
FACOLTÀ DI INGEGNERIA T - tmancini.di.uniroma1.ittmancini.di.uniroma1.it/teaching/tesi/pdf/Marco...
209
UNIVERSITÀ DEGLI STUDI DI ROMA “LA SAPIENZA” FACOLTÀ DI INGEGNERIA TESI DI LAUREA IN INGEGNERIA INFORMATICA GENERAZIONE AUTOMATICA DI CASI DI TEST CON LA METODOLOGIA A SCATOLA BIANCA TRAMITE LA PROGRAMMAZIONE A VINCOLI Relatore: Prof. Toni Mancini Laureando: Marco Santelli ANNO ACCADEMICO 2006-2007
Transcript of FACOLTÀ DI INGEGNERIA T - tmancini.di.uniroma1.ittmancini.di.uniroma1.it/teaching/tesi/pdf/Marco...

UNIVERSITÀ DEGLI STUDI DI ROMA
“LA SAPIENZA”
FACOLTÀ DI INGEGNERIA
TESI DI LAUREA IN
INGEGNERIA INFORMATICA
GENERAZIONE AUTOMATICA DI CASI DI TEST CON LA
METODOLOGIA A SCATOLA BIANCA TRAMITE LA
PROGRAMMAZIONE A VINCOLI
Relatore:
Prof. Toni Mancini
Laureando:
Marco Santelli
ANNO ACCADEMICO 2006-2007

2
a nonna Giulia
ed ai miei genitori

3
Ringraziamenti
Ringrazio sinceramente il prof. Toni Mancini per avermi sempre guidato, con estrema cortesia e disponibilità, durante lo svolgimento della tesi. Ringrazio tutti coloro che in questi anni mi hanno sempre sostenuto ed incoraggiato. Ci tengo a dire un grande grazie a Marco, Dennis, Giuseppe, Stefano ed Assia. Rivolgo un ringraziamento particolare a Simone e Luigi, per essermi sempre vicini e riuscire a sopportarmi.

4
Indice
Indice....................................................................................................................... 4 Introduzione ............................................................................................................ 7 Capitolo 1 La fase di test nel ciclo di sviluppo del software .......................... 10
1.1 Test Strutturale o a scatola bianca......................................................... 15 1.1.1 Criteri di copertura nel test a scatola bianca ................................. 16 1.1.2 Criterio di copertura tramite cammini nel grafo di controllo........ 19
Capitolo 2 Automazione della generazione dei casi di test ............................ 25 2.1 Informazioni generali ............................................................................ 25
2.1.1 Grafo di controllo.......................................................................... 27 2.2 Generazione casi di test......................................................................... 29
2.2.1 Generazione casi di test random ................................................... 32 2.2.2 Generazione casi di test path-oriented .......................................... 32 2.2.3 Generazione casi di test goal-oriented .......................................... 35 2.2.4 Problemi della generazione di casi di test ..................................... 38
2.3 Un approccio tramite programmazione a vincoli: INKA...................... 39 Capitolo 3 Programmazione a vincoli ............................................................ 45
3.1 Informazioni Generali ........................................................................... 45 3.2 Problema di soddisfacimento di vincoli (CSP) ..................................... 47
3.2.1 Definizioni.....................................................................................47 3.2.2 Esempi di problemi di soddisfazione di vincoli............................ 50
3.3 Un framework generale........................................................................ 52 3.3.1 Preprocess ..................................................................................... 53 3.3.2 Happy e Atomic ............................................................................ 53 3.3.3 Split ............................................................................................... 54 3.3.4 Proceed by Cases........................................................................... 56 3.3.5 Constraint Propagation.................................................................. 57
3.4 Il linguaggio OPL.................................................................................. 60 Capitolo 4 Modello per la generazione di casi di test..................................... 62
4.1 Costrutti del linguaggio java supportati ................................................ 64 4.2 Variabili e costanti utilizzate nel modello............................................. 66 4.3 Vincoli del modello...............................................................................69
4.3.1 Inizializzazione Variabili .............................................................. 70 4.3.2 Istruzione di assegnazione............................................................. 70 4.3.3 Istruzione if then else .................................................................... 72 4.3.4 Istruzione While............................................................................ 75 4.3.5 Istruzione Do While ...................................................................... 78 4.3.6 Istruzione For ................................................................................ 80

5
4.3.7 Istruzione Switch........................................................................... 85 4.3.8 Gestione condizioni complesse..................................................... 89 4.3.9 Gestione accesso array .................................................................. 92 4.3.10 Vincoli Cammino.......................................................................... 93 4.3.11 Strategia di ricerca......................................................................... 93
Capitolo 5 Modello per la generazione di una base di cammini indipendenti 95 5.1 Variabili e costanti utilizzate nel modello............................................. 96 5.2 Vincoli del modello...............................................................................98
5.2.1 Vincoli per imporre un corretto inizio e fine ad ogni cammino.... 99 5.2.2 Vincoli continuità del cammino.................................................. 100 5.2.3 Vincoli per unificare e rendere coerenti le due matrici di variabili 104 5.2.4 Vincolo per l’indipendenza lineare dei cammini ........................ 105 5.2.5 Strategia di ricerca....................................................................... 106
Capitolo 6 Risultati Sperimentali.................................................................. 108 6.1 Modello per la generazione dei cammini indipendenti ....................... 118
Esperimenti programma massimo............................................................... 118 Esperimenti programma sommaTuttiElementiVettore ............................... 118 Esperimenti programma bubbleSort ........................................................... 119 Esperimenti programma selectionSort ........................................................ 120 Esperimento programma sommaDueElementiVettore ............................... 121 Esperimento programma sample................................................................. 122 Esperimento programma puntoSella........................................................... 123
6.2 Modello generazione casi di test ......................................................... 124 Esperimento programma massimo.............................................................. 125 Esperimento programma sommaTuttiElementiVettore .............................. 125 Esperimenti programmi bubleSort e selectionSort ..................................... 126 Esperimento programma sommaDueElementiVettore ............................... 127 Esperimento programma sample................................................................. 128
Capitolo 7 Conclusioni e sviluppi futuri....................................................... 130 7.1 Una possibile unione dei due modelli ................................................. 131
7.1.1 Modifiche al modello per la generazione casi di test.................. 132 7.1.2 Modifiche al modello per la generazione di una base di cammini 133 7.1.3 Problemi relativi all’unione dei due modelli............................... 138
Riferimenti bibliografici...................................................................................... 140 Appendice ........................................................................................................... 142
Modello per la generazione di una base di cammini linearmente indipendenti......................................................................................................................... 142 Modello per la generazione di casi di test....................................................... 145
Programma Massimo .................................................................................. 145 Programma sommaTuttiElementiVettore ................................................... 151 Programma bubbleSort................................................................................ 157 Programma selectionSort ............................................................................ 168

6
Programma sommaDueElementiVettore .................................................... 179 Programma sample......................................................................................187 Esempio di modello unione del modello per la generazione di casi di test e per quello per la generazione di una base di cammini linearmente indipendenti................................................................................................. 200

7
Introduzione
Al giorno d’oggi i computer fanno sempre più parte della nostra società: dalla semplice calcolatrice, ai sistemi elettronici delle vetture (ABS,ecc), passando per la gestione delle centrali nucleari, il sistemi a bordo degli aerei, ecc. I software che vengono utilizzati per questi scopi passano da piccoli programmi semplici, a complessi programmi strutturati. Dalla raccolta dei requisiti, alla consegna del prodotto software funzionante il processo di produzione del software è molto lungo e complesso, e per assicurare che il prodotto finale sia conforme agli obiettivi, ogni fase del processo di sviluppo va validata e testata. Se un errore nella versione finale è, al livello dell’utilizzatore medio, ‘relativamente trascurabile’, nel senso che esso può portare alla perdita di ore di lavoro (dati andati perduti), in altri ambiti non è la stessa cosa. In effetti, nel caso di software critici, come quelli che dirigono una centrale nucleare o quelli che servono a pilotare un aereo, un errore nel software finale può avere conseguenze ben più gravi, essendo in gioco delle catastrofi umane o naturali. L’affidabilità di un software è, quindi, molto imporante, ed è per questo che la fase di test è fondamentale nello sviluppo del software. Il processo di test di un software, però, non è per nulla banale e facile da realizzare, esso richiede grandi investimenti di tempo e di denaro, ed inoltre i sistemi stanno evolvendo verso una sempre maggiore complessità, rendendo il test ancora più complesso e più importante. Automatizzare la fase di test porterebbe grandi benefici, sia a chi produce software, riducendo il tempo e quindi il costo di sviluppo, sia a chi utilizza il software, potendo avere a sua disposizione un prodotto sicuramente più efficiente ed affidabile. L’obiettivo di questa tesi è proprio sviluppare una metodologia che permetta di generare automaticamente casi di test, nel test a scatola bianca, utilizzando la programmazione a vincoli. In questi ultimi vent’anni la ricerca si è occupata molto di questo problema, proponendo varie tecniche e tool. Il problema dell’automazione è, comunque, molto difficile da affrontare, essendo i linguaggi di programmazione moderni molto potenti, e permettendo quindi di gestire strutture dati e programmi molto complessi. Nell’ambito di questa tesi si presenteranno i vari approcci che sono emersi in questi anni, soffermandosi su quelli orientati al test a scatola bianca. Fra questi verrà approfondito ulteriormente quello presentato da Gotlieb[10][11], in quanto basato anch’esso sulla programmazione a vincoli. Esso prevede, però, l’utilizzo di

8
risolutore di vincoli con funzionalità aggiuntive, dedicate alla risoluzione di questo particolare problema. In questa tesi viene, invece, praticato un approccio all’utilizzo della programmazione a vincoli più ad alto livello: viene completamente separato l’aspetto di modellazione, ossia creare un modello che rappresenti il problema che si vuole risolvere, dall’aspetto implementativo-risolutivo, ossia come analizzare i vincoli del modello per determinare una soluzione. Questa netta distinsione ha lo scopo di voler realizzare uno studio su come affrontare il problema della generazione dei casi di test attraverso la programmazione a vincoli, determinando una metodologia per costruire un modello che rappresenti il problema. Dopo di che, questo modello può essere utilizzato con un qualsiasi risolutore di vincoli. Questa separazione dei due aspetti ha notevoli benefici, tra cui ad esempio quello di poter sfruttare nuovi risolutori più efficienti, senza dover modificare nulla, ma semplicemente realizzando il modello nella sintassi specifica del risolutore in questione. La metodologia che verrà presentata è basata sulla generazione di due modelli del programma da testare: uno orientato a determinare quali cammini testare, ed uno orientato a determinare dei valori di input per i quali questi cammini vengono eseguiti. I modelli verrano sviluppatti nel linguaggio OPL, e successivamente verrano testati con l’utilizzo di OPL-Studio, fornito dalla ILOG. Durante lo svolgimento della tesi è stato implementato un tool che, prendendo un file java in input ed il nome del metodo da testare, genera i due modelli corrispondenti. Questa tesi risulta strutturalmente divisa in tre parti fondamentali: una prima parte dedicata all’introduzione al test del software ed alla sua possibile automazione, una dedicata all’introduzione alla programmazione a vincoli, e la terza, fondamentale, in cui si presenta la metodologia sviluppata, i primi risultati ottenuti e possibili sviluppi.
• Nel Capitolo 1 viene presentata la fase di test del software e le sue relazioni con il processo di sviluppo del software. Viene presentato sia il test funzionale che il test strutturale, soffermandosi su quest’ultimo.
• Nel Capitolo 2 viene mostrato in che modo può essere automatizzato il processo di testing del software. Vengono mostrati i vari approcci che si sono sviluppati negli anni, ed infine viene descritto il tool Inka, sviluppato da Gotlieb ed altri [10][11], che come detto precedentemente è il più vicino all’approccio proposto in questa tesi.
• Nel Capitolo 3 viene introdotta la programmazione a vincoli, presentando i concetti e le definizioni fondamentali
• Nei Capitolo 4 e Capitolo 5 viene presentata la metodologia sviluppata in questa tesi, presentando sia il modello per la generazione di una base di cammini indipendenti, sia il modello per le generazione dei casi di test dato un cammino.

9
• Nel Capitolo 6 vengono mostrati i primi risultati sperimentali ottenuti utilizzando i modelli sviluppati.
• Nel Capitolo 7 vengono presentate le conclusioni e dei possibili sviluppi futuri.

10
Capitolo 1 La fase di test nel ciclo di sviluppo del software
Il ruolo del software ha subito un enorme cambiamento nell’arco di poco più di 50 anni. Gli straordinari progressi delle prestazioni dell’hardware, le profonde innovazioni nell’architettura dei computer, l’incremento consistente delle capacità di memoria, centrale e periferica, e la vasta gamma di dispositivi di input ed output hanno portato alla realizzazione di sistemi di elaborazione sempre più sofisticati e complessi. Dando una rapida occhiata al passato possiamo evidenziare cinque periodi fondamentali[20] che hanno visto il software evolversi dai primi programmi dedicati, sviluppati ad hoc, fino ad arrivare ai giorni nostri in cui il software è diventato un elemento indispensabile in ogni ambito:
• 1950 – 1965 : programmi batch, distribuzione limitata, software ad hoc
• 1965 – 1975 : multiuser, real-time, database, software prodotto
• 1975 – 1985 : sistemi distribuiti, hardware low-cost (Pc IBM), mercato di massa
• 1985 – 1995 : Object Oriented technologies, sistemi user friendly,
• 1995 – … : internet, distributed computing, j2ee, web services,…
E’ evidente come i sistemi software, spinti dalla sempre maggior disponibilità di hardware potente, siano diventati sempre più complessi, rendendo quindi sempre più difficile la loro gestione. Negli anni si è concretizzata quindi l’esigenza di abbandonare un approccio artigianale per sistematizzare e disciplinare lo produzione del software, come in ogni altro campo dell’ingegneria, dando vita all’ingegneria del software (il termine nasce in una conferenza della NATO del 1968). Essa abbraccia un campo molto vasto e complesso, facendo uso di modelli astratti, teorie, metriche, metodi, tecnologie, strumenti ed ha come obiettivo finale e principale quello della qualità del software prodotto. Uno degli aspetti chiave dell’ ingegneria del software è il Processo di Produzione del Software. Le sue fasi principali, viste in modo molto schematico, sono:
• Progetto
• Sviluppo
• Test

11
• Manutenzione
Sono stati sviluppati nel corso degli anni vari modelli che lo rappresentano, con l’obiettivo di portare ordine in un’attività intrinsecamente caotica: modello sequenziale, prototipale, Rad (Rapid Application Development), incrementale, a spirale, sviluppo concorrente, modelli basati sui metodi formali ecc., ognuno con le sue peculiarità, i suoi pregi ed i suoi difetti. Però, quale che sia il modello utilizzato, per raggiungere l’obiettivo di un “buon software prodotto” una fase cruciale è rappresentata dal Test del software prodotto. Infatti anche seguendo le migliori metodologie di progetto e sviluppo è impossibile generare un software perfetto. In [8] Deutsch afferma che “lo sviluppo di sistemi software comporta una serie di attività produttive nelle quali le occasioni di inserire errori umani abbondano. Gli errori possono verificarsi fin dal principio del processo, quando gli obiettivi possono essere specificati in modo errato od imperfetto, fino alle ultime fasi di progettazione e sviluppo. A causa dell’incapacità umana di operare e comunicare in modo perfetto, lo sviluppo di software è affiancato da un’attività di garanzia di qualità”. Il test è un elemento critico della garanzia di qualità del software e costituisce l’esame definitivo della specifica, della progettazione e della stesura del codice. La fase di test ha un impatto economico notevole sul costo di sviluppo di un prodotto software (cf. Figura 1), ed è per questo che esso va ben pianificato ed articolato. Non è raro il caso in cui un produttore software spenda tra il 30% ed il 40% del lavoro totale di un progetto nel test. In casi estremi, il test di software critico (ad esempio software di bordo degli aerei, programmi di sorveglianza di reattori nucleari) può costare da 3 a 5 volte più di tutte le altre attività combinate.
Figura 1 : Ripartizione costo del software
Analizzando la fase di test del software si evidenzia subito un’importante differenza sul piano psicologico da tutte le altre attività dell’ingegneria del software: esso è distruttivo, a differenza delle altre che sono tutte costruttive. Il test è un processo che viene realizzato con lo specifico scopo di trovare difetti nel programma prima della consegna all’utente, non, invece, di dimostrarne l’assenza.

12
Edsger Dijkstra disse eloquentemente nel 1972: “Il test può solo mostrare la presenza degli errori, non la loro assenza”. Questo è un punto fondamentale: infatti nessuna attività di test potrà mai dimostrare l’assenza di errori. Il test esaustivo è infatti impraticabile, basti pensare che un semplice programma che prenda in ingresso tre interi ha 296 possibili input (per interi a 32 bit), il tempo necessario per analizzarli tutti, considerando 220Test/secondo sarebbe di 276 secondi, cioè 251 anni (circa 1015). In [16] Myers indica alcune regole che sono da considerare dei buoni obiettivi per un test efficace:
• Il test consiste nell’eseguire un programma al fine di scoprire un errore
• Un caso di test è di buona qualità se ha un’alta probabilità di scoprire un errore ancora ignoto
• Un test ha avuto successo se ha scoperto un errore prima ignoto
Questo aspetto della fase di test ha effetti anche sulla decisione, all’interno delle aziende, di chi deve effettuarla: si preferisce che siano persone, settori diversi da quelli che si sono occupati di sviluppare il codice, infatti l’uomo è meno incline per sua natura ad ammettere che quello che ha fatto presenti errori. A seconda del livello del sistema a cui viene condotta la fase di test, o del punto nel processo di sviluppo, il test può essere differenziato in :
• Test di unità
• Test di integrazione
• Test di sistema
• Test di accettazione
• Test di regressione
Il test di unità (chiamato anche test dei componenti) è il processo che controlla i singoli componenti del sistema, al fine di trovare il maggior numero possibile di errori presenti. A questo livello sono diversi i tipi di componenti che possono essere testati:
• singole funzioni o metodi all’interno di un oggetto;
• classi di oggetti che hanno diversi attributi e metodi;
• componenti composti costruiti da diversi oggetti o funzioni, con un’interfaccia definita che viene utilizzata per accedere alle loro funzionalità.
La singola funzione o metodo è il tipo più semplice di unità ed i test sono un insieme di chiamate a questa routine con diversi parametri di input. Nel caso, invece, di test delle classi di oggetti una buona metodologia prevede: il test isolato di tutte le operazioni associate all’oggetto, l’impostazione e l’interrogazione di tutti gli attributi associati all’oggetto, la prova dell’oggetto in tutti i possibili stati,

13
comportando questo, che andrebbero simulati tutti gli eventi che causano una modifica allo stato dell’oggetto. Naturalmente nel caso in cui si utilizzi l’ereditarietà nella fase di test se ne deve considerare la presenza, e questo complica la generazione dei casi di test. Spesso i componenti di un sistema non sono semplici funzioni o singoli oggetti, ma sono composti da diversi oggetti interagenti e si accede alle loro funzionalità attraverso un’interfaccia ben definita. In questo caso, testare i componenti ha come primo obiettivo verificare che l’interfaccia si comporti secondo le sue specifiche. Quest’ultimo caso prende il nome di test delle interfacce ed è particolarmente importante per lo sviluppo orientato agli oggetti e basato su componenti. In questo scenario gli oggetti ed i componenti sono definiti dalle loro interfacce e possono essere riutilizzati in combinazione con altri componenti in sistemi diversi. Gli errori nelle interfacce dei componenti composti non possono essere individuati testando i singoli oggetti o componenti, poiché possono sorgere a causa di interazioni tra le varie parti. I componenti siano essi sviluppati da zero, o riutilizzati ed adattati ad un particolare sistema, devono essere integrati per formare il sistema software nella sua interezza. Il test di integrazione controlla che questi lavorino effettivamente assieme, siano chiamati in modo corretto, e trasferiscano i dati giusti al momento giusto attraverso le loro interfacce. Uno dei maggiori problemi che sorgono durante il test di integrazione è quello della localizzazione degli errori: essendoci interazioni complesse tra i vari componenti del sistema quando viene scoperto un comportamento anomalo può essere difficile determinare dov’è l’errore. Per questo motivo normalmente si usa un approccio incrementale all’integrazione ed al test dei relativi componenti. Si può seguire sia una strategia top-down, sviluppando prima lo scheletro del sistema ed aggiungendo successivamente i singoli componenti, oppure una strategia bottom-up integrando prima i componenti dell’ infrastruttura che forniscono i servizi comuni e successivamente gli altri componenti funzionali; in entrambi i casi si sviluppa del codice aggiuntivo per simulare gli altri componenti, chiamati (stub) o chiamanti (driver). Quando esiste un sistema minimo integrato, e quindi successivamente al test di integrazione, viene effettuato il test di sistema. Esso viene eseguito determinando casi di test sia relativi ai requisiti funzionali dell’intero sistema, sia per analizzare le prestazioni del sistema e misurare alcuni attributi di qualità (tempo di risposta, spazio occupato, robustezza, ecc.). A valle del test di sistema viene eseguito il test di accettazione, il cui scopo è quello di confermare che il sistema è pronto all’utilizzo operazionale. Normalmente è eseguito dall’utente che deve dimostrare l’effettiva funzionalità del sistema e della relativa documentazione; se avviene presso lo sviluppatore prende il nome di test alfa, mentre nel caso in cui sia effettuato presso il cliente viene denominato test beta. La maggiore differenza con il test di sistema è che ora i casi di test vengono eseguiti in un contesto quasi operazionale, ossia il sistema viene testato utilizzando l’hardware, il software e l’ambiente utente per cui è stato realizzato.

14
Ultimo nell’elenco precedente, il test di regressione viene eseguito a valle di una modifica del programma, controllando che le modifiche non abbiano apportato nuovi problemi, e che nel caso in cui la modifica derivasse da problemi segnalati, che questi siano stati effettivamente risolti, analizzando anche se sia il caso di apportare modifiche analoghe in altre parti del programma. Per realizzare i vari tipi di test bisogna progettare i casi di test a cui sottoporre il software, determinando gli input da sottoporre al sistema sotto analisi e gli output attesi. Nel tempo si è evoluta una grande varietà di metodi per la progettazione di casi di test per il software. Questi metodi offrono una soluzione sistematica al problema, ed offrono meccanismi per garantire la completezza e per massimizzare la probabilità di scoprire gli errori. Questi metodi possono essere divisi in due categorie principali:
• test a scatola nera (black box)
• test a scatola bianca (white box).
Il test di unità e di integrazione possono essere effettuati seguendo entrambi gli approcci, mentre quello di sistema e di accettazione solamente attraverso la metodologia a scatola nera. Il test a scatola bianca si fonda su un esame meticoloso degli aspetti interni del software, sfruttando la conoscenza del codice. Essendo questo l’approccio su cui si basa la tesi, viene approfondito meglio nel paragrafo successivo. Il test a scatola nera, invece, viene condotto dall’interfaccia esterna, esso esamina certi aspetti fondamentali del sistema senza preoccuparsi della struttura logica interna; la progettazione dei casi di test viene condotta sulla base delle specifiche e delle funzionalità offerte, da qui anche il nome di test funzionale in contrapposizione al test strutturale, che è quello a scatola bianca. Il test black-box tende a rivelare errori appartenenti alle seguenti categorie: funzioni errate o mancanti, errori di interfaccia, errori nelle strutture dati o negli accessi a database esterni, errori di comportamento o prestazionali, errori di inizializzazione o terminazione. Le principali tecniche che si utilizzano nella metodologia a scatola nera sono:
• tecnica di copertura della classi di equivalenza (definite sull’input)
• tecnica di analisi dei valori estremi (individuati sull’input e sull’ output)
• tecnica di copertura delle funzionalità (desunte dalle specifiche)
Le prime due derivano dall’osservazione che il test esaustivo è impossibile da fare in pratica e quindi bisogna individuare un sottoinsieme dei dati di ingresso con la maggior probabilità di trovare errori. Nel caso delle classi di equivalenza il dominio dell’input viene ripartito in un numero finito di classi di equivalenza, secondo il criterio che due elementi dello stesso insieme devono generare un uguale comportamento del sistema software. La tecnica dell’analisi dei valori estremi, invece, trae spunto dall’esperienza, che mostra che casi di test che esplorino condizioni estreme sono molto produttivi, hanno cioè un’alta probabilità

15
di trovare errori. Infine la tecnica di copertura delle funzionalità si riferisce alle specifiche e determina i casi di test per analizzare tutte le funzionalità testabili. Come ultima considerazione generale è doveroso precisare che le due metodologie, a scatola bianca ed a scatola nera, non sono da considerarsi in alternativa una all’altra, ma invece come due tecniche complementari, in quanto scoprono errori differenti, che altrimenti non sarebbero rivelati.
1.1 Test Strutturale o a scatola bianca Il test a scatola bianca si fonda, come è stato accennato precedentemente, su un esame attento degli aspetti procedurali del software, sfruttando la conoscenza del suo codice sorgente. Lo “stato del programma” può essere esaminato in vari punti per verificare se il comportamento previsto coincide con quello effettivo. Come è stato precedentemente precisato il test white-box è complementare a quello black-box; questo perché analizzando le specifiche proprietà del codice è possibile trovare errori che con un approccio basato solo sulla conoscenza dei requisiti non verrebbero portati alla luce, non potendo sollecitare con dei test appropriati le condizioni che ne causerebbero il verificarsi. La motivazione di tutto ciò risiede nella natura di alcuni difetti del software:
• gli errori logici e le assunzioni errate sono inversamente proporzionali alla probabilità che un certo cammino venga eseguito. Gli errori tendono a verificarsi quando si progettano ed implementano funzioni, condizioni e controlli secondari. L’elaborazione normale tende ad essere ben compresa (e quindi attentamente esaminata), mentre i casi particolari sono più esposti agli errori.
• spesso si crede che un certo cammino logico sia eseguito solo raramente, mentre in realtà lo è regolarmente. Il flusso logico di un programma segue talvolta via inattese; di conseguenza, le assunzioni che si fanno inconsciamente sul flusso di controllo e dei dati possono provocare errori di progettazione che si scoprono solo attraverso il test.
• gli errori di battitura sono casuali. Quando si scrive il codice sorgente di un programma, si possono compiere errori di battitura, molti dei quali vengono rivelati dai meccanismi automatici di controllo della sintassi, mentre altri sopravvivono fino alla fase di test. Questi errori si presentano con la stessa probabilità sia nei cammini logici che vengono eseguiti raramente, sia in quelli che vengono eseguiti frequentemente.
Queste tipologie di errori possono facilmente sfuggire ai collaudi black-box, per quanto accuratamente vengano effettuati, mentre con un’attenta analisi white-box possono essere efficacemente rilevati. Naturalmente per quanto accurato e dettagliato possa essere il test a scatola bianca non può dimostrare l’assenza di errori, ma solo rivelarne la presenza. Infatti anche potendo esaminare il codice del programma non è possibile testare ogni possibile

16
situazione che può verificarsi mentre esso funziona (cioè un test esaustivo non è realizzabile neanche nell’approccio a scatola bianca). Anche per programmi molto piccoli il numero dei cammini che si possono verificare diventa rapidamente intrattabile. Basti pensare che un programma di poche righe, con due cicli, uno annidato nell’altro, ciascuno dei quali può essere eseguito da uno a venti volte a seconda dei dati di input, con all’interno del ciclo annidato la presenza di quattro costrutti if then else porta all’esistenza di 1014 possibili cammini di esecuzione: impossibile testarli tutti. Per avere un’idea pratica, reale, del numero dei cammini precedentemente dedotto si può supporre di avere a disposizione un dispositivo “magico” (in quanto nella realtà non esiste) che sia in grado di predisporre un caso di prova, eseguirlo e valutarne il risultato in un millisecondo: lavorando 24 ore al giorno per 365 giorni l’anno ci vorrebbero 3.170 anni per testare tutto il programma. Visto che un test esaustivo di tutte le possibili condizioni che si potrebbero verificare nell’esecuzione del software non è possibile, si sono sviluppati nel corso degli anni vari criteri di copertura, che hanno lo scopo di sfruttare la conoscenza del codice sorgente per determinare dei casi di test che garantiscano dei requisiti minimi sul controllo delle situazioni che potrebbero verificarsi.
1.1.1 Criteri di copertura nel test a scatola bianc a Nella metodologia del test a scatola bianca sono stati elaborati più metodi che permettano di realizzare il test in modo sistematico, prendendo in considerazione la copertura di alcuni requisiti che si vuole imporre, ossia che determinate parti del codice vengano eseguite. Questi metodi prendono il nome di criteri di copertura, e sono, in ordine crescente di complessità, i seguenti:
• Copertura delle istruzioni
• Copertura delle decisioni
• Copertura delle condizioni
• Copertura delle condizioni e decisioni
• Copertura tramite cammini nel grafo di controllo.
Il criterio di copertura delle istruzioni è il più semplice che possiamo considerare per un test a scatola bianca ragionevole. Esso ha come obiettivo quello di determinare un insieme di casi di test sufficiente a far eseguire almeno una volta tutte le istruzioni. Consideriamo il semplice programma java in Figura 2 come esempio.

17
Figura 2 : semplice programma java
Considerando il criterio di copertura delle istruzioni ed il caso di test costituito da un valore per ‘x’ qualsiasi, ma diverso da 0 , ed un qualsiasi valore per ‘y’ esso risulta soddisfatto, in quanto tutte le istruzioni vengono eseguite. Questo piccolo esempio già mostra un potenziale problema di questo criterio, infatti anche per programmi che non presentano cicli la sola condizione che tutte le istruzioni vengano eseguite non garantisce che vengano eseguiti tutti i cammini possibili, e questo presenta delle conseguenze negative, come in questo esempio dove con il caso di test considerato non viene scoperto l’errore dalla possibile divisione per 0 nell’istruzione ‘D’. Passiamo quindi a considerare il criterio di copertura delle decisioni, che include propriamente il criterio di copertura delle istruzioni. Esso prende in considerazione tutte le possibili decisioni all’interno di un programma (nelle istruzioni if, for, do, while,switch). L’obiettivo che si pone questo criterio è quello di individuare un insieme di casi di test sufficiente a garantire che ciascuna decisione assuma il valore ‘vero’ almeno una volta, ed il valore ‘falso’ almeno una volta. Consideriamo ancora l’esempio in Figura 2, questa volta un possibile insieme di casi di test è rappresentato da:
• valore per ‘x’ qualsiasi, ma diverso da 0, ed il valore di ‘y’ qualsiasi
• valore di ‘x’ fissato uguale a 0, ed il valore di ‘y’ ancora qualsiasi;
questo insieme di casi di test assicura che l’ unica decisione presente assuma il valore ‘vero’ ed il valore ‘falso’ almeno una volta, quindi copre le decisioni e di conseguenza anche le istruzioni (includendo propriamente il criterio di copertura delle istruzioni). Inoltre il secondo caso di test evidenzia l’errore della possibile divisione per 0 nell’ istruzione ‘D’. Questo criterio risulta quindi sicuramente più efficiente nella scoperta di errori del criterio della copertura delle istruzioni, ma è facile dimostrare che in alcuni casi può risultare insufficiente.

18
Figura 3 : semplice programma java con condizioni composte
In Figura 3 è presente un altro programma java, esso presenta sempre una sola istruzione if , ma in questo caso la condizione al suo interno non è semplice: è composta dall’OR di due condizioni semplici. Vediamo questo cosa comporta considerando il seguente insieme di casi di test costituito da:
• t=0, z=5, w=5
• t=0, z=5, w=-5
Il primo caso di test rende la decisione ‘vera’, mentre il secondo la rende ‘falsa’ quindi il criterio di copertura delle decisioni risulta soddisfatto, ed inoltre il secondo caso di test rivela l’errore della possibile divisione per 0 nell’istruzione ‘D’. Il problema è che non viene assolutamente rivelato l’errore della possibilità di divisione per 0 nell’istruzione ‘C’: infatti in entrambi i test il valore di ‘z’ risulta essere diverso da 0. Risulta quindi evidente come nel caso in cui le decisioni non siano composte da condizioni semplici si debba ricorrere ad un criterio che prenda in considerazione la struttura ed i componenti della decisione. Da queste considerazioni nasce il criterio di copertura delle condizioni. Esso prende in considerazione tutte le possibili condizioni atomiche nell’ambito di ogni decisione presa dal programma. Il suo obiettivo è individuare un insieme di casi di test che sia sufficiente a garantire che ciascuna condizione atomica, che appare nelle decisioni, assuma il valore ‘vero’ almeno una volta, ed il valore ‘falso’ almeno una volta. E’ facile vedere come tra il criterio di copertura delle condizioni ed il criterio di copertura delle decisioni non sussista nessuna relazione di inclusione propria: ossia il primo non include propriamente il secondo e viceversa. Questo ha una conseguenza negativa sull’ efficienza del criterio nello scoprire errori. Consideriamo ancora il programma java in Figura 3 ed il seguente insieme di casi di test:
• t=0, z=0, w=-5
• t=0, z=5, w=5.
Il primo caso di test fa si che la prima condizione (‘z==0’) assuma il valore ‘vero’ e la seconda condizione (‘w>0’) assuma il valore ‘falso’, mentre il secondo caso di test fa esattamente il contrario rendendo ‘falsa’ la prima condizione e ‘vera’ la seconda condizione: questo insieme di casi di test quindi soddisfa il criterio di copertura delle condizioni, ma non soddisfa il criterio di copertura delle decisioni.

19
Infatti la decisione è in entrambi i casi ‘vera’, e questo ha come conseguenza che benché questo insieme di casi di test permetta di scoprire l’errore della possibile divisione per 0 nell’istruzione ‘C’, non permette di rilevare l’errore della possibile divisione per 0 in ‘D’. Dopo queste considerazioni è evidente come nella progettazione dei casi di test vadano prese in considerazione sia le decisioni che le condizioni, e questo è quello che viene fatto attraverso il criterio di copertura delle decisioni e delle condizioni. Esso include propriamente sia il criterio di copertura delle decisioni, che il criterio di copertura delle condizioni. In questo caso l’obiettivo perseguito dal criterio è duplice: individuare un insieme di casi di test sufficiente a garantire che
• ciascuna decisione assuma il valore ‘vero’ almeno una volta ed il valore ‘falso’ almeno una volta
• ciascuna condizione che appare nelle decisioni assuma il valore ‘vero’ almeno una volta ed il valore ‘falso’ almeno una volta
Considerando ancora il programma java in Figura 3 ed il seguente insieme di casi di test:
• t=0, z=0, w=5
• t=0, z=5, w=-5
possiamo vedere come il primo caso di test faccia sì che tutte le condizioni atomiche assumano il valore ‘vero’, mentre il secondo le renda tutte ‘false’ quindi il criterio di copertura delle condizioni e decisioni è soddisfatto, ed i due casi di test rivelano entrambi gli errori, ossia la possibile divisione per 0 nell’istruzione ‘C’ ed nell’ istruzione ‘D’. Una volta determinato che il criterio ottimale da seguire nel progettare test a scatola bianca è quello della copertura delle decisioni e delle condizioni bisogna trovare un modo sistematico ed efficace per metterlo in atto; infatti in generale esistono varie combinazioni di casi di test che garantiscono la sua soddisfacibilità, ma non sempre è semplice trovarne una. Con questo scopo viene introdotto il criterio di copertura tramite cammini nel grafo di controllo.
1.1.2 Criterio di copertura tramite cammini nel gra fo di controllo
Il criterio di copertura tramite cammini nel grafo di controllo si basa:
• sul criterio di copertura delle decisioni e delle condizioni
• sul grafo di controllo del programma
ed ha come obiettivo quello di fornire un metodo semplice per garantire la copertura delle decisioni e delle condizioni. Prima di descrivere il criterio introduciamo rapidamente il concetto di grafo di controllo (o grafo di flusso); una definizione più rigorosa è riportata in 2.1.1. Il

20
grafo di controllo rappresenta il flusso logico di controllo di un programma, in cui le istruzioni sono rappresentate da nodi, ed il flusso viene rappresentato tramite archi che collegano i nodi. Nel caso in cui l’istruzione da rappresentare è un’ istruzione condizionale od un ciclo, il nodo ha più di un arco in uscita, e prende il nome di nodo predicato. Un arco deve sempre terminare in un nodo, anche se il nodo non rappresenta alcuna istruzione; è ad esempio il caso di un istruzione if then else, come si può vedere in Figura 4. Infine un’ aerea delimitata da archi e da nodi è detta regione, tenendo conto che anche l’aerea esterna al grafo è una regione, quando queste devono essere contate.
Figura 4 : grafi di controllo dei principali costru tti condizionali
Figura 5 : Grafo di flusso di un semplice programma
Il grafo di flusso così descritto però risulta essere inadeguato per i nostri scopi: esso infatti non permette di tenere in considerazione in modo adeguato le decisioni composte da più condizioni. Considerando infatti il programma java di Figura 3 ed il suo relativo grafo di flusso rappresentato Figura 6 risulta evidente come considerando i due possibili cammini che sono possibili su di esso non potremmo considerare le singole condizioni di cui è composta la decisione ‘B’.
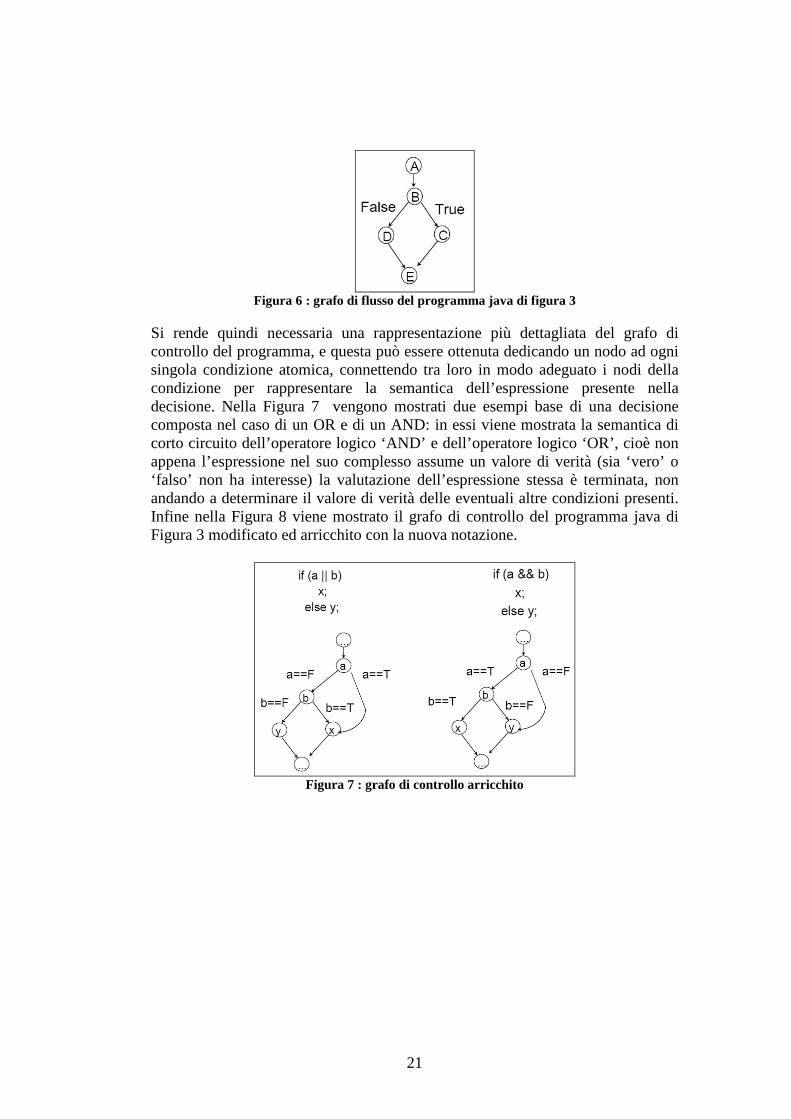
21
Figura 6 : grafo di flusso del programma java di figura 3
Si rende quindi necessaria una rappresentazione più dettagliata del grafo di controllo del programma, e questa può essere ottenuta dedicando un nodo ad ogni singola condizione atomica, connettendo tra loro in modo adeguato i nodi della condizione per rappresentare la semantica dell’espressione presente nella decisione. Nella Figura 7 vengono mostrati due esempi base di una decisione composta nel caso di un OR e di un AND: in essi viene mostrata la semantica di corto circuito dell’operatore logico ‘AND’ e dell’operatore logico ‘OR’, cioè non appena l’espressione nel suo complesso assume un valore di verità (sia ‘vero’ o ‘falso’ non ha interesse) la valutazione dell’espressione stessa è terminata, non andando a determinare il valore di verità delle eventuali altre condizioni presenti. Infine nella Figura 8 viene mostrato il grafo di controllo del programma java di Figura 3 modificato ed arricchito con la nuova notazione.
Figura 7 : grafo di controllo arricchito

22
Figura 8 : grafo di controllo arricchito del programma java di figura 3
Il grafo di controllo così arricchito ci permette di perseguire il nostro obiettivo di soddisfare il criterio di copertura delle decisioni e delle condizioni. Infatti i valori booleani (‘vero’ e ‘falso’) per le condizioni e le decisioni presenti nel programma corrispondono a determinati archi sul grafo di controllo e quindi determinando un insieme di casi di test che faccia in modo che tutti gli archi del grafo di controllo vengano percorsi implica la copertura delle decisioni e delle condizioni. Il numero di cammini presenti in un programma però può essere molto grande, basti pensare che esso cresce esponenzialmente con il numero di istruzioni if, e può diventare infinito con la presenza di cicli. Per questo non è possibile esaminare tutti i cammini, ma bisogna determinare un insieme di cammini limitato, sufficiente però a garantire che tutti gli archi del grafo di controllo vengano percorsi almeno una volta. Un buon criterio di scelta è quello indicato da McCabe attraverso la complessità ciclomatica. La complessità ciclomatica è una misura quantitativa della complessità logica di un programma. Ci sono tre modi per poterla calcolare:
• il numero delle regioni di un grafo di controllo corrisponde alla complessità ciclomatica;
• la complessità ciclomatica V(G) di un grafo di controllo G è data da V(G)=E-N+2, dove E è il numero degli archi del grafo e N è il numero dei nodi.
• La complessità ciclomatica V(G) di un grafo di controllo G è data da V(G)=P+1, dove P è il numero dei nodi predicato del grafo a due vie; per i nodi predicato a n vie ogni nodo vale come n-1 nodi a due vie.
Bisogna precisare che i metodi appena elencati sono validi solo se il grafo è planare, e questo è sempre verificato se non si fa uso di costrutti non strutturati, come ad esempio le istruzioni di salto incondizionato. McCabe ha mostrato che il numero di cammini indipendenti in un grafo di controllo sia proprio uguale alla complessità ciclomatica del grafo. Un cammino del grafo di controllo si dice indipendente se introduce almeno un nuovo insieme

23
di istruzioni o una nuova condizione, quindi se attraversa un arco del grafo non ancora percorso. Un insieme di cammini indipendenti ed in numero pari alla complessità ciclomatica del grafo prende il nome di base (non è unica). Intuitivamente ogni altro cammino ingresso – uscita del grafo può essere ottenuto come combinazione lineare dei cammini di una base. Il valore della complessità ciclomatica ci dà un valore massimale, un estremo superiore del numero di casi di test che vanno progettati per ottenere la copertura delle decisioni e condizioni. Questa risulta essere una scelta ragionevole, in quanto mette in relazione il numero di test da effettuare con la complessità strutturale del software da testare; sperimentalmente si è visto che il numero di errori cresce con la complessità ciclomatica. Una regola empirica sconsiglia di realizzare moduli software con complessità ciclomatica superiore a 10; nel caso venga superata si consiglia di separare il modulo software in uno o più moduli di complessità minore.
Figura 9 : Base di cammini linearmente indipendenti
Nel metodo della copertura dei cammini di base non sono previste necessariamente molte iterazioni dei cicli. Se un ciclo viene iterato più di una volta, il cammino risultante è comunque linearmente dipendente dal cammino in cui il ciclo è iterato una sola volta. Per determinare i casi di test bisogna fare delle scelte sul numero di iterazioni, ad esempio limitando il numero delle iterazioni ad n (n-copertura dei cicli). Un’ ultima osservazione sul metodo di copertura dei cammini di base: non sempre tutti i cammini indipendenti possono essere eseguiti separatamente. Questo avviene quando la combinazione dei dati necessaria a percorrere il cammino non può verificarsi nel flusso normale del programma (unfeasible path). In questi casi il cammino deve essere testato come parte di un altro cammino. Per gli scopi del lavoro presentato in questa tesi, in cui si affronta il problema del test delle unità, si utilizzerà la metodologia di test a scatola bianca, ed in particolare il criterio di copertura dei cammini indipendenti.

