CORSO BASE DINFORMATICA Diego Marianucci. I LUCIDI ONLINE Scaricate i lucidi direttamente dal sito:

CORSO SPECIALE DI DURATA ANNUALE PER IL CONSEGUIMENTO DELL’ABILITAZIONEALL’INSEGNAMENTO NELLA SCUOLA SECONDARIA DI I e II GRADO
Indirizzo Fisico - Informatico - Matematico a.a. 2006/07 - Classe 42A - Informatica
ALGORITMIDocente: Prof. Domenico Cantone
Modulo: STRUTTURE DATI ELEMENTARI
Lucidi a cura del Dott. Salvatore Cristofaro

Strutture dati elementari
Liste
• Una lista L e una sequenza finita (ed ordinata) di oggetti
x0 x1 x2 . . . xn−1
chiamati elementi (della lista).
• Il primo elemento, x0, e chiamato la testa (head ) della lista.
• Il numero n di oggetti contenuti nella lista e la lunghezza della lista.
• Generalmente, ogni elemento xi di una lista e un oggetto costituito da diversi campi, che contengono vari
tipi di informazioni. Uno dei campi viene usualmente distinto come la chiave, indicata con Key(xi), che,
in alcuni casi, individua in maniera univoca l’oggetto stesso. (Es. lista degli utenti di una compagnia
telefonica, dove la chiave potrebbe essere il codice fiscale.)
• Operazioni su una lista
– Query (o interrogazioni): sono operazioni che permettono di carpire informazioni pertinenti alla
lista (non ne modificano in alcun modo la struttura)
Es. determinare la lunghezza di una lista, controllare se un dato oggetto e un elemento della lista,
determinare il massimo di una lista, etc.
– Operazioni di Modifica: sono operazioni che permettono di manipolare una lista, a seguito delle
quali ne viene modificata o soltanto l’organizzazione dei suoi elementi (Es. ordinamento di una lista),
o ne viene cambiata anche la lunghezza (Es. inserimenti e cancellazioni)
• Una lista su cui sono previsti inserimenti e/o cancellazioni e chiamata lista dinamica.

Strutture dati elementari
• Operazioni su una lista (cont.)
– Query:
1. Visita (o Attraversamento): Visit(L)
2. Ricerca di un elemento: Search(L, x)
– Operazioni di Modifica:
3. Inserimento di un nuovo elemento: Insert(L, x)
4. Eliminazione di un elemento: Delete(L, x)
• Implementazioni di una lista
– Array: implementazione statica in cui la lunghezza massima della lista viene fissata a priori.
Permette di implementare in maniera semplice ed efficiente varie operazioni su una lista. Poco effi-
ciente per inserimenti e cancellazioni. Puo comportare notevole spreco di spazio nel caso di liste con
lunghezza molto variabile.
– Linked-List (Liste-Linkate): implementazione dinamica in cui, in linea di principio, non viene
fissato alcun limite massimo sulla lunghezza della lista (dipende dalla memoria fisica che si ha a
disposizione).
Molto flessibile e permette di implementare efficientemente operazioni di inserimento e cancellazione.
Altre operazioni possono tuttavia risultare piu dispendiose (e difficili da implementare) che non nel
caso degli array. Non comporta spreco di spazio.

Strutture dati elementari
Array• Un array A e un insieme di “celle contigue” contenenti tutte lo stesso tipo di dato (Es. “array di interi”,
“array di caratteri”, “array di stringhe”, etc.)
• Il numero delle celle che compongono un array viene fissato al momento in cui l’array stesso viene creato.
• Ogni cella e indicizzata da un numero intero a partire da 0.
• Un array e una struttura dati ad accesso diretto, nel senso che si puo accedere ai suoi elementi sem-
plicemente conoscendo la relativa posizione nell’array (indice della cella che contiene quell’elemento).
L’elemento che si trova nella cella i e A[i].
• La lunghezza di un array sara indicata con L[A].
Pertanto, ogni riferimento alle celle A[L[A]], A[L[A] + 1], A[L[A] + 2], . . . comportera un errore.
A
A[0]
0 1
A[1]
2
A[2]
L[A] − 1
A[L[A] − 1]
• Rappresenteremo una lista mediante un array A dotato dell’attributo Last[A] che indicizza l’ultimo ele-
mento della lista. Pertanto, gli elementi della lista verranno memorizzati nelle celle A[0], . . . , A[Last[A]].
La lista e vuota quando Last[A] = −1.

Strutture dati elementari
Operazioni su Array
• Attraversamento (o visita)
Visit(A)
1. i := 0
2. while (i ≤ Last[A]) do
3. print (A[i])
4. i := i + 1
• Ricerca
Search(A, key)
1. i := 0
2. while ((i ≤ Last[A]) and (A[i] 6= key)) do
3. i := i + 1
4. if (i > Last[A]) then
5. return (−1)
6. else
7. return (i)

Strutture dati elementari
• Complessita di un algoritmo
Visit(A)
1. i := 0 (costo c1)
2. while (i ≤ Last[A]) do (costo c2)
3. print (A[i]) (costo c3)
4. i := i + 1 (costo c4)
Sia n il numero di elementi della lista correntemente contenuta nell’array A (cioe n = Last[A] + 1)
1. La condizione in linea 2. viene testata n + 1 volte, e quindi contribuisce con un costo totale pari a
(n + 1) · c2
2. Le istruzioni delle linee 3. e 4. vengono eseguite ciascuna n volte, per un costo totale pari a n·c3+n·c4
3. Considerando anche l’istruzione in linea 1., si ha quindi che il “costo totale dell’algoritmo”, o running-
time , e dato da
T (n) = c1 + (n + 1) · c2 + n · c3 + n · c4 = n · (c2 + c3 + c4) + (c1 + c2) .
Poiche
limn−→∞
T (n)
n= c2 + c3 + c4 ,
esiste una constante c tale che T (n) ≤ c · n definitivamente, e quindi T (n) = O(n).
Notazioni Asintotiche
In generale, date due finzioni f(n) e g(n), scriviamo f(n) = O(g(n)) (risp., f(n) = Ω(g(n))) se esistono
una costante c e un intero ν tali che f(n) ≤ c · g(n) (risp., c · g(n) ≤ f(n)) per ogni n ≥ ν. Scriviamo
f(n) = Θ(g(n)) se f(n) = O(g(n)) e f(n) = Ω(g(n)).

