
PCSV DFT 3.ppt - Università degli Studi di Roma "Tor Vergata" · manifestazione di difetti...
41
Affidabilità
Transcript of PCSV DFT 3.ppt - Università degli Studi di Roma "Tor Vergata" · manifestazione di difetti...

Affidabilità

Introduzione
• I circuiti e sistemi elettronici sono inevitabilemnte • I circuiti e sistemi elettronici sono inevitabilemnte affetti dalla presenza di guasti non solo in produzione ma anche durante la loro vita utile
• L’affidabilità (reliability) di un circuito e sistema elettronico rappresenta la sua capacità di operare correttamente durante un periodo di tempo.
• Lo scopo della progettazione finalizzata alla tolleranza ai guasti (fault tolerant design) è quello di tolleranza ai guasti (fault tolerant design) è quello di applicare metodologie che migliorino l’affidabilità a livello di sistema

Tipi di guasto
• Durante il funzionamento i guasti possono essere di due tipi:
• Durante il funzionamento i guasti possono essere di due tipi:– Guasti permanenti: dovuti ad esmpio alla manifestazione di difetti presenti in fase di produzione o anche dovute a invecchiamento (esempio elettromigrazione) o radiazioni che corrompono il reticolo cristallino o altri fenomeni ad effetto permanente
– Guasti transitori: ad esempio SEU (single event upset nelle memorie) dovuti alla iniezione di cariche nel substrato che possono causare l’inversione del valore nelle memorie) dovuti alla iniezione di cariche nel substrato che possono causare l’inversione del valore memorizzato su elementi di memorie. Effetti temporanei possono anche causare metastabilità.
• I guasti transitori possono essere riparati se rilevati
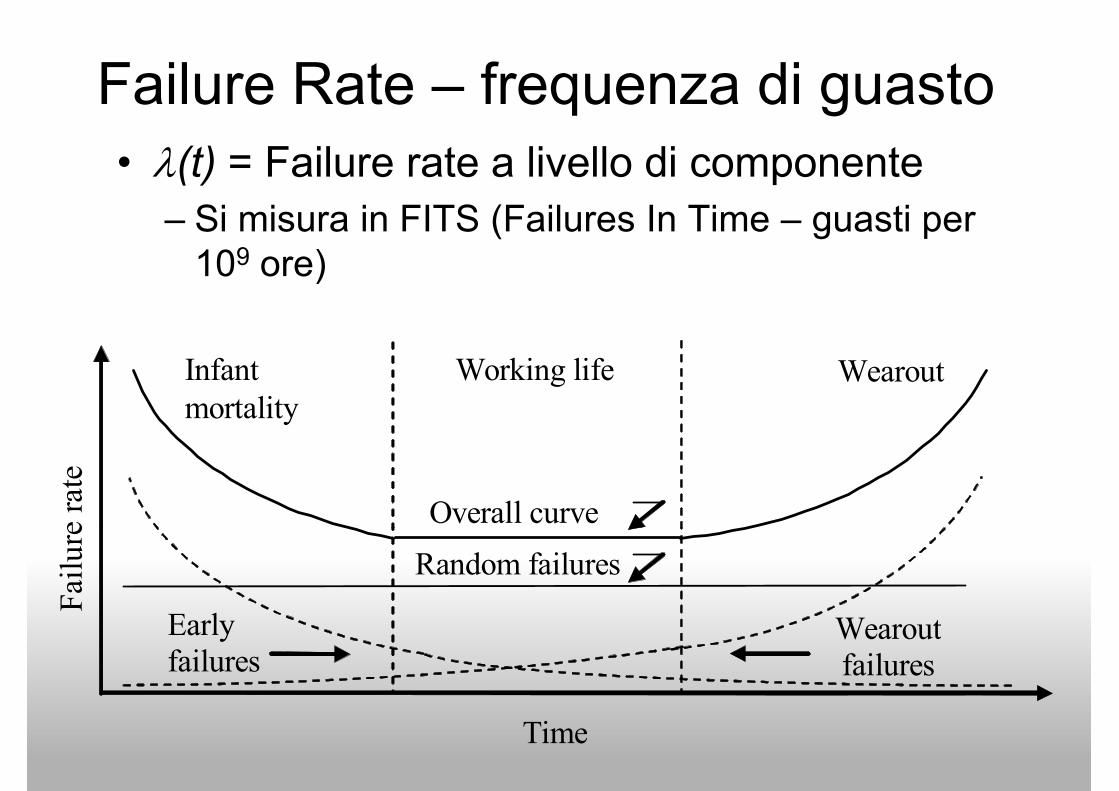
Failure Rate – frequenza di guasto
• λ(t) = Failure rate a livello di componente– Si misura in FITS (Failures In Time – guasti per
109 ore)109 ore)
Infant
mortality
Working life Wearout
Failure rate
Overall curve
Early
failures Wearout
failures
Random failures
Time
Failure rate
Overall curve

