
Elementi di probabilità - POLIsmanettoni · 2013-12-04 · evenienze del tipo di interesse (m), o...
37
•1 1 Elementi di probabilità Argomenti: introduzione; elementi di teoria delle probabilità: variabili deterministiche e casuali; istogrammi; funzione di distribuzione di probabilità; funzione di distribuzione cumulativa; modello Gaussiano. 2 Caratteristiche di casualità, cioè di assoluta imprevedibilità, possono essere osservate praticamente in qualsiasi esperimento. Ripetizioni anche immediate di misure di una grandezza possono fornire risultati leggermente diversi. Questa variabilità è dovuta a condizioni ambientali non controllate o non controllabili, oppure a una mancanza di precisione nel processo di misura (strumento o procedura) riconducibile anch’essa ad elementi non controllati/ controllabili. In alcuni casi le casualità (variabili non controllate) hanno un effetto sui dati predominante ed è difficile, o addirittura impossibile, individuare una relazione analitica che leghi il cambiamento della variabile considerata a fronte della variazione dei parametri controllati. Ci accorgeremo come, utilizzando tecniche probabilistiche, si possono descrivere i fenomeni casuali determinandone caratteristiche utili al loro utilizzo in ambito ingegneristico, sebbene non si riesca a definirne tutti i rapporti con le variabili di ingresso. La teoria delle probabilità ci permetterà di costruire modelli dei fenomeni casuali non basati sul rapporto di causa-effetto. Introduzione
Transcript of Elementi di probabilità - POLIsmanettoni · 2013-12-04 · evenienze del tipo di interesse (m), o...

•1
1
Elementi di probabilità
Argomenti:
introduzione;
elementi di teoria delle probabilità:
variabili deterministiche e casuali;
istogrammi;
funzione di distribuzione di probabilità;
funzione di distribuzione cumulativa;
modello Gaussiano.
2
Caratteristiche di casualità, cioè di assoluta imprevedibilità, possono essere osservate praticamente in qualsiasi esperimento.
Ripetizioni anche immediate di misure di una grandezza possono fornire risultati leggermente diversi.
Questa variabilità è dovuta a condizioni ambientali non controllate o non controllabili, oppure a una mancanza di precisione nel processo di misura (strumento o procedura) riconducibile anch’essa ad elementi non controllati/ controllabili.
In alcuni casi le casualità (variabili non controllate) hanno un effetto sui dati predominante ed è difficile, o addirittura impossibile, individuare una relazione analitica che leghi il cambiamento della variabile considerata a fronte della variazione dei parametri controllati.
Ci accorgeremo come, utilizzando tecniche probabilistiche, si possono descrivere i fenomeni casuali determinandone caratteristiche utili al loro utilizzo in ambito ingegneristico, sebbene non si riesca a definirne tutti i rapporti con le variabili di ingresso.
La teoria delle probabilità ci permetterà di costruire modelli dei fenomeni casuali non basati sul rapporto di causa-effetto.
Introduzione

•2
3
Intuitivamente possiamo suddividere le variabili in due macro categorie:
deterministiche;
casuali.
Una grandezza il cui valore è prevedibile e ripetibile, quindi descrivibile mediante modelli deterministici, viene classificata come variabile deterministica.
Una grandezza che non rientri in questa categoria viene classificata come casuale ed è caratterizzabile solo in termini di comportamento statistico invece che attraverso una relazione analitica.
Le grandezze misurate sono considerate come variabili casuali (dette anche random) nel senso che ad una variazione deterministica della grandezza, causata da un cambiamento nelle variabili controllate, si somma una modifica casuale generata, secondo modalità non note, dalle variabili non controllate.
Una variabile casuale può essere continua (es. la vita di una lampadina o la misura della velocità) o discreta (es. i risultati di un lancio di dadi o l’esito positivo/negativo di un controllo di qualità).
Variabili deterministiche e casuali
4
Richiami
Alcuni elementi interessanti dal punto di vista statistico sono unpatrimonio relativamente assodato; per esempio le calcolatricitascabili sono in grado di effettuare i calcolo di alcune grandezzestatistiche di comune impiego (media, varianza, regressione lineare ecoefficiente di correlazione).
Media: date N osservazioni xi la media vale:
La media è considerata la miglior stima del valore vero, in assenza di altre informazioni, e la dev. std. è assunta come indicatore di dispersione.
1
1 N
i
i
x xN =
= ∑
Deviazione standard delle misure: radice quadrata della media degli scarti quadratici (detta anche varianza). Ha la stessa dimensione fisica della misura. Dev. std. campionaria, N-1 a dividere, usata soprattutto se si hanno poche misure.
2S varianza=
( )2
1
1 N
i iS x xN
= !∑

•3
5
Interpretazione fisica del concetto di media
Possiamo vedere il calcolo della media di una serie di valori come ilcalcolo della posizione del baricentro di un corpo monodimensionalecostituito da particelle, tutte di massa uguale, posizionate incorrispondenza di ogni dato:
Coordinata xCG come rapporto tra i momenti statici di ordine 1 e di ordine0 delle masse.
1 1 1 1 1
/ / 1 /N N N N N
CG i i i i i
i i i i i
x x m m m x m x N= = = = =
= = =
∑ ∑ ∑ ∑ ∑
CGxix
im CG
Richiami
6
La varianza è il momento di inerzia baricentrico rapportato alla massatotale o rapporto tra i momenti statici di ordine 2 e di ordine 0 dellemasse:
A parità di massa un momento di inerzia maggiore indica una dimensionemaggiore del corpo.
Nelle misure una varianza maggiore è sintomo, a parità di valore medio,di una maggiore dispersione dei dati
Ma abbiamo bisogno di qualcosa di più robusto
di una analogia formale
2
1 1
2 2 2
1 1 1
/ ( ) /
1( ) / 1 ( )
N N
CG i CG i i
i i
N N N
i CG i CG
i i i
I M x x m m
m x x m x x SN
= =
= = =
= ! =
! = ! =
∑ ∑
∑ ∑ ∑
Richiami

•4
13
Modelli probabilistici
Esempi tipici di fenomeni casuali: intensità della turbolenza atmosferica, altezza delle onde, errori di misura, …
Ammettiamo di sapere come determinare le forze su di una piattaforma off-shore a seguito di ondate di altezza nota; come prevedere l’altezza dell’onda da utilizzare per il dimensionamento della struttura?
Ci servono strumenti che forniscano informazioni utilizzabili e affidabili, cioè probabili, anche se non il valore specifico di un evento.
Si tratta di compiere misurazioni ed elaborare opportunamente i dati ottenuti per ricavarne un modello matematicodel fenomeno.
14
Posizioniamo un sistema in grado di misurare l’altezza delle onde con una adeguata cadenza temporale nel sito previsto per l’installazione della piattaforma.
Il grafico non mostra alcun andamento e non fornisce informazioni utili perché il fenomeno non è dipendente dal tempo, unica variabile controllata/misurata.
L’altezza delle onde dipende da altri fattori (es. velocità del vento) che non sono controllati.
Bisogna adottare una strategia di elaborazione che si concentri sulla sola grandezza esaminata e non su cosa abbia prodotto la variazione.
Modelli probabilistici
0 20 40 60 80 100 120 140 160 180 2000
1
2
3
4
5
6
7
8
9
10
tempo
alte
zza
ond
e (m
)
Supponiamo di avere ottenuto, al termine del periodo di osservazione, «rappresentativo» ed «omogeneo», qualcosa del genere:
Il diagramma mostra la distribuzione dei dati nel tempo.
•5
15
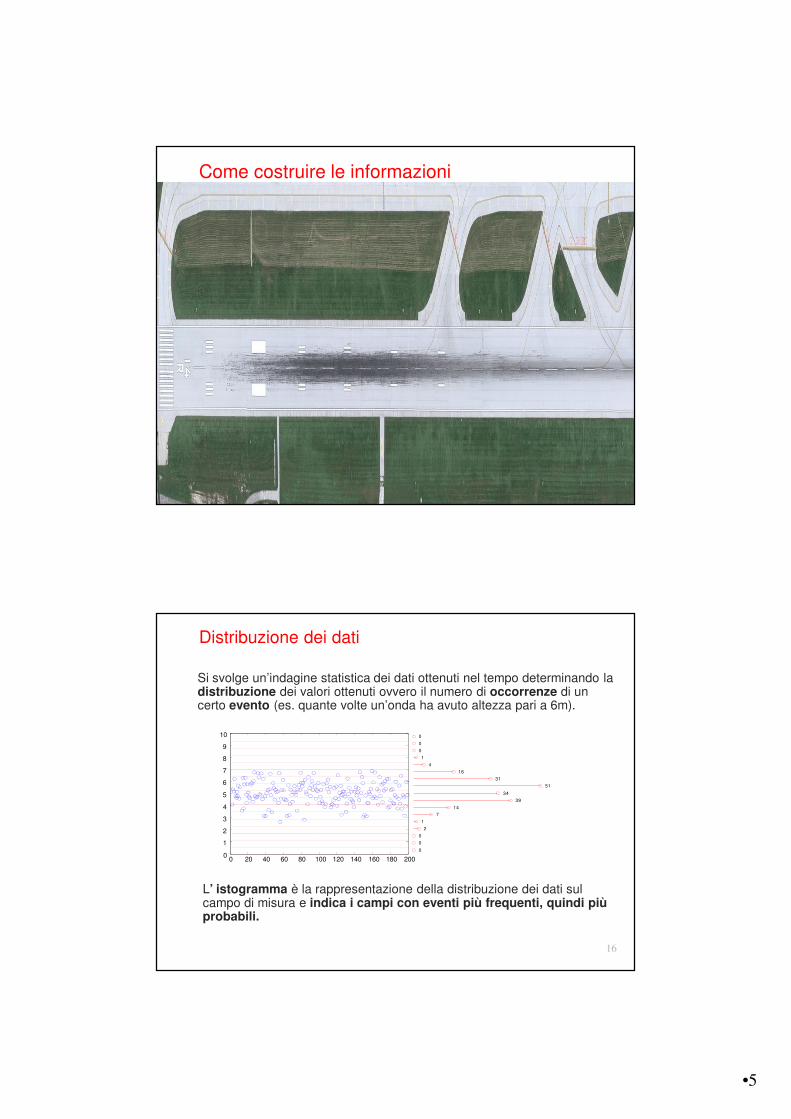
Come costruire le informazioni
16
Si svolge un’indagine statistica dei dati ottenuti nel tempo determinando la distribuzione dei valori ottenuti ovvero il numero di occorrenze di un certo evento (es. quante volte un’onda ha avuto altezza pari a 6m).
L’ istogramma è la rappresentazione della distribuzione dei dati sul campo di misura e indica i campi con eventi più frequenti, quindi più probabili.
Distribuzione dei dati
0
0
0
2
1
7
14
39
34
51
31
16
4
1
0
0
0
0 20 40 60 80 100 120 140 160 180 2000
1
2
3
4
5
6
7
8
9
10

