
Gianluca Giulinin - FAO
18
AUTOMATIC TRANSLATION IN CPA TRANSLATION WORKFLOW: STRENGTHS AND WEAKNESSES Gianluca Giulini, Coordinator (Programming and Language Support) Conference, Council and Protocol Affairs Division, FAO
-
Upload
riilp -
Category
Data & Analytics
-
view
57 -
download
0
Transcript of Gianluca Giulinin - FAO

AUTOMATIC TRANSLATION IN
CPA TRANSLATION WORKFLOW:
STRENGTHS AND WEAKNESSES
Gianluca Giulini, Coordinator (Programming and Language Support)
Conference, Council and Protocol Affairs Division, FAO

WHO WE ARE
CPAM Meeting Programming and Documentation Service
Plan and organization of meetings
Interpretation for FAO meetings in Arabic, Chinese, English, French, Russian and Spanish
Translation into Arabic, Chinese, English, French, Russian and Spanish of all major publications and official documents of FAO Governing Bodies.
Schedule and monitor of documentation and publications for meetings
Terminology and Reference services
Printing services

CPA TRANSLATION SERVICES
CPA translates an average of 12 million words per year in the 6 official languages.
Our strengths:
High quality standards: consistent application of terminology and production of clear and coherent translated texts
Sound use of linguistic resources: Translation memories, Terminology database and Corpus of bilingual texts
Continual Services Improvement: periodical evaluation of our translation process and identification of streamlining opportunities so to improve the efficiency without hampering the quality

WHY MACHINE TRANSLATION WAS
INTRODUCED TO CPA TRANSLATION PROCESS
Identify: Translators often relied on freeware
automatic translation engines (Google Translate, SDL
BeGlobal) for a preliminary quick translation of
segments not present in translation memories.
Analyse: Identify a Machine Translation software that
could be trained on our corpus of documents and fully
integrated with our CAT tool.
Improve: TAPTA was chosen thanks to our participation in the International Annual Meeting on Computer-Assisted Translation and Terminology (JIAMCATT).
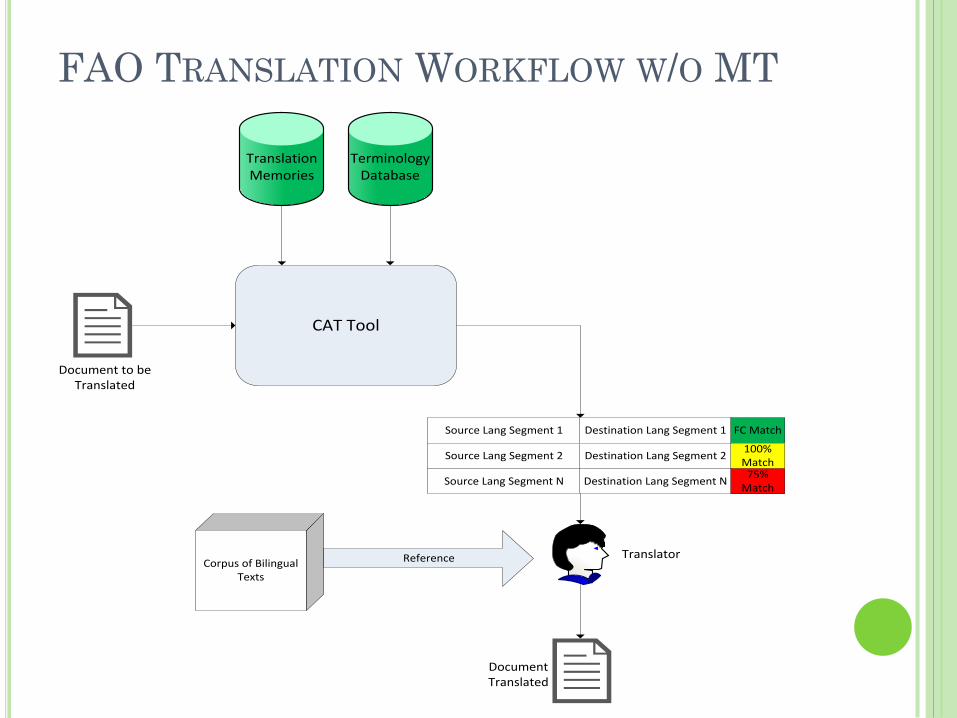
FAO TRANSLATION WORKFLOW W/O MT
Document to be Translated
Document Translated
Translation Memories
CAT Tool
Corpus of Bilingual Texts
Terminology Database
Reference
Source Lang Segment 1
Source Lang Segment 2
Source Lang Segment N
Destination Lang Segment 1
Destination Lang Segment 2
Destination Lang Segment N
FC Match
100% Match75%
Match
Translator
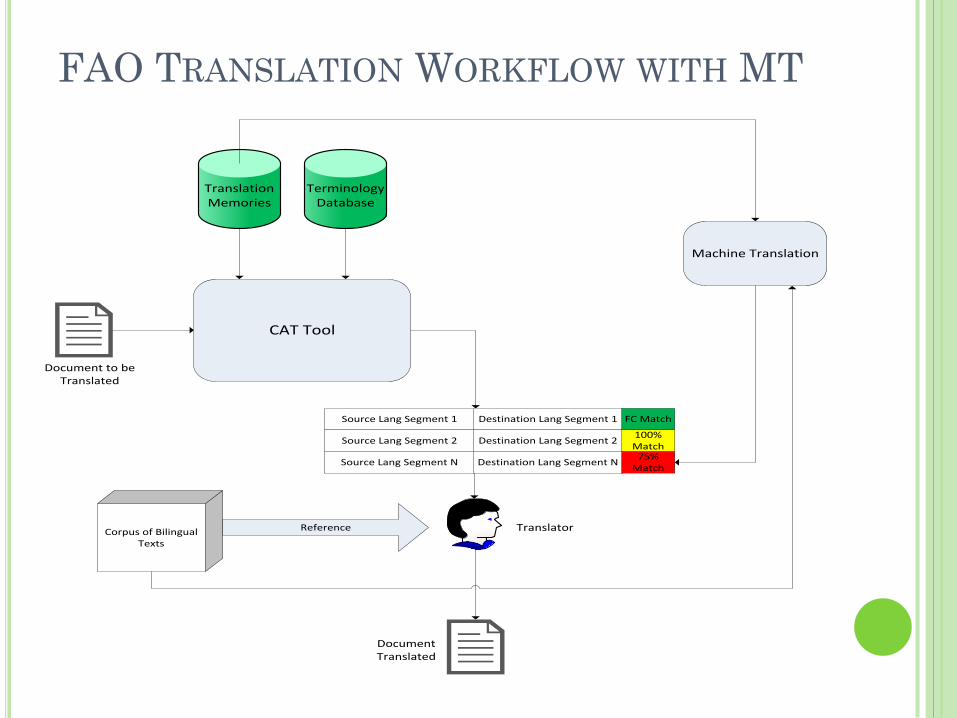
FAO TRANSLATION WORKFLOW WITH MT
Document to be Translated
Document Translated
Translation Memories
CAT Tool
Corpus of Bilingual Texts
Terminology Database
Reference
Source Lang Segment 1
Source Lang Segment 2
Source Lang Segment N
Destination Lang Segment 1
Destination Lang Segment 2
Destination Lang Segment N
FC Match
100% Match75%
Match
Machine Translation
Translator

