
Integrazione di un linguaggio accademico in un ambiente ...scorzell/cscheme/tesi.pdf ·...
186
UNIVERSITA’ DEGLI STUDI ROMA TRE FACOLTA’ DI INGEGNERIA CORSO DI STUDIO INGEGNERIA INFORMATICA Integrazione di un linguaggio accademico in un ambiente CAD industriale RELATORE: Prof. Alberto Paoluzzi LAUREANDO: Giorgio Scorzelli Anno Accademico 1999-2000
Transcript of Integrazione di un linguaggio accademico in un ambiente ...scorzell/cscheme/tesi.pdf ·...

UNIVERSITA’ DEGLI STUDI ROMA TRE
FACOLTA’ DI INGEGNERIA
CORSO DI STUDIO INGEGNERIA INFORMATICA
Integrazione di un linguaggio accademico
in un ambiente CAD industriale
RELATORE: Prof. Alberto Paoluzzi
LAUREANDO: Giorgio Scorzelli
Anno Accademico 1999-2000


Indice
Introduzione 1
1 Un ambiente funzionale 11
1.1 Caratteristiche principali di Scheme . . . . . . . . . . . . . . . . . . . . 12
1.2 Allocazione della memoria . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.3 I sistemi ad oggetti in Scheme . . . . . . . . . . . . . . . . . . . . . . . . 18
1.4 La Foreign Function Interface (FFI) . . . . . . . . . . . . . . . . . . . . 19
1.4.1 I problemi di una FFI . . . . . . . . . . . . . . . . . . . . . . . . 20
1.4.2 Le azioni di una FFI . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.5 Applicazioni ibride . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
1.6 Una implementazione di Scheme: PLT MzScheme . . . . . . . . . . . . . 25
1.6.1 La tecnica di Garbage Collecting . . . . . . . . . . . . . . . . . . 26
1.6.2 Il sistema ad oggetti di MzScheme . . . . . . . . . . . . . . . . . 29
1.6.3 La FFI di MzScheme . . . . . . . . . . . . . . . . . . . . . . . . . 36
2 Un ambiente di progettazione assistita 53
2.1 Il linguaggio CDL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
2.1.1 Il concetto di handle di oggetto . . . . . . . . . . . . . . . . . . . 58
i

INDICE ii
2.1.2 Le classi persistenti e le classi serializzabili . . . . . . . . . . . . 61
2.1.3 Le classi generiche e le classi istanza . . . . . . . . . . . . . . . . 62
2.1.4 Il parser e l’estrattore . . . . . . . . . . . . . . . . . . . . . . . . 63
2.1.5 Lo spazio dei nomi . . . . . . . . . . . . . . . . . . . . . . . . . . 65
2.2 I componenti software CDL . . . . . . . . . . . . . . . . . . . . . . . . . 66
2.2.1 Le classi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
2.2.2 I packages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
2.2.3 I tipi primitivi . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
2.2.4 Le enumerazioni . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
2.2.5 I tipi importati . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
2.2.6 Gli alias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
2.2.7 Le eccezioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
2.2.8 I puntatori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
2.2.9 Gli schema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
2.2.10 Gli eseguibili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
2.3 Il linguaggio CDL a confronto con il linguaggio C++ . . . . . . . . . . . 87
2.3.1 La definizione delle variabili . . . . . . . . . . . . . . . . . . . . . 88
2.3.2 Modalita di passaggio delle variabili . . . . . . . . . . . . . . . . 96
2.3.3 L’invocazione di un metodo . . . . . . . . . . . . . . . . . . . . . 98
2.4 I servizi fondamentali di Open Cascade . . . . . . . . . . . . . . . . . . 109
2.4.1 Il package TCollection . . . . . . . . . . . . . . . . . . . . . . . . 109
3 Integrazione degli ambienti 113
3.1 Le strutture dati della FFI . . . . . . . . . . . . . . . . . . . . . . . . . . 115

INDICE iii
3.1.1 Il livello delle conversioni . . . . . . . . . . . . . . . . . . . . . . 116
3.1.2 Una lista di conversioni . . . . . . . . . . . . . . . . . . . . . . . 117
3.1.3 Il tipo primitivo Integer . . . . . . . . . . . . . . . . . . . . . . . 119
3.1.4 Gli oggetti Scheme . . . . . . . . . . . . . . . . . . . . . . . . . . 120
3.1.5 Le variabili C++ in istanze di classe HCvar . . . . . . . . . . . . 122
3.1.6 La conversione tra tipi . . . . . . . . . . . . . . . . . . . . . . . . 136
3.1.7 I metodi statici del package . . . . . . . . . . . . . . . . . . . . . 136
3.2 L’estrattore Scheme della FFI . . . . . . . . . . . . . . . . . . . . . . . . 139
3.2.1 Le azioni dell’estrattore . . . . . . . . . . . . . . . . . . . . . . . 143
3.3 La conversione delle librerie fondamentali . . . . . . . . . . . . . . . . . 149
3.4 La conversione delle libreria geometriche . . . . . . . . . . . . . . . . . . 150
4 Esempi di utilizzo delle librerie geometriche 153
4.1 La creazione di solidi primitivi . . . . . . . . . . . . . . . . . . . . . . . 153
4.2 Le operazioni geometriche . . . . . . . . . . . . . . . . . . . . . . . . . . 155
4.3 Esportazione dei modelli . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
4.4 Esempi di generazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
4.4.1 Modello con sfere . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
4.4.2 Modello toroidale . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
4.4.3 Grafico della funzione sombrero . . . . . . . . . . . . . . . . . . . 163
4.4.4 Generazione di labirinti . . . . . . . . . . . . . . . . . . . . . . . 167
Conclusioni 173
Bibliografia 177

INDICE iv

Introduzione
L’obiettivo di questa tesi e la realizzazione di un sistema software complesso che per-metta la collaborazione e l’integrazione tra due applicazioni rilasciate con licenza opensource: Open Cascade, un motore geometrico object oriented della societa Matra Da-tavision, e MzScheme, una particolare implementazione multipiattaforma della RiceUniversity del linguaggio funzionale Scheme.
Open Cascade e un sistema di classi che offrono l’infrastruttura per la costruzione rapida(Rapid Application Framework) di programmi orientati alla modellazione geometricao, piu in generale, orientati al disegno in uno specifico dominio di interesse, come adesempio CAD evoluti, sistemi di simulazione o tools per la visualizzazione.
Le librerie di Open Cascade definiscono strutture dati e algoritmi di calcolo che ope-rano in tutti i settori della modellazione: i servizi piu a basso livello permettono lacreazione di strutture geometriche[15], siano esse semplici solidi tridimensionali o com-plesse superfici NURBS o di Bezier. A piu alto livello sono invece definite le primitiveper l’applicazione delle operazioni booleane (unione, intersezione etc.)[17], per il calcolodelle proprieta locali e globali di un oggetto[19] (volume, centro di massa etc.) e infineper l’esportazione e la visualizzazione dei modelli generati[21, 23].
In realta e riduttivo pensare ad Open Cascade come ad un semplice, per quanto evoluto,motore CAD nel senso tradizionale. Una delle sue caratteristiche piu importanti einfatti quella di fornire dei servizi particolarmente innovativi che operano in un contestocompletamente differente da quello della modellazione geometrica.
Sono servizi che si occupano di assistere il programmatore in tutte le fasi dello svilup-po di una applicazione: dalla definizione dell’interfaccia dei componenti software allagenerazione automatica o semiatomatica dei files di progetto; dalla fase di testing e didebugging di una applicazione all’utilizzo delle librerie in un contesto distribuito.
1

Introduzione 2
Open Cascade
ComponentDefinitionLanguage OcasApplication
Framework WorkshopOrganizationKit
Librerie Geometriche
Architetturadei servizi di
Open Cascade
Figura 1: I servizi di Open Cascade.
I servizi non geometrici sono suddivisi in tre categorie principali:
CDL [29]. Il Component Definition Language e il linguaggio di Open Cascade per ladefinizione dell’interfaccia dei componenti software.
Un file CDL e cioe un file che stabilisce quale e la struttura “interna” dei datiC++. Ad esempio una classe CDL descrive costruttori di classi, operatori diconversione, metodi di istanza e variabili di stato.
OCAF [25]. L’Open Cascade Application Framework definisce dei servizi per la mo-dellazione in cui sia possibile associare delle informazioni “utente” (user-data)non necessariamente geometriche ai modelli geometrici parametrici.
Attraverso un meccanismo automatico di generazione delle applicazioni (appli-cation template) e di documenti1 sono inoltre implementate alcune funzionalitaper la memorizzazione non solo dei risultati di una sessione di lavoro ma anche esoprattutto dello script di comandi, cioe del codice generatore.
WOK [27]. Il Workshop Organization Kit e l’insieme dei tools per lo sviluppo delleapplicazioni CDL based.
I tools in questione sono: una shell di sistema per l’esecuzione di comandi e perla strutturazione del codice; tools per la generazione del codice attraverso degli
1I documenti sono una sorta di contenitore dei risultati del processo di modellazione. E’ comunque
previsto che l’utente possa definire dei propri tipi di dati che possono beneficiare degli stessi servizi.

Introduzione 3
appositi programmi di estrazione; programmi per la costruzione automatica deiMakefile di progetto e per la compilazione delle librerie.
Scheme[2, 6] e un dialetto del Lisp inventato da Guy Lewis Steel Jr.e Gerald JaySussman; la sua prima apparizione e datata 1975 cui seguira poi nel 1978 un documentoin cui gia compariva un tentativo di implementazione a cura dell’istituto MIT[3].
Il documento ufficiale di riferimento che descrive in modo formale la sintassi e lasemantica di Scheme e un report pubblicato nel 1998[4].
Scheme e un linguaggio di programmazione funzionale che e stato progettato con l’obiettivo primario di essere il piu possibile intuitivo, chiaro e di immediata comprensioneanche verso gli utenti non esperti. Si basa quindi su un numero veramente ridotto diregole sintattiche per la costruzione delle espressioni con pochissime restrizioni circa laloro composizione.
Scheme e un particolare caso di linguaggio weakly object oriented. Questo non significache sia un linguaggio object oriented nel senso tradizionale del termine: il comitatoresponsabile della standardizzazione del linguaggio non ha infatti rilasciato alcuna spe-cifica circa l’implementazione di un sistema ad oggetti; ne risulta quindi evidente cheuno Scheme Standard non abbia nessuna primitiva per la costruzione di classi e tanto-meno istanze di classe. Il termine weakly object oriented significa semplicemente che ivalori che l’interprete gestisce sono oggetti in memoria la cui identita e realmente “si-gnificativa”: e possibile ad esempio confrontare i valori di due puntatori per verificarel’uguaglianza del loro stato interno (equal values) ma e anche possibile controllare sereferenzino esattamente lo stesso oggetto (very equal values) .
Scheme e un linguaggio di programmazione particolarmente adatto per l’implementa-zione di nuovi linguaggi e per “scrivere programmi che scrivano programmi”. In altritermini i programmi Scheme possano essere modificati ed estesi con grande facilita.
Il problema della cooperazione tra linguaggi funzionali e linguaggi imperativi e ampia-mente conosciuto e si desidera approfondirne i contenuti essenziali.
I linguaggi di programmazione sono tradizionalmente classificati rispetto alle loro ca-ratteristiche fondamentali che ne determinano il potere espressivo e che si riflettonosullo stile di programmazione[28].
Il linguaggio base di un elaboratore, anche detto linguaggio macchina, e un linguaggio

Introduzione 4
che consente di specificare in un programma solo le operazioni che l’elaboratore puo’eseguire direttamente, attraverso una forma sintattica molto elementare basata sull’usodi un codice di tipo numerico binario.
Questo tipo di linguaggio e quindi piu fortemente orientato alla macchina piuttosto cheai problemi trattati. Per questa ragione esso viene detto linguaggio a basso livello, cioepiu vicino al livello hardware.
Una prima evoluzione dei linguaggi a basso livello si e avuta con l’introduzione dilinguaggi ancora orientati alla macchina nel senso stretto, ma di tipo simbolico. Questilinguaggi, detti assemblativi, pur mantenendo le caratteristiche e gli inconvenienti deilinguaggi binari, consentono tuttavia l’uso di descrizioni simboliche delle variabili e deicodici delle istruzioni.
Linguaggi piu evoluti sono stati successivamente definiti verso la meta degli anni ’50come tentativo di astrazione della macchina cioe con lo scopo di permettere di specificareoperazioni di piu alto livello rispetto a quelle elementari che l’elaboratore puo’ eseguiredirettamente. Questi linguaggi sono detti linguaggi ad alto livello di tipo imperativo.Esempi tipici di linguaggi imperativi sono il Basic, il C/C++, il Pascal etc.
Nei linguaggi imperativi ad alto livello sono utilizzati i concetti su cui e basato il linguag-gio macchina. Infatti le variabili sono astrazioni della cella di memoria e l’istruzione diassegnazione corrisponde al trasferimento di un valore di memoria. I programmi sonouna sequenza di istruzioni e l’evoluzione del calcolo e essenzialmente rappresentata dauna variazione di stato della memoria ottenuta come effetto delle istruzioni eseguite.
Una svolta ancora piu decisiva nel campo dei linguaggi di programmazione si e avutaquando ci si e posti il problema di definire il linguaggio ponendosi direttamente comeobiettivo quello di fornire un mezzo espressivo per specificare all’elaboratore il compitoda eseguire in modo semplice e sintetico.
Sono cosı stati definiti una serie di linguaggi di impostazione completamente diversadalla precedente per cui l’esecuzione di un programma puo’ essere considerato come ilcalcolo del valore di una funzione (come nei linguaggi funzionali tipo il Lisp o Scheme)oppure come la dimostrazione della veridicita di una asserzione (come nei linguaggidichiarativi logici, tipo il Prolog).
I linguaggi funzionali sono basati sul concetto di funzione matematica e su quello diapplicazione di una funzione ad argomenti. Per questo motivo sono spesso detti anchelinguaggi applicativi.

Introduzione 5
I linguaggi funzionali hanno la caratteristica di non calcolare gli effetti ma di calcolarevalori. Il nucleo di un linguaggio funzionale e costituito: dal meccanismo di applicazionedelle funzioni; dalla ricorsione e dal costrutto condizionale come strumenti di controllo;dalle liste come tipo di dato primitivo.
Attorno ai linguaggi funzionali sono stati costruiti sistemi di programmazione in gradodi offrire al programmatore un’interazione di livello elevato e quindi di facilitare losviluppo di programmi di notevoli complessita e dimensioni. Il modo di programmarerisulta essere un’attivita altamente interattiva e gran parte delle inefficienze legate alciclo redazione/compilazione/esecuzione dei linguaggi imperativi vengono eliminate.
Nonostante le caratteristiche sicuramente avanzate ed innovative dei linguaggi funzio-nali, e indiscutibile che ancora oggi la stragrande maggioranza del software esistentesia stato sviluppato utilizzando linguaggi imperativi. E la situazione non e probabil-mente destinata a cambiare nell’immediato futuro. Cosı come e indubbio che spesso ilinguaggi funzionali sono relegati ad un settore dello sviluppo di grande interesse mapur sempre di “nicchia”: quello della ricerca.
Le ragioni di tale situazione sono svariate e sono riassunte in un articolo di Philip Wadler2, “Why no one uses functional languages”, pubblicato su “SIGPLAN Notices”[20]:
Compatibilita I linguaggi funzionali tendono ad essere “isolati” cioe difficilmenteintegrabili con librerie software esterne.
Disponibilita Le distribuzioni sono nella maggioranza dei casi il risultato di progettiuniversitari e sono quindi distribuzioni non definitive e instabili. Sono pochissimeinvece le distribuzioni commerciali che offrono un servizio di supporto tecnico pergli sviluppatori.
Tools Per essere realmente usabile un sistema per lo sviluppo di software deve fornirealmeno un debugger ed un profiler. Raramente le distribuzioni dei linguaggifunzionali implementano qualcosa di piu della semplice interfaccia read-eval-print.
In linea con gli obiettivi di questa tesi si cerchera di attenuare il piu possibile, se noneliminare del tutto, i problemi appena citati. Rispetto al problema della disponibilitae della inadeguatezza dei tools si e optato per l’adozione di un sistema integrato perlo sviluppo (Integrated Development Environment) estremamente completo ed affida-bile, quello di MzScheme[1]. Rispetto al problema della compatibilita saranno invece
2Philip Wadler lavora nei laboratori della Bell Labs nei gruppi Unix e ML; e’ uno degli autori del
linguaggi Haskell; ed e infine capo redattore del “Journal of Functional Programming”.

Introduzione 6
s e r v e r
c l i e n tC OR B A
LibrerieOcas
Scheme
ForeignFunctionInterface
Cooperazionedistribuita
Cooperazione"locale"
Figura 2: CORBA e le Foreign Function Interface
implementati dei nuovi algoritmi attraverso cui le librerie C++ potranno integrarsifacilmente con l’interprete funzionale.
Al di la delle efficienze e delle inefficienze evidenti e oggettive dei linguaggi imperativirispetto ai linguaggi funzionali, si e comunque di fronte a filosofie della programmazionemolto differenti. Ogni linguaggio ha cioe dei propri campi di applicazione “naturali”.
Il vero problema non e quello di stabilire se un linguaggio di programmazione sia “supe-riore” ad un altro; il vero problema e invece quello di far cooperare i linguaggi imperativicon i linguaggi funzionali o, piu in generale, far interagire oggetti software che operanoin un contesto eterogeneo.
Negli ultimi anni si e assistito ad una notevole diffusione delle piattaforme distribuite,quali ad esempio CORBA e DCOM[26], in cui ogni oggetto opera in modo indipendenteda tutti gli altri ed espone dei servizi in qualita di server. Tale diffusione e la provatangibile della volonta di riutilizzo di software e soprattutto e la dimostrazione che nonesiste un linguaggio adatto per tutte le occasioni.
Negli obiettivi di questa tesi si cerchera di risolvere il problema dell’integrazione tralinguaggi imperativi (nello specifico le librerie C++ di Open Cascade) e linguaggi fun-zionali (nello specifico l’interprete di MzScheme) da un punto di vista piu limitato inquanto gli oggetti client e server sono in realta in esecuzione all’interno dello stessoprocesso, condividono lo stesso spazio degli indirizzi e possono di conseguenza accederealle stesse strutture dati.

Introduzione 7
Il componente che si occupera di tradurre3 le strutture dati di un linguaggio in modoche possano essere utilizzate in un contesto differente da quello di provenienza e laForeign Function Interface.
Per comprendere a fondo la modalita di funzionamento della FFI si devono neces-sariamente premettere alcune nozioni fondamentali in merito al funzionamento deicompilatori C++. Il tradizionale ciclo di produzione di software in linguaggio C++prevede:
1. La scrittura del codice sorgente, codice che e normalmente suddiviso tra gli headerfiles che descrivono il contenuto delle classi e codice di implementazione.
2. La generazione degli object files da parte del compilatore.
3. L’operazione di linking degli object files con altri files di libreria esterni per lagenerazione dei binari del programma.
Il lavoro piu importante e pero’ svolto dal compilatore nella prima fase del processo: eil compilatore che alloca le regioni di memoria (record di attivazione) per l’invocazionedi una funzione; e il compilatore che controlla la correttezza delle operazioni di assegna-zione degli argomenti attuali rispetto ai corrispondenti argomenti formali e, in caso dimancata compatibilita, esegue delle conversioni implicite[22] (nell’ordine: conversioniesatte, conversioni per promozione, conversioni standard e conversioni utente); ed e in-fine il compilatore che opera da risolutore dell’overloading (overloading solver), cioe nelcaso in cui sia presente una collisione di nome invoca la funzione che offra la migliorecorrispondenza attraverso l’applicazione di un algoritmo che elimina le ambiguita (la“regola di intersezione”).
Il compilatore e in grado di eseguire tutte queste operazioni perche conosce la strutturainterna dei dati C++, struttura che e univocamente definita dagli header files.
E’ inoltre importante evidenziare come la conoscenza sui tipi delle variabili C++ sia per-sa in modo non recuperabile all’atto della generazione dei files binari: non esiste infattialcun modo (almeno nessun modo che faccia parte di uno standard imposto ed accet-tato dai produttori dei compilatori C++4) per recuperare a run time le informazionisui tipi C++.
3La necessita di dover operare una traduzione dei dati e evidente se si considerano le notevoli
differenze, sia da un punto di vista teorico che da un punto di vista operativo, tra linguaggi funzionali

Introduzione 8
compilatorestatico
FFI(compilatore"dinamico")
headerfiles
CDL files
implementazione C++
script Scheme coninvocazione delle
C++foreign function
generazione dieseguibili e librerie
esecuzionedinamica delle
funzioni di libreria
Conoscenza Conoscenza
Figura 3: Compilatori statici e compilatori dinamici.
Vengono adesso esaminate le condizioni operative nel caso in cui le funzioni C++ sianoinvocate ed eseguite all’interno dell’ambiente interpretato Scheme: l’utente sviluppacodice che puo’ accedere alle foreign functions C++. Rispetto a tale codice non verramai generato un object file statico, in quanto la modalita di invocazione deve sempreseguire una logica dinamica.
L’interprete deve quindi farsi carico di invocare le funzioni, cioe di caricare nello stackgli argomenti di ingresso e di restituire i valori di uscita; di verificare la compatibilitatra dati applicando le operazioni di conversione; ed infine di risolvere le collisioni deinomi. Cio giustifica la presenza di un componente di interfaccia tra interprete e librerieC++; la FFI simula quindi la presenza di un compilatore dinamico.
Rispetto al problema della conoscenza dei dati C++ il problema viene affrontato erisolto nel seguente modo.
Il compilatore C++ tradizionale sa come gestire i dati perche conosce il contenutodegli header files: da una definizione di classe sa ad esempio quali costruttori o qualioperatori di conversione possono essere invocati.
Il compilatore dinamico non ha invece a priori una conoscenza dei dati delle librerieC++; ne’ i files binari possono servire allo scopo avendo perso ogni informazione rispettoal codice C++ che li ha generati.
e linguaggi imperativi.4L’eccezione a questa regola consiste nella generazione di object files che contengano delle informa-
zioni per il debugging. In questo caso il compilatore puo’ memorizzare dei meta dati tra cui anche le
informazioni in relazione al tipo delle variabili C++. Il formato di tali informazioni e pero’ specifico
per ogni compilatore.

Introduzione 9
La FFI puo’ comunque acquisire tale conoscenza in diversi modi: puo’ ad esempioleggere nuovamente gli header files della libreria; oppure puo’ effettuare il parsing diqualche altro file di interfaccia in un formato proprietario, formato che generalmenteha una sintassi semplificata rispetto a quella del linguaggio C++.
Le piattaforme CORBA e DCOM adottano quest’ultimo approccio definendo due diffe-renti formati di Interface Definition Language (IDL) tra loro, purtroppo, incompatibili5.
Anche nei risultati di questa tesi si e adottato la soluzione del formato proprietario: levariabili C++ sono quindi tipizzate attraverso il formato CDL di Open Cascade.
La struttura dei capitoli che seguiranno e la seguente.
Nel primo capitolo sara descritto il linguaggio funzionale Scheme e se ne evidenzieran-no le caratteristiche piu importanti. In particolare sara approfondita la modalita difunzionamento dei componenti che piu di altri influenzano l’architettura del sistema: ilmanager della memoria, il sistema ad oggetti (Object System) di MzScheme ed infinei servizi attraverso cui si possano aggiungere all’interprete nuove primitive e nuovi tipidi dato.
Nel secondo capitolo sara invece descritta la complessa infrastruttura delle librerie diOpen Cascade: verranno introdotti i fondamenti del linguaggio CDL e sara inoltreanalizzata la sintassi di tutti i componenti software. Sara inoltre affrontato in modosistematico il problema della conversione dei dati.
Nel terzo capitolo il problema dell’integrazione delle librerie C++ all’interno dell’inter-prete di MzScheme sara spiegato da un punto di vista piu tecnico: si vedra concretamen-te quali sono le soluzioni adottate e soprattutto si entrera nei dettagli implementatividel codice.
Nel quarto capitolo saranno infine illustrati alcuni esempi pratici di utilizzo dell’am-biente, nello specifico saranno utilizzate le librerie di Open Cascade per la generazionedi alcuni modelli geometrici.
5In realta il problema delle piattaforme distribuite non e quello della assenza di un compilatore ma
la condivisione della conoscenza dei tipi dei dati attraverso un servizio di Interface Repository.

Introduzione 10

Capitolo 1
Un ambiente funzionale
In questo capitolo verra fornita una sintetica descrizione del linguaggio di programma-zione Scheme[2, 6]. Scheme e un dialetto del Lisp inventato da Guy Lewis Steel Jr. eGerald Jay Sussman; la sua prima apparizione e datata 1975 cui seguira poi nel 1978un documento, rivisto e corretto, in cui gia compariva un tentativo di implementazionea cura dell’istituto MIT[3].
Tra il 1981 e i 1982 vennero istituiti tre nuovi corsi di programmazione al MIT[7], aYale[8] e alla Indiana University[9] che adottavano Scheme come linguaggio di riferi-mento.
Dal 1982 in poi il linguaggio Scheme ha subito un notevole sviluppo diventando sem-pre piu diffuso soprattutto in ambito accademico. E’ in particolare da evidenziare lacrescente attivita e il massiccio scambio di esperienze e di informazioni che coinvolgonola comunita che si occupa di sviluppo in Scheme: esistono molti forums di discussio-ne, decine di mailing lists e molte conferenze annuali che contribuiscono alla crescitagiorno per giorno di Scheme; crescita di cui in realta hanno poi beneficiato tutti glisviluppatori che lavorano nell’ambito dei linguaggi funzionali.
Attualmente il documento ufficiale di riferimento che descrive in modo formale la sintas-si (in formato BNF) e la semantica di Scheme e un report, piuttosto sintetico, pubblicatonel 1998[4].
La particolarita che probabilmente piu caratterizza Scheme e che lo differenzia daglialtri linguaggi di programmazione, siano essi imperativi o funzionali, e quello di esserestato progettato con l’obiettivo primario di essere il piu possibile intuitivo, chiaro, diimmediata comprensione anche per gli utenti non esperti.
11

CAPITOLO 1. UN AMBIENTE FUNZIONALE 12
Scheme si basa quindi su un numero veramente ridotto di regole sintattiche per la co-struzione delle espressioni con pochissime restrizioni circa la loro composizione. Non perquesta sua estrema semplicita viene pero’ sacrificato qualcosa in termini di espressivitarispetto agli altri linguaggi. E’ anzi vero che tutti i principali paradigmi di program-mazione trovano in Scheme delle immediate traduzioni e in alcuni casi delle alternativeche rendono piu leggibile il codice sorgente.
Nei paragrafi che seguono verranno evidenziate alcune tra le caratteristiche piu impor-tanti del linguaggio Scheme: ci si soffermera in particolare sul modo con cui l’interpreteScheme associa una informazione di “tipo” agli oggetti in memoria.
Verra inoltre affrontato il problema della gestione della memoria soprattutto in rela-zione alle politiche di deallocazione degli oggetti nel momento in cui essi non sonopiu “potenzialmente” referenziabili. Si metteranno a confronto le tecniche di alloca-zione/deallocazione “tradizionali”, come ad esempio quelle normalmente utilizzate daicompilatori C++, con delle tecniche piu “intelligenti” quali ad esempio la GarbageCollection.
Si illustrera quindi il funzionamento delle Foreign Function Interface (FFI) cioe di queicomponenti di “interfaccia” che permettono l’integrazione di codice realizzato con unlinguaggio di programmazione funzionale ad alto livello con il codice sviluppato con unlinguaggio di programmazione imperativo.
Saranno infine esaminate le caratteristiche della particolare implementazione multipiat-taforma Scheme scelta: MzScheme.
1.1 Caratteristiche principali di Scheme
In questo paragrafo si vedra quali sono i concetti e le caratteristiche piu importanti diScheme. In particolare saranno illustrate le motivazioni che hanno portato alla sceltadi Scheme come linguaggio funzionale di riferimento del sistema sviluppato.
Le variabili sono statically scoped. Scheme e un linguaggio statically scoped : l’am-biente (environment) che contiene le associazioni tra le variabili e i loro valori, eche quindi e “utilizzato” al momento dell’esecuzione del codice di una procedura,e l’ambiente nel quale la procedura e stata creata (semantica statica), e non quelloin cui la procedura e stata invocata (semantica dinamica).

CAPITOLO 1. UN AMBIENTE FUNZIONALE 13
Piu che voler dare una spiegazione formale al significato di statically scoped sivuole qui fornire un esempio dimostrativo:
(define x 1)
(define (f x) (g 2))
(define (g y) (+ x y))
(f 5)
Il valore restituito sara l’intero 3, e non 7 come il programmatore C potrebbepensare.
In questo caso con la primitiva define1 sono state create le variabili f e g contenentiognuna un valore di tipo procedura. Nell’environment in cui la procedura g operala variabile x ha quindi un valore 1 e non 52.
E’ da sottolineare il fatto che la caratteristica di static scoping semplifica dimolto la lettura del codice sorgente: e possibile stabilire quale sia il bindingdi una variabile semplicemente dalla lettura del testo del programma stesso; ilvalore che verra infatti utilizzato dall’interprete non puo’ dipendere dall’“ordine”di esecuzione delle procedure. Per questo si usa spesso dire che lo static scopinge sinonimo di lexical scoping.
I tipi sono latent. I tipi delle strutture dati in Scheme sono detti latent in contrap-posizione con i linguaggi di programmazione con tipi manifest [12]. L”interpreteScheme associa l’informazione sui tipi agli oggetti piuttosto che alle variabili3.
Questa caratteristica ha reso particolarmente complicata la condivisione dellestrutture dati tra C/C++ e interprete Scheme soprattutto a causa della totalemancanza di supporto, da parte del linguaggio C, per l’introspezione sui dati.
La soluzione alla quale alla fine si e pervenuti e stata quella di fornire ad ognivalore del C/C++ una meta-informazione circa la sua tipizzazione4.
1La primitiva define viene anche detta Top-Level Definition in quanto ha come effetto quella di
estendere l’environment attuale piuttosto che crearne un nuovo.2Il valore di x potrebbe essere 5 solo se l’environment utilizzato dall’interprete fosse quello creato
dinamicamente, cioe vincolato ai records di attivazione dello stack.3In C/C++ cosı come nel Pascal e in molti altri linguaggi di programmazione, si deve predichiarare
l’utilizzo di una variabile specificandone il tipo. Cio permette al compilatore di riservare lo spazio in
memoria che servira successivamente per la memorizzazione del dato. Non e di solito permesso che una
variabile cambi tipo a tempo di esecuzione.4L’informazione sui tipi delle strutture dati e ottenuta dal parsing dei files in formato Open Cascade
Definition Language (CDL); tali files svolgono quindi funzione di manifest files rispetto all’interprete
Scheme, garantendo quindi la possibilita di introspezione rispetto alle strutture dati stesse.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 14
Gli oggetti hanno unlimited extent. Tutti gli oggetti creati durante la fase di cal-colo, procedure incluse, non verranno mai distrutte e saranno quindi sempredisponibili.
Il programma non andra comunque incontro a problemi di esaurimento dellamemoria disponibile (run out of memory) in quanto esiste una tecnica di recuperomemoria, anche detta di garbage collection, che si occupa appunto di “recuperare”lo spazio assegnato ad un certo oggetto, qualora si possa dimostrare che l’oggettostesso non potra piu essere utilizzato dall’utente in futuro.
Si vedra in seguito come sia possibile far cooperare il memory manager di OpenCascade con il garbage collector di Scheme.
Proper tail recursion. Le fasi di calcolo iterative possono essere eseguite dall’inter-prete Scheme in uno spazio di memoria costante anche se l’algoritmo e descrittotramite una procedura ricorsiva.
Ogni qual volta una procedura Scheme richiama se stessa in un modo equivalentea quanto potrebbe fare tramite una qualsiasi istruzione di loop 5, Scheme auto-maticamente ottimizza la procedura in modo che non usi ulteriore memoria dellostack.
L’idea che sta alla base della proper tail recursion[5] e che non e necessario, eanzi inutilmente dispendioso in termini di occupazione dello spazio di memoriaa disposizione dello stack, che il controllo dell’esecuzione torni ad una procedurala cui unica istruzione che rimanga da eseguire sia l’istruzione di return. Adesempio:
(define (foo)
(bar)
(baz))
La chiamata alla procedura baz e una chiamata tail in quanto la procedura foodovra semplicemente restituire il valore ottenuto dall’esecuzione baz ; non esistequindi realmente la necessita di creare un nuovo record di attivazione nello stack,essendo infatti sufficiente eseguire una istruzione di tipo goto6.
Alcuni compilatori Lisp e C eseguono una limitata ottimizzazione delle chiamatetail ; al contrario Scheme tratta tali chiamate in modo piu generale e standardiz-zato.
5Non si vuole in questa sede entrare nei dettagli del problema; problema che e comunque ampiamente
discusso e approfondito in letteratura.6Tecnicamente si dice che l’interprete non salva nello stack lo stato del chiamante.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 15
Si e dovuto considerare in fase di realizzazione del progetto che tutte le nuove pri-mitive scritte in C/C++ devono essere il piu possibile conformi a questa modalitadi chiamata.
Le procedure sono First Class. Le procedure Scheme sono oggetti, il che significache si possono creare dinamicamente, possono essere memorizzate in strutturedati, possono essere valori di ritorno di altre procedure e cosı via.
Tecnicamente si usa dire che le procedure sono first class object, cioe e possibiletrattarle esattamente come un qualsiasi altro tipo di dato.
Una caratteristica che differenzia Scheme rispetto agli altri linguaggi di program-mazione e quella di utilizzare per le procedure un namespace unificato: esiste ununico identificatore per la variabile che contiene la procedura e per la procedurastessa. Ad esempio:
(define (min a b)
(if (< a b)
a
b))
L’istruzione di define implica l’esecuzione di tre azioni:
1. La creazione della procedura in senso stretto.
2. La creazione della normal variable min.
3. L’inizializzazione della variabile min con il valore del puntatore alla proce-dura.
Considerando le evidenti differenze di comportamento tra C++ e Scheme si vedracome sia possibile far condividere dati di tipo procedura tra i due ambienti.
E’ possibile che un metodo di una classe C++ riceva come argomento un valoredi tipo procedura Scheme.
Non e invece possibile che una funzione C++ sia un argomento di una proce-dura Scheme: non esiste infatti in CDL il concetto di puntatore a funzione. E’quindi necessario, in questo ultimo caso, “passare” direttamente come argomentol’oggetto che contiene il metodo.
Gli argomenti sono passati per valore. Gli argomenti che le procedure Scheme“ricevono” sono passati per valore, cioe l’interprete Scheme valuta le espressio-ni associate agli argomenti prima che il controllo passi alla procedura invocata,

CAPITOLO 1. UN AMBIENTE FUNZIONALE 16
indipendentemente dalla circostanza se poi tale argomento verra effettivamenteutilizzato dalla procedura. In questo caso il comportamento di Scheme e simile aquello di altri linguaggi di programmazione quali ad esempio ML e C[11].
I concetti di bindings e di environment. Un identificatore che non sia una parolachiave per il linguaggio puo’ essere utilizzato come nome per una variabile; talenome quindi referenzia la locazione di memoria in cui il dato verra memorizzato.La variabile e in questo caso detta bound alla locazione. Una variabile puo’ esserebound senza che per questo le sia gia stato assegnato un valore. In questo caso ilsuo stato si dice unassigned.
Un environment e un insieme di bindings di variabili. Una variabile che non abbiaun binding nell’environment si dice unbound.
E’ permessa la creazione di un environment a partire da un altro gia esistentetramite l’operazione di extending. Cio non comporta la modifica dell’environmentche subisce l’estensione: ogni nuova operazione di tipo define infatti opera allivello dell’ environment locale.
Ad esempio nel seguente script:
(define x 4)
(define (f y)
(let
((x 2))
(+ x y)))
l’“ambiente” locale, creato attraverso l’uso della primitiva let, avra un nuovobinding di x che maschera il binding di x dell’environment principale (shadowbinding).
Le chiamate alle procedure come let, let* e letrec provocano la creazione diun nuovo environment. Al contrario le Top Level Definition, come ad esempio laset! e la define, aggiungono o modificano un binding nell’environment attuale.
External Representation Un importante concetto introdotto da Scheme e quello chegli oggetti possono avere come external representation una sequenza di caratteri.
Ad esempio l’intero 28 puo’ avere come external representation sia la stringa ’28’che la stringa ’x1c’ (rappresentazione esadecimale). Cio dimostra tra l’altro chel’external representation di un oggetto non e necessariamente unica.
Questa caratteristica e molto importante e facilita in modo significativo la scrit-tura di programmi quali interpreti e compilatori; cioe programmi che trattino il

CAPITOLO 1. UN AMBIENTE FUNZIONALE 17
codice sorgente come semplice oggetto e viceversa. E’ una caratteristica larga-mente utilizzata nel sistema realizzato in cui gli script vengono eseguiti da shelleffettuando una chiamata alla primitiva scheme eval.
Si vuole introdurre infine, in modo semplificato, la convenzione sui nomi adottata daScheme. Cio sara utile in seguito per la comprensione del codice proposto.
I nome delle procedure che abbiano come valore di ritorno un boolean devono terminarecon un carattere ’?’. Queste procedure sono a tutti gli effetti dei predicati.
I nomi delle procedure che modifichino il contenuto di una locazione di memoria prece-dentemente allocata dovrebbero terminare con il carattere ’!’. Queste procedure sonocomunemente chiamate mutuation procedure.
Infine le procedure che ricevano in ingresso un oggetto di un determinato tipo e restitui-scano come valore di uscita un oggetto di un altro tipo, eseguendone una conversione,solitamente contengono la stringa ’->’ (es list->vector).
1.2 Allocazione della memoria
Nei linguaggi di programmazione “tradizionali” la gestione della memoria e spesso unodegli aspetti piu delicati. E’ infatti compito specifico del programmatore gestire ognidata object esistente in memoria rilasciandone le risorse detenute (regioni di memoria,lock sui files etc) al termine del loro utilizzo.
Un programma in cui una o piu variabili non venissero correttamente deallocate potreb-be andrebbe incontro, in tempi piu o meno lunghi, a problemi di memoria insufficiente.
A complicare ancora di piu la situazione e il fatto che non sempre e possibile stabilireuna politica di “rilascio” assolutamente corretta ed esente da errori. E’ stato infattidimostrato che piu i progetti software sono complessi, e quindi implicano la creazionedi strutture dati nidificate, piu e problematico stabilire se una variabile sia ancorareferenziata, cioe ancora potenzialmente utilizzabile, o piuttosto se ne e possibile ladistruzione.
E’ per questo che spesso si fa uso di tecniche piu intelligenti che tentano di risol-vere il problema alla radice automatizzando completamente la fase di rilascio dellamemoria[13].

