Ristorazione - Speciale Linea Bi-color / Catering - Bi-color Special Line

UNIVERSITA DEGLI STUDI DI GENOVAFACOLTA DI INGEGNERIA
Corso di Laurea Specialistica in Ingegneria Gestionale
Dispense per le esercitazioni dell’insegnamento
Business Intelligence
Prof. Davide Anguita
A cura di: Alessandro Ghio
Anno Accademico 2008 - 2009
Documento realizzato in LATEX

Indice
Prefazione 5
Principali acronimi utilizzati 7
1 Introduzione 9
1.1 Cos’e il Data Mining? . . . . . . . . . . . . . . . . . . . . . . . 9
1.2 Terminologia di base . . . . . . . . . . . . . . . . . . . . . . . 12
1.3 Data Mining Process . . . . . . . . . . . . . . . . . . . . . . . 14
1.3.1 Definizione degli obiettivi . . . . . . . . . . . . . . . . 14
1.3.2 Organizzazione dei dati . . . . . . . . . . . . . . . . . . 15
1.3.3 Analisi esplorativa dei dati . . . . . . . . . . . . . . . . 15
1.3.4 Scelta delle metodologie di analisi . . . . . . . . . . . . 19
1.3.5 Analisi dei dati . . . . . . . . . . . . . . . . . . . . . . 20
1.3.6 Valutazione dei metodi statistici e dei risultati ottenuti 20
1.3.7 Implementazione dell’algoritmo . . . . . . . . . . . . . 21
1.4 Il software che useremo: WEKA . . . . . . . . . . . . . . . . . 21
1.5 Organizzazione della dispensa . . . . . . . . . . . . . . . . . . 24
2 Organizzazione dei dati 25
2.1 Tipi di attributi . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.1.1 Variabili qualitative . . . . . . . . . . . . . . . . . . . . 26
2.1.2 Variabili quantitative . . . . . . . . . . . . . . . . . . . 26
2.2 La matrice dei dati . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.1 Gestione delle variabili . . . . . . . . . . . . . . . . . . 28
2.3 Normalizzazione di un dataset . . . . . . . . . . . . . . . . . . 29
3 Analisi esplorativa dei dati 31
3.1 Distribuzioni di frequenza . . . . . . . . . . . . . . . . . . . . 31
1

3.1.1 Distribuzioni univariate . . . . . . . . . . . . . . . . . 31
3.1.2 Distribuzioni bivariate e multivariate . . . . . . . . . . 32
3.2 Analisi esplorativa univariata . . . . . . . . . . . . . . . . . . 33
3.2.1 Richiami su stimatori e loro caratteristiche . . . . . . . 33
3.2.2 Indici di posizione . . . . . . . . . . . . . . . . . . . . . 34
3.2.3 Indici di variabilita . . . . . . . . . . . . . . . . . . . . 35
3.2.4 Indici di eterogeneita . . . . . . . . . . . . . . . . . . . 36
3.3 Analisi esplorativa bivariata e multivariata . . . . . . . . . . . 38
3.4 Esempi di analisi con WEKA . . . . . . . . . . . . . . . . . . 40
3.5 Riduzione di dimensionalita . . . . . . . . . . . . . . . . . . . 43
3.6 Esempi di riduzione di dimensionalita utilizzando WEKA . . . 44
4 Classificazione 48
4.1 Zero Rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.1.1 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 49
4.1.2 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 49
4.1.3 Estensione al caso multiclasse . . . . . . . . . . . . . . 49
4.1.4 Esempio di analisi in WEKA . . . . . . . . . . . . . . . 49
4.2 Naive Bayesian Classifier . . . . . . . . . . . . . . . . . . . . . 54
4.2.1 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 54
4.2.2 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 55
4.2.3 Estensione al caso multiclasse . . . . . . . . . . . . . . 55
4.2.4 Esempio di analisi in WEKA . . . . . . . . . . . . . . . 56
4.3 Reti neurali: MultiLayer Perceptrons . . . . . . . . . . . . . . 56
4.3.1 Cenni storici: il percettrone . . . . . . . . . . . . . . . 56
4.3.2 Architettura di un MLP . . . . . . . . . . . . . . . . . 60
4.3.3 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 62
4.3.4 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 64
4.3.5 Estensione al caso multiclasse . . . . . . . . . . . . . . 64
4.3.6 Esempio di analisi in WEKA (I) . . . . . . . . . . . . . 64
4.3.7 Esempio di analisi in WEKA (II) . . . . . . . . . . . . 66
4.3.8 Validation set e test set . . . . . . . . . . . . . . . . . 67
4.4 Support Vector Machines . . . . . . . . . . . . . . . . . . . . . 68
4.4.1 Il problema del classificatore a massimo margine . . . . 68
4.4.2 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 71
4.4.3 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 73
2

4.4.4 Estensione al caso multiclasse . . . . . . . . . . . . . . 73
4.4.5 SVM e la probabilita . . . . . . . . . . . . . . . . . . . 74
4.4.6 Esempio di analisi in WEKA . . . . . . . . . . . . . . . 75
4.4.7 SVM per feature selection . . . . . . . . . . . . . . . . 76
4.5 Decision Trees . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.5.1 La nascita degli alberi di decisione . . . . . . . . . . . 80
4.5.2 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 82
4.5.3 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 86
4.5.4 Estensione al caso multiclasse . . . . . . . . . . . . . . 86
4.5.5 Esempio di analisi in WEKA . . . . . . . . . . . . . . . 87
5 Regressione 90
5.1 Zero Rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.1.1 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 90
5.1.2 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 90
5.1.3 Esempio di analisi in WEKA . . . . . . . . . . . . . . . 91
5.2 Support Vector Regression . . . . . . . . . . . . . . . . . . . . 91
5.2.1 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 92
5.2.2 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 93
5.2.3 Esempio di analisi in WEKA . . . . . . . . . . . . . . . 93
5.3 Regression Trees . . . . . . . . . . . . . . . . . . . . . . . . . 93
5.3.1 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 93
5.3.2 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 94
5.3.3 Esempio di analisi in WEKA . . . . . . . . . . . . . . . 94
6 Clustering 96
6.1 k–Means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.1.1 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 97
6.1.2 Fase in avanti . . . . . . . . . . . . . . . . . . . . . . . 98
6.1.3 Esempio di analisi in WEKA . . . . . . . . . . . . . . . 98
7 Association rules 100
7.1 Apriori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
7.1.1 Apprendimento . . . . . . . . . . . . . . . . . . . . . . 101
7.1.2 Esempio di analisi in WEKA (I) . . . . . . . . . . . . . 104
7.1.3 Esempio di analisi in WEKA (II) . . . . . . . . . . . . 106
3

8 Valutazione comparativa di algoritmi di Data Mining 108
8.1 Metodi (pratici) per la comparazione fra algoritmi . . . . . . . 108
8.1.1 Training set (TS) . . . . . . . . . . . . . . . . . . . . . 108
8.1.2 Validation set (VS) . . . . . . . . . . . . . . . . . . . . 109
8.1.3 K–Fold Cross Validation (KCV) . . . . . . . . . . . . . 109
8.2 Analisi in WEKA explorer . . . . . . . . . . . . . . . . . . . . 110
8.2.1 Metodo TS . . . . . . . . . . . . . . . . . . . . . . . . 110
8.2.2 Metodo VS . . . . . . . . . . . . . . . . . . . . . . . . 111
8.2.3 Metodo KCV . . . . . . . . . . . . . . . . . . . . . . . 111
8.3 Analisi in WEKA KF . . . . . . . . . . . . . . . . . . . . . . . 112
8.3.1 Input . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
8.3.2 Selezione della classe . . . . . . . . . . . . . . . . . . . 113
8.3.3 Creazione delle k fold per la KCV . . . . . . . . . . . . 113
8.3.4 Inserimento dei blocchi per le SVM . . . . . . . . . . . 113
8.3.5 Elaborazione dei risultati . . . . . . . . . . . . . . . . . 114
8.3.6 Uscita a video . . . . . . . . . . . . . . . . . . . . . . . 114
8.3.7 Configurazione finale ed esecuzione . . . . . . . . . . . 114
8.4 Note conclusive . . . . . . . . . . . . . . . . . . . . . . . . . . 115
Bibliografia 117
4

Prefazione
Il termine Business Intelligence (BI ) e piuttosto vago. Una definizione
che comunemente puo essere rintracciata in letteratura [14] e la seguente:
Con il termine business intelligence (BI) ci si puo solitamente
riferire a: un insieme di processi aziendali per raccogliere ed ana-
lizzare informazioni strategiche; la tecnologia utilizzata per rea-
lizzare questi processi; le informazioni ottenute come risultato di
questi processi.
Per quanto abbia riscosso sempre maggiore interesse solo negli ultimi
anni, il processo di BI venne definito come tale nel 1958 da H. P. Luhn,
ricercatore dell’IBM: ovviamente, all’epoca non si avevano a disposizione
gli strumenti di oggi (a partire dal computer stesso, almeno nell’accezione
moderna di PC), ma gia era nata l’idea che i dati, specialmente quando sono
numerosi, debbano essere interpretati al fine di fornire informazioni utili. Non
solo: le stesse informazioni devono essere a loro volta analizzate per trovare
indici (quanto piu completi e sintetici) in grado di velocizzare il processo
decisionale.
E immediato, quindi, comprendere come una parte fondamentale del pro-
cesso di BI sia costituita dal Data Mining (DM ). Traducendo letteralmente
il termine Mining, esso deriva da to mine, ovvero estrarre (come si fa, nella
pratica, in miniera) risorse preziose dalle viscere dei (numerosi, in generale)
dati a disposizione. Proprio per questo motivo, al Data Mining viene spes-
so affiancato il concetto di Knowledge Discovery (KD): e quindi frequente
sentire parlare non solo di DM, ma, piu in generale, di KDDM.
Nel corso di questo insegnamento vedrete che il DM fa parte di un pro-
cesso molto complesso, che comprende progettazione ed interrogazione di da-
tabase, creazione di Data Marts, reportistica, ecc. Durante le esercitazioni,
data l’esiguita del tempo a nostra disposizione, ci concentreremo solamente
5

sulla presentazione dei principali algoritmi di DM per BI: sia, quindi, ben
chiaro che:
• queste esercitazioni (sfortunatamente) non potranno coprire per intero
il problema della BI;
• verranno presentati solo alcuni algoritmi (i piu famosi ed usati, seppure
in moltissime varianti che non analizzeremo), scelti tra la miriade di
tecniche a disposizione in letteratura.
Per queste dispense, ho tratto ispirazione da [10], sebbene Wikipedia1
offra sempre ottimi spunti di approfondimento.
1http://wikipedia.it/
6

Principali acronimi utilizzati
Acronimo Significato
BI Business Intelligence
DM Data Mining
KD Knowledge Discovery
KDDM Knowledge Discovery & Data Mining
MBA Market Basket Analysis
ML Machine Learning
MLP MultiLayer Perceptrons
NN Neural Networks (reti neurali)
SLT Statistical Learning Theory
SVM Support Vector Machine
NBC Naive Bayesian Classifier
IT Information Technology
OLAP OnLine Analytical Processing
KF Knowledge Flow (programma di WEKA)
CV Coefficiente di variazione
IQR Inter–Quartile Range
PCA Principal Component Analysis
SVD Singular Value Decomposition
MAE Mean Absolute Error
RMSE Root Mean Squared Error
TP True Positives
FP False Positives
CM Confusion Matrix
7

Acronimo Significato
BP BackPropagation
WTA Winner Take All
CCQP Constrained Convex Quadratic Problem
SMO Sequential Minimal Optimization
KKT Condizioni di Karush–Kuhn–Tucker
OVA One Vs. All
AVA All Vs. All
DT Decision Trees
SVR Support Vector Regression
RT Regression Trees
KCV K–Fold Cross Validation
8

Capitolo 1
Introduzione
1.1 Cos’e il Data Mining?
Posto nella Prefazione che in queste dispense ci occuperemo solamente
dei principali algoritmi di Data Mining (DM) per Business Intelligence (BI),
vediamo di approfondire meglio cosa si intende per Data Mining.
Consideriamo il caso di una catena di supermercati e supponiamo di avere
tre centri di vendita: per esempio, Genova, Savona e La Spezia. Ipotizziamo
inoltre di aver sede a Genova e di avere a disposizione un enorme database in
cui salviamo tutte le transazioni (i.e., tutte le vendite) di ogni supermercato.
Da questa montagna di dati vorremmo estrarre, per esempio, informazioni di
piu alto livello, come le relazioni fra prodotti venduti. Per renderci conto di
quanti dati potremmo avere a disposizione, basti pensare che, in media, un
supermercato di dimensione medio–grande in una giornata puo effettuare piu
di 2000 vendite in giorni feriali e 3000 nei festivi. Supponiamo di collezionare
dati per il mese di luglio 2008, che comprende 8 giorni festivi e 23 feriali.
Considerando i 3 supermercati della nostra piccola catena abbiamo:
(2000 · 23 + 3000 · 8) · 3 = 210000,
piu di 200000 dati! E solo in un mese!! E abbastanza intuitivo capire che
analizzare ad occhio piu di 200mila dati non e banale...
Supponiamo ora di disporre di un algoritmo A in grado di identificare
relazioni fra prodotti venduti: potrebbe sovente capitare che il cliente che
acquista Coca Cola compri anche degli snack. Il nostro algoritmo A indivi-
duera in automatico tali relazioni, che potranno poi essere sfruttate al fine di
9

sistemare Coca Cola e snack in maniera strategica all’interno degli scaffali,
oppure per organizzare le offerte commerciali da proporre ai clienti. Non
solo: si possono utilizzare altri algoritmi B, C,... per individuare altri tipi di
indici o estrarre altre informazioni, dividendo queste ultime sulla base della
citta in cui il supermercato e situato o per tipologia di prodotto. Questo
tipo di problema viene detto Market Basket Analysis (MBA) ed e una delle
situazioni in cui le metodologie di BI (e, in particolare, le tecniche di DM)
trovano applicazione.
Altri migliaia di esempi potrebbero essere portati in questa sede. Quello
che ci interessa maggiormente e, ora, cercare di dare una definizione di Data
Mining [9]:
Data mining is the process of selection, exploration, and modelling
of large quantities of data to discover regularities or relations that
are at first unknown with the aim of obtaining clear and useful
results for the owner of the database.
Le metodologie utilizzate dal DM provengono da due mondi diversi, in
generale:
1. alcuni algoritmi sono stati sviluppati nell’ambito del Machine Lear-
ning (ML), il cui scopo e di cercare di rappresentare nel miglior modo
possibile il processo di generazione dei dati, in modo tale da evitare
la mera memorizzazione dei dati in favore di un piu efficace proces-
so di generalizzazione del modello anche a casi non ancora osservati.
Il primo esempio di algoritmo di ML e stato il percettrone di Rosen-
blatt [21], dal quale hanno avuto origine modelli sempre piu complessi
come i MultiLayer Perceptrons (MLP), facenti parte della categoria
delle reti neurali (Neural Networks, NN ), di cui torneremo a parlare
a tempo debito. Negli ultimi dieci anni circa, ha preso sempre piu
piede, nel campo del ML, l’algoritmo Support Vector Machine (SVM ),
che, basandosi su una teoria statistica molto solida e chiamata Stati-
stical Learning Theory (SLT ) [23], costituisce l’attuale stato dell’arte
nel campo del Machine Learning, almeno per quanto riguarda l’ambito
della classificazione;
2. altri metodi sono stati invece sviluppati nell’ambito delle cosiddette
statistica multivariata e statistica computazionale: e il caso, per esem-
10

pio, di algoritmi basati sulle teorie di Bayes, come il Naive Bayesian
Classifier (NBC ) [12].
Volendo unire assieme nel mondo del DM i principi della statistica e del
ML, possiamo dire che negli algoritmi di DM devono permettere un’analisi
approfondita dei dati (come i modelli statistici), ma devono anche garanti-
re una sorta di non–memorizzazione del dato (la generalizzazione del ML).
Nelle analisi degli algoritmi di DM, si parte dal principio che ogni dato sia
in qualche modo affetto da rumore: tornando all’esempio del supermercato,
il rumore consiste nel fatto che ognuno di noi ha gusti diversi. Ad esempio,
qualcuno potrebbe gradire acquistare Coca Cola abbinata a salatini, men-
tre qualcun altro abbina l’acquisto della Coca Cola ad una torta dolce. Se
noi memorizzassimo ogni possibile associazione, senza cercare di estrarre in-
formazione, non avremmo piu Data Mining, per la precisione non avremmo
piu il Mining! Si viene, quindi, a porre un trade–off tra memorizzazione e
capacita di generalizzazione dei dati disponibili: in pratica, non dovremo ave-
re ne un modello troppo complicato (ovvero, che memorizza perfettamente
sia il dato disponibile sia il rumore che affligge per definizione i dati a no-
stra disposizione), ne troppo generale, ovvero non piu in grado di descrivere
adeguatamente la sorgente dei nostri dati.
Come ogni algoritmo, anche i metodi di DM generano un output, che
sara di natura diversa a seconda del tipo di applicazione che ci troviamo ad
analizzare (rimandiamo di qualche paragrafo ulteriori chiarimenti a riguar-
do). Spesso, l’output del nostro modello, nell’ambito della BI, puo fornire
nuova ispirazione per raccogliere altri dati, oppure per generare nuovi indici
o ipercubi per l’analisi: ecco perche, in applicazioni di tipo business, si parla
di circolo virtuoso della conoscenza [5], in quanto l’estrazione di conoscenza
porta a nuove informazioni, che possono a loro volta essere usate per ottenere
ulteriori e piu approfondite nozioni a riguardo. Per questi motivi, il DM non
e semplicemente l’utilizzo di uno o piu algoritmi o tecniche statistiche su dati
utilizzando un calcolatore; il DM e un processo di BI che dev’essere usato
insieme a tutti gli strumenti di Information Technology (IT ) al fine di fornire
un supporto alle decisioni in ambito aziendale. Non solo: tale informazione
dev’essere utile, quanto piu corretta possibile e di facile interpretazione per
tutti, dal consigliere di amministrazione all’impiegato dell’area logistica.
11

Temperatura Pressione Guasto
32 111 0
35 110 0
44 144 1
28 109 0
27 108 0
31 110 0
Tabella 1.1: Esempio di controllo sul funzionamento di un macchinario.
1.2 Terminologia di base
Prima di avventurarci in maggiori dettagli, elenchiamo un po’ di termini
di base.
Viene definito dataset un insieme di dati a disposizione per l’analisi: puo
essere un data warehouse, un data mart o parte di essi. In particolare, il
dataset utilizzato per creare un modello viene detto training set, in quanto
utilizzato nella fase di training, ovvero di creazione del modello stesso. Que-
st’ultimo, cosı trovato, verra quindi usato nella cosiddetta fase in avanti o
feedforward, ovvero lo step di applicazione a run–time. Distingueremo piu
avanti in questa dispensa, invece, i validation set e test set.
Un dataset e composto, come dice il nome stesso, di dati: ogni osserva-
zione viene chiamata pattern. Ogni pattern e caratterizzato da un insieme
di valori, detti variabili (variables), attributi (attributes) o features. Ad ogni
pattern puo essere assegnato un target, ovvero un valore indicante una par-
ticolare proprieta di ogni pattern. In pratica, una feature svolge il ruolo di
target, se cosı deciso da noi. Un paio di esempi chiariranno il tutto.
Consideriamo il dataset di Tab. 1.1: ogni riga del dataset e un pattern,
mentre ogni colonna rappresenta una feature. Questo dataset, in particolare,
e composto da 6 pattern, ognuno dei quali e costituito da 3 variabili (feature).
Possiamo, pero, considerare il seguente problma da analizzare: a seconda del
livello di temperatura e pressione, vogliamo controllare se un macchinario e
guasto o funzionante. In tal caso, Guasto svolge il ruolo di target, quindi il
nostro dataset e composto da 6 pattern, 2 attributi e un target.
Nel caso del dataset di Tab. 1.2, invece, abbiamo 6 pattern e 5 feature: in
questo caso, tuttavia, e difficile identificare una feature come target. Difficile
12

Vendita Coca Cola Snack Pane Gelato
110500 0 1 0 1
110501 1 1 0 0
110502 1 1 0 0
110503 1 1 0 0
110504 0 1 0 1
110505 0 1 0 1
Tabella 1.2: Esempio di vendite in un supermercato.
ma non impossibile: per esempio, potremmo voler prevedere se un cliente
acquistera o meno gelato sulla base degli acquisti di Coca Cola, snack e
pane, per quanto analisi di questo tipo non siano particolarmente utili. In
generale, e l’applicazione e il tipo di analisi che ci guidano a selezionare
(eventualmente) una feature come target.
Esistono, peraltro, target di diverso tipo (ove presenti), a seconda del
problema che si vuole affrontare. Normalmente, si usa la seguente notazione
per indicare un dataset dotato di target: {(x1, y1), ...., (xl, yl)}, con xi ∈ �m
indicanti i pattern. Quindi, m e il numero di feature, l e il numero di pattern,
mentre yi varia, come detto, a seconda del tipo di problema:
• se yi ∈ {−1, 1} oppure yi ∈ {0, 1}, si parla di classificazione biclasse:
considerando Guasto come target, il dataset di Tab. 1.1 e un esempio
di dataset per classificazione binaria, in cui le feature Temperatura e
Pressione sono utilizzate per cercare una relazione fra esse e, appunto,
Guasto. Tale target puo assumere solo due valori binari, in quanto una
macchina puo solo essere guasta o funzionante (anche se vedremo che
si puo introdurre un discorso di tipo probabilistico, ma ne riparleremo
a tempo debito);
• se yi ∈ S ⊂ ℵ, ovvero il target puo assumere solo un certo set di
valori interi, si parla di classificazione multiclasse, semplice estensione
di quanto descritto al punto precedente;
• se yi ∈ � si parla di regressione, ed equivale di fatto a trovare una
relazione f(·) del tipo y = f(x).
13

1.3 Data Mining Process
Viene definita Data Mining Process una serie di operazioni che vanno
dalla definizione preliminare degli obiettivi per l’analisi fino alla valutazione
dei risultati ottenuti. Di seguito, elenchiamo le varie attivita caratterizzanti
il DM Process, quindi, nei successivi paragrafi, daremo maggiori dettagli sulle
varie fasi di progetto:
1. Definizione degli obiettivi per l’analisi;
2. Selezione, organizzazione ed eventuale preprocessing dei dati;
3. Analisi esplorativa dei dati ed eventuale trasformazione di questi;
4. Scelta delle metodologie di analisi da usare (e comparare);
5. Analisi dei dati, sulla base dei metodi scelti al passo precedente;
6. Comparazione e valutazione delle prestazioni dei diversi metodi; scelta
della metodologia di analisi da utilizzare a run–time;
7. Implementazione del modello scelto, interpretazione dei risultati che
esso fornisce ed utilizzo di questi ultimi nel processo decisionale azien-
dale.
1.3.1 Definizione degli obiettivi
Sebbene questa fase sembri la piu immediata e semplice, non e sempre
cosı: spesso gli obiettivi e le problematiche aziendali non sono cosı chiari, ne
e chiaro quali dati, coefficienti o tipologie di analisi debbano essere applicate.
Di sicuro, la grande massa di dati a disposizione non aiuta in questo step:
torniamo al caso della catena di supermercati, ad esempio. Supponiamo
che l’obiettivo prefissato sia di voler aumentare i profitti: che tipo di analisi
vogliamo effettuare sui dati? Trovare le associazioni fra prodotti per orga-
nizzare meglio la disposizione degli scaffali o le offerte? Trovare l’andamento
dei guadagni per prodotto e/o supermercato per, eventualmente, decidere di
ingrandire un market o un reparto, o aprirne direttamente uno nuovo?
Questa fase e di certo la piu critica, e spesso viene sottovalutata: e
importante che gli obiettivi dell’analisi siano definiti precisamente a priori e
non persistano dubbi prima di passare alle fasi successive.
14

1.3.2 Organizzazione dei dati
Una volta terminata la fase 1.3.1, iniziamo a considerare i dati a nostra
disposizione. Normalmente, in un’azienda si ha a disposizione un grande
database di dati, il data warehouse, da cui estraiamo i data marts.
La prima fase consiste in una preliminare pulizia del dataset, detta data
cleansing : si analizzano tutte le variabili che caratterizzano i dati alla ricerca
di possibili valori mancanti (missing), palesemente sbagliati (incorrect) o
inutili (per esempio, considerando il dataset di Tab. 1.2, il codice della
vendita in molti casi non ha utilita alcuna per un’analisi sui dati). Questa
fase aiuta anche, in maniera retroattiva, a migliorare (se necessario) la qualita
della sorgente dati. Inoltre, il data cleansing permette di effettuare anche una
scelta tra variabili utili e inutili al fine dell’analisi (per esempio, eliminando
feature con molti valori missing).
La seconda fase consiste nella creazione di subset di dati: questo step e
necessario soprattutto quando ci troviamo a trattare masse davvero impo-
nenti di dati, per le quali l’utilizzo di tutto il data mart spesso porta ad avere
meno informazione (meglio, un’informazione meno “pulita”) rispetto all’uti-
lizzo di sottoinsiemi di esso opportunamente scelti. In generale, l’utilizzo di
dataset troppo grandi puo portare al fenomeno dell’overfitting, ovvero alla
memorizzazione dei dati (e della realizzazione particolare del rumore che li
affligge). Inoltre, vedremo piu avanti nella nostra trattazione come i dati non
selezionati possano diventare ottimo banco di prova per verificare le presta-
zioni del modello durante la fase 1.3.6. La selezione dei subset, tuttavia, e
tutt’altro che banale, ed e stata affrontata spesso in letteratura [4, 3].
1.3.3 Analisi esplorativa dei dati
Un’analisi esplorativa dei dati e spesso determinante al fine di incremen-
tare la qualita dei risultati ottenuti. Queste metodologie di analisi, simili
nella loro filosofia alle tecniche OLAP (OnLine Analytical Processing), per-
mettono di comprendere meglio l’origine dei nostri dati e trovare relazioni di
base che possono risultare di cruciale importanza per il modello operativo.
L’analisi dei dati passa anche attraverso una selezione dei dati stessi e, in
particolare, si parla di:
• feature selection (altresı variable selection);
15