TAPTA AND MOSES
Tapta is based on open-source Moses Statistical Machine Translation Engine
TAPTA was developed in World Intellectual Property Organization (WIPO) and installed in various organizations under the auspices of Intra-Organization collaborations,
TAPTA has helped in developing useful exchanges (technology, know-how, data) among different organizations
Moses is a statistical machine translation system that allows you to automatically train translation models for any language pair.

MOSES FEATURES
Moses offers two types of translation models:
1. Phrase-based:
Foreign input is segmented in phrases
Each phrase is translated into the target language
Phrases are reordered
2. Tree-based
Tree-based models operate on so-called grammar rules
whilst splitting, dropping, reordering and substituting
sentences
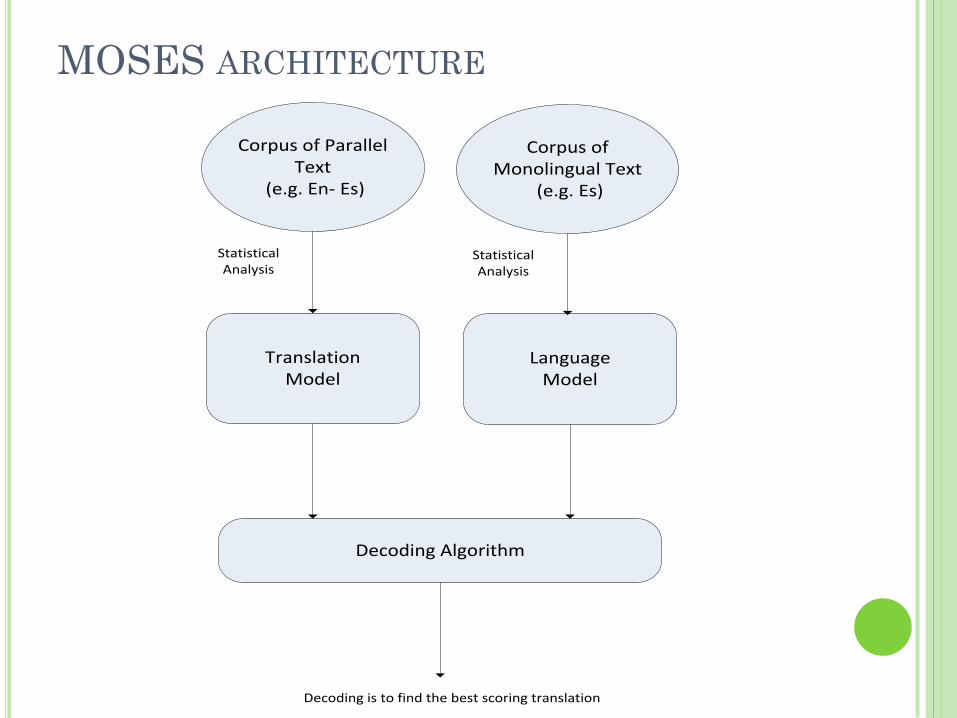
MOSES ARCHITECTURE
Statistical Analysis
TranslationModel
Corpus of Parallel Text
(e.g. En- Es)
Language Model
Decoding Algorithm
Statistical Analysis
Corpus of Monolingual Text
(e.g. Es)
Decoding is to find the best scoring translation