CAPITOLO 1. UN AMBIENTE FUNZIONALE 18
Tali tecniche sono assolutamente necessarie per una programmazione completamentemodulare: una routine software che operi su una certa struttura dati non dovrebbedipendere da altre routines che debbano operare sulla stessa struttura, a meno che cionon sia strettamente necessario per coordinare la loro attivita (es semafori, mutex etc).
Se gli oggetti dovessero essere deallocati “manualmente”, almeno uno dei moduli ope-rerebbe da manager delle risorse condivise. Cioe i due moduli dovrebbero “conoscer-si” reciprocamente, almeno per quanto riguarda l’ accesso ai dati in memoria e alleoperazioni “lecite” sui dati stessi. Cio a scapito della modularita che viene richiesta.
Il linguaggio Scheme adotta appunto una di queste tecniche avanzate di gestione dellamemoria: la Garbage Collection. Il funzionamento di tale algoritmo sara spiegato nelparagrafo 1.6.1.
1.3 I sistemi ad oggetti in Scheme
Il comitato responsabile della standardizzazione del linguaggio di programmazioneScheme non ha rilasciato alcuna specifica circa l’implementazione di un sistema adoggetti.
Ne risulta quindi evidente che uno Scheme Standard non abbia nessuna primitiva perla costruzione di classi e tantomeno istanze di classe.
Nonostante cio esistono diverse eccezioni che fanno si che la tecnica di programmazioneorientata agli oggetti (OOP) sia comunque diffusa presso la comunita Scheme.
I due approcci piu diffusi per l’inserimento di un Object System all’interno dell’inter-prete sono:
• La costruzione dell’ Object System direttamente in linguaggio Scheme. Cio siattua con l’utilizzo di strutture dati e procedure scheme. Il principale vantaggiodi un simile approccio e quello di scrivere codice Scheme puro, cioe indipendentedalle differenze tra gli interpreti, e che quindi sara realmente portabile su diversepiattaforme.
• L’utilizzo di Object System proprietari, cioe direttamente forniti dal produttoredell’interprete. Cio ostacola di fatto la portabilita del codice sorgente tra inter-preti differenti. Allo stesso tempo pero’ gli Object System proprietari sono spessopiu veloci in virtu del fatto di essere stati scritti in linguaggio C/C++.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 19
Rispetto agli obiettivi di questa tesi si e deciso di utilizzare l’Object System proprietariodi MzScheme. Si avra modo di illustrare il funzionamento di questo sistema ad oggettinel paragrafo 1.6.2.
1.4 La Foreign Function Interface (FFI)
Il termine Foreign Function Interface (FFI) fu introdotto per la prima volta in Lisp perindicare il meccanismo di invocazione di funzioni “esterne” al linguaggio, funzioni chenel caso specifico erano realizzate in C. Tali funzioni erano state appunto denominate“foreign function” o “call out function”.
Il termine ha successivamente assunto significati piu generali. A tutt’oggi FFI indica lacollaborazione tra codice precompilato scritto con diversi linguaggi di programmazione;librerie cioe il cui codice venga eseguito in uno spazio degli indirizzi condiviso.
E’ questa la sostanziale differenza tra la FFI e le altre tecniche di comunicazione qualiad esempio i sockets, RMI, DCOM, CORBA, in cui i processi client e server sonodistinti e indipendenti, e quindi con differenti spazi degli indirizzi 7.
Il miglior modo per illustrare il funzionamento di una FFI e di fornire un esempiopratico di utilizzo:
int fact(int n) {
if (n <= 1) return 1;
else return n*fact(n-1);
}
Affinche la funzione fact sia accessibile da uno scripting language e necessaria lascrittura di codice che operi da interfaccia tra i due sistemi.
Ad esempio e possibile introdurre la fact all’interno di una shell Tcl nel seguente modo:
int wrap_fact(ClientData clientData,
Tcl_Interp *interp,
int argc, char *argv[]) {
int _result,_arg0;7Cio comunque non esclude la possibilita che i processi client e server risiedano sulla stessa stazione..

CAPITOLO 1. UN AMBIENTE FUNZIONALE 20
if (argc != 2) {
interp->result = "wrong # args";
return TCL_ERROR;
}
_arg0 = atoi(argv[1]);
_result = fact(_arg0);
sprintf(interp->result,"%d", _result);
return TCL_OK;
}
1.4.1 I problemi di una FFI
I problemi piu importanti che una FFI deve affrontare e risolvere sono i seguenti:
• Differenti tecniche di gestione della memoria: ad esempio la malloc e la free
in C; tecniche di reference counting in Python; garbage collection in Java, Lisp,Scheme etc.
• Mapping tra strutture dati, cioe tra inside e outside type.
• Problemi di side effect. In generale le librerie C gestiscono i dati “strutturati” perriferimento; invece nei linguaggi funzionali si tende a passare tutti gli argomentiper valore evitando il piu possibile il side effect.
• Problemi dovuti a differenze di gestione delle situazioni di errore.
• Nei linguaggi ad alto livello le funzioni sono oggetti first class.
Il caso piu frequente di utilizzo di una FFI e quello in cui si abbia un linguaggio ad altolivello (che nel nostro specifico e Scheme) che si vuole estendere con una ApplicationPrograms Interface (API) esterna.
Esistono comunque delle situazioni in cui l’approccio di una comunicazione basata suFFI puo’ non essere soddisfacente. A volte la FFI puo’ infatti essere molto lenta: deveeffettuare conversioni tra variabili, deve effettuare un controllo accurato sui tipi etc.Questa puo’ essere una limitazione di non particolare rilievo quando il lavoro che laFFI deve svolgere e ridotto; non certamente nel caso in cui una funzione FFI debbaessere invocato migliaia di volte.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 21
Linguaggiofunzionale
ForeignFunctionInterface
Linguaggioimperativo
up
pe
rle
ve
lm
idd
lele
ve
llo
we
rle
ve
l
1. function call
2. data inputconversion
3. data outputconversion
4. return value
Figura 1.1: Funzionamento di una FFI.
Rispetto al sistema sviluppato non e possibile prevedere in modo netto quale sia ilcontesto di utilizzo del programma: l’interfaccia utente e costituita da una shell dallaquale e possibile sviluppare codice sul cui contenuto non e posta alcuna limitazione.
Sara quindi possibile realizzare semplici prototipi, per i quali il fattore prestazionale nondovrebbe essere determinante. In questo contesto e molto piu importante l’espressivitadel sistema, cioe la facilita con cui le primitive geometriche di Ocas possono essereinvocate.
D’altra parte sara anche possibile sviluppare complessi programmi che sono invece scrit-ti facendo un massiccio uso della ricorsione8: questo tipo di programmi saranno quelliche risentiranno pesantemente del lavoro svolto dalla FFI. Se l’esecuzione dovesse risul-tare eccessivamente rallentata esiste comunque la possibilita di “trasferire” le primitiveparticolarmente complesse dal linguaggio Scheme (upper layer) a livello di libreria C++(lower layer).
1.4.2 Le azioni di una FFI
Le azioni che una FFI deve eseguire sono le seguenti:
Library loading . L’interprete funzionale deve poter accedere o in modo statico o in8Il fattore che determina piu di altri un rallentamento della velocita di esecuzione e il continuo
passaggio tra l’esecuzione di codice dell’ambiente funzionale e l’esecuzione di codice del linguaggio a
basso livello. E’ infatti durante questo cambio di “contesto” che la FFI opera.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 22
Linker
library
source-code
function call(...)
static ordinamic
function 1
function 2
function 3
function 4
[...]
Figura 1.2: Operazione di linking.
modo dinamico alla libreria da integrare.
Nel primo caso e sufficiente linkare il codice precompilato della libreria nellospazio degli indirizzi del processo.
Nel secondo caso la situazione e invece piu complessa: e necessario che esista unaprimitiva apposita dell’interprete che permetta il caricamento dinamico dei filesdi libreria. Ad esempio in AutoLisp9 esiste una istruzione del tipo:
(define handle (ffi_LoadLibrary "library-name"))
Address binding Si deve qui fornire una breve introduzione a problemi che riguarda-no delle operazioni che sono normalmente eseguite dal compilatore o dal linker.Per far questo si fara riferimento al linguaggio C.
Esistono due differenti tipi di libreria che il programmatore C puo’ creare: libreriestatiche e librerie dinamiche. Ogni qual volta il programmatore C invoca unafunzione di libreria il comportamento del linker e differente a seconda del tipo dilibreria.
Rispetto alle librerie statiche l’istruzione di invocazione della funzione di libreriaviene “tradotta” in una istruzione di tipo goto.
Nel caso di linking dinamico la risoluzione del cross reference sara invece eseguitasolo all’atto del caricamento dell’eseguibile.
A complicare ulteriormente il quadro della situazione bisogna anche considerarei seguenti aspetti:
9AutoLisp e una versione free del Lisp disponibile in Microsoft Windows.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 23
• Spesso il nome della funzione all’interno della libreria e diverso dal nomesimbolico attribuito dal programmatore. Non esiste rispetto a questo pro-blema nessuno standard imposto, per cui un compilatore potrebbe utilizzaredei nomi differenti da un altro compilatore10.
• In C/C++ e possibile attribuire lo stesso nome a funzioni che ricevanoparametri di ingresso differenti (problema dell’overloading).
Rispetto alla problema dell’address binding la FFI puo’ comportarsi in due modidifferenti. Nell’approccio statico sono sempre il compilatore e il linker a risolverei riferimenti. Nell’approccio dinamico e invece la stessa FFI che deve farsi caricodel recupero dell’indirizzo corretto11. Ad esempio con una istruzione del tipo:
(ffi_GetProcAddress handle "function-name")
Per quanto e stato possibile appurare non esiste attualmente nessun algoritmoche risolva il problema dell’address binding in modo completamente dinamico. Sifa invece spesso ricorso a tecniche miste.
Input Parameters La FFI deve caricare nello stack gli argomenti che la funzionedeve ricevere come parametri di ingresso. Cio implica la gestione di strutturedati che potrebbero12 dover subire alcune operazioni di conversione.
Per avere una idea piu precisa del problema del passaggio degli argomenti vieneriportato qui di seguito un tipico esempio di FFI realizzata in codice assembler:
ffi_call_explicit(...){
switch(ParamsTypes[i]){
case T_INT:
asm{
mov eax,Params[i]
push eax
}
break;
[...]10Questo e uno dei motivi per cui e praticamente impossibile in C linkare tra loro object files di
compilatori differenti.11Il problema di tradurre i nomi in indirizzi si complica ancora di piu nel C++, linguaggio nel quale
possono essere presenti namespaces multipli (es. classi nidificate)12Cio avviene spesso. Ma ancora una volta sono istruzioni che il compilatore esegue in modo
automatico.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 24
Low Layer
ConnessioniTCP/IP
Motoregeometrico
Top Layer
Libreriedi sistema
Interprete SchemeEstensioniScheme
Foreign Function Interface
Figura 1.3: Struttura a due layer
};
}
Output Parameter La FFI deve gestire il valore di ritorno della funzione invocata ememorizzarlo in una struttura dati in modo che sia accessibile da shell.
1.5 Applicazioni ibride
Tutte le applicazioni che si basano sulla “collaborazione” tra codice sviluppato conlinguaggi di programmazioni differenti possono considerarsi applicazioni ibride, cioecostituite da codice sorgente in parte scritto in implementation language (che e il lin-guaggio a basso livello) e in parte scritto in extension language (il linguaggio funzionalead alto livello).
Queste applicazioni saranno quindi schematizzabili come se fossero composte da duedifferenti layer:
• Low level layer. E’ lo strato composto da codice C/C++ che supporta le funzio-nalita base del programma.
• Top level layer. E’ lo strato con codice Scheme, codice che l’interprete esegue arun-time.
I fattori che determinano la scelta se destinare una funzione ad un layer piuttosto cheall’altro sono svariati:

CAPITOLO 1. UN AMBIENTE FUNZIONALE 25
• La funzione ha particolari esigenze di efficienza?. In caso affermativo la funzionedeve essere implementata in C/C++. Ad esempio Open Cascade, che e il motoregeometrico che e stato scelto per il sistema, e interamente scritto in C++.
• La funzione deve interfacciarsi con caratteristiche particolari di piattaforma? An-che in questo caso e opportuno usufruire delle librerie di sistema, il cui link e piusemplice se effettuato in C/C++. Ad esempio per creare delle connessioni direte TCP/IP si possono usare le Application Programming Interface del sistemaoperativo, piuttosto che utilizzare le funzioni di networking di MzScheme (comead esempio tcp-connect, tcp-accept o altre).
• In quale linguaggio la funzione puo’ essere espressa piu “naturalmente”? Adesempio una funzione che effettua il parsing e il tokenize di una stringa puo’essere realizzata con meno codice in Scheme, a meno di non far uso di toolsC/C++ specifici.
• E’ previsto che l’utente debba modificare le funzioni? In questo caso e preferi-bile utilizzare codice Scheme; si dara cosı la possibilita all’utente di modificare isorgenti senza dover effettuare la ricompilazione dei files di libreria.
Dal punto di vista dell’utente finale esiste un solo modo per interagire con l’interpreteScheme e invocare i metodi delle librerie C/C++: impartire comandi o interi scripttramite la shell. Non sara neppure necessario sapere se una determinata funzione siain realta una funzione Scheme o C++.
E’ importante sottolineare come l’introduzione di una FFI all’interno di una applica-zione influenzi in modo determinante l’architettura dell’applicazione stessa.
1.6 Una implementazione di Scheme: PLT MzScheme
In questo paragrafo verranno esposte le caratteristiche piu importanti dell’implemen-tazione Scheme che e stata utilizzata: MzScheme[1].
Le motivazioni che hanno portato a preferire MzScheme rispetto alle altre numeroseimplementazioni disponibili sul mercato sono svariate:
• MzScheme e rilasciato con licenza open source cioe il suo utilizzo e libero nell’am-bito dello sviluppo di programmi non commerciali. Sono disponibili sia i files di

CAPITOLO 1. UN AMBIENTE FUNZIONALE 26
libreria precompilati, sia i sorgenti. Questo ha permesso di effettuare sessioni didebugging e di testing molto approfondite.
• MzScheme e una implementazione particolarmente “sensibile” al processo di stan-dardizzazione che sta avvenendo presso la comunita Scheme. E’ quasi com-pletamente 13 conforme alle disposizioni del Revised Report on the AlgorithmicLanguage Scheme.
• MzScheme e realmente multipiattaforma. Esistono versioni per praticamente tuttii sistemi operativi esistenti sul mercato. Il comportamento e allineato tra tutte leversioni. Da non trascurare, infine, la possibilita di scambiare files precompilati(una via di mezzo tra binari puri e sorgenti scheme) tra versioni che girano supiattaforme diverse, a tutto vantaggio della velocita di esecuzione.
• MzScheme fornisce importanti migliorie e aggiunte rispetto allo Scheme Standard :un sistema di classi e oggetti; un sistema di unit per facilitare la separazione inmoduli dei programmi; un sistema di eccezioni usato per tutti gli errori primitivi ;il supporto alla creazione di pre-emptive threads; il supportato a namespacesmultipli etc.
MzScheme e stato progettato specificatamente in modo da essere embeddable, cioeintegrabile nelle applicazioni scritte in C o C++.
MzScheme e solo una parte, per quanto importante, di un intero ambiente integrato perlo sviluppo di codice in linguaggio Scheme: fanno parte dell’ ambiente l’editor graficoPLT DrScheme[10], che incorpora un debugger e le librerie grafiche wxWindows, e ilsoftware PLT MysterX[14] che permette l’inserimento dell’interprete di MzScheme inun infrastruttura distribuita basata sullo standard Microsoft DCOM.
Nei prossimi paragrafi verranno riesaminate le problematiche introdotte nei paragrafi1.2 1.3 e 1.4 facendo riferimento in modo specifico all’implementazione MzScheme.
1.6.1 La tecnica di Garbage Collecting
Scheme fa uso di una tecnica “intelligente” di gestione della memoria: la GarbageCollection.
13Manca il supporto per la define-syntax, per la let-syntax e per la letrec-syntax. Tali funzioni
sono comunque supportate attraverso l’uso di una libreria esterna.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 27
L’algoritmo di Garbage Collection e responsabile di registrare tutti gli oggetti creatinella heap memory, e di deallocare automaticamente, senza che venga richiesto l’inter-vento diretto del programmatore, la memoria non piu referenced, cioe non piu accessibileattraverso un traversal delle strutture dati in memoria.
Si usa spesso dire che un oggetto persiste per un tempo infinito (infinite extent); inrealta cio e vero solo fino a che l’oggetto e utilizzato o potenzialmente utilizzabile dalprogramma in esecuzione, cioe fino a che l’informazione che il dato incapsula e ancoraaccessibile.
Esistono due tipi di algoritmi che effettuano la Garbage Collection: algoritmi di tipocopy e algoritmi di tipo sweep. Nei primi alla fine della fase di mark 14, avviene lospostamento degli oggetti ancora utilizzati in nuove aree di memoria. Negli algoritmidi tipo sweep tale trasferimento di dati al contrario non avviene.
La libreria di Garbage Collection che MzScheme utilizza e di tipo mark-sweep. E’una libreria free realizzata da Xerox Corporation e Silicon Graphics in linguaggioC/C++[16].
Sara ora esaminato nel dettaglio il funzionamento di tale algoritmo:
• Preparation Phase. Ogni oggetto in memoria ha associato un mark-bit che indicase esso e raggiungibile dal traversal delle strutture dati a partire dai root pointersstatici. L’aggiunta di un nuovo segmento root da “esplorare” avviene tramite laprimitiva:
void GC add roots(void* pointer )
In fase di inizializzazione della procedura i mark-bit sono impostati tutti al valorefalse (oggetto irraggiungibile).
• Mark Phase. Imposta al valore true tutti i mark-bit degli oggetti raggiungibili apartire dai puntatori root.
• Sweep Phase. Effettua uno scan della memoria alla ricerca delle strutture dati conmark-bit a false inserendole in una apposita lista di aree di memoria collectablee quindi potenzialmente riutilizzabili.
14Si definisce fase di mark la fase in cui avviene la segnalazione delle aree di memoria ancora
referenziate

CAPITOLO 1. UN AMBIENTE FUNZIONALE 28
• Deallocation Phase. Viene infine deallocata la memoria. E’ eventualmente possi-bile richiedere al Garbage Collector di attivare prima del rilascio opportune fun-zioni dette call-back function o finalizzatori. La primitiva che svolge tale funzioneha il seguente prototipo:
void GC register finalizer(...)
La deallocazione con finalizzatore e necessaria quando esistano delle risorse (eshandle di files, connessioni di rete etc.) che necessitino di particolari operazionidi “chiusura”.
Il Garbage Collector puo’ agire in diversi “momenti” dell’esecuzione del programma.Nella modalita incrementale la fase di scan e effettuata ogni volta che viene invocata unaqualsiasi delle funzioni della libreria; in modalita non incrementale il rilascio delle risorseinterviene solo quando una richiesta di allocazione di nuova memoria comporterebbeun errore di memory-fault, cioe di esaurimento dello spazio heap.
Il Garbage Collector permette la creazione di differenti tipi di oggetti in memoria:
Uncollectable objects . La primitiva:
void * GC malloc uncollectable(size t nbytes )
permette di creare oggetti in memoria che sono persistenti cioe che non possonoessere deallocati. Il sistema effettua comunque lo scan di questa porzione dimemoria alla ricerca di puntatori a oggetti collectable.
Atomic Objects . Sono oggetti che contengono dati binari cioe privi di puntatori adaltre strutture dati collectable. La primitiva per la creazione di oggetti pointer-freee la seguente:
void * GC malloc atomic(size t nbytes )
Normal Objects . Sono oggetti che verranno automaticamente deallocati quandonon piu referenziati. La primitiva per l’allocazione di questo tipo di oggetti e laseguente;
void * GC malloc(size t nbytes )
Stubborn Objects . Sono oggetti collectable che possono contenere anche puntatoriad oggetti a loro volta collectable, cioe sono oggetti non atomici. La primitiva diallocazione e la seguente:

CAPITOLO 1. UN AMBIENTE FUNZIONALE 29
void * GC malloc stubborn(size t nbytes )
La particolarita degli stubborn objects consiste nel fatto che il loro “stato” nonpuo’ cambiare, cioe il programmatore garantisce che il dato in essi contenuto nonsara piu modificato.
Il Conservative Pointer Finding
Un’altra caratteristica dell’algoritmo di GC di MzScheme e quello di effettuare il cosid-detto Conservative Pointer Finding. Fino ad ora si e infatti cercato di semplificare ilpiu possibile la trattazione ipotizzando implicitamente che l’algoritmo di GC conoscatutti i dati contenuti in memoria; e che in particolare ne conosca la “struttura” interna.
Cio non e vero in quanto i compilatori C++ non forniscono alcuno strumento per ilrecupero della tipizzazione dei dati allocati in memoria a run-time.
Si rende di conseguenza necessario presumere che tutta la memoria sia un insiemedi puntatori potenziali: il contenuto di una locazione in memoria e considerato unpuntatore se puo’ essere un riferimento valido alla memoria heap. Non sono invecepuntatori tutte le locazioni che contengono riferimenti ad indirizzi non corretti, checioe non indirizzano allo spazio heap (out of range).
Tale tecnica e chiaramente non esatta: puo’ andare incontro ad errori di valutazione;puo’ impedire il rilascio di aree di memoria mai utilizzate; puo’ scambiare interi perpuntatori etc. Si e pero’ dimostrato che la probabilita di incorrere in tali errori sonominime se sono adottati particolari accorgimenti.
1.6.2 Il sistema ad oggetti di MzScheme
Una classe in MzScheme e composta da:
• Un insieme di variabili di istanza (instance variables); tali variabili sono respon-sabili sia della memorizzazione dello stato interno dell’oggetto (istanza) di classesia dell’esposizione dell’interfaccia pubblica attraverso la quale lo stato stessodell’oggetto puo’ essere modificato.
• Un insieme di valori per l’inizializzazione delle variabili di istanza (initial value ex-pressions); tali valori sono utilizzati dall’interprete Scheme all’atto della creazione

CAPITOLO 1. UN AMBIENTE FUNZIONALE 30
di una nuova istanza di classe: al local environment dell’oggetto sono aggiunti inuovi bindings delle variabili di istanza settandoli con i valori di inizializzazione.
• Un insieme di variabili di inizializzazione (initialization variables); tali variabiliservono per dichiarare all’interprete la necessita di specificare uno o piu argomenti(actual parameters) all’atto della creazione di una nuova istanza di classe15.
Un oggetto MzScheme e un insieme di associazioni tra variabili di istanza e valoriattuali (bindings). Non viene fatta alcuna distinzione tra “metodi” e “variabili diistanza”; un metodo e infatti semplicemente una variabile di istanza che contiene unaprocedura. I metodi sono cioe first class object.
La caratteristica principale di un sistema orientato agli oggetti e la sua capacita didefinire nuove strutture dati (derived class) a partire da strutture dati preesistenti(superclass) attraverso l’uso di:
• inheritance. Un oggetto di una classe derivata istanzia, oltre alle variabilidichiarate nel suo body, anche le variabili dichiarate nella classe da cui deriva.
• overriding. Una variabile dichiarata nella super-class puo’ essere ridefinita nelladerived-class. In questo caso la nuova definizione “maschera” quella precedente.
Una interfaccia e una collezione di nomi di variabili di istanza che una classe deveimplementare; nessuna ulteriore indicazione viene invece fornita circa l’implementazionedelle variabili. La primitiva che permette la creazione di una nuova interfaccia e lainterface:
(interface (super-interface ...) variable ...)
Ognuna delle variable elencate deve essere unica. Inoltre ogni super interface deveessere a sua volta una interfaccia per MzScheme; in caso contrario viene generata unaeccezione.
Una classe implementa una interfaccia quando:
• Dichiara o eredita tutte le variabili di istanza specificate nell’interfaccia.15Esiste in C++ un analogo meccanismo per l’inizializzazione delle istanze di classe: i costruttori di
classe. Al contrario del C++ tuttavia in Scheme e prevista la presenza di un solo costruttore.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 31
• E’ derivata da ogni classe per cui l’interfaccia richiede esplicitamente una deriva-zione.
• Dichiara esplicitamente di implementare tale interfaccia.
Una classe inoltre implementa in modo automatico ogni interfaccia che la classe dacui deriva implementa a sua volta. E cosı via salendo nell’albero della gerarchia dellederivazioni.
Le primitive che consentono la creazione di nuove classi sono le primitive class*/names,class* e class. Per semplicita viene esaminata in questo paragrafo solamente lasintassi ridotta di class*:
class:: (class* superclass-expr (interface-expr...)initialization-variablesinstance-variable-clause. . . )
initialization-variables:: variable —(variable . . . variable-with-default . . . )(variable . . . variable-with-default . . . . variable)
variable-with-default :: (variable default-value-expr)
instance-variable-clause:: (sequence expr . . . ) —(public public-var-declaration . . . ) —(override public-var-declaration . . . ) —(private private-var-declaration . . . ) —(inherit inherit-var-declaration . . . ) —(rename rename-var-declaration . . . )
Attraverso il valore della variabile superclass-expr viene definita quale e la classe dallaquale si desidera derivare. Un valore nullo sottintende la derivazione dalla classe didefault Object%.
Ogni valore interface-expr specifica invece l’interfaccia che la classe attuale sta imple-mentando; vale a dire in questa fase la classe si impegna a dichiarare nel suo corpotutte le variabili di istanza presenti nell’interfaccia.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 32
Gli initialization-variables sono invece variabili istanziate dall’interprete all’atto dellacreazione di un nuovo oggetto di classe.
Esistono tre differenti costrutti che specificano i parametri di ingresso. Nella primaforma tutti gli argomenti di inizializzazione sono contenuti in una variabile di tipolista. Nella seconda forma ogni singolo argomento e assegnato ai singoli argomenti.Nell’ultima forma l’assegnazione singola avviene solo per gli argomenti che precedonoil dot ; a destra del dot e invece creato un valore di tipo lista16.
Le instance variables sono invece i veri e propri contenitori dello stato dell’oggetto diclasse.
Sebbene i concetti fin qui esposti risultino abbastanza simili a quelli degli altri sistemi adoggetti viene qui fornita una sintetica descrizione delle varie sezioni della grammatica:
sequence In questa sezione non viene introdotta nessuna nuova variabile di istanza.Sono invece elencate le espressioni che devono essere valutate ogni volta che vienecreata una nuova istanza di oggetto.
public Dichiara nuove variabile di istanza che sono visibili anche all’esterno dellaclasse. Una classe derivata puo’ effettuare l’overriding di una dichiarazionepubblica.
override e simile a public; esiste pero’ il vincolo che la variabile deve gia esisterenella parent class.
private dichiara una variabile di istanza che puo’ essere utilizzata solo all’interno dellaclasse. Non e quindi possibile effettuarne l’overriding.
inherit dichiara variabili di istanza che devono essere definite nella parent class.
rename effettua la ridenominazione di una variabile di istanza della super-class; ilnuovo nome e pero’ “riconosciuto” solo dall’interno del body della classe.
Le istanze di classe e le istanze di interfaccia sono tutti first class values.16Nel linguaggio C+++ esiste il triple dot per i metodi con numero di argomenti non prefissato.
Nell’Open Cascade Definition Language (CDL) non e invece prevista la possibilita di specificare un
numero variabile di argomenti.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 33
Esempio di applicazione
Allo scopo di rendere i concetti fin qui esposti piu familiari, e soprattutto allo scopodi approfondirne le caratteristiche piu utilizzate nella realizzazione del progetto, vienedi seguito fornito un esempio di creazione di una classe stack%17, da cui sono derivatesuccessivamente altre due classi, rispettivamente la named-stack% e la double-stack%.
(define stack<%>
(interface () push! pop! empty?))
(define stack%
(class* object% (stack<%>) ()
(private
[stack null])
(public
[name ’stack]
[push! (lambda (v)
(set! stack (cons v stack)))]
[pop! (lambda ()
(let ([v (car stack)])
(set! stack (cdr stack))
v))]
[empty?
(lambda () (null? stack))]
[print-name
(lambda () (display name) (newline))])
(sequence (super-init))))
(define named-stack%
(class stack% (stack-name)
(override
[name stack-name])
(sequence
(super-init))))
(define double-stack%17In MzScheme e utilizzata la convenzione che un identificatore seguito dalla stringa “%” indica una
Class.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 34
(class stack% ()
(inherit push!)
(override
[name ’double-stack])
(public
[double-push!
(lambda (v)
(push! v)
(push! v))])
(sequence (super-init))))
Viene dapprima definita una nuova interfaccia stack<%>, che contiene i “canonici”metodi push!, pop! e empty?.
Sono quindi definite tre nuove classi che implementano la suddetta interfaccia,: rispet-tivamente le classi stack%, named-stack% e double-stack%:
stack% La classe stack% contiene la variabile di istanza name.
Anche i metodi push!, pop!, empty? e print-name sono variabili di istanza chepero’ contengono oggetti di tipo procedura; il che e facilmente riconoscibile dallapresenza della primitiva lambda.
named-stack% La classe named-stack illustra il concetto di derivazione e il concettodi overriding.
La classe named-stack% viene derivata a partire dalla parent class stack%, concui ne condivide le variabili di istanza.
La variabile di istanza name viene qui ridefinita; il suo valore e impostato alvalore della variabile di inizializzazione stack-name, cioe in modo che memorizzila stringa che l’utente fornisce all’atto della chiamata del costruttore di classe.
double-stack% La classe double-stack% mostra come sia possibile utilizzare un me-todo della super-class all’interno della derived-class; e necessario predichiararetale metodo nell’apposita sezione inherit.
La primitiva make-object permette la creazione di una istanza di classe. Se ad esempiosi desidera creare alcune istanze delle classi appena viste:

CAPITOLO 1. UN AMBIENTE FUNZIONALE 35
(define stack (make-object stack%))
(define fred (make-object named-stack% ’Fred))
(define double-stack (make-object double-stack%))
L’accesso alle variabili di istanza e invece garantito dalle primitive ivar e send. Laprima effettua una ricerca della variabile nell’environment a partire dal nome:
((ivar stack push!) fred)
La primitiva send facilita invece l’accesso ai metodi di una classe. Dapprima utilizzala procedura ivar per estrarre il valore di una variabile; quindi applica gli argomentidi ingresso al metodo stesso:
(send stack push! fred)
Le restanti primitive che operano nel contesto del sistema ad oggetti sono le seguenti:
(object? v) Restituisce il valore #t se la variabile v e un oggetto di tipo classe.
(class? v) Restituisce il valore #t se la variabile v e una classe.
(interface? v) Restituisce il valore #t se la variabile v e una interfaccia.
(is-a? v interface) Restituisce il valore #t se la variabile v contiene l’istanza di unaclasse che implementa l’interfaccia interface.
(is-a? v class) Restituisce il valore #t se la variabile v contiene una istanza dellaclasse class.
(ivar-in-interface? symbol interface) Restituisce il valore #t se l’interfaccia inter-face contiene la variabile di istanza symbol.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 36
1.6.3 La FFI di MzScheme
I problemi affrontati nel paragrafo 1.4 devono essere riesaminati da un punto di vista piuspecifico, facendo cioe direttamente riferimento ai servizi che la libreria dell’interpretedi MzScheme espone.
Le soluzioni adottate rispetto ai problemi delle FFI sono le seguenti:
Library loading Le librerie C/C++ sono linkate staticamente al codice dell’interpreteScheme. La scelta fatta in merito a questo problema e dettata da motivazionistrettamente pratiche: si vuole infatti creare un software CAD stand alone.
E’ comunque presente in MzScheme una primitiva18che permette il caricamentodinamico dei files di libreria.
Le due alternative sono assolutamente equivalenti sia dal punto di vista dellafacilita di utilizzo sia dal punto di vista delle funzionalita che esse offrono.
Address binding Il problema dell’address binding e risolto in modo totalmente stati-co. Cio non comporta nessuna limitazione pratica ma ha l’effetto indesiderato diprodurre maggior codice di servizio (detto glue code) che permetta al compilatoredi risolvere i riferimenti incrociati.
Input Parameters I parametri di ingresso sono convertiti da un apposito algorit-mo di conversione dati. Attualmente tale algoritmo e stato realizzato seguendoil piu possibile le indicazioni del comitato ANSI per la standardizzazione delcomportamento tra compilatori C/C++.
Output Parameter I parametri di uscita sono gestiti esattamente come i parametri diingresso. Esistono solo delle differenze che sono legate ad alcuni aspetti particolaridella sintassi CDL, differenze che saranno approfondite successivamente.
Dovrebbe essere a questo punto sufficientemente chiaro quali siano i requisiti che laFFI deve soddisfare. Deve offrire un canale di comunicazione tra l’interprete Schemee librerie C++ non eccessivamente evoluto, in considerazione del fatto che la maggiorparte dei problemi sono risolti a livello di compilatore e di linker.
La FFI in questione dovra inoltre garantire pieno supporto per i dati di tipo classe delC++; il che implica supporto per i costruttori, distruttori, operatori, per l’ereditarietaetc.
18La primitiva in questione e la load-extension.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 37
Per quanto riguarda invece le conversioni tra dati si avra bisogno di salvare in memoriadelle strutture dati che l’interprete possa interrogare a run time per il recupero dellatipizzazione dei dati stessi.
Una semplice interfaccia
Esistono due possibilita per interfacciarsi con l’interprete MzScheme: e possibile invo-care esplicitamente le procedure primitive per la costruzione di oggetti Scheme oppuree possibile valutare interi script eseguendo la scheme eval string[18].
Un semplice programma che legge i comandi da console, li valuta e ne visualizza infineil risultato e il seguente:
#include <stdio.h>
#include <stdlib.h>
#include "scheme.h"
int main()
{
Scheme_Env *e=scheme_basic_env();
Scheme_Object *curout=scheme_get_param(
scheme_config,MZCONFIG_OUTPUT_PORT);
Scheme_Object *v;
char buffer[255];
while(gets(buffer)){
v=scheme_eval_string(buffer,e);
scheme_display(v,curout);
scheme_display(scheme_make_string("\n> s"),curout);
}
return 0;
}
Il principio di funzionamento dell’interprete all’interno del sistema sviluppato e moltosimile: si offre all’utente l’accesso ad una shell MzScheme dalla quale e possibile inserirecomandi atomici o interi script.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 38
L’environment
In fase di inizializzazione MzScheme crea l’environment principale che contiene tuttele definizioni standard di Scheme. E’ possibile ottenere il valore dell’handle di dettoenvironment tramite l’invocazione della primitiva scheme basic env:
Scheme_Env *e=scheme_basic_env();
MzScheme implementa il tipo di dato environment attraverso la struttura Scheme Env:
typedef struct Scheme_Env {
Scheme_Type type; /* scheme_namespace_type */
short no_keywords;
Scheme_Hash_Table *globals;
Scheme_Hash_Table *loaded_libraries;
struct Scheme_Comp_Env *init;
} Scheme_Env;
Il campo init permette di estendere un environment a partire da un environment“parente”. Il valore di una qualsiasi variabile viene dapprima ricercato all’internodell’environment attuale; se la ricerca fallisce si andra ad interrogare l’environmentpuntato da init, e cosı via in modo ricorsivo.
Il campo globals di Scheme Env e il puntatore ai bindings dell’environment. L’ag-giunta di un nuovo elemento alla lista avviene attraverso l’invocazione della procedurascheme add global:
void scheme_add_global(
const char *name,
Scheme_Object *val,
Scheme_Env *env);

CAPITOLO 1. UN AMBIENTE FUNZIONALE 39
Gli oggetti Scheme
Il tipo di dato fondamentale di MzScheme e lo Scheme Object:
typedef struct Scheme_Object {
Scheme_Type type;
union
{[...]} u;
} Scheme_Object;
Lo Scheme Type e un valore di tipo short che determina il tipo dell’oggetto Scheme.L’elenco dei tipi supportati e contenuto nel file stype.h. Il campo u contiene invece larappresentazione interna binaria dell’oggetto.
Esistono numerose macro che permettono di accedere e interrogare la struttura di unqualsiasi Scheme Object. Se ad esempio si desidera stabilire se un determinato oggettosia un intero e possibile usare la macro:
SCHEME_INTP(scheme_obj)
In Scheme si sarebbe potuto scrivere in modo del tutto equivalente:
(int? scheme_obj)
Per ogni Scheme Object esistono costruttori specifici. Ad esempio per la creazione diun nuovo dato di tipo stringa si utilizza la primitiva:
Scheme_Object *scheme_make_string(const char *chars);
In MzScheme e possibile stabilire l’uguaglianza tra due oggetti attraverso il predicatodi equivalenza eq?:
(eq? obj1 obj2)
Il valore di ritorno sara #t solo se sono verificate le seguenti condizioni:

CAPITOLO 1. UN AMBIENTE FUNZIONALE 40
• Lo Scheme Type degli oggetti e lo stesso.
• I valori obj1 e obj2 puntano alla stessa locazione di memoria cioe referenzianolo stesso Scheme Object.
La funzione C che implementa il predicato eq? e la scheme eq:
int scheme_eq (Scheme_Object *obj1, Scheme_Object *obj2)
Se invece si desidera confrontare non i puntatori ma il contenuto degli oggetti si puo’utilizzare il predicato di equivalenza scheme equal.
L’aggiunta di nuove primitive
Esistono delle procedure particolari in MzScheme, chiamate procedure primitive (comead esempio la car) che sono state implementate non con codice Scheme ma con codicein linguaggio C. E’ possibile testare se una procedura sia in realta una primitiva nelseguente modo:
(primitive-procedure? object)
o alternativamente utilizzando la macro C:
SCHEME_PRIMP(scheme_obj)
La scheme make prim w arity aggiunge all’interprete nuove procedure primitive:
Scheme_Object *scheme_make_prim_w_arity(
Scheme_Prim prim,
const char *name,
short mina, short maxa)
dove name e il nome della primitiva; mina e maxa indicano il numero di argomentiminimo e massimo che la procedura accetta (in questo modo l’interprete puo’ eseguireautomaticamente un controllo sulla correttezza dell’invocazione ancora prima che vengaeseguito il codice della primitiva).
Una Scheme Prim e un tipo di dato con la seguente struttura:

CAPITOLO 1. UN AMBIENTE FUNZIONALE 41
typedef struct Scheme_Object * (Scheme_Prim)(
int argc,
struct Scheme_Object *argv[]);
dove argc e il numero di argomenti e argv e invece l’array contenente gli argomenti.
Un tipo particolare di procedura primitiva e la closure primitive che e una proceduraalla quale viene passato, oltre alla lista di argomenti argv, anche un puntatore di tipovoid*. Ad esempio se si desiderasse tradurre in C il seguente script:
(define (make-adder n)
(lambda (m) (+ n m)))
(define f (make-adder 4))
si sarebbe potuto scrivere:
#include <stdio.h>
#include <stdlib.h>
#include "scheme.h"
Scheme_Object *sch_make_adder(int,Scheme_Object**);
Scheme_Object *sch_inner(void*,int,Scheme_Object**);
int main(){
Scheme_Object *v1,*v2;
Scheme_Env *e=scheme_basic_env();
Scheme_Object *curout=scheme_get_param(
scheme_config,MZCONFIG_OUTPUT_PORT);
scheme_add_global("make-adder",
scheme_make_prim_w_arity(
sch_make_adder,"make-adder", 1, 1),e);
v1=scheme_eval_string(
"(define funzione (make-adder 4))",e);
scheme_display(v1,curout);
v2=scheme_eval_string("(funzione 10)",e);
scheme_display(v2,curout);
return 1;

CAPITOLO 1. UN AMBIENTE FUNZIONALE 42
}
static Scheme_Object *sch_inner
(void *closure_data, int argc,Scheme_Object **argv){
Scheme_Object *n = (Scheme_Object *)closure_data;
Scheme_Object *plus;
Scheme_Object *a[2];
plus = scheme_lookup_global(
scheme_intern_symbol("+"),
scheme_get_env(scheme_config));
a[0] = n;a[1] = argv[0];
return _scheme_apply(plus, 2, a);
}
static Scheme_Object *sch_make_adder
(int argc,Scheme_Object**argv){
return scheme_make_closed_prim_w_arity(
sch_inner,argv[0],"adder",1, 1);
}
L’aggiunta di nuovi tipi di dato
Il programmatore ha un ulteriore strumento per estendere le funzionalita dell’interpreteScheme: aggiungere nuovi tipi primitivi. I tipi primitivi possono essere considerati comeuna sorta di wrapper intorno ai tipi di dati C/C++, cosı come le procedure primitiveesaminate in precedenza erano dei wrapper delle procedure C/C++.
E’ necessario comunicare anzitutto all’interprete la volonta di creare un nuovo tipo didato con la funzione scheme make type:
Scheme_Type tipo= scheme_make_type(nome_tipo);
Il valore tipo dovra essere conservato in una apposita variabile statica in quanto sarautilizzato come “etichetta” (tag) per identificare in modo univoco il tipo delle strutturadati. E’ infatti necessario che ogni oggetto che il programmatore crea abbia come primocampo uno Scheme Type:
struct {

CAPITOLO 1. UN AMBIENTE FUNZIONALE 43
Scheme_Type tipo;
[...]
}NewType
Un esempio di utilizzo
Si spighera adesso quali siano le operazioni da eseguire al fine di introdurre in MzSchemedelle nuove funzionalita per la modellazione geometrica19. In tal caso si avra bisognodi:
• Un nuova struttura dati che contenga i dati geometrici dei modelli.
• Nuove procedure primitive (ad esempio la translate e la scale) che operino sultipo di dato appena introdotto.
La struttura dati che potrebbe essere utilizzata per la memorizzazione del contenutobinario dell’oggetto e la seguente:
typedef struct {
Scheme_Type type;
int dim;
void* val;
}poliedro;
dove type e il valore restituito dalla funzione scheme make type; val e il puntatore adun array binario; dim e la dimensione dell’array.
Viene quindi definita una primitiva che consenta all’utente di costruire nuovi modelligeometrici:
Scheme_Object *make_poliedro
(int argc,Scheme_Object **argv)
{
plasm_poliedro *ret;
int dimensione;19Il codice proposto adotta delle soluzioni molto diverse da quelle che sono state poi effettivamente
utilizzate.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 44
[...]
ret= (Stringa *)scheme_malloc(sizeof(poliedro));
ret->type=poliedro_tipo;
ret->val=scheme_malloc(dimensione);
return (Scheme_Object *)ret;
}
E’ importante sottolineare che l’allocazione di nuove aree di memoria deve necessaria-mente essere comunicato al Garbage Collector attraverso la funzione scheme malloc.In questo modo ci si assicura che la memoria referenziata da ret verra deallocata ognivolta che il dato e riconosciuto come collectable.
Le procedure primitive translate e scale non sono qui riportate per brevita. Il loroprototipo e comunque identico alla make poliedro.
L’ultimo passo da compiere consiste nel comunicare all’interprete che si desidera ag-giungere tre nuove primitive all’environment principale:
Scheme_Object *plasm_poliedro_initialize
(Scheme_Env *env)
{
scheme_add_global("make-plasm-poliedro",
scheme_make_prim_w_arity(
make_plasm_poliedro,
"make-plasm-poliedro",0, 0),env}
scheme_add_global("plasm-translate",[...]);
scheme_add_global("plasm-scale",[...]);
[...]
return env;
}
La FFI del sistema ad oggetti
Vengono ora esaminate le principali funzioni della FFI di MzScheme per la manipola-zione delle classi e delle interfacce.
La primitiva scheme make class aggiunge all’interprete una nuova classe Scheme:

CAPITOLO 1. UN AMBIENTE FUNZIONALE 45
Scheme_Object* scheme_class(char* name,
Scheme_Object* sup,
Scheme_Method_Prim* init_funct,
int num_methods);
dove name e il nome della classe; sup e la parent class dalla quale la classe attualederiva; init funct e il costruttore di classe; infine num methods e il numero di metodiche verranno aggiunti alla classe.
La primitiva scheme add method permette l’aggiunta dei metodi di classe:
Scheme_Object* scheme_add_method(Scheme_Object* cl,
char* name,
Scheme_Method_Prim *f);
dove cl e la classe di appartenenza del metodo; name e il nome della funzione; infine fe la funzione vera e propria che implementa il metodo.
Le funzioni C che implementano un metodo di classe sono molto simili alle closedprimitive function che sono gia state esaminate in precedenza: oltre agli argomenti chel’utente fornisce sono infatti passati due ulteriori valori:
• Un puntatore all’istanza dell’oggetto. Cio permette di accedere ai fields (variabiliC++) che sono incapsulati all’interno della classe.
• Un valore numerico di tipo integer che indica il numero degli argomenti chel’utente ha fornito.
In alternativa alla scheme add method e possibile utilizzare la seguente primitiva:
Scheme_Object*
scheme_add_method_w_arit(Scheme_Object* cl,
char* name,
Scheme_Method_Prim *f,
short mina,
short maxa);

CAPITOLO 1. UN AMBIENTE FUNZIONALE 46
In questo caso e possibile specificare il numero minimo e massimo di argomenti chel’utente puo’ fornire.
Per completare il processo di creazione di una nuova classe e infine necessaria unaoperazione di “chiusura” attraverso la primitiva scheme made class:
Scheme_Object* scheme_made_class(Scheme_Object* c);
Dopo l’invocazione di tale primitiva non sara piu possibile aggiungere altri nuovi metodi.
La funzione scheme make object permette di creare una nuova istanza di classe apartire da una lista eventualmente vuota di argomenti per l’inizializzazione.
E’ possibile accedere alle variabili di istanza attraverso la scheme find ivar che ricevein ingresso un oggetto e un valore di tipo symbol e che restituisce in uscita il puntatoreall’oggetto (o il valore NULL nel caso in cui la ricerca sia terminata con un errore).
Nel manuale di riferimento di MzScheme e esplicitamente dichiarato che e possibilel’interfacciamento tra le classi C++ e le classi Scheme utilizzando l’apposita utilityxctocc. E che la procedura da eseguire e descritta nel documento C++ Glue GeneratorManual.
In realta cio e stato nettamente smentito dalle verifiche approfondite che sono statefatte nel corso della realizzazione del sistema.
Contattando lo stesso autore dell’interprete MzScheme e infatti emerso che l’utilityxctocc utilizza delle chiamate di libreria segnalate come deprecated 20. E che inoltrel’utility in questione e stata realizzata esclusivamente al fine di integrare all’interno diMzScheme una versione abbastanza datata del prodotto wxWindows21.
E’ quindi praticamente precluso un utilizzo di xctocc al di fuori del contesto per ilquale l’utility stessa e stata ideata22.
20Cioe funzioni delle quali non viene garantito il supporto nelle future versioni.21La libreria wxWindows e servita per la creazione di un ambiente grafico (DrScheme) per lo sviluppo
di codice scheme.22In realta l’utility xctocc e estremamente “primitiva” nel trattamento dei dati. Cioe non sarebbe
comunque potuta essere utilizzata all’interno del nostro progetto in cui abbiamo bisogno di offrire pieno
supporto alle classi CDL, classi la cui struttura e piu complessa delle classi di wxWindows.

CAPITOLO 1. UN AMBIENTE FUNZIONALE 47
Esempio di integrazione di una classe C++
Verra adesso fornito un tipico esempio di utilizzo delle nuove funzioni che, in sostituzionedelle funzioni di xctocc, permettano l’integrazione delle classi C++. La definizionedella classe C++ Tree e la seguente:
#include "escheme.h"
class Tree{ private:int refcount;
public:Tree *left_branch, *right_branch;int leaves;void *user_data;
Tree(int init_leaves){left_branch = right_branch = NULL;leaves = init_leaves;refcount = 1;user_data = NULL;}
virtual void Grow(int n){if (left_branch)
left_branch->Grow(n);else
left_branch = new Tree(n);if (right_branch)
right_branch->Grow(n);else
right_branch = new Tree(n);}
void Graft(Tree *left, Tree *right){Drop(left_branch);Drop(right_branch);left_branch = left;right_branch = right;Add(left_branch);Add(right_branch);
}
static void Add(Tree *t){if (t)

CAPITOLO 1. UN AMBIENTE FUNZIONALE 48
t->refcount++;}
static void Drop(Tree *t){if (t) {
t->refcount--;if (!t->refcount)
delete t;}
}};
E’ necessario definire quindi la classe mzTree che verra aggiunta all’environment del-l’interprete:
static Scheme_Object *tree_class; static Scheme_Object
*grow_method;
class mzTree:public Tree{ public:
mzTree(int c):Tree(c) {}
virtual void Grow(int n){
Scheme_Object *scmobj;
Scheme_Object *overriding;
scmobj = (Scheme_Object *)user_data;
if (!grow_method){
scheme_register_extension_global(
&grow_method,sizeof(grow_method));
grow_method = scheme_get_generic_data(
tree_class,scheme_intern_symbol("grow"));
}
overriding = scheme_apply_generic_data(
grow_method,scmobj,0);
if (overriding){
Scheme_Object *argv[1];
argv[0] = scheme_make_integer(n);

CAPITOLO 1. UN AMBIENTE FUNZIONALE 49
_scheme_apply(overriding, 1, argv);
} else {
TreeGrow(n);
}
}
};
E’ opportuno evidenziare che il metodo Grow della classe Tree era stato precedentemen-te dichiarato virtual: cioe e permesso che l’utente possa ridefinirne l’implementazionein Scheme. Per questo si e reso necessario riscrivere l’implementazione del metodo Growall’interno della classe mzTree.
A questo punto e possibile scrivere il corpo dei metodi che verranno richiamati dal-l’interprete Scheme ogni qual volta venga invocato, attraverso la primitiva send, unmetodo della classe.
Tali metodi sono responsabili di:
1. Verificare che il numero di argomenti in ingresso sia corretto.
2. Verificare la correttezza dei parametri di ingresso rispetto al prototipo dellafunzione.
3. Invocare il metodo corrispondente della classe C++.
4. Convertire il valore di ritorno in uno Scheme Object.
Il primo metodo e il costruttore di classe:
#define SCHEME_CPP_OBJ(obj) \\(((Scheme_Class_Object *)(obj))->primdata)
void FreeTree(void *scmobj, void *t){TreeDrop((Tree *)t);}
Scheme_Object *Make_Tree(Scheme_Object *obj,int argc,Scheme_Object **argv){
if (argc != 1)scheme_wrong_count(
"tree% initialization", 1, 1, argc, argv);

CAPITOLO 1. UN AMBIENTE FUNZIONALE 50
if (!SCHEME_INTP(argv[0]))scheme_wrong_type(
"tree% initialization","fixnum", 0, argc, argv);
Tree *t = new mzTree(SCHEME_INT_VAL(argv[0]));t->user_data = obj;SCHEME_CPP_OBJ(obj) = t;scheme_add_finalizer(obj, FreeTree, t);return obj;
}
Nel corpo del codice del costruttore sono effettuati i controlli sui dati in ingresso e, nelcaso in cui tali controlli abbiano esito positivo, e quindi costruita una nuova istanza diclasse Tree, classe che e contenuta all’interno dello Scheme Object* (campo primdata).
Piuttosto semplice e la scrittura del codice della funzione Grow e di Graft, che nonpresentano aspetti innovativi rispetto al costruttore di classe:
Scheme_Object *Grow(Scheme_Object *obj,int argc,Scheme_Object **argv){
Tree *t;int n;if (!SCHEME_INTP(argv[0]))
scheme_wrong_type("tree%’s grow","fixnum", 0, argc, argv);
n = SCHEME_INT_VAL(argv[0]);t = (Tree *)SCHEME_CPP_OBJ(obj);t->TreeGrow(n);return scheme_void;
}
Scheme_Object *Graft(Scheme_Object *obj,int argc,Scheme_Object **argv){
Tree *t, *l, *r;
if (!SCHEME_FALSEP(argv[0]) &&!scheme_is_a(argv[0], tree_class))
scheme_wrong_type("tree%’s graft", "tree% object or #f", 0, argc, argv);
if (!SCHEME_FALSEP(argv[1]) &&

CAPITOLO 1. UN AMBIENTE FUNZIONALE 51
!scheme_is_a(argv[1], tree_class))scheme_wrong_type(
"tree%’s graft", "tree% object or #f", 1, argc, argv);
t = (Tree *)SCHEME_CPP_OBJ(obj);l = (SCHEME_FALSEP(argv[0]) ?
(Tree *)NULL :(Tree *)SCHEME_CPP_OBJ(argv[0]));r = (SCHEME_FALSEP(argv[1]) ?
(Tree *)NULL :(Tree *)SCHEME_CPP_OBJ(argv[1]));t->Graft(l, r);return scheme_void;}
Si avra inoltre bisogno di una funzione che crei uno Scheme Object* a partire da unistanza di classe Tree:
Scheme_Object *MarshalTree(Tree *t){if (!t)
return scheme_false;else if (!t->user_data){
Scheme_Object *scmobj;scmobj = scheme_make_uninited_object(tree_class);t->user_data = scmobj;SCHEME_CPP_OBJ(scmobj) = t;return scmobj;}
elsereturn (Scheme_Object *)t->user_data;
}
E’ inoltre necessario implementare dei metodi per la modifica delle variabili all’internodella classe C++:
Scheme_Object *Get_Left(Scheme_Object *obj,int argc,Scheme_Object **argv){
Tree *t = (Tree *)SCHEME_CPP_OBJ(obj);return MarshalTree(t->left_branch);
}
Scheme_Object *Get_Right(Scheme_Object *obj,int argc,

CAPITOLO 1. UN AMBIENTE FUNZIONALE 52
Scheme_Object **argv){Tree *t = (Tree *)SCHEME_CPP_OBJ(obj);return MarshalTree(t->right_branch);
}
Scheme_Object *Get_Leaves(Scheme_Object *obj,int argc,Scheme_Object **argv){
Tree *t = (Tree *)SCHEME_CPP_OBJ(obj);return scheme_make_integer(t->leaves);
}
Si dovra quindi aggiungere la classe mzScheme all’environment :
Scheme_Object *scheme_initialize(Scheme_Env *env){scheme_register_extension_global(
&tree_class, sizeof(tree_class));tree_class = scheme_make_class(
"tree%", /* name */NULL, /* superclass */Make_Tree, /* init func */5); /* num methods */
scheme_add_method_w_arity(tree_class, "grow", Grow, 1, 2);
scheme_add_method_w_arity(tree_class, "graft", Graft, 2, 2);
scheme_add_method_w_arity(tree_class, "get-left", Get_Left, 0, 0);
scheme_add_method_w_arity(tree_class, "get-right",Get_Right, 0, 0);
scheme_add_method_w_arity(tree_class, "get-leaves",Get_Leaves, 0, 0);
scheme_made_class(tree_class);scheme_add_global("tree%", tree_class, env);return scheme_void;
}
Scheme_Object *scheme_reload(Scheme_Env *env){scheme_add_global("tree%", tree_class, env);return scheme_void;}

Capitolo 2
Un ambiente di progettazione
assistita
Open Cascade e un sistema di classi sviluppato dalla societa Matra Datavision. Le classidi Open Cascade offrono l’infrastruttura per la costruzione rapida (Rapid ApplicationFramework) di programmi orientati alla modellazione geometrica o, piu in generale,orientati al “disegno” in uno specifico dominio di interesse, come ad esempio CADevoluti, sistemi di simulazione o tools per la visualizzazione.
Il progetto CAS.CADE1 inizio nel 1990 quando la societa Matra Datavision, che gia eraproduttrice di un sistema CAD “tradizionale” chiamato EUCLID, decise di sviluppareun nuovo software per la progettazione.
Si decise di adottare delle tecnologie per quei tempi molto avanzate: tutta l’applica-zione sarebbe infatti stata sviluppata seguendo l’approccio object oriented del linguag-gio C++. Per questo motivo sia le strutture dati che gli algoritmi geometrici furonototalmente riscritti.
Dopo tre anni di sviluppo il nucleo delle librerie su cui doveva basarsi CAS.CADE erafinalmente pronto. Nel 1995 anche il modeling kernel poteva dirsi completato. Fu allorache si inizio a testarlo e successivamente a proporlo sul mercato.
Alla fine del 1999 CAS.CADE poteva contare su una base di software installato di circa130 unita; l’utenza era equamente distribuita tra Stati Uniti, Inghilterra, Germania,Giappone ed Italia. Sempre nel 1999 si verifico un importante cambiamento all’interno
1Il nome CAS.CADE deriva dall’anagramma delle parole CASE e CAD.
53

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 54
Visualization
FoundationClass
ModelingData
ModelingAlgorithms
ApplicationFramework
Data ExchangeProcessor
Figura 2.1: Struttura di Open Cascade
della Matra Datavision: da casa produttrice di software si e infatti strutturata comesocieta fornitrice di servizi software. Questo cambiamento ha comportato l’adozione dinuove strategie nei confronti della distribuzione del software.
Soprattutto in modo da garantire la sopravvivenza e l’evoluzione a lungo termine diCAS.CADE, si e infatti deciso di pubblicare i sorgenti dell’applicazione con licenzaOpen Source; da qui il nuovo nome di Open Cascade.
Dal gennaio 2000 il parco software installato e praticamente triplicato e i mancatiguadagni derivanti dalla vendita delle licenze sono stati piu che compensati dalla venditadi servizi (documentazione, corsi tecnici, assistenza etc.).
L’architettura del software e la seguente: tutte le classi sono organizzate in packagesin modo da evitare conflitti di nome; ogni package a sua volta appartiene a una librarydi Open Cascade; infine piu librerie formano un module. Il raggruppamento in modulie stato pensato in modo che le librerie che offrono la stessa classe di servizi a livellologico e soprattutto a livello operativo appartengano allo stesso modulo.
Le librerie di Open Cascade offrono svariati servizi:

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 55
Strumenti per la modellazione geometrica 2D e 3D Le librerie di Open Casca-de che si occupano di modellazione geometrica sono: la libreriaModeling Data[17]e la libreria Modeling Algorithms[19].
Tali librerie offrono dei servizi per la costruzione di primitive geometriche (pri-smi, cilindri, coni etc.); dei servizi per l’applicazione di operazioni geometriche(addizione, sottrazione, intersezione etc); e infine dei servizi per il calcolo delleproprieta dei modelli realizzati (volume, superficie, centro di gravita, curvaturaetc).
Servizi per la visualizzazione . La libreria Visualization permette la visualizzazio-ne dei modelli generati[21]. E’ possibile gestire diverse viste su un singolo oggettoattraverso la rotazione, lo zoom, lo shading etc.
Open Cascade Application Framework (OCAF) . Sono disponibili delle libreriededicate specificatamente alla modellazione parametrica[25] che associano delleinformazioni non geometriche alla struttura del modello stesso.
Importazione e esportazione di modelli geometrici . E’ supportato lo scambiodei modelli geometrici con altri prodotti commerciali per la modellazione: almomento sono disponibili i drivers dei formati Iges e Step[23].
Nel paragrafo 2.1 verranno introdotti i fondamenti del linguaggio CDL[29]. Nel pa-ragrafo 2.2 saranno invece analizzati, uno per uno, tutti i componenti software CDLed in particolare sara illustrato il meccanismo attraverso cui il programma estrattore(CPPExtractor) di Open Cascade converte i file di interfaccia CDL in header files C++.Nel paragrafo 2.3 saranno messi a confronto il linguaggio C++ con il linguaggio CDL;cioe ponendoci dal punto di vista del programmatore C++ saranno evidenziate le par-ticolari restrizioni del linguaggio CDL soprattutto in merito alle modalita di passaggiodegli argomenti di ingresso e alle modalita di restituzione dei valori di uscita. Infine nelparagrafo 2.4 sara completata la trattazione rispetto alle classi fondamentali di OpenCascade analizzando i servizi della libreria Foundation Classes[15].
2.1 Il linguaggio CDL
Il Component Definition Language (CDL) e il linguaggio ufficiale di Open Cascade perla definizione dei componenti software.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 56
L’obiettivo che piu o meno esplicitamente CDL si propone e quello di facilitare losviluppo delle applicazioni attraverso una generazione del codice automatica o semiau-tomatica. In questo modo si ottiene anche l’ulteriore effetto di rendere piu difficile lascrittura di codice “fuori standard”, cioe difficilmente portabile su piu piattaforme.
Questo e l’elenco dei componenti che CDL attualmente supporta:
Cdl_Declaration : Package
| Interface
| Schema
| Engine
| Client
| Executable
| Component
| Class
Il componente software primario in ogni sistema per lo sviluppo orientato agli oggettie, come noto, la classe; cosı avviene nel linguaggio C++ e cosı avviene anche in CDLdove la classe e appunto l’elemento cardine su cui tutti gli altri componenti software sibasano.
Puo’ tuttavia accadere che la classe sia un componente troppo a basso livello per esserel’unita base, e quindi primaria, per lo sviluppo; questo e un problema ancora piuimportante nella costruzione di tutti i progetti software particolarmente complessi e digrandi dimensioni, che constano di migliaia di risorse (files, documenti, codice sorgente,files di interfaccia etc), Open Cascade compreso. Basti dire che in Open Cascadeesistono circa diecimila header files di altrettanti files di classi C++; e che ognuno diessi deve essere compilato e linkato negli appositi files di libreria.
Per questo motivo CDL offre la possibilita di raggruppare le classi in un unico compo-nente: il package.
Un package riunisce un numero variabile di classi che abbiano in comune la caratteristicadi operare nello stesso contesto semantico; vale a dire che cooperino per la risoluzionedi una certa classe di problemi in qualche dominio di interesse per l’applicazione.
Ad esempio un package geometrico, che in Open Cascade sono poi la stragrande mag-gioranza, potrebbe contenere la definizione di punto, linea e altro; e ognuno delle entitaall’interno del package sarebbe definito come classe CDL.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 57
enumerationsexceptionsClasses
Package
Interface Exec
Packages, classese methodsselezionati
Packages
Figura 2.2: La costruzione di applicazioni in Ocas.
Gli altri componenti CDL, e soprattutto i dettagli della sintassi e della semantica quiappena accennata, saranno analizzati in modo piu approfondito nel paragrafo 2.2.
CDL e il linguaggio che permette di definire la struttura interna dei dati. Non e percioun linguaggio di programmazione, cioe non si occupa di descrivere l’implementazionedei programmi e non contiene primitive da eseguire.
CDL definisce solo l’architettura dell’applicazione e le varie strutture dati che l’appli-cazione stessa utilizzera: si limita cioe solo a modellare (design phase) l’insieme deicomponenti software che permettono al programmatore di descrivere, nel modo piuappropriato, i concetti che sono contenuti nelle specifiche del programma che si starealizzando.
Una volta che la design phase sara terminata si potra quindi procedere alla generazioneautomatica dei files che saranno poi necessari per la scrittura dell’implementazione verae propria.
Il che principalmente significa che a partire dai files in formato CDL si potranno fargenerare, da appositi tools delWorkshop Organization Kit [27] (WOK) di Open Cascade2, gli header files dai quali sara possibile scrivere l’implementazione (behavior) dei
2E’ evidente che l’intera infrastruttura di Open Cascade richiederebbe una trattazione molto piu
approfondita di quanto lo spazio a nostra disposizione ci permette di fare. Il linguaggio CDL e infatti
solo un elemento, per quanto importante, di un intero Object System orientato allo sviluppo. Ocas
comprende tools piu o meno proprietari per la generazione automatica o semiautomatica del codice;
tools per la compilazione; tools per il trattamento dei files di testo etc. Esiste anche una shell di sistema

