
Appunti delle Lezioni di Ottimizzazione di Sistemi Complessi -...
40
Appunti delle Lezioni di Ottimizzazione di Sistemi Complessi a cura di G. Liuzzi 1 Master in Ottimizzazione e Data Mining 1 [email protected], http://www.iasi.cnr.it/∼liuzzi
Transcript of Appunti delle Lezioni di Ottimizzazione di Sistemi Complessi -...

Appunti delle Lezioni di Ottimizzazione
di Sistemi Complessi
a cura di G. Liuzzi1
Master in Ottimizzazione e Data Mining
[email protected], http://www.iasi.cnr.it/∼liuzzi

Capitolo 1
Programmazione Multiobiettivo
1.1 Introduzione
Un problema matematico di ottimizzazione puo essere definito come la minimizzazione omassimizzazione di una funzione a valori reali su un insieme specificato. L’importanzadi questo modello matematico deriva ovviamente dal fatto che molti problemi reali ven-gono affrontati facendovi ricorso. Tuttavia quasi ogni problema reale di ottimizzazione ecaratterizzato dalla presenza contemporanea di piu obiettivi, cioe funzioni a valori reali damassimizzare e/o minimizzare, tipicamente in contrasto tra loro.Nel seguito considereremo il seguente problema di ottimizzazione multiobiettivo:
min (f1(x)f2(x) . . . fk(x))⊤
x ∈ F(MOP)
ove k ≥ 2 e fi : IRn → IR, per i = 1, . . . , k.D’ora in avanti chiameremo IRk spazio degli obiettivi e IRn spazio delle variabili di decisione.Un vettore x ∈ IRn sara pertanto un vettore di decisioni mentre z ∈ IRk un vettore di obiettivi.Indicheremo, inoltre, con f(x) il vettore delle funzioni obiettivo (f1(x)f2(x) . . . fk(x))⊤ e conZ = f(F) l’immagine della regione ammissibile F nello spazio degli obiettivi (vedi figura) ecioe
Z = f(F) =
z ∈ IRk : ∃x ∈ F , z = f(x)
.
In particolare diremo che un vettore di obiettivi z ∈ IRk e ammissibile quando risulti z ∈ Z.Definiamo , inoltre, il vettore ideale degli obiettivi zid come il vettore di componenti Vettore ideale
zidi = min fi(x)
x ∈ FQuello che vogliamo fare e minimizzare tutte le funzioni obiettivo simultaneamente. Senon ci fossero conflitti tra le funzioni obiettivo, una soluzione banale al problema sarebbequella ottenibile risolvendo separatamente k problemi di ottimizzazione (uno per ogni fun-zione obiettivo) ottenendo quindi come soluzione proprio il vettore ideale zid. Non sarebbepertanto necessario applicare nessuna tecnica specifica di soluzione. Per evitare il sorgeredi tale caso banale, supporremo che zid 6∈ Z. Questo significa assumere che le funzionif1(x), f2(x), . . . , fk(x) siano, almeno in parte, in contrasto tra loro.Con B(x, δ) = y ∈ IRn| ‖x− y‖ < δ indicheremo la sfera aperta di centro x ∈ IRn e raggio
δ > 0. Dato un insieme A, indicheremo con ∂A la frontiera di A, con
A l’interno e con A lachiusura di A.
1

1z
2z
1x
2x
f
3x
S Z=f(S)
Dati due insiemi A e B definiamo l’insieme differenza A\B come quell’insieme costituito datutti e soli gli elementi di A che non appartengono a B, ovvero
A\B =
x ∈ A : x 6∈ B
.
Dato un vettore b ∈ IRn ed un insieme A ⊂ IRn, definiamo traslazione di A rispetto a bl’insieme
b+A =
x ∈ IRn : x = b+ a per ogni a ∈ A
.
In maniera del tutto analoga definiamo l’insieme
b−A =
x ∈ IRn : x = b− a per ogni a ∈ A
.
Se I e un insieme di indici e v un vettore, con vI indicheremo il sottovettore costituito dallecomponenti di v con indici in I. Sia infine IRk
+ l’ortante positivo dello spazio degli obiettivicioe
IRk+ =
z ∈ IRk : z ≥ 0
.
1.2 Ottimalita secondo Pareto
Prima di procedere, e necessario definire con chiarezza cosa si intende per soluzione ot-tima di un problema di programmazione multiobiettivo. La definizione che adottiamo eche e riportata nel seguito, e stata proposta per la prima volta da Edgeworth nel 1881 esuccessivamente ripresa da Vilfredo Pareto nel 1896 [4] che la approfondı ulteriormente.
Definizione 1.2.1 Dati due vettori z1, z2 ∈ IRk, diciamo che z1 domina z2 secondo Pareto(z1 ≤P z2) quando risulta
z1i ≤ z2
i per ogni i = 1, 2, . . . , k e
z1j < z2
j per almeno un indice j ∈ 1, . . . , k.
La relazione binaria ≤P e un ordinamento parziale (non riflessivo) nello spazio delle k-uple dinumeri reali. Sfruttando la relazione ≤P possiamo dare la definizione di ottimalita secondoPareto.
Definizione 1.2.2 Un vettore di decisioni x⋆ ∈ F e un ottimo di Pareto se non esiste Ottimo di Pareto
un’altro vettore x ∈ F tale che:
f(x) ≤P f(x⋆).
2

Ottimi globali
Ottimi locali
Figura 1.1: Ottimi locali e globali di Pareto.
Corrispondentemente diremo che un vettore di obiettivi z⋆ ∈ Z e ottimo secondo Paretoquando non esiste un altro vettore z ∈ Z tale che
z ≤P z⋆.
Quindi se ci troviamo in un punto ottimo secondo Pareto e vogliamo ulteriormente diminuireil valore di una o piu funzioni obiettivo dobbiamo essere disposti ad accettare un conseguenteaumento in alcune (o tutte) le rimanenti funzioni del problema. In tal senso possiamoaffermare che, nello spazio degli obiettivi, gli ottimi di Pareto sono punti di equilibrio che sitrovano sulla frontiera dell’insieme Z.
Definizione 1.2.3 Diciamo frontiera efficiente l’insieme degli ottimi di Pareto del problema Frontiera
efficiente(MOP)
La definizione di ottimo secondo Pareto e ovviamente, una definizione di ottimo globale datoche si richiede la validita di una certa proprieta su tutto l’insieme ammissibile del problema(MOP). E evidentemente possibile, pero, dare una definizione di ottimo locale secondoPareto.
Definizione 1.2.4 Un vettore di decisioni x⋆ ∈ F e un ottimo locale di Pareto se esiste un Ottimo locale
di Paretonumero δ > 0 tale che x⋆ e ottimo secondo Pareto in F ∩ B(x⋆, δ).
In figura 1.1 si riportano gli ottimi globali e locali di Pareto per un insieme Z.Ovviamente, ogni ottimo globale e anche un ottimo locale di Pareto. Il viceversa e vero solose facciamo alcune ipotesi sulla struttura del problema (MOP). Se (MOP) e convesso cioese
i- l’insieme ammissibile F e convesso e
ii- tutte le funzioni obiettivo fi(x) (con i = 1, 2, . . . , k) sono convesse.
allora si puo dimostrare che ogni ottimo locale di Pareto e anche un ottimo globale.
Teorema 1.2.5 Sia (MOP) un problema di programmazione multiobiettivo convesso. Allo- Equivalenza tra
ottimi locali e
globali
di Pareto
ra, ogni ottimo locale di Pareto e anche un ottimo globale.
La definizione di ottimo secondo Pareto puo essere leggermente indebolita ottenendo cosı ladefinizione di ottimo debole secondo Pareto.
Definizione 1.2.6 Un vettore x⋆ ∈ F e un ottimo di Pareto debole per il problema (MOP) Ottimalita debole
secondo Paretose non esiste un punto x ∈ F tale che
f(x) < f(x⋆).
3

2
Z1
Z
Ottimi deboli di Pareto
Ottimi di Pareto
Figura 1.2: Gli ottimi di Pareto sono individuati dalla linea doppia a tratto continuo. La linea tratteggiata
individua invece gli ottimi deboli che non sono ottimi di Pareto.
Ovviamente, l’insieme degli ottimi secondo Pareto e contenuto nell’insieme degli ottimideboli di Pareto.Anche qui, come gia si era fatto per gli ottimi di Pareto, e possibile dare una definizione diottimo locale debole.
Definizione 1.2.7 Un vettore di decisioni x⋆ ∈ F e un ottimo locale debole (secondo Ottimo locale
debole di ParetoPareto) se esiste un numero δ > 0 tale che x⋆ e ottimo debole di Pareto in F ∩ B(x⋆, δ).
In figura 1.2 sono riportati, per maggiore chiarezza, ottimi e ottimi deboli secondo Pareto.Anche per gli ottimi deboli secondo Pareto vale una proprieta analoga a quelle espressa dalteorema 1.2.5 e cioe se il problema (MOP) e convesso ogni ottimo locale (debole) e ancheottimo globale (debole) di Pareto.
1.2.1 Esercizio
Sia dato il seguente problema di ottimizzazione vettoriale:
min (x1 + x2, x1 − x2)⊤
x21 + x2
2 ≤ 2
x21 − x2 ≤ 0
x1 ≥ 0
(1)
In questo caso, in cui il vettore delle decisioni ha dimensione due, e semplicissimo tracciarela regione ammissibile nello spazio delle variabili di decisione. Inoltre, poiche il vettore degliobiettivi ha dimensione due e le funzioni obiettivo sono lineari, possiamo determinare larappresentazione grafica di Z = f(F). Vediamo nel dettaglio come fare.Le relazioni che dobbiamo prendere in considerazione sono le seguenti due trasformazionilineari:
z1 = f1(x1, x2) = x1 + x2
z2 = f2(x1, x2) = x1 − x2
(2)
La regione ammissibile degli obiettivi e ottenibile da quella delle decisioni mediante rotazionee scalatura, come messo in evidenza dalla figura 1.3Sempre per via grafica, e facile risolvere i sottoproblemi ad un solo obiettivo associati al
4

