Presentazione corso di statistica a.a. 2004-2005 · • BORRA, S. e DI CIACCIO, A. (2008)...
71
1 1 Statistica Alessandro Attanasio mail: [email protected] 2 Testi • PICCOLO, D. (2001) Statistica - Il Mulino - Bologna. • BORRA, S. e DI CIACCIO, A. (2008) Statistica: metodologia per le scienze sociali ed economiche – McGraw-Hill – Milano. Prima Parte Introduzione alla probabilità
Transcript of Presentazione corso di statistica a.a. 2004-2005 · • BORRA, S. e DI CIACCIO, A. (2008)...

1
1
Statistica
Alessandro Attanasio
mail: [email protected]
2
Testi
• PICCOLO, D. (2001) Statistica - Il Mulino -
Bologna.
• BORRA, S. e DI CIACCIO, A. (2008)
Statistica: metodologia per le scienze sociali ed
economiche – McGraw-Hill – Milano.
Prima Parte
Introduzione alla probabilità

2
il calcolo
combinatorio
5
Disposizioni e combinazioni
• Disposizioni: importante l’ordine degli
elementi!!!
• Combinazioni: non è importante l’ordine
degli elementi!!!
6
Disposizioni (con ripetizione)
Consideriamo 4 elementi in gruppi da 2.
ddcdbdad
dcccbcac
dbcbbbab
dacabaaa

3
7
disposizioni con ripetizione
• si definiscono disposizioni con ripetizione di n
elementi di classe k, i gruppi di k elementi (diversi
o uguali fra loro) in modo che vengano ritenuti
differenti due gruppi se differiscono tra loro per
un elemento oppure per l’ordine degli elementi
• esse sono precisamente
kn
8
Disposizioni (senza ripetizione)
Consideriamo 4 elementi in gruppi da 2.
ddcdbdad
dcccbcac
dbcbbbab
dacabaaa
9
disposizioni senza ripetizione
• di definiscono disposizioni senza ripetizione di n
elementi di classe k, i gruppi di k elementi (tutti
diversi) che differiscono tra loro per almeno un
elemento oppure per l’ordine degli elementi
• queste sono precisamente
121 knnnnn k

4
10
permutazioni
le disposizioni senza ripetizione di n di
classe n sono dette anche permutazioni e
sono in numero di:
!12321 n.....nnn
11
Combinazioni (senza ripetizione)
Consideriamo 4 elementi in gruppi da 2.
ddcdbdad
dcccbcac
dbcbbbab
dacabaaa
12
combinazioni senza ripetizione
si definiscono combinazioni senza ripetizione di n di
classe k, i gruppi di k elementi tutti diversi che si
possono formare in modo che due gruppi sono
considerati differenti se differiscono tra loro per
almeno un elemento e sono in numero di:
!!
!
knk
n
k
n

5
13
Consigli utili
!1!
!1!
110111112113
1
!113
!109
8990!88
!90
hnhn
hnn
n
n
14
Consigli utili
!
1
!1
1
!
1
!1!
n
n
nn
nnn
15
Esercizio
• Quanti sono i possibili anagrammi della
parola “fortuna”?
Sol: 7!
• Quanti sono i possibili anagrammi di
“juventus”?
Sol: 8!/2!

6
16
Esercizio
Dimostrare che
0 , 1
1
1
0 , 1
1
12 5
7
77
5
5
kknk
n
k
n
k
n
kknk
kn
k
n
k
n
nnnnn
17
definizione classica della
probabilità (esempio)
• Lancio un dado e fra tutte le 6 possibili facce la
probabilità che esca quella con 5 è 1/6 !
• La probabilità che esca un numero dispari è 3/6 !
• La probabilità che esca un numero maggiore di
due è 4/6 !
18
momenti fondamentali della
assiomatizzazione (Kolmogoroff 1932)!
• individuazione dei concetti primitivi
• enunciazione dei postulati o assiomi
• dimostrazione dei teoremi

7
19
concetti primitivi della
probabilità
• prova : esperimento soggetto ad incertezza
• evento : uno dei possibili risultati della
prova
• probabilità : numero associato al verifi-
carsi di un evento
I diagrammi di Venn
A
B
AB
I diagrammi di Venn
A
B
AB

8
I diagrammi di Venn
A A A
23
Definizioni di eventi
• Evento semplice (elementare)
• Evento composto
• Spazio campione
24
Esempio
Lancio di un dado:
• Evento elementare: esce il numero 1
• Evento composto: esce un numero dispari
• Spazio campione: Ω={1,2,3,4,5,6}

9
25
• Eventi incompatibili (se la loro
intersezione è l’insieme vuoto)
• Eventi necessari (se la loro
unione è l’evento certo)
• Spazio degli eventi: tutti i
possibili sottoinsiemi di Ω
26
• Spazio campione (Evento certo )
| |=n
• Spazio degli eventi A
| A |=2n
• Evento impossibile Ø
× spazi
finiti
27
Esempio
Lancio di una moneta:
• Spazio campione: Ω={T,C}
• Spazio degli eventi: A={Ø,{T},{C},Ω}

10
28
Esempio Lancio di due monete:
• Spazio campione:
Ω={(T,T),(T,C),(C,T),(C,C)}
• Spazio degli eventi:
A={Ø,{(T,T)},{(T,C)},{(C,T)},{(C,C)},
{(T,T),(T,C)},{(T,T),(C,T)},{(T,T),(C,C)} {(T,C),(C,T)},{(T,C),(C,C)} {(C,T),(C,C)} {(T,T),(T,C),(C,T)},{(T,T),(T,C),(C,C)} {(T,T),(C,T),(C,C)}, {(T,C),(C,T),(C,C)}, Ω}
29
perché | A | proprio 2n ?
• si ricordi il binomio di Newton!
• nel nostro caso abbiamo
n
k
knknyx
k
nyx
0
n
nkk
n
n
nnnnn2......
3210,...,0
30
spazio di probabilità
( , A, P )

11
31
spazio di probabilità
• spazio campionario.
• A è una famiglia di sottoinsiemi di tale che:
- , Ø sono elementi di A;
- se B appartiene ad A, allora anche il suo complementare è elemento di A;
- se B e C sono elementi di A, allora la loro unione è elemento di A.
32
spazio di probabilità
• P è una probabilità, ovvero
una funzione P: A [0,1] che
verifica i seguenti postulati
33
I postulati della probabilità
• 1)
• 2)
• 3)
iE 0P ogniper iE
1P
patibiliB inceenti Acon gli ev
BPAPBAP
om

12
34
Principali teoremi
• 1)
)()()( ABPABPBP
B A
ABPABPBPABABB
35
Principali teoremi
• 2)
Basta porre, nel teorema 1, B=Ω. Quindi
APAP 1
APAP
APAP
APAPP
1
1
)()()(
36
Principali teoremi
• 3)
E’ una conseguenza del teorema 2, in quanto
0)Ø( P
01)( PP Ø

