
ANALISI DI MERCATO CLEA -...
40
1 ANALISI DI MERCATO CLEA INTEGRAZIONE AL CAPITOLO 5 L. Molteni, G. Troilo (a cura di) Ricerche di marketing, McGraw-Hill, Milano, 2003 IL CAMPIONAMENTO: TEORIA E ESERCIZI Versione 1.0 A.A. 2010/2011
Transcript of ANALISI DI MERCATO CLEA -...

1
ANALISI DI MERCATO
CLEA
INTEGRAZIONEAL CAPITOLO 5
L. Molteni, G. Troilo (a cura di)
Ricerche di marketing,McGraw-Hill, Milano, 2003
IL CAMPIONAMENTO:
TEORIA E ESERCIZI
Versione 1.0
A.A. 2010/2011

2

Capitolo 1
Il campionamento casualesemplice
1. Introduzione
La validita delle indagini campionarie fu posta per la prima volta nel 1895 da
Anders N. Kiaer, direttore dell’Ufficio centrale di statistica della Norvegia, nella
riunione dell’Istituto Internazionale di Statistica in cui presento le inchieste sulla
distribuzione dei redditi in Osservazioni e esperienze riguardanti le rilevazioni
rappresentative. Il metodo si basava su una selezione delle unita della popolazione,
dalle fonti censuarie, al fine di costruirne un’immagine simile con un numero
ridotto di unita, una miniatura della realta oggetto di indagine.
La rappresentativita e intesa in termini intuitivi e il procedimento richiede
la conoscenza di informazioni a priori, come quelle ottenute da un censimento.
2. Censimento e campionamento
Per popolazione obiettivo (target population) o universo, P si intende un gruppo
di elementi, N , definiti in accordo con gli obiettivi dell’indagine nei contenuti,
nello spazio, e nel tempo: Ω = 1, 2, . . . , N. I suoi membri sono chiamati unita
statistiche o unita di analisi.
Esempio: caratteristiche degli acquirenti di scarpe per adulti.
La popolazione obiettivo deve essere definita nei
1. contenuti (eta dei clienti),
2. nello spazio (area geografica, Italia o regione o citta),
3. nel tempo (nell’anno 2010).
3

4 Capitolo 1. Il campionamento casuale semplice
La caratteristica di interesse o carattere sara indicata con Y e con y1, y2, . . . , yN .
si indicheranno i valori che essa assumera nelle unita 1, 2, . . . , N.Il periodo di riferimento e la data rispetto alla quale raccogliere le informa-
zioni e deve essere lo stesso per tutti al fine di ottenere dati “omogenei”.
Il censimento, detto anche rilevazione totale, e un modo di raccogliere i
dati che comporta l’acquisizione delle le caratteristiche designate per ciascun
elemento costituente la popolazione obiettivo.
Il campionamento, detto anche rilevazione parziale, e un modo di raccoglie-
re i dati che comporta l’acquisizione delle caratteristiche designate solo per gli
elementi di un sottoinsieme della popolazione obiettivo, detto campione.
Il campione e un sottoinsieme composto da n unita selezionate tra le N
unita della popolazione obiettivo. Il campione rappresenta, quindi, la popolazione
obiettivo che in tale contesto e detta anche popolazione di riferimento (Fabbris,
1989). Gli elementi che appartengono al campione sono detti unita statistiche
campionarie.
I fattori che determinano i vantaggi/svantaggi sono i seguenti.
1. Costi ridotti per la realizzazione
Una rilevazione totale comporta una spesa molto piu onerosa di una rilevazione
parziale perche la raccolta dei dati ha un costo per ogni individuo. La struttura
organizzativa di base, poi, deve essere molto ampia per dirigere i lavori e svolgere
la supervisione. Il numero dei rilevatori necessari per raccogliere i dati e elevato
e questi devono essere anche addestrati.
2. Tempi piu brevi per la raccolta dei dati
La rilevazione totale richiede una notevole quantita di tempo per essere condotta
a termine, mentre un’indagine campionaria puo essere realizzata in un tempo
ragionevolmente inferiore. si noti che un tempo troppo lungo per raccogliere i
dati potrebbe vanificare la loro utilita.
3. Qualita dei dati raccolti piu elevata
In una rilevazione totale e piu difficile controllare o ricontrollare i dati osservati
e l’operato dei rilevatori, naturalmente sempre a causa dei tempi e dei costi;
mentre, in una indagine parziale i dati possono essere raccolti con una precisione
maggiore e una quantita minore di errori.
4. Quantita di informazioni piu elevata
In una rilevazione totale il numero di informazioni che si raccolgono sono limitate
perche entrare nei particolari aumenta le difficolta della rilevazione dei dati.

3.. La lista 5
3. La lista
La lista o base campionaria (list or frame) e l’elenco delle unita della popolazione
e rappresenta la fonte per effettuare la scelta. Le unita selezionate dalla lista
costituiscono il campione.
Per ottenere un buon campionamento bisogna procurarsi una buona lista,
cioe una lista esente da difetti perche un campione non puo dare risultati piu
precisi della lista da cui e stato estratto. In realta, le liste disponibili presentano
diversi limiti:
— Incompletezza che genera sottocopertura,
— Sovracompletezza che genera sovracopertura,
— Ridondanza o registrazione multipla di unita,
— Inesistenza o registrazione di unita bianche
— Inattualita o non aggiornamento della lista
— Imprecisioni (errori di codifica, di trascrizione, di immissione.
4. Parametri e stimatori
Alcuni parametri della popolazione P sono riportati nella tabella 1.1. Seguono
due esempi di parametri, stimatori, e stime.
Esempio 1
Sia θ il livello potenziale della domanda di un bene nella popolazione (obiettivo)
P costituita da N unita. Sia θ il parametro non noto, θ =∑N
i=1 Xi/N , dove Xi
vale 1 se l’i-esimo soggetto acquisterebbe il bene e 0 altrimenti.
Si estrae un campione di n unita da P . La proporzione di consumatori in-
tervistati che dichiarano di essere disposti a acquistarlo costituisce uno stimatore
di θ; ossia, lo stimatore e T =∑n
i=1 Xi/n.
Il valore dello stimatore che si ottiene per questo campione, θ = t =∑ni=1 xi/n, e la stima del parametro θ della popolazione P .
Esempio 2
Sia Y il reddito delle unita della popolazione P . Si consideri il reddito medio,
µY , relativo a tutti i potenziali consumatori, che e dato dalla media dei redditi
delle N unita che formano la popolazione P . Il parametro non noto e costituito
da µY =∑N
i=1 Yi/N .
Si estrae un campione di n unita da P . La media (campionaria) dei redditi
(delle unita statistiche incluse nel campione) puo essere lo stimatore di µY . Allora,
T = Y =∑n
i=1 Yi/n, dove (Y1, . . . , Yn) e il vettore di osservazione.

6 Capitolo 1. Il campionamento casuale semplice
Tabella 1.1: Parametri della popolazione spesso oggetto di stima
Totale Y =∑N
i=1 Yi
Media Y =
∑Ni=1 Yi
N=
Y
N
Proporzione Py =Y
N
Y =∑N
i=1 Xi ∧ Xi ∼ Ber(P )
Varianza S2y =
∑Ni=1(Yi − Y )2
N[formula per calcolo S2
y =
∑Ni=1 Y
2i
N− Y 2
]S′2y =
∑Ni=1(Yi − Y )2
N − 1
Varianza di un carattere dicotomo S2y = N Py (1− Py)
Deviazione standard o SQM Sy =
√∑Ni=1(Yi − Y )2
N
=
√∑Ni=1 Y
2i
N− Y 2
Coefficiente di variazione (C.V.) CVy =Sy
Y
CV 2y =
S2y
Y 2
C.V. di un carattere dicotomo CV 2y =
N Py (1− Py)
(N Py)2=
1
N
1− Py
Py
Il valore dello stimatore che si ottiene dalle rilevazioni eseguite in questo
campione, che fornisce un vettore osservato (y1, . . . , yn), e la stima di µY ; ossia,
µY = y =∑n
i=1 yi/n.
5. Campionamento probabilistico
Il campionamento probabilistico richiede l’uso di procedimenti oggettivi, che non
coinvolgono l’intervento dell’operatore, e casuali, che assegnano a ogni unita una
probabilita di essere inclusa nel campione maggiore di zero.
Esso definisce, quindi, un approccio alla selezione delle unita nel campione
che soddisfa le seguenti condizioni.
1. Si deve poter definire l’insieme di tutti i possibili campioni, S = s1, . . . , sM,

