
Corso di Laboratorio di Informatica II - disi.unige.it · Nelle scienze sperimentali, i dati...
57
Corso di Laboratorio di Informatica II Stefano Rovetta 1 aprile 2003
Transcript of Corso di Laboratorio di Informatica II - disi.unige.it · Nelle scienze sperimentali, i dati...

Corso di Laboratorio di Informatica II
Stefano Rovetta
1 aprile 2003


Indice
1 Introduzione 51.1 Argomento del corso . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2 Perché metodi automatici? . . . . . . . . . . . . . . . . . . . . . . . 51.3 Alcuni esempi di dati . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3.1 Botanica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3.2 Medicina . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3.3 Immagini . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.4 DNA microarray . . . . . . . . . . . . . . . . . . . . . . . . 7
1.4 Traccia del corso . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 I dati bio-medici: rilevamento, trattamento e modellazione 112.1 Caratteristiche dei dati biomedici . . . . . . . . . . . . . . . . . . . . 11
2.1.1 Misure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.1.2 Tipologie di dati . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Rappresentazione dei dati . . . . . . . . . . . . . . . . . . . . . . . . 132.2.1 Come si rappresentano i dati in un programma . . . . . . . . 132.2.2 Come si organizzano i dati . . . . . . . . . . . . . . . . . . . 142.2.3 Come si memorizzano i dati su un file . . . . . . . . . . . . . 152.2.4 Interpretazione matematica . . . . . . . . . . . . . . . . . . . 15
2.3 Elaborazioni preliminari sui dati . . . . . . . . . . . . . . . . . . . . 162.3.1 Tipi di elaborazioni preliminari . . . . . . . . . . . . . . . . 162.3.2 Ripulitura . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.3.3 Normalizzazione . . . . . . . . . . . . . . . . . . . . . . . . 182.3.4 Estrazione delle feature . . . . . . . . . . . . . . . . . . . . . 202.3.5 Criteri per la normalizzazione . . . . . . . . . . . . . . . . . 20
2.4 La metodologia statistica . . . . . . . . . . . . . . . . . . . . . . . . 212.4.1 Generalità . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.4.2 Stima dal campione . . . . . . . . . . . . . . . . . . . . . . . 222.4.3 Valutazione della confidenza . . . . . . . . . . . . . . . . . . 22
2.5 Modelli probabilistici dei dati . . . . . . . . . . . . . . . . . . . . . . 23
3 Il problema della classificazione 253.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1.1 La classificazione . . . . . . . . . . . . . . . . . . . . . . . . 253.1.2 Metodi di classificazione . . . . . . . . . . . . . . . . . . . . 26
3.2 Teoria bayesiana della decisione . . . . . . . . . . . . . . . . . . . . 273.3 Superfici discriminanti . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3.1 Il caso di fenomeni con modello Gaussiano semplice . . . . . 29
3

Indice
3.3.2 Altri casi . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.4 Apprendimento automatico . . . . . . . . . . . . . . . . . . . . . . . 31
3.4.1 L’apprendimento da esempi . . . . . . . . . . . . . . . . . . 313.4.2 Procedimento e nomenclatura . . . . . . . . . . . . . . . . . 323.4.3 Stima della qualità di un classificatore . . . . . . . . . . . . . 333.4.4 Quanto è affidabile la stima che abbiamo fatto? . . . . . . . . 33
3.5 Un modello parametrico . . . . . . . . . . . . . . . . . . . . . . . . 343.6 Modelli non parametrici . . . . . . . . . . . . . . . . . . . . . . . . 35
3.6.1 Nearest neighbor . . . . . . . . . . . . . . . . . . . . . . . . 353.6.2 Perceptron . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.6.3 Separabilità lineare . . . . . . . . . . . . . . . . . . . . . . . 403.6.4 Multi-Layer Perceptron . . . . . . . . . . . . . . . . . . . . . 413.6.5 Support vector machines . . . . . . . . . . . . . . . . . . . . 43
4 Il problema del clustering 454.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.1.1 Il clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.1.2 Distanze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 464.1.3 Come effettuare i raggruppamenti . . . . . . . . . . . . . . . 47
4.2 Clustering partitivo . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.2.1 L’algoritmok-means . . . . . . . . . . . . . . . . . . . . . . 484.2.2 Validazione dei cluster . . . . . . . . . . . . . . . . . . . . . 49
4.3 Clustering gerarchico . . . . . . . . . . . . . . . . . . . . . . . . . . 504.3.1 Il principio del clustering gerarchico . . . . . . . . . . . . . . 504.3.2 Scelta della distanza e dellinkage . . . . . . . . . . . . . . . 514.3.3 Esempio di algoritmo . . . . . . . . . . . . . . . . . . . . . . 53
4.4 Attenzione a come si procede . . . . . . . . . . . . . . . . . . . . . . 534.4.1 Normalizzazioni . . . . . . . . . . . . . . . . . . . . . . . . 534.4.2 Inizializzazione . . . . . . . . . . . . . . . . . . . . . . . . . 544.4.3 Instabilità . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4

1 Introduzione
Sommario
Motivazioni – Esempi di dati bio-medici – Traccia del corso
1.1 Argomento del corso
Ci interessano metodi automatici per il trattamento dei dati provenienti da fenomeni dinatura biologica.
1.2 Perché metodi automatici?
1. Per ottenere risultati oggettivi e ripetibili, non soggetti al giudizio individualedel ricercatore o alle sue impressioni del momento.
2. Perché si vuole poter immagazzinare l’esperienza di uno o diversi esperti su unargomento e utilizzarla anche in assenza degli esperti.
3. Per risparmiare tempo, fatica e anche soldi (gli esperti costano, e in generalel’intervento umano è sempre costoso).
4. Perché non si può fare altro (molti dati sono per loro naturamultidimensionali,per esempio le immagini e i dati da DNA microarray, oppureenormementeabbondanti, come le sequenze geniche e proteiche) e impossibili da trattare inmaniera manuale).
5. Per curiosità scientifica (l’imitazione del comportamento intelligente,intelli-genza artificialeecibernetica, è uno degli obiettivi che ha dato vita alla scienzadei calcolatori).
5

1 Introduzione
Figura 1.1 –Le misure sugli iris (dati tratti da [3])
1.3 Alcuni esempi di dati
1.3.1 Botanica
Nel 1935 il celebre statistico Ronald A. Fisher pubblicò uno studio sull’analisi statisti-ca di misure multiple nell’indagine biologica [3]. La statistica è la scienza che sta allabase delle tecniche di decisione automatica che studiamo noi.
Fisher riporta un esempio di campione statistico che riguarda tre varietà di fiori di Iris.Dei fiori vengono misurati lunghezza e larghezza dei petali e lunghezza e larghezza deisepali. Le tre varietà sono:
• Iris Setosa
• Iris Versicolor
• Iris Virginica
e per ogni varietà sono misurati 50 esemplari.
La figura 1.1 illustra, su un diagramma cartesiano, i punti le cui coordinate sono rispet-tivamente la lunghezza dei petali e dei sepali per ciascun esemplare; varietà diversesono illustrate con simboli diversi.
Avendo 4 misure, non è possibile disegnare in un unico diagramma dei punti che illu-strano tutti e 4 i valori (nessuno possiede un foglio quadridimensionale su cui tracciareil grafico).
1.3.2 Medicina
Una cartella clinica descrive le osservazioni che il medico effettua sul paziente. Es-sa riporta i dati anagrafici, i dati ricavati dalle interviste al paziente, i dati da proveeffettuate dal medico nel corso della visita, i dati da analisi su campioni biologici...
6

1.3 Alcuni esempi di dati
Figura 1.2 –Un esempio (di una parte) di immagine di microarray a DNA
In generale una cartella clinica comprende molte osservazioni. Esse sono utili in pri-mo luogo per determinare la diagnosi, e successivamente per valutare il decorso dellamalattia.
Un esempio di analisi di dati medici multipli è il database “thiroid disease”, che sipuò trovare in rete nel “Machine Learning Database Repository” dell’Università dellaCalifornia a Irvine [1].
Si tratta di una serie di casi di malattia della tiroide. Ognuno dei 6 gruppi di osserva-zioni comprende circa 3800 pazienti e 29 variabili misurate per ogni paziente.
È chiaro che non è possibile pensare di osservare questi dati senza l’aiuto di metodi didescrizione e decisione automatica.
1.3.3 Immagini
Le immagini sono segnali, cioè sono dati catturati da un sensore che rileva grandezzefisiche (la macchina fotografica, che rileva variazioni di luminosità e colore).
Una immagine viene digitalizzata. Cioè viene trasformata in una sequenza di numeri.
I numeri corrispondono ai livelli di luminosità misurati in molti punti dell’immagi-ne: l’immagine viene infatti divisa in quadrettini molto piccoli, approssimativamentepuntiformi.
Per esempio, può essere divisa in una griglia di 500 x 500 puntini. Ogni puntino sichiamapixel (picture element). 500 x 500 significa che avrò 500 righe composte di500 pixel ciascuna.
Il livello di luminosità di ogni pixel viene misurato, rappresentato come un numero, ememorizzato in una sequenza prestabilita. La sequenza più usata è la scansione raster(la stessa usata nei televisori):
• prima tutti i pixel della prima riga, da sinistra a destra;
• poi tutti i pixel della seconda riga, da sinistra a destra;
• poi tutti i pixel della terza riga, da sinistra a destra;
...
• infine tutti i pixel dell’ultima riga, da sinistra a destra.
7

1 Introduzione
1.3.4 DNA microarray
Un DNA microarray è un vetrino su cui sono depositate, in una matrice di dimensionimolto ridotte, dellesonde(probes) di cDNA oppure oligonucleotidi.
L’ibridazione delle sonde con un campione biologico viene rivelata attraverso la fluo-rescenza dovuta alla marcatura del campione (target).
Si ottiene un’immagine in cui, p.es., 50-100 campioni sono esaminati alla ricerca dellivello di espressione di 1000-10000 geni contemporaneamente.
A ogni coppia campione/gene corrisponde un’area luminosa, che viene trasformataalla fine in un numero.
Si ha quindi una tabella con (p.es.) 500000 numeri da esaminare.
1.4 Traccia del corso
Il corso inizia illustrando la natura dei dati biologici, il modo in cui sono rappresentati,trattati e modellati (ossia spiegati attraverso unmodello).
Successivamente sono presentati richiami a principi e tecniche diinferenza statistica,ossia come scegliere un modello che spiega i dati sperimentali.
Il seguito del corso è dedicato a presentare tecniche che usano uncampione(cioé uninsieme di osservazioni sperimentali), e si basano sull’inferenza statistica (oltre ad altriprincipi) per risolvere importanti problemi di analisi dei dati bio-medici.
Alcuni di questi problemi sono:
• il problema dellaclassificazione(o analisi discriminante o riconoscimento):
Io so che esistono due o piùclassio categorie di dati, e nel campioneho osservazioni relative a tutte le categorie. Devo trovare la legge chemi permette di assegnare le osservazioni (quelle che ho già e quelleche verranno) alla classe corretta.
• il problema delclustering (o cluster analysiso class discovery):
Io presumo che esistano due o piùclassi o categorie di dati, manel campione ho osservazioni di cui non conosco la categoria. Devotrovare associazioni naturali tra dati, usando qualche criterio di so-miglianza, in modo da raggruppare le osservazioni simili e scoprirecosìdelleclassi naturali.
• il problema dellaselezione del modello:
Ho un problema di uno dei tipi precedenti e voglio scoprire qualisono legrandezze da misurareche sono utili (o le più utili) allasua soluzione (selezione delle variabili); inoltre voglio scoprire qualisono letrasformazioni matematicheche mettono meglio in evidenzale proprietà delle variabili ai fini del mio problema (selezione dellefeature).
8

1.4 Traccia del corso
Il corso si concentra sui primi due problemi:classificazioneeclustering.
Vengono descritte varie tipologie di modello matematico, e gli usi tipici per ciascunmodello. Il corso tratta anche il particolare (ma importantissimo) problema dellese-quenze di dati non metrici o stringhe o sequenze simboliche(non metrico = nonnumerico), della loro archiviazione, ricerca e confronto.
9

1 Introduzione
10

2 I dati bio-medici: rilevamento,trattamento e modellazione
Sommario
Caratteristiche – Rappresentazione – Trattamento preliminare (preprocessing) – Lametodologia statistica – Modellazione probabilistica
2.1 Caratteristiche dei dati biomedici
2.1.1 Misure
Nelle scienze sperimentali, i dati vengono sempremisurati a partire da fenomeninaturali.
La misura di una proprietà fisica di un fenomeno è il processo di associare alla pro-prietà un valore (numerico o di altro tipo).
È importante notare che laproprietà fisica e la suamisura sono cosedifferenti .
1. Una misura deve mantenere le proprietà interessanti del fenomeno in esame, manon descrivere tutte le proprietà.
Per esempio, un medico valuta il dolore attraverso una scala VAS (Visual AnalogScore), su cui il paziente individua il proprio livello di dolore. Ma ovviamentequesta scala è soggettiva e quindi non possiede la proprietà per cui valori uguali(in pazienti diversi) corrispondono a livelli di dolore uguali.
Quindi una scala VAS può servire per capire se un paziente ha più o meno dolorerispetto all’ultima visita, ma non per confrontare il suo livello di dolore conquello di un altro paziente.
2. Un altro aspetto è l’errore di misura . Esistono 2 tipi di errore:
• L’errore sistematicoè introdotto dallo strumento o dal procedimento dimisura ed èsempre uguale.Esempio: un righello con centimetri non precisi.
11

