
Tesi di laurea Anno Accademico 1996 - 1997 - web.tiscali.itweb.tiscali.it/graz_site/tesi.pdf ·...
292
POLITECNICO DI MILANO Facoltà di Ingegneria Corso di Laurea in Ingegneria Gestionale ANALISI DI COINTEGRAZIONE IN PRESENZA DI BREAK STRUTTURALI; UN’APPLICAZIONE RELATIVA AL MERCATO DEI CAMBI Relatore: Prof. Rocco Mosconi Tesi di Laurea di: Maria LEALI Matr. 605973 Graziano VIGANO’ Matr. 622167 Anno Accademico 1996 - 1997
Transcript of Tesi di laurea Anno Accademico 1996 - 1997 - web.tiscali.itweb.tiscali.it/graz_site/tesi.pdf ·...

POLITECNICO DI MILANO Facoltà di Ingegneria Corso di Laurea in Ingegneria Gestionale ANALISI DI COINTEGRAZIONE IN PRESENZA DI BREAK STRUTTURALI; UN’APPLICAZIONE RELATIVA AL MERCATO DEI CAMBI Relatore: Prof. Rocco Mosconi Tesi di Laurea di: Maria LEALI Matr. 605973 Graziano VIGANO’ Matr. 622167 Anno Accademico 1996 - 1997


Si ringraziano i professori Giorgio Fodor e Fabio Sdogati per i consigli forniti relativamente all’applicazione macroeconomica e Bent Nielsen dell’Università di Oxford per quelli inerenti la parte metodologica. Si ringraziano inoltre tutti gli amici che ci hanno sostenuto e incoraggiato durante la stesura di questo lavoro. Esso è dedicato ai nostri genitori, grazie ai quali tutto questo è stato possibile.


Oh Shiva, che cos’è la tua realtà? Che cos’è quest’universo colmo di stupore?
Che cosa forma il seme? Chi fa da mozzo alla ruota dell’universo?
Che cos’è questa vita al di là della forma che pervade le forme?
Come possiamo entrarvi pienamente, al di sopra dello spazio e del tempo, dei nomi e dei connotati?
Chiarisci i miei dubbi!
(da un testo sacro dello shivaismo kashmiro)


Premessa
LO stato dell’arte, per quel che concerne l’analisi di cointegrazione in presenza di processi vettoriali autoregressivi non stazionari, è tuttora tale da permettere ampi spunti di discussione. In particolare, uno dei temi sulla frontiera della letteratura econometrico-metodologica è costituito dalle estensioni dei modelli volte ad adattarli a situazioni in cui siano presenti cambiamenti di regime, o break strutturali. L’urgenza di disporre di modelli appropriati a tali circostanze è ovvia a chiunque abbia qualche pratica di modellazione empirica di variabili macroeconomiche. I lavori fin qui svolti a riguardo sono dovuti principalmente a Søren Johansen e al “gruppo di Copenhagen” che con lui collabora. L’analisi inferenziale su modelli atti a spiegare tali tipi di processi viene da loro svolta in modo sequenziale: l’ottica seguita consiste nell’ampliare il modello di partenza (in cui non è contemplato alcun tipo di andamento deterministico delle variabili) mediante l’aggiunta di componenti deterministiche atte a modellare cambiamenti nelle medie e/o nelle pandenze dei trend delle variabili coinvolte nell’analisi. Nel lavoro che ci apprestiamo a svolgere, vogliamo porci sulla frontiera dei risultati fin qui raggiunti, dando un nostro contributo innovativo sia di tipo modellistico sia di tipo inferenziale. Lo spunto ci viene offerto proprio dai lavori di Johansen e l’idea che qui viene sviluppata riguarda l’assunzione di una prospettiva diversa per quel che concerne l’approccio alla modellizzazione delle componenti deterministiche. A nostro parere, in questo ambito, i modelli attualmente proposti in letteratura, come pure la strategia per l’individuazione del modello ottimale per un certo set di dati, possono essere migliorati. Il problema riguarda l’interpretazione che deve essere data alle componenti deterministiche: l’orientamento assunto fino ad ora pare non dare molto peso a questo aspetto e ciò, probabilmente, è dovuto al fatto che l’attenzione si è focalizzata maggiormente sugli aspetti matematico-modellistici che non su quelli economico-interpretativi. Di conseguenza, la modellizzazione delle componenti deterministiche in funzione della loro interpretabilità, soprattutto per quel che concerne i break strutturali, è stata messa in “secondo piano” rispetto, ad esempio, ai problemi di determinazione del numero di relazioni stazionarie fra le variabili che compaiono nei modelli trattati. Per noi, tuttavia, tale aspetto risulta essere di cruciale importanza se non

ci si vuole fermare ad un’analisi puramente statistica, senza associare ai modelli econometrici una interpretazione basata su teorie economiche.
Benchè la finalità principale del nostro lavoro sia quella di riesaminare la letteratura metodologica relativa all’analisi di cointegrazione in presenza di break strutturali, formulando in tale ambito alcune proposte innovative, abbiamo ritenuto opportuno includere nella tesi una parte applicata, completamente originale, volta ad illustrare con un esempio le potenzialità degli strumenti metodologici proposti.
Per eseguire tale applicazione, abbiamo preso spunto dalle teorie economiche riguardanti le relazioni internazionali ed il mercato dei cambi. Le analisi bilaterali che sono state svolte riguardano i rapporti fra il nostro paese e quelli più rappresentativi dell’economia mondiale, ovvero la Germania, gli Stati Uniti e il Giappone. In particolare, si è focalizzata l’attenzione sulle questioni riguardanti la Parità del potere d’Acquisto e la Parità dei Tassi di Interesse, con l’intento di verificare se queste sussistono o meno come relazioni di lungo periodo, nell’ambito di una modellizzazione che tiene conto della presenza di break, spiegati da eventi di natura politico-economica, che hanno influenzato i rapporti fra i suddetti paesi.
Precisiamo che tale applicazione non ha l’intento di entrare nel merito della teoria economica per metterne in dubbio la validità. Essa, piuttosto, traendo spunto da quella, vuole essere esemplificativa del fatto che i risultati ottenuti sul piano metodologico rappresentano uno strumento valido per lo svolgimento di tale analisi.

INDICE Introduzione ................................................................................................................... 1
I.1 Le serie storiche ed il loro uso in modelli econometrici....................................... 1 I.2 Modellizzazione di relazioni tra variabili di serie storiche: il modello
VAR...................................................................................................................... 2 I.3 Relazioni d’equilibrio e il lungo periodo.............................................................. 3 I.4 Stazionarietà e relazioni d’equilibrio .................................................................... 5 I.5 Equilibrio e specificazione di modelli dinamici ................................................... 6 I.6 Problematiche nella stima delle relazioni di lungo periodo.................................. 8 I.7 La modellizzazione di componenti deterministiche ............................................. 9 I.8 Articolazione della tesi ....................................................................................... 10
PARTE I IL MODELLO VAR DI BASE
Capitolo 1 Il modello VAR per variabili stazionarie.................................................................... 15
1.1 Il processo autoregressivo e sue rappresentazioni .............................................. 15 1.2 Analisi statistica di processi stazionari ............................................................... 18 1.3 Proprietà asintotiche degli stimatori ................................................................... 19 1.4 Un modo più “econometrico” per eseguire la stima dei VAR............................ 20 1.5 Il problema della determinazione del numero di variabili ritardate nel
modello VAR...................................................................................................... 22

ii INDICE
Capitolo 2 Modello VAR per variabili co-integrate......................................................................25
2.1 Concetti e definizioni ..........................................................................................25 2.2 Dalla rappresentazione AR a quella MA per variabili I(1): il teorema
di rappresentazione di Granger ...........................................................................29 2.3 La procedura a due stadi di Engle-Granger.........................................................33
Capitolo 3 Determinazione del rango di co-integrazione: stima e distribuzione .......................35
3.1 Analisi statistica di modelli I(1): determinazione del rango di cointegrazione .....................................................................................................35
3.2 Derivazione delle distribuzioni asintotiche dei test sul rango di cointegrazione .....................................................................................................41
3.2.1 Alcuni risultati utili .......................................................................................41 3.2.2 Risultati asintotici sulla convergenza delle matrici dei prodotti
incrociati .......................................................................................................44 3.2.3 Distribuzione asintotica del Trace-test .........................................................47
Capitolo 4 Proprietà asintotiche degli stimatori ...........................................................................53
4.1 Il problema dell’identificazione ..........................................................................54 4.2 Distribuzioni asintotiche degli stimatori .............................................................54
4.2.1 Una conveniente normalizzazione di β .........................................................55 4.2.2 Consistenza degli stimatori ...........................................................................56 4.2.3 Distribuzione asintotica degli stimatori di β e α ..........................................57 4.2.4 Altre distribuzioni asintotiche .......................................................................60
Capitolo 5 Vincoli lineari sullo spazio di co-integrazione ............................................................63
5.1 Identificazione del modello mediante vincoli su β .............................................63 5.2 Distribuzione asintotica dei parametri identificati da restrizioni ........................68 5.3 Test d’ipotesi per i coefficienti β di lungo periodo.............................................69
5.3.1 Gradi di libertà .............................................................................................69 5.3.2 Restrizioni lineari su β..................................................................................72
5.4 Distribuzioni asintotiche dei tests d’ipotesi..........................................................79

INDICE iii
PARTE II IL MODELLO VAR CON
COMPONENTI DETERMINISTICHE Capitolo 6 IL modello VAR per processi a media non nulla in tutte le loro componenti......... 85
6.1 Il modello e la sua interpretazione...................................................................... 85 6.4 Analisi statistica del modello.............................................................................. 89 6.5 Determinazione del test sul rango di cointegrazione .......................................... 91
6.5.1 Alcuni risultati utili ...................................................................................... 91 6.5.2 Risultati asintotici......................................................................................... 92 6.5.3 Distribuzione asintotica del Trace-test ........................................................ 93
6.6 Proprietà asintotiche degli stimatori ................................................................... 95 6.7 Test per ipotesi su βc e loro distribuzioni asintotiche ......................................... 96 6.8 Variabili con comportamento stagionale ............................................................ 97
Capitolo 7 Modello VAR per variabili con tendenza ................................................................. 101
7.1 Il modello e le sue interpretazioni..................................................................... 101 7.2 Analisi statistica del modello: il trace-test ........................................................ 103 7.3 Risultati asintotici sulle matrici dei prodotti incrociati..................................... 107 7.4 Distribuzione asintotica del trace-test............................................................... 112 7.5 Proprietà asintotiche degli stimatori ................................................................. 112 7.6 Ipotesi su β e loro distribuzioni ........................................................................ 114
Capitolo 8 Variabili con break strutturali .................................................................................. 115
8.1 Il modello per un caso semplice di break ......................................................... 116 8.1.1 Determinazione del test per il rango di co-integrazione............................ 118 8.1.2 Stima del modello ....................................................................................... 124
8.2 Modello con più break strutturali...................................................................... 124 8.2.1 Stima del modello con più break ................................................................ 126
8.3 Break strutturali nelle tendenze deterministiche............................................... 127 8.3.1 Distribuzione asintotica del trace-test ....................................................... 130 8.3.2 Stima del modello con tendenze deterministiche........................................ 131 8.3.3 Modello con più break nelle tendenze ........................................................ 133

iv INDICE
Capitolo 9 Modello statistico e DGP.............................................................................................135
9.1 Modelli I(1) per le componenti deterministiche................................................136 9.2 L’approccio di Johansen alla modellizzazione di componenti
deterministiche in modelli VAR cointegrati .....................................................139 9.3 Confronto tra i due approcci..............................................................................143 9.4 Efficienza nella stima del rango di cointegrazione mediante il
“modello generale”: una simulazione esemplificativa ......................................147 9.5 La stima dei coefficienti delle componenti deterministiche in serie
simulate .............................................................................................................151
PARTE III IL CASO APPLICATIVO
E LE SIMULAZIONI
Capitolo 10 Il ruolo del tasso di cambio nelle relazioni internazionali: un caso applicativo ....157
10.1 La teoria economica alla base dell’analisi ......................................................159 10.1.1 Il regime di tassi di cambio fissi e flessibili..............................................160 10.1.2 La parità del potere d’acquisto PPP ........................................................163 10.1.3 La parità dei tassi di interesse UIP ..........................................................164 10.1.4 Combinazione della PPP e della UIP.......................................................166
10.2 La base dati .....................................................................................................167 10.3 L’analisi dei break strutturali nelle serie storiche ...........................................171 10.4 L’analisi univariata delle serie storiche ..........................................................176 10.5 Il modello multivariato....................................................................................181 10.6 Analisi Italia/Germania ...................................................................................185 10.7 Analisi Italia/USA...........................................................................................191 10.8 Analisi Italia/Giappone ...................................................................................202 10.9 Grafici delle serie ............................................................................................208 10.10 Residui e correlogrammi dell’analisi Italia/USA............................................214

INDICE v
Capitolo 11 La simulazione della distribuzione asintotica del test sul rango di cointegrazione.............................................................................................................. 219
11.1 L’espressione del trace-test per la simulazione della distribuzione asintotica......................................................................................................... 219
11.2 Come utilizzare Ranktest................................................................................ 223 11.3 La procedura Ranktest .................................................................................... 225
PARTE IV APPENDICI
Appendice A Richiami di teoria asintotica ...................................................................................... 231
A.1 Il moto browniano univariato ........................................................................... 231 A.2 Il teorema del limite centrale funzionale .......................................................... 233 A.3 Il teorema della corrispondenza continua ......................................................... 235 A.4 Applicazioni a processi con radici unitarie....................................................... 236 A.5 Estensione a processi multivariati..................................................................... 239
Appendice B Elementi di algebra delle matrici .............................................................................. 243
B.1 Le matrici e le loro proprietà ............................................................................ 243 B.2 Sistemi di equazioni e matrici........................................................................... 254 B.3 Spazi e sottospazi vettoriali .............................................................................. 256 B.4 Elementi di calcolo differenziale ...................................................................... 269
Bibliografia .................................................................................................................. 275


Introduzione
QUESTO lavoro considera l’analisi econometrica di processi sia stazionari che non stazionari, i quali sono collegati da relazioni di equilibrio. Verranno esposti i principali strumenti, tecniche, modelli, concetti e distribuzioni legati alla modellizzazione di serie storiche non stazionarie.
Ci si focalizzerà, in modo particolare, sui concetti come quello di equilibrio, di cointegrazione e correzione d’errore che sono strettamente connessi come vedremo in seguito. L’analisi inizierà con una discussione di modelli empirici stazionari; si passerà poi a mostrare come i processi integrati possano essere ricondotti a questo caso, tramite opportune trasformazioni, determinando così le relazioni dette di “cointegrazione”, ossia di equilibrio.
Prima di iniziare l’analisi, che si conclude con un caso applicativo di natura economica, è opportuno introdurre alcuni importanti concetti riguardo l’analisi di serie storiche e la teoria dei processi stocastici.
I concetti saranno qui introdotti in modo volutamente molto qualitativo, per essere poi ripresi in modo più rigoroso nel seguito della tesi.
I.1 Le serie storiche ed il loro uso in modelli econometrici Con il termine serie storica ci si riferisce ad un campione x1, x2,...,xT in cui i pedici denotano istanti o periodi di tempo. In un generico modello econometrico si assume che ciascuna osservazione di un dato campione sia una realizzazione di diverse variabili casuali.
Nel caso di serie storiche, assumiamo che le variabili casuali corrispondenti al campione siano solo una parte di un’infinita serie di variabili casuali. Di conseguenza, viene associata una variabile casuale xt ad ogni istante di tempo t=0,1,2,... . Tale

Pag. 2 Introduzione
sequenza prende il nome di processo stocastico. Più precisamente, si dice che è un processo a tempo discreto, poiché t assume solo valori interi1.
L’econometria delle serie storiche è legata alla modellazione congiunta di più variabili, ciascuna delle quali è osservata in istanti temporali consecutivi. Le relazioni tra queste variabili possono essere complesse; in particolare, il valore di ognuna di esse può dipendere da quello assunto dalle altre in istanti di tempo precedenti. Di conseguenza, l’effetto che un cambiamento di una variabile ha su un’altra, dipende dall’orizzonte temporale che si sta considerando: è facile immaginare esempi in cui il cambiamento nel valore di una variabile ha un effetto irrilevante all’inizio e sostanziale in seguito.
Alternativamente, una variabile può avere un sostanziale effetto su un’altra per un certo periodo, che tuttavia si esaurisce col tempo. E’ utile quindi distinguere quelle che spesso sono chiamate relazioni di lungo periodo da quelle di breve periodo. Mentre per queste ultime ci si riferisce a relazioni che non persistono all’equilibrio, le prime determinano relazioni che permangono e a cui il sistema tende anche dopo perturbazioni.
I.2 Modellizzazione congiunta di più serie storiche: il modello VAR
Il modello VAR (Vector AutoRegressive) è un’estensione del modello autoregressivo scalare. In tal caso, una data variabile xt all’istante di tempo t viene regredita su valori precedenti di se stessa variabile, dando luogo al processo
xt = a1xt-1 + a2xt-2 + … + akxt-k + εt ,
dove k sta ad indicare il numero di ritardi da cui dipende xt . In questo caso diremo che xt è un processo autoregressivo di ordine k, solitamente indicato con AR(k).
Estendendo questo discorso al caso vettoriale, abbiamo che ciascuna variabile è regredita non solo sui propri ritardi, ma anche su quelli delle altre variabili del processo vettoriale. In formule si ha
X X Xt t k t k t= + + +− −Π Π1 1 ... ε t=1,...,T (1.1)
per valori fissati di X-k+1 ,...,X0. I vettori Xt-1 , ... , Xt-k , di dimensioni p×1 (p è il numero di variabili del modello), sono i ritardi del vettore Xt . Inoltre le matrici Πi , di dimensioni p×p, sono costituite dai coefficienti delle variabili ritardate, mentre εt è il
1 Se le variabili di un processo stocastico sono una sequenza εt di variabili casuali indipendenti ed identicamente distribuite, si parla di processo white noise.

Introduzione Pag. 3
vettore degli errori, che per ipotesi supponiamo essere indipendenti e identicamente distribuiti (i.i.d.) come una normale Np (0,Ω), ossia come una Gaussiana con media zero e matrice di varianze-covarianze Ω.
Nel caso di processi non stazionari la parametrizzazione VAR non riesce a discriminare le relazioni di lungo periodo da quelle di breve. A tale scopo, in seguito, introdurremo il meccanismo a correzione d’errore il quale si dimostrerà essere una riparametrizzazione del modello VAR (e quindi non dà alcuna informazione in più rispetto a quest’ultimo). Tramite essa è possibile derivare le stime e le statistiche dei test per le ipotesi sulle relazioni d’equilibrio e su quelle di aggiustamento.
L’espressione del modello ECM risulta essere la seguente
∆Xt=ΠΧ t-1+ Γ ii
k
=
−
∑1
1∆Χt-i+εt ,
dove Π = Π ii
kI−
=∑
1 e Γi = −
= +∑Π jj i
k
1.
Questa rappresentazione risulta essere utile per dare una condizione necessaria e sufficiente sulla stazionarietà del processo autoregressivo (si veda il capitolo 1); in brevi parole il processo è non stazionario se la matrice Π è di rango ridotto, ovvero se può essere scitta come
Π = αβ′ ,
con α e β matrici p×r di rango r. Il primo coefficiente è responsabile del processo d’aggiustamento, mentre il secondo stabilisce quali siano le relazioni stazionarie tra le varibili integrate del processo.
Il modello VAR, essendo una stilizzazione del reale fenomeno economico, dovrebbe
essere considerato uno strumento utile per la descrizione della variazione statistica dei dati, in modo tale da avere una maggior efficienza nella descrizione delle interrelazioni tra variabili economiche.
I.3 Relazioni d’equilibrio e il lungo periodo Uno stato d’equilibrio di un sistema è definito, in generale, come quello in cui non è presente una inerente tendenza al cambiamento. Uno stato di equilibrio può o meno avere la proprietà di stabilità; pertanto può essere vero o meno che il sistema tenda a ritornare all’equilibrio una volta perturbato. Nel nostro lavoro ci focalizzeremo solo sugli equi

Pag. 4 Introduzione
Fatta questa premessa, si può dire che gli equilibri sono stati verso cui il sistema è “attratto”: in certe circostanze, è possibile vedere le forze che spingono il sistema verso l’equilibrio come dipendenti dall’ampiezza delle deviazioni dall’equilibrio stesso in un dato istante2.
Una relazione d’equilibrio può essere espressa tramite una funzione implicita del tipo
f(x1 , x2 , … , xn)=0,
che descrive le interdipendenze che esistono tra le n variabili, quando il processo è in equilibrio.
L’espressione “equilibrio di lungo periodo” è anche utilizzata per denotare relazioni d’equilibrio a cui un sistema converge nel tempo.
Vista in un’altra ottica, una relazione di lungo periodo riguarda un movimento sistematico e coordinato nel lungo periodo tra le variabili di un sistema economico; pertanto, al fine di denotare una relazione di tale tipo fra le variabili x1 e x2 , si scriveranno equazioni rappresentanti questi movimenti senza usare l’indice temporale, come avviene, per esempio, per l’equazione x1=βx2.
Dal punto di vista geometrico, quest’equazione definisce l’insieme, chiamato attrattore, nello spazio bidimensionale in cui sono rappresentate le serie storiche delle due variabili. Più precisamente l’insieme attrattore è costituito dalla retta, la cui inclinazione è data dal coefficiente β (si veda fig. I.1). Esso viene detto attrattore poiché è il luogo dei punti che costituiscono gli stati di equilibrio di lungo periodo. Pertanto, se un ipotetico sistema economico si trovasse in stati rappresentati da punti al di fuori di tale insieme (ad esempio Pt), entrerebbero in gioco delle forze di mercato o delle politiche governative3 tali da indurre il sistema verso l’equilibrio e quindi sull’insieme attrattore A.
2 Questo comportamento può essere modellizzato tramite un modello a correzione d’errore che verrà
trattato in seguito. 3 Un esempio di tale politica può essere quella che le banche centrali attuano per evitare che la crescita
economica crei un eccessivo aumento dei prezzi, grazie all’intervento sui tassi d’interesse (politica monetaria).

Introduzione Pag. 5
In questa sede verranno esposti dei metodi per indagare queste relazioni d’equilibrio,
i quali portano a discutere aspetti di analisi di serie storiche, di modellizzazione dinamica, di cointegrazione, correzione d’errore e inferenza su dati non stazionari.
Il primo passo è quello di chiarire la nozione statistica di stazionarietà ed i suoi collegamenti col concetto d’equilibrio.
I.4 Stazionarietà e relazioni d’equilibrio Nella teoria economica, il concetto di equilibrio risulta essere ben definito. In ambito statistico, tale concetto può essere accostato a quello di processo stazionario. In modo più formale, un processo stocastico xt è stazionario se
• E[xt] = µ per ogni t • var (xt) < ∞ per ogni t • cov ( xt , xt+k ) = E[(xt−µ)(xt+k−µ)] = γk per ogni t e k. L’ultimo termine è detta autocovarianza, poichè misura la dipendenza lineare tra
membri di una singola serie storica. Per k = 0 , 1 , 2 , … abbiamo una sequenza γk di autocovarianze che prende il nome di funzione di autocovarianza.
Le tre condizioni sopra esposte, in poche parole affermano che un processo stocastico è stazionario se i suoi momenti sono indipendenti dal tempo.4
4 Se il processo xt è distribuito secondo una normale la condizione di indipendenza dal tempo deve essere verificata solo dai primi due momenti, dato che la distribuzione normale è specificata in toto da questi ultimi due.
x1t
x2t-
A
Pt x2t
Fig. I.1: Insieme attrattore di due variabili.

Pag. 6 Introduzione
In termini molto qualitativi, si dice che esiste una relazione d’equilibrio tra le due variabili x1 e x2 se la quantità εt≡f(x1t , x2t), che rappresenta le deviazioni attuali da questo equilibrio, è un processo stazionario , non necessariamente, a media nulla. Detto ciò, la deviazione dall’equilibrio εt non deve avere la tendenza a crescere nel tempo.
Un’estensione del concetto di stazionarietà è quello di trend-stazionarietà: secondo
la definizione rigorosa di stazionarietà, un processo stocastico con un trend crescente non è stazionario; tuttavia possiamo affermare che il valore di equilibrio di tale processo si muova lungo il trend e quindi esso risulta stazionario una volta depurato dal trend.
Questo fa sì che il vero problema della non stazionarietà sia legato alla dipendenza dal tempo dei momenti superiori al primo, in special modo della varianza. Il caso più semplice di processo non stazionario è definito dal random walk ossia
xt = ε ii
t
=∑
1
+ x0 ,
dove, se gli εi sono indipendenti e identicamente distribuiti secondo una normale con media zero e varianza σ2, il processo xt ha media che dipende dal valore iniziale x0 ma non dal tempo, mentre la sua varianza è pari a tσ2 ed ovviamente dipende dal tempo. Tale processo viene anche detto integrato di ordine 1, poichè esso può essere reso stazionario mediante una differenziazione; infatti
∆xt = εt
è stazionario per le ipotesi su εt .
I.5 Equilibrio e specificazione di modelli dinamici Se esiste un equilibrio stabile x1=βx2 , la deviazione x1t −βx2t contiene evidentemente un’informazione utile su come il sistema si muoverà verso quell’equilibrio.
Infatti, se supponiamo, per semplicità, che x2t sia una variabile esogena, la deviazione o errore x1t −βx2t dovrebbe essere una variabile utile per spiegare la successiva direzione di cambiamento di x1t . In particolare, un valore positivo per x1t −βx2t sta a significare che x1t è troppo grande relativamente a x2t ed in media ci potremmo aspettare una caduta di x1t nel futuro.
Il termine x1t-1−βx2t-1 , che rappresenta il disequilibrio precedente, viene chiamato meccanismo a correzione d’errore ed è quindi presente in una regressione dinamica.
Il parametro β, che caratterizza la relazione d’equilibrio, non è noto in generale. Tuttavia, ciò non significa che il meccanismo a correzione d’errore non sia utile, poiché i parametri non noti possono essere stimati o in un’analisi a priori (si vede la procedura

Introduzione Pag. 7
a due stadi usata in Engle-Granger(1987)) o tramite una particolare regressione detta di rango ridotto.
Inoltre, il meccanismo a correzione d’errore si dimostra essere equivalente ad altre trasformazioni di un modello lineare generale che incorpora i valori che le variabili hanno assunto nel passato5.
Un particolare vantaggio del meccanismo a correzione d’errore è che il grado di aggiustamento, in un dato istante, alle deviazioni dall’equilibrio è fornito dalle equazioni stimate senza ulteriori calcoli. Inoltre tale forma consente di constatare direttamente la presenza delle relazioni di lungo periodo.
Questo modo di affrontare l’analisi ha beneficiato della formalizzazione del concetto di cointegrazione (Granger (1981), Engle-Granger (1987)). La definizione informale di equilibrio statistico, discussa in precedenza, è basata su un caso particolare di cointegrazione. Inoltre, la modellizzazione di serie storiche cointegrate è strettamente connessa ai meccanismi a correzione d’errore: un comportamento a correzione d’errore, infatti, indurrà relazioni di cointegrazione tra le corrispondenti serie storiche e viceversa.
Una serie storica che tende a crescere nel tempo, non può certamente essere stazionaria6, ma le trasformazioni di tale serie possono esserlo. Per esempio, se consideriamo un oggetto non avente una posizione media fissata, attorno cui si muove, possiamo affermare che la serie storica contenente i valori nel tempo delle sue posizioni non è stazionario. Tuttavia, quest’oggetto può possedere un’accelerazione o una velocità che risultano essere stazionarie.
E’ utile, a questo punto introdurre il concetto di serie integrata; una serie storica viene detta integrata di ordine 1, I(1), se è non stazionaria di per sé, ma stazionaria dopo una differenziazione. Allo stesso modo, una serie (o processo stocastico) è integrata di ordine 2, I(2), se può essere resa stazionaria tramite una doppia differenziazione.
In generale, un processo è integrato di ordine d se viene reso stazionario dopo d differenziazioni.
Analizziamo, ora, il concetto di cointegrazione, la sua relazione con l’equilibrio di lungo periodo ed il suo utilizzo all’interno di una descrizione statistica del comportamento delle serie storiche che soddisfano alcune relazioni d’equilibrio.
Un semplice esempio riguarda due serie, ciascuna delle quali è integrata di ordine 1. Assumiamo che la relazione d’equilibrio tra queste variabili sia lineare e precisamente del tipo x1=βx2 . Allora (x1−βx2) deve essere pari a zero.
5 Un esempio può essere dato dalla rappresentazione a media mobile che verrà introdotta in seguito
per indagare sulle proprietà asintotiche delle variabili del processo. 6 Tuttavia è possibile che una serie, che cresce nel tempo, sia stazionaria intorno ad una tendenza
deterministica, parleremo, in questo caso, di serie trend-stazionaria.

Pag. 8 Introduzione
La definizione di cointegrazione data da Engle-Granger (1987), richiede la stazionarietà della deviazione x1t −βx2t . Se ciò si verifica, usando la notazione CI(1,1), diremo che le variabili x1 e x2 sono cointegrate (1,1), cioè le due variabili sono integrate di ordine 1 ed esiste una combinazione lineare x1t −βx2t che è integrata di ordine inferiore, nella fattispecie zero (I(0)).
Più in generale, si può parlare di variabili CI(a,b) quando a>b e b>0, dove a è l’ordine massimo di integrazione delle variabili e b è la riduzione di tale ordine d’integrazione, prodotta dalla combinazione lineare, la quale ha ordine d’integrazione pari ad a-b.
Finora si è parlato di una sola combinazione lineare; in realtà potrebbero sussistere diverse combinazioni di tal tipo, tra loro indipendenti, le quali fanno diminuire l’ordine d’integrazione del processo. Il numero di tali combinazioni prende il nome di rango di cointegrazione. Il fatto di considerare più di una relazione cointegrante porta ad ulteriori complicazioni, in quanto il rango di cointegrazione, se non noto, dovrà essere stimato consistentemente dai dati a disposizione.
In seguito si vedrà come le relazioni tra variabili cointegrate possano essere rappresentate usando un meccanismo a correzione d’errore e come tali relazioni possano essere valutate in modellizzazioni empiriche.
I.6 Problematiche nella stima delle relazioni di lungo periodo Come accennato sopra, in generale non si conoscono le relazioni d’equilibrio, e quindi queste ultime, che si identificano con le relazioni cointegranti, devono essere necessariamente stimate. Si è detto, inoltre, che esse possono essere rappresentate attraverso un meccanismo (o modello) a correzione d’errore ECM (Error Correction Model); pertanto è su tale modello che si deve operare la stima. In seguito si dimostrerà come un tale modello non sia altro che una riparametrizzazione del modello VAR, che mette di evidenziare non solo le relazioni di equilibrio di lungo periodo, ma anche il processo di aggiustamento (ovvero la dinamica di breve periodo) che viene seguito affinché il sistema, descritto dal modello, ritorni in una situazione di equilibrio.
Il fatto di considerare combinazioni lineari di variabili cointegrate implica che queste
siano integrate. Nel prosieguo di questo lavoro ipotizzeremo che esse abbiano, al massimo, ordine di integrazione pari a 1.
Questo porta a dei problemi inferenziali nelle regressioni di variabili di questo tipo. Consideriamo, per esempio, una variabile scalare yt ed un vettore di variabili Xt; la stima dei minimi quadrati, OLS (Ordinary Least Square), del vettore β nel semplice modello Y=Xβ+ε è data da

Introduzione Pag. 9
$β = (X′X)-1X′Y.
Questa stima, se le variabili sono stazionarie, ha una distribuzione normale intorno al valore vero β, a condizione che, una volta normalizzata da T, la quantità X′X converga in probabilità ad una matrice di costanti.
Se le variabili sono I(1), tale convergenza non è verificata, e quindi la distribuzione asintotica di β non è normale, bensì una mistura di gaussiane, così come è definita in Mood et al.(1991). Questa distribuzione dipende da diversi parametri di disturbo (si veda Stock (1987)), al punto che per ogni regressione bisognerebbe tabularne la distribuzione.
Pertanto, non si possono applicare gli usuali test t nelle regressioni statiche tra variabili I(1), anche se queste sono cointegrate.
Questo problema può essere risolto seguendo due approcci: 1. approccio a due stadi (Engle-Granger (1987)); 2. approccio basato sulla verosimiglianza (Johansen (1995)).
Di questi due, il primo presenta diversi problemi applicativi, alcuni dei quali sono risolti mediante il secondo approccio.
In quest’ultimo, l’inferenza si basa sulla funzione di verosimiglianza di modelli VAR cointegrati. Questo sarà il tipo di approccio che seguiremo lungo tutto il lavoro.
I.7 La modellizzazione di componenti deterministiche Con l’introduzione di componenti deterministiche nei modelli VAR cointegrati, quali costanti, tendenze o dummy, si verifica che queste ultime influenzano la distribuzione del test sul rango di cointegrazione. Per tale motivo la Parte II del presente lavoro è stata dedicata a tale problematica.
Nell’ambito di questo lavoro le componenti deterministiche vengono introdotte nei modelli come segue
A(L)(Xt − fDt) = εt .
dove Dt è una qualsiasi funzione deterministica.7, mentre A(L) è il polinomio autoregressivo introdotto nel capitolo successivo. Come si può vedere, si modellizzano variabili che una volta depurate dalla componente deterministica abbiano un andamento autoregressivo con radice unitaria.
7 In questa sede ci si limita a una costante , trend più costante, dummy con e senza trend.

Pag. 10 Introduzione
Questo modo di procedere risulta essere diverso da quello adottato finora in letteratura, ove le componenti deterministiche sono inserite nel modello al di fuori del polinomio autoregressivo, ossia
A(L) Xt = ΦDt + εt.
Nel capitolo 9 verranno posti a confonto i due approcci evidenziandone i punti di forza e di debolezza, nonché le ragioni che ci hanno spinto a seguire una strada alternativa a quella già esistente.
I.8 Articolazione della tesi La tesi si articola nel seguente modo.
Nella prima parte, dopo aver presentato nel capitolo 1 il modello VAR per variabili stazionarie, si analizza, nel capitolo successivo, il VAR in presenza di non stazionarietà nel caso base, ovvero in quello che contempla l’assenza di componenti deterministiche.
Nel capitolo 3, si ricava la forma del trace-test per tale modello che, come si vedrà nel seguito, permette di stimare il rango di cointegrazione.
Nel capitolo 4, vengono analizzate le proprietà asintotiche degli stimatori per questo stesso modello, che consentono di derivare le distribuzioni appropriate per testare le varie ipotesi sulle relazioni di cointegrazione, come specificato nel capitolo 5.
La modifica della distribuzione asintotica per la determinazione del rango, dovuta alla presenza di componenti deterministiche di vario tipo che caratterizzano le serie, viene analizzata nella seconda parte del lavoro. Essa è posta in evidenza sia per modelli illustrati nei capitoli 6 e 7, riguardanti, rispettivamente, i processi con costante e con trend in tutte le loro componenti, sia, nel capitolo 8, su cui focalizzeremo maggiormente la nostra attenzione, per i modelli che presentano break strutturali e per i quali verrà specificata la procedura di stima dei parametri.
Nel capitolo successivo, alla luce dei risultati ottenuti nella parte precedente del lavoro, l’accento viene posto in particolare sulla necessità di rivedere l’approccio usato in letteratura fino ad ora alla modellizzazione di processi diversi per quel che concerne la parte deterministica, sottolineando la validità dell’analisi qui svolta e basata sull’ottica del porsi nel “modello più generale possibile” in grado di rispecchiare al meglio il processo sottostante alla descrizione dei dati.
La terza parte del lavoro è di natura “applicativa”. Il capitoli 10 è dedicato all’applicazione dei risultati ottenuti sul piano metodologico
alla teoria macroeconomica che descrive la relazione nel mercato dei cambi fra Italia e, rispettivamente, Stati Uniti, Germania e Giappone.
Il capitolo successivo, invece, riguarda l’implementazione del software relativo alla determinazione della distribuzione asintotica del rango di cointegrazione: viene

Introduzione Pag. 11
specificata la procedura di simulazione adottata per la tabulazione delle tabelle di distribuzione e viene proposto un esempio di utilizzo di tale software.
L’ultima parte del lavoro è costituita dalle appendici.


Parte I
Il modello VAR di base


Capitolo 1 Il modello VAR per variabili stazionarie
IL presente capitolo ha lo scopo di presentare il modello VAR (Vector AutoRegressive), non vincolato, nel caso in cui il processo sia stazionario. Verrà quindi fornita una condizione necessaria e sufficiente affinché ciò si verifichi. Tale condizione è un importante strumento diagnostico per le applicazioni e, pertanto, dovrebbe essere verificata ogni volta che si lavora con serie storiche.
L’articolazione del capitolo è la seguente: nel primo paragrafo verrà fornita l’equazione vettoriale che permette di rappresentare il processo, con la corrispondente soluzione generale. Si daranno inoltre le condizioni che i parametri devono soddisfare affinché il processo diventi stazionario. Nel secondo paragrafo verrà derivata la stima di massima verosimiglianza dei parametri (che, assumendo normalità degli errori, coincide con quella dei minimi quadrati), con le rispettive proprietà asintotiche. Poiché si tratta di un argomento ben conosciuto, non si entrerà nel dettaglio delle singole questioni, rimandando, per eventuali chiarimenti ed approfondimenti a Hamilton (1994).
1.1 Il processo autoregressivo e sue rappresentazioni Consideriamo il processo autoregressivo p-dimensionale
X X Xt t k t k t= + + +− −Π Π1 1 ... ε t=1,...,T (1.1)
per valori fissati di X-k+1 ,...,X0. I vettori Xt-1 , ... , Xt-k , di dimensioni p×1 (p è il numero di variabili del modello), sono i ritardi del vettore Xt . Inoltre le matrici Πi , di dimensioni p×p, sono costituite dai coefficienti delle variabili ritardate, mentre εt è il vettore degli errori, che per ipotesi supponiamo essere indipendenti e identicamente

Pag. 16 Il modello VAR per processi stazionari
distribuiti (i.i.d.) come una normale Np (0,Ω), ossia come una Gaussiana con media zero e matrice di varianze-covarianze Ω.
In ogni singola equazione di questo processo vettoriale, la singola xit considerata, appartenente al vettore Xt , dipende non solo dai propri ritardi, ma anche da quelli delle altre componenti del vettore.
Nel seguito verrà usato l’operatore ritardo L, che consente di semplificare la notazione che compare nella (1.1). Tale operatore è definito nel seguente modo
LXt=Xt-1 ,
ovvero la sua applicazione all’elemento di un processo stocastico consente di ottenere lo stesso elemento, ritardato di un periodo.
Applicando due volte l’operatore L si ottiene che
L2Xt=Xt-2
e, più in generale,
LnXt=Xt-n ,
dove n è un intero positivo. Fatte queste considerazioni, la (1.1) può essere scritta tramite questo operatore come
(I − Π1 L − Π2 L2 − … − ΠkLk ) Xt = εt .
Il termine tra parentesi non è altro che un polinomio in L e sarà indicato con A(L); pertanto la (1.1) può scritta anche come
A(L) Xt = εt (1.2)
Alla matrice A(L) è quindi associato il polinomio caratteristico del processo vettoriale, pari a
A z I zii
i
k( ) = −
=∑Π
1,
con determinante A(z) . E’ possibile fornire, così come fatto in Johansen (1995), la soluzione dell’equazione
(1.1) come funzione dei valori iniziali e degli errori (solitamente indicati col termine innovazioni) εt . Tale soluzione ha la seguente espressione , più comunemente nota come rappresentazione a media mobile o MAR (Moving Average Representation) del processo autoregressivo (1.1)

Il modello VAR per processi stazionari Pag. 17
X C X X X Ct t s s ss
k
k k j t jj
t= + + + +− + −
=− −
=
−
∑ ∑( ... )Π Π Π0 1 11
10
1ε (1.3)
con C0=I e
C Cn n j jj
k n
= −=∑ Π
1
min ,
(Cn è definito ricorsivamente).
Come si può vedere, con tale formulazione il processo è espresso in funzione dei valori iniziali (primi k valori, con k indicante il numero dei ritardi) e degli εi , moltiplicati per un opportuno coefficiente, che dà un’idea del “peso” che essi hanno in funzione del ritardo dall’istante t considerato.
La soluzione (1.3) è valida per ogni insieme di parametri dell’equazione vettoriale (1.1). Vediamo, ora, come questi parametri devono essere vincolati per definire un processo autoregressivo stazionario.
Assumiamo che il polinomio caratteristico A(z) soddisfi la condizione che esso abbia radici, in modulo, maggiori o uguali ad uno (si esclude, quindi, la presenza di radici “esplosive”); sotto tale assunzione, una condizione necessaria e sufficiente affinché Xt sia stazionario è che A(1)≠ 0, ossia che la matrice A(1) non sia di rango ridotto (per una definizione di rango di una matrice, si veda l’appendice B).
In questo caso il processo avrà la seguente rappresentazione a media mobile
Xt= Cn t nn
ε −=
∞
∑0
= C(L)εt .
A C(L) è associato il polinomio caratteristico infinito C z z Cnn
n( )= ∑
=
∞
0, che altro non è
che una serie di potenze, la quale è convergente se z <1+ η, per ogni η>0. Per tali valori di z abbiamo inoltre che C(L)=[A(L)]-1 (per una dimostrazione si veda Johansen (1995)).
Ritornando ora alla rappresentazione VARR (Vector AutoRegressive Representation), è possibile vedere come, riparametrizzando opportunamente la (1.1), si giunga ad un modello a correzione d’errore ECM (Error Correction Model), ossia
∆Xt=ΠΧ t-1+ Γ ii
k
=
−
∑1
1∆Χt-i+εt ,
dove Π = Π ii
kI−
=∑
1 e Γi = −
= +∑Π jj i
k
1.
Il legame fra questa forma e quella indicata dalla (1.1) è dato dal fatto che il polinomio caratteristico A(z) può essere riscritto come

Pag. 18 Il modello VAR per processi stazionari
A(z) = (1 − z) I − Πz − Γii
k
=
−
∑1
1(1 − z) zi.
Si noti che A(1)=−Π e quindi assumere che nel processo siano presenti solo componenti stazionarie equivale ad assumere che la matrice Π sia di rango pieno.
In seguito verrà utilizzata la seguente matrice, detta matrice ritardo, la cui espressione è la seguente
Γ Π Γ Π= − = + − == ==
−
∑∑dA zdz
I iz
i ii
k
i
k( )
1 11
1.
1.2 Analisi statistica di processi stazionari Dato il modello autoregressivo (1.1) e supponendo che esso sia stazionario, introduciamo la seguente notazione
Z X X Xt t t t k
k
' ( , ,..., )( , ,..., )
= ′ ′ ′′ =
− − −1 2
1 2ϑ Π Π Π
che ci consente di riscrivere la (1.1) come
X Zt t t= ′ +ϑ ε t=1, ... ,T.
L’ipotesi in base alla quale gli errori sono gaussiani ci permette di stimare i parametri ϑ e Ω mediante la massimizzazione della funzione di verosimiglianza, scritta in forma logaritmica.
In formule si ha che
log , ) log( ) log ( ) ( )L( T T X Z X Zt tt
T
t tϑ π ϑ ϑΩ Ω Ω= − − − − ′ ′ − ′=
−∑12
2 12
12 1
1
dalla cui massimizzazione si ottengono le equazioni per la stima di ϑ e di Ω
X Z Z Zt tt
T
t tt
T′ = ′ ′
= =∑ ∑
1 1ϑ (1.4)
$ϑ = ′
′
=
−
=∑ ∑Z Z Z Xt tt
T
t tt
T
1
1
1

Il modello VAR per processi stazionari Pag. 19
$ $ $ .Ω= − ′
− ′
′−
=∑T X Z X Zt t t tt
T1
1
ϑ ϑ
Definendo le seguenti matrici dei prodotti incrociati
Sxx=T-1 X Xt tt
T′
=∑
1, Szz=T-1 Z Zt t
t
T′
=∑
1 e Sxz=T-1 X Zt t
t
T′
=∑
1,
si ottiene che
$ϑ =Szz-1Szx e $Ω =Sxx-SxzSzz
-1Szx
A meno di una costante, si ha che
L Tmax
$− =2 Ω .
1.3 Proprietà asintotiche degli stimatori Vediamo, ora, le proprietà asintotiche degli stimatori nel modello VAR, nel caso in cui il processo Xt è stazionario e con gli εt i.i.d. N(0, Ω). Sostituendo nell’equazione (1.4) l’espressione di Xt in funzione di Zt, si ottiene che
ϑ′ Z Zt tt
T′
=∑
1+ ε t t
t
TZ ′
=∑
1= $ϑ Z Zt t
t
T′
=∑
1
e quindi
$ϑ -ϑ′ = Z Zt tt
T′
=
−
∑1
1
ε t tt
TZ ′
=∑
1.
Poiché il processo è stazionario, segue che l’ultimo termine di quest’espressione
converge con tasso pari a T-1/2 (si veda appendice A). Pertanto T-1/2 ε t tt
TZ ′∑
=1converge in
distribuzione ad una Gaussiana con media nulla e matrice di varianza-covarianza data da Σ⊗Ω , dove Σ e la matrice di varianza-covarianza della variabile stazionaria Zt , la quale è stimata consistentemente da Szz .
Traducendo questo discorso in formule si ha che
→T Nw1 2 10( $ ) ( , )ϑ ϑ− ⊗−Σ Ω

Pag. 20 Il modello VAR per processi stazionari
dove
→SzzP Σ
→T t tt
TP−
=
′∑1
1
ε ε Ω
1.4 Un modo più “econometrico” per eseguire la stima dei VAR Come è stato visto al § 1.2, le matrici dei prodotti incrociati sono state definite con la notazione Sij , con i e j indicanti le variabili coinvolte nel prodotto. Tale notazione è legata a quella di stampo più prettamente econometrico, di cui diamo qui un cenno, al fine di evidenziare la congruenza con la notazione precedentemente usata e quindi con il contenuto informativo che ne sta alla base.
Consideriamo il modello VAR stazionario indicato dalla (1.1) e qui sotto riportato
Xt=Π1Xt-1+...+ΠkXt-k+εt .
In presenza di T osservazioni del campione, possiamo scrivere il seguente sistema di equazioni
X1=Π1X0+...+ΠkX-k+1+ε1
X2=Π1X1+...+ΠkX-k+2+ε2 (1.5)
...
XT=Π1XT-1+...+ΠkXT-k+εT
Ogni variabile Xi e εi , come già specificato in precedenza, è in realtà un vettore p-dimensionale di variabili scalari ed i coefficienti Πi di tali vettori sono matrici p×p di costanti.
La scrittura di tali sistemi può essere ricondotta ad una forma più compatta e quindi più efficiente, almeno dal punto di vista econometrico. Tale impostazione porta a scrivere

Il modello VAR per processi stazionari Pag. 21
X=
x x xx x x
x x x
p
p
T T Tp
11 12 1
21 22 2
1 2
...
......
...
, E=
TpTT
p
p
εεε
εεεεεε
......
...
...
21
22221
11211
, Z=X X X
X X X
k
T T T k
0 1 1
1 2
' ' '
' ' '
......
...
− − +
− − −
.
Ricordando che Xi=(x1i , x1i , ..., xpi)′ , per ogni i=-k+1, ..., T-1, allora il sistema (1.5) può essere riscritto in forma compatta come
X=ZB+E (1.6)
B può essere stimato mediante OLS e tale stima coincide con quella LM data da
$B=(Z′′′′Z)-1Z′′′′X (1.7)
Sostituendo a X il valore dato dalla (1.6), si ottiene
$B-B=( Z′′′′Z)-1Z′′′′E
e tale stima equivale a quella ottenuta nel paragrafo (1.3). Pertanto possiamo dire che
Szz=T-1Z′′′′Z
Szε=T-1Z′′′′E
Inoltre valgono le seguenti proprietà di convergenza
T-1Z′′′′Z→p Σ
T-1/2Z′′′′E→w N(0,Σ⊗Ω ).
Analogamente a quanto visto nel § 1.3, si ha
T1/2( $B-B)=(T-1Z′′′′Z)-1T-1/2Z′′′′E→w Σ-1N(0,Σ⊗Ω )=N(0,Σ-1⊗Ω ).
Come si può vedere, il vantaggio di questa formula in termini di immediatezza comprensiva è chiaro, in virtù della compattezza che la caratterizza. Tuttavia tale semplicità notazionale presenta il difetto di una scarsa flessibilità a livello operativo di esecuzione della stima, allorquando si rende necessario analizzare meglio le questioni relative al comportamento asintotico dei processi integrati con componenti deterministiche.

Pag. 22 Il modello VAR per processi stazionari
Infatti, come vedremo successivamente, il tasso di convergenza di queste componenti può essere meglio chiarito solo se esse risultano in qualche modo evidenziate “separatamente” all’interno dell’array complessivo di variabili e questo intento, dal quale non possiamo prescindere in virtù dell’importanza che riveste per la nostra analisi la questione dell’asintoticità dei processi, può essere raggiunto solo a spese di una minore semplicità computazionale. Nonostante ciò, come si vedrà nel prosieguo del lavoro, la simbologia adottata non è tale da aggiungere un grado significativo di incomprensibilità notazionale; la perdita di “chiarezza visiva immediata” a sostegno di quella concettuale risulta necessaria e, d’altra parte, come si potrà costatare successivamente, la simbologia, sebbene apparentemente ostica, risulterà “ex post” certamente più efficace.
1.5 Il problema della determinazione del numero di variabili ritardate nel modello VAR
Il problema della determinazione del numero di ritardi presenti nel modello risulta di fondamentale importanza per una corretta specificazione dello stesso. Risulta essere buona prassi cercare di evitare di aggiungere troppi ritardi, in quanto che, all’aumentare del loro numero, anche la complessità del modello cresce, a causa del crescere del numero di parametri da stimare (se si aggiunge, ad esempio, un ritardo, devono essere stimati ulteriormente p2 parametri nella matrice Πk). D’altra parte la condizione di bianchezza dell’errore, da cui non si può prescindere per una corretta modellizzazione, ci spinge a non trascurare alcuna ipotesi sul numero di ritardi, quand’anche esso fosse elevato.
Poiché la teoria in seguito sviluppata ha come uno dei suoi punti cardine l’indipendenza degli errori, allora una metodologia usata per determinarlo è data dalla verifica di incorrelazione delle innovazioni.
Il modo più semplice per andare a verificarla consiste nel plottare le funzioni di auto-correlazione e cross-correlazione per le serie dei residui. Un altra tecnica si basa sull’esecuzione di test sequenziali: partendo da un modello con un gran numero di ritardi, la procedura consiste nell’andare a testare in “cascata” che l’ultimo ritardo abbia coefficiente nullo. Ad esempio, per il modello autoregressivo (1.1) si può applicare il test del rapporto di verosimiglianza per l’ipotesi nulla H0: Πk=0, che è asintoticamente distribuito come una χ2 con p2 gradi di libertà.
Ad ogni modo, qualora il numero di ritardi sembri essere eccessivo, la soluzione più intelligente risulta essere quella di rivedere il modello ed in particolare i nessi causali considerati per supportare l’introduzione di certe variabili piuttosto che altre: a livello

Il modello VAR per processi stazionari Pag. 23
modellistico, talvolta risulta più efficace inserire un’ulteriore variabile piuttosto che aumentare il numero di ritardi delle variabili già considerate.


Capitolo 2 Modello VAR per variabili cointegrate
IN questo capitolo verrà definito in modo più preciso il concetto di co-integrazione di variabili integrate, fornendo anche degli esempi che possano chiarirne maggiormente il significato. Un importantissimo risultato è costituito dal teorema di rappresentazione di Granger (Engle&Granger(1987)), il quale fornisce condizioni necessarie e sufficienti affinché il processo sia integrato di ordine 1. Per questo scopo si riparametrizzerà il modello VAR nella forma ECM, la quale è importante poiché consente di evidenziare, e di conseguenza stimare, le relazioni di equilibrio che definiscono lo spazio di co-integrazione. Il teorema di rappresentazione di Granger consentirà di passare dalla forma autoregressiva a quella a media mobile, nel caso di processi I(1), consentendo, quindi, un’analisi approfondita delle varie componenti del processo (stazionarie e non), che risulterà utilissima per la determinazione della distribuzione asintotica del test sul rango di co-integrazione.
Si accennerà anche all’approccio a due stadi, che consente di stimare i parametri che caratterizzano una relazione di co-integrazione, evidenziandone le limitazioni che hanno spinto all’utilizzo dell’approccio di Johansen, il quale, a sua volta, verrà affrontato nel capitoli successivi.
2.1 Concetti e definizioni Nello spiegare qualitativamente cosa significhi il termine cointegrazione, si è parlato di processo integrato. Diamo ora una definizione rigorosa di quest’ultimo concetto.
♦ DEF 1. Un processo stocastico Yt , che soddisfa la condizione Yt-E(Yt)= Cii=∞∑ 0
εt-i ,
è detto essere I(0) se C= Cii=∞∑ 0
≠0.

Pag. 26 Il modello VAR per variabili co-integrate
♦ DEF 2. Un processo stocastico Xt è detto integrato di ordine d, I(d), d=0,1,2,... se Dd(Xt-E(Xt)) è I(0).
Nel presente lavoro si tratteranno processi che, hanno ordine di integrazione massimo pari a 1, ossia processi I(0) e I(1). In Johansen (1995) vengono affrontate anche le problematiche relative ai processi I(2).
La seconda definizione ha la proprietà di essere invariante a trasformazioni lineari non-singolari del processo; ciò significa che, se xt è I(1) e A è una matrice p×p di rango pieno, allora Axt è anch’esso un processo I(1).
Una conseguenza della seconda definizione è che la parte stocastica di un processo I(1) è non stazionaria. Considerando infatti un processo Yt stazionario e I(0), il processo Xt è determinabile nel seguente modo: sia data l’equazione
∆Χi = Yi ;
sommando tale espressione da 0 a t otteniamo che
Xt = X0 + Yii
t
=∑
1 ;
conoscendo la validità della relazione
C(z) = C + C*(z) (1 − z)
e sapendo che C è di rango pieno (dato che Yt è I(0)), possiamo scrivere la seguente espressione
Xt = X0 + C ε ii
t
=∑
1 + Yt
* − Y0*, (2.1)
dove Yt* = Cii
*=
∞∑ 0 εt-i .
Nella (2.1) si nota la presenza di un termine che è la causa della non stazionarietà di Xt , in quanto lo rende non stazionario in varianza; tale termine è ε ii
t=∑ 1 e prende il
nome di random walk. Consideriamo, ora, un vettore β in Rp e moltiplichiamo da sinistra la (2.1) per tale
vettore, ottenendo
β′Xt = β′X0 + β′C ε ii
t
=∑
1 + β′Yt
* − β′Y0 ;

Il modello VAR per variabili co-integrate Pag. 27
se tale vettore rappresenta una relazione di co-integrazione, per quanto detto nell’introduzione β′Xt deve essere I(0) e pertanto deve valere la condizione secondo cui β′C = 0.
Basandoci su quest’idea, diamo una definizione rigorosa di co-integrazione.
♦ DEF. 3 Sia Xt un processo I(1). Diremo che Xt è co-integrato con vettore di cointegrazione β≠0 se β′Xt può essere reso stazionario da un’opportuna scelta della sua distribuzione iniziale. Il rango di co-integrazione è il numero di relazioni di co-integrazione linearmente indipendenti e lo spazio generato da tali relazioni prende il nome di spazio di co-integrazione. Diamo, qui di seguito degli esempi per illustrare le nozioni di integrazione e co-
integrazione.
ESEMPIO 2.1 Consideriamo il processo bidimensionale Xt , con t=1, ... ,T dato da
X1t = ε11
ii
t
=∑ + ε2t ,
X2t = a ε11
ii
t
=∑ + ε3t .
I processi X1t e X2t , e quindi Xt stesso, sono I(1). Essi cointegrano grazie al vettore di cointegrazione β′=(a , −1), dal momento che la combinazione lineare β′Xt =aX1t −X2t = aε2t − ε3t è stazionaria.
Se al vettore Xt venisse aggiunto il processo stazionario
X3t = ε4t
allora Xt' = (X1t , X2t , X3t) rimarrebbe un processo vettoriale I(1), ma con due vettori di
cointegrazione, che formano la matrice di cointegrazione β nella forma
β =a 01 0
0 1−
.
Come si può notare da questo esempio, anche un vettore unitario può essere considerato, con un certo abuso di linguaggio, un vettore di cointegrazione.

Pag. 28 Il modello VAR per variabili co-integrate
Ciò dimostra che, inserendo una variabile stazionaria fra quelle del processo, la dimensione dello spazio di cointegrazione cresce di una unità.
ESEMPIO 2.2
Definiamo il processo tridimensionale dato da
X1t =i
t
jj
i
ii
t
= = =∑ ∑ ∑+
11
12
1ε ε ,
X2t = ai
t
jj
i
ii
tb
= = =∑ ∑ ∑+
11
12
1ε ε + ε3t ,
X3t = c ε 21
ti
t
=∑ + ε4t .
In tale circostanza, X1t e X2t sono processi I(2), mentre X3t è un processo I(1). Quindi il processo Xt′ = (X1t , X2t , X3t) è un processo I(2) e cointegra, in quanto
aX1t − X2t = (a − b) ε 21
ti
t
=∑ − ε3t
è I(1), mentre
acX1t − cX2t − (a − b) X3t = − cε3t − (a − b) ε4t
è I(0). Possiamo così affermare che (a, −1, 0) è un vettore di cointegrazione che cambia l’ordine del processo da 2 a 1, mentre il vettore [ac , − c , − (a − b)] cambia l’ordine di integrazione da 2 a 0.
Un’altra possibilità è la seguente: si definisca il processo X3t come
X3t = ci
t
jj
i
= =∑ ∑
12
1ε + ε4t .
In questo caso si può notare un fenomeno di tipo diverso. Infatti , mentre la combinazione lineare aX1t−X2t è ancora un processo I(1), la
stazionarietà è rilevabile mediante la seguente espressione
c (aX1t − X2t) − (a − b) ∆X3t = − cε3t − (a − b) ∆ε4t .

Il modello VAR per variabili co-integrate Pag. 29
Si può notare quindi che le differenze di X3t sono necessarie al fine di rendere stazionario il processo I(1), espresso dalla combinazione lineare precedente.
Questa proprietà va sotto il nome di cointegrazione polinomiale.
2.2 Dalla rappresentazione AR a quella MA per variabili I(1): il teorema di rappresentazione di Granger
In questo paragrafo si fornirà uno strumento, noto come teorema di rappresentazione di Granger, che consente di passare da un rappresentazione in forma autoregressiva a quella a media mobile nel caso in cui si abbia a che fare non più con variabili stazionarie, ma con variabili integrate di ordine 1. Questo teorema è di fondamentale importanza per lo studio di processi non stazionari in genere, in quanto consente di esprimere in modo organico il processo Xt , evidenziandone e distinguendone le componenti stazionarie da quelle che non sono tali.
Attraverso questo teorema, si forniscono delle condizioni necessarie e sufficienti che i coefficienti Πi del modello autoregressivo devono soddisfare per avere processi integrati di ordine 1, escludendo la presenza di componenti I(2); ciò significa che, differenziando le variabili Xt , si ottengono solo variabili stazionarie. A questo scopo conviene riparametrizzare il modello VAR come un modello ECM introdotto precedentemente.
Il teorema di rappresentazione di Granger parte da un’espansione nel punto z=1 del polinomio caratteristico A(z), la cui forma è la seguente
A(z) = A(1) + (1 − z) A*(z).
Detto ciò, il processo è riscrivibile come
A(L) Xt = − ΠXt + A*(L) ∆Xt = εt . (2.2)
Il teorema afferma che, se A(z) ha radici unitarie,ossia se il rango di Π è r<p, allora esistono due matrici α e β di dimensioni p×r, di rango r, tali per cui
Π = αβ′ .
Inoltre una condizione necessaria e sufficiente affinché ∆Xt e β′Xt-1 siano stazionarie è che α⊥ ′Γβ ⊥ sia di rango pieno.
In tal caso la soluzione dell’equazione (2.2) ha la rappresentazione
Xt = C ii
tε
=∑
1 + C1(L)εt + Pβ⊥
X0 (2.3)

Pag. 30 Il modello VAR per variabili co-integrate
con C = β⊥ (α⊥ ′Γβ ⊥ )−1α⊥ ′. Ciò significa che Xt è un processo dato da un random walk, un processo stazionario e
il valore iniziale X0. Da questa rappresentazione segue immediatamente che β′Xt è stazionario, in quanto β′C=0. La matrice C è di fondamentale importanza per la comprensione dei modelli I(1). Per grandi valori di t, il processo è dominato da un random walk e la sua varianza, pari a CΩC′, è detta varianza di lungo periodo. La
matrice C mostra come i termini α ε⊥ =′ ∑ ii
t1 , che sono responsabili della non
stazionarietà e sono definiti come tendenze comuni, entrano nel processo Xt attraverso la matrice β⊥ . Questa rappresentazione evidenzia, separandole, la dinamica di lungo periodo, definita dal primo termine della (2.3) e quella di breve periodo, costituita dagli altri due termini.
Dimostrazione. Consideriamo l’equazione vettoriale
A(L) Xt = −ΠXt + A*(L) ∆Xt = εt (2.4)
con Π = αβ′ . Consideriamo poi le proiezioni nello spazio di α e α⊥ dell’equazione (2.4)
α′αβ′ Xt + α′A*(L) ∆Xt = α′ε t (2.5)
α⊥ ′A*(L) ∆Xt = α⊥ ′εt. (2.6)
Introduciamo ora le nuove variabili
Zt = ′β Xt = (β′β)-1β′Xt
Yt = β⊥' ∆Χt = (β⊥ ′β⊥ )-1β⊥ ′∆Χ t
E’ possibile allora scrivere
∆Χi = ( Pβ⊥+ Pβ) ∆Χi = β⊥ Yi + β∆Ζi (2.7)
con Pβ β β β β⊥
= ′ ′⊥ ⊥ ⊥−
⊥( ) 1 pari alla proiezione nello spazio definito dalle colonne di β⊥ e
Pβ β β β β= ′ ′−( ) 1 pari alla proiezione nello spazio definito dalle colonne di β (per una
definizione più precisa di proiezione in spazi vettoriali, si veda l’appendice B, § 3.5). Sommando da 1 a t la (2.7) si ricava che

Il modello VAR per variabili co-integrate Pag. 31
Xt = X0 + β⊥ Yii
t
=∑
1 + β(Ζt − Z0) = β⊥ Yi
i
t
=∑
1 + βΖt + Pβ⊥
X0 . (2.8)
Il termine Yiit=∑ 1 rappresenta la parte non stazionaria del processo, mentre βZt è quella
stazionaria. Per come Zt e Yt sono state definite, è necessario dimostrare che sono stazionarie e
ricavare l’espressione da inserire nell’equazione (2.8), così da ricondurci alla formulazione del processo secondo Granger.
La stazionarietà di Zt e Yt viene dimostrata sostituendo nella (2.5) e nella (2.6) le variabili, secondo la loro definizione, ricavando l’espressione del polinomio caratteristico e verificando che il suo determinante, nel punto z =1, non è nullo.
Analiticamente si ha
− α′αβ′β Zt + α′A*(L) β⊥ ∆Zt + α′A*(L) β⊥ Yt = α′ε t (2.5′)
α⊥ ′A*(L) β∆Zt + α⊥ ′ A*(L) β⊥ Yt = εt.. (2.6′)
In forma matriciale
~ (A L)ZY
t
t
+ [α,α⊥ ]′ εt
con
~ ( )( ) ( ) ( )
( ) ( ) ( )
* *
* *A z
A z z A zA z z A z
=− ′ ′ + ′ − ′
′ − ′
⊥
⊥ ⊥ ⊥
α αβ β α β α βα β α β
11
=′′
[ ]
⊥
αα
A z z( ) ( )β β 1−⊥−1 .
Per z =1 si ha
~ ( )A 10
=− ′ ′ ′
′
⊥
⊥ ⊥
α αβ β αα
ΓβΓβ
. (2.9)
e il suo determinante è α′αβ′βα ⊥ ′Γβ ⊥ . Poiché nel teorema si è ipotizzato che le matrici α, β e α′Γβ ⊥ siano di rango pieno,
allora ~( )A 1 0≠ , ovvero z =1 non è una radice di ~A .

Pag. 32 Il modello VAR per variabili co-integrate
Per z ≠1 possiamo scrivere
~A (z) =α′α A(z)β′β (1 − z)− (p − r)
ovvero
~A (z) = 0 implica A(Z) = 0 e z>1.
Dato ciò, possiamo concludere che il sistema formato dalle equazioni (2.5′) e (2.6′) è invertibile, Yt e Zt sono stazionarie ed in forma matriciale si ha
ZY
Ct
t
= ~ (L) [α,α⊥ ]′ εt
con ~( ) ~ ( ) ~( ) ( )~ ( )*C z A z A z C z= = + −− −1 11 1 .
Pertanto
ZY
At
t
= ~ (L)−1 [α,α⊥ ]′ εt + ~*C (L) [α,α⊥ ]′ ∆εt .
Per ricavare l’espressione di β⊥ Yiit=∑ 1 , consideriamo solo le ultime p-r righe del
sistema matriciale definito sopra (le righe risultano in numero p-r poiché questo è il numero di variabili non stazionarie e non cointegrate del modello VAR originario)
Yt = [0,Ip-r] ~A (L)−1 [α,α⊥ ]′ + ~*C (L) [α,α⊥ ]′
β⊥ Yii
t
=∑
1= [0,β⊥ ] ~A (L)-1 [α,α⊥ ]′ εi
i
t
=∑
1+ [0,β⊥ ] ~*C (L) [α,α⊥ ]′ (εt − ε0 ).
Inserendo quest’espressione nella (2.8) si dimostra la (2.3). Troviamo, ora, l’espressione del coefficiente del random walk, ossia della
matrice C
C = [0,β⊥ ] − ′ ′ ′
′
⊥
⊥ ⊥
−α αβ β αα
ΓβΓβ0
1
[α,α⊥ ]′
= [0,β⊥ ] ( )
( )− ′ ′
′
−
⊥ ⊥−
α αβ βα
1
1
00 Γβ
[α,α⊥ ]′

Il modello VAR per variabili co-integrate Pag. 33
= β⊥ (α⊥ ′Γβ ⊥ )−1α⊥ ′.
Infine dimostriamo che le condizioni, tali per cui Π = αβ′ e ′⊥ ⊥α Γβ siano di rango
pieno, sono necessarie. Poiché il processo Xt è di tipo I(1) allora Π è una matrice di rango ridotto, ossia è
possibile determinare r<p relazioni di cointegrazione che rendono il processo stazionario. Pertanto è possibile definire due matrici α e β di rango pieno r, tali per cui αβ′=Π , in modo tale da poter costruire le variabili Zt = ′β Xt e Yt = ′⊥β ∆Xt . Se Xt è I(1),
ne consegue che Yt e Zt sono stazionari, ma questo è vero se e solo se ~( )A 1 ha rango
pieno , ovvero se α⊥ ′Γβ ⊥ è di rango pieno.
2.3 La procedura a due stadi di Engle-Granger In Engle&Granger (1987) viene proposta una stima a due stadi per modelli con variabili co-integrate. Nel primo stadio, i parametri del vettore di co-integrazione sono stimati eseguendo una regressione statica nei livelli delle variabili. Nel secondo stadio, queste stime sono usate nel modello a correzione d’errore.
Entrambi gli stadi richiedono solo stime OLS, le quali si dimostrano essere consistenti per tutti i parametri.
La procedura è conveniente poiché la dinamica può non essere specificata prima che sia stimato il modello a correzione d’errore. Una volta effettuata la stima nel primo stadio del vettore di co-integrazione, la stima nel secondo stadio può essere condotta nel modo standard poiché sono implicati nel modello solo termini stazionari1.
Tuttavia tale approccio presenta l’inconveniente di assumere che il rango di co-integrazione sia pari a 1; quindi l’approccio non considera la stima di modelli in cui siano presenti più relazioni di co-integrazione linearmente indipendenti.
Questo problema è risolto completamente utilizzando, come già detto, l’approccio basato sulla massima-verosimiglianza, che verrà illustrato nel capitolo successivo.
1 Infatti nel modello ECM troviamo β′Χ t e differenze di Xt , le quali sono variabili stazionarie, essendo Xt un
processo I(1).