•6
17
Distribuzione dei dati
Operativamente per ottenere la distribuzione dei dati:
si misura il fenomeno acquisendo l’informazione numerica;
si divide il campo di osservazione in intervalli;
per ogni intervallo si contano le occorrenze/eventi che ricadono all’interno di esso (per segnali continui si misura il tempo di permanenza del segnale nell’intervallo).
per ogni intervallo si traccia un segmento di lunghezza pari al numero di occorrenze (se si utilizza un rettangolo si deve ricordare che la base non ha significato, per es. non è pari all’intervallo).
Per la determinazione del numero di intervalli, avendo N dati (N>40; N <40 istogramma non significativo), si può utilizzare la formula:
Il numero di eventi in un intervallo deve essere significativo (" 5)altrimenti la distribuzione risulterebbe dipendente da come è stata fattala discretizzazione del campo di misura. In caso contrario è megliodiminuire il numero di intervalli.
0.40BinsN 1.87(N 1) 1= ! +
18
All’aumentare del numero di dati è ragionevole aumentare il numerodi intervalli risolvendo meglio il campo di variabilità.
La rappresentazione migliora tendendo ad una funzione continua.
Istogrammi

•7
19
Diverse serie di dati relativi allo stesso processo daranno distribuzioni di probabilità leggermente diverse.
Nei grafici sono riportate 20 serie, di 10000 dati ciascuna, relative a due differenti tipologie di distribuzione.
Per ciascuna serie si riporta anche il valore medio (rosso) e deviazione standard (verde).
Media e dev. std. sono molto stabili tanto che i tratti che le rappresentano sono praticamente sovrapposti.
La forma della distribuzione unita ai due dati statistici consente di costruire un modello matematico probabilistico della grandezza casuale.
•-5 •-4 •-3 •-2 •-1 •0 •1 •2 •3 •4 •5•0
•0.1
•0.2
•0.3
•0.4
•0.5•Gaussiana
•-5 •-4 •-3 •-2 •-1 •0 •1 •2 •3 •4 •5•0
•0.05
•0.1
•0.15
•0.2•Uniforme
Istogrammi
20
Il numero di eventi per ogni intervallo da solo non è un’informazione particolarmente significativa.
Dividendo il numero di occorrenze in un intervallo per il numero di misure totali si esprimono i dati in termini di frequenza relativa.
L’informazione contenuta in pi è che vi sono ni possibilità, su N, che un nuovo dato cada nell’intervallo i-esimo.
Definiamo la probabilità come quantificazione numerica della possibilità di un evento.
La distribuzione di probabilità calcola la possibilità di effettuare una particolare osservazione:
ii
np
N=
1( )j
ki j
k i
nP x x x
N+
=
# < =∑La somma delle frequenze relative fornisce la probabilità per un intervallo più ampio:
Probabilità
1( ) ii i
nP x x x
N+# < =

•8
21
Il concetto di probabilità ci è già noto per altra via e sotto una forma leggermente diversa.
La probabilità (A) di un evento discreto esprime il peso dell’evento in rapporto a tutti gli eventi possibili ed è ottenuta dividendo il numero di evenienze del tipo di interesse (m), o esiti positivi, per il numero totale di soluzioni possibili (N), cioè dei possibili esiti.
Probabilità dell’evento A=m/N
Es. c’è il 50% di probabilità che il lancio di una moneta dia testa.
Es. se lanciamo due dadi la probabilità di ottenere un doppio 1 è 1/36 in quanto c’è una sola possibilità dell’esito voluto a fronte di 36 possibili eventi (6 indipendenti per ciascun dado).
La probabilità discreta è un numero, compreso tra 0 ed 1, che esprime la possibilità dell’occorrenza di un evento relativamente a tutte le finitepossibilità dello spazio matematico indagato.
Probabilità: caso discreto
22
Partendo dal concetto di probabilità discreta si può arrivare a concepire intuitivamente la probabilità in termini continui come la tendenza ad infinito del numero di soluzioni possibili.
La probabilità continua è un valore numerico, compreso tra 0 e 1, che esprime la possibilità di occorrenza di un evento, , rispetto agli infiniti casi possibili.
La probabilità è il numero che esprime la verosimiglianza dell’occorrenza di un evento relativamente a tutte le possibilità dello spazio relativo (±∞) che essendo la totalità dei casi possibili ha, per definizione, un valore unitario.
La probabilità quantifica la possibilità di un evento
Probabilità: caso continuo
( )a x b# #
( ) ( )( )
( ) 1
P a x b P a x bP a x b
P x
# # # #= = # #
!$ # # +$

•9
23
Diversi istogrammi di uno stesso fenomeno possono non esseredirettamente confrontabili: il risultato dipende dal numero, N, di dati acquisiti e dalla quantità di intervalli, NBins, impiegata per suddividere il campo di osservazione.
NBins variabile con N NBins costante con N
La frequenza relativa, grazie alla normalizzazione, rende confrontabili gli istogrammi ma solo a parità di numero dei sottointervalli.
Per ottenere un risultato invariante è necessaria una ulteriore normalizzazione: rispetto alla dimensione del sottointervallo.
Questo porta ad un modello continuo: la funzione di densità di probabilità.
Densità di probabilità
24
Normalizzando la frequenza relativa rispetto all’ampiezza degli intervalli si ottiene una funzione indipendente dal numero di osservazioni e di intervalli: ciò equivale a definire una funzione continua, costante nell’intervallo, a parità di integrale (probabilità).
Uguaglianza delle probabilità:
Nell’ipotesi di densità costante:
Valore della densità dell’intervallo:
I risultati di osservazioni diverse sono adesso confrontabili, indipendentemente dal numero di eventi osservati e/o dal numero e dall’ampiezza degli intervalli.
La funzione p(x) ha il significato di densità di probabilità e caratterizza il fenomeno casuale.
1 1
1
1
( )
( ) ( ) ( )
/
i i
i i
ii i
x x
i i i ix x
ii
nP x x x
N
P x x x p x dx p x dx p x
np x
N
+ +
+
+
# # =
# # = = = %
= %
∫ ∫
Densità di probabilità

•10
25
( )j
ki j
k i
nP x x x
N=
# # =∑
( ) ( )j
i
x
i jx
P x x x p x dx# # = ∫
Utilizzando la distribuzione di probabilità,la probabilità è data dalla sommatoria:
Utilizzando la funzione di densità diprobabilità si dovrà integrare:
La probabilità che si faccia una misurache appartenga ad un intervallo è datadall’integrale della funzione densità diprobabilità esteso a quell’intervallo:
In particolare la probabilità di un valoreassegnato è nulla:
La funzione densità è positiva el’integrale su tutto il dominio dellafunzione è unitario: la probabilità che unamisura vi rientri deve infatti essere 100%.
( ) 0
( ) ( ) 1
p x
p x dx P x$
!$
>
= !$ < < $ =∫
( ) ( )b
a
P a x b p x dx# # = ∫
( ) ( ) 0a
a
P x a p x dx= = =∫
Densità di probabilità
27
Attraverso la funzione di densità di probabilità possiamo determinare i parametri statistici fondamentali di una grandezza, non soltanto la probabilità che un certo evento avvenga.
L’integrale della funzione di densità di probabilità p(x) della grandezza x,pesata per la grandezza stessa, ne fornisce il valore atteso (expectedvalue). Solo in alcuni casi esso coincide con il valore più probabile.
Valore atteso (momento di ordine 1):
L’integrale della funzione di densità di probabilità p(x) della grandezza x,pesata per il quadrato della distanza tra la variabile x e il suo valore atteso, ne fornisce la varianza:
Varianza (momento di ordine 2):
( ) ( )E x x p x dxµ$
!$
= = ∫
( )22 ( )V x p x dx& µ$
!$
= = !∫
Densità di probabilità: valore atteso e varianza

