetto di un nuovo database può rendersi necessario.
In XML non c’è bisogno della normalizzazione. Nell’esempio riportato, dove tutti gli ordini che si riferiscono ad un fornitore sono memorizzati nello stesso oggetto, le anomalie non possono esserci. Il documento può esistere anche senza neanche un ordine e quindi le informazioni del fornitore non sono perdute quando gli ordini vengono cancellati.
Di fatto un oggetto XML potrebbe da solo contenere l’intero database. Questa è comunque consigliabile solo per database di dimensioni molto piccole, caso in cui rimane una tecnica valida: un esempio è il Data Source Objects (DSO) di Microsoft si basa su questo tipo di approccio. Ogni DSO costituisce un piccolo database sul sito client. Nel database di un’impresa è tuttavia necessario spezzare un insieme molto ampio di dati in diversi oggetti più piccoli e connetterli con dei link. Un link è un riferimento diretto, mentre un JOIN relazionale deve richiedere il confronto del contenuto di una chiave esterna e di una chiave primaria.
Dunque XML consente agli elementi ridondanti di essere isolati e di sostituire le loro occorrenze con dei link. La forza di XML tuttavia sta nella capacità di immagazzinare in modo flessibile le informazioni complesse e strutturate. L’uso della decomposizione in XML è – al contrario della tecnologia relazionale – un’eccezione invece che una regola.

Come effettuare Query in XML – 19
Dopo questo esempio è possibile comprendere il dilemma con cui ci si deve confrontare oggi nella scelta e utilizzo di un RDBMS per documenti di tipo XML.: un intero documento XML può essere memorizzato in un unico oggetto, rendendo in tal caso impossibile indicizzare i singoli elementi. Oppure il documento può essere decomposto in singoli elementi che sono indicizzati separatamente. Le operazioni di retrieval dei dati devono quindi leggere tutti gli elementi separatamente e riunirli insieme, con un’operazione costosa in termini prestazionali. L’RDBMS deve dunque ricostruire il “puzzle” dei dati ogni volta. Inoltre le regole di integrità e l’imposizione di limiti sono necessari per conservare l’integrità dell’oggetto.
Un altro problema è il “locking”: durante un processo di aggiornamento un documento deve essere bloccato (locked) per evitare che altri utenti tentino l’accesso ad esso. In un RDBMS in cui un documento (come ad esempio un documento XML) è spezzato in numerosi pezzi, ogni singolo pezzo deve essere bloccato separatamente. Ecco perché diverse aziende di software hanno proposto la commercializzazione di server nativi XML. Un server nativo XML (ovvero XDBMS) può offrire operazioni di ricerca note all’ambiente degli RDBMS ( ad esempio selezionare tutti gli ordini con l’attributo PRODOTTO = FishEyeLens35).
Ma un XDBMS offre una maggiore flessibilità in quanto è possibile inserire nuovi tags XML “al volo” – nessun aggiornamento dello schema è richiesto. Allo stesso tempo il server può mantenere un livello di performance pari ad una lettura per ogni documento (o anche meno grazie a tecniche di caching). I Benchmarks dimostrano che i servers XML nativi possono superare gli RDBMS nelle prestazioni di un ordine di grandezza, ovviamente nel caso in cui vengano utilizzati per la memorizzazione di complessi oggetti XML.
II.3.3 Come effettuare Query in XML
Nei paragrafi precedente sono stati messi a confronto il modello relazionale dei dati e il modello dei dati XML e si è compreso quanto sia importante l’uso di tecnologie di server nativi in XML per gestire la richiesta di nuovi modelli di dati e documenti.
In questa parte si introducono i metodi di interrogazione per le sorgenti di dati in XML. Come sopra anche in questo caso verrà analizzato un semplice esempio:
I documenti XML che verranno analizzati negli esempi successivi sono i seguenti:
<?XML version="1.0"?> <!DOCTYPE librocat SYSTEM "http://www.libri.it/librocat.dtd">
<libro> <titolo> Doppio Sogno </titolo>

Come effettuare Query in XML – 20
<autore> Arthur Schnitzler </autore>
<edizione anno=1998> <casaeditrice> Adelphi </casaeditrice> <isbn>0-0703-2809-76</isbn> <prezzo valuta=EUR>6.5</prezzo>
</edizione> <edizione anno=1977>
<caseditrice> Morgante </casaeditrice> <isbn>0-41-524089-4</isbn> <prezzo valuta=ITL>1376</prezzo>
</edizione> <edizione anno=1991>
<casaeditrice> Ficher Verlag </casaeditrice> <isbn>0-28-08197-8</isbn> <prezzo valuta=ITL>8500</prezzo>
</edizione>
</libro>
<?XML version="1.0"?> <!DOCTYPE recensione SYSTEM "http://www.libri.it/recensione.dtd"> <recensione>
<isbn> 0-28-08197-8 </isbn> <titolo> Doppio Sogno </titolo> <recensore href="http://www.frz.it/index.htm"> Francesco Romano </recensore> <commenti> In un giorno la vita di un medico viene
sconvolta dai fantasmi e le trappole della gelosia </commenti> </recensione>
Nel passato sono state sottoposte numerose proposte al WWW Consortium per ciò che concerne i linguaggi di query nei documenti XML. Queste proposte includono XQL, XML QL, Xquery, QL’ 98, ma anche Quilt. La lista cresce con il crescere del numero dei ricercatori che lavorano su queste problematiche.
Di solito quando si parla di “query” si fa riferimento ad SQL. SQL viene utilizzato come abbiamo visto per accedere alle tabelle o a combinazioni di esse in database relazionali.
Ma con XML la situazione è molto diversa. Un documento XML combina già di per se diversi elementi informativi in un’unica entità fisica. Mentre in SQL l’enfasi si pone sulla capacità di combinare dati da differenti tabelle normalizzate in un unico risultato, in XML l’enfasi si pone nell’estrazione dei singoli elementi in un documento.
Esiste uno standard in grado di fare proprio questo. XPath è la raccomandazione attuale del W3C e viene usata in molti altri standard come XSL, Xpointer, Xlink,

Implementazione di XML nel web – 21
etc., come la tecnologia base per l’indirizzamento di singoli elementi all’interno di un documento.
Una semplice query effettuata secondo lo standard Xpath è ad esempio la seguente: “/libro/edizione/casaeditrice” che indirizza tutti gli elementi casaeditrice contenuti negli elementi edizione nel documento libro.
Si può notare la familiarità dell’espressione con il tradizionale path dei file utilizzato in UNIX o nella specifica delle URL (Uniform Resource Locator). L’unica differenza è che qui si indirizza un elemento in un documento e non un file in una struttura a directory o una pagina web in un sito web.
Le somiglianze sintattiche di un’espressione Xpath con un file path o una URL suggeriscono che Xpath può essere utilizzato non solo per l’estrazione degli elementi in un documento ma anche essere ben impiegata per effettuare ricerche di documenti in un server nativo XML.
Nei paragrafi precedenti si è visto che un intero sito web o il contenuto di un server XML potrebbe essere visto come un singolo documento XML. Una sorgente di dati può essere vista come un grande documento contenente tutti gli altri documenti come suoi elementi. Basti ricordare che una directory per un sito web costituisce una struttura ad albero, così come ogni documento presenta anch’esso una struttura ad albero.
La ricerca di documenti da un sito può essere espressa in linguaggio simile selezionando gli elementi da un documento. Si ha dunque una visione consistente dei dati dal livello del sito web fino al livello del documento. Questo rende Xpath un linguaggio di query eccellente. Un esempio: www.frz.it/serverxml/libreria/libro/edizione/casaeditrice, in questo caso “www.frz.it” specifica un dominio web, “serverxml” il server db che gestisce i documenti XML nativi, “libreria”è una collezione di documenti XML, e i restanti elementi del Path sono quelli visti precedentemente.
Se si possiede una cospicua libreria di libri, il risultato di una query del genere è sostanzialmente il seguente: prendi gli elementi casaeditrice di tutti i libri immagazzinati nella libreria. Alcune caratteristiche del linguaggio XPath vengono utilizzate proprio per effettuare query. Una implementazione di XPath è supportata dall’interfaccia DOM di Microsoft, da XSL e da altri standard vicini a XML, ed è utilizzata nel prototipo, come vedremo in seguito.
II.3.4 Implementazione di XML nel web
In termini di implementazione c’è una grande differenza se si usa un linguaggio come Xpath per il processamento di documenti (come nel caso di XSL) o per la ricerca di documenti da una sorgente di dati XML:

Implementazione di XML nel web – 22
• Innanzitutto, la ricerca di documenti è una tecnologia server. Tipicamente, un client web come ad esempio un browser invia una query XML. Il server allora restituisce il risultato della query ad esempio sotto forma di una pagina XML generata dinamicamente. Il client può quindi applicare una qualche formattazione al risultato ricevuto utilizzando un foglio di stile XSL.
Figura: Caso in cui si dispone di un browser in grado di leggere documenti
XML/XSL.
Questa configurazione richiederebbe l’uso di un browser abilitato alla visualizzazione di documenti XML/XSL. In un ambiente aperto non si può fare un assunto del genere. I vecchi browser, i web phone, gli apparecchi per la Web Tv, i PDA (Personal Data Assistant) e i palmtop supportano tipicamente HTML 3.1 ma non XML e XSL.
In un tale ambiente l’XSL basato sul server può essere usato insieme alle query XML. Questo è un aspetto che va discusso insieme ad altri aspetti riguardanti l’XSL.

Implementazione di XML nel web – 23
Figura: Caso di utilizzo di un comune browser HTML con supporto ai CSS
(Cascading Style Sheet)
Tornando ad Xpath, una seconda modalità di implementazione (vedi Figura sopra) prevede che il meccanismo di accesso fisico per reperire e richiedere un documento in una sorgente dati sia completamente differente dal meccanismo utilizzato per selezionare gli elementi da un singolo documento. In particolare in un ambiente aziendale, un archivio XML può ospitare un enorme numero di pagine XML, possibilmente milioni. In tali condizioni si richiede l’uso di tecnologie di database sofisticate per gestire efficientemente le query.
L’ottimizzazione delle query, il caching, e le tecniche di indicizzazione sono alcune delle parole chiave conosciute nel mondo delle tecnologie relazionali e che sono importanti anche per i server XML.
L’indicizzazione in particolare, una tecnologia chiave in tutti i sistemi di database, pone alcune problematiche di interesse. Innanzitutto vanno identificati gli elementi adatti a fare da chiavi. Il DBMS a questo punto costruisce tabelle indici o alberi indici che consentono di trovare rapidamente un oggetto secondo una certa chiave. Utilizzando gli indici il carico elaborativo e il tempo richiesti per il reperimento di un oggetto vengono ridotti da n a log(n). In particolare negli archivi di grandi dimensioni la differenza può salire a diversi ordini di grandezza. L’indicizzazione è la principale ragione per cui i DBMS (inclusi i server XML) sono molto più performanti dei file system cosidetti “flat”. Nel mondo relazionale, uno dei primi compiti nella progettazione di un’applicazione è la definizione di strutture dati e l’identificazione delle chiavi. Se lo schema di un database viene implementato, si conoscono bene quali sono i campi utilizzati come chiavi e quali no. Un repository XML d’altra parte lavora in un ambiente aperto, ma si avvantaggia dell’indicizzazione grazie all’uso dello schema dei documenti sotto forma – ad esempio – di DTD.

Il modello dei dati XML – 24
I client possono inviare query di ogni tipo, cosi che tipicamente non è prevedibile determinare i migliori tag da prendere in considerazione per l’indicizzazione. Si potrebbe pensare di indicizzare tutti i tag ed attributi. Ma in questo modo si comporterebbe un grande overhead, rendendo lente le operazioni di aggiornamento. Inoltre i processori XML devono essere in grado di processare qualsiasi documento XML ben-formato, anche se la definizione dello schema (ad es. la DTD di cui sopra) non si conosce o viene perduta. In tali casi sia la struttura dei documenti che la natura delle query non sono prevedibili per l’archivio XML, è davvero difficile pianificare in anticipo una struttura di indicizzazione.
II.3.5 Il modello dei dati XML
Abbiamo precedentemente discusso le caratteristiche del linguaggio Xpath, ora è necessario chiarire alcuni aspetti del modello dei dati XML. Le seguenti caratteristiche differenziano il modello dei dati XML dal modello dei dati relazionale:
• Metadati come le etichette (tags) e i nomi degli attributi sono contenuti nei documenti.
• I documenti hanno una struttura ad albero.
• Gli elementi dei documenti possono essere annidati e contenere degli attributi.
• Sono permessi più elementi con stessi tag in uno stesso documento.
• Sono rilevanti la sequenza e la posizione.
Diversamente da SQL, un linguaggio di query per XML deve essere dunque in grado di navigare la gerarchia degli elementi e indirizzare gli elementi tramite la posizione e la sequenza.
Nell’accedere ad un documento, XPath guarda al documento come ad una struttura ad albero fatta di nodi. Sul livello concettuale un nodo può essere l’entità stessa del documento, ogni elemento o attributo, una processing instruction (PI) o un commento. Il documento stesso costituisce il nodo radice, che contiene una lista di nodi che sono figli diretti del nodo radice. Questi nodi possono a loro volta contenere una lista di nodi e così via. Questo approccio unificante alla struttura dei documenti XML rende XPath semplice e potente.

Il linguaggio XPath – 25
Figura: La struttura dell’esempio del <libro>. E’ stato evidenziato <edizione>
con un segno + per indicare l’occorrenza di più edizioni. Gli attributi sono presentati come figli degli elementi che li possiedono e sono identificati dal
carattere @.
Sul livello fisico XPath non prescrive un formato fisso per i nodi. Un nodo può essere rappresentato da testo XML, da un sottoalbero DOM (Document Object Model), da alcune strutture dati che descrivono delle sottoregioni nel documento, etc.
II.3.6 Il linguaggio XPath
A causa della struttura annidata dei documenti XML e per il fatto che XML consente la ripetizione degli elementi, il linguaggio XPath deve fornire dei mezzi per specificare le relazioni gerarchiche, le relazioni di sequenza, e le posizioni. Tuttavia quella che viene impiegata maggiormente nelle query è la sintassi abbreviata, che è possibile vedere nella tabella successiva, spesso all’interno di un linguaggio esteso come Xquery o XQL.
Alcuni operatori di XPath (ed esempi tratti dal documento XML precedente) Espressione di Query
Semantica Esempio Risultato
/Q1 Nodo radice del documento
/libro Tutti i documenti con il nodo radice <libro>
//Q1 Un elemento arbitrario del documento
//edizione Tutti gli elementi <edizione> in ogni documento
Q1/Q2 Relazione padre-figlio
/libro/edizione Tutti gli elementi <edizione> che sono figli diretti del nodo radice <libro>
Q1//Q2 Relazione antenato/discendente
/libro//isbn Tutti gli elementi <isbn> che sono discendenti del nodo radice <libro>
@ Attributo @anno Tutti gli attributi anno= * Wild card /libro/*/isbn Tutti gli elementi <isbn> che
sono nipoti del nodo radice

Il linguaggio XPath – 26
<libro> . Nodo corrente .//@anno Tutti gli attributi anno che
sono discendenti del nodo corrente
.. Nodo genitore ..//@anno Tutti gli attributi anno che sono discendenti del nodo genitore
Q1,Q2 Concatenazione /libro//(titolo,autore,isbn,prezzo)
La lista contenente i nodi specificati
Q1[n] Nodo indicizzato /libro/edizione[1,last()] La prima e l’ultima edizione di un libro
Q1[Q2] Filtro /libro/edizione[@anno=’199?]/isbn
Tutti i nodi <isbn> dal 1990 al 1999
=, != Uguaglianza, disuguaglianza
/libro[autore = ‘Bret Easton Ellis’]
Tutti i libri con autore ‘Bret Easton Ellis’
>, >=, <, <= Confronto /libro//casaeditrice[. >= ‘E’] Restituisce la lista di tutte le case editrici dalla lettera ‘E’ in poi.
?. * Wild cards /libro[.//@anno = ‘199?’] Seleziona tutti I libri dal 1990 al 1999
Or OR booleano /libro/edizione[@anno=’197?’ or @anno=’198?’]
Tutti I nodi <edizione> dal 1970 al 1989
And AND booleano /libro[.//@anno=’1997’ and .//casaeditrice=‘Vizianello’]
Tutti i libri pubblicati nel 1997 da Vizianello
+,-,*, div, mod
Operatori aritmetici
/libro//prezzo * 0.7 Calcola uno sconto speciale per il prezzo dei libri
Oltre agli operatori XPath supporta una serie di funzioni, per verificare delle condizioni, per tradurre e confrontare il contenuto. Poiché Xpath riconosce solo quattro tipi di dato (insieme di nodi o node-set, stringa, numerico, booleano) ci sono funzioni diverse per ognuno di questi tipi di dato. Not() per esempio è una delle funzioni booleane.
Poiché ogni contenuto in un documento XML è costituito di caratteri, i confronti lavorano basandosi ‘di default’ sulle stringhe. Per esempio l’espressione “24” < “7” risulta vera secondo questa logica, perché è il valore della stringa ad essere confrontato e non i numeri. Per confrontare i nodi sulla base dei numeri è necessario convertirli precedentemente ai valori numerici: “number(“24”) < number(“7”) risulta allora falso.
Il confronto tra stringhe si basa su Unicode. Questo vuol dire anche che i confronti tra stringhe sono sempre case sensitive. Comunque è possibile tradurre le stringhe tramite una tabella di traslazione dei caratteri, che renda case insensitive (cioè indifferenti alla presenza o meno di una diversa disposizione di maiuscole e minuscole in una stessa stringa di lettere) il confronto: translate(“Film”,“abcdefghijklmnopqrstuvwxyz”,“ABCDEFGHIJKLMNOPQRSTUVWXYZ”) che traduce il testo del primo operando.
Viene definita anche una funzione contains() per ricercare una data sottostringa in un ampio blocco di testo. Possono essere usate con contains() le wild cards o i caratteri jolly come “?” e “*”.
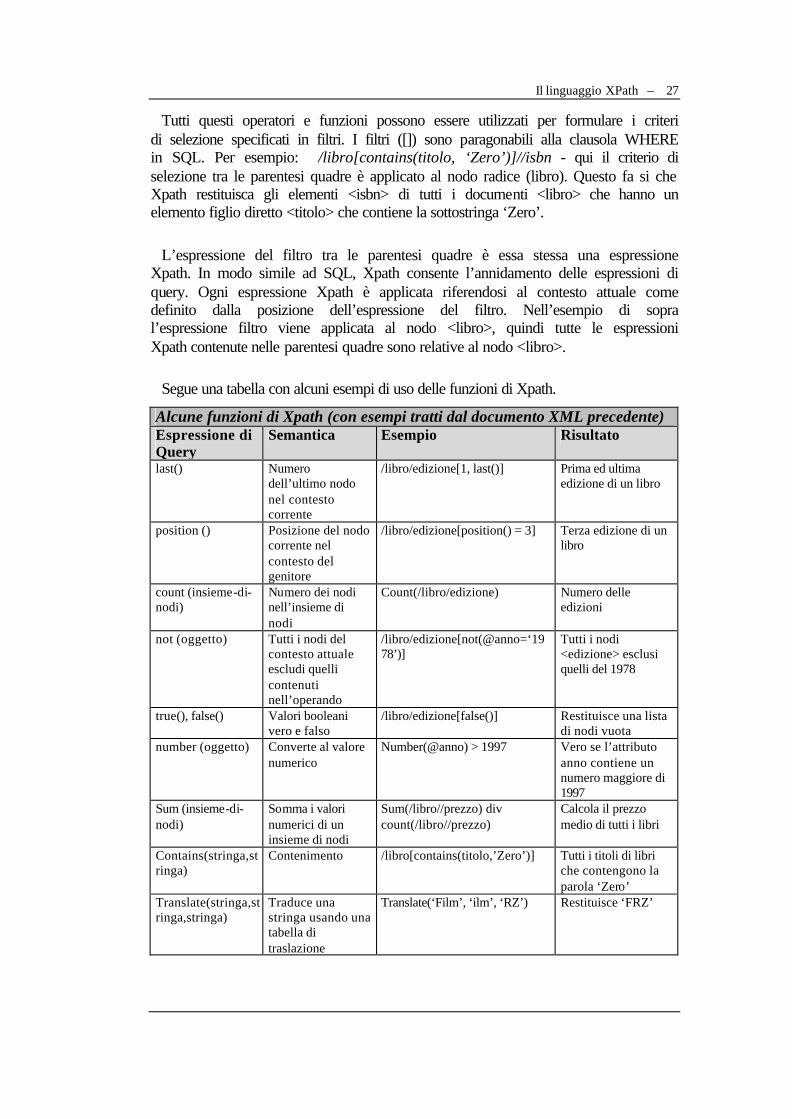
Il linguaggio XPath – 27
Tutti questi operatori e funzioni possono essere utilizzati per formulare i criteri di selezione specificati in filtri. I filtri ([]) sono paragonabili alla clausola WHERE in SQL. Per esempio: /libro[contains(titolo, ‘Zero’)]//isbn - qui il criterio di selezione tra le parentesi quadre è applicato al nodo radice (libro). Questo fa si che Xpath restituisca gli elementi <isbn> di tutti i documenti <libro> che hanno un elemento figlio diretto <titolo> che contiene la sottostringa ‘Zero’.
L’espressione del filtro tra le parentesi quadre è essa stessa una espressione Xpath. In modo simile ad SQL, Xpath consente l’annidamento delle espressioni di query. Ogni espressione Xpath è applicata riferendosi al contesto attuale come definito dalla posizione dell’espressione del filtro. Nell’esempio di sopra l’espressione filtro viene applicata al nodo <libro>, quindi tutte le espressioni Xpath contenute nelle parentesi quadre sono relative al nodo <libro>.
Segue una tabella con alcuni esempi di uso delle funzioni di Xpath.
Alcune funzioni di Xpath (con esempi tratti dal documento XML precedente) Espressione di Query
Semantica Esempio Risultato
last() Numero dell’ultimo nodo nel contesto corrente
/libro/edizione[1, last()] Prima ed ultima edizione di un libro
position () Posizione del nodo corrente nel contesto del genitore
/libro/edizione[position() = 3] Terza edizione di un libro
count (insieme-di-nodi)
Numero dei nodi nell’insieme di nodi
Count(/libro/edizione) Numero delle edizioni
not (oggetto) Tutti i nodi del contesto attuale escludi quelli contenuti nell’operando
/libro/edizione[not(@anno=‘1978’)]
Tutti i nodi <edizione> esclusi quelli del 1978
true(), false() Valori booleani vero e falso
/libro/edizione[false()] Restituisce una lista di nodi vuota
number (oggetto) Converte al valore numerico
Number(@anno) > 1997 Vero se l’attributo anno contiene un numero maggiore di 1997
Sum (insieme-di-nodi)
Somma i valori numerici di un insieme di nodi
Sum(/libro//prezzo) div count(/libro//prezzo)
Calcola il prezzo medio di tutti i libri
Contains(stringa,stringa)
Contenimento /libro[contains(titolo,’Zero’)] Tutti i titoli di libri che contengono la parola ‘Zero’
Translate(stringa,stringa,stringa)
Traduce una stringa usando una tabella di traslazione
Translate(‘Film’, ‘ilm’, ‘RZ’) Restituisce ‘FRZ’

Espressione di vincoli sui dati e le carenze della DTD – 28
Gran parte dei linguaggi di query utilizzati oggi per XML fanno riferimento in qualche modo ad XPath. Poiché XPath non è in grado di caratterizzare i costrutti tipici che si trovano nei linguaggi di query dei database, le implementazioni pratiche del linguaggio di query estendono le funzionalità di Xpath. Degli esempi – che dipendono dall’implementazione – sono l’operatore di sort, l’operatore di join (per combinare diversi documenti, o l’operatore di derefereziazione (per risolvere i riferimenti ipertestuali). Ad esempio nel DBMS XML utilizzato in questa realizzazione viene fornito il supporto ad una versione di XQuery che utilizza gran parte della sintassi base di XPath.
Infine è opportuno introdurre i tipi di dato. Come è stato detto tutti i dati in XML sono sotto forma di stringhe. La Document Type Definition (DTD) non permette la definizione di tipi di elementi o attributi. Questo fatto pone dei problemi quando è necessario confrontare o riordinare i dati. Se vengono confrontate le stringhe di due date, ad esempio “6-12-1999” con “1-1-2000” il confronto delle due stringhe darebbe un risultato sbagliato: verrebbe riconosciuta come posteriore la prima data e non la seconda. In modo simile il numero di un conto “00703-280878” potrebbe risultare uguale a “703-280878”. Xpath prova a risolvere questo problema fornendo delle funzioni che possono convertire una stringa in un numero o in un valore booleano. Questa soluzione va bene in molti casi, ma non nei due esempi prima riportati del numero di conto e della data a confronto. Il problema è ben noto nella comunità di sviluppatori XML ed è stato affrontato con la proposta di XML Schema.
Nel paragrafo successivo saranno introdotti i concetti fondamentali di DTD (Document Type Definition) e XML Schema. XML Schema al posto dei DTD consente la risoluzione dei problemi esposti.
II.3.7 Espressione di vincoli sui dati e le carenze della DTD
Un metodo molto comune per dichiarare la semantica degli oggetti di dati ad una generica applicazione informatica è quello di definire dei vincoli sui dati. In SQL, per esempio, i vincoli sono definiti attraverso le regole di integrità e le limitazioni. Questo consente ad un processore SQL di rifiutare le operazioni di aggiornamento non valide. In un certo senso il processore SQL comprende la semantica dei dati.
In XML la possibilità di inserire dei vincoli nei documenti è minima. Un documento XML senza un Document Type Definition non ha alcun vincolo. In questo caso il processore XML verifica solamente la correttezza sintattica: il documento si dice quindi “ben-formato”. Se viene fornito un DTD con il documento, allora il processore XML può verificare se il documento aderisce alla struttura definita nella DTD. Se la verifica è positiva il documento si dice “Valido”.

Espressione di vincoli sui dati e le carenze della DTD – 29
Le DTD consentono la definizione di alcuni vincoli strutturali. Per esempio esse possono stabilire che un certo elemento o attributo devono esistere nel documento. Si può dare un vincolo ad esempio per un elemento di prezzo, stabilendo che esso possa contenere solo dati di tipo carattere (e che non deve essere lasciato vuoto o contenere altri elementi). Si può inoltre stabilire che abbia un attributo “valido_da” : <prezzo valido_da=’2001-05-19’> 10.3 </prezzo>. Per la maggior parte delle applicazioni tuttavia questi vincoli non sono sufficienti. Per esempio si vorrebbe poter limitare il contenuto dell’elemento prezzo all’uso di dati decimali con una precisione di due cifre. Altra richiesta potrebbe essere quella di poter scartare i prezzi con valore negativo o essere certi che l’attributo “valido_da” contenga solo date valide secondo il formato definito da ISO-8601. Ed è in questi aspetti che le DTD falliscono. Le DTD infatti riconoscono solo i dati di tipo carattere generici (PCDATA), le enumerazioni di valori (potrebbe ad esempio essere possibile enumerare tutte le possibili valute di denaro), e possono anche essere usati alcuni tipi di dati specifici di XML (ID, IDREF, IDREFS, ENTITY, ENTITIES, NMTOKEN, NMTOKENS, NOTATION). Questa è un’eredità del passato SGML con il suo approccio orientato al documento.
Si possono riassumere alcuni dei problemi che sorgono quando tutti gli elementi vengono considerati come testo. Per esempio:
• Il numero a virgola mobile “7.3e-6” sarebbe riconosciuto come maggiore di “1.6e+19”.
• Il numero negativo “-3” sarebbe considerato più piccolo di “-6”.
• Due elementi numerici con lo stesso valore ma diversa formattazione non verrebbero considerati uguali. Per esempio il numero di telefono (011) 732878 sarebbe considerato diverso da 011-732 878.
• Il confronto dei valori delle date e date aritmetiche è praticamente impossibile.
• Se si incontra un elemento <prezzo> 150.000 </prezzo> non è possibile sapere come interpretarlo. In un contesto internazionale sarebbe interpretato come “CentoCinquantaMila”, ma in un contesto europeo dovremmo leggerlo come “CentoCinquanta”.
Vi sono severe restrizioni, soprattutto nell’ambito del commercio elettronico, per cui gran parte dei dati contiene numeri, date, e altri dati con un tipo particolare. L’introduzione dei tipi di dato in XML risulta quindi di grande aiuto alla creazione ed interpretazione dei dati per il business. Questo serve a potenziare anche l’usabilità di un linguaggio di query. Ma oltre alla mancanza dei tipi di dato la DTD soffre di altre mancanze. Essa infatti non fornisce un supporto adeguato per la modularizzazione e il riuso degli schemi di documento. Le stesse definizioni devono essere inserite ogni volta, cosa che non rende tanto difficile la creazione di schemi con DTD quanto piuttosto il loro mantenimento.

XML Schema – 30
Infine le DTD non sono documenti XML ma seguono una sintassi diversa. Quindi tutti gli strumenti software utilizzati per i documenti XML non possono essere impiegati per creare, editare, effettuare il parsing o l’interpretazione delle DTD.
II.3.8 XML Schema
Tutte le motivazioni esposte sulle carenze delle DTD hanno spinto allo sviluppo di un nuovo metodo di definizione per gli schemi XML. Negli ultimi tre anni sono stati presentati e messi in discussione alcuni linguaggi per la definizione di schemi per XML. Come risultato si è giunti al rilascio dell’ XML Schema pubblicato dal W3C. Adesso XML Schema è definitivo e considerato stabile (è stata da poco rilasciata la raccomandazione dal W3C) ma anche il Working Draft, rilasciato nell’aprile del 2000 era sufficientemente stabile.
Analizzando il punto di vista adottato da XML Schema per i tipi di dato si può osservare che il sistema dei tipi di XML schema si basa sul concetto duale dello Spazio dei Valori e dello Spazio Lessicale: uno Spazio dei Valori è una collezione astratta di valori permessi per i tipi di dato. Ogni valore nello spazio dei valori può avere diverse rappresentazioni testuali nello spazio lessicale. La rappresentazione lessicale è ciò che appare nel documento XML. La definizione dei tipi di dato definisce appunto la corrispondenza tra i due spazi di valori e lessicale.
Figura: Possibili rappresentazioni lessicali di due esempi di valori di data.
Ogni tipo di dato è definito da un certo numero di sfaccettature:
• Le caratteristiche fondamentali definiscono le proprietà di base di ogni tipo di dato. Sono “facet” fondamentali ad esempio Equal, Order, Bounds, Cardinality, Numeric.

XML Schema – 31
• Caratteristiche di vincolo o non fondamentali sono lenght, minLenght, maxLenght, pattern, enumeration, maxInclusive, maxExclusive, minInclusive, minExclusive, precision, scale, encoding, duration, period.
XML Schema definisce anche un ricco insieme di tipi di dato predefiniti. Alcuni di questi tipi di dato sono primitive, ad esempio non fanno riferimento alla definizione di altri tipi di dato.
Altri sono derivati da preesistenti tipi primitivi o da altri tipi di dato derivati.
• I tipi di dato primitivi predefiniti comprendono i tipi già noti nelle DTD (come ID, IDREF, etc. per gli attributi) ma introducono anche nuovi tipi di dato sia per gli attributi che per gli elementi: string, boolean, float, double, decimal, timeDuration, recurringDuration, binary, uriReference, QName.
• I tipi di dato predefiniti di tipo derivato sono language, Name, NCName, integer, nonPositiveInteger, negativeInteger, long, int, short, byte, nonNegativeInteger, unsignedLong, unsignedInt, unsignedShort, unsignedByte, positiveInteger, timeInstant, time, timePeriod, date, month, year, century, recurringDate, recurringDay ma includono anche tipi di dato presi dalle DTD (IDREFS, NMTOKEN, etc. per gli attributi)
Figura: la gerarchia dei tipi introdotta da XML Schema

Tipi di dato definiti dagli utenti in XML Schema – 32
II.3.9 Tipi di dato definiti dagli utenti in XML Schema
I tipi di dato definiti dagli utenti consentono ai progettisti di schemi di creare tipi di dato personalizzati. Questi possono essere definiti in diversi modi:
• Per enumerazione: per esempio è possibile definire un tipo di dato
“colorePerNome” enumerando i possibili valori: rosso, verde, blu, etc. <simpleType name=”colorePerNome” base=”string”> <enumeration value=”rosso”/> <enumeration value=”verde”/> <enumeration value=”blu”/> <!-- tutti gli altri colori a seguire .. --> </simpleType>
Si noti che una enumerazione si basa sempre sul vincolo di un altro tipo di dato preesistente, in questo caso “string”.
• Per derivazione di un tipo di dato da un tipo di dato predefinito e da un altro tipo di dato definito dall’utente. Metodi possibili per la derivazione sono la “restrizione” (consiste nell’aggiungere altri vincoli alle caratteristiche di un tipo) e la “lista” (consiste nel costruire una lista da diversi valori atomici). Per esempio è possibile definire un tipo di dato coloreRgb derivandolo dal tipo di dato predefinito unsignedShort.
<simpleType name=”unsignedShortList” base=”unsignedShort” derivedBy=”list”/> <simpleType name=”coloreRgb” base=”unsignedShortList”> <lenght value=”3”/> </simpleType>
Questa definizione permette di utilizzare la rappresentazione del colore nella forma di terne: per esempio 0 255 0. In questo modo i tipi di dato definiti dall’utente sono sempre derivati da altri tipi di dati. La loro definizione deve far riferimento ad un tipo predefinito o ad un atro tipo definito dall’utente.
Guardando alle definizioni date negli esempi si può rilevare che una definizione di tipo di dato comincia con il tag simpleType. Ovviamente si devono poter definire anche tipi complessi. E si definiscono come nell’esempio seguente:
<element name=’prezzo’> <complexType base=’decimal’ derivedBy=’extension’> <attribute name=’valuta’ type=’string’/> </complexType> </element>

Tipi di dato definiti dagli utenti in XML Schema – 33
I tipi di dato complesso sono specificati come definizioni di elemento. Queste mettono in relazione le definizioni di elementi come date nelle DTD, ma introducono vincoli aggiuntivi. I tipi di dato complessi possono essere definiti anche per:
• Estensione. In questo caso elementi o attributi addizionali vengono aggiunti ad un elemento base. Nell’esempio riportato il tipo di dato base è “decimal”. Il tipo di dato complesso “prezzo” è costruito aggiungendo un attributo “valuta” del tipo “string”. La definizione di sopra permette l’uso di elementi XML come <prezzo valuta=’ITL’>10000</prezzo>
• Restrizione. In questo caso si costruiscono tipi complessi aggiungendo vincoli ad una definizione di elemento preesistente. Per esempio è possibile limitare il numero delle occorrenze di un elemento o specificare un tipo per un sottoelemento dove non sono stati fissati precedentemente dei vincoli.
La definizione di tipi di dato complessi in XML Schema include le possibilità che sono messe a disposizione con il modello dei gruppi conosciuto nei DTD. Gli elementi possono essere definiti come:
• Empty. L’elemento non deve avere contenuto. Ma può avere degli attributi.
• Gruppi “choice” e “sequence”. L’elemento può contenere solamente una o più occorrenze di un elemento o di un modello di gruppo. Un modello di gruppo consiste di un tipo di composizione (sequence, choice, all) che combina le definizioni di altri elementi.
• Mixed. Consente la definizione di elementi che contengono sia dati a caratteri che elementi figli. Gli elementi “mixed” di XML Schema differiscono dagli elementi mixed del DTD in quanto essi definiscono un ordine ed un numero degli elementi figli.
I tipi di dato definiti con XML Schema possono essere utilizzati nelle definizioni di elementi ed attributi di uno schema di documento XML. Ma è anche possibile usare i tipi di dati nei documenti XML in maniera più dinamica e mirata: è possibile far riferimento a definizioni di tipi di dato direttamente dall’interno di un tag di elemento. Questo consente di utilizzare i tipi di dato anche per i documenti XML per i quali non sono stati definiti schemi o DTD. Questo viene fatto specificando un attributo “xsi:type” (il prefisso xsi identifica il namespace o spazio dei nomi per le istanze di XML Schema) nel tag dell’elemento e fornendo come valore la URL che si riferisce alla definizione dei tipi:
<?xml version="1.0"?> <ordine xmlns:xsi='http://www.w3.org/1999/XMLSchema-instance'

Unicità e chiavi in XML Schema – 34
dataOrdine="2000-04-07"> <inviareA xsi:type='http://www.frz.it/schemaordine/indirizzo'> <nome>Stanley Kubrick</nome> <via>via tomino 79</via> <citta>Tokio</citta> <CAP>030310</CAP> </inviareA> … </ordine>
In questo esempio nel documento non viene specificato uno schema. Vi è invece un riferimento alla definizione di tipo complesso “indirizzo” dato per l’elemento “inviareA”. Questo consente ai processori XML di verificare l’elemento con la definizione del tipo “indirizzo”.
II.3.10 Unicità e chiavi in XML Schema
In XML Schema viene introdotta la definizione di elementi chiave per i documenti XML. Una definizione “unique” può consentire l’univocità per diverse occorrenze di elementi. Data la definizione:
<element name="libro"> … <unique> <selector>edizione</selector> <field>isbn</field> </unique> </element>
un documento ‘libro’ può contenere diversi elementi ‘edizione’, ma tutti gli elementi ‘edizione’ devono avere un unico ISBN.
XML Schema consente la definizione dell’unicità attraverso la combinazione di elementi, semplicemente dando una lista di campi all’interno della clausola “unique”. Le definizioni di chiavi sono simili. La clausola “key” definisce elementi o combinazioni di elementi come chiavi primarie, mentre la “keyRef” definisce le chiavi esterne. Con queste definizioni un documento XML può modellare completamente un database relazionale, includendo le definizioni di chiave.

Meccanismi di riuso in XML Schema – 35
II.3.11 Meccanismi di riuso in XML Schema
Esistono alcuni meccanismi in XML Schema per il riutilizzo di preesistenti definizioni:
• Gruppi di attributi. I gruppi di attributi combinano diverse definizioni in un’unica definizione. Si può dunque fare riferimento al gruppo nel suo complesso specificando il nome del gruppo. I gruppi di attributi hanno senso se la stessa combinazione di attributi viene usata di frequente negli elementi.
• Definizione di tipi astratti. Le definizioni di tipo classificate come astratte possono solo essere utilizzate per derivare altre definizioni di tipo, e non per definire direttamente elementi o attributi. Si può fare un paragone con le classi astratte nella programmazione ad oggetti.
• Inclusione di schema. Uno schema può includere una definizione di schema esterna attraverso l’indicazione del suo URL. Questo consente la modularizzazione delle definizioni di schema e il riutilizzo di componenti di schema preesistenti.
Riassumendo con la sua ricchezza di tipi di dato predefiniti, la possibilità di definire tipi di dato da parte dell’utente, e i meccanismi di riuso delle definizioni di schema, l’XML Schema riesce a potenziare l’uso di XML da un linguaggio per la descrizione di documenti ad un linguaggio di descrizione dei dati generico.
Dove XML Schema non risulta sufficiente è nel campo dei vincoli di elemento incrociati. Considerando il seguente esempio:
<pacco> <altezza> 6 </altezza> <larghezza> 8 </larghezza> <profondita> 7 </profondita> </pacco>
Nonostante XML Schema consenta di mettere vincoli in ogni singola dimensione (altezza, larghezza, profondità), esso non consente di vincolare il volume del pacco ad esempio imponendo che altezza*larghezza*profondita < 45.
Ad ogni modo le attuali possibilità fornite dall’XML Schema rappresentano un grande passo avanti rispetto a quanto era possibile fare con le sole DTD.