• feature analysis (altresı variable analysis);
• outlier detection.
La feature selection consta nella selezione di un sottoinsiemi di variabi-
li, caratterizzanti ogni dato, che permettono di preparare e riorganizzare il
nostro data mart (ad esempio) in modo da rendere piu semplice e piu per-
formante le analisi dei passi successivi. Un esempio dovrebbe chiarire meglio
questo concetto.
Torniamo al caso della catena di supermercati, e supponiamo che il nostro
data mart sia piuttosto piccolo e sia rappresentato in Tab. 1.2: ovviamente,
non e un caso reale, ma ci serve come spunto per qualche riflessione. La
prima colonna rappresenta il codice univoco di una vendita, per esempio il
numero seriale dello scontrino fiscale; le colonne successive rappresentano
4 prodotti che possono essere acquistati: uno 0 indica che quel prodotto
non e stato venduto in quella particolare transazione, mentre un 1 indica
la vendita del prodotto. Notiamo subito due cose: in questo caso, tutti
hanno acquistato snack, e nessuno ha acquistato pane. Pertanto, sia gli
snack sia il pane ci danno informazioni di base (ovvero che ai nostri clienti
piacciono moltissimo i nostri snack e che dobbiamo cambiare panettiere...)
ma sono variabili che potrebbero essere inutili per analisi piu sofisticate, non
permettendo distinzioni tra le varie vendite. Come accorgersi di tutto cio in
casi reali con migliaia di vendite e prodotti? Semplice, basta controllare le
colonne a varianza nulla, ad esempio, o utilizzare appositi algoritmi di ranking
per classificare l’informativita delle variabili (ne parleremo piu avanti).
Selezionare un sottoinsieme di variabili puo essere utile in quanto:
• spesso feature poco informative peggiorano le prestazioni di un modello;
• molti algoritmi soffrono la curse of dimensionality in rapporto al nu-
mero di feature.
Non e sempre vantaggioso, comunque, ridurre il numero di variabili, in
quanto tutto dipende dal tipo di analisi che vogliamo affrontare. Tornando
alla Tab. 1.2, eliminare la colonna snack, in quanto poco informativa, potreb-
be essere una buona scelta in alcune metodologie, ma potrebbe, ad esempio,
farci perdere delle relazioni importanti nel caso di cui abbiamo discusso nel
paragrafo 1.1. Morale della favola: la feature selection va applicata con molta
16
0 0.2 0.4 0.6 0.8 10
0.5
1
1.5
2
2.5
3
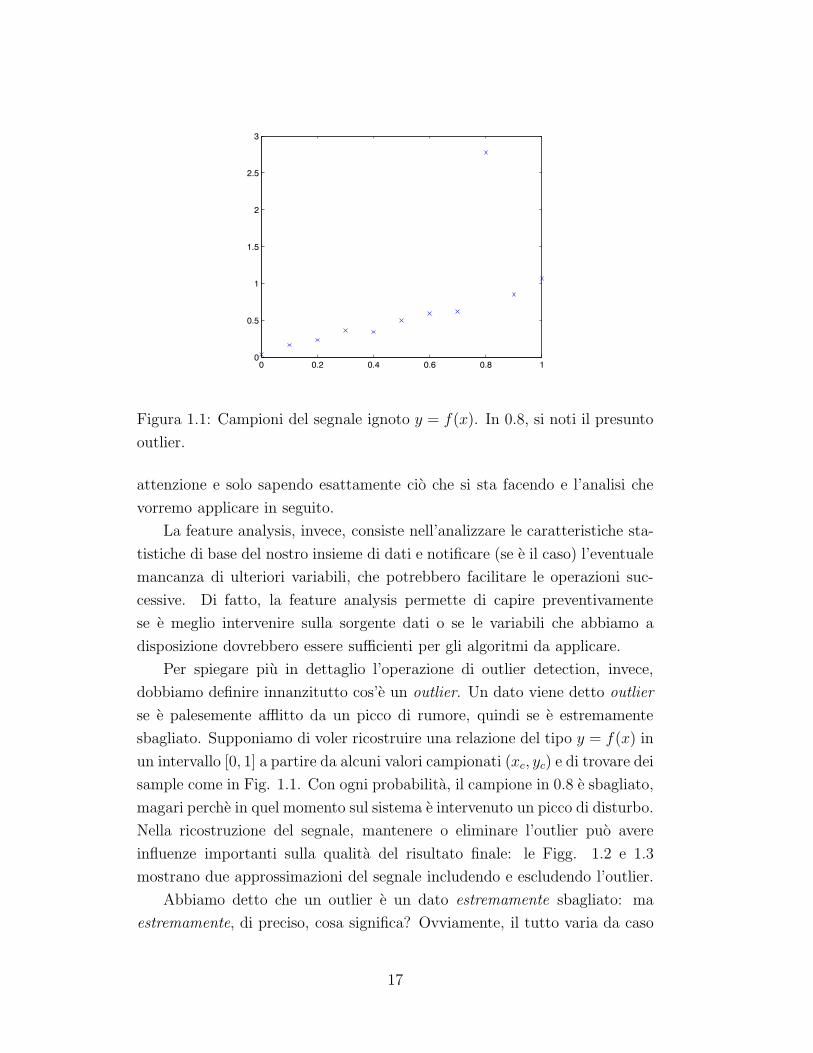
Figura 1.1: Campioni del segnale ignoto y = f(x). In 0.8, si noti il presunto
outlier.
attenzione e solo sapendo esattamente cio che si sta facendo e l’analisi che
vorremo applicare in seguito.
La feature analysis, invece, consiste nell’analizzare le caratteristiche sta-
tistiche di base del nostro insieme di dati e notificare (se e il caso) l’eventuale
mancanza di ulteriori variabili, che potrebbero facilitare le operazioni suc-
cessive. Di fatto, la feature analysis permette di capire preventivamente
se e meglio intervenire sulla sorgente dati o se le variabili che abbiamo a
disposizione dovrebbero essere sufficienti per gli algoritmi da applicare.
Per spiegare piu in dettaglio l’operazione di outlier detection, invece,
dobbiamo definire innanzitutto cos’e un outlier. Un dato viene detto outlier
se e palesemente afflitto da un picco di rumore, quindi se e estremamente
sbagliato. Supponiamo di voler ricostruire una relazione del tipo y = f(x) in
un intervallo [0, 1] a partire da alcuni valori campionati (xc, yc) e di trovare dei
sample come in Fig. 1.1. Con ogni probabilita, il campione in 0.8 e sbagliato,
magari perche in quel momento sul sistema e intervenuto un picco di disturbo.
Nella ricostruzione del segnale, mantenere o eliminare l’outlier puo avere
influenze importanti sulla qualita del risultato finale: le Figg. 1.2 e 1.3
mostrano due approssimazioni del segnale includendo e escludendo l’outlier.
Abbiamo detto che un outlier e un dato estremamente sbagliato: ma
estremamente, di preciso, cosa significa? Ovviamente, il tutto varia da caso
17

0 0.2 0.4 0.6 0.8 1−0.5
0
0.5
1
1.5
2
2.5
3
Figura 1.2: Approssimazione escludendo l’outlier.
0 0.2 0.4 0.6 0.8 1−0.5
0
0.5
1
1.5
2
2.5
3
Figura 1.3: Approssimazione includendo l’outlier.
18

a caso, e molto si basa sulle eventuali informazioni a priori che potremmo
avere a disposizione. Nel caso di Fig. 1.1, qualora sapessimo che i dati
hanno un andamento lineare, ovviamente l’outlier deve essere escluso; senza
informazioni a priori, corriamo comunque un rischio.
Una nota conclusiva: spesso, proprio per i motivi precedentemente pre-
sentati, l’outlier detection e considerata, a tutti gli effetti, un metodo stati-
stico da valutare attentamente sulla base della qualita dei risultati ottenuti
e viene pertanto spostata dalla fase di analisi esplorativa dei dati alle fasi
successive del DM Process.
1.3.4 Scelta delle metodologie di analisi
Ci sono moltissimi metodi statistici e ognuno di essi e stato implementato
in una miriade di algoritmi: e importante, quindi, una classificazione di tali
metodi, al fine di fare un po’ di ordine. La scelta del metodo dipende dal tipo
di analisi che vogliamo fare, che a sua volta dipende dagli obiettivi prefissati
e dai dati che abbiamo a disposizione. Per questo motivo, si dice che il Data
Mining Process e guidato dall’applicazione.
Le principali classi di metodi statistici sono:
1. Metodi descrittivi;
2. Metodi predittivi;
3. Metodi locali.
Nei prossimi paragrafi, li presentiamo brevemente.
Metodi descrittivi
Anche detti metodi non supervisionati (unsupervised) o indiretti, mira-
no a raggruppare i dati sulla base di relazioni non note (e potremmo dire
“non notabili”) a priori o con un’analisi esplorativa. Nel dataset, non e pre-
sente il target. Tra i vari problemi affrontati con metodi descrittivi, noi ci
occuperemo principalmente del clustering.
19

Metodi predittivi
Anche detti metodi supervisionati (supervised) o diretti, hanno come
obiettivo trovare relazioni tra feature e target, al fine di identificare relazioni
di classificazione o predizione. Nel dataset utilizzato e sempre presente un
target. E il caso dei problemi di classificazione biclasse e multiclasse e della
regressione.
Metodi locali
Hanno come obiettivo identificare particolari caratteristiche e relazioni su
sottoinsiemi del dataset. Esempi sono le association rules, che abbiamo citato
indirettamente nel nostro esempio introduttivo nel paragrafo 1.1. Non solo:
come anticipato in precedenza, anche il problema della outlier detection puo
essere considerato un metodo locale e, come tale, potra poi essere sottoposto
ad attenta valutazione negli step successivi del DM Process.
1.3.5 Analisi dei dati
A questo punto, scelto il metodo (o i metodi) con cui vogliamo affrontare
l’analisi dei dati, scelti gli algoritmi e scelti gli obiettivi, non ci rimane che
dare inizio alle operazioni. In questa fase, potrebbero essere usati software
ad hoc, ma, piu in generale, ci si affida ad applicazioni gia sviluppate (e te-
state) disponibili in commercio o per il libero download. Daremo brevemente
un’occhiata a questi software nel paragrafo 1.4, concentrandoci in particolar
modo sul software che useremo: il freeware WEKA.
1.3.6 Valutazione dei metodi statistici e dei risultati
ottenuti
Terminata l’analisi con tutti i metodi prescelti, non ci resta che definire
(se non l’abbiamo gia fatto in precedenza) dei coefficienti per la compara-
zione. Per esempio, nel caso di classificazione, un buon termine di paragone
potrebbe essere l’errore previsto a run–time per ogni metodo e algoritmo, al
fine di scegliere quello che sbagliera meno. Per trovare questi (o altri) coeffi-
cienti, e affinche essi siano affidabili, e necessario, di norma, affidarsi a metodi
di tipo statistico: analizzeremo piu avanti in queste dispense alcune di queste
20

tecniche, come la Cross Validation. Tali tecniche ci devono permettere una
valutazione rapida, semplice e affidabile.
Spesso un coefficiente per la comparazione non e sufficiente, ma e neces-
sario considerare altri fattori quali vincoli temporali o di risorse, qualita e
stabilita del risultato ottenuto, e molto altro ancora.
1.3.7 Implementazione dell’algoritmo
Concludiamo questa carrellata sul DM Process con la fase di realizzazione
del modello: una volta scelto, esso dovra essere implementato a tutti gli effetti
per entrare in funzione (la gia citata fase feedforward) nel nostro business
aziendale. Anche in questo caso, ci si puo affidare ad eseguibili in commercio
o freeware. Data l’usuale semplicita di implementazione della fase in avanti di
molti algoritmi, si possono realizzare codici e programmi ad hoc, ottimizzati
e customizzati sulle esigenze aziendali e di analisi.
1.4 Il software che useremo: WEKA
Negli ultimi anni e cresciuto in modo esponenziale il numero di software
per BI che comprendono al loro interno suite per il DM: basti citare Oracle
e Microsoft SQL Server. Date le caratteristiche di prodotti commerciali a
prezzi tutt’altro che contenuti e data l’oggettiva difficolta di apprendimento
in strumenti piu professionali che divulgativi, si e deciso di utilizzare un
programma freeware chiamato Waikato Enviroment for Knowledge Analysis,
in breve WEKA. Esso e stato sviluppato in Nuova Zelanda presso l’Universita
di Waikato ed e scaricabile gratuitamente1. Al proprio interno, comprende
moltissime routine per training e fase in avanti di moltissimi algoritmi.
WEKA e realizzato in Java, pertanto necessita solo della Java Virtual
Machine (JVM) installata sulla propria macchina (e possibile scaricare la
JVM assieme a WEKA in un unico pacchetto dal sito neozelandese). Nel
caso di utilizzo su macchine Windows (qualsiasi versione, Vista incluso), e
possibile installare il programma, che viene compilato con opzioni di com-
pilazione standard. Su altri sistemi operativi (Mac piuttosto che Linux) e
obbligatorio (su Windows e solo opzionale) scaricare i sorgenti e compilarli
prima di eseguire WEKA. La riga di compilazione e la seguente:
1http://www.cs.waikato.ac.nz/ml/weka/
21

Figura 1.4: Interfaccia di base di WEKA.
java -jar weka.jar
e sara la JVM a occuparsi del resto. Ulteriori opzioni di compilazione sono
possibili per aumentare la dimensione dello stack o simili.
In Fig. 1.4 viene mostrata l’interfaccia di base di WEKA. Quattro opzioni
sono possibili:
• Simple CLI apre una finestra a riga di comando per qualsiasi tipo di
operazione e analisi sui dati. Essendo poco “user–friendly”, e facilmente
utilizzabile solo da utenti esperti e dopo un po’ di pratica;
• Explorer lancia una finestra GUI per ogni tipo di analisi e operazio-
ne sui dati. Explorer e decisamente piu intuitivo rispetto alla CLI,
quindi, almeno nei primi tempi, ci dedicheremo soprattutto a questa
applicazione;
• Experimenter permette di confrontare fra loro piu metodi di analisi,
comparandone le prestazioni. Il setup di Experimenter non e banale
e necessita di un po’ di esperienza, ma i risultati sono decisamente
interessanti;
22

• Knowledge Flow assomiglia all’ambiente Simulink di MATLAB e con-
sente di costruire confronti fra metodi (tipo Experimenter) ma sotto
forma di diagrammi a blocchi, quindi in modo piu intuitivo.
Si noti che WEKA non comprende direttamente al proprio interno un
software per la fase in avanti degli algoritmi: abbiamo anticipato nel para-
grafo 1.3.7 come spesso si preferiscano realizzazioni ad hoc, quindi gli autori
di WEKA si sono concentrati sui passi 1–6 del DM Process piuttosto che sul
7. Ciononostante, mostreremo come Explorer e KF possano essere utilizzati
anche per implementare la fase in avanti degli algoritmi.
Dedichiamo qualche cenno al formato dei file in input a WEKA. I dataset
possono essere passati al software in tre differenti modi:
• file ARFF (che analizzeremo a breve);
• indirizzo web (per database di tipo Java DB);
• file locale Java DB.
Premesso che probabilmente nel corso dell’insegnamento utilizzeremo
esclusivamente i file locali ARFF, analizziamone la struttura (puo essere utile
per scrivere eventuali convertitori da altri formati per dataset). Ogni riga
preceduta dal carattere jolly ‘%’ e considerata un commento, mentre sono
necessari i seguenti campi:
• un campo @relation, seguito dal nome del dataset;
• l’elenco degli attributi, uno per riga, aventi la seguente struttura:
– la parola chiave @attribute;
– il nome dell’attributo;
– il set di valori che la variabile puo assumere (per attributi di tipo
qualitativo o quantitativo discreto) o, in alternativa, il tipo di
feature (real o integer);
• la parola chiave @data, seguita nella linea successiva da tutti i pattern.
Ogni pattern e costituito dalle feature, divise dal carattere ‘,’. Un
missing e contraddistinto da ‘?’.
23

1.5 Organizzazione della dispensa
Questa dispensa e organizzata sulla base del flusso del Data Mining Pro-
cess, di cui analizzeremo (per motivi di tempo) solamente alcuni aspetti. In
particolare:
• nel Capitolo 2, affronteremo il problema dell’organizzazione dei dati,
delle trasformazioni applicabili ai pattern e dei tipi di variabili;
• nel Capitolo 3, approfondiremo alcuni concetti su parametri statistici
e caratteristiche del nostro dataset;
• nel Capitolo 4, invece, cominceremo ad analizzare alcuni algoritmi per
la classificazione di pattern;
• nel Capitolo 5 affronteremo il problema della regressione;
• il clustering sara, invece, l’argomento centrale del Capitolo 6;
• trovare le regole di associazione tra feature di un dataset e il problema
affrontato nel Capitolo 7;
• termineremo presentando alcuni metodi pratici per il confronto fra algo-
ritmi e introducendo l’utilizzo di WEKA Knowledge Flow nel Capitolo
8.
24

Capitolo 2
Organizzazione dei dati
In questo capitolo andiamo ad affrontare brevemente le problematiche
relative all’organizzazione dei dati. Dati per scontati concetti quali data
warehouse e data marts, partiamo dal presupposto di avere a disposizione
un dataset, composto da l pattern e m feature, come definito nel paragrafo
1.2. Al momento, non ci interessa se il dataset e dotato di target o meno.
Tralasciamo per il momento, inoltre, la selezione di un subset adatto: e un
problema decisamente complesso, che richiameremo solo in parte a tempo
debito, negli ultimi capitoli di queste dispense.
Per quanto riguarda le prime applicazioni usando WEKA, rimandia-
mo alla fine del prossimo capitolo, quando avremo terminato questa breve
carrellata sull’analisi e l’organizzazione dei dati.
2.1 Tipi di attributi
Le feature possono essere organizzate in due principali categorie, a loro
volta divise in due sottocategorie:
1. Variabili qualitative:
(a) nominali;
(b) ordinali;
2. Variabili quantitative:
(a) discrete;
25

(b) continue.
Nei prossimi paragrafi dettagliamo i tipi di attributi precedentemente
elencati.
2.1.1 Variabili qualitative
Le feature di tipo qualitativo sono di solito legate ad aggettivi riferiti ad
un particolare attributo e possono essere classificate in livelli, detti categorie.
Esempi sono il codice postale o il sesso di una persona.
Variabili qualitative nominali
Una variabile qualitativa e detta nominale se e organizzata su diverse
categorie, per le quali non e possibile definire un ordine preciso. In parti-
colare, e possibile definire rapporti di uguaglianza e disuguaglianza (= e �=)
tra diversi livelli. Esempio sono le codifiche per il sesso: e possibile definire
rapporti di uguaglianza (ad esempio, M = M), ma non un ordine fra sessi
(non si puo definire un rapporto M < F , ad esempio).
Variabili qualitative ordinali
Viceversa, sono dette ordinali le variabili qualitative per le quali e possi-
bile stabilire un ordine (operazioni <, >, =), ma senza la possibilita di quan-
tificare la differenza fra livelli. Un esempio e una classifica di una gara podi-
stica: se noi non indichiamo i distacchi, ma solo le posizioni finali, da esse si
puo stabilire l’ordine d’arrivo ma non quantificare la distanza fra un atleta e
l’altro.
2.1.2 Variabili quantitative
Le feature quantitative sono strettamente legate alle quantita numeriche
che le descrivono ed e possibile non solo stabilire un ordine (operazioni <, >
, =), ma anche quantificare la distanza (in senso generico) fra vari livelli. E
il caso dell’eta di una persona, ad esempio: e possibile non solo dire che una
persona di 20 anni e piu giovane di una di 45, ma anche che ci sono 25 anni
di differenza fra i due.
26

Variabili quantitative discrete
Una variabile quantitativa e discreta solo se puo assumere un numero
finito di valori. E il caso di segnali campionati, per esempio. Si distingue dalle
variabili qualitative nominali perche e possibile definire quantitativamente la
distanza fra i livelli.
Variabili quantitative continue
Una variabile quantitativa e continua se puo assumere un numero infinito
di valori. Per esempio, una temperatura registrata da un sensore ad alta
precisione puo essere considerata a tutti gli effetti una variabile quantitativa
continua. A tutti gli effetti, ricordiamo comunque che variabili continue su
un calcolatore non possono ne potranno mai esistere, sebbene 32 (o 64) bit
di precisione siano piu che sufficienti per approssimare ogni variabile discreta
come continua.
2.2 La matrice dei dati
Abbiamo anticipato nel paragrafo 1.2 la rappresentazione di una matrice
dati, notazione che ripetiamo per comodita:
{x1, ...., xl} , (2.1)
e rappresentante un dataset composto da l pattern (in questo caso, suppo-
niamo non sia presente target). Abbiamo inoltre stabilito che ogni pattern
xi ∈ �m, ovvero abbiamo m feature. Viene chiamata matrice dei dati (data
matrix ) la rappresentazione matriciale di tale dataset:
X =
⎡⎢⎢⎢⎢⎢⎢⎢⎣
x1,1 · · · x1,j · · · x1,m
......
......
...
xi,1 · · · xi,j · · · xi,m
......
......
...
xl,1 · · · xl,j · · · xl,m
⎤⎥⎥⎥⎥⎥⎥⎥⎦. (2.2)
Quindi, l’elemento ij–esimo xi,j rappresenta la j–esima feature dell’i–
esimo pattern della matrice. D’ora in poi, questa notazione verra utilizzata
27

implicitamente, anche quando non ci riferiremo espressamente alla matrice
dei dati X.
2.2.1 Gestione delle variabili
Come detto, i nostri dati possono essere rappresentati utilizzando una
matrice o, in alternativa, una rappresentazione ad insiemi. Le variabili xi,j
devono essere, quindi, quantita numeriche. Inoltre, in molti algoritmi la
distanza tra pattern svolge un ruolo centrale nella scelta del modello ottimo.
Se, di solito, non ci sono problemi per quanto riguarda le variabili quantitative
(in quanto rappresentate gia da valori numerici), possono sorgere difficolta
per le feature qualitative.
Siano attributi qualitativi nominali o ordinali, spesso essi vengono salvati
nel data warehouse (in generale) sotto forma “testuale”. La trasformazione
in variabili numeriche avviene attraverso la cosiddetta binarizzazione, ovve-
ro l’assegnazione di un codice binario per ognuno dei valori assunti dalla
feature. Supponiamo che una variabile sia di tipo qualitativo e possa assu-
mere r distinti livelli. Verranno create, quindi, r nuove variabili quantitative
binarie in codice one hot, ovvero la variabile binaria equivarra a 1 solo se
corrispondente all’originale livello della variabile qualitativa.
Un esempio dovrebbe chiarire il tutto. Supponiamo di considerare una
variabile qualitativa v che puo assumere 3 distinti livelli: a, b oppure c.
Codifichiamo i 3 livelli utilizzando un codice binario one hot, come quello
rappresentato in Tab. 2.1. Supponendo di avere una matrice di dati X
come in Eq. (2.3), caratterizzata da 5 pattern e 2 feature, attraverso la
binarizzazione otteniamo la matrice dei dati finale Xf di Eq. (2.4), avente
sempre 5 pattern, ma 4 attributi:
X =
⎡⎢⎢⎢⎢⎢⎢⎣1.1 a
3.5 b
1.4 b
9.0 c
3.1 a
⎤⎥⎥⎥⎥⎥⎥⎦ . (2.3)
28