2 I dati bio-medici: rilevamento, trattamento e modellazione
• L’errore casualeè introdotto dai limiti fisici dello strumento o procedi-mento, dalla variabilità del fenomeno, dalle condizioni ambientali. . . , ed èdifferente ad ogni misurazione.Esempio: la misura dei decimi di millimetro usando un righello millime-trato.
2.1.2 Tipologie di dati
I dati possono essere misurati a varilivelli di misura . Ci sono dati che, per loro natura,non possono essere misurati che in un modo, e ci sono altri dati che possono esseremisurati a più di un livello.
Le tipologie (livelli) generalmente considerate sononominale, ordinale, intervallare(e intervallare logaritmica ), metrica, assoluta.
Descrizione delle tipologie (livelli di misura):
Nominale: Si usano simboli. I simboli possono essere numeri o nomi, non impor-ta. Tra i simboli non c’è alcuna relazione d’ordine (non c’è un maggiore e unminore). Si può solo verificare se due simboli sono uguali o diversi.
Esempi: Sì/no. Bianco/rosso/verde/nero. I numeri dei giocatori in una squadradi calcio (il portiere è 1 ma non è “minore” del capitano!).
Ordinale: Si usano numeri interi. Esiste una relazione d’ordine. Due valori corri-spondono a due numeri in modo tale che il numero maggiore corrisponde all’og-getto maggiore. Quindi serve a rappresentare dati che possiedono, per natura,un ordinamento.
Esempi: Il numero di posizione nella coda di un negozio (rappresenta il tempodi arrivo, ma ne preserva solo l’ordinamento, non il valore assoluto letto sull’o-rologio). La velocità di eritrosedimentazione (VES) come misura dell’intensitàdi uno stato patologico.
Intervallare: Si usano numeri reali, su una scala in cuil’origine (lo zero) eil fattoredi scala (unità di misura) sono arbitrari. La misura rappresentadifferenze travalori , per esempio rispetto a un valore di riferimento convenzionale (lo zerodella scala), ma non ha senso in assoluto.
Esempi: La temperatura (in gradi Fahrenheit o Celsius). La data sul calendario(Giuliano, Gregoriano, Islamico, Ebraico. . . ).
Intervallare logaritmico: Si usano numeri reali, su una scala in cuil’origine (lozero) e il fattore di scala (unità di misura) sono arbitrari. La misura rap-presentarapporti tra valori , per esempio rispetto a un valore di riferimentoconvenzionale (l’unità di misura), ma non ha senso in assoluto.
Esempi: La densità (massa diviso volume). L’efficienza energetica (potenza resadiviso potenza fornita).
Metrico (razionale): Si usano numeri reali su una scala in cui solo l’unità di misuraè arbitraria. Ha senso calcolare sia differenze sia rapporti.
Esempi: Lunghezza. Durata (in secondi per esempio).
12

2.2 Rappresentazione dei dati
Assoluto: Si usano numeri su una scala in cui niente è arbitrario. Non si può cam-biare l’unità di misura e non si può cambiare l’origine.
Esempi: Il numero di membri di una famiglia. Un valore di probabilità.
Tra queste tipologie le più importanti (QUELLE DA CONOSCERE ) sono:
1. I dati nominali . Sonodiscreti. Si usano per descrivere categorie.
2. I dati ordinali . Sonodiscreti. Si usano per descrivere quantitànumerabili(ossia conteggi e classifiche).
3. I dati metrici o razionali . Possono esserecontinui.
È sempre necessario definire il tipo di misura per sapere quali manipolazionimatematiche sono consentite (hanno senso) e quali no.
Per esempio, un errore tipico è quello di utilizzare grandezze nominali, usare i simbolinumerici 1, 2, 3. . . (come nell’esempio dei calciatori), e poi dimenticarsi che si trat-ta di simboli e usarli come valori ordinali (capitano> portiere) o addirittura metrici(calciatore medio = somma dei calciatori / 11).
Un altro esempio è il “numero” di codice fiscale, che non è affatto un numero ma unvalore simbolico su cui non si possono fare confronti d’ordine (né tantomeno sommee differenze), ma solo confronti di uguaglianza.
BISOGNA SEMPRE RICORDARSI di NON FARE OPERAZIONI CHE NONHANNO SENSO. Sui dati nominali hanno senso SOLO L’ASSEGNAZIONE EIL CONFRONTO DI UGUAGLIANZA.
2.2 Rappresentazione dei dati
2.2.1 Come si rappresentano i dati in un programma
Quando scrivo un programma, devo prendere delle decisioni sul tipo delle variabili checonterranno i miei dati.
(Anche se il programma non lo scrivo io, è comunque opportuno che io sappia quelloche succede. Non è mai una buona idea far prendere il controllo al calcolatore!)
Dunque, come si possono memorizzare i dati secondo il livello di misura?
1. I dati nominali si possono rappresentare constringhe. P.es. rosso/nero/verde.Questo modo è chiaro ma non comodo.
Oppure si possono rappresentare connumeri interi . Allora bisogna decidereuna tabella di corrispondenza: Sì = 1, No = 0; rosso = 1, nero = 2, verde = 3.
13

2 I dati bio-medici: rilevamento, trattamento e modellazione
In linguaggio C
int risposta;
risposta = 1;if (risposta==0)
printf("Risposta negativa\n");else
printf("Risposta affermativa\n");
2. I dati ordinali si possono tranquillamente rappresentare con numeri interi.
In linguaggio C
int posizione;
posizione = 3;posizione = posizione - 1;if (posizione==0)
printf("Sei arrivato alla fine\n");
3. I dati metrici o razionali si rappresentano con numeri reali.
In linguaggio C
double lunghezza1, lunghezza2, lunghezzamedia;
lunghezza1 = 3.23;lunghezza2 = 5.49;lunghezzamedia = (lunghezza1 + lunghezza2) / 2 ;
(ho usato il tipo reale adoppia precisione, che –come dice il nome– usa più bited è più preciso. Poi c’è il tipo float, a precisione singola.)
2.2.2 Come si organizzano i dati
Una organizzazione molto usata, molto semplice, è quella che useremo per la maggio-ranza dei casi.
I dati vengono semplicemente organizzati in una tabella.
Le righe della tabella corrispondono alle singoleosservazioni(p.es.: un singolo pa-ziente; un singolo reperto biologico; un singolo esemplare di specie animale o vegetale;ecc.)
Le colonne della tabella corrispondono alle singolevariabili osservate (p.es.: età;VES; lunghezza petali).
In questa rappresentazione non c’è una struttura (p.es. voci con sotto-voci). Le varia-bili sono solo elencate una accanto all’altra. Quindi ogni riga della tabella è matema-ticamente unvettore, e la tabella è unamatrice.
14

2.2 Rappresentazione dei dati
In linguaggio C
/* definisco le dimensioni, come costanti */#define dim 10 /* dim. vettore */#define N 100 /* num. osservazioni */
/* definisco un singolo vettore di dati */double x[dim];
/* definisco un’intera matrice di dati */double dati[N][dim];
2.2.3 Come si memorizzano i dati su un file
Una matrice si può memorizzare come un file difoglio di calcolo (spreadsheet)oppure come un semplicefile di testo ASCII.
Nel primo caso (foglio di calcolo) ci sono vantaggi:
• si possono facilmente fare calcoli e grafici
• si possono vedere i dati sullo schermo in forma chiara
• si possono riordinare e selezionare con operazioni molto semplici
ma anche svantaggi:
• tabelle molto grosse non si possono manipolare
• si possono fare solo le operazioni che sono previste dal programma di foglio dicalcolo
Si ricorre quindi al secondo caso (file di testo) quando si vuole usare un programma chefa operazioni particolari, ma che non è in grado di leggere i file del mio spreadsheet,per esempio un programma scritto da me stesso; oppure quando i dati sono troppi peri limiti previsti dal foglio di calcolo.
Esistono anche programmi specializzati che hanno una loro forma di rappresentazionedelle tabelle dati. Tuttavia il foglio elettronico Microsoft Excel è così diffuso che lagrande maggioranza dei programmi è in grado di leggere i suoi file.
2.2.4 Interpretazione matematica
Come già detto, i possono essere considerati vettori in senso matematico (vettori didati).
In fisica, i vettori sono “applicati”. È dato un punto di applicazione nello spazio, e ilvettore esprime uno spostamento (in qualche direzione e di qualche entità) rispetto aquel punto.
15

2 I dati bio-medici: rilevamento, trattamento e modellazione
In matematica è più semplice. In matematica, i vettori non hanno punto di applica-zione. Sono tutti applicati nell’origine (che è il punto con tutte le coordinate pari azero).
Quindi un vettore coincide con unpunto nello spazio. Ossia, se il vettore implica unospostamento, tale punto nello spazio è il punto di arrivo dello spostamento a partiredall’origine.
E, simmetricamente, le coordinate di un punto nello spazio formano unvettore.
Se hod variabili osservate per ogni osservazione, avrò un vettored-dimensionale(ossia un punto in uno spaziod-dimensionale):
x = (x1,x2, . . . ,xd)
Se i vettori sono formati tutti da datimetrici , possiamo applicare le normali regole delcalcolo vettoriale.
Possiamo calcolare, per esempio:
La distanza tra due vettori (N.B.: è uno scalare):
dist(x,y) = ||x−y||=
√d
∑i=1
(xi −yi)2 (2.1)
Il prodotto scalare tra due vettori (N.B.: è uno scalare):
x ·y =d
∑i=1
xiyi
Il vettore medio di un insieme di n vettori (N.B.: è un vettore):
avg{x1 . . .xn}=1n
n
∑i=1
x(i) =
=1n
(n
∑i=1
x(i)1 ,
n
∑i=1
x(i)2 , . . . ,
n
∑i=1
x(i)d
)
=
(1n
n
∑j=1
x( j)1 ,
1n
n
∑j=1
x( j)2 , . . . ,
1n
n
∑j=1
x( j)d
)
Il vettore (o punto) medio di un insieme di vettori è anche detto il suobaricentro.
2.3 Elaborazioni preliminari sui dati
2.3.1 Tipi di elaborazioni preliminari
Normalmente non è possibile elaborare i dati così come arrivano dal sistema di rileva-mento.
Occorre effettuare delleelaborazioni preliminari (pre-processing).
Gli esempi più comuni di pre-processing sono i seguenti:
16

2.3 Elaborazioni preliminari sui dati
• Ripulitura dei dati: eliminare i dati chiaramente errati e quelli che non sonoragionevolmente consistenti con la maggioranza (quindi probabilmente erratianch’essi, o magari provenienti da condizioni sperimentali diverse dal resto deidati).
• Normalizzazione dei dati: molte tecniche funzionano o funzionano meglio quan-do i dati sono tutti sulla stessa scala, e quindi non ci sonoanisotropie nel-lo spazio dei dati. Per effettuare questa operazione si usano trasformazionialgebriche.
• Estrazione dellefeature: in certi casi i dati grezzi hanno un significato nasco-sto, e occorre estrarre dellevariabili derivate (feature) a partire dalle variabiliosservate.
Per esempio, i pixel di una immagine esprimono solo livelli di luminosità e colo-re; un algoritmo di identificazione forme lavora esaminando i contorni; quindi ilpre-processing consiste nell’effettuare una estrazione di contorni per poi usare,anzichè le variabili misurate (i valori dei pixel), le feature calcolate (posizione egeometria dei contorni).
Vediamo alcune tecniche per ciascuna di queste operazioni.
2.3.2 Ripulitura
La prima fase nello studio di una tabella dati consiste nell’eliminare le osservazionicontenenti dati errati.
Alcuni tipi di errore sono evidenti. P.es. un valore negativo di una variabile che puòessere solo positiva. P.es. un valore di percentuale superiore a 100.
Altri tipi di errore possono essere identificati solo con analisi un po’ più dettagliate.
Un criterio spesso utilizzato in ambito biomedico:
• si prende una variabile che si sa essere distribuita secondo una Gaussiana
• si calcola la mediax
• si calcola la deviazione standardσx
• quindi si buttano via tutte le osservazioni in cui quel dato si discosta di più di3σx dax, in più o in meno.
La considerazione che sta alla base di questo criterio è che, per dati gaussiani, rispettoalla media:
– entro±σx sta il 68% dei dati
– entro±2σx sta il 95% dei dati
– entro±3σx sta il 98% dei dati
17