Visualizzazione di documenti XML: la terna di XSL – 36
II.3.12 Visualizzazione di documenti XML: la terna di XSL
Finora sono stati discussi aspetti riguardanti la memorizzazione e interrogazione di dati XML in sorgenti di dati XML. Abbiamo incontrato più volte una struttura ad albero. E’ possibile affermare che tra una tale struttura ad albero e l’immagine fotografica di un vero albero con tronco e foglie verdi passa una differenza simile a quella che passa tra un documento XML e il modo con cui esso viene visualizzato dopo l’applicazione di un foglio di stile XSL.
E’ stato già introdotto il concetto secondo il quale in XML il contenuto informativo è separato dalla sua rappresentazione. Progettato per includere le funzionalità dei CSS (Cascading Stile Sheets) e DSSSL (Document Style Semantic & Specification Language), l’XSL (eXtensible Stylesheet Language) ha come compito specifico quello di essere il linguaggio di formattazione per XML.
Formattare le informazioni è un compito quotidiano. Per comprendere il ruolo di XML possiamo riferirci al seguente esempio: assumiamo che il nostro cervello memorizzi le informazioni in una struttura simile ad XML – un albero. Se abbiamo bisogno di trasferire certe informazioni ad un’altra persona attraverso un documento (a anche attraverso la voce), abbiamo bisogno di formattare le nostre informazioni in un qualche modo che dipende dal mezzo che intendiamo impiegare. Con un documento di carta, per esempio possiamo usare il testo stampato, dei disegni, delle foto, e possiamo organizzare tutti questi elementi all’interno di linee, colonne, pagine. Il ricevente verifica il documento e ne estrae le informazioni che saranno rappresentate sotto forma di un’altra struttura ad albero nel suo cervello. Sembra un processo semplice, ma nella realtà le cose sono un pò diverse. L’informazione ricevuta differisce quasi sempre dall’informazione originale in quanto il canale informativo (il supporto) potrebbe non essere adatto a trasferire tutte le sfumature dell’informazione originale, o perché le conoscenze di base di mittente e destinatario sono diverse. Il processo di comunicazione è in realtà molto più complesso: prima di inviare informazione, il mittente applica una trasformazione ai dati per poterli rendere maggiormente comprensibili al destinatario. Questa trasformazione dipende dal modello che lui possiede del destinatario. Basti pensare al modo con cui generalmente un adulto si rivolge ad un bambino piccolo, ben diverso dal modo con cui un politico si rivolge ai giornalisti.
Quindi la formattazione e l’abbellimento sono processi applicati non all’informazione originale ma ad una sua forma trasformata. D’altro canto, dopo la verifica, il destinatario che anch’esso possiede un modello del mittente, prova a trasformare la struttura informativa che ha ricevuto sotto forma di un documento in una struttura a lui più consona, in rapporto alla sua visione delle cose.
E’ proprio in questo che si riconosce il modello di elaborazione dell’XSL:
XSL = transformation + formatting

Visualizzazione di documenti XML: la terna di XSL – 37
Questi compiti vengono svolti separatamente in XSL. Sono tre i documenti rilasciati dal W3C per XSL, i primi due riguardano la trasformazione e l’ultimo la formattazione: Xpath, XSLT, XSL FO. Xpath definisce le modalità di selezione degli elementi in un documento XML. XSLT definisce la modalità di trasformazione dell’albero XML sorgente in un albero richiesto. XSL FO (Formatting objects) definisce la parte restante, cioè gli strumenti di formattazione.
Xpath lo abbiamo visto precedentemente, sappiamo che definisce i modi di accedere ad un nodo (elemento, attributo, etc.) in un oggetto XML. Xpath è stato separato dalla specifica di XSL, in quanto può essere utilizzato come linguaggio di query, ed è anche alla base di altri standard come Xpointer e Xlink.
XSLT descrive la parte di trasformazione dell’XSL. Anch’esso è separato da XSL principalmente perché XSLT da solo può essere utilizzato per convertire documenti XML in altri formati, come ad esempio HTML. In XSLT gli elementi di controllo principali sono le regole di modello, dei “template”. Per comprendere come funzionano queste regole, è utile conoscere come lavora un sistema esperto basato su regole: XSLT è un linguaggio dichiarativo.
Ogni regola di modello consta di un elemento di intestazione e di un corpo. L’elemento intestazione (match=) specifica una espressione Xpath per il confronto con un modello. Quando un processore XSL elabora un documento, esso parte dal nodo radice della struttura ad albero del documento. Esso verifica che le regole del modello siano verificate o meno dal nodo radice. Se si riconoscono più regole verificate dal nodo, viene selezionata la regola che combacia meglio:
1. Le regole definite nel foglio di stile attuale vengono preferite alle regole definite in fogli di stile importati.
2. Si sceglie il risultato che combacia meglio nel confronto delle espressioni indicate dalle regole.
Il risultato di un confronto è una lista di nodi (ad esempio di sotto alberi) che dipendono dall’espressione di confronto stessa.
Esempio: Una regola di template con l’espressione di confronto ‘/’ confronterà direttamente il nodo radice. La lista di nodi risultanti consiste di tutti i figli diretti del nodo radice.
Una regola di template con l’espressione di confronto ‘/rivenditore/indirizzo’ verificherà se il nodo radice possiede un figlio ‘rivenditore’ con a sua volta un nodo figlio ‘indirizzo’. Sarà preferita rispetto alla prima regola in quanto più specifica. La lista di nodi risultanti

Visualizzazione di documenti XML: la terna di XSL – 38
consiste nel nodo figlio di ‘indirizzo’.
• Il corpo della regola che viene meglio verificata viene quindi applicato alla lista di nodi risultanti dal confronto.
• Il testo contenuto nel corpo della regola viene inviato in uscita (informazione di decorazione).
• I Formatting Objects (il cui prefisso è “fo:” ) vengono trascritti sul canale di uscita. Insieme con le decorazioni questi vengono elaborati dal processore di formattazione.
• Le istruzioni XSL (il cui prefisso è “xsl:” ) vengono eseguite.
In particolare, l’istruzione “xsl:apply-templates” ripete il processo di confronto per la lista di nodi corrente (o per una lista di nodi specificata esplicitamente). Altre istruzioni “xsl:” forniscono strutture di controllo addizionali come esecuzione condizionale o loop. L’istruzione “xsl:value-of” scrive il contenuto del nodo corrente (o di un nodo esplicitamente specificato) sull’uscita.
Listato di esempio:
<?xml version='1.0'?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/XSL/Transform/1.0" <!—Si definisce l’ ID del namespace ID --> <xsl:template match="/"> <!—intestazione della regola template, percorso per il nodo radice --> <HTML> <!-- qui inizia l’output generato -->
<BODY> <TABLE BORDER="2" CELLPADDING="6"
STYLE="margin-left:1.5cm;"> <TR>
<TH>Nome</TH> <TH>Colore</TH> <TH>NumeroOrdine</TH>
</TR> <!—segue il loop sui prodotti attraverso
dettaglioProdotto --> <xsl:for-each
select="PRODOTTO/DETTAGLIOPRODOTTO"> <TR>
<TD STYLE="letter-spacing:8pt; font-size:24pt;">
<xsl:value-of select="/PRODOTTI/NOME"/> </TD> <!-- inserisce il nome --> <TD><xsl:value-of select="COLORE"/>

Visualizzazione di documenti XML: la terna di XSL – 39
</TD> <!-- inserisce il colore --> <TD><I><xsl:value-of select="NUMEROORDINE"/></I> </TD> <!-- inserisce il numero d’ordine -->
</TR> < /xsl:for-each> <!-- termina il loop --> </TABLE>
</BODY> </HTML> </xsl:template> </xsl:stylesheet>
Questo esempio trasforma un catalogo di prodotti XML in una tabella HTML.
Il foglio di stile contiene solamente una singola regola di template che si confronta con il nodo radice. Viene usato una dichiarazione for-each per
effettuare il vaglio di tutti i prodotti con un loop. Poiché l’uscita è in HTML, gli fo , formatting objects, non sono usati ma viene applicata della formattazione
CSS.
XSLT consente la parametrizzazione delle regole di template con le variabili. Questo permette il riutilizzo delle regole esistenti per diversi scopi , fornendo differenti parametri. Possono essere definite delle variabili a livello di regola o a livello globale.
L’uso delle variabili in XSLT dimostra anche le limitazioni dell’XSLT stesso: in effetti non si tratta di un linguaggio di programmazione “general purpose”. Il modello elaborativo di XSLT è privo di stato e i valori sono assegnati ad una variabile quando questa variabile viene definita (variabile di default), oppure quando un parametro viene passato ad una regola di template. In particolare, non è presente in XSLT un operatore di assegnazione. Questo rende il modello di elaborazione semplice, ma non permette di utilizzare le variabili per contare qualcosa.
A confronto con il preesistente standard CSS, XSL fornisce una gestione migliore e specializzata per i documenti XML. Tra le nuove caratteristiche vi sono la paginazione, il supporto per l’internazionalizzazione, e le trasformazioni dipendenti dal contenuto (come nell’esempio sopra riportato). Con HTML e CSS tali funzionalità richiedono l’uso di JavaScript o di pagine web dinamicamente generate dal server.
Il supporto dell’XSL da parte dei browser è tuttavia ancora poco diffuso. Sulla versione 5 di Internet Explorer di Microsoft viene implementata una versione working draft di XSLT, mentre la raccomandazione finale XSLT 1.0 viene implementata nella versione più recente IE5.5. Quest’implementazione si basa su modulo MSXSL.DLL che rende effettivamente XSL un servizio del sistema operativo. Qui non sono supportati tuttavia i Formatting Objects.

Visualizzazione di documenti XML: la terna di XSL – 40
Ci vorranno alcuni anni perché la maggior parte dei browser web installati siano in grado di elaborare XSL. Nel dettaglio, su web phone, Personal Digital Assistant, e altri terminali sui quali il supporto ad HTML è inserito su memoria non volatile si hanno le maggiori difficoltà.
Questo rende XSL di interesse soprattutto dal lato server per i prossimi anni. I fogli di stile XSLT saranno utilizzati per convertire le pagine XML ad HTML prima di inviarle al client. Il codice HTML così generato può contenere elementi di formattazione CSS ulteriori per fornire un output più sofisticato.
In figura: Un processore XSL server based (servlet) converte le pagine XML e i
fogli di stile XSL in HTML (possibilmente con formattazione CSS), che può essere visualizzato da gran parte dei web browser.
Un possibile compromesso è quello di supportare i vecchi client e i client compatibili con XSL separatamente fornendo i fogli di stile in due versioni diverse. Esistono attualmente alcune implementazioni sperimentali di servlet XSLT, realizzate da Lotus, James Clark (che ha lavorato alla realizzazione del W3C XSL Working Draft e che è stato interpellato nella risoluzione di alcune ambiguità sull’uso dei namespaces nei fogli di stile costruiti per il nostro prototipo), e altri.
In ambiente intranet tuttavia le cose cambiano. Qui il supporto lato client all’XSL può essere introdotto in tempi relativamente brevi e può essere utilizzata una formattazione completamente XSL.

Visualizzazione di documenti XML: la terna di XSL – 41
In Figura: Utilizzando un browser abilitato all’XSL, i documenti XML possono
essere instradati fino all’applicazione web client
L’uso di XSL lato server può ridurre il tempo di trasmissione solo se una piccola parte di informazione deve essere estratta da un documento XML, mentre può aumentare il tempo di trasmissione se viene richiesta l’aggiunta di molti elementi decorativi.
Tutte queste considerazioni pongono problemi di interesse per i motori di ricerca. Qual’e’ a questo punto il documento che deve essere indicizzato? E’ il documento nella sua forma originale, è quello che viene trasmesso dal server o infine è quello che viene visualizzato (o anche ascoltato) dall’utente? Mentre si pone questo problema per i motori di ricerca, le query XML inviate ad un server XML nativo sono ben definite.
Si può sempre far riferimento al contenuto non formattato della sorgente dei dati. I risultati restituiti come risposta ad una query sono delle pagine XML generate dinamicamente. Queste possono anche subire una formattazione, con XSL.
II.4 Programmare con XML
Si è visto come il linguaggio di stile XSL possa essere utilizzato per trasformare e formattare un documento XML. Esso risulta di particolare interesse nelle operazioni di visualizzazione o stampa di documenti XML, ma non consente la comprensione di un documento XML da parte di un programma.
Discutiamo le Application Program Interface (API) per XML. Non è infatti di interesse esclusivo dei web browser ma anche delle applicazioni poter elaborare XML. Attualmente risulta difficile utilizzare diffusamente XML, come abbiamo

Parsers standard – 42
detto, nella maggioranza dei browser web. XML risulta di grande aiuto per la sua portabilità e la flessibilità con cui il formato dei documenti può essere cambiato: è uno strumento ideale per l’interoperabilità delle applicazioni, utilissima nell’ambito del business. Mentre i dati sono formattati solitamente in formato binario (come nel caso dei dati EDI o dei dati provenienti da un database relazionale), i dati XML sono testuali. Per valutare un documento XML è quindi necessario effettuare il parsing del documento e convertirlo in formato binario che possa essere elaborato più agevolmente da un’applicazione. Questo procedimento può essere equiparato al parsing del codice sorgente del programma di un elaboratore: le informazioni testuali sono tradotte in formato binario che può essere interpretato dalla macchina.
II.4.1 Parsers standard
Ci sono due diversi metodi di base standardizzati per effettuare il parsing di un documento XML: la Simple API for XML (SAX) e il Document Object Model (DOM).
• La Simple API for XML (SAX)
La SAX una API (Application Program Interface lo standard per il parsing event-based di XML. SAX non è uno standard W3C ma è stato sviluppato congiuntamente dai membri della mailing-list XML-DEV. Sono di pubblico dominio le versioni Java e C++ dei parser SAX.
Essendo un parser basato sugli eventi, SAX scansiona un documento in maniera sequenziale. Quando una unità sintattica viene riconosciuta il parser informa il chiamante (callback) di questo evento. Il gestore del documento che chiama il SAX e che viene informato di questi eventi può decidere cosa fare: ignorare l’evento, modificare lo stato dell’applicazione, o fermare il parsing.
Gli eventi supportati da SAX sono: startDocument, endDocument, startElement, characters, ignorableWhitespace, e processingInstruction. Il vantaggio della tecnica SAX è che il parser non richiede molte risorse: non necessita di tenere tutto il documento in memoria, in quanto lo legge in maniera sequenziale, carattere per carattere. Per il programmatore la API di SAX è la più semplice non c’è un gran numero di tipi di evento da dover gestire. Comunque, per il parsing un documento complesso può essere richiesto un certo sforzo di programmazione.
• Document Object Model (DOM)
DOM è una interfaccia di programmazione completa per documenti HTML e XML. Utilizzando DOM i programmatori possono creare o caricare documenti

Parsers standard – 43
XML, navigare la loro struttura, e ricercare, aggiungere, modificare, o cancellare elementi e contenuto. DOM è progettato per essere usato con qualunque linguaggio di programmazione. DOM lavora in maniera completamente diversa rispetto al SAX. Quando DOM legge un documento esso analizza la struttura completa del documento e costruisce un albero di tutti i nodi del documento nella memoria. Il controllo viene restituito al processo chiamante solo dopo aver elaborato tutto il documento. L’applicazione può allora usare la API DOM per navigare l’albero e ricercare ed estrarre contenuto, modificare i nodi, cancellarli, o inserirne di nuovi.
In figura è riportato un esempio grafico che mostra come DOM rappresenta la
struttura di un documento XML.
Il vantaggio del DOM è che l’intera struttura del documento viene presentata alla applicazione chiamante, che può dunque navigare avanti e indietro liberamente nei nodi del documento, cosa impossibile con SAX. Le applicazioni possono anche modificare i documenti o creare nuovi documenti. Tuttavia poiché questo modello deve adattarsi a tutti i documenti XML, le strutture dati generate sono molto generiche. La struttura dati prodotta è indipendente dalla specifica classe di documento, ma segue il modello delle informazioni XML.
Ogni contenuto viene presentato come testo. Questo richiede un certo “overhead” da parte dell’applicazione per localizzare gli elementi dei documenti e richiedere e interpretare il contenuto. Questo significa anche che la conoscenza circa la struttura del documento deve essere “immersa” nell’applicazione, una caratteristica non certo buona per la manutenzione nel caso in cui la struttura del documento cambi.
La API DOM è molto ricca di funzionalità (l’interfaccia Element da sola ha 27 metodi diversi e DOM ha 17 diverse interfacce, vedremo il dettaglio successivamente). Sia SAX che DOM sono parser standard che trattano i documenti XML al livello di XML generico, così che il processo di parsing è indipendente dalla specifica classe di documento. Alcune implementazioni di

Costruire applicazioni XML con Document Object Model di Microsoft – 44
SAX e DOM possono verificare il documento elaborato per la sua validità verificandolo assieme alla specifica DTD o XML Schema.
II.4.2 Costruire applicazioni XML con Document Object Model
di Microsoft
Uno dei principali obiettivi per cui è stato creato e diffuso XML è l’interscambio dei dati. Risulta determinante, quindi, la scelta di utilizzare il formato testo che abbatte le differenze tra le diverse piattaforme oggi disponibili. Abbiamo accennato al fatto che essendo XML un linguaggio a marcatori, in cui ogni blocco di informazione viene etichettato da un tag, vi sono dei problemi per lo sviluppatore di applicazioni, poiché la gestione di un tale file è più scomoda: non esiste infatti un modo per individuare una specifica informazione, se non andando alla ricerca dei marcatori che la identificano. E’ in questa fase che interviene il Document Object Model (DOM), creato con l’intento di trasformare un documento XML in un’entità più maneggevole del file di testo che lo contiene. DOM ha i seguenti vantaggi, alcuni dei quali già visti nel precedente paragrafo: DOM è indipendente dal linguaggio e dalla piattaforma che consente allo sviluppatore di accedere dinamicamente al contenuto, alla struttura e allo stile di un documento e si avvia a diventare, insieme all’HTML e all’XML, la tecnologia universale per la manipolazione, la condivisione e la rappresentazione di informazioni in ambiente Internet e Intranet.
Un documento XML non può per definizione essere visualizzato, se non attraverso rappresentazioni convenzionali di comodo. Mentre XML contiene l’informazione, l’HTML fornisce una sua specifica rappresentazione visualizzabile con un comune browser. Un documento costruito con entrambi realizza l’indipendenza del contenuto dalla rappresentazione. Dunque i vantaggi di uno scenario del genere sono i seguenti:
• Il documento XML contiene i soli dati. Data la sua natura è portabile una volta specificato il set di caratteri.
• Il documento HTML contiene le informazioni di visualizzazione, quindi l’interfaccia utente. Anch’esso è portabile, a meno della sezione in cui viene creato il componente DOM, che dipende dall’implementazione utilizzata.
Il DOM descrive una struttura all’interno della quale si può caricare tutto il documento, e definisce anche i metodi e le proprietà che possono essere utilizzate al fine di manipolare tale struttura, secondo un tipico approccio object-oriented. Con i suoi metodi e le sue proprietà DOM consente di navigare nella struttura dei dati memorizzata non più in formato file testo ma in un opportuno formato adatto alla lettura da parte delle applicazioni: tra le operazioni consentite, quelle basilari sono l’individuazione dei nodi, attraverso la navigazione degli elementi padre e figlio e dei fratelli, l’accesso al contenuto e agli attributi dei singoli nodi e alcune
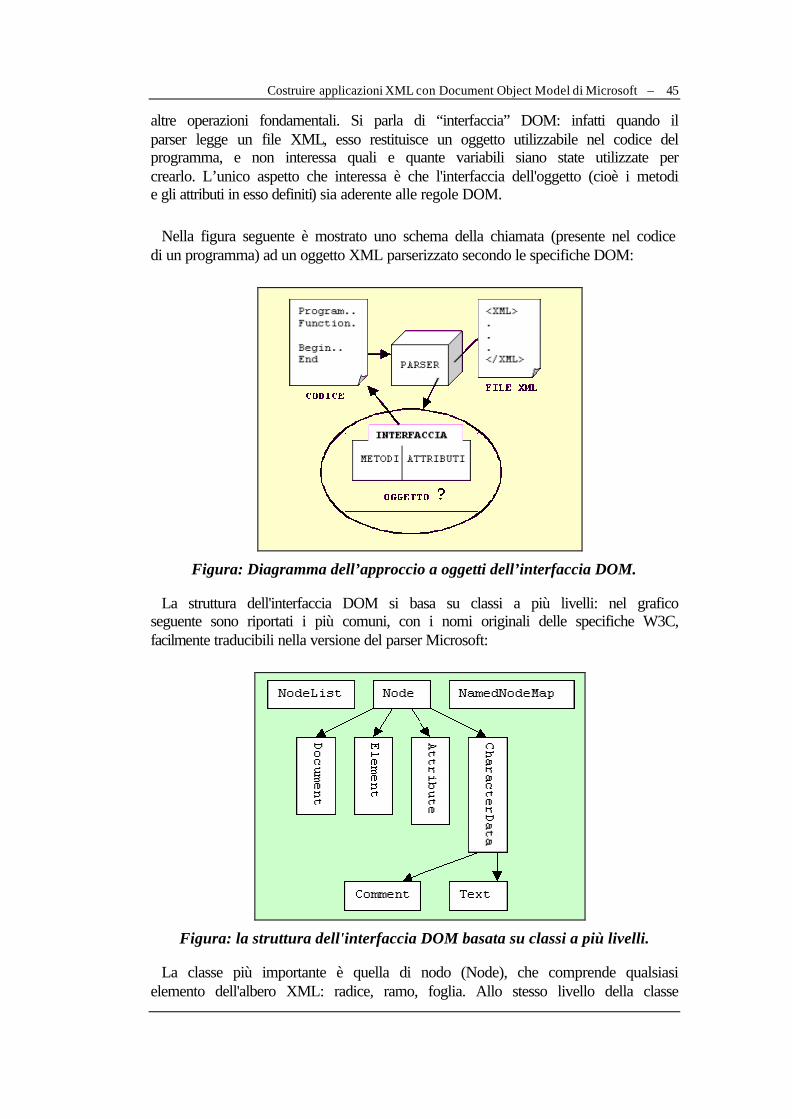
Costruire applicazioni XML con Document Object Model di Microsoft – 45
altre operazioni fondamentali. Si parla di “interfaccia” DOM: infatti quando il parser legge un file XML, esso restituisce un oggetto utilizzabile nel codice del programma, e non interessa quali e quante variabili siano state utilizzate per crearlo. L’unico aspetto che interessa è che l'interfaccia dell'oggetto (cioè i metodi e gli attributi in esso definiti) sia aderente alle regole DOM.
Nella figura seguente è mostrato uno schema della chiamata (presente nel codice di un programma) ad un oggetto XML parserizzato secondo le specifiche DOM:
Figura: Diagramma dell’approccio a oggetti dell’interfaccia DOM.
La struttura dell'interfaccia DOM si basa su classi a più livelli: nel grafico seguente sono riportati i più comuni, con i nomi originali delle specifiche W3C, facilmente traducibili nella versione del parser Microsoft:
Figura: la struttura dell'interfaccia DOM basata su classi a più livelli.
La classe più importante è quella di nodo (Node), che comprende qualsiasi elemento dell'albero XML: radice, ramo, foglia. Allo stesso livello della classe

Costruire applicazioni XML con Document Object Model di Microsoft – 46
Node, ma senza figli, troviamo le classi NodeList e NodeNamedMap. Si tratta di oggetti temporanei che vengono generati durante la lettura dell'albero XML, per memorizzare dei gruppi di fratelli (ad esempio tutti i figli o tutti gli attributi di un elemento.
Nelle tabelle seguenti sono riportati gli elenchi delle interfacce W3C, riportando nell'ultima colonna il corrispettivo Microsoft delle varie interfacce DOM (con il prefisso IDOM che ne caratterizza i nomi). I metodi e le proprietà in esse implementate sono quelle definite dal W3C. Vi sono anche interfacce più ricche che vanno oltre lo standard W3C. Queste interfacce cominciano per IXMLDOM (con alcune funzioni molto utili, come selectNodes o transformNode).
Lo strumento preposto alla creazione di un oggetto DOM è, come anticipato, il parser, cioè il componente software che legge il file XML e "crea" se necessario il DOM. Non tutti i parser creano un DOM; alcuni per ragioni di performance si limitano a scandire il documento (come nel caso del SAX affrontato in un paragrafo precedente).
Molto diffuso è il parser distribuito assieme alla quinta release del browser Microsoft, Internet Explorer 5.x. In precedenza Microsoft aveva già distribuito con Internet Explorer 4.0 (IE4) la versione 1.0 del componente MSXML che implementava quanto descritto nelle prime bozze di definizione del DOM.
La versione distribuita con Internet Explorer 5 (IE5) è totalmente compatibile con la versione 1.0 del DOM rilasciata sotto forma di raccomandazione ufficiale del W3C il 1 ottobre 1998. Il parser Microsoft è un oggetto COM e con un proprio ProgID che ne consente l'uso da Visual Basic, JavasScript o da ASP ad esempio. Le versioni implementate da Microsoft nei suoi browser hanno l’identificatore ProgID del parser diverso, tra la versione di IE5 e quella di IE4. I nomi sono “Microsoft.XMLDOM” e “MSXML” rispettivamente, ma sul sito di Microsoft è anche disponibile per il download la versione 3.0 del parser MSXML.
Le funzionalità aggiunte da XMLDOM, rispetto alle interfacce standard, sono raggruppabili in tre categorie:
1. Gestione avanzata dei tipi. Il W3C richiede che le informazioni contenute in un nodo generico sia di tipo stringa, XMLDOM supporta anche diversi tipi, fornendo i metodi per la conversione tra l’uno e l’altro.
2. Extensible Style Sheet (XSL). Utilizzando il metodo IXMLDOMNode.transformNode è possibile applicare uno stylesheet XSL al sottoalbero che ha per radice il nodo chiamato (e quindi applicabile anche all’intero documento XML, visto che il metodo IXMLDOMDocument deriva da questo). Si tratta di una funzionalità molto importante, che consente di passare dal contenuto di un documento a una sua rappresentazione visualizzabile (esempio trasformazione dei dati in codice HTML) in maniera totalmente automatica. Per

Implementare le tecnologie nel prototipo per Teca Fast – 47
visualizzare un documento XML con DOM ci sono due alternative. La prima consiste nell’utilizzare il DOM per estrarre gli elementi da importare a runtime nella pagina HTML. La seconda nell’applicare uno stylesheet XSL che trasformi il codice XML in qualcos’altro ad esempio in HTML (o altro). Questo è proprio ciò di cui si occupa il metodo transformNode. Essendo anche XSL stesso un vocabolario XML, anch’esso può essere rappresentato tramite il DOM, ed il metodo transformNode accetta infatti come unico parametro la radice di tale rappresentazione di XSL.
3. XSL Pattern. E’ l’implementazione di un linguaggio per l’interrogazione di basi di dati XML, XPath. Mentre le specifiche del DOM originali non prevedono meccanismi per ricercare un nodo all’interno dell’albero del documento, XMLDOM implementa questa funzionalità attraverso i metodi selectNodes e selectSingleNode.
II.4.3 Implementare le tecnologie nel prototipo per Teca Fast
Gli strumenti affrontati in questo capitolo sono stati impiegati nell’implementazione del prototipo di sistema gestione metadati audiovisivi secondo le specifiche richieste: uso di un DBMS Server XML nativo, uso di query Xpath/XQL, implementazione di interfacce di amministrazione, inserimento/modifica documenti di descrizione e ricerca basati sul web (tecnologie: XSL, Javascript, DOM), accessibili attraverso un comune browser web di ultima generazione (Internet Explorer 5 o superiore – condizione che si può porre dato l’ambiente di applicazione tipicamente aziendale – la rete interna di Teca fast Rai).
Il dettaglio sull’architettura realizzata per il DBMS e l’implementazione delle strutture dati delle interfacce di interazione basate sul web è affrontato nel capitolo 5 di questo documento di tesi.

Implementare le tecnologie nel prototipo per Teca Fast – 48
III° Capitolo: Studio sui sistemi di archivio di Teche RAI e Teca Fast digitale
III.1 Il sistema teche RAI: patrimonio, architetture, sistemi
informativi
Il patrimonio di archivio della televisione pubblica nazionale è attualmente distribuito in strutture di diverse tipologie e dimensioni dislocate sul territorio nazionale. L’archivio principale è l’archivio Teca Master o Teca Centrale, che raccoglie nella sede di Roma una quantità impressionante di supporti audiovisivi di diverso tipo, dalle pellicole alle cassette video analogiche e digitali. L’archivio è di dimensioni ragguardevoli e viene gestito attraverso un sistema automatico che movimenta i contenitori di supporti archiviati con delle gru robotizzate. All’interno di una impressionante quantità di cestelli sono conservati circa 400.000 ore di filmati, che costituiscono la storia televisiva italiana dal 1954 al 1997. La Teca Master è suddivisa in due sezioni, denominate Teca Fiction e Teca News, dove quest’ultima è preposta all’archiviazione e gestione dei filmati di telegiornali trasmessi sui tre canali nazionali. Quasi 100.000 ore di filmati sono conservati nelle altre Teche di sede regionale dell’azienda, che si vanno a sommare alle oltre 50.000 ore di trasmesso degli ultimi anni (dal 1998) tra programmi, tv e sport.
Nelle tre tabelle che seguono è possibile conoscere alcuni dati indicativi della consistenza del patrimonio storico della Rai, secondo quanto riportato in un documento divulgativo rilasciato da Rai Teche lo scorso ottobre:
CONSISTENZA PATRIMONIO TELEVISIVO (Tabella 1) Anno 2000
(TECA CENTRALE – CSS1) 1954/1997 368.000 Ore ca. TRASMESSO STORICO
TECA NAZIONALE SPORT (C/O CPTV MI 1954/1997)
137.000 Ore ca.
(PROGRAMMI, TELEVISIONE E SPORT) DAL 1998
oltre 52.000 Ore TRASMESSO QUOTIDIANO
TECHE DI SEDE REGIONALE Oltre 97.000 Ore ca.
TOTALE Oltre 654.000 Ore
TG NAZIONALI 15.000 Ore ca.
GREZZO GIRATO TG REGIONALI 40.000 Ore ca.
PATRIMONIO RAI - AREA RADIOFONICA NAZIONALE (Tabella 2) Anno 2000 ARCHIVIO NASTRI ESECUZIONI MUSICALI 30.000 Ore ca.

Implementare le tecnologie nel prototipo per Teca Fast – 49
GIORNALE RADIO 60.000 Ore ca.
PROGRAMMI 200.000 Ore ca.
TOTALE 290.000 Ore ca.
DISCHI D’ACQUISTO 900.000 Brani ca.
COPIONI 50.000 Documenti ca.
ARCHIVI CARTACEI
SPARTITI, PARTITURE, PARTI D’ORCHESTRA e LIBRETTI
120.000 Documenti ca.
CONSISTENZA PATRIMONI DI BIBLIO-MEDIATECA RAI (Tabella 3) Anno 2000
LIBRI 60.000 unità ca.
RIVISTE 500 RACCOLTE
GIORNALI QUOTIDIANI 50 RACCOLTE
ALTRI MATERIALI
PRODOTTI EDITORIALI SU CD-ROM Oltre 150 PRODOTTI
ARCHIVIO RAI 300.000 Foto FOTOTECA NAZIONALE
ARCHIVIO EX RADIOCORRIERE 900.000 Foto
Nelle varie sedi italiane dell’azienda vi sono diversi archivi regionali audiovisivi e radiofonici di minore entità, che costituiscono comunque un patrimonio di grande valore per Rai.
Oltre ad una serie di iniziative di recupero dei materiali di archivio (riversamento su supporti video digitali delle vecchie cassette deteriorate: la Direzione Rai Teche sta intensificando le attività di riconversione dei vecchi supporti video come nastri magnetici da 1 e 2 pollici, pellicole a 16 e a 35 mm., vecchi supporti Beta) parallelamente le Teche RAI perseguono l’obiettivo del completamento di un Catalogo Multimediale.
Il progetto delle Teche RAI interseca tutte le strutture tecniche e produttive della Rai, e viene portato avanti dalla Direzione Rai Teche, che ha alcune responsabilità dirette ed altre di integrazione del sistema, con la collaborazione delle Divisioni Produzione Rai di Roma, la Divisione Radiofonia, e con la Direzione Information Communication Tecnology e il Centro Ricerche e Innovazione Tecnologica Rai di Torino.
Ogni archivio presenta un sistema informativo interno per la gestione delle risorse, spesso si tratta di sistemi diversi che adottano modelli di descrizione dei materiali differenti. Con il Catalogo Multimediale e il sistema Octopus sempre di Rai è possibile effettuare ricerche dalla intranet sui contenuti catalogati dai diversi archivi nazionali. La situazione è complicata dalla presenza dei cataloghi anagrafici e dell'Archivio Diritti, quest’ultimo nato con l’intenzione di ricostruire, incrociando fonti e dati, la lista completa di tutto il trasmesso Rai in TV e radio,

Implementare le tecnologie nel prototipo per Teca Fast – 50
con relativi diritti sia per i prodotti acquistati che per quelli realizzati dall'azienda. Una articolata banca dati dei diritti, all'interno della quale sono stati archiviati oltre 15.000 titoli di produzione esterna e che conterrà progressivamente anche tutti i dati relativi alla produzione interna, anche questo archivio costituisce una risorsa aziendale preziosa per la migliore valorizzazione e utilizzo dei prodotti audiovisivi.
Il catalogo multimediale progettato dal Centro Ricerche Rai con i Sistemi Informativi aziendali e importanti partners tecnologici a livello internazionale, è stato uno dei primi sistemi evoluti di catalogazione di materiale audiovisivo di un grande broadcaster in Europa, basato su un data base relazionale a oggetti, e in buona parte automatizzato (le operazioni di documentazione e di correzione dei tagli delle scene sono affidate a operatori esperti e società di documentazione).
La Direzione Rai Teche non ha responsabilità diretta ma di coordinamento sulla realizzazione delle teche digitali ad uso produttivo, che dipendono dalla Divisione Produzione TV e dalla Divisione Radiofonia.
La Teca Fast è la videoteca digitale di Rai, inizialmente progettata per contenere materiale digitalizzato a media qualità, è stata poi elevata al rango di unica teca digitale per l’accesso “veloce” a risorse di archivio. La Teca Fast comprende una architettura di codifica automatica del materiale televisivo trasmesso in diretta dai tre canali nazionali di Rai, e offre funzionalità di accesso on-line ai contenuti, tramite un’architettura client-server e reti ad alta capacità in fibra ottica per il trasporto delle sequenze codificate con l'obiettivo di fornire il materiale in qualità utilizzabile per le hard news, per le produzioni tematiche e ad uso broadband, con funzioni anche di disaster recovery, di premontaggio, e obiettivi di evoluzione verso il montaggio virtuale dalla stessa consolle del ricercatore o montatore. La Teca Fast è stata oggetto di ulteriore approfondimento, e i risultati sono riportati nel seguito.
Il lavoro di recupero, documentazione e catalogazione multimediale del trasmesso pregresso prevede ancora almeno tre anni di lavoro. Importanti saranno le strategie e le tecniche adottate per i processi intrapresi, importanti per consentire alla Rai e alla nazione di disporre integralmente del patrimonio audiovisivo (salvo alcuni materiali che sono andati dispersi e come tali non sono riproducibili) di quanto il servizio pubblico italiano ha trasmesso in televisione e in radio dalle sue origini.
Per facilitare il lavoro anche nelle fasi transitorie è stato realizzato un motore di ricerca integrato (Octopus) in grado di connettersi in contemporanea a tutti gli archivi testuali tradizionali aziendali. Il sistema consente anche di salvare le ricerche in un proprio profilo utente. Soffre ovviamente di un problema basilare: la diversità non solo dei sistemi informativi dei vari archivi, ma anche dei modelli di descrizione, catalogazione, identificazione delle numerose risorse.

Dettagli sugli archivi principali e il Catalogo Multimediale – 51
Figura: il Sistema Teche Rai
La valorizzazione dei materiali di teca si traduce in vantaggi sulla produzione: per i canali via etere l'uso dell'archivio già da due anni è aumentato oltre del 10%. Alcuni esempi noti sono l'inserimento di spezzoni di sequenze di archivio in numerose trasmissioni di intrattenimento basate anche sulla nostalgia, la realizzazione di film soltanto a base di repertorio, la costruzione di nuovi format basati su prodotti di teca, i programmi di ricostruzione storica, le produzioni culturali in grado di mettere a confronto immagini di ieri e di oggi. Altro aspetto è la valorizzazione dei materiali di teca per le offerte della Rai sui nuovi media: l'archivio oggi alimenta interi canali tematici satellitari..
La Rai ha la possibilità di far fruttare al meglio il suo archivio sul nuovo mercato digitale, e grazie al suo grande patrimonio di contenuti in costante crescita è decisamente in una posizione di forza rispetto a tutti i suoi competitor, non soltanto italiani. Questo significa anche per l’azienda un grande impegno e la necessità di organizzare con tecniche sempre più all’avanguardia la gestione del complesso sistema teche.
III.1.1 Dettagli sugli archivi principali e il Catalogo Multimediale
L’accesso da parte degli operatori alle risorse dell’archivio Centrale Rai prevede diversi passi, molti dei quali gestiti manualmente. La procedura complessiva, dalla consultazione del catalogo per la documentazione fino alla consegna dei programmi, cioè di una copia del materiale filmato su supporto cassetta video, può richiedere anche diversi giorni. Questi tempi, che pesano sulla produzione, vengono ora ridotti drasticamente con l’implementazione e uso del Catalogo Multimediale e della Teca Fast automatizzata. Sistema per adesso disponibile agli

Dettagli sugli archivi principali e il Catalogo Multimediale – 52
utenti interni come produttori, registi, giornalisti e, in generale, a tutti coloro che operano nel settore della produzione.
Il Catalogo Multimediale è nato come strumento di ricerca che consenta agli utenti di individuare le sequenze audiovisive desiderate nell’immensa mole di materiali archiviati, con il dettaglio in grado di scendere alla singola inquadratura del filmato, sempre nel tentativo di eliminare progressivamente la necessità di visionare i materiali su supporto video per la scelta dei brani. Per tale motivo, all’interno del catalogo non sono contenute solo informazioni di tipo testuale, ma anche le fotografie correlate ai programmi televisivi e i segmenti audio associati. Il catalogo è strutturato in modo da rendere possibile individuare non solo i programmi, ma anche i segmenti e le singole inquadrature. La descrizione del Catalogo fa riferimento di solito alla documentazione del materiale televisivo (che rappresenta il caso più comune) ma può essere applicata anche, con piccole modifiche, alla radio e alle fotografie. Il catalogo e le teche devono inoltre essere mantenute “allineate” in modo che l’utente, dopo avere consultato il catalogo ed individuato i segmenti dei programmi di interesse, possa inviare i codici di identificazione relativi alla teca appropriata (“ordini di lavoro”) e ricevere una copia del materiale scelto eliminando completamente la necessità di visionare i materiali. Risulta tuttavia più facile ottenere l’allineamento tra il catalogo e le teche per quelle parti del catalogo che vengono realizzate utilizzando i materiali di documentazione già presenti nelle teche, nel qual caso l’identificazione del materiale e i riferimenti temporali corretti possono essere determinati immediatamente. Invece, nel caso di un inserimento parallelo nel catalogo e nelle teche di materiale registrato in precedenza, o di contributi trasmessi in diretta, l’allineamento tra il catalogo e le teche rappresenta un’operazione più complessa e alla quale lavora la Divisione Produzione e la Direzione ICT di Rai.
Il catalogo prevede la consultazione contemporanea da parte di numerosi utenti, attraverso interfacce web accessibili dalla rete intranet della RAI mediante un comune browser. L’accesso alle risorse di Teche (cioè alle funzionalità di richiesta on-line di materiali di Teca Fast e Teca Master) è ristretto a un numero limitato di persone che operano nell’ambiente della produzione, questo sia per motivi di tutela del materiale, che allo scopo di mantenere sotto controllo il carico della rete. I materiali selezionati possono essere consegnati all’utente richiedente in diversi formati, a seconda del collegamento disponibile: sotto forma di file (Teca Fast) o sotto forma di nastri video (Teca Master).
Attualmente la Teca Master (la teca Centrale) contiene video in formato digitale e analogico memorizzati su supporti video convenzionali e non è gestita in modo completamente automatico. I supporti sono custoditi su “pallet” contenuti in un magazzino, le posizioni dei supporti e dei pallet sono gestibili via computer e il movimento dei pallet è eseguito da un robot (traslatore). Utilizzando una tecnologia completamente digitale e automatizzata per l’archivio Teca Fast, si è scelto un modo versatile e sicuro di memorizzazione e di gestione dei materiali audiovisivi, in grado di garantire per esempio l’indipendenza dai formati, difficilmente ottenibile con le apparecchiature audio-video dedicate. Nella Teca

Organizzazione del Catalogo Multimediale – 53
Fast il materiale è organizzato in file e memorizzato su due diversi livelli di memoria, Il primo livello è rappresentato dallo memorizzazione su hard disk accessibili on-line, mentre il secondo livello è costituito da memorie su nastro automatiche. Un processo di caching gestisce il trasferimento tra il primo e il secondo livello di memoria.
L’utilizzazione di due livelli della memoria è stata suggerita in fase di progettazione del sistema dall’analisi costi-prestazioni. Infatti, a causa della grande quantità di materiale video, una memoria basata solamente su hard disk audiovideo risulterebbe estremamente costosa. In questo modo però i tempi di accesso del materiale immagazzinato su nastri possono risultare molto più lenti e non soddisfacenti in taluni casi, come in quello particolare di un grande numero di accessi contemporanei alle risorse archiviate.
III.1.2 Organizzazione del Catalogo Multimediale
I compiti che attualmente deve svolgere il Catalogo Multimediale sono essenzialmente due: l’interazione coi documentatori, per svolgere il ruolo fondamentale di deposito degli oggetti multimediali e delle informazioni raccolte e generate durante le diverse fasi del processo di documentazione, e il supporto alle funzioni di ricerca, navigazione e visione veloce della documentazione e delle anteprime per arrivare fino all’ordine di consegna del prodotto finale all’utente, tramite opportuni collegamenti con le teche dei contenuti. Un’altra applicazione in fase di sviluppo da parte delle Teche con il Centro Ricerche, potrà garantire funzionalità di estrazione dei contenuti in formati adatti alla produzione di siti web.
In conseguenza delle diverse limitazioni correlate ai due ruoli assegnati al catalogo, è stata scelta un’architettura basata su due sottosistemi accoppiati: il primo sottosistema, detto Catalogo di Documentazione, si occupa dell’acquisizione dell’oggetto multimediale (estrazione dei cambi scena dal flusso televisivo trasmesso dai canali nazionali) e supporta la fase di documentazione e le fasi della convalida; il secondo sottosistema, detto Catalogo delle Pubblicazioni, è il sistema visibile agli utenti, che riceve i documenti di palinsesto opportunamente descritti e convalidati, e offre le funzionalità di ricerca, navigazione e anteprima audio e immagini, con le sopramenzionate connessioni in rete alle teche per l’invio delle richieste di ordine o download del contenuto selezionato (funzione detta di grabber).
III.1.3 Il catalogo di documentazione e l’acquisizione dei
documenti multimediali.
L’acquisizione dei materiali multimediali di descrizione dei programmi, come le immagini di cambio scena delle sequenze video o l’anteprima in formato audio

Il catalogo di documentazione e l’acquisizione dei documenti multimediali. – 54
compresso a bassa qualità, è un’operazione affidata ad apposite workstation biprocessore che, ricevendo come input un segnale video composito e un riferimento temporale, svolgono in tempo reale le attività seguenti: digitalizzazione e compressione dell’audio, rivelazione delle modifiche delle inquadrature, estrazione di un fotogramma principale per ciascuna inquadratura, associazione del tempo di inizio e della durata dell’inquadratura a ogni fotogramma principale.
Durante i periodi di collaborazione effettuati nell’ambito del lavoro di tesi presso il CRIT Rai di Torino, è stato possibile acquisire maggiori informazioni riguardo al processo di generazione della documentazione multimediale del catalogo: quando la stazione di acquisizione è alimentata con il segnale in diretta relativo a un canale di tramissione tv, e non è disponibile in tale fase alcuna informazione sul programma, l’identificazione dei fotogrammi principali e dell’audio avviene sulla base dei loro tempi di acquisizione ed è quindi spesso necessaria una elaborazione e una lavorazione ulteriore da parte di personale specializzato per le operazioni di suddivisione del flusso di immagini estratte dallo stream in opportuni item di programma. Il flusso di documenti di descrizione o item di programma viene poi inviato ad una serie di server connessi in rete ad alta velocità con le workstation delle società di documentazione. Queste ultime si occupano della documentazione (inserimento delle informazioni sul titolo del programma riconosciuto, autori, partecipanti, contributori, e una serie di altre informazioni come riassunti testuali dei contenuti). Qui si trova un fattore critico del sistema, che richiederebbe l’implementazione di un modello di descrizione unico e standard, e di tesauri e dizionari per limitare la dispersione terminologica delle descrizioni.
In effetti l’assenza di uno standard per la descrizione dei metadati audiovisivi rende ancora eterogenee e poco consistenti le operazioni di documentazione, che presentano gradi di approfondimento molto variabili a seconda del tipo di programma, delle informazioni in possesso di ogni operatore o società che realizza l’immissione dei dati e che rimanda indietro i documenti completati destinati ai server del Catalogo di Documentazione. Si riconosce la necessità nella manutenzione e sviluppo del catalogo di ricercare soluzioni per l’implementazione di strutture dati di descrizione conformi ad un modello standard, consistente e portabile che faccia da base ottimale per l’implementazione delle informazioni di descrizione, garantendone un valore anche maggiore in vista di possibili riutilizzi del materiale di catalogo per servizi di ricerca e produzione accessibili anche dall’esterno della rete aziendale.
Uno standard per gli strumenti di descrizione è necessario, anche per consentire l’interoperabilità con diversi sistemi di ricerca. In futuro i sistemi intelligenti di ricerca con competenze di commercio elettronico saranno anche parzialmente o completamente automatizzati, come nel caso delle tecnologie basate sugli agenti intelligenti: ad esempio l’agente intelligente (software) di TeleXY potrà cercare un documentario sul Vesuvio a meno di 500 euro per minuto di trasmissione destinato al suo canale satellitare, e altri agenti intelligenti di emittenti diverse

Il catalogo di documentazione e l’acquisizione dei documenti multimediali. – 55
avranno lo stesso tipo di necessità per la loro programmazione, magari con offerte monetarie differenti; Rai potrà mettere a disposizione dei suoi agenti automatici di vendita diversi documentari sul Vesuvio, con differenti prezzi di acquisto dei diritti d’uso. In casi come questo si comprende immediatamente l’importanza dell’uso di strutture dati e linguaggi di descrizione puntualmente definiti, potenti nella ricchezza espressiva, ma anche stabili sufficientemente da garantire la completa comprensibilità e accessibilità anche a sistemi di ricerca esterni, pilotati da sistemi automatici o da esseri umani che effettuano ricerche.
Mpeg-7 offre una buona parte delle soluzioni. In più fornisce uno standard e diffonde una serie di strumenti su cui basare applicazioni per la descrizione molto accurata degli oggetti multimediali. Secondo il punto di vista proposto da Mpeg-7, tutte le sequenze audiovisive possono essere scomposte e descritte ai minimi termini e in diverse modalità: dal punto di vista delle caratteristiche di basso livello, come i segnali, le texture, i colori, le forme degli oggetti riconoscibili, il moto e le relazioni di questi oggetti, fino alle caratteristiche di più alto livello, come la descrizione di strutture semantiche, la descrizione strutturata dei concetti, delle azioni descritte in un contenuto multimediale, e molto altro, oltre naturalmente ad una lunga serie di strumenti per la descrizione basata sui metadati tradizionali testuali, oggetto dello studio e della realizzazione del prototipo descritto in questa tesi, e descritti nella parte Multimedia Description Schemes (MDS) dell’Mpeg-7.
Un’altra necessità è quella di stabilire (creandolo ex-novo od utilizzandone uno preesistente) l’uso di uno o più tesauri per l’utilizzo di terminologia e dizionari ad hoc per l’applicazione. Mpeg-7 non standardizza questa parte, che viene lasciata allo sviluppo esterno, e che vede alcune importanti realizzazioni negli schemi di classificazione proposti dalle iniziative europee come Tv Anytime o EBU- Escort. Questa è una delle attività che si prevede di affidare alle fasi successive all’implementazione della prima proposta di sistema di ricerca basato su Mpeg-7.
Tornando al catalogo multimediale, come accennato il flusso continuo di oggetti multimediali acquisiti dal sistema di estrazione dei cambi scena e anteprime è preventivamente elaborato prima del passaggio ai documentatori e al Catalogo di Documentazione, con lo scopo di creare le item di programma da inserire nel database. Attualmente, questa operazione è eseguita manualmente, supportata dalle informazioni riguardo ai tempi di inizio e di fine della trasmissione di ogni programma, caricati in modo automatico da un database amministrativo. La precisione disponibile nelle informazioni temporali, sufficiente per le operazioni amministrative, non è adeguata a una segmentazione completamente automatica dei programmi; per tale motivo, è necessaria la presenza di un operatore allo scopo di selezionare in modo preciso i punti di taglio. Questo passo è semplificato nella catena di digitalizzazione per materiali di repertorio in quanto esiste molto spesso una corrispondenza biunivoca tra i nastri e i programmi, anche se non sempre è così (spesso si incontrano casi di singoli supporti video di archivio che contengono più programmi differenti).