24

25
Capitolo 2 Automazione della generazione dei casi di test
2.1 Informazioni generali La fase di test, come è stato indicato nel capitolo precedente, riveste un ruolo fondamentale nella progettazione del software, ma a causa della sua grande complessità non è assolutamente facile da realizzare: essa richiede un grande impegno, sia in risorse umane, che di tempo e quindi di denaro. Uno studio risalente al 2002, commissionato dal NIST (National Institute of Standards and Technology) [27] sull’impatto dell’inadeguatezza dei processi di test nello sviluppo del software, ha mostrato che il costo di questa insufficienza poteva essere quantificata in 60 miliardi di dollari per l’economia americana. E’ evidente, quindi, come l’impegno in questa fase della progettazione del software sia in continuo aumento, anche a causa della sempre maggiore complessità dei sistemi da progettare, facendo lievitare in modo significativo il costo dello sviluppo del software. Questo potrebbe essere ridotto, anche in modo significativo, se il processo di test fosse automatizzato, ed inoltre l’automazione porterebbe anche ad avere un software più affidabile. Un modo per ottenere questo risultato è quello di generare i dati di input per il software da testare, analizzando in modo automatico il programma stesso. Nel corso degli anni sono stati presentati diversi metodi per generare i casi di test in modo automatico, e seguendo una classificazione introdotta da Korel e Ferguson [9] nel 1996, essi possono essere divisi in tre classi principali:
• random
• path-oriented
• goal-oriented.
Questa classificazione è molto appropriata in relazione alla generazione dei casi di test con la metodologia a scatola bianca, benché non consideri separatamente la scelta del cammino: infatti questa selezione generalmente interessa tutti i processi di generazione automatica di casi di test.

26
Figura 10 : architettura generale di un sistema di generazione automatica di test
In Figura 10 viene presentato un modello di un tipico sistema di generazione automatica di casi di test: esso è composto di tre parti principali: program analyzer, path selector e test data generator. Il codice sorgente del programma viene passato in input al program analyzer, il quale produce i dati necessari che poi verranno usati dal path selector e dal test data generator. Il path selector analizza il codice del programma per determinare dei cammini al suo interno che siano adeguati, naturalmente adeguati secondo il criterio di copertura selezionato. I cammini così determinati sono passati come parametri al test data generator, il quale deriva i dati di input del programma in analisi, che facciano sì che i cammini vengano eseguiti. Il test data generator può fornire, in alcuni casi, al path selector informazioni (feedback) riguardo i cammini che risultano non percorribili (unfeasible). Un qualsiasi programma P può essere considerato come una funzione,
RSP →: Dove S è l’insieme di tutti i possibili input, e R è l’insieme di tutti i possibili output. Più formalmente diciamo che S è l’insieme di tutti i possibili vettori x=(d1,d2,…,dn) tali che di∈Dxi, dove Dxi è il dominio della variabile di input xi. Una variabile di input x di P è una variabile che o appare come un parametro di input di P, oppure in un’istruzione di input di P, ad esempio ‘read(x)’. L’esecuzione di P con un dato insieme di input x è denotato come P(x). Nel capitolo precedente è già stato introdotto il concetto di grafo di flusso (o grafo di controllo), come rappresentazione grafica della struttura di controllo del programma; riprendiamo ora il concetto per darne una definizione più accurata. In

27
letteratura esistono molte definizioni di grafo di flusso, per gli i nostri scopi si può considerare appropriata quella che viene fornita da Korel ed altri in [9][13].
2.1.1 Grafo di controllo Definizione (Grafo di controllo). Un grafo di controllo di un programma P è un grafo diretto G=(N,E,s,e), dove N è l’insieme dei nodi del grafo, E={(n,m)| n,m∈ N} è l’insieme degli archi, ed s ed e sono due nodi speciali, s rappresenta il punto di ingresso del programma, ed e rappresenta il punto di uscita. Ogni nodo è definito come un ‘basic block’ in cui possono essere presenti un sequenza ininterrotta di istruzioni, dove il flusso di controllo entra all’inizio della sequenza ed esce alla fine, senza alcuna presenza di istruzioni ‘halt’ o di divisione del flusso. Intuitivamente questo significa che se una qualsiasi istruzione del blocco è eseguita, allora l’intero blocco sarà eseguito. Inoltre non possono essere presenti salti che hanno come target un’istruzione interna al blocco. Un arco presente tra due nodi n e m indica che il flusso di controllo può passare dal nodo n al nodo m. Tutti gli archi hanno un etichetta che rappresenta la condizione che deve essere soddisfatta affinché quell’arco possa essere percorso (branch predicate). Se l’etichetta è vuota, allora vuol dire che la condizione è sempre ‘vera’. In un qualsiasi istante un nodo non può avere due archi etichettati con due condizioni che siano entrambe vere, altrimenti il grafo sarebbe non-deterministico.
Definizione (Cammino specifico). Un cammino (specifico, preciso) è definito come una sequenza di nodi p=⟨p1,p2,…pq⟩, dove pq è l’ultimo nodo del cammino p, e (pi, pi+1) ∈ E, per 1≤ i ≤q-1. Quando un esecuzione di P(x) percorre un cammino p, si dice che x attraversa p.
Definizione (Cammino Completo). Un cammino completo è un cammino che inizia con il nodo s e termina con il nodo e, mentre nel caso contrario è detto cammino incompleto o path-segment.
Definizione (Cammino feasible). Un cammino è detto feasible se esiste un input x∈S che attraversa il cammino, è detto unfeasible nel caso contrario.
Definizione (Concatenazione). Siano p=⟨p1,p2,…pq⟩ e w=⟨w1,w2,…wz⟩ due cammini qualsiasi, allora pw=⟨p1,p2,…pq, w1,w2,…wz⟩ rappresenta la concatenazione di p e w.
Definizione (Cammino non specifico). Indichiamo ora con first(p) il primo nodo p1 del cammino p, ed analogamente last(p) l’ultimo nodo pq del cammino p, allora si dice che la concatenazione di p e

28
w è un cammino non specifico (unspecific-path) se (last(p), first(w)) ∉ E, dove E è l’insieme degli archi del grafo. Nel caso contrario, invece, si dice che i due cammini connettono. Inoltre un cammino t complementa pw se e solo se ptw è un cammino specifico.
Definizione (Chiusura). Dato un cammino non specifico p=⟨p1,p2,…pq⟩, si definisce la chiusura di p, indicata con p*, l’insieme di tutti i cammini ⟨p1,q1, p2,q2 p3,q3… pn,qn⟩ tali che qi complementi pipi+1.
Figura 11 :semplice programma con tre parametri interi

29
Figura 12 : grafo di controllo del programma in Figura 11
Informalmente possiamo dire che un unspecific-path è un cammino in cui qualche path-segment è mancante. Ad esempio p=⟨3,10,13⟩ in Figura 12 è un unspecific-path, composto da ⟨3⟩ e ⟨10,13⟩. Inoltre il path-segment ⟨4,5,7,8⟩ è un cammino complemento di p, in quanto ⟨3,4,5,7,8,10,13⟩ è uno specific-path. E’ stato detto che affinché l’esecuzione del programma proceda attraverso un arco, la corrispondente condizione sull’etichetta del nodo deve essere ‘vera’. Quindi affinché il programma attraversi un particolare cammino una congiunzione C=c1∧ c2∧…∧cn di branch-predicate deve essere ‘vera’. C è detta path-predicate.
2.2 Generazione casi di test Una volta considerate le definizioni sopra elencate siamo in grado di definire il problema della generazione automatica di casi di test come segue: dato un programma P e un (unspecific) cammino u, generare un insieme di input x∈S, affinché x attraversi u. Tenendo presente la modularizzazione presentata in Figura 10, verrà analizzato ora il test data generator. Nelle considerazioni successive non ci occuperemo del program analyzer e del path selector, supporremo che essi siano presenti e che rispettivamente forniscano, uno tutte le informazioni relative al programma: grafo di controllo, grafo delle dipendenze dei dati, ecc; l’altro fornisca, invece, i

30
cammini per i quali vanno generati i casi di input, a seconda del sistema che si sta usando questi ultimi possono essere cammini specifici o unspecific. L’obiettivo finale del generatore è trovare un’istanza dei valori di input che attraversi i cammini ricevuti come parametro dal path selector. Questo può essere fatto in due passi: primo, determinare il path-predicate per il cammino in questione; secondo, risolvere il path-predicate in relazione alle variabili di input. La soluzione sarà, quindi, un insieme di uguaglianze (o disuguaglianze) che descrivono come dovrebbe essere l’input affinché attraversi il cammino. Prima di proseguire è interessante considerare un esempio: determinare un path-predicate per il seguente cammino, relativo al grafo in Figura 12
p = ⟨1,2,3,5,6,7,8,10,13⟩.
Invece di determinare subito il path-predicate vediamo cosa accadrebbe se il programma venisse eseguito con l’input (5,4,4). Analizzando il codice del programma in Figura 11 è evidente che il cammino p venga attraversato. Costruiamo ora un path-predicate, che indicheremo con P’, che è la congiunzione di tutte le condizioni presenti come etichette degli archi attraversati dal cammino p,
P’= (a > b) ∧ (a ≤ c) ∧ (b > c) ∧ (a = b) ∧ (b ≠ c).
Effettuando le seguenti assegnazioni: a=5, b=4, c=4, dobbiamo verificare se P’ risulti verificato, infatti, poiché (5,4,4) attraversa il cammino p, ogni predicato relativo a p deve risultare soddisfatto.
P’= (5 > 4) ∧ (5 ≤ 4) ∧ (4 > 4) ∧ (5 = 4) ∧ (4 ≠ 4).
E’ evidente che non è questo il caso. Come mai non risulta verificato, benché l’input (5,4,4) attraversa il cammino p? La risposta risiede nel modo in cui è stato costruito il path-predicate: infatti è stata ignorata l’esecuzione dei nodi 1,2,6 e 10 (cf. Figura 11 e Figura 12). Di conseguenza, non propagando i side effect delle istruzioni nel path-predicate, questo alla fine risulta incorretto. Ad esempio, possiamo considerare che il programma venga eseguito con l’input (5,4,4) e che l’esecuzione del programma venga arrestata quando viene raggiunto il nodo 7. A questo punto ci si aspetta che a=4 e b=5, perché nel cammino verso il nodo 7 è stata eseguita l’istruzione swap(a,b), che ha appunto settato i valori di a e b rispettivamente a 4 e 5. Nel determinare il predicato P’ l’istruzione swap(a,b) non è stata considerata, e quindi a e b saranno ancora uguali a 5 e 4, rispettivamente.
Figura 13 : schema che mostra le dipendenze dei dati con i branch predicate

31
Lo schema in Figura 13 illustra le dipendenze dei dati con i branch-predicate. Ogni riga dipende dall’esecuzione di se stessa, oltre che delle righe precedenti. Ad esempio, prima di verificare se (a=b) alla riga 7 è verificato, le seguenti istruzioni devono essere eseguite: int type=PLAIN; swap(a, b); swap(b, c); . Quindi, per tenere in considerazione nel modo adeguato queste dipendenze nel calcolo dei branch-predicate, si procede nel seguente modo. Si inizia dalla prima riga, eseguendo il suo codice. Si aggiornano quindi tutte le righe successive (inclusa la condizione corrente) tenendo conto dei side effects dovuti alle istruzioni. Si prosegue, poi, con la riga successiva, finché tutte le righe non sono state correttamente processate.
Figura 14 : schema delle dipendenze dei dati con i branch-predicate dopo la seconda
iterazione
Figura 15 : delle dipendenze dei dati con i branch-predicate dopo la quarta iterazione
Dopo varie iterazioni si arriva al punto in cui ogni riga corrisponde ad un branch-predicate, che è stato giustamente modificato in accordo alla sequenza di nodi che è stata seguita nel cammino in esame. Nell’esempio considerato dopo 4 iterazioni si giunge alla configurazione rappresentata in Figura 15, avendo ora considerato in modo adeguato l’esecuzione dei nodi 1, 2, 6 e 10. Possiamo, quindi, ora determinare un nuovo path-predicate per il cammino p,
P = (a > b) ∧ (b ≤ c) ∧ (a > c) ∧ (b = c) ∧ (c ≠ a).
Sostituendo adesso i valori a=5, b=4, c=4 :
P = (5 > 4) ∧ (4 ≤ 4) ∧ (5 > 4) ∧ (4 = 4) ∧ (4 ≠ 5),
è evidente che P risulta verificato. Quindi P è un valido path-predicate per p = ⟨1,2,3,5,6,7,8,10,13⟩.

32
Fondamentalmente esistono tre approcci usati per costruire un test data generator: generare i casi di test in modo random, generarli per un cammino unspecific, oppure generarli per un cammino specifico. Questi tre approcci ricadono perfettamente nelle tre categorie di generazione automatica di casi di test elencati precedentemente: random, goal-oriented, path-oriented. Ognuno di essi può essere implementato staticamente o dinamicamente. Nel primo caso il programma non viene eseguito per determinare i casi di test, e l’analisi viene, invece, condotta solo attraverso la conoscenza delle specifiche, nel caso di test black-box, oppure attraverso la conoscenza del codice sorgente nel test white-box. Nel secondo caso, invece, il programma viene fatto eseguire, spesso con degli input generati casualmente e si monitorizza il suo comportamento, ed eventualmente si modificano gli input per ottenere il risultato voluto.
2.2.1 Generazione casi di test random Il random testing è il modo più semplice per generare casi di test. Può essere utilizzato per generare valori di ingresso per ogni tipo di programma, dal momento che qualsiasi tipo di dato (intero, in virgola mobile, stringa, ecc) è rappresentato da una sequenza di bit. Di conseguenza, per ciascuna funzione da testare, è possibile generare casualmente una sequenza di bit ed utilizzarla come parametro di ingresso. Tuttavia, le performance del random testing sono chiaramente scadenti in termini di copertura. Infatti, basandosi sulla probabilità, risulta poco efficace nello scovare errori localizzati in piccoli segmenti di codice, i quali spesso sono eseguiti per una piccola percentuale dei dati di input.
Figura 16 : programma con un'istruzione eseguita con probabilità bassa
Consideriamo ad esempio il codice in Figura 16, la probabilità di eseguire l’istruzione ‘write(1)’ è 1/n, dove n è il massimo intero, visto che affinché questa istruzione venga eseguita le due variabili a e b devono essere uguali. E’ facile immaginare come nel caso in cui l’input sia costituito da strutture più complesse la probabilità di eseguire alcune parti del codice diventi ancora più bassa.
2.2.2 Generazione casi di test path-oriented La generazione di casi di test path-oriented è la più ‘forte’ tra i tre approcci elencati. Essa non dà al generatore di casi di test la possibilità di selezionare un cammino tra un insieme fornito in ingresso, ma ne impone uno specifico. Questo se da una parte porta ad una migliore previsione della copertura del codice realizzata, dall’altra complica e rende più difficile la ricerca dei dati di input.

33
L’analisi path-oriented può essere effettuata sia dinamicamente che staticamente. Come abbiamo già accennato, la generazione statica di casi di test si basa sull’analisi del programma senza ricorrere ad un’esecuzione del programma stesso. La tecnica più utilizzata in questo ambito viene denominata esecuzione simbolica.
2.2.2.1 Esecuzione Simbolica L’esecuzione simbolica in realtà non è un’esecuzione vera e propria, ma indica, invece, il processo di assegnare vincoli ed espressioni alle variabili durante l’attraversamento del codice del programma. L’idea principale su cui si basa l’esecuzione simbolica è quella di utilizzare valori simbolici, invece di dati effettivi, come valori di input del programma, e rappresentare quindi le variabili interne al programma come espressioni simboliche. Quindi alla fine della computazione del programma il risultato sarà espresso come una funzione dei valori simbolici di input. Lo stato di programma eseguito simbolicamente include i valori (simbolici) delle variabili del programma, una path-condition (PC) ed un program counter. La path-condition è costituita da una formula booleana su i valori simbolici di input; essa rappresenta i vincoli che le variabili di input devono soddisfare affinché il programma segua il cammino selezionato. Il program counter, invece, definisce la prossima istruzione che deve essere eseguita. L’esecuzione simbolica di un programma è caratterizzata da un albero di esecuzione simbolica: i nodi rappresentano gli stati del programma, mentre gli archi sono transizioni tra stati.

34
Figura 17 : codice che scambia il valore di due variabili e relativo albero simbolico di
esecuzione
Consideriamo ad esempio il codice in Figura 17, in cui il valore di due variabili intere x ed y viene scambiato, quando x è maggiore di y; in figura è presente anche il corrispettivo albero di esecuzione simbolica. Inizialmente PC è ‘vero’, e x ed y hanno i valori simbolici X ed Y, rispettivamente. In ogni punto di branch, PC è aggiornato con i nuovi vincoli sull’input coerentemente con il ramo scelto. Ad esempio, dopo l’esecuzione della prima istruzione, entrambi i rami, then ed else dell’istruzione if sono possibili, e quindi PC è aggiornato in modo conseguente. Se una path-condition assume il valore ‘falso’, cioè quando non esiste un insieme di valori di input che possa soddisfarla, significa che lo stato dell’esecuzione simbolica corrispondente non è raggiungibile, e quindi l’esecuzione simbolica non procede oltre in quel cammino. Ad esempio l’istruzione (6) è irraggiungibile. Le principali difficoltà nell’applicazione dell’esecuzione simbolica derivano dalla crescita delle espressioni simboliche intermedie, dalla gestione delle chiamate a procedura (che richiederebbe di allargare l’analisi alla funzione invocata), e dalla gestione degli array e dei puntatori (vedi paragrafo 2.2.4).
2.2.2.2 Approccio dinamico alla generazione di casi di test path-oriented
Per superare i limiti dell’analisi statica del codice sono stati sviluppati negli anni degli approcci dinamici, che prevedono di eseguire un’analisi a run-time del programma. In questo modo, alcuni problemi legati all’uso degli array e dei puntatori non si presentano, in quanto una volta che il programma viene eseguito il loro valore viene effettivamente conosciuto. Durante l’esecuzione, viene monitorato il flusso del programma e se si verifica una deviazione dal flusso desiderato, possono essere utilizzati vari algoritmi per

35
individuare le variabili di ingresso responsabili del comportamento non desiderato, permettendo quindi di modificarne il valore. Un approccio del genere è presentato da Korel in [13]. Lo svantaggio principale di questo approccio è che la procedura di ricerca risulta particolarmente onerosa, richiedendo potenzialmente numerose iterazioni prima di trovare un valido insieme di valori di input, richiedendo quindi numerose esecuzioni del programma. Questo processo, quindi, risulta anche rallentato dalla velocità di esecuzione del programma stesso, divenendo impraticabile per programmi che abbiano tempi di esecuzione lunghi.
2.2.3 Generazione casi di test goal-oriented L’approccio goal-oriented impone dei vincoli meno stringenti sulle caratteristiche che devono avere i dati di input. Invece di cercare di generare valori di ingresso che attraversino il programma dall’inizio alla fine seguendo un determinato cammino, genera input per un dato cammino non specifico u. Di conseguenza, per il generatore è sufficiente trovare dei valori di ingresso per uno qualsiasi tra i cammini (specifici) p∈ u*. Questo riduce il rischio di incontrare cammini non percorribili (unfeasible path). L’obiettivo di questo approccio è ottenuto, da un punto di vista molto generale, tramite la classificazione delle diramazioni del grafo di controllo del programma, come critica, semi-critica, e non essenziale rispetto al nodo obiettivo. Una diramazione critica è un arco del grafo di controllo che impedisce di raggiungere il nodo obiettivo. Pertanto, una funzione obiettivo dovrà forzatamente selezionare la diramazione opposta per giungere al nodo obiettivo. In caso la diramazione alternativa non sia percorribile il processo termina senza aver raggiunto l’obiettivo. Una diramazione semi-critica è un arco del grafo di controllo che conduce al nodo obiettivo, ma solo attraverso l’arco di ritorno di un ciclo. In questo caso, se possibile, viene ancora selezionata la diramazione alternativa. Tuttavia, se questo non fosse possibile, il processo non termina, come nel caso precedente, ma l’esecuzione continua nella speranza che all’iterazione successiva del ciclo la diramazione alternativa diventi effettivamente percorribile. Infine, una diramazione non essenziale è una diramazione che non è né critica né semi-critica. In pratica è una diramazione che non determina in alcun modo se il nodo obiettivo sarà raggiunto o meno.

36
Figura 18 : diramazioni critiche (C), semi-critiche (S), non essenziali (N), rispetto al
raggiungimento del nodo 5
Consideriamo ad esempio il programma in Figura 18, l’obiettivo è il raggiungimento del nodo 5. Le diramazioni false uscenti dal nodo 1 e dal nodo 3 sono critiche, perché impediscono di raggiungere il nodo 5. La diramazione uscente dal nodo 4 è semi-critica perché, sebbene il flusso di esecuzione diverga dall’obiettivo, questi può comunque essere raggiunto ad una successiva iterazione del ciclo. Infine, le restanti diramazioni sono non essenziali perché non hanno alcuna influenza sul raggiungimento dell’obiettivo. Negli anni sono state proposte più tecniche che usano questo approccio, le più significative sono le seguenti. In [9] Korel presenta un approccio denominato Chaining (a catena). L’approccio a catena utilizza il concetto di sequenza di eventi come passo intermedio per stabilire il tipo di cammino richiesto per l’esecuzione fino al nodo obiettivo. Una sequenza di eventi è una successione di nodi del programma che devono essere eseguiti. La caratteristica di questo metodo è di utilizzare le dipendenze sui dati per individuare una catena di nodi che sono vitali per soddisfare un dato criterio di copertura e poi utilizzare l’approccio appena esposto per raggiungere questi nodi. In [14] Korel ed altri presentano un altro approccio che fa uso di asserzioni. Le asserzioni sono condizioni che vengono inserite nel codice per verificarne la corretta esecuzione. Possono esprimere pre e post-condizioni, oppure invarianti. Se un’asserzione non viene soddisfatta, vuol dire che esiste un errore o

37
nell’implementazione del programma o nell’asserzione stessa. L’obiettivo del test basato su asserzioni è di trovare un qualsiasi cammino che conduce all’asserzione. Un altro approccio che è stato presentato negli ultimi anni è quello proposto da Gotlieb ed altri in [10], questo approccio fa uso della programmazione a vincoli, ed essendo quindi più vicino degli altri agli scopi di questa tesi verrà trattato separatamente più avanti. Presentiamo, infine, per completezza, due tipologie di approccio al problema della generazione automatica di casi di test, relativamente più recenti. Un approccio fa uso degli algoritmi genetici, ed uno, invece, del model checking. Il primo fa uso degli algoritmi genetici per generare automaticamente i casi di test. Gli algoritmi genetici[22] affondano le proprie radici nella teoria dell’evoluzione e si basano sulla manipolazione di un insieme di potenziali soluzioni per un problema di ottimizzazione o di ricerca. Le potenziali soluzioni sono rappresentate come cromosomi, composti da una sequenza di geni, equivalente al materiale genetico degli esseri umani. A ciascuna soluzione è associata una funzione di fitness che indica quanto una soluzione è buona rispetto alle altre. Come in natura, la funzione di fitness gioca un ruolo chiave nel selezionare quali soluzioni sono destinate a sopravvivere. Le popolazioni successive sono ottenute sfruttando due tecniche, anch’esse mutuate dalla natura, l’incrocio e la mutazione. Lo scopo è di far evolvere il sistema verso una soluzione globale. Nel caso specifico del testing, i casi di test sono rappresentati come cromosomi, mentre la funzione di fitness è il grado di copertura dei medesimi[17][18][23]. Infine analizziamo l’approccio basato sul model checking. Un model-checker, normalmente, viene utilizzato per analizzare una rappresentazione finita di stati relativi ad una data applicazione al fine di verificarne alcune proprietà (tipicamente proprietà di safety o di liveness). Esso prende in input un modello che descrive una macchina a stati finiti (anche più macchine a stati finiti concorrenti), una proprietà da verificare ed analizza l’albero di computazione per determinare se la proprietà risulta verificata. Se non rileva alcuna violazione alla proprietà, allora essa si assume valida e verificata, se, invece, il model-checker raggiunge uno stato in cui la proprietà non è verificata, viene restituito un contro-esempio che contiene la sequenza di stati che hanno portato allo stato incriminato. Il model checking ha goduto negli anni di grande popolarità in svariati campi, e più recentemente ha trovato applicazione nel software testing [3][6][12][25]. Il model checking dei programmi, però, risulta difficoltoso, soprattutto perché il model checker presenta il problema dell’esplosione dello spazio degli stati e quindi normalmente richiede di essere eseguito con un sistema chiuso, imponendo varie limitazioni. In [26] viene presentato un approccio che unisce al model checking l’utilizzo dell’esecuzione simbolica per riuscire a superare parte di questi problemi. Esso è presentato per un utilizzo prevalentemente black-box, ma ne viene mostrato anche l’uso con il test a scatola bianca. Da un punto di vista molto generale, viene realizzata un traslazione source to source al fine di aggiungere al programma originario delle istruzioni che permettano di realizzare l’esecuzione simbolica. Questa viene poi realizzata attraverso il model checking

38
del programma. L’esecuzione simbolica è stata comunque estesa per permettere la gestione di alcune strutture dati complesse.
2.2.4 Problemi della generazione di casi di test In questo paragrafo presentiamo in modo generale alcuni problemi legati alla generazione automatica dei casi di test, che si incontrano qualsiasi sia l’approccio utilizzato. E’ principalmente dovuto alla complessità che questi problemi portano nella generazione, se la maggioranza dei lavori di ricerca in questo campo sono orientati verso programmi non reali, ma generalmente più piccoli, meno complessi, e che hanno delle restrizioni riguardo i costrutti supportati. Un primo problema è quello della gestione degli array e dei puntatori. Il loro utilizzo conduce a problemi molto simili, solo che a volte un tipo specifico è più evidente per uno che non per l’altro. Nell’esecuzione simbolica, ad esempio, array e puntatori complicano il processo di sostituzione, dato che il loro valore non è conosciuto.
Figura 19 : Generazione Automatica, il problema degli array
Consideriamo ad esempio il frammento di codice in Figura 19, in cui un’istruzione condizionale usa un elemento di un array, indicizzato attraverso una variabile. Se i è uguale a j, allora a[j] all’interno dell’istruzione if vale 1, altrimenti il suo valore è 3. Questo è un problema, sarebbe come dire ‘(qualcosa=3)’. Lo stesso problema si presenta nell’uso dei puntatori. Inoltre un altro problema che si presenta è quello di determinare, nella generazione, la struttura dei dati di ingresso che hanno una struttura dati complessa (ad esempio strutture collegate). Il problema risiede sia nella definizione della struttura in sé, che nella determinazione della sua dimensione. Negli ultimi anni sono stati presentati vari metodi per cercare di gestire queste situazioni, anche se spesso per un sottoinsieme di casi. Un’ altra classe di problemi che ci si trova a dover affrontare deriva dall’uso dei linguaggi object-oriented. Questi portano sia a problemi analoghi a quelli dei puntatori, in quanto normalmente gli oggetti vengono allocati dinamicamente, sia a problemi di natura diversa, derivanti dai concetti di classe astratta, ereditarietà e polimorfismo. Questi concetti rendono impossibile sapere a tempo di compilazione quale sarà il codice effettivamente eseguito. Generalmente un programma è diviso in funzioni e moduli, e questo porta al problema della possibilità di accedere al codice dei moduli chiamati, in quanto spesso questo non è disponibile, ad esempio nel caso di librerie pre-compilate.

39
Questo problema risulta rilevante, ad esempio, nell’esecuzione simbolica e negli approcci basati sul metodo a scatola-bianca. Infine un problema importante è rappresentato dalla presenza di possibili cammini non percorribili (unfeasible paths). Infatti determinare staticamente se un cammino sia percorribile o meno è un problema indecidibile nel caso generale[1], e questo potrebbe portare il generatore ad un gran numero di iterazioni prima di determinare che il cammino non è percorribile, oppure a non terminare nel caso di cicli infiniti.
2.3 Un approccio tramite programmazione a vincoli: INKA
Dopo aver presentato la generazione automatica di casi di test nei suoi aspetti generali, nei principali approcci e nelle problematiche che lo caratterizzano, si vuole presentare l’approccio che più riguarda da vicino questa tesi, essendo basato sulla programmazione a vincoli: questo approccio è stato presentato da Gotlieb, Botella, e Rueher in [10], ed ha portato allo sviluppo di un prototipo denominato INKA. La metodologia proposta da Gotlieb e gli altri è del tipo goal-oriented, essendo orientata a trovare casi di test che permettano l’esecuzione di una particolare istruzione presente nel codice del programma. Essa può essere vista composta da due fasi principali. La prima fase vede il programma essere staticamente trasformato in un sistema di vincoli attraverso l’uso della Static Single Assignment (SSA) Form e delle control–dependencies. Il sistema di vincoli così generato viene denominato Kset ed è formato da due insiemi di vincoli: uno che rappresenta l’intero programma, l’altro generato per lo specifico punto da eseguire. Nella seconda fase il sistema di vincoli così generato viene risolto per determinare se almeno un cammino attraverso il punto selezionato esista, ed in caso affermativo viene generato l’insieme dei dati di input per un qualsiasi cammino che sia soluzione del sistema di vincoli. Di seguito viene analizzata più in dettaglio la metodologia proposta. L’SSA-Form è un versione semanticamente equivalente di un programma, in cui ogni variabile ha un’unica definizione ed ogni uso della variabile è raggiunto da questa definizione. Inizialmente l’ssa-form venne proposta per le ottimizzazioni da effettuare nei compilatori, per ovviare al problema dell’aggiornamento distruttivo delle variabili, permesso in quasi tutti i linguaggi procedurali, rendendo impossibile trattare le variabili del programma come variabili logiche. L’ssa-form di sequenze lineari di codice è ottenuta attraverso una semplice rinominazione delle variabili (i→i1, i→i2). Nel caso, invece, delle strutture di controllo l’ssa-form introduce delle speciali istruzioni di assegnazione, denominate φ–funzioni, nei nodi di unione (join) del grafo di flusso. Una φ–funzione restituisce uno dei suoi argomenti in base al flusso di controllo che è stato seguito.

40
Figura 20 : Esempio
Figura 21 : grafo di controllo del esempio di Figura 20
Figura 22 : SSA-Form dell'esempio in Figura 20
Consideriamo ad esempio l’istruzione if nell’esempio di Figura 20, e consideriamo l’ssa-form corrispondente mostrata in Figura 22; la φ–funzione

41
all’istruzione 6 ritornerà i3 se il flusso seguirà la parte then dell’if, mentre restituirà i2 nell’altro caso. Nel caso di strutture di controllo più complesse, come i cicli, la φ–funzione viene introdotta in una speciale intestazione del ciclo (cf. Figura 22). In letteratura sono presenti vari algoritmi per la costruzione dell’ssa-form, come in [7] e [4], valido quest’ultimo solo per programmi strutturati. Il sistema di vincoli che deve essere poi risolto, come abbiamo già detto, è costituito da due parti, una derivante dall’intero programma, l’altra dall’istruzione che deve essere eseguita. Per generare la prima parte si prende l’ssa-form, appena generata, e si trasforma in un sistema di vincoli che ne rappresenti la semantica. Questo viene realizzato attraverso l’utilizzo e la definizione di vincoli atomici e vincoli globali, dove questi ultimi non sono altro che un insieme di vincoli atomici, gestiti in modo particolare, al fine di renderli più efficienti, mentre un vincolo atomico non è altro che una relazione tra variabili logiche. Ogni dichiarazione di variabile di un tipo base, sia locale che come parametro di input, viene rappresentato tramite un vincolo atomico del tipo [ ]maxmin,∈x , dove min e max rappresentano il minimo ed il massimo del dominio. Le istruzioni elementari, come le assegnazioni e le espressioni nelle condizioni, vengono trasformate in vincoli atomici. Ad esempio, la riga 1 in Figura 20 genera il vincolo 10 =j .
Per gestire, invece, le altre istruzioni vengono definiti dei vincoli globali, di cui poi viene definita una semantica operazionale, che permetta di gestire in modo efficiente i vincoli atomici corrispondenti. Verrano mostrati di seguito due esempi, uno per l’istruzione condizionale if then else, ed uno per l’istruzione di ciclo while. L’istruzione condizionale if then else viene rappresentata tramite il vincolo globale ITE/3 (dove /3 denota il numero di argomenti del vincolo), mostrato in Figura 23, dove con pKset(s) si indica l’insieme dei vincoli che rappresentano
l’istruzione s, e →
iv rappresenta il vettore delle variabili modificate o definite in uno
dei due rami.
Figura 23 : vincolo globale ITE
La semantica operazionale per gestire questo vincolo globale viene mostrata in Figura 24, dove σ rappresenta l’insieme dei vincoli attuali (constraint store).

42
Figura 24 : semantica operazionale del vincolo globale ITE
Le prime due regole rappresentano la semantica propria dell’istruzione if, ossia se dai vincoli attuali si deduce che c è implicato, allora si unisce all’insieme dei vincoli attuali l’insiene dei vincoli che rappresentano il tamo then. Se, viceversa, si deduce che c¬ è implicato, allora si uniscono al constraint store i vincoli che rappresentano il ramo else. Le altre due regole servono a identificare possibili cammini non percorribili, e propagare velocemente i vincoli che ne derivano, i quali impongono alla condizione dell’if di essere o meno verificata. L’istruzione di ciclo while viene rappresentata tramite il vincolo globale W/5, mostrato in Figura 25, dove con pKset(s), analogamente a prima, si indica
l’insieme dei vincoli che rappresentano l’istruzione s, e →
iv rappresenta un vettore
di variabili. Vengono utilizzati tre vettori, →
0v ,→
1v ,→
2v con i seguenti significati: il
primo rappresenta le variabili definite prima del ciclo while, il secondo rappresenta le variabili definite dentro al corpo del ciclo ed, infine, il terzo rappresenta le variabili referenziate sia all’interno che all’esterno del ciclo.
Figura 25 : vincolo globale W/5

43
Figura 26 : semantica operazionale del vincolo globale W/5
Per la valutazione di questo vincolo è necessario permettere che vengano generati
nuovi vincoli e nuove variabili. La sostituzione
←→→
cvvsubs ,21 è il meccanismo
attraverso cui vengono generati i nuovi vincoli. Essa genera un nuovo vincolo
avente la struttura di c, ma dove il vettore di variabili →
1v viene sostituito dal
vettore →
2v . Ad esempio, se ( )111 , yxv =→
e ( )222 , yxv =→
, allora
=+←→→
3, 1121 yxvvsubs è ( )322 =+ yx .
La semantica operazionale per gestire questo vincolo globale viene mostrata in Errore. L'origine riferimento non è stata trovata., dove σ rappresenta l’insieme dei vincoli attuali (constraint store). Le prime due regole rappresentano la semantica operazionale del ciclo while. Le altre regole, analogamente a quanto visto per il vincolo ITE, servono ad identificare parti non percorribili della struttura. In particolare, la terza regola è applicata se può essere provato che i vincoli interni al corpo del ciclo sono inconsistenti con il constraint store; questo significa che il corpo del ciclo non può essere eseguito neanche una volta e, quindi, il vettore di variabili di uscita,
→
2v , deve essere uguale al vettore delle variabili di ingresso, →
0v . Il caso opposto è
gestito dalla quarta regola. L’aspetto fondamentale del vincolo globale W/5 è che esso si comporta come un generatore di vincoli. Per generare la seconda parte del sistema di vincoli, ossia i vincoli associati con il punto n nel grafo di flusso che si voglia vanga eseguito, si sfruttano le control-

44
dependencies del punto selezionato. Queste vengono determinate sintatticamente nei programmi strutturati, e vengono direttamente tradotte in vincoli. Il sistema di vincoli così generato viene poi risolto attraverso constraint-solver, determinando in valori delle variabili di input.