F
Z
2
z 1
zid
Ottimi di Pareto
x2
x
f
1
2
1 2
-2
-1
1
2
2 3
1
1
z
Figura 1.3: Esempio
problema (1) che sono:
zid1 = min x1 + x2
x21 + x2
2 ≤ 2
x21 − x2 ≤ 0
x1 ≥ 0
x1⋆ = (0, 0)⊤
e
zid2 = min x1 − x2
x21 + x2
2 ≤ 2
x21 − x2 ≤ 0
x1 ≥ 0
x2⋆ = (0,√
2)⊤
ricavando, in tal modo, il vettore ideale degli obiettivi zid = (0,−√
2)⊤. Notiamo subito chenon essendo zid contenuto in Z = f(F), il problema vettoriale non e risolvibile semplice-mente minimizzando separatamente le due funzioni obiettivo.E altresı facile individuare, in figura 1.3, la frontiera efficiente secondo Pareto dell’insiemeZ. Come ci aspettavamo, essendo il problema (1) convesso, tutti gli ottimi locali di Paretosono anche globali.
1.3 Condizioni di Ottimalita
Nelle sezioni precedenti abbiamo dato delle definizioni fondamentali della programmazionemultiobiettivo. In particolare, dato che lo spazio delle k-uple di numeri reali e solo parzial-mente ordinato, abbiamo dovuto definire cosa si intende per minimo di un vettore difunzioni.Quello che dobbiamo fare ora, e dare una caratterizzazione analitica dei punti di ottimosecondo Pareto. Come vedremo, tutte le condizioni di ottimo per la programmazione multi-obiettivo, comprendono come caso particolare quelle per la programmazione nonlineare (conuna sola funzione obiettivo). Per ulteriori approfondimenti sull’argomento di questa sezionesi rimanda al testo [1] citato in bibliografia.
5
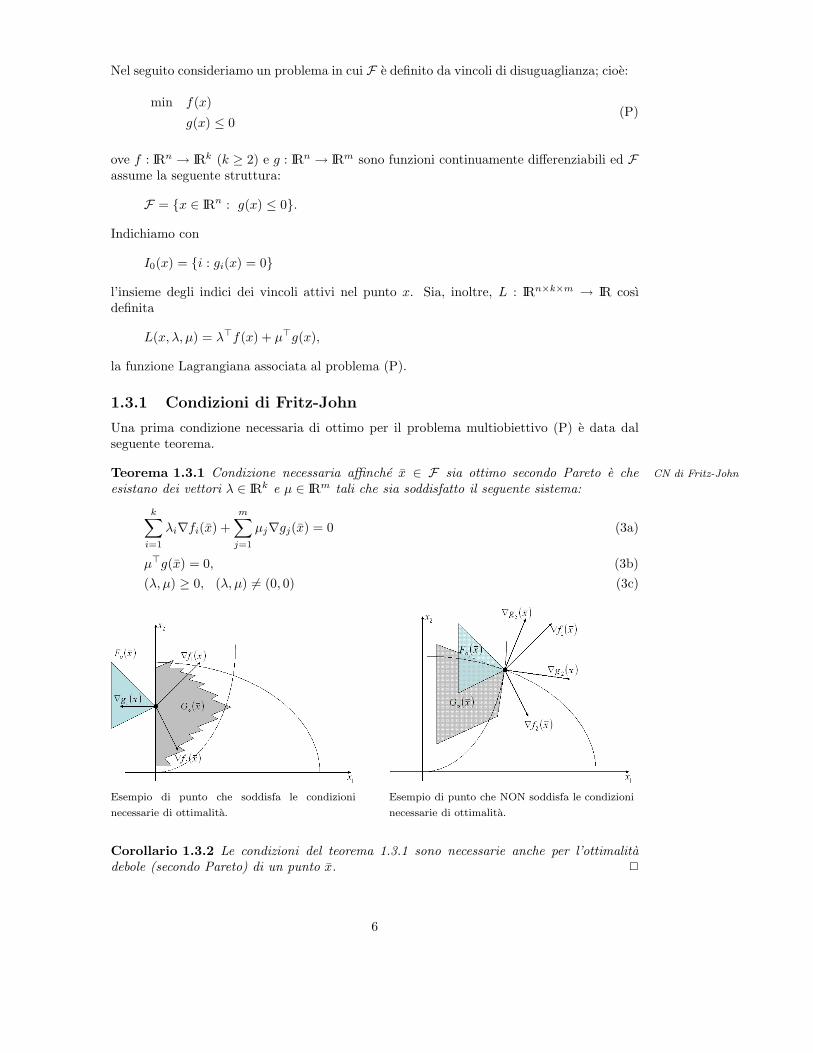
Nel seguito consideriamo un problema in cui F e definito da vincoli di disuguaglianza; cioe:
min f(x)
g(x) ≤ 0(P)
ove f : IRn → IRk (k ≥ 2) e g : IRn → IRm sono funzioni continuamente differenziabili ed Fassume la seguente struttura:
F = x ∈ IRn : g(x) ≤ 0.
Indichiamo con
I0(x) = i : gi(x) = 0
l’insieme degli indici dei vincoli attivi nel punto x. Sia, inoltre, L : IRn×k×m → IR cosıdefinita
L(x, λ, µ) = λ⊤f(x) + µ⊤g(x),
la funzione Lagrangiana associata al problema (P).
1.3.1 Condizioni di Fritz-John
Una prima condizione necessaria di ottimo per il problema multiobiettivo (P) e data dalseguente teorema.
Teorema 1.3.1 Condizione necessaria affinche x ∈ F sia ottimo secondo Pareto e che CN di Fritz-John
esistano dei vettori λ ∈ IRk e µ ∈ IRm tali che sia soddisfatto il seguente sistema:
k∑
i=1
λi∇fi(x) +
m∑
j=1
µj∇gj(x) = 0 (3a)
µ⊤g(x) = 0, (3b)
(λ, µ) ≥ 0, (λ, µ) 6= (0, 0) (3c)
Esempio di punto che soddisfa le condizioni
necessarie di ottimalita.
Esempio di punto che NON soddisfa le condizioni
necessarie di ottimalita.
Corollario 1.3.2 Le condizioni del teorema 1.3.1 sono necessarie anche per l’ottimalitadebole (secondo Pareto) di un punto x. 2
6

Definizione 1.3.3 (tripla di FJ) Una tripla (x, λ, µ) ∈ IRn×k×m e una tripla di Fritz-John quando soddisfa il sistema (3) cioe:
∇xL(x, λ, µ) = 0
g(x) ≤ 0
µ⊤g(x) = 0
(λ, µ) ≥ 0 (λ, µ) 6= (0, 0).
Definizione 1.3.4 (punto di FJ) Un vettore di decisioni x ∈ IRn e un punto di FJ seesistono dei vettori λ ∈ IRk e µ ∈ IRm tali che (x, λ, µ) e una tripla di FJ.
1.3.2 Condizioni di Karush-Kuhn-Tucker
Si pufacilmente far vedere che esistono casi in cui un punto ammissibile potrebbe essere unpunto di FJ indipendentemente dalle funzioni obiettivo. Motivati da questa considerazioneintroduciamo in questo paragrafo le condizioni di KKT con le quali in pratica forziamo igradienti di alcune funzioni obiettivo ad avere un peso non nullo nell’espressione (3a).Preliminarmente introduciamo la seguente definizione.
Definizione 1.3.5 Un punto ammissibile x ∈ F e un punto di regolarita per i vincoli del LICQ
problema (P) se in x sono linearmente indipendenti i gradienti dei vincoli attivi.
A questo punto possiamo dare la seguente ulteriore condizione necessaria di ottimalitasecondo Pareto.
Teorema 1.3.6 Sia x un punto ammissibile per il problema (P) e siano linearmente in- CN di KKT
dipendenti i gradienti dei vincoli attivi in x. Allora, condizione necessaria affinche x sia unottimo di Pareto (locale o globale) e che sia ammissibile il seguente sistema:
k∑
i=1
λi∇fi(x) +m∑
j=1
µj∇gj(x) = 0, (4a)
µ⊤g(x) = 0, (4b)
(λ, µ) ≥ 0, λ 6= 0. (4c)
Corollario 1.3.7 Le condizioni del teorema 1.3.6 sono necessarie anche per l’ottimalitadebole (secondo Pareto) di un punto x. 2
Le condizioni di KKT (come quelle di FJ) sono condizioni solo necessarie di ottimo il chevuol dire che potrebbero essere verificate anche in punti non ottimi secondo Pareto. Etuttavia possibile dare condizioni sufficienti di ottimalita, senza ricorrere all’uso delle derivateseconde, a patto pero di fare alcune ipotesi aggiuntive sulla struttura del problema (P).
Teorema 1.3.8 Siano le fi(x) (per ogni i = 1, 2, . . . , k) e gj(x) (per ogni j = 1, 2, . . . ,m) CS di ottimo
secondo Paretoconvesse. Condizione sufficiente affinche un punto x ∈ F sia ottimo secondo Pareto e cheesistano dei vettori di moltiplicatori λ ∈ IRk e µ ∈ IRm tali che
∇xL(x, λ, µ) = 0, (5a)
µ⊤g(x) = 0, (5b)
λ > 0, µ ≥ 0. (5c)
7

Si noti che nelle condizioni sufficienti di KKT appena viste si richiede che tutti i moltiplicatoridelle funzioni obiettivo siano strettamente positivi mentre nelle condizioni necessarie almenoun λi e strettamente positivo.Per quanto riguarda i punti di ottimo debole secondo Pareto, e possibile stabilire, sempresotto le ipotesi di convessita, un risultato ancora piu forte. Per tali punti si possono darecondizioni necessarie e sufficienti di ottimo.
Teorema 1.3.9 Siano le fi(x) (per ogni i = 1, 2, . . . , k) e gj(x) (per ogni j = 1, 2, . . . ,m) CNS di KKT
convesse. Condizione necessaria e sufficiente affinche un punto x ∈ F sia ottimo debolesecondo Pareto e che esistano dei moltiplicatori λ ∈ IRk e µ ∈ IRm tali che
∇xL(x, λ, µ) = 0,
µ⊤g(x) = 0,
(λ, µ) ≥ 0, λ 6= 0.
1.4 Metodi di Soluzione
Generare le soluzioni ottime secondo Pareto costituisce una parte essenziale della program-mazione vettoriale ed anzi, matematicamente parlando, nella maggior parte dei casi, il prob-lema (P) si considera risolto una volta che sia stato individuato l’insieme degli ottimi diPareto. Tuttavia, non sempre ci si puo accontentare semplicemente di aver trovato l’insiemedegli ottimi secondo Pareto. Alcune volte e infatti necessario ordinare tutte le soluzionitrovate e quindi selezionare la migliore rispetto a tale ordinamento. Per questo motivo ab-biamo bisogno di un decisore cioe di qualcuno che ci dica, in base alle sue preferenze, comeordinare l’insieme degli ottimi di Pareto del problema (P).In base al ruolo svolto dal decisore nella strategia di soluzione del problema, i metodirisolutivi della programmazione multiobiettivo vengono spesso suddivisi in quattro grandicategorie.
• Metodi senza preferenze nei quali il decisore non ha nessun ruolo e si considera soddis-facente l’aver trovato un qualunque ottimo di Pareto.
• Metodi a posteriori nei quali si genera l’insieme di tutti gli ottimi di Pareto e poi lo sipresenta al decisore che sceglie la soluzione per lui migliore.
• Metodi a priori nei quali il decisore specifica le sue preferenze prima che abbia inizioil processo risolutivo. In base alle informazioni avute dal decisore viene direttamentetrovata la soluzione ottima migliore, senza dover dunque generare tutti gli ottimi diPareto.
• Metodi interattivi nei quali il decisore specifica le sue preferenze mano a mano chel’algoritmo procede, guidando in tal modo il processo risolutivo verso la soluzione perlui piu soddisfacente.
Al di la di questa distinzione, tutti i metodi di soluzione per la programmazione multio-biettivo si basano sulla medesima idea di fondo, ovvero quella di trasformare il problemaoriginario in uno con una sola funzione obiettivo. La tecnica mediante la quale si ottiene ilproblema mono obiettivo a partire dal problema (P) e nota come scalarizzazione.
1.4.1 Metodi Senza Preferenze
Nei metodi senza preferenze ci si accontenta di generare una soluzione ottima di Pareto,qualunque essa sia, senza tenere in considerazione le indicazioni del decisore.
8

Il metodo che presentiamo e noto come metodo GOAL (cfr. [3, sez. 2.1]). Quello chesi fa e cercare la soluzione che minimizza, nello spazio degli obiettivi, la distanza tra laregione ammissibile (Z) e un qualunque punto di riferimento zref 6∈ Z = f(F). Il vettoredi riferimento sara costituito dai valori auspicabili per le singole funzioni obiettivo. Inparticolare, una possibile scelta di zref e zref = zid. Il problema che otteniamo e percio ilseguente:
min ‖f(x) − zid‖p
g(x) ≤ 0(Pp)
ove ‖ · ‖p indica la norma p di un vettore (con 1 ≤ p ≤ ∞). In particolare, se p = ∞, ilproblema (Pp) e noto come problema di Tchebycheff. Supponiamo di conoscere il vettoreideale globale degli obiettivi. Sotto tali ipotesi, il problema (Pp) ammette sempre soluzione.Valgono le seguenti proprieta.
Proposizione 1.4.1 Ogni soluzione globale del problema (Pp) (con 1 ≤ p <∞) e un ottimoglobale di Pareto per il problema (P).
Estendiamo ora il risultato precedente al caso dei minimi locali (cfr. [3]).
Proposizione 1.4.2 Ogni ottimo locale del problema (Pp) (con 1 ≤ p < ∞) e un ottimolocale di Pareto per il problema (P). 2
Nel caso in cui p = ∞ vale invece la seguente proprieta (cfr. [3]).
Proposizione 1.4.3 Ogni ottimo locale (globale) del problema di Tchebycheff (P∞) e unottimo locale (globale) debole di Pareto del problema (P). 2
Tuttavia, la seguente proposizione, ci assicura l’esistenza di almeno una soluzione di (P∞)ottima secondo Pareto per il problema (P).
Proposizione 1.4.4 Il problema di Tchebycheff (P∞) ha almeno una soluzione che e ottimasecondo Pareto. 2
Le scelte di p = 1 e p = ∞ sono particolarmente vantaggiose nel caso in cui il problemamultiobiettivo originario e lineare (fi(x), gj(x) lineari per ogni i e j). Mediante semplicimanipolazioni sul problema (Pp) e infatti possibile ottenere ancora un problema lineare equindi adottare le ben note tecniche della PL per la sua soluzione. Supponiamo che (P) sialineare ovvero
min (c⊤1 x, c⊤2 x, . . . , c
⊤k x)
Ax ≤ b
• Norma p = 1.Il problema scalarizzato
min
k∑
i=1
|c⊤i x− zidi |
Ax ≤ b
puo essere facilmente trasformato in un problema di PL con l’aggiunta di k variabili ausiliarie,αi per i = 1, 2, . . . , k, ottenendo:
min
k∑
i=1
αi
|c⊤i x− zidi | ≤ αi i = 1, 2, . . . , k
Ax ≤ b
9

x2
F
1
1
1
2
x2
Figura 1.4: Regione ammissibile
• Norma p = ∞.In questo caso, il problema scalarizzato
min maxi=1,...,k
|c⊤i x− zidi |
Ax ≤ b
puo essere facilmente trasformato in un problema di PL con l’aggiunta di una sola variabileausiliaria, α, ottenendo:
min α
|c⊤i x− zidi | ≤ α i = 1, 2, . . . , k
Ax ≤ b
Esempio
Si consideri il seguente problema di programmazione multiobiettivo:
min (x1, x2)
x21 + x2
2 ≥ 1
0 ≤ x1 ≤ 2
0 ≤ x2 ≤ 2
(Pes)
In questo esempio, vedi figura 1.4, le regioni ammissibili nello spazio delle variabili didecisione ed in quello degli obiettivi coincidono essendo
z1 = x1
z2 = x2
Possiamo inoltre facilmente calcolare il vettore ideale degli obiettivi ottenendo cosı: zid =(0, 0)⊤. In figura 1.5a sono riportati gli ottimi di Pareto del problema (Pes).A questo punto applichiamo il metodo GOAL con p = 1, 2,∞.
10

