
Introduzione al KDD - dm.uniba.itdelbuono/KDD_datamining0910.pdf · llDM...
51
1 Introduzione al KDD Il processo KDD I metodi di DM Introduzione al KDD Knowledge Discovery in Databases (KDD): processo automatico di esplorazione dei dati allo scopo di identificare pattern validi, utili, ignoti processo effettuato su insiemi di dati di grandi dimensioni e elevata complessità Data Mining (DM): cuore del processo KDD Data mining: insieme di meccanismi automatici progettati per consentire l’esplorazione di grandi moli di dati alla ricerca di tendenze consistenti e/o relazioni sistematiche tra variabili, e successivamente per validare le scoperte attraverso l’applicazione di comportamenti rilevati su nuovi sottoinsiemi di dati sviluppo e utilizzo di diversi algoritmi per l’esplorazione dei dati Le ragioni del DM e del KDD: accessibilità e abbondanza dei dati in formato elettronico problematiche: lenta capacità di utilizzo delle informazioni rispetto la crescitadella capacità di accumulo di dati (i.e., internet)
Transcript of Introduzione al KDD - dm.uniba.itdelbuono/KDD_datamining0910.pdf · llDM...

1
Introduzione al KDD
Il processo KDD
I metodi di DM
Introduzione al KDD
� Knowledge Discovery in Databases (KDD): processo automatico di esplorazione dei dati allo scopo di identificare pattern validi, utili, ignoti� processo effettuato su insiemi di dati di grandi dimensioni e elevata
complessità
� Data Mining (DM): cuore del processo KDD� Data mining: insieme di meccanismi automatici progettati per
consentire l’esplorazione di grandi moli di dati alla ricerca di tendenze consistenti e/o relazioni sistematiche tra variabili, e successivamente per validare le scoperte attraverso l’applicazione di comportamenti rilevati su nuovi sottoinsiemi di dati
� sviluppo e utilizzo di diversi algoritmi per l’esplorazione dei dati
� Le ragioni del DM e del KDD: � accessibilità e abbondanza dei dati in formato elettronico
� problematiche: lenta capacità di utilizzo delle informazioni rispetto la crescitadella capacità di accumulo di dati (i.e., internet)

2
Caratteristiche del processo
KDD
� Il processo KDD è iterativo e interattivo
� iterativo perché composto di passi successivi
� iterazione a ogni passo (può essere necessario ripetere alcuni passi prima di completare l’intero processo)
� interattivo perché è necessario comprendere il processo e le possibilità di sviluppo a ogni passo
� non è possibile definire un meccanismo o una formula che sia sempre valida in ogni situazione
� Nel processo KDD si possono generalmente individuare diversi passi distinti
� si comincia con la comprensione del dominio e si termina con l’acquisizione di nuova conoscenza
I passi del processo KDD
1. Comprensione del dominio applicativo
� passo introduttivo per definire obiettivi e scelte successive
� formulazione precisa del problema che si sta provando a risolvere per evitare spreco tempo e denaro
2. Esplorazione iniziale dei dati :
� Fase che include diversi meccanismi di preparazione dei dati
� “pulitura” dei dati (per esempio per identificare e rimuovere dati codificati in modo errato),
� trasformazione dei dati, la selezione di sottoinsiemi di record,preliminare selezione delle caratteristiche
� descrizione e visualizzazione dei dati (per esempio utilizzando statistiche descrittive, correlazioni, scatterplot, box plot, ecc.).
� La descrizione dei dati consente di ottenere una fotografia delle caratteristiche importanti dei dati (come ad esempio la tendenzacentrale e le misure di dispersione). Le tendenze sono spesso più facili da individuare visivamente che attraverso liste e tabelle numeriche.

3
I passi del processo KDD
Nell’esplorazione iniziale dei dati è possibile
individuare fasi distinte:
2.a Selezione dei dati
� dati disponibili, dati addizionali, dati da integrare
� trade-off tra gestione di più informazioni possibili e
organizzazione di un dataset semplice da gestire
2.b Pre-processing
� gestione di missing values, rumore, outliers, 7
2.c Trasformazione dei dati
� feature selection, discretizzazione, 7
DATA
PRE-
PROCESSING
I passi del processo KDD
3. Selezione del compito di DM
� classificazione, regressione, clustering
4. Selezione dell’algoritmo di DM
� scelta fra metodi precisi (es. reti neurali)
o interpretabili (es. alberi di decisione)
� utilizzo di tecniche di meta-learning per
selezionare il modello (l’algoritmo)
5. Impiego dell’algoritmo di DM
� implementazione dell’algoritmo (da
iterare più volte se necessario)
DATA
MINING

4
I passi del processo KDD
6. Valutazione� valutazione e interpretazione dei risultati rispetto agli
obiettivi definiti al passo 1
� generalmente la valutazione del modello decisionale ottenuto avviene utilizzando due criteri (talvolta in conflitto tra loro)
� Accuratezza� Diversi metodi di valutazione
� Suddivisione dei dati in sottoinsiemi di addestramento/test (75%vs 25%)
� validazione incrociata v-fold (se non si hanno dati sufficienti)
� Comprensibilità� Es. alberi decisionali e modelli di regressione lineare sono meno
complicati e più semplici di modelli quali le reti neurali più semplici da interpretare anche se si potrebbe dover essere costretti a rinunciare ad una maggiore accuratezza predittiva
7. Utilizzo della conoscenza scoperta� incorporare la conoscenza in un altro sistema per ulteriori
operazioni
KDD e DM
� Gli stadi che caratterizzano un processo KDD sono statiidentificati nel 1996 da Fayyad, Piatetsky-Shapiro e Smyth
� Nell’elencare e descrivere le diverse fasi di un processo KDD particolare attenzione è stata posta allo stadio del DM, cioè a tuttiquegli algoritmi per l’esplorazione e lo studio dei dati.
� Il DM è ritenuta la fase più importante dell’intero processo KDD e questa sua enorme importanza rende sempre più difficile, soprattutto in termini pratici, distinguere il processo KDD dal DM.
� Alcuni ricercatori usano i termini DM e KDD come sinonimi noicercheremo di separare i due aspetti e di considerare il DM la fase più significativa del processo KDD, ma non perfettamentecoincidente con esso.