•11
29
Scriviamo l’espressione del valore atteso utilizzando le approssimazioni e i dati utilizzati per costruire un istogramma, ricordando:
p(x) costante in un intervallo:
la definizione di frequenza relativa:
Dove si è indicato con M il numero di intervalli.
Il valor medio di una serie è un’approssimazione del valore atteso della grandezza casuale che ha prodotto i dati.
( )
11 2 221
1 1 1
11
1 1
1 1 1
( )2 2
2
1
ii
i i
xxM M Mi i
i i i
i i ix x
M Mi i
i i i i i
i i
M M Ni
i i i j
i i j
x xxx p x dx x p dx p p
x xp x x p x x
nf x x x x
N N
µ++$
+
= = =!$
++
= =
= = =
!= = = =
+! = % =
= = =
∑ ∑ ∑∫ ∫
∑ ∑
∑ ∑ ∑
i ii
f np
x N x= =
% %
1( ) peri i ip x p x x x += # #
Densità di probabilità: valore atteso e varianza
30
Essendo l’integrale di p(x) unitario per definizione, senza modificare la definizione di valore atteso:
Ritroviamo il rapporto tra i momenti statici di ordine 1 e 0 della funzione di densità di probabilità già evidenziati nel caso discreto:
il valore atteso di una variabile descritta mediante la sua densità di probabilità è dato dal baricentro della stessa
La varianza è in analogia con il momento di inerzia baricentrico:
La differenza rispetto al caso della media e della varianza di una serie, discreta e finita, risiede nella continuità della funzione che rende necessaria la formulazione integrale.
( ) ( ) / ( )E x x p x dx p x dxµ$ $
!$ !$
= = ∫ ∫
( ) ( )2 22 ( ) ( )CG
L
V x p x dx I x x m x dx& µ$
!$
= = ! = !∫ ∫
Densità di probabilità: valore atteso e varianza

•12
32
Variabili Casuali
Si può ora definire in maniera più sistematica il concetto di variabile casuale:
Una variabile casuale rappresenta una grandezza il cui accadimento è descrivibile solo in termini di comportamento
I modelli deterministici non sono validi e la grandezza non è direttamente prevedibile
La previsione può avvenire in senso probabilistico a partire dal comportamento sintetizzato nella distribuzione di probabilità ed espresso in termini di parametri sintetici : il valore atteso e la varianza (o ladeviazione standard che ne è la radice quadrata) unitamente alla forma della densità di probabilità descrivono il processo casuale.
L’incertezza di una misura è considerata una variabile casuale a valor medio nullo e centrata sulla stima della misura.
33
La forma della funzione di densità di probabilità è una caratteristica del fenomeno.
E’ stato osservato che il comportamento di alcune classi di problemi è abbastanza bene descritto da alcune leggi.
Densità di probabilità

•13
34
Distribuzioni di interesse ingegneristico e applicazioni tipiche:
Binomia (Binomial): distribuzione discreta. Utilizzata nel controllo di qualità (scarto di prodotti difettosi), nelle analisi successo/ insuccesso buono/cattivo.
Normale (Normal) o Gaussiana: continua e simmetrica; largamente impiegata nell’analisi sperimentale e nella fisica. Utilizzata per la spiegazione del comportamento di variabili casuali nella sperimentazione.
Student's t: continua e simmetrica; utilizzata per l’analisi della varianza quando il numero di campioni è limitato (<30). Per un numero di campioni superiore si comporta come la distribuzione normale.
''''2: continua, nonsimmetrica; usata per l’analisi della varianza di campioni di popolazione e per valutare la qualità del fitting di una distribuzione.
Densità di probabilità
35
Weibul: continua, non simmetrica; usata per descrivere i fenomeni di durata di parti e componenti.
Esponenziale: continua, non simmetrica; usata per l’analisi di affidabilità di sistemi completi e assemblaggi di parti.
Lognormal: continua, non simmetrica; utilizzata per lo studio della vita e della durata di parti e componenti.
Uniform: continua, simmetrica; usata per la stima delle probabilità di variabili random per la simulazione.
Poisson: discreta; utilizzata quando le occorrenze degli eventi sono osservabili ma non lo sono le non occorrenze (es i guasti in un impianto o i black-out in una zona)
Densità di probabilità

•14
37
Calcolo di probabilità:
Calcolo del valore atteso:
Calcolo della varianza prevista:
( )a
P x a p(x)dx!$
# = ∫ ( ) 1 ( )P x a P x a> = ! #
( ) 0P x a= =
( )22
( ) ( )
( )
E x x p x dx
V x p x dx
µ
& µ
$
!$
$
!$
= =
= = !
∫
∫
( ) 1 ( )P x a P x a" = ! #
( )b
a
P a x b p(x)dx# # = ∫
Riassumendo
38
Come si costruiscono le distribuzioni di probabilità.
Come si passa concettualmente alla funzione di densità di probabilità.
Come si caratterizza una variabile casuale (media e varianza).
Come prevedere il comportamento di una grandezza casuale con un
margine di errore e un livello di fiducia.
Come ci si esprime in termini di probabilità”di avvenimento di una
grandezza casuale.
Rimane aperto il problema di come operare con più grandezze casuali
interagenti o meno.
Da ricordare
•15
39
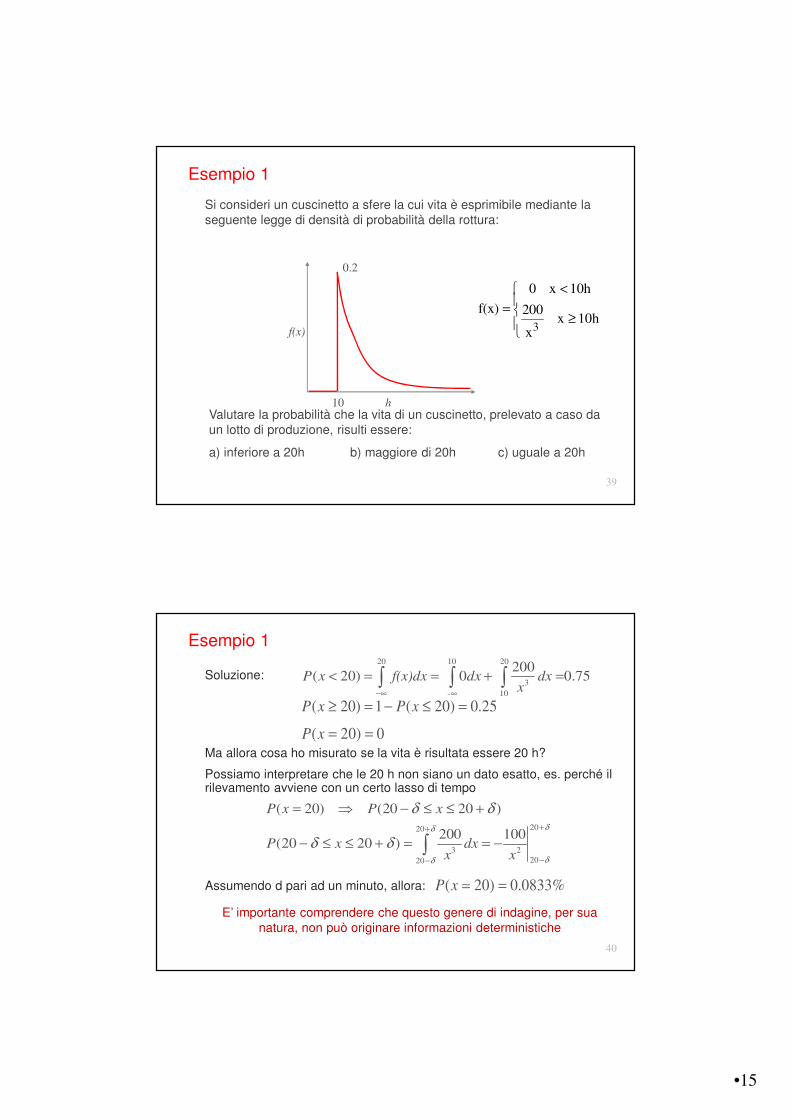
Valutare la probabilità che la vita di un cuscinetto, prelevato a caso da un lotto di produzione, risulti essere:
a) inferiore a 20h b) maggiore di 20h c) uguale a 20h
Si consideri un cuscinetto a sfere la cui vita è esprimibile mediante la seguente legge di densità di probabilità della rottura:
10
0.2
f(x)
h
3
0 x 10h
f(x) 200x 10h
x
<
= "
Esempio 1
40
Soluzione:
Ma allora cosa ho misurato se la vita è risultata essere 20 h?
Possiamo interpretare che le 20 h non siano un dato esatto, es. perché il rilevamento avviene con un certo lasso di tempo
Assumendo d pari ad un minuto, allora:
20 10 20
3
- 10
200( 20) 0 0.75P x f(x)dx dx dx
x!$ $
< = = + =∫ ∫ ∫
2020
3 22020
( 20) (20 20 )
200 100(20 20 )
P x P x
P x dxx x
((
((
( (
( (++
!!
= ⇒ ! # # +
! # # + = = !∫
( 20) 0P x = =
( 20) 1 ( 20) 0.25P x P x" = ! # =
( 20) 0.0833%P x =
Esempio 1
E’ importante comprendere che questo genere di indagine, per sua natura, non può originare informazioni deterministiche
•16
41
Soluzione:
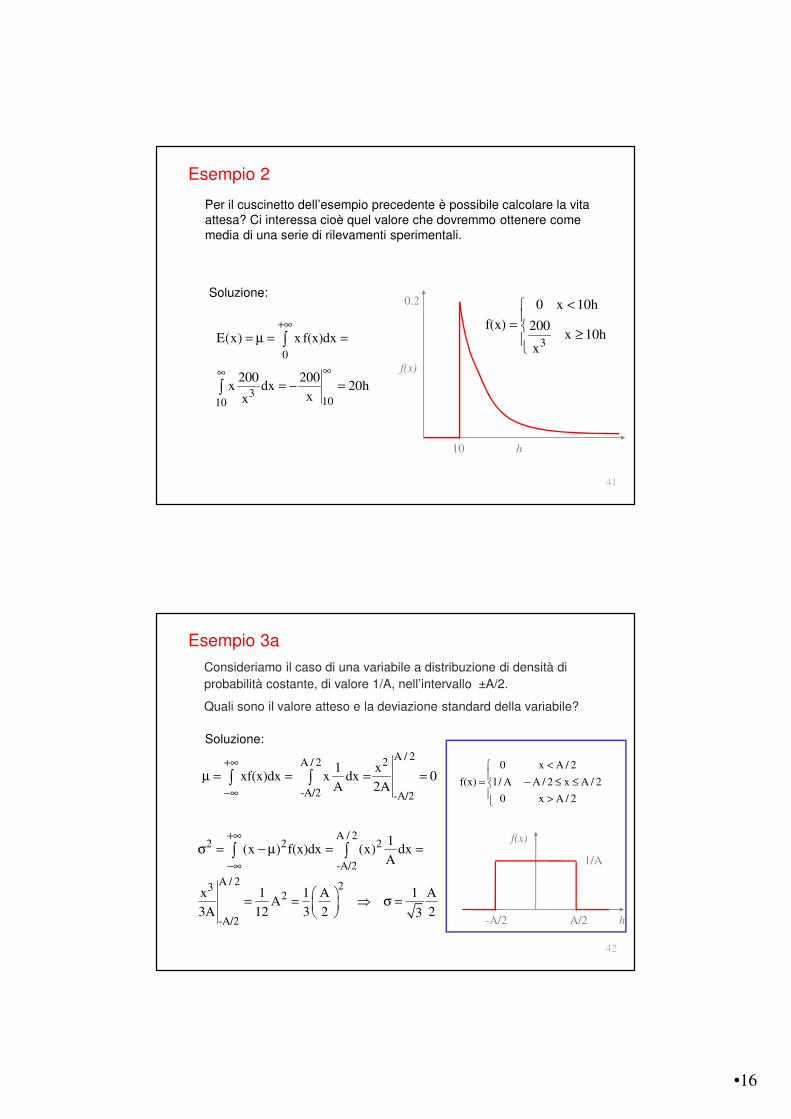
Per il cuscinetto dell’esempio precedente è possibile calcolare la vita attesa? Ci interessa cioè quel valore che dovremmo ottenere come media di una serie di rilevamenti sperimentali.
3
0 x 10h
f(x) 200x 10h
x
<
= "
10
0.2
f(x)
h
0
31010
E(x) x f(x)dx
200 200x dx 20h
xx
+$
$$
= µ = =
= ! =
∫
∫
Esempio 2
42
Soluzione:
Consideriamo il caso di una variabile a distribuzione di densità di
probabilità costante, di valore 1/A, nell’intervallo ±A/2.
Quali sono il valore atteso e la deviazione standard della variabile?
A / 22 2 2
-A/2
A / 2 232
-A/2
1(x ) f(x)dx (x) dx
A
x 1 1 A 1 AA
3A 12 3 2 23
+$
!$
& = ! µ = =
= = ⇒ & =
∫ ∫
0 x A / 2
f(x) 1/ A A / 2 x A / 2
0 x A / 2
<
= ! # # >
-A/2
1/A
f(x)
hA/2
A / 22A / 2
-A/2 -A/2
1 xxf(x)dx x dx 0
A 2A
+$
!$
µ = = = =∫ ∫
Esempio 3a