45
Capitolo 3 Programmazione a vincoli
3.1 Informazioni Generali Il termine programmazione in programmazione a vincoli è espressione delle radici che essa affonda nel campo dei linguaggi di programmazione. Esistono, infatti, vari paradigmi di programmazione, ad esempio programmazione procedurale, programmazione orientata agli oggetti, programmazione funzionale, programmazione logica, ed ognuna di esse ha i propri vantaggi ed i propri svantaggi, per varie classi di problemi. La programmazione a vincoli ha fatto il suo ingresso nel campo dei linguaggi di programmazione recentemente, ed un suo primo obiettivo è quello di ridurre la divisione esistente tra la descrizione ad alto livello di un problema di ottimizzazione e l’algoritmo implementato poi per risolverlo. La programmazione a vincoli è un’interessante ed affascinante tecnologia per una vasta gamma di problemi di ricerca, poiché essa può ridurre il tempo di sviluppo di applicazioni, per risolvere questi problemi, di vari ordini di grandezza. Questa miglior produttività si basa soprattutto sull’alto livello di astrazione fornita dalla programmazione a vincoli nell’assistere le due fondamentali attività relative agli algoritmi di ottimizzazione combinatoria: constraint reasoning e ricerca. Per l’attività di constraint reasoning i linguaggi di programmazione a vincoli sono dotati di sofisticati algoritmi di risoluzione di vincoli, a cui si ha accesso specificando lo spazio di ricerca e l'insieme dei vincoli che devono essere soddisfatti da un suo generico elemento, affinché possa essere considerato una soluzione del problema. Per quanto riguarda la ricerca, invece, i linguaggi di programmazione a vincoli forniscono dei costrutti non deterministici che sollevano il programmatore dal doversi occupare direttamente degli aspetti implementativi della gestione dell’albero di ricerca. Di conseguenza risolvere un problema attraverso l’utilizzo di un linguaggio di programmazione a vincoli ha due fasi generalmente: definire uno spazio di ricerca ed un insieme di vincoli che devono essere soddisfatti e descrivere come ricercare le soluzioni. Abbiamo già detto come il grande beneficio nella produttività della programmazione a vincoli derivi in larga misura dalla sua natura dichiarativa, caratteristica questa comune ai linguaggi di modellazione. I vincoli specificano delle proprietà che le soluzioni devono avere, ed intuitivamente possono esser visti come delle restrizioni sul dominio del problema. Comunque, essi non specificano una procedura particolare per trovare queste soluzioni: cioè i vincoli

46
indicano solo cosa le soluzioni devono soddisfare, senza specificare come cercarle. Questo aspetto dichiarativo dei vincoli ha molti vantaggi: l’ordine in cui i vincoli vengono imposti non ha importanza, e quindi nuovi vincoli, che rappresentano nuove proprietà che le soluzioni devono soddisfare, possono essere semplicemente aggiunti, senza doversi preoccupare dell’interazione con i vincoli preesistenti o della procedura di ricerca. Di conseguenza ci si può concentrare sugli aspetti di modellazione del problema, tralasciando qualsiasi dettaglio implementativo di basso livello. La programmazione a vincoli è, quindi, un approccio alternativo alla programmazione in cui il processo di programmazione è limitato alla generazione dei requisiti (vincoli), e la soluzione di questi requisiti viene ottenuta per mezzo di metodi che possono essere sia generali, che specifici del dominio in questione. I metodi generali sono normalmente relativi a tecniche utilizzate per ridurre lo spazio di ricerca, come la propagazione dei vincoli, ed algoritmi avanzati per l’esplorazione dello spazio di ricerca. Invece, i metodi specifici del dominio normalmente sono forniti come algoritmi specializzati o packages. Esempi di questi ultimi sono programmi che risolvono sistemi di equazioni lineari, librerie per la programmazione lineare, un’implementazione dell’algoritmo di unificazione (elemento fondamentale della dimostrazione automatica di teoremi). I problemi che normalmente possono essere affrontati in modo naturale attraverso la programmazione a vincoli sono quelli per i quali mancano efficienti algoritmi (ad esempio problemi computazionalmente difficili da trattare), o problemi per i quali la formalizzazione in termini di leggi (ad esempio problemi di elettrotecnica) portano ad un più flessibile stile di programmazione, in cui le dipendenze tra le variabili possono essere espresse in un modo più generale. Esistono, poi, molti problemi che necessitano di essere risolti attraverso i calcolatori, che non sono definiti in modo preciso, oppure una precisa definizione del problema dipende della qualità della soluzione di un iniziale versione del problema (ad esempio la velocità con cui essa viene determinata). Quando si devono risolvere problemi di questo tipo l’unico modo di procedere è quello attraverso iterazioni successive. Effettuare una modellazione di questi problemi attraverso vincoli può risultare vantaggioso. Un ulteriore aspetto introdotto dalla programmazione a vincoli è che modellare un problema attraverso vincoli porta ad una rappresentazione attraverso relazioni. In alcune circostanze questa rappresentazione permette di usare lo stesso programma per differenti scopi, e questo può risultare utile in più casi; ad esempio quando è necessario riuscire a capire quale input porti ad un determinato output. Nei normali linguaggi di programmazione le relazioni sono state traslate in funzioni e quindi questa possibilità è andata persa. L’utilizzo delle relazioni per la formulazione del problema può far vedere qualche somiglianza con i sistemi di basi di dati, ad esempio le basi di dati relazionali. La differenza è che nei sistemi di basi di dati queste relazioni sono normalmente esplicitamente date e l’obiettivo è efficientemente effettuare delle ricerche su di esse, mentre nella programmazione a vincoli queste relazioni sono date spesso implicitamente e l’obiettivo è risolverle.

47
Si può ricapitolare quanto detto sulla programmazione a vincoli nel seguente modo:
• il processo di programmazione consiste si due fasi: la generazione della rappresentazione del problema attraverso vincoli (modellazione) e la risoluzione di essa.
• la rappresentazione di un problema attraverso i vincoli è molto flessibile, poiché i vincoli possono essere aggiunti, rimossi e modificati senza generare nessun problema.
• l’utilizzo di relazioni per rappresentare i vincoli riduce la differenza tra input ed output, e questo rende possibile utilizzare lo stesso programma per scopi diversi.
La programmazione a vincoli è stata già applicata con successo in molti campi, tra cui problemi di ricerca operativa, biologia molecolare (DNA sequencing), elettrotecnica (per trovare guasti nei circuiti), progettazione di circuiti, calcolo numerico (risolvere equazioni algebriche con precisione garantita), ecc. Inoltre recentemente ha trovato applicazione anche nel campo dell’ ingegneria del software.
3.2 Problema di soddisfacimento di vincoli (CSP)
3.2.1 Definizioni Al fine di essere più precisi riguardo la programmazione a vincoli è necessario introdurre un concetto fondamentale per questo campo: il problema di soddisfacimento di vincoli (Constraint Satisfaction Problems, CSP)[2]. Intuitivamente, un problema di soddisfazione di vincoli consiste in un insieme finito di relazioni su determinati domini. Viene usata una sequenza finita di variabili, con i rispettivi domini associati, ed un vincolo su una sequenza di variabili è un sottoinsieme del prodotto cartesiano dei loro domini. Quindi, informalmente, un problema di soddisfazione di vincoli è costituito da una sequenza finita di variabili con i rispettivi domini, insieme ad un insieme finito di vincoli, ognuno dei quali definito su una sottosequenza di queste variabili. Una definizione più formale può essere data introducendo i concetti seguenti. Si consideri una sequenza finita di variabili Y=y1,…,yk, dove k>0, con i rispettivi domini associati D=D1,…,Dk. Con un vincolo C su Y si indica un sottoinsieme di D1×…×Dk. Se C è uguale a D1×…×Dk, allora si dice che C è risolto.
Nel caso estremo in cui k=0, vengono ammessi due vincoli, indicati con ⊤ e ⊥ che, rispettivamente, rappresentano il vincolo vero (ad esempio 0=0) ed il vincolo falso (ad esempio 0=1).

48
Definizione (Problema di Soddisfazione di Vincoli) Si definisce, quindi, con Problema di Soddisfazione di Vincoli (CSP – Constraint Satisfaction Problem) una sequenza finita di variabili X= x1,…,xn, con i rispettivi domini associati D=D1,…,Dn, insieme ad un insieme finito di vincoli C, ognuno definito su una sottosequenza di X. Un CSP viene indicato con ⟨C; Dε⟩, dove Dε= x1 ∈ D1,…, xn ∈ Dn, e ogni costrutto della forma x ∈ D viene detto domain expression.
Definizione (CSP Risolto) Un CSP è detto risolto se tutti i suoi vincoli sono risolti e nessun dominio è vuoto;
è detto, invece, fallito se, o contiene il vincolo falso ⊥, o qualcuno dei suoi domini è vuoto.
Bisogna ora definire il concetto di soluzione di un problema di soddisfazione di vincoli. Intuitivamente, una soluzione di un CSP è una sequenza di valori assunti da tutte le variabili tali che tutti i vincoli siano soddisfatti.
Definizione (Soluzione di un CSP) Si consideri un CSP ⟨C; Dε⟩, con Dε= x1∈ D1,…, xn ∈ Dn; si dice che una n-upla (d1,…,dn) ∈ D1×…×Dn è una soluzione di ⟨C; Dε⟩ se per ogni vincolo C∈C, definito sulle variabili xi1,…,xim, abbiamo che (di1,…,dim) ∈ C.
Definizione (CSP consistente) Un CSP è detto consistente se esso ammette almeno una soluzione, è detto inconsistente nel caso opposto.
Naturalmente ogni CSP che è risolto è consistente, ed ogni CSP che è fallito è inconsistente. Quindi, praticamente, se un CSP ⟨C; x1∈ D1,…, xn ∈ Dn ⟩ è risolto, allora ogni d∈ D1×…×Dn è una soluzione del CSP stesso. Per le discussioni successive è utile introdurre un’ulteriore notazione.
Definizione (Proiezione) Si consideri una sequenza di variabili X= x1,…,xn, con i rispettivi domini associati D=D1,…,Dn, e si consideri un elemento d=(d1,…,dn) di D1×…×Dn ed una sottosequenza Y= xi1,…,xik di X. Allora viene denotata con d[Y], e viene chiamata proiezione di d su Y, la sequenza (di1,…,dik).
Quindi dato un problema di soddisfazione di vincoli P, una tupla di valori presi dai rispettivi domini è una soluzione di esso, se per ogni vincolo C di P la proiezione della tupla sulla sequenza di variabili del vincolo C soddisfa C stesso. Si prenda in esame, come esempio, il CSP seguente: ⟨x2+y2=z2, x=u2+1; x∈Z, y∈Z, z∈Z, u∈Z,⟩, dove Z denota l’insieme degli interi. La sequenza (11, 2, 5, 3) è una soluzione del CSP, in quanto la sottosequenza (11, 2, 5) soddisfa il primo vincolo, x2+y2=z2, mentre la sottosequenza (11,3) soddisfa il secondo vincolo, x=u2+1.

49
Per risolvere un CSP spesso lo si trasforma in un altro CSP finché o tutte le soluzioni sono state trovate, oppure è ormai evidente che soluzioni non ne esistono. La trasformazione di un CSP in un altro, pone come necessità primaria quella che i due CSP siano equivalenti in un modo appropriato. Si considerino, come primo caso, due CSP P1 e P2 aventi la stessa sequenza di variabili. Si dice che P1 e P2 sono equivalenti se hanno lo stesso insieme di soluzioni. Ad esempio i due seguenti CSP ⟨3x-5y=4; x∈[0..9], y∈[1..8]⟩ e ⟨3x-5y=4; x∈[3..8], y∈[1..4]⟩ sono equivalenti, infatti entrambi hanno x=3, y=1 e x=8, y=4 come uniche soluzioni. La definizione appena data di equivalenza però risulta troppo limitativa, in quanto non permette di confrontare CSP con differenti sequenze di variabili. Situazione che potrebbe verificarsi nel modificare un CSP aggiungendo od eliminando una variabile. Questo porta a dare una definizione più generale e completa di equivalenza tra CSP.
Definizione (Equivalenza tra CSP) Si considerino due CSP P1 e P2 e una sequenza X di variabili comuni, cioè X è una sottosequenza dia di X1 che di X2, dove X1 e X2 sono rispettivamente la sequenza di variabili di P1 e la sequenza di variabili di P2. Allora P1 e P2 sono detti equivalenti rispetto ad X se:
• per ogni soluzione d di P1 esiste una soluzione di P2 che coincide con d nelle variabili in X
• per ogni soluzione e di P2 esiste una soluzione di P1 che coincide con e nelle variabili in X.
Utilizzando la nozione di proiezione, precedentemente introdotta, è possibile dare una definizione più succinta di equivalenza tra CSP: P1 e P2 sono detti equivalenti rispetto ad X se e solo se:
{ d[X] | d è una soluzione di P1}={ d[X] | d è una soluzione di P2}.
Naturalmente, due CSP con la stessa sequenza di variabili X sono equivalenti se e solo se sono equivalenti rispetto ad X, ed è quindi evidente come l’ultima definizione di equivalenza data sia una generalizzazione della prima definizione. Normalmente, quando si trasforma un CSP si vuole preservare l’equivalenza rispetto all’iniziale sequenza di variabili. Si consideri, ad esempio il problema di risolvere la seguente equazione
2x5- 5x4+5=0,
con x definita sull’insieme dei reali. Un modo di procedere, nel cercare di trovare una soluzione, è quello di definire una nuova variabile y, e trasformare la precedente equazione nelle due seguenti
2x5- y+5=0,
y=5x4,

50
affinché in ogni equazione ogni variabile occorra al massimo una volta. Ora il CSP costituito dalla prima equazione, e quello costituito dalle due equazioni successive sono equivalenti rispetto ad {x}. Una volta che il problema di soddisfazione di vincoli è stato posto esso va risolto. Normalmente si è interessati a :
• determinare se un CSP ha almeno una soluzione (se quindi è consistente),
• trovare una soluzione (o rispettivamente tutte le soluzioni) del CSP,
• trovare una soluzione ottima del CSP, ottima rispetto a qualche funzione di misura.
La programmazione a vincoli si basa, come è stato detto in precedenza, sul risolvere un problema di soddisfazione di vincoli. Per fare questo, naturalmente, prima il problema in questione deve essere espresso come un CSP. Di conseguenza esso va formulato usando:
• un insieme di variabili definite su uno specifico dominio e, un insieme di vincoli su queste variabili;
• un linguaggio in cui i vincoli possano essere espressi.
Questa parte della programmazione a vincoli prende il nome di modellazione. Successivamente il problema va risolto e, per far questo si utilizzano, come detto precedentemente, o dei metodi specifici del dominio in esame, oppure dei metodi generali.
3.2.2 Esempi di problemi di soddisfazione di vincol i
3.2.2.1 SEND + MORE = MONEY Questo è un esempio classico di un cosiddetto cryptarithmetic problem. E’ un puzzle matematico in cui i numeri sono rimpiazzati da lettere dell’alfabeto o da altri simboli. Il problema in considerazione, in particolare, richiede che le lettere vangano sostituite con cifre differenti in modo che la somma, rappresentata in Figura 27, sia corretta.
Figura 27 : esempio di CSP, SEND+MORE=MONEY
In questo caso le variabili sono S,E,N,D,M,O,R,Y. Poiché S e M sono le cifre più significative, il loro dominio è costituito dall’intervallo di interi [1..9]. Il dominio delle restanti variabili, invece, è dato dall’intervallo di interi [0..9]. Un modo di

51
formulare il problema è attraverso il vincolo di uguaglianza mostrato in Figura 28, insieme a 28 vincoli di disuguaglianza x≠y con x,y∈{ S,E,N,D,M,O,R,Y }.
Figura 28 : vincolo di uguaglianza
Naturalmente di un problema non esiste un’unica modellazione, ed infatti anche per questo problema è possibile considerare delle variabili, definite sull’intervallo intero [0..1], che rappresentino il carry ed, invece, di utilizzare un unico vincolo di uguaglianza, usarne 4, uno per ogni colonna, come mostrato in Figura 29, dove C1, C2, C3, C4 sono appunto le variabili di carry.
Figura 29 : 4 vincoli di uguaglianza per il CSP 3.2.2.1
Questo problema ammette un’unica soluzione, mostrata in Figura 30, quindi entrambe le modellazioni in CSP mostrate ammetteranno un’unica soluzione.
Figura 30 : unica soluzione del CSP 3.2.2.1
3.2.2.2 Problema delle n regine Questo è probabilmente il CSP più conosciuto. Esso richiede di piazzare n regine su una scacchiera n×n, con n≥4, in modo tale che non si attacchino. In Figura 31, viene presentata una soluzione nel caso di n=8. Per modellare questo problema come un CSP è possibile usare n variabili x1,…,xn, ognuna con dominio l’intervallo intero [1..n]. L’idea è che ogni variabile xi indichi la posizione della regina nella riga i-esima. Ad esempio, la soluzione presentata in Figura 31 corrisponde alla sequenza (5,3,1,7,2,8,6,4). I vincoli per rappresentare il problema possono essere espressi attraverso le seguenti disuguaglianze, dove i∈[1..n-1] e j∈[i+1..n]:
• xi ≠ xj (non possono esserci due regine sulla stessa colonna)
• xi - xj ≠ i – j (non possono esserci due regine lungo la diagonale nord-ovest/sud-est)

52
• xi - xj ≠ j – i (non possono esserci due regine lungo la diagonale sud-ovest/nord-est).
Figura 31 : problema delle n-regine, una soluzione per n=8
3.3 Un framework generale In questo paragrafo verrà illustrato in un modo semplice ed intuitivo l’insieme delle tecniche che costituiscono la programmazione a vincoli. A questo scopo viene presentato un framework generale. Prima di tutto, come è stato precedentemente esposto, il problema da affrontare va formulato come un problema di soddisfazione di vincoli. Questo processo non è banale, esso in particolare riguarda la scelta delle variabili, dei domini e dei vincoli da imporre su queste variabili. Questa fase, come è stato detto, prende il nome di modellazione, e rispetto al programmare negli altri stili di programmazione risulta essere più lunga e complessa. La modellazione è più un arte per molti aspetti, che una scienza, e regole ed euristiche risultano spesso di aiuto in questa fase. Una volta che il CSP è stato definito, ad esso viene applicato la procedura solve presentata in Figura 32, dove la variabile continue è locale alla procedura solve e, procede by cases genera una chiamata ricorsiva di solve per ogni nuovo CSP che viene formato. La procedura solve rappresenta il ciclo base della programmazione a vincoli.

53
Figura 32 : procedura SOLVE
Verranno ora analizzate le varie procedure richiamate dalla procedura solve, rimandando la trattazione della constraint propagation alla fine, essendo essa centrale e di fondamentale importanza nella programmazione a vincoli.
3.3.1 Preprocess L’obiettivo di questa procedura è di portare il CSP su cui viene chiamata la procedura solve in una desiderata forma sintattica. Naturalmente il CSP risultante deve essere equivalente al CSP originale rispetto all’insieme originale di variabili. Allo scopo di illustrare meglio la procedura si consideri un semplice esempio basato su dei vincoli booleani. La maggior parte delle procedure che lavorano su vincoli booleani assume che siano in una precisa forma sintattica. Una ben conosciuta forma sintattica per le formule booleane è la forma normale disgiuntiva, in cui la formula booleana è una disgiunzione di clausole, ognuna delle quali è una congiunzione di letterali, dove un letterale è una variabile booleana o la sua negazione. Ad esempio il vincolo
)()()( zxzyxyx ¬∧¬∨∧∧¬∨¬∧
è in forma normale disgiuntiva. In questo caso il preprocessing consiste in un insieme di regole che trasformino una formula arbitraria in una equivalente in forma normale disgiuntiva.
3.3.2 Happy e Atomic Informalmente, happy indica che l’obiettivo per il CSP iniziale è stato raggiunto. Quale sia in particolare l’obiettivo dipende dal particolare CSP, comunque i casi più comuni sono:

54
• che una soluzione sia stata trovata,
• che tutte le soluzioni siano state trovate,
• che un’inconsistenza è stata trovata, e quindi non esistono soluzioni,
• che è stata trovata una forma risolta da cui è possibile generare tutte le soluzioni
• che una soluzione ottima, rispetto ad una funzione di misura, è stata trovata,
• (nel caso di vincoli sui reali) che tutti gli intervalli dei domini sono stati ridotti alla grandezza minore che era stata precedentemente fissata ε.
La procedura atomic, invece, controlla se il CSP può essere ulteriormente spezzato (splitting), o se la ricerca negli eventuali CSP derivanti dallo divisione è ancora necessaria.
3.3.3 Split La procedura split viene eventualmente applicata dopo l’esecuzione della constraint propagation. Se dopo quest’ultima il CSP corrente non è ancora nella forma desiderata, e quindi il test happy fallisce, e analogamente accade per il test atomic, allora il CSP corrente viene diviso in due (o più) CSP, l’unione dei quali è equivalente al CSP corrente. In generale questa divisione del CSP è ottenuta o dividendo un dominio o dividendo un vincolo. Vengono presentati di seguito due esempi di divisione del dominio, in cui una regola trasforma un’espressione di un dominio in due espressioni di dominio separate dal simbolo “|”.
• Labelling. Si assume che il dominio D sia finito e che contenga almeno due elementi. Allora la seguente regola può essere usata, con a∈D:
}{|}{ aDxax
Dx
−∈∈∈
• Bisection. Si assume che il dominio sia un intervallo dei reali non vuoto, scritto come [a,b]. Allora la seguente regola può essere utilizzata:
[ ]
+∈
+∈
∈
bba
xba
ax
bax
,2
|2
,
,

55
Vengono, invece, ora presentati di seguito due esempi di divisione di vincoli, sempre rappresentando la divisione con una regola, il cui significato è analogo al caso precedente.
• Vincoli disgiuntivi. Si suppone che il vincolo è un’espressione boolena di disgiunzione. I due elementi della disgiunzione possono essere due vincoli arbitrari. Allora è possibile applicare la seguente regola:
21
21
|CC
CC ∨
• Vincoli in forma “composta”. In questo caso l’idea che si vuole sfruttare è che tali vincoli siano divisi in componenti sintatticamente più semplici, che poi possano essere affrontati direttamente. Si supponga, ad esempio, di saper affrontare direttamente le equazioni polinomiali sui reali, e che il vincolo in questione sia |p(X)|=a, dove p(X) è un polinomio nelle variabili X e a è una costante. Allora è possibile applicare la seguente regola:
aXpaXp
aXp
−===
)(|)(
)(
Ogni divisione di dominio o di vincolo porta ad una sostituzione del CSP corrente con 2 o più CSP, che differiscono da quello corrente nel dominio o nel vincolo, rispettivamente, che è stato diviso. Per esempio, considerando il caso del labelling, questo porta a rimpiazzare il CSP
⟨C; Dε, x∈D⟩ con due CSP:
⟨C; Dε, x∈{ a} ⟩ e
⟨C; Dε, x∈D-{ a} ⟩.
In generale la procedura di split determina quale di queste regole deve essere applicata, in quanto normalmente più di una possibilità è presente contemporaneamente. In questa fase si utilizzano delle euristiche: quale variabile scegliere, quale valore scegliere, quale vincolo scegliere. Esempi di euristiche sono scegliere la variabile presente in più vincoli (most constrained variable), oppure per un dominio che è un intervallo degli interi selezionare l’elemento centrale.

56
3.3.4 Proceed by Cases Una volta che è stata eseguita la procedura split, che ha generato due (o più) nuovi CSP, questi devono essere analizzati, ed è a questo scopo che viene chiamata la procedura proceed by cases. L’ordine in cui questi nuovi CSP sono considerati dipende dalla tecnica di ricerca adottata. In generale, con l’utilizzo ripetuto della procedura split viene generato un albero, binario nel caso di divisione in due CSP. L’obiettivo della funzione proceed by cases è quello di attraversare quest’albero in un dato ordine, aggiornando coerentemente il CSP con nuove informazioni che vengono generate (ad esempio nella ricerca di una soluzione ottima). Le due tecniche più conosciute al riguardo, sono il backtracking e, nel caso di ricerca della soluzione ottima, il branch and bound. Informalmente, dato un albero finito, la ricerca attraverso l’algoritmo backtracking parte dalla radice dell’albero e procede scendendo verso il suo primo figlio, e questo processo continua finché non viene raggiunta una foglia. Dopodiché il processo procede tornando indietro, al nodo padre, e selezionando un altro figlio, se questo esiste. Il processo continua finché non si torna alla radice e tutti i figli sono stati visitati. Quando si arriva ad una foglia il CSP è risolto o fallito (tutte le variabili infatti hanno assegnato un valore); le soluzioni quindi, se presenti, corrispondono ad alcune foglie. In Figura 33 è mostrato come procede il backtracking nel caso di un semplice albero binario.
Figura 33 : Backtracking search
L’algoritmo del branch and bound è una modifica del backtracking, che considera anche il valore di una funzione obiettivo definita su alcune variabili. Questo valore è inizializzato a -∞ se viene ricercato il massimo della funzione, mentre viene inizializzato a +∞ nel caso contrario. In ogni fase il miglior valore corrente della funzione obiettivo è mantenuto. Esso è utilizzato per evitare di scendere a visitare nodi che, anche nelle migliori ipotesi, non possono portare ad un miglioramento del valore ottimo corrente per la funzione obiettivo; permette, quindi di tagliare pezzi dell’albero di ricerca. Entrambe le strategie di ricerca, backtracking e branch and bound, possono essere combinate con delle appropriate istanze della procedura constraint propagation, portando a delle forme di ricerca ancora più complesse, tipiche della

57
programmazione a vincoli. Due di queste tecniche molto conosciute sono forward checking e il look ahead.
3.3.5 Constraint Propagation Dopo aver analizzato tutte le altre procedure chiamate all’interno di solve, rimane da illustrare la procedura constraint propagation, che viene chiamata, ad ogni iterazione, dopo la procedura di preprocess. Questa procedura rimpiazza un dato CSP con uno più semplice, preservando naturalmente l’equivalenza tra CSP. L’idea per la quale questa azione viene fatta, è che questa sostituzione, se realizzata in modo efficiente, risulta molto vantaggiosa, dato che la ricerca che deve essere effettuata dopo, attraverso le chiamate alle procedure split e procede by cases, viene effettuata su uno spazio di ricerca ridotto. In generale, cosa si voglia indicare di preciso con “CSP più semplice” dipende dall’applicazione; tipicamente, comunque, si vuole indicare che i domini e/o i vincoli divengono più piccoli. La constraint propagation è realizzata attraverso una ripetuta riduzione dei domini e/o dei vincoli, preservando, naturalmente, l’equivalenza tra i vari CSP così generati. Per illustrare meglio il funzionamento di questa procedura vengono di seguito considerati alcuni esempi, in cui, come nel caso dello split, si usano delle regole per rappresentare le azioni che vengono intraprese; questa volta però, esse indicano una sostituzione tra CSP. Vengono considerati prima due esempi di riduzione del dominio.
• CSP arbitrari (Regola di Proiezione) Si considera un vincolo C, si sceglie una variabile x del vincolo con dominio D. Sul dominio si effettua la seguente operazione: si rimuovono da D tutti i valori che non partecipano ad una soluzione di C. Questa operazione viene chiamata proiezione di C su di x; essa sfrutta l’idea che i valori che vengono rimossi in questo modo non avrebbero mai potuto far parte di una soluzione del CSP considerato.
• Disequazioni lineari sugli interi Si assume che i domini siano intervalli di interi non vuoti, scritti come [a,b], e che i vincoli siano delle disequazioni lineari della forma x < y. E’ allora possibile applicare la seguente regola:
[ ] [ ][ ] [ ]yxyyxx
yyxx
hllyhhlxyx
hlyhlxyx
)..1,max(,)1,min(..;
..,..;
+∈−∈<
∈∈<
L’idea che si vuole sfruttare è che x < y e y ≤ hy implica che sia anche x ≤ hy-1. Questo, in congiunzione con x ≤ hx implica che sia x ≤ min(hx, hy-1), ed analogamente per la variabile y. Di seguito viene presentata un’applicazione di questa regola, il CSP iniziale è:

58
⟨x < y; x∈[50..200], y∈[0..100] ⟩
e viene trasformato nel CSP seguente
⟨x < y; x∈[50..99], y∈[51..100] ⟩
in cui il dominio è chiaramente più piccolo. Viene considerata ora la riduzione dei vincoli. Anche in questo caso si farà ricorso a due esempi, ed in ognuno di essi verrà introdotto un nuovo vincolo: questo può essere visto come una riduzione del vincolo originale. Infatti, l’introduzione di un nuovo vincolo, ad esempio sulle variabili X, porta ad un nuovo elemento nella congiunzione dei vincoli imposti su X (nel caso in cui non ne sia presente nessuno, si assume che il vincolo universale vero sia presente su X). La nuova congiunzione di vincoli è semanticamente un sottoinsieme della precedente. Di seguito vengono elencati i due esempi.
• Transitività dell’operatore < sui reali.
La regola seguente sfrutta la transitività della relazione di < sui reali. Essa introduce un nuovo vincolo, x < z.
εεDzxzyyx
Dzyyx
;,,
;,
<<<<<
• Regola di risoluzione.
Questa regola viene applicata alle clausole che siano disgiunzioni di letterali (si ricorda che un letterale è una variabile booleana, o la sua negazione). Siano C1 e C2 due clausole, L un letterale e L il letterale
negato, tale che sia xx =¬ e xx ¬= . La regola di seguito illustrata introduce un nuovo vincolo, rappresentato dalla clausola 21 CC ∨ .
ε
ε
DCCLCLC
DLCLC
;,,
;,
2121
21
∨∨∨
∨∨
In generale molte tecniche, prese dal campo dell’algebra lineare, della programmazione lineare, della programmazione intera, o dalla dimostrazione automatica di teoremi possono essere viste come regole di riduzione di vincoli. Le regole che sono state appena mostrate rappresentano dei passi di riduzione atomica in cui un dominio o un vincolo viene ridotto. Gli algoritmi di propagazione di vincoli gestiscono la schedulazione di questi passi atomici di riduzione. In particolare, questi algoritmi cercano di evitare che vengano applicate

59
riduzioni atomiche inutili. Per determinare quando i passi di riduzione atomica non vanno più applicati si utilizza un criterio basato sulla consistenza locale, cioè l’algoritmo di propagazione di vincoli termina quando il CSP a cui si è giunti soddisfa una specifica proprietà di consistenza locale. La nozione di consistenza locale risulta quindi cruciale nella programmazione a vincoli. In letteratura sono state presentate molte nozioni di consistenza locale, qui ne verranno presentati due che riguardano gli esempi di riduzione di dominio mostrati prima. Si consideri un CSP arbitrario e si supponga di applicare per ogni vincolo ed ogni variabile di esso la regola di proiezione vista in precedenza. La nozione di consistenza locale che corrisponde a questo passo atomico di riduzione di dominio è la seguente:
“per ogni vincolo C ed ogni variabile x con dominio D, ogni valore per x preso da D partecipa in una soluzione di C”.
Questa proprietà prende il nome di consistenza di iper-arco (hyper-arc consistency). Nel caso di vincoli binari è detta consistenza d’arco (arc consistency), ed è la nozione di consistenza locale più nota. Per introdurre un’altra nozione di consistenza locale si consideri adesso un CSP i cui domini sono intervalli di interi, ed i vincoli sono rappresentati da disequazioni lineari del tipo x < y. Si supponga di applicare per ognuno di questi vincoli la regola di riduzione presentata in precedenza. La nozione di consistenza locale relativa a questo passo atomico di riduzione è la seguente:
“per ogni vincolo C ed ogni variabile x con dominio D, ogni estremo del dominio D partecipa in una soluzione di C”.
In questo caso la nozione di consistenza locale prende il nome di bounds consistency, ed essa risulta essere più efficiente da testare, rispetto all’ arc-consistency, per vincoli lineari su intervalli interi. Si deve precisare che, in generale, un CSP localmente consistente non è detto che sia poi consistente. Un tipico esempio al riguardo è il seguente CSP:
⟨x ≠ y, y ≠ z, z ≠ x ; x∈{0,1}, y∈{0,1}, z∈{0,1} ⟩,
esso soddisfa la consistenza d’arco, in quanto i valori del dominio partecipano alle soluzioni dei singoli vincoli, ma non è consistente, non ammettendo alcuna soluzione. Quindi, infine, ricapitolando ogni algoritmo di propagazione di vincoli riduce un dato CSP in un altro CSP equivalente, che soddisfi una qualche proprietà di consistenza locale. Quale sia la specifica proprietà di consistenza locale dipende dal tipo di CSP considerato.

60
3.4 Il linguaggio OPL OPL (Optimization Programming Language) [24] è un linguaggio di modellazione sviluppato specificatamente per problemi di ottimizzazione combinatoria. Lo sviluppo di OPL è dovuto soprattutto all’apprezzata implementazione di linguaggi di modellazione matematica come AMPL e GAMS. Questi linguaggi di modellazione permettono di rappresentare i tradizionali problemi, espressi in una notazione algebrica, attraverso una equivalente forma adatta per essere usata su un computer. Allo stesso modo di AMPL e GAMS, OPL fornisce un supporto totale alla programmazione lineare ed alla programmazione intera, fornendo anche accesso agli algoritmi per la programmazione lineare. La principale e fondamentale differenza di OPL con gli altri linguaggi di programmazione è che esso fornisce anche supporto alla programmazione a vincoli, sia nei suoi aspetti di modellazione, sia nei suoi aspetti legati alla ricerca della soluzione. Quindi OPL permette di specificare sia il problema che deve essere risolto, sia una strategia di ricerca specifica per il problema stesso. OPL fornisce un supporto ad alto livello che è completamente nuovo rispetto agli altri linguaggi di modellazione: esso si basa sull’idea di sfruttare contemporaneamente le caratteristiche sia della programmazione matematica, che quelle della programmazione a vincoli nella risoluzione del problema, dando quindi la possibilità di utilizzare un approccio ibrido nell’affrontare il problema. Tutto questo, insieme a nuovi concetti che OPL introduce, quali vincoli di ordine superiore, costrutti pensati esplicitamente per modellare problemi di scheduling e l’allocazione di risorse, aumentano notevolmente la leggibilità e l’espressività di questo linguaggio, dando la possibilità di concentrarsi sugli aspetti fondamentali del problema, tralasciando i dettagli superflui. OPL Studio è l’ambiente di modellazione che verrà utilizzato nell’ambito di questa tesi, sfruttandone soprattutto le caratteristiche orientate alla programmazione a vincoli. Un modello OPL è strutturato in quattro parti fondamentali:
• dichiarazione dello schema dell’istanza del problema;
• dichiarazione dello spazio di ricerca;
• dichiarazione dei vincoli da soddisfare;
• dichiarazione di una procedura di ricerca.

61
Figura 34 : esempio di modello OPL
Nella prima parte del modello vengono dichiarate le strutture ed i dati che rappresentano lo schema l’istanza del problema in esame. Ad esempio, nel modello in Figura 34, che rappresenta il problema delle n-regine, la dichiarazione dell’istanza è rappresentata dalla costante intera n, che fissando il numero delle regine fissa la dimensione della scacchiera, e dalla definizione del range Domain. Nella seconda parte si definisce lo spazio di ricerca del problema dichiarando le variabili che lo rappresentano. Nell’esempio considerato precedentemente (cf. Figura 34) lo spazio di ricerca è rappresentato dall’array di variabili queens, che ha lo scopo di indicare per ogni riga della scacchiera la colonna in cui si trova la regina. Nella terza parte del modello vengono dichiarati i vincoli che devono essere soddisfatti dall’insieme delle variabili affinché la soluzione sia corretta. Questa parte è definita all’interno del costrutto solve, oppure all’interno del costrutto maximize/minimize f(x) subject to per problemi di ottimizzazione, in cui f(x) è la funzione obiettivo. Nell’esempio precedentemente considerato (cf. Figura 34) questa parte è realizzata nei tre vincoli all’interno del costrutto forall. Essi esprimono che le posizioni delle regine devono essere tali che nessuna di esse sia sotto scacco. Infine, eventualmente, può essere presente una parte in cui si dichiara in che modo si preferisce venga esplorato lo spazio di ricerca. Questa parte è opzionale, in quanto OPL ha delle strategie standard per effettuare la ricerca, ma a volte può essere utile specificare una strategia diversa, per sfruttare le conoscenze sulle specificità del problema in esame. Essa viene dichiarata all’inetrno del costrutto search. Nell’esempio precedente (cf. Figura 34) la procedura è costituita dal costrutto generate(queens[i]) all’interno del forall, che esplora lo spazio di ricerca facendo branch prima sulle variabili con il dominio più piccolo.

62
Capitolo 4 Modello per la generazione di casi di test
L’obiettivo della tesi, come è stato precedentemente detto, è quello di sviluppare una metodologia per modellare il problema del test di un modulo java attraverso la programmazione a vincoli. L’approccio non è nuovo, ed ha come parente più stretto quello presentato da Gotlieb ed altri in [10][11]. Le motivazioni di questo lavoro, però, risiedono nella fondamentale differenza in cui si vuole utilizzare la programmazione a vincoli. Mentre nei lavori precedenti si utilizzano le tecniche della programmazione a vincoli, specializzandole per lo specifico problema, nel lavoro presentato in questa tesi effettua un’astrazione maggiore: la modellazione del problema avviene più ad alto livello. Ossia, viene completamente separato l’aspetto di modellazione, ossia creare un modello che rappresenti il problema che si vuole risolvere, dall’aspetto implementativo-risolutivo, ossia come analizzare i vincoli del modello per determinare una soluzione. Realizzando questa netta distinzione, si vuole presentare una metodologia che permetta di affrontare il problema della generazione dei casi di test attraverso la programmazione a vincoli, generando un modello che rappresenti il problema, astraendo completamente dagli aspetti implementativi del risolutore. Questo fa sì che il modello, successivamente, possa essere utilizzato con un qualsiasi risolutore di vincoli, effettuando, al limite una semplice traduzione di sintassi. Questa separazione dei due aspetti ha notevoli benefici. Infatti, la programmazione a vincoli, anche relativamente recente, è una tecnologia molto promettente in molti campi, e negli ultimi anni ha fatto progressi molto significativi. Non ci sono motivi per cui questo processo di miglioramento si arresti, quindi, attraverso questa modellazione ad alto livello, in futuro sarà possibile sfruttare nuovi risolutori più efficienti, senza dover modificare nulla, ma semplicemente tradurre il modello, eventualmente, in una sintassi diversa. Inoltre, è noto come un modello realizzato attraverso la programmazione a vincoli può essere tradotto in un problema SAT [5][15]. Anche in questo campo ci sono stati molti progressi, e potrebbe essere interessante verificare che prestazioni si potrebbero ottenere. I modelli ed i costrutti che si utilizzeranno per presentare la metodologia faranno uso del linguaggio OPL. Esso non limita il livello di astrazione voluto, in quanto questo linguaggio è molto generale flessibile. Il modello che si vuole realizzare, come detto precedentemente, è orientato a permettere di realizzare il test di un generico metodo presente in una classe java.

63
Scopo del modello è quindi permettere di generare un’istanza dei valori delle variabili di input del modello, per le quali un particolare cammino venga eseguito. Il metodo java che si vuole testare viene tradotto in un modello, nel linguaggio OPL, che ne rappresenti il comportamento dinamico durante l’esecuzione. L’idea di base è quella di considerare un modello che simuli, istante per istante, l’istruzione del programma java originario che viene eseguita, simulando il flusso di controllo che viene seguito durante l’esecuzione. Questo viene realizzato, da un punto di vista astratto, realizzando una simulazione temporale del programma, in cui tutte le istruzioni, presenti nel metodo java originario, vengono numerate, e ad ogni istante viene indicato qual’è l’istruzione eseguita dal programma, indicandone il numero identificativo. Il modello per ogni istruzione considerata dovrà rappresentare la semantica dell’istruzione stessa, rappresentando le azioni che vengono intraprese al suo interno ed indicare quale istruzione deve essere eseguita successivamente. Questa informazione, in alcuni casi (istruzioni condizionali, cicli) può dipendere dal verificarsi di determinate condizioni ed anche questo va rappresentato per la singola istruzione. Tutto questo viene realizzato imponendo determinati vincoli sulle variabili utilizzate per rappresentare il programma. Nel modello saranno presenti due tipi di vincoli: un primo tipo, generati dalle varie istruzioni, che esprimeranno la semantica dell’istruzione stessa, ed un secondo tipo, che, invece, ha lo scopo di imporre il cammino desiderato. L’insieme delle variabili utilizzate ed i vincoli del primo tipo rappresentano il modello del metodo vero e proprio, ed una volta generato non deve più essere modificato. A questo modello, poi, per ogni cammino desiderato si aggiungono i vincoli del secondo tipo al fine di imporre che il programma segua quel cammino. Per realizzare la generazione del modello del metodo java, durante la fase di parsing vengono numerate tutte le istruzioni e tutte le condizioni. Il programma, così numerato, viene poi inserito come commento in testa al rispettivo modello generato. In Figura 35 è presentato un esempio di programma numerato.