Capitolo 3 Determinazione del rango di co-
integrazione: stima e distribuzione
QUESTO capitolo contiene un’analisi della funzione di verosimiglianza del modello VAR non stazionario, la quale consente di determinare la statistica per il rango di co-integrazione. In particolare si troverà la stima dello spazio di co-integrazione che massimizza tale funzione e per questo scopo si riparametrizzerà il modello VAR nella forma ECM, che risulta importante poichè consente di evidenziare, e di conseguenza stimare, le relazioni di equilibrio che definiscono lo spazio di co-integrazione.
Verrà usato il teorema di rappresentazione di Granger, in quanto permette un’analisi approfondita delle varie componenti del processo (stazionarie e non), che risulterà utilissima per la determinazione della distribuzione asintotica del test sul rango di co-integrazione. Come si vedrà in seguito, quest’ultima non è standard, bensì risulta essere una combinazione di moti browniani. Pertanto, per quest’ultimo scopo si renderanno necessarie nozioni di teoria asintotica ed in particolare quelle relative ai moti browniani, le quali sono esposte nell’appendice A.
L’articolazione del capitolo è la seguente: nel paragrafo 3.1 viene svolta un’analisi statistica del modello scritto in forma ECM, mentre nel paragrafo 3.2 viene esposta la procedura seguita per la determinazione della statistica del test sul rango di co-integrazione.
3.1 Analisi statistica di modelli I(1): determinazione del rango di cointegrazione
Scopo principale di questo paragrafo è la derivazione della statistica per testare la ipotesi sul rango di cointegrazione; una peculiarità dei processi I(1) è costituita dal fatto che la stima dei parametri è una stima di rango ridotto, poichè si ha che la matrice Π, nel

Pag. 36 Determinazione del rango di cointegrazione: stima e distribuzione
caso di radici unitarie, può essere scissa nelle due matrici α e β di rango pieno r, comportando, quindi, una parte non lineare αβ′ . In più, oltre al problema di stima puntuale, è presente un problema inferenziale non banale, in quanto r, ovvero il rango di cointegrazione, non è noto, ma deve essere stimato.
Per risolvere questi problemi, occorre dare alcuni strumenti; il primo di questi è costituito dalla verosimiglianza concentrata. Per meglio chiarire questo concetto, consideriamo per semplicità una generica regressione del tipo
Yt = Bxt + Czt + εt , (3.1)
in cui è possibile “concentrare” la verosimiglianza rispetto a C, scrivendo al suo posto la rispettiva stima di massima-verosimiglianza, espressa come funzione di B. Definendo, poi, la nuova variabile
Y*t = Yt − BXt ,
posso scrivere la (3.1) come
Y*t = Czt + εt
e quindi trovare lo stimatore di massima-verosimiglianza di C, il quale è funzione di B. Inserendo ora la stima di C nell’ espressione (3.1), risulta che l’unico parametro da stimare è costituito da B, il quale viene stimato nel modo usuale.
L’altro strumento è costituito dalla seguente proprietà: data una funzione scalare di matrici, f:Rp××××r→R, tale per cui
f(x) =′′
x Mxx Nx
,
tale funzione risulta massimizzata su tutte le matrici $x di dimensione p×r, date da
$x = [v1 , … ,vr],
dove v1 , … ,vr sono gli autovettori associati agli r autovalori più grandi che si determinano risolvendo il problema agli autovalori generalizzato seguente (vedi anche appendice B, § 1.3)
|λN − M| = 0.
In generale, per tale problema agli autovalori, valgono le seguenti relazioni
V′ΝV = Ir , V′MV = Λr

Determinazione del rango di cointegrazione: stima e distribuzione Pag. 37
dove
Λr =
λλ
λ
1
2
0 00 0
0 0
L
L
M M M
L r
e V = [v1 , … ,vr] .
Avendo scelto come stima di β i primi r autovettori, abbiamo che
f( $x ) = I
Ir r
r
− Λ = λ i
i
r
=∏
1.
Grazie a questi due strumenti possiamo ora ricavare la stima del modello scritto in forma ECM
∆Xt = αβ′Xt−1 + Γii
k
=
−
∑1
1∆Xt −i + εt t = 1, … ,T
con εt i.i.d. ∼ N(0,Ω) e con i parametri (α , β , Γ, … , ΓK−1 , Ω) che variano liberamente. Introduciamo ora la notazione Z0t = ∆Xt , Z1t = Xt −1 e poniamo Z2t = (∆Xt −1′, … ,
∆Xt − k + 1′)′, ψ = (Γ1 , … , ΓK − 1). Quindi Z2t è un vettore di dimensione p(k −1) e ψ è una matrice di dimensione p × p (k −1).
Il modello espresso in queste variabili diventa
Z0t = αβ′Z1t + ψZ2t + εt t = 1, … ,T. (3.3)
Il logaritmo della funzione di verosimiglianza relativa a questo modello è pari, a meno di una costante, a
logL(ψ, α, β, Ω) = − 12
TlogΩ− 12 1
(t
T
=∑ Z0t − αβ′Z1t − ψZ2t )′ Ω-−1 (Z0t − αβ′Z1t − ψZ2t),
la quale, massimizzata rispetto a ψ, porta alla seguente equazione
(t
T
=∑
1Z0t − αβ′Z1t − ψZ2t) Z2t′ = 0. (3.4)
Introduciamo, per semplicità, la seguente notazione
Mij = T-1 Z Zitt
T
jt=∑ ′
1 i , j = 1, 2 ;

Pag. 38 Determinazione del rango di cointegrazione: stima e distribuzione
la (3.4) diventa
M02 − αβ′M12 − $ψ M22 = 0 ;
risolvendola, si ottiene la stima di massima-verosimiglianza di ψ, ossia
$ψ = M02 M22−1 − αβ′M12 M22
−1.
Come si vede tale stima è funzione dei parametri α e β. Sostituendo ora quest’espressione per $ψ nella (3.3) otteniamo la seguente regressione
(Z0t − M02M22−1Z2t) = αβ′(Z1t − M12M22
−1Z2t) + εt .
In essa le espressioni tra le parentesi altro non sono che i residui di due regressioni preliminari, di Z0t contro Z2t e Z1t contro Z2t rispettivamente: chiamiamo questi residui R0t e R1t .
A questo punto, la stima di α può essere ricavata massimizzando, così come fatto per ψ, la funzione di verosimiglianza relativa alla seguente equazione di regressione
R0t = αβ′R1t + εt ,
ottenendo l’equazione
(t
T
=∑
1R0t − αβ′R1t) R1t′ = 0.
Introduciamo, sempre per comodità di scrittura e secondo quanto specificato al § 1.4, la seguente notazione
Sij = T-1 R Ritt
T
jt=∑ ′
1 = Mij − Mi2M22
−1M2j i , j = 0 , 1 ;
per valori di β fissati, le stime di α e di Ω sono date da
$α = S01β (β′S11β)−1
$Ω =T−1 (t
T
=∑
1R0t − $α β′R1t) (R0t − $α β′R1t)′
= S00 − S01β (β′S11β)−1 β′S10 (3.5)

Determinazione del rango di cointegrazione: stima e distribuzione Pag. 39
e, a parte la costante (2πe)p, che scompare quando si farà il rapporto per il test, si ricava
L−2/T( $α (β) , β , $Ω (β)) = L−2/T(β) = $Ω (β) = S00 − S01β (β′S11β)−1 β′S10 .
Applicando le modalità di calcolo del determinante delle matrici a blocchi (si veda appendice B, § 1.10), si ha
S SS S00 01
10 11
ββ β β′ ′
= S00β′ S11β − β′S10 S00−1 S01β
=β′ S11β S00 − S01β (β′S11β)−1 β′S10 ;
si trova pertanto che
$Ω (β) = S00 − S01β (β′S11β)− 1β′S10 = S00′ −
′
−β β
β β
( )S S S S
S11 10 00
101
11. (3.6)
La massimizzazione della funzione di verosimiglianza implica la minimizzazione dell’ultimo termine della (3.6), ossia
′ −
′
−β β
β β
( )S S S S
S11 10 00
101
11.
A questo punto utilizziamo il secondo strumento fra quelli introdotti precedentemente, in modo tale che sia possibile trovare la stima di β; per fare ciò, si sceglie
[ ]$ , . . . ,β = v vr1 , dove v1 , ... ,vr sono gli autovettori associati agli r più grandi
autovalori del problema
ρ S11 − (S11 − S10 S00− 1 S01) = 0
o, in modo equivalente, ponendo λ = 1−ρ, a quelli del problema
λ S11 − S10 S00−1 S01 = 0. (3.7)
Con questa scelta di $β troviamo che
L-2/T(β) = S00$ ( )$
$ $
′ −
′
−β β
β β
S S S S
S
11 10 001
01
11
= S00 ( $ )11
−=
∏ λ ii
r
. (3.8)

Pag. 40 Determinazione del rango di cointegrazione: stima e distribuzione
Pertanto, diagonalizzando simultaneamente le matrici S11 e S10 S00-−1 S01 , possiamo
stimare lo spazio r-dimensionale di co-integrazione con lo spazio generato dagli autovettori corrispondenti agli r autovalori più grandi.
Il valore massimo della funzione di verosimiglianza, quando r=p, e quindi
nell’ipotesi di rango pieno H(p), è dato da
S00 ( $ )11
−=
∏ λ ii
r
E’ possibile, in questo modo, ricavare il test del rapporto di verosimiglianza, o test LR (Likelihood Ratio), per testare l’ipotesi H(r) in H(p), il quale risulta essere
[Q(H(r) H(p))]−2/T = S
S
ii
r
ii
p
001
001
1
1
( $ )
( $ )
−
−
=
=
∏
∏
λ
λ;
passando al logaritmo otteniamo
− 2logQ(H(r) H(p)) = −T log( $ )11
−= +∑ λ i
i r
p
.
Questo test viene chiamato TRACE-TEST. La statistica appena vista, va bene per testare l’ipotesi che il rango di co-integrazione
sia r contro quella che sia p, quando tale rango è r. Pertanto, se quest’ultimo non fosse noto a priori, non sapremmo neppure quale distribuzione asintotica utilizzare, poichè questa dipende dal rango di co-integrazione e varia con esso. In tal caso si dovrà stimare r dai dati a disposizione; per fare ciò si userà la seguente procedura (si veda Pantula (1989)):
1. si inizializza r a zero; 2. si testa H(r) contro H(p); 3. se si accetta l’ipotesi, ci si ferma ed il rango di cointegrazione è dato
dall’ultimo valore di r per cui si è accettata l’ipotesi; 4. se si rifiuta si incrementa r di 1, ovvero si pone r = r + 1, e si torna al punto
2. In Johansen (1992) si dimostra che l’errore di prima specie, associato a questa
procedura di test, è limitato.

Determinazione del rango di cointegrazione: stima e distribuzione Pag. 41
3.2 Derivazione delle distribuzioni asintotiche dei test sul rango di cointegrazione
Discutiamo ora le proprietà del processo I(1) dato da
∆Xt = αβ′Xt-1 + ψZ2t + εt t = 1 , … , T, (3.9)
che può essere rappresentato, come abbiamo già visto, nella sua forma a media mobile (MA) data da
Xt = C εii
t
=∑
1 + C1 (L) εt + Pβ⊥
X0 , (3.10)
dove C = β⊥ (α⊥ ′Γβ ⊥ )-1 α⊥ ′. Esamineremo il comportamento del processo nelle diverse direzioni e applicheremo
questi risultati per trovare le proprietà asintotiche dei termini che riguardano le statistiche dei tests LR. Tutti questi tests sono derivati sotto l’assunzione che gli errori siano gaussiani, indipendenti, con media zero e matrice di varianze-covarianze Ω.
3.2.1 Alcuni risultati utili Sotto l’assunzione di processo I(1) e co-integrato, abbiamo che β′Xt e ∆Xt sono stazionari.
Definiamo la seguente matrice di varianze-covarianze condizionate ai valori che il processo ha assunto nel passato (Z2t)
Var∆ Σ Σ
Σ ΣX
XZt
tt′
=
−ββ
β ββ12
00 0
0
con
Σ00 = Var (∆Xt Z2t)
Σββ = Var (β′Xt −1 Z2t)
Σ0β = Cov (∆Xt , β′Xt −1 Z2t ).
Valgono le seguenti relazioni
Σ00 = αΣββα′ + Ω (3.11)

Pag. 42 Determinazione del rango di cointegrazione: stima e distribuzione
Σ00 = αΣβ0 + Ω (3.12)
Σ0β = αΣββ (3.13)
Dimostrazione.La (3.11) può essere dimostrata nel seguente modo
Σ00 = Var (∆Xt Z2t) = αVar (β′Xt −1 Z2t) + Var (εt) = αΣββα′ + Ω.
La (3.12) si dimostra attraverso i seguenti passi
Σ00 = Var (∆Xt Z2t ) = E[∆Xt ∆Xt′ | Z2t ]
= E[αβ′Xt −1 ∆Xt′ | Z2t ] + E[εt ∆Xt′ | Z2t ]
= αCov (∆Xt , Xt −1′β Z2t ) + E[εt ∆Xt′ | Z2t ]
= Σβ0 + E[εt εt′] + E[εt Xt −1′β | Z2t ] ;
poichè β′Χ t −1 è stazionario, assume la generica espressione β′Xt −1 = ϑ ii=
∞
∑0
εt −i −1 , con
ϑ i che decrescono esponenzialmente; allora l’ultimo fattore può essere scritto come
E[εt Xt −1′β | Z2t ] = Ei=
∞
∑0
[εt εt′] ϑ i′ = 0,
in quanto gli errori sono indipendenti; da quanto detto si ottiene la (3.12). La (3.13) si dimostra nello stesso modo.
Altre relazioni utili per il seguito sono le seguenti
(α′ Σ00−1 α)−1 α′Σ 00
−1 = (α′Ω −1 α)−1 α′Ω −1 (3.14)
Σ00−1 − Σ00
−1 α (α′ Σ00−1 α)−1 α′Σ 00
−1 = α⊥ (α⊥ ′Σ00 α⊥ )−1 α⊥ ′ (3.15)
= Ω−1 − Ω−1 α (α′Ω −1 α)−1 α′Ω −1 = α⊥ (α⊥ ′Ωα⊥ )−1α⊥ ′
Σββ (Σβ0 Σ00−1 Σ0β)−1 Σββ − Σββ = (α′Ω −1 α)−1 (3.16)

Determinazione del rango di cointegrazione: stima e distribuzione Pag. 43
(α′ Σ00−1 α)−1 = Σββ + (α′ Σ00
−1 α)−1 (3.17)
Σββ−1 − ( Σββ − Σβ0 Σ00
−1 Σ0β )−1 = − α′Ω −1α. (3.18)
Dimostrazione.Per dimostrare la (3.14) moltiplico da destra per α e ottengo Ir = Ir ;
moltiplico sempre da destra per Σ Ωα00α ⊥ ⊥= (basta moltiplicare da destra la (3.11) per
α ⊥ ) e ottengo 0=0. Pertanto, poichè la matrice (α,Ωα⊥ ) è di rango pieno, risulta
dimostrata la (3.14). La (3.15) si dimostra nello stesso modo. Per dimostrare la (3.16), inseriamo l’espressione α = Σ Σ0
1β ββ
− e otteniamo
(α′ Σ00−1 α)−1 − Σββ = (α′Ω −1 α)−1. (3.16’)
Questa relazione può essere dimostrata moltiplicando da destra la (3.14) per
Σ00 α (α′α )−1 = (α Σββ α′ + Ω) α (α′α )−1 ;
infatti
(α′Σ 00−1 α)−1 α′ Σ00
−1 Σ00 α (α′α )−1 = (α′Ω -−1 α)−1 α′Ω −1 (α Σββ α′ + Ω) α (α′α )−1
(α′ Σ00−1 α)−1 α′α (α′α )−1 = Σββ + (α′Ω −1 α)−1.
La (3.17) segue direttamente dalla (3.16’). Infine la (3.18) può essere scritta come
Σββ−1 − ( Σββ − Σββ α′Σ 00
−1 αΣββ)−1 = − α′Ω −1 α
Σββ−1 − ( Σββ − Σββ ( Σββ + (α′Ω −1 α)−1 )−1 Σββ)−1 = − α′Ω −1 α. (3.18’)
Ma
Σββ − Σββ ( Σββ + (α′Ω −1 α)−1 )−1 Σββ =
−Σββ ( Σββ + (α′Ω −1 α)−1 )−1 ( Σββ + (α′Ω −1 α)−1 − Σββ ) =
− Σββ ( Σββ + (α′Ω −1 α)−1 )−1 (α′Ω −1 α)−1 ,
allora la (3.18’) diventa
Σββ−1 − Σββ
−1 ( Σββ+ (α′Ω −1 α)−1 )( α′Ω −1 α ) = Σββ−1 − α′Ω −1 α − Σββ
−1 = − α′Ω −1 α.

Pag. 44 Determinazione del rango di cointegrazione: stima e distribuzione
e risulta così dimostrata la (3.18).
3.2.2 Risultati asintotici sulla convergenza delle matrici dei prodotti incrociati
Nell’appendice A si dimostra che le proprietà asintotiche di un processo non stazionario vengono descritte da un moto browniano W(u) p-dimensionale nell’intervallo unitario
[0,1]. Questo moto browniano è infatti il limite del random walk εiit=∑ 1 , che compare
nella rappresentazione (3.10), in quanto è possibile riscalare le ascisse dei tempi ed esprimere il generico istante t ∈ [0,T] intero come t = [Τu], con u ∈ [0,1] . Quindi
ε ii
t
=∑
1=
[ ]ε i
i
Tu
=∑
1 e T−1 (ε1 + ε2 + … + ε [Tu] ) = XT
*(u) .
Si è visto inoltre che T XT*(u)→w W(u).
Dalla rappresentazione (3.10) segue che Xt è composto da un random walk
(C εiit=∑ 1 ), da un processo stazionario, che è lineare con coefficienti decrescenti
esponenzialmente, e dal valore iniziale P Xβ⊥ 0 . Le proprietà asintotiche di Xt dipendono
da quali parti del processo consideriamo. Ad esempio, β′Xt risulta essere stazionaria, poichè β′C = 0, mentre in β′⊥ Xt risulta
dominante il random walk. In particolare il comportamento del processo Xt nella direzione β′⊥ può essere
ricavato nel seguente modo
T−1/2 β⊥ ′Xt = T−1/2 β⊥ ′C ε ii
t
=∑
1+ T−1/2 β⊥ ′ C1 (L) εt + T−1/2 β⊥ ′ Pβ⊥
X0 ;
per T→∞, l’unico termine che non va a zero è il primo e abbiamo visto precedentemente che converge ad un moto browniano, ovvero
T−1/2 ′⊥β X[Tu] →w ′⊥β CW(u).
Per comodità introduciamo il moto browniano G definito come
G(u) = ′⊥β CW(u)
con VAR (G(u)) = ′⊥β CΩC′ β⊥ .
Pertanto si ottiene che

Determinazione del rango di cointegrazione: stima e distribuzione Pag. 45
T−1/2 ′⊥β X[Tu] →w G(u).
Usando questi risultati, è possibile descrivere le proprietà asintotiche del test LR. Grazie ad essi, infatti, siamo in grado di sapere a cosa convergono le matrici dei prodotti incrociati Sij definite al § 3.1. In particolare valgono le seguenti relazioni
S00 →P Σ00 (3.19)
β′S11β→P Σββ (3.20)
β′S10→P Σβ0 (3.21)
T-1 ′⊥β S11 β⊥ →w GG′∫0
1du (3.22)
′⊥β S1ε = ′⊥β (S10 − S11βα′)→w G dW( )′∫0
1 (3.23)
′⊥β S11 β ∈ Op (1). (3.24)
Dimostrazione. Applichiamo i risultati della teoria asintotica visti nell’appendice A e che per comodità conviene qui riassumere. I presupposti su cui si basano sono i seguenti: se Yjt è un processo I(j), con j = 0,1, allora
T Y Y Y Y tY tYtt
T
tt
T
tt
T
t tt
T
tt
T−
=
−
=
−
=
−
=
−
=∑ ∑ ∑ ∑ ∑1
02
1
212
1
10
11
3 20
1
5 21
1
T T T T, , , ,
sono tutti normalizzati a convergere debolmente.
Ricordiamo, inoltre, che le matrici Sij sono espresse come Sij = T−1 R Rit jttT ′=∑ 1 e che
R0t = Z0t − M02 M22−1 Z2t ,
R1t = Z1t − M12 M22−1 Z2t ,
con Mij = T−1 Z ZittT
jt=∑ ′1 .

Pag. 46 Determinazione del rango di cointegrazione: stima e distribuzione
Fatta questa premessa, per la legge dei grandi numeri e poichè ∆Χt e β′Χ t sono stazionari e a media nulla, abbiamo le seguenti convergenze in probabilità
S00 →P Var (∆Χt) − Cov (∆Χt , Z2t )( Var (Z2t ) )−1 Cov (Z2 , ∆Χt ) = Σ00
β′S11β→P Var (β′Χ t) − Cov ( β′Χ t , Z2t ) ( Var ( Z2t ) )−1 Cov ( Z2 , β′Χ t) = Σββ
β′S10→P Cov (β′Χ t , ∆Χt ) − Cov (β′Χ t , Z2t )( Var (Z2t ))−1 Cov (Z2 , ∆Χt ) = Σβ0
e sono così dimostrate le (3.19), (3.20), (3.21).
Per la (3.22), abbiamo che
T-1 ′⊥β S11 β⊥ = T−1 ′⊥β T−1 X Xt tt
T
− −=
′∑ 1 11
β⊥ +
−T−1 ′⊥β T−1 Xtt
T
−=∑ 1
1
Z2t′ T Z Zt tt
T−
=
−
′
∑1
2 21
1
T-1 Z tt
T
21=
∑ Xt-1′ β⊥ .
Consideriamo il primo termine T-1 ′⊥=∑ βt
T
1T-1/2Xt-1Xt-1′T-1/2 β⊥ : la parte interna alla
sommatoria converge a G(u)[G(u)]′ e quindi, per il continuos mapping theorem, si ha
T-1 ′⊥=∑βt
T
1
T-1/2Xt-1Xt-1′T-1/2 ′⊥β →w GG′∫0
1du = ′⊥∫ β
0
1CWW′C′ β⊥ du .
Per il secondo termine abbiamo che ′⊥β Χt−1 è I(1) e Z2t è I(0); ne segue che
T XttT−
−=∑111 Z2t′ è convergente, così come lo è T Z Xt tt
T−−= ′∑1
2 11 . Quindi, la presenza di
un fattore T-1 in più assicura che il secondo termine tenda a zero per T→∞. Risulta così dimostrata la (3.22).
Discutiamo ora la (3.23): ricordando l’espressione dei residui Rit , S10 può essere scritto come
S10 = T−1 R Rt tt
T
1 01
′=∑ = T−1 R t
t
T
11
(=∑ αβ′ R1t + εt )′ = S11 βα′ + S1ε ,
dove

Determinazione del rango di cointegrazione: stima e distribuzione Pag. 47
S1ε = T−1 Xt tt
T
−=
′∑ 11
ε − T−1 Xtt
T
−=∑ 1
1
Z2t′ T Z Zt tt
T−
=
−
′
∑1
2 21
1
Z t tt
T
21
′=∑ ε .
Allora
′⊥β S1ε = T−1 ′⊥=∑βt
T
1
Xt−1 εt′ − T−1 ′⊥=∑βt
T
1
Xt−1 Z2t′ T Z Zt tt
T−
=
−
′
∑1
2 21
1
Z t tt
T
21
′=∑ ε ,
dove il primo termine converge a G dW( )′∫0
1.
Consideriamo ora il secondo termine riscritto come
T T X Z T Z Z T Zt tt
T
t tt
T
t tt
T− −
⊥ −=
−
=
−
=
′ ′ ′
′
∑ ∑ ∑1 2 11 2
1
12 2
1
11 2
21
β ε ,
in cui i termini T X Zt ttT−
⊥ −= ′ ′∑11 21β , T Z Zt tt
T−= ′∑1
2 21 , T Z t ttT−= ′∑1 2
21 ε sono convergenti.
Si vede che, per T→∞, esso tende a zero, poichè la parte racchiusa da parentesi quadre è stazionaria. E’ così dimostrata anche la (3.23).
Infine la (3.24) si dimostra tenendo conto che β′⊥ Χt−1 è I(1) e che β′Χ t−1 è I(0) e che si esegue il prodotto fra qualcosa che è nello spazio di β (β′Χ t−1) e qualcosa che sta in quello di β⊥ (β′⊥ Χt−1) .
3.2.3 Distribuzione asintotica del Trace-test Assumiamo sempre che εt siano i.i.d. e ∼ NP(0,Ω) e consideriamo il modello scritto come
∆Χt = ΠΧ t−1 + ψZ2t + εt.
Sotto l’ipotesi che il rango di cointegrazione sia r (H(r)), il modello diventa
∆Χt = αβ′Χ t−1 + ψZ2t + εt,
con α e β matrici di rango r. La statistica per testare H(r) in H(p) è
− 2log Q (H(r) H(p)) = −T log( $ )11
−= +∑ λ i
i r
p
,
dove $ , , $λ λr p+1 K sono le p-r più piccole radici date da

Pag. 48 Determinazione del rango di cointegrazione: stima e distribuzione
λS S S S11 10 001
01 0− =− . (3.25)
Siano S(λ) = λS11 − S10 S00−1 S01 e AT = (β,T−1/2 β⊥ ) una matrice di rango pieno p;
quindi risolvere il problema (3.25) equivale a risolvere il problema
′ =A S AT T( ) ,λ 0
ovvero
λβ β β β λ β β β β
λ β β β β λ β β β β′ − ′ ′ − ′
′ − ′ ′ − ′
=
− −⊥
− −⊥
−⊥
−⊥
−⊥
−⊥ ⊥
−⊥
−⊥
S S S S T S T S S ST S T S S S T S T S S S
11 10 001
011 2
111 2
10 001
011 2
111 2
10 001
011
111
10 001
01
0.
Per T→∞ quest’espressione, ricordando i risultati asintotici visti in precedenza al § 3.2.2, diventa
λΣ
λ
λΣλ
λΣ λ
ββ β β
ββ β β
ββ β β
−
′
=
−
′
− ′ =
−
−
−
−
∫
∫
∫
Σ Σ Σ
Σ Σ Σ
Σ Σ Σ
0 001
0
0
1
0 001
0
0
1
0 001
0 0
1
0
0
00
00
0
GG du
I
IGG du
GG du
p r
r
.
=
In cui λΣ ββ β β− −Σ Σ Σ0 001
0 =0 dà r radici (poichè Σ Σ Σβ β0 001
0− e Σββ sono matrici di rango
r) positive, mentre λ GG du′∫ =01 0 dà p-r radici nulle (poichè GG′ è una matrice (p−r)×(p
−r)). Questo mostra che le p-r più piccole radici di (3.25) che compaiono nella statistica
del test convergono a zero. Cerchiamo di capire con quale tasso. Per prima cosa consideriamo la decomposizione seguente
( , ) ( )( , )( ) ( )( ) ( )
β β λ β ββ λ β β λ ββ λ β β λ β⊥ ⊥
⊥
⊥ ⊥ ⊥
′ =′ ′′ ′
=S
S SS S
′ ′ − ′ ′ ′ =⊥ ⊥ ⊥−
⊥β λ β β λ β β λ β β λ β β λ βS S S S S( ) ( ) ( ) [ ( ) ] ( )1

Determinazione del rango di cointegrazione: stima e distribuzione Pag. 49
′ ′ − ′ ′⊥−
⊥β λ β β λ λ β β λ β β λ βS S S S S( ) ( ) ( ) [ ( ) ] ( ) 1 . (3.26)
Supponiamo ora che le radici λ i convergano a zero con un tasso pari a T, in modo tale che ρ = Tλ sia fissato per T→∞. Fatta questa considerazione, per quanto visto nel paragrafo relativo ai risultati asintotici, abbiamo che
→′ = ′ − ′ −− −β λ β ρ β β β βS T S S S S P( ) 111 10 00
101 Σ Σ Σβ β0 00
10
−
e quindi il primo termine di (3.26) non ha radici. Inoltre si verifica che
′ = ′ − ′ =⊥−
⊥ ⊥−β λ β ρ β β β βS T S S S S( ) 1
11 10 001
01 − ′⊥ −β βS10 001
0Σ Σ + Op(1).
Pertanto, trascurando i termini di ordine superiore a 1, il secondo termine di (3.26) diventa
ρ β β β βT S S S−⊥ ⊥ ⊥
−⊥′ − ′ +− 1
11 10 001
01Σ
( )( ) ( ) ( )− ′ − − +⊥− − − −
⊥β ββ β β βS S Op10 001
0 0 001
01
0 001
01 1Σ Σ Σ Σ Σ Σ Σ
= ′ − ′ − − +−⊥ ⊥ ⊥
− − − − −⊥ρ β β β ββ β β βT S S S Op1
11 10 001
001
0 0 001
01
0 001
01 1( ( ) ) ) ( ).Σ Σ Σ Σ Σ Σ Σ Σ
Ponendo, per semplicità, N = Σ Σ Σ Σ Σ Σ Σ Σ001
001
0 0 001
01
0 001− − − − −− −β β β β( ) si ottiene
ρ β β β βT S S NS Op−⊥ ⊥ ⊥ ⊥′ − ′ +1
11 10 01 1( ). (3.27)
Sapendo, inoltre, che vale la relazione (3.15) e che per la (3.13) α = Σ Σ01
β ββ− ,
si ha che il membro di sinistra di quest’espressione risulta essere
Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ
Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ
001
001
01 1
0 001
01 1 1
0 001
001
001
01
0 001
01 1
0 001
− − − − − − − − −
− − − − − − −
− =
− =
β ββ ββ β β ββ ββ β
β ββ ββ β β ββ ββ β
( )
( )
Σ Σ Σ Σ Σ Σ Σ Σ Ωα001
001
0 0 001
01
0 001 1− − − − −
⊥ ⊥ ⊥−
⊥− = = ′ ′ =β β β β α α α( ) ( )N
α α α⊥ ⊥−
⊥′ ′( ( )) .VAR W 1
Sostituendo ora quest’espressione per N nella (3.27),si ricava

Pag. 50 Determinazione del rango di cointegrazione: stima e distribuzione
ρ β β β α α α βT S S VAR W S−⊥ ⊥ ⊥ ⊥ ⊥
−⊥ ⊥′ − ′ ′ ′1
11 101
01( ( ))
e considerando che
′ = ′ − ′ = ′⊥ ⊥ ⊥ ⊥ ⊥ ⊥β α β βα α β αεS S S S10 10 11 1( )
la (3.27) diventa
ρ β β β α α α βε εT S S VAR W S−⊥ ⊥ ⊥ ⊥ ⊥
−⊥ ⊥′ − ′ ′ ′1
11 11
1( ( )) .
Tenuto conto della (3.22) e (3.23), si ottiene che
( , ) ( )( , ) ( ) ( ( )) .β β λ β β ρ αβ β⊥ ⊥−
⊥−′ → − ′ − ′ ′ ′∫ ∫ ∫S GG du G dW VAR W dWGw Σ Σ Σ0 00
10 0
1
0
1 1
0
1
Questo risultato implica che le p-r soluzioni più piccole dell’equazione (3.25) convergono, una volta normalizzate da T, a quelle dell’equazione
ρ αGG du G dW VAR W dWG′ − ′ ′ ′ =∫ ∫ ∫⊥−
0
1
0
1 1
0
10( ) ( ( )) . (3.28)
Notiamo che le radici di questa equazione sono invarianti alle trasformazioni lineari di G e di α′ ⊥ W . Definiamo, quindi, il seguente moto browniano standard
B C C CW C C G= ′ ′ ′ = ′ ′⊥ ⊥−
⊥ ⊥ ⊥−( ) ( ) .β β β β βΩ Ω1 2 1 2
Da questa definizione si vede che B è una trasformazione lineare di α′ ⊥ W (si ricordi che C=β⊥ (α′ ⊥ Γβ⊥ )-1α′ ⊥ ); pertanto quest’ultimo può essere sostitutito da B e la (3.28) diventa
( )ρ BB du B dB dB B′ − ′ ′ =∫ ∫ ∫0
1
0
1
0
10( ) . (3.29)
Ritorniamo, ora, alla statistica per il test sul rango di cointegrazione e facciamone un’espansione di Taylor arrestata agli elementi del primo ordine; in formule abbiamo che
−2logQ(H(r) H(p)) = −T log( $ ) $ ( )1 11 1
− = += + = +∑ ∑λ λi
i r
p
ii r
p
T Op .
In precedenza abbiamo sottolineato che le radici che compaiono in tale statistica convergono proprio con un tasso T e, più precisamente, a quelle dell’espressione (3.29); di conseguenza si ottiene che

Determinazione del rango di cointegrazione: stima e distribuzione Pag. 51
−2logQ(H(r) H(p) ) wi
r
p
→ == +∑ρ
1 1
tr BB du B dB dBB( ' ) ( )0
1 1
0
1
0
1
∫ ∫ ∫−
′ ′
=
tr dBB BB B dB′ ′∫ ∫ ∫−
0
1 10
1
0
1( ' du) ( ) .


Capitolo 4 Proprietà asintotiche degli stimatori
IN questo capitolo ci concentreremo sulle proprietà asintotiche degli stimatori che compaiono nella regressione di rango ridotto trattata nel capitolo precedente, tenendo presente il problema d’identificazione di alcuni di tali stimatori. Tale problema si presenta nella stima di α e di β e può essere risolto tramite due modi: il primo si basa su una normalizzazione che permette di identificare i parametri da stimare; l’altro riguarda l’introduzione di vincoli ben posti su tali parametri e sarà discusso nel successivo capitolo.
Dopo aver visto come identificare β attraverso delle normalizzazioni, si ricaverà la distribuzione asintotica di tale parametro identificato; si mostrerà che tale distribuzione è una mistura di gaussiane.
Il concetto di mistura di gaussiana è il seguente (tratto da Mood et al. (1991)): sia f(x;θ) una famiglia di funzioni di densità parametrizzate da θ e sia Θ la totalità dei valori che θ può assumere. Se Θ è un intervallo (eventualmente infinito) e g(θ) è una funzione di densità di probabilità nulla per tutti i valori non appartenenti a Θ, allora
∫Θf(x;θ)g(θ)dθ
è ancora una funzione di densità, che prende il nome di mistura di distribuzione. Nel nostro caso, la funzione di densità è una normale, poiché si è assunto che gli
errori siano identicamente distribuiti secondo una gaussiana; inoltre la funzione g(θ), che contiene i parametri di mistura, è rappresentata da un insieme di moti browniani. La peculiarità della mistura di gaussiana è che la sua distribuzione, condizionata ai parametri di mistura, risulta essere una normale.
Dalla distribuzione di β risulterà poi più semplice risalire alle distribuzioni degli altri parametri presenti nel modello in forma ECM, in quanto questi sono i parametri di

Pag. 54 Proprietà asintotiche degli stimatori
variabili stazionarie1. Pertanto la loro distribuzione asintotica sarà di tipo standard ed in particolare sarà una normale.
4.1 Il problema dell’identificazione Scrivendo la matrice Π come αβ′ , con α e β matrici p×r di rango pieno r, è possibile dare significato ai coefficienti delle variabili del vettore Xt . Infatti β rappresenta l’insieme degli r vettori di cointegrazione, mentre α è la matrice che misura l’aggiustamento verso l’equilibrio di lungo periodo delle variabili cointegrate.
E’ bene sottolineare che i parametri α e β non sono identificati univocamente: data ogni scelta di α e β e data una qualsiasi matrice ξ di dimensioni r×r che non sia singolare, il prodotto α1β1′, con α1 = αξ e β1 =β(ξ′ )−1, dà la stessa matrice Π e quindi determina la stessa distribuzione di probabilità per tutte le variabili.
Possiamo quindi dire che le uniche cose determinabili sono lo spazio coperto dalle colonne di β (ovvero lo spazio di cointegrazione) e lo spazio coperto dalle colonne di α (spazio di “aggiustamento”) -per un ulteriore approfondimento, si veda l’appendice B, § 3.4-.
In generale, le funzioni stimabili sono quelle che soddisfano la proprietà ƒ(β) =ƒ(βξ), per ogni scelta di ξ, matrice r×r. Un esempio di ciò può essere dato dalla seguente normalizzazione di β: data una matrice c p×r, tale per cui c′β ha rango pieno, definiamo βc = β(c′β)−1, in modo tale che c′βc =Ir .
Allora si ha che
ƒ (β) = β(c′β)−1 = βξ (c′βξ )−1 = ƒ (βξ)
per ogni matrice ξ di rango pieno e di dimensione r × r ; pertanto ƒ (β) = βc è stimabile. Un altro modo per identificare β può essere quello di imporre diversi vincoli fra i
coefficienti che ne costituiscono gli elementi. In ogni caso, solo specificando relazioni ben precise fra di essi (siano esse
normalizzazioni o altre identificazioni) è possibile fare una stima, anche se certe ipotesi sui parametri non richiedono necessariamente un’identificazione preliminare.
4.2 Distribuzioni asintotiche degli stimatori Come si è detto poc’anzi, uno dei problemi che si incontra durante la stima di α e β è che essi non sono identificati. Deriveremo le proprietà asintotiche di questi stimatori sotto l’assunzione che essi siano stati stimati senza vincoli, ma normalizzati o
1 Si ricordi che gli altri parametri sono quelli che compaiono in β′Xt-1 e i coefficienti delle differenze nei livelli di Xt.

Proprietà asintotiche degli stimatori Pag. 55
identificati univocamente da una matrice c di dimensioni (p×r). Troveremo quindi le proprietà asintotiche dello stimatore
$ $( $ )β β βc c = ′ −1
e quelle dello stimatore
$ $ $α αβc c.= ′
4.2.1 Una conveniente normalizzazione di ββββ
Scegliendo il sistema di coordinate (β , β⊥ ) in Rp, è possibile espandere $β come
$ $ $β ββ β β β β= ′ + ′⊥ ⊥
dove β β β β= ′ −( ) .1
Definiamo lo stimatore
~ $( $ ) ~ ~.β β β β β β β β β β β β= ′ = + ′ = + = ′−⊥ ⊥ ⊥ ⊥
1 U con UT T
Si vede che ~β β− è contenuto in Sp(β⊥ ); inoltre, poiché ~β è una trasformazione lineare
delle colonne di $β , questi soddisfa l’equazione di verosimiglianza. Tuttavia questa
normalizzazione non è utile, in quanto dipende da β; in ogni caso, risulta conveniente
derivare le proprietà di ~β , per poi ricavare quelle di βc dall’espansione di $ $( $)β β βc c= ′ −1 intorno al valore vero β. In particolare (vedi Magnus & Neudecker (1988)
e appendice B, § 4.2) si ha che
$ (~) ~( ~) $ ( ) ( ) (~( ~) )β β β β β β β β β βc cc c c = ′ = + = ′ + ′− − −1 1 1h d
= ′ + ′ − ′ ′ ′ +−β β β β β β( ) ( ) ( ) ( ) ( ).c c c c c- - -1 1 1 1 2h h O hp
Per la consistenza di ~β (che verrà dimostrata più avanti) è possibile sostituire a h
l’espressione ~β β− ottenendo
$ ( ) (~ )( ) ( ) (~ )( ) ~ )β β β β β β β β β β β β βc- - -c c c c c = ′ + − ′ − ′ ′ − ′ + −−1 1 1 1
2Op(

Pag. 56 Proprietà asintotiche degli stimatori
= ′ + − ′ ′ − ′ + −−β β β β β β β β β( ) ( ( ) )(~ )( ) ~ ).c c c c- -1 1 12
I Op(p
Quest’espressione può essere semplificata scegliendo la matrice c tale per cui c′β=Ιr e quindi
$ ( )(~ ) ~ ).β β β β β β βc c= + − ′ − + −I Op(p
2 (4.1)
4.2.2 Consistenza degli stimatori
Dimostriamo che gli stimatori ~ $( $ )β β β β= ′ −1 , ~ $ $ $α αβ β= ′ e Ω sono consistenti, ~ ( )β β− ∈ −Op T 1 2 e che
→
→
~ ~ ( ) ,~ ( ) .
′ = ′ +
′ = ′ +
−
−
β β β β
β β
ββ
β
S S Op T
S S Op T
P
P
11 111 2
10 111 2
0
Σ
Σ
( . )( . )4 24 3
Dimostrazione. La stima di β deriva dagli autovettori del problema agli autovalori dato da
λS S S S11 10 001
01 0− =− . (4.4)
Moltiplichiamo da destra per la matrice, di rango pieno p, AT = (β, T-1/2 β⊥ ) e da sinistra
per la sua trasposta, ottenendo
λ ′ − ′ =−A S A A S S S AT T T T11 10 001
01 0 . (4.5)
Questa equazione ha gli stessi autovalori della (4.4) e autovettori AT-1V (V sono gli
autovettori associati agli autovalori del problema (4.4)). Per T→∞ la (4.5) converge a
λΣ λββ β β− ′ =− ∫Σ Σ Σ0 001
0 0
10GG du
e lo spazio generato dai primi r autovettori di (4.5) converge a quello generato dai primi r autovettori unitari o, equivalentemente, allo spazio generato da vettori con degli zero nelle ultime p-r coordinate.
Lo spazio generato dagli autovettori della (4.5) è sp(AT-1 $β ) = sp(AT
-1 ~β ) (si ricordi che ~β è una trasformazione lineare delle colonne di $β e quindi copre lo stesso spazio), dove
A T I T UT T−
⊥= ′ = ′1 1 2 1 2~ ( , ) ~ ( , )β β β β .

Proprietà asintotiche degli stimatori Pag. 57
Quindi, per quanto detto sopra, →T UTP1 2 0, ossia UT∈ Op(T-1/2). Questo prova la
consistenza di ~β in quanto ~ )β β− ∈ − Op(T 1 2 .
Consideriamo ora l’espressione
~ ~ ( ) ( )
.′ = + ′ +
= ′ + ′ ′ + ′ + ′ ′⊥ ⊥
⊥ ⊥ ⊥ ⊥
β β β β β β
β β β β β β β β
S U S US U S U S U U S
T T
T T T T
11 11
11 11 11 11
Poichè UT∈ Op(T-1/2), ′ ∈ ′ ∈⊥ ⊥ ⊥β β β βS Op T) S Op11 11 1( ( ) e , segue che
→~ ~ ( ) .′ = ′ + −β β β β ββS S Op T P11 11
1 2 Σ
La dimostrazione della (4.3) è simile.
La (4.2) e la (4.3) implicano la consistenza di ~ ~(~ ~)α β β β= ′ −S S01 111 , che converge a
Σ Σ01
β ββ α− = .
Infine lo stimatore di Ω è
$ ~(~ ~) ~ ,Ω= − ′ ′−S S S S00 01 111
10β β β β
il quale, per la (4.3) e la (4.4), converge a
Σ Σ Σ Σ Σ Ω00 01
0 001− = − ′ =− −
β ββ β ββαΣ α .
4.2.3 Distribuzione asintotica degli stimatori di ββββ e αααα
Prima di derivare la distribuzione asintotica degli stimatori $βc e $α c , è utile derivare
quelle degli stimatori ~ ~β α e .
Si dimostrerà che la distribuzione asintotica di ~β è una mistura di Gaussiane data da
TU T GG du G dVTw= ′ − → ′
′⊥
−
∫ ∫β β β α(~ ) ( ),0
1 1
0
1
quindi ~ ( ).β β− ∈ −Op T 1 La varianza condizionale (ossia per valori fissati di G) della
distribuzione limite è data da
GG du′
⊗ ′∫−
− −0
1 11 1( ) .α αΩ
La distribuzione asintotica di ~α è data da

Pag. 58 Proprietà asintotiche degli stimatori
→T Nwp r
1 2 0 1(~ ) ( , ).α α ββ− ⊗×−Ω Σ
Si ricordi che G e Vα = (α′Ω −1α)−1α′Ω −1W sono indipendenti.
Dimostrazione. Poichè gli stimatori ~ ~α β e soddisfano le equazioni di verosimiglianza, il
punto (~,~)α β è un punto di stazionarietà della funzione log L, ovvero
dlog L (α,β,Ω) = 0.
Risolvendo tale equazione (si veda appendice B, § 4.1), si ottengono i seguenti risultati
~ ( ~~ )
( ~~ )~ .
′ − ′ =
− ′ =
−α αβ
αβ β
Ω 101 11
01 11
0
0
S S
S S
( . )( . )4 64 7
Definiamo
S T R S St tt
T
ε ε αβ11
11
01 11= ′ = − ′−
=∑
^.
Consideriamo l’equazione (4.6) ed inseriamo S S S01 1 11= + ′ε αβ , per ottenere
0 1
01 111
1 11 11
11 11 11
= ′ − ′ = ′ + ′ − ′
= ′ − − ′ − − ′
− −
−
~ ( ~~ ) ~ ( ~~ )~ ( ~(~ ) (~ ) ).
α αβ α αβ αβ
α α β β α α βε
ε
Ω Ω
Ω
S S S S S
S S S
Moltiplichiamo ora per β⊥ da destra ed inseriamo ~ ;β β β− = ⊥ UT si ottiene quindi
0 11
111 11= ′ − ′ ′ − − ′−
⊥−
⊥ ⊥~ ( ~ ( ) (~ ) ).α β α β β α α βεΩ S TU T S ST
Dai risultati asintotici ottenuti sopra e per la consistenza di ~α gli ultimi termini tendono
a zero e la consistenza di $Ω implica che
TU T S S Op(T = ′ ′ ′ +−⊥
−⊥
− − −[ ] ( ) )111
11
1 1 1 1β β β α α αεΩ Ω ,
il quale converge a
GG du G dW GG du G dV′
′ ′ = ′
′∫ ∫ ∫ ∫−
− − −−
0
1 1
0
1 1 1 1
0
1 1
0
1( ) ( ) ( )Ω Ωα α α α .
Questo risultato implica che ~ ( )β β− ∈ −Op T 1 e quindi ~β risulta essere superconsistente,
poiché converge al suo valore vero β con un tasso T anziché T1/2. Consideriamo ora l’equazione (4.7) ed inseriamo S S S01 1 11= + ′ε αβ ; si ottiene

Proprietà asintotiche degli stimatori Pag. 59
0 1 11 11
1 11 11
= + ′ − ′
= − − ′ − − ′
( ~~ )~
( ~ (~ ) ~ (~ )~ ~).
S S S
S S Sε
ε
αβ αβ β
β α β β β α α β β
Moltiplicando per T1/2 si ha
T S T S T S
T S T S T S
1 211
1 21
1 211
1 21
1 21
1 211
(~ )~ ~ ~ (~ ) ~
(~ ) (~ ) ~.
α α β β β α β β β
β β β α β β βε
ε ε
− ′ = − − ′
= + − − − ′
Poichè ~ ( )β β− ∈ −Op T 1 , gli ultimi due termini tendono a zero e il primo converge
debolmente, per il teorema del limite centrale, a Np r× ⊗( , )0 Ω Σββ . Dal momento che
→~ ~′β β ββS P11 Σ , si ha
→T Nwp r
1 2 0 1(~ ) ( , ).α α ββ− ⊗×−Ω Σ
Forniamo ora il risultato per $β , normalizzato dalla matrice c che, per comodità, viene
scelta in modo tale che ′ = ′ =c cβ β$ .I r Fatta questa considerazione, si ottiene che
→ [ ]T I GG du G dVw( $ ) ( ) ( )β β β β α− − ′ ′ ′⊥
−
∫ ∫c0
1 1
0
1. (4.8)
Quindi, la distribuzione asintotica è una mistura di Gaussiane con varianza condizionale data da
[ ]( ) ( ) ( ) .I GG du I− ′ ′ ′ − ′ ⊗ ′⊥
−
⊥− −∫c cβ β β β α α
0
1 11 1Ω
La distribuzione asintotica di $α , quando $β è normalizzato da c, è data da
→T Nwp r
1 2 0 1( $ ) ( , ).α α ββ− ⊗×−Ω Σ (4.9)
Dimostrazione.Considerando l’espansione (4.1) si ottiene che
T I T Op( $ ) ( ) (~ ) ~β β β β β β β− = − ′ − + −
c
2
e da quanto visto precedentemente si ha
T I TU OpT( $ ) ( ) ~β β β β β β− = − ′ + −
⊥c
2.

Pag. 60 Proprietà asintotiche degli stimatori
Poichè ~ ( )β β− ∈ −2 2Op T e TUT è convergente , la (4.8) risulta dimostrata. Per la
dimostrazione della (4.9), definiamo
$ ~~ ~((~ ) ) ~;α αβ α β β αc c c= ′ = − ′ +
da questa equazione segue che
T T T1 2 1 2 1 2( $ ) (~ ) ~((~ ) ),α α α α α β β− = − + − ′c
la quale ha la stessa distribuzione limite di T1 2 (~ )α α− , poiché ~ ( )β β− ∈ −Op T 1 .Risulta
così dimostrata la (4.9).
4.2.4 Altre distribuzioni asintotiche I risultati ottenuti nella sezione precedente possono essere utilizzati per ricavare la distribuzione asintotica degli stimatori dei rimanenti parametri. Dapprima deriviamo quella dello stimatore dei parametri ϑ=(α,Γ 1,…,Γk-1), sfruttando la loro proprietà di essere tutti coefficienti delle variabili stazionarie β′Χ t e ∆Χt . Definiamo
Z X X Xt t t t k( ) (( ) , , . .. , ).β β′ = ′ ′ ′ ′− − − +1 1 1∆ ∆
Si noti che E(β′Χ t)=E(∆Χt)=0. Inoltre poniamo Σ =Var Zt( ( )).β
Se β è normalizzato da c′β=I, allora la distribuzione asintotica dello stimatore $ ( $ , $ ,..., $ )ϑ α= −Γ Γ1 1k è data da
→T Nwp r k p
1 21)
10( $ ) ( , ),( ( )ϑ ϑ− ⊗× + −−Ω Σ
dove Σ è stimata consistentemente da
→T Z Z Var Zt tt
TP
t−
=
′ =∑1
1
( $ )( ( $ ) ( ( )).β β βΣ
Dimostrazione. Consideriamo il modello scritto come
∆X Zt t t= +ϑ β ε( ) .
Per valori fissati di β, questa è proprio un’equazione di regressione, in cui la stima di massima verosimiglianza di ϑ è data da

Proprietà asintotiche degli stimatori Pag. 61
= ′ + ′ − ′== =∑∑ ∑ϑ β β ε β ϑ β βZ Z Z Z Zt t t tt
T
t
T
t tt
T
( ))( ( )) ( ( )) $ ( ))( ( ))11 1
da cui si ottiene che
T T Z Z T Zt tt
T
t tt
T1 2 1
1
1 2
1
( $ ) ( ))( ( )) ( ( ))ϑ ϑ β β ε β− ′
= ′−
=
−
=∑ ∑
e quindi, per il teorema del limite centrale, si ha che
→T Nwp r k p
1 21)
10( $ ( ) ) ( , ).( ( )ϑ β ϑ− ⊗× + −−Ω Σ
Qui Σ è il limite in probabilità di
T Z Zt tt
T−
=′∑1
1( )( ( ) .β β
Inoltre, poiché $β è superconsistente, possiamo sostituire β con la sua stima e quindi
otteniamo il risultato voluto. Analizziamo ora le distribuzioni asintotiche dei parametri Π e C che compaiono,
rispettivamente, in modelli in forma ECM e MA. Queste distribuzioni sono date da
→T Nwp p
1 2 10( $ ) ( , ),Π Π Ω− ⊗ ′×−βΣ βββ (4.10)
→T C C N C Cwp p
1 2 10( $ ) ( , )− ′ ⊗ ′×−Ω Σζ ζ , (4.11)
con ′ = ′ ′ − ′ ′ζ α(( )~, , . . . , ).C I C CΓ
Dimostrazione. Sia β normalizzato dalla matrice c definita sopra; applicando i risultati visti precedentemente si ottiene che
T T T Op(T1 2 1 2 1 2 1 2( $ ) ( $ ) ( $ ) ),Π Π− = ′ − ′ = − ′ + −αβ αβ α α β
poiché ~ ( )β β− ∈ −Op T 1 ed avendo già ricavato la distribuzione asintotica della stima di
α, la (4.10) risulta dimostrata. Per la dimostrazione della (4.11) facciamo la seguente premessa: se si sceglie $α ⊥ in
modo che
$ ( $ ) $α α α α α α α⊥ ⊥−
⊥= − ′ ′1 ,

Pag. 62 Proprietà asintotiche degli stimatori
allora $ $′ =⊥α α 0 e $ ( $ ) ).α α α α α α⊥ ⊥ ⊥−− = − − ′ +Op(T 1
La superconsistenza di $β implica che è possibile rimpiazzare $β⊥ con β⊥
nell’espressione per $C , con un errore di Op(T-1), ottenendo
$ $ ( $ $ $ ) $ ( $ $ ) $C= ′ ′ = ′ ′⊥ ⊥ ⊥−
⊥ ⊥ ⊥ ⊥−
⊥β α β α β α β αΓ Γ1 1
[ ]= ′ + − ′ + ′ − + −⊥ ⊥ ⊥ ⊥ ⊥ ⊥ ⊥ ⊥
−
⊥ ⊥ ⊥β α α α α β α α αΓβ Γβ Γ Γ( $ ) $ ( $ ) ( $ )1
= − ′ − ′ ′ ′⊥ ⊥ ⊥−
⊥ ⊥ ⊥ ⊥ ⊥−
⊥C β α α α α α( ) ( $ ) ( )Γβ Γβ Γβ1 1
− ′ ′ − ′ ′⊥ ⊥ ⊥−
⊥ ⊥ ⊥ ⊥−
⊥β α α β α α( ) ( $ ) ( )Γβ Γ Γ Γβ1 1
+ ′ − ′⊥ ⊥ ⊥−
⊥ ⊥β α α α( ) ( $ ) .Γβ 1
Inserendo ora l’espressione $ ( $ ) )α α α α α α⊥ ⊥ ⊥−− = − − ′ +Op(T 1 e usando la definizione
di C troviamo che
$ ( $ ) ( ) ( $ ) ) ( $ ) ),C C C C I C C Op(T C Op(T− = − ′ − − − + = − +− −α α α ϑ ϑ ζΓ Γ Γ 1 1
con ′ = ′ ′ − ′ ′ζ α(( )~, , ... , )C I C CΓ , essendo Γ Γ= −=
−
∑I ii
k
1
1e ϑ α= −( , ,..., ).Γ Γ1 1k Resta così
dimostrata anche la (4.11).

Capitolo 5 Vincoli lineari sullo spazio di co-
integrazione
NEL capitolo precedente si è detto che i parametri α e β possono essere identificati tramite dei vincoli ben posti. Oltre a questo scopo, i vincoli lineari, soprattutto su β, possono servire per verificare ipotesi di natura economica riguardanti le relazioni di equilibrio.
Il capitolo in questione tratterà in maniera specifica questi argomenti; in particolare si vedrà come risolvere il problema dell’identificazione di β tramite vincoli, dando delle condizioni sufficienti per ottenere tale identificazione. Successivamente si deriveranno le statistiche per testare particolari ipotesi sullo spazio di co-integrazione ed infine se ne ricaverà la distribuzione.
Come si dimostrerà in seguito, quest’ultima risulta essere sempre una χ2 con opportuni gradi di libertà, il cui numero dipende dall’ipotesi considerata. Un problema sollevato dalla loro determinazione riguarda la presenza di restrizioni sui parametri non lineari; per risolverlo verrà illustrato un teorema, tratto da Johansen(1995), che consente di ricavare i gradi di libertà nel caso di vincoli non lineari.
5.1 Identificazione del modello mediante vincoli su ββββ Si è detto in precedenza che, ponendo dei vincoli sui coefficienti di lungo periodo, il problema dell’identificazione viene risolto; tuttavia, questa condizione di per sè non basta: è necessario, infatti, che questi vincoli siano ben posti.
Un esempio di quanto detto può essere il seguente: sia Xt un vettore 4×1 pari a (x1,x2,x3,x4)′ e supponiamo che vi sia una relazione di lungo periodo fra le prime due variabili scalari del vettore, tali per cui la loro differenza risulti stazionaria (è una relazione di cointegrazione). La condizione per cui i coefficienti di x1 e x2 sono uguali ma con segno opposto, può essere espressa tramite la parametrizzazione

Pag. 64 Vincoli lineari sullo spazio di co-integrazione
R′β = 0 con R′ = [1,1,0,0].
E’ possibile esprimere questo vincolo mediante una sorta di “esplicitazione” rispetto a β, scrivendo
β = Hϕ con H R= =−
⊥
1 0 01 0 0
0 1 00 0 1
e ϕϕϕϕ
=
1
2
3
;
da tale equazione deriva che β ϕ ϕ ϕ ϕ=[ − ]′1 1 2 3 .
Si può notare come quest’ipotesi sia formulata senza necessariamente identificare a priori le relazioni di cointegrazione.
La condizione secondo cui β=Hϕ è espressa geometricamente come un vincolo sullo spazio di cointegrazione sp(β) in base al quale sp(β)⊂ sp(H) -per ulteriori chiarimenti, si veda l’appendice B, § 3-.
Ritornando all’esempio precedente, possiamo anche chiederci se la differenza tra x1 e x2 sia stazionaria, ovvero se il vettore b′=[1,-1,0,0] sia un vettore appartenente allo spazio di cointegrazione. Quest’ultimo può essere espresso come β=[b,ψ], con b matrice p×s degli s vettori noti di cointegrazione e ψ matrice p×(r−s) degli r−s vettori di cointegrazione da stimare.
Questa ipotesi è geometricamente corrispondente a sp(b)⊂ sp(β) -si veda l’appendice B, § 3.1-. Sottolineamo che tale formulazione di vincoli può essere usata per fare ipotesi sulla stazionarietà di alcuni elementi di Xt ; infatti, con riferimento all’esempio precedente, porre b′=[0,0,1,0] significa ipotizzare che x3 sia stazionaria.
Questa considerazione risulta importante, in quanto ci permette di fare ipotesi sulla stazionarietà di certe variabili, semplicemente aggiungendo alla matrice di cointegrazione β un “vettore extra” (ovvero aggiungendo una dimensione allo spazio sp(β) da identificare, come già si è visto nel capitolo 2, esempio 2.2).
Riprendiamo nuovamente l’esempio fatto e chiediamoci se esista, ad esempio, una relazione di cointegrazione fra le sole prime due variabili scalari di Xt e fra le sole ultime due. Tale ipotesi è del tipo
β = ( H1ϕ1 , H2ϕ2 )
con

Vincoli lineari sullo spazio di co-integrazione Pag. 65
H1
1 00 10 00 0
=
; ϕϕϕ1
11
21=
; H2
0 00 01 00 1
=
; ϕϕϕ2
12
22=
.
Nella formulazione più generale, ciò che ipotizziamo è
β = [H1ϕ1, … , Hrϕr]
con i = 1 , 2 , … , r ; Hi ha dimensione p×si e ϕi dimensione si × 1 (r è il rango di cointegrazione, si è il numero di variabili coinvolte nella stessa relazione di cointegrazione e infine 1 ≤ si ≤ p ).
Facendo in tal modo, scriviamo p-si vincoli per ogni vettore di cointegrazione. Dal punto di vista geometrico (si veda appendice B, § 3.1), ciò corrisponde a dire che sp(β)∩sp(Hi) è di dimensione al più pari a 1.
La condizione di rango, applicata a questo problema, porta a dire che β è identificato se e solo se i parametri soddisfano la seguente condizione
rango (Ri′β) = rango (Ri′(Hi ϕi , … , Hr ϕr )) = r−1.
Essa presenta però il difetto di dipendere da β, ovvero dalla conoscenza di una base dello spazio di cointegrazione. Per ovviare a questo problema, si procede talvolta alla verifica delle condizioni di identificazione “fittizia”, fatta generando parametri casuali che soddisfino l’equazione
β = ( Hi ϕi , … , Hr ϕr ).
Un metodo più preciso è quello che si basa sul teorema di identificazione di Johansen, il quale afferma quanto segue:
l’insieme dei vincoli H1 ,…,Hr identifica, a meno di una costante moltiplicativa, il vettore di cointegrazione βi , se per ogni k = 1,…,r-1 e per ogni insieme di indici 1≤ j1< … < jk≤ r non contenente i si ha che
rango(Ri′Η j1 ,… , Ri′ Hjk ) ≥ k
con Ri = Hi⊥ . Se tale condizione vale per ogni i, il sistema è identificato e il numero di
vincoli è pari a

Pag. 66 Vincoli lineari sullo spazio di co-integrazione
( )p r sii
r− − +
=∑ 1
1.
Ogni vettore βi dello spazio di cointegrazione è esattamente identificato se p-r−si = 0, mentre è sovraidentificato se p-r-si>0.
Anche se il teorema è apparentemente complesso, in realtà la sua applicazione è
semplice, come possiamo vedere dall’esempio seguente; supponiamo che il nostro vettore di co-integrazione sia vincolato nel seguente modo
β
β ββ β
β β ββ β β
=−
11 21
11 32
14 24 34
15 25 35
00
0 0 0
tale struttura è rilevabile mediante le matrici Hi
H1
1 0 01 0 0
0 0 00 1 00 0 1
=−
; H2
1 0 00 0 00 0 00 1 00 0 1
=
; H3
0 0 01 0 00 0 00 1 00 0 1
=
ovvero tramite le corrispondenti matrici Ri
R1
1 01 00 10 00 0
=
; R2
0 01 00 10 00 0
=
; R3
1 00 00 10 00 0
=
.
Volendo verificare se il primo vettore della matrice di co-integrazione sia identificato, poniamo i =1; in tal caso, secondo il teorema, k=2, j1=2 e jk=3 e rango(R1′[H2,H3])=1<2.
Questo ci porta ad affermare che il primo vettore della matrice di cointegrazione non è identificato (infatti, semplicemente guardando la matrice β, si nota che una combinazione lineare fra il secondo e il terzo vettore colonna porta ad avere un vettore di co-integrazione che, vincolato, non aggiunge nessuna informazione rispetto ai vincoli posti sul primo dei tre, in quanto, formalmente, sono indistinguibili).

Vincoli lineari sullo spazio di co-integrazione Pag. 67
Una classe di vincoli,che solitamente viene introdotta nell’identificazione di β, è quella dei vincoli di normalizzazione. Ogni vettore βi viene normalizzato nel seguente modo
βi = hi + Hiψi
con ψi vettore colonna (si −1)×1, hi vettore in sp(Hi), e sp(hi,Hi) = sp(Hi). Nell’operare tale normalizzazione, di solito si procede ponendo un 1 in
corrispondenza della variabile endogena (nell’esempio di prima potrebbe essere la x1 e la x3) della i-esima equazione. Se tale variabile è la j-esima, allora, nella matrice Hi, la j-esima riga deve essere nulla.
Nell’esempio precedentemente esposto, in cui si aveva β = (H1 ϕ1 , H2 ϕ2 ) e X′= (x1 , x2 , x3 , x4 ) , si ottiene
h1
1000
=
; H1
0100
=
; h2
0010
=
; H2
0001
=
.
Dal punto di vista geometrico, si ha che hi giace nello spazio di Hi e sp( hi , Hi ) = sp(Hi).
Osservazione: identificazione formale ed empirica La distinzione si rende necessaria qualora alcuni parametri di β, sebbene numericamente diversi da 0, siano statisticamente trascurabili. Se, ad esempio, operiamo con la matrice β tale per cui:
β
ββ
ββ β ββ β β
=
11
22
33
14 24 34
15 25 35
0 00 00 0
allora possiamo parlare di esatta identificazione generica (o formale) ma di assenza di identificazione empirica, se il parametro β11 risulta essere non significativo.
Un esempio è dato dall’introduzione, nelle equazioni di domanda ed offerta, di variabili diverse fra loro ma irrilevanti: in tal caso l’identificazione formale è possibile, ma quella “reale” non sussiste.
Per quanto riguarda l’identificazione di β, un’ulteriore specificazione è data nell’appendice B, § 3.4.

Pag. 68 Vincoli lineari sullo spazio di co-integrazione
5.2 Distribuzione asintotica dei parametri identificati da restrizioni
Diamo qui un risultato (vedi Johansen (1995b)) sulla distribuzione asintotica di $β ,
quando viene stimato sotto vincoli di identificazione. Siano R1, … ,Rr i vincoli, tali per cui Ri′βi = 0. Poniamo Hi = Ri⊥ e consideriamo il
modello β = (Hiϕi,...,Hrϕr). Normalizziamo poi i vettori β in modo tale che β = hi + Hiψi , con sp(hi,Hi) = sp(Hi).
Sia Ai la matrice diagonale a blocchi , con blocchi Ai , e sia Aij la matrice a blocchi, con blocchi Aij.
La stima di massima verosimiglianza di β identificato è consistente e la distribuzione asintotica è una mistura di Gaussiane. Uno stimatore della varianza condizionale
asintotica di T( $ )β β− è data da
THi $ρ ijHi′S11Hj -1Hj′ , con $ρ ij = $α ′ $Ω -1 $α j .
La difficoltà della dimostrazione di quanto detto risiede nella discussione della consistenza. Dal momento che lo stimatore di massima verosimiglianza non è esplicitamente definito, è necessario derivare la consistenza dal comportamento asintotico della funzione di verosimiglianza. Illustriamo il risultato con un esempio.
ESEMPIO 5.1 Consideriamo il modello di base
∆Xt = αβ′Xt-1 + εt , t = 1, … ,T ,
con p = 4 , r = 2 e β nella forma
β
χ
ϕψ η
=
10 1
0 , (ϕ,ψ,χ,η) ∈ R4.
Si può notare che la condizione di rango è soddisfatta per β se ϕ≠0: in tal caso, β è esattamente identificato.
Definiamo ora le matrici

Vincoli lineari sullo spazio di co-integrazione Pag. 69
h1
1000
=
, H1
0 00 01 00 1
=
, h2
0100
=
, H 2
1 00 00 00 1
=
.
I vincoli di identificazione possono essere espressi come
βϕψ1 1
1= +
h H , β
χη2 2
2= +
h H .
La distribuzione asintotica degli stimatori di (ϕ,ψ,χ,η) è una mistura di gaussiane attorno ai veri valori con una varianza condizionale, per T(( $ , $ , $ , $ ) ( , , , ,))ϕ ψ χ η ϕ ψ χ η− ′
stimata da
T H S H H S HH S H H S H
$ $
$ $
ρ ρ
ρ ρ11
111
112
111
2
212
111
222
112
1′ ′
′ ′
−
, con $ $ $ $ρ α αij i j= −Ω 1 . (5.1)
Quindi l’inferenza asintotica riguardante i parametri può essere condotta come se questi fossero Gaussiani con matrice di varianza e covarianza data dalla (5.1); i parametri che compaiono sono stimati con il metodo della massima verosimiglianza.
Il risultato che si ottiene può essere scritto come
→T H S H T H S HT H S H T H S H
T N Iw− −
− −
−′ ′
′ ′
−−−−
111
111
1 112
111
2
121
211
1 122
211
2
1 2
4 0$ $
$ $
$
$
$
$
( , ).ρ ρ
ρ ρ
ϕ ϕψ ψχ χη η
5.3 Test d’ipotesi per i coefficienti ββββ di lungo periodo In questo paragrafo si deriveranno le statistiche dei tests, sotto le ipotesi espresse come restrizioni lineari dei coefficienti di lungo periodo β. Per fare ciò, si ripeterà lo stesso procedimento visto nel capitolo 3 e basato sulla stima di rango ridotto. A questa trattazione, premettiamo un risultato sul calcolo dei gradi di libertà.
5.3.1 Gradi di libertà Come si vedrà in seguito, tutti i tests su β sono distribuiti asintoticamente come delle χ2. Cerchiamo di capire, ora, come determinare i gradi di libertà di tali distribuzioni.
Per cominciare, consideriamo il modello di una regressione generica

Pag. 70 Vincoli lineari sullo spazio di co-integrazione
yt = θ′Xt + εt ,
in cui yt e εt sono scalari, θ′ è un vettore riga e Xt è un vettore colonna; in forma matriciale possiamo scrivere
Y = Xθ + ε,
dove Y′= (y1, … ,yt) , X′= [X1, … ,Xt] e ε′= (ε1, … ,εt). Lo spazio generato dalle colonne di X dà la dimensione del modello o il numero di
parametri liberi. Se sui parametri sono imposte delle restrizioni lineari del tipo θ =Ηϕ, viene definito un sottomodello e la dimensione dello spazio generato da XH dà il numero di parametri liberi dell’ipotesi. La diminuzione in numero dei parametri da stimare fornisce i gradi di libertà per il test.
Per modelli non lineari abbiamo che, in generale
yt = θ(η)′Xt + εt ,
ovvero θ è funzione non lineare di η. Possiamo applicare un’espansione di Taylor,
arrestata al primo ordine, per avere linearità localmente e quindi
θ η θ η θ η η( ) ( ) ( ; ) ( ),+ = + +u d u r u
dove rη(u)/||u||→0 se u→0 (si veda appendice B, § 4.3). Quindi l’approssimazione sarà tanto migliore quanto più u è piccolo; in particolare, considerando u= −$η η , data la
consistenza dello stimatore di massima verosimiglianza, si ha che per T→∞ esso tende a zero.
Il differenziale di θ può essere espresso come (vedi Magnus&Neudecker (1988)): dθ(η;u)=Dθ(u), dove Dθ è la matrice Jacobiana della funzione vettoriale θ; posso quindi rimpiazzare il modello non lineare con quello lineare avente come regressori (Dθ)′Χ t , tale per cui il numero di parametri è dato dallo spazio generato dalle colonne di XDθ. Da ciò deduciamo che lo spazio tangente della funzione non lineare (dθ) gioca il ruolo dello spazio lineare nella solita regressione e la sua dimensione dà il numero di parametri liberi.
Pertanto, una restrizione non lineare dà un sottospazio con un nuovo spazio tangente, il quale è contenuto nello spazio tangente originario e la differenza delle loro dimensioni fornisce i gradi di libertà per il test.
Queste considerazioni valgono anche nel caso di funzioni matriciali non lineari (basta introdurre l’operatore vec (si veda appendice B) che consente di trasformare una matrice

Vincoli lineari sullo spazio di co-integrazione Pag. 71
m×n in un vettore mn×1). Quindi il numero di parametri è dato dalla dimensione dello spazio tangente alla funzione matriciale non lineare.
In un modello di cointegrazione, che è una restrizione non lineare su Π espressa da Π=αβ′ , dovremo innanzitutto determinare la dimensione dello spazio tangente in un punto in cui α e β sono di rango pieno (ovvero la dimensione dello spazio generato dal differenziale di Π=αβ′) e poi usare questo risultato per determinare i gradi di libertà del test per qualcuna delle restrizioni su β discusse precedentemente.
Il differenziale di Π=αβ′ è dato da(vedi Magnus&Neudecker (1988))
dΠ = dαβ′ + α (dβ)′
e quindi lo spazio tangente è dato da
Τ = dαβ′ + α (dβ)′ dα (p×r), dβ (p×r) .
E’ più facile determinare la dimensione dello spazio ortogonale allo spazio tangente nel punto (α,β). Questo spazio deve soddisfare le condizioni
N =M tr ( M( dαβ′+ α (dβ)′) = 0, ∀ dα, dβ (p×r)
=M Mα =0 e β′M =0 .
Poichè α e β sono di rango pieno r, non c’è perdita di generalità se si suppone che
α β= =
I r
0.
Scriviamo inoltre M come M MM M
11 12
21 22
. Allora, la condizione Mα=0 implica che
M11=M21=0, mentre β′M=0 implica che M11=M12=0, così che gli unici parametri che rimangono nella matrice sono quelli di M22, che sono in numero (p−r)(p−r) (M22 è una matrice (p−r)×(p−r)). Quindi lo spazio ortogonale ha dimensione (p−r)2 e pertanto quello tangente ha dimensione p2−(p−r)2.
Un altro semplice modo per andare a verificare il numero di gradi di libertà è il
seguente. Nell’ipotesi di rango ridotto della matrice Π, la matrice di cointegrazione β può essere scomposta in due blocchi tali per cui
β′=[ ]β β11 12M .