•17
43
Per la distribuzione triangolare indicatavalutare
Esempio 3b
0
2 2
0
1 1( ) 0
6 6
a
a
x x a ax p x dx x dx x dx
a a a aµ
$
!$ !
= = + + ! = ! + =
∫ ∫ ∫
0 2 2 22 2 2 2
2 2
0
1 1( )
12 12 6
a
a
x x a a au x p x dx x dx x dx
a a a a
$
!$ !
= = + + ! = + =
∫ ∫ ∫
2 2
1 1( 0) (0 )
x xp a x p x a
a a a a! # # = + # # = !
2
0
1( ) ( ) 2 ... 0.65
ax
P x p x dx dxa a
& &$
!$
! # # = = ! = =
∫ ∫
, e ( )P xµ & & &! # #
6
au =
48
Funzione di distribuzione cumulativa
L’«Integrazione» ha due forme:
Poi, almeno per il secondo caso, è arrivato il calcolo numerico…
Volendo oggi abbiamo anche Matlab (e altri) con:
Una regola importante:
Se dobbiamo calcolare ripetutamente l’integrale definito di una funzionesu intervalli diversi può essere conveniente determinare la funzioneintegrale una volta per tutte: poi si opererà per differenze
;ba
F(x)= f(x)dx I = f(x)dx∫ ∫
1
Nb
i iai
I = f(x)dx w (x ))=∑∫
int(sym(fun)
integral(fun,xmin,xmax)ba
F(x)= f(x)dx
I = f(x)dx
=
=
∫
∫
ba
I = f(x)dx F(b) F(a)= !∫
•18
49
Distribuzione cumulativa
La funzione di distribuzione cumulativa (Cumulative distributionfunction) permette di valutare la probabilità che una variabile x descritta dalla funzione di densità di probabilità f(x), assuma valori minori od uguali ad un valore assegnato, , avendo eseguito l’integrazione una volta per tutte in forma analitica.
Definizione:
Se si possono dimostrare le seguenti relazioni:
Vantaggi:
non serve più svolgere l’integrale: è sufficiente la singola valutazioneo la differenza di due valutazioni della funzione;
il processo di calcolo può essere facilmente invertito (a differenza dell’integrale), calcolando la funzione inversa.
x
F(x x) F(x) f(x)dx P(x x)!$
# = = * #∫
P(x a) F(a)# =
P(x a) 1 F(a)> = !b
a
P(a x b) f(x)dx F(b) F(a)# # = = !∫
x
50
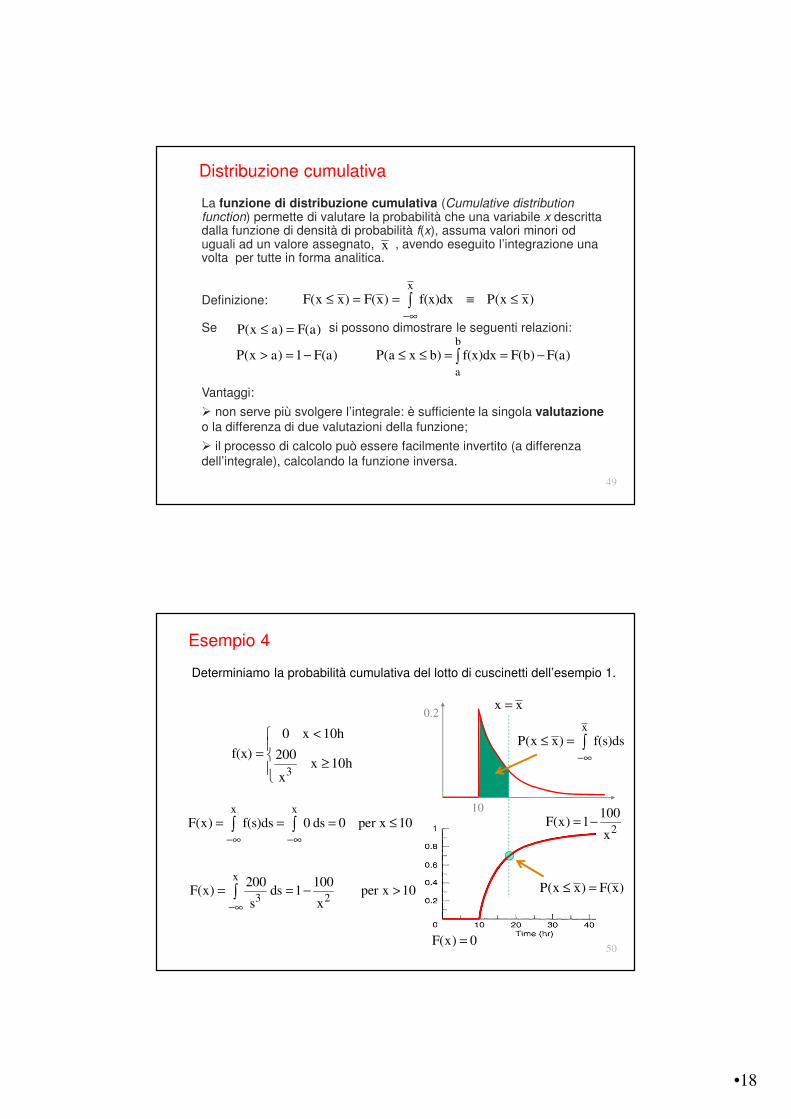
Determiniamo la probabilità cumulativa del lotto di cuscinetti dell’esempio 1.
x x
F(x) f(s)ds 0 ds 0 per x 10!$ !$
= = = #∫ ∫
x
3 2
200 100F(x) ds 1 per x 10
s x!$
= = ! >∫
10
0.2
3
0 x 10h
f(x) 200x 10h
x
<
= "
x
P(x x) f(s)ds!$
# = ∫
x x=
2
100F(x) 1
x= !
F(x) 0=
P(x x) F(x)# =
Esempio 4

•19
51
Per il lotto di cuscinetti dell’esempio 1, qual è la probabilità che un
cuscinetto abbia una vita inferiore a 15 o 20 ore?
Soluzione: si utilizza la funzione di distribuzione cumulativa dell’esempio 4.
F(x) 0 per x 10= #
2
100F(x) 1 per x 10
x= ! >
Per 15 ore si ha una probabilità di 0.55
Per 20 ore si ottiene 0.75
Non occorre effettuare gli integrali ogni volta: è sufficiente calcolare lafunzione per il valore di interesse.
La probabilità di un intervallo sarà dato dalla differenza dei valori.
Probabilità di cedimento
Esempio 5
52
Volendo garantire, con l’80% di probabilità, la vita di un cuscinetto dello
stesso lotto, quanto devo dichiarare?
La funzione di distribuzione cumulativa fornisce la probabilità di cedimento dopo un certo tempo.
Garantire l’80% di probabilità la vita di un cuscinetto equivale a garantire che, nello stesso tempo, se ne rompano al più il 20%.
Occorre quindi individuare la durata corrispondente al complemento della funzione data: 1-F(x).
10
0.2
x x#
x x=Probabilità dirottura per
Esempio 6