Strutture dati elementari
• Inserimento
Insert(A, key)
1. if Last[A] = L[A] − 1 then
2. print (ERROR)
3. else
4. Last[A] := Last[A] + 1
5. A[Last[A]] := key
T (n) = O(1)
Insert∗(A, key, position)
1. for i := Last[A] downto position do
2. A[i + 1] := A[i]
3. A[position] := key
4. Last[A] := Last[A] + 1
T (n) = O(n)
• Eliminazione
Delete(A, key)
1. i := Search(A, key)
2. if i = −1 then
3. print (ERROR)
4. else
5. for j := i + 1 to Last[A] do
6. A[j − 1] := A[j]
7. Last[A] := Last[A] − 1
T (n) = O(n)

Strutture dati elementari
Esempi
• Determinare il massimo di un array di numeri interi (si assuma che Last[A] ≥ 0)
Max(A)
1. max := A[0]
2. i := 1
3. while i ≤ Last[A] do
4. if A[i] > max then
5. max := A[i]
6. i := i + 1
7. return (max)
T (n) = O(n)
• Determinare la somma degli elementi di un array di numeri interi
Somma(A)
1. somma := 0
2. i := 0
3. while i ≤ Last[A] do
4. somma := somma + A[i]
5. i := i + 1
6. return (somma)
T (n) = O(n)
RS(A, i)
1. somma := 0
2. if (i ≤ Last[A]) then
3. somma := A[i]+ RS(A, i + 1)
4. return (somma)
Somma(A)
1. return (RS(A, 0))
Ricorsione

Strutture dati elementari
• Contare il numero di volte che un oggetto di chiave key occorre in un array A
Count(A, key)
1. count := 0
2. i := 0
3. while i ≤ Last[A] do
4. if A[i] = key then
5. count := count + 1
6. i := i + 1
7. return (count)
T (n) = O(n)
• Controllare se un array A contiene due elementi consecutivi uguali
Check(A)
1. i := 0
2. while i < Last[A] do
3. if A[i] = A[i + 1] then
4. return (true)
5. i := i + 1
6. return (false)
T (n) = O(n)

Strutture dati elementari
• Controllare se un array A contiene doppioni
isNotSet(A)
1. i := 0
2. while i < Last[A] do
3. j := i + 1
4. while j ≤ Last[A] do
5. if A[i] = A[j] then
6. return (true)
7. j := j + 1
8. i := i + 1
9. return (false) T (n) = O(n2)
isNotSet(A)
1. for i := 0 to Last[A] − 1 do
2. for j := i + 1 to Last[A] do
3. if A[i] = A[j] then
4. return (true)
5. return (false)
• Controllare se un array A di numeri interi e ordinato (in senso non decrescente)
isOrd(A)
1. i := 0
2. while i < Last[A] do
3. j := i + 1
4. while j ≤ Last[A] do
5. if A[i] > A[j] then
6. return (false)
7. j := j + 1
8. i := i + 1
9. return (true) T (n) = O(n2)
isOrd(A)
1. for i := 0 to Last[A] − 1 do
2. for j := i + 1 to Last[A] do
3. if A[i] > A[j] then
4. return (false)
5. return (true)

Strutture dati elementari
Operazioni su Array-Ordinati
Un lista
x0 x1 x2 . . . xn−1
e ordinata rispetto alle chiavi, o, semplicemente, ordinata, se Key(x0) ≤ Key(x1) ≤ · · · ≤ Key(xn−1).
• Inserimento
InsertOrd(A, key)
1. i := 0
2. while ((i ≤ Last[A]) and (A[i] < key)) do
3. i := i + 1
4. for j := Last[A] downto i do
5. A[j + 1] := A[j]
6. A[i] := key
7. Last[A] := Last[A] + 1
T (n) = O(n)
InsertOrd(A, key)
1. i := 0
2. while ((i ≤ Last[A]) and (A[i] < key)) do
3. i := i + 1
4. Insert∗(A, key, i)
Strutture dati elementari
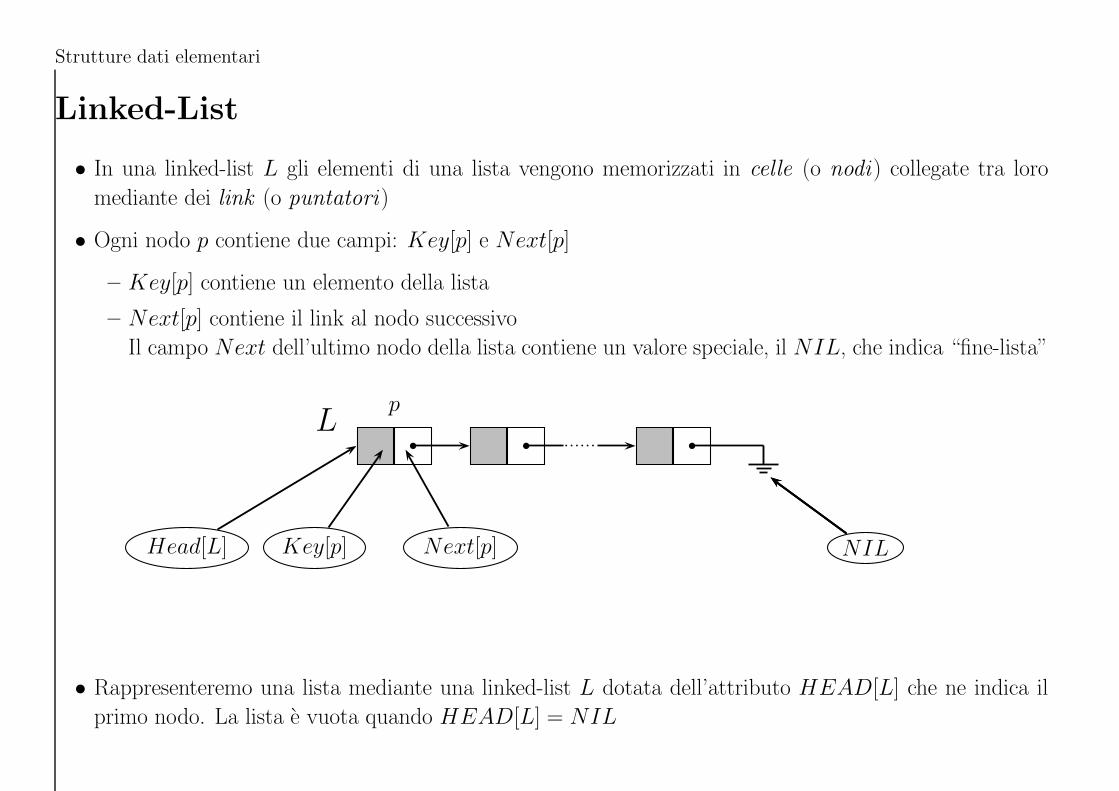
Linked-List
• In una linked-list L gli elementi di una lista vengono memorizzati in celle (o nodi) collegate tra loro
mediante dei link (o puntatori)
• Ogni nodo p contiene due campi: Key[p] e Next[p]
– Key[p] contiene un elemento della lista
– Next[p] contiene il link al nodo successivo
Il campo Next dell’ultimo nodo della lista contiene un valore speciale, il NIL, che indica “fine-lista”
Lp
Head[L] NILKey[p] Next[p]
• Rappresenteremo una lista mediante una linked-list L dotata dell’attributo HEAD[L] che ne indica il
primo nodo. La lista e vuota quando HEAD[L] = NIL

Strutture dati elementari
Operazioni su Linked-List• Attraversamento (o visita)
Visit(L)
1. p := HEAD[L]
2. while (p 6= NIL) do
3. print (Key[p])
4. p := Next[p]
T (n) = O(n)
VL(q)
1. if (q 6= NIL) then
2. print (Key[q])
3. VL(Next[q])
Ricorsione
Visit(L)
1. VL(HEAD[L])
• Ricerca
Search(L, key)
1. p := HEAD[L]
2. while ((p 6= NIL) and (Key[p] 6= key)) do
3. p := Next[p]
4. return (p) T (n) = O(n)
• Inserimento
Insert(L, key)
1. p := AllocateNode() // crea un nuovo nodo della lista
2. Key[p] := key
3. Next[p] := HEAD[L]
4. HEAD[L] := p T (n) = O(n)