Il Catalogo delle pubblicazioni e il trasferimento degli item di programma – 56
In questa fase, è creata nel database un’entità correlata ai programmi che collega le informazioni multimediali ad alcune informazioni di base riguardo alla classificazione, come il nome del programma i titoli di coda, i codici di identificazione del programma, il nastro o i nastri corrispondenti nella biblioteca principale, etc.
Attualmente la documentazione dei programmi è eseguita da società esterne, tramite l’implementazione di un’architettura informatica che comprende le isole di documentazione indipendenti delle società esterne collegate al Catalogo di Documentazione tramite una rete dedicata. In questo modo, gli oggetti multimediali sono trasferiti dal Catalogo di Documentazione a un server situato in ogni società di documentazione e collegato attraverso la rete locale alle stazioni di documentazione. La documentazione da esse prodotta è rinviata al Catalogo di Documentazione e posizionata nell’item di programma corrispondente nel database. Prima della sua diffusione tale documentazione deve essere convalidata da una struttura apposita della Direzione Teche.
III.1.4 Il Catalogo delle pubblicazioni e il trasferimento degli
item di programma
I programmi che sono stati oggetto di documentazione e successiva convalida, prevedono il trasferimento della documentazione relativa nel catalogo di pubblicazione, dove sono messi a disposizione degli utenti attraverso le funzioni di ricerca, navigazione e ascolto e visione di anteprima.
Data la grande quantità di materiali audiovisivi, radiofonici, cartacei e fotografici che la Rai possiede nei suoi molteplici archivi, in costante aumento, il Catalogo Multimediale che ne effettua la documentazione è anch’esso di grandi dimensioni. Un singolo database contenente l’intero catalogo sarebbe costituito da un numero molto elevato di documenti e avrebbe prestazioni non soddisfacenti. Per questo in fase realizzativa si è deciso di suddividere i database a seconda del tipo di materiali contenuti, mantenendo allo stesso tempo la capacità di effettuare ricerche in parallelo in tutte le sezioni, attendendosi una riduzione significativa delle dimensioni di ogni database e una corrispondente riduzione di utenti contemporaneamente presenti in ogni sezione. Questo in nome di un aumento nelle prestazioni e nella flessibilità e scalabilità del sistema. Mantenere un database distribuito prevede costi superiori dovuti alla maggiore complessità rispetto ad un database centralizzato.
In quest’ottica si inserisce la filosofia di realizzazione del progetto di un sistema locale di descrizione di primo livello per la Teca Fast, che proponga l’utilizzo di tecnologie server XML che combinate con le strutture dati standard di Mpeg-7 sono in grado di fornire un’ulteriore vantaggio nell’implementazione di database distribuiti flessibili (grazie alla gestione delle informazioni basata su documenti strutturati in xml), compatibili e scalabili.

Il Catalogo delle pubblicazioni e il trasferimento degli item di programma – 57
Vi sono quindi tabelle di dati indirizzati per mezzo di linguaggi SQL tradizionali per l’implementazione delle funzioni di ricerca testuale. Un tale approccio, alla costituzione del catalogo era l’unico possibile per ottenere la flessibilità necessaria a supportare le successive releases del sistema sviluppate allo scopo di tenere conto delle nuove esigenze e di sfruttare le nuove tecnologie. La tecnologia ORDB si è dimostrata in fase di progettazione del sistema (1997-98) più efficace, rispetto a un database relazionale tradizionale, nello realizzazione delle funzioni di navigazione tra gli oggetti multimediali che costituiscono la documentazione dei programmi. Adesso è il momento di valutare le promettenti potenzialità dei sistemi di database basati su tecnologie completamente XML, che non prevedono tabelle e relazioni, ma strutture ad albero definite dal semplice linguaggio a marcatori.
Il materiale del catalogo è strutturato logicamente secondo un modello di dati che considera un programma come parte di una serie che, a sua volta, è parte di un prodotto. Un programma può essere suddiviso in segmenti composti dalle inquadrature, dove i diversi livelli sono definiti da:
• Prodotto, che è una raccolta di collezioni, costituisce un programma televisivo completo o “titolo”. Può essere definito anche come “tutti i programmi che hanno lo stesso titolo”.
• Serie, cioè un insieme di programmi (la raccolta) correlati allo stesso prodotto.
• Programma, un oggetto multimediale con un’unica timeline, dove un oggetto multimediale costituisce un’entità nel database multimediale. Può essere parte di una o più raccolte e può essere suddiviso in uno o più segmenti. Un programma può essere definito anche come “un episodio di un prodotto”.
• Segmento, una parte di un programma dotata di un significato semantico chiuso.
• lnquadratura, un’inquadratura video estratta da un programma, secondo alcuni criteri di carattere tecnico come un cambio, una dissolvenza, etc.
Ai primi quattro livelli di dati sono associate delle note come, ad esempio, il prodotto, la serie, il programma e il segmento. Ogni item di programma è composto da immagini statiche, audio compresso, campi formattati e testo libero.
Le immagini sono costituite dai fotogrammi principali estratti dai programmi televisivi, ridotti a 1/4 della risoluzione originale e compressi in formato JPEG. L’anteprima audio è costituita dalla colonna sonora associata al programma televisivo, compresso con il sistema MPEG layer-3 a 8 kbps. I campi formattati e il testo libero contengono le informazioni riguardanti la classificazione, ottenute con un’importazione di dati dai vecchi database di archivio se presenti e una

Il Catalogo delle pubblicazioni e il trasferimento degli item di programma – 58
documentazione minima generata nella fase della produzione del Catalogo della Documentazione costituita, ad esempio, dal titolo, dai titoli di coda e dalle annotazioni inserite al terminale dai documentatori durante la fase di documentazione. Le funzionalità che il catalogo delle Pubblicazioni mette a disposizione degli utenti finali del sistema, sono principalmente la ricerca, navigazione e l’interfaccia di palinsesto, oltre alla connessione con le varie teche.
Tuttavia, essendo presenti campi di documentazione diversi a seconda del tipo di materiali, per poter effettuare un’interrogazione su tutto il materiale in Catalogo il sistema di ricerca può basarsi solamente sul sottoinsieme dei campi di documentazione comune a tutte le tipologie della stessa.
È possibile effettuare ricerche composte utilizzando operatori logici e cercando la parola esatta, una parola simile o un sinonimo, secondo modalità di ricerca impostate dall’utente prima di dare avvio all’operazione di ricerca. Il risultato dell’interrogazione della ricerca è costituito dal numero e dall’elenco (titoli) di occorrenze trovate. Selezionando una voce dall’elenco delle occorrenze ottenute si apre l’interfaccia di navigazione che consente all’utente di spostarsi all’interno della documentazione del programma selezionato.
Questa soluzione è confluita nel sistema di ricerca definito “OCTOPUS”, in grado di effettuare ricerche anche nei soli data base testuali, unificando nell’accesso in modalità web le ricerche su tutti i vecchi archivi aziendali. Questi archivi tuttavia prevedono campi di descrizione spesso molto eterogenei, oltre a diversi tipi di identificatori delle risorse. I risultati di un’interrogazione possono essere costituiti da qualsiasi tipo di oggetti documentati, e cioè prodotti, serie, programmi, segmenti o inquadrature.
Il processo di documentazione completo di un programma trasmesso, a partire dal momento della cattura in diretta dei fotogrammi principali, fino all’upload della documentazione convalidata nel catalogo delle pubblicazioni, richiede diver-si giorni. Per alcuni generi, come le news, gli oggetti multimediali associati alla classificazione e i dati relativi alla trasmissione del programma corrispondente costituiscono già una fonte di informazioni preziosa per alcuni tipi di utenti.
Per tale motivo i materiali non documentati sono già scaricati nel Catalogo Multimediale il giorno successivo alla trasmissione, senza attendere la conclusione del processo di documentazione e sono resi visibili con anteprime in formato MPEG-4 (full motion), codificati in processi separati da quelli di acquisizione del flusso di cambi scena e anteprime audio.
L’interfaccia per navigare sui programmi in base all’orario di trasmissione è chiamata “Interfaccia di Palinsesto”. Sono elencati tutti i programmi trasmessi in un giorno specificato insieme alla trasmissione relativa, ai tempi di inizio e di fine e ai titoli.

Il Catalogo delle pubblicazioni e il trasferimento degli item di programma – 59
Il catalogo multimediale contiene anche i dati di identificazione dei file dei supporti contenenti il video, l’audio, il codice relativo al tempo di inizio e alla durata di ogni inquadratura. Per tale motivo, attraverso la consultazione del catalogo è possibile selezionare una parte di un programma in base alla documentazione relativa. La parte selezionata è associata al file o all’identificatore del supporto e ai codici temporali iniziali e finali. Se il contenuto è richiesto a una teca digitale automatizzata, come Teca fast, i parametri di indirizzamento sono trasferiti automaticamente al server della libreria, in questo caso un SQL Server, che localizza i file inclusi nell’intervallo temporale richiesto, estrae la porzione di programma richiesta e la mette a disposizione del richiedente sulla rete – ovviamente con i tempi necessari per l’evasione della richiesta. Un esempio di applicazione già in uso della Teca Fast è quella relativa all’evasione degli ordini di lavoro provenienti dalle redazioni dei telegiornali.
III.2 Altri archivi audiovisivi in Italia
Un archivio audiovisivo di grande importanza, sempre in Italia, è quello dell’istituto LUCE, dove sono conservati numerosi cinegiornali e documentari, con materiale che va dagli albori della cinematografia fino agli anni ottanta della cronaca italiana e già da decenni è aperto a storici, registi e ricercatori nazionali e internazionali. La catalogazione digitale dell’archivio, con la parallela digitalizzazione dei supporti filmici, consente alla LUCE di dare un ordinamento alle centinaia di migliaia di notizie che formano la trama di un immenso tessuto di immagini. Il lavoro di informatizzazione è stato affidato ad un gruppo qualificato di dipendenti LUCE, con l’affiancamento di una società di consulenza, il "Consorzio Roma Ricerche" che dichiara anche l'incarico specifico di impedire la proliferazione incontrollata dei termini dei thesaurus, che sono la cartina di tornasole di ogni catalogazione tecnologica moderna e razionale.
Un altro importante esempio di archivio audiovisivo in Italia è la Cineteca Nazionale della Scuola Nazionale di Cinema (ex Centro Sperimentale di Cinematografia) che conserva un’ampia collezione di film ricostruita nel dopoguerra. Nel 1949 la Cineteca del Centro ha aderito alla FIAF (Fédération Internationale des Archives du Film) e, nello stesso anno, con un'apposita legge, essa è stata denominata Cineteca Nazionale e investita del compito di raccogliere, preservare e diffondere, a scopo di studio, un patrimonio di cui veniva ufficialmente riconosciuta la rilevanza culturale. La Cineteca Nazionale è l'organismo destinato per legge alla raccolta (anche grazie al deposito obbligatorio dei film di lungo e corto metraggio di produzione o coproduzione italiana), alla conservazione, al restauro e alla circolazione dell'intera cinematografia italiana; il suo patrimonio è attualmente di circa 28.000 titoli (35.000 tra matrici e copie), costituiti da una notevole collezione relativa alla cinematografia nazionale dalle origini al dopoguerra, da pressoché tutta la produzione cinematografica italiana a partire dal 1949 e, dai titoli più significativi della storia del cinema mondiale (acquisiti soprattutto grazie agli scambi con le cineteche della FIAF).

Il Catalogo delle pubblicazioni e il trasferimento degli item di programma – 60
III.3 L’ambiente applicativo: la TECA FAST Rai
Viene ora riportata un’analisi più approfondita dell’architettura della Teca Fast digitale di Rai, la struttura cui è indirizzata la prima implementazione del prototipo realizzato in questo lavoro di tesi. Come è stato detto, la Teca Fast Rai opera la digitalizzazione dei materiali trasmessi dalle 3 tre reti televisive nazionali RAI, costantemente, 24 ore al giorno oltre che ad una parte di materiali audiovisivi di Archivio). Gli utenti del sistema, in una prima fase solo operatori che accedono agli studi di montaggio attrezzati in azienda, possono usufruire di funzionalità di accesso in rete ad alta velocità alle risorse digitalizzate, con un servizio chiamato di VTR (Video Tape Recorder) virtuale. Tra i servizi che la Teca Fast fornisce vi è l’interfacciamento con i sistemi di descrizione del palinsesto dell’emittente (l’interfaccia di “Palinsesto” accessibile sul sito intranet di ricerca), e con i banchi di messa in onda per il recupero del segnale audiovideo e delle informazioni di identificazione del programma. Il sistema impiega inoltre dei video server per consentire l’accesso simultaneo di più utenti ad una stessa risorsa di archivio.
Il formato utilizzato per la codifica digitale e l’archiviazione dei filmati è dimensionato sul tipo di attività di post-produzione previste, attività cioè che non richiedono elaborazioni complesse del segnale audio-video, essendo essenzialmente destinate alla produzione di programmi per canali tematici, di retrospettiva, dossier, ricerche, che richiedono un editing piuttosto semplice.
Per questi motivi si è scelto l’algoritmo di compressione MPEG2 ML@MP 4:2:2 a 10 Mbit/s, che consente di mantenere una qualità audiovisiva più che sufficiente per la produzione broadcast, insieme ad una considerevole riduzione dei costi di archiviazione (minor spazio occupato anche fisicamente dai supporti di memorizzazione e dagli archivi robotizzati che li gestiscono). Per garantire un allineamento con il materiale presente nell’archivio Teca Master analogico viene utilizzato il riferimento al time code assoluto riferito all’orologio nucleare dell’Istituto Galileo Ferraris di Torino, sia per quanto concerne i filmati di archivio sia per quelli generati dal sistema automatico che si occupa di digitalizzare i segnali di messa in onda in diretta sui canali nazionali.
L’utente del sistema, anche da remoto se connesso con il servizio di Teca Fast, può visionare e riversare velocemente le risorse di archivio digitale e scegliere i punti di inizio per le operazioni di ricerca o riversamento in ogni punto del filmato semplicemente scegliendo il valore corretto di time code assoluto registrato con gli originali. Non è il sistema di Teca Fast a fornire direttamente funzionalità di editing in remoto, che spetta alla attrezzature di edizione nelle workstation di studio, nella fase successiva al riversamento delle risorse di teca.

Il Catalogo delle pubblicazioni e il trasferimento degli item di programma – 61
L’architettura del sistema di acquisizione, memorizzazione e accesso ai filmati digitalizzati delle Teca Fast è stata sviluppata in collaborazione con una società esterna a Rai. Il modello del sistema utilizzato è client-server e destinato alla fornitura del servizio alla rete interna aziendale di Rai, con possibili estensioni web. La distribuzione del video digitale compresso in alta qualità è infatti limitata al livello di area locale. Le tre sedi Rai di Roma sono connesse in fiber channel con protocolli TCP/IP e dispongono di propri apparati di codifica e decodifica in locale. Il sistema di acquisizione è composto da un video server collegato alla libreria (dei dati su cassette digitali) robotizzata, a un sistema di archiviazione gerarchico in architettura SAN (Storage Area Network) e alle apparecchiature specializzate nella codifica dei canali audiovisivi nel formato prescelto MPEG2.
La libreria dati a nastri digitali è gestita automaticamente da un server Sun, attraverso dei silos robotizzati, ognuno in grado di gestire circa 6.000 supporti a nastro digitale, con una dotazione di dieci drive di accesso ad alto bit rate (circa 10 MB/s). Per consentire la distribuzione del video in formato MPEG2 fino a 10 Mbit/s ad un numero di 40 utenti simultanei almeno, e poter gestire un quantitativo (previsto in fase di progettazione in base al censimento di Teca Master) di quasi 400.000 ore di video, il sistema di video server è realizzato con due potenti unità Silicon Graphics Origin 2000, con 8 processori e 2 GB di memoria centrale, corredati di una unità dischi RAID (Redundant Arrays of Independent Disks). Le connessioni ad alta velocità per il trasporto del video codificato avvengono tramite una dozzina di schede per il collegamento a una rete di codifica e visualizzazione in modalità fiber channel switched.
Il sistema di video server prevede la separazione dei sottosistemi di codifica per quanto riguarda la gestione dei flussi provenienti dalla codifica in tempo reale del materiale trasmesso giornalmente dalle tre reti RAI, e per la produzione continua di un flusso audio-video sempre associato ad un time-code generato in sincrono con l’orologio nucleare dell’Istituto Galileo Ferraris di Torino.
La codifica dei flussi audio-video di sorgente viene eseguita da una o più apparecchiature Tektronix Profile, nel formato MPEG-2 4:2:2 previsto. Il compito del video server si limita al solo trasferimento dei dati da e verso i Tektronix Profile ai quali è demandata la funzione di encoding e decoding.
Nel caso dell’operazione di inserimento di contenuti audiovisivi nell’archivio Teca Fast, lo schema di processo è quello esemplificato nella figura seguente, dove il modulo Tektronix Profile del video server viene alimentato dalla sorgente audio/video preesistente, ed effettua la codifica dei dati raccolti in formato MPEG 4:2:2 in opportuni file che vengono trasferiti attraverso la propria scheda fiber al modulo Silicon Graphics Origin 2000 del sistema di gestione DHSM (Dynamic Hierarchical Storage Management).

Il Catalogo delle pubblicazioni e il trasferimento degli item di programma – 62
Figura: Schema concettuale operazioni di inserimento audiovisivi nel sistema
Teca Fast .
Qui i files vengono trasmessi attraverso un’altra scheda fiber channel al sistema RAID, dal quale passa ai dispositivi di scrittura-lettura su nastro digitale per l’archiviazione. In parallelo al processo di archiviazione dei files codificati dal flusso di ogni canale audiovisivo in ingresso, il DBMS provvede ad archiviare i dati di controllo del file in apposite tabelle. Quindi per la comunicazione viene impiegata la rete fiber channel, mentre nella fase finale di trasferimento dei file dal sistema RAID ai lettori a nastro viene impiegato un canale SCSI differenziale.
Nel caso della richiesta di play-out di risorse dall’archivio, il modulo Tektronix Profile del video server si va ad alimentare con i file conservati sul sistema RAID e prelevati dalla libreria a nastri robotizzata.
Confrontando i dati di controllo presenti nelle tabelle del DBMS, attraverso la scheda di rete Fiber Channel installata sul modulo Silicon Graphics Origin 2000 del sistema DHSM (Dynamic Hierarchical Storage Management), il file richiesto viene trasmesso al Tektronix Profile (che può trovarsi in una sede diversa dalla teca, ad esempio in prossimità di una sala montaggio aziendale). All’ingresso del Tektronix il file viene preso da un’altra scheda fiber channel e inviato tramite un cavo audio/video in uscita agli apparati di saletta e da qui eventualmente ad un’uscita su monitor PAL di sala.
La comunicazione avviene su rete fiber channel, e come nel processo inverso di inserimento di contenuti in archivio, il trasferimento dei file dalla libreria a nastri robotizzata al sistema RAID avviene invece su canale SCSI differenziale. Il flusso di play-out è schematizzato nella figura seguente.

Il Catalogo delle pubblicazioni e il trasferimento degli item di programma – 63
Figura: Schema concettuale operazioni di richiesta contenuti dall’archivio del
sistema Teca Fast.
I supporti di memorizzazione utilizzati sono di tipo gerarchico-dinamico (DHSM): una libreria di nastri, un sistema di dischi, un sistema di database.
L’archivio di tutti i file video è memorizzato nella libreria di nastri. I dischi sono invece utilizzati come supporto di memorizzazione dei file video più richiesti (Video Cache), per evitare di doverli ricaricare tutte le volte dal nastro con conseguente saturazione della banda di uscita della libreria di nastri, compensando in tal modo il ritardo dovuto ai lunghi tempi di accesso dei nastri. Il sistema di dischi RAID alloca per la componente di codifica e play-out dischi in grado di contenere fino a 72 GB, corrispondenti a circa 12 ore effettive di registrazione video.
Fino ad ora è stato illustrato il sistema presente nella sede centrale di Teca Fast. Le sedi secondarie connesse alla Teca Fast ripropongono la stessa architettura, restando prive della libreria dati robotizzata e del sistema RAID, e dotate di memoria e capacità elaborativa inferiori; le sedi secondarie in grado di connettersi sono quelle di Saxa Rubra, Teulada e Teca Centrale (CSS1), in grado di svolgere solo funzionalità di play-out, quindi di richiesta di contenuti di archivio digitale.
A livello del software, il sistema centrale è ripartito su quattro ambienti distinti in comunicazione tra loro attraverso un software demone definito come “Agente”. L’Agente intercetta e reinstrada tutte le richieste che pervengono alla Teca Fast. Le richieste provenienti dagli utenti attraverso l’interfaccia al DBMS e il Query Manager vengono reinstradate verso un Device Manager per il prelievo dei dati dalla libreria dati robotizzata ovvero al Profile Manager per il trasferimento dei dati richiesti. Viceversa le richieste provenienti dal Profile Manager, tipicamente di ingestion vengono reinstradate al DHSM per il trasferimento su disco e da qui al Device Manager per l’archiviazione su nastro. Il Device Manager, a sua volta, è

Architettura di rete e software dell’archivio Teca Fast – 64
composto dal Tape Manager che contiene il vero e proprio driver che pilota il lettore, TMFBASE.
La gestione del sistema RAID e del traffico I/O su relativi moduli, dischi e partizioni è affidata al DHSM (Dynamic Hierarchical Storage Manager) al cui interno è contenuta l’applicazione che genera il processo Main da cui si origina il software demone Agente. Sia l’inserimento di audiovisivo che il play-out video per l’utente vengono gestiti da un software realizzato appositamente. Il riversamento del materiale avviene in maniera automatica con codifica in tempo reale.
III.3.1 Architettura di rete e software dell’archivio Teca Fast
Come già menzionato, la codifica dei contenuti video e la generazione di file MPEG2 è gestita dai Tektronix Profile, ma il controllo delle comunicazioni con i Tektronix Profile avviene attraverso il demone Agente e il Profile Manager.
Sull’apparecchiatura Tektronix Profile girano due applicazioni realizzate ad hoc che gestiscono la codifica in real time e il trasferimento al sistema RAID dei files dal video server e da questo ai dispositivi a nastro.
La codifica in tempo reale avviene sulle sorgenti A/V trasmesse attraverso la preesistente infrastruttura del Centro Servizi Salario 2 (CSS2). Tre apparati Tektronix Profile sono riservati ai tre canali televisivi nazionali RAI, RAIUNO, RAIDUE, RAITRE (per la codifica di quest’ultimo non sono per ora disponibili le programmazioni regionali) e gli altri Tektronix sono impiegati nella codifica e immissione nella nastro teca digitale delle sorgenti A/V provenienti dalle librerie a nastro tradizionale, tipicamente di tipo SONY Betacam, per la codifica di materiali di archivio.
Il database che si interfaccia col sistema è un database SQL relazionale puro e contiene informazioni sui contenuti della Teca Fast e sullo stato delle attività (vale a dire come memoria temporanea del sistema).
Quest’ultima funzione permette di evitare il ricorso a protocolli di comunicazione per la sincronizzazione e la gestione di tutti i sistemi connessi, riservando banda. I vari elementi del sistema agiscono quindi come macchine “disaccoppiate” con funzionalità che possono svolgersi in modo indipendente dagli eventi che si verificano al di fuori del proprio campo di azione. La gestione di questo DBMS è affidata anch’essa al DHSM.
Sui client della Teca Veloce è installato un software realizzato appositamente che consente di visionare e riversare sequenze video e di ascoltare l’audio associato, impiegando le principali funzioni disponibili per un VTR (play, stop/still, fast forward/rewind, ecc.) comparabili a quelli ottenibili dall’impiego di

Architettura di rete e software dell’archivio Teca Fast – 65
strumenti tradizionali (visualizzazione time code, video a schermo pieno, a 25 frame/sec. garantiti, audio stereo di qualità elevata - MPEG Layer II - , etc.). Il software installato sulle postazioni client prevede anche un’applicazione per la manipolazione del clip su Tektronix Profile con la possibilità di impiegare un modulo di controllo per postazioni dotate di centralina video e uno per postazioni prive di centralina video.
L’interrogazione dell’archivio e la richiesta di informazioni sullo stato delle richieste avviene attraverso un’interfaccia grafica, e il software client si interfaccia con il DBMS relazionale, un Microsoft SQL Server 7.
Per effettuare richieste di contenuti audiovisivi archiviati, il client deve inviare al DBMS solamente poche informazioni riguardanti, per quanto riguarda i contenuti codificati dai tre canali televisivi nazionali di Rai, la data di trasmissione sulla rete, l’identificatore della rete di emittenza, l’orario di inizio trasmissione della sequenza di interesse (un istante qualsiasi della giornata di trasmissione, con la precisione del secondo) e l’orario di fine della sequenza da estrarre. Sono queste le informazioni che forniscono all’atto della richiesta di materiale in Teca Fast anche i sistemi di ricerca accessibili con Octopus e Catalogo Multimediale. Il prototipo di Repository di Metadati Mpeg-7 richiesto nell’ambito di questo lavoro di tesi, deve essere anch’esso messo in condizioni di effettuare richieste a Teca Fast fornendo la quadrupletta di dati sopra indicata, necessari per la richiesta al sistema DBMS SQL Server.

Prima di MPEG-7: proposte per descrizione risorse audiovisive – 66
IV° Capitolo: Mpeg-7 MDS e costruzione di un profilo applicativo per la descrizione di archivi audiovisivi
basata su metadati – Caso di Teca Fast Rai
IV.1 Considerazioni preliminari su Mpeg-7 e l’uso dei metadati
audiovisivi
Per consentire una agevole ricerca di documenti audiovisivi all’interno di un archivio digitale si rende necessario definire degli standards per la descrizione del contenuto o degli standards di metadati adatti a risorse multimediali anche complesse.
In particolare questo e’ il primo obiettivo dell’MPEG-7 chiamato “Multimedia Content Description Interface” l’ultimo standard del gruppo MPEG in via di rilascio nella sua versione definitiva.
Fino ad oggi, parallelamente al lavoro svolto per l’MPEG-7, il problema dei metadati per la descrizione di risorse audiovisive è stato affrontato attraverso l’applicazione di set meno specifici al mondo del multimedia, set di descrittori come il Dublin Core (DC) o schemi di descrizione come l’RDF (Resource Description Format). Tuttavia in questi ambienti gli sforzi fatti nella definizione di schemi in grado di validare le descrizioni dei contenuti video (evitandone anche la dispersione terminologica) e i modelli dei dati loro associati, non sono sufficienti alle esigenze di produzione e scambio di contenuti audiovisivi in un mercato orientato al commercio elettronico e alla fornitura di contenuti sui nuovi media.
Schemi di questo tipo sono indubbiamente necessari per lo sviluppo di strumenti in grado di abbassare notevolmente i costi e l’usabilità delle operazioni di generazione semi-automatica ed editing di metadati per il video. Le specifiche di MPEG-7 rispondono a queste necessità.
Lo scopo di questo capitolo è illustrare una proposta per uno schema di descrizione di contenuti audiovisivi all’interno di un archivio digitale basato sul MPEG-7 nella sua versione FCD (Final Committe Draft).
IV.1.1 Prima di MPEG-7: proposte per descrizione risorse
audiovisive
Il set di descrittori Dublin Core, sviluppato in ambiente bibliotecario, è stato progettato specificamente per la generazione di metadati che facilitassero il

Prima di MPEG-7: proposte per descrizione risorse audiovisive – 67
reperimento di risorse di tipo testuale. Tuttavia fino ad oggi sono stati discussi numerosi casi di applicazione del set di descrittori Dublin Core a documenti non testuali come immagini, suoni, e video, focalizzandosi principalmente sulle possibili estensioni dei 15 elementi base DC attraverso l’uso di sub-elementi e schemi specifici ai materiali audiovisivi, per descrivere informazioni di tipo bibliografico piuttosto che il contenuto stesso.
Dalla combinazione di Dublin Core e RDF, come è stato rilevato nei recenti studi di Hunter e Iannella, "The Application of Metadata Standards to Video Indexing", Second European Conference on Research and Advanced Technology for Digital Libraries, Crete, Greece, September, 1998 [1], risulta possibile descrivere la struttura e i dettagli del contenuto video utilizzando appunto i 15 elementi DC con l’aggiunta di qualificatori e utilizzando il modello RDF.
In un approccio "puramente Dublin Core" si possono ottenere livelli multipli di informazione descrittiva. In questo caso al livello più alto si usavano i 15 elementi DC per descrivere le informazioni di tipo bibliografico sul documento completo (come Title, Author, Contributor, Date..). Questo consentiva una ricerca non specializzata e interdisciplinare, indipendente comunque dal tipo di risorsa, o media, descritto.
Potevano essere applicate estensioni o qualificatori per specifici elementi DC (Type, Description, Relation, Coverage) ai livelli più bassi (livello di scena, shot o frame) per fornire funzionalità di ricerca più fini, specifiche del tipo di media o di un contesto disciplinare.
Lo svantaggio risultava comunque dal fatto che l’arricchimento semantico di DC attraverso l’uso di qualificatori poteva comunque portare ad una perdita di una caratteristica considerata fondamentale: l’interoperabilità semantica.
Un approccio diverso era di tipo “ibrido”, in cui RDF (o un altro framework) è stato usato per combinare i semplici e non qualificati descrittori Dublin Core con i descrittori di MPEG-7 in un contenitore di descrizione unico. Si proponeva così utilizzare DC per effettuare ricerche e reperimento di tipo generico e indipendente dal media, mentre con MPEG-7 era possibile effettuare queries specifiche del media descritto e a maggior dettaglio.
L’obiettivo del nuovo standard MPEG-7 ("Multimedia Content Description Interface") è proprio quello di specificare un set standard di descrittori e schemi di descrizione (e un linguaggio per crearne di nuovi o estenderli) per descrivere il contenuto delle informazioni audiovisive, e multimediali in genere.
Dalla letteratura sullo standard e sulle base richieste maturate nell’ambito delle applicazioni illustrate, si sono riconosciute alcune delle specifiche necessarie per uno schema di metadata per il video:

Prima di MPEG-7: proposte per descrizione risorse audiovisive – 68
1- La Definizione di strutture gerarchiche: lo schema deve ad esempio consentire la definizione di una struttura in cui il documento “descrizione dell’audiovisivo”, o “descrizione di una collezione audiovisiva” siano posizionati ad un livello alto. Questi a loro volta possono contenere sequenze, ognuna delle quali può essere costituita da scene, che contengono shots (riprese), a loro volta costituite da frames, costituiti da oggetti o attori. In MPEG-7 si può scendere ad una descrizione di livello davvero basso, con degli strumenti di descrizione per segmenti spazio temporali individuati all’interno delle sequenze o delle singole immagini, e delle caratteristiche dei segnali audio e video.
2- Ogni livello (o classe) nella gerarchia deve poter possedere solo degli attributi specifici.
3- Deve essere possibile specificare sottoclassi con l’ereditarietà degli attributi e degli elementi dalle classi superiori nelle inferiori. Inoltre le sottoclassi devono essere in grado di avere i loro attributi ed elementi addizionali. Questo consente un efficiente riutilizzo e customizzazione degli schemi di documento.
4- Deve essere possibile limitare i valori degli attributi a certi tipi di dati. I tipi di dati supportati devono includere tipi di dati primitivi come gli schemi, i tipi di dato enumerato, i vocabolari controllati, i tipi di files, i localizzatori di risorsa come le URI e i tipi di dato complessi (istogrammi del colore, vettori 3D, grafi, valori RGB, etc..) così come tipi di dato e schemi alternativi per particolari attributi.
5- Deve essere rappresentabile la cardinalità degli attributi, ad esempio se un attributo può avere zero, uno o più valori.
6 – Lo schema deve essere in grado di supportare la specifica di caratteristiche Spazio-Temporali come l’inizio e la fine di segmenti video e la loro durata. In maniera simile deve essere in grado di supportare rappresentazioni spaziali, come delle regioni di un’immagine o il moto lungo una traiettoria.
7- La possibilità di rappresentare relazioni di tipo spaziale, temporale e concettuale. Relazioni spaziali come la vicinanza di due oggetti e temporali come segmenti in sequenza o parallelo.
8 – Una delle specifiche che si richiedono è che le descrizioni e lo schema stesso siano comprensibili alla lettura da parte di un essere umano.
9 – Non da ultimo la disponibilità di tecnologie di supporto come parsers (in grado di validare le descrizioni inserite), databases e linguaggi di query.
Questi requisiti sono stati utilizzati nella definizione dei requisiti dello standard MPEG-7, e nello specifico della seconda parte, la MPEG-7 DDL Description

Gli strumenti di MPEG-7 – 69
Definition Language che definisce il linguaggio per la definizione ed estensione degli schemi di descrizione e descrittori, basato essenzialmente sull’ XML Schema versione 1.0 di W3C da cui si discosta esclusivamente per la definizione di alcuni tipi di dato aggiuntivi per la rappresentazione del tempo e della durata.
IV.1.2 Gli strumenti di MPEG-7
MPEG-7 fornisce una serie di strumenti (descrittori, schemi di descrizione, un linguaggio per la definizione di descrittori, sistemi per la codifica, trasporto, aggiornamento e navigazione di descrizioni strutturate, etc..) per lo sviluppo di applicazioni di descrizione multimediale che possono essere immagazzinate (on-line oppure off-line) o trasmesse (ad es. broadcasting).
MPEG-7 si propone di operare indifferentemente in ambiente real-time (Inline nella semantica dello standard) o non real-time (in documenti esterni alla risorsa multimediale che viene descritta).
Agire in un ambiente real-time o Inline vuol dire associare le descrizioni MPEG-7 direttamente al codice che rappresenta il contenuto nel momento in cui quest'ultimo viene catturato o codificato opportunamente.
Per sfruttare tutte le potenzialità delle descrizioni MPEG-7 sono indubbiamente necessari degli applicativi per l’estrazione automatica degli attributi, una modalità che non sempre è possibile.
Più alto è il livello di astrazione, più difficoltosa si rivela l'estrazione automatica degli attributi, fino a diventare impossibile (un esempio sono le informazioni sulla creazione del contenuto, come autore, titolo, contributori, che non possono essere estratte dal contenuto stesso); diventa quindi di chiara utilità l’uso di eventuali strumenti di estrazione interattivi, ma solo per un dato tipo di attributi di basso livello. Per gli attributi di più alto livello si rende necessario fornire strumenti di assistenza alla documentazione manuale (tesauri, attributi con un range limitato di scelte possibili, etc..) in grado di rendere più efficace la descrizione (evitando per quanto possibile l’uso di campi a testo libero ad esempio).
Comunque gli algoritmi di estrazione automatica degli attributi, non compaiono all'interno del campo di azione dello standard.
La principale ragione di questa scelta è che la standardizzazione di tali algoritmi non è richiesta per garantire l'interoperabilità. Allo stesso tempo si lascia spazio, in questo modo, alla competizione industriale.
Un'altra ragione per cui non vengono standardizzate le applicazioni per l’estrazione degli attributi, è rappresentata dalla possibilità di sfruttare i miglioramenti attesi in questi campi grazie anche alla competizione industriale.

Gli strumenti di MPEG-7 – 70
Anche i motori di ricerca non sono specificati all'interno del campo di azione dello standard.
Consideriamo l'esempio di una informazione visiva: un livello di astrazione più basso, potrebbe essere rappresentato dalla descrizione di forma, dimensioni, texture, colore, movimento (traiettoria) e posizione. Per l'audio lo stesso si può dire per tonalità, ritmo, cambi di ritmo.
Ad un livello di astrazione più alto possiamo trovare informazioni sulla semantica: potremmo descrivere uno scenario, dove compare un signore che parla sulla destra, una foglia che cade a terra sulla sinistra, ed infine un sottofondo sonoro frutto del passaggio di un jet nel cielo. Tutte queste descrizioni sono ovviamente codificate in maniera da rendere efficiente la ricerca dello scenario.
Lo standard, al di là di questo esempio, prevede anche livelli di astrazione intermedi. Il livello di astrazione va messo in relazione con le differenti modalità di estrazione degli attributi: molti attributi di basso livello possono essere estratti in modo completamente automatico, mentre attributi di alto livello necessitano di una più alta interazione umana.
Dopo aver fornito una descrizione del materiale, può essere richiesto di includere altre informazioni sui dati multimediali in nostro possesso. Alcune informazioni rilevanti sono ad esempio quelle di:
1. FORMATO: Un esempio di formato è il tipo di codifica usato (JPEG, MPEG2, altri), oppure la mole totale di dati. Queste informazioni permettono di stabilire se l'utente è in grado di leggere il materiale.
2. ACCESSO AL MATERIALE: Questa voce può tenere in considerazione aspetti quali informazioni sul copyright o prezzo del materiale.
3. CLASSIFICAZIONE: Può includere la catalogazione del contenuto all'interno di categorie predefinite.
4. LINKS AD ALTRO MATERIALE RILEVANTE: Questo tipo di informazione può velocizzare la ricerca da parte di un utente di materiale correlato.
5. CONTESTO: Nel caso di contenuti di natura non cinematografica o più in generale non fittizia, se questi sono registrati è molto importante conoscere in quale occasione è avvenuta la registrazione (per esempio una determinata partita di pallavolo delle olimpiadi del 2000).

Gli strumenti di MPEG-7 – 71
In molti casi è utile ricorrere ad informazioni testuali per le descrizioni di un materiale audiovisivo. Un esempio dell'utilità di tale accorgimento è dato dall'aggiunta di metadati fondamentali come il nome dell'autore, il titolo di un film, l'indicazione di un luogo, la data di trasmissione o pubblicazione.
Come preannunciato i dati di tipo MPEG-7 possono essere fisicamente localizzati assieme al materiale audiovisivo cui si riferiscono: in particolare essi si possono trovare nello stesso flusso di dati, o possono essere memorizzati nella stessa periferica, ma le descrizioni degli oggetti di interesse potrebbero essere situate da qualche altra parte sul globo.
Se il contenuto è separato dalle sue descrizioni, si ricorre a meccanismi che creano un link tra le due entità. I links ottenuti in tal modo, possono essere "percorsi" in entrambe le direzioni.
Fornire soluzioni per l’indirizzamento di documenti di tipo esclusivamente testuali non fa parte degli obiettivi di MPEG7: maggiore enfasi viene riservata, naturalmente, alla descrizione di contenuto audiovisivo e multimediale in genere. In questo senso si potranno descrivere anche testi o riferimenti a testi.
Al di là dei descrittori specificati dallo standard, è la modalità utilizzata per la strutturazione di un database che li contenga ad avere un'influenza cruciale sulle funzionalità e prestazioni nel recupero finale delle informazioni: l'organizzazione dei dati indicizzati in forma gerarchica o associativa favorisce l'esigenza di ottenere risposte rapide all'interrogativo: “il materiale reperito è di interesse o no per gli scopi della ricerca?”. Ci sono molte applicazioni che possono trarre beneficio dallo standard MPEG7.
Il modo con cui i dati MPEG7 sono usati per rispondere alle query di un utente, non risiede nel campo di competenza dello standard. In linea di principio, qualunque tipo di file audiovisivo, può essere recuperato con query formate da materiale di qualsiasi tipo. Ciò significa, per esempio, che informazioni video possono essere richieste ricorrendo a musica, parlato o un altro video. Sarà il motore di ricerca ad operare il matching tra i dati della query e le descrizioni MPEG7 del materiale audiovisivo. Vediamo alcuni esempi di query su vari tipi di media:
1-Per la musica: E' possibile suonare alcune note su una tastiera ed ottenere in risposta una lista di brani musicali contenenti la sequenza sonora richiesta, o immagini che in qualche modo possono essere accoppiate alle note, ad esempio in termini di emozioni.
2- Per la grafica: E' possibile tracciare alcune linee su uno schermo ed ottenere in risposta un set di immagini contenenti logo, ideogrammi, grafica in generale, somiglianti al disegno realizzato dall'utente.

Possibili applicazioni di MPEG-7 – 72
3- Per le immagini: E' possibile definire oggetti, incluse chiazze di colore o texture, ed ottenere in risposta esempi tra cui selezionare altri oggetti che interessano all'utente per comporre la sua immagine.
4- Per il moto di oggetti: Dato un set di oggetti, è possibile descrivere movimenti e relazioni tra essi, ed ottenere in risposta una lista di animazioni soddisfacente alle specifiche spaziali e temporali richieste.
5- Scenario: Su un dato scenario, è possibile descrivere azioni ed ottenere in risposta una lista di altri scenari all'interno dei quali avvengono azioni simili.
6- Query basate sulla voce: Usando un brano di un cantante, è possibile ottenere in risposta una lista dei dischi realizzati dal cantante in questione, oppure video clips dove lo stesso canta o semplicemente compare.
IV.1.3 Possibili applicazioni di MPEG-7
Indubbio vantaggio dall’utilizzo degli strumenti dello standard MPEG-7 ne possono trarre le librerie digitali (cataloghi di immagini, dizionari musicali…), i servizi di multimedia directory (una sorta di Pagine Gialle multimediali), la selezione di servizi di broadcasting (canali radio e televisivi), il Multimedia editing (servizi di informazione elettronica personalizzati).
I descrittori MPEG-7 consentono di costruire applicazioni per la gestione di contenuti multimediali anche molto complessi, costituiti da oggetti diversi relazionati tra di loro tramite relazioni di tempo e di spazio (sequenze o presentazione di contenuti in parallelo, esempio audio, video immagini e animazioni 3d) o relazioni di struttura (è possibile definire una collezione di contenuti multimediali come immagini con delle relazioni descritte da un grafo) e relazioni di tipo semantico (descrivere le azioni degli oggetti in un video ad esempio un’azione di “dribbling” in una sequenza che riprende un goal su un campo di calcio) o anche descrivere dei concetti.
Le applicazioni potenziali si estendono ai domini della produzione televisiva e del giornalismo: è possibile reperire i discorsi di un certo uomo politico ricorrendo ad informazioni quali il suo nome, o meglio la sua voce o l’immagine della sua faccia. Innumerevoli sono le applicazioni per la fornitura di servizi di vario genere, dall’informazione turistica, all’ intrattenimento (ricerca di un gioco, karaoke), i servizi investigativi, i sistemi di informazioni geografiche, le applicazioni mediche, il commercio elettronico (consentendo la ricerca di un determinati articoli in un catalogo) e i servizi sociali.
Ma indubbio vantaggio ne viene alle applicazioni di consultazione di archivi video, radio e cinematografici di estese dimensioni e descritte da sistemi informativi connessi in rete geografica, di cui un esempio importante in Italia sono senza dubbio gli archivi delle Teche Rai e il Catalogo Multimediale.