64
Figura 35 : esempio numerazione istruzioni e condizioni di un metodo java
Un modello OPL è costituito da due parti: una prima parte, in cui vengono dichiarate tutte le variabili e le costanti utilizzate, ed una seconda parte in cui si dichiarano, invece, i vincoli che devono essere rispettati dalle variabili stesse.
4.1 Costrutti del linguaggio java supportati Il linguaggio Java è un linguaggio di programmazione orientato agli oggetti, derivato dal C++, che è stato creato da James Gosling ed altri ingegneri della Sun Microsystem; le prime idee risalgono al 1991, ma fu annunciato ufficialmente nel 1995. Da questa data in poi Java ha subito una fortissima diffusione, arrivando ad essere utilizzato nello sviluppo di moltissime applicazioni, ed è per questo che il lavoro presentato in questa tesi analizza la possibilità di generare in modo automatico casi di test per programmi scritti in questo linguaggio. Nonostante questa volontà, esso viene considerato in questa sede con notevoli limitazioni rispetto all’uso standard che ne viene fatto nell’industria del software. Questo, per concentrarsi sugli aspetti primari della modellazione che si vuole effettuare, lasciando ad ulteriori estensioni successive la possibilità di considerare gli aspetti più complessi del linguaggio. La prima caratteristica fondamentale del linguaggio java, come è stato detto, è che esso è orientato agli oggetti. L’idea di base, nel paradigma di programmazione orientata agli oggetti, è che qualsiasi entità venga considerata, essa è vista sotto forma di oggetto. Un oggetto è caratterizzato da delle proprietà, le variabili o attributi, che ne definiscono lo stato, e da metodi che possono essere applicati all’oggetto stesso, per modificarne lo stato o estrarne informazioni. L’orientazione agli oggetti porta con se l’introduzione e l’utilizzo di alcuni concetti quali l’ereditarietà, il polimorfismo, utilizzo di interfacce, ecc. Questi concetti introducono notevoli complicazioni in un analisi statica del codice, in quanto ad esempio non è sempre possibile sapere a tempo di compilazione quale metodo è

65
effettivamente chiamato, dipendendo dalle situazioni che si verificano durante l’esecuzione del programma (cf. paragrafo 2.2.4). Nel lavoro che viene presentato in questa tesi, questi ultimi aspetti non sono stati presi in considerazione, quindi non sono permesse classi che ereditano da altre classi, non è permessa la definizione di interfacce. Gli aspetti base però degli oggetti, ossia la presenza di attributi viene permessa, ed è correttamente gestita. Un’ulteriore limitazione che è stata imposta è quella riguardante le chiamate a procedura: esse non sono permesse. Queste, infatti, introducevano notevoli problemi nella modellazione di un sistema chiuso di vincoli, come deve essere un modello in OPL. Con chiuso si vuole indicare che nel modello non possono essere aggiunti vincoli e/o variabili durante l’esecuzione del modello stesso, e questo non rendeva possibile gestire, in questo primo approccio, in modo corretto le chiamate a procedura, dovendo in quel caso tenere conto dello stack delle procedure chiamate, e delle relazioni intercorrenti tra di esse. Per esempio, se una chiamata a procedura fosse presente all’interno di un ciclo, il cui numero di iterazioni non fosse noto a priori, ma dipendente, invece, dal valore di una variabile di ingresso, il numero di volte che questa chiamata viene effettivamente eseguita non è nota a priori, e quindi non potrebbe essere correttamente rappresentato il suo codice all’interno del modello. Inoltre, problema questo più generale e riguardante la metodologia a scatola bianca in sè, il codice sorgente di una funzione chiamata non sempre è disponibile. L’insieme di costrutti del linguaggio che vengono considerati sono quelli base riguardanti il controllo del flusso del programma, ossia l’istruzione condizionale if then else, l’istruzione condizionale switch, le istruzioni di ciclo while, do while, for. Le istruzioni di controllo non strutturate, come i salti incondizionati, non sono permesse, con un’unica eccezione: l’istruzione break, all’interno del costrutto switch è permessa. Non vengono inoltre gestite le strutture di controllo finalizzate alla cattura delle eccezioni, quali il try catch. All’interno delle condizioni presenti nelle istruzioni condizionali o di ciclo sono ammesse anche le condizioni composte, ossia condizioni unite tramite gli operatori logici and, or, o l’operatore di negazione. Per l’operatore and ed or sono ammesse solo le configurazioni con semantica di cortocircuito (‘&&’ e ‘||’), ossia quelle in cui non appena la decisione presa in analisi assume un valore di verità, ‘vero’ o ‘falso’ che sia, l’analisi della decisione stessa viene interrotta, non procedendo a considerare altre condizioni eventualmente presenti. Per quel che riguarda i tipi di dato, sono permessi il tipo intero int e gli array di interi, anche multi-dimensionali, sia come variabili locali al metodo, sia come parametri di ingresso, oppure come attributi della classe. Nel primo caso essi devono essere inizializzati contestualmente alla loro definizione, attraverso il costrutto new, oppure elencandone gli elementi racchiusi tra parentesi graffe. Negli altri due casi, invece, viene richiesto, durante la generazione del modello, di indicare per ogni dimensione il numero di elementi che sono presenti. L’accesso ad un elemento dell’array può anche essere realizzato attraverso un’altra variabile, ma questa non deve essere, a sua volta, un array. Non è permessa l’assegnazione

66
tra array, ma solo quella tra gli elementi di un array. Questo perché l’array non è altro che un oggetto puntato dalla variabile che lo rappresenta, e questo porta tutti i problemi relativi alle presenza di puntatori nel codice, come il problema dell’aliasing, che sono stati presentati nella sezione 2.2.4. Nelle istruzioni di assegnazione, l’espressione destra non può essere un’assegnazione a sua volta (cosa permessa in java, potendo quindi anche realizzare catene di assegnazioni: a=b=c;). Inoltre le assegnazioni non possono essere presenti all’interno delle condizioni, nelle istruzioni condizionali. Infine il nome che può essere assegnato alle variabili deve essere unico, indipendentemente dalla visibilità che esse hanno all’interno del programma e dal tipo. Questa limitazione è minima, infatti, sarebbe comunque sufficiente, nel caso contrario, una fase di preprocessamento in cui le variabili vengano oppurtunatamente rinominate. Di seguito viene riassunto in modo schematico il sottoinsieme del linguaggio che viene analizzato e gestito nel modello presentato in questa tesi.
• Classi che non estendano altre classi, e che non implementino interfacce
• Tipi di dato interi
• Array di interi: inizializzati contestualmente alla definizione se variabili locali, altrimenti la dimensione va fissata in fase di generazione del modello
• L’espressione destra di un assegnazione non può essere un’assegnazione a sua volta
• Niente assegnazioni nelle condizioni delle istruzioni condizionali
• Istruzione if then else
• Istruzione switch, in cui è permessa la presenza dell’istruzione break
• Istruzione di ciclo while
• Istruzione di ciclo do while
• Istruzione di ciclo for
• Condizioni composte: condizione negata, condizioni unite attraverso l’operatore and o or con semantica di cortocircuito
• Variabili tutte con nomi distinti
4.2 Variabili e costanti utilizzate nel modello Nella prima parte del modello, come è stato detto, vengono dichiarate tutte le variabili, le costanti e definiti gli intervalli, che verranno poi utilizzati nel modello.

67
Le costanti che vengono definite nel modello sapienza sono:
• time_limit,
• n_instructions,
• mymax.
Come si è detto in precedenza, il modello vuole realizzare una simulazione temporale del metodo java da testare. La costante time_limit viene definita per fissare un orizzonte temporale in cui simulare il programma. Infatti tramite questa costante viene definito il range time, che rappresenta l’intervallo di tempo in cui sono definite tutte le variabili del modello, e quindi le variabili del programma. Esso viene posto uguale all’intervallo avente come estremo inferiore il valore 0, e come estremo superiore time_limit. Per determinare il valore da assegnare a time_limit, nel caso in cui, come normalmente avviene, il modello è utilizzato imponendo uno specifico cammino, si può utilizzare la lunghezza del cammino stesso che si vuole imporre venga eseguito La costante n_instructions viene definita per determinare l’insieme delle istruzioni del metodo java preso in considerazione. Essa viene posta uguale al numero delle istruzioni presenti nel metodo java, dove vengono considerate istruzioni anche le singole condizioni utilizzate nel modello. Questa costante viene poi utilizzata per definire l’intervallo instructions, il cui estremo inferiore viene posto uguale a 0, mentre l’estremo superiore viene posto esattamente uguale a n_instructions. Come è facile immaginare, esso rappresenta l’insieme di tutte le istruzioni presenti nel metodo. La costante mymax viene definita per limitare i valori delle variabili intere ad un intervallo di interesse, restringendo quindi i possibili valori assunti da esse, per limitare lo spazio di ricerca. Tramite il valore di questa costante, infatti, viene definito l’intervallo myInt, che avrà come estremo inferiore ed estremo superiore, rispettivamente –mymax e +mymax. Una volta definite le costanti e gli intervalli del modello, vengono definite le variabili. Una di esse non ha relazione con le variabili presenti nel metodo java, ed la variabile progCounter. Essa è definita per rappresentare nel modello un ‘puntatore’ all’istruzione eseguita in un dato instante di tempo. La variabile progCounter è definita come un array, avente come dimensioni l’intervallo time, e come dominio per i suoi elementi l’intervallo instructions. Quindi il valore del suo elemento i-esimo, progCounter[i], rappresenta l’istruzione eseguita all’istante i-esimo. Nel modello si utilizza un valore particolare, non corrispondente a nessuna istruzione, con il quale si indica che la computazione è terminata: questo valore è 0. Nel modello, se il metodo restituisce un valore, viene definita una variabile valoreRitorno, che vuole rappresentare appunto il valore di ritorno restituito dal metodo. Essa è definita avendo come dominio l’intervallo myInt. Naturalmente se il metodo non restituisce nessun valore, questa variabile non viene definita.

68
Nel modello vengono, poi, definite tante variabili quante sono gli attributi della classe, le variabili locali ed parametri del metodo. Esse avranno lo stesso nome che presentano nel programma, ma subiranno una modifica nella loro struttura: esse saranno tutte definite come array. Nel caso delle variabili che nel programma originario sono scalari, nel modello diventeranno array monodimensionali, aventi per dimensione l’intervallo time. Nel caso, invece, che le variabili siano già degli array nel programma java, nel modello diventeranno array con una dimensione ulteriore che sarà definita sull’intervallo time. La dimensione aggiuntiva viene posta per prima nell’ordine di definizione delle dimensioni. In entrambi i casi, il dominio degli elementi degli array così definiti sarà l’intervallo myInt. Questa modifica alla struttura delle variabili, rispetto a come esse sono definite nel programma java originario, ha lo scopo di poter rappresentare il valore che esse assumono durante l’esecuzione del programma. Infatti le variabili che vengono definite in OPL sono variabili logiche, e quindi diverse dalle variabili presenti in un linguaggio di programmazione, quale java appunto. In quest’ ultimo caso, infatti, le variabili subiscono il cosiddetto aggiornamento distruttivo quando subiscono un’assegnazione, mentre le variabili logiche assumono un valore che rimane costante in tutto il modello. Quindi considerando solo la dimensione nuova di queste variabili, il valore dell’elemento i-esimo rappresenta il valore che la variabile originaria del programma assumerà all’istante i-esimo. Nella Figura 36 viene mostrato un esempio di dichiarazioni di variabile nel modello, con sopra riportato anche il codice java corrispondente.

69
Figura 36 : Dichiarazione Variabili e Costanti in un esempio di modello
4.3 Vincoli del modello In questa sezione verranno presentati tutti i vincoli che vengono imposti nel modello alle variabili, affinché il modello rappresenti correttamente la semantica del programma java.

70
4.3.1 Inizializzazione Variabili I primi vincoli che vengono inseriti nel modello sono relativi all’inizializzazione delle variabili. In questo contesto, con il termine inizializzazione, si vuole intendere l’assegnazione di un valore all’istante 0 a tutte le variabili che non siano parametri di ingresso del metodo oppure attributi della classe. Questo si rende necessario per evitare che ci siano soluzioni identiche in ogni altro valore assegnato alle variabili del modello, tranne che in questi primi valori: avremmo quindi delle soluzioni simmetriche inutili. E’ giusto precisare che queste soluzioni sarebbero uguali in tutti gli altri valori in quanto, come verrà mostrato nelle sezioni successive, tutte le istruzioni impongono poi dei vincoli di uguaglianza, tra istanti successivi, per le variabili che non subiscono modifiche. Questa assegnazione iniziale non modifica la semantica del programma. Infatti essa viene applicata solo alle variabili che corrispondono a variabili locali del metodo originario, e poiché in un programma java tutte le variabili devono essere inizializzate prima di essere usate, esse subiranno sicuramente un’assegnazione all’interno del programma prima di dover essere utilizzate: quindi l’assegnazione che viene fatta, relativa all’istante 0, non ha conseguenze sul valore che esse assumo nel corso dell’esecuzione, ma è utile, invece, per eliminare le simmetrie sopra citate nella soluzione. Naturalmente le variabili che rappresentano parametri di ingresso o attributi della classe (che vengono comunque considerati al pari dei parametri di ingresso) non subiscono questa inizializzazione, in quanto il loro valore all’istante 0 è proprio il valore che si vuole ottenere, esso rappresenta il valore di input cercato. Le variabili vengono inizializzate assegnandogli il valore –mymax, o nel caso abbiano domini particolari, il valore minimo del dominio corrispondente. In Figura 37 è mostrato un esempio, riguardante lo stesso modello e programma java mostrato in Figura 36.
Figura 37 : inizializzazione variabili, esempio relativo al modello di Figura 36
4.3.2 Istruzione di assegnazione In un’istruzione di assegnazione il valore attuale di una variabile del programma java viene modificato, assumendo un nuovo valore, che è rappresentato dalla parte destra dell’assegnazione. Come è stato precedentemente precisato, quest’ultima non può essere a sua volta un’asseganzione, ma può comunque essere una qualsiasi espressione, complessa quanto si vuole. Il vincolo che deve rappresentare semanticamente quest’istruzione deve imporre che all’istante successivo la variabile presente nell’espressione sinistra dell’assegnazione abbia il valore presente nell’espressione destra. Deve poi imporre che il valore di tutte le

71
altre variabili rimanga inalterato. Inoltre deve essere gestito correttamente il flusso di controllo del programma java, ossia visto che il modello simula l’esecuzione delle varie istruzioni attraverso l’uso della variabile progCounter, all’istante in questione il suo valore dovrà essere uguale al numero dell’istruzione di assegnazione, mentre all’istante successivo il progCounter dovrà indicare l’istruzione successiva da eseguire. Si consideri un’istruzione di assegnazione nella seguente forma:
* α* nome_Variabile=espressione;
* β* istruzione successiva;
Il vincolo per modellare l’istruzione di assegnazione α sarà così fatto:
forall(t in 0..time_limit-1){progCounter[t]= α => (progCounter[t+1]= β
&nome_Variabile[t+1]=espressione[t]
&altraVariabile[t+1]=altraVariabile[t]);
};
Questo vincolo impone che, per ogni istante di tempo t, nell’intervallo 0 time_limit-1, se il progCounter a quell’istante assume il valore corrispondente ad α, allora deve essere imposto che: all’istante successivo il progCounter valga β (gestione flusso istruzione successiva), la variabile oggetto dell’assegnazione (nome_Variabile) all’istante successivo assuma il valore che l’espressione destra (espressione) ha in questo instante (gestione semantica dell’assegnazione), e che inoltre tutte le altre variabili, diverse da quella oggetto dell’assegnazione, abbiano all’istante successivo il medesimo valore avuto a questo istante. Nel vincolo t viene fatta variare da 0 fino a time_limit-1, perché all’interno del vincolo stesso si fa accesso agli elementi degli array, che rappresentano le variabili, usando l’indice t+1, e quindi se t variasse fino a time_limit si genererebbe un errore di accesso all’array, eccedendo la grandezza della dimensione in questione. Infatti, quando verrebbe analizzato il vincolo per t=time_limit, le variabili in cui figura t+1 vi sarebbe un accesso all’elemento time_limit+1, che non esiste, essendo l’intervallo di definizione della dimensione in questione [0..time_limit]. In Figura 38 viene mostrato un esempio di utilizzo di questo tipo di vincolo, mostrando anche l’istruzione java da cui deriva.

72
Figura 38 : Istruzione Assegnazione e vincolo corrispondente
4.3.3 Istruzione if then else L’istruzione if then else è l’istruzione condizionale per eccellenza. Essa impone che, a seconda del valore di verità assunto da una condizione, venga eseguita un’istruzione piuttosto che un’altra. Più dettagliatamente, se la condizione presente nell’istruzione if assume il valore ‘vero’ viene eseguita l’istruzione (o le istruzioni) presente nel ramo then, viceversa, se la condizione assume il valore ‘false’ viene eseguita l’istruzione (o le istruzioni) presenti nel ramo else, se esso è presente, altrimenti viene eseguita l’istruzione successiva all’istruzione if. Alla fine dell’esecuzione delle istruzioni presenti nei rami, sia then che else, il flusso di controllo passa in ogni caso all’istruzione successiva all’if. Nella generazione dei vincoli (perché saranno più di uno) che devono rappresentare la semantica di questa istruzione si dovranno quindi considerare i seguanti aspetti: gestione del flusso di controllo tramite vincoli sul progCounter, tenendo però in considerazione anche il valore della condizione, e l’invarianza dei valori delle variabili prima che vengano eseguite le istruzioni del ramo then,else, o l’istruzione successiva. Prendiamo in considerazione una generica istruzione if, essa avrà la forma seguente:
* α*if(* π*condizione) then * β*istruzione1; [else * δ* istruzione2;]
* ε* istruzioneSuccessiva;
dove la parte racchiusa tra parentesi quadre è opzionale.

73
Figura 39 : flusso di controllo dell'istruzione if presentata
Nell’astrazione realizzata in questo modello il flusso di controllo segue quest’ordine (cf. grafo di flusso in Figura 39): viene prima eseguita l’istruzione *α* , senza modificare alcuna variabile, dopo viene eseguita *π* , successivamente il flusso di controllo seguirà *β* , se la condizione *π* è ‘vera’, oppure *δ* o *ε* , a seconda che il ramo else sia presente oppure no. I vincoli che rappresentano la gestione del flusso di controllo avranno la struttura seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* α*) => (progCounter[t+1]=* π*
&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[t ]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&(condizione)) =>
(progCounter[t+1]=* β*);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)¬(condizione)) =>
(progCounter[t+1]=* δ*);
};
dove nel primo vincolo è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, ad eccezione naturalmente di progCounter. Inoltre nel terzo vincolo, se il ramo else non è presente , invece di progCounter[t+1]=δ, sarà presente progCounter[t+1]=ε. Attraverso i vincoli presentati è stato gestito il flusso di controllo del programma, ma non il fatto che durante la valutazione della condizione le variabili rimangano inalterate. Questo non può essere fatto semplicemente aggiungendo, nel secondo e terzo vincolo sopra elencati, una serie di uguaglianze poste in and con l’uguaglianza relativa al progCounter all’istante t+1. Infatti essere verrebbero così

74
implicate solo quando entrambe le precondizioni sono vere, e questo potrebbe ritardare di molto la propagazione di questi vincoli, soprattutto nel caso in cui la condizione dipenda dai valori di input del metodo. Quindi per avere una maggiore propagazione dei vincoli, e mantenere separati i due aspetti, gestione del flusso di controllo e gestione dell’invarianza delle variabili nelle decisioni, viene introdotto un altro vincolo, con la forma seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* π*) => (&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[ t]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
dove è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, a parte la variabile progCounter. Con la presenza di questi quattro vincoli la semantica dell’istruzione if è correttamente rappresentata. Al fine, però, di ottenere una maggiore propagazione di vincoli, e quindi restringere ulteriormente lo spazio di ricerca, vengono introdotti altri due vincoli allo scopo di imporre, implicandolo, il valore della condizione nel momento in cui sono già determinati il valore del progCounter all’istante t ed il valore all’istante t+1. Per maggiore chiarezza, se il progCounter all’istante t vale *π* ed all’istante t+1 vale *β* , allora il valore della condizione deve essere vero, perché non sono possibili cammini nel grafo di flusso che passino consecutivamente per queste due istruzioni e non abbiano il valore della condizione come vero. Analogamente per il caso in cui la condizione è falsa, prendendo in considerazione, in questo caso, per il progCounter i valori *π* e *δ* (*ε* se il ramo else non è presente) per gli istanti t e t+1, rispettivamente. I vincoli corrispondenti avranno la seguente forma:
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* β*)) => (condizione);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* δ*)) => (not(condizione));
};
Naturalmente nella generazione dei vincoli relativi all’istruzione, o relativi all’ultima istruzione nel caso ne siano presenti più di una, presente nel ramo then, e nel ramo else se presente, andrà tenuto conto che l’istruzione successiva è quella successiva all’istruzione if. In Figura 40 viene presentato un esempio di generazione di vincoli per l’istruzione if, con il codice java relativo.

75
Figura 40 : Vincoli Istruzione if e relativo codice java
4.3.4 Istruzione While L’istruzione while è un’istruzione di ciclo, in cui le istruzioni interne al ciclo vengono eseguite finché la condizione presente nell’istruzione risulta verificata; quando essa diventa falsa, allora l’esecuzione del programma procede con l’istruzione immediatamente successiva al while. Per modellare la semantica di

76
questa istruzione con i vincoli si devono considerare gli stessi aspetti presenti nel caso dell’istruzione if, cioè: gestione del flusso di controllo tramite vincoli sul progCounter, tenendo in considerazione anche il valore della condizione, e l’invarianza dei valori delle variabili prima che vengano eseguite le istruzioni del corpo del ciclo, o l’istruzione successiva. Si consideri il seguente ciclo while generico:
* α*while(* π*condizione) * β*istruzione;
* ε* istruzioneSuccessiva;
Figura 41 : flusso dell’istruzione while presentata
Nell’astrazione realizzata in questo modello il flusso di controllo segue quest’ordine (cf. grafo di flusso in Figura 41): viene prima eseguita l’istruzione *α* , senza modificare alcuna variabile, dopo viene eseguita *π* , successivamente il flusso di controllo seguirà *β* , se la condizione *π* è ‘vera’, oppure *ε* se la condizione è ‘falsa’. Nel caso in cui l’istruzione è *β* , dopo di essa va di nuovo eseguita l’istruzione *α* , proseguendo, poi, come prima. Nel caso in cui nel corpo del while siano presenti più istruzioni, esse vanno eseguite una di seguito all’altra, e quando viene eseguita l’ultima, la successiva sarà di nuovo l’istruzione *α* . Dell’aspetto relativo alla gestione del flusso di controllo per l’istruzione successiva a *β* , o dell’ultima istruzione del corpo, va tenuto conto mentre si generano i vincoli relativi all’istruzione *β* stessa, o delle istruzioni del corpo, facendo quindi in modo che, correttamente, l’istruzione successiva sia in ogni caso *π* . I vincoli che rappresentano la gestione del flusso di controllo avranno la struttura seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* α*) => (progCounter[t+1]=* π*
&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[t ]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};

77
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&(condizione)) =>
(progCounter[t+1]=* β*);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)¬(condizione)) =>
(progCounter[t+1]=* ε*);
};
dove nel primo vincolo è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, ad eccezione naturalmente di progCounter. Attraverso i vincoli presentati è stato gestito il flusso di controllo dell’istruzione while, ma non il fatto che durante la valutazione della condizione le variabili rimangano inalterate. Analogamente al caso dell’istruzione if, questo non può essere fatto semplicemente aggiungendo, nel secondo e terzo vincolo sopra elencati, una serie di uguaglianze poste in and con l’uguaglianza relativa al progCounter all’istante t+1, per le stesse motivazioni presentate precedentemente. Quindi, anche in questo caso, per avere una maggiore propagazione dei vincoli, e mantenere separati i due aspetti, gestione del flusso di controllo e gestione dell’invarianza delle variabili nelle decisioni, viene introdotto un altro vincolo, con la forma seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* π*) => (&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[ t]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
dove è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, a parte la variabile progCounter. Con la presenza di questi quattro vincoli la semantica dell’istruzione while è correttamente rappresentata. Analogamente al caso dell’istruzione if, però, per ottenere una maggiore propagazione di vincoli, e quindi restringere ulteriormente lo spazio di ricerca, vengono introdotti altri due vincoli allo scopo di imporre, implicandolo, il valore della condizione nel momento in cui sono già determinati il valore del progCounter all’istante t ed il valore all’istante t+1. I vincoli corrispondenti avranno la seguente forma:
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* β*)) => (condizione);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* ε*)) => (not(condizione));

78
};
In Figura 42 viene presentato un esempio di generazione di vincoli per l’istruzione while, con il codice java relativo.
Figura 42 : Vincoli Istruzione while e codice java corrispondente
4.3.5 Istruzione Do While L’istruzione do while è un’istruzione di ciclo, in cui le istruzioni interne al ciclo vengono eseguite finché la condizione presente nell’istruzione risulta verificata;

79
quando essa diventa falsa, allora l’esecuzione del programma procede con l’istruzione immediatamente successiva al do while. Rispetto al while, però, c’è una differenza fondamentale: le istruzioni interne al ciclo vengono sempre eseguite almeno una volta. Analogamente ai casi precedenti, per modellare la semantica di questa istruzione con i vincoli si considererà: la gestione del flusso di controllo, il valore della condizione, e l’invarianza dei valori delle variabili. Si consideri il seguente ciclo do while generico:
* α*do * β*istruzione;
while(* π*condizione);
* ε* istruzioneSuccessiva;
Nell’astrazione realizzata in questo modello il flusso di controllo segue quest’ordine: viene prima eseguita l’istruzione *α* , senza modificare alcuna variabile, dopo viene eseguita *β* , dopo di essa viene eseguita l’istruzione *π* . Nel caso in cui nel corpo del do while siano presenti più istruzioni, esse vanno eseguite una di seguito all’altra, e quando viene eseguita l’ultima, la successiva sarà di l’istruzione *π* . Successivamente il flusso di controllo tornerà ad *β* , se la condizione *π* è ‘vera’, oppure andrà a *ε* se la condizione è ‘falsa’. Dell’aspetto relativo alla gestione del flusso di controllo per l’istruzione successiva a *β* , o dell’ultima istruzione del corpo, va tenuto conto mentre si generano i vincoli relativi all’istruzione *β* stessa, o delle istruzioni del corpo, facendo quindi in modo che, correttamente, l’istruzione successiva sia in ogni caso *π* . I vincoli che rappresentano la gestione del flusso di controllo avranno la struttura seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* α*) => (progCounter[t+1]=* β*
&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[t ]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&(condizione)) =>
(progCounter[t+1]=* β*);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)¬(condizione)) =>
(progCounter[t+1]=* ε*);
};

80
dove nel primo vincolo è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, ad eccezione naturalmente di progCounter. Attraverso i vincoli presentati è stato gestito il flusso di controllo dell’istruzione do while, ma non il fatto che durante la valutazione della condizione le variabili rimangano inalterate. Analogamente a quanto visto prima (istruzione if e while) e, per le stesse motivazioni questo va fatto attraverso un altro vincolo,che ha la forma seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* π*) => (&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[ t]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
dove è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, a parte la variabile progCounter. Con la presenza di questi quattro vincoli la semantica dell’istruzione do while è correttamente rappresentata. Analogamente, però, ai casi precedenti, per ottenere una maggiore propagazione di vincoli, e quindi restringere ulteriormente lo spazio di ricerca, vengono introdotti altri due vincoli allo scopo di imporre, implicandolo, il valore della condizione nel momento in cui sono già determinati il valore del progCounter all’istante t ed il valore all’istante t+1. I vincoli corrispondenti avranno la seguente forma:
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* β*)) => (condizione);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* ε*)) => (not(condizione));
};
In questo caso un esempio di applicazione dei vincoli non viene presentata, essendo analoga, a parte lievi differenze al caso del ciclo while.
4.3.6 Istruzione For L’istruzione for è un’istruzione di ciclo che comprende nella sua dichiarazione, oltre all’istruzione da eseguire internamente al ciclo (o le istruzioni), anche la definizione (eventuale) ed inizializzazione di variabili, le istruzioni di incremento da eseguire alla fine di ogni iterazione, e la condizione di terminazione del ciclo. Quindi quando in un programma viene incontrata un’istruzione for per prima cosa viene eseguita la parte di inizializzazione del ciclo, in cui sono presenti sia le eventuali dichiarazioni di nuove variabili, sia l’inizializzazione delle variabili stesse (nuove o precedentemente definite all’interno del programma).

81
Successivamente viene valutata la condizione di terminazione, e come per ogni altro ciclo, se essa risulta verificata viene eseguito il corpo del for, mentre se risulta falsa viene eseguita l’istruzione immediatamente successiva al for. Rispetto agli due cicli analizzati, però, nel ciclo for, quando l’esecuzione del corpo è terminato, non si torna alla valutazione della condizione, si eseguono, invece, le istruzioni di incremento indicate nella dichiarazione del for stesso. Al termine dell’ultima di queste istruzioni si esegue di nuovo la valutazione della condizione, per determinare se il ciclo va iterato ancora, oppure no. L’istruzione for può essere realizzato attraverso un’istruizone while e delle istruzioni di assegnazione correttamente posizionate (cf. Figura 43).
Figura 43 : istruzione for e while equivalenti
La semantica dei vincoli generati è quindi di rapida comprensione, considerando questa similitudine con il ciclo while e le istruzioni di assegnazione. Per quel che riguarda la dichiarazione di nuove variabili, esse naturalmente vanno inserite tra le variabili del modello, dichiarate all’inizio del modello stesso. Si consideri la seguente istruzione for generica:
* α*for(* η*varIniz=espressione;* π*condizione;* ϕ*varIniz++)
* β*istruzione;
* ε* istruzioneSuccessiva;
essa è equivalente alla seguente serie di istruzioni:
* η*varIniz=espressione;
* λ*while(* π*condizione){
* β*istruzione; * ϕ*varIniz++;}

82
Figura 44 : grafo di flusso dell'istruzione for presentata
I vincoli che rappresentano la gestione del flusso di controllo avranno la struttura seguente (cf. grafo di flusso in Figura 44):
forall(t in 0..time_limit-1){(progCounter[t]=* α*) => (progCounter[t+1]=* η*
&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[t ]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
forall(t in 0..time_limit-1){(progCounter[t]=* η*) => (progCounter[t+1]=* π*
&varIniz[t+1]=espressione[t]
&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[t ]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&(condizione)) =>
(progCounter[t+1]=* β*);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)¬(condizione)) =>
(progCounter[t+1]=* ε*);
};

83
forall(t in 0..time_limit-1){(progCounter[t]=* ϕ*) => (progCounter[t+1]=* π*
&varIniz[t+1]=varIniz[t]+1
&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[t ]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
dove nel primo vincolo è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, ad eccezione naturalmente di progCounter, mentre la stessa uguaglianza nel secondo e nell’ultimo vincolo è presente per ogni variabile, ad eccezione oltre che del progCounter, anche della variabile modificata. Naturalmente, nella generazione dei vincoli per l’istruzione *β* , si dovrà fare in modo che al termine della sua esecuzione il valore successivo del progCounter sia uguale a *ϕ* . Attraverso i vincoli presentati è stato gestito il flusso di controllo dell’istruzione for, ma non il fatto che durante la valutazione della condizione le variabili rimangano inalterate. Analogamente a quanto visto prima e per le stesse motivazioni deve essere introdotto un altro vincolo, con la struttura seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* π*) => (&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[ t]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
dove è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, a parte la variabile progCounter. Con la presenza di questi sei vincoli la semantica dell’istruzione for è correttamente rappresentata. Analogamente, però, ai casi precedenti, per ottenere una maggiore propagazione di vincoli, e quindi restringere ulteriormente lo spazio di ricerca, vengono introdotti altri due vincoli allo scopo di imporre, implicandolo, il valore della condizione nel momento in cui sono già determinati il valore del progCounter all’istante t ed il valore all’istante t+1. I vincoli corrispondenti avranno la seguente forma:
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* β*)) => (condizione);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* ε*)) => (not(condizione));
};
In Figura 45 viene mostrato un esempio di applicazione di questi vincoli, con il codice java del ciclo for.

84
Figura 45 : Istruzione for, vincoli e codice java corrispondente

85
4.3.7 Istruzione Switch L’istruzione switch è un’istruzione condizionale in cui, in base al valore di una variabile, viene selezionata l’istruzione, o le istruzioni, da eseguire tra un insieme di possibilità elencate. L’espressione utilizzata per indicizzare le possibilità deve essere una costante. La semantica precisa dello switch, in realtà, è di saltare all’istruzione corrispondente al valore assunto dalla variabile, e quindi eseguire tutte le istruzioni successive, comprese quelle appartenenti ad altre opzioni, ma elencate successivamente. Questo a meno ché sia presente l’istruzione break, che fa terminare l’esecuzione dello switch e procedere con l’istruzione successiva. Se il valore assunto dalla variabile non è tra quelli elencati ci sono due possibilità, a seconda che sia o meno dichiarata l’opzione di default. Se essa è presente il programma salta all’esecuzione di questa istruzione, mentre se non è presente viene eseguita l’istruzione immediatamente successiva allo switch. Nella modellazione attraverso i vincoli della semantica di questa istruzione, come negli altri casi andrà gestita l’invarianza delle variabili durante la valutazione delle condizioni, ma a differenza degli altri casi la gestione del flusso di controllo diviene un po’ più complessa per le alternative che sono presenti: break presente oppure no, default presente oppure no. Si consideri la seguente istruzione switch generica:
* α*switch(variabile){
case a: * β*istruzione1;
[* δ*break;]
case b: * κ*istruzione1;
[* λ*break;]
[default: * η*istruzione2;
* ϕ*break;]}
* ε*istruzioneSuccessiva;

86
Figura 46 : flusso di controllo dell'istruzione switch presentata
Nell’astrazione realizzata in questo modello il flusso di controllo segue quest’ordine (cf. flusso di controllo in Figura 46): viene eseguita per prima l’istruzione *α* , viene quindi confrontato il valore di variabile con quelli presenti nei case. Se il valore assunto dalla variabile è a l’istruzione successiva sarà *β* , se il valore assunto dalla variabile è b l’istruzione successiva sarà *κ* , mentre se variabile assume un valore diverso da a e da b, allora sono possibili due casi: se il default è presente l’istruzione successiva sarà *η* , mentre se esso non è stato dichiarato l’istruzione successiva sarà *ε* . Si considerino ora i primi due casi che sono stati prospettati come possibili. In essi viene eseguita *β* [*κ* ], per l’istruzione successiva da eseguire vi sono due possibilità: se il break è presente viene eseguita l’istruzione *δ* [*λ* ], che non fa nulla e successivamente ancora viene eseguita l’istruzione *ε* ; se, invece, il break non è presente viene eseguita l’istruzione del case successivo, *κ* [*η* ]. Nell’altro caso, quello in cui viene eseguita *η* , il comportamento è analogo al precedente, in base alla presenza o meno dell’istruzione di break. I vincoli per realizzare la semantica dell’istruzione switch precedentemente indicata sono, a seconda dei casi, i seguenti:
forall(t in 0..time_limit-1){((progCounter[t]=* α*)&(variabile=a)) =>
(progCounter[t+1]=* β*);
};
forall(t in 0..time_limit-1){((progCounter[t]=* α*)&(variabile=b)) =>
(progCounter[t+1]=* κ*);
};

87
Di questi vincoli ne è presente uno per ogni case dichiarato.
forall(t in 0..time_limit-1){((progCounter[t]=* α*)&(variabile<>a) &(variabile<>b) =>
(progCounter[t+1]=* η* | progCounter[t+1]=* ε*);
};
In cui nella prima riga, in generale, oltre a (variabile<>a)&(variabile<>b) saranno presenti in and altre disuguaglianze, una per ogni ulteriore case dichiarato. Mentre nella seconda riga, il vincolo conterrà la prima alternativa se il default è presente, la seconda in caso contrario.
forall(t in 0..time_limit-1){(progCounter[t]=* δ*) => (progCounter[t+1]=* ε*);
};
forall(t in 0..time_limit-1){(progCounter[t]=* λ*) => (progCounter[t+1]=* ε*);
};
Di questi vincoli, in generale, ne sarà presente uno per ogni istruzione break presente nello switch. Naturalmente nella generazione dei vincoli per l’istruzione, o le istruzioni, nel case si dovrà prendere in considerazione la presenza o meno del break e generare di conseguenza in modo coerente le istruzioni successive. Facendole, cioè, ‘puntare’ all’istruzione di break, se presente, oppure all’istruzione del case successivo. Attraverso i vincoli presentati è stato gestito il flusso di controllo dell’istruzione switch, ma non il fatto che durante la valutazione della condizione le variabili rimangano inalterate. Analogamente a quanto visto prima e per le stesse motivazioni, viene introdotto un ulteriore vincolo, con la struttura seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* α*) => (&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[ t]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
dove è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, a parte la variabile progCounter. Nella gestione dell’istruzione switch, a differenza degli altri casi analizzati, non è possibile aggiungere dei vincoli per una maggiore propagazione dei vincoli, relativamente al valore assunto dalla condizione. Questo perché nel caso particolare in cui un case non contenga nessuna istruzione, neanche il break quindi, sia nel caso in cui la variabile valga il valore indicato in quel case, sia nel caso in cui valga quello del case successivo, l’istruzione successiva eseguita sarebbe quella del case successivo. Ossia, si avrebbe che la coppia di valori del

88
progCounter consecutivi nel tempo, uguali rispettivamente all’istruzione switch stessa ed all’istruzione del case seguente quello privo di istruzioni, non sarebbe più legata univocamente al valore indicato nel case successivo. Se, ad esempio, si considera l’istruzione switch, e relativo modello, presentato in Figura 47, è possibile vedere come la coppia di valori per il progCounter data da progCounter[t]=2&progCounter[t+1]=3 sarebbe coerente sia con n[t]=1 , che con n[t]=2 .
Figura 47 : Istruzione Switch, vincoli e codice java relativo

89
4.3.8 Gestione condizioni complesse Nella trattazione delle varie istruzioni che si è fatta finora si è sempre supposto che la condizione, presente nelle istruzioni condizionali, fosse una condizione atomica. In generale, questo non è vero, in quanto, come si è indicato nel paragrafo Errore. L'origine riferimento non è stata trovata., relativo al linguaggio java trattato in questa tesi, sono possibili anche condizioni composte, ed arbitrariamente complesse. Verrà presentato ora in che modo la loro presenza modifica la generazione dei vincoli. Le condizioni composte vengono trattate come una sequenza ordinata di condizioni atomiche. In pratica si inizia analizzando la prima, ed a seconda del proprio valore di verità e delle ripercussioni sul valore di verità dell’intera decisione di cui fa parte, viene determinata la condizione da analizzare successivamente, oppure l’istruzione da eseguire nel caso in cui la decisione stessa abbia assunto un valore di verità. Questo è reso possibile da fatto che le condizioni atomiche sono tutte numerate, allo stesso modo delle istruzioni. Si consideri, ad esempio la seguente condizione composta:
( ) ( )0*4*||7*3*&&9*2*||3*1* >=== ZTYX
Figura 48 : flusso di controllo relativo alla condizione complessa presentata
Nell’astrazione realizzata in questo modello, il flusso di controllo durante la valutazione della precedente condizione composta segue il seguente ordine (cf. grafo di flusso in Figura 48): prima viene valutata la condizione *1* , X=3, se essa è valutata essere vera si passa ad analizzare la condizione *3* , mentre se essa è falsa la successiva condizione ad essere analizzata è la *2* . Questo per la semantica della condizione logica stessa. Nel primo caso, se anche la condizione *3* risulta soddisfatta la valutazione della condizione termina (semantica di cortocircuito), e l’istruzione successiva sarà quella prevista per il caso in cui la decisione assuma il valore vero. Mentre, se la condizione *3* non risulta soddisfatta, allora la successiva condizione ad essere analizzata sarà la *4* . Se quest’ultima risulterà vera, allora, come nel caso precedente, tutta la decisione

90
risulterà vera e quindi l’istruzione successiva sarà quella prevista per il valore ‘vero’, ma se, invece, anche la condizione *4* dovesse risultare non verificata, allora l’intera decisione risulterebbe falsa, e quindi l’istruzione successiva sarebbe quella coerente con questa situazione. La gestione del flusso di controllo durante la valutazione della condizione composta viene realizzato, come negli altri casi, attraverso il progCounter. Ossia le condizioni atomiche sono viste come normali istruzioni ‘puntate’ dal progCounter. Si consideri la seguente istruzione if con una condizione composta da due condizioni atomiche in and tra loro.
* α*if(* π*condizione1&&* θ*condizione2) then * β*istruzione1
else * δ*istruzione2
I vincoli per modellare la semantica di quest’istruzione avranno la forma seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* α*) => (progCounter[t+1]=* π*
&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[t ]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&(condizione1)) =>
(progCounter[t+1]=* θ*);
};
forall(t in 0..time_limit-1){
((progCounter[t]=* π*)¬(condizione1)) => (progCounter[t+1]=* δ*);
};
forall(t in 0..time_limit-1){((progCounter[t]=* θ*)&(condizione2)) =>
(progCounter[t+1]=* β*);
};
forall(t in 0..time_limit-1){
((progCounter[t]=* θ*)¬(condizione2)) => (progCounter[t+1]=* δ*);
};
dove nel primo vincolo è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, ad eccezione

91
naturalmente di progCounter. Il primo vincolo fa parte della semantica standard dell’istruzione if vista in precedenza, mentre il secondo, terzo e quarto vincolo realizzano la semantica di cortocircuito della condizione presente nell’istruzione if. Analogamente a tutte la altre situazioni in cui sono presenti condizioni, rimane da modellare il fatto che durante la valutazione della condizione le variabili rimangano inalterate. Questo viene realizzato nello stesso modo visto negli altri casi, cioè viene introdotto un altro vincolo, con la forma seguente:
forall(t in 0..time_limit-1){(progCounter[t]=* π*) => (&variabile_1_Non_Varia[t+1]=variabile_1_Non_Varia[ t]
&variabile_N_Non_Varia [t+1]=variabile_N_Non_Varia[ t]);
};
dove è presente un’uguaglianza del tipo variabile[t+1]=variabile[t] per ogni variabile presente nel modello, a parte la variabile progCounter. Verrà introdotto un vincolo per ogni condizione atomica. Inoltre, analogamente ai casi precedenti, per ottenere una maggiore propagazione di vincoli, e quindi restringere ulteriormente lo spazio di ricerca, vengono introdotti altri due vincoli per ogni condizione atomica, allo scopo di imporre, implicandolo, il valore della condizione nel momento in cui sono già determinati il valore del progCounter all’istante t ed il valore all’istante t+1. Nel caso particolare presentato i vincoli saranno quattro:
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* θ*)) => (condizione1);
};
forall(t in 0..time_limit-1){((progCounter[t]=* π*)&
(progCounter[t+1]=* δ*)) => (not(condizione1));
};
forall(t in 0..time_limit-1){((progCounter[t]=* θ*)&
(progCounter[t+1]=* β*)) => (condizione2);
};
forall(t in 0..time_limit-1){((progCounter[t]=* θ*)&
(progCounter[t+1]=* δ*)) => (not(condizione2));
};
La gestione degli altri casi possibili, derivanti dal modo di combinare logicamente due condizioni atomiche, viene realizzata in modo analogo.

