
Elementi di crittografia - Dipartimento...
68
1 Elementi di crittografia Aprile 2005 Autrici: Monia Lanni Daniela Vittiglio versione: 3.draft Sommario 1 Elementi di Crittografia………………………………………… ……………………………1 1.1 Introduzione…………………………………………………………………………………1 1.2 Motivazione per la cripto……………………………………………………………………3 1.3 Tecniche Crittografiche……………………………………………………………………..3 1.4 Algoritmi a chiave simmetrica………………………………………………………………8 1.5 Algoritmi a chiave asimmetrica……………………………………………………………..9 1.6 Funzioni Hash………………………………………………………………………………10 1.1 2 Elementi di Steganografia……………………………………………………………………1 3 2.1 Introduzione……………………………………………………………………………….13 2.2 Tecniche Steganografiche ………………………………………………………………...14 2.2.1. Steganografia Selettiva………………………………………………………………….18 2.2.2. Steganografia Costruttiva……………………………………………………………….19 2.2.3. Principio di Kerckhoff …………………………………………………………………19 2.3 Watermark: diritti d’autore e commercio elettronico……………………………………...21 2.4 Il Sistema Steganografica …………………………………………………………………22 2.5 Fasi Steganografiche………………………………………………………………………22
-
Upload
nguyenkhanh -
Category
Documents
-
view
217 -
download
1
Transcript of Elementi di crittografia - Dipartimento...

1
Elementi di crittografia
Aprile 2005
Autrici: Monia Lanni
Daniela Vittiglio
versione: 3.draft
Sommario
1 Elementi di
Crittografia…………………………………………
……………………………1
1.1 Introduzione…………………………………………………………………………………1
1.2 Motivazione per la cripto……………………………………………………………………3
1.3 Tecniche Crittografiche……………………………………………………………………..3
1.4 Algoritmi a chiave simmetrica………………………………………………………………8
1.5 Algoritmi a chiave asimmetrica……………………………………………………………..9
1.6 Funzioni Hash………………………………………………………………………………10
1.1 2 Elementi di
Steganografia……………………………………………………………………1
3
2.1 Introduzione……………………………………………………………………………….13
2.2 Tecniche Steganografiche ………………………………………………………………...14
2.2.1. Steganografia Selettiva………………………………………………………………….18
2.2.2. Steganografia Costruttiva……………………………………………………………….19
2.2.3. Principio di Kerckhoff …………………………………………………………………19
2.3 Watermark: diritti d’autore e commercio elettronico……………………………………...21
2.4 Il Sistema Steganografica …………………………………………………………………22
2.5 Fasi Steganografiche………………………………………………………………………22

2
2.6 La Stegoanalisi ………………………………………………………………………….22
2.6.1. Stegosistema esteso……………………………………………………………………..23
2.2 3 Steganografia
nell’Audio……………………………………………………………………..25
3.1 Introduzione……………………………………………………………………………….25
3.2 Tecniche utilizzate………………………………………………………………………...25
3.2.1 Phase encoding…………………………………………………………………………..25
3.2.2 Spread spectrum encoding………………………………………………………………26
3.2.3 LSB encoding……………………………………………………………………………26
3.2.4 Echo data heading……………………………………………………………………….26
3.2.5 S-Tools…………………………………………………………………………………..26
3.2.6 MP3 Stego……………………………………………………………………………….27
3.2.7 Filigrana Digitale Audio………………………………………………………………...28
3.2.7.1 COPYCODE: un esempio di audio filigranato………………………………………..29
3.2.7.2 Requisiti della Filigrana Digitale…………………………………………………….29
3.2.7.3 Il Watermarking ed il Digital Right Management (DRM) per la gestione
di diritti digitali ………………………………………………………………………..30
3.2.7.4 Efficacia ed applicabilità del Digital Watermarking …………………………………31
4 Steganografia nelle
Immagini………………………………………………………………..33
4.1 Introduzione……………………………………………………………………………….33
4.2 Formati di compressione delle immagini………………………………………………….34
4.2.1 Il formato GIF…………………………………………………………………………...34
4.2.2 Il formato JPEG………………………………………………………………………….34
4.2.3 Il formato BMP………………………………………………………………………….35
4.3 Altri programmi steganografici……………………………………………………………35
4.4 Attacchi alle Immagini…………………………………………………………………….36
4.5 Teoria e tecniche di watermarking nelle immagini fisse.…………………………………36
4.5.1 Autenticazione ………………………………………………………………………….3
7

3
4.5.2 Lo Spread
Spectrum………………………………………………………………….….38
4.5.3 La
Modulazione…………………………………………………………………………39
4.5.4 Recupero del
marchio…………………………………………………………………...42
4.5.5 Caratteristiche dei segnali di
Watermarks……………………………………………….42
4.5.6 Schema di inserzione e rivelazione della
firma………………………………………….43
4.5.6.1 L’inserzione……………………………………………………………………………
43
4.5.6.2 La
rivelazione………………………………………………………………………….44
4.5.7 Tecniche di
watermarking……………………………………………………………….45
4.5.7.1 Metodo del
LSB……………………………………………………………………….45
4.5.7.2 Watermarking nel dominio spaziale(metodo di
Kutter)………………………………45
4.5.7.3 Watermarking nel dominio delle frequenze(metodo di
Cox)…………………………46
4.5.8 Attacchi e
Robustezza…………………………………………………………………...47
4.5.8.1 Esempi di dead
lock…………………………………………………………………...48
3.3 5 Steganografia nel
Video………………………………………………………………………50
5.1 Introduzione……………………………………………………………………………….50
5.2 Video Editing in MPEG-4…………………………………………………………………51
5.3 Watermark Embedding……………………………………………………………………52
5.4 Recupero del Watermark…………………………………………………………………..55
5.5 Risultati Sperimentali……………………………………………………………………...56

4
5.5.1 Esperimenti sulla Visibilità...…………………………………………………………...57
5.5.2 Robustezza e Diminuzione del Bit-Rate………………………………………………...58
5.5.3 Robustezza e Frame Dropping…………………………………………………………..60
5.5.4 Confidence Measure……………………………………………………………………..62
6 Steganografia in JPEG2000………………………………………………………………….63
6.1 Codifica JPEG2000………………………………………………………………………..
6.2 Informazioni Nascoste in JPEG2000………………………………………………………
6.2.1 Challenges di Informazioni Nascoste…………………………………………………..
6.2.2 Embedding Progressivo di un‘Immagine Nascosta e suoi svantaggi…………………..
6.2.3 Informazioni Nascoste con codifica in modo Lazy…………………………………….
6.2.4 Selezione dei Passi di Raffinamento per l’Embedding………………………………….
6.2.5 Perdita nel Backward Embedding……………………………………………………….
6.2.6 Stegoanalisi di Informazioni Nascoste………………………………………………….
6.3 Risultati Sperimentali………………………………………………………………

5
1 Elementi di Crittografia
4.4 Introduzione
La criptografia è la scienza che consente di mantenere segrete le informazioni che non si vogliono
divulgare pubblicamente, in maniera tale che la possibilità di accedervi sia data soltanto ad uno o
ad un ristretto numero di persone autorizzate.
L'operazione tramite la quale si nascondono le informazioni è chiamata cifratura oppure
criptazione, ed è effettuata tramite un apposito algoritmo, che sfrutta come mezzo fondamentale
una chiave per convertire il testo chiaro in testo cifrato o criptogramma.
Naturalmente il processo di criptografia deve essere reversibile e consentire, quindi, di rendere
intelleggibile un documento precedentemente criptato. Con "decriptazione" si intende la
conversione da testo cifrato a testo chiaro e anch'essa sfrutta la chiave del cifrario.
Si supponga che qualcuno desideri inviare un messaggio ad un destinatario e voglia essere sicuro
che nessun altro possa leggerlo. Nella terminologia della crittografia, il messaggio è chiamato
testo in chiaro (plaintext o cleartext). Con il termine crittografare (vd fig) si intende codificare il
contenuto del messaggio in modo che risulti non comprensibile da estranei.
Il messaggio crittografato è quindi denominato testo cifrato (ciphertext). Il processo di recupero
del testo in chiaro dal testo cifrato è denominato decrittazione. I processi di codifica e decodifica
fanno normalmente uso di una chiave, e il metodo di codifica è costruito in modo che la decodifica
possa essere effettuata soltanto conoscendo la chiave appropriata. La moderna crittografia tratta
tutti gli aspetti della messaggistica sicura, dell'autenticazione, delle firme elettroniche, del denaro
Figura 1 – Schema di crittografia

6
elettronico e altre applicazioni. I moderni algoritmi non possono essere eseguiti da esseri umani,
ma solo da computer o dispositivi hardware specializzati: essi utilizzano una chiave che è
sottoposta ai due processi di codifica e decodifica in modo che un messaggio possa essere
decrittato solo se la chiave corrisponde a quella di criptazione.
Ci sono due classi di algoritmi basati su chiave:
• simmetrici (o a chiave segreta): utilizzano la stessa chiave per la codifica e la decodifica.
• asimmetrici (o a chiave pubblica): usano una chiave differente per i due processi di codifica e di
decodifica; inoltre la chiave per la decodifica non può essere derivata da quella di codifica. Gli
algoritmi asimmetrici permettono di rendere pubblica la chiave di codifica, cosicché chiunque può
essere in grado di codificarli, ma solo chi conosce la chiave di decodifica (chiave privata) può
interpretare il messaggio.
I sistemi a crittografia pubblica offrono alcuni vantaggi rispetto a quelli a chiave simmetrica. Per
esempio, la chiave pubblica può essere facilmente distribuita senza il timore di compromettere la
sicurezza; non è neanche necessario inviarne una copia a tutti i corrispondenti: essa può essere
prelevata da un server di chiavi pubblico mantenuto da un'autorità di certificazione. Un altro
vantaggio della crittografia a chiave pubblica è quella di permettere di autenticare il creatore del
messaggio. Nella pratica, come, per esempio, nell'implementazione di PGP, gli algoritmi a chiave
asimmetrica e quelli a chiave simmetrica sono spesso utilizzati insieme: con la chiave pubblica
viene codificata una chiave di crittografia generata casualmente, questa ultima è utilizzata per
crittografare il messaggio utilizzando un algoritmo simmetrico. Molti ottimi algoritmi di
crittografia sono disponibili pubblicamente attraverso libri, uffici brevetti o Internet: proprio per
questo motivo, l'algoritmo di pubblico dominio è soggetto alla revisione di centinaia di esperti che
ne scoprono e sistemano le eventuali debolezze.
La chiave è una funzione particolare opportunamente progettata e consiste di una stringa
relativamente corta. La caratteristica fondamentale è la possibilità di cambiare la chiave quando è
necessario o quando si desidera. La lunghezza della chiave è un parametro di progetto critico. È
infatti questa lunghezza che determina il tempo necessario per decifrare il testo in cifra. In base al
numero di cifre che compongono una chiave, varia il numero di chiavi disponibili con una data
tecnica. Se la stringa è formata da 2 cifre si possono individuare 100 possibili chiavi da (00 a 99);
se la stringa è formata da 3 cifre si hanno 1000 chiavi possibili e se la stringa è formata da 6 cifre
si hanno 1000000 di possibili chiavi. Quindi più lunga è la chiave e maggiore è il tempo
necessario (work factor) per un crittanalista per individuare la chiave. In genere il work factor è
proporzionale all'esponente della lunghezza della chiave. La segretezza consiste nell'avere un buon
algoritmo di dominio pubblico ed una chiave abbastanza lunga ma segreta.

7
1.2 Motivazioni per la crypto
Difendere la privacy individuale in un'era di crescente computerizzazione sta diventando un
problema cardine con il quale alla fine tutti avranno a che fare. Ci sono due casi generali in cui è
necessario avvalersi dell'appoggio della crittografia:
• quando l'informazione, una volta crittata, deve semplicemente essere conservata sul posto e
dunque confezionata in modo tale da renderla invulnerabile ad accessi non autorizzati
• quando l'informazione deve essere trasmessa in qualche luogo e dunque la crittazione è
necessaria, perché se qualcuno la intercettasse non potrebbe capirne il senso.
Riguardo al primo caso, un crittosistema a chiave segreta (simmetrica) è quello più consono, sia
perché è più veloce sia perché non esiste alcun problema connesso con lo scambio e la validazione
delle chiavi. Il secondo caso è quello che richiama l'attenzione della maggior parte delle
compagnie produttrici di software crittografico. In effetti, l'utilizzo sempre più esteso della
telematica sta introducendo nella tecnica delle comunicazioni quella che a pieno diritto può essere
definita una rivoluzione. Il punto cardine di questa rivoluzione è rappresentato dall'accesso di
massa alla posta elettronica, tramite la quale è consentita la libera espressione e la libera
circolazione di idee su scala mondiale, rendendo inoltre possibile questa circolazione nella
direzione dal singolo alla moltitudine e non solo nel verso opposto. Se si esamina dal punto di
vista tecnico uno dei mezzi principali attraverso cui questa libera circolazione d'idee avviene, ossia
Internet, appare chiaro che essa, così come si verifica per la rete telefonica e per il traffico di dati
su carta, costituisce un canale di comunicazione che di per se non garantisce la segretezza dei dati
che vi circolano.
Se si osserva l'intestazione di un qualunque messaggio è possibile rendersi conto di come prima di
arrivare a destinazione i messaggi transitino attraverso diversi nodi. Maggiore è il numero di nodi
attraverso cui il messaggio deve passare prima di giungere alla destinazione finale, maggiore è la
probabilità che tale messaggio possa essere intercettato e manomesso da qualcuno. Da qui,
l'esigenza di adoperare algoritmi, a chiave simmetrica, a chiave pubblica o una qualche
combinazione delle due che siano così potenti da resistere a tutti i tipi di attacchi oggi conosciuti,
che consentano, insomma, a tutti gli utilizzatori di Internet di poter comunicare con tranquillità.
1.3 Tecniche crittografiche
Le tecniche usate per ottenere un testo cifrato da un testo in chiaro sono:
•Sostituzione
•Trasposizione

8
•One-time pads
Nel progettare un algoritmo si considerano due principi basilari:
1. il messaggio crittato deve contenere della ridondanza in modo tale che gli intrusi non possano
mandare dei messaggi casuali che possono essere interpretati come messaggi validi;
2. i messaggi crittati devono raggiungere la destinazione entro un certo intervallo di tempo
altrimenti vengono rigettati. Questo secondo principio nasce dall'esigenza di impedire all'intruso di
trasmettere nuovamente il messaggio di inizio sessione presentandosi come il precedente
interlocutore.
Sostituzione
La sostituzione è una delle tecniche utilizzate per crittografare un'informazione.
Nel substitution cipher ogni lettera o gruppo di lettere del messaggio iniziale è sostituita da
un'altra lettera o da un altro gruppo di lettere. Per ottenere un alfabeto cifrato bisogna seguire la
seguente procedura: si considera l'alfabeto e si trasla l'origine dell'alfabeto stesso di k posizioni
successivamente si sostituisce ogni lettera del testo originale con la corrispondente lettera
dell'alfabeto cifrato.
In questo caso k è la chiave dell'algoritmo. Per esempio, dall'alfabeto anglosassone
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
si ottiene l'alfabeto cifrato
Q R S T U V W X Y Z A B C D E F G H I J K L M N O P
dove k =16 è la chiave. La relazione matematica che descrive tale algoritmo è data da:
nkxy ii += (1)
dove yi è la lettera cifrata, xi è il carattere in chiaro dell'alfabeto, k il valore della chiave e n il
numero di lettere che costituiscono l'alfabeto.
Questo metodo è chiamato sostituzione mono alfabetica ed è molto semplice. Ipotizzando un
alfabeto si 26 caratteri, le possibili sostituzioni sono pari a 25 x (26!), cioè circa 9.7 x 1027 modi
differenti, dove 25 sono i possibili valori assegnabili a k e 26! è il numero di modi in cui si può

9
riscrivere l'alfabeto. Pur essendo abbastanza semplice, questo algoritmo è molto sicuro a fronte di
un attacco di tipo brute-force; ipotizzando che in ogni microsecondo possa essere effettuato un
tentativo, il tempo di analisi richiede 1014 anni. Tuttavia, a causa delle proprietà statistiche del
linguaggio parlato, con una piccola quantità di testo cifrato si è in grado di trovare la chiave.
Esistono ovviamente delle tecniche di sostituzione più sofisticate rispetto a quella presentata
nell'esempio.
Una variante del suddetto algoritmo consiste nella codifica poli-alfabetica. Partendo dalla tabella
del Vigenere (ved fig.) è possibile estrarne alcune colonne sulla base di una chiave di crittografia
(ad esempio: DANTE).
Figura 2:
Supponendo quindi che il testo in chiaro sia:
Lasciate ogni speranza
Il carattere viene codificato prendendo la riga indicizzata dalla lettera chiave attualmente utlizzata,
e la colonna corrispondente alla lettera che si vuole codificare:
Testo in chiaro:
L A S C I A T E O G N I S P E R A N Z A

10
Chiave:
D A N T E D A N T E D A N T E D A N T E
Testo cifrato:
O A F V M D T R H K Q I F I I U A A S E
Anche in questo caso, però, la frequenza di una lettera all'interno della frase può ancora essere
ottenuta dividendo il testo cifrato in blocchi di lunghezza pari alla lunghezza della chiave:
Tabella 3 – Tabella per la ricerca del testo in chiaro
O A F V M
D T R H K
Q I F I I
U A A S E
A questo punto ogni colonna viene analizzata poiché è ottenuta da alfabeti diversi. Si tenga
presente che la lunghezza della chiave non è nota, quindi la ricerca è una complicazione che
aumenta il grado di sicurezza.
I due metodi presentati sono comunque vulnerabili agli attacchi basati sull'analisi del testo alla
ricerca della frequenza di una lettera nel messaggio.
Trasposizione
La trasposizione è una delle tecniche utilizzate per crittografare un'informazione.
Il transposition cipher è un algoritmo che riordina le lettere del testo originale in modo da ottenere
il testo cifrato. Uno dei metodi è la trasposizione per colonna. La chiave è una parola oppure una
frase che non contiene lettere ripetute al suo interno. Si considerino come testo originale il
seguente:
please tranfer one million dollars to my swiss bank account six two two
Si sceglie come chiave la parola megabuck e si ordina il tutto nel seguente modo:
7 4 5 1 2 8 3 6

11
M E G A B U C K
p l e a s e t r
a n s f e r o n
e m i l l i o n
d o l l a r s t
o m y s w i s s
b a n k a c c o
u n t s i x t w
o t w o a b c d
In base alla parola chiave si enumerano le colonne in modo crescente e tale da fare corrispondere
il numero 1 alla lettera della chiave più vicina alla lettera A, origine dell'alfabeto. In questo caso
alla colonna individuata da M si associa 7, alla colonna individuata da E si associa 4, alla colonna
individuata da G si associa 5, alla colonna individuata da A si associa 1, alla colonna individuata
da B si associa 2, alla colonna individuata da U si associa 8, alla colonna individuata da C si
associa 3, alla colonna individuata da K si associa 6. Partendo dalla colonna corrispondente al
numero 1 si legge per colonna ottenendo il testo cifrato:
afllskso selawaia toossctc lnmomant esilyntw rnntsowd paedobuo eriricxb.
One-time pads
Il one-time pads è una delle tecniche utilizzate per crittografare un'informazione.
L'algoritmo è il seguente:
• si sceglie in modo casuale una stringa di bit come chiave
• si converte il testo originale in formato di stringa di bit
• successivamente si effettua l'operazione di EXCLUSIVE OR (XOR) tra la chiave e il testo da
crittare.
Questo metodo ha degli inconvenienti:
• la chiave non può essere memorizzata così che sia il mittente che il destinatario devono avere
una copia della chiave stessa
• la quantità di dati che può essere trasmessa è limitata dalle dimensioni della chiave
• il metodo è molto sensibile alla perdita o all'inserimento di caratteri
• il metodo è sensibile alla sincronizzazione tra la sorgente ed il destinatario.