Failure Rate a livello di sistema
• Un sistema è costruito con componenti• Un sistema è costruito con componenti
• Se non c’è tolleranza ai guasti (Fault
Tolerance):
– Se un qualunque componente si guasta allora
tutto il sistema è guasto
k
∑=
=k
i
icsys
1
,λλ

Affidabilità - Reliability
• Se un componente funziona a tempo 0
– R(t) = è la probabilità che funzioni ancora a tempo t– = è la probabilità che funzioni ancora a tempo
• Legge di guasto esponenziale
– Se si assume che il failure rate è costante
• E’ una buona approssimazione dopo la fase di mortalità infantile
tλ−= tetR λ−=)(

Affidabilità per un sistema serie
• Sistema serie• Sistema serie
– Tutti i componenti devono funzionare affinchè il
sistema funzioni
∏=
=N
i
isys RR1
7
A B C
CBAsys RRRR =

Affidabilità per un sistema
parallelo
• Sistema parallelo• Sistema parallelo
– Tutti i componenti devono essere guasti affinchè
il sistema non funzioni
∏=
−−=N
i
isys RR1
)1(1B
A
C
D
)1)(1)(1)(1(1 DCBAsys RRRRR −−−−−=
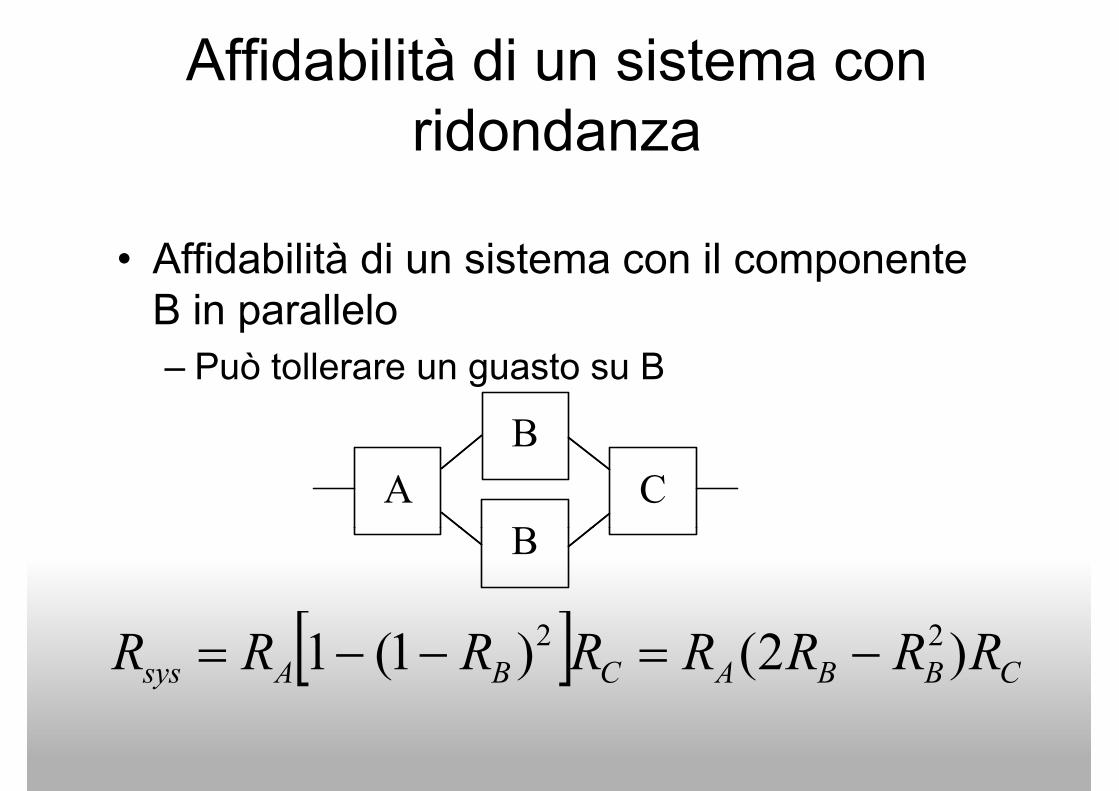
Affidabilità di un sistema con
ridondanza
• Affidabilità di un sistema con il componente • Affidabilità di un sistema con il componente
B in parallelo
– Può tollerare un guasto su B
A
B
C
BB
[ ] CBBACBAsys RRRRRRRR )2()1(1 22 −=−−=