92
4.3.9 Gestione accesso array Nel sottoinsieme del linguaggio java che viene preso in considerazione nell’ambito di questa tesi possono essere presenti variabili array, i cui elementi vengono acceduti tramite un’altra variabile, con la limitazione, però, che essa non sia a sua volta un array (cf. paragrafo Errore. L'origine riferimento non è stata trovata.). L’accesso ad un array tramite un’altra variabile porta a dei problemi nel modello che deve essere generato, motivo per cui questo tipo di accesso viene gestito in modo differente. Il problema ha origine nel modo in cui sono gestiti i vincoli da OPL durante la propagazione e la ricerca della soluzione. Quando viene imposto un vincolo di implicazione, sia il vincolo implicante che il vincolo implicato devono sempre essere definiti, infatti OPL utilizza entrambi indifferentemente nel tentativo di determinare la soluzione. Si consideri un vincolo di implicazione semplice, come il seguente:
BA⇒
dove A e B sono vincoli, OPL propaga due tipi di informazione:
• quando A è implicato dall’insieme dei vincoli correnti (constraint store), allora B è aggiunto all’insieme dei vincoli correnti.
• quando la negazione di B è implicata dall’insieme dei vincoli correnti, allora la negazione di A è aggiunta all’insieme dei vincoli correnti.
Quindi OPL utilizza sia A che B, di conseguenza essi devono essere sempre definiti. I vincoli in OPL sono detti, per questo motivo, multi-direzionali. Si è visto precedentemente, nel paragrafo 4.2, che le variabili che sono degli array nel programma java, nel modello vengono rappresentati attraverso array che hanno una dimensione in più, per simulare l’evoluzione temporale. Si consideri, nel programma java originario, un istruzione in cui sia presente un accesso ad un array attraverso il valore di un’altra variabile scalare, ad esempio in questo modo: variabile1=array[variabile]. L’espressione destra dell’assegnazione appena considerata, potrebbe essere tradotta direttamente nel modello OPL come array[t,variabile[t]]. Infatti anche OPL permette di indicizzare gli array con altre variabili. L’espressione che se ne genera, però, potrebbe portare ad un tentativo di acceso fuori dai limiti delle dimensioni dell’array, anche se nel programma originario questo fosse impossibile. Infatti l’espressione array[t,variabile[t]] verrebbe valutata per ogni valore di t, e potrebbe capitare che per alcuni valori variabile[t] assuma un valore che eccede le dimensioni dell’array. In questo caso OPL terminerebbe non trovando soluzioni. Questo problema si presenta ogni volta che si deve accedere ad un array attraverso una variabile, indipendentemente da dove questo viene fatto, cioè sia se viene utilizzato come espressione destra di un assegnazione, sia se ne è l’espressione sinistra, sia se viene utilizzato dentro la valutazione di una condizione.

93
Per risolvere il problema si è realizzata una modellazione in cui l’accesso agli elementi di un array avviene solo attraverso costanti. Questo viene reso possibile considerando tutti i possibili valori della dimensione in cui compare la variabile, e per ognuno di essi si genera una congiunzione di vincoli, in cui il primo uguaglia la variabile al valore costante considerato, e nel secondo si considera l’espressione dove compare l’array, accedendovi tramite il valore costante corrispondente. Tutti i possibili casi che si generano in questo modo vengono messi in or tra loro. In Figura 49 viene mostrato un esempio, relativo ad un assegnazione del valore di un elemento dell’array ad una variabile.
Figura 49 : Accesso array tramite variabile
4.3.10 Vincoli Cammino Una volta che il modello del programma è stato realizzato, bisogna mostrare come imporre un particolare cammino. Questo può essere fatto in modo molto semplice e diretto, imponendo per ogni istante di tempo il valore del progCounter, il che equivale a imporre in ogni istante qual’è l’istruzione eseguita. Il cammino viene quindi imposto aggiungendo al modello una serie di vincoli così fatti:
progCounter[t]=* α*;
uno per ogni istruzione del cammino.
4.3.11 Strategia di ricerca In OPL è possibile impostare una strategia di ricerca, al fine di gestire e sfruttare le peculiarità del problema che si sta modellando. Empiricamente si è visto che non è conveniente, comunque, andare a complicare troppo la procedura di ricerca attraverso tutti i costrutti che OPL mette a disposizione, in quanto in questo modo

94
il modello diventa spesso inefficiente. Spesso, invece, è conveniente semplicemente specificare in che ordine devono essere generati i valori per le variabili del modello. Questa è stata la scelta anche per questo modello. Per ogni istante di tempo vengono fatti generare i valori del progCounter, e delle variabili del programma originario che differiscono da quelle di input. Dopo che sono stati generati questi valori, e che quindi tutti i vincoli sono stati propagati, viene generato il valore della variabile che rappresenta il valore di ritorno, se il metodo restituisce un valore, e vengono poi generati i valori delle variabili che rappresentano i parametri di input del metodo. In questo modo, lo spazio di ricerca su queste variabili è ridotto, avendo già propagato tutti i vincoli imposti dal cammino selezionato. In OPL questo può essere realizzato tramite delle funzioni predefinite dedicati alla generazione di valori per le variabili. Questi funzioni prendono come parametro una variabile discreta, o un array di variabili discrete, e generano valori per queste variabili. Alcune di esse sono:
• generate e generateSize, che genera valori per le variabili fornite come argomento, generando prima valori per la variabile con il dominio minore;
• generateSeq, che genera i valori delle variabili nell’ordine fissato nell’array;
• generationMin e generationMax, che considerano prima la variabile con il dominio più piccolo e più grande, rispettivamente
Queste funzioni, per essere utilizzate, devono essere inserite in un’opportuna procedura di ricerca. Come esempio si consideri la seguente:
search{
forall(istante in time ordered by increasing istan te){
generate(progCounter[istante]);
generate(variabileNoInput[istante]);
};
[generate(valoreRitorno);]
generate(variabileInput);
};

95
Capitolo 5 Modello per la generazione di una base di
cammini indipendenti
Nel test a scatola bianca un buon criterio di copertura, come è stato mostrato nel paragrafo 1.1.2, è rappresentato dalla copertura tramite cammini indipendenti del grafo di controllo. Prima di procedere con la descrizione del modello è opportuno richiamare brevemente alcuni concetti. Una base di cammini linearmente indipendenti è un insieme massimale di cammini che siano indipendenti tra loro, dove con indipendenza si intende che ogni altro cammino del grafo possa essere ottenuto attraverso una combinazione lineare dei cammini della base. Una base è formata da un numero di cammini pari alla complessità ciclomatica del grafo; essa non è unica. Una buona rappresentazione dei cammini può essere ottenuta considerando una matrice binaria cammini/archi, ogni riga corrisponde ad un cammino, ed ogni colonna rappresenta uno specifico arco del grafo. Il valore dell’elemento (i, j) è pari ad uno se l’arco j-esimo è presente nel cammino i-esimo, mentre è uguale a 0 nel caso contrario. Un esempio è mostrato in Figura 50.
Figura 50 : cammini linearmenti indipendenti e rispettiva matrice cammini/archi

96
In questa rappresentazione dei cammini, nel caso di cicli, non viene considerato quante volte il ciclo viene iterato, ma solo se il ciclo è percorso oppure no. Questa, infatti, è l’unica informazione riguardante i cicli che è possibile mostrare attraverso questa rappresentazione. Si consideri, inoltre, che cammini che differiscano tra loro solo per un numero di iterazioni diverse di un ciclo risultano linearmente dipendenti, ed hanno la medesima rappresentazione nella matrice precedente. Una volta quindi ottenuta la base di cammini indipendenti, la scelta di quante volte iterare un ciclo è indipendente da essa, e può essere effettuata seguendo vari criteri: n-copertura dei cicli, considerazioni sul fatto che il ciclo sia definito (ad esempio for) o indefinito, e così via. Il modello che verrà ora presentato ha come obiettivo quello di determinare una base di cammini linearmente indipendenti, dato un grafo di controllo di un programma. Nel modello si userà un duplice approccio, uno orientato allo stabilire se un arco è presente oppure no nel cammino, l’altro orientato, invece, a determinare una possibile sequenza di nodi che rappresenti lo stesso cammino. Questo duplice approccio è dovuto all’impossibilità di imporre sulla sola matrice dei cammini/archi dei vincoli che garantissero che il cammino generato fosse continuo e non contraddittorio, ossia che ad esempio nel caso di un’istruzione if non venissero selezionati entrambi i rami, then ed else.Questo verrà mostrato meglio durante la presentazione dei vincoli relativi. Non è stato usato solo l’approccio attraverso la sequenza di nodi in quanto l’indipendenza risultava più semplice da essere imposta attraverso la matrice cammini/archi e perché, inoltre, la generazione dei cammini solo considerando la sequenza dei nodi poteva essere molto più dispendiosa, essendo lo spazio di ricerca molto più vasto in quel caso. Nella presentazione del modello si seguirà lo stesso metodo usato per il modello del programma per la generazione dei casi di test, cioè prima si illustrerà la dichiarazione delle costanti e delle variabili, e successivamente i vincoli che si impongono per determinare la soluzione.
5.1 Variabili e costanti utilizzate nel modello Nel modello per la generazione di una base di cammini linearmente indipendenti vengono definite le seguenti costanti:
• numero_Nodi_Grafo
• numero_Archi_Grafo
• matrice_Incidenza_Nodi
• matrice_Nodi_Archi
• numero_Cammini
• MaxTime.

97
Le prime due sono due costanti che indicano, come è facile intuire dal nome, il numero dei nodi ed il numero degli archi del grafo di controllo presenti. La matrice_Incidenza_Nodi è la classica matrice di adiacenza dei nodi utilizzata per rappresentare un grafo. Rispetto al grafo di controllo del programma però essa ha un nodo in più: il nodo 0. Questo è aggiunto per indicare nella sequenza dei nodi che il cammino è terminato. Quindi la matrice sarà una matrice quadrata di dimensione (numero_Nodi_Grafo+1× numero_Nodi_Grafo+1). Un suo elemento generico (i, j) assumerà il valore -1 se dal nodo i al nodo j non esiste alcun arco, mentre assumerà un valore uguale all’arco esistente nel caso contrario. Naturalmente la prima riga e la prima colonna saranno costituite da tutti -1. La matrice_Archi_Grafo è un altro classico modo di rappresentare un grafo, in cui per ogni nodo ed arco presenti nel grafo si indica se l’arco è entrante nel nodo, uscente, oppure nessuno dei due. Anche in questo caso, naturalmente, è presente il nodo 0, per lo stesso motivo indicato precedentemente. Quindi la matrice sarà una matrice rettangolare di dimensione (numero_Nodi_Grafo+1× numero_Archi_Grafo). Un suo elemento generico (i, j) assumerà il valore -1 se l’arco j risulta uscente dal nodo i, assumerà il valore +1 se l’arco j risulterà entrante nel nodo i, mentre assumerà il valore 0 in ogni altro caso. Naturalmente la prima riga sarà formata da tutti 0. All’interno del modello si utilizza una rappresentazione ridondante del grafo di flusso per motivi di efficienza. Infatti alcuni vincoli, che verranno mostrati successivamente, risultano molto più facili ed efficienti da imporre sfruttando una rappresentazione piuttosto che l’altra. La costante numero_Cammini viene definita per indicare il numero di cammini che compongono la base di cammini cercata. Essa viene posta uguale alla complessità ciclomatica del programma, da cui è scaturito il grafo di flusso analizzato. La costante MaxTime viene introdotta per fissare un orizzonte temporale massimo alla sequenza dei nodi. Nel modello vengono, quindi, definite le seguenti variabili:
• matrice_Cammini_Archi
• matrice_Cammini_Sequenza_Nodi.
La prima viene utilizzata per indicare, come è stato precedentemente esposto, per ogni cammino se un arco è presente oppure no. Essa è quindi una matrice rettangolare di dimensioni numero_Cammini × numero_Archi_Grafo, definita sull’intervallo [0..1]. Un suo elemento generico (i, j) assumerà il valore 0 se nel cammino i non è presente l’arco j, assumerà il valore 1 nel caso contrario. La matrice_Cammini_Sequenza_Nodi viene utilizzata per rappresentare una possibile sequenza di nodi corrispondente al cammino rappresentato dall’insieme degli archi presente nel cammino stesso. Essa, quindi, sarà una matrice rettangolare di dimensioni numero_Cammini × MaxTime definita sull’insieme dei nodi del grafo, più il nodo 0. Un suo elemento generico (i, j) assumerà il valore α

98
se nel cammino i all’istante j viene selezionato il nodo α. Se il cammino è terminato α assume il valore 0. In Figura 51 viene presentato un esempio di dichiarazione di variabili e costanti per il modello dei cammini indipendenti. Naturalmente le due matrici di variabili devono essere mantenute coerenti una con l’altra, e questo è ottenuto imponendo degli opportuni vincoli, come è mostrato successivamente.
Figura 51 : esempio dichiarazione variabili e costanti modello cammini indipendenti
5.2 Vincoli del modello I vincoli che sono presenti nel modello possono essere raggruppati in quattro categorie, a seconda della funzione che essi svolgono nel modello stesso. Esse sono:
• vincoli per imporre che ogni cammino inizi con il nodo start e termini con il nodo fine
• vincoli per imporre la continuità del cammino

99
• vincoli per mantenere la coerenza tra le due matrici di variabili: matrice_Cammini_Archi e matrice_Cammini_Sequenza_Nodi (channelling constraints)
• vincolo per imporre l’indipendenza lineare dei cammini.
5.2.1 Vincoli per imporre un corretto inizio e fine ad ogni cammino
I cammini del grafo di flusso che si vogliono trovare, devono essere prima di tutto cammini completi (cf. definizione in 2.1.1). Quindi ogni cammino deve iniziare con il nodo start e terminare con il nodo fine. Sono stati sviluppati vincoli per imporre queste proprietà ad ogni cammino, prendendo in considerazione sia la matrice_Cammini_Archi, sia la matrice_Cammini_Sequenza_Nodi. Nel primo caso la proprietà si traduce in due vincoli. Il primo esprime il fatto che per ogni cammino esista uno ed un solo arco tale che esso sia presente nel cammino e che sia uscente dal nodo start. Questo naturalmente implica che il nodo start faccia parte del cammino, e che quest’ultimo inizi proprio con il nodo start, non avendo il nodo start archi entranti. Nel linguaggio OPL questo può essere realizzato attraverso il seguente vincolo:
forall(cammino in 0..numero_Cammini-1)
sum(arco in 0..numero_Archi_Grafo-1) (matrice_Cammini_Archi[cammino,arco]=1
&matrice_Nodi_Archi[1,arco]=-1)=1;
Il costrutto forall impone che il vincolo valga per ogni cammino, mentre il costrutto sum(arco..)(proprietà)=1 impone che esista uno ed un solo arco che verifichi la proprietà racchiusa tra parentesi tonde. La proprietà all’interno del sum è costituita da due vincoli di uguaglianza, il primo dei quali impone all’arco considerato di essere presente nel cammino, matrice_Cammini_Archi[cammino,arco]=1, ed il secondo, invece, impone che esso sia un arco uscente dal nodo start del grafo (il nodo 1 è sempre il nodo start), matrice_Nodi_Archi[1,arco]=-1. Una volta imposto che il cammino inizi dal nodo start, bisogna imporre che esso termini nel nodo fine. Questo viene realizzato con un vincolo analogo al precedente, in cui per ogni cammino si impone che esista uno ed un solo arco, appartenente al cammino, che sia entrante nel nodo fine. Questo implica, naturalmente, che il cammino termini nel nodo fine, non avendo quest’ultimo alcun arco uscente. Nel linguaggio OPL questo può essere realizzato attraverso il seguente vincolo:
forall(cammino in 0..numero_Cammini-1)

100
sum(arco in 0..numero_Archi_Grafo-1) (matrice_Cammini_Archi[cammino,arco]=1
&matrice_Nodi_Archi[2,arco]=1)=1;
La struttura del vincolo è analoga al precedente, ed i costrutti hanno lo stesso significato. L’unica differenza risiede nel secondo vincolo di uguaglianza imposto all’interno del sum. Esso impone che l’arco preso in considerazione sia un arco entrante nel nodo fine, essendo questo sempre il nodo 2. Come è stato detto precedentemente, la stessa proprietà viene imposta anche nella rappresentazione del cammino come sequenza di nodi. In questo caso si tratta di imporre che il nodo iniziale della sequenza sia il nodo start e, che esista un istante di tempo in cui venga raggiunto il nodo fine. Questo nel linguaggio OPL può essere realizzato attraverso il seguente vincolo:
forall(cammino in 0..numero_Cammini-1)
matrice_Cammini_Sequenza_Nodi[cammino,0]=1&
sum(istante in 0..MaxTime)
(matrice_Cammini_Sequenza_Nodi[cammino,istante]=2)=1;
Analogamente agli altri casi il costrutto forall impone che il vincolo valga per tutti i cammini. Il primo vincolo di uguaglianza che si incontra, matrice_Cammini_Sequenza_Nodi[cammino,0]=1, serve ad imporre che il nodo iniziale sia proprio il nodo start, mentre il vincolo successivo, realizzato con un sum, assicura che esista un instante di tempo in cui nella sequenza dei nodi ci sia il nodo fine (nodo 2).
5.2.2 Vincoli continuità del cammino Questi vincoli hanno come obiettivo quello di garantire che i cammini generati siano continui, cioè che siano cammini specifici (cf. definizione in 2.1.1). Analogamente al caso precedente, vengono considerate entrambe le rappresentazioni del cammino: come sequenza di nodi e come insieme di archi. Per imporre la continuità del cammino nella rappresentazione tramite la matrice_Cammini_Sequenza_nodi sono necessari tre vincoli che prendono in considerazione tre aspetti diversi del problema. Il primo vincolo viene realizzato per imporre che in ogni cammino, presi due qualsiasi nodi consecutivi che siano diversi dal nodo 0, essi siano collegati tramite un arco del grafo. Nel linguaggio OPL questo può essere realizzato tramite il vincolo seguente:
forall(cammino in 0..numero_Cammini-1,istante in 0. .MaxTime-1)
(
(matrice_Cammini_Sequenza_Nodi[cammino,istante]>0

101
&matrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0 )
=>
matrice_Incidenza_Nodi[matrice_Cammini_Sequenza_Nod i[cammino, istante],matrice_Cammini_Sequenza_Nodi[cammino,ista nte+1]]>=0
);
Analogamente agli altri casi, il costrutto forall esprime una quantificazione universale sui cammini e gli istanti di tempo, ossia il vincolo deve valere per ogni cammino e per ogni istante di tempo in [0, MaxTime-1], dove il secondo estremo è MaxTime-1 per tenere conto che nel vincolo si usa l’istante successivo (istante+1) e non realizzare, quindi, un accesso all’array fuori dai limiti su cui è definito. Il vincolo che viene imposto debba valere è un vincolo di implicazione, in cui l’implicante è costituito da due vincoli di disuguaglianza posti in and che assicurano che i nodi consecutivi presi in considerazione non siano il nodo 0, mentre l’implicato impone che il valore della matrice di incidenza dei nodi, per i nodi indicati nell’implicante, sia maggiore o uguale a zero, ossia che sia presente un arco tra di essi. Gli altri due vincoli che vengono realizzati per la continuità del cammino, nella rappresentazione come sequenza di nodi, si riferiscono ad una corretta gestione della fine del cammino stesso. Il primo ha lo scopo di imporre che, se ad un certo istante il nodo corrente è il nodo fine (nodo 2), allora all’istante successivo il nodo corrente deve essere il nodo 0. Nel linguaggio OPL questo può essere espresso tramite il seguente vincolo:
forall(cammino in 0..numero_Cammini-1,istante in 0. .MaxTime-1)
matrice_Cammini_Sequenza_Nodi[cammino,istante]=2
=> matrice_Cammini_Sequenza_Nodi[cammino,istante+1] =0;
Questo vincolo è di facile lettura, ed impone, appunto, che per ogni cammino C e per ogni istante di tempo T, in [0..MaxTime-1] per il medesimo motivo di prima, se nel cammino C il nodo all’istante T è il nodo 2 (nodo fine), allora il nodo all’istante successivo, T+1, deve essere il nodo 0. Un ulteriore vincolo viene imposto per gestire correttamente la presenza del nodo 0 nella sequenza, ed esso esprime il fatto che se ad un certo istante di tempo il nodo corrente è il nodo 0, allora all’istante successivo sicuramente sarà presente il nodo 0, mentre per l’istante precedente si possono verificare due casi: il nodo può essere il nodo 0, oppure il nodo 2 (nodo fine). Questo può essere espresso nel linguaggio OPL tramite il seguente vincolo:
forall(cammino in 0..numero_Cammini-1,istante in 1. .MaxTime-1)
matrice_Cammini_Sequenza_Nodi[cammino,istante]=0 =>

102
(
(matrice_Cammini_Sequenza_Nodi[cammino,istante+1]= 0)
&
(matrice_Cammini_Sequenza_Nodi[cammino,istante-1]=0
\/
matrice_Cammini_Sequenza_Nodi[cammino,istante-1]= 2)
);
Questo vincolo impone, appunto, che per ogni cammino C ed ogni istante di tempo T, in [0..MaxTime-1] per il medesimo motivo di prima, se nel cammino C all’istante T il nodo corrente della sequenza è 0, allora il nodo all’istante T+1 per il cammino C sarà 0 e, deve essere vera una delle due seguenti affermazioni:
• il nodo nel cammino C all’istante T-1 è 0
• il nodo nel cammino C all’istante T-1 è 2 (nodo fine).
Attraverso i tre vincoli sopra elencati si impone la continuità del cammino nella rappresentazione attraverso sequenza di nodi. Si vuole imporre ora la continuità del cammino anche nella rappresentazione attraverso la matrice_Cammini_Archi, e per fare questo si generano due vincoli. Il primo vincolo ha lo scopo di imporre che per ogni arco presente in un cammino deve esistere un nodo in cui questo arco entra, e deve esistere un secondo arco uscente da questo nodo che appartiene al cammino, oppure il nodo in cui entra l’arco è il nodo fine. Nel linguaggio OPL questo può essere espresso attraverso il seguente vincolo:
forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1)
matrice_Cammini_Archi[cammino,arco]=1 =>
(
sum(nodo in 1..numero_Nodi_Grafo:nodo<>2,seco ndoArco in 0..numero_Archi_Grafo-1)
(matrice_Nodi_Archi[nodo,arco]=1
&matrice_Nodi_Archi[nodo,secondoArco]=-1
&matrice_Cammini_Archi[cammino,secondoArco]=1
)>=1
\/matrice_Nodi_Archi[2,arco]=1);
Questo vincolo impone che per ogni cammino C ed ogni arco A, se l’arco A appartiene al cammino C allora, uno dei due seguenti vincoli deve essere vero:

103
• esiste un nodo N, che non sia il nodo fine, ed un secondo arco A2, tali che il primo arco A entri nel nodo N, l’arco A2 esca da questo nodo, e l’arco A2 appartenga al cammino C;
• l’arco A è un arco entrante nel nodo fine (nodo 2).
L’altro vincolo che viene realizzato per imporre la continuità del cammino nella rappresentazione tramite la matrice_Cammini_Archi è il duale del precedente, nel senso che, dato un arco non impone la continuità per l’arco successivo, ma, invece, per quello precedente. Più dettagliatamente, si vuole imporre che per ogni arco di un cammino esista un nodo da cui esso esca, e nel caso in cui questo non sia il nodo di start, esista un altro arco, appartenente al cammino, che entri in questo nodo. Questo può essere espresso nel linguaggio OPL tramite il seguente vincolo:
forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1)
matrice_Cammini_Archi[cammino,arco]=1 =>
(
sum(nodo in 2..numero_Nodi_Grafo,secondoArco in 0..numero_Archi_Grafo-1)
(matrice_Nodi_Archi[nodo,arco]=-1
&matrice_Nodi_Archi[nodo,secondoArco]=1
&matrice_Cammini_Archi[cammino,secondoArco] =1
)>=1
\/matrice_Nodi_Archi[1,arco]=-1
);
Questo vincolo impone che per ogni cammino C ed ogni arco A, se l’arco A appartiene al cammino C, allora uno dei due seguenti vincoli deve essere verificato:
• esiste un nodo N, che non sia il nodo start, ed esiste un secondo arco A2 tali che, l’arco A esca dal nodo N, l’arco A2 entri nel nodo N, ed A2 appartenga al cammino C;
• l’arco A esca dal nodo start (nodo 1).
Gli ultimi due vincoli presentati, che hanno lo scopo di imporre la continuità del cammino nella rappresentazione tramite la matrice_Cammini_Archi, hanno un problema: essi non impediscono che in caso di istruzioni come l’ if then else vengano selezionati in un cammino gli archi di entrambi i rami dell’if. Questo perché considerati singolarmente, questi archi risulterebbero continui rispetto agli archi precedenti ed agli archi successivi. Ma naturalmente questo non sarebbe un cammino specifico e completo. Utilizzando, però, solo la rappresentazione tramite

104
la matrice_Cammini_Archi non è possibile imporre vincoli che tengano in considerazione la presenza di archi mutuamente esclusivi tra loro. Per questo è stata introdotta anche la rappresentazione di un cammino tramite sequenza di nodi.
5.2.3 Vincoli per unificare e rendere coerenti le d ue matrici di variabili
I vincoli presentati finora fanno si che i cammini presenti nelle due matrici di variabili rappresentino effettivamente dei cammini specifici e completi. Ma essi non impongono nessun legame tra i cammini in una rappresentazione ed i cammini nell’altra. I vincoli che verranno presentati ora hanno proprio lo scopo di unificare e rendere coerenti le due matrici, in modo che esse rappresentino gli stessi cammini. Il primo vincolo che viene realizzato ha lo scopo di imporre che ogni arco, che colleghi due nodi consecutivi temporalmente nella rappresentazione di un cammino come sequenza di nodi, appartenga al cammino stesso. Questo può essere espresso in OPL tramite il seguente vincolo:
forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1,istante in 0..MaxTime-1)
(matrice_Cammini_Sequenza_Nodi[cammino,istante]>0
&matrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0
&(matrice_Incidenza_Nodi[matrice_Cammini_Sequenza_N odi[cammino,istante],matrice_Cammini_Sequenza_Nodi[cammino,i stante+1]]=arco)
)
=> matrice_Cammini_Archi[cammino,arco]=1;
Questo vincolo impone che per ogni cammino C, per ogni arco A, ed ogni istante di tempo T, se il nodo all’istante T del cammino C non è il nodo 0, se il nodo all’istante T+1 del cammino C non è il nodo 0, e l’arco che collega questi due nodi è A, allora A deve appartenere al cammino C. Il prossimo vincolo realizzato per unificare le due matrici è il duale del precedente, ossia esso impone che se un arco appartiene ad un cammino, allora dovranno esistere almeno due nodi, consecutivi temporalmente nel cammino stesso, che siano collegati tramite questo nodo. Nel linguaggio OPL questo può essere espresso tramite il seguente vincolo:
forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1)
matrice_Cammini_Archi[cammino,arco]=1 =>
(

105
sum(istante in 0..MaxTime-1)
(matrice_Cammini_Sequenza_Nodi[cammino,istante]>0
&matrice_Cammini_Sequenza_Nodi[cammino,istante+1]> 0 &matrice_Incidenza_Nodi[matrice_Cammini_Sequenza_No di[cammino,istante],matrice_Cammini_Sequenza_Nodi[cammino,is tante+1]]=arco)>=1
);
Questo vincolo impone che per ogni cammino C e per ogni arco A tali che, l’arco A appartenga al cammino C, allora esiste almeno un istante di tempo T, tale che il nodo all’istante T nel cammino C sia diverso dal nodo 0, che il nodo all’istante T+1 nel cammino C sia diverso dal nodo 0, e che l’arco che unisca questi nodi sia proprio l’arco A. Il vincolo che verrà presentato di seguito è l’ultimo che viene realizzato per unire le due matrici di variabili. Il suo obiettivo è duplice:
• vuole imporre che se un arco non è presente in un cammino, allora non devono esistere due nodi consecutivi temporalmente in quel cammino, tali che siano collegati tramite quell’arco;
• vuole imporre che se non esistono due nodi consecutivi temporalmente in un cammino collegati da un determinato arco, allora quell’arco non deve appartenere al cammino.
Questo può essere espresso in OPL tramite il seguente vincolo:
forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1)
(sum(istante in 0..MaxTime-1)
(matrice_Cammini_Sequenza_Nodi[cammino,istante]> 0
&matrice_Cammini_Sequenza_Nodi[cammino,istante+1 ]>0 &matrice_Incidenza_Nodi[matrice_Cammini_Sequenza_No di[cammino,istante],matrice_Cammini_Sequenza_Nodi[cammino,is tante+1]]=arco
)=0
)<=> matrice_Cammini_Archi[cammino,arco]=0;
Questo vincolo impone che per ogni cammino C e per ogni arco A, non esiste un istante T tale che, il nodo del cammino C all’istante T sia diverso dal nodo 0, che il nodo del cammino C all’istante T sia diverso dal nodo 0, e che i due nodi siano collegati tramite l’arco A, se e solo se l’arco A non appartiene al cammino.
5.2.4 Vincolo per l’indipendenza lineare dei cammin i Sia in 1.1.2 che in 0 è stato spiegato dettagliatamente cosa si intenda per base di cammini linearmente indipendenti: un insieme di cammini attraverso la cui

106
combinazione lineare è possibile ottenere un qualsiasi altro cammino del grafo di controllo. Per il calcolo di una base di cammini indipendenti esiste una regola pratica così fatta: partendo da un primo cammino qualsiasi, il secondo deve avere almeno un arco non presente nel primo cammino. Il terzo cammino deve avere almeno un arco non presente nei due cammini precedenti, e così via fino al cammino n-simo, dove n è il numero ciclomatico. Questa regola ci permette di sviluppare un vincolo che imponga che i cammini calcolati siano linearmente indipendenti. Il vincolo ha questa forma:
forall(cammino in 1..numero_Cammini-1)
sum(arco in 0..numero_Archi_Grafo-1)
(matrice_Cammini_Archi[cammino,arco]=1
&sum(secondoCammino in 0..cammino-1)
(matrice_Cammini_Archi[secondoCammino,arco]=1
)=0
)>0;
Questo vincolo impone che per ogni cammino C successivo al cammino 0 deve esistere un arco A, tale che A appartenga al cammino C, e che non esista un secondo cammino C2 tra i cammini precedenti a C, tale che l’arco A appartenga al cammino C2. Quindi questo vincolo assicura che in ogni cammino, successivo al primo, presente nella matrice_Cammini_Archi è presente almeno un arco che non è presente nei cammini superiori della matrice, e quindi che esso consideri un arco nuovo, non ancora considerato. Questo fa si che i cammini siano linearmente indipendenti.
5.2.5 Strategia di ricerca In considerazione delle osservazioni presentate in 4.3.11, anche in questo caso non conviene realizzare una procedura di ricerca complessa, ma limitarsi ad indicare in che ordine devono essere generati i valori delle variabili. In questo caso si è dimostrata migliore come strategia quella di considerare in sequenza i vari cammini, e per ognuno di essi generare prima la matrice_Cammini_Archi e successivamente la matrice_Cammini_Sequanza_Nodi. Questo perché la prima matrice ha uno spazio di ricerca più piccolo, ridotto, inoltre, dalla presenza dei vari vincoli presentati precedentemente. Una volta che la riga relativa ad un dato cammino è stata generata nella matrice_Cammini_Archi, la generazione della riga corrispondente nella matrice_Cammini_Sequanza_Nodi risulta più efficiente, in quanto lo spazio di ricerca risulta molto limitato dai vincoli di unione e coerenza presentati prima, oltre che da quelli relativi agli altri aspetti della modellazione. La procedura di ricerca è la seguente:
search{

107
forall(i in 0..numero_Cammini-1 ordered by increas ing i){
generate(matrice_Cammini_Archi[i]);
generate(matrice_Cammini_Sequenza_Nodi[i]);
};
};
Per concludere la presentazione del modello Sapienza per il calcolo di una base di cammini linearmente indipendenti si vuole mettere in evidenza come alcuni dei vincoli presentati precedentemente siano ridondanti. Questo è stato fatto affinché ci fosse una maggiore propagazione di vincoli ed, una conseguente riduzione dello spazio di ricerca.

108
Capitolo 6 Risultati Sperimentali
In questo capitolo vengono presentati i test che sono stati effettuati, a conclusione del lavoro svolto, per validare i modelli sviluppati ed avere una prima idea dei tempi di risposta che OPL potesse avere nel gestire istanze di questo tipo. I test sono stati effettuati utilizzando, per generare i modelli, dei programmi java con complessità ciclomatica crescente, partendo da un valore pari a tre ed arrivando a un valore pari a nove. Si ricorda che valori prossimi al dieci, come complessità ciclomatica, vengono considerati alti, e quando possibile si consiglia di realizzare moduli con complessità minori. I programmi java utilizzati, in ordine di complessità maggiore, sono i seguenti:
• massimo
• sommaTuttiElementiVettore
• bubbleSort
• selectionSort
• sommaDueElementiVettore
• sample
• puntoSella.
Il codice sorgente di tutti i programmi, ed i relativi modelli vengono presentati nell’appendice A.
Massimo
� Input: un array di interi
� Output: il valore massimo presente
� Complessità ciclomatica: 3
Il programma, come suggerisce il nome, prende un vettore di interi in ingresso, ne calcola l’elemento massimo e lo restituisce come output. In Figura 52 è riportato il codice java, ed in Figura 53 il grafo di flusso.

109
Figura 52 : programma Massimo
Figura 53 : grafo del flusso di controllo del programma massimo
SommaTuttiElementiVettore
� Input: un array di interi
� Output: somma di tutti gli elementi
� Complessità ciclomatica: 4
Il programma prende un vettore di interi in ingresso, calcola la somma di tutti gli elementi e la restituisce come output. In Figura 54 è riportato il codice java, ed in Figura 55 il grafo di flusso.

110
Figura 54 : programma SommaTuttiElementiVettore
Figura 55 : grafo del flusso di controllo del programma sommaTuttiElementiVettore
BubbleSort
� Input: un array di interi
� Output: nessuno
� Complessità ciclomatica: 4
Questo programma esegue l’ordinamento degli elementi dell’array implementando l’algoritmo bubble-sort. In Figura 56 è riportato il codice java, ed in Figura 63 il grafo di flusso.

111
Figura 56 : programma BubbleSort
Figura 57 : grafo del flusso di controllo del programma bubbleSort
SelectionSort
� Input: un array di interi
� Output: nessuno
� Complessità ciclomatica: 4

112
Questo programma esegue l’ordinamento degli elementi dell’array implementando l’algoritmo selection-sort. In Figura 58 è riportato il codice java, ed in Figura 63 il grafo di flusso.
Figura 58 : programma SelectionSort
Figura 59 : grafo del flusso di controllo del programma selectionSort
SommaDueElementiVettore
� Input: un array di interi e due interi
� Output: la somma dei due elementi indicati

113
� Complessità ciclomatica: 6
Il programma, come suggerisce il nome, prende in un vettore di interi, e due altri interi che rappresentano due indici, eventualmente coincidenti, verifica che gli indici rientrino nell’intervallo della dimensione del vettore, calcola la somma degli elementi corrispondenti e ne restituisce il valore in output. La complessità di questo programma sale a sei. Questo è dovuto alla presenza di una condizione complessa, costituta da quattro condizioni atomiche messe in Or tra loro. In Figura 60 è riportato il codice java, ed in Figura 61 il grafo di flusso.
Figura 60 : programma SommaDueElementiVettore

114
Figura 61 : grafo del flusso di controllo del programma sommaDueElementiVettore
Sample
� Input: due array di interi ed un intero
� Output: la somma dei due elementi indicati
� Complessità ciclomatica: 7
Il programma sample è l’esempio presentato da Gotlieb ed altri in [10] e [11]. Esso è considerato un esempio non banale. La struttura di controllo, infatti, risulta complessa: sono presenti due cicli, con istruzioni condizionali al loro interno; un ciclo, inotre, fa parte del ramo then di un’istruzione condizionale. Questo porta la complessità ciclomatica del programma al valore sette. In Figura 62 è riportato il codice java, ed in Figura 63 il grafo di flusso.

115
Figura 62 : programma Sample

116
Figura 63 : grafo del flusso di controllo del programma sample
PuntoSella
� Input: un array bidimensionale
� Output: il valore dell’elemento che è il punto di sella se c’è, -1 altrimenti
� Complessità ciclomatica: 9
Il programma puntoSella calcola il ‘punto di sella’ di una matrice bidimensionale; esso viene definito come l’elemento della matrice che sia il minimo della riga cui appartiene, ed il massimo della colonna cui appartiene. La complessità ciclomatica di questo programma assume il valore nove. In Figura 64 è riportato il codice java. In questo caso il grafo di flusso non viene riportato, in quanto molto complesso, ed inutile ai fini della presentazione dei risultati.

117
Figura 64 : programma PuntoSella
I test, relativamente ad ogni programma, sono stati effettuati nel seguente modo:
• prima è stato testato il modello per la generazione di una base di cammini
• successivamente per ogni cammino, ragionevole, della base di cammini determinata attraverso il punto precedente, è stato testato il modello per la generazione dei casi di test.
Per cammino ragionevole, precedentemente, si intende un cammino che contenga un numero di iterazioni adeguate rispetto al codice. Infatti, come è stato detto in 0, la soluzione del modello dei cammini indipendenti è una matrice cammini/archi che indica solo se un arco è presente o meno. Questo determina il cammino, a meno del numero di iterazioni da compiere nei cicli. In alcuni casi il numero di iterazioni può dipendere dai dati di ingresso, ed in questo caso è più difficile determinare il giusto numero di iterazioni per il quale esistano delle soluzioni. Nel caso in cui, invece, il numero delle iterazioni è determinato (cicli for, oppure cicli in cui le variabili non dipendo dai parametri di input), allora nel cammino in questione è bene imporre lo stesso numero di iterazioni, altrimenti non verrebbero trovate soluzioni, sempre che esse esistano.

118
6.1 Modello per la generazione dei cammini indipendenti
I test per il modello dei cammini indipendenti sono stati effettuati impostando la variabile MaxTime, che, si ricorda, fissa un orizzonte temporale per la sequenza dei nodi che vengono generati, al valore 40. I test sono stati eseguiti più di una volta, considerando poi il valore medio riscontrato; questo per tenere conto di condizioni particolari che si potesso venire a creare sulla macchina su cui venivano effettuati i test.
Esperimenti programma massimo Negli esperimenti relativi al programma massimo il modello per la generazione di una base di cammini indipendenti si è comportato molto bene, determinando una base in un tempo inferiore al secondo. In questo caso, essendo la complessità ciclomatica tre, la base cercata ha dimesione tre. Di seguito (cf. Figura 65) vengono riportati graficamente i cammini determinati, rappresentandoli nel grafo di flusso con linee diverse. Le linee continue indicano i percorsi comuni a tutti i cammini.
Figura 65 : cammini di una base determinata per il programma massimo
Dei tre cammini della base determinata solo due sono percorribili. Questo per la struttura stessa del programma che impone che il ciclo venga eseguito un numero fissato di volte; quindi il cammino costituto dai nodi 1-5-4-2 non potrà mai essere eseguito.
Esperimenti programma sommaTuttiElementiVettore Negli esperimenti relativi al programma sommaTuttiElementiVettore il modello si è comportato molto bene, analogamente al caso precedente, determinando una

119
base in un tempo di circa un secondo. In questo caso, essendo la complessità ciclomatica quattro, la base cercata ha dimesione quattro. Di seguito (cf. Figura 66) vengono riportati graficamente i cammini determinati, rappresentandoli nel grafo di flusso con le convenzioni analoghe al caso precedente.
Figura 66 : cammini di una base determinata per il programma sommaTuttiElementiVettore
Dei quattro cammini determinati, solo uno è percorribile: quello che esegue il ciclo. Questo per le stesse motivazioni del programma massimo, ossia il ciclo non può non essere eseguito. Il cammino percorribile è: 1-5-3-5-4-9-7-2. A differenza di prima, in questo caso sarebbe possibile generare altri due cammini percorribili, corrispondenti a due di quelli generati dal modello, ma eseguendo il ciclo. Quindi sarebbe possibile trovare una base di cammini linearmente indipendenti in cui tre cammini su quattro sono percorribili. Naturalmente la base di cammini non è unica, ed è stata rappresentata solo la prima soluzione trovata dal modello. Una base massimale di cammini linearmente indipendenti, non avrà comunque mai tutti i cammini percorribili: quello che non esegue il ciclo deve, infatti appartenere ad una base massimale, ed esso non è percorribile.
Esperimenti programma bubbleSort Negli esperimenti relativi al programma bubbleSort il modello si è comportato bene, anche se, rispetto ai casi precedenti, il tempo per determinare una base è salito, attestandosi su un valore di circa 11 secondi. Anche in questo caso, essendo la complessità ciclomatica quattro, la base cercata ha dimesione quattro. Di seguito (cf. Figura 67) vengono riportati graficamente i cammini determinati, rappresentandoli nel grafo di flusso con le convenzioni analoghe al caso precedente.

120
Figura 67 : cammini di una base determinata per il programma bubbleSort
Dei quattro cammini appartenenti alla base determinata dal modello, solo due sono percorribili: essi sono quelli che prevedono l’esecuzione di entrambi i cicli presenti; questo per motivazioni analoghe a quelle dei programmi precedenti. In questo caso, però, non è possibile trovare una base massimale con più di due cammini percorrbili. Infatti due cammini saranno sempre relativi alle possibilità di non eseguire i cicli, cosa che per come è scritto il codice non può verificarsi.
Esperimenti programma selectionSort Negli esperimenti relativi al programma selectionSort il modello si è comportato in modo analogo al caso del programma bubbleSort. Il tempo per determinare una base è stato di circa 11 secondi. Anche in questo caso, essendo la complessità ciclomatica quattro, la base cercata ha dimesione quattro. Di seguito (cf. Figura 68) vengono riportati graficamente i cammini determinati, rappresentandoli nel grafo di flusso con le convenzioni analoghe al caso precedente.