5
DM: alcune definizioni
� Il DM è la non banale estrazione di informazione implicita, precedentemente sconosciuta e potenzialmente utile attraverso l’utilizzo di differenti approccci tecnici (Frawley, Piatetsky-Shapiro e Matheus, 1991).
� ll DM è una combinazione di potenti tecniche che aiutano a ridurre i costi e i rischi come anche ad aumentare le entrateestraendo informazione dai dati disponibili (T.Fahmy).
� Il DM consiste nell’uso di tecniche statistiche da utilizzare con i databases aziendali per scoprire modelli e relazioni chepossono essere impiegati in un contesto di business (Trajectalexicon).
� Il DM è l’esplorazione e l’analisi, attraverso mezzi automatici e semiautomatici, di grosse quantità di dati allo scopo discoprire modelli e regole significative (Berry, Linoff, 1997).
DM: alcune definizioni
� Il DM si riferisce all’uso di una varietà di tecniche per identificare “pepite” di informazione e di conoscenza per ilsupporto alle decisioni e alle previsioni.
� I dati sono spesso voluminosi ma, così come sono, hanno un basso valore e nessun uso diretto può esserne fatto; èl’informazione nascosta nei dati che è utile (Clementine user guide).
� Il DM è la ricerca di relazioni e modelli globali che sonopresenti in grandi database, ma che sono nascostinell’immenso ammontare di dati, come le relazioni tra i dati deipazienti e le loro diagnosi mediche. Queste relazionirappresentano una preziosa conoscenza del database e, se ildatabase `e uno specchio fedele, del mondo reale contenutonel database. (Holshemier e Siebes, 1994).

6
Il modello CRISP-DM
� Un modello alternativo è rappresentato dal
Cross Industry Standard Process for Data
Mining (CRISP-DM)
� Tale modello di data mining è stato
sviluppato da un consorzio di numerose
società
� Il modello CRISP-DM è costituito da sei fasi,
Fasi del modello CRISP-DM
1. Comprensione di business� attenzione è posta principalmente sugli obiettivi e le
richieste del progetto da una prospettiva prettamente di business
� viene fornita una definizione del problema di DM
2. Comprensione dei dati� obiettivo principale è collezionare dati e formulare ipotesi
3. Preparazione dei dati� obiettivo: individuazione di tabelle, record, variabili
� pulitura dei dati in funzione degli strumenti prescelti per la modellizzazione (punto 4)

7
Fasi del modello CRISP-DM
4. Modellizzazione
� Obiettivo: selezione e applicazione di una o più
tecniche di data mining
5. Valutazione
� Tramite l’analisi dei risultati si valuta se sono stati
raggiunti gli obiettivi iniziali prefissati
� Si ipotizza anche una futura applicazione del modello
6. Implementazione
� Se il modello raggiunge gli obiettivi, si crea un piano
di azione per implementarlo
CRISP-DM vs KDD-DM
� Le fasi 1 e 2 del CRISP-DM rappresentano l’identificazione delle finalità di un processo KDD-DM
� La fase 3 combina le fasi di pre-processingdel modello KDD-DM
� Le fasi finali di entrambi I modelli corrispondono
� Approfondimenti sul CRISP-DM: www.crisp-dm.org
8
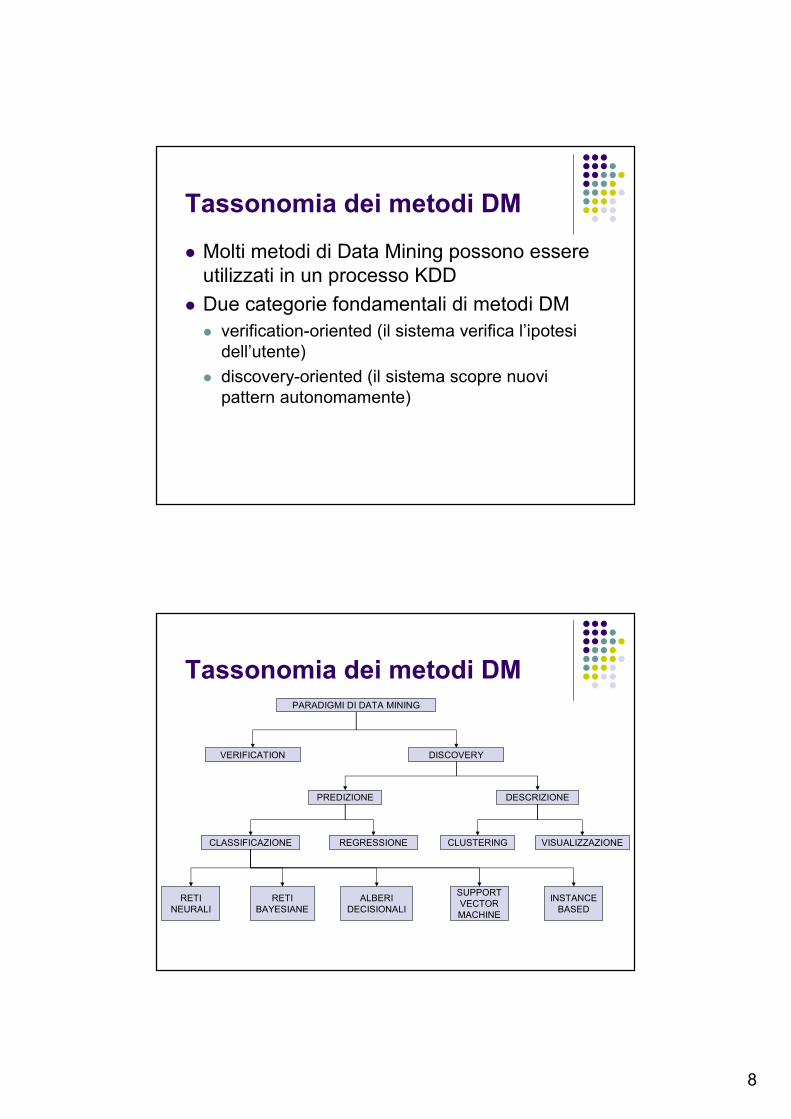
Tassonomia dei metodi DM
� Molti metodi di Data Mining possono essere
utilizzati in un processo KDD
� Due categorie fondamentali di metodi DM
� verification-oriented (il sistema verifica l’ipotesi
dell’utente)
� discovery-oriented (il sistema scopre nuovi
pattern autonomamente)
Tassonomia dei metodi DM PARADIGMI DI DATA MINING
VERIFICATION DISCOVERY
PREDIZIONE DESCRIZIONE
CLASSIFICAZIONE REGRESSIONE
RETI
NEURALI
RETI
BAYESIANE
ALBERI
DECISIONALI
SUPPORT
VECTOR
MACHINE
INSTANCE
BASED
CLUSTERING VISUALIZZAZIONE