Mean-Time-to-Failure (MTTF)
• Tempo medio prima che il sistema si guasti• Tempo medio prima che il sistema si guasti
– Uguale all’area sotto la curva di affidabilità
• Nel caso di legge di guasto esponenziale
dttRMTTF ∫∞
=0
)(
• Nel caso di legge di guasto esponenziale
λλ 1
0
== ∫∞
− dteMTTF t

Schemi per la tolleranza ai guasti
• Aggiungere tolleranza ai guasti a un progetto• Aggiungere tolleranza ai guasti a un progetto
– Migliora l’affidabilità del sistema
– Richiede ridondanza
• Hardware
• Tempo
• Informazione

Ridondanza Hardware
• Implica la replica delle unità hardware
– Ad ogni livello del progetto
• A livello di porta logica, modulo, chip, piastra• A livello di porta logica, modulo, chip, piastra
• Tre tipologie
– Statica (anche detta passiva)
• Il guasto viene mascherato piuttosto che rilevato
– Dinamica (anche detta attiva)
• Il guasto viene rilevato e si riconfigura verso un hardware • Il guasto viene rilevato e si riconfigura verso un hardware
di riserva
– Ibrida
• Combina gli approcci attivo e passivo

Ridondanza statica
• I guasti vengono mascherati in modo tale • I guasti vengono mascherati in modo tale
che non ci siano output errati
– Fornisce un funzionamento ininterrotto
– Importante nel caso di sistemi real-time
• Non c’è tempo per riconfigurare o riprovare
l’operazione
– Semplice e autosufficiente
• Non c’è bisogno di tenere traccia dello stato del
sistema per rollback

Triple Module Redundancy (TMR)
• Ben noto schema di ridondanza statica
– Tre copie di un modulo
– Si usa un majority voter per determinare l’uscita – Si usa un majority voter per determinare l’uscita
finale
– Un errore in un modulo viene escluso per
minoranza dagli altri due
Module
1
Module
3
Module
2
1
Majority
Voter

Affidabilità e MTTF del TMR
• Il TMR funziona se almeno 2 moduli
qualunque funzionanoqualunque funzionano
– Rm = affidabilità di ogni modulo
– Rv = affidabilità del voter
• MTTF per il TMR
)23()]1(3[])1(3
[ 322333
2
mmvmmmv
i
m
i
m
i
vTMR RRRRRRRRRi
RR −=−+=−
= −
=∑
• MTTF per il TMR
vmvm
ttt
mmvTMRTMR dteeedtRRRdtRMTTF mmv
λλλλ
λλλ
+−
+=
−=−== ∫∫∫∞
−−−∞∞
3
2
2
3
)23()23(0
32
0
32
0

Comparazione con il Simplex
• Ignorando il fault rate del voter poichè è • Ignorando il fault rate del voter poichè è
progettato per essere molto minore dei
moduli si può riscrivere il MTTF
• Pertanto il TMR ha un MTTF più basso del
simplex
mmm
TMR MTTFMTTF6
51
6
5
3
2
2
3=
=−=λλλ
• Pertanto il TMR ha un MTTF più basso del
simplex ma
– Può tollerare guasti temporanei
– Ha un’affidabilità più alta per missioni brevi