Variabile qualitativa Codifica
v v′1 v′
2 v′3
a 1 0 0
b 0 1 0
c 0 0 1
Tabella 2.1: Esempio di codifica per variabile qualitativa.
Xf =
⎡⎢⎢⎢⎢⎢⎢⎣1.1 1 0 0
3.5 0 1 0
1.4 0 1 0
9.0 0 0 1
3.1 1 0 0
⎤⎥⎥⎥⎥⎥⎥⎦ . (2.4)
La binarizzazione e estremamente utile in molti casi, ma comporta un
aumento del numero di feature: abbiamo gia discusso nel paragrafo 1.3.3
che questa non e sempre una scelta ottimale. Un analisi preliminare serve
anche per cercare una codifica efficace e/o per eliminare, ove consentito, il
salvataggio di variabili di tipo qualitativo in memoria (agendo sulla sorgente
di osservazioni).
2.3 Normalizzazione di un dataset
La normalizzazione di valori e una delle operazioni che piu di frequente
vengono effettuate su un dataset per svariati motivi. Numerici, innanzitutto,
in quanto eventuali valori nell’ordine di 103 o superiori possono portare a
problemi di overflow (e viceversa, ovvero valori sotto 10−3 possono portare
all’underflow).
Esistono diverse tecniche per la normalizzazione: le piu comuni prevedo-
no di riportare i dati della nostra matrice X all’interno dell’intervallo [0, 1]
o [−1, 1]. Dovrebbe ora risultare piu chiaro come mai si sia tanto insistito
su data cleansing e analisi dei dati nel capitolo 1. Supponiamo di avere una
matrice di dati
29

X =
⎡⎢⎢⎢⎢⎢⎢⎣1.1 4.1
3.5 6.5
1.4 108
9.0 1.9
3.1 5.0
⎤⎥⎥⎥⎥⎥⎥⎦ : (2.5)
con ogni probabilita, x3,2 = 108 rappresenta un errore di misura. Se non ce
ne accorgessimo, potremmo semplicemente normalizzare la nostra matrice fra
[0, 1] e ottenere una matrice con elementi < 10−7, ad eccezione di x′3,2 = 1.
30

Capitolo 3
Analisi esplorativa dei dati
In questo capitolo, affronteremo brevemente il problema dell’analisi esplo-
rativa dei dati, presentando alcuni indici statistici. Questo capitolo poten-
zialmente potrebbe coprire un intero insegnamento, quindi ci limiteremo a
qualche nozione di base, anche in relazione agli strumenti operativi forniti da
WEKA. Per maggiori dettagli, gli interessati possono fare riferimento a [10].
3.1 Distribuzioni di frequenza
3.1.1 Distribuzioni univariate
A volte e utile analizzare le distribuzioni dei valori che puo assumere una
variabile di tipo qualitativo, oppure quantitativa discreta. Questo tipo di
analisi puo essere estesa anche alle variabili quantitative continue, cercan-
do gli intervalli ottimi in cui dividere i valori assunti dalle feature (ce ne
occuperemo brevemente quando parleremo di alberi di decisione).
Supponiamo di considerare una variabile v e che essa possa assumere
un numero finito k di livelli, ovvero v = {v∗1, ..., v
∗k}. Si definisce frequenza
assoluta il numero di occorrenze ni di un livello in un dataset. Ad esempio,
Tab. 3.1 riporta le distribuzioni assolute per la seconda feature della matrice
X dell’Eq. (2.3).
Si definisce frequenza relativa la frequenza assoluta normalizzata per il
numero totale di pattern, ovvero:
pi =ni
l. (3.1)
31

Livello Frequenza
na 2
nb 2
nc 1
Tabella 3.1: Esempio di frequenza assoluta per una feature qualitativa.
Livello Frequenza
pa 0.4
pb 0.4
pc 0.2
Tabella 3.2: Esempio di frequenza relativa per una feature qualitativa.
Tab. 3.2 riporta le frequenze relative per il dataset X. Proprieta banali sono
che∑
i ni = l e∑
i pi = 1.
3.1.2 Distribuzioni bivariate e multivariate
Nel precedente paragrafo abbiamo considerato sempre solo una variabile
per volta; ora, invece, siamo interessati ad una statistica “incrociata” delle
variabili. Inoltre, sarebbe possibile estendere il ragionamento a piu feature,
ma per brevita ci limiteremo a descrivere le distribuzioni bivariate.
Analogamente a quanto visto nel paragrafo precedente, supponendo di
avere due variabili qualitative v e z, che possono assumere, rispettivamente,
k e h livelli, si definisce frequenza assoluta congiunta nvz(v∗i , z
∗j ) il numero
di osservazioni in cui, contemporaneamente, la variabile v assume livello v∗i
e la feature z vale z∗j . Si definisce frequenza relativa congiunta pvz(v∗i , z
∗j ) la
frequenza assoluta congiunta, normalizzata per il numero totale di pattern l.
E possibile, inoltre, trovare una matrice, detta matrice di contingenza
C ∈ �k×h, che comprende al proprio interno tutti i valori di frequenze assolute
congiunte. In pratica, l’elemento ij–esimo Cij equivale alla frequenza assoluta
congiunta nvz(v∗i , z
∗j ).
32

3.2 Analisi esplorativa univariata
Abbiamo visto nel precedente paragrafo come si possano analizzare le
frequenze univariate o bivariate per le occorrenze di variabili qualitative (con
eventuale estensione al caso di feature quantitative). Ora ci occupiamo di
estrarre una descrizione di massima del nostro dataset, sulla base di indici
di posizione, varibilita ed eterogeneita. Prima, pero, un breve richiamo sulle
caratteristiche degli stimatori (in poche parole, gli indici che andremo a breve
a presentare), utili per capire alcuni concetti dei prossimi paragrafi.
3.2.1 Richiami su stimatori e loro caratteristiche
Supponiamo di considerare un generico parametro da stimare α e con-
sideriamo un suo stimatore α. A titolo di esempio, si potrebbe considerare
come parametro da stimare l’eta media di tutta la popolazione mondiale e
come stima l’eta media di un campione di N persone. Esistono due quantita
che definiscono la qualita di uno stimatore e sono:
1. la polarizzazione o bias;
2. la stabilita.
Se uno stimatore e non polarizzato (unbiased) e stabile viene detto consi-
stente. Tutti gli stimatori che presenteremo nei prossimi paragrafi sono consi-
stenti, ad eccezione di uno (la stima della varianza), per il quale presenteremo
la variante biased e consistente.
Bias di uno stimatore
Viene definito bias di uno stimatore la quantita:
b = α − E {α |α} , (3.2)
dove
E {α |α} =
∫ +∞
−∞· · ·∫ +∞
−∞α p (x1, ..., xN |α) dx1 · · · dxN (3.3)
e il valor medio condizionale della stima. Uno stimatore e detto unbiased se
vale
33

limN→+∞
b = 0, (3.4)
ovvero se, al crescere all’infinito del numero di osservazioni, il valore vero del
parametro e la sua stima tendono a coincidere asintoticamente.
Stabilita di uno stimatore
La stabilita di uno stimatore viene calcolata utilizzando la varianza esatta
dello stimatore (riparleremo nei prossimi paragrafi di varianza, ma in quel
caso faremo riferimento allo stimatore della varianza):
σ2α = E
{α2 |α}− E {α |α}2 . (3.5)
Al crescere del numero di osservazioni, ci aspettiamo che il nostro valore
stimato si avvicini in media sempre piu al valore da stimare (bias nullo), ma
anche che tale valore medio sia stabile rispetto alle oscillazioni del parametro
reale (varianza nulla). Pertanto, la seconda condizione che poniamo per la
consistenza di uno stimatore e che
limN→+∞
σ2α = 0. (3.6)
3.2.2 Indici di posizione
Il piu comune indice di posizione e la media aritmetica, definita su un set
di N osservazioni come:
x =
∑Ni=1 xi
N(3.7)
ed e calcolabile solo nel caso di variabili quantitative. Ovviamente, la media
da se ha poco significato, in quanto puo fortemente risentire di possibili valori
fuori scala. Vedremo come essa vada integrata nell’analisi da altri indici.
Solo nel caso di variabili quantitative discrete (che possono assumere un
numero finito k di valori), avendo a disposizione le distribuzioni di frequenza,
in particolare le frequenze relative pi di cui al paragrafo 3.1.1, la media puo
anche essere calcolata come:
x =
k∑i=1
pix∗i , (3.8)
34

dove x∗i rappresentano i k livelli che la variabile puo assumere.
Un secondo importante indice di posizione e la moda: essa puo essere
calcolata sia per variabili qualitative che quantitative (nel caso di variabili
continue, si rende necessaria un’apposita discretizzazione) e corrisponde al
valore (o all’intervallo) della variabile caratterizzata dalla piu alta frequenza
assoluta.
Un terzo indice e la mediana: in una sequenza ordinata di dati, la me-
diana e il punto per il quale meta dati sono maggiori di esso e meta sono
piu piccoli. In altre parole, la mediana e il punto per il quale la probabilita
che un valore caschi alla sinistra di esso o alla destra di esso e pari al 50%.
Necessitando di un ordine fra dati, le operazioni <, >, = devono poter esse-
re definite: pertanto, la mediana e calcolabile per le variabili quantitative e
qualitative ordinali.
3.2.3 Indici di variabilita
Altro indice importante e la variabilita, ovvero la dispersione di una
distribuzione. Esistono diverse tecniche per valutare la variabilita, ma tutte
sono solamente applicabili alle variabili quantitative: e necessario, infatti,
non solo essere in grado di definire un ordine tra i valori, ma anche poterne
definire una misura di distanza.
La prima consiste nel considerare il valore minimo e massimo che l’at-
tributo puo assumere: e una tecnica piuttosto elementare, ma che risente
enormemente della presenza di eventuali outliers non identificati. Viene,
quindi, poco usata.
La seconda tecnica consiste nel calcolare la varianza: attenzione, nel
paragrafo 3.2.1 abbiamo parlato di varianza di uno stimatore, qui stiamo
parlando di stima della varianza, ovvero cercare di valutare la varianza della
popolazione utilizzando un campione limitato. La varianza viene calcolata
come:
σ2 =1
N
∑(xi − x)2, (3.9)
dove x e la media. Spesso, dato che l’Eq. (3.9) rappresenta uno stimatore
della varianza della popolazione, si utilizza s2 invece di σ2.
Sfortunatamente, si puo facilmente dimostrare che lo stimatore di Eq.
(3.9) e biased. Uno stimatore unbiased e invece il seguente:
35

σ2 =1
N − 1
∑(xi − x)2. (3.10)
In alternativa alla varianza, si puo utilizzare la deviazione standard σ,
che e semplicemente la radice quadrata della varianza.
Altro indice e rappresentato dal coefficiente di variazione (CV ), calcola-
bile quando la media non e nulla:
CV =σ
|x| . (3.11)
In alternativa agli indici di variabilita fin qui presentati, e talvolta uti-
lizzata l’analisi dei quartili : un quartile e ognuno dei tre punti che divide
un dataset in aree al 25% di probabilita. In particolare, il secondo quartile
equivale alla mediana. I tre quartili vengono definiti come Qi, con i = 1, 2, 3.
Un indice di variabilita e dato dall’Inter–Quartile Range (IQR):
IQR = Q3 − Q1, (3.12)
cioe dalla differenza fra il valore del terzo e del primo quartile. E inoltre
possibile calcolare gli upper bound e lower bound del nostro dataset, definiti
come T1 e T2:
T1 = max(minimo valore osservato, Q1 − 1.5 · IQR) (3.13)
T2 = min(massimo valore osservato, Q3 + 1.5 · IQR). (3.14)
A partire dai quartili e dai bound, e possibile tracciare i cosiddetti box-
plot, che identificano graficamente le quantita descritte in precedenza. Fig.
3.1 mostra un esempio di boxplot, in cui vengono anche segnalati eventuali
outliers, calcolati semplicemente (ma, spesso, efficacemente) come tutti quei
valori assunti dalla nostra variabile piu piccoli (piu grandi) di T1 (T2).
3.2.4 Indici di eterogeneita
Gli indici fin qui analizzati sono utili quasi esclusivamente in caso di
variabili quantitative. Comunque, risulta utile, in molti casi, avere anche
misure in grado di descrivere feature di tipo qualitativo, siano esse nominali
o ordinali. L’indice piu comune per gli attributi qualitativi e l’eterogeneita.
36

Figura 3.1: Esempio di boxplot.
Consideriamo una variabile qualitativa x, che puo assumere k distinti
livelli. Supponiamo di aver calcolato le frequenze relative pi per ogni livello,
come mostrato nel paragrafo 3.1.1. Una definizione generale di eterogeneita
puo essere la seguente:
• si ha eterogeneita minima (si parla anche, in questo caso, di omoge-
neita) quando non abbiamo variazioni nei livelli delle feature, ovvero
una certa pi = 1 e vale pj = 0, ∀j �= i;
• viceversa, si ha eterogeneita massima quando le osservazioni si distri-
buiscono uniformemente su tutti i livelli, ovvero pi = 1/k, ∀i.
Esistono due indici molto comuni di eterogeneita. Il primo e il cosiddetto
Gini index :
G = 1 −k∑
i=1
p2i , (3.15)
per il quale e facile mostrare come, se siamo in condizioni di omogeneita, si
ha G = 0, mentre in condizioni di massima eterogeneita si ha G = 1 − 1k.
Dato che spesso puo essere utile normalizzare i valori degli indici affinche
siano compresi in [0, 1], si puo definire il Gini index normalizzato:
G′ =G
(k − 1)/k. (3.16)
Altro indice piuttosto comune e l’entropia, definita come:
E = −k∑
i=1
pi log pi, (3.17)
37

che vale 0 in caso di omogeneita e log k in caso di massima eterogeneita. An-
che in questo caso, e possibile definire l’entropia normalizzata nell’intervallo
[0, 1]:
E ′ =E
log k. (3.18)
3.3 Analisi esplorativa bivariata e multivaria-
ta
Analogamente a quanto visto in precedenza per le distribuzioni di fre-
quenza, e ovviamente possibile effettuare analisi incrociate sulle caratteri-
stiche dei nostri dati anche dal punto di vista del calcolo di indici. Dato
che questo tipo di analisi e tutt’altro che banale, ne daremo solo alcuni brevi
cenni, rimandando poi gli interessati ad ulteriori approfondimenti su appositi
testi.
Per quanto riguarda l’analisi bivariata, normalmente un buon metodo
per trovare eventuali relazioni fra feature consiste nell’utilizzare l’approccio
grafico. A tal proposito, molto utilizzato e lo strumento della scatterplot
matrix, in cui gli attributi vengono messi in relazione a coppie. Ogni cella
della matrice e detta scatterplot diagram. Un esempio di scatterplot matrix
e riportato in Fig. 3.2.
Analogamente a quanto visto nel precedente paragrafo, sarebbe possibile
definire moltissimi indici anche per l’analisi bivariata: per brevita citiamo,
in questa sede, solo l’indice di concordanza, ovvero la tendenza ad osservare
alti (bassi) valori di un attributo in accordo con alti (bassi) valori di un’altra
feature. In questo senso, la misura piu utilizzata e la covarianza, definita
come:
Cov(x, y) =1
N
N∑i=1
(xi − x) (yi − y) . (3.19)
E immediato notare che Cov(x, x) = σ2. Ovviamente, analogamente a quan-
to visto nel paragrafo 3.1.2, e possibile costruire una matrice di varianza–
covarianza, simile alla matrice di contingenza. In alternativa alla covarianza,
e possibile utilizzare la correlazione (lineare):
38

Figura 3.2: Esempio di scatterplot matrix.
r(x, y) =Cov(x, y)
σxσy
, (3.20)
dove σx e σy rappresentano le deviazioni standard delle due variabili. La
correlazione lineare ha le seguenti proprieta:
• r(x, y) = 1 quando tutti i punti nello scatterplot diagram sono posi-
zionati su una retta a pendenza positiva, e r(x, y) = −1 quando la
pendenza e negativa. Proprio per questa relazione di tipo lineare, r
viene chiamata correlazione lineare;
39

Feature Descrizione Tipo
outlook Condizioni del meteo Qualitativa nominale
temperature Temperatura atmosferica Quantitativa continua
humidity Umidita atmosferica Quantitativa continua
windy Situazione del vento Qualitativa nominale
play (Target) Giocare o meno a golf Qualitativa nominale
Tabella 3.3: Il dataset weather.
• se r(x, y) = 0, le due variabili non sono assolutamente legate da alcuna
relazione lineare, e si dicono scorrelate;
• in generale, −1 ≤ r(x, y) ≤ 1.
Si potrebbero ora approfondire le analisi di tipo multivariato, ma risul-
tano piuttosto complesse, in quanto e forte in questi casi la distinzione fra i
vari tipi di attributo. Quindi, rimandiamo gli interessati ad approfondimenti
su appositi testi.
3.4 Esempi di analisi con WEKA
Analizziamo un dataset piuttosto elementare utilizzando WEKA. In par-
ticolare, analizziamo in questo paragrafo il dataset chiamato weather, e ri-
ferito ad una collezione di osservazioni riferite al meteo (sereno, nuvoloso o
piovoso), temperatura, umidita e situazione del vento (presente o assente).
La classe e costituita da una variabile binaria riferita alla possibilita o meno
di giocare a golf, sulla base delle condizioni climatiche. Le feature e il target
di questo dataset sono ricapitolati in Tab. 3.3.
Lanciamo quindi WEKA ed avviamo l’explorer. Sull’interfaccia, clic-
chiamo su “Open file...” e selezioniamo, dalla cartella “Data”, il file “wea-
ther.arff”. Dovrebbe apparire una finestra simile a quanto mostrato in Fig.
3.3. Interpretiamo un po’ tutte le informazioni che ci vengono fornite.
In alto troviamo una serie di tasti, i primi per caricare dataset, men-
tre gli ultimi due servono per editare (sfruttando una GUI) e salvare il no-
stro dataset (per esempio, per verificare eventuali missing, completare i dati,
correggere valori palesemente sbagliati e via dicendo).
40

Figura 3.3: Esempio dell’interfaccia explorer di WEKA.
Scendendo, troviamo la possibilita di scegliere dei filtri da appicare ai
dati. Cliccando sul pulsante di scelta, si apre una box ricca di filtri, sia
supervisionati (tengono conto del target) che non supervisionati (viceversa).
A loro volta, i metodi sono divisi in metodi che agiscono sugli attributi o
sulle singole istanze. Lasciando poi alla vostra curiosita maggiori dettagli
su molti di questi filtri, da usare sempre e comunque con un obiettivo ben
fissato, supponiamo di scegliere fra gli unsupervised che agiscono sulle singole
osservazioni (istances) il Randomize, e vediamo di cosa si occupa. Una volta
scelto, clicchiamo sul nome del filtro e si apre una finestra come quella di
Fig. 3.4: ci viene fornita una breve spiegazione del filtro (semplicemente,
randomizza l’ordine dei pattern all’interno del dataset, azione utile quando
vengono usate tecniche per la stima delle performance di un metodo nei
casi di dataset ordinati rispetto al target), con la possibilita di saperne di
piu (pulsante “More”); quindi, ci vengono proposte le possibili opzioni. In
questo caso, possiamo solo modificare il seed dell’algoritmo di random.
Altro filtro molto usato e la normalizzazione (normalize), che troviamo
tra gli unsupervised sia per attributi che per singole istanze. La differenza
sta nel fatto che il primo normalizza tutta la matrice dati nell’intervallo [0, 1],
mentre il secondo normalizza ogni singolo pattern affinche la sua norma p sia
41

Figura 3.4: Esempio di box con dettagli per un filtro.
uguale ad un certo valore:
‖xi‖p = s, ∀i = 1, .., n, (3.21)
dove p e il valore desiderato s sono assegnati dall’utente.
Torniamo a WEKA explorer. Ci vengono fornite, di seguito, alcune infor-
mazioni sul dataset: nome, numero di pattern e di attributi (target incluso).
Seguono l’elenco degli attributi e la possibilita di rimuoverne uno o piu dal-
l’elenco. A destra, troviamo, per l’attributo evidenziato, le caratteristiche di
distribuzione di frequenza o di indici statistici a seconda che si tratti, rispet-
tivamente, di una feature qualitativa o quantitativa. Piu in basso, troviamo
la possibilita di scegliere un attributo come classe e, a seguire, l’istogramma
rappresentativo delle distribuzioni viene rappresentato, utilizzando piu colori
per rappresentare i pattern afferenti alle diverse classi. Nel caso di variabili
continue, il range viene suddiviso in un numero adeguato di intervalli.
Agendo su queste opzioni grafiche e sui filtri, un’analisi esplorativa di base
dei dati puo essere facilmente eseguita. Non solo: agendo sul tab “Visualize”
in alto, viene mostrata la scatterplot matrix, con la possibilita di visualizzare
i singoli scatterplot diagram cliccando sulle celle della matrice: un esempio
e mostrato in Fig. 3.5.
42

Figura 3.5: Esempio di scatterplot matrix e scatterplot diagram.
3.5 Riduzione di dimensionalita
Abbiamo gia parlato in fase di introduzione di riduzione di dimensionalita
e dei possibili pro e contro di questo approccio. Premettendo che esistono mi-
gliaia di tecniche per selezionare un subset di variabili, noi ci concentreremo
su uno dei piu utilizzati: la Principal Component Analysis (PCA) [13, 17].
Vedremo piu avanti che non sempre la PCA rappresenta la soluzione ottima
per la feature selection, ma essa rimane una delle tecniche piu diffuse.
La PCA consta di alcuni passaggi:
1. calcolo della matrice di covarianza, che definiamo C ∈ �m×m, dove m
e il numero di feature;
2. calcolo degli autovettori e autovalori di C e diagonalizzazione di C. Vie-
ne trovata una matrice diagonale D ∈ �m×m, i cui elementi di,i = λi,
ovvero sulla diagonale troviamo gli autovalori precedentemente calco-
lati;
3. gli autovalori e i corrispondenti autovettori vengono ordinati in maniera
decrescente;
43

4. viene calcolata l’energia cumulativa totale di tutti gli autovettori come
g =m∑
i=1
di,i; (3.22)
5. viene stabilita una soglia percentuale gth sull’energia cumulativa totale
g;
6. vengono mantenuti solo gli mPCA autovettori e autovalori che permet-
tono di ottenere un’energia cumulativa parziale gp ≥ gth.
Tutto cio cosa significa? La parte piu difficile di tutta la PCA e esat-
tamente questa: interpretare i risultati. In pratica, il calcolo degli autovet-
tori implica che noi andiamo ad effettuare nient’altro che una combinazione
lineare delle nostre feature, ottenendo mPCA nuove feature. L’operazione
di sogliatura significa, semplicemente, tagliare quelle componenti che meno
influiscono sulla descrizione dello spazio degli ingressi.
Ovviamente, se il nostro scopo e, in aggiunta alla riduzione della dimen-
sionalita, mantenere anche l’interpretabilita degli attributi, la PCA non e
di certo la via piu adatta da seguire. Ciononostante, e possibile effettua-
re, sfruttando le proprieta della cosiddetta Singular Value Decomposition
(SVD), la trasformazione inversa nell’ambito dello spazio originale degli at-
tributi: il problema, in questo caso, e che non possiamo permetterci di esclu-
dere alcun autovettore, quindi non effettuiamo di fatto alcuna riduzione di
dimensionalita!
3.6 Esempi di riduzione di dimensionalita u-
tilizzando WEKA
Proviamo ora ad applicare la PCA in WEKA. Prima di tutto, lanciato
explorer e caricato il dataset weather, spostiamoci sul tab “Select attributes”
e selezioniamo dal menu la PCA (“PrincipalComponents”). Lasciamo intatte
le opzioni di default, utilizziamo il ranker di WEKA (classifica le variabili
usando indici basati sull’entropia) e forziamo WEKA a usare tutto il training
set (lasciamo per ora perdere la Cross Validation, di cui parleremo piu avanti
in queste dispense). Selezionata la classe (“play”), lanciamo l’esecuzione
della PCA.
44

L’output di WEKA conterra, in ordine: un riepilogo del dataset e dei me-
todi selezionati; la matrice di correlazione (usata in alternativa alla matrice
di covarianza); gli autovalori, la porzione di energia corrispondente, l’energia
cumulativa totale fino a quell’autovalore e il corrispondente autovettore; la
matrice degli autovettori; il ranking delle variabili (in questo caso, le combi-
nazioni lineari calcolate con la PCA), ordinate dal ranker di WEKA. Notiamo
che, avendo una variabile nominale qualitativa (il meteo) che puo assumere
3 possibili livelli, WEKA effettua la binarizzazione; la situazione del vento e
anch’essa qualitativa, ma binaria e non necessita di ulteriore binarizzazione.
Alla fine, abbiamo 6 attributi da considerare. Notiamo che compaiono solo 5
autovalori, il che equivale a dire che il sesto autovalore e nullo; questo fatto
e confermato anche dall’energia cumulativa, che raggiunge il 100% con solo i
primi 5 autovalori.
Passiamo ora a capire meglio le opzioni della PCA. Possiamo settare:
• il massimo numero di attributi che vogliamo visualizzare nella combi-
nazione lineare (per semplicita di lettura);
• se vogliamo normalizzare i dati fra [0, 1], qualora non l’avessimo gia
fatto;
• un flag per trasformare nuovamente le feature della PCA nello spazio
originario attraverso SVD;
• la percentuale di energia cumulativa che vogliamo garantire.
Analizzando il ranking ottenuto in precedenza:
Ranked attributes:
0.675990846445273472 1 0.578temperature...
0.411301353536642624 2 -0.68outlook=overcast...
0.195956514975330624 3 0.567outlook=sunny...
0.063841150150769192 4 0.738windy...
0.000000000000000111 5 0.748temperature...
notiamo che la quinta componente della PCA ha un ranking davvero basso, e
stesso dicasi per la quarta. Potrebbe essere, quindi, una buona idea abbassare
la soglia per l’energia cumulativa: portiamolo al 90%, ad esempio, valore
piuttosto tipico. Prima di lanciare la simulazione, diamo un’occhiata anche
alle opzioni del ranker:
45