9
Metodi verification-oriented
� I metodi verification-oriented valutano le ipotesi
generate da una sorgente esterna
� es: un esperto umano
� I metodi v-o comprendono tecniche statistiche
� test delle ipotesi,
� analisi della varianza
� ecc.
� I metodi v-o hanno rilevanza minore nell’ambito del
Data Mining
Metodi discovery-oriented
� I metodi discovery-oriented sono in grado di
identificare automaticamente pattern nei dati
� Si suddividono in:
� metodi descrittivi: orientati all’interpretazione dei dati
(clustering, visualizzazione)
� metodi predittivi: costruiscono modelli di
comportamento per previsioni su nuovi esempi
� I metodi d-o si basano sul learning induttivo
� il modello è costruito generalizzando da esempi di
training ed è applicato su nuove istanze sconosciute

10
Unsupervised e supervised
learning
� I metodi di learning unsupervised raggruppano
gli esempi senza uno schema pre-specificato
� sono unsupervised una parte dei metodi d-o
descrittivi (es: clustering)
� I metodi di learning supervised scoprono la
relazione fra attributi di input e di output dei dati
� la relazione input/output è alla base di un fenomeno
descritto dal dataset ed è rappresentata nel modello
finale
Modelli di classificazione e di
regressione
� I metodi di learning supervised costruiscono
modelli di due categorie: classificazione e
regressione
� Un regressore pone lo spazio di input in
corrispondenza con un dominio a valori reali
� Un classificatore pone lo spazio di input in
corrispondenza con un insieme pre-definito di
classi

11
I Dati
Dati
Dati strutturati
Feature
I dati (1/2)
� I dati alla base di un processo di data mining
si classificano in:
� dati strutturati
� dati semi-strutturati
� dati non strutturati
DATI TRADIZIONALI
DATI non TRADIZIONALI
(o MULTIMEDIALI)

12
I dati (2/2)
� La maggior parte dei database scientifici contengono dati strutturati
� formati da campi ben definiti
� rappresentati da valori numerici o alfanumerici
� Esempi di dati semi-strutturati:
� immagini elettroniche di documenti medici
� la maggior parte dei documenti web
� Esempio di dati non strutturati:
� registrazioni video e multimediali di eventi e processi
� Questi dati richiedono trattamenti per estrarre e strutturare le informazioni in essi contenute
I dati strutturati (1/2)
� Rappresentati in forma di tabella (singola
relazione)
� le colonne sono le feature (caratteristiche) degli oggetti
� le righe sono i valori delle feature per una entità
(esempio)
ESEMPI
FEATURE
FEATURE
VALUE PER
UN DATO
ESEMPIO

13
I dati strutturati (2/2)
� Ai dati è associato il problema della loro qualità
� pre-processing
� I dati devono essere
� accurati
� immagazzinati in accordo al “tipo di dato” (dati
numerici, dati character, dati interi, dati reali, 7)
� non ridondanti (dati ridondanti vanno eliminati)
� completi (trattamento dei missing value)
� (Analizzeremo alcune tecniche di pre-processing dei
dati)
Feature dei dati
� Esistono diversi tipi di feature
� caratterizzano le variabili o attributi associati ai dati
� Possono esistere anche variabili non osservate
� influenzano il modello, ma per ridurre la complessitànon sono raccolte
� Tipi di feature più comuni:
� feature numeriche
� feature categoriche (o simboliche)
� Altre tipi di feature:
� feature discrete
� feature continue

14
Feature numeriche
� Le feature numeriche includono valori reali o
interi
� es: età, lunghezza, velocità, 7
� Importanti proprietà delle feature numeriche:
� relazione d’ordine (2 < 5)
� relazione di distanza ( d(2.3,4.2)=1.9 )
Feature categoriche
� Le feature categoriche (o simboliche) non hanno
caratteristiche numeriche (non sono misurabili)
� es: colore degli occhi, nazionalità, sesso, 7
� Le feature categoriche non soddisfano relazioni
di ordine o di distanza
� Fra feature categoriche esiste solo la relazione
di uguaglianza
� i valori di una feature categorica possono essere
uguali oppure no (blu=blu, rosso≠nero)

15
Trattamento delle feature
categoriche
� Una feature categorica a due valori può essere
convertita in una variabile numerica binaria
� valori consentiti: 0, 1
� Una feature categorica a � valori può essere
convertita in � variabili numeriche binarie
� una variabile binaria per ogni valore nella categoria
� Le feature categoriche così trattate si dicono
“Dummy variables”
� es: colore degli occhi
� blu � 1000; nero � 0100; verde: 0010; marrone � 0001
Feature continue e feature
discrete
� Feature continue: sono anche dette variabili
quantitative (o metriche)
� Sono misurate utilizzando:
� scala di intervallo (interval scale)
� scala di rapporto (ratio scale)
� Feature discrete: sono anche dette variabili
qualitative
� Sono misurate utilizzando:
� scala nominale
� scala ordinale

16
Feature continue – scala di
intervallo e scala di rapporto
� Le feature continue sono rappresente con numeri reali o interi
� La scala di intervallo e la scala di rapporto si differenziano per la definizione dello zero
� Interval scale: zero posizionato arbitrariamente (non indica assenza di ciò che è misurato)
� es: temp. Fahrenheit � 0°F non è assenza di calore
� Ratio scale: zero posizionato in modo assoluto
� es: peso, altezza, salario, 7
� La relazione di rapporto non è valida nella “intervalscale”, è valida nella “ratio scale”
Feature discrete – scala
nominale
� Le feature discrete sono rappresentate
utilizzando simboli o numeri
� La scala nominale è una scala senza relazione
d’ordine (order-less scale) che usa simboli o
numeri
� es: codice identificativo di utente
� residenziale � A (oppure 1), commerciale � B (oppure 2)
� I numeri indicano solo diversi valori dell’attributo e
non hanno ordine

17
Feature discrete – scala
ordinale
� La scala ordinale consiste in un ordinamento (elenco) ordinato (ordered ranking)
� Una feature discreta in scala ordinale è una variabile categorica per cui vale la relazione d’ordine, ma non di distanza
� es: votazione studenti
� Le relazioni ordinali non sono lineari
� es: d(studente classificato 4°, studente classificato 5°) ≠ d(studente classificato 15°, studente classificato 16°)
� Le relazioni tra attributi che possono essere stabilite in scalaordinale:
� maggiore/uguale; uguale; minore/uguale
� Le variabili ordinali sono strettamente legate alle cosiddette variabili linguistiche (fuzzy)
� es: ETA’ (giovane, mezza età, vecchio)
Casi speciali di feature
� Le feature periodiche sono variabili discrete per le quali esiste una relazione di distanza, ma non d’ordine
� es: giorni della settimana, giorni del mese, mesi dell’anno
� Dati classificati rispetto al tempo
� dati statici: dati che non cambiano con il tempo
� dati dinamici (o temporali): dati che cambiano con il tempo
� La maggior parte delle tecniche di DM hanno a che fare con dati statici