TAPTA FEATURES: FROM DATA TO MOSES
MODELS
• Fully automatic (preparation/training/publishing etc.)
• Fast translations (on the fly)
• Free to use (open source + in-house development)
• Runs on physical servers / virtual machines / cloud
• Confidentiality
• Various User interfaces
• Fully integrated in CAT tool, “translation accelerator”
clean re-clean train-model
post-filter prune binarize optimize Publish sentence-
align

ORGANIZATIONS THAT ADOPTED TAPTA

WHEN TAPTA WAS INTRODUCED TO FAO
TAPTA was trained with FAO Corpus and installed between July and August 2015.
Only available internally
TAPTA Plugin for TRADOS was also installed to all internal
translators and language revisers.

CURRENT USAGE OF TAPTA
NOT accessible from outside FAO due to security restrictions.
SPANISH translation group: used in all internal translations.
ARABIC translation group: partially used in translations of text regarding certain subject areas.
FRENCH translation group: rarely used as most of the translations are done by external translators.
RUSSIAN translation group: rarely used.
CHINESE translation group: rarely used.
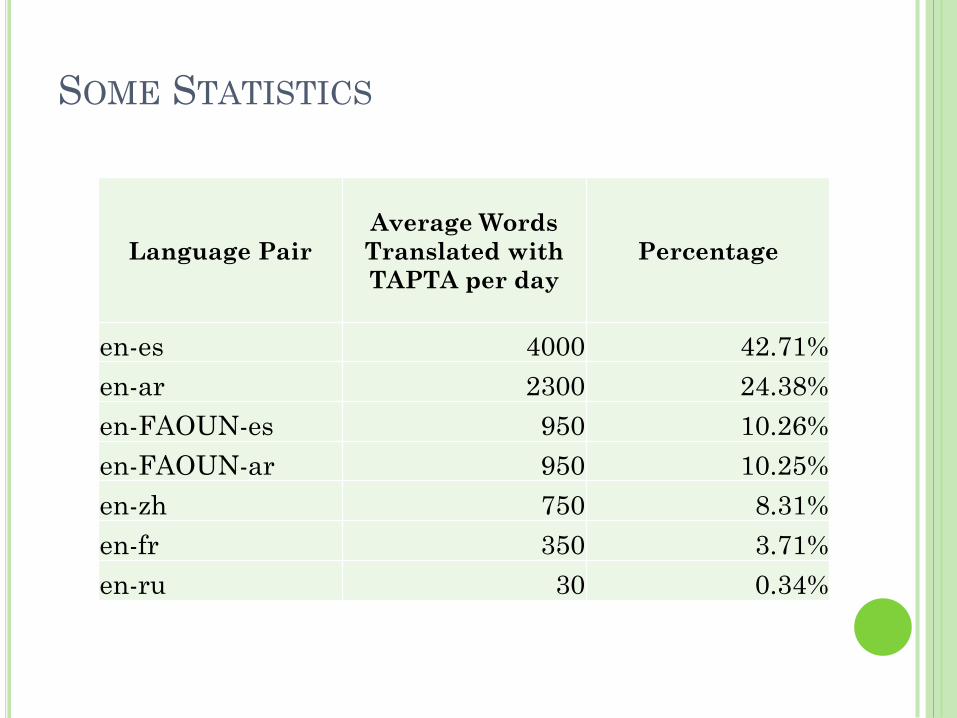
SOME STATISTICS
Language Pair Average Words
Translated with
TAPTA per day Percentage
en-es 4000 42.71%
en-ar 2300 24.38%
en-FAOUN-es 950 10.26%
en-FAOUN-ar 950 10.25%
en-zh 750 8.31%
en-fr 350 3.71%
en-ru 30 0.34%
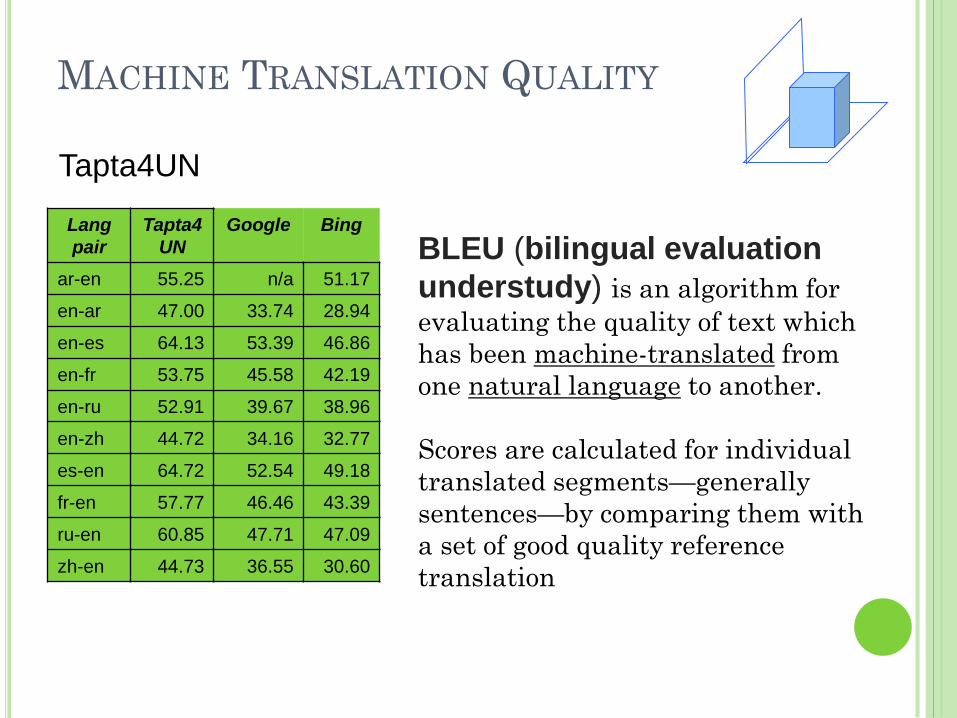
MACHINE TRANSLATION QUALITY
Lang
pair
Tapta4
UN
Google Bing
ar-en 55.25 n/a 51.17
en-ar 47.00 33.74 28.94
en-es 64.13 53.39 46.86
en-fr 53.75 45.58 42.19
en-ru 52.91 39.67 38.96
en-zh 44.72 34.16 32.77
es-en 64.72 52.54 49.18
fr-en 57.77 46.46 43.39
ru-en 60.85 47.71 47.09
zh-en 44.73 36.55 30.60
Tapta4UN
BLEU (bilingual evaluation
understudy) is an algorithm for
evaluating the quality of text which
has been machine-translated from