Strutture dati elementari
• Eliminazione
Delete(L, key)
1. p := HEAD[L]
2. pred := NIL
3. while ((p 6= NIL) and (Key[p] 6= key)) do
4. pred := p
5. p := Next[p]
6. if p 6= NIL then
7. if pred 6= NIL then
8. Next[pred] := Next[p]
9. else HEAD[L] := Next[p]
10. else print (ERROR) T (n) = O(n)
Esempi
• Numero di elementi di una linked-list
Length(L)
1. q := HEAD[L]
2. count := 0
3. while (q 6= NIL) do
4. count := count + 1
5. q := Next[q]
6. return (count)
RL(q)
1. count := 0
2. if (q 6= NIL) then
3. count := 1+ RL(Next[q])
4. return (count)
Length(L)
1. return RL(HEAD[L])
Ricorsione

Strutture dati elementari
• Controllare se due Linkde-List L1 e L2 sono uguali
CheckEq(L1, L2)
1. q := HEAD[L1]
2. p := HEAD[L2]
3. while (q 6= NIL and p 6= NIL and Key[q] = Key[p]) do
4. q := Next[q]
5. p := Next[p]
6. if (q = NIL and p = NIL) then
7. print (Y ES)
8. else print (NO)
• Appiattimento di una linked-list: eliminare tutti gli elementi consecutivi uguali lasciandone uno solo
Flat(L)
1. q := HEAD[L]
2. while q 6= NIL do
3. p := Next[q]
4. while (p 6= NIL and Key[p] = Key[q]) do
5. p := Next[p]
6. Next[q] := p
7. q := p

Strutture dati elementari
• Inversione di una lista: stampare gli elementi di una lista in ordine inverso
Invert(L)
1. q := HEAD[L]
2. h := NIL (Creiamo una nuova lista, di testa h, che contiene L in ordine inverso)
3. while (q 6= NIL) do
4. p := AllocateNode()
5. Key[p] := Key[q]
6. Next[p] := h
7. h := p
8. q := Next[q]
9. p := h (Attraversiamo h)
10. while (p 6= NIL) do
11. print (Key[p])
12. p := Next[p]
Ricorsione
RI(q)
1. if (q 6= NIL) then
2. RI(Next[q])
3. print(Key[q])
Invert(L)
1. RI(HEAD[L])
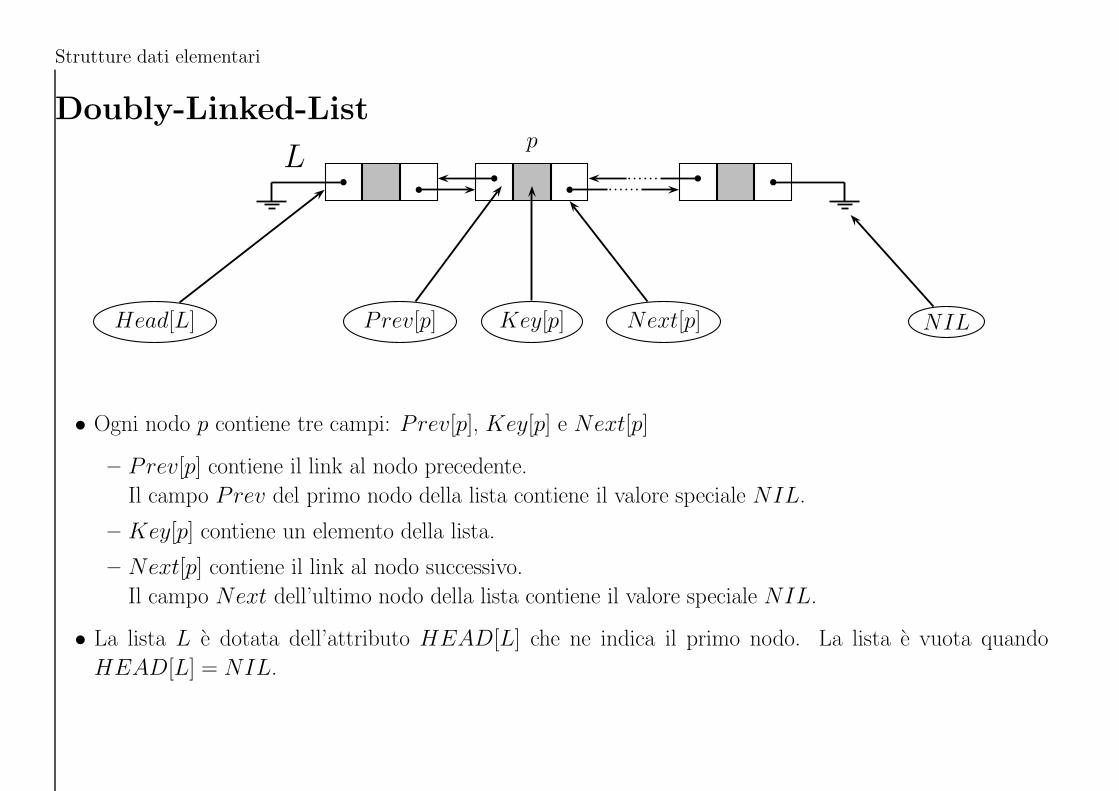
Strutture dati elementari
Doubly-Linked-List
Lp
Head[L] NILKey[p] Next[p]Prev[p]
• Ogni nodo p contiene tre campi: Prev[p], Key[p] e Next[p]
– Prev[p] contiene il link al nodo precedente.
Il campo Prev del primo nodo della lista contiene il valore speciale NIL.
– Key[p] contiene un elemento della lista.
– Next[p] contiene il link al nodo successivo.
Il campo Next dell’ultimo nodo della lista contiene il valore speciale NIL.
• La lista L e dotata dell’attributo HEAD[L] che ne indica il primo nodo. La lista e vuota quando
HEAD[L] = NIL.