•20
53
Soluzione: si utilizza ancora la funzione di distribuzione cumulativa.
2
100 100F(x) 0 per x 10 F(x) 1 per x 10 o x
1 P(x)x= # = ! > =
!
Probabilità ricercata: 80% di vita utile.
Disponendo della probabilità di rottura cumulativa F(x) si deve ricercare la probabilità equivalente di vita in termini complementari:
F(x)=1- 80% = 20%
Risolvendo la distribuzione cumulativa per F(x)=20% si ottiene x=11.18
Occorrerà quindi dichiarare circa 11 ore.
Probabilità di cedimento
Esempio 6
54
Statistica degli errori sperimentali
Vogliamo individuare una funzione di densità di probabilità utile per la descrizione delle problematiche sperimentali.
Possiamo definire dei requisiti per tale funzione ricordando che vogliamo rappresentare gli errori casuali.
Requisiti fondamentali:
funzione simmetrica;
valori centrali più probabili.
Requisiti utili:
funzione analitica (continua, integrabile e derivabile);
definibile da pochi parametri.

•21
55
Densità di probabilità gaussiana
Una distribuzione di particolare interesse poiché soddisfa i requisiti che ci eravamo dati per descrivere gli errori sperimentali è quella gaussiana:
E’ simmetrica centrata sul valore medio µ dove assume valore massimo pari a:
A distanza ±& dalla media la funzione presenta un flesso.
µ valore centrale coincidente con la media dei valori x.
& parametro di regolazione della distribuzione attorno al valor medio.
max
1( )
2p p µ
& += =
21 1
( ) exp22
xp x
µ
&& +
! = !
& coincide con la deviazione standard della variabile x.
Il coefficiente moltiplicativo fuori dall’esponenziale rende unitario l’integrale come richiesto ad una funzione di densità di probabilità.
56
La funzione di densità di probabilità gaussiana descrive in modo soddisfacente l’andamento di una gran parte degli errori presenti nelle misure.
In particolare essa rappresenta correttamente la dispersione di dati sperimentali, conseguenza di fattori casuali, quando l’evenienza di deviazioni positive e negative di pari entità è egualmente probabile, con misure vicino al valore medio più probabili.
E’ una funzione continua: essendo derivabile è adatta a manipolazioni analitiche.
Anche se gli errori individuali non seguono questa distribuzione, la media dei campioni della misura hanno una distribuzione tendente a quella gaussiana se il numero di campioni presi in considerazione elevato (teorema del limite centrale).
Si tratta di un modello non fisico poiché, essendo la gaussiana una funzione non limitata, garantisce una probabilità, seppur minima, che avvenga la misura di un valore estremamente lontano dal valore medio (anche se ciò è fisicamente poco probabile).
Densità di probabilità gaussiana

•22
58
Densità di probabilità gaussiana normalizzata
Notando la struttura dell’esponente, è naturale introdurre la variabile z come rapporto tra la distanza dal valor medio e il parametro di distribuzione:
2
1 1 22 1
0
0 0
( ) 1
20 1
1 1( ) ( )
2 2
xx zz z
zx z
P x x x e dx e dz f z dz
µ
& && + & +
!! !
< < = = =∫ ∫ ∫
xz
µ
&
!=
21
21
( )2
z
f z e+
!
=Avendo definito la funzione densità di probabilità normale o standard come:
21 1
( ) exp22
xp x
µ
&& +
! = !
dx dz&=Per la probabilità di evenienza di un intervallo si ottiene:
59
La funzione di densità normalizzata
Ha:
media nulla e
deviazione standard unitaria.
La variabile z esprime la distanza di x dal valore medio come moltiplicatore della deviazione standard della distribuzione, &.
Z=0
21
21
( )2
z
f z e+
!
=
z x& µ= !
Densità di probabilità gaussiana normalizzata
&=1
•23
60
Applicando la definizione di probabilità cumulativa (integrale indefinito):
2
( ) ( )
1exp
22
z
z
F z f z dz
zdz
+
!$
!$
= =
∫
∫
la probabilità espressa come differenza dei valori che la densità cumulativa assume ai due estremi dell’intervallo di interesse:
1
00 1 1 0( ) ( ) ( ) ( )
z
zP x x x f z dz F z F z< < = = !∫
-5 -4 -3 -2 -1 0 1 2 3 4 50
0.2
0.4
0.6
0.8
1
Pro
ba
bili
tà
•Densità cumulativa (Gauss)
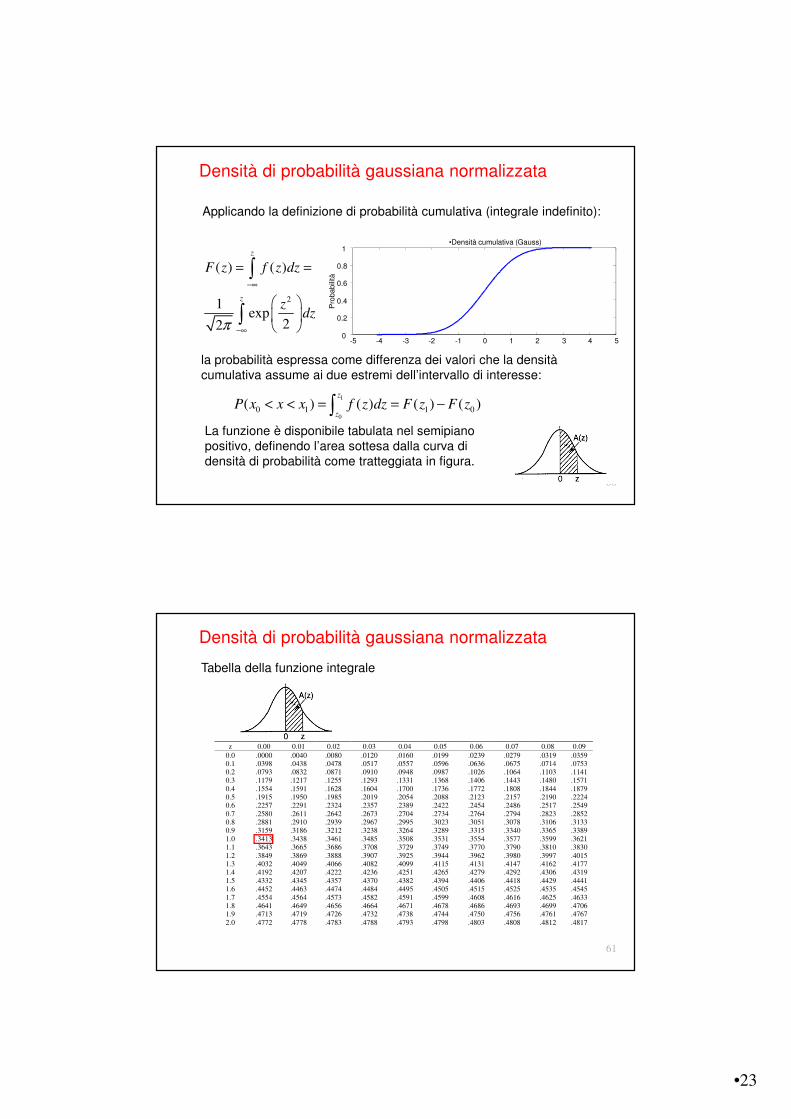
La funzione è disponibile tabulata nel semipiano positivo, definendo l’area sottesa dalla curva di densità di probabilità come tratteggiata in figura.
Densità di probabilità gaussiana normalizzata
61
Tabella della funzione integrale
z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0.0 .0000 .0040 .0080 .0120 .0160 .0199 .0239 .0279 .0319 .03590.1 .0398 .0438 .0478 .0517 .0557 .0596 .0636 .0675 .0714 .07530.2 .0793 .0832 .0871 .0910 .0948 .0987 .1026 .1064 .1103 .11410.3 .1179 .1217 .1255 .1293 .1331 .1368 .1406 .1443 .1480 .15710.4 .1554 .1591 .1628 .1604 .1700 .1736 .1772 .1808 .1844 .18790.5 .1915 .1950 .1985 .2019 .2054 .2088 .2123 .2157 .2190 .22240.6 .2257 .2291 .2324 .2357 .2389 .2422 .2454 .2486 .2517 .25490.7 .2580 .2611 .2642 .2673 .2704 .2734 .2764 .2794 .2823 .28520.8 .2881 .2910 .2939 .2967 .2995 .3023 .3051 .3078 .3106 .31330.9 .3159 .3186 .3212 .3238 .3264 .3289 .3315 .3340 .3365 .33891.0 .3413 .3438 .3461 .3485 .3508 .3531 .3554 .3577 .3599 .36211.1 .3643 .3665 .3686 .3708 .3729 .3749 .3770 .3790 .3810 .38301.2 .3849 .3869 .3888 .3907 .3925 .3944 .3962 .3980 .3997 .40151.3 .4032 .4049 .4066 .4082 .4099 .4115 .4131 .4147 .4162 .41771.4 .4192 .4207 .4222 .4236 .4251 .4265 .4279 .4292 .4306 .43191.5 .4332 .4345 .4357 .4370 .4382 .4394 .4406 .4418 .4429 .44411.6 .4452 .4463 .4474 .4484 .4495 .4505 .4515 .4525 .4535 .45451.7 .4554 .4564 .4573 .4582 .4591 .4599 .4608 .4616 .4625 .46331.8 .4641 .4649 .4656 .4664 .4671 .4678 .4686 .4693 .4699 .47061.9 .4713 .4719 .4726 .4732 .4738 .4744 .4750 .4756 .4761 .47672.0 .4772 .4778 .4783 .4788 .4793 .4798 .4803 .4808 .4812 .4817
Densità di probabilità gaussiana normalizzata

