
Arvaia - Cittadini coltivatori biologici, Bologna - 26.02.2016
1
DataBase Biologici

2
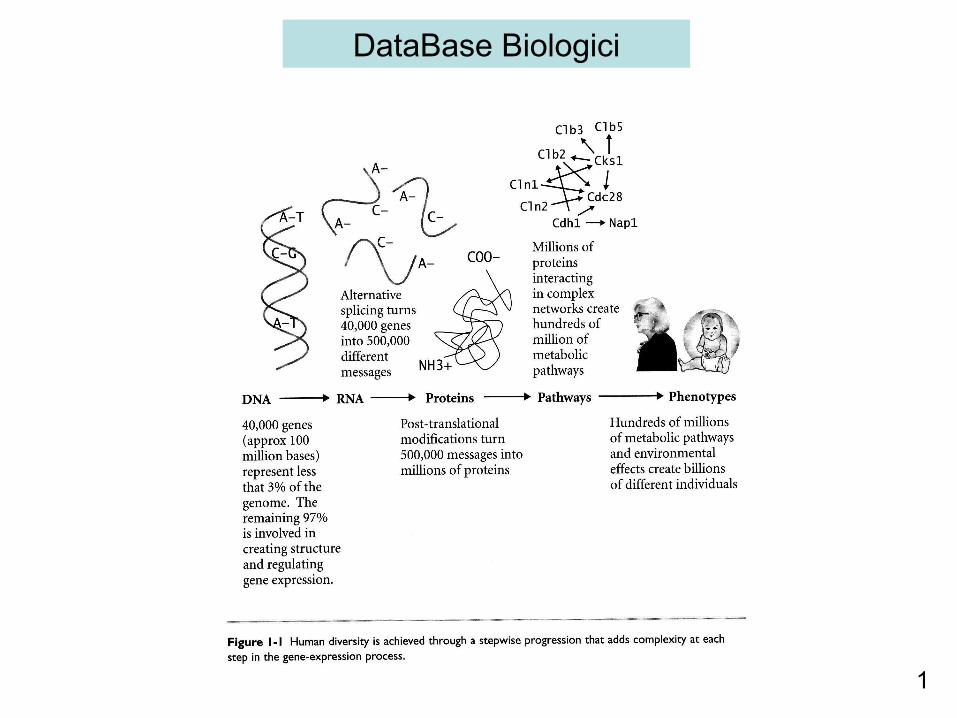
Lo sviluppo di tecnologie strumentali sempre più sofisticate ha portato ad una enorme produzione di dati biologici.Per la gestione di questi dati è quindi necessario disporre di potenti sistemi di archiviazione e di strumenti per accedere alle loro informazioni.
Database biologici (banche di dati biologici)
- Sono essenzialmente dei contenitori ordinati di informazioni costruiti per introdurre e mantenere dati di tipo biologico e permettere una facile consultazione (query)
- raccolgono informazioni e dati derivati dalla letteratura e da analisi effettuate in laboratorio oppure attraverso l’applicazione di analisi bioinformatiche o analisi in silico.
- sono generalmente accessibili liberamente e possono essere consultati via web.
-ogni banca dati è caratterizzata da un elemento centrale attorno al quale viene costruita la entry della banca dati.
Ad esempio, l’elemento centrale per le banche dati di sequenze di acidi nucleici è la sequenza nucleotidica di DNA o di RNA

3
ENTREZE’ il punto di partenza per eseguire query su tutti o parte dei database dell’NCBI
Esistono molti e differenti DB biologici, più o meno specialistici, che sono in continua evoluzione.
E’ ‘relativamente facile’ ricercare dati particolari …. se si conosce l’esistenza del DB che li contiene.