2 I dati bio-medici: rilevamento, trattamento e modellazione
quindi si ha probabilità 0.98 di buttar via un dato effettivamente errato e solo 0.02 dibuttar via un dato corretto ma anomalo.
Un caso speciale sono i dati mancanti. Quando un dato manca si può buttare via tuttal’osservazione, oppure si può “tappare il buco” con una stima più o meno sofisticata:
– con il valore medio di quella variabile calcolato su tutta la tabella di dati
– con un valore ragionevole basato sui dati restanti di quella osservazione
– con un valore stimato con qualche complessa tecnica statistica a partire dai datirestanti di quella osservazione
2.3.3 Normalizzazione
Molte tecniche funzionano o funzionano meglio quando i dati sono tutti sulla stessascala. Quando uno spazio non presenta direzioni preferenziali si dice che èisotropo(significa: se mi muovo in una direzione qualunque è lo stesso).
La stessa scala significa che i miei dati devono essere tutti contenuti in uno stessointervallo che decido io, e riempirlo più o meno uniformemente.
Posso decidere di volere dati nell’intervallo[0,1] oppure[−1,1] oppure[0,10]. Questodipende dal mio gradimento e dal metodo di analisi che voglio applicare.
Per fissare le idee stabiliamo che:
• il nostro intervallo partirà dal valorex0 e sarà ampio una quantitàρ;
• la variabile originale si chiameràx e quella normalizzatax′;
• negli esempi di programmazione useremo i nomix exnorm perchè non possia-mo usare il simbolox′.
Per portare i dati tutti sulla stessa scala si usano trasformazioni algebricheaffini , cioédella forma:
x′ = ax+b (2.2)
(NOTA sulla nomenclatura matematica: seb = 0, è una trasformazionelineare; seb 6= 0 si chiamaaffine)
Tali trasformazioni, possibili in unospazio metrico, corrispondono a cambiare unitàdi misura (usando il coefficientea) e valore di riferimento, ossia origine dell’assex(usando l’intercettab).
In linguaggio C
double x, xnorm;double a, b;
/* normalizzazione dati - formula generica */xnorm = a*x + b;
I vari tipi di normalizzazione differiscono per la scelta dei parametri di normalizzazio-nea eb.
18

2.3 Elaborazioni preliminari sui dati
Normalizzazione tra massimo e minimo. Se conosco il massimo e il minimovalore possibile dei miei dati, posso applicare la normalizzazione tra massimo eminimo.
Questa trasformazione mi garantisce che i dati trasformati non eccederanno maiil massimo e il minimo che stabilisco io.
Se la variabilex varia traxmax exmin, la trasformazione è:
x′ = ρ(x−xmin)
(xmax−xmin)+x0
quindia = ρ/(xmax−xmin)
eb = x0−ρxmin/(xmax−xmin) .
In linguaggio C
double x, xnorm;double rho, x0;double xmax, xmin;
... /* qui vengono calcolati xmax e xmin */
/* normalizzazione dati - formula con rho e x0 */xnorm = rho * (x - xmin)/(xmax - xmin) + x0
Normalizzazione rispetto a media e varianza. In questo caso possiamo appli-care le considerazioni viste prima e assumere che, se una variabile è distribuitain modo gaussiano (con mediax e deviazione standardσx), il 100% dei daticapiterà nell’intervallox±2σx (con un errore del 5%) oppurex±3σx (con unerrore del 2%).
Supponiamo di accettare un errore del 5%. Allora l’intervallo sarà descritto dax0 = x−2σx e ρ = 4σx.
A questo punto applico la trasformazione vista prima (eq. (2.2) e ho finito. Inquesto modo so che statisticamente il 95% dei dati cadrà entro l’intervallo cherichiedo io.
NOTA: se applico la trasformazione conρ = σx e x0 = x−σx ottengox′ distri-buitanormalmente, cioè secondo una distribuzione Gaussiana normale, ciè conmedia nulla edeviazione standard unitaria.
Normalizzazione tra percentili. Se la distribuzione dei dati è ignota o se si sa cheè “strana”, è più prudente agire sui percentili.
Dato un campione sperimentale, un dato si trova alpercentile n-esimo(con ntra 0 e 100) sel’ n per cento dei dati ha valore inferiore ad esso.
Quindi il valore minimo è il percentile 0-esimo, il massimo è il percentile 100-esimo, e lamediana il percentile 50-esimo.
19

2 I dati bio-medici: rilevamento, trattamento e modellazione
Per fare un errore del 5%, devo assumerex0 pari al 2,5-esimo percentile eρ parial valore del 97.5-esimo percentile−x0
A questo punto applico la trasformazione (2.2).
2.3.4 Estrazione delle feature
Il termine (inglese)feature indica una “caratteristica” dei dati in esame.
Tale caratteristica può essere semplicemente misurata (e allora non c’è nessuna “estra-zione”).
Oppure può essere prodotta applicando delle trasformazioni agli ingressi misurati.
Tali trasformazioni possono essere molto semplici o molto complesse.
Il confine tra normalizzazione ed estrazione delle feature è confuso.
Noi consideriamo per convenzione che:
– se si applica allax una trasformazione affine (eq. 2.2), stiamo facendo unanormalizzazione
– se si applica una trasformazione di altro tipo (più complessa) oppure una trasfor-mazione che coinvolge più variabili, stiamo estraendo delle feature.
Esempi tipici di estrazione di feature sono:
• La trasformazione logaritmica. Una misura che assume solo valori positivinon può essere distribuita in modo gaussiano (per definizione la Gaussiana hadue “code” che vanno a±∞). Se ho unax distribuita asimmetricamente, logxpuò essere più somigliante a una variabile con distribuzione Gaussiana.
• Proiezioni. Se riesco a individuaredirezioni importanti per la mia elaborazio-ne, posso proiettare i dati su tali direzioni (che sono poi delle rette). Geometri-camente si tratta di applicare trasformazioni lineari (b = 0).
Per esempio, potrei trovare una direzione in cui i miei dati sono nettamente divisitra quelli caratteristici di uno stato patologico e quelli che indicano lo stato dinormalità. Proiettando i dati su tale direzione, sono in grado di effettuare ladiscriminazione.
2.3.5 Criteri per la normalizzazione
Effettuare una normalizzazione può essere molto importante. Alcuni metodi automa-tici non funzionano affattose non si fa una corretta normalizzazione.
Però per sapere quanto è importante la normalizzazione e come farla, bisogna cono-scere bene:
• le caratteristiche dei dati
• le caratteristiche del metodo
20

2.4 La metodologia statistica
(Questo è uno dei motivi per cui, anche se si usa un programma preconfezionato,occore comunque conoscerne i dettagli.)
Seguono due criteri da applicare per questa scelta.
1. Se i dati sono metricie il metodo automatico fa uso del concetto di distanza,allora ènecessarionormalizzare ciascuna variabile (ciascun componente delvettore).
Questo perché nella sommatoria che definisce la distanza, equazione (2.1), se al-cuni termini sono molto più grandi di altri, i più grandi saranno sempre prevalentie i più piccoli (anche se magari importanti) finiranno “soffocati”.
In generale, metodi che usano le distanze funzionano meglio se i dati sono di-stribuiti in modo uniforme nelle varie direzioni, cioè se disegnando i dati suun diagramma cartesiano (vedi esempio Iris) i punti sono distribuiti in modo“globulare” e non “lineare” o “oblungo”.
2. Se in più i dati sono tutti omogenei, cioè hanno tutti la stessa natura, la norma-lizzazione non si deve fare sulle singole variabili di ogni osservazione (prima lacomponente 1, poi la componente 2, . . . , poi la componented), ma sututte levariabili insieme.
Più precisamente, nelle formule viste prima, dove è scrittomedia non si deveintendere “media della singola variabilexi su tutte le osservazioni”, bensìmediadi tutte le variabili su tutte le osservazioni. E così per tutti gli altri parametri(massimo, minimo, deviazione standard, percentili. . . )
Cosa si intende per “dati omogenei”? Si intende dati che, per ogni osservazione,si ottengono dalla misura di tanti fenomeni che io mi aspetto abbiano lo stessocomportamento: per esempio, i livelli di espressione di molti geni misurati conun DNA microarray.
Se poi invece ci sono differenze che io non mi aspettavo, usando la stessa nor-maizzazione per tutti i dati tali differenze verranno mantenute e io potrò scoprir-le. Se invece uso una normalizzazione diversa per ogni variabile, le differenzevengono eliminate e io non posso più scoprirle.
2.4 La metodologia statistica
2.4.1 Generalità
La statistica è la scienza che studia come estrarre l’informazione utile dai dati speri-mentali. Tale informazione utile può essere nella forma di distribuzioni di probabilitào, più facilmente, di particolari parametri (dettistatistiche) che danno indicazioni suaspetti interessanti dei dati.
Il parametro più comune è lamedia.
La media di una variabile casualex è data dalla seguente formula:
µx =∫
xP(x)dx
21

2 I dati bio-medici: rilevamento, trattamento e modellazione
Questa operazione si chiamavalore attesoo expectation e consiste, a parole, nelcalcolare l’integrale del valore della variabile su tutto l’asse reale, integrale pesato conle rispettive probabilità in ogni punto.
Dato un campione, io calcolo lamedia campionariao media campione:
x =n
∑i=0
1n
xi
dovex approssimaµ perché l’integrale è approssimato con una sommatoria e la proba-bilità P(x) è approssimata con lafrequenza(1/n).
Altre statistiche sono la varianza o la deviazione standard e i percentili.
La metodologia statistica si basa su due concetti fondamentali:
1. la stima di una statistica dal campione;
2. la valutazione di confidenza.
2.4.2 Stima dal campione
I dati sperimentali sono generati da fenomeni, sconosciuti, secondo un certomodelloprobabilistico: cioè, ogni osservazionex ha una certa probabilità di verificarsi e questaprobabilità dipende da qual è il fenomeno che genera i dati.
Per esempio, il fenomenoinfluenza genera la variabiletemperatura corporea conuna certa probabilità al di sopra dei 37 gradi e una minore al di sotto.
Una grandezza per cui assumo un modello probabilistico è dettavariabile aleatoria.
La metodologia di indagine statistica si basa sul formulare una ipotesi di partenza dettaipotesi nulla: “i miei dati vengono generati in modo completamente casuale” (cioèp.es. non siamo in presenza di influenza); e successivamente sul verificare se i mieidati forniscano o no una conferma a tale ipotesi. Se l’ipotesi nullanon è confermata,allora può esservi influenza.
2.4.3 Valutazione della confidenza
Poichè i dati sono uncampione, se raccolgo gli stessi dati in due esperimenti diver-si(p.es. misuro la temperatura a 10 pazienti oggi oppure domani) non avrò le stessemisure due volte.
Quindi calcolando la media o la varianza o un’altra statistica non avrò la stessa misuradue volte. Media, varianza, e qualunque statistica sono anch’essegenerate da unmodello probabilistico.
Perciò le conclusioni tratte al punto precedente hanno una certa probabilità di esseresbagliate (in quanto basate su variabili aleatorie).
In statistica, tali conclusioni vengono accettate solo se, controllando su apposite tabel-le, risulta che il valore della statistica utilizzata è tale dagarantire una probabilità dierrore minore di un valore minimo accettabile.
22

2.5 Modelli probabilistici dei dati
Figura 2.1 – Questi sono dati bidimensionali disegnati su un diagramma cartesia-no. Sono stati generati da due fenomeni, entrambi modellabili con una distribuzio-ne Gaussiana (bidimensionale), ciascuno con propria media (posizione del centro) epropria deviazione standard (ampiezza della nuvola).
Questo valore minimo viene chiamatoconfidenza statistica, è indicato con il simboloPe convenzionalmente si stabilisce di farlo valere 0.05 oppure 0.01 (dipende se nel miocaso sono disposto ad accettare, rispettivamente, di sbagliare una volta su 20 oppureuna volta su 100).
2.5 Modelli probabilistici dei dati
A un evento, cioè a una condizione sperimentaleω, è associata una probabilitàP.
Supponiamo che siano possibili le due condizioninormale e patologico. Chiamiamoω0 la normalità eω1 lo stato patologico.
Allora avremo una data probabilità di osservare ciascuno dei due stati:P(ω0), P(ω1).
Se questi stati esauriscono tutte le possibilità, allora
P(ω0)+P(ω1) = 1.
Questa proprietà (la somma delle probabilità di tutti gli eventi possibili è pari a uno) èuna caratteristica fondamentale delle probabilità.
Anche l’osservazione di un vettore di misurex ha una sua probabilità di verificarsi:P(x).
Però, secondo il fenomeno da cui i dati sono stati generati (vedi esempio sopra: in-fluenza), tale probabilità sarà diversa.
Questo fatto si esprime scrivendo unaprobabilità condizionata: la probabilità che,dato un evento, si verifichi una specifica osservazione.
P(x|ω).
La probabilità delle osservazioni sperimentali condizionata a uno specifico eventocostituisce una spiegazione di come l’evento si manifesta attraverso i dati osservabili.
Essa è unmodello probabilistico dell’evento.
23