•24
62
La forma integrale è disponibile in forma tabulare con passo z/100
----------------------------------------------------------------
z 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
----------------------------------------------------------------
0.0 00000 00399 00798 01197 01595 01994 02392 02790 03188 03586
0.1 03983 04380 04776 05172 05567 05962 06356 06749 07142 07355
0.2 07926 08317 08706 09095 09483 09871 10257 10642 11026 11409
…
2.7 49653 49664 49674 49683 49693 49702 49711 49720 49728 49736
2.8 49744 49752 49760 49767 49774 49781 49788 49795 49801 49807
2.9 49813 49819 49825 49831 49836 49841 49846 49851 49856 49861
…
5.0 50000 50000 50000 50000 50000 50000 50000 50000 50000 50000
----------------------------------------------------------------
z=2.83 I(2.83)= ?=0.49767=2.8 + 0.03
z=.83
P(0<z<2.83)=0.49767 La tabella è data per valori di scostamento positivi, ma vale anche per valori negativi: la funzione densità di probabilità è simmetrica.
Densità di probabilità gaussiana normalizzata
63
-5 -4 -3 -2 -1 0 1 2 3 4 50
0.2
0.4
0.6
0.8
1
Pro
ba
bili
tà
Densità cumulativa (Gauss)
z0 z1
1
0
1
0
0 1 0 1
2
( ) ( ) ( )
1exp
22
z
z
Z
Z
P x x x P z z z f z dz
zdz
+
< < = < < = =
∫
∫
0 1
0 1 1 0
, 0
( ) ( ) ( )
z z
P z z z F z F z
>
< < = !
0( )F z
1( )F z
( ) ( ) 0F z F z z= ! <
0 1
1 0 0 1
1 0
, 0
( ) ( ) ( )
( ) ( )
z z
P z z z F z F z
F z F z
<
< < = !
= !
Caso di valori con lo stesso segno
Densità di probabilità gaussiana normalizzata
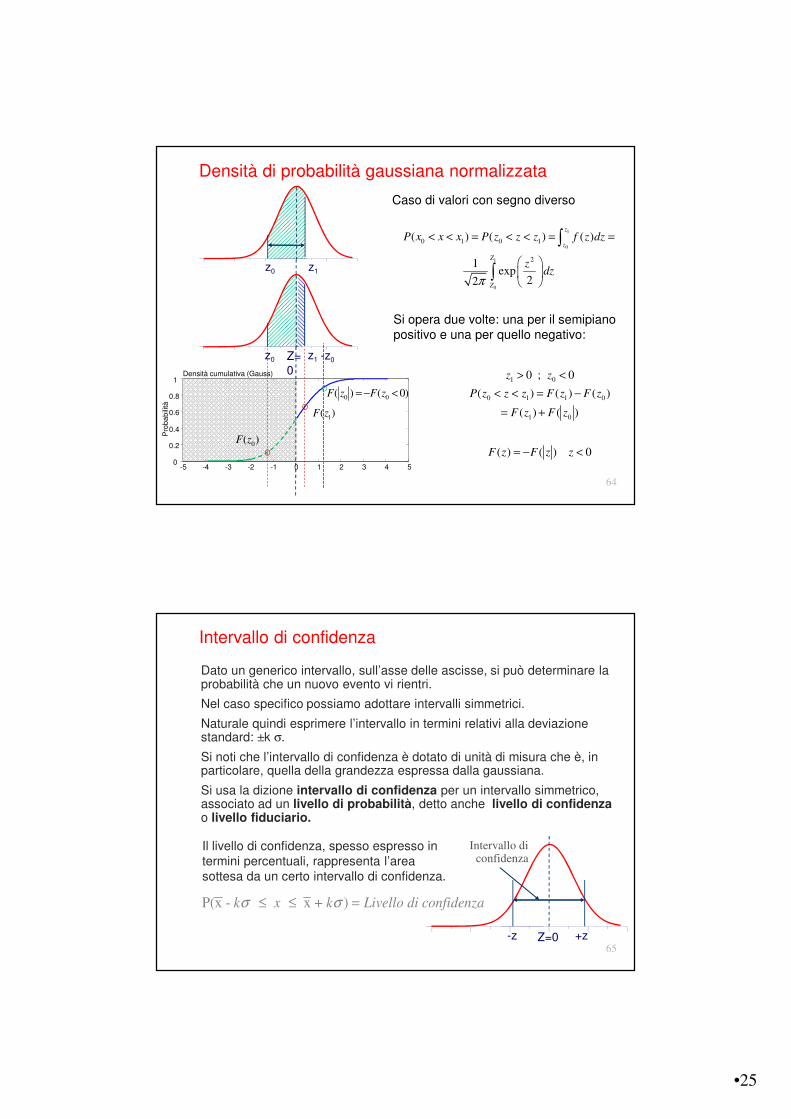
•25
64
1
0
1
0
0 1 0 1
2
( ) ( ) ( )
1exp
22
z
z
Z
Z
P x x x P z z z f z dz
zdz
+
< < = < < = =
∫
∫
1 0
0 1 1 0
1 0
0 ; 0
( ) ( ) ( )
( ) ( )
z z
P z z z F z F z
F z F z
> <
< < = !
= +
( ) ( ) 0F z F z z= ! <
Caso di valori con segno diverso
-5 -4 -3 -2 -1 0 1 2 3 4 50
0.2
0.4
0.6
0.8
1
Pro
ba
bili
tà
Densità cumulativa (Gauss)
0( )F z
1( )F z
0 0( ) ( 0)F z F z= ! <
z0 z1
Z=0
z0 z1 -z0
Si opera due volte: una per il semipiano positivo e una per quello negativo:
Densità di probabilità gaussiana normalizzata
65
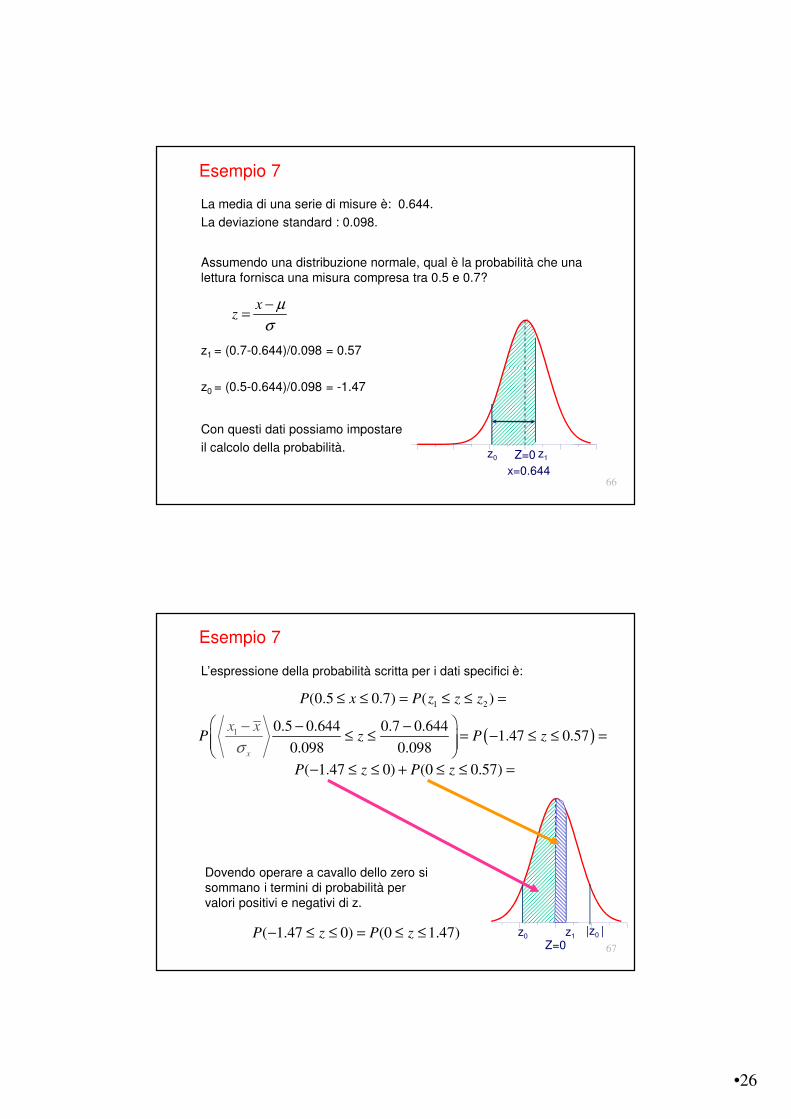
Intervallo di confidenza
Dato un generico intervallo, sull’asse delle ascisse, si può determinare la probabilità che un nuovo evento vi rientri.
Nel caso specifico possiamo adottare intervalli simmetrici.
Naturale quindi esprimere l’intervallo in termini relativi alla deviazione standard: ±k &.
Si noti che l’intervallo di confidenza è dotato di unità di misura che è, in particolare, quella della grandezza espressa dalla gaussiana.
Si usa la dizione intervallo di confidenza per un intervallo simmetrico, associato ad un livello di probabilità, detto anche livello di confidenza o livello fiduciario.
Z=0-z +z
Intervallo diconfidenza
P(x - x + ) k x k Livello di confidenza& &# # =
Il livello di confidenza, spesso espresso in termini percentuali, rappresenta l’area sottesa da un certo intervallo di confidenza.
•26
66
Assumendo una distribuzione normale, qual è la probabilità che una lettura fornisca una misura compresa tra 0.5 e 0.7?
z1 = (0.7-0.644)/0.098 = 0.57
z0 = (0.5-0.644)/0.098 = -1.47
Con questi dati possiamo impostare
il calcolo della probabilità.
La media di una serie di misure è: 0.644.
La deviazione standard : 0.098.
Z=0z0 z1
x=0.644
xz
µ
&
!=
Esempio 7
67
L’espressione della probabilità scritta per i dati specifici è:
( )1
1 2(0.5 0.7) ( )
0.5 0.644 0.7 0.6441.47 0.57
0.098 0.098x
P x P z z z
Px x
z P z&
# # = # # =
! !# # = ! # # =
!
Z=0z0 z1
|z0 |
Dovendo operare a cavallo dello zero si sommano i termini di probabilità per valori positivi e negativi di z.
( 1.47 0) (0 0.57)P z P z! # # + # # =
( 1.47 0) (0 1.47)P z P z! # # = # #
Esempio 7
•27
68
z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 ... ... ... ... ... ... ... ... ... ... ... 0.4 .1554 .1591 .1628 .1604 .1700 .1736 .1772 .1808 .1844 .1879 0.5 .1915 .1950 .1985 .2019 .2054 .2088 .2123 .2157 .2190 .2224 0.6 .2257 .2291 .2324 .2357 .2389 .2422 .2454 .2486 .2517 .2549 0.7 .2580 .2611 .2642 .2673 .2704 .2734 .2764 .2794 .2823 .2852 0.8 .2881 .2910 .2939 .2967 .2995 .3023 .3051 .3078 .3106 .3133 0.9 .3159 .3186 .3212 .3238 .3264 .3289 .3315 .3340 .3365 .3389 1.0 .3413 .3438 .3461 .3485 .3508 .3531 .3554 .3577 .3599 .3621 1.1 .3643 .3665 .3686 .3708 .3729 .3749 .3770 .3790 .3810 .3830 1.2 .3849 .3869 .3888 .3907 .3925 .3944 .3962 .3980 .3997 .4015 1.3 .4032 .4049 .4066 .4082 .4099 .4115 .4131 .4147 .4162 .4177 1.4 .4192 .4207 .4222 .4236 .4251 .4265 .4279 .4292 .4306 .4319 1.5 .4332 .4345 .4357 .4370 .4382 .4394 .4406 .4418 .4429 .4441 1.6 .4452 .4463 .4474 .4484 .4495 .4505 .4515 .4525 .4535 .4545 ... ... ... ... ... ... ... ... ... ... ...
Quindi:
La probabilità che si verifichi la condizione 0.5# x #0.7 è del 64%.
(0 1.47) (0 0.57)P z P z# # + # # =
( ) ( ) ( ) ( )1 2 1.47 0.57I z I z I I+ = +
z=1.47
z=0.57
0.4292= 0.2157 0.6449+ =
Esempio 7
69
Esempio 8
Qual è la probabilità che una misura, di una grandezza a distribuzione gaussiana, a media 0.644 e deviazione standard 0.098, siano maggiori di 0.8?
( )
( ) ( )
0.8 0.644(0.8 )
0.098
1.5918 0.5 0.44408 0.056
P x I I
I I
! # # $ = $ ! =
$ ! = ! =
Quindi la probabilità che si verifichi la condizione x " 0.8 è del 5.6%.
Z=0z1