18
Trasformazioni di dati
Trasformazioni
Normalizzazione
Smoothing
Differenze e rapporti
Missing values
Outliers
Trasformazione dei dati
� Molte metodi verification-oriented richiedono
l’informazione a priori dell’esistenza di una qualche
correlazione tra i dati (es. correlazione lineare), di
specifiche tipologie di distribuzioni (es. normali),
l’assenza di outliers
� Molti algoritmi discovery-oriented hanno la capacità
di trattare automaticamente la presenza di non-
linearità e non-normalità dei dati
� Gli algoritmi lavorano comunque meglio se tali problemi
sono trattati in fase di pre-processing

19
Trasformazioni di dati
� La trasformazione dei dati può migliorare i risultati delle tecniche di DM e alleviare alcune problematiche quali
� Dati con errori o incompleti
� Dati mal distribuiti
� Forte asimmetria nei dati
� Presenza di molti picchi di valori
� La trasformazione da applicare dipende dal tipo di dati, dal loro numero, dalle caratteristiche del problema, 7
Trasformazione dei dati:
obiettivi
� Definire una trasformazione T sull’attributo X, Y= T(X) tale che:
� Y preserva l’informazione “rilevante”di X
� Y elimina almeno una o più delle problematiche presenti in X
� Y è più “utile” di X
� Scopi principali:
� Ustabilizzare le varianze
� Unormalizzare le distribuzioni
� Ulinearizzare le relazioni tra variabili
� Scopi secondari:
� semplificare l'elaborazione di dati che presentano caratteristiche
non gradite
� rappresentare i dati in una scala ritenuta più adatta

20
Trasformazioni
� Trasformazioni esponenziali
� esponenziali con a,b,c,d e p valori reali
� preservano l’ordine
� preservano alcune statistiche di base
� sono funzioni continue
� ammettono derivate
� sono specificate tramite funzioni semplici
=+
≠+=
0)(p log
0)(p )(
dxc
baxxT
p
p
Trasformazioni
� Trasformazioni lineari
� 1€= 1936.27 Lit.
� p=1, a= 1936.27 ,b =0
� ºC= 5/9(ºF -32)
� p = 1, a = 5/9, b = -160/9
� Obiettivo: migliorare l’interpretabilità
baxxT p
p +=)(

21
Trasformazioni
� Trasformazione logaritmica
U
� Si applica a valori positivi
� omogeneizza varianze di distribuzioni lognormali
� Esempio: normalizza picchi stagionali
� Obiettivo: stabilizzare le varienze
dxcxTp += log)(
Trasformazioni
� Altre trasformazioni che stabilizzano le varianze
� Trasformazione in radice� p = 1/c, c numero intero
� per omogeneizzare varianze di distribuzioni particolari, e.g., di Poisson
� Trasformazione reciproca� p < 0
� per l’analisi di serie temporali, quando la varianza aumenta in modo molto pronunciato rispetto alla media
baxxT p
p +=)(

22
Normalizzazione
� La normalizzazione dei dati è utile quando è necessario calcolare le distanze tra punti in uno spazio n dimensionale
� Una tecnica largamente utilizzata consiste nel cambiamento dei valori numerici in modo che essi siano scalati in uno specifico intervallo
� es: [-1,1] o [0,1]
� La normalizzazione è particolarmente utile quando si utilizzano tecniche di DM basate sulle distanze
� Si evitare che le variabili che assumono un range di valori più ampio non siano pesate più di quelle feature che in media presentano un range di valori più piccolo
� L’applicazione di una tecnica di normalizzazione va considarata in tutte le fasi del processo di DM e su tutti i nuovi dati
� i parametri di normalizzazione devono essere conservati
Esempi di normalizzazione � Normalizzazione tramite scaling decimale
� sposta il punto decimale dividendo ogni valore numerico per la stessa potenza di 10
� valori scalati nell’intervallo [-1,1]
� Siano v il vettore delle feature, v(i) la i.sima componente, il vettore scalato si ottiene:
( )( ) , argmin(max ( ) 1)
10K i
v iv i K v i= = <
� Come si procede:
� assegnata la feature v
� si cerca il max di v(i)
� si scala il punto decimale fino a che
� si applica il divisore a tutti gli altri elementi di v(i)
max ( ) 1i
v i <

23
Esempi di normalizzazione � Normalizzazione min-max
� tecnica appropriata quando sono noti i valori minimo e
massimo di una variabile
� La formula da applicare è la seguente:
( ) min ( )( )
max ( ) min ( )
i
ii
v i v iv i
v i v i
−=
−
� newmax e newmin specificano i nuovi valori di minimo e
massimo per la variabile in questione
� Se il range in cui si desidera scalare la variabile è costituito
dall’intervallo [0,1] la formula si semplifica come segue:
)(min)(max
minmin)max)((min)()(
iviv
newnewnewiviviv
−+−−
=
Esempi di normalizzazione
� Normalizzazione della standard deviation (z-score normalization):
� Trasformazione appropriata per essere utilizzata con algoritmi di DM dasati su misure di distanza
� Svantaggio:trasforma i dati in modo da renderli non riconoscibili
� Particolarmente utile quando il massimo e il minimo non sono noti
� Siano v il vettore delle feature, mean(v) e sd(v) la media e la deviazione standard. La normalizzazione z-score converte il valore in un punteggio standard attraverso la seguente formula:
( ) ( )( )
( )
v i mean vv i
sd v
−=

24
Data Smoothing
� Molte tecniche di DM sono insensibili a piccole differenze (non significative) nei valori di una feature� in molte applicazioni le differenze tra i valori di una variabile
non sono significative e possono spesso essere considerate come variazioni random di uno stesso valore
� può essere vantaggioso in alcuni casi regolarizzare i valori di una variabile
� Ridurre il numero di valori distinti di una feature può ridurre la dimensionalità dello spazio dei dati
� Smoothers possono essere utilizzati per discretizzare delle feature continue (trasformandole in feature discrete)
Differenze e rapporti
� Per migliorare le performance (e per diminuire il
numero delle feature) si possono applicare semplici
trasformazioni delle variabili
� es: dati medici � al posto di peso (p) e altezza (h) si
considera BMI (indice di massa corporea)
� BMI = rapporto pesato tra p e h di un paziente
� Le trasformazioni di questo tipo sono utilizzate per
comporre nuove feature