Strutture dati elementari
Operazioni su Doubly-Linked-List
• Inserimento / Eliminazione
Insert(L, key)
1. p := AllocateNode()
2. Key[p] := key
3. Next[p] := HEAD[L]
4. Prev[p] := NIL
5. if HEAD[L] 6= NIL then
6. Prev[HEAD[L]] := p
7. HEAD[L] := p
Delete(L, key)
1. p := HEAD[L]
2. while ((p 6= NIL) and (Key[p] 6= key)) do
3. p := Next[p]
4. if p 6= NIL then
5. if Prev[p] 6= NIL then
6. Next[Prev[p]] := Next[p]
7. else
8. HEAD[L] := Next[p]
9. if Next[p] 6= NIL then
10. Prev[Next[p]] := Prev[p]
11. else
12. print (ERROR)

Strutture dati elementari
• Eliminazione (2)
Delete∗(L, p)
1. if Prev[p] 6= NIL then
2. Next[Prev[p]] := Next[p]
3. else
4. HEAD[L] := Next[p]
5. if Next[p] 6= NIL then
6. Prev[Next[p]] := Prev[p]
Delete(L, key)
1. p := Search(L, key)
2. if p 6= NIL then
3. Delete∗(L, p)
4. else
5. print (ERROR)
Esempi
• Inversione di una doubly-linked-list
Invert(L)
1. q := HEAD[L]
2. while (q 6= NIL and Next[q] 6= NIL) do
3. q := Next[q]
4. while (q 6= NIL) do
5. print (Key[q])
6. q := Prev[q]

Strutture dati elementari
Confronto tra Array e Linked-List
• Nell’implementazione di una lista usando un array bisogna specificare il massimo numero di elementi che
dovra contenere la lista a tempo di compilazione (cioe quando l’array viene creato). Se non si conosce
a priori un bound sulla lunghezza massima che puo raggiungere la lista e piu consigliabile usare una
linked-list invece di un array.
• Certe operazioni risultano piu dispendiose in una implementazione invece che in un’altra. Ad esempio,
inserimenti e cancellazioni in testa possono essere eseguite in tempo costante su di una linked-list, ma
richiedono tempo proporzionale al numero di elementi che seguono nel caso in cui is usi un array. Viceversa,
operazioni come
– EndList(L) che mi ritorna l’ultimo elemento di una lista, o
– Retrieve(L, p) che mi ritorna il p-esimo elemento di una lista
richiedono tempo costante con gli array ma risultano molto dispendiose con le linked-list (se p e grande).
• L’implementazione con array puo sprecare molto spazio, dato che essa usa l’ammontare massimo di
spazio allocato per l’array indipendentemente dal numero degli elementi della lista attualmente contenuti
nell’array stesso. L’implementazione con linked-list usa invece spazio proporzionale al numero degli
elementi correntemente contenuti nella lista.

Strutture dati elementari
Stack
• Uno stack e una lista in cui inserimenti e cancellazioni avvengono tutti ad una stessa estremita chiamata
TOP. (Es. pila di libri, pila di piatti, etc.)
• Uno stack implementa una politica di tipo LIFO (LAST-IN-FIRST-OUT), ovvero, l’elemento ad
essere rimosso e sempre quello che e stato inserito per ultimo.
• Le operazioni di inserimento e di eliminazione in uno stack vengono chiamate PUSH e POP, rispetti-
vamente:
– Push(S, x) inserisce l’elemento x al TOP dello stack S
– Pop(S) elimina (e ritorna) l’elemento che si trova al TOP dello stack S
• Implementeremo uno stack usando un array S dotato di un attributo Top[S] che ne indica il TOP.
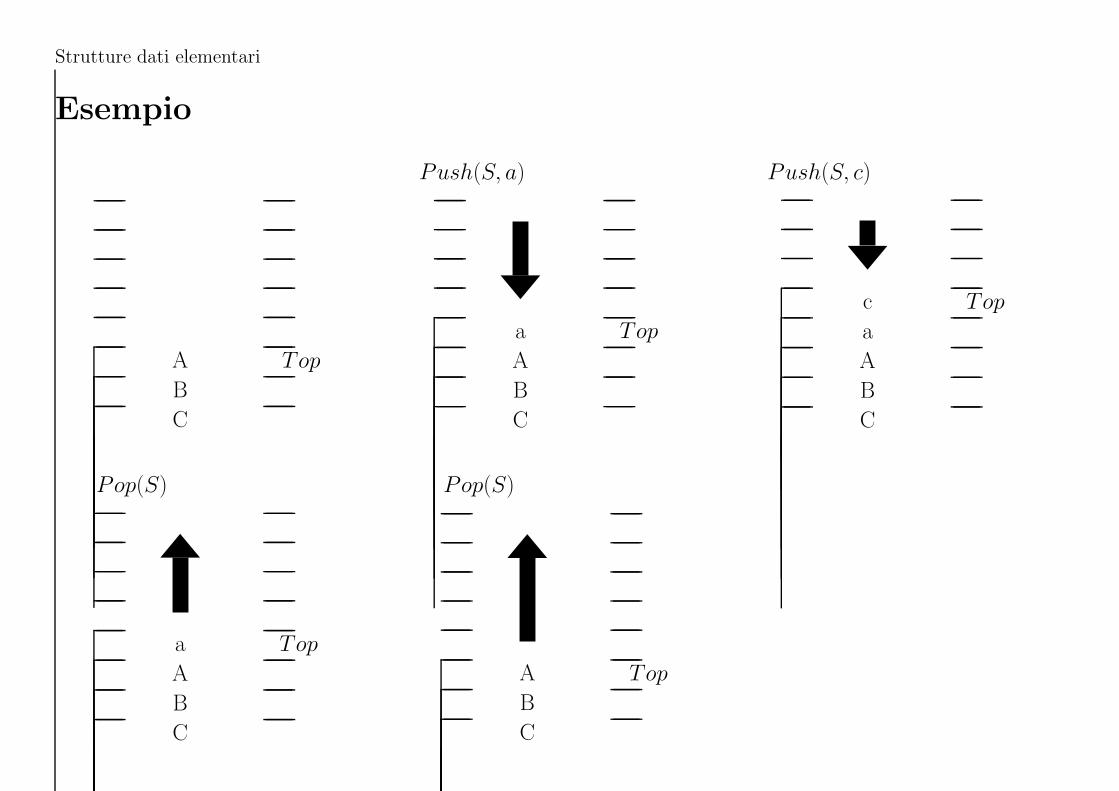
Strutture dati elementari
Esempio
A Top
B
C
Push(S, a)
a Top
A
B
C
Push(S, c)
c Top
a
A
B
C
Pop(S)
a Top
A
B
C
Pop(S)
A Top
B
C

Strutture dati elementari
Operazioni su Stack
• Emptyness
EmptyStack(S)
1. if Top[S] = −1 then
2. return (true)
3. else
4. return (false)
• Inserimento
Push(S, x)
1. Top[S] := Top[S] + 1
2. S[Top[S]] := x
• Eliminazione
Pop(S)
1. if EmptyStack(S) then
2. print (ERROR: Stack “underflow”)
3. else
4. Top[S] := Top[S] − 1
5. return (S[Top[S] + 1])

Strutture dati elementari
Esempio: valutazione di espressioni aritmetiche
• Formato delle espressioni aritmetiche
– Forma Infissa (o standard/tradizionale): l’operatore viene posto tra gli operandi
Es.
1 + 2 (1 + 2) + 3 4 × ((1 + 2) + 3)
– Forma Postfissa (o polacca): l’operatore viene posto subito dopo gli operandi
Es.
1 2 + 1 2 + 3 + 4 1 2 + 3 + ×
– Forma Prefissa: l’operatore viene posto subito prima degli operandi
Es.
+ 1 2 + + 1 2 3 × 4 + + 1 2 3
• Considereremo i seguenti problemi
– Valutare un’espressione aritmetica che si presenta in forma Postfissa
– Convertire un’espressione aritmetica dalla forma Infissa alla forma Postfissa
– Valutare un’espressione aritmetica che si presenta in forma Infissa
– Convertire un’espressione aritmetica dalla forma Postfissa alla forma Infissa