Pag. 72 Vincoli lineari sullo spazio di co-integrazione
Il blocco β11 risulta essere una matrice quadrata; se ha rango pieno, allora β può essere normalizzato nel modo seguente
αβ′= (αβ11)(β111− β′) = ~~ 'αβ ,
con ~α =αβ11 e ~ 'β =[ ]I r M β β111
12− .
Come si può vedere, r2 parametri della matrice ~ 'β sono posti uguali a 1, mentre
rimangono liberi r(p−r) parametri contenuti nel blocco β β111
12− .
Pertanto il numero totale di parametri liberi risulta essere pari alla somma dei pr
contenuti in ~α e di quelli contenuti in ~ 'β , ossia pari a r(2p−r) (si veda
Johansen&Juselius(1994)).
5.3.2 Restrizioni lineari su ββββ 1.Stessa restrizione su tutto β. Consideriamo l’ipotesi H0: β=Hϕ, con H matrice (p×s) e ϕ matrice (s×r). Allora, sotto tale ipotesi, il modello in forma ECM può essere scritto come
∆Xt = αϕ′H′Xt-1 + ψZ2t + εt .
Servendoci della funzione di verosimiglianza, stimiamo i parametri ψ, α, Ω e ϕ considerando il modello scritto come
∆Xt = αϕ′ Xt−1* + ψZ2t + εt , (5.2)
dove Xt-1*=H′Xt-1 è un vettore s×1.
Massimizzando il logaritmo della funzione di verosimiglianza concentrata rispetto a ψ,si ricava
$ ,*ψ αϕ= − ′− −M M M M02 221
12 221
dove M T X Z T H X Z H Mt tt
Tt t
t
T12
11 2
1
11 2
112
* *= ′∑ = ′ ′∑ = ′−−
=
−−
=(Mit , i=0,1,2 , sono quelli usati
per il test del rango di cointegrazione; si veda il capitolo precedente). Sostituendo $ψ al
posto di ψ nel modello (5.2) ottengo la seguente regressione nei residui
R Rt t t0 1= ′ +αϕ ε* $ , (5.3)
dove R X M M Z H Rt t t t1 1 12 221
2 1* * * .= − = ′−
− (Rit , i=0,1, sono gli stessi residui che abbiamo
incontrato precedentemente)

Vincoli lineari sullo spazio di co-integrazione Pag. 73
Massimizzando il logaritmo della funzione di verosimiglianza associata al modello (5.3), ottengo
$ ( ) ( )* *α ϕ ϕ ϕ ϕ= ′ −S S01 111
$ ( ) ( )α ϕ ϕ ϕ ϕ= ′ ′ −S H H S H01 111
e
$ $ ( )( )( $ ( ))Ω= − ′ ′ ′S H S H00 11α ϕ ϕ ϕ α ϕ
= − ′ ′ ′ ′S S H H S H H S00 01 11 10ϕ ϕ ϕ ϕ( ) .
Sappiamo che, a parte la costante (2πe)p,
L S S H H S H H STmax ( ) $ ( ) ( )− = = − ′ ′ ′ ′2
00 01 11 10ϕ ϕ ϕ ϕ ϕ ϕΩ
=′ ′ −
′ ′
−S H S S S S HH S H
00 11 10 001
01
11
ϕ ϕ
ϕ ϕ
( ). (5.4)
La massimizzazione della funzione di verosimiglianza equivale alla minimizzazione
dell’ultimo fattore di (5.4). Per trovare la matrice ϕ^
(s×r) che minimizza tale
espressione si deve risolvere il problema agli autovalori dato da
λ ′ − ′ =−H S H H S S S H11 10 001
01 0,
che mi dà s autovalori λ1*, … ,λs
* >0. Se assumiamo che r < s, allora per calcolare $ϕ
consideriamo gli r autovettori associati agli r più grandi autovalori, cioè
$ϕ =[v1,...,vr].
Dalla scelta di $ϕ abbiamo che
$ $′ ′ =ϕ ϕH S H I r11 e $ ( ) $ ,..., )* * *′ ′ − = =−ϕ ϕ λ λH S S S S H diag( r11 10 001
01 1 Λ
e quindi
L SI
IST r
ri
i
rmax
**( )−
==
−= −∏2
00 001
1Λ
λ ,

Pag. 74 Vincoli lineari sullo spazio di co-integrazione
ovvero
−2logQ(H0(r) H(r)) =T i ii
r
( ) ( $ )*1 11
− −=∑ λ λ .
Questa statistica è distribuita come una χ2 con r(p-s) gradi di libertà. Infatti il numero di parametri da stimare sotto H(r) è, per quanto visto precedentemente,
p2−(p−r)2=2pr−r2 (5.5)
mentre il numero di parametri da stimare sotto H0(r) è
ps−(p−r)(s−r) = −r2 +pr + rs = r (p + s − r). (5.6)
La differenza tra la (5.5) e la (5.6) dà i gradi di libertà del test e cioè
r(p−s).
2.Ipotesi su qualche vettore di β. Si tratta di considerare l’ipotesi H0: β=(b,ϕ), dove b è una matrice p×s che raccoglie i vettori di cointegrazione supposti noti e ϕ è una matrice p×(r−s), la quale raccoglie i vettori di cointegrazione su cui non si fa alcuna ipotesi. Per comodità consideriamo la seguente scomposizione
α=(α1,α2)
dove α1 è una matrice p×s e α2 è una matrice p×(r−s). Allora sotto H0(r) possiamo scrivere che
Π=αβ′=α1b′+α2ϕ′
e il modello in forma ECM diventa
∆Χt =α1b′Χ t-1 + α2ϕ′Χ t-1 + ψZ2t + εt .
Dalla massimizzazione del logaritmo della funzione di verosimiglianza concentrata rispetto a ψ, trovo $ ( , , )ψ α α ϕ= 1 2 . Sostituendo a ψ la sua stima otteniamo
R b Rt t t0 1 2 1= ′ + ′ +( ) $α α ϕ ε ,
dove R0t e R1t sono gli stessi residui che abbiamo incontrato precedentemente. Concentriamo, ora, la funzione di verosimiglianza rispetto a α1 , cioè
R R b Rt t t t0 2 1 1 1− ′ = ′ +α ϕ α ε$ ; (5.7)

Vincoli lineari sullo spazio di co-integrazione Pag. 75
dalla massimizzazione, rispetto α1 ,della funzione di verosimiglianza associata al modello (5.7) otteniamo
( )
$ ( ) ( ) .
R b R R R b
S b S b b S bS b b S b S b b S b
t t t tt
T
0 1 1 2 1 11
01 2 11 1 11
1 01 111
2 11 111
0
0
− ′ − ′ ′ =
− ′ − ′ =
= ′ − ′ ′
=
− −
∑ α α ϕ
α ϕ α
α α ϕ
Sostituendo la stima di α1 in (5.7), otteniamo
R S b b S b b R R S b b S b b Rt t t t t0 01 111
1 2 1 11 111
1− ′ ′ = ′ − ′ ′ +− −( ) ( ( ) ) $$ ;α ϕ ε
definisco i nuovi residui
R R S b b S b b RR R S b b S b b R
t t
t t
0 0 01 111
1
1 1 11 111
1
.bt
.bt
( )( )
= − ′ ′= − ′ ′
−
−
e le matrici
S S S b b S b b S T R Rij ij i i i jt
T
.b .bt .bt( )= − ′ ′ = ′− −
=∑1 11
11
1
1 i,j=0,1.
Allora, massimizzando rispetto α2 il logaritmo della funzione di verosimiglianza del modello espresso come
R Rbt bt t0 2 1. . $$ ,= ′ +α ϕ ε
si ottiene
( ).bt .bt .bt
.b .b
R R R
S St
T
0 2 1 11
01 2 11
0
0
− ′ ′ =
− ′ ==∑ α ϕ ϕ
ϕ α ϕ ϕ
e quindi
$ ( ) ( )$ ( ) ( ) .
. .
. . . .
α ϕ ϕ ϕ ϕ
ϕ ϕ ϕ ϕ ϕ2 01 11
1
00 01 111
10
= ′
= − ′ ′
−
−
S S
S S S Sb b
b b b bΩ
Di conseguenza

Pag. 76 Vincoli lineari sullo spazio di co-integrazione
L S S S S
SS S S S
S
SS S S S
S
Tmax .b .b .b .b
.b.b .b .b .b
.b
.b.b .b .b .b
.b
( )
( ).
− −
−
−
= − ′ ′ =
′ − ′′
=
′ −′
200 01 11
110
0011 10 00
101
11
0011 10 00
101
11
ϕ ϕ ϕ ϕ
ϕ ϕ ϕ ϕϕ ϕ
ϕ ϕϕ ϕ
notiamo che se ϕ sta nello spazio generato da b, sia il numeratore che il denominatore sono pari a zero; focalizziamo perciò la nostra attenzione sui vettori che stanno nello spazio generato da b⊥ ,ovvero poniamo
ϕ=b⊥ δ ,
dove δ è una matrice (p−s)×(r−s) e b⊥ è una matrice p×(p−s). Otteniamo che
L Sb S S S S b
b S bT
max .b.b .b .b .b
.b
( )− ⊥
−⊥
⊥ ⊥=
′ ′ −′ ′
200
11 10 001
01
11
δ δδ δ
.
Massimizzare L significa minimizzare L-2/T, ossia
′ ′ −
′ ′⊥
−⊥
⊥ ⊥
δ δδ δ
b S S S S bb S b
( ).b .b .b .b
.b
11 10 001
01
11. (5.8)
Per trovare la matrice ψ che minimizza la (5.8) si deve risolvere il problema agli autovalori dato da
λ ′ − ′ =⊥ ⊥ ⊥−
⊥b S b b S S S b11 10 001
01 0.b .b .b .b ,
che mi dà p-s autovalori ~ ,...,~ .λ λ1 0p s− >
Poichè s<r (s è il numero di vettori di cointegrazione di b, il quale è contenuto in β),
per stimare $δ considero gli r-s autovettori associati agli r-s più grandi autovalori cioè
$ [ , , ]δ= −v v r s1 K .
Dalla scelta di $δ abbiamo che
$ $.′ ′ =⊥ ⊥ −δ δb S b Ib r s11 e $ $ ~ ,...,~ ) ~
. . .′ ′ = =⊥−
⊥ −δ δ λ λb S S S b diag(b b b r s10 001
01 1 Λ ;
quindi

Vincoli lineari sullo spazio di co-integrazione Pag. 77
L SI
IST r s
r si
i
r s
max .b .b
~( ~ ).− −
− =
−=
−= −∏2
00 001
1Λ
λ
Inoltre, S00.b può essere scritto come
SS S b b S b b S
SS
b S S S S bb S b
S ii
s
0000 01 11
110
0000
11 10 001
01
1100
11
− ′ ′=
′ −′
= −− −
=∏
( ) ( )( ~ )ρ ,
ove ~ρi sono gli autovalori del problema
ρS S S S S11 11 10 001
01 0− − =−( ) ,
il quale dà ~ ... ~ ~ ... ~ ,ρ ρ ρ ρ1 1 0> > > = = =+s s p poichè b è di rango pieno s.
Pertanto otteniamo che
L STi
i
s
ii
r s
max ( ~ ) ( ~ )−
= =
−= − −∏ ∏2
001 1
1 1ρ λ
e quindi la statistica per stimare H0(r) in H(r) risulta essere
−2logQ(H0(r) H(r)) =T ii
r s
ii
r
i
slog( ~ ) ( ~ ) ( )
^1 1 11
1 11− + − − −
=
−
==∑ ∑∑ ρ λ λ
Questa statistica è distribuita asintoticamente come una χ2 con s(p−r) gradi di libertà. Infatti il numero di parametri da stimare sotto H(r), come già visto, è pari a
r(2p−r), (5.9)
mentre sotto H0(r), poichè αβ′= α1b′+ α2δ′b⊥ ′, il numero di parametri da stimare è
ps + p(p−s) − (p−(r−s)) (p−s−(r−s)) =
ps + p(p−s) − p(p−s) − (r−s)2 + p(r−s) + (p−s)(r−s) =
ps−(r−s)2 + pr − ps + pr + s2 − ps − sr =
r (2p−r)−s(p−r). (5.10)
Sottraendo la (5.10) dalla (5.9), ottengo i gradi di libertà richiesti, ossia

Pag. 78 Vincoli lineari sullo spazio di co-integrazione
s(p−r).
3.Restrizioni individuali su β. Per cominciare, consideriamo il modello definito dalla restrizione β=(H1ϕ1,H2ϕ2), dove Hi è p×si e ϕi è si×ri (i=1,2).
Seguendo la procedura precedente, decomponiamo la matrice α come (α1,α2), dove αi è p×ri . L’equazione dei residui, che si ottiene sostituendo nel modello in forma ECM la stima di ψ, diventa la seguente
R0t =α1ϕ1′H1′R1t + α2ϕ2′H2′R1t + $ε t . (5.11)
Si tratta sempre di un problema di rango ridotto, ma con 2 condizioni ; la soluzione non è data da quella determinata per un problema agli autovalori, ma dal seguente algoritmo, facile da implementare e convergente. Inoltre esso presenta la proprietà che la funzione di verosimiglianza aumenta di valore ad ogni passo.
L’algoritmo è basato sull’osservazione che, per valori noti di ϕ1, l’analisi dell’equazione (5.11) è proprio una regressione di rango ridotto di R0t su H2′R1t , corretto per β1′R1t = ϕ1′H1′R1t, che è il caso incontrato in precedenza.
Come valori iniziali di β1 prendiamo, tra gli r vettori dello stimatore non vincolato $β ,
un totale di r1 combinazioni lineari più vicine possibili allo spazio di H1. Questo può essere fatto risolvendo il problema agli autovalori
λβ β β β$ $ $ ( ) $′ − ′ ′ ′ =−H H H H1 1 11
1 0
e scegliendo, come valori iniziali per l’iterazione, i vettori $ $( ,..., ).β β1 1 1= v v r
L’algoritmo consiste, quindi, nei seguenti passi:
1. Stimare β1 e β2 non vincolati e costruire una stima iniziale $β1 e $β2 come
descritto sopra.
2. Per valori fissati di $β1 , stimare ϕ2 e α2 dalla regressione di rango ridotto di R0t su
H2′R1t , corretto da $β1 R t1 . Ciò permette di definire $ $ .β ϕ2 2 2=H
3. Per valori fissati di β β2 2= $ , stimare ϕ1 e α1 dalla regressione di rango ridotto di
R0t su H1′R1t, corretta per $ .β 2 1R t Questo definisce $ $ .β ϕ1 1 1=H
4. Tornare ai passi 2 e 3 finchè non si ha convergenza. Riassumendo, abbiamo che il modello H0: β=(H1ϕ1,H2ϕ2) è stimato dall’algoritmo
descritto sopra e il valore della funzione di verosimiglianza è dato da
L STi
i
r
ii
r
max ( $ ) ( $ )−
= =
= − −∏ ∏200
1 1
1 11 2
ρ λ ,

Vincoli lineari sullo spazio di co-integrazione Pag. 79
dove 1 1 2> > >$ ... $λ λ s sono le soluzioni del problema, per β β1 1= $ , dato da
λ β β β β′ − ′ =−H S H H S S S H2 11 2 2 10 001
01 21 1 1 10. . . .
e 1 1 1> > >$ ... $ρ ρs sono definiti dal problema agli autovalori, per β β2 2= $ , dato da
λ β β β β′ − ′ =−H S H H S S S H1 11 1 1 10 001
01 12 2 2 20. . . . .
I gradi di libertà per questo test sono dati da (p−s1−r1)r2 + (p−s2−r2)r1 . Questo risultato è generalizzabile al caso in cui il modello sia β=(H1ϕ1,H2ϕ2,…,Hrϕr),
con Hi di dimensioni p×si e ϕi di dimensioni si×1 : si applica ancora il precedente algoritmo switching e la distribuzione asintotica del test del rapporto di verosimiglianza risulta essere una χ2 con numero di gradi di libertà pari a ( )i
rip r s=∑ − − +1 1 .
5.4 Distribuzioni asintotiche dei tests d’ipotesi In questa sezione mostreremo che le statistiche del test del rapporto di verosimiglianza per le ipotesi su β sono distribuite asintoticamente come una χ2. Questo deriva dal fatto che l’espansione di Taylor della funzione di verosimiglianza intorno al suo valore massimo fornisce un’approssimzione quadratica e, condizionando al parametro di mistura, si ottiene una distribuzione asintotica χ2.
Per cominciare, deriveremo un’approssimazione del secondo ordine della funzione di verosimiglianza per poi fornire la distribuzione asintotica della statistica del test per varie ipotesi su β.
Per un ulteriore approfondimento del tipo di ipotesi sui coefficienti di cointegrazione
si rimanda a Johansen&Juselius(1992). 1.Ipotesi su tutti i vettori di cointegrazione di β. Il test del rapporto di verosimiglianza sotto questa ipotesi è dato da
−2logQ(β H(r)) = ′ − ′ −−Ttr S( )(~ ) (~ )α α β β β βΩ 111 + −Op T( )1 , (5.12)
che è asintoticamente distribuito come
tr dV G GG du G dV( ) ( ) ( ) ,′ ′ ′
′
−−
∫ ∫ ∫α α α αΩ 1
0
1
0
1 1
0
1 (5.13)
la cui distribuzione è una χ2 con r(p−r) gradi di libertà. Dimostrazione. Il test del rapporto di verosimiglianza ha la forma

Pag. 80 Vincoli lineari sullo spazio di co-integrazione
− =−2 2log ( ( )) log( ( ) (~)),max maxQ H r L Lβ β β
dove
L S S S S S STmax ( ) ( ) .− −= ′ − ′2
00 11 10 001
01 11β β β β β
Per le considerazioni che verranno fatte in seguito, è utile valutare l’ordine di grandezza dei vari termini
(~ ) ( ),
(~ ) (~ ) ( ),
(~ ) ( ).
β β β β β
β β β β β β
β β β
− ′ = ′ ′ ∈
− ′ − = ′ ′ ∈
− ′ = ′ ′ ∈
⊥−
⊥ ⊥−
⊥−
S U S Op T
S U S U Op T
S U S Op T
T
T T
T
11 111
11 111
10 101
Dall’espansione di Taylor, arrestata al secondo ordine, di log( ( ))maxL T−2 β intorno al
valore β β=~ troviamo che
− + =− +
+ ′ − ′ −
− − ′ − ′ −
− ′ ′ ′ ′ +
− − −
− − − −
2 2
11 10 001
011
11 10 001
01
11 10 001
01 11 10 001
011
11 10 001
01
log( (~ )) log( (~))
(~ ( )~) (
( )~(~ ( )~) ~ ( ))
(~ ~) ( ~ (~ ~) ~ (
max maxL h L
Ttr S S S S h S S S S
S S S S S S S S S S S S h
Ttr S S S S S Op h
β β
β β
β β β β
β
11−1
11 11 11−1
11β η − β β β β 3).
A questo punto, ponendo h= −β β~ , troviamo che
− =− +
=+ ′ − − ′ −
− − ′ − ′ − −
− ′ − ′ −
− − −
− − − −
−
2 2 2
11 10 001
011
11 10 001
01
11 10 001
01 11 10 001
011
11 10 001
01
111
11 11
log ( ( )) log( ( )) log( (~))
(~ ( )~) (~ ) (
( )~(~ ( )~) ~ ( ))(~ )
(~ ~) (~ ) (
max maxQ H r L L
Ttr S S S S S S S S
S S S S S S S S S S S S
Ttr S S S
β β β
β β β β
β β β β β β
β β β β
~(~ ~) ~ )(~ ) (~ ) .β β β β β β β β′ ′ − + −
−S S Op111
113
Per quel che concerne il secondo termine, si ha che
Ttr ′ − ′ − ′ ′ −
= − ′ − +
− −
− −
(~ ~) (~ ) ( ~(~ ~) ~ )(~ )
(~ ) (~ ) ( ) ,
β β β β β β β β β β
β β β βββ
S S S S S
Ttr S Op T11
111 11 11
111
111
1Σ
mentre per il primo termine si trova che

Vincoli lineari sullo spazio di co-integrazione Pag. 81
→~ ( )~ ;
(~ ) ( )(~ ) (~ ) (~ ) ( );
(~ ) ( )~ ( ).
′ − −
− ′ − − = − ′ − +
− ′ − =
− −
− −
− −
β β
β β β β β β β β
β β β
ββ β βS S S S
S S S S S Op T
S S S S Op T
P11 10 00
101 0 00
10
11 10 001
01 112
11 10 001
011
Σ Σ Σ Σ
Combinando questi risultati troviamo che
− | = [ − − ] − ′ − +− − − −2 0 001
01 1
111log ( ( )) ( ) (~ ) (~ ) ( )Q H r Ttr S Op Tβ β β β βββ β β ββ Σ Σ Σ Σ Σ .
Dalla (3.18) si vede che il termine nelle parentesi quadre è pari a α′Ω -1α e risulta così
dimostrata la (5.12). Poichè ~β β β− = ⊥ UT si ha che
− | = ′ ′ ′ +− −⊥ ⊥
−2 1 111
1log ( ( )) ( ( ( ) ( )Q H r Ttr TU T S TU Op TT Tβ α α β β Ω ,
che per T→∞ converge alla (5.13).
Si noti che, condizionatamente a G, la matrice ( )dV Gα ′∫01 di dimensione r×(p-r) è
Gaussiana con varianza condizionale
( ) ;′ ⊗ ′− − ∫α αΩ 1 10
1GG du
pertanto la variabile
Z dV G GG du= ′ ′ ′
−−
∫ ∫( ) ( )α α αΩ 1 1 20
1
0
1 1 2
è una Nr×(p-r)(0,I) e quindi trZZ′ è una χ2 con r(p-r) gradi di libertà. Questo risultato, purtroppo, non è sufficiente per le applicazioni in cui, tipicamente,
si vuol testare ipotesi del tipo β=Hϕ, β=(b,δ), β=(H1ϕ1, H2ϕ2) etc. Per ognuna di queste ipotesi, comunque, il metodo è lo stesso: si esegue un’espansione della log-verosimiglianza intorno al suo punto di massimo con e senza restrizioni; sottraendo i due termini, si trova un’espressione per la distribuzione asintotica, che risulta essere una χ2 con gradi di libertà diversi a seconda del tipo di ipotesi.


Parte II
Il modello VAR con
componenti deterministiche


Capitolo 6 Il modello VAR per processi a media non
nulla in tutte le loro componenti
CON questo modello si vogliono rappresentare quelle variabili, le cui deviazioni da una costante deterministica presentano un comportamento autoregressivo. Si tratta dunque di un’estensione del modello VAR di base, che risulta essere “nested” in quello in cui il termine costante è diverso da zero.
Si vedrà, innanzitutto, la forma ECM associata a questo modello, nonché quella MA, al fine di analizzare i comportamenti del processo, diversi a seconda delle componenti che si considerano. Così come fatto per il caso base, si deriveranno poi la statistica per il test di cointegrazione e le stime di massima verosimiglianza dei vari parametri, con le relative distribuzioni asintotiche.
Successivamente, si prenderanno in considerazione variabili che hanno una media stagionale, le quali vengono modellizzate attraverso variabili dummy; si dimostrerà che la loro presenza non influenza la distribuzione asintotica del test sul rango di co-integrazione.
6.1 Il modello e la sua interpretazione Il processo che consideriamo ora è caratterizzato dalla presenza di variabili aventi un comportamento autoregressivo, una volta depurate dalla costante deterministica; questo processo può essere modellizzato nel seguente modo: sia Xt il vettore delle variabili che lo caratterizzano, mentre ~Xt quello delle variabili che definiscono un processo analogo
a quello visto nella parte 1, ovvero un processo autoregressivo puro senza componenti deterministiche. La relazione tra queste due tipologie di variabili è la seguente

Pag. 86 Il modello VAR per processi a media non nulla in tutte le loro componenti
Xt = ~Xt +m0 . (6.1)
Come si può vedere, per caratterizzare il nuovo vettore di variabili si procede aggiungendo semplicemente a quelle del modello VAR di base un vettore di costanti m0.
Sapendo che ~Xt è un processo autoregressivo puro, allora esso può essere
modellizzato come
A L Xt t( )( ~ )=ε
e quindi , ricordando la (6.1),
A L X mt t( )( )− =0 ε . (6.2)
Un’importante questione riguarda l’interpretazione che può essere data al vettore di costanti m0 . Si è già detto che esso rappresenta quella parte deterministica, attorno alla quale le variabili del processo assumono un comportamento autoregressivo. Di primo acchito, dunque, si potrebbe “azzardare” l’idea che m0 sia il valore atteso delle variabili Xt , ovvero la loro media.
Da un’analisi più approfondita, ciò risulta essere vero solo parzialmente; infatti, nella trattazione relativa al modello VAR di base si è constatato che, pur avendo a che fare con un processo autoregressivo senza componenti deterministiche, alcune variabili presentavano una media diversa da zero. Più precisamente, si è notato che le variabili non stazionarie avevano un valore atteso che dipendeva dal valore iniziale assunto dalle variabili del processo. Tutto ciò equivale a dire che m0 è riconducibile alla media di una sola parte del processo, ovvero quella stazionaria.
Questa osservazione qualitativa è traducibile in termini più formali. Dal momento che lo spazio generato da β e β⊥ copre tutto lo spazio R p-dimensionale, vale la seguente relazione
m0 = ( Pβ + Pβ⊥)m0 , (6.3)
dove Pβ e Pβ⊥sono le proiezioni nello spazio coperto dalle colonne di β e β⊥
rispettivamente. Applicando al processo descritto dalla (6.2) il teorema di rappresentazione di
Granger, è possibile ricavarne la corrispondente rappresentazione a media mobile, ottenendo il seguente risultato
X m C C L) P Xt ii
t
t− = + +=∑ ⊥0
11 0ε ε β( ~ ;

Il modello VAR per processi a media non nulla in tutte le loro componenti Pag.87
portando m0 a destra dell’uguaglianza, l’equazione diventa
X m C C L) P Xt ii
t
t= + + +=∑ ⊥0
11 0ε ε β( ~ .
Ricordando la relazione (6.1), abbiamo che
~X0 = X0 − m0
e quindi, inserendo al posto di m0 l’espressione (6.3), si ottiene
X C C L) P X P mt ii
t
t= + + +=∑ ⊥
ε ε β β1
1 0 0( .
Analizzando il processo nelle sue due distinte direzioni β e β⊥ , che danno rispettivamente le componenti stazionarie e non del processo, otteniamo che i valori attesi di tali componenti sono, in primo luogo, diversi e dati rispettivamente da
E[β′Χ t] = β′m0 , (6.4)
E[β⊥ ′Χ t] = β⊥ ′X0 = β⊥ ′ ~X0 +β⊥ ′m0 . (6.5)
Poiché si è detto che i vettori della matrice p-dimensionale (β,β⊥ ) costituiscono una base per lo spazio Rp, il vettore m0 risulta scomposto come segue
m0 = βδ0 + β⊥ η0 ,
ovvero lo si scinde in una parte che appartiene allo spazio di β (βδ0) ed in una che appartiene allo spazio di β⊥ (β⊥ η0).
Di conseguenza, la (6.4) e la (6.5) mostrano come solo quella parte di m0 appartenente allo spazio di β rappresenti effettivamente la media delle variabili (in particolare di quelle stazionarie), mentre quella parte di m0 che giace nello spazio di β⊥ è responsabile di una media non nulla, la quale però viene “inglobata” nel valore iniziale.
Questa situazione porta ad un problema di identificazione di m0 , in quanto nelle componenti non stazionarie esso è indistinguibile dal valore iniziale del processo. Di conseguenza m0 risulta non essere identificato, a meno che β non sia di rango pieno p, implicando che β⊥ =0, ossia che m0∈ Sp(β)≡Rp.
Questo problema dell’identificazione di m0 può essere rilevato considerando la rappresentazione ECM associata al modello (6.2), che si ottiene applicando la solita espansione del polinomio A(L) data da

Pag. 88 Il modello VAR per processi a media non nulla in tutte le loro componenti
A(L)=−ΠL + (1−L)I− Γii
k
=
−
∑1
1(1−L)Li ;
si ha
∆ Π Γ ∆X X m Xt t i t ii
k
t= − + +− −=
−
∑( )1 01
1ε .
Sotto l’ipotesi di rango ridotto Hc(r): Π=αβ′ , con α e β matrici p×r di rango pieno r<p, si ha
∆ Γ ∆X X m Xt t i t ii
k
t= ′ − ′ + +− −=
−
∑αβ αβ ε1 01
1, (6.6)
che, ponendo −β′m0=ρ0 , può essere riscritto in forma compatta come
∆ Γ ∆X X Xtc
tc
i t ii
k
t= ′ + +− −=
−
∑α β ε( ) 11
1, (6.6’)
dove βc e Xt-1c sono definiti come
βc =′
βρ0
, XX
tc t− =
1 1
.
Si noti che il problema di identificazione di m0 è dovuto al fatto che esso entra nel modello (6.6’) solo attraverso β. Ricavando, infatti, l’espressione per m0 in funzione di ρ0 si trova che Pβm0= −βρ0 , da cui si vede che, una volta identificato ρ0 , è identificata
univocamente solo la proiezione nello spazio di β di m0. Un modo per identificare m0 potrebbe essere quello di vincolarlo a stare nello spazio
di cointegrazione; in questo caso abbiamo che
m P P m P m0 0 0= + =⊥
( )β β β .
Per il modello (6.6’) è possibile ricavare le distribuzioni asintotiche della statistica per il test del rango di cointegrazione, le stime di massima verosimiglianza di α, β, ρ0, Γ1 , …, Γk-1 e testare le relative ipotesi. In particolare, le ipotesi su m0 sono legate a quelle su ρ0; ad esempio, se si volesse escludere la presenza di una costante (m0=0), si dovrebbe testare l’ipotesi H0: ρ0=0. In sostanza, ciò che si è fatto è stato aggiungere una dimensione a ciascun vettore di cointegrazione, che si è tradotta nell’inserimento di una costante in ciascuna relazione di equilibrio; la dimensione dei vettori di cointegrazione risulta perciò pari a (p+1)×1. Per quanto detto sopra, si conclude che ipotizzare ρ0=0

Il modello VAR per processi a media non nulla in tutte le loro componenti Pag.89
porta ad escludere la costante nelle componenti stazionarie ma non in quelle non stazionarie.
6.2 Analisi statistica del modello Questo paragrafo contiene un’analisi della funzione di verosimiglianza del modello con intercetta e la conseguente determinazione del rango di cointegrazione, così come fatto per il modello di base. Attraverso l’uso della verosimiglianza concentrata, infatti, si deriveranno le stime di α,β,ρ0,Γ1,…,Γk-1 e la statistica per il test del rango di cointegrazione.
Il punto di partenza dell’analisi è l’espressione (6.6’). Si noti la forte analogia con il
modello VAR di base riscritto nella forma ECM: basta infatti aumentare di una unità la dimensione del vettore dei livelli Xt-1 ; si userà, pertanto, lo stesso procedimento usato in quella sede.
Definiamo il modello ECM di rango ridotto come
∆X X Ztc
tc
t t= ′ + +−α β ψ ε( ) ,1 2 t =1,...,T (6.8)
dove ψ=(Γ1, … ,Γk−1) e Z2t′=(∆Χ t−1′, …, ∆Χt − k +1′). Ricaviamo, ora, la stima di ψ, concentrando la verosimiglianza, ciò significa
risolvere l’equazione
( $ ) ,∆X X Z Ztc
tc
t
T
t t− ′ − ′ =−=∑ αβ ψ1
12 2 0
che porta a
$ ,ψ αβ= − ′− −M M M Mc c02 22
112 22
1
dove M02 e M22 sono le stesse quantità viste per il caso base, mentre
M T X Zctc
tt
T
121
1 21
= ′−−
=∑ . A questo punto sostituisco la stima di ψ nella (6.8) ed ottengo la
seguente regressione
R Rtc c
tc
t0 1= ′ +αβ ε$ , (6.9)
con

Pag. 90 Il modello VAR per processi a media non nulla in tutte le loro componenti
R X M M ZR X M M Z
tc
t t
tc
tc c
t
0 02 221
2
1 1 12 221
2
= −= −
−
−−
∆,
residui di due regressioni preliminari, più precisamente di ∆Χt contro Z2te Xct-1 contro
Z2t rispettivamente. Calcolo, ora, le stime di α e Ω, concentrando la verosimiglianza rispetto ad α ed
ottengo
$ ( ) ( )α β β β βc c c c c cS S= ′ −01 11
1
$ ( ) ,Ω= − ′ ′ ′−S S S Sc c c c c c c c00 01 11
110β β β β
dove S T R Rij itc
jtc
t
T
= ′−
=∑1
1
con i , j = 0,1. Si noti che
S Sc00 00= , S
S T X
T X
ct
t
T
tt
T11
111
11
11
1
1=
′
−−
=
−−
=
∑
∑ e S
S
T Xc
tt
T10
10
1
1
= ′
−
=∑ ∆ ,
l’espressione per Sij è quella definita nel capitolo 3. Il valore della funzione di verosimiglianza, in funzione di β, è dato da
L SS S S S
ST c c c
c c c c c c c c
c c cmax ( ) $ ( )
( )−
−
= =
′ − ′
′2
00
11 10 001
01
11
β ββ β β β
β βΩ .
Quindi, la massimizzazione di Lmax equivale alla minimizzazione rispetto a βc del termine
β β β β
β β
c c c c c c c c
c c c
S S S S
S
′ − ′
′
−11 10 00
101
11
( ),
che, a sua volta, equivale a risolvere il seguente problema agli autovalori
λS S S Sc c c c11 10 00
101 0− =−( ) .

Il modello VAR per processi a media non nulla in tutte le loro componenti Pag.91
Siano λ i gli autovalori di tale problema e vi gli autovettori ad essi associati; allora la funzione di verosimiglianza sarà massimizzata scegliendo βc dato dagli r autovettori associati agli r più grandi autovalori λ i. Pertanto
SS S S S
SSc
c c c c c c c c
c c c
ci
i
r
00
11 10 001
01
11
001
1$ $ $ ( ) $
$ $( $ )
β β β β
β βλ
′ − ′
′= −
−
=∏
è il valore massimo della verosimiglianza sotto l’ipotesi di rango r, H(r). Ripetendo gli stessi passaggi per l’ipotesi di rango pieno, ottengo il valore massimo
della verosimiglianza sotto questa ipotesi. Pertanto, Il valore del test LR per verificare che il rango di co-integrazione sia r contro l’alternativa che esso sia p risulterà pari a
−2 11
1
log ( ( ) ( )) log( $ ).Q H r H p Tc ci
i r
p
=− −= +
+
∑ λ
6.3 Determinazione del test sul rango di cointegrazione Discutiamo ora le proprietà del processo dato da
∆X X Ztc
tc
t t= ′ + +−α β ψ ε( ) ,1 2 t=1,...,T ;
come per il caso base, analizzeremo il comportamento di tale processo nelle diverse direzioni e applicheremo questi risultati per derivare le proprietà asintotiche dei termini che compaiono nella statistica per il rango di cointegrazione.
6.3.1 Alcuni risultati utili Si tratta di ricavare, per questo tipo di processo, gli analoghi risultati ottenuti per il caso base; si ricordi che βc′Χ c
t e ∆Χt sono stazionari (infatti, rispetto al modello di base, si è solo aggiunto al vettore Χt un 1). Possiamo definire la seguente matrice di varianze-covarianze condizionate ai valori che il processo ha assunto nel passato (Z2t)
VARX
XZt
ctc t
C
C C C
∆ Σ ΣΣ Σβ
β
β β β′
=
−12
00 0
0,
con

Pag. 92 Il modello VAR per processi a media non nulla in tutte le loro componenti
Σ ∆
Σ
Σ ∆
00 2
1 2
0 1 2
=
= ′
= ′
−
−
VAR X Z
VAR X Z
COV X X Z
t t
ct t
tc
t t
c c
c
( ),
,
, ,
β β
β
β
β
pertanto la matrice di varianze-covarianze è la stessa di quella vista per il modello base e quindi valgono le relazioni derivate nel paragrafo 3.2.1.
6.3.2 Risultati asintotici Visto che la matrice di varianze-covarianze è la stessa del modello base, abbiamo che
→S VAR X X COV X Z VAR Z COV Z Xc Pt t t t t t t00 2 2
12 00( , ) ( , )( ( )) ( , ) ,∆ ∆ ∆ ∆ Σ− =−
→β β
β β
c c P ctc
t
ctc
t t t t
S COV X X
COV X Z VAR Z COV Z X c
′ ′ +
− ′ =
−
−−
10 1
1 2 21
2 0
( , )
( , )( ( )) ( , ) ,
∆
∆ Σ
→β β β
β β β β
c c c P ctc
ctc
t t tc
tc
S VAR X
COV X Z VAR Z COV Z X c c
′ ′ +
− ′ ′ =
−
−−
−
11 1
1 2 21
2 1
( )
( , )( ( )) ( , ) Σ
Definiamo, ora, la seguente matrice (p+1)×(p-r+1)
BT
c ′ =
⊥β 00 1 2
;
allora si ottiene che
T B S BT X X T X
T XOp(c c c
t tt
T
tt
T
tt
T−
−⊥ − −
=⊥
−⊥ −
=
−−
=⊥
′ =′ ′ ′
′
+∑ ∑
∑1
11
21 1
1
3 21
1
3 21
1
11
β β β
β
/
/)
e
B S B S ST X
TOp(c c c c c
t tt
T
tt
T′ = ′ − ′ =
′ ′
′
+
−⊥ −
=
−
=
∑
∑1 10 11
11
1
1 2
1
1ε βαβ ε
ε( ) ) .

Il modello VAR per processi a media non nulla in tutte le loro componenti Pag.93
Ricordando i risultati asintotici del paragrafo precedente, si ha che queste quantità convergono rispettivamente a
GG du Gdu
G du
G Gdu
′
′
=
′∫ ∫
∫∫0
1
0
1
0
1 0
1
1 1 1 e G dW
W
GdW( )
( ( ))( )′
′
=
′∫ ∫0
1
0
1
1 1,
dove G è il moto brownoiano definito nel capitolo 3.
6.3.3 Distribuzione asintotica del Trace-test Abbiamo visto che la statistica per testare il modello Hc(r) in Hc(p) è
−2 11
1
log ( ( ) ( )) log( $ ),Q H r H p Tc ci
i r
p
=− −= +
+
∑ λ
dove $ ,..., $λ λr p+ +1 1 sono le p-r+1 più piccole radici date da
S S S S Sc c c c c( ) ( ) .λ λ= − =−11 10 00
101 0 (6.10)
Individuiamo, ora, le proprietà asintotiche di Sc(λ), in base a quanto visto sopra. Consideriamo la matrice (p+1)×(p+1) AT
c data da (βc,T-1/2Bc); si vede che ATc è di rango
pieno p+1 e quindi il problema (6.10) equivale a risolvere il problema agli autovalori dato da
A S ATc c
Tc′ =( )λ 0 ,
il quale, per T→∞ converge al problema
λΣ λββ β β− ′ =− ∫Σ Σ Σ0 001
0 0
10G G duc c , con G
Gc =
1
.
Questa equazione ha p-r+1 radici nulle, date dal secondo termine, e r radici positive non nulle date dal primo termine. Poiché a noi interessano le p-r+1 radici più piccole, considereremo, analogamente a quanto fatto per il modello VAR di base, la seguente scomposizione
( , ) ( )( , )β λ βc c c c cB S B′ =0 ,

Pag. 94 Il modello VAR per processi a media non nulla in tutte le loro componenti
la quale, supponendo che le radici λ i convergano a zero con un tasso pari T (in modo tale che ρ=Tλ sia fissato per T→∞), risulterà essere uguale a
ρ α α αT B S B B S VAR W S B Opc c c c c cTc−
⊥ ⊥−
⊥′ − ′ ′ ′ +1
11 101
01 1( ( )) ( ) .
I risultati visti precedentemente implicano che le p-r+1 radici più piccole di (6.10), una volta normalizzate da T, convergono a quelle date dall’equazione
ρ αG G du G dW VAR W dWGc c c c′ − ′ ′ ′ =∫ ∫∫ ⊥−
0
1 10
1
0
10( ) ( ( )) . (6.11)
Definendo il moto Browniano standard
FC C G B
=′ ′
=
⊥ ⊥−( )β βΩ 1/2
1 1,
la (6.11) diventa
ρ FF du F dB dBF′ − ′ ′ =∫ ∫∫0
1
0
1
0
10( ) .
Pertanto, considerando, l’espressione del test LR si trova che
−2 1 11
1
1
1
log ( ( ) ( )) log( $ ) $ )Q H r H p T T Op(c ci
i r
p
ii r
p
=− − = += +
+
= +
+
∑ ∑λ λ
→wi
i r
p
$ρ= +
+
∑1
1
= ′
′ ′
∫ ∫ ∫−
tr FF du F dB dBF0
1 1
0
1
0
1( )
= ′ ′
′
∫ ∫ ∫−
tr dBF FF du F dB0
1
0
1 1
0
1( ) .
6.4 Proprietà asintotiche degli stimatori Come per il modello di base, α e βc non sono identificati univocamente, pertanto essi, per poter essere stimati, dovranno essere normalizzati da una matrice c di dimensioni

Il modello VAR per processi a media non nulla in tutte le loro componenti Pag.95
p×r oppure essere identificati mediante dei vincoli. Nel primo caso si considererà lo stimatore dato da
$ ( $ )( $ )
$
$β β β
ρ ββρc
c
c
cc
c = ′′ ′
=
−
−
1
01
0
,
e quelle dello stimatore
$ $ $α αβc c= ′ .
Detto ciò, per la determinazione asintotica di questi stimatori, si attuerà la stessa procedura vista per il modello VAR di base: In Johansen (1991) viene fornito un risultato circa la distribuzione asintotica dei parametri βc e ρ0c: in particolare si ha che
T( $βc -βc)→w (I-βcc′) β⊥ GG du G dV′
′∫ ∫−
0
1 1
0
1( )α ,
la cui varianza condiziale è stimata in modo consistente da
T(I- $βc c′) [I,0] $ $v vc c ′[I,0]′ (I- $βc c′)′⊗ (α′Ω -1α)-1;
mentre per ρ0c abbiamo che
T( $ρ0c -ρ0c) →w G G du G dV2 1 2 10
1 1
2 10
1. . . ( )′
′∫ ∫−
α ,
dove
G2.1=1− ′ ′
∫∫
−G du GG du G
0
1
0
1 1;
la varianza condizionale di tale stimatore è stimata in modo consistente da
T[0,1] $ $v vc c ′[0,1]′⊗(α′Ω -1α)-1.
Qui ( $βcc , $vc ) sono gli autovettori del problema agli autovalori (8.10).
Per $α si ottiene sempre che
( )→T Nwp r c c
1 2 10/ $ ( , )α α β β− ⊗×−Ω Σ ,
Mentre per $ , $ϑ Π c si ottiene rispettivamente che

Pag. 96 Il modello VAR per processi a media non nulla in tutte le loro componenti
( )→ ( )T Nwp r k p
1 21)
10/( ( )
$ ,ϑ ϑ− ⊗× + −−Ω Σ ,
( )→T Nc c wp p
c c1 21)
10/(
$ ,Π Π Ω Σ− ⊗ ′
× +
−β βββ .
6.5 Test per ipotesi su ββββc e loro distribuzioni asintotiche E’ possibile formulare ipotesi del tipo visto per il caso base, per i coefficienti di lungo periodo βc, i cui test saranno sempre distribuiti, asintoticamente, come delle χ2 con gradi di libertà opportuni a seconda del tipo di ipotesi, per il cui calcolo si applicano i medesimi procedimenti visti nel capitolo 5, tenendo presente che ora abbiamo a che fare con una matrice dei coefficienti di lungo periodo (βc) che ha dimensione (p+1)×r e non più p×r. E’ inutile, quindi, una riesposizione di tale procedimento.
Conviene, tuttavia, vedere come testare la presenza o meno della costante m0 nel processo in considerazione; in altre parole si vuole testare l’ipotesi nulla H0: m0=0, contro l’ipotesi Ha: m0≠0. Poiché tutte le statistiche e le relative distribuzioni asintotiche, sono state ricavate per la forma ECM di tale processo, vediamo come si traducono, per questo tipo di rappresentazione, le ipotesi viste sopra.
In particolare, ipotizzare m0=0 nella rappresentazione AR, equivale ad ipotizzare ρ0=0 nella rappresentazione VECM (si ricordi che ρ0=−βm0) e quindi significa
ipotizzare che βc sia pari aβ0
. Questa ipotesi può essere espressa nella sua forma
esplicita βc=Hβ, dove H=Ip
0
. Tuttavia si è visto in precedenza che non vale il
viceversa: ipotizzare che ρ0=0 non significa che m0=0, ma che Pβm0=0. In sostanza si sta testando il modello di base contro quello in cui le variabili del processo sono a media non nulla, e la statistica per questo test è data dal rapporto tra le due verosimiglianze, ossia
− =2log( ( ( ))Q H H rc cβ β .
Questa statistica risulta essere distribuita come una χ2 con r gradi di libertà; r, infatti, quantifica la diminuzione del numero di parametri da stimare, a causa dell’ipotesi in questione.

Il modello VAR per processi a media non nulla in tutte le loro componenti Pag.97
6.6 Variabili con comportamento stagionale Finora si è considerato un modello le cui variabili hanno una media diversa da zero e, più precisamente, pari ad una costante. Consideriamo, ora, il caso in cui le deviazioni da un comportamento stagionale delle variabili, siano di tipo autoregressivo.
Questo è un altro modo di trattare serie storiche stagionali, il quale tratta questo tipo di comportamento come uno deterministico (per la modellizzazione della stagionalità stocastica si veda Hylleberg (1991)).
Questo modo di affrontare la stagionalità dei processi richiede l’introduzione nei modelli VAR di variabili dummy. Una variabile dummy non è altro che una variabile binaria deterministica, ossia vale 1 se si verificano certe condizioni e 0 altrimenti.
Nel caso in esame, esse sono variabili del tipo
djt =
10 se t j altrimenti.
∈
Il simbolo j si riferisce alla stagione. Per comodità supponiamo che l’unità di tempo della stagionalità coincida con quella
del campione a disposizione1. Analogamente a quanto fatto precedentemente, vediamo di costruire un modello
VAR che modellizzi le deviazioni da un comportamento stagionale delle variabili. Sia ~Xt un processo VAR di base, mentre Xt sia un processo VAR in cui le variabili hanno
una media diversa da zero è stagionale. La relazione tra questi due processi è la seguente
Xt = ~Xt + c jj
s
=∑
1
djt, (6.12)
dove s è il numero di stagioni all’interno di un anno2. Sapendo che ~Xt è un processo VAR di base, abbiamo che
A(L) ~Xt = εt
e quindi, dalla (6.12) si ha che
A(L)( Xt − c jj
s
=∑
1
djt) = εt.
1 Ad esempio se la stagionalità è mensile, t rappresenterà i mesi in cui si osservano le variabili. Questo
ci consente sviluppi ed espansioni dei polinomi in L più semplici

Pag. 98 Il modello VAR per processi a media non nulla in tutte le loro componenti
In generale, queste dummy stagionali possono non essere centrate, ovvero il loro contributo dopo s periodi può non essere pari a zero; in formule questo si traduce nello scrivere
c jj
s
=∑
1
djt = m ≠ 0,
ovvero non si vincola i coefficienti delle dummy stagionali a dare un contributo nullo su un anno; pertanto in generale è sempre possibile scrivere
c jj
s
=∑
1
djt =
ms
+ c jj
s*
=∑
1
djt, (6.13)
dove i coefficienti c*j sono vincolati in modo tale che il contributo delle dummy sia
nullo dopo s periodi ( infatti si è isolato il termine m0 =m/s che costituisce la media delle variabili dummy su un anno).
Sostituendo la (6.13) nella (6.12) e sviluppando il polinomio A(L) nel solito modo si ottiene il seguente modello ECM
∆Χt = ΠΧ t-1 − Πmo + Γii
k
=
−
∑1
1
∆Χt-i +A(L) c jj
s*
=∑
1
djt. (6.14)
E’ possibile dimostrare che
A(L) c jj
s*
=∑
1dj
t = γ jj
s
=∑
1dj
t = ΓsDt,
dove Γs=[γ1,γ2,γ3γ4] e Dt=[d1t,d2
t,d3t,d4
t]′ ed inoltre rimane la proprietà tale per cui queste dummy stagionali siano centrate, ossia
Γs
1111
=0.
Sotto l’ipotesi di rango ridotto r, Hs(r), Π=αβ′ e quindi il modello (6.14) diventa
∆Χt = αβ′Χ t-1 − αβ′mo + Γii
k
=
−
∑1
1
∆Χt-i + A(L) c jj
s*
=∑
1
djt,
2 Se si vuole una stagionalità trimestrale s=4, se mensile s=12 e così via.
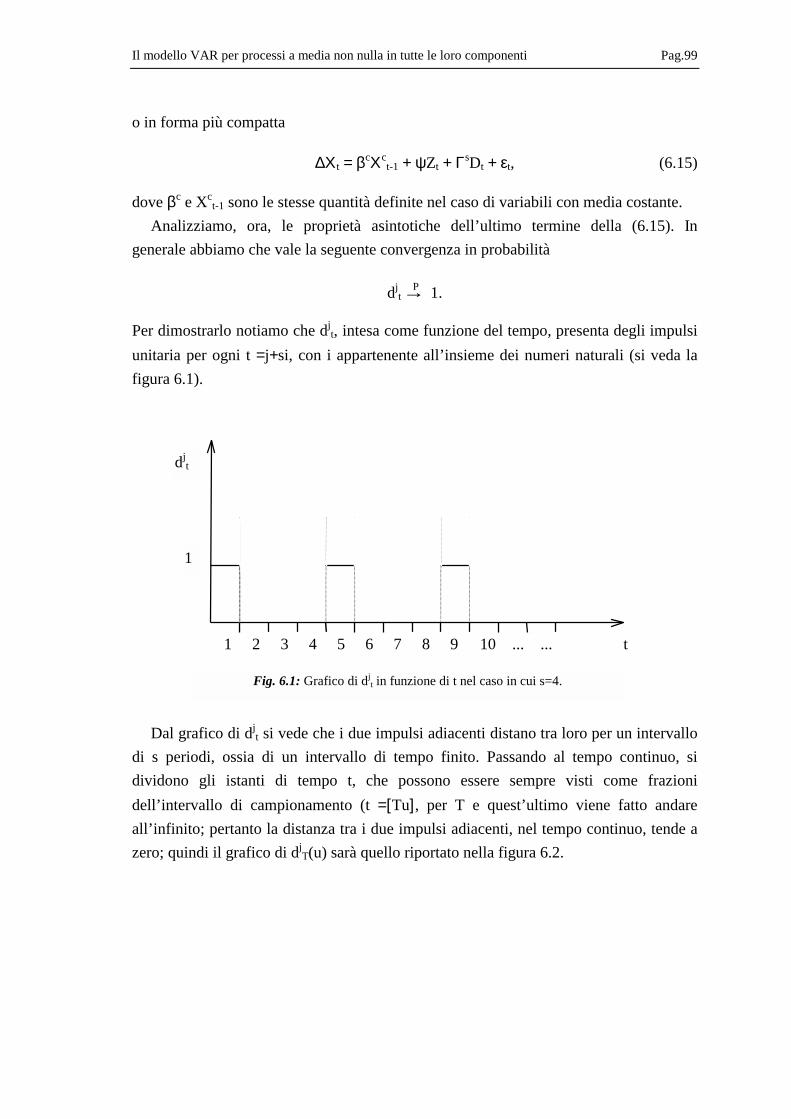
Il modello VAR per processi a media non nulla in tutte le loro componenti Pag.99
o in forma più compatta
∆Χt = βcΧct-1 + ψZt + ΓsDt + εt, (6.15)
dove βc e Xct-1 sono le stesse quantità definite nel caso di variabili con media costante.
Analizziamo, ora, le proprietà asintotiche dell’ultimo termine della (6.15). In generale abbiamo che vale la seguente convergenza in probabilità
djt→P 1.
Per dimostrarlo notiamo che djt, intesa come funzione del tempo, presenta degli impulsi
unitaria per ogni t =j+si, con i appartenente all’insieme dei numeri naturali (si veda la figura 6.1).
Dal grafico di dj
t si vede che i due impulsi adiacenti distano tra loro per un intervallo di s periodi, ossia di un intervallo di tempo finito. Passando al tempo continuo, si dividono gli istanti di tempo t, che possono essere sempre visti come frazioni dell’intervallo di campionamento (t =[Tu], per T e quest’ultimo viene fatto andare all’infinito; pertanto la distanza tra i due impulsi adiacenti, nel tempo continuo, tende a zero; quindi il grafico di dj
T(u) sarà quello riportato nella figura 6.2.
1 2 3 4 5 6 7 8 9 10 ... ... t
djt
1
Fig. 6.1: Grafico di djt in funzione di t nel caso in cui s=4.
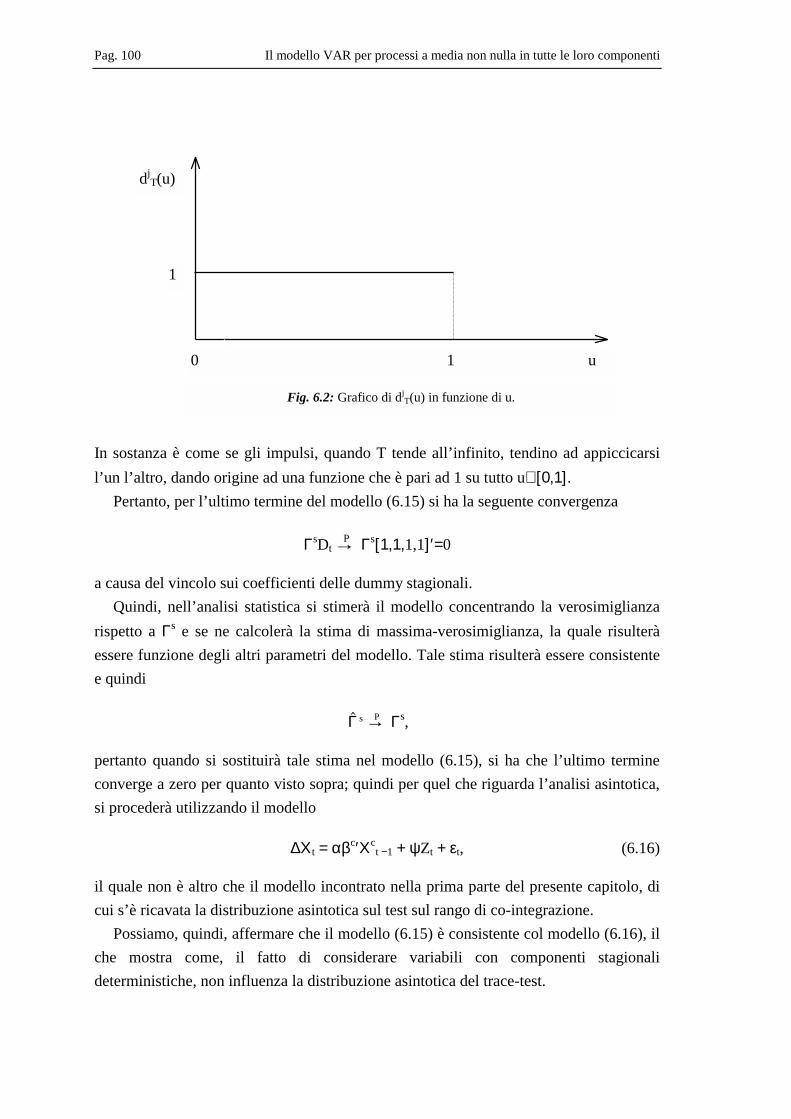
Pag. 100 Il modello VAR per processi a media non nulla in tutte le loro componenti
In sostanza è come se gli impulsi, quando T tende all’infinito, tendino ad appiccicarsi l’un l’altro, dando origine ad una funzione che è pari ad 1 su tutto u∈[0,1] .
Pertanto, per l’ultimo termine del modello (6.15) si ha la seguente convergenza
ΓsDt→P Γs[1,1,1,1]′=0
a causa del vincolo sui coefficienti delle dummy stagionali. Quindi, nell’analisi statistica si stimerà il modello concentrando la verosimiglianza
rispetto a Γs e se ne calcolerà la stima di massima-verosimiglianza, la quale risulterà essere funzione degli altri parametri del modello. Tale stima risulterà essere consistente e quindi
→$Γ s P Γs,
pertanto quando si sostituirà tale stima nel modello (6.15), si ha che l’ultimo termine converge a zero per quanto visto sopra; quindi per quel che riguarda l’analisi asintotica, si procederà utilizzando il modello
∆Χt = αβc′Χ ct −1 + ψZt + εt, (6.16)
il quale non è altro che il modello incontrato nella prima parte del presente capitolo, di cui s’è ricavata la distribuzione asintotica sul test sul rango di co-integrazione.
Possiamo, quindi, affermare che il modello (6.15) è consistente col modello (6.16), il che mostra come, il fatto di considerare variabili con componenti stagionali deterministiche, non influenza la distribuzione asintotica del trace-test.
djT(u)
1
Fig. 6.2: Grafico di djT(u) in funzione di u.
0 1 u

Capitolo 7 Modello VAR per variabili con tendenza
IN tale capitolo vogliamo modellizzare variabili, le cui deviazioni da una costante ed una tendenza risultano essere dei processi autoregressivi con radice unitaria. Si tratta quindi di un’estensione applicata al modello VAR per variabili a media non nulla, il quale risulta essere “nested” in quello per variabili con una tendenza.
L’analogia modellistica con i capitoli precedenti si traduce anche in una generale analogia di procedimenti, tenuto conto delle differenze, soprattutto in campo asintotico, che si incontrano a causa delle presenza di questa tendenza deterministica.
7.1 Il modello e le sue interpretazioni Il fatto che le variabili del processo, una volta depurate da una costante e da una tendenza deterministica, abbiano un comportamento autoregressivo, può essere modellizzato come segue: sia Xt il vettore delle variabili di questo tipo di processo, mentre ~Xt sia il vettore delle variabili incontrate nel capitolo precedente, ossia variabili
le cui deviazioni da una costante sono di tipo autoregressivo. La relazione tra queste due categorie di variabili è la seguente
Xt = ~Xt + m1t , (7.1)
e corrisponde all’ aggiunta alle variabili di ~Xt di una tendenza.
Con considerazioni analoghe a quelle del precedente capitolo, si ottiene che
A(L)(Xt −mo−m1t) =εt . (7.2)
L’interpretazione che viene data a m1t è meno ambigua di quella data a m0 ; infatti, m1t rappresenta in modo univoco una tendenza lineare in tutte le componenti del processo,

Pag. 102 Il modello VAR per variabili con tendenza
siano esse stazionarie o non stazionarie, mentre per m0 rimangono i problemi di interpretazione e di identificazione visti precedentemente.
Infatti, la rappresentazione a media mobile del processo dato dalla (7.2) è la seguente
X P X P m m t C C L)t ti
tt= + + + ∑ +
⊥ =β β ε ε0 0 1
11 ( ; (7.3)
si noti che Xt e ~Xt hanno lo stesso valore iniziale.
Da questa rappresentazione si vede che m1 è distinto dalle condizioni iniziali e quindi risulta essere identificato. Questa proprietà può essere vista anche da un’altra prospettiva: si consideri la forma ECM del processo (7.1), che si ricava sempre attraverso la solita espansione del polinomio A(L) e data da
∆ Π Π Γ Γ ∆X X m m t I m Xt t ii
k
ii
k
t i t= − − + + −
+ +−=
−
=
−
−∑ ∑( )1 0 11
1
11
1
ε .
Sotto l’ipotesi di rango ridotto r, HT(r), sapendo che I ii
k
+ − ==
−
∑Π Γ Γ1
1
, abbiamo che
∆ Γ Γ ∆X X m m t m Xt t ii
k
t i t= ′ − ′ − ′ + + +−=
−
−∑αβ αβ αβ ε1 0 1 11
1
= ′ + + + +−=
−
−∑αβ µ µ εX X tt ii
k
t i t11
1
0 1Γ ∆ , (7.4)
la quale, ponendo rispettivamente µ0 = −αβ′m0+Γm1 = αρ0+ α⊥ γ0 e µ1 = −αβ′m1 = αρ1 , può essere riscritta come
∆ Γ ∆X X XtT
tT
ii
k
t i t= ′ + + +−=
−
−∑αβ µ ε11
1
0 . (7.5)
dove si è posto
ββρ
T =′
1, X
Xtt
T t−
−=
1
1 , ψ = ( Γ1, … ,Γk-1 ) ,
Z2t = (∆Χ′ t-1, … ,∆Χt−k+1) ′.
In questo modo i parametri α, β, ρ0, µ0, Γ1, … ,Γk−1 possono essere stimati mediante la regressione di rango ridotto.

Modello VAR per variabili con tendenza Pag. 103
Ricaviamo ora l’espressione di m0 e di m1 in funzione di ρ0, γ0 e ρ1. Dall’espressione per µ1 si ha che
αρ αβ1 1= − ′m ;
moltiplicando da sinistra per ′α e per β si ottiene
P mβ βρ1 1= − .
L’espressione per µ0 può essere esplicitata come
αρ α γ αβ β β0 0 0 1+ =− ′ + +⊥ ⊥m P P mΓ( )
= − ′ − + ′⊥ ⊥αβ βρ β βm m0 1 1Γ Γ
esplicitando rispetto a m1 si ottiene
Γ Γβ β α ρ β α γ βρ⊥ ⊥ ⊥′ = + ′ + +m m1 0 0 0 1( ) .
Moltiplicando da sinistra per ′⊥α si ottiene
′ ′ = + ′⊥ ⊥ ⊥ ⊥α β β γ α βρΓ Γm1 0 1 ,
ossia
′ = ′ + ′ ′⊥ ⊥ ⊥−
⊥ ⊥−
⊥β α β γ α β α βρm11
01
1( ) ( )Γ Γ Γ
e moltiplicando sempre da sinistra per β⊥ si ha che
P mβ β α β γ β α β α βρ⊥
= ′ + ′ ′⊥ ⊥ ⊥−
⊥ ⊥ ⊥−
⊥11
01
1( ) ( )Γ Γ Γ .
Sapendo, infine, che P P Ipβ β⊥+ = , si trova che
m11
01
1 1= + −⊥−
⊥−
⊥ ⊥ ⊥ ⊥ ⊥β γ β ρ βρα β α β α βΓ Γ Γ ,
dove Γ Γα β α β⊥
= ′⊥ e Γ Γα β α β⊥ ⊥
= ′⊥ ⊥ .
Ripetendo lo stesso procedimento, è possibile ricavare l’espressione per m0 , e cioè
P mβ αβ α β αβ α β α β αββ γ β ρ β ρ βρ01
01
1 1 0= + − −⊥ ⊥ ⊥ ⊥ ⊥ ⊥ ⊥
− −Γ Γ Γ Γ Γ Γ .

Pag. 104 Il modello VAR per variabili con tendenza
Si noti che, identificando univocamente ρ0, γ0 e ρ1 , m1 risulta anch’esso identificato univocamente, a differenza di m0 ; è infatti identificata solo quella parte di m0 che sta nello spazio di β. Inoltre m0 sarebbe identificato se anche β fosse di rango pieno p.
7.2 Analisi statistica del modello: il trace-test In questo paragrafo si deriveranno le stime dei parametri che compaiono nel modello (7.5) e la statistica per il rango di co-integrazione, usando la tecnica di stima di rango ridotto, a cui si è ricorso precedentemente; rispetto ai due casi visti, ora si deve tenere in considerazione la presenza di un termine deterministico, il quale, nel modello ECM, è libero di giacere sia nello spazio di α che in quello di α⊥ . Questo fatto implica che tale termine non può più essere “appeso” al vettore che contiene i livelli ritardati delle variabili del processo.
Lo strumento di fondamentale importanza si dimostrerà essere sempre quello della verosimiglianza concentrata, che permette di stimare i paramatri del modello ECM ad uno ad uno. Si comincerà con la stima di µ0 , la quale si ricava dopo aver concentrato rispetto ad esso la verosimiglianza, risolvendo l’equazione
(t
T
=∑
1∆Χt − αβ′Χ t −1 − ψΖ2t − µ0 )=0
e quindi
$µ = T-1 (t
T
=∑
1
∆Χt − αβ′Χ t-1 − ψΖ2t)
= ∆ X − αβ′ X T − ψ Z ,
dove
X T =T X
T t
XT
tt
T
t
T
−−
=
−
=
∑
∑
=
11
1
1
1
2/.
Sostituendo a µ0 la sua stima di massima-verosimiglianza, otteniamo la seguente regressione

Modello VAR per variabili con tendenza Pag. 105
(∆Χt −∆ X ) = αβ′(XTt-1− X T) + ψ(Z2t − Z ) + εt . (7.6)
I termini tra parentesi non sono altro che i residui di tre regressioni preliminari, ossia quelli di ∆Xt , Xt
t-1 e Z2t rispettivamente contro la costante µ0. Concentrando la verosimiglianza di (7.6) rispetto a ψ si ottiene che la stima di tale
parametro è data da
$ ( )ψ αβ= − ′ −S S SzT
xz zz∆1 ,
dove per comodità si è posto
S∆z = T−1 (t
T
=∑
1
∆Χt −∆ X )(Z2t − Z )′
Sxz = T−1 (t
T
=∑
1
ΧTt-1 − X T )(Z2t − Z )′
Szz = T−1 (t
T
=∑
1
Z2t − Z )(Z2t − Z )′.
A queste espressioni ne aggiungiamo altre due che verranno usate in seguito e cioè
S∆∆ = T-1 (t
T
=∑
1∆Χt −∆ X )(∆Χt −∆ X )′
Sxx = T-1 (t
T
=∑
1ΧT
t-1− X T)(ΧTt-1 − X T)′.
A questo punto, sostituendo nella (7.6) a ψ la sua stima, si ottiene la seguente regressione nei residui
RT0t = αβ′RT
1t + εt ,
dove
RT0t = (∆Χt −∆ X ) − S∆z Szz
−1(Z2t − Z )
e
RT1t = (ΧT
t-1 − X T ) − Sxz Szz−1(Z2t − Z ).

Pag. 106 Il modello VAR per variabili con tendenza
E’ possibile notare come, volutamente, ci si sia ricondotti alla regressione nei residui che compare anche nei due casi precedenti; pertanto, seguendo la stessa procedura, si giunge alla stima di α e Ω, le quali sono date rispettivamente da
$α β β β= ′ ′
−
S ST T T T T01 11
1
$ ,Ω = − ′
′−
S S S ST T T T T T T T00 01 11
1
10β β β β
dove, in generale, Stij = T-1 Rit
TtT=∑ 1 Rt
jt′, con i,j=0,1. In seguito verranno usate le seguenti
espressioni per STij
1
ST11 = Sxx −SxzSzz
−1Szx
ST00 = S∆∆ −S∆zSzz
−1Sz∆
ST01 = S∆x −S∆zSzz
−1Szx.
Come si può vedere, tutte queste stime sono funzione di βT. A questo punto, in modo analogo a quanto fatto nei capitoli precedenti, si trova il massimo della verosimiglianza, la quale risulta essere unicamente funzione del parametro βT. Tale problema di massimo si risolve risolvendo il solito problema agli autovalori dato da
λS S S ST T T T11 10 00
101 0− =−( )
e prendendo come stima di βT gli autovettori associati agli r autovalori più grandi del problema in esame; posso così determinare la statistica per il test sul rango di cointegrazione, che è pari a
− = − −= +
+
∑2 11
1
log ( ( ) ( )) log( $ )Q H r H p T iT
i r
p
λ . (7.6)
1 Tali relazioni si ottengono sostituendo ai residui, le rispettive espressioni.

Modello VAR per variabili con tendenza Pag. 107
7.3 Risultati asintotici sulle matrici dei prodotti incrociati Guardando la rappresentazione MA del processo, possiamo notare che esso è costituito dalle seguenti componenti: un termine costante, rappresentato da Pβm0 e Pβ⊥
m0 , una
tendenza lineare (m1t), un random walk (C ε tit=∑ 1 ) e un processo stazionario (Yt).
In una prima analisi, consideriamo il processo nelle direzioni β e β⊥ , in modo da ottenere, rispettivamente, le componenti stazionarie e quelle non stazionarie.
Moltiplicando per la trasposta di β otteniamo
β′Χ t = β′m1t + β′Yt + β′m0.
Come si può notare, β′Χ t non è stazionario nel vero senso della parola, poichè è presente una tendenza che lo rende non stazionario in media; parleremo in tal caso di componente trend-stazionaria. Del resto nelle matrici dei prodotti incrociati compare il vettore Xt
t-1 , il quale, quando viene moltiplicato per βT′, fornirà un processo stazionario senza tendenza o, usando un termine tecnico, “detrendizzato”. Infatti
βT′ Xtt −1 = [β′,ρ1]
XttT−
1
= β′Xt −1 + ρ1t .
Ricordando l’espressione a media mobile (7.3) e la relazione tra m1 e ρ1si ha che
βT′ Xtt −1 = ρ1t −ρ1t + β′Yt + β′m0 = β′Yt + β′m0,
pertanto βT′(Xtt −1 − X T )→P Var(βT′ Xt
t −1). Possiamo pertanto definire la seguente matrice di varianze-covarianze, condizionate
ai valori passati racchiusi in Z2t , così come fatto precedentemente; formalmente si ha
VarX X
X XZt
TtT T t
T
T T T
( )
( )
∆ ∆ Σ ΣΣ Σ
−′ −
=
−β
β
β β β12
00 0
0
.
Ricavando le espressioni delle matrici dei prodotti incrociati e ricordando le espressioni al § 7.3, abbiamo che
ST11 = T−1 (
t
T
=∑
1
ΧTt −1 − X T )( ΧT
t −1 − X T )′ +

Pag. 108 Il modello VAR per variabili con tendenza
−T-1 (t
T
=∑
1ΧT
t-1− X T)(Z2t − Z )′T (Z Z2tt=1
T
2t− − ′
∑
−
Z Z)( )1
T-1 (t
T
=∑
1Z2t − Z )(ΧT
t-1− X T)′.
Per analizzare le proprietà asintotiche di tale matrice nella direzione β, moltiplichiamo da destra per βT e da sinistra per βT′ ; in questo modo si considereranno solo le componenti stazionarie e senza tendenza (per quanto visto sopra) e potremo applicare la legge debole dei grandi numeri per verificare la convergenza in probabilità. Formalmente abbiamo che
βT′ST11βT→P Var(βT′XT
t-1) − Cov(βT′XTt-1 , Z2t)(Var(Z2t))-1Cov(Z2t , βT′XT
t-1) = Σβ βT T .
Osservando inoltre che anche ∆Χt è un processo senza tendenza (vedi equazione (7.5)), abbiamo che
T-1 (t
T
=∑
1∆Χt − ∆ X )→P Var(∆Χt) ;
pertanto si verifica che valgono le seguenti convergenze in probabilità
βT′ST10→P ΣβT 0
ST00→P Σ00.
Tra queste matrici di varianze-covarianze esiste lo stesso tipo di relazioni ricavate nel paragrafo 3.2.1.
Consideriamo, ora, le proprietà del processo nella direzione β⊥ , ovvero in quella
direzione in cui compaiono solo le componenti non stazionarie. Per far ciò, moltiplichiamo le variabili del processo Xt per la matrice β⊥ ′ ; in formule si ha che
β⊥ ′Xt = β⊥ ′X0 + β⊥ ′m1t + β⊥ ′Yt + β⊥ ′C ε ii
t
=∑
1;
come si può notare, in queste componenti del processo dominano due comportamenti: uno riconducibile al random walk; l’altro alla tendenza lineare. In Johansen (1995), poichè questi due termini hanno un tasso di convergenza diversi2, in generale si propone
2 Per l’esattezza il random walk converge con un tasso pari a T-1/2, mentre la tendenza lineare con un
tasso pari a T (si veda appendice A).

Modello VAR per variabili con tendenza Pag. 109
di scomporre a sua volta β⊥ in due direzioni: una in cui sia dominante la tendenza, l’altra, ortogonale alla prima, in cui sia presente solo il random walk.
In ciascuna direzione, quindi, il processo verrà premoltiplicato in modo opportuno per avere la convergenza desiderata. In particolare, la direzione in cui domina la tendenza può essere scelta come
τ = Pβ⊥m1.
In questo modo abbiamo che
T-1 ′τ Xt = T-1 ′τ Pβ⊥m1t + Op(1) = T-1t + Op(1);
ricordando inoltre che t può essere espresso come frazione del campione, [Tu] con u∈[0,1] , otteniamo la seguente convergenza in probabilità
T-1 ′τ Xt→P u .
Per avere la direzione in cui sia dominante solo il random walk, scegliamo una matrice γ, di dimensione p×(p−r−1) la quale appartenga sempre allo spazio generato da β⊥ , ma allo stesso tempo sia ortogonale a τ; ciò significa che deve valere la seguente condizione
γ′τ = γ′ Pβ⊥m1 = 0;
in questo modo, moltiplicando da sinistra l’espressione che dà la forma a media mobile del processo per γ′, si ha che la tendenza sparisce e che l’unico termine dominante è costituito dal random walk; formalmente
T-1/2γ′Xt = T-1/2γ′C ε ii
t
=∑
1+ Op(1)
e quindi, per T→∞, si ottiene la seguente convergenza in distribuzione
T-1/2γ′Xt →w γ′CW(u).
Tutte queste considerazioni valgono, in generale, quando si ha un termine con tendenza deterministica nel modello ECM, ossia quando il rispettivo coefficiente non è vincolato a giacere nello spazio di α3.
3 Si tratta del modello alla Johansen relativo al caso (a) (si veda paragrafo 7.2). Per questo modello, si
rimanda a Johansen (1995) e a Johansen-Nielsen(1993).

Pag. 110 Il modello VAR per variabili con tendenza
Se invece consideriamo il modello ECM in cui tale coefficiente è vincolato a stare in Sp(α), si avranno dei risultati sostanziali che differenziano la trattazione riguardante le proprietà asintotiche del processo, quando si considerano le componenti non stazionarie.
Per evidenziare questa differenza, vediamo a cosa convergono i residui che compaiono nelle matrici dei prodotti incrociati del modello che stiamo considerando in questo capitolo. In particolare, analizziamo il comportamento di tali residui nelle direzioni τ e γ rispettivamente; si dimostrerà che lungo τ i residui sono nulli pertanto risulta inutile la scomposizione di β⊥ , in quanto lungo questa direzione esiste solo il random walk.
Dal paragrafo precedente si ricorda che
Stij = T-1 Rit
Tt
T
=∑ 1RT
jt′
e che a sua volta
RT1t = (Xt
t-1 − X T ) − Sxz Szz−1 (Z2t − Z ).
E’ possibile notare che RT1t è un vettore di dimensione p+14, mentre τ, per come è stato
definto, è un vettore di dimensione p. Pertanto, per analizzare il comportamento del residuo nella direzione τ, introduciamo il seguente vettore
τT = τ
−
1
,
in cui si è semplicemente “appeso” un −1 al vettore τ. Se moltiplichiamo il residuo per τ T ′, abbiamo che
[ τ ′,−1] RT1t = [ τ ′,−1] (ΧT
t-1 − X T ) +
−T-1 [ ′ − − − ′
−
=∑ τ , ]( )( )1 1 2
1
X X Z ZtT T
tt
T
Szz-1 (Z2t − Z ).
Consideriamo separatamente il termine
[ τ ′,−1] (ΧTt-1 − X T );
sviluppando i calcoli si ottiene che
4 Infatti si è aggiunta una dimensione agli r vettori di co-integrazione, dovuta alla tendenza che sta
nello spazio di α.

Modello VAR per variabili con tendenza Pag. 111
[ τ ′,−1] X Xt T
t− −−
1
2/ = τ ′ (Xt-1 − X ) − t + T
2.
Ricordando la forma MA del processo e sostituendola a Xt , si ha che
[ τ ′,−1] X Xt T
t− −−
1
2/ = t − T
2 − t + T
2 = 0.
Questo risultato fa vedere come il residuo nella direzione τ in realtà sia nullo; pertanto, anche in questa direzione sarà dominante solo il random walk5; risulta perciò inutile la scomposizione di β⊥ nelle due direzioni τ e γ. Infatti, in ciascuna di queste il tasso di convergenza della quantità dominante è la stessa ed in particolare è pari a T-1/2.
Quindi, useremo, così come fatto nel caso di processo a media non nulla, una matrice definita come segue
Bm T
T =− ′
⊥
⊥−
ββ
0
11 2/
,6
che porterà ai seguenti risultati asintotici
→T B S BG Gu
G Gu
du G G duT T T w T T− ′ −−
−−
′
= ′∫ ∫111 1
20
112
0
1
→B S G dWT T w T′ ′∫1 0
1ε ( )
B S OpT T T′ ∈11 1β ( ).
(G è il moto Browniano definito nel capitolo 1 e G è la sua media).
5 Tale random walk converge ad un moto browniano una volta normalizzato da T-1/2. 6 La presenza di T1/2 garantisce che la tendenza che si è appesa al vettore Xt-1 , in Xt
t-1 , converga in probabilità a u-1/2.

Pag. 112 Il modello VAR per variabili con tendenza
7.4 Distribuzione asintotica del trace-test Fatte queste considerazioni circa i risultati asintotici sulle matrici dei prodotti incrociati, il processo sarà studiato tramite l’uso della seguente matrice (p+1)×(p+1) di rango pieno
A T BTT T= −[ ]/β M 1 2 .
Ora, applicando lo stesso procedimento visto per i modelli VAR di base e quello a media non nulla, si vede che i p-r+1 più piccoli autovalori che compaiono nella (7.6) convergono, una volta normalizzati da T, a quelle del seguente problema
ρ α α αG G du G dW Var W dW GT T T T0
1
0
1 10
10∫ ∫ ∫′ − ′ ′ ′ ′ =⊥ ⊥
−⊥( ) ( ( )) ( ) ,
Definendo, ora, il moto Browniano standard
FC C G G
uB Bu
=′ ′ −
−
=
−−
⊥ ⊥−( ) ( )/β βΩ 1 2
12
12
,
la statistica per il rango di co-integrazione (7.6) converge in distribuzione a
tr dB F FF du F dB( ) ( )′ ′
′
∫ ∫ ∫−
0
1
0
1 1
0
1.
Si noti che alla fine l’espressione letteraria della statistica è sempre la stessa; si deve tuttavia tener presente che, a seconda dei casi che stiamo considerando, F assumerà un’espressione diversa.
7.5 Proprietà asintotiche degli stimatori Si può verificare che per tutte le distribuzioni, fatta eccezione per quella dei
parametri racchiusi da ϑ, si ottiene un’aspressione identica a quelle viste precedentemente, considerando però che i moti browniani che compaiono non sono perfettamente gli stessi. Anche in questo caso, per poter stimare i coefficienti α e βT, è necessario che questi siano identificati o tramite una matrice c di dimensione p×r, oppure attraverso dei vincoli di identificazione.
Per la stima di ϑ=(α,Γ 1,…,Γk-1), approfittiamo del fatto che essi sono i coefficienti di variabili stazionarie senza tendenza, che possiamo racchiudere in Zt(β) definita come

Modello VAR per variabili con tendenza Pag. 113
Z X X XtT T
tT
t t k( ) , ,...,β β′ = ′
′′ ′
− − − +1 1 1∆ ∆ .
Detto ciò la distribuzione asintotica della stima di ϑ risulta essere
→T Nwp r k p
1 21)
10/( ( )( $ ) ( , )ϑ ϑ− ⊗× + −
−Ω Σ ,
dove Σ è stimata consistentemente da
T Z Z Z Z Var ZtT
TT
tT
TT
t
TP
tT−
=
− − ′ → =∑1
1
( ( $ ) ( $ ))( ( $ ) ( $ )) ( ( ))β β β β βΣ .
Rispetto ai casi visti precedentemente, in questo modello si ha un parametro in più da stimare, ossia µ0. In Johansen (1995) si fornisce la distribuzione asintotica di tale parametro, che risulta essere la somma di una mistura di gaussiane e di una normale. Tuttavia nel modello che stiamo considerando, cioè quello con tendenza lineare in tutto il processo, la stima di µ0, da sola, non è di alcuna utilità per la stima di m1; infatti, nella relazione tra questi parametri è presente una matrice (per l’esattezza Γ ) che non è nota, ma deve essere stimata.
In questo modo, risulta impossibile imporre e/o testare restrizioni sulle tendenze di componenti individuali, siano esse stazionarie che non stazionarie, come per esempio
1.una data componente non stazionaria non ha tendenza; 2.due date componenti stazionarie o non stazionarie hanno la stessa tendenza 3.la tendenza di una componente è la somma delle tendenze di altre due
componenti. In Mosconi (1993) si cerca di ovviare a tale impossibilità, utilizzando, per la stima e
per i tests, degli algoritmi “switching” del tipo visto in precedenza per testare l’ipotesi su β data da
β = [H1ϕ1 , H2ϕ2].
Questi algoritmi risultano essere convergenti. Una volta stimato il modello, si trova il test LR, che risulterà sempre distribuito come una χ2 con gradi di libertà opportuni a seconda del tipo d’ipotesi fatta.

Pag. 114 Il modello VAR per variabili con tendenza
7.6 Ipotesi su ββββ e loro distribuzioni Anche in questo caso è possibile formulare ipotesi per i coefficienti di lungo periodo βT, i quali risultano essere distribuiti sempre come delle χ2 con gradi di libertà opportuni a seconda del tipo di ipotesi, tenendo presente che βT ha dimensione (p+1)×r.

Capitolo 8 Variabili con break strutturali
IN questo capitolo si affronterà l’argomento relativo alla modellizzazione di variabili che contengano dei break strutturali. Con questo termine ci si riferisce a quei cambiamenti strutturali dovuti a dei fattori esterni, che influenzano le variabili descritte nel modello.
Tali break strutturali, se non modellizzati opportunamente, vengono interpretati come fluttuazioni casuali rispetto al comportamento descritto dal modello; questa interpretazione è tuttavia errata da un punto di vista concettuale, per la natura stessa del break che, essendo strutturale, e quindi sistematico, non può essere trattato come un fenomeno casuale. In sostanza è come se si stesse utilizzando un modello non idoneo alla descrizione dei dati.
In modelli econometrici questo problema è risolto con l’introduzione di variabili dummy le quali non sono altro che delle variabili binarie che assumono il valore 1 se si verificano certe condizioni (nel caso di serie storiche la condizione riguarda l’appartenenza ad un intervallo di tempo) ed il valore zero altrimenti.
La peculiarità di queste variabili, rispetto ai casi precedenti, consiste nella loro discontinuità. Quest’ultima, nel caso di modelli VAR, e maggiormente in quelli con radici unitarie, comporta delle problematiche soprattutto di calcolo, poiché nello sviluppo dei polinomi in L si ha un numero minore di semplificazioni.
Per quel che riguarda il nostro scopo, consideremo dei modelli VAR con radici unitarie, in cui si ipotizza che le deviazioni delle variabili da un andamento discontinuo, rappresentante il break, abbiano un comportamento autoregressivo. Si inizierà col caso semplice di un solo break, in cui la componente deterministica ha un grafico a scalino; successivamente si considererà il caso di più break, che intervengono sempre sulla media del processo; infine si estenderanno questi risultati al caso di più break che riguardano la tendenza deterministica del processo.

Pag. 116 Variabili con break strutturali
8.1 Il modello per un caso semplice di break Vediamo ora, in modo formale, come modellizzare questo break strutturale. Innanzitutto definiamo la seguente variabile scalare dummy dt
dt = 01
0
0
per t per t
≤ =[ ]> =[ ]
t aTt aT
con a∈[0,1]
Come si può notare, l’istante in cui si verifica la discontinuità viene espresso come frazione dell’intervallo in cui si dispone delle osservazioni; il motivo di tale scelta risulterà chiaro nel seguito, quando si parlerà di distribuzioni asintotiche, ossia quando si passerà dalla trattazione in tempo discreto a quella in tempo continuo.
Sia Xt il vettore delle variabili che presentano un comportamento autoregressivo
attorno ad un break, mentre ~Xt sia il vettore delle variabili descritte nel modello VAR
di base; per quanto detto sopra, dovrà valere la seguente relazione
Xt = ~Xt + mdt
e quindi, analogamente a quanto fatto nei due capitoli precedenti, si presuppone un modello scritto come
A(L)(Xt − mdt) = εt . (8.1)
In questo modo si sta ipotizzando che il processo, una volta depurato dal break, abbia un comportamento autoregressivo.
La rappresentazione a media mobile di questo tipo di modello è la seguente
Xt = mdt + C ( )ε ii
t
=∑
1
+ C1(L) (εt) + Pβ⊥X0, (8.2)
dove si può notare come tale break influenzi tutte le variabili del processo. Tale rappresentazione sarà utile nella derivazione delle proprietà asintotiche dell’intero processo, in quanto consente di evidenziarne le diverse componenti.
Per quel che riguarda la stima, sarà necessario ricavare la forma ECM del modello, applicando la solita espansione del polinomio A(L); in formule abbiamo che
∆Xt = ΠXt-1 − Πmdt-1 + Γ ∆ Γ ∆ii
k
t i i t ii
k
X m d=
−
− −=
−
∑ ∑−1
1
0
1
+ εt
con Γ0 =−I. Nell’ipotesi di rango ridotto, Hd(r), Π = αβ′ , l’espressione sopra diventa

Variabili con break strutturali Pag. 117
∆Xt = − αβ′ Xt−1 − αβ′mdt−1 + Γ ∆ Γ ∆ii
k
t i i t ii
kX m d
=
−
− −=
−
∑ ∑−1
1
0
1+ εt . (8.3)
E’ possibile notare come, a differenza dei casi precedenti, la componente deterministica permanga anche in quella parte del modello che descrive la dinamica del processo. Ciò è dovuto al fatto che i modelli autoregressivi hanno una memoria e quindi anche successivamente all’istante in cui la dummy assume valore unitario si risentirà dell’effetto del break (da un punto di vista economico, si tratta di un termine rappresentante effetti di breve periodo). Avremo infatti che all’istante t0 scatterà la dummy delle variabili non ritardate, all’istante t0+1 scatterà la dummy delle variabili ritardate di un periodo e così via finche non si supererà l’istante t0+k, quando cioè il break sarà assorbito dall’intero processo.
Vediamo questo discorso in modo più formale, considerando il modello nei seguenti tre intervalli di tempo [−k+1,t0], (t0,t0+k] e (t0+k,T], la cui unione dà l’intervallo temporale in cui si dispone delle osservazioni del processo Xt . Abbiamo quindi a che fare con tre casi.
Caso 1.t < t0: il modello assume la forma seguente
∆Xt = αβ′ Xt−1 + Γ ∆ii
k
t iX=
−
−∑1
1
+ εt .
In tale circostanza, infatti, il break non si è ancora verificato e pertanto il processo è modellizzabile come nel caso base, ossia nell’ipotesi che non vi siano componenti di carattere deterministico.
Caso 2.t0< t ≤ t0+ k: il modello risulta essere del tipo
∆Xt = αβ′ Xt-1 + Γ ∆ii
k
t iX=
−
−∑1
1
− αβ′m − Γt-to+1 + εt.
Caso 3.t>t0 + k : in tal caso, l’equazione (8.3) diventa
∆Xt = − αβ′m + αβ′ Xt-1 + Γ ∆ii
k
t iX=
−
−∑1
1
+ εt,
che altro non è se non il modello VAR con variabili a media non nulla in forma ECM, visto nella seconda parte.
Si può notare come i casi 1) e 3) rappresentino situazioni di regime per quel che
riguarda la parte deterministica; infatti in tutto il processo descritto nel caso 1) non si è

Pag. 118 Variabili con break strutturali
ancora verificato il break, mentre nel caso 3) quest’ultimo è presente nell’intero processo.
Viceversa, il caso 2) rappresenta una situazione transitoria in cui successivamente ciascuna variabile ritardata risentirà del break.
Per il prosieguo è utile riparametrizzare il modello (8.3) nel seguente modo
∆Χt = αβd′ Xdt-1 + ψZt + γWt + εt (8.3’)
dove
βd = [β′ M -β′m ]′, Xdt-1 = [Xt-1′ M dt-1]′,
ψ = [Γ1MLMΓk-1] , Zt′ = [∆Χt-1′ MLM ∆Χt-k+1′] ,
γ = − [ Γ0mMLMΓk-1m ] , Wt = (∆dt , … , ∆dt-k+1)′.
8.1.1 Determinazione del test per il rango di co-integrazione Per la determinazione del rango di co-integrazione, si utilizzerà la stessa procedura usata nei casi precedenti. In particolare si userà lo strumento della verosimiglianza concentrata, ricavando le stime di massima verosimiglianza di γ, ψ, α e Ω rispettivamente, in funzione di β. Fatto ciò, si ricaverà la stima di β, sapendo che la funzione di verosimiglianza sarà massimizzata scegliendo β tra gli autovettori associati al problema agli autovalori che ne consegue.
Analisi statistica: il Trace-test
Come accennato sopra, l’analisi statistica segue gli stessi passi visti nei casi precedenti; tralasceremo, quindi, tutti i passaggi intermedi a illustrazione dell’analisi, in quanto già sviluppati.
Concentrando la verosimiglianza rispetto a γ, otteniamo che la stima di questo parametro è data da
$γ = S∆w Sww−1 − αβ′ Sxw Sww
−1 − ψ Szw Sww−1,
dove

Variabili con break strutturali Pag. 119
S∆w = ∆Xtt
T
=∑
1
Wt′ = [ ∆Χto+1M L M ∆Χto+k ] ,
Sxw = X td
t
T
−=∑ 1
1
Wt′ = [ Χdto+1M L M Χd
to+k ] ,
Szw = Ztt
T
=∑
1
Wt′ = [ Zto+1M L M Zto+k ] ,
Sww = Wtt
T
=∑
1
Wt′ = Ik .
L’ultimo risultato si ottiene tenendo conto che le differenze di dummy ritardate che compaiono in γ, sono impulsi tra loro mutuamente esclusivi, nel senso che
∆di∆dj = 0 se i j
se i = j.≠
∆di
Inoltre si può notare che ∆dttT=∑ 1 =1, poiché l’impulso rappresentato dalla differenza di
dummy è 1 in t0, il quale, per come è stato definito appartiene all’intervallo [1,T]. Detto ciò, la stima di γ risulta essere
$γ = S∆w −αβ′Sxw − ψSzw.
Sostituendo a γ la sua stima nel modello in forma ECM si ottiene
( ∆Χt−S∆wWt ) = αβd′ ( Xdt−1 − SxwWt ) + ψ( Zt − SzwWt ) + εt .
Come già visto, i termini tra parentesi non sono altro che i residui di tre regressioni preliminari di ∆Χt , Xd
t-1 , Zt contro Wt rispettivamente. Per comodità di notazione, poniamo le seguenti uguaglianze
Z0t = ∆Χt − S∆wWt
Z1t = Xdt−1 − SxwWt
Z2t = Zt − SzwWt
in modo che il modello ECM assuma la classica forma

Pag. 120 Variabili con break strutturali
Z0t = αβd ′ Ζ1t + ψΖ2t + εt .
Grazie a questa formulazione, è possibile ripetere gli stessi procedimenti visti per il modello VAR di base, al fine di ottenere la stima dello spazio di co-integrazione. In particolare, tale stima sarà data scegliendo gli autovettori associati agli autovalori del problema
|λS11 − S10 S00-1 S01| = 0,
con Sij = Mij −Mi2M22−1 M2j ( i , j = 0,1 ) e Mkl = T −1 Zktt
T=∑ 1 Zlt (k , l = 0, 1, 2).
Quindi il test sul rango di co-integrazione risulta essere dato dalla solita statistica
−2logQ( Hd (r) | Hd (p) ) = T −1 ( $ )i r
p
i= +
+
∑ −1
1
1 λ
Risultati asintotici per le matrici dei prodotti incrociati
Secondo la procedura solita, il comportamento asintotico del modello deve essere analizzato nelle direzioni di β e β⊥ rispettivamente, poiché presenta diversi tassi di convergenza.
Per quel che riguarda la parte stazionaria, procediamo come segue: S00 può essere scritta come
S00 = M00 −M02 M22−1M20.
L’espressione del primo termine, per come è stato definito, risulta essere
M00 = T −1 Z tt
T01=∑ Z0t′ .
Dimostriamo che il processo Z0t è stazionario e a media nulla, in modo tale da poter affermare che M00 converga in probabilità alla varianza di Z0t stesso.
Tale processo può essere scritto, per quanto detto sopra, come
∆Χt −[∆Χto+1M L M ∆Χto+k] Wt . (8.5)
Ricordando l’espressione a media mobile di Xt , abbiamo che
∆Χt = m∆dt + ∆Yt ,
dove Yt , e quindi anche ∆Yt , è un processo stazionario e a media nulla. Da ciò segue che anche (8.5) è stazionario. Dimostriamo, ora, che esso è anche a media nulla; per far ciò consideriamo solo la parte deterministica di (8.5), la quale è responsabile della

Variabili con break strutturali Pag. 121
media di tale processo. In formule avremo che, ricordando le proprietà che hanno le differenze di dummy esposte sopra,
m∆dt − m[1 , 0 , … , 0][∆dt , … , ∆dt-k+1]′=0 C.V.D.
Pertanto Z0t è un processo stazionario e a media non nulla; analogo discorso può essere fatto per Z2t e quindi vale la seguente convergenza in probabilità
S00→P Var ( Z0t | Z2t ) = Σ00.
Consideriamo ora il termine βd′S11βd; occorre dimostrare anche in questo caso che βd′Z1t è stazionario e a media non nulla.
Per far ciò occorre semplicemente notare che βd′ Xdt-1 è un processo stazionario e a
media nulla; infatti
βd′ Xdt-1 = β′ Χt-1 − β′ mdt-1.
Sostituendo ad Xt-1 la sua espressione a media mobile, otteniamo che
βd′ Xdt-1 = β′Yt-1.
Da ciò segue che anche Z1t è un processo stazionario e a media nulla, pertanto vale la seguente convergenza in probabilità
βd′ S11 βd→P Var(βd′ Z1t | Z2t ) =Σβ βd d .
Con analoghi ragionamenti si ricava che
βd′S10→P Cov (βd′Z1t , Z0t | Z2t ) =Σβd 0 .
Fatte queste importanti osservazioni, abbiamo che tra Σ00, Σβ βd d e Σβd 0 esistono le
stesse relazioni incontrate nel capitolo 3. Analizziamo, ora, le proprietà asintotiche delle matrici Sij nella direzione di β⊥ , in
cui dominano le componenti non stazionarie. Per far ciò consideriamo, inizialmente, le prime p righe di Z1t (tralasciandone l’ultima) e moltiplichiamole per T −1/2 β⊥ ′
T −1/2 β⊥ ( Xt-1− [Xto+1M L M Xto+k ] [∆dtM L M ∆dt-k+1]′ ).
I termini della prima parte di tale espressione, una volta normalizzati da T−1/2, convergono a dei moti browniani, mentre per le differenze di dummy abbiamo i seguenti risultati. La variabile dummy è una funzione convergente ad una funzione definita sull’intervallo [0,1], ossia
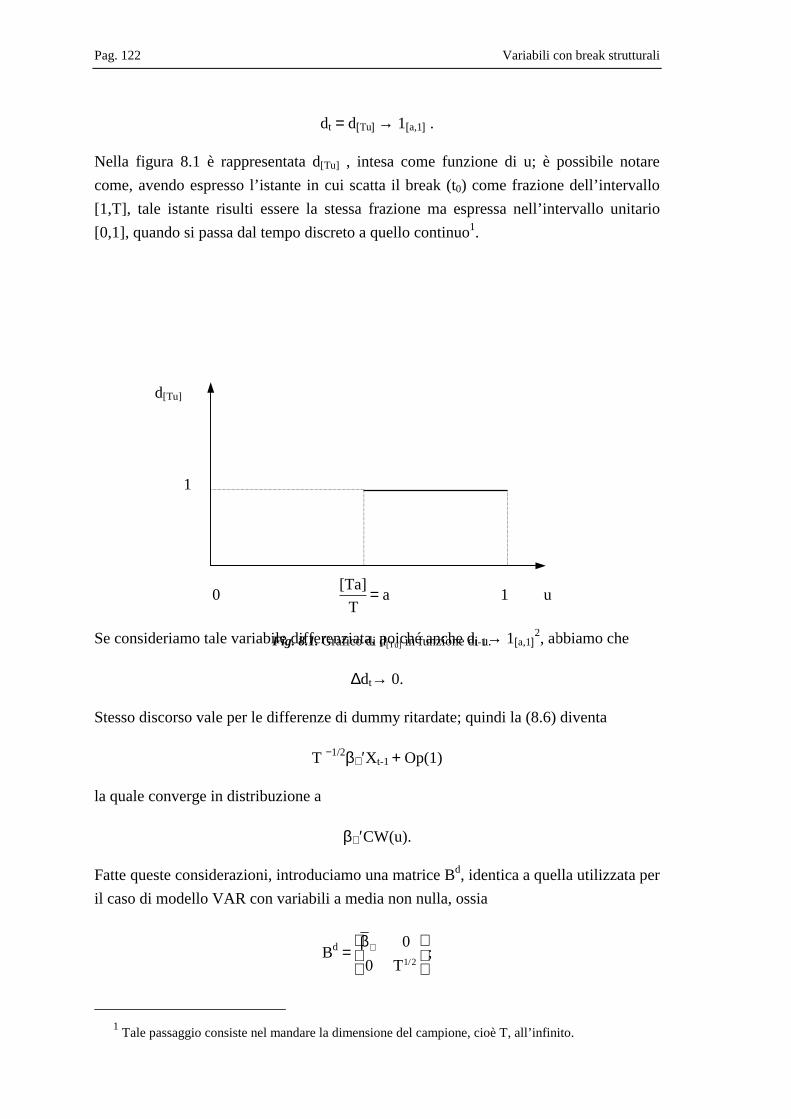
Pag. 122 Variabili con break strutturali
dt = d[Tu] → 1[a,1] .
Nella figura 8.1 è rappresentata d[Tu] , intesa come funzione di u; è possibile notare come, avendo espresso l’istante in cui scatta il break (t0) come frazione dell’intervallo [1,T], tale istante risulti essere la stessa frazione ma espressa nell’intervallo unitario [0,1], quando si passa dal tempo discreto a quello continuo1.
Se consideriamo tale variabile differenziata, poiché anche dt-1→ 1[a,1]
2, abbiamo che
∆dt→ 0.
Stesso discorso vale per le differenze di dummy ritardate; quindi la (8.6) diventa
T −1/2β⊥ ′Xt-1 + Op(1)
la quale converge in distribuzione a
β⊥ ′CW(u).
Fatte queste considerazioni, introduciamo una matrice Bd, identica a quella utilizzata per il caso di modello VAR con variabili a media non nulla, ossia
Bd =β⊥
00 1 2T /
;
1 Tale passaggio consiste nel mandare la dimensione del campione, cioè T, all’infinito.
0 [Ta]T
= a 1 u
d[Tu]
1
Fig. 8.1. Grafico di d[Tu] in funzione di u.

Variabili con break strutturali Pag. 123
in tal caso si ha che
T −1Bd′S11Bd =T X X T X d
T d X T d dOp
t tt
T
t tt
T
t tt
T
t tt
T
−⊥ − −
=⊥
−⊥ − −
=
−− − ⊥
=
−− −
=
′ ′ ′
′
+∑ ∑
∑ ∑
21 1
1
3 21 1
1
3 21 1
1
11 1
1
1β β β
β
/
/( ) (8.7)
Bd′S10 =T X
T dOp
t tt
T
t tt
T
−⊥ −
=
−−
=
′ ′
′
+∑
∑
11
1
1 21
1
1β ε
ε/( ) , (8.8)
le quali, per quanto detto sopra convergono in distribuzione rispettivamente a
G G dud d ′∫01
e G dWd ( ) ′∫01
con Gd = [G′ M 1[a,1]]′.
Distribuzione asintotica del Trace-test
La statistica per testare il modello Hd(r) in Hd(p) è data dal rapporto di verosimiglianza
−2logQ(Hd(r)|Hd(p)) = −T log($
)11
1
−= +
+
∑ λ ii r
p
,
in cui $ , ... , $λ λr p+ +1 1 sono le p−r+1 radici più piccole date da
λS S S S11 10 001
01− −( ) = 0,
per le quali si può dimostrare, come fatto nel caso base che, una volta normalizzate da T, convergono a quelle dell’equazione
ρ α α αG G du G dW Var W dWGd d d d′ − ′ ′ ′ ′ =∫ ∫∫ ⊥ ⊥−
⊥0
1 10
1
0
10( ) ( ( )) .
Infine, normalizzando i moti browniani in G si ha che
−2logQ(H(r)|H(p))→wi
i r
p$ρ
= +
+
∑1
1
= tr dBF FF du F dB′ ′
′∫ ∫ ∫−
0
1
0
1 1
0
1( ) ,
2 Infatti nel tempo continuo l’istante corrispondente a t-1 è indistinguibile da quelle corrispondente a t.

Pag. 124 Variabili con break strutturali
con F=[Β′ M 1[a,1]]′ .
8.1.2 Stima del modello Per la stima del modello (8.1) non è possibile usare il modello (8.3’) in quanto, in quest’ultimo i parametri contenuti in λ non sono liberi. Pertanto, per la stima del modello (8.1) si dovrà usare un algoritmo switching:
ALGORITMO 1: quando i parametri in α, β, Γ1, … , Γk−1 sono noti, m può essere
stimato nel modello
Rt = Btm + εt (8.8)
dove Rt = A(L)Xt e Bt = A(L)dt. Quando m è noto, gli altri parametri possono essere stimati nel modello
∆Xt* = αβ′Xt-1
* + Γ ii
k
=
−
∑1
1
∆Xt−i* + εt , (8.9)
dove Xt* = Xt − mdt .
Dati i valori iniziali per α, β, Γ1, … , Γk−1, la stima di tutti i parametri può essere derivata “saltando” dal modello (8.8) al modello (8.9) finché non si ha convergenza.
8.2 Modello con più break strutturali Fino ad ora si è considerato il semplice caso in cui il break viene rappresentato con una funzione a scalino, dove, nell’istante in cui si verifica tale break, si ha il passaggio da un regime ad un altro. Più precisamente, il primo regime era quello di un modello VAR di base, mentre il secondo quello di un modello con variabili a media non nulla.
Un altro tipo di break potrebbe essere quello che causa un passaggio da un regime associato al modello con variabili a media non nulla ad un altro dello stesso tipo. Tale break può essere modellizzato tramite la seguente funzione
ft = m1d1t + m2d2
t ,
dove
d1t =
10
0
0
per t per t
≤ =[ ]> =[ ]
t aTt aT

Variabili con break strutturali Pag. 125
d2t =
01
0
0
per t per t
≤ =[ ]> =[ ]
t aTt aT
.
E’ possibile notare come queste due dummy siano mutuamente esclusive; questa proprietà semplificherà l’analisi statistica del modello.
Il modello ECM da considerare diventa il seguente
∆Xt = αβd′ Xt−1d + ψZt + Γ i
i
k
=
−
∑1
1
m1 ∆dt−i1 + Γi
i
k
=
−
∑1
1
m2 ∆dt−12 + εt .
Sapendo che vale la relazione ∆dt1 = − ∆dt
2 = −∆dt , il modello diventa
∆Xt = αβd′ Xt−1d + ψZt + Γi
i
k
=
−
∑1
1(m1 − m2) ∆dt−i + εt (8.10)
Ripetendo gli stessi procedimenti visti precedentemente, si vede che ai fini della distribuzione asintotica, è possibile utilizzare il modello dato da
∆Xt = αβd′ Xt−1d + εt ,
che porta alla solita espressione della distribuzione asintotica trace-test, in cui il vettore F risulta essere pari a
F′ = [ B(u)′ M [0,a] M 1(a,1] ].
Più in generale, se si considerano n break, e quindi n +1 regimi, tale vettore assume la forma
F′ = [ Β(u)′ M 1[0,a1] M 1(a1,a2] M L M 1(an,1] ].
In questo caso ho n +1 regimi associati tutti a modelli con variabili a media non nulla. Se volessi considerare dei regimi associati al modello VAR di base, non dovrei fare altro che eliminare dal vettore F la riga relativa all’intervallo del regime in questione, in quanto che, secondo questa notazione, essa risulterebbe essere un vettore di zeri3.
8.2.1 Stima del modello con più break Partiamo dal caso più semplice di un break solo. Poiché vale la relazione
3Nella trattazione fatta per il modello VAR di base, la matrice F presentava solo un numero di righe
pari al numero di direzioni non stazionarie. Coerentemente con la notazione utilizzata in questo contesto, possiamo vedere tale matrice come se fosse privata dei vettori riga nulli dovuti all’assenza di regimi a media diversa da zero.

Pag. 126 Variabili con break strutturali
dt1 = 1 − dt
2,
il modello può essere riparametrizzato come segue
A(L) (Xt − m1 − m2,1 dt2 ) = εt , (8.11)
dove m2,1 = m2 − m1 . Il modello (8.11) può essere stimato tramite il seguente algoritmo switching ALGORITMO 2: quando i parametri in α, β, ρ, Γ1, … , Γk−1 sono noti, m2,1 può
essere stimato nel modello
Rt = Btm21 + εt (8.12)
dove Rt = A(L)Xt − αρ e Bt = A(L)dt2.
Quando m21 è noto, gli altri parametri possono essere stimati nel modello
∆Xt* = αβc ′Xt-1
c + Γ ii
k
=
−
∑1
1∆Xt-i
* + εt , (8.13)
dove Xt* = Xt − m2,1 dt
2 , βc = [ β′ M ρ ]′ e Xt-1c = [ Xt-1
* ′ M 1]′ .
Dati i valori iniziali per α, β, ρ, Γ1, … , Γk−1, la stima di tutti i parametri può essere derivata “saltando” dal modello (8.12) al modello (8.13) finché non si ha convergenza.
Si noti che con tale algoritmo si riesce a stimare solo quella parte di m1 che sta nello
spazio di β ed il salto che il processo subisce nella media passando dal primo regime al secondo. Questo problema è legato al fatto che nelle componenti non stazionarie il coefficiente m1 è indistinguibile dalle condizioni iniziali (si veda cap. 6).
Generalizzando al caso in cui ho n break, il modello può essere riparametrizzato come segue
A(L)(Xt − m1 − mi
i
n,1
2
1
=
+
∑ dti ) = εt , (8.14)
dove mi,1 = mi − m1. Il modello (8.14) può essere stimato dal seguente algoritmo switching, il quale è una
generalizzazione dell’algoritmo 2 ALGORITMO 2’: quando i parametri in α, β, ρ, Γ1, … , Γk−1 sono noti, m2,1, …
,mn+1,2 possono essere stimati nel modello

Variabili con break strutturali Pag. 127
Rt = Bt M + εt (8.15)
dove Rt = A(L) Xt − αρ , Bt = [A(L)dt2M L M A(L)dt
n+1 ], M = [m2,1M L M mn+1,1] Quando m2,1, … , mn+1,1 sono noti, gli altri parametri possono essere stimati nel
modello
∆Xt* = αβc ′Xt-1
c + Γ ii
k
=
−
∑1
1∆Xt-i
* + εt , (8.16)
dove Xt* = Xt − m di
ti
i
n ,12
1
=
+∑ , βc = [ β′ M ρ ]′ e Xt−1c = [ Xt-1
* ′ M 1 ]′ .
Dati i valori iniziali per α, β, ρ, Γ1, … , Γk−1, la stima di tutti i parametri può essere derivata “saltando” dal modello (8.15) al modello (8.16) finché non si ha convergenza.
8.3 Break strutturali nelle tendenze deterministiche Consideriamo il caso in cui uno o più break intervengano anche sulla tendenza; in sostanza si ipotizzano dei cambiamenti di pendenza nelle variabili come conseguenza di shock avvenuti in qualche istante, noto a priori.
Considerando il caso semplice in cui vi sia un solo break, il modello può essere scritto come
A(L)(Xt − (m01 + m1
2)dt1 − (m0
2 + m12 )dt
2 ) = εt , (8.17)
dove dt1 e dt
2 sono le stesse dummy definite nel paragrafo precedente. Tale modellizzazione è quella di un processo che presenta un comportamento autoregressivo attorno ad un tendenza spezzata.
Si noti che il modello (8.17), in generale, non solo ipotizza un cambiamento di pendenza, ma anche un drift nella media. Questo può essere visto rappresentando graficamente la parte deterministica di tale modello (fig. 8.2).

Pag. 128 Variabili con break strutturali
Se volessimo un modello che rappresentasse solo un cambiamento di pendenza,
dovremmo imporre la continuità tra le due semirette nel punto t0 e quindi imporre il seguente vincolo
m01 + m1
1 t0 = m02 + m1
2 t0 .
Tuttavia questo vincolo, non influenzerà, così come i vincoli sullo spazio di co-integrazione, la distribuzione asintotica del test sul rango di co-integrazione.
Consideriamo, quindi, il modello (8.17) ed applichiamogli la solita espansione del polinomio A(L)
A(L) = (1−L)I − ΠL − Γii
k
=
−
∑1
1(1−L)Li.
Prima di eseguire i calcoli, facciamo delle considerazioni preliminari; in generale
L(m0 + m1 t)dt = (m0 + m1 t −m1 ) dt−1 ,
(1−L)(m0 + m1t )dt = m0 ∆dt + m1t ∆dt + m1dt−1 ,
(1−L)Li (m0 + m1t) dt =m0 ∆dt−i + m1 (t−i) ∆dt−i + m1 dt−1−i
= (m0 + m1 t −m1i ) ∆dt−i + m1 dt−1−i.
Applicando questi risultati al modello (8.17), si ottiene la seguente forma a correzione d’errore
m01
m02
t0 TFig. 8.2. Grafico della componente deterministica del processo Xt.

Variabili con break strutturali Pag. 129
∆Χt = ΠXt−1 −Πm11 tdt-1
1 −Πm12 tdt-1
2 + ψΖt + δ1Dt1 + δ2Dt
2 + γWt + ηtWt + εt, (8.18)
dove
Wt=[∆dt2M …M ∆dt-k+1
2]′,
mentre
Dti=
dt d d
t k d d
ti
ti
ti
ti
t ki
−
−
−
+
− + +
1
1
1
∆
∆M
( )
con i=1,2. In base a considerazioni asintotiche, per quanto visto precedentemente, abbiamo che
dt-1i→1[0,a],
Wti→0,
Dt1→[ 1M L M 1 ]1[0,a],
Dt2→ [ 1M L M 1 ] 1(a,1].
Inoltre è possibile dimostrare che l’ultimo termine della (8.18) non influenza la distribuzione asintotica del trace-test4
Pertanto il modello (8.18) è asintoticamente uguale al seguente
∆Χt = ΠXt-1 − Πm11t − Πm1
2t + µ1dt1 + µ2dt
2 + εt ,
che, sotto l’ipotesi di rango ridotto, diventa5
∆Χt = αβd ′Xdt-1 + µ1dt
1 + µ2dt2 + εt , (8.19)
con Xt-1d ′ = [ Xt-1′ M dt
1tM dt2t] e βd′=[β′ M −β′m1
1M -β′m12].
4 La dimostrazione può essere condotta seguendo gli stessi passi svoli nel § 8.1, ossia concentrando la
verosimiglianza rispetto a η, ricavandone la stima e sostituendola al suo valore vero in (8.18). 5 Non vengono considerate le differenze ritardate delle variabili del processo, poiché queste non
influenzano la distribuzione asintotica del test sul rango di co-integrazione (si vedano i casi precedenti).

Pag. 130 Variabili con break strutturali
Data l’uguaglianza asintotica tra i due modelli, per la determinazione della distribuzione asintotica del test sul rango di co-integrazione ci serviamo del modello (8.19).
8.3.1 Distribuzione asintotica del trace-test Come al solito, procediamo concentrando la verosimiglianza rispetto ai parametri µ1 e ricaviamone la stima
(t
T
=∑
1∆Χt − αβd ′Xd
t-1 − µ1dt1 − µ2dt
2)dt1=0.
Per la mutua esclusione delle due dummy, quanto sopra scritto porta alla seguente stima
$µ1 = (aT)−1 (t
T
=∑
1∆Χtdt
1) − αβd ′(aT) (t
T
=∑
1Xd
t−1dt1).
Ripetendo lo stesso ragionamento per µ2 si ottiene
$µ2 =((1 − a)T)−1 (t
T
=∑
1
∆Χtdt2) − αβd ′((1 − a)T)−1 (
t
T
=∑
1Xd
t−1dt2).
A questo punto, sostituendo queste stime nel modello (8.19) e ponendo le seguenti uguaglianze
Z0t = ∆Χt − (aT)−1 ∆X dt tt
T1
1=∑
dt1− ((1 − a)T)−1 ∆X dt t
t
T2
1=∑
dt2,
Z1t = Xt−1d − (aT)−1 X dt
dt
t
T
−=∑
1
1
1
dt1− ((1−a)T)−1 X dt
dt
t
T
−=∑
1
2
1
dt2,
si ottiene la solita regressione di rango ridotto data da
Z0t = αβd ′Z1t + εt .
Da qui in poi, l’analisi statistica viene svolta nel solito modo. Per capire a cosa converge il Trace-test, andiamo a vedere il limite in distribuzione di Z1t nella direzione in cui prevalgono i random walk. Per far ciò utilizziamo la seguente matrice di normalizzazione

Variabili con break strutturali Pag. 131
T −1/2 Bd = T −1/2
β
β
β
⊥
⊥−
⊥−
− ′
− ′
0 0
0
011 1 2
12 1 2
m T
m T
/
/
,
ottenendo la seguente convergenza
T −1/2 Bd′ Z1t→w
G u G du G du
u a
u aa
a
( )
,
( ,
− −
−
− +
1 2
0
1
12
1 12
[ ]
]
,
con
G1= (a)−1 Ga
0∫ (u)du1( 0 , a ], G2 = (1−a)−1 Ga
1
∫ (u)du1(a , 1 ].
Questo porta a concludere che il Trace-test ha la seguente distribuzione asintotica
tr dBF FF du F dB′ ′
′∫ ∫ ∫−
0
1
0
1 1
0
1( ) ,
con
F =
B u B du B du
u a
u aa
a
( )
,
( ,
− −
−
− +
1 2
0
1
21
12
1
[ ]
]
.
8.3.2 Stima del modello con tendenze deterministiche Per la stima, usiamo la seguente riparametrizzazione del modello (8.19)
A(L)(Xt − m01 − m0
2,1dt2 − m1
1 tdt1 − m1
2 tdt2 ) = εt ;
a questo punto la stima sarà ottenuta tramite l’algoritmo switching: ALGORITMO 3: quando i parametri in α, β, ρ, Γ1, … , Γk−1 sono noti, m0
2,1, m11,
m12 possono essere stimati nel modello

Pag. 132 Variabili con break strutturali
Rt = BtM + εt (8.20)
dove Rt = A(L)Xt −αρ , Bt = [ A(L)dt2MLM A(L)dt
n+1], M = [m02,1MLMmn+1,1]
Quando m02,1, m1
1, m12 sono noti, gli altri parametri possono essere stimati nel
modello
∆Xt* = αβc ′Xt-1
c + Γ ii
k
=
−
∑1
1∆Xt-i
* + εt , (8.21)
dove Xt* = Xt − m0
2,1dt2 − m1
1 tdt1− m1
2 tdt2 , βc = [ β′ M ρ ]′ e Xt-1
c = [ Xt-1* ′ M 1]′ .
Dati i valori iniziali per α, β, ρ, Γ1, … , Γk−1, la stima di tutti i parametri può essere derivata “saltando” dal modello (8.20) al modello (8.21) finché non si ha convergenza.
Si noti che questo algoritmo è utilissimo nel testare l’ipotesi di continuità della
componente deterministica ft in t0 (istante del break); sappiamo infatti che il vincolo in forma esplicita ha la seguente espressione
m01 + m1
1 t0 = m02 + m1
2t0
e quindi
m02,1 = m1
1 t0 − m12 t0;
questa relazione si traduce in un’ipotesi su M del modello (8.20) del tipo
M = Hϕ,
con
ϕ=
mm
11
12
, H = t t0 0
1 00 1
−
.
Una scelta naturale per testare tale ipotesi si basa sul test LR
− 2log L HL HA
max
max
( )( )
0 ,
dove Lmax(HA) è il massimo della funzione di verosimiglianza del modello (8.20) non vincolato, mentre Lmax(H0) è il massimo della verosimiglianza nel modello vincolato. Poiché con tale ipotesi vengono vincolati tutti i p parametri contenuti in m0
21, tale test sarà distribuito come una χ2 con p gradi di libertà.

Variabili con break strutturali Pag. 133
8.3.3 Modello con più break nelle tendenze Consideriamo, per concludere, il caso più generale possibile in cui vi sono n break che intervengono sulle tendenze deterministiche del modello e che caratterizzano n+1 regimi. Il modello diventa
A(L)( Xt − ft ) = εt
con ft = ( )m m t di iti
i
n
0 11
1+
=
+
∑
In tal caso la distribuzione asintotica del trace test ha la solita espressione dove il vettore F è dato da
F =
B u B
ua
ua a
ua
a
a a
nan
( ) ~
.
.
( ,
( ,
( ,
−
−
−+
−+
10
1 2
1
21
21
12
1
1
1 2
]
]
]
,
dove a1, ... , an sono le percentuali del campione a cui scattano i relativi break, mentre
~ ( ) ( ) ( ) ( ) ( ) ( )( , ] ( , ] ( , ]B a B u du a a B u du a B u dua
a a
a
a a n a an
n= + − + + −− −∫ ∫ ∫1
1
0 0 2 11 1
11
11
1
1 21 1 1 1 L .
Per quel che riguarda la stima si userà una generalizzazione dell’algoritmo 3, ossia ALGORITMO 3’: quando i parametri in α, β, ρ, Γ1, … , Γk−1 sono noti, m0
2,1, ... ,m0
n+1,1, m11, ... , m1
n+1 possono essere stimati nel modello
Rt=BtM + εt (8.22)
dove Rt = A(L)Xt −αρ , Bt = [A(L)dt2M L M A(L)dt
n+1M A(L)tdt1M L M A(L)tdt
n+1], M = [m0
2,1M L M m0n+1,1M m1
1M L M m1n+1]
Quando m02,1, … , m0
n+1,1, m11, … , m1
n+1 sono noti, gli altri parametri possono essere stimati nel modello
∆Xt* = αβc ′Xt-1
c + Γii
k
=
−
∑1
1
∆Xt-i* + εt , (8.23)

Pag. 134 Variabili con break strutturali
dove Xt* = Xt − m d m di
ti
i
ni
ti
i
n
01
2
1
11
1
=
+
=
+
∑ ∑− , βc = [β′ M ρ]′ e Xt-1c = [Xt-1
* ′ M 1]′ .
Dati i valori iniziali per α, β, Γ1, … , Γk−1, la stima di tutti i parametri può essere derivata “saltando”dal modello (8.22) al modello (8.23) finché non si ha convergenza.
E’ possibile, inoltre, testare l’ipotesi di continuità della componente deterministica ft
negli istanti dei break, in quanto esse si traducono in ipotesi in forma esplicita sui parametri in M.

Capitolo 9 Modello statistico e DGP
L’OBIETTIVO del presente capitolo è di mostrare che, una volta scelto il modello statistico ritenuto più idoneo alla descrizione dei dati, tutte le restrizioni imposte sui parametri di tale modello non hanno alcuna influenza sulla distribuzione asintotica del test sul rango di cointegrazione. Questo punto è di fondamentale importanza, in quanto consente di separare la determinazione del rango di cointegrazione da quella del processo di generazione dei dati (Data Generation Process). Infatti, sebbene sia difficile capire con esattezza quale sia il DGP del fenomeno che si sta studiando, da un’analisi grafica delle serie storiche associate alle diverse variabili è possibile avere un’idea di quale modello considerare e di conseguenza scegliere quello che possa contenere il DGP. Ad esempio, nel caso in cui si presuma che qualche componente del processo, di cui si ignora se sia stazionaria o meno, sia affetta da una tendenza, si ritiene opportuno utilizzare un modello VAR con tendenza in tutte le componenti; su di esso si farà inferenza per determinare il rango di cointegrazione, utilizzando la distribuzione asintotica idonea. In un secondo momento, è possibile individuare il DGP andando a testare le varie ipotesi sui parametri ed in particolare sui coefficienti dei trend delle varie componenti.
Il “trucco” usato per evitare una determinazione congiunta del rango di cointegrazione e del DGP consiste nel considerare il modello statistico più generale che si ritiene possa contenere il DGP stesso.
Questo approccio alla stima di modelli VAR con componenti deterministiche si vuole porre come alternativa a quello adottato da Soren Johansen, in cui, invece, sia il rango di cointegrazione che il DGP sono determinati congiuntamente utilizzando una tecnica alla Pantula, che a nostro avviso complica notevolmente l’inferenza.
E′ importante sottolineare che l’approccio da noi adottato è valido solo in ambito asintotico, ossia nell’ambito di analisi svolte con campioni molto grandi; infatti, se da un lato è vero che l’introduzione nel modello statistico di variabili aggiuntive rispetto al DGP non comporta stime distorte, dall’altro lato, avendo a che fare con piccoli

Pag. 136 Modelli I(1) e DGP
campioni, si ha un problema di efficienza delle stesse in quanto si dispone di poca informazione rispetto al numero di parametri da stimare. Questo fatto assume un’enfasi ancora maggiore quando si ha a che fare con distribuzioni non standard, ma con distribuzioni asintotiche che per loro definizione sono valide solo per grandi campioni.
L’evidenza empirica di quanto esposto è illustrata nel § 9.4: essa è stata ottenuta mediante l’uso di serie storiche simulate in modo che, noto con esattezza il DGP, sia possibile il confronto con i vari modelli statistici che lo contengano.
Avendo accennato all’approccio seguito da Johansen in tutti i suoi lavori, è inevitabile un confronto fra esso e quello da noi utilizzato; in sintesi, la differenza tra i due consiste nel diverso modo in cui sono introdotte le componenti deterministiche nei modelli VAR. Si può notare come i modelli privi di break, visti in precedenza, coincidono con alcuni modelli introdotti da Johansen1, mentre quelli con break sono solo asintoticamente equivalenti a quelli da lui usati2.
9.1 Modelli I(1) per le componenti deterministiche I modelli introdotti precedentemente (ad esclusione, per il momento, di quelli con break strutturali), formano una sequenza di modelli nested, ossia
H(r) ⊂ Hc(r) ⊂ HT(r).
Si consideri ora il modello più generale, ovvero quello con tendenza in tutte le componenti: mostreremo come le ipotesi sulle componenti deterministiche non influenzino la distribuzione asintotica del trace-test.
Supponiamo, per iniziare, che il DGP sia quello in cui solo le componenti non stazionarie presentino una tendenza. Ciò significa imporre il seguente vincolo nel modello HT
β′m1 = 0. (9.1)
Facendo inferenza sul modello generale HT per la determinazione del rango di cointegrazione, il trace-test assume la seguente espressione
− =− −= +
+
∑2 11
1
log ( ( ) ( )) log( $ )Q H r H p TT TiT
i r
p
λ ;
1 Questo non significa che noi escludiamo alcuni modelli per il DGP, in quanto resta valido il discorso
fatto precedentemente su DGP e modello statistico. 2 Pertanto entrambi i tipi di modelli possiedono le stesse distribuzioni asintotiche del test sul rango di
cointegrazione.

Modelli I(1) e DGP Pag. 137
per vedere se la distribuzione asintotica di tale test cambia sotto l’ipotesi (9.1), bisogna verificare se cambiano le convergenze incontrate nel cap.7.
E’ possibile notare che ciò non avviene, in quanto la matrice di normalizzazione BT non muta.
Consideriamo, ora, il caso in cui il DGP sia tale per cui non è presente alcuna tendenza, sia nelle componenti stazionarie che in quelle non stazionarie. In questo caso, la restrizione da imporre è m1 = 0. La matrice di normalizzazione BT diventa
BT = β⊥
−
00 1 2T /
.
Pertanto, poiché il DGP è dato da
Xt = C ε ii
t
=∑
1
+ Yt + P mβ 0 + P Xβ⊥ 0 ,
abbiamo che
T-1/2 BT′ XtT →w
G u G
u
( )−
−
12
.
Di conseguenza la distribuzione asintotica del trace-test non cambia anche in questo caso.
Infine, consideriamo il caso in cui il DGP sia quello dove solo le componenti non stazionarie abbiano media diversa da zero, ossia il modello VAR di base. In questo caso le restrizioni da imporre sono m0 = m1 = 0. E’ facile notare come, anche in questo caso, la distribuzione asintotica del trace-test non cambi.
Lo stesso discorso vale se si considera il modello statistico Hc con DGP dato dal modello VAR di base.
Analoghe conclusioni possono essere ottenute considerando modelli con break strutturali; in tal caso avremo la seguente sequenza di modelli nested
H(r) ⊂ Hc(r) ⊂ HT(r) ⊂ Hb(r) .
Deve essere precisato che, in realtà, Hb(r) è il modello con tendenze spezzate in tutte le componenti; esso contiene il modello HT(r) nel senso che quest’ultimo può essere derivato dal primo imponendo il vincolo di uguaglianza dei coefficienti delle tendenze e delle intercetta nei vari regimi3. Anche in questo caso, se il DGP è un sottomodello di
3 Pertanto, per quanto visto precedentemente, il modello Hb(r) contiene gli stessi modelli che contiene
HT(r).

Pag. 138 Modelli I(1) e DGP
quello statistico, si vede che la distribuzione asintotica rimane sempre quella relativa a quest’ultimo modello, poiché la matrice di normalizzazione assume la seguente espressione
Bb =
ββ
β
0 00
0
11 2
11 2
L
L
M M M M
L
−
−
−
−
m T
m T
/
/
.
In aggiunta, è bene notare che il modello Hb(r) è anche quello generale di un’innumerevole combinazione di modelli in cui ad ogni regime possa essere associato un’opportuna componente deterministica.
Questo rende l’approccio da noi considerato molto flessibile, soprattutto in quei casi di incertezza, dove poco si può dire circa la specificazione a priori del processo di generazione dei dati; in tale circostanza, infatti, è possibile utilizzare il modello più generale possibile da cui partire con l’analisi del rango di cointegrazione, fino alla completa specificazione del DGP.
La suddetta analisi di rango avviene nel seguente modo: si sceglie il modello statistico, che non necessariamente deve coincidere con il DGP (è richiesto solo che quest’ultimo sia contenuto nel primo); tale modello (indicato con l’asterisco nell’espressione che segue), a seconda di quale sia il rango di cointegrazione, forma la seguente sequenza di modelli nested
H*(0) ⊂ H*(1) ⊂ … ⊂ H*(p).
Dato che la distribuzione asintotica cambia in base al rango ipotizzato, per la determinazione di quest’ultimo deve essere adottata una tecnica alla Pantula schematizzata nel seguente algoritmo

Modelli I(1) e DGP Pag. 139
In Johansen (1992) si dimostra che l’errore di prima specie, associato a questa
procedura di test, è limitato. Fatto ciò si farà inferenza sul modello statistico in modo da determinare il DGP
del fenomeno da studiare.
9.2 L’approccio di Johansen alla modellizzazione di componenti deterministiche in modelli VAR cointegrati In letteratura, ed in particolare in tutti i lavori di Johansen, ci si è sempre concentrati all’introduzione di termini deterministici al di fuori del polinomio A(L). Nel caso in cui tale termine sia dato da una costante, questo modo di procedere sta a significare l’utilizzo di un modello del tipo
A L Xt t( ) = +ε µ 0 . (9.2)
Si noti innanzitutto che questo modello e quello introdotto nel cap. 6 (si veda l’equazione (6.2)) non sono equivalenti in generale; l’aggiunta della costante al di fuori del polinomio autoregressivo, nel caso in cui quest’ultimo abbia radici unitarie, implica, in generale, modellizzare variabili che assumono comportamenti diversi a seconda che
r = 0
ACCETTO H(r) ?
no r = r + 1
IL RANGO E’ r
STOP
START
sì

Pag. 140 Modelli I(1) e DGP
siano stazionarie o meno: nelle prime ci sarà solo una media diversa da zero, mentre, nelle seconde, a questa si aggiungerà una tendenza deterministica.
In modo formale, questo può essere visto ricavando la rappresentazione a media mobile del modello (9.2), attraverso il teorema di rappresentazione di Granger; in particolare si ha
X C C L) P X
C C t C L) P X
t ii
t
t
ii
t
t
= + − ′− ′ ′
′
′ + +
= + − ′ + +
=
−
⊥ ⊥⊥
=
∑
∑
⊥
⊥
( ) ( , )( )
( , ) (
( ) ( .
ε µ βα αβ β
αα α µ ε
ε µ βα µ ε
β
β
01
1
0 1 0
10 0 1 0
00
0 Γβ
Si vede come, nel caso in cui µ0 non sia vincolato , Xt non solo presenti una media diversa da zero, ma anche una tendenza lineare; in sostanza è come se il termine deterministico aggiunto in (9.2) venisse “integrato”, nel senso matematico della parola. Inoltre, il processo presenta comportamenti diversi a seconda che si considerino componenti stazionarie o non stazionarie: le prime saranno prive di un trend, a differenza delle seconde. E′ possibile constatare ciò analiticamente: le componenti stazionarie si ottengono moltiplicando il processo Xt per la trasposta della matrice contenente i vettori di cointegrazione, ovvero
′ = ′ + ′ − ′ + ′=∑β β ε β µ α µ β εX C C t C Lt ii
t
t( ) ( )1
0 0 1 ;
poiché β′C = 0, sia la tendenza che i common trend spariscono. Questo discorso implica che nelle relazioni di equilibrio (quelle stazionarie) non ci sia una tendenza deterministica.
Per fare in modo che tale tendenza non interessi alcuna componente del processo, deve essere rispettata la condizione per cui Cµ0 0= , la quale implica che µ0 debba stare
nello spazio di α, ossia µ0 = αρ0 .
Le problematiche legate a questo tipo di modellizzazione derivano principalmente dal fatto che la distribuzione del test per il rango di cointegrazione è diversa a seconda che si considerino i seguenti due casi
caso (a): µ0 è libero di stare nello spazio di α e di α⊥ ; caso (b): µ0 è vincolato a stare nello spazio di α.

Modelli I(1) e DGP Pag. 141
A seconda che il DGP sia dato da (a) o da (b) le distribuzioni asintotiche del Trace-test sono diverse. Infatti nel secondo caso si ha che la tendenza nel processo sparisce e conseguentemente (si veda Johansen (1989)) la distribuzione del trace-test diventa
tr ∫dB(B(u) − B )′ [ ∫(B(u) − B )(B(u) − B )′du]-1 ∫ (B(u) − B )(dB)′.
Nel caso (a), invece, si ha che la distribuzione asintotica (si veda Johansen (1992)) è data da
tr ∫ dB F′ [ ∫ F Fdu]-1 ∫ F (dB)′,
con
B u B
B u B
up r p r
1 1
1 1
12
( )
( )
−
−
−
− − − −
M.
Questo implica che, se non si conoscesse, a priori, quale sia il rango di cointegrazione e quale dei due modelli sia vero, questi ultimi dovrebbero essere stimati dai dati a disposizione, utilizzando una tecnica alla Pantula, che risulta essere più complessa rispetto a quella vista precedentemente. Questa tecnica, infatti, si basa su una strategia di test sequenziali dal “particolare al generale” da applicare non solo ai modelli che si ottengono qualora si ipotizzino valori per il rango di cointegrazione diversi, ma, in ciascuno di essi, anche per i modelli relativi ai due casi visti sopra ( si veda Johansen (1992)).
Anche per quel che riguarda l’introduzione di una tendenza lineare quale componente deterministica, in letteratura ci si è sempre concentrati su modelli che pongono tale tendenza al di fuori del polinomio autoregressivo e più precisamente
A(L)Xt=µ0+µ1t+εt ;
supponendo di essere nell’ipotesi di rango ridotto, tale modello ha la seguente rappresentazione ECM
∆Χt = αβ′Χ t-1 + Γii
k
=
−
∑1
1∆Χt-i + εt .
Da questa espressione possiamo individuare i seguenti cinque modelli

Pag. 142 Modelli I(1) e DGP
µ0 = αρ0 + α⊥ γ0 µ1 = αρ1 + α⊥ γ1 (M.1)
µ0 = αρ0 + α⊥ γ0 µ1 = αρ1 (M.2)
µ0 = αρ0 + α⊥ γ0 µ1 = 0 (M.3)
µ0 = αρ0 µ1 = 0 (M.4)
µ0 = 0 µ1 = 0. (M.5)
L’ultimo modello non è altro che quello VAR di base visto nella parte I; il secondo è quello in cui tutte le componenti del processo hanno media non nulla. Focalizziamo ora l’attenzione sui primi tre. In (M.3), come già visto nel precedente capitolo, si ipotizza la presenza di una tendenza lineare solo nelle componenti non stazionarie, per il fatto che µ0 non è vincolato a stare nello spazio di α.
In (M.1) non solo si avrà una tendenza lineare in tutto il processo, ma, per quel che riguarda le componenti non stazionarie, sarà presente anche una tendenza quadratica, poiché µ1 appartiene anche allo spazio di α⊥ . Considerando, infatti, la rappresentazione a media mobile di tale modello, abbiamo che
X t t C C L P Xt ti
t
t= + + + + +=∑ ⊥
τ τ τ ε ε β0 1 22
11 0
12
( ) ,
dove
τ2 = Cµ1 ,
da cui si deduce, data l’espressione di C, che tale tendenza quadratica può venire eliminata dalle combinazioni lineari contenute in β (le relazioni di cointegrazione, che sono relazioni stazionarie).
Infine, il modello (M.2) presenta, oltre una media non nulla, anche una tendenza lineare in tutto il processo. Infatti, vincolando µ1 a stare nello spazio di α, abbiamo che, data l’espressione della matrice C, τ2 è pari a zero e quindi la corrispondente forma MA è la seguente
X t C C L P Xt ti
t
t= + + + +=∑ ⊥
τ τ ε ε β0 11
1 0( ) .

Modelli I(1) e DGP Pag. 143
In Johansen (1995) si mostra che l’espressione per τ1 è la seguente
τ β γ β ρ βρα β α β α β11
01
1 1= + −⊥−
⊥−
⊥ ⊥ ⊥ ⊥ ⊥Γ Γ Γ ;
come si può notare, questa altro non è che lo stesso tipo di espressione che si ricavava per m1 , passando alla forma ECM. Pertanto è possibile affermare che il modello analizzato al capitolo precedente ed il modello (M.2) risultano essere identici.
Infine, per quel che riguarda i break strutturali, in Johansen-Nielsen (1994) si ha per
essi la seguente modellizzazione
A(L)Xt= ( µ 01 + µ1
1 t) dt1 + … + ( µ 0
n + µ1n t) d t
n +εt .
In tali modelli rimane il problema legato al fatto che la distribuzione cambia a seconda che i parametri delle componenti deterministiche appartengano o meno allo spazio di α.
9.3 Confronto tra i due approcci Come si può vedere dal lavoro svolto da Johansen, il problema della determinazione del rango di cointegrazione è legato al fatto che essa non è svincolata da quella del DGP, quando quest’ultimo non è noto a priori.
Infatti, come visto precedentemente, a seconda di quale esso sia, la distribuzione asintotica del trace-test relativa ai modelli (M.1) e (M.3) non è la stessa. Pertanto, al fine di stabilire quale sia l’ “esatto” modello di riferimento per il fenomeno in esame, si dovrà usare la seguente strategia di test sequenziali, basata sempre su una tecnica alla Pantula:
1.Si inizializza r = 0 2. Si inizializza i = 5 3. Si considera il test sul rango di cointegrazione per il modello (M.i) sotto H(r). 4. Se l’ipotesi viene accettata, ci si ferma e si prende come valore di r l’ultimo per cui
si è accettata l’ipotesi; se l’ipotesi viene rifiutata e i > 1 si torna al punto 3 con i = i − 1; se l’ipotesi viene accettata e i = 1, si torna al punto 2 con r = r + 1.

Pag. 144 Modelli I(1) e DGP
Questa procedura “dal particolare al generale”, formalmente semplice, presenta il
vantaggio di rimediare al problema di errata specificazione dello spazio parametrico di
r = 0
ACCETTO H(r) in M.i?
sì r = r + 1
IL RANGO E’ r IL DGP E’ M.i
STOP
START
i = 5
i = 1 ?
i = i − 1
sì
no
no

Modelli I(1) e DGP Pag. 145
interesse, ma risulta essere scarsamente “user friendly” sul piano della trattazione generale del problema della determinazione del test di rango.
Relativamente a questa analisi specifica, l’approccio da noi utilizzato risulta, a nostro riguardo, meno complessa, in quanto è possibile distinguere e trattare separatamente i problemi di stima dei parametri e quello della determinazione del rango di β. Ciò si ottiene operativamente grazie ad un’osservazione preliminare delle serie storiche associate al vettore di variabili Xt da cui è deducibile, in prima approssimazione, l’ordine massimo di trend del processo complessivo. Operando in tal modo, si ottiene il risultato di escludere a priori dall’analisi alcuni dei modelli analizzati da Johansen e quindi le relative distribuzioni asintotiche; la stima dei parametri sarà eseguita in un passo successivo alla determinazione del rango effettuata sul modello ipotizzato. Tale approccio può risultare a prima vista riduttivo, in quanto tendente ad escludere alcuni dei casi possibili, quali quelli rappresentati dai modelli (M.1) e (M.3), ma in realtà, poiché questi modelli sono contenuti negli altri, si pone in un’ottica generale di analisi di modelli (in maniera specifica, il modello (M.2) e un ipotetico modello (M.0) che presenta trend quadratico in tutte le componenti del processo), “nesting” quelli menzionati.
Un esempio di quanto detto si ha guardando al modello (7.2). Il fatto di orientare l’analisi fin dall’inizio verso un modello con tendenza lineare in tutto il processo, analogamente al caso visto nel cap. 6 relativoa variabili a media non nulla, rende più facile la procedura di determinazione del rango di cointegrazione, che viene disgiunta da quella del tipo di modello da considerare, che può essere effettuata in un primo momento con un’analisi grafica delle serie storiche del processo.
Un ragionamento analogo può essere ripetuto nel caso in cui nelle componenti deterministiche siano presenti delle variabili dummy; se, ad esempio, si ritiene che il processo sia affetto da più break strutturali che intervengono sulla media o sull’eventuale tendenza del processo, ma non si sa a priori con esattezza in quale sua componente, si opterà per l’utilizzo del modello statistico più generale possibile, ovvero di quello che presenti i break in tutte le componenti.
Un indiscutibile vantaggio della procedura “alla Johansen” è dato dal fatto che i parametri del termine deterministico entrano direttamente nel modello in forma ECM e quindi la loro stima, effettuata basandosi su quest’ultimo, risulta essere immediata e priva di problemi di identificazione.
D’altra parte, utilizzando un approccio “classico”, rimane il problema di dare un’interpretazione ai vari termini deterministici, introdotti al di fuori del polinomio autoregressivo; è necessario, infatti ricorrere alla rappresentazione MA, la quale risulta tanto più complicata da ricavarsi quanto più complesso risulta essere il termine deterministico considerato (si noti la maggior difficoltà a ricavare la forma MA nel caso relativo alla presenza di trend che non nel caso in cui ci sia solo la costante µ0).

Pag. 146 Modelli I(1) e DGP
Per quel che riguarda il caso in cui le dummy facciano parte della componente deterministica del processo, le differenze tra i due approcci vengono amplificate.
Innanzitutto, come sottolineato in § 8.1, c’è una sostanziale differenza nel fatto di considerare le dummy al di fuori o all’interno del polinomio autoregressivo. Tale differenza si traduce in un diverso modo di modellizzare il transitorio che si verifica tra un regime e l’altro: infatti, l’introduzione delle dummy nel polinomio autoregressivo si traduce nell’aggiustamento istantaneo al nuovo regime delle variabili del processo che subiscono un break, mentre la loro esclusione implica che le variabili passano al nuovo regime seguendo la dinamica descritta dal polinomio autoregressivo. A transitorio esaurito, ossia dopo un numero di istanti pari al numero di ritardi del processo autoregressivo, si constata che, a parità di altre condizioni, i due approcci modellizzano lo stesso comportamento delle variabili (si veda sempre il § 8.1).
Otre a ciò, per la determinazione del rango di cointegrazione si ha che, nel caso di approccio alla Johansen con intervention dummy, la tecnica alla Pantula vista sopra risulta di difficile (se non impossibile) estensione, poiché, essendo previsto che debba essere eseguita per ogni dummy che si ipotizza essere presente nel processo, implica la conoscenza a priori del numero di tali dummy.
Risulta pertanto impossibile con tale approccio cautelarsi da ogni dubbio circa il processo di generazione dei dati, mediante l’inserimento di una dummy aggiuntiva rispetto al presunto DGP; tale difficoltà non sussiste, invece, con l’approccio da noi utilizzato, che presenta l’ulteriore vantaggio di non “appesantire” ulteriormente la procedura di determinazione del rango di cointegrazione.
D’altra parte, l’analisi statistica dei modelli con dummy secondo l’approccio di Johansen risulta molto semplice in quanto tali variabili entrano direttamente nella forma ECM, e non attraverso il polinomio autoregressivo, come invece avviene con l’approccio da noi utilizzato.
Il difetto che esso presenta è proprio legato alla complessità che si incontra nell’analisi statistica dei modelli con break: avendo a che fare con vincoli non banali sui coefficienti delle differenze di dummy che compaiono nel modello, per la sua stima deve essere utilizzato un algoritmo switching (si veda il cap. 8). Questo gap può essere superato considerando, per la determinazione del rango di cointegrazione, il modello generale che non contiene tali vincoli; infatti essi hanno a che fare solo con un particolare modo di modellizzare il transitorio relativo al passaggio da un regime all’altro e perciò possono essere ritenuti un particolare ininfluente per quel che riguarda la stima suddetta. Considerando, per semplicità, il caso di due regimi con tendenza in tutte le componenti; è conveniente usare la seguente riparametrizzazione del modello (8.19)
A(L)(Xt−m0−m1t−m0ddt−m1dtdt )=εt ,

Modelli I(1) e DGP Pag. 147
dove m0d = m02 − m0
1 , m1d = m12 − m1
1 e dt = d2t .
La forma ECM del modello diventa la seguente
∆Xt = αβ*′X*t-1+ Γ(L) ∆Xt + µ0 − αβ′m0ddt-1+ Γ(L)m0d∆dt + Γ(L)m1d∆(tdt) + εt .
E’ facile constatare che il modello generale che contiene quello sopra è il seguente
∆Xt = αβ*′X*t-1 + Γ(L) ∆Xt + µ0 + µod dt + γ(L)∆(tdt) + εt , (9.3)
con γ(L) = γ1+ γ2L + … + γkLk-1. Basandosi sul modello espresso dalla (9.3), si ricava il Trace-test utilizzando la solita regressione di rango ridotto e, di conseguenza, si stima il rango di cointegrazione.
Il modello (9.3) può rappresentare il punto di partenza anche per la verifica di ipotesi sui vettori di cointegrazione, ovvero sulle relazioni di lungo periodo. Inoltre esso può essere utilizzato per la stima dei parametri inclusi nelle componenti deterministiche, una volta esaurito il transitorio che ha portato al nuovo regime il processo.
Per illustrare queste proprietà, nei due paragrafi seguenti sono riportate, a titolo di esempio, alcuni casi simulati.
9.4 Efficienza nella stima del rango di cointegrazione mediante il “modello generale”: una simulazione esemplificativa Come è stato sottolineato nel paragrafo precedente, per la stima del rango di cointegrazione è opportuno basarsi su un modello che tenga conto del comportamento dinamico del processo nel breve periodo. Anche se questa modellizzazione, sul piano asintotico, è ininfluente per la descrizione della dinamica del processo, in campioni di dimensioni finite il problema di una migliore specificazione del modello rimane rilevante ai fini della stima del rango di cointegrazione. Da questo punto di vista, il modello generale definito dall’equazione (9.3) si rivela essere migliore sul piano dell’efficienza della stima rispetto a quello implementato nei lavori di Johansen. La verifica di quanto detto è stata ottenuta mediante un processo di simulazione che, permettendo il confronto fra il valore del trace-test ottenuto in campioni di dimensioni finite con quelli tabulati nell’appropriata tabella statistica (si veda il § 11.1), ha consentito di avere un’idea della bontà dei modelli utilizzati per spiegare il processo di generazione dei dati.
Per implementarla, si è proceduto costruendo “ad hoc” un processo caratterizzato da un break unico collocato ad un istante corrispondente al 50% del campione e da un rango di cointegrazione e da un numero di ritardi pari a due.

Pag. 148 Modelli I(1) e DGP
In particolare, le serie storiche sono state create grazie alla procedura CREATE.SRC presente nel programma MALCOLM, mediante la definizione delle matrici dei coefficienti che compaiono nel processo, la cui espressione risulta essere la seguente
∆yt = µ0 + µ1t + Γ ∆ii
k
tY=
−
−∑1
1
1 Πyt-1+ εt (9.4)
dove µ0 = ( I− Π ii
k
=∑
1
) m0 + ( i ii
k
Π=∑
1
) m1 e µ1 = ( I− Π ii
k
=∑
1
) m1 .
L’equazione (9.4) risulta essere a sua volta la riparametrizzazione dell’equazione
yt = µ0 + µ1t + Π ii
k
t iY=
−∑1
+ εt
che deriva dall’aver considerato il processo seguente
yt = zt + m0 + m1t (9.5)
con
zt = ( )A A Aii
k
0 01
1
−
=∑ zt-i + εt (9.6)
La matrice A0 è quella che permette di creare la dipendenza fra i p=4 processi univariati indipendenti dati da
wmt = 1 11
−
=∏ ρ ii
k
L wmt + vmt (9.7)
con m = 1,…, p e vmt errori i.i.d.∼ N(0, σ2m).
In forma matriciale, tali processi risultano essere pari a
wt = A wi t ii
k
−=∑
1
+ vt ,
dove wt = (w1t , w2t , …, wmt)′, Ai è una matrice diagonale di coefficienti, così come diagonale risulta essere cov(vt)=E[vt vt′]=Σ, con vt=( v1t , …, vmt)′.Nel nostro esempio, m=4.
La dipendenza è creata definendo zt = A0wt e εt = A0vt , che ci permettono di scrivere l’equazione (9.6).
Il processo da noi generato è tale per cui

Modelli I(1) e DGP Pag. 149
A0 =
1 0 1 00 1 0 10 0 1 00 0 0 1
−
, m01 =
15303060
, m02 =
18282564
, m11 =
0 5010
,,4
, m12 =
0 80 1
1 20 2
,,
,,
−
−
,
dove m01 e m02 sono i coefficienti definiti nell’equazione (9.5), modificata per tener conto di un numero di regimi pari a i; nel processo qui generato, i=2, in quanto, come già specificato, vi è un break in corrispondenza del 50% del campione.
Inoltre, considerando un numero di ritardi pari a 2, la matrice che definisce le radici del processo dato dalla (9.7) risulta essere
R=
10 3 1522 42 51 42 51 22
,,
,
mentre le innovazioni sono estratte casualmente da una distribuzione normale la cui varianza è pari a 3.
Guardando la matrice R, si può notare come essa sia costruita in modo che il processo presenti due radici unitarie, le quali risultano responsabili del rango di cointegrazione.
I parametri così definiti consentono di creare “ad hoc” il set di dati che costituiscono le serie storiche: il DGP, pertanto, risulta essere noto a priori.
La simulazione viene fatta ipotizzando per tali serie una lunghezza pari a 100 e 400,
ritenendo queste due dimensioni sufficientemente appropriate per discriminare fra campioni di piccole e grandi dimensioni, anche se finite.
Applicando iterativamente ai due modelli considerati la procedura EIGENSOLVE.SRC presente nel programma MALCOLM, si ricava il valore del trace-test per ogni rango che risulta essere compreso fra 0 e p−1 e lo si confronta con quello tabulato nella tabella della distribuzione asintotica associata al DGP ipotizzato.
Alla luce della conoscenza del DGP, il confronto fra i risultati ottenuti con i due campioni, nei due modelli ipotizzati per descrivere il processo tenendo conto dei transitori di breve periodo, ha dato esiti nel complesso maggiormente favorevoli all’utilizzo del modello generale. Tale conclusione è deducibile guardando ai risultati della simulazione (si veda la tavola 9.1): eseguendo un numero di iterazioni pari a 5000, con un campione di 100 dati il modello generale ha individuato correttamente il rango di cointegrazione nel 65,34% dei casi, mentre il modello “alla Johansen” nel 75,16% delle volte. Le migliori prestazioni del secondo modello rispetto al primo sono dovute probabilmente al fatto che, in quest’ultimo, il numero di parametri da stimare risulta

Pag. 150 Modelli I(1) e DGP
essere maggiore e quindi, con piccoli campioni, si ha perdita di efficienza rispetto all’altro. Con un campione di 400 osservazioni i risultati ottenuti simulando con il modello generale sono invece decisamente migliori: il rango è stato stimato correttamente nel 93,56% dei casi, mentre con il modello di Johansen l’ipotesi corretta sul rango è stata accettata nell’ 89,26% dei casi, a testimonianza del fatto che, con grandi campioni, è più appropriato utilizzare il modello generale, in grado di spiegare correttamente la dinamica legata al transitorio.
Ad ogni modo, al crescere del numero di dati a disposizione la stima del rango di cointegrazione tende ad essere più precisa per entrambi i modelli considerati.4 Ciò risulta essere coerente con il fatto che, all’aumentare delle dimensioni del campione, anche l’informazione disponibile risulta essere maggiore e quindi la stima è più efficiente.
Un’ulteriore interessante simulazione è stata effettuata al fine di sottolineare come l’analisi del test di rango non venga inficiata qualora venga effettuata basandosi su un un modello che includa il DGP senza coincidere con esso. Per mostrare ciò, sono state effettuate 5000 iterazioni dell’algoritmo per la stima del rango di cointegrazione, servendosi di un modello che fosse quello generale e che includesse il DGP, caratterizzato dall’assenza di break ma dalla presenza di trend in tutte le componenti del processo. I risultati sono tabulati nella tavola 9.2 e mettono in evidenza come in grandi campioni la probabilità di accettare l’ipotesi sul valore corretto del rango sia alta (pari pressoché al 94% dei casi), così come si verifica per la simulazione effettuata tenendo conto della coincidenza fra modello e DGP. Il problema continua a sussistere, purtroppo, nei piccoli campioni: in tal caso, infatti, il rango “giusto” viene rifiutato nel 35,62% dei casi (si veda la tavola 9.2) e ciò è sintomatico dell’inefficienza che si incontra nella stima qualora le osservazioni siano disponibili in numero molto limitato.
La quantità di dati a disposizione risulta essere, quindi, un punto critico da cui non si può prescindere in un’analisi empirica “reale”, quale, ad esempio, quella di natura macroeconomica presentata nella terza parte del presente lavoro.
Il problema della scarsa disponibilità di osservazioni risulta essere rilevante: alla luce di esso, qualsiasi risultato empirico deve essere valutato con la dovuta cautela.
4Infatti, come visto, l’errore di prima specie presenta un valore decrescente col crescere del numero di
osservazioni.
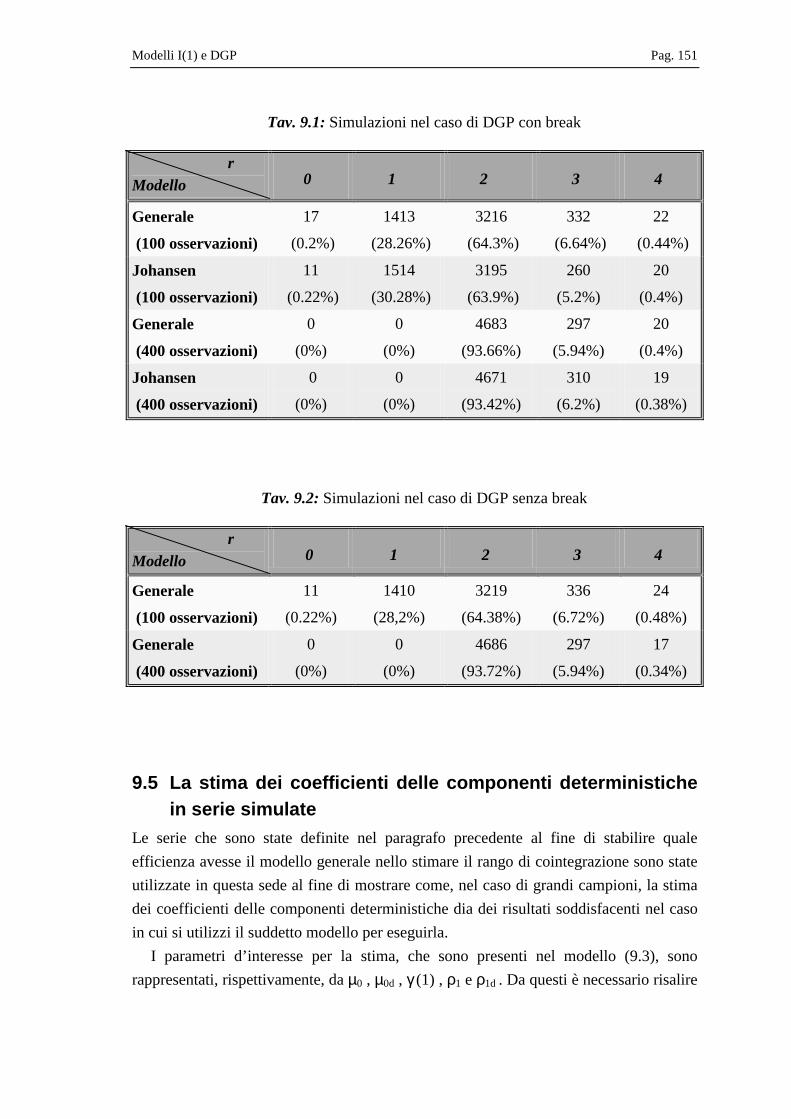
Modelli I(1) e DGP Pag. 151
Tav. 9.1: Simulazioni nel caso di DGP con break
r Modello 0 1 2 3 4
Generale
(100 osservazioni)
17
(0.2%)
1413
(28.26%)
3216
(64.3%)
332
(6.64%)
22
(0.44%)
Johansen
(100 osservazioni)
11
(0.22%)
1514
(30.28%)
3195
(63.9%)
260
(5.2%)
20
(0.4%)
Generale
(400 osservazioni)
0
(0%)
0
(0%)
4683
(93.66%)
297
(5.94%)
20
(0.4%)
Johansen
(400 osservazioni)
0
(0%)
0
(0%)
4671
(93.42%)
310
(6.2%)
19
(0.38%)
Tav. 9.2: Simulazioni nel caso di DGP senza break
r Modello 0 1 2 3 4
Generale
(100 osservazioni)
11
(0.22%)
1410
(28,2%)
3219
(64.38%)
336
(6.72%)
24
(0.48%)
Generale
(400 osservazioni)
0
(0%)
0
(0%)
4686
(93.72%)
297
(5.94%)
17
(0.34%)
9.5 La stima dei coefficienti delle componenti deterministiche in serie simulate
Le serie che sono state definite nel paragrafo precedente al fine di stabilire quale efficienza avesse il modello generale nello stimare il rango di cointegrazione sono state utilizzate in questa sede al fine di mostrare come, nel caso di grandi campioni, la stima dei coefficienti delle componenti deterministiche dia dei risultati soddisfacenti nel caso in cui si utilizzi il suddetto modello per eseguirla.
I parametri d’interesse per la stima, che sono presenti nel modello (9.3), sono rappresentati, rispettivamente, da µ0 , µ0d , γ (1) , ρ1 e ρ1d . Da questi è necessario risalire

Pag. 152 Modelli I(1) e DGP
alle stime dei coefficienti che compaiono nelle componenti deterministiche; ciò può essere fatto considerando le seguenti relazioni
m11
01
1 1= ′ + ′ ′ −⊥ ⊥ ⊥−
⊥ ⊥ ⊥−
⊥β α β µ β α β α βρ βρ( ) ( )Γ Γ Γ ,
β′m0 = ′α Γ − ′α µ0
m d d d d11
01
1 11= ′ + + ′ ′ −⊥ ⊥ ⊥−
⊥ ⊥ ⊥−
⊥β α β µ γ β α β α βρ βρ( ) ( ( )) ( )Γ Γ Γ
β′m0d = ′α Γ − ′α ( µ0d + γ (1) )
Esse rappresentano un’estensione dei risultati visti nel cap. 7, in cui relazioni analoghe venivano determinate considerando un modello che presentasse un unico regime con trend in tutte le componenti.
La determinazione di tali coefficienti si è rivelata essere abbastanza precisa, confrontando tali valori con quelli corretti, ovvero con quelli presenti nel DGP costruito ad hoc per la simulazione, come si può vedere dalla tavola 9.1 e dalla figura 9.1, in cui sono rappresentate le componenti trend-stazionarie evidenziando, per ciascuna di esse la parte deterministica e quella stocastica.5
Tav. 9.3: Valori veri e stimati dei coefficienti della componente deterministica nelle relazioni di cointegrazione
ββββ′′′′m01 ββββ′′′′m02 ββββ′′′′m11 ββββ′′′′m12
Valore vero
stima Valore vero
stima Valore vero
stima Valore vero
stima
-15.0000 -15.2639 -7.0000 -6.9172 -0.5000 -0.5174 -0.4000 -0.3941
-30.0000 -29.4793 -36.000 -39.5968 0.4000 0.4062 0.1000 0.1154
5 Si ricordi che a causa della riparametrizzazione m0d = m02 − m01 e m1d = m12 − m11 .
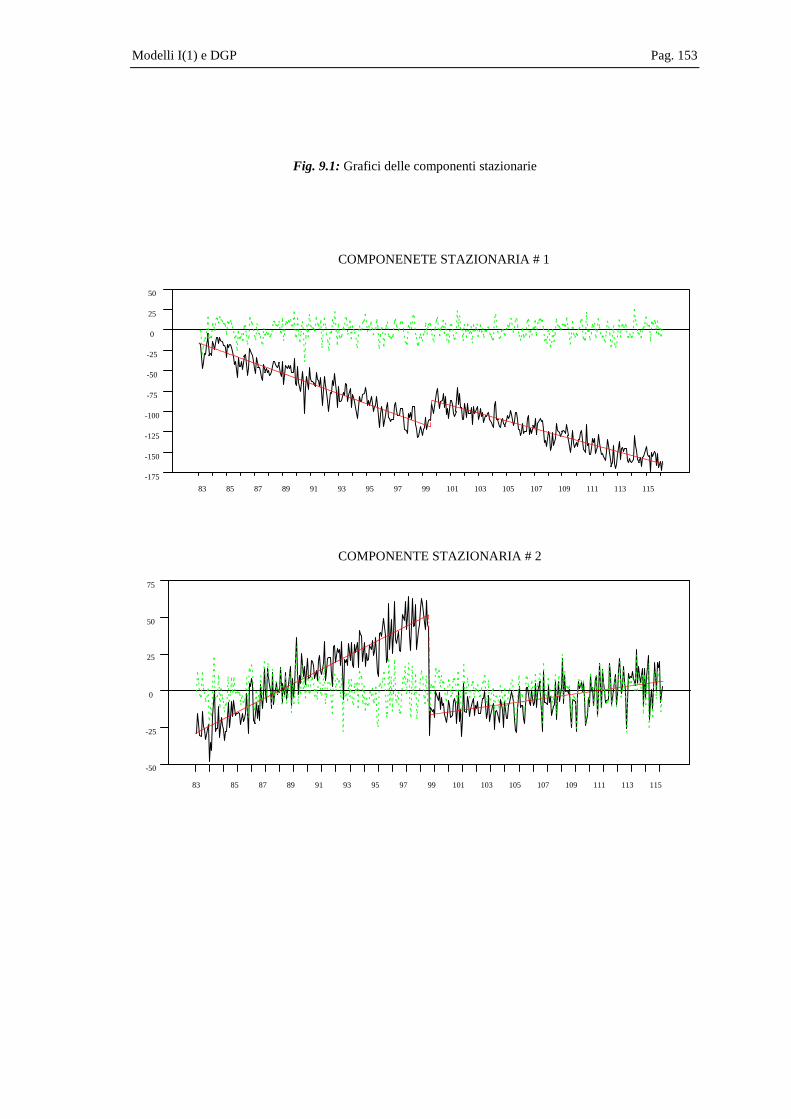
Modelli I(1) e DGP Pag. 153
Fig. 9.1: Grafici delle componenti stazionarie
COMPONENETE STAZIONARIA # 1
83 85 87 89 91 93 95 97 99 101 103 105 107 109 111 113 115-175
-150
-125
-100
-75
-50
-25
0
25
50
COMPONENTE STAZIONARIA # 2
83 85 87 89 91 93 95 97 99 101 103 105 107 109 111 113 115
-50
-25
0
25
50
75


Parte III
Il Caso Applicativo
E Le Simulazioni


Capitolo 10 Il ruolo del tasso di cambio nelle relazioni
internazionali: un caso applicativo
LA teoria sopra esposta, riguardante la cointegrazione di variabili non stazionarie in presenza di break, trova la sua ragione di successo nel fatto di essere in grado di spiegare alcune delle relazioni che vengono dibattute nel mondo economico, quali, ad esempio, la parità del potere d’acquisto relativa (PPP relativa) o la parità dei tassi di interesse (UIP). L’analisi riguardante l’esistenza di tali relazioni viene svolta prendendo in considerazione le relazioni internazionali che sussistono fra Italia e rispettivamente Germania, Stati Uniti e Giappone. E’ stato scelto questo campione di nazioni per il raffronto con l’Italia, in quanto si è ritenuto che esso sia il più significativo nel rispecchiare le relazioni che l’Italia ha con il resto del mondo: mentre, infatti, la Germania rappresenta il punto di riferimento per le economie europee, gli Stati Uniti risultano essere certamente quello cardine dell’economia mondiale; il confronto con il Giappone, in quest’ottica, è stato fatto in quanto tale paese è rappresentativo di un’economia che va assumendo sempre più peso a livello mondiale e alla quale perciò si rapportano con intensità sempre maggiore quelle dei paesi sopra citati.
I risultati delle tre analisi bilaterali svolte nei paragrafi 10.6, 10.7 e 10.8 verranno esposti dopo aver dato qualche delucidazione sulla natura dei dati a disposizione (si veda il § 10.2) e dei criteri seguiti per effettuare le stesse. A monte di tutto ciò, introdurremo brevemente le teorie macroeconomiche, le quali offrono uno spunto valido per un’analisi econometrica basata sull’applicazione dei concetti di cointegrazione. Infatti, le variabili economiche che entrano in gioco nelle equazioni che sintetizzano tali teorie di per se stesse non hanno caratteristiche di stazionarietà; queste dovrebbero essere tuttavia soddisfatte dalle relazioni definite fra di esse. A tale proposito, ricordiamo che il nostro scopo non è quello di entrare nel merito specifico della teoria economica per metterne in dubbio la validità, ma piuttosto quello di offrire uno strumento in grado di ampliare l’orizzonte possibile dell’analisi in tale campo. In altri

Pag. 158 Il ruolo del tasso di cambio nelle relazioni internazionali
termini, l’approccio qui seguito non ha la pretesa di innovatività da un punto di vista economico teorico, quanto piuttosto quella di proporsi come stimolo ad un’ulteriore approfondimento degli strumenti di analisi, secondo una logica differente da quella utilizzata fino al momento attuale. Inoltre è bene ricordare come fino ad ora le analisi econometriche non abbiano dato risultati sempre concordanti.1 e, come quelle, non ha la pretesa di dare risposte conclusive.
L’analisi inizia con una breve descrizione della teoria economica da cui traiamo spunto per l’analisi econometrica successiva, legata alla verifica della PPP relativa e della UIP (si vedano le equazioni (10.1) e (10.2) nel primo paragrafo). L’idea sottesa da queste relazioni è che vi sia una qualche dinamica dovuta ad un processo di aggiustamento che porti alla stabilità dei cambi e alla convergenza dei tassi di inflazione: quelli dei due paesi considerati convergono solo se guidati dal denominatore comune rappresentato dal tasso di cambio (ERM: Exchange Rate Mechanism). Si ipotizza che esso rimanga fisso qualora le inflazioni dei due paesi convergano, mentre il loro divergere, dovuto, ad esempio, ad un aumento maggiore dei prezzi di un paese, relativamente a quelli del paese di confronto, porta ad un aumento del differenziale competitivo rappresentato dal tasso di cambio, che, secondo la teoria della PPP relativa, dovrebbe essere pari all’entità della divergenza dei tassi di inflazione. La verifica della UIP, invece, vuole dare conto dell’efficienza del mercato dei capitali: l’aggiustamento dinamico coinvolge, in tal caso, i tassi di interesse dei due paesi in relazione alle aspettative sul tasso di cambio.
L’articolazione del capitolo, per quel che concerne i paragrafi successivi, è la seguente.
Nel secondo paragrafo, vengono descritte le serie storiche che sono state utilizzate come base dati per l’analisi econometrica, precisandone la fonte di reperimento.
Dai loro grafici, riportati per maggior chiarezza nel § 10.9, è possibile risalire ai break che vengono ipotizzati nel modello e che sono analizzati al § 10.3.
Nel § 10.4 è svolta un’analisi preliminare univariata sulle serie introdotte al § 10.2, per verificare quale sia il grado di integrazione delle variabili; lo strumento che verrà utilizzato è rappresentato dai test di radice unitaria (si veda Said - Dickey (1984)).
Il paragrafo 10.5 introduce l’analisi econometrica multivariata, che tiene conto delle interrelazioni fra le variabili di interesse. Le analisi bilaterali sono svolte nei paragrafi successivi e riguardano i rapporti fra l’Italia e rispettivamente la Germania, gli Stati Uniti e il Giappone. I risultati ottenuti, volti alla verifica delle relazioni macroeconomiche suddette, saranno brevemente commentati.
1 Si veda, ad esempio, Sdogati-Chowdhury (1993), in cui la PPP viene accettata come relazione di lungo periodo per quel che concerne l’analisi bilaterale Italia/Germania, oppure Juselius (1995), in cui, ad

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 159
10.1 La teoria economica alla base dell’analisi Le relazioni economiche internazionali sono di fondamentale importanza nello spiegare i fenomeni che si verificano nei sistemi economici di ogni paese che in qualche modo interagisce con altri sul piano delle transazioni commerciali o finanziarie. Le prime si esplicano attraverso lo scambio di beni, mentre le seconde hanno a che fare con la finanza e l’investimento in attività estere.
Qualsiasi scambio che si verifica fra diversi paesi comporta un passaggio di valore fra di essi, che si traduce in trasferimenti di moneta. Ogni paese è dotato della propria unità di conto e questo fa in modo che, all’atto di tale trasferimento, sia necessario stabilire un parametro di raffronto fra le due valute in modo tale per cui la transazione abbia luogo nei giusti termini.
Tale indice di confronto è rappresentato dal tasso di cambio bilaterale nominale, che indica il rapporto esistente fra le unità monetarie di due paesi. Ad esempio, se si considera un tasso di cambio lira/dollaro pari a 1.500, ciò significa che occorrono 1.500 lire italiane per acquistare un dollaro statunitense. Il tasso di cambio così definito è un valido mezzo di comparazione dei prezzi esistenti nelle due nazioni in questione in relazione allo stesso bene: dato il tasso di cambio, i prezzi di quel determinato bene sono confrontabili in quanto esprimibili in un’unica unità monetaria.
Finora ci siamo riferiti al tasso di cambio come a una grandezza nominale, in quanto definita come numero di unità monetarie di una valuta di un paese per unità di un’altra relativa ad un paese diverso. E’ possibile, tuttavia, definire una grandezza capace di rendere conto dei differenziali di competitività dei paesi: si tratta del tasso di cambio reale, che è il rapporto fra i prezzi relativi, espressi nella stessa valuta, di due panieri equivalenti di beni.
Ricordiamo, a tale proposito, che la teoria economica vorrebbe veder verificata quella che risulta essere definita come parità del potere d’acquisto, la quale prevede che il tasso di cambio reale non vari mai, ovvero esprima una relazione di equilibrio.
La definizione formale di tasso di cambio reale risulta essere la seguente:
R=eP*/P
in cui R è pari al tasso di cambio reale, e è il tasso di cambio nominale e P* e P sono i prezzi esteri e interni, espressi nella rispettiva unità di conto.
esempio, la PPP assoluta nell’analisi bilaterale Danimarca/Germania non viene accettata in senso stretto. Si veda inoltre Johansen-Juselius (1992), in cui la PPP non è verificata per la Gran Bretagna.

Pag. 160 Il ruolo del tasso di cambio nelle relazioni internazionali
Come si può vedere, il livello o la variazione di R dipendono dal valore che tali variabili assumono e dal loro cambiamento, dipendente a sua volta dalle politiche economiche applicate o dai processi di aggiustamento seguenti a tali politiche.
Procediamo perciò descrivendo cosa accade al variare di tali variabili, secondo l’approccio in base al quale una o più di esse viene ritenuta esogena, ovvero controllabile, mentre le altre sono endogene, ovvero seguono un andamento dettato principalmente dalle regole dell’economia.
10.1.1 Il regime di tassi di cambio fissi e flessibili Il punto di partenza è dato dalla distinzione che va operata fra tassi di cambio (nominali) fissi e variabili. Il primo tipo di regime dei tassi di cambio prevede che questi non possano subire oscillazioni che superino una determinata banda di valori ed è questo, ad esempio, il tipo di regime che sussiste fra i paesi aderenti alla comunità europea con lo SME a partire dal 1979, ad eccezione dell’Italia, che ne uscì nel 1992, in quanto non in grado di rispettare i limiti di oscillazione previsti. Il regime di cambi fissi fu anche quello che caratterizzò le relazioni fra i paesi europei ed extra-europei in base agli accordi di Bretton Woods (1945-1973); al decadere di questi ultimi, i tassi di cambio sono tornati ad essere flessibili per quanto riguarda i rapporti fra Europa e resto del mondo.
Nell’ambito del nostro lavoro il regime di tassi di cambio fissi è quello che
caratterizza le relazioni fra Italia e Germania durante il periodo di appartenenza allo SME del nostro paese (si veda il confronto Italia/Germania al § 10.6).
Se analizziamo quale sia il processo di aggiustamento legato ad uno squilibrio esterno sotto tale regime, vediamo come il ripristino dell’equilibrio sia raggiungibile attraverso due canali: la politica economica e l’aggiustamento per mezzo di “meccanismi automatici”. Nel primo caso, le soluzioni adottabili fanno riferimento a misure fiscali o monetarie, ad imposizione di dazi doganali, alla svalutazione della moneta nazionale. Nella seconda circostanza, gli squilibri della bilancia dei pagamenti si riflettono sull’offerta di moneta e quindi sulla spesa, mentre la disoccupazione ha effetto su prezzi e salari e quindi sulla competitività del paese.
Per capire meglio come tali forze agiscano, risulta necessario specificare il ruolo dei prezzi nelle relazioni internazionali. Per fare ciò, ci appelliamo alla definizione di tasso di cambio reale che precedentemente abbiamo introdotto e ipotizziamo l’esogenità di P* e di e.
Dalla teoria economica risulta che la domanda aggregata dipende dal livello dei prezzi nel senso che, all’aumentare di questi, l’offerta reale di moneta diminuisce, i tassi di interesse aumentano e la spesa diminuisce.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 161
In un’economia aperta, un aumento dei prezzi riduce la spesa principalmente per due ragioni: da un lato i tassi di interesse aumentano; dall’altro la competitività diminuisce. Quest’ultimo fenomeno è spiegabile principalmente con il fatto che, dato il tasso di cambio, all’aumentare dei prezzi interni si ha una diminuzione relativa dei prezzi esteri e ciò porta ad un calo delle esportazioni e ad un incremento delle importazioni.
Come conseguenza di ciò, la bilancia commerciale va in disavanzo e per ripristinarne l’equilibrio, in regime di cambi fissi, la Banca Centrale può intervenire usando le proprie riserve. Questa soluzione, anche se accettabile nel breve periodo, non può tuttavia permanere nel lungo e ciò significa che non è possibile finanziare un disavanzo prolungato nel conto delle partite correnti.
Come abbiamo specificato, il riequilibrio si raggiunge grazie ad un meccanismo di aggiustamento automatico o grazie a manovre di politica economica.
Il primo è definito come “aggiustamento classico” e la dinamica sottostante che lo caratterizza è la seguente: all’aumentare dei prezzi, vi è una tendenza all’aumento dei tassi di cambio; al fine di mantenerlo pressoché fisso (in una banda prefissata di oscillazione), la Banca Centrale soddisfa l’accresciuta domanda di moneta estera, provocando così la diminuzione delle riserve e l’aumento dell’offerta interna di moneta. La curva di domanda aggregata è costruita a partire da una data offerta di moneta; al variare di quest’ultima, anche la curva suddetta subisce degli spostamenti fino a quando complessivamente non si è raggiunto il nuovo equilibrio fra essa e la curva di offerta aggregata, il cui spostamento è dovuto a sua volta all’aumento della disoccupazione e al conseguente calo di salari e costi. Una volta raggiunto il nuovo equilibrio, la pressione sul tasso di cambio cessa di sussistere.
Lo svantaggio legato a questo processo di aggiustamento è imputabile alla lentezza con cui esso avviene. Per ovviare a tale problema, si adottano delle politiche economiche di intervento, le quali però risultano essere in conflitto fra di loro, nel caso in cui l’equilibrio interno preveda una ripresa dell’occupazione e quello esterno un contenimento dell’avanzo o, viceversa, nella circostanza in cui vi sia sovraoccupazione e disavanzo. Tali situazioni vengono definite come “dilemmi di politica economica”, poiché una qualsiasi politica restrittiva o espansiva agisce in favore di un equilibrio ma a sfavore dell’altro.
Se il problema è rappresentato, ad esempio, da disavanzo della bilancia dei pagamenti e da sovraoccupazione, allora esso può essere risolto tramite la svalutazione della moneta: essa rappresenta la politica di riallocazione della spesa che, combinata a quelle monetarie o fiscali restrittive, consente di ristabilire l’equilibrio della bilancia; perciò è lecito affermare che, in un regime di cambi fissi, il tasso di cambio è uno strumento di politica economica.

Pag. 162 Il ruolo del tasso di cambio nelle relazioni internazionali
I sostenitori dell’approccio monetario ritengono tuttavia che una svalutazione sia in grado di migliorare la bilancia dei pagamenti solo nel breve periodo: con il passare del tempo, l’aumento dell’offerta di moneta, dovuto alla svalutazione e quindi al miglioramento della bilancia dei pagamenti, fa aumentare la domanda aggregata e quindi i prezzi finché il sistema non ritorna alla piena occupazione e all’equilibrio esterno. Date queste considerazioni, l’approccio monetario è corretto nel sottolineare la prospettiva di lungo periodo in cui, in regime di cambi fissi, i prezzi e lo stock di moneta si aggiustano e il sistema raggiunge l’equilibrio esterno ed interno.
Analizziamo ora la relazione esistente fra moneta, prezzi e tassi di cambio, nel caso
in cui questi ultimi siano flessibili. Un tale tipo di regime è quello che caratterizza i rapporti successivi agli accordi di Bretton Woods e, in particolare, alla luce di questo lavoro, quelli fra Italia e Stati Uniti e Italia e Giappone (si vedano il § 10.7 e il § 10.8). L’ipotesi sottesa alle teorie sull’equilibrio che vogliamo evidenziare è che i capitali siano perfettamente mobili fra i paesi e che siano molto sensibili ai differenziali dei tassi di interesse fra gli stessi: al diminuire/aumentare anche minimo dei tassi di interesse di un paese rispetto ad un altro, si ha deflusso/afflusso di capitali; a causa di ciò, la bilancia dei pagamenti va in disavanzo/avanzo e il cambio si deprezza/si apprezza.
Se i prezzi sono dati, un’espansione monetaria in tale regime porta a un deprezzamento e ad una crescita del reddito; nel caso in cui i prezzi possano variare, l’aggiustamento della produzione risulta essere solo transitorio: nel lungo periodo, un’espansione monetaria conduce ad un deprezzamento del cambio e a prezzi più elevati senza alcuna variazione della competitività. La velocità di aggiustamento delle variabili al nuovo valore di equilibrio non è, tuttavia, istantanea e nemmeno la stessa per i prezzi e il tasso di cambio: i primi, infatti, si muovono molto più lentamente del secondo e perciò nel breve periodo si può assistere ad una variazione notevole della competitività, dovuta al deprezzamento immediato del cambio non seguito dall’aggiustamento repentino dei prezzi; tale fenomeno risponde al nome di oveshooting del tasso di cambio.
Osservazione In genere si sostiene che, in regime di tassi di cambio flessibili, le politiche economiche dei vari paesi siano indipendenti. In realtà, l’interdipendenza esiste, qualunque sia il regime di tassi di cambio. Un esempio è rappresentato dalla politica monetaria restrittiva adottata negli Stati Uniti a partire dal 1980: l’aumento dei tassi di interesse ha portato ad un afflusso di capitali dall’estero, causando un apprezzamento del dollaro nei confronti delle altre valute e quindi ad un aumento della produzione negli altri paesi e a quello della disoccupazione negli Stati Uniti.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 163
Tutto ciò ha portato alla definizione di sincronizzazione delle politiche economiche fra i diversi paesi: le grandi variazioni nei tassi di cambio che si hanno quando le politiche economiche dei vari paesi non sono completamente sincronizzate rappresentano la maggiore minaccia per lo sviluppo del commercio internazionale.
Per tale ragione, in regime di cambi flessibili, l’interdipendenza sussiste ed in maniera anche marcata.
10.1.2 La parità del potere d’acquisto PPP La neutralità della moneta nel lungo periodo, di cui si è parlato in precedenza, ci permette di spiegare il ruolo fondamentale assunto dai tassi di cambio nel compensare gli effetti di variazioni nel livello dei prezzi nazionali ed esteri. Secondo la teoria della parità del potere d’acquisto, in regime di cambi flessibili i tassi di cambio si muovono in risposta ad una variazione dei prezzi interni in modo che vengano mantenute costanti le ragioni dello scambio. Il movimento dei tassi di cambio riflettono principalmente tassi di inflazione diversi nei paesi di interesse.
Nel parlare di parità del potere d’acquisto PPP, è necessario distinguere fra parità assoluta e relativa.
Nel primo caso, ricordando la relazione che esprime il tasso di cambio reale come rapporto dei prezzi nei diversi paesi espressi nella stessa valuta, si afferma che R=1, ovvero che il tasso di cambio bilaterale è dato semplicemente dal rapporto fra i prezzi di un paniere identificativo e confrontabile di beni dei due paesi.2 In tale circostanza, una variazione relativa dei prezzi in un paese rispetto all’altro porta automaticamente all’aggiustamento del tasso di cambio. In altre parole, la PPP assoluta afferma che i livelli dei prezzi, qualora siano espressi nella stessa valuta, sono uguali.
Nel secondo caso, si afferma che le variazioni percentuali dei tassi di cambio delle valute nei due paesi eguagliano le variazioni percentuali dei livelli dei prezzi nazionali. In modo formale, la PPP relativa fra i paesi con unità di conto A e B si esprime come
∆e = (eA/B,t − eA/B,t-1)/eA/B,t-1 = πA,t − πB,t (10.1)
dove πA,t e πB,t sono il tasso di inflazione, ovvero la variazione percentuale dei prezzi, del paese A e del paese B, mentre eA/B è il tasso di cambio nominale della valuta di A rispetto a quella di B, indicizzato in base all’istante considerato.
La PPP relativa può essere definita solo con riferimento ad un determinato intervallo di tempo durante il quale sono variati i prezzi e il tasso di cambio, ma rimane comunque più significativa della parità assoluta, in quanto quest’ultima prevede di confrontare
2Ci stiamo riferendo alla forma forte della PPP assoluta; é nota anche una forma debole della stessa, la
quale afferma che R è pari ad una costante.

Pag. 164 Il ruolo del tasso di cambio nelle relazioni internazionali
indici di prezzo calcolati sulla base di panieri che non necessariamente sono uguali fra i paesi.
In tale situazione, comparare le variazioni percentuali del tasso di cambio con le differenze di inflazione è corretto e quindi risulta essere giustificabile la formulazione della parità del potere d’acquisto in termini relativi.
Nell’ambito delle teorie economiche, è “luogo comune” ritenere che la PPP valga nel lungo periodo: ciò è giustificato col fatto che essa vale di fronte ad un aumento della quantità di moneta, che causa una variazione dei prezzi, i quali si aggiustano in seguito solo con lentezza.
Tuttavia, il tasso di cambio risponde anche nel breve periodo a perturbazioni monetarie e non, come avviene, ad esempio, nel caso di un aumento della produzione potenziale, che causa un peggioramento delle condizioni di scambio e quindi una diminuzione del prezzo relativo interno.
Ciò significa che nel lungo periodo non necessariamente i tassi di cambio e i prezzi si muovono insieme, come avviene, ad esempio, in un mondo in cui tutte le perturbazioni sono di natura monetaria; si possono avere invece ampie variazioni dei prezzi relativi, che sono in contrasto con la visione dei cambi fondata sulla PPP.
10.1.3 La parità dei tassi di interesse UIP Analogamente alla PPP, per quanto riguarda le relazioni internazionali fra paesi, le teorie economiche prevedono una relazione di lungo periodo nell’ambito degli scambi che avvengono nel mercato dei capitali. Il mercato valutario è in equilibrio quando il differenziale dei tassi di interesse nei due paesi uguaglia il differenziale del tassi di cambio atteso ed effettivo fra gli stessi. In formule si ha
iA,t − iB,t = (EeA/B,t − eA/B,t)/eA/B,t (10.2)
dove iA,t e iB,t sono i tassi di interesse nominali dei paesi A e B all’istante t, eA/B,t è il tasso di cambio definito precedentemente e Ee
A/B,t è il tasso di cambio atteso, valutato in t, per il periodo t+1.
Per chiarire i possibili effetti di una variazione del tasso di cambio sui tassi di interesse, ipotizziamo che siano dati il tasso Ee
A/B,t e il tasso iB,t . In tale circostanza, all’aumentare/diminuire di eA/B,t (ovvero al deprezzarsi/apprezzarsi del cambio del paese A rispetto al paese B) si verifica una diminuzione/aumento dei differenziali dei tassi di interesse, ovvero i rendimenti espressi nella valuta del paese A, ma relativi ad investimenti effettuati nella moneta del paese B, risultano essere più bassi/alti.
Questo processo può risultare a prima vista controintuitivo, ma in realtà è giustificato dall’ipotesi di costanza del tasso di cambio atteso. Infatti, in tale caso, un ipotetico deprezzamento della moneta del paese A nei confronti di quella del paese B rende

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 165
minore il futuro deprezzamento atteso di tale valuta, ovvero fa in modo che il suo apprezzamento atteso sia maggiore; rimanendo invariati i tassi di interesse, i rendimenti relativi al paese B risultano essere minori.
L’equilibrio dei tassi di interesse dei due paesi si ha quando il tasso di cambio bilaterale uguaglia quello atteso: ad esempio, riferendoci a quanto detto sopra, se il tasso effettivo eA/B,t è superiore a Ee
A/B,t , allora vi è attesa per un apprezzamento della moneta di A; ciò implica che i capitali si spostino da B a A, causando un eccesso di domanda di valuta di A. Questo processo induce ad un aumento del suo prezzo, ovvero ad una riduzione del tasso di cambio fino all’equilibrio.
Se ci si chiedesse come variano i tassi di cambio al variare dei tassi di interesse, la conclusione a cui si giungerebbe è che un aumento del differenziale dei tassi di interesse nazionale ed estero conduce ad in apprezzamento della valuta nazionale. Supponiamo, ad esempio, che sia dato il tasso di cambio atteso e il tasso di interesse del paese estero B; un aumento del differenziale dei tassi di interesse significa un aumento dei tassi di interesse nazionali (nel nostro caso, si tratta di quelli del paese A) e, come conseguenza di ciò, in corrispondenza del tasso eA/B,t , il tasso atteso Ee
A/B,t risulta essere maggiore, portando ad un apprezzamento della valuta interna.
Se analizziamo invece gli effetti di una variazione dei tassi attesi di cambio sui tassi di cambio correnti, possiamo constatare che un aumento/diminuzione di Ee
A/B,t si riflette in un aumento/diminuzione del tasso eA/B,t . La spiegazione di questo fenomeno risulta semplice: se, ad esempio, ipotizziamo un aumento di Ee
A/B,t , allora significa che ci aspettiamo un aumento del tasso di deprezzamento della valuta di A e quindi un aumento dei tassi di interesse di B; ciò si riflette sul tasso di cambio effettivo eA/B,t , che quindi aumenta.
La condizione di equilibrio espressa dalla equazione (10.2) vale nel caso in cui i titoli in valuta nazionale ed estera siano dei sostituti perfetti. Quando ciò non si verifica, allora l’equilibrio sul mercato delle valute richiede che la differenza fra i tassi di interesse interno ed estero uguagli la variazione percentuale dei tassi di cambio attesa, aggiustata per tener conto di un premio per il rischio τ, in grado di riflettere la differenza nella rischiosità dei titoli nazionali ed esteri. Allora, l’equazione (10.2) viene modificata nel seguente modo
iA,t − iB,t = (EeA/B,t − eA/B,t)/eA/B,t + τ (10.3)
Questo modello alternativo di equilibrio nel mercato dei cambi richiede che il premio per il rischio dipenda in modo positivo dall’ammontare di debito pubblico (che indichiamo con B), al netto delle attività nazionali detenute dalla Banca Centrale (indicate con A), ovvero

Pag. 166 Il ruolo del tasso di cambio nelle relazioni internazionali
τ = τ(B−A).
Ciò significa che il premio per il rischio sui titoli nazionali aumenta al crescere dello stock di titoli pubblici nazionali collocati presso il settore privato e diminuisce all’aumentare delle attività della Banca Centrale nazionale. La giustificazione economica di questo risultato è dovuta al fatto che gli investitori privati diventano più vulnerabili a variazioni inattese dei tassi di cambio della valuta nazionale al crescere dello stock di titoli pubblici che essi detengono: gli investitori non vorranno assumere il maggior rischio che deriva dalla detenzione di debito pubblico, a meno che essi non siano compensati da un maggior tasso di rendimento atteso sulle attività denominate in valuta nazionale. Analogamente, quando la Banca Centrale acquista attività nazionali, il mercato non deve più detenerle e quindi la vulnerabilità del settore privato al rischio sul cambio diventa inferiore e cala il premio per il rischio sulle attività denominate nella valuta nazionale.
10.1.4 Combinazione della PPP e della UIP Data la condizione di parità dei tassi di interesse espressa precedentemente dall’equazione (10.2), ci chiediamo ora come questa possa combinarsi con l’altra ipotizzata sul lungo periodo, ovvero quella del potere di acquisto espressa dalla (10.1).
Secondo la PPP in termini relativi, la variazione percentuale del tasso di cambio fra gli ipotetici paesi A e B in t+1 deve uguagliare la differenza fra i tassi di inflazione dei due paesi nello stesso istante. Dal momento che gli agenti economici conoscono questa relazione, deve essere vero che essi si aspettano che la variazione percentuale del tasso di cambio sia pari al differenziale di inflazione dei due paesi. La PPP ci permette allora di affermare che, se pensiamo che valga in termini relativi, allora la differenza fra i tassi di interesse fra i due paesi sarà pari alla differenza fra i tassi attesi di inflazione, per il periodo considerato, di A e di B.
Il tasso di inflazione atteso di un paese è definito come l’aumento percentuale dei prezzi previsto per l’anno successivo, ovvero, in formule
πe = (Pe−P)/P
dove Pe è il prezzo atteso fra un anno da oggi. Se risulta soddisfatta la parità del potere d’acquisto in termini relativi, allora chi opera sul mercato si aspetta che essa sia valida; ciò significa che il deprezzamento effettivo e i tassi di inflazione espressi nell’equazione (10.1) possono essere sostituiti con i valori attesi corrispondenti, ovvero
(EeA/B − eA/B)/eA/B = πe
A − πeB , (10.4)
dove EeA/B e eA/B sono gli stessi definiti nell’equazione (10.2).

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 167
Ricordando l’espressione della parità dei tassi di interesse, possiamo riscrivere l’equazione (10.4) come
iA = iB + (EeA/B − eA/B)/eA/B
ovvero
iA − iB = πeA − πe
B . (10.5)
Se, come prevede la PPP, ci aspettiamo un deprezzamento per bilanciare il differenziale di inflazione, espresso nell’equazione (10.5) da πe
A − πeB , allora la differenza fra i tassi
di interesse deve uguagliare il tasso atteso di inflazione. Tale relazione di lungo periodo fra l’inflazione e i tassi di interesse è nota con il
nome di effetto Fisher.
A conclusione di quanto detto a proposito della parità del potere d’acquisto assoluta, analisi empiriche hanno dato esiti negativi riguardo la sua sussistenza. Le ragioni di ciò sono principalmente da addebitare al fatto che vi sono restrizioni allo scambio, nel senso che alcuni beni non risultano essere oggetto di transazioni commerciali internazionali ed al fatto che pratiche di natura oligopolistica possono interagire con barriere allo scambio quali i costi di trasporto, indebolendo ulteriormente il legame fra prezzi di beni simili venduti in paesi diversi.
10.2 La base dati Il panel di dati di cui disponiamo per l’analisi riguarda i tassi di interesse e i prezzi di quattro nazioni: Italia, Stati Uniti, Germania e Giappone, oltre che i tassi di cambio bilaterali fra Italia e gli altri paesi citati. Tali serie storiche coprono un arco temporale che, partendo dal gennaio 1973, giunge al marzo 1996 e i dati sono trimestrali; disponiamo perciò di un numero di osservazioni pari a 93, per quanto riguarda le serie delle variabili in livelli, che dipende dalla disponibilità alle fonti.3 Quest’ultima ha costituito un problema dal punto di vista sia della definizione che dell’omogeneità delle serie stesse. Più precisamente, per quanto riguarda il primo punto si è reso necessario svolgere qualche trasformazione delle serie al fine di renderle omogenee; così, ad esempio, laddove i dati sui tassi di cambio risultavano essere disponibili con frequenza mensile, si è proceduto col farne una media sui tre periodi coincidenti con ogni singolo trimestre, seguendo, d’altra parte, una prassi tipica delle
3Ad esempio, i dati sui tassi di interesse giapponesi sono disponibili solo a partire dal 1973
sull’International Financial Statistics (FMI).

Pag. 168 Il ruolo del tasso di cambio nelle relazioni internazionali
stesse fonti di riferimento per gli stessi.4 Per quanto riguarda il secondo, la necessità di disporre non solo di tutte le osservazioni del campione scelto, ma anche di serie storiche il più possibile omogenee su tutto l’arco temporale considerato e confrontabili per i diversi paesi scelti per l’analisi, ci ha spinto a scegliere fonti di reperimento dei dati diverse, ma comunque autorevoli, privilegiando quelle di matrice internazionale, in cui le serie sono riportate con l’intento di permettere una valutazione comparata fra i diversi paesi. Inoltre, per far fronte alla mancanza di un certo numero di dati su di una fonte si è fatto ricorso a quelli presenti su un’altra, in cui la serie fosse confrontabile con quella della precedente in termini di descrizione della stessa. Il risultato di questo lavoro di comparazione è stato il rilevamento di campioni non del tutto omogenei, sul piano del valore attribuito ai dati confrontabili sulle due fonti. Ipotizziamo che ciò sia dovuto principalmente al fatto che le serie subiscano delle revisioni o degli aggiornamenti tali da modificarle in via marginale. Rilevando che le discontinuità fossero effettivamente piccole, abbiamo ritenuto di poter trascurare questo problema.
Per fare chiarezza sulla base di dati utilizzata, riportiamo qui di seguito qualche dettaglio sulle serie rilevate, specificando la fonte di reperimento per esse e il nome che viene dato loro nell’analisi econometrica svolta nei paragrafi successivi.
Tassi di cambio Si tratta di tassi di cambio bilaterali nominali, mediati sul periodo.
I dati sono disponibili a frequenza trimestrale per quel che concerne il periodo che va dal gennaio 1981 al marzo 1996 e sono stati tratti dal Bollettino Economico della Banca d’Italia (1983- ); i dati del periodo precedente sono invece mensili e sono stati tratti dal Bollettino della Banca d’Italia (1950-1983).
I dati per l’arco temporale che, partendo dal primo trimestre 1973, giunge all’ultimo trimestre 1980 e per quello compreso fra il terzo trimestre 1983 e il primo trimestre 1996 sono espressi in lire per unità di valuta estera, ovvero, nel nostro caso, lit./USD, lit./DM, lit./YEN.
I dati relativi invece al periodo che va dal primo trimestre 1981 al secondo trimestre 1983 sono espressi come valute per USD, ovvero, nel nostro caso, come lit./USD, DM/USD, YEN/USD. Per uniformare tali serie a quelle precedenti, si è proceduto calcolando i tassi bilaterali nominali nel seguente modo
lit./DM = lit USDDM USD
.//
; lit./YEN = lit USDYEN USD
.//
4Si veda, ad esempio, l’ International Financial Statistics per quel concerne la descrizione dei tassi di

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 169
Per quel che concerne l’analisi econometrica, tali variabili sono state definite come ERDEU (tasso di cambio lit./DM), ERUSD (tasso di cambio lit./USD), ERJAP (tasso di cambio lit./YEN). La loro trasformazione in logaritmi, resa necessaria dall’analisi (si veda il § 10.5), prevede che esse vengano etichettate mediante l’aggiunta del prefisso “L” al nome originario.5 La successiva differenziazione applicata ai logaritmi porta a ridefinire tali variabili anteponendo al loro nome una “D”.6
Indice dei prezzi Si tratta dell’indice dei prezzi al consumo; i dati hanno frequenza mensile.
Le serie sono state trasformate in modo che la base pari a100 fosse il 1970. Per fare ciò, i valori espressi nelle basi poste pari a 100 negli anni successivi (ovvero, a seconda dei dati, nel 1975, nel 1980 e nel 1985) sono stati moltiplicati per un coefficiente di raccordo, ottenuto rapportando a 100 il valore medio annuale dell’indice relativo all’anno che rappresenta la base più recente, espresso nei termini della base non aggiornata. Ad esempio, per ottenere dati in base 1980=100 da quelli espressi in base 1985=100, si è proceduto facendo una media sui dodici mesi degli indici relativi all’anno 1985 espressi però in base 1980=100; il valore ottenuto è stato diviso per 100 e il coefficiente di raccordo così ottenuto è stato moltiplicato per gli indici espressi in base 1985=100.
Abbiamo optato per questa serie, in alternativa a quella dei prezzi alla produzione, in quanto, a differenza della seconda, risulta essere omogenea fra le diverse nazioni da noi considerate. Tuttavia, il problema legato all’uso di questa serie riguarda il fatto che, nella determinazione dell’indice, non si tiene conto del fatto che alcuni beni non sono completamente commerciabili fra diversi paesi e quindi l’utilizzo di tali dati nell’analisi della PPP può in qualche modo portare a distorsioni nei risultati.
Per quanto riguarda i dati relativi al Giappone del periodo compreso fra il gennaio 1973 e il dicembre 1975, si ricorda che essi sono relativi all’intero paese, esclusa la prefettura di Okinawa.
Quelli tedeschi successivi all’ottobre 1990 riguardano la Germania unita. Per quanto riguarda le fonti, i dati mensili relativi al periodo 1976-1996 sono tratti da
Eurostatistiche (EUROSTAT).7 I dati mensili relativi al periodo 1973-1975 sono tratti da Monthly Bulletin of Statistics (UN).
interesse a lungo dei paesi qui considerati ed in particolare dell’Italia.
5 Perciò i logaritmi dei tassi di cambio sono definiti come LERDM, LERUSD e LERJEN. 6 Le variabili risultanti sono i differenziali dei cambi definiti su un trimestre e si chiamano DLERDM,
DLERUSD e DLERJEN. 7 I dati per Stati Uniti e Giappone relativi al periodo 1983-1984 sono stati tratti da International
Financial Statistics supplement No 12 (1986), perchè non disponibili su Eurostatistiche.

Pag. 170 Il ruolo del tasso di cambio nelle relazioni internazionali
I prezzi, nell’analisi econometrica, sono definiti come PRITA, PRDEU, PRUSA e PRJAP. I logaritmi di tali variabili e i differenziali sono definiti concordemente a quanto fatto con le serie dei tassi di cambio.8
Tassi di interesse Si tratta di dati trimestrali sui tassi di interesse a scadenza dei titoli di Stato a lungo periodo; sono dati medi, valutati al lordo di imposta.
Le serie non risultano essere omogenee fra i vari paesi9 e, per ognuno di essi, su tutto l’arco temporale considerato. La non omogeneità riguarda non solo la specificità del titolo propria di ogni nazione, ma anche la definizione di “lungo periodo” che attiene ad ogni singola serie. Purtroppo non è stato possibile reperire serie dotate di gradi di uniformità maggiori rispetto a quelle che abbiamo rilevato a che riteniamo essere comunque accettabili, in relazione alla fonte da cui sono tratte. Per questioni di maggiore chiarezza, riportiamo qualche ulteriore nota esplicativa su tali serie per ogni paese, ricordando che esse sono state tratte dall’International Financial Statistics pubblicato dal Fondo Monetario Internazionale.10
ITALIA La serie relativa al periodo compreso fra il primo trimestre 1973 e il secondo trimestre 1992 è omogenea e riguarda i tassi di interesse sui Btp con vita residua compresa fra i 15 e i 20 anni.
I dati relativi al periodo successivo riguardano invece i Btp con vita residua compresa fra i 9 e i 10 anni.
USA La serie che copre il periodo che va dal primo trimestre 1976 al primo trimestre 1986 è relativa ai tassi di interesse su titoli emessi dallo Stato con durata pari a 20 anni. La serie precedente riguarda i titoli con durata superiore ai 10 anni, mentre quella successiva ha a che fare con titoli con durata pari a 10 anni.
8 I tassi di inflazione sono perciò definiti come DLPRITA, DLPRDEU, DLPRUSA, DLPRJAP (la
loro rilevanza risulterà chiara nell’analisi econometrica successiva). 9Per una descrizione più precisa, si veda la fonte di riferimento, ovvero l’ International Financial
Statistics del Fondo Monetario Internazionale 10 I dati relativi all’Italia per il periodo che va dal terzo trimestre 1992 al secondo trimestre 1993 sono
tratti da Assemblea Generale Ordinaria dei Partecipanti - Appendice -(Banca d’Italia) relativa agli anni 1992 e 1993, perché non disponibile su IFS.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 171
Per quanto concerne i valori numerici di queste serie, si rilevano piccole discontinuità e ciò fa pensare che il peso attribuito ai titoli con durata pari a 10 anni nella valutazione dell’indice sia comunque superiore a quello dei titoli con altra durata.
GERMANIA I tassi di interesse relativi al periodo che parte dal gennaio 1973 e arriva fino al dicembre 1979 sono i rendimenti alla scadenza (media pesata) delle emissioni speciali. Quelli successivi riguardano tutti i titoli con vita residua superiore ai tre anni; i rendimenti sono calcolati come medie pesate, in cui i pesi sono riferiti al totale dei titoli in circolazione
Nonostante la definizione non sia la stessa per le serie dei due periodi, non si sono rilevate discontinuità nella serie dei dati.
GIAPPONE La serie fa riferimento ai rendimenti alla scadenza di tutti i titoli emessi dallo Stato con vita residua pari a sette anni. La serie risulta essere omogenea su tutto il periodo di riferimento.
I tassi di interesse, nell’ambito dell’analisi econometrica svolta nel seguito,11 sono
denominati IRITA, IRDEU, IRUSA e IRJAP. Tali variabili, qualora vengano ritardate di un periodo (come risulterà necessario nell’analisi), sono definite come LIRITA; LIRDEU; LIRUSA e LIRJAP.
10.3 L’analisi dei break strutturali nelle serie storiche Osservando i grafici delle serie storiche relative alle variabili considerate nel nostro modello (si veda il § 10.9), si nota la presenza di cambiamenti, talvolta anche notevoli, nell’andamento delle stesse. Le variazioni che si possono rilevare riguardano sia la modifica del tipo di andamento (ovvero, ad esempio, il passaggio da una condizione di aggiustamento attorno ad un trend a quella di assestamento attorno ad una costante) sia una modifica all’interno dello stesso modello di descrizione dei dati (ovvero, ad esempio, il passaggio da un aggiustamento attorno ad un trend a quello attorno ad un altro con pendenza e valore medio diversi).
L’analisi parte dall’osservazione delle serie storiche dei tassi di cambio. Quella relativa al cambio lit./USD, ad esempio, pone in risalto un andamento
altalenante dei valori dei tassi per quel che concerne il periodo 1973-1996; esso trova
11 Si veda il § 10.4.

Pag. 172 Il ruolo del tasso di cambio nelle relazioni internazionali
una sua giustificazione sul piano politico ed economico, che andiamo ora a definire basandoci su quanto è riportato dalla letteratura economica a riguardo.12
Il break che pare sussistere a cavallo fra il 1979 e il 1980 fu determinato probabilmente dal verificarsi di due eventi quasi in concomitanza: la formazione dello SME e i mutamenti nella politica monetaria statunitense. Per quanto riguarda il primo, esso si pose come ulteriore passo all’unificazione europea, cominciata nel 1957 con il Trattato di Roma, che sancì la creazione della CEE. Il secondo fu dovuto principalmente alle conseguenze economiche di alcune scelte politiche concordate dalle potenze mondiali. Infatti, dopo il summit economico di Bonn del 1978, nel quale gli Stati Uniti, la Germania e il Giappone decisero di farsi promotori congiuntamente della ripresa economica mondiale, resa critica dallo shock petrolifero del 1973, l’adozione delle politiche espansive concordate condusse alla diminuzione della disoccupazione solo negli ultimi due dei tre paesi suddetti. L’incremento sempre maggiore dei tassi di inflazione negli Stati Uniti13 portò ad un indebolimento persistente del dollaro. Al fine di ripristinare la fiducia nei confronti della moneta americana, il presidente statunitense Carter nominò presidente della Federal Reserve Paul A. Volker, grande esperto di finanza internazionale, il quale, nell’ottobre del 1979, annunciò la svolta della politica monetaria statunitense, che passò da espansiva a restrittiva, e l’intento di adottare misure di controllo più rigorose della crescita dell’offerta di moneta.
La politica monetaria restrittiva attuata da Volker agli inizi del 1980, ristabilendo la fiducia per una diminuzione dell’inflazione negli Stati Uniti, spinse il dollaro ad un notevole apprezzamento, soprattutto nei confronti del marco tedesco. L’effetto fu accentuato ulteriormente dalla nomina di Reagan a presidente degli Stati Uniti nel 1980: egli optò per una politica fiscale espansiva che, combinata con quella monetaria restrittiva,14 portò ad un aumento dei tassi di interesse statunitensi, ovvero ad un apprezzamento ulteriore del dollaro nei confronti delle altre valute ed in particolare della lira. Il crescere notevole dei tassi di interesse e il conseguente apprezzamento del dollaro indusse negli agenti economici aspettative di un dollaro ancora più forte. Ciò creò un notevole incremento dei prezzi relativi dei beni statunitensi rispetto a quelli degli altri paesi, agendo negativamente su produzione e disoccupazione all’interno. Questo risultato non fu comunque di conforto per le altre nazioni che intrattenevano rapporti commerciali con gli Stati Uniti, fra i quali, appunto, l’Italia, la Germania e il Giappone. Infatti la spinta ad una ripresa della produzione causò a sua volta una tendenza all’aumento dell’inflazione. La necessità di controllare quest’ultima, indusse gli altri
12La giustificazione qui data per spiegare i break presenti nelle serie segue la teoria riportata sul testo Economia Internazionale (Krugman-Obstfeld (1995)), parte IV.
13 Si veda la serie dei tassi di inflazione statunitensi al § 10.9.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 173
paesi ad attuare politiche economiche restrittive, quali, ad esempio, la riduzione della crescita monetaria mediante l’aumento dei tassi di interesse. Queste contrazioni monetarie sincronizzate, che si possono rilevare semplicemente osservando le serie plottate (si veda il § 10.9) portarono ad un’alta disoccupazione e a recessione in tutto il mondo, in concomitanza anche con lo shock petrolifero sfavorevole del 1979.
La politica adottata da Reagan doveva teoricamente permettere al paese di riprendersi dalla recessione, ma in realtà la produzione nazionale cominciò a risalire solo nel 1982, in corrispondenza con una diminuzione dei tassi di interesse interni, non seguita da un analogo provvedimento negli altri paesi industrializzati, intimoriti da una possibile nuova impennata dell’inflazione. La politica fiscale reaganiana contribuì alla ripresa mondiale, mentre il disavanzo statunitense continuò a crescere fino a livelli preoccupanti nel 1987. I tassi di interesse, comunque alti negli Stati Uniti per tutto il quinquennio 1980-1985, causarono un continuo apprezzamento del dollaro15 e ciò spinse il governo americano, sotto forti pressioni interne, ad attuare manovre protezionistiche nei confronti degli altri paesi. Temendo seri problemi a livello di commercio internazionale, i rappresentanti economici del Gruppo dei Cinque (ovvero Stati Uniti, Gran Bretagna, Francia, Germania e Giappone) decisero di operare la svalutazione del dollaro, che avvenne nel settembre 1985.16
La svalutazione proseguì per tutto il 1986 in misura diversa per i diversi partner commerciali: come si può osservare confrontando fra loro le serie dei tassi di cambio della lira contro il marco e contro lo yen,17 il deprezzamento del dollaro nei confronti di queste tre valute fu notevole. Ad accentuarne la caduta contribuirono manovre speculative (“speculative bubbles”) da parte degli altri paesi, non disposti a modificare le loro politiche di correzione della spesa a sostegno del dollaro. Il suo deprezzamento rallentò all’inizio del 1987, quando l’amministrazione statunitense intervenne sul mercato valutario. Infatti, dopo l’incontro tenutosi al Louvre di Parigi nel 22 febbraio dello stesso anno, si decise, nonostante il regime di cambi flessibili vigente, di stabilire delle bande di oscillazione per i tassi di cambio, stabilizzandoli tuttavia su livelli troppo alti per permettere una ripresa dell’economia statunitense. Poiché il deficit americano non accennava a diminuire, il dollaro subì pressioni al ribasso; per evitare una crisi
14Si veda il modello macroeconomico di Mundell-Fleming, per la cui trattazione rimandiamo a
Macroeconomia (Dornnbusch-Fischer; casa editrice “Il Mulino”) 15Si veda, ad esempio, la serie dei tassi di cambio lit./USD nel § 10.9. 16Si veda, ad esempio, la serie dei tassi di cambio lit./USD nel § 10.9. 17Si nota dalle serie dei tassi di cambio plottate al § 10.9 che la lira si apprezza nei confronti del
dollaro, ma il cambio lit./DM e lit./YEN rimane pressoché costante e ciò significa che il cambio USD/DM e USD/YEN sta aumentando, ovvero il dollaro si sta deprezzando.

Pag. 174 Il ruolo del tasso di cambio nelle relazioni internazionali
economica ancora maggiore, il nuovo presidente della Federal Reserve, Alan Greenspan, decise di diminuire i tassi di interesse.18
Per quel che riguarda i rapporti con l’Italia, la fase di deprezzamento del dollaro termina praticamente nel 1992, in concomitanza con l’uscita della prima dallo SME: la valuta statunitense subisce un forte apprezzamento iniziale, seguito da un assestamento ad un valore pressoché costante. L’eco di questo break si fa sentire con intensità differente anche nelle relazioni che l’Italia tiene con il resto del mondo.19 Questo break risulta essere ancor più evidente nell’analisi del tasso di cambio lit./DM; in questa serie, infatti, ciò che risulta chiaro è l’andamento costantemente crescente, ma con limitata pendenza, del tasso di cambio, a riflesso del sistema vigente dei cambi fissi nei paesi aderenti alla Comunità Europea a partire dal 1979. Tale crescita uniforme cessa di sussistere proprio nel 1992: i dati successivi della serie sembrano rilevare ampie fluttuazioni dei cambi su valori comunque più alti rispetto a quelli del periodo precedente, a riflesso di un’economia dotata di scarsa stabilità dei prezzi, qual è quella italiana.
Infatti, per quanto riguarda i prezzi,20 in particolare per la serie italiana, quel che si può notare è una crescita continua e simile del loro livello. Ciò non sembra verificarsi per la serie relativa al Giappone, per la quale si nota una tendenza all “appiattimento” a partire dal 1980. Per quanto riguarda le altre serie, è rilevabile una lieve diminuzione di tale livello nel 1985, dovuto probabilmente allo shock petrolifero favorevole, che produsse una diminuzione della componente esterna dell’inflazione21, meglio controllata in Germania e Stati Uniti rispetto che non in Italia.
Un indicazione riassuntiva dei break più rilevanti che si sono verificati nell’arco temporale considerato nella nostra analisi è riportata nella tabella seguente (tav. 10.1), in cui si mettono in evidenza, oltre che gli eventi di interesse per quei break, anche in quali relazioni bilaterali hanno avuto influenza.
Tav. 10.1: I break nelle serie storiche
18Si veda la serie relativa ai tassi di interesse statunitensi al § 10.9. 19 Si veda la serie dei tassi di cambio lit./YEN e lit./DM al § 10.9. 20 Si veda la serie dei prezzi dei paesi in questione al § 10.9. 21 Si veda la serie dei tassi di inflazione dei paesi in questione al § 10.9.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 175
ANNO EVENTI Rilevanti nelle relazioni fra:
Italia/Stati Uniti Italia/Germania Italia/Giappone
1979 Formazione dello SME X X
1979 Shock petrolifero (sfavorevole) X X X
1980 Cambiamento delle
politiche monetaria e fiscale statunitense
X
1985 Svalutazione del dollaro X
1992 Uscita dell’Italia dalloSME
X X X
Come si può notare dalla tabella, i break che sembrano avere la maggior rilevanza sul
piano delle relazioni fra l’Italia e gli altri paesi oggetto dell’analisi sono quelli che si sono verificati nel 1979 e nel 1992. Per tale ragione, nel seguito dell’analisi si è deciso di trascurare il break che pare essersi verificato nel 1985.22 Per quanto riguarda il break avvenuto nel 1980 è necessario fare un’osservazione. Dal momento che esso è molto vicino a quello verificatosi nel 1979, non può che essere accorpato a quest’ultimo. Ciò si rende necessario al fine di semplificare l’analisi: infatti, modellizzare due shock così vicini (la distanza temporale è pari a tre trimestri e quindi corrisponde a tre dati nell’analisi econometrica) non è significativo nell’ambito di questo lavoro.23
10.4 L’analisi univariata delle serie storiche Le fondamenta teoriche poste nella prima e nella seconda parte di questo lavoro costituiscono la base di partenza per l’analisi econometrica che ci accingiamo a svolgere. Essa richiede uno studio preliminare delle variabili che entrano in gioco nelle relazioni che vogliamo verificare (legate alla teoria sulla PPP e sulla UIP). Per fare ciò,
22 D’altra parte, ad esso viene dato un peso relativamente piccolo nell’ambito delle relazioni
internazionali anche sul testo di Krugman-Obstfeld, a cui si è fatto riferimento per l’analisi dei break. 23 L’analisi degli aggiustamenti che avvengono fra due break è poco significativa se fatta con soli tre
dati.

Pag. 176 Il ruolo del tasso di cambio nelle relazioni internazionali
è necessario eseguire un’analisi che metta in evidenza le caratteristiche di tali variabili in termini di stazionarietà o non stazionarietà e che rappresenta il punto di partenza dell’analisi multivariata successiva (si veda il § 10.5). In particolare, l’analisi univariata viene svolta effettuando i test di radice unitaria (si veda Said-Dickey (1984)) sia sulle variabili in livelli che sulle loro differenze prime e, in alcune circostanze, come si vedrà in seguito, sulle differenze seconde, al fine di verificare se le componenti del processo sono stazionarie o integrate di ordine 1 o 2.
E′ bene specificare che, nell’ambito di un’analisi multivariata quale è quella da noi svolta, l’uso di tali test non è del tutto appropriato, in quanto non è in grado di tener conto delle interazioni fra variabili, espresse dalle relazioni di cointegrazione.
Ad ogni modo, dall’analisi univariata alcune delle variabili considerate sembrano essere I(2) (si vedano, ad esempio, i valori del test ottenuti per i prezzi italiani nella tavola 10.2a): in tale circostanza, l’analisi multivariata risulta essere piuttosto complessa e gli strumenti econometrici a disposizione per verificare l’ordine di integrazione delle variabili in tali modelli sono pochi e non utili al nostro caso specifico.24
Per quanto riguarda i processi I(2), la teoria che sta alla base della loro modellizzazione esula dagli scopi del presente lavoro, ma riteniamo comunque utile darne un cenno, ricordando che essa fornisce uno spunto per orientare in modo diverso l’analisi del caso applicativo qui proposto.
Come si è visto nella parte I di questo lavoro, la condizione di rango ridotto è quella
che ci permette di introdurre il concetto di cointegrazione, ovvero è quella che ci consente di ricavare relazioni stazionarie fra variabili che sono I(1). Note tali relazioni, il processo multivariato è parametrizzabile in modo tale da evidenziare solo le componenti stazionarie (si veda il teorema di Granger al cap.2). Le condizioni tali per cui si possa parlare di variabili I(1) in un VAR sono le seguenti: 25 - Π ha rango ridotto ed è tale per cui
Π = αβ′ ;
- ψ ha rango pieno ed è tale per cui
ψ = α⊥ ′Γβ ⊥ ;
ciò ci permette di dire che
24 Le tabelle con le distribuzioni asintotiche per la determinazione congiunta del rango di
cointegrazione e del numero di componenti I(2) del processo non esistono per modelli che prevedono la presenza di break strutturali; qualche chiarimento è dato in Johansen (1993) e Paruolo (1993).
25 Per una trattazione teorica formale, si veda la parte I di tale lavoro.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 177
C = β⊥ ψ−1α⊥ ′ .
Se ψ ha rango ridotto, ovvero se è tale per cui
ψ = ϕη′ ,
con ϕ e η matrici (p−r)×s1 e s1< p−r, allora si parla di processi vettoriali in cui sono presenti componenti di tipo I(2).
In tale circostanza, β⊥ , che costituisce il sottospazio delle direzioni non stazionarie nel caso di processi I(1), è a sua volta scomponibile nelle due direzioni β⊥
1 e β⊥2 tali per
cui
β⊥1 = β⊥ η,
con β⊥ matrice di dimensioni p×(p−r) e η di dimensioni (p−r) ×s1 ;
β⊥2 = β⊥ (β⊥ ′β⊥ )−1η⊥ ,
con η⊥ di dimensioni (p−r) ×s2 e s2 + s1 = (p−r). Il processo ha le seguenti proprietà: - β⊥
2 ′zt è l’insieme delle componenti I(2) (zt è il vettore delle variabili che costituiscono
il processo); - β′zt e β⊥
1 ′zt sono gli insiemi delle componenti I(1);
- β⊥1 ′∆zt , β⊥
2 ′∆2zt , β′zt + ω′∆zt sono gli insiemi delle componenti I(0) (ω è una matrice
di pesi dati alle differenze prime delle variabili del processo). Come si può vedere, β′zt è reso stazionario da un’opportuna combinazione delle variabili I(2) differenziate, mentre β⊥
1 ′zt e β⊥2 ′zt sono resi stazionari mediante
differenziazione. Per la stima di tali modelli, gli studi più recenti propongono di seguire una procedura
a due stadi: - nel primo stadio, dato il rango di cointegrazione r, vengono stimati i parametri in α e
in β in un modello in cui non viene posto alcun vincolo di rango ridotto α⊥ ′Γβ ⊥ =ϕη′ ; - nel secondo stadio, dati i parametri in α e in β e dato s1 = (p−r) −s2 , vengono stimati
tutti gli altri parametri nel modello, imponendo il vincolo di rango ridotto α⊥ ′Γβ ⊥ =ϕη′ . Se r e s1 non sono noti a priori, i due stadi precedenti vengono ripetuti, secondo una logica sequenziale alla Pantula, per ogni coppia (r, s1) (con r = 0, 1,…,p e s1 = 0, 1,…, p−r), in modo da calcolare un test per l’ipotesi H rs1
: rango (Π) ≤ r ; rango (α⊥ ′Γβ ⊥ ) ≤

Pag. 178 Il ruolo del tasso di cambio nelle relazioni internazionali
s1 . Il valore viene confrontato con una tabella di valori critici e si seleziona in base alla logica sopra menzionata la prima coppia (r, s1) per cui l’ipotesi H rs1
viene accettata.
Come specificato, in questo lavoro non entriamo nel merito dei modelli I(2); pertanto
l’analisi del grado di integrazione delle variabili verrà fatta basandosi su test univariati di radice unitaria, tenendo conto, nella valutazione dei risultati, del fatto che essa è solo parzialmente valida.
L’output del test è riportato alle tavole 10.2 a e b, le quali richiedono un breve commento.
Il test utilizzato è il test Augmented Dickey Fuller con parametro di troncamento dei ritardi pari a 6. E′ stato scelto questo valore per coerenza con l’analisi dei ritardi eseguita nel paragrafo successivo. I valori tabulati riguardano sia il test condotto su un modello privo di trend (si veda il valore di t(µ)), sia su un modello che prevede stazionarietà attorno ad un trend deterministico (si veda il valore di t(τ)). Ad eccezione dei tassi di interesse, il test è stato effettuato non sulle variabili che costituiscono le serie originarie ma su quelle che sono alla base della modellizzazione considerata per il caso applicativo.26 In particolare si è eseguito il test considerando, come variabili, i tassi di interesse dei diversi paesi (IRITA, IRUSA, IRDEU, IRJAP) e le loro differenze prime, i tassi di cambio in forma logaritmica (LERUSD, LERDM, LERJEN) e le loro differenze prime e il logaritmo dei prezzi (LPRITA, LPRUSA, LPRDEU, LPRJAP), per i quali sono stati effettuati i test di radice unitaria non solo sui livelli e sulle differenze prime, ma anche sulle differenze seconde (i risultati sono tabulati alla tavola 10.2b). Questa ulteriore analisi è stata aggiunta a quella svolta per tutte le altre variabili, in quanto che c’è qualche evidenza a favore della ipotesi che i prezzi siano I(2), come si può vedere dalla tavola 10.2a, in riferimento, soprattutto, ai prezzi italiani, statunitensi e tedeschi.
Tav. 10.2a: Test di radice unitaria
Variabili Livelli delle variabili
Differenze prime delle variabili
t(µµµµ)(a) t(ττττ)(b) t(µµµµ)(a) t(ττττ)(b)
26 Ad esempio, in esso viene contemplata la variabile tasso di inflazione trimestrale, che dal punto di
vista dell’analisi econometrica equivale al differenziale primo dei logaritmi dei prezzi.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 179
LPRITA −2.52 −0.77 −1.71 −2.45 LPRUSA −1.86 −0.99 −2.42 −2.86 LPRDEU −1.21 −2.04 −2.42 −2.63 LPRJAP −3.17* −2.61 −4.9* −5.78* IRITA −1.6 −2.10 −3.55* −3.62* IRUSA −1.38 −1.74 −4.10* −4.45* IRDEU −3.30* −3.38 −3.74* −3.75* IRJAP −1.5 −3.26 −3.87* −3.85*
LERUSD −1.91 −2.00 −3.03* −3.17* LERDM −2.43 −2.67 −3.38* −3.69* LERJEN −1.37 −2.19 −3.48* −3.54*
(a) C.V. 95% = −2.89 (b) C.V. 95% = −3.45 * E′ rifiutata l’ipotesi di radice unitaria.
Le variabili tassi di interesse e logaritmo dei tassi di cambio risultano essere integrate di ordine 1, in quanto dai test risulta che le differenze prime sono I(0). Il test sulla variabile logaritmo dei prezzi differenziata una volta (ovvero sul tasso di inflazione trimestrale) ha dato esiti favorevoli all’ipotesi di presenza di radice unitaria nel caso dei prezzi italiani, statunitensi e tedeschi e, nel caso dei prezzi giapponesi, solo qualora il test sia condotto ipotizzando la presenza di un trend (t(τ)). Pertanto si è proceduto applicando lo stesso test sulle suddette variabili, differenziate due volte. Gli esiti di tale analisi portano ad escludere la presenza di componenti di ordine ancora maggiore, come risulta dalla tavola 10.2b seguente.
Tav. 10.2b: Test univariati di radice unitaria sulle differenze seconde dei prezzi
Variabili Differenze seconde delle Variabili t(µµµµ)(a) t(ττττ)(b)
LPRITA −7.37* −7.37*

Pag. 180 Il ruolo del tasso di cambio nelle relazioni internazionali
LPRUSA −3.42* −3.43 LPRDEU −4.68* −4.71* LPRJAP −7.05* −6.97*
(a) C.V. 95% = −2.89 (b) C.V. 95% = −3.45 * E′ rifiutata l’ipotesi di radice unitaria.
La sintesi dei risultati ottenuti sui test di radice unitaria è data nella tavola 10.3
seguente.
Tavola 10.3: Risultati del test di radice unitaria
Variabili I(1) I(2) LPRITA X LPRUSA X LPRDEU X LPRJAP X(*) IRITA X IRUSA X IRDEU X IRJAP X
LERUSD X LERDM X LERJEN X
(*) Gli esiti sono discordanti per i due test t(µ) e t(τ), in quanto il primo dei due porta ad
accettare l’ipotesi che i prezzi giapponesi siano I(0), mentre il secondo che siano I(1).
10.5 Il modello multivariato Prima di introdurre l’analisi econometrica alla base di questo caso applicativo, è necessario fare una precisazione. Come specificato nel paragrafo precedente, dall’analisi univariata svolta si evidenzia la presenza di componenti I(2) per quel che riguarda le serie storiche dei prezzi. Questo porta ad un problema nell’applicazione dei modelli trattati in questo lavoro, poiché essi

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 181
sono utilizzabili solo in presenza di processi con ordine di integrazione massimo pari ad 1.
Pertanto, per eseguire correttamente l’analisi multivariata dovrebbe essere usato un modello I(2), di cui, tuttavia, non si conoscono ancora le distribuzioni asintotiche del test sul rango di cointegrazione in presenza di dummy, come richiesto dal nostro approccio modellistico.
Dato, comunque, che lo scopo di questo esempio macroeconomico è quello di mostrare l’uso delle tecniche econometriche viste in precedenza, proseguiamo nella direzione dei modelli che hanno a che fare con variabili con ordine massimo di integrazione pari a 1. Per fare ciò, si opera considerando le trasformazioni delle variabili originarie in virtù dei risultati ottenuti al paragrafo precedente e tenuto conto dell’obiettivo di verifica delle relazioni teorizzate dalla economia internazionale. Riportiamo qui il set di variabili su cui abbiamo deciso di focalizzare l’attenzione, per maggiore chiarezza: - il tasso di inflazione trimestrale dei due paesi posti a confronto (DLPRITA e, di volta
in volta, DLPRDEU,DLPRUSA,DLPRJAP), che si determina calcolando le differenze prime del logaritmo dei prezzi;
- i tassi di interesse italiani, ritardati di un passo al fine di rendere conto della omogeneità temporale con il differenziale dei tassi di cambio27 (LIRITA e , a seconda dell’analisi specifica, LIRDEU, LIRUSA, LIRJAP); tali tassi di interesse sono necessari al fine di verificare la UIP;
- il differenziale dei tassi di cambio (DLERDM, DLERUSD, DLERJEN, in base all’analisi specifica), che si ottiene dalle variabili originarie (ERDM, ERUSD, ERJEN), mediante una trasformazione logaritmica e differenziazione. In realtà, dato che il tasso di cambio risulta essere I(1), la sua differenza prima è I(0): tuttavia, se assumiamo che gli agenti siano razionali in senso forte, possiamo ritenere che la variazione del tasso di cambio coincida con quella che gli agenti si attendono. Tale trasformazione delle variabili, si rende necessaria al fine di verificare la PPP relativa e la UIP.
Queste variabili risultano essere integrate di ordine 1, ad eccezione dei differenziali dei tassi di cambio, che risultano essere I(0), e perciò è da attendersi che le relazioni individuabili fra di esse siano stazionarie. Per come sono state definite, tali variabili ci permettono di rimanere nell’ambito di una modellizzazione di processi che siano I(1), equivalente a quella da noi discussa a livello teorico nelle prime due parti di questo lavoro. Ciò è vantaggioso, in quanto, come già detto, lo studio di modelli VAR che
27 Si veda l’equazione (10.2).

Pag. 182 Il ruolo del tasso di cambio nelle relazioni internazionali
presentino variabili I(2) è complesso e confinato ancora ad articoli di tipo metodologico.28
Il fatto di escludere a priori le variabili in livelli presenta tuttavia anche degli svantaggi: ad esempio, operando in tal modo, non risulta possibile testare la PPP assoluta, per la quale sono richiesti nel modello sia i livelli dei prezzi, sia quello del tasso di cambio.
Per quel che riguarda l’introduzione di variabili dummy, atte a catturare i break strutturali incontrati nel § 10.3, si è ritenuto di sintetizzare le informazioni ad esse associate, considerando solo i break più evidenti, ovvero quelli del 1979 e 1992, rispettivamente legati all’istituzione dello SME e all’uscita da quest’ultimo dell’Italia e della Gran Bretagna.
Dal punto di vista delle variabili utilizzate nel modello econometrico, la necessità di tener conto della modellizzazione dei transitori di breve periodo, che sussistono quando le variabili si aggiustano a seguito di shock, ci ha indotto a considerare nel modello descritto nel seguito delle variabili esogene corrispondenti a trend-dummy denominate TDUM1t e TDUM2t e due intervention-dummy chiamate DUM1t e DUM2t. TDUM1t e DUM1t sono definite per il periodo che va dal primo trimestre 1979 al secondo trimestre 1992, mentre TDUM2t e DUM2t sono definite sull’ultimo intervallo di tempo considerato (terzo trimestre 1992 - secondo trimestre 1996).29
In base a queste considerazioni, il modello usato risulta essere simile a quello
indicato come “generale” nell’equazione (9.3) e più precisamente la sua espressione risulta essere
∆Xt = αβ*′X*t-1 + Γ(L) ∆Xt + µ0 + µ1d DUM1t + µ2d DUM2t +
γ1(L)∆(TDUM1t) + γ2(L)∆(TDUM2t) + εt , (10.6)
dove
DUM t110
=≤
se 79:1 < t 92:2 altrimenti,
28 Si veda Johansen (1993) e Paruolo (1993). 29 In base a come è stato parametrizzato il modello, i valori ottenuti per i coefficienti di queste
variabili devono essere sommati a quelli corrispondenti calcolati per la costante e il trend modellizzati nel primo periodo (quello che va dal primo trimestre 1973 all’ultimo del 1978) al fine di valutare la media e la pendenza dell’eventuale trend negli intervalli corrispondenti ai break.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 183
DUM t210
=≥
se t 92:3 altrimenti,
TDUM1t = t DUM1t , TDUM2t = t DUM2t e, infine
X
XTDUMTDUM
t
t
t
t
t−
−
−
−
=
−
1
1
1
1
12
1
* .
Xt è un vettore di dimensione 5 e contiene le variabili relative a: inflazione italiana annuale (DPITA), inflazione annuale del paese estero (a seconda del paese DPUSA, DPDEU, DPJAP), differenze prime dei tassi di cambio nominali su base annuale (a seconda del paese DERUSD, DERDM, DERYEN), il tasso di interesse italiano (LIRITA) e infine il tasso d’interesse del paese estero ( a seconda dei casi LIRUSA, LIRDEU, LIRJAP).
Mentre le variabili “tassi di interesse”, per come sono indicate, corrispondono a quelle definite precedentemente, l’inflazione e i differenziali dei tassi di cambio meritano un’ulteriore specificazione. Precedentemente, infatti, queste variabili sono state calcolate come trimestrali;30 per ottenere le corrispondenti, valutate su base annuale, si è proceduto moltiplicando il loro valore per 4. Tale tipo di trasformazione risulta necessaria al fine di comparare tali variabili con i tassi di interesse31 e per poter quindi testare le ipotesi sulle relazioni macroeconomiche di lungo periodo considerate nell’analisi.
Le analisi bilaterali che seguono, riguardanti le relazioni fra il nostro paese e,
rispettivamente, la Germania, gli Stati Uniti ed il Giappone, sono fatte utilizzando il modello visto sopra.
Tale modello può essere facilmente implementato tramite l’uso del programma MALCOLM, anche se la parte di analisi che sarà eseguita per la determinazione del rango di cointegrazione delle variabili considerate deve essere affidata a strumenti diversi, quali, ad esempio, l’uso della procedura Ranktest che tabula le distribuzioni asintotiche appropriate per tale modello (si veda il § 11.1 e la tavola 10.6, ad esempio).
La modellizzazione dei transitori, nel caso di ipotesi di presenza di break nel DGP, prevede che sia necessario dar peso alle differenze ritardate delle dummy fino all’esaurimento del transitorio stesso, che avviene dopo un numero di istanti coincidente
30 Infatti, per calcolare DLPRITA, DLPRDEU, DLPRUSA, DLPRJAP, DLERDM, DLERUSD e DLERJEN, sono state calcolate le differenze prime dei logaritmi.

Pag. 184 Il ruolo del tasso di cambio nelle relazioni internazionali
con il numero k di ritardi considerati nel modello. A tale fine, come già specificato precedentemente, l’implementazione del modello in MALCOLM viene fatta definendo come esogene le variabili responsabili del trend ad ogni break (le cosiddette “trend-dummy”), mentre le “intervention-dummy” risultano essere necessarie alla modellizzazione del salto.
A tale proposito va ricordato che il modello contempla due break (si veda il § 10.3), ovvero tre regimi. Per evitare problemi di collinearità fra le dummy che definiscono tali shock, è necessario che quelle relative al secondo e terzo periodo, coincidenti con gli intervalli temporali 1979-1992 e 1992-1996, siano espresse in funzione di quella che descrive le tendenze nel periodo 1973-1980. Dal punto di vista della modellizzazione, ciò può essere ottenuto definendo un trend comune a tutte le componenti su tutto l’arco temporale considerato (1973-1996), ovvero definendo nel modello una costante in tutto lo spazio e un trend vincolato nello spazio di α32 e definendo poi due trend-dummy esogene e due intervention-dummy responsabili degli ulteriori cambiamenti di pendenza nel secondo e terzo intervallo temporale.
Il modello così specificato dà modo di eseguire le analisi di interesse per il nostro campione. A tale riguardo ricordiamo che, a causa delle trasformazioni operate sulle variabili in livelli originarie e a causa del numero di ritardi stimati in ogni singola analisi bilaterale, esso risulta esser decurtato di un certo numero di osservazioni (quelle iniziali, per la precisione) e quindi le sue dimensioni sono destinate a diminuire (per la precisione, i dati a disposizione risultano essere pari a 91).
Ogni analisi bilaterale inizia con una fase preliminare necessaria per valutare sia il
numero di ritardi k da cui dipendono le variabili del processo sia il rango di cointegrazione. La fase successiva si concentra sulla determinazione congiunta delle relazioni di cointegrazione, al fine di rendere conto delle ipotesi sottostanti la teoria economica alla base di questo caso applicativo, ovvero dei meccanismi responsabili dell’aggiustamento di lungo periodo nelle interrelazioni economiche dei due paesi.
Dal punto di vista metodologico, i test congiunti sono stati eseguiti imponendo per la
matrice dei vettori di cointegrazione β33 vincoli del tipo
β = (H1ϕ1 , H2ϕ2 , …, Hrϕr),34
31 Che sono, appunto, calcolati su base annua. 32 Si veda la teoria sviluppata nei capitoli 7 e 8. 33 Si veda, per ulteriori chiarimenti, la teoria esposta nella prima parte di questo lavoro ed in
particolare il capitolo 2. 34 Si veda il § 5.3.2.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 185
dove Hi ( con i = 1,…, r) è la matrice p×si di vincoli imposti sul vettore di cointegrazione i-esimo e ϕi è il vettore si×1 di parametri da stimare.
Il numero n di gradi di libertà per il test, che risulta essere distribuito come una χ2(n), è pari a
n = ( )ir
ip r s=∑ − − +1 1 ;(per le tavole di tale distribuzione, si veda, ad esempio, Mood et
al.(1991)). Per ognuna delle singole analisi bilaterali sono stati imposti vincoli diversi, che
verranno analizzati nella sede specifica (si vedano i § 10.6, 10.7 e 10.8). L’accettazione o meno delle ipotesi sulla struttura dei vettori di cointegrazione e la conseguente stima del valore dei coefficienti dei loro elementi per ognuno dei casi esaminati, oltre a quella inerente i coefficienti della matrice di correzione α, ha permesso di trarre interessanti conclusioni sulle relazioni economiche ipotizzate nei paragrafi precedenti di questo capitolo. Esse sono oggetto delle analisi bilaterali che stiamo per sviluppare; in ognuna di esse diamo qualche ulteriore informazione macroeconomica preliminare riguardante i rapporti internazionali fra i paesi interessati dall’analisi specifica, al fine di rendere più chiari i successivi commenti alle relazioni di cointegrazione stimate.
10.6 Analisi Italia/Germania A partire dal periodo successivo al decadimento degli accordi di Bretton Woods, Italia e Germania hanno visto fluttuare liberamente il loro tasso di cambio bilaterale soltanto fino al 1979, quando entrò in vigore il regime dei tassi di cambio fisso fra i paesi aderenti alla Comunità Economica Europea. In realtà quest’ultimo non era destinato ad assumere un valore “fisso” unico, ma gli accordi riguardanti lo SME prevedevano per esso una banda di oscillazione, posta per l’Italia, nei confronti delle altre nazioni europee, ad un valore del ± 6%. La definizione di questo limite ha sempre rappresentato una sorta di “valvola di sicurezza” per il funzionamento dello SME, in quanto il mantenimento del cambio ad un unico valore fisso si sarebbe prospettato troppo difficoltoso per paesi con caratteristiche economiche (in termini di inflazione e disoccupazione) molto differenti.35 Negli anni ′70 e ′80 l’Italia era caratterizzata da un’inflazione particolarmente elevata e una banda di tale ampiezza aveva lo scopo di dare una maggiore libertà di scelta delle politiche monetarie rispetto agli altri paesi della
35 Si pensi, ad esempio, al fatto che, quando lo SME entrò in vigore nel 1979, l’Italia aveva un tasso di
inflazione pari al 12,15%, mentre quello tedesco era pari al 2,7%.

Pag. 186 Il ruolo del tasso di cambio nelle relazioni internazionali
CEE.36 Agli inizi del 1990 l’Italia adottò la banda più ristretta del ± 2,25%, ma l’eccessiva fluttuazione dei prezzi e l’instabilità portarono il nostro paese ad uscire dal sistema dei cambi fissi nel settembre del 1992.
E′ bene ricordare che lo SME subì parecchi riallineamenti nei primi tempi della sua entrata in vigore (ben undici, dal marzo 1979 al gennaio 1987) e che comunque fu un sistema in grado di tenere sotto controllo gli attacchi speculativi alle monete dei diversi paesi membri, mediante controlli valutari che limitavano la vendita della moneta interna da parte dei residenti contro quella straniere. Nel periodo successivo al 1987, la rimozione graduale dei controlli sulle valute ha accresciuto la possibilità di attacchi speculativi e i paesi che hanno rinunciato a questi controlli hanno ridotto notevolmente la loro possibilità di perseguire obiettivi in termini di inflazione e occupazione tramite la politica monetaria nazionale.
La crisi emerse in tutti i paesi aderenti allo SME nel 1992, quando i problemi macroeconomici interni diventarono più urgenti di quelli comunitari, inducendo da un lato un allargamento della banda di oscillazione del cambio fino al ± 15%, dall’altro l’uscita dal regime di cambi fissi da parte dell’Italia.
Si può forse dire che il nostro paese trasse giovamento dalla permanenza nello SME? In altre parole, il sistema monetario europeo ebbe successo nel creare un’area di tassi di cambio stabili? Se l’analisi econometrica evidenziasse una sostanziale equilibrio fra il differenziale dei tassi di inflazione dell’Italia e della Germania (che è il paese scelto come riferimento nell’ambito delle relazioni che l’Italia ha con la Comunità Europea) e la variazione del tasso di cambio, secondo quanto prospettato dalla PPP relativa, a testimonianza dell’integrazione fra le economie dei due paesi, allora la risposta a questa domanda non potrebbe che essere positiva. Da una semplice analisi grafica delle serie plottate (si veda il § 10.9), quel che si può notare è una diminuzione dell’inflazione in Italia dopo il 1980, la quale porta a concludere che siano stati effettuati degli sforzi nel tentativo di far convergere l’inflazione interna a quella dei paesi europei più stabili economicamente.37
La conferma di ciò sembrerebbe data dai risultati che seguono. Il primo passo di tale analisi riguarda la specificazione del modello VAR, la quale
inizia dalla determinazione del suo ordine massimo k. La tavola 10.4 riporta una serie di test utilizzati a tale scopo. Nell’analisi sono stati presi in considerazione tutti i possibili valori di k fino a 6.38 Nella tavola sono riportati i criteri informativi di Akaike (AIC),
36 In ciò era seguita anche da Spagna, Portogallo e Gran Bretagna; per le altre nazioni, la banda era
fissata ad un ± 2,25%. 37 Si veda, ad esempio, Krugman-Obstfeld (1995), pag. 717. 38 La scelta di un valore massimo di troncamento del VAR pari a 6 è dettata dal fatto che disponiamo
di un campione troppo piccolo se confrontato con il numero di parametri da stimare; abbiamo, di
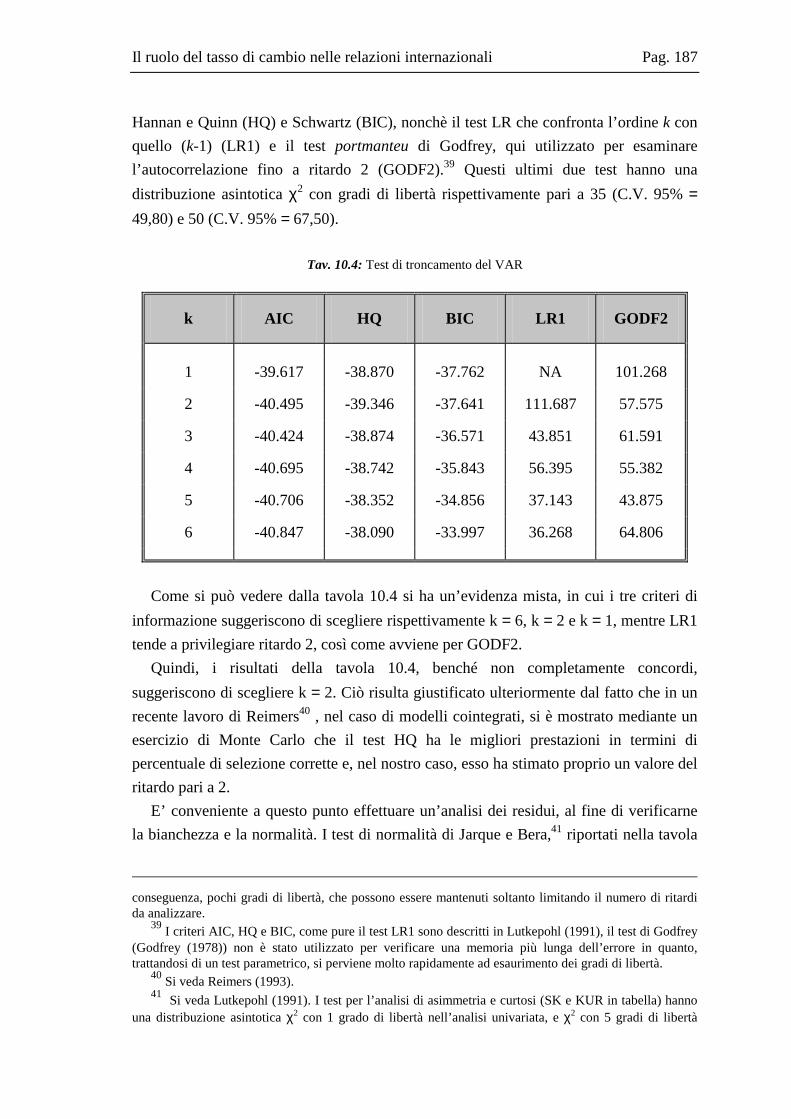
Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 187
Hannan e Quinn (HQ) e Schwartz (BIC), nonchè il test LR che confronta l’ordine k con quello (k-1) (LR1) e il test portmanteu di Godfrey, qui utilizzato per esaminare l’autocorrelazione fino a ritardo 2 (GODF2).39 Questi ultimi due test hanno una distribuzione asintotica χ2 con gradi di libertà rispettivamente pari a 35 (C.V. 95% = 49,80) e 50 (C.V. 95% = 67,50).
Tav. 10.4: Test di troncamento del VAR
k AIC HQ BIC LR1 GODF2
1 -39.617 -38.870 -37.762 NA 101.268
2 -40.495 -39.346 -37.641 111.687 57.575
3 -40.424 -38.874 -36.571 43.851 61.591
4 -40.695 -38.742 -35.843 56.395 55.382
5 -40.706 -38.352 -34.856 37.143 43.875
6 -40.847 -38.090 -33.997 36.268 64.806
Come si può vedere dalla tavola 10.4 si ha un’evidenza mista, in cui i tre criteri di
informazione suggeriscono di scegliere rispettivamente k = 6, k = 2 e k = 1, mentre LR1 tende a privilegiare ritardo 2, così come avviene per GODF2.
Quindi, i risultati della tavola 10.4, benché non completamente concordi, suggeriscono di scegliere k = 2. Ciò risulta giustificato ulteriormente dal fatto che in un recente lavoro di Reimers40 , nel caso di modelli cointegrati, si è mostrato mediante un esercizio di Monte Carlo che il test HQ ha le migliori prestazioni in termini di percentuale di selezione corrette e, nel nostro caso, esso ha stimato proprio un valore del ritardo pari a 2.
E’ conveniente a questo punto effettuare un’analisi dei residui, al fine di verificarne la bianchezza e la normalità. I test di normalità di Jarque e Bera,41 riportati nella tavola
conseguenza, pochi gradi di libertà, che possono essere mantenuti soltanto limitando il numero di ritardi da analizzare.
39 I criteri AIC, HQ e BIC, come pure il test LR1 sono descritti in Lutkepohl (1991), il test di Godfrey (Godfrey (1978)) non è stato utilizzato per verificare una memoria più lunga dell’errore in quanto, trattandosi di un test parametrico, si perviene molto rapidamente ad esaurimento dei gradi di libertà.
40 Si veda Reimers (1993). 41 Si veda Lutkepohl (1991). I test per l’analisi di asimmetria e curtosi (SK e KUR in tabella) hanno
una distribuzione asintotica χ2 con 1 grado di libertà nell’analisi univariata, e χ2 con 5 gradi di libertà
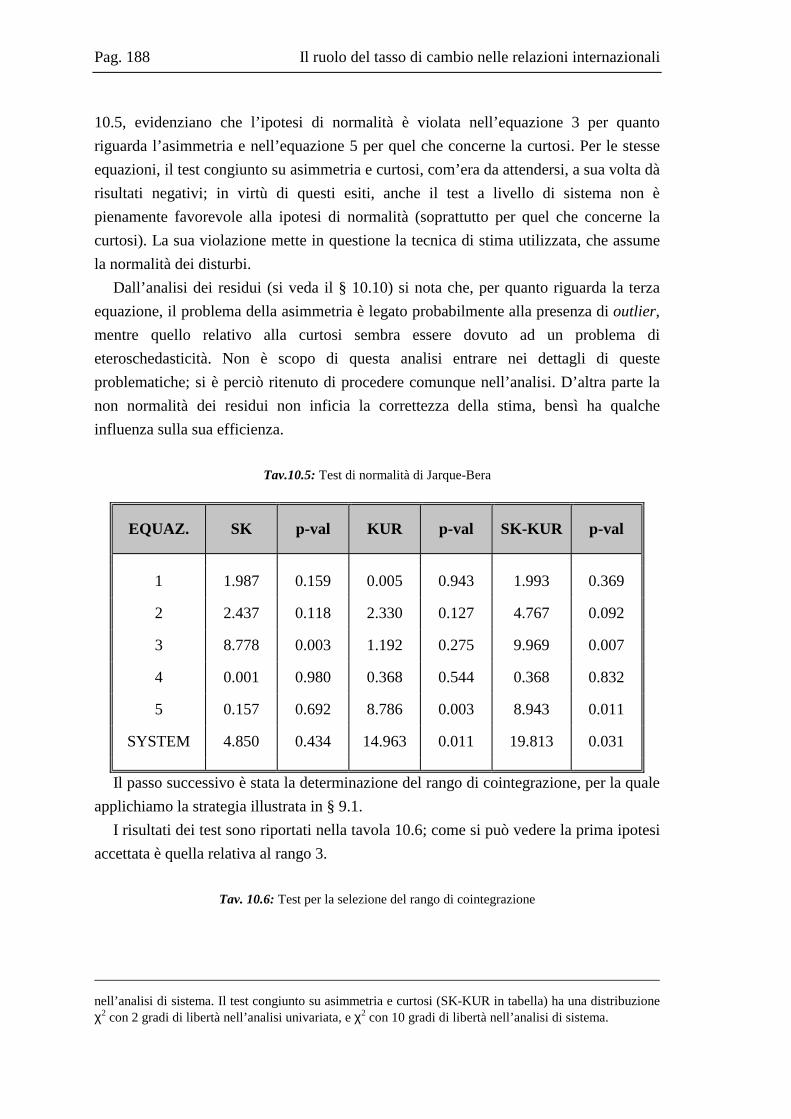
Pag. 188 Il ruolo del tasso di cambio nelle relazioni internazionali
10.5, evidenziano che l’ipotesi di normalità è violata nell’equazione 3 per quanto riguarda l’asimmetria e nell’equazione 5 per quel che concerne la curtosi. Per le stesse equazioni, il test congiunto su asimmetria e curtosi, com’era da attendersi, a sua volta dà risultati negativi; in virtù di questi esiti, anche il test a livello di sistema non è pienamente favorevole alla ipotesi di normalità (soprattutto per quel che concerne la curtosi). La sua violazione mette in questione la tecnica di stima utilizzata, che assume la normalità dei disturbi.
Dall’analisi dei residui (si veda il § 10.10) si nota che, per quanto riguarda la terza equazione, il problema della asimmetria è legato probabilmente alla presenza di outlier, mentre quello relativo alla curtosi sembra essere dovuto ad un problema di eteroschedasticità. Non è scopo di questa analisi entrare nei dettagli di queste problematiche; si è perciò ritenuto di procedere comunque nell’analisi. D’altra parte la non normalità dei residui non inficia la correttezza della stima, bensì ha qualche influenza sulla sua efficienza.
Tav.10.5: Test di normalità di Jarque-Bera
EQUAZ. SK p-val KUR p-val SK-KUR p-val
1 1.987 0.159 0.005 0.943 1.993 0.369
2 2.437 0.118 2.330 0.127 4.767 0.092
3 8.778 0.003 1.192 0.275 9.969 0.007
4 0.001 0.980 0.368 0.544 0.368 0.832
5 0.157 0.692 8.786 0.003 8.943 0.011
SYSTEM 4.850 0.434 14.963 0.011 19.813 0.031
Il passo successivo è stata la determinazione del rango di cointegrazione, per la quale applichiamo la strategia illustrata in § 9.1.
I risultati dei test sono riportati nella tavola 10.6; come si può vedere la prima ipotesi accettata è quella relativa al rango 3.
Tav. 10.6: Test per la selezione del rango di cointegrazione
nell’analisi di sistema. Il test congiunto su asimmetria e curtosi (SK-KUR in tabella) ha una distribuzione χ2 con 2 gradi di libertà nell’analisi univariata, e χ2 con 10 gradi di libertà nell’analisi di sistema.
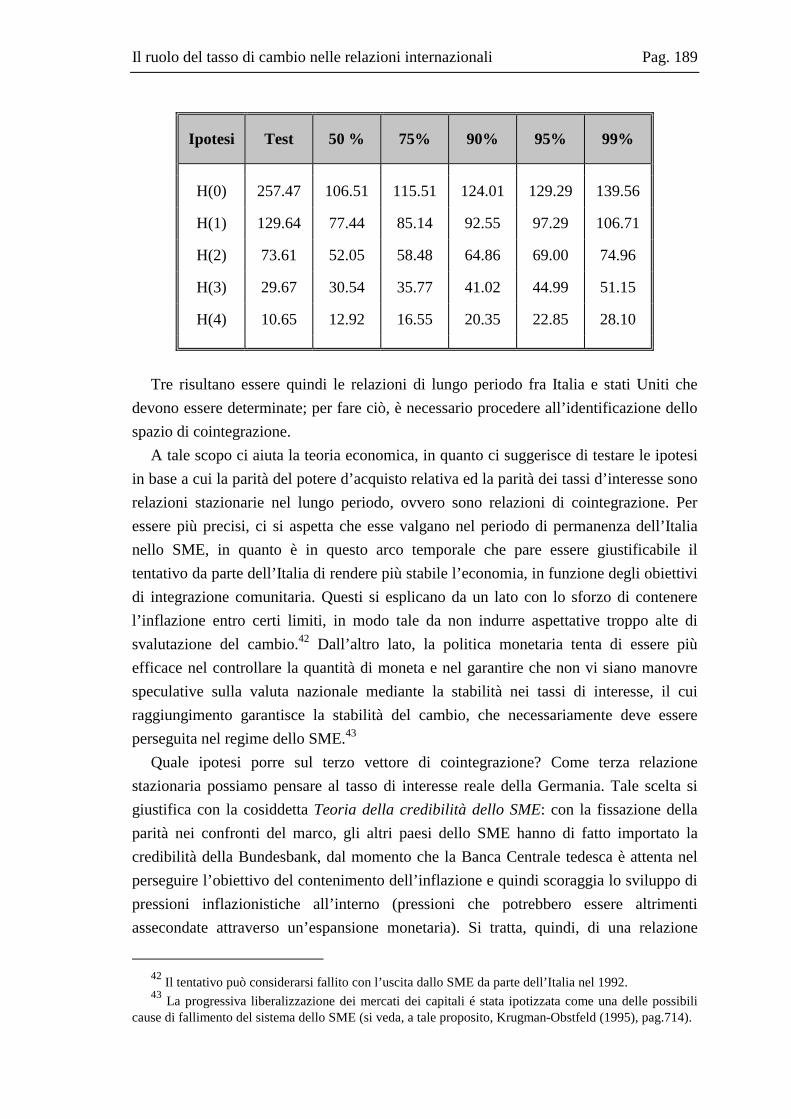
Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 189
Ipotesi Test 50 % 75% 90% 95% 99%
H(0) 257.47 106.51 115.51 124.01 129.29 139.56
H(1) 129.64 77.44 85.14 92.55 97.29 106.71
H(2) 73.61 52.05 58.48 64.86 69.00 74.96
H(3) 29.67 30.54 35.77 41.02 44.99 51.15
H(4) 10.65 12.92 16.55 20.35 22.85 28.10
Tre risultano essere quindi le relazioni di lungo periodo fra Italia e stati Uniti che
devono essere determinate; per fare ciò, è necessario procedere all’identificazione dello spazio di cointegrazione.
A tale scopo ci aiuta la teoria economica, in quanto ci suggerisce di testare le ipotesi in base a cui la parità del potere d’acquisto relativa ed la parità dei tassi d’interesse sono relazioni stazionarie nel lungo periodo, ovvero sono relazioni di cointegrazione. Per essere più precisi, ci si aspetta che esse valgano nel periodo di permanenza dell’Italia nello SME, in quanto è in questo arco temporale che pare essere giustificabile il tentativo da parte dell’Italia di rendere più stabile l’economia, in funzione degli obiettivi di integrazione comunitaria. Questi si esplicano da un lato con lo sforzo di contenere l’inflazione entro certi limiti, in modo tale da non indurre aspettative troppo alte di svalutazione del cambio.42 Dall’altro lato, la politica monetaria tenta di essere più efficace nel controllare la quantità di moneta e nel garantire che non vi siano manovre speculative sulla valuta nazionale mediante la stabilità nei tassi di interesse, il cui raggiungimento garantisce la stabilità del cambio, che necessariamente deve essere perseguita nel regime dello SME.43
Quale ipotesi porre sul terzo vettore di cointegrazione? Come terza relazione stazionaria possiamo pensare al tasso di interesse reale della Germania. Tale scelta si giustifica con la cosiddetta Teoria della credibilità dello SME: con la fissazione della parità nei confronti del marco, gli altri paesi dello SME hanno di fatto importato la credibilità della Bundesbank, dal momento che la Banca Centrale tedesca è attenta nel perseguire l’obiettivo del contenimento dell’inflazione e quindi scoraggia lo sviluppo di pressioni inflazionistiche all’interno (pressioni che potrebbero essere altrimenti assecondate attraverso un’espansione monetaria). Si tratta, quindi, di una relazione
42 Il tentativo può considerarsi fallito con l’uscita dallo SME da parte dell’Italia nel 1992. 43 La progressiva liberalizzazione dei mercati dei capitali é stata ipotizzata come una delle possibili
cause di fallimento del sistema dello SME (si veda, a tale proposito, Krugman-Obstfeld (1995), pag.714).

Pag. 190 Il ruolo del tasso di cambio nelle relazioni internazionali
“interna” al paese estero, volta a verificare, in un certo senso, la sua stabilità a livello economico.
Dal punto di vista dell’analisi econometrica, queste ipotesi definiscono vincoli sui coefficienti di β* che possono essere scritti in forma esplicita mediante le matrici seguenti
H1
1 0 01 0 01 0 0
0 0 00 0 00 1 00 0 10 1 0
=
−−
−
H2
0 0 00 0 01 0 01 0 0
1 0 00 1 00 0 10 1 0
=−
−
H3
01001
000
=−
con le associate matrici dei vincoli in forma implicita
R1
1 1 0 0 01 0 0 0 00 1 0 0 00 0 1 0 00 0 0 1 00 0 0 0 10 0 0 0 00 0 0 0 1
=
R2
1 0 0 0 00 1 0 0 00 0 0 1 00 0 1 0 00 0 1 1 00 0 0 0 10 0 0 0 00 0 0 0 1
=−
R3
1 0 0 0 0 0 00 1 0 0 0 0 00 0 1 0 0 0 00 0 0 1 0 0 00 1 0 0 0 0 00 0 0 0 1 0 00 0 0 0 0 1 00 0 0 0 0 0 1
=
Come si può vedere, i primi cinque vincoli riguardano le relazioni suddette; gli ultimi tre hanno a che fare con i trend modellizzati. In particolare, nelle prime due relazioni si ipotizza l’assenza di trend nel secondo periodo, imponendo che il coefficiente di TDUM1 sia uguale ma di segno opposto a quello del trend. Il coefficiente di TDUM2 , al contrario, è libero di assumere qualsiasi valore.
Nella terza relazione, invece, i vincoli sui trend sono posti in modo tale da annullarli in tutti e tre i periodi considerati nell’analisi.
Sulla base della teoria di identificazione, tutte le equazioni risultano identificate ed il
numero di vincoli è pari a 11; il test LR, distribuito secondo una χ2 con 11 gradi di libertà, assume valore 18.66 ( p-value = 0.07 ). L’ipotesi è pertanto accettata.
Le stime vincolate sono le seguenti

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 191
(DERDM − DPITA + DPDEU) = + 0.0032 t − 0.0032 TDUM1 +
− 0.0258 TDUM2 − 0.0338 +
+ 0.0257 DUM1 + 2.1015 DUM2 + z1
(LIRITA − LIRDEU − DERDM) = + 0.0021 t − 0.0021 TDUM1 +
− 0.0121 TDUM2 − 0.1075 +
+ 0.1289 DUM1 − 2.1591 DUM2 + z2
(LIRDEU − DPDEU) = 0.0326 + 0.0201 DUM1 + 0.0121 DUM2 + z3
In figura 10.1 sono riportati i grafici delle componenti stazionarie stimate, incluse la loro parte deterministica e quella stocastica.
Come si può notare dai grafici, la prima componente sembra essere stazionaria
attorno ad un trend nel primo e nel terzo regime; la PPP relativa, che è la relazione sottesa a tale componente, nei suddetti periodi parrebbe allora non essere verificata: in essi si osserva che qualora il cambio sia lasciato libero di fluttuare, il divergere dei tassi di inflazione dei paesi considerati non è catturato dalle variazioni che il tasso di cambio subirà nel futuro. In altre parole, ciò significa che i tassi di cambio non si adeguano per compensare le differenze che si hanno fra i tassi di inflazione dei paesi oggetto dell’analisi. La non stazionarietà attorno a una costante che pare sussistere in tali intervalli temporali non è priva di significato dal punto di vista degli eventi che si sono verificati a livello internazionale: infatti, nel primo dei due periodi, lo SME non era stato ancora istituito, mentre dopo il 1992 l’Italia ne uscì. Quest’ultimo fatto fu sintomatico di una crisi che intaccò il sistema vigente dello SME:44 molti dei paesi che vi aderivano non erano in grado di contenere l’inflazione entro limiti imposti dall’obiettivo di integrazione del mercato europeo (resa operativa dal sistema dei cambi fissi) e l’Italia fu uno di quelli che più drasticamente subì tale crisi.
Ciononostante, dall’analisi econometrica pare risultare che durante il periodo di permanenza dell’Italia nello SME gli sforzi messi in atto per contenere l’inflazione ed
44 Nell’agosto del 1993 la banda di fluttuazione ammessa per la maggior parte delle monete dello
SME sono state ampliate al ±15% in risposta ai continui attacchi speculativi.

Pag. 192 Il ruolo del tasso di cambio nelle relazioni internazionali
allinearsi alle economie più stabili (ad esempio, quella tedesca) abbiano dato qualche risultato positivo.
Infatti, osservando il grafico della prima componente stazionaria nel secondo regime, relativo alla permanenza del nostro paese nello SME, si nota che la tendenza di tale componente si annulla e che la media della relazione stazionaria è prossima allo zero (8.2 10-3 ). Questo sembrerebbe mostrare che la PPP relativa valga in tale regime, ovvero che la convergenza dei tassi di inflazione dei paesi considerati, associata alla stabilità del cambio, sia stato un obiettivo effettivamente raggiunto.45
Per quel che concerne la seconda relazione di cointegrazione identificata, legata alla parità dei tassi di interesse, quel che si nota è l’assenza di trend da tale relazione nel secondo dei due intervalli temporali considerati, ovvero in quello coincidente con la permanenza dell’Italia nello SME. Tuttavia, la media della relazione stazionaria non risulta essere pari a zero, ma assume il valore 0,0214.46 Ciò significa che la UIP non è verificata in senso “stretto”, ovvero in quello specificato dall’equazione (10.2), bensì sembra essere verificata secondo quanto espresso dall’equazione (10.3). Essa tiene conto, per la valutazione dell’equilibrio nel mercato dei cambi, di un premio per il rischio, che riflette la maggiore rischiosità dei titoli italiani rispetto a quelli tedeschi, dovuta al fatto che il debito pubblico italiano è alto. Gli investitori sono disposti ad acquistare quote di tale debito solo se sono compensati da un premio maggiore, che tenga conto appunto del rischio assunto nel detenerle.
La terza relazione riguarda il tasso di interesse reale tedesco. Il grafico relativo a tale relazione pare confermare il fatto che esso sia privo di trend in tutti e tre i periodi considerati, anche se con valor medio differente. Da un valore del 3.26% si passa, nel periodo relativo allo SME, ad un valore del 5.27%, a testimonianza di un controllo ancora più stretto della Bundesbank, in tale intervallo temporale, sui tassi di interesse nominali, messo in atto con l’obiettivo di cautelarsi da eventuali pressioni sul tasso di cambio, indesiderate in un regime di cambi fissi. Nell’ultimo periodo esso scende al 4.47%. Ciò potrebbe essere giustificato analizzando gli eventi economici successivi all’unificazione tedesca: la spinta inflazionistica, dovuta ad un aumento della spesa da parte dei tedeschi dell’Est (i quali avevano ricevuto sovvenzioni in marchi dall’Ovest), probabilmente non fu compensata dall’ulteriore stretta monetaria attuata dalla Banca Centrale tedesca.
A tale proposito, è necessario specificare che questa politica creò in qualche modo scompiglio nelle economie degli altri paesi europei, alle prese con la recessione
45 Per una conferma di quanto detto, si veda Krugman-Obstfeld (1995), pag. 717, fig. 21.2. 46 Tale valore, è dato da − 0.1075 + 0.1289 DUM1, con DUM1 = 1 nell’intervallo considerato.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 193
economica, dovuta sia all’espansione della domanda aggregata in Germania,47 sia al concomitante rallentamento dell’economia statunitense. La decisione da parte della Germania di aumentare i tassi di interesse pose gli altri paesi dello SME nel dilemma di dover scegliere fra la svalutazione della moneta nazionale e l’aumento dei propri tassi di interesse, al fine di mantenere le parità dello SME. Per quanto riguarda l’Italia, essa reagì uscendo dal sistema dei cambi fissi; di conseguenza, la variazione attesa del tasso di cambio non fu più in grado di catturare il differenziale nei tassi di interesse dei due paesi, la cui fluttuazione ha finito con l’essere indipendente con quella del tasso di cambio, come si può vedere dal grafico relativo alla seconda componente stazionaria (quella che rappresenta la UIP) nel terzo regime, ovvero in quello successivo al 1992. In esso, come nel primo regime, si può notare che la relazione risulta stazionaria attorno ad un trend, il che potrebbe essere spiegato dal fatto che non ci si trova più in un regime di cambi fissi e, quindi, le variazioni del tasso di cambio non sono in grado di spiegare il differenziale dei tassi d’interesse.
Riassumendo, i risultati empirici di questa analisi sembrano evidenziare il fatto che, quantomeno nel periodo corrispondente allo SME, la parità del potere d’acquisto e quella dei tassi di interesse, aggiustata per tener conto del premio per il rischio, si sono verificate. Ciò sembra favorire l’idea in base a cui un sistema di tassi di cambio fissi è in grado di rendere più stabili le economie dei paesi che vi aderiscono, in quanto garantisce una maggiore stabilità economica.
47 Con il conseguente aumento dei tassi di interesse in Germania e nei paesi dello SME (si veda anche
il grafico relativo alla seconda componente stazionaria di questa analisi).
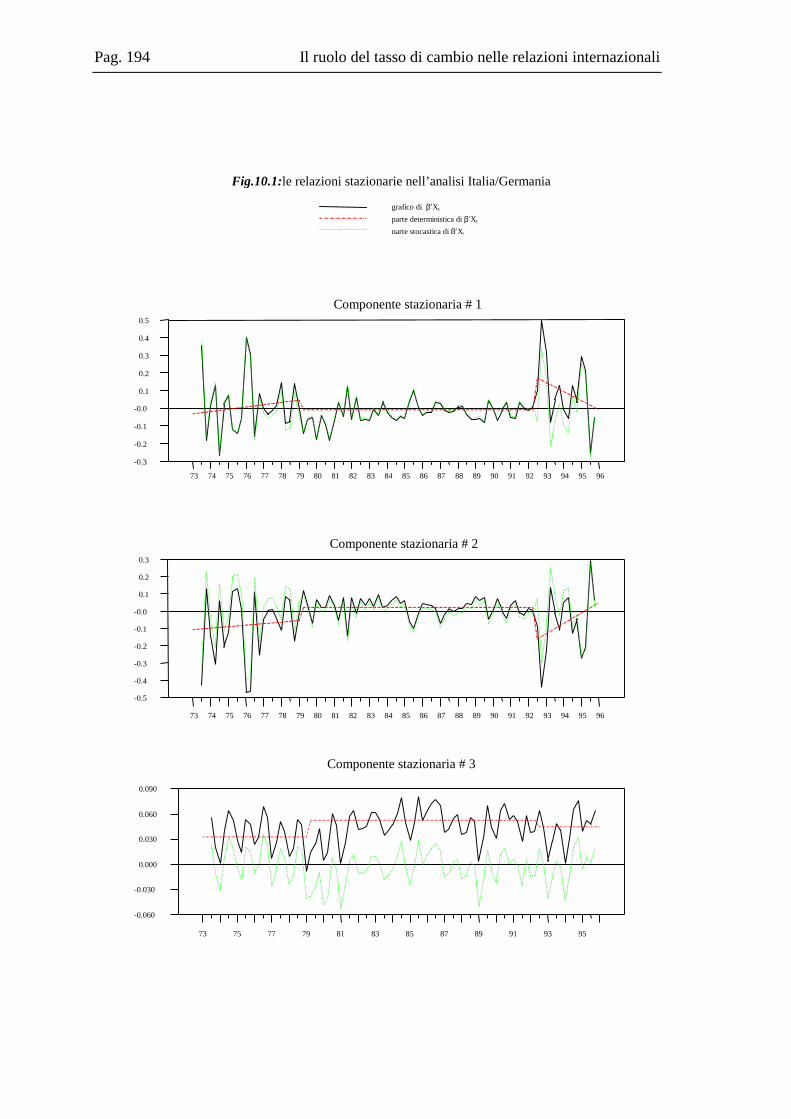
Pag. 194 Il ruolo del tasso di cambio nelle relazioni internazionali
Componente stazionaria # 1
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.3
-0.2
-0.1
-0.0
0.1
0.2
0.3
0.4
0.5
Fig.10.1:le relazioni stazionarie nell’analisi Italia/Germania grafico di β′Xt parte deterministica di β′Xt parte stocastica di β′Xt
Componente stazionaria # 2
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.5
-0.4
-0.3
-0.2
-0.1
-0.0
0.1
0.2
0.3
Componente stazionaria # 3
73 75 77 79 81 83 85 87 89 91 93 95
-0.060
-0.030
0.000
0.030
0.060
0.090
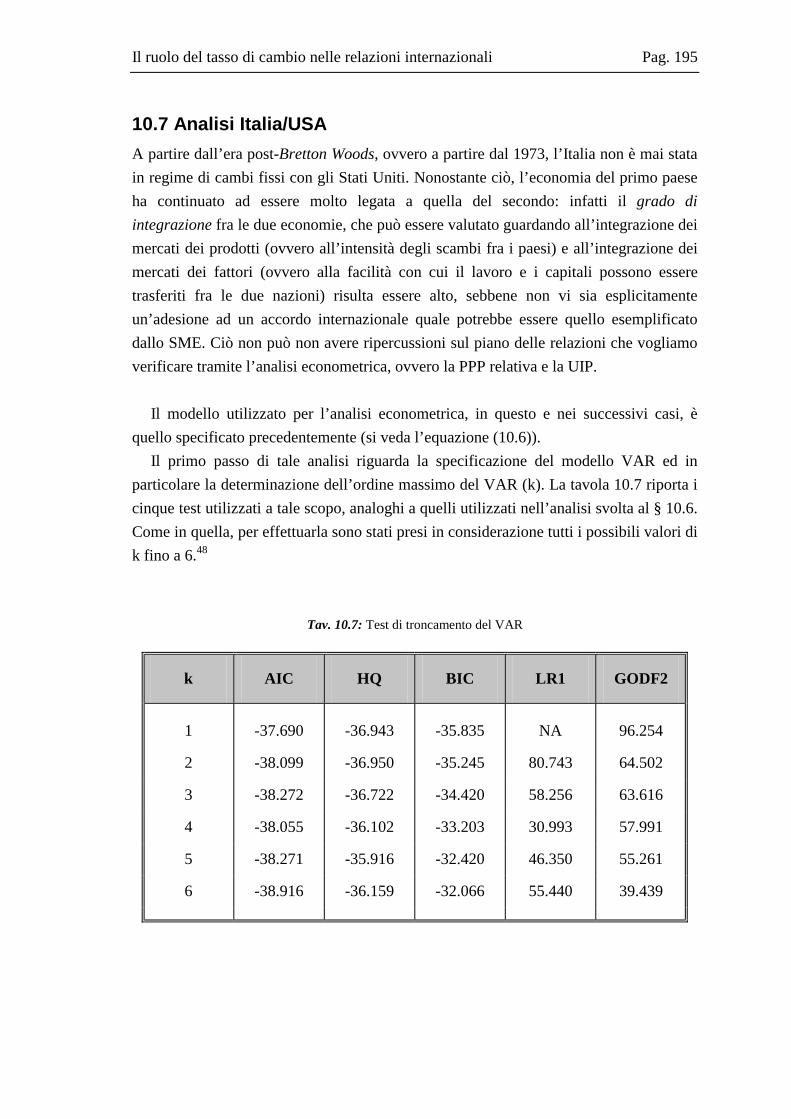
Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 195
10.7 Analisi Italia/USA A partire dall’era post-Bretton Woods, ovvero a partire dal 1973, l’Italia non è mai stata in regime di cambi fissi con gli Stati Uniti. Nonostante ciò, l’economia del primo paese ha continuato ad essere molto legata a quella del secondo: infatti il grado di integrazione fra le due economie, che può essere valutato guardando all’integrazione dei mercati dei prodotti (ovvero all’intensità degli scambi fra i paesi) e all’integrazione dei mercati dei fattori (ovvero alla facilità con cui il lavoro e i capitali possono essere trasferiti fra le due nazioni) risulta essere alto, sebbene non vi sia esplicitamente un’adesione ad un accordo internazionale quale potrebbe essere quello esemplificato dallo SME. Ciò non può non avere ripercussioni sul piano delle relazioni che vogliamo verificare tramite l’analisi econometrica, ovvero la PPP relativa e la UIP.
Il modello utilizzato per l’analisi econometrica, in questo e nei successivi casi, è
quello specificato precedentemente (si veda l’equazione (10.6)). Il primo passo di tale analisi riguarda la specificazione del modello VAR ed in
particolare la determinazione dell’ordine massimo del VAR (k). La tavola 10.7 riporta i cinque test utilizzati a tale scopo, analoghi a quelli utilizzati nell’analisi svolta al § 10.6. Come in quella, per effettuarla sono stati presi in considerazione tutti i possibili valori di k fino a 6.48
Tav. 10.7: Test di troncamento del VAR
k AIC HQ BIC LR1 GODF2
1 -37.690 -36.943 -35.835 NA 96.254
2 -38.099 -36.950 -35.245 80.743 64.502
3 -38.272 -36.722 -34.420 58.256 63.616
4 -38.055 -36.102 -33.203 30.993 57.991
5 -38.271 -35.916 -32.420 46.350 55.261
6 -38.916 -36.159 -32.066 55.440 39.439
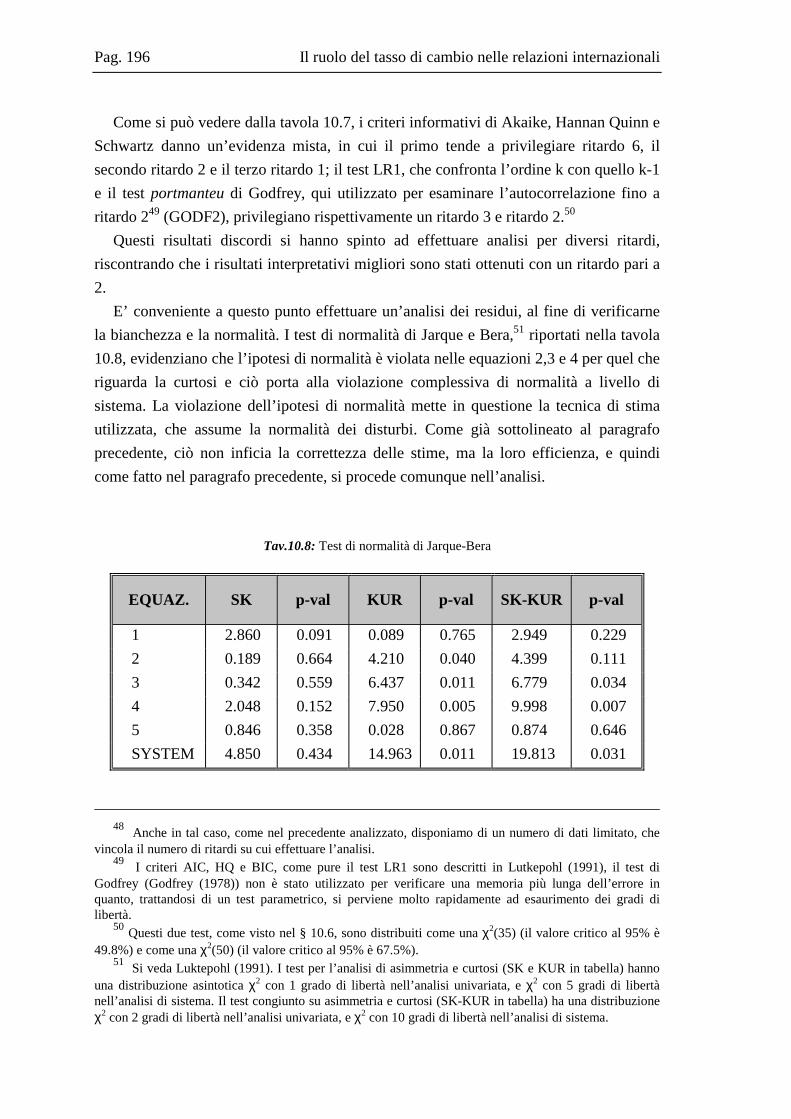
Pag. 196 Il ruolo del tasso di cambio nelle relazioni internazionali
Come si può vedere dalla tavola 10.7, i criteri informativi di Akaike, Hannan Quinn e Schwartz danno un’evidenza mista, in cui il primo tende a privilegiare ritardo 6, il secondo ritardo 2 e il terzo ritardo 1; il test LR1, che confronta l’ordine k con quello k-1 e il test portmanteu di Godfrey, qui utilizzato per esaminare l’autocorrelazione fino a ritardo 249 (GODF2), privilegiano rispettivamente un ritardo 3 e ritardo 2.50
Questi risultati discordi si hanno spinto ad effettuare analisi per diversi ritardi, riscontrando che i risultati interpretativi migliori sono stati ottenuti con un ritardo pari a 2.
E’ conveniente a questo punto effettuare un’analisi dei residui, al fine di verificarne la bianchezza e la normalità. I test di normalità di Jarque e Bera,51 riportati nella tavola 10.8, evidenziano che l’ipotesi di normalità è violata nelle equazioni 2,3 e 4 per quel che riguarda la curtosi e ciò porta alla violazione complessiva di normalità a livello di sistema. La violazione dell’ipotesi di normalità mette in questione la tecnica di stima utilizzata, che assume la normalità dei disturbi. Come già sottolineato al paragrafo precedente, ciò non inficia la correttezza delle stime, ma la loro efficienza, e quindi come fatto nel paragrafo precedente, si procede comunque nell’analisi.
Tav.10.8: Test di normalità di Jarque-Bera
EQUAZ. SK p-val KUR p-val SK-KUR p-val
1 2.860 0.091 0.089 0.765 2.949 0.229 2 0.189 0.664 4.210 0.040 4.399 0.111 3 0.342 0.559 6.437 0.011 6.779 0.034 4 2.048 0.152 7.950 0.005 9.998 0.007 5 0.846 0.358 0.028 0.867 0.874 0.646 SYSTEM 4.850 0.434 14.963 0.011 19.813 0.031
48 Anche in tal caso, come nel precedente analizzato, disponiamo di un numero di dati limitato, che
vincola il numero di ritardi su cui effettuare l’analisi. 49 I criteri AIC, HQ e BIC, come pure il test LR1 sono descritti in Lutkepohl (1991), il test di
Godfrey (Godfrey (1978)) non è stato utilizzato per verificare una memoria più lunga dell’errore in quanto, trattandosi di un test parametrico, si perviene molto rapidamente ad esaurimento dei gradi di libertà.
50 Questi due test, come visto nel § 10.6, sono distribuiti come una χ2(35) (il valore critico al 95% è 49.8%) e come una χ2(50) (il valore critico al 95% è 67.5%).
51 Si veda Luktepohl (1991). I test per l’analisi di asimmetria e curtosi (SK e KUR in tabella) hanno una distribuzione asintotica χ2 con 1 grado di libertà nell’analisi univariata, e χ2 con 5 gradi di libertà nell’analisi di sistema. Il test congiunto su asimmetria e curtosi (SK-KUR in tabella) ha una distribuzione χ2 con 2 gradi di libertà nell’analisi univariata, e χ2 con 10 gradi di libertà nell’analisi di sistema.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 197
Seguendo gli stessi passi del paragrafo 10.6, si determina il rango di cointegrazione. I risultati dei test sono riportati nella tavola 10.9, in cui si vede che la prima ipotesi
accettata è quella relativa al rango 2. Tav. 10.9: Test per la selezione del rango di cointegrazione
Ipotesi Test 50 % 75% 90% 95% 99%
H(0) 167.88 106.51 115.51 124.01 129.29 139.56
H(1) 104.43 77.44 85.14 92.55 97.29 106.71
H(2) 57.59 52.05 58.48 64.86 69.00 74.96
H(3) 32.65 30.54 35.77 41.02 44.99 51.15
H(4) 14.26 12.92 16.55 20.35 22.85 28.10
Le due relazioni di cointegrazione che l’analisi economica suggerisce di testare
riguardano la PPP relativa e la UIP. Per testare queste ipotesi, sono stati imposti vincoli sui coefficienti di β* scritti, in
forma esplicita, mediante le matrici
H1
1 0 0 01 0 0 0
0 1 0 00 0 0 00 0 0 00 0 1 00 0 0 10 0 1 0
=
−
−
H 2
0 0 00 0 01 0 01 0 0
1 0 00 1 00 1 00 0 1
=−
−
a cui sono associate le matrici dei vincoli in forma implicita

Pag. 198 Il ruolo del tasso di cambio nelle relazioni internazionali
R1
1 0 0 01 0 0 00 0 0 00 1 0 00 0 1 00 0 0 10 0 0 00 0 0 1
=
R2
0 0 1 0 00 0 0 1 01 1 0 0 01 0 0 0 00 1 0 0 00 0 0 0 10 0 0 0 10 0 0 0 0
=
−
Dalle matrici si nota come i vincoli sui trend, per quel che riguarda la prima relazione, sono dello stesso tipo di quelli visti per l’analisi Italia/Germania relativamente alle prime due relazioni, ossia riguardano l’eliminazione del trend nel secondo periodo. Per quel che concerne la seconda relazione, si è lasciato libero il coefficiente del trend nel primo periodo, mentre si sono vincolati quelli dei periodi successivi ad avere segno uguale e contrario.
Sulla base della teoria di identificazione, tutte le equazioni risultano identificate ed il numero di vincoli è pari a 7; il test LR, distribuito secondo una χ2 con 7 gradi di libertà, assume valore 10.86 ( p-value = 0.145 ). L’ipotesi è pertanto accettata.
Le stime vincolate sono le seguenti
(DPUSA − DPITA + 0.437 DERUSD) = − 0.0022 t + 0.0022 TDUM1 +
− 0.0061 TDUM2 − 0.0147 +
− 0.0181 DUM1 + 0.7442 DUM2 + z1
(LIRITA − LIRUSA − DLEUSD) = 0.0102 t − 0.0069 TDUM1 +
+ 0.0069 TDUM2 − 0.1629 +
− 0.0176 DUM1 − 1.3289 DUM2
In figura 10.2 sono riportati i grafici delle componenti stazionarie, incluse la loro parte deterministica e quella stocastica.
Quale interpretazione economica dare ad ognuna di esse? Come si può notare dai vincoli imposti, la prima delle due relazioni che sono state
testate non corrisponde alla PPP relativa, dato che il coefficiente davanti a DERUSD non è pari ad uno. Più precisamente, la relazione trovata mostra come le variazioni del tasso di cambio nominale lit./USD crescano ma non della stessa misura al crescere del

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 199
differenziale delle inflazioni tra Italia e USA (l’aumento di una unità del secondo porta ad in aumento pari circa alla metà del primo). In altre parole, la variazione del differenziale del tasso di cambio è una risposta solo parziale a quella delle differenze dei tassi di inflazione.
Osservando il grafico, si nota che questa relazione risulta essere stazionaria una volta depurata dai trend che permangono nei periodi relativi al primo e terzo regime: questo fatto sembrerebbe dimostrare come la relazione sia stabile nel periodo di appartenenza dell’Italia allo SME. Da un lato, ciò può indurre a pensare che l’adesione ad un accordo fortemente vincolante per l’Italia abbia avuto i suoi effetti anche sulle relazioni fra essa e un paese quale gli Stati Uniti, alla cui economia è molto legata. Dall’altro, tuttavia, non conforta il fatto che tali relazioni non riguardino la PPP relativa, la quale non risulta verificata: lo scetticismo circa la verificabilità della PPP relativa come relazione di lungo periodo rimane, quindi, almeno in questa analisi. In ogni caso viene trovata una relazione di cointegrazione tra le variabili coinvolte nella PPP relativa che potrebbe essere vista come una forma debole di tale relazione.
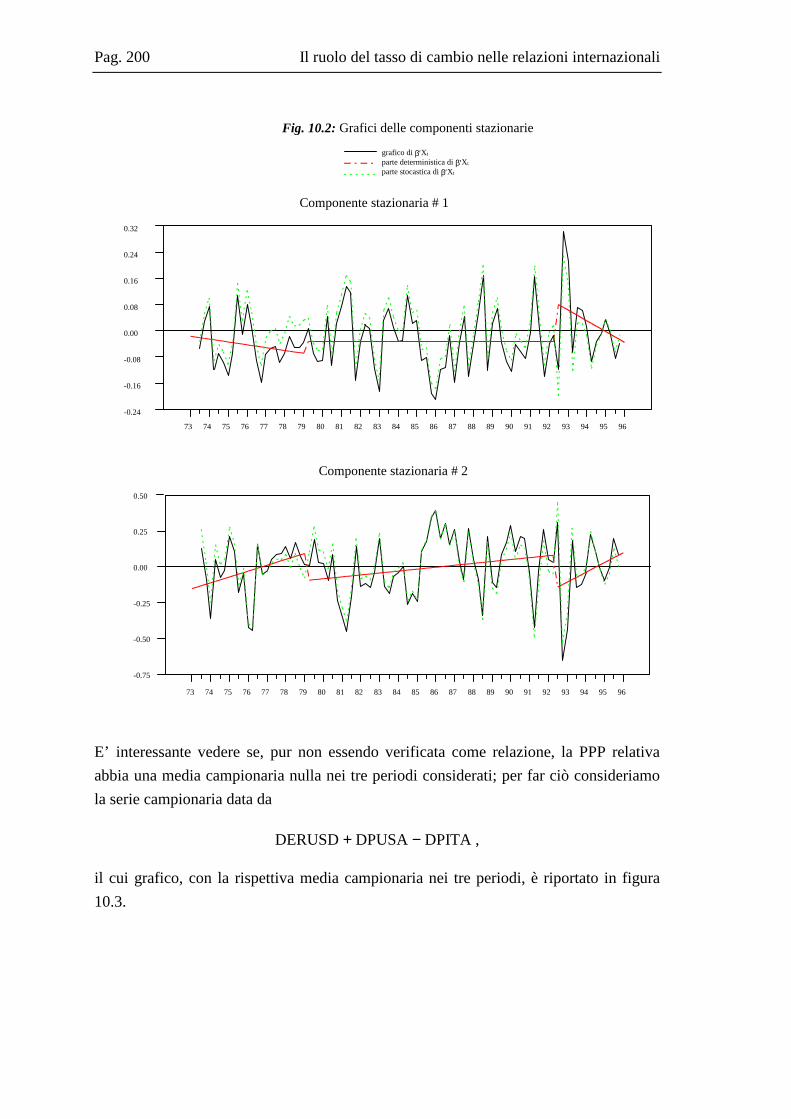
Pag. 200 Il ruolo del tasso di cambio nelle relazioni internazionali
Componente stazionaria # 1
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.24
-0.16
-0.08
0.00
0.08
0.16
0.24
0.32
0.50
Componente stazionaria # 2
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.75
-0.50
-0.25
0.00
0.25
grafico di β′Xt
parte deterministica di β′Xt
parte stocastica di β′Xt
Fig. 10.2: Grafici delle componenti stazionarie
E’ interessante vedere se, pur non essendo verificata come relazione, la PPP relativa abbia una media campionaria nulla nei tre periodi considerati; per far ciò consideriamo la serie campionaria data da
DERUSD + DPUSA − DPITA ,
il cui grafico, con la rispettiva media campionaria nei tre periodi, è riportato in figura 10.3.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 201
73 76 79 82 85 88 91 94-0.50
-0.25
0.00
0.25
0.50
0.75
Fig. 10.3: Grafico della PPP relativa con relativa media campionaria
PPP realtiva media campionaria nei tre periodi
Come si può vedere dal grafico, le medie campionarie dell’espressione della PPP relativa sono prossime allo zero per i primi due periodi (0.00742 e 0.015) e significativamente diversa da zero nel terzo periodo; tuttavia per quest’ultimo i dati sono troppo pochi (15 osservazioni) per trarre una conclusione attendibile. Pertanto, fatta eccezione per l’ultimo regime, sembrerebbe che la PPP relativa, pur non essendo stata accettata come relazione stabile di lungo periodo, abbia una media nulla e ciò porta a pensare che in un certo qual modo il tasso di cambio si muova per compensare i differenziali dei tassi d’inflazione tra i due paesi in esame.
In aggiunta, il grafico 10.3 sembrerebbe suggerire la presenza di un break nel 1985, a conforto di quanto spiegato nel paragrafo 10.3 relativamente ai break strutturali.
Per quanto concerne la seconda relazione stazionaria trovata, essa è equivalente alla verifica della UIP come relazione di lungo periodo. Essa non sembra essere stazionaria: infatti la variabile casuale
LIRITA − LIRUSA − DERUSD
risulta avere una media diversa da zero. Questo risultato potrebbe essere spiegato dal fatto che nella relazione che definisce la
parità dei tassi di interesse (si veda l’equazione (10.2)) si prescinde dal rischio paese ed in particolare da quello associato all’Italia. I commenti alle relazioni determinate nell’analisi Italia/Germania mostrano tuttavia che è necessario tenerne conto, in quanto l’Italia ha una situazione economica incerta, dovuta ad alto debito pubblico, alta

Pag. 202 Il ruolo del tasso di cambio nelle relazioni internazionali
inflazione ed alta disoccupazione. Tale incertezza pare riflettersi soprattutto nel mercato dei capitali, che è molto sensibile a qualsiasi informazione riguardante lo “stato di salute” dell’economia di un paese. Il fatto che questa non sia buona per l’Italia costituisce probabilmente la causa della mancata verifica della UIP.
Infatti, guardando il grafico relativo alla componente stazionaria, si vede come la media (che varia nel tempo ed in particolare negli istanti relativi ai break) sia sempre crescente in ciascuno dei tre regimi considerati. Questo sembrerebbe mostrare come la differenza tra i tassi italiani e quelli statunitensi, una volta depurata dalle variazione attesa sul tasso di cambio, cresca negli istanti di tempo successivi ad ogni break, a testimonianza del fatto che il differenziale dei tassi di cambio non è in grado di far fronte alle differenze fra i tassi di interesse dei due paesi, le quali aumentano sempre più, dal momento che i tassi italiani restano alti, nell’intenzione di riguadagnare credibilità agli occhi delle altre nazioni europee, mentre quelli statunitensi restano bassi, nella necessità di agevolare la ripresa economica.
10.8 Analisi Italia/Giappone Si tratta dell’ultimo dei tre casi analizzati in questo contesto, con riferimento alla verifica della PPP e della UIP. Perché l’analisi si è orientata verso questo paese? La risposta è che l’economia giapponese va assumendo sempre più un ruolo di primo piano a livello mondiale, non solo per quanto riguarda il commercio in beni (si pensi al “classico” mercato delle automobili), ma anche per quel che concerne il livello di integrazione finanziaria con il resto del mondo.52
L’analisi procede secondo gli stessi passi visti nei due paragrafi precedenti e quindi saremo qui più brevi nel descriverli.
La scelta del numero di ritardi viene fatta in base ai risultati tabulati nella tavola 10.10. Il test HQ, LR1 e GODF253 sono concordi nell’accettare un valore di k pari a 2 e perciò si è scelto questo numero di ritardi.
52 Si veda Krugman-Obstfeld (1995), pag.766. 53 Si vedano le note 49 e 50 per chiarimenti sull’implementazione e sulle distribuzioni dei test.
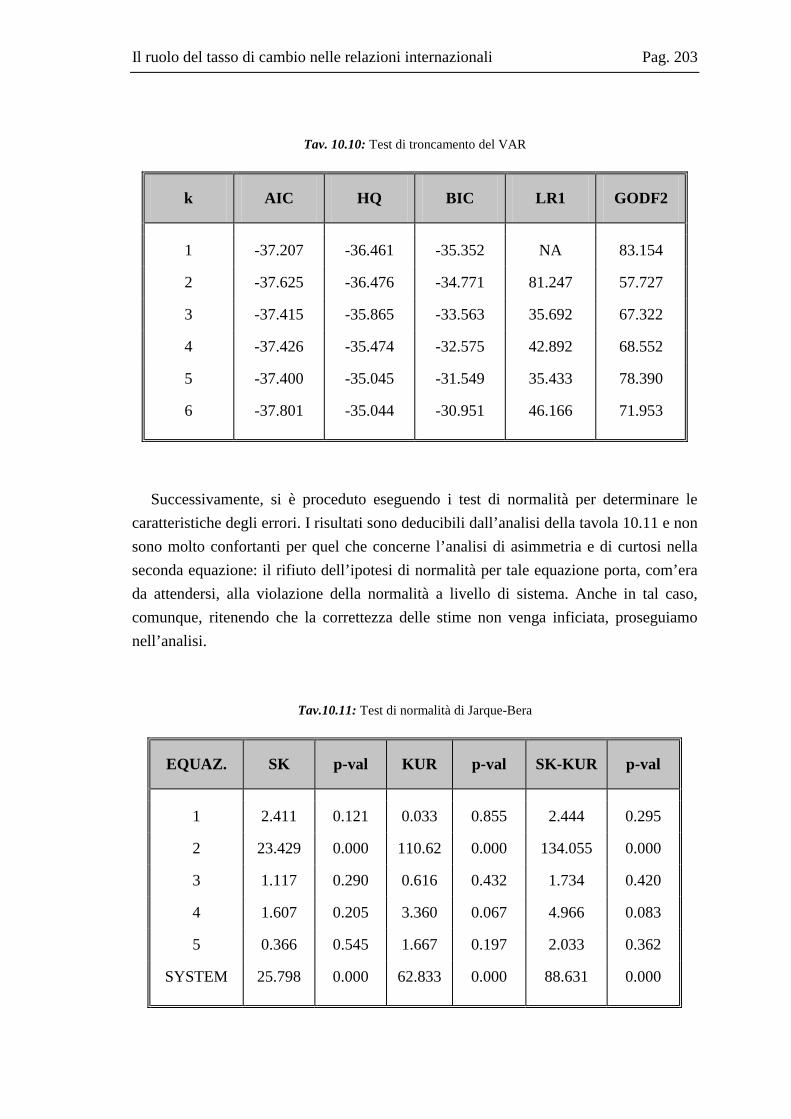
Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 203
Tav. 10.10: Test di troncamento del VAR
k AIC HQ BIC LR1 GODF2
1 -37.207 -36.461 -35.352 NA 83.154
2 -37.625 -36.476 -34.771 81.247 57.727
3 -37.415 -35.865 -33.563 35.692 67.322
4 -37.426 -35.474 -32.575 42.892 68.552
5 -37.400 -35.045 -31.549 35.433 78.390
6 -37.801 -35.044 -30.951 46.166 71.953
Successivamente, si è proceduto eseguendo i test di normalità per determinare le
caratteristiche degli errori. I risultati sono deducibili dall’analisi della tavola 10.11 e non sono molto confortanti per quel che concerne l’analisi di asimmetria e di curtosi nella seconda equazione: il rifiuto dell’ipotesi di normalità per tale equazione porta, com’era da attendersi, alla violazione della normalità a livello di sistema. Anche in tal caso, comunque, ritenendo che la correttezza delle stime non venga inficiata, proseguiamo nell’analisi.
Tav.10.11: Test di normalità di Jarque-Bera
EQUAZ. SK p-val KUR p-val SK-KUR p-val
1 2.411 0.121 0.033 0.855 2.444 0.295
2 23.429 0.000 110.62 0.000 134.055 0.000
3 1.117 0.290 0.616 0.432 1.734 0.420
4 1.607 0.205 3.360 0.067 4.966 0.083
5 0.366 0.545 1.667 0.197 2.033 0.362
SYSTEM 25.798 0.000 62.833 0.000 88.631 0.000
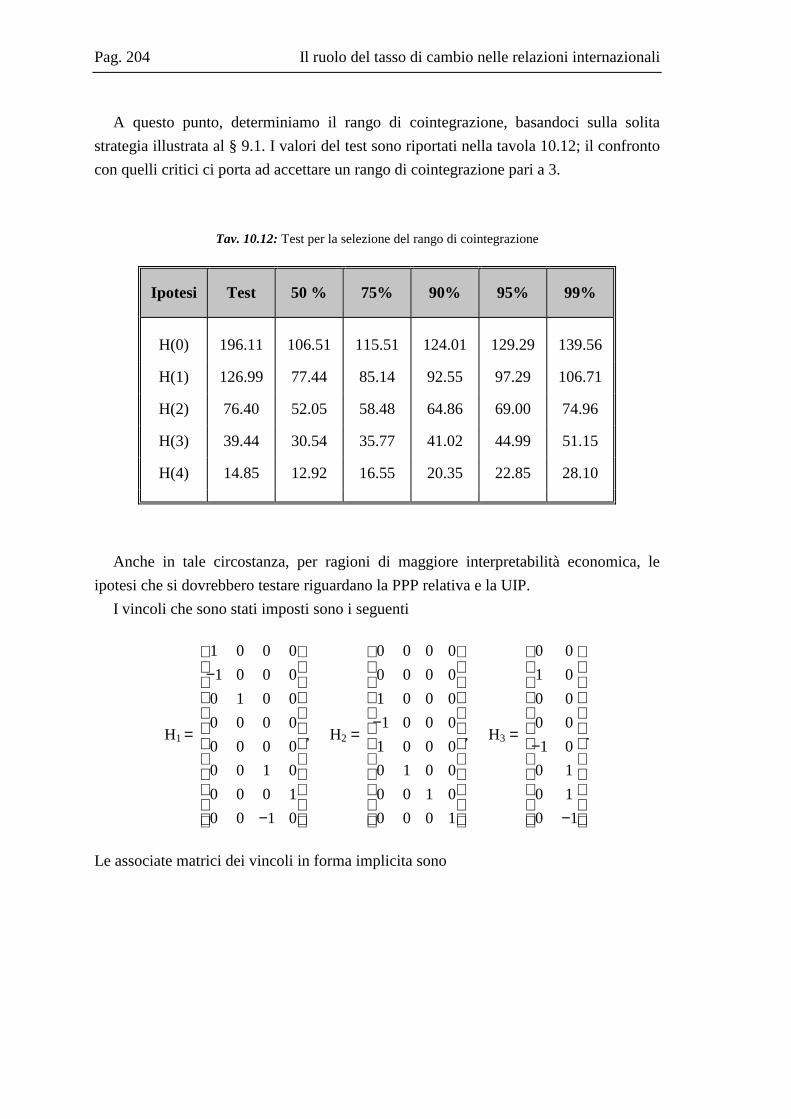
Pag. 204 Il ruolo del tasso di cambio nelle relazioni internazionali
A questo punto, determiniamo il rango di cointegrazione, basandoci sulla solita strategia illustrata al § 9.1. I valori del test sono riportati nella tavola 10.12; il confronto con quelli critici ci porta ad accettare un rango di cointegrazione pari a 3.
Tav. 10.12: Test per la selezione del rango di cointegrazione
Ipotesi Test 50 % 75% 90% 95% 99%
H(0) 196.11 106.51 115.51 124.01 129.29 139.56
H(1) 126.99 77.44 85.14 92.55 97.29 106.71
H(2) 76.40 52.05 58.48 64.86 69.00 74.96
H(3) 39.44 30.54 35.77 41.02 44.99 51.15
H(4) 14.85 12.92 16.55 20.35 22.85 28.10
Anche in tale circostanza, per ragioni di maggiore interpretabilità economica, le
ipotesi che si dovrebbero testare riguardano la PPP relativa e la UIP. I vincoli che sono stati imposti sono i seguenti
H1 =
1 0 0 01 0 0 0
0 1 0 00 0 0 00 0 0 00 0 1 00 0 0 10 0 1 0
−
−
, H2 =
0 0 0 00 0 0 01 0 0 01 0 0 0
1 0 0 00 1 0 00 0 1 00 0 0 1
−
, H3 =
0 01 00 00 01 0
0 10 10 1
−
−
.
Le associate matrici dei vincoli in forma implicita sono

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 205
R1
1 0 0 01 0 0 00 0 0 00 1 0 00 0 1 00 0 0 10 0 0 00 0 0 1
=
, R2 =
1 0 0 00 1 0 00 0 1 10 0 1 00 0 0 10 0 0 00 0 0 00 0 0 0
−
, R3 =
1 0 0 0 0 00 0 0 1 0 00 1 0 0 0 00 0 1 0 0 00 0 0 1 0 00 0 0 0 1 00 0 0 0 0 10 0 0 0 1 1
.
Come si può notare, i vincoli imposti sui trend delle tre relazioni sono del tipo visto per l’analisi Italia/Germania, con la differenza che, nella la seconda relazione, non si annulla il trend del secondo periodo, mentre nella terza non viene annullato quello relativo al primo.
Le equazioni risultano identificate e il numero di vincoli è pari a 8. Il test congiunto è
distribuito come una χ2 con 8 gradi di libertà ed assume valore pari a 9.57 (p-value = 0.296). L’ipotesi è pertanto accettata.
Le stime vincolate ci consentono di scrivere le seguenti relazioni
(DPITA − DPJAP) = 0.449 DERJEN − 0.0079 t + 0.0079 TDUM1 +
− 0.0181 TDUM2 + 0.103 +
− 0.1265 DUM1 + 2.2102 DUM2 + z1
(LIRITA − LIRJAP − DERJEN) = 0.0061 t − 0.003 TDUM1 +
+ 0.0532 TDUM2 − 0.161 +
− 0.0886 DUM1 − 5.1675 DUM2
(LIRJAP− DPJAP) = 0.0066 t − 0.0066 TDUM1 +
− 0.0066 TDUM1 − 0.104 +
+0.1788 DUM1 − 0.1608 DUM2
Analogamente a quanto visto nel § 10.7, la prima componente stazionaria testata non è la PPP relativa. Essa, tuttavia, è la stessa di quella testata nell’analisi svolta in tale paragrafo, ovvero è una relazione che sembra stabilire come, nel lungo periodo, la

Pag. 206 Il ruolo del tasso di cambio nelle relazioni internazionali
differenza percentuale fra il tasso di cambio atteso54 e quello attuale catturi solo parzialmente le differenze che si determinano fra i tassi di inflazione dei due paesi considerati.
Forse non è un caso che sia stata identificata la stessa relazione nei due casi analizzati in questo paragrafo e nel precedente.55 Infatti, le relazioni fra Italia e Stati Uniti e Italia e Giappone, per quanto riguarda il regime dei tassi di cambio, sono le stesse e quindi ci si può aspettare che anche l’aggiustamento nel lungo periodo alle differenze delle inflazioni sia analogo, come si può notare dal confronto fra i grafici delle prime due componenti stazionarie di entrambi i casi (si vedano le figure 10.2 e 10.4).
Se ciò non può essere di aiuto nella interpretazione economica della relazione trovata,56 comunque paiono sorgere dei dubbi sul fatto che il regime di tassi di cambio flessibili sia in grado di garantire la stabilità economica fra vari paesi nel lungo periodo, ovvero la convergenza degli obiettivi di politica economica, attraverso l’aggiustamento dinamico dei tassi di cambio.
La seconda delle equazioni stimate pare confermare il fatto che la UIP non sia una relazione stazionaria, ovvero che nei rapporti fra Italia e Giappone la deviazione dei tassi di interesse italiani da quelli giapponesi non è compensata da una uguale variazione dei tassi di cambio.
Per quanto riguarda la terza, essa ha a che fare con la stazionarietà dei tassi di interesse reali giapponesi. Questa può essere considerata, in un certo senso, una specie di verifica di una relazione “interna” al paese estero considerato per l’analisi bilaterale, atta a determinare se in esso vi sia una qualche relazione che sia indice di stabilità economica.57 I risultati, che sono graficamente riportati nella figura 10.4, in relazione alla terza componente stazionaria, sembrano mostrare che questa stabilità è stata conseguita nel periodo successivo al 1979, anche se in quello antecedente il 1992 il valor medio di assestamento del tasso di interesse reale è più alto. Le ragioni per cui ciò si verifichi non sono del tutto chiare, ma probabilmente tale fenomeno è legato ad una politica più o meno restrittiva attuata nei suddetti periodi da parte del Giappone, influenzata anche indirettamente dalle decisioni prese dai governi europei.
54 In ipotesi di razionalità degli agenti economici, esso coincide con quello effettivo del periodo
successivo. 55 Ricordiamo che, nell’analisi svolta al § 10.6, è stata testata la PPP relativa. 56 l’unica cosa che si può dire, è che viene verificata una sorta di “PPP relativa debole”. 57 La stessa osservazione vale nel caso dell’analisi bilaterale Italia/Germania, in cui viene testata
un’ipotesi simile a questa.

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 207
COMPONENTE STAZIONARIA # 1
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.36
-0.24
-0.12
0.00
0.12
0.24
0.36
COMPONENTE STAZIONARIA # 2
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.75
-0.50
-0.25
0.00
0.25
0.50
0.75
1.00
COMPONENTE STAZIONARIA # 3
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.30
-0.25
-0.20
-0.15
-0.10
-0.05
-0.00
0.05
0.10
Fig.10.4: le relazioni stazionarie nell’analisi Italia/Giappone
grafico di β′Xt
parte deterministica di β′Xt
parte stocastica di β′Xt
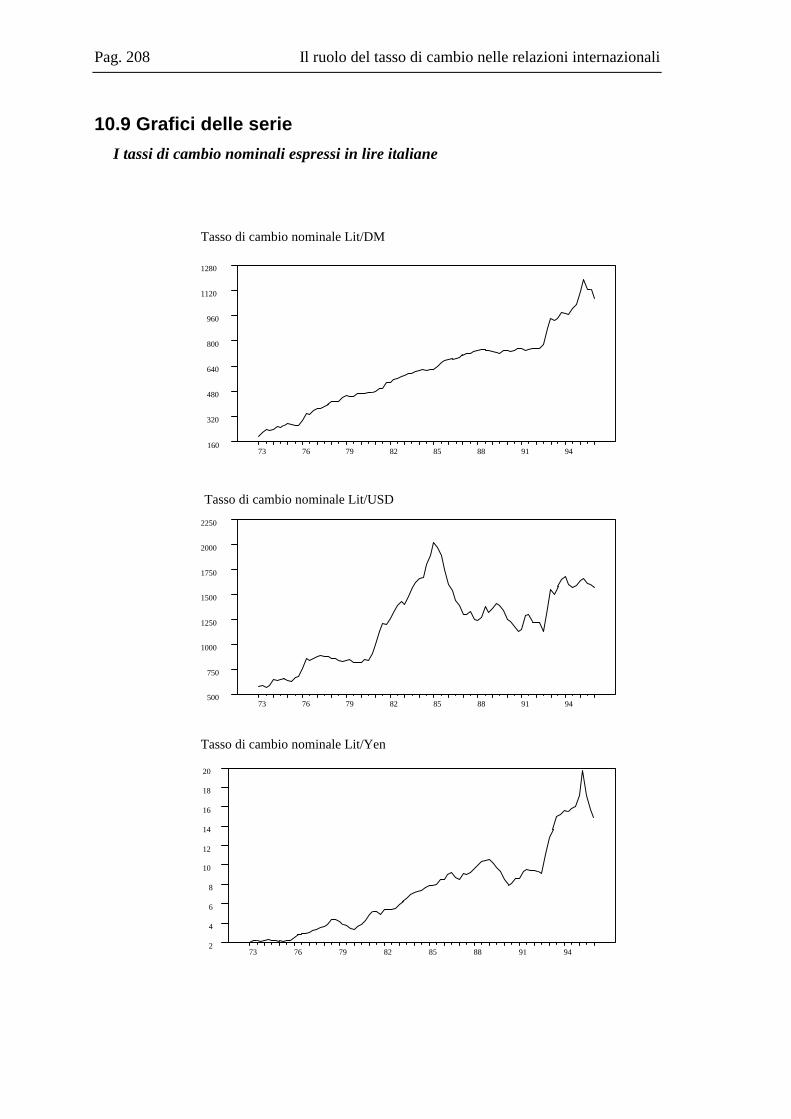
Pag. 208 Il ruolo del tasso di cambio nelle relazioni internazionali
10.9 Grafici delle serie I tassi di cambio nominali espressi in lire italiane
Tasso di cambio nominale Lit/USD
500
750
1000
1250
1500
1750
2000
2250
73 76 79 82 85 88 91 94
Tasso di cambio nominale Lit/DM
160
320
480
640
800
960
1120
1280
73 76 79 82 85 88 91 94
Tasso di cambio nominale Lit/Yen
2
4
6
8
10
12
14
16
18
20
73 76 79 82 85 88 91 94
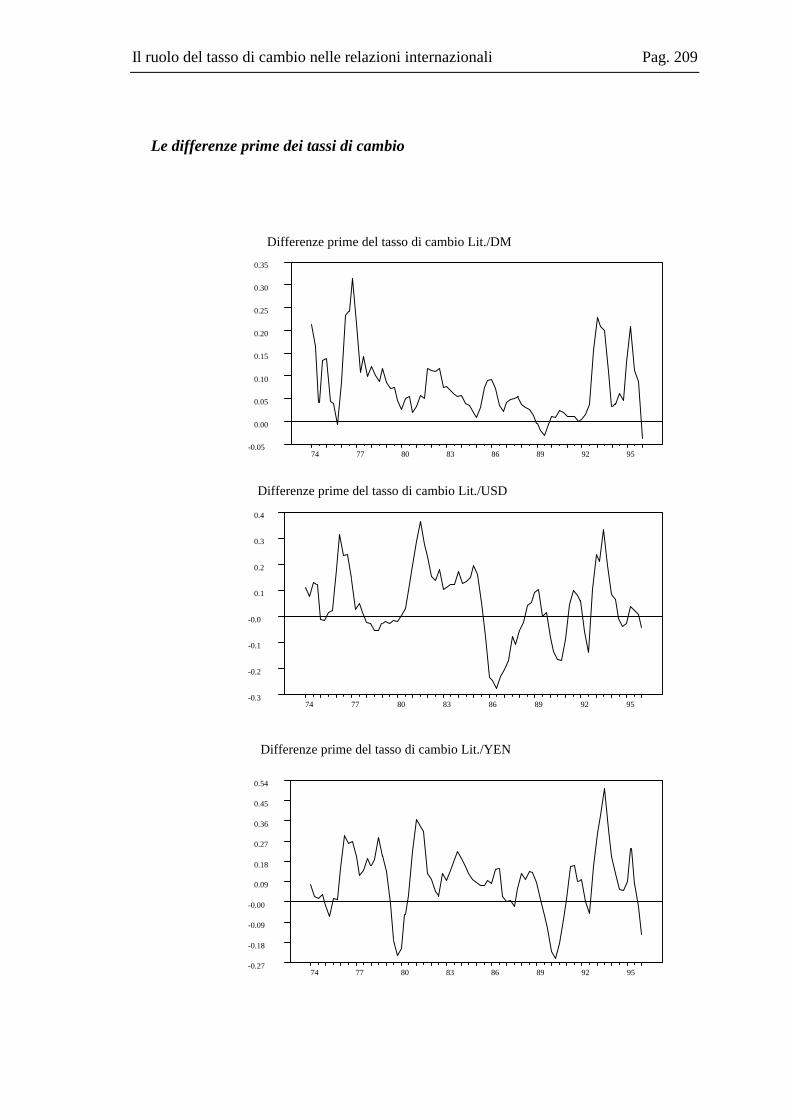
Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 209
Le differenze prime dei tassi di cambio
Differenze prime del tasso di cambio Lit./USD
-0.3
-0.2
-0.1
-0.0
0.1
0.2
0.3
0.4
74 77 80 83 86 89 92 95
Differenze prime del tasso di cambio Lit./DM
74 77 80 83 86 89 92 95-0.05
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
Differenze prime del tasso di cambio Lit./YEN
-0.27
-0.18
-0.09
-0.00
0.09
0.18
0.27
0.36
0.45
0.54
74 77 80 83 86 89 92 95

Pag. 210 Il ruolo del tasso di cambio nelle relazioni internazionali
Il livello dei prezzi nei vari paesi
Livello dei prezzi in Italia
73 76 79 82 85 88 91 940
250
500
750
1000
1250
Livello dei prezzi in USA
73 76 79 82 85 88 91 94100
150
200
250
300
350
400
Livello dei prezzi in Germania
73 76 79 82 85 88 91 94112
128
144
160
176
192
208
224
240
256
Livello dei prezzi in Giappone
73 76 79 82 85 88 91 94100
125
150
175
200
225
250
275
300
325

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 211
Le differenze prime dei logaritmi dei prezzi
Differenze prime del logaritmo dei prezzi italiani
73 75 77 79 81 83 85 87 89 91 93 95
-0.008
0.000
0.008
0.016
0.024
0.032
0.040
0.048
0.056
0.064
Differenze prime del logaritmo dei prezzi tedeschi
73 75 77 79 81 83 85 87 89 91 93 95
-0.005
0.000
0.005
0.010
0.015
0.020
0.025
Differenze prime del logaritmo dei prezzi USA
73 75 77 79 81 83 85 87 89 91 93 95
-0.005
0.000
0.005
0.010
0.015
0.020
0.025
0.030
0.035
0.040
-0.02
0.00
0.02
0.04
0.06
0.08
0.10
Differenze prime del logaritmo dei prezzi giapponesi
73 75 77 79 81 83 85 87 89 91 93 95
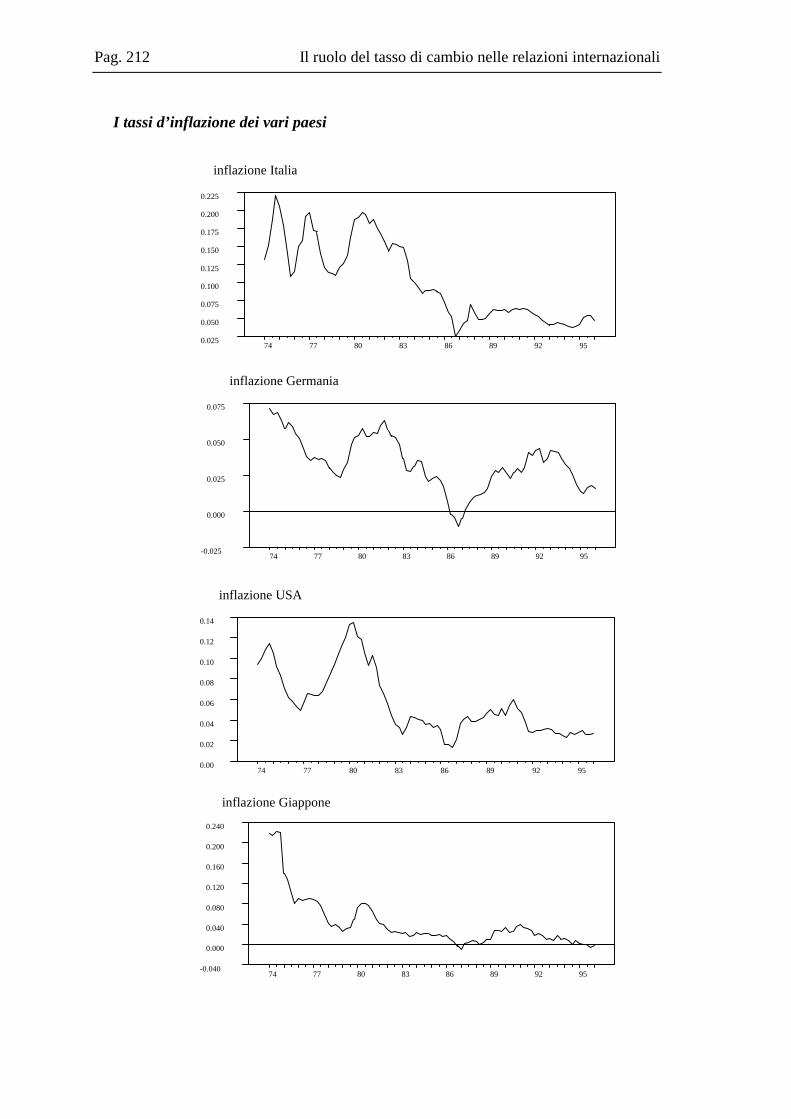
Pag. 212 Il ruolo del tasso di cambio nelle relazioni internazionali
I tassi d’inflazione dei vari paesi
inflazione Italia
74 77 80 83 86 89 92 950.025
0.050
0.075
0.100
0.125
0.150
0.175
0.200
0.225
inflazione USA
74 77 80 83 86 89 92 950.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
inflazione Germania
74 77 80 83 86 89 92 95-0.025
0.000
0.025
0.050
0.075
inflazione Giappone
74 77 80 83 86 89 92 95-0.040
0.000
0.040
0.080
0.120
0.160
0.200
0.240

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 213
I tassi d’interesse nei vari paesi (in punti percentuali)
Tassi di interesse Italia
73 76 79 82 85 88 91 945.0
7.5
10.0
12.5
15.0
Tassi di interesse USA
73 76 79 82 85 88 91 944.8
5.6
6.4
7.2
8.0
8.8
9.6
10.4
11.2
Tassi di interesse Germania
73 76 79 82 85 88 91 945.0
7.5
10.0
12.5
15.0
17.5
20.0
22.5
Tassi di interesse Giappone
73 76 79 82 85 88 91 942
3
4
5
6
7
8
9
10
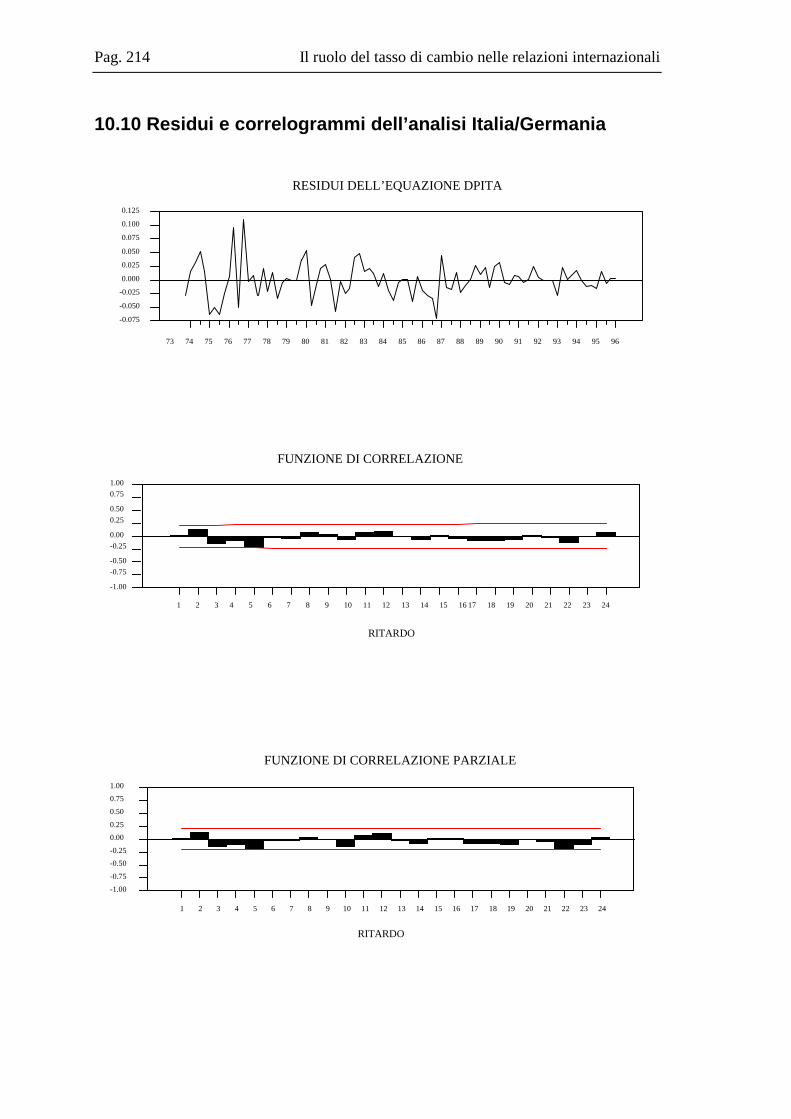
Pag. 214 Il ruolo del tasso di cambio nelle relazioni internazionali
10.10 Residui e correlogrammi dell’analisi Italia/Germania
RESIDUI DELL’EQUAZIONE DPITA
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.075
-0.050
-0.025
0.000
0.025
0.050
0.075
0.100
0.125
RITARDO
FUNZIONE DI CORRELAZIONE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
-1.00
-0.75-0.50
-0.250.00
0.250.50
0.751.00
FUNZIONE DI CORRELAZIONE PARZIALE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
-1.00
-0.75
-0.50-0.25
0.000.25
0.50
0.75
1.00
RITARDO

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 215
RESIDUI DELL’EQUAZIONE DPDEU
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.04-0.03-0.02-0.01
0.000.010.020.030.040.05
RITARDO
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
-1.00-0.75
-0.50-0.25
0.00
0.25
0.500.75
1.00
FUNZIONE DI CORRELAZIONE
FUNZIONE DI CORRELAZIONE PARZIALE
-1.00-0.75
-0.50-0.25
0.000.25
0.50
0.751.00
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
RITARDO
Pag. 216 Il ruolo del tasso di cambio nelle relazioni internazionali
RESIDUI DELL’EQUAZIONE DERDM
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.3
-0.2
-0.1
-0.0
0.1
0.2
0.3
0.4
FUNZIONE DI CORRELAZIONE
RITARDO
-1.00-0.75
-0.50-0.25
0.000.250.500.75
1.00
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
FUNZIONE DI CORRELAZIONE PARZIALE
RITARDO
-1.00
-0.75
-0.50
-0.25
0.00
0.25
0.50
0.75
1.00
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24

Il ruolo del tasso di cambio nelle relazioni internazionali Pag. 217
RESIDUI DELL’EQUAZIONE LIRITA
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.015
-0.010
-0.005
0.000
0.005
0.010
0.015
0.020
RITARDO
FUNZIONE DI CORRELAZIONE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
-1.00-0.75
-0.50-0.25
0.000.25
0.500.75
1.00
FUNZIONE DI CORRELAZIONE PARZIALE
RITARDO
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
-1.00-0.75
-0.50-0.25
0.000.25
0.50
0.751.00
Pag. 218 Il ruolo del tasso di cambio nelle relazioni internazionali
RESIDUI DELL’EQUAZIONE LIRDEU
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
-0.0100
-0.0075
-0.0050
-0.0025
0.0000
0.0025
0.0050
0.0075
0.0100
RITARDO
-1.00-0.75-0.50-0.250.000.250.500.751.00
FUNZIONE DI CORRELAZIONE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
-1.00-0.75
-0.50-0.25
0.000.25
0.50
0.751.00
FUNZIONE DI CORRELAZIONE PARZIALE
RITARDO

Capitolo 11 La simulazione della distribuzione asintotica
del test sul rango di cointegrazione
QUESTO capitolo è dedicato alle simulazioni che sono state effettuate, riguardanti la determinazione delle tavole della distribuzione asintotica del test sul rango di cointegrazione, di cui si è discusso al capitolo 3.
Il valore del trace-test, ad ogni iterazione, viene ricavato applicando ad un campione di dimensione ampia ma finita la teoria sui moti browniani. La discretizzazione di tali moti, unitamente alle considerazioni legate alla modellizzazione del processo per quel che riguarda la parte deterministica, permette di ricavare la forma opportuna dei fattori che compaiono nell’espressione del trace-test e, di conseguenza, il valore dello stesso.
11.1 L’espressione del trace-test per la simulazione della distribuzione asintotica
Come visto al capitolo 3, la distribuzione asintotica per il test sul rango di cointegrazione è data dall’espressione
tr ( ) ( )dB F FF du F dB′ ′
′
∫ ∫∫
−
0
1 1
0
1
0
1
(12.1)
Nel caso di campioni di dimensioni finite T, tale distribuzione viene approssimata da
tr [ ]ε εt t t t t tt
T
t
T
S S S S′ ′ ′
−
==∑∑ 1
11
(12.2)
dove St è scelto opportunamente, in base al modello che stiamo ipotizzando come contenente il DGP.

Pag. 220 la simulazione dela distribuzione asintotica del test sul rango di cointegrazione
Per quanto riguarda l’implementazione delle simulazioni necessarie per tabulare le
distribuzioni asintotiche del test di rango, è necessario fare una precisazione. La conclusione che possiamo trarre dalla teoria asintotica è che il test statistico per l’ipotesi che il rango sia r contro l’alternativa che sia p, espressa come -2logQ(H(r)/H(p)), coincide con quella che testa l’ipotesi H(0) in H(p-r). Ciò, ad esempio, significa che testare Π=0 nel modello
∆Χt = ΠΧ t-1 + εt , con Π di dimensione (p−r)×(p−r), significa simulare il sistema di dimensione (p−r) espresso da
∆Χt = εt , per t=1, … , T e εt i.i.d.∼ N(0, I).
Sommando su t si ha
Xt = ε ii
t
=∑
1
+ X0 ,
ovvero si ha il random walk. Le tavole statistiche risultano quindi tabulate sulla base del numero di direzioni non
stazionarie. Come si è detto, St che compare nell’equazione (12.2) è il corrispondente nel tempo
discreto di F nella equazione (12.1); a seconda del modello che stiamo considerando, F assume forma e dimensioni diverse e di conseguenza anche St varierà nella simulazione. L’espressione che St assume di volta in volta e che può essere dedotta guardando all’input del programma al § 12.3 è definita per ogni modello, in base al termine deterministico a correzione del processo autoregressivo, come segue.
Assenza del termine deterministico Il vettore F che compare nell’espressione del trace-test è il moto browniano normalizzato Bi (u), con u∈[ 0,1], di dimensioni p−r. In tal caso, allora , St è il random walk Xt-1 .
Processo corretto per una costante L’espressione per F risulta essere la seguente

La simulazione della distribuzione asintotica del test sul rango di cointegrazione Pag. 221
Fi (u) = Bi (u) i = 1, … , p−r
Fi (u) =1(0,1 ] i = p − r +1
e di conseguenza, nella simulazione, St risulta essere il vettore (Xt-1′, 1)′ per ogni t, dove Xt-1′ è un moto browniano di dimensioni p−r.
Processo corretto per un trend L’espressione per F è la seguente
Fi (u) = Bi (u) −Bi = Bi (u)− B u dui ( )0
1
∫ i = 1, … , p−r
Fi (u) = u − u (du0
1
∫ ) = u − 12
i =p−r+1
e quindi St è dato da (Xt-1′−Χ′ , t − 1/2(T + 1))′, in cui Xt-1 è un random walk corretto per la mediaΧ , di dimensioni p−r.
Processo corretto per più break Il break che si verifica può sortire due effetti sul processo, ovvero può causare una variazione della media oppure del trend nell’intervallo temporale considerato.
In tal caso, l’espressione di F è una generalizzazione di quella vista precedente per i casi in cui il processo sia autoregressivo una volta depurato da una costante o da un trend unici su tutto l’intervallo campionario.
Supponiamo che i regimi siano pari a n+1 (ciò equivale a dire che i break sono n). Allora, nel caso in cui i break causino una variazione della media del processo, ovvero siano rappresentabili da una dummy a scalino, F ha la seguente espressione
Fi (u) = Bi (u) i = 1, … , p−r
Fi (u) = ( ]11a aj j, +
i=p−r+1 per ogni j =.0, 1, … , n.
In tale formulazione, (aj , aj +1] è l’intervallo espresso come percentuale del campione in cui si verifica il break j-esimo, con a0 = 0 e an +1 =1.

Pag. 222 la simulazione dela distribuzione asintotica del test sul rango di cointegrazione
Le serie simulate prevedono allora che St sia pari al vettore (Xt-1′, ( ]11a T a Tj j, +
)′, in cui
ajT è l’istante “discreto” a cui si verifica il break j-esimo. Nel caso in cui il break sia causa di una variazione del trend attorno a cui il processo
risulta essere autoregressivo, ovvero sia modellizzabile tramite una trend-dummy, allora in presenza di n +1 regimi, si ha
Fi (u) = Bi (u) − B i i = 1, 2, … , p−r
Fi (u) = (u − (aj +aj +1)/2) ( ]11a aj j, +
per ogni j = 0 , 1, 2, … , n.
In tale formulazione, si ha che
Bi =1
10
1
a aB u du
j jj
n
ia
a
j
j
+= −∑ ∫+
( ) con a0 =0 e an+1 =1.
L’intervallo (aj , aj+1] ha lo stesso significato del modello precedente. Dal punto di vista dell’implementazione della simulazione, si ha che
St = ( Xt-1′−Χ′ , t− 1
1
1
[ ] [ ] [ ]
[ ]
a T a Tt
j j t a T
a T
j
j
+ =−
+
∑ )
con Χ = 1
1
1
[ ] [ ] [ ]
[ ]
a T a TX
j jt
t a T
a T
j
j
+ =−
+
∑ .
La tabella con l’output delle simulazioni per la determinazione delle distribuzioni
relative al rango di cointegrazione, riportata a titolo di esempio qui sotto, è stata elaborata per un numero di iterazioni pari a 100.000 e per un numero di osservazioni pari a 400; per default, il programma tabula le distribuzioni asintotiche per 100 iterazioni e per 400 osservazioni. Esso risulta essere alquanto flessibile per quanto riguarda la scelta del modello su cui basare il calcolo della distribuzione asintotica: infatti, quest’ultima può essere tabulata per un numero qualsiasi di iterazioni, osservazioni e break, siano essi modellizzati da un salto, da una rampa o da entrambi. Nell’esempio qui specificato, i break considerati sono pari a due e si verificano ad istanti temporali che corrispondono al 27% e all’84% del campione.

La simulazione della distribuzione asintotica del test sul rango di cointegrazione Pag. 223
p −−−− r 50% 75% 90% 95% 99%
1 12.91861 16.55254 20.35028 22.85035 28.09524
2 30.54185 35.77126 41.01970 44.99299 51.14856
3 52.04816 58.48472 64.86293 69.00091 76.96423
4 77.43591 85.14294 92.54931 97.43138 106.71084
5 106.59355 115.50524 124.01023 129.28625 139.56123
Osservando i valori dei percentili ricavati e confrontandoli con quelli tabulati in
Johansen (1995) si può notare come quelli qui riportati abbiano valori maggiori. Ciò non deve sorprendere, in quanto, coerentemente con la teoria asintotica, le dimensioni del vettore B variano al variare del tipo di modello che viene considerato: se questo prevede la presenza di più break, allora il valore del test deve crescere ed anche la sua distribuzione risulta essere più alta.
Tuttavia questo fatto può costituire un problema in sede di determinazione del rango di cointegrazione, in quanto un modello ipotizzato per spiegare il DGP che preveda un gran numero di regimi, a causa dei valori dei percentili più alti rispetto ad un modello con meno break, tenderà a sovrastimare il numero di stazionarietà e quindi ad accettare un rango di cointegrazione più alto. Per tale ragione l’analisi delle serie per stabilire quale possa essere il modello più opportuno per spiegare il DGP deve essere fatta con sufficiente accuratezza prima di iniziare l’analisi econometrica vera e propria.
Nel seguito viene specificata la modalità di utilizzo della procedura per la determinazione della distribuzione del rango di cointegrazione.
11.2 Come utilizzare Ranktest La procedura Ranktest è contenuta nel file sorgente Prova6.src ed è stata scritta in linguaggio RATS. La sua implementazione è analoga a quella di una qualsiasi istruzione RATS, a cui devono essere passati parametri, opzioni e etichette supplementari, secondo lo schema seguente:
ISTRUZIONE (opzioni) parametri # etichetta supplementare n0 1 # etichetta supplementare n0 2 # … Per quanto riguarda i primi, l’unico che deve essere reso noto alla procedura riguarda
il numero n di break presenti nel modello che stiamo ipotizzando. Le opzioni hanno a che fare, secondo l’ordine in cui devono essere indicate, sia con il numero massimo di

Pag. 224 la simulazione dela distribuzione asintotica del test sul rango di cointegrazione
direzioni non stazionarie che vengono ipotizzate (MAXDIM) e che coincidono con un valore del rango compreso fra 0 e p−11, sia con il numero di iterazioni (ITER) necessarie per determinare la statistica. Per default, la prima delle due ha valore pari a cinque, mentre la seconda uguale a cento2. Le etichette supplementari sono necessarie per definire correttamente i break; il loro numero è pari infatti a quello (passato come parametro) di shock ipotizzati per il modello ed ognuna prevede due indici: il primo è il valore percentuale corrispondente all’istante del break che si sta considerando, mentre il secondo è il tipo di modello, passato tramite un numero compreso fra zero e tre, secondo lo schema seguente:
- valore 0: il processo non è corretto da alcun termine deterministico; - valore 1: il processo è corretto da una costante (dummy a scalino); - valore 2: il processo è corretto da un trend (dummy a rampa). Alla scrittura di ogni riga che compone l’intera istruzione secondo lo schema
precedente deve seguire un INVIO. Come esempio di utilizzo della procedura, si consideri la distribuzione tabulata a
pag.173. L’input per ricavare tale distribuzione risulta essere il seguente: sou(noecho) prova6.src @ranktest (MAXDIM=5 ITER=100) 3 #0 2 #.27 2 #.84 2 La prima riga di input corrisponde all’istruzione di RATS che consente di richiamare,
senza compilarlo, il file sorgente che contiene la procedura (si ved il § 12.3). A quest’ultima, quando viene chiamata, vengono passate le opzioni MAXDIM e ITER (in tal caso possono essere omesse, in quanto coincidenti con i valori di default) e il parametro relativo al numero di regimi3. Le etichette supplementari indicano che i break danno luogo a variazioni di trend e sono presenti al 27% e all’84% del campione.
Il listato del programma è riportato nel paragrafo seguente.
1p è il numero di variabili endogene che costituiscono il processo vettoriale. 2Per quanto riguarda quest’ultimo valore, ricordiamo che all’aumentare del numero di iterazioni i
tempi.di simulazione crescono esponenzialmente, raggiungendo anche gli ordini di ore nel caso in cui esse superino il numero di 100.000. Questo problema si presenta anche qualora aumenti il numero di osservazioni o quello dei regimi, in quanto nell’implementazione del programma sono coinvolti prodotti reiterati più volte fra matrici di dimensioni notevoli.
3Due break implicano tre regimi.

La simulazione della distribuzione asintotica del test sul rango di cointegrazione Pag. 225
11.3 La procedura Ranktest PRO RANKTEST REG OPT INT MAXDIM 5 OPT INT OBS 400 OPT INT ITER 100 LOC INT I J K COUNT1 COUNT2 COUNT3 COUNT4 COUNT5 MOD BRODIM LOC INT L DIM SCOOBY LOC REA IB LOC SER ST LOC IMATRIX PARAM LOC VEC D LOC REC F C U AVGX X E RFUN LOC SYM A DIM PARAM(REG+1,2) COM COUNT1=0 COM COUNT3=0 COM COUNT4=0 COM PARAM(REG+1,1)=OBS DO I=1,REG ENT IB MOD COM PARAM(I,1)=FIX(IB*OBS) COM PARAM(I,2)=MOD IF MOD==0 COM COUNT1=COUNT1+1 IF MOD==1 COM COUNT3=COUNT3+1 END DO I INF(ACT=DEF,PRO,LOW=1,UPP=ITER*MAXDIM) 'Simulating' DIS ' ' DIS @5 'Quantiles of the likelihood ratio test for cointegrating rank' DIS ' ' DIS 'Number of iterations (N):' ITER

Pag. 226 la simulazione dela distribuzione asintotica del test sul rango di cointegrazione
DIS 'Number of observations (T):' OBS DIS
'______________________________________________________________________' DIS ' ' DIS ' p-r 50.0% 75.0% 90.0% 95.0% 99.0% ' DIS
'______________________________________________________________________' DIS ' ' DIM U(OBS,REG-COUNT1-COUNT3) RFUN(REG-COUNT1,OBS) COM SCOOBY=0 EWI RFUN(I,J)=0 EWI U(I,J)=0 DO I=1,%ROWS(PARAM)-1 IF PARAM(I,2)==1 DO J=PARAM(I,1)+1,PARAM(I+1,1) COM RFUN(I-COUNT2,J)=1 END DO J COM COUNT4=COUNT4+1 ELSE IF PARAM(I,2)==2 DO J=PARAM(I,1)+1,PARAM(I+1,1) COM RFUN(I-COUNT2,J)=J-(PARAM(I+1,1)+PARAM(I,1)+1)/2. COM U(J,I-COUNT2-COUNT4)=(PARAM(I+1,1)-PARAM(I,1))**-1 END DO J ELSE;COM COUNT2=COUNT2+1 END DO I SET ST 1 ITER =0 DO DIM=1,MAXDIM COM BRODIM=DIM+REG-COUNT1 DIM F(BRODIM,OBS) AVGX(DIM,REG-COUNT1-COUNT3) X(DIM,OBS)
E(DIM,OBS) IF %COLS(U)<>0 DO K=1,ITER INF(CUR=K+SCOOBY)

La simulazione della distribuzione asintotica del test sul rango di cointegrazione Pag. 227
COM E=%RAN(1) EWI X(I,J)=%IF(J<>1,X(I,J-1)+E(I,J-1),0) COM AVGX=X*U COM COUNT5=0 DO L=1,REG IF PARAM(L,2)==2 COM COUNT5=COUNT5+1 EWI X(I,J)=%IF(J>PARAM(L,1).AND.J<=PARAM(L+1,1),X(I,J)-
AVGX(I,COUNT5),X(I,J)) END DO L EWI F(I,J)=%IF(I<=DIM,X(I,J),RFUN(I-DIM,J)) COM A=F*TR(F) COM ST(K)=%SUM(%MQFORMDIAG(INV(A),F*TR(E))) END DO K ELSE; DO K=1,ITER INF(CUR=K+SCOOBY) COM E=%RAN(1) EWI X(I,J)=%IF(J<>1,X(I,J-1)+E(I,J-1),0) EWI F(I,J)=%IF(I<=DIM,X(I,J),RFUN(I-DIM,J)) COM A=F*TR(F) COM ST(K)=%SUM(%MQFORMDIAG(INV(A),F*TR(E))) END DO K COM SCOOBY=SCOOBY+ITER STA(NOPRINT,FRACTILES) ST DIS ' ' DIM %MEDIAN %FRACT75 %FRACT90 %FRACT95 %FRACT99 END DO DIM DIS
'______________________________________________________________________' DIS ' ' INF(ACT=REM) END RANKTEST


Parte IV
Appendici


Appendice A Richiami di teoria asintotica
SCOPO di questa appendice è quello di fornire i minimi strumenti indispensabili di teoria asintotica, per poter determinare la combinazione di moti browniani a cui converge la statistica del test per il rango di cointegrazione. Per una maggiore chiarezza cominciamo col caso univariato per poi estenderne i risultati a quello multivariato.
A.1 Il moto browniano univariato
Si consideri il seguente random walk (processo stocastico con radice unitaria)
yt = yt-1 + εt (A.1)
in cui εt è i.i.d. e ∼ N(0,1); se il processo ha origine con y0 = 0, ne segue che
y t ii
t
==∑ε
1
e yt∼ N(0,t).
In più, la variazione nel livello di y tra gli istanti t e s, cioè
y ys t t s− = + ++ε ε1 K ,
è essa stessa una variabile N(0,(s-t)), ed è indipendente dalle variazioni di y tra le date r e q, per qualsiasi date t < s < r < q (grazie all’ipotesi di indipendenza dei residui).
Si consideri ora la variazione tra yt e yt-1, ossia
yt − yt-1 = εt
e si supponga di considerare εt come la somma di due variabili gaussiane indipendenti

Pag. 232 Richiami di teoria asintotica
εt = e1t + e2t , con eit ∼ N(0,1/2) i = 1, 2 ;
potremmo allora associare e2t alle variazioni tra yt e yt-(1/2), ossia yt − yt-(1/2) = e2t e analogamente
yt-(1/2) − yt-1 = e1t .
Allo stesso modo potremmo pensare di partizionare la variazione di y tra t−1 e t in N sottoperiodi separati
yt − yt-1 = e1t + … + eNt (A.2)
dove eit ∼ N(0,1/N) e se ne ricaverebbe un processo con tutte le proprietà di (A.1). Il limite per N→∞ di (A.2) è un processo in tempo continuo, noto come moto
browniano standard. Il valore di tale processo in t viene indicato con b(t). Un processo in tempo continuo è una variabile casuale che assume valori ad ogni
istante temporale reale non negativo t, in contrapposizione a quanto avviene per i processi discreti, i quali sono definiti solo per valori interi di t. Per enfatizzarne la differenza, un processo stocastico in tempo continuo verrà indicato con b(t), mantre
quello in tempo discreto con yt t=∞
1 .
Una realizzazione di un processo in tempo continuo può essere considerata come una funzione stocastica, indicata come b ( )⋅ in cui b: t∈[ 0,∞)→ℜℜℜℜ 1. In particolare una
realizzazione di un moto browniano si rivela essere funzione continua di t, in quanto la variazione tra t e t+∆ è N(0,∆) e diventa arbritariamente piccola al contrarsi di ∆ a zero.
Riassumendo, un moto browniano standard può essere definito come un processo in tempo continuo, che associa ad una data t∈[ 0,1] un valore scalare b(t), tale per cui
a) b(0) = 0
b) per qualsiasi date 0 ≤ t1 < t2 < … < tk ≤ 1, le variazioni [b(t2) − b(t1)], [b(t3) − b(t2)], … , [b(tk) − b(tk-1)] sono variabili casuali normali e indipendenti, con [b(s) − b(t)] ∼ N(0(s − t))
c) per qualsiasi realizzazione, b(t) è continuo in t.
Altri processi possono essere generati a partire da un moto browniano standard. Ad
esempio, w(t) = σb(t) ha incrementi indipendenti e le sue realizzazioni sono distribuite come una N(0,σ2t).

Richiami di teoria asintotica Pag. 233
A.2 Il teorema del limite centrale funzionale
Se εt è i.i.d. ∼ N(0,σ2), allora la media campionaria ε εT tt i
TT= −=∑1 soddisfa
→T NTwε σ( , )0 2 .
Si consideri ora uno stimatore basato sul seguente principio: dato un campione di ampiezza T, se ne calcoli la media della prima metà e se ne scartino le restanti osservazioni
[ ]
[ ]ε εT t
t
T
T21
212
==∑[ ]
con [T/2] si indica il valore intero più alto che sia minore o uguale a T/2;cioè [T/2] =T/2 se T pari e [T/2] = (T − 1)/2 se T dispari.
Applichiamo il teorema del limite centrale per questo stimatore
[ ]→[ ] ( , )T NTw2 02
2ε σ .
In più, questo stimatore è indipendente dallo stimatore basato sull’uso della seconda metà del campione. Più in generale, possiamo costruire una varibile XT(u), a partire dalla prima frazione u-esima di osservazioni, u∈[ 0,1], definito da
[ ]
X uTT t
t
Tu
( )==∑1
1ε ;
∀ data realizzazione, XT(u) è una funzione a gradini in u, con
X
u TT T u T
T T u T
T u
T
T
=
≤ <≤ <
+ ≤ <
+ + =
0 0 11 22 3
1
1
1 2
1
εε ε
ε ε
( ). .. .. .
( ... ) .
(A.3)
Si ha quindi
[ ] [ ]
TX uT
TuT TuT t
t
Tu
tt
Tu
( ) [ ][ ]
= == =∑ ∑1 1
1 1
ε ε

Pag. 234 Richiami di teoria asintotica
ma [ ] →1 012/ [ ] ( , )Tu Ntt
Tu wε σ=∑ e →[ ]/Tu T uP , pertanto →TX u N uTw( ) ( , )0 2σ .
Inoltre se u2 > u1
→T X u X u N u uT Tw( ( ) ( )) / ( ,( ))2 1 2 10− −σ
Se ne deduce, quindi , che la sequenza di funzioni stocastiche TXT T( ) /⋅
=
∞σ
1 ha una
legge probabilistica asintotica descritta da un moto browniano, ossia
→TX bTw( ) / ( )⋅ ⋅σ
in particolare se u = 1, allora XTT t
t
T( )1 1
1= ∑
=ε e quindi
→TX bTw( )/ ( )1 1σ ∼ N(0,1).
Vediamo ora la convergenza in legge per funzioni stocastiche. Sia S ( )⋅ un processo
stocastico in tempo continuo e S(u) il suo valore ad una certa data u con u∈[ 0,1]. Si
supponga che S ( )⋅ sia una funzione continua. Data una sequenza ST T( )⋅ =∞
1di funzioni
continue di tale tipo, diremo che ST ( )⋅ →w S ( )⋅ se si verificano le seguenti condizioni:
a)∀ insieme finito di k date, 0 ≤ u1 < u2 < … < uk ≤ 1, la sequenza di vettori k-
dimensionali YT T=∞
1 converge in distribuzione al vettore Y dove si ha
Y
S u
S u
T
T
T k
=
( )...( )
1
e Y
S u
S uk
=
( )...
( )
1
b)per qualsiasi coppia di date u1e u2 che non distano più di δ l’una dall’altra, la probabilità che ST(u1) differisca da ST(u2) va a zero uniformemente in T quando δ→0
c)P ST (0) > λ→ 0 uniformemente in T quando λ→ ∞. (Si veda Billingsley (1968) e Hall&Heyde (1980)). Passiamo ora alla convergenza in probabiltà per funzioni stocastiche. Siano
VT T( )⋅ =∞
1 e ST T( )⋅ =∞
1 sequenze di funzioni stocastiche continue con ST: u∈[ 0,1]→ℜℜℜℜ 1.
Sia YT uno scalare che rappresenta il valore massimo per cui ST (u) differisce da VT(u) per ∀ u, ovvero

Richiami di teoria asintotica Pag. 235
[ ]
Y S u V uTu
T T≡ −∈sup ( ) ( )
,0 1.
limite probabilistico utilizzando la classica definizione di convergenza in probabilità.
Se la sequenza di scalari YT T=∞
1 converge in probabilità a zero, allora diremo che la
sequenza delle funzioni ST ( )⋅ converge in probabilità a VT ( )⋅ . Ciò equivale a dire che
l’espressione ST ( )⋅ →P VT ( )⋅ è interpretata per concludere che
[ ]
→sup ( ) ( ),u
T TPS u V u
∈−
0 10 .
In particolare se VT T( )⋅ =∞
1 e ST T( )⋅ =∞
1sono sequenze di funzioni continue con
ST ( )⋅ →P VT ( )⋅ e ST ( )⋅ →w S ( )⋅ e S ( )⋅ è una funzione continua, allora VT ( )⋅ →w S ( )⋅
(Stinchcombe-White (1993)).
A.3 Il teorema della corrispondenza continua
Sappiamo che se xT T=∞
1 è una sequenza di variabili casuali con xT→w x e se g:
ℜℜℜℜ 1→ℜℜℜℜ 1 è una funzione continua, allora si ha che g(xT) →w g(x). Un risultato simile si ottiene con sequenza di funzioni di variabili casuali. In questo caso, il concetto analogo alla funzione g ( )⋅ è un funzionale continuo, che fa corrispondere ad una variabile
casuale reale y una funzione stocastica S ( )⋅ . Per esempio, y S u du=∫ ( )01 e y S u du=∫ [ ( )]2
01
sono funzionali continui. In questo contesto, continuità di funzionale g ( )⋅ significa che,
per ogni ε>0 esiste un δ>0 tale per cui, se h(u) e k(u) sono funzioni continue e limitate su [0,1], h: [0,1]→ℜ 1 e k: [0,1]→ℜ 1, per le quali sia h(u)-k(u) <δ ∀ u∈[ 0,1], allora g h g k[ ( )] [ ( )]⋅ − ⋅ <ε .
Il teorema della corrispondenza continua (Hall&Heyde (1980)) stabilisce che se
ST ( )⋅ →w S ( )⋅ e g ( )⋅ è un funzionale continuo, allora si ha g(ST ( )⋅ )→w g(S ( )⋅ ).
Il teorema della corrispondenza continua si applica pure a funzionali continui
g ( )⋅ che fanno corrispondere una funzione continua e limitata su [0,1] ad un’altra
funzione continua e limitata sempre su [0,1]. Per esempio, se g h h[ ( )] ( )⋅ = ⋅σ e se
S u TX uT T( ) ( )= , allora
→g S g S bTw[ ( )] [ ( )] ( )⋅ ⋅ = ⋅σ = w(u).

Pag. 236 Richiami di teoria asintotica
Pertanto, poichè b(u)∼ N(0,u),
TX u N uT ( ) ( , )≈ 0 2σ .
Inoltre se S u TX uT T( ) [ ( )]= 2 , allora →S bTw( ) [ ( )]⋅ ⋅σ2 2 .
A.4 Applicazioni a processi con radici unitarie Consideriamo il semplice random walk
y yt t t= +−1 ε
con εt i.i.d. e ∼ N(0,σ2). Se y0 = 0 allora
y t ii
t=
=∑ε
1.
Questa equazione può essere utilizzata per esprimere la funzione stocastica XT(u), definita dalla(A.3), come
X
u Ty T T u Ty T T u T
y T u
T
T
=
≤ <≤ <≤ <
=
0 0 11 22 3
1
1
2
. .
. .
. ..
La fig, A.1 rappresenta XT(u), intesa come funzione di u. Si noti che l’area sottostante alla funzione a gradini è la somma di T rettangoli. Il t-esimo rettangolo ha ampiezza 1/T ed altezza yt-1/T, e quindi area pari a yt-1/T2. L’integrale di XT(u) è quindi equivalente a
X u duyT T
yT T
yT TTT
0
1 1 2 11 1 1∫ = + + + −( ) ... .
Moltiplicando entrambi i membri di quest’espressione per T1/2, si ottiene che
TX u du T yT tt
T
0
1 3 21
1∫ ∑= −
−=
( ) .
Richiami di teoria asintotica Pag. 237
Fig. A.1: Grafico di XT(u) in funzione di u.
Poichè il funzionale “integrale” è un funzionale continuo, allora posso applicare il teorema della corrispondenza continua e per T→∞ si ha
→TX u du b u du w u duTw
01
01
01∫ ∫ = ∫( ) ( ) ( )σ ;
questo implica che →T y b u du w u dutt
Tw−
−=∑ ∫ ∫=3 2
11
0
1
0
1σ ( ) ( ) .
Consideriamo ora la seguente decomposizione
T y Ttt
T
T−
−=
−−∑ = + + + + + + +3 2
11
3 21 1 2 1 2 1[ ( ) ... ( ... )]ε ε ε ε ε ε
= − + − + + − −−−T T T T T T
3 21 2 11 2 1[( ) ( ) ... ( ( )) ]ε ε ε
= − + + + + −
−
=−∑T T T Tt
t
T
T T3 2
11 2 12 1ε ε ε ε ε( ... ( )
= −−
=
−
=∑ ∑T T ttt
T
tt
T1 2
1
3 2
1
ε ε
0 1/T 2/T 3/T 4/T ... ... u
XT(u)
y1/T
y2/T y3/T

Pag. 238 Richiami di teoria asintotica
ricordando che →T b wtt
tw−
=∑ =1 2
11 1ε σ ( ) ( ) , allora
→T t w w u dutt
tw−
=∑ ∫−3 2
10
11ε ( ) ( ) .
Consideriamo ora S u TX uT T( ) [ ( )]= 2 ; allora
S u duyT T
yT T
yT TTT
0
1 12
22
121 1 1
∫ = + + + −( ) ...
→= =−−
=∑ ∫ ∫T y b u du w u dutt
tw2
12
1
20
1 2
0
1 2σ ( ) [ ( )] .
Altri risultati utili sono
→T ty T tT
y ub u du uw u dutt
T
tt
Tw−
−=
−−
=∑ ∑ ∫ ∫= =5 2
11
3 21
10
1
0
1σ ( ) ( )
e
→T ty T tT
y u b u du u w u dutt
T
tt
Tw−
−=
−−
=∑ ∑ ∫ ∫= =3
12
1
21
2
1
2 20
12
0
1σ [ ( )] [ ( )] .
Si consideri ora la seguente statistica
T y T y y TyT
Tt tt
T
t tt
T
tt
TT
tt
T−
−=
−−
=
−
=
−
=∑ ∑ ∑ ∑= − − = −1
11
1 21
2
1
1 2
1
1 2
1
12
12
12
12
ε ε ε( )
che può essere scritta come
T y S Tt tt
T
T tt
T−
−=
−
=∑ ∑= −1
11
1 2
1
12
1 12
ε ε( ) .
Poichè →T tt
TP−
=∑1 2
1
2ε σ in virtù della legge dei grandi numeri, e
→S b w uTw( ) [ ( )] [ ( )]1 12 2 2σ = , allora
→T y w ut tt
Tw−
−=∑ −1
11
2 212
ε σ([ ( )] ) .

Richiami di teoria asintotica Pag. 239
A.5 Estensione a processi multivariati Sviluppiamo i risultati fin qui ottenuti, per i processi vettoriali. Partiamo dalla definizione di moto browniano standard vettoriale, che non è altro che la raccolta di p processi indipendenti, indicati con b1(u), b2(u), … , bp(u), in un vettore B(u) di dimensione p×1.
In moto browniano p-dimensionale standard B( )⋅ è un processo in tempo continuo
che associa ad ogni data u∈[ 0,1] il vettore B(u) p×1 che soddisfa le seguenti condizioni: a)B(0) = 0 b)∀ data 0 ≤ u1 < u2 < … < uk ≤ 1, le variazioni [Β(u2) − B(u1)], … , [Β(u2) − B(u1)]
sono gaussiane multivariate indipendenti, con [Β(s) − B(u)] ∼ N(0 , (s − u) IP) c) ∀ realizzazione, B(u) è continua in u.
Supponiamo che VT t=∞
1 sia un processo discreto vettoriale con E[Vt]=0 e
E[VtVt′]=IP e sia
[ ]~ ( ) ( ... ),*X u T V VT Tu= + +−1
1
allora, generalizzando i risultati visti nel caso univariato, si ottiene che
→TX u B uTw~ ( ) ( )* ∼ N(0,uIP).
Consideriamo inoltre un processo p-dimensionale i.i.d. ε t t=∞
1 , con media zero e
matrice di varianze-covarianze date da Ω. Sia inoltre P una matrice tale che Ω = PP′ ; allora potremmo pensare a εt come generato da
εt = PVt.
Sia
[ ] [ ]X u T PT V V PX uT Tu Tu T* *( ) ( ... ) ( ... ) ~ ( )≡ + + = + + =− −1
11
1ε ε ,
allora per il teorema della corrispondenza continua, generalizzato al caso vettoriale (continuos mapping theorem), si trova che
[ ]
→T TX u PB utt
Tu
Tw−
=∑ =1 2
1ε * ( ) ( ) = W(u) ∼ N(0 , Ω).

Pag. 240 Richiami di teoria asintotica
Considerando, ora, il continuos mapping theorem applicato al funzionale
x x u x u du→ ′∫ ( ) ( )0
1, si dimostra che valgono le seguenti relazioni
→T W u W u duii
t
t
T
ii
tw−
== =∑∑ ∑ ∫
′
′2
11 10
1ε ε ( ) ( )
→T W u dWii
t
t
T
tw−
==∑∑ ∫
′ ′1
110
1ε ε ( )( ) .
(per una definizione di “dW” si veda Phillips(1988)). Inoltre se FT (t) è una sequenza di funzioni deterministiche definite per t = 1, … , T,
che converge a una funzione F definita su [0,1], tale che FT ([Tu])→P F(u), allora, sempre per il continuos mapping theorem, si ottiene che
→T F t F utt
T
Tw−
=∑ ∫′ ′1 2
10
1ε dW ( ) ( )
→T F t W u F u duii
t
t
T
Tw−
==∑∑ ∫
′ ′32
110
1ε ( ) ( ) ( ) .
Nell’analisi di modelli autoregressivi, si incontrano molti processi generati da combinazioni lineari degli errori εt; si rende pertanto necessario dare gli stessi risultati visti sopra, per tali processi lineari. Definiamo i processi lineari
Ut= ϑ ii=
∞
∑0
εt-i, Vt= ψ ii=
∞
∑0
εt-i,
assumiamo che i coefficiente ϑ i e ψi decrescano esponenzialmente, in modo che i due processi siano stazionari; è possibile verificare che, inoltre, vale la seguente formula
γuv = Cov(Ut , Vt+h ) = ϑ ψi i hi
Ω ′+=
∞
∑0
.
Sotto queste assunzioni, si ottiene che
T−1/2 max1≤ ≤t T
|Ut|→P 0 ,

Richiami di teoria asintotica Pag. 241
T−1/2 UV
t
tt
Tu
=
[ ]
∑1
→w ϑψ
( )( )11
W(u).
In aggiunta abbiamo che
T-2 →( )( ) ( )U V Wii
t
t
T
ii
tw
== =∑∑ ∑ ∫′
11 10
11ϑ (u)W(u)′duψ(1)′,
T-1 ( Uii
t
t
T
==∑∑
11)Vt′→w ϑ ( )1
0
1W∫ (dW)′ ψ(1)′+ γuv
h=
∞
∑0
(h),
T-1/2 ε tt
T
=∑
1Vt′→w N(0,Ω⊗ψ(1)Ωψ(1)′ ).
Infine, se FT([Tu]) è una sequenza di funzioni deterministiche che convergono ad una funzione F(u), allora
T-3/2 ( Uii
t
t
T
==∑∑
11)FT(t)′ →w ϑ ( )1
0
1W∫ (u)F(u)′du,
e
T-1/2 Uii
t
=∑
1FT(t)′ →w ϑ ( )1
0
1dW∫ F′.
Per una dimostrazione di tali risultati si veda Johansen (1995).


Appendice B Elementi di algebra delle matrici
I modelli con cui abbiamo a che fare in questo lavoro sono scritti in forma “compatta”, nel senso che i parametri e le variabili che compaiono in essi sono in realtà matrici o vettori, la cui esplicitazione analitica si traduce in sistemi di equazioni.
Tale formulazione, sebbene sia comoda e semplice, può tuttavia creare delle difficoltà per coloro i quali non hanno dimestichezza con l’uso delle matrici.
Perciò diamo qui di seguito qualche nozione di algebra matriciale al fine di rendere più semplice la comprensione della formulazione usata e per chiarire alcuni dei concetti inerenti gli spazi vettoriali, che spesso compaiono nel presente lavoro.
B.1 Le matrici e le loro proprietà
B.1.1 Definizione di matrice Una matrice A è definita come un insieme di elementi strutturati nel seguente modo
A
a a aa a a
a a a
n
n
m m mn
=
11 12 1
21 22 2
1 2
...
......
...
Gli elementi ai1, ai2,...ain sono gli elementi della riga i-esima, mentre gli elementi a1j, a2j,...amj sono gli elementi della colonna j-esima. Il numero di righe è pari a m, mentre quello delle colonne è n.

Pag. 244 Elementi di algebra matriciale
Ogni elemento è un numero reale ed il numero totale di elementi è pari al prodotto m×n, definito come ordine o dimensione della matrice; quest’ultima definizione è legata al fatto che, come vedremo successivamente, le matrici si possono tradurre in relazioni nello spazio pluridimensionale.
Alcune definizioni - Vettore: é la matrice m×n in cui m=1 (vettore riga) oppure n=1 (vettore colonna). - Matrice nulla: é la matrice avente tutti gli elementi pari a zero. - Matrice quadrata: è la matrice avente il numero di righe pari a quello delle colonne. - Diagonale principale: si intende, nel caso in cui la matrice sia quadrata, la diagonale che congiunge gli elementi aij, con i=j. - Traccia della matrice: è la somma degli elementi della diagonale principale di A e si indica con tr(A). Affinchè si possa parlare di traccia della matrice, è necessario che essa sia quadrata.
B.1.2 Determinante di una matrice Sia data una matrice A quadrata di ordine n. Il suo determinante si indica con det A o con A e si calcola nel seguente modo.
Consideriamo la matrice A tale per cui
A
a a aa a a
a a a
n
n
n n nn
=
11 12 1
21 22 2
1 2
...
......
...
Si considera ogni elemento di posizione (i,j) e si elimina la riga i-esima e la colonna j-esima. Il determinante della matrice che ne risulta è detta minore di ordine n-1. Indicando tale minore con B ij, il determinante di A risulta essere
det A = ( )− +
=∑ 1
1
i jij
j
n
ija B .
I termini cij = (−1)i+jB ij sono detti complementi algebrici. I determinanti delle matrici godono delle seguenti proprietà (per la loro
dimostrazione, si veda, ad esempio, Strang(1981)): - un determinante cambia di segno quando si scambiano due colonne o due righe fra loro; - il determinante di una matrice con due righe o colonne uguali è nullo ( come vedremo

Elementi di algebra matriciale Pag. 245
nel § B.1.11, ciò ha delle importanti implicazioni per quanto riguarda il rango di una matrice ); se ciò si verifica, allora la matrice è detta essere singolare;
- se ogni elemento di una riga o colonna della matrice A è moltiplicato per uno scalare α in modo da ottenere una nuova matrice B, allora B = α A ;
- se ogni elemento della matrice A è moltiplicato per lo scalare α, allora α A = αnA , con n pari all’ordine della matrice;
- un determinante non cambia di valore se ad una riga o colonna si somma una qualsiasi altra riga o colonna moltiplicata per un numero qualunque;
- il determinante del prodotto di matrici è pari al prodotto dei loro rispettivi determinanti.
La proprietà di non singolarità, ad esempio, compare nel presente lavoro al capitolo 2, in relazione alla dimostrazione del teorema di Granger. Infatti la condizione di rango pieno della matrice ′⊥ ⊥α Γβ dimostra che la matrice A(z), definita nel capitolo suddetto, in
z=1 è di rango pieno, ovvero è non singolare, cioè ha determinante non nullo ed è perciò invertibile. Interpretazione geometrica del determinante Il determinante di una matrice rappresenta il volume di un parallelepipedo P nello spazio n-dimensionale, i cui lati sono segmenti di rette individuati dai vettori colonna che costituiscono la matrice A oppure individuati dalle righe della stessa matrice (vedi fig.(B.1)).
In tal caso, il parallelepipedo sarà diverso, in quanto orientato diversamente nello spazio, ma il suo volume resta identico.
(a13 ,a23 ,a33)
(a11 ,a21 a31)
(a12 ,a22 ,a32)
z
y
x
Fig. B.1: Interpretazione geometrica del determinante di una matrice.

Pag. 246 Elementi di algebra matriciale
Per mostrare ciò, consideriamo dapprima il caso in cui il parallelepipedo sia retto. Il suo volume è dato dal prodotto delle lunghezze dei suoi lati ( nel caso di uno spazio n-dimensionale, si ha che tale volume è l1 l2 l3 … ln ).
Consideriamo il parallelepipedo “generato” dalle righe della matrice A, che risultano essere ortogonali, in quanto il parallelepipedo considerato è ortogonale e consideriamo il prodotto AA′ dato da
AA′ =a a
a a
a a
a a
ll
l
n
n nn
n
n nnn
11 1
1
11 1
1
12
22
2
0 00 0
0 0
......
...
......
...
...
...... ...
...
=
in cui li rappresenta la lunghezza della riga i-esima, ovvero il lato i-esimo del parallelepipedo.
Considerando il determinante di AA′, si ottiene
det(AA′) = (detA)(detA′) = (detA)2 = l l l ln12
22
32 2K
Il volume del parallelepipedo è
l l l ln12
22
32 2K = l1 l2 l3 … ln = (det )A 2 = detA .
Se il parallelepipedo non è rettangolo, il procedimento da seguire è quello di trasformare la righe non ortogonali in righe ortogonali, sottraendo da ogni riga la sua proiezione sullo spazio individuato dalle righe precedenti. Poichè il determinante di una matrice non varia se si sottrae il multiplo di una riga da un’altra, allora il risultato è che anche il volume non cambia.
B.1.3 Autovalori ed autovettori di una matrice Sia A una matrice quadrata di ordine n e λ una variabile complessa.
Il polinomio caratteristico della matrice A è dato da
det (λI − A)
Gli autovalori della matrice A sono i λ i, i=1,…,n , soluzioni dell’equazione caratteristica
det (λI − A) = 0

Elementi di algebra matriciale Pag. 247
Condizioni necessarie e sufficienti affinchè λ i sia autovalore della matrice A sono le seguenti: - esiste un vettore non nullo x tale per cui Ax=λx e tale vettore, associato all’autovalore
i-esimo, è detto autovettore; - la matrice λI − A è singolare; - det (λI − A) = 0. Valgono inoltre le seguenti proprietà:
- det A ii
n=
=∏λ
1
- λ ii
n
iji j
na
= = =∑ ∑=
1 1
- un autovettore non può essere associato a due autovalori distinti; - se α è un numero diverso da 0 e se wi è un autovettore associato all’autovalore λ i,
allora anche αwi è un autovettore associato a quell’autovalore; - data una matrice A quadrata di ordine n, essa è diagonalizzabile se i suoi autovalori
sono distinti. Ricordiamo che una matrice è diagonalizzabile qualora sia identificabile una matrice P non singolare tale per cui P-1AP è una matrice diagonale.
Se la matrice P è la matrice degli autovettori di A, allora la matrice P-1AP, indicata con Λ, è la matrice diagonale con gli autovalori sulla diagonale principale.
In tal caso si ha che AP = PΛ.
Problema agli autovalori generalizzato Siano M e N due matrici simmetriche, con M semi-definita positiva e N definita positiva. L’equazione
λ N − M = 0
ha come soluzioni p autovalori λ1 ≥ λ2 ≥ … ≥ λp ≥ 0, a cui corrispondono gli autovalori v1 , … , vp , tali per cui
Nλ ivi = Mvi , con i =1, … , p,
o, in notazione matriciale
NVΛ = MV
V′NV = I

Pag. 248 Elementi di algebra matriciale
V′MV = Λ.
B.1.4 Matrici definite positive Una matrice è definita positiva se, per ogni vettore x ≠ 0, si ha che x’Ax > 0.
Proprietà delle matrici definite positive - tutti gli autovalori λ i di A sono positivi : λ i > 0; - tutte le sottomatrici Ak della matrice A hanno determinanti positivi: det (Ak) > 0; - esiste una matrice non singolare W tale per cui A = WW′. Nel caso in cui le matrici siano semi-definite positive, le prime due proprietà continuano a valere ma con disuguaglianza non stretta; la terza proprietà vale, ma W può essere anche una matrice singolare.
B.1.5 Uguaglianza di matrici e operazioni con le matrici Due matrici A e B sono uguali se sono dello stesso ordine e se ogni elemento di A è uguale al corrispondente elemento di B, ovvero se aij = bij.
Somma di due matrici Se A e B sono due matrici dello stesso ordine, la loro somma A+B è una matrice C i cui elementi cij sono pari alla somma dei corrispondenti elementi di A e B, ovvero aij + bij. Prodotto di uno scalare per una matrice Dato uno scalare α, il prodotto αA, con A matrice m×n, è pari ad una matrice i cui elementi sono dati dal prodotto dello scalare per ogni elemento della matrice A, ovvero αaij.
Moltiplicazione di due matrici Data una matrice A di dimensione m×n e una matrice B di ordine n×p, il prodotto AB è una matrice C di ordine m×p i cui elementi di posto (i,j) sono dati da
c a bij ik kjk
n= ∑
=1
Il prodotto di matrici è possibile solo se le matrici sono conformabili, ovvero se il numero di colonne della matrice che premoltiplica è uguale a quello delle righe della matrice postmoltiplicata.

Elementi di algebra matriciale Pag. 249
Ciò porta ad una importante considerazione: il prodotto di matrici AB non gode della proprieta commutativa, ovvero non esiste BA, eccetto il caso in cui le due matrici A e B siano quadrate e della stessa dimensione. Inoltre, in quest’ultima circostanza, non necessariamente si verifica che AB = BA.
Date tre matrici A,B e C, si ha che: - vale la proprietà associativa dell’addizione, ovvero (A + B) + C = A + (B + C); - vale la proprietà associativa del prodotto, ovvero (AB) C = A (BC), nell’ipotesi in cui
le matrici siano conformabili a due a due; - vale la proprietà distributiva, ovvero A(B+C) =AB+AC, nell’ipotesi di conformabilità
delle matrici.
B.1.6 Matrice diagonale Una matrice diagonale è una matrice quadrata avente elementi non nulli solo sulla diagonale principale, ovvero è una matrice del tipo
A
aa
a nn
=
11
22
0 00 0
0 0
...
......
...
Se gli elementi sulla diagonale principale sono tutti unitari, allora la matrice è detta matrice unità o matrice identica e si indica con In (il pedice indica l’ordine della matrice).
Se gli elementi sulla diagonale principale sono tutti uguali, ma non unitari, la matrice è detta matrice scalare.
B.1.7 Matrice trasposta Data una matrice A di ordine m×n, con elementi aij, la sua trasposta A′ è una matrice i cui elementi sono ottenuti scambiando le righe con le colonne di A, ovvero l’elemento di posto (i,j) di A′ è pari ad aji .
Se A′=A, allora A è detta matrice simmetrica ed è, naturalmente, una matrice quadrata.
Proprietà delle matrici trasposte - Se A è una matrice m×n, il prodottoAA′ è diverso dal prodotto A′A, ma entrambi
questi prodotti sono simmetrici, di ordine differente ed hanno la stessa traccia.

Pag. 250 Elementi di algebra matriciale
- Data una matrice A di ordine m×n, si ha che: (A′)′ = A;
(A + B)′ = A′ + B′; (AB)′ = B′A′; (ABC)′ = C′B′A′ (C è una matrice conformabile a B);
B.1.8 Matrice inversa Data una matrice A quadrata, la sua inversa, se esiste, è una matrice B tale per cui AB = BA = I (I è la matrice identità già definita precedentemente). L’inversa di A si indica con A-1 ed esiste se il determinante di A non è nullo.
Per determinare la matrice A-1 si prosegue nel seguente modo: - si calcola la matrice (adj A), detta matrice aggiunta di A, costituita dai complementi
algebrici di ogni elemento aij di A; - si considera la trasposta di questa matrice, ovvero (adj A)′; - si moltiplica per (detA)-1. La matrice così ottenuta è quella cercata.
Proprietà delle matrici inverse - Date due matrici A e B conformabili e invertibili, si ha che (AB)-1 = B-1A-1; - date le matrici A,B e C conformabili e invertibili, si ha che (ABC)-1 = C-1B-1A-1; - data una matrice A invertibile, si ha che: (A-1)-1 = A; (A-1)′ = (A′)-1; det(A-1) = 1/detA ;
B.1.9 Matrici a blocchi Una matrice a blocchi è una matrice in cui sono individuabili submatrici che presentano una qualche caratteristica particolare (ad esempio sono diagonali, identiche...).
Una matrice diagonale a blocchi è una matrice che si presenta nella forma
A = A
A11
22
00
dove A11 e A22 sono matrici qualsiasi, mentre 0 è la matrice nulla. Le operazioni di addizione e di moltiplicazione si applicano anche alle submatrici,
purchè esse risultino conformi.

Elementi di algebra matriciale Pag. 251
Addizione di matrici Consideriamo, ad esempio, le matrici A e B scritte come
AA AA A
=
11 12
21 22 , B
B BB B
=
11 12
21 22
dove Aij e Bij sono blocchi di matrici tali per cui l’ordine di Aij è uguale a quello di Bij. Si ha che:
A + B = A B A BA B A B
11 11 12 12
21 21 22 22
+ ++ +
.
Moltiplicazione di matrici Sia A una matrice di ordine m×n suddivisibile in blocchi Aij e sia B una matrice n×p a sua volta scomponibile in blocchi, tali per cui
blocchi dimensioni A11 r×q A12 r×(n-q) A21 (m-r)×q A22 (m-r)×(n-q) B11 q×k B21 (n-q)×(p-k)
Considerando le submatrici come normali elementi, il prodotto AB esiste ed è dato da
ABA AA A
BB
=
11 12
21 22
11
21
A B A BA B A B
11 11 12 21
21 11 22 21
++
Tale risultato è lo stesso che si sarebbe ottenuto moltiplicando fra di loro semplicemente gli elementi delle due matrici.

Pag. 252 Elementi di algebra matriciale
B.1.10 Prodotto di Kronecker Un’importante forma di moltiplicazione di matrici è il prodotto di Kronecker o prodotto diretto di matrici, che si rappresenta con il simbolo ⊗ .
Sia A una matrice di ordine m×n e B una matrice di ordine p×q; allora il prodotto di Kronecker è dato da una matrice di ordine mq×nq la cui espressione è la seguente
A B
a B a B a Ba B a B a B
a B a B a B
n
n
m m mn
⊗ =
11 12 1
21 22 2
1 2
...
......
...
Proprietà del prodotto di Kronecker - Se A e B sono matrici quadrate dello stesso ordine e non singolari, si ha che
(A⊗ B)-1 = A-1⊗ B-1. - Se la matrice A è ripartita in modo conforme, allora è possibile calcolare l’inversa di
una sua submatrice. Tale calcolo si effettua nel seguente modo.Sia A una matrice non singolare esprimibile come
AA AA A
=
11 12
21 22
dove A11 e A22 sono entrambe matrici non singolari. Si definisce la sua inversa, ripartita in modo conforme, come
AE FG H
− =
1
in modo tale che
AA-1 = A-1A = I
I0
0
dove anche la matrice unità è stata ripartita in modo conforme. Sostituendo ad A e a A-1 la loro espressione in funzione delle submatrici e
considerando l’uguaglianza sopra, si ha che A-1 può essere scritta in funzione di uno dei suoi blocchi (ad esempio E), il quale, a sua volta, é funzione dei blocchi della matrice A.
Nel nostro caso particolare si ha

Elementi di algebra matriciale Pag. 253
A-1 = E EA A
A A E A A A EA A−
− +
−
− − − −12 22
1
221
21 221
221
21 12 221
dove E = (A11 − A12 A 221− A21)-1.
Da questa proprietà deriva direttamente che, se A è non singolare ed è diagonale a blocchi, allora
A-1 = A
A11
1
221
00
−
−
Calcolo del determinante delle matrici a blocchi Sia A una matrice diagonale a blocchi data da
AA AA A
=
11 12
21 22
Nell’ipotesi che A22 sia non singolare, definiamo
B1 =I A A
I−
−12 22
1
0 e B2 =
IA A I
0
221
21−
− .
Allora si ha
B1AB2 = A A A A
A11 12 22
121
22
00
−
−.
Poichè B1 = B2 = 1, si ha che
A = A22 A11 − A12 A 221− A21 .
Analogamente, se A11 è non singolare, si ha che
A = A11 A22 − A21 A 111− A12 .
( Per una dimostrazione più rigorosa, si veda Anderson (1981)).
Le proprietà delle matrici a blocchi risultano rilevanti, ad esempio, nel calcolo di $ ( )Ω β ,
ovvero del massimo della funzione di verosimiglianza trasformata L-2/T: il calcolo del

Pag. 254 Elementi di algebra matriciale
determinante di tale matrice rappresenta il primo passo verso la determinazione della distribuzione asintotica del rango di cointegrazione.
B.1.11 Rango di una matrice Il rango di una matrice A di ordine m×n è il numero di righe o colonne linearmente indipendenti. Il rango massimo della matrice è pari al minimo fra m e n. Se la matrice ha rango massimo, allora si dice che essa è di rango pieno. Se cio non si verifica, allora la matrice è detta essere di rango ridotto.
Proprietà delle matrici in relazione al loro rango - una matrice è di rango ridotto se e solo se il suo determinante è nullo; da ciò segue che
una matrice singolare è di rango ridotto; - una matrice C di dimensioni m×n e di rango ridotto r è esprimibile come il prodotto di
due matrici A e B di dimensioni m×r e r×n di rango pieno.
Quest’ultima proprietà è soddisfatta dalla matrice Π, costituita dai coefficienti delle variabili ritardate, in livello, che compare nel modello scritto in forma ECM. Secondo il teorema di Granger, il rango ridotto della matrice p×p Π è condizione necessaria e sufficiente affinchè il processo sia scrivibile in forma MA, ovvero nella forma che permette di evidenziare le sue varie componenti. In particolare, se Π è di rango r, questa condizione ci permette di scrivere Π come prodotto delle matrici α e β′, con α e β matrici di dimensioni p×r. La condizione di rango pieno deve essere soddisfatta anche, ad esempio, dalla matrice A(z), nel punto z=1, definita come polinomio caratteristico del processo vettoriale descritto nel capitolo 1. Infatti, la condizione per cui A(1)≠ 0 è necessaria e sufficiente affinchè il processo Xt sia stazionario.
Dopo aver visto quali sono alcune delle più importanti proprietà delle matrici, passiamo a vedere quali sono le loro relazioni con i sistemi di equazioni.
B.2 Sistemi di equazioni e matrici
B.2.1 Sistema di equazioni generico Consideriamo il seguente sistema di equazioni:
y1 = a11x1 + a12x2 + … + a1nxn + b1

Elementi di algebra matriciale Pag. 255
y2 = a21x1 + a22x2 + … + a2nxn + b2 (B.2.1)
...
ym = am1x1 + am2x2 + … +amnxn + b3
Il modo più semplice e rapido per scrivere tale sistema consiste nel servirsi di matrici, grazie alle quali la formulazione risulta essere, oltre che più compatta, anche “visivamente” più comprensibile, in quanto immediatamente associabile alle equazioni scalari.
Definendo con Y il vettore di dimensioni (m×1) dato dall’insieme delle variabili endogene yi , con A la matrice di dimensioni (m×n) dei coefficienti delle variabili esogene, con X il vettore di dimensioni (n×1) delle variabili esogene xi e con B il vettore di dimensioni (m×1) degli elementi bi tali per cui
Y
yy
ym
=
1
2
..., A
a a aa a a
a a a
n
n
m m mn
=
11 12 1
21 22 2
1 2
...
......
...
, X
xx
xn
=
1
2
..., B
bb
bm
=
1
2
... ,
allora il sistema (B.1) può essere scritto come
Y = AX + B (B.2.2)
Come si può vedere, la combinazione lineare delle variabili xi attraverso i coefficienti aij è ottenuta grazie al prodotto della matrice A e del vettore X; il risultato, coerentemente con le proprietà algebriche delle matrici, è un vettore (m×1), ovvero delle stesse dimensioni di Y, il quale è a sua volta sommato al vettore B, anch’esso (m×1).
Consideriamo ora il sistema dato dall’espressione (B.2), in cui poniamo, per semplicità, B pari al vettore nullo. Si ottiene il sistema
Y = AX
Le sue proprietà risultano essere le seguenti: - se A è una matrice quadrata non singolare, allora, per qualunque Y, è possibile scrivere
X = A-1Y ;
- se A e Y sono matrici nulle, allora ci sono infinite soluzioni per X; - se A è una matrice nulla e Y≠0, non c’è nessuna soluzione per X.

Pag. 256 Elementi di algebra matriciale
Le ultime due proprietà valgono anche nel caso in cui la matrice A non sia quadrata.
B.2.2 Sistemi di equazioni omogenee Consideriamo l’espressione (B.2) e modifichiamola in modo tale per cui Y e B siano vettori nulli; si ottiene che
AX = 0
ovvero, in forma di sistema di equazioni
a11x1 + a12x2 + a13x3 + … + a1nxn = 0
a21x1 + a22x2 + a23x3 + … + a2nxn = 0
... (B.2.3)
am1x1 + am2x2 + am3x3 + … + amnxn = 0
Se l’unica soluzione di tale sistema è xi = 0 per ogni i=1 , … , n, allora si dice che le equazioni sono linearmente indipendenti. Tale caratteristica si traduce a sua volta in una proprietà della matrice dei coefficienti aij: se le colonne della matrice A sono linearmente indipendenti, allora il sistema (B.2.3) soddisfa la proprietà di indipendenza delle sue equazioni.
Si può dimostrare che il numero di colonne linearmente indipendenti di una matrice è pari al numero di righe con la stessa proprietà; inoltre, come già visto al § B.1.11, tale indipendenza si traduce in una condizione di rango sulla matrice A.
Il numero massimo di equazioni linearmente indipendenti nel sistema (B.2.3) è pari al rango della matrice A, che coincide con il minimo fra m e n, se A è di rango pieno.
Dopo questa introduzione ai sistemi di equazioni e ai loro nessi con le matrici,
vediamo come tutto ciò può essere tradotto in termini di spazi vettoriali.
B.3 Spazi e sottospazi vettoriali Consideriamo, come esempio, il seguente sistema
AX = B (B.3.1)

Elementi di algebra matriciale Pag. 257
con A matrice di coefficienti noti m×n, X vettore colonna n×1 delle incognite e B vettore colonna m×1 di termini noti.
Tale sistema risulta essere risolubile solo se B soddisfa certe condizioni particolari,
ovvero se il vettore B è una combinazione lineare delle colonne di A. In termini.geometrici,si dice che il sistema è risolubile se B giace nello spazio individuato dai vettori colonna della matrice A, detto, appunto, spazio colonna di A.
Per chiarire meglio questo concetto facciamo un esempio numerico e grafico (vedi fig.B.2)). Ipotizziamo per A, X e B un ordine pari rispettivamente a 3×2, 2×1 e 3×1. Il sistema è riscrivibile come
xaaa
xaaa
bbb
11
11
21
31
21
12
22
32
11
21
31
+
=
.
Scritto in questo modo, la soluzione risulta essere data dai valori di x11 e x21 che soddisfano l’uguaglianza.
Ciò significa che B deve costituire una combinazione qualsiasi delle colonne di A. Ad esempio, nello spazio tridimensionale, i vettori dati dai segmenti che
congiungono l’origine (0,0,0) rispettivamente con i punti (a11,a21,a31) e (a12,a22,a32) individuano un piano; affinchè il sistema abbia soluzione è necessario che B giaccia in tale piano.
Quest’ultimo è in realtà un sottospazio, ovvero è a sua volta uno spazio vettoriale che, nel nostro esempio specifico, definiamo come spazio delle colonne di A, poichè risulta generato dalle sue colonne.
Quanto detto finora a proposito degli spazi e sottospazi vettoriali ci permette di dare
alcuni chiarimenti a proposito dei vincoli lineari sullo spazio di cointegrazione.che compaiono nel capitolo 5. Infatti, identificando le matrici che compaiono nel sistema (B.1.4) rispettivamente con H, ϕ e β presenti nel paragrafo (5.1), possiamo scrivere
β = Hϕ
e quindi, per quanto affermato precedentemente, possiamo dire che sp(β) ⊂ sp(H). Gli spazi vettoriali godono delle seguenti proprietà:
- la somma di due vettori qualsiasi nello spazio è un vettore che giace ancora in tale spazio;
- il prodotto fra uno scalare e un vettore qualsiasi nello spazio è un vettore multiplo del

Pag. 258 Elementi di algebra matriciale
primo, che giace a sua volta nello stesso spazio. Per lo spazio delle colonne di una matrice, è possibile individuare due casi particolari: - se la matrice A è nulla, allora lo spazio delle sue colonne contiene solo un vettore (più
precisamente il vettore nullo); questo spazio è il più piccolo possibili; - se la matrice A è la matrice identità n-dimensionale, allora lo spazio delle sue colonne
è tutto lo spazio ad n dimensioni ed ogni vettore colonna con n componenti può essere prodotto dalle colonne (vettori unitari) della matrice identità.
Lo spazio di tutti i vettori reali ad n dimensioni si indica con Rn. Nel nostro esempio particolare, il piano rappresenta uno spazio bidimensionale.
B.3.1 Basi di spazi vettoriali e dimensioni L’esempio precedente costituisce un punto di partenza per la definizione di base dello spazio vettoriale. In tale esempio abbiamo parlato di spazio generato dalle colonne della matrice A.
In via generale, possiamo dire che, se uno spazio vettoriale V è composto da tutte le combinazioni lineari dei vettori vi, allora questi vettori generano lo spazio.
A loro volta, i vettori vi sono esprimibili come combinazioni di altri vettori “particolari”.
Ad esempio, un qualsiasi vettore generico x = ( x1 , x2 , … , xn )′ può essere espresso come
x = x1e1 + x2e2 + … + xnen
z
x
y
(a11 ,a21 ,a31)
(a12 ,a22 ,a32)
Fig. B.2: Rappresentazione garfica di uno spazio bidimesionale generato da una coppia di vettori

Elementi di algebra matriciale Pag. 259
con e1 = (1, 0 , 0 , … ,0)’, e2 = (0 , 1 , 0 , 0 , …)’, … , en = (0 , 0 , 0 , …, 1)’ e x1 , x2 , … , xn coefficienti pari agli elementi del vettore x. I vettori ei possono essere aggregati a costituire una matrice E di ordine n×n nella forma
E=
1 0 00 1 0
00 0 1
...
......
...
(B.3.2)
Tale matrice è formata da vettori linearmente indipendenti e perciò è di rango pieno n; inoltre, in virtù di questa indipendenza, lo spazio da essa generato è Rn.
Da ciò possiamo dedurre che rango di una matrice, numero di righe o colonne linearmente indipendenti e dimensioni dello spazio generato da tali vettori componenti la matrice sono concetti che si equivalgono fra loro.
La matrice E ci permette di introdurre anche il concetto di base di uno spazio vettoriale. Quest’ultima è un insieme di vettori che hanno le proprietà espresse anche dalla matrice E, ovvero: - sono linearmente indipendenti; - generano l’intero spazio. Come esempio, consideriamo il piano (x,y) della fig. B.3. I tre vettori v1, v2 e v3 giacciono in questo piano, ma solo due di essi sono linearmente indipendenti e formano lo spazio definito dal piano (x,y). La scelta su quale dei due considerare per definire la base è arbitraria e ciò ci permette di constatare che la base di uno spazio vettoriale non è unica. Tuttavia, due basi qualsiasi dello spazio devono avere lo stesso numero di vettori: questo costituisce la dimensione dello spazio e ne dà il numero di “gradi di libertà”.
y v3
v2
x
v1
Fig. B.3: Rappresentazione grafica della base di uno spazio vettoriale

Pag. 260 Elementi di algebra matriciale
In un sottospazio di dimensione k, nessun insieme che contenga più di k vettori può essere linearmente indipendente e nessun insieme con meno di k vettori può generare l’intero spazio. Come esempio della precedente argomentazione, consideriamo il vincolo posto sulla matrice β nel paragrafo (5.1) ed espresso come
β = [b,ψ] .
In quel contesto, b è l’insieme dei vettori noti di cointegrazione; essendo questi linearmente indipendenti da ψ, esprimono un sottoinsieme della base della matrice β, e perciò, per quanto detto precedentemente, si ha che sp(b) ⊂ sp(β).
Per concludere, possiamo vedere cosa accade nel caso generale in cui ogni elemento della matrice β sia vincolato linearmente. Dal punto di vista geometrico, ciò equivale a scrivere
β = [ H1ϕ1 , … , Hrϕr ] ,
dove r è il rango di cointegrazione, ovvero è il numero di colonne di β. Il numero di vincoli di ogni vettore di cointegrazione è pari a p-si , con si uguale al numero di righe di ogni vettore ϕi . Ciò significa che ogni vettore i-esimo di β è vincolato a stare nello spazio definito dal rispettivo vincolo Hiϕi , ovvero sp(β) ∩ sp(Hi) è di dimensione massima pari a 1.
B.3.2 Spazio nullo di una matrice Consideriamo ora il sistema dato da
AX = 0
con A matrice di dimensioni m×n e x vettore n×1. L’insieme delle soluzioni di questo sistema è uno spazio vettoriale, detto spazio nullo
di A, che risulta essere un sottospazio dello spazio Rn. Se A è una matrice di rango r, allora solo r delle m equazioni definite dal sistema
sono indipendenti.
In relazione a quanto visto a proposito della matrice di cointegrazione β, si può dire che lo spazio nullo di β, indicato con sp(β⊥ ), è uno spazio di attrazione per il vettore non stazionario Xt . Infatti, per quanto visto al § 2.2, se consideriamo il processo Xt scritto in forma MA e tale per cui t sia un numero sufficientemente grande da rendere dominante

Elementi di algebra matriciale Pag. 261
la parte non stazionaria (random walk) rispetto a quella stazionaria, allora possiamo affermare che
β′Xt = 0 . (B.3.3)
Supponiamo, per semplicità, che β sia una matrice di dimensioni 3×2, data da
ββ ββ ββ β
=
11 12
21 22
31 32
e che Xt sia il vettore di dimensioni 3×1 dato da (x1 , x2 , x3)′. La relazione (B.3.3) può essere scomposta nel sistema dato da due equazioni e due
incognite seguente
β11x1 + β21x2 + β31x3 = 0
β12x1 + β22x2 + β32x3 = 0
Esso definisce lo spazio di attrazione per Xt , che geometricamente è dato da una retta definita dall’intersezione dei due piani (a tratteggio orizzontale e obliquo nella fig. B.4) rappresentati analiticamente dalle due equazioni del sistema. Questa retta è il vettore sp(β⊥ ), detto spazio attrattore per il processo Xt .
sp(β⊥ ) x3
x1
x2
Fig. B.4: Intersezione di piani definiti dai vettori di cointegrazione: lo spazio attrattore.

Pag. 262 Elementi di algebra matriciale
Il modello scritto in forma MA ci permette di evidenziare come il processo Xt sia
spinto lungo lo spazio attrattore dai cosiddetti trends comuni dati da α ε⊥ =∑'ii
t
1 (vedi
§2.2). Uno shock al sistema lo fa allontanare da tale spazio in direzione perpendicolare ad esso; il successivo processo di aggiustamento viene esplicato dai coefficienti α.
Il modello MA è, in un certo senso, complementare al modello ECM: mentre il primo è costruito basandosi sul concetto di common trends, il secondo poggia le basi sul concetto di errore di disequilibrio. Infatti, considerando le relazioni di equilibrio β′Xt=C, con C pari ad un processo stazionario, si ha che l’errore di disequilibrio è dato dallo scostamento da tali relazioni, ovvero da β′Xt−C. Gli agenti economici reagiscono a tale errore, “riaggiustando le variabili tramite il coefficiente di aggiustamento α. Per come è definito, l’errore di disequilibrio è ortogonale allo spazio che definisce le relazioni di equilibrio, ovvero quelle di lungo periodo.
Una spiegazione più formale di spazio ortogonale è data nel paragrafo seguente.
B.3.3 Ortogonalità di vettori e sottospazi Prima di introdurre il concetto di ortogonalità di sottospazi, è necessario dare una definizione di lunghezza di un vettore.
Consideriamo, come caso semplice, quello in cui il vettore (x1 , x2 , x3) sia la diagonale del parallelepipedo individuato dai vettori (x1 , 0 , 0), (0 , x2 , 0) e (0 , 0 , x3).
La lunghezza della diagonale, che indichiamo con x , é la radice quadrata di x1
2 + x22 + x3
2 .
Generalizzando al caso n-dimensionale, si ha che
x 2 = x ii
n2
1=∑ .
Vettori ortogonali Per constatare che due vettori x e y sono ortogonali (si veda fig. B.5), è necessario che sia verificata la seguente relazione
x y x y2 2 2+ = − .
Nel caso n-dimensionale, questa condizione diviene

Elementi di algebra matriciale Pag. 263
( )x y x yii
n
ii
n
i ii
n2
1
2
1
2
1= = =∑ ∑ ∑+ = − (B.3.4)
La relazione (B.6) risulta essere vera nel caso in cui, al secondo membro, i prodotti incrociati siano 0, ovvero
x yi ii
n
=∑
1= 0.
In forma matriciale, ciò equivale a scrivere che
xy′ = [ ]x x x
yy
y
n
n
1 2
1
2......
= 0.
Tale prodotto è detto prodotto scalare dei due vettori o prodotto interno. Una proprietà dei prodotti fra vettori è la seguente:
se i vettori non nulli v1, v2,...vk sono reciprocamente ortogonali, allora essi sono linearmente indipendenti. Sottospazi ortogonali Due sottospazi V e W nello spazio n-dimensionale Rn si dicono ortogonali se ogni vettore v in V è ortogonale a ogni vettore w in W, ovvero se v′w = 0 per ogni v e w.
Un caso particolare, ma rilevante, è il seguente:
x3
x1 x2
x
y x-y
Fig. B.5: Rappresenatzione grafica di due vettori ortogonali.

Pag. 264 Elementi di algebra matriciale
data una matrice A di dimensioni m×n, lo spazio nullo di tale matrice, che indichiamo con N(A), e lo spazio delle righe di A, che indichiamo con R(A′), sono sottospazi ortogonali di Rn.
Ciò è vero in quanto che, se supponiamo che w sia un qualsiasi vettore colonna nello spazio nullo N(A), allora si ha che Aw = 0.
Ciò significa che il vettore w è ortogonale alla prima riga di A, o, equivalentemente, alla prima colonna di A′.
Lo stesso discorso può essere ripetuto per lo spazio nullo di A′ e lo spazio delle colonne di A: entrambi sono sottospazi ortogonali in Rm.
Dato un sottospazio V di Rn, lo spazio di tutti i vettori ortogonali a V è detto complemento ortogonale di V ed è indicato con V⊥ .
Perciò si deduce che lo spazio nullo della matrice A è il complemento ortogonale dello spazio delle righe di A.
Un esempio di quanto detto è dato da β⊥ , che rappresenta il complemento ortogonale della matrice di cointegrazione ed è definito come l’insieme dei vettori x tali per cui β′x=0.
E’ importante notare che due sottospazi V e W possono essere ortogonali senza
essere complementi ortogonali uno dell’altro. Ad esempio, nello spazio a tre dimensioni la retta v individuata dal vettore (1,0,0) è
ortogonale alla retta W individuata da (0,1,0), ma le due non sono complementi ortogonali l’uno dell’altro.
Infatti, il complemento ortogonale di W, ad esempio, è il piano (1,0,1), di cui la retta v costituisce un sottospazio (si veda fig. B.6).
Perciò, affinchè si abbia la complementarietà ortogonale fra spazi, è necessario che la somma delle loro dimensioni sia pari a quella dell’intero spazio.
w
w
v
v
Fig. B.6: Complemento ortoganale di un vettore.

Elementi di algebra matriciale Pag. 265
Basi ortogonali e matrici ortogonali La costruzione di una base di vettori costituisce un punto di partenza per collegare i concetti della geometria con quelli algebrici. La scelta di una base ortogonale ci permette di semplificare i calcoli.
Un’ulteriore semplificazione è data dall’introduzione di quella che viene definita base ortonormale.
Una base ortonormale è tale per cui
′ =≠
v Vi j0 se i j (garanzia di ortogonalità)1 se i= j (garanzia di normalità)
Un esempio è dato dalla base standard in Rn, costituita dall’insieme di vettori colonna che formano In.
Se consideriamo un sottospazio di Rn, anche in tal caso esiste una base ortonormale; la sua costruzione è nota come “metodo di ortogonalizzazione di Gram-Schmidt”, per la cui trattazione rimandiamo a testi specifici (si veda, ad esempio, Anderson (1984)).
B.3.4 Coppie di sottospazi e prodotti di matrici Valgono, per le coppie di sottospazi, le seguenti proprietà. - Se V e W sono entrambi sottospazi di un dato spazio vettoriale, allora anche V∩W è
un sottospazio in esso. Geometricamente, ad esempio, si può dire che l’intersezione di due piani passanti per l’origine, nello spazio Rn, è anch’esso un sottospazio, rappresentato da una retta passante per l’origine.
- L’intersezione di due sottospazi ortogonali V e W è il sottospazio 0 . - L’unione V∪ W di due sottospazi non è, in genere, un sottospazio, eccetto il caso in cui
V⊆ W oppure W⊆ V. Come caso semplice, si consideri quello in cui siano dati i due vettori (1,0) e (0,1); essi rappresentano due assi ortogonali nel piano (x,y) e la loro unione non dà un sottospazio (ovvero una retta) che stia o su un asse o sull’altro.
- Se V e W sono entrambi sottospazi in un dato spazio, tale è la loro somma V+W. - Se V e W sono complementi ortogonali in Rn, la loro somma dà l’intero spazio
Rn.Ogni vettore x in tale spazio è la somma delle sue proiezioni ortogonali v in V e w in W. Tale proprietà risulta applicata nel § 2.2 del presente lavoro, in cui si vede come la somma delle proiezioni delle variabili Xt negli spazi di β e di β⊥ definisca l’intero spazio p×p delle variabili suddette (si veda anche il § B.3.5).
- Se V è lo spazio delle colonne di una matrice A e W è lo spazio delle colonne di una matrice B, allora V+W è lo spazio delle colonne della matrice combinata Q=[A B].

Pag. 266 Elementi di algebra matriciale
- La dimensione di V+W può essere minore della somma delle dimensioni di V e W, perchè i due sottospazi possono sovrapporsi ed è pari al rango della matrice Q.
- La dimensione di V∩W è pari alla dimensione dello spazio nullo di Q. - Da queste ultime due considerazioni deriva la seguente proprietà:
dim(V+W) + dim(V∩W) = rango di Q + nullità di Q =
= numero di colonne di Q.
Gli spazi fondamentali per il prodotto AB Nel caso di prodotto di matrici, i risultati sono i seguenti: - lo spazio nullo di AB contiene lo spazio nullo di B; - lo spazio delle colonne di AB è contenuto nello spazio delle colonne di A; - lo spazio nullo di (AB)′ contiene lo spazio nullo di A′; - lo spazio delle righe di AB è contenuto nello spazio delle righe di B. Per quanto riguarda il prodotto di matrici e il loro significato geometrico, un esempio che può risultare significativo è quello dato dal problema dell’identificazione di β (vedi § 5.1). Il modello scritto in forma ECM, con Π di rango ridotto dato da αβ′ , non è distinguibile dal modello ECM che presenta i coefficienti delle variabili ritardate come αQQ-1β′, con Q matrice non singolare e quadrata di ordine r. Infatti il prodotto Q-1β non definisce, in tal caso, un nuovo spazio, bensì una matrice β∗ delle stesse dimensioni di β e che, quindi, ne copre lo stesso spazio colonna. Supponiamo, ad esempio, che β sia una matrice di dimensioni 3×2; geometricamente, essa rappresenta un piano nello spazio tridimensionale. La matrice β∗ non è altro che lo stesso piano, individuato, però, da coordinate diverse rispetto al sistema cartesiano di riferimento scelto per β.
In altre parole, β è indistinguibile dalle sue combinazioni lineari Q-1β, in quanto queste rappresentano solo un modo diverso di indicare lo stesso spazio.
In riferimento alla fig.B.7, possiamo scrivere
ββ ββ ββ β
=
11 12
21 22
31 32
=[ ]β β1 2 , con β1 e β2 vettori 3×1 e

Elementi di algebra matriciale Pag. 267
β∗ = βQ-1 = [ ]β β1 211 12
21 22
q qq q
= β ββ ββ β
11 12
21 22
31 32
∗ ∗
∗ ∗
∗ ∗
= [ ]β β1 2∗ ∗ , con β1
∗ e β2∗ vettori 3×1
dello spazio di β. Graficamente si ottiene
B.3.5 Proiezioni in sottospazi, approssimate mediante i minimi quadrati
Consideriamo il sistema espresso dalla (B.3.1), con A matrice m×n. La matrice A individua uno spazio (spazio delle colonne di A), in cui vogliamo proiettare il vettore B.Ciò può essere fatto, riconducendoci ad un problema di minimizzazione della distanza del vettore B dallo spazio individuato da A, che può essere risolto mediante la minimizzazione dell’errore espresso da Ax B− .
La perpendicolarità ad uno spazio si esprime nel modo seguente. Ogni vettore nello spazio delle colonne di A è una combinazione lineare delle
colonne con coefficienti yi, i=1,...n, ovvero è un vettore nella forma Ay. Questi vettori devono essere perpendicolari ad A x −B, con x tale da minimizzare
l’errore precedente, ovvero
z
x
y
ββββ1
ββββ2
ββββ1′′′′
ββββ2′′′′
Fig. B.7: Piano individuato dai vettori di cointegrazione

Pag. 268 Elementi di algebra matriciale
B
colonna 2
colonna 1 A x -B
p=A x
Fig. B.8: Proiezione di B nello spazio delle colonne di A
(Ay)′(A x − B) = 0
Da ciò si ricava che
y′(A′A x − A′B) = 0
Affinchè ciò sia vero per ogni y, è necessario che
A′A x − A′B = 0
ovvero
x =(A′A)-1A′B
La proiezione di B nello spazio delle colonne di A è allora dato da
A x =A(A’A)-1A’B
Per un esempio grafico, si veda la fig.B.8, in cui A si presenta di dimensioni 3×2 e B è un vettore 3×1;con colonna 1 abbiamo indicato il primo vettore colonna della matrice A, ovvero (a11,a21,a31)′,mentre con colonna 2 abbiamo indicato il secondo, ovvero (a12,a22,a23)′; B è il vettore (b11,b21,b31)′.
La matrice che descrive la costruzione geometrica della proiezione di un vettore in uno spazio di colonne di una matrice è detta matrice di proiezione ed è indicata con PA
PA=A(A′A)-1A′.

Elementi di algebra matriciale Pag. 269
In riferimento al nostro lavoro, troviamo un’applicazione dei concetti qui esposti nella dimostrazione del teorema di Granger svolta nel § 2.2.
Dopo questa trattazione di carattere generale sulle matrici, procediamo descrivendo quelle relative al calcolo differenziale.
B.4 Elementi di calcolo differenziale
B.4.1 Differenziabilità e approssimazione lineare nel caso unidimensionale
Consideriamo la seguente equazione
lim ( ) ( )u
c u cu→
+ −=
0
φ φφ′(c) (B.4.1)
Essa esprime la derivata della funzione φ(⋅), calcolata in c ed equivale a scrivere
φ(c+u)=φ(c)+uφ′(c)+rc(u) (B.4.2)
con rc(u) tale per cui lim( )
ucr uu→0
= 0.
L’equazione (5.2) è definita formula di Taylor arrestata al primo ordine. L’espressione uφ′(c) è detta differenziale del primo ordine di φ(⋅) nel punto c con incremento pari a u e si indica anche come dφ(c;u), in cui c è un punto di differenziabilità per φ, mentre u assume un valore qualsiasi.
Il differenziale uφ′(c) è la parte lineare dell’incremento φ(c+u)-φ(c) ed è espresso geometricamente sostituendo la curva con la sua tangente nel punto c.
Analogamente, se esiste una quantità α, dipendente da c ma non da u, tale che
φ(c+u) = φ(c) + uα + r(u)
con lim ( )u
r uu→0
= 0, cioè se è possibile approssimare φ(c+u) con una funzione lineare in u
in modo che la differenza fra la funzione e la sua approssimazione lineare tenda a 0 più velocemente dell’incremento u, allora φ è differenziabile nel punto c.
α è detta derivata della funzione φ(⋅) in c e si indica con φ′(c).

Pag. 270 Elementi di algebra matriciale
B.4.2 Differenziabilità nel caso pluridimensionale:il differenziale di una funzione vettoriale
Sia f:S→Rm una funzione definita per ogni valore di di S, sottoinsieme di Rn; sia c un punto dell’insieme S e sia B(c;r) un intorno n-dimensionale di c in S. Inoltre sia u un punto in Rn tale per cui u <r (cosicchè c+u appartiene a tale intorno); se esiste una matrice reale A di dimensioni m×n, dipendente da c ma non da u, tale per cui
f(c + u) = f(c) + A(c)u + rc(u) (B.4.3)
per ogni u ∈ Rn, con u <r e lim ( )u
r uu→0
=0, allora la funzione f è detta essere
differenziabile nel punto c. La matrice A(c) di dimensioni m×n è detta essere la derivata prima di f in c e il vettore m×1,che è dato da A(c)u, è definito come df(c;u) ed è una funzione lineare di u, è detto differenziale del primo ordine di f in c (con incremento u).
Il differenziale di una funzione in un punto è unico; inoltre, se la funzione f è differenziabile in ogni punto di un sottoinsieme aperto E di S, allora diciamo che f è differenziabile in E.
Per fare un esempio, consideriamo la funzione f(x,y):R2→R definita come f(x,y)=xy2. In base alle considerazioni precedenti, si ha
φ(x + u , y + v ) = (x + u)(y + v)2 =
xy2 + (y2u + 2xyv + (xv2 + 2yuv + uv2) =
φ(x,y) + dφ(x,y;u,v) + r(u,v),
con dφ(x,y;u,v) = [y2 2xy]uv
e r(u,v) = xv2 + 2yuv + uv2.
Poichè r u vu v
( , )( )2 2 1 2 0
+→ se (u,v)→(0,0), allora φ è differenziabile in ogni punto di
R2.
B.4.3 Il differenziale di funzioni matriciali Sia F:S→Rm×p una funzione matriciale definita in S, sottoinsieme in Rn×p. Sia C un punto interno a S e sia B(c;r) un insieme sferico con centro in C, raggio r e sottoinsieme

Elementi di algebra matriciale Pag. 271
di S; sia inoltre U un punto in Rn×p con U <r (cosicchè C+U ∈ B(C;r)Se esiste una matrice A mp×nq, dipendente da C ma non da U tale per cui
vecF(C + U) vecF(C) + A(C)vecU + vecRc(U) (B.4.4)
per ogni U ∈ Rn×q, con U <r e lim( )
UcR UU→0
=0, allora la funzione F è detta
differenziabile in C. La matrice dF(C,U), tale per cui vecdF(C;U)=A(C)vecU, di dimensioni m×p, è detta
essere il differenziale primo di F in C (con incremento U) e la matrice A(C), di dimensioni mp×nq, è la derivata prima di F in C.
In virtù di questa definizione, è bene dare alcune definizioni. Ricordiamo che la norma di una matrice reale X è definita da
X = (tr(X′X))1/2 ,
mentre una sfera in Rn×q è data da
B(C;r) = X X R X C rn q: ,∈ − <× .
Inoltre, data una matrice A di dimensioni m×n, la cui colonna j-esima è data dal vettore aj , si definisce con vec(A) l’operatore che trasforma la matrice A in un vettore colonna mn×1, ottenuto disponendo una sotto l’altra le colonne di A
vecA =
aa
a
a
j
n
1
2
..
..
.
Alcune proprietà facilmente verificabili di tale operatore sono le seguenti: - se A è un vettore colonna , allora vecA′ = vecA = A; - se A e B sono vettori colonna , allora vecAB′ = B⊗ A; - se A e B sono matrici, allora (vecA)′vecB = tr(A′B). Grazie a questi ultimi risultati sull’operatore vec, è possibile ricondurre il calcolo delle derivate delle funzioni matriciali a quello di funzioni vettoriali, considerando, invece della funzione matriciale F, la funzione vettoriale f:vecS→Rmp definita da
f(vecX) = vecF(X) (B.4.5)

Pag. 272 Elementi di algebra matriciale
Da questa considerazione ricaviamo che le relazioni fra il differenziale di F e di f è data da
vecdF(C;U) = df(vecC;vecU) (B.4.6)
Inoltre possiamo definire la matrice Jacobiana di F nel punto C come
DF(C) = Df(vecC) . (B.4.7)
Questa è una matrice mp×nq, il cui elemento di posto ij è la derivata parziale della componente i-esima di vecF(X) rispetto al j-esimo elemento di vecX, valutato in X=C.
Se φ è una funzione scalare di un vettore X di dimensioni n×1, la derivata di φ è data da
Dφ(X) = [D1 φ(X) D2φ(X) … Dnφ(X)] = δφδ
( )'
XX
.
Se f è una funzione vettoriale di dimensioni m×1 dello stesso vettore X, allora la sua derivata (o matrice Jacobiana) è la matrice m×n data da
Df(X) = δδf XX( )
' .
Generalizzando questo concetto a funzioni matriciali di matrici, si ha che, data una funzione F matriciale reale differenziabile di una matrice X di dimensione n×q e reale, allora la matrice Jacobiana di F in X è la matrice mp×nq data da
DF(X) = δδvecF XvecX
( )( ) ' . (B.4.8)
Confrontando questa equazione con la (4.7), si nota che DF(X) e δδF X
X( ) contengono le
stessederivate parziali, ma l’ordine delle due matrici è diverso: infatti DF(X) è di ordine
mp×nq, mentre δδF X
X( ) è di ordine mn×pq.
Grazie all’equazione (4.8), è possibile ridurre lo studio di funzioni matriciali di matrici allo studio di funzioni vettoriali di vettori, poichè F(X) e X vengono trasformati mediante l’operatore vec(⋅). In realtà la prima espressione risulta essere “più comoda” da utilizzare.
Differenziali di funzioni matriciali Diamo qui di seguito alcuni utili risultati riguardanti i differenziali di matrici.

Elementi di algebra matriciale Pag. 273
Sia A una matrice di costanti reali e U e V siano funzioni matriciali; siha che
dA = 0
d(αU) = αdU
d(U ± V) = dU ± dV
d(UV) = (dU)V + U(dV)
d(U⊗ V) = dU ⊗ V + U ⊗ dV
d(U′) = (dU)′
d(vecU) = vec(dU)
d(trU) = tr(dU) .
Differenziali di una matrice inversa Ci soffermiamo su questo risultato, in quanto tornerà utile, come vedremo in seguito, nel calcolo del differenziale di primo ordine della funzione di verosimiglianza, il cui calcolo è essenziale per derivare le proprietà statistiche degli stimatori ottenuti.
Sia T l’insieme delle matrici reali non singolari appartenenti allo spazio Rm×m e sia S un sottoinsieme aperto di Rn×q. Se la funzione matriciale F: S→T è k volte differenziabile con continuità in S, allora tale è anche la funzione matriciale inversa F-1: S→T, definita come F-1(X) = (F(X))-1 e si ha che
dF-1 = − F-1 (dF)F-1.
(Per una dimostrazione di questa proprietà, si veda Magnus&Neudecker(1988)).
Un esempio significativo di calcolo di differenziali, che riportiamo in appendice e che risulta necessario nella determinazione delle distribuzioni asintotiche degli stimatori di αe di β fatto al capitolo 4, è dato da quello relativo al differenziale primo della funzione di log-verosimiglianza. La sua espressione risulta essere la seguente
LogL(α,β,Ω) = − − − −12
2 12
12
1T T tr Zlog log ( )π Ω Ω ,
con Z = ( )( )'iT
i iy y=∑ − −1 µ µ .
Differenziando la funzione, tenendo conto di quanto visto precedentemente, si ottiene

Pag. 274 Elementi di algebra matriciale
dLogL =− − −− −12
12
12
1 1Td tr d Z tr dZ(log ) ( )Ω Ω Ω =
( )− + +− − −12
12
1 1 1Ttr d tr d Z Ω Ω Ω Ω Ω
+ 12
1
11
tr y d d yi ii
T
i
T
Ω−
==
− + −
∑∑( )( ) ( ) ( )' 'µ µ µ µ =
= ( ) ( )12
1 1 1
1
tr d Z T d yii
T
Ω Ω Ω Ω Ω− − −
=
− + − =∑( ) ( )'µ µ
= ( ) ( )12
1 1 1tr d Z T T d y Ω Ω Ω Ω Ω− − −− + −( ) ( )'µ µ .
Le condizioni del primo ordine sono
( )Ω Ω Ω− −−1 1Z T = 0 , e ( )Ω− −1 y µ = 0
Nel caso specifico trattato nel lavoro (vedi § 4.2.3), si ha che Z= ( )( )' ' 'R R R Rt tt
Tt t0 11 0 1−∑ −= αβ αβ e Ω è la varianza dei vettori εt .
Il differenziale primo è dato dalla seguente espressione
dlogL(α,β,Ω)= − + − −
− − −
=∑1
212
1 1 10 1
10 1tr d tr d R R R Rt t
t
T
t t( ) ( ) ( )( )' ' 'Ω Ω Ω Ω Ω αβ αβ +
− − −
−
=∑1
21
0 11
0 1tr d R R R Rt tt
T
t tΩ ( )( )' ' 'αβ αβ
= ( )12
10 1 0 1
1
1tr d R R R R Tt t t tt
T
Ω Ω Ω Ω−
=
−− − −
+∑( )( )' ' 'αβ αβ
+ tr Ω Ω−
=
−
=
−
+ −
∑ ∑10 1 1
1
10 1 1
1
( ) ( )' ' ' ' ' 'R R R d tr R R R dt t tt
T
t t tt
T
αβ β α α αβ β
che porta alle seguenti condizioni per la massimizzazione
( )~ ~~' 'α αβΩ− −101 11S S = 0
( )S S01 11−~~ ~'αβ β = 0 .

BIBLIOGRAFIA - ANDERSON, T. W. (1984), An Introduction to Multivariate Statistical Analysis,
John Wiley & Son Inc., New York. - ASSEMBLEA GENERALE ORDINARIA DEI PARTECIPANTI TENUTA IN ROMA
IL GIORNO 31 MAGGIO 1993: ANNO 1992 - APPENDICE -, Banca d’Italia. - ASSEMBLEA GENERALE ORDINARIA DEI PARTECIPANTI TENUTA IN ROMA
IL GIORNO 31 MAGGIO 1994: ANNO 1993 - APPENDICE -, Banca d’Italia. - BAILLIE, R. T. - BOLLERSLEV, T. (1994), Cointegration, Fractional
Cointegration and Exchange Rate Dynamics, The Journal of Finance, 49: 737-745. - BANERJEE, A. - DOLADO, J. J. - GALBRAITH, J. W. - and HENDRY, D. F.
(1993), Cointegration, Error Correction and the Econometric Analysis of Non-stationarity Data, Oxford University Press, Oxford.
- Van Den BERG, H. - JAYANETTI, S. C. (1993), A Novel Test of the monetary Approach Using Black Market Exchange Rates and the Johansen-Juselius Cointegration Method, Economics Letters, 41: 413-418.
- BILLINGSLEY, P. (1968), Convergence of Probability Measures, John Wiley & Son Ltd., New York.
- BOLLETTINO (1950 - 1983), Banca d’Italia. - BOLLETTINO ECONOMICO (1983 - ), Banca d’Italia. - CHOWDHURY, A. R. - SDOGATI, F. (1993), Purchasing Power Parity in the
Major EMS Countries: The Role of Price and Exchange Rate Adjustment, Journal of Macroeconomics, 15: 25-45.
- CLEMENTS, M. P. - HENDRY, D. F. (1996), Intercept Corrections and Structural Change, Journal of Applied Econometrics, 2: 475-494.
- DIEBOLD, F. X. - GARDEAZABAL, J. - YILMAZ, K. (1994), On Cointegration and Exchange Rate Dynamics, The Journal of Finance, 49: 727-735.
- DORNBUSCH, R. - FISHER, S. (1988), Macroeconomia, Il Mulino, Bologna. - DROPSY, V. (1996), Real Exchange Rates and Structural Breaks, Applied
Economics, 28: 209-219.

Pag. 276 Bibligrafia
- ENGLE, R. F. - GRANGER, C. W. J. (1987), Cointegration and Error Correction: Representation, Estimation and Testing, Econometrica, 55: 251-76.
- EUROSTATISTICHE: DATI PER L’ANALISI DELLA CONGIUNTURA (1979- ), Eurostat, Lussemburgo.
- FISHER, P. G. - TANNA, S. K. - TURNER, D. S. - WALLIS, K. F. - WHITLEY, J. D. (1990), Econometric Evaluation of the Exchange Rate in Models of the UK Economy, The Economic Journal, 100: 1230-1244.
- GIANNINI, C. - MOSCONI, R. (1989), Non Stazionarietà, Integrazione, Cointegrazione: analisi di alcuni aspetti operativi della letteratura recente, Quaderni di ricerca del Dipartimento di Economia dell’Università di Ancona, n.14.
- GODFREY, L.G. (1978), Testing for Higher order Serial Correlation in Regression Equations when the Regressors Include Lagged Dependent Variables, Econometrica, 46: 1303-1310.
- GRANGER, C. W. J. (1981), Some properties of Time Series Data and their use in Econometric Model Specification, Journal of econometrics, 16: 121-30.
- GREENE, W. H. (1995), Econometric Analysis, Macmillan Publishing Company, New York.
- HAMILTON, J. D. (1994), Time Series Analysis, Princeton University Press, Princeton.
- HALL, P. - HEYDE, C. C. (1980), Martigale Limit Theory and Its Application, New York Academic Press, New York.
- HARBOE, I. - JOHANSEN, S. - NIELSEN, B. - RAHBEK, A. (1995), Test for Cointegrating Rank in Partial Systems, Prestampa, Istituto di Statistica Matematica dell’Università di Copenhagen.
- HYLLEBERG, S. (1992c), Modelling Seasonality, Oxford University Press, Oxford.
- HYLLEBERG, S - ENGLE R. F. - GRANGER, C. W. J. - YOO, S. B. (1990), Seasonal Integration and Cointegration, Journal of Econometrics, 44: 215-38.
- INTERNATIONAL FINANCIAL STATISTICS (1948- ), International Monetary Fund, Washington.
- JOHANSEN, S. (1988), Statistical Analysis of Cointegration Vectors, Journal of economic Dynamics and Control, 12: 231-54.
- JOHANSEN, S. (1989), Likeihood Based Inference on Cointegration: Theory and Applications, Appunti per un corso tenuto al Seminario estivo di Econometria, Centro Studi Sorelle Clarke, Bagni di Lucca.
- JOHANSEN, S. (1991), Estimation and Hyphotesis Testing of Cointegration Vectors in Gaussian Vector Autoregressive Models, Econometrica, 59: 1551-1580.

Blbliografia Pag. 277
- JOHANSEN, S. (1992), Determination of Cointegration Rank in the Presence of a Linear Trend, Oxford Bulletin of Economics and Statistics, 54: 383-97.
- JOHANSEN, S. (1995), Statistical Analysis of Some Non-stationary time Series, Paper presentato al “Symposium at the Centennial of Ragnar Frisch” nell’Accademia Norvegese di Scienza e Letteratura, Oslo.
- JOHANSEN, S. (1995a), Likelihood-based Inference in Cointegrated Vector Auto-Regressive Models, Oxford University Press, Oxford.
- JOHANSEN, S. (1995b), Identifying Restrictions of Linear Equation with Applications to Simultaneous Equations and Cointegration, Journal of Econometrics, 69: 111-32.
- JOHANSEN, S. (1995c), The Role of Ancillarity in Inference for Non Stationary Variables, The Economic Journal, 105: 302-320.
- JOHANSEN, S. - NIELSEN, B. G. (1993), Manual for the Simulation Program DisCo, Manual Version 1.0 and DisCo Version 1.0, Istituto di Statistica Matematica dell’Università di Copenhagen.
- JOHANSEN, S. - JUSELIUS, K. (1992), Testing Structural Hyphoteses in a Multivariate Cointegration Analysis of the PPP and UIP for UK, Journal of Econometrics, 53: 211-44.
- JOHANSEN, S. - JUSELIUS, K. (1994), Identification of the Long-run and Short-run Structure: an Application to the ISLM Model, Journal of Econometrics, 63: 7-36.
- JUSELIUS, K. (1995), Do Purchasing Power Parity and Uncovered Interest Rate Parity hold in the Long-run? An Example of Likelihood Inference in a Multivariate time-Series Model, Journal of Econometrics, 69: 211-240.
- KRUGMAN P. R., - OBSTFELD M. (1995), Economia Internazionale;Teoria e Politica Economica, Hoepli, Milano.
- LUTKEPOHL, H. (1991), Introduction to Multiple Time Series Analysis, Springer-Verlag, New-York.
- MacDONALD, R. (1993), Long-run Purchasing Power Parity: is It for Real?, The Review of Economics and Statistics, 75: 690-695.
- MAGNUS, J. R. - NEUDECKER, H. (1988), Matrix Differential Calculus with Application in Statistics and Econometric, John Wiley & Son Ltd, New York.
- MONTHLY BULLETIN OF STATISTICS (1947- ), United Nations, New York. - MOOD A. M., - GRAYBILL, F. A., - BOES, D. C. (1992), Introduzione alla
Statistica, McGraw-Hill Libri Italia srl, Milano. - MOSCONI, R. (1993), Analysis of Deterministic Trends in Cointegrated System;
preliminary version, Dipartimento di Economia e Produzione del Politecnico di Milano.

Pag. 278 Bibligrafia
- MOSCONI, R. (1993), Cointegrazione e Modelli Econometrici. Teoria e Applicazioni, Ricerche Quantitative per la Politica Economica 1993, vol.II, Convegno Banca d’Italia, CIDE.
- MOSCONI, R. (1997), MALCOLM: The Theory and Practice of Cointegration Analysis in RATS, prossima pubblicazione a cura della c. ed. Cafoscarina, Venezia.
- NIEUWLAND, F. G. M. C. - VERSCHOOR, W. F. C. - WOLFF, C. C. P. (1994), Stochastic Trends and Jumps in EMS Exchange Rates, Journal of International Money and Finance, 13: 699-727.
- PANTULA, S. G. (1989), Testing for Unit Roots in Time Series data, Econometric Theory, 5: 256-71.
- PARUOLO, P. (1993), On the Determination of Integration Indices in I(2) Systems, Working paper, Università di Bologna, Dipartimento di Statistica.
- PHILLIPS, P. C. B. (1988), Regression Theory for near integrated time series, Econometrica, 56: 1021-44.
- PHILLIPS, P. C. B. (1991), Optimal Inference in Cointegrated Systems, Econometrica, 59: 283-306.
- PHILLIPS, P. C. B. - PERRON, P. (1988), Testing for Unit Root in Time Series Regression, Biometrika, 75: 335-346.
- REIMERS, H. E. (1993), Lag Order Determination in Cointegrated VAR Sistems with Application to Small German Macro-Models, paper presentato al Congresso ESEM ‘93, Uppsala, Agosto.
- SAID, S.E. - DICKEY, D.A. (1984), Testing for Unit Roots in Autoregressive-Moving Average Models of Unknown Order, Biometrika, 71: 599-608.
- STOCK, J. H. (1987), Asymptotic Properties of Least Squares Estimates of Cointegration Vectors, Economtrica, 55: 1035-56.
- STRANG, G. (1981), Linear Algebra and its Applications, Academic Press Inc., New York.
- TRONZANO, M., (1994), Unit Roots, Real Exchange Rates and Stuctural Breaks: Further evidence(1955-1992), Giornale degli Economisti, 53: 567-585.


