13
37
Principali teoremi
• 4)
)(P(P BA)BA
B
A
APABPAPBPABAB
38
Principali teoremi
• 5)
E’ una conseguenza del teorema 4. Infatti
1)(0 AP
0
1
APA
APA
Ø
39
Principali teoremi
• 6)
ABPAPBAPABABA
B A
)()()()( BAPBPAPBAP

14
40
Esercizio
Un’urna contente 6 palline bianche e 4
gialle. Se ne estraggono due senza
reimmissione. Determinare:
1. La probabilità che la prima pallina sia
gialla.
2. La probabilità che la seconda pallina sia
gialla.
41
Esercizio
Tre cacciatori A,B e C avvistano una lepre e
sparano contemporaneamente alla povera bestiola.
Le probabilità di colpire l’animale sono,
rispettivamente P[A]= 0.3; P[B]= 0.4 e P[C]= 0.7 (i
relativi eventi sono indipendenti fra loro). Calcolare
la probabilità dell’evento E ={la lepre è colpita}.
42
Esercizio
Un’azienda possiede 3 stabilimenti A, B e C
che producono rispettivamente il 10%, 30%,
60% della produzione totale. E’ noto che dai 3
stabilimenti provengono dei pezzi difettosi in
percentuale rispettivamente del 10%, 5%, 5%.
Qual è la probabilità che un pezzo preso a
caso sia difettoso?

15
43
Esercizio
Tre dadi non equi hanno la probabilità di far
uscire il 5 rispettivamente con 0.1 0.2 e 0.3.
Scegliendo a caso un dado, qual è la
probabilità che esca il 5?
44
Esercizio
Sono date due urne:
1. U1: 5 rosse, 3 bianche, 8 azzurre;
2. U2: 3 rosse, 5 bianche.
Viene lanciato un dado: se si presenta 3 o 6
viene estratta una pallina dalla seconda urna,
altrimenti dalla prima. Determinare la
probabilità che venga estratta una pallina rossa.
45
Probabilità condizionata
B
BABA
P
PP
o subordinata

16
46
Esercizio
Una popolazione si compone del 40% di
fumatori e del 60% di non fumatori. Si sa che
il 25% dei fumatori ed il 7% dei non fumatori
sono affetti da una malattia respiratoria. Si
seleziona una persona scelta a caso e risulta
malata. Qual è la probabilità che sia un
fumatore?
47
Esercizio
Tre mobili, tra loro uguali, contengono due cassetti. In
particolare:
1. Il primo ha una moneta d’oro in entrambi i cassetti;
2. Il secondo ha moneta d’argento nel primo ed una d’oro nel secondo;
3. Il terzo una moneta d’argento in entrambi i cassetti.
Si apre a caso un cassetto e si trova una moneta d’oro.
Qual è la probabilità che anche l’altro contenga una
moneta d’oro?
48
dismutazioni
sono le permutazioni che non hanno elementi
uguali nello stesso posto e sono in numero di:
Ni
i
iNN
,....,1,0 !
)1(!!
ad esempio: !3=2; !4=9 ; !5=44; !6=264

17
49
dismutazioni
Consideriamo il numero 123. Le possibili
permutazioni sono:
132, 213, 231, 312, 321
Di queste solo 231 e 321 sono dismutazioni.
50
Esercizio
Due critici gastronomici devono valutare i 6 migliori
ristoranti di Parigi. Iniziano e finiscono negli stessi
giorni, visitando entrambi un ristorante al giorno
(solo la sera a cena) e scegliendo in modo del tutto
casuale i ristoranti da valutare. Qual è la probabilità
che non si incontrino mai? (Ovviamente per
entrambi la scelta del ristorante è sì a caso
ma…senza ripetizioni!)
51
dismutazioni
il rapporto fra dismutazioni e permutazioni, per
N tende ad e vi converge pure molto
rapidamente !
36787901
!
!lim .
eN
N
N
e
1

18
52
Eventi indipendenti
• Due eventi A e B si dicono indipendenti se
e solo se
• oppure
ABA PP
BABA PPP
53
Esercizio
Siano A e B due eventi tali che:
Determinare P(A|B) e P(B|A)
3/4B)P(A 3.
5/8P(B) 2.
3/8P(A) 1.
54
Eventi mutuamente
indipendenti
• Una collezione di eventi
sono mutuamente indipendenti se, per ogni
gruppo di m > 1 eventi, risulta che
,....,, 321 EEE
m
m
EEE
EEE
P........PP
).......(P
21
21

19
55
Osservazione
Va ricordato che indipendenza e incompa-
tibilità non hanno nessun legame tra
loro: la prima è una relazione tra probabilità,
la seconda tra eventi!!!
Possiamo solo dire che se due eventi incom-
patibili hanno probabilità positive, allora non
possono essere indipendenti.
56
una riflessione sulla
• Si ha che
• oppure
)(P)(P)(P ABABA
)(P)(P)(P BABBA
57
Teorema di Bayes
(formulazione ridotta)
B
AABBA
P
PPP

20
58
Esercizio (Monty Hall Problem)
Ci sono 3 porte A, B, C ed una sola contiene
un premio. Il conduttore del gioco chiede al
concorrente di selezionare una porta. Dopo il
conduttore apre una delle altre due porte
(aprendo sempre quella senza premio). A
questo punto da al concorrente la possibilità di
cambiare porta. Cosa dovrebbe fare?
le variabili casuali
60
la variabile casuale (v.c.) X
una grandezza numerica che non conosciamo
ancora (al nostro livello di informazione):
• la temperatura domani alle 12 ad Aquila;
• il cambio $/€ del prossimo fine settimana;
• il numero di figli degli sposi Z e W fra 10 anni;
• il valore delle azioni Fiat alla borsa questa sera

21
61
Variabili aleatorie
Una variabile aleatoria è una regola (funzione)
che associa ad ogni evento un numero reale.
RX :
62
Esercizio
Un dado non equo ha la peculiarità di avere la
probabilità, per ciascuna faccia, proporzionale
al doppio del numero impresso sulla stessa.
Definire X la v.c. corrispondente al risultato
del lancio del dado.
63
Esercizio
Una moneta viene truccata in modo che la pro-
babilità di testa sia 2/3. La moneta viene
lanciata 3 volte. Rappresentare la v.a.
X = numero massimo di teste consecutive

22
64
valore atteso di una v.c. discreta
se X è una v.c. discreta (finita o numerabile) si definisce il
suo valore atteso nella maniera che segue:
XIi
ii xpXE
65
valore atteso di una v.c. discreta
si prenda ad esempio il risultato (X) del lancio di
un dado regolare
5.366
12
6
11
6
1
XIi
ii xpXE
66
Varianza
XIi
ii xpX22VAR

23
67
la v. c. X di Bernoulli
• è legata all’esperimento più semplice che si
può immaginare, tipo: pari/dispari;
testa/croce; in generale successo/insuccesso
pq
pX
1 0
1
68
la v. c. X di Bernoulli
caratteristiche teoriche
media= X = p
varianza = X2= p·(1-p)= p·q
69
la v. c. X geometrica
E’ legata al semplice esperimento :
quanti lanci debbo fare per ottenere la prima testa?
,........2,1)1()( 1 kppkXP k