Per le specifiche ricerche nei DB biologici, sono di aiuto strumenti (tools) messi a disposizione dai principali centri di bioinformatica, in particolare ENTREZ all’NCBI (negli USA) e EMBL-EBI (in Europa)
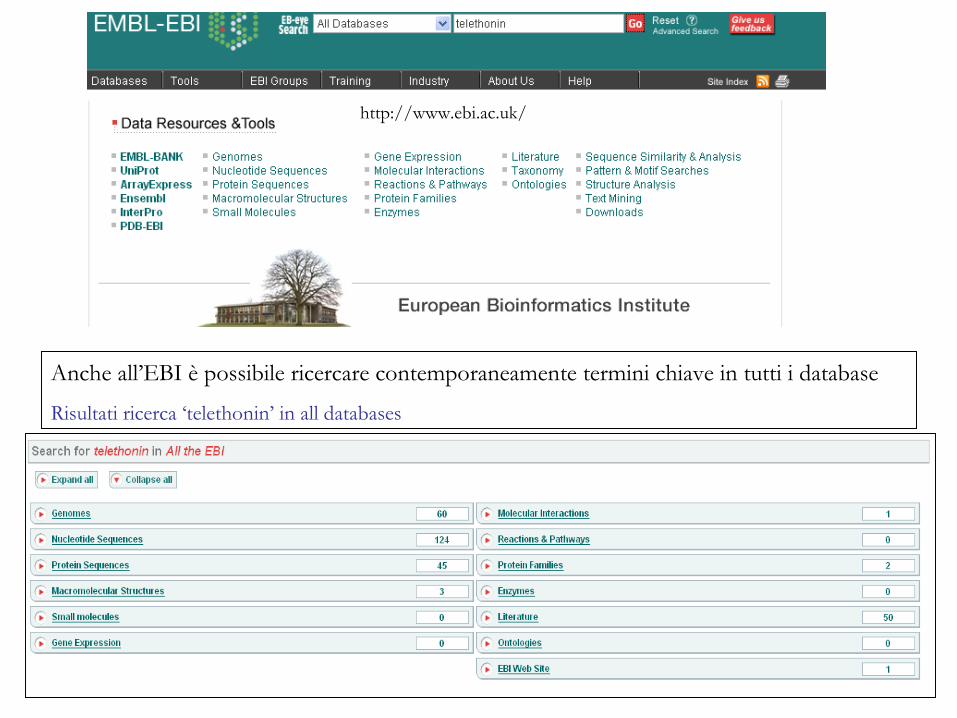
4
http://www.ebi.ac.uk/
Anche all’EBI è possibile ricercare contemporaneamente termini chiave in tutti i database
Risultati ricerca ‘telethonin’ in all databases

5
Come tutti i database, l’oggetto principale è il ‘record’, una unità riconoscibile grazie ad un identificatore univoco; il record possiede una descrizione organizzata in campi standardizzati riconoscibili grazie ad ‘Header’ (etichette dei campi) univoci nella banca dati; esempio Identificatore , Autore , Data , ecc.
Generalmente, ogni banca di dati biologici è presente in due forme:Flat-file: un file di testo semplice, formattato, non interattivoHTML (o XML): interattivo, di facile consultazione attraverso la rete Web.
Organizzazione di un database biologico
I DB biologici, in formato html (consultabili via internet), contengono spesso riferimenti (link) a record di altri database (cross-references). Questi link sono molto utili: permettono di navigare tra record di differenti DB tra loro correlati (ricerca interattiva) ‘cliccando’ semplicemente nei link.
Troveremo questi cross-reference nelle prossime lezioni e nelle esercitazioni. E’ importante riconoscerli
CCDS DB Consensus CDS GeneID Gene DBHGNC ‘HUGO Gene Nomenclature Committee’ (Unique Gene Symbols and names )HPRD Human Protein Reference DatabaseMIM OMIM: DB malattie genetiche
Nei DB biologici i cross-reference a specifici database sono spesso preceduti dalla definizione ‘db_xref=‘ seguito dalla abbreviazione del database e dall’ID o Accession number del record ‘linkato’. Esempio:

6
Esempi di Cross-references
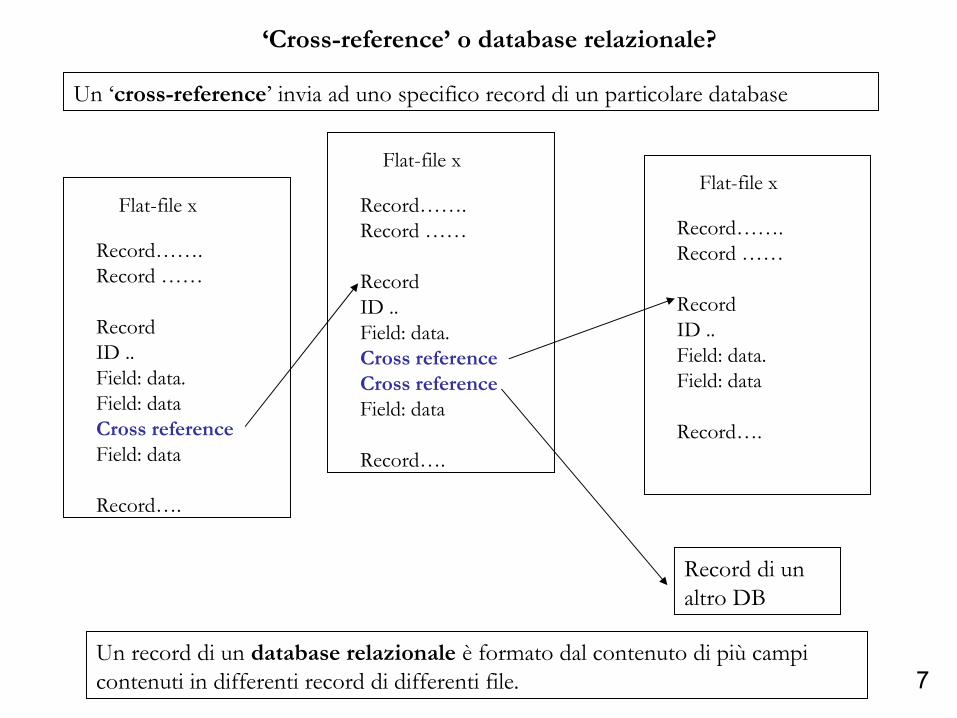
7
‘Cross-reference’ o database relazionale?