(c)(b)(a)
(d)
Figura 1.5: Differenti soluzioni in corrispondenza a differenti tipi di norme.
• p = 1. Il problema scalarizzato con questo tipo di norma ha due soluzioni (vedi figura1.5b).
• p = 2. Il problema che otteniamo usando la norma euclidea ha infinite soluzioni (comesi vede in figura 1.5c) e cioe tutte le soluzioni del problema (Pes).
• p = ∞. Il problema di Tchebycheff ha una sola soluzione (vedi figura 1.5d)
1.4.2 Metodi a Posteriori
I metodi appartenenti a questa classe sono anche noti come metodi per generare l’insiemedelle soluzioni di Pareto. Infatti, siccome le preferenze del decisore vengono consideratesolo al termine del processo risolutivo, quello che si fa e generare tutti i punti ottimi sec-ondo Pareto. Una volta che l’insieme delle soluzioni di Pareto e stato generato, esso vienepresentato al decisore che seleziona il o i vettori per lui migliori.L’inconveniente principale di questa strategia sta nel fatto che il processo di generazione degliottimi di Pareto e, molto spesso, computazionalmente oneroso. Inoltre, potrebbe non esseresemplice, per il decisore, scegliere una soluzione tra gli ottimi che gli vengono presentati, inspecial modo se questi sono numerosi. Per questo motivo, e molto importante il modo conil quale le soluzioni vengono presentate al decisore.
Metodo dei Pesi (cfr. [3, sez. 3.1])
Consideriamo il seguente problema
min
k∑
i=1
wifi(x)
g(x) ≤ 0
(Pw)
11

ove w ∈ IRk+ e i coefficienti wi si intendono normalizzati cioe tali che
k∑
i=1
wi = 1.
Esiste una relazione tra le soluzioni di (Pw) e i punti di Pareto di (P). La seguenteproposizione mette in evidenza proprio questa relazione (cfr. [3]).
Proposizione 1.4.5 Ogni soluzione locale (globale) del problema (Pw) e un ottimo debolelocale (globale) di Pareto per il problema (P). 2
Nel caso in cui il problema (Pw) ammette una unica soluzione allora si puo stabilire unrisultato un po’ piu forte del precedente (cfr. [3]).
Proposizione 1.4.6 Se il problema (Pw), fissato il vettore dei pesi w ≥ 0, ammette unaunica soluzione allora essa e un ottimo di Pareto per il problema (P).
Allo stesso modo, se i pesi wi sono tutti strettamente positivi e possibile dimostrare laseguente
Proposizione 1.4.7 Se wi > 0 per ogni indice i, ogni soluzione locale (globale) del problema(Pw) e un ottimo locale (globale) di Pareto per il problema (P). 2
Nell’ipotesi in cui il problema multiobiettivo (P) e convesso, e possibile stabilire la seguenteproprieta di esistenza (cfr. [3])
Proposizione 1.4.8 Sia x⋆ un ottimo di Pareto per il problema (P). Se (P) e convessoallora esistono dei pesi w ∈ IRk
+ con
k∑
i=1
wi = 1
e tali che x⋆ e soluzione anche del problema (Pw). 2
Metodo degli ε-vincoli (cfr. [3, sez. 3.2])
Si seleziona una funzione obiettivo fl(x) tra gli obiettivi di (P) e poi si trasformano tutte lealtre funzioni fi(x) (con i = 1, 2, . . . , k i 6= l) in vincoli, imponendo degli upper bound suiloro valori. Il problema che otteniamo e allora il seguente:
min fl(x)
fi(x) ≤ εi ∀i = 1, 2, . . . , k i 6= l
g(x) ≤ 0
(Pε)
ove l ∈ 1, 2, . . . , k.Proposizione 1.4.9 (cfr. [3]) Ogni soluzione di (Pε) e un ottimo debole secondo Paretoper il problema (P). 2
La prossima proposizione fornisce condizioni necessarie e sufficienti di ottimalita (secondoPareto) per il problema (P) delle soluzioni di (Pε).
Proposizione 1.4.10 Un vettore x⋆ ∈ F e ottimo secondo Pareto di (P) se e solo se esoluzione di (Pε) per ogni scelta di l ∈ 1, 2, . . . , k ed essendo εi = fi(x
⋆) con i 6= l.
Proposizione 1.4.11 (cfr. [3]) Se il punto x⋆ ∈ F e l’unica soluzione del problema (Pε)per qualche l ∈ 1, 2, . . . , k e con εj = fj(x
⋆) per ogni j 6= l allora esso e Pareto ottimo peril problema (P). 2
12

Capitolo 2
Programmazione con Incertezza
2.1 Nozioni preliminari
E noto che un generico problema di ottimizzazione puo essere posto nella forma [2]
minx f(x)
c.v. x ∈ D,
ove x ∈ IRn e detto vettore delle variabili di decisione, f : IRn → IR e detta funzione obiettivoe D ⊆ IRn e detto insieme ammissibile. A seconda delle proprieta della funzione f(x) edell’insieme D parleremo di ottimizzazione lineare o non lineare, ottimizzazione vincolata onon vincolata, ottimizzazione continua o combinatoria e cosı via.Per quanto concerne queste note e comodo introdurre la seguente funzione obiettivo estesaf : IRn → IR tale che
f(x) =
f(x) se x ∈ D,+∞ se x 6∈ D,
per cui e possibile riscrivere il generico problema di ottimizzazione come
minxf(x).
Dato uno spazio di probabilita (Ω,F , P ), sia ω : (Ω,F) → (IRn,Bn) una v.a. e supponiamoche la funzione obiettivo f(x, ω) e l’insieme ammissibile D(ω) dipendano dalle realizzazionidi ω. Anche in questo caso possiamo pensare alla funzione obiettivo estesa definita come
f(x, ω) =
f(x, ω) se x ∈ D(ω),
+∞ se x 6∈ D(ω).
Nel caso attuale, in cui i dati del problema dipendono esplicitamente dalla v.a. ω, non e piuimmediato riconoscere un problema di ottimizzazione nel senso che non e ben chiaro cosadobbiamo ottimizzare e con quali vincoli dato che sia la funzione obiettivo che la regioneammissibile dipendono da un elemento incerto ovvero dalle realizzazioni della v.a. ω. Inaltri termini, non ha certamente senso considerare il problema
minxf(x, ω) (1)
13

2.1.1 Formulazione deterministica
Ci sono diversi modi di trattare l’incertezza in un problema di ottimizzazione. Un primomodo consiste nello stimare un valore della v.a. (come per esempio il suo valore attesoIEω [ω]), sia esso ω, e quindi risolvere il problema
minxf(x, ω) (2)
In questo caso, la funzione obiettivo f(x, ω) non dipende piu dalla v.a. ω che e fissataal valore ω e quindi il problema e nuovamente un problema, per cosı dire, deterministicoche puo essere risolto come usualmente si farebbe. Questo approccio, benche perfettamentegiustificabile in alcuni ambiti applicativi, potrebbe non avere molto senso e, a volte, portarea soluzioni certamente non ottime come vedremo piu avanti con alcuni esempi.
2.1.2 Osservazione e ottimizzazione
In alcuni casi e possibile posticipare la scelta delle variabili di decisione x ad un momentosuccessivo alla osservazione della v.a. ω il che corrisponde a quella che viene comunementedefinita strategia wait-and-see. In questo caso, ci troviamo a dover risolvere un problema diottimizzazione in x che dipende da ω come parametro. Potremmo cosı pensare di risolvereil problema (2) solo per il valore ω corrispondente alla realizzazione della v.a. oppurepotremmo concentraci sulla determinazione del valore ottimo
ψ(ω) = infxf(x, ω)
e dell’insieme di soluzioni ottime
Ψ(ω) = argminxf(x, ω),
entrambi funzione della variabile aleatoria ω.
2.1.3 Ottimizzazione e osservazione
Contrariamente al caso precedente, potrebbe non essere possibile posticipare la scelta di xfin dopo aver osservato la realizzazione della v.a. ovvero e necessario adottare quella checomunemente viene definita strategia here-and-now. In questo assetto le decisione vannoprese subito avendo a disposizione solo la conoscenza sulla v.a. ω che ci viene dalla suaf.d. In questo caso e necessario riflettere sul fatto che per ogni scelta delle variabili x nonabbiamo un valore certo f(x) ma, piuttosto, un valore incerto f(x, ω). In altri termini, perogni realizzazione della v.a. ω abbiamo una funzione ω 7→ f(x, ω) ovvero, potremmo pensaread f(x, ω) come ad una v.a. composta.
Il caso peggioreIn questo assetto possiamo pensare di risolvere il problema minx f(x) dove
f(x) = supω
f(x, ω).
Ovviamente, questo significa concentrarsi esclusivamente sul peggiore risultato ottenibileavendo fissato le variabili x senza alcun tentativo di distinguere le realizzazioni della v.a. inbase alla sua distribuzione di probabilita.
14

Programmazione stocasticaQuesto approccio consiste nell’interpretare, per ogni x, f(x, ω) a sua volta come una v.a.che eredita la sua f.d. da quella della v.a. ω. E dunque possibile, per ogni x, calcolare ilvalore atteso f(x) = IEω [f(x, ω)] e quindi risolvere il problema
minxf(x). (3)
2.1.4 Esempio: il problema del venditore di giornali
Questo problema, meglio noto con il nome di newsvendor problem, e probabilmente il piusemplice esempio di ottimizzazione in presenza di incertezza ed e, pertanto, particolarmenteadatto per familiarizzare con alucni fondamentali concetti della programmazione in presenzadi incertezza. Il problema e il seguente.Il ragazzo che vende i giornali al semaforo deve decidere quanti giornali x acquistare alleprime luci dell’alba dall’editore al costo di c euro per giornale. Durante la mattinata potrarivendere i giornali al prezzo di s euro l’uno e, a fine mattinata, puo rivendere all’editore igiornali non venduti ricavando r euro l’uno. Ovviamente vale la seguente relazione
0 ≤ r < c < s.
Il grosso problema del venditore e che, al momento in cui deve scegliere quanti giornali (x)acquistare dall’editore, non conosce con esattezza il numero di clienti che acquisteranno ilgiornale da lui al semaforo. In altri termini, la sua domanda giornaliera di quotidiani puoessere considerata come una variabile aleatoria la cui realizzazione accadra in un momentosuccessivo a quello in cui deve acquistare i giornali dall’editore.Indichiamo conD la v.a. che descrive il numero di giornali effettivamente venduti al semaforodurante la mattinata. La tabella che segue riporta i costi, i ricavi e il profitto del venditorenella mattinata in funzione della variabile di decisione x e della v.a. D.
Costi Ricavi
acquisto giornali: cx
vendite al semaforo:
sx se x < D
sD se x ≥ D
vendite all’editore:
0 se x < D
r(x −D) se x ≥ D
profitto: −f(x,D) = −cx+ sminx,D + rmax0, x−DIl problema da risolvere sarebbe dunque il seguente
minx≥0
f(x,D),
e cioe un problema della forma di (1) in cui la v.a. ω = D.Supponiamo ora che il venditore possa decidere quanti giornali acquistare dall’editore dopoaver avuto notizia di quanti giornali potra vendere nella mattinata. Siamo nel caso wait-and-see (cfr. sottosezione 2.1.2) in cui la v.a. D e trattata come un parametro. In questocaso la f(x,D) e funzione della sola variabile x e dipende parametricamente da D.
x
f(x,D)
D
15