24
70
lancio un tetraedro regolare,
qual è la probabilità che esca
la prima volta il 3 al terzo
lancio?
Pr[X=3] = (1/4)*(1-1/4)2 = 0.140625
71
la v. c. X geometrica
caratteristiche teoriche
media= X = 1/p
varianza = X2= (1-p)/p2
72
la v. c. X binomiale
è legata ad n prove bernoulliane, indipendenti e
tutte uguali fra loro; k indica il numero di
successi nelle n prove, mentre p è la probabilità
di successo nella singola prova
nk
ppk
nkXP knk
,...,2,1,0
)1()(

25
73
la v. c. X Binomiale
caratteristiche teoriche
media= X = n·p
varianza = X2=n · p ·(1-p)= n · p · q
74
Esercizio
Una moneta viene lanciata 6 volte.
Determinare la probabilità che escano due
teste. Rappresentare, inoltre, la v.a.
X = numero di teste uscite.
75
una bella….distribuzione da
un problema pratico!!!!!
un’urna contiene H palle di
cui b blu e le altre H-b nere
qual è la probabilità che
estraendone n senza reim-
missione k di queste siano
blu?

26
76
la v.c. X ipergeometrica
),min(),0max( bnkbHn
n
H
k
b
kn
bH
kXP
77
la v.c. X ipergeometrica
• è legata alle estrazioni in blocco!
• in ciascuna delle estrazioni la pro-
babilità si modifica in funzione del
risultato precedente
78
Esercizio
Mario gioca 2 due numeri al gioco del lotto.
Qual è la probabilità di fare ambo?
Qualora giocasse 7 numeri, quale sarebbe la
probabilità di fare ambo?

27
Seconda parte:
Statistica
80
Argomenti
• Statistica descrittiva: natura delle variabili; rappresentazioni grafiche; indici di posizione e di variabilità.
• Modello di regressione lineare: teoria ed applicazioni.
• Statistica inferenziale: stimatori; test d’ipotesi (cenni).
81
Prima di iniziare……
Facciamo alcuni esempi:
• Serie storiche: magnitudo del sisma
aquilano.
Fonte dei dati ISIDE.
http://iside.rm.ingv.it/iside/standard/index.jsp

28
82
83
84

29
85
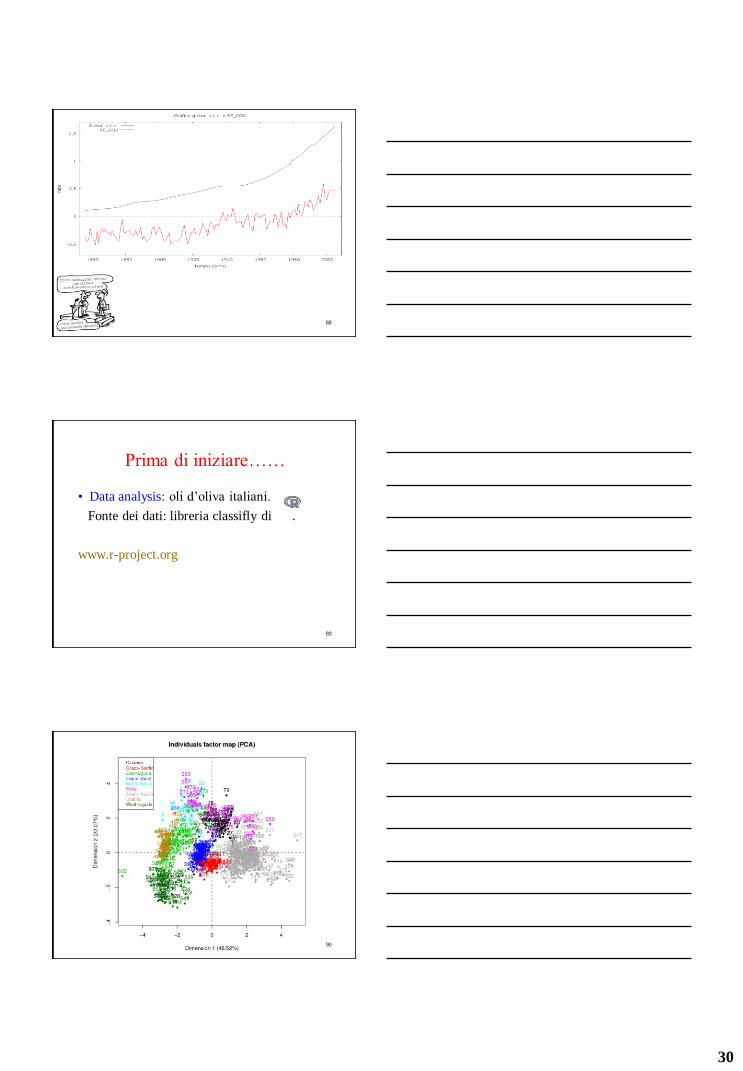
Prima di iniziare……
• Serie storiche: Temperatura e CO2.
Fonte dei dati: Climate Research Unit at the
University of East Anglia; Carbon Dioxide
Information Analysis Center.
http://www.cru.uea.ac.uk/
http://cdiac.esd.ornl.gov/
86
87
30
88
89
Prima di iniziare……
• Data analysis: oli d’oliva italiani.
Fonte dei dati: libreria classifly di .
www.r-project.org
90

31
91
quindi………….
Ci si rende subito conto che le
rappresentazioni grafiche, semplici o
complesse, possano essere
utili ai fini di un’indagine statistica.
L’uso del computer diventa fondamentale!!!
92
FASI DI UN’ANALISI
1 Definizione degli obiettivi della ricerca
2 Rilevazione dei dati
3 Rappresentazione dei dati
4 Presentazione ed interpretazione dei risultati
5 Utilizzazione dei risultati della ricerca
93
Le rilevazioni statistiche
• Popolazione
• Unità statistica
• Variabile
• Modalità

32
94
Tipi di variabili
Quantitative:
Continue e discrete
Qualitative:
Ordinabili e non
ordinabili
95
Due problemi fondamentali
• Come rappresentare i dati?
• Come visualizzare i dati?
Come rappresentare i dati ?
La forma di matrice (o di tabella) è quella
più comune,
le righe rappresentano gli individui
statistici
e le colonne le variabili

33
97
Come visualizzare i dati?
• Diagrammi a barre
• Diagrammi a torta
• Istogrammi
• Rappresentazioni cartesiane
98
Esempio sul dataset oli
Il dataset è composto da 572 oli d’oliva italiani
provenienti dalle seguenti aree regionali:
Calabria, Sicily, Umbria, North and South
Apulia, West and East Liguria, Inland and
Coast Sardinia.
99
Esempio sul dataset oli
Sono state rilevate le seguenti variabili
quantitative:
• palmitic acid
• palmitoleic acid (in simboli p_eic)
• stearic acid
• oleic acid
• linoleic acid
• linolenic acid (in simboli l_eic)
• arachidic acid
• eicosenoic acid