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 58
Analisi
Specifiche diprogramma
Design Phase
Programming
Unit Testing
IntegrationTesting
Figura 2.3: Lo sviluppo di una applicazione.
metodi in linguaggio C/C++.
Saranno adesso esaminati i concetti piu importanti introdotti dal linguaggio CDL,concetti che non risultano tra l’altro particolarmente innovativi se confrontati con altriObject System piu diffusi (primo fra tutti quello del C++). Tale descrizione e comunquenecessaria per la comprensione dei paragrafi successivi.
2.1.1 Il concetto di handle di oggetto
La classe e un tipo di dato primitivo per CDL. Le classi appartengono a due diversecategorie a seconda della modalita di gestione, da parte del compilatore, dello statodella classe:
• Lo stato e gestito per valore.
• Lo stato e gestito tramite un handle (cioe per riferimento).
Nel primo caso (dati manipolati per valore) e possibile accedere allo stato della classein modo diretto, senza livelli “intermedi”; e quindi garantito un accesso veloce al dato.Solo questi tipi CDL sono gestiti per valore:
• Tipi primitivi.personalizzata per Open Cascade. La sigla WOK sta appunto ad indicare l’insieme di questi tools per
la programmazione.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 59
Valore
Valore
Handle
Manipolati per valore Manipolati tramite handle
Figura 2.4: La manipolazione dei dati in Ocas.
• Tipi enumerazione.
• Classi CDL che non derivino dalle classe Persistent o Transient in modo direttoo indiretto.
Nel secondo caso (dati manipolati per riferimento) per accedere allo stato della classee invece necessario utilizzare un handle, che e una sorta di riferimento all’oggetto. E’possibile per adesso pensare ad un handle come ad un puntatore C3. Questo ulteriorelivello intermedio, che al momento potrebbe apparire solo come una inutile complica-zione, e stato introdotto per permettere al Memory Manager di Ocas di effettuare ilrilascio della memoria in modo automatico: il che avviene appunto solo per i valorigestiti per riferimento. Un handle punta sempre ad un oggetto che deriva dalla classePersistent o dalla classe Transient4.
Un esempio di creazione di un nuovo handle a cui sia assegnato un nuovo valoremanipolato per riferimento e il seguente:
Handle(myClass) m = new myClass;3Un handle e in realta una vera e propria classe generata automaticamente da WOK che contiene
un puntatore all’oggetto referenziato4Le istanze delle classi Persistent e Transient incapsulano, tra i loro fileds, un campo di tipo
contatore che contiene il numero degli handle che referenziano l’istanza stessa.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 60
Gli oggetti manipolati per riferimento dovrebbero essere utilizzati solo limitatamenteai casi in cui sia necessaria la condivisione delle strutture dati. In tutti gli altri casi einvece consigliato l’uso delle classi manipolate per valore.
Il tipo che un handle referenzia viene definito tipo statico5. Un handle puo’ anchereferenziare un oggetto di una sottoclasse rispetto al suo tipo statico. Ad esempio siconsideri il seguente caso in cui il tipo CartesianPoint e sottoclasse di Point:
Handle(Geom_Point) p1;
Handle(Geom_CartesianPoint) p2;
p2=newGeom_CartesianPoint;
p1=p2;//Ok i tipi sono compatibili!
E’ anche possibile convertire un handle di un tipo in un handle che referenzia un tipo didato piu specifico; solo che in questo caso il programmatore deve utilizzare l’operazionedi type casting in modo esplicito:
Handle(Geom_Point) p1;
Handle(Geom_CartesianPoint) p2,p3;
p2=newGeom_CartesianPoint;
p1=p2;//OK p1 punta ad un oggetto
CartesianPoint p3=p1;//ERRORE!
p3=Handle(Geom_CartesianPoint)::DownCast(p1);//OK
Al momento non esiste alcun modo per effettuare da shell una operazione di downcastingrispetto agli handle.
Nel caso in cui l’operazione di conversione non sia compatibile, il valore dell’handleverrebbe automaticamente azzerato; cio non comporta l’esecuzione di una eccezione.
Una volta che un handle referenzia correttamente un oggetto e possibile utilizzarloesattamente come se fosse un pointer C++. Ad esempio:
Standard_Real x=1,y=2,z=3;
Handle(PGeom_CartesianPoint) center=
new PGeom_CartesianPoint(0,0,0);
center->Coord(x,y,z);
5Il tipo statico coincide con il tipo dichiarato al compilatore.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 61
2.1.2 Le classi persistenti e le classi serializzabili
Un oggetto persistent e un oggetto che puo’ essere memorizzato su file durante l’esecu-zione del programma. In altre parole e permesso il suo riutilizzo sia nell’applicazioneche lo ha creato sia in una applicazione differente6.
Per far si che un oggetto sia persistente deve essere dichiarato come classe CDL; taleclasse deve inoltre ereditare dalla classe Persistent o in modo diretto (tramite laprimitiva inherits) o in modo indiretto (cioe una delle sue parent class deve derivaredalla classe Persistent). Un esempio di oggetto persistente e il seguente:
class Watch inherits Persistent...
Se durante l’esecuzione del programma viene istanziato un oggetto di tipo Watch, sarasempre possibile la memorizzazione del suo stato in un file in modo “esclusivo” o inassociazione con altri dati persistenti.
Le procedure affinche venga effettuata l’operazione di salvataggio sono le seguenti:
1. Creazione di un I/O driver di file:
FSD_Archive f(&ar);
2. Instanziazione dello Schema che e responsabile del processamento delle informa-zioni persistenti. Lo Schema sara utilizzato dal sistema per l’esecuzione di tuttele operazioni di lettura e di scrittura. Ad esempio se ShapeSchema e il nome delloschema:
Handle(ShapeSchema) s =new ShapeSchema;
3. Creazione di un nuovo oggetto di tipo container che e “riempito” con la primitivaAddRoot:
Handle(Storage_Data) d=new Storage_Data;
d->AddRoot("ObjectName",aPShape);
4. Salvataggio delle classi all’interno di un file:
s->Write(f,d);
6Il concetto di persistenza e analogo al concetto di serializzazione del linguaggio Java.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 62
Non e invece possibile salvare oggetti che siano istanze di classe che derivino dalla classeStorable. E’ pero’ possibile salvare questi dati come campi di un oggetto persistente.Ad esempio:
-- Non memorizzabile
class WatchSpring inherits Storable...
-- Memorizzabile
class Watch inherits Persistent is
[...]
fields
-- field memorizzabile in quanto incapsulato
powersource:WatchSpring;
end;
In realta esiste un’altra istruzione da eseguire per far si che questo meccanismo diserializzazione dati su file sia operativo: la creazione di uno Schema.
2.1.3 Le classi generiche e le classi istanza
Spesso esiste la necessita per il programmatore di creare delle strutture dati il cuiutilizzo sia volutamente generico rispetto ad una determinata classe di problemi.
Ad esempio si potrebbe voler implementare una classe di tipo lista in modo generico;cioe indipendente dal tipo di dati che la lista stessa dovra gestire.
Si usa spesso dire che la classe dovra essere parametrizzata rispetto ad uno o piu tipidi dati di istanza che il programmatore potra specificare in una fase successiva.
Le classi generiche di CDL sono classi che realizzano il concetto di template del C++senza pero’ farne direttamente uso. In Ocas si e infatti cercato di evitare di utilizzarecostrutti C++ difficilmente portabili su piattaforme diverse. Per questo motivo nonvengono utilizzati i template del C++, in sostituzione dei quali si utilizza quindi unmeccanismo di generazione automatico di classi specifiche (instance class) a partire daclassi generali ( generic class); il tutto avviene tramite l’esecuzione di una operazionedi istanziazione.
Ad esempio:

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 63
generic class List(Item) is ...
definisce il tipo di dato lista parametrizzato rispetto all’argomento Item. Tale argo-mento puo’ essere un qualsiasi tipo CDL.
Nel momento in cui si definisce un nuovo package e si desidera istanziare una classeList specifica, e possibile utilizzare la primitiva instantiates:
class ListOfInteger instantiater List(Integer);
L’ambiente WOK sara responsabile della generazione dei files appropriati che dovrannopoi essere aggiunti al Makefile di progetto.
2.1.4 Il parser e l’estrattore
I files CDL sono dei veri e propri file di interfaccia: si limitano cioe a descrivere qualesia la composizione interna delle strutture dati e quale siano i metodi esposti verso iclient, che sono i reali utilizzatori dei servizi della classe.
Cio sicuramente non e sufficiente per la costruzione di una applicazione completa; enecessario infatti che il programmatore compia almeno un ulteriore passo: la scritturadell’implementazione dei metodi. Attualmente Ocas fornisce il supporto per la scritturadell’implementazione “solo” in linguaggio C++.
Ecco quali solo le fasi principali dello sviluppo di un componente software in OpenCascade:
1. Scrittura dei files CDL. Tutto la restante parte del capitolo sara dedicato allaspiegazione di questo punto.
2. Conversione dei files CDL in strutture dati dinamiche. Il parser di Open Cascadesi occupa di elaborare i files CDL e di costruire di conseguenza delle strutturedati in memoria che sia possibile interrogare a run time.
Tutto il package MS di Ocas e dedicato alla memorizzazione dei tipi CDL.
Un esempio di classe CDL e il seguente:
class Enum from MS inherits NatType from MS

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 64
SorgentiCDL
Strutture dinamichedel package MS
Sorgenti Cpp:file hxx e cxx
CDL Front
CPP ExtractorCPP
Extractor
Sviluppo dell'implementazione
automatico
manuale
Figura 2.5: Generazione di codice in CDL.
uses HSequenceOfHAsciiString from TColStd,
HAsciiString from TCollection
is
Create(aName, aPackage, aContainer: HAsciiString;
aPrivate: Boolean) returns mutable Enum from MS;
Enum(me: mutable; aEnum: HAsciiString);
Enums(me) returns HSequenceOfHAsciiString from TColStd;
Check(me);
fields
myEnums: HSequenceOfHAsciiString from TColStd;
end Enum from MS;
3. Costruzione degli header files. Il programma CPP Extractor si occupera di in-terrogare le strutture dati MS e di generare gli header files che saranno aggiuntial Makefile del progetto.
L’operazione di mapping dal linguaggio CDL al linguaggio C++ e particolarmen-te importante rispetto al progetto sviluppato: una parte consistente del tempoimpiegato e stato infatti dedicato alla risoluzione dei problemi relativi al “tratta-mento” dei dati e all’esecuzione di operazioni di conversione da un tipo di datoall’altro 7.
7Operazioni che sono di solito svolte dal compilatore e che nel nostro caso sono invece svolte a run

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 65
Strutture dinamichedel package MS
SchemeExtractor
ShellScheme
generazione distub code
Classi CDL
Figura 2.6: Classi CDL in Scheme.
4. Scrittura dell’implementazione dei metodi delle classi. Nel far cio si dovra far usodei prototipi generati dal CPP Extractor.
E’ utile anticipare a questo punto della trattazione parte degli obiettivi di questa tesi.
Attraverso le strutture dati del package MS e stato realizzato il programma Scheme
Extractor8 che renda disponibili i tipi CDL all’interno della shell Scheme. Da shellsara possibile scrivere ed eseguire comandi in linguaggio funzionale Scheme.
Cio comporta problemi di “collaborazione” tra i due ambienti che sono principalmenteproblemi di condivisione di tipologie strutturate di dati. Il contenuto delle istanzedelle classi di MS saranno utilizzate proprio per comunicare all’interprete Scheme lacomposizione dei tipi disponibili in Open Cascade.
2.1.5 Lo spazio dei nomi
Con il termine namespace (o scope) di una componente CDL viene indicato il contestonel quale il tipo di dato e accessibile.
Puo’ accadere che due classi che appartengano a packages differenti abbiano lo stessonome; e puo’ accadere che debbano essere utilizzate all’interno del corpo di un terzopackage.
time.8Il nome Scheme Extractor e volutamente simile al suo omologo CPP Extractor, in considerazione
del fatto che le operazioni svolte dai due programmi sono molto simili.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 66
Ogni qual volta esistano dei conflitti tra namespace di elementi CDL l’ambiguita puo’essere risolta a favore di un elemento piuttosto che all’altro utilizzando la primitivafrom. La sintassi formale e la seguente:
class-name:: identifier [from package-name]
exception-name:: identifier [from package-name]
enumeration-name:: identifier [from package-name]
All’interno della descrizione di un package la primitiva from deve essere quindi utilizzataogni volta che ci si riferisca ad un tipo di dato la cui definizione sia esterna rispetto alpackage corrente.
Il programma Cpp Extractor procedera alla creazione dei nomi dei tipi C++ in questomodo: antepone al nome (in senso stretto) della classe CDL il nome del package al qualeappartiene. Ad esempio il seguente nome:
TColStd_HAsciiString
indica la classe HAsciiString9 all’interno del package TColStd.
2.2 I componenti software CDL
Saranno adesso esaminati, uno per uno, tutti i componenti software del linguaggio CDL.Verra posta particolare attenzione alla modalita con cui il programma Cpp Extractor
(paragrafo 2.1.4) “traduce” le definizioni CDL in costrutti sintattici C++.
Nel paragrafo 2.2.1 sara esaminata la sintassi e la semantica della classe CDL. Nelparagrafo 2.2.2 verranno esaminati i componenti che aggregano piu classi in una uni-ca entita: i packages. Dal paragrafo 2.2.3 al paragrafo 2.2.8 saranno esaminati glialtri componenti CDL che possono essere definiti all’interno di un package. Infine ver-ranno esaminati i componenti per la memorizzazione dello stato di una classe su file(Schema) e i componenti per la creazione di un eseguibile (Executable) rispettivamentenei paragrafi 2.2.9 e 2.2.10.
9La lettera H preposta al nome della classe indica che si tratta di una classe manipolata per
riferimento, cioe tramite Handle.
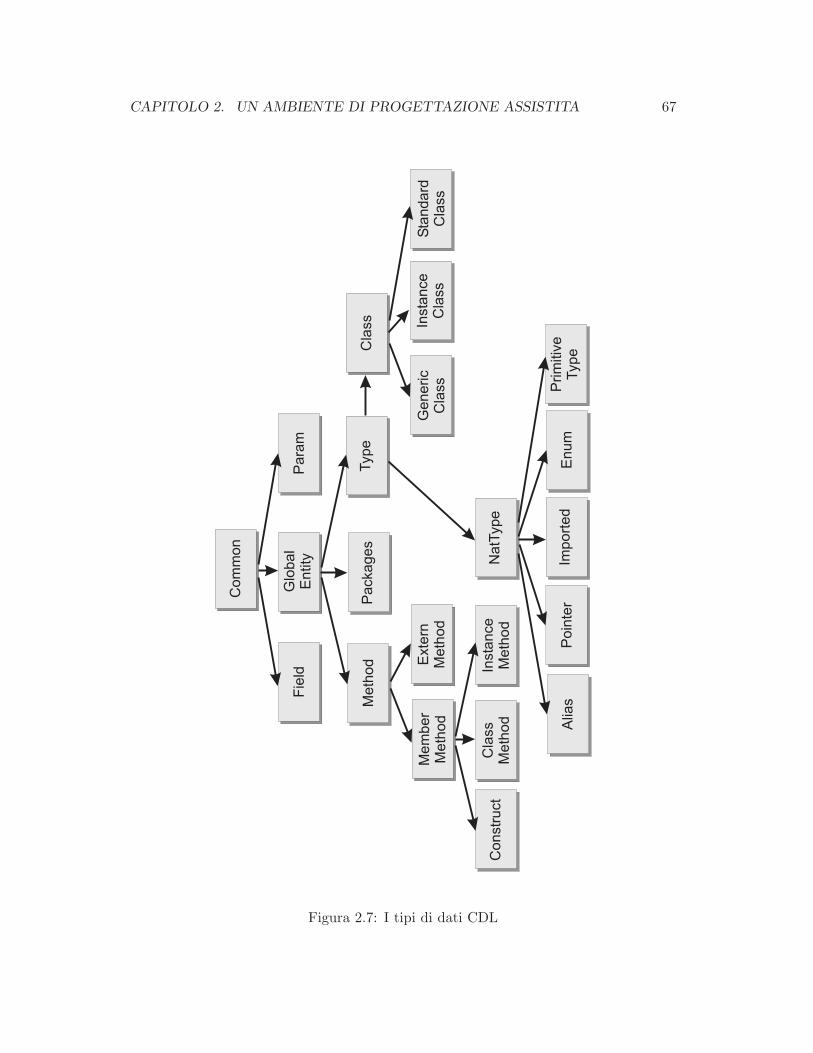
CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 67
Co
mm
on
Fie
ldG
lob
al
En
tity
Pa
ram
Pa
cka
ge
sM
eth
od E
xte
rnM
eth
od
Co
nstr
uct
Me
mb
er
Me
tho
d
Cla
ss
Me
tho
dIn
sta
nce
Me
tho
d
Typ
eC
lass
Ge
ne
ric
Cla
ss
Insta
nce
Cla
ss
Sta
nd
ard
Cla
ss
Na
tTyp
e
Alia
sP
oin
ter
Imp
ort
ed
En
um
Prim
itiv
eTyp
e
Figura 2.7: I tipi di dati CDL

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 68
2.2.1 Le classi
La classe e l’elemento principale per la creazione di nuovi di tipi di dati in linguag-gio CDL. La definizione di una nuova classe implica implicitamente l’introduzione nelsoftware di un nuovo data type.
Indipendentemente dalla categoria di appartenenza della classe (manipolazione conhandle o per valore; classi persistenti o transient etc) la sintassi CDL e comunque lastessa:
simple-class:: class class-name from package-name
[uses data-type {’,’ data-type}]
[raises exception-name {’,’ exception-name}]
is
class-definition
end [class-name] ’;’
data-type::= enumeration-name |
class-name |
exception-name |
primitive-type
package-name::= identifier class-name::= identifier
identifier:: letter{[underscore]alphanumeric}
class-definition::= [{member-method}]
[declaration-of fields]
[declaration-of-friends]
Una classe CDL e quindi composta da:
• Il comportamento (behavior) della classe. Cioe costruttori e metodi di istanza.
• Gli invariants. Cioe i metodi di classe.
• La rappresentazione interna (internal representation); cioe l’insieme dei fields diclasse.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 69
• I metodi e le classi friends.
Una classe appartiene sempre al package identificato da packagename. E’ necessarioche una classe sia predichiarata nel corpo del package di appartenenza.
Una classe puo’ dover far riferimento ad uno o piu data types di altri packages; inquesto caso il loro utilizzo deve essere sempre esplicitamente dichiarato nella appositasezione uses. Esiste una unica eccezione a questa regola: tutti i tipi primitivi definitinel package Standard sono visibili ovunque, per cui una loro predichiarazione e deltutto superflua.
E’ possibile che in CDL una classe derivi da una altra classe precedentemente defini-ta. E’ pero’ imposto che tutto il sistema di classi possa essere rappresentato con undiagramma aciclico, anche detto instance graph.
Tipi di classe
Una classe appartiene sempre ad una ed una sola delle seguenti categorie:
Ordinary classes Sono le classi ordinarie (simple class). Le caratteristiche delle classiordinarie e dei metodi in essa contenuti (member methods) saranno esaminate piua fondo nei paragrafi successivi.
Deferred classes Le classi deferred sono classi il cui scopo e quello di definire uncomportamento generico all’interno di una gerarchia di derivazione. Cioe sonoclassi di cui non si vuole fornire l’implementazione.
Le classi deferred saranno successivamente tradotte in classi astratte C++ attra-verso una operazione di mapping.
La sintassi di una classe deferred e identica a quella delle classi ordinarie; e ne-cessario anteporre la direttiva deferred al corpo della classe stessa. Ogni classedeferred deve contenere almeno un metodo di istanza di tipo deferred.
Generic classes Sono classi che definiscono un insieme di comportamenti “generici”(behavior) rispetto ad una certa tipologia di dati.
La sintassi di una generic class e la seguente:
generic-class:: [deferred] generic class class-name
’(’ generic-type {’,’ generic-type}’)’

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 70
[inherits class-name]
[uses data-type {’,’ data-type}]
[raises exception-name{’,’ exception-name}]
[{[visibility] declaration-of-a-class}]
is
class-definition
end [class-name] ’;’
generic-type:: identifier as type-constraint
type-constraint:: any |
class-name [’(’data-type{’,’data-type}’)’]
E’ da sottolineare il fatto che possono essere presenti delle nuove definizioni al-l’interno di una classe generica . Cio favorisce la separazione tra classi private eclassi pubbliche.
Metodi di classe
Il behavior di un oggetto classe e l’insieme dei suoi metodi, siano essi procedure op-pure funzioni10. Il behavior definisce l’interfaccia pubblica della classe, cioe i metodiattraverso i quali la classe espone dei “servizi” verso i clients.
Ogni volta che due o piu metodi di classe condividono lo stesso nome si dice che avvienel’overloading dei metodi. Non e pero’ possibile effettuare l’overloading di metodi le cuidefinizioni differiscano solo per:
• Il valore di ritorno.
• Il nome o la modalita di passaggio di un solo parametro (in, out oppure in out).
• Il nome o la “mutabilita” di un solo parametro (mutable, immutable oppure any).
• Il valore di default di un solo parametro.
Cio e comunque ovvio se si considera che il programma CPP Extractor generera unfile che deve essere poi successivamente elaborato dal compilatore C++. Le restrizioni
10Le funzioni, al contrario delle procedure, sono metodi con un valore di uscita.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 71
che sono imposte per la sintassi CDL sono in realta restrizioni imposte dal linguaggioC++.
Esistono tre diversi tipi di metodi di classe:
Costruttori Un costruttore e una funzione che permette la creazione di istanze diclasse. La sintassi CDL per la definizione di un costruttore e la seguente:
constructor-declaration::= Create [simple-formal-part]
return-type
[exception-declaration]
simple-formal-part::= ’(’ initialization-parameter
{’;’initialization-parameter} ’)’
initialization-parameter::= identifier{’,’parameter}’:’
parameter-access datatype
[’=’initial-value]
parameter-access:= mutable | immutable
initial-value::=numeric-constant |
literal-constant |
named-constant
return-type:= returns [mutable] class-name;
Il nome di un costruttore e sempre Create. Se la classe e manipolata attraversoun handle e necessario specificare che il valore di ritorno e mutable: in questomodo si potra successivamente modificarne il contenuto.
Tutti i tipi CDL utilizzati dal costruttore devono essere elencati nella sezioneuses .
Se un parametro di ingresso del costruttore e di tipo manipolato tramite handlee necessario specificare anche i “diritti di accesso”: se cioe si prevede che possaessere modificato all’interno del body, il parameter-access deve essere impostatoal valore mutable; altrimenti il comportamento di default imposta tale campo alvalore immutable.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 72
Tutte le classi devono avere almeno un costruttore; in caso contrario non sarebbeinfatti possibile costruire le istanze di classe.
Metodi di istanza Un metodo di istanza e una procedura o una funzione che operanel contesto dell’istanza di classe alla quale appartiene.
La sintassi CDL e la seguente:
instance-method::= identifier formal-part
[return-type]
[exceptions]
formal-part::= ’(’ me [’:’
passing-mode
parameter-access]
{’;’parameter}’)’
parameter::= identifier {’,’ identifier}’:’
passing-mode parameter-access
data-type [’=’ initial value ]
passing-mode::= [in] | out| in out
parameter-access::= mutable | [immutable]
return-type::= returns return-access data-type
return-access::= mutable|[immutable]|any
L’attributo passing-mode specifica se il contenuto dell’oggetto, sia esso l’istanzadi classe o uno degli argomenti del costruttore, possa essere modificato. E’ impor-tante evidenziare che il valore attribuito al parametro passing-mode si riferiscesempre e solo all’oggetto che viene effettivamente “trasmesso” alla funzione:
Oggetti manipolati per valore Il parameter-access si riferisce direttamenteall’oggetto manipolato per valore. La direttiva in indica che il valore inquestione puo’ solo essere letto (comportamento di default); altrimenti enecessario specificare out, nel qual caso ne sara invece permessa la modifica.
Oggetti manipolati per riferimento Il parameter-access si riferisce non al-l’oggetto che l’handle referenzia ma direttamente all’handle stesso .

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 73
L’attributo parameter-access e invece significativo solo per gli oggetti manipo-lati per riferimento: specifica appunto i diritti di accesso rispetto al contenutodell’oggetto referenziato tramite handle. L’attributo mutable ne permette unaccesso in scrittura.
Metodi di classe Un metodo di classe e una funzione o una procedura che opera nelcontesto della classe ma che non si applica a nessuna particolare istanza di classe.Sono cioe dei metodi statici C++. La sintassi CDL e la seguente:
class-method::= identifier formal-part
[declaration-of-returned-type]
[exceptions]
formal-part::= ’(’ myclass {’;’parameter}’)’
Modalita restituzione valori
Esistono delle direttive di pre-processing che personalizzano ulteriormente il compor-tamento del programma CPP Extractor rispetto ai valori di ritorno di tutti i metodiappena illustrati11. E’ sufficiente postporre al prototipo CDL del metodo le seguentidirettive:
• ---C++:alias operator. Indica che il metodo in questione e anche un operatore.In questo caso la modalita di chiamata con operatore e in realta un alias verso ilmetodo CDL.
• ---C++:inline. Indica che la modalita di chiamata C++ del metodo deve essereinline, cioe espansa nel punto esatto di invocazione.
• ---C++:alias ~. Indica che il metodo corrente e il distruttore di classe, cioe e ilmetodo che sara invocato nel momento in cui l’oggetto sara deallocato.
• ---C++:return const&. Indica che il valore di ritorno e di tipo “riferimentocostante”.
• ---C++:return const. Indica che il valore di ritorno e di tipo “costante”.
• ---C++:return &. Indica che il valore di ritorno e di tipo “riferimento”.11Le stesse considerazioni valgono anche per i metodi di package che saranno esaminati nel paragrafo
2.2.2.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 74
• ---C++:alias. Indica che esiste un metodo che e in realta un alias verso ilmetodo CDL attuale.
Eccezioni
Ogni metodo di classe puo’ dichiarare (primitiva raises) di poter generare una ecce-zione in occasione del verificarsi di particolari situazioni di errore:
exception::= raises exception-name {’,’ exception-name}
Ogni exception-name deve corrispondere al nome di una classe precedentemente defi-nita, classe che deve necessariamente derivare da Failure. Le eccezioni di ogni metododi classe devono comparire nella sezione uses.
Attributi dei metodi
Verra adesso esaminato il significato di alcuni particolari attributi che e possibileassociare ai metodi descritti:
Redefined methods Una classe che deriva da una qualsiasi parent class puo’ dichia-rare di voler ridefinire (direttiva refefined) l’implementazione di uno dei metodoche eredita:
redefined-method::= identifier formal-part
[returned-type]
[exceptions]
is redefined [visibility]
L’attributo redefined puo’ essere applicato solo ad un instance method, maiad un costruttore o ad un metodo di classe (che come noto non possono essereereditati neanche in C++). Un metodo ridefinito non puo’ modificare la sintassidel metodo da cui deriva.
Deferred methods Una classe puo’ non voler fornire l’implementazione per uno opiu dei suoi metodi di istanza; tali metodi sono detti deferred:

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 75
deferred-methods::= identifier formal-part
[returned-type]
[exceptions]
is deferred [visibility]
Solo i metodi di istanza possono essere deferred. Se una classe deferred ha alsuo interno dei fields allora e necessario che sia presente un costruttore di classedeferred. I metodi deferred hanno tutti il nome Initialize 12.
Virtual methods Un metodo CDL virtual e a tutti gli effetti un metodo C++virtual. La sintassi CDL per la sua definizione e la seguente:
virtual-method::= identifier formal-part
[return-type]
[exceptions]
is virtual [visibility]
Lo stato di una classe
Ogni oggetto classe memorizza il proprio stato all’interno di una regione di memoriaprivata cioe non accessibile dai clients. E’ questa una importante distinzione rispettoal C++ nel quale le variabili della classe sono invece accessibili se sono state dichiaratepublic.
Lo stato di una classe consiste in un insieme di fields CDL:
class-status::= fields field {field}
field::= identifier {’,’ identifier}’:’ data-type
[’[’ integer{’,’ integer}’]’]’;’
Tutti i fields dovrebbero essere inizializzati dai costruttori di classe ogni volta che vienecreato una nuova istanza di classe. E’ prevista inoltre la possibilita di specificare unalista di interi che permetta la costruzione di array multidimensionali con dimensionestatica.
12Questo per distinguerli dai costruttori delle classi “ordinarie” che hanno il nome Create.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 76
Le classi generiche
Per completare la trattazione delle classi CDL e necessario illustrare in modo piu ap-profondito il funzionamento delle classi generiche. La creazione di una classe genericaimplica l’esecuzione di due azioni:
1. Si dichiara la classe generica stabilendo un “modello” di comportamento.
2. Si istanzia la classe generica fornendo delle informazioni circa la tipizzazione deigeneric types.
La sintassi per la creazione di una generic class e la seguente:
generic-class::= [deferred] generic class class-name
’(’ generic-type {’,’generic-type}’)’
[inherits class-name]
[uses data-type {’,’data-type}]
[raises exception-name {’,’exception-name}]
[{[visibility] class-declaration}]
is
class-definition
end [class-name];
generic-type::= identifier as type-constraint;
type-constraint::= any |
class-name [’(’data-type{’,’data-type’})’]
class-declaration::= no-generic-declaration |
declaration-of-a-non-generic-class |
instantiation-of-a-generic-class
L’identificatore di un tipo generico diventa un nuovo tipo di dato che e possibile utiliz-zare all’interno del body di classe. Il tipo generico e visibile solo all’interno della classegenerica che lo definisce; in questo modo e possibile utilizzare lo stesso nome di tipogenerico all’interno di due generic class distinte senza avere problemi di collisione deinomi.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 77
Un tipo generico puo’ essere una qualsiasi classe CDL precedentemente definita; puo’persino essere un’altra classe generica della quale e fornita la particolare istanziazione.
Una classe generica puo’ anche essere deferred, nel qual caso ci si aspetta che uno deisuoi metodi non abbia implementazione.
Una classe non generica puo’ derivare da una classe generica.
Esistono diversi contesti nei quali una classe generica puo’ venire istanziata:
• All’interno di un package. In questo caso tutti i metodi di package e tutte lestrutture dati del package hanno accesso alla classe.
• All’interno di una classe generica. In questo caso la classe istanziata sara privatacioe accessibile solo dai metodi di classe.
La sintassi per l’istanziazione di una classe generica e la seguente:
instance-class::= [deferred] class class-name
instantiates class-name
’(’ data-type {’,’ data-type}’);’
Il seguente codice CDL crea una tipica classe generica:
generic class SingleList(Item as Storable)
inherits Persistent
raises NoSuchObject
is
Create returns mutable SingleList;
IsEmpty(me) returns Boolean;
SwapTail(me:mutable;S:in out mutable SingleList);
Value(me) returns Item;
Tail(me) returns mutable SingleList;
fields
Data:Item;
Next:SingleList;
end SingleList;
La SingleList e istanziata con il tipo Point del package gp:

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 78
class SingleListOfPoint instantiates SingleList(Point);
All’interno di una classe generica e possibile definire nuove classi locali anche dettenested class. Le classi locali possono essere di tre tipi:
• declaration-of-a-non-generic-class. E’ la definizione di una classe stan-dard.
• instantiation-of-a-generic-class. E’ l’istanziazione di una classe generica.
• no-generic-declaration. E’ la dichiarazione di una classe standard la cuidefinizione e presente nel package.
Le nested class sono a tutti gli effetti delle classi generiche: fanno infatti uso deigeneric types della classe di appartenenza. Per ogni classe nidificata e inoltre possibilespecificare i diritti di accesso: il comportamento di default e una loro dichiarazio-ne public ma e comunque possibile proteggerne l’accesso dall’esterno attraverso ledirettive protected o private.
2.2.2 I packages
Un package e essenzialmente un raggruppamento di classi CDL. Ad esempio nel packageStandard sono presenti tutte le risorse predefinite del linguaggio CDL.
La sintassi per la definizione di un package e la seguente:
package-def:: package package-name
[uses package-name {’,’ package-name}]
is
package-definition
end [package-name] ’;’
package-name:: identifier
package-definition:: [{type-declaration}]
[{package-method}]

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 79
type-declaration:: [private] enumeration-declaration |
[private] class-declaration |
[private] exception-declaration |
[private] alias-declaration |
[private] imported-declaration |
[private] primitive-declaration |
[private] pointer-declaration
package-method:: identifier [simple-formal-part]
[returned-type] [error-declaration] [is private] ’;’
All’interno del file di package sono contenute le predichiarazioni di classi (package class,anche dette definizioni separated) e i metodi di package (extern method).
I “metodi di package” sono generalmente utilizzati per creare funzioni di inizializzazio-ne. La sintassi CDL e la seguente:
package-method::= identifier [simple-formal-part]
[return-type]
[exceptions]
[is private];
La sintassi e la semantica dei metodi di package e la stessa dei metodi di classe descrittinel paragrafo 2.2.1. L’unica differenza consiste nel fatto che non facendo parte di unaclasse vera e propria sono in realta metodi statici; cioe non possono accedere a nessunfield di classe13.
All’interno di un package non possono essere presenti due tipi CDL con lo stesso nome;al contrario cio e permesso tra due componenti di packages differenti.
I componenti elencati nella sezione uses sono i package che contengono le classi rispettoai quali il package corrente svolge la funzione di client.
E’ possibile nascondere certi tipi di dati contenuti all’interno del corpo di un packagesemplicemente dichiarandoli private; cio permette di scrivere codice realmente mo-dulare: impedisce infatti l’accesso ai componenti di cui sia previsto solo un utilizzo“interno”.
13Un package non puo’ contenere variabili al suo interno; infatti un package e un componente, per
definizione, privo di stato (stateless).