• possiamo scegliere se fare effettuare il ranking o no;
• possiamo settare il numero massimo di feature da mantenere;
• possiamo selezionare un subset iniziale di attributi;
• possiamo stabilire una soglia per il valore dell’entropia sotto la quale
la variabile viene esclusa dal dataset.
Lasciamo le impostazioni di default, e lanciamo la PCA. Come previsto,
otteniamo solo 4 componenti. Possiamo continuare a fare analisi di questo
tipo, ma adesso vogliamo effettuare una verifica: la sesta componente e dav-
vero nulla? Settiamo la soglia di energia al 100%, ovvero includiamo tutto.
In effetti, il sesto autovettore e nullo:
eigenvalue proportion cumulative
1.94405 0.32401 0.32401 0.578temperature...
1.58814 0.26469 0.5887 -0.68outlook=overcast...
1.29207 0.21534 0.80404 0.567outlook=sunny...
0.79269 0.13212 0.93616 0.738windy...
0.38305 0.06384 1 0.748temperature...
0 0 1 -0.588outlook=rainy...
ma possiamo notare che, curiosamente, dal punto di vista entropico ha la
stessa importanza del quinto autovettore:
Ranked attributes:
0.675990846445273472 1 0.578temperature...
0.411301353536642624 2 -0.68outlook=overcast...
0.195956514975330624 3 0.567outlook=sunny...
0.063841150150769192 4 0.738windy...
0.000000000000000111 6 -0.588outlook=rainy...
0.000000000000000111 5 0.748temperature...
L’ultima prova che vogliamo effettuare riguarda la possibilita di effet-
tuare il mapping inverso attraverso SVD nello spazio originale. Settiamo le
apposite opzioni e lanciamo la SVD. L’output e il seguente:
46

PC space transformed back to original space.
(Note: can’t evaluate attributes in the original space)
Ranked attributes:
1 3 outlook=rainy
1 1 outlook=sunny
1 2 outlook=overcast
1 6 windy
1 4 temperature
1 5 humidity
La nota, sebbene sembri allarmante, in verita fornisce un’informazione
alquanto intuitiva: la PCA non puo ottenere esattamente lo spazio di par-
tenza, semplicemente perche abbiamo binarizzato la matrice (per quanto la
matrice non binarizzata potrebbe essere facilmente ricavata). In questo ca-
so, non possiamo tagliare alcun autovalore ne autovettore, quindi l’eventuale
riduzione di dimensionalita e affidata per intero al ranker (che, in questo ca-
so, non riesce a fare molto, essendo anche il dataset usato molto semplice e
piccolo).
47

Capitolo 4
Classificazione
Addentriamoci ora nel problema della classificazione di pattern. In que-
sto capitolo supporremo di utilizzare sempre un dataset X, per il quale un
attributo e utilizzato come target. Ad ogni valore del target corrisponde una
classe. Tornando all’esempio weather considerato nei paragrafi 3.4 e 3.6, il
target e la variabile play, ovvero la decisione di giocare a golf o meno.
I problemi di classificazione si possono dividere in due sottocategorie,
come gia avevamo visto nel paragrafo 1.2:
• si parla di classificazione binaria quando il target puo assumere sola-
mente due valori. Un esempio e il gia citato weather : le due classi
corrispondono alla decisione di giocare o no a golf. Normalmente, i
target sono del tipo yi ∈ {0, 1} oppure yi ∈ {−1, 1};
• si parla di classificazione multiclasse quando il target puo assumere
un numero finito di valori interi numerici, ovvero yi ∈ S ⊂ ℵ, dove ℵrappresenta l’insieme dei numeri naturali non negativi. Un esempio e il
dataset iris, sempre incluso tra gli esempi di WEKA, in cui tre tipi di
fiore vengono distinti sulla base delle caratteristiche di petalo e sepalo:
in questo caso, yi ∈ {1, 2, 3}, dove ogni classe corrisponde ad un preciso
fiore.
Alcuni algoritmi nascono nell’ottica della classificazione binaria: inizie-
remo con l’analisi per questo problema e mostreremo, quindi, le tecniche per
la generalizzazione al problema multiclasse.
48

4.1 Zero Rules
4.1.1 Apprendimento
Il classificatore Zero Rules (0–R) e davvero elementare: la classe viene
scelta sulla base della moda. Cio significa che assegneremo ogni pattern a
run–time alla classe piu ricorrente del nostro training set (in caso di parita, la
scelta avviene una volta per tutte randomicamente). Ovviamente, non e un
metodo particolarmente furbo ne utile, e spesso viene utilizzato nella pratica
solo per trovare le frequenze relative e assolute delle varie classi.
Supponendo di avere a disposizione un dataset X con 15 pattern e 3
classi, e ipotizzando di avere 7 pattern afferenti alla classe 2 e 4 pattern
ciascuno per le classi 1 e 3, sceglieremo la classe 2 in quanto moda del nostro
dataset.
4.1.2 Fase in avanti
La fase feedforward a run–time di 0–R consistera semplicemente nell’as-
segnare la classe piu frequente del training set ad ogni nuovo pattern che
arrivi in ingresso al nostro sistema.
4.1.3 Estensione al caso multiclasse
L’algoritmo Zero Rules si adatta gia nella sua forma originaria a problemi
binari e multiclasse.
4.1.4 Esempio di analisi in WEKA
Torniamo a considerare il dataset weather. Lanciamo explorer di WEKA
e carichiamo il dataset. Ora, spostiamoci sul tab “Classify” in alto e selezio-
niamo come metodo di classificazione “ZeroR” nella sottocategoria “Rules”.
Aprendo la finestra delle opzioni, notiamo subito che l’unica opzione a dispo-
sizione si riferisce ad eventuali output di debug: settiamo a true. Tornando
ad explorer, nell’area “Test options” settiamo l’uso dell’intero training set
(le altre opzioni verranno presentate piu avanti). Clicchiamo poi su “More
options” e abilitiamo “Output predictions”. Scelta la classe (play, nel nostro
caso), lanciamo l’analisi.
A parte un po’ di output di riepilogo, ci viene precisato che:
49

ZeroR predicts class value: yes
essendo yes la classe piu ricorrente del nostro dataset. Passando ai risultati
successivi, analizziamo le voci che ci vengono fornite.
Predictions on training set
Viene presentato un riepilogo del comportamento del nostro classificatore
sul training set. Abbiamo a disposizione le seguenti voci:
• numero del pattern;
• valore reale della classe;
• valore ottenuto dal classificatore;
• un flag di errore corrispondente ai pattern per i quali sbagliamo la
previsione;
• la probabilita di indovinare la previsione. Tale calcolo coinvogle il pat-
tern, il training set ed il particolare classificatore che usiamo. Il valore
piu alto fra quelli a disposizione e contraddistinto da ‘*’.
(In)Correctly Classified Instances
Equivale al numero di classificazioni corrette o errate. A seguire, tro-
viamo le percentuali relative al numero totale di pattern: nel nostro caso,
sbagliamo circa nel 36% dei casi.
Kappa statistic
La statistica Kappa [7] (anche nota come Kappa di Cohen o semplicemen-
te Kappa) e basato su considerazioni statistiche e sull’uso di cosiddetti rater,
cioe valutatori. Rappresenta un metodo abbastanza rapido per valutare la
robustezza di un algoritmo. L’indice K viene calcolato come
K =P (A) − P (E)
1 − P (E), (4.1)
dove P (A) rappresenta l’accuratezza, ovvero la percentuale che il nostro pre-
dittore azzecchi, e P (E) e la probabilita che il classificatore indovini per pura
coincidenza:
50

P (E) =nc∑i=1
pi · qi, (4.2)
dove nc rappresenta il numero di classi, pi e la frequenza relativa di ogni classe
nel training set e qi e la frequenza relativa dell’output del nostro classificatore.
Vale K ∈ (−∞, 1]:
• K < 0 e indice di un classificatore che sbaglia volutamente;
• K = 0 rappresenta un classificatore che, quando indovina, lo fa per
puro caso;
• K = 1 e indice di massima robustezza del predittore.
Nel caso in esame, il nostro classificatore 0–R e caratterizzato da Kappa
nulla, il che mostra la scarsa affidabilita di 0–R. Controlliamo il risultato. Le
quantita che caratterizzano il nostro 0–R sono:
• P (A) ≈ 64.29% e l’accuratezza;
• p1 ≈ 64.29%, p2 ≈ 35.71%, q1 = 100% e q2 = 0%. Pertanto, P (E) ≈64.29%.
Ne risulta, appunto, K = 0.
Mean absolute error
Rappresenta l’errore medio assoluto (MAE), quantita che nei problemi
di classificazione ha poca importanza. Comunque sia, esso e definito in que-
sto caso come la distanza media tra la probabilita di classificazione corretta
e il target originario del dataset. In pratica, fornisce una misura comples-
siva del comportamento del classificatore relativa al particolare dataset che
utilizziamo.
Il MAE ha, invece, enorme importanza nei problemi di regressione, che
affronteremo a breve, in quanto in quei casi rappresenta la differenza media
tra l’output del nostro sistema e quello originario del dataset.
51

Root mean squared error
Per l’errore quadratico medio (RMSE) valgono molte delle considerazioni
fatte in precedenza per il MAE: infatti, il RMSE e calcolato (sia per regres-
sione che per classificazione) come il MAE, tranne che ogni volta calcoliamo
il quadrato della differenza fra output (o probabilita) e valore originario.
Relative absolute error e Root relative squared error
Queste misure sono ottenute come rapporto, rispettivamente, fra MAE e
RMSE e i valori ottenuti col worst case, ovvero con un classificatore 0–R. Dato
che in questo caso usiamo un classificatore 0–R, non abbiamo miglioramenti
e l’errore relativo e pari al 100%.
Detailed Accuracy By Class e Confusion Matrix
Analizziamo ora i dati relativi alla tabella di accuratezza della previsione.
Otteniamo un output di questo tipo:
TP Rate FP Rate Precision Recall F-Measure Class
1 1 0.643 1 0.783 yes
0 0 0 0 0 no
Prima di addentrarci nella spiegazione dei termini riportati, consideriamo
la matrice di confusione:
a b <-- classified as
9 0 | a = yes
5 0 | b = no
La matrice di confusione (CM) va analizzata nel seguente modo: nelle
colonne, troviamo le classificazioni ottenute col metodo selezionato; nelle
righe, il numero di dati afferenti alle due classi nel training set. Spieghiamoci
meglio: nel nostro caso, abbiamo 9 dati, originalmente appartenenti alla
classe “yes”, che sono stati classificati come “yes”; abbiamo inoltre 5 dati
che nel training set appatrtenevano alla classe “no” (seconda riga), ma che
sono comunque stati classificati come “yes”. In Eq. (4.3), riportiamo un
esempio di confusion matrix CM con k classi, nel quale: Cii indica le caselle
contenenti il numero di dati della classe i correttamente classificati; Cij indica
52

il numero di dati appartenenti ad una classe i, ma erroneamente attribuiti
dal metodo alla classe j.
CM =
⎡⎢⎢⎢⎢⎣C11 C12 · · · C1k
C21 C22 · · · C2k
... · · · . . ....
Ck1 Ck2 · · · Ckk
⎤⎥⎥⎥⎥⎦ . (4.3)
Torniamo ora all’accuratezza per classe. Definita la CM, Analizziamo
voce per voce:
• iniziando dal fondo, “Class” indica la classe a cui i precedenti coeffi-
cienti sono riferiti: la prima riga si riferisce ai dati classificati come
classe “yes”, la seconda riga e riferita ai dati classificati come “no”;
• TP rate indica il True Positives rate, ovvero la percentuale dei dati
appartenenti alla classe c, i quali sono stati effettivamente classificati
in modo corretto. Nel nostro caso, il 100% dei dati afferenti alla classe
“yes” sono stati classificati correttamente, mentre nessun pattern e
stato classificato come “no”;
• FP rate indica il False Positives rate, ovvero la percentuale dei dati
appartenenti alla classe c, i quali sono stati classificati in modo errato.
Nel nostro caso, qualsiasi dato non afferente a “yes”, e stato comunque
classificato come “yes”, quindi il FP rate di questa classe e il 100%.
Viceversa, nessun pattern e stato classificato come “no”, quindi anche
il FP rate di questa classe e 0%;
• Precision indica la percentuale di dati, classificati come appartenenti
alla classe c, correttamente classificati in quella classe. Nel nostro caso,
il 100% dei dati “yes” sono stati correttamente classificati, mentre lo
0% dei “no” e stato attribuito a tale classe dallo 0–R;
• Recall e la parte di classe che e stata correttamente “scoperta”: coincide
quindi con il TP rate;
• la F–measure unisce Precision e Recall in un unico indice.
In termini formali, si puo scrivere (i pedici c si riferiscono ad una generica
classe), riferendoci alla notazione di Eq. (4.3):
53

TPc =Ccc∑ki=1 Cci
, (4.4)
FPc =
∑kj=1 Ccj∑ki=1 Cci
, ∀ j �= c, (4.5)
Precc =Ccc∑ki=1 Cic
, (4.6)
Recc = TPc, (4.7)
Fmc =2 · Precc · Recc
Precc + Recc. (4.8)
4.2 Naive Bayesian Classifier
Terminata la rassegna sul poco utile classificatore 0–R, passiamo a qual-
che metodo piu complesso ma anche decisamente piu efficace. Iniziamo la
rassegna con il Naive Bayesian Classifier, anche noto come NBC.
4.2.1 Apprendimento
L’idea di base di NBC consiste nel classificare un dato sulla base del da-
to stesso, ovvero della probabilita di classe dato il pattern p (C = c |X = x),
dove C indica una variabile random per la classe, X un vettore di varia-
bili random per gli attributi, c una particolare classe e x una particolare
osservazione. NBC si basa su due ipotesi semplificative:
1. tutte le feature sono indipendenti fra loro, data una classe;
2. non esistono attributi nascosti (e non presenti nel dataset) che influen-
zino in qualche modo il processo decisionale sulla classe.
Dato che spesso, nella realta, queste due ipotesi sono tutt’altro che stretta-
mente rispettate, le prestazioni del classificatore talvolta peggiorano.
Proseguiamo con l’analisi. Il teorema di Bayes ci dice che, dato un nuovo
pattern da classificare x, possiamo scegliere la classe sulla base delle seguenti
probabilita condizionali:
p (C = ci |X = x) =p(C = ci)p (X = x |C = ci )
p (X = x), ∀ i, (4.9)
54

scegliendo quindi la classe ci a probabilita maggiore. In questo caso, p(C =
ci) rappresenta la probabilita a priori di classe, mentre
p (X = x |C = ci ) = p(∧
j Xj = xj |C = ci
)=
=∏
j p (Xj = xj |C = ci ) ,(4.10)
avendo supposto indipendenti le feature data la classe. Inoltre, il termine
p (X = x) viene spesso trascurato, essendo soltanto un fattore di normaliz-
zazione.
Il termine di Eq. (4.10) e facile da calcolare per variabili non continue;
nel caso di attributi continui, si puo ipotizzare che la distribuzione di tali
valori sia gaussiana, ottenendo
p (Xj = xj |C = ci ) =1√2πσ2
j
exp
(−(xj − xj)
2
2σ2j
), (4.11)
con xj e σ2j che rappresentano media e varianza dell’attributo xj , calcolate
sui pattern del training set. Di fatto, l’apprendimento si esaurisce nel calcolo
di media e varianza sul dataset usato per l’apprendimento. Una nota: in
alternativa all’Eq. (4.11), e possibile utilizzare un mapping non–lineare dei
dati attraverso funzioni kernel (che riprenderemo piu avanti), le quali compli-
cano la trattazione e non sono particolarmente didattiche al momento. Per
chi fosse interessato a maggiori dettagli, si veda [12].
4.2.2 Fase in avanti
La fase feedforward del NBC e stata gia definita all’interno del paragrafo
sull’apprendimento: all’arrivo di un nuovo pattern, si utilizza l’Eq. (4.9) e si
sceglie la classe con probabilita condizionale piu alta.
4.2.3 Estensione al caso multiclasse
Come risulta chiaro dalla trattazione e, in particolare, dall’Eq. (4.9),
NBC e nativamente multiclasse: e sufficiente iterare il calcolo della probabi-
lita condizionale di classe su tutte i valori che il target puo assumere.
55

4.2.4 Esempio di analisi in WEKA
Utilizziamo il nostro solito dataset, weather, e vediamo come si comporta
con NBC. Innanzitutto, da WEKA explorer, selezioniamo il classificatore
“NaiveBayes” dalla sottocategoria “Bayes”. Il classificatore permette tre
personalizzazioni:
1. alcuni ulteriori output di debug (si possono attivare o no);
2. passare ad un mapping non–lineare attraverso kernel dei nostri ingressi
(lo lasceremo a false in questa analisi);
3. rappresentare le variabili continue non attraverso una distribuzione nor-
male, ma attraverso una discretizzazione dell’attributo in appositi inter-
valli (di fatto, rendere la variabile discreta o, se vogliamo, qualitativa).
Anche in questo caso, lasceremo false questa opzione.
Appurandoci di effettuare il training su tutto il training set e, se vogliamo,
avendo attivato l’uscita di tipo probabilistico, lanciamo l’analisi.
In questo caso, abbiamo ben 13 classificazioni esatte su 14 pattern di trai-
ning, valori medi di errore bassi e una Kappa elevata (sopra lo 0.8). Premesso
che per un test piu accurato e necessario l’utilizzo di dati non appartenenti
al training set, i valori che ritroviamo sono decisamente incoraggianti. Anche
la CM e:
a b <-- classified as
9 0 | a = yes
1 4 | b = no
ovvero l’unico errore e un “no” che classifichiamo come “yes”. Quantomeno
abbiamo cominciato a distinguere due classi, e gia un bel passo in avanti.
4.3 Reti neurali: MultiLayer Perceptrons
4.3.1 Cenni storici: il percettrone
Prima di lanciarci nell’analisi del percettrone multistrato, e bene comin-
ciare a capire cosa sia un percettrone. Introdotto da Rosenblatt nel 1958
[21], esso rappresentava per l’epoca un’innovazione incredibile: in pratica,
56

esso consisteva in una funzione matematica in grado di “imparare” dai dati
attraverso un algoritmo di apprendimento vero e proprio. Infatti, fino ad ora,
sia 0–R sia NBC non effettuano un vero e proprio learning dai dati: il primo
fa un semplice conto sulla frequenza, il secondo al massimo calcola media e
varianza per fittare una gaussiana.
Il percettrone e un classificatore binario che mappa i suoi ingressi x ∈ �m
in un valore scalare y = f(x) ∈ �, calcolato come
y = f(x) = χ (w · x + b) , (4.12)
dove w e un vettore di pesi da applicare agli ingressi, b e detto bias ed e
un termine costante che non dipende dagli ingressi, e χ(z) e la funzione di
attivazione. Le scelte piu comuni per χ(z) sono:
χ(z) = Θ(z) (4.13)
χ(z) = z Θ(z) (4.14)
χ(z) = tanh(z) (4.15)
χ(z) =1
1 + e−z(4.16)
χ(z) = z, (4.17)
dove Θ(z) e la cosiddetta funzione Heaviside:
Θ(z) =
⎧⎪⎨⎪⎩0 se z < 012
se z = 0
1 se z > 0
. (4.18)
Non e raro vedere riformulata l’Eq. (4.12) come
y = f(x) = χ (w · x) , (4.19)
esattamente equivalente all’Eq. (4.12), ma nella quale abbiamo aggiunto
al vettore dei pesi il termine del bias e al vettore degli ingressi un termine
costante a 1. Uno schema grafico del percettrone e presentato in Fig. 4.1.
L’algoritmo di apprendimento e iterativo di tipo error backpropagation
(BP), ovvero la differenza tra l’uscita reale e quella ottenuta dal percettrone
ad ogni passo viene usata come feedback per adattare i pesi. Sfortunata-
mente, il percettrone riusciva a riconoscere dopo l’addestramento solamente
57

Figura 4.1: Schema grafico di un percettrone.
funzioni linearmente separabili, ovvero senza sovrapposizione fra le classi (le
Figg. 4.2 e 4.3 mostrano due esempi di dataset linearmente e non linear-
mente separabili): in particolare, Minsky e Papert [16] mostrarono che il
percettrone non era in grado di apprendere nemmeno l’elementare funzione
logica XOR. Questo perche, come mostrato in Fig. 4.4, lo XOR non e un
problema linearmente separabile (i simboli ‘x’ mostrano le uscite a 1 e i ‘o’
rappresentano gli output a 0).
−8 −6 −4 −2 0 2 4 6 8−8
−6
−4
−2
0
2
4
6
8
Figura 4.2: Esempio di due classi di dati linearmente separabili.
Dopo, quindi, un iniziale straordinario successo, il percettrone rimase
58
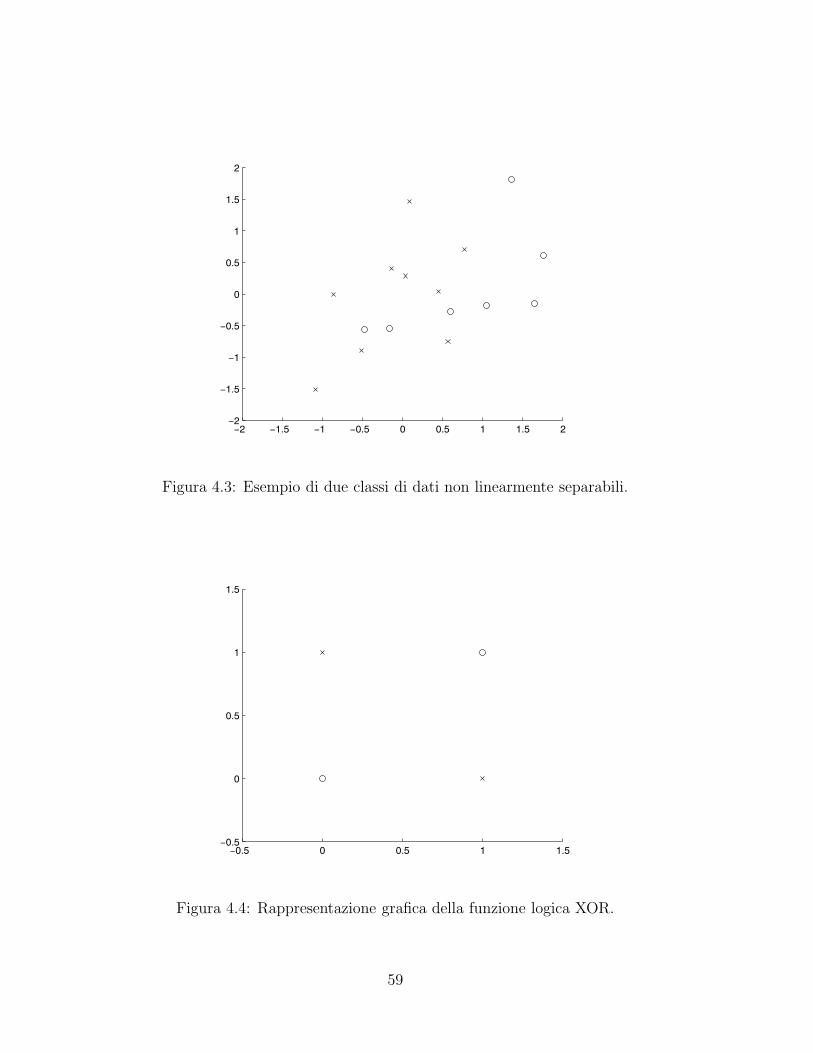
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
Figura 4.3: Esempio di due classi di dati non linearmente separabili.
−0.5 0 0.5 1 1.5−0.5
0
0.5
1
1.5
Figura 4.4: Rappresentazione grafica della funzione logica XOR.
59

quasi inutilizzato per una decina d’anni, fino a quando non vennero sviluppate
le cosiddette reti multistrato, cioe le MLP.
4.3.2 Architettura di un MLP
La struttura generale di un MLP e costituita da tre strati di neuroni:
1. il primo strato viene detto input layer ed e in contatto diretto con i
dati di ingresso;
2. lo strato intermedio viene detto hidden layer e non ha contatti diretti
con l’esterno, in quanto riceve i dati dall’input layer e li invia allo strato
di neuroni di uscita;
3. l’ultimo livello e l’output layer, il quale riceve i dati dai neuroni dello
strato intermedio e si interfaccia con l’uscita.
Dato che, spesso, per la rappresentazione del MLP si utilizzano grafi, si par-
la di topologia di una rete, in alternativa al piu classico termine architettura
della rete. Un esempio di MLP e presentato in Fig. 4.5. Talvolta, lo strato
hidden e assente e i layer di ingresso ed uscita coincidono: si parla in quel
caso di Single Layer Perceptron, ma non analizzeremo questo tipo di rete.
Il layer hidden puo, inoltre, contenere diversi layers al proprio interno. Il
MLP rappresenta il primo esempio di Artificial Neural Network o piu sem-
plicemente Rete Neurale (NN) che abbia avuto davvero successo, anche dal
punto di vista pratico.
Iniziamo a considerare l’architettura di un MLP: supponiamo che esso
contenga, al proprio interno, n neuroni nell’input, h nell’hidden e p neuroni
nell’output layer. I pesi wik, con i = 1, ..., n e k = 1, ..., h, permettono
l’interfacciamento fra i neuroni di input e quelli di hidden; i pesi zkj, con k =
1, ..., h e j = 1, ..., p, connettono i neuroni di hidden con quelli di output. Per
quanto riguarda la determinazione del numero di neuroni e strati per l’hidden
layer, non esiste un metodo preciso in letteratura, ma di solito si procede
ad un confronto fra architetture per scegliere quella ottimale. I neuroni di
hidden, quindi, ricevono informazione dai neuroni di input attraverso i pesi w,
e producono l’uscita hk = f(x, wk), dove f(·) e la funzione di attivazione del
neurone. I neuroni di output, a loro volta, ricevono i dati dall’hidden layer,
60