Lo sviluppo dello standard MPEG-7 – 73
IV.1.4 Lo sviluppo dello standard MPEG-7
Il metodo di sviluppo di MPEG7, è confrontabile con quello dei precedenti standard MPEG.
Dopo aver definito i requisiti, si è proseguito con una richiesta di proposte aperta (cioè sostanzialmente accessibile a chiunque sia interessato). Lo scopo di tale chiamata è stato la ricerca di tecnologie adatte ai requisiti.
Successivamente ad una valutazione delle tecnologie suggerite, si sono operate delle scelte, e lo sviluppo è proseguito con lo sfruttamento delle proposte migliori. Nel corso del processo di sviluppo, si sono incentivate ulteriori proposte. Dato che il nuovo standard richiede tecnologie in aree non sufficientemente rappresentate nella comunità MPEG, si sono cercati nuovi esperti in tali campi.
Come in passato, il working group MPEG è aperto ai contributi e alla partecipazione di chiunque sia interessato allo sviluppo di MPEG-7, anche successivamente al rilascio della prima versione definitiva dello standard internazionale (prevista nel settembre 2001).
IV.2 Le necessità di progetto
Nell’ambito del progetto Internet TV Vivai D’Impresa-Elis si è affrontato presso il CRIT Rai, il problema dell’identificazione di un set base di strumenti dello standard MPEG-7 necessari alla descrizione dei contenuti di un archivio video digitale, seguendo le specifiche fornite dalla Teca Fast Rai.
MPEG-7 risulta molto ricco nelle possibilità di descrizione di contenuti multimediali, e la difficoltà iniziale è stata quella di comprendere l’ampia definizione di “contenuto multimediale” e combinazione di esso adottata dai suoi ideatori. Il primo passo è stato quindi quello di individuare le strutture dati e i descrittori e description schemes specifici per l’applicazione richiesta e riferiti alla tipologia di contenuto audiovisivo o meglio televisivo digitale, da utilizzare poi per la creazione di uno strumento di descrizione ad hoc per l’applicazione, secondo le direttive standard.
Dall’analisi dello standard nel suo complesso si è ristretto il campo di interesse alla parte 5 del documento completo, la MPEG-7 Multimedia Description Schemes o MDS, dove è stato possibile riconoscere gli strumenti necessari alla creazione di un’applicazione in grado di soddisfare le specifiche del prototipo di database orientato ai metadati audiovisivi.
Le parti dello standard ritenute non cruciali nella risoluzione delle specifiche del progetto sono demandate a una successiva fase di studio e implementazione, già

Struttura dei Multimedia Description Schemes – 74
prospettata con l’azienda committente e per l’implementazione delle quali la realizzazione di un sistema come quello oggetto di questa tesi risulta precondizione necessaria.
Si tratta delle parti che definiscono e approfondiscono le funzionalità specifiche di riconoscimento all’interno di database multimediali di attributi visivi o audio (parte 3 e parte 4 dello standard) nonché la parte Systems (parte 1) per la definizione di sistemi di codifica delle descrizioni MPEG-7, con comandi di accesso, aggiornamento, funzionalità di memorizzazione, trasporto, navigazione nelle descrizioni da parte delle applicazioni (es. encoders e players di descrizioni MPEG-7 con contenuto allegato direttamente o meno).
IV.2.1 Struttura dei Multimedia Description Schemes
MPEG-7 Multimedia DSs è suddiviso nelle seguenti aree: Basic Element, Content Description, Content Management, Content Organization, Navigation and access e User Interaction.
• Basic Element fornisce specifici data-types e strutture matematiche come vettori e matrici che sono importanti per la descrizione di contenuto audio –video. Sono anche inclusi in Basic Elements costrutti per il collegamento ai media files e per localizzare i segmenti, regioni e altro. Molti dei basic elements specificano elementi necessari alla descrizione del contenuto come la descrizione di tempo, persone, individui, gruppi, organizzazioni e altre annotazioni testuali.
• Content Management descrive differenti aspetti della creazione e produzione, codifica del media, formati di files, memorizzazione e uso del contenuto.
• Content description specifica elementi per descrivere la struttura ( regions, video frames, segmenti audio) e la semantica (oggetti, eventi, nozioni astratte).
• Navigation and Access definisce decomposizioni, partizioni e sommari per facilitare la navigazione e il reperimento del contenuto multimediale.
• Content Organization fornisce gli strumenti per modellare e organizzare collezioni di contenuti audio-video e collezioni di descrizioni.
• User Interaction definisce gli strumenti per descrivere le preferenze dell’utente e la storia dell’uso del materiale multimediale.

Struttura dei Multimedia Description Schemes – 75
Nella definizione di una struttura dati MPEG-7 MDS adatta allo scopo abbiamo individuato come fondamentale la necessità di riconoscere gli strumenti per l’identificazione e localizzazione della risorsa base memorizzata nell’archivio Teca Fast. Gli strumenti di Mpeg-7 consentirebbero infatti di fare riferimento direttamente ai files audiovisivi codificati in MPEG-2 e memorizzati nel sistema robotizzato a nastri digitali, cioè di referenziare direttamente la risorsa fisica, ogni singolo file codificato, in un ambiente di rete o un file system. Tuttavia tra le specifiche di questo progetto si è previsto di non inserire riferimenti diretti alla struttura fisica con cui sono archiviate le risorse nella Teca, ma di far lavorare il sistema di descrizione e ricerca basato su metadati come un motore di ricerca esterno, in grado di interagire attraverso la rete intranet con il sistema Teca Fast per effettuare richieste di sequenze video di archivio. Il sistema deve dunque interfacciarsi al server SQL di Teca Fast che accoglie già tutte le richieste provenienti dagli utenti abilitati sulla rete aziendale, e che gestisce in maniera autonoma il colloquio con le risorse di Teca, la coda di richieste, l’evasione degli ordinativi, che ovviamente non possono avvenire in tempo reale ma richiedono un’accurata gestione da parte del sistema interno.
Dunque la specifica prevede che per l’individuazione di una risorsa di Teca Fast, come accade per i preesistenti sistemi di ricerca aziendali Octopus e Catalogo Multimediale, il sistema di ricerca basato su metadati in sviluppo sia in grado di fornire le informazioni necessarie di time code assoluto di inizio e di fine trasmissione della sequenza audiovisiva, l’identificativo del canale televisivo sul quale è avvenuta la trasmissione in rete televisiva pubblica, e naturalmente la data in cui è avvenuta la trasmissione. Queste informazioni devono quindi essere sempre necessariamente presenti in ogni documento di descrizione risorsa, in quanto senza di esse non sarebbe possibile impiegare il sistema per l’accesso alle risorse della Teca Fast.
La struttura logica cui si è fatto riferimento nella scelta del modello di descrizione MPEG-7 dei contenuti video è una struttura gerarchica che descrive ogni “unità di programma” (ad esempio una singola trasmissione televisiva, intesa come puntata singola, o una edizione giornaliera di un Telegiornale) come composta da una serie di “Sequenze” intese come risorse fisiche o logiche di materiale televisivo digitale collegate tra di loro da una relazione di sequenza (è possibile utilizzare questo modello per relazionare tra di loro tutti i clip che compongono l’unità di un programma descritto, quindi per localizzare e relazionare le clip fisiche).
Secondo le possibilità fornite dagli elementi descrittori di MPEG-7 opportunamente combinati tra loro, ogni “sequenza” può corrispondere o meno ad un file fisico ed essere ulteriormente segmentata e descritta.
Per le specifiche del prototipo si è previsto di fermare il livello di dettaglio dei documenti di descrizione conformi ad Mpeg-7 MDS al livello di “programma” inteso come puntata di programma televisivo trasmesso.

Una breve carrellata degli strumenti di descrizione – 76
IV.2.2 Una breve carrellata degli strumenti di descrizione
L'elemento principale della parte di Content Description è il Segment DS che indirizza la descrizione degli aspetti fisici e logici del contenuto audiovisuale. I Segment DSs possono essere usati per formare strutture ad albero dei segmenti.
MPEG-7 specifica inoltre un Graph DS che permette la rappresentazione di relazioni complesse tra i segmenti audiovisivi. E' usato per descrivere relazioni spazio-temporali tra segmenti che non sono descritti per mezzo di una struttura ad albero.
Un segmento rappresenta una sezione di un istanza di contenuto audiovisivo. Il Segment DS è definito come una classe astratta (nel senso della programmazione ad oggetti) ed ha nove sotto classi principali: Multimedia Segment DS, AudioVisual Region DS, AudioVisual Segment DS, Audio Segment DS, Still Region DS, Still Region3D DS, Moving Region DS, Video Segment DS e Ink Segment DS. Un segmento temporale può essere un set di frame in una sequenza video rappresentata da un Video Segment DS o da una combinazione di informazioni audio e video descritti da un AudioVisual Segment DS.
Vedremo nel seguito in dettaglio il ContentDescriptionType e la definizione di segmenti temporali di tipo audiovisivo.
Il Segment DS essendo un tipo astratto non può essere istanziato in un elemento: è utilizzato per la definizione di proprietà comuni alle sue sotto-classi.
Ogni segmento può essere descritto da informazioni sulla sua creazione (Creation Information), sull'uso (Usage Information), sul media (Media Information) e da annotazioni testuali (Textual Annotation).
Inoltre un segmento può essere decomposto in sotto-segmenti attraverso Segment Decomposition DS.
Un segmento non è necessariamente connesso ma può essere una composizione di diversi componenti non connessi. Qui per connettività si fa riferimento ad entrambi i domini spaziale e temporale. Un segmento temporale (Video Segment, Audio Segment, AudioVisual Segment) si dice di tipo connesso temporalmente, se una è una sequenza continua di video frames o di campioni audio.
Il description scheme di tipo astratto Segment DS è ricorsivo e può essere suddiviso in sottosegmenti e questi possono formare una gerarchia (struttura ad albero). La struttura ad albero dei segmenti che ne risulta viene utilizzata per definire il media sorgente, e la struttura temporale e/o spaziale del contenuto audiovisivo.

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 77
Per esempio un programma video può essere segmentato temporalmente in vari livelli di scene, shots, e microsegmenti; una tavola dei contenuti può essere generata basandosi su questa struttura. E strategie simili possono essere usate per i segmenti spaziali e spazio-temporali.
Un segmento può inoltre essere suddiviso in vari media sorgenti come per esempio diverse tracce audio o vari punti di vista da diverse inquadrature. La suddivisione gerarchica è utile per delineare efficienti strategie di ricerca (ricerche globali o ricerche locali) e permette inoltre alla descrizione di essere scalabile: un segmento può essere descritto dal suo diretto set di descrittori e DSs (schemi di descrizione) ma può anche essere descritto dall'unione dei descrittori e delle DSs relativi ai suoi sottoelementi.
Da notare è che un segmento può essere suddiviso in diversi sottosegmenti di diverso tipo, per esempio un segmento video può essere decomposto in regioni in movimento che possono essere a loro volta decomposte in regioni statiche.
IV.2.3 Impiego del Multimedia Description Schemes (MDS)
Mpeg-7
Gli strumenti di descrizione, vale a dire Ds (descrittori) e DSs (Schemi di Descrizione), illustrati nel documento Final Draft Committe rilasciato nel marzo 2001, sono strutturati principalmente sulla base delle funzionalità che forniscono. Una vista d’insieme della struttura degli strumenti è descritta nella figura seguente.
Figura: Vista d’insieme degli strumenti di Mpeg-7 MDS

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 78
Al livello inferiore della figura precedente si possono trovare gli elementi base.Si tratta degli Schema Tools (elemento radice, elemento di livello superiore e package), i tipi di dato basilari (basic datatypes), le strutture matematiche, collegamenti e localizzatori di supporto (linking and media localization) , e strumenti come Schemi di Descrizione (DSs) di base, che si possono trovare come componenti elementari o DSs più complessi.
Basati su questo livello basso, possono essere definiti gli elementi di descrizione del contenuto e di gestione (content description & management). Questi strumenti di descrizione descrivono il contenuto di un singolo documento multimediale da diversi punti di vista. Attualmente cinque punti di vista sono definiti: creazione e Produzione, Media, Utilizzo, Aspetti Strutturali e Aspetti Semantici. I primi tre strumenti di descrizione indirizzano principalmente le informazioni relative alla gestione del contenuto (content management) mentre le ultime due sono più dedicate alla descrizione di informazione percepibile (content description).
La seguente tabella definisce in maniera più precisa le funzionalità di ogni gruppo di strumenti di descrizione:
Tavola: Lista degli Strumenti per la descrizione e gestione del contenuto
Insieme di strumenti di descrizione
Funzionalità
Media Descrizione del supporto di memorizzazione: le caratteristiche tipiche includono il formato di memorizzazione, la codifica del contenuto multimediale, l’identificazione del supporto. Si noti che possono essere descritte diverse istanze di supporto per uno stesso contenuto multimediale.
Creazione e Produzione (Creation)
Meta dati che descrivono la creazione e produzione del contenuto: tipiche caratteristiche sono il titolo, il creatore, la classificazione, lo scopo della creazione, etc. Questa informazione è in gran parte generata dall’autore dal momento che non è possibile estrarla dal contenuto.
Utilizzo (Usage) Meta dati relativi all’uso del contenuto: caratteristiche tipiche sono i proprietari dei diritti, i diritti di accesso, pubblicazione, e le informazioni finanziarie. Tale informazione è molto probabilmente soggetta a variazioni nel ciclo di vita del contenuto multimediale.
Aspetti Strutturali Descrizione del contenuto multimediale dal punto di vista della sua struttura: la descrizione è strutturata intorno ai segmenti che rappresentano i componenti fisici spaziali, temporali o spazio-temporali del contenuto multimediale. Ogni segmento può essere descritto da caratteristiche basate

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 79
Ogni segmento può essere descritto da caratteristiche basate sui segnali (signal based: come colore, texture, forma, moto, e caratteristiche audio) e alcune elementari informazioni semantiche.
Aspetti Semantici Descrizione del contenuto multimediale dal punto di vista della sua semantica e delle nozioni concettuali. Questo si basa sui concetti di oggetti, eventi, concetti astratti e loro relazioni.
Questi cinque insiemi di strumenti di descrizione sono stati presentati come entità distinte. Come vedremo nel seguito, questi sono correlati e possono essere parzialmente incluse in ogni altro. Per esempio gli elementi Media, Utilizzo o Creazione e Produzione possono essere allegati a singoli segmenti coinvolti nella descrizione strutturale del contenuto. A seconda dell’applicazione, alcune aree della descrizione del contenuto possono essere enfatizzate ed altre possono essere minimizzate o scartate.
Accanto alla diretta descrizione del contenuto fornita dai cinque insiemi di strumenti di descrizione appena descritti, sono stati definiti anche strumenti per la navigazione e l’accesso: il Browsing è supportato dagli strumenti di descrizione di riassunto o “summary description tools” ed è anche fornita informazione circa le possibili variazioni del contenuto. Variazioni del contenuto multimediale possono sostituire l’originale, se necessario, per adattare diverse presentazioni multimediali alle capacità dei terminali clienti, alle condizioni della rete o alle preferenze dell’utente.
Un altro insieme di strumenti (Organizzazione del contenuto) indirizza l’organizzazione del contenuto tramite la classificazione, con la definizione di collezioni di documenti multimediali e con la creazione di modelli. Infine, l’ultimo insieme di strumenti che fa riferimento alla parte di interazione dell’utente (user Interaction) descrive le preferenze dell’utente per ciò che concerne il consumo del materiale multimediale.
Alcuni termini ricorrenti nella documentazione del Multimedia Description Schemes Mpeg-7 sono i tipi di dato (datatypes), i descrittori (descriptors, indicati con Ds) e schemi di descrizione (Description Schemes, o DSs):
• Datatype – un elemento di descrizione che non è specifico del dominio multimediale e che corrisponde a un tipo di base riutilizzabile o ad una struttura impiegata da più Descrittori e Schemi di Descrizione.
• Descriptor (D) – indica un elemento di descrizione che rappresenta una caratteristica multimediale o un attributo o un gruppo di attributi di un’entità

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 80
multimediale. Un descrittore non partecipa in relazioni molti-a-uno con altri elementi di descrizione.
• Description Schemes (DS) – un elemento di descrizione che rappresenta entità o relazioni nel dominio multimediale. Uno Schema di Descrizione possiede informazioni descrittive e può partecipare a relazioni molti-a-uno con altri elementi di descrizione.
Per poter specificare i tipi di dato o Datatypes, i Descriptors e i Descripition Schemes, lo standard utilizza i costrutti forniti dal linguaggio specificato nell’ ISO/IEC 15938-2, come “element”, “attribute”, “simpleType” e “complexType”.
I nomi associati a questi costrutti sono indicati nella documentazione sulla base delle seguenti convenzioni:
• Se il nome è composto di varie parole, la prima lettera di ogni parola è maiuscola. La regola di rendere maiuscola la prima parola dipende dal tipo di costrutto ed è descritta in seguito.
• Assegnazione di nomi agli elementi (Element): la prima lettera della prima parola è maiuscola (per esempio l’elemento TimePoint del tipo TimeType)
• Assegnazione di nomi agli attributi (Attribute): la prima lettera della prima parola non è maiuscola (per esempio l’attributo timeUnit del tipo IncrDurationType)
• Assegnazione di nomi ai tipi composti (complexType): la prima lettera della prima parola è maiuscola, il suffisso “Type” viene utilizzato alla fine del nome assegnato (per esempio PersonType)
• Assegnazione di nomi ai tipi semplici (simpleType): la prima lettera della prima parola non è maiuscola, il suffisso “Type” può essere usato alla fine del nome (per esempio timePointType).
Si noti che il suffisso “Type”non è utilizzato nel fare riferimento a complexType o simpleType nelle definizioni di datatype, Descriptor o Descriptor Schemes.
Per esempio nel testo del documento si fa riferimento a “Time datatype” (al posto di “TimeType datatype”), a “MediaLocator D” (invece che “MediaLocatorType D”), e a “Person DS” (invece che PersonType DS).
La semantica di ogni tipo di dato, Descriptor e Description Scheme è specificata utilizzando un formato a tabella, dove ogni riga contiene il nome e una definizione di un tipo, elemento o attributo:

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 81
Nome Definizione TipoDiEsempio Specifica un tipo di dato primoelemento Descrive il nome di un elemento primoattributo Descrive il nome di un attributo
In questo documento, come accade nella documentazione originale di Mpeg-7 parte MDS, vengono riportati anche degli esempi non-normativi, che sono inclusi in sotto clausole separate e mostrate utilizzando un font e uno sfondo a parte:
<Esempio primoattributo="valore attributo di esempio"> <Elemento1>contenuto di un elemento di esempio</Elemento1> </Esempio>
Inoltre, lo schema definito da MDS Schema segue un approccio orientato al tipo di dato, con la conseguenza che vengono definiti pochissimi elementi (nel senso inteso dallo Schema XML).
Gran parte degli strumenti di descrizione forniti da Mpeg-7 MDS Schema sono specificati solo attraverso la definizione di tipi di dato complessi o semplici.
Nel creare una descrizione, si deve assumere che un elemento di un dato tipo (che sia un tipo di dato semplice o complesso) sia stato dichiarato da qualche parte nello schema, per esempio come un membro di un altro tipo, complesso o semplice.
Nell’esempio indicato nelle sottoclausole di sopra si è dato per scontato la seguente dichiarazione:
<element name="Esempio" type="mpeg7:ExampleType">
In tal modo si può dire che l’esempio mostrato sopra è una descrizione valida. Nella tabella seguente viene riportata la distinzione terminologica considerata nell’ambito di Mpeg-7 MDS:
Terminologia Base Descrizione
Audio-visivo (Audio-visual):
Si riferisce al contenuto che consiste sia in audio che video
Caratteristica (Feature):
Proprietà del contenuto multimediale che significa qualcosa per un osservatore umano, come ad esempio il colore “color” o la trama “texture”.
Multimedia: Fa riferimento al contenuto che comprende un contenuto o sua modalità o tipi di contenuto, come immagini, audio, video, modelli 3D, inchiostro elettronico, e altro.
Strumenti dello schema
Questa parte specifica l’organizzazione del tipo di gerarchia base dei Descriptors e dei Description Schemes,
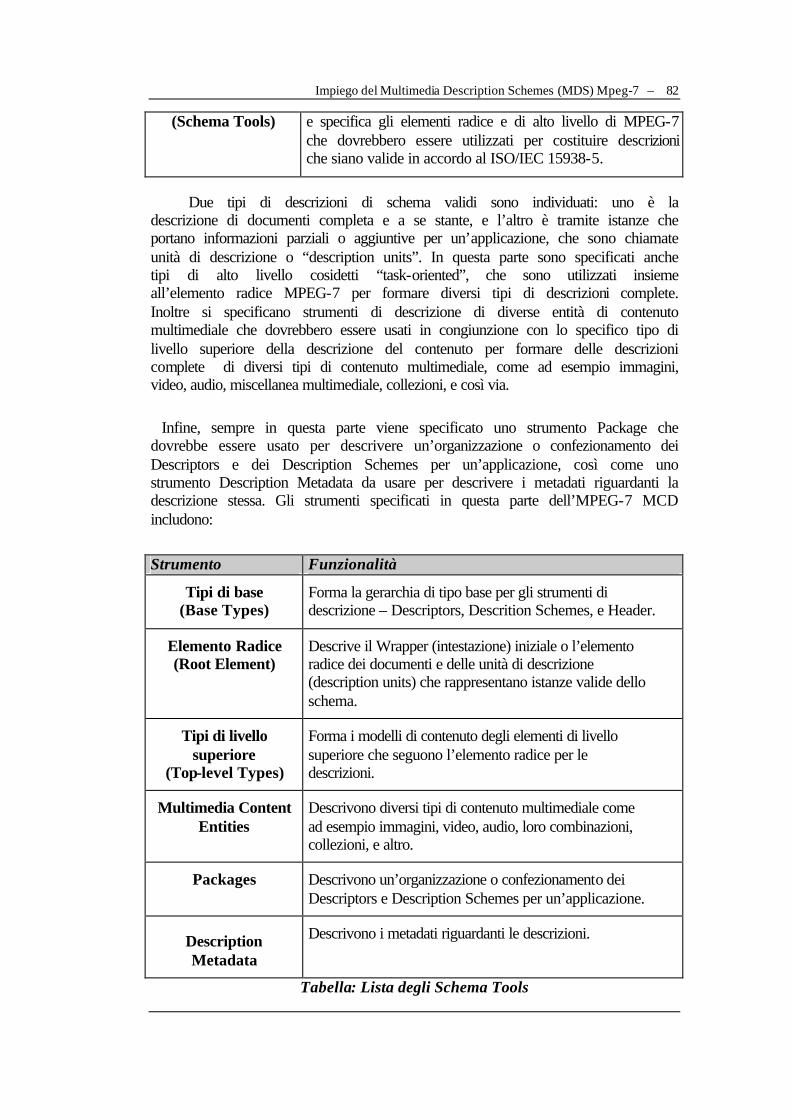
Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 82
(Schema Tools) e specifica gli elementi radice e di alto livello di MPEG-7 che dovrebbero essere utilizzati per costituire descrizioni che siano valide in accordo al ISO/IEC 15938-5.
Due tipi di descrizioni di schema validi sono individuati: uno è la descrizione di documenti completa e a se stante, e l’altro è tramite istanze che portano informazioni parziali o aggiuntive per un’applicazione, che sono chiamate unità di descrizione o “description units”. In questa parte sono specificati anche tipi di alto livello cosidetti “task-oriented”, che sono utilizzati insieme all’elemento radice MPEG-7 per formare diversi tipi di descrizioni complete. Inoltre si specificano strumenti di descrizione di diverse entità di contenuto multimediale che dovrebbero essere usati in congiunzione con lo specifico tipo di livello superiore della descrizione del contenuto per formare delle descrizioni complete di diversi tipi di contenuto multimediale, come ad esempio immagini, video, audio, miscellanea multimediale, collezioni, e così via.
Infine, sempre in questa parte viene specificato uno strumento Package che dovrebbe essere usato per descrivere un’organizzazione o confezionamento dei Descriptors e dei Description Schemes per un’applicazione, così come uno strumento Description Metadata da usare per descrivere i metadati riguardanti la descrizione stessa. Gli strumenti specificati in questa parte dell’MPEG-7 MCD includono:
Strumento Funzionalità
Tipi di base (Base Types)
Forma la gerarchia di tipo base per gli strumenti di descrizione – Descriptors, Descrition Schemes, e Header.
Elemento Radice (Root Element)
Descrive il Wrapper (intestazione) iniziale o l’elemento radice dei documenti e delle unità di descrizione (description units) che rappresentano istanze valide dello schema.
Tipi di livello superiore
(Top-level Types)
Forma i modelli di contenuto degli elementi di livello superiore che seguono l’elemento radice per le descrizioni.
Multimedia Content Entities
Descrivono diversi tipi di contenuto multimediale come ad esempio immagini, video, audio, loro combinazioni, collezioni, e altro.
Packages Descrivono un’organizzazione o confezionamento dei Descriptors e Description Schemes per un’applicazione.
Description Metadata
Descrivono i metadati riguardanti le descrizioni.
Tabella: Lista degli Schema Tools

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 83
I concetti di elemento radice, elementi di livello superiore, elementi globali, tipi globali, e altri concetti sono definiti come segue:
• Schema valid description: una descrizione che è sintatticamente valida in accordo con lo schema definito in ISO/IEC 15938-5.
• Description document: una completa descrizione che è completa nel senso di provvedere una completa, indipendente descrizione del contenuto multimediale per un’applicazione.
• Description unit: una unità di descrizione valida secondo lo schema e che trasporta informazione parziale o aggiuntiva per un’applicazione. Le unità descrittive possono essere usate in specifiche applicazioni dove il client richiede in maniera additiva parti di una descrizione completa da un server. Le “description units” possono anche essere usate nel contesto della distribuzione in streaming delle descrizioni.
• Root element (elemento radice): l’elemento iniziale di una istanza di documento o una description unit valida secondo lo schema.
• Top-level type (tipo di livello superiore): serve come intestazione di definizione di strumenti per un particolare “task” di descrizione.
• Top-level element (elemento di livello superiore): un elemento che immediatamente segue l’elemento radice, che determina se la descrizione fornisce una istanza di documento o una description unit validi secondo lo schema.
• Global element: un elemento dello schema che è dichiarato al livello globale. Ad esempio nello schema definito in ISO/IEC 15938-5, solo l’elemento radice è dichiarato globalmente.
• Global Type : un modello o tipo di contenuto definito immediatamente trasformando l’elemento <schema> nello schema definito in ISO/IEC 15938-5.
• Package: un’organizzazione di Descriptors e di Description Schemes che impacchetta gli strumenti per un’applicazione.
Nella seguente figura è possibile osservare l’organizzazione gerarchica dei tipi di base degli strumenti di descrizione:

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 84
Figura: Organizzazione dei tipi di base di MPEG7RootType, DSType, Dtype, e HeaderType.
Nella sottosezione Mpeg7RootType sono definiti i seguenti tipi di base:
• Mpeg7RootType : fornisce il tipo astratto di base della gerarchia dei tipi. Description Schemes, Descriptors e Header derivano da Mpeg7RootType. L’elemento radice Mpeg7 contiene un elemento del tipo Mpeg7RootType.
o Dtype : estende Mpeg7RootType per fornire un tipo astratto di base per Descriptors visuali e audio. Tutti gli Mpeg7 Descriptors si basano su Dtype.
§ VisualDType : estende Dtype per fornire un tipo astratto di base per i Descriptors visuali. Tutti i “visual descriptors” che devono essere usati nel descrivere segmenti visuali derivano da VisualDType.
§ AudioDType : estende Dtype per fornire un tipo astratto base per i Descriptors Audio. Tutti i Descriptors audio che vengono usati nella descrizione di segmenti audio derivano da AudioType.
o DSType : estende Mpeg7RootType per fornire un tipo astratto base per i Description Schemes visuali e audio. Tutti i Description Schemes derivano da DSType.
§ VisualDSType : estende DSType per fornire un tipo astratto base per i Description Schemes di tipo “visual”. Tutti i Description Schemes che sono usati nel descrivere i segmenti visivi derivano da VisualDSType.

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 85
§ AudioDSType : estende DSType per fornire un tipo astratto base per i Description Schemes di tipo “audio”. Tutti i Description Schemes audio che sono usati per descrivere segmenti audio derivano da AudioDSType.
o HeaderType : estende Mpeg7RootType per fornire un tipo astratto base per descrivere le intestazioni nelle descrizioni. L’intestazione è destinata a raccogliere l’informazione comune ai componenti (chiamata “body part”) della descrizione e può essere istanziata senza alcun elemento DSType.
Mpeg-7 fornisce un elemento radice per ogni tipo di descrizione, da utilizzare come elemento iniziale di una descrizione.
Segue la semantica di Mpeg7Type: Nome Definizione
Mpeg7Type Utilizzato come tipo dell’elemento radice di MPEG-7.
DescriptionMetadata Descrive i metadati per le descrizioni contenute all’interno dell’elemento radice (opzionale). I metadati della descrizione si propagano (si applicano) alle descrizioni contenute all’interno dell’elemento radice, finché non vengono specificati nuovi metadati della descrizione per qualche parte interna.
xml:lang Identifica il linguaggio del contenuto della descrizione (è opzionale). Se non specificato non è indicato il linguaggio della descrizione.
Type Identifica il tipo della descrizione. Questo attributo può avere uno dei seguenti valori:
• descriptionUnit – la descrizione è una unità descrittiva con una struttura valida.
• complete – la descrizione è una descrizione completa con una struttura valida secondo lo schema.
Il valore di default, ove non specificato, è descriptionUnit.
La semantica dell’elemento radice Mpeg7:
Nome Definizione
Mpeg7 Fa da elemento radice di una descrizione.

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 86
Nome Definizione
DescriptionUnit Descrive una istanza di uno degli strumenti Mpeg-7.
ContentDescription Descrive dati multimediali o astrazioni di contenuto multimediale (opzionale). ContentDescription corrisponde al tipo di base astratto di differenti modelli per la descrizione dei diversi tipi e astrazioni di contenuto multimediale.
ContentManagement Descrive la gestione dei dati multimediali (è opzionale). ContentManagement corrisponde al tipo astratto di base dei differenti modelli per la descrizione della gestione di contenuto multimediale.
Figura: Diagramma dell’elemento radice Mpeg7.
Vengono ora descritti i tipi di livello superiore, che vengono impiegati per la definizione degli elementi ‘Top level’. Questi fanno la loro comparsa subito dopo l’elemento radice Mpeg7 in un’istanza di documento valida secondo lo schema Mpeg7 MDS. I tipi di livello superiore includono in maniera selettiva alcuni strumenti dello schema che sono adatti ad alcuni compiti di descrizione specifici.
Questi tipi “Top-Level” fanno da introduzione agli strumenti con compiti specifici di descrizione, e dal documento ISO/IEC 15938-5 Mpeg7 MDS FCD vengono definiti i seguenti:
• BasicDescription (astratto): fornisce la specifica di una base astratta per i tipi di livello superiore ContentDescription e ContentManagement.
o ContentDescription (astratto): fornisce la specifica di una base astratta per i tipi di livello superiore ContentEntity e ContentAbstraction per la descrizione di contenuto multimediale.

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 87
§ ContentEntity: fornisce un modello di contenitore per descrivere diversi tipi di entità di contenuto multimediale come immagini, video, audio, collezioni, etc.
§ ContentAbstraction (astratta): fornisce la specifica di una base astratta per vari tipi di livello superiore per la descrizione di contenuti multimediali (questi tipi sono WorldDescription; ModelDescription; SummaryDescription; ViewDescription;VariationDescription)
o ContentManagement (astratto): fornisce la specifica di una base astratta per i tipi di livello superiore seguenti per la descrizione delle operazioni di gestione dei contenuti multimediali:
§ UserDescription: fornisce un modello di contenitore per la descrizione di un utente in un sistema multimediale.
§ CreationDescription: fornisce un modello di contenitore per la descrizione del processo di creazione del contenuto multimediale.
§ UsageDescription: fornisce un modello di contenitore per la descrizione dei modi d’uso di un contenuto multimediale.
§ ClassificationDescription: fornisce un modello di contenitore per la descrizione di uno schema di classificazione relativo al contenuto multimediale.
I tipi di livello superiore sono organizzati secondo la gerarchia mostrata nella figura seguente:

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 88
Figura: L’organizzazione della gerarchia dei tipi per i tipi di livello superiore. Gli elementi Mpeg7 utilizzano i tipi di livello superiore per ContentDescription
e ContentManagement.
I tipi di dato BasicDescription costituiscono i tipi di dato astratto base della gerarchia. Al di sotto di BasicDescription, i tipi di livello superiore (top-level types nella documentazione originale) sono divisi in due percorsi di derivazione: Content Description e Content Management.
ContentDescription descrive il contenuto multimediale e le sue astrazioni, fornendo una specifica di base per i tipi top-level ContentEntity e ContentAbstraction.
Nel listato finale dello schema MDS rilasciato nel documento ISO/IEC 15938-5 è possibile trovare tutte le definizioni dei tipi, e anche la sintassi del tipo ContentDescription.La semantica di ContentDescriptionType:
Nome Definizione
ContentDescriptionType Descrive il contenuto multimediale e le sue astrazioni. ContentDescriptionType è un tipo astratto e fornisce una specifica di base per i tipi top-level ContentEntity e ContentAbstraction.
Affective Descrive la risposta emotiva dell’utente al contenuto multimediale.
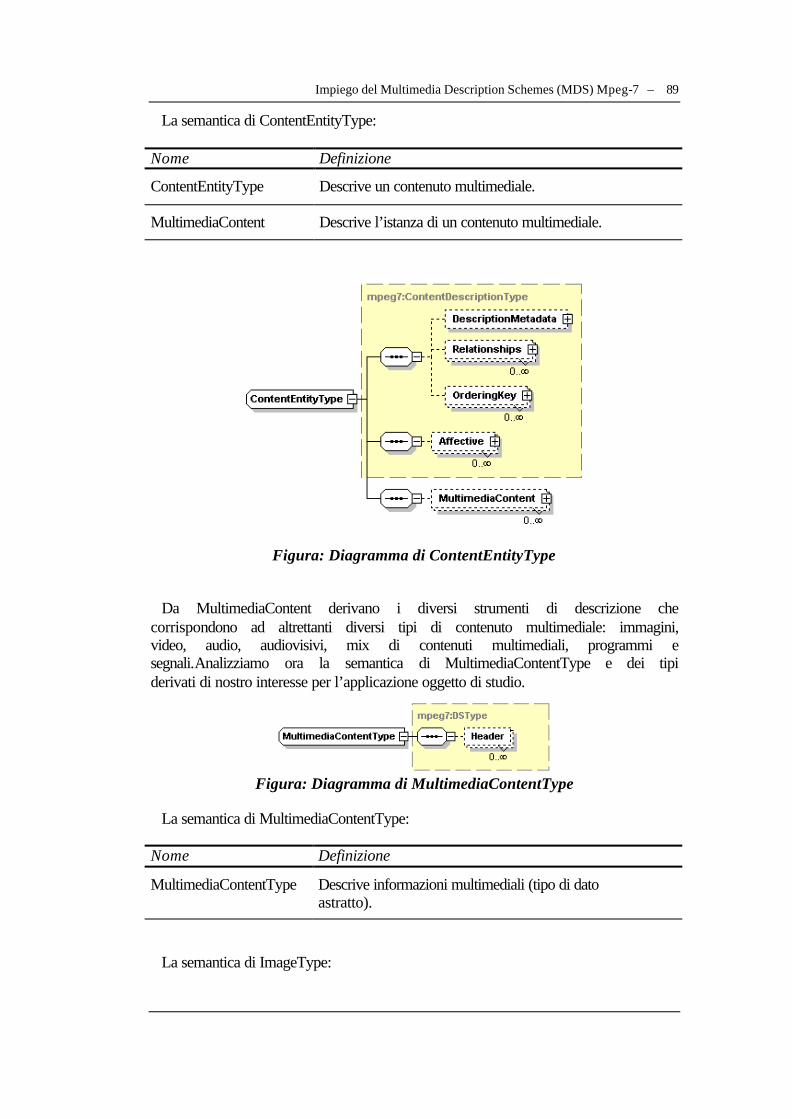
Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 89
La semantica di ContentEntityType:
Nome Definizione
ContentEntityType Descrive un contenuto multimediale.
MultimediaContent Descrive l’istanza di un contenuto multimediale.
Figura: Diagramma di ContentEntityType
Da MultimediaContent derivano i diversi strumenti di descrizione che corrispondono ad altrettanti diversi tipi di contenuto multimediale: immagini, video, audio, audiovisivi, mix di contenuti multimediali, programmi e segnali.Analizziamo ora la semantica di MultimediaContentType e dei tipi derivati di nostro interesse per l’applicazione oggetto di studio.
Figura: Diagramma di MultimediaContentType
La semantica di MultimediaContentType:
Nome Definizione
MultimediaContentType Descrive informazioni multimediali (tipo di dato astratto).
La semantica di ImageType:

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 90
Nome Definizione
ImageType Descrive un’immagine.
Image Descrive l’istanza di un’immagine.
La semantica di VideoType:
Nome Definizione
VideoType Descrive un video.
Video Descrive un’istanza di un video.
La semantica di AudioType:
Nome Definizione
AudioType Descrive l’audio.
Audio Descrive un’istanza di contenuto audio.
La semantica di AudioVisualType:
Nome Definizione
AudioVisualType Descrive contenuto audiovisivo.
AudioVisual Descrive un’istanza di contenuto audiovisivo.
Vi sono inoltre presenti nello schema MultimediaType, MultimediaCollectionType, MultimediaProgramType, SignalType, ElectronikInkType, VideoEditingType sempre derivati da MultimediaContentType.
Il seguente esempio illustra l’uso di MultimediaContent per la creazione della descrizione di un audiovisivo.
<!—Esempio di descrizione di un audiovisivo --> <Mpeg7 xmlns="http://www.mpeg7.org/2001/MPEG-7_Schema" type="complete"> <DescriptionMetadata> <Version>1.0</Version> <Rights> ... </Rights>

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 91
</DescriptionMetadata> <ContentDescription xsi:type="ContentEntityType"> <MultimediaContent xsi:type="AudioVisualType"> <AudioVisual> <CreationInformation> <Creation> <Title> Telegiornale TG1 </Title> </Creation> </CreationInformation> </AudioVisual> </MultimediaContent> </ContentDescription> </Mpeg7>
Nell’ambito di questo lavoro si fa riferimento al tipo di dato complesso AudioVisualType, che, come possiamo vedere dal codice che lo definisce (in xml secondo il linguaggio DDL di Mpeg-7) istanzia un elemento “AudioVisual” di tipo AudioVisualSegmentType.
Il Descriptor Scheme AudioVisualSegment descrive una sequenza di informazioni audiovisive, che corrisponde agli insiemi di campioni audio e dei frames che sono presenti in uno stesso intervallo temporale o segmento. Il segmento audiovisivo può essere o meno connesso nel dominio del tempo. Ad esempio per questo scopo il descrittore TemporalMask descrive la composizione di singole componenti temporali che formano un segmento audiovisivo non-connesso. La semantica di AudioVisualSegmentType è riportata nella tabella successiva:
Nome Definizione
AudioVisualSegmentType
Descrive un intervallo temporale o un segmento di informazione audiovisiva, che corrisponde all’insieme di campioni audio e frames video nello stesso intervallo temporale o segmento (il segmento audiovisivo può anche non essere connesso temporalmente).
MediaTime Descrive la localizzazione temporale del segmento audiovisivo attraverso la specifica del tempo di inizio e della durata del segmento. Se il segmento non è connesso temporalmente, la durata dovrebbe essere pari o maggiore alla somma delle durate dei segmenti temporali connessi all’interno del segmento audiovisivo complessivo.
Per esempio se un segmento audiovisivo è composto di due componenti connesse di durata rispettivamente di 2 e 3 secondi e vi è un intervallo di 1 secondo tra i due, allora la durata dell’intervallo temporale connesso che include il
Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 92
Nome Definizione segmento audiovisivo dovrebbe essere maggiore od uguale a 6 secondi.
L’elemento MediaTime include a sua volta un elemento MediaTimePoint e un elemento MediaDuration opzionale.
Il frame video o il campione audio posizionati esattamente all’istante finale del segmento audiovisivo appartengono al segmento stesso.
MediaTime viene descritto opzionalmente nei casi in cui il segmento audiovisivo faccia riferimento ad un intero clip audiovisivo.
TemporalMask Descrive la composizione di componenti connessi che formano un segmento audiovisivo non-connesso (è opzionale).
Se è assente, il segmento è composto dal solo intervallo connesso nel tempo definito dall’elemento MediaTime.
Se presente, il segmento fa riferimento all’insieme di sotto intervalli non sovrapposti nel tempo definiti dall’elemento TemporalMask.
SpatialDecomposition
Descrive una decomposizione spaziale del segmento audiovisivo in uno o più sotto-segmenti (opzionale).
TemporalDecomposition
Descrive una decomposizione temporale del segmento audiovisivo in uno o più sotto-segmenti (opzionale).
SpatioTemporalDecomposition
Descrive una decomposizione spazio-temporale del segmento audiovisivo in uno o più sotto-segmenti (opzionale).
MediaSourceDecomposition
Descrive una decomposizione in sorgenti di diversi media del segmento audiovisivo in uno o più sotto-segmenti (opzionale).