121
Figura 68 : cammini di una base determinata per il programma selectionSort
Dei quattro cammini appartenenti alla base determinata dal modello, solo due sono percorribili: essi sono quelli che prevedono l’esecuzione di entrambi i cicli presenti. Anche in questo caso il massimo numero di cammini percorribili in una base è due. Le motivazioni e le considerazioni su di esse sono identiche al caso del programma bubbleSort.
Esperimento programma sommaDueElementiVettore Negli esperimenti relativi al programma sommaDueElementiVettore il modello si è comportato meglio rispetto agli ultimi due casi, determinado una base di cammini linearmente indipendenti in un tempo prossimo ai due secondi e mezzo. Questo nonostante la complessità ciclomatica salisse, essendo sei. La base cercata ha, quindi, dimesione sei. Di seguito (cf. Figura 69) vengono riportati graficamente i cammini determinati, rappresentandoli nel grafo di flusso con le convenzioni analoghe al caso precedente.

122
Figura 69 : cammini di una base determinata per il programma sommaDueElementiVettore
In questo caso, i cammini della base sono tutti percorribili.
Esperimento programma sample Negli esperimenti relativi al programma sample il modello ha determinato la soluzione in un tempo più che soddisfacente, data la complessità del grafo di flusso. Infatti, per determinare una base di cammini linearmente indipendenti ha impiegato circa 750 secondi (12 minuti). Questo aumento è dovuto sia alla maggiore complessità ciclomatica, sia alla presenza di due cicli. La base cercata ha dimesione sette, essendo questo il valore della complessità ciclomatica. Di seguito (cf.) vengono riportati graficamente i cammini determinati, rappresentandoli nel grafo di flusso con le convenzioni analoghe al caso precedente.

123
Figura 70 : cammini di una base determinata per il programma sample
In questo caso dei sette cammini determinati, solo uno è percorribile. Questo per le motivazioni analoghe ai casi precedenti. Il cammino percorribile è: 1-5-3-8-7-5-4-11-10-20-19-21-2.
Esperimento programma puntoSella Negli esperimenti relativi al programma puntoSella il modello ha mostrato delle difficoltà, esso infatti non ha trovato una soluzione entro un tempo prestabilito (tre ore). Questo fondamentalmente perché il programma ha una complessità ciclomatica molto alta: nove.
I risultati ottenuti mostrano come i tempi di risposta aumentino con il valore della complessità ciclomatica, ma non solo. Infatti, si evidenzia dagli esperimenti che a parità di complessità ciclomatica, la presenza di cicli, oltrettutto annidati, porti a un tempo di elaborazione per il modello, maggiore. Questo può essere visto osservando i test relativi ai programmi sommaTuttiElementi, bubbleSort e selectionSort. Essi hanno tutti complessità ciclomatica uguale a quattro, ma mentre il primo ha mostrato tempi di esecuzione prossimi al secondo, i due programmi relativi agli algoritmi di ordinamento hanno presentato tempi di
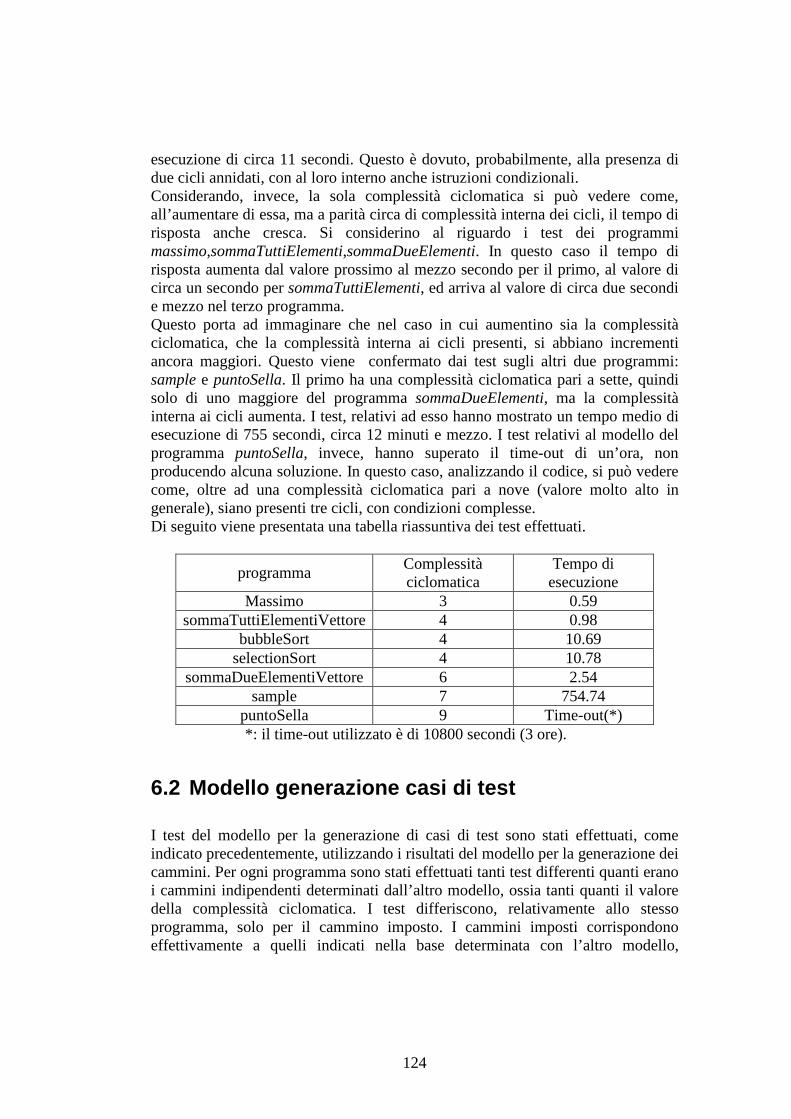
124
esecuzione di circa 11 secondi. Questo è dovuto, probabilmente, alla presenza di due cicli annidati, con al loro interno anche istruzioni condizionali. Considerando, invece, la sola complessità ciclomatica si può vedere come, all’aumentare di essa, ma a parità circa di complessità interna dei cicli, il tempo di risposta anche cresca. Si considerino al riguardo i test dei programmi massimo,sommaTuttiElementi,sommaDueElementi. In questo caso il tempo di risposta aumenta dal valore prossimo al mezzo secondo per il primo, al valore di circa un secondo per sommaTuttiElementi, ed arriva al valore di circa due secondi e mezzo nel terzo programma. Questo porta ad immaginare che nel caso in cui aumentino sia la complessità ciclomatica, che la complessità interna ai cicli presenti, si abbiano incrementi ancora maggiori. Questo viene confermato dai test sugli altri due programmi: sample e puntoSella. Il primo ha una complessità ciclomatica pari a sette, quindi solo di uno maggiore del programma sommaDueElementi, ma la complessità interna ai cicli aumenta. I test, relativi ad esso hanno mostrato un tempo medio di esecuzione di 755 secondi, circa 12 minuti e mezzo. I test relativi al modello del programma puntoSella, invece, hanno superato il time-out di un’ora, non producendo alcuna soluzione. In questo caso, analizzando il codice, si può vedere come, oltre ad una complessità ciclomatica pari a nove (valore molto alto in generale), siano presenti tre cicli, con condizioni complesse. Di seguito viene presentata una tabella riassuntiva dei test effettuati.
programma Complessità ciclomatica
Tempo di esecuzione
Massimo 3 0.59 sommaTuttiElementiVettore 4 0.98
bubbleSort 4 10.69 selectionSort 4 10.78
sommaDueElementiVettore 6 2.54 sample 7 754.74
puntoSella 9 Time-out(*) *: il time-out utilizzato è di 10800 secondi (3 ore).
6.2 Modello generazione casi di test I test del modello per la generazione di casi di test sono stati effettuati, come indicato precedentemente, utilizzando i risultati del modello per la generazione dei cammini. Per ogni programma sono stati effettuati tanti test differenti quanti erano i cammini indipendenti determinati dall’altro modello, ossia tanti quanti il valore della complessità ciclomatica. I test differiscono, relativamente allo stesso programma, solo per il cammino imposto. I cammini imposti corrispondono effettivamente a quelli indicati nella base determinata con l’altro modello,

125
variando solo il numero di iterazioni nei cicli, e tenendo conto di eventuali condizioni collegate tra loro, al fine di aumentare il numero dei cammini realmente percorribili. Naturalmente, e per le stesse motivazioni relative all’altro modello, tutti i test sono stati effettuati più volte, considerando poi il valore medio ottenuto per ogni singolo test.
Esperimento programma massimo Gli esperimenti per il programma massimo sono stati effettuati imponendo i tre cammini determinati con il modello per la generazione di una base di cammini. I cammini vengono riportati, per comodità, sul grafo di flusso del programma in Figura 71.
Figura 71 : cammini di una base per il programma massimo
Il cammino che non prevede l’esecuzione del ciclo non è percorribile, ed infatti modello determina che non ci sono soluzioni. Per gli altri due cammini, invece, vengono trovate due soluzioni. Nel caso in cui il ciclo viene eseguito, ma la il ramo then dell’istruzione condizionale al suo interno non viene eseguita la soluzione trovata è il seguente vettore {-10,-10,-10,-10,-10}. Nel caso in cui, invece, nel ciclo venga eseguita anche l’istruzione nel ramo then la soluzione trovata è {-9,-8,-7,-6,-5}. Questo perché in entrambi i casi il ramo then viene o non viene eseguito per tutte le iterazioni del ciclo nel cammino. In tutti i casi, comunque, il modello si è rilevato molto efficiente, determinando se una soluzione esistesse o no in meno di un secondo.
Esperimento programma sommaTuttiElementiVettore Gli esperimenti per il programma sommaTuttiElementiVettore sono stati effettuati, analogamente al caso precedente, imponendo i quattro cammini determinati con il modello per la generazione di una base di cammini. I cammini vengono riportati, per comodità, sul grafo di flusso del programma in Figura 72.

126
Figura 72 : cammini di una base per il programma sommaTuttiElementiVettore
In questo caso un solo cammino è risultato percorribile, quello in cui il ciclo viene eseguito. Per quelli non percorribili il modello non trova, giustamente, soluzioni, mentre per quello ch esegue il ciclo viene determinata la seguente soluzione, per l’array in ingresso: {-10,0,0,10,10}. In tutti i casi, comunque, il modello si è rivelato molto efficiente, determinando se una soluzione esistesse o no in meno di un secondo.
Esperimenti programmi bubleSort e selectionSort Gli esperimenti per il programma bubbleSort e selectionSort vengono presentati insieme in quanto, hanno il medesimo grafo di flusso, e quindi sono stati provati con gli stessi cammini. I risultati ottenuti coincidono come soluzioni trovate e, i tempi sono quasi identici. Gli esperimenti sono stati effettuati, analogamente al caso precedente, imponendo i quattro cammini determinati con il modello per la generazione di una base di cammini. I cammini vengono riportati, per comodità, sul grafo di flusso del programma in Figura 73.

127
Figura 73 : cammini di una base per i programmi bubbleSort e selectionSort
Dei quattro cammini, solo due sono percorribili. Essi sono quelli in cui i cicli vengono eseguiti entrambi. Nel caso in cui le istruzioni nel ramo then dell’istruizone if nel ciclo annidato vengano eseguite la soluzione determinata è: {-7,-8,-9,-10}, ossia viene generato, correttamente, il vettore ordinato in modo inverso. Se le istruzioni nel ramo then non vengono eseguite la soluzione determinata è: {-10,-10,-10,-10}. Sia in questi due casi, che negli altri due in cui non esistono soluzioni il modello si è comportato molto efficientemente, terminando in meno di un secondo.
Esperimento programma sommaDueElementiVettore Gli esperimenti per il programma sommaDueElementiVettore sono stati effettuati, analogamente ai casi precedenti, imponendo i sei cammini determinati con il modello per la generazione di una base di cammini. I cammini vengono riportati, per comodità, sul grafo di flusso del programma in Figura 74.

128
Figura 74 : cammini di una base per il programma sommaDueElementiVettore
In questo caso i sei cammini della base sono tutti percorribili, e per ognuno di essi il modello ha determinato un caso di test, rappresentato dai valori degli elementi dell’array in ingresso, e dal valore delle due variabili che rappresentano gli indici dei due elementi. Si ricorda che questi indici possono coincidere. Di seguito vengono riportate tutte le soluzioni determinate.
• {-10,-10,-10,-10,-10}, indice1=5, indice2=-10;
• {-10,-10,-10,-10,-10}, indice1=-10, indice2=-10;
• {-10,-10,-10,-10,-10}, indice1=0, indice2=5;
• {5,-10,-10,-10,-10}, indice1=0, indice2=0;
• {-5,-10,-10,-10,-10}, indice1=5, indice2=-10;
• {-10,-10,-10,-10,-10}, indice1=0, indice2=-10;
In tutti i casi il modello si è comportato in modo efficiente, terminando in meno di un secondo.
Esperimento programma sample Gli esperimenti per il programma sample sono stati effettuati, analogamente ai casi precedenti, imponendo i sei cammini determinati con il modello per la generazione di una base di cammini. I cammini vengono riportati, per comodità, sul grafo di flusso del programma in Figura 75.

129
Figura 75 : cammini di una base per il programma sample
Inoltre, sono stati effettuati altri test, imponendo cammini derivati da quelli della base, tenendo in considerazione il legame esistente tra alcune condizioni nelle istruzioni condizionali nel codice sorgente. In tutti i casi il modello si rivelato molto efficiente, determinando se esistesse o meno una soluzione in un tempo inferiore al secondo.
Il programma puntoSella non è stato utilizzato nei test di questo modello. In tutti i test effettuati, come è stato mostrato, OPL ha risposto sempre benissimo, dando la risposta in tempi sempre inferiori al secondo. Questo anche nei casi, come l’ordinamento dei vettori, in cui essendo il cammino particolarmente lungo, il numero delle variabili aumentasse. Ad esempio, nel selectionSort, per il cammino che prevedeva di eseguire i due cicli eseguendo tutte le istruzioni previste, il che corrispondeva a dover generare un vettore di ingresso ordinato inversamente all’ordinamento voluto, OPL ha trovato una soluzione in un tempo di circa 0.20 sec. Questi test mostrano come il modello sviluppato permetta una forte propagazione dei vincoli, e quindi una forte riduzione dello spazio di ricerca, una volta naturalmente imposto il cammino.

130
Capitolo 7 Conclusioni e sviluppi futuri
In questa tesi è stato presentato un nuovo approccio alla generazione automatica di casi di test. Esso è basato sulla metodologia a scatola bianca e sull’utilizzo della programmazione a vincoli. La combinazione di queste ultime non è nuovo, infatti in letteratura è possibile trovarne altri esempi, ma il nostro approccio presenta delle differenze sostanziali nel modo in cui è concepito. L’obiettivo della tesi, infatti, è stato quello di determinare una metodologia che permettesse di affrontare il problema della generazione automatica di casi di test attraverso la programmazione a vincoli, utilizzando quest’ultima ad alto livello. Negli altri approcci, infatti, vengono sì utilizzate le tecniche della programmazione a vincoli, ma specializzandole per questo tipo di problema, rendendo quindi strettamente legati l’aspetto di modellazione del problema e quello di risoluzione. Nel lavoro presentato in questa tesi l’idea fondamentale che si è voluta realizzare è di tenere separati questi ultimi due aspetti: ossia utilizzare le tecniche standard di programmazione a vincoli per modellare il problema della generazione di casi di test. La metodologia che viene presentata, quindi, si occupa solo degli aspetti relativi alla modellazione del problema come problema di soddisfacibilità di vincoli, e non delle tecniche implementative per risolverlo. Il lavoro svolto ha portato allo sviluppo di due modelli:
• modello per la generazione di una base di cammini indipendenti;
• modello per la generazione di casi di test.
Il primo affronta il problema di determinare, dato il grafo di flusso di un programma, una base di cammini linearmente indipendenti; il secondo, invece, ha come obiettivo quello di generare dei valori per i parametri di ingresso di un metodo java, affinché venga percorso un determinato cammino. I modelli sono stati sviluppati utilizzando il linguaggio OPL, per la sua espressività e generalità. Successivamente, sono stati realizzati degli esperimenti, utilizzando il risolutore della ILOG OPL Studio, per verificare l’efficienza dei due modelli, e la loro effettiva usabilità. I risultati ottenuti sono incoraggianti, in quanto i tempi di risoluzione sono sempre stati buoni, tranne che in un caso, relativamente al primo modello, in cui data la notevole complessità (cf. il programma puntoSella, di complessità ciclomatica pari a 9) era immaginabile che i tempi aumentassero in modo notevole. In particolare, mentre il modello per la generazione di casi di test ha risposto sempre

131
con tempi molto bassi (inferiori al secondo), l’altro modello ha mostrato un incremento dei tempi legato alla presenza di cicli ed all’aumentare della complessità ciclomatica del programma, rimanendo comunque accettabile anche per complessità alte (ad eccezione del caso menzionato precedentemente). Nel corso del lavoro svolto è stato anche realizzato un tool che, prendendo il codice sorgente di un metodo java, genera in modo automatico i due modelli corrispondenti. Potrebbe essere interessante, pensando a sviluppi futuri, tradurre i modelli presentati in corrispondenti problemi SAT, al fine di vedere se i grandi progressi negli algoritmi per la risoluzioni di SAT, compiuti negli ultimi anni, possano produrre risultati ancora più efficienti. Considerato, poi il buon comportamento dei due modelli, è interessante l’idea di poterli unire, in modo da generare un modello che dato un modulo java, calcoli una base di cammini linearmente indipendenti e percorribili, ritornando anche i valori per i parametri di input ????. Questo naturalmente non è sempre possibile, ossia non sempre esiste una base di cammini linearmente indipendenti che siano tutti percorribili. In questi casi si potrebbe pensare di fare vari tentativi, diminuendo progressivamente il numero di cammini cercati, oppure trasformando il problema in un problema di ottimizzazione, in cui la funzione obiettivo da massimizzare sia il numero dei cammini appartenenti alla base. Una primo tentativo di come unire i due modelli, senza renderlo un problema di ottimizzazione, viene presentato di seguito.
7.1 Una possibile unione dei due modelli I due modelli che sono stati presentati nei paragrafi precedenti sono stati sviluppati con lo scopo di trovare i valori di input di un metodo java, dato un cammino, il primo, e di determinare una base di cammini indipendenti per il test di un metodo java, di cui viene fornito il grafo di flusso, il secondo. Nel secondo caso, una volta determinata la base, come è stato già specificato in precedenza, essa non indica quante volte un ciclo vada iterato, questo deve essere scelto indipendentemente dal modello, per poi determinare il cammino effettivo che, si vuole imporre, venga percorso. Infatti, anche se nel modello il cammino viene anche rappresentato come sequenza di nodi, essa ha solo lo scopo di permettere di imporre dei vincoli che rendano il cammino continuo e non contraddittorio, per i motivi visti in precedenza (presenza ad esempio di entrambi i rami di un istruzione condizionale). Non vengono imposti vincoli sui cicli, in quanto l’obiettivo era la determinazione della matrice_Cammini_Archi. L’obiettivo era determinare quest’ultima, per poi fornirla in ingresso ad un programma esterno che prendendo in considerazione questi cammini, ed altri requisiti, come la n-copertura, generasse la sequenza di istruzioni che rappresentano il cammino. Verrà mostrato, nel capitolo successivo, come OPL abbia un buon comportamento nel gestire questi modelli. Quindi, successivamente, con lo scopo di esaminare

132
possibili estensioni e sviluppi, si è voluto esaminare la possibilità di unire i due modelli insieme, per determinare una base di cammini e i rispettivi casi di test. Questo problema diventa, però, molto più complesso. Di seguito verranno presentate le modifiche che è necessario apportare ai due modelli per poterli fondere in unico modello, e successivamente vengono presentati i problemi più grandi che si presentano, con delle possibili soluzioni.
7.1.1 Modifiche al modello per la generazione casi di test Le modifiche che devono essere apportate al modello per la generazione dei casi di test riguardano soprattutto la struttura delle variabili, e di conseguenza si ripercuotono sulla struttura dei vincoli. Ma, cosa fondamentale, non deve essere aggiunto alcun vincolo. Le variabili, come è stato mostrato precedentemente, sono tutti degli array, a parte l’eventuale variabile valoreRitorno che viene definita solo se il metodo restituisce un valore. Esse subiranno tutte una modifica nella loro struttura: verrà aggiunta una dimensione, che servirà a definire una variabile per ogni cammino. Anche valoreRitorno diventerà un array, avente come dimensione proprio questa nuova dimensione. La nuova dimensione sarà definita sull’intervallo [0..numero_Cammini-1], dove numero_Cammini è la costante che è definita nell’altro modello, che naturalmente nella fusione dei due modelli viene quindi definita per entrambi, o se si preferisce viene definita per il nuovo modello unione dei due. Di consequenza, tutti i vincoli precedentemente mostrati, andranno replicati per tutti i cammini, introducendo nel forall anche un parametro cammini, definito sull’intervallo dei cammini. Ad esempio, la definizione delle variabili nel esempio mostrato alla fine del paragrafo 4.3.11 diventano le seguenti:
int time_limit = 40; int mymax=10; int numero_Cammini=3; int n_instructions =10 ; range instructions [0..n_instructions]; range myInt [-mymax..mymax]; range time [0..time_limit]; var instructions progCounter[0..numero_Cammini-1,ti me]; var myInt valoreRitorno[0..numero_Cammini-1]; var myInt vett[0..numero_Cammini-1,time,0..4]; var myInt result[0..numero_Cammini-1,time]; var myInt size[0..numero_Cammini-1,time]; var myInt i[0..numero_Cammini-1,time];
Mentre come esempio dei nuovi vincoli, dello stesso modello vengono presentati i vincoli modificati corrispondenti ai primi quattro del modello precedente.
forall(cammino in 0..numero_Cammini-1) result[cammi no,0]=-mymax; forall(cammino in 0..numero_Cammini-1) size[cammino ,0]=-mymax;

133
forall(cammino in 0..numero_Cammini-1) i[cammino,0] =-mymax;
forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1) {progCounter[cammino,t]=1 => (progCounter[cammino,t +1]=2 &((result[cammino,t+1]=-10)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); };
7.1.2 Modifiche al modello per la generazione di un a base di cammini
Il modello per la generazione di una base di cammini deve, invece, subire delle modifiche più sostanziose, con l’introduzione di nuove costanti, nuove variabili e, nuovi vincoli. Tutto questo si rende necessario, in quanto dalla rappresentazione dei cammini presente nel modello, bisogna determinare la sequenza di valori che deve assumere il progCounter. Prima di procedere, vengono presentate di seguito alcune parti dei due modelli relative ad un programma molto semplice, in modo da richiamare alcuni dettagli presentati nei capitoli precedenti.
Figura 76 : dichiarazione variabili di un modello per la generazione dei casi di test

134
Figura 77 : alcuni vincoli di un modello per generazione dei casi di test
Figura 78 : dichiarazione variabili e schema dell'istanza per un modello per la generazione di
una base di cammini indipendenti
Nel modello per la generazione di una base di cammini (cf. Figura 78) i cammini vengono rappresentati attraverso le due matrici di variabili matrice_Cammini_Archi e la matrice_Cammini_Sequenza_nodi, cioè o indicando la presenza o meno di un arco, oppure indicando la sequenza di nodi del grafo di flusso. Non c’è, però, una corrispondenza uno a uno tra i nodi del grafo e le istruzioni del programma, cioè ad ogni istruzione del programma non corrisponde un nodo del grafo di flusso. Se, ad esempio, sono presenti una serie di assegnazioni in sequenza, queste vengono rappresentate come un unico nodo, in quanto se ne viene eseguita una, sicuramente vengono eseguite tutte, il flusso di controllo è cioè unico in quel punto. Nel modello per la generazione di casi di test un cammino che deve essere eseguito viene rappresentato come sequenza dei valori della variabile progCounter. Si ricorda che quest’ultima assume valori che indicano la singola istruzione del programma, essendo state queste precedentemente numerate. Il

135
cammino viene indicato in questo modo perché i vincoli che esprimono la semantica delle singole istruzioni fa riferimento proprio ai valori del progCounter (cf. Figura 77). Per unire i due modelli è quindi necessario creare una corrispondenza tra la sequenza di nodi del grafo (e le relative istruzioni al loro interno) e la sequenza dei valori del progCounter. Per affrontare questo problema si procede come indicato di seguito. Per prima cosa si definisce una nuova costante, costituita da un array, che indichi per ogni nodo del grafo quante istruzioni esso contiene. Questo valore può, naturalmente, anche essere pari a 0 se il nodo non contiene istruzioni o condizioni, mentre è pari al loro numero di esse nel caso contrario. Questa costante prende il nome di matrice_Istruzioni_Nodo, ed ha un’unica dimensione che è definita sull’intervallo [0..numero_Nodi_Grafo]. Il suo elemento generico matrice_Istruzioni_Nodo[i] rappresenta quindi il numero di istruzioni o condizioni presenti nel nodo i. Si ricorda, al riguardo, che il grafo di flusso che viene generato nel caso delle condizioni, ha un nodo per ogni condizione atomica. Poiché tra la sequenza dei nodi e la sequenza delle istruzioni non c’è una corrispondenza biunivoca, anche gli istanti di tempo dei due modelli non coincidono. E’ necessario, quindi, rappresentare la relazione che intercorre tra di essi. A questo scopo viene definita una variabile che, per ogni cammino e per ogni istante di tempo relativo alla sequenza di nodi, indichi a che istante nella sequenza delle istruzioni ci si deve riferire. Questa variabile prende il nome di matrice_Cammini_Sequenza_IstantiPC, essa è un array bidimensionale le cui dimensioni sono definite, rispettivamente, sull’insieme dei camini, e sull’intervallo [0..MaxTime], mentre il dominio dei suoi elementi è il range time definito nell’altro modello. Quindi un suo elemento generico matrice_Cammini_Sequenza_IstantiPC[i,j]=a, indica che nel cammino i, all’istante j nella sequenza dei nodi, nella sequenza delle istruzioni si è arrivati a utilizzare l’istante a-1, e che quindi per la prima istruzione corrispondente all’nodo della sequenza all’istante j+1 deve essere a. Il valore degli elementi di questa variabile viene fissato in base ai nodi presenti nella sequenza rappresentante il cammino, e vengono imposti tramite due vincoli, di seguito mostrati. Il primo vincolo serve a gestire il primo nodo della sequenza, ed ha la struttura seguente:
forall(cammino in 0..numero_Cammini-1)
matrice_Cammini_Sequenza_IstantiPC[cammino,0]= matrice_Istruzioni_Nodo[matrice_Cammini_Sequenza_No di[cammino,0]];
Esso impone che per ogni cammino C, il valore della matrice_Cammini_Sequenza_IstantiPC del cammino C per l’istante 0 sia proprio pari al numero di istruzioni presenti nel nodo della sequenza all’istante 0.

136
Il secondo vincolo serve, invece, a gestire gli istanti di tempo successivi, e per far questo fa riferimento nel vincolo al valore della stessa matrice all’istante precedente. Il vincolo ha la seguente struttura:
forall(cammino in 0..numero_Cammini-1,istante in 1. .MaxTime) matrice_Cammini_Sequenza_IstantiPC[cammino,istante ]=
matrice_Cammini_Sequenza_IstantiPC[cammino,istante- 1]
+matrice_Istruzioni_Nodo[matrice_Cammini_Sequenza_N odi[cammino,istante]];
Esso impone che, per ogni cammino C e per ogni istante di tempo T successivo all’istante 0 e relativo alla sequenza di nodi, il valore della matrice_Cammini_Sequenza_IstantiPC sia uguale alla somma del valore della stessa matrice, per il medesimo cammino C all’istante T-1, e del numero di istruzioni presenti nel nodo presente all’istante T nella sequenza dei nodi del cammino C. I valori della variabile matrice_Cammini_Sequenza_IstantiPC sono, quindi, del tutto determinati non appena vengono assegnati i valori alla variabile matrice_Cammini_Sequenza_nodi. L’idea, naturalmente, è di generare prima i valori di quest’ultima, attraverso una procedura di ricerca opportuna. I vincoli successivi che vengono introdotti nel modello hanno lo scopo di imporre i corretti valori della variabile progCounter affinché rappresenti il cammino selezionato. Essi realizzano quindi il collegamento finale tra i due modelli, facendo sì che una soluzione del primo diventi un’insieme di cammini da soddisfare nel secondo. Questo viene realizzato attraverso una serie di vincoli simili tra loro, e generati per ogni nodo che abbia almeno un’istruzione o una condizione al suo interno. Nel caso del nodo start, i vincoli saranno di due tipi, uno relativo all’istante della sequenza di nodi 0 ed, uno relativo agli istanti successivi. Per gli altri nodi, invece, si generano i vincoli solo relativamente agli istanti successivi, in quanto il nodo all’istante 0 deve essere per forza il nodo start: questo è imposto tramite un vincolo presentato in 5.2.1. Vengono presentati per primi i vincoli relativi al nodo start. Nel caso dell’istante iniziale, e considerando un nodo iniziale che abbia 2 istruzioni o condizioni al suo interno, il vincolo avrà la forma seguente:
forall(cammino in 0..numero_Cammini-1)
matrice_Cammini_Sequenza_Nodi[cammino,0]=1=> (
progCounter[cammino,0]=1
&progCounter[cammino,1]=2
);
Esso impone che, per ogni cammino C, se il nodo start (nodo 1) è il nodo iniziale della sequenza, allora il progCounter del cammino C all’istante 0 deve ‘puntare’

137
alla prima istruzione presente nel nodo start, mentre all’istante successivo deve ‘puntare’ alla seconda istruzione. L’altro vincolo, relativo al nodo start, che viene presentato è analogo al precedente, ma si riferisce ad un qualsiasi istante successivo al primo, relativamente alla sequenza di nodi. Esso ha la struttura seguente:
forall(cammino in 0..numero_Cammini-1,istante in 1. .MaxTime)
matrice_Cammini_Sequenza_Nodi[cammino,istante]=1 =>
(progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=1
&progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]+1]=2
);
Esso impone che, per ogni cammino C ed ogni istante di tempo T successivo al primo relativamente alla sequenza di nodi, se il nodo N della sequenza di nodi all’istante T è il nodo start, allora il progCounter del cammino C all’istante t, dato dal valore della matrice_Cammini_Sequenza_IstantiPC del cammino C all’istante T-1, deve ‘puntare’ alla prima istruzione del nodo start, mentre all’istante t+1 deve ‘puntare’ alla seconda istruzione. Con i vincoli appena presentati si stabilisce una relazione tra la sequenza di nodi ed i valori del progCounter relativamente al solo nodo start. Per realizzare la stessa cosa per gli altri nodi, si introduce un vincolo, simile al secondo visto per il nodo start, per ogni nodo del grafo di controllo che abbia almeno un’istruzione o una condizione. Il nodo avrà la seguente struttura:
forall(cammino in 0..numero_Cammini-1,istante in 1. .MaxTime)
matrice_Cammini_Sequenza_Nodi[cammino,istante]= ω=> (progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]= α
);
dove nell’implicato saranno presenti tanti vincoli di uguaglianza quante sono le istruzioni del nodo in questione, tutti messi in and tra loro. Il significato del vincolo è analogo al secondo vincolo del nodo start. Un ultimo vincolo viene introdotto per la gestione del nodo fine. Infatti, se ad un certo punto della sequenza di nodi è presente il nodo fine, bisogna imporre che il progCounter all’istante relativo valga 0, indicando che l’esecuzione è terminata. Il vincolo ha la seguente struttura:
forall(cammino in 0..numero_Cammini-1,istante in 1. .MaxTime)

138
matrice_Cammini_Sequenza_Nodi[cammino,istante]=2 => (progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=0
);
Il significato del vincolo è analogo a quello dei vincoli precedenti, con la sola differenza che il valore del progCounter viene imposto valga 0, ossia il valore che indica la fine dell’esecuzione.
7.1.3 Problemi relativi all’unione dei due modelli Nei paragrafi precedenti è stato presentato un modo per unire i due modelli presentati precedentemente, al fine di costituire un unico modello che permetta di determinare una base di cammini indipendenti ed, i casi di test per ogni cammino della base. Il modello unione presenta, però, dei problemi. Il primo problema a dover essere risolto è quello di legare in qualche modo i due orizzonti temporali: time_limit e MaxTime, che, si ricorda, sono i valori massimi per gli istanti temporali, nel modello per la generazione di casi di test, nel primo caso e, per la sequenza dei nodi nel modello per la generazione di una base di cammini indipendenti, nel secondo caso. Infatti, in caso contrario si potrebbe verificare un accesso fuori dai limiti dell’array. Si consideri ad esempio un caso un cui il valore di MaxTime fosse molto superiore a time_limit. Allora nell’applicare i vincoli di unione tra i due modelli relativi al progCounter, si potrebbe verificare un accesso a quest’ultima variabile per un valore dell’istante superiore al valore time_limit, essendo il valore dell’istante legato all’istante nella sequenza dei nodi del nodo in questione. Una possibile soluzione è porsi in una condizione molto conservativa, e considerare qual è il numero massimo di istruzioni presenti in un nodo e porre, quindi, il valore di time_limit proprio uguale al prodotto tra il massimo numero di istruzioni in un nodo e MaxTime. Questo corrisponde a considerare il caso peggiore in cui in tutti gli istanti della sequenza di nodi venisse eseguito questo nodo. I modelli presentati sono stati sviluppati con lo scopo di generare prima i cammini, e successivamente imporre i cammini nell’altro modello. Questa successione la si vorrebbe mantenere anche nel modello unione. Questo può essere imposto tramite un’opportuna procedura di ricerca, in cui si generino prima le variabili relative ai cammini, e successivamente quelle relative ai casi di test. Al riguardo esistono due possibilità, entrambe plausibili:
• generare prima tutti i cammini e, successivamente i casi di test per tutti i cammini;
• generare un cammino alla volta e per ognuno i casi di test.
Seguendo, in entrambi i casi, per le due matrici di variabili relative ai cammini, l’ordine indicato nel modello dei cammini.

139
Entrambi gli approcci hanno dei vantaggi e dei difetti. Nel primo caso i cammini generati sarebbero linearmente indipendenti, ma non è detto che siano percorribili. Questo porterebbe a fare spesso backtracking nella generazione dei cammini, perdendo ogni volta tutto il lavoro fatto anche per i cammini che, invece risultavano percorribili. Nel secondo caso, invece, generando un cammino alla volta si potrebbe determinare subito se esso è percorribile, e quindi procedere oltre solo in caso affermativo. In questo modo, però, si potrebbe arrivare ad un punto in cui non è possibile generare un nuovo cammino, che sia linearmente indipendente dai precedenti. Questo potrebbe portare a perdere tutto il lavoro già fatto. I possibili problemi derivano, principalmente, dalla possibile presenza di cammini non percorribili. Questo sia relativamente ai due approcci indicati prima, sia relativamente al trovare una soluzione in generale. Infatti, una base di cammini indipendente esiste sempre, ma non è detto che i cammini siano effettivamente percorribili. Nel momento in cui si determina che una soluzione non esiste, si potrebbe riprovare riducendo il numero dei cammini richiesti. Il problema è che prima di determinare che non ci sono soluzioni, potrebbe essere necessario analizzare uno spazio di ricerca eccessivamente grande. Questi problemi erano preventivati, e sono dovuti alla complessità del problema. Per questo i due modelli sono stati sviluppati principalmente per un uso indipendente, in quanto dividendo i due aspetti del problema, esso presenta una complessità minore. In questo modo, infatti, per generare i cammini si usa sì, il modello per determinare la base, ma poi i cammini effettivi, vengono determinati tenendo in considerazione altri aspetti del codice. Ossia, come si è detto, nella base per ogni cammino, in caso di presenza di cicli, non viene indicato quante volte iterare ogni ciclo. Si potrebbe, quindi, prendere il cammino indicato nella base e decidere il numero delle iterazioni considerando il tipo di ciclo, ad esempio se esso è un ciclo definito imporre un numero di iterazioni pari al numero previsto nel codice sorgente. In questo modo si riducono anche i cammini non percorribili che si possono generare.

140
Riferimenti bibliografici
[1] A. Aho, R. Sethi, J. Ullman. Compilers Principles, techniques and tools. Addison-Wesley Publishing Company, Inc, 1986. [2] K. R. Apt. Principles of Constraint Programming. Cambridge University Press [3] T. Ball e S. K. Rajamani. Automatically validating temporal safety properties of Interfaces. In Proc. 8th International SPIN Workshop on Model Checking of Software, pages 103–122, 2001. [4] M. M. Brandis, H. Mössenböck. Single-Pass Generation of Static Single Assignment Form for Structured Languages. Transactions on Programming Languages and Systems 16, 6 (November 1994), 1684-1698. [5] M. Cadoli, A. Schaerf. Compiling problem specifications into {SAT}. AIJ 2005, (162), 89-120 [6] J. Corbett, M. Dwyer, J. Hatcliff, C. Pasareanu, Robby, S. Laubach, e H. Zheng. Bandera: Extracting finite-state models from Java source code. In Proc. 22nd International Conference on Software Engineering (ICSE), Giugno 2000. [7] R. Cytron, J. Ferrante, B. K. Rosen, M. N. Wegman, F. K. Zadeck. Efficently Computing Static Single Assignment Form and the Control Dependence Graph. Transactions on Programming Languages and Systems 13, 4 (October 1991), 451-490. [8] M. Deutsch, Verification and Validation in Software Engineering, Prentice-Hall, 1979 [9] R.Ferguson e B.Korel. The chaining approach for software test data generation. IEEE Transactions on Software Engineering, 5(1):63-86, Gennaio 1996. [10] A.Gotlieb, B.Botella, M.Rueher. Automatic Test Data Generation using Constraint Solving Techniques. ISSTA 98. [11] A.Gotlieb, B.Botella, M.Rueher. A clp framework for computing structural test data. In Proc. Of Computational Logic (CL ‘2000) ,LNAI 1891, pages 399-413, London, UK, Luglio 2000. [12] T. A. Henzinger, R. Jhala, R. Majumdar, e G. Sutre. Software verification with blast. In Proceedings of the Tenth International SPIN Workshop on Model Checking of Software, volume 2648 of LNCS, 2003. [13] B. Korel. Automated software test data generation. IEEE Transactions on Software Engineering, 16(8):870-879, Agosto 1990.