•28
70
( ) ( )
( 2 2 ) ( 2 2 )
( 2 2 ) ( 2 2)
2 2 0.4772 0.4772 0.9544
x x x x x
x x x
P x x x P x z x x
P x z x x P z
I I
& & & & &
& & &
! < < + = ! < + < + =
= ! < + < + = ! < < + =
= + ! = + =
Esempio 9
Qual è la probabilità che una misura cada in un intervallo attorno al valor medio pari a due volte la deviazione standard?
Quindi la probabilità che la condizione si verifichi è del 95.44%.
x
x
x xz x z x&
&
!= ⇒ = +
( 2 2 )?x xP x x x& &! < < +
Dalla definizione della variabile z si ottiene che essa definisce un intervallo attorno alla media in termini di deviazione standard:
Sostituendo e con semplici passaggi:
Z=0-z0 z0
71
Esempio 10
Nella produzione di banchi motore, la tolleranza sul diametro D ha
distribuzione gaussiana. Il D medio misurato è µ=4 in con una
deviazione &=0.002 in. Qual è la probabilità delle seguenti condizioni:
a) un cilindro sia misurato con D # 4.002 in;
b) D " 4.005 in;
c) 3.993 # D #4.003 in;
d) se i cilindri con deviazione >2& sono eliminati, che percentuale totale
verrà eliminata?
•29
72
( 1) ( 0) (0 1)
.5 .3413 .8413 84.3%
P z P z P z!$ # # = !$ # # + # # =
= + = =
b) Cilindro sia misurato con D " 4.005 in;
4.005 4.0002.5
0.002
Dz
µ
&
! != = =
(2.5 ) (0 ) (0 2.5)
0.5 0.4938 0.0062 0.62%
P z P z P z# # +$ = # # +$ ! # # =
! = =
4.002 4.0001
0.002
Dz
µ
&
! != = =
Soluzione:
a) cilindro con D # 4.002 in
Z=0z1
Z=0z1
Esempio 10
73
d) Se il criterio di rigetto è pari a 2& , i
banchi che vengono accettati sono:
( 2 2) 2 (0 2) 95.44%P z P z! # # + = # # + =
mentre quelli che vengono eliminati sono:
1 0.9544 0.0456 4.56%! = =
c) Probabilità 3.993 # D #4.003 in;
1 2
3.993 4.0 4.003 4.03.5 ; 1.5
0.002 0.002z z
! != = ! = = +
( 3.5 1.5) ( 3.5 0) (0 1.5)
.4998 .4332 .933 93.3%
P z P z P z! # # + = ! # # + # # =
= + = =
z1=-3.5 z2=1.5
-z1 z1
z1-z1
Esempio 10

•30
74
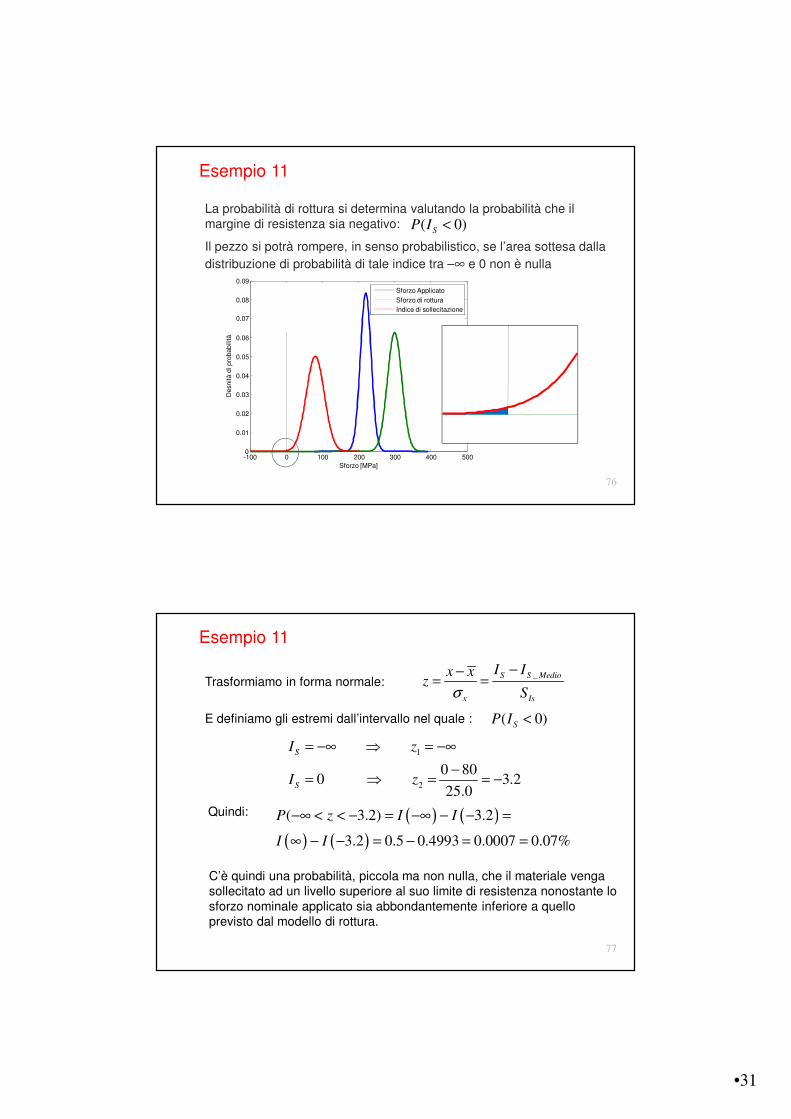
Esempio 11
La sperimentazione su di un lotto di provini di un materiale fragile ha portato a definire lo sforzo di rottura medio e la sua deviazione standard.
Se lo sforzo generato da un carico applicato è anch’esso noto in termini di valore medio e di deviazione standard, ipotizzando che entrambi abbiano distribuzione casuale, quale è la probabilità che un provino si rompa?
300 25
220 15
R
A
MPa
MPa
&
&
= ±
= ±
Il problema di rottura in termini probabilistici è definito come la probabilità che lo sforzo agente (rosso) superi quello limite del materiale (blu).
-100 0 100 200 300 400 5000
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
Sforzo [MPa]
Desn
ità d
i pro
babili
tà
Sforzo applicato
Sforzo di rottura
75
Possiamo definire una variabile di supporto come differenza tra lo sforzo di rottura e quello applicato che chiameremo margine di resistenza:
La variabile casuale di interesse, distanza tra lo sforzo di rottura e quello applicato, è una gaussiana, ed è completamente definita come:
La differenza di due variabili casuali, come capiremo meglio nel proseguo del corso, ha come valore medio la differenza dei valori medi e come varianza la somma delle varianze:
1_ 2_
2 2 2
_ 1_ 2 _
medio medio medio
d medio x medio x medio
d x x
S S S
= !
= +
S R AI & &= !
80 25.0SI MPa= ±
_ _
2 2 2 2
300 220 80
20 15 25.0R A
S R medio A medio
Is
I MPa
S S S MPa& &
& &= ! = ! =
= + = + =
Quindi:
Esempio 11
•31
76
La probabilità di rottura si determina valutando la probabilità che il margine di resistenza sia negativo:
Il pezzo si potrà rompere, in senso probabilistico, se l’area sottesa dalla
distribuzione di probabilità di tale indice tra –$ e 0 non è nulla
( 0)SP I <
Esempio 11
-100 0 100 200 300 400 5000
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
Sforzo [MPa]
Desn
ità d
i pro
babili
tà
Sforzo Applicato
Sforzo di rottura
Indice di sollecitazione
77
Trasformiamo in forma normale:_S S Medio
x Is
I Ix xz
S&
!!= =
E definiamo gli estremi dall’intervallo nel quale : ( 0)SP I <
Quindi:
C’è quindi una probabilità, piccola ma non nulla, che il materiale venga sollecitato ad un livello superiore al suo limite di resistenza nonostante lo sforzo nominale applicato sia abbondantemente inferiore a quello previsto dal modello di rottura.
1
2
0 800 3.2
25.0
S
S
I z
I z
= !$ ⇒ = !$
!= ⇒ = = !
( ) ( )( ) ( )
( 3.2) 3.2
3.2 0.5 0.4993 0.0007 0.07%
P z I I
I I
!$ < < ! = !$ ! ! =
$ ! ! = ! = =
Esempio 11