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 93
Figura: Diagramma di AudioVisualSegmentType.
Nel seguente esempio viene illustrato l’uso di AudioVisualSegment DS per la descrizione di un segmento audiovisivo costituito da due tracce audio ed una traccia video. In questo esempio, il segmento audiovisivo TelegiornaleTG1_AVS rappresenta l’intera sequenza video che è scomposta in due segmenti audio, TelegiornaleTG1_Track1AS e TelegiornaleTG1_Track2AS, e una sequenza video, TelegiornaleTG1_VS, che corrispondono rispettivamente alle sorgenti audio e video. Ogni segmento è connesso nel tempo e/o nello spazio.
<!-— Esempio di decomposizione temporale del segmento audiovisivo --> <!-- chiamato TelegiornaleTG1_AVS --> <AudioVisualSegment id="TelegiornaleTG1_AVS"> <TextAnnotation> <FreeTextAnnotation> Telegiornale nazionale italiano </FreeTextAnnotation>

Impiego del Multimedia Description Schemes (MDS) Mpeg-7 – 94
</TextAnnotation> <MediaTime> <MediaTimePoint>T00:00:00</MediaTimePoint> <MediaDuration>PT20M30S</MediaDuration> </MediaTime> <!-- descrizione di MediaSourceDecomposition: TelegiornaleTG1_AVS è la sorgente scomposta in segmenti video e audio: * TelegiornaleTG1_VS: start = 0:0:0, duration = 20 mins, 30 secs * TelegiornaleTG1_AS: start = 0:0:0, duration = 20 mins, 30 secs --> <MediaSourceDecomposition gap="false" overlap="false"> <VideoSegment id="TelegiornaleTG1_VS "> <MediaTime> <MediaTimePoint>T00:00:00</MediaTimePoint> <MediaDuration>PT2M30S</MediaDuration> </MediaTime> <GOFGOPColor> ... </GOFGOPColor> </VideoSegment> <AudioSegment id="TelegiornaleTG1_Track1AS"> <MediaTime> <MediaTimePoint>T00:00:00</MediaTimePoint> <MediaDuration>PT20M30S</MediaDuration> </MediaTime> </AudioSegment> <AudioSegment id="TelegiornaleTG1_Track2AS"> <MediaTime> <MediaTimePoint>T00:00:00</MediaTimePoint> <MediaDuration>PT20M30S</MediaDuration> </MediaTime> </AudioSegment> </MediaSourceDecomposition> </AudioVisualSegment>
Nel contesto applicativo della Teca Fast, in questa prima implementazione, non saranno considerate decomposizioni temporali. Per le specifiche di progetto di questo primo prototipo infatti il dettaglio della descrizione si ferma al livello di “puntata o episodio di programma tv”, ad esempio la sequenza audiovisiva costituita dall’edizione serale del Telegiornale viene descritta nella sua interezza (utilizzando MediaTime per identificare data e ora di inizio e fine della sequenza audiovisiva) e non vengono individuati e descritti i singoli servizi giornalistici che ne fanno parte (funzionalità di particolare interesse che si prevede di implementare successivamente). E’ stata comunque introdotta la tematica della decomposizione temporale delle sequenze audiovisive per mostrare le potenzialità degli strumenti che Mpeg-7 mette a disposizione per la creazione di metadati descrittivi a diversi livelli di granularità spaziale, temporale, spazio-temporale o di flussi sorgenti.

La struttura dati Mpeg-7 creata per il prototipo – 95
IV.3 La struttura dati Mpeg-7 creata per il prototipo
Sulla base delle argomentazioni affrontate è stato identificato un primo nucleo di descrizione che potrà servire da base per le possibili estensioni utili allo sviluppo di un archivio di contenuti audiovisivi secondo le esigenze riscontrate nell’ambiente applicativo della Teca Fast Rai.
Il primo set di descrizioni identificato è applicato alla descrizione del programma televisivo “Passaggio a Nord Ovest”, trasmesso il 10 Marzo 2001 sul primo canale televisivo pubblico italiano (RaiUno). Sono riportate di seguito in una serie di figure le strutture gerarchiche del documento base costruito, e a seguire una serie di listati di esempio che mostrano con crescente dettaglio il codice xml prodotto per la descrizione del programma.
Figura: Schema semplificato che illustra la struttura dati ad albero per la descrizione basata su metadati del programma creato.
Listato: Struttura dati del documento di descrizione basato su metadati compatibili con le specifiche Mpeg-7 di un programma Tv.
Profilo applicativo realizzato con gli strumenti di descrizione di Mpeg-7 Multimedia Description Schemes (Versione FCD).
<Mpeg7>
<ContentDescription> <DescriptionMetadata/> <MultimediaContent>
<AudioVisual> <MediaInformation>

La struttura dati Mpeg-7 creata per il prototipo – 96
<MediaIdentification/> <MediaProfile>
<MediaFormat/> </MediaProfile>
</MediaInformation> <CreationInformation>
<Creation> <Title/> <Abstract/> <Creator>
<Role> <Name/>
</Role> <Agent>
<Name/> <Affiliation> <Organization/> </Affiliation>
</Agent> </Creator> <CreationCoordinates/> <CreationTool/> </Creation> <Classification/>
</CreationInformation> <UsageInformation>
<Rights/> </UsageInformation> <MediaTime>
<MediaTimePoint/> <MediaDuration/>
</MediaTime> </AudioVisual>
</MultimediaContent> </ContentDescription>
</Mpeg7>

La struttura dati Mpeg-7 creata per il prototipo – 97
Figura: Struttura dati di descrizione implementata.
Facendo riferimento all’introduzione fatta sui tipi di dato, i descrittori e i DS (description schemes) base impiegati da Mpeg-7 MDS Schema, vediamo ora nel dettaglio i singoli strumenti di descrizione che sono stati implementati nella costruzione della struttura dati del documento di descrizione basato su metadati della risorsa audiovisiva “programma tv”. Il primo è l’elemento DescriptionMetadata.
Figura: Struttura dati documento di descrizione implementato: Dettaglio dell’Elemento DescriptionMetadata
DescriptionMetadata fa riferimento a DescriptionMetadata DS per descrivere le informazioni riguardanti la descrizione stessa (metadati sui metadati).

La struttura dati Mpeg-7 creata per il prototipo – 98
Il DescriptionMetadata DS può essere inserito in uno strumento di descrizione nel modo mostrato nello schema di figura, e riporta informazioni riguardanti l’identificazione della descrizione (privata o pubblica), la creazione della descrizione, e i diritti associati alla descrizione stessa (che diventa un contenuto di valore).
La semantica di DescriptionMetadata DS viene riportata nella seguente tabella, nella quale “la descrizione alla quale questo DS è collegato” fa riferimento all’elemento XML che contiene una istanza di DescriptionMetadata DS. Questo è l’elemento di un livello superiore nell’albero di descrizione. Questo elemento potrebbe essere un DS, un elemento di livello superiore o un elemento radice. Molti elementi sono opzionali e non vengono impiegati nello schema di documento creato.
La semantica di DescriptionMetadata DS:
Nome Descrizione
Confidence Indica il livello di riservatezza nella descrizione alla quale questo DS viene allegata (è opzionale).
Il valore zero rappresenta una mancanza di riservatezza, mentre il valore 1.0 indica riservatezza totale. Tutti gli altri valori tra zero e uno rappresentano livelli intermedi di riservatezza.
Version Specifica la versione della descrizione alla quale questo DS viene allegato. Il formato per l’informazione di versione è dipendente dal tipo di applicazione (e comunque opzionale).
LastUpdated Specifica l’istante in cui è stato aggiornato per l’ultima volta l’informazione di descrizione alla quale questo DS viene allegato (è opzionale).
Comment Descrive i commenti riguardo alla descrizione a cui viene allegato tale DS, utilizzando una annotazione di tipo testuale (Opzionale).
PublicIdentifier Identifica la descrizione alla quale viene allegato questo DS utilizzando un identificatore pubblico, unico a livello globale (è opzionale).
Questo identificatore può essere usato per identificare univocamente le descrizioni e non dipende dal file o dal flusso in cui la descrizione compare, o ogni altro incorporamento fisico di metadati. Diversi identificatori pubblici possono essere associati ad una descrizione.
PrivateIdentifier Identifica la descrizione alla quale questo DS è collegato utilizzando un identificatore privato dipendente

La struttura dati Mpeg-7 creata per il prototipo – 99
utilizzando un identificatore privato dipendente dall’applicazione (è opzionale).
Il formato di questo identificatore è definito dall’applicazione e non si richiede che sia unico. Possono essere associati ad una descrizione diversi identificatori privati.
Creator Descrive un autore della descrizione cui viene allegato questo DS (è opzionale).
Questo può essere una persona, un’organizzazione, o un’applicazione software che genera automaticamente i metadati. Diversi creatori sono consentiti se i metadati sono stati creati come risultato della cooperazione di diversi soggetti.
CreationLocation Descrive la località in cui la descrizione cui è allegato tale DS è stata creata.
CreationTime Descrive l’istante in cui la descrizione cui tale DS è allegato è stata creata.
Instrument Le apparecchiature/procedure e I parametri di settaggio utilizzati per la creazione dei metadati, così come gli strumenti utilizzati per l’estrazione dei metadati o i parametri di estrazione (è opzionale).
Rights Descrive I diritti associati con la descrizione cui tale DS (Description Metadata DS) è allegato e come tale descrizione può essere utilizzata (è opzionale).
Package Descrive un package associato alla descrizione che descrive gli strumenti che sono utilizzati dalla descrizione stessa (è opzionale).
Il codice implementato nel documento è visibile per la parte di DescriptionMetadata nel seguente listato:
L’elemento DescriptionMetadata nel prototipo di documento costruito
<DescriptionMetadata> <LastUpdate>2001-05-11T10:00:00+00:00</LastUpdate> <Comment> <FreeTextAnnotation>Descrizione delle informazioni descrittive di un contenuto audiovisivo di teca. </FreeTextAnnotation> </Comment> <CreationTime>2001-05-11T11:00</CreationTime> </DescriptionMetadata>

Identificazione e localizzazione del media: MediaInformation DS – 100
IV.3.1 Identificazione e localizzazione del media:
MediaInformation DS
Passiamo adesso alla parte riguardante la descrizione del supporto e le caratteristiche di formato del contenuto audiovisivo, per descrivere le quali si utilizza l’elemento MediaInformation, elemento figlio di AudioVisual. E’ possibile vedere un dettaglio nello schema di figura:
Figura: Struttura del documento di descrizione implementato: Dettaglio dell’Elemento MediaInformation.
Il contenuto descritto dalle descrizioni MPEG-7 può essere disponibile in diverse modalità, formati, schemi di codifica, e di esso possono essere disponibili diverse istanze. Per esempio un evento sportivo può essere registrato in due diverse modalità, audio e audiovideo. Ognuna di queste due modalità può essere codificata con diversi algoritmi di codifica. Questo comporta la creazione di diversi profili del media. Inoltre possono essere rese disponibili diverse istanze o copie di uno stesso contenuto multimediale per una data codifica.
La figura seguente illustra i concetti di modalità, profilo e istanza.

Identificazione e localizzazione del media: MediaInformation DS – 101
Figura: Punto di vista di Mpeg-7 per la descrizione (modello di content entity, profilo e istanza)
Gli strumenti di descrizione definiti da MPEG-7 possono gestire tutti questi aspetti. Gli strumenti specifici per questo scopo sono i Media Information tools.
I Media Information Tools descrivono le informazioni riguardanti il media specifico della risorsa multimediale. Il MediaInformation DS è incentrato attorno ad un identificatore per l'entità di contenuto e ad un set di parametri di codifica raggruppati in profili. Il MediaIdentification DS permette la descrizione dell'entità del contenuto. Le diverse istanze di MediaProfile DS permettono la descrizione di diversi parametri di codifica per differenti profili.
Nei Media Information tools sono definite le seguenti entità:
1. Content Entity: l'entità di contenuto al più alto livello di astrazione è la realtà, ovvero nell'esempio riportato sopra, una realtà come l'evento sportivo che può essere rappresentato da diversi tipi di media, e che ha una specifica struttura per la rappresentazione di questa realtà.
2. MediaInformation: descrive il formato fisico del contenuto multimediale. Un'istanza del MediaInformation DS è allegata ad una entità di contenuto (la Content Entity di cui sopra) per descriverla. Il MediaInformation DS include un identificatore della Content Entity

Identificazione e localizzazione del media: MediaInformation DS – 102
(EntityIdentifier), che può essere ad esempio un ISAN, ed un set di descrittori per il formato dell'entità sorgente (AudioDomain, VideoDomain, ImageDomain).
3. MediaProfile: Una Content Entity può avere uno o più MediaProfile che corrispondono a diverse versioni di codifica dell'entità stessa. Uno di questi profili è il profilo originale di codifica, chiamato “master profile”, che corrisponde al profilo di creazione o registrazione iniziale. Gli altri profili sono trascodificati a partire dal profilo master. Se un contenuto multimediale è codificato con la stessa codifica software o hardware ma con differenti parametri, si vengono a creare differenti profili. Fra i componenti del MediaProfile abbiamo: MediaFormat, MediaTrascodingHints, MediaQuality e MediaInstance.
4. MediaInstance: una Content Entity (ovvero una realtà descritta da una registrazione mediale) può essere rappresentata (istanziata) in un'entità fisica che assume la denominazione di “media istance”. Il MediaIstance DS identifica e localizza le differenti istanze (copie) disponibili di un dato profilo di media. La localizzazione viene effettuata attraverso un MediaLocator che verrà descritto in seguito.
5. CreationInformation: descrive l'informazione sul processo di creazione di una Content Entity. Una descrizione del DS può essere allegata alla entità di contenuto da descrivere.
6. UsageInformation: descrive l'informazione relativa all'utilizzo della entità di contenuto.
La descrizione del supporto o media viene dunque incapsulata in MPEG-7 attraverso il MediaInformation DS. Questo è composto da un MediaIdentification DS opzionale e da uno o più MediaProfile DSs.
MediaProfile DS è composto di: un descrittore MediaFormat opzionale, un MediaTrascodingHints D opzionale, un MediaQuality D opzionale, e zero o più MediaInstance DSs.
E’ presente anche uno schema di descrizione (DS) ComponetMediaProfile che permette la descrizione di profili di media multiplexati, che sono Media Profiles di contenuti multimediali composti da altri contenuti mediali come ad esempio i differenti oggetti multimediali in uno stream MPEG-4 o il video stream e gli stream audio multilingue in un DVD; un altro esempio possono essere i differenti video streams che provengono da diverse telecamere in un video stream multiplexato.
Lo strumento utilizzato è dunque in questa parte il descrittore MediaInformation, che identifica e descrive le informazioni specifiche del

Identificazione e localizzazione del media: MediaInformation DS – 103
supporto e del formato del contenuto multimediale. Segue la semantica di MediaInformationType:
Nome Definizione
MediaInformationType Descrive il formato fisico dell’informazione multimediale.
MediaIdentification Identifica l’entità di contenuto multimediale che rappresenta una realtà.
MediaProfile Descrive un Media Profile del contenuto multimediale.
Figura: Diagramma di MediaInformationType
Il descrittore MediaIdentification identifica il contenuto multimediale indipendentemente dalle differenti istanze che sono disponibili. I diversi Media Profile di un contenuto multimediale sono descritti attraverso il loro elemento di descrizione MediaProfile e per ogni profilo ci possono essere diverse istanze di media disponibili (come vedremo tra poco).
La semantica di MediaIdentificationType:
Nome Definizione
MediaIdentificationType Identifica l’entità di contenuto indipendentemente dalle diverse istanze e profili disponibili di questo.
EntityIdentifier Identifica univocamente una particolare entità di contenuto multimediale. Per esempio gli identificatori definiti da ISO o l’ISAN.
AudioDomain Descrive una creazione, acquisizione e/o uso di un’entità di contenuto audio. Se una entità di contenuto è audiovisiva, AudioDomain e VideoDomain sono utilizzati simultaneamente. Un esempio di Schema di Classificazione (CS) è MPEG7AudioDomainCS.

Identificazione e localizzazione del media: MediaInformation DS – 104
Nome Definizione
VideoDomain Descrive una creazione, acquisizione e/o uso di una entità di contenuto video. Un esempio di schema di classificazione è MPEG7VideoDomainCS (CS sta per Classification Scheme).
ImageDomain Descrive una creazione, acquisizione e/o uso di una entità di contenuto di tipo immagine. Un esempio di schema di classificazione è MPEG7ImageDomainCS (CS sta per Classification Scheme).
Figura: Diagramma dell’elemento MediaInformationType/Mediaidentification
Il description scheme MediaProfile descrive un profilo del contenuto multimediale oggetto della descrizione. Il concetto di profilo fa riferimento alle diverse variazioni che possono essere prodotte da un supporto mediale originale o master, a seconda dei valori scelti di volta in volta per la codifica, il formato di memorizzazione, etc. Il profilo corrispondente al documento multimediale originale o ad una sua copia master viene considerato come il profilo master o “master media profile”. Per ogni profilo possono esserci una o più istanze del profilo master.
La semantica di MediaProfileType è la seguente:
Nome Definizione
MediaProfileType Descrive il profilo del supporto del contenuto multimediale oggetto della descrizione.
ComponentMediaProfile Descrive uno dei Media profile componenti di un Media Profile multiplexato, tale cioè da descrivere un contenuto multimediale che si presenta composto di diversi contenuti multimediali.

Identificazione e localizzazione del media: MediaInformation DS – 105
Nome Definizione
MediaFormat Descrive il formato del Media Profile.
MediaTranscodingHints Descrive i suggerimenti di trascodifica per il Media Profile.
MediaQuality Descrive la qualità del segnale corrispondente al dato profilo.
MediaInstance Identifica e localizza una istanza di supporto (Media Instance) del Media Profile.
Master Indica se il Media Profile corrisponde all’originale o al profilo master dell’entità di contenuto multimediale.
La ricorsività del MediaProfile consente la descrizione di flussi multiplexati, vale a dire flussi multimediali composti di diversi flussi componenti. Tipici esempi includono:
• I diversi oggetti multimediali in un flusso MPEG-4.
• I diversi flussi audio presenti in un DVD da sincronizzare con il video per il supporto ai vari linguaggi
• Un flusso video multiplexato contenente diversi flussi audio e video (sincronizzati nel loro insieme) che provengono da differenti microfoni e videocamere, che possa consentire all’utente di selezionare diversi punti di vista di uno stesso evento.
Il descrittore MediaFormat (il tipo che definisce l’omonimo elemento MediaFormat istanziato nel nostro documento di descrizione) fornisce informazioni relative al formato del file e ai parametri di codifica del MediaProfile. Importante è analizzarne la semantica, ricca di elementi che descrivono il formato dell’istanza di contenuto multimediale (nel nostro caso del programma audiovisivo codificato nell’archivio digitale Teca Fast):
Semantica di MediaFormatType:
Nome Definizione
MediaFormatType Descrive il formato e i parametri di codifica del MediaProfile.
Content Identifica il media presente nel contenuto multimediale.
other Indica se il valore è in testo libero, piuttosto che membro di una lista enumerata associata alla definizione dei valori di
Identificazione e localizzazione del media: MediaInformation DS – 106
Nome Definizione una lista enumerata associata alla definizione dei valori di ContentType.
Medium Descrive il supporto di memorizzazione fisica sul quale il Mediaprofile è memorizzato. Un esempio di schema di classificazione è MPEG7MediumCS.
FileFormat Descrive il formato file del MediaProfile. Esempi di schemi di classificazione per i valori di questo elemento sono MPEG7FileFormatCS e IPTCMimeTypeCS.
FileSize Indica la dimensione in bytes del file in cui il MediaProfile è memorizzato.
System Descrive il formato del profilo del media a livello broadcast, un esempio di valore è il sistema televisivo “PAL”, un esempio di schema di classificazione è MPEG7SystemCS.
Bandwidth Indica la larghezza di banda in Hz coperta dal contenuto multimediale codificato. Il suo valore dipende dai filtri di acquisizione e/o dalle trascodifiche applicate al Media Profile.
BitRate Indica il bit rate nominale in bit/s del Media Profile.
variable Indica se il bitrate è variabile o fissato. Se il bitrate è variabile, tre attributi opzionali possono essere usati per specificare il valore di bitrate minimo, massimo e medio.
minimum Indica come sopra indicato il minimo valore numerico di BitRate nel caso di bitrate variabile.
maximum Indica come sopra indicato il massimo valore numerico di BitRate nel caso di bitrate variabile.
average Indica come sopra indicato il valore numerico medio di BitRate nel caso di bitrate variabile.
TargetChannelBitRate
Indica il bit rate nominale in bit/s del canale al quale questo MediaProfile è rivolto.
ScalableCoding Indica la scalabilità utilizzata nella codifica. I valori della codifica scalabile sono quelli seguenti:
• spatial – La scalabilità è spaziale.
• temporal – La scalabilità è temporale.

Identificazione e localizzazione del media: MediaInformation DS – 107
Nome Definizione
• snr – La scalabilità è sull’ SNR (Signal to Noise Ratio – rapporto segnale rumore).
• fgs – La scalabilità è FGS (Fine Granularity Scalability).
VisualCoding Descrive la codifica della componente visiva del MediaProfile. Se una entità di contenuto è audiovisiva, VisualCoding e AudioCoding sono entrambe utilizzati.
VisualCoding/Format
Descrive il formato di codifica della componente video del MediaProfile. Come sopra, se una entità di contenuto multimediale è audiovisiva, VisualCoding e AudioCoding sono entrambe utilizzati. Un esempio di schema di classificazione è MPEG7VisualCodingFormatCS.
colorDomain Descrive il dominio del colore dell’immagine o del video. I valori del dominio del colore sono definiti come segue:
• binary – L’immagine o il video sono binari (solo due colori: bianco e nero).
• color – L’immagine o il video sono a colori.
• graylevel – L’immagine o il video sono a scala di grigio.
• colored – L’immagine o il video sono stati colorati (da un originale a scala di grigio che è stato colorato).
Pixel Descrive i pixel dell’immagine o dei frames video.
resolution Indica la risoluzione delle immagini e dei frames in dpi (dots per inch – punti per pollice).
aspectRatio Descrive l’aspect ratio (fattore di forma) dei pixel (larghezza/altezza).
bitsPer Indica l’accuratezza del campione visivo (pixel) in bit per pixel (profondità di pixel).
Frame Descrive il frame dell’immagine e i frame video.
height Indica l’altezza delle immagini e dei frames in pixel.
width Indica la larghezza delle immagini e dei frames in pixel. Il quoziente di larghezza e altezza è il fattore di forma del campionamento, che è come il fattore di forma
Identificazione e localizzazione del media: MediaInformation DS – 108
Nome Definizione campionamento, che è come il fattore di forma dell’immagine ottica se il pixel è quadrato.
aspectRatio Descrive il fattore di forma ottico dell’immagine. E’ il quoziente di larghezza ed altezza nelle unità di presentazione non basate sul numero di pixel (ad esempio le dimensioni dello schermo per i film).
rate Indica il frame rate in Hz.
structure Descrive la struttura di campionamento temporale utilizzata per la codifica del video. I valori sono definiti come segue:
• progressive – La struttura di campionamento è progressiva (non-interlacciata).
• interlaced – La struttura di campionamento è interlacciata (2:1 due campi interlacciati in ogni frame).
AudioCoding Descrive la codifica della componente audio del MediaProfile.
Se una entità di contenuto è audiovisiva, VisualCoding e AudioCoding sono entrambe utilizzati.
AudioCoding/Format
Descrive il formato di codifica della componente audio del Mediaprofile. Come sopra, se una entità di contenuto multimediale è audiovisiva, VisualCoding e AudioCoding sono entrambe utilizzati. Un esempio di schema di classificazione è MPEG7AudioCodingFormatCS.
AudioChannels Descrive il numero e opzionalmente la configurazione dei canali audio nel Media Profile. Le informazioni sulla configurazione dei canali possono essere descritte utilizzando gli attributi ‘front’, ‘side’, ‘rear’, e ‘lfe’. Nel caso di flussi audio multilingue o multitraccia, il numero delle tracce può essere descritto nell’attributo ‘track’.
front Il numero dei canali frontali.
side Il numero dei canali laterali.
rear Il numero dei canali posteriori.
lfe Il numero dei canali LFE (Low Frequency Enhancement).
track Il numero di tracce audio indipendenti utilizzate in un flusso audio multilingue o multitraccia.

Identificazione e localizzazione del media: MediaInformation DS – 109
Nome Definizione audio multilingue o multitraccia.
Sample Descrive i campioni audio.
rate Indica la velocità di campionamento dell’audio in Hz.
bitsPer Indica la profondità di bit per i campioni audio.
Emphasis Identifica la preenfasi audio utilizzata nella codifica.
other Indica se il valore è di testo libero, piuttosto che membro di una lista enumerata associata ai valori di AudioEmphasisType.
Presentation Descrive il formato di presentazione audio del MediaProfile. Un esempio di schema di classificazione è MPEG7AudioPresentationCS. AudioChannels consente di definire la configurazione dei canali in maniera molto più dettagliata.
La sintassi completa di MediaInformation D è presente nel listato completo di Mpeg-7 MDS Schema e nel capitolo 8 (Media Description Tools) del documento MDS FCD N3966.
Nella figura seguente è riepilogata la struttura dell’elemento MediaInformation implementata nel prototipo di documento descrittivo di risorse di teca:
Figura: Struttura dati del documento di descrizione implementato: Dettaglio di MediaIdentification e MediaProfile.

L’elemento CreationInformation: aspetti di creazione e classificazione. – 110
Il codice implementato nel documento è visibile per la parte di DescriptionMetadata nel seguente listato:
L’elemento MediaIdentification nel prototipo di documento costruito
<MediaInformation> <MediaIdentification> <Identifier IdName="Numero_Identificazione_Risorsa(esempio)" IdOrganization="Rai_TecheRai_TecaFast(esempio)"> <IdValue>MPEG7.eXperimental.TECAFAST.2001</IdValue> </Identifier> </MediaIdentification> <MediaProfile id="Media_Profile_Programma"> <MediaFormat> <FileFormat>MPEG</FileFormat> <System>PAL</System> <Medium>DigitalCassette200GB</Medium> <Color>color</Color> <Sound>mono</Sound> <FileSize>5005321704</FileSize> <AudioChannels>1</AudioChannels> <AudioLanguage>italian</AudioLanguage> <Resolution>2</Resolution> <FrameWidth>720</FrameWidth> <FrameHeight>576</FrameHeight> <AspectRatio Width="766" Height="576"/> <FrameRate>25.0</FrameRate> <AudioSamplingRate>44100</AudioSamplingRate> <CompressionFormat>MPEG-2</CompressionFormat> <BitRate>10</BitRate> <Bandwidth>10</Bandwidth> </MediaFormat> </MediaProfile> </MediaInformation>
IV.3.2 L’elemento CreationInformation: aspetti di creazione e
classificazione.
I metadati riguardanti la creazione (titolo, regia, produttore, etc.) e la classificazione (format, genere, etc.) del programma televisivo sono contenuti nell’elemento CreationInformation della struttura dati progettata. Nella figura seguente si vede in un primo dettaglio che tali informazioni sono suddivise in due sottoblocchi separati, inglobate negli elementi Creation e Classification.

L’elemento CreationInformation: aspetti di creazione e classificazione. – 111
Figura: Struttura del documento di descrizione implementato: Dettaglio dell’Elemento CreationInformation.
Si fa riferimento agli strumenti di descrizione necessari alla descrizione di metadata generati da operatori umani o estratti da altri database riguardanti il processo di generazione/produzione del contenuto multimediale, nel nostro caso del programma televisivo.
Gli strumenti specificati in questa parte dal documento MDS Schema Mpeg-7 (versione FCD) sono i seguenti:
Strumento Funzione
Strumenti di Creazione e Produzione
Questi strumenti descrivono I metadati riguardanti la creazione e produzione del contenuto multimediale.
Il CreationInformation DS è composto di un Creation DS, zero o un Classification DS, di zero o più RelatedMaterial DSs.
Creation DS contiene gli strumenti di descrizione per i metadati generati dall’autore circa il processo di creazione (tipicamente i titoli di coda o credits).
Classification DS contiene gli strumenti di descrizione per la classificazione del contenuto multimediale utilizzando gli schemi di classificazione e anche le recensioni soggettive.
RelatedMaterial DS contiene gli strumenti di descrizione per la classificazione che consentono la descrizione di materiale addizionale che è relativo al contenuto multimediale.
Il CreationInformation DS contiene:

L’elemento CreationInformation: aspetti di creazione e classificazione. – 112
• Informazioni riguardanti il processo di creazione che non possono essere percepite nel materiale audiovisivo o multimediale ( ad esempio l’autore della sceneggiatura, il regista, il personaggio, il target di utenza, etc.) e informazioni sul processo di creazione che si percepisce nel contenuto multimediale ( ad esempio gli attori nel video, i musicisti in un concerto).
• Le informazioni di classificazione ( ad esempio l’audience, il genere, la fasci di età consigliata, etc.)
Questo DS può essere allegato ad ogni elemento di tipo Segment DS. Invece, una descrizione completa può contenere segmenti che sono annotati con un dettaglio maggiore e questi segmenti possono essere stati prodotti e utilizzati indipendentemente e/o in diversi materiali multimediali e segmenti.
Semantica di CreationInformationType:
Nome Definizione
CreationInformationType Descrive le caratteristiche legate alla creazione del contenuto multimediale.
Creation Descrive da chi, quando, dove, etc. il contenuto multimediale è stato creato.
Classification Descrive la classificazione orientata all’utente e orientata al servizio del contenuto multimediale.
RelatedMaterial Descrive informazioni addizionali circa il materiale cui si fa riferimento nel contenuto multimediale.
Un diagramma di CreationType viene riportato nella seguente figura (diagramma realizzato processando il codice di MDS Schema v.FCD con il software XML Spy versione 3.5):
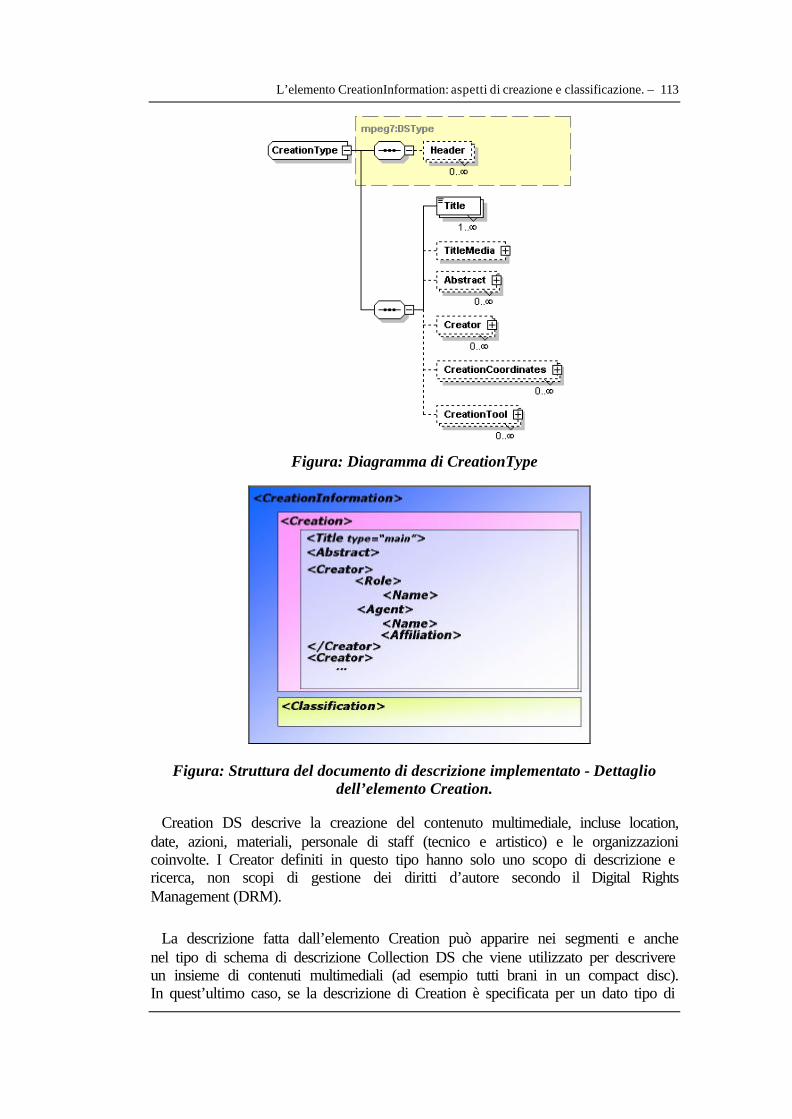
L’elemento CreationInformation: aspetti di creazione e classificazione. – 113
Figura: Diagramma di CreationType
Figura: Struttura del documento di descrizione implementato - Dettaglio dell’elemento Creation.
Creation DS descrive la creazione del contenuto multimediale, incluse location, date, azioni, materiali, personale di staff (tecnico e artistico) e le organizzazioni coinvolte. I Creator definiti in questo tipo hanno solo uno scopo di descrizione e ricerca, non scopi di gestione dei diritti d’autore secondo il Digital Rights Management (DRM).
La descrizione fatta dall’elemento Creation può apparire nei segmenti e anche nel tipo di schema di descrizione Collection DS che viene utilizzato per descrivere un insieme di contenuti multimediali (ad esempio tutti brani in un compact disc). In quest’ultimo caso, se la descrizione di Creation è specificata per un dato tipo di
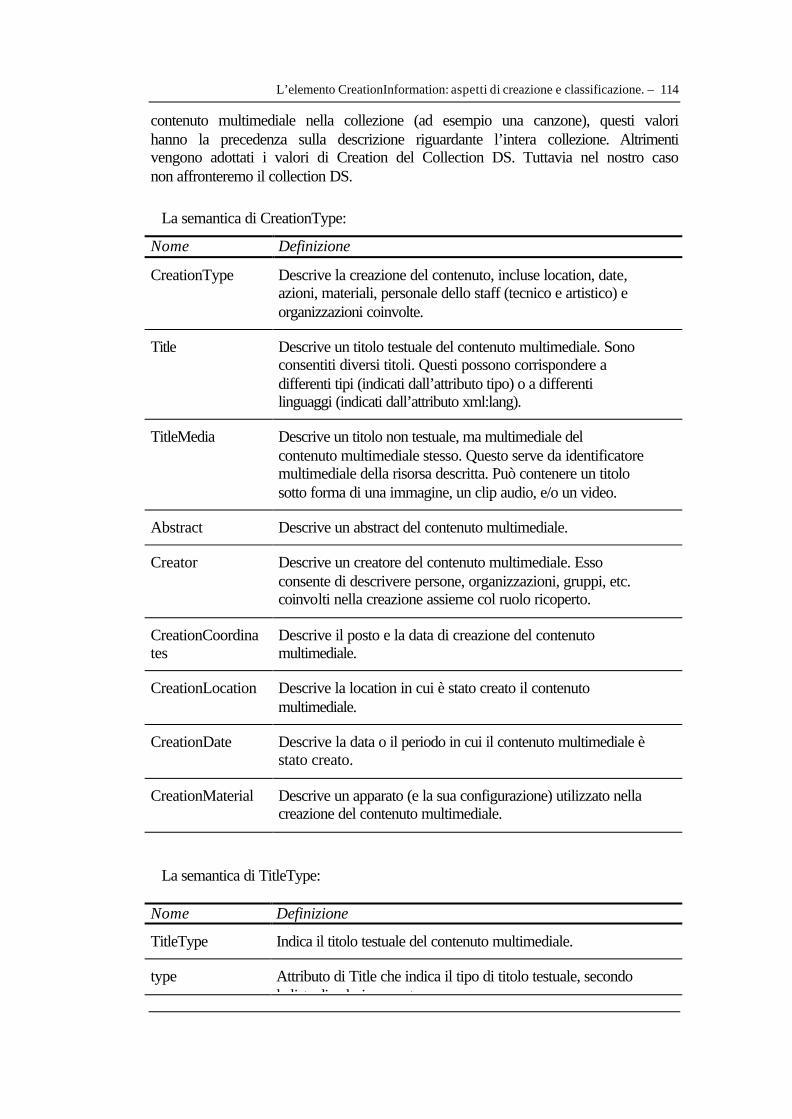
L’elemento CreationInformation: aspetti di creazione e classificazione. – 114
contenuto multimediale nella collezione (ad esempio una canzone), questi valori hanno la precedenza sulla descrizione riguardante l’intera collezione. Altrimenti vengono adottati i valori di Creation del Collection DS. Tuttavia nel nostro caso non affronteremo il collection DS.
La semantica di CreationType:
Nome Definizione
CreationType Descrive la creazione del contenuto, incluse location, date, azioni, materiali, personale dello staff (tecnico e artistico) e organizzazioni coinvolte.
Title Descrive un titolo testuale del contenuto multimediale. Sono consentiti diversi titoli. Questi possono corrispondere a differenti tipi (indicati dall’attributo tipo) o a differenti linguaggi (indicati dall’attributo xml:lang).
TitleMedia Descrive un titolo non testuale, ma multimediale del contenuto multimediale stesso. Questo serve da identificatore multimediale della risorsa descritta. Può contenere un titolo sotto forma di una immagine, un clip audio, e/o un video.
Abstract Descrive un abstract del contenuto multimediale.
Creator Descrive un creatore del contenuto multimediale. Esso consente di descrivere persone, organizzazioni, gruppi, etc. coinvolti nella creazione assieme col ruolo ricoperto.
CreationCoordinates
Descrive il posto e la data di creazione del contenuto multimediale.
CreationLocation Descrive la location in cui è stato creato il contenuto multimediale.
CreationDate Descrive la data o il periodo in cui il contenuto multimediale è stato creato.
CreationMaterial Descrive un apparato (e la sua configurazione) utilizzato nella creazione del contenuto multimediale.
La semantica di TitleType:
Nome Definizione
TitleType Indica il titolo testuale del contenuto multimediale.
type Attributo di Title che indica il tipo di titolo testuale, secondo la lista di valori seguente:

L’elemento CreationInformation: aspetti di creazione e classificazione. – 115
Nome Definizione la lista di valori seguente:
• main – Il titolo è il titolo principale dato dal creatore. Questo è il tipo predefinito per il titolo.
• secondary – Il titolo è il titolo secondario dato dal creatore.
• alternative – Il titolo è un titolo alternativo dato dal creatore.
• original – Il titolo è quello originale dato dal creatore.
• popular – Il titolo è un titolo popolare dato dal pubblico e dai media.
• opusNumber – il titolo corrisponde al numero dell’opera.
• songTitle – Il titolo corrisponde ad una canzone.
• albumTitle – Il titolo corrisponde ad un album.
• seriesTitle – Il titolo corrisponde ad una serie.
• episodeTitle – Il titolo corrisponde ad un episodio di una serie. Questo è dato a complemento del titolo della serie.
Semantica di TitleMediaType:
Nome Definizione
TitleMediaType Specifica il titolo del contenuto multimediale utilizzando un documento multimediale.
TitleImage Specifica il titolo del contenuto multimediale sotto forma di un’immagine (per esempio un thumbnail).
TitleVideo Specifica il titolo del contenuto multimediale sotto forma di un video (ad esempio un video clip).
TitleAudio Specifica il titolo del contenuto multimediale sotto forma di audio (ad esempio un jingle).
Semantica di CreatorType:
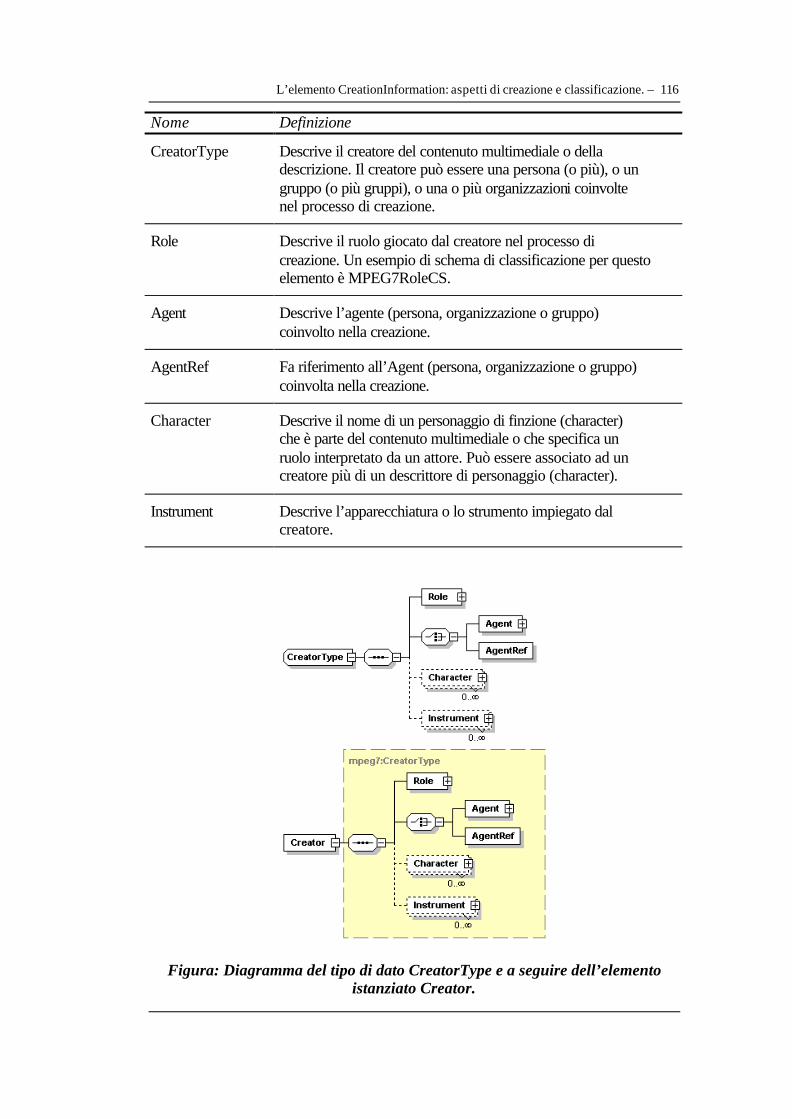
L’elemento CreationInformation: aspetti di creazione e classificazione. – 116
Nome Definizione
CreatorType Descrive il creatore del contenuto multimediale o della descrizione. Il creatore può essere una persona (o più), o un gruppo (o più gruppi), o una o più organizzazioni coinvolte nel processo di creazione.
Role Descrive il ruolo giocato dal creatore nel processo di creazione. Un esempio di schema di classificazione per questo elemento è MPEG7RoleCS.
Agent Descrive l’agente (persona, organizzazione o gruppo) coinvolto nella creazione.
AgentRef Fa riferimento all’Agent (persona, organizzazione o gruppo) coinvolta nella creazione.
Character Descrive il nome di un personaggio di finzione (character) che è parte del contenuto multimediale o che specifica un ruolo interpretato da un attore. Può essere associato ad un creatore più di un descrittore di personaggio (character).
Instrument Descrive l’apparecchiatura o lo strumento impiegato dal creatore.
Figura: Diagramma del tipo di dato CreatorType e a seguire dell’elemento istanziato Creator.