Figura 4.5: Esempio di architettura di un MLP
vi applicano gli opportuni pesi z e quindi producono l’output yj = g(h, zj).
Unendo le due funzioni, l’uscita del j–esimo neurone e quindi:
yj = g
(∑k
hkzkj
)= g
(∑k
zkjf
(∑i
xiwik
)). (4.20)
Questa equazione mostra come il mapping degli ingressi in un MLP sia
altamente non lineare. E, pero, necessario trovare i pesi che caratterizzano
la rete. Possiamo identificare tre tipi di MLP:
• MLP con pesi fissati: di fatto, non contemplano una fase di appren-
dimento, ma i pesi vengono determinati sulla base di informazioni a
priori. Non ci occuperemo di questo tipo di reti, in quanto davvero
poco usate;
• Supervised learning MLP: nel training set abbiamo definito un target
e, quindi, e possibile definire una funzione di errore rispetto all’output
ottimo;
• Unsupervised learning MLP: anche note come Self Organizing Maps o
Mappe di Kohonen, dal nome di chi le ha introdotte, non prevedono la
definizione di un target nel training set. Sono abbastanza usate, ma
per motivi di tempo non ce ne occuperemo. Per chi fosse interessato,
[15] puo risultare utile.
61

Come anticipato nelle precedenti righe, ci concentreremo in queste di-
spense solo sui Supervised learning MLP, per i quali analizziamo l’algoritmo
per l’apprendimento.
4.3.3 Apprendimento
L’algoritmo di learning in assoluto piu usato e la gia citata backpropa-
gation (BP). Iniziamo a definire la funzione errore per il j–esimo nodo; per
esempio, possiamo scegliere:
ej = dj − yj, (4.21)
nella quale dj rappresenta il target voluto e yj l’uscita della nostra rete.
Possiamo definire la funzione energia, che nel nostro caso risulta essere:
E =1
2
∑j
e2j . (4.22)
Attraverso l’errore, e quindi attraverso yj, la funzione energia dipende
dai nostri pattern di training in maniera altamente non lineare, come appare
chiaro dall’Eq. (4.20). Al fine di trovare i pesi ottimi, quindi, siamo costretti
a ricorrere ad un algoritmo di tipo iterativo, appunto come la BP, col pericolo
peraltro di ritrovarci bloccati in qualche minimo locale.
Supponiamo di inizializzare i pesi della rete con valori random, trovando
w(0). Definiamo l’errore allo step s come e(s)j . Dalla teoria dei differenziali,
si puo dimostrare che il passo di aggiornamento per i pesi e
Δw(s)ji = ηδ
(s)j y
(s)i , (4.23)
nella quale δ(s)j e
δ(s)j = −∂E(s)
∂υ(s)j
(4.24)
dove υ(s)j e l’output del neurone j allo step s, e η ∈ [0, 1] e il cosiddetto
learning rate, che e un parametro da fissare prima di iniziare l’apprendimento.
Proprio per questo motivo, piu che un vero e proprio parametro, e considerato
un iperparametro, ovvero una quantita da stabilire come trial and error e
che determina il comportamento globale dell’algoritmo. Se troppo piccolo,
l’algoritmo converge molto lentamente; se troppo grande, l’algoritmo inizia
62

ad oscillare, divenendo instabile. Normalmente, 0.2 < η < 0.8 in molte
applicazioni pratiche.
Il valore di δ(s)j puo essere calcolato in maniera differente a seconda che
il j–esimo neurone faccia parte dell’output o dell’hidden layer. Se j e un
neurone di output, e facile dimostrare che vale:
δ(s)j = e
(s)j χ′
(υ
(s)j
), (4.25)
con χ′(υ
(s)j
)che rappresenta la derivata prima della funzione attivazione.
Se, invece, ci occupiamo di un neurone dell’hidden layer, otteniamo:
δ(s)j = χ′
(υ
(s)j
)∑k
δ(s)k w
(s)kj . (4.26)
Dato che la precedente formula dipende da wkj, essa e anche dipendente dalle
variazioni dei pesi nel nodo k. In questo appare chiaro il significato della BP.
A volte, puo aiutare la convergenza l’aggiunta di un altro termine al-
l’Eq. (4.23), ovvero del cosiddetto momento m ∈ [0, 1]: sfortunatamente,
anch’esso e un iperparametro ed e estremamente difficile settarne il valore
ottimo, quantomeno a priori. Anche per il momento valgono le considerazio-
ni fatte per η, ovvero normalmente 0.2 < m < 0.8. L’Eq. (4.23) risulta cosı
modificata:
Δw(s)ji = ηδ
(s)j y
(s)i + mΔw
(s−1)ji . (4.27)
Un altra difficolta consta nel criterio di stop da utilizzare per bloccare
l’algoritmo. I metodi piu utilizzati sono:
• stabilire un numero massimo di iterazioni;
• fissare un tempo massimo di esecuzione;
• fermare l’algoritmo se l’errore scende sotto una soglia predeterminata;
• stop se il valore dell’errore per un certo numero di step non scende oltre
un valore prefissato;
• utilizzare come parametro l’errore su un validation set (ne discuteremo
nel paragrafo 4.3.6).
63

4.3.4 Fase in avanti
Una volta trovati e salvati i pesi, la fase in avanti e semplicemente realiz-
zata attraverso l’Eq. (4.20), nella quale vengono applicati i pesi trovati con
la BP.
4.3.5 Estensione al caso multiclasse
L’estensione al caso multiclasse e particolarmente semplice: e sufficiente
inserire tanti neuroni nello strato di output quante sono le classi del nostro
problema. Per esempio, un problema di classificazione binaria avra due neu-
roni di uscita, un problema multiclasse con 5 classi avra 5 neuroni di uscita.
Qualora piu di un neurone di uscita sia attivato, il neurone con output analo-
gico maggiore vince e la classe viene assegnata di conseguenza: questa viene
anche detta tecnica Winner–Take–All (WTA).
4.3.6 Esempio di analisi in WEKA (I)
Consideriamo nuovamente il dataset weather. Da WEKA explorer, sele-
zioniamo il classificatore “MultiLayerPerceptron”, che possiamo trovare nel-
la sottocategoria “functions”. WEKA utilizza solo funzioni di attivazione
di tipo sigmoidale, come da Eq. (4.16). Analizziamo le opzioni a nostra
disposizione:
• “GUI” permette di utilizzare un’interfaccia grafica per visualizzare la
rete creata. Se settato a false, attiviamolo;
• “autobuild”, se attivato, consente a WEKA di modificare i neuroni di
hidden in maniera automatica. Spesso utile, conviene mantenere su
true l’opzione;
• “debug” e la solita opzione per eventuali output di debug;
• “decay” consente a WEKA di abbassare iterativamente il learning rate
nel caso di reset della rete (vedi sotto). Settiamolo in queste prove a
false;
• “hiddenLayers” rappresenta il numero di neuroni hidden. Esistono
alcune wildcards per questo valore:
64

– a = #attributi+#classi2
;
– i = #attributi;
– o = #classi;
– t = 2 · a;
• “learningRate” e “momentum” sono le quantita η e m di cui abbiamo
parlato nel paragrafo 4.3.3. In queste prove, li lasceremo pari ai valori
di default, cioe η = 0.3 e m = 0.2;
• “nominalToBinary” e utilizzato per binarizzare la matrice dei dati nel
caso di variabili qualitative (per noi, true);
• “normalizeAttributes” viene utilizzato per normalizzare le feature tra
[−1, 1]. Anche in questo caso setteremo true;
• “normalizeNumericClasses” normalizza i valori numerici dei target tra
[−1, 1] (true);
• “randomSeed” e il seed per l’algoritmo di random per la selezione del
punto di partenza e per lo shuffling dei dati (settiamo seed pari a 16,
un numero casuale ma che ci permette analisi consistenti);
• “reset” consente all’algoritmo di resettare la rete nel caso durante l’ese-
cuzione il valore delle uscite tenda a divergere rispetto al target voluto.
Settiamolo a false;
• “trainingTime” fissa il criterio di stop sul numero massimo di iterazioni
da eseguire. Settiamolo a 1000;
• “validationSetSize” e “validationThreshold” vengono utilizzati come
criterio di stop in alternativa al numero di iterazioni. Il primo va-
lore, se diverso da 0, fissa percentualmente il numero di pattern del
training set che non verranno utilizzati per trovare i pesi. Una volta
trovati i pesi coi restanti pattern, la rete verra testata sul validation
set e verra trovato un errore. Tale errore scendera per un certo nu-
mero di iterazioni, poi la rete tendera ad overfittare (in generale) e
l’errore tendera a salire: “validationThreshold” fissa dopo quante ite-
razioni consecutive con peggioramento dell’errore dobbiamo fermarci.
65

Per il momento, manteniamo disattivato tale criterio di stop, fissando
“validationSetSize” a 0.
Figura 4.6: Esempio di GUI di WEKA per le reti neurali MLP.
Passate in rassegna le opzioni, lanciamo la nostra analisi. Si aprira in
automatico una finestra come quella di Fig. 4.6. Notiamo che l’input layer
e rappresentato direttamente con nodi aventi il nome degli attributi (le va-
riabili qualitative sono state binarizzate); avendo settato ad a il valore degli
hidden layers, abbiamo a = (6 + 2)/2 = 4 neuroni di hidden. Mediante ap-
posito pulsante, lanciamo l’analisi. Una volta terminata, chiudiamo la GUI e
accettiamo il modello cosı trovato. Torneremo ora ad explorer, che ci mostra
i pesi e i bias dei neuroni e le caratteristiche statistiche del classificatore.
Notiamo che non commettiamo errori, i valori di MAE e RMSE sono
molto bassi, tanto da apportare il 95% circa di miglioramento in termini di
errore rispetto a 0–R. Anche la Kappa e massima, essendo pari a 1.
4.3.7 Esempio di analisi in WEKA (II)
Manteniamo le stesse opzioni, ma cambiamo dataset e complichiamo un
po’ la vita al MLP. Scegliamo come dataset iris, composto da 150 pattern,
4 feature (riguardanti le dimensioni di sepalo e petalo) e un target (3 classi
per 3 tipi differenti di fiori).
66

Proviamo a lanciare l’analisi con NBC e vediamo come si comporta. Il
classificatore bayesiano commette 6 errori, pari al 4%, ha un’ottima Kappa
(0.94) e si comporta egregiamente in termini di MAE e RMSE (in questo
caso, miglioriamo pero “solo” del 70% rispetto allo 0–R). Proviamo con il
MLP. Questa volta, commettiamo solo 2 errori (1.33%), la Kappa e anche
migliore (0.98) e il miglioramento percentuale del RMSE e circa pari all’82%.
Proviamo ad utilizzare ora una nuova opzione, finora mai utilizzata. In
WEKA explorer, nell’area “Test options”, settiamo di splittare il dataset a
nostra disposizione in un training set, composto dal 67% dei dati (100 pat-
tern), e un validation set, sul quale confronteremo le performance di NBC
e MLP. Lanciamo le analisi con i due classificatori. Questa volta confronte-
remo solo l’errore sul validation set. NBC commette 2 errori (4%), contro
un solo errore (2%) del MLP, che quindi, utilizzando questo criterio, sembra
avere una migliore performance.
4.3.8 Validation set e test set
Quando abbiamo introdotto nel paragrafo 1.2 i termini dataset e training
set, abbiamo anticipato che ci saremmo occupati solo piu avanti di validation
e test set.
Il validation set e un insieme di dati, indipendenti da quelli del training
set, che possono essere utilizzati per stimare le performance di un modello,
trovato usando solo il training set. Nel caso precedente, abbiamo effettua-
to l’apprendimento su 100 dati e poi abbiamo verificato le performance sui
restanti 50, costituenti appunto il validation set. L’utilizzo di un validation
set si rende necessario quando vogliamo confrontare diversi metodi statisti-
ci (ad esempio, NBC e MLP) oppure verificare le performance al variare di
parametri e/o iperparametri. Ad esempio, potremmo verificare su iris come
cambiano le performance portando momento e learning rate entrambi a 0.8:
l’errore in termini percentuli resta uguale, ma con i due iperparametri settati
a valori piu alti sale leggermente il RMSE.
Il test set, infine, e un terzo set di dati, indipendente da validation e
training set, che viene utilizzato alla fine solo dopo aver scelto il model-
lo definitivo, come banco di prova prima dell’implementazione della fase in
avanti. Il test set viene utilizzato, quindi, solo su un metodo statistico, quello
prescelto utilizzando (per esempio) il validation set.
67

Occorre prestare molta attenzione, perche spesso in rete, in letteratura e
anche in WEKA si fa molta confusione: la nomenclatura presentata in questo
paragrafo va tenuta come riferimento all’interno di questo insegnamento.
4.4 Support Vector Machines
4.4.1 Il problema del classificatore a massimo margine
Abbiamo analizzato nel precedente paragrafo pregi e difetti dei MLP: a
fronte di una classificazione efficace, l’apprendimento tramite BP e alquanto
problematico, a partire dal fatto che il problema da risolvere non e convesso
e puo presentare miriadi di minimi locali.
Mentre molti studiosi tra Stati Uniti ed Europa dibattevano negli anni
’60 e ’70 su percettrone, XOR e MLP, in Unione Sovietica due matematici,
Vapnik e Chervonenkis, svilupparono una teoria, detta Statistical Learning
Theory (SLT ), che avrebbe trovato definitiva applicazione solo nella seconda
meta degli anni ’90 e che avrebbe rivoluzionato il mondo delle reti neura-
li. L’idea si basa su due concetti fondamentali, che gia in parte abbiamo
analizzato:
1. un classificatore dev’essere sufficientemente complesso da riuscire a clas-
sificare efficacemente set di dati anche particolarmente mal posizionati;
2. tale classificatore non deve essere, pero, troppo complicato, altrimenti
si subirebbero gli effetti dell’overfitting.
Dal bilanciamento dei punti 1 e 2 otteniamo il classificatore ottimo, che
si puo dimostrare essere il cosiddetto classificatore a massimo margine. Il
concetto piu innovativo della teoria di Vapnik consta proprio nella definizione
del concetto di margine, ovvero di distanza fra i punti di due classi (per ora,
poniamoci nel caso biclasse) piu vicini fra loro. L’illustrazione grafica di Fig.
4.7 dovrebbe chiarire costa intendiamo per margine: abbiamo preso due set
di dati di due classi linearmente separabili e abbiamo tratteggiato i limiti del
margine massimo.
Nacque cosı la Support Vector Machine (SVM ): spiegheremo meglio a
tempo debito il significato di questo nome. L’iniziale scarso successo della
SVM e dovuto a diversi fattori: innanzitutto, la teoria e stata sviluppata in
68

−6 −4 −2 0 2 4 6−10
−8
−6
−4
−2
0
2
4
6
8
Figura 4.7: Esempio di dataset linearmente separabile. Tratteggiati, abbiamo
rappresentato i limiti del massimo margine ottenibile.
piena Guerra Fredda nell’URSS, quindi non e stata volutamente divulgata “al
di qua di Trieste”, per dirla con Churchill; in secondo luogo, la SVM presen-
tava non pochi problemi pratici. Per realizzare, infatti, l’obiettivo di evitare
l’overfitting, era stata sviluppata una teoria, detta di Vapnik–Chervonenkis
o VC Theory, che permetteva di calcolare il grado di complessita di una fami-
glia di classificatori, ma in maniera tutt’altro che pratica. Inoltre, la versione
originale di SVM era in grado di trattare solo dataset linearmente separabili.
Fu solo negli anni ’90, al termine della Guerra Fredda, che Vapnik inizio a
lavorare negli USA presso il laboratorio di ricerca della AT&T e, grazie al fon-
damentale aiuto di Corinna Cortes, nacque la SVM cosı come la conosciamo
oggi [23, 8].
Consideriamo un dataset {(x1, y1), ...., (xl, yl)}, dove xi ∈ �m e yi =
±1. La formulazione originaria di SVM (pre–Cortes, potremmo dire) e la
seguente:
minw,b
1
2‖w‖2 (4.28)
yi (w · x + b) ≥ 1 ∀i ∈ [1, . . . , l] (4.29)
69

dove w e un vettore di pesi, b e il bias e il piano (o, a piu dimensioni,
l’iperpiano) separatore tra le due classi e descritto dall’equazione
w · x + b = 0, (4.30)
analogamente a quanto visto per il percettrone. Si puo dimostrare che il mar-
gine e pari a 1/‖w‖2, quindi andiamo a massimizzarlo attraverso il problema
di minimo vincolato (4.28).
Il problema, in molti casi pratici, consisteva nel fatto che il vincolo (4.29)
era tutt’altro che facile da rispettare, perche prevedeva che non vi fosse so-
vrapposizione fra classi. L’idea fondamentale in questo senso e stata l’intro-
duzione di variabili di slack ξi ≥ 0, che permettessero ad alcuni dati di violare
il vincolo. La formulazione, detto problema primale di SVM, e la seguente:
minw,b,ξ
1
2‖w‖2 + CeT ξ (4.31)
yi (w · x + b) ≥ 1 − ξi ∀i ∈ [1, . . . , l] (4.32)
ξi ≥ 0 ∀i ∈ [1, . . . , l] (4.33)
con ei = 1, ∀i, e eT ξ che rappresenta quindi la somma degli errori che com-
mettiamo nella classificazione del training set. C e un iperparametro che
bilancia la componente di massimizzazione del margine (tendenza all’under-
fitting) e quella di minimizzazione dell’errore (tendenza all’overfitting).
L’analisi sarebbe, quindi, completa, se non fosse per il fatto che il proble-
ma (4.31) e tutt’altro che banale da risolvere. Fortunatamente, utilizzando la
tecnica dei moltiplicatori di Lagrange, introducendo l moltiplicatori αi (uno
per pattern), si ottiene il cosiddetto problema duale di SVM :
minα
1
2αT Qα + rT α (4.34)
0 ≤ αi ≤ C ∀i ∈ [1, . . . , l] (4.35)
yT α = 0 (4.36)
dove ri = −1, ∀i, e Q = {qij} ∈ �l×l e una matrice simmetrica semidefinita
positiva:
qij = yiyjK(xi, xj), (4.37)
70

Kernel Funzione
Lineare K(xi, xj) = xi · xj
Polinomiale K(xi, xj) = (xi · xj + 1)p
Gaussiano K(xi, xj) = exp(−γ ‖xi − xj‖2
2
)Tabella 4.1: Funzioni kernel piu comuni.
nella quale K(xi, xj) e detta funzione kernel ed effettua un mapping non
lineare degli ingressi in uno spazio (in generale) a maggiore dimensionalita,
dove la classificazione dovrebbe essere piu semplice. In poche parole, la
SVM classifica i dati mediante un separatore lineare, esattamente come il
nostro buon vecchio percettrone, ma in uno spazio in cui tale classificazione
e piu semplice; in tale spazio i dati vengono mappati attraverso i kernel. Le
funzioni kernel piu comuni sono quelle presentate in Tab. 4.1: nel caso di
kernel gaussiano e polinomiale, possiamo notare l’introduzione di un ulteriore
iperparametro oltre a C, rispettivamente γ e p, che regolano l’ampiezza della
gaussiana e il grado del polinomio classificatore.
Torniamo al problema (4.34): il grande successo di SVM e dovuto al fatto
che il problema duale e un cosiddetto Constrained Convex Quadratic Problem
(CCQP), ovvero, essendo convesso, esso ha una sola soluzione ottima e non
presenta minimi locali. Rispetto ai MLP questo e un vantaggio enorme: se
anche in SVM abbiamo uno (o piu) iperparametro(/i) da settare, essi non
determinano la possibilita di trovare o meno una soluzione, solo stabiliranno
una maggiore o minore qualita di tale soluzione.
4.4.2 Apprendimento
La fase di training di SVM consta nel risolvere il problema duale e tro-
vare i moltiplicatori di Lagrange ottimi α e il bias b che, per quanto non
appaia in forma esplicita in (4.34), ci e necessario poi per la fase in avan-
ti. Per risolvere il problema duale sono state sviluppate moltissime tecniche,
ma la piu usata e la cosiddetta Sequential Minimal Optimization (SMO): il
CCQP viene decomposto in tanti problemi elementari, in cui viene trovata
la soluzione per due pattern per volta. E necessario trovare la soluzione per
due pattern semplicemente a causa della presenza del vincolo di uguaglianza
71

di Eq. (4.36), per il quale ad ogni “spostamento” di un αi deve corrispondere
un’altra modifica di un altro parametro.
SMO si ferma (in quanto ha trovato la soluzione ottima) nel momento
in cui sono rispettati tutti i vincoli di ottimalita (a meno di una prefissata
precisione di macchina), detti condizioni di Karush–Kuhn–Tucker o KKT.
Per semplicita e brevita, non presentiamo in questo testo le KKT, per le
quali e necessario esplicitare il passaggio da problema primale a duale: per
chi fosse interessato, consigliamo [6]. Le KKT, oltre a fornire la soluzione
ottima α, consentono anche di calcolare il bias, considerando che l’iperpiano
separatore normalmente (anche se, in teoria, non sarebbe obbligatorio) viene
posto a meta del margine. Ad esempio, recuperando l’esempio di Fig. 4.7, il
piano separatore e quello di Fig. 4.8.
−6 −4 −2 0 2 4 6−10
−8
−6
−4
−2
0
2
4
6
8
Figura 4.8: Esempio di piano separatore: tratteggiati, i limiti del margine;
con tratto breve–lungo, il piano separatore.
Una nota conclusiva: dato che la matrice Q ∈ �l×l, la SVM soffre grandi
dimensioni non in termini di numero di feature, bensı in termini di numero
di pattern. Per questo, spesso, una feature selection applicata prima di SVM
spesso non risolve alcun problema e, anzi, talvolta peggiora la qualita della
classificazione.
72

4.4.3 Fase in avanti
La fase in avanti consiste nel verificare il segno della funzione che descrive
il piano separatore. In termini di problema primale, supponendo target del
tipo yi = ±1, la classificazione di un nuovo pattern x avviene tramite:
y = ϑ (w · x + b) , (4.38)
dove la funzione ϑ(·) e definita come:
ϑ(z) =
⎧⎪⎨⎪⎩+1 se z > 0
−1 se z < 0
random(±1) se z = 0
. (4.39)
Sfortunatamente, risolvendo il problema duale non possiamo conoscere
esplicitamente i pesi w. Si puo dimostrare che la forma nel duale per la
funzione di classificazione e la seguente:
y = ϑ
(l∑
i=1
yiαiK (x, xi) + b
), (4.40)
per la quale conosciamo ogni termine. In pratica, i coefficienti αi pesano
quanto ogni dato del training set sia di supporto alla decisione finale, ovvero
al calcolo del target stimato y, come appare evidente dall’Eq. (4.40): da qui,
il nome Support Vector Machine, ovvero macchina a supporto vettoriale.
4.4.4 Estensione al caso multiclasse
Al contrario dei metodi fin qui analizzati, l’estensione al caso multiclasse
per SVM non e banale. Tralasciando moltissime tecniche, seppur interessanti,
le piu comunemente utilizzate sono la One Vs. All (OVA) e la All Vs. All
(AVA).
La tecnica OVA prevede che vengano istruite tante SVM in maniera tale
che ognuna delle classi venga distinta dalle altre mediante un problema bina-
rio. In pratica, supponendo di avere k classi, dovremo istruire k SVM (classe
1 vs. le altre, classe 2 vs. le altre,...) e attribuiremo un nuovo pattern alla
classe risultante dalle classificazioni binarie o, in caso di incertezza, alla clas-
se con output analogico piu alto. Per output analogico di SVM intendiamo
il valore
73

f(x) =
l∑i=1
yiαiK (x, xi) + b (4.41)
che passiamo alla funzione ϑ(·).La tecnica AVA, invece, crea tante SVM binarie in modo tale che ogni
classe venga distinta contro ognuna delle altre classi. Supponendo di avere,
quindi, 3 classi avremo: 1 vs. 2, 1 vs. 3 e 2 vs. 3, per un totale di 3
classificatori. Il problema consta nel fatto che, al crescere del numero di
classi, il numero di classificatori necessari esplode, essendo pari a k(k− 1)/2.
Tuttavia, AVA talvolta offre performance migliori rispetto a OVA ed e quindi
un’opzione valida se k e piccolo. E la tecnica utilizzata per la classificazione
multiclasse da WEKA.
Un’altra tecnica e l’Augmented Binary [2], che prevede la modifica del
dataset di training in modo tale da trasformarlo in un problema binario
risolvibile con una sola SVM (a fronte, pero, di un aumento di dimensionalita
sia in termini di pattern che di feature): non approfondiremo, pero, questa
tecnica.
4.4.5 SVM e la probabilita
Facciamo un passo indietro e torniamo ai problemi binari. Spesso, una
uscita di tipo digitale ±1 puo non essere sufficiente. Supponiamo di consi-
derare il caso di una SVM utilizzata per identificare se un paziente in un
ospedale e malato o no: se voi foste il paziente, vi basterebbe un’uscita di-
gitale o vorreste anche conoscere la probabilita di tale uscita, ovvero (in un
certo senso) il grado di sicurezza di tale output? Decisamente, un’uscita di
tipo probabilistico e spesso necessaria.
Una tecnica per “convertire” l’output analogico di SVM di Eq. (4.41) in
un valore di tipo probabilistico e stata proposta da Platt [18]: la probabilita
di errore pe di classificazione per un pattern verra fornita attraverso l’utilizzo
di una sigmoide
pe(x) =1
1 + eAf(x)+B, (4.42)
dove A e B sono due parametri che vengono fissati risolvendo un problema
di Maximum Likelihood. Non approfondiremo oltre questo argomento.
74