2 I dati bio-medici: rilevamento, trattamento e modellazione
24

3 Il problema della classificazione
Sommario
La classificazione – Teoria bayesiana della decisione – Funzioni discriminanti –Apprendimento automatico – Un modello parametrico: Naïve Bayes – Modelli nonparametrici: Nearest Neighbor, Perceptron, Multi-Layer Perceptron, Support VectorMachines
3.1 Introduzione
3.1.1 La classificazione
Il problema dellaclassificazione(o analisi discriminante o riconoscimento) consistenell’attribuire le osservazioni sperimentali a una trac differenti categoriegià note.
Nel problema della classificazione, mi interessa trovare la legge che mi permette diassegnare le osservazioni alla classe corretta.
TERMINOLOGIA: pattern = punto = vettore = osservazione
Esiste tutta una categoria di elaborazioni (una vera e propria disciplina scientifica) cheusa la teoria della probabilità come strumento per modellare i dati e le elaborazioni chesui dati vengono fatte. Tale disciplina si chiamapattern recognition statistica.
Nell’uso di modelli probabilistici, gli eventiωi sono le differenti classi da riconoscere.I modelli P(x|ωi) descrivono il modo in cui ciascuna classe genera dei casi osservabilisperimentalmente.Esistono problemi di classificazione a più classi, ma noi persemplicità consideriamo solo quelli in cui si deve distinguere fra due classi.
Quando dispongo di una osservazione sperimentalex, un classificatore (ossia un me-todo automatico di classificazione) mi permette di stabilire se tale osservazione vaattribuita a una classe o ad un’altra.
25

3 Il problema della classificazione
3.1.2 Metodi di classificazione
Il progetto di un classificatore consiste nello stabilire il criterio di classificazione inmodo da rendere massime le prestazioni. Le prestazioni di un classificatore si misuranovalutando lacapacità di generalizzazione.
Generalizzazione significa attribuire a ogni nuova osservazione sperimentale la classecorretta. Un modo per quantificare questa proprietà è ilrischio di classificazione. Ilrischio di classificazione si può valutare come segue.
Poniamo che un classificatore sia rappresentato da una funzioneC(x) che mi dà unarisposta (0 o 1) per ogni osservazionex (che può essere una risposta corretta o errata).
Poniamo poi che la classe vera sia rappresentata da una funzioneT(x) che mi dà unarisposta (sempre 0 o 1) per ogni osservazionex, in questo caso risposta sempre corretta.
L’errore di classificazione del patternx quindi la differenza traT(x) eC(x), che chia-miamo funzione di perdita (loss function) e vale 1 per ogni errore e 0 per ognidecisione corretta (0/1 loss).
L(x) = |T(x)−C(x)|
L’errore globale sarà quindi valutato vedendo come si comporta la funzione di perditasu tutto lo spazio dei dati. Ne facciamo la media (expectation) e otteniamo un singolovalore:
R=∫ d
∞perr (x)dx (3.1)
R sta per rischio. In questo caso, in cui il rischio è valutato su tutto lo spazio dei dati,abbiamo calcolato ilvalore atteso(expected value) del rischio.
Se sono noti i modelli probabilistici delle classi, si può applicare il cosiddettocriteriodi classificazione bayesiano(prossima sezione). Se poi tali modelli danno luogo aequazioni particolarmente semplici (come nel caso Gaussiano, sezione successiva), sipuò trovare la formulazione analitica della superficie discriminante che garantisce ilminimo valore diR.
Se invece non sono noti tali modelli (come nei casi successivi) occorre utilizzare un si-stema adapprendimento automatico. Tali sistemi usano dati che qualcuno ha giàclassificato per ”apprendere” come deve essere fatto il classificatore. Questo saràl’argomento della Sezione 3.4.
I tipi di classificatore differiscono per quanto segue:
• Nei metodiparametrici si cerca un buon modello per i dati.
• Nei metodinon parametrici si cerca una buona superficie discriminante.
26
3.2 Teoria bayesiana della decisione
3.2 Teoria bayesiana della decisione
Supponiamo che siano possibili le due condizioninormale e patologico. Chiamiamoω0 la normalità eω1 lo stato patologico.
Allora avremo una data probabilità di osservare ciascuno dei due stati:P(ω0), P(ω1).
Sappiamo che, se questi stati esauriscono tutte le possibilità, allora
P(ω0)+P(ω1) = 1.
Queste sono dette leprobabilità a priori dei due eventi.
Sono a priori perché sono valutate senza guardare i dati sperimentali. Io so che, apriori, su 100 pazienti che mi si presenteranno nel futuro, una proporzioneP(ω1) saràmalata, mentre gli altri saranno sani.
Mi arriva il campione biologico di un paziente e io posso misurare tutti i dati chevoglio. Quindi produco un vettore di osservazioni sperimentalix.
Qualcosa cambia nelle mie probabilità. Che cosa?
Per esempio, se ho misurato la VES, non mi interessa più saperea priori quante pro-babilità avrà il paziente di essere malato, ma voglio sapere,dato il risultato di quellamisura, che probabilità ci sono che sia effettivamente malato.
Matematicamente, stiamo cercando unaprobabilità condizionata: la probabilità che,data una osservazione, si verifichi un evento.
P(ω1|x).
Come procediamo?
Utilizziamo le seguenti probabilità con la corrispondente nomenclatura:
Simbolo Nome Significato
P(x) Evidenza Probabilità dell’osservazione sperimentalex
P(ωi) Probabilità a priori Probabilità dell’evento ωi in assenza diosservazioni sperimentali
P(x|ωi) Verosimiglianza Probabilità dell’osservazionex quando si sache è verificato l’eventoωi
P(ωi |x) Probabilità a posteriori Probabilità che si sia verificato l’eventoωi
quando si rileva l’osservazionex
Questa nomenclatura è tipica delmetodo Bayesiano.
Noi possiamo misurare (facendo un po’ di statistica sulle analisi effettuate nel passato)quale sia la probabilità a priori delle osservazioni sperimentali.
27

3 Il problema della classificazione
Figura 3.1 –Reverendo Thomas Bayes (Londra, 1702 – Tunbridge Wells, 1761).
Oppure possiamo organizzare un campionamento “randomizzato”, cioè fare in modoche tutte le osservazioni sperimentali siano equiprobabili.
In altre parole, noi abbiamo modo di conoscere l’evidenza, ossia la probabilità
P(x).
Se poi abbiamo unmodellodella malattia, cioè sappiamo che la tale malattia genera iltale quadro clinico, possiamo stimare la probabilità del quadro clinicodata la malattia,ossia abbiamo modo di misurare la verosimiglianza, ossia la probabilità condizionata
P(x|ω1).
Esiste la seguente regola.
Teorema di Bayeso Legge della probabilità totale. PerN condizioni mutuamenteesclusiveω0 . . .ωN, la probabilità (totale) di una osservazionex si calcola come:
P(x) =N
∑i=1
P(x|ωi)P(ωi)
Da questa regola si tira fuori la versione utile (facendo un minimo di passaggi):
P(ωi |x) =P(x|ωi)P(ωi)
P(x)(3.2)
La probabilità condizionata che si calcola con questa regola si chiamaprobabilità aposteriori, perché è calcolatadopoavere esaminato le osservazioni sperimentali.
28

3.3 Superfici discriminanti
Procedimento di decisione bayesiana(nel caso diN = 2)
• Per ogni condizione, calcolo tutte le probabilità che mi servono:
– P(x|ω0) eP(x|ω1) dal modello (cioè da quello che il medico mi dice sullaspecifica malattia in questione)
– P(ω0) e P(ω1) dai dati precedentemente accumulati o anche dalle statisti-che pubblicate in letteratura
– P(x) dal confronto con i dati precedentemente accumulati
• Per ogni condizione, applico la regola di Bayes (3.2) e calcolo la probabilità diquella condizione sulla base delle mie osservazioni, cioè dix.
• Decisione:affermo che si è verificata la condizione che ha probabilità a poste-riori più elevata.
Questa formulazione fornisce una base teorica al problema della classificazione.
3.3 Superfici discriminanti
Si dice superficie discriminante il luogo dei punti nello spazio dei dati tali che leprobabilità a posteriori sono uguali. Da un lato della superficie si decide per una classee dall’altro lato per l’altra classe.
Si tratta di una superficie nel caso generale multidimensionale; se i punti sono invecebidimensionali, la superficie si riduce a una linea.
La superficie discriminante si ottiene dall’equazione che eguaglia le probabilitá a po-steriori delle due classi.
3.3.1 Il caso di fenomeni con modello Gaussiano semplice
Supponiamo per semplicità probabilità a priori uguali:P(ω0) = P(ω1) (e quindi,siccome la somma deve fare 1,P(ω0) = P(ω1) = 1/2).
(Tuttavia i calcoli seguenti non sono complessi e si possono eseguire anche con proba-bilità differenti.)
Supponiamo che il modello probabilistico delle nostre classi sia Gaussiano sferico:
P(x|ω0) =1√
(2π)σ0e||x−c0||2/σ2
0
P(x|ω1) =1√
(2π)σ1e||x−c1||2/σ2
1
Sferico significa che in ogni direzione la deviazione standard è la stessa. Quindi inogni direzione la gaussiana si estende allo stesso modo (e quindi la nuvola di punti chesi ottiene come grafico ha forma globulare).
Vogliamo trovare il luogo dei punti tali cheP(ω0|x) = P(ω1|x)
29