12
1.4 Algoritmi a chiave simmetrica
Nei crittosistemi a chiave segreta (vd fig.) viene usata una sola chiave (secret key), detta appunto
segreta, utilizzata come parametro di una funzione (per la cifratura e la decifratura) unidirezionale
e invertibile, permettendo così di elaborare il testo del messaggio da trasmettere rendendolo
incomprensibile agli intercettatori (attacker). Essendo la funzione invertibile, il destinatario deve
soltanto elaborare nuovamente il testo cifrato richiamando l'inversa della funzione di cifratura
avente come parametro la stessa chiave utilizzata dal mittente.
Figura 2 – Cifratura con crittografia a chiave segreta
Ovviamente, la tecnica si basa sulla capacità del mittente e del destinatario di mantenere segreto il
codice di cifratura. Con il sistema a chiave segreta, il mittente e il destinatario devono raggiungere
un accordo sulla scelta della chiave. La cosa non è facile se essi si trovano agli estremi di un
canale di comunicazione insicuro di migliaia di chilometri. Un tempo coppie di chiavi identiche
erano inventate presso un mezzo centrale di generazione delle chiavi e poi trasmesse alla loro
destinazione da un corriere (canale sicuro?!). Naturalmente, un metodo di questo tipo si dimostrò
subito inadeguato. Nacque allora spontaneo pensare di trasmettere tali chiavi, precedentemente
cifrate, sulla rete stessa. Una soluzione a tale problema, di seguito esposta, fu ideata nel 1985
sfruttando una gestione gerarchica delle chiavi. Un'organizzazione sceglie una chiave principale e
la distribuisce mediante un corriere a ciascuno dei suoi uffici, raggruppati in regioni. Ogni
capoufficio regionale sceglie, a sua volta, una chiave regionale. Queste vengono cifrate usando la
chiave principale e distribuite su tutta la rete. Se due uffici della stessa regione vogliono
comunicare, uno di essi sceglie una chiave di sessione e la invia all'altro, cifrata mediante quella
regionale. Oppure può essere creata la chiave di sessione da un processo di gestione esterno,

13
inviata ad ambedue gli uffici e codificata con la chiave regionale. Si nota che è sempre necessario
un corriere esterno per la diffusione della chiave principale e nel caso di dubbia sicurezza di
questa, essa dovrà essere subito sostituita.
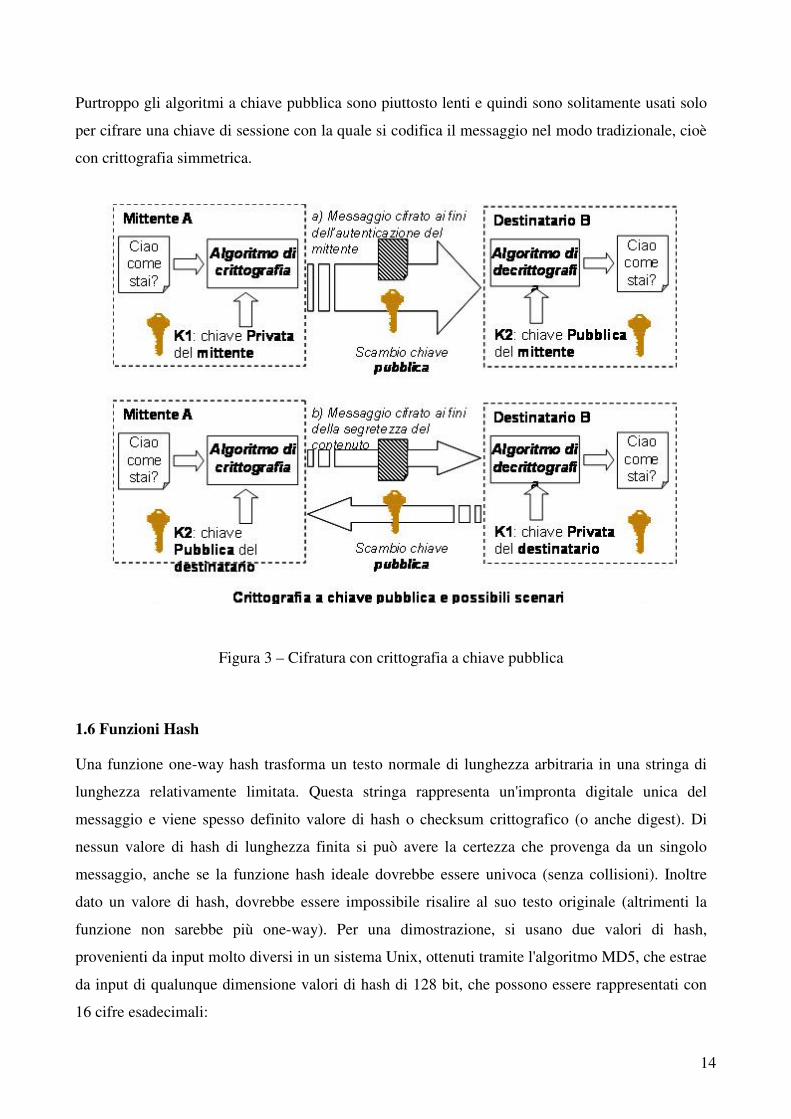
1.5 Algoritmi a chiave asimmetrica
La cifratura a chiave pubblica ha rivoluzionato il mondo della crittografia. La sua potenzialità è
legata al fatto che non è necessario che le parti in comunicazione si scambino alcuna chiave, così
come avviene per la crittografia a chiave segreta. Ogni parte possiede, infatti, due chiavi: una
pubblica e l'altra privata.
Il metodo si basa su due concetti fondamentali:
1. Un messaggio codificato con una delle due chiavi può essere decifrato solo con l'altra
2. Non è matematicamente possibile ricavare una chiave dall'altra.
Non è possibile, quindi, risalire alla chiave privata (tenuta segreta dal proprietario) partendo da
quella pubblica (resa disponibile a tutti).
I due scenari di impiego della crittografia a chiave pubblica sono i seguenti:
a) Il mittente cripta il messaggio con la propria chiave privata (K1); il destinatario, che conosce
l'identità di chi gli invia il messaggio, lo decripta utilizzando la chiave pubblica (K2) del mittente.
In questo contesto, si garantiscono l'autenticazione del mittente e l'integrità del messaggio. Non è
garantita la confidenzialità poiché la chiave pubblica del mittente è a disposizione di tutti, quindi
tutti possono decritittografare il messaggio;
b) Il mittente cripta il messaggio con la chiave pubblica del destinatario, che è nota a tutti; il
destinatario riconosce che il messaggio è per lui e lo decripta con la propria chiave privata, nota
solo a lui. Solo il destinatario, che conosce la chiave segreta corrispondente alla chiave pubblica
utilizzata dal mittente, sarà in grado di leggere il messaggio. Così si garantisce la confidenzialità.
È possibile autenticare oltre al mittente anche il contenuto del messaggio: il mittente potrebbe
effettuare un hashing del testo da inviare, cioè applicare una funzione unidirezionale che a partire
da un certo messaggio fornisce un valore di hash (di lunghezza fissa) e tale che se il messaggio
venisse alterato questo valore cambierebbe. Il mittente, una volta aggiunto tale valore in fondo al
suo messaggio, passa alla cifratura con la sua chiave personale. Chiunque può decodificare con la
chiave pubblica del mittente il testo inviato o solo il valore di hash per verificare che sia stata
proprio lui a scriverlo e che il valore di hash non sia modificato, ma corrisponda sempre a quel
messaggio. Questa modalità è alla base del concetto di Firma Elettronica.
14
Purtroppo gli algoritmi a chiave pubblica sono piuttosto lenti e quindi sono solitamente usati solo
per cifrare una chiave di sessione con la quale si codifica il messaggio nel modo tradizionale, cioè
con crittografia simmetrica.
Figura 3 – Cifratura con crittografia a chiave pubblica
1.6 Funzioni Hash
Una funzione one-way hash trasforma un testo normale di lunghezza arbitraria in una stringa di
lunghezza relativamente limitata. Questa stringa rappresenta un'impronta digitale unica del
messaggio e viene spesso definito valore di hash o checksum crittografico (o anche digest). Di
nessun valore di hash di lunghezza finita si può avere la certezza che provenga da un singolo
messaggio, anche se la funzione hash ideale dovrebbe essere univoca (senza collisioni). Inoltre
dato un valore di hash, dovrebbe essere impossibile risalire al suo testo originale (altrimenti la
funzione non sarebbe più one-way). Per una dimostrazione, si usano due valori di hash,
provenienti da input molto diversi in un sistema Unix, ottenuti tramite l'algoritmo MD5, che estrae
da input di qualunque dimensione valori di hash di 128 bit, che possono essere rappresentati con
16 cifre esadecimali:

15
"% echo "a" ¦ md5
valore di hash corrispondente:
60B725F10C9C85C70D97880DFE8191B3
"% cat congressional-minutes.txt ¦ md5
valore di hash corrispondente:
EDED6F6C520DEB812BA7154D093AD43.
Le funzioni one-way hash svolgono due funzioni molto importanti nella crittografia:
1. verifica dell'integrità: se il valore di hash di un certo messaggio è uguale prima e dopo la
trasmissione, allora vi sono ottime possibilità che il messaggio ricevuto sia rimasto invariato
2. concisione: nei calcoli matematici risulta più facile usare un'impronta a 128 bit quanto non lo
sia un testo normale.
La lunghezza dei valori di hash varia a seconda degli algoritmi. Quelli a 128 bit sono i più comuni
e i preferiti, per il maggiore numero dei bit. Si pensi che una funzione hash a 4 bit non è di alcuna
utilità per una verifica dell'integrità perché 1/16 dei possibili messaggi sono mappati su uno dei 16
possibili valori di hash. Un hacker che modifica un messaggio può farlo agevolmente in modo tale
da lasciare lo stesso valore di hash. Se invece si usa un valore di hash da 160 bit, l'hacker
dovrebbe modificare il messaggio in 2159 maniere diverse per ottenere il corretto valore di hash.
Le funzioni di hash possono essere usate per la creazione di firme digitali. Molti crittosistemi
richiedono calcoli molto lunghi e complessi per apporre la propria firma digitale su un file di
grosse dimensioni, mentre, grazie a queste funzioni, si può semplicemente calcolare e firmare il
valore di hash del file sicuramente di dimensioni molto ridotte, risparmiando risorse.
MD2 (Message Digest 2)
inventato da Ron Rivest della RSA Data Security, è una funzione nata per essere utilizzata con la
Privacy Enhaced Mail (PEM). Produce un valore di hash di 128 bit e richiede come input multipli
di 16 byte. MD2 esegue il pad (cioè aggiunge i bit mancanti) dei messaggi d'ingresso che non

16
hanno la lunghezza integrale. Questo algoritmo è stato violato dalla crittoanalisi e quindi ne è
ovviamente sconsigliato l'uso.
MD4
Inventato da Ron Rivest della RSA Data Security, MD4 crea anch'esso, come il precedente, valori
di hash di 128 bit ma i calcoli sono ottimizzati per i registri a 32 bit come quelli che si possono
trovare nella famiglia dei processori Intel 80x86. Sicuramente più veloce di MD2, MD4 richiede
pad (aggiunta di bit) a multipli di 512 bit. Inoltre il padding comprende sempre un valore di 64 bit
che indica la lunghezza del messaggio che non ha subito il pad. In questo modo MD4 è più sicuro
del suo antecedente, perché se già è difficile produrre due messaggi che abbiano stesso valore di
hash di 128 bit, è ancora più difficile fare lo stesso con due messaggi che abbiano la stessa
lunghezza con modulo 264.
MD5
MD5, come i precedenti, è stato ideato da Ron Rivest della RSA Data Security. È nato per
sostituire MD4 che sta per essere violato. Non cambia molto sulla struttura, ma è solo
un'estensione del suddetto anche se un pò più lento:
• il testo è diviso in blocchi lunghi 512 bit
• viene generato un hash di 128 bit (4x32)
• sono usate quattro variabili per l'inizio
• è basato su XOR e operazioni logiche
• le operazioni sono iterate.
SHA
SHA (Secure Hash Algorithm) è un algoritmo hash prodotto dal National Istitute of Standard and
Tecnology (NIST) e della National Security Agency (NSA) del governo degli Stati Uniti. Molto
simile a MD4, produce valori di 160 bit a partire da stringhe di lunghezza variabile. É ritenuto
abbastanza sicuro ed è relativamente nuovo.
nota: SHA-1 (ossia SHA-160) era stato pensato per Skipjack-80
Tiger
Tiger è un nuovo algoritmo sviluppato da Anderson e Biham.

17
2 Elementi di Steganografia
2.1 Introduzione
Negli ultimi anni il settore delle telecomunicazioni è stato caratterizzato da una fase di sviluppo
molto rapida (l’avvento di Internet,la trasmissione via satellite e la diffusione dei telefoni cellulari).
La trasmissione delle informazioni però se da un lato consente di comunicare con maggiore facilità
dall’altro rende i dati accessibili anche a chi non è autorizzato a riceverli. Per risolvere questo
problema viene chiamata in causa la crittografia che è una tecnica che altera i documenti originali e
permette di ripristinarli solo a chi è in possesso della chiave corretta.
La crittografia dunque nasconde il contenuto di un messaggio,mentre esiste un’altra tecnica detta
steganografia che nasconde le comunicazioni nell’interno di altri veicoli in modo che non sia
possibile la semplice scoperta del messaggio segreto.
Uno dei primi esempi di steganografia, utilizzato già nell'Evo Antico, prevedeva la rasatura della
testa di un messaggero e il tatuaggio del messaggio sul suo cuoio capelluto. Il messaggio non
poteva essere scoperto una volta che i capelli erano ricresciuti. Un'altra forma comune di
steganografia, in uso nella seconda guerra mondiale, era l'inchiostro invisibile: una lettera
apparentemente innocente poteva contenere tra le righe un messaggio molto diverso.
La steganografia o watermark (detta anche filigrana elettronica) è un sistema di marcatura
utilizzato per inserire all'interno di dati delle informazioni nascoste o poco visibili. La marcatura
può essere inserita per identificare in un secondo momento il dato come proprio e quindi
dimostrarne la proprietà verso terzi oppure per inserire delle informazioni generali come metadati
che possono essere utili per la classificazione o per mettere in relazione il contenuto digitale con
altri contenuti o con siti WWW o per dimostrarne l'autenticità.
Il watermark può essere più o meno invisibile, nell'eccezione odierna viene quasi sempre inteso
come invisibile o viene preteso che lo sia. Il watermark può essere utilizzato anche per comunicare
informazioni che vengono con tale tecnica nascoste in immagini, video, documenti o file audio. È
pertanto possibile con tale tecnica inserire attraverso opportuni algoritmi piccole modifiche
nell'informazione all'interno di informazioni da distribuire. Spesso, colui che riceve tali
informazioni non è a conoscenza del fatto che queste contengono una marcatura. Questo metodo
può essere utilizzato anche per l'invio di informazioni sensibili e segrete. Il watermark nascosto
può contenere informazioni delle più varie e può essere decomposto in varie parti e anche
codificato e criptato. In molti casi è possibile aggiungere vari marchi ad uno stesso dato (per
esempio immagine) e questi possono o meno danneggiarsi a vicenda.

18
In alcuni casi il watermark può essere rimosso per ottenere il dato nella sua forma originale. Nella
maggior parte dei casi gli algoritmi sono studiati per impedire questa possibilità rendendo il dato e
il marchio indivisibili senza il deterioramento della qualità del dato stesso. Ovviamente, vi sono
svariate tecniche che permettono di confondere il watermark presente su un'immagine o su un
audio rendendo la sua rilettura impossibile. Questo tipo di tecnica di attacco non riproduce il dato
in forma originale, ma produce un dato che non contiene di fatto il marchio e pertanto non può
essere rivendicato dal proprietario.
Il watermark è un campo di ricerca relativamente nuovo, praticamente la parte più importante è
stata sviluppata negli ultimi 4-5 anni sotto la pressione delle necessità del mercato. Negli Stati
Uniti il commercio elettronico ha avuto un'evoluzione molto accelerata però la stessa cosa non si
può dire sulla ricerca del metodi e meccanismi per la protezione dei dati trasmessi nella rete. Solo
nel campo musicale la Recording Industry Association of America (RIAA) ha affermato che
l'esistenza di siti pirata che offrono la possibilità di scaricare liberamente musica comporta un
danno di 2 miliardi di dollari all'industria del campo. Questo fatto crea una situazione non usuale
nel campo della ricerca e sviluppo. I possessori di copyright ed i distributori del materiale
proprietario mettono sotto pressione gli sviluppatori per la creazione di meccanismi che
garantiscano la protezione dei loro diritti nel caso di trasmissione o distribuzione via rete. Con
tutto ciò la ricerca e ancora lontana dal soddisfare le esigenze del mercato. Certe aree di ricerca
(watermark su immagini e sul video) sono in una fase più evoluta rispetto alle altre (watermark sul
testo o sul audio).
2.2 Tecniche Steganografiche
Secondo un sistema di classificazione le tecniche steganografiche possono essere ripartite in tre
classi: teganografia sostitutiva, steganografia selettiva e steganografia costruttiva.
Le tecniche del primo tipo sono di gran lunga le più diffuse, tanto che in genere con il termine
steganografia ci si riferisce implicitamente a esse. Tali tecniche si basano sulla seguente
osservazione: la maggior parte dei canali di comunicazione (linee telefoniche, trasmissioni radio,
ecc.) trasmettono segnali che sono sempre accompagnati da qualche tipo di rumore. Questo rumore
può essere sostituito da un segnale - il messaggio segreto - che è stato trasformato in modo tale che,
a meno di conoscere una chiave segreta, è indistinguibile dal rumore vero e proprio, e quindi può
essere trasmesso senza destare sospetti.
Quasi tutti i programmi che sono facilmente reperibili si basano su questa idea, sfruttando la grande
diffusione di file contenenti una codifica digitale di immagini, animazioni e suoni; spesso questi file
sono ottenuti da un processo di conversione analogico/digitale e contengono qualche tipo di rumore.