Comparazione con il Simplex
• Punto di intersezione• Punto di intersezione
( ) simplex
m
ttt
simplexTMR
MTTFtRisolvendo
eee
RR
mmm
7.02ln
2332
≈=⇒
=−
=−−−
λ
λλλ
• RTMR > Rsimplex quando
– La durata della missione è minore del 70% del
MTTF del simplex
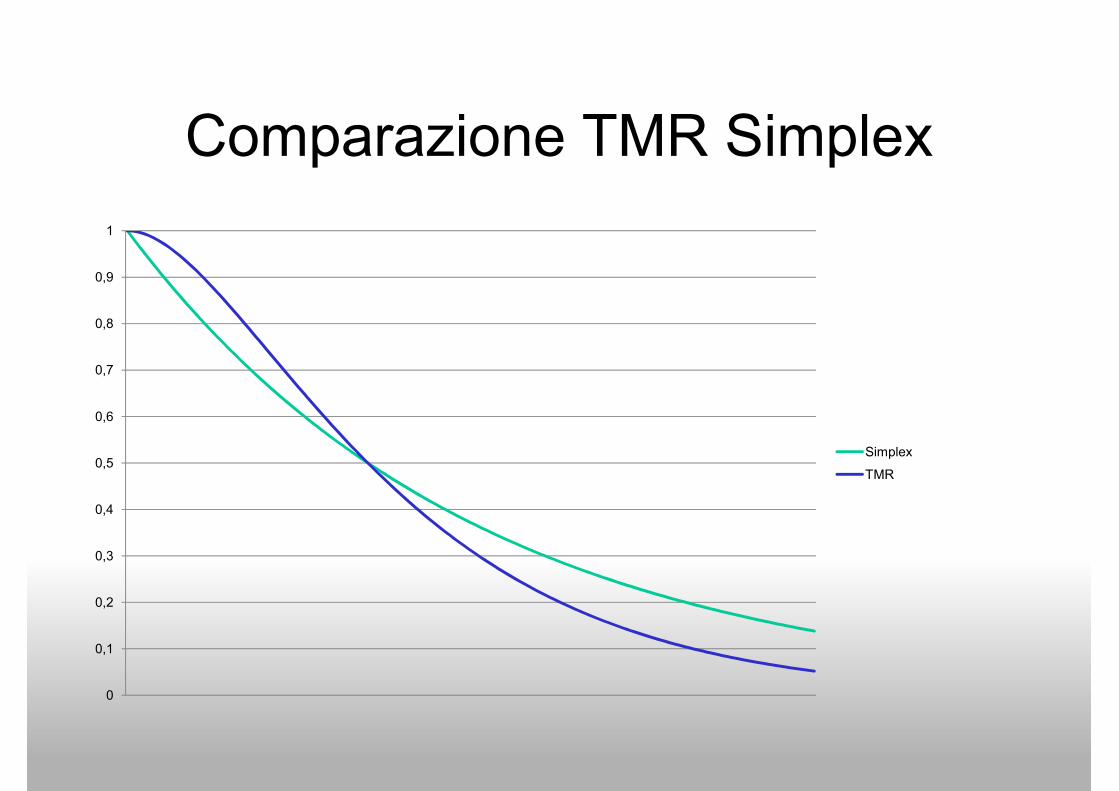
Comparazione TMR Simplex
1
0,4
0,5
0,6
0,7
0,8
0,9
Simplex
TMR
0
0,1
0,2
0,3

N-Modular Redundancy (NMR)
• NMR
– N moduli più il majority voter– N moduli più il majority voter
• Il TMR è un caso speciale del NMR
– E’ in grado di mascherare fino a (N-1)/2 moduli guasti
– Al crescere di N, il MTTF diminuisce
• Ma l’affidabilità per le missioni brevi aumenta
• Se l’obiettivo è solo quello di tollerare i guasti
temporanei è sufficiente usare il TMR

Ridondanza Dinamica
• Implica
– Rilevazione del guasto – Rilevazione del guasto
– Localizzazione dell’unità guasta
– Riconfigurazione del sistema per usare l’unità di
riserva non guasta