Ovviamente, la soluzione ottima risulta essere x = D e il valore ottimo (c − s)D ovvero,coerentemente con la notazione fin qui adottata,
ψ(D) = (c− s)D,
e
Ψ(D) = x ∈ IR : x = D.
Ovviamente, questa tecnica risolutiva ha senso solo quando e lecito supporre che ci sia unasorta di oracolo che predice al venditore il numero di giornali che potra vendere al semaforo.In ogni altro caso, questa tecnica risolutiva non ha molto senso.Supponiamo ora che D sia una v.a. discreta cioe abbia la seguente f.d. di probabilita
evento FD(·)D = 30 1/7
D = 40 2/7
D = 50 2/7
D = 60 1/7
D = 100 1/7
Un altro modo di approcciare il problema consiste, come accennato nella sottosezione 2.1.1,nel risolvere un problema in cui si fissa il valore della v.a., per esempio, al suo valore attesoIE[D] = D = 370/7 e quindi risolvere il problema per D = D. In questo caso la soluzione e,banalmente, Ψ(D) cioe x = D, y1 = D e y2 = 0 con valore ottimo ψ(D) = (c− s)D.Come visto nella sottosezione 2.1.3, un ulteriore modo di procedere e quello di risolvere ilproblema
minx≥0
max30≤D≤100
f(x,D).
Considerato il fatto che la funzione f(x,D) e in questo caso non crescente rispetto allavariabile D,
D
f(x,D)
x
risulta max30≤D≤100 f(x,D) = f(x, D), con D = 30. D’altra parte, siccome, come si verificafacilmente, la funzione f(x, 30)
x
f(x, 30)
30
16

e decrescente per 0 ≤ x ≤ 30 e crescente per x ≥ 30, il problema minx≥0 f(x, 30) ha soluzione
ottima x = D = 30 con valore ottimo (c − s)x = 30(c − s). Questa soluzione corrispondeperfettamente all’atteggiamento del venditore che, cautamente, sceglie di acquistare il mag-gior numero di giornali nell’ipotesi di venderne il minor numero possibile. I limiti di questoapproccio sono evidenti. Nel caso, per esempio, in cui sia possibile anche l’evento D = 0la strategia che dovremmo adottare sarebbe x = 0 ovvero il venditore non acquista alcungiornale per limitare i danni nel caso peggiore in cui gli dovesse capitare di non vendernenessuno.Per concludere la rassegna dei vari approcci al problema rimane da analizzare quello dettodi stochastic programming (programmazione stocastica). Secondo quanto visto nella sot-tosezione 2.1.3, questo tipo di approccio consiste nel considerare, per ogni valore x ammis-sibile, la f(x,D) come una nuova v.a. per la quale e possibile calcolare il valore attesoIED[f(x,D)] e quindi risolvere il problema
minx≥0
IED[f(x,D)]. (4)
Nel caso in esame, in cui D e una v.a. discreta, la funzione che otteniamo e
f(x) = IED[f(x,D)] =1
7f(x, 30) +
2
7f(x, 40) +
2
7f(x, 50) +
1
7f(x, 60) +
1
7f(x, 100)
che e una funzione convessa, lineare a tratti e continua ma non differenziabile. Sia ∂f(x) ilsubdifferenziale di f in x cosı definito:
∂f(x) = t ∈ IR : f(y) ≥ f(x) + t(y − x) per ogni y ∈ IR.
Per la funzione f(x) risulta
∂f(x) ∋
(c− s) se x < 3017 (c− r) + 6
7 (c− s) se 30 ≤ x < 4037 (c− r) + 4
7 (c− s) se 40 ≤ x < 5057 (c− r) + 2
7 (c− s) se 50 ≤ x < 6067 (c− r) + 1
7 (c− s) se 60 ≤ x < 100
(c− r) se x ≥ 100
ovvero, piu sinteticamente,
∂f(x) ∋ (c− r)P [D ≤ x] + (c− s)P [D > x]
= (c− r)FD(x) + (c− s)(1 − FD(x))
= (c− s) + (s− r)FD(x).
Come e noto, considerata la convessita di f(x), x⋆ e un punto di minimo di f(x) se e solo se
0 ∈ ∂f(x⋆).
Nel caso in esame in cui f(x) e funzione di una sola variabile e ∂f(x) ∋ c− s < 0, per ognix < 30 , e possibile determinare il punto di minimo di f(x) cercando il piu piccolo x⋆ ∈ IRtale per cui
∂f(x⋆) ∋ (c− s) + (s− r)FD(x⋆) > 0,
da cui otteniamo
x⋆ = F−1D
(
s− c
s− r
)
17

avendo indicato con F−1D (α) = minx : FD(x) ≥ α ovvero l’α-quantile della distribuzione
di probabilita FD(ω). Notiamo che x⋆ corrisponde al punto in cui la pendenza di f(x) passada negativa (f(x) decrescente) a positiva (f(x) crescente).La figura che segue riporta l’andamento della funzione f(x), quando r = 0.8, c = 1.6 es = 1.8, da cui e facile riconoscere che il valore ottimo del problema (4) e
x⋆ = F−1D (0.2) = 40.
x
IED[f(x,D)]
30 40 50 60 100
Supponiamo ora che D sia una v.a. continua, cioe una v.a. con f.d. FD(ω) continua, percui risulta
f(x) = IE[f(x,D)] =
∫ ∞
0
f(x, ω)dFD(ω).
Notiamo che, anche in questo caso, essendo la funzione f(x,D) convessa (e lineare a trattirispetto ad x), anche la funzione f(x) e convessa rispetto ad x. Allora
f(x) = cx+
∫ x
0
[−rx− (s− r)ω]dFD(ω) − sx
∫ ∞
x
dFD(ω),
da cui, mediante integrazione per parti, otteniamo
f(x) = (c− s)x+ (s− r)
∫ x
0
FD(ω)dω.
Derivando rispetto a x, otteniamo, come nel caso precedente,
f ′(x) = (c− s) + (s− r)FD(x).
Percui, ricordando che f(x) e convessa rispetto a x, x⋆ e punto di minimo se e solo se
f ′(x⋆) = (c− s) + (s− r)FD(x⋆) = 0,
da cui, anche in questo caso, otteniamo
FD(x⋆) =s− c
s− r
e quindi, nuovamente,
x⋆ = F−1D
(
s− c
s− r
)
.
18

2.2 Fondamenti di Programmazione Stocastica
Come gia in parte anticipato nel corso della precedente sezione, le principali caratteristichedella programmazione stocastica sono le seguenti:
1. here-and-now, vale a dire che, non ostante l’ingente coinvolgimento di accadimentifuturi, ogni cosa e mirata al miglioramento di decisioni che devono essere prese nelpresente ovvero prima che qualunque v.a. possa realizzarsi;
2. ricorsione, ovvero l’opportunita che e data al modellista di tenere conto del fattoche le decisioni prese nel presente possano essere, almeno in parte, corrette in tempisuccessivi;
3. informazione e osservazione, le decisioni in tempi successivi possono rispondere a in-formazioni che si sono rese disponibili da quando sono state prese le decisioni iniziali.Questa informazioni e modellata mediante l’osservazione di v.a.;
4. convessita, teoria e metodi risolutivi di programmazione stocastica sono sviluppatisotto l’ipotesi restrittiva di convessita;
5. indipendenza delle misure di probabilita dalle decisioni, si assume cioe che le v.a. sianoindipendenti dalle decisioni.
Uno degli aspetti piu caratteristici della programmazione stocastica ed anche quello che mag-giormente la differenzia dalla programmazione matematica e certamente quello dinamico.Piu precisamente, in un contesto di programmazione stocastica e opportuno familiarizzarecon il cosı detto processo ricorsivo nel quale le decisioni si alternano con le osservazioni. Inparticolare possiamo pensare al seguente processo ricorsivo
u0 ∈ IRn0 decisione iniziale
ω1 ∈ Ω1 osservazione
u1 ∈ IRn1 decisione di ricorsione
ω2 ∈ Ω2 osservazione
u2 ∈ IRn2 decisione di ricorsione
...
ωN ∈ ΩN osservazione
uN ∈ IRnN decisione di ricorsione
In questo processo ricorsivo, abbiamo uno stadio iniziale nel quale viene presa la decisioneu0 ∈ IRn0 e successivamente N stadi di ricorsione ciascuno composto da una osservazione,nella quale una v.a. si realizza, e da una decisione, che dovrebbe essere la risposta al-l’osservazione appena avvenuta. Alla fine di questo processo ricorsivo, avremo un vettore didecisioni
u = (u0, u1, . . . , uN) ∈ IRn con n = n0 + n1 + · · · + nN
e un vettore di osservazioni che potremmo definire la storia delle osservazioni e rappresentarecome
ω = (ω1, . . . , ωN ) ∈ Ω con Ω = Ω1 × · · · × ΩN .
Un altro ingrediente essenziale e il costo del processo ricorsivo che puo essere pensato comeuna funzione f : IRn × Ω → IR con
f(u, ω) = f(u0, u1, . . . , uN , ω1, . . . , ωN).
19

Naturalmente la funzione f(u, ω) ha valori nello spazio esteso dei reali ovvero puo assumereanche il valore +∞. Piu precisamente, f(u, ω) = +∞ quando u 6∈ C(ω).A questo punto, potremmo pensare che lo scopo dell’ottimizzatore sia quello di risolvere ilseguente problema
minuIEω [f(u, ω)],
ovvero un problema come il problema (3). Ovviamente, questo non e il caso. Infatti sefacessimo cosı, ci troveremmo, nuovamente, a dover scegliere u = (u0, u1, . . . , un) prima diconoscere ω = (ω1, . . . , ωN ), il che distruggerebbe immediatamente tutti i vantaggi di averedecisioni e osservazioni mescolate le une con le altre. In particolare, nel nostro caso, seci poniamo nello stadio k-esimo possiamo partizionare il vettore ω = (ω1, . . . , ωN ) nei duesottovettori
(ω1, . . . , ωk) informazione disponibile
(ωk+1, . . . , ωN) incertezza residua.
Nel fare questo, bisogna sempre tenere presente che il fine ultimo dell’ottimizzazione e quellodi produrre una decisione iniziale u0 e che le v.a. ωi, i = 1, . . . , N , non saranno maiveramente osservate ma, piuttosto, si potra al piu supporre che lo siano state. Per esempio,al generico stadio k ci troveremo a dover determinare uk supponendo che siano state osservateω1, . . . , ωk. Questo e il motivo per cui, allo stadio k, siamo interessati a determinare, nontanto un vettore uk ∈ IRnk , quanto piuttosto una funzione di ricorsione definita sullo spazioΩ1 × · · · × Ωk
uk(·) : (ω1, . . . , ωk) 7→ uk(ω1, . . . , ωk) ∈ IRnk .
Nello scegliere una tale funzione uk(·) stiamo, in sostanza, specificando nel presente (here-and-now) come risponderemo ad ogni possibile realizzazione delle prime k osservazioni.Definiamo strategia una funzione u : Ω → IRn ovvero
u(ω) = (u0, u1(ω1), u2(ω1, ω2), . . . , uN (ω1, . . . , ωN )). (5)
Indichiamo con U l’insieme di tutte le possibili funzioni u(·) di questo tipo. Notiamo chela componente uk(ω) dipende da ω1, . . . , ωk e non da ωk+1, . . . , ωN . Questa proprieta, det-ta non anticipo delle strategie, serve a garantire che le decisioni non siano basate sullaconoscenza di eventi futuri prima che questi accadano. Il problema al quale arriviamo e ilseguente
minu(ω)∈U
IEω [f(u(ω), ω)],
dove u(ω) e dato da (5). E importante notare che il precedente e un problema di ottimiz-zazione in cui le variabili di decisione sono particolari funzioni distinte dalla proprieta sopracitata di “non anticipo”.
2.2.1 Esempio: financial planning and control
Una famiglia americana sta progettando di mandare il proprio figlio al college. I genitorisanno che tra Y = Nv anni, e cioe quando il figlio avra raggiunto l’eta per potersi iscrivere,la retta per l’intero periodo degli studi sara di G = 80000 euro. Al momento i genitoridispongono di un budget di b = 55000 euro (b < G) e devono decidere come investire questirisparmi. Al termine degli Y anni i genitori potranno
1. prendere in prestito (con un interesse r = 4%) i soldi che servono per arrivare a coprirela retta di G euro per l’iscrizione al college; oppure
20