25
Missing data
� Esistono diverse cause che producono dataset non
completi, ovvero dataset in cui sono presenti valori
mancanti (missing value)
� “difficoltà” (temporali/fisiche ecc) nel calcolare il valore
per uno specifico campione
� Mancanza di conoscenza
� Diversi fattori che spingono gli intervistati a non
risposndenre a questionari e/o interviste
Missing data
� I dati mancanti si possono classificare in
� “do not care” value : valori di una feature non registrati
perché considerati irrilevanti
� “lost ” value: valori di una feature non registrati perché
sono stati dimenticati o sono stati erroneamente
cancellati

26
Missing data
� Missing completely at random (MCAR)
� I dati mancanti sono distribuiti random su tutte le
features
� La presenza di MCAR può essere confermata
suddividendo i campioni in due gruppi (con e
senza dati mancanti) e effettuando un t-tests sulle
differenze medie tra le features per evidenziare se
i due gruppi di campioni presentano (o meno)
differenze significative
Missing data
� Missing at random (MAR)
� I dati mancanti non sono distribuiti random su tutte le
feature ma solo in alcune
� MAR sono più comuni dei MCAR.
� Non-ignorable missingness (Missing Not at random)
� Esempi di dati mancanti più probelmatici da trattare
� I missing values non sono distribuiti random su tutte le
osservazioni, ma la probabilità di trovare un dato mancante
non può essere stimata utilizzando le variabili nel modello
� Trattamento: sostituire il dato mancante in base a altri dati
esterni al compito di DM

27
Missing data
� Come trattare i missing value?
� Non esiste una soluzione semplice e “safe” per
risolvere i casi in cui alcuni attributi presentano un
numero significativo di valori mancanti
� Se possibile, si dovrebbe cercare di valutare
l’importanza dei dati mancanti sperimentando la/e
tecniche di DM con e senza gli attributi che
presentano tali dati
Missing data
� In generale, i metodi per il trattamento dei dati
mancanti si possono suddividere in:
� metodi sequenziali (o metodi di pre-processing)
� il dataset incompleto è convertito in un dataset completo e
successivamente si applica una tecnica di DM
� metodi paralleli (metodi in cui i valori mancanti sono
considerati all’interno del processo di acquisizione di
conoscenza)
� modificare l’algoritmo di DM per permettergli di gestire tali
dati

28
Missing data: metodi sequenziali
� Riduzione del dataset (soluzione più semplice)
� eliminazione degli esempi con valori mancanti (listwise o
casewise deletion)
� metodo utilizzabile quando la dimensione del dataset è
grande e/o la percentuale dei missing value è bassa
� produce una perdita (a volte significativa) di informazioni
� Sostituzione dei missing value con valori costanti
� un valore globale (il valore più comune della feature)
� media della corrispondente feature (per attributi di tipo
numerico)
� media della feature della classe (nei problemi di classificazione)
Missing data: metodi sequenziali
� Global closest fit: sostituire il valore mancante con il valore dell’attributo più somigliante
� si confrontano due vettori di feature (quello contente il missing value, ed il candidato ad essere il closest fit)
� ricerca effettuata su tutte le feature
� si calcola una distanza tra i due vettori
� il vettore con la minima distanza viene usato per determinare il valore mancante
� la distanza usata è
� NB: sostituire i dati mancanti introduce un bias

29
Missing data: metodi sequenziali
� La distanza usata nel metodo Global Closest Fit è:
≠−
==
≠=
=
= ∑=
iiiiii
ii
ii
ii
ii
n
i
ii
yxyxr
yx
yx
yxyx
yx
yxdist
yxdistyxdist
e numeri sono e se||
? o ? o
e simboliche sono , se1
se0
),(
),(),(1
r = differenza tra il massimo ed il minimo valore della feature
contenente il missing value
� Nei problemi di classificazione si utilizza Class closest Fit
Missing data
� Soluzioni più sofisticate per il trattamento dei
missing values si basano sulla predizione dei
valori mediante un algoritmo di data mining.
� In questo caso predire i valori mancanti
diviene un particolare problema di DM di tipo
predittivo

30
Analisi degli outlier
� Outlier: valori dei dati inusuali (non consistenti o
significativamente diversi dal resto degli esempi)
� Una definizione esatta di un outlier dipende dalle
assunzioni relative alla struttura dei dati e
all’applicazione della tecnica di DM
� Definizioni generali:
� Hawkins (Identification of Outlier. Chapman and Hall.
1980) “Osservazione che devia così tanto dalle altre
osservazioni da suscitare il sospetto che sia stata generata
da un meccanismo diverso ”
Analisi degli outlier
� Barnett e Lewis (Outlier in Statistical Data. John Wiley
1994) “un outlier è una osservazione che sembra deviare
notevolmente dalle altri componenti dell’esempio in cui
esso occorre”
� Johnson (Applied Multivariate Statistical Analysis. Prentice
Hall, 1992) “osservazione in un dataset che sembra essere
inconsistente con il rimanente insieme dei dati”
� La scoperta degli outlier può rappresentare un vero e
proprio processo di DM
� individuazione di transazioni economiche fraudolente con carte
di credito, intrusioni non autorizzate in reti private, ecc.

31
Analisi degli outlier
� Molti metodi di DM cercano di minimizzare l’influenza degli outlier o di eliminarli durante la fase di pre-processing
� l’eliminazione di outlier è un processo delicato (può far perdere informazioni)
� Formalmente:
� il processo di individuazione ed eliminazione degli outlier può essere descritto come il processo di selezione di K degli n esempi che sono dissimili, eccezionali o inconsistenti con il resto del dataset
Analisi degli outlier:
tassonomia dei metodi
� I metodi per l’identificazione degli outlier possono essere suddivisi in:
� metodi univariati (assumono che i dati siano iid)
� metodi multivariati
� metodi parametrici (o statistici)
� assumono che sia nota una distribuzione delle osservazioni o unastima statistica di essa
� etichettano come outlier quelle osservazioni che si discostano dalle assunzioni sul modello
� inadatti per dataset di dimensione elevata e/o dataset privi di conoscenza a priori sulla distribuzione dei dati
� metodi non parametrici (metodi model-free)
� metodi basati sulla distanza
� tecniche di clustering (cluster di piccole dimensioni considerati come cluster di outlier)