Riserve non alimentate (fredde)• Una riserva fredda raddoppia il MTTF
– Assumendo che i guasti vengano sempre rilevatie che il circuito di riconfigurazione non si guastie che il circuito di riconfigurazione non si guastimai
• Svantaggio della riserva fredda
– Tempo richiesto per accendere e inizializzare
– Non può essere usato per rilevare i guasti
– La rilevazione dei guasti richiede uno deiseguenti approcci
– La rilevazione dei guasti richiede uno deiseguenti approcci• test offline fatto periodicamente
• online testing usando ridondanza di tempo o diinformazione
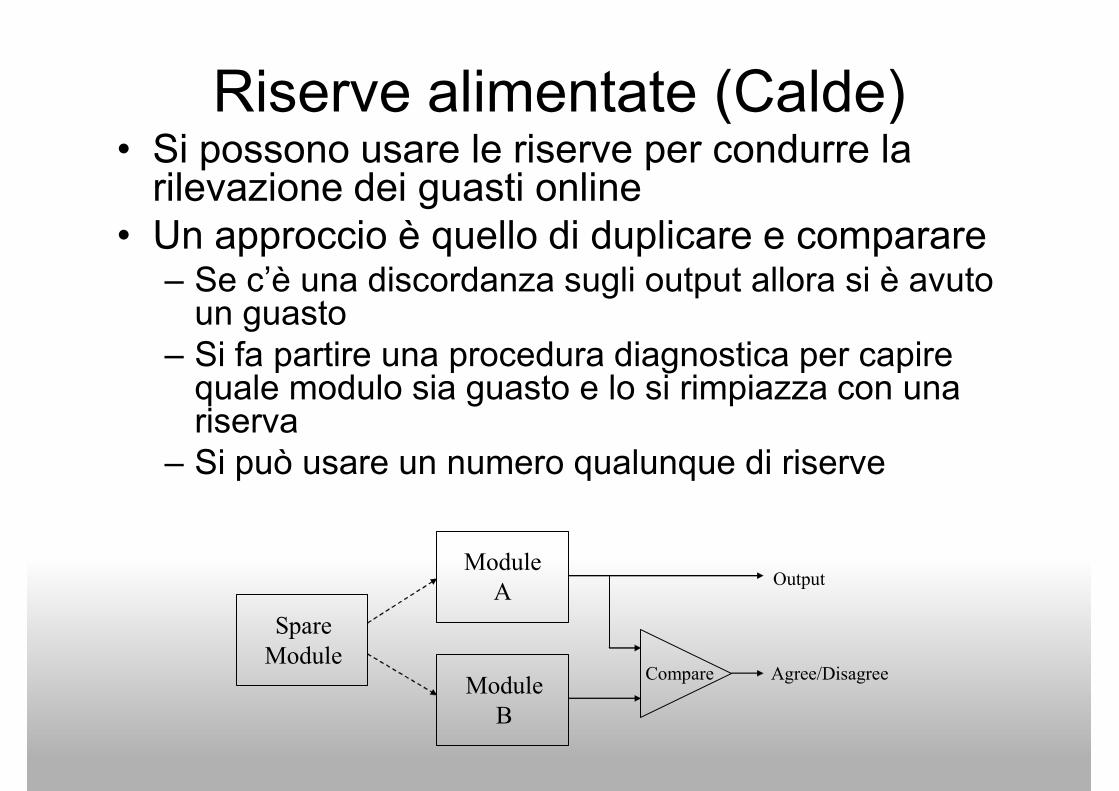
Riserve alimentate (Calde)• Si possono usare le riserve per condurre la rilevazione dei guasti online
• Un approccio è quello di duplicare e comparare– Se c’è una discordanza sugli output allora si è avuto– Se c’è una discordanza sugli output allora si è avutoun guasto
– Si fa partire una procedura diagnostica per capirequale modulo sia guasto e lo si rimpiazza con unariserva
– Si può usare un numero qualunque di riserve
Module
B
Spare
Module
Module
A
Compare
Output
Agree/Disagree

Ridondanza ibrida
• Combina sia la ridondanza statica e quella • Combina sia la ridondanza statica e quella
dinamica
– Maschera i guasti come la ridondanza statica
– Rileva e riconfigura come la ridondanza
dinamica

TMR con riserve
• Se un modulo del TMR si guasta• Se un modulo del TMR si guasta
– Rimpiazzato da una riserva
• Può essere sia una riserva calda o fredda
– Fintanto che il sistema ha tre moduli funzionanti
• Il TMR fornirà fault masking per mantenere
un’operatività ininterrotta

Ridondanza Self-Purging
• Usa un voter a soglia invece di un voter a
maggioranza
– Threshold voter mette in uscita 1 se il numero di
ungressi uguali ad 1 è maggiore della soglia
• Altrimenti mette in uscita 0
– Richiede riserve calde

Ridondanza temporale
• Vantaggio• Vantaggio
– Meno hardware
• Svantaggio
– Potrebbe non rilevare guasti permanenti
• Se si rileva un errore
– Il sistema deve ritornare a uno stato precedente – Il sistema deve ritornare a uno stato precedente
che si sa essere buono prima di ripartire con le
operazioni

Esecuzione Ripetuta
• L’operazione viene ripetuta due volte• L’operazione viene ripetuta due volte
– E’ il metodo di ridondanza temporale più
semplice
– Rileva guasti temporanei che avvengono
durante un’esecuzione (ma non in entrambe)
• Causa una differenza tra i risultati
– Può riutilizzare lo stesso hardware per entrambe
le esecuzioni
• Serve solo una copia dell’hardware funzionale

Esecuzione Ripetuta
• Richiede un meccanismo per memorizzare e • Richiede un meccanismo per memorizzare e comparare i risultati di entrambe le esecuzioni
– In un processore, si può memorizzare sullamemoria o su un disco e usare un software per fare la comparazione
• Costo principale• Costo principale
– Tempo addizionale per l’esecuzione ridondantee la comparazione
• Problema con i guasti permanenti

Ricomputazione in diversità
• Si usa lo stesso hardware, ma si fa la • Si usa lo stesso hardware, ma si fa la
computazione in modo diverso la seconda
volta
– Può rilevare i guasti permanenti che influenzano
solo una computazione
• Per operazioni logiche o aritmetiche• Per operazioni logiche o aritmetiche
– Si fa lo shift degli operandi quando si fa la
seconda computazione [Patel 1982]

Ridondanza di Informazione
• Basata su codici per la rilevazione e • Basata su codici per la rilevazione e
correzione d’errore
• Vantaggi
– Rileva sia guasti temporanei che permanenti
– L’hardware in eccesso necessario è minore di
quando si usano più copie di un solo moduloquando si usano più copie di un solo modulo
• Svantaggio
– Progettazione più complessa

Rilevazione d’errore
• Codici a rilevazione d’errore usati per • Codici a rilevazione d’errore usati per
rilevare gli errori
– Se un errore viene rilevato
• Si ritorna a uno stato precedente non guasto
(rollback)
• Si riprova l’operazione

Rollback
• Richiede di aggiungere capacità di• Richiede di aggiungere capacità dimemorizzazione per salvare lo stato precedente
– L’entità del rollback dipende dalla latenza del meccanismo di rilevazione
– Rilevazione d’errore senza latenza• Il rollback è implementato impedendo al sistema diaggiornare il suo stato
– Se gli errori vengono rilevati dopo n cicli– Se gli errori vengono rilevati dopo n cicli• Bisogna avere un sistema di rollback in grado di restaurarelo stato del sistema a quello di almeno n cicli di clock precedenti

Checkpoint
• L’esecuzione viene suddivisa in sottoinsiemi di• L’esecuzione viene suddivisa in sottoinsiemi dioperazioni– Prima che ciascuna operazione venga eseguita
• Viene creato un checkpoint dove viene memorizzato lo stato del sistema
– Se viene rilevato un errore durante l’operazione• Si ritorna (rollback) all’ultimo checkpoint e si riproval’operazione
– Se si rileva un errore in molteplici repliche– Se si rileva un errore in molteplici replichedell’operazione• L’operazione si ferma e il sistema segnala che è avvenutoun guasto permanente

Teoria dei Codici• Codici
– Si usano più bit del necessario per rappresentare idatidati
– E’ un modo per rilevare gli errori• Gli errori avvengono quando i bit di informazione vengonoinvertiti per qualche motivo
• Codici a rilevazione d’errore
– Ne esistono molti tipi
– Possono rilevare diverse classi di errori
– Usano diversi livelli di ridondanza
– Presentano diversi livelli di difficoltà per la codfica e la decodifica dei dati
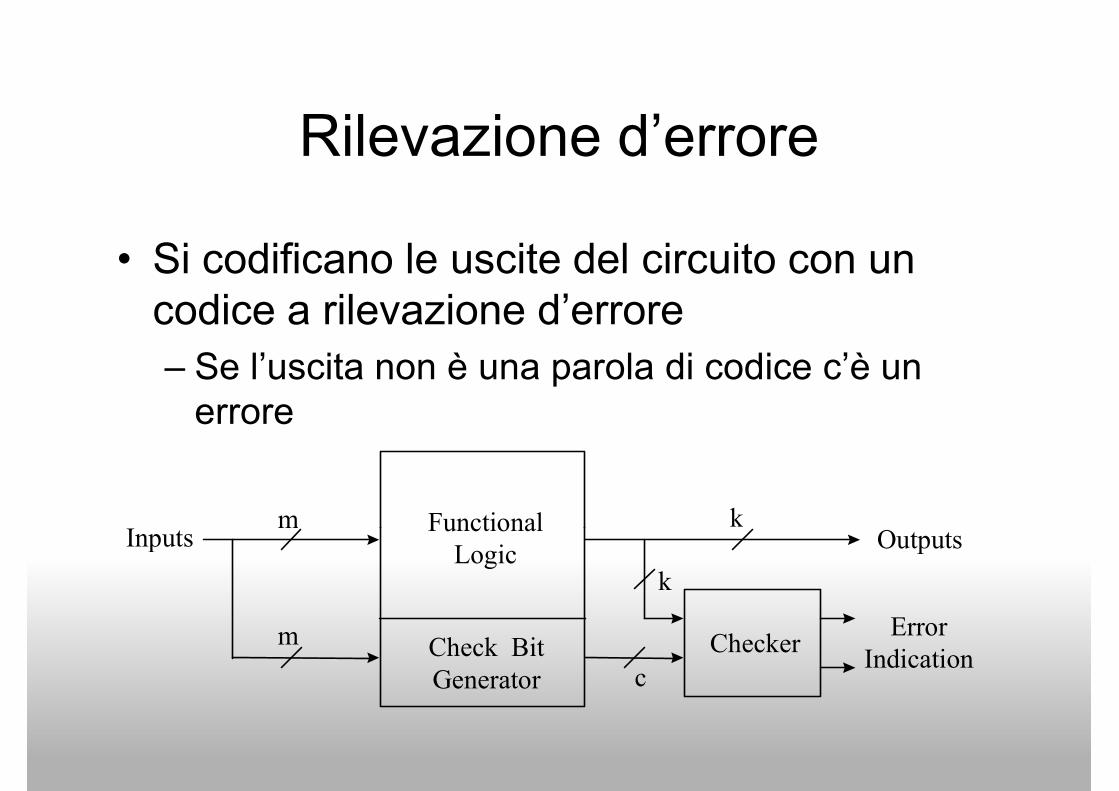
Rilevazione d’errore
• Si codificano le uscite del circuito con un • Si codificano le uscite del circuito con un
codice a rilevazione d’errore
– Se l’uscita non è una parola di codice c’è un
errore
m kInputs
FunctionalOutputs
m
m
k
c
Inputs
Checker
Functional
Logic
Check Bit
Generator
k
Outputs
Error
Indication
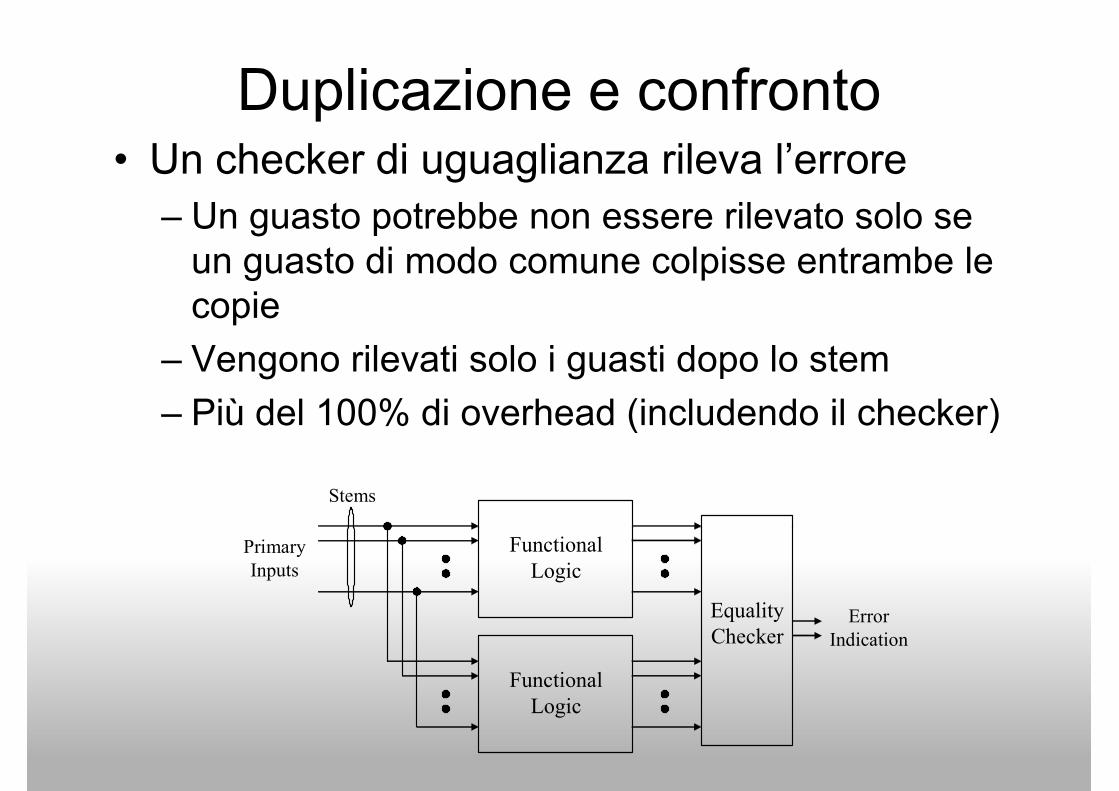
Duplicazione e confronto• Un checker di uguaglianza rileva l’errore
– Un guasto potrebbe non essere rilevato solo se
un guasto di modo comune colpisse entrambe le un guasto di modo comune colpisse entrambe le
copie
– Vengono rilevati solo i guasti dopo lo stem
– Più del 100% di overhead (includendo il checker)
Stems
Functional
Logic
Functional
Logic
Equality
CheckerError
Indication
Primary
Inputs
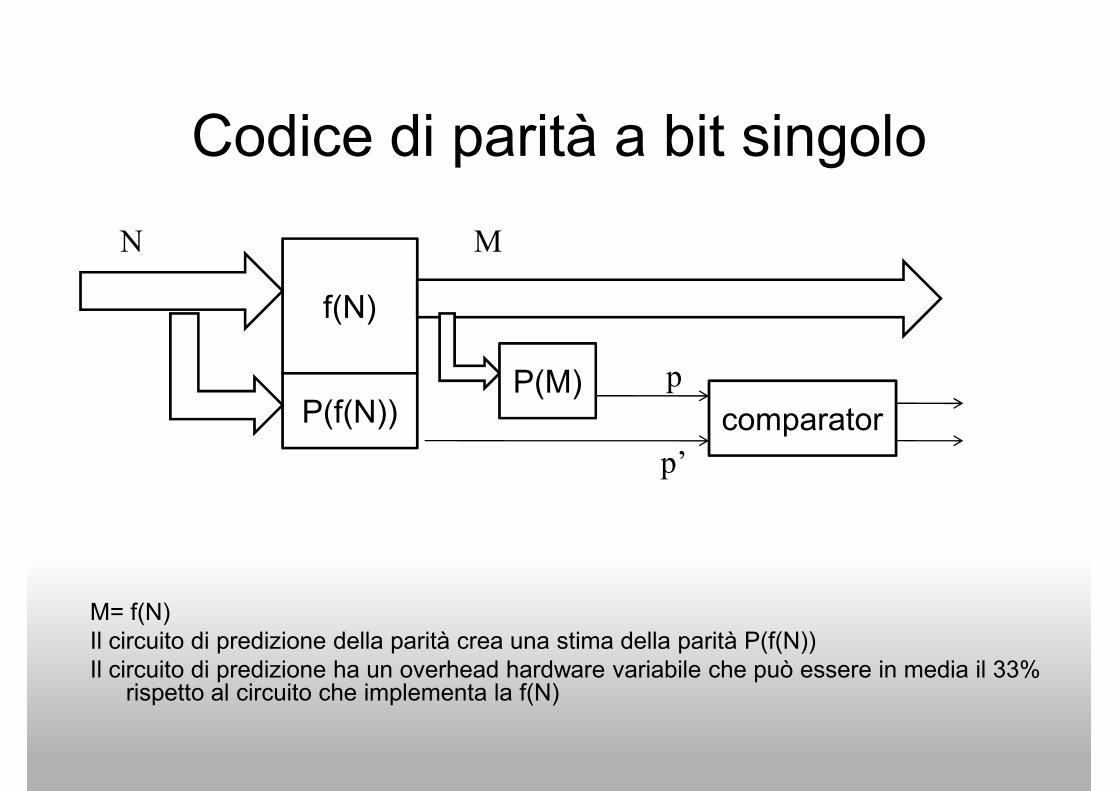
Codice di parità a bit singolo
N M
f(N)
P(f(N))P(M) p
p’
comparator
M= f(N)
Il circuito di predizione della parità crea una stima della parità P(f(N))
Il circuito di predizione ha un overhead hardware variabile che può essere in media il 33% rispetto al circuito che implementa la f(N)

Codice di parità a bit singolo
• Non si può rilevare un numero pari di errori • Non si può rilevare un numero pari di errori
sui bit
– Si può evitare un numero pari di errori sui bit
generando ogni output con un cono di logica
indipendente
• Si è nella assunzione di avere un singolo guasto per
cui si evita che un guasto si propaghi su due outputcui si evita che un guasto si propaghi su due output
• Tipicamente implica un grosso overhead

Distanza di un codice
• Distanza tra due parole di codice:
– Numero di bit in cui le due parole differiscono
• Distanza di un codice
– Minima distanza due parole di codice nel codice
– Se n=k (nessuna ridondanza), la distanza è = 1
– Parità a bit singolo distanza = 2
• Codice con distanza d• Codice con distanza d
– Rileva d-1 errori
– Corregge fino a (d-1)/2 errori

Codici a correzione d’errore
• Codice con distanza 3• Codice con distanza 3– Chiamato anche single error correcting (SEC) code (codice a correzione di errore singolo)
• Codice con distanza 4– Chiamato anche single error correcting and double error detecting (SEC-DED) code (codice a correzione di errore singolo e rilevazione di erroredoppio)doppio)
• Procedura per costruire un codice SEC– Descritto in [Hamming 1950]
– Ogni matrice H con tutte le colonne distinte e nessuna colonna con tutti 0 è SEC

Memory Scrubbing
• Ogni locazione di memoria viene letta su• Ogni locazione di memoria viene letta su
base regolare
– Riduce la probabilità che si accumulino più errori
nel tempo
– Si può implementare facendo in modo che il
controllore della memoria faccia questa attivitàcontrollore della memoria faccia questa attività
durante I periodi di idle


