2. depositare in un libretto di risparmio (con un interesse q = 1%) i soldi avanzati dopoil pagamento della retta di iscrizione.
La famiglia puo investire su I tipi diversi di investimento e puo cambiare investimento ogniv anni. I genitori hanno, quindi, N = Y/v differenti periodi di investimento.Supponiamo, per semplicita di trattazione, che I = 2 (due soli tipi di investimento: stocko bond), N = 3 (tre periodi) e v = 5 (5 anni di durata minima di ogni investimento). Aseconda dell’andamento dei mercati finanziari, si puo avere un interesse di 1.25 per gli stocke 1.14 per i bond oppure 1.06 per gli stock e 1.12 per i bond con uguali probabilita (incondizione di massima incertezza).Il processo decisionale e quella gia visto in precedenza in cui abbiamo N = 3 stadi diricorsione ovvero
u0 = (u10, u
20)
T ∈ IR2 decisione iniziale
ω1 ∈ Ω osservazione
u1(ω1) = (u11(ω1), u
21(ω1))
T ∈ IR2 decisione di ricorsione
ω2 ∈ Ω osservazione
u2(ω1, ω2) = (u12, u
22)
T ∈ IRn2 decisione di ricorsione
ω3 ∈ Ω osservazione
u3(ω1, ω2, ω3) = (u13(ω1, ω2, ω3), u
23(ω1, ω2, ω3))
T ∈ IR2 decisione di ricorsione
dove Ω = up, down contiene i due soli andamenti possibili per i mercati finanziari a cuicorrispondono i tassi di interesse degli investimenti disponibili.
Stadio iniziale: Le variabili di decisione sono indipendenti dalle v.a. (non anticipo)e rappresentano l’ammontare degli investimenti in stock e bond, rispettivamente,all’inizio degli Y = 15 anni. Esse devono soddisfare il seguente vincolo
u10 + u2
0 = b,
ovvero, inizialmente, gli investimenti devono essere esattamente uguali al budget dib euro disponibili all’inizio del periodo di investimento. Potremmo scrivere questovincolo, sinteticamente, come
∑
i∈I
ui0 = b.
Primo stadio: Le variabili di decisione di primo stadio dipendono dalla v.a. ω1 manon da ω2 e ω3 (deve valere la proprieta di non anticipo). Come visto nel corso dellasezione e considerato il fatto che ω1 e una v.a. discreta, e possibile definire le funzioniu1
1(ω1) e u21(ω1) in forma tabellare ovvero definendo le variabili u1
1(up), u11(down),
u21(up) e u2
1(down) che rappresentano le azioni intraprese nei due scenari di primostadio possibili (ed equiprobabili), ovvero ω1 = up e ω1 = down. Queste variabili diprimo stadio devono soddisfare i vincoli
1.25u10 + 1.14u2
0 = u11(up) + u2
1(up)
1.06u10 + 1.12u2
0 = u11(down) + u2
1(down),
cioe, qualunque sia la realizzazione della v.a. ω1, quello che si investe nel quinto annodeve essere uguale al capitale disponibile nel quinto anno. Sintetizzando, possiamoscrivere questi vincoli come
∑
i∈I
tω1,iui0 =
∑
i∈I
ui1(ω1), ∀ ω1 ∈ Ω.
21

Secondo stadio: Le variabili di decisione di secondo stadio dipendono dalle v.a. ω1 eω2 ma non (sempre per la proprieta di non anticipo) dalla v.a. ω3. Anche in questocaso e possibile definire le funzioni u1
2(ω1, ω2) e u22(ω1, ω2) mediante l’introduzione di
tante variabili di decisione quanti sono i possibili scenari di secondo stadio. Dato chei possibili scenari sono dati da tutte le possibili combinazioni di una realizzazione diω1 con una realizzazione di ω2, dobbiamo introdurre complessivamente 8 variabili eprecisamente:
u12(up, up), u1
2(up, down), u12(down, up), u1
2(down, down),
u22(up, up), u2
2(up, down), u22(down, up), u2
2(down, down).
Queste variabili devono soddisfare i vincoli
1.25u11(up) + 1.14u2
1(up) = u12(up, up) + u2
2(up, up)
1.06u11(up) + 1.12u2
1(up) = u12(up, down) + u2
2(up, down)
1.25u11(down) + 1.14u2
1(down) = u12(down, up) + u2
2(down, up)
1.06u11(down) + 1.12u2
1(down) = u12(down, down) + u2
2(down, down)
cioe, qualunque siano le realizzazione delle v.a. ω1 e ω2, quello che si investe nel decimoanno deve essere uguale al capitale disponibile nel decimo anno. Anche qui, possiamoriscrivere i vincoli di secondo stadio nel modo seguente.
∑
i∈I
tω2,iui1(ω1) =
∑
i∈I
ui2(ω1, ω2), ∀ ω1, ω2 ∈ Ω.
Ultimo stadio: Anche nell’ultimo stadio vale un discorso analogo a quello fatto nei duestadi precedenti. Infatti, le variabili di decisione dell’ultimo stadio sono funzione diω1, ω2 e ω3. La variabile u1
3(ω1, ω2, ω3) rappresenta quanto denaro deve essere presoin prestito con interesse di r% per poter avere G euro per pagare la rata di iscrizioneal college. Al contrario, la variabile u2
3(ω1, ω2, ω3) rappresenta l’ammontare che puoessere versato su un libretto di risparmio con interesse di q%, dopo aver pagato laretta di G euro per il college. Anche in questo ultimo caso, le funzioni u1
3(ω1, ω2, ω3) eu2
3(ω1, ω2, ω3) possono essere definite mediante l’introduzione di tante variabili quantesono le possibili combinazioni delle realizzazioni delle v.a. ωi, i = 1, 2, 3. Tali variabilidevono soddisfare i seguenti vincoli
1.25u12(up, up) + 1.14u
22(up, up) = G − u
13(up, up, up) + u
23(up, up, up)
1.25u12(up, down) + 1.14u
22(up, down) = G − u
13(up, down, up) + u
23(up, down, up)
1.25u12(down, up) + 1.14u
22(down, up) = G − u
13(down, up, up) + u
23(down, up, up)
1.25u12(down, down) + 1.14u
22(down, down) = G − u
13(down, down, up) + u
23(down, down, up)
1.06u12(up, up) + 1.12u
22(up, up) = G − u
13(up, up, down) + u
23(up, up, down)
1.06u12(up, down) + 1.12u
22(up, down) = G − u
13(up, down, down) + u
23(up, down, down)
1.06u12(down, up) + 1.12u
22(down, up) = G − u
13(down, up, down) + u
23(down, up, down)
1.06u12(down, down) + 1.12u
22(down, down) = G − u
13(down, down, down) + u
23(down, down, down)
cioe, qualunque siano le realizzazione delle v.a. ω1, ω2 e ω3, quello di cui si disponenel quindicesimo anno deve essere pari all’importo della retta G, eventualmente pren-dendo a prestito la quantita u1
3 oppure depositando i contanti in avanzo u23 in un
libretto di risparmio. Anche questo ultimo gruppo di vincoli possono essere riscrittisinteticamente come
∑
i∈I
tω3,iui2(ω1, ω2) + u1
3(ω1, ω2, ω3) − u23(ω1, ω2, ω3) = G, ∀ ω1, ω2, ω3 ∈ Ω.
22

Supponiamo che le tre v.a. siano indipendenti l’una dalle altre, cosicche avremo
p(ω1, ω2, ω3) = p(ω1)p(ω2)p(ω3) = 0.125,
e, quindi, per la funzione obiettivo (da massimizzare)
f(u, ω) =∑
ω1∈Ω
∑
ω2∈Ω
∑
ω3∈Ω
p(ω1, ω2, ω3)(−ru13(ω1, ω2, ω3) + qu2
3(ω1, ω2, ω3)).
Risolvendo il problema otteniamo la seguente soluzione ottima:
u10 = 41479.3, u2
0 = 13520.7
ω1 ω2 ω3 u1
1 u2
1 u1
2 u2
2 u1
3 u2
3
up up up 0 24799.9
up up down83839.9 0
0 8870.3
up down up 0 1428.57
up down down
65094.6 2168.140 71428.6
0 0
down up up 0 1428.57
down up down0 71428.6
0 0
down down up 0 0
down down down
36743.2 2236864000 0
12160 0
2.3 Programmazione Stocastica lineare a due stadi
Consideriamo nuovamente il caso nel venditore ambulante di giornali visto nella sezioneprecedente. E piuttosto facile ravvisare nel problema del venditore un problema di pro-grammazione stocastica a due stadi con una sola v.a. (la domanda D di giornali).
x ∈ IR primo stadio: decisione sul numero di giornali da acquistare
D ∈ Ω osservazione: diventa noto il numero di giornali venduti
u1 ∈ IR2 secondo stadio: decisioni di ricorsione
il vettore delle decisioni di ricorsione e composto di due elementi e precisamente
u11 ≡ giornali venduti al semaforo = minx,D e
u12 ≡ giornali rivenduti all’editore = max0, x−D.
Riassumendo, il venditore deve decidere “here-and-now” quanti giornali x ∈ IR acquistaredall’editore non sapendo quanto varra la domanda D nella mattinata. Tuttavia, quale chesia la realizzazione della v.a. D, egli reagira all’osservazione della v.a. con una decisionedi secondo stadio o funzione di ricorsione u1(D) : Ω → IR2 essendo (u1(D))1 il numero digiornali venduti al semaforo e (u1(D))2 il numero di giornali rivenduti all’editore.Piu on generale, in un modello stocastico a due stadi si indica con
- x ∈ IRn1 il vettore delle decisioni di primo stadio;
- ω ∈ Ω la v.a. la cui realizzazione fa da margine tra primo e secondo stadio;
- y(ω) ∈ IRn2 il vettore delle decisioni di secondo stadio.
23