Strutture dati elementari
• Valutare un’espressione aritmetica che si presenta in forma Postfissa
1. Assumiamo che l’espressione sia rappresentata da un array Expr[0 .. L − 1]
2. Esaminiamo l’espressione da sinistra verso destra
3. Usiamo uno stack S per mantenere i risultati parziali
4. Assumiamo una funzione Val(x, y, oper) che fornisce il risultato dell’operazione rappresentata da
“oper” e applicata agli operandi x e y (Es. Val(2, 3, +) = 5, Val(2, 3,×) = 6, etc.)
PostfixVal(Expr)
1. for i := 0 to L − 1 do
2. if 〈Expr[i] e un “operando”〉 then
3. Push(S, Expr[i])
4. else
5. x := Pop(S)
6. y := Pop(S)
7. Push(S, Val(x, y, Expr[i]))
8. return (S[Top[S]])

Strutture dati elementari
• Convertire un’espressione aritmetica dalla forma Infissa alla forma Postfissa
1. Usiamo uno stack S per mantenere gli operatori
2. Se incontriamo un operando lo stampiamo
3. Se incontriamo un operatore lo “pushiamo” nello stack
4. Se incontriamo una parentesi chiusa, “poppiamo” lo stack e stampiamo l’operatore
InfixToPostfix(Expr)
1. for i := 0 to L − 1 do
2. if 〈Expr[i] e un “operando”〉 then
3. print (Expr[i])
4. else
5. if 〈Expr[i] e un “operatore”〉 then
6. Push(S, Expr[i])
7. else
8. if 〈Expr[i] = “ ) ”〉 then
9. oper := Pop(S)
10. print (oper)

Strutture dati elementari
• Valutare un’espressione aritmetica che si presenta in forma Infissa
1. Usiamo uno stack S per mantenere i risultati parziali
2. Usiamo uno stack S′ per mantenere gli operatori
3. Assumiamo una funzione Val(x, y, oper) che fornisce il risultato dell’operazione rappresentata da
“oper” e applicata agli operandi x e y (Es. Val(2, 3, +) = 5, Val(2, 3,×) = 6, etc.)
InfixVal(Expr)
1. for i := 0 to L − 1 do
2. if 〈Expr[i] e un “operando”〉 then
3. Push(S, Expr[i])
4. else
5. if 〈Expr[i] e un “operatore”〉 then
6. Push(S′, Expr[i])
7. else
8. if 〈Expr[i] = “ ) ”〉 then
9. x := Pop(S)
10. y := Pop(S)
11. oper := Pop(S′)
12. Push(S, Val(x, y, oper))
13. return (S[Top[S]])

Strutture dati elementari
• Convertire un’espressione aritmetica dalla forma Postfissa alla forma Infissa
1. Usiamo uno stack S per mantenere le “sotto-espressioni” parziali
2. Se incontriamo un operando lo “pushiamo” nello stack
3. Se incontriamo un operatore, “poppiamo” due volte lo stack, formiamo l’espressione corretta e la
“pushiamo” nello stack
PostfixToInfix(Expr)
1. for i := 0 to L − 1 do
2. if 〈Expr[i] e un “operando”〉 then
3. Push(S, Expr[i])
4. else
5. x := Pop(S)
6. y := Pop(S)
7. Push(S, “(y Expr[i] x)”)
8. return (S[Top[S]])

Strutture dati elementari
Coda
• Una coda (queue) e una lista in cui gli inserimenti avvengono ad una estremita chiamata tail e le can-
cellazioni all’estremita opposta, chiamata head. (Es. fila di persone ad uno sportello postale)
• Una coda implementa una politica di tipo FIFO (FIRST-IN-FIRST-OUT), ovvero, l’elemento ad
essere rimosso e sempre quello che e stato inserito per primo.
• Le operazioni di inserimento e di eliminazione in una coda vengono chiamate ENQUEUE e DE-
QUEUE, rispettivamente:
– Enqueue(Q, x) inserisce l’elemento x nel tail della coda Q
– Dequeue(Q) rimuove (e ritorna) l’elemento che si trova nell’head della coda Q
• Implementeremo una coda usando un “array circolare” Q dotato dei due attributi Head[Q] e Tail[Q]
che indicizzano l’head e il tail della coda, rispettivamente. In particolare ...

Strutture dati elementari
(1) Gli elementi della coda saranno quelli “compresi” tra Head[Q] e Tail[Q] − 1:
Q
0 Head[Q] Tail[Q] n − 1
Q
0 Tail[Q] Head[Q] n − 1
dove n e la lunghezza dell’array.
(2) La coda e vuota quando Head[Q] = Tail[Q]. Inizialmente Head[Q] = Tail[Q] = 0;
(3) La coda e piena quando Head[Q] = Tail[Q] + 1;

Strutture dati elementari
Operazioni sulle Code
• Emptyness
EmptyQueue(Q)
1. if Head[Q] = Tail[Q] then
2. return (true)
3. else
4. return (false)
• Inserimento / Eliminazione
Enqueue(Q, x)
1. Q[Tail[Q]] := x
2. if Tail[Q] = L[Q] − 1 then
3. Tail[Q] := 0
4. else
5. Tail[Q] := Tail[Q] + 1
Dequeue(Q)
1. if EmptyQueue(Q) then
2. print (ERROR: Queue “underflow”)
3. else
4. x := Q[Head[Q]]
5. if Head[Q] = L[Q] − 1 then
6. Head[Q] := 0
7. else
8. Head[Q] := Head[Q] + 1
9. return (x)

Strutture dati elementari
Insiemi Dinamici
• Un insieme dinamico e un insieme il cui contenuto puo cambiare nel corso del tempo a seguito della
esecuzione di certe operazioni sull’insieme stesso (Es. l’insieme S(L) degli elementi di una lista L quando
sulla lista vengono eseguite operazioni di inserimento e/o cancellazione.)
• Un insieme puo essere agevolmente rappresentato come una lista, semplicemente ordinando gli elementi
dell’insieme in una qualche maniera prefissata. Pertanto risulta naturale implementare un insieme di-
namico usando Array o Linked-List come abbiamo visto in precedenza per le liste. Tuttavia, tali tipi di
implementazioni possono rivelarsi poco efficienti quando la dimensione dell’insieme e molto grande e/o
quando gli elementi dell’insieme sono organizzati mediante certe relazioni (Es. l’insieme dei discendenti
di un’antica famiglia organizzati dalla relazione 〈Padre, F iglio〉).
• Una stessa operazione su un insieme dinamico verra implementata in maniera diversa a seconda che si usi
una certa struttura dati per rappresentare l’insieme piuttosto che un’altra. Molto spesso, diverse strutture
dati suggeriscono (e comportano) implementazioni molto differenti, dal punto di vista dell’efficienza, di
una stessa operazione sull’insieme.
• Come per le liste, gli elementi di un insieme dinamico sono caratterizzati da vari campi, uno dei quali si
distingue come la chiave. Se tutte le chiavi sono differenti, possiamo identificare ogni elemento dell’insieme
con la relativa chiave, e quindi riguardare l’insieme come un insieme di chiavi. Alcuni insiemi dinamici
presuppongono che le chiavi provengano tutte da uno stesso insieme (o universo) totalmente ordinato.
In questo caso e possibile definire, ad esempio, il minimo (o il massimo) di un insieme di chiavi, o di
confrontare le chiavi mediante una relazione di successore (e di predecessore).