19
Per esempio, uno scanner può essere visto come uno strumento di misura più o meno preciso.
Un'immagine prodotta da uno scanner, da questo punto di vista, è il risultato di una specifica misura
e come tale è soggetta a essere affetta da errore.
La tecnica base impiegata dalla maggior parte dei programmi, consiste semplicemente nel sostituire
i "bit meno significativi" delle immagini digitalizzate con i bit che costituiscono il file segreto (i bit
meno significativi sono assimilabili ai valori meno significativi di una misura, cioè quelli che
tendono a essere affetti da errori.) Spesso l'immagine che ne risulta non è distinguibile a occhio
nudo da quella originale ed è comunque difficile dire se eventuali perdite di qualità siano dovute
alla presenza di informazioni nascoste oppure all'errore causato dall'impiego di uno scanner poco
preciso, o ancora alla effettiva qualità dell'immagine originale prima di essere digitalizzata. Per
fissare meglio le idee, ecco un esempio concreto. Uno dei modi in cui viene solitamente
rappresentata un'immagine prodotta da uno scanner è la codifica RGB a 24 bit: l'immagine consiste
di una matrice MxN di punti colorati (pixel) e ogni punto è rappresentato da 3 byte, che indicano
rispettivamente i livelli dei colori primari rosso (Red), verde (Green) e blu (Blue) che costituiscono
il colore. In questo modello i colori possibili sono 224 = 16777216; i cosiddetti grigi sono i colori in
cui i livelli di rosso, verde e blu sono coincidenti e quindi sono soltanto 256. Supponiamo che uno
specifico pixel di un'immagine prodotta da uno scanner sia rappresentato dalla tripla (12, 241, 19)
(si tratta di un colore tendente al verde, dato che la componente verde predomina fortemente sulle
altre due); in notazione binaria, le tre componenti sono:
===============
12 = 00001100
241 = 11110001
19 = 00010011
===============
quelli che in precedenza abbiamo chiamato i "bit meno significativi" dell'immagine sono gli ultimi a
destra, cioè 0-1-1, e sono proprio quelli che si utilizzano per nascondere il messaggio segreto. Se
volessimo nascondere in quel pixel l'informazione data dalla sequenza binaria 101, allora
bisognerebbe effettuare la seguente trasformazione:

20
==============================
00001100 --> 00001101 = 13
11110001 --> 11110000 = 240
00010011 --> 00010011 = 19
==============================
La tripla è così diventata (13, 240, 19); si noti che questo tipo di trasformazione consiste nel
sommare 1, sottrarre 1 o lasciare invariato ciascun livello di colore primario, quindi il colore
risultante differisce in misura minima da quello originale. Dato che un solo pixel può contenere
un'informazione di 3 bit, un'immagine di dimensioni MxN può contenere un messaggio segreto
lungo fino a (3*M*N)/8 byte, per esempio un'immagine 1024x768 può contenere 294912 byte.
La tecnica appena descritta rappresenta il cuore della steganografia sostitutiva, anche se di fatto ne
esistono numerose variazioni. Innanzitutto è ovvio che tutto quello che abbiamo detto vale non solo
per le immagini, ma anche per altri tipi di media, per esempio suoni e animazioni digitalizzati.
Inoltre - e questo è meno ovvio - lavorando con le immagini come file contenitori non sempre si
inietta l'informazione al livello dei pixel, ma si è costretti a operare su un livello di rappresentazione
intermedio; è questo il caso, per esempio, delle immagini in formato JPEG, nel quale le immagini
vengono memorizzate solo dopo essere state compresse con una tecnica che tende a preservare le
loro caratteristiche visive piuttosto che l'esatta informazione contenuta nella sequenza di pixel. Se
iniettassimo delle informazioni in una bitmap e poi la salvassimo in formato JPEG, le informazioni
andrebbero perdute, poiché non sarebbe possibile ricostruire la bitmap originale. Per poter utilizzare
anche le immagini JPEG come contenitori, è tuttavia possibile iniettare le informazioni nei
coefficienti di Fourier ottenuti dalla prima fase di compressione.
Esiste un altro caso interessante che merita di essere discusso, ed è quello dei formati di immagini
che fanno uso di palette. La palette (tavolozza) è un sottoinsieme prestabilito di colori. Nei formati
che ne fanno uso, i pixel della bitmap sono vincolati ad assumere come valore uno dei colori
presenti nella palette: in questo modo è possibile rappresentare i pixel con dei puntatori alla palette,
invece che con la terna esplicita RGB (red, green and blue). Ciò in genere permette di ottenere
dimensioni inferiori della bitmap, ma il reale vantaggio è dato dal fatto che le schede grafiche di
alcuni anni fa utilizzavano proprio questa tecnica e quindi non potevano visualizzare direttamente
immagini con un numero arbitrario di colori. Il caso più tipico è quello delle immagini in formato
GIF con palette di 256 colori, ma le palette possono avere anche altre dimensioni. Come è facile
immaginare, un'immagine appena prodotta da uno scanner a colori sarà tipicamente costituita da più

21
di 256 colori diversi, tuttavia esistono algoritmi capaci di ridurre il numero dei colori utilizzati
mantenendo il degrado della qualità entro limiti accettabili. Si può osservare che, allo stesso modo
in cui avviene con il formato JPEG, non è possibile iniettare informazioni sui pixel prima di
convertire l'immagine in formato GIF, perché durante il processo di conversione c'è perdita di
informazione (osserviamo anche che questo non vale per le immagini a livelli di grigi: tali immagini
infatti sono particolarmente adatte per usi steganografici.) La soluzione che viene di solito adottata
per usare immagini GIF come contenitori è dunque la seguente: si riduce il numero dei colori
utilizzati dall'immagine a un valore inferiore a 256 ma ancora sufficiente a mantenere una certa
qualità dell'immagine, dopodiché si finisce di riempire la palette con colori molto simili a quelli
rimasti. A questo punto, per ogni pixel dell'immagine, la palette contiene più di un colore che lo
possa rappresentare (uno è il colore originale, gli altri sono quelli simili ad esso che sono stati
aggiunti in seguito), quindi abbiamo una possibilità di scelta. Tutte le volte che abbiamo una
possibilità di scelta fra più alternative, abbiamo la possibilità di nascondere un'infor mazione:
questo è uno dei principi fondamentali della steganografia. Se le alternative sono due possiamo
nascondere un bit (se il bit è 0, scegliamo la prima, se è 1 la seconda); se le alternative sono quattro
possiamo nascondere due bit (00 -> la prima, 01 -> la seconda, 10 -> la terza, 11 -> la quarta) e così
via.
La soluzione appena discussa dell'utilizzo di GIF come contenitori è molto ingegnosa ma purtroppo
presenta un problema: è facile scrivere un programma che, presa una GIF in ingresso, analizzi i
colori utilizzati e scopra le relazioni che esistono tra di essi; se il programma scopre che l'insieme
dei colori utilizzati può essere ripartito in sottoinsiemi di colori simili, è molto probabile che la GIF
contenga infor mazione steganografata. Di fatto, questo semplice metodo di attacco è stato portato
avanti con pieno successo da diverse persone ai programmi che utilizzano immagini a palette come
contenitori, tanto che qualcuno ha finito per sostenere che non è possibile fare steganografia con
esse.
Per mostrare quanto sia ampia la gamma di tecniche steganografiche, accenniamo a un'altra
possibilità di nascondere informazioni dentro immagini GIF. Come abbiamo detto, in questo
formato viene prima memorizzata una palette e quindi la bitmap (compressa con un algoritmo che
preserva completamente le informazioni) consistente di una sequenza di puntatori alla palette. Se
scambiamo l'ordine di due colori della palette e corrispondentemente tutti i puntatori ad essi,
otteniamo un file diverso che corrisponde però alla stessa immagine, dal punto di vista
dell'immagine il contenuto informativo dei due file è identico. La rappresentazione di immagini con
palette è quindi intrinsecamente ridondante, dato che ci permette di scegliere un qualsiasi ordine dei
colori della palette (purché si riordinino corrispondentemente i puntatori a essi). Se i colori sono

22
256, esistono 256! modi diversi di scrivere la palette, quindi esistono 256! file diversi che
rappresentano la stessa immagine. Inoltre è abbastanza facile trovare un metodo per numerare
univocamente tutte le permutazioni di ogni data palette (basta, per esempio, considerare
l'ordinamento sulle componenti RGB dei colori). Dato che abbiamo 256! possibilità di scelta, è
possibile codificare log(256!) = 1683 bit, cioè 210 byte. Si noti che questo numero è indipendente
dalle dimensioni dell'immagine, in altre parole è possibile iniettare 210 bytes anche su piccole
immagini del tipo icone 16x16 semplicemente permutando in modo opportuno la palette.
Dopo avere esaminato alcune tecniche steganografiche di tipo sostitutivo, discutiamo adesso i
problemi relativi alla loro sicurezza. Innanzitutto premettiamo che le norme che valgono
generalmente per i programmi di crittografia dovrebbero essere osservate anche per l'utilizzo dei
programmi steganografici. Per ciò che riguarda le specifiche caratteristiche della steganografia, si
tengano presente i seguenti principi: in primo luogo si eviti di usare come contenitori file prelevati
da siti pubblici o comunque noti (per esempio, immagini incluse in pacchetti software, ecc.); in
secondo luogo si eviti di usare più di una volta lo stesso file contenitore (l'ideale sarebbe quello di
generarne ogni volta di nuovi, mediante scanner e convertitori da analogico a digitale, e distruggere
gli originali dopo averli usati).
Come si è visto, queste tecniche consistono nel sostituire un elemento di scarsa importanza (in certi
casi di importanza nulla) da file di vario tipo, con il messaggio segreto che vogliamo nascondere.
Quello che viene ritenuto il principale difetto di queste tecniche è che in genere la sostituzione
operata può alterare le caratteristiche statistiche del rumore presente nel media utilizzato. Lo
scenario è il seguente: si suppone che il nemico disponga di un modello del rumore e che utilizzi
tale modello per controllare i file che riesce a intercettare. Se il rumore presente in un file non è
conforme al modello, allora il file è da considerarsi sospetto. Si può osservare che questo tipo di
attacco non è per niente facile da realizzare, data l'impossibilità pratica di costruire un modello che
tenga conto di tutte le possibili sorgenti di errori/ rumori, tuttavia in proposito esistono degli studi
che in casi molto specifici hanno avuto qualche successo.
La steganografia selettiva e quella costruttiva hanno proprio lo scopo di eliminare questo difetto
della steganografia sostitutiva. Vediamo di cosa si tratta.
2.2.1 Steganografia Selettiva
La steganografia selettiva ha valore puramente teorico e, per quanto se ne sappia, non viene
realmente utilizzata nella pratica. L'idea su cui si basa è quella di procedere per tentativi, ripetendo
una stessa misura fintanto che il risultato non soddisfa una certa condizione. Facciamo un esempio
per chiarire meglio. Si fissi una funzione hash semplice da applicare a un'immagine in forma

23
digitale (una funzione hash è una qualsiasi funzione definita in modo da dare risultati ben distribuiti
nell'insieme dei valori possibili; tipicamente questo si ottiene decomponendo e mescolando in
qualche modo le componenti dell'argomento); per semplificare al massimo, diciamo che la funzione
vale 1 se il numero di bit uguali a 1 del file che rappresenta l'immagine è pari, altrimenti vale 0 (si
tratta di un esempio poco realistico ma, come dicevamo, questa discussione ha valore
esclusivamente teorico). Così, se vogliamo codificare il bit 0 procediamo a generare un'immagine
con uno scanner; se il numero di bit dell'immagine uguali a 1 è dispari ripetiamo di nuovo la
generazione, e continuiamo così finché non si verifica la condizione opposta. Il punto cruciale è che
l'immagine ottenuta con questo metodo contiene effettivamente l'informazione segreta, ma si tratta
di un'immagine "naturale", cioè generata dallo scanner senza essere rimanipolata successivamente.
L'immagine è semplicemente sopravvissuta a un processo di selezione (da cui il nome della
tecnica), quindi non si può dire in alcun modo che le caratteristiche statistiche del rumore
presentano una distorsione rispetto a un modello di riferimento. Come è evidente, il problema di
questa tecnica è che è troppo dispendiosa rispetto alla scarsa quantità di informazione che è
possibile nascondere. Ad ogni modo, alla fine del capitolo si proporrà un esempio di programma
che implementa una steganografia di tipo generativo, utilizzando con successo l'idea di base della
steganografia selettiva di nascondere le informazioni procedendo per tentativi.
2.2.2 Steganografia Costruttiva
La steganografia costruttiva affronta lo stesso problema nel modo più diretto, tentando di sostituire
il rumore presente nel medium utilizzato con l'informazione segreta opportunamente modificata in
modo da imitare le caratteristiche statistiche del rumore originale. Secondo questa concezione, un
buon sistema steganografico dovrebbe basarsi su un modello del rumore e adattare i parametri dei
suoi algoritmi di codifica in modo tale che il falso rumore contenente il messaggio segreto sia il più
possibile conforme al modello. Questo approccio è senza dubbio valido, ma presenta anche alcuni
svantaggi. Innanzitutto non è facile costruire un modello del rumore: la costruzione di un modello
del genere richiede grossi sforzi ed è probabile che qualcuno, in grado di disporre di maggior tempo
e di risorse migliori, riesca a costruire un modello più accurato, riuscendo ancora a distinguere tra il
rumore originale e un sostituto. Inoltre, se il modello del rumore utilizzato dal metodo
steganografico dovesse cadere nelle mani del nemico, egli lo potrebbe analizzare per cercarne
possibili difetti e quindi utilizzare proprio il modello stesso per controllare che un messaggio sia
conforme a esso. Così, il modello, che è parte integrante del sistema steganografico, fornirebbe
involontariamente un metodo di attacco particolarmente efficace proprio contro lo stesso sistema.

24
2.2.3 Il principio di Kerckhoff
A causa di questi problemi, la semplice tecnica iniettiva di base rimane quella più conveniente da
usare. Se si hanno particolari esigenze di sicurezza, esiste sempre una strategia molto semplice e
allo stesso tempo molto efficace: quella che consiste nell'utilizzare contenitori molto più ampi
rispetto alla quantità di informazioni da nascondere. Per esempio, invece di utilizzare i bit meno
significativi di tutti i pixel di un'immagine, si può giocare sul sicuro utilizzando solo un pixel ogni
10, o anche più, fino a rendere impossibile, a tutti gli effetti pratici, la rilevazione di una distorsione
delle caratteristiche statistiche del rumore. Su questo punto si tornerà in seguito.
Resta da affrontare un'ultima questione molto importante. Abbiamo accennato all'eventualità che i
dettagli di funzionamento di un sistema steganografico possano cadere nelle mani del nemico. In
ambito crittografico si danno le definizioni di vari livelli di robustezza di un sistema, a seconda
della capacità che esso ha di resistere ad attacchi basati su vari tipi di informazioni a proposito del
sistema stesso. In particolare, i sistemi più robusti sono quelli che soddisfano i requisiti posti dal
principio di Kerckhoff, che formulato in ambito steganografico suona più o meno così: la sicurezza
del sistema deve basarsi sull'ipotesi che il nemico abbia piena conoscenza dei dettagli di progetto e
implementazione del sistema stesso; la sola informazione di cui il nemico non può disporre è una
sequenza (corta) di numeri casuali - la chiave segreta - senza la quale, osservando un canale di
comunicazione, non deve avere neanche la più piccola possibilità di verificare che è in corso una
comunicazione nascosta.
Se si vuole aderire a questo principio, è evidente che le tecniche esposte fin qui non sono ancora
soddisfacenti per caratterizzare un sistema steganografico completo. Infatti, se i dettagli di
implementazione dell'algoritmo sono resi di dominio pubblico, chiunque è in grado di accedere a
eventuali informazioni nascoste, semplicemente applicando il procedimento inverso (nell'esempio
visto, ciò si ottiene "riaggregando" i bit meno significativi dell'immagine). Per affrontare questo
problema, è necessario introdurre una fase di pre-elaborazione del file segreto, che lo renda non
riconoscibile - da parte del nemico - come portatore di informazioni significative. La soluzione più
ovvia è quella di impiegare un sistema di crittografia convenzionale (per esempio, il PGP), il quale
garantisce appunto l'inaccessibilità da parte del nemico al messaggio vero e proprio.
La storia purtroppo non è finita qui, perché in questo meccanismo a due stadi il secondo processo è
reversibile; in altri termini, chiunque può estrarre il file costituito dalle informazioni che fluiscono
dal primo al secondo stadio. Poiché si presume che un crittoanalista esperto possa facilmente
riconoscere un file prodotto da un programma di crittografia convenzionale, questo schema è ancora
da considerarsi incompleto. Questo punto è di importanza fondamentale, perché rende
definitivamente non valido il sistema steganografico, indipendentemente dal fatto che il contenuto