•32
78
Avendo visto che ad un intervallo si accompagna una probabilità, è ragionevole associare le due informazioni assumendo che la conoscenza della probabilità comporti avere «confidenza» nell’intervallo stesso
Dichiarando un intervallo unitamente alla probabilità ad esso associata potremo esprimerci in termini di intervallo di confidenza e di livello di confidenza o fiduciario
Il problema dell’intervallo di confidenza si può porre nelle due forme:
a) che intervallo occorre assumere se è necessario conseguire un certo livello di confidenza?
Per rispondere a questa domanda occorre trovare il k tale per cui l’intervallo µ±k& sottende un’area corrispondente alla probabilità assegnata attraverso il livello di confidenza.
b) quale livello di confidenza è assicurato da un dato intervallo (generalmente espresso in rapporto alla deviazione standard)?
In questi caso occorre valutare quale probabilità è associata all’intervallo ±k &.
Intervallo di confidenza
79
Problema a), che intervallo occorre assumere se è necessario conseguire un certo livello di confidenza?
Se l’intervallo di confidenza è simmetrico occorre trovare il valore pari alla metà del livello richiesto nella tabella e dedurre il parametro z corrispondente, se non è simmetrico P-50%.
Se ci interessa un livello di probabilità del 90% per il caso simmetrico dovremo cercare 0.45, che si ottiene per 1.64 # z # 1.65, nel caso asimmetrico 0.40, cui corrisponde 1.28 # z # 1.29.
z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 ... ... ... ... ... ... ... ... ... ... ... 0.4 .1554 .1591 .1628 .1604 .1700 .1736 .1772 .1808 .1844 .1879 0.5 .1915 .1950 .1985 .2019 .2054 .2088 .2123 .2157 .2190 .2224 1.0 .3413 .3438 .3461 .3485 .3508 .3531 .3554 .3577 .3599 .3621 1.1 .3643 .3665 .3686 .3708 .3729 .3749 .3770 .3790 .3810 .3830 1.2 .3849 .3869 .3888 .3907 .3925 .3944 .3962 .3980 .3997 .4015 1.3 .4032 .4049 .4066 .4082 .4099 .4115 .4131 .4147 .4162 .4177 1.4 .4192 .4207 .4222 .4236 .4251 .4265 .4279 .4292 .4306 .4319 1.5 .4332 .4345 .4357 .4370 .4382 .4394 .4406 .4418 .4429 .4441 1.6 .4452 .4463 .4474 .4484 .4495 .4505 .4515 .4525 .4535 .4545 ... ... ... ... ... ... ... ... ... ... ...
Intervallo di confidenza
L’intervallo di confidenza sarà quindi x=µ±1.64& nel caso simmetrico ex< 1.28& o x< -1.28& nel caso asimmetrico (quale delle due equazioni usare nel caso asimmetrico dipende dal problema che si sta affrontando).

•33
80
Problema b) quale livello di confidenza è assicurato da un dato intervallo di confidenza espresso in k volte la deviazione standard?
Con la tabella di densità cumulativa è possibile valutare i livelli di confidenza degli intervalli, ovvero la probabilità di un nuovo evento entro l’intervallo di confidenza definito da una semiampiezza pari a k volte la deviazione standard, attorno al valor medio:
Intervallo di confidenza Livello di confidenza
± 1 & 2 x .3413 = 68.26%
± 2 & 2 x .4772 = 95.44%
± 3 & 2 x .4987 = 99.74%
± 3.5 & 2 x .4998 = 99.96%
L’intervallo 2& (95%) è frequentemente utilizzato: significa che ogni 20 misure una sola dovrebbe cadere all’esterno dell’intervallo.
5& è spesso assunto come livello di certezza probabilistica:P(5 &)> 99.998% circa 1 su 1’000’000
Intervallo di confidenza
84
Domande?

•34
85
Da ricordare
Come si caratterizzare una grandezza casuale.
Esistono vari funzioni di densità di probabilità per la descrizione delle grandezze casuali.
Le misure sono modellate attraverso una funzioni di densità di probabilità gaussiana.
La gaussiana normalizzata.
Concetto di intervallo di confidenza e livello di confidenza.
Concetti di insiemistica per la gestione di eventi dipendenti da grandezze casuali.
87
Approfondimento: proprietà della probabilità e gestione di variabili casuali multiple

•35
88
Una variabile casuale si caratterizza come un esito tra tutti quelli possibili.
Chiamiamo evento (event) l’esito della realizzazione di una variabile casuale (es. un esperimento con la misura di una grandezza).
L’evento è il valore di una variabile casuale continua, x, e la probabilità di tale evento è rappresentata da una funzione, P(x).
La previsione della probabilità di un evento è uno degli scopi dell’analisi probabilistico-statistica.
Proprietà della probabilità
89
Esaminiamo le proprietà più significative relative alla probabilità.
Ricordiamo le proprietà di base:
la probabilità, e quindi anche la funzione di densità di probabilità, è sempre positiva con valore massimo unitario:
0 < P(x or Xi) < 1
se l’occorrenza di un evento, A, è certa:
P(A) = 1
se è certo che un evento, A, non avviene allora:
P(A) = 0
se esiste un evento A* complementare all’evento A (cioè se avviene l’evento A, l’evento A* non avviene):
P(A)=1-P(A*)
Proprietà della probabilità

•36
90
Se due eventi A e B sono mutualmente esclusivi (cioè se la probabilità di evenienza simultanea è nulla), la probabilità di occorrenza dell’evento A o B è:
P(A or B)=P(A)+P(B)
Per esempio, nel caso di un lancio di dati la possibilità di ottenere 3 o 6 è:
In generale:
P(A)P(B)
P(A)+P(B)
1
( , 1, )N
i ii
P a i N P=
, = =∑
Variabili casuali multiple
91
Se gli eventi A e B sono indipendenti (cioè se il loro accadimento non dipende uno dall’altro), la probabilità che entrambi avvengano è:
P(AB)=P(A)P(B)
Es. Consideriamo l’assemblaggio di due pezzi, A e B, prodotti da differenti aziende. Sappiamo che c’è la possibilità del 5% che il pezzo A sia difettoso contro il 2% del pezzo B. La probabilità che il pezzo assemblato contenga sia A che B difettosi è:
P(AB)=0.05 - 0.02 = 0.001 o 0.1%
P(A)P(B)
P(AB)
Variabili casuali multiple

•37
92
La probabilità di evenienza di A o B o entrambi, rappresentata da P(A .B) (probabilità dell’unione di A e B), è:
La probabilità è quindi inferiore alla somma delle singole probabilità in quanto si deve tenere conto della probabilità che un pezzo presenti entrambe le evenienze.
Nell’es. precedente, la probabilità di avere A o B o entrambi difettosi è:P(A . B)=0.05 + 0.02 – 0.001 = 0.069 cioè 6.9%
P(A . B)= 1-P(A*)P(B*)= 1-(1-P(A))(1-P(B))=P(A)+P(B)-P(AB)
In generale:
P(A) P(B)
P(AB)
P(A . B) =P(A)+P(B)-P(AB)
P(AB)P(A)+P(B)-P(AB)
*
1
( , 1, ) 1N
i i
i
P tutti a i N P=
= = !/
Variabili casuali multiple
93
Sappiamo quindi come trattare problemi nei quali compaiano più variabili casuali che possono essere tra loro indipendenti o meno.
Applicazioni:
analisi della presenza di difettosità;
analisi del tasso di guasto e di affidabilità di un sistema;
analisi di montaggio e installazione.
Variabili casuali multiple


