Strutture dati elementari
Operazioni su Insiemi Dinamici
Come per le liste, anche per gli insiemi dinamici, si parlera di Query e di Operazioni di Modifica.
• Query
– Visit(S): “esamina” tutti gli elementi dell’insieme dinamico S ;
– Search(S , k): ritorna un elemento x di S contenente la chiave k;
– Minimum(S): ritorna un elemento di S avente chiave minima;
– Maximum(S): ritorna un elemento di S avente chiave massima;
– Successor(S , x): ritorna il successore di x in S ;
– Predecessor(S , x): ritorna il predecessore di x in S ;
• Operazioni di Modifica
– Insert(S , x): aggiunge l’elemento x all’insieme dinamico S ;
– Delete(S , x): rimuove l’elemento x dall’insieme dinamico S ;
Una struttura dati che supporta efficientemente le varie operazioni su un insieme dinamico, e che serve come
base per altri tipi di strutture dati, e la struttura dati ad Albero Binario di Ricerca (Binary-Search-
Tree.)
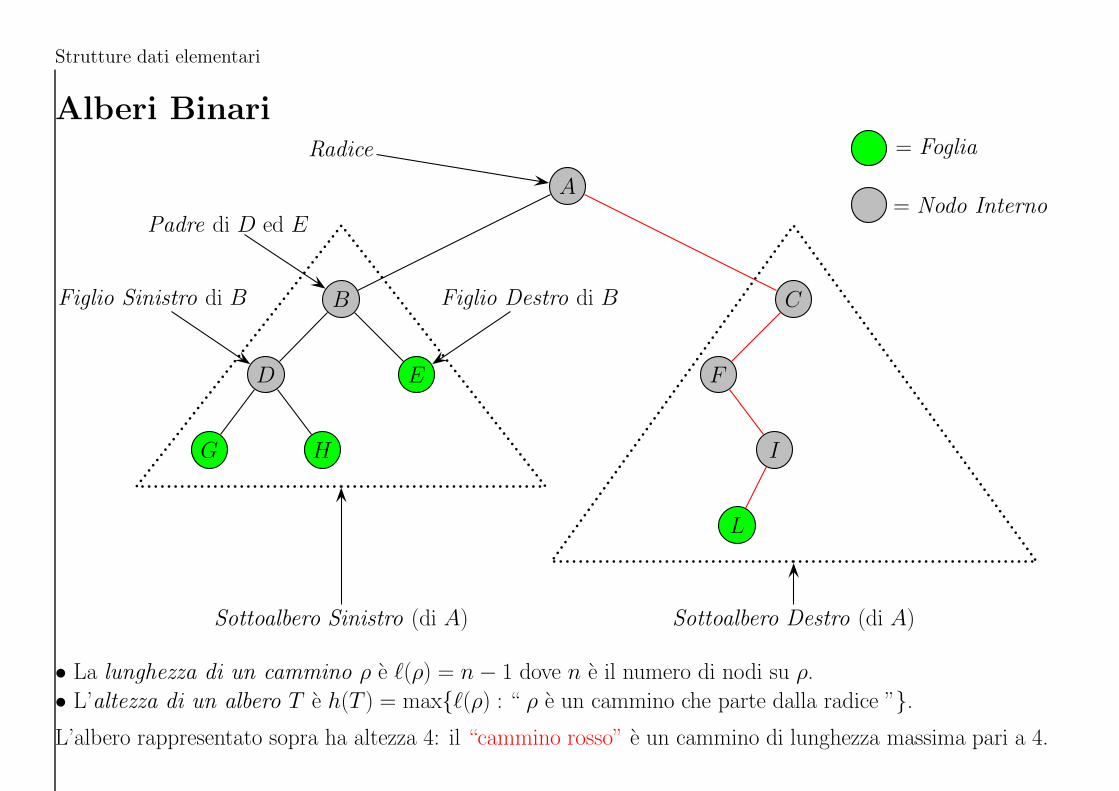
Strutture dati elementari
Alberi BinariRadice
A
B
Padre di D ed E
C
D
Figlio Sinistro di B
E
Figlio Destro di B
F
G H I
L
Sottoalbero Sinistro (di A) Sottoalbero Destro (di A)
= Foglia
= Nodo Interno
• La lunghezza di un cammino ρ e ℓ(ρ) = n − 1 dove n e il numero di nodi su ρ.
• L’altezza di un albero T e h(T ) = maxℓ(ρ) : “ ρ e un cammino che parte dalla radice ”.
L’albero rappresentato sopra ha altezza 4: il “cammino rosso” e un cammino di lunghezza massima pari a 4.

Strutture dati elementari
Alcune definizioni e proprieta
Sia T un albero binario.
• Un nodo x di T e una foglia se x non ha ne figlio sinistro e neppure figlio destro.
• Un nodo che non sia una foglia e chiamato nodo interno.
• Un cammino in T e una sequenza di nodi ρ = (x0, x1, . . . , xn), con n ≥ 0, in cui xi+1 e un figlio di xi,
per i = 0, 1, . . . , n − 1. La lunghezza di ρ e ℓ(ρ) = n.
• La profondita p(x) di un nodo x e la lunghezza dell’unico cammino dalla radice fino a quel nodo. La
radice ha profondita 0.
• L’altezza di T e h(T ) = maxℓ(ρ) : “ ρ e un cammino che parte dalla radice ”.
• L’albero T e pieno se per ogni p < h(T ) ogni nodo di T di profondita p ha esattamente due figli.
Lemma 1. Se T e pieno, allora ci sono esattamente 2h nodi a profondita h, per ogni h ≤ h(T ).
Lemma 2. Se T e pieno, allora esso contiene esattamente 2h(T )+1 − 1 nodi.
Teorema 1. Se T contiene n nodi, allora
log2
n + 1
2≤ h(T ) ≤ n − 1 .

Strutture dati elementari
Rappresentazione di alberi binari
Un albero binario sara rappresentato mediante un insieme T di nodi in cui ogni nodo x e formato dai seguenti
campi:
1. Key[x] che contiene la chiave memorizzata in x;
2. Left[x] che contiene un link che punta la figlio sinistro di x;
3. Right[x] che contiene un link che punta al figlio destro di x;
4. Parent[x] che contiene un link che punta al padre x.
Se un nodo x non ha figlio sinistro allora il campo Left[x] contiene il valore speciale NIL, e analogamente
per Right[x]. Se x e la radice di T allora il campo Parent[x] contiene NIL. (Si noti che la radice e l’unico
nodo il cui campo Parent contiene il NIL.)
Pertanto, un nodo x
• e la radice di T se e solo se Parent[x] = NIL;
• e una foglia se e solo se Left[x] = Right[x] = NIL;
• e un nodo interno se e solo se Left[x] 6= NIL o Right[x] 6= NIL.
La radice di T sara indicata con Root[T ]. Inoltre, se x e un nodo di T indicheremo con Tx il sottoalbero di
T avente radice x.