5.. Campionamento probabilistico 7
di ampiezza fissata n ottenibili, detto spazio campionario.
2. A ogni possibile campione s deve essere associata una probabilita nota di
selezione, p(s), definita su S e detta piano di campionamento, tale che:
p(s) ≥ 0;∑
s∈S p(s) = 1 .
3. La procedura deve assegnare a ogni unita della popolazione una probabilita
maggiore di zero di essere estratta (probabilita di inclusione).
4. Si seleziona un solo campione con un meccanismo casuale per il quale ogni
possibile campione s ha probabilita p(s) di essere estratto.
Il meccanismo casuale di estrazione si puo realizzare con un esperimento casuale
o modello d’urna: si inserisce in un’urna un biglietto per ogni unita della popo-
lazione; ogni biglietto identifica univocamente una sola unita. L’urna contiene,
allora, N biglietti. Ogni biglietto e diverso dagli altri e ha la stessa possibilita di
essere estratto.
Sia P = 1, . . . , N la popolazione, con ciascun elemento contrassegnato da
un’etichetta o codice. L’esecuzione di n estrazioni genera una sequenza di indici
(i1, . . . , in) denominata campione ordinato, dove il simbolo ij (per j = 1, . . . , n)
indica l’etichetta dell’unita della popolazione selezionata nella j-esima estrazione.
I vari tipi di campionamento sono riportati nello schema seguente.
Tabella 1.2: Metodi di campionamenti probabilistici e non probabilistici
Probabilistici Campionamento Casuale Semplice (CCS)
Campionamento Sistematico (CSist)
Campionamento Stratificato (CStr)
Campionamento a grappoli (CG)
Campionamento a due o piu stadi
NON Probabilistici Campionamento per quote
Campionamento a scelta ragionata
Campionamento per convenienza

8 Capitolo 1. Il campionamento casuale semplice
6. Campionamento casuale semplice senza reim-
missione
Il Campionamento Casuale Semplice consiste nell’estrarre senza reimmissione
(CCS-SR) n unita campionarie da una popolazione obiettivo, P, costituita da
N unita. Ne consegue che ogni unita estratta non ha piu la possibilita di essere
estratta di nuovo e il numero di campioni possibili e B(N, n).
Il piano di campionamento attribuisce a ciascuno dei B(N,n) campioni
possibili la stessa probabilita, 1/B(N, n), di essere estratto:
p(s) =n
N
n− 1
N − 1
n− 2
N − 2· · · 1
N − n+ 1=
1
B(N,n)=
1(N
n
) . (1.1)
6.1. Stima della media
Si supponga di voler stimare la media, Y , del reddito Y della popolazione dei
potenziali consumatori di un bene. Per il principio di corrispondenza, lo stimatore
di Y e la media campionaria, y. Per il seguito si veda Cochran (1977).
Teorema 6..1 Sia dato un piano di campionamento probabilistico che preve-
da l’estrazione senza reimmissione di n unita. La media campionaria y e uno
stimatore corretto della media della popolazione Y .
Teorema 6..2 Sia dato un piano di campionamento probabilistico che preveda
l’estrazione senza reimmissione di n unita. La varianza della media campionaria,
s2y, e uguale a
s2y = Var (y) = E(y − Y
)2=
S2
n
N − n
N − 1. (1.2)
Si noti solo che il primo termine del secondo membro, S2/n, e la varianza del-
la media in un campionamento casuale semplice con reimmissione. Il secondo
termine, il fattore (N − n)/(N − 1), e chiamato fattore di correzione per popo-
lazioni finite e rappresenta la riduzione di incertezza ottenuta con il mancato
reinserimento delle unita estratte.
Si ricorda che la varianza campionaria, data dalla media degli scarti dalla
media elevati al quadrato, e una stima distorta della varianza della popolazione
(nel nostro caso S ′2).
E(s2) = E
[∑ni=1(yi − y)2
n
]=
n− 1
nS ′2 . (1.3)

7.. Campionamento casuale semplice con reimmissione 9
6.2. Stima della proporzione
Sia Y un carattere dicotomo in P . La proporzione P del carattere presente in Psara
P =Y
N= Y =
∑Ni=1 Yi
N=
A
N. (1.4)
La variabile casuale Yi e dicotoma, ossia Yi ∼ Ber(P ) e lo stimatore di P sara
p =y
n= y =
∑ni=1 yin
=a
n. (1.5)
Proposizione 6..3 Lo stimatore p di P e non distorto
E (p) = P. (1.6)
Proposizione 6..4 La varianza della popolazione per un carattere dicotomo e
S2 = P (1− P ). (1.7)
Proposizione 6..5 Sia Y una variabile casuale dicotoma con valore atteso P e
sia dato un piano di campionamento casuale semplice senza reimmissione di n
unita. La varianza dello stimatore p di P e
Var(p) = Var(y) =S2
n
N − n
N − 1=
P (1− P )
n
N − n
N − 1. (1.8)
7. Campionamento casuale semplice con reim-
missione
Il Campionamento Casuale Semplice con reimmissione (CCS-SR) consiste nel-
l’estrarre n unita campionarie da una popolazione obiettivo, P , costituita da N
unita, reinserendo nell’urna ciascuna unita estratta prima di eseguire l’estrazione
successiva. Ne consegue che ogni unita estratta ha la possibilita di essere estratta
di nuovo e il numero di campioni possibili e Nn.
Il piano di campionamento e tale che ciascuno degli Nn campioni possibili
abbia la stessa probabilita, 1/Nn, di essere estratto.
p(s) =1
N
1
N
1
N· · · 1
N=
1
Nn(1.9)

10 Capitolo 1. Il campionamento casuale semplice
7.1. Stima della media
In analogia al caso precedente si riportano lo stimatore della media e la sua
varianza corrispondente, ma si noti che le espressioni sono quelle esposte in un
corso di statistica di primo livello.
Teorema 7..1 Sia dato un piano di campionamento probabilistico che prevede
l’estrazione con reimmissione di campioni di ampiezza fissata n. Siano y1, . . . , yn
le osservazioni campionarie. Allora, uno stimatore corretto della media e dato
da:
y =1
n
n∑i=1
yi (1.10)
e la varianza dello stimatore assume la forma
Var(y) =S2
n. (1.11)
e puo essere stimata correttamente con
var(y) =s′2
n=
1
n
[1
n− 1
n∑i=1
(yi − y)2]. (1.12)
8. Effetto del disegno: deff
L’effetto del disegno (deff dall’inglese design effect) esprime la variazione del-
la precisione campionaria dovuta alla modalita di esecuzione del campione. La
precisione delle stime del CCS-SR e presa come riferimento di qualunque altro
disegno di campionamento e il deff e dato dal rapporto tra la varianza delle stime
del disegno oggetto di valutazione (•) o confronto e la varianza ottenuta da un
CCS-SR:
deff(•, CCS − SR) =V•(y)
VCCS−SR(y). (1.13)
Si ha, allora, che il campionamento casuale semplice con reimmissione produce
varianze della stima del totale (o della media o della proporzione) piu elevate e,
quindi, e meno efficiente; infatti,
deff(CR, SR) =S2
nS2
nN−nN−1
=N − 1
N − n> 1 . (1.14)
Se deff e maggiore di 1, allora si e persa precisione per non avere usato il CCS-SR;
se deff e minore di 1, allora si e guadagnato in precisione rispetto al CCS-SR.

9.. Dimensione del campione 11
9. Dimensione del campione
La determinazione della dimensione del campione e importante perche comporta,
quasi sempre, un conflitto tra le risorse disponibili e la precisione desiderata delle
stime: piu il campione e grande, piu aumentano i costi; piu il campione e piccolo,
piu i risultati sono imprecisi o inaffidabili.
La dimensione del campione in base alla precisione desiderata delle stime
si determina esaminando ciascuna variabile oggetto di stima. Si distinguono,
pertanto, le variabili qualitative dalle variabili quantitative; per semplificare i
calcoli, si considerano solo variabili qualitative dicotome.
9.1. Variabili qualitative dicotome
Sia P la proporzione di elementi della popolazione che hanno un determinato
attributo e (1 − P ) la proporzione di quelli che non l’hanno. Sia e l’errore o la
distanza massima desiderata tra il possibile valore risultante dal campione e il
valore della popolazione P . Sia α il livello di errore in termini di probabilita di
osservare un campione che produca una stima maggiore di quella desiderata. In
termini di probabilita si puo scrivere come segue:
Pr(|p− P | ≥ e) = α.
L’espressione precedente si puo standardizzare usando lo scarto quadratico medio
di p e da lı ricavare l’espressione per il calcolo di n.
α = Pr
|p− P |√P (1− P )
n
N − n
N − 1
≥ e√P (1− P )
n
N − n
N − 1
.
Lo stimatore si puo considerare distribuito secondo una normale standardizzata,
per cui l’uguaglianza si ha in z1−α/2:
z1−α/2 =e√
P (1− P )
n
N − n
N − 1
Risolvendo si ha:
n =z21−α/2
P (1− P )
e2
1 +1
N
(z21−α/2 P (1− P )
e2− 1
) (1.15)

12 Capitolo 1. Il campionamento casuale semplice
Il numeratore e indicato, in genere, con n0 e si riferisce alla dimensione cam-
pionaria per popolazioni infinite; cosı, il fattore al denominatore rappresenta la
correzione della dimensione per popolazioni finite. Si scrivera, allora
n0 = z21−α/2
P (1− P )
e2(1.16)
n =n0
1 +n0 − 1
N
. (1.17)
Nella tabella seguente sono riportati alcuni calcoli di dimensione campionaria
per un errore del 5% (e = 0, 05) e un errore dell’1% (e = 0, 01), per un livello di
rischio del 5% (α = 0, 05) che implica un valore di z1−α/2 = 1, 96 (approssimato
a 2, per semplicita). Il valore massimo della dimensione campionaria si ottiene
quando P = 1/2. In mancanza di informazioni sul possibile valore di P nella
popolazione, si puo assumere P = 1/2 ottenendo cosı il valore massimo di n.
Tabella 1.3: Dimensioni campionarie: (e = 0, 05), (α = 0, 05), z1−α/2 = 2
N n0,max e = 0, 05 n0,max e = 0, 01
n022×0,5×(1−0,5)
(0,05)2400 22×0,5×(1−0,5)
(0,01)210000
100 4001+ 399
100
≃ 80 100001+ 9999
100
≃ 99
400 4001+ 399
400
≃ 200 100001+ 9999
400
≃ 385
1000 4001+ 399
1000
≃ 286 100001+ 9999
1000
≃ 909
5000 4001+ 399
5000
≃ 370 100001+ 9999
5000
≃ 3333
10000 4001+ 399
10000
≃ 386 100001+ 9999
10000
≃ 5000
20000 4001+ 399
20000
≃ 392 100001+ 9999
20000
≃ 6666
Se la P di interesse e minore del 10% o maggiore del 90%, se si vuole
stimare il totale di unita appartenenti alla modalita (categoria) di interesse,
N P , si preferisce controllare l’errore relativo, r. Con un procedimento analogo
al precedente si ha che la dimensione del campione in assenza di correzione per
popolazione finita, n0, e data da
n0 = z21−α/2
P (1− P )
e2= z21−α/2
P (1− P )
r2 P 2=
z21−α/2
r2(1− P )
P. (1.18)

9.. Dimensione del campione 13
Quando P assume valori molto piccoli, inferiori al 10%, allora piccole variazioni
sulle valutazioni di P conduce a forti variazioni di n0
α = 0, 05 z1−α/2 = 2
e = 0, 05 ⇒ r =P − (P − 0, 05)
P= 0, 5
n0 =22
(0, 5)20, 90
0, 10= 144
n0 =22
(0, 5)20, 99
0, 01= 1584.
A parita di errore relativo la dimensione del campione n0 cresce al diminuire di
P . Inoltre, dai numeri riportati si deduce che e elevata la possibilita di estrarre
campioni troppo piccoli o troppo grandi per gli obiettivi che si devono conseguire.
9.2. Variabili quantitative
Sia Y una variabile casuale quantitativa relativa a una popolazione. Il controllo
dell’errore, e, non puo piu essere espresso in termini assoluti perche e difficile
quantificare in termini immediati l’entita dell’errore che si puo ancora esprimere
in termini di distanza massima desiderata dal parametro da stimare: Y o Y .
Si puo controllare piu agevolmente l’errore relativo. Sia α il livello di errore in
termini di probabilita di osservare un campione che produca una stima maggiore
di quella desiderata. In termini di probabilita si puo scrivere come segue:
Pr(| y − Y |Y
≥ r) = Pr(|N y −N Y |N Y
≥ r) = α.
L’espressione precedente si puo standardizzare usando lo scarto quadratico medio
di y e da lı ricavare l’espressione per il calcolo di n.
α = Pr
|y − Y |√S2
n
N − n
N − 1
≥ r Y√S2
n
N − n
N − 1
.
Lo stimatore si puo considerare distribuito secondo una normale standardizzata,
per cui l’uguaglianza si ha in z1−α/2:
z1−α/2 =r Y√
S2
n
N − n
N − 1

14 Capitolo 1. Il campionamento casuale semplice
Risolvendo si ha:
n =z21−α/2
S2
Y 2 r2
1 +1
N
(z21−α/2 S2
Y 2 r2− 1
) . (1.19)
Il numeratore e indicato, in genere, con n0 e si riferisce alla dimensione cam-
pionaria per popolazioni infinite; cosı, il fattore al denominatore rappresenta la
correzione della dimensione per popolazioni finite. Si scrivera, allora
n0 = z21−α/2
S2
Y 2 r2(1.20)
n =n0
1 +n0 − 1
N
. (1.21)
Si puo assumere che y ∼ N(Y , σ2
y
). La dimensione del campione dipende dai
dati non noti della popolazione: Y , S2.
9.3. Esempi e esercizi
Esercizio 1
La popolazione di imprese di una certa regione e composta da N = 50000 unita.
Si vuole condurre una indagine per stimare la proporzione di imprese che applica
una nuova forma contrattuale. Si suppone che la proporzione, P , si aggiri tra il
10% e il 20%.
a) Determinare la dimensione di un CCS senza reimmissione con un livello di
fiducia del 95% e un errore assoluto del 5% per P .
b) Determinare la dimensione di un CCS senza reimmissione con un livello di
fiducia del 95% e un errore relativo del 15% di P .
Soluzione
a) Si considerano le dimensioni per le due percentuali ipotizzate.
P1 = 20%
n1 =
z21−α P (1− P )
e2
1 +1
N
(z21−α P (1− P )
e2− 1
)
=
(1, 96)2 0, 20 (1− 0, 20)
(0, 05)2
1 +1
50000
((1, 96)2 0, 20 (1− 0, 20)
(0, 05)2− 1
) = 244, 7

9.. Dimensione del campione 15
P2 = 10%
n2 =
(1, 96)2 0, 10 (1− 0, 10)
(0, 05)2
1 +1
50000
((1, 96)2 0, 10 (1− 0, 10)
(0, 05)2− 1
) = 137, 9 .
b) La seconda domanda ha le sue motivazioni sul basso valore di P . Si possono
applicare le formule precedenti sostituendo all’errore assoluto il suo valore corri-
spondente alla percentuale del 15% di P oppure utilizzare le formule con l’errore
relativo.
P1 = 20%
e1 = 0, 15× 0, 2 = 0, 03 errore assoluto pari al 15% di P
n1 =
z21−α (1− P )
r2 P
1 +1
N
(z21−α (1− P )
r2 P− 1
) =N z21−α (1− P )
(N − 1) P r2 + z21−α (1− P )
=50000 (1, 96)2 (1− 0, 20)
(50000− 1) 0, 20 (0, 15)2 + (1, 96)2 (1− 0, 20)= 673, 8
P2 = 10%
e2 = 0, 15× 0, 1 = 0, 015 errore assoluto pari al 15% di P
n2 =50000 (1, 96)2 (1− 0, 10)
(50000− 1) 0, 10 (0, 15)2 + (1, 96)2 (1− 0, 10)= 1490, 9 .
Esercizio 2
Si vuole stimare la proporzione di famiglie italiane che non va in vacanza per piu
di 10 giorni l’anno, mediante un campionamento casuale semplice senza reim-
missione e un errore assoluto del 2,5%. Quanto deve essere la dimensione del
campione?
Soluzione
1. La dimensione,N , di P e elevata; quindi, si ignora la correzione per popolazione
finita.
2. Senza informazioni a priori si assume P = 0, 5. Se la realta e diversa, come e
molto probabile, allora si avra, in pratica, una minore incertezza di quella fissata
all’inizio che e pari al 2,5%:
n =z21−α P (1− P )
e2=
(1, 96)2 0, 5 (1− 0, 5)
(0, 025)2= 1536, 64 .

16 Capitolo 1. Il campionamento casuale semplice
Esercizio 3
Si vuole stimare la proporzione di famiglie italiane che possiede una barca, me-
diante un campionamento casuale semplice senza reimmissione e un errore del 2%.
Quanto deve essere la dimensione del campione, ipotizzando che la percentuale
di famiglie sia dell’ordine del 5%?
Soluzione
1. La dimensione, N , di P e elevata; si ignora, percio, la correzione per popola-
zione finita.
2. Il testo non specifica se si tratta di errore assoluto o relativo, ma dato il basso
valore della percentuale in P si deve usare l’errore relativo.
n =z21−α (1− P )
r2 P=
(1, 96)2 (1− 0, 05)
(0, 02)2 0, 05= 182476 .
Esercizio 4
Una comunita, P , e formata da Nf = 3000 famiglie. Si sa che, in un anno, la
media di film visti per famiglia e 56,8 con una deviazione standard pari a 23,166.
Quanto deve essere la dimensione del campione, ipotizzando che la stima si debba
ottenere con un livello di fiducia del 95% e un errore relativo del 10%?
Soluzione
La soluzione, qui come in sede di esame, consiste nell’applicazione della formula
per il calcolo di n per variabili continue; infatti, sono (e saranno) fornite la media
e la deviazione standard.
n =
z21−α S2
r2 Y 2
1 +1
N
(z21−α S2
r2 Y 2− 1
)
=
(1, 96)2 (23, 166)2
(0, 1)2 (56, 8)2
1 +1
3000
((1, 96)2 (23, 166)2
(0, 1)2 (56, 8)2− 1
) = 62, 59 .

Capitolo 2
Campionamento sistematico
La popolazione P abbia le N unita numerate progressivamente da 1 a N .
SiaK = ⌊N/n⌋ il passo di campionamento (sampling interval), ossia l’intero
piu vicino a N/n; infatti, il simbolo ⌊·⌋ indica la parte intera.
Si estragga un numero casuale r tale che 1 ≤ r ≤ K.
Si chiama campionamento sistematico l’insieme di unita contraddistinte
dalle etichette: r, r +K, r + 2K, . . . , r + (n− 1)K. Il altri termini (Sarndal,
Swensson, Wretman, 1992),
• N = nK + q;
• si genera un numero casuale con probabilita 1/K;
• s = i : i = r + (j − 1)K ≤ N ; j = 1, . . . , ns e il campione casuale
selezionato di dimensione ns
ns =n+ 1 se 1 ≤ r ≤ qn se q < r ≤ K .
La procedura di realizzazione del campionamento sistematico e semplice: gli ele-
menti sono selezionati scorrendo la lista e scegliendo un elemento ogniK a partire
dal soggetto che nei primi K elementi occupa una posizione scelta secondo un
numero casuale, r, compreso tra 1 e K e detto partenza casuale (random start).
Esistono almeno due situazioni in cui il campionamento sistematico puo
condurre a errori considerevoli.
• I soggetti ordinati secondo un criterio sistematico non alfabetico e, comun-
que, non assimilabile al caso. Per esempio, i soggetti sono elencati secondo
il prestigio, il grado gerarchico, la classe sociale, il tipo di mansioni svolte,
l’anzianita.
17

18 Capitolo 2. Campionamento sistematico
• La lista presenta ricorrenze cicliche il cui periodo coincide con la frazione
di campionamento. Per esempio, se si intervistano consumatori che escono
da un supermercato tutti i giovedı dalle 12 alle 13, cio puo a un errore.
Osservazioni
O.1. Se la lista e molto lunga o bisogna scegliere un campione molto grande,
il campionamento sistematico diventa piu conveniente del campionamento
casuale semplice.
O.2. Se i soggetti sono stati inseriti (elencati) nella lista in modo casuale, al-
lora il campionamento sistematico puo considerarsi a tutti gli effetti un
campionamento casuale semplice.
O.3. Nel campionamento sistematico si estrae un solo numero casuale.
O.4. Gli elenchi alfabetici sono una buona base di campionamento.
1. Stimatori e efficienza
Teorema 1..1 Sia dato un piano di campionamento sistematico con passo di
campionamento K. Sia ySM la corrispondente media campionaria, allora
E (ySM) = Y
e la sua varianza e data da
Var(ySM) =S2
n
(N − n
N − 1
)[1 + (n− 1) ρW ]
dove ρW e il coefficiente di correlazione tra le coppie di unita che sono nello
stesso campione sistematico (Within)
ρW =E[(yij − Y ) (yil − Y )
]E[(yij − Y )2
] . (2.1)
Il numeratore e mediato sulle K n (n − 1)/2 coppie distinte e il numeratore su
tutti gli N valori di yij.
In genere il deff(SM, SR) > 1 perche ρW e spesso maggiore di zero; ma
se ρW < 0, allora deff(SM, SR) < 1.

Capitolo 3
Campionamento stratificato
Le conoscenze disponibili sulla popolazione obiettivo, P composta di N unita,
permettono di suddividerla in H sottogruppi o strati disgiunti, all’interno dei
quali le unita siano omogenee secondo i criteri definiti in base alla conoscenze
iniziali, e tali che N = N1 +N2 + · · ·+NH .
Da ogni strato si estrae in modo indipendente un campione sicche la di-
mensione complessiva del campione e data da n = n1 + n2 + · · ·+ nH .
Il piano campionario risultante e detto campionamento casuale stratificato.
Osservazioni.
(a) Gli strati devono essere il piu possibile omogenei internamente e eterogenei
tra loro.
(b) La definizione dell’omogeneita dipende dalle finalita che si devono conseguire
con la stratificazione. Il singolo strato potrebbe costituire un dominio di studio.
(c) La stratificazione puo essere eseguita in base a uno o piu caratteri.
Vantaggi della stratificazione
1. Riduzione dell’errore delle stime dei parametri di P.
2. Incremento dell’efficienza (delle stime) per unita di costo.
3. Precisione per strato (eventualmente) delle stime dei parametri di P .
4. Convenienza operativa perche le informazioni su P sono spesso raggruppate
in base a determinati caratteri a fini amministrativi, contabili, e altro.
5. Differenziazione per strato dei problemi di campionamento.
Quando e perche la stratificazione
1. Quando le stime sono richieste separatamente per ogni suddivisione della
popolazione obiettivo, quali aree geografiche, strati sociali, gruppi etnici.
19

20 Capitolo 3. Campionamento stratificato
2. Quando la composizione per strato e molto variabile e si vuole includere
nel campione elementi appartenenti a strati poco numerosi.
3. Quando la caratteristica oggetto di stima ha una varianza molto elevata;
come, il numero degli addetti, il fatturato, il reddito.
4. Quando differenti procedure campionarie devono essere adottate in uno o
piu strati differenti, in accordo con la natura della sottopopolazione.
5. Multi-stadificazione. La stratificazione puo essere adottata anche a diffe-
renti stadi del campionamento. Per esempio, in una indagine sul compor-
tamento al consumo delle famiglie si selezionano le citta di interesse e in
ogni citta si stratificano le famiglie in base al numero dei loro componenti.
6. Post-stratificazione. In fase di elaborazione dei dati raccolti si puo assumere
che una variabile oggetto di stima, X, provenga da una stratificazione.
1. Stima della media e della varianza
Per illustrare gli aspetti formali di una strategia di campionamento si definisco-
no, in genere, subito l’insieme degli indici e dei simboli utilizzati nelle formule.
Nella tabella 3.1 sono riportate le grandezze che appaiono nei risultati inerenti
al campionamento stratificato. In particolare, le espressioni della media e della
varianza della popolazione e del campione, rispettivamente.
2. Stima della dimensione campionaria
La dimensione del campione puo essere determinata anche in ogni singolo stra-
to, nh, con il procedimento descritto in precedenza e con precisioni desiderate
eventualmente diverse, ma preferibilmente uguali, per strato. Il numero totale di
unita da selezionare, allora, sara n = n1 + n2 + · · · + nH . Diversamente, si puo
determinare la dimensione totale del campione considerando tutta la popolazione
(indipendentemente dagli strati) e, dopo, procedere al calcolo della dimensione
dei campioni per ogni strato, nh. Si descrivono due procedure di determinazio-
ne di nh, quando e nota la dimensione totale, n, del campione: l’allocazione
proporzionale e l’allocazione ottimale.

2.. Stima della dimensione campionaria 21
Tabella 3.1: Simboli e formule utilizzate nel processo di stima
Nh Numero di unita per strato della popolazione
nh Numero di unita per strato del campione
Wh =Nh
NPeso dello strato nella popolazione
wh =nh
nPeso dello strato nel campione
fh =nh
NhFrazione campionaria per strato
Yh =
∑Nhi=1 YhiNh
=YhNh
Media della popolazione per strato
yh =
∑nhi=1 yhinh
=yhnh
Media del campione per strato
S′2h =
∑Nhi=1(Yhi − Yh)
2
Nh − 1Varianza popolazione per strato
s′2h =
∑nhi=1(yhi − yh)
2
nh − 1Varianza campionaria per strato
2.1. Allocazione proporzionale
La procedura mantiene le proporzioni tra la consistenza della popolazione per
strato e le corrispondenti dimensioni del campione (Cochran, 1977):
nh
n=
Nh
N→ nh
Nh
=n
N→ fh = f (3.1)
dove N = N1 + · · · + NH . Si ottengono gli stessi risultati se si impone che nel
calcolo della media campionaria si utilizzano gli stessi “pesi” che figurano nel-
l’espressione della media relativa alla popolazione. L’allocazione proporzionale
fornisce un campione autoponderante (self-wieghting); ossia, l’ammontare del-
le unita nel campione per strato e proporzionale a quella corrispondente della
popolazione.
Teorema 2..1 In ogni strato, la media campionaria, yh, e uno stimatore corretto
della media della popolazione, Yh. Allora, la media campionaria pesata, yST, euno stimatore corretto della media della popolazione, Y .
E(yST) = E
(H∑
h=1
wh yh
)=
H∑h=1
wh E (yh) =H∑
h=1
wh Yh = Y .

22 Capitolo 3. Campionamento stratificato
Teorema 2..2 Se i campioni sono estratti indipendentemente in ciascun strato,
allora la varianza della media campionaria, yST, e data da
Var(yST) = H∑
h=1
W 2h Var (yh) =
H∑h=1
W 2h
S2h
nh
Nh − n
Nh − 1(3.2)
dove Var(yh) e la varianza di yh per campioni (ripetuti) nell’h-esimo strato.
Da questi due teoremi deriva che la Var(yST) dipende solo dalla varianza
delle stime della media per strato. All’aumentare del numero degli strati in una
data popolazione di dimensione fissata, N , diminuisce la varianza; la stratifica-
zione diventa sempre piu efficiente fino a quando in ogni strato si hanno elementi
uguali tra loro (strati perfettamente omogenei), ossia yhi = yhj, ∀i, j = 1, . . . , Nh.
2.2. Allocazione ottimale
Il costo di una intervista e spesso costante, ma, a volte, puo avere variazioni
anche complicate. Si puo dimostrare che la dimensione del campione per strato,
nh, e piu grande se
• lo strato e piu numeroso
• lo strato ha piu variabilita interna
• il costo per unita di rilevazione e piu economico, cioe il campione costa
meno all’interno dello strato rispetto agli altri.
Con un costo di rilevazione costante per strato si ha l’allocazione ottimale di
Neyman.
Teorema 2..3 In un campionamento stratificato con funzione di costo lineare
C = C0 +H∑
h=1
c nh,
la varianza dello stimatore della media (campionaria) e minima per una dimen-
sione del campione totale fissata, n, quando
nh = nWh Sh∑Hh=1 Wh Sh
= nNh Sh∑Hh=1 Nh Sh
(3.3)

3.. Esempi e esercizi 23
3. Esempi e esercizi
Esercizio 5
La popolazione di imprese, P , di un certo comune e composta da N = 3000 unita
e per ogni azienda, i, si conosce il numero di addetti Yi. Si vuole condurre una
indagine sul 10% di P, sapendo che le imprese sono suddivise per strati, come
riportato nella tabella seguente
Tabella 3.2: Numero di imprese e deviazioni standard per classe di addetti
Classe addetti Nh Sh
A: 1–9 1200 1,5
A: 10–19 900 4
A: 20–49 500 8
A: 50–99 260 16
A: >=100 140 100
Totale 3000 60
a) Determinare la dimensione del campione negli strati con il metodo dell’allo-
cazione proporzionale.
b) Determinare la dimensione del campione negli strati con il metodo dell’allo-
cazione ottimale di Neyman.
Soluzione
a) La dimensione del campione deve essere il 10% di N , per cui si ha n = 10×3000/100 = 300. Nell’allocazione proporzionale si ha nh = nNh/N , ossia il 10%
della popolazione dello strato Nh, come riportato in tabelle 3.3. Per la prima
classe (A: 1–9) si ha npr; 1 = 300 × 1200/3000 = 120, Per la seconda classe (A:
10–19) si ha npr; 2 = 300× 900/3000 = 90, e cosı via.
b) Per eseguire semplicemente le operazioni conviene calcolare la colonna Nh Sh:
il totale diventera il denominatore dell’equazione 3.3, mentre il numeratore sara
dato dal prodotto di n per il valore della cella (Nh Sh). Per la prima classe (A:
1–9) si ha nott; 1 = 300 × (1200 × 1, 5)/27560 = 20, Per la seconda classe (A:
10–19) si ha nott; 2 = 300× (900× 4)/27560 = 39, e cosı via.
Dopo l’esecuzione dei calcoli, si verifica che in uno strato (l’ultimo) la dimen-
sione del campione e superiore alla dimensione della popolazione. In tali casi, si
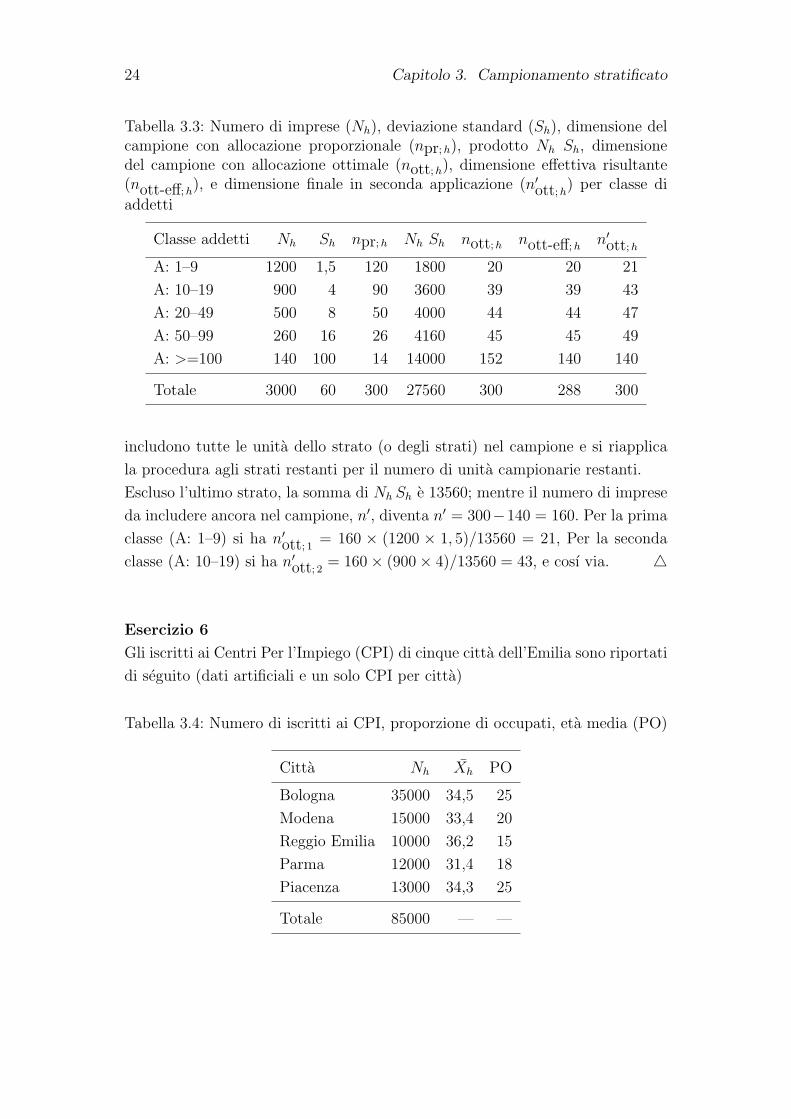
24 Capitolo 3. Campionamento stratificato
Tabella 3.3: Numero di imprese (Nh), deviazione standard (Sh), dimensione delcampione con allocazione proporzionale (npr;h), prodotto Nh Sh, dimensionedel campione con allocazione ottimale (nott;h), dimensione effettiva risultante(nott-eff;h
), e dimensione finale in seconda applicazione (n′ott;h) per classe di
addetti
Classe addetti Nh Sh npr;h Nh Sh nott;h nott-eff;hn′ott;h
A: 1–9 1200 1,5 120 1800 20 20 21
A: 10–19 900 4 90 3600 39 39 43
A: 20–49 500 8 50 4000 44 44 47
A: 50–99 260 16 26 4160 45 45 49
A: >=100 140 100 14 14000 152 140 140
Totale 3000 60 300 27560 300 288 300
includono tutte le unita dello strato (o degli strati) nel campione e si riapplica
la procedura agli strati restanti per il numero di unita campionarie restanti.
Escluso l’ultimo strato, la somma di Nh Sh e 13560; mentre il numero di imprese
da includere ancora nel campione, n′, diventa n′ = 300−140 = 160. Per la prima
classe (A: 1–9) si ha n′ott; 1 = 160 × (1200 × 1, 5)/13560 = 21, Per la seconda
classe (A: 10–19) si ha n′ott; 2 = 160× (900× 4)/13560 = 43, e cosı via.
Esercizio 6
Gli iscritti ai Centri Per l’Impiego (CPI) di cinque citta dell’Emilia sono riportati
di seguito (dati artificiali e un solo CPI per citta)
Tabella 3.4: Numero di iscritti ai CPI, proporzione di occupati, eta media (PO)
Citta Nh Xh PO
Bologna 35000 34,5 25
Modena 15000 33,4 20
Reggio Emilia 10000 36,2 15
Parma 12000 31,4 18
Piacenza 13000 34,3 25
Totale 85000 — —

3.. Esempi e esercizi 25
a) Proporre una ripartizione adeguata di un campione di n = 1000 iscritti in
base ai dati forniti.
Soluzione
a) Per rispondere al quesito, qui e in sede di esame, occorre valutare gli elementi
forniti con la tabella. Si tratta di un campionamento stratificato perche le citta
si possono considerare come strati; pertanto, bisogna definire se si deve ap-
plicare l’allocazione proporzionale o l’allocazione ottimale. Tale scelta si
effettua come segue:
(1) se NON sono state fornite le deviazioni standard per strato (Sh), allora si
applica l’allocazione proporzionale;
(2) se sono state fornite le deviazioni standard per strato (Sh), allora si applica
l’allocazione ottimale.
In questo caso, sono state fornite informazioni che non si riferiscono alla de-
viazione standard (per rendere il testo simile nei due casi); pertanto, si DEVE
applicare l’allocazione proporzionale.
Nell’allocazione proporzionale si ha nh = nNh/N .
Per Bologna si ha npr; 1 = 1000× 35000/85000 = 411, 8.
Per Modena si ha npr; 2 = 1000×15000/85000 = 176, 5, e cosı via, come riportato
nella tabella di seguito. La dimensione e stata indicata con una cifra decimale.
Tabella 3.5: Numero di iscritti ai CPI, proporzione di occupati, eta media (PO)
Citta Nh Xh PO npr;h
Bologna 35000 34,5 25 411,8
Modena 15000 33,4 20 176,5
Reggio Emilia 10000 36,2 15 117,6
Parma 12000 31,4 18 141,2
Piacenza 13000 34,3 25 152,9
Totale 85000 — — 1000,0
Esercizio 7
Gli iscritti ai Centri Per l’Impiego (CPI) di cinque citta dell’Emilia sono riportati
di seguito (dati artificiali e un solo CPI per citta)

26 Capitolo 3. Campionamento stratificato
Tabella 3.6: Numero di iscritti ai CPI, tempi di attesa in mesi (X)
Citta Nh Xh Sh
Bologna 35000 15,8 15,5
Modena 15000 14,5 12,4
Reggio Emilia 10000 13,9 15,2
Parma 12000 16,2 20,4
Piacenza 13000 16,1 25,2
Totale 85000 — —
a) Proporre una ripartizione adeguata di un campione di n = 1000 iscritti in
base ai dati forniti.
Soluzione
a) Per rispondere al quesito, qui e in sede di esame, occorre valutare, come sopra,
gli elementi forniti con la tabella. Si tratta di un campionamento stratificato
perche, come sopra, le citta si possono considerare come strati; pertanto, bisogna
scegliere tra allocazione proporzionale e allocazione ottimale. Tale scelta
si effettua considerando lo schema esposto nell’esercizio precedente.
In questo caso, sono state fornite deviazioni standard di una variabile quantitativa
(tempo di attesa per trovare un lavoro); pertanto, si DEVE applicare l’allocazione
ottimale e nh = nNh Sh/(∑H
h=1 Nh Sh
)Per Bologna si ha nott; 1 = 1000× 542500/1452900 = 373, 4.
Per Modena si ha nott; 2 = 1000 × 186000/1452900 = 128, 0; e cosı via, come
riportato nella tabella di seguito. La dimensione e stata indicata con una cifra
decimale.
Si puo riflettere sulle differenze delle dimensioni campionarie ottenute con i due
metodi in base agli obiettivi di stima e alle informazioni disponibili all’inizio.
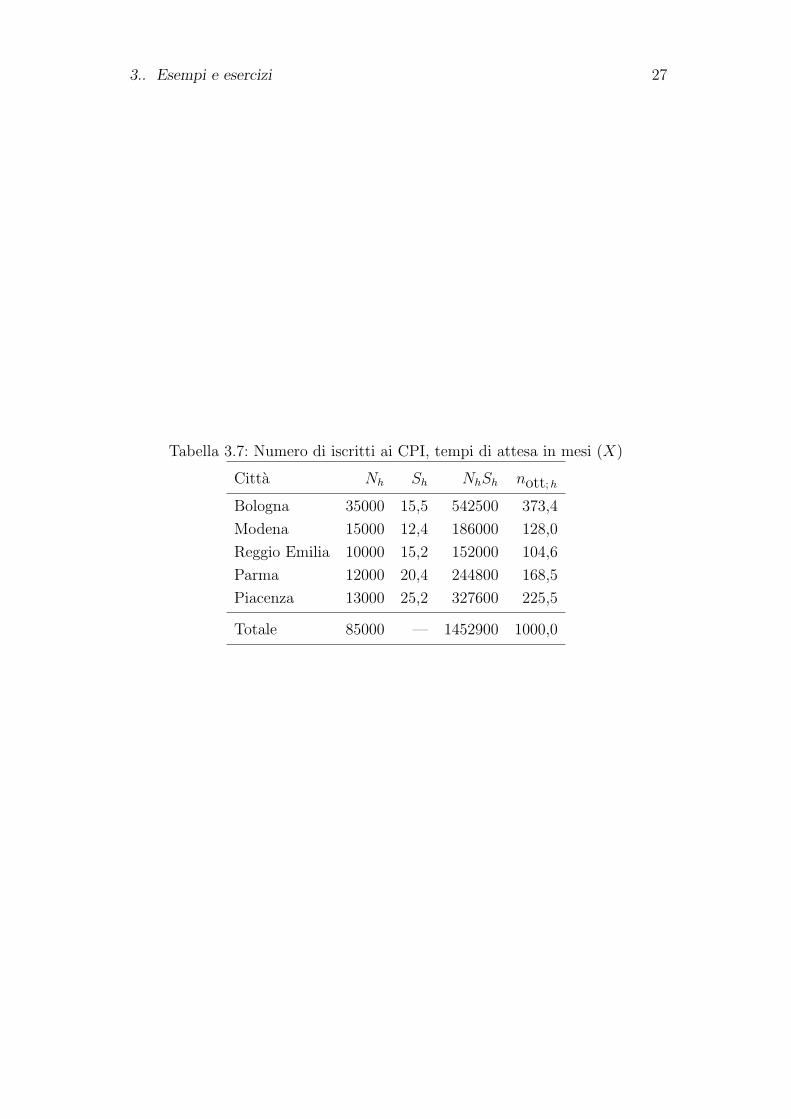
3.. Esempi e esercizi 27
Tabella 3.7: Numero di iscritti ai CPI, tempi di attesa in mesi (X)
Citta Nh Sh NhSh nott;h
Bologna 35000 15,5 542500 373,4
Modena 15000 12,4 186000 128,0
Reggio Emilia 10000 15,2 152000 104,6
Parma 12000 20,4 244800 168,5
Piacenza 13000 25,2 327600 225,5
Totale 85000 — 1452900 1000,0

28 Capitolo 3. Campionamento stratificato

Capitolo 4
Campionamento a grappoli
La popolazione P e suddivisa in un numero elevato di gruppi (grappoli, cluster).
Le unita nel procedimento di selezione sono i grappoli e tutti gli elementi
dei grappoli selezionati sono rilevati.
La procedura richiede, per essere efficace, che i grappoli siano al loro interno
eterogenei al massimo, in quanto non si selezionano i soggetti bensı i grappoli
(campionamento a grappoli a un solo stadio).
Si usa per ridurre i costi di raccolta dei dati e per non costruire la lista.
Nel campionamento a grappoli (a uno stadio) non vi e errore di campio-
namento all’interno del grappolo in quanto tutti i soggetti di appartenenza sono
inclusi nel campione. L’errore di campionamento deriva, allora, dalla differenza
tra i grappoli sicche si richiede che i grappoli siano eterogenei al loro interno e
siano omogenei tra loro. Nel caso estremo, un grappolo solo dovrebbe essere una
“mini-immagine” (o una “miniatura”) della popolazione.
I simboli per formalizzare la strategia del campionamento a grappoli sono
riportati nella tabella 4.1 (Cochran, 1977).
Per il campionamento a grappoli si avra S ′2i = s′2i .
Teorema 0..1 Sia dato un piano di campionamento a grappoli a un solo stadio
in cui i grappoli sono selezionati con un procedimento analogo al campionamento
casuale semplice. Se i grappoli sono estratti con probabilita uguali, ossia secondo
un campionamento casuale semplice, si ha che lo stimatore della media della
popolazione e yCG =
∑ni=1 Mi yi ·∑n
i=1 Mi
(4.1)
e la varianza corrispondente e
Var(yCG
)=
1
n
(∑Ni=1(Yi · − ¯Y )2
N
)N − n
N − 1(4.2)
(4.3)
29

30 Capitolo 4. Campionamento a grappoli
Tabella 4.1: Simboli e formule utilizzate nel processo di stima
N Numero di grappoli nella popolazione
n Numero di grappoli nel campione
Mi Numero di unita nel grappolo i
M· =∑N
i=1Mi Numero di unita nella popolazione
Yij Valore di Y nell’unita j del grappolo i in P
yij Valore di Y nell’unita j del grappolo i in un ∫
Yi · =
∑Mij=1 Yij
MiMedia per grappolo in P
Yi · =∑Mi
j=1 Yij Totale per grappolo in P
yi · =
∑Mij=1 yij
MiMedia campionaria per grappolo
yi · =∑Mi
j=1 yij Totale campionario per grappolo
dove ¯Y = Y· ·/N esprime il totale medio del carattere Y per grappolo, mentre
Y· · indica il totale del carattere Y (Cicchitelli, Herzel, Montanari, 1997).
Teorema 0..2 Sia dato un piano di campionamento a grappoli a un solo stadio
in cui i grappoli sono selezionati con un procedimento analogo al campionamento
casuale semplice. Se i grappoli sono estratti con probabilita uguali, ossia secondo
un campionamento casuale semplice si ha che il rapporto tra la varianza del-
lo stimatore della media della popolazione e la corrispondente varianza di un
campionamento casuale semplice e data da
Var(yCG
)Var
(ySRS
) = 1 + ρi (M − 1) (4.4)
dove ρi e il coefficiente di correlazione intra-classi e M e il numero medio di
unita nei grappoli.
Generalmente sara ρi > 0 che implica Var(yCG
)> Var
(ySRS
). Il coefficiente ρi
esprime una misura di omogeneita dei grappoli: piu i grappoli sono omogenei,
piu ρi risulta maggiore di zero. Si ha ρi < 0 quando i grappoli sono piu eterogenei
di quanto ci si potrebbe aspettare se i grappoli si formassero per effetto del caso,
che e abbastanza raro.
Si noti che le tecniche di inferenza statistica non si applicano facilmente a
dati ottenuti da un campionamento a grappolo.

Capitolo 5
Miscellanea
1. Confronto dell’efficienza tra i vari metodi
La relazione tra le varianze dei diversi metodi si puo sintetizzare come segue:
Var(yCst−Ott
)≤ Var
(yCst−Prop
)≤ Var
(yCCS−SR
)≤ Var
(yCCS−CR
)Rispetto al CCS-SR, si ha per gli altri metodi
Var(yCCS−SR
)≤ Var
(yCsist
)se ρW ≥ 0; diversamente vale >
≤ Var(yCG
)se ρi ≥ 0; diversamente vale >
Dalla catena di relazioni si evince l’efficienza dei diversi metodi.
L’efficienza del campionamento a grappoli diminuisce rispetto al campione
casuale semplice, all’aumentare della dimensione media dei grappoli, N . In gene-
rale, il campionamento a grappoli e meno efficiente anche rispetto agli altri tipi
di campionamento.
2. Il campionamento non probabilistico
Studiare il paragrafo 5.2.2 (o il corrispondente della nuova edizione) del testo
adottato: Molteni L. e Troilo G. (a cura di), Ricerche di marketing, McGraw-Hill,
Milano, 2003 (1.a edizione).
31

32 Capitolo 5. Miscellanea
3. Indagini longitudinali
La composizione di quasi tutte le popolazioni (individui, famiglie, imprese) cam-
bia con il tempo. Gli elementi entrano nella popolazione in oggetto quando na-
scono, immigrano, o raggiungono lo stato utilizzato per definirla; gli elementi
escono o abbandonano la popolazione quando muoiono (cessano), emigrano, o
perdono lo stato che li fa appartenere a essa; percio, si parlera di entrate e uscite.
Per appurare le modifiche avvenute si devono eseguire indagini ripetute nel
tempo o che ricostruiscono il passato (retrospettive) che, per semplicita, si deno-
mineranno longitudinali. Gli obiettivi fondamentali conseguibili con tali indagini
sono (Duncan, Kalton, 1987):
(a) stima dei parametri della popolazione in periodi distinti del tempo; per
esempio, il tasso di disoccupazione trimestrale;
(c) stima della variazione netta (net changes) ovvero della differenza tra le
medie al livello aggregato; per esempio, la variazione inter-trimestrale del
tasso di disoccupazione;
(d) stima dei cambiamenti individuali (gross changes) e di altri componenti
soggetti a variazione tra gli individui; per esempio, la variazione di spesa
del bilancio famigliare da un anno all’altro o del reddito di un individuo;
4. Tipi di indagine per fenomeni temporali
I fenomeni che si svolgono nel tempo richiedono indagini periodiche e tra i vari
metodi di campionamento si distinguono i seguenti casi.
4.1. Indagini ripetute (distinte, periodiche)
Questo schema si riferisce a osservazioni (misure) simili effettuate tramite cam-
pioni distinti estratti da una popolazione equivalente in momenti diversi del
tempo (Duncan, Kalton, 1987). Una popolazione equivalente e definita da preci-
se caratteristiche che la individuano in modo univoco e la sua composizione puo
cambiare nel tempo. Una indagine ripetuta, che si riferisce a campioni realizza-
ti in periodi di tempo regolari, viene anche chiamata periodica. Ogni campione
corrisponde a una indagine trasversale, detta anche per contemporanei, che mi-
sura i caratteri delle unita statistiche alla data di riferimento, ossia tra loro
contemporanee.

4.. Tipi di indagine per fenomeni temporali 33
L’indagine ripetuta nel tempo consente di perseguire gli obiettivi (a), (c);
ma non l’obiettivo (d). Risulta anche relativamente piu semplice delle altre
tipologie.
4.2. Indagini panel
Lo schema di indagine panel richiede che si effettuino le stesse misure sullo stes-
so campione a momenti diversi del tempo; si hanno quindi osservazioni ripetute
a date diverse sugli stessi elementi (soggetti, famiglie, imprese) selezionati al
momento della costituzione iniziale del campione (Lazarsfeld, Fiske, 1938; La-
zarsfeld, 1940). Altra denominazione e indagine longitudinale, che e preferibile,
comunque, usarla nel contesto di una indagine trasversale (cross-section survey)
nella quale i dati sono acquisiti retrospettivamente, come suggeriscono Duncan e
Kalton (1987). La terminologia non e ancora consolidata; cosı le indagini panel
concernenti sottogruppi di popolazione che hanno sperimentato lo stesso evento
nello stesso periodo di tempo, come il numero di coppie che hanno celebrato il
matrimonio o il numero di laureati in un dato anno, sono chiamate studi di coorti
o di (per) generazioni.
La disponibilita dello stesso campione nel tempo consente di perseguire in
modo piu efficiente gli obiettivi (c), (d); ma con meno efficienza l’obiettivo (a).
Indagini panel versus indagini ripetute
I due metodi di indagine sono alle estremita delle possibilita.
Svantaggi delle indagini panel sulle indagini distinte
Auto-selezione iniziale. La costituzione di un panel richiede persone volontarie,
disposte a essere intervistate successivamente, ma cio incrementa la quota dei
mancate partecipazioni.
Attrito. La perdita di soggetti nel tempo non e alta come all’inizio, ma rimane
costante nei vari periodi di indagine per stanchezza, noia, apatia oppure perche
si sono perse le loro tracce. Genera il cosiddetto logoramento del campione. Per
limitare la distorsione introdotta dal logoramento si possono interpolare i dati
mancanti o aggiustare i dati attraverso i pesi per compensare la mancata risposta
(Kish, 1990).
Mobilita. Gli elementi della popolazione si spostano spesso da un luogo all’altro
e la loro reperibilita diventa difficile. La mobilita si distingue dall’attrito perche
la causa della scomparsa dell’elemento nel campione e diversa.

34 Capitolo 5. Miscellanea
Natalita e Mortalita. In tutte le popolazioni si verificano entrate e uscite: gli
individui nascono e muoiono, le imprese cessano la loro attivita. Il movimento
avviene anche per immigrazione e emigrazione.
Vantaggi delle indagini panel sulle indagini distinte
Potenzialita di analisi. Solo i panel forniscono dati sui cambiamenti individuali
e, quindi, e possibile stimare parametri di modelli inerenti ai cambiamenti indivi-
duali (d), cumulare i dati individuali nel tempo (e), collezionare dati per costruire
la storia degli eventi e correggere gli errori telescopici (g).
Famigliarita. Possibilita di facilitazione del flusso informativo.
Efficienza nella stima della variazione netta. Siano y1 e y2 le medie della variabile
in esame ai tempi t = 1 e t = 2 e sia ∆ = (y2 − y1) lo stimatore della variazione
netta. Allora,
Var(∆) = Var(y1) + Var(y2)− 2 ρ [Var(y1) Var(y2)]1/2 (5.1)
e la varianza relativa, dove ρ e il coefficiente di correlazione tra y1 e y2. In una
indagine ripetuta i due campioni sono indipendenti e ρ = 0; in una indagine panel,
invece, i valori individuali della y dovrebbero essere positivamente correlati nel
tempo e produrre stime piu precise della variazione netta.
4.3. Indagini panel rotante
In questo schema di indagine, gli elementi del campione hanno una permanenza
limitata nel panel: man mano che alcuni di essi lasciano il campione, altri elementi
vengono aggiunti. L’indagine panel rotante e denominata semplicemente indagine
rotata (overlapping design). Le differenziazioni che si hanno tra i vari disegni di
campionamento riguardano l’ammontare, P , e il tipo di rotazione tra i periodi.
L’entrata e l’uscita degli elementi, quindi, e determinata da regole precise.
1. Sovrapposizione completa, P = 1; in tutto il periodo di rotazione si hanno
gli stessi elementi: aaa- aaa- aaa- ....
2. Sovrapposizione parziale, 0 < P < 1; ogni periodo di tempo mostra solo
una quota dei soggetti presenti nel periodo precedente: abc- cde- efg- ...
dove P = 1/3 e tale valore sembra ottimale (Kish, 1989) per stimare sia i
valori dei parametri della popolazione corrente, sia la variazione netta.
3. Non sovrapposizione, P = 0; in ogni periodo di tempo il campione viene
completamente sostituito, si ottiene cosı un’indagine ripetuta o periodica:
aaa- bbb- ccc- ....

4.. Tipi di indagine per fenomeni temporali 35
L’indagine panel rotante, tramite la sostituzione degli elementi del campione con
altri estratti dalla popolazione nel periodo corrente, cerca di ridurre gli inconve-
nienti dell’indagine panel come il logoramento dovuto all’abbandono o al rifiuto
di rispondere per l’onerosita che comporta l’intervista, la perdita di rappresen-
tativita dovuta agli ingressi (e alle uscite) che avvengono nella popolazione, il
condizionamento delle risposte nelle fasi successive dell’inchiesta rispetto a quelle
date in precedenza.
L’indagine panel rotante si usa per conseguire gli obiettivi (a), (c). L’obiet-
tivo (d) e limitato dalla breve permanenza degli elementi nel campione.
4.4. Indagini split panel
Questo schema di indagine e una combinazione di una indagine panel e una in-
dagine ripetuta o un panel rotante. La componente indagine panel consente di
ottenere gli obiettivi (c), (d). La componente indagine ripetuta o panel rotante,
invece, puo essere utilizzata per tenere conto degli ingressi e delle uscite che si
verificano nella popolazione, per controllare la distorsione dovuta al condizio-
namento e alla perdita dei soggetti o logoramento del campione che si verifica
nell’indagine panel. Entrambe le componenti consentono di ottenere gli obiettivi
(a), (b), (c).
4.5. Indagini trasversali con domande retrospettive
Questo schema coincide con una indagine trasversale (cross-sectional survey), ma
la rilevazione dei dati relativi alle differenti unita hanno periodi di riferimento
multipli, cioe si riferiscono sia al momento in cui generalmente si realizza la misu-
ra, sia a momenti o tempi precedenti attraverso domande retrospettive. Il metodo,
detto anche indagine retrospettiva, si basa sul ricordo dei soggetti intervistati per
ricostruire il flusso delle informazioni nel tempo.
Le domande retrospettive rilevano dati che possono essere affetti da errori
di memoria notevoli perche gli intervistati dimenticano gli eventi oppure non ri-
cordano con precisione quando siano avvenuti e la loro entita (effetto telescopico).
Non e possibile, inoltre, portare indietro di molto la raccolta delle informazioni
perche la memoria degli intervistati e notoriamente labile. Si e osservato che non
si ricordano anche eventi importanti, come la disoccupazione o i ricoveri ospe-
dalieri, e non si e in grado di fornire informazioni attendibili sulle esperienze
soggettive.

36 Capitolo 5. Miscellanea
Con tale schema di indagine si possono conseguire con precisione solo alcuni
obiettivi rispetto all’ultimo periodo di riferimento. Gli obiettivi (a), (b), (c) sono
difficili da conseguire. Con le limitazioni descritte e possibile ottenere (d).
5. Stadificazione
Le indagini riferite a un territorio ampio e popolazione numerosa o di indi-
sponibilita della lista, la strategia consigliata e quella del campionamento a
stadi.
Il campionamento a uno stadio e il campionamento a grappoli.
Il campionamento a due stadi e un piano di campionamento consistente
nell’estrarre, senza ripetizione, un campione casuale di grappoli e nel selezionare,
senza ripetizione, da ogni grappolo estratto un certo numero di unita statistiche
elementari (Cicchitelli, Herzel, Montanari, 1997). Il piano e detto anche campio-
namento a grappoli con sottocampionamento: i grappoli sono le Unita di Primo
Stadio (UPS) o unita primarie, mentre le unita elementari che costituiscono i
grappoli sono le Unita di Secondo Stadio (USS) o unita secondarie. La definizione
si puo facilmente generalizzare a tre o piu stadi.
Esempi di indagine a due stadi sono la Rilevazione Continua delle Forze
di Lavoro (RCFL) e l’indagine sui consumi condotte dall’Istat; L’indagine sui
bilanci delle famiglie condotta dalla Banca d’Italia.
Vantaggi
(1) Occorre costruire la lista solo per i grappoli selezionati.
(2) Per ogni grappolo si puo adattare precisione e strategia di campionamento
(3) La mobili ta territoriale degli intervistatori e ridotta.
Svantaggi
(1) L’efficienza finale del campionamento e modesta.
(2) La determinazione dell’errore finale e complessa.
6. Il campionamento nella ricerca qualitativa
Studiare il paragrafo 5.5 (o il corrispondente della nuova edizione) del testo adot-
tato: Molteni L. e Troilo G. (a cura di), Ricerche di marketing, McGraw-Hill,
Milano, 2003 (1.a edizione).

7.. Errori non campionari 37
7. Errori non campionari
La teoria della probabilita ci permette di valutare il rischio di commettere errori
che possono essere diversi l’uno dall’altro unicamente per la casualita delle estra-
zioni, dato che il carattere Y , oggetto di rilevazione, presenti una certa variabilita
nella popolazione di riferimento. L’errore generato da tale processo e detto errore
campionario o anche di campionamento.
La rilevazione campionaria e un processo costituito da un complesso di ope-
razioni, interdipendenti e sequenziali, che si sviluppano in piu fasi e coinvolgono
numerose persone. I momenti e le cause in cui si possono generare errori, diversi
da quelli del caso, sono molteplici: nella misura, nella codifica, nella trascrizione,
nell’immissione su supporto magnetico. Essi non dipendono dal piano di campio-
namento e, percio, sono detti errori non campionari (Diana, Salvan 1989; Kish,
1965).
Una tradizionale suddivisione dei vari tipi di errori e la seguente.
7.1. Errori di copertura
Gli errori di copertura derivano dalle imprecisioni presenti nella lista o base
campionaria e sono stati gia elencati in precedenza, come l’incompletezza, la
molteplicita, la sovracompletezza, la ridondanza.
Si ha, in tal caso, una distorsione da mancata copertura. Per esempio, l’in-
completezza contempla il caso in cui la popolazione non e interamente inclusa
nella lista, come per le indagini telefoniche.
7.2. Errori da mancate risposte
Gli errori da mancate risposte derivano dall’impossibilita di procedere alla ri-
levazione di alcune unita campionarie sia per l’impossibilita di rintracciare le
unita selezionate (per errore nei nominativi, cambio di indirizzo, emigrazione,
decesso, assenza temporanea, stile di vita), sia per il loro rifiuto di partecipare
all’indagine. Si parla, allora, di mancate risposte totali e di distorsione da man-
cata risposta perche possono generare un errore nel conseguimento delle stime
per ragioni simili a quelle della mancata copertura. Il rifiuto puo verificarsi anche
solo per qualche domanda del questionario; allora, si parla di mancata risposta
parziale.
La mancata risposta ha rilevanza solo se vi sono motivi per ritenere che
la non partecipazione all’indagine dipenda in qualche misura dai caratteri che si

38 Capitolo 5. Miscellanea
rilevano con l’indagine. La dipendenza e, in genere, il caso piu frequente; percio,
si adottano diverse strategie per ridurre il fenomeno.
Le mancate risposte parziali possono essere trattate solo in fase di pre-
elaborazione dei dati con procedimenti di imputazione per attribuire un dato
alla mancata rilevazione (Frosini, Montinaro, Nicolini, 1999; Kish, 1965).
7.3. Errori di misurazione
Gli errori di misurazione si sovrappongono, in parte, a quelli da mancata risposta
perche l’assenza di una risposta potrebbe dipendere proprio da una formulazione
ambigua o inadeguata della domanda.
La misurazione comporta, in generale, che il processo applicato goda di
alcune proprieta fondamentali: la validita, quando rileva effettivamente l’inten-
sita o la proprieta del concetto in esame, ossia, consegue gli obiettivi fissati;
l’attendibilita, quando applicato piu volte agli stessi fenomeni, nelle stesse con-
dizioni, riproduce (entro certi limiti) gli stessi risultati; la precisione, quando c’e
la possibilita di valutare i sottomultipli dell’unita di misura.
Una distinzione degli errori di misurazione e basata sulla causa che li ha
prodotti.
• (1) Errori di strumenti. Sono riconducibili al questionario per domande
formulate in modo ambiguo, ordinate in modo inadeguato, o batterie dei
test non tarati bene, e cosı via.
• (2) Errori di tecniche. Sono legati al tipo di tecnica utilizzata, come il
questionario postale, l’intervista auto-somministrata, l’intervista telefonica,
la batteria di test.
• (3) Errori dell’intervistatore, derivanti dalla influenza che esercita sull’in-
tervistato sia nell’incentivare o disincentivare la sua partecipazione, sia nel
fornire o non fornire una data risposta.
• (4) Errori dell’intervistato. Sono connessi alla capacita di comprensione
dell’intervistato o di ricordare gli eventi accaduti, alla sua idoneita e volonta
di fornire risposte veritiere.
7.4. Osservazioni finali
Non e sufficiente ridurre l’errore di campionamento e non vale neanche la pena di
ridurlo oltre ogni limite perche comporta un aumento forte di costi e di unita da
rilevare che ha, come conseguenza, un aumento della mole di lavoro e del rischio

8.. Bibliografia 39
di commettere errori. Occorre operare, quindi, in modo da ridurre anche gli errori
non campionari. Sia la precisione desiderata delle stime e sia una elevata qualita
dei dati sono limitate dalle risorse disponibili che pongono un limite superiore
sia alla dimensione del campione e sia al controllo sulla qualita dei dati.
Se le liste non sono complete o una grande percentuale di persone si rifiuta
di rispondere ci si trova, in pratica, a avere un campione non probabilistico.
8. Bibliografia
Ardilly P., Tille Y. (2006). Sampling Methods: Exercises and Solutions, New
York: Springer-Verlag.
Cicchitelli, G., A. Herzel, G.E. Montanari (1997). Il campionamento statistico,
nuova edizione, il Mulino: Bologna.
Cochran W. G. (1977). Sampling Techniques, 3.rd edition, New York: John Wiley
& Sons.
Diana G., Salvan A. (1989). Campionamento da popolazioni finite, CLEUP,
Padova.
Duncan G.J., Kalton G. (1987). Issue of design and analysis of surveys across
time, International Statistic Review, 55, 97–117.
Fabbris, L. (1989). L’indagine campionaria. Metodi, disegni e tecniche di cam-
pionamento, NIS: La Nuova Italia Scientifica, Roma.
Frosini, B.F., M. Montinaro, G. Nicolini (1999). Il campionamento da popolazioni
finite. Metodi e applicazioni, UTET, Torino.
Hansen, M.H., W.N. Hurwitz, W.G. Maddow (1953). Sample Survey Methods
and Theory, voll. I e II, John Wiley & Sons, New York.
Kish, L. (1965). Survey Sampling, John Wiley & Sons, New York.
Lazarsfeld, P.F., M. Fiske (1938). The panel as a new tool for measuring opinion,
Public Opinion Quarterly, 2, 596–612.
Lazarsfeld, P.F. (1940). “Panel” Studies, Public Opinion Quarterly, 4, 122–128.
Levy P. S., Lemeshow S. (1991). Sampling of Populations: Methods and Appli-
cations, New York: John Wiley & Sons.
Sarndal, C.E., B. Swensson, J. Wretman (1992).Model Assisted Survey Sampling.
New York: Springer-Verlag.
Stuart A. (1984). The Ideas of Sampling, Charles Griffin, High Wycombe. Trad.
it. (1996). I sondaggi di opinione. Idee per il campionamento, Tascabili
Newton Compton, Roma.

40 Capitolo 5. Miscellanea


