141
[14] B.Korel e A. M. Al-Yami. Assertion-oriented automated test data generation. In Proceedings of the 18th International Conference on Software Engineering (ICSE 1996), pages 71-80. IEEE, 1996. [15] Y. Lierler, M. Maratea. Cmodels-2: {SAT}-based {A}nswer {S}et {S}olver enhanced to non-tight programs. lpnmr-04, 346—350. [16] G. Myers, The art of Software Testing, Wiley, 1979 [17] P. McMinn. Search-based software test data generation: a survey. Software Testing, verification & Reliability (STVR), 14(2):105–156, 2004. [18] R. P. Pargas, M. J. Harrold, e R. Peck. Test-data generation using genetic algorithms. Software Testing,Verification & Reliability (STVR), 9(4):263–282, 1999. [19] R. S. Pressman, Principi di Ingegneria del Software, McGraw-Hill [20] G. Santucci. Slides del corso di Ingegneria del Software, Univarsità degli studi “La Sapienza”, Roma. [21] I. Sommerville, Ingegneria del Software, Pearson. [22] M. Srinivas e L. M. Patnaik. Genetic algorithms: A survey. IEEE Computer, 27(6):17-26, 1994. [23] P. Tonella. Evolutionary testing of classes. In ISSTA’04: Proceedings of the 2004 ACM SIGSOFT international symposium on Software testing and analysis, pages 119–128, New York, NY, USA, 2004.ACM Press. [24] P. Van Hentenryck. The {OPL} Optimization Programming Language. 1999. MIT [25] W. Visser, K. Havelund, G. Brat, S.-J. Park, e F. Lerda. Model Checking Programs . Automated Software Engineering Journal, 10(2), April 2003. [26] W. Visser, C. S. Pasareanu, S. Khurshid. Test Input Generation with Java PathFinder. ISSA’04. [27] The economic impacts of inadequate infrastructure for software testing. Technical report, RTI, 2002. RTI Project number 7007.011. (http://www.nist.gov/director/prog-ofc/report02-3.pdf)

142
Appendice
All’interno di questa appendice viene riportato il codice OPL per i modelli utilizzati negli esperimenti. Poiché il modello per la generazione della base di cammini linearmente indipendenti è indipendente nei vincoli dalla particolare istanza, di seguito ne verrà riportato solo un esempio. Mentre per l’altro modello, viene riportato il modello relativo ad ogni programma utilizzato.
Modello per la generazione di una base di cammini linearmente indipendenti Viene mostrato di seguito un esempio di modello completo. //Modello per determinare i cammini indipendenti ne l grafo di controllo del metodo: eseguiSample int numero_Nodi_Grafo=8; int numero_Archi_Grafo=9; int matrice_Incidenza_Nodi[0..numero_Nodi_Grafo,0..nume ro_Nodi_Grafo]=[ [-1,-1,-1,-1,-1,-1,-1,-1,-1], [-1,-1,-1,-1,-1,0,-1,-1,-1], [-1,-1,-1,-1,-1,-1,-1,-1,-1], [-1,-1,-1,-1,-1,-1,-1,-1,3], [-1,-1,8,-1,-1,-1,-1,-1,-1], [-1,-1,-1,1,2,-1,-1,-1,-1], [-1,-1,-1,-1,-1,-1,-1,6,-1], [-1,-1,-1,-1,-1,7,-1,-1,-1], [-1,-1,-1,-1,-1,-1,4,5,-1] ]; int matrice_Nodi_Archi[0..numero_Nodi_Grafo,0..nume ro_Archi_Grafo-1]=[ [0,0,0,0,0,0,0,0,0], [-1,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,1], [0,1,0,-1,0,0,0,0,0], [0,0,1,0,0,0,0,0,-1], [1,-1,-1,0,0,0,0,1,0], [0,0,0,0,1,0,-1,0,0],

143
[0,0,0,0,0,1,1,-1,0], [0,0,0,1,-1,-1,0,0,0] ]; int numero_Cammini=3; int MaxTime=40; int matrice_Istruzioni_Nodo[0..numero_Nodi_Grafo]=[0,3, 0,0,1,2,1,1,2]; var int matrice_Cammini_Archi[0..numero_Cammini-1,0..numero_Archi_Grafo-1] in 0..1; var int matrice_Cammini_Sequenza_Nodi[0..numero_Cam mini-1,0..MaxTime] in 0..numero_Nodi_Grafo; //var time matrice_Cammini_Sequenza_IstantiPC[0..nu mero_Cammini-1,0..MaxTime]; solve{ //Vincolo per imporre che ogni cammino inizi con i l nodo start //e termini nel nodo fine forall(cammino in 0..numero_Cammini-1) matrice_Cammini_Sequenza_Nodi[cammino,0]=1&
sum(istante in 0..MaxTime)(matrice_Cammini_Sequenza_Nodi[cammino,i stante]=2)=1;
forall(cammino in 0..numero_Cammini-1)
sum(arco in 0..numero_Archi_Grafo-1) (matrice_Cammini_Archi[cammino,arco]=1
&matrice_Nodi_Archi[1,arco]=-1)=1; forall(cammino in 0..numero_Cammini-1)
sum(arco in 0..numero_Archi_Grafo-1) (matrice_Cammini_Archi[cammino,arco]=1&matrice_Nodi _Archi[2,arco]=1)=1;
//Vincolo per imporre la continuita' del cammino forall(cammino in 0..numero_Cammini-1,istante in 0 ..MaxTime-1) ((matrice_Cammini_Sequenza_Nodi[cammino,istante]>0 &matrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0)=>matrice _Incidenza_Nodi[matrice_Cammini_Sequenza_Nodi[cammino,istante],mat rice_Cammini_Sequenza_Nodi[cammino,istante+1]]>=0); forall(cammino in 0..numero_Cammini-1,istante in 0 ..MaxTime-1)

144
matrice_Cammini_Sequenza_Nodi[cammino,istante]=2=> matrice_Cammini_Sequenza_Nodi[cammino,istante+1]=0; forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime-1) matrice_Cammini_Sequenza_Nodi[cammino,istante]=0=> ((matrice_Cammini_Sequenza_Nodi[cammino,istante+1]=0)&(matric e_Cammini_Sequenza_Nodi[cammino,istante-1]=0\/matrice_Cammini_Sequenza_Nodi[cammino,istante -1]=2)); forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1) matrice_Cammini_Archi[cammino,arco]=1=> (sum(nodo in 1..numero_Nodi_Grafo:nodo<>2,secondoArco in 0..nume ro_Archi_Grafo-1) (matrice_Nodi_Archi[nodo,arco]=1&matrice_Nodi_Archi [nodo,secondoArco]=-1&matrice_Cammini_Archi[cammino,secondoArco]=1 )>=1 \/matrice_Nodi_Archi[2,arco]=1); forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1) matrice_Cammini_Archi[cammino,arco]=1=> (sum(nodo in 1..numero_Nodi_Grafo:nodo<>1,secondoArco in 0..nume ro_Archi_Grafo-1) (matrice_Nodi_Archi[nodo,arco]=-1&matrice_Nodi_Archi[nodo,secondoArco]=1&matrice_Ca mmini_Archi[cammino,secondoArco]=1)>=1 \/matrice_Nodi_Archi[1,arco]=-1); //Vincolo per unificare e rendere coerenti le due m atrici di variabili forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1,istante in 0..MaxTime-1) (matrice_Cammini_Sequenza_Nodi[cammino,istante]>0& matrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0&(matrice_I ncidenza_Nodi[matrice_Cammini_Sequenza_Nodi[cammino,istante],matri ce_Cammini_Sequenza_Nodi[cammino,istante+1]]=arco))
� matrice_Cammini_Archi[cammino,arco]=1; forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1) (sum(istante in 0..MaxTime-1) (matrice_Cammini_Sequenza_Nodi[cammino,istante]>0&m atrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0

145
& matrice_Incidenza_Nodi[matrice_Cammini_Sequenza_Nod i[cammino,istante],matrice_Cammini_Sequenza_Nodi[cammino,istante+1 ]]=arco)=0)<=> matrice_Cammini_Archi[cammino,arco]=0; forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1) matrice_Cammini_Archi[cammino,arco]=1=>
(sum(istante in 0..MaxTime-1) (matrice_Cammini_Sequenza_Nodi[cammino,istante]>0&m atrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0& matrice_Incidenza_Nodi[matrice_Cammini_Sequenza_Nod i[cammino,istante],matrice_Cammini_Sequenza_Nodi[cammi no,istante+1]]=arco)>=1);
//Vincolo per l'indipendenza dei cammini forall(cammino in 1..numero_Cammini-1) sum(arco in 0..numero_Archi_Grafo-1) (matrice_Cammini_Archi[cammino,arco]=1& sum(secondoCammino in 0..cammino-1)(matrice_Cammini_Archi[secondoCammino,arco]=1)=0) >0;
}; search{ forall(i in 0..numero_Cammini-1 ordered by increas ing i){ generate(matrice_Cammini_Archi[i]); generate(matrice_Cammini_Sequenza_Nodi[i]); }; };
Modello per la generazione di casi di test
Programma Massimo Per concludere la presentazione del modello Sapienza per la generazione di casi di test di un metodo java, viene mostrato di seguito un esempio di modello completo, con il relativo codice java. /* Codice java del metodo selezionato, con Istruzio ni Numerate public int massimo(int[] vett) { int result; **1** result=-10; int size; **2** size=5; int i; **3** i=0;

146
**4** while (**5**i<size) { **6** if (**7**vett[i]>result) **8** result=vett[i]; **9** i++; } **10**return result; } Fine codice Java */ int time_limit = 40; int mymax=10; int n_instructions =10 ; range instructions [0..n_instructions]; range myInt [-mymax..mymax]; range time [0..time_limit]; var instructions progCounter[time]; var myInt valoreRitorno; var myInt vett[time,0..4]; var myInt result[time]; var myInt size[time]; var myInt i[time]; solve { result[0]=-mymax; size[0]=-mymax; i[0]=-mymax; forall(t in 0..time_limit-1){progCounter[t]=1 => (progCounter[t+1]=2 &((result[t+1]=-10)) /*Tutto il resto non varia*/ &size[t+1]=size[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; forall(t in 0..time_limit-1){progCounter[t]=2 => (progCounter[t+1]=3 &((size[t+1]=5)) /*Tutto il resto non varia*/ &result[t+1]=result[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] );

147
}; forall(t in 0..time_limit-1){progCounter[t]=3 => (progCounter[t+1]=4 &((i[t+1]=0)) /*Tutto il resto non varia*/ &result[t+1]=result[t] &size[t+1]=size[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; forall(t in 0..time_limit-1){(progCounter[t]=4) => (progCounter[t+1]=5 /*Tutto il resto non varia*/ &result[t+1]=result[t] &size[t+1]=size[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; forall(t in 0..time_limit-1){(progCounter[t]=5&((i[t]<size[t]))) => (progCoun ter[t+1]=6); }; forall(t in 0..time_limit-1){(progCounter[t]=5¬((i[t]<size[t]))) => (progCounter[t+1]=10); }; forall(t in 0..time_limit-1){(progCounter[t]=6) => (progCounter[t+1]=7 /*Tutto il resto non varia*/ &result[t+1]=result[t] &size[t+1]=size[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; forall(t in 0..time_limit-1){(progCounter[t]=7&(((((i[t])=0))&(vett[t,0]>resu lt[t])) \/((((i[t])=1))&(vett[t,1]>result[t])) \/((((i[t])=2))&(vett[t,2]>result[t])) \/((((i[t])=3))&(vett[t,3]>result[t])) \/((((i[t])=4))&(vett[t,4]>result[t])) )) => (progCounter[t+1]=8);

148
}; forall(t in 0..time_limit-1){(progCounter[t]=7¬(((((i[t])=0))&(vett[t,0]>r esult[t])) \/((((i[t])=1))&(vett[t,1]>result[t])) \/((((i[t])=2))&(vett[t,2]>result[t])) \/((((i[t])=3))&(vett[t,3]>result[t])) \/((((i[t])=4))&(vett[t,4]>result[t])) )) => (progCounter[t+1]=9); }; forall(t in 0..time_limit-1){progCounter[t]=8 => (progCounter[t+1]=9 &(((((i[t])=0))&(result[t+1]=vett[t,0])) \/((((i[t])=1))&(result[t+1]=vett[t,1])) \/((((i[t])=2))&(result[t+1]=vett[t,2])) \/((((i[t])=3))&(result[t+1]=vett[t,3])) \/((((i[t])=4))&(result[t+1]=vett[t,4])) ) /*Tutto il resto non varia*/ &size[t+1]=size[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; forall(t in 0..time_limit-1){progCounter[t]=9 => (progCounter[t+1]=4 &((i[t+1]=i[t]+1)) /*Tutto il resto non varia*/ &result[t+1]=result[t] &size[t+1]=size[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; forall(t in 0..time_limit-1){progCounter[t]=10 => (progCounter[t+1]=0 &((valoreRitorno=result[t])) /*Tutto il resto non varia*/ &result[t+1]=result[t] &size[t+1]=size[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); };

149
forall(t in 0..time_limit-1){progCounter[t]= 0 => (progCounter[t+1]= 0 /*Tutto il resto non varia*/ &result[t+1]=result[t] &size[t+1]=size[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; //Invarianza Variabili nelle condizioni forall(t in 0..time_limit-1){(progCounter[t]=5) => ( result[t+1]=result[t] &size[t+1]=size[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; forall(t in 0..time_limit-1){(progCounter[t]=7) => ( result[t+1]=result[t] &size[t+1]=size[t] &i[t+1]=i[t] &vett[t+1,0]=vett[t,0] &vett[t+1,1]=vett[t,1] &vett[t+1,2]=vett[t,2] &vett[t+1,3]=vett[t,3] &vett[t+1,4]=vett[t,4] ); }; //Vincoli Aggiuntivi Propagazione Valore Condizione forall(t in 0..time_limit-1){(progCounter[t]=5&prog Counter[t+1]=6) => (i[t]<size[t]); }; forall(t in 0..time_limit-1){(progCounter[t]=5&progCounter[t+1]=10) => (not(i [t]<size[t])); }; forall(t in 0..time_limit-1){(progCounter[t]=7&prog Counter[t+1]=8) => (((((i[t])=0))&(vett[t,0]>result[t])) \/((((i[t])=1))&(vett[t,1]>result[t])) \/((((i[t])=2))&(vett[t,2]>result[t]))

150
\/((((i[t])=3))&(vett[t,3]>result[t])) \/((((i[t])=4))&(vett[t,4]>result[t])) ); }; forall(t in 0..time_limit-1){(progCounter[t]=7&prog Counter[t+1]=9) => (not(((((i[t])=0))&(vett[t,0]>result[t])) \/((((i[t])=1))&(vett[t,1]>result[t])) \/((((i[t])=2))&(vett[t,2]>result[t])) \/((((i[t])=3))&(vett[t,3]>result[t])) \/((((i[t])=4))&(vett[t,4]>result[t])) )); }; //Vincoli Cammino progCounter[0]=1; progCounter[1]=2; progCounter[2]=3; progCounter[3]=4; progCounter[4]=5; progCounter[5]=6; progCounter[6]=7; progCounter[7]=8; progCounter[8]=9; progCounter[9]=4; progCounter[10]=5; progCounter[11]=6; progCounter[12]=7; progCounter[13]=8; progCounter[14]=9; progCounter[15]=4; progCounter[16]=5; progCounter[17]=6; progCounter[18]=7; progCounter[19]=8; progCounter[20]=9; progCounter[21]=4; progCounter[22]=5; progCounter[23]=6; progCounter[24]=7; progCounter[25]=8; progCounter[26]=9; progCounter[27]=4; progCounter[28]=5; progCounter[29]=6; progCounter[30]=7; progCounter[31]=8; progCounter[32]=9; progCounter[33]=4; progCounter[34]=5; progCounter[35]=10; progCounter[36]=0;

151
}; search{ forall(istante in time ordered by increasing istan te){ generate(progCounter[istante]); generate(size[istante]); generate(i[istante]); generate(result[istante]); }; generate(valoreRitorno); generate(vett); }; //Fine Modello
Programma sommaTuttiElementiVettore /* Codice java del metodo selezionato, con Istruzio ni Numerate public int sommaTuttiElementiVettore(int[] vett) { int size; **1** size=5; int i; **2** i=0; int result; **3** result=0; **4** while (**5**i<size) { **6** result=result+vett[i]; **7** i++; } **8** if (**9**result<10&&**10**result>-10) **11**return result; else **12**return 0; } Fine codice Java */ int time_limit = 40; int mymax=10; int numero_Cammini=1; int n_instructions =12 ; range instructions [0..n_instructions]; range myInt [-mymax..mymax]; range time [0..time_limit]; var instructions progCounter[0..numero_Cammini-1,ti me]; var myInt valoreRitorno[0..numero_Cammini-1]; var myInt vett[0..numero_Cammini-1,time,0..4]; var myInt size[0..numero_Cammini-1,time]; var myInt i[0..numero_Cammini-1,time]; var myInt result[0..numero_Cammini-1,time]; solve { forall(cammino in 0..numero_Cammini-1) size[cammino ,0]=-mymax;

152
forall(cammino in 0..numero_Cammini-1) i[cammino,0] =-mymax; forall(cammino in 0..numero_Cammini-1) result[cammi no,0]=-mymax; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=1 => (progCounter[cammino ,t+1]=2 &((size[cammino,t+1]=5)) /*Tutto il resto non varia*/ &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=2 => (progCounter[cammino ,t+1]=3 &((i[cammino,t+1]=0)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=3 => (progCounter[cammino ,t+1]=4 &((result[cammino,t+1]=0)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4) => (progCounter[cammi no,t+1]=5 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3]

153
&vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=5&((i[cammino,t]<size[ca mmino,t]))) => (progCounter[cammino,t+1]=6); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=5¬((i[cammino,t]<size [cammino,t]))) => (progCounter[cammino,t+1]=8); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=6 => (progCounter[cammino ,t+1]=7 &(((((i[cammino,t])=0))&(result[cammino,t+1]=result [cammino,t]+vett[cammino,t,0])) \/((((i[cammino,t])=1))&(result[cammino,t+1]=result [cammino,t]+vett[cammino,t,1])) \/((((i[cammino,t])=2))&(result[cammino,t+1]=result [cammino,t]+vett[cammino,t,2])) \/((((i[cammino,t])=3))&(result[cammino,t+1]=result [cammino,t]+vett[cammino,t,3])) \/((((i[cammino,t])=4))&(result[cammino,t+1]=result [cammino,t]+vett[cammino,t,4])) ) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=7 => (progCounter[cammino ,t+1]=4 &((i[cammino,t+1]=i[cammino,t]+1)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=8) => (progCounter[cammi no,t+1]=9

154
/*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=9&((result[cammino,t]<10 ))) => (progCounter[cammino,t+1]=10); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=9¬((result[cammino,t] <10))) => (progCounter[cammino,t+1]=12); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=10&((result[cammino,t]>- 10))) => (progCounter[cammino,t+1]=11); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=10¬((result[cammino,t ]>-10))) => (progCounter[cammino,t+1]=12); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=11 => (progCounter[cammin o,t+1]=0 &((valoreRitorno[cammino]=result[cammino,t])) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=12 => (progCounter[cammin o,t+1]=0 &((valoreRitorno[cammino]=0)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] );

155
}; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]= 0 => (progCounter[cammin o,t+1]= 0 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; //Vincoli Invarianza Variabili Condizioni forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 5 => ( size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 9 => ( size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 10 => ( size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] );

156
}; //Vincoli Propagazioni Valori Condizioni forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=5&progCounter[cammino,t+ 1]=6) => (i[cammino,t]<size[cammino,t]); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=5&progCounter[cammino,t+ 1]=8) => (not(i[cammino,t]<size[cammino,t])); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=9&progCounter[cammino,t+ 1]=10) => (result[cammino,t]<10); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=9&progCounter[cammino,t+ 1]=12) => (not(result[cammino,t]<10)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=10&progCounter[cammino,t +1]=11) => ((result[cammino,t]>-10)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=10&progCounter[cammino,t +1]=12) => (not(result[cammino,t]>-10)); }; progCounter[0,0]=1; progCounter[0,1]=2; progCounter[0,2]=3; progCounter[0,3]=4; progCounter[0,4]=5; progCounter[0,5]=8; progCounter[0,6]=9; progCounter[0,7]=12; progCounter[0,8]=0; }; search{ forall(cammino in 0..numero_Cammini-1 ordered by in creasing cammino){ forall(istante in time ordered by increasing ist ante){ generate(progCounter[cammino,istante]); generate(size[cammino,istante]); generate(i[cammino,istante]); generate(result[cammino,istante]); }; generate(valoreRitorno[cammino]); generate(vett[cammino]); }; };

157
Programma bubbleSort /* Codice java del metodo selezionato, con Istruzio ni Numerate public int bubbleSort(int[] vett) { int size; **1** size=4; int temp; int index; **2** index=size-1; **3** while (**4**index>=0) { int j; **5** j=1; **6** while (**7**j<=index) { **8** if (**9**vett[j-1]>vett[j]) { **10** temp=vett[j]; **11** vett[j]=vett[j-1]; **12** vett[j-1]=temp; } **13** j++; } **14** index--; }} Fine codice Java */ int time_limit = 80; int mymax=10; int numero_Cammini=1; int n_instructions =14 ; range instructions [0..n_instructions]; range myInt [-mymax..mymax]; range time [0..time_limit]; var instructions progCounter[0..numero_Cammini-1,ti me]; var myInt valoreRitorno[0..numero_Cammini-1]; var myInt vett[0..numero_Cammini-1,time,0..3]; var myInt size[0..numero_Cammini-1,time]; var myInt temp[0..numero_Cammini-1,time]; var myInt index[0..numero_Cammini-1,time]; var myInt j[0..numero_Cammini-1,time]; solve { forall(cammino in 0..numero_Cammini-1) size[cammino ,0]=-mymax; forall(cammino in 0..numero_Cammini-1) temp[cammino ,0]=-mymax; forall(cammino in 0..numero_Cammini-1) index[cammin o,0]=-mymax; forall(cammino in 0..numero_Cammini-1) j[cammino,0] =-mymax; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=1 => (progCounter[cammino ,t+1]=2

158
&((size[cammino,t+1]=4)) /*Tutto il resto non varia*/ &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=2 => (progCounter[cammino ,t+1]=3 &((index[cammino,t+1]=size[cammino,t]-1)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=3) => (progCounter[cammi no,t+1]=4 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4&((index[cammino,t]>=0) )) => (progCounter[cammino,t+1]=5); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4¬((index[cammino,t]> =0))) => (progCounter[cammino,t+1]=0); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=5 => (progCounter[cammino ,t+1]=6 &((j[cammino,t+1]=1)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1]

159
&vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=6) => (progCounter[cammi no,t+1]=7 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7&((j[cammino,t]<=index[ cammino,t]))) => (progCounter[cammino,t+1]=8); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7¬((j[cammino,t]<=ind ex[cammino,t]))) => (progCounter[cammino,t+1]=14); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=8) => (progCounter[cammi no,t+1]=9 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=9& (((((j[cammino,t]-1)=0))&(((j[cammino,t])=0))&(vett[cammino,t,0]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=1))&(vett[cammino,t,0]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=2))&(vett[cammino,t,0]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=3))&(vett[cammino,t,0]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=0))&(vett[cammino,t,1]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=1))&(vett[cammino,t,1]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=2))&(vett[cammino,t,1]>vett [cammino,t,2]))

160
\/((((j[cammino,t]-1)=1))&(((j[cammino,t])=3))&(vett[cammino,t,1]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=0))&(vett[cammino,t,2]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=1))&(vett[cammino,t,2]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=2))&(vett[cammino,t,2]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=3))&(vett[cammino,t,2]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=0))&(vett[cammino,t,3]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=1))&(vett[cammino,t,3]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=2))&(vett[cammino,t,3]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=3))&(vett[cammino,t,3]>vett [cammino,t,3])) )) => (progCounter[cammino,t+1]=10); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=9¬(((((j[cammino,t]-1)=0))&(((j[cammino,t])=0))&(vett[cammino,t,0]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=1))&(vett[cammino,t,0]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=2))&(vett[cammino,t,0]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=3))&(vett[cammino,t,0]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=0))&(vett[cammino,t,1]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=1))&(vett[cammino,t,1]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=2))&(vett[cammino,t,1]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=3))&(vett[cammino,t,1]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=0))&(vett[cammino,t,2]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=1))&(vett[cammino,t,2]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=2))&(vett[cammino,t,2]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=3))&(vett[cammino,t,2]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=0))&(vett[cammino,t,3]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=1))&(vett[cammino,t,3]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=2))&(vett[cammino,t,3]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=3))&(vett[cammino,t,3]>vett [cammino,t,3])) )) => (progCounter[cammino,t+1]=13);

161
}; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=10 => (progCounter[cammin o,t+1]=11 &(((((j[cammino,t])=0))&(temp[cammino,t+1]=vett[cam mino,t,0])) \/((((j[cammino,t])=1))&(temp[cammino,t+1]=vett[cam mino,t,1])) \/((((j[cammino,t])=2))&(temp[cammino,t+1]=vett[cam mino,t,2])) \/((((j[cammino,t])=3))&(temp[cammino,t+1]=vett[cam mino,t,3])) ) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=11 => (progCounter[cammin o,t+1]=12 &( ((((j[cammino,t])=0))&(((j[cammino,t]-1)=0))&(vett[cammino,t+1,0]=vett[cammino,t,0])) \/((((j[cammino,t])=0))&(((j[cammino,t]-1)=1))&(vett[cammino,t+1,0]=vett[cammino,t,1])) \/((((j[cammino,t])=0))&(((j[cammino,t]-1)=2))&(vett[cammino,t+1,0]=vett[cammino,t,2])) \/((((j[cammino,t])=0))&(((j[cammino,t]-1)=3))&(vett[cammino,t+1,0]=vett[cammino,t,3])) \/((((j[cammino,t])=1))&(((j[cammino,t]-1)=0))&(vett[cammino,t+1,1]=vett[cammino,t,0])) \/((((j[cammino,t])=1))&(((j[cammino,t]-1)=1))&(vett[cammino,t+1,1]=vett[cammino,t,1])) \/((((j[cammino,t])=1))&(((j[cammino,t]-1)=2))&(vett[cammino,t+1,1]=vett[cammino,t,2])) \/((((j[cammino,t])=1))&(((j[cammino,t]-1)=3))&(vett[cammino,t+1,1]=vett[cammino,t,3])) \/((((j[cammino,t])=2))&(((j[cammino,t]-1)=0))&(vett[cammino,t+1,2]=vett[cammino,t,0])) \/((((j[cammino,t])=2))&(((j[cammino,t]-1)=1))&(vett[cammino,t+1,2]=vett[cammino,t,1])) \/((((j[cammino,t])=2))&(((j[cammino,t]-1)=2))&(vett[cammino,t+1,2]=vett[cammino,t,2])) \/((((j[cammino,t])=2))&(((j[cammino,t]-1)=3))&(vett[cammino,t+1,2]=vett[cammino,t,3])) \/((((j[cammino,t])=3))&(((j[cammino,t]-1)=0))&(vett[cammino,t+1,3]=vett[cammino,t,0])) \/((((j[cammino,t])=3))&(((j[cammino,t]-1)=1))&(vett[cammino,t+1,3]=vett[cammino,t,1]))

162
\/((((j[cammino,t])=3))&(((j[cammino,t]-1)=2))&(vett[cammino,t+1,3]=vett[cammino,t,2])) \/((((j[cammino,t])=3))&(((j[cammino,t]-1)=3))&(vett[cammino,t+1,3]=vett[cammino,t,3])) ) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &((((j[cammino,t])<>0)) => (vett[cammino,t+1,0]=vett[cammino,t,0])) &((((j[cammino,t])<>1)) => (vett[cammino,t+1,1]=vett[cammino,t,1])) &((((j[cammino,t])<>2)) => (vett[cammino,t+1,2]=vett[cammino,t,2])) &((((j[cammino,t])<>3)) => (vett[cammino,t+1,3]=vett[cammino,t,3])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=12 => (progCounter[cammin o,t+1]=13 &(((((j[cammino,t]-1)=0))&(vett[cammino,t+1,0]=temp[cammino,t])) \/((((j[cammino,t]-1)=1))&(vett[cammino,t+1,1]=temp[cammino,t])) \/((((j[cammino,t]-1)=2))&(vett[cammino,t+1,2]=temp[cammino,t])) \/((((j[cammino,t]-1)=3))&(vett[cammino,t+1,3]=temp[cammino,t])) ) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &((((j[cammino,t]-1)<>0)) => (vett[cammino,t+1,0]=vett[cammino,t,0])) &((((j[cammino,t]-1)<>1)) => (vett[cammino,t+1,1]=vett[cammino,t,1])) &((((j[cammino,t]-1)<>2)) => (vett[cammino,t+1,2]=vett[cammino,t,2])) &((((j[cammino,t]-1)<>3)) => (vett[cammino,t+1,3]=vett[cammino,t,3])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=13 => (progCounter[cammin o,t+1]=6 &((j[cammino,t+1]=j[cammino,t]+1)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0]

163
&vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=14 => (progCounter[cammin o,t+1]=3 &((index[cammino,t+1]=index[cammino,t]-1)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]= 0 => (progCounter[cammin o,t+1]= 0 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; //Vincoli Invarianza Variabili Condizioni forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 4 => ( size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 7 => ( size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0]

164
&vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 9 => ( size[cammino,t+1]=size[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &index[cammino,t+1]=index[cammino,t] &j[cammino,t+1]=j[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; //Vincoli Propagazione Valore Condizione forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=4&progCounter[cammino,t+ 1]=5) => (index[cammino,t]>=0); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=4&progCounter[cammino,t+ 1]=0) => (not(index[cammino,t]>=0)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=7&progCounter[cammino,t+ 1]=8) => ((j[cammino,t]<=index[cammino,t])); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=7&progCounter[cammino,t+ 1]=14) => (not(j[cammino,t]<=index[cammino,t])); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=9&progCounter[cammino,t+ 1]=10) => ( ((((j[cammino,t]-1)=0))&(((j[cammino,t])=0))&(vett[cammino,t,0]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=1))&(vett[cammino,t,0]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=2))&(vett[cammino,t,0]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=3))&(vett[cammino,t,0]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=0))&(vett[cammino,t,1]>vett [cammino,t,0]))

165
\/((((j[cammino,t]-1)=1))&(((j[cammino,t])=1))&(vett[cammino,t,1]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=2))&(vett[cammino,t,1]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=3))&(vett[cammino,t,1]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=0))&(vett[cammino,t,2]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=1))&(vett[cammino,t,2]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=2))&(vett[cammino,t,2]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=3))&(vett[cammino,t,2]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=0))&(vett[cammino,t,3]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=1))&(vett[cammino,t,3]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=2))&(vett[cammino,t,3]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=3))&(vett[cammino,t,3]>vett [cammino,t,3])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=9&progCounter[cammino,t+ 1]=13) => ( (not((((j[cammino,t]-1)=0))&(((j[cammino,t])=0))&(vett[cammino,t,0]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=1))&(vett[cammino,t,0]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=2))&(vett[cammino,t,0]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=0))&(((j[cammino,t])=3))&(vett[cammino,t,0]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=0))&(vett[cammino,t,1]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=1))&(vett[cammino,t,1]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=2))&(vett[cammino,t,1]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=1))&(((j[cammino,t])=3))&(vett[cammino,t,1]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=0))&(vett[cammino,t,2]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=1))&(vett[cammino,t,2]>vett [cammino,t,1])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=2))&(vett[cammino,t,2]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=2))&(((j[cammino,t])=3))&(vett[cammino,t,2]>vett [cammino,t,3])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=0))&(vett[cammino,t,3]>vett [cammino,t,0])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=1))&(vett[cammino,t,3]>vett [cammino,t,1]))

166
\/((((j[cammino,t]-1)=3))&(((j[cammino,t])=2))&(vett[cammino,t,3]>vett [cammino,t,2])) \/((((j[cammino,t]-1)=3))&(((j[cammino,t])=3))&(vett[cammino,t,3]>vett [cammino,t,3])) )); }; //Vincoli Cammino progCounter[0,0]=1; progCounter[0,1]=2; progCounter[0,2]=3; progCounter[0,3]=4; progCounter[0,4]=5; progCounter[0,5]=6; progCounter[0,6]=7; progCounter[0,7]=8; progCounter[0,8]=9; progCounter[0,9]=10; progCounter[0,10]=11; progCounter[0,11]=12; progCounter[0,12]=13; progCounter[0,13]=6; progCounter[0,14]=7; progCounter[0,15]=8; progCounter[0,16]=9; progCounter[0,17]=10; progCounter[0,18]=11; progCounter[0,19]=12; progCounter[0,20]=13; progCounter[0,21]=6; progCounter[0,22]=7; progCounter[0,23]=8; progCounter[0,24]=9; progCounter[0,25]=10; progCounter[0,26]=11; progCounter[0,27]=12; progCounter[0,28]=13; progCounter[0,29]=6; progCounter[0,30]=7; progCounter[0,31]=14; progCounter[0,32]=3; progCounter[0,33]=4; progCounter[0,34]=5; progCounter[0,35]=6; progCounter[0,36]=7; progCounter[0,37]=8;

167
progCounter[0,38]=9; progCounter[0,39]=10; progCounter[0,40]=11; progCounter[0,41]=12; progCounter[0,42]=13; progCounter[0,43]=6; progCounter[0,44]=7; progCounter[0,45]=8; progCounter[0,46]=9; progCounter[0,47]=10; progCounter[0,48]=11; progCounter[0,49]=12; progCounter[0,50]=13; progCounter[0,51]=6; progCounter[0,52]=7; progCounter[0,53]=14; progCounter[0,54]=3; progCounter[0,55]=4; progCounter[0,56]=5; progCounter[0,57]=6; progCounter[0,58]=7; progCounter[0,59]=8; progCounter[0,60]=9; progCounter[0,61]=10; progCounter[0,62]=11; progCounter[0,63]=12; progCounter[0,64]=13; progCounter[0,65]=6; progCounter[0,66]=7; progCounter[0,67]=14; progCounter[0,68]=3; progCounter[0,69]=4; progCounter[0,70]=5; progCounter[0,71]=6; progCounter[0,72]=7; progCounter[0,73]=14; progCounter[0,74]=3; progCounter[0,75]=4; progCounter[0,76]=0; }; search{ forall(cammino in 0..numero_Cammini-1 ordered by in creasing cammino){ forall(istante in time ordered by increasing ist ante){ generate(progCounter[cammino,istante]); generate(size[cammino,istante]);

168
generate(temp[cammino,istante]); generate(index[cammino,istante]); generate(j[cammino,istante]); }; generate(valoreRitorno[cammino]); generate(vett[cammino]); }; };
Programma selectionSort /* Codice java del metodo selezionato, con Istruzio ni Numerate public static void selectionSort(int[] vett) { int size; **1** size=4; int i,int j; int min,int temp; **2** i=0; **3** while (**4**i<size-1) { **5** min=i; **6** j=i+1; **7** while (**8**j<size) { **9** if (**10**vett[j]<vett[min]) **11** min=j; **12** j++; } **13** temp=vett[i]; **14** vett[i]=vett[min]; **15** vett[min]=temp; **16** i++; }} Fine codice Java */ int time_limit = 40; int mymax=10; int numero_Cammini=1; int n_instructions =16 ; range instructions [0..n_instructions]; range myInt [-mymax..mymax]; range time [0..time_limit]; var instructions progCounter[0..numero_Cammini-1,ti me]; var myInt vett[0..numero_Cammini-1,time,0..3]; var myInt size[0..numero_Cammini-1,time]; var myInt i[0..numero_Cammini-1,time]; var myInt j[0..numero_Cammini-1,time]; var myInt min[0..numero_Cammini-1,time]; var myInt temp[0..numero_Cammini-1,time]; solve { forall(cammino in 0..numero_Cammini-1) size[cammino ,0]=-mymax; forall(cammino in 0..numero_Cammini-1) i[cammino,0] =-mymax; forall(cammino in 0..numero_Cammini-1) j[cammino,0] =-mymax;

169
forall(cammino in 0..numero_Cammini-1) min[cammino, 0]=-mymax; forall(cammino in 0..numero_Cammini-1) temp[cammino ,0]=-mymax; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=1 => (progCounter[cammino ,t+1]=2 &((size[cammino,t+1]=4)) /*Tutto il resto non varia*/ &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=2 => (progCounter[cammino ,t+1]=3 &((i[cammino,t+1]=0)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=3) => (progCounter[cammi no,t+1]=4 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4&((i[cammino,t]<size[ca mmino,t]-1))) => (progCounter[cammino,t+1]=5); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4¬((i[cammino,t]<size [cammino,t]-1))) => (progCounter[cammino,t+1]=0

170
); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=5 => (progCounter[cammino ,t+1]=6 &((min[cammino,t+1]=i[cammino,t])) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=6 => (progCounter[cammino ,t+1]=7 &((j[cammino,t+1]=i[cammino,t]+1)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7) => (progCounter[cammi no,t+1]=8 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=8&((j[cammino,t]<size[ca mmino,t]))) => (progCounter[cammino,t+1]=9); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=8¬((j[cammino,t]<size [cammino,t]))) => (progCounter[cammino,t+1]=13); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=9) => (progCounter[cammi no,t+1]=10

171
/*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=10&(((((j[cammino,t])=0) )&(((min[cammino,t])=0))&(vett[cammino,t,0]<vett[cammino,t,0])) \/((((j[cammino,t])=0))&(((min[cammino,t])=1))&(vet t[cammino,t,0]<vett[cammino,t,1])) \/((((j[cammino,t])=0))&(((min[cammino,t])=2))&(vet t[cammino,t,0]<vett[cammino,t,2])) \/((((j[cammino,t])=0))&(((min[cammino,t])=3))&(vet t[cammino,t,0]<vett[cammino,t,3])) \/((((j[cammino,t])=1))&(((min[cammino,t])=0))&(vet t[cammino,t,1]<vett[cammino,t,0])) \/((((j[cammino,t])=1))&(((min[cammino,t])=1))&(vet t[cammino,t,1]<vett[cammino,t,1])) \/((((j[cammino,t])=1))&(((min[cammino,t])=2))&(vet t[cammino,t,1]<vett[cammino,t,2])) \/((((j[cammino,t])=1))&(((min[cammino,t])=3))&(vet t[cammino,t,1]<vett[cammino,t,3])) \/((((j[cammino,t])=2))&(((min[cammino,t])=0))&(vet t[cammino,t,2]<vett[cammino,t,0])) \/((((j[cammino,t])=2))&(((min[cammino,t])=1))&(vet t[cammino,t,2]<vett[cammino,t,1])) \/((((j[cammino,t])=2))&(((min[cammino,t])=2))&(vet t[cammino,t,2]<vett[cammino,t,2])) \/((((j[cammino,t])=2))&(((min[cammino,t])=3))&(vet t[cammino,t,2]<vett[cammino,t,3])) \/((((j[cammino,t])=3))&(((min[cammino,t])=0))&(vet t[cammino,t,3]<vett[cammino,t,0])) \/((((j[cammino,t])=3))&(((min[cammino,t])=1))&(vet t[cammino,t,3]<vett[cammino,t,1]))

172
\/((((j[cammino,t])=3))&(((min[cammino,t])=2))&(vet t[cammino,t,3]<vett[cammino,t,2])) \/((((j[cammino,t])=3))&(((min[cammino,t])=3))&(vet t[cammino,t,3]<vett[cammino,t,3])) )) => (progCounter[cammino,t+1]=11); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=10¬(((((j[cammino,t]) =0))&(((min[cammino,t])=0))&(vett[cammino,t,0]<vett[cammino,t,0])) \/((((j[cammino,t])=0))&(((min[cammino,t])=1))&(vet t[cammino,t,0]<vett[cammino,t,1])) \/((((j[cammino,t])=0))&(((min[cammino,t])=2))&(vet t[cammino,t,0]<vett[cammino,t,2])) \/((((j[cammino,t])=0))&(((min[cammino,t])=3))&(vet t[cammino,t,0]<vett[cammino,t,3])) \/((((j[cammino,t])=1))&(((min[cammino,t])=0))&(vet t[cammino,t,1]<vett[cammino,t,0])) \/((((j[cammino,t])=1))&(((min[cammino,t])=1))&(vet t[cammino,t,1]<vett[cammino,t,1])) \/((((j[cammino,t])=1))&(((min[cammino,t])=2))&(vet t[cammino,t,1]<vett[cammino,t,2])) \/((((j[cammino,t])=1))&(((min[cammino,t])=3))&(vet t[cammino,t,1]<vett[cammino,t,3])) \/((((j[cammino,t])=2))&(((min[cammino,t])=0))&(vet t[cammino,t,2]<vett[cammino,t,0])) \/((((j[cammino,t])=2))&(((min[cammino,t])=1))&(vet t[cammino,t,2]<vett[cammino,t,1])) \/((((j[cammino,t])=2))&(((min[cammino,t])=2))&(vet t[cammino,t,2]<vett[cammino,t,2])) \/((((j[cammino,t])=2))&(((min[cammino,t])=3))&(vet t[cammino,t,2]<vett[cammino,t,3])) \/((((j[cammino,t])=3))&(((min[cammino,t])=0))&(vet t[cammino,t,3]<vett[cammino,t,0])) \/((((j[cammino,t])=3))&(((min[cammino,t])=1))&(vet t[cammino,t,3]<vett[cammino,t,1])) \/((((j[cammino,t])=3))&(((min[cammino,t])=2))&(vet t[cammino,t,3]<vett[cammino,t,2]))

173
\/((((j[cammino,t])=3))&(((min[cammino,t])=3))&(vet t[cammino,t,3]<vett[cammino,t,3])) )) => (progCounter[cammino,t+1]=12); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=11 => (progCounter[cammin o,t+1]=12 &((min[cammino,t+1]=j[cammino,t])) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=12 => (progCounter[cammin o,t+1]=7 &((j[cammino,t+1]=j[cammino,t]+1)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=13 => (progCounter[cammin o,t+1]=14 &(((((i[cammino,t])=0))&(temp[cammino,t+1]=vett[cam mino,t,0])) \/((((i[cammino,t])=1))&(temp[cammino,t+1]=vett[cam mino,t,1])) \/((((i[cammino,t])=2))&(temp[cammino,t+1]=vett[cam mino,t,2])) \/((((i[cammino,t])=3))&(temp[cammino,t+1]=vett[cam mino,t,3])) ) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] );

174
}; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=14 => (progCounter[cammin o,t+1]=15 &(((((i[cammino,t])=0))&(((min[cammino,t])=0))&(vet t[cammino,t+1,0]=vett[cammino,t,0])) \/((((i[cammino,t])=1))&(((min[cammino,t])=1))&(vet t[cammino,t+1,1]=vett[cammino,t,1])) \/((((i[cammino,t])=1))&(((min[cammino,t])=2))&(vet t[cammino,t+1,1]=vett[cammino,t,2])) \/((((i[cammino,t])=1))&(((min[cammino,t])=3))&(vet t[cammino,t+1,1]=vett[cammino,t,3])) \/((((i[cammino,t])=2))&(((min[cammino,t])=1))&(vet t[cammino,t+1,2]=vett[cammino,t,1])) \/((((i[cammino,t])=2))&(((min[cammino,t])=2))&(vet t[cammino,t+1,2]=vett[cammino,t,2])) \/((((i[cammino,t])=2))&(((min[cammino,t])=3))&(vet t[cammino,t+1,2]=vett[cammino,t,3])) \/((((i[cammino,t])=3))&(((min[cammino,t])=1))&(vet t[cammino,t+1,3]=vett[cammino,t,1])) \/((((i[cammino,t])=3))&(((min[cammino,t])=2))&(vet t[cammino,t+1,3]=vett[cammino,t,2])) \/((((i[cammino,t])=3))&(((min[cammino,t])=3))&(vet t[cammino,t+1,3]=vett[cammino,t,3])) ) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &((((i[cammino,t])<>0)) => (vett[cammino,t+1,0]=vett[cammino,t,0])) &((((i[cammino,t])<>1)) => (vett[cammino,t+1,1]=vett[cammino,t,1])) &((((i[cammino,t])<>2)) => (vett[cammino,t+1,2]=vett[cammino,t,2])) &((((i[cammino,t])<>3)) => (vett[cammino,t+1,3]=vett[cammino,t,3])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=15 => (progCounter[cammin o,t+1]=16 &(((((min[cammino,t])=0))&(vett[cammino,t+1,0]=temp [cammino,t]))