34
100
Esempio sul dataset oli Area geog. Numero oli (f.a) Percentuale (f.r.%)
North Apulia 25 4.37%
South Apulia 206 36.01%
Calabria 56 9.79%
Sicily 36 6.29%
Inland Sardinia 65 11.36%
Coast Sardinia 33 5.77%
East Liguria 50 8.74%
West Liguria 50 8.74%
Umbria 51 8.92%
101
102
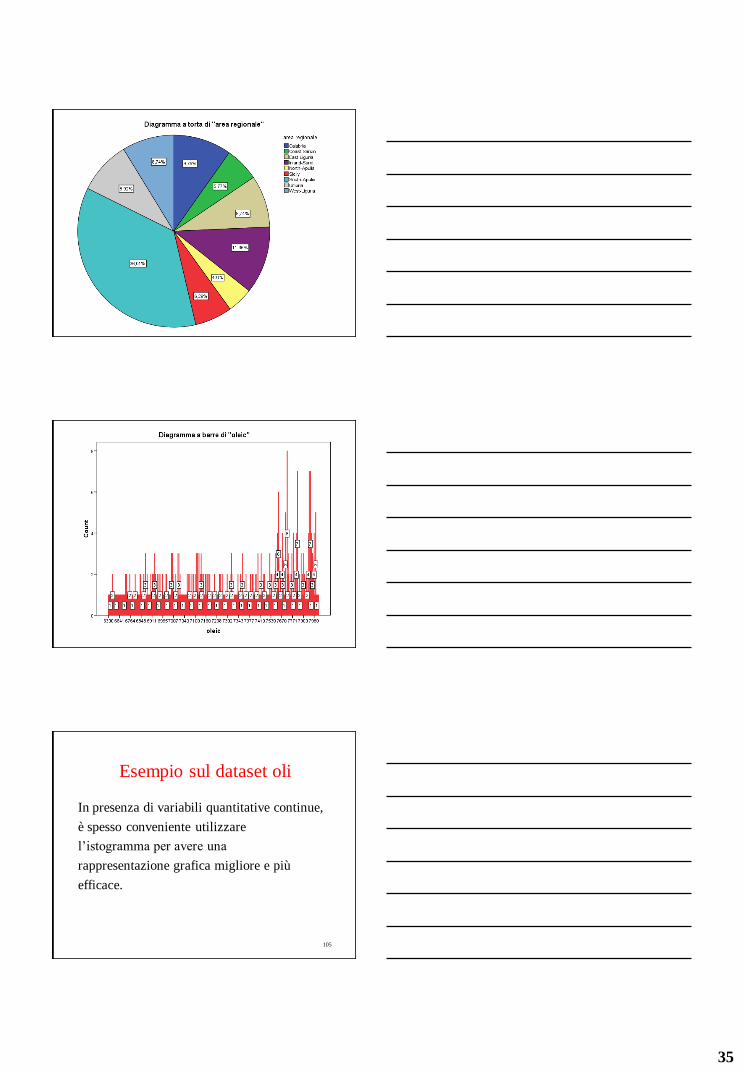
35
103
104
105
Esempio sul dataset oli
In presenza di variabili quantitative continue,
è spesso conveniente utilizzare
l’istogramma per avere una
rappresentazione grafica migliore e più
efficace.

36
106
Esempio sul dataset oli
Ad esempio, dividiamo l’insieme dei possibili
oleic in valori di 3 intervalli disgiunti di
uguale ampiezza.
Classi Frequenze assolute
[6300,7004) 146
[7004,7708) 291
[7708,8412) 135
107
Istogramma di oleic
oleic
fre
qu
en
ze
asso
lute
6500 7000 7500 8000
05
01
00
15
02
00
25
03
00
108
Esempio sul dataset oli
• ATTENZIONE: nella rappresentazione
dell’istogramma, considerare le frequenze assolute
(o relative) nell’asse delle ordinate ha senso solo
se le classi hanno la stessa ampiezza!!!
In caso contrario, occorrerà considerare le densità
assoluta (relativa), ovvero il rapporto tra le
frequenza assoluta (relativa) e l’ampiezza della
classe corrispondente.

37
109
soggettività negli istogrammi?
• il numero delle classi
• l’ampiezza delle classi
sono tutte scelte demandate a colui che effettua
l’analisi, quindi soggettive!!
p.s. il problema attualmente può dirsi….. risolto (con il metodo
del nucleo o istogramma perequato) ma richiede elementi che
ancora non si possiedono, quindi verrà ripreso
successivamente.
Le distribuzioni di frequenze
semplici
• frequenze assolute
• frequenze relative
(percentuali)
• frequenze cumulate
Frequenze assolute
La frequenze assoluta di una modalità è il
numero di volte che tale modalità si presenta
all’interno dell’insieme costituito dalle n
unità statistiche.

38
Frequenze assolute
X è una variabile misurata su n elementi e
può assumere le k modalità x1, x2,…, xk . Le
quantità n1, n2,…, nk sono le frequenze
assolute caratterizzate dal vincolo:
ninkn....2n1nk1,...,i
113
Frequenze relative La frequenza relativa di una modalità xi è
semplicemente il rapporto tra la rispettiva
frequenza assoluta ed il numero n di unità
statistiche.
1
,,1
,...,1
ki
i
ii
f
kin
nf
114
Frequenze cumulate Ordinate le modalità in ordine crescente, la
frequenza cumulata di una modalità xi è la
frequenza con cui si presentano modalità di
ordine inferiore o uguale a xi.
In sostanza è la somma delle prime i frequenze
relative (assolute)
kifxF
ij
ji ,,1
,,1

39
115
Esempio sul dataset oli
Riprendiamo le classi precedenti.
Classi f.r. (f.a.) f.r. cumulate
[6300,7004) 0.26 (146) 0.26
[7004,7708) 0.51 (291) 0.77
[7708,8412) 0.23 (130) 1
Indici statistici di posizione
media aritmetica
mediana
moda
117
Media aritmetica
Si calcola solo per variabili quantitative. Sia
X una variabile quantitativa che assume
valori x1,…,xn per le rispettive n unità
statistiche: definiamo media aritmetica la
quantità
n
i
ii
k
i
ii
n
i
i xfxnn
xn
x
111
11

40
118
Media aritmetica Le proprietà più rilevanti della media aritmetica
sono:
xcxcg
xx
n
i
i
n
i
i
1
2
1
min)(min .2
0 .1
119
Problema!!! All’entrata di una scuola il preside rileva, oltre al
nome, l’età di 7 ragazzi (entrati in ritardo):
15, 13, 18, 14, 17, 17, 41
19x outlier
120
Mediana
La mediana rappresenta il valore centrale in
una successione di valori ordinati.
Per calcolare la mediana occorre:
1. Ordinare in ordine non decrescente, rispetto alle
modalità, le unità statistiche.
2. Se n è dispari, la mediana sarà la modalità nella
posizione (n+1)/2.
3. Se n è pari, si avranno due valori centrali nelle
posizioni n/2 è n/2 + 1.