Strutture dati elementari
Visita di alberi binari
Considereremo tre differenti procedure di visita di un albero binario:
• Visita Inorder (Inorder-Tree-Walk)
• Visita Postorder (Postorder-Tree-Walk)
• Visita Preorder (Preorder-Tree-Walk)
• Visita Inorder
La visita inorder di un albero binario T puo essere definita ricorsivamente come segue:
1. Se T e l’albero vuoto (cioe se Root[T ] = NIL), non si esegue nessuna operazione e la visita termina;
2. Se T non e vuoto, detta r la radice di T , si eseguono le seguenti tre operazioni (nell’ordine indicato):
(Op.1) si esegue la visita inorder del sottoalbero sinistro di r
(Op.2) si stampa la chiave Key[r]
(Op.3) si esegue la visita inorder del sottoalbero destro di r

Strutture dati elementari
• Visita Postorder
La visita postorder di un albero binario T puo essere definita ricorsivamente come segue:
1. Se T e l’albero vuoto (cioe se Root[T ] = NIL), non si esegue nessuna operazione e la visita termina;
2. Se T non e vuoto, detta r la radice di T , si eseguono le seguenti tre operazioni (nell’ordine indicato)
(Op.1) si esegue la visita postorder del sottoalbero sinistro di r
(Op.2) si esegue la visita postorder del sottoalbero destro di r
(Op.3) si stampa la chiave Key[r]
• Visita Preorder
La visita preorder di un albero binario T puo essere definita ricorsivamente come segue:
1. Se T e l’albero vuoto (cioe se Root[T ] = NIL), non si esegue nessuna operazione e la visita termina;
2. Se T non e vuoto, detta r la radice di T , si eseguono le seguenti tre operazioni (nell’ordine indicato)
(Op.1) si stampa la chiave Key[r]
(Op.2) si esegue la visita preorder del sottoalbero sinistro di r
(Op.3) si esegue la visita preorder del sottoalbero destro di r
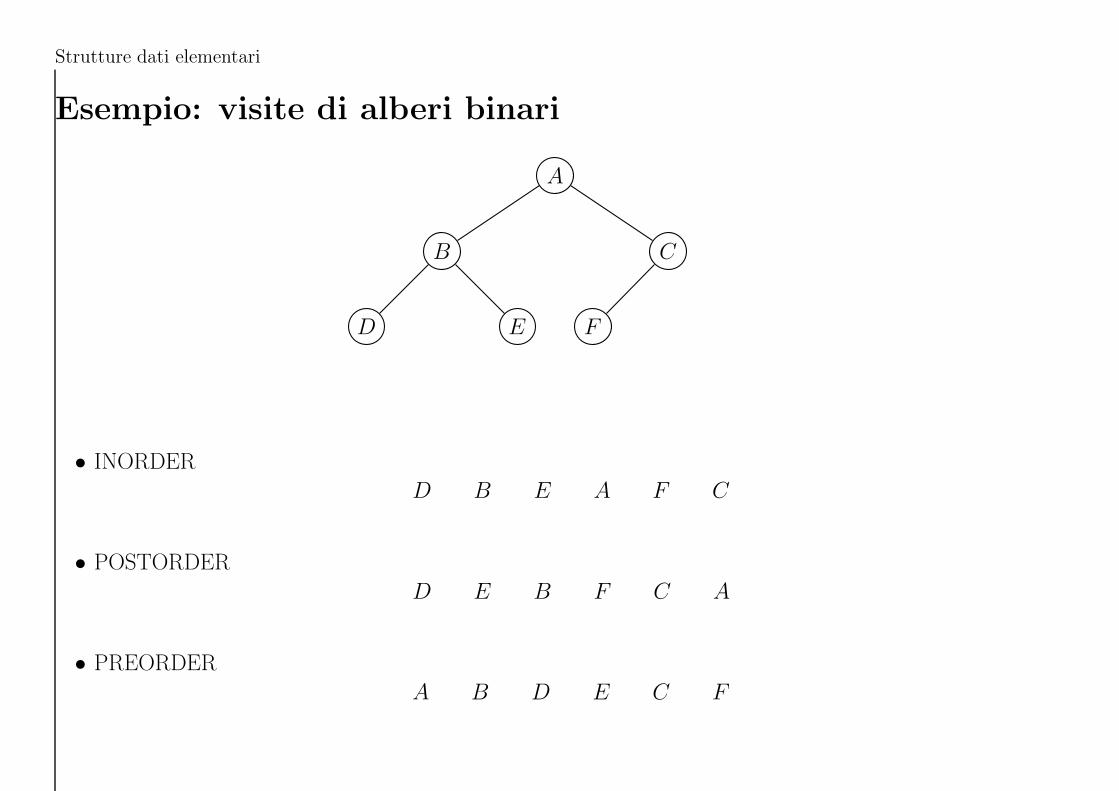
Strutture dati elementari
Esempio: visite di alberi binari
A
B C
D E F
• INORDER
D B E A F C
• POSTORDER
D E B F C A
• PREORDER
A B D E C F

Strutture dati elementari
Implementazione delle operazioni di visita
• La seguenti tre procedure ricorsive ricevono in input un nodo x di un albero binario T ed effettuano le
visite inorder, postorder e preorder del sottoalbero Tx:
Inorder-Tree-Walk(x)
1. if (x 6= NIL) then
2. Inorder-Tree-Walk(Left[x])
3. print (Key[x])
4. Inorder-Tree-Walk(Right[x])
Postorder-Tree-Walk(x)
1. if (x 6= NIL) then
2. Postorder-Tree-Walk(Left[x])
3. Postorder-Tree-Walk(Right[x])
4. print (Key[x])
Preorder-Tree-Walk(x)
1. if (x 6= NIL) then
2. print (Key[x])
3. Preorder-Tree-Walk(Left[x])
4. Preorder-Tree-Walk(Right[x])
• Una chiamata a Inorder-Tree-Walk(Root[T ]) produrra la visita inorder dell’intero albero binario T e
similmente per Postorder-Tree-Walk(Root[T ]) e Preorder-Tree-Walk(Root[T ]).

Strutture dati elementari
Alberi Binari di Ricerca (Binary-Search-Trees)
Un Albero Binario di Ricerca e un albero binario T che soddisfa la seguente proprieta:
Per ogni coppia di nodi x e y di T :
• se y e un nodo nel sottoalbero di radice Left[x], allora Key[y] ≤ Key[x];
• se y e un nodo nel sottoalbero di radice Rigth[x], allora Key[y] ≥ Key[x].
10
6 15
3 9 10
0 5 11
Si osservi che la visita inorder dell’albero binario di ricerca rappresentato sopra produce l’ordinamento in
senso non decrescente delle chiavi contenute nei nodi dell’albero: 0 3 5 6 9 10 10 11 15
Questa proprieta e valida in generale.

Strutture dati elementari
Operazioni su Alberi Binari di Ricerca
• Ricerca: dato un nodo x di un albero T e data una chiave k, la seguente procedura ritorna un nodo y
nel sottoalbero Tx tale che Key[y] = k. Se un tale nodo non esiste, allora la procedura ritorna NIL
Tree-Search(x, k)
1. y := x
2. while (y 6= NIL) and (k 6= Key[y]) do
3. if (k < Key[y]) then
4. y := Left[y]
5. else
6. y := Right[y]
7. return (y)
Tree-Search(x, k)
1. y := x
2. if (y = NIL) or (k = Key[y]) then
3. return (y)
4. if (k < Key[y]) then
5. return Tree-Search(Left[y], k)
6. else
7. return Tree-Search(Right[y], k)
Ricorsione
• Nel caso peggiore bisogna esaminare tutti i nodi presenti su un cammino che parte da x e termina in una
foglia. Pertanto la complessita di Tree-Search(x, k) e O(h(Tx)), dove h(Tx) e l’altezza del sottoalbero
Tx.
• Per effettuare la ricerca di k nell’intero albero T si effettua una chiamata a Tree-Search(Root[T ], k).

Strutture dati elementari
• Minimum / Maximum: Tree-Minimum(x) ritorna il primo nodo (in inorder) avente chiave minima
nel sottoalbero Tx. Tree-Maximum(x) ritorna l’ultimo nodo (in inorder) avente chiave massima nel
sottoalbero Tx.
Tree-Minimum(x)
1. y := x
2. while Left[y] 6= NIL do
3. y := Left[y]
4. return (y)
Complessita = O(h(Tx))
Tree-Maximum(x)
1. y := x
2. while Right[y] 6= NIL do
3. y := Right[y]
4. return (y)
Complessita = O(h(Tx))
• Successor / Predecessor: Tree-Successor(x) ritorna il successore del nodo x relativamente all’ordinamento
determinato dalla visita inorder (analogamente per Tree-Predecessor(x))
Tree-Successor(x)
1. if Right[x] 6= NIL then
2. return Tree-Minimum(Right[x])
3. y := Parent[x]
4. while y 6= NIL and x = Right[y] do
5. x := y
6. y := Parent[y]
7. return (y)
Complessita = O(h(Tx))
Tree-Predecessor(x)
1. if Left[x] 6= NIL then
2. return Tree-Maximum(Left[x])
3. y := Parent[x]
4. while y 6= NIL and x = Left[y] do
5. x := y
6. y := Parent[y]
7. return (y)
Complessita = O(h(Tx))

Strutture dati elementari
• Inserimento: inserire la chiave k nell’albero T
Tree-Insert(T , k)
1. z := AllocateTreeNode() // crea un nuovo nodo dell’albero
2. Key[z] := k
3. Left[z] := Right[z] := NIL
4. x := Root[T ]
5. y := NIL
6. while (x 6= NIL) do
7. y := x
8. if k < Key[x] then
9. x := Left[x]
10. else
11. x := Right[x]
12. Parent[z] := y
13. if y = NIL then
14. Root[T ] := z
15. else
16. if k < Key[y] then
17. Left[y] := z
18. else
19. Right[y] := z
La complessita della procedura Tree-Insert(T , k) e O(h), dove h e l’altezza dell’albero T .

Strutture dati elementari
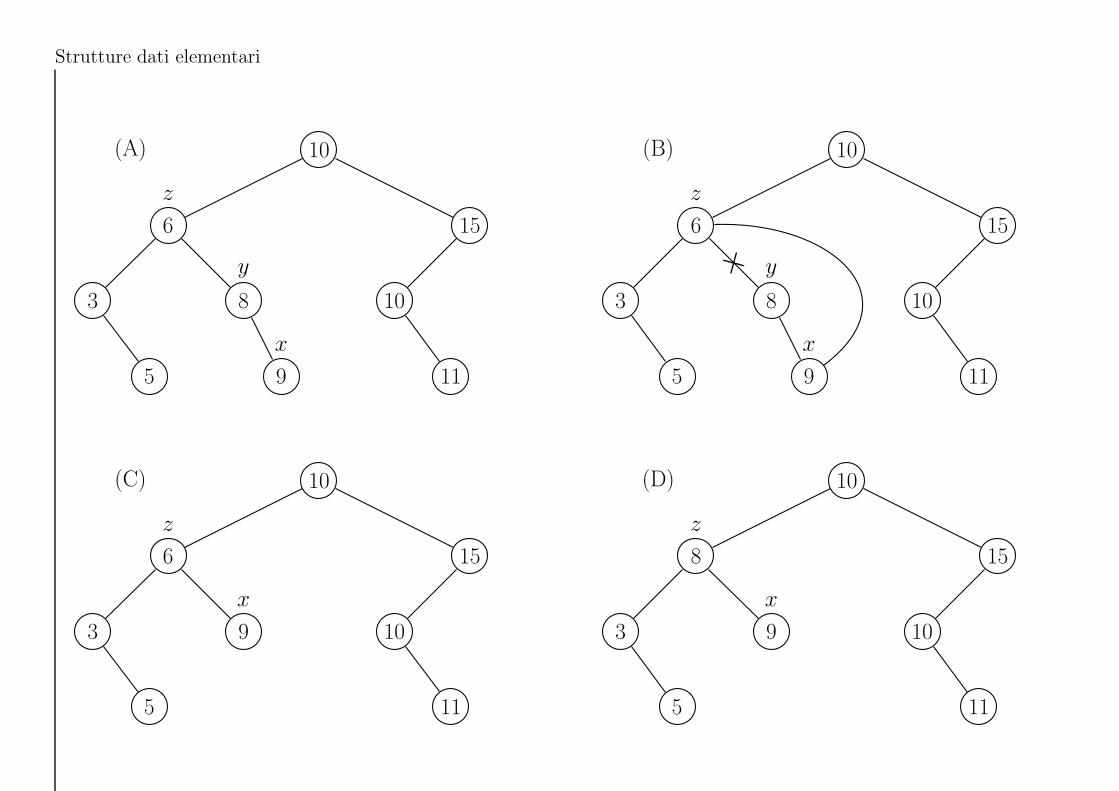
• Eliminazione: eliminare il nodo z dall’albero T
Tree-Delete(T , z)
1. if Left[z] = NIL or Right[z] = NIL then
2. y := z
3. else
4. y := Tree-Successor(z)
5. if Left[y] 6= NIL then
6. x := Left[y]
7. else
8. x := Right[y]
9. if x 6= NIL then
10. Parent[x] := Parent[y]
11. if Parent[y] = NIL then
12. Root[T ] := x
13. else
14. if y = Left[Parent[y]] then
15. Left[Parent[y]] := x
16. else
17. Right[Parent[y]] := x
18. if y 6= z then
19. Key[z] := Key[y]
La complessita della procedura Tree-Delete(T , z) e O(h), dove h e l’altezza dell’albero T .
Strutture dati elementari
(A) 10
6
z
15
3 8
y
9
x
10
5 11
(B) 10
6
z
15
3 8
y
9
x
10
5 11
×
(C) 10
6
z
15
3 9
x
10
5 11
(D) 10
8
z
15
3 9
x
10
5 11


![Algoritmi e Strutture Dati - Algoritmi Golosi (Greedy)computerscience.unicam.it/merelli/algoritmi06/[12]strategiaGolosa.pdf · Algoritmi e Strutture Dati Algoritmi Golosi (Greedy)](https://static.fdocumenti.com/doc/165x107/5c71c4f409d3f2cc4d8b53b1/algoritmi-e-strutture-dati-algoritmi-golosi-greedy-12strategiagolosapdf.jpg)