3 Il problema della classificazione
Regola di Bayes:
P(ωi |x) =P(x|ωi)P(ωi)
P(x)
ATTENZIONE: di qui in poi CALCOLI VETTORIALI. Tuttavia, formalmente(come uso dei simboli), si possono affrontare come se fossero calcoli su grandezzescalari, con la seguente avvertenza: il prodotto tra vettori è ilprodotto scalare, che siindica con il punto:x ·c (in inglese infatti si chiama anche dot product).
Supponiamo di avererandomizzatogli esperimenti. Ossia abbiamo fatto in modo cheP(x) sia costante (e quindi pari a 1/N conN numero osservazioni).
Allora:
P(ω0|x) =P(x|ω0)(1/2)
1/N
P(ω1|x) =P(x|ω1)(1/2)
1/N
Facciamo il confronto:P(x|ω0)(1/2)
1/N=
P(x|ω1)(1/2)1/N
Semplifichiamo dividendo per i coefficienti comuni ad ambo i membri:
P(x|ω0) = P(x|ω1)
Sostituiamo l’espressione analitica:
1√(2π)σ0
e||x−c0||2/σ22 =
1√(2π)σ1
e||x−c1||2/σ21
Logaritmo di ambo i membri:
ln(1√
(2π)σ0)+
||x−c0||2
σ22
= ln(1√
(2π)σ1)+
||x−c1||2
σ21
Se le varianze sono uguali, si semplificano sia i termini additivi (cioè i logaritmi) sia icoefficienti 1/σ0 = 1/σ1. Quindi:
||x−c0||2 = ||x−c1||2
x ·x−2x ·c0 +c0 ·c0 = x ·x−2x ·c1 +c1 ·c1
Ora i termini di secondo gradox ·x si semplificano e si ottiene:
x · (c0−c1)+12
(c0 ·c0−c1 ·c1) = 0
Le soluzioni di questa equazione sono tutti i punti che giacciono su unpiano. Questopiano (nel caso a due dimensioni una linea retta) è la superficie discriminante che ciinteressa.
Dalla geometria analitica, sappiamo che il coefficiente dellax nell’equazione di unpiano è ilvettore normalea tale piano.
Questo significa che la superficie discriminante è un pianoche taglia ortogonalmentela congiungente i due centri c0 ec1.
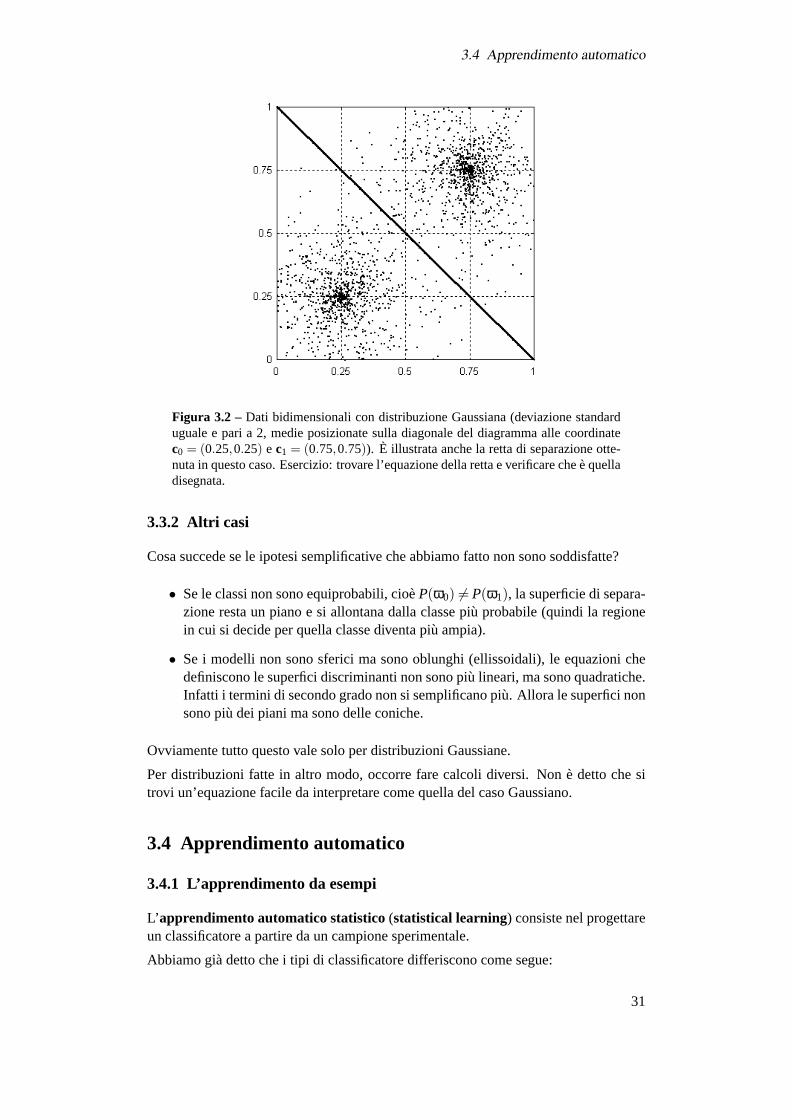
Le conclusioni sono illustrate in Figura 3.2.
30
3.4 Apprendimento automatico
Figura 3.2 – Dati bidimensionali con distribuzione Gaussiana (deviazione standarduguale e pari a 2, medie posizionate sulla diagonale del diagramma alle coordinatec0 = (0.25,0.25) e c1 = (0.75,0.75)). È illustrata anche la retta di separazione otte-nuta in questo caso. Esercizio: trovare l’equazione della retta e verificare che è quelladisegnata.
3.3.2 Altri casi
Cosa succede se le ipotesi semplificative che abbiamo fatto non sono soddisfatte?
• Se le classi non sono equiprobabili, cioèP(ω0) 6= P(ω1), la superficie di separa-zione resta un piano e si allontana dalla classe più probabile (quindi la regionein cui si decide per quella classe diventa più ampia).
• Se i modelli non sono sferici ma sono oblunghi (ellissoidali), le equazioni chedefiniscono le superfici discriminanti non sono più lineari, ma sono quadratiche.Infatti i termini di secondo grado non si semplificano più. Allora le superfici nonsono più dei piani ma sono delle coniche.
Ovviamente tutto questo vale solo per distribuzioni Gaussiane.
Per distribuzioni fatte in altro modo, occorre fare calcoli diversi. Non è detto che sitrovi un’equazione facile da interpretare come quella del caso Gaussiano.
3.4 Apprendimento automatico
3.4.1 L’apprendimento da esempi
L’ apprendimento automatico statistico(statistical learning) consiste nel progettareun classificatore a partire da un campione sperimentale.
Abbiamo già detto che i tipi di classificatore differiscono come segue:
31

3 Il problema della classificazione
• Nei metodiparametrici si cerca un buon modello per i dati.
• Nei metodinon parametrici si cerca una buona superficie discriminante.
Quindi un classificatore ad apprendimento automatico, se parametrico, farà una ipotesia priori sulle classi. Se è giusta o sbagliata non si può sapere, perche non si puòmaiconoscere tutta la realtà ma solo una quantità finita di osservazioni.
Questa ipotesi a priori (che è per noi data dalle funzioni di probabilitàP(x|ωi) eP(ωi),ossia dalle verosimiglianze e dalle probabilità a priori) conterrà dei parametri. Taliparametri saranno stimati usando i dati sperimentali disponibili.
Per esempio, se l’ipotesi è che gli eventi siano Gaussiani sferici, i parametri da stimaresaranno le mediec0 ec1 e le deviazioni standardσ0 e σ1.
Se il classificatore è invece non parametrico, farà una ipotesi sulla superficie di sepa-razione (il che è molto più prudente).
La superficie di separazione sarà allora data da una funzione matematica. Per otteneresuperfici complesse, si può anche usare l’unione di più funzioni semplici che, messeinsieme, danno luogo alla superficie di separazione della forma più adatta.
Il principale esempio di modello semplice è ildiscriminante lineare, cioè un classifi-catore che assume che la superficie di separazione sia un piano.
Modelli complessi possono invece essere formati dall’unione di molti piani, o di su-perfici circolari, o di tasselli poliedrici.
Nel caso del piano, che ha equazionex ·w + b = 0, occorrerà stimare dal campione ivalori dei parametriw eb.
Nel caso dell’unione dih piani, occorrerà stimareh coppie di parametriw1,b1,w2,b2,. . . ,wh,bh. E così via: ogni tipo di funzione avrà i suoi parametri.
3.4.2 Procedimento e nomenclatura
Si procede nel seguente modo:
1. Ci si procura una collezione di osservazioni sperimentaliper le quali sia nota laclasse. Questo insieme di dati si chiamainsieme di addestramento(trainingset) e la classe di ciascuna osservazione si chiamatarget. Il target è l’obiettivodell’apprendimento: èciò che va appreso.
2. Ci si procura anche una collezione di osservazioni sperimentali (anche questegià classificate da qualcuno) da usare per collaudare il classificatore. Questoinsieme di dati è l’insieme di verifica(test set).
3. Si effettua la stima statistica delle grandezze che ci interessano (i parametri deimodelli oppure i parametri della superficie discriminante). Tale stima è fatta sultraining set e si definiscetraining o addestramento.
4. Si stima il rischio attesoR usando il test set, che costituisce unavalutazioneindipendenteperché non è stato usato per il training.
32

3.4 Apprendimento automatico
Figura 3.3 – Metodologia di apprendimento automatico: un semplice training sete un semplice test set per lo stesso (ipotetico) problema. Notare che nel test set lacolonna del target non è utilizzata. Notare anche che le osservazioni sono in quantitàdiversa nel training set e nel test set.
3.4.3 Stima della qualità di un classificatore
Abbiamo detto che un classificatore è tanto migliore quanto più basso è ilrischio cheriesce ad ottenere.
Il rischio atteso è definito dall’Equazione (3.1). È il valore atteso o expectation delrischio su tutte le osservazioni sperimentali possibili.
Ricordando che le probabilità non si possono conoscere, come si può valutare (stimare,approssimare) questa quantità?
La stima (approssimazione) di un integrale si fa con una sommatoria. Se il campiona-mento è equiprobabile (esperimenti randomizzati), allora la stima della probabilità è1/N.
Quindi il rischio atteso si stima così:
Remp=1N
N
∑l=1
L(x) (3.3)
Remp sta per rischio empirico. Empirico significa stimato dai dati sperimentali. Inparticolare, si calcola sul test set.
La capacità di un classificatore di ottenere un buon valore diR si chiamacapacità digeneralizzazione.
3.4.4 Quanto è affidabile la stima che abbiamo fatto?
Un problema addizionale è capire che errore si fa approssimandoR (l’integrale –ricordiamoci che è teorico perché include una probabilità che non si può conosce-re) conRemp (la sommatoria, che invece si può calcolare). Quanto è buona questaapprossimazione?
Esiste una teoria sviluppata dallo statistico russo Vladimir Vapnik [6] che risponde aquesta domanda.
Questa teoria è molto elegante scientificamente, perché risponde a questa domandainqualunque casoecon qualunque distribuzione di punti.
Secondo la teoria di Vapnik, basta conoscere due informazioni:
33

3 Il problema della classificazione
Figura 3.4 –Vladimir Vapnik (Russia, ??).
1. il numero di osservazioni sperimentaliN nel mio training set;
2. un parametro che ècaratteristico del mio classificatore, é unnumero intero,ed è chiamatodimensione di Vapnik e ChervonenkisdVC.
e posso affermare, con una probabilità 1−η a mia scelta, che:
R< Remp+
√dVC (log(2N/dVC)+1)+ logη/4
N(3.4)
Cioè so che il rischio atteso è pari al rischio empirico più un termine “peggiorativo”che dipendesoltanto da quanti dati ho nel training set (N) e dal parametro relativoal mio classificatore (dVC). E quando faccio questa affermazione, ho probabilità disbagliare pari aη, cioè la disequazione è vera con probabilità 1−η.
Uno svantaggio di questa teoria è che è così generale, che spesso il calcolo non mi dànessuna informazione utile in casi reali.
Per esempio può venire fuori che il rischio è minore del 150% (che è una cosa chesapevo già senza fare tanti calcoli, perchè più che il 100% delle volte non possosbagliare).
Ovviamente esistono sviluppi di questa teoria: più utili ma molto più complicati.
3.5 Un modello parametrico
Applicando la regola di Bayes e fingendo di avere tutte le informazioni che mi servonoio posso creare un classificatore “ingenuo” o “il Bayes degli idioti”.
Si chiamaNaïve Bayesun classificatore che finge di conoscere il modello (verosimi-glianza di bayes)P(x|ωi).
Tale modello viene calcolato come segue.
Si assume che le variabili osservatex = (x1,x2, ...,xd) non dipendano mai l’una dal-l’altra. Questo è evidentemente falso, perchè è ovvio che se guardo i sintomi di una
34

3.6 Modelli non parametrici
malattia essi saranno presenti insieme o assenti insieme in molti casi, anche se in altricasi alcuni ci saranno e altri no. (E qui sta l’“ingenuità” del metodo).
Quindi posso far finta che ogni variabile osservata abbia la sua distribuzione di proba-bilità, per esempio Gaussiana.
Stimo media e deviazione standard di ogni singola variabile usando il training set di-viso in due parti, una con tutte le osservazioni di classeω0 (N0 osservazioni) e una contutte le osservazioni di classeω1 (N1 osservazioni). OvviamenteN0 +N1 = N.
• SugliN0 campioni di classe 0:
x0,i =N0
∑l=1
x(l)i σ0,i =
N0
∑l=1
(x(l)
i
)2− x2
i
• SugliN1 campioni di classe 1:
x1,i =N1
∑l=1
x(l)i σ1,i =
N1
∑l=1
(x(l)
i
)2− x2
i
Quando più variabili sono indipendenti, la probabilità della loro combinazione è datadal prodotto delle singole probabilità:
P(x|ω0) =d
∏i=1
1√2πσ0,i
e(xi−x0,i)2P(x|ω1) =
d
∏i=1
1√2πσ1,i
e(xi−x1,i)2
Poi stimoP(ω0) = 1/N0, P(ω1) = 1/N1, eP(x) = 1/N.
A questo punto ho tutto quello che mi serve (ammesso che possa fidarmi delle assun-zioni ingenue) e posso applicare la regola di bayes.
3.6 Modelli non parametrici
Nei modelli non parametrici noi non facciamo alcuna assunzione sulla distribuzionedelle probabilità.
Cerchiamo direttamente di passare dai dati alla risposta che cerchiamo (nel nostro caso:qual è la classe delle osservazioni sperimentali).
3.6.1 Nearest neighbor
Abbiamo detto che il criterio di classificazione ideale è:cercare la classeωi per laqualeP(ωi |x) è massima.
Il criterio di Occam (orasoio di Occam) prescrive che, in assenza di informazioni piùdettagliate, noi dobbiamo basarci sull’ipotesi più semplice fra quelle possibili.
In base a questo principio, possiamo fare la seguente assunzione:
35

3 Il problema della classificazione
Figura 3.5 – William of Ockham (Ockham, Inghilterra, 1280 – Monaco di Baviera,Germania, 1349.
Se io ho un punto di trainingx che so appartenere alla classeωi , e pren-do un nuovo puntox′ di cui non so la classe, che si trova vicino ax, èprobabile che anchex′ appartenga alla stessa classeωi .
Questo criterio di classificazione si chiamaNearest Neighbor[2], ossia “il vicino piùprossimo.
È un criterio basato più che altro sul buon senso, e dà luogo al seguente algoritmo diclassificazione:
• Training: memorizzo il training set in una tabella
• Classificazione di una nuova osservazione x′:
1. Calcolo la distanza dix′ da tutti i puntix(1), x(2). . .x(N) del training set
2. Seleziono il puntox(nn) nel training set che ha distanza minima dax′
3. Classificazione: decido chex′ ha classet(nn), cioè il target (la classe) delpuntonn-esimo nel training set (il suo vicino più prossimo).
Questa procedura non è affatto ottimale. Il vicino più prossimo può essere lontano, eallora l’ipotesi di partenza non è realistica.
Oppure il vicino più prossimo può essere proprio al di là della superficie discriminante,ed essere quindi di classe diversa anche se vicino.
Tuttavia, è stata dimostrata la proprietà seguente.
Si sa che l’errore ottimale di classificazione si ha nel caso ideale, quello che viene dalprocedimento di classificazione bayesiana.
È ottimale e teorico, perché prevede la conoscenza delle probabilità.
Ebbene, nel caso in cui il training set abbia molti punti (N → ∞), si dimostra che iltasso di errore (rischio atteso) della tecnica Nearest neighbor non è mai più del doppiodi quello ideale, di Bayes.
In pratica questo mi dice che la tecnica “non fa brutti scherzi”: se ottengo più osserva-zioni nel training set, otterrò anche errore minore.
36

3.6 Modelli non parametrici
In linguaggio C
double xtraining[N][d];int target[N];
double x[d];double dist[N];
int nn;int i, l, classe;
/* calcola le distanze */for (l=0; l<N; l++) {
dist[l]=0.0;for (i=0; i<d; i++) {
dist[l] = dist[l]+(x[i]-xtraining[l][d])*(x[i]-xtraining[l][d]);/* (purtroppo in C non esiste l’operatore di potenza *//* e per fare A al quadrato devo scrivere A * A ) */
}}
/* cerca la distanza minima */nn=1;for (l=0; l<N; l++) {
if (dist[l]<dist[nn])nn = l;
}
/* assegna la classe del nearest neighbor */classe = target[nn];
3.6.2 Perceptron
Nel 1957 lo psicologo Frank Rosenblatt, ispirandosi al funzionamento della retina, feceun modello del funzionamento percettivo del sistema nervoso. Lo battezzòPerceptron[4] e ne dimostrò le proprietà come sistema di elaborazione e riconoscimento immagini(o configurazioni di ingresso di altro genere).
Il modello del cervello proposto da Rosenblatt presentava le seguenti caratteristicheche lo rendevano molto interessante:
• Modello connessionista: prevedeva solo l’interconnessione di modelli di neuro-ni (matematici, formali, e non fisiologici) senza alcun supervisore, senza cal-colatori su cui eseguire un programma che controllasse il funzionamento; ilfunzionamento derivava solo dalla struttura e dalle intensità di comunicazione“sinaptiche”
• Degradazione non catastrofica (graceful degradation): errori, perdite di con-nessioni, variazioni delle intensità sinaptiche di connessione non bloccavano ilfunzionamento, ma ne riducevano gradualmente l’efficacia
37

3 Il problema della classificazione
Figura 3.6 –Un neurone.
• Capace di percezione: prevedeva una sorta di retina, strati di neuroni di proiezio-ne e strati di neuroni associativi, che effettuavano elaborazioni dei segnali rice-vuti (nel nostro linguaggio: facevano delle trasformazioni lineari di più variabili,quindiestrazione di feature)
• Capace di riconoscimento: uno strato di neuroni di riconoscimento, analogo allacorteccia primaria, si eccitava quando riceveva dagli strati percettivi un segnaleche era riconosciuto come noto (nel nostro linguaggio:classificazione)
• Capace di apprendimento: era in grado di modificare le proprie connessionisinaptiche per adattarsi a riconoscere concetti presentati attraverso esempi, ossiaapprendere dall’esperienza (nel nostro linguaggio:si addestrava su un trainingset)
Lo schema di un Perceptron è illustrato in Figura 3.7. Gli ingressix1, x2, . . . ,xd sonoottenuti dal procedimento di feature extraction (che Rosenblatt chiama strati proiettivie associativi).
La parte ad apprendimento automatico è solo quella illustrata, che riguarda le unità(o neuroni) che prendono la decisione finalec. La parte di estrazione feature non èaddestrabile, è prefissata.
Ogni ingressoxi è applicato al neurone con un pesowi . Questo peso corrispondeall’intensità della connessione sinaptica.
L’integrazione effettuata dalla membrana neurale è rappresentata dall’operazione disomma pesata:
N
∑i=1
wixi
che è un modello matematico semplificato delpotenziale di membrana.
L’attivazione del neurone avviene confrontando il livello ottenuto in questo modo conunasoglia di attivazionepropria del neurone,θ.
La funzione “a gradino” illustrata nella figura mostra che, a seconda del segno dellagrandezza
r =N
∑i=1
wixi −θ (3.5)
38

3.6 Modelli non parametrici
Figura 3.7 –Schema del Perceptron con le relative grandezze.
l’uscita sarà inattiva (c = 0) se il segno è negativo, oppure attiva se il segno è positivo(c = 1).
Quindi l’uscita sarà data dalla funzione “gradino”,H (r), che vale appunto 1 perr > 0e 0 altrimenti:
c = H (r) (3.6)
Una semplice analisi geometrica mostra che questo modello è unclassificatore linea-re. I parametri di questo classificatore sono i pesiwi e la sogliaθ, che corrispondonoai parametriw e−b che abbiamo già visto per una superficie discriminante lineare.
Rosenblatt ideò anche un algoritmo per stimare i parametri da un training set.
Questo algoritmo èiterativo , ossia funziona con una piccola modifica ad ogni nuovaosservazione.
L’algoritmo è come segue:
1. Prendo una nuova osservazionex(l)
2. La classifico usando le equazioni (3.5) e (3.6)
3. se la classificazione è corretta (c = t(l)) allora non faccio niente
4. altrimenti cambio il vettore dei pesi in questo modo:w(k+1) = w(k)+ηt(l)cx(l)
Qui η è un parametro prefissato, minore di 1, che decide la velocità dell’apprendimen-to; se è troppo piccolo ci si mette molto tempo, se è troppo grosso ogni aggiornamentoprevale sulla storia passata ed è come ricominciare da capo – e quindi ci si mette moltotempo ugualmente.
L’interpretazione geometrica di quello che succede è la seguente:
• ηt(l)c è una quantità scalare.
• Questa quantità scalare viene moltiplicata per un vettore,x.
39

3 Il problema della classificazione
• Moltiplicando un vettorex per uno scalareα si ottiene un vettore che ha perdirezione la stessa direzione dix, e per intensità il prodotto traα e l’intensità dix, cioèα||x||.
• Quindi il vettore dei pesi subisce uno spostamentonella direzione opposta a xedi intensità proporzionale a η.
In realtà nell’algoritmo non abbiamo scritto come si fa ad adattareθ, la soglia.
Si usa un trucco: si definisce come ingresso al Perceptron un nuovo vettorex che had+1 componenti. Le componenti ˆx1,. . . ,xd sono le componenti del vettore di ingressooriginale: xi = xi ∀i = 1, . . . ,N. La componente ˆxd+1 è invece pari a−1 sempre.
A questo punto, si definisce un nuovo vettore di pesiw, anch’esso ad+1 componenti.Le componenti ˆw1,. . . ,wd sono le componenti del vettore di pesi originale: ˆwi = wi
∀i = 1, . . . ,N. La componente ˆwd+1 è invece pari aθ.
In questo modo, nel nuovo spazio ad + 1 dimensioni l’equazione della superficie diseparazione è
x · w = 0
Possiamo vedere che è esattamente equivalente all’altra:
d+1
∑i=1
xiwi =d
∑i=1
xiwi +(−1)θ =d
∑i=1
xiwi −θ
Oraθ fa parte del vettore di pesi e si adatta con la stessa regola di tutti gli altri pesi.
Esiste un teorema che mi garantisce quanto segue: se esiste una superficie discrimi-nante lineare che risolve il problema, allora questo algoritmo la trova in un numerofinito di passi (iterazioni).
3.6.3 Separabilità lineare
Cosa significa “se esiste una superficie discriminante lineare che risolve il problema”?Potrebbe non esistere?
Ebbene, sì. Non tutti i training set possono essere separati con una retta.
Per esempio, il training set in Figura 3.8non si puó dividere con una rettain unazona di sole crocette e una zona di soli quadretti. (Provare.)
Quindi il perceptron non è in grado di apprendere qualunque training set.
Per risolvere questo problema l’unica strada consiste nel fare unaestrazione di featurenon lineari. Infatti trasformazioni lineari non sono in grado di scambiare la posizionedei punti: sono solo rotazioni, traslazioni, e deformazioni di scala.
Questo è stato fatto nel 1985 usando unPerceptron a molti strati, e nel 1995 usandounmetodo a kernel.
40

3.6 Modelli non parametrici
Figura 3.8 – Il problema dell“OR esclusivo” (XOR). Una classe è segnata concrocette e l’altra con quadretti.
3.6.4 Multi-Layer Perceptron
Il problema di mettere più strati nel Perceptron era noto a Rosenblatt.
Il Perceptron originale comprende effettivamente più strati. Però il problema tecnolo-gico era nell’addestramento.
Infatti gli strati del perceptron non apprendono: solo l’ultimo è adattabile, quindi dalpunto di vista dell’apprendimento il Perceptron è una “macchina” ad uno strato solo.
Nel 1985, Rumelhart, McClelland e il loro gruppo di lavoro [5] pubblicarono una lievemodifica al Perceptron che gli permise di creare unMulti-Layer Perceptron dotato diun algoritmo di addestramento.
Tale struttura fu dimostrata in grado di rappresentare superfici discriminanti di formaarbitraria .
La piccola modifica consisteva in questo: al posto della funzione gradinoH (r), chenon si può derivare perché non è continua, era stata messa una funzione sigmoidesigm(r) fatta come illustrato in figura 3.9 e analiticamente espressa come:
sigm(r) =1
1+e−r/T(3.7)
SeT → 0, la sigmoide tende di nuovo al gradino. Ma per valori finiti diT, la sigmoideè continua e derivabile.
Ma perchè ci interessa la derivabilità?
Perchè vogliamo trovare i pesi cheminimizzano una determinata funzione di costo,e, come insegna la teoria di Lagrange (o come sappiamo dalle superiori), i punti diminimo di una funzione hanno derivata pari a zero.
Inventò poi un algoritmo in grado di fare l’addestramento di unastruttura a pù strati .
Una struttura di questo genere è essenzialmente costituita da una interconnessione dimolti Perceptron, uguali a quelli di Rosenblatt tranne per la modifica di cui sopra(sigmoide).
41

3 Il problema della classificazione
Figura 3.9 – Linea pesante: una sigmoide. Linee tratteggiate: diminuendo ilparametroT la sigmoide tende alla funzione gradino.
Figura 3.10 –Un multi-layer perceptron o Perceptron a più strati. In questo caso,oltre a ingresso e uscita, ci sono 2 strati nascosti.
42

3.6 Modelli non parametrici
In Figura 3.10 è schematizzato un multi-layer Perceptron.
Il gruppo di Rumelhart inventò questo modello matematico.
Nel gergo deimulti-layer Perceptron, lo strato formato dalle unità “sensoriali” sichiamastrato di ingresso. Le unità dello strato di ingresso hanno come uscita sempli-cemente il valore letto, e c’è una unità per ogni variabile osservata (quindi ce ne sonod).
Lo strato formato dalla o dalle unità che forniscono l’uscita si chiamastrato di uscita.
Lo strato o gli strati che non sonovisibili né dal lato dell’ingresso, né dal lato dell’u-scita, si chiamanostrati nascosti.
Ogni collegamento, illustrato con una linea, rappresenta una connessione sinaptica epertanto prevede un coefficiente di peso sinaptico.
L’algoritmo di Rumelhart per adattare tali pesi si basa sul seguente principio:
• valuto l’errore di classificazione sullo strato d’uscita
• propago tale errore all’indietro attraverso gli strati precedenti, proporzionalmen-te ai pesi
Per questo motivo si chiamaalgoritmo di error back-propagation .
3.6.5 Support vector machines
Le support vector machines sono lo stato dell’arte nella classificazione.
Sono l’unica famiglia di tecniche in grado diGARANTIRE determinate prestazionidi generalizzazione. Nessun altro metodo può fare analoghe garanzie supportate dateoremi oggettivi.
Si basa su una trasformazione dell’ingresso che può essere non lineare. Tale mappaturasi fa con delle funzioni che hanno caratteristiche di simmetria, che sono dettefunzionikernel.
Nello spazio così trasformato, viene identificata lasuperficie lineare di separazioneche rende massimo il margine di classificazione.
Risulta che:
• la superficie di separazione dipende solo dai pattern, non a altri parametri. Oc-corre solo scegliere i pattern opportuni che si chiamano support vectors
• il problema da risolvere semplice e ha come risultato di dare un coefficiente = 0a tutti i pattern che non sono support vectors
Attraverso la teoria di Vapnik, è possibile dimostrare che la soluzione a massimomargine è anche la soluzione a massima generalizzazione.
43

3 Il problema della classificazione
44

4 Il problema del clustering
Sommario
Concetto di clustering – Definizioni di distanze – Modalità di raggruppamento – Clu-stering con la tecnica k-Means – Clustering gerarchico – Cautele nell’applicazionedei metodi di clustering
4.1 Introduzione
4.1.1 Il clustering
Il problema delclustering (o cluster analysiso class discovery) consiste nell’attri-buire le osservazioni sperimentali a una trac differenti categoriee allo stesso temponello scoprire tali categorie.
Nel problema del clustering, come nella classificazione, mi interessa trovare la leggeche mi permette di assegnare le osservazioni alla classe corretta; ma, a differenza dellaclassificazione, devo anche trovare una plausibile suddivisione delle classi.
Mentre nella classificazione ho un aiuto che proviene dal target (la classificazione chemi viene fornmita nel training set), nel caso del clustering non posso basarmi su alcunainformazione aggiuntiva e devo dedurre le classi studiando la distribuzione spaziale deidati.
Le zone dello spazio in cui si addensano i dati corrispondono a gruppi (ocluster) diosservazioni simili. Se riesco a identificare osservazioni che sono simili fra loro e, allostesso tempo, sono differenti da quelle di un altro cluster, posso ipotizzare che a questidue cluster corrispondano condizioni differenti.
Per esempio, potrei avere un gruppo di osservazioni botaniche (fiori) in cui i petali e isepali tendono a essere piccoli, e un altro gruppo in cui petali e sepali tendono a esseregrandi. Posso quindi fare l’ipotesi che i due gruppi corrispondano a varietà differenti,e avrei quindiscopertole corrispondenti due classi.
TERMINOLOGIA: il problema della classificazione, come abbiamo visto in prece-denza, era un problemasupervisionato, perché un ipotetico supervisore mi ha fornitoun training set completo di classificazioni da cui apprendere.
45

4 Il problema del clustering
Il problema del clustering è invece un problemanon supervisionato, perché nessunsupervisore mi ha fornito classificazioni da cui apprendere. Nel training set non èpresente nessun target.
I training set senza target sono comuni. Ottenere una osservazione può essere relati-vamente facile; invece attribuirle una classe affidabile è spesso più difficile, o comeminimo più costoso.
Nel solito esempio medico, una osservazione può essere costituita da un insieme disintomi; mentre una classe è una diagnosi. Per misurare la temperatura o per effettuareun prelievo di sangue o descrivere le caratteristiche di un esantema basta un infermiere.Per fare una diagnosi a partire dai sintomi ci vuole un medico.
Esistono diversi problemi non supervisionati. Tra questi ci sono:
• prima esplorazione di nuovi dati ancora sconosciuti
• identificazione di un modello probabilistico di un fenomeno (ossia stima diprobabilità)
• ricerca di una rappresentazione più economica per i dati (eventualmente appros-simando, cioè buttando via dell’informazione)
• identificazione di classi naturali (class discovery)
Il clustering è uno strumento per affrontare molti di questi problemi.
Vediamo ora i due argomenti seguenti:
– come si decide che i dati vanno raggruppati (definizione della distanza);
– come si effettua il raggruppamento.
Il concetto didistanza e il modo per definire ungruppo sono i due ingredienti chedescrivono un algoritmo di clustering.
4.1.2 Distanze
Il clustering consiste nell’identificare concentrazioni o raggruppamenti di dati. Ta-li concentrazioni possono essere definite una volta che si è scelto come definire ilconcetto divicinanzaoppuredistanza. (Ovviamente vicinanza = 1/distanza.)
Allora, si potrà dire che un insieme di osservazioni forma un cluster se le osservazioniin tale insieme tendono ad essere piùvicine fra loro che alle altre osservazioni.
Per dati metrici , che formano veri e propri vettori in senso matematico, si può usareil concetto di distanza euclidea:
d(x,y) = ||x−y||=d
∑i=1
(xi −yi) (4.1)
Per dati nominali, che formano semplici sequenze dette anchestringhe, si possonousare vari concetti di distanza.
46

4.1 Introduzione
(Esempio IMPORTANTISSIMO di dati biologici nominali: sequenze genomiche oproteomiche. Per esempio, una sequenza di DNA si può rappresentare come un insie-me di variabili nominali ognuna delle quali assume un valore tra i quattro seguenti: A,G, C, T.)
Una possibile distanza fra due stringhe:il numero di simboli che non coincidononelle due stringhe.
Per esempio, fra le due stringhe seguenti:
A C A G T C A G A T C A G AA C T G T G A G T T C A G A
la distanza così definita vale 3 perché ci sono 3 basi diverse.
Un’altra possibile distanza fra stringhe, più sofisticata: fissato un insieme di operazionidi modifica (editing) possibili, per esempio le seguenti:
• inserire un simbolo;
• cancellareun simbolo;
• modificare un simbolo,
si può dire che la distanza fra due stringhe è ilminimo numero di operazioni, fraquelle prestabilite, necessario a passare dall’una all’altra stringa.
Una distanza calcolata in questo modo si chiamaedit distance.
Questo concetto, o altro simile, è alla base dei programmi diallineamento fra strin-gheche si usano per confrontare frammenti di genoma (BLAST, FASTA. . . ) e quindiper studiare i polimorfismi, per analizzare la somiglianza e l’evoluzione delle specie. . .
4.1.3 Come effettuare i raggruppamenti
Una volta che si è scelto un modo per calcolare la distanza, occorre deciderecomeformare i gruppi , cioè i cluster.
Si possono seguire due strade generali:
• clustering partitivo
• clustering gerarchico
Il clustering partitivo funziona facendo unapartizione dello spazio dei dati.
Lo spazio dei dati viene cioè suddiviso in tante sotto-zone; l’unione di tutte le sotto-zone dà lo spazio completo, e ogni sotto-zona non è sovrapposta (neanche in parte) adaltre sotto-zone. (Matematicamente, questa si chiama una partizione.)
Il principale algoritmo di clustering di questo tipo ha vari nomi. Si chiamac medieo k medie o, in inglese,c meanso k meansoppure ancheISODATA , cioè Iterative
47

4 Il problema del clustering
Self-Organizing Data Analysis Technique (A? Algorithm?), che è una versione un po’più sofisticata rispetto all’allestimento base.
Il clustering gerarchico funziona facendo unagerarchia di dati. I dati vengonodescritti attraverso unalbero tassonomicosimile a quelli utilizzati in sistematica.
Questo processo si può fare in due modi:
– persuddivisioni successive: si dividono i dati in due parti, poi ciascuna parte indue parti, poi ciascuna parte in due parti. . .
– oppure, come si fa più di frequente, peraggregazioni successive: si unisconocoppie di osservazioni simili, poi si uniscono coppie di coppie, poi coppie dicoppie di coppie. . .
Il primo tipo si può giustificare attraverso la teoria.
Il secondo tipo invece no, ma (nelle sue due varianti) è molto usato nelle scienze dellavita (= biologia + medicina). Infatti è facile da far funzionare e da interpretare. Perònon mi dà dei veri gruppi di dati (cluster) come li abbiamo definiti prima, ma solo unatassonomia.
4.2 Clustering partitivo
4.2.1 L’algoritmo k-means
Il più comune algoritmo di clustering partitivo crea le partizioni dello spazio dei datiusando il concetto divicino più prossimo.
Si usanok punti{y1, . . . , yk}, posizionati nello spazio dei dati.
Questi punti vengono chiamatiprototipi perché ciascuno viene usato comerappre-sentativo di un cluster.
La quantitàk si sceglie minore diN (numero osservazioni), perché i prototipi devonoessere un “riassunto” dei dati.
La partizionej-esima è formata da tutti i punti che sono più vicini al prototipoy j cheagli altri prototipi.
Quindi il problema del clustering, stabilito il numerlk di prototipi, consiste nel trovarela posizione più adatta per ik prototipi.
Ma cosa significa “più adatta”?
Nel caso della classificazione avevamo un criterio abbastanza univoco: la misura del-la qualità della classificazione ottenuta. Misuravamo la qualità della classificazioneattraverso la stima delrischio. Si possono usare criteri diversi, ma non molto diversi.
Nel caso del clustering, dobbiamo stabilire un criterio basato sulla distanza.
Nell’algoritmo k-means, si usa un criterio che tende a mantenere minima la distanzamedia tra ogni punto dati e il prototipo a cui viene associato.
L’algoritmo è piuttosto semplice:
48

4.2 Clustering partitivo
0. Inizializzo i k prototipi in qualche modo; per esempio, assegno loro posizionicasuali
1. Calcolo la distanza di ciascun punto del training set da ciascun prototipo
2. Assegno ciascun punto al prototipo più prossimo
3. Ricalcolo i prototipi comemedie dei rispettivi cluster
y j = ∑l∈clusterj
xl
4. Ripeto da 1 finché i prototipi non smettono di spostarsi
Il prototipo calcolato come media dei punti di un cluster viene anche chiamatocen-troide. In realtà, poi, non è altro che il baricentro del gruppo di punti.
Questo algoritmo ha dei pregi.
Innanzitutto èsemplice da comprendere. Poi è anche giustificabile con lateoria(la semplice regola viene fuori da calcoli di minimizzazione del criterio di distanzamedia). Infine si può dimostrare checonverge, ossia che prima o poi si ferma.
Ovviamente ha anche dei difetti.
Bisogna fare una certaquantità di calcoli, quindi può non essere adatto a training setmolto grossi. Bisognascegliere il numerok di prototipi senza avere indicazioni sucome sceglierlo (l’algoritmo non mi dice niente su qualek va meglio). Infine converge,ma potrebbe convergere a una soluzione che non è la migliore in assoluto, bensì lamigliore intorno al punto di partenza scelto. Si dice che tale soluzione è unminimolocale.
Per quest’ultimo problema la soluzione più semplice è riprovare tante volte l’algorit-mo, inizializzando in altrettanti diversi modi l’insieme deik prototipi.
Altre soluzioni più sofisticate richiedono modifiche all’algoritmo.
4.2.2 Validazione dei cluster
Una volta trovata una soluzione di clustering con l’algoritmok-means, come faccio asapere che è una soluzione di buona qualità?
Posso aggiungere deicriteri di validità dei cluster .
Un cluster viene quindi consideratovalido se rispetta determinati requisiti: per esem-pio, se è sufficientementecompatto e ben separato.
Il criterio di validazione dei clustersarà quindi un parametro numerico che valutaqueste proprietà. Si usano formule che includono per esempio distanze massime eminime tra i centroidi, oppure distanze fra punti dello stesso cluster e distanze frapunti qualunque, oppure la varianza inter-cluster e intra-cluster (ossia all’interno deicluster e totale).
Esistono moltissimi modi per fare questi calcoli.
49
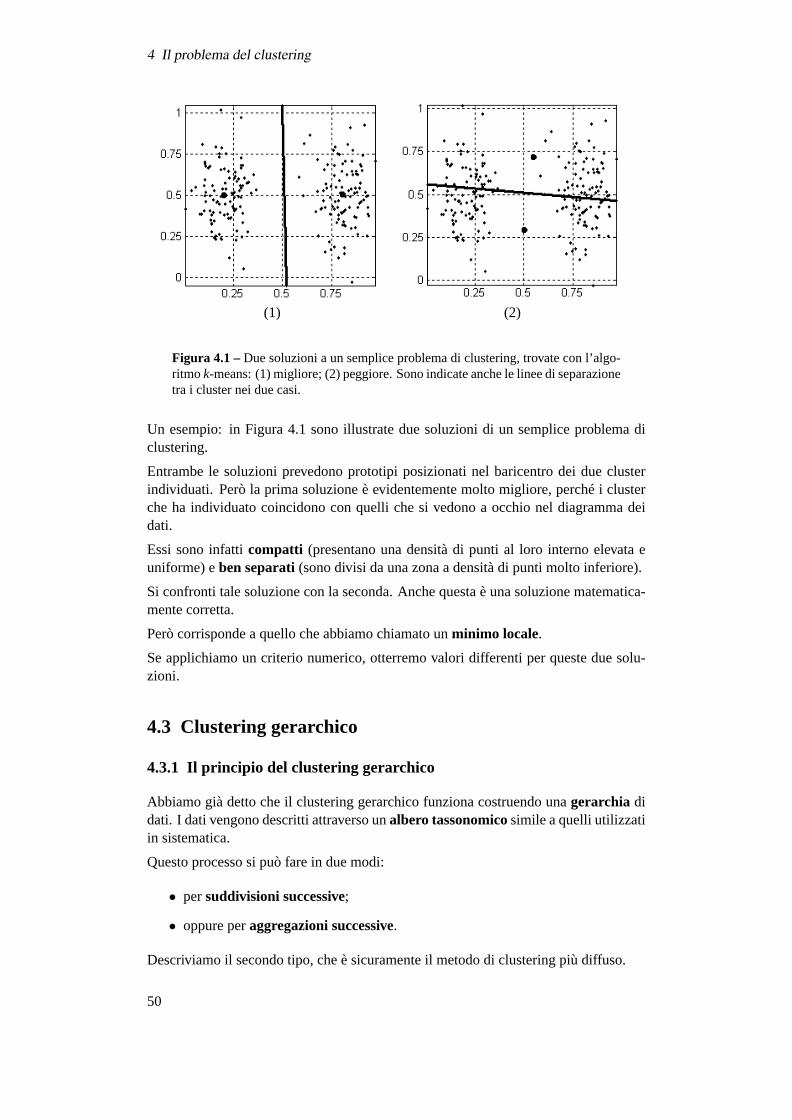
4 Il problema del clustering
(1) (2)
Figura 4.1 –Due soluzioni a un semplice problema di clustering, trovate con l’algo-ritmo k-means: (1) migliore; (2) peggiore. Sono indicate anche le linee di separazionetra i cluster nei due casi.
Un esempio: in Figura 4.1 sono illustrate due soluzioni di un semplice problema diclustering.
Entrambe le soluzioni prevedono prototipi posizionati nel baricentro dei due clusterindividuati. Però la prima soluzione è evidentemente molto migliore, perché i clusterche ha individuato coincidono con quelli che si vedono a occhio nel diagramma deidati.
Essi sono infatticompatti (presentano una densità di punti al loro interno elevata euniforme) eben separati(sono divisi da una zona a densità di punti molto inferiore).
Si confronti tale soluzione con la seconda. Anche questa è una soluzione matematica-mente corretta.
Però corrisponde a quello che abbiamo chiamato unminimo locale.
Se applichiamo un criterio numerico, otterremo valori differenti per queste due solu-zioni.
4.3 Clustering gerarchico
4.3.1 Il principio del clustering gerarchico
Abbiamo già detto che il clustering gerarchico funziona costruendo unagerarchia didati. I dati vengono descritti attraverso unalbero tassonomicosimile a quelli utilizzatiin sistematica.
Questo processo si può fare in due modi:
• persuddivisioni successive;
• oppure peraggregazioni successive.
Descriviamo il secondo tipo, che è sicuramente il metodo di clustering più diffuso.
50