32
Analisi degli outlier – Caso
monodimensionale
� Analisi statistica di media e varianza (metodo piùsemplice)
� Calcolando media e varianza è possibile stabilire un valore di soglia che sia funzione della varianza� tutti i valori che superano la soglia sono potenziali outlier
� Problema: assunzione a priori di una distribuzione dei dati (nei casi reali la distribuzione è incognita)� es: ETA’={3,56,23,39,156,52,41,22,9,28,139,55,20,
-67,37,11,55,45,37}
� media: 39.9, standard deviation: 45.65
� soglia: threshold = media ± 2×standard deviation [-54.1, 131.2]
� età numero positivo � [0, 131.2]
� I valori 156, -67, 139 sono outlier (presumibilmente typo-error)
Analisi degli outlier – Caso
multidimensionale
� Individuazione degli outlier in base alle distanze
� gli outlier sono gli esempi che non hanno abbastanza esempi
vicini
� Formalmente:
� un esempio si è un outlier se almeno un sottoinsieme (frazione)
di p esempi nel dataset si trova ad una distanza da si maggiore
di una prefissata quantità d
� Il metodo si basa sull’assegnazione a-priori dei parametri
p e d
� La complessità computazionale del metodo è data dal
calcolo di una misura di distanza tra tutti gli esempi di un
dataset n-dimensionale

33
Analisi degli outlier – Caso
multidimensionale
� Diversi tipi di distanze possono essere adottate
� Distanza di Mahalanobis
� Calcolo della matrice di covarianza associata al dataset
� La distanza di Mahalanobis per ciascun dato multivariato (viene
calcolata per tutti gli n campioni) è:
� outlier � osservazione con valore Mi grande
∑=
−−−
=n
i
T
ninin xxxxn
V1
)()(1
1
nixxVxxMn
i
nin
T
nii ,...,1 )()(
2/1
1
1 =
−−= ∑
=
−
Analisi degli outlier – Tecniche
basate sulla deviazione
� Le tecniche basate sulla deviazione simulano il modo umano di riconoscere gli esempi inusuali
� Questa classe di metodi si basa su funzioni di dissimilarità(sequential-exception technique):� si stabiliscono le caratteristiche di base per un insieme di esempi
� si riconoscono gli outlier tra gli elementi i cui valori deviano da tali caratteristiche
� Esempio di funzione di dissimilarità per un insieme di n dati:� varianza totale dell’insieme di dati
� Occorre inoltre definire un sottoinsieme di esempi da rimuovere dal dataset per determinare la massima riduzione del valore della funzione di dissimilarità quando questa ècalcolata sull’insieme residuo

34
Esplorazione grafica di
dati multivariati
N. Del Buono
Introduzione
� I metodi di esplorazione grafica (o visuale) permettono l’identificazione di strutture nei dati
� I metodi visuali rivestono un ruolo primario nell’esplorazione dei dati in virtù della capacità (acquisita in millenni di evoluzione) del sistema occhi-cervello di individuare strutture che presentano delle similarità
� I metodi visuali rivestono un ruolo importante nel processo di KDD-DM, sebbene presentino numerose limitazioni soprattutto nel trattamento di dataset molto grandi
� I metodi visuali sono noti anche come metodi “data-drivenhypothesis generation” e si contrappongono ai metodi di verifica “hypothesis testing”

35
Introduzione
� Esamineremo alcuni metodi di esplorazione grafica
cosiddetti “informali”, che sono stati largamente
utilizzati in diversi contesti per l’analisi dei dati
� semplici statistiche
� meccanismi per la visualizzazione di singole variabili
� meccanismi per il rilevamento di relazioni tra due variabili
� meccanismi per il rilevamento di relazioni tra più di due
variabili
Riassumere i dati mediante
semplici statistiche
� La media aritmetica dei dati (“sample mean” ) rappresenta una semplice informazione sul valore medio dei dati (stima del valore medio reale della variabile aleatoria di cui i dati rappresentano una campionatura)
∑=i n
iv )(µ⌢
� û è il valore “centrale” nel senso che minimizza la somma delle differenze al quadrato tra esso e i dati
� û è una misura del “posizionamento” (o misura diposizione) dei dati

36
Riassumere i dati mediante
semplici statistiche
� Una ulteriore misura del “posizionamento” dei dati è
fornita dalla mediana
� La mediana è definita come quel valore che divide
a metà l’insieme dei dati, pertanto l'insieme dei
valori è per metà minore e per metà maggiore
della mediana
� valore che possiede uno stesso numero di punti al di sotto
e al di sopra di essi
� è il dato centrale della distribuzione
� è meno sensibile della media aritmetica ai valori estremi
Riassumere i dati mediante
semplici statistiche
� Fasi operative per il calcolo della mediana
1. ordinamento crescente dei dati
2. se il numero di dati n è dispari, la mediana
corrisponde al dato che occupa la (n+1)/2-ima
posizione
3. se il numero di dati n è pari, la mediana è data
dalla media aritmetica dei due dati che occupano
la posizione n/2 e quella n/2+1

37
Riassumere i dati mediante
semplici statistiche
� Esempio di calcolo della mediana
� dati : {8, 5, 7, 6, 35, 5, 4}
� ridisposizione in ordine crescente: {4, 5, 5, 6, 7, 8, 35}
� Calcolo della posizione centrale (n+1)/2 = 4,� la mediana è 6
� Valore tipico nel senso che si avvicina ad una buona parte dei valori
del campione.
� dati : {8, 5, 7, 6, 5, 4}
� ridisposizione in ordine crescente: {4, 5, 5, 6, 7, 8},
� n è pari, la mediana è la media dei valori che occupano le posizioni
(n/2) ed [(n/2)+1] nell'insieme ordinato dei numeri
� elemento di posizione (n/2) = 3 è elemento di posizione
[(n/2)+1]= 4 � la mediana vale (5+6)/2=5.5
Riassumere i dati mediante
semplici statistiche
� Quando una variabile è di tipo quantitativo discreto (o continua categorizzata), l’indice di tendenza centrale adeguato a rappresentare la distribuzione è la moda
� La moda è l’osservazione che si riscontra con maggiore frequenza in una data distribuzione
� Si possono avere anche più valori modali (distribuzione bimodale, multimodale)
� La moda è molto sensibile alla grandezza e al numero delle classe

38
Riassumere i dati mediante
semplici statistiche
� Confronto tra diversi indici di tendenza centrale� la moda è l’indice meno informativo in quanto, essendo
calcolato sulle frequenze, prescinde totalmente dallanatura numerica dalle osservazioni,� fornisce conoscenza sul dato che ha la maggiore
probabilità di presentarsi
� la mediana è più informativa della moda e considera anchel’ordine tra le osservazioni� utilizzata per suddividere la distribuzione in parti uguali
� vantaggio di non essere influenzata da grandi differenzequantitative tra i dati, ma solo dalla posizione
� la media è l’indice più informativo in quanto consideraanche la distanza tra le osservazioni� si utilizza per esprimere un concetto di equidistribuzione
Riassumere i dati mediante
semplici statistiche
� Altre misure di posizione dei dati individuano diverse
regioni dalla distribuzione dei valori dei dati
� percentili o centili: valori al di sotto dei quali si trova una
determinata percentuale della distribuzione dei dati
� i quartili separano i dati in 4 parti uguali
� 25° percentile o primo quartile (la mediana della parte
inferiore dei dati)
� 50° percentile � mediana
� 75° percentile o terzo quartile (la mediana della parte
superiore dei dati)