Un ‘cross-reference’ invia ad uno specifico record di un particolare database
Flat-file x
Record…….Record ……
Record ID ..Field: data.Field: dataCross referenceField: data
Record….
Un record di un database relazionale è formato dal contenuto di più campi contenuti in differenti record di differenti file.
Flat-file x
Record…….Record ……
Record ID ..Field: data.Cross referenceCross referenceField: data
Record….
Flat-file x
Record…….Record ……
Record ID ..Field: data.Field: data
Record….
Record di un altro DB
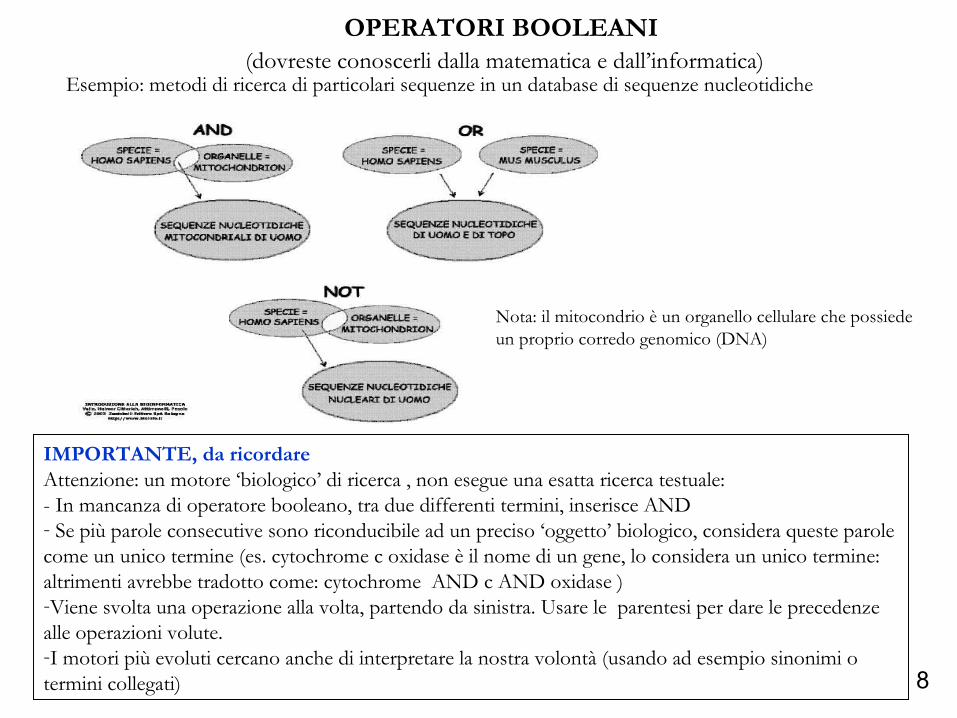
8
OPERATORI BOOLEANI (dovreste conoscerli dalla matematica e dall’informatica)
Esempio: metodi di ricerca di particolari sequenze in un database di sequenze nucleotidiche
Nota: il mitocondrio è un organello cellulare che possiede un proprio corredo genomico (DNA)
IMPORTANTE, da ricordareAttenzione: un motore ‘biologico’ di ricerca , non esegue una esatta ricerca testuale:- In mancanza di operatore booleano, tra due differenti termini, inserisce AND- Se più parole consecutive sono riconducibile ad un preciso ‘oggetto’ biologico, considera queste parole come un unico termine (es. cytochrome c oxidase è il nome di un gene, lo considera un unico termine: altrimenti avrebbe tradotto come: cytochrome AND c AND oxidase )-Viene svolta una operazione alla volta, partendo da sinistra. Usare le parentesi per dare le precedenze alle operazioni volute.-I motori più evoluti cercano anche di interpretare la nostra volontà (usando ad esempio sinonimi o termini collegati)

9
Interrogazioni delle Banche Dati
RICERCHE TESTUALI (QUERY)Restituiscono i record di un database che soddisfano i criteri richiesti (ricerca di tipo letterale, individua termini uguali) attraverso l’utilizzo di programmi di RETRIEVAL (cioè di ricerca, reperimento dati).Ricordo che i database devono essere tutti standardizzati (tag, separatori, headers, segni di punteggiatura ecc) questo rende rapida la ricerca)
RICERCHE PER SIMILARITÀ(su sequenze nucleotidiche o proteiche)Restituiscono le sequenze di un database più simili ad una sequenza fornita come query. Non sono delle vere e proprie query in quanto richiedono l’esecuzione di programmi anche piuttosto complessi (ad esempio BLAST che vedremo nelle prossime lezioni).
Domande: Trovare la sequenza nucleotidica del gene ‘telethonin’ è una ricerca testuale o di similarità?Ricercare un sequenza proteica di homo sapiens è una query o una ricerca per similarità?
In questa prima parte del corso ci occuperemo delle ricerche di tipo testuali

10
- Rivista dove è pubblicato (nome, data di pubblicazione, volume, pagina )
- Titolo
- Autori
- Abstract (Riassunto dell’articolo)
- Introduzione
- Opzionali: ringraziamenti
- References (Bibliografia)
Struttura di un articolo scientifico
Materiali e metodi
Risultati, discussione, conclusione
Descrizione del lavoro
DB bibliografico di articoli scientifici e relativa ricercaVediamo prima come è strutturato un articolo scientifico:

11
12
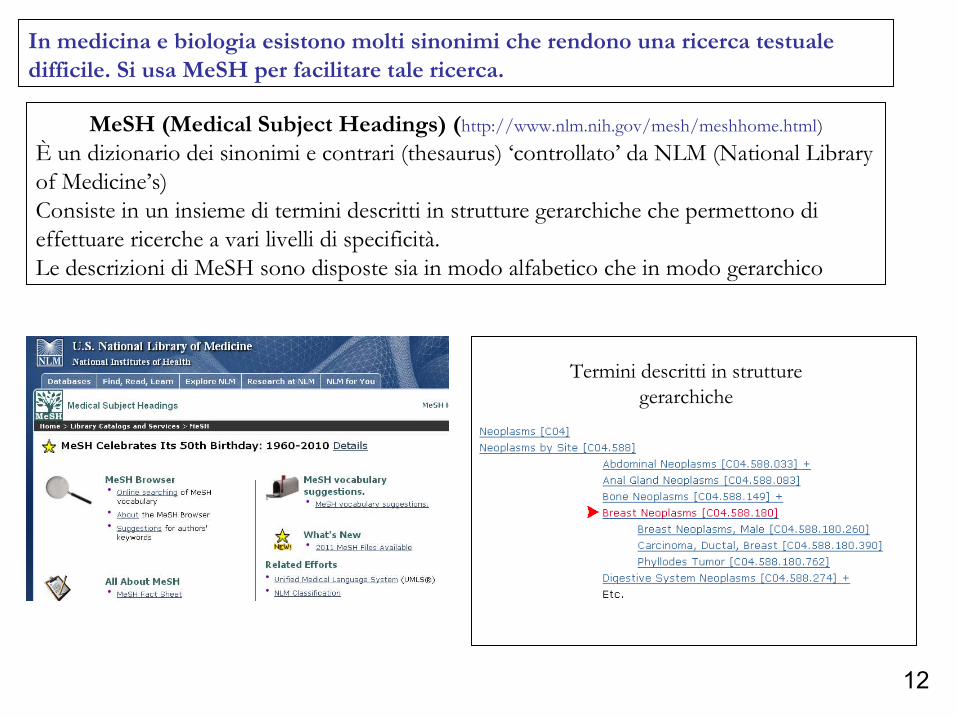
MeSH (Medical Subject Headings) (http://www.nlm.nih.gov/mesh/meshhome.html)È un dizionario dei sinonimi e contrari (thesaurus) ‘controllato’ da NLM (National Library of Medicine’s)Consiste in un insieme di termini descritti in strutture gerarchiche che permettono di effettuare ricerche a vari livelli di specificità.Le descrizioni di MeSH sono disposte sia in modo alfabetico che in modo gerarchico
In medicina e biologia esistono molti sinonimi che rendono una ricerca testuale difficile. Si usa MeSH per facilitare tale ricerca.
Termini descritti in strutture gerarchiche

13
Il database è prodotto dalla National Library of Medicine (NLM), contiene soprattutto gran parte della letteratura scientifica prodotta nell'ambito della biologia, della medicina e della biochimica.I principali dati degli articoli scientifici (provenienti da più di 5200 riviste) sono classificati e memorizzati in specifici campi. Un articolo scientifico è rappresentato da uno specifico record.Per permettere una veloce ricerca, il database è indicizzato su differenti campi e per l’indicizzazione viene utilizzato il vocabolario controllato Medical Subject Headings (MeSH)
MEDLINE è disponibile gratuitamente via internet attraverso "PubMed".
MEDLINE (Medical Literature Analysis and Retrieval System Online) database bibliografico (e altro)
Record MEDLINE
14
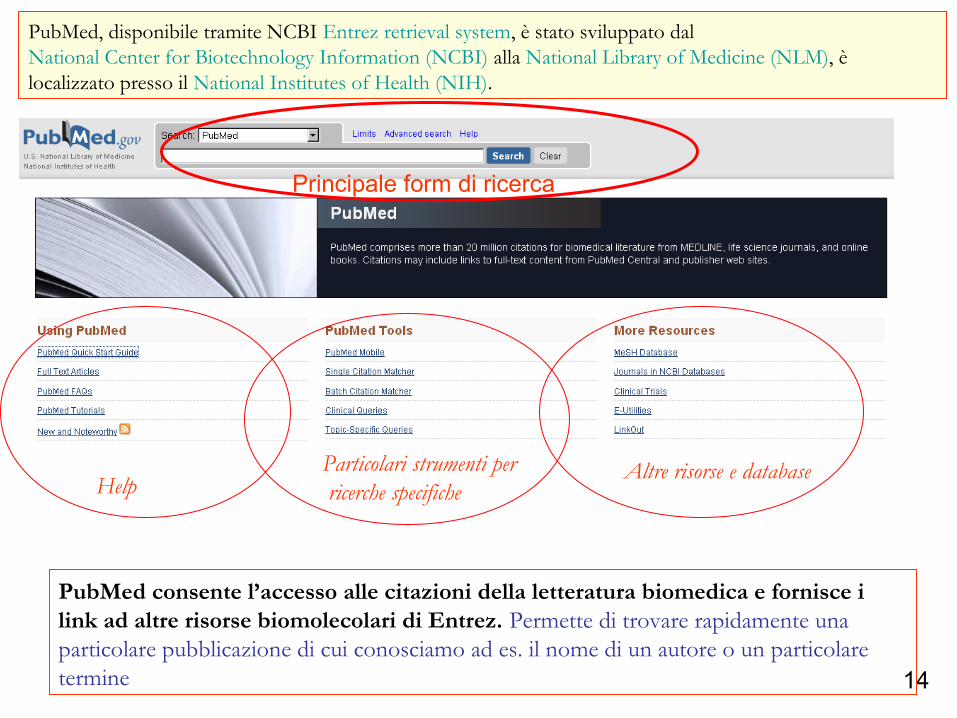
PubMed, disponibile tramite NCBI Entrez retrieval system, è stato sviluppato dal National Center for Biotechnology Information (NCBI) alla National Library of Medicine (NLM), è localizzato presso il National Institutes of Health (NIH).
PubMed consente l’accesso alle citazioni della letteratura biomedica e fornisce i link ad altre risorse biomolecolari di Entrez. Permette di trovare rapidamente una particolare pubblicazione di cui conosciamo ad es. il nome di un autore o un particolare termine
Principale form di ricerca
Particolari strumenti per ricerche specifiche
Altre risorse e databaseHelp
15
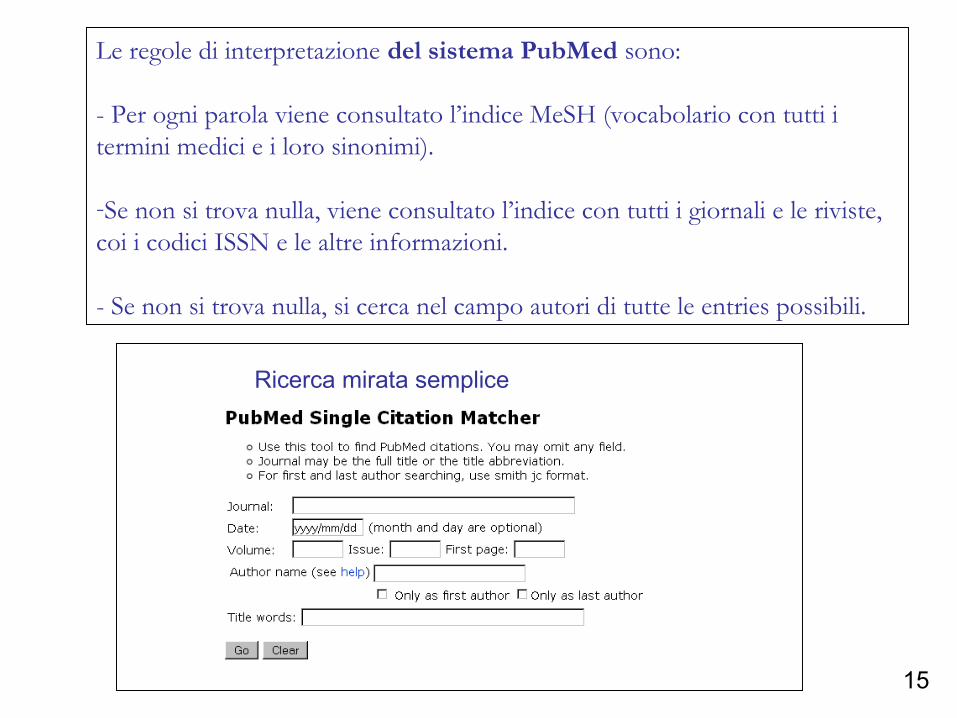
Le regole di interpretazione del sistema PubMed sono:
- Per ogni parola viene consultato l’indice MeSH (vocabolario con tutti i termini medici e i loro sinonimi).
-Se non si trova nulla, viene consultato l’indice con tutti i giornali e le riviste, coi i codici ISSN e le altre informazioni.
- Se non si trova nulla, si cerca nel campo autori di tutte le entries possibili.
Ricerca mirata semplice
16
Per poter effettuare complesse ricerche è necessario conoscere a fondo la struttura dei database, l’esatta denominazione dei campi e la sintassi dei comandi (AND OR ecc.).
Ma ci vengono in aiuto alcune ‘utility’……
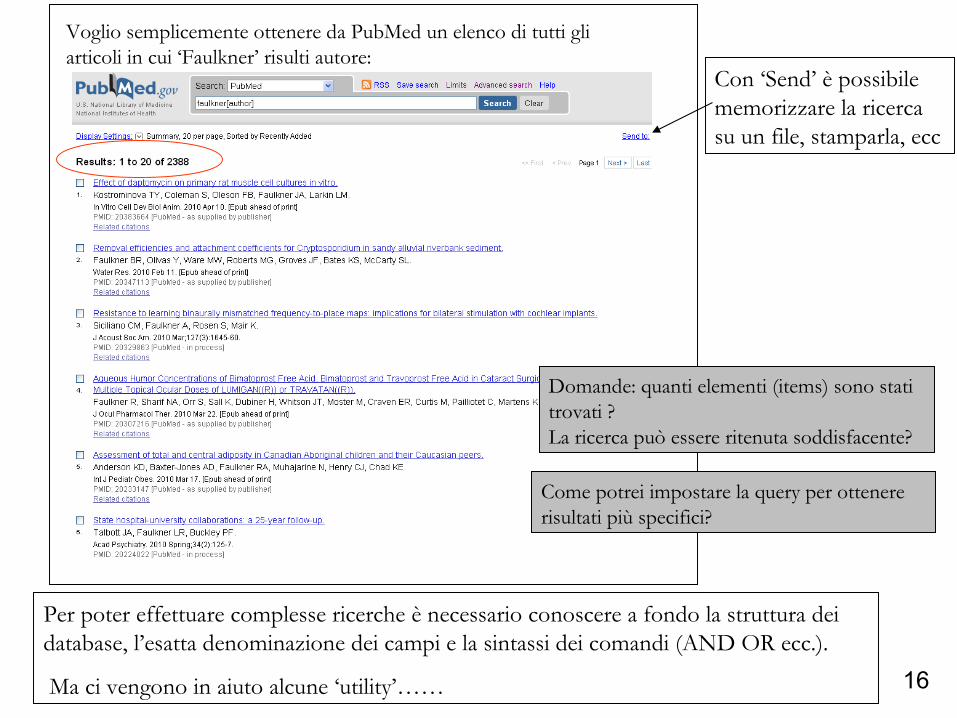
Voglio semplicemente ottenere da PubMed un elenco di tutti gli articoli in cui ‘Faulkner’ risulti autore:
Come potrei impostare la query per ottenere risultati più specifici?
Domande: quanti elementi (items) sono stati trovati ?La ricerca può essere ritenuta soddisfacente?
Con ‘Send’ è possibile memorizzare la ricerca su un file, stamparla, ecc
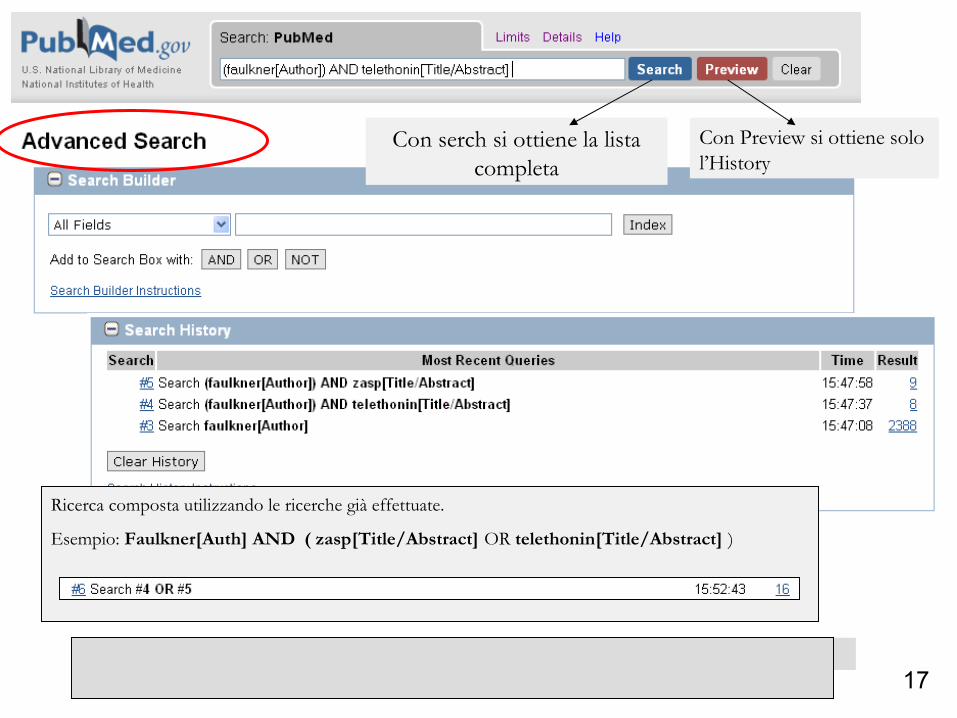
17
Ricerca composta utilizzando le ricerche già effettuate.
Esempio: Faulkner[Auth] AND ( zasp[Title/Abstract] OR telethonin[Title/Abstract] )
Cosa ci aspettiamo con #4 AND #5 ?
Con serch si ottiene la lista completa
Con Preview si ottiene solo l’History
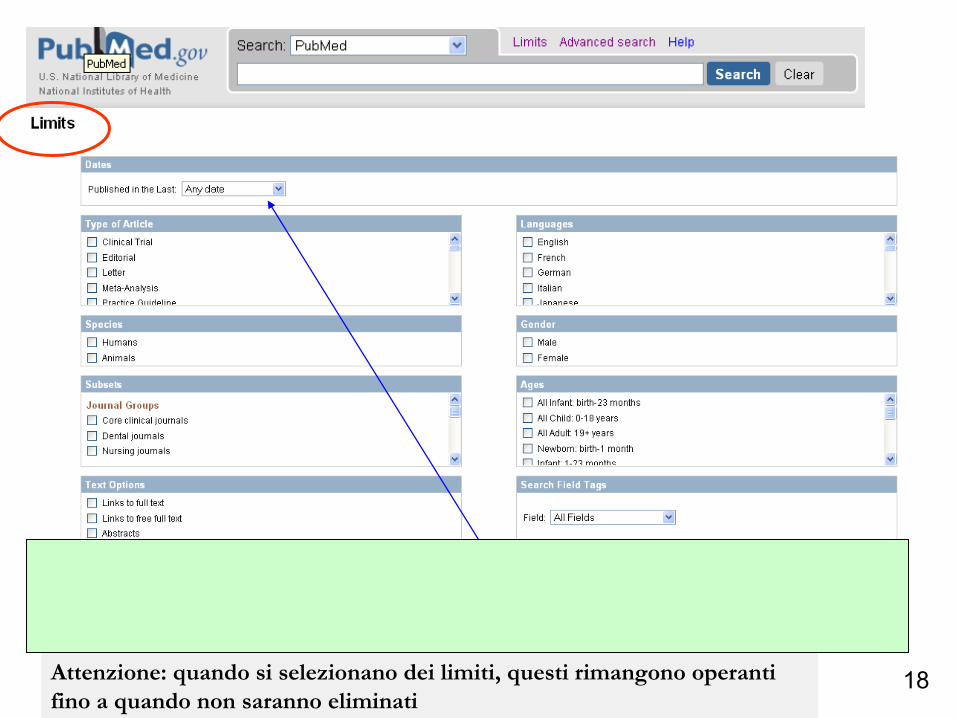
18
Esempio: impostando il limite ‘in the last 2 years’
Attenzione: quando si selezionano dei limiti, questi rimangono operanti fino a quando non saranno eliminati
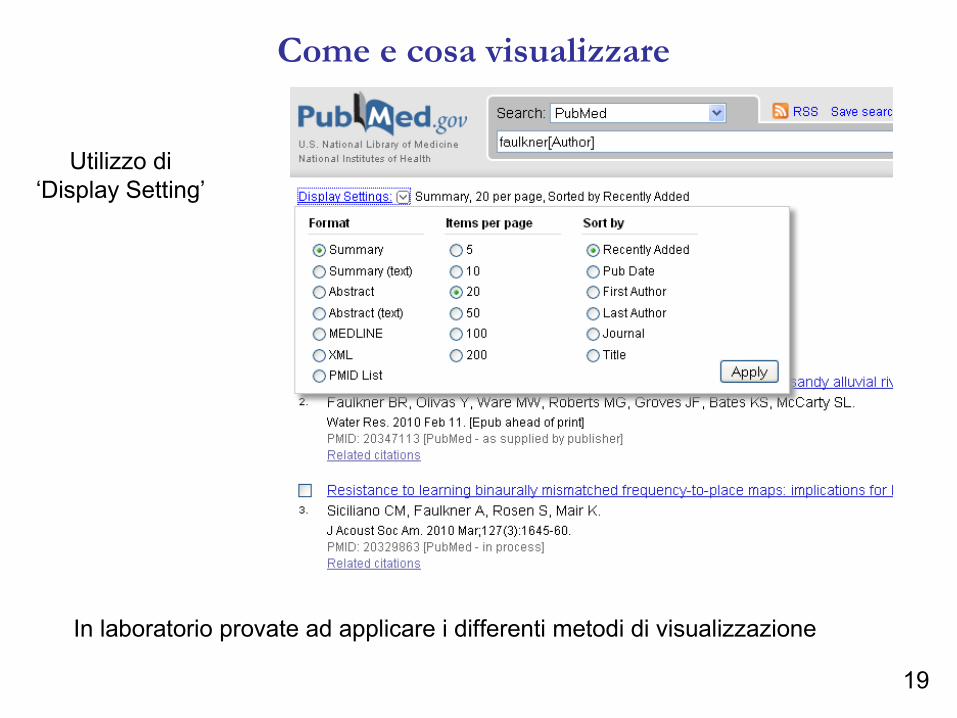
19
Come e cosa visualizzare
Utilizzo di ‘Display Setting’
In laboratorio provate ad applicare i differenti metodi di visualizzazione

20
‘Cliccando’ sul titolo del record si arriva qui, da dove, se l’articolo è ‘free’, sarà possibile accedere integralmente all’articolo scientifico
‘Cliccando’ sull’icona dell’editore, sarà possibile scaricare l’articolo.
( Solo se l’articolo è ‘free’ , altrimenti sarà necessario pagare)
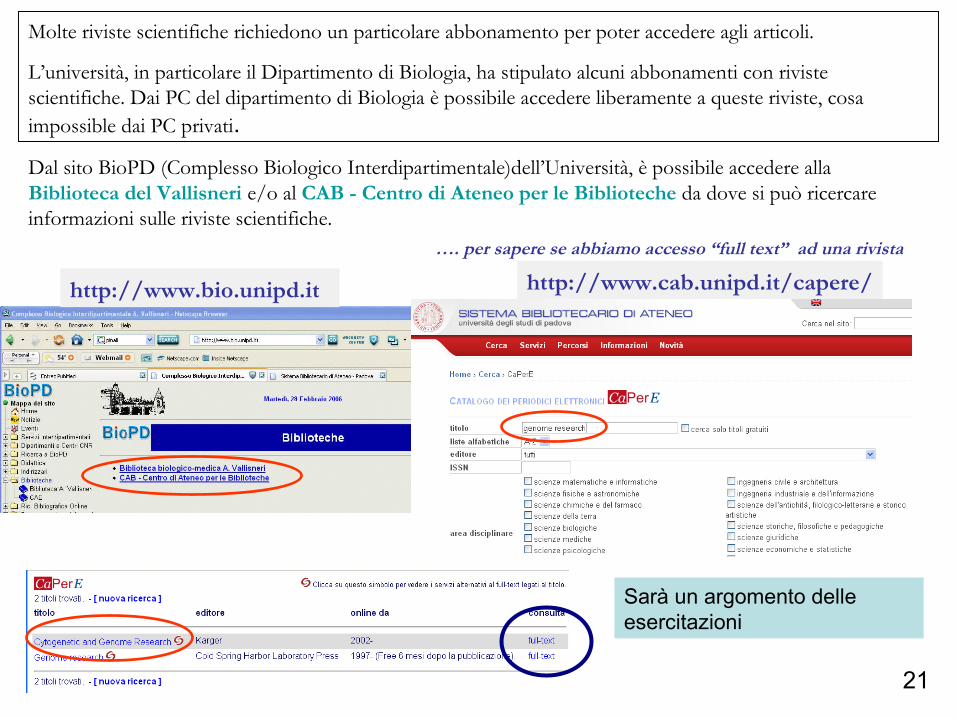
21
…. per sapere se abbiamo accesso “full text” ad una rivista
http://www.bio.unipd.it http://www.cab.unipd.it/capere/
Molte riviste scientifiche richiedono un particolare abbonamento per poter accedere agli articoli.
L’università, in particolare il Dipartimento di Biologia, ha stipulato alcuni abbonamenti con riviste scientifiche. Dai PC del dipartimento di Biologia è possibile accedere liberamente a queste riviste, cosa impossible dai PC privati.
Dal sito BioPD (Complesso Biologico Interdipartimentale)dell’Università, è possibile accedere alla Biblioteca del Vallisneri e/o al CAB - Centro di Ateneo per le Biblioteche da dove si può ricercare informazioni sulle riviste scientifiche.
Sarà un argomento delle esercitazioni


