25
dell'informazione segreta resti inaccessibile. Mentre il progettista di un algoritmo di crittografia
assume che il nemico impiegherà tutte le risorse possibili per decrittare il messaggio, il progettista
di un sistema steganografico deve supporre infatti che il nemico tenterà di rilevare la sola esistenza
del messaggio. In altre parole, la crittografia fallisce il suo scopo quando il nemico legge il
contenuto del messaggio: la steganografia invece fallisce quando il nemico si rende semplicemente
conto che esiste un messaggio segreto dentro il file contenitore, pur non potendolo leggere. È
opportuno quindi che il messaggio crittografato, prima di essere immerso nel contenitore, venga
"camuffato" in modo da diventare difficilmente distinguibile da semplice rumore. A questo scopo,
sono stati escogitati diversi metodi. Il più semplice è quello di eliminare dal file crittato da PGP
tutte le informazioni che lo identificano come tale: il PGP, infatti, genera un file che rispetta un
particolare formato, contenente, oltre al blocco di dati cifrati vero e proprio, informazioni piuttosto
ridondanti che facilitano la gestione del file da parte dello stesso PGP (o di shell in grado di trattare
con questo for mato). Esiste un piccolo programma, Stealth, capace di togliere - e di reinserire nella
fase di ricostruzione - tutte le infor mazioni diverse dal blocco di dati cifrati. Il file che esce da
Stealth appare come una sequenza di bit del tutto casuale, che è molto difficile distinguere da
rumore ad alta entropia. Naturalmente, chiunque può provare ad applicare il procedimento inverso
(prima Stealth per ricostruire l'intestazione, quindi il PGP), ma solo disponendo della chiave giusta
si potrà alla fine accedere al messaggio in chiaro. In caso contrario non si potrà neppure capire se il
fallimento sia dovuto al fatto di non disporre della chiave giusta oppure, verosimilmente, al fatto
che l'immagine non contiene alcun messaggio nascosto.
Un metodo alternativo all'uso congiunto di PGP e Stealth è dato dall'uso di programmi
espressamente progettati per trasfor mare un file in rumore apparente (per esempio, Wnstorm, White
Noise Storm). Riassumendo, un sistema steganografico completo deve comprendere due fasi
fondamentali: trasformazione del messaggio in chiaro in rumore apparente. Questa fase prevede
l'uso di un sistema di crittografia convenzionale e quindi di un qualche tipo di chiave; iniezione nel
(o generazione del) messaggio contenitore.
2.3 Watermark:diritti d’autore e commercio elettronico
L'uso delle tecniche di watermark possono essere utilizzate anche per dimostrare la proprietà di un
documento digitale (immagini, video, audio, testo, spartiti musicali, etc...) e quindi come forma di
protezione dei diritti di autore. Il meccanismo di controllo della proprietà di un documento avviene
attraverso un lettore di watermark il quale ha il compito di individuare all'interno del documento il
codice nascosto dall'autore stesso. Il watermarking, di fatto, non fa nulla per impedire che un CD o
un file audio compresso possa essere copiato: per questo motivo viene considerato un meccanismo

26
di protezione "passivo". Il suo scopo, a differenza delle tradizionali tecnologie anticopia oggi
adottate su numerosi CD audio, è identificare univocamente un contenuto digitale anche quando
questo viene copiato svariate volte e subisce molti processi di degradazione (derivanti, ad
esempio, dalla compressione a perdita di informazione): in questo modo è sempre possibile risalire
al legittimo proprietario. Il watermarking potrebbe divenire una tecnologia chiave per la
distribuzione di musica attraverso Internet: in questo caso, infatti, è possibile integrare "al volo"
un watermark personalizzato all'interno di un file compresso che tenga ad esempio conto dei dati,
come quelli ottenibili dalla carta di credito, utilizzati dall'utente per fare l'acquisto. Per quanto
riguarda i CD, l'uso dei watermark potrebbe essere limitato agli album in versione promo inviati a
persone o società facilmente identificabili, come radio, deejay, giornalisti, ecc.
2.4 Il Sistema Steganografico
Nel sistema steganografico il cover (contenitore) è un file che contiene e nasconde un messaggio
segreto (embedded). La funzione steganografica incapsula il messaggio segreto all’interno del
cover utilizzando una chiave K nota sia alla sorgente che al ricevente.Nella steganografia a chiave
pubblica vi è la codifica/decodifica del messaggio nascosto.Il vantaggio consiste nella difficoltà di
interpretare il messaggio nascosto,lo svantaggio è che cercare di decifrare tutti i potenziali file stego
è un’operazione difficile.A seconda degli approcci usati si distinguono due software steganografici:
• Iniettivi
• Generativi
Nel primo caso si nasconde il messaggio all’interno di un contenitore già esistente,nel secondo caso
si parte dal messaggio segreto e si costruisce un contenitore ad hoc.
2.5 Fasi Steganografiche
Le fasi steganografiche sono tre tipi:
• Trovare i bit ridondanti che sono bit del cover scelti per l’inserimento del messaggio
nascosto.In genere si tratta di bit meno significativi
• Scegliere i cover bit (sottoinsieme dei bit ridondanti per nascondere il messaggio segreto) in
modo equiprobabile tra i bit ridondanti per scongiurare gli attacchi.
• L’Embedding consiste nell’incapsulamento dei dati nascosti:si nascondono i bit segreti nei bit
meno significativi.
La Matrix-Encoding invece utilizza tre parametri che sono il numero di bit selezionati tra quelli
racchiusi nel cover bit,il numero di bit da incapsulare e il numero di bit che si possono al più
modificare.

27
2.6 La Stegoanalisi
Come con la crittoanalisi per la crittografia, la stegoanalisi è definita come la scienza (nonché l’arte)
del rompere la sicurezza di un sistema steganografico. Siccome lo scopo della steganografia è di
nascondere l’esistenza di un messaggio segreto, un attacco con successo ad uno stegosistema
consiste nello scoprire che un determinato file contiene dati nascosti anche senza conoscerne il loro
significato.
Come in crittoanalisi, si assume che il sistema steganografico sia conosciuto dall’attaccante e quindi
che la sicurezza dello stegosistema dipenda dal solo fatto che la chiave segreta non è nota
all’attaccante (principio di Kerckhoff).
2.6.1 Lo Stegosistema Esteso
Lo stegosistema visto in precedenza può essere esteso per includere situazioni di attacchi simili agli attacchi crittografici. Nel diagramma seguente un cerchio (rosso o blu) indica un punto in cui un attaccante può avere accesso: i punti in cui l’attaccante ha accesso definiscono il tipo di attacco.
Figura 1: Lo stegosistema esteso
C’è una distinzione da fare tra attacchi attivi e attacchi passivi: mentre nel primo tipo gli attaccanti
riescono solo ad intercettare i dati (nel diagramma, cerchio blu), nel secondo riescono anche a
manipolarli (cerchio rosso).
Ecco in cosa consistono gli attacchi:

28
• stego-only-attack: l’attaccante ha intercettato il frammento stego ed è in grado di
analizzarlo. È il più importante tipo di attacco contro il sistema steganografico perché è
quello che occorre più di frequente nella pratica;
• stego-attack: il mittente ha usato lo stesso cover ripetutamente per nascondere dati.
L’attaccante possiede un frammento stego diverso ma originato dallo stesso cover. In
ognuno di questi frammenti stego è nascosto un diverso messaggio segreto;
• cover-stego-attack: l’attaccante ha intercettato il frammento stego e sa quale cover è stato
usato per crearlo. Ciò fornisce abbastanza informazioni all'attaccante per poter risalire al
messaggio segreto;
• cover-emb-stego-attack: l’attaccante ha "tutto": ha intercettato il frammento stego, conosce
il cover usato e il messaggio segreto nascosto nel frammento stego;
• manipulating the stego data: l’attaccante è in grado di manipolare i frammenti stego. Il che
significa che l’attaccante può togliere il messaggio segreto dal frammento stego (inibendo la
comunicazione segreta);
• manipulating the cover data: l’attaccante può manipolare il cover e intercettare il
frammento stego. Questo può significare che con un processo più o meno complesso
l’attaccante può risalire al messaggio nascosto.
Lo stego-attack e il cover-stego-attack possono essere prevenuti se il mittente agisce con cautela.
Un utente non dovrebbe mai usare come cover più volte lo stesso file, né files facilmente reperibili
(es. logo di Yahoo) o di uso comune (es. file audio dell’avvio di Windows).

29
3 Steganografia nell’Audio
3.1 Introduzione
La musica è uno dei soggetti più popolari in Internet. Questo è uno dei motivi che ha portato allo
sviluppo dello standard MP3 che garantisce un'ottima compressione e qualità del file audio. Gli
studi di registrazione, gli artisti ed i compositori concordano quando richiedono la piena protezione
del copyright come condizione necessaria per la distribuzione dei loro prodotti via rete. Riuscire ad
inserire informazioni nascoste da la possibilità di rintracciare un'eventuale utilizzo non autorizzato
del materiale acquistato tramite rete o nei CD-ROM. Con l'evoluzione degli standard MPEG
(MPEG1, Audio Layer 3, MP3) questo è diventato de facto lo standard per i file audio vista la
dimensione piccola del file e l'alta qualità del suono. Ci sono già in rete server che offrono musica in
formato MP3 e che utilizzano varie tecniche per la protezione. Ci sono anche motori di ricerca che
offrono aree riservate per la ricerca di file MP3.
L'attenzione ai watermarks apposti su documenti audio è stata recentemente amplificata dal caso Napster. La coscienza
dell'illiceità dello scambio indiscriminato di files .mp3 protetti da copyright e della perdurante difficoltà di reprimere in
maniera definitiva il fenomeno, ha portato alla ricerca affannosa di soluzioni alternative. Tra queste è stata da più parti
ipotizzata la regolare vendita via internet di canzoni, accompagnata dalla loro marchiatura,onde impedirne l'illecita
diffusione.Non a caso sono molte le aziende impegnate nello sviluppo di watermarks che hanno studiato servizi ad hoc
per i documenti .mp3. In particolare, accanto alle classiche informazioni su autore/produttore/acquirente codificate
all'interno dei files, alcune companies offrono soluzioni che integrano la tecnologia di marchiatura con l'e-
commerce.Anche i watermarks apposti su documenti audio devono essere particolarmente robusti e resistenti alla
diffusione con tecnologia di streaming (ad esempio, tramite il Real Player).
3.2 Tecniche Utilizzate
I file audio digitali sono molto flessibili e pertanto adatti al ruolo di cover.Le tecniche più usate per
nascondere informazioni nei file audio sono LSB, Echo-data-hiding,S-Tools, mp3stego, filigrana
digitale audio.
3.2.1 Phase encoding
Lavora sostituendo la fase di un segmento di dati audio con una fase di riferimento in modo da
mantenere lo sfasamento relativo tra vari segmenti. Il problema è che se si introducono forti
alterazioni di fase il file con watermark non soddisfa più i requisiti di qualità.
3.2.2 Spread spectrum encoding

30
Lavora disperdendo il segnale sulla parte più grande possibile dello spettro di frequenza,
permettendo cosi il ritrovamento dell'informazione nascosta anche nel caso di disturbi su certe
frequenze.
3.2.3 LSB encoding
È il metodo più semplice per introdurre informazioni addizionali nelle strutture dati. Il metodo
consiste nel sostituire il bit meno significativo (LSB) per ogni punto di campionamento con il
valore del bit da codificare per ogni campione. Lo svantaggio è che l'informazione aggiunta è
facilmente rimovibile tramite aggiunta di rumore o ricampionamento.
3.2.4 Echo-data-hiding
Inserisce dati dentro ad un segnale audio introducendo un ecco. A seconda dell'area del segnale da
modificare l'inserimento è più o meno possibile.
Nel caso di inserimento di watermark nei file audio le tecniche adottate sono ancora in fase di
evoluzione e non riescono a soddisfare le richieste del mercato. In aggiunta, attualmente non ci
sono algoritmi validi in grado di operare con buoni risultati sui file audio compressi MPEG.
L'informazione nascosta viene diluita in svariati millisecondi di filmato. In questo caso, è possibile
nascondere grandi quantità di informazione. Questa informazioni viene ripetuta ad intervalli
regolari in modo da garantire il suo recupero anche da frammenti.
Quando si modifica il file aggiungendo un forte rumore di fondo facilmente avvertibile l’edh
elimina questo inconveniente.
3.2.5 S-Tools
E’ un software per audio e immagini S-Tools, scritto da Andy Brown, è tra i programmi
steganografici più diffusi, facilmente reperibile in rete presso i più comuni siti di software freeware.
L’uso del programma, infatti, è completamente gratuito ed illimitato nel tempo. La versione 4 è stata
rilasciata nel 1996 e da allora non sono state prodotte nuove versioni. Il programma gira su un
qualunque PC con sistema operativo Windows in tutte le versioni, lo spazio richiesto su hard disk è
trascurabile. Supporta i formati WAV, BMP e GIF come file contenitori. Per quanto riguarda
l'hiding dei file WAV, il software lavora su file WAV a 8 o 16 bits avviene secondo lo schema LSB
cioè vengono considerati ridondanti i bits meno significativi di ogni byte. I Cover Bits, ovvero il
sottoinsieme di bits che effettivamente verranno rimpiazzati vengono scelti in base alla passphrase
inserita in input. Infatti, S-tools usa un generatore di numeri pseudo-casuale che genera il suo output
a partire dalla passphrase e lo usa per scegliere la posizione del prossimo bit del cover da

31
rimpiazzare. Se, ad esempio, il file WAV ha 100 bits disponibili per l'embedding e si vogliono
nascondere solo 10 bits, S-Tools non sceglierà i bits da 0 a 9 perché risulterebbero facilmente
individuabili da un attaccante. Piuttosto, sceglierà i bits 63, 32, 89, 2, 53, 21, 35, 44, 99, 80 o altri
dieci, il tutto dipendente dalla passphrase inserita. In questo modo un attaccante si troverà in grossa
difficoltà. La particolarità di questo programma è un'interfaccia utente basata esclusivamente sul
drag & drop. I menu infatti si presentano molto scarni. Lo schema di utilizzo è il seguente:
1)Si trascina il file contenitore da una finestra di un file manager nella finestra principale di S-
Tools. Viene visualizzata l'onda che rappresenta il file WAV e in basso viene mostrata la sua
capacità;
2)Si trascina il file segreto sul file contenitore;
3)Si sceglie la passphrase e l'algoritmo di cifratura: si può scegliere tra IDEA, DES, Triple DES o
MDC, tutti utilizzati in modalità CFB. Ai files da nascondere viene applicata una compressione che
si può impostare nel menù FILE/PROPERTIES;
4)A questo punto viene generato il nuovo file contenente il messaggio segreto ed è possibile
salvarlo. Il risultato è osservabile nella figura in basso. Come si può notare, i due files, all'ascolto,
non presentano alcuna differenza.
Per estrarre il messaggio segreto dal contenitore si segue uno schema simile:
1)Si trascina il file contenitore da una finestra di un file manager nella finestra principale di S-
Tools;
2)Si seleziona Reveal cliccando col tasto destro del mouse sul file contenitore trascinato;
3)Si sceglie la passphrase e l'algoritmo di cifratura;
4)Se la passphrase è giusta compare un elenco dei file nascosti ed è possibile salvarli.
Analizziamo un esempio. Il file "ORIGINAL.wav" è un file audio mono a 8 bit campionato a 11025
Hz e dura circa 5,625 secondi. Quindi, la dimensione del cover = 8 x 11025 x 5,625 = 496125 bits
≈ 60,6 Kbyte. A questo punto, calcoliamoci la sua capacità. Sappiamo che, i bits ridondanti sono
costituiti dal bit meno significativo di ogni byte del file, quindi #bits ridondanti = dimensione del
file in byte = 496125 bits / 8 ≈ 62015. Quindi la capacità del cover (in bytes) = #bits ridondanti /
8;ovvero, capacità del cover (in bytes) = 62015 / 8 ≈ 7752 bytes.
3.2.6 MP3 Stego
E’un software che effettua l’embedding sfruttando la tecnica dell’Echo-data-hiding.
L’algoritmo di encoding Mp3 è lossy, ovvero comprime i dati in input con perdita di informazione
fornendo un output molto simile ma non identico all’input. Per questo motivo, l’embedding deve
essere necessariamente effettuato nel processo di trasformazione da wav ad Mp3.Mp3Stego è stato

32
rilasciato nell’agosto del 1998 ed è disponibile sia per i sistemi operativi Microsoft che per Linux.
Oltre all’eseguibile, l’autore Fabien Petitcolas (Computer Laboratori, Cambridge (UK)) distribuisce
anche il sorgente liberamente. Il programma si basa su un’interfaccia a linea di comando anche se è
possibile scaricare una interfaccia grafica ancora da migliorare. Esistono due comandi: encode e
decode. Questa tecnica, come già detto, è ottima dal punto di vista qualitativo (all'udito il suono di
input e quello di output sono identici) ma la capacità attribuita ai cover è modesta.In questo
esempio, il file in input ("in.wav") ha dimensioni di circa 1,73 MB e la sua capacità è di soli 1582
bits; "messaggio segreto.txt" è grande 71 bytes (568 bits) e può essere incapsulato senza problemi. Il
programma prende in input il file da nascondere in formato txt (nel nostro esempio "messaggio
segreto.txt"), il contenitore in formato wav (nel nostro esempio "in.wav") e una passphrase,
dopodiché provvede a comprimere il file wav iniettando, durante la fase di compressione, il file txt e
generando in output il file mp3 (nel nostro esempio "out.mp3"). Per estrarre il file nascosto si
utilizza il comando decode in questo modo: decode -X output.mp.Con questo comando si
decomprimerà il file out.mp3 in out.mp3.pcm, tentando di estrarre eventuali informazioni nascoste e
salvandole in out.mp3.txt.
3.2.7 Filigrana Digitale Audio
Il termine “filigrana digitale” e’ strettamente correlato alle scienze steganografiche. .In audio la
filigrana digitale e’ una tecnica per l’accorpamento di informazioni addizionali (si parla in questo
caso di metadata) che devono servire al monitoraggio dei dati audio attraverso gli esistenti canali di
distribuzione digitale. Studi recenti hanno portato all’elaborazione di meccanismi per l’annessione ai
file di informazioni relative all’identita’ dell’utente e del materiale audio trasferito in rete. Mentre i
sistemi più conosciuti operano nel cosiddetto “Linear Domain” (e’ il caso del PCM Watermarking
che opera sul formato audio lineare, ovvero non compresso ) ,alcuni sono capaci di aggiungere la
filigrana digitale nel materiale audio compresso, in questo caso si parlerà di tecnologia “Bitstream
Watermarking”L’idea di base del sistema si basa sull’accorpamento ad un dato file di ulteriori
informazioni, per l’appunto una sorta di audio-filigrana digitale. Queste informazioni sono
ovviamente “nascoste” e possono essere “lette” solo successivamente da uno speciale “estrattore”
opportunamente istruito per tale scopo. L’aggiunta dei dati relativi alla filigrana digitale viene
dunque effettuata secondo le caratteristiche di una chiave di lettura che deve quindi essere
“conosciuta” dall’apposito decoder al momento della sua estrazione.
3.2.7.1 COPYCODE: un esempio di audio filigranato
Con il declino dell'era analogica, la nuova era digitale vede l'introduzione sul mercato di nuovi
supporti audio già a partire dagli anni '80. Nel 1982 in risposta al proliferare di DAT e CD, il

33
RIAA chiese alla corte americana di imporre sui nuovi dispositivi di ascolto un sistema di filigrana
digitale, Copycopde, elaborato dalla CBS di allora (oggi Sony).
In realtà questo primo ed interessante esperimento si risolse presto in un gigantesco flop
ingegneristico, oltre che in un netto rifiuto della corte di giustizia americana. Questa ultima
intervenne nello stesso anno e, ribadendo il principio del "fair use" espresso nell’Audio Home
Recording Act (AHRA), respinse le richieste avanzate dalle principali industrie discografiche che
puntavano all’introduzione di questa tecnologia nella protezione dei loro cataloghi e dei loro artisti.
Il sistema si riproponeva di creare un segnale aggiuntivo da accorpare alle tracce audio, una sorta di
filigrana appunto, che contenesse ulteriori informazioni relative al brano, all'artista e ovviamente
alla protezione dei diritti, così da impedire gli utilizzi illeciti e la duplicazione seriale. Test
governativi dimostrarono che questo sistema, pur operando all'interno di uno spettro di frequenze
non percepibile dall'orecchio umano, finiva spesso per alterare la qualità dell' audio ed in più era
inaffidabile poiché poteva comunque essere raggirato da persone relativamente esperte. Così nel
1991 il RIAA commissionò alla BBN la creazione di un nuovo meccanismo di protezione,
compagnia del Massachussets leader in soluzioni acustiche. Ne derivò un sistema di filigrana
digitale analogo a Copycode, anche qui un segnale aggiuntivo a scopi di filigrana che doveva essere
di 19 decibels inferiore al livello generale della registrazione audio.
Oltre all'utilizzo di frequenze non percepibili dall'orecchio umano, il sistema utilizzava anche
un'avanzata tecnica di compressione dell'audio (analoga a quella dell'MP3).
Di sicuro quest’evoluzione rappresentava un reale progresso in termini di qualità della musica che si
generava con questo meccanismo di protezione, non certo però in termini di efficacia. Con la
successiva decompressione dell'audio il segnale di protezione aggiunto finiva infatti per svanire
permettendo, attraverso un nuovo encoding, la successiva riproduzione seriale.
3.2.7.2 Requisiti della filigrana digitale
Un sistema di filigranatura digitale ben progettato, sfrutta alcune proprietà che sono essenziali per la
sicurezza e la manipolazione dei files. La filigrana digitale al fine di assolvere il suo compito
primario dovrebbe essere:
1)Nascosta, quindi nel caso di materiale audio, questa non dovrebbe essere percepibile all’ascolto
dell’orecchio umano.
2)Statisticamente invisibile
3)Robusta contro gli attacchi e le operazioni di “processing” o manipolazione del segnale
4)Accorpata al materiale audio tout-court, dunque non ridotta ad una semplice intestazione tipo
“header” posta all’inizio di un determinato file audio.

34
5)Dipendente dalla successiva chiave di estrazione.
Questi requisiti vengono raggiunti tramite l’applicazione e la combinazione di due tecniche
fondamentali: la Psicoacustica e la Modulazione ad Ampio Spettro.
La prima assicura la non-udibilità delle informazioni aggiuntive di filigrana, tenendo in
considerazione le proprietà dell’apparato uditivo umano. La modulazione ad ampio spettro fornisce
al sistema una grande robustezza dagli attacchi e dalle manipolazioni del segnale, tramite la
diffusione delle informazioni di filigrana lungo l’intera durata della frequenza, non solamente
all’inizio o alla fine del file audio.
3.2.7.3 Il Watermarking ed il Digital Right Management (DRM) per la gestione dei diritti
digitali
Il DRM (Digital Rights Management) e’ spesso considerato come la principale ed a volte l’unica
applicazione della filigrana digitale. Nonostante i contrastanti dibattiti in merito e le continue
evoluzioni della tecnologia, la filigrana digitale può effettivamente fornire un valido sostegno per il
rispetto e la tutela dei diritti d’autore, dunque per la protezione dei contenuti digitali audio presenti
nella rete.
Le tre applicazioni principali cui il sistema di filigrana DRM da supporto sono:
1)La certificazione della proprietà, ovvero l’identificazione della “paternità della musica” che
costituirà un aspetto sempre più importante nel trasporto della cosiddetta Digital Music.
In quest’ottica si da per scontato che le copie senza Filigrana Digitale non possono essere
pubblicamente disponibili. Nella quasi totalità dei casi l’innesto delle informazioni di filigrana su un
determinato file audio avviene in ambiente lineare e non compresso, usando quindi un sistema
cosiddetto “ PCM Watermarking”.
2)Il controllo dell’Accesso: questa e’ un’altra applicazione che viene tutelata con il sistema di
Filigrana Digitale. Il principio e’ quello di aggiungere una filigrana che permetta di verificare se il
contenuto e’ effettivamente autorizzato ad essere riprodotto e/o scaricato su hard drive.
3)Il monitoraggio delle copie illegali :l’idea anche qui e’ quella di aggiungere una filigrana
personalizzata nel segnale audio compresso (Bitstream Watermarking), che sarà poi interpretata
secondo i meccanismi propri di una chiave di lettura appositamente conosciuta dal decoder in fase
di riproduzione.
Se il consumatore trasferisce il bitstream in un ambiente illegale (per esempio il suo sito web
personale o su di un qualsiasi supporto) deve dunque essere consapevole che esiste una Filigrana
Digitale contenente anche alcune sue informazioni personali e che esistono in tal modo gli estremi

35
per l’identificazione della sua violazione. In questo caso l’utente potrebbe quindi essere ritenuto
responsabile per l’utilizzo del materiale audio al di fuori dell’ambiente legalmente autorizzato.
Il beneficio della Filigrana Digitale rispetto ai tradizionali metodi di crittografia e’ che in questo
contesto, anche il segnale audio decompresso contiene delle informazioni di filigrana, perfino in
una sua rappresentazione analogica. Quindi, effettuando magari una decompressione del segnale ed
un nuovo encoding del file audio in ambiente digitale, non risulta possibile eliminare quelle
informazioni di identificazione. Di conseguenza queste risulteranno essere sempre presenti in tutti i
successivi trasferimenti del segnale audio, generando fastidiosi fruscii e rumori di fondo, ovvero
deteriorando la sua risoluzione al momento dell’ascolto.
3.2.7.4 Efficacia ed applicabilita’ del digital watermarking
Entrati ufficialmente nell’era post-Napster, risulta per molti ragionevole che gli artisti debbano e
forse meritino di essere pagati per l’utilizzo dei loro lavori. Nel tentativo di controllare questa
situazione , il gruppo del RIAA cerca ormai da tempo di sviluppare soluzioni capaci di arginare la
digital-piracy. L’industria discografica, assieme alle migliori compagnie dell’high tech si adoprano
già da tempo attraverso la Secure Digital Music Iniziative (SDMI) per lo sviluppo e l’impiego di
tecnologie che proteggano la digital music. Una tecnologia centrale e’ dunque rappresentata dal
DRM watermarking, ovvero da meccanismi di filigrana digitale per la gestione dei diritti digitali.
Come abbiamo potuto osservare in precedenza, questi consentono di proteggere e monitorare il
traffico non autorizzato dei file audio prevenendone in tal modo la duplicazione illecita.
Vohn Lohman dell’ Electronic Frontier Foundation, suggerisce come il Digital Watermarking possa
aiutare le case discografiche a mantenere le tracce di quale stazione radio stia trasmettendo le hits
dei loro artisti, fornendo quindi un supporto valido per la riscossione delle royalties.
Un esempio curioso di “Digital Watermarking” che merita di essere citato e’ costituito dalla
compagnia statunitense “Verance Confirmedia”. Questa offre una sorta di mega portale web,
collegato al broadcast nazionale sia radio che TV e ad un network capace di fornire informazioni 24
ore su 24 su dove e come un determinato contenuto audio sia stato usato. Mediante l’accorpamento
di cosiddetti “metadata” al flusso di bit audio, ovvero informazioni addizionali riguardanti alcune
caratteristiche del file stesso, si rende possibile con l’utilizzo di un’apposita chiave di lettura leggere
nuovamente il segnale audio che risulterà in tal modo protetto da una sorta di “involucro digitale”.
Una soluzione più recente e’ quella che prevede l’introduzione di un chip addizionale sui PC e sui
dispositivi di ogni utente, capace di riconoscere il segnale audio opportunamente protetto.

36
Diverse implicazioni testimoniano come però questi sistemi siano poco affidabili, oltre che
raggirabili in tempo breve da parte di mani relativamente esperte.
Si presentano anche una serie di questioni riguardo la leicita’ di tali misure e di rispetto per la
privacy degli utenti. Si rischierebbe di proibire il download e l’ascolto di un determinato brano da
due postazioni diverse, esempio dal PC o da un dispositivo portatile, nonostante il brano in
questione sia stato regolarmente acquistato in precedenza.
Impedendo il trasferimento su altro supporto o su altro dispositivo si viola apertamente il principio
del « fair use » sancito dal DMCA nel 1998, contravvenendo alla « first sale doctrine » ed
impedendo la libera circolazione di materiale audio già precedentemente acquistato ad esempio tra
gli amici (altro principio cardine regolato dalle 2 legislazioni principali in materia di copyright
audio,quali Audio Home Recording Act e Digital Millenium Copyright Act).

37
4 Steganografia nelle Immagini
4.1 Introduzione
Anche se la ricerca in questo campo e relativamente recente sono state proposte diverse tecniche sia
in campo accademico sia in campo industriale. Una possibile classificazione delle tecniche di
watermark può essere condotta sulla base della caratteristica del immagine che è sottoposta a
modifiche. In questo senso si possono distinguere tecniche nel dominio spaziale, tecniche nel
dominio della trasformata di Fourier e tecniche ibride. Tutte le tecniche sopracitate garantiscono la
permanenza dell'informazione nascosta durante modifiche dell'immagine fatte con o senza scopo di
rimozione del watermark. Il mercato è molto ricco di strumenti per l'elaborazione di immagini in
formato digitale e l'effetto sull'immagine può essere classificato come una modifica dell'immagine
considerata come segnale e distorsioni geometriche. La resistenza alle distorsioni geometriche è
molto importante in quanto esse non diminuiscono la qualità dell'immagine è possono essere fatte
proprio allo scopo di rendere il watermark illeggibile. Se un'immagine viene ruotata di 0.5 gradi o
viene scalata a 101% la differenza dall'originale non e rilevante però il lettore di watermark
potrebbe non essere più in grado di leggerlo. Oltre questo deve essere garantita la possibilità di
leggere le informazioni inserite anche dalla stampa dell'immagine (quindi da una sorgente con
distorsioni geometriche). Altre possibile modifiche sono nell'area del colore dell'immagine. Una
riduzione dei colori o una diversa mappatura di questi può portare facilmente alla perdita del
watermark.
L'applicazione più classica e diffusa della tecnologia di watermarking consiste nell'apposizione all'interno di un'immagine
di una serie di informazioni, invisibili all'occhio umano, riguardanti, ad esempio, il produttore, il titolare del copyright,
l'acquirente, il tipo di licenza, la data della transazione, un numero progressivo di identificazione, ecc. L'inserimento del
marchio digitale avviene tramite un software oppure un semplice plugin per i maggiori programmi di fotoritocco (ad
esempio: Photoshop), forniti dalla società proprietaria della tecnologia di watermarking, che in genere riconosce i formati
più diffusi di compressione delle immagini (gif, jpeg, tiff, bitmap) e crea un marchio resistente alle modifiche apportate
all'immagine stessa. Alcune società rendono la loro tecnologia disponibile non solo per i documenti digitali, ma anche per
quelli cartacei, per i quali è particolarmente importante certificare l'autenticità (documenti di riconoscimento, passaporti,
fotografie personali) o la provenienza (si pensi ai documenti provenienti dagli studi legali o dagli studi medici). La
tecnologia necessaria per l'implementazione e la successiva verifica del watermark sul documento cartaceo può essere
anche sorprendentemente economica: alcune aziende vendono infatti servizi e software che sfruttano una semplice
stampante a getto d'inchiostro a 600 dpi affiancata ad un comune scanner piano A4.All'inserimento di un watermark
nell'immagine digitale si accompagna frequentemente un servizio di monitoraggio e tracciamento della circolazione
abusiva del documento protetto da copyright su internet, con conseguente indicizzazione dei siti che contengono
immagini marchiate e reperimento dell'originale colpevole dell'illecita diffusione (la cui identità è registrata nel
watermark).

38
Le immagini per le loro dimensioni e il loro comune utilizzo sono molto usate per scopi
steganografici.
4.2 Formati di compressione delle immagini
4.2.1 Il formato GIF
Il formato GIF utilizza una palette di 256 colori che formano un ’immagine. I pixel sono dei
puntatori ad uno dei colori della palette. Ciò che viene fatta è l ’acquisizione dell’immagine;
si limita il numero di colori a 256; si effettua la conversione in GIF riempiendo la parte restante
della palette con dei colori molto simili a quelli rimasti. Ogni volta che si dovrà rappresentare un
colore si potrà scegliere di rappresentarlo o con il colore originale (0) oppure con il colore simile
all’originale (1).Siccome non conta l’ordine con cui i colori sono memorizzati nella
palette,un’immagine GIF può essere rappresentata in 256! Modi diversi, purché venga cambiata
opportunamente la sequenza dei puntatori. Quindi i bit che si possono nascondere sono log(256!) =
1683 bit,indipendentemente dalle dimensioni dell’immagine.
EzStego è un programma che lascia la palette inalterata (evita il problema precedente) e riesce a
nascondere un bit di dati in ogni pixel in una data immagine.
4.2.2 Il formato JPEG
JPEG è un algoritmo di compressione lossy mantiene le informazioni più importanti e scarta le
informazioni meno significative dal punto di vista visivo. L’embedding deve essere effettuato in
fase di compressione. La chiave della compressione è la DCT (Discrete Cosine Trasfom :operatore
matematico che cambia la natura della matrice fondamentale,convertendo un segnale dal dominio
spaziale al dominio delle frequenze).I programmi steganografici non fanno altro che inserire
informazioni laddove risiedono i coefficienti DCT meno importanti.
JSteg Shell è un programma che riesce a nascondere un bit di dati segreti in ogni coefficiente non-
zero. Tutti i possibili valori dei coefficienti sono accoppiati ai valori simili e ad ognuno viene
assegnato un 1 o uno 0.Il coefficiente di ogni blocco viene poi cambiato per fissare lo stego bit. I
messaggi nascosti con Jsteg non sono così vulnerabili come i file GIF agli attacchi visuali,ma, come
EzStego, Jsteg subisce il fatto che i coefficienti accoppiati tendono a bilanciarsi l’uno con l’altro,
favorendo attacchi statistici.

39
4.2.3 Il formato BMP
Nel formato BMP un’immagine,dal punto di vista digitale,è una matrice MxN di piccoli punti
colorati detti pixel. Un file BMP true color a 24 bit è formato da pixel RGB. Un pixel RGB è
formato da 3 byte ognuno dei quali rappresenta i livelli ( da 0 a 255 ) dei colori primari ( red, green,
blue) che costituiscono la tonalità di colore di quel determinato pixel. Un’operazione di
steganografia sostitutiva su questo tipo di file consiste nel sostituire i bit meno significativi dei
singoli byte con quelli dei messaggi segreti. Ad occhio nudo,le variazioni di colore risultano
praticamente impercettibili. Per inserire un byte del messaggio segreto occorrono 8 byte del
messaggio contenitore. In generale,per un file grafico MxN : Dimensione messaggio segreto (byte)
= (MxNx3) / 8 .
E’ possibile utilizzare i due ,tre o quattro bit meno significativo di ogni byte,aumentando
notevolmente la capacità del cover ma peggiorando la qualità dell’immagine stego che desterà più
sospetti nell’attaccante. Si può procedere per tentativi e trovare un ragionevole compromesso.
BPCS Steganography è una tecnica che invece di considerare solo i bit meno significativi sceglie
delle regioni dell’immagine nelle quali effettuare l’embedding senza alterare in modo significativo
l’immagine.
L’immagine viene divisa in blocchi 8x8 .Su ogni blocco viene effettuato un testo che ne determina
la complessità. Se la complessità è minore di una determinata soglia (parametro variabile dipendente
dall’immagine) l’embedding può essere effettuato .Un’immagine RBG P può essere vista come: P =
(PR1, PR2, …, PRn, PG1, PG2, …, PGn, PB1, PB2, …, PBn), dove PR1,PG1,PB1 è la bit-plan più
significativa ( immagine formata dai bit più significativa di tutti i pixel dell’immagine) e PRn, PGn,
PBn è la bit-plan meno significativa. Più ci si allontana dalla bit-plan più significativa più
l’immagine diventa complessa. Ogni bit-plan viene divisa in regioni. Le regioni shape-informative
(zone “semplici”) non possono essere modificate perché contengono informazioni significative per
l’immagine. Le regioni noise-looking (zone “complesse”) non contengono informazioni rilevanti e
possono essere rimpiazzate.
4.3 Altri programmi Steganografici
Digital Picture Envelop è un software che usa la BPCS Steganography. Riesce a nascondere dati
aventi dimensione fino al 50% di quella del cover (5-10 volte più degli altri software).Ha due
programmi :Encoder e Decoder.
Steganos Security Suite 5 è un programma che può essere scaricato gratuitamente in versione
shareware.La versione 5 è per piattaforme Intel con sistema operativo windows 95 ,98,ME,NT 4.0 e
2000. E’ una suite di strumenti per la sicurezza. Per effettuare il recupero di dati nascosti è

40
necessario il file contenitore e una opportuna password. Viene utilizzato l’algoritmo di AES per la
cifratura.
Gif-it-up 1.0 è un programma che supporta il formato GIF come contenitore. Funziona su tutte le
versioni di windows esclusa la 2000.
4.4 Attacchi alle immagini
Gli attacchi alle immagini sono di due tipi:
• Attacchi visuali :sono in correlazione con le capacità visive umane. Il file stego viene
filtrato con un algoritmo ( di filtering ) dipendente dalla funzione di embedding utilizzata per
nascondere il messaggio. L’immagine filtrata viene osservata per determinare se è stato
nascosto un messaggio o meno. L’operazione risulta lenta se la mole di immagini da
analizzare è considerevole.
• Attacchi statistici : effettuano test statistici sul file stego. L’idea dell’attacco statistico è di
confrontare la distribuzione di frequenza dei colori di un potenziale file stego con la
distribuzione di frequenza teoricamente attesa per un file stego. In questo caso dopo
l’embedding le frequenze si eguagliano a due a due.
4.5 Teoria e tecniche di watermarking nelle immagini fisse
Grazie alla larga diffusione di strumenti quali computer e stampanti, e allo sviluppo delle reti di
comunicazione, oggi molto economico trasmettere immagini e sequenze video usando le reti di dati
invece di spedire le copie tramite posta. Inoltre le immagini possono essere salvate in database in
forma digitale. Questo fenomeno ha avuto nuovi impulsi grazie all'avvento di Internet. Inizialmente
le applicazioni erano confinate alla distribuzione di lavori di pubblico accesso o a pubblicità
commerciale. In un secondo momento, col diffondersi della distribuzione elettronica, si è reso
necessario invece realizzare sistemi per garantire una sicura manipolazione, pubblicazione e
duplicazione di documenti, data la facilità di intercettazione, copia e ridistribuzione di documenti
nella loro forma originaria; dove per documento viene inteso un qualsiasi prodotto digitale che
possa venire trasferito su di una rete di comunicazione come: un testo scritto, un'immagine, uno
stream video o audio, ecc...
Esistono due diversi aspetti legati al problema della sicurezza:
1° Aspetto: garantire che un determinato prodotto digitale sia effettivamente mio e impedire che
qualcun altro sia in grado di manipolarlo e farlo passare per mio.
2° Aspetto: dimostrare che un determinato prodotto digitale sia effettivamente mio e impedire a
qualcun altro di farlo passare per proprio infrangendo così i miei diritti d'autore.

41
Il primo aspetto stato affrontato è risolto dall’autenticazione di un prodotto che consiste
nell'inserzione di una firma in grado di dimostrare l'autenticità di un mio documento.
Il secondo aspetto è invece stato risolto utilizzando una tecnica di watermarking che consiste
nell'inserimento di un marchio (o firma) indelebile all'interno del documento che non possa venire
alterato o rimosso. Le caratteristiche salienti del watermark possono essere così sintetizzate:
Non si devono introdurre nel documento artefatti che siano visibili ad un osservatore.
Non deve essere possibile la rimozione del watermark a meno di un sensibile degrado della qualità
del documento.
Sono necessari codici di controllo d'errore e tecniche di firma digitale per assicurare in modo
attendibile la presenza e l'autenticità del marchio presente nel documento.
Il marchio può essere scritto nella forma di una stringa di caratteri che, con opportune tecniche, si
tramutano in una grande quantità di informazioni ridondanti. Questo ha dirette implicazioni per
l'attendibilità della trasmissione del marchio perché più corto è il marchio, più grande è la
probabilità di rilevarlo senza errore. E' possibile accorciare il marchio usando appropriati metodi
di codifica.
4.5.1 Autenticazione
Un fondamentale problema di tutte le transazioni è di provare che chi firma i documenti sia in realtà
la persona che dice di essere. Le comunicazioni elettroniche tramite e-mail, fax ed internet sono
problematiche in quanto bisogna dimostrare l'autenticità dei documenti. E' quindi necessario un
metodo per autenticare con una firma digitale le informazioni spedite.
• Un metodo molto semplice di applicare una firma digitale è di usare un CRC (cyclic
redundancy check) o altre forme di checksum (letteralmente controlli sulle somme). I
checksum sono usati per rilevare errori sui canali di comunicazione, numeri ISBN, codici a
barre e numeri di carte di credito. La probabilità di scegliere con successo un numero a caso
che risponde alle semplici regole date dal checksum è molto bassa. Comunque i checksum
non sono particolarmente sicuri perché è spesso banale dedurre la regola usata per
implementare un checksum da un numero di esempi.
• Un altro metodo un po' più sicuro è stato proposto da Walton che ha opportunamente
combinato la tecnica dei checksum con sicure sequenze pseudo-casuali rendendo così più
difficile la decifrazione dell'algoritmo usato per produrre la firma.
• Un ultimo metodo molto più sicuro per autenticare un documento è l'utilizzo dell'algoritmo
RSA (Rivest Shamir Adelman) o algoritmo di criptaggio a chiave pubblica. Quest'ultimo è

42
un metodo molto elegante ed estremamente sicuro; può venire utilizzato sia per criptare le
informazioni che per l'autenticazione dei messaggi.
I principi su cui si basa l'RSA sono i seguenti:
• Criptaggio di informazioni: Un utente, chiamato X, ha due chiavi. Una chiave è tenuta
privata ed è conosciuta solo da X mentre l'altra è pubblica. Un altro utente chiamato Y può
spedire messaggi a X in segreto perché i messaggi criptati usando la chiave pubblica di X
possono solo essere decodificati usando la chiave privata di X.
• Autenticazione: Per fare questo X può mandare un messaggio criptato usando la sua chiave
privata e la chiave pubblica di Y, Y può solo decodificare questo messaggio usando la
chiave pubblica di X e la sua chiave privata avendo così una prova che il messaggio viene
da X.
4.5.2 Lo Spread Spectrum
Le comunicazioni attendibili sono state provate da Shannon essere teoricamente possibili se il tasso
di informazione non eccede una soglia conosciuta come capacità del canale. Uno delle maggiori
deduzioni che possono essere fatte dal teorema di Shannon sulla codifica su un canale rumoroso è
che in ogni canale di comunicazione c'è un fondamentale compromesso tra larghezza di banda e
rapporto segnale rumore. Nel watermark di immagini possiamo assumere che il trasferimento di
informazioni avviene sotto condizioni che implicano un basso rapporto segnale rumore. Quindi una
comunicazione attendibile può solo essere assicurata incrementando la larghezza di banda per
compensare il basso rapporto segnale rumore. Nel watermarking di immagini è desiderabile trovare
il massimo numero di posizioni per nascondere l'informazione nell'immagine. L'idea di base dello
spread spectrum consiste nel distribuire la firma su tutta l'immagine aumentando così la
robustezza e la sicurezza del watermark presente nell'immagine. La difficoltà nelle tecniche di
watermark non sta tanto nell'inserire una firma nell'immagine quanto ad essere poi in grado di
rivelarla in modo sicuro. La firma viene distribuita su tutta l'immagine mediante particolari
algoritmi di ''Spreading'' rendendone così più facile la rivelazione solo se si è a conoscenza
dell'algoritmo utilizzato. Se l'algoritmo di spreading utilizzato nella codifica non è noto, sarà
praticamente impossibile non solo leggere la firma all'interno dell'immagine ma addirittura
accorgersi della sua presenza. L'utilizzo dello spread spectrum è quindi praticamente essenziale se
si vuole raggiungere un certo livello di sicurezza. Gli algoritmi di spreading si basano su un set di
frequenze ortogonali non sovrapposte in grado di nascondere le informazioni b all'interno di un
segnale di watermark w(x,y).

43
∑=
Φα=N
1iii )y,x(b)y,x()y,x(w (2)
Questo metodo, largamente usato da Kutter verrà ripreso in seguito.
4.5.3 La Modulazione
La modulazione può essere definita in modo semplificativo come l'unione di due segnali. Nel
nostro contesto ci riferiamo al processo di inserimento di una sequenza di bit in un documento,
soggetto alla condizione che questa sia invisibile all'occhio umano ma che possa essere letta
attraverso strumenti elettronici. I fattori che determinano la scelta del metodo nel watermark
d'immagine sono piuttosto complessi. Il primo fattore è il requisito della robustezza. Ogni
operazione fatta sull'immagine del tipo tagli, compressioni, quantizzazione vettoriale o scanning
non deve degradare la trasmissione del watermarking. Il secondo fattore è la visibilità. E' intuitivo
che nelle regioni piatte dell'immagine prive di dettagli può essere nascosta meno informazione.
Dovrebbe essere possibile incorporare più informazione in quelle parti dell'immagine che
contengono più testo o nelle vicinanze dei contorni. Si deve inoltre tener conto nella trasmissione di
informazioni nascoste, dei fenomeni psicovisuali. Contributi allo sviluppo di una forma di
watermark che rispettasse i fattori sopra elencati sono venuti da diversi studiosi. Brassil ad esempio
ha elaborato diversi metodi per marcare testi all'interno di documenti con un'unica parola di codice
binaria che servisse ad identificare gli utenti legittimi del documento. La parola di codice è inserita
nel documento operando una lieve modifica alla struttura del documento come una modulazione
della larghezza della linea, degli spazi tra parole o la modifica del carattere di scrittura. La presenza
di una parola di codice non degrada visibilmente il documento, ma può essere rilevato facendo una
comparazione con l'originale. Kurak e McHugh partendo dallo studio della trasmissione di virus nel
basso ordine di bit di uno stream di dati, notarono che guardare soltanto un'immagine non è
sufficiente per rilevare la presenza di alcune forme di corruzione. Arrivarono alla conclusione che
sfruttando il limitato range dinamico dell'occhio umano si possono nascondere immagini di bassa
qualità all'interno di altri immagini.
Matsui e Tanaka hanno applicato algoritmi di predizione lineare per applicare i watermark a
parecchi diversi tipi di comunicazione quali video, facsimile, immagini a colori e grey scale. Tirkel
e van Schyndel hanno prodotto watermark resistenti al filtraggio, ai tagli nell'immagine e
ragionevolmente robusti agli attacchi. In più l'immagine originale non è richiesta per decodificare il

44
marchio.Recenti lavori hanno indicato progressi verso la produzione di watermark più robusti. Zhao
e Koch hanno lavorato sul watermarking basato sull'algoritmo di compressione del JPEG. Inoltre in
collaborazione con Caronni che marchia variando la media all'interno di blocchi dell'immagine,
hanno implementato il metodo di posizionare i blocchi in posizioni casuali dell'immagine in modo
da ottenere una protezione contro gli attacchi. Boland, O' Ruanaidh e Dautzenberg hanno descritto
un algoritmo che inserisce il watermark in una immagine digitale nel dominio trasformato. Il primo
passo è dividere un'immagine in blocchi rettangolari. Ciascun blocco è poi trasformato usando la
DCT, la trasformata di Walsh o la trasformata Wavelet. I bit sono sistemati incrementando un
coefficiente selezionato per codificare un ''1'', e decrementandolo per codificare uno ''0''. I
coefficienti sono selezionati rispettando il criterio basato sul contenuto di energia. Gli schemi di
modulazione del dominio trasformato posseggono diverse caratteristiche desiderabili; per prima
cosa uno può marcare in accordo con la distribuzione di energia che significa che uno può
adattativamente sistemare i watermark dove essi sono meno notabili all'interno della trama di
un'immagine. Come risultato nel dominio trasformato il watermark ha uno spettro molto simile a
quello dell'immagine originale. In secondo luogo il watermark è distribuito in modo irregolare sui
blocchi dell'intera immagine e ciò rende più difficile rilevarlo e per nemici in possesso di copie
indipendenti dell'immagine di decodificare e leggere il marchio.
Questo approccio di piazzare i bit dove questi sono meno visibili può essere una potenziale
debolezza. Gli algoritmi di compressione dell'immagine con perdita sono realizzati per ignorare le
informazioni ridondanti. I bit d'informazione piazzati dentro la trama dell'immagine sono quindi più
vulnerabili agli attacchi. C'è quindi un compromesso da trovare tra il nascondere una grande
quantità di bit d'informazione dove essi possono essere meno visibili, ma dove sono più vulnerabili
agli attacchi negli algoritmi di compressione con perdita, o piazzare meno bit su minore trama ma
su porzioni più sicure d'immagine. Di seguito viene presentato un esempio di un algoritmo di
watermarking sviluppato da O'Ruanaidh, Boland e Dowling che è basato sull'uso della
Trasformata discreta di Fourier. Questo metodo differisce fondamentalmente da quello delle
tecniche del dominio trasformato in quanto non sono i coefficienti trasformati che portano
l'informazione ma la fase della trasformata discreta di Fourier. La DFT di un'immagine reale è
generalmente di tipo complesso con una fase e un modulo. Lim ha studiato l'importanza della fase e
del modulo nell'intelligibilità di un immagine concludendo che la fase è molto più importante. Ciò è
molto interessante dal nostro punto di vista per parecchie ragioni. Per prima cosa, un watermark che
è inserito nella fase della DFT sarebbe più robusto alle manipolazioni. Il nocciolo dell'informazione
contenuta nei watermark è quasi sempre codificato con un alto grado di ridondanza. Quindi le
distorsioni di fase deliberatamente introdotte da un nemico per impedire la trasmissione di un

45
watermark dovrebbe essere notevolmente grandi per avere successo. Questo causerebbe
inaccettabili danni della qualità dell'immagine. Secondo, dalla teoria della comunicazione, è ben
noto che la modulazione d'angolo possiede immunità superiore al rumore comparata con la
modulazione d'ampiezza. Infine la fase è relativamente robusta ai cambiamenti nel contrasto
dell'immagine.
La figura 1 mostra un'immagine grey-scale di dimensioni 256x256 pixel. Su questa immagine è
stato posto un watermark usando la DFT. Un blocco 8x8 è stato usato per l'algoritmo di
watermarking. In Figura 2 è mostrata l'immagine con dentro il watermark. Solo la fase della DFT è
usata per inserire la parola di codice. Un totale di 9920 bit è stato inserito in Figura 2. Nonostante la
presenza del watermark, la figura non contiene nessun visibile artefatto.
La figura 3 mostra la differenza gamma assoluta tra l'immagine originale e quella marcata. E'
interessante notare che la più grande differenza si ha nelle regioni di testo e vicino ai contorni.
a) b) c)
Figura 1 a) ; b) c) .
4.5.4 Recupero del marchio
Ci sono parecchi distinti metodi per recuperare il watermark da un'immagine marchiata. Il primo,
che è anche il più ovvio, consiste semplicemente nel comparare l'immagine marchiata con quella
originale di partenza. Il secondo metodo che non richiede comparazione è meno ovvio. Se
l'informazione è quantizzata prima del marking allora la deviazione dai campioni quantizzati
potrebbe essere usata per trasportare informazione. Quantizzazioni grossolane permettono marking
più profondi al fine di dare maggiore robustezza al marchio. Comunque questo va a scapito della
riduzione dell'informazione dell'immagine degradata. La soluzione ottima tra questi fattori è
fortemente dipendente da considerazioni psicovisuali. Il terzo metodo, che non richiede anch'esso la
comparazione con l'originale, dipende dalle specifiche proprietà del segnale usato per inserire il
marchio. Esempi del metodo sono presentatati da Tirkel e van Schyndel.

46
4.5.5 Caratteristiche dei segnali di watermarks
• Invisibilità Inserire un segnale di watermark comporta necessariamente un seppur lieve
degrado dell'immagine; questo degrado deve essere il più lieve possibile in modo da non
alterare la percezione visiva dell'immagine. Il grado d'alterazione dell'immagine deve essere
decisa dal proprietario dell'immagine, il quale può scegliere tra forti alterazioni che danno
una garanzia di robustezza ad eventuali attacchi, e deboli alterazioni che non degradano il
prodotto.
• Complessità I segnali di watermark sono tutti caratterizzati da una grande complessità.
Questa è necessaria per impedire che qualcun'altro sia in grado di riprodurre lo stesso
segnale di watermark. Un altro vantaggio della complessità del watermark è che assicura
delle proprietà statistiche affidabili e la loro presenza può essere rivelata con grande certezza
statistica.
• Codifica a chiave.:ogni segnale di watermark è associato ad una particolare sequenza di bit
detta chiave (key). La chiave (che può essere rappresentata da un numero intero) serve sia
per produrre il segnale di watermark che per riconoscerlo all'interno di un'immagine. La
chiave è privata e caratterizza univocamente il legittimo proprietario dell'immagine. Solo chi
è in possesso della chiave (il proprietario o un ente autorizzato) è in grado di dimostrare la
presenza del watermark nel prodotto digitale. Il numero di chiavi possibili deve essere
enorme.
• Efficienza statistica:Un'immagine firmata con un segnale di watermark deve essere
facilmente riconoscibile se si conosce la giusta chiave. La probabilità che la chiave (nella
fase di riconoscimento) venga rifiutata pur essendo corretta deve essere sufficientemente
bassa. (Per ogni watermark la chiave corrispondente deve essere unica).
• Invisibilità statistica Il possesso di un gran numero di immagini digitali tutte firmate con la
stessa chiave non deve rendere riconoscibile (e quindi eliminabile) la firma. Diversi prodotti
firmati con la stessa chiave devono generare segnali di watermark differenti. Dobbiamo
essere sicuri che il riconoscimento della chiave all'interno dell'immagine da parte di terzi sia
impossibile.
• Watermark multiplo Deve essere possibile inserire un elevato numero di segnali di
watermark all'interno della stessa immagine; ognuno di questi segnali può essere
riconosciuto mediante la corrispondente chiave.
• Robustezza Sulle immagini digitali possono venir fatte numerose operazioni per migliorare
la loro qualità o per comprimere la loro dimensione. I segnali di watermark devono essere

47
tali da non venire eliminati da questo tipo di operazioni (filtraggio, taglio, JPEG-MPEG
compressione,...)
4.5.6 Schema di inserzione e rivelazione della firma
Lo schema del watermarking è divisibile in tre particolari algoritmi:
• Il Watermark Productoin Algorithm (WPA)
• Il Watermark Embedding Algorithm (WEA)
• Il Watermark Detection Algorithm (WDA)
Gli algoritmi di cui sopra sono pubblici e possono essere applicati da chiunque. La sicurezza del
watermark è basata esclusivamente sulla segretezza della chiave di watermark.
4.5.6.1 .L'inserzione
Il WPA è l' algoritmo di produzione della firma con cui autenticare il documento, è applicato
avendo come input la chiave privata e le informazioni del prodotto digitale, ciascuna coppia
(chiave, prodotto) è trasformata in segnale digitale di watermark. Passando le informazioni del
prodotto nell'algoritmo, riusciamo ad ottenere un watermark che abbia invisibilità statistica, perché
è presumibilmente diverso da quelli ottenuti su altri prodotti, e non lascia riconoscere la chiave. Gli
algoritmi WPA sono basati su generatori di numeri pseudocasuali o/e sistemi fortemente caotici. La
determinazione di una chiave che produce un segnale di watermark predefinito è impossibile, per
esempio la produzione del watermark è una procedure non invertibile per prevenire watermark
contraffatti.
Il WEA è l' algoritmo di applicazione del watermark, richiede come argomenti il prodotto digitale e
il watermark prodotto. Esso inserisce il watermark nell'immagine digitale o in un frame di un video
attraverso la produzione di alterazioni nella luminanza dei pixel. Per i segnali audio, le alterazioni
sono eseguite sull'ampiezza del segnale. Le alterazioni sono di bassa energia e sono progettate
tenendo conto delle principali caratteristiche del sistema visivo ed uditivo dell'uomo. L'inserimento
del watermark può essere fatto anche nel dominio trasformato (per esempio il dominio della DCT).
Dal momento che i segnali video ed audio richiedono larga quantità di memoria, le informazioni
sono inserite nel WEA e marchiate sequenzialmente. Per il watermark dei video, i vettori di
spostamento calcolati dall'algoritmo dell' MPEG dovrebbero essere usati per incrementare le
performance dell'algoritmo.

48
4.5.6.2 La rivelazione
La rivelazione è la parte più cruciale della struttura del watermark. Il WDA è l'algoritmo di
riconoscimento del watermark, dovrebbe essere attendibile e non produrre falsi errori. Quindi il
risultato del rivelatore dovrebbe essere un'indicazione indiscutibile della proprietà del prodotto
digitale. I WDA sono basati su test di ipotesi statistiche. Essi forniscono la certezza che caratterizza
una possibile decisione che accetta l'esistenza di un particolare watermark. Esperimenti numerici
indicano che la rivelazione del watermark è abbastanza attendibile e adatto a provare la proprietà
dei copyright. I WDA non dovrebbero richiedere il prodotto digitale originale per procedere alla
rivelazione del watermark. Questa caratteristica è un grande vantaggio in quanto esso fornisce una
veloce ed automatica implementazione.
4.5.7 .Tecniche di Watermarking
4.5.7.1 Metodo del LSB (Last Perceptible Bits)
La tecnica più semplice consiste nel sostituire il piano (o i piani) di bit meno significativi con la
firma, dato che cambiando i bit meno significativi non si altera visibilmente l'immagine. Questa
tecnica è semplice, ma insicura e poco robusta perché si conosce dove è posta la firma ed è
facilmente alterabile senza che i cambiamenti siano facilmente visibili.

49
Come si vede dall'immagine, l'informazione racchiusa nel bit plane 1 (quello meno significativo)
non porta informazioni essenziali all'immagine e la sua rimozione non comporterebbe una grossa
perdita di qualità.
4.5.7.2 Watermarking nel dominio spaziale (Metodo di Kutter)
Watermark 1D: La Firma spalmata sulla dimensione di una linea dell'immagine (ad esempio
ripetendo più volte ogni bit), viene codificata tramite una sequenza pseudocasuale PN (pseudo-
noise) che è la chiave segreta e sommata all'immagine linea per linea. Per riconoscere la firma le
linee dell'immagine firmata vengono moltiplicate per la sequenza PN, sommate e confrontate con
un valore di soglia.
Questo metodo non ha bisogno dell'immagine originale per il recupero ed è robusto perché la firma
è posta su tutta l'immagine.
Estensione 2D (di Kutter): In questo caso le chiavi segrete sono un set di sequenze ortogonali non
sovrapposte.

50
4.5.7.3 Watermarking in frequenza (Metodo di Cox)
La firma si somma alla DCT dell'immagine sul maggior numero possibile di coefficienti, i valori
della firma vengono scalati in modo da non essere percettibili dall'occhio umano, viene poi fatta la
IDCT della DCT firmata. Per controllare la firma si sottrae dalla DCT dell'immagine firmata la
DCT dell'originale e si verifica se questa firma estratta è simile alla firma originale. Questa tecnica
è robusta perché la firma è sull'intera immagine, la compressione elimina solo componenti
spettrali poco importanti e il restringimento elimina solo le componenti ad alta frequenza, ma
necessita dell'immagine e firma originale. Esistono poi anche tecniche di firme adattative; tecniche
mediante le quali l'algoritmo di spreading non è fisso ma si adatta a seconda della tipologia
d'immagine.

51
4.5.8 Attacchi e robustezza
Si sono presentati diversi problemi nel provare a screditare il watermarking, alcuni indicabili come
debolezze al processing che lo rendono inutilizzabile altri come attacchi per impedirne il
funzionamento detti deadlock (stallo) attack. Per non essere intaccato dal processing il
watermarking deve resistere a compressione, filtraggio lineare e non, distorsioni geometriche
(cambi di scala, rotazioni, ...).
Figura
Il modo più semplice per inserire la firma è il dominio spaziale; qui per non essere percepibile la
firma viene introdotta nei bit plane meno significativi, ma questo la rende poco sicura; per renderla
più sicura viene introdotta nel dominio delle frequenze. Per renderla robusta alla compressione e alla
decimazione, che generalmente elimina le componenti ad alta frequenza, la firma è replicata più
volte con delle tecniche di spreading, ad esempio ripetendo il singolo pixel o coefficiente DCT più
volte o ripetendo più volte la firma stessa. Per renderla robusta a traslazioni, cambiamenti di scala,
rotazioni si usano principalmente due tecniche: l'inserimento della firma in domini invarianti a
queste operazioni, e l'introduzione di griglie nascoste che permettono di determinare e invertire la
distorsione prima della verifica della firma.
4.5.8.1 Esempi di deadlock
Dato che anche un multiplo watermarking ha piccoli effetti percettivi l'attacco più semplice è porre
la propria firma su un'immagine già firmata.

52
In questo caso sembrerebbe che entrambi possano reclamare il diritto di proprietà, il riconoscimento
non è quindi sufficiente per reclamare i diritti di proprietà.Per risolvere la contesa viene richiesta ad
entrambi l'immagine originale, ipotizzandola non firmata, e si verificherà la firma di ognuno con
l'originale dell'altro, la firma del vero possessore sarà invece presente sulla falsa immagine darà un
risultato di firma vera, mentre la firma dell'impostore non sarà presente sulla immagine originale e
darà un risultato di firma falsa.
• Attacco SWICO (contraffazione dell'immagine originale con singola watermarked).
L'impostore può cercare di ottenere una falsa originale rimuovendo la firma dall'immagine
firmata dal vero proprietario e lasciando circolare un'immagine watermarked con la firma di
entrambi, in modo che quando si cercherà la firma dell'altro sulla sua immagine non sarà
presente, quindi la contesa non sarà possibile risolverla neanche con gli originali. La firma
può essere rimossa invertendo l'algoritmo di watermarking utilizzando una firma falsa che
usata al posto di quella del proprietario nel riconoscimento della proprietà venga
riconosciuta come firma originale. Per resistere agli attacchi SWICO è sufficiente che il
processo di watermarking sia non invertibile, è invertibile se si riesce a togliere
completamente la firma, è quasi invertibile se si riesce a togliere buona parte della firma in
modo da renderla irriconoscibile.
• Attacco TWICO (contraffazione dell'immagine originale con doppia watermarked) :In
questo caso a differenza dell'attacco SWICO, oltre a fare una falsa originale, l'impostore

53
produrrà come immagine firmata la sua falsa originale con la sua firma, a differenza del
SWICO saranno così presenti due immagini watermarked entrambe con una sola firma. Per
resistere agli attacchi TWICO invece deve essere anche non quasi invertibile. Per essere
robusto quindi il watermarking deve resistere al processing, deve essere non quasi
invertibile, non dovrebbe avere bisogno dell'immagine originale, dovrebbero esserne
standardizzati schemi e protocolli.
5 Steganografia nel Video
5.1 Introduzione
Anche per il segnale video si è fatto sentire il bisogno di protezione. Infatti,in applicazioni quali la
Pay TV e il Video on Demand si richiede che solo chi paga un regolare abbonamento riesca a
visualizzare ciò che viene trasmesso. Analogamente,nelle video conferenze è importante che solo gli
autorizzati condividano le informazioni scambiate. Tuttavia,andare ad alterare completamente il
segnale video con gli algoritmi di crittografia tradizionali (simmetrici e a chiave pubblica ) significa
perdere la possibilità di processare in tempo reale , dato che le sue elevate dimensioni impediscono
di elaborarlo velocemente. Ecco perché vengono studiate delle tecniche che agiscono solo su alcune
parti dello strema,principalmente su quelle che influenzano di più il processo di ricostruzione delle
immagini. Ad esempio ,nel caso del video codificato MPEG ,lo standard più diffuso ,è possibile
trovare la descrizione di numerosi algoritmi che operano sui coefficienti a bassa frequenza della
DCT,sui macroblocchi INTRA e sui vettori di movimento che sono le informazioni più rilevanti dal
lato della ricezione. Tali dati vengono alterati utilizzando o algoritmi già esistenti (ad esempio
DES) o semplici operazioni logiche ,soprattutto lo XOR, effettuate tra le informazioni e la chiave.
Inoltre ,per garantire un’adeguata velocità, le tecniche proposte sono simmetriche ,cioè vengono
applicate alla stessa maniera in trasmissione e in ricezione.
L’attività di ricerca è attualmente focalizzata sullo sviluppo di un nuovo algoritmo di crittografia per
il segnale video che, per crittare le informazioni ,utilizza informazioni caotiche. Quest’ultime
rappresentano una novità nel settore:frequentemente adottate per la crittografia del testo ,sono state
raramente impiegate per cifrare il segnale video e in alcuni casi il loro impiego pregiudicava la
possibilità di processare il segnale in tempo reale. L’algoritmo caotico proposto consente di
rispettare tale requisito e permette anche di raggiungere una buona sicurezza. Il livello di sicurezza

54
offerto dall’algoritmo necessita di una valutazione di tipo “oggettivo”. Risulta interessante anche
una valutazione “ soggettiva”,basata sul confronto tra l’immagine “in chiaro” e l’immagine crittata.
5.2 Video Editing in MPEG-4
La maggiorparte degli algoritmi di watermarking nelle applicazioni video si è sviluppata
velocemente negli ultimi anni. I metodi di watermarking video esistenti possono essere
classificati in due gruppi principali dipendenti dal tipo di lavoro che occorre eseguire:
• Raw-video watermarking :eseguito prima della compressione
• Bit-stream watermarking :eseguito dopo la compressione.
Hartung e Girod lavorano attualmente al primo metodo quello cioè riguardante la raw-video
watermarking. L’appoccio ,ispirato al metodo dello spread spectrum,consiste nel convertire i dati
rappresentandoli mediante una stringa binaria la cui lunghezza è adattata alla lunghezza del data
host .Tale stringa viene successivamente modulata da una sequenza di pseudo-noise e un
pixelwise viene aggiunto alla componente del video.
Il recupero è compiuto attraverso un metodo basato sulla correlazione.Questo approccio è molto
sensibile al frame tagliato e cambiato ed è possibile usare in alternativa una variante del metodo
modellando la sequenza video come bitplane ( pixel plane in due dimensioni).
Hsu e Wu si occupano dello stesso argomento utilizzando la trasformata DCT applicata blocco
dopo blocco al video.Infatti il watermarking viene eseguito imponendo particolari relazioni tra
frequenza e coefficienti DCT appartenenti a blocchi spazialmente vicini di “intracoded frames”o
blocchi temporalmente vicini di “intercoded frames”.Alla fine per ottenere la sequenza video
criptata si calcola la IDCT di ogni frame.
Anche Swanson si è occupato della raw-video watermarking.Il suo lavoro consiste in un metodo in
cui il watermak è inserito in componenti temporali statiche e dinamiche generate dalla trasformata
wavelet temporale del video.Le ditribuzioni nel tempo e in frequenza del watermark sono
controllate dalle caratteristiche di masking del segnale host video per ottenere un ragionevole
tradeoff tra visibilità e robustezza.I coefficienti wavelet dei frame sono convertiti nel dominio del
tempo usando la trasformata wavelet invera.

55
Il sistema proposto da Kalker per il raw_video watermarking considera il video come una
sequenza di immagini fisse.Nella sequenza video è inserito lo stesso watermark in tutti i frames.Il
processo di embedding è eseguito aggiungendo campioni di watermark ,i quali sono tracciati
indipendentementeda una distibuzione normale con valore medio e deviazione standard pari a 0 e
1,rispettivamente,per i valori del pixel del frame considerato.In altre parole il watermark è
semplice rumore bianco additivo.La rilevazione del watermark è eseguita dalla correlazione
spaziale.
Deguillaume ha proposto uno schema di watermarking 3_Dimensionale in cui il raw_video è
visto come un segnale 3_D con due dimensioni nello spazio e una nel tempo.Il video è prima
diviso in pezzi consecutivi di lunghezza fissata e poi è eseguita una 3_D DFT per ogni pezzo.
Due informazioni sono nascoste :watermark e template.Il watermark,che è lo stesso per ogni
pezzo,è un segnale spread_spectrum aggiunto al 3_D DFT.Template è una griglia 3_D che
determina e inverte le trasformazioni geometriche..
Hartung e Girod hanno proposto un algoritmo per il bit_stream watermarking.Il watermark,
consistente in un segnale spread_spectrum,è trasformato con la DCT.I coefficenti DCT sono poi
aggiunti ai coefficienti DCT nonzero del video bitstream codificato con MPEG-2 facendo
attenzione a non aumentare il bit_rate .
Anche Langelaar ha proposto un interessante metodo sul bit_stream watermarking.Ogni bit di
watermark (stringa binaria) è incastrato in una regione di 16 blocchi 8x8 intoducendo una
differenza di energia tra i coefficenti DCT ad alta frequenza della metà superiore ed inferiore
della regione di immagine.Il valore del bit di embedding è definito dal segno della differenza di
energia introdotta.Questa differenza è ottenuta scartando i coefficienti DCT che nella scansione a
zig_zag sono posti dopo un punto di cutoff e appartengono a una delle due regoni precedenti.
Piva ha proposto un algoritmo di watermarking video mediante l’utilizzo di MPEG_4.Un
algoritmo di watermarking basato su DWT ,originariamente sviluppato per immagini fisse,è
applicato al watermarking di singoli oggetti MPEG_4.L’algoritmo opera frame per frame
aggiungendo pseudo_random watermark alle bande ad alta risoluzione di ogni oggetto..Lo
svantaggio di questo sistema è che il rilevatore può svelare solo la presenza di un watermark noto.
5.3 Watermark Embedding
L’algoritmo di watermarking proposto nasconde un bit del codice di watermark in ogni blocco di
luminanza appartenente a un insieme di MBs (macroblocco) selezionato su base pseudo_random.
L’algoritmo è abilitato a lavorare quando un MPEG4 bit_stream è disponibile.

56
Se un MB è saltato anche un bit è saltato.Il codice di watermarking è ripetuto sul VOP (Video
Object Plane) completo.Il watermark embedding è eseguito su un frame base;cioè su ogni VOP
dello stesso VOL (Video Object Layer) il codice è incastrato di nuovo iniziando dal primo bit.
Ogni bit è cosi incastrato più di una volta durante una sequenza di VOPs,ma alcuni bit sono
incastrati meno frequentemente che altri.In figura è mostrato lo schema di watermak embedding.
L’embedding del watermark nel video è eseguito nei seguenti step:
1) Selezione dei MBs e dei coefficenti DCT quantizzati per essere modificati;
2) Per ciascun blocco appartenente al MB selezionato:
a) calcolo dell’intervallo di frequenza
b) uso dell’intervallo per calcolare l’ampiezza del watermark;
c) modifica ,secondo la regola dell’algoritmo,dei coefficenti selezionati creando il
blocco criptato.
All’inzio di ogni VOP una sequenza binaria pseudo_random è generata per scegliere gli MBs dove
il codice di watermarking è incastrato e i coefficenti sono stati modificati.Tale sequenza è basata
su una chiave segreta e sulle caratteristiche (numero di MBs) del suo VOP.
Se l’MB scelto non è saltato, un bit del codice di watermark è incastrato in esso imponendo una
particolare relazione tra le coppie dei coefficenti selezionate che appartengono a ogni blocco di
luminanza del MB.Se un MB è saltato, anche un bit è saltato .L’uso di una sequenza
pseudo_random permette di migliorare la sicurezza del watermark prevenendo la possibilità che
l’attaccante alteri il codice di watermarking dopo aver identificato le posizioni di embedding del
watermark.E’ noto che applicando uno stesso watermark a ogni frame di un video si ha il

57
problema di mantenere l’invisibilità statistica.Per prevenire gli attacchi statistici ,la sequenza
pseudo_random che lo genera è anche VOP dipendente .
Per ottenere un tradeoff tra l’esigenza di invisibilità e robustezza ,solo i coefficenti DCT
quantizzati appartenenti al centro banda sono considerati per watermark embedding (come
mostrato in figura)
.Il watermark è la differenza tra le grandezze:
W(u1,v1,u2,v2) = |QF(u1,v1)| - |QF(u2,v2)| (1)
Dove (u1,v1) e (u2,v2) sono le coordinate dei due coefficenti di una di queste coppie.
W(u1,v1,u2,v2) è un processo casuale non stazionario avente valore medio nullo e varianza media.
Se {QF(u1,v1),QF(u2,v2)} è una coppia selezionata casualmente la corrispondente coppia criptata
sarà indicata con {QF’(u1,v1),QF’(u2,v2)}.In particolare l’embedding è eseguita in modo che la
differenza in (1) è maggiore di 0 se un bit informativo 1 è stato trasmesso ,e minore di 0 se il bit
informativo è 0.Supponendo che il bit di embedding è 1 ,ci sono tre casi da analizzare:

58
• entrambi i coefficenti della coppia sono diverse da zero e la differenza delle loro grandezze
è ≥ n AF.
• entrambi i coefficenti della coppia sono diverse da zero e la differenza delle loro grandezze
è < n AF.
• uno o entrambi i coefficenti della coppia sono 0.
Nel primo caso non è eseguita nessuna modifica dei coefficienti .Nel secondo caso,il watermark è
inserito con massima resistenza:il segno dei coefficienti non è cambiato mentre le rispettive
grandezze diventano
2
An)v,u(QF)v,u(QF()u,u(QF F
22'
11'
11'
++=
e
>−
=altrove0
0)v,u(QFseAn)v,u(QF)v,u(QF 22
'F11
'
22'
mantenere il watermark invisibile perché l’effetto della maschera tra le componenti frequenziali
DCT è assente.In questo caso,i coefficienti della coppia sono cambiati meno pesantemente.
>
=altrove0
)v,u(QF)v,u(QFse)v,u(QF)v,u(QF 221111
11'
>
=altrove0
)v,u(QF)v,u(QFse)v,u(QF)v,u(QF 221122
11'
Per l’embedding di un bit 0 ,l’algoritmo è simile,ma i ruoli dei coefficienti sono cambiati ,e
così,per le coppie dove un bit 0 ha subito embedding, risulta W’(v1, u1, v2, u2) ≤ 0.
5.4 Recupero del Watermark
Il recupero del watermark è eseguito in due steps come mostrato nella fig.4.Il primo step è
analogo al primo step del processo di embedding e richiede la conoscenza dei parametri usati nella
fase di embedding (la chiave segreta e il numero di coppie modificate in ogni blocco

59
selezionato)per identificare correttamente gli MBs e le coppie di coefficienti dove il watermark era
nascosto.Nel secondo step sono analizzate le relazioni tra i coefficienti delle coppie selezionate.
La conoscenza della lunghezza del codice di watermarking per ricalcolare lo step del codice di
watermarking in ogni VOP. Per leggere il j-esimo bit del codice di watermarking si considera un
accumulatore, dove sono sommati i valori di W’(v1,u1,v2,u2) corrispondenti a tutte le coppie di
coefficienti dove è inserito il bit.
Chiamiamo ψ j l’insieme di tali coppie:
∑ψ
=j
j)v,u,v,u(WA 2211
'cc
Tale somma è poi confrontata con la soglia TD per valutare il valore dell’embedding del bit bj :
<
≤≤−
>
=
Dcc
DccD
Dcc
j
TAif0
TATifateminerdetin
TAif1
b
j
j
j
Per minimizzare la probabilità di errore totale il valore TD deve essere zero;infatti ci si aspetta che
A è positivo quando il bit di embedding è 1 e negativo in caso opposto.
Scegliendo TD = 0 induciamo la lettura del codice di watermark anche quando su nessun codice è
eseguito l’embedding.Per ovviare questo problema ,la misura dell’affidabilità del bit letto è
stabilita per ogni bit recuperato.Con questo fine notiamo che solo una delle seguenti situazioni è
possibile: • Hp.A:Il VOL non è marcato;
• Hp.B:Il VOL è marcato
Indichiamo con E[Acc|A] e σ2
Acc|A il valore medio e la varianza di Acc condizionato a
Hp.A,rispettivamente.
Per ciascun bit si ha
E[Acc|A] = 0
ed è data la stima di σ2
Acc|A basata sui valori dei coefficienti DCT che costituiscono blocchi di
nonwatermark (blocchi non selezionati da chiavi random).
Data σ2
Acc|A ,definiamo per ogni bit
Cj = Accj/ σ Acc|A
Più è piccolo questo valore e più è probabile che la sequenza sia di nonwatermark.

60
5.5 Risultati sperimentali
Discutiamo alcuni esperimenti per provare l’efficacia dell’algoritmo proposto.Il test del software è
stato implementato in modo che esso prende,nella fase di embedding,un VOL MPEG-4,una chiave
segreta (rappresentata da un intero) ,il numero di coppie che sarebbe modificato in un blocco,un
codice di watermarking binario,e un numero in virgola mobile che rappresenta la massima
lunghezza di AF , detta AMAX, del segnale di watermarking,come ingresso.Nella fase di
ricostruzione il software implementato prende il VOL,la lunghezza del codice di watermarking,
una chiave segreta e un numero di coppie che sono modificate in un blocco come ingresso e da il
codice di watermarking e il valore di Cj per ogni bit letto.
Due tipi di test sono condotti su tre differenti sequenze video per testare da un lato l’invisibilità del
watermark che ha subito l’embedding e dall’altro la robustezza contro tutti i processi che non
degradaano seriamente la qualità del video.
Tra le sequenze video testate, evidenziamo i risultati raggiunti dalle sequenze video standard
“News” e “Stefan”.
Questi sono codificati usando piani α binari e consistono di 300 frame in formato CIF con un rate
di 25 fr/sec.
”News” è composto di 4 Vos come mostrato in figura
“Stefan” è composto di 2 Vos come mostrato in figura.
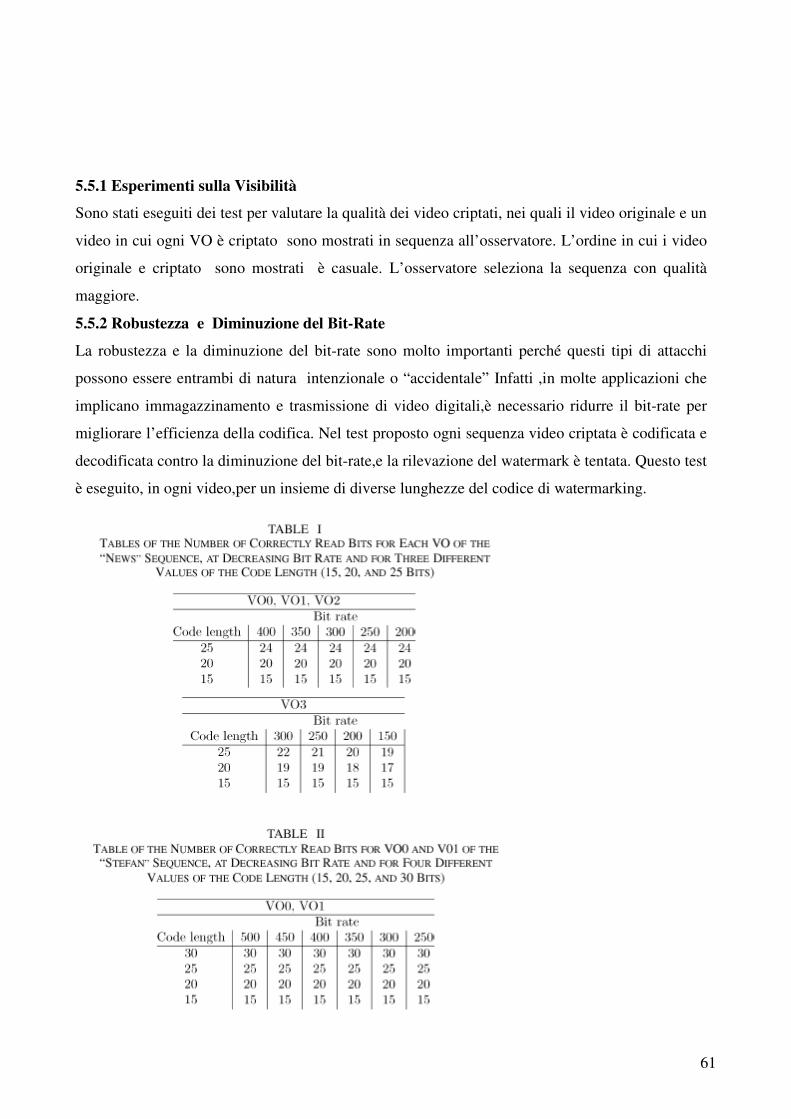
61
5.5.1 Esperimenti sulla Visibilità
Sono stati eseguiti dei test per valutare la qualità dei video criptati, nei quali il video originale e un
video in cui ogni VO è criptato sono mostrati in sequenza all’osservatore. L’ordine in cui i video
originale e criptato sono mostrati è casuale. L’osservatore seleziona la sequenza con qualità
maggiore.
5.5.2 Robustezza e Diminuzione del Bit-Rate
La robustezza e la diminuzione del bit-rate sono molto importanti perché questi tipi di attacchi
possono essere entrambi di natura intenzionale o “accidentale” Infatti ,in molte applicazioni che
implicano immagazzinamento e trasmissione di video digitali,è necessario ridurre il bit-rate per
migliorare l’efficienza della codifica. Nel test proposto ogni sequenza video criptata è codificata e
decodificata contro la diminuzione del bit-rate,e la rilevazione del watermark è tentata. Questo test
è eseguito, in ogni video,per un insieme di diverse lunghezze del codice di watermarking.

62
5.5.3 Robustezza e Frame Dropping
L’algoritmo di watermarking inserisce il watermark senza modificare i coefficienti zero;per questa
ragione la lunghezza del watermark che ha subito embedding è più alta nei VOPs codificati con
INTRA rispetto ai VOPs codificati con INTER. I cambi nella struttura GOV sono critici. E’anche
ovvio che uno dei casi peggiori si ottiene quando il primo frame del video è abbassato. In questo
caso,ogni VOP codificato INTRA diventa l’ultimo VOP codificato INTER nella struttura GOV.
Nei test eseguiti ogni sequenza video crittata è codificata e decodificata di nuovo dopo aver
eliminato il primo frame e si tenta di rilevare il watermark.
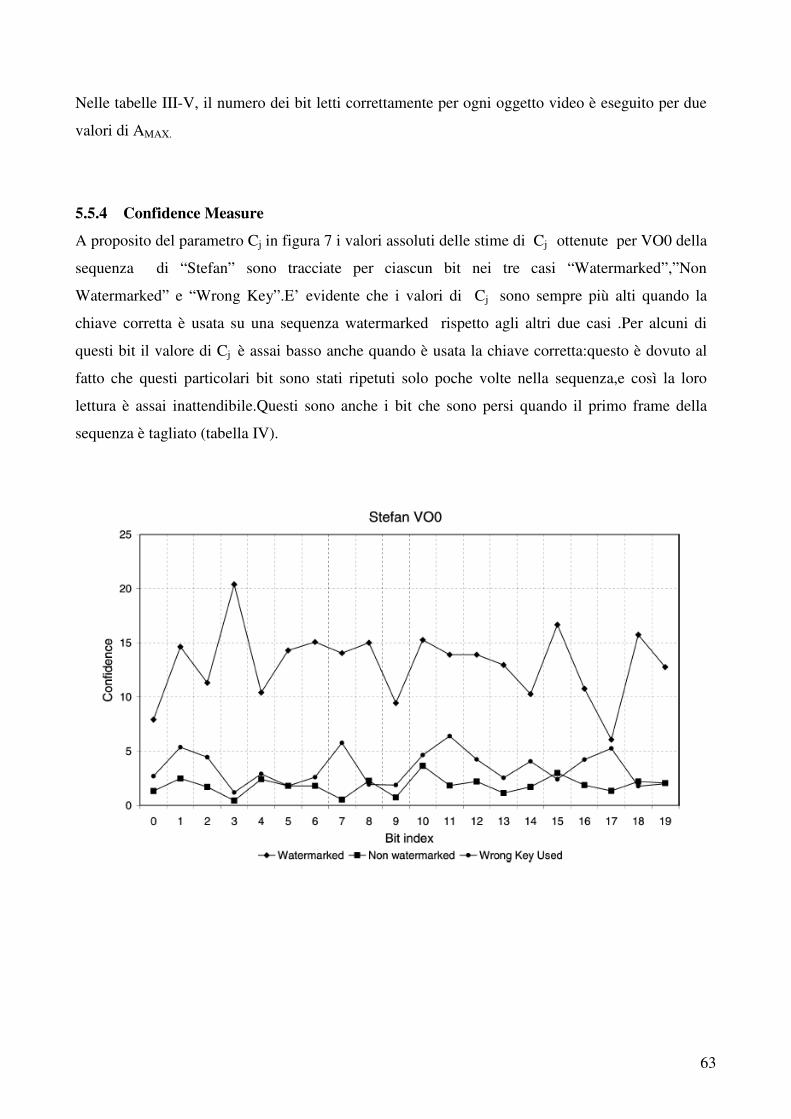
63
Nelle tabelle III-V, il numero dei bit letti correttamente per ogni oggetto video è eseguito per due
valori di AMAX.
5.5.4 Confidence Measure
A proposito del parametro Cj in figura 7 i valori assoluti delle stime di Cj ottenute per VO0 della
sequenza di “Stefan” sono tracciate per ciascun bit nei tre casi “Watermarked”,”Non
Watermarked” e “Wrong Key”.E’ evidente che i valori di Cj sono sempre più alti quando la
chiave corretta è usata su una sequenza watermarked rispetto agli altri due casi .Per alcuni di
questi bit il valore di Cj è assai basso anche quando è usata la chiave corretta:questo è dovuto al
fatto che questi particolari bit sono stati ripetuti solo poche volte nella sequenza,e così la loro
lettura è assai inattendibile.Questi sono anche i bit che sono persi quando il primo frame della
sequenza è tagliato (tabella IV).

64
2 Steganografia in JPEG2000
6.1 Codifica JPEG2000
Il diagramma a blocchi di JPEG2000 è mostrato in Figura 1.Dal lato encoder
l’immagine originale prima subisce la trasformata wavelet.I coefficienti wavelet
risultanti sono poi quantizzati e codificati.Il modello di codifica di JPEG2000 può
essere visto come disposto su due file sovrapposte.Un controllo è applicato nei
passi di codifica e quantizzazione per ottenere il Bit Rate desiderato.Il lato decoder
inverte le operazioni decodificando e dequantizzando il Bit Stream e applicando la
trasformata inversa per ricostruire l’immagine.
Sulla prima fila della struttura gli indici di quantizzazione di ogni sottobanda sono
partizionati in blocchi di codice.Il blocco di codice è codificato un Bit Plane alla
volta iniziando dal più significativo al meno significativo.Ogni Bit Plane è
codificato con tre passi di codifica.Il primo passo di codifica è significance
propagation pass , che trasmette significato e informazione per campioni che non
hanno significato e devono averlo.Il secondo passo di codifica è magnitude
refinement pass . Tutti i bit diventati significativi in un precedente Bit Plane sono
portati in questo passo usando simboli binari.Il terzo passo è cleanup pass nel
quale tutti i bit che non sono stati codificati nei precedenti passi lo diventano.I
simboli generati dai primi due passi sono codificati grossolanamente o
entropicamente da un codificatore aritmetico binario adattativi e context_based
(codificatore MQ).L’uscita del processo di codifica sulla prima fila è quindi una
collezione di rappresentazioni compatte di passi di codifica dei blocchi di codice.

65
Tier-2 di codifica sulla seconda fila opera sulla informazione riassunta dei
blocchi di codice ,che determinano dei blocchi che contribuiscono al flusso dei
codici binari.Il bit-stream di ogni blocco di codice è troncato in modo da
dimezzare la distorsione.Fondamentalmente il troncamento può capitare solo alla
fine di un passo di codifica.Per minimizzare la distorsione l’esatto punto di
troncamento è scelto tra quelli possibili in ogni blocco.I passi di codifica sono poi
raggruppati in pacchetti a formare il flusso di codice finale.L’ordine dei pacchetti
nel flusso di codice facilita la trasmissione progressiva dell’immagine attraverso
fedeltà,risoluzione o componenti.Poiché l’algoritmo del tasso di distorsione del
Tier-2 di codifica è applicato dopo a tutti i campioni che sono stati compressi nel
Tier-1 di codifica,il meccanismo del tasso di controllo di JPEG2000 è chiamata
ottimizzazione Post-Compression Rate-Distorsion (PCRD).Inoltre alcuni passi di
codifica possono essere scartati da questa procedura di troncamento ottimizzata
cosicché il Tier-2 di codifica è un’altra sorgente primaria di perdita di
informazione nel percorso di codifica oltre la quantizzazione.
6.2 Informazioni Nascoste in JPEG2000
6.2.1 Challenges di Informazioni Nascoste
L’obbiettivo è sviluppare uno schema che nascondi le informazioni sotto la
struttura di JPEG2000 cosicchè un alto volume di dati può essre trasmesso
segretamente in modo più sicuro.Come prima cosa determiniamo una posizione
appropriata nel flusso di codifica di JPEG2000 per nascondere le
informazioni.Dalla struttura data dalla Figura1 ci sono tre posizioni da considerare
e ne esaminiamo di seguito la convenienza per nascondere informazioni.
• Trasformata dell’immagine: Dopo la trasformata intra dell’ immagine i dati
sono trasformati in coefficienti wavelet.Per il watermarking digitale il
payload è basso e può essere applicato un embedding multiplo con
rivelazione maggiore oppure un concetto di spread-spectrum
.L’informazione che ha subito l’embedding può così avere sufficiente
robustezza contro la compressione di un altro codec.L’embedding multiplo
non è conveniente nelle applicazioni che nascondono dati .

66
• Quantizzazione: è un importante step nella compressione delle immagini
che riduce la ridondanza visuale per codifica efficiente .La quantizzazione è
una sorgente primaria di perdita di informazione.
• Codifica: Se l’informazione ha subito embedding all’uscita di Tier-2 di
codifica allora si può garantire che questa sarà ricevuta senza errore e in
ordine corretto perché evitiamo le due maggiori sorgenti di perdita di
informazione,quantizzazione e troncamento del bit-stream.però abbiamo
difficoltà nella modifica dei pacchetti per eseguire l’embedding della
informazione poiché il bit-stream può essere stoto compresso da un
codificatore aritmetico.
6.2.2 Embedding Progressivo di un’Immagine Nascosta e suoi svantaggi

67
68






![Sql: esempi di linguaggio sql nell'implementazione mysql 1 CREATE SCHEMA che nel DBMS mysql diventa: CREATE DATABASE [IF NOT EXIST] nome_database La clausola.](https://static.fdocumenti.com/doc/165x107/5542eb66497959361e8d294f/sql-esempi-di-linguaggio-sql-nellimplementazione-mysql-1-create-schema-che-nel-dbms-mysql-diventa-create-database-if-not-exist-nomedatabase-la-clausola.jpg)





![PGP [PRETTY GOOD PRIVACY] · Pgp Zip che crea archivi sicuri criptati contenenti uno o più files, ma anche intere directory usando vari criteri di compressione; Pgp Virtual Disk](https://static.fdocumenti.com/doc/165x107/5f608ba3f6d91227a454de42/pgp-pretty-good-privacy-pgp-zip-che-crea-archivi-sicuri-criptati-contenenti-uno.jpg)