39
Riassumere i dati mediante
semplici statistiche
Misure di dispersione o di variabilità
� La media è la misura della localizzazione centrale della distribuzione di una serie di dati� Dati con la stessa media possono avere un grado molto
diverso di variazione
� Per esprimere tali variazioni si utilizza la media come punto di riferimento di ciascun valore e si calcola la deviazione di ciascun valore dalla media� deviazione standard (radice quadrata della varianza)
� varianza
� più σ2 e σ sono piccoli più i dati sono concentrati
� più σ2 e σ sono grandi più i dati sono dispersi
∑ −=
i n
iv 22 )ˆ)(( µ
σ
Riassumere i dati mediante
semplici statistiche
� Un ulteriore modo di esprimere la variabilità di un
insieme di dati è quello di utilizzare il range o
campo di variazione
� range: differenza tra il più grande e il più piccolo valore
presente nei dati
� rappresenta l’ampiezza dell’intervallo dei dati
� tiene conto solo dei valori estremi trascurando tutti gli altri
� nel caso in cui i dati siano pochi si ottiene una stima
erronea del range di popolazione
� tende ad aumentare con l’aumento del numero delle
osservazioni

40
Riassumere i dati mediante
semplici statistiche
� Range o differenza interqualile: differenza tra
il terzo ed il primo quartile
� elimina l’influenza dei valori estremi
� relativamente indipendente dalla numerosità del
campione
Visualizzazione grafica di
singole variabili: istogramma
� Un istogramma è un grafico compatto per
rappresentare una serie di dati
(generalmente continui)
� Costruire un istogramma per dati continui
� dividere il range dei dati in intervalli (detti classi
di intervallo, celle, o semplicemente colonne)
� se possibile, le colonne dovrebbero essere di uguale
“larghezza”, per aumentare l’informazione visiva

41
Visualizzazione grafica di
singole variabili: Pareto chart
� Una significativa variazione dell’istogramma è il
diagramma di Pareto (Pareto Chart)
� in economia “principio di Pareto” : modo di
rappresentare in forma grafica gli aspetti prioritari da
affrontare per risolvere un problema
� usato nei processi di miglioramento della qualità, dove
i dati di solito presentano diversi tipi di difetti, errori e
non conformità, o altre categorie di interesse per
l’analisi
Visualizzazione grafica di
singole variabili: Pareto chart
� Diagramma di Pareto è un istogramma con
celle ordinate in senso decrescente affiancato
dal grafico delle frequenze cumulate (detto
curva di Lorenz)
� le categorie sono ordinate in modo tale che quella con
maggior frequenza si trovi sulla sinistra del grafico,
seguita da quelle di frequenza minore
� permette di stabilire quali sono i maggiori fattori che
hanno influenza su un dato fenomeno

42
Visualizzazione grafica di
singole variabili: box-plot
� Un buon sistema per rappresentare
graficamente i dati è la cosiddetta
� "Tecnica dei 5 numeri" o "Box and wiskers plot"
(letteralmente: diagramma a scatola e baffi)
� la "scatola" comprende la mediana ed è delimitata
dal 25° e dal 75° percentile
� i "baffi" limitano i valori minimo e massimo
Visualizzazione grafica di singole
variabili: box-plot
� Box-and-whisker plots sono utili per interpretare la
possibile distribuzione dei dati
� Rappresentano il grado di dispersione o
variabilità dei dati (rispetto mediana e/o
media)
� evidenziano le eventuali simmetrie
� evidenziano la presenza di valori anomali
� evidenziano il range inter-quartile ovvero la
dispersione dei dati

43
Visualizzazione grafica di singole
variabili: box-plot (esempio)
� Esempio di costruzione di un box-plot
� Dati relativi ai punteggi acquisiti da un insieme di studenti� dati: 80, 75, 90, 95, 65, 65, 80, 85, 70, 100
� Si ordinano i dati in ordine crescente
� si determina il primo quartile, la mediana, il terzo quartile, il più grande ed il più piccolo valore:� mediana = 80
� primo quartile = 70
� terzo quartile = 90
� Valore minimo = 65
� Valore massimo = 100
Visualizzazione grafica di singole
variabili: box-plot (esempio)
65, 65, 70, 75,80, 80, 85, 90, 95 ,100
Primo quartile Terzo quartile
Mediana
(secondo quartile)
65 70 80 85 95 10075 90

44
Visualizzazione grafica di
coppie di variabili: Scatterplot
� Scatter plot o diagramma di dispersione(scatter plot) è un grafico cartesiano formatodai punti ottenuti rilevazione di due variabilinumeriche� Variabile descrittiva (explanatory variable)
� Variabile suscettibile (response variable)
Visualizzazione grafica di
coppie di variabili: Scatterplot
� Alcune proprietà statistiche della distribuzione
(posizione, dispersione, correlazione, dati
anomali) possono essere dedotte dalla nuvola
di punti
� posizione, coesione interna, orientamento,
presenza di punti isolati
� possibili associazioni tra due variabili
� Associazione positiva� trend in salita
� Associazione negativa � trend in discesa
� Nessun trend � mancanza di associazione

45
Visualizzazione grafica di dati
multivariabili: Scatter-matrix
� Un insieme di dati multivariati (più di due variabili) permette di ottenere diversi scatterplot per ciascuna coppia di variabili
� Si ottiene cosi la matrice degli scatterplot
� matrice simmetrica p×p (le p righe e pcolonne corrispondono a ciascuna variabile) di scatterplot bivariati
� nella posizione ij � grafico della variabile jrispetto la variabile i
� la stessa variabile compare nella posizione jiin cui gli assi x ed y sono scambiati
Visualizzazione grafica di dati
multivariabili: Co-plot
� Un grafico coplot è una successione di scatter-plot di tipo “conditionato”� ciascun diagramma corrisponde a un particolare intervallo
di valori di una terza variabile o fattore di condizionamento
� Metodo di visualizzazione che permette dievidenziare come una variabile di output dipende dauna variabile di input date altre variabili descrittive
� Diverse modalità di rappresentazione� Given panels: intervalli di variabilità della variabile
“condizionata”
� Dependence panels: scatterplot bivariati della variabile“suscettibile” rispetto le restanti variabili descrittive

46
Visualizzazione grafica di dati
multivariabili: diagrammi di Trellis
� I coplot sono esempi di metodi di visualizzazione
più generali noti come diagrammi di Trellis.
� I diagrammi (o grafici) di Trellis permettono di
visualizzare l’esistenza di strutture nei dati
mediante l’utilizzo di grafici 1D,2D o 3D.
� Visualizzazione le relazioni all’interno di grandi
dataset distinguendo diversi gruppi di variabili
Visualizzazione grafica di dati
multivariabili: diagrammi di Trellis
� Multipanel conditioning
� Visualizzazione del cambiamento delle relazioni
tra due variabili in funzione di una o più variabili
condizionate
� Rappresentazione di diversi tipi di grafici in un
range di valori relativo alle variabili selezionate.