41
121
Mediana Per variabili quantitative, la mediana è data
da
dispari èn se
pari èn se 2/
2/)1(
)12/()2/(
n
nn
e
x
xx
M
122
Mediana Riprendiamo l’esercizio di prima:
1. Ordinamento
13, 14, 15, 17, 17, 18, 41
2. n=7 dispari, allora la mediana si trova nella posizione
(n+1)/2=4, quindi
Mediana = 17
outlierdell'
risentenon
123
Moda
La moda è la modalità con la frequenza
assoluta (o relativa) più elevata.
Nel caso di modalità suddivise in classi, se
queste hanno ampiezze diverse occorrerà
considerare le rispettive densità.

42
Indici statistici di variabilità
varianza 2
scarto quadratico medio
coefficiente di variazione Cv
scarto standard
deviazione standard
125
Varianza e deviazione standard La varianza di una variabile X è data dalla
formula
2
1
2
1
2
1
22 11
n
i
ii
k
i
ii
n
i
i xxfxxnn
xxn
126
Coefficiente di variazione Il coefficiente di variazione è il rapporto tra la
deviazione standard e la media aritmetica,
ovvero
xCV

43
127
Forma di una distribuzione
Non solo, occorre analizzare anche
l’istogramma.
In quante classi dividere l’istogramma?
Bella domanda!!!!
128
kn° delle classi di un istogramma
alcune proposte:
• Sturges (1926)
• Doane (1976)
• Scott (1979)
• Friedman e Diaconis (1981)
1)ln(4427.11)(log2 nnk
61ln4427.11 1
nnk
3/1
5.3
minmaxnk
3/1
132
minmaxn
QQk
129
Esempio dataset oli

44
130
Esempio dataset oli
Le formule precedenti suggeriscono:
Sturges: k = 10
Doane: k = 11
Scott: k = 12
FD: k = 13
131
132
Istogramma perequato Non necessita della specificazione di un numero di
classi!!!
nih
xxk
hnxf i
,...,1
1)(ˆ
kernelbanda
di ampiezza

45
133
134
istogramma perequato
x
densità
6500 7000 7500 8000 8500
0e
+0
02
e-0
44
e-0
46
e-0
48
e-0
4
135
istogramma
x
conte
ggio
6500 7500 8500
020
60
100
istogramma perequato
x
densità
6500 7500 8500
0e+
00
4e-0
48e-0
4
istogramma
x
conte
ggio
6500 7500 8500
020
60
100
istogramma e relativa normale
x
densità
6000 7000 8000
0e+
00
4e-0
48e-0
4
x

46
LA CORRELAZIONE
L’indice di correlazione lineare di Pearson
YX
XY
YX
n
i
YiXi
XYσσ
σ
σσ
μyμx1-n
1
ρ
covarianza
piccola nota per il calcolo veloce di XY
YX
ni
ii
XYn
yxnyx
)1(
)(,...,1
138
L’indice di correlazione
lineare di Pearson
• se X ed Y sono indipendenti allora
XY = 0
ma non è vero il viceversa; e cioè
se XY =0 X ed Y non sono necessaria-
mente indipendenti !
1ρ1ρρ XYYXXY e
X1 0XY
Y1ρ

47
139
Correlazioni
1.935.752.797-.116-.603.280
.9351.736.873.146-.665.569
.752.7361.814-.243-.594.162
.797.873.8141.124-.821.532
-.116.146-.243.1241-.127.773
-.603-.665-.594-.821-.1271-.395
.280.569.162.532.773-.3951
prezzo in €
costo/km in Cent di €
cilindrata
potenza max in KW
giri al min x potenza max
accelerazione
(0-100km/h) in sec.consumo misto
prezzo in €
costo/km in
Cent di € (x
3 anni e
45000 km)cilindrata
potenza
max in KW
giri al min x
potenza max
accelerazione
(0-100km/h)
in sec.
consumo
misto
matrice (simmetrica) delle correlazioni
La correlazione…spuria!!!
Il prezzo dei cavolini di Bruxelles venduti a Londra
e la corrispondente altezza del Tamigi misurate in
successione oraria evidenzia una fortissima
correlazione………….?
Il consumo di tabacco dal 1881 al 1971 e la vita
media alla nascita della popolazione italiana
riferita agli 8 censimenti, mostrano una correla-
zione di 0.87! Come dire il consumo di tabacco ha
favorito l’allungamento della vita media…….(sic!)
Legami…….spuri!!!
Una vecchia indagine (anni 50!) svolta negli USA su
un campione di donne evidenziò un forte legame
positivo tra il portare le calze di seta ed avere una
cancro ai polmoni! Poiché certamente non erano le
calze di seta a indurre il cancro la realtà era che
queste erano abbinate ad un comportamento
sociale che vedeva anche la sigaretta come elemento
distintivo. Ecco dunque il legame cancro ai
polmoni-sigarette è mediato da un fattore, le calze
di seta, estraneo alla relazione di casualità.

48
Il modello di regressione
lineare semplice
solo alcune importanti considerazioni!!!!
la correlazione è il primo
passo verso la costruzione
di un modello statistico
in altre parole si costruisce un modello
se….ne vale la pena! cioè se la correlazione
è abbastanza grande ( in valore assoluto),
cioè se è significativamente diversa da 0!
il più semplice modello
statistico fra due variabili
è quello lineare
xy 10
variabile
dipendente variabile
indipendente
Coefficienti
costanti

49
come si chiama questo modello ?
è indicato in generale come il
modello di:
regressione lineare semplice
attenzione!!
il ruolo di variabile dipendente ed indipendente
non è simmetrico!
inoltre, fermo restando che l’aggettivo
indipendente nulla ha a che fare con il concetto di
indipendenza statistica, alla y viene attribuito il
ruolo di variabile da stimare, prevedere ecc.,
riconoscendo alla x il ruolo di variabile più facile
da trovare oppure quella di cui si conoscono i
valori mentre della y no!
147
come si ……...costruisce un modello
di regressione lineare semplice ?
• si parte da un campione di n osserva-
zioni: (xi;yi); i=1,…,n
• si stimano i coefficienti 0 e 1 mediante
i dati osservati
• si valuta poi globalmente la bontà del
modello in termini di capacità esplicativa

50
quale tecnica si adotta per
stimare il modello di
regressione?
la tecnica è quella che va sotto il nome dei
minimi quadrati (LS Least Squares)
(dovuta al solito K. F. Gauss !)
149
n costoaKm prezzo
1 52 19617
2 51 22617
3 63 25251
4 60 27651
5 50 20171
……………………………………………...
19 45 14551
20 43 15101
21 . 16678
22 36 12751
23 34 13951
24 48 16651
……………………………………………………….
la 21-ma auto
non ha il costo al
Km!
sarà possibile
stimarlo?
daihatsu Terios
attenzione!!
a partire dai dati ed al problema attribuiremo il
ruolo di variabile indipendente x al prezzo e quello
di variabile dipendente y al costoaKm!
fare il viceversa è sbagliato concettualmente e porta
a risultati numericamente diversi!!