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 80
Un package CDL viene tradotto dal programma Cpp Extractor in una classe senzavariabili che cioe contiene solo metodo statici. Questo fatto conferma ancora una voltache i metodi di package e i metodi statici di classe sono tra loro molto simili.
2.2.3 I tipi primitivi
Un tipo di dato primitive e un tipo di dato atomico per l’ambiente WOK, cioe lacui implementazione non e ottenuta tramite sintassi CDL. Tutti i tipi primitivi sonomanipolati per valore.
Ogni programma CDL dovrebbe dichiarare i propri tipi primitivi all’interno del packageStandard. Cio non e in realta strettamente necessario ma favorisce la separazione tratipi di dati primitivi e strutturati. In realta nel sistema sviluppato sono stati introdottidei nuovi tipi primitivi all’interno del package SchemePack.
I tipi primitivi di Open Cascade che derivano dalla classe Storable sono i seguenti:
Boolean Tipo di dato per la memorizzazione di valori logici. Solo due valori sonopermessi: True e False.
Byte Un numero a 8 bit.
Character Indicano un carattere Ascii a 8 bit.
ExtCharacter Un carattere esteso, ad esempio Unicode.
Integer Un tipo di dato intero.
Real Un numero reale.
ShortReal Un reale con un range di valori piu ridotto rispetto a Real, e di conseguenzaminore occupazione di memoria.
Esistono inoltre tipi di dati primitivi che non ereditano ne’ direttamente ne’ indiretta-mente dalla classe Storable, e sono precisamente:
CString Tipo di dato per la memorizzazione di stringhe.
ExtString Tipo di dato per la memorizzazione di stringhe estese, cio contenenti unalista di ExtCharacter.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 81
Address Tipo di dato per la memorizzazione dell’indirizzo di qualche locazione dimemoria.
E’ possibile associare ai tipi di dati primitivi CDL appena introdotti le loro corrispon-denti definizioni C/C++:
typedef int Standard_Integer;
typedef double Standard_Real;
typedef unsigned int Standard_Boolean;
typedef float Standard_ShortReal;
typedef char Standard_Character;
typedef short Standard_ExtCharacter;
typedef unsigned char Standard_Byte;
typedef char* Standard_CString;
typedef void* Standard_Address;
typedef short* Standard_ExtString;
#define Standard_False (Standard_Boolean) 0
#define Standard_True (Standard_Boolean) 1
La sintassi CDL per la creazione di un nuovo tipo primitive all’interno di un packagee la seguente:
primitive primitive-name
[inherits inherit-name [from package-name]];
La possibilita di specificare se il tipo di dato primitivo deriva da qualche altra clas-se CDL e di fondamentale importanza dal punto di vista dell’esecuzione del codice:e infatti necessario risalire all’informazione se esso sia o meno una istanza delle clas-si Persistent o Storable. Cio permettera una eventuale “serializzazione” del suocontenuto su file.
La creazione di un nuovo tipo primitivo non comporta nessuna azione da parte del CPPExtractor; sara compito del programmatore inserire nel progetto gli header files checontengano gli appropriati typedef.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 82
2.2.4 Le enumerazioni
Le enumerazioni sono insiemi di costanti letterali che hanno in comune l’appartenenzaad uno stesso tipo di dato.
Cosı come avviene per il C++ (istruzione enum), viene definito in CDL una enumera-zione ogni volta che i valori che un certo parametro puo’ assumere appartengono ad uninsieme con cardinalita finita.
L’uso di enumerazioni facilita la comprensione del codice sorgente. Permette inoltre alcompilatore C++ di effettuare controlli di tipo piu accurati.
In CDL la sintassi per la creazione di una enumeration all’interno di un package e laseguente:
enumeration:: enumeration enumeration-name
is
identifier {’,’ identifier}
end [enumeration-name] ’;’
Ad esempio con la seguente istruzione:
enumeration MagnitudeSign is Negative, Null, Positive;
viene definito il tipo MagnitudeSign che “contiene” tre costanti enumerative.
Il programma CPP Extractor provvede a tradurre ogni CDL enumeration in unaenumerazione C14.
2.2.5 I tipi importati
La direttiva imported permette di includere nell’ambiente la definizione di un nuovotipo di classe15 la cui descrizione completa non e pero’ disponibile in formato CDL.
14Non e possibile in CDL, come e invece possibile in C, specificare il valore numerico intero associato
ad ogni costante enumerativa. Non e neanche possibile che due costanti enumerative assumano lo stesso
valore. Al primo elemento sara assegnato automaticamente il valore 0, al secondo il valore 1 e cosı via.15Questa e la sostanziale differenza tra tipi imported e i tipi primitive; cioe non si tratta di tipi
atomici ma di tipi strutturati.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 83
All’interno del package di appartenenza e possibile dichiarare la creazione di un nuovotipo di dato imported utilizzando la seguente sintassi CDL:
imported-type:: [private] imported type-name ’;’
Cosı come per i primitive types, nessuna azione di estrazione e eseguita dal program-ma Cpp Extractor. E’ pero’ compito del programmatore aggiungere al Makefile diprogetto i seguenti files:
//*** File hxx ***
#ifndef _PackName_ImportName_HeaderFile #define
_PackName_ImportName_HeaderFile #include <Standard_Type.hxx>
//definizione del dato imported
[...] const Handle(Standard_Type)& TYPE(PackName_ImportName);
//*** File cxx ***
#ifndef _PackName_ImportName_HeaderFile #include
<PackName_ImportName.hxx> #endif
const Handle(Standard_Type)& TYPE(PackName_ImportName){
static Handle(Standard_Type) _aType=
new Standard_Type("PackName_ImportName",
sizeof(PackName_ImportName));
return _aType;
}
2.2.6 Gli alias
Un alias e una sorta di link tra un tipo di dati preesistente e un nuovo tipo di dato. Lasintassi CDL per la creazione di un nuovo alias all’interno di un package e la seguente:
alias:: [private] alias AliasName is
SourceTypeName [from SourcePackageName];
Il programma Cpp Extractor provvedera alla creazione di un nuovo header file conte-nente una direttiva typedef:

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 84
#define PackageName_AliasName_Type_()
SourcePackageName_SourceTypeName_Type_()
2.2.7 Le eccezioni
Una eccezione serve a rappresentare una particolare condizione di errore che puo’ av-venire durante l’esecuzione del programma16. La sintassi CDL per la creazione di unanuova eccezione e la seguente:
exception:: exception exception-name
inherits exception-name ’;’
La parent class di tutte le eccezioni, cioe la classe da cui tutte le altre eccezioni devonoderivare in modo diretto o indiretto, e la classe Failure del package Standard.
La classe Failure fornisce quindi gli “strumenti” principali per:
1. La segnalazione dell’errore.
2. L’associazione all’errore di una spiegazione sulle motivazioni per cui l’errore eavvenuto.
3. Intercettare l’errore allo scopo di evitare una uscita prematura e quindi indeside-rata dal programma.
Ogni metodo, indipendentemente se sia statico di package (extern method), o di clas-se (member method), deve dichiarare che puo’ eseguire una eccezione attraverso laprimitiva raises. Ad esempio il prototipo CDL:
Solid(S :Shape from TopoDS) returns Solid from TopoDS
raises TypeMismatch from Standard;
indica che il contenuto del parametro S potrebbe non essere corretto. Ad esempiopotrebbe non essere possibile generare un Solid dallo Shape. In tal caso verrebbeappunto “lanciata” una eccezione TypeMismatch:
16In termini tecnici si usa spesso dire che una eccezione e “eseguita” a run time.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 85
TypeMismatch::Raise("Error message...");
Dalla parte del codice “chiamante” sara invece possibile eseguire una operazione di tipocatch rispetto al blocco di codice da “proteggere”:
try{
[...]
}catch(DomainError){
Handle(DomainError) error=DomainError::Caught();
cout<<error<<endl;
}
Gli error handlers sono controllati nell’ordine in cui appaiono a partire dal piu vicinoal blocco try fino al piu lontano. Per questo e necessario che un handler di un tipodi eccezione piu generale rispetto alla gerarchia delle eccezioni segua un handler piuspecifico.
Nessuna istruzione deve inoltre precedere o seguire un gestore di eccezioni; in casocontrario si andra incontro a comportamenti differenti a seconda della piattaforma sucui il programma e in esecuzione, e cioe a seconda di come sia stato implementato ilmeccanismo delle eccezioni sulla piattaforma specifica.
2.2.8 I puntatori
E’ prevista in Ocas la creazione di un tipo puntatore attraverso la primitiva pointer:
pointer:: pointer PointerName
to DestTypeName [from DestPackName];
In corrispondenza di ogni nuova definizione di tipo pointer il CppExtractor provvedea creare un nuovo header file con il seguente contenuto:
typedef DestPackName_DestTypeName* PackName_PointerName;
E’ importante sottolineare come nel linguaggio CDL l’utilizzo dei puntatori e statofortemente “limitato” rispetto al suo omologo in C/C++. Non e permesso17 indirizzare
17Il programma CDL Front non segnala nessun errore; ma si andra poi incontro a numerosi errori di
compilazione. Infatti il tipo di dati puntato e sempre predichiarato come classe.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 86
valori diversi da istanze di classi CDL. Ad esempio non e possibile creare un puntatorealla primitiva Integer del package Standard.
Questa scelta, che a prima vista potrebbe apparire come una inutile complicazione del-l’ambiente e che tra l’altro ha causato numerosi problemi nel corso dello sviluppo delprogetto, e in realta una delle caratteristica imprescindibili per il corretto funziona-mento del Memory Manager di Ocas. Se fosse infatti permesso l’uso “generalizzato”dei puntatori senza alcun tipo di controllo, non potrebbe funzionare correttamente ilmeccanismo di rilascio automatico della memoria, che, come gia accennato, si basa suun algoritmo di reference counting.
L’utilizzo di puntatori a classi e comunque permesso ed utilizzato in sostituzione degliHandle allo scopo di evitare riferimenti incrociati tra strutture dati in memoria18.
2.2.9 Gli schema
Uno Schema permette la creazione di un modulo software che effettui il salvataggio sufile delle classi Persistent.
Un package e detto persistent se contiene almeno una classe persistente. Uno Schema
raggruppa insieme dei package persistenti.
La sintassi per la definizione di uno Schema e la seguente:
declaration-of-a-schema::= schema <SchemaName>
is
{package <PackageName>}
{class <ClassName>}
end;
2.2.10 Gli eseguibili
Un executable permette la creazione di un programma eseguibile il cui scopo e princi-palmente quello di testare il buon funzionamento dei packages. Un eseguibile e di solitoprivo di front end cioe dell’interfaccia per interagire con l’utente.
18Due strutture dati che si referenzino mutuamente attraverso Handle impedirebbero il rilascio di
detti oggetti: il loro contatore sarebbe infatti sempre impostato ad un valore superiore o uguale ad 1.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 87
La sintassi CDL per la creazione di un executable e la seguente:
definition-of-an-executable::= executable <ExecName>
is{
executable <ExecPart>
[uses
[<Identifier] as external]
[{’,’<Identifier as external}]
[<UnitName> as library]
[{’,’<UnitName> as library}]
is
{<FileName> [as C++|c|fortran|object];}
end;
}
2.3 Il linguaggio CDL a confronto con il linguaggio C++
Il linguaggio CDL e, come piu volte ribadito, un linguaggio di “interfaccia” nel sensoche non definisce l’implementazione dei componenti software ma solo i servizi che icomponenti stessi espongono.
Il ruolo di un file CDL all’interno di un progetto di Open Cascade e analogo al ruolosvolto dagli header files in un progetto C++.
In realta esistono pero’ delle differenze sostanziali tra il linguaggio CDL e il linguaggioC++, differenze che derivano principalmente dal fatto che CDL e un linguaggio moltosemplice e in alcuni casi addirittura “primitivo” rispetto al C++ 19.
19E’ molto raro che le FFI utilizzino come files di interfaccia direttamente gli header files del C++;
e nel caso in cui adottino questa soluzione sono comunque poste molte limitazioni soprattutto nei
confronti della gestione dei valori di tipo classe.
Due esempi tra i piu significativi di questo tipo di FFI sono i seguenti:
SWIG [24] E’ possibile utilizzare sia gli header files del C++ che degli altri files di interfaccia in
formato proprietario Swig. Il supporto ai dati di tipo classe e comunque in entrambi i casi
piuttosto limitato.
SILOON Il programma usa un estrattore C++ commerciale molto accurato e completo. Il supporto
alle funzioni sovrapposte e agli operatori di conversione e pero’ meno avanzato rispetto alla FFI
che e stata sviluppata.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 88
E’ quindi evidente che se si desidera realizzare delle proprie librerie C++ da utilizzareall’interno dell’interprete Scheme e necessario prima di tutto descrivere tali servizi inappositi files CDL.
Nel paragrafo 2.3.1 saranno spiegate le differenze tra i due linguaggi in merito alladefinizione e all’utilizzo delle variabili. Nel paragrafo 2.3.2 saranno illustrate le differentimodalita di gestione delle variabili come parametri di ingresso e come valori di ritorno diuna funzione. Infine nel paragrafo 2.3.3 sara analizzato il comportamento del risolutoredell’overloading che e il componente che si occupa di convertire gli argomenti di ingressoe di passarli alla funzione invocata.
2.3.1 La definizione delle variabili
In questo paragrafo verranno esaminati tutti i tipi di dato che un compilatore ANSIC++[22] puo’ gestire e contemporaneamente si vedra quali costrutti sono permessi equali invece non sono supportati dal linguaggio CDL.
Le costanti
Quando all’interno di un programma si incontra un valore (ad esempio 0xFF) esso vienedefinito come costante letterale; letterale in quanto e possibile riferirsi a essa solo intermini del suo valore; costante, perche il suo valore non puo’ cambiare.
Il comportamento del compilatore dinamico nei confronti delle costanti e, nel caso spe-cifico, trascurabile. Le modalita di passaggio di un qualsiasi valore dall’ambiente Sche-me all’ambiente C++/Open Cascade avverra esclusivamente attraverso il passaggio divariabili simboliche, mai attraverso costanti.
I tipi di dati predefiniti
Il C++ fornisce un insieme predefinito di tipi di dati e un insieme di operatori pergestirli.
I tipi di dati supportati permettono la rappresentazione di numeri interi o numeri invirgola mobile:

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 89
Valori interi. I tipi short, long. char, short, int e long sono globalmente definiticome tipi interi. I tipi interi possono essere sia signed che unsigned.
Valori reali. I tipi float, double, long double rappresentano valori in virgola mo-bile rispettivamente in precisione singola, doppia ed estesa.
In Ocas vengono ridefiniti tutti i tipi di dati primitivi del linguaggio C++:
Tipi Ocas Tipi C++
Standard Character charStandard Short shortStandard Integer intSchemePack Long longStandard Boolean boolStandard Real doubleStandard ShortReal floatnon supportato long double
Non e invece possibile specificare se il tipo CDL sia signed o unsigned; tutti i tipi diOpen Cascade sono infatti implicitamente signed. Cio pero’ non preclude la possibilitadi definire nuovi tipi primitivi20.
Variabili puntatore
Una variabile di tipo puntatore contiene valori che sono indirizzi ad oggetti in memoria.Attraverso un puntatore un oggetto puo’ essere referenziato indirettamente. Utilizzitipici di puntatori sono la creazione di liste concatenate e la gestione di oggetti riservatidurante l’esecuzione del programma.
La definizione di un puntatore avviene prefissando l’operatore di indirizzamento indi-retto (“*”) all’identificatore. Ad esempio:
unsigned char *ucp;
Un puntatore puo’ essere inizializzato attraverso l’assegnamento dell’indirizzo di unoggetto dello stesso tipo. Si ricordi che un oggetto che appare alla destra di un asse-
20Attraverso la primitive abbiamo introdotto nell’ambiente il tipo SchemePack Integer.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 90
gnamento contiene il suo r-value21. Per ottenere l’indirizzo di quell’oggetto, e quindiil suo l-value, dovra essere applicato uno speciale operatore definito come operatoreindirizzo-di (“&”).
Ad un puntatore di qualunque tipo puo’ essere assegnato un valore 0 (NULL), che indicache quel puntatore non sta attualmente indirizzando alcun oggetto. Vi e anche ilpuntatore void* al quale puo’ essere assegnato l’indirizzo di un oggetto di qualunquetipo.
E’ possibile specificare che i puntatori siano dei riferimenti costanti. Ad esempio:
char c=’a’;
const char *p1;
char *const p2=&c;
La prima definizione dichiara p1 puntatore ad un carattere costante, cioe il contenutodel tipo di dato puntato non puo’ essere modificato:
(*p1)=’a’; //errore.
La seconda definizione indica invece che e proprio la variabile puntatore a non poteressere modificata. Il valore in essa contenuto sara quindi inizializzato una volta pertutte all’atto della sua definizione.
In CDL si cerca il piu possibile di limitare l’utilizzo dei puntatori al posto dei quali siutilizzano di solito gli handle di Open Cascade, almeno limitatamente ai dati di tipoclasse.
Esistono pero’ delle significative eccezioni:
• Il tipo Address del package Standard e definito come void*; di conseguenza puo’essere utilizzato in sostituzione ad un puntatore di qualsiasi tipo22.
21Sia le variabili simboliche che le costanti letterali sono memorizzate ed hanno un tipo ad esse
associato. La differenza tra le due consiste nel fatto che una variabile simbolica e indirizzabile, ossia vi
sono due valori associati:
• Il valore memorizzato in qualche locazione di memoria (detto anche r-value).• Il valore della sua locazione, ossia l’indirizzo di memoria nel quale tale valore e memorizzato(detto anche l-value).
22In C++ la conversione di un puntatore di qualsiasi tipo verso il tipo void* e eseguita attraverso

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 91
• Il tipo CString del package Standard e definito come tipo char*, cioe comepuntatore a carattere.
• Il tipo Object del package SchemePack e uno scheme object*; e quindi un pun-tatore ad un oggetto dell’interprete Scheme. Cio consentira l’interfacciamento trale librerie C++ e l’interprete.
Le variabili di tipo riferimento
Il tipo “indirizzamento semplice” viene definito facendo seguire allo specificatore di tipol’operatore di indirizzo-di. Ad esempio:
int valore=10;
int &valore=valore;
Il tipo indirizzo viene qualche volta definito alias o link, a significare che serve comenome alternativo per l’oggetto con il quale e stato inizializzato. Tutte le operazioniapplicate al riferimento agiscono in realta sull’oggetto stesso a cui esso si riferisce.
Un riferimento puo’ essere pensato come uno speciale tipo di puntatore; tuttavia, adifferenza di un puntatore, un riferimento deve essere sempre inizializzato. Una voltainizializzato non puo’ divenire l’alias di un altro oggetto.
Un riferimento non costante puo’ essere inzializzato univocamente con un l-value delsuo tipo.
Anche le variabili di tipo riferimento possono essere dichiarate come costanti, indicandocon questo la volonta che attraverso quel particolare alias non si desidera modificareil particolare oggetto riferito. Ad esempio il seguente codice genererebbe un errore dicompilazione:
int valore=10;
const int &rifer=valore;
rifer=18; //errore!
L’utente scheme non puo’ gestire i valori di riferimento in modo diretto, cioe nonesiste una primitiva del linguaggio Scheme per accedere alla locazione di una qualsiasiuna conversione standard (cioe di terzo livello); l’operazione inversa richiede invece un type casting
esplicito.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 92
variabile in memoria. Sara invece la FFI che automaticamente eseguira delle opportuneistruzioni per fare in modo che:
1. gli argomenti di ingresso di una funzione passati per riferimento possano esseremodificati.
2. il valore di uscita di una funzione possa essere modificato dall’interprete se passatoper riferimento.
La soluzione adottata e la seguente: e creata una nuova struttura dati per ogni variabileC++, indifferentemente dalla sua modalita di passaggio (per valore o per riferimento).
All’interno di detta struttura sara presente un puntatore di tipo void* che puo’ quindireferenziare tutti gli oggetti C++.
In funzione della modalita di passaggio si avranno due comportamenti differenti:
Passaggio per valore L’oggetto C++ referenziato sara creato ex-novo. Il suo conte-nuto e ottenuto copiando il valore di uscita della funzione.
Passaggio per riferimento L’oggetto C++ referenziato e esattamente l’oggetto di”ritorno” della funzione.
L’argomento verra approfondito nel paragrafo 3.1.5.
I tipi enumerativi
Una enumerazione e un insieme di costanti simboliche. Gli elementi di una enumerazio-ne vengono definiti come enumeratori e differiscono dalle loro equivalenti dichiarazionidi tipo const per il fatto che non vi e alcuna variabile indirizzabile associata a ciascunenumeratore.
La convenzione comune e quella di assegnare al primo enumeratore della lista il valore0. A un enumeratore puo’ anche essere esplicitamente assegnato un valore che non deveessere necessariamente unico.
Ciascuna enumerazione provvista di un nome definisce un unico tipo. I valori associatiall’insieme sono i soli valori che possono essere legalmente assegnati agli oggetti diun’enumerazione.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 93
In CDL e possibile creare nuovi tipi enumerati attraverso la primitiva enumerate (vediparagrafo 2.2.4).
I vettori
Un vettore e un’insieme di oggetti appartenenti a un singolo tipo di dato. I singoli og-getti non hanno un nome; a ciascuno di essi e possibile accedere attraverso la posizione.Questa forma di accesso viene definita indicizzazione.
La definizione di un vettore consiste dello specificatore di tipo, di un identificatore edella dimensione del vettore.
Un vettore non puo’ essere inizializzato con un altro vettore ne’ puo’ essere assegnato adun altro vettore; inoltre non e permessa la dichiarazione di un vettore di tipo riferimento:
int &vettore[]={0,1,2}; //errore
E’ possibile definire anche vettori multidimensionali. Ciascuna dimensione viene speci-ficata dalla coppia di parentesi a essa relative.
L’identificatore del vettore corrisponde all’indirizzo in memoria del primo elementocontenuto nel vettore stesso. La nozione di puntatore e di vettore sono dunque equi-valenti. I metodi per mezzo dei quali l’identificatore del vettore e il puntatore riesconoad indirizzare quella zona di memoria sono pero’ molto differenti:
• La definizione di un vettore riserva un blocco di memoria sufficiente a contenereil numero specificato di elementi.
• La definizione di un puntatore fornisce la memoria sufficiente per poter contene-re un indirizzo di memoria. La dimensione di detta variabile e dipendente dalcompilatore utilizzato.
In CDL i vettori possono essere gestiti solo tramite l’utilizzo dei puntatori, cioe tramiteil tipo CDL Address.
Esiste una unica eccezione che riguarda i fields di una classe, cioe le variabile incapsulateall’interno di una classe. I fields possono essere infatti valori multidimensionali. Adesempio tramite l’istruzione:

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 94
matrix:Integer[2][3];
viene creato un field con nome matrix e dimensioni 2 e 3.
Le classi
Il tipo di dato classe definito dall’utente in C++ consiste di un aggregato di elementicon un nome e un insieme di operazioni per la manipolazione. Solitamente una classee utilizzata per introdurre un nuovo tipo di dato all’interno del programma.
Attraverso l’uso delle classi e possibile attuare il mascheramento dell’informazione: leparole chiave public, protected, private controllano l’accesso agli elementi dellaclasse.
Solitamente la definizione della classe e memorizzata in un file di intestazione separatodetto header file.
Lo sviluppatore piuttosto che creare i propri file di intestazione delega la loro genera-zione al programma CPP Extractor.
Un altro utilizzo importante del tipo classe e la definizione di relazioni di sottotipo. Essae realizzata attraverso un meccanismo di ereditarieta. Il che significa che una classederivata eredita (cioe condivide) gli elementi della classe da cui deriva. I costruttori nonsono ereditati perche servono come funzioni di inizializzazione specifiche per la classe.
La capacita di assegnare oggetti di classi derivate a oggetti di una classe base permettealle sub-classi di essere utilizzate anche scambiandole tra di loro. Cio pero’ e vincolatoal tipo di derivazione effettuata che deve essere necessariamente public.
Nel meccanismo di ereditarieta, e soprattutto di interscambio tra classi ereditate e classibase, e particolarmente importante il concetto di funzione virtuale, la cui realizzazionedipende dal tipo di classe. La risoluzione dell’opportuna chiamata a funzione non e, inquesto caso, risolta all’atto della compilazione ma e risolta a run-time, cioe in mododinamico.
In CDL e possibile definire nuovi tipi di classi attraverso la primitiva class.
Esistono comunque delle differenze sostanziali tra le classi C++ e classi CDL:
• Le variabili di una classe CDL non sono mai public, ma solo protected (com-

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 95
portamento di default) o private. Bisognera quindi fornire dei metodi (tipo set
o get) per permettere comunque l’accesso e/o l’interrogazione delle variabili inquestione.
• E’ supportata solo la derivazione public tra classi CDL.
• Non e supportata la multiereditarieta.
• La possibilita di definire una classe all’interno di una altra classe CDL e permessasolo limitatamente alle generic class.
• Non e permesso che una classe CDL derivi da una classe generica.
Definizione degli alias di tipi
I vettori, i riferimenti e i puntatori vengono talvolta definiti come tipi derivati. Essisono cioe costruiti a partire da altri tipi applicando opportuni operatori (indicizzazione,indirizzo-di, indirizzamento indiretto etc); tali operatori possono essere visti come dei“costruttori di tipo”.
Il meccanismo typedef fornisce una funzionalita generale per introdurre dei sinonimicon cui assegnare un nome a tipi di dati predefiniti, derivati o definiti dall’utente.
E’ importante capire che un typedef non e equivalente all’espansione di una macro.Ad esempio la seguente definizione di tipo con la successiva instanziazione:
typedef char *stringa;
const stringa aux;
non e equivalente alla dichiarazione:
const char* aux;
ma piuttosto indica un puntatore costante ad una stringa:
char *const aux;
I typedef del C++ sono supportati in CDL attraverso la primitiva alias. Il program-ma CPP Extractor provvedera automaticamente alla creazione degli header files checontengano i typedef corrispondenti.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 96
2.3.2 Modalita di passaggio delle variabili
Funzioni diverse di uno stesso programma possono comunicare in due modi: il primo,di scarso interesse, utilizza le variabili globali; il secondo utilizza invece gli argomentidelle funzioni.
La lista degli argomenti di una funzione, insieme con il tipo di dati restituito, costitui-scono l’interfaccia pubblica della funzione stessa. La lista degli argomenti viene anchedetta firma di una funzione perche e spesso utilizzata per distinguere istanza diversedella stessa funzione.
Alle funzioni viene riservata della memoria in una apposita struttura dati denominata“stack del programma”. Tale memoria rimane assegnata fino a che la funzione nontermina la sua esecuzione.
Le variabili come argomenti di ingresso di una funzione
La lista degli argomenti di una funzione descrive i suoi argomenti formali. A ciascunodegli argomenti formali, in funzione dello specificatore di tipo, viene assegnata unacerta quantita di memoria all’interno del record di attivazione.
Il passaggio degli argomenti in C++ avviene normalmente copiando gli r-value degli ar-gomenti effettivi nell’area di memoria allocata dedicata agli argomenti formali. Questoprocedimento viene denominato passaggio per valore.
Con il passaggio degli argomenti per valore la funzione non ha mai accesso agli argo-menti effettivi della chiamata, I valori che la funzione gestisce sono delle copie localimemorizzate nello stack. Le modifiche fatte su questi valori non si riflettono quindisugli argomenti effettivi.
Le alternative al modello di comportamento del passaggio delle variabili per valore sonodue:
• Passaggio di una variabile di tipo puntatore. in questo caso le modifiche vengo-no fatte sulle locazioni di memoria indirizzate dal puntatore, e quindi sul datoeffettivo dell’invocazione.
• Passaggio della variabile di tipo riferimento. Ad esempio
void scambio (int &v1, int &v2);

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 97
Ogni volta che si desidera che un argomento passato per riferimento non venga modi-ficato dalla funzione e buona pratica dichiarare const l’argomento. In questo modo sipermette al compilatore C++ di prevenire modifiche non desiderate.
CDL non supporta tutte le modalita di passaggio dei parametri di ingresso del C++.
E’ possibile specificare solo i seguenti attributi rispetto ad un parametro di ingresso:
in L’argomento non verra modificato dalla funzione. Viene preposto al tipo C++ ladirettiva const.
in out L’argomento puo’ essere modificato dalla funzione.
L’algoritmo utilizzato dal programma CPP Extractor per la “costruzione” del proto-tipo C++ a partire dalla definizione CDL e il seguente:
if (!IsDefined(TypeName))[const] <TypeName>&;
else{if (IsClass(TypeName)){
if (IsPersistent(TypeName) || IsTransient(TypeName))[const] Handle_<TypeName>&;
else[const] <TypeName>&;
}
if (IsImported(TypeName) || IsPointer(TypeName) ||IsItem(TypeName)|| IsOut(TypeName))
[const] <TypeName>&;else{
if (IsOut())[const] <TypeName>&;
else[const] <TypeName>;
}}
La variabile come valore di ritorno di una funzione
Il valore restituito da una funzione C++ puo’ essere un tipo di dati predefinito (comeint o double); un tipo di dati derivato (come int& o double*); oppure un tipo di dati

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 98
definito dall’utente (come una enumerazione o una classe). Infine il tipo void indical’assenza di un valore di “ritorno”.
Il tipo di dati restituito non puo’ essere ne’ un vettore ne’ una funzione. Al loro postopuo’ essere dichiarato un puntatore ad un vettore o ad una funzione.
CDL supporta tutte le modalita di restituzione dei valori del C++; e sufficiente speci-ficare una delle seguenti direttive:
Direttiva CDL Traduzione in C++
nessuno specificatore [Handle ]TypeName—C++:return & [Handle ]TypeName&—C++:return const const[Handle ]TypeName—C++:return const& const [Handle ]TypeName&
2.3.3 L’invocazione di un metodo
In questo paragrafo verra esaminato il comportamento di un compilatore ANSI C++ogni qual volta viene invocata una funzione, il che comporta, almeno nei casi non banali,il passaggio e la conversione dei parametri di ingresso e la conversione e la restituzionedel valore di uscita.
Verra quindi confrontato tale comportamento con il comportamento della FFI che, nelcaso specifico, opera come se fosse un compilatore “dinamico”.
Le operazioni di type casting
Se si considera la memorizzazione dei dati a livello della macchina fisica tutti i tipidi dati si mescolano in un flusso contiguo di bit. La conversione di un tipo di datipredefinito in un altro modifica una o piu proprieta di quel tipo di dati, ma non lastruttura sottostante dei bit.
Le due notazioni seguenti:
type (espr)
(type) espr
vengono definite cast o conversioni esplicite.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 99
Una ragione per applicare una conversione esplicita concerne la possibilita di scavalcareil controllo sui tipi di dati predisposto dal linguaggio. In generale il C+ consenteche un qualsiasi tipo di dati possa essere convertito in un altro tipo di dati qualsiasi.Immettendo una conversione esplicita il programmatore si assume la responsabilitadella sicurezza connessa a quella conversione.
Una seconda ragione per utilizzare una conversione esplicita e stabilite un criterio ope-rativo univoco in una situazione di ambiguita, cioe nella quale sia possibile applicarepiu di una conversione.
Non e previsto che in shell Scheme venga eseguita una operazione di conversione espli-cita, a meno che non si modifichino manualmente le informazioni all’“interno” delleistanze di HCvar23.
Oltre alle conversioni esplicite esistono le conversioni implicite che sono quelle che piudi altre sono importanti per capire il funzionamento della FFI.
Una conversione implicita e una conversione eseguita dal compilatore seguendo un in-sieme di regole prefissate senza alcun intervento da parte del programmatore. Adesempio:
void ff(int);
double val=3.14;
ff(val);
La costante letterale double 3.14 viene assegnata alla variabile simbolica val. Ilcompilatore e quindi in grado di convertire il valore double nel valore int attraversouna conversione standard troncando il valore 3.14 in 3.
La FFI dovra quindi simulare la presenza di un compilatore tutte le volte che vengainvocata una funzione C++ i cui argomenti di ingresso necessitino di qualche tipo diconversione.
Controllo sui tipi di dati
Il C++ e un liguaggio con il controllo dei tipi estremamente accurato. Tutte le inizia-lizzazioni e gli assegnamenti dei valori sono quindi controllati durante la compilazione
23Cio implica l’accesso alle informazioni relative alla tipologia e al valore della variabile (vedi
paragrafo 3.1.5).

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 100
per assicurarsi che i tipi siano corretti; se non lo sono ma esiste comunque una rego-la (conversione di tipo) per poterli rendere compatibili il compilatore applica questaregola.
Se non vi e invece nessuna regola applicabile viene segnalato dal compilatore un errore.Cio si rende necessario perche un’inizializzazione o un assegnamento senza una regoladi conversione e una operazione molto rischiosa, che probabilmente provochera deglierrori durante l’esecuzione del programma.
Si consideri la definizione della seguente funzione:
int mcd(int v1,int v2);
La funzione mcd richiede esplicitamente due argomenti di tipo int. Le operazionieseguite dalla funzione sono quindi “lecite” solo su due operandi interi.
Il risultato desiderabile e che quindi il compilatore produca una segnalazione di errorenei seguenti casi:
mcd("stringa1","stringa2");//invalid argument types
mcd(0);//missing value for argoment two
Se al contrario si fosse invocata la funzione con il passaggio di due argomenti double unasegnalazione di errore sarebbe probabilmente stata troppo severa. Infatti gli argomentipotrebbero essere convertiti implicitamente in int. Poiche tale conversione e versoun tipo piu ristretto di double viene di solito fornito al compilatore un messaggio diavvertimento (warning).
Sia la lista di argomenti che il tipo di dati restituito da ciascuna funzione sono quindicontrollati rispetto al tipo a tempo di compilazione. Se non vi e corrispondenza trail tipo effettivamente passato e il tipo dichiarato nel prototipo della funzione vieneapplicata, quando possibile, una conversione implicita; se cio non e possibile o se ilnumero degli argomenti non e corretto viene generato un errore durante la compilazione.
Il prototipo della funzione fornisce al compilatore l’informazione necessaria sui tipi didati affinche tale controllo possa essere effettuato. Questo e anche il motivo per cuiuna funzione non puo’ essere invocata prima di essere dichiarata.
Per accedere alle funzioni di libreria C++ da Scheme il controllo sui tipi deve essereeffettuato dalla FFI. Bisogna infatti considerare che se “normalmente” le conversioni di

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 101
tipo sono applicate dal compilatore all’atto della creazione degli object files di progetto,in questo caso non verranno invece mai creati degli object files rispetto al codice sorgenteScheme.
Tale controllo deve essere rigoroso per evitare di incorrere in errori a run time; edeve essere il piu possibile conforme al comportamento di un compilatore ANSI C++“standard”.
Sovrapposizione dei nomi di funzione
Si dice che una parola e sovrapposta quando ha due o piu significati differenti. Ilsignificato che si intende dare all’interno di un particolare utilizzo di quella parola efunzione del contesto. Una parola ambigua puo’ avere due o piu significati ugualmentepossibili.
Se il contesto in cui occorre un identificatore e insufficiente a rendere chiaro il suosignificato il compilatore segnala un errore.
In C++ e possibile assegnare lo stesso nome a due o piu funzioni a patto che la listadi argomenti identifichi univocamente ogni singola istanza o per il numero o per il tipodi dati degli argomenti. Ad esempio:
int massimo(int,int);
int massimo(const int*, int);
int massimo(const Lista&);
Dal punto di vista dell’utente vi e una sola operazione, quella che determina il massimotra due valori.
E’ responsabilita del compilatore, e non del programmatore, operare la distinzionenecessaria tra le due istanze. La sovrapposizione dei nomi di funzioni e una soluzionealla complessita lessicale che deriverebbe dalla necessita di definire differenti nomi difunzioni per ogni istanza.
Quando un nome di funzione viene dichiarato piu di una volta in un programma ilcompilatore interpreta la seconda e le successive dichiarazioni come segue:
• Se sia il tipo di dati restituito, sia la lista di argomenti delle due funzioni sonouguali, il secondo nome viene considerato una nuova dichiarazione del primo.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 102
• Se le liste degli argomenti delle due funzioni sono uguali ma il tipo di dati re-stituito no, la seconda dichiarazione viene considerata una nuova dichiarazionedella prima funzione e viene prodotto un errore di compilazione. Cioe il tipo didati restituito dalla funzione non viene considerato quando si differenziano dueistanze sovrapposte.
• Se le liste degli argomenti delle due funzioni differiscono nel numero o nel tipo didati dei loro argomenti le due istanze della funzione sono considerate sovrapposte.
In un insieme di funzioni sovrapposte la lista di argomenti di una funzione distingue uni-vocamente quell’istanza dalle altre. Una chiamata di una funzione sovrapposta vienerisolta in favore di una particolare istanza attraverso un processo denominato corri-spondenza tra gli argomenti che puo’ essere pensato come un processo che elimina leambiguita. La corrispondeza tra argomenti consiste nel raffrontare gli argomenti effet-tivi della chiamata con gli argomenti formali di ciascuna istanza dichiarata. Esistonotre possibili risultati di una chiamata di funzione sovrapposta:
• Esiste una corrispondenza. La chiamata viene risolta in favore della particolareistanza.
• Non esiste alcuna corrispondenza.
• Esiste una corrispondenza ambigua. L’argomento effettivo puo’ corrispondere adue o piu istanze definite.
La corrispondenza tra argomenti puo’ essere ottenuta con uno di questi quattro metodi,col seguente ordine di precedenza:
• Una corrispondenza esatta. Il tipo dell’argomento effettivo corrisponde al tipodell’istanza definita.
• Una corrispondenza per promozione. Se non esiste una corrispondenza esatta vie-ne fatto un tentativo di ottenere una “compatibilita” attraverso una promozionedell’argomento effettivo. Ad esempio:
void ff(int);
ff(’a’\); //il carattere viene promosso a intero

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 103
• Una corrispondenza ottenuta attraverso l’applicazione di una conversione stan-dard. Se non esiste una corrispondeza esatta e nemmeno una corrispondenza perpromozione viene fatto un tentativo di ottenere una corrispondenza attraversouna conversione standard dell’argomento effettivo. Ad esempio:
void ff(char *);
ff(0); //coversione standard a char*
• Se al termine di tutti i tentativi precedentemente fatti non e stata ancora trovataalcuna corrispondenza si tenta l’applicazione di una conversione definita dall’uten-te. Un operatore di conversione consente a una classe di definire il proprio insiemedi conversioni standard, sia attraverso costruttori che attraverso operatori.
La FFI gestisce tutti e quattro i tipi di conversioni, in perfetta conformita con ledisposizioni ANSI C++ 24.
Dettagli di una corrispondenza esatta
Ogni volta che i tipi dell’argomento formale e argomento effettivo coincidono esatta-mente si dice che esiste una corrispondenza esatta.
La corrispondenza tra argomenti puo’ fare distinzione tra puntatori costanti e noncostanti e argomenti indirizzo (o di riferimento) costanti o non costanti. Ad esempio:
void ff(const char*);
void ff(char*);
char *cp;
const char *pcc;
ff(pcc);//invoca la ff(const char*)
ff(cp);//invoca la ff(char *)
Anche la FFI puo’ fare questa distinzione.
Oltre alle corrispondenze esatte in senso stretto esistono anche delle corrispondenzeottenute attraverso delle conversioni banali25. Ad esempio:
24In realta esistono delle eccezioni di regole di conversione che non sono state implementate, eccezioni
sulle quali torneremo nel seguito.25Anche le conversioni banali sono supportate dalla FFI.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 104
void ff(const int&);
int ival;
ff(ival); // int -> const int&
Un’altra conversione banale e quella tra un vettore ed un puntatore che referenzia lostesso tipo di dati.
Dettagli di una corrispondenza per promozione
Le seguenti regole sono applicabili nell’ambito delle corrispondenze per promozione:
• Un argomento char, unsigned char o short puo’ promosso a int se la dimen-sione a livello macchina di int e maggiore di quella di short, altrimenti vienepromosso a unsigned int.
• Un argomento float puo’ essere promosso a double.
• Un argomento appartenente a una enumerazione puo’ essere promosso a int.
Non esistono conversioni per promozione applicabili nei confronti delle classi C++.
Tutte le regole di conversione per promozione sono implementate nella FFI.
Dettagli di una corrispondenza con conversione standard
Se non esiste alcuna risoluzione della chiamata di una funzione per mezzo di una cor-rispondenza esatta viene fatto un tentativo di creare una corrispondenza per mezzo diuna conversione standard dei tipi di dati.
Le regole per l’applicazione di una corrispondenza standard sono le seguenti:
1. Qualunque tipo numerico corrisponde a un argomento formale di qualunque altrotipo numerico.
2. I tipi enumerazione corrispondono ad argomenti di tipo numerico.
3. Il valore zero corrisponde sia a un argomento di tipo puntatore che a un argomentodi tipo numerico.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 105
4. Un puntatore di qualsiasi tipo di dati puo’ corrispondere a un argomento di tipovoid*.
Tutte le conversioni standard fin qui trattate vengono considerate con lo stesso livellodi precedenza. Se piu di una corrispondenza standard risulta possibile la chiamata eambigua e viene segnalato un errore. Ad esempio:
void ff(unsigned int);
void ff(float);
ff(’a’);//errore! chiamata ambigua
Tutte queste regole di conversione standard, ad eccezione della regola numero 3, sonosupportate dalla FFI.
Per quanto riguarda i dati C++ di tipo classe sono possibili quattro ulteriori conversionistandard:
• Un oggetto della classe derivata viene implicitamente convertito in un ogget-to della classe fondamentale pubblica26. La regola non si estende alle classifondamentali protette o private. La FFI implementa questa regola di conversione.
• Un riferimento di una classe derivata viene implicitamente convertito in un rife-rimento della classe fondamentale pubblica. La FFI implementa questa regola diconversione.
• Un puntatore alla classe derivata viene implicitamente convertito in un punta-tore della classe fondamentale pubblica. La FFI implementa questa regola diconversione.
• Un puntatore a un elemento della classe fondamentale viene implicitamente con-vertito in un puntatore all’elemento della classe derivata in modo pubblico. Que-sta regola di conversione non e supportata dalla FFI: infatti nessun field all’internodi una classe CDL e accessibile dall’“esterno”.
• Un puntatore i qualunque oggetto di una classe viene implicitamente convertitoin un puntatore void*. La FFI implementa questa regola di conversione.
26Una classe fondamentale pubblica e una classe da cui la classe attuale e stata derivata in modo
pubblico.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 106
Per gli oggetti di tipo classe e importante il livello di vicinanza al tipo di dati dellaclasse fondamentale. Viene quindi data la precedenza ad una conversione standard piuvicina nella gerarchia delle derivazioni.
Dettagli di una conversione utente
Le conversioni standard per i tipi di dati predefiniti dal linguaggio prevengono unaesplosione combinatoria di operatori e di funzioni sovrapposte.
Il C++ fornisce un meccanismo per mezzo del quale ogni classe puo’ definire un insiemedi conversioni applicabili agli oggetti della classe. Ad esempio:
class Intero{
public:
operator int();
}
Un operatore di conversione ha la seguente forma generale:
operator <tipo> ();
dove <tipo> viene rimpiazzato da un tipo di dati predefinito, derivato o definitodall’utente.
Non sono ammessi operatori di conversione sia per i vettori che per le funzioni.
Un altro tipo di conversione definita dall’utente e quella che si attua attraverso ladefinizione di costruttori di classe che richiedano un solo argomento.
Ad esempio invece che definire l’operatore int sarebbe stato possibile definire, in mododel tutto equivalente, il seguente costruttore:
class Intero{ public:
Intero(int);
}
Se necessario viene applicata una conversione standard ai tipi di dati effettivi primadella chiamata del costruttore (il che non avviene invece per gli operatori).