47
Esempio: IRIS data
� Classificazione di tre tipi di fiori iris: Setosa,
Versicolor, Virginica.
Iris Setosa Iris Versicolor Iris Virginica
Esempio: IRIS data
� Il dataset IRIS è costituito da 150 esempi di fiori
iris catalogati in base ad una analisi di 4 attributi
(variabili di input):
� Lunghezza e larghezza dei sepali (elementi
costitutivi del calice del fiore)
� Lunghezza e larghezza dei petali (elemento
costitutivo della corolla del fiore)
� Ogni campione del data set è un vettore di 5
dimensioni (4 variabili continue, 1 categorica)attributi dei fiori (input)
5.4 3.9 1.7 0.4
classe (output)
Iris-virginica
48
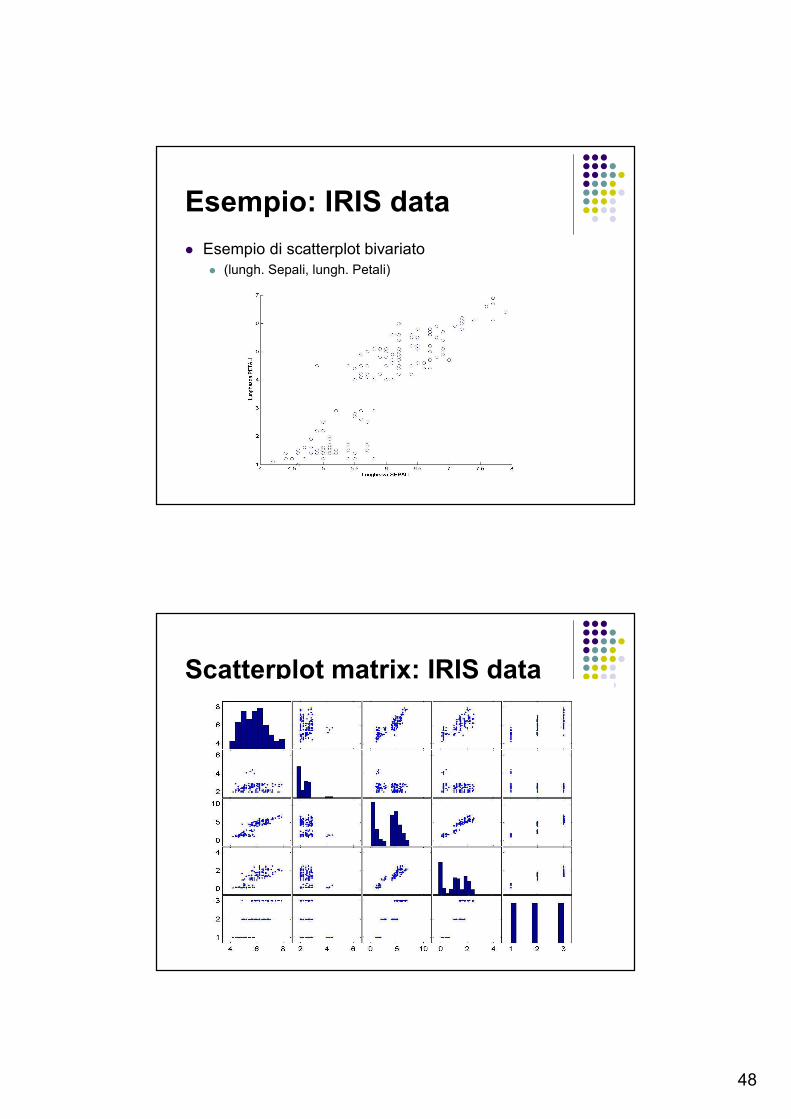
Esempio: IRIS data
� Esempio di scatterplot bivariato
� (lungh. Sepali, lungh. Petali)
Scatterplot matrix: IRIS data

49
Box-and-whisker plot: IRIS data
Diagramma di Trellis: Iris Data
� Esempio di diagramma di Trellis
� Grafico 3D
� lunghezza dei sepali (asse x),
� larghezza dei sepali (asse y)
� larghezza dei petali (asse z)
� Condizionato alla:
� Lunghezza dei petali
� Specie di fiore

50
Diagramma di Trellis: Iris Datasetosa setosa
Petal L.: [1.0 4.4] Petal L.: [4.4 7.1]
versicolor versicolor
Petal L.: [1.0 4.4] Petal L.: [4.4 7.1]
WEKA
� Che cosa è WEKA?
� WEKA acronomo di “Waikato Environment for Knowledge
Analysis”
� sviluppato dall’Università di Waikato (Nuova Zelanda) a
partire dal 1993
� collezione di algoritmi di machine learning per il Data
Mining
� contiene algoritmi per il pre-processing, la classificazione,
la regressione, il clustering, la visualizazione grafiac, ecc.
� scritto in Java, open source, rilasciato con licenza GNU

51
WEKA
� L'interfaccia grafica di Weka è composta da:
� Simple CLI: l'interfaccia dalla linea di comando;
� Explorer: consente di esplorare i dati attraverso i
comandi WEKA
� Experimenter: permette di testare diversi algoritmi
di data mining
� Sito Ufficiale:
http://www.cs.waikato.ac.nz/ml/weka/







![I RAPPORTI TRA L’ORDINAMENTO STATALE E … · 3 Il brocardo latino “panem et circenses” èla sintesi della coscienza ... Giovenale: « [...] [il popolo] due sole cose ansiosamente](https://static.fdocumenti.com/doc/165x107/5c69802109d3f2f5638d44c9/i-rapporti-tra-lordinamento-statale-e-3-il-brocardo-latino-panem-et-circenses.jpg)