175
\/((((min[cammino,t])=1))&(vett[cammino,t+1,1]=temp [cammino,t])) \/((((min[cammino,t])=2))&(vett[cammino,t+1,2]=temp [cammino,t])) \/((((min[cammino,t])=3))&(vett[cammino,t+1,3]=temp [cammino,t])) ) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &((((min[cammino,t])<>0)) => (vett[cammino,t+1,0]=vett[cammino,t,0])) &((((min[cammino,t])<>1)) => (vett[cammino,t+1,1]=vett[cammino,t,1])) &((((min[cammino,t])<>2)) => (vett[cammino,t+1,2]=vett[cammino,t,2])) &((((min[cammino,t])<>3)) => (vett[cammino,t+1,3]=vett[cammino,t,3])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=16 => (progCounter[cammin o,t+1]=3 &((i[cammino,t+1]=i[cammino,t]+1)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]= 0 => (progCounter[cammin o,t+1]= 0 /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; //Vincoli Invarianza Variabili Condizioni

176
forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 4 => ( size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 8 => ( size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 10 => ( size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &j[cammino,t+1]=j[cammino,t] &min[cammino,t+1]=min[cammino,t] &temp[cammino,t+1]=temp[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] ); }; //Vincoli Propagazione Valore Condizione forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=4&progCounter[cammino,t+ 1]=5) => (i[cammino,t]<size[cammino,t]-1); };

177
forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=4&progCounter[cammino,t+ 1]=0) => (not(i[cammino,t]<size[cammino,t]-1)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=8&progCounter[cammino,t+ 1]=9) => ((j[cammino,t]<size[cammino,t])); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=8&progCounter[cammino,t+ 1]=13) => (not(j[cammino,t]<size[cammino,t])); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=10&progCounter[cammino,t +1]=11) => (((((j[cammino,t])=0))&(((min[cammino,t])=0))&(vet t[cammino,t,0]<vett[cammino,t,0])) \/((((j[cammino,t])=0))&(((min[cammino,t])=1))&(vet t[cammino,t,0]<vett[cammino,t,1])) \/((((j[cammino,t])=0))&(((min[cammino,t])=2))&(vet t[cammino,t,0]<vett[cammino,t,2])) \/((((j[cammino,t])=0))&(((min[cammino,t])=3))&(vet t[cammino,t,0]<vett[cammino,t,3])) \/((((j[cammino,t])=1))&(((min[cammino,t])=0))&(vet t[cammino,t,1]<vett[cammino,t,0])) \/((((j[cammino,t])=1))&(((min[cammino,t])=1))&(vet t[cammino,t,1]<vett[cammino,t,1])) \/((((j[cammino,t])=1))&(((min[cammino,t])=2))&(vet t[cammino,t,1]<vett[cammino,t,2])) \/((((j[cammino,t])=1))&(((min[cammino,t])=3))&(vet t[cammino,t,1]<vett[cammino,t,3])) \/((((j[cammino,t])=2))&(((min[cammino,t])=0))&(vet t[cammino,t,2]<vett[cammino,t,0])) \/((((j[cammino,t])=2))&(((min[cammino,t])=1))&(vet t[cammino,t,2]<vett[cammino,t,1])) \/((((j[cammino,t])=2))&(((min[cammino,t])=2))&(vet t[cammino,t,2]<vett[cammino,t,2])) \/((((j[cammino,t])=2))&(((min[cammino,t])=3))&(vet t[cammino,t,2]<vett[cammino,t,3]))

178
\/((((j[cammino,t])=3))&(((min[cammino,t])=0))&(vet t[cammino,t,3]<vett[cammino,t,0])) \/((((j[cammino,t])=3))&(((min[cammino,t])=1))&(vet t[cammino,t,3]<vett[cammino,t,1])) \/((((j[cammino,t])=3))&(((min[cammino,t])=2))&(vet t[cammino,t,3]<vett[cammino,t,2])) \/((((j[cammino,t])=3))&(((min[cammino,t])=3))&(vet t[cammino,t,3]<vett[cammino,t,3])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=10&progCounter[cammino,t +1]=12) => (not(((((j[cammino,t])=0))&(((min[cammino,t])=0))& (vett[cammino,t,0]<vett[cammino,t,0])) \/((((j[cammino,t])=0))&(((min[cammino,t])=1))&(vet t[cammino,t,0]<vett[cammino,t,1])) \/((((j[cammino,t])=0))&(((min[cammino,t])=2))&(vet t[cammino,t,0]<vett[cammino,t,2])) \/((((j[cammino,t])=0))&(((min[cammino,t])=3))&(vet t[cammino,t,0]<vett[cammino,t,3])) \/((((j[cammino,t])=1))&(((min[cammino,t])=0))&(vet t[cammino,t,1]<vett[cammino,t,0])) \/((((j[cammino,t])=1))&(((min[cammino,t])=1))&(vet t[cammino,t,1]<vett[cammino,t,1])) \/((((j[cammino,t])=1))&(((min[cammino,t])=2))&(vet t[cammino,t,1]<vett[cammino,t,2])) \/((((j[cammino,t])=1))&(((min[cammino,t])=3))&(vet t[cammino,t,1]<vett[cammino,t,3])) \/((((j[cammino,t])=2))&(((min[cammino,t])=0))&(vet t[cammino,t,2]<vett[cammino,t,0])) \/((((j[cammino,t])=2))&(((min[cammino,t])=1))&(vet t[cammino,t,2]<vett[cammino,t,1])) \/((((j[cammino,t])=2))&(((min[cammino,t])=2))&(vet t[cammino,t,2]<vett[cammino,t,2])) \/((((j[cammino,t])=2))&(((min[cammino,t])=3))&(vet t[cammino,t,2]<vett[cammino,t,3]))

179
\/((((j[cammino,t])=3))&(((min[cammino,t])=0))&(vet t[cammino,t,3]<vett[cammino,t,0])) \/((((j[cammino,t])=3))&(((min[cammino,t])=1))&(vet t[cammino,t,3]<vett[cammino,t,1])) \/((((j[cammino,t])=3))&(((min[cammino,t])=2))&(vet t[cammino,t,3]<vett[cammino,t,2])) \/((((j[cammino,t])=3))&(((min[cammino,t])=3))&(vet t[cammino,t,3]<vett[cammino,t,3])) )); }; }; search{ forall(cammino in 0..numero_Cammini-1 ordered by in creasing cammino){ forall(istante in time ordered by increasing ist ante){ generate(progCounter[cammino,istante]); generate(size[cammino,istante]); generate(temp[cammino,istante]); generate(i[cammino,istante]); generate(j[cammino,istante]); generate(min[cammino,istante]); }; generate(vett[cammino]); }; };
Programma sommaDueElementiVettore /* Codice java del metodo selezionato, con Istruzio ni Numerate public int sommaDueElementiVettore(int[] vett,int i ndice1,int indice2) { int size; **1** size=5; int result; **2** result=0; **3** if (**4**indice1>=5||**5**indice1<0||**6**indice2>=5|| **7**indice2<0) **8**return -1; else { **9** result=vett[indice1]+vett[indice2]; **10** if (**11**result>9) **12**return 10; else **13**return 0; }}

180
Fine codice Java */ int time_limit = 40; int mymax=10; int numero_Cammini=1; int n_instructions =13 ; range instructions [0..n_instructions]; range myInt [-mymax..mymax]; range time [0..time_limit]; var instructions progCounter[0..numero_Cammini-1,ti me]; var myInt valoreRitorno[0..numero_Cammini-1]; var myInt vett[0..numero_Cammini-1,time,0..4]; var myInt indice1[0..numero_Cammini-1,time]; var myInt indice2[0..numero_Cammini-1,time]; var myInt size[0..numero_Cammini-1,time]; var myInt result[0..numero_Cammini-1,time]; solve { forall(cammino in 0..numero_Cammini-1) size[cammino ,0]=-mymax; forall(cammino in 0..numero_Cammini-1) result[cammi no,0]=-mymax; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=1 => (progCounter[cammino ,t+1]=2 &((size[cammino,t+1]=5)) /*Tutto il resto non varia*/ &indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=2 => (progCounter[cammino ,t+1]=3 &((result[cammino,t+1]=0)) /*Tutto il resto non varia*/ &indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=3) => (progCounter[cammi no,t+1]=4 /*Tutto il resto non varia*/

181
&indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4&((indice1[cammino,t]>= 5))) => (progCounter[cammino,t+1]=8); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4¬((indice1[cammino,t ]>=5))) => (progCounter[cammino,t+1]=5); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=5&((indice1[cammino,t]<0 ))) => (progCounter[cammino,t+1]=8); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=5¬((indice1[cammino,t ]<0))) => (progCounter[cammino,t+1]=6); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=6&((indice2[cammino,t]>= 5))) => (progCounter[cammino,t+1]=8); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=6¬((indice2[cammino,t ]>=5))) => (progCounter[cammino,t+1]=7); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7&((indice2[cammino,t]<0 ))) => (progCounter[cammino,t+1]=8); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7¬((indice2[cammino,t ]<0))) => (progCounter[cammino,t+1]=9); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=8 => (progCounter[cammino ,t+1]=0 &((valoreRitorno[cammino]=-1)) /*Tutto il resto non varia*/ &indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2]

182
&vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=9 => (progCounter[cammino ,t+1]=10 &(((((indice1[cammino,t])=0))&(((indice2[cammino,t] )=0))&(result[cammino,t+1]=vett[cammino,t,0]+vett[cammino,t,0])) \/((((indice1[cammino,t])=0))&(((indice2[cammino,t] )=1))&(result[cammino,t+1]=vett[cammino,t,0]+vett[cammino,t,1])) \/((((indice1[cammino,t])=0))&(((indice2[cammino,t] )=2))&(result[cammino,t+1]=vett[cammino,t,0]+vett[cammino,t,2])) \/((((indice1[cammino,t])=0))&(((indice2[cammino,t] )=3))&(result[cammino,t+1]=vett[cammino,t,0]+vett[cammino,t,3])) \/((((indice1[cammino,t])=0))&(((indice2[cammino,t] )=4))&(result[cammino,t+1]=vett[cammino,t,0]+vett[cammino,t,4])) \/((((indice1[cammino,t])=1))&(((indice2[cammino,t] )=0))&(result[cammino,t+1]=vett[cammino,t,1]+vett[cammino,t,0])) \/((((indice1[cammino,t])=1))&(((indice2[cammino,t] )=1))&(result[cammino,t+1]=vett[cammino,t,1]+vett[cammino,t,1])) \/((((indice1[cammino,t])=1))&(((indice2[cammino,t] )=2))&(result[cammino,t+1]=vett[cammino,t,1]+vett[cammino,t,2])) \/((((indice1[cammino,t])=1))&(((indice2[cammino,t] )=3))&(result[cammino,t+1]=vett[cammino,t,1]+vett[cammino,t,3])) \/((((indice1[cammino,t])=1))&(((indice2[cammino,t] )=4))&(result[cammino,t+1]=vett[cammino,t,1]+vett[cammino,t,4])) \/((((indice1[cammino,t])=2))&(((indice2[cammino,t] )=0))&(result[cammino,t+1]=vett[cammino,t,2]+vett[cammino,t,0])) \/((((indice1[cammino,t])=2))&(((indice2[cammino,t] )=1))&(result[cammino,t+1]=vett[cammino,t,2]+vett[cammino,t,1])) \/((((indice1[cammino,t])=2))&(((indice2[cammino,t] )=2))&(result[cammino,t+1]=vett[cammino,t,2]+vett[cammino,t,2])) \/((((indice1[cammino,t])=2))&(((indice2[cammino,t] )=3))&(result[cammino,t+1]=vett[cammino,t,2]+vett[cammino,t,3])) \/((((indice1[cammino,t])=2))&(((indice2[cammino,t] )=4))&(result[cammino,t+1]=vett[cammino,t,2]+vett[cammino,t,4])) \/((((indice1[cammino,t])=3))&(((indice2[cammino,t] )=0))&(result[cammino,t+1]=vett[cammino,t,3]+vett[cammino,t,0]))

183
\/((((indice1[cammino,t])=3))&(((indice2[cammino,t] )=1))&(result[cammino,t+1]=vett[cammino,t,3]+vett[cammino,t,1])) \/((((indice1[cammino,t])=3))&(((indice2[cammino,t] )=2))&(result[cammino,t+1]=vett[cammino,t,3]+vett[cammino,t,2])) \/((((indice1[cammino,t])=3))&(((indice2[cammino,t] )=3))&(result[cammino,t+1]=vett[cammino,t,3]+vett[cammino,t,3])) \/((((indice1[cammino,t])=3))&(((indice2[cammino,t] )=4))&(result[cammino,t+1]=vett[cammino,t,3]+vett[cammino,t,4])) \/((((indice1[cammino,t])=4))&(((indice2[cammino,t] )=0))&(result[cammino,t+1]=vett[cammino,t,4]+vett[cammino,t,0])) \/((((indice1[cammino,t])=4))&(((indice2[cammino,t] )=1))&(result[cammino,t+1]=vett[cammino,t,4]+vett[cammino,t,1])) \/((((indice1[cammino,t])=4))&(((indice2[cammino,t] )=2))&(result[cammino,t+1]=vett[cammino,t,4]+vett[cammino,t,2])) \/((((indice1[cammino,t])=4))&(((indice2[cammino,t] )=3))&(result[cammino,t+1]=vett[cammino,t,4]+vett[cammino,t,3])) \/((((indice1[cammino,t])=4))&(((indice2[cammino,t] )=4))&(result[cammino,t+1]=vett[cammino,t,4]+vett[cammino,t,4])) ) /*Tutto il resto non varia*/ &indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=10) => (progCounter[camm ino,t+1]=11 /*Tutto il resto non varia*/ &indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); };

184
forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=11&((result[cammino,t]>9 ))) => (progCounter[cammino,t+1]=12); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=11¬((result[cammino,t ]>9))) => (progCounter[cammino,t+1]=13); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=12 => (progCounter[cammin o,t+1]=0 &((valoreRitorno[cammino]=10)) /*Tutto il resto non varia*/ &indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=13 => (progCounter[cammin o,t+1]=0 &((valoreRitorno[cammino]=0)) /*Tutto il resto non varia*/ &indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]= 0 => (progCounter[cammin o,t+1]= 0 /*Tutto il resto non varia*/ &indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; //Vincoli Invarianza Variabili nelle Condizioni

185
forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 4 => ( indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 5 => ( indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 6 => ( indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 7 => ( indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4]

186
); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 11 => ( indice1[cammino,t+1]=indice1[cammino,t] &indice2[cammino,t+1]=indice2[cammino,t] &size[cammino,t+1]=size[cammino,t] &result[cammino,t+1]=result[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; //Vincoli Aggiuntivi Propagazione Valore Condizione forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=4&progCounter[cammino,t+ 1]=8) => (indice1[cammino,t]>=5); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=4&progCounter[cammino,t+ 1]=5) => (not(indice1[cammino,t]>=5)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=5&progCounter[cammino,t+ 1]=8) => (indice1[cammino,t]<0); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=5&progCounter[cammino,t+ 1]=6) => (not(indice1[cammino,t]<0)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=6&progCounter[cammino,t+ 1]=8) => (indice2[cammino,t]>=5); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=6&progCounter[cammino,t+ 1]=7) => (not(indice2[cammino,t]>=5)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=7&progCounter[cammino,t+ 1]=8) => (indice2[cammino,t]<0); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=7&progCounter[cammino,t+ 1]=9) => (not(indice2[cammino,t]<0)); };

187
forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=11&progCounter[cammino,t +1]=12) => (result[cammino,t]>9); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=11&progCounter[cammino,t +1]=13) => (not(result[cammino,t]>9)); }; progCounter[0,0]=1; progCounter[0,1]=2; progCounter[0,2]=3; progCounter[0,3]=4; progCounter[0,4]=5; progCounter[0,5]=8; progCounter[0,6]=0; }; search{ forall(cammino in 0..numero_Cammini-1 ordered by in creasing cammino){ forall(istante in time ordered by increasing ist ante){ generate(progCounter[cammino,istante]); generate(size[cammino,istante]); generate(indice1[cammino,istante]); generate(indice2[cammino,istante]); generate(result[cammino,istante]); }; generate(valoreRitorno[cammino]); generate(vett[cammino]); }; };
Programma sample //Modello OPL del Metodo eseguiSample contenuto nel file D:\Test\sample.java /* Codice java del metodo selezionato, con Istruzio ni Numerate public int sample(int[] a,int[] b,int target) { int i,int fa,int fb,int out; **1** i=0; **2** fa=0; **3** fb=0; **4** while (**5**i<=2) { **6** if (**7**a[i]==target) **8** fa=1; **9** i++; } **10** if (**11**fa==1)

188
{ **12** i=0; **13** fb=1; **14** while (**15**i<=2) { **16** if (**17**b[i]!=target) **18** fb=0; **19** i++; }} **20** if (**21**fb==1) **22** out=1; else **23** out=0; **24**return out; } Fine codice Java */ int time_limit = 47; int mymax=10; int numero_Cammini=1; int n_instructions =24 ; range instructions [0..n_instructions]; range myInt [-mymax..mymax]; range time [0..time_limit]; var instructions progCounter[0..numero_Cammini-1,ti me]; var myInt valoreRitorno[0..numero_Cammini-1]; var myInt a[0..numero_Cammini-1,time,0..2]; var myInt b[0..numero_Cammini-1,time,0..2]; var myInt target[0..numero_Cammini-1,time]; var myInt i[0..numero_Cammini-1,time]; var myInt fa[0..numero_Cammini-1,time]; var myInt fb[0..numero_Cammini-1,time]; var myInt out[0..numero_Cammini-1,time]; solve { forall(cammino in 0..numero_Cammini-1) i[cammino,0] =-mymax; forall(cammino in 0..numero_Cammini-1) fa[cammino,0 ]=-mymax; forall(cammino in 0..numero_Cammini-1) fb[cammino,0 ]=-mymax; forall(cammino in 0..numero_Cammini-1) out[cammino, 0]=-mymax; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=1 => (progCounter[cammino ,t+1]=2 &((i[cammino,t+1]=0)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2]

189
); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=2 => (progCounter[cammino ,t+1]=3 &((fa[cammino,t+1]=0)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=3 => (progCounter[cammino ,t+1]=4 &((fb[cammino,t+1]=0)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4) => (progCounter[cammi no,t+1]=5 /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=5&((i[cammino,t]<=2))) = > (progCounter[cammino,t+1]=6); };

190
forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=5¬((i[cammino,t]<=2)) ) => (progCounter[cammino,t+1]=10); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=6) => (progCounter[cammi no,t+1]=7 /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7&(((((i[cammino,t])=0)) &(a[cammino,t,0]=target[cammino,t])) \/((((i[cammino,t])=1))&(a[cammino,t,1]=target[camm ino,t])) \/((((i[cammino,t])=2))&(a[cammino,t,2]=target[camm ino,t])) )) => (progCounter[cammino,t+1]=8); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7¬(((((i[cammino,t])= 0))&(a[cammino,t,0]=target[cammino,t])) \/((((i[cammino,t])=1))&(a[cammino,t,1]=target[camm ino,t])) \/((((i[cammino,t])=2))&(a[cammino,t,2]=target[camm ino,t])) )) => (progCounter[cammino,t+1]=9); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=8 => (progCounter[cammino ,t+1]=9 &((fa[cammino,t+1]=1)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); };

191
forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=9 => (progCounter[cammino ,t+1]=4 &((i[cammino,t+1]=i[cammino,t]+1)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=10) => (progCounter[camm ino,t+1]=11 /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=11&((fa[cammino,t]=1))) => (progCounter[cammino,t+1]=12); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=11¬((fa[cammino,t]=1) )) => (progCounter[cammino,t+1]=20); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=12 => (progCounter[cammin o,t+1]=13 &((i[cammino,t+1]=0)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2]

192
); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=13 => (progCounter[cammin o,t+1]=14 &((fb[cammino,t+1]=1)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=14) => (progCounter[camm ino,t+1]=15 /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=15&((i[cammino,t]<=2))) => (progCounter[cammino,t+1]=16); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=15¬((i[cammino,t]<=2) )) => (progCounter[cammino,t+1]=20); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=16) => (progCounter[camm ino,t+1]=17 /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0]

193
&b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=17&(((((i[cammino,t])=0) )&(b[cammino,t,0]<>target[cammino,t])) \/((((i[cammino,t])=1))&(b[cammino,t,1]<>target[cam mino,t])) \/((((i[cammino,t])=2))&(b[cammino,t,2]<>target[cam mino,t])) )) => (progCounter[cammino,t+1]=18); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=17¬(((((i[cammino,t]) =0))&(b[cammino,t,0]<>target[cammino,t])) \/((((i[cammino,t])=1))&(b[cammino,t,1]<>target[cam mino,t])) \/((((i[cammino,t])=2))&(b[cammino,t,2]<>target[cam mino,t])) )) => (progCounter[cammino,t+1]=19); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=18 => (progCounter[cammin o,t+1]=19 &((fb[cammino,t+1]=0)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=19 => (progCounter[cammin o,t+1]=14 &((i[cammino,t+1]=i[cammino,t]+1)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); };

194
forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=20) => (progCounter[camm ino,t+1]=21 /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=21&((fb[cammino,t]=1))) => (progCounter[cammino,t+1]=22); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=21¬((fb[cammino,t]=1) )) => (progCounter[cammino,t+1]=23); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=22 => (progCounter[cammin o,t+1]=24 &((out[cammino,t+1]=1)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=23 => (progCounter[cammin o,t+1]=24 &((out[cammino,t+1]=0)) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2]

195
); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=24 => (progCounter[cammin o,t+1]=0 &((valoreRitorno[cammino]=out[cammino,t])) /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]= 0 => (progCounter[cammin o,t+1]= 0 /*Tutto il resto non varia*/ &target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; //Vincoli Invarianza Variabili Condizioni forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 5 => ( target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); };

196
forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 7 => ( target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 11 => ( target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 15 => ( target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 17 => ( target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t]

197
&out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 21 => ( target[cammino,t+1]=target[cammino,t] &i[cammino,t+1]=i[cammino,t] &fa[cammino,t+1]=fa[cammino,t] &fb[cammino,t+1]=fb[cammino,t] &out[cammino,t+1]=out[cammino,t] &a[cammino,t+1,0]=a[cammino,t,0] &a[cammino,t+1,1]=a[cammino,t,1] &a[cammino,t+1,2]=a[cammino,t,2] &b[cammino,t+1,0]=b[cammino,t,0] &b[cammino,t+1,1]=b[cammino,t,1] &b[cammino,t+1,2]=b[cammino,t,2] ); }; //Vincoli Propagazione Valore Condizione forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=5&progCounter[cammino,t+ 1]=6) => (i[cammino,t]<=2); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=5&progCounter[cammino,t+ 1]=10) => (not(i[cammino,t]<=2)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=7&progCounter[cammino,t+ 1]=8) => (((((i[cammino,t])=0))&(a[cammino,t,0]=target[camm ino,t])) \/((((i[cammino,t])=1))&(a[cammino,t,1]=target[camm ino,t])) \/((((i[cammino,t])=2))&(a[cammino,t,2]=target[camm ino,t])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=7&progCounter[cammino,t+ 1]=9) => (not(((((i[cammino,t])=0))&(a[cammino,t,0]=target[ cammino,t]))

198
\/((((i[cammino,t])=1))&(a[cammino,t,1]=target[camm ino,t])) \/((((i[cammino,t])=2))&(a[cammino,t,2]=target[camm ino,t])) )); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=11&progCounter[cammino,t +1]=12) => (fa[cammino,t]=1); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=11&progCounter[cammino,t +1]=20) => (not(fa[cammino,t]=1)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=15&progCounter[cammino,t +1]=16) => (i[cammino,t]<=2); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=15&progCounter[cammino,t +1]=20) => (not(i[cammino,t]<=2)); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=17&progCounter[cammino,t +1]=18) => (((((i[cammino,t])=0))&(b[cammino,t,0]<>target[cam mino,t])) \/((((i[cammino,t])=1))&(b[cammino,t,1]<>target[cam mino,t])) \/((((i[cammino,t])=2))&(b[cammino,t,2]<>target[cam mino,t])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=17&progCounter[cammino,t +1]=19) => (not(((((i[cammino,t])=0))&(b[cammino,t,0]<>target [cammino,t])) \/((((i[cammino,t])=1))&(b[cammino,t,1]<>target[cam mino,t])) \/((((i[cammino,t])=2))&(b[cammino,t,2]<>target[cam mino,t])) )); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=21&progCounter[cammino,t +1]=22) => (fb[cammino,t]=1); };

199
forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=21&progCounter[cammino,t +1]=23) => (not(fb[cammino,t]=1)); }; //Vincoli Cammino progCounter[0,0]=1; progCounter[0,1]=2; progCounter[0,2]=3; progCounter[0,3]=4; progCounter[0,4]=5; progCounter[0,5]=6; progCounter[0,6]=7; progCounter[0,7]=9; progCounter[0,8]=4; progCounter[0,9]=5; progCounter[0,10]=6; progCounter[0,11]=7; progCounter[0,12]=9; progCounter[0,13]=4; progCounter[0,14]=5; progCounter[0,15]=6; progCounter[0,16]=7; progCounter[0,17]=9; progCounter[0,18]=4; progCounter[0,19]=5; progCounter[0,20]=10; progCounter[0,21]=11; progCounter[0,22]=20; progCounter[0,23]=21; progCounter[0,24]=23; progCounter[0,25]=24; progCounter[0,26]=0; }; search{ forall(cammino in 0..numero_Cammini-1 ordered by in creasing cammino){ forall(istante in time ordered by increasing ist ante){ generate(progCounter[cammino,istante]); generate(i[cammino,istante]); generate(fa[cammino,istante]); generate(fb[cammino,istante]); generate(out[cammino,istante]); }; generate(valoreRitorno[cammino]);

200
generate(a[cammino]); generate(b[cammino]); generate(target[cammino]); }; };
Esempio di modello unione del modello per la genera zione di casi di test e per quello per la generazione di una base di cammini linearmente indipendenti /* Codice java del metodo selezionato, con Istruzio ni Numerate public int eseguiSample(int[] vett) { int result; **1** result=-10; int size; **2** size=5; int i; **3** i=0; **4** while (**5**i<size) { **6** if (**7**vett[i]>result) **8** result=vett[i]; **9** i++; } **10**return result; } Fine codice Java */ int time_limit = 40; int mymax=10; int numero_Cammini=3; int n_instructions =10 ; range instructions [0..n_instructions]; range myInt [-mymax..mymax]; range time [0..time_limit]; var instructions progCounter[0..numero_Cammini-1,ti me]; var myInt valoreRitorno[0..numero_Cammini-1]; var myInt vett[0..numero_Cammini-1,time,0..4]; var myInt result[0..numero_Cammini-1,time]; var myInt size[0..numero_Cammini-1,time]; var myInt i[0..numero_Cammini-1,time]; int numero_Nodi_Grafo=8; int numero_Archi_Grafo=9; int matrice_Incidenza_Nodi[0..numero_Nodi_Grafo,0..nume ro_Nodi_Grafo]=[ [-1,-1,-1,-1,-1,-1,-1,-1,-1], [-1,-1,-1,-1,-1,0,-1,-1,-1], [-1,-1,-1,-1,-1,-1,-1,-1,-1], [-1,-1,-1,-1,-1,-1,-1,-1,3],

201
[-1,-1,8,-1,-1,-1,-1,-1,-1], [-1,-1,-1,1,2,-1,-1,-1,-1], [-1,-1,-1,-1,-1,-1,-1,6,-1], [-1,-1,-1,-1,-1,7,-1,-1,-1], [-1,-1,-1,-1,-1,-1,4,5,-1] ]; int matrice_Nodi_Archi[0..numero_Nodi_Grafo,0..nume ro_Archi_Grafo-1]=[ [0,0,0,0,0,0,0,0,0], [-1,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,1], [0,1,0,-1,0,0,0,0,0], [0,0,1,0,0,0,0,0,-1], [1,-1,-1,0,0,0,0,1,0], [0,0,0,0,1,0,-1,0,0], [0,0,0,0,0,1,1,-1,0], [0,0,0,1,-1,-1,0,0,0] ]; int MaxTime=40; int matrice_Istruzioni_Nodo[0..numero_Nodi_Grafo]=[0,3, 0,0,1,2,1,1,2]; var int matrice_Cammini_Archi[0..numero_Cammini-1,0..numero_Archi_Grafo-1] in 0..1; var int matrice_Cammini_Sequenza_Nodi[0..numero_Cam mini-1,0..MaxTime] in 0..numero_Nodi_Grafo; var time matrice_Cammini_Sequenza_IstantiPC[0..nume ro_Cammini-1,0..MaxTime]; solve { forall(cammino in 0..numero_Cammini-1) result[cammi no,0]=-mymax; forall(cammino in 0..numero_Cammini-1) size[cammino ,0]=-mymax; forall(cammino in 0..numero_Cammini-1) i[cammino,0] =-mymax; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=1 => (progCounter[cammino ,t+1]=2 &((result[cammino,t+1]=-10)) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2]

202
&vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=2 => (progCounter[cammino ,t+1]=3 &((size[cammino,t+1]=5)) /*Tutto il resto non varia*/ &result[cammino,t+1]=result[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=3 => (progCounter[cammino ,t+1]=4 &((i[cammino,t+1]=0)) /*Tutto il resto non varia*/ &result[cammino,t+1]=result[cammino,t] &size[cammino,t+1]=size[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=4) => (progCounter[cammi no,t+1]=5 /*Tutto il resto non varia*/ &result[cammino,t+1]=result[cammino,t] &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=5&((i[cammino,t]<size[ca mmino,t]))) => (progCounter[cammino,t+1]=6); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=5¬((i[cammino,t]<size [cammino,t]))) => (progCounter[cammino,t+1]=10); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=6) => (progCounter[cammi no,t+1]=7 /*Tutto il resto non varia*/

203
&result[cammino,t+1]=result[cammino,t] &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7&(((((i[cammino,t])=0)) &(vett[cammino,t,0]>result[cammino,t])) \/((((i[cammino,t])=1))&(vett[cammino,t,1]>result[c ammino,t])) \/((((i[cammino,t])=2))&(vett[cammino,t,2]>result[c ammino,t])) \/((((i[cammino,t])=3))&(vett[cammino,t,3]>result[c ammino,t])) \/((((i[cammino,t])=4))&(vett[cammino,t,4]>result[c ammino,t])) )) => (progCounter[cammino,t+1]=8); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){(progCounter[cammino,t]=7¬(((((i[cammino,t])= 0))&(vett[cammino,t,0]>result[cammino,t])) \/((((i[cammino,t])=1))&(vett[cammino,t,1]>result[c ammino,t])) \/((((i[cammino,t])=2))&(vett[cammino,t,2]>result[c ammino,t])) \/((((i[cammino,t])=3))&(vett[cammino,t,3]>result[c ammino,t])) \/((((i[cammino,t])=4))&(vett[cammino,t,4]>result[c ammino,t])) )) => (progCounter[cammino,t+1]=9); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=8 => (progCounter[cammino ,t+1]=9 &(((((i[cammino,t])=0))&(result[cammino,t+1]=vett[c ammino,t,0])) \/((((i[cammino,t])=1))&(result[cammino,t+1]=vett[c ammino,t,1])) \/((((i[cammino,t])=2))&(result[cammino,t+1]=vett[c ammino,t,2])) \/((((i[cammino,t])=3))&(result[cammino,t+1]=vett[c ammino,t,3])) \/((((i[cammino,t])=4))&(result[cammino,t+1]=vett[c ammino,t,4])) ) /*Tutto il resto non varia*/ &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1]

204
&vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=9 => (progCounter[cammino ,t+1]=4 &((i[cammino,t+1]=i[cammino,t]+1)) /*Tutto il resto non varia*/ &result[cammino,t+1]=result[cammino,t] &size[cammino,t+1]=size[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]=10 => (progCounter[cammin o,t+1]=0 &((valoreRitorno[cammino]=result[cammino,t])) /*Tutto il resto non varia*/ &result[cammino,t+1]=result[cammino,t] &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time _limit-1){progCounter[cammino,t]= 0 => (progCounter[cammin o,t+1]= 0 /*Tutto il resto non varia*/ &result[cammino,t+1]=result[cammino,t] &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; //Vincoli Invarianza Variabili Condizioni forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 5 => ( result[cammino,t+1]=result[cammino,t] &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0]

205
&vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){progCounter[cammino,t]= 7 => ( result[cammino,t+1]=result[cammino,t] &size[cammino,t+1]=size[cammino,t] &i[cammino,t+1]=i[cammino,t] &vett[cammino,t+1,0]=vett[cammino,t,0] &vett[cammino,t+1,1]=vett[cammino,t,1] &vett[cammino,t+1,2]=vett[cammino,t,2] &vett[cammino,t+1,3]=vett[cammino,t,3] &vett[cammino,t+1,4]=vett[cammino,t,4] ); }; //Vincoli Propagazione Valore Condizione forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=5&progCounter[cammino,t+ 1]=6) => (i[cammino,t]<size[cammino,t]); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=5&progCounter[cammino,t+ 1]=10) => (not(i[cammino,t]<size[cammino,t])); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=7&progCounter[cammino,t+ 1]=8) => (((((i[cammino,t])=0))&(vett[cammino,t,0]>result[c ammino,t])) \/((((i[cammino,t])=1))&(vett[cammino,t,1]>result[c ammino,t])) \/((((i[cammino,t])=2))&(vett[cammino,t,2]>result[c ammino,t])) \/((((i[cammino,t])=3))&(vett[cammino,t,3]>result[c ammino,t])) \/((((i[cammino,t])=4))&(vett[cammino,t,4]>result[c ammino,t])) ); }; forall(cammino in 0..numero_Cammini-1,t in 0..time_ limit-1){(progCounter[cammino,t]=7&progCounter[cammino,t+ 1]=9) => (not(((((i[cammino,t])=0))&(vett[cammino,t,0]>resu lt[cammino,t])) \/((((i[cammino,t])=1))&(vett[cammino,t,1]>result[c ammino,t]))

206
\/((((i[cammino,t])=2))&(vett[cammino,t,2]>result[c ammino,t])) \/((((i[cammino,t])=3))&(vett[cammino,t,3]>result[c ammino,t])) \/((((i[cammino,t])=4))&(vett[cammino,t,4]>result[c ammino,t])) )); }; //Vincolo per imporre che ogni cammino inizi con il nodo start //e termini nel nodo fine forall(cammino in 0..numero_Cammini-1) matrice_Cammini_Sequenza_Nodi[cammino,0]=1& sum(istante in 0..MaxTime)(matrice_Cammini_Sequenza_Nodi[cammino,i stante]=2)=1; forall(cammino in 0..numero_Cammini-1) sum(arco in 0..numero_Archi_Grafo-1) (matrice_Cammini_Archi[cammino,arco]=1&matrice_Nod i_Archi[1,arco]=-1)=1; forall(cammino in 0..numero_Cammini-1) sum(arco in 0..numero_Archi_Grafo-1) (matrice_Cammini_Archi[cammino,arco]=1&matrice_Nodi _Archi[2,arco]=1)=1; //Vincolo per imporre la continuita' del cammino forall(cammino in 0..numero_Cammini-1,istante in 0 ..MaxTime-1) ((matrice_Cammini_Sequenza_Nodi[cammino,istante]>0 &matrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0)=>matrice _Incidenza_Nodi[matrice_Cammini_Sequenza_Nodi[cammino,istante],mat rice_Cammini_Sequenza_Nodi[cammino,istante+1]]>=0); forall(cammino in 0..numero_Cammini-1,istante in 0 ..MaxTime-1) matrice_Cammini_Sequenza_Nodi[cammino,istante]=2=> matrice_Cammini_Sequenza_Nodi[cammino,istante+1]=0; forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime-1) matrice_Cammini_Sequenza_Nodi[cammino,istante]=0=> ((matrice_Cammini_Sequenza_Nodi[cammino,istante+1]=0)&(matric e_Cammini_Sequenza_Nodi[cammino,istante-1]=0\/matrice_Cammini_Sequenza_Nodi[cammino,istante -1]=2)); forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1) matrice_Cammini_Archi[cammino,arco]=1=>

207
(sum(nodo in 1..numero_Nodi_Grafo:nodo<>2,secondoArco in 0..nume ro_Archi_Grafo-1) (matrice_Nodi_Archi[nodo,arco]=1&matrice_Nodi_Archi [nodo,secondoArco]=-1&matrice_Cammini_Archi[cammino,secondoArco]=1 )>=1 \/matrice_Nodi_Archi[2,arco]=1); forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1) matrice_Cammini_Archi[cammino,arco]=1=> (sum(nodo in 1..numero_Nodi_Grafo:nodo<>1,secondoArco in 0..nume ro_Archi_Grafo-1) (matrice_Nodi_Archi[nodo,arco]=-1&matrice_Nodi_Archi[nodo,secondoArco]=1&matrice_Ca mmini_Archi[cammino,secondoArco]=1)>=1 \/matrice_Nodi_Archi[1,arco]=-1); //Vincolo per unificare e rendere coerenti le due matrici di variabili forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1,istante in 0..MaxTime-1) (matrice_Cammini_Sequenza_Nodi[cammino,istante]>0& matrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0&(matrice_I ncidenza_Nodi[matrice_Cammini_Sequenza_Nodi[cammino,istante],matri ce_Cammini_Sequenza_Nodi[cammino,istante+1]]=arco)) => matrice_Cammini_Archi[cammino,arco]=1; forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1) (sum(istante in 0..MaxTime-1) (matrice_Cammini_Sequenza_Nodi[cammino,istante]>0&m atrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0& matrice_Incidenza_Nodi[matrice_Cammini_Sequenza_Nod i[cammino,istante],matrice_Cammini_Sequenza_Nodi[cammino,istante+1 ]]=arco)=0)<=> matrice_Cammini_Archi[cammino,arco]=0; forall(cammino in 0..numero_Cammini-1,arco in 0..numero_Archi_Grafo-1) matrice_Cammini_Archi[cammino,arco]=1=> (sum(istante in 0..MaxTime-1) (matrice_Cammini_Sequenza_Nodi[cammino,istante]>0&m atrice_Cammini_Sequenza_Nodi[cammino,istante+1]>0& matrice_Incidenza_Nodi[matrice_Cammini_Sequenza_Nod i[cammino,istante],matrice_Cammini_Sequenza_Nodi[cammino,istante+1 ]]=arco)>=1); //Vincolo per l'indipendenza dei cammini forall(cammino in 1..numero_Cammini-1)

208
sum(arco in 0..numero_Archi_Grafo-1) (matrice_Cammini_Archi[cammino,arco]=1& sum(secondoCammino in 0..cammino-1)(matrice_Cammini_Archi[secondoCammino,arco]=1)=0) >0; //Vincoli per gli istanti di tempo del ProgCounter relative ai macroNodi forall(cammino in 0..numero_Cammini-1) matrice_Cammini_Sequenza_IstantiPC[cammino,0]= matrice_Istruzioni_Nodo[matrice_Cammini_Sequenza_No di[cammino,0]]; forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime) matrice_Cammini_Sequenza_IstantiPC[cammino,istante ]=matrice_Cammini_Sequenza_IstantiPC[cammino,istante-1]+matrice_Istruzioni_Nodo[matrice_Cammini_Sequenza _Nodi[cammino,istante]]; forall(cammino in 0..numero_Cammini-1) matrice_Cammini_Sequenza_Nodi[cammino,0]=1=> ( progCounter[cammino,0]=1 &progCounter[cammino,1]=2 &progCounter[cammino,2]=3 ); forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime) matrice_Cammini_Sequenza_Nodi[cammino,istante]=1= > ( progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=1 &progCounter[cammino,matrice_Cammini_Sequenza_Ista ntiPC[cammino,istante-1]+1]=2 &progCounter[cammino,matrice_Cammini_Sequenza_Ista ntiPC[cammino,istante-1]+2]=3 ); forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime) matrice_Cammini_Sequenza_Nodi[cammino,istante]=4= > ( progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=10 ); forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime) matrice_Cammini_Sequenza_Nodi[cammino,istante]=5= > ( progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=4 &progCounter[cammino,matrice_Cammini_Sequenza_Ista ntiPC[cammino,istante-1]+1]=5 );

209
forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime) matrice_Cammini_Sequenza_Nodi[cammino,istante]=6= > ( progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=8 ); forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime) matrice_Cammini_Sequenza_Nodi[cammino,istante]=7= > ( progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=9 ); forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime) matrice_Cammini_Sequenza_Nodi[cammino,istante]=8= > ( progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=6 &progCounter[cammino,matrice_Cammini_Sequenza_Ista ntiPC[cammino,istante-1]+1]=7 ); forall(cammino in 0..numero_Cammini-1,istante in 1 ..MaxTime) matrice_Cammini_Sequenza_Nodi[cammino,istante]=2 => ( progCounter[cammino,matrice_Cammini_Sequenza_Istan tiPC[cammino,istante-1]]=0 ); };


