51
151 prezzo in €
3000020000100000
co
sto
/km
in
C
ent
di €
(x 3
an
ni e
450
00
km
)
70
60
50
40
30
20
152 prezzo in €
3000020000100000
co
sto
/km
in
C
ent
di €
(x 3
an
ni e
450
00
km
)
70
60
50
40
30
20
fra le infinite rette del piano
quale si sceglie?
si prende quella che minimizza la somma del
quadrato degli scarti (o errori )!
tranne casi limite questa retta è unica!

52
154 prezzo in €
3000020000100000
costo
/km
in C
ent di € (
x 3 a
nni e 4
5000 k
m)
70
60
50
40
30
20
.min,...,1
2 ni
i
i iii yy ˆ
ii xy 10ˆ
scarti o errori
il calcolo dei coefficienti avviene
tramite le relazioni seguenti:
2
,...,1
10
2
,...,1 ,...,1
2
min
ˆminmin
ni
ii
ni ni
iii
xy
yyQ
relazione in cui sono incogniti solo 0 e 1
il calcolo dei coefficienti avviene
tramite le relazioni seguenti:
0)(2
0)(2
0
0
10
,...,1
10
,...,1
1
0
ii
ni
i
ii
ni
xyx
xy
Q
Q
il valore minimo si ottiene annullano le
due derivate che forniscono così un
sistema di due equazioni in due incognite!

53
sistema la cui soluzione fornisce i seguenti
valori calcolabili a partire dai dati iniziali
xy
xx
yyxx
ni
i
ni
ii
10
,...,1
2
,...,1
1
media delle xi
media delle yi
la retta di regressione
passa per il baricentro!
158 prezzo in €
3000020000100000
costo
/km
in C
ent di € (
x 3 a
nni e 4
5000 k
m)
70
60
50
40
30
20
i
x
y
la retta di regressione
passa per il baricentro!
0019520
726.10
1
0
.
costoaKm = 10.726 + 0.001952× prezzo
159 costo/km in Cent di € (x 3 anni e 45000 km)
706050403020
pre
zzo
in
€
30000
20000
10000
0
prezzo = -2798.8 + 448.17 costoaKm
i =prezzo -prezzo (stimato)

54
160
I legami tra regressione e
l’indice di correlazione
22 R
x
y
1
da cui 0 R2 1
Indice di bontà di adattamento, indicato anche
come “Rsq”
161
I legami tra regressione e l’indice di
bontà di adattamento
residuaDevianza
spiegataDevianza
totaleDevianza
niii
nii
nii
yyeDev
yyyDev
yyyDev
,...,1
2
,...,1
2
,...,1
2
ˆ)ˆ(
ˆ)ˆ(
)(
Dev(y)=Dev(y)+Dev(e)
162
I legami tra regressione e l’indice di
bontà di adattamento
2
,...,1
2
,...,12
)(
)ˆ(
)(
)ˆ(
nii
nii
yy
yy
yDev
yDevR
devianza totale
devianza spiegata

55
163
I legami tra regressione e l’indice di
bontà di adattamento
2
,...,1
,...,1
2
2
)(
ˆ1
)(
)ˆ(1
nii
nii
yy
e
yDev
eDevR
devianza totale
devianza residua
164
A cosa serve un modello statistico?
• permette di descrivere
• permette di interpretare
• permette di fare previsioni
• permette di simulare
• permette di ricostruire dati mancanti
Come si usa un modello di
regressione semplice in previsione?
Nel caso di prezzo-costoaKm se ho un’auto il cui
prezzo è 16678 € ne posso stimare il costo al Km
usando i coefficienti del modello :
costoaKm= 10.726 + 0.001952 prezzo
che mi forniranno il valore di 43.28 centesimi
56
166
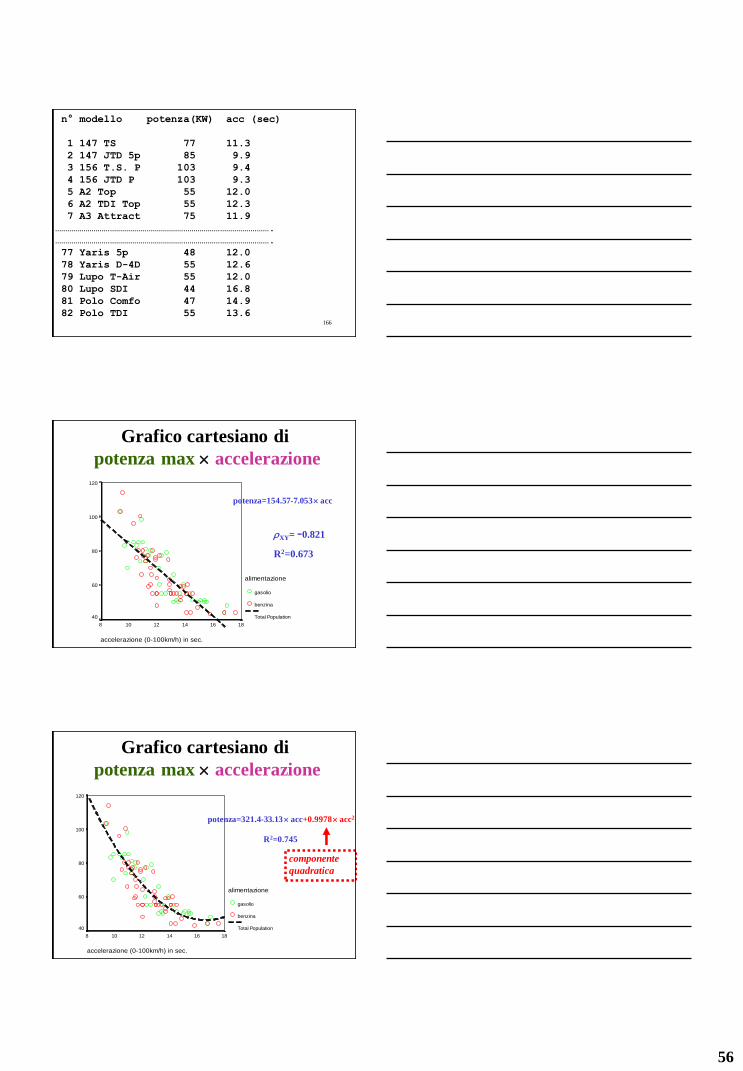
n° modello potenza(KW) acc (sec)
1 147 TS 77 11.3
2 147 JTD 5p 85 9.9
3 156 T.S. P 103 9.4
4 156 JTD P 103 9.3
5 A2 Top 55 12.0
6 A2 TDI Top 55 12.3
7 A3 Attract 75 11.9
…………………………………………………………………………………………….
…………………………………………………………………………………………….
77 Yaris 5p 48 12.0
78 Yaris D-4D 55 12.6
79 Lupo T-Air 55 12.0
80 Lupo SDI 44 16.8
81 Polo Comfo 47 14.9
82 Polo TDI 55 13.6
Grafico cartesiano di
potenza max accelerazione
accelerazione (0-100km/h) in sec.
18161412108
po
ten
za m
ax
in K
W
120
100
80
60
40
alimentazione
gasolio
benzina
Total Population
potenza=154.57-7.053 acc
XY= -0.821
R2=0.673
Grafico cartesiano di
potenza max accelerazione
accelerazione (0-100km/h) in sec.
18161412108
po
ten
za m
ax
in K
W
120
100
80
60
40
alimentazione
gasolio
benzina
Total Population
potenza=321.4-33.13 acc+0.9978 acc2
R2=0.745
componente
quadratica
57
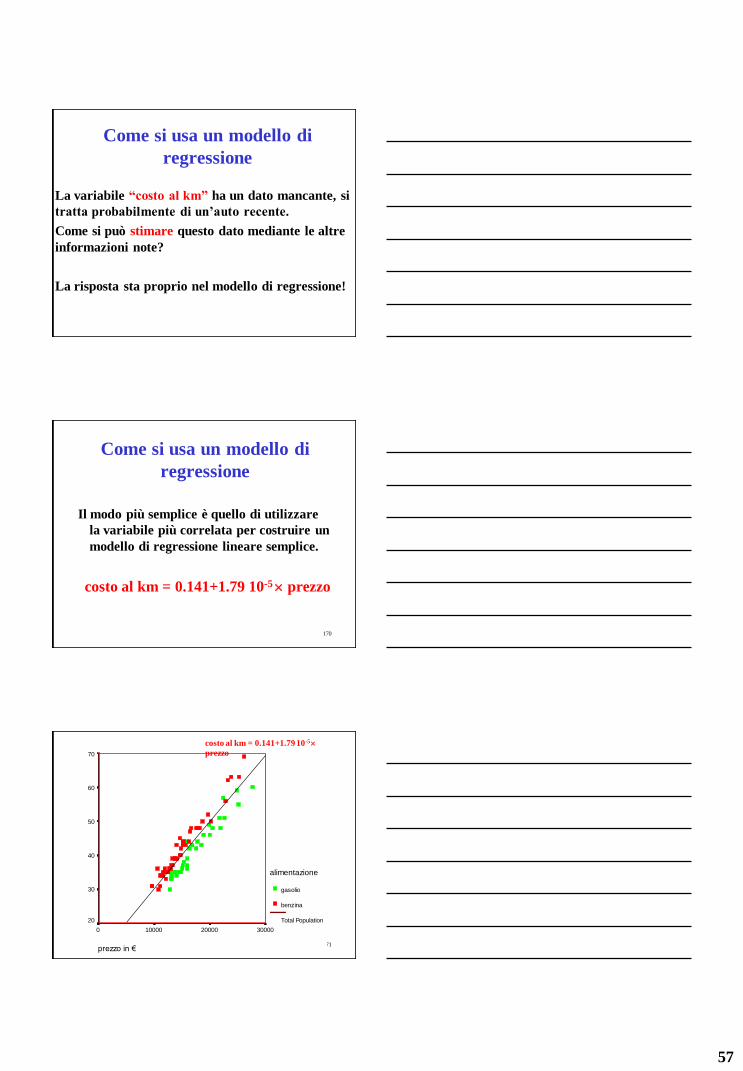
Come si usa un modello di
regressione
La variabile “costo al km” ha un dato mancante, si
tratta probabilmente di un’auto recente.
Come si può stimare questo dato mediante le altre
informazioni note?
La risposta sta proprio nel modello di regressione!
170
Come si usa un modello di
regressione
Il modo più semplice è quello di utilizzare
la variabile più correlata per costruire un
modello di regressione lineare semplice.
costo al km = 0.141+1.79 10-5 prezzo
171 prezzo in €
3000020000100000
co
sto
/km
in
C
en
t d
i €
(x
3 a
nn
i e
45
00
0 k
m)
70
60
50
40
30
20
alimentazione
gasolio
benzina
Total Population
costo al km = 0.141+1.79 10-5
prezzo