L’elemento CreationInformation: aspetti di creazione e classificazione. – 117
Semantica di CreationToolType:
Nome Definizione
CreationTool Strumenti e impostazioni utilizzati per la creazione del contenuto multimediale o della sua descrizione.
Tool Descrive uno strumento utilizzato nel processo di creazione. Per esempio: software, lenti, pellicole, strumenti musicali, microfoni, etc.
Settings Indica le impostazioni (parametri) per lo strumento impiegato durante la creazione. I nomi e valori delle impostazioni dello strumento sono specifici di questo strumento e non vengono specificati dallo standard Mpeg-7.
Name Attributo di Settings che indica il nome dell’impostazione (parametro) per lo strumento.
Value Attributo di Settings che indica il valore del paramentro specificato. Tutti i parametri sono rappresentati come stringhe. Per esempio, potrebbe essere la lunghezza focale di una lente di una video camera o un valore di input per una applicazione software.
Il listato del documento costruito prevede il seguente codice per l’elemento Creation (si fa sempre riferimento all’esempio della descrizione del programma “passaggio a Nord Ovest”). Si considera per semplicità il solo titolo principale in questa prima implementazione.
L’elemento Creation nel prototipo di documento costruito
<Creation> <Title type="main">PASSAGGIO A NORD - OVEST</Title> <Abstract> <FreeTextAnnotation>Programma di Alberto Angela. Angela spiega i motivi per cui l' antica statua equestre dell' imperatore Marco Aurelio, dopo ….. vedi testo completo nel listato finale…….. e rifinitura presso l' " Istituto Poligrafico e Zecca dello Stato ".</FreeTextAnnotation> </Abstract> <Creator> <Role href="TecaFastXmCreatorCS*"> <Name>Autore</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Alberto Angela</GivenName> </Name>

L’elemento CreationInformation: aspetti di creazione e classificazione. – 118
<Affiliation> <Organization> <Name>RAI Televisione Italiana</Name> </Organization> </Affiliation> </Agent> </Creator> <!-- ….segue…. --> <!-- il listato completo è presente in fondo al capitolo --> <!-- ….segue…. --> <Creator> <Role href="TecaFastXmCreatorCS*"> <Name>Emittente</Name> </Role> <Agent xsi:type="OrganizationType"> <Name>RAIUNO</Name> <Affiliation> <Organization/> </Affiliation> </Agent> </Creator> <CreationCoordinates> <CreationLocation> <Name>Roma, Lazio, Italia</Name> <Role> <Name>Production studio</Name> </Role> <AstronomicalBody> <Name>Earth</Name> </AstronomicalBody> <Country>it</Country> <AdministrativeUnit>Studio Rai Saxa Rubra - 2</AdministrativeUnit> </CreationLocation> <CreationDate> <TimePoint>2001-05-03</TimePoint> </CreationDate> </CreationCoordinates> <CreationTool> <Tool> <Name>Televison camera Betacam SP Sony</Name> </Tool> </CreationTool> </Creation>
Passando all’elemento Classification, lo schema di descrizione a cui si riferisce all’interno di Mpeg-7 Multimedia Description Schemes è Classification DS. Questo descrive le informazioni di classificazione del contenuto multimediale. Le descrizioni risultanti facilitano la ricerca e filtraggio di contenuti multimediali basandosi sulle preferenze dell’utente (come ad esempio lingua, stile, genere, etc.) e le classificazioni orientate al servizio (come ad esempio scopo, fasce d’età, segmentazione del mercato, recensione da parte dei media, etc.). Nella figura

L’elemento CreationInformation: aspetti di creazione e classificazione. – 119
seguente si vede un primo dettaglio dei componenti dell’elemento Classification istanziati nel documento del prototipo.
Figura: Struttura del documento di descrizione implementato: Dettaglio dell’elemento Classification.
La semantica di ClassificationType, per la parte di interesse per l’applicazione, è la seguente:
Nome Definizione
ClassificationType Descrive la classificazione del contenuto multimediale.
Form Descrive il tipo di produzione del documento, come ad esempio, film, telegiornale (news), programma, magazine, documentario, etc. Un esempio di schema di classificazione reale è TVAnytime_v0.1FormatCS.
Genre Descrive di cosa si occupa il contenuto multimediale (classificazione più ampia) come ad esempio sport, politica, economia, etc.
Subject Descrive il soggetto (classificazione specifica) del contenuto multimediale. Il soggetto consente una annotazione testuale per la classificazione del contenuto.
Purpose Descrive uno scopo per il quale il contenuto multimediale è stato creato. Un esempio di schema di classificazione è quello definito da TVAnytime_v0.1IntentionCS.
Language Descrive una lingua dei dialoghi del programma.
L’elemento CreationInformation: aspetti di creazione e classificazione. – 120
Nome Definizione
SubtitleLanguage Descrive una lingua utilizzata nei sottotitoli, che costituiscono la sovrapposizione di testo che descrive i dialoghi del programma.
Release Descrive la data e la nazione cui fa riferimento la release del contenuto multimediale.
Country Indica gli stati in cui il contenuto multimediale è stato rilasciato per la prima volta. Questo localizzatore può essere differente dal luogo in cui è stato creato.
Date Indica la data in cui il contenuto è stato rilasciato per la prima volta. Questa data può essere diversa dalla data o date in cui è stato creato.
Target Descrive il target del contenuto multimediale in termini di classificazione di mercato, età e nazionalità.
Market Descrive un mercato targettizzato del contenuto. Un esempio di schema di classificazione è TVAnytime_v0.1TargetGroupCS.
Age Descrive l’intervallo di età del target di utenti per il contenuto.
Country Descrive la nazione alla quale il contenuto è destinato.
ParentalGuidance Descrive una classificazione di fascia di età consigliata (parental guidance) per il contenuto multimediale.
MediaReview Descrive una recensione riguardante il contenuto.
Semantica di GenreType:
Nome Definizione
GenreType Descrive il genere (classificazione più ampia) del contenuto multimediale. Un esempio di schema di classificazione è TVAnytime_v0.1ContentCS.
Type Indica il tipo del genere del contenuto. I tipi di genere sono definiti come segue:
• main – Il genere è il principale, o primario. Questo è il valore di default.

L’elemento UsageInformation: aspetti riguardanti l’uso del contenuto audiovisivo – 121
Nome Definizione
• secondary – Il genere specificato è un genere secondario, come un sottogenere.
• other – Il genere specificato è un genere alternativo, come un genere definito o utilizzato da terze parti.
Il listato del documento costruito prevede il seguente codice per l’elemento Classification (si fa sempre riferimento all’esempio della descrizione del programma “Passaggio a Nord Ovest”).
L’elemento Classification nel prototipo di documento costruito
<Classification> <Form href="TecaFastXmFormCS*"> <Name>Documentario</Name> </Form> <Genre href="TecaFastXmGenreCS*"> <Name>Cultura</Name> </Genre> <Release date="2001-10-03T18:16:08"> <Country>it</Country> </Release> <Target> <Age min="6"/> </Target> </Classification>
IV.3.3 L’elemento UsageInformation: aspetti riguardanti l’uso
del contenuto audiovisivo
L’elemento UsageInformation fa riferimento alla parte di descrizione che specifica le informazioni riguardo l’uso del contenuto multimediale. Nella figura seguente è possibile vedere la collocazione gerarchica di tale elemento nella struttura del documento Mpeg-7 di descrizione del programma di esempio “Passaggio a Nord Ovest”.

L’elemento UsageInformation: aspetti riguardanti l’uso del contenuto audiovisivo – 122
Figura: Struttura del documento di descrizione implementato: Dettaglio dell’elemento UsageInformation.
Si fa riferimento agli strumenti di descrizione della parte Usage di MDS Schema, che sono:
Strumento Funzionalità
Usage Tools Questi strumenti descrivono I metadati riguardo all’uso del contenuto multimediale.
UsageInformation DS include un descrittore Rights, uno o nessun FinancialResults DS, e diversi Availability DSs e associati UsageRecord DS.
Rights D contiene riferimenti ai proprietari dei diritti per poter ottenere informazioni sui diritti.
Financial D contiene la descrizione dei costi e dei ricavi generati dal contenuto multimediale.
Availability DS descrive i dettagli riguardanti la disponibilità del contenuto multimediale per l’uso.
UsageRecord DS descrive i dettagli concernenti l’uso del contenuto multimediale.
E’ importante notare che la descrizione di UsageInformation DS incorporerà nuove descrizioni ogni volta che il contenuto multimediale verrà utilizzato (ad esempio in UsageRecord DS, in Income nel Financial D), o quando vi saranno nuove modalità di accesso al contenuto stesso (Availability DS).
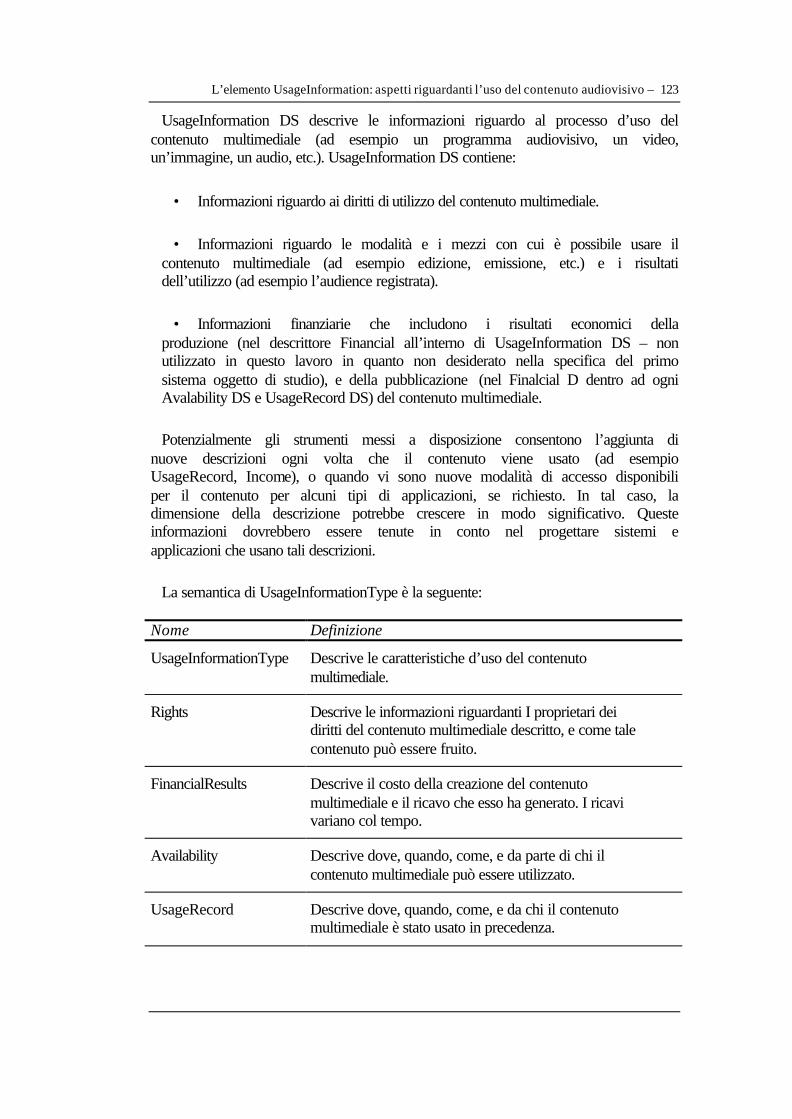
L’elemento UsageInformation: aspetti riguardanti l’uso del contenuto audiovisivo – 123
UsageInformation DS descrive le informazioni riguardo al processo d’uso del contenuto multimediale (ad esempio un programma audiovisivo, un video, un’immagine, un audio, etc.). UsageInformation DS contiene:
• Informazioni riguardo ai diritti di utilizzo del contenuto multimediale.
• Informazioni riguardo le modalità e i mezzi con cui è possibile usare il contenuto multimediale (ad esempio edizione, emissione, etc.) e i risultati dell’utilizzo (ad esempio l’audience registrata).
• Informazioni finanziarie che includono i risultati economici della produzione (nel descrittore Financial all’interno di UsageInformation DS – non utilizzato in questo lavoro in quanto non desiderato nella specifica del primo sistema oggetto di studio), e della pubblicazione (nel Finalcial D dentro ad ogni Avalability DS e UsageRecord DS) del contenuto multimediale.
Potenzialmente gli strumenti messi a disposizione consentono l’aggiunta di nuove descrizioni ogni volta che il contenuto viene usato (ad esempio UsageRecord, Income), o quando vi sono nuove modalità di accesso disponibili per il contenuto per alcuni tipi di applicazioni, se richiesto. In tal caso, la dimensione della descrizione potrebbe crescere in modo significativo. Queste informazioni dovrebbero essere tenute in conto nel progettare sistemi e applicazioni che usano tali descrizioni.
La semantica di UsageInformationType è la seguente:
Nome Definizione
UsageInformationType Descrive le caratteristiche d’uso del contenuto multimediale.
Rights Descrive le informazioni riguardanti I proprietari dei diritti del contenuto multimediale descritto, e come tale contenuto può essere fruito.
FinancialResults Descrive il costo della creazione del contenuto multimediale e il ricavo che esso ha generato. I ricavi variano col tempo.
Availability Descrive dove, quando, come, e da parte di chi il contenuto multimediale può essere utilizzato.
UsageRecord Descrive dove, quando, come, e da chi il contenuto multimediale è stato usato in precedenza.

L’elemento UsageInformation: aspetti riguardanti l’uso del contenuto audiovisivo – 124
Il descrittore Rights D descrive le connessioni coi proprietari dei diritti d’autore del contenuto multimediale (IPR, Intellectual Property Rights) e i diritti di accesso (Access Rights).
La proprietà dei diritti è dinamica e in quanto tale può passare da un proprietario ad un altro. Per esempio, i diritti per una produzione televisiva (o parte di essa) sono spesso licenziati e assegnati. Per consentire a dei sistemi informatici di rilevare la situazione attuale dei diritti, Rights DS trasporta un identificatore che può essere interpretato attraverso una apposita agenzia. Per gli scopi della gestione dei diritti (peraltro oggetto di un successivo lavoro di sviluppo da parte dei committenti di questo lavoro) tali agenzie e sistemi devono progressivamente essere in grado di abilitare i proprietari di diritti d’autore a dichiarare l’identità del proprietario attuale dei diritti stessi.
In questa prima fase si intende la proprietà dei diritti come un’entità trattata staticamente, prevedendo inizialmente che tali informazioni vengano inserite all’atto della creazione della descrizione del contenuto audiovisivo di un programma. Si prevede in successive revisioni di approfondire questa tematica di grande interesse per i proprietari di diritti sui contenuti di grandi dimensioni come la RAI. La semantica di RightsType è qui riportata:
Nome Definizione
RightsType Descrive una connessione al proprietario di diritti d’autore per l’accesso alle informazioni sui diritti.
Questo porta un identificatore (ID, come specificato nell’MPEG4 IP Intellectual Property Data Set) che consente l’accesso alle informazioni riguardanti l’attuale proprietario dei diritti circa il contenuto multimediale o la descrizione (consentendo l’uso di appositi database di gestione dei diritti d’autore).
RightsId Identifica il collegamento all’attuale proprietario dei diritti.
Un esempio di implementazione dell’elemento UsageInformation, con gli elementi selezionati per il prototipo, è il seguente:
L’elemento usageInformation nel prototipo di documento:
<UsageInformation> <Rights> <RightsId> <IDOrganization> <Name>Rai Produzione Radio Televisiva (esempio)</Name> </IDOrganization> <IDName> <Name>Rai TV Rights (esempio)</Name> </IDName> <UniqueID>RAICANALE1-TV001-ITALY-

La localizzazione temporale dell’audiovisivo: l’elemento MediaTime – 125
335666548(esempio)</UniqueID> </RightsId> </Rights> </UsageInformation>
IV.3.4 La localizzazione temporale dell’audiovisivo: l’elemento
MediaTime
Come mostrato dalla seguente figura, l’ultimo degli elementi figli di AudioVisual, nella struttura dati costruita per il prototipo, è MediaTime, nel quale vengono racchiuse informazioni fondamentali per la corretta descrizione del programma televisivo, come la data e l’ora di trasmissione sulla rete nazionale pubblica (uno dei tre canali televisivi RAI ad esempio) e la durata del programma inteso come sequenza audiovisiva.
Figura: Struttura dati del documento di descrizione implementato: Dettaglio dell’elemento MediaTime.
Le informazioni di inizio trasmissione (data e ora) e fine trasmissione (data e ora ricavabili facilmente dalla durata dell’audiovisivo) sono fondamentali per l’individuazione della risorsa attraverso gli attuali sistemi di richiesta audiovisivi all’interno degli archivi RAI.
In particolare per specifica di progetto dettata dai responsabili dell’archivio digitale Teca Fast, al quale si rivolge questo lavoro, le tre informazioni temporali di time code di inizio, fine e data di trasmissione sono necessarie per poter effettuare una richiesta del programma individuato attraverso una connessione intranet al sistema Teca Fast (assieme all’altra informazione fondamentale dell’identificatore del canale televisivo sul quale è stato trasmesso il programma).

La localizzazione temporale dell’audiovisivo: l’elemento MediaTime – 126
L’elemento AudioVisual consente di istanziare un elemento figlio proprio di tipo MediaTime, che risulta quindi molto utile per l’identificazione ad un livello gerarchico sufficientemente elevato di queste informazioni fondamentali.
Passando ad una descrizione generale del tipo MediaTime, esso specifica una nozione del tempo che è codificato con il media descritto. Per l’individuazione degli intervalli di tempo, in accordo con le specifiche temporali memorizzate nel media, il tipo di dato MediaTime è composto di due elementi, il tempo di inizio e la durata. Se deve essere specificato un solo riferimento temporale, la durata può essere omessa. La semantica di MediaTimeType è la seguente:
Nome Definizione
MediaTimeType Uno schema di descrizione per la specifica di un riferimento temporale del media o di un intervallo temporale del media, che utilizza I descrittori seguenti per specificare il tempo.
MediaTimePoint Un elemento che specifica un riferimento temporale del media utilizzando la data Gregoriana e il tempo giornaliero.
MediaRelTimePoint Un elemento che specifica un riferimento temporale del media utilizzando un numero di giorni e l’ora giornaliera.
MediaRelIncrTimepoint Un elemento che specifica un riferimento temporale nel media relativo ad una base dei tempi che conta le unità temporali.
MediaDuration Un elemento che specifica la durata di un periodo di tempo del media fornendo i giorni e l’orario (opzionale).
MediaIncrDuration Un elemento che specifica la durata di un periodo di tempo del media contando le unità temporali.
Il tipo di dato MediaTime utilizza due diverse modalità per descrivere un riferimento temporale o un periodo:
• Utilizzando il formato Gregoriano di data e orario (MediaTimePoint, MediaRelTimePoint, MediaDuration).
• Contando le unità temporali specificate attraverso degli attributi (MediaRelIncrTimePoint, MediaIncrDuration). Nel caso di segmenti video per esempio, queste unità temporali possono corrispondere al frame rate o ad un riferimento di temporizzazione codificato nel media.

La localizzazione temporale dell’audiovisivo: l’elemento MediaTime – 127
Questo consente di specificare il tempo del media in modo conforme al formato di tempo utilizzato per le specifiche temporali del media stesso. Un diagramma della struttura di mediaTimeType viene riportato nella seguente figura:
Figura: Diagramma del tipo di dato MediaTimeType.
Il tipo di dato MediaTimePoint specifica un istante di tempo, secondo la data e l’orario Gregoriani, delle informazioni temporali che sono contenute nel media. Il formato si basa sulla norma ISO 8601. Per ridurre i problemi di conversione solamente un sottoinsieme del formato ISO 8601 viene utilizzato. Le frazioni di secondo sono specificate secondo il tipo di dato timePoint.
La semantica del tipo di dato mediaTimePoint è la seguente:
Nome Definizione
mediaTimePointType Un tipo di dato che specifica un riferimento temporale del media utilizzando la data e l’orario Gregoriani senza specificare il TZD, Time Zone Difference (a questo proposito si rimanda alla definizione del tipo di dato TimePoint nel listato completo di MDS Schema Mpeg-7 documento FCD N3966):
YYYY-MM-DDThh:mm:ss:nnnFNNN
I simboli utilizzati per le cifre dei corrispondenti elementi di data e tempo sono i seguenti:
• Y: Year, Anno che può essere un numero variabile di cifre.
• M: Month, Mese.
• D:Day, Giorno.
• h: hour, ora.

La localizzazione temporale dell’audiovisivo: l’elemento MediaTime – 128
Nome Definizione
• m: minute, minuto.
• s: second, secondo.
• n: numero di frazioni, nnn può essere un numero arbitrario di cifre tra 0 e NNN-1 (NNN e con esso nnn possono avere un numero di cifre arbitrario).
• N: numero di frazioni di un secondo che vengono tenute in conto da nnn. NNN può avere un numero arbitrario di cifre non limitato a tre.
Vengono utilizzati anche dei delimitatori per la specifica dell’orario (T) e il numero delle frazioni di secondo (F).
Parallelamente alla specifica della data Gregoriana, per consentire una precisione maggiore del secondo, è disponibile la specifica del time code di orario con il conteggio del numero (nnn) delle frazioni di secondo (FNNN). Se viene utilizzato il conteggio delle frazioni, il numero di frazioni che costituiscono un singolo secondo (FNNN) deve essere specificato insieme al numero di conteggio delle frazioni (nnn). Attraverso FNNN si definisce intervallo di valori del numero conteggiato di frazioni di secondo (nnn). Quindi l’intervallo di valori di ‘nnn’ è limitato tra 0 e FNNN-1. Per supportare l’attuale pratica utilizzata nell’ambito degli audiovisivi, le espressioni di tempo specificano una frazione di secondo conteggiando le frazioni predefinite al posto dell’espressione decimale utilizzata con i tipi di dato che definiscono data e orario in XML Schema. Ad esempio per istanziare un riferimento temporale timeIstant al valore T13:20:01.235 bisognerebbe esprimerlo utilizzando il tipo di dato timePoint con T13:20:01:235F1000. In accordo col numero di cifre decimali utilizzate il numero di frazioni di ogni secondo sono 1000 come specificato nel tipo di dato timePoint.
Il tipo di dato mediaDuration specifica come abbiamo detto la durata di un periodo di tempo in accordo con i valori di giorno e orario di una notazione temporale codificata all’interno del media. Il formato fa riferimento ad un sottoinsieme della norma ISO 8601 (per ridurre i problemi di conversione). Le frazioni di secondo sono specificate in accordo al tipo di dato timePoint.
La semantica di mediaDuration è riportata nella tabella seguente:
Name Definition
mediaDurationType Un tipo di dato che specifica la durata di un periodo di tempo in accordo alle nozioni di tempo in giorni e ore codificate nel media senza specificare una differenza in TZD (al proposito si fa riferimento al tipo di dato

La struttura dati progettata per il prototipo di descrizione metadati audiovisivi secondo Mpeg-7 – 129
Name Definition ‘duration’).
Un tipo di dato semplice simpleType che rappresenta una durata temporale utilizzando una rappresentazione lessicale in giorni (nD), durata temporale e specifica della frazione (TnHnMnSnN) includendo la specifica del numero di parti in cui è frazionato il secondo (nF):
(-)PnDTnHnMnSnNnF
Il tipo mediaDurationType è derivato da basicDurationType per restrizione.
Le espressioni regolari che sono specificate all’interno dei particolari del Pattern sono illustrate in dettaglio nella parte Annex E del documento N3966 che specifica l’MDS Schema Mpeg-7 versione FCD.)
Un esempio di implementazione dell’elemento MediaTime è il seguente:
<MediaTime> <MediaTimePoint>2001-10-03T18:16:08</MediaTimePoint> <MediaDuration>PT52M55S</MediaDuration> </MediaTime>
IV.3.5 La struttura dati progettata per il prototipo di descrizione
metadati audiovisivi secondo Mpeg-7
Dopo aver analizzato le strutture dati di Mpeg-7 MDS impiegate e alcuni esempi della loro implementazione, vediamo adesso il prototipo del documento completo costruito per descrivere con metadati audiovisivi le risorse ‘programma televisivo’ all’interno dell’archivio di Teca Fast. Il listato del codice prodotto è riportato in appendice.

Considerazioni sull’uso di un DBMS XML nativo rispetto ai DBMS tradizionali – 130
V° Capitolo – Realizzazione del prototipo di sistema Mpeg-7 Metadata eXperimental Repository su DBMS
Server XML nativo
V.1 Le specifiche di progetto: la ricerca, lo sviluppo e
l’applicazione di nuove tecnologie Mpeg-7 nella realizzazione di
un sistema di gestione metadati audiovisivi.
Nel capitolo IV si è analizzato lo standard di descrizione Mpeg-7 ed è stato illustrata la costruzione della struttura dati per il prototipo descritto in questo capitolo, mostrando l’impiego degli strumenti del Multimedia Description Scheme Mpeg-7 (MDS Schema versione FCD) nella definizione ex-novo di un profilo applicativo “custom” adatto ad un prototipo di descrizione e gestione metadati audiovisivi per il sistema di Teca Rai. Il risultato del lavoro svolto sullo standard Mpeg-7 è stata la produzione di una prima struttura dati per il generico documento di descrizione metadati riferiti all’entità “programma televisivo”, dettagliatamente illustrato nel capitolo IV, che riporta anche il codice completo della descrizione di un programma tv utilizzato come esempio.
Successivamente si è passati alla implementazione del prototipo di sistema per la gestione di metadati audiovisivi, con la preparazione della piattaforma hardware e software e della connettività in rete Internet. Come suggerito dalle specifiche e data la complessità della struttura dati individuata è stato scelto come software il Tamino XML DataBase Server, un DBMS (Database Management System) che implementa tecnologie native XML, il cui componente fondamentale è un engine (chiamato X-Machine) in grado di interpretare, gestire e archiviare documenti e dati in formato standard XML, senza necessità di operazioni di trasformazione o mappatura in un sottosistema relazionale. Si è tenuto in considerazione anche la presenza sul territorio della casa madre che realizza e distribuisce il prodotto, la Software AG, nello specifico la sede italiana, che ci ha assistito nella configurazione del sistema, riconoscendo l’importanza strategica di un progetto come questo orientato alle nuove applicazioni verticali di gestione di risorse di archivio multimediale.
V.1.1 Considerazioni sull’uso di un DBMS XML nativo rispetto ai
DBMS tradizionali
L’introduzione e l’integrazione delle tecnologie XML è stata ampliamente trattata nel precedente capitolo II. Abbiamo visto che esse rappresentano uno dei maggiori passi avanti nella gestione e nello scambio dei dati attraverso ambienti internet-intranet.

Considerazioni sull’uso di un DBMS XML nativo rispetto ai DBMS tradizionali – 131
In passato XML è stato spesso incompreso e etichettato come semplice successore di HTML. In realtà si è visto che HTML è destinato a permanere (sotto le spoglie ad esempio di XHTML) nella parte di formattazione e visualizzazione di documenti web. XML va a prendere posizione nella gestione dei dati che stanno dietro la pubblicazione (pubblicazione via web, wap, set-top-box, terminali di vario tipo o anche formati di stampa etc.). XML da subito porta grandi vantaggi nella gestione e scambio di risorse di archivio, con particolare predisposizione alla rappresentazione di ogni tipo di struttura dati. Alcune considerazioni sull’uso di una piattaforma per la gestione dei metadati basata su XML nativo:
• XML è un metalinguaggio che può definire e descrivere ogni tipo di informazione ed è per definizione estensibile. Utenti singoli, gruppi di lavoro, e organismi di standardizzazione utilizzano XML come un tipo di grammatica indipendente dalla piattaforma per definire linguaggi basati sui marcatori.
• Si basa sul testo ed è facile da leggere: i documenti possono essere compresi sia dalle applicazioni che da utenti umani. Sempre per definizione il contenuto di documenti XML è etichettato con i tag. I tag come <Title> o <Name> chiaramente specificano quale tipo di informazione è contenuta all’interno di un elemento del documento. Poiché questi tag sono espressi in ogni documento, i documenti XML possono essere compresi anche se non si dispone dell’applicazione che li ha generati. Anche utenti umani possono leggere l’XML in quanto i documenti sono in testo piano formato ASCII (o, come nel caso preso in esame, in UNICODE), cosa che ne consente una manutenzione più semplice.
• E’ ideale per i documenti contenenti informazioni strutturate gerarchicamente. Gli elementi dei documenti XML possono essere annidati per costruire strutture informative complesse. In linea di principio è possibile convertire documenti XML con una struttura complessa in modo da utilizzare DBMS a tecnologia relazionale, ma si tratta di un’operazione tutt’altro che ottimale. Mappare elementi XML con il contenuto di tabelle relazionali è un processo molto spesso lento e che richiede un grande sforzo di normalizzazione e ottimizzazione prima che un documento XML possa essere archiviato in maniera appropriata.

Considerazioni sull’uso di un DBMS XML nativo rispetto ai DBMS tradizionali – 132
Figura: Un confronto sull’impiego di un DBMS relazionale e un DBMS XML
nativo per la gestione di dati descritti in linguaggio XML
• XML è indipendente dalla modalità di presentazione: separa il contenuto del documento dalla sua visualizzazione. I fogli di stile definiscono come gli elementi del documento devono essere formattati per l’uscita verso una varietà di terminali o supporti di visualizzazione. Gli standard associati ad XML consentono, come abbiamo visto nel capitolo II, la personalizzazione di un dato elemento informativo senza la necessità di modificare il contenuto del documento originale.
• XML è multilingua, basato sulla codifica UNICODE. La capacità di rappresentare caratteri in quasi tutti i linguaggi mondiali – inclusi il Cinese e il Giapponese – facilita enormemente lo scambio di dati e documenti in un comunità globale. Gli strumenti XML generalmente non devono essere riscritti per supportare formati di testo scritti in lingue orientali, rendendo gran parte dei prodotti sviluppati per le nazioni occidentali immediatamente disponibili in tutto il mondo.
• L’uso di un linguaggio standard come XML favorisce l’integrazione degli aspetti di business abbattendo gran parte delle barriere al commercio elettronico: Le attuali soluzioni di Electronic Data Interchange (EDI) sono difficili e costose da implementare e mantenere. Con l’uso di tecnologie XML ci si avvantaggia della flessibilità nella definizione di vocabolari specifici per settori industriali, e diviene anche possibile per le piccole e medie imprese accedere alle reti EDI utilizzando standard semplici ed economici basati su Internet.
• E’ un metalinguaggio aperto e lo standard viene supportato da tutti i grandi produttori software: compagnie come IBM, Microsoft, Oracle, Sun Microsystem, e la stessa Software AG che è stata una delle prime a realizzare un sistema con un engine XML nativo. Tutte queste aziende hanno pesantemente investito sull’XML e sono attive nel contribuire al processo di standardizzazione.

Considerazioni sull’uso di un DBMS XML nativo rispetto ai DBMS tradizionali – 133
Questi sono solo alcuni degli aspetti che giustificano l’impiego di un Server XML nativo per la gestione di strutture dati basate completamente su XML, poiché, come abbiamo ampliamente visto, lo standard Mpeg-7 e in particolare il Description Definition Language e il Multimedia Description Schemes sono completamente basati su questo linguaggio. La piattaforma software implementata, Tamino v.2.2.9 di Software AG, è proprio un Information Server basato su XML, che gestisce in modo nativo il formato XML per memorizzare ed estrarre dati di ogni tipo. Utilizzando l’XML come una “meta-Struttura”, il server DBMS XML Tamino consente di comporre le informazioni da dati che possono essere originati da differenti sistemi di memorizzazione e DBMS. Sfruttando la capacità di XML di descrivere i dati di tipi differenti (per esempio dati di un DB relazionale, grafica, suoni, video o documenti di testo) esso garantisce un’interoperabilità di sistemi e funzioni strettamente legata alla produzione di servizi web e di rete in genere. Ma nel nostro caso la scelta di un DBMS XML è nata, come è stato più volte ricordato, all’atto della definizione delle specifiche prevedendo la gestione di strutture di metadati descritte in linguaggio XML (le complesse descrizioni Mpeg-7 dei metadati audiovisivi), che viene gestita in maniera più efficiente e senza trasformazioni di struttura rispetto ad ogni altro tipo di DBMS relazionale e a oggetti.
Tamino, che sta per “Transaction Architecture for the Management of INternet Objects” offre da subito un ambiente di sviluppo completamente orientato ai servizi Internet/Intranet (una delle specifiche principali di progetto). Le informazioni memorizzate nel server DB XML vengono da subito rese disponibili come “Internet Objects” accessibili non solo tramite comandi innestati nella URL, ma anche con delle URL assolute che puntano direttamente ai documenti XML archiviati come se fossero memorizzati direttamente nel file system del server web.
Inoltre la piattaforma implementa funzionalità avanzate di accesso e scambio dati con tutti i principali DBMS, oltre ad avere un DBMS SQL interno oltre al DBMS XML nativo, risultando anche in questo senso un sistema preferenziale per le esigenze dell’azienda committente del prototipo, come la Rai e le Teche Rai, che necessitano di accedere e scambiare dati con i diversi sistemi preesistenti nei vari archivi e con le organizzazioni verso le quali si intendono offrire applicazioni web based (nel caso specifico acquirenti di contenuti e diritti televisivi, società di documentazione e operatori della produzione audiovisiva).
Nelle figure seguenti viene mostrata schematicamente l’architettura della piattaforma software Tamino utilizzata per il prototipo, a livello di componenti di sistema e protocolli, linguaggi e standard impiegati:
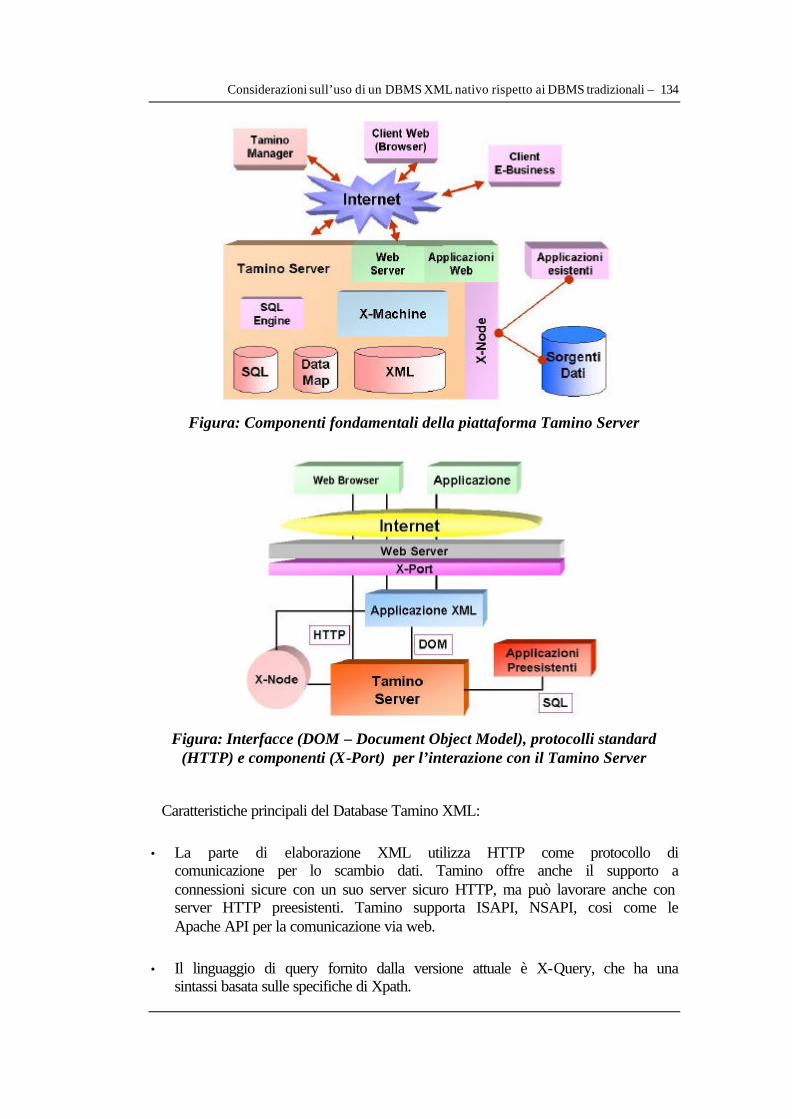
Considerazioni sull’uso di un DBMS XML nativo rispetto ai DBMS tradizionali – 134
Figura: Componenti fondamentali della piattaforma Tamino Server
Figura: Interfacce (DOM – Document Object Model), protocolli standard
(HTTP) e componenti (X-Port) per l’interazione con il Tamino Server
Caratteristiche principali del Database Tamino XML:
• La parte di elaborazione XML utilizza HTTP come protocollo di comunicazione per lo scambio dati. Tamino offre anche il supporto a connessioni sicure con un suo server sicuro HTTP, ma può lavorare anche con server HTTP preesistenti. Tamino supporta ISAPI, NSAPI, cosi come le Apache API per la comunicazione via web.
• Il linguaggio di query fornito dalla versione attuale è X-Query, che ha una sintassi basata sulle specifiche di Xpath.

Considerazioni sull’uso di un DBMS XML nativo rispetto ai DBMS tradizionali – 135
• Supporta l’elaborazione dei fogli di stile utilizzando oggetti XML (XSL, CSS) in modalità server side (attraverso l’impiego di servlet Java).
• Supporta l’uso degli XML namespace.
• Implementa il Document Object Model (DOM) standard ed esteso (funzionalità specifiche della piattaforma).
• Interfaccia i DBMS esterni tramite il componente X-Node che utilizza ODBC.
• Supporta SQL dinamico ed embedded (per programmi C) con il SQL Engine interno.
Nella figura seguente si vede la struttura a strati della piattaforma impiegata:
Figura: vista a livelli della piattaforma di archiviazione, gestione, elaborazione
e comunicazione implementata nel Server XML del prototipo del sistema di gestione metadati Mpeg-7.
Diverse API consentito di accedere a Tamino da differenti ambienti di programmazione (Java, C++, ...). Alcune forniscono i comandi di elaborazione e inserimento documenti, definizione schemi di struttura ed elaborazione di query, che verranno in seguito mostrate nell’implementazione delle interfacce web realizzate per il prototipo. E‘ possibile eseguire in remoto tutte le classiche funzioni di amministrazione grazie ad esempio al System Management Hub che vedremo successivamente in dettaglio.
Il componente principale del Server XML è X-Machine composto a sua volta di un Parser, un interprete di interrogazioni in linguaggio Xquery-Xpath, un Object Processor e un Object Composer, rispettivamente per l’elaborazione e costruzione di oggetti dati in formato XML, il Data Map per la descrizione delle strutture dati,

Configurazioni hardware e software per il prototipo server e i client. – 136
ed un XML Data Store nativo. Le loro funzionalità verranno approfondite in seguito nell’analisi di X-Machine, e sono riportate nella figura seguente.
Figura: Componenti e protocolli di comunicazione della piattaforma Tamino
Server. Dettaglio dei componenti chiave per la gestione di risorse XML: il Parser XML, gli Object Processor e Composer, il Data Map e il Native XML
Data Store
V.1.2 Configurazioni hardware e software per il prototipo server
e i client.
La piattaforma hardware/software impiegata per il server (chiamato TAMINO1) su cui gira il DBMS XML Tamino e gli altri servizi come il web server e i servlet Java è la seguente:
Configurazione del Server TAMINO1 impiegato per il prototipo: (Mpeg7 eXperimental Metadata Repository – Internet Tv – Vivai d’Impresa)
Hardware:
• Processore Pentium III 800 Mhz di clock, Memoria RAM 512 Mbytes, Disco fisso Eide Ultra Ata 10 Gbytes, Monitor 17 pollici flat panel HP-LG, Connessione a rete di alimentazione con backup, Scheda di rete Ethernet 10/100 Mbit/sec, Connessione di rete con linea HDSL 2 Mbit/sec dedicata verso la dorsale Interbusiness – connettività ottenuta grazie al contributo di Telecom Italia al progetto Vivai d'Impresa Elis – con indirizzo IP pubblico.
Software:
• Sistema operativo Microsoft Windows 2000 Professional, Web server: Apache

Configurazioni hardware e software per il prototipo server e i client. – 137
WebServer 1.3.12, Servlets: Apache Jserv 1.1, Ambiente Java: JRE 1.2.2, Browser HTML: Microsoft Internet Explorer 5.5, Parser XML : Microsoft MSXML v.3.0, TAMINO XML DB Server Development Edition v.2.2.9 di Software AG, System Management HUB di Software AG, XTS Proxy Server, Software di editing codice HTML: Macromedia Dreamveawer 3.0, Software editing e validazione XML, DTD e XML Schema: XML SPY v.3.5, Software di editing codice testuale: UltraEdit v.8.1.
La configurazione hardware e software delle postazioni impiegate come client per lo sviluppo e il test:
Postazione Client 1: Internet Tv 1
Hardware:
• Processore Pentium III 800 Mhz, Memoria RAM 128 Mbytes, Disco fisso Eide Ultra Ata 8 Gbytes, Monitor 17 Pollici, Scheda di rete Ethernet 10/100 Mbit/sec, Connessione con linea HDSL 2Mbit/sec con indirizzo IP statico pubblico.
Software:
• Sistema Operativo Microsoft Windows 98, Browser Web Microsoft Internet Explorer 5.5, Service pack con Microsoft MSXML Parser versione 3.0, Software di editing documenti XML: XML SPY v.3.5, Software editing fogli di stile XSL: Stylus di Excelon Software.
Postazione Client 2: Internet TV 2
Hardware:
• Processore Pentium III 800 Mhz, Memoria RAM 128 Mbytes, Disco fisso Eide Ultra Ata 8 Gbytes, Monitor 17 Pollici, Scheda di rete Ethernet 10/100 Mbit/sec, Connessione di rete Elis-Internet 2 con dorsale in fibra ottica a 155Mbit/sec fornita da Telecom Italia per il progetto Reseau, condivisa con la sottorete di Vivai d’impresa, con indirizzo IP privato.
Software:
• Sistema Operativo Microsoft Windows 2000 Professional, Browser Web Microsoft Internet Explorer 5.5, Service pack con Microsoft MSXML Parser versione 3.0, Software di editing documenti XML: XML SPY v.3.5, Software editing pagine HTML e form Javascript: Microsoft FrontPage 2000. Excelon Software, Software di editing codice testuale: UltraEdit v.8.1.
Il server su cui è stato sviluppato il prototipo di Repository Metadati Mpeg-7 possiede un proprio indirizzo IP pubblico ed è connesso alla rete internet tramite una linea HDSL dedicata, con velocità di connessione 2 Mbit/sec, interconnessa alla dorsale di rete Interbusiness di Telecom Italia. Un semplice schema che riporta le connessioni di rete del server e di uno dei due client utilizzati nel laboratorio Internet TV di Vivai d’Impresa – Elis, configurati appositamente per lo sviluppo del prototipo, è il seguente:

L’elaborazione dei documenti xml: X-Machine – 138
Figura: ambiente di rete del prototipo con server DBMS implementato (parte del laboratorio di progetto Internet TV – presso i Vivai d’Impresa, Elis)
V.1.3 L’elaborazione dei documenti xml: X-Machine
Tra le funzionalità base del server DBMS Tamino c’è l’immagazzinamento di dati in formato XML, che non subisce operazioni di conversione in altri formati dati, come ad esempio le tabelle relazionali.
Questa funzionalità è fornita dal componente fondamentale della piattaforma, chiamato X-Machine. Esso si occupa di memorizzare e gestire oggetti XML (ben formati o validi) all’interno di XML Data Store. X-Machine è in grado di gestire anche dati non-XML (come testo, file binari) e integra le informazioni contenute in sorgenti dati e applicazioni esterne attraverso il componente X-Node. L’accesso ai documenti XML archiviati avviene utilizzando il linguaggio di interrogazione Xpath, con alcune estensioni. E’ possibile vedere uno schema dell’architettura di X-Machine nella figura seguente:

L’elaborazione dei documenti xml: X-Machine – 139
Figura: architettura di X-Machine e vista dei componenti che gestiscono i
documenti XML e non-XML.
Tornando alle funzionalità di X-Machine, quella principale è l’elaborazione di documenti XML, che passano attraverso diversi passi e componenti.
Gli oggetti XML che devono essere memorizzati da X-Machine sono descritti dal relativo schema (il DTD) inserito nel Data Map di Tamino. Il componente Data Map contiene tutte le informazioni per la memorizzazione, l’indicizzazione e l’elaborazione di oggetti XML per un’efficiente gestione dei dati. Tra le sue funzionalità la costruzione e configurazione di parametri di indicizzazione standard e testuali, l’integrazione con applicazioni esterne, la memorizzazione di strutture dati in tabelle SQL e file Adabas.
Il primo passo è l’elaborazione da parte del parser interno ad X-Machine, che controlla la correttezza sintattica degli schemi e si assicura che gli oggetti XML in ingresso siano ben formati. Successivamente gli oggetti XML vengono passati all’ Object Processor per la memorizzazione. Gli schemi contenuti nel Data Map consentono all’Object Processor di ottenere le informazioni necessarie a memorizzare dati nell’ XML Store, e/o in tabelle SQL o file Adabas esterni. Queste sorgenti dati esterne sono integrate attraverso il componente X-Node di Tamino. Quando l’informazione deve essere richiesta dall’XML Store, entra in gioco l’Object Composer. Utilizzando le regole di memorizzazione e richiesta definite nel Data Map, Object Composer costruisce gli oggetti informativi e li restituisce come documenti XML, anche se si tratta di dati non memorizzati all’interno ma provenienti da altre sorgenti dati. Nel caso più semplice, quello previsto da questa prima implementazione, gli oggetti richiesti tramite un’interrogazione sono memorizzati internamente come oggetti XML. Nei casi più complessi viene richiesta la comunicazione con il componente X-Node per costruire un documento di risultato in XML da dati non-XML (ad esempio per l’estrazione-caricamento di dati in altri DBMS non XML nativi).