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 107
Se sono possibili due operatori di conversione, ma uno solo e in corrispondenza esattamentre l’altro richiede una conversione standard ulteriore, non vi e ambiguita e vienescelto il primo.
Si supponga che il tipo di dati richiesto non corrisponda esattamente a nessuno deidati previsti dagli operatori di conversione: ci si domanda se viene ancora chiamato unqualche operatore di conversione:
• Viene applicata una ulteriore conversione se il tipo di dati richiesto puo’ essereottenuto attraverso l’applicazione di una conversione standard.
• Non viene applicata una ulteriore conversione se, per ottenere il tipo di dati richie-sto, deve essere applicato un secondo operatore di conversione definito dall’utente.La regola generale stabilisce infatti che puo’ essere applicato una sola conversioneutente.
Hanno comunque precedenza nella risoluzione dell’ambiguita le conversioni utente sem-plici piuttosto che quelle supportate da una conversione standard.
Gli operatori di conversione, ma non i costruttori e/o gli operatori di assegnamento,sono ereditati allo stesso modo degli altri elementi della classe.
I costruttori di conversione e gli operatori di conversione hanno la stessa precedenza.
Tutte le conversioni utente, siano esse tramite operatore o tramite costruttore, sonosupportate dalla FFI. Cio puo’ tuttavia rallentare eccessivamente l’esecuzione27. Do-vrebbe quindi essere possibile disabilitare le conversioni utente; al momento questaopzione non e presente.
Chiamate con piu argomenti
Una chiamata con piu argomenti viene risolta applicando le regole di corrispondenza aciascun argomento. La funzione prescelta e quella per la quale la risoluzione di ciascunargomento e:
1. Migliore o uguale a quella di tutte le altre funzioni dell’insieme.27E’ molto oneroso, in termini di tempo, cercare nella definizione della classe CDL un qualche
costruttore o operatore che renda possibile l’applicazione di una conversione utente.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 108
2. Strettamente migliore di tutte le altre funzioni per almeno un argomento.
Questo algoritmo di corrispondenza per argomenti multipli viene denominato regola diintersezione.
La FFI applica la regola di intersezione in modo rigoroso nel tentativo di risolvere leambiguita. E’ da sottolineare che molto raramente le altre FFI hanno caratteristichesimili o superiori, soprattutto in relazione al problema dell’overloading.
Una chiamata e considerata ambigua se nessuna delle istanze della funzione contieneuna corrispondenza migliore, oppure se piu di una istanza della funzione contiene unacorrispondenza migliore.
Inizializzatori degli argomenti di default
L’istanza di una funzione sovrapposta con inizializzatori di argomenti di default corri-sponde a una chiamata che fornisce tutti o qualche sottoinsieme dei suoi argomenti.
Il numero di argomenti specificati dall’utente non da alcuna precedenza alle funzionicon minor numero di argomenti inizializzati.
Una funzione puo’ specificare un valore di default per uno o piu dei suoi argomentiutilizzando l’apposita sintassi di inizializzazione all’interno della lista di argomenti. Adesempio:
void *funzione(int altezza,int larghezza=80);
Una funzione che assegna valori di default ad alcuni dei suoi argomenti puo’ essereinvocata specificando o meno gli argomenti corrispondenti. Se un argomento vieneeffettivamente passato durante la chiamata esso sovrascrive il valore di default. In casocontrario viene utilizzato il valore di default.
Anche in CDL e permesso specificare dei valori di default per gli argomenti, che pero’al momento non sono “riconosciuti” dalla FFI.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 109
2.4 I servizi fondamentali di Open Cascade
Le Foundation Classes forniscono molteplici servizi dedicati alla risoluzione di problemigenerici rispetto allo sviluppo di un software: gestione automatica della memoria28,servizi per la costruzione di dati general purpose (liste, array etc), servizi per la gestionedelle eccezioni, supporto per la creazione di plug-in etc.
E’ stata gia fornito una anticipazione rispetto ai servizi presenti nei packages Standarde MMgt. Sono infatti questi ultimi i packages che contengono le definizioni delle tipologieprimitive dei dati oltre alle definizioni delle classi Persistent e Transient.
2.4.1 Il package TCollection
E’ opportuno dedicare maggiore attenzione alle classi contenute all’interno del packageTCollection, prima fra tutte la classe HAsciiString 29.
Tale classe permette la creazione di stringhe “dinamiche”, cioe la cui dimensione puo’cambiare a tempo di esecuzione, e la cui deallocazione e effettuata automaticamentedal Memory Manager.
Il seguente esempio mostra la creazione di una istanza della classe HAsciiString;e dimostra come si possano applicare all’oggetto delle semplici operazioni tramite laprimitiva send:
(define stringa
(make-object TCollection_HAsciiString% "Ocas"))
(send stringa AssignCat " and ")
(send stringa AssignCat "Scheme")
(send stringa ToCString)
”Ocas and Scheme”
Nonostante l’apparente semplicita dello script proposto sono diverse le azioni che laFFI deve eseguire per permettere la collaborazione tra l’interprete Scheme e le libreriedi Open Cascade. Ad esempio:
28La gestione automatica della memoria e disponibile solo per i valori gestiti per riferimento, cioe
tramite Handle.29Il carattere H preposto al nome della classe sta ad indicare una gestione del valore tramite Handle.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 110
scheme_string
scheme_string
char*
char*
TCollection_HAsciiString
1. conversionedella FFI
4. conversionedella FFI
2. creazione istanza(make-object)
3. Invocazione metodoToCString
FFI
Figura 2.8: Lavoro di conversione della FFI.
• All’atto della creazione della istanza di classe deve convertire lo scheme string
(valore "Ocas") in un char*.
• All’atto dell’invocazione del metodo ToCString deve convertire il tipo di datochar* (valore "Ocas and Scheme") in una scheme string.
Si ricorda infatti che i due ambienti definiscono tipi primitivi che sono tra loro incom-patibili (nel caso specifico cio coinvolge i tipi di dati scheme string e i char*).
E’ quindi necessaria una mapping function che converta i dati dall’ambiente Schemeall’ambiente Ocas, e viceversa. Dalla figura nella pagina dovrebbe risultare sufficiente-mente chiaro quale e il “livello” nel quale la FFI opera.
L’oggetto stringa appena creato e a tutti gli effetti un oggetto C++ incapsulato al-l’interno della shell Scheme. E’ possibile accedere ai metodi della classe (le cosiddettevariabili di istanza della classe Scheme) attraverso la primitiva send. Ad esempio conla seguente istruzione:
(send stringa Capitalize)
e comunicata alla shell l’intenzione di voler effettuare una operazione di capitalizesulla stringa.
Il metodo ToCString si occupa invece di restituire il valore di tipo stringa contenuto

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 111
all’interno della classe HAsciiString. Tale valore sara quindi convertito dalla FFI inun valore di tipo scheme string.
Verranno adesso analizzati i servizi offerti dai packages TCollection e TColStd:
• Costruzione di dati di tipo array. Gli arrays sono strutture dati a dimensioneprefissata, e quindi caratterizzate da tempi di accesso molto rapidi.
• Costruzione di dati di tipo sequences. Le sequences sono strutture dati a dimen-sioni dinamica, i cui tempi di accesso sono pero’ tra i piu lunghi rispetto a tuttele altre strutture dati analoghe.
• Costruzione di dati di tipo maps. Sono strutture dinamiche ottimizzate in modoche i tempi di accesso si mantengano comunque su livelli accettabili. La di-mensione di una map si adatta automaticamente al numero di elementi inseriti.L’accesso ad un elemento avviene tramite una chiave di accesso (key); chiave chee convertita, tramite una apposita hashing function, nel valore numerico (bucket)che indica la posizione dell’elemento all’interno della map stessa.
Tutte le strutture dati appena descritte sono in realta delle classi CDL generiche (gene-ric class), cioe possono essere istanziate rispetto a tipi di dati specificati dall’utente30.
Il codice CDL che definisce la classe Array1 e il seguente:
generic class Array1 from TCollection
(Array1Item as any)
is
Create (Low, Up: Integer from Standard) returns Array1;
Length (me) returns Integer;
Lower (me) returns Integer;
Upper (me) returns Integer;
SetValue (me : out; Index: Integer;Value: Array1Item);
Value (me; Index:Integer) returns any Array1Item;
fields
myLowerBound : Integer;
myUpperBound : Integer;
myStart : Address;30Ad esempio nel nostro progetto abbiamo utilizzato gli array e le sequence per la classe HCvar del
package SchemePack.

CAPITOLO 2. UN AMBIENTE DI PROGETTAZIONE ASSISTITA 112
end Array1;
E’ possibile ad esempio istanziare tale classe rispetto al tipo di dato primitivo Integer:
class Array1OfInteger instantiates Array1 (Integer);
ottenendo quindi un oggetto di tipo “array di interi”. La modalita di utilizzo dellaclasse Array1OfInteger tramite shell e particolarmente intuito:
(define array (make-object TColStd_Array1OfInteger% 1 3))
(send array Lower)
(send array SetValue 2 255)
(send (send array Value 2) DeepValue)
Per terminare la trattazione sulle Foundation Classes e necessario esaminare i seguentitipi di dati:
Vettori e matrici. Le classi Vector e Matrix forniscono il supporto per la creazionedi vettori e matrici di valori reali. Sono inoltre implementate le piu comunioperazioni quali addizioni, moltiplicazioni, inversioni etc.
Ad esempio e possibile creare una nuova matrice all’interno della shell con laseguente istruzione:
(define mat (make-object Math_Vector% 2 3))
Tipi geometrici primitivi. Il package gp definisce le principali entita geometricheprimitive (punti 2d e 3d; linee; parabole; cerchi etc) e le principali trasformazioni(rotazione; traslazione, mirroring etc).
A partire dalle classi del package gp saranno poi derivate tutte le restanti classidelle librerie di Ocas, classi che permetteranno una modellazione piu ad altolivello.

Capitolo 3
Integrazione degli ambienti
Nei capitoli precedenti e stata offerta una paronamica generale rispetto ai problemi dicollaborazione tra interprete Scheme e librerie C++ (con files di interfaccia CDL) diOpen Cascade.
In questo capitolo verranno rianalizzati tutti i problemi proposti da un punto di vistapiu pratico e tecnico: si vedra cioe concretamente quali sono le soluzioni adottate esoprattutto si entrera nei dettagli implementativi rispetto alla struttura interna delcodice e dell’architettura dell’applicazione.
Si intende inoltre discutere quali siano le motivazioni che hanno portato a preferirealcune soluzione piuttosto che altre, evidenziandone non solo i risvolti positivi maanche e soprattutto i limiti. Non si ha infatti la pretesa di aver trovato e soprattuttoimplementato le soluzioni migliori in ogni ambito della collaborazione tra i due sistemi.Gia nel paragrafo 1.4.2 si e potuto constatare come gli algoritmi per la risoluzionedelle collisioni dei nomi sono estremamente complessi, e che quindi molti miglioramentipossono e potranno sicuramente essere attuati (ad esempio nell’ambito dell’ addressbinding).
Alcuni aspetti dei problemi sono quindi stati, per precise scelte progettuali, omessi e/otrascurati; ad altri si e invece dato ampio risalto. Non e stata per adesso stabilitanessuna precisa scadenza e/o gerarchia rispetto ai problemi che piu di altri hannonecessita di essere affrontati e risolti; molto, in questo senso, dipendera dai risultati diquesta tesi.
Quanto detto non deve tuttavia apparire come un tentativo di giustificare una qual-che debolezza strutturale di progetto. E’ anzi vero che la FFI realizzata e tra le piu
113

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 114
SchemeCDL
SchemePack
OcasPack
OcasGeomPack
Parser edestrattori
Tipi Scheme perle variabili C++
Liberie fondamentalidi Open Cascade
Librerie geometrichedi Open Cascade
MzScheme
Figura 3.1: Architettura del codice.
avanzate tra tutte quelle disponibili in ambiente Scheme, e presenta inoltre aspettiparticolarmente innovativi quali ad esempio il supporto per le conversioni di quar-to livello (conversioni utente) sia tramite operatore che tramite costruttore di classe.Caratteristica questa che nessun altro sistema FFI attualmente supporta.
Nei paragrafi che seguiranno si cerchera di entrare nei dettagli implementativi dell’ap-plicazione realizzato con il preciso scopo di fornire una documentazione di riferimentoche sia di aiuto verso i programmatori che desiderassero modificare direttamente ilcodice sorgente.
Nel paragrafo 3.1 verra illustrata la struttura dei nuovi tipi di dato che e necessarioaggiungere all’interprete Scheme in modo che possa gestire le variabili C++. Verraquindi spiegato il funzionamento dell’estrattore Scheme che e il componente che generain modo automatico gli header files del C++ e la FFI. Per finire nei paragrafi 3.3 e 3.4si vedra quali sono i packages di Open Cascade che sono stati aggiunti all’interprete.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 115
3.1 Le strutture dati della FFI
Il package SchemePack e stato appositamente realizzato per fornire all’interprete Sche-me l’infrastruttura per poter accedere alle variabili C++, infrastruttura che e quindicomposta da classi C++ e da metodi statici o di istanza.
Il problema principale e stato quello di “comunicare” all’interprete Scheme la composi-zione interna dei dati primitivi o strutturati del C++1. In tal senso i file di interfacciaCDL stabiliscono in modo univoco la sintassi e la semantica dei componenti software.
Attraverso il linguaggio CDL sara inoltre possibile eseguire sui dati C++ delle “con-versioni di tipo”: conversioni che possono operare sia in un contesto omogeneo (adesempio i quattro tipi di conversioni del C++) sia in un contesto misto (ad esempio itipi primitivi di Scheme sono mappati nei tipi primitivi di Open Cascade e viceversa).
Il contenuto del file di package SchemePack.cdl e il seguente 2:
package SchemePackuses Standard,TCollection,TColStd,MS,EDL
isenumeration ConversionLevel is
None,Exact,Promotion,Standard,User;
class HKeyAndHSequenceOfReal;--inherits transient
primitive Integer;alias Long is Integer from SchemePack;
primitive Object;primitive PointerToObject; --Is a SchemeObject**
class HCvar;class HConversion; --inherits Transient
primitive ClassCallerFunction;primitive PackageCallerFunction;
1Rispetto ai tipi primitivi la “conoscenza” e statica, cioe fissata nei sorgenti dell’applicazione. Ri-
spetto ai dati strutturati invece la “conoscenza” e dinamica in quanto legata all’interpretazione dei files
di interfaccia CDL.2Ancora una volta si ricorda che tutti i file di interfaccia sono stati significativamente semplificati
rispetto alle versioni che sono presenti nella distribuzione dell’applicazione. Cio con lo scopo di facilitare
la trattazione e concentrarci piu sui concetti generali che sui dettagli dell’implementazione.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 116
class HPackageCaller; --inherits Transientclass HClassCaller; --inherits Transientclass Caller;
MetaSchema returns MetaSchema from MS ;GetType(name:HAsciiString from TCollection)
returns Type from MS;
CallPackageMethod(packagename:CString ;methodname:CString ;args:in out HSequenceOfHCvar from SchemePack)returns HCvar from SchemePack;
---C++: return &
CallClassMethod(classname:CString ;methodname: CString ;obj:in out HCvar from SchemePack;args:in out HSequenceOfHCvar from SchemePack;mode:Integer )returns HCvar from SchemePack is private;
---C++: return &
GetLastTrace returns CString ;
end SchemePack;
Verranno ora esaminati i singoli componenti CDL.
3.1.1 Il livello delle conversioni
Il tipo enumerativo ConversionLevel specifica quali siano le operazioni di conversione“consentite” tra tipi di dati C++. Ad un valore costante piu basso corrisponde sempre3
una operazione di conversione che ha precedenza rispetto alle altre che seguono. Talevalore sara quindi di fondamentale importanza per determinare quale sia la funzioneda scegliere nel caso in cui sia presente una collisione di nomi4.
La definizione CDL del tipo ConversionLevel e la seguente:3In realta esiste l’eccezione del valore None che ha priorita piu bassa rispetto a tutte le altre
conversioni.4Come gia illustrato nel paragrafo 2.3.3 la risoluzione delle collisioni avviene nel pieno rispetto della
“regola di intersezione”.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 117
enumeration ConversionLevel is
None,Exact,Promotion,Standard,User;
Le conversioni consentite sono tutte e solo quelle previste dal comitato ANSI C++:
1. None (valore numerico 0). Non esiste nessuna conversione possibile tra argomentoeffettivo e argomento formale della funzione invocata.
2. Exact (valore numerico 1). Il tipo dell’argomento effettivo e identico al tipodell’argomento formale. E’ eventualmente prevista l’esecuzione di una conversionebanale alla quale e attribuito un valore numerico 1.1.
3. Promotion (valore numerico 2). Attraverso una operazione di “conversione perpromozione” e possibile creare una corrispondenza tra argomento effettivo e for-male.
4. User (valore numerico 3). Attraverso una conversione tramite operatore o co-struttore di classe e possibile far corrispondere l’argomento effettivo all’argomentoformale.
3.1.2 Una lista di conversioni
La classe HKeyAndHSequenceOfReal permette la memorizzazione dei “livelli” di con-versione tra una lista di argomenti effettivi e una lista di argomenti formali.
E’ noto infatti che esiste una regola che permette di effettuare operazioni di conversionetra un solo argomento effettivo e l’argomento formale ad esso connesso5. E’ necessariopero’ estendere il concetto di corrispondenza anche alle liste degli argomenti, in modoassolutamente analogo a quanto gia fatto nel capitolo 2.3.3.
Il contenuto del file SchemePack HKeyAndHSequenceOfReal.cdl e il seguente:
class HKeyAndHSequenceOfReal from SchemePackinherits TransientusesHSequenceOfReal from TColStd,Integer from SchemePack
isCreate returns HKeyAndHSequenceOfReal from SchemePack;5La classe HConversion e responsabile di eseguire tali operazioni di conversione.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 118
Create(seq:HSequenceOfReal from TColStd;key:Integer from SchemePack)returns HKeyAndHSequenceOfReal from SchemePack;
Sequence(me:in out;seq:HSequenceOfReal from TColStd);Sequence(me) returns HSequenceOfReal from TColStd;
Key(me:in out;key: Integer from SchemePack);Key(me) returns Integer from SchemePack;
fieldsmySeq: HSequenceOfReal from TColStd;myKey:Integer from SchemePack;
end;
Dovrebbe risultare piuttosto intuitivo il “modo di operare” della classe: essa memorizzaal suo interno, come stato di classe, le seguenti informazioni:
mySeq . Una lista di valori reali che rappresentano i livelli delle conversioni degliargomenti.
myKey . Un valore numerico di tipo chiave che distingue in modo univoco un metodoCDL all’interno della sua parent class.
Puo’ essere utile fornire un esempio pratico di utilizzo. Si ipotizzi che sia stato definitoil seguente metodo CDL:
Add(me; n:Integer; m:Integer);
Si supponga di invocare il metodo CDL con la seguente istruzione C++:
Add(5,’a’);
in modo che sul secondo argomento sia necessaria l’esecuzione di una conversione perpromozione. Si supponga inoltre che il metodo Add abbia indice 0 (cioe e il primometodo) rispetto al package o la classe nel quale e stato definito. In questo caso l’oggettoHKeyAndHSequenceOfReal verra istanziato con i seguenti argomenti6:
6Il codice proposto e in realta una esemplificazione del caso reale. Non e infatti possibile costruire
un oggetto HSequenceOfReal nel modo proposto.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 119
HKeyAndHSequenceOfReal(HSequenceOfReal(0.0,1.0),0);
Il primo valore della sequenza di reali (valore 0.0) indica una corrispondenza esatta;il secondo (valore 1.0) indica una corrispondenza per promozione. Tale vettore sarasuccessivamente utilizzato dall’algoritmo che applica la regola di intersezione 7 (vediparagrafo 2.3.3).
3.1.3 Il tipo primitivo Integer
Nel package SchemePack e stato definito un nuovo tipo di dati primitivo Integer:
primitive Integer;
alias Long is Integer from SchemePack;
L’alias Long e stato aggiunto con lo scopo di facilitare la leggibilita del codice sorgente.
La motivazione principale per cui e stato introdotto il tipo Integer e la seguente:nelle librerie di Open Cascade si fa uso quasi esclusivamente di valori numerici di tipoReal per la manipolazione dei modelli geometrici. I dati di tipo Integer sono inveceutilizzati come valori “contatore”, ed e per questo che sono definiti come tipi C++ int8.
In MzScheme invece tutti i valori interi sono in realta dei long. Per evitare quindiproblemi di conversione e di approssimazione9 e stato adottato come tipo “riferimento”rispetto ai valori interi i long di MzScheme.
Quindi il contenuto del file SchemePack Integer.hxx e il seguente:
typedef long SchemePack_Integer;
7E’ evidente che l’unico metodo che puo’ avere precedenza rispetto alla funzione Add proposta e un
metodo che esegua due conversioni esatte.8Gli int hanno solitamente una occupazione in byte minore rispetto al tipo long9L’utente potrebbe voler implementare dei propri algoritmi geometrici in Scheme (che cioe effettuino
calcoli e “gestiscano” numeri) per poi passare i risultati ottenuti a qualche funzione di Ocas. Se la
conversione fosse “diretta” potrebbero esserci dei problemi di “troncamento dei valori”.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 120
ValoriScheme
ValoriScheme
ValoriC++
ValoriC++
FunzioniMapping e Unmapping
(1)
(2a
)e
(2b
)
Figura 3.2: Le direzioni delle conversioni degli oggetti.
3.1.4 Gli oggetti Scheme
Esiste un altro tipo di dato primitivo che e stato introdotto nel package SchemePack
oltre agli Integer, il tipo Object:
primitive Object;
primitive PointerToObject;
il cui typedef C++ e il seguente:
typedef Scheme_Object* SchemePack_Object;
typedef Scheme_Object** SchemePack_PointerToObject;
Per comprendere a fondo il reale “significato” degli oggetti di questo tipo, nonche laloro modalita di utilizzo, e necessaria una breve premessa. La collaborazione tra isistemi Open Cascade e Scheme puo’ essere vista come se avvenisse in due differenti“direzioni”:
1. Conversioni di oggetti C++ in oggetti Scheme accessibili da shell.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 121
2. Conversioni di oggetti Scheme in oggetti C++ accessibili dal codice delle librerie.Nell’ambito delle collaborazioni di questo tipo esistono due ulteriori sotto-casisignificativi:
(a) Conversioni che possono avvenire creando valori noti rispetto all’ambienteCDL, siano essi dati primitivi o strutturati. Ad esempio un valore intero diScheme (scheme integer) e mappato nel tipo Long del package SchemePack.
(b) Conversioni che operano su dati sconosciuti rispetto all’ambiente CDL, cioela cui descrizione non e disponibile attraverso un file di interfaccia. Il tipoObject serve proprio per gestire valori di questo tipo.
Un valore di tipo Object permettere quindi alle funzioni C++ di “accedere” diret-tamente alle strutture dati dell’interprete Scheme senza che queste siano manipolateda un qualche algoritmo di conversione: nel caso in qui la FFI non sappia infatti co-me convertire il dato Scheme in un dato CDL lo “traduce”10 automaticamente in unoSchemePack Object.
Se una funzione C++ richiede come argomento uno scheme object*, esiste una corri-spondenza esatta tra lo scheme object* stesso e l’oggetto SchemePack Object 11.
Un esempio puo’ facilitare la comprensione dei concetti fin qui esposti. Si suppongaquindi di definire una funzione che abbia il seguente prototipo CDL:
Add(me;add_function:Object from SchemePack;
n:Integer;m:Integer) returns Integer;
Il programma Cpp Extractor creera il seguente prototipo C++:
int Add(scheme_object* obj,int n,int m);
La funzione Add il questo caso deve valutare la somma12 dei due valori n ed m applicandouna “generica” funzione Scheme add function.
10Viene qui usato impropriamente il termine “traduce” in quanto non viene applicata nessuna
conversione: l’oggetto e incapsulato direttamente all’interno di una struttura HCvar.11Rispetto al tipo Object, cosı come per tutti i tipi primitivi, e possibile applicare solo una cor-
rispondenza esatta. Non sono invece possibili corrispondenze attraverso conversioni per promozione,
standard o utente.12Il termine “somma” in questo caso non significa somma algebrica di due valori numerici, ma indica
una generica operazione binaria.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 122
Ad esempio in Scheme e possibile eseguire il seguente script:
(define add_function
(lambda (n m)(+ (* n n) (*m m)))
(send <obj> Add add_function 2 3)
La funzione C++ Add dovra quindi invocare la procedura Scheme add function:
Scheme_Object *args[2];
args[0] = n;
args[1] = m;
scheme_apply(add_function, 2,args);
ottenendo, come ovvio, il risultato numerico 13 (il quadrato di 2 addizionato al quadratodi 3)
Si noti come i valori dell’interprete 2 e 3 siano gia stati convertiti dalla FFI in valoriC++ di tipo int.
Il tipo primitivo PointerToObject e stato infine introdotto in SchemePack in modo dapermettere ad una funzione C++ di ricevere in ingresso un array di argomenti.
3.1.5 Le variabili C++ in istanze di classe HCvar
La classe HCvar e sicuramente la classe piu importante di tutto il sistema sviluppato.Tutto quanto e gia stato detto in relazione alle strutture dati e alla loro condivisionetra i due sistemi Scheme e Open Cascade trova immediata applicazione nell’invocazionedegli appositi metodi di questa classe.
E’ stato introdotto nell’interprete Scheme un nuovo tipo di oggetto che svolga le fun-zioni di “variabile C/C++”; cio implica principalmente “gestire” e/o manipolare datistrutturati ai quali viene associato un tipo, e il cui contenuto (metodi, variabili diistanza etc) e noto effettuando il parsing dei files di interfaccia CDL.
In merito al nome della classe va fatta una importante precisazione: all’interno dellelibrerie di Ocas e di solito utilizzata la convenzione di anteporre al nome delle classi“manipolate tramite handle” (cioe che derivano dalle classi Persistent o Transient)

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 123
la lettera “H”, cio appunto con lo scopo di individuare immediatamente quali siano glioggetti in memoria che verranno deallocati in modo automatico dal Memory Managerdi Ocas13.
Nella prima versione del programma si era deciso che la classe HCvar dovesse derivaredalla classe Transient:
class HCvar inherits Transient from Standard
Si e pero’ successivamente constatato come tale scelta comportava svariati problemiin particolari condizioni operative del programma: potevano infatti crearsi infatti deicircular references che di fatto impedivano il rilascio di alcune zone di memoria; e inoltrenon era possibile far “cooperare” correttamente l’algoritmo di Garbage Collecting diMzScheme con il Memory Manager di Ocas.
Si e quindi deciso di dichiarare la classe HCvar come oggetto “manipolato per valore”.Il nome HCVar e pero’ rimasto per ragioni “storiche”.
Questo tra l’altro conferma come la classe HCvar sia il componente CDL che piu di altriha subito notevoli modifiche nel corso dell’evoluzione del progetto.
Caratteristiche della classe HCvar
Queste sono le caratteristiche piu importanti che dovrebbero caratterizzare il compor-tamento della classe HCvar:
Completezza E’ necessario stabilire un insieme possibilmente minimo di operazioniche e possibile eseguire rispetto alle variabili C/C++14.
Una volta stabilito tale insieme si dovra quindi verificare che l’interfaccia dellaclasse esponga dei servizi “sufficienti” per fare in modo che tutte le operazioni ditale insieme possano essere eseguite.
Questo non vuol dire che il rapporto tra operazioni e metodi esposti sia di “unoad uno”: e possibile che una data operazione sia eseguibile “componendo” piumetodi di classe.
13Al contrario sappiamo che per gli oggetti “manipolati per valore” e il programmatore stesso che
deve eseguire le operazioni di deallocazione.14In realta sarebbe piu corretto dire “variabili CDL” piuttosto che “variabili C++” in quanto il
linguaggio CDL stabilisce precisi limiti in relazione alle variabili e alle modalita di passaggio dei valori.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 124
Espressivita La classe HCvar e il principale strumento di comunicazione tra la FFI eil programmatore.
L’interazione con i servizi della classe dovra quindi essere il piu possibile semplifi-cato e dovra inoltre essere possibile compiere operazioni anche piuttosto complessecon poco codice.
Semplicita E’ necessario che l’utente capisca a fondo il funzionamento “interno” deimetodi di classe in modo che:
1. Possa facilmente capire quali siano i servizi dei quali usufruira.
2. Incorra difficilmente in situazioni di errore.
Soprattutto in relazione a questo punto non sono ancora stati raggiunti risultati“definitivi”.
E’ necessaria una ulteriore precisazione: dal punto di vista dell’interprete un oggettoHCvar e un oggetto atomico e indipendente rispetto a tutti gli altri tipi CDL, siano essiclassi o package.
Se ad esempio si crea una istanza User del package MyPack:
(define inst (make-object MyPack_User% ...))
tale oggetto sara sempre per l’interprete Scheme una istanza di MyPack User e mai unaistanza della classe SchemePack HCvar.
Questo avviene anche se in realta la inst e a tutti gli effetti una struttura dati ditipo HCvar sia nei “contenuti binari” (la classe C++ utilizzata e la stessa) sia nelcomportamento.
Cio che in realta cambia e che, avendo definito l’oggetto in questione come una istanzadi MyPack User, sara possibile invocare i metodi specifici e “proprietari” della classeUser attraverso la primitiva send:
(send inst method-name arg ...)
cosa che invece non sarebbe stata possibile nel caso in cui l’interprete “veda” la inst
come una struttura HCvar.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 125
Poiche pero’ sara comunque necessario invocare un metodo della HCvar su un oggetto ditipo “classe CDL” (il che tra l’altro e logico come si e visto anche da un punto di vistasemantico) e stato introdotto per ogni metodo della HCvar un corrispondente metodostatico, che quindi riceve come primo argomento l’oggetto sul quale deve operare.
Ad esempio per invocare il metodo Dump 15 la seguente istruzione causerebbe un errore:
(send inst Dump)
in quanto la inst in senso stretto non contiene i metodi della HCvar. E’ necessarioinvece invocare il metodo statico ad essa associato:
(SchemePack_HCvar_Dump inst)
E’ adesso possibile analizzare il contenuto della classe HCvar.
Lo stato della classe HCvar
Lo stato di ogni oggetto HCvar e univocamente definito dai seguenti fields:
class HCvar [...]
fields
myType:Type from MS;
IsConst:Boolean;
IsRef:Boolean;
Address:Integer from SchemePack;
end HCvar;
Il significato di tali campi e il seguente:
myType Ogni oggetto in memoria che sia accessibile dalla FFI e tipizzato cioe gliviene associato una informazione di “tipo CDL”. Di solito l’utente non dovrebbemodificare direttamente il valore di questo campo.
15Il metodo in questione stampa a video alcune informazioni sul contenuto dell’oggetto quali: il tipo,
il valore etc.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 126
IsConst Nel linguaggio CDL un variabile puo’ essere un valore di sola lettura, cioetutte le operazioni di scrittura sull’r-value della variabile sono impedite 16.
IsRef Questo campo indica se il valore della variabile e in realta un riferimento con-diviso con qualche altra variabile.
Una modifica su una delle due istanze linkate influenzera anche il contenutodell’altra istanza in quanto entrambe puntano in realta alla stessa regione dimemoria.
I motivi per cui e stato necessario aggiungere il campo IsRef sono i seguenti:
1. E’ fondamentale sapere se una variabile e in realta un riferimento ad un al-tro oggetto in memoria in quanto la distruzione della prima variabile “riferi-mento” non deve mai implicare la deallocazione della memoria referenziata;memoria che al contrario potrebbe essere ancora utilizzata dalla variabile“non riferimento”.
2. Per alcune tipologie di dati, quali ad esempio i tipi CDL primitivi, la moda-lita di restituzione di un valore per “riferimento” deve essere gestito in modoparticolare.
Si consideri ad esempio il seguente metodo di classe che restituisce un valoreInteger per riferimento:
MyMethod returns Integer;
---C++: return &
Il valore di riferimento potrebbe essere un alias verso una variabile incapsu-lata nel body della classe.
Ci si aspetterebbe che una qualsiasi modifica rispetto a tale dato si debba“riflettere” anche e soprattutto sul dato “originale”17.
Se il valore di ritorno fosse semplicemente mappato in un oggetto “copia” ditipo scheme integer18 la “riflessione” non potrebbe essere attuata in quantole due variabili farebbero riferimento a due locazioni di memoria differenti.
16Per gli argomenti di “ingresso” si specifica l’attributo out. Per i valori di uscita si specifica la
direttiva CDL “---C++:return const[&]”.17E’ molto probabile che sia proprio per questo motivo che il programmatore ha specificato che la
restituzione del dato deve essere di tipo referenced.18In tutti i linguaggi funzionali le operazioni con side effect non sono solo di solito impedite, ma
sono anche “mal viste”. Noi invece stiamo percorrendo la strada esattamente opposta, cioe abbiamo
“pesantemente” introdotto il side effect all’interno dell’interprete Scheme. Non avremmo comunque
potuto agire diversamente, in quanto vogliamo costruire un ambiente sintatticamente omogeneo (sintassi
di Scheme) ma semanticamente eterogeoneo (semantica di Scheme e del C++).