58
Come si usa un modello di
regressione
E’ possibile migliorare questo risultato utilizzando
le altre informazioni per stimare questo dato?
La risposta è ancora sì e sta proprio nel modello di
regressione multipla che è….un po’ più complesso!
Modello di regressione multipla
....22110 xxy
coefficienti costanti
prima variabile seconda variabile
174
Come si usa un modello di
regressione multipla?
Qui entrano in gioco i moderni software che
offrono un’ampia gamma di programmi
praticamente…tutti uguali per fortuna!
Il nostro ha stimato il seguente modello:
costo/km= -2.99 +0.002 prezzo +2.505 10-2 cons. misto +0.003 cilindrata

59
175
le caratteristiche di un modello di
regressione multipla
• significatività dei coefficienti
• bontà del modello “Rsq”
• il coefficiente “Rsq” ed il “Rsq corretto”
• il principio di “parsimonia”
176
Rsq corretto
Allo scopo di far diminuire il valore dell’indice Rsq
di una quantità che diventi trascurabile se il
rapporto tra numero di variabili esplicative (p)
ed il numero di osservazioni (n) è piccolo, Theil
introdusse, nel 1961, la seguente correzione:
1pn
Rsq)p(1RsqsqR
sqR
177 prezzo in €
3000020000100000
co
sto
/km
in
C
en
t d
i €
(x
3 a
nn
i e
45
00
0 k
m)
70
60
50
40
30
20
costoaKm=8.879+0.0022*prezzo
=0.983
R2=0.966
modello di regressione solo per auto a benzina

60
178
modello di regressione solo per auto a gasolio
prezzo in €
280002600024000220002000018000160001400012000
co
sto
/km
in
C
en
t d
i €
(x
3 a
nn
i e
45
00
0 k
m)
70
60
50
40
30
20
costoaKm=7.488+0.00198prezzo
=0.968
R2=0.937
179 prezzo in €
3000020000100000
cost
o/k
m in
Cent di € (
x 3 a
nni e 4
5000 k
m)
70
60
50
40
30
20
alimentazione
gasolio
benzina
Modello di regressione
con variabili dummy (binaria)
1
02110 xy
coefficienti costanti
variabile indipendente variabile dummy

61
181
Come si usa un modello di
regressione dummy?
Il nostro software ha stimato il seguente modello:
costo/km= 10.258 +0.002 prezzo -5.090 01(variabile dummy - alimentazione)
182
un momento di riflessione…..
• col modello di regressione lineare semplice la
stima del costoaKm della…. è di 43.28 cent.
• col modello di regressione lineare multipla la
stima risulta di 45.96 cent.
• col modello di regressione semplice limitata ai
modelli omogenei a benzina risulta 45.74 cent.
• col modello di regressione lineare con dummy la
stima risulta di 45.59 cent.
quale valore sarà da preferire, e….perchè?
183
R2 calcolato tramite software
Attenzione ai software statistici nel calcolo dell’R2
quando si elimina l’intercetta!
(termine noto 0=0).
In questi casi l’R2 calcolato non è equiparabile o
confrontabile ai valori precedenti in cui c’era il
termine noto è , in generale, quasi privo di
significato!