La piattaforma basata sul web: web server e componenti di rete – 140
Le interrogazioni sui dati vengono processate dal Query Interpreter prima di agire sull’Object Composer. Il Query Interpreter infatti riceve le richieste X-Query e interagisce con l’Object Composer per richiedere oggetti XML in accordo a quanto specificato dalla struttura degli schemi dei DocType memorizzati nel Data Map.
V.1.4 La piattaforma basata sul web: web server e componenti di
rete
La comunicazione con il sistema Tamino avviene tramite una interfaccia http standard. Al momento dell’installazione il DBMS Tamino viene connesso con il web server (nel nostro caso Apache WebServer 1.3.12) attraverso il modulo X-Port. Tamino viene richiamato attraverso una URL della forma << http://webserver/tamino/taminodbname >> dove al posto di “webserver” nel nostro caso viene utilizzato l’indirizzo IP del server su cui è installato Tamino e gli altri componenti, ma che generalmente indica il nome di dominio del server web, mentre “tamino” è un nome fissato durante l’installazione, e “taminodbname” è il nome del DataBase Tamino a cui viene indirizzata la richiesta sotto forma di URL.
Alla chiamata, il server web attiva il modulo X-Port che passa la richiesta con una comunicazione TCP/IP al database indirizzato. Il numero di porta IP per la comunicazione tra il componente X-Port e il database viene definito all’atto dell’installazione del database e non dovrebbe essere utilizzato da nessun’altra applicazione.
Figura: la comunicazione tra applicazione client (ad esempio il browser web) e
il Server XML Tamino avviene tramite protocollo HTTP, e l’impiego del componente X-Port.

L’amministratore del server e il System Management HUB – 141
V.1.5 L’amministratore del server e il System Management HUB
Il componente Tamino Manager è una applicazione client/server che consente l’amministrazione del server Tamino (e di altri server Tamino eventuali). Il componente client è l’interfaccia web dell’utente chiamata System Management Hub. Alternativamente è disponibile una interfaccia batch per la chiamata di funzioni di DBA (DataBase Administration) su linea di comando. Con l’installazione del server XML e del System Management Hub si configurano sulla postazione server anche degli agenti software chiamati Tamino Agents, come l’Administration Agent che, da componente attivo, effettua operazioni di controllo come: creazione e cancellazione di Database, avvio e stop di processi software sul server, gestione operazioni di backup e restore, controllo dei parametri. Nella figura seguente viene mostrato lo schema di comunicazione dell’interfaccia del Tamino Manager:
Figura: l’interfaccia del Tamino Manager e la comunicazione con
l’Administration Agent e il server XML.
V.1.6 Configurazione del DBMS XML e procedura di creazione
DB prototipo
Il procedimento di creazione del database, come ogni altra operazione di amministrazione, avviene attraverso il System Management Hub connesso al Tamino Manager, un software applicativo accessibile tramite un comune browser web (può gestire diversi nodi server Tamino dislocati in rete locale o su internet).
Per la creazione del database, dopo aver installato i componenti del server Tamino, è possibile utilizzare il Tamino Manager: l’operazione di “Create Database” configura il kernel del server e alloca e inizializza gli spazi di

Configurazione del DBMS XML e procedura di creazione DB prototipo – 142
memorizzazione fisica del database. Per distinguere le diverse istanze di Database Tamino ad ognuno viene assegnato un nome unico (nel caso del prototipo “tecafast2”). Tamino utilizza il concetto di locazione (location) che identifica i contenitori (spazi fisici) allocati. E’ possibile settare anche diversi parametri riguardanti le risorse del server (dimensioni della cache, accessi, etc.) e le dimensioni del database (dimensione degli spazi di memoria allocati su disco), oltre a parametri di ottimizzazione. In seguito alla procedura di creazione del database, il nuovo nome del Tamino DB Server diviene visibile nel sottoalbero dei Database del Tamino Manager.
Figura: Immagine del System Management Hub e della lista dei database creati
e attivi nel server DB.
V.2 La struttura dati: costruzione dello schema del documento
Mpeg-7 creato
Il database Tamino risulta in grado di memorizzare documenti XML anche se non viene definita una struttura nella mappa dati (Data Map). Il server XML Tamino utilizza le definizioni di struttura di documenti xml (chiamati DocType) nella Data Map oltre che per controllare la correttezza dei documenti inseriti, anche per migliorare le prestazioni di ricerca. La definizione della DocType all’interno del Data Map consente infatti l’indicizzazione dei dati contenuti nei documenti XML, abilitando anche il controllo sui tipi di dato, sulla mappatura nella struttura di dati contenuti in DB esterni (SQL, Adabas, etc.).
L’interfaccia che viene fornita per accedere alla definizione dei DocType e degli elementi della struttura è il Tamino Schema Editor. Essa consente di caricare le Document Type Definition dei documenti xml, di definire tali DTD come DocType nella Data Map, definendo anche le collection che raggruppano le DocType all’interno di ogni DB.

Definizione della gerarchia di Collezione e del DocType nel DB – 143
Per quanto riguarda la struttura dati del prototipo di documento di metadati Mpeg-7, esso è stato costruito facendo riferimento alle specifiche di MDS Schema, utilizzato per validare i documenti costruiti per il test del DB (la descrizione dei quattro programmi tv trasmessi sulla rete nazionale RAIUNO il 10 marzo 2001).
Non è possibile far processare nel Data Map l’intero codice di Mpeg-7 MDS Schema, in quanto la Data Map per questa versione non supporta ancora il processamento di XML Schema, ma solo DTD tradizionali. Inoltre non sarebbe conveniente comunque processare l’intero MDS Schema in quanto il codice tanto vasto da risultare ingestibile, codice peraltro in buona parte non utilizzato in questa prima implementazione basata sull’uso dei soli metadati testuali. Si è scelto di processare i documenti di descrizione Mpeg-7 fornendo una DTD per la definizione della struttura dati nella Data Map.
Una fase di sviluppo è stata quindi impiegata nella costruzione del codice della DTD della struttura del documento di descrizione Mpeg-7, non ricavabile automaticamente da un processo di conversione da XML a DTD (implementato ad esempio nel software XML Spy). Manualmente sono stati ricostruiti nella sintassi DTD i vincoli e le regole sui tipi e le strutture di dato previsti dall’MDS Schema, con i limiti di descrizione di struttura analizzati nel capitolo II. I documenti di descrizione dei quattro programmi TV di test sono stati dunque validati nuovamente per verificare la correttezza della DTD che definisce l’albero della struttura dati. Il codice della DTD costruita è riportato interamente nell’appendice C.
V.2.1 Definizione della gerarchia di Collezione e del DocType nel
DB
La definizione della DocType o Schema del documento di descrizione metadati nel DB avviene utilizzando l’applicazione Schema Editor di Tamino. Questa applicazione consente non solo di definire le gerarchie di Collection (che raggruppano gli schemi-DocType di documento) e la DocType stessa, ma anche di navigare nella struttura dati con un’interfaccia grafica che mostra l’intero albero e consente di controllare i parametri per ogni elemento e attributo della schema, compresi aspetti di mappatura dei dati con DB e applicazioni esterne.

Definizione della gerarchia di Collezione e del DocType nel DB – 144
Figura: L’interfaccia grafica dell’applicazione Tamino Schema Editor:
Caricamento della Document Type Definition e definizione della Collection e del DocType (Schema) nel Data Map del server XML.
Figura: alcuni dettagli della struttura dati definita nel DocType “Mpeg7” nella
visualizzazione ad albero fornita dallo Schema Editor

Definizione della gerarchia di Collezione e del DocType nel DB – 145
Una Collection raggruppa logicamente i Doctypes (schemi di documento) che consentono di raggruppare i dati riguardanti diverse aree di applicazione (ad esempio i documenti di descrizione separatamente dalle immagini o dai fogli di stile). I doctype possono avere gli stessi nomi in diverse Collection. Per questo ad ogni accesso alle risorse del Server DB deve essere indicato il nome della Collection oltre che del Doctype. Tutti i documenti per i quali non viene definito uno schema nella Data Map vengono memorizzati in una Collection speciale chiamata ino:etc. Un documento viene riconosciuto come appartenente ad un dato Doctype confrontando il nome di quest’ultimo con il nome dell’elemento radice.
Per creare lo schema di documento e definire il Doctype in Tamino, utilizzando lo Schema Editor, è stato processato il file della DTD realizzato in precedenza con la definizione della struttura. Alle informazioni contenute nella DTD lo Schema Editor aggiunge alcune opzioni specifiche.
Figura: Caricamento del file della DTD nello Schema Editor e definizione dello Schema/Doctype con la struttura di documento nella Data Map del server XML.
Figura: Procedura di definizione dello Schema/Doctype a partire dalla DTD,
utilizzando lo Schema Editor o l’interfaccia web.

Definizione della gerarchia di Collezione e del DocType nel DB – 146
Nel prototipo all’interno del database chiamato “tecafast2” è stata definita la Collection “tecafast2collection” come predefinita. In questa Collection è stato definito lo schema/Doctype principale “Mpeg7” e uno secondario “immagini” per effettuare dei test sulla gestione di documenti non-XML (nello specifico file di immagini) all’interno del DB. Un ulteriore Doctype può contenere documenti del tipo fogli di stile, e nella figura seguente si vede un esempio di raggruppamento degli schemi di definizione struttura all’interno della collection definita (nel Data Map del server).
Figura: Nel Data Map del server XML è stata definita la collection e alcuni
doctype, il principale è Mpeg7, che definisce la struttura di documento in modalità nativa XML.
Dall’amministratore del server accessibile con il System Management Hub (SMH) in remoto è possibile controllare anche il Data Map di ogni DB. Nella figura seguente all’interno del Data Map del DB si vedono definiti i Doctype Mpeg7 (di tipo XML nativo) e Immagini (non-XML). Un’immagine della sezione di DataMap nell’interfaccia del SMH è riportata nella figura seguente:
Figura: vista del Data Map del DB XML attraverso l’interfaccia
dell’amministratore remoto (System Management Hub)

Definizione della gerarchia di Collezione e del DocType nel DB – 147
V.3 Implementazione delle interfacce web di interazione con il
DB XML del prototipo
E’ stato realizzato un sito web per rendere visibili in rete le informazioni riguardanti il progetto Internet Tv di Vivai d’Impresa e Rai, e per fornire l’accesso alla prima versione delle applicazioni web per l’interazione con il prototipo DB, denominato “Mpeg-7 Metadata eXperimental Repository” o Mpeg7-MXR. La home page del sito costruito e pubblicato on-line con dominio web http://www.tville.it è visibile nella seguente immagine:
Figura: La home page del sito sviluppato per pubblicare i risultati e le
interfacce di test del prototipo di sistema per la gestione di metadati Mpeg-7
Attraverso un collegamento ipertestuale si accede alla Web Interactive Interface sviluppata per il prototipo. Lo scopo di questa prima versione è mostrare le potenzialità del sistema e la facilità di accesso alle risorse attraverso l’impiego di un web browser di ultima generazione (si richiede almeno la versione 5 di Microsoft internet Explorer, abilitato alla visualizzazione di documenti XML).
La pagina principale dell’interfaccia interattiva creata per il sistema Mpeg-7 MXR (Metadata eXperimental Repository) è mostrata nella seguente figura:

Costruzione dell’interfaccia interattiva di inserimento documenti nel DB – 148
Figura: La home page dell’interfaccia interattiva realizzata che dà accesso alle
varie funzionalità di ricerca, inserimento e eliminazione documenti e definizione strutture dati nel DB del prototipo tramite il browser web.
V.3.1 Costruzione dell’interfaccia interattiva di inserimento
documenti nel DB
Viene ora mostrato il codice con il quale è stata costruita una delle interfacce di interazione fondamentali accessibili dal web: l’interfaccia di inserimento di documenti di descrizione nel DB. Vengono utilizzate due funzioni Javascript e due form per consentire all’utente di impostare l’indirizzo del DB Server con il quale si vuole interagire (funzione utile in fase di sviluppo) e di scegliere un file contenente il codice XML con la descrizione dei programmi tv basata sulla struttura di metadati Mpeg-7 implementata. L’invio della richiesta avviene attraverso il metodo POST del protocollo standard HTTP, invocando il comando “_PROCESS” delle Application Program Interface di Tamino, con il passaggio dell’indirizzo del server, del DB e della collection su cui memorizzare il file inviato.
Codice della pagina di interfaccia web per l’inserimento di files XML nel DB prototipo:
<!-- codice realizzato per la pagina web dell’interfaccia di inserimento documenti XML nel DB --> <HTML> <HEAD> <META http-equiv="Content-Type" content="text/html; charset=utf-8"> <TITLE>Mpeg-7 eXperimental Metadata Repository – Web Interactive Interface</TITLE> <script Language="JavaScript">
var defaultCollection="/tecafast2collection" ;

Costruzione dell’interfaccia interattiva di inserimento documenti nel DB – 149
var defaultDB="/tecafast2"; var defaultPath="/tamino"; var DatabaseURLsuggerita=null; var mylocation=null; var host="195.103.122.59"; var protocol="http:"; var server=""; var port=80; DatabaseURLsuggerita="http://195.103.122.59"+defaultPath+defaultDB+defaultCollection; server=protocol+"//"+host; DatabaseURLsuggerita=server+defaultPath+defaultDB+defaultCollection; function setup() { if (DatabaseURLsuggerita) document.forms[0].nomedb_da_impostare.value=DatabaseURLsuggerita; } function setAction() { var action_da_impostare= document.forms[0].nomedb_da_impostare.value; //alert("Il nome del database sarà cambiato" + action_da_impostare ); document.forms[1].action = action_da_impostare; defaultStatus = "URL del Database impostato a" + action_da_impostare;
} <!-- inserisce il valore indicato nel campo azione del form di invio della POST html -->
</script> </HEAD> <BODY onload="setup()"> <!-- …. Segue codice HTML .. -->
<form> <!-- .... --> <input type=text size=52 name=nomedb_da_impostare value="http://195.103.122.59/tamino/tecafast2/tecafast2collection"> <input type="button" value="Imposta DB" onclick="setAction()"> <!-- pulsante per l’impostazione del valore del db indicato dall’utente -->
<!-- .... --> </form>
<form action="http://localhost/tamino/my-database" method=POST enctype="multipart/form-data" target=frame_output>
<!-- form di invio richiesta di tipo POST al web server del prototipo sul quale è installato il DB Tamino, con invio della pagina risultante al frame “frame_output” dell’interfaccia -->
<!-- .... -->
<input type=file size=40 name=_Process>

Costruzione dell’interfaccia interattiva di eliminazione documenti nel DB – 150
<!-- input di selezione del file da inserire nel DB utilizzando il comando di “_PROCESS” di Tamino --> <!-- .... --> <input type=submit value=Esegui>
<!-- pulsante per l’invio della POST con il comando di “_PROCESS” del file indicato -->
<input type=reset value=Reset> <!-- .... --> </form> <!-- .... -->
</BODY> </HTML>
Figura: Immagine dell’interfaccia web realizzata per l’inserimento dei
documenti di descrizione nel server XML del prototipo
V.3.2 Costruzione dell’interfaccia interattiva di eliminazione
documenti nel DB
E’ stata implementata anche un’interfaccia per l’eliminazione di documenti dal Database sul server XML, che richiede l’invio di una query in sintassi X-Query/Xpath per l’individuazione del documento da eliminare. Viene impiegata nuovamente una richiesta http di tipo POST che invia il comando “_DELETE” al server passando la query come parametro. Anche questa interfaccia consente all’utente di scegliere il database e la collection cui inviare le richieste di cancellazione.
Codice della pagina di interfaccia web per l’eliminazione di documenti dal DB prototipo:
<!-- codice interfaccia di eliminazione --> <HTML>

Costruzione dell’interfaccia interattiva di eliminazione documenti nel DB – 151
<HEAD> <!-- .... --> <script Language="JavaScript"> <!-- ...variabili e funzioni javascript simile all’interfaccia di inserimento vista precedentemente.. --> </script> </head> <BODY onload="setup()"> <!-- .... --> <form>
<!-- .... --> <input type=text size=52 name=nomedb_da_impostare value="http://195.103.122.59/tamino/tecafast2/tecafast2collection">
<input type="button" value="Imposta DB" onclick="setAction()"> <!-- come nell’interfaccia di inserimento dopo viene impostata l’URL selezionata nel campo Action del form successivo -->
<!-- .... --> </form>
<form action="http://localhost/tamino/my-database" method=POST enctype="multipart/form-data" target=frame_output>
<!-- form di invio richiesta di tipo POST al web server del prototipo sul quale è installato il DB Tamino, con invio della pagina risultante al frame “frame_output” dell’interfaccia -->
<!-- .... --> <input type=text size=57 name=_Delete value="//Mpeg7[@ino:id=]">
<!-- campo in cui l’utente inserisce la stringa in formato Query Xpath, che viene inviata come argomento del comando _DELETE al server Tamino -->
<!-- .... --> <input type=submit value=Esegui> <input type=reset value=Reset> <!-- .... --> </form> <!-- .... -->
</BODY> </HTML>
Figura: Nel frame principale della pagina viene mostrata l’interfaccia di
selezione e cancellazione dei documenti dal server XML

Costruzione dell’interfaccia interattiva di definizione Doctype dei documenti nel DB – 152
V.3.3 Costruzione dell’interfaccia interattiva di definizione
Doctype dei documenti nel DB
Per poter definire un Doctype o schema di documento in remoto utilizzando il browser web senza installare l’applicativo Tamino Schema Editor, si è implementata una interfaccia web che impiega funzioni Javascript e form HTML per consentire all’utente l’invio di file (già pronti nel formato Tamino Schema) al server XML, tramite una POST HTTP che invoca il comando “_DEFINE” passando il file selezionato con un form.
Codice della pagina di interfaccia web per la definizione di un DocType in una collection del DB prototipo:
<!-- codice della pagina che consente l’inserimento di uno schema DTD in una collection del Data Map del DB Tamino --> <HTML> <HEAD>
<META http-equiv="Content-Type" content="text/html; charset=utf-8"> <TITLE>Mpeg-7 eXperimental Metadata Repository – Web Interactive Interface</TITLE> <script Language="JavaScript"> <!-- ...variabili e funzioni javascript simile all’interfaccia di inserimento vista precedentemente.. --> </script> </head> <BODY onload="setup()"> <!-- .... --> <!-- .... --> <form>
<!-- .... --> <input type=text size=52 name=nomedb_da_impostare value="http://195.103.122.59/tamino/tecafast2/tecafast2collection">
<input type="button" value="Imposta DB" onclick="setAction()">
<!-- viene impostata l’URL selezionata nel campo Action del form successivo --> <!-- .... -->
</form>
<form action="http://localhost/tamino/my-database" method=POST enctype="multipart/form-data" target=frame_output>
<!-- form di invio richiesta di tipo POST al web server del prototipo sul quale è installato il DB Tamino, con invio della pagina risultante al frame “frame_output” dell’interfaccia --> <!-- .... --> <input type=file size=40 name=_Define> <!-- campo per l’inserimento di un file XML con la definizione dello schema del documento che viene inviata come argomento del comando _DEFINE al server Tamino --> <!-- .... -->

Costruzione dell’interfaccia interattiva di definizione Doctype dei documenti nel DB – 153
<input type=submit value=Esegui> <input type=reset value=Reset> <!-- .... --> </form> <!-- .... --> </Body> </HTML>
Figura: L’interfaccia creata per la selezione di file di schema di documento e
l’invio del comando di definizione dello schema nella Data Map del server XML
Per il codice dell’interfaccia che consente di togliere la definizione di un dato DocType da una collection:
Codice della pagina di interfaccia web per la cancellazione di un DocType in una collection del DB prototipo:
<!-- codice per la cancellazione di uno schema DTD in una collection del Data Map del DB Tamino --> <HTML> <HEAD> <!-- .... -->
<script Language="JavaScript"> <!-- ...variabili e funzioni javascript simili all’interfaccia di inserimento vista precedentemente.. --> </script> </HEAD> <BODY onload="setup()"> <!-- .... --> <form>
<!-- .... --> <input type=text size=52 name=nomedb_da_impostare value="http://195.103.122.59/tamino/tecafast2/tecafast2collection">
<input type="button" value="Imposta DB" onclick="setAction()"> <!-- viene impostata l’URL selezionata nel campo Action del form successivo -->
<!-- .... -->

Preparazione dei documenti di descrizione dei programmi televisivi di test – 154
</form>
<form action="http://localhost/tamino/my-database" method=POST enctype="multipart/form-data" target=frame_output>
<!-- form di invio richiesta di tipo POST al web server del prototipo sul quale è installato il DB Tamino, con invio della pagina risultante al frame “frame_output” dell’interfaccia -->
<!-- .... --> <input type=text size=57 name=_Undefine>
<!-- campo per l’inserimento di una stringa Xpath che identifichi il percorso dello schema del documento (DocType) da cancellare nella collection del DB, inviata come argomento del comando _UNDEFINE al server Tamino -->
<!-- .... --> <input type=submit value=Esegui> <input type=reset value=Reset> <!-- .... --> </form>
<!-- .... --> </BODY> </HTML>
Figura: interfaccia implementata per l’eliminazione di un Doctype da una
Collection nel Data Map del server XML
V.3.4 Preparazione dei documenti di descrizione dei programmi
televisivi di test
Per la prima implementazione del prototipo si è scelto di prendere a riferimento quattro programmi televisivi trasmessi dal canale nazionale RaiUno il 10 Marzo 2001. Si tratta dei programmi “Passaggio a Nord Ovest”, “Easy-Driver”, “Check Up” e “La Vecchia Fattoria”. Per costruire una credibile descrizione di tali risorse audiovisive, che rientrano tra i programmi già codificati e archiviati nella Teca Fast Rai, si è fatto riferimento alle informazioni di palinsesto (per gli orari di trasmissione), a quelle di documentazione del Catalogo Multimediale e ai dati di gestione dei file codificati con relativi parametri del sistema di gestione (SQL Server) di Teca Fast Rai.

Costruzione interfaccia per la restituzione di tutti i documenti di test nel DB – 155
Questa integrazione di dati mette in luce la diversità dell’approccio di un sistema di gestione metadati basato su strutture Mpeg-7: non solo la gestione di metadati descrittivi di alto livello (titolo, autori, location, argomenti, etc. come avviene nel Catalogo Multimediale) ma anche di parametri di più basso livello (tipo di codifica, formato audio e video, campionamento, fattore di forma del frame, dimensioni in byte del programma archiviato in formato digitale, time code di inizio e fine assoluti, etc. gestiti dal sistema di Teca Fast), il prototipo intende evidenziare la capacità di gestire in maniera integrata entrambe gli aspetti, utilizzando standard portabili e dettagliati come Mpeg-7. La fase di raccolta dati e realizzazione dei documenti descrittivi dei quattro programmi impiegati per il primo sviluppo è avvenuta in collaborazione con i responsabili di Teca Fast Rai, utilizzando gli strumenti di ricerca sulla intranet aziendale per la raccolta di alcuni dati e metadati già presenti in catalogo.
Per la compilazione e validazione dei documenti di descrizione individuati è stato impiegato l’ambiente di editing e validazione XML Spy v.3.5.
V.3.5 Costruzione interfaccia per la restituzione di tutti i
documenti di test nel DB
Per poter effettuare dei test sulle funzionalità di base del sistema è stata realizzata una interfaccia web per la richiesta dei documenti di test attualmente caricati nel server DB. Alla richiesta il server risponde con un documento XML (la struttura generica di un documento di risposta del server viene illustrata successivamente contestualmente all’analisi delle interfacce di interrogazione) contenente tutti i documenti presenti nel DB del tipo richiesto (ad esempio tutte le istanze di descrizione del programma tv “La Vecchia Fattoria” memorizzate con diversi identificatori – ogni documento inserito in una Doctype viene associato con un identificatore, chiamato ino:id, unico all’interno del DB. “ino” è il namespace di default per gli elementi xml definiti da Tamino).
Codice della pagina di interfaccia web per la richiesta e visualizzazione dei documenti di prova memorizzati nel DB del prototipo:
<!-- codice di una interfaccia web che fornisce i link attraverso Query Xpath per la richiesta e visualizzazione del codice XML dei documenti di descrizione Mpeg-7 realizzati per i quattro programmi TV di esempio. Il codice viene visualizzato in un frame di uscita della pagina chiamato frame_output --> <HTML> <HEAD>
<META http-equiv="Content-Type" content="text/html; charset=utf-8"> <TITLE>Mpeg-7 eXperimental Metadata Repository – Web Interactive Interface</TITLE> </HEAD>

Costruzione interfaccia per la restituzione di tutti i documenti di test nel DB – 156
<BODY > <!-- .... --> <div align="center"><font size="2"><b>Le schede di esempio inserite riguardano 4 programmi TV trasmessi su RAIUNO il 10 Marzo 2001:<br> Cliccando sul titolo si visualizza il codice XML del documento di descrizione Mpeg-7: </b></font></div>
<!-- .... --> <a href="http://195.103.122.59/tamino/tecafast2/tecafast2collection/Mpeg7?_xql=/Mpeg7%5B//Title%7E=%27*passaggio*%27%5D" target="frame_output">"Passaggio a Nord Ovest"</a> <!-- .... --> <a href="http://195.103.122.59/tamino/tecafast2/tecafast2collection/Mpeg7?_xql=/Mpeg7%5B//Title%7E=%27*check*%27%5D" target="frame_output">"Check-UP"</a> <!-- .... --> <a href="http://195.103.122.59/tamino/tecafast2/tecafast2collection/Mpeg7?_xql=/Mpeg7%5B//Title%7E=%27*driver*%27%5D" target="frame_output">"Easy Driver"</a> <!-- .... --> <a href="http://195.103.122.59/tamino/tecafast2/tecafast2collection/Mpeg7?_xql=/Mpeg7%5B//Title%7E=%27*fattoria*%27%5D" target="frame_output">"La vecchia fattoria"</a>
<!-- .... --> </BODY> </HTML>
Figura: La pagina di richiesta dei documenti di test presenti nel DB del
prototipo (le descrizioni dei quattro programmi tv immesse per il test)

Operazioni di query in rete tramite URL e XQuery/Xpath nel DB popolato – 157
Figura: La risposta del server alla query nascosta in ogni link dell’interfaccia è un documento XML che contiene tutti i documenti con il titolo del programma
tv selezionato. Questo documento di risposta viene visualizzato nel frame di uscita della pagina web, in basso
V.3.6 Operazioni di query in rete tramite URL e XQuery/Xpath
nel DB popolato
Il server XML nella versione attuale (quella configurata è la v.2.2.9) utilizza per le interrogazioni il Query Language XML di Tamino, che segue buona parte delle specifiche dello standard Xpath del W3C, analizzato nella terza sezione del capitolo II. In più esso presenta delle estensioni per la ricerca di testo, l’ordinamento e altre operazioni. Le interrogazioni vengono eseguite dal server XML utilizzando il comando “_XQL”, e si richiede di indicare sempre il nome della Collection in cui deve essere effettuata la ricerca, che può essere indicata in due modi diversi:
• Nella URL: ad esempio http://localhost/tamino/tecafast2/tecafast2collection?_xql=/Mpeg7
• Oppure come parametro addizionale del comando: http://localhost/tamino/tecafast2?_xql=/Mpeg7&_collection=tecafast2collection
L’elaborazione della richiesta di interrogazione avviene da parte del Request Interpreter secondo i seguenti passi mostrati anche nella figura successiva:
• Request Parser: controlla sintatticamente l’interrogazione XML che arriva al server.
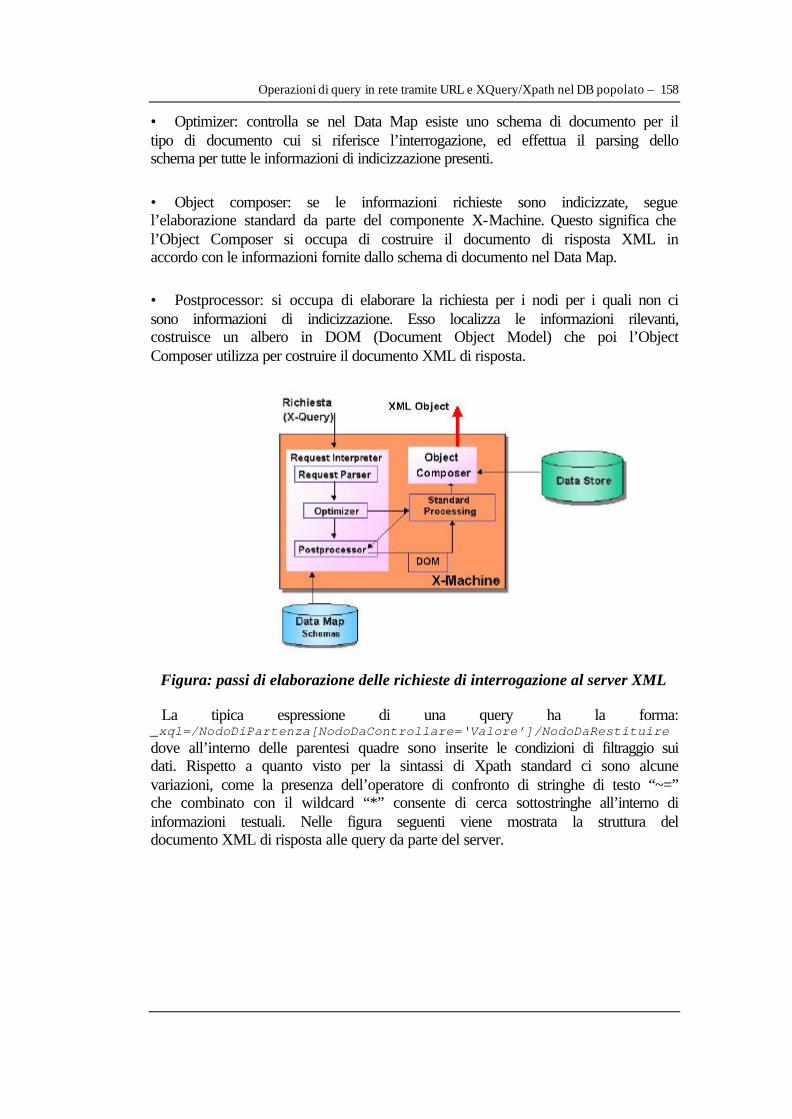
Operazioni di query in rete tramite URL e XQuery/Xpath nel DB popolato – 158
• Optimizer: controlla se nel Data Map esiste uno schema di documento per il tipo di documento cui si riferisce l’interrogazione, ed effettua il parsing dello schema per tutte le informazioni di indicizzazione presenti.
• Object composer: se le informazioni richieste sono indicizzate, segue l’elaborazione standard da parte del componente X-Machine. Questo significa che l’Object Composer si occupa di costruire il documento di risposta XML in accordo con le informazioni fornite dallo schema di documento nel Data Map.
• Postprocessor: si occupa di elaborare la richiesta per i nodi per i quali non ci sono informazioni di indicizzazione. Esso localizza le informazioni rilevanti, costruisce un albero in DOM (Document Object Model) che poi l’Object Composer utilizza per costruire il documento XML di risposta.
Figura: passi di elaborazione delle richieste di interrogazione al server XML
La tipica espressione di una query ha la forma: _xql=/NodoDiPartenza[NodoDaControllare=‘Valore’]/NodoDaRestituire dove all’interno delle parentesi quadre sono inserite le condizioni di filtraggio sui dati. Rispetto a quanto visto per la sintassi di Xpath standard ci sono alcune variazioni, come la presenza dell’operatore di confronto di stringhe di testo “~=” che combinato con il wildcard “*” consente di cerca sottostringhe all’interno di informazioni testuali. Nelle figura seguenti viene mostrata la struttura del documento XML di risposta alle query da parte del server.

Costruzione di una prima applicazione web per le query – 159
Figura: Ogni documento memorizzato nel DB XML viene identificato da un
identificatore univoco “ino:id” che viene sempre allegato ai documenti di risposta alle query effettuate tramite il comando “_xql”
Figura: Viene mostrata la struttura generale di ogni documento XML di
risposta costruito all’atto dell’elaborazione dei risultati di una query sul server XML
V.3.7 Costruzione di una prima applicazione web per le query
Vengono ora illustrate le interfacce web che consentono di effettuare interrogazioni nel DB. La prima interfaccia di cui viene mostrato il codice utilizza una richiesta HTTP con metodo POST per l’invio di una stringa Xpath indicata dall’utente in un form. Questa stringa viene inviata come parametro per il comando “_XQL” che attiva la funzione di interpretazione della query passata al server Tamino.
Codice della pagina di interfaccia web per l’invio di interrogazioni in

Costruzione di una prima applicazione web per le query – 160
sintassi XPath al DB del prototipo:
<!-- codice per l’interfaccia di selezione DB/collection e inserimento stringa Xpath di query da inviare al server Tamino con il comando XQL in una richiesta http-POST, con i risultati visualizzati in codice XML di risposta nel frame di uscita frameoutput dell’interfaccia, utilizzando la visualizzazione standard del codice XML da parte del browser Internet Explorer abilitato (versione da 5 in poi) --> <HTML> <HEAD> <!-- ..... --> <script Language="JavaScript"> <!-- ...variabili e funzioni javascript simili all’interfaccia di inserimento vista precedentemente.. --> </script> </HEAD> <BODY onload="setup()"> <!-- ..... --> <form>
<!-- ..... --> <input type=text size=52 name=nomedb_da_impostare value="http://195.103.122.59/tamino/tecafast2/tecafast2collection">
<input type="button" value="Imposta DB" onclick="setAction()"> <!-- viene impostata l’URL selezionata nel campo Action del form successivo -->
<!-- ..... --> </form>
<form action="http://localhost/tamino/my-database" method=POST enctype="multipart/form-data" target=frame_output> <!-- form di invio richiesta di tipo http-POST al web server del prototipo sul quale
è installato il DB Tamino, con invio della pagina di risposta in xml al frame “frame_output” dell’interfaccia-->
<!-- ..... --> <input type=text size=57 name=_XQL(1,16)>
<!-- campo per l’inserimento di una stringa Xpath che identifichi i parametri di ricerca (elementi, valori, filtri, operatori e funzioni secondo la sintassi Xpath estesa da X-Query di Tamino) e i parametri di uscita (i valori da restituire) inviata come argomento del comando _XQL(1,16) al server Tamino -->
<!-- ..... --> <input type=submit value=Esegui> <input type=reset value=Reset> <!-- ..... --> </form><!-- ..... -->
</BODY> </HTML>

Costruzione di una prima applicazione web per le query – 161
Figura: l’interfaccia web di ricerca basata sull’invio di una POST http al server
DB contenente un comando “_xql” e come argomento una query Xpath indicata dall’utente
Figura: la risposta viene inviata dal server XML sotto forma di un documento XML visualizzato in un frame di uscita, quello in basso, della pagina web con
l’interfaccia di ricerca
Vediamo un esempio di query: //Mpeg7//Comment/FreeTextAnnotation che ricerca tutti gli elementi di testo libero in tutti i commenti contenuti nei documenti con elemento radice Mpeg7 all’interno del DB (e della collection specificata nell’interfaccia). Il path completo della query diretta in forma di URL inviata al web server che si interfaccia col DB server Tamino ‘tecafast2’ è il seguente: http://195.103.122.59/tamino/tecafast2/tecafast2collection/Mpeg7?_xql=//Mpeg7//Comment//FreeTextAnnotation .
Un altro esempio molto semplice di query Xpath, che ricerca tutti gli elementi di testo libero (anche non figli di un elemento “comment” come nel caso precedente) in tutti i documenti con elemento radice Mpeg7 ha il path completo seguente: http://195.103.122.59/tamino/tecafast2/tecafast2collection/Mpeg7?_xql=//Mpeg7//FreeTextAnnotation.

Realizzazione di un’interfaccia di query con oggetti DOM e fogli di stile XSL – 162
Come abbiamo visto la query Xpath “//Mpeg7” o “Mpeg7” restituisce tutti i documenti di tipo Mpeg7 (di DocType) della collezione selezionata nel DB del prototipo.
V.3.8 Realizzazione di un’interfaccia di query con oggetti DOM e
fogli di stile XSL
Viene ora mostrato il codice della pagina di interfaccia web realizzata per l’invio di interrogazioni in sintassi XPath al DB del prototipo, con l’utilizzo di programmazione Javascript e oggetti DOM (Document Object Model) ActiveX di Microsoft (in riferimento al parser XML fornito con il browser Microsoft Internet Explorer 5.5) per l’applicazione di una trasformazione basata su un foglio di stile XSL: in questo caso il documento restituito dal DB Tamino in risposta alla query (in codice XML) viene caricato in un oggetto DOM lato client (nel browser abilitato) e qui processato utilizzando il metodo TransformNode (visto nel capitolo III) con il foglio di stile (anch’esso caricato in un oggetto DOM come codice XML).
Codice dell’interfaccia di invio di query Xpath al server Tamino del prototipo utilizzando oggetti DOM ActiveX istanziati lato client, con funzioni e variabili Javascript e la trasformazione con foglio di stile XSL.
<!-- In questo caso non viene inviata una richiesta http-POST come in precedenza, ma direttamente la richiesta di una risorsa al web server tramite URL (contenente la stringa di ricerca in formato Xpath). La pagina XML restituita dal DB Tamino viene caricata nell’oggetto DOM. Viene caricato col comando load in un oggetto DOM anche il codice xml del foglio di stile XSL da applicare. Infine viene invocato il metodo TransformNode dell’oggetto DOM contenente l’albero del documento di risposta e inviato il codice HTML risultante (la lista dei titoli di programma presenti nel prototipo che soddisfano la query) ad una nuova finestra del browser – richiede un browser Internet Explorer abilitato (versione da 5 in poi) --> <HTML>
<HEAD> <!-- ..... -->
<script language="JavaScript"> function sendQuery()
{ var temp=document.form_parametri; var flag; var query="http://195.103.122.59/tamino/tecafast2/tecafast2collection/Mpeg7?_xql="; flag=0; if (temp.campo_input1.value!="") { flag++; query= query + temp.campo_input1.value ; } <!-- se è stato inserito un valore per la stringa di Xpath la variabile flag viene incrementata e il valore concatenato al percorso base preimpostato per l’accesso al DB ‘tecafast2’ collection ‘tecafast2collection’ sul server Tamino del prototipo--> switch (flag) {

Realizzazione di un’interfaccia di query con oggetti DOM e fogli di stile XSL – 163
case 0:{ alert("Inserisci almeno un valore!"); break; } case 1:{ <!-- alert("Sto inviando la query: " + query); -->
var doc=new ActiveXObject("Microsoft.XMLDOM"); <!-- Viene istanziato un oggetto DOM di nome doc --> doc.async="false"; <!-- Viene settato il modo sincrono di caricamento dati --> doc.load(query); <!-- Viene caricato il documento XML (prelevato da Tamino attraverso l’URL con la query Xpath contenuta nella variabile “query”) nell'oggetto DOM --> var style = new ActiveXObject("Microsoft.XMLDOM"); style.async="false"; style.load("xslprova.xsl"); <!-- Analogo a sopra, ma per il foglio di stile --> var win1 = window.open("", "myWindow", "toolbar=, width=800, height=500, resizable, scrollbars=yes"); <!--viene istanziata una variabile di tipo nuova finestra del browser --> win1.document.open(); <!-- viene aperta una nuova finestra del browser --> win1.document.writeln("<title>Search Result</title>" +
"<BODY><h4>Query: " + query +"</h4><DIV id='tabella_risultato'></DIV></BODY>");
<!-- Viene inviato alla nuova finestra il codice di una semplice pagina HTML che indica la query Xpath in forma di URL completa che è stata inviata al server del prototipo Tamino e identifica una zona con l’id “tabella_risultato” --> win1.tabella_risultato.innerHTML = doc.transformNode(style); <!-- viene inserito nel codice HTML della finestra aperta il risultato della trasformazione del documento di risposta XML con il foglio di stile indicato, utilizzando il metodi transformNode dell’oggetto doc di tipo DOM --> win1.document.close(); break; } default: alert("Hai inserito più di un valore!"); } } </script> </HEAD> <BODY > <!-- ..... --> <form name="form_parametri"> <!-- ..... --> <input name="campo_input1" type="text"/> <!-- ..... --> <input type="button" value="invia" onClick="sendQuery()" name="button"/> <!-- pulsante di input che invoca la funzione javascript sendQuery() --> <input type="reset" value="azzera" name="reset"/>

Realizzazione di un’interfaccia di query con oggetti DOM e fogli di stile XSL – 164
</form> <!-- ..... --> </BODY> </HTML>
Figura: L’interfaccia di ricerca basata sull’inserimento da parte dell’utente di
query in sintassi X-Query/XPath al server XML che gestisce il DB. La trasformazione del codice risultante avviene tramite l’impiego di oggetti DOM
istanziati nel browser client con il processamento di un foglio di stile XSL trasferito dal server
Il codice del foglio di stile XSL realizzato per questa interfaccia è il seguente:
Codice estratto dal documento “xmlprova.xsl” che definisce il foglio di stile XSL processato attraverso l’uso di DOM e Javascript per il processamento lato client.
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/TR/WD-xsl"> <xsl:template match="/"> <!-- si definiscono i parametri di formattazione al livello radice --> <html> <body> <table border="1" bordercolor="black" cellpadding="5" style="margin-left:1.5cm;"> <tr> <th>Titolo Programma</th><th><Canale Televisivo</th> <th>Data e Ora Trasmissione</th><th>Durata</th> <th>Identificatore Risorsa</th><th>Scheda Programma</th> </tr> <xsl:for-each select="ino:response/xql:result/Mpeg7"> <tr> <td><xsl:value-of select="ContentDescription//Title"/> </td> <td><xsl:value-of select="ContentDescription//Creator[Role/Name='Emittente']/Agent/Name"/> </td> <td><xsl:value-of select="ContentDescription//MediaTime/MediaTimePoint"/> </td>