4.3 Clustering gerarchico
Figura 4.2 – Un esempio di dendrogramma. Sull’asse delle ordinate: le “etichette”che identificano le osservazioni. Quando due osservazioni o due sottocluster vengonouniti, il valore di somiglianza che essi presentano è rappresentato dall’altezza vertica-le della loro unione. Quindi sull’asse delle ordinate si legge il livello di somiglianzatra due osservazioni/sottocluster.
1. Si cercano le due osservazioni più simili fra loro
2. Si aggregano a formare un cluster
3. Si sostituisce il cluster alle due osservazioni e si riparte (finché ci sono almenodue cluster o osservazioni rimaste)
Ad ogni unione, si traccia una parte dell’albero. L’ultima unione definisce laradicedell’albero, ossia la parte da cui tutto il resto si dirama.
Rappresentando graficamente questa serie di operazioni, si ottiene un diagramma chesi chiamadendrogramma.
Un esempio di dendrogramma è illustrato in figura 4.2.
Sull’asse delle ascisse sono riportati gli identificativi delle osservazioni (numeri d’or-dine, codici, lettere come in questo caso, o quel che si vuole).
Sull’asse delle ordinate, invece, si misura la distanza.
Due rami si uniscono a una certa altezza nel dendrogramma. Tale altezza rappresentala distanza tra i due rami.
Un cluster ben definito presenta molti rami che si riuniscono entro una ristretta gammadi distanze, e poi rami più lunghi che rappresentano le distanze (che sono maggiori)verso gli altri cluster.
Invece, un campione con cluster non bene definiti presenterà unioni distribuite un po’a tutte le distanze (altezze sull’asse delle ordinate).
4.3.2 Scelta della distanza e dellinkage
Il concetto di base delclustering gerarchico agglomerativoè che:
– Le osservazioni più simili (vicine) tra loro vengono unite a formare un cluster.
51

4 Il problema del clustering
– Un cluster si aggrega al cluster che gli è più simile, a formare un cluster di livellogerarchico superiore.
– Anche una osservazione si aggrega al cluster che le è più simile, in un cluster dilivello superiore.
Dobbiamo quindi definire due criteri:
1. come si valuta la somiglianza/distanza tra due osservazioni
2. come si valuta la somiglianza/distanza tra due cluster
(Il terzo caso, la distanza tra una osservazione e un cluster, si può trattare come un casoparticolare del secondo, in cui uno dei cluster è formato da una sola osservazione.)
Per definire la distanza tra osservazioni, si ricorre semplicemente a una delle defini-zioni viste in precedenza o ad altre.
La scelta della distanza è fatta in base a cosa lo studioso considera “somigliante”.Quindi è una scelta soggettiva.
Per definire la distanza tra cluster, si usa la stessa distanza che si è scelta per leosservazioni singole. Ora però bisogna applicarla aosservazioni rappresentative deidue cluster da confrontare.
Bisogna cioè scegliere, tra i punti contenuti in ciascun cluster, quello che ne riassumele caratteristiche.
La scelta delle osservazioni rappresentative si può ovviamente fare in molti modi. An-che in questo caso dipende da cosa sto cercando. Deciso quale punto è rappresentativodi ciascun cluster, ho deciso il modo dicollegaredue cluster. Questa operazione sichiamalinkage.
Le scelte tipiche sono:
Single linkage: si confrontano leosservazioni più vicine tra loronei due cluster.
Il collegamento si fa quindi considerando un solo “punto di contatto” (per cui“single”).
Complete linkage: si confrontano leosservazioni più lontane tra loro nei duecluster da confrontare.
Il collegamento si fa quindi considerando tutti i punti dei due cluster da con-frontare (per cui “complete”), che ovviamente sono tutti a distanza inferiore allamassima.
Average linkage: si confrontano leosservazioni mediedei due cluster, ossia i ba-ricentri.
Il collegamento si fa quindi considerando i punti medi dei due cluster da con-frontare (per cui “average”).
52

4.4 Attenzione a come si procede
4.3.3 Esempio di algoritmo
Vediamo ora come si procede per effettuare un clustering con un algoritmo di tipoclustering gerarchico agglomerativo con average linkage(che si può trovare sottoil nome inglesehierarchical agglomerative clustering with average linkage).
0. Si prende una matriceD, di dimensioniN×N.
In ogni elemento della matrice si mette la distanza tra l’osservazionex(i) el’osservazionex( j):
Di j = dist(
x(i),x( j))
(Nota: questa matrice avrà tutta la diagonale principale fatta di zeri, perché ladistanza di ogni osservazione con sè stessa è nulla; sarà inoltre simmetrica, per-ché la distanza tra l’osservazionex(i) e l’osservazionex( j) è uguale alla distanzatra l’osservazionex( j) e l’osservazionex(i), per cuiDi j = D ji .
Perciò di questa matrice me ne serve meno di metà.)
1. Si sceglie la coppia{
x( j),x(i)}
per cui la distanza è minima (cioè si calcolamini, j Di j ).
2. Si calcola il baricentro della coppia a distaza minima{
x( j),x(i)}
:
x =12(x( j) +x(i))
3. Nel training set, si eliminanox( j) ex(i) e si sostituiscono conx.
Ossia, si sostituisce la coppia a distanza minima con il suo baricentro, cheabbiamo scelto come “punto rappresentativo”.
4. Si ricalcola una nuova matriceD′, che ora è(N−1)× (N−1), e si ricominciadal passo 1 con la nuova matrice.
In figura 4.3 è illustrato un semplice training set di esempio e la relativa matrice didistanze.
4.4 Attenzione a come si procede
4.4.1 Normalizzazioni
Il clustering è in sè una tecnica sempre basata su un concetto didistanza.
La distanza si può scegliere in vari modi.
Nei casimetrici , ossia quando abbiamo valori vettoriali,diventa particolarmenteimportante la normalizzazione.
Le considerazioni generali le abbiamo già fatte parlando della normalizzazione comepre-processing.
Qui bisogna aggiungere che il fatto di normalizzare, e soprattutto ilmodo di norma-lizzare, devvono essere decisi dallo studioso in base alla sua conoscenza diretta del-l’argomento, perchè solo lui può rendersi conto del significato preciso delle operazioniche sta facendo sui dati.
53

4 Il problema del clustering
Training set0.1 0.70.0 0.50.2 0.40.2 0.50.2 0.1
Distanze0.000 0.224 0.316 0.224 0.6080.224 0.000 0.224 0.200 0.4470.316 0.224 0.000 0.100 0.3000.224 0.200 0.100 0.000 0.4000.608 0.447 0.300 0.400 0.000
(1) (2)
Figura 4.3 –Un semplice esempio di problema di clustering agglomerativo. In (1) iltraining set; in (2) la relativa matrice delle distanze, usando distanza euclidea. Notareche ha la diagonale nulla ed è simmetrica. Esercizio: costruire l’albero gerarchico edisegnare il dendrogramma relativo.
4.4.2 Inizializzazione
L’algoritmo k-means richiede una inizializzazione.
Se si ha un’idea di come siano disposti i cluster nello spazio dei dati, è bene provvederea una inizializzazione che ne tenga conto, anziché andare completamente a caso.
In questo modo si può sperare di ottenere meno minimi locali e raggiungere più infretta (in meno tentativi) soluzioni di buona qualità.
(Ovviamente la qualità è misurata attraverso il calcolo di un criterio di validità comequelli a cui abbiamo accennato.)
4.4.3 Instabilità
Alcuni algoritmi presentano delleinstabilità .
Con questo termine si intende dire che essi, per piccole variazioni dei dati in ingresso,possono produrre risultati molto diversi.
Gli algoritmi di clustering gerarchico agglomerativo presentano questo problema.
Se tolgo o aggiungo un dato, è possibile che l’albero tassonomico che ottengo sia moltodifferente.
Per avere un’idea di quanta incertezza ci sia in un dato albero tassonomico, possoricorrere a tecniche che gli statistici chiamano diricampionamento.
In realtà si tratta di tecniche diriciclaggio del campione. Infatti non si effettuano nuo-vi campionamenti sul campo o in laboratorio, ma si riusano in vari modi le osservazionidel training set originale.
Una di queste tecniche, molto popolare, si chiamabootstrap.
Il bootstrap consiste nel generare nuovi campioni, di numerositàN pari all’originale,col seguente criterio:
Prendo l’osservazione xl con probabilità1/N
54

4.4 Attenzione a come si procede
Cioè, ogni nuova osservazione è scelta a caso tra leN vecchie osservazioni. Il nuo-vo campione può quindi essere formato da tutte le stesse osservazioni del campioneoriginale, oppure avere alcune osservazioni ripetute e altre mancanti.
Il nuovo campione si chiamacampione di bootstrapo replica Bootstrap.
Ci sono moltissime repliche Bootstrap possibili per un dato training set, quindi ilricampionamento si può fare per esempio 1000 volte.
Su 1000 repliche bootstrap, io posso stimare quanto varia il mio risultato di clustering,cioè il mio albero tassonomico o il mio dendrogramma.
Questa tecnica richiede molti calcoli. È basata sulla considerazione che questi calcolinon mi stanco a farli, perché sono ripetitivi e li fa il calcolatore.
(Bootstrap significacinghia degli stivali. Uno modo di dire inglese è ”to pull oneselfup by the bootstraps”, sollevarsi per la cinghia dei propri stivali. Significa un po’ come“si è fatto da sè”.
Gli stivali avevano una cinghia posteriore con cui aiutarsi per calzarli. È possibilesollevare un’altra persona attraverso tale cinghia; è molto più difficile sollevare sèstessi.
Un campione statistico che si autogenera si chiama campione di bootstrap per questomotivo. Anche un calcolatore che parte da solo senza avere alcun programma caricatofa un’operazione che si chiama “bootstrap”, o abbreviato “boot”.)
55

4 Il problema del clustering
56

Bibliografia
[1] C.L. Blake and C.J. Merz. UCI repository of machine learning databases, 1998.URL: http://www.ics.uci.edu/∼mlearn/MLRepository.html.
[2] Richard O. Duda and Peter E. Hart.Pattern Classification and Scene Analysis.John Wiley and Sons, New York (USA), 1973.
[3] Ronald A. Fisher. The use of multiple measurements in taxonomic problems.Annual Eugenics, 7, part II:179–188, 1936.
[4] Frank Rosenblatt.Principles of Neurodynamics. Spartan, New York, 1962.
[5] D. E. Rumelhart and J. L. McClelland.Parallel Distributed Processing. MITPress, Cambridge MA, 1986.
[6] Vladimir Naumovich Vapnik.The Nature of Statistical Learning Theory. Springer-Verlag, New York, 1995.
57


















![dercole.faculty.polimi.it1) Due serbatoi in cascata hanno coefficienti di deflusso (misurati in [gg-l], gg=giorni) pari rispettivamente a 1](https://static.fdocumenti.com/doc/165x107/5f021db87e708231d402a685/1-due-serbatoi-in-cascata-hanno-coefficienti-di-deflusso-misurati-in-gg-l-gggiorni.jpg)