62
Test d’ipotesi
185
la v.c. normale N(2)
2
2
2
2
1)(
x
exf
non è una probabilità!
media varianza
186
NORM
1400120010008006004002000
NO
RM
ALE
1.2
1.0
.8
.6
.4
.2
0.0
simmetrica rispetto al
valore centrale
NORM
1400120010008006004002000
NO
RM
ALE
1.2
1.0
.8
.6
.4
.2
0.0
area=0.5

63
187
NORM
1400120010008006004002000
NO
RM
ALE
1.2
1.0
.8
.6
.4
.2
0.0
2.3%
13.6%
34.1%
-2 - + +2 68.2%
95.4%
aree importanti sottese alla normale!
188
standardizzare una variabile
xz
variabile standardizzata
variabile iniziale con media e varianza 2
189
la normale standardizzata
N(0,1)
2
2
2
1)(
x
exf
media varianza

64
190
NORM
1400120010008006004002000
NO
RM
ALE
1.2
1.0
.8
.6
.4
.2
0.0
2.3%
13.6%
34.1%
-2 -1 0 1 2 68.2%
95.4%
aree importanti sottese alla normale standardizzata
191
NORM
1400120010008006004002000
NO
RM
ALE
1.2
1.0
.8
.6
.4
.2
0.0
0 z
(z)= area fino a z !
(z)
z e (z) sono i valori che si trovano sulle tavole nei libri
192
come si calcola una probabilità……
qualunque probabilità relativa ad una normale
generica può essere ricondotta al calcolo di quella
normalizzata!!
N(X ,2)
XXXr
XXXrr
bXaP
bXaPbXaP
N(0,1)

65
193
esercizio: le auto sulla A24 Roma-Aq
la velocità X segue una distribuzione
normale con
= 75 km/h e = 8 km/h
quale proporzione di auto ha superato
il limite di velocità di 70 km/h ?
194
NORM
1400120010008006004002000
NO
RM
ALE
1.2
1.0
.8
.6
.4
.2
0.0
70 75
195
calcolo del valore standardizzato
625.08
7570
z

66
196
trovare l’area probabilità
è necessario trovare l’area dal valore di ascissa
z = - 0.625 e si ricorda che, per la simmetria della
funzione di densità, (-z) = 1- (z)
nelle tavole si trovano i valori per 0.62 e 0.63 cui
corrispondono rispettivamente 0.7324 e 0.7357
l’area cercata, cui corrisponde il valore di
probabilità richiesto, è, “mediando”, 0.7341
197
inferenza statistica
l’inferenza statistica è il procedimento attraverso il
quale i risultati sulle caratteristiche di un cam-
pione vengono riportati a tutta la popolazione!
• la stima dei parametri (puntuale o ad intervallo)
• la verifica di ipotesi
198
la media campionaria
• la media di un campione è
• lo scarto quadratico medio
• l’errore standard della media è
n
X
Xni
i
,...,1
1
)(,...,1
2
n
XXni
i
nX
ecco perché più misure si fanno e più si è precisi!

67
teorema del limite
centrale
...anche se una v.c. non è normale
la sua somma (standardizzata),
da un certo punto in poi, lo è
con buona approssimazione !!!!!
in parole …povere!
200
intervallo di confidenza per la media ( noto)
nzX
dove z è quel valore tale che l’area sottesa
alla curva normale standardizzata tra -z e z
è pari ad (1-)
201
intervallo di confidenza per la media ( noto)
in generale un intervallo di confidenza del 95% è
interpretato come se il 95% degli intervalli presi
su tutti i campioni possibili contengono la media
della popolazione e solo il 5% non la comprende!

68
202
intervallo di confidenza per la media ( noto)
esempio: se un’azienda produce pifferi. Il processo di produzione impone che essi abbiano una lunghezza media di 33 cm. e =0.06 cm. Qual è l’intervallo di confidenza al 95% per la media se un campione di 100 pifferi ha una lunghezza pari a 32.994 cm.?
00576.3398224.32
01176.0994.32100
06.0)96.1(994.32
X
203
terminologia dei test di ipotesi
il test è una regola basata sullo spazio campionario, cioè sull’insieme che può essere generato da tutti i campioni. Esisteranno dei valori del campione (x1,x2,…,xn)R0 per i quali la regola impone di rifiutare H0 ed altri valori (x1,x2,…,xn)R0.
la regione R0 è detta regione critica (RC) o di rifiuto per H0, quella complementare è la
regione di accettazione.
204
terminologia dei test di ipotesi
per ipotesi nulla H0: si intende l’ipotesi preesi-
stente rispetto alla fase di campionamento, quella
cioè che sussiste fino a prova contraria, mentre
l’ipotesi alternativa H1: è la situazione
complementare rispetto ad H0.

69
205
errori nei test di ipotesi
H0: è vera è falsa
accetto H0 rifiuto H0 rifiuto H0 accetto H0
errore di I tipo errore di II tipo
206
errori nei test di ipotesi
• è la probabilità dell’errore di I tipo,
denominata anche come livello di significatività
del test, od ampiezza del test
• è la probabilità dell’errore di II tipo
• =1- è la probabilità di rifiutare correttamente
H0 ed è indicata come potenza del test
207
test di ipotesi per la media
( noto)
tornando all’Enel si deve verificare se un
certo valore di consumi registrato può
essere in linea con la media nazionale
(368kw) o meno, allora il test risulta
H0: = 368
contro
H1: 368

70
208
test di ipotesi per la media
( noto)
assumendo noto il valore di , la media campionaria avrà
una distribuzione normale e si ottiene il seguente test Z
per la media:
n
XZ
209
NORM
1400120010008006004002000
NO
RM
ALE
1.2
1.0
.8
.6
.4
.2
0.0
regione di rifiuto
-1.96 +1.96 Z
regione di accettazione
test a due code: aree della verifica di ipotesi per la media
regione di rifiuto
210
test di ipotesi per la media
( noto)
Fissato il valore di =0.05, la regione di rifiuto avrà
un’area pari a 0.05 e si possono calcolare i valori critici
per Z, che è normale standardizzata. La regione di
rifiuto coincide con le due code della distribuzione,
quindi l’area a sinistra e a destra ha 0.025 cui
corrispondono i valori limite di 1.96. La regola di
decisione del test diventa:
rifiutare H0 se z >1.96 oppure z <-1.96
viceversa accettare H0

71
211
test di ipotesi per la media
( noto)
• questo significa che ho i due valori limite
entro i quali accettare H0 ovvero
rifiutarla
• tanto per esemplificare nel caso in esame
si accetta H0 se la media calcolata rientra
nei valori 368 ± 5.06
212
test t (di Student) dei parametri
della regressione semplice
col metodo dei min. quad. si stimano i valori di 0 e
di 1!
• H0 : β =0 contro H1 : β ≠ 0
• =0.05 e posto
t
con | t | > 2 si rifiuta l’ipotesi
nulla H0 che β=0
e si accetta il valore calcolato
test t (di Student) dei parametri
della regressione semplice