4.4.6 Esempio di analisi in WEKA
Lanciato WEKA explorer, carichiamo il dataset weather, tanto per ini-
ziare, e quindi spostiamoci sui tool di classificazione. Vogliamo iniziare con
un kernel lineare. Nella sottocategoria “functions” troviamo la SVM sotto le
mentite spoglie del nome SMO (SVM e un marchio registrato). Analizziamo
le principali opzioni:
• “buildLogisticModel” consente di ottenere l’uscita in termini proba-
bilistici, utilizzando il metodo di Platt del paragrafo 4.4.5. Per ora,
settiamolo a false;
• “c” e il valore dell’iperparametro C. Settiamolo a 1;
• “cacheSize” e la dimensione della cache per la memorizzazione della
matrice Q;
• “debug” rappresenta eventuali output di debug;
• “epsilon” rappresenta lo zero di macchina per la rappresentazione di
coefficienti, bias, ecc. Conviene lasciarlo invariato;
• “exponent” e l’esponente p del kernel polinomiale. Settiamolo a p = 1;
• “featureSpaceNormalization” permette di effettuare la normalizzazione
dei dati nello spazio non lineare descritto attraverso le funzioni kernel.
Per ora, lasciamolo a false;
• “filterType” permette di applicare filtri ai dati. Settiamolo sulla nor-
malizzazione del training set;
• “gamma” e il valore di γ per il kernel gaussiano. Settiamo γ = 1;
• “lowOrderTerms” include o meno il termine ‘+1’ nel kernel polinomiale.
Per le definizioni di Tab. 4.1, setteremo questo parametro a false se
usiamo un kernel lineare e a true se il grado del polinomio p e piu
grande di 1. Per ora lasciamolo a false;
• “numFolds” permette di utilizzare la cross validation (la analizzeremo
nei prossimi capitoli) per cercare i valori di A e B per la sigmoide della
probabilita. Settiamo il valore −1 per disattivare l’opzione;
75

• “randomSeed” e il seed della funzione random per mescolare i dati
prima dell’eventuale cross validation;
• “toleranceParameter” e la tolleranza per il rispetto delle KKT. Il valore
di default 10−3 e un buon valore;
• “useRBF” e un flag per utilizzare il kernel gaussiano (per ora, false).
Lanciamo l’analisi su tutto il training set. Notiamo che commettiamo
2 errori, l’errore medio e abbastanza elevato e la Kappa e buona ma non
eccezionale (0.68). Notiamo un peggioramento rispetto al MLP: questo per-
che il MLP e nativamente non lineare, mentre noi abbiamo applicato una
classificazione lineare.
Settiamo “useRBF” a true e lasciamo invariati gli altri parametri: no-
tiamo che l’errore si annulla del tutto e abbiamo una Kappa massima. Di
fatto, abbiamo il nostro classificatore ideale.
Mettiamo alla prova ora SVM con iris, e torniamo ad un kernel lineare.
WEKA utilizza il metodo AVA per gestire il problema multiclasse. Utilizzia-
mo l’intero training set, per il momento. Commettiamo 5 errori, e la Kappa
e l’errore medio si pongono a meta tra MLP e NBC. Questa volta, anche con
un kernel gaussiano le cose non vanno meglio: sembrerebbe quindi il MLP
l’ottimo per iris. Lasciamo C = 1, ma settiamo γ = 100: otteniamo 0 errori
e nuovamente il classificatore ottimo che cercavamo. E stato sufficiente agire
un po’ sugli iperparametri per trovare una soluzione molto buona.
Con l’ultima configurazione usata, lanciamo l’analisi su 100 pattern di
training e vediamo come si comporta la SVM sui 50 rimanenti di valida-
tion. Commettiamo 3 errori, quindi avremmo la peggiore performance fra i
3 metodi. Settando γ = 10, pero, si possono ottenere 2 soli errori.
Abbiamo brevemente visto, in questo paragrafo, la grande potenza di
SVM, con tutte le opzioni di cui dispone, ma anche il suo piu grande limite:
la necessita molto forte di un tuning particolareggiato degli iperparametri.
4.4.7 SVM per feature selection
Algoritmo
Abbiamo analizzato nel paragrafo 3.5 la PCA e il suo utilizzo per la
selezione di feature. Purtroppo, la PCA utilizza come input il dataset che
76

forniamo e rielabora le feature al fine di creare nuove variabili attraverso le
proiezioni, ottenute mediante gli autovettori: questo significa che e possibile
trovare un ranking di feature, ma riferito agli attributi nello spazio della PCA
(in cui poi saremmo costretti a lavorare), come mostrato anche negli esempi
del paragrafo 3.6. Non solo: la PCA e un metodo unsupervised, quindi
non tiene conto della classe di appartenenza dei pattern. Semplicemente,
seleziona gli autovettori che forniscono un contributo di energia maggiore al
dataset, ma tali componenti potrebbero non favorire la classificazione (ad
esempio), ma addirittura renderla piu complessa.
Se ci occupiamo di problemi di classificazione, il nostro desiderio po-
trebbe essere quello, invece, di utilizzare una tecnica in grado di estrarre le
componenti, che ci permettono di classificare meglio le nostre osservazioni, e
di eliminare gli attributi “dannosi” per i nostri scopi. E possibile, quindi, uti-
lizzare una SVM come algoritmo per effettuare la feature selection, cercando
di estrarre le componenti che piu ci aiutano a creare un classificatore efficace.
La tecnica che andiamo a presentare venne proposta nel 2002 [11] e, dato un
set X con m feature, viene inizializzato creando due insiemi di indici, r e s,
rappresentanti rispettivamente gli attributi per i quali e gia stato effettuato
ranking e le variabili ancora da ordinare. Al primo step, s contiene tutti gli
attributi del dataset originario. L’algoritmo procede, quindi, iterativamente
fino a quando s ≡ ∅, seguendo alcuni semplici passi:
1. si crea un subset Xi di X, il quale include solo le feature contenute nel
set di indici s;
2. si risolve la SVM, vincolata ad essere una SVM lineare, e viene
calcolato il vettore α;
3. per ogni feature, si calcolano i pesi del primale wj, j = 1, ..., ‖s‖0, dove
la norma–0 rappresenta la cardinalita dell’insieme (i.e., il numero di
elementi che compongono il set);
4. si calcola il coefficiente di ranking come cj = w2j , in modo che l’impor-
tanza di una variabile sia calcolata sulla base del suo contributo nel
calcolo del margine;
5. si trova la feature j∗ = arg min c;
77

6. si elimina la feature j∗ dal set s e la si inserisce in testa al vettore r. In
questo modo, l’ultima variabile, eliminata nel processo iterativo, risulta
essere la prima (la piu informativa) nel vettore r.
Ovviamente, e immediata la generalizzazione al caso in cui si vogliano elimi-
nare piu di una feature per step nel processo iterativo.
Non ci rimane che capire come possano essere calcolati i pesi w2j per le
varie feature e il perche del vincolo ad avere una SVM lineare. Ancora una
volta, come gia per il bias, ci vengono in aiuto le KKT, per le quali otteniamo
che e possibile calcolare i pesi del primale come:
w =
l∑i=1
yiαiφ(xi), (4.43)
dove φ(x) e una funzione tale per cui un kernel puo essere definito come:
K(xi, xj) = φ(xi) · φ(xj). (4.44)
Avevamo detto che il kernel effettua un mapping non lineare ed implicito
dei dati, attraverso funzioni piu o meno complesse; di fatto, un kernel e
un prodotto scalare tra due funzioni φ(·), le quali effettuano, in maniera
questa volta esplicita, tale mapping sui singoli dati. Se, nel caso lineare, vale
φ(x) = x, sfortunatamente per molti altri kernel (ad esempio, il gaussiano)
non e possibile calcolare le φ(·), ma solo K(xi, xj). Ecco, quindi, il motivo
per il quale e necessario utilizzare una SVM lineare: almeno, conosciamo la
φ(·) ed e possibile procedere con il ranking.
L’estensione alla SVM non–lineare e comunque abbastanza semplice, an-
che se dispendiosa (in termini di risorse). Il coefficiente di ranking puo essere
definito come:
cd =1
2
∑i
∑j
αiαjqij − 1
2
∑i�=d
∑j �=d
αiαjqij, (4.45)
ovvero calcoliamo, in termini di peso nel margine e per ogni feature di s, l’in-
fluenza di ogni feature. Per il resto, l’algoritmo e identico a quello presentato
in precedenza.
78

Esempio di applicazione in WEKA
Lanciato WEKA explorer, dopo aver scelto il dataset weather ed esser-
ci spostati nel tab per la selezione degli attributi, optiamo per l’algoritmo
“SVMAttributeEval” e analizziamone le opzioni:
• “attsToEliminatePErIteration” rappresenta il numero di attributi da
eliminare per ogni step;
• “complexityParameter” e il C di SVM lineare. Sfortunatamente, WE-
KA non dispone di un’estensione al caso non–lineare;
• “epsilonParameter” ha lo stesso significato visto nel caso di SVM;
• “filterType” permette di applicare filtri al training set;
• “percentThreshold” indica la percentuale di feature sotto la quale si
passa da un’eliminazione percentuale ad una costante delle feature.
Spieghiamoci meglio. In alternativa ad eliminare un certo numero (fis-
sato) di feature per step, e possibile definire una percentuale sul totale
di attributi da estrarre; quando si scende sotto una certa soglia, si pas-
sa da un’eliminazione di variabili percentuale ad una costante per ogni
step. Settiamo a 0 questa opzione, in modo che essa venga disattivata;
• “percentToEliminatePerIteration” si riferisce alla percentuale di feature
da eliminare per step. Anche in questo caso, disattiviamo l’opzione,
settandola a 0;
• “toleranceParameter” e la tolleranza per SMO: 10−3 e normalmente un
valore accettabile.
Settato C = 1, lanciamo l’analisi e otteniamo un errore: tutte le variabili
devono essere quantitative o binarizzate. L’algoritmo non applica l’apposito
filtro in automatico: dobbiamo quindi spostarci nel tab di preprocessing e
applicare il filtro apposito per trasformare variabili nominali in binarie. Ap-
plicato il filtro, torniamo alla SVM per feature selection e lanciamo l’analisi.
Otteniamo la seguente “classifica”:
Ranked attributes:
6 6 windy
79

5 2 outlook=overcast
4 1 outlook=sunny
3 5 humidity
2 4 temperature
1 3 outlook=rainy
Verifichiamo ora la stabilita di tale ranking anche al variare di C. Set-
tiamo, quindi, C = 100 e lanciamo nuovamente l’analisi. Otteniamo:
Ranked attributes:
6 5 humidity
5 2 outlook=overcast
4 4 temperature
3 6 windy
2 1 outlook=sunny
1 3 outlook=rainy
Notiamo che il ranking e stato profondamente modificato: in questo caso,
sarebbe quindi necessario un doppio lavoro di ricerca di iperparametro per la
classificazione e per la feature selection. Comunque, in molti casi reali, dove
i dataset sono caratterizzati da un maggior numero di pattern, le indicazioni
del ranking sono spesso piu stabili.
4.5 Decision Trees
4.5.1 La nascita degli alberi di decisione
Abbiamo analizzato fino a questo punto molti metodi per la classifica-
zione. Sfortunatamente, queste tecniche forniscono come output un modello,
al quale viene dato in pasto un nuovo pattern e che restituisce il target sti-
mato dopo elaborazioni piu o meno complesse sulle feature che compongono
l’istanza stessa. Nasce quindi il problema dell’interpretabilita del classifi-
catore: avere un modello che classifichi stupendamente, ma che non sia in
grado di spiegarci (almeno in termini comprensibili) il fenomeno sottostante,
spesso non ci basta. Nei casi in cui abbiamo bisogno di regole interpretabili,
le quali portano poi alla classificazione di un pattern, dobbiamo ricorrere agli
alberi di decisione (decision trees, DT ).
80

Introdotti dall’australiano Quinlan [20], hanno avuto un ottimo successo
ed hanno subito diverse evoluzioni. La prima versione del software implemen-
tante i DT fu ID3, negli anni ’80: in ID3 si potevano utilizzare solo variabili
di tipo qualitativo, l’albero era solo binario (2 sotto–alberi per nodo al mas-
simo) e l’algoritmo di apprendimento era piuttosto lento. Ciononostante, la
distribuzione gratuita del software1 (realizzato in C++) favorı la diffusione
di ID3.
Agli inizi degli anni ’90 nacque poi C4.5: evoluzione di ID3 (in verita, di
una versione intermedia fra i due freeware, ovvero M5), era in grado di gestire
i missing e le variabili continue (solo con split di tipo binario, dopo sara tutto
piu chiaro). Inoltre, veniva introdotto un nuovo algoritmo di apprendimento,
piu rapido, e la fase di pruning (che ci riserviamo di analizzare nei prossimi
paragrafi), che favorisce la generalizzazione del modello trovato. C4.5 ha
subito, nel corso degli anni, svariate migliorie, che hanno portato alla nascita
di una nuova versione del software per DT: Quinlan ha voluto mantenere il
nome C4.5, ma qualcuno ha ridefinito questa ulteriore release come C4.5+
o, piu comunemente, C4.8 (in quanto si trattava dell’ottava release di C4.5).
Anche C4.5 (o C4.8 che dir vogliate) e disponibile free in rete sulla homepage
di Quinlan. Tra le novita in C4.8, la possibilita di gestire split multipli su
variabili continue e alcune nuove implementazioni per favorire l’esecuzione
parallela su piu processori.
Ultima evoluzione, non piu free ma commerciale, See5/C5.0: migliora-
menti al codice hanno portato ad un algoritmo piu veloce e che necessita di
meno memoria durante l’esecuzione. Non solo: nuovi algoritmi di pruning
migliorano le caratteristiche di generalizzazione in molti casi reali.
Come detto, il vantaggio dei DT e l’output dell’apprendimento: un mo-
dello sotto forma di regole if...then...else, dove gli if sono semplicemente
condizioni sul valore degli attributi. Un esempio di DT grafico e riportato in
Fig. 4.9. Spesso, l’interpretabilita va a scapito di prestazioni e, soprattutto,
generalizzazione nei casi reali. Tutto sara piu chiaro dopo aver analizzato in
breve l’algoritmo di learning.
1http://www.rulequest.com/Personal/
81

Figura 4.9: Esempio di Decision Tree.
4.5.2 Apprendimento
Analizziamo l’algoritmo di apprendimento per C4.5 in versione origina-
le, in quanto decisamente piu semplice: solo alla fine di questo paragrafo
chiariremo le differenze e le novita di C4.8. L’apprendimento consiste di due
step:
• crezione dell’albero;
• pruning dell’albero.
Creazione dell’albero
Per capire bene l’apprendimento di un DT, dobbiamo partire col definire
alcune quantita. Al fine di comprendere meglio i parametri che andremo
a presentare, faremo degli esempi riferiti al dataset weather, presentato in
formato testuale in Tab. 4.2.
Definiamo come XG il dataset weather. Data una distribuzione di proba-
bilita di una variabile, per esempio la distribuzione relativa di un attributo,
si definisce informativita di una variabile la quantita
I(P ) = −∑
i
pi log2 pi, (4.46)
82

Meteo Temperatura Umidita Vento Giocare a golf?
sunny 85 85 FALSE no
sunny 80 90 TRUE no
overcast 83 86 FALSE yes
rainy 70 96 FALSE yes
rainy 68 80 FALSE yes
rainy 65 70 TRUE no
overcast 64 65 TRUE yes
sunny 72 95 FALSE no
sunny 69 70 FALSE yes
rainy 75 80 FALSE yes
sunny 75 70 TRUE yes
overcast 72 90 TRUE yes
overcast 81 75 FALSE yes
rainy 71 91 TRUE no
Tabella 4.2: Dataset weather.
equivalente all’entropia della variabile. L’informativita del nostro dataset, in
particolare, equivale all’informazione necessaria ad identificare una classe nel
nostro dataset. In termini matematici, vale
Info(X) = I(PX) = −k∑
i=1
pi log2 pi, (4.47)
con k che rappresenta il numero di classi. Ad esempio, nel dataset del golf
abbiamo 9 esempi appartenenti alla classe “yes” e 5 alla “no”. Pertanto,
abbiamo
Info (XG) = − 9
14log2
9
14− 5
14log2
5
14≈ 0.94. (4.48)
L’informativita e massima se le classi sono equidistribuite ed e minima se
una classe e assente.
Supponiamo per il momento di avere a disposizione solo variabili quali-
tative. Se dividiamo il nostro dataset X sulla base dei valori assunti da una
particolare variabile v, possiamo calcolare l’informativita del nostro dataset
relativamente alle partizioni che andiamo a calcolare. In pratica, vogliamo
calcolare l’informazione necessaria per identificare una classe in X, dopo che
83

un particolare valore di una variabile qualitativa e stato determinato. Ipo-
tizzando che la variabile possa assumere n valori vi, i = 1, ..., n, possiamo
definire in breve Info(v, X):
Info(v, X) =
n∑i=1
‖Xi‖0
‖X‖0
· Info (Xi) , (4.49)
nella quale Xi rappresentano i subset di X in cui un certo valore vi si mantiene
costante e la norma–0 ‖·‖0 e definita come la cardinalita di un dataset, ovvero
il numero di pattern che sono in esso contenuti. Nell’esempio del golf, per
l’attributo meteo possiamo calcolare l’informativita relativa:
Info(v, XG) =5
14·I(
2
5,3
5
)+
4
14·I(
4
4, 0
)+
5
14·I(
3
5,2
5
)≈ 0.694. (4.50)
Infine, vogliamo trovare il guadagno, in termini di informativita, nell’in-
troduzione della variabile v rispetto all’identificazione a priori di una classe.
Il guadagno viene definito come:
Gain(v, X) = Info(X) − Info(v, X). (4.51)
Nel caso del meteo, otteniamo dalle Eqq. (4.48) e (4.50)
Gain(v, XG) = 0.94 − 0.694 ≈ 0.246. (4.52)
Si potrebbe mostrare che il guadagno della variabile vento e circa 0.094,
quindi l’introduzione nell’analisi di meteo porta ad un vantaggio maggiore
rispetto all’introduzione di vento. Il guadagno sara esattamente la quantita
che guidera la creazione del nostro albero.
Talvolta, in alternativa al guadagno, si utilizza il guadagno normalizzato,
definito come:
GainRatio(v, X) =Gain(v, X)
SplitInfo(v, X), (4.53)
dove la quantita SplitInfo(v, X) e definita sulla base dell’informativita do-
vuta allo splitting del dataset in subset nei quali una variabile qualitativa
mantiene valore costante:
SplitInfo(v, X) = I
(‖X1‖0
‖X‖0
,‖X2‖0
‖X‖0
, ...,‖Xn‖0
‖X‖0
). (4.54)
84

Non ci rimane che generalizzare le quantita precedenti al caso di variabili
quantitative. Per quanto riguarda le feature discrete, se il numero di livelli
non e enorme si puo supporre tali attributi come se fossero qualitativi ordi-
nali. In caso contrario o per variabili continue, si segue questa procedura.
Si suppone che la variabile possa assumere solamente i valori presenti nel
dataset, ottenendo quindi un insieme vi, i = 1, ..., h. A questo punto, la
variabile continua dev’essere suddivisa (split) in due subset. Per trovare il
valore ottimo di split, si considerano tutti i vi e si calcolano tutti i guadagni
(eventualmente normalizzati) per i dataset splittati. Il punto di split che ga-
rantisce guadagno ottimo viene assunto come valore di riferimento, e il Gain
cosı calcolato diviene il guadagno dell’attributo, che, a quel punto, diviene
una sorta di variabile qualitativa a tutti gli effetti.
L’algoritmo di apprendimento, a questo punto, procede con chiamate
ricorsive alla funzione di creazione dell’albero (ipotizziamo di utilizzare Gain,
ma anche con il valore normalizzato non cambia assolutamente nulla), routine
che definiamo createTree e il cui schema e il seguente:
1. se il set di dati passato in ingresso contiene solo dati appartenenti ad
una stessa classe, si inserisce una foglia corrispondente a tale classe e
si ritorna il controllo al chiamante;
2. se nel set di dati non sono piu presenti feature, ma solo il target, si inse-
risce una foglia corrispondente al classe con frequenza assoluta maggiore
nel set e si ritorna il controllo al chiamante;
3. calcoliamo i Gain per tutti gli attributi;
4. sia v∗ l’attributo con Gain massimo. Tale feature puo assumere h
valori;
5. si creano gli h subset di dati contenenti ognuno un valore costante di
v∗. In essi, si elimina la feature v∗ dal set;
6. per ognuno di essi, si crea un ramo dell’albero e si lancia la funzione
createTree.
Una volta conclusa l’operazione, abbiamo generato l’albero. La principale
differenza in C4.8 sta nella possibilita di non eliminare al passo 5 la variabile
dai subset se essa e continua: questo permette split multipli sui valori delle
85

variabili continue. Questa scelta e stata talvolta criticata, ma permette di
migliorare almeno parzialmente le performance del DT in casi in cui C4.5
andava profondamente in crisi, ovvero quando il numero di feature era molto
piu alto del numero di pattern.
Notiamo che, se ci bloccassimo a questo punto, di fatto overfitteremmo
moltissimo il training set, cosa che non vogliamo. L’unica (e molto parziale)
generalizzazione e infatti contenuta nel passo 2, quando scegliamo la classe
di una foglia sulla base della classe piu frequente. Il pruning viene proprio
utilizzato per favorire la generalizzazione dell’albero.
Pruning
Letteralmente, si traduce con potare: in effetti, rami dell’albero vengono
tagliati per favorire la generalizzazione del DT. Premesso che in letteratura
esistono innumerevoli tecniche per il pruning, una semplice strategia consiste
nel stimare l’errore nel caso di eliminazione di una parte dell’albero rispetto al
mantenimento della stessa. Se l’errore stimato e sotto una certa soglia, e con-
siderato accettabile e il sotto–albero viene prunato; in caso contrario, viene
mantenuto. La stima dell’errore avviene utilizzando la formula di Laplace:
err =l − n + k − 1
l + n, (4.55)
nella quale l e il numero di pattern contenuti nel subset riferito ad un nodo,
n e il numero di pattern del subset afferenti alla classe maggioritaria c e k e
il numero totale di classi. Se err e sotto la soglia, detta fattore di confidenza,
si sostituisce il sotto–albero con una foglia corrispondente alla classe c.
4.5.3 Fase in avanti
Nella fase in avanti, si applicano semplicemente le regole, trovate durante
l’apprendimento, ad ogni nuovo pattern: l’uscita corrispondera alla foglia
individuata nel tree mediante tali regole.
4.5.4 Estensione al caso multiclasse
Come gia per NBC, MLP e 0–R, i DT sono nativamente multiclasse,
quindi non necessitano di estensioni.
86