Realizzazione di un’interfaccia di query con oggetti DOM e fogli di stile XSL – 165
<td><xsl:value-of select="ContentDescription//MediaTime/MediaDuration"/> </td> <td><xsl:value-of select="ContentDescription//MediaInformation/MediaIdentification/Identifier/IdValue"/> </td> <td><xsl:value-of select="@ino:id"/></td> </tr> </xsl:for-each> </table> </body> </html> </xsl:template> </xsl:stylesheet>
Figura: La risposta sotto forma di documento XML restituito dal server viene
processata col metodo “TransformNode” dell’oggetto DOM istanziato nell’applicazione Javascript sulla postazione client. Al metodo viene passato
come argomento un altro oggetto DOM con la struttura del foglio di stile XSL. Il risultato, processato dal browser client, è visibile in figura. Si tratta di una
nuova finestra del browser con una tabella HTML che riporta la lista dei documenti del DB che soddisfano la query inviata
Per scopi dimostrativi è stata implementata anche una interfaccia per la restituzione veloce (senza parametri di ingresso) di una lista di tutti i documenti contenuti al momento dell’invio della richiesta nel DB prototipo, con una tabella ottenuta da una trasformazione XSL realizzata con l’uso di oggetti ActiveX DOM sulla base della precedente interfaccia di Query. In questo caso viene direttamente richiesta la lista xml di tutti i documenti del DB inviando al web server una URL contenente la stringa di ricerca in formato Xpath. La pagina XML restituita dal DB Tamino viene caricata nell’oggetto DOM. Viene caricato col comando load in un oggetto DOM anche il codice xml del foglio di stile XSL da applicare. Infine viene invocato il metodo TransformNode dell’oggetto DOM contenente l’albero del documento di risposta e inviato il codice HTML risultante (la lista dei titoli di

L’interfaccia avanzata di ricerca con elaborazione lato server dei fogli di stile XSL – 166
programma presenti nel prototipo che soddisfano la query) ad una nuova finestra del browser – richiede un browser Internet Explorer.
V.3.9 L’interfaccia avanzata di ricerca con elaborazione lato
server dei fogli di stile XSL
Viene ora mostrato il codice della pagina di interfaccia web realizzata per fornire funzionalità di ricerca di stringhe di testo (in questo caso viene mascherata la sintassi Xpath) in elementi specifici della struttura di descrizione basata su metadati Mpeg-7. Questa interfaccia mostra la possibilità di effettuare ad esempio la ricerca specifica di una stringa di caratteri o una parola all’interno dei soli campi di tipo “Titolo” (elemento Title nella struttura di descrizione Mpeg-7 implementata), o dei soli campi “Nome e cognome autore” (elementi GivenName in Creation nella struttura dati), o dei soli campi di descrizione a testo libero (elementi freeTextAnnotation nella struttura dati).
Il codice è facilmente estensibile per costruire ulteriori applicazioni web per la combinazione di criteri di ricerca molto articolati. Cercare una data stringa di testo in determinati elementi nella gerarchia della struttura dati, come ad esempio condizioni multiple sul nome degli autori, sul titolo, sulla data e orario e contemporaneamente su caratteristiche di formato di codifica o location di produzione di un dato programma tv. Grazie alla struttura del DocType definita – e facilmente estensibile – nel Data Map, le ricerche di questo tipo risultano comunque gestibili efficientemente, mostrando un altro dei vantaggi di un sistema di gestione dati strutturati completamente basato su XML nativo.
In questa interfaccia non viene impiegata l’elaborazione dal lato client, quindi non vengono istanziati oggetti DOM sul browser dell’utente. Viene infatti utilizzato un Java Servlet per il processamento lato server del documento xml con i risultati della query restituita dal DB del prototipo. L’URL stessa non si riferisce direttamente al DB Tamino ma alla Servlet configurata (in questo caso il path è preceduto dall’indicazione di “servlet” e dal nome del servlet specifico chiamato “tecafast2style” per il processamento del foglio di stile XSL.
Inoltre l’utilizzo di un parser SAX (affrontato nella terza sezione del capitolo II) completamente standard implementato nella servlet consente di implementare tutte le potenti funzioni dello standard XSL di trasformazione (il linguaggio XSL supportato dal DOM Microsoft ha ancora delle limitazioni rispetto allo standard, ad esempio non è in grado di gestire xsl:variable). Il foglio di stile restituisce con pochi semplici comandi non solo la lista dei risultati della query in HTML ma costruisce anche i link che contengono il riferimento alla scheda di ogni programma (il titolo dei programmi restituiti nella finestra di risposta alla query contiene un link costruito dinamicamente che punta allo specifico documento XML di descrizione del programma stesso). L’impiego di un’interfaccia “leggera” come quella illustrata di seguito consente alcuni vantaggi rispetto all’impiego

L’interfaccia avanzata di ricerca con elaborazione lato server dei fogli di stile XSL – 167
dell’interfaccia Javascript-DOM di processamento lato client, uno dei principali è la compatibilità: il servlet elabora lato server il codice xml con la XSL, restituendo al client web una pagina HTML standard, consentendo così l’impiego di un qualunque browser standard HTML (o altro browser, ad esempio wap, se il foglio di stile viene programmato opportunamente).
Codice dell’interfaccia di ricerca avanzata di stringhe di testo su elementi specifici della struttura di descrizione a metadati del prototipo DB, utilizzando l’elaborazione lato server del foglio di stile XSL.
<!-- interfaccia web con funzionalità avanzate di ricerca di stringhe di testo (mascherando la sintassi Xpath) in elementi specifici della struttura di descrizione basata su metadati Mpeg-7 --> <HTML> <HEAD> <!-- ..... --> <script language="JavaScript"> function sendQueryServlet()
{ var temp=document.form_parametri; var flag; var query="http://195.103.122.59/servlets/tecafast2style/tamino/tecafast2/tecafast2collection/Mpeg7?_xql="; var xsltransf="&_xslsrc=http://195.103.122.59/prova2.xsl"; <!--comando destinato al servlet “_xslsrc” identifica il file del foglio di stile XSL da applicare --> var criteriostart="Mpeg7["; var criteriovalorestart="'*"; var criteriovaloreend="*']"; var criterioutente=temp.select_criterioutente.value; var criterioconfronto="~="; var valorecriterio=""; flag=0; if (temp.campoutente1.value!="")
{ flag++; query= query + criteriostart + criterioutente + criterioconfronto + criteriovalorestart + temp.campoutente1.value + criteriovaloreend + xsltransf; } switch (flag) { case 0:{ alert("Inserisci almeno un valore!"); break; } case 1:{ <!-- alert("Sto inviano la query: " + query); --> window.open(query); break; } default: alert("Hai inserito più di un valore!"); } } </script> </HEAD> <BODY> <!-- ....Ricerca di testo nel DB XML con risposta elaborata da un servlet java (Apache JServ) che applica una trasformazione XSL lato server restituendo al client il codice HTML ..... -->

L’interfaccia avanzata di ricerca con elaborazione lato server dei fogli di stile XSL – 168
<!-- ..... --> <form name="form_parametri"> <!-- ..... --> <input name="campoutente1" type="text"/> <!-- ..... --> <select name="select_criterioutente" size="1">
<option value="//AudioVisual//Title" selected>su Titolo</option> <option value="//AudioVisual//Creator//GivenName">su Autori</option> <option value="//AudioVisual//FreeTextAnnotation">su Descrizioni</option>
</select> <!-- ..... --> <input type="button" value="invia" onClick="sendQueryServlet()" name="button"/> <input type="reset" value="azzera" name="reset"/> </form> <!-- ..... --> </BODY> </HTML>
Il codice del foglio di stile costruito per la visualizzazione (ed elaborato del servlet) è il seguente:
Listato del foglio di stile XSL utilizzato per il processamento lato server (file “prova2.xsl” indicato nel codice dell’interfaccia web precedente)
<?xml version="1.0" encoding="ISO-8859-1"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:ino="http://namespaces.softwareag.com/tamino/response2" xmlns:xql="http://metalab.unc.edu/xql/" xmlns:mpeg="http://www.mpeg7.org/2001/MPEG-7_Schema" exclude-result-prefixes="xql ino mpeg" version="1.0"> <xsl:variable name="query">http://195.103.122.59/servlets/tecafast2style/tamino/tecafast2/tecafast2collection?_xql=Mpeg7[@ino:id=</xsl:variable> <xsl:variable name="style">&_xslsrc=http://localhost/xslprova.xsl</xsl :variable> <xsl:template match="/"> <!-- si definiscono i parametri di formattazione al livello radice -->
<html> <body> <table border="1" bordercolor="black" cellpadding="5" style="margin-left:1.5cm;" width="572">
<tr> <th>Titolo Programma</th><th>Canale Televisivo</th><th>Data e Ora Trasmissione</div></th><th>Durata</th><th>Identificatore Risorsa (test-provvisorio)</th><th>Scheda Programma (ino:id)</th> </tr>

L’interfaccia avanzata di ricerca con elaborazione lato server dei fogli di stile XSL – 169
<xsl:for-each select="//mpeg:Mpeg7">
<xsl:variable name="number"> <xsl:value-of select="./@ino:id"/>
</xsl:variable> <!-- ..... --> <a>
<xsl:attribute name="href"> <xsl:value-of select="concat($query,$number,']',$style)"/>
</xsl:attribute> <xsl:value-of select="mpeg:ContentDescription//mpeg:Title"/>
</a> <!-- ..... --> <xsl:value-of select="mpeg:ContentDescription//mpeg:Creator[mpeg:Role/mpeg:Name='Emittente']/mpeg:Agent/mpeg:Name"/> <!-- ..... --> <xsl:value-of select="mpeg:ContentDescription//mpeg:MediaTime/mpeg:MediaTimePoint"/> <!-- ..... --> <xsl:value-of select="mpeg:ContentDescription//mpeg:MediaTime/mpeg:MediaDuration"/> <!-- ..... --> <xsl:value-of select="mpeg:ContentDescription//mpeg:MediaInformation/mpeg:MediaIdentification/mpeg:Identifier/mpeg:IdValue"/> <!-- ..... --> <xsl:value-of select="$number"/>
<!-- ..... --> </xsl:for-each> <!-- ..... -->
</body> </html> </xsl:template> <xsl:template match="/ino:response/ino:message"/> <xsl:template match="/ino:response/xql:query"/> </xsl:stylesheet>
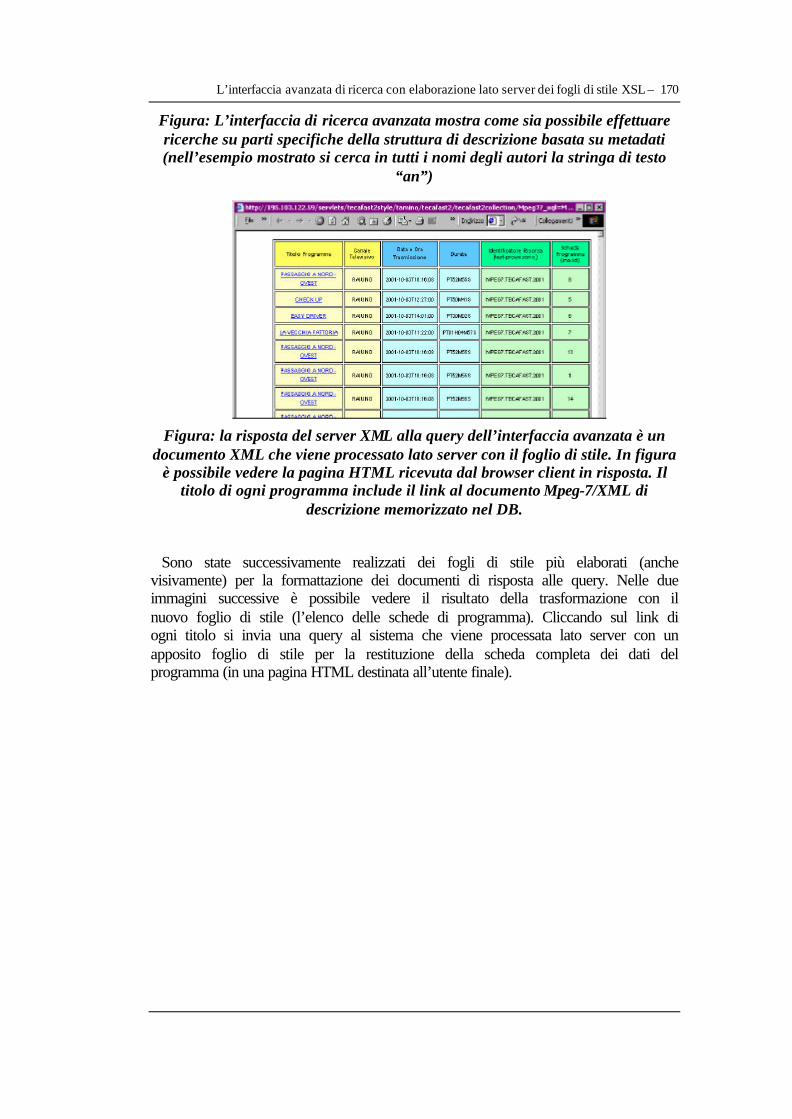
L’interfaccia avanzata di ricerca con elaborazione lato server dei fogli di stile XSL – 170
Figura: L’interfaccia di ricerca avanzata mostra come sia possibile effettuare ricerche su parti specifiche della struttura di descrizione basata su metadati (nell’esempio mostrato si cerca in tutti i nomi degli autori la stringa di testo
“an”)
Figura: la risposta del server XML alla query dell’interfaccia avanzata è un
documento XML che viene processato lato server con il foglio di stile. In figura è possibile vedere la pagina HTML ricevuta dal browser client in risposta. Il
titolo di ogni programma include il link al documento Mpeg-7/XML di descrizione memorizzato nel DB.
Sono state successivamente realizzati dei fogli di stile più elaborati (anche visivamente) per la formattazione dei documenti di risposta alle query. Nelle due immagini successive è possibile vedere il risultato della trasformazione con il nuovo foglio di stile (l’elenco delle schede di programma). Cliccando sul link di ogni titolo si invia una query al sistema che viene processata lato server con un apposito foglio di stile per la restituzione della scheda completa dei dati del programma (in una pagina HTML destinata all’utente finale).
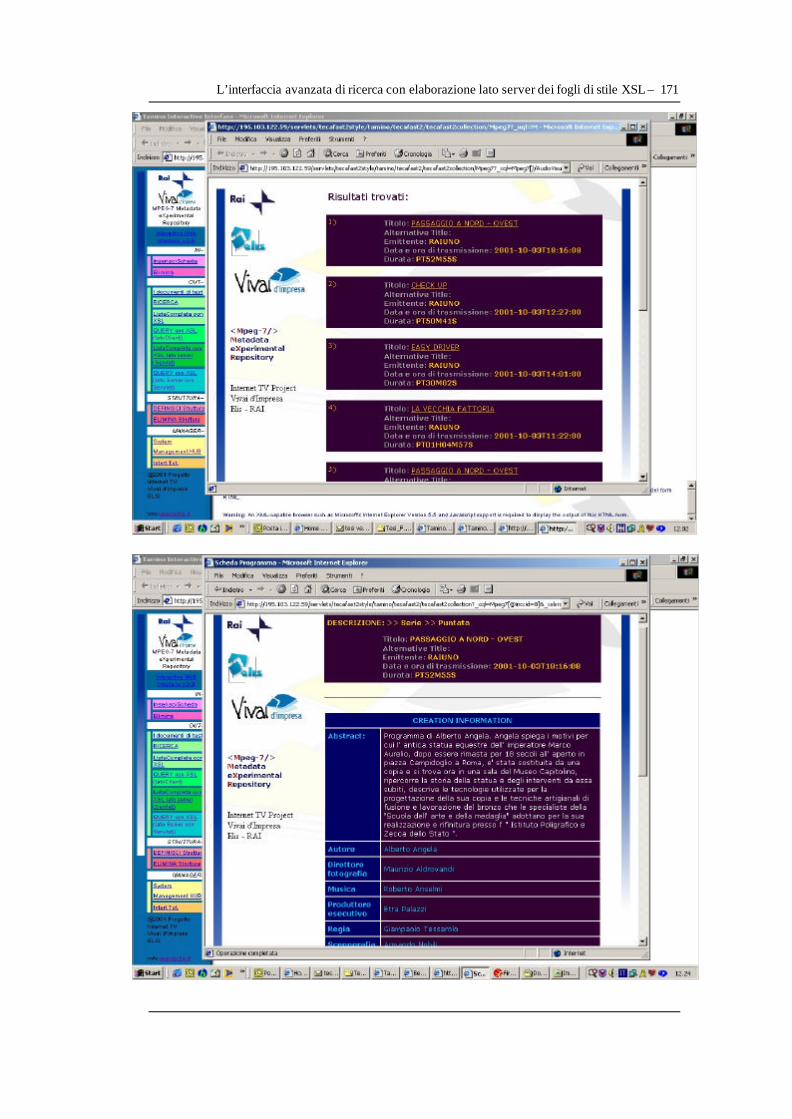
L’interfaccia avanzata di ricerca con elaborazione lato server dei fogli di stile XSL – 171

Sviluppi previsti del progetto e di progetti similari di gestione di database multimediali – 172
V.3.10 Sviluppi previsti del progetto e di progetti similari di
gestione di database multimediali
Alcuni degli sviluppi auspicati e auspicabili per il prosieguo del lavoro intrapreso con la realizzazione di questo prototipo per la gestione metadati audiovisivi secondo lo standard Mpeg-7:
• La costruzione di interfacce di ricerca user friendly, con possibilità di effettuare ricerche puntuali
• La costruzione di interfacce web e applicazioni per la modifica e inserimento guidata dei metadati e dei documenti che li contengono all’interno del DB, da parte degli utenti della Intranet e degli operatori di documentazione qualificati in internet ad accesso protetto.
• L’ implementazione del sistema nella intranet di Teca Fast Rai per la messa in funzione dell’accesso al DB di Teca Fast e la mappatura dei campi dalle tabelle del DBMS preesistente, studio e progettazione di un sistema di maggiori dimensioni che preveda l’interfacciamento con i numerosi Database degli archivi di Teche Rai e con le strutture dati del Catalogo Multimediale verificando l’opportunità della rimappatura nel nuovo sistema delle informazioni di documentazione già inserite in questi anni.
• L’implementazione di descrizioni riguardanti le singole sequenze video contenute in ogni entità di programma televisivo
• L’integrazione di titoli e metadati non solo testuali ma anche in formato multimediale immagini, audio e/o video codificati)
• L’integrazione di funzionalità di ricerca sul DB basata sul contenuto multimediale
• L’integrazione di funzionalità per la gestione degli accessi utente e per la protezione della connessione e la sicurezza dei dati contenuti nel repository di metadati.
• L’implementazione di funzionalità per la navigazione del sistema di metadati da parte di utenti internet, con strumenti integrati per la gestione dinamica delle recensioni, collegamenti ad altri contenuti, commenti e note lasciate dagli utenti-visitatori.
• L’integrazione di Dizionari-Tesauri e Classification Schemes per il controllo della terminologia delle descrizioni basate su metadati

Sviluppi previsti del progetto e di progetti similari di gestione di database multimediali – 173
• L’integrazione di tecnologie per la gestione dei linguaggi degli agenti intelligenti
• L’implementazione delle strutture dati Mpeg-7 per la descrizione dei diritti associati ai contenuti audiovisivi e ai metadati descrittivi, in maniera dinamica con l’utilizzo che viene fatto del contenuto archiviato
• L’implementazione di soluzioni nell’ambito dello sviluppo di Mpeg-21 per l’interoperabilità con altri sistemi di gestione risorse multimediali in rete, e con sistemi di ricerca su database multimediali distribuiti.
• L’applicazione dei risultati teorici e pratici raggiunti con lo sviluppo del prototipo alla gestione di progetti di gestione di altri archivi digitali audiovisivi o multimediali.

Bibliografia: Capitolo I: Mercato ICT, nuovi media e archivi multimediali – 174
VI° Capitolo – Bibliografia, risorse in rete
VI.1 Capitolo I: Mercato ICT, nuovi media e archivi multimediali
• “Il Multimedia nelle organizzazioni: Nuovi modelli di conoscenza e comunicazione - DOSSIER DI INGENIUM” di:Beppe Croce – Rivista Ingenium Anno XII n. 25 - Settembre 1999
• Rapporto Settore 1 - INFORMATICA E TELECOMUNICAZIONI MEMBRI DEL GRUPPO DI LAVORO ‘Settore 1 - INFORMATICA E TELECOMUNICAZIONI’ http://web.tiscalinet.it/GianlucaRipa/personal/ecom/convergenza.htm.
• Archivi digitali” di Tommaso Russo – da “Archivi e Database”- Servizio del 28 dicembre 1998 del programma Mediamente – disponibile all’indirizzo internet http://www.mediamente.rai.it/home/tv2rete/mm9899/98122801/s981228.htm
• “Mediaset come la CNN: i video trasmessi subito editabili dai Pc dei giornalisti” di mdg, del 25 gennaio 2001 dal sito web “www.goa.it” all’indirizzo http://www.goa.it/articles/Tecnologie/3215.html
• M. Marandola. Diritto d'autore. Roma: AIB, 1996.
• M. Marandola. Il Nuovo diritto d'autore: quale futuro ?. In L'automazione delle biblioteche del Veneto: 9 seminario Angela Vinay : l'irruzione della multimedialità. Venezia, 1997.
• P.A. Bruck. The content challenge: Electronic Publishing and the new content industries. In Future perspectives in electronic publishing. Frankfurt Bookfair, 1997.
• G. Vitiello. Biblioteche, editoria e diritto d'autore. In "Biblioteche oggi", genn-febbr. 1997, p. 8-15.
• C. Revelli. Discussioni sul copyright. In "Biblioteche oggi", dic. 1997, , n.10, p. 46-54.
• Sito web dell’Istituto Luce http://www.luce.it
• Sito Web della Scuola Nazionale di Cinema http://www.snc.it
• Sito web della SIAE: http://www.siae.it/Site2/SiaeMainSite.nsf/html/It_MMLicenza.html
VI.2 Capitolo II: Metadati, standard MPEG, tecnologie XML e integrazione con i Database
VI.2.1 Paragrafo 1: I Metadati:
• “<indecs> Metadata Framework: Principles, model and dictionary”, ID WP1a-006-2.0, Godfrey Rust, MUZE inc; Mark Bide, EDItEUR.
• “Metadata Watch Report #3”, Makx Dekkers, PrincewaterhouseCoopers, 20 Novembre 2000, SCHEMAS-PwC-WP2-D24-Final-20001120

Bibliografia: Capitolo II: Metadati, standard MPEG, tecnologie XML e integrazione con i Database – 175
• C. Oppenheim. “Legal issues associated with Electronic Copyright Management Systems”.
• A. Ramsden. “Copyright Management Technologies”.
• B. Tuck. “Electronic Copyright Management Systems”.
• “Unique identifiers : a brief introduction” / by G. Greene and Mark Bide.
• Sito web del W3C Consortium http://www.w3.org/
o Metadati: http://www.w3.org/metadata
• Nell’ambito della commissione della Comunità Europee.
o Progetti Telematics for Libraries (DGXIII - CCE) al sito web: http://www2.echo.lu/libraries/en/libraries.html
o Open Information Interchange http://www2.echo.lu/oii/en/oii-info.html
• Nell’ambito dell’UKOLN http://ukoln.ac.uk/
o Interoperabilità: http://ukoln.ac.uk/interop-focus
o Metadati: http://ukoln.ac.uk/metadata
o E-lib Standards Guidelines http://www.ukoln.ac.uk/services/elib/papers/other/standards/version2/intro.html
• IFLA - Digital Libraries http://ifla.inist.fr/II/index.htm
• Dublin Core, siti ufficiali: http://purl.org/dc/ , http://dublincore.org
o Conversione DublinCore-Unimarc: sito web http://www.ukoln.ac.uk/metadata/interoperability/dc_unimarc.html
o Progetti http://purl.org/DC/projects/index.htm
• Progetto EULER http://www.emis.de/projects/EULER
• Progetto ECUP+ : http://www.kaapeli.fi/~eblida/ecup
• Progetto Decomate: http://cdservera.blpes.lse.ac.uk/decomate
• Progetto IMPRIMATUR: http://www.imprimatur.alcs.co.uk/
• Progetto CANDLE: http://www.sbu.ac.uk/litc/candle
• Progetto ATHENS: http://www.athens.ac.uk/
VI.2.2 Paragrafo 2: La famiglia di standard MPEG
• “IL SISTEMA DI COMPRESSIONE AUDIO/VIDEO MPEG-2” di Francesco Cisternino - Tesina realizzata per il Corso sulle nuove tecnologie di comunicazione all'interno del Corso di Teorie e Tecniche del Linguaggio Radiotelevisivo del Prof. P. L. Capucci, a.a. 1999/2000, con la collaborazione del dott. Massimiliano Neri, e dell'ing. Leonardo Chiariglione.

Bibliografia: Capitolo III: Il Sistema Teche RAI e la Teca Fast – 176
• “MPEG: Il presente ed il futuro del multimediale”A cura di Gianfranco Giannini – Pixel Magazine, indirizzo web http://www.pixelmagazine.com/pag32.htm.
• “Una rete d’ingegno” di Leonardo Chiariglione – Focus “Libri e copyright: la sfida digitale” dal sito web de “IlSole24Ore” indirizzo http://sole.ilsole24ore.com/cultura/domenica/focus7_05/06.htm
VI.2.3 Paragrafo 3 e 4: Tecnologie XML e DB e programmare XML
• “XML and Related Technologies” distribuito da Software Ag sul sito www.softwareag.com/xml.
• “Guida SQL” di Lucio Benfante – sito internet http://www.html.it/sql, e-mail [email protected].
• “Microsoft XML Document Object Model” di Gianluca Musella – articolo pubblicato sullo Speciale XML della rivista “Computer Programming” n.90 di Aprile 2000.
• Document Object Model Level 1 Specification Version 1.0, reperibile all’indirizzo http://www.w3.org/TR/REC-DOM-Level-1/
• “Architetture software per oggetti formativi definiti con XML” Tesi di Laurea di Paolo Diomede Tesi, sviluppata presso la Scuola Superiore G. Reiss Romoli (Telecom Italia, L'Aquila)
• S.Land, XML: The ASCII of the future, MSDN News n.3, Maggio/Giugno 1999.
• Document Object Model Overview, MSDN Library July 1999.
• XML DOM User Guide, MSDN Library July 1999.
• S.Mohr, Designing Distribuited Applications with XML, Wrox Press, 1999.
• Per XQL: http://www.w3.org/TandS/QL/QL98/pp/ibmpos.html).
VI.3 Capitolo III: Il Sistema Teche RAI e la Teca Fast
• Presidenza del consiglio dei Ministri Italiano – Forum per la società dell’informazione. Documento disponibile on-line all’indirizzo http://www.palazzochigi.it/fsi/doc_piano/techerai.html.
• “Sistema Teche – Patrimonio Rai – Catalogo Multimediale” - testo divulgativo rieditato da Barbara Scaramucci (Direttore Teche Rai), da un testo di Roberto del Pero, Giorgio Dimino e Mario Stroppiana del Centro Ricerche Rai.
VI.4 Capitolo IV: Creazione di un profilo applicativo di Mpeg-7 MDS
• Hunter J., Iannella R., "The Application of Metadata Standards to Video Indexing", Second European Conference on Research and Advanced Technology for Digital Libraries, Crete, Greece, September, 1998.
• Overview of the MPEG-7 Standard, Version 5.0, Marzo 2001, ISO/IEC JTC1/SC29/WG11 N4031

Bibliografia: Capitolo V: Il prototipo di Mpeg-7 Metadata eXperimental Repository e le interfacce – 177
• Documento Mpeg-7 ISO/IEC 15938-5 Multimedia Description Schemes Versione FCD N3966, 12 Marzo 2001, Singapore, ISO/IEC JTC 1/SC 29/WG 11/N3966.
• J. Hunter, L. Armstrong, "A Comparison of Schemas for Video Metadata Representation", WWW8, Toronto, May 10-14, 1999 - link : http://archive.dstc.edu.au/RDU/staff/jane-hunter/www8/paper.html
VI.5 Capitolo V: Il prototipo di Mpeg-7 Metadata eXperimental Repository e le interfacce
• Tamino DB Server Developer edition v.2.2.9 manuale e documentazione elettronica fornita con il prodotto.
• “Accesso a database via Web” di Luca Mari, edizioni Apogeo, 2001.

Appendice A: Terminologia e abbreviazioni – 178
VII° Capitolo: Appendici
VII.1 Appendice A: Terminologia e abbreviazioni
Termini e definizioni:
AV: Audio-visual
CIF: Common Intermediate Format
CS: Classification Scheme
D: Descriptor
Ds: Descriptors
DDL: Description Definition Language
DS: Description Scheme
DSs: Description Schemes
IANA: Internet Assigned Numbers Authority
IPMP: Intellectual Property Management Protocol
JPEG: Joint Photographic Experts Group
MDS: Multimedia Description Scheme
MPEG: Moving Picture Experts Group
MPEG-7: ISO/IEC 15938
MP3: MPEG1/2 layer 3 (audio coding)
QCIF: Quarter Common Intermediate Format
SMPTE: Society of Motion Picture and Television Engineers
TZ: Time Zone
TZD: Time Zone Difference
URI: Uniform Resource Identifier (IETF Standard is RFC 2396)
URL: Uniform Resource Locator (IETF Standard is RFC 2396)
XM: eXperimentation Model
XML: eXtensible Markup Language

Appendice B: Listato del documento descrittivo realizzato secondo Mpeg-7 MDS – 179
VII.2 Appendice B: Listato del documento descrittivo realizzato
secondo Mpeg-7 MDS
Descrizione di un programma Tv archiviato in Teca (caso studio del programma “Passaggio a Nord ovest”) basata su metadati e su strutture di descrizione Mpeg-7 MDS Multimedia Description Schemes Prototipo di documento descrittivo realizzato con gli strumenti di descrizione di Mpeg-7 MDS (Versione FCD). <?xml version="1.0" encoding="UTF-8"?> <Mpeg7 xmlns="http://www.mpeg7.org/2001/MPEG-7_Schema" xmlns:xsi="http://www.w3.org/2000/10/XMLSchema-instance" xsi:schemaLocation="http://www.mpeg7.org/2001/MPEG-7_Schema"> <ContentDescription xsi:type="ContentEntityType"> <DescriptionMetadata> <LastUpdate>2001-05-11T10:00:00+00:00</LastUpdate> <Comment> <FreeTextAnnotation>Descrizione delle informazioni descrittive di un contenuto audiovisivo di teca.</FreeTextAnnotation> </Comment> <CreationTime>2001-05-11T11:00</CreationTime> </DescriptionMetadata> <MultimediaContent xsi:type="AudioVisualType"> <AudioVisual> <MediaInformation> <MediaIdentification> <Identifier IdName="Numero_Identificazione_Risorsa(esempio)" IdOrganization="TecheRai_TecaFast"> <IdValue>MPEG7.TECAFAST.2001</IdValue> </Identifier> </MediaIdentification> <MediaProfile id="Media_Profile_Programma"> <MediaFormat> <FileFormat>MPEG</FileFormat> <System>PAL</System> <Medium>DigitalCassette200GB</Medium> <Color>color</Color> <Sound>mono</Sound> <FileSize>5005321704</FileSize> <AudioChannels>1</AudioChannels> <AudioLanguage>italian</AudioLanguage> <Resolution>2</Resolution> <FrameWidth>720</FrameWidth> <FrameHeight>576</FrameHeight> <AspectRatio Width="766" Height="576"/> <FrameRate>25.0</FrameRate> <AudioSamplingRate>44100</AudioSamplingRate> <CompressionFormat>MPEG-2</CompressionFormat> <BitRate>10</BitRate> <Bandwidth>10</Bandwidth> </MediaFormat> </MediaProfile> </MediaInformation> <CreationInformation> <Creation> <Title type="main">PASSAGGIO A NORD - OVEST</Title> <Abstract> <FreeTextAnnotation>Programma di Alberto Angela. Angela spiega i motivi per cui l' antica statua equestre dell' imperatore Marco Aurelio, dopo essere ….segue.. presso l' " Istituto Poligrafico e Zecca dello Stato ".</FreeTextAnnotation> </Abstract> <Creator> <Role href="TecaFastXmCreatorCS*">

Appendice B: Listato del documento descrittivo realizzato secondo Mpeg-7 MDS – 180
<Name>Autore</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Alberto Angela</GivenName> </Name> <Affiliation> <Organization> <Name>RAI Televisione Italiana</Name> </Organization> </Affiliation> </Agent> </Creator> <Creator> <Role href="TecaFastXmCreatorCS*"> <Name>Direttore fotografia</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Maurizio Aldrovandi</GivenName> </Name> <Affiliation> <Organization/> </Affiliation> </Agent> </Creator> <Creator> <Role href="TecaFastXmCreatorCS*"> <Name>Musica</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Roberto Anselmi</GivenName> </Name> <Affiliation> <Organization/> </Affiliation> </Agent> </Creator> <Creator> <Role href="TecaFastXmCreatorCS*"> <Name>Produttore esecutivo</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Etra Palazzi</GivenName> </Name> <Affiliation> <Organization/> </Affiliation> </Agent> </Creator> <Creator> <Role href="TecaFastXmCreatorCS*"> <Name>Regia</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Giampaolo Tessarolo</GivenName> </Name> <Affiliation> <Organization/> </Affiliation> </Agent> </Creator> <Creator> <Role href="TecaFastXmCreatorCS*">

Appendice B: Listato del documento descrittivo realizzato secondo Mpeg-7 MDS – 181
<Name>Scenografia</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Armando Nobili</GivenName> </Name> <Affiliation> <Organization/> </Affiliation> </Agent> </Creator> <Creator> <Role href="TecaFastXmCreatorCS*"> <Name>Direttore di produzione</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Ottavio Nicolo'</GivenName> </Name> <Affiliation> <Organization/> </Affiliation> </Agent> </Creator> <Creator> <Role href="TecaFastXmCreatorCS*"> <Name>Emittente</Name> </Role> <Agent xsi:type="OrganizationType"> <Name>RAIUNO</Name> <Affiliation> <Organization/> </Affiliation> </Agent> </Creator> <CreationCoordinates> <CreationLocation> <Name>Roma, Lazio, Italia</Name> <Role> <Name>Production studio</Name> </Role> <AstronomicalBody> <Name>Earth</Name> </AstronomicalBody> <Country>it</Country> <AdministrativeUnit>Studio Rai Saxa Rubra - 2</AdministrativeUnit> </CreationLocation> <CreationDate> <TimePoint>2001-05-03</TimePoint> </CreationDate> </CreationCoordinates> <CreationTool> <Tool> <Name>Televison camera Betacam SP Sony</Name> </Tool> </CreationTool> </Creation> <Classification> <Form href="TecaFastXmFormCS*"> <Name>Documentario</Name> </Form> <Genre href="TecaFastXmGenreCS*"> <Name>Cultura</Name> </Genre> <Release date="2001-10-03T18:16:08"> <Country>it</Country> </Release>

Appendice C: Document Type Definition del documento di descrizione metadati – 182
<Target> <Age min="6"/> </Target> </Classification> </CreationInformation> <UsageInformation> <Rights> <RightsId> <IDOrganization> <Name>Rai Produzione Radio Televisiva (esempio)</Name> </IDOrganization> <IDName> <Name>Rai TV Rights (esempio)</Name> </IDName> <UniqueID>RAICANALE1-TV001-ITALY-335666548(esempio)</UniqueID> </RightsId> </Rights> </UsageInformation> <MediaTime> <MediaTimePoint>2001-10-03T18:16:08</MediaTimePoint> <MediaDuration>PT52M55S</MediaDuration> </MediaTime> </AudioVisual> </MultimediaContent> </ContentDescription> </Mpeg7>
VII.3 Appendice C: Document Type Definition del documento di
descrizione metadati
La DTD costruita per definire nel Data Map la struttura del tipo di documento “Mpeg7”. (Fare riferimento al capitolo IV e all’appendice B per il codice xml del documento di descrizione risorsa “programma Tv” realizzato sulla base degli strumenti di descrizione di Mpeg-7 MDS Schema) <?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT Mpeg7 (ContentDescription)> <!ATTLIST Mpeg7 xmlns CDATA #REQUIRED xmlns:xsi CDATA #REQUIRED xsi:schemaLocation CDATA #IMPLIED > <!ELEMENT ContentDescription (DescriptionMetadata, MultimediaContent)> <!ATTLIST ContentDescription xsi:type CDATA #FIXED "ContentEntityType" > <!ELEMENT DescriptionMetadata (LastUpdate?, Comment?, CreationTime?)> <!ELEMENT Comment (FreeTextAnnotation)> <!ELEMENT MultimediaContent (AudioVisual)> <!ATTLIST MultimediaContent xsi:type CDATA #FIXED "AudioVisualType" > <!ELEMENT AudioVisual (MediaInformation, CreationInformation, UsageInformation, MediaTime)> <!ELEMENT MediaInformation (MediaIdentification, MediaProfile?)> <!ELEMENT MediaIdentification (Identifier)> <!ELEMENT Identifier (IdValue?)> <!ATTLIST Identifier IdName CDATA #IMPLIED IdOrganization CDATA #IMPLIED > <!ELEMENT MediaProfile (MediaFormat)> <!ATTLIST MediaProfile

Appendice C: Document Type Definition del documento di descrizione metadati – 183
id CDATA #IMPLIED master CDATA #IMPLIED > <!ELEMENT MediaFormat (FileFormat?, System?, Medium?, Color?, Sound?, FileSize?, AudioChannels?, AudioLanguage?, Resolution?, FrameWidth?, FrameHeight?, AspectRatio?, FrameRate?, AudioSamplingRate?, CompressionFormat?, BitRate?, Bandwidth?)> <!ELEMENT CreationInformation (Creation, Classification)> <!ELEMENT Creation (Title*, Abstract, Creator+, CreationCoordinates, CreationTool)> <!ELEMENT Abstract (FreeTextAnnotation+)> <!ELEMENT Creator (Role, Agent)> <!ELEMENT Role (Name?)> <!ATTLIST Role href (TecaFastXmCreatorCS) #IMPLIED > <!ELEMENT Agent (Name?, Affiliation)> <!ATTLIST Agent xsi:type (PersonType | PersonGroupType | OrganizationType) #REQUIRED > <!ELEMENT Affiliation (Organization)> <!ELEMENT CreationCoordinates (CreationLocation, CreationDate)> <!ELEMENT CreationDate (TimePoint?)> <!ELEMENT CreationLocation (Name?, Role?, AstronomicalBody?, Country?, AdministrativeUnit?)> <!ELEMENT AstronomicalBody (Name?)> <!ELEMENT CreationTool (Tool)> <!ELEMENT Classification (Form, Genre, Release, Target)> <!ELEMENT Form (Name?)> <!ATTLIST Form href (TecaFastXmFormCS) #REQUIRED > <!ELEMENT Genre (Name?)> <!ATTLIST Genre href (TecaFastXmGenreCS) #REQUIRED > <!ELEMENT Release (Country?)> <!ATTLIST Release date CDATA #IMPLIED > <!ELEMENT Target (Age)> <!ELEMENT MediaTime (MediaTimePoint, MediaDuration)> <!ELEMENT AdministrativeUnit (#PCDATA)> <!ELEMENT Age EMPTY> <!ATTLIST Age max CDATA #IMPLIED min CDATA #IMPLIED > <!ELEMENT AspectRatio EMPTY> <!ATTLIST AspectRatio Width CDATA #REQUIRED Height CDATA #REQUIRED > <!ELEMENT AudioChannels (#PCDATA)> <!ELEMENT AudioLanguage (#PCDATA)> <!ELEMENT AudioSamplingRate (#PCDATA)> <!ELEMENT Bandwidth (#PCDATA)> <!ELEMENT BitRate (#PCDATA)> <!ELEMENT Color (#PCDATA)> <!ELEMENT CompressionFormat (#PCDATA)> <!ELEMENT Country (#PCDATA)> <!ELEMENT CreationTime (#PCDATA)> <!ELEMENT FileFormat (#PCDATA)> <!ELEMENT FileSize (#PCDATA)> <!ELEMENT FrameHeight (#PCDATA)> <!ELEMENT FrameRate (#PCDATA)> <!ELEMENT FrameWidth (#PCDATA)> <!ELEMENT FreeTextAnnotation (#PCDATA)> <!ELEMENT GivenName (#PCDATA)> <!ELEMENT IDName (Name?)> <!ELEMENT IDOrganization (Name?)> <!ELEMENT IdValue (#PCDATA)> <!ELEMENT LastUpdate (#PCDATA)> <!ELEMENT MediaDuration (#PCDATA)> <!ELEMENT MediaTimePoint (#PCDATA)>

Appendice C: Document Type Definition del documento di descrizione metadati – 184
<!ELEMENT Medium (#PCDATA)> <!ELEMENT Name (#PCDATA | GivenName)*> <!ATTLIST Name xml:lang (it | en) #IMPLIED > <!ELEMENT Organization (Name?)> <!ELEMENT Resolution (#PCDATA)> <!ELEMENT Rights (RightsId)> <!ELEMENT RightsId (IDOrganization, IDName, UniqueID?)> <!ELEMENT Sound (#PCDATA)> <!ELEMENT System (#PCDATA)> <!ELEMENT TimePoint (#PCDATA)> <!ELEMENT Title (#PCDATA)> <!ATTLIST Title type (main | secondary | alternative | original | popular | opusNumber | songTitle | albumTitle | seriesTitle | episodeTitle) #REQUIRED > <!ELEMENT Tool (Name?)> <!ELEMENT UniqueID (#PCDATA)> <!ELEMENT UsageInformation (Rights)>

Ringraziamenti – 185
Ringraziamenti:
v Si ringraziano per la collaborazione alla tesi il Prof. Alessandro Neri e il Prof. Alessandro Toscano dell’Università degli Studi Roma Tre.
v Hanno consentito la realizzazione del progetto e della tesi presso la RAI, l’Ing. Gabriel Rascio e l’Ing. Lorenzo Annibali (Rai Produzione Roma), l’Ing. Mario Stroppiana e l’Ing. Alberto Messina (CRIT – Centro Ricerche e Innovazione Tecnologica Rai – Torino) cui vanno i miei ringraziamenti.
v Si ringraziano la Rai Radio Televisione Italiana e la Telecom Italia per le infrastrutture e le risorse messe a disposizione nell’ambito del progetto Vivai D’Impresa Elis.
v Si ringraziano l’Ing.Paolo Bellifemine e l’Ing. Leonardo Chiariglione del Telecom Italia Lab di Torino.
v Si ringrazia la Software AG Italia per averci messo a disposizione la piattaforma software per lo sviluppo del prototipo e Paolo Diomede per il suo supporto nelle fasi di realizzazione e la sua grande disponibilità.
v Un ringraziamento speciale va a Michele Crudele, a Mario Filippa, a Pietro Papoff, a Marco Nicchi, a Girolamo Inzerillo, a Giuseppe Cinque, a Stefano Epifani, ad Antonio Albanese, a Giuseppe Tomeno, a Pierlugi Bartolomei, a Roberto Sorrenti e a tutti i responsabili, tutor e personale del Centro Elis di Roma, per il loro supporto e il loro impegno eccellenti in questi mesi.
v Un particolare ringraziamento va a Giuseppe Murati, mio collega nel progetto-master Internet TV presso i Vivai d’impresa, per la splendida collaborazione portata avanti in questi mesi con grande professionalità e competenza.
v Ringrazio il personale dell’ A.D.I.S.U. dell’Università degli Studi Roma Tre che con il loro lavoro di Azienda per il Diritto allo Studio ha contribuito alla prosecuzione della mia carriera universitaria.
v Ringrazio tutti quelli che mi sono stati vicini con sincerità in questi anni anche se fisicamente lontani.
Dedicata a E., con Stefania S. e Tiziano M.,
ed a Stanley K.
Francesco Romano FRZ 1995-2001
Corso Hyperion 1992-1995 (703)

Venezia, Luglio 1995 - Roma, Luglio 2001


