Il problema e dunque quello di risolvere
minx,y(ω)
IEω [f(x, y(ω))],
potendo f(x, y(ω)) essere una generica funzione (non lineare) e a valori sullo spazio estesoIR. Poniamoci ora in un contesto lineare. In questo assetto alla decisione di primo stadio xcorrisponde un costo lineare cTx e dei vincoli lineari in forma standard Ax = b, x ≥ 0. Allosteso modo, alla decisione di secondo stadio y(ω) corrispondera un costo lineare q(ω)T y(ω)e dei vincoli lineari W (ω)y(ω) = h(ω) − T (ω)x, y(ω) ≥ 0. Il problema e dunque
min cTx+ IEω [q(ω)T y(ω)]
Ax = b, x ≥ 0
W (ω)y(ω) = h(ω) − T (ω)x q.c.
y(ω) ≥ 0 q.c.
(6)
ove le matrici W (ω) e T (ω) sono dette, rispettivamente, matrice di ricorsione e matrice dellatecnologia. Se la matrice W non dipende dalla v.a. ω si parla di problema con ricorsionefissa.Notiamo che i vincoli di secondo stadio dipendono dalla realizzazione della v.a. ω. Nelseguito supporremo che tali vincoli siano soddisfatti q.c. ovvero quasi certamente cioe chesiano soddisfatti per ogni ω ∈ Ω tranne che al piu per ogni ω ∈ A con Pω(A) = 0 (ovvero Ainsieme con probabilita nulla).Se pensiamo ad x e ω come parametri, ovvero ci poniamo nel secondo stadio quando ladecisione iniziale e stata presa e la v.a. si e realizzata, il problema che ci troviamo adaffrontare e il seguente:
min q(ω)T y
W (ω)y = h(ω) − T (ω)x
y ≥ 0.
Sia ora Q(x, ω) = infq(ω)T y : W (ω)y = h(ω) − T (ω)x, y ≥ 0 e Q(x) = IEω [Q(x, ω)].Definiamo problema proiettato il seguente
min cTx+ Q(x)
Ax = b, x ≥ 0
ove, in pratica, e stata eliminata la dipendenza esplicita dalla v.a. ω. Abbiamo ricorsionerelativamente completa quando Q(x) assume valori finiti per ogni x ∈ IRn1 tale che Ax = be x ≥ 0. Diciamo, invece, che si ha ricorsione completa quando Q(x) assume valori finiti perogni x ∈ IRn1 .
2.4 Esempi di modelli stocastici lineari a due stadi
2.4.1 Il problema dell’azienda agricola
Una azienda agricola europea e specializzata nella coltivazione di grano, frumento e barba-bietole da zucchero e nell’allevamento di mucche da latte. In totale l’azienda possiede 500acri di terra che possono essere utilizzati per i diversi tipi di coltivazione. E noto che ognianno sono necessari per l’allevamento del bestiame almeno 200 Ton. di farina e 240 Ton. difrumento. Naturalmente l’azienda puo fare fronte a queste necessita o con il proprio raccolto
24
oppure acquistando da un grossista della zona. La produzione agricola dell’azienda oltre aservire per l’allevamento del bestiame puo essere venduta sul mercato ad un prezzo di 170euro per una Ton. di farina e 150 euro per una Ton. di frumento. I prezzi di acquisto difarina e frumento dal grossista sono maggiorati del 40% per via dei costi di trasporto chequest’ultimo deve sostenere. Per quanto riguarda la barbabietola, il prezzo di vendita e di36 euro/Ton; tuttavia, la commissione europea ha imposto all’azienda una quota di pro-duzione per le barbabietole di 6000 Ton. l’anno. La quantita di barbabietola eventualmenteprodotta oltre questa quota potra essere venduta ad un prezzo ribassato e precisamente a10 euro/Ton.Basandosi sulla propria esperienza passata, l’azienda agricola sa che ogni acro di terra colti-vato a frumento, grano o barbabietola frutta rispettivamente 2.5, 3 e 20 Ton. Per finire,per ogni acro di terra l’azienda deve sostenere dei costi di semina che sono di 150 euro, 230euro e 260 euro rispettivamente per grano, frumento e barbabietole. La tabella che segueriassume i dati fin qui esposti:
Grano Frumento Barbabietole
Raccolto (Ton./acri) 2.5 3 20
Costo di semina (euro/acri) 150 230 260
Prezzo di vendita (euro/Ton.) 170 150 36 sotto 6000 Ton.
10 sopra 6000 Ton.
Prezzo di acquisto (euro/Ton.) 238 210 –
Richieste min. (Ton.) 200 240 –
Per scegliere le migliore strategia di semina, l’azienda dovrebbe ricorrere al seguente modellolineare.Siano:
x1 = acri di terra piantati a grano;
x2 = acri di terra piantati a frumento;
x3 = acri di terra piantati a barbabietole;
w1 = ton. di grano venduto;
y1 = ton. di grano acquistato;
w2 = ton. di frumento venduto;
y2 = ton. di frumento acquistato;
w3 = ton. di barbabietole vendute a prezzo pieno;
w4 = ton. di barbabietole vendute a prezzo ribassato;
25

Il problema da risolvere e il seguente:
min 150x1 + 230x2 + 260x3 + 238y1 − 170w1+
+210y2 − 150w2 − 36w3 − 10w4
c.v. x1 + x2 + x3 ≤ 500
2.5x1 + y1 − w1 ≥ 200
3x2 + y2 − w2 ≥ 240
20x3 − w3 − w4 ≥ 0
w3 ≤ 6000
xi, yj , wh ≥ 0 i = 1, 2, 3, j = 1, 2, h = 1, 2, 3, 4.
Risolvendo il problema precedente otteniamo la seguente soluzione ottima
Coltivazione Grano Frumento Barbabietole
xi 120 80 300
Raccolto (Ton.) 300 240 6000
wi 100 – 6000 (w4 = 0)
yi – –
Profitto complessivo: 118600 euro
L’azienda agricola pur soddisfatta da questa soluzione ottima sa perfettamente che di annoin anno e a parita di seminato, i raccolti possono variare sensibilmente. in particolare none usuale avere stagioni con raccolti che sono superiori o inferiori del 20% rispetto alle stimeusate nel problema precedente. Piu precisamente, nel caso di una stagione particolarmentebuona ogni acro seminato a grano, frumento e barbabietole fruttera, rispettivamente, 3, 3.6e 24 Ton. di raccolto. Vice versa, nel caso di una stagione sotto la media ogni acro seminatoa grano, frumento e barbabietole fruttera, rispettivamente, 2, 2.4 e 16 Ton. di raccolto.Possiamo a questo punto risolvere due ulteriori problemi di ottimizzazione corrispondentiagli scenari di stagione sopra e sotto la media e ottenere le seguenti soluzioni ottime:
stagione sopra la media: raccolto + 20%
Coltivazione Grano Frumento Barbabietole
xi 183.33 66.67 250
Raccolto (Ton.) 550 240 6000
wi 350 – 6000 (w4 = 0)
yi – –
Profitto complessivo: 167667 euro
26

stagione sotto la media: raccolto - 20%
Coltivazione Grano Frumento Barbabietole
xi 100 25 375
Raccolto (Ton.) 200 60 6000
wi – – 6000 (w4 = 0)
yi – 180
Profitto complessivo: 59950 euro
Ragionando sul problema in esame e facile convincersi del fatto che la decisione sulle quantitadi terra da seminare con le differenti colture (xi, i = 1, 2, 3) deve essere presa prima diconoscere l’esito della stagione (se nella norma, sopra la media o sotto la media). Al contrariole quantita da vendere e comprare dei differenti prodotti (yi, i = 1, 2 e wj , j = 1, 2, 3, 4)dipendono dal raccolto.Supponiamo di assegnare a ciascuno dei tre scenari disponibili (sotto la media, in media esopra la media) un indice s = 1, 2, 3 e definire le variabili wjs, j = 1, 2, 3, 4 e yis, i = 1, 2dove, per esempio, w32 rappresenta la quantita di barbabietole vendute a prezzo pieno nelcaso di un raccolto nella media.Se ipotiziamo che l’s-esimo scenario abbia probabilita ps = 1/3 con
∑3s=1 ps = 1 allora
possiamo scrivere il seguente problema
min 150x1 + 230x2 + 260x3+
+ 13 (238y11 − 170w11 + 210y21 − 150w21 − 36w31 − 10w41)
+ 13 (238y12 − 170w12 + 210y22 − 150w22 − 36w32 − 10w42)
+ 13 (238y13 − 170w13 + 210y23 − 150w23 − 36w33 − 10w43)
c.v. x1 + x2 + x3 ≤ 500
2x1 + y11 − w11 ≥ 200
2.4x2 + y21 − w21 ≥ 240
16x3 − w31 − w41 ≥ 0
w31 ≤ 6000
2.5x1 + y12 − w12 ≥ 200
3x2 + y22 − w22 ≥ 240
20x3 − w32 − w42 ≥ 0
w32 ≤ 6000
3x1 + y13 − w13 ≥ 200
3.6x2 + y23 − w23 ≥ 240
24x3 − w33 − w43 ≥ 0
w33 ≤ 6000
xi, yjs, whs ≥ 0 i = 1, 2, 3, j = 1, 2, h = 1, 2, 3, 4, s = 1, 2, 3.
Risolvendo questo problema otteniamo la soluzione seguente:
27
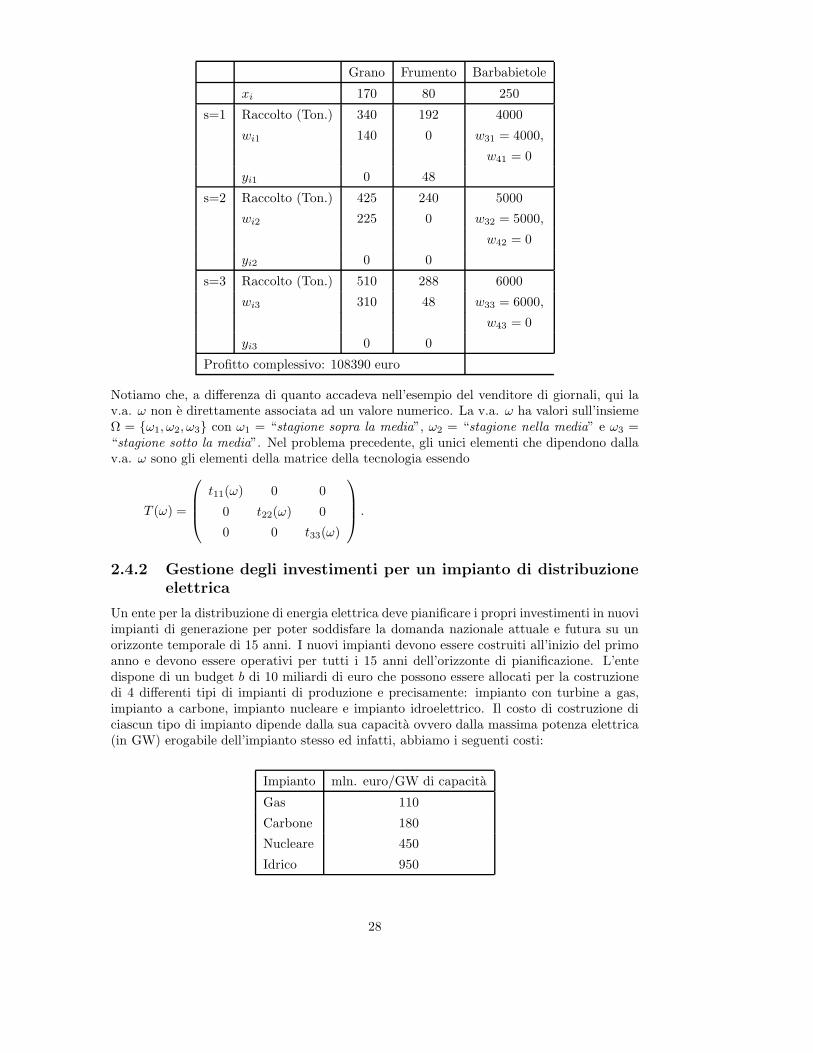
Grano Frumento Barbabietole
xi 170 80 250
s=1 Raccolto (Ton.) 340 192 4000
wi1 140 0 w31 = 4000,
w41 = 0
yi1 0 48
s=2 Raccolto (Ton.) 425 240 5000
wi2 225 0 w32 = 5000,
w42 = 0
yi2 0 0
s=3 Raccolto (Ton.) 510 288 6000
wi3 310 48 w33 = 6000,
w43 = 0
yi3 0 0
Profitto complessivo: 108390 euro
Notiamo che, a differenza di quanto accadeva nell’esempio del venditore di giornali, qui lav.a. ω non e direttamente associata ad un valore numerico. La v.a. ω ha valori sull’insiemeΩ = ω1, ω2, ω3 con ω1 = “stagione sopra la media”, ω2 = “stagione nella media” e ω3 =“stagione sotto la media”. Nel problema precedente, gli unici elementi che dipendono dallav.a. ω sono gli elementi della matrice della tecnologia essendo
T (ω) =
t11(ω) 0 0
0 t22(ω) 0
0 0 t33(ω)
.
2.4.2 Gestione degli investimenti per un impianto di distribuzione
elettrica
Un ente per la distribuzione di energia elettrica deve pianificare i propri investimenti in nuoviimpianti di generazione per poter soddisfare la domanda nazionale attuale e futura su unorizzonte temporale di 15 anni. I nuovi impianti devono essere costruiti all’inizio del primoanno e devono essere operativi per tutti i 15 anni dell’orizzonte di pianificazione. L’entedispone di un budget b di 10 miliardi di euro che possono essere allocati per la costruzionedi 4 differenti tipi di impianti di produzione e precisamente: impianto con turbine a gas,impianto a carbone, impianto nucleare e impianto idroelettrico. Il costo di costruzione diciascun tipo di impianto dipende dalla sua capacita ovvero dalla massima potenza elettrica(in GW) erogabile dell’impianto stesso ed infatti, abbiamo i seguenti costi:
Impianto mln. euro/GW di capacita
Gas 110
Carbone 180
Nucleare 450
Idrico 950
28
Inoltre, data la limitata disponibilita di corsi d’acqua utilizzabili per produrre elettricita, uneventuale nuovo impianto idroelettrico non potra avere una capacita superiore a 5 GW.Oltre all’investimento iniziale per la costruzione, ciascun tipo di impianto comporta anchedei costi di esercizio (espressi in euro/KWh) come riportato nella tabella seguente in cui siriporta anche il costo per l’acquisto di un KWh di energia elettrica da un fornitore estero.
Impianto costo di eser. euro/KWh
Gas ωG
Carbone ωC
Nucleare 0.0140
Idrico 0.0040
Acquisto 0.1500
I costi per la produzione di un KWh di energia elettrica con impianto a gas e a carbone sonov.a. discrete indipendenti con le seguenti distribuzioni:
ωG P (ωG) ωC P (ωC)
0.0310 0.1 0.0170 0.1
0.0330 0.2 0.0210 0.2
0.0390 0.4 0.0240 0.4
0.0450 0.2 0.0290 0.2
0.0490 0.1 0.0310 0.1
Per pianificare al meglio i propri investimenti, l’ente si basa sulla conoscenza dell’andamentodella richiesta di potenza elettrica per il primo anno. In particolare, sono stati individuati5 blocchi di consumo e per ciascuno di essi e nota la durata in ore (nell’anno) e la potenzarichiesta (dj in GW) come riportato nella tabella che segue
Blocco j dj (GW) Durata (ore)
# 1 10.0 490
# 2 8.4 730
# 3 6.7 2190
# 4 5.4 3260
# 5 4.3 2090
Cosı, e noto che, nel corso del primo anno, ci sara una richiesta di 10 GW di potenzaper un ammontare complessivo di 490 ore. La richiesta sara di 8.4 GW per 730 ore, 6.7GW per 2190 e cosı via. Basandosi sui dati in suo possesso e grazie a delle approfonditericerche di mercato, l’ente ha stabilito che nei prossimi 15 anni (periodo di pianificazionedell’investimento), si potranno verificare i seguenti trend di incremento/decremento dellerichieste di potenza elettrica:
29