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 127
Al contrario sara creata una nuova istanza HCvar in cui il campo myType esettato sul tipo Integer e il cui campo IsRef e impostato al valore true.
Successivamente sara spiegato come sia possibile modificare il valore dei fieldsdella classe HCvar (primitiva cset) e come sia possibile creare un nuovooggetto Scheme “nativo” a partire da una variabile “riferimento” (primitivaDeepValue).
Address Il campo Address e una variabile di tipo indirizzo che punta alle variabiliC/C++ vere e proprie, cioe le variabili C++ che vengono integrate nell’interpreteScheme.
L’indirizzo e memorizzato come uno SchemePack Integer cioe come un dato ditipo long.
I costruttori della classe HCvar
I costruttori e i distruttori “tradizionali” della classe HCvar (cioe il costruttore didefault, il costruttore di copia etc) sono i seguenti:
Create returns HCvar from SchemePack;Create(source:HCvar)returns HCvar from SchemePack;Destroy(me:in out);
Particolare attenzione deve essere invece riservata al costruttore che ha come parametrodi ingresso il tipo della variabile:
Create(type:Type from MS) returns HCvar from SchemePack;
In questo caso viene allocata la memoria per la memorizzazione delle informazionidi “contorno” (quella che precedentemente e stata indicata come “infrastruttura”) inrelazione alla variabile C++; viene tipizzata tale variabile attraverso l’argomento type;ma la variabile non viene inizializzata e quindi tantomeno viene allocata la memorianecessaria per contenere il dato C++ incapsulato.
Per facilitare la creazione di alcuni particolari dati primitivi, dei quali sicuramente eprevisto un utilizzo piu frequente rispetto a tutti gli altri, sono stati aggiunti anchedegli altri costruttori specifici:

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 128
Create (val:CString) returns HCvar from SchemePack;Create (val:Boolean) returns HCvar from SchemePack;Create (val:Character) returns HCvar from SchemePack;Create (val:Integer) returns HCvar from SchemePack;Create (val:Real) returns HCvar from SchemePack;Create (val:ExtCharacter) returns HCvar from SchemePack;Create (val:ExtString) returns HCvar from SchemePack;Create (val:Address) returns HCvar from SchemePack;Create (val:Byte) returns HCvar from SchemePack;Create (val:ShortReal) returns HCvar from SchemePack;Create (val:Integer from SchemePack)returns HCvar from SchemePack;
Create (val:Object from SchemePack)returns HCvar from SchemePack;
Si vuole sottolineare tra tutti l’importanza dell’ultimo costruttore che riceve in ingressoun valore di tipo Object. In questo caso l’istanza di classe HCvar incapsula al suointerno il dato Scheme cosı da permettere alle librerie C++ un accesso diretto ai datidell’interprete.
Creazione di variabili C++ in Scheme
In realta tutti questi costruttori sono “nascosti” all’utente Scheme e possono essereinvocati solo tramite codice in linguaggio C++19. E’ quindi necessario fornire al pro-grammatore alcuni metodi statici di classe che funzionino da link rispetto ai metodi dicui sopra:
cstring(myclass;val:CString)returns HCvar from SchemePack;cbool(myclass;val:Boolean) returns HCvar from SchemePack;cchar(myclass;val:Character)returns HCvar from SchemePack;cint(myclass;val:Integer)returns HCvar from SchemePack;cdouble(myclass;val:Real)returns HCvar from SchemePack;cshort(myclass;val:ExtCharacter)returns HCvar from SchemePack;
cbyte(myclass;val:Byte)returns HCvar from SchemePack;cfloat(myclass;val:ShortReal)returns HCvar from SchemePack;clong(myclass;val:Integer from SchemePack)returns HCvar from SchemePack;
cschemeobj(myclass;val:Object from SchemePack)19Le motivazioni di questa limitazione, che siamo sicuri in questo momento possa apparire totalmente
ingiustificata, saranno chiari nel momento in cui spiegheremo il funzionamento della primitiva Map

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 129
returns HCvar from SchemePack;cshortstar(myclass;val:Integer from SchemePack)returns HCvar from SchemePack;
caddress(myclass;val:Integer from SchemePack)returns HCvar from SchemePack;
Se ad esempio da shell si desiderasse “costruire” un valore di tipo booleano:
(SchemePack_HCvar_cbool #t)
Per invocare un metodo statico di classe e necessario anteporre al nome del metodo ilnome della classe di appartenenza (che e appunto SchemePack HCvar20); devono quindiseguire gli argomenti di ingresso.
Ci si chiedera il motivo per il quale una variabile booleana debba essere creata attraversola cbool quando in Scheme e sufficiente utilizzare la primitiva define:
(define var #t)
La spiegazione e pero’ ovvia se si analizza a fondo il reale significato delle due istruzioniprecedenti: la var dichiarata in Scheme non puo’ essere infatti una variabile C++; cioenon e un oggetto in memoria il cui contenuto binario possa essere modificato21.
La var non puo’ neppure essere passata come argomento ad una funzione che richiedesseun valore booleano C++ passato per “riferimento”:
MyFunction(me;val:in out Boolean);
D’altronde il caso e molto simile a quello che si e gia visto precedentemente in me-rito ai valori di ritorno di una funzione: e possibile creare un nuovo valore di tiposcheme boolean solo quanto l’oggetto restituito e passato per valore, non certo quandoquesto e passato per riferimento, nel qual caso e invece esplicitamente richiesto chel’oggetto sia condiviso tra piu variabili.
20Il nome completo di classe e sempre formato dal nome del package e dal nome della classe in senso
stretto separati dal carattere “ ”.21In realta la stessa define potrebbe essere vista come istruzione con side effect ma cio’ avviene in
modo molto diverso rispetto al C++: un nuovo define, piuttosto che creare una variabile, crea infatti
una nuova definizione nell’environment.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 130
I concetti esposti saranno comunque ulteriormente approfonditi quanto verra spiegatonel dettaglio il funzionamento del codice che implementa le funzioni Map e UnMap.
Metodi per la modifica dello stato
I seguenti metodi servono invece per impostare o interrogare il tipo associato ad unaistanza di HCvar:
Type(me) returns Type from MS;Type(me:in out;type:Type from MS);TypeName(me) returns CString;TypeName(me:in out;name:CString);IsVoid(me) returns Boolean ;IsSameType(me;type:Type from MS) returns Boolean ;IsSameType(me;name:CString) returns Boolean ;
IsString(me)returns Boolean;IsBool(me)returns Boolean;IsChar(me)returns Boolean;IsByte(me)returns Boolean;IsShort(me) returns Boolean;IsInteger(me)returns Boolean;IsLong(me)returns Boolean;IsFloat(me)returns Boolean;IsReal(me)returns Boolean;IsSchemeObject(me)returns Boolean;IsAddress(me)returns Boolean;IsExtString(me)returns Boolean;IsHCvar(me)returns Boolean;
Sebbene sia comunque permesso che l’utente possa variare manualmente il tipo asso-ciato ad una variabile HCvar, si dovra comunque fare in modo che il contenuto dellavariabile sia “allineato” con il tipo dichiarato; in caso contrario si andra sicuramenteincontro ad errori a tempo di esecuzione.
Il comportamento e in questo caso esattamente analogo a quanto avverrebbe in C++se venissero effettute in modo indiscriminato delle operazioni statiche di type castingrispetto ad un puntatore void*22.
22Una differenza sostanziale tra i linguaggi funzionali e il C++ consiste nel fatto che nel linguaggio
C++ il programmatore puo’ praticamente intervenire fino al livello del contenuto binario della memoria,

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 131
E’ possibile inoltre accedere in lettura e in scrittura allo stato della classe attraverso iseguenti metodi:
IsConst(me:in out;value:Boolean);IsConst(me)returns Boolean ;IsRef(me:in out;value:Boolean);IsRef(me)returns Boolean;SetValue(me:in out;address:Integer from SchemePack);GetValue(me) returns Integer from SchemePack;SetConstValue(me:in out;address:Integer from SchemePack);GetConstValue(me) returns Integer from SchemePack;
Un esempio pratico di utilizzo e il seguente: si supponga di voler creare una variabilereferenced costante. Attraverso il nuovo link si desidera che sia impedito l’accesso inscrittura all’ oggetto C++:
(define (build-ref source-var)(begin
(define ret (make-object SchemePack_HCvar%))(send ret Type (send source-var Type))(send ret SetConstValue (send source-var GetConstValue))(send ret IsRef #t)ret))
E’ necessario prima di tutto creare l’oggetto (make object); se ne imposta il tipo(send ret Type); e infine il campo Address e impostato al valore dell’indirizzo dellasource-var (SetConstValue).
Debugging della FFI
E’ stato introdotto nella classe HCvar un metodo che faciliti il debugging degli scriptScheme:
Dump(me) returns CString;
Il metodo Dump provvede a stampare a video tutte le informazioni significative associatealla variabile (tipo, indirizzo etc):
cosa che e assolutamente vietata ad esempio in Scheme. Ancora una volta siamo quindi di fronte a
filosofie di programmazione completamente differenti.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 132
(send (SchemePack_HCvar_cbool #t) Dump)
THIS = 58677784TYPE= Standard_BooleanINTERNAL ADDRESS = 58677832IS CONSTANT = 0IS REFERENCE = 0DEEP VAL = #t
Un’altra funzione particolarmente importante della HCvar e la funzione DeepValue:
DeepValue(me) returns Object from SchemePack;
Per adesso e sufficiente dire che tale funzione cerca di accedere al valore contenutoin una istanza di classe HCvar e cerca di creare un nuovo oggetto Scheme “nativo”(scheme object*) inizializzandolo con il valore “di copia” contenuto nella HCvar.
Nel caso in cui la DeepValue fallisse, ad esempio perche l’oggetto C++ non e traducibilein nessuna struttura dati “nativa” dell’interprete, il valore restituito e nullo.
Le funzioni Map ed Unmap
Verra adesso analizzato il comportamento di due funzioni particolarmente importantidella FFI, la Map e la UnMap:
Map(myclass;obj:Object from SchemePack)
returns HCvar from SchemePack;
---C++: return &
UnMap(me) returns Object from SchemePack;
Nel momento in cui viene invocata una qualche funzione di libreria C++ da parte delprogrammatore Scheme, e cioe ogni volta in cui esiste la necessita di accedere ad unafunzione esterna all’interprete, la FFI provvedera a “preprocessare” gli argomenti diingresso attraverso la funzione Map, trasformandoli quindi in oggetti di tipo HCvar.
Tutte le funzioni all’interno della classe SchemePack, a partire dal “risolutore dellecollisioni” fino ad arrivare alla classe che effettua le conversioni C++, possono operaresolo ed esclusivamente su strutture dati HCvar.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 133
invocazioneda shell
operazione di
degli argomentimapping
risoluzione dellachiamata
esecuzione funzionelibreria
creazione valoredi ritorno
operazione di
del valore di ritornounmapping
controllo alla shell
Figura 3.3: Operazioni della FFI.
Gli argomenti di ingresso in questione possono appartenere a quattro categorie distinte:
• Oggetti “nativi” Scheme che possono essere convertiti in variabili C++ da inglo-bare in una istanza di classe HCvar. La “tabella delle conversioni” e la seguente:
Valori Scheme Variabile HCvar
scheme true truescheme false falsescheme char SCHEME CHAR VAL(obj)scheme int SCHEME INT VAL(obj)scheme dbl SCHEME DBL VAL(obj)scheme string SCHEME STR VAL(obj)
Vengono quindi invocati gli opportuni costruttori della HCvar e viene inoltre im-postato a true il valore del field IsConst. Infatti, in conformita alle regole chestabiliscono il comportamento di un compilatore ANSI C++, la creazione di unnuovo oggetto in memoria crea una variabile “temporanea” che non puo’ esserepassata per riferimento.
• Oggetti di classe CDL precedentemente creati dalla FFI. In questo caso e suf-

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 134
ficiente recuperare l’oggetto HCvar contenuto nello scheme object attraverso ilcampo primdata:
(*((SchemePack_HCvar*)schobj->primdata))
• Oggetti di classe HCvar. Valgono le considerazioni del caso precedente. Si e infattigia dimostrato come in realta gli oggetti HCvar siano assolutamente compatibilia livello binario con gli oggetti di tipo classe CDL.
• Altri tipi di oggetti. Vale la regola che tutti gli scheme object* che rispettoalla FFI non hanno significato, e che quindi non possono essere convertiti, sonodirettamente inglobati all’interno della HCvar come SchemePack Object.
Nel momento in cui si ha a disposizione l’oggetto HCvar e possibile finalmente utilizzarloper invocare la funzione C++23.
Il valore di ritorno sara quindi processato dalla funzione UnMap che opera una conver-sione del valore C++ 24 in uno scheme object.
E’ necessario distinguere tre differenti casi:
• Valori che sono convertibili in oggetti Scheme “nativi” con modalita di passaggioper valore (IsRef e impostato a false). La “tabella delle conversioni” e laseguente:
Valori Scheme Variabile HCvar
Standard CString scheme trueStandard Boolean scheme falseStandard Character scheme make charStandard Integer scheme make integerStandard Real scheme make doubleStandard ExtCharacter scheme make integerStandard Byte scheme make charStandard ShortReal scheme make doubleSchemePack Integer scheme make integerSchemePack Object scheme object*
23In realta potrebbero essere necessarie delle conversioni di tipo.24In realta non e un valore C++ ma una variabile HCvar costruita dalla FFI e cioe nello specifico
costruita dal codice generato dal programma Scheme Extractor.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 135
• Valori di classi CDL. E’ creata una nuova classe attraverso la scheme make class
e il campo primdata e impostato al valore restituito. E’ indifferente se talevariabile sia passata per riferimento o meno.
• Altri valori. E’ creata una nuova istanza di classe HCvar. Analogamente al casoprecedente l’oggetto Scheme incapsulera la variabile C++ nel campo primdata.
I dettagli della costruzione dei valori di ritorno e della modalita di recupero dei datiincapsulati all’interno delle variabili HCvar saranno approfonditi nel paragrafo 3.1.5.
E’ importate ribadire l’importanza che riveste il campo IsRef rispetto all’algoritmo diUnMapping: non e infatti previsto che l’interprete Scheme possa modificare variabili.
E’ per questo che la FFI non puo’ tradurre i “valori per riferimento” senza far ricorso adun qualche tipo di struttura “aggiunta” che simuli il comportamento di un compilatoreC++. Tale struttura aggiunta e appunto la HCvar che pero’ e utilizzata il meno possibilee solo quando e strettamente necessario, cioe quando il valore di IsRef e impostato atrue.
L’operazione di assegnazione del C++ in Scheme
L’ultimo metodo della classe HCvar che rimane da esaminare e la funzione cset; talemetodo serve a simulare la presenza dell’operazione di assegnazione del C++ in Scheme:
cset(me:in out;val:in out HCvar from SchemePack);
La funzione cset prova anzitutto ad effettuare una conversione in modo che il valorefornito come argomento di ingresso possa essere compatibile con il “tipo destinazione”della HCvar; se la conversione ha successo effettua quindi l’assegnazione C++ verae propria. Cio comporta la modifica della locazione di memoria puntata dal campoAddress della HCvar.
Si supponga di dover modificare un oggetto HCvar referenced il cui DeepValue sia unbooleano che si desidera impostare a false:
(SchemePack_HCvar_cset obj #t)
Se il booleano in questione e una variabile condivisa con qualche altra variabile dilibreria C++, entrambe verranno “aggiornate”.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 136
3.1.6 La conversione tra tipi
La classe HConversion e responsabile dell’esecuzione delle operazioni di conversioni travariabili C++, operazioni che si suddividono in quattro categorie: conversioni esatte,per promozione, standard o utente.
Ogni volta che una istanza di classe HCvar e il parametro attuale rispetto all’invocazionedi una funzione, si tenta di renderla compatibile con il parametro formale il cui tipo e icui attributi (const, reference o altro ) sono determinati dal file di interfaccia CDL.
Il prototipo della classe HConversion e il seguente:
Create(source:in out HCvar from SchemePack;dest:Param from MS)
returns HConversion from SchemePack;
Execute(me:in out;upto:ConversionLevel from SchemePack)returns Boolean from Standard;
GetLastConversionOutput(me) returns HCvar from SchemePack;---C++: return &
E’ necessario invocare il costruttore per creare un nuovo oggetto HConversion.
Quindi viene eseguita la conversione invocando la primitiva Execute; si puo’ eventual-mente stabilire fino a che livello la Execute puo’ cercare di stabilire la corrisponden-za. Ad esempio si possono escludere le conversioni utente nel caso in cui la velocitadell’applicazione risultasse eccessivamente rallentata.
Infine viene invocata la funzione GetLastConversionOutput per ottenere il risultatodella Execute.
3.1.7 I metodi statici del package
All’interno del package SchemePack sono presenti dei metodi di package (anche dettiExtern Method per distinguerli dai Member Method di classe) che offrono dei servizi diutilita generale rispetto ai tipi CDL fin qui presentati.
I metodi di package siano molto simili a tutti gli altri tipi di metodi di classe: un packagee infatti “tradotto” dal programma Cpp Extractor in una classe statica C++.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 137
I prototipi CDL di SchemePack sono i seguenti:
MetaSchema returns MetaSchema from MS ;
GetType(name:HAsciiString from TCollection)returns Type from MS;
CallPackageMethod(packagename:CString;methodname:CString;args:in out HSequenceOfHCvar from SchemePack)returns HCvar from SchemePack;
CallClassConstructor(classname:CString from Standard;args:in out HSequenceOfHCvar from SchemePack)returns HCvar from SchemePack ;
---C++: return &
CallClassInstanceMethod(classname:CString from Standard;methodname: CString from Standard;obj:in out HCvar from SchemePack;args:in out HSequenceOfHCvar from SchemePack)returns HCvar from SchemePack;
---C++: return &
CallClassStaticMethod(classname:CString from Standard;methodname: CString from Standard;args:in out HSequenceOfHCvar from SchemePack)returns HCvar from SchemePack;
---C++: return &
GetLastTrace returns CString ;
Il primo metodo restituisce un valore MetaSchema che e a una sorta di “contenitore”delle classi e dei packages CDL: il programma CDL Front, nel momento in cui effettuail parsing dei files di interfaccia, aggiunge le definizioni al Metaschema.
Il metodo GetType restituisce un valore MS Type che serve per la tipizzazione delleHCvar. Ad esempio si supponga di creare una nuova variabile Integer:
(define var (make-object SchemePack_HCvar%))

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 138
(define name(make-object TCollection_HAsciiString% ’"Standard_Integer"))
(send var Type (SchemePack_GetType name))
Si sarebbe potuto ottenere lo stesso risultato utilizzando il metodo TypeName dellaclasse HCvar.
I metodi Call sono responsabili di invocare dinamicamente le funzioni C++ alle qualivengono applicati gli argomenti che l’utente fornisce dinamicamente. Ad esempio nelloscript che segue:
(define args (make-object SchemePack_HSequenceOfHCvar% 1))(send args Append (SchemePack_HCvar_cint 255))(define ret(SchemePack_CallClassStaticMethod
"ClassName" "MethodName" args)
la variabile args contiene i parametri di ingresso per invocare la funzione. Il valore diritorno ret sara sempre una istanza HCvar; si puo’ tentare di convertirlo in un oggettoScheme invocato la funzione UnMap.
Dopo l’esecuzione di ogni azione da parte della FFI e possibile stampare a video unaschermata che contenga tutti i dettagli delle azioni e delle conversioni effettuate. Adesempio:
(define val (make-object TCollection_HAsciiString% "hello"))(SchemePack_GetLastTrace)
Calling Class MethodClass name = TCollection_HAsciiStringMethod name = TCollection_HAsciiStringArgs number = 11. ADDRESS=58676352
TYPE=Standard_CStringISCONST=1 ISREF=0DEEPVAL=hello
Caller address = 10106976Number of methods 67Class Constructor Call
(ID 2) Candidate conversion:TCollection_HAsciiString::Create(Standard_CString)

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 139
const Standard_CString->(exact) 1.100000
(ID 7) Candidate conversion:TCollection_HAsciiString::Create(TCollection_AsciiString)const Standard_CString->(user::constructor) 4.110000
(ID 8) Candidate conversion:TCollection_HAsciiString::Create(TCollection_HAsciiString)const Standard_CString->(user::constructor) 4.110000
(ID 9) Candidate conversion:TCollection_HAsciiString::Create(TCollection_HExtendedString)const Standard_CString->(user::constructor) 4.110000
(ID 2) Best conversionTCollection_HAsciiString::Create(Standard_CString)const Standard_CString->(exact) 1.100000)Executing...DONE.
Si noti come nel tentativo di costruire un oggetto di tipo HAsciiString a partire dallascheme string esistono diverse corrispondenze possibili.
Ad esempio la scheme string puo’ essere convertita in una Standard CString at-traverso una conversione esatta banale (valore 1.1), cioe attraverso l’esecuzione delsecondo costruttore di classe (ID=2).
Oppure e possibile convertire la scheme string in una HAsciiString applicando unaconversione utente di quarto livello (valore 4.11); in questo caso e necessario eseguireil codice del settimo costruttore di classe (ID=7).
Tutti i 67 metodi della classe HAsciiString sono esaminati alla ricerca della best con-version fino a che l’Overloading Solver 25 non stabilisce quale sia metodo miglioresecondo la “regola di intersezione”.
3.2 L’estrattore Scheme della FFI
Nei paragrafi precedenti si e spiegato come sia possibile introdurre nella shell Schemele variabili del C++ tipizzandole a tempo di esecuzione con i files di interfaccia CDL.
25Nel paragrafo 3.2.1 esamineremo nel dettaglio il comportamento dell’Overloading Solver e degli
altri componenti della FFI.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 140
SchemeCDL
SchemeTest
SchemePack
OcasPackage
OcasGeomPack
Low level
Upper Level
Figura 3.4: Architettura del progetto.
Non si e pero’ ancora visto ne’ quale sia il reale comportamento degli estrattori ne’come sia possibile invocare il processo di estrazione.
Dal punto di vista dell’architettura del software il package SchemeCDL e il componentepiu a basso livello rispetto a tutte le librerie fin qui descritte.
Il package SchemeCDL contiene le definizioni e le implementazioni degli estrattori, cioedei componenti che generano in modo automatico i seguenti files di progetto:
Header files C++ . Sono i files generati dal programma Cpp Extractor.
Il processo per la creazione del codice C++ e stato gia ampiamente spiegato nelparagrafo 2.2.
Il programma Cpp Extractor e precompilato all’interno della distribuzione “ori-ginale” di Open Cascade e non e stato modificato in modo signicativo 26
Files della FFI Sono i files generati dal programma Scheme Extractor cioe i files chepermettono la comunicazione vera e propria tra i sistemi Scheme e Open Cascade.
Il package SchemeCDL non definisce nessun nuovo componente software di tipo classe;e cioe costituito da soli metodi statici.
Il metodo ParseCommand riceve in ingresso una stringa di comando (cmd) che specificaquali siano i package da “esaminare” (packs); quali packages devono essere “elaborati”
26In realta cio e vero solo parzialmente. E’ infatti da considerare che i tools che riguardano il
linguaggio CDL sono stati concepiti in modo da funzionare unicamente all’interno di una shell basata su
TCL. Da parte nostra abbiamo quindi eliminato tale vincolo costruendo un nuovo front-end attraverso
cui invocare i servizi di CDL tramite la normale shell di sistema. Cio ha comportato quindi uno studio
approfondito del codice sorgente della libreria TKWok.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 141
ParseCommand CDLFront
CPPExtract
SchemeExtract
packs
cpppacks
schemepacks
Figura 3.5: Funzionamento del programma schemeext.
dal Cpp Extractor (cpppacks) e infine quali packages devono essere elaborati dalloScheme Extractor (schemepacks):
ParseCommand(cmd: HSequenceOfHAsciiString;packs: in out HSequenceOfHAsciiString;cdldirs: in out HSequenceOfHAsciiString;cpppacks: in out HSequenceOfHAsciiString;cppdirs: in out HSequenceOfHAsciiString;schemepacks: in out HSequenceOfHAsciiString;schemedirs: in out HSequenceOfHAsciiString;usage:in out HAsciiString)returns Boolean;
Il metodo CDLFront provvede a “caricare” un file di package e ad effettuare il parsingper la costruzione delle strutture dati MS:
CDLFront(packagename:CString;cdldir:CString );
Uno volta che tali strutture sono disponibili in memoria, e sono quindi pronte peressere interrogate a run time, e possibile generare il codice C++ attraverso la funzioneCppExtract:
CPPExtract(packagename:CString;outdir:CString );
Inoltre ogni package che debba essere utilizzato all’interno della shell dovra essereelaborato dallo Scheme Extractor per la generazione dei files della FFI:

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 142
SchemeExtract(packagename:CString;outdir:CString );
Sintassi di invocazione
Tutti i metodi di cui sopra possono essere “invocati” tramite l’esecuzione del comandoschemeext27 che ha la seguente sintassi:
Parse Command Syntax:-h -> Print this help-cdldir -> Set cdl directory (DEFAULT ./)-cppext -> Do CPP extraction-!cppext -> Don’t do CPP extraction (DEFAULT))-cppdir <dir> -> Set CPP output dir (DEFAULT ./)-schemeext -> Do SCHEME extraction-!schemeext -> Don’t do SCHEME extraction (DEFAULT)-schemedir <dir> -> Set SCHEME output dir (DEFAULT ./)
Dove:
cdldir indica quale e la directory che contiene i files CDL di package.
cppext indica se invocare (-cppext) o non invocare (-!cppext) il CppExtractor.
schemeext indica se invocare (-schemeext) o non invocare (-!schemeext)lo Scheme Extractor.
schemedir indica la directory nella quale si desidera la memorizzazionedei files generati.
Il programma schemeext provvedera quindi a:
1. Eseguire il metodo ParseCommand per interpretare la stringa di comando fornitadall’utente.
2. Eseguire il metodo CDLFront per elaborare i files CDL.
3. Eseguire gli estrattori CPPExtract e SchemeExtract per la generazione del codice.
Ad esempio con la seguente istruzione:27Il comando schemeext e disponibile come eseguibile per Dos o per shell Linux.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 143
Initializer
SwitchCaller
OverloadingSolver
UpperCaller
startup
dynamic call
Figura 3.6: Sezioni del codice generato dallo Scheme Extractor.
bin\win32\schemeext -cdldir ./src/OcasPackage/ Standard MMgtStdFail TCollection TColStd Quantity SortTools OSD EDLWOKTools MS -cdldir ./src/ -cppext -schemeext SchemePack
e effettuato il parsing di tutti i packages ma l’estrazione del solo package SchemePack.Quello che segue e il messaggio che il programma schemeext stampa come output:
Info : Doing ConversionInfo : Standard MMgt StdFail TCollection TColStdInfo : Quantity SortTools OSD EDL WOKTools MS SchemePackInfo :Info : Step 1 (of 3). CDL parsing...Info : Standard MMgt StdFail TCollection TColStd QuantityInfo : SortTools OSD EDL WOKTools MS SchemePackInfo :Info : Step 2 (of 3). Cpp ExtractionInfo : SchemePackInfo :Info : Step 3 (of 3). Scheme ExtractionInfo : SchemePack
3.2.1 Le azioni dell’estrattore
Rimane ancora da analizzare quale sia il contenuto dei files generati dal programmaScheme Extractor. Ogni file e composto da quattro sezioni principali:

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 144
Initializer Un initializer si occupa di aggiungere all’interprete nuove primitive (fun-zione scheme add global) e nuovi tipi di classi (funzione scheme make class).
Un initializer crea inoltre i collegamenti (link) tra le funzioni delle classi C++ ele variabili di istanza delle classi Scheme.
E’ necessario che l’initializer di package sia invocato all’inizio di ogni nuova ses-sione di lavoro; cio permette all’interprete di essere costantemente aggiornatorispetto alla struttura interna dei componenti CDL.
Il seguente esempio mostra il contenuto dell l’initializer del package Standard:
Scheme_Object* Standard_Type_initialize(Scheme_Env *env) {scheme_register_extension_global(
&Standard_Type_class,sizeof(Standard_Type_class));
Standard_Type_class = scheme_make_class("Standard_Type%",Standard_Transient_class,scheme_Standard_Type,13);
scheme_add_method_w_arity(Standard_Type_class,"Name",scheme_Standard_Type_Name,0,-1);
[...] scheme_made_class(Standard_Type_class); return scheme_void;}
Upper Caller . Un upper caller e il metodo che viene invocato dall’interprete Schemeogni volta che l’utente accede ad una variabile di istanza attraverso la primitivasend.
Se ad esempio viene invocato il costruttore della classe GUID28:
(make-object Standard_Guid%)
verra invocato il corrispondente upper caller di classe:
Scheme_Object* scheme_Standard_GUID(Scheme_Object *obj,int argc,
28Il costruttore di GUID non riceve parametri di ingresso.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 145
Scheme_Object **argv){Handle(SchemePack_HSequenceOfHCvar) args=SchemePack_HCvar::Map(argc,argv);
SchemePack_HCvar& ret=SchemePack::CallClassConstructor("Standard_GUID",args);
return ret.UnMap(obj);}
Un upper caller e quindi responsabile di:
1. effettuare il mapping dei dati, cioe creare le nuove strutture HCvar derivantidalla traduzione degli oggetti Scheme.
2. invocare il risolutore dell’overloading (CallClassConstructor).
3. effettuare l’unmapping del valore restituito cioe convertire le variabili HCvarin oggetti Scheme.
Overloading Solver . L’Overloading Solver si occupa di cercare il metodo che offrala miglior corrispondenza nel rispetto della “regola dell’intersezione”. Eventual-mente effettua delle conversioni sugli argomenti effettivi per renderli compatibilicon i tipi degli argomenti formali:
for (i=1;i<=metodi->Length();i++){metodo=metodi->Value(i);if (metodo->Name()->IsSameString(methodname))if (SchemePack_HConversion::Execute(args,metodo->Params()))
lista->Append(i);}
metodo=metodi->Value(best);SchemePack_HConversion::Execute(args,metodo->Params()); return(*caller)(best,newargs);
Switch Caller . Una volta che le conversioni sono state effettuate e che la corrispon-denza migliore e stata trovata, e quindi stabilito senza ambiguita quale sia ilmetodo da eseguire.
Lo switch caller e una sorta di contenitore che ingloba al suo interno tutte lechiamate dei metodi di package o di classe29.
Ad esempio lo switch caller della classe GUID e il seguente:29Abbiamo gia affrontato il problema dell’address binding nel paragrafo 1.4.2. Rispetto a tale pro-
blema il nostro approccio e totalmente statico: lo switch caller invoca tutti i metodi di package o di

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 146
SchemePack_HCvar&Class_Caller_Standard_GUID(
Standard_Integer index,SchemePack_HCvar& obj,Handle(SchemePack_HSequenceOfHCvar)& args)
{char* name="Standard_GUID";MS_Type type=SchemePack::GetType(name);
switch(index){case 1:SchemePack_HCvar* ret=new SchemePack_HCvar(type);Standard_GUID* pointer=new Standard_GUID(type);ret->SetValue((SchemePack_Integer)pointer);return *ret;
[...]}
}
Lo switch caller riceve in ingresso una lista di variabili HCvar che contengono gliargomenti effettivi che sono gia stati convertiti dall’upper caller.
Azione di recupero dell’argomento C++
La modalita di recupero dell’argomento vero e proprio (escludendo quindi l’infrastrut-tura della HCvar) dipende dal tipo di oggetto referenziato dal campo Address:
Oggetti manipolati per riferimento Sono oggetti il cui accesso avviene tramitehandle.
Nel caso in cui sia possibile modificare sia l’handle che l’oggetto referenziato siprocede al recupero del valore nel seguente modo:
(* ( Handle_TypeName*)(ArgName.GetValue()))
Nel caso in cui siano invece negati i diritti in scrittura sia rispetto all’handle cheall’oggetto, sara utilizzato un riferimento costante:
classe e lascia quindi che sia il compilatore a risolvere i riferimenti alle funzioni di libreria in modo
statico, cioe a tempo di generazione degli object files. Nell’approccio dinamico avremmo invece dovuto
calcolare l’indirizzo della funzione di libreria a tempo di esecuzione, senza invocare esplicitamente il
metodo.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 147
(* (const Handle_TypeName*)(ArgName.GetConstValue()))
Oggetti manipolati per valore All’interno del campo Address di HCvar e contenutol’indirizzo dell’oggetto.
Nel caso in cui sia possibile modificare l’oggetto, viene utilizzato un riferimentonon costante:
(* ( TypeName*)(ArgName.GetValue()))
altrimenti viene utilizzato un riferimento costante:
(* (const TypeName*)(ArgName.GetConstValue()))
il che implica che la funzione utilizzera l’argomento come valore di sola lettura.
Ogni funzione puo’ restituire in uscita un qualche valore che e il risultato dell’esecuzionedel suo body.
Normalmente il valore in uscita e direttamente gestito dal compilatore. Nel sistamasviluppato e invece necessario costruire una nuova istanza di classe HCvar per ognunodi questi valori.
Tipi di valori di ritorno
Il valore restituito puo’ essere un:
Valore di tipo void Nel caso in cui una funzione specifichi nel proprio prototipo CDLdi non restituire nessun valore di uscita e comunque necessario che il Callerrestituisca una variabile HCvar:
@template Void_Caller(%Function,%Args)isSchemePack_HCvar* ret=new SchemePack_HCvar;%Function(%Args);
La variabile ret risultera non tipizzata e non inizializzata.
Oggetto manipolato tramite handle Un oggetto manipolato tramite handle e unoggetto che deriva dalla classe Transient o dalla classe Persistent.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 148
Il Memory Manager di Open Cascade e in questo caso responsabile della deal-locazione della memoria: l’invocazione del distruttore di un handle comportasempre il decremento del reference counter dell’oggetto; nel caso in cui tale con-tatore dovesse essere impostato al valore 0 l’oggetto referenziato verra a sua voltadeallocato.
Si deve impedire che un oggetto che potrebbe ancora essere potenzialmente uti-lizzato dall’interprete Scheme sia involontariamente deallocato.
La soluzione a questo problema consiste nel creare un nuovo handle non dichia-randolo localmente nel corpo dello switch caller ma invocando la primitiva new
del C++ . In questo modo viene effettuata una operazione di lock sull’oggetto,cioe il contatore viene incrementato in modo permanente.
L’istanza HCvar che incapsula il risultato e creata in modo differente a secondadella direttiva CDL che l’utente ha specificato nel prototipo:
Nessun flag Viene salvato, nel campo Address della HCvar, il valore dell’indi-rizzo del nuovo handle:
ret=new SchemePack_HCvar("%TypeName");Handle(%TypeName) handle=%Function(%Args);ret->SetValue(new Handle_%TypeName(handle));
valore di ritorno costante L’oggetto referenziato dall’handle e un valore alquale e possibile accedere solo in lettura:
ret=new SchemePack_HCvar("%TypeName"));Handle(%TypeName) handle=%Function(%Args);ret->SetConstValue(new Handle_%TypeName(handle));
valore di ritorno per riferimento Non viene creato nessun nuovo handle. Ilcampo Address dell’istanza HCvar conterra infatti l’indirizzo dell’handlerestituito dalla funzione come ”valore riferimento”:
ret=new SchemePack_HCvar("%TypeName");Handle(%TypeName)& handle=%Function(%Args);ret->SetValue(&handle); ret->IsRef(true);
Il contatore associato all’oggetto non viene in questo caso incrementato:l’handle e infatti condiviso.
valore di ritorno costante e riferimento Valgono le considerazioni dei duecasi precedenti:

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 149
ret=new SchemePack_HCvar("%TypeName");const Handle(%TypeName)& handle=%Function(%Args);ret->SetConstValue(&handle); ret->IsRef(true);
Oggetto manipolato per valore E’ sufficiente che il campo Address della HCvar
punti all’oggetto restituito dalla funzione.
Anche in questo caso la modalita con cui viene costruita la HCvar dipende dalledirettive CDL specificate dall’utente:
Nessun flag Viene invocato il costruttore di copia rispetto all’oggetto restituito.Il campo Address della HCvar punta al nuovo oggetto allocato:
ret=new SchemePack_HCvar("%TypeName");%TypeName value=%Function(%Args);ret->SetValue(new %TypeName(value));
valore di ritorno costante Valgono le considerazioni del caso precedente conla sola eccezione che l’oggetto puntato non puo’ essere modificato:
ret=new SchemePack_HCvar("%TypeName");const %TypeName value=%Function(%Args);ret->SetConstValue(new %TypeName(value);
valore di ritorno per riferimento La HCvar punta esattamente al valore diritorno della funzione e non ad un “oggetto copia”.
L’oggetto e quindi condiviso tra piu variabili C++:
ret=new SchemePack_HCvar(("%TypeName");%TypeName* pointer=&%Function(%Args);ret->SetValue(pointer); ret->IsRef(true);
valore di ritorno costante e riferimento Valgono le considerazioni dei duecasi precedenti:
ret=new SchemePack_HCvar("%TypeName");const %TypeName* pointer=&%Function(%Args);ret->SetConstValue(pointer); ret->IsRef(true);
3.3 La conversione delle librerie fondamentali
La libreria OcasPackage e compilata a partire dai files generati dallo SchemeExtractor.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 150
I servizi che tale libreria ingloba sono quelli minimi dal punto di vista del funzionamentodel software, cioe incapsula tutti e solo i package che permettono all’ambiente di gestirele strutture dati MS.
Nessun package della libreria si occupa in modo diretto di modellazione geometrica.
Di seguito viene fornita una sintetica descrizione di ogni package:
Standard Fornisce i servizi minimi per permettere agli altri toolkit di funzionare.Definisce una interfaccia per creare ed accedere ai dati persistenti.
MMgt Fornisce alcuni servizi per la gestione della memoria.
StdFail Contiene la definizione della classe Failure che e la classe dalla quale tuttele eccezioni devono derivare.
TCollection Fornisce alcuni servizi per la costruzione di strutture dati Transient ditipo lista.
TColStd Istanzia alcune classi del package TCollection.
Quantity Definisce alcune quantita: tempo, data etc.
SortTools Fornisce tools per il sorting delle strutture dati.
OSD Sono i servizi Operating System Dependent cioe la cui implementazione e diversaa seconda della piattaforma utilizzata.
EDL Permettono la creazione di file di testo di tipo template per la generazioneautomatica del codice.
WOKTools Definisce particolari strutture dati utilizzate dal Workshop OrganizationKit.
MS Definisce i Meta Schema per la costruzione di strutture dati dinamiche che con-tengano le definizioni dei componenti CDL.
3.4 La conversione delle libreria geometriche
La libreria OcasGeomPack e composta dai packages che permettono la costruzione dimodelli geometrici.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 151
I servizi che si e deciso di utilizzare sono quelli a piu alto livello tra tutti quelli imple-mentati in Open Cascade: in questo modo si potranno costruire dei modelli geometriciin modo molto semplice e immediato.
Segue una breve descrizione dei packages che compongono la libreria:
gp Implementa dei tipi per il calcolo algebrico e definisce tipi geometrici primitivi nellospazio bidimensionale e tridimensionale.
GeomAbs Definisce risorse per le applicazioni geometriche (es tipi di curve, tipi disuperfici etc).
TopAbs Definisce strutture dati topologiche e algoritmi topologici.
Bnd Supporta i Bounding Volumes cioe permette di costruire oggetti di cui sia possi-bile dire se un punto e interno o esterno.
TColgp Istanzia alcune classi di TCollection con i tipi del package gp.
TopLoc Definisce tipi per la creazione di sistemi di coordinate locali.
Primitives Contiene primitive per la costruzione di strutture dati topologiche (esbuilder, wedge etc).
Sweep Permette la costruzione di modelli 3d di tipo sweep.
TopoDS Contiene la descrizione delle Topological Data Structure.
Poly Definisce servizi per la costruzione di poligoni 2d, poligoni 3d e poliedri 3d.
Geom Utilizza il package gp per fornire servizi “geometrici” a piu alto livello: definiscenuovi oggetti geometrici persistenti e operazioni applicabili rispetto agli oggettistessi.
Geom2d Definisce oggetti geometrici nello spazio 2d.
TopTools Fornisce dei servizi ad alto livello per le Topological Data Structure.
GeomTools Definisce insiemi di curve e insiemi di superfici che sono persistenti.
TopExp Implementa alcuni algoritmi per esplorare le strutture dati topologiche.
BRep Definisce la Boundary Representation di un modello geometrico.
BRepLib Definisce servizi base rispetto al package BRep.

CAPITOLO 3. INTEGRAZIONE DEGLI AMBIENTI 152
BRepTools Offre servizi per confrontare strutture topologiche.
BRepSweep Definisce l’operazione di sweep rispetto alle Boundary Representation.
BRepPrim Definisce primitive ad alto livello per la modellazione (cilindro, cono, sferaetc).
BRepBuilderAPI Definisce operazioni ad alto livello per la modellazione al contorno(operazioni booleane, calcolo di proprieta dei volumi etc).
BRepPrimAPI Definisce alcune classi per la costruzione di oggetti geometrici inmodo molto semplice.

Capitolo 4
Esempi di utilizzo delle librerie
geometriche
In questo capitolo verranno forniti alcuni esempi pratici di utilizzo del sistema OpenCascade/Scheme. I modelli che saranno generati utilizzano alcuni servizi delle libreriegeometriche di Open Cascade che sono stati descritti nel paragrafo 3.4.
4.1 La creazione di solidi primitivi
Il package BRepPrimApi fornisce una Application Programming Interface (API) per lacostruzione di strutture dati topologiche di tipo BRep. Le classi all’interno del packagesono le seguenti:
package BRepPrimAPI uses [...] isclass MakeHalfSpace;class MakeBox;class MakeWedge;deferred class MakeOneAxis;class MakeCylinder;class MakeCone;class MakeSphere;class MakeTorus;class MakeRevolution;deferred class MakeSweep;class MakePrism;class MakeRevol;
153

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 154
end BRepPrimAPI;
Ogni classe del package definisce tanti costruttori quanti sono le differenti modalita dicreazione per ogni solido.
Il costruttore Create della classe MakeBox riceve come parametri di ingresso le tredimensioni della struttura:
Create(dx, dy, dz : Real) returns MakeBox from BRepPrimAPIraises DomainError;
Si definisce quindi una nuova funzione scheme make-box che operi da wrapper rispettoalla foreign function Create:
(define (make-box x y z)(make-object BRepPrimApi_MakeBox% x y z))
Si e piu volte ribadito come all’interno del package BRepPrimApi sono definite le funzionipiu ad alto livello per la modellazione; a conferma di cio si sarebbe ugualmente potutocostruire la stessa struttura utilizzando altre, piu a basso livello, funzioni di OpenCascade. Ad esempio utilizzando i metodi della classe Wedge del package BRep:
myWedge(gp_Ax2(pmin(gp_Pnt(0,0,0),dx,dy,dz),
gp_Dir(0,0,1),gp_Dir(1,0,0)),
Abs(dx),Abs(dy),Abs(dz))
La classe che permette la creazione di sfere e la MakeSphere. Tale classe contiene ilseguente costruttore:
Create(R : Real) returns MakeSphere from BRepPrimAPI;
La sfera avra raggio R e sara centrata nel punto (0,0,0).
Viene quindi definita una nuova funzione Scheme sphere che, analogamente al casoprecedente, operi da wrapper rispetto al costruttore:

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 155
(define (sphere radius)(make-object BRepPrimApi_MakeSphere% radius))
Infine la classe che crea oggetti toroidali e la MakeTorus:
Create(R1, R2 : Real) returns MakeTorus from BRepPrimAPIraises DomainError from Standard;
dove R1 e il raggio dell’anello e R2 e invece il raggio del cerchio attraverso cui saraeseguita l’operazione di “estrusione” lungo la prima circonferenza.
Viene quindi definita la funzione scheme torus :
(define (torus radius circle)(make-object BRepPrimApi_MakeTorus% radius circle))
4.2 Le operazioni geometriche
La funzione make-compound “combina” due oggetti geometrici (siano essi box, sfere,tori o altro) in una unica struttura dati gerarchica:
(define (make-compound x y)(let (
(compound (make-object TopoDS_Compound%))(builder (make-object BRep_Builder%)))(begin
(send builder MakeCompound compound)(send builder Add compound x)(send builder Add compound y)compound)))
La soluzione qui proposta preveda l’istanziazione di un nuovo builder ; un builder e untool per la creazione di forme BRep.
Si dovra quindi aggiungere all’istanza TopoDS Compound gli oggetti x e y specificati comeparametri di ingresso della make-compound (send builder Add x e send builder
Add y).
Si avra inoltre bisogno di una funzione che crei una struttura complessa a partire dauna lista non vuota di oggetti geometrici:

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 156
(define (composite lis)(if (list? lis)
(cond((= (length lis) 0) (error "empty list"))((= (length lis) 1) (car lis))(else (make-compound (car lis) (composite (cdr lis)))))
(error "Not a list")))
La funzione translate esegue invece una traslazione di un oggetto BRep:
(define (translate obj x y z)(let (
(theTranslation (make-object gp_Vec% x y z))(theTransform (make-object gp_Trsf%)))(begin
(send theTransform SetTranslation theTranslation)(send(make-object
BRepBuilderAPI_Transform% obj theTransform #t)Shape))))
E’ necessario preventivamente definire la direzione lungo la quale tale trasformazionesara effettuata (gp Vec). Sara quindi possibile applicare la trasformazione vera e propriaattraverso la SetTranslation.
4.3 Esportazione dei modelli
La funzione print-brep invoca la primitiva BRepTools Write per l’esportazione di unmodello su file:
(define (print-brep shape filename)(BRepTools_Write shape filename))
dove shape puo’ essere sia un oggetto primitivo (ad esempio creato con la MakeSphere)o strutturato (ottenuto applicando ad esempio la make-compound).
Le librerie di Open Cascade permettono l’esportazione dei modelli geometrici nei for-mati Iges o Step. Sebbene tali formati siano i veri e propri standard di riferimen-to, soprattutto nel settore industriale, non sono particolarmente adatti per effettuaresemplici operazioni di visualizzazione e/o navigazione nel modello.

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 157
Spesso si incorre infatti in errori di conversione che causano il blocco del programma 1.E’ auspicabile che in futuro sia possibile esportare i modelli generati in qualche formatopiu diffuso (come ad esempio il VRML).
Come formato di esportazione si e quindi utilizzato il formato proprietario BRep il cuiprincipale limite e pero’ quello di essere importabile solo all’interno del viewer di OpenCascade.
4.4 Esempi di generazione
Nei paragrafi che seguono verranno generati dei modelli di esempio; si utilizzerannoquindi tutte le primitive illustrate nei paragrafi 4.1, 4.2 e 4.3: primitive per la creazionedi solidi (make-box, sphere e torus); primitive per la costruzione di strutture complesse(make-compound, composite e translate); e infine la primitiva per l’esportazione deimodelli (print-brep).
4.4.1 Modello con sfere
In questo paragrafo verra generata una struttura complessa composta da sole sfere.
La funzione sphere-in-space crea una sfera e la centra nel punto (x,y,z):
(define (sphere-in-space radius x y z)(translate (sphere radius) x y z))
La funzione pyramid crea il modello finale:
(define (pyramid x y z radius from step)(let ((nr (* radius 0.5))
(ns (- step 1))(v (* (* radius 3) 0.5))(ret (sphere-in-space radius x y z)))
(if(eq? step 0)
1Abbiamo incontrato non poche difficolta nel tentativo di visualizzare i file esportati sia in formato
Step che nel formato Iges, soprattutto nei casi in cui il contenuto del modello non fosse banale. Non e
chiaro se pero’ cio dipenda da problemi attribuibili agli algoritmi di esportazione di Ocas o da problemi
specifici dei visualizzatori utilizzati.

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 158
ret(begin
(if (not (eq? from 3))(set! ret
(make-compound ret(pyramid (+ x v) y z nr 1 ns))))
(if (not (eq? from 4))(set! ret
(make-compound ret(pyramid x (+ y v) z nr 2 ns))))
(if (not (eq? from 1))(set! ret
(make-compound ret(pyramid (- x v) y z nr 3 ns))))
(if (not (eq? from 2))(set! ret
(make-compound ret(pyramid x (- y v) z nr 4 ns))))
(if (not (eq? from 6))(set! ret
(make-compound ret(pyramid x y (+ z v) nr 5 ns))))
(if (not (eq? from 5))(set! ret
(make-compound ret(pyramid x y (- z v) nr 6 ns))))
ret))))
Il modello e generato in modo ricorsivo affiancando delle sfere che sono traslate lungotutte e sei le direzioni degli assi del sistema di riferimento. Man mano che ci si allontanadal centro del sistema di riferimento, il raggio delle sfere viene decrementato (* radius
0.5).
Con la seguente istruzione viene esportato un modello da visualizzare:
(print-brep (pyramid 0 0 0 10 0 3) "sphere.brep")

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 159
Figura 4.1: Visualizzazione del modello a sfere.
Figura 4.2: Vista dall’alto del modello a sfere.

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 160
4.4.2 Modello toroidale
In questo paragrafo verra creato un modello geometrico composto da una sfera circon-data da oggetti di tipo toroidale.
Si desidera che il raggio di ogni anello che circonda la sfera sia calcolato in base allaposizione dell’anello stesso lungo l’asse z:
(define (radius z)(sqrt (- 1 (* z z))))
l’effetto visivo che si desidera ottenere e quello di avere piu anelli disposti lungo lo stessoasse che sembrino restringersi come se fossero “appoggiati” su di una sfera concentricarispetto a quella che sara generata nel modello finale.
La funzione torus-on-sphere crea una lista di anelli con queste caratteristiche:
(define (torus-on-sphere positions)(composite
(map(lambda (z)(translate
(torus (radius z) 0.05) 0.0 0.0 z))positions)))
Le posizioni degli anelli lungo l’asse z sono le seguenti:
(define position(list -0.93 -0.75 -0.5 -0.25 0 0.25 0.5 0.75 +0.93))
La funzione anim genera il modello finale:
(define (anim ratio filename)(print-brep
(structure(sphere 0.3)(torus-on-sphere(map (lambda (x) (* x ratio)) position)))
filename)

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 161
dove ratio indica il livello di ”compressione” delle posizioni degli anelli lungo l’assedella struttura: un valore 0 indica che tutti gli anelli sono posizionati nel punto (0,0,0);una valore 1 indica che i valori della lista position non subiscono variazioni.
Vengono quindi creati dei modelli di esempio da visualizzare:
(anim 1.0 "torus.brep")(anim 0.1 "torus1.brep")(anim 0.4 "torus2.brep")(anim 0.7 "torus3.brep")

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 162
Figura 4.3: Visualizzazione del modello torus.brep
Figura 4.4: Visualizzazione dei modelli torus1.brep, torus2.brep, torus3.brep.

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 163
4.4.3 Grafico della funzione sombrero
Si desidera graficare la seguente funzione “sombrero”:
z = f(x, y) = ksin√
h(x2 + y2)
in modo che ogni punto della funzione sia rappresentato da un piccola sfera centratanel punto (x,y,f(x,y)).
La funzione make-list crea una lista di valori reali dal valore from al valore to;l’argomento step indica di quanti elementi deve essere composta la lista:
(define (make-list from to step)(if(or (<= to from) (eq? from to))(list from)(cons from(make-list
(+ from (/ (- to from) (- step 1))) to (- step 1)))))
La reduce applica una funzione f ad una lista lis nel seguente modo:
• Se la lista e vuota restituisce l’argomento init.
• Se la lista e composta da un solo elemento si applica la funzione f all’argomentoinit e all’elemento stesso.
• Altrimenti la f e invocata in modo ricorsivo.
Il codice Scheme della reduce e il seguente:
(define (reduce f init lis)(cond
((null? lis) init)((eq? (length lis) 1) (f init (car lis)))(else (reduce f (f init (car lis)) (cdr lis)))))
La funzione al (append left) crea una nuova lista anteponendo ad ogni elemento dellasource-list l’oggetto item:

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 164
(define (al source-list item)(map (lambda(x) (list x item)) source-list))
Infine la funzione mult effettua il prodotto cartesiano tra le due liste list1 e list2:
(define (mult list1 lits2)(reduce
append ’() (map (lambda(x) (al list1 x)) list2)))
Ad esempio:
(mult ’(1 2 3) ’(4 5))((1 4) (1 5) (2 4) (2 5) (3 4) (3 5))
La funzione apply-f applica una funzione fun alla lista di coordinate coords:
(define (apply-f fun coords)(map(lambda (coord)
(list(car coord)(car (cdr coord))(fun coord)))
coords))
dove la fun e la funzione sombrero:
(define (myfun coord)(let ((x (car coord))
(y (car (cdr coord))))(* 0.5 (sin (sqrt (* 12.56
(+ (* x x) (* y y))))))))
La funzione make-list-of-sphere crea una lista non vuota di oggetti di tipo sfera:
(define (make-list-of-sphere dim step)(cond
((= step 0) (error "empty list"))((= step 1) (list (sphere dim)))(else
(cons (sphere dim) (make-list-of-sphere (- step 1))))))

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 165
Quindi viene definito il dominio e il codominio della funzione e vengono inoltre traslatele sfere in base ai punti calcolati:
(define domain(mult
(make-list -1.0 1.0 20)(make-list -1.0 1.0 20)))
(define codomain (apply-f myfun domain))
(define (spheres-in-space dim)(composite
(maptranslate(make-list-of-sphere dim (length codomain))codomain)))
E’ quindi possibile visualizzare un modello di esempio:
(print-brep (spheres-in-space 0.4) "./sin.brep")

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 166
Figura 4.5: Vista della funzione sombrero dall’alto.
Figura 4.6: Vista della funzione sombrero dal basso

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 167
4.4.4 Generazione di labirinti
L’esempio che verra illustrato in questo paragrafo riguarda il problema della generazioneautomatica di labirinti di dimensioni arbitrarie.
Come algoritmo per la generazione dei labirinti si e utilizzato il materiale a disposizionesu Internet: non sara spiegata in questa tesi la modalita di funzionamento di talealgoritmo. Dal punto di vista dell’utilizzatore Scheme basti dire che e stata definita unnuova classe CDL che espone la seguente interfaccia:
class Maze from SchemeTest usesBoolean,Integer
Create(dimx:Integer;dimy:Integer)returns Maze from SchemeTest;
Up(me;px:Integer;py:Integer) returns Boolean;Down(me;px:Integer;py:Integer) returns Boolean;Left(me;px:Integer;py:Integer) returns Boolean;Right(me;px:Integer;py:Integer) returns Boolean;
fieldsmymaze:Address;mydimx,mydimy:Integer;
end;
Si dovra quindi istanziare (Create) un nuovo oggetto labirinto (make-object) delladimensione desiderata. Gli altri metodi di classe serviranno per interrogare l’oggettoin questione circa la posizione dei muri della “cella” di coordinate (px,py).
Vengono quindi definite alcune “geometrie di base” per la costruzione del labirinto,nello specifico i muri di ogni singola cella:
(define wallsize 1.0)(define celldim 6.0)(define wallheight 3.0)
(define (leftwall) (make-box celldim wallsize wallheight))
(define (upwall) (make-box wallsize celldim wallheight))

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 168
generatorelabirintiC++
Create
IsLeft
IsRight
IsDown
IsUp
libreriegeometricheOcas
interpreteScheme
make-box
translate
maze-builder
Figura 4.7: Collaborazione tra interprete Scheme e librerie C++.
(define (rightwall)(translate (leftwall) 0 (- celldim 1) 0))
(define (downwall)(translate (upwall) (- celldim 1) 0 0))
(define (make-single-cell IsLeft? IsUp? IsRight? IsDown?)(composite
(map(lambda (func arg) (func arg))(list IsLeft? IsUp? IsRight? IsDown?)(list (leftwall) (upwall) (rightwall) (downwall)))))
Ogni singola cella del labirinto sara generato dalla make-single-cell.
La funzione move-cell opera una traslazione della singola cella sul piano:
(define (move-cell cell deltax deltay)(translate cell (* deltax celldim) (* deltay celldim) 0))
La funzione make-list genera in modo “combinatorio” tutte le coordinate possibilidelle celle del labirinto :
(define (make-list from to)(if
(= from to)

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 169
Figura 4.8: Generazione di una singola cella.
(list from)(cons from (make-list (+ 1 from) to))))
La funzione maze-builder genera quindi il labirinto:
(define (maze-builder dim filename)(let*
((v (make-list 0 (- dim 1)))(array (mult v v))(maze (make-object SchemeTest_Maze% dim dim))(make-a-cell
(lambda (coord)(let
((x (car coord))(y (car (cdr coord))))
(move-cell(make-single-cell(send maze Left x y)(send maze Up x y)(send maze Right x y)(send maze Down x y)) x y))))
(lis (map make-a-cell array))(ret (composite lis)))(print-brep ret filename)))

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 170
La maze-builder crea un array con tutte le coordinate del labirinto2; quindi la funzionemake-a-cell genera la singola cella in posizione coord.
Si potra quindi costruire il modello finale (composite lis) che e esportato eseguendola print-brep:
(maze-builder 5 "maze5.brep")
Viene inoltre proposto un esempio di labirinto che e stato generato apportando dellepiccole modifiche al codice appena analizzato: e stata infatti applicata ad ogni cellauna traslazione lungo l’asse z.
2E’ stata utilizzata la funzione mult definita nel paragrafo 4.4.3.

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 171
Figura 4.9: Visualizzazione del labirinto 5x5.
Figura 4.10: Visualizzazione del labirinto in “discesa”.

CAPITOLO 4. ESEMPI DI UTILIZZO DELLE LIBRERIE GEOMETRICHE 172

Conclusioni
In questa tesi e stato affrontato il problema dell’integrazione e della collaborazionetra linguaggi imperativi, nello specifico le librerie object oriented di Open Cascade, elinguaggi funzionali, nello specifico l’interprete MzScheme del Programming LanguageTeam della Rice University.
Gli algoritmi che sono stati descritti ed implementati non utilizzano le tecniche “tra-dizionali” per la collaborazione tra componenti software indipendenti: ad esempio nonsi e fatto uso dell’infrastruttura delle piattaforme CORBA o DCOM che, come noto,distribuiscono il calcolo ed i servizi (di Interface Repository, di Name Server etc.) sudi un network.
Al contrario la collaborazione e stata realizzata in modo da avvenire in un contestolocale, cioe in modo che gli oggetti clients e servers possano essere eseguiti all’internodello stesso processo e che quindi possano condividere le stesse strutture dati.
Il componente che traduce le strutture dati delle librerie di Open Cascade in Scheme(e viceversa) e la Foreign Function Interface (FFI). La FFI opera quindi sia come uncomponente di interfaccia per la distribuzione della conoscenza dei tipi CDL, sia comeun canale di comunicazione tra i sistemi.
I risultati piu significativi che hanno segnato le tappe fondamentali di questo lavoro ditesi, e che ne hanno confermato di volta in volta il buon andamento, sono i seguenti:
WOK Si e contribuito alla diffusione tra l’utenza di Open Cascade dei tools perlo sviluppo delle applicazioni CDL based, cioe dei componenti del WorkshopOrganization Kit (WOK).
La diffusione degli strumenti di WOK era, nel momento in cui e stata rilasciatala prima versione stabile di Open Cascade, abbastanza limitata in quanto non
173

Conclusioni 174
esisteva (e non esiste tutt’ora) nessun documento ”ufficiale” che spiegasse comeconfigurare l’ambiente WOK e soprattutto come configurare la shell TCL per lastrutturazione del codice in classi, packages, schema etc.
Dopo un approfondito studio del codice sorgente si e riusciti ad individuare leoperazioni fondamentali per la configurazione di WOK e si e inoltre riusciti, pri-mi all’interno della comunita di Ocas, a ricompilare tali tools sotto il sistemaoperativo Windows, aggiornandoli all’ultima versione (la 8.0) di TCL.
Sito WEB E’ stato realizzato un sito WEB 3 nel quale sono riassunti i concetti ed irisultati piu importanti di questa tesi e nel quale verranno pubblicati, si spera abreve, i sorgenti del codice sviluppato.
Con lo scopo di favorire l’ulteriore evoluzione del sistema si e inoltre in costantecontatto sia con i programmatori della Rice University, soprattutto nella per-sona di Matthew Flatt al quale va un ringraziamento particolare, sia con glisviluppatori del gruppo WOK di Open Cascade.
Open Cascade Core Team Attraverso la pubblicazione su WEB del software svilup-pato, il gruppo CAD dell’Universita di Roma Tre e diventato Core Team pressola MATRA Datavision, cioe l’ attivita di tale gruppo e segnalata direttamentesul sito (non commerciale) di Open Cascade4.
Il fatto di essere stati riconosciuti come Core Team e un elemento di grandeimportanza ed e un segno tangibile che il lavoro svolto e stato giudicato moltosignificativo dal punto di vista dell’architettura di Open Cascade.
Cio permettera in futuro di ricevere documentazione ”privata” e early versionsdelle distribuzioni. E’ stato cioe creato una sorta di canale di comunicazioneprivilegiato con la societa Matra Datavision e con tutti gli altri Core Teams.
Al di la di questi risvolti positivi e comunque doveroso accennare anche ad alcuni proble-mi che non sono stati ancora risolti in relazione a particolari aspetti della collaborazionetra i due ambienti. I problemi piu importanti che devono essere risolti prima che siapossibile distribuire una versione del programma sufficientemente stabile ed affidabilesono i seguenti:
Deallocazione della memoria Attualmente la memoria allocata dalla Foreign Func-tion Interface non viene mai rilasciata. Affinche il Garbage Collector dell’inter-prete MzScheme possa recuperare i puntatori dei foreign objects C++ non piu
3www.dia.uniroma3.it/ scorzell/index.htm4www.opencascade.org

Conclusioni 175
referenziati, e quindi possa correttamente deallocare gli oggetti non piu accessibi-li, sara necessario effettuare la ricompilazione delle Foundation Classes di OpenCascade.
Velocita di esecuzione E’ noto che le FFI devono eseguire delle complesse opera-zioni di traduzione tra tipi di dati strutturati appartenenti a linguaggi differen-ti e, proprio per questo motivo, possono contribuire in modo determinante alrallentamento del programma.
Nonostante sia quindi stato previsto che gli script Scheme che invocano metodiC++ attraverso la FFI non dovrebbero essere particolarmente veloci, i tempi chesono stati riscontrati per la generazione dei modelli del capitolo 4 sono comunquerisultati troppo lunghi.
Tale situazione puo’ dipendere da un uso probabilmente eccessivo di variabilidi tipo classe C++ per l’implementazione degli algoritmi di traduzione5, tipi divariabili che comportano sempre la generazione di codice binario non ottimizzato.Sarebbe quindi necessario effettuare delle sessioni di lavoro apposite per il profilingdel codice.
Parsing dei files CDL Tutti i files di interfaccia CDL sono rielaborati, attraversol’operazione di parsing descritta nel paragrafo 2.1.4, ad ogni nuovo avvio delsistema.
Tale operazione di traduzione permette la costruzione delle strutture dati di-namiche per l’acquisizione della conoscenza rispetto ai tipi CDL e quindi perl’esecuzione delle foreign functions all’interno dell’ambiente interpretato.
Sarebbe opportuno che i risultati prodotti dal programma CDL Front possanoessere memorizzati su appositi files di output : in questo modo potrebbe essereridotto il tempo di attesa in fase di inizializzazione (start up) del programma.
Dimensioni del codice prodotto dalla FFI Le notevoli dimensioni del codice diservizio (glue code) generato dai programmi estrattori (vedi paragrafo 3.2) e cau-sa di lunghe attese nel momento in cui viene effettuata l’operazione di linkingper la creazione dei files binari6. Il problema potrebbe essere attenuato mo-dificando parte del codice sorgente dell’interprete MzScheme ed adottando unapproccio parzialmente dinamico nei confronti del problema dell’address binding(vedi paragrafo 1.4.2).
5In realta l’uso delle variabili di tipo classe ha comunque permesso la realizzazione, in tempi piuttosto
brevi, di una versione del programma funzionante.6Bisogna comunque considerare che le librerie non geometriche di Open Cascade occupano da sole
circa 30 megabytes.

Conclusioni 176
Protezione dagli errori Il meccanismo per la protezione dagli errori a run time estato implementato utilizzando le ”tradizionali” istruzioni C++ di try e di catch.E’ probabile che esistano delle tecniche ancora piu sofisticate (ad esempio tecnicheche accedano direttamente alle strutture dati dello stack del programma) cheimpediscano l’uscita dal sistema al verificarsi di ogni condizione di errore.
Nessuno dei problemi citati dovrebbe comunque presentare particolari difficolta a livelloconcettuale, e si spera quindi che possano essere risolti in breve tempo.

Bibliografia
[1] Flatt, M. PLT MzScheme: Language manual. Technical Report TR97-280, RiceUniversity, 1997.
[2] Chris Hanson, the MIT Scheme Team, and a cast of thousands. MIT SchemeReference Manual, for Scheme Release 7.1.3. Mass. Inst. of Technology, Cambridge,MA, 1.1 edition, November 1991.
[3] Guy Lewis Steele Jr. and Gerald Jay Sussman. Revised Report on SCHEME ADialect of LISP. AI Memo 452, Massachusetts Institute of Technology, ArtificialIntelligence Laboratory, January 1978.
[4] Kelsey, R., W. Clinger and J. Rees (Eds.). The revised 5 report on the algorithmiclanguage Scheme. ACM SIGPLAN Notices, 33(9), September 1998.
[5] Clinger, W. D. Proper tail recursion and space efficiency. In ACM SIGPLANConference on Programming Language Design and Implementation, pages 174–185, June 1998.
[6] IEEE Computer Society, New York. IEEE Standard for the Scheme ProgrammingLanguage, IEEE STD 1178-1990, 1991.
[7] Jonathan A. Rees and Norman I. Adams IV. T:A dialect of Lisp or, lambda: Theultimate software tool. In Conference Record of the 1082 ACM Symposium on Lispand Functional Programming,pages 114-122.
[8] MIT Department of Electrical Engineering and Computer Science. Scheme manual,seventh edition. September 1984.
[9] Carol Fessenden, William Clinger, Daniel P. Friedman, and Christopher Haynes.Scheme 311 versione 4 reference manual. Indiana University Computer ScienceTechnical Report 137, February 1983.
177

BIBLIOGRAFIA 178
[10] Findler, R., Flanagan, C., Flatt, M., Krishnamurthi, S., and Felleisen, M. Dr-Scheme: A pedagogic programming environment for scheme. In InternationalSymposium on Programming Language Implementation and Logic Programming(1997).
[11] E. Crank and M. Felleisen. Parameter-passing and the lambda calculus. In Proc.ACM Conference on Principles of Programming Languages, 1990
[12] Robert Cartwright and Mike Fagan. Soft typing. In Proceedings of the ACM SIG-PLAN ’91 Conference on Programming Language Design and Implementation,pages 278–292, Ontario, Canada, June 1991.
[13] G. Morrisett, M. Felleisen, and R. Harper. Abstract models of memory manage-ment. In Functional Programming Languages and Computer Architecture 1995,pages 66–77. ACM Press, 1995.
[14] Paul A. Steckler. MysterX: A Scheme Toolkit for Building Interactive Applica-tions with COM. In Proc. Technology of Object-Oriented Languages and Systems,August 1999
[15] Matra Datavision, Foundation Classes User’s Guide. Part of Matra Datavisionsoftware distribution, December 1999.
[16] Hans Boehm, Alan Demers, and Mark Weiser. A garbage collector for C and C++.www.hpl.hp.com/personal/Hans Boehm/gc/.
[17] Matra Datavision, Modeling Data User’s Guide. Part of Matra Datavision softwaredistribution, December 1999.
[18] Matthew Flatt. Inside PLT MzSchemel. Part of PLT software distribution, October1999.
[19] Matra Datavision, Modeling Algorithms user’s Guide. Part of Matra Datavisionsoftware distribution, December 1999.
[20] Philip Wadler, Functional Programming: Why no one uses functional languages.SIGPLAN Notices, pages 23–27, August 1998
[21] Matra Datavision, Visualization User’s Guide. Part of Matra Datavision softwaredistribution, December 1999.
[22] Stanley B. Lippman, C++ Corso di programmazione. Addison-Wesley PublishingCompany, November 1991.

BIBLIOGRAFIA 179
[23] Matra Datavision, Data Exchange User’s Guide. Part of Matra Datavision softwaredistribution, December 1999.
[24] David M. Beazley. SWIG: An easy to use tool for integrating scripting languageswith C and C++. In USENIX Association, editor, 4th Annual Tcl/Tk Workshop’96, July 10–13, 1996. Monterey, CA, pages 129–139, Berkeley, CA, USA, July1996. USENIX.
[25] Matra Datavision, Application Framework User’s Guide. Part of Matra Datavisionsoftware distribution, December 1999.
[26] P. Emerald Chung, Yennun Huang, Shalini Yajnik, Deron Liang, Joanne C. Shih,Chung-Yih Wang, Yi-Min Wang DCOM and CORBA, Side by Side. Step by Stepand Layer by Layer C++ Report, Volume 10, No. 1, SIGS Publications, January1998
[27] Matra Datavision,Workshop Organization Kit. Part of Matra Datavision softwaredistribution, December 2000.
[28] C.Batini, L. Carlucci Aiello, M.Lenzerini, A.Marchetti Spaccamela, A.Miola,Fondamenti di programmazione dei calcolatori elettronici. FrancoAngeli, 1994.
[29] Matra Datavision, Component Definition Language User’s Guide. Part of MatraDatavision software distribution, March 2000.

BIBLIOGRAFIA 180


