4.5.5 Esempio di analisi in WEKA
Avviato WEKA explorer, consideriamo weather e, nel tab per la classifi-
cazione, selezioniamo i DT. In particolare, dovremo andare nella sottocatego-
ria “trees”, nella quale C4.8 (WEKA utilizza questa versione) e identificato
come J4.8 (in quanto realizzato in Java e non in C++). Le opzioni a nostra
disposizione sono:
• “binarySplits” forza split di tipo binario anche su variabili qualitati-
ve. Permette, di fatto, il ritorno a ID3. A noi interessa C4.8, quindi
manterremo a false questa opzione;
• “confidenceFactor” e il fattore di confidenza per il pruning: piu basso
e, piu l’albero viene prunato. Valori tra 0.15 e 0.30 di solito sono i piu
gettonati. Noi per ora settiamo 0.25;
• “debug” sono le solite stampe di debug;
• “minNumObj” permette di settare il numero minimo di istanze prima
di fissare una foglia nell’albero. Normalmente, si setta a 2;
• “numFolds” e il numero di fold per una tecnica di pruning efficace ma
complessa, la reduced error pruning, che non abbiamo analizzato;
• “reducedErrorPruning” e la citata tecnica. Settiamo a false;
• “saveInstanceData” permette di salvare i dati di training nella visua-
lizzazione dell’albero;
• “seed” e il seed per l’algoritmo di random per la reduced error pruning;
• “subtreeRaising” permette all’algoritmo di pruning di valutare la modi-
fica dei sotto–alberi al fine di migliorare le performance. Normalmente,
e settato a true;
• “unpruned” e utilizzato per disattivare il pruning (false);
• “useLaplace” permette di usare l’indice di Laplace per il pruning. Da-
to che spesso e un indice troppo conservativo, talvolta si disattiva
l’opzione. Anche noi, in effetti, la setteremo a false.
87

Lanciamo l’analisi e otteniamo ottimi risultati, paragonabili a quelli che
solo una SVM non lineare era riuscita a raggiungere. Anche scegliendo come
dataset iris, i risultati sono ottimi: solamente 3 errori e una Kappa molto
vicina a 1 (0.97). C’e inoltre da considerare che il DT ci fornisce anche
l’interpretabilita del modello, come mostrato in Fig. 4.10, quindi i parametri
di controllo sulla forma del sepalo e petalo del fiore: potrebbe esserci utile.
Per attivare la visualizzazione dell’albero, cliccate col tasto destro sul modello
nel menu “Result list” e selezionate la visualizzazione dell’albero.
Figura 4.10: Albero di decisione per il dataset iris.
88

Sappiamo, pero, che uno dei principali difetti di C4.8 e la capacita di
generalizzazione. Pertanto, l’ultima prova consiste nell’utilizzo di 100 dati
di training e 50 di validation. Lasciando inalterati i settaggi, si ottengono
2 errori sul validation: un ottimo risultato. Per controllare se il pruning
ha influenza su questo risultato, settiamo a true l’opzione “unpruned” e
analizziamo i risultati: commettiamo nuovamente soli 2 errori, il che significa
che gia il DT originale forniva un’ottima interpretazione del dataset.
89

Capitolo 5
Regressione
Terminata la nostra rassegna sugli algoritmi per la classificazione, passia-
mo al problema della regressione. Anche in questo caso, supporremo di avere
sempre a disposizione un dataset X, per il quale abbiamo definito un target
y ∈ � di tipo numerico. L’obiettivo che ci prefiggiamo e trovare una relazione
fra feature e target per calcolare un output di tipo analogico efficace e con
un basso errore nella fase in avanti. Per verificare le prestazioni del nostro
modello, utilizzeremo i gia analizzati RMSE e MAE ed introdurremo l’uti-
lizzo del coefficiente di correlazione r (vedi paragrafo 3.3) tra le uscite reali
del nostro training o volidation set e quelle stimate dal modello: ricordiamo
che r ∈ [−1, 1] e r = 0 indica correlazione minima (e prestazioni pessime).
5.1 Zero Rules
Abbiamo analizzato nel paragrafo 4.1 il classificatore elementare 0–R.
Chiameremo, per evitare confusione, 0–RR il regressore Zero Rules.
5.1.1 Apprendimento
Analogamente a quanto visto per la classificazione, 0–RR utilizza come
uscita del modello la media dei target numerici del training set.
5.1.2 Fase in avanti
Qualunque sia l’ingresso al sistema, 0–RR restituisce come uscita stimata
la media dei target del training set.
90

5.1.3 Esempio di analisi in WEKA
E facile attendersi che la qualita di questo regressore sia davvero bassa; in
effetti, e proprio cosı. Lanciamo WEKA explorer e selezioniamo come dataset
per la regressione CPU (file cpu.arff ): tramite 6 attributi (caratteristiche di
alcune CPU), si cerca di stimarne le performance. Anche per la regressione
utilizzeremo il tab “classify” (WEKA non fa distinzione di sorta).
Per utilizzare 0–RR, selezioniamo l’algoritmo “ZeroR” (lo stesso usato nel
paragrafo 4.1.4) e lanciamo l’analisi. Il coefficiente di correlazione ottenuto e
pari a 0, il minimo possibile, e l’errore (sia in termine di MAE che di RMSE) e
molto alto. D’altra parte, il sistema stima sempre, a prescindere dal pattern
in ingresso, un’uscita y ≈ 99.33. Se forziamo WEKA a stampare a video
anche le uscite del nostro training set, notiamo che ci sono anche valori come
−800, per i quali commettiamo un errore enorme. E quindi facile immaginare
che 0–RR (come il suo omologo 0–R) sia davvero poco usato.
5.2 Support Vector Regression
La Support Vector Regression (SVR) si basa sugli stessi principi della
SVM, con la quale condivide anche il principale autore [23]. L’idea di base
e quella di cercare una funzione ignota y = f(x) che sia caratterizzata da
un errore basso (ma non nullo) rispetto ai dati di training. Esistono svariati
metodi per il calcolo dell’errore, ma noi analizzeremo solo uno dei piu usati
(nonche quello utilizzato da WEKA): la ε–insensitive loss function, per la
quale viene definita
|z|ε =
{0 se |z| < ε
|z| − ε se |z| ≥ ε. (5.1)
L’inconveniente di tale funzione di errore sta nel fatto che aggiungiamo un
nuovo iperparametro, ε, da settare in modo appropriato.
Il problema primale della SVR viene definito come [22]:
91

minw,b,ξ,ξ∗
1
2‖w‖2 + C
l∑i=1
(ξi + ξ∗i ) (5.2)
yi − (w · x + b) ≤ ε + ξi ∀i ∈ [1, . . . , l] (5.3)
(w · x + b) − yi ≤ ε + ξ∗i ∀i ∈ [1, . . . , l] (5.4)
ξi, ξ∗i ≥ 0 ∀i ∈ [1, . . . , l] (5.5)
ovvero in una forma sostanzialmente identica alla SVM a meno dell’introdu-
zione di una doppia variabile di slack affinche la stima dell’output yi possa
essere sia minore che maggiore rispetto all’output reale yi. In Fig. 5.1, pre-
sentiamo un esempio grafico che dovrebbe meglio chiarire il significato del
doppio slack.
Figura 5.1: Rappresentazione grafica della ε–insensitive loss function.
Il problema duale di SVR puo essere calcolato in maniera analoga a quan-
to visto per la SVM utilizzando il metodo dei moltiplicatori di Lagrange,
ottenendo:
minα,α∗
{12
∑li=1
∑lj=1 (αi − α∗
i )(αj − α∗
j
)K(xi, xj)+
−ε∑l
i=1 (αi + α∗i ) +
∑li=1 yi (αi − α∗
i )(5.6)
0 ≤ αi, α∗i ≤ C ∀i ∈ [1, . . . , l] (5.7)
l∑i=1
(αi − α∗i ) = 0. (5.8)
5.2.1 Apprendimento
Tramite passaggi non troppo complessi, per i quali rimandiamo a [22],
e possibile ricondurre il problema (5.6) alla formulazione duale (4.34) della
92

SVM, pertanto risolvibile usando SMO. Ed e infatti proprio questo algorit-
mo che utilizzeremo per trovare la soluzione ottima, che nel caso di SVR
comprende sia α che α∗, oltre, ovviamente, al bias, calcolabile sfruttando le
KKT.
5.2.2 Fase in avanti
Anche la fase in avanti della SVR ricorda molto da vicino la funzione
feedforward di SVM. Nella fattispecie, vale:
y = f(x) =
l∑i=1
(αi − α∗i )K (x, xi) + b. (5.9)
5.2.3 Esempio di analisi in WEKA
Lanciamo WEKA explorer, selezionando CPU come dataset. Nel tab di
classificazione, selezioniamo “SMOreg” dalla sottocategoria “functions” per
selezionare la SVR. Le opzioni sono sostanzialmente le stesse della SMO per
la classificazione, per le quali rimandiamo al paragrafo 4.4.6. Unico cam-
biamento, l’aggiunta dell’opzione “epsilon” per la tolleranza dell’omonima
ε–insensitive loss function: setteremo ε = 0.001.
Partiamo con un kernel lineare e C = 1. Lanciamo l’analisi e otteniamo
risultati di sicuro buoni, ma non esaltanti: l’errore presenta un miglioramento
in termini assoluti pari a circa il 78% rispetto a 0–RR, e il coefficiente di
correlazione e oltre 0.9. Con un kernel gaussiano possiamo fare di meglio?
Settiamo γ = 1 e otteniamo un errore veramente piccolo (miglioramento in
termini assoluti del 98% rispetto a 0–RR) e un coefficiente di correlazione
sostanzialmente equivalente a 1. Portiamo γ = 100: otteniamo addirittura
r = 1 e un errore quasi nullo. Davvero un’ottima performance.
5.3 Regression Trees
5.3.1 Apprendimento
I Regression Trees (RT) ricordano non solo nel nome i DT: infatti, l’al-
goritmo di apprendimento e assolutamente identico a quanto analizzato nel
paragrafo 4.5.2. L’unica differenza consta nello stabilire il valore di una foglia:
93

se, nel caso dei DT, si sceglieva la classe maggioritaria, nei RT si considera
la media dei target del subset “sopravvissuto” ai precedenti split.
5.3.2 Fase in avanti
Anche per la fase feedforward, rimandiamo alla discussione sui DT e, in
particolare, al paragrafo 4.5.3.
Alcune considerazioni vanno fatte, invece, sulle performance dei RT, spes-
so insufficienti in molti casi reali. Anche lo stesso Quinlan ha portato avanti
i RT parallelamente ai DT a partire dall’algoritmo M5 (sviluppato prima di
C4.5) fino a C4.5 stesso. Da C4.8 in poi, date le scarse performance degli RT
(specie in dataset caratterizzati da un alto rapporto fra numero di pattern e
numero di attributi), essi non sono stati piu inclusi nei pacchetti distribuiti
in rete.
5.3.3 Esempio di analisi in WEKA
Anche WEKA risente dell’abbandono nello sviluppo dei RT in C4.8: il
gia citato algoritmo J4.8 non contempla la possibilita di creare un albero per
regressione. A causa di cio, utilizzeremo l’algoritmo piu vecchio (M5) [19],
reso (parzialmente) piu performante da alcune migliorie in stile C4.8 [24]: tra
queste, l’utilizzo di un problema di regressione lineare sulle foglie al posto
della media. Rimandiamo agli articoli citati per coloro che volessero maggiori
dettagli: le differenze nel learning rispetto a C4.5/C4.8 sono minime.
Sono minime anche le differenze in WEKA rispetto alle opzioni per J4.8:
selezionato l’algoritmo “M5P” (dove ‘P’ indica Plus, ovvero dotato delle mo-
difiche apportate in [24]), i parametri da settare sono quelli analizzati nel
paragrafo 4.5.5; unica aggiunta, il parametro che regola l’implementazione di
un RT “buildRegressionTree” (per noi, sara true). Merita una nota aggiun-
tiva il parametro “minNumIstances”: se nel caso dei DT avevamo settato
tale parametro a 2, ora conviene aumentare il numero minimo di istanze ne-
cessarie per consentire un ulteriore split. Se, infatti, nel calcolo del valore di
una foglia dovessero rimanere troppi pochi pattern, il valore mediato potreb-
be essere di poco significato. Un buon valore puo essere considerato 4; con
tanti pattern, meglio aumentare ulteriormente tale limite (ma non troppo,
altrimenti potremmo addirittura non riuscire a creare l’albero). L’opzione
“useUnsmoothed” equivale alla “useLaplace” dei DT.
94

Lanciamo l’analisi su CPU e otteniamo un errore piuttosto alto: ottenia-
mo un miglioramento pari circa al solo 60% rispetto a 0–RR e il coefficiente
di correlazione non e alto (circa 0.8).
SVR sembra il miglior algoritmo per la regressione: lo sara anche su un
validation set, separato dal training set? Trascurando 0–RR, di sicuro pessi-
mo, utilizziamo il 67% dei dati per il training e il restante come validation.
Con RT, otteniamo sul validation i tre seguenti valori:
• r = 0.85;
• errore MAE relativo a 0–RR: 44.21%;
• errore RMSE relativo a 0–RR: 54.89%.
Lanciamo SVR con kernel gaussiano e i parametri identificati nel para-
grafo 5.2.3. I valori ottenuti sono decisamente migliori:
• r = 0.97;
• errore MAE relativo a 0–RR: 18.08%;
• errore RMSE relativo a 0–RR: 22.86%.
95

Capitolo 6
Clustering
Altro problema interessante da affrontare in ottica BI e il clustering : esso
consiste nel raggruppamento di elementi omogenei in un insieme di dati. Le
tecniche di clustering si basano sul concetto di distanza, che risulta quindi
centrale nell’analisi: elementi “vicini” (secondo una certa metrica) sono da
considerarsi omogenei e vanno inseriti nello stesso cluster; pattern eterogenei
saranno “distanti” ed inclusi in differenti insiemi.
Le tecniche di clustering vengono utilizzate spesso quando si hanno a
disposizione dati eterogenei e si e alla ricerca di elementi anomali: un caso
tipico riguarda le compagnie telefoniche, le quali utilizzano le tecniche di
clustering per cercare di individuare in anticipo gli utenti che diventeranno
morosi. Essi, infatti, tendono ad avere un comportamento diverso rispetto
alla normale utenza e le tecniche di clustering riescono sovente ad individuarli
o almeno a definire un cluster, nel quale vengono concentrati tutti gli utenti
che hanno un’elevata probabilita di diventare morosi.
Per il clustering, in generale, non avremo a disposizione un target, ma
semplicemente un dataset X, composto da un certo numero di feature. Spesso
non si conosce nemmeno il numero di cluster k a priori: in questo caso,
k diviene una sorta di iperparametro, il cui valore ottimo va ricercato per
tentativi.
6.1 k–Means
Per quanto riguarda il clustering, analizzeremo solo un algoritmo: il k–
means. E un algoritmo piuttosto semplice, ma spesso efficace. Negli ultimi
96

anni sono stati sviluppati anche algoritmi piu complessi, ma un po’ per motivi
di tempo e un po’ per gli scarsi miglioramenti conseguiti tralasceremo tali
metodi.
6.1.1 Apprendimento
L’algoritmo per l’apprendimento e di tipo iterativo e necessita di due
ingressi (oltre al training set X, ovviamente):
• una metrica di distanza tra pattern: spesso viene usata la distanza eu-
clidea ‖x1 − x2‖22. Ovviamente, usando tale distanza i cluster avranno
forma di (iper)sfere, il cui centro viene detto centroide;
• il numero di cluster k < l (se non disponibile, bisogna procedere per
tentativi), dove l e il numero di pattern di training.
La funzione che intendiamo minimizzare e:
CKM = minμ1,...,μk
k∑i=1
∑xj∈Sj
∥∥xj − μj
∥∥2
2, (6.1)
dove μj, j = 1, ..., k, indicano i k centroidi e Sj sono i k cluster. In generale,
il centroide non e un punto del training set, ma viene individuato mediando
la posizione dei punti appartenenti al cluster; nel caso in cui non si usi la
media delle coordinate dei punti del cluster, bensı la mediana, si parla di
k–medoids, di cui noi non ci occuperemo.
L’algoritmo viene inizializzato scegliendo k centroidi randomicamente tra
i punti del training set. A questo punto, l’apprendimento procede seguendo
questi step:
1. si calcolano i cluster, assegnando ogni pattern al cluster il cui centroide
dista meno;
2. si modificano i centroidi, ricalcolandoli sulla base dei nuovi punti ap-
partenenti al cluster;
3. se i centroidi non sono stati modificati (o hanno subito un cambiamento
inferiore ad una certa soglia), l’algoritmo termina; altrimenti si procede
dal punto 1.
97

Ovviamente, la qualita del risultato dipende anche dall’inizializzazione ran-
domica dei centroidi: per questo motivo, e spesso preferibile lanciare diverse
istanze di k–means, partendo da centroidi differenti. Alla fine, si opta per la
configurazione a CKM minimo.
6.1.2 Fase in avanti
La fase feedforward del k–means consiste, per un nuovo pattern x, nel
calcolarne la distanza dai centroidi e nell’attribuirlo al cluster il cui centroide
dista meno.
6.1.3 Esempio di analisi in WEKA
In WEKA non esistono dataset creati ad hoc per il clustering; d’altra
parte, e possibile utilizzare alcuni dataset, originalmente creati per la classi-
ficazione, e vedere come si comporta il k–means in questi casi. Tra l’altro,
per questi dataset conosciamo il numero di cluster, essendo coincidente con
il numero di classi.
Iniziamo con il gia noto iris e selezioniamo il tab “Cluster”; tra i me-
todi disponibili, optiamo per il “SimpleKMeans”, le cui opzioni riguardano
semplicemente il numero di cluster (per iris, k = 3) e il seed per l’algorit-
mo di inizializzazione random (inizialmente, lasciamo 10). Essendo il nostro
dataset iris nato per algoritmi di classificazione, selezioniamo tra i “Cluster
mode” l’opzione “Classes to cluster evaluation”, che ci offre un termine di
paragone diretto con la classificazione nell’output dei risultati.
L’output del k–means per la nostra analisi e il seguente:
Number of iterations: 6
Within cluster sum of squared errors: 6.99811
Cluster centroids:
Cluster 0
Mean/Mode: 5.8885 2.7377 4.3967 1.418
Std Devs: 0.4487 0.2934 0.5269 0.2723
Cluster 1
Mean/Mode: 5.006 3.418 1.464 0.244
98

Std Devs: 0.3525 0.381 0.1735 0.1072
Cluster 2
Mean/Mode: 6.8462 3.0821 5.7026 2.0795
Std Devs: 0.5025 0.2799 0.5194 0.2811
ovvero ci viene presentato il numero di iterazioni totale, l’errore quadratico
intra–cluster (di fatto, il costo CKM) e i centroidi dei cluster, sotto forma di
media (o moda nel caso di variabili qualitative) e varianza (usata piu che altro
come indice di stabilita del centroide). Segue, quindi, il numero di pattern
del training set assegnato ad ogni cluster e una sorta di Confusion Matrix
riferita ai cluster. Conclude l’elenco dei risultati il numero e la percentuale
di assegnazioni errate ai cluster (misurate sulla base dell’appartenenza alle
varie classi). Nel caso di iris abbiamo l’11.3% di errore (valore alto, se riferito
a quelli ottenuti nel capitolo 4).
Proviamo a modificare il seed e settiamolo a 356 (un valore a caso): otte-
niamo gli stessi risultati dell’esecuzione precedente. Si possono provare molti
valori di seed e vedere se la percentuale precedente migliora. Un’ultima nota:
dall’analisi della pseudo–Confusion Matrix, si evince che la classe 0 (“Iris–
setosa”) viene sempre clusterizzata in modo perfetto e quindi, probabilmente,
e facilmente distinguibile dalle altre due classi.
In fase di introduzione a questo capitolo, abbiamo detto che spesso il clu-
stering e utilizzato per trovare clienti morosi: in WEKA, e incluso il dataset
labor, per classificazione binaria, in cui, sulla base del profilo di alcuni lavo-
ratori, si prova a stimare se essi siano dei buoni lavoratori o meno. Proviamo
ad applicare il k–means, con k = 2 e seed pari a 10: sbagliamo nel 23% circa
dei casi. Non solo, tali errori sono particolarmente gravi, in quanto quasi
per intero si riferiscono a cattivi lavoratori che vengono, invece, caratteriz-
zati nella classe “good”. Proviamo a cambiare seed, settandolo a 1000: la
situazione peggiora (passiamo quasi al 40% di errore), e questa volta siamo
troppo “cattivi” (consideriamo troppi lavoratori come “bad”). Causa di que-
ste scarse performance potrebbe essere la presenza di molti missing tra i dati
di labor.
99

Capitolo 7
Association rules
Uno dei primi esempi che abbiamo presentato in queste dispense riguar-
dava la catena di supermercati, in cui volevamo cercare possibili associazioni
fra prodotti (o fra prodotto e acquirente) per regolamentare la disposizione
delle merci nei nostri supermercati. In questi casi, e in moltissimi altri nella
vita di tutti i giorni prima ancora che nel mondo della BI, e necessario tro-
vare regole che leghino fra loro alcune variabili; in termini di Data Mining,
dobbiamo trovare eventuali relazioni causali tra feature che descrivono una
qualche entita.
Gli algoritmi per trovare association rules ricevono, in ingresso, un data-
set X, composto da l pattern e m feature, senza alcun target: l’obiettivo e
trovare relazioni del tipo if x1 = 10 ∨ x6 > 33 then x3 = false, ovvero relazioni
di causalita, similmente a quanto visto per i DT. In questo caso, a differenza
degli alberi, pero, il nostro obiettivo non e trovare una sorta di “percorso
ottimo” che, dagli ingressi, attraverso un certo numero di regole ci porti verso
le uscite, bensı vogliamo trovare un qualsiasi legame che colleghi in qualche
modo due o piu feature del nostro dataset. In termini meno informali, diremo
che, mentre i DT erano un metodo supervised (sapevamo cosa volevamo
trovare, ovvero il target), gli algoritmi di association rules sono unsupervised,
in quanto partiamo dal principio di non conoscere nulla del nostro dataset e di
voler cercare di ottenere informazioni attraverso l’applicazione di un qualche
algoritmo. Non solo: nel caso delle association rules l’algoritmo si conclude,
di fatto, con la fase di apprendimento, in quanto una vera fase in avanti non
esiste. Infatti, cio che ci interessa non e trovare un modello da applicare a
run–time, ma solo identificare relazioni all’interno di X. Per questo motivo,
100

non definiremo per l’algoritmo che analizzeremo alcun indice di qualita, in
quanto non definibile di per se.
Esistono diversi algoritmi per trovare le regole di associazioni tra feature:
noi analizzeremo uno dei piu usati, Apriori. A prescindere dall’algoritmo che
si vuole usare, normalmente le implementazioni di association rules preve-
dono di trattare solo feature di tipo qualitativo: qualora avessimo variabili
quantitative, dovremo procedere ad una discretizzazione ad hoc, magari uti-
lizzando le tecniche gia brevemente analizzate per i DT (si veda paragrafo
4.5.2).
7.1 Apriori
Apriori [1] e uno degli algoritmi in assoluto piu utilizzati e si basa su
alcune quantita, piuttosto semplici da calcolare. Le regole che verranno tro-
vate saranno nella forma if A then B, rappresentate alternativamente come
A → B, dove A e detto antecedente o body mentre B e detto conseguente o
head. Al fine di chiarire meglio alcuni concetti, utilizzeremo come esempio il
dataset weather : dato che esso contiene, nella sua forma originaria, alcune
variabili quantitative, utilizzeremo la versione discretizzata di queste ultime.
Per semplicita, proponiamo il dataset in Tab. 7.1.
7.1.1 Apprendimento
Partiamo con alcune definizioni. Viene detto supporto la percentuale di
pattern nel dataset per le quali una determinata condizione e verificata:
support(A) =lAl
, (7.1)
dove lA rappresenta il numero di pattern in cui la condizione A e soddisfatta
e l il numero totale di pattern nel dataset. Ad esempio, nel dataset di Tab.
7.1, abbiamo:
support(meteo = rainy) =5
14≈ 0.36. (7.2)
Talvolta, il supporto viene inteso in termini assoluti e non relativi: in tal
caso, non si divide per l. Ad esempio, per il caso della condizione meteo =
rainy, avremmo un supporto pari a 5.
101

Meteo Temperatura Umidita Vento Giocare a golf?
sunny hot high FALSE no
sunny hot high TRUE no
overcast hot high FALSE yes
rainy mild high FALSE yes
rainy cold normal FALSE yes
rainy cold normal TRUE no
overcast cold normal TRUE yes
sunny mild high FALSE no
sunny cold normal FALSE yes
rainy mild normal FALSE yes
sunny mild normal TRUE yes
overcast mild high TRUE yes
overcast hot normal FALSE yes
rainy mild high TRUE no
Tabella 7.1: Dataset weather in forma discretizzata, con variabili solo di tipo
qualitativo.
102