ωR P (ωR)
-0.01 0.2
0.01 0.2
0.03 0.2
0.05 0.2
0.07 0.2
E inoltre noto che le tre v.a. ωG, ωC e ωR sono indipendenti tra di loro. Quindi, se indichiamocon ΩG, ΩC e ΩR, rispettivamente, lo spazio di tutti i possibili eventi associati alle tre v.a.ωG, ωC e ωR, avremo che Ω = ΩG × ΩC × ΩR e lo spazio degli scenari possibili che sonocomplessivamente pari a |ΩG × ΩC × ΩR| = 5 × 5 × 5 = 125. Pertanto, ogni scenarioω = (ωG, ωC , ωR) ∈ Ω ha una probabilita data dal prodotto delle probabilita dei singolieventi cioe: P (ω) = P (ωG)P (ωC)P (ωR).Indichiamo con:
- xi, i = 1, 2, 3, 4, la capacita (in GW) dei nuovi impianti, rispettivamente, a Gas, aCarbone, Nucleare e Idroelettrico.
- ci, i = 1, 2, 3, 4, i costi di costruzione (in milioni di euro/GW) associati ai 4 differentitipi di impianto.
- yijk(ω), i = 1, . . . , 5, j = 1, . . . , 5 e k = 1, . . . , 5, la frazione di capacita elettrica(in GW) utilizzata per produrre elettricita con impianto di tipo i, per il blocco dirichiesta j nell’anno k. Notiamo che, quando i = 5, y5jk indichera la quantita dielettricita acquistata da un fornitore estero per soddisfare la domanda nel blocco jdell’anno k. Queste variabili sono, in realta funzioni della v.a. ω.
- q1(ω), q2(ω), q3, q4, q5, i costi di esercizio (in euro/KWh), rispettivamente, di impianti aGas, Carbone, Nucleare, Idroelettrico e per l’acquisto da un fornitore estero. Notiamoche i primi due costi dipendono dalle realizzazioni della v.a. ω ∈ Ω.
- hj , j = 1, 2, 3, 4, 5, la durata (in ore) di ciascun blocco di consumo.
- Djk(ω), j = 1, . . . , 5 e k = 1, . . . , 15, la potenza richiesta (in GW) nel blocco j dell’annok. In particolare, vale la relazione Djk(ω) = dj (1 + (k− 1)ωR), per ogni j = 1, . . . , 5 ek = 1, . . . , 15, dove dj indica la richiesta nel primo anno per i vari blocchi di domanda.Le informazioni sulle quantita Djk(ω) possono essere cosı riassunte:
j ωR Dj1(ω) Dj2(ω) ... Dj14(ω) Dj15(ω)
1 -0.1 10 9.9 ... 8.7 8.6
1 0.1 10 10.1 ... 11.3 11.4
1 0.3 10 10.3 ... 13.9 14.2
1 0.5 10 10.5 ... 16.5 17.0
1 0.7 10 10.7 ... 19.1 19.8
......
...... · · ·
......
5 -0.1 4.3 4.257 ... 3.741 3.698
5 0.1 4.3 4.343 ... 4.859 4.902
5 0.3 4.3 4.429 ... 5.977 6.106
5 0.5 4.3 4.515 ... 7.095 7.31
5 0.7 4.3 4.601 ... 8.213 8.514
30

Riassumendo, otteniamo il seguente problema di programmazione stocastica lineare a duestadi.
minx,y
cTx+ IEω
5∑
i=1
5∑
j=1
15∑
k=1
qi(ω)hjyijk(ω)
cTx ≤ 10000
x4 ≤ 5.0
x ≥ 0
yijk(ω) ≤ xi, j = 1, . . . , 5, k = 1, . . . , 15, i = 1, . . . , 4,5∑
i=1
yijk(ω) ≥ Djk(ω), j = 1, . . . , 5, k = 1, . . . , 15
yijk(ω) ≥ 0, j = 1, . . . , 5, k = 1, . . . , 15, i = 1, . . . , 5.
Risolvendo il problema, otteniamo il seguente piano di investimenti, in termini di capacitainstallate (variabili xi, i = 1, . . . , 4):
Impianto i Capacita xi
Gas 1 3.366 GW
Carbone 2 3.953 GW
Nucleare 3 4.313 GW
Idrico 4 5.000 GW
Il costo atteso complessivo del piano di investimento all’ottimo e pari a 15828.81856 milionidi euro. Il piano di investimenti ottimo prevede, tra l’altro, che, date le installazioni ottimedi capacita x⋆ come riportate nella tabella che precede, un trend di crescita della domandadel 7% e i costi operativi delle centrali a gas e carbone rispettivamente di 3.9 e 2.4 eurocentper KWh, le potenze erogate dai singoli impianti nel 15 anno siano pari a (yij15(ω) peri = 1, . . . , 5, j = 1, . . . , 5 e dove ω = (ωG, ωC , ωR) con ωG = 0.039, ωC = 0.024 e ωR = 0.07).
Blocco di domandaImpianto
1 2 3 4 5
Gas 3.366 3.366 0.469 0 0
Carbone 3.953 3.953 3.953 1.757 0
Nucleare 4.313 4.313 4.313 4.313 3.815
Idrico 5 5 5 5 5
Fornitore 3.868 0.588 0 0 0
2.5 Programmazione stocastica lineare a due stadi con
ricorsione fissa
Consideriamo nuovamente il problema (6) ove W (ω) = W ovvero
min cTx+ IEω [q(ω)T y(ω)]
Ax = b, x ≥ 0
Wy(ω) = h(ω) − T (ω)x q.c.
y(ω) ≥ 0 q.c.
31

oppure, equivalentemente, il problema proiettato
min cTx+ IEω [Q(x, ω)]
Ax = b, x ≥ 0(7)
dove
Q(x, ω) = inf qT y
Wy = h− Tx
y ≥ 0.
(8)
Sia Q(x) = IEω [Q(x, ω)] la cosı detta funzione di ricorsione mediante la quale possiamoscrivere, come gia visto, il problema proiettato seguente
min cTx+ Q(x)
Ax = b, x ≥ 0.(9)
2.5.1 Esempio: il problema del venditore di giornali
Consideriamo nuovamente l’esempio visto in sezione 2.1.4. Come gia abbiamo visto, ilproblema del venditore di giornali puo essere formulato come problema di programmazionestocastica lineare a due stadi con risorsione fissa. La situazione del venditore e infatti laseguente
x ∈ IR primo stadio: decisione sul numero di giornali da acquistare
D ∈ Ω osservazione: diventa noto il numero di giornali venduti
y ∈ IR2 secondo stadio: decisioni di ricorsione
In particolare, una volta acquistati gli x giornali dall’editore e avvenuta la realizzazione dellav.a. D, il venditore adottera le decisioni di secondo stadio ovvero decidera quanti giornalivendere al semaforo e quanti rivenderne all’editore a fine mattinata. Il problema e quindi
minx cTx+ Q(x)
x ≥ 0,
con Q(x) = IED[Q(x,D)] e
Q(x,D) = infy
−sy1 − ry2
y1 + y2 = x
y1 ≤ D
y1, y2 ≥ 0.
La regione ammissibile del problema primale, vale a dire l’insieme Y (h−Tx), e sempre nonvuota e anzi il problema primale ammette sempre soluzione ottima (qualunque sia il valoredi x e D) pari a
(
y⋆1
y⋆2
)
=
(
x
D − x
)
se x ≤ D
(
D
x−D
)
se x > D
32

Ricordando che, nell’esempio in esame T = (−1, 0)T , abbiamo che il subdifferenziale ∂Q(x,D)contiene il subgradiente −s se −sx = −sy⋆
1 − ry⋆2 e −r se −rx −D(s − r) = −sy⋆
1 − ry⋆2 o
entrambi se −rx−D(s− r) = −sx. Percui, se vogliamo stabilire come e fatto il subdifferen-ziale ∂Q(x,D) quando x = D = 30 e s = 1.8, c = 1.6 e r = 0.8, allora dobbiamo confrontareil valore Q(30, 30) = −30s con i valori all’ottimo della funzione obiettivo duale ovvero −30se −30r − 30(s− r) = −30s. Pertanto
∂Q(30, 30) = conv−s,−r,
ovvero il subdifferenziale contiene i subgradienti −s e −r e tutte le loro combinazioniconvesse.Ovviamente, potranno esistere valori di x e D per cui la funzione Q(x,D) e differenziabileovvero per cui il subdifferenziale si riduce ad un singleton contenente come suo unico ele-mento il gradiente ∇Q(x,D). Per esempio, se consideriamo per D = 30 il punto x = 40,abbiamo che Q(40, 30) = −30s− 10r = −40r − 30(s− r), pertanto,
∂Q(40, 30) = ∇Q(40, 30) = −r.
2.6 Indicatori di validita e attendibilita della Program-
mazione Stocastica
Come gia abbiamo avuto modo di osservare in precedenza, risolvere un problema di pro-grammazione stocastica e, in taluni casi, equivalente alla soluzione di un problema di grandidimensioni cioe con un elevato numero di variabili e/o di vincoli. Pertanto, in generale,determinare la soluzione di un problema di programmazione stocastica lineare e molto cos-toso. Ha quindi senso chiedersi quando e quanto sia conveniente abbandonare il problemastocastico e risolvere, invece, un problema piu semplice. In particolare, e lecito chiedersiin che misura approcci piu semplici al problema, come per esempio quello che prevede disostituire alla v.a. il suo valor medio, forniscano soluzioni che si discostano dall’ottimo ofine a che punto questi approcci “alternativi” non siano completamente inaccurati.Una risposta a queste domande puo essere fornita da due importanti indicatori di bontadell’approccio stocastico che sono:
1. l’EVPI (Expected Value of Perfect Information) ovvero il valore atteso in condizionidi informazione completa e,
2. l’VSS (Value of Stochastic Solution) ovvero il valore della soluzione stocastica.
Al fine di definire chiaramente questi due importanti indicatori, introduciamo brevementealcune definizioni che ci faranno comodo nel seguito.Sia ω ∈ Ω una v.a. discreta ovvero che puo avere solo un numero finito N di realizzazioniω1, . . . , ωN . Sia f(x⋆(ωi), ωi) il valore ottimo del problema di programmazione stocasticaquando si fissa la v.a. ω al valore ωi, i = 1, . . . , N . Percui, data una realizzazione ωi
della v.a. ω ∈ Ω, associamo ad essa il valore all’ottimo del corrispondente problema diprogrammazione matematica f(x⋆(ωi), ωi). f(x⋆(ω), ω) e pertanto una v.a. composta percui e possibile definire il valore atteso. Infatti, definiamo soluzione wait-and-see
WS = IEω [f(x⋆(ω), ω)],
il valore atteso della v.a. f(x⋆(ω), ω). Definiamo, invece, soluzione here-and-now come ilvalore della soluzione del problema di programmazione stocastica
HN = minxIEω [f(x, ω)].
33