one natural language to another.
Scores are calculated for individual
translated segments—generally
sentences—by comparing them with
a set of good quality reference
translation

STRENGTHS AND WEAKNESSES
Improved the efficiency of two language groups.
Fully integrated with our SDL Studio environment.
Trained also with UN Corpus which in certain subject areas improves the quality.
Open source and allow for integration with other UN-based corpus.
Lack of internal resources for maintaining the server and re-training the engine with the most updated documents.
Chinese and Russian unsatisfactory quality.
Unavailability to External translators.
Complex to maintain as it requires an in-depth knowledge of Linux and Java development environment.

FUTURE EXPECTATIONS
Improvement of the Cat Tool Plug-In so to facilitate the selection of the most suitable segment from the proposed list of segments
Subject-based segment retrieval which would allow filtering of results based on the segment context (by adding metadata).
Availability of a TAPTA user friendly tool so to periodically re-train the engine.
Weight assignation to subsets of the corpus.
Improvement of Chinese and Russian response addressing their specific linguistic issues (e.g. gender in Russian, character position in Chinese).

TAKE AWAY MESSAGE
MT in a working environment is good for
preliminary quick translation of segments not
present in translation memory. So we still need
GOOD HUMAN TRANSLATORS
MT works well in specialized contexts where a
coherent and standard language and terminology
exist.
Machine translation is not perfect, but useful.
What to expect in the future: Better models (e.g.. syntax) Better machine learning (e.g. neural networks)
More data (for many language pairs, lots of text available)
Closer integration with target application (i.e. computer
aided translation)

















