
MUTAZIONE: cambio di un bit - chem.uniroma1.it · i t=tempo (ciclo dell’iterazione) ... La...
26
Transcript of MUTAZIONE: cambio di un bit - chem.uniroma1.it · i t=tempo (ciclo dell’iterazione) ... La...


MUTAZIONE: cambio di un bit
Viene effettuata con bassa frequenza, ad es. 1bit ogni 1000
Ha la funzione di recupero di eventuali perdite di informazione

SCHEMI
Indichiamo uno schema con la lettera H
Esempi:
*111*
0*1**
*indica un carattere indeterminato
Il numero di schemi possibili, nel caso di alfabeto binario, è 3l, dove l è la lunghezza della stringa
Il numero di schemi possibili, nel caso di alfabeto di cardinalità K, è (K+1)l
Ordine O(H) dello schema H è il numero di posizioni determinate dello schema.
Lunghezza (H) dello schema H è la distanza tra la prima e l’ultima posizione determinata
dello schema.

Riproduzione
Ai stringa (individuo) n=numero totale di stringhe (popolazione)
fi=fitness di Ai t=tempo (ciclo dell’iterazione)
Probabilità di riproduzione di Ai: pi
fi t
f j tj 1
n
Probabilità di riprodurre un individuo appartenente allo schema H:
piH
iH 1
n fiH t
f j tj 1
n
iH 1
nfiH t
iH 1
n
f j tj 1
n
piH
iH 1
n
è una sommatoria estesa ai soli individui appartenenti allo schema H

Indicando con m(H,t) il numero di individui appartenenti allo schema H,
e con f(H,t) la loro fitness media, ovvero:
f H,t
fiH tiH 1
n
m H,t
da cui deriva: fiH tiH 1
n
f H,t m H,t
si potrà scrivere: piH
iH 1
n
m H,tf H,t
f j tj 1
n

Poiché la popolazione rimane costante nel tempo, la scelta di un individuo per la riproduzione
viene effettuato n volte. Indicando con m(H,t+1) il numero di individui appartenenti allo
schema H al ciclo t+1, si avrà mediamente:
m H,t 1 n m H,tf H,t
f j tj 1
n
Indicando con la fitness media della popolazione al tempo t:f t f t
f j tj 1
n
n
si ricava infine:
m H,t 1 m H,tf H,t
f t

Esemplificazione per capire l’andamento nel tempo del numero degli individui appartenenti ai
vari schemi.
Si può scrivere:
f H,t f t cf t f t 1 c
da cui: m H,t 1 m H,tf t 1 c
f tm H,t 1 c
Nell’ipotesi (molto estrema) di fattore c costante nel tempo (nei vari cicli), si ottiene che la
popolazione al tempo t è data, in funzione di quella iniziale (al tempo 0) dalla relazione:
m H,t m H,0 1 ct
Il che significa che se c è negativo (fitness media dello schema minore della fitness media della
popolazione), si ha un decremento esponenziale del numero di individui appartenenti a quello
schema, mentre se c è positivo si ha un incremento esponenziale.

Crossing over
Esempio di taglio in un individuo appartenente al seguente schema:
* 1 * * * * 0
crossing over
(H) = 7 - 2 = 5
Probabilità (data per eccesso) di distruzione pd dello schema H: pd
H
l 1
Se pc è la probabilità con cui viene effettuato il crossing over : pd pc
H
l 1
Probabilità di sopravvivenza ps dello schema H : ps 1 pd 1 pc
H
l 1
Tenuto conto anche del crossing over, la valutazione (per difetto) della popolazione diviene:
m H,t 1 m H,tf H,t
f t1 pc
H
l 1

Mutazione
Probabilità che una posizione venga mutata : pm
Probabilità che una posizione rimanga immutata : 1 - pm
Probabilità che un individuo, dopo le mutazioni, continui ad appartenere allo schema H :
1 pm
o H
Se pm << 1, si può scrivere: 1 pm
o H1 o H pm
Tenendo conto anche della mutazione, si ottiene infine il teorema degli schemi
o teorema fondamentale degli algoritmi genetici:
m H,t 1 m H,tf H,t
f t1 pc
H
l 1o H pm
Notare che nel prodotto del fattore crossing over con quello della mutazione, è stato trascurato,
poiché piccolo, il termine: pc
H
l 1o H pm

Sono detti schemi in competizione, quelli con le stesse caratteristiche “geometriche”, ovvero con
fattore uguale; la variazione nel tempo delle rispettive
popolazioni dipenderà dalla loro fitness media.
1 pc
H
l 1o H pm
Indicando 2 schemi in competizione con a e b, e una loro generica posizione con il pedice i, sono
caratterizzati dalle due alternative:
•ai = bi = *
•ai ≠ * , bi ≠ * con ai ≠ bi in almeno una posizione i
esempio :
* 0 0 *
* 0 1 *
* 1 0 *
* 1 1 *
Il numero di schemi in competizione in un gruppo è dato da 2o(H)
Il numero di gruppi diversi di schemi in competizione con lo stesso ordine o(H) è dato da :
l
o H
dove l è la lunghezza della stringa
Il numero totale di gruppi diversi di schemi è dato da : 2l

Efficienza dell’algoritmo genetico
Il numero degli schemi processati può essere valutato come proporzionale a n3, per una
popolazione di n individui rappresentati con alfabeto binario.
Questa caratteristica, per cui con operazioni su n individui si esaminano e sottopongono a
evoluzione un numero proporzionale a n3 schemi, è detta parallelismo implicito.
Dal teorema fondamentale degli algoritmi genetici:
m H,t 1 m H,tf H,t
f t1 pc
H
l 1o H pm
si desume l’altra caratteristica degli algoritmi genetici, ovvero che sono efficienti quando
le soluzioni ottimali del problema sono ottenibili assemblando degli schemi corti, ovvero
con (H) piccolo.
Questa caratteristica è detta building block hypothesis.




Linee guida nella codificazione del problema1) Schemi corti e poco correlati con altri schemi che hanno bit definiti lontani nella stringa,
devono essere rilevanti nella soluzione del problema.
2) L’alfabeto usato deve avere bassa cardinalità (possibilmente binario).
Si dimostra che con alfabeto binario si ha un numero di schemi possibili maggiore che con
qualsiasi altra cardinalità.
Poiché il numero di punti dello spazio in cui rappresentiamo il problema è lo stesso:
2l
Kl'
l'l
lg2Knumero di schemi possibili:
cardinalità 2 cardinalità K
3l K 1
l 'K 1
l
lg2 K
facendo il lg2 del numero degli schemi possibili:
l lg2 3l
lg2 Klg2 K 1
e dividendo per l, si ottiene:
lg2 3 lg2 K 1
lg2 K
ma si ha che lg2 3lg2 K 1
lg2 Kper K>2
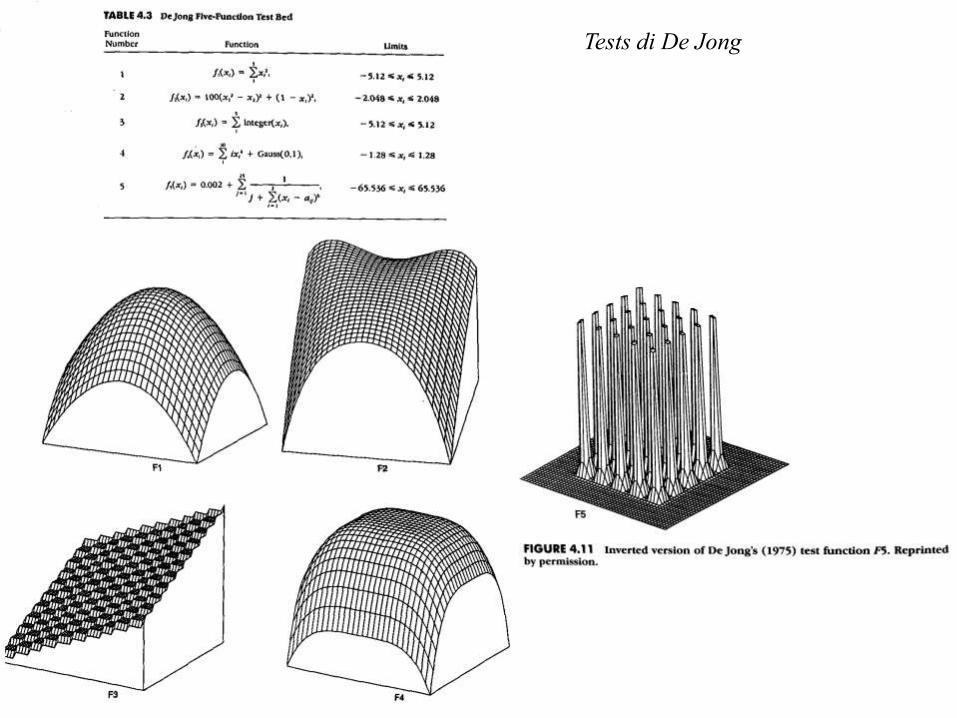
Tests di De Jong

Criteri di valutazione dell’algoritmo genetico
On-line performance: xl s1
Tfl t
t 1
T
dove l è l’ambiente (il problema), s la strategia (il particolare algoritmo genetico adottato),
t è il ciclo, T il numero totale di cicli effettuati, f è il valore migliore della funzione di
valutazione.
Off-line performance: xl
*s
1
Tfl
*t
t 1
T
dove f*(t) è il valore migliore della funzione di valutazione al ciclo t, tra tutte le esecuzioni
effettuate.

Valutazioni generali sui parametri dell’algoritmo genetico semplice
Popolazione n
n grande: migliore off-line performance
n piccolo: migliore on-line performance
Probabilità di crossing over pc: 0.6 pc 1.0
Probabilità di mutazione pm: pm elevato recupera i bit persi, ma diminuisce
la performance (pm =.5 coincide con ricerca
casuale)
Sovrapposizione della popolazione G: G = 1 per ottimizzazioni statiche;
G < 1 per macchina che apprende

Alcune varianti dell’algoritmo genetico semplice
Scalatura della funzione di valutazione: f ' af b
dove f è la funzione originaria
Fattore di affollamento CF: il nuovo individuo generato sostituisce il più simile scelto
in un gruppo di CF individui della vecchia popolazione.

NICCHIA e condivisione tra gli individui delle risorse della nicchia
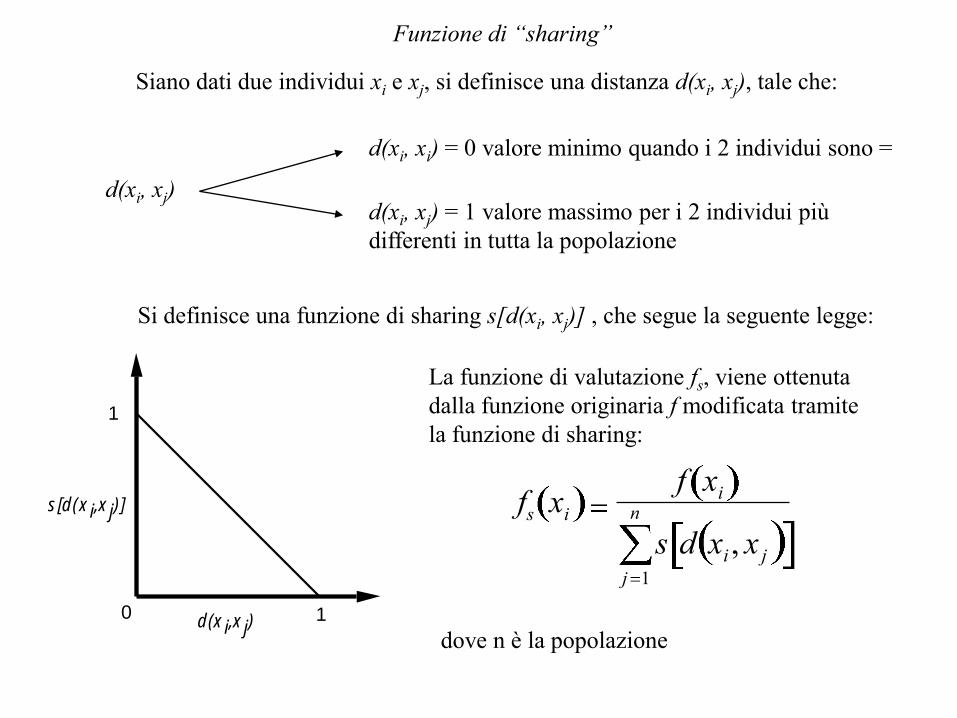
Funzione di “sharing”
Siano dati due individui xi e xj, si definisce una distanza d(xi, xj), tale che:
d(xi, xj)
d(xi, xi) = 0 valore minimo quando i 2 individui sono =
d(xi, xj) = 1 valore massimo per i 2 individui più
differenti in tutta la popolazione
Si definisce una funzione di sharing s[d(xi, xj)] , che segue la seguente legge:
0 1
1
d(xi,xj)
s[d(xi,xj)]
La funzione di valutazione fs, viene ottenuta
dalla funzione originaria f modificata tramite
la funzione di sharing:
fs xi
f xi
s d xi , x j
j 1
n
dove n è la popolazione


Capacità adattativa degli algoritmi genetici
Si intende la capacità di adattarsi a trovare soluzioni ad un problema che cambia nel tempo
Viene incrementata con i seguenti accorgimenti:
1) mantenimento di soluzioni di precedenti cicli:
a) fattore di affollamento CF, che diversifica le soluzioni
b) G < 1, che mantiene individui dei cicli precedenti
2) inserire la capacita di evoluzione nello stesso algoritmo,
introducendo nella stringa dell’individuo i parametri di
controllo pc, pm, G, che quindi possono essere modificati
nel tempo

Applicazioni nell’ambito di strutture molecolari
•Generazione di strutture che rispettino i dati NMR
•Ottimizzazione della conformazione di catene laterali di proteine globulari
•Previsione delle modificazioni strutturali a seguito di sostituzione di catene
laterali (mutazione) in proteine (ingegneria genetica)
•Tentativi di previsione di struttura terziaria in proteine, a partire dalla conoscenza
della sequenza primaria


