A questo punto, definiamo l’EVPI (valore atteso in condizioni di informazione completa)come
EV PI = HN −WS.
Nel caso dell’esempio del venditore di giornali, abbiamo che, come risulta dalla tebella chesegue, WS = −10.57142
i pi Di x⋆(Di) f(x⋆(Di), Di)
1 1/7 30 30 -6
2 2/7 40 40 -8
3 2/7 50 50 -10
4 1/7 60 60 -12
5 1/7 100 100 -20
Risulta, inoltre, x⋆ = 40,
Q(x⋆) =−1.8D1 − 0.8(x⋆ −D1)
7− 6
1.8x⋆
7
e quindi HN = 1.6x⋆ + Q(x⋆) = −6.57142. Otteniamo cosı EV PI = 4. Questo valore epari alla quantita di euro che il venditore sarebbe disposto a pagare ogni mattina pur disapere quanti giornali potra vendere al semaforo.
Quando ci si trova a dover risolvere un problema di ottimizzazione con incertezza, moltospesso si ritiene di poter ottenere una buona approssimazione della soluzione ottima sem-plicemente risolvendo il problema
EV = minxf(x, ω),
dove si e sostituita la v.a. ω con il suo valore atteso ω = IEω [ω]. La soluzione di questoproblema e nota come soluzione EV (expected value) ovvero soluzione di valor medio. L’indi-catore VSS e quello che ci dice quanto la soluzione EV sia lontana dall’essere ottima per ilproblema di programmazione stocastica. In particolare, una volta nota la soluzione ottimax⋆(ω) del problema EV, definiamo
EEV = IEω[f(x⋆(ω), ω)] = cTx⋆(ω) + Q(x⋆(ω))
ovvero il valore atteso quando si usa la soluzione di valor medio. Il VSS e definito come
V SS = EEV −HN.
Di nuovo, nel caso del venditore di giornali, abbiamo che x⋆(D) = 370/7 e EV = −10.57142.Come risulta dalla tabella che segue abbiamo
i pi Di cx⋆(D) +Q(x⋆(D), Di) f(x⋆(D), Di)
1 1/7 30 1.6x⋆(D) − 1.8D1 − 0.8(x⋆(D) −D1) 12.28571
2 2/7 40 1.6x⋆(D) − 1.8D2 − 0.8(x⋆(D) −D2) 2.28571
3 2/7 50 1.6x⋆(D) − 1.8D3 − 0.8(x⋆(D) −D3) -7.71429
4 1/7 60 1.6x⋆(D) − 1.8x⋆(D) -10.57143
5 1/7 100 1.6x⋆(D) − 1.8x⋆(D) -10.57143
34

EEV = IED[f(x⋆(D), D)] = −2.81634 e quindi V SS = 3.75508 che ci dice esattamente diquanto la soluzione del problema EV si discosta dalla soluzione HN.
Consideriamo ora l’esempio dell’azienda agricola. Come gia abbiamo visto, in questo casoHN = −108390. Calcoliamo ora WS. Nel caso in cui ω = ω1 (stagione sotto la media),risulta z(x(ω1), ω1) = −59950; quando ω = ω2 (stagione nella media), z(x(ω2), ω2) =−118600; quando ω = ω3 (stagione sopra la media), z(x(ω3), ω3) = −167667; cosiccheWS = z(x(ω1), ω1)/3 + z(x(ω2), ω2)/3 + z(x(ω3), ω3)/3 = −115405.56. Quindi otteniamo
EV PI = HN −WS = 7015.6
il che significa che l’azienda sarebbe disposta a pagare 7015.6 euro ogni anno per poterconoscere quale sara l’andamento della stagione.Calcoliamo ora l’EV dell’esempio dell’azienda agricola che otteniamo semplicemente risol-vendo il problema in cui si e fissata la v.a. al suo valor medio il che, ovviamente, equivale a ri-solvere il problema nel caso di stagione nella media per cui otteniamo x(ω) = (120, 80, 300)T .Possiamo ora calcolare l’EEV che risulta EEV = −107240 per cui otteniamo
V SS = EEV −HN = 1150.
2.7 Richiami sulle funzioni convesse
Indichiamo con IR e ¯IR gli insiemi estesi IR∪ +∞ e IR∪ −∞,+∞, rispettivamente. Sia
f : S → ¯IR con S ⊆ IRn. L’insieme
(x, µ) : x ∈ S, µ ∈ IR, f(x) ≤ µ
e detto epigrafo di f ed e indicato epi f . Diciamo che f e una funzione convessa su S seepi f e un sottoinsieme convesso di IRn+1. Il dominio effettivo della funzione f su S e laproiezione su IRn dell’epigrafo di f ovvero
dom f = x : ∃µ, (x, µ) ∈ epi f = x : f(x) < +∞.
Notiamo che data una funzione f su S convessa, e sempre possibile ottenere una funzionef ′ definita su IRn e ancora convessa. Per fare questo e sufficiente considerare la funzione
f ′(x) =
f(x) se x ∈ S,
+∞ se x 6∈ S.
Dal momento che le funzioni che stiamo calcolando hanno valori nello spazio esteso ¯IR, enecessario fornire delle regole che specifichino il risultato delle operazioni aritmetiche fonda-mentali quando sono coinvolti i simboli +∞ o −∞. In particolare, adotteremo le seguentiregole:
1. α+ ∞ = ∞ + α = ∞ per ogni −∞ < α ≤ ∞;
2. α−∞ = −∞ + α = −∞ per ogni −∞ ≤ α <∞;
3. α∞ = ∞α = ∞, α(−∞) = (−∞)α = −∞ per ogni 0 < α ≤ ∞;
4. α∞ = ∞α = −∞, α(−∞) = (−∞)α = ∞ per ogni −∞ ≤ α < 0;
5. 0∞ = ∞0 = 0 = 0(−∞) = (−∞)0, −(−∞) = ∞;
6. ∞−∞ = −∞ + ∞ = ∞;
35

7. inf ∅ = +∞, sup ∅ = −∞.
Una funzione convessa f e detta propria se f(x) < +∞ per almeno un x e f(x) > −∞ perogni x. Una funzione convessa che non e propria e detta impropria. In particolare se f euna funzione convessa finita definita sull’insieme convesso C, la funzione f ′ definita su tuttoIRn
f ′(x) =
f(x) se x ∈ C,
+∞ se x 6∈ C.
e una funzione convessa e propria.
Proposizione 2.7.1 Sia f : C → IR, dove C ⊆ IRn. f e una funzione convessa su C se esolo se
1. C e un insieme convesso;
2. comunque scelti x, y ∈ C risulta
f((1 − λ)x+ λy) ≤ (1 − λ)f(x) + λf(y), 0 < λ < 1.
Proposizione 2.7.2 Sia f : IRn → ¯IR. f e una funzione convessa se e solo se comunquepresi due punti x, y ∈ IRn per cui esistono due scalari α, β < +∞ tali che f(x) < α ef(y) < β allora
f((1 − λ)x + λy) < (1 − λ)α + λβ, 0 < λ < 1.
Proposizione 2.7.3 (Disuguaglianza di Jensen) Sia f : IRn → IR. Allora f e convessase e solo se
f(λ1x1 + · · · + λmxm) ≤ λ1f(x1) + · · · + λmf(xm),
comunque scelti i vettori xi ∈ IRn, i = 1, . . . ,m, dove gli scalari λi sono tali che λi ≥ 0,i = 1, . . . ,m e
m∑
i=1
λi = 1.
2.8 Definizioni
Dato S ⊂ IRn, diciamo che S e un insieme convesso quando, comunque presi due puntix, y ∈ S, risulta, per ogni scalare λ ∈ [0, 1]
λx+ (1 − λ)y ∈ S.
Sia S ⊂ IRn un insieme convesso. Diciamo che la funzione f : IRn → IR e convessa suS quando, comunque presi due punti x, y ∈ S, risulta, per ogni scalare λ ∈ [0, 1]
f(λx+ (1 − λ)y) ≤ λf(x) + (1 − λ)f(y).
36

Data una funzione f : IRn → IR convessa sul’insieme convesso X e un punto xo ∈ X ,diciamo che un vettore η ∈ IRn e un subgradiente di f(x) in xo quando:
f(x) ≥ f(xo) + ηT (x− xo), ∀ x ∈ X.
Data una funzione f : IRn → IR convessa sul’insieme convesso X e un punto xo ∈ X ,definiamo il subdifferenziale di f(x) in xo come segue:
∂f(xo) = convη ∈ IRn : f(x) ≥ f(xo) + ηT (x − xo), ∀ x ∈ X.
Una funzione f(x) si dice positivamente omogenea quando, comunque preso uno scalareλ ≥ 0, risulta f(λx) = λf(x).
Sia S ⊂ IRn un insieme convesso. Definiamo funzione di supporto dell’insieme S lafunzione σS : IRn → IR
σS(x) = supy∈S
xT y.
37

Indice
1 Programmazione Multiobiettivo 11.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Ottimalita secondo Pareto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.1 Esercizio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 Condizioni di Ottimalita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.1 Condizioni di Fritz-John . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3.2 Condizioni di Karush-Kuhn-Tucker . . . . . . . . . . . . . . . . . . . . 7
1.4 Metodi di Soluzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.4.1 Metodi Senza Preferenze . . . . . . . . . . . . . . . . . . . . . . . . . . 81.4.2 Metodi a Posteriori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2 Programmazione con Incertezza 132.1 Nozioni preliminari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1.1 Formulazione deterministica . . . . . . . . . . . . . . . . . . . . . . . . 142.1.2 Osservazione e ottimizzazione . . . . . . . . . . . . . . . . . . . . . . . 142.1.3 Ottimizzazione e osservazione . . . . . . . . . . . . . . . . . . . . . . . 142.1.4 Esempio: il problema del venditore di giornali . . . . . . . . . . . . . . 15
2.2 Fondamenti di Programmazione Stocastica . . . . . . . . . . . . . . . . . . . 192.2.1 Esempio: financial planning and control . . . . . . . . . . . . . . . . . 20
2.3 Programmazione Stocastica lineare a due stadi . . . . . . . . . . . . . . . . . 232.4 Esempi di modelli stocastici lineari a due stadi . . . . . . . . . . . . . . . . . 24
2.4.1 Il problema dell’azienda agricola . . . . . . . . . . . . . . . . . . . . . 242.4.2 Gestione degli investimenti per un impianto di distribuzione elettrica . 28
2.5 Programmazione stocastica lineare a due stadi con ricorsione fissa . . . . . . 312.5.1 Esempio: il problema del venditore di giornali . . . . . . . . . . . . . . 32
2.6 Indicatori di validita e attendibilita della Programmazione Stocastica . . . . . 332.7 Richiami sulle funzioni convesse . . . . . . . . . . . . . . . . . . . . . . . . . . 352.8 Definizioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
38

Bibliografia
[1] M.S. Bazaraa, H.D. Sherali, C.M. Shetty, “Nonlinear Programming: Theory andAlgorithms”, Wiley, New York, 1979.
[2] J.R. Birge, F. Louveaux, “Introduction to Stochastic Programming”, Springer Series inOperations Research and Financial Engineering, Springer, Berlin, 1997.
[3] K. Miettinen, “Nonlinear Multiobjective Optimization”, Kluwer Academic Publishers,Boston, 1999.
[4] V. Pareto, “Cours d’economie Politique”, Rouge, Lausanne, Switzerland, 1896.
39


