Viene definita confidenza di una regola A → B il rapporto fra il supporto
della regola e il supporto dell’antecedente A:
confidence(A → B) =support(A → B)
support(A)=
lA→B
lA. (7.3)
Consideriamo la regola if (meteo = sunny) then play = yes e calcoliamone
la confidenza. Partiamo col definirne il supporto: e immediato calcolare
che support(meteo = rainy → play = yes) = 3/14 ≈ 0.21. Abbiamo gia
calcolato che il supporto dell’antecedente e circa uguale a 0.36. Pertanto, la
confidenza e:
confidence(meteo = rainy → play = yes) =3
5= 0.6. (7.4)
Infine, definiamo il lift di una regola A → B come il rapporto fra la
confidenza della regola e il supporto del conseguente, ovvero:
lift(A → B) =confidence(A → B)
support(B)=
support(A → B)
support(A)support(B). (7.5)
Ad esempio, si ottiene facilmente che lift(meteo = rainy → play = yes) ≈0.60.64
≈ 0.94. Si potrebbero definire altre quantita, talvolta utilizzate (leverage
e convinction su tutte), ma sono piuttosto complesse ed esulano dalla nostra
analisi. Ci interessa, invece, analizzare una misura, detta di significanza
(significance, interestingness): il chi–quadro (χ2), spesso utilizzata per il
ranking delle regole di associazione e definita come:
χ2(A → B) =(support(A → B) − support(A)support(B))2
support(A)support(B). (7.6)
Definite le principali quantita che dovremo considerare nella creazione
delle regole, diamo un’occhiata all’algoritmo. Apriori e un metodo iterativo,
che procede creando cosiddetti itemset, ovvero insiemi di regole per le qua-
li alcune condizioni sono verificate. Tipicamente, si pongono condizioni sul
supporto e sulla confidenza o, in alternativa a quest’ultima, sul lift. Un’ulte-
riore selezione puo essere fatta sul livello di significanza di una regola, usando
χ2. Supponiamo di aver definito una soglia di supporto minimo suppm e una
soglia di confidenza minima confm. Analizziamo i passi di Apriori.
103

Al primo passo, vengono considerati i supporti di tutte le possibili com-
binazioni di variabili presenti in X. Le combinazioni il cui supporto supera
suppm entrano a far parte dell’itemset 1.
Al passo successivo, si parte da tutte le relazioni dell’itemset 1, si tro-
vano tutte le loro possibili combinazioni e, per ognuna di esse, si calcolano
i supporti: entreranno a far parte dell’itemset 2 tutte le combinazioni che
superano la soglia di supporto.
Si procede iterativamente a creare itemset, fino a quando non si finiscono
le possibili combinazioni e/o nessuna nuova combinazione ha un supporto
maggiore rispetto alla soglia. A questo punto, si trovano le prime regole, nelle
quali la relazione aggiunta nell’ultimo itemset risulta essere l’head mentre le
precedenti costituiscono il body. Ad esempio, se nell’ultimo itemset troviamo
una relazione del tipo:
humidity=normal windy=FALSE play=yes
play=yes costituira l’head e l’AND delle due relazioni precedenti (humidity=
normal e windy=FALSE) sara il body. Una volta terminate queste relazioni,
si continua a creare regole utilizzando le ultime due istanze come head (es.,
windy=FALSE e play=yes) e le restanti come body (es., humidity=normal).
Il passo successivo consiste nel ripetere queste operazioni per tutti gli itemset
precedenti, escluso l’itemset 1 (per il quale avevamo ancora solo una relazio-
ne). Alla fine, per ogni regola viene calcolata la confidenza e, se necessario, la
significanza: vengono prese in considerazione le sole regole aventi confidenza
maggiore di confm (e, se definita, significanza maggiore di una soglia χ2m).
7.1.2 Esempio di analisi in WEKA (I)
Abbiamo detto che spesso, per analisi di tipo association rules, neces-
sitiamo di dataset composti da variabili solo di tipo qualitativo. E questo
il caso di WEKA. Se vogliamo, quindi, cominciare le nostre analisi con un
dataset semplice quale weather, dobbiamo utilizzarne la versione composta
da sole variabili qualitative, cioe weather.nominal.
Nel tab “Associate”, selezioniamo il metodo “Apriori”, le cui opzioni
sono:
• “delta” rappresenta il decremento iterativo del supporto dal suo valore
massimo al suo valore minimo (settiamo 0.05);
104

• “lowerBoundMinSupport” e il minimo supporto necessario affinche un
insieme di relazioni venga ammesso in un itemset (0.3 e un buon valore);
• “metricType” definisce la metrica con cui vengono definite le regole
ammesse a far parte del set finale (useremo la confidenza);
• “minMetric” e il valore minimo della metrica necessario affinche la
regola venga inclusa nel set finale (settiamo 0.9);
• “numRules” e il numero massimo di regole richieste (ad esempio, 10
regole);
• “outputItemSets” stampa a video i vari itemset (e utile settarlo a true
per analizzare come funziona l’algoritmo);
• “removeAllMissingColumns” rimuove feature in cui sono presenti mis-
sing (false);
• “significanceLevel” e il livello di significanza minimo χ2 (disattiviamo
l’opzione settando -1);
• “upperBoundMinSupport” e il massimo supporto necessario (1);
• “verbose” produce alcune stampe di debug.
Lanciamo l’analisi e otteniamo le seguenti regole:
1. humidity=normal windy=FALSE 4 ==> play=yes 4 conf:(1)
2. temperature=cool 4 ==> humidity=normal 4 conf:(1)
3. outlook=overcast 4 ==> play=yes 4 conf:(1)
Avevamo richiesto 10 regole, ma solo 3 riescono a soddisfare i vincoli su
supporto e confidenza. Se abbassiamo il limite minimo per il supporto a 0.2,
otteniamo:
1. humidity=normal windy=FALSE 4 ==> play=yes 4 conf:(1)
2. temperature=cool 4 ==> humidity=normal 4 conf:(1)
3. outlook=overcast 4 ==> play=yes 4 conf:(1)
4. temperature=cool play=yes 3 ==> humidity=normal 3 conf:(1)
5. outlook=rainy windy=FALSE 3 ==> play=yes 3 conf:(1)
6. outlook=rainy play=yes 3 ==> windy=FALSE 3 conf:(1)
105

7. outlook=sunny humidity=high 3 ==> play=no 3 conf:(1)
8. outlook=sunny play=no 3 ==> humidity=high 3 conf:(1)
ovvero qualche regola in piu, ma a minore supporto (solo 3 esempi in tutto
il dataset).
7.1.3 Esempio di analisi in WEKA (II)
E se avessimo solamente a disposizione un dataset con variabili quantita-
tive? Perche non possiamo trovare relazioni, ad esempio, in iris? Per poter
utilizzare anche questi dataset, e necessario applicare un filtro ai dati stessi.
Nel tab di preprocessing dei dati, selezioniamo iris e optiamo per il filtro
“Discretize” nelle sottocategorie “unsupervised” e “attribute”. Le opzioni
del filtro sono:
• “attributeIndices” rappresenta l’elenco degli indici degli attributi nu-
merici da discretizzare (“last-first” indica che vogliamo discretizzare
tutti gli attributi, se numerici);
• “bins” rappresenta il numero di intervalli (per esempio, potremmo
settarlo a 5);
• “desiredWeightOfIstancesPerInterval” permette di settare un peso per
ogni pattern in ogni intervallo (disattiveremo l’opzione, settando -1);
• “findNumBins” ricerca automaticamente il numero di intervalli in cui
splittare una feature (tra 1 e il valore di “bins”). Settiamo true;
• “invertSelection” discretizza solo le variabili non selezionate nella prima
opzione (false);
• “makeBinary” binarizza le feature dopo averle discretizzate (false);
• “useEqualFrequency” trova gli intervalli sulla base di indici di frequenza
e non in intervalli di uguale dimensione (false).
Applichiamo il filtro e, quindi, lanciamo l’analisi di Apriori, richiedendo
un supporto minimo del 30%. Troviamo le seguenti regole:
106

1. petallength=’(-inf-2.18]’ 50 ==> class=Iris-setosa 50 conf:(1)
2. class=Iris-setosa 50 ==> petallength=’(-inf-2.18]’ 50 conf:(1)
3. petalwidth=’(-inf-0.58]’ 49 ==> petallength=’(-inf-2.18]’ class=Iris-setosa 49 conf:(1)
4. petallength=’(-inf-2.18]’ petalwidth=’(-inf-0.58]’ 49 ==> class=Iris-setosa 49 conf:(1)
5. petalwidth=’(-inf-0.58]’ class=Iris-setosa 49 ==> petallength=’(-inf-2.18]’ 49 conf:(1)
6. petalwidth=’(-inf-0.58]’ 49 ==> class=Iris-setosa 49 conf:(1)
7. petalwidth=’(-inf-0.58]’ 49 ==> petallength=’(-inf-2.18]’ 49 conf:(1)
8. petallength=’(-inf-2.18]’ 50 ==> petalwidth=’(-inf-0.58]’ class=Iris-setosa 49 conf:(0.98)
9. class=Iris-setosa 50 ==> petallength=’(-inf-2.18]’ petalwidth=’(-inf-0.58]’ 49 conf:(0.98)
10. petallength=’(-inf-2.18]’ class=Iris-setosa 50 ==> petalwidth=’(-inf-0.58]’ 49 conf:(0.98)
Siamo quindi in grado di trovare 10 regole anche su variabili quantitative: la
prima regola potrebbe infatti essere scritta anche come If petal length ≤ 2.18
then class = Iris–setosa.
Una nota conclusiva: avevamo notato gia nel capitolo sul clustering al
paragrafo 6.1.3 che, in iris, la classe Iris–setosa era particolarmente facile
da riconoscere: in effetti, Apriori ci spiega perche. Infatti, e sufficiente con-
trollare la lunghezza del petalo: se e sotto una certa cifra (2.18), abbiamo la
certezza (confidenza pari al 100%) che si tratti di questo tipo di fiore.
107

Capitolo 8
Valutazione comparativa di
algoritmi di Data Mining
8.1 Metodi (pratici) per la comparazione fra
algoritmi
Premettiamo subito che in questo capitolo non affronteremo davvero nei
particolari la comparazione fra algoritmi, che sarebbe davvero un argomen-
to difficile ed impegnativo, ne analizzeremo tutte le tecniche disponibili in
letteratura. Quello che intendiamo fare, invece, e proporre alcune sempli-
ci metodologie, che possono essere usate anche in WEKA e permettono di
ottenere velocemente semplici parametri di valutazione di metodi statistici.
8.1.1 Training set (TS)
Il primo metodo, il piu semplice, prevede la valutazione delle performance
di un algoritmo di DM sulla base del numero di errori che il modello commette
sul training set. E la tecnica che abbiamo utilizzato nelle nostre prime analisi
in WEKA. Il problema sta nel fatto che valutare le performance di un metodo
sugli stessi dati su cui e stato creato il modello puo portare ad overfitting:
per questo motivo, questa tecnica e davvero poco utilizzata.
108

8.1.2 Validation set (VS)
Molto piu appropriato per i nostri scopi e utilizzare un validation set
separato dal training set, che possiamo fornire in un file separato o ottenere
splittando in training e validation il dataset che abbiamo a disposizione.
Selezioneremo alla fine il modello che, istruito sul training set, meglio si
comporta sul validation set.
8.1.3 K–Fold Cross Validation (KCV)
La tecnica di valutazione forse piu usata e, pero, la k–Fold Cross Vali-
dation (KCV ): essa prevede che il dataset che abbiamo a disposizione venga
diviso in k subset, detti fold, di uguali dimensioni (nel caso in cui il numero di
pattern l non sia esattamente divisibile per k, normalmente, si duplicano dei
dati presenti nel dataset originario). A turno, k − 1 fold vengono usate per
l’apprendimento e la restante fold come validation: ad esempio, ipotizzando
10 fold, al primo passo useremo le fold dalla 1 alla 9 per il training e la 10
come validation; al secondo step, dalla 1 alla 8 e la 10 come training e la 9
come validation, e cosı via. Su ogni fold di validation, e possibile calcolare il
numero di errori ei, i = 1, ..., k. Alla fine, il parametro per il confronto tra
metodi sara pari a:
e =
∑ki=1 ei
l. (8.1)
Il vantaggio della KCV e che, se abbiamo un singolo dataset (quindi,
senza validation separato), non sprechiamo dati per il training, dato che a
turno tutti i pattern vengono usati per l’apprendimento; non solo, abbiamo
anche un validation set molto grande, essendo alla fine composto anch’esso,
di fatto, da tutte le istanze del dataset. Lo svantaggio consiste nel dover
ripetere k volte l’apprendimento: questo significa lunghi tempi di attesa nel
caso di dataset con molti pattern di training.
Un paio di note conclusive. Spesso, prima di applicare la KCV e neces-
sario un rimescolamento casuale dei dati del dataset: questo per evitare che
una fold per il training sia costituita da soli dati di una classe, ad esempio.
Fissare k potrebbe essere considerato come una ricerca di iperparametro: in
verita, la pratica ha ampiamente dimostrato che k = 5 e k = 10 sono valori
ottimi da utilizzare.
109

Metodo Errore TS Errore test
NBC 18.33% 22.96%
MLP 2.33% 4.81%
SVM lin 3.27% 5.31%
SVM gauss 1.00% 2.84%
DT 1.00% 3.83%
Tabella 8.1: Risultati per il metodo training set (TS): in grassetto, le migliori
percentuali ottenute.
8.2 Analisi in WEKA explorer
Per le nostre prove, considereremo un dataset finora mai introdotto, seg-
ment, rappresentante porzioni di immagini da classificare in 7 classi sulla base
del materiale in esse rappresentato (erba, cemento,...). Il dataset e composto
da ben 1500 pattern, ma, cosa a noi ancor piu gradita, e incluso un test set:
cio significa che partiremo a confrontare metodi statistici per la classifica-
zione (NBC, MLP, SVM lineare, SVM gaussiana, DT), ne sceglieremo uno
per ogni tecnica di confronto (TS, VS, KCV) e verificheremo poi sul test set
quale si comportava meglio. In particolare, per SVM useremo C = 100 e, nel
caso di SVM gaussiana, γ = 1.
8.2.1 Metodo TS
Carichiamo il dataset di training in WEKA explorer. Partiamo con il
TS. I risultati sono presentati in Tab. 8.1: i metodi migliori appaiono essere
la SVM gaussiana e gli alberi. Per valutare l’errore sul file di test, utilizziamo
“Supplied test set” nel menu “Test options” e selezioniamo il file di test per
segment. Notiamo che le previsioni di stima sul training set sono effettiva-
mente verificate: i metodi che meglio si comportano in termini di errore sul
training set sono quelli che meglio vanno anche sul test set. In questo caso,
quindi, presumiamo che il training set sia un buon campione del problema
che stiamo analizzando.
Ciononostante, notiamo due cose:
• il metodo TS stima come ugualmente performanti SVM gaussiana e
DT, anche se, in verita, sul test set vi e poi una differenza pari quasi
110

Metodo Errore VS Errore test
NBC 19.87% 22.96%
MLP 4.40% 4.81%
SVM lin 4.93% 5.31%
SVM gauss 3.47% 2.84%
DT 5.60% 3.83%
Tabella 8.2: Risultati per il metodo validation set (VS): in grassetto, le
migliori percentuali ottenute.
all’1%. D’altra parte, era lecito attenderselo: sappiamo che i DT, al di
la del pruning, tendono all’overfitting;
• la stima dell’errore e molto ottimistica, nonostante si stia trattando un
buon campione: nella migliore delle ipotesi, tra errore sul test set e sul
train c’e una differenza quasi del 2%.
8.2.2 Metodo VS
Usiamo ora il 50% dei dati per il training e lasciamo la restante meta
come validation. Anche in questo caso, analizziamo i risultati in Tab. 8.2:
il risultato migliore corrisponde solo alla SVM gaussiana, che effettivamente
e quella che meglio si comporta sul test set. Non solo: la stima dell’errore
sul validation set e decisamente migliore rispetto a quella del training set,
essendo addirittura peggiorativa rispetto al rate ottenuto.
8.2.3 Metodo KCV
Terminiamo l’analisi con la KCV, settando k = 10 e selezionando l’appo-
sita opzione in WEKA explorer tra le “Test options”. Presentiamo in Tab.
8.3 i risultati per la Cross Validation: anche in questo caso, la SVM gaussia-
na risulta il metodo statistico che meglio si comporta. La stima dell’errore,
in piu, e molto buona, dato che la differenza e nell’ordine dello 0.1%.
111

Metodo Errore KCV Errore test
NBC 18.93% 22.96%
MLP 3.27% 4.81%
SVM lin 4.13% 5.31%
SVM gauss 2.73% 2.84%
DT 4.27% 3.83%
Tabella 8.3: Risultati per il metodo k–Fold Cross Validation (KCV): in
grassetto, le migliori percentuali ottenute.
8.3 Analisi in WEKA KF
Fino ad ora, nella nostra analisi, abbiamo utilizzato solamente WEKA
explorer. Tra i vari applicativi disponibili in WEKA e pero presente anche
un altro strumento molto comodo: WEKA Knowledge Flow, che chiameremo
KF per brevita. KF e molto simile nell’aspetto e nell’utilita al tool Simulink
di MATLAB: in pratica, il modello simulativo viene creato come schema a
blocchi, in cui ad ogni blocco corrisponde una particolare elaborazione sul
dato.
E impensabile riuscire ad analizzare ogni blocco di KF, ma la guida di-
sponibile con il software e abbastanza completa e user–friendly. Noi andremo
a creare, invece, un modello passo–passo per vedere come si puo implementa-
re quanto gia fatto con WEKA explorer in questo strumento, da molti punti
di vista ancora piu potente.
KF e costituito da una serie di tab, ognuno rappresentante: blocchi per
l’input dati; blocchi per l’output dati; filtri da applicare al dataset; algoritmi
per classificazione e regressione; algoritmi di clustering; blocchi per la valu-
tazioni delle performance dei metodi statistici; blocchi per la visualizzazione
dell’output a video.
Ci poniamo come obiettivo la realizzazione di una valutazione compara-
tiva tra una SVM gaussiana e una SVM lineare sul dataset segment con una
KCV a 10 fold. Vediamo passo–passo come fare.
112

8.3.1 Input
Il primo passo corrisponde alla selezione del dataset. Essendo sotto forma
di file arff, selezioniamo il tab per gli input e trasciniamo nello spazio per la
creazione del modello il blocco “ArffLoader”. Clicchiamo col tasto destro e
configuriamo il blocco, selezionando il file per il nostro dataset.
8.3.2 Selezione della classe
Caricato il dataset, siamo interessati ad un problema di classificazione.
Pertanto, dobbiamo definire un attributo come classe: nel tab “Evaluation”,
trasciniamo nel progetto il blocco “Class Assigner”.
A questo punto, dobbiamo connettere al blocco il dataset, caricato al
passo 8.3.1: clicchiamo sul blocco “ArffLoader” col tasto destro e, nella
sottocategoria “Connections”, colleghiamo il dataset con il “Class Assigner”.
Non ci resta che configurare il blocco “Class Assigner”, usando sempre il
tasto destro: selezioneremo l’attributo voluto (class) come classe. Il prefisso
“(Nom)” indica che l’attributo e di tipo nominale.
8.3.3 Creazione delle k fold per la KCV
Per creare le k fold per la cross validation, aggiungiamo il blocco “Cross
Validation Fold Maker”, disponibile sempre nel tab “Evaluation”. Configu-
riamolo per utilizzare 10 fold, quindi connettiamo il dataset in output dal
blocco “Class Assigner” a “Cross Validation Fold Maker”.
8.3.4 Inserimento dei blocchi per le SVM
A questo punto, non ci rimane che aggiungere i blocchi per la SVM
lineare e la SVM gaussiana. Nel tab “Classifiers”, troviamo “SMO”: tra-
sciniamo due istanze nel nostro progetto, configurandone una per la SVM
lineare (supponiamo C = 100) e l’altra per la SVM gaussiana (C = 100 e
γ = 1).
Aggiungiamo le connessioni: in uscita dal blocco “Cross Validation Fold
Maker”, connettiamo sia “TrainingSet” che “TestSet” (che, in verita, e il
validation set) ai due blocchi per la SVM. A questo punto, tutto e pronto
per la valutazione comparativa: ci manca solo un blocco per elaborare i
risultati e uno per visualizzare questi ultimi a video.
113

8.3.5 Elaborazione dei risultati
Sappiamo che il parametro di valutazione della KCV consiste nell’errore
commesso sulle varie istanze del validation set. Abbiamo, quindi, necessita
di un blocco che riunisca tali valori: “Classifier Performance Evaluator”,
disponibile nel tab “Evaluation”, ha proprio questo scopo.
Aggiunti due blocchi (uno per ogni SVM), connettiamo il “batchClassi-
fier” in uscita dai blocchi “SMO” con “Classifier Performance Evaluator”, in
modo da valutare le performance dei classificatori.
8.3.6 Uscita a video
Ultimo step: porre in uscita a video i nostri risultati. Aggiungiamo, quin-
di, un blocco “Text Viewer” (disponibile nel tab “Visualization”) e connettia-
mo le uscite testuali (“text”) dei blocchi “Classifier Performance Evaluator”
al visualizzatore. Non ci resta che eseguire il tutto.
Figura 8.1: Esempio di schema realizzato in WEKA KF.
8.3.7 Configurazione finale ed esecuzione
Abbiamo terminato gli step necessari, dovremmo avere ora a disposizio-
ne una struttura tipo quella mostrata in Fig. 8.1. Non ci resta che lanciare
l’analisi: clicchiamo col tasto destro su “ArffLoader” e, nella sottocategoria
“Actions”, optiamo per “Start loading”. Attendiamo il termine dell’esecuzio-
ne (ci viene comunicato nella barra dei log sottostante), quindi clicchiamo col
tasto destro sul “Text viewer” e selezioniamo “Show results”: nella finestra
di testo, sulla sinistra, possiamo selezionare i risultati per i metodi inseriti
nel progetto e visualizzarli. E facilmente verificabile che i valori, come ci si
attendeva, sono gli stessi di Tab. 8.3.
114

8.4 Note conclusive
E possibile che, specialmente nel caso si utilizzi la KCV su dataset con un
numero di pattern elevato, i modelli creati per la valutazione di un metodo
statistico siano piuttosto “ingombranti” in termini di occupazione di me-
moria. Spesso, si deve ricorrere ad un heap piu capiente: a questo scopo, e
necessario ricompilare WEKA da riga di comando. In particolare, l’istruzione
di compilazione diventa:
java -Xmx512m -jar weka.jar
identica alla riga di compilazione originaria, presentata nel paragrafo 1.4, a
meno dell’opzione di compilazione -Xmx, indicante la dimensione dello stack,
seguita dalla dimensione di quest’ultimo (nel caso citato, 512 MB).
115

Bibliografia
[1] R. Agrawal e R. Srikant. Fast algorithms for mining association rules in largedatabases. In Proc. of the Int. Conf. on Very Large Databases, pagg. 478–499,1994.
[2] D. Anguita, S. Ridella, e D. Sterpi. Testing the augmented binary multiclasssvm on microarray data. In Proc. of the IEEE Int. Joint Conf. on NeuralNetworks, IJCNN 2006, pagg. 1966–1968, 2006.
[3] M. Aupetit. Homogeneous bipartition based on multidimensional ranking.In Proc. of the European Symposium on Artificial Neural Networks, ESANN2008, 2008.
[4] V. Barnett. Elements of Sampling Theory. Arnold, 1975.[5] M. Berry e G. Linoff. Data Mining Techniques for Marketing, Sales, and
Customer Support. John Wiley & Sons, 1997.[6] C. J. C. Burges. A tutorial on support vector machines for classification.
Data Mining and Knowledge Discovery, 2:121–167, 1998.[7] J. Cohen. A coefficient of agreement for nominal scales. Educational and
Psychological Measurement, 20(1):37–46, 1960.[8] C. Cortes e V. Vapnik. Support–vector networks. Machine Learning, 27:273–
297, 1991.[9] U. Fayaad. Proceedings of the First Int. Conf. on Knowledge Discovery and
Data Mining. Montreal, Canada, 1995.[10] P. Giudici. Applied Data Mining: Statistical Methods for Business and
Industry. John Wiley & Sons, 2003.[11] I. Guyon, J. Weston, S. Barnhill, e V. Vapnik. Gene selection for cancer
classification using support vector machines. Machine Learning, 46:389–422,2002.
[12] G. H. John e P. Langley. Estimating continuous distributions in bayesianclassifiers. In Proc. of the 11th Int. Conf. on Uncertainity in ArtificialIntelligence, pagg. 338–345, 1998.
[13] I. T. Jolliffe. Principal component analysis. In Springer Series in Statistics,2002.
116

[14] R. Kimball e M. Ross. The Data Warehouse Toolkit (2nd edition). JohnWiley & Sons, 2002.
[15] T. Kohonen. Self–Organizing Maps (3rd edition). Springer, 2001.[16] M. L. Minsky e S. A. Papert. Perceptrons. Cambridge Press, 1969.[17] K. Pearson. On lines and planes of closest fit to systems of points in space.
Philosophical Magazine, 2(6):559–572, 1901.[18] J. C. Plat. Probabilistic outputs for support vector machines and comparison
to regularized likelihood methods. In Advances in Large Margin Classifiers.MIT Press, 2000.
[19] J. R. Quinlan. Learning with continuous classes. In Proc. of the AustralianJoint Conf. on Artificial Intelligence, pagg. 343–348, 1992.
[20] J. R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann,1993.
[21] F. Rosenblatt. The perceptron: A probabilistic model for information storageand organization in the brain. Psychological Review, 65(6):386–408, 1958.
[22] A. J. Smola e B. Schoelkopf. A tutorial on support vector regression.Rapporto tecnico, Statistics and Computing, 1998.
[23] V. Vapnik. The Nature of Statistical Learning Theory. Springer, 2001.[24] Y. Wang e I. H. Witten. Induction of model trees for predicting continuous
classes. In Proc. of the European Conference on Machine Learning, 1997